
L1 Terminal Fault를 사용한 커널 사이드 채널 공격 - CVE-2018-3620 & CVE-2018-3646
갱신됨
이 정보가 도움이 되었나요?
피드백이 취소되었습니다
Red Hat은 Intel에서 제조한 x86 마이크로 프로세서에 영향을 미치는 Spectre 및 Meltdown 취약점과 유사한 새로운 컴퓨터 마이크로 프로세서 하드웨어 구현 (마이크로 아키텍쳐) 관련 문제를 인지하고 있습니다. 이러한 보안 취약점으로 인해 관련 권한이 없는 공격자는 이 결함을 사용하여 기존의 메모리 보안 제한 메커니즘을 무시하고 권한이 없는 사용자가 액세스할 수 없는 메모리 리소스에 액세스할 수 있습니다. 본 보안 취약점은 세 가지 부분으로 구성되어 있습니다. 첫 번째 부분은 Intel “SGX” 보안 영역에만 영향을 미치며 운영 체제와 독립적으로 마이크로 코드 업데이트를 통해 문제를 해결할 수 있습니다. 다른 두 가지 부분은 운영 체제 및 하이퍼바이저에서 소프트웨어 업데이트를 통해 문제를 해결해야 합니다. 가상화를 사용하는 환경에서 신뢰할 수 없는 게스트 가상 머신의 공격을 피하려면 시스템 관리자가 특정 완화 조치를 수행해야 합니다.
이러한 운영 체제 취약점은 CVE-2018-3620 로 지정되어 있으며 가상화 관련 취약점은 CVE-2018-3646로 지정되어 있습니다. 본 문제는 업계에서 L1TF (L1 Terminal Fault)라고 하며 보안 관계자 사이에서는 “Foreshadow” 라고 합니다.
L1 Terminal Fault 취약점을 이용하여 악의적인 공격자는 운영 체제나 하이퍼바이저에 의해 일반적으로 설정 및 관리되는 메모리 액세스의 보안 메커니즘을 무시할 수 있습니다. 이러한 취약점을 통해 공격자는 프로세서의 L1 데이터 캐시에 캐시되는 물리적 메모리 위치를 읽을 수 있습니다. 일반적으로 운영 체제 및 하이퍼 바이저에 의해 관리되는 "페이지 테이블"은 응용 프로그램, 운영 체제 커널 및 게스트 가상 머신 인스턴스에서 액세스 할 수 있는 메모리 위치 정보를 프로세서에 제공합니다. 이러한 페이지 테이블은 테이블 항목의 유효성을 나타내는 "현재"의 비트가 포함된 PTE (페이지 테이블 항목)으로 구성됩니다. L1TF 취약점을 통해 공격자는 유효한 PTE를 식별하는 Intel 프로세서 논리 코드를 악용할 수 있습니다.
L1 데이터 캐시 (일반적 크기 32KB)는 온칩 고속 프로세서 메모리 데이터 계층의 첫 번째 레벨로 외부 (프로세서에 대한)의 메인 메모리 칩에 보관된 데이터 사본이 포함되어 있습니다. 프로그램에 의해 메모리가 사용되면 캐시된 데이터가 생성되며 일반적으로 여러 레벨로 나뉩니다. L1 캐시는 프로그램 내에서 실제 계산을 처리하는데 사용되는 프로세서의 기능 단위에 가장 가까운 작고 빠른 최상위 레벨 캐시인 반면 대형 저속 캐시는 계산 기능 단위에서 멀리 떨어져 있습니다. L1은 Intel 프로세서 코어에서 두 개의 피어 하이퍼 스레드 사이에서 공유됩니다. 각 코어에는 약간 더 큰 L2 캐시도 있습니다. L3 (LLC 또는 최종 레벨 캐시라고도 함)는 프로세서 내의 모든 코어에서 공유되며 크기는 더 커집니다 (예: 32MB). 데이터가 사용되면 이는 메모리에서 L3으로 이동한 후 L1으로 이동합니다.
프로세서 칩에서 캐시 메모리에 액세스하는 것은 메인 메모리로의 액세스보다 빠른 속도로 수행되므로 성능을 크게 향상시킬 수 있습니다. 또한 추측 실행 또는 비순차적 명령어 (Out-of-Order) 처리 중에 수행되는 작업의 부작용으로 캐시된 데이터가 생성됩니다. 그 결과 메모리와 비교하여 캐시 성능은 상대적으로 다르기 때문에 악성 소프트웨어 코드를 사용하여 캐시 동작을 유추할 수 있습니다. 이는 사이드 채널 분석이라고 하며, Meltdown 및 Spectre 취약점으로 게재되어 있습니다. 이러한 보안 취약점에서 공격자는 L1TF에 "가젯"이라고 하는 특정 소프트웨어 시퀀스를 생성하고 취약한 프로세서를 악용하여 추측 실행 중에 캐시 동작을 관찰할 수 있습니다.
L1TF는 Meltdown과 유사하며 취약한 프로세서가 추측 실행을 구현하는 방식 (이 경우 메모리 페이지 테이블 검색, 테이블 워크라고도함)을 이용합니다. 프로세서는 최상의 성능을 제공하도록 설계되어 있으므로 페이지 테이블 항목이 유효하고 필요한 유효성 검사를 완료하기 전에 기본 메모리 위치에 액세스할 수 있습니다. 프로세서는 페이지 테이블 항목에 대해 L1 데이터 캐시를 사전 검색하여 물리적 주소와 일치하는 항목을 찾고 종속적 추측 작업에 대해 일치하는 항목을 전송합니다. 잠시 후 프로세서는 페이지 테이블 항목이 유효하지 않음을 감지하고 내부의 "terminal fault"를 알립니다. 그 후 프로세서는 이전에 추측한 실행 결과를 취소 (삭제)하지만 캐시에서 확인할 수 있는 정보는 그대로 유지됩니다.
