
Kernel Side-Channel Attack using L1 Terminal Fault - CVE-2018-3620 和 CVE-2018-3646
已更新
红帽已了解到一个新的、与 Spectre 和 Meltdown 类似的计算机微处理器硬件实现(微架构)的安全漏洞,这个安全漏洞会影响到 Intel x86 微处理器。利用这个安全漏洞,一个没有相关权限的用户可以绕过内存安全限制机制来访问没有权限访问的内存数据。这个安全漏洞包括 3 个部分。第一个部分只会影响到 Intel “SGX”,这个问题可以通过更新 microcode 解决,而不需要更新操作系统。其它两个部分需要通过在操作系统和 hypervisor 中进行软件更新来解决。为了避免从虚拟环境中不被信任的虚拟机系统上发起的攻击,需要系统管理员进行特定的操作。
CVE-2018-3620 是这个问题的操作系统漏洞在 CVE 中的 ID,CVE-2018-3646 是这个问题中与虚拟化相关的安全漏洞在 CVE 中的 ID。这个问题在业界通常被称为 L1 Terminal Fault(L1TF),而安全研究人员通常会把它称为 “Foreshadow”。
利用 L1 Terminal Fault 安全漏洞,一个恶意的攻击者可以绕过通常由操作系统和虚拟机管理程序(hypervisor)控制的内存访问安全机制。攻击者可以读取缓存在处理器的 L1 数据缓存中的物理内存位置。在正常情况下,操作系统和 hypervisor 所管理的 “page tables(内存页表)” 会向处理器提供哪些内存地址可以被应用程序、操作系统内核以及虚拟机访问的信息。这些页表由页表项(PTE)组成,PTE 包括一个 “present” 位来代表这个项是否有效。通过 L1TF 漏洞,攻击者可以滥用 Intel 处理器中关于识别有效 PTE 的逻辑代码。
L1 数据缓存(通常为 32KB)是芯片上处理器内存数据分级结构的第一级,它所包括的数据也包括在处理器外的主内存芯片中。当内存被使用时,就会产生缓存数据,这些缓存数据通常会被分为不同级别。L1 缓存是一个小的、快速的最高级缓存,它与处理器中用来处理程序计算的功能单元最接近,而其它大的、较慢的缓存会位于与计算功能单元较远的地方。Intel 处理器内核中的两个平等的超线程会共享 L1。每个内核还会有一个稍大的 L2 缓存。另外,L3(也被称为 LLC 或 Last Level Cache)由处理器中的所有内核共享,它通常比较大(例如,32MB)。数据在被使用时,会从内存先移到 L3,并逐步移到 L1。
访问位于处理器芯片上的缓存的速度比范围主内存的速度要快许多,因此会显著提高性能。而作为一个“附产品”,缓存数据也会在进行预测执行或乱序执行时产生。因为缓存的速度与内存的速度有显著的不同,因此恶意的软件代码就有可能利用此特性对数据进行推断,这被称为“侧信道分析(side-channel analysis)”,它是 Meltdown 和 Spectre 常用的手段。在这些安全漏洞中,攻击者可以在 L1TF 中创建一组特定的软件序列(被称为 “gadgets”)来在具有这类安全漏洞的处理器数中产生可以用来进行数据分析的、由预测执行功能所产生的缓存数据。
L1TF 和 Meltdown 类似,它会利用处理器的预测执行的实现方式中(在这里,是搜索内存页表)的问题。对于处理器,它的设计原则是尽最大可能获得最好的性能,因此会在所需的有效性检查完成前,预测内存页表的项是有效的,并允许访问底层的内存位置。处理器会抢先在 L1 数据缓存中搜索内存页表的项,以找出任何与物理地址匹配的项,并把匹配的项用于依赖的预测操作中。在经过一个非常短的时间后,处理器会发现内存页表的项是无效的,并发出一个内部的 “terminal fault” 信号。然后,处理器就会逆转(丢弃)以前的预测执行结果,但是在缓存中却会留下可以被观察到的信息。
