
Attaque noyau « side-channel » par L1 Terminal Fault - CVE-2018-3620 & CVE-2018-3646
Mis à jour
Est-ce que cette infomation vous a été utile ?
Red Hat a été informé d'un nouveau problème de microarchitecture de microprocesseur qui ressemble à Spectre et Meltdown, et qui a été signalé comme affectant les microprocesseurs x86 fabriqués par Intel. Des attaquants non privilégiés peuvent ainsi utiliser cette faille pour contourner les restrictions de sécurité de la mémoire et accéder à des données stockées dans la mémoire normalement inaccessibles. Il y a trois aspects à cette vulnérabilité. Le premier ne concerne que les enclaves sécurisées Intel "SGX" et le risque est atténué par des mises à jour de microcodes indépendamment du système d'exploitation. Les deux autres aspects nécessitent des mesures d'atténuation du risque au niveau logiciel effectuées par les systèmes d'exploitation et les hyperviseurs. Pour éviter au maximum une attaque potentielle par des machines virtuelles invitées non fiables dans un environnement utilisant la virtualisation, il faudra une action spécifique de la part d'un administrateur système.
CVE-2018-3620 est l'identificateur CVE attribué à la vulnérabilité du système d'exploitation pour ce problème. CVE-2018-3646 est l'identifiant CVE attribué à l'aspect virtualisation de la vulnérabilité. Cette question est désignée sous le nom « L1 Terminal Fault (L1TF) » par l'industrie en général et sous le nom de « Foreshadow » par le chercheur en sécurité.
La vulnérabilité L1 Terminal Fault permet à un acteur malveillant de contourner les contrôles de sécurité d'accès à la mémoire habituellement imposés et gérés par le système d'exploitation ou l'hyperviseur. Un attaquant peut utiliser cette vulnérabilité pour lire n'importe quel emplacement de mémoire physique mis en cache dans le cache L1 de données du processeur. Normalement, le système d'exploitation et les « tableaux de pages » gérées par hyperviseur fournissent au processeur des informations sur les emplacements de mémoire qui devraient être accessibles à une application, le noyau du système d'exploitation lui-même et les instances de machines virtuelles invitées. Ces tableaux de pages sont formés à partir d'entrées de tableaux de pages (PTE) (de l'anglais Page Table Entries) qui comprennent un bit « présent » indiquant la validité. En exploitant L1TF, un attaquant abuse de la logique du processeur Intel qui reconnaît les PTE valides.
La mémoire cache de données L1 (généralement de 32 Ko) est le premier niveau d'une hiérarchie de mémoire de processeur sur puce rapide qui contient des copies de données également conservées dans les puces de mémoire principale externes (au processeur). Les caches sont remplis au fur et à mesure que la mémoire est utilisée par les programmes, généralement séparés en plusieurs niveaux. Un petit cache de niveau le plus élevé et rapide (L1) est ce qui se raproche le plus des unités fonctionnelles du processeur qui effectuent les calculs réels au sein d'un programme, tandis que les caches qui sont plus grands et plus lents sont conceptuellement situés plus loin. L1 est partagé entre deux hyperthreads pairs au sein d'un noyau de processeur Intel. Chaque noyau possède également une mémoire cache L2 légèrement plus grande. Le L3 (aussi appelé LLC ou Last Level Cache) est partagé par tous les cœurs du processeur et est beaucoup plus gros (ex. 32MB). Les données se déplacent de la mémoire vers le niveau L3 et vers L1 lorsqu'il est utilisé.
Les accès à la mémoire cache à l'intérieur de la puce du processeur sont plus rapides que sortir vers la mémoire principale, de sorte qu'ils sont utilisés en large mesure pour améliorer les performances. Le cache de données est également rempli suite aux opérations effectuées pendant l'exécution spéculative « Out-of-Order ». En raison de cette différence relative de performance des caches par rapport à la mémoire, il est possible que des logiciels malveillants infèrent l'activité du cache. C'est ce qu'on appelle l'analyse des canaux latéraux (side-channel), et elle a été popularisée par Meltdown et Spectre. Dans ces vulnérabilités, comme dans L1TF, des séquences logicielles spécifiques, connues sous le nom de « gadgets » peuvent être créées pour exploiter un processeur vulnérable et provoquer une activité de cache observable pendant la spéculation.
L1TF est similaire à Meltdown, dans la mesure où il exploite la façon dont les processeurs vulnérables mettent en œuvre une forme de spéculation, dans ce cas, lors de la recherche de tableaux de page (connu sous le nom de « table walk »). Le processeur est conçu pour offrir un mode de performance des plus agressifs possibles, donc il assume que les entrées de tableaux de pages sont valides et permettent d'accéder à l'emplacement de mémoire sous-jacent avant d'effectuer les contrôles de validité nécessaires. Le processeur effectuera une recherche préventive dans sa mémoire cache de données L1 à la recherche de toute adresse physique correspondant à des bits dans l'entrée du tableau de pages, transférant tout élément correspondant aux opérations spéculatives dépendantes. Après un court laps de temps, le processeur détectera que l'entrée du tableau de pages n'est pas valide et signalera une « faille de terminal » interne. Le processeur rejetera ensuite les résultats précédemment spéculés, mais l'impact observable sur la mémoire cache va demeurer.