가상화 게스트 인스턴스의 경우 L1TF 취약점은 "확장 페이지 테이블 (Extended Page Tables, EPT)"이라는 Intel 프로세서 내의 기술 구현으로 인해 발생합니다. 이러한 하드웨어 성능 기능을 통해 하이퍼 바이저 (예: KVM)가 페이지 테이블 관리의 일부를 게스트 가상 머신에 위임할 수 있습니다. 각 메모리 액세스에는 게스트에 의한 변환 및 호스트 페이지 테이블에 의한 변환이라는 두 가지 주소 변환이 적용됩니다. 이렇게 하면 EPT 이전에 필요했던 하이퍼 바이저의 반복된 지원으로 인해 발생하는 오버 헤드를 줄일 수 있습니다. 보안 취약점으로 인해 악의적인 게스트가 "존재하지 않는" 페이지 테이블 항목을 생성하여 일반적인 두 단계의 주소 변환 과정을 단축할 수 있으므로 L1 데이터 캐시에 복사본이 있을 경우 게스트는 호스트 하이퍼 바이저 또는 다른 게스트의 물리적 메모리를 읽을 수 있습니다.
최종 사용자는 다음의 두 가지 유형의 공격 유형을 방지해야 합니다. 첫 번째 공격 유형은 시스템 상의 공격자가 물리적 시스템에서 데이터를 읽는 것이고 두 번째 공격 유형은 악성 게스트 OS 또는 컨테이너가 다른 게스트 또는 호스트의 정보에 액세스하는 것입니다. 본 취약점은 CVE-2017-5754 ("Meltdown")과 유사하지만 가상 메모리 주소에서 물리적 메모리 주소로 변환할 때 추측 실행하여 MMU (Memory Management Unit)와 L1 데이터 캐시 간의 상호 작용을 악용합니다. 따라서 이전의 마이크로 아키텍처 취약점 ( "Meltdown", "변형 3")에 대한 기존 완화 조치만으로는 이러한 새로운 취약점으로 부터 시스템을 완전히 보호할 수 없습니다.
Red Hat은 고객이 사용 가능한 업데이트를 적용한 후 특정 커널 매개 변수를 수동으로 활성화하거나 Intel 하이퍼 스레딩과 같은 기능을 비활성화하는 등의 조치를 취할 것을 적극 권장합니다. 자세한 내용은 이 문서의 완화 방법 부분에서 확인하십시오.
배경 정보
최신 운영 체제는 '가상 메모리' 체계를 구현하여 여러 작업/프로세스에서 사용 가능한 메인 메모리를 효율적으로 사용합니다. 물리적 시스템은 물리적 주소 공간을 형성하는 고정된 용량의 메인 메모리가 있습니다 . 이 주소 공간은 페이지라고 하는 작은 관리 단위 (예 : 4KB)로 나뉩니다. 운영 체제는 실행중인 각 프로그램 (프로세스라고 함)마다 가상 주소 공간을 만듭니다. 각 가상 주소는 메모리 관리 장치 (Memory Management Unit, MMU)라고 하는 프로세서 내의 하드웨어의 특정 부분을 사용하여 기본 물리적 주소로 변환됩니다. 프로세서에 의해 프로그램 실행이 예약되면 해당 명령과 데이터가 가상 주소로 매핑됩니다. 프로그램은 가상 주소를 사용하여 메모리 위치를 참조합니다. 프로세서의 MMU는 페이징이라는 개념을 사용하여 가상 주소와 기본 매핑된 물리적 메모리 주소 간의 변환을 수행합니다.

페이징 기술은 페이지 테이블로 알려진 계층적 페이징 구조를 사용하여 각 가상 주소를 물리적 주소로 변환합니다. 이는 페이지 테이블의 구성 요소 인덱스로 주소의 비트를 사용하여 가상 주소 부분을 변환합니다. 페이지 테이블은 다른 페이징 구조 항목 또는 매핑된 메모리 페이지를 가리키는 물리적 주소가 있는 고정 크기 레코드/항목으로 구축됩니다. 물리적 주소와 함께 페이징 구조 항목도 물리적 주소에 대한 다양한 속성 비트를 유지합니다. 여기에는 물리적 메모리에 페이지가 교체되지 않고 존재하는지 (P flag) 여부를 나타내는 비트가 포함됩니다 . 존재하지 않는 것으로 표시된 페이지 테이블 항목은 프로세서의 MMU에 의해 무시되어야 합니다.
페이지 구조 항목:
Intel 소프트웨어 개발자 설명서 (제 3 권 4 장)에는 가상 주소에서 물리적 주소로 변환하는 동안 물리적 주소를 저장하는 데 사용되는 64 비트 페이지 테이블 항목 (PTE)을 포함하여 Intel 프로세서에서 사용하는 하드웨어 페이지 구조가 정의되어 있습니다.
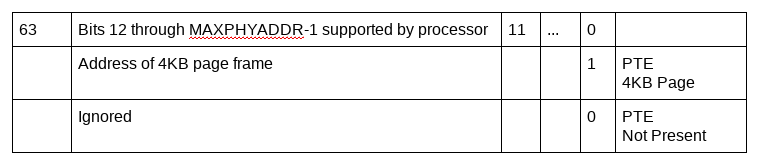
주소 변환 중에 프로세서는 페이지 테이블 구조를 검사하고 결국 특정 가상 주소에 대한 물리적 변환 정보를 포함하는 메모리 페이지 테이블 엔트리에 도달하게 됩니다. 가상 주소가 물리적 메모리에 매핑된 페이지 프레임으로 해석되거나 페이징 구조 항목에 따라 메인 메모리에 필요한 페이지 프레임이 존재하지 않음 (P flag(bit zero) = 0)을 나타내는 경우 또는 예약된 비트 세트 가 있는 경우 이러한 주소 변환 프로세스가 종료됩니다. 이러한 항목에서 물리적 주소에 액세스하면 페이지 오류 예외 (일명 “terminal fault”)가 발생합니다.