对于虚拟客户机的情况,出现这个问题的原因是因为 Intel 处理器中的一个名为 EPT(Extended Page Tables)的技术。这是一个与硬件性能相关的功能,它允许 hypervisor(例如 KVM)对虚拟客户机的内存页表进行部分管理。每个内存访问都涉及到两个地址转换 - 首先是虚拟客户机的转换,然后是主机内存页表的转换。这样,可以减少因为需要重复使用 hypervisor(以前,在 EPT 前需要使用 hypervisor)造成的系统消耗。因为这个安全漏洞,一个恶意的虚拟客户机可以创建一个 “not present” 内存页表的项,它会简化通常的两个阶段的地址转换过程。当 L1 数据缓存中存在数据的复本时,虚拟客户机可以读主机 hypervisor 的内存数据或其它虚拟客户机的数据。
最终用户需要防止两类攻击:系统上的恶意用户读物理系统上的数据;恶意的虚拟客户机 OS 或容器获取其它客户机或虚拟主机上的数据。 这个安全漏洞和 CVE-2017-5754(也称为 “Meltdown”)类似,不同之处是,它在执行虚拟地址和物理地址转换时,利用了预测执行操作中的 MMU(Memory Management Unit)和 L1 数据缓存间的交互。当前存在的,适用于解决微架构安全漏洞(“Meltdown,” 也称为 “变体 3”)的缓解方案并不能完全防止这个新的安全漏洞。
红帽强烈推荐,在进行相应的更新前,用户应该采取预防措施,包括手工启动特定的内核参数、考虑禁用 Intel Hyper-Threading 等功能。更详细的信息包括在本文档的缓解方案一节中。
背景资料
现代的操作系统使用了一个 ‘虚拟内存’ 的机制来在多个任务和进程间有效地利用主内存。物理系统有固定数量的主内存,它组成了物理地址空间。这个地址空间被分为小的可管理单元(例如,4KB)。操作系统为每个运行的程序(称为进程)创建虚拟地址空间。而每个虚拟地址都会通过处理器中的一个特殊的硬件(内存管理单元,简称 MMU)转会为底层的物理地址。当处理器调度执行一个程序时,这个程序的指令和数据会被映射为虚拟地址,程序使用虚拟地址来指定内存的位置。处理器的 MMU 使用名为 Paging 的技术来在虚拟地址和它们底层的物理内存地址间进行转换。

Paging 技术使用一个被称为内存页表的分层的页结构来进行虚拟地址到物理地址的转换。它们使用地址中的几位作为索引,把虚拟地址的不同部分映射到内存页表的不同部分。内存页表由固定大小的项组成,每个项包括了一个指向另外一个页结构项或映射的内存页的物理地址。除了物理地址,页结构项还包括了与物理地址相关的不同属性位,这其中就包括一个 P flag 位用来标识这个页是否在物理内存中存在,或已被交换出内存。如果一个内存页表的项被标识为没有在物理内存中,则应该被处理器的 MMU 忽略。
内存页结构项:
Intel 软件开发人员手册(第 3 卷,第 4 章)中定义了 Intel 处理器使用的硬件页结构,包括在把虚拟地址转换为物理地址时用来保存物理地址的 64 位内存页项(Page Table Entry,简称 PTE)。
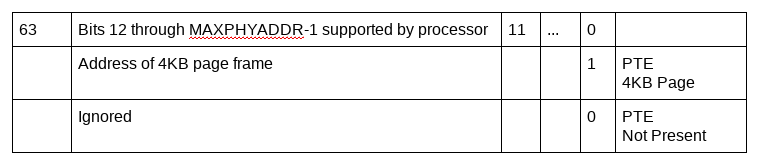
在地址转换过程中,处理器会检查内存页表结构,最终找到包括了可能是映射到一个特定虚拟地址的物理地址转换信息的内存页表项。当虚拟地址被确认映射到物理内存的某个映射的页时,或页结构项中的标识指出所需的页在主内存中不存在 (P flag(bit zero) = 0),或它的reserved bits 被设置,地址转换过程就会被终止。如果访问这类项中的地址时,就会出现一个 page-fault 异常(也被称为 “terminal fault”)。
致谢
红帽愿籍此机会感谢 Intel Inc. 和业界的合作伙伴报告此问题,并就此问题提供协助。
额外参考信息
如需了解更多与此类问题相关的问题,请参阅 Intel 的网站
技术详解视频 - 10 分钟
其它红帽参考资料
可以解决 CVE-2018-3620 和 CVE-2018-3646 的 CPU Microcode 是否已可用?