Dans le cas d'instances invitées virtualisées, la vulnérabilité L1TF se manifeste en raison d'un aspect de l'implémentation d'une technologie inhérente aux processeurs Intel: « Extended Page Tables » (EPT). Cette fonction de performance du matériel permet aux hyperviseurs (comme KVM) de déléguer une partie de la gestion des tableaux de pages à des machines virtuelles invitées. Chaque accès mémoire fait l'objet de deux traductions - d'abord par l'invité, puis par les tableaux de la page d'accueil. Cela permet d'économiser les besoins d'assistance répétés de la part de l'hyperviseur, ce qui était nécessaire avant l'EPT. Dans les implémentations vulnérables, un invité malveillant est capable de créer une entrée de tableau de page "non présente" qui raccourcira les deux étapes normales de traduction, permettant ainsi à l'invité de lire l'hyperviseur de l'hôte ou autre mémoire physique de l'invité s'il en existe une copie dans le cache de données L1.
Les utilisateurs finaux devront se protéger contre deux types d'attaques : un utilisateur malveillant sur un système qui lit des données sur le système physique ou un SE invité ou un conteneur malveillant qui accède à des informations provenant d'autres invités ou de l'hôte. Cette vulnérabilité est similaire à CVE-2017-5754 (aka "Meltdown") mais exploite une interaction entre l'unité de gestion de la mémoire (MMU) (de l'anglais Memory Management Unit) et le cache de données L1 sous spéculation lors de la traduction d'adresse de mémoire virtuelle en mémoire physique. Les mesures d'atténuation du risque existantes applicables pour les vulnérabilités microarchitecturales antérieures ("Meltdown", alias "Variante 3") ne sont pas suffisantes pour se protéger contre cette nouvelle vulnérabilité.
Red Hat recommande fortement aux clients de prendre des mesures correctives, y compris l'activation manuelle de paramètres spécifiques du noyau ou de fonctionnalités potentiellement désactivantes comme Intel Hyper-Threading, après l'application des mises à jour disponibles. Plus de détails peuvent être trouvés dans la section Atténuation du risque de cet article.
Informations générales
Les systèmes d'exploitation modernes opèrent un schéma de « mémoire virtuelle » pour utiliser efficacement la mémoire principale disponible à travers de multiples tâches/processus. Les systèmes physiques ont des quantités de mémoire principale fixes qui constituent l'espace adresse physique . Cet espace d'adressage est divisé en petites unités gérées appelées pages (par ex. 4KB). Le système d'exploitation crée des espaces d' adresse virtuelle pour chaque programme en cours d'exécution (connu sous le nom de processus). Chaque adresse virtuelle est traduite en une adresse physique sous-jacente à l'aide d'un élément matériel spécial au sein du processeur, connu sous le nom d' Unité de gestion de la mémoire (MMU). Lorsqu'un processeur planifie l'exécution d'un programme, ses instructions et ses données sont mappées dans des adresses virtuelles. Les programmes utilisent des adresses virtuelles pour référencer les emplacements de mémoire. L'unité de gestion de la mémoire (MMU) du processeur utilise le concept de Paging pour effectuer la traduction entre les adresses virtuelles et leurs adresses de mémoire physique mappées sous-jacentes.

La technique de Paging traduit chaque adresse virtuelle en adresse physique en utilisant des structures hiérarchiques de pagination connues sous le nom de tableaux de pages. Ceux-ci traduisent des parties de l'adresse virtuelle en utilisant des bits de l'adresse comme index de composants de tableaux de pages. Les tableaux de pages sont construits à partir d'enregistrements/entrées de taille fixe qui contiennent une adresse physique pointant soit vers une autre entrée de la structure de pagination, soit vers la page de mémoire mappée. En plus de l'adresse physique, une entrée de structure de pagination contient également divers bits d'attribut sur l'adresse physique. Celles-ci incluent un bit indiquant si la page est présente (P flag) dans la mémoire physique ou non (swapped out). Une entrée de table de page marquée comme non présente est supposée être ignorée par la logique MMU du processeur.
Entrée de structure de pagination :
Le manuel du développeur de logiciels Intel (volume 3, chapitre 4) définit les structures de pagination de matériel utilisé par les processeurs Intel, y compris l'entrée de tableau de page 64 bits (PTE) utilisé pour stocker l'adresse physique lors d'une traduction d'adresse virtuelle en adresse physique.
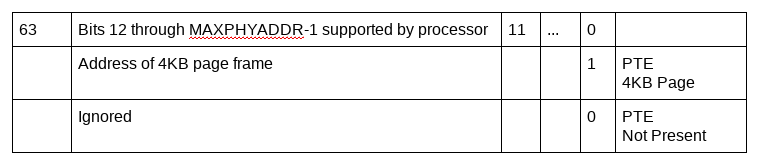
Au cours de la traduction d'adresse, le processeur parcourt les structures des tableaux de pages, pour finalement arriver à une entrée de tableau de pages qui contient une traduction physique possible pour une adresse virtuelle particulière. Ce processus de traduction d'adresse se termine lorsque l'adresse virtuelle génère un bloc page mappé dans la mémoire physique OU lorsqu'une entrée de structure de pagination indique que le bloc page requis est non présent (P flag(bit zero) = 0) dans la mémoire principale OU qu'il a moins de sets de bits réservés. L'accès à l'adresse physique à partir d'une telle entrée entraîne l'exception « page-fault » (aka « terminal fault »).