감사의 말
Red Hat은 본 문제에 대해 보고하고 완화 조치에 대해 협력해 주신 Intel Inc. 및 업계 파트너에게 감사의 말씀을 전합니다.
기타 참고 자료
본 문제에 대한 자세한 내용은 Intel 웹사이트에서 참조하십시오.
Everything you need to know about L1TF in 3 minutes
기술적 내용 설명 동영상 - 10 분
Understanding L1 Terminal Fault 블로그
Managing Risk in the Modern World 블로그
기타 Red Hat 제품 관련 자료
Is CPU Microcode available to address CVE-2018-3620 and CVE-2018-3646?
The "tuned-adm" command hangs when changing to the "cpu-partitioning" profile with CPUs disabled
영향을 받는 제품
Red Hat 제품 보안팀은 본 취약점 CVE-2018-3620 & CVE-2018-3646 의 보안 영향 수준을 중요로 분류하고 있습니다.
영향을 받는 Red Hat 제품 버전은 다음과 같습니다:
Red Hat Enterprise Linux 5
Red Hat Enterprise Linux 6
Red Hat Enterprise Linux 7
Red Hat Atomic Host
Red Hat Enterprise MRG 2
Red Hat OpenShift Online v3
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) for RHEL7
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7
Red Hat OpenStack Platform 8.0 (Liberty)
Red Hat OpenStack Platform 8.0 (Liberty) director
Red Hat OpenStack Platform 9.0 (Mitaka)
Red Hat OpenStack Platform 9.0 (Mitaka) director
Red Hat OpenStack Platform 10.0 (Newton)
Red Hat OpenStack Platform 11.0 (Ocata)
Red Hat OpenStack Platform 12.0 (Pike)
Red Hat OpenStack Platform 13.0 (Queens)
Red Hat Virtualization (RHEV-H/RHV-H)
Red Hat의 Linux Container는 커널 문제의 직접적인 영향을 받지 않지만 보안은 호스트 커널 환경의 무결성에 달려 있으므로 Red Hat은 최신 컨테이너 이미지를 사용할 것을 권장합니다. Red Hat Container Catalog에서 제공하는 Container Health Index를 사용하여 Red Hat 컨테이너의 보안 상태를 확인할 수 있습니다. 사용중인 컨테이너의 개인 정보를 보호하려면 컨테이너 호스트 (Red Hat Enterprise Linux 또는 Atomic Host등)가 이러한 보안 취약점에 대해 업데이트되었는지 확인해야 합니다. Red Hat은 이 보안 문제에 대한 업데이트된 Atomic Host 버전을 출시하고 있습니다.
공격 내용 및 영향
기존 호스트에 대한 공격:
프로세서가 명령의 추측 실행을 지원하는 경우 물리적 주소로 해결할 수 없는 가상 주소에서의 추측 실행된 로드에 의해 주소 변환 과정에서 페이지 오류 예외가 발생합니다. 이 페이지 오류 예외가 처리되기 전에 로드 명령의 추측 실행은 존재하지 않는 (P flag = 0) 또는 예약된 비트 세트의 페이징 구조 항목의 물리적 주소를 사용하여 실제 메모리에 액세스합니다. 물리적 메모리가 L1 데이터 캐시에 저장된 경우, 추측 실행된 로드는 부적합한 물리적 메모리 위치에서 데이터를 읽습니다. 결과적으로 이후의 추측 실행 시 이 데이터가 사용되므로 공격자가 권한이 없는 데이터를 읽을 때 사용할 수 있는 캐시에 중요한 영향을 미칠 수 있습니다.
권한이 없는 시스템 사용자 또는 프로세스는 L1TF 취약점을 악용하여 데이터가 L1 데이터 캐시에 먼저 로드된 경우 시스템에서 실행중인 커널 및 다른 프로세스의 임의의 물리적 메모리 위치에서 데이터를 읽을 수 있습니다. L1 데이터 캐시에 로드되는 것은 프로세서의 고유 기능이기 때문에 공격자는 정상 작업을 수행하는 동안 중요한 정보가 포함된 프로그램이 비밀 정보를 로드하는 것을 기다려야 합니다. 이러한 정보에는 암호화 키 및 기타 데이터가 포함됩니다.
가상 시스템에 대한 공격:
가상 게스트 환경에서 이러한 취약점을 악용한 경우 영향이 가중됩니다. 가상 환경에서 게스트는 베어 메탈 호스트 시스템에서 실행되는 것과 같은 방식으로 메모리를 관리합니다. 게스트 운영 체제는 가상 머신 모니터 (VMM, 예: KVM) (하이퍼 바이저라고도 함)에 의해 생성된 호스트의 가상 주소 공간을 물리적 메모리로 인식하고 있습니다. 하이퍼바이저는 실제 호스트의 물리적 메모리를 제어하는 메모리 가상화 계층을 도입하여 호스트의 물리적 메모리에 대한 액세스를 관리하면서 수많은 게스트로 분리된 가상 주소 공간을 제공합니다. 즉 이는 가상 환경에 두 가지 수준의 메모리 변환이 있다는 것을 의미합니다.

게스트 물리 주소에서 호스트 물리 주소로 효율적으로 변환하기 위해 하드웨어 프로세서에 Extended Page Table (EPT) 기능을 도입하고 있습니다.