在 CPU 被禁用的情况下,修改 "cpu-partitioning" profile 会导致 "tuned-adm" 命令无法完成
受影响的产品
红帽产品安全团队把 CVE-2018-3620 和 CVE-2018-3646 的严重性级别定为 Important(重要)。
以下红帽产品版本会受到影响:
Red Hat Enterprise Linux 5
Red Hat Enterprise Linux 6
Red Hat Enterprise Linux 7
Red Hat Atomic Host
Red Hat Enterprise MRG 2
Red Hat OpenShift Online v3
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) for RHEL7
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7
Red Hat OpenStack Platform 8.0 (Liberty)
Red Hat OpenStack Platform 8.0 (Liberty) director
Red Hat OpenStack Platform 9.0 (Mitaka)
Red Hat OpenStack Platform 9.0 (Mitaka) director
Red Hat OpenStack Platform 10.0 (Newton)
Red Hat OpenStack Platform 11.0 (Ocata)
Red Hat OpenStack Platform 12.0 (Pike)
Red Hat OpenStack Platform 13.0 (Queens)
Red Hat Virtualization (RHEV-H/RHV-H)
虽然红帽的 Linux Container 不会直接受到内核问题的影响,但是它们的安全性取决于主机内核环境是否安全。红帽建议您使用最新版本的容器镜像。作为 Red Hat Container Catalog 一部分的 Container Health Index 可以被用来验证 Red Hat container 的安全状态。为了保证所使用容器的隐私,您需要确保容器主机(如 Red Hat Enterprise Linux 或 Atomic Host)已进行了针对此安全问题的更新。红帽已针对这个安全问题提供了一个更新的 Atomic Host。
攻击描述及影响
对传统主机的攻击:
如果一个处理器支持指令的预测执行功能,当从一个无法解析到一个物理地址的虚拟地址加载预测执行负载时,在进行地址转换的过程中会导致一个“page-fault”异常。在这个 page-fault 异常被处理前,预测执行的指令负载会使用 not present (P flag = 0) 或 reserved bits 被设置的内存页结构项来访问物理内存。如果物理内存位于 L1 数据缓存的缓存区中,预测执行指令负载就会从一个不恰当的物理地址位置读数据。因此,后续的预测执行操作就会使用这个数据,从而可能导致攻击者利用这个问题读取到应该没有权限读取的数据。
一个没有相关权限的系统用户或进程可以利用 L1TF 安全漏洞,从相关系统上的内核或其它进程所使用的的一些物理地址上读取数据(这些数据需要已被加载到 L1 数据缓存中)。因为把数据加载到 L1 数据缓存是处理器的一个固有特性,所以恶意攻击者只需要等待一个程序在正常运行时,加载相关的秘密数据。这些数据包括加密密钥以及其它数据。
对虚拟系统的攻击:
虚拟客户机环境会加剧利用这个安全漏洞进行攻击所造成的影响。在虚拟环境中,虚拟客户机通常运行的操作系统管理内存的方式会象它们在物理主机上运行的内存管理方式一样。不同的是,虚拟客户机处理的所谓物理内存实际是主机的一个虚拟内存空间,这个虚拟内存空间由 Virtual Machine Monitor(VMM,也被称为 hypervisor,例如 KVM)创建。hypervisor 使用一个内存虚拟化层来确保它可以控制实际的主机物理内存,从而达到为在其控制的虚拟客户机提供相互独立的虚拟地址空间的目的。这意味着,虚拟环境有两级内存地址转换。

为了有效地进行虚拟客户机物理地址到主机物理地址地转换,硬件处理器会包括一个 Extended Page Table (EPT) 功能。
EPT 和主机操作系统用来进行虚拟地址到物理内存地址转换的分级 Paging 结构相似。当进行虚拟客户机物理地址到主机物理地址转换时,和主机上的 page-fault 异常类似,EPT Violation 异常会导致 VM 退出,这意味着指定的虚拟客户机的物理地址无法转换到一个主机物理地址,或虚拟客户机没有权限访问指定的主机内存。
与主机的情况类似,利用缓存侧信道攻击的方式,一个虚拟客户机用户所产生的预测执行指令可以利用由 VM 退出所产生的 EPT 错误读来自于主机物理内存的数据。因为虚拟客户机的操作系统可以控制 EPT 内存页项中的虚拟客户机物理地址位, 所以一个虚拟客户机的用户就可能针对主机的特定物理地址(包括主机内存,在主机上运行的其它客户机/进程的内存),通过 L1 数据缓存读取其数据。