Remerciements
Red Hat tient à remercier Intel Inc. et ses partenaires de l'industrie pour avoir signalé ce problème et collaboré aux mesures de mitigation du risque.
Références supplémentaires
Pour obtenir plus d'informations sur ce genre de problèmes, veuillez consulter le site web d'Intel
Tout ce que vous avez besoin de savoir sur L1TF en 3 minutes
Vidéo d'explication technique- 10 minutes
Blog pour comprendre L1 Terminal Fault
Blog sur la gestion du risque dans le monde moderne
Considérations de performance liées à L1TF
Références à des produits Red Hat supplémentaires
Produits concernés
Red Hat Product Security a évalué l'impact de sécurité de CVE-2018-3620 & CVE-2018-3646 au niveau Important.
Les versions de produits Red Hat suivants sont concernées :
Red Hat Enterprise Linux 5
Red Hat Enterprise Linux 6
Red Hat Enterprise Linux 7
Red Hat Atomic Host
Red Hat Enterprise MRG 2
Red Hat OpenShift Online v3
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) for RHEL7
Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7
Red Hat OpenStack Platform 8.0 (Liberty)
Red Hat OpenStack Platform 8.0 (Liberty) director
Red Hat OpenStack Platform 9.0 (Mitaka)
Red Hat OpenStack Platform 9.0 (Mitaka) director
Red Hat OpenStack Platform 10.0 (Newton)
Red Hat OpenStack Platform 11.0 (Ocata)
Red Hat OpenStack Platform 12.0 (Pike)
Red Hat OpenStack Platform 13.0 (Queens)
Red Hat Virtualization (RHEV-H/RHV-H)
Bien que les conteneurs Linux de Red Hat ne soient pas directement affectés par les problèmes du noyau, leur sécurité dépend de l'intégrité de l'environnement du noyau hôte. Red Hat vous recommande d'utiliser les versions les plus récentes de vos images de conteneurs. Le Container Health Index, qui fait partie du catalogue de conteneurs de Red Hat (Red Hat Container Catalog ), peut toujours être utilisé pour vérifier l'état de sécurité des conteneurs Red Hat. Pour protéger la confidentialité des conteneurs utilisés, vous devrez vous assurer que l'hôte du conteneur (comme Red Hat Enterprise Linux ou Atomic Host) a été mis à jour contre ces attaques. Red Hat a publié une mise à jour d'Atomic Host pour ce cas d'utilisation.
Description et impact de l'attaque
Vecteur d'attaque d'hôte traditionnel :
Lorsqu'un processeur prend en charge l'exécution spéculative d'instructions, une charge spéculative d'adresse virtuelle qui ne peut pas être traduite en adresse physique entraîne une exception de faute de page pendant son processus de traduction. Avant que cette exception «page-fault » ne soit produite, l'exécution spéculative de l'instruction de chargement utilise l'adresse physique de l'entrée de la structure de pagination non présent (P flag = 0) OU sets de bits réservés pour accéder à la mémoire physique. Si l'emplacement de mémoire physique a été mis en cache dans le cache de données L1, la charge spéculative lit les données à partir d'un emplacement de mémoire physique inapproprié. Par conséquent, les opérations spéculatives ultérieures utilisent ces données et cela peut avoir un impact mesurable sur les caches qu'un attaquant peut utiliser pour lire des données non autorisées.
Un processus ou un utilisateur système non privilégié pourrait exploiter la vulnérabilité L1TF pour lire des données à partir d'emplacements de mémoire physique arbitraires du noyau et/ou d'autres processus s'exécutant sur le système, si les données sont d'abord chargées dans le cache de données L1. Comme les chargements dans le cache de données L1 sont un composant intrinsèque du processeur, un attaquant malveillant n'a qu'à attendre qu'un programme contenant des secrets intéresseants pour charger ces secrets tout en effectuant des opérations normales. Cela peut inclure des clés cryptographiques et d'autres données.
Vecteur d'attaque de virtualisation :
Les environnements d'invités virtualisés aggravent l'impact de l'exploitation de cette vulnérabilité. Dans les environnements virtualisés, les invités exécutent souvent un système d'exploitation qui gère la mémoire comme s'il s'agissait d'un système hôte bare metal (nu). Ce que le système d'exploitation invité perçoit comme mémoire physique est en réalité un espace d'adressage virtuel sur l'hôte, créé par le moniteur de machine virtuelle (VMM, par exemple KVM), également connu sous le nom d'hyperviseur. L'hyperviseur introduit une couche de virtualisation de la mémoire pour s'assurer qu'il a le contrôle de la véritable mémoire physique de l'hôte et qu'il peut fournir des espaces d'adresses virtuelles isolés à de nombreux invités tout en gérant leur accès à la mémoire physique de l'hôte. Cela signifie que les environnements virtualisés ont deux niveaux de traduction mémoire.

Afin de faciliter la traduction efficace des adresses physiques des invités en adresses physiques de l'hôte, les processeurs matériels ont mis en place la fonction Extended Page Table (EPT).