EPT는 가상 주소를 물리적 메모리 주소로 변환하기 위해 호스트 운영 체제에서 사용하는 계층적 페이징 구조와 유사합니다. 호스트의 페이지 오류 예외와 마찬가지로 게스트의 물리적 주소를 호스트 물리 주소로 변환하는 동안 EPT 위반 예외로 인해 가상 머신이 종료되어 지정된 게스트 물리 주소를 호스트 물리 주소로 변환할 수 없거나 지정된 호스트 메모리에 액세스할 수 있는 권한이 게스트에게 없음을 나타냅니다.
호스트와 마찬가지로 게스트 사용자에 의한 명령의 추측 실행은 EPT 위반으로 인한 가상 머신 종료를 이용하여 캐시 사이드 채널 공격을 통해 호스트의 물리적 메모리에서 데이터를 읽을 수 있습니다. 게스트 운영 체제가 EPT 페이징 항목에서 게스트 물리 주소 비트를 제어할 수 있기 때문에 게스트 사용자는 모든 호스트 커널 메모리나 호스트에서 실행 중인 다른 게스트/프로세스의 메모리를 포함하여 L1 데이터 캐시를 통해 특정 호스트 물리적 주소를 지정하고 데이터를 가져올 수 있습니다.
SMT에 대한 공격:
최신 프로세서는 SMT (simultaneous multithreading)를 사용하여 별도의 논리 프로세서에서 여러 명령 스트림을 동시에 실행함으로써 시스템 성능을 향상시킵니다. 즉 CPU는 아키텍처 상태를 형성하는 데이터 레지스터, 컨트롤 레지스터, 세그먼트 레지스터 등의 두 개 이상의 논리 프로세서를 만듭니다. 이러한 논리 프로세서는 동일한 실행 엔진, 프로세서 캐시, TLB, 시스템 버스 인터페이스 등을 공유하면서 별도의 명령 스트림을 실행합니다.
두 개의 논리 프로세서가 프로세서 캐시를 공유한다는 것은 하나의 논리 프로세서가 수행하는 모든 캐시 작업을 다른 프로세서에서 확인할 수 있다는 것입니다. 하나의 논리 프로세서에서 실행되는 응용 프로그램/게스트는 L1TF 및 명령의 추측 실행을 사용하여 다른 프로세스와 공유 데이터 캐시의 커널에 있는 모든 메모리 내용을 읽을 수 있습니다.
Intel 하이퍼 스레딩의 동시적 기능은 피어 논리 프로세서에서 실행되는 가상 머신 인스턴스를 전환할 때 해당 논리 프로세서에서 캐시를 플러시하는 동안 피어가 암호를 다시 로드하고 악의적인 공격자가 볼 수 있도록 다른 논리 프로세서에서 코드를 실행할 수 있습니다. 현재로서는 이런 일이 발생하지 않도록 하기 위한 표준 방법이 없습니다.
결과적으로 가상 환경에서는 두 개의 서로 다른 가상 머신이 하나의 코어에서 두 개의 논리 프로세서를 공유하도록 예약해서는 안됩니다. 또한 전체 Linux 스택이 호스트에서 실행중인 경우 인터럽트와 같은 이벤트에 대한 응답으로 자체 암호를 로드할 수 있지만 논리적 프로세서에서 신뢰할 수없는 게스트를 실행하는 경우 하이퍼 스레딩을 사용하는 것은 안전하지 않습니다.
성능에 미치는 영향
가상 환경을 사용하지 않는 베어 메탈 환경에서 L1TF를 완화하면 성능에 미미한 영향을 미치지만 적절한 업데이트를 설치하는것 외에는 다른 특별한 조치가 필요하지 않습니다.
가상 환경에서 L1TF를 완화하려면 가상 머신 코드 실행을 시작할 때마다 하이퍼바이저가 다른 가상 머신 (또는 호스트)에서 L1 데이터 캐시 (L1D) 중 민감한 데이터가 삭제되어 있는지 여부를 확인해야 합니다. 워크로드에 따라 하이퍼 스레딩에서 실행되는 악성 가상 머신이 피어 스레드에서 다른 가상 머신을 공격하지 못하도록 Intel 하이퍼 스레딩을 비활성화해야 할 수도 있습니다.
L1 데이터 캐시는 메인 메모리보다 훨씬 빠르게 데이터를 CPU에서 사용할 수 있도록 하며 메모리에서 로드된 모든 데이터는 이를 통과해야 합니다. L1 데이터 캐시가 삭제되면 CPU는 하위 레벨의 캐시에서 해당 항목을 다시 채우기 위해 수백 사이클이 걸립니다. 즉, 데이터 액세스에 소요되는 비용이 높아집니다. 상대적 효율성면에서 L1 데이터 캐시는 1x CPU 사이클을 사용하는 반면, 하위 레벨 캐시에서 동일한 데이터 액세스에는 4x CPU 사이클을 사용할 수 있습니다. 메인 메모리에서의 데이터 액세스에는 60-70x 또는 그 이상의 사이클이 필요할 수 있습니다. L1에 포함된 데이터는 상위 레벨 캐시에도 포함되기 때문에 일반적으로 L2 캐시에서 데이터를 다시 로드할 때 성능에 미치는 영향은 적습니다. 이러한 오버 헤드는 외부 인터럽트 및 기타 이벤트 지연을 가중시킵니다.
마찬가지로 하이퍼 스레딩 (SMT 구현)은 둘 이상의 명령 스트림을 동시에 실행하여 시스템 성능을 향상시킵니다. 이러한 스레드를 비활성화하면 시스템에서 볼 수있는 논리 CPU 수가 절반으로 줄어들기 때문에 전반적인 시스템의 처리량과 성능이 크게 저하됩니다.