对 SMT 的攻击:
SMT(Simultaneous multithreading)通过同时在独立的逻辑处理器(如 CPU 创建的两个或多个逻辑处理器,每个逻辑处理器都有自己的一组数据寄存器、控制寄存器、数据段寄存器)上执行多个指令流来提高系统性能。这些逻辑处理器在执行独立的指令流时会共享相同的执行引擎、处理器缓存、TLB、系统总线接口等。
因为两个逻辑处理器会共享处理器的缓存,因此一个逻辑处理器产生的缓存操作对另外一个逻辑处理器是可见的。例如,在一个逻辑处理器上运行的一个应用程序或虚拟客户机可以利用 L1TF 漏洞,通过指令的预测执行来访问共享数据缓存中的其它进程的内存数据。
Intel 的 Hyper-threading 功能具有同时性,这意味着,切换在其上运行的虚拟机时,逻辑处理器清除(flush)缓存数据会有一个短暂的重叠窗口,在这个窗口期内,其数据可能会被其它系统重新加载。因此,在其它逻辑处理器上运行代码的恶意攻击者就有可能利用这个特点访问到其它系统中的敏感数据。当前,还没有一个标准的方法来保证这个问题不会发生。
因此,虚拟环境不应该调度两个不同的虚拟机来共享来自于同一个处理器内核的两个不同逻辑处理器。另外,当一整套 Linux 环境在主机上运行时,在出现如中断等事件时,可能会加载自己的秘密数据。因此,如果在一个逻辑处理器上运行不信任的虚拟客户机时,启用超线程(hyperthreading)功能是不安全的。
性能影响
在裸机环境中解决 L1TF 问题不会对性能造成太大影响,在安装相应的更新后不需要进行其它特别的操作。
在虚拟环境中缓解 L1TF 的方法是,在开始运行一个虚拟机代码时,hypervisor 需要检查其它虚拟机(或主机)的敏感数据是否已从 L1 数据缓存(L1D)中清除。根据负载的情况,也可能需要禁用 Intel Hyper-threading 功能,以防止在一个超线程上运行的恶意虚拟机对相应线程上的其它虚拟机进行安全攻击。
CPU 访问 L1 数据缓存的速度比访问主内存的速度要快许多,几乎所有从内存加载的数据都会经过 L1 数据缓存。当 L1 数据缓存中的数据被清除后,CPU 需要花费上百个周期来从较低级别的缓存中重新生成这些项。这意味着,对数据访问的成本变高。在 L1 数据缓存使用 1 个 CPU 周期的情况下,从低级别缓存中获取相同的数据需要使用 4 个 CPU 周期,而从主内存访问同样数据可能会需要 60-70 个或更多周期。因为包括在 L1 中的数据也可能包括在其它高级别缓存中,因此如果从 L2 缓存中重新加载数据对性能产生的影响就不会很大。这些额外的消耗同时也会增加外部中断以及其它事件的延迟。
与此类似,Hyper-Threading(SMT 的一个实现)会同时执行多个指令流来提高性能。禁用这些线程将会使系统可见的逻辑 CPU 数量降低一半,因此会影响到系统整体的性能。
请注意,这些方案所造成的具体性能影响会根据负载的不同而有所不同。如果了解更多与特定负载相关的信息,请参阅L1 Terminal Fault 对性能的影响
诊断漏洞
运行检测脚本来检查您的系统当前是否会受这个安全漏洞的影响。为了验证脚本的真实性,可以下载相关的 GPG 签名。这个脚本的当前版本是 1.2。
另外,以下提供了两个 Ansible playbook。第一个(CVE-2018-3620-fix_disable_ht.yml)可以用来,在不需要重启系统的情况,在系统上禁用 Hyper-Threading 功能。这个 playbook 会尽量判断系统是否是一个 hypervisor,以及是否有运行的 VM,但请注意,禁用 Hyper-Threading 可能会导致带有特定内核/线程关联的应用程序出现预料外的行为。如果系统的内核不包括所需功能,则操作会失败,并显示相关信息。如果出现这种情况,我们建议您升级到最新的内核,并使用第二个 playbook。第二个 playbook 会使用针对 L1TF 的内核功能。
为了使用 CVE-2018-3620-fix_disable_ht.yml playbook,只需要在调用 ansible-playbook 时使用 HOSTS 指定需要修改的主机:
ansible-playbook -e "HOSTS=webservers,db01,portal" CVE-2018-3620-fix_disable_ht.yml
第二个 playbook(CVE-2018-3620-apply_settings.yml)会使用最新内核中针对 L1TF 的功能来帮助缓解 L1TF 的影响。您可以进行 3 个设置:
- FLUSH=1 会在每个 VM 进入时,强制内核和 kvm-intel 内核模块清除 L1 数据缓存,而不是在内核发现需要清除时才进行清除。这会对性能造成一定影响,但可以保证信息不会在不同 VM 间共享,并可以防止信息泄漏(如 ASLR derandomization)。只有在您的 hypervisor 会运行不信任虚拟客户机的情况才需要进行这个设置。