L'EPT est similaire aux structures hiérarchiques de pagination utilisées par le système d'exploitation hôte pour traduire les adresses virtuelles en adresses de mémoire physique. Lors de la traduction des adresses physiques des invités en adresses physiques de l'hôte, tout comme les exceptions «page-fault» sur l'hôte, les exceptions EPT Violation entraînent des sorties de VM, indiquant que la traduction de l'adresse physique de l'invité ne peut pas être résolue en adresse physique de l'hôte OU que l'invité n'a pas les permissions d'accéder à la mémoire de l'hôte donnée.
Comme pour l'hôte, l'exécution spéculative d'instructions par un utilisateur invité peut tirer parti de ces sorties de VM induites par les violations EPT pour lire les données de la mémoire physique de l'hôte par le biais d'attaques de cache «side-channel». Comme le système d'exploitation invité peut contrôler les bits d'adresse physique des invités dans l'entrée de pagination EPT, un utilisateur invité peut cibler des adresses physiques spécifiques de l'hôte et lire les données via le cache de données L1, y compris la mémoire arbitraire du noyau de l'hôte et/ou la mémoire des autres invités/processus s'exécutant sur l'hôte.
Vecteur d'attaque multithreading en simultané (SMT) :
Le multithreading simultané (SMT) permet aux processeurs modernes d'améliorer les performances du système en exécutant simultanément plus d'un flux d'instructions sur des processeurs logiques séparés. C'est-à-dire que le CPU crée deux ou plusieurs processeurs logiques avec leur propre jeu de registres de données, registres de contrôle, registres de segments, etc. qui forment leur état architectural. Ces processeurs logiques exécutent des flux d'instructions séparés tout en partageant le même moteur d'exécution, les caches de processeur, les TLB, l'interface de bus système, etc.
Si deux processeurs logiques se partagent le cache du processeur, une opération de manipulation du cache effectuée par un processeur logique sera visible pour l'autre. C'est-à-dire qu'une application/invité s'exécutant sur un processeur logique pourrait tirer parti de L1TF et de l'exécution spéculative d'instructions pour lire le contenu arbitraire de la mémoire d'autres processus et du noyau à partir du cache de données partagé.
La nature simultanée de l'Intel Hyper-threading fait que vider le cache sur un processeur logique pair lors d'un changement d'instances de machines virtuelles exécutant dessus laisse une petite fenêtre de temps pendant laquelle les secrets peuvent être rechargés par le pair et pendant laquelle les secrets sont visibles à un attaquant malveillant exécutant du code sur l'autre processeur logique. Il n'existe actuellement aucun moyen standard pour garantir que cela ne puisse pas se produire,
Par conséquent, les environnements virtualisés ne devraient pas programmer deux machines virtuelles différentes pour partager deux processeurs logiques à partir d'un seul noyau. En outre, lorsqu'une pile Linux complète s'exécute sur l'hôte, capable de charger ses propres secrets en réponse à des événements tels que des interruptions, il n'est pas prudent d'activer l'hyperthreading si on exécute des invités non fiables sur un processeur logique.
Impact sur la performance
Essayer de mitiger le risque L1TF dans des environnements bare metal (nus) qui n'utilisent pas la virtualisation a un impact négligeable sur les performances et ne nécessite pas d'action spécifique au-delà des mises à jour.
L'atténuation du risque L1TF dans les environnements virtualisés exige que l'hyperviseur vérifie s'il doit vider le cache de données L1 (L1D) des secrets potentiels d'autres machines virtuelles (ou de l'hôte) chaque fois qu'il commence à exécuter le code de la machine virtuelle. Selon la charge de travail, il peut également être nécessaire de désactiver l'Intel Hyper-threading, afin d'empêcher une machine virtuelle malveillante s'exécutant sur un hyperthread d'en attaquer une autre sur son thread pair.
Le cache de données L1 met les données à la disposition du processeur beaucoup plus rapidement que la mémoire principale et (presque) toutes les données chargées à partir de la mémoire doivent passer par lui. Une fois que le cache de données L1 est vidé, le CPU doit passer des centaines de cycles pour remplir à nouveau ces entrées à partir des caches de niveau inférieur. Cela coûte cher en termes de temps consacré à l'accès aux données. En termes d'efficacité relative, le cache de données L1 prend 1x cycles CPU, alors que le même accès aux données à partir de caches de niveau inférieur peut prendre 4x cycles CPU. L'accès aux données à partir de la mémoire principale peut prendre 60-70x ou plus de cycles. Comme les données contenues dans le cache de données L1 sont également contenues dans les caches de niveau supérieur, elles seront généralement rechargées à partir du cache L2 avec un impact modeste sur la performance. Cette surcharge augmente également la latence des interruptions externes et autres événements.
De même, l' Hyper-Threading (une implémentation SMT) exécute plus d'un flux d'instructions simultanément pour améliorer les performances du système. Désactiver ces threads réduirait de moitié le nombre de processeurs logiques vus par le système, réduisant ainsi de manière significative le débit de calcul global d'un système et sa performance.
Il est à noter que l'incidence réelle de ces mesures sur la performance dépend de la charge de travail et peut varier d'une charge de travail à l'autre. Pour obtenir des informations supplémentaires sur l'impact spécifique de la charge de travail sur la performance, consulter : Performance considerations for L1 Terminal Fault
Diagnostiquer votre vulnérabilité
Utilisez le script de détection pour déterminer si votre système est actuellement vulnérable à cette vulnérabilité. Pour vérifier la légitimité du script, vous pouvez télécharger la signature GPG détachée également. La version actuelle du script est 1.2.