이 방법의 실제 성능에 미치는 영향은 워크로드에 따라 달라질 수 있습니다. 워크로드 별 성능에 미치는 영향에 대한 자세한 내용은 L1 Terminal Fault의 성능 고려 사항를 참조하십시오.
취약점 진단
진단 스크립트를 사용하여 시스템에 현재 보안 결함이 있는지 확인합니다. 정규 스크립트임을 확인하려면 GPG 서명도 다운로드하십시오. 현재 스크립트 버전은 1.2입니다.
또한 다음에는 두 가지 Ansible Playbook이 제공됩니다. 첫 번째 CVE-2018-3620-fix_disable_ht.yml은 시스템을 다시 시작하지 않고 하이퍼 스레딩을 비활성화하기 위해 L1TF에 대응하도록 업데이트되지 않은 시스템에 적용할 수 있습니다. Playbook은 시스템이 하이퍼 바이저로 작동하는지와 실행중인 가상 머신이 있는지 확인하지만 하이퍼 스레딩을 비활성화하면 특정 코어/스레드 연결이 있는 응용 프로그램에서 예기치 않은 동작이 발생할 수 있습니다. 시스템의 커널에 필요한 기능이 포함되어 있지 않으면 해당 기능에 대해 실행 실패했다는 메시지가 표시됩니다. 이 경우 최신 커널로 업데이트하고 L1TF에 해당하는 커널 기능을 사용하는 두 번째 playbook을 사용하는 것이 좋습니다.
CVE-2018-3620-fix_disable_ht.yml Playbook을 사용하려면 HOSTS 추가 변수에서 지정한 변경하고자 하는 호스트에서 ansible-playbook을 호출합니다:
ansible-playbook -e "HOSTS=webservers,db01,portal" CVE-2018-3620-fix_disable_ht.yml
두 번째 Playbook인 CVE-2018-3620-apply_settings.yml은 L1TF의 영향을 완화하기 위해 최신 커널을 사용합니다. 다음의 세 가지 설정을 지정할 수 있습니다.
- FLUSH=1은 커널이 플러시가 필요하다는 것을 감지했을 때 뿐만 아니라 커널과 kvm-intel 커널 모듈의 동작을 변경하여 모든 가상 머신에서 L1 데이터 캐시를 플러시합니다. 이는 성능 구현에 영향을 미칠 수 있지만 가상 머신간의 정보가 공유되지 않도록 하고 ASLR의 비랜덤화와 같이 정보 유출이 발생하지 않도록 합니다. 이 설정은 신뢰할 수 없는 게스트 시스템에서 하이퍼 바이저를 실행하는 경우에만 필요합니다.
- SMT=1은 라이브 시스템 또는 부팅시 하이퍼 스레딩 기능을 비활성화합니다. 첫 번째 Playbook과 마찬가지로 프로세스가 기존 연결 설정을 비활성화하지 못하도록 하기 위해 활성 게스트가 있는지 확인하려고 시도합니다.
- FORCE=1은 SMT=1과 함께 사용하면 런타임시 /sys/devices/cpu/smt/control 인터페이스를 통해 SMT가 다시 활성화되지 않도록 합니다. FORCE 지정되어 있지 않은 경우 권한이 있는 사용자는 런타임에 SMT를 다시 활성화 또는 비활성화할 수 있습니다.
또한 Playbook은 RESET=1 인수를 제공하여 위의 완화 조치를 제거하고 시스템의 기본 동작으로 가상 머신에서 활성화된 SMT 및 조건부 L1 데이터 캐시 플러시를 사용합니다. RESET=1을 사용하면 시스템을 재부팅해야 합니다.
CVE-2018-3620-apply_settings.yml을 사용하려면 필요에 따라 적절한 추가 변수를 설정하고 HOSTS 변수로 대상 시스템을 지정합니다. 예 :
SMT는 해제되지만 런타임 변경을 허용하고 조건부 L1 데이터 캐시 플러시의 기본 동작을 그대로 두려면 다음을 수행합니다.
ansible-playbook -e "HOSTS=webservers SMT=1" CVE-2018-3620-apply_settings.yml
모든 완화 조치를 적용하고 런타임 변경을 방지하려면 다음을 수행합니다.
ansible-playbook -e "HOSTS=vmserver01 FLUSH=1 SMT=1 FORCE=1" CVE-2018-3620-apply_settings.yml
L1TF 설정을 기본 상태로 재설정하려면 다음을 수행합니다.
ansible-playbook -e "HOSTS=webservers RESET=1" CVE-2018-3620-apply_settings.yml
완화 Playbook 다운로드
대응 방법
영향을 받는 Red Hat 제품 버전을 사용하는 Red Hat 고객은 관련 패치가 릴리스되는 즉시 업데이트할 것을 권장합니다. 사용 가능한 업데이트를 즉시 적용하고 적절한 완화 조치를 취하십시오.
패치 적용 순서는 중요하지 않지만 펌웨어 및 하이퍼 바이저를 업데이트한 후 새 하드웨어 유형을 인식시키려면 모든 시스템 및 가상 시스템을 종료했다가 다시 시작해야 합니다.