- SMT=1 会禁用 Hyper-Threading 功能(包括实施系统以及在引导时)。和第一个 playbook 一样,它会试图判断是否有活跃的虚拟客户机以防止禁用已有关联设置的进程。
- FORCE=1 在和 SMT=1 一起使用时,会防止通过 /sys/devices/cpu/smt/control 接口在运行时重新启用 SMT 功能。如果没有设置 FORCE,具有相关权限的用户可以在运行时重新启用或禁用 SMT。
另外,playbook 还提供了一个 RESET=1 参数,它可以删除以上的缓解措施,从而使系统回到它的默认状态:启用 SMT,在 VM 进入时有条件地清除 L1 数据缓存。在设置 RESET=1 后,需要重启系统以使其生效。
为了使用 CVE-2018-3620-apply_settings.yml,根据需要设置相应的设置,并在 HOSTS 中指定需要进行改变的主机。例如:
关闭 SMT,但允许在运行时进行改变,并有条件地清除 L1 数据缓存(默认):
ansible-playbook -e "HOSTS=webservers SMT=1" CVE-2018-3620-apply_settings.yml
应用所有缓解方案并不允许在运行时进行改变:
ansible-playbook -e "HOSTS=vmserver01 FLUSH=1 SMT=1 FORCE=1" CVE-2018-3620-apply_settings.yml
把 L1TF 设置重置为它们的默认状态:
ansible-playbook -e "HOSTS=webservers RESET=1" CVE-2018-3620-apply_settings.yml
下载缓解 Playbook
采取行动
我们强烈建议,运行受影响红帽产品的用户在相关勘误可用后,尽快对相关产品进行更新。用户需要尽快应用相关的更新,并根据情况启用相关的缓解措施。
应用补丁的顺序并不重要,但在更新了 firmware 和 hypervisor 后,每个系统/虚拟机都需要关机,然后再重启以识别新的硬件类型。
更新受影响的产品
| 产品 | 软件包 | 公告/更新 |
| Red Hat Enterprise Linux 7 (z-stream) | kernel | RHSA-2018:2384 |
| Red Hat Enterprise Linux 7 | kernel-rt | RHSA-2018:2395 |
| Red Hat Enterprise Linux 7 | microcode_ctl | RHEA-2018:2397 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | kernel | RHSA-2018:2387 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | microcode_ctl | RHEA-2018:2398 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | kernel | RHSA-2018:2388 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | microcode_ctl | RHEA-2018:2399 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | kernel | RHSA-2018:2389 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2400 |
| Red Hat Enterprise Linux 6 (z-stream) | kernel | RHSA-2018:2390 |
| Red Hat Enterprise Linux 6 | microcode_ctl | RHEA-2018:2300 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | kernel | RHSA-2018:2391 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | microcode_ctl | RHEA-2018:2304 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | kernel | RHSA-2018:2392 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2302 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | kernel | RHSA-2018:2393 