De plus, deux playbooks Ansible sont fournis ci-dessous. Le premier, CVE-2018-3620-fix_disable_ht.yml, peut être appliqué aux systèmes qui n'ont pas été mis à jour pour adresser L1TF et désactiver l'Hyper-Threading sans redémarrer le système. Le playbook fera un effort pour déterminer si le système agit en tant qu'hyperviseur et s'il a des VM en cours d'exécution, mais il faut savoir que la désactivation de l'Hyper-Threading (hors ligne) peut provoquer un comportement inattendu dans les applications avec une affinité cœur/thread spécifique. Si le noyau du système n'inclut pas les fonctionnalités nécessaires, il échouera avec un message à cet effet. Dans ce cas, il est recommandé de mettre à jour le dernier noyau et d'utiliser le deuxième playbook pour bénéficier des fonctionnalités d'un noyau compatibles avec L1TF.
Pour utiliser le playbook CVE-2018-3620-fix_disable_ht.yml, il vous suffit d'invoquer ansible-playbook avec les hôtes que vous souhaitez modifier dans HOSTS extra var:
ansible-playbook -e "HOSTS=webservers,db01,portal" CVE-2018-3620-fix_disable_ht.yml
Le deuxième playbook, CVE-2018-3620-apply_settings.yml, vous aidera à activer les mesures d'atténuation de risque provenant d'un noyau compatible avec L1TF. Il y a trois paramètres que vous pouvez spécifier :
- FLUSH=1 changera le comportement du noyau et du module du noyau kvm-intel pour vider le cache de données L1 à chaque entrée de VM, pas seulement quand le noyau détecte qu'un vidage est nécessaire. Bien qu'il y ait des implications en termes de performance, cela nous fournira une meilleure garantie que l'information n'est pas partagée entre les VM, et devrait empêcher les fuites d'information telles que la déréandomisation de l'ASLR. Ce réglage ne devrait être nécessaire que quand vous utilisez un hyperviseur avec des systèmes invités non fiables.
- SMT=1 désactivera l'Hyper-Threading, aussi bien pour le système live que pour le démarrage. Comme pour le premier playbook, on tente de déterminer s'il y a des invités actifs afin d'empêcher les discussions hors ligne possédant une affinité définie.
- FORCE=1 empêchera, lorsqu'il est combiné avec SMT=1, de réactiver le SMT au moment de l'exécution via l'interface /sys/devices/cpu/smt/control. Si FORCE n'est pas spécifié, les utilisateurs ayant suffisamment de permissions peuvent réactiver ou désactiver le SMT au moment de l'exécution.
De plus, le playbook fournit un argument RESET=1 qui supprimera les mesures d'atténuation du risque ci-dessus, et ramènera le système à son comportement par défaut de SMT activé et de vidages de cache de données L1 conditionnel dès l'arrivée d'une VM. Un redémarrage est nécessaire après RESET=1.
Pour utiliser CVE-2018-3620-apply_settings.yml, spécifiez les fonctionnalités que vous souhaitez définir dans les vars supplémentaires, ainsi que les systèmes que vous souhaitez cibler dans la variable HOSTS. Par exemple :
Pour désactiver le SMT, mais autoriser les changements en cours d'exécution, et conserver le comportement de vidage par défaut conditionel du cache de données L1 :
ansible-playbook -e "HOSTS=webservers SMT=1" CVE-2018-3620-apply_settings.yml>.
Pour appliquer toutes les mesures d'atténuation de risque et empêcher les changements en cours d'exécution :
ansible-playbook -e "HOSTS=vmserver01 FLUSH=1 SMT=1 FORCE=1" CVE-2018-3620-apply_settings.yml.
Pour redéfinir L1TF à ses valeurs par défaut :
ansible-playbook -e "HOSTS=webservers RESET=1" CVE-2018-3620-apply_settings.yml
Télécharger le système d'atténuation de risque par les playbooks
Action
Il est fortement recommandé aux clients de Red Hat qui utilisent des versions affectées de ces produits Red Hat de les mettre à jour dès que des errata sont disponibles. Les clients sont instamment priés d'appliquer immédiatement les mises à jour disponibles et d'activer les mesures de mitigation qu'ils jugent appropriées.
L'ordre dans lequel les correctifs sont appliqués n'est pas important, mais après la mise à jour du firmware et des hyperviseurs, chaque système/machine virtuelle devra être éteinte et démarrée à nouveau pour pouvoir reconnaître un nouveau type de hardware.