영향을 받는 제품 업데이트
| 제품 | 패키지 | 권고/업데이트 |
| Red Hat Enterprise Linux 7 (z-stream) | kernel | RHSA-2018:2384 |
| Red Hat Enterprise Linux 7 | kernel-rt | RHSA-2018:2395 |
| Red Hat Enterprise Linux 7 | microcode_ctl | RHEA-2018:2397 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | kernel | RHSA-2018:2387 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | microcode_ctl | RHEA-2018:2398 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | kernel | RHSA-2018:2388 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | microcode_ctl | RHEA-2018:2399 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | kernel | RHSA-2018:2389 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2400 |
| Red Hat Enterprise Linux 6 (z-stream) | kernel | RHSA-2018:2390 |
| Red Hat Enterprise Linux 6 | microcode_ctl | RHEA-2018:2300 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | kernel | RHSA-2018:2391 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | microcode_ctl | RHEA-2018:2304 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | kernel | RHSA-2018:2392 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2302 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | kernel | RHSA-2018:2393 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | microcode_ctl | RHEA-2018:2303 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | kernel | RHSA-2018:2394 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | microcode_ctl | RHEA-2018:2297 |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | kernel | pending |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | microcode_ctl | pending |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | kernel | pending |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | microcode_ctl | pending |
| RHEL Atomic Host | kernel | respin pending |
| Red Hat Enterprise MRG 2 | kernel-rt | RHSA-2018:2396 |
| Red Hat Virtualization 4 | redhat-virtualization-host | RHSA-2018:2403 |
| Red Hat Virtualization 4 | rhvm-appliance | RHSA-2018:2402 |
| Red Hat Virtualization 3 Extended Lifecycle Support* | rhev-hypervisor7 | RHSA-2018:2404 |
| Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7 | director 이미지 | respin pending |
| Red Hat OpenStack Platform 8.0 (Liberty) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 9.0 (Mitaka) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 10.0 (Newton) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 11.0 (Ocata) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 12.0 (Pike) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 12.0 (Pike) | 컨테이너 | respin pending |
| Red Hat OpenStack Platform 13.0 (Queens) | director 이미지 | respin pending |
| Red Hat OpenStack Platform 13.0 (Queens) | 컨테이너 | respin pending |
*이 패치에 액세스하려면 활성 ELS 서브스크립션이 필요합니다. 사용 계정에 활성 ELS 서브스크립션이 없을 경우 보다 자세한 내용은 Red Hat 영업팀 또는 해당 지역 영업 담당자에게 문의하시기 바랍니다.
**이 패치에 액세스하려면 활성 EUS 서브스크립션이 필요합니다. 사용 계정에 활성 EUS 서브스크립션이 없을 경우 보다 자세한 내용은 Red Hat 영업팀 또는 해당 지역 영업 담당자에게 문의하시기 바랍니다.
Red Hat Enterprise Linux Extended Update Support 서브스크립션이란?
***RHEL AUS에서 이러한 패치에 액세스하려면 활성 AUS 서브스크립션이 필요합니다.
AUS (Advanced mission critical Update Support)란 무엇입니까?
****RHEL TUS에서 이러한 패치에 액세스하려면 활성 TUS 서브스크립션이 필요합니다.
***** 서브스크립션 사용자는 하드웨어 OEM에 연락하여 CPU 마이크로 코드/펌웨어의 최신 버전을 받으십시오.
완화 방법
현재 완화 조치에는 하드웨어 OEM의 CPU 마이크로 코드/펌웨어와 함께 벤더 소프트웨어 업데이트 적용이 포함됩니다. Red Hat 제품을 사용하는 고객은 패치가 제공되는 즉시 벤더 솔루션을 적용하여 CPU, 시스템 BIOS (필요에 따라)를 패치하고 커널을 업데이트해야 합니다. 하이퍼스레딩 (Hyper-Threading)을 비활성화하는 경우를 제외하고는 모든 완화 조치가 기본적으로 활성화되어 있으므로 고객은 수동으로 비활성화해야 합니다. 고객은 이 문제를 확인하고 대응 시 위험 기반 접근 방식을 사용하여 보안 위험과 완화 범위 및 성능에 미치는 영향을 평가하여 완화 전략을 세워야 합니다. 높은 수준의 보안과 신뢰를 필요로 하는 시스템에 우선 순위를 부여하고 악용 위험을 줄이기 위해 해당 시스템에 대응 조치를 적용하기 전 까지는 신뢰할 수없는 시스템과 격리시켜야 합니다. 이러한 문제를 완전히 해결하고자 하는 고객은 보다 안전하게 시스템을 관리하는 방법을 검토하고 경우에 따라 모든 공격 경로를 차단하기 위해 하이퍼 스레딩 (Hyper-Threading) 기능의 비활성화도 고려해야 합니다.
완화/개선:
L1 Terminal Fault를 완전하게 완화하려면 페이지 테이블 반전 (업데이트된 커널에서 기본적으로 제공되고 활성화되는 커널의 소규모 변경), 가상 머신 간 전환시 L1 데이터 캐시 플러시 및 SMT 비활성화라는 세 가지 변경이 필요합니다. 이러한 각각의 변경 사항은 독립적이고 대처하는 공격 유형도 다릅니다.
Red Hat에서 제공하는 업데이트된 커널에서 존재하지 않는 페이지 테이블 항목을 조작하는 경우 페이지 테이블 반전 (Meltdown 완화에 추가된 페이지 테이블 분리와 다름)은 기본적으로 수행됩니다.
L1 데이터 캐시 플러시는 선택 사항이며 업데이트된 마이크로 코드 또는 업데이트된 커널로 구현할 수 있습니다. 현재 가상 게스트 시스템을 실행할 때 기본적으로 활성화되지만 커널 매개 변수를 통해 사용자가 이를 제어할 수 있습니다.
SMT 비활성화는 시스템 보안을 강화하기 위한 선택 사항으로 가상 머신을 실행하는 신뢰할 수없는 공유 환경을 보호하는데 사용됩니다. 이는 소프트웨어 업데이트를 통해 커널에 새로운 제어 인터페이스를 추가합니다. BIOS 펌웨어에서 Intel 하이퍼 스레딩을 비활성화할 수 있지만 문제가 발생하기 쉽기 때문에 권장되는 방법이 아닙니다.