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | microcode_ctl | RHEA-2018:2303 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | kernel | RHSA-2018:2394 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | microcode_ctl | RHEA-2018:2297 |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | kernel | 待定 |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | microcode_ctl | 待定 |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | kernel | 待定 |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | microcode_ctl | 待定 |
| RHEL Atomic Host | kernel | respin 待定 |
| Red Hat Enterprise MRG 2 | kernel-rt | RHSA-2018:2396 |
| Red Hat Virtualization 4 | redhat-virtualization-host | RHSA-2018:2403 |
| Red Hat Virtualization 4 | rhvm-appliance | RHSA-2018:2402 |
| Red Hat Virtualization 3 Extended Lifecycle Support* | rhev-hypervisor7 | RHSA-2018:2404 |
| Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7 | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 8.0 (Liberty) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 9.0 (Mitaka) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 10.0 (Newton) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 11.0 (Ocata) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 12.0 (Pike) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 12.0 (Pike) | 容器 | respin 待定 |
| Red Hat OpenStack Platform 13.0 (Queens) | director 镜像 | respin 待定 |
| Red Hat OpenStack Platform 13.0 (Queens) | 容器 | respin 待定 |
*需要有效的 ELS 订阅才可以获得这个补丁。如果您的账户中没有有效的 ELS 订阅,请联系红帽销售人员。
**需要有效的 EUS 订阅才可以获得这个补丁。如果您的账户中没有有效的 EUS 订阅,请联系红帽销售人员。
什么是 Red Hat Enterprise Linux 7.1 延长的更新支持订阅?
***需要一个有效的 AUS 订阅才可以获得这个补丁。
什么是 AUS(Advanced mission critical Update Support)?
****需要一个有效的 TUS 订阅才可以获得这个补丁。
***** 订阅用户需要联系相关的硬件 OEM 厂商来获得最新版本的 CPU microcode/firmware。
缓解方案
当前的缓解方案包括应用厂商的软件更新,以及硬件 OEM 的 CPU microcode/firmware。所有红帽用户都需要应用厂商的解决方案来对 CPU、BIOS(如果需要)打补丁,并在内核补丁程序可用时尽快更新内核。除了禁用 Hyper-Threading(用户需要手工执行相关操作来禁用它)外,其它缓解方案都会默认被启用。我们建议用户采取基于风险的方式来处理这个安全问题。用户需要评估这个安全问题带来的安全风险、可以使用的缓解方案以及这些缓解方案对性能造成的影响,从而制定一个具体的问题缓解策略。需要高安全性和高度信任的系统需要被优先处理,在彻底解决这个问题的解决方案可用前,把这些系统和不被信任的系统相隔离,以减少这个安全漏洞带来的风险。需要完全避免这个安全漏洞的用户可能需要考虑更安全的方案,并可能需要禁用 Hyper-Threading 以避免所有可能的攻击渠道。