Mises à jour des produits concernés
| Produit | Paquet | Alerte/Mise à jour |
| Red Hat Enterprise Linux 7 (z-stream) | noyau | RHSA-2018:2384 |
| Red Hat Enterprise Linux 7 | kernel-rt | RHSA-2018:2395 |
| Red Hat Enterprise Linux 7 | microcode_ctl | RHEA-2018:2397 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | noyau | RHSA-2018:2387 |
| Red Hat Enterprise Linux 7.4 Extended Update Support** | microcode_ctl | RHEA-2018:2398 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | noyau | RHSA-2018:2388 |
| Red Hat Enterprise Linux 7.3 Extended Update Support** | microcode_ctl | RHEA-2018:2399 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | noyau | RHSA-2018:2389 |
| Red Hat Enterprise Linux 7.2 Update Services for SAP Solutions, & Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2400 |
| Red Hat Enterprise Linux 6 (z-stream) | noyau | RHSA-2018:2390 |
| Red Hat Enterprise Linux 6 | microcode_ctl | RHEA-2018:2300 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | noyau | RHSA-2018:2391 |
| Red Hat Enterprise Linux 6.7 Extended Update Support** | microcode_ctl | RHEA-2018:2304 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | noyau | RHSA-2018:2392 |
| Red Hat Enterprise Linux 6.6 Advanced Update Support***,**** | microcode_ctl | RHEA-2018:2302 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | noyau | RHSA-2018:2393 |
| Red Hat Enterprise Linux 6.5 Advanced Update Support*** | microcode_ctl | RHEA-2018:2303 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | noyau | RHSA-2018:2394 |
| Red Hat Enterprise Linux 6.4 Advanced Update Support*** | microcode_ctl | RHEA-2018:2297 |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | noyau | en attente |
| Red Hat Enterprise Linux 5 Extended Lifecycle Support* | microcode_ctl | en attente |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | noyau | en attente |
| Red Hat Enterprise Linux 5.9 Advanced Update Support*** | microcode_ctl | en attente |
| RHEL Atomic Host | noyau | respin pending |
| Red Hat Enterprise MRG 2 | kernel-rt | RHSA-2018:2396 |
| Red Hat Virtualization 4 | redhat-virtualization-host | RHSA-2018:2403 |
| Red Hat Virtualization 4 | rhvm-appliance | RHSA-2018:2402 |
| Red Hat Virtualization 3 Extended Lifecycle Support* | rhev-hypervisor7 | RHSA-2018:2404 |
| Red Hat Enterprise Linux OpenStack Platform 7.0 (Kilo) director for RHEL7 | director images | respin pending |
| Red Hat OpenStack Platform 8.0 (Liberty) | director images | respin pending |
| Red Hat OpenStack Platform 9.0 (Mitaka) | director images | respin pending |
| Red Hat OpenStack Platform 10.0 (Newton) | director images | respin pending |
| Red Hat OpenStack Platform 11.0 (Ocata) | director images | respin pending |
| Red Hat OpenStack Platform 12.0 (Pike) | director images | respin pending |
| Red Hat OpenStack Platform 12.0 (Pike) | conteneurs | respin pending |
| Red Hat OpenStack Platform 13.0 (Queens) | director images | respin pending |
| Red Hat OpenStack Platform 13.0 (Queens) | conteneurs | respin pending |
*Un abonnement ELS actif est exigé pour pouvoir accéder à ce correctif. Veuillezcontacter l'équipe de vente de Red Hat ou bien, votre représentant commercial particulier pour obtenir plus d'informations si votre compte n'a pas d'abonnement ELS actif.
**Un abonnement EUS actif est exigé pour pouvoir accéder à ce correctif. Veuillezcontacter l'équipe de vente de Red Hat ou bien, votre représentant commercial particulier, pour obtenir plus d'informations si votre compte n'a pas d'abonnement EUS actif.
Qu'est- ce qu'un abonnement Red Hat Enterprise Linux Extended Update Support ?
*Un abonnement AUS actif est exigé pour pouvoir accéder à ce correctif dans RHEL AUS.
*Un abonnement TUS actif est exigé pour pouvoir accéder à ce correctif dans RHEL TUS.
***** Les abonnés doivent contacter leurs FEO pour obtenir les versions de micro-code/firmware CPU les plus récentes.
Mesures d'atténuation du risque
Les mesures actuelles d'atténuation du risque comprennent l'application des mises à jour logicielles fournisseur combinées aux micro-code/firmware CPU des FEO. Tous les clients Red Hat doivent appliquer les solutions proposées par le fournisseur pour patcher leurs CPU, le système BIOS (si nécessaire) et mettre à jour le noyau dès que des correctifs sont disponibles. Toutes les mesures d'atténuation du risque sont activées par défaut, à l'exception de la désactivation de l'Hyper-Threading, que les clients doivent effectuer manuellement. Il est conseillé aux clients d'adopter une approche basée sur le risque de sécurité lorsqu'ils examinent cette question et tentent de réagir. Les clients devront évaluer le risque de sécurité, l'éventail des mesures d'atténuation de risque, et leurs impacts sur la performance pour créer une stratégie d'atténuation du risque. Les systèmes qui exigent un degré de sécurité et de fiabilité élevés doivent être traités en premier et isolés des systèmes non fiables jusqu'à ce que l'on puisse appliquer des solutions à ces systèmes pour réduire le risque d'exploitation. Les clients désireux d'atténuer ce risque au maximum devront envisager une gestion de la sécurité plus renforcée et éventuellement désactiver l'Hyper-Threading pour clore tous les vecteurs d'attaque.