이 문제는 세 가지 요인이 있으므로 개선을 위한 3 가지 방법이 필요합니다.
- Not Present (존재하지 않음) (P flag = 0) 페이지 테이블 항목 (PTE) 또는 예약된 비트 세트는 초기화되지 않은 물리 주소로 설정되어 있습니다. 해당 물리적 주소는 L1 데이터 캐시에 저장됩니다.
- 추측 실행으로 인한 L1 데이터 캐시 업데이트는 제거되지 않습니다. 이는 후속 프로세스에 의해 확인될 수 있습니다.
- SMT (simultaneous multi-threads)는 L1 데이터 및 TLB 캐시와 같은 실행 엔진과 온칩 프로세서의 캐시를 공유합니다.
페이지 테이블 반전:
프로세서는 추측 실행을 기반으로 Not Present PTE로 부터 물리적 주소에 접근하고 이 물리적 주소의 내용이 L1 데이터 캐시에 저장되면 메모리 액세스가 성공합니다. 따라서 물리적 주소의 컨텐츠가 캐시에 저장되어 있지 않으면 메모리 액세스는 데이터를 유출하지 않습니다. 페이지 테이블 반전 완화는 메모리에 없거나 캐시할 수 없는 물리적 주소를 가리키도록 상위 주소 비트를 설정하여 Not Present PTE의 물리적 주소를 업데이트합니다. 따라서 이 내용은 L1 데이터 캐시에 존재하지 않게 됩니다.
업데이트된 커널 패키지는 다음과 같이 sysfs 인터페이스를 통해 시스템의 현재 상태를 표시합니다.
# cat /sys/devices/system/cpu/vulnerabilities/l1tf
Mitigation: PTE Inversion; VMX: SMT vulnerable, L1D conditional cache flushes
#
L1 데이터 캐시 플러시
시스템에 마이크로 코드가 업데이트되면 Intel x86 프로세서는 IA32_FLUSH_CMD Machine Specific Register (MSR)를 제공합니다. L1 데이터 캐시를 해제하는데 사용할 수 있습니다. IA32_FLUSH_CMD MSR에 대한 지원은 /proc/cpuinfo 플래그 또는 CPU 플래그를 나열하는 lscpu(1) 명령을 통해 확인할 수 있습니다.
# lscpu
Flags: … ssbd ibrs ibpb stibp spec_ctrl intel_stibp flush_l1d
#
flush_l1d 플래그를 사용할 수없는 경우 시스템에 업데이트된 마이크로 코드가 설치되어 있고 해당 시스템이 재부팅되었는지 확인하십시오.
업데이트된 마이크로 코드가 설치되어 있지 않은 경우 flush_l1d 플래그를 사용할 수 없습니다. 업데이트된 커널은 여전히 소프트웨어에서 L1 데이터 캐시를 플러시합니다. 이 동작은 하드웨어 flush_l1d 인터페이스에 비해 속도가 느립니다 .
업데이트된 커널 패키지는 L1TF 완화를 제어하기 위해 다음과 같은 커널 및 KVM 모듈 매개 변수가 포함되어 있습니다.
l1tf=[full/full,force/flush/flush,nosmt/flush,nowarn/off]
영향을 받는 CPU에서 L1TF 문제의 완화를 제어하는 커널 부팅 매개 변수입니다. 다음 값 중 하나를 취할 수 있습니다.
full : L1TF 문제의 완화를 모두 사용합니다.
- 각 가상 머신이 작업을 시작할 때 L1 데이터 캐시 플러시를 사용합니다.
- 하이퍼 스레딩 (SMT)을 비활성화합니다.
L1 데이터 캐시 플러시와 SMT는 모두 부팅 후 런타임에서 sysfs 인터페이스를 통해 제어할 수 있습니다.
full,force: L1TF 문제의 완화를 모두 사용합니다.
- 각 가상 머신이 작업을 시작할 때 L1 데이터 캐시 플러시를 사용합니다.
- 하이퍼 스레딩 (SMT)을 비활성화합니다.
force 매개 변수를 사용하면 sysfs 인터페이스를 통해 L1TF 완화 조치를 비활성화할 수 없습니다. 사용자는 런타임에서 SMT를 활성화할 수 없습니다.
flush : L1 데이터 캐시 플러시만 사용합니다.
- 조건부로 L1 데이터 캐시를 플러시하는 기본 L1 데이터 캐시의 플러시 완화를 활성화합니다.
- 하이퍼스레딩 (SMT)이 비활성화되어 있지 않습니다.
위의 두 설정은 모두 sysfs 인터페이스를 통해 제어할 수 있습니다. SMT가 활성화되어 있는지 또는 L1 데이터 캐시의 플러시가 비활성화되어 있는 경우와 같이 하이퍼 바이저 (KVM) 설정이 안전하지 않은 상태에서 게스트르 시작하면 경고 메세지가 표시됩니다.
flush, nosmt: 하이퍼 스레딩 (SMT)을 비활성화합니다.
- 조건부 L1 데이터 캐시 플러시 완화를 활성화합니다.
- 하이퍼 스레딩 (SMT)을 비활성화합니다.
위의 두 설정은 모두 sysfs 인터페이스를 통해 제어할 수 있습니다. SMT가 활성화되어 있는지 또는 L1 데이터 캐시의 플러시가 비활성화되어 있는 경우와 같이 하이퍼 바이저 (KVM) 설정이 안전하지 않은 상태에서 게스트르 시작하면 경고 메세지가 표시됩니다.
flush, nowarn : 실행 중인 게스트 설정이 안전하지 않은 경우 KVM 모듈이 경고 메세지를 표시한다는 것을 제외하고는 위의 플러시 옵션과 유사합니다.
off: 하이퍼 바이저 완화를 비활성화합니다. KVM은 가상 머신에서 L1 데이터 캐시를 플러시하지 않습니다.