缓解方案/补救措施:
完全缓解 L1 Terminal Fault 所带来的问题需要进行 3 个改变:Page Table Inversion(内核的一个小改变,它在更新的内核中提供并被默认启用)、在虚拟机间进行切换时清除 L1 数据缓存、以及可能需要禁用 SMT。其中的每个改变都会针对利用这个安全漏洞进行攻击的不同方面进行防御。
在红帽所提供的内核更新中,当处理“not present”内存页项时,Page Table Inversion(与 Meltdown 缓解方案中的 Page Table Isolation 不同)会默认执行。
清除 L1 数据缓存是可选的,它可以通过更新的 microcode 或更新的内核实现。当前,在运行虚拟客户机时,它会被默认启用,但用户可以通过内核参数来控制它。
禁用 SMT 是一个可选的方案,它可以在需要运行虚拟机的不信任的共享环境中使用来加强系统的安全性。这个功能通过软件更新为内核增加了一个新的控制接口。另外,也可以在 BIOS firmware 中禁用 Intel Hyper-threading,但这样做容易出现问题,因此不推荐使用这个方法。
补救方案需要同时考虑这三个方法,因为这个安全漏洞包括三个问题:
- Not Present (P flag = 0) PTE 或 reserved bits 已被设置 的情况下会带有一个未初始化的物理地址。这个物理地址会被缓存到 L1 数据缓存中。
- 由预测执行操作所带来的 L1 数据缓存更新不会被清除。它们可能会被后续的进程观察到。
- SMT(Simultaneous multi-threads)会共享执行引擎,以及芯片上的处理器缓存,如 L1 数据和 TLB 缓存。
Page Table Inversion:
处理器会根据预测,预先访问来自于 Not Present PTE 的物理地址,如果这个物理地址的内容已被缓存到 L1 数据缓存中,对内存的访问将会成功。因此,如果物理地址中的内容没有被缓存,则对内存访问不会造成数据泄漏的问题。Page Table Inversion 缓解方案会更新 Not Present PTE 中的物理地址(设置高位地址位,使它指向一个不在内存中的物理地址,或不能被缓存的地址),这样,它的内容就不会出现在 L1 数据缓存中。
更新的内核软件包通过 sysfs 接口显示系统当前的状态。如下:
# cat /sys/devices/system/cpu/vulnerabilities/l1tf
Mitigation: PTE Inversion; VMX: SMT vulnerable, L1D conditional cache flushes
#
清除 L1 数据缓存:
当在系统上更新 microcode 后,Intel x86 处理器会提供一个 IA32_FLUSH_CMD MSR(Machine Specific Register)。它可以把 L1 数据缓存数据设置为无效。按照以下方式使用 lscpu(1) 命令列出 CPU flag 可以查看对 IA32_FLUSH_CMD MSR 支持的情况:
# lscpu
Flags: … ssbd ibrs ibpb stibp spec_ctrl intel_stibp flush_l1d
#
如果没有 flush_l1d flag,请确认已在系统上安装了更新的 microcode,而且系统已被重启。
如果没有安装更新的 microcode,则 flush_l1d flag 不可用。更新的内核将仍会在软件中删除(flush)L1 数据缓存,这会比硬件 flush_l1d 接口慢。
更新的内核软件包包括了以下内核和 KVM 模块参数来控制 L1TF 的缓解方案:
l1tf=[full/full,force/flush/flush,nosmt/flush,nowarn/off]
这是在受影响 CPU 上控制 L1TF 问题缓解方案的内核引导参数。它可以是以下值之一:
full: 启用针对 L1TF 问题的所有缓解方案。
- 在每个 VM 进入操作时清除 L1 数据缓存的数据。
- 禁用 Hyper-Threading (SMT)。
在系统引导后,L1 数据缓存清除功能和 SMT 功能都可以通过 sysfs 接口在运行时进行控制。
full,force: 启用针对 L1TF 问题的所有缓解方案。
- 在每个 VM 进入操作时清除 L1 数据缓存的数据。
- 禁用 Hyper-Threading (SMT)。
这里的“force”参数禁止用户通过 sysfs 接口禁用以上针对 L1TF 的缓解方案。用户不能在运行时启用 SMT。
flush: 只启用 L1 数据缓存清除缓解方案
- 启用默认的 L1 数据缓存缓解方案:有条件地清除 L1 数据缓存。
- 不禁用 Hyper-Threading (SMT)。
以上两个设置仍然可以通过 sysfs 接口进行控制。如果一个虚拟客户机以不安全的配置进行启动(如启用 SMT,或禁用 L1 数据缓存删除功能),hypervisor (KVM) 会发出一个警告信息。