Mesures d'atténuation du risque / Outils de correction
Pour une réduction de risque lié à « L1 Terminal Fault » maximale, trois changements sont nécessaires : l'inversion des tableaux de pages (une petite modification du noyau qui est fournie et activée par défaut dans les noyaux mis à jour), le vidage du cache de données L1 lors des changements de machines virtuelles, et éventuellement la désactivation du SMT. Chacun de ces changements fournit indépendamment une certaine protection contre les différents aspects d'une attaque.
L'inversion des tableaux de pages (qui n'est PAS la même chose que l' Isolation des tableaux de pages ajoutée pour l'atténuation du risque avec Meltdown) est effectuée par défaut lors de la manipulation d'entrées de tableaux de pages non présentes dans les noyaux mis à jour fournis par Red Hat.
Le vidage du cache de données L1 est facultatif et peut être implémenté par une mise à jour du microcode ou du noyau. Il est actuellement activé par défaut lors de l'exécution de machines virtuelles invitées, mais peut être contrôlé par l'utilisateur par le biais des paramètres du noyau.
SMT Disable est utilisé en option pour sécuriser un environnement partagé non sécurisé exécutant des machines virtuelles. Cela passe par des modifications logicielles au niveau du noyau pour ajouter une nouvelle interface de contrôle. Il est également possible de désactiver l' Hyper-threading d'Intel dans le firmware du BIOS, mais c'est beaucoup plus difficile et ce n'est pas l'approche conseillée.
La solution implique cette approche tripartite car cette faille a trois facteurs contribuant :
- Une entrée PTE (de l'anglais Page table Entry) non présente (P flag = 0) OU qui a un set de bits réservés contient une adresse physique non initialisée, et cette adresse physique is mise en cache dans le cache de données L1.
- Les mises à jour causées par les opérations spéculatives dans le cache de données L1 ne sont pas effacées. On peut s'en rendre compte grâce à un processus supplémentaire.
- Les multi-threads simultanés (SMT) partagent le moteur d'exécution et les caches des processeurs on-chip comme les caches de données L1 et TLB.
Inversion des tableaux de pages :
Le processeur accède spéculativement à l'adresse physique à partir d'un PTE Non présent et si le contenu de cette adresse physique est mis en cache dans le cache de données L1, l'accès à la mémoire réussit. Par conséquent, si le contenu de l'adresse physique n'est pas mis en cache, l'accès à la mémoire n'entraîne pas de fuite de données. La façon d'atténuer le risque d'inversion des tableaux de pages est de mettre à jour l'adresse physique dans les PTE Non présents en réglant les bits d'adresse d'ordre élevé, de façon à pointer vers une adresse physique qui n'est pas en mémoire et/ou qui n'est pas mise en cache. Ainsi, son contenu ne peut pas être présent dans le cache de données L1.
Le paquet du noyau mis à jour montre l'état actuel du système via l'interface sysfs comme indiqué :
# cat /sys/devices/system/cpu/vulnerabilities/l1tf
Mitigation: PTE Inversion; VMX: SMT vulnerable, L1D conditional cache flushes
#
Vidage du Cache de données L1 :
Les processeurs Intel x86 offrent un IA32_FLUSH_CMD Machine Specific Register (MSR), lorsque le microcode mis à jour est installé sur le système. Il peut être utilisé pour invalider le cache de données L1. On peut observer le support de IA32_FLUSH_CMD MSR via les indicateurs de /proc/cpuinfo OU via la commande lscpu(1) qui liste les indicateurs de CPU :
# lscpu
Flags: … ssbd ibrs ibpb stibp spec_ctrl intel_stibp flush_l1d
#
Si l'indicateur flush_l1d n'est pas disponible, veuillez confirmer que le microcode mis à jour est installé sur le système et que le système a été redémarré.
Si le microcode mis à jour n'est pas installé, l'indicateur flush_l1d ne sera pas disponible. Alors, le noyau mis à jour vide toujours le cache de données L1 dans le logiciel. Ceci sera plus lent par rapport à l'interface de hardware flush_l1d .
Le paquet de noyau mis à jour introduit les paramètres suivants de noyau et du module KVM pour contrôler les mesures d'atténuation de risque pour L1TF :
l1tf=[full/full,force/flush/flush,nosmt/flush,nowarn/off]
Il s'agit d'un paramètre d'amorçage du noyau pour contrôler le problème L1TF sur les processeurs affectés. Il peut prendre l'une des valeurs suivantes
full: permet toutes les mesures d'atténuation du risque pour le problème L1TF.
- Active le vidage du cache de données L1 à chaque opération d'entrée de VM.
- Désactivation de l' Hyper-Threading (SMT).
Le vidage du cache de données L1 et le SMT peuvent tous deux être contrôlés au moment de l'exécution, après l'amorçage, via l'interface sysfs.
full,force: permet toutes les mesures d'atténuation du risque pour le problème L1TF.
- Active le vidage du cache de données L1 à chaque opération d'entrée de VM.
- Désactivation de l' Hyper-Threading (SMT).
Le paramètre « force » empêche les utilisateurs de désactiver les mesure d'atténuation du risque L1TF ci-dessus via l'interface sysfs. Les utilisateurs ne peuvent pas activer l'hyper-threading (SMT) au moment de l'exécution.
flush: only enable L1 data cache flush
- Active l'atténuation du risque de vidage du cache des données L1 par défaut, qui consiste à vider conditionnellement le cache de données L1.
- Ne désactive pas l' Hyper-Threading (SMT).