기본 l1tf 부팅 매개 변수 값은 위의 플러시 완화 옵션으로 설정됩니다.
kvm-intel.vmentry_l1d_flush : 각 가상 머신에서 L1 데이터 캐시 플러시 작업을 제어하는데 사용되는 KVM 모듈 매개 변수입니다. 다음과 같은 값을 설정할 수 있습니다.
always 모든 VMENTER에서 L1D 캐시를 플러시합니다.
cond 조건부 L1D 캐시를 플러시합니다. .
never L1D 캐시 플러시 완화를 비활성화합니다.
cond는 VMEXIT와 VMENTER 사이에서 실행되는 코드가 안전하다고 판단되는 경우 VMENTER에서 L1D 캐시 플러시를 피하려고 합니다. 즉,
L1D에 민감한 데이터를 가져 오지 않습니다 .
# cat /sys/module/kvm_intel/parameters/vmentry_l1d_flush
cond
#
이 매개 변수는 기본적으로 cond에 설정됩니다. 가상 머신의 선택적 항목 인스턴스에서 L1 데이터 캐시를 플러시하면 L1 데이터 캐시 플러시의 성능에 미치는 영향을 줄일 수 있습니다.
SMT 제어:
SMT (simultaneous multi-threads, 동시 멀티 스레딩) 또는 하이퍼 스레딩 기술을 사용하는 경우 동일한 코어 및 공유 프로세서 캐시 리소스에서 실행중인 관련없는 스레드는 L1TF를 사용하여 L1 데이터 캐시에서 각각의 데이터를 읽을 수 있습니다. 신뢰할 수없는 공유 환경을 실행하는 경우 완화 대책의 일부로 SMT 기능을 비활성화하는 것을 고려해야 합니다. 일반적으로 SMT는 시스템의 BIOS에서 활성화 또는 비활성화로 설정할 수 있습니다.
업데이트된 커널 패키지에 새로운 명령 줄 매개 변수 nosmt가 포함되어 있습니다.
nosmt: SMT를 비활성화합니다. sysfs 인터페이스를 통해 런타임에서 다시 활성화할 수 있습니다.
nosmt=force: SMT를 비활성화합니다. 런타임에서 다시 활성화할 수 없습니다.
참고: 커널 sysfs 인터페이스에는 런타임시에 멀티 스레드를 관리하는 제어 기능이 있습니다. SMT기능을 다시 활성화하면 잘못된 동작이 발생할 수 있으므로 SMT를 활성화/비활성화하려면 BIOS 설정 또는 위에 나열된 커널 부팅 매개 변수를 사용하는 것이 좋습니다. 여기서 런타임 플래그에 대한 정보는 참조 용으로만 설명됩니다.
/sys/devices/system/cpu/smt/active
/sys/devices/system/cpu/smt/control
위의 active 파일은 읽기 전용 인터페이스입니다. active 파일에 ‘1’이 포함된 경우, SMT가 활성화되고 형제 스레드가 온라인 상태임을 의미합니다. 커널이 nosmt’ 매개 변수로 부팅되면 본질적으로 위의 active 파일에 ‘0’을 기록합니다.
위의 제어 파일은 SMT를 제어하기위한 읽기/쓰기 인터페이스입니다. 다음 값을 설정할 수 있습니다.
on : SMT가 활성화됩니다. 형제 스레드가 오프라인 상태인 경우 이를 활성화하십시오.
off : SMT가 비활성화됩니다. 형제 스레드가 온라인 상태인 경우 이를 비활성화하십시오.
forceoff : SMT가 강제로 비활성화되어 있어 변경할 수 없습니다.
런타임시에 제어하거나 변경할 수 없습니다 .
notsupported: 프로세서는 하이퍼스레딩 (SMT)을 지원하지 않습니다.
EPT 비활성화:
KVM 게스트의 EPT (Extended Page Tables)을 비활성화하면 기본적으로 VMM/Hypervisor가 게스트의 주소 변환을 관리할 수 있으므로 L1TF 문제가 완화됩니다. EPT를 비활성화한 경우 위에 나열된 것처럼 하이퍼 스레드 (SMT)를 비활성화하고 L1 데이터 캐시를 플러시할 필요가 없습니다.
참고: EPT를 비활성화하면 시스템 성능이 크게 저하되므로 이는 올바른 선택이 아닐 수도 있습니다.
EPT는 kvm-intel.ept 매개 변수를 통해 하이퍼 바이저에서 비활성화할 수 있습니다. 이는 기본적으로 활성화되어 있습니다.
Red Hat은 즉시 고객이 하드웨어 또는 CPU 벤더가 제공하는 마이크로 코드/펌웨어 업데이트를 적용하고 업데이트된 커널을 설치할 것을 권장합니다. 소프트웨어 업데이트는 하드웨어 마이크로 코드와는 별도로 적용할 수 있지만 CPU 펌웨어가 업데이트된 후에 만 가능합니다.
Tuned
새로운 L1TF 커널은 런타임 또는 커널 부팅시 사용자에게 하이퍼 스레딩을 비활성화할 수 있는 제어 기능을 제공합니다. 이러한 두 가지 방법 중 하나를 사용하면 시스템은 다음 네 가지 tuned profile 중 하나를 실행합니다:
cpu-partitioning
realtime
realtime-virtual-host
realtime-virtual-guest
업데이트된 tuned가 필요합니다. 이는 RHEL 7.4z 및 7.5z에만 영향을 미칩니다. BIOS에서 하이퍼 스레딩이 비활성화되어 있는 경우 업데이트된 tuned는 필요하지 않습니다.
Comments