flush,nosmt: 禁用 Hyper-Threading (SMT)
- 启用有条件的 L1 数据缓存清除缓解方案。
- 禁用 Hyper-Threading (SMT)
以上两个设置仍然可以通过 sysfs 接口进行控制。如果一个虚拟客户机以不安全的配置进行启动(如启用 SMT,或禁用 L1 数据缓存删除功能),hypervisor (KVM) 会发出一个警告信息。
flush,nowarn: 与上面的 flush 选项类似,只是在虚拟机以不安全的配置运行时,KVM 模块不发出警告信息。
off: 禁用 hypervisor 缓解方案,如 KVM 不在 VM 进入时清除 L1 数据缓存。
默认的 l1tf 引导参数值被设置为上面的 flush 缓解方案选项。
kvm-intel.vmentry_l1d_flush: KVM 模块参数,用来控制在 VM 进入时 L1 数据缓存清除的操作。它可能被设置为以下值:
always 每个 VMENTER 都需要进行 L1D 缓存清除。
cond 有条件的 L1D 缓存清除。
never 禁用 L1D 缓存清除的缓解方案。
cond 的目的是,如果在 VMEXIT 和 VMENTER 间执行的代码被认为是安全的(例如,不会把敏感数据带到 L1D),
避免进行 L1D 缓存清除。
# cat /sys/module/kvm_intel/parameters/vmentry_l1d_flush
cond
#
这个参数被默认设置为 cond,它会有选择地在 VM 进入时执行 L1 数据缓存清除操作。这可以减小 L1 数据缓存清除操作带来的对性能的影响。
控制 SMT:
在使用 SMT 或 Hyper-Threading 时,运行在相同内核并共享处理器缓存资源的不相关的线程,可以利用 L1TF 从 L1 数据缓存中读取其它线程的数据。如果您正在运行一个不信任的共享环境,则需要考虑禁用 SMT 作为缓解方案的一部分。一般情况下,SMT 可以通过系统的 BIOS 进行启用或禁用。
更新的内核软件包包括了一个新的命令行参数 nosmt。
nosmt: 禁用 SMT(simultaneous multithreading)。它可以在运行时通过 sysfs 接口重新被启用。
nosmt=force: 禁用 SMT(simultaneous multithreading)。它不能在运行时被重新启用。
请注意:内核的 sysfs 接口可以在运行时管理多线程,但是使用它重新启用 SMT 可能会出现错误。因此,我们强烈建议使用 BIOS 设置,或上面列出的内核引导参数来启用/禁用 SMT。这里关于运行时 flag 的信息只作为参考:
/sys/devices/system/cpu/smt/active
/sys/devices/system/cpu/smt/control
上面的 active 文件是一个只读的接口。当 active 文件包括 ‘1’ 时,意味着 SMT 已启用,兄弟(sibling)线程在线。当内核在引导时使用 ‘nosmt’ 参数,它会向以上的 active 文件写 ‘0’。
上面的 control 文件是一个用来控制 SMT 的可读写接口。它可以有以下值:
on : SMT 被启用。如果兄弟(sibling)线程离线,则启用它们。
off : SMT 被禁用。如果兄弟线程在线,则禁用它们。
forceoff : SMT 被强制禁用,并且不能被改变。它不能在
运行时被控制或改变。
notsupported: 处理器不支持 Hyper-Threading (SMT)。
禁用 EPT:
为 KVM 虚拟客户机禁用 EPT(Extended Page Tables)可以缓解 L1TF 问题,因为它让 VMM/Hypervisor 为虚拟客户机管理地址转换。如果 EPT 被禁用,则不需要禁用前面列出的 Hyper-Threads (SMT) 和清除 L1 数据缓存。
请注意:禁用 EPT 会对系统性能有很大影响。这可能不是一个可行的选择。
通过 kvm-intel.ept 参数可以在 hypervisor 上禁用 EPT。它会被默认启用。
红帽建议用户尽快应用硬件厂商或 CPU 厂商提供的 microcode/firmware 更新,并安装执行更新的内核。软件更新可以独立于硬件 microcode 进行,但只有在 CPU firmware 被升级后才会起作用。
Tuned
新的 L1TF 内核为用户提供了在运行时或在内核引导时禁用 Hyper-Threading 的功能。如果使用了其中的一种方式,系统会运行以下 4 个 tuned profile 之一:
cpu-partitioning
realtime
realtime-virtual-host
realtime-virtual-guest
然后,将需要一个更新的 tuned。这只会影响到 RHEL 7.4z 和 7.5z。如果 Hyper-Threading 在 BIOS 中被禁用,则不需要更新的 tuned。
Comments