Ils peuvent tous deux être contrôlés via l'interface sysfs. L'hyperviseur (KVM) émet un avertissement si un invité est démarré avec des configurations non sécurisées telles qu'avec le SMT activé OU le vidage de cache de données L1 désactivé.
flush,nosmt: disables the Hyper-Threading (SMT)
- Permet la solution de mitigation de vidage conditionnelle du cache de données L1
- Désactiver l' Hyper-Threading (SMT).
Ils peuvent tous deux être contrôlés via l'interface sysfs. L'hyperviseur (KVM) émet un avertissement si un invité est démarré avec des configurations non sécurisées telles qu'avec le SMT activé OU le vidage de cache de données L1 désactivé.
flush,nowarn: similaire à l'option de vidage ci-dessus, à part les avertissements du module KVM concernant les invités dont la configuration n'est pas sécurisée qui sont supprimés.
off : désactive les mitigations niveau hyperviseur, c'est-à-dire que KVM ne videra pas le cache de données L1 à l'entrée de la VM.
La valeur par défaut du paramètre l1tf boot est définie sur l'option d'atténuation de risque de vidage ci-dessus.
kvm-intel.vmentry_l1d_flush : paramètre du module KVM pour contrôler les opérations de vidage du cache de données L1 à chaque entrée de la VM. Il peut avoir des valeurs possibles comme indiqué ici :
always vidage de cache L1D à chaque VMENTER.
cond vidage de cache L1D conditionel.
never désactive la mitigation par vidage du cache L1D.
cond essaie d'éviter les vidages de cache L1D sur VMENTER si le code exécuté entre VMEXIT et VMENTER est considéré comme sûr, c'est-à-dire qu'il n'apporte aucune
information intéressante dans L1D qui puisse être exploitée.
# cat /sys/module/kvm_intel/parameters/vmentry_l1d_flush
cond
#
Ce paramètre est réglé par défaut sur « cond by default »; il effectue un vidage du cache de données L1 sur des instances d'entrée sélectives de la VM. Cela devrait contribuer à réduire l'impact du vidage du cache de données L1 sur la performance.
Contrôle SMT :
Lorsque la technologie de multithreading ou Hyper-Threading simultané est utilisée, des threads non liés s'exécutant sur le même cœur et partageant les ressources de cache du processeur peuvent lire les données de l'autre dans le cache de données L1 en exploitant la vulnérabilité L1TF. Si vous utilisez un environnement partagé non fiable, vous devrez envisager de désactiver le SMT dans le cadre de votre stratégie d'atténuation du risque. En général, le SMT peut être activé ou désactivé à partir du Bios système.
Les paquets de noyau mis à jour comprennent un nouveau paramètre de ligne de commande « nosmt ».
nosmt : désactive le multithreading simultané (SMT). Il peut être réactivé au moment de l'exécution via une interface sysfs.
nosmt=force : désactive le multithreading simultané (SMT). Il ne peut pas être réactivé au moment de l'exécution.
REMARQUE : il existe des contrôles dans l'interface sysfs du noyau pour gérer le multithreading au moment de l'exécution, bien que leur utilisation puisse conduire à des comportements erronés lorsque le SMT est réactivé. Par conséquent, il est fortement recommandé d'utiliser les paramètres du BIOS ou les paramètres d'amorçage du noyau énumérés ci-dessus pour activer/désactiver le SMT. Les indicateurs de durée d'exécution ne sont décrits ici qu'à titre de référence :
/sys/devices/system/cpu/smt/active
/sys/devices/system/cpu/smt/control
Le fichier actif ci-dessus est une interface en lecture seule. Lorsque le fichier actif contient «1», cela signifie que le SMT est activé et que les threads frères sont en ligne. Lorsque le noyau est démarré avec le paramètre «nosmt», il écrit essentiellement «0» dans le fichier actifci-dessus.
Le fichier de contrôle mentionné ci-dessus est une interface de lecture/écriture pour contrôler le SMT. Il peut avoir les valeurs suivantes :
on : le SMT est activé. Active les threads frères et sœurs s'ils étaient hors ligne.
off : le SMT est désactivé. Désactiver les threads frères s'ils étaient en ligne.
forceoff : le SMT est désactivé de force et ne peut pas être modifié. Il ne peut pas être
contrôlé ni modifié au moment de l'exécution.
notsupporte : le processeur ne prend pas en charge l'Hyper-Threading (SMT).
Désactiver EPT :
La désactivation de l'EPT (Extended Page Tables) pour les invités KVM atténue le problème L1TF, car elle permet essentiellement au VMM/Hyperviseur de gérer les traductions d'adresses pour l'invité. Si l'EPT est désactivé, il n'est pas nécessaire de désactiver Hyper-Threads (SMT) et de vider le cache de données L1 comme indiqué ci-dessus.
Veuillez noter que la désactivation de l'EPT entravera considérablement les performances du système. Ce n'est peut-être pas une option viable.
L'EPT peut être désactivé dans l'hyperviseur via le paramètre kvm-intel.ept . Il est activé par défaut.
Red Hat recommande aux clients d'appliquer la mise à jour du microcode/firmware conseillée par votre fournisseur de matériel ou de processeur et d'installer ces noyaux mis à jour dès que possible. Les mises à jour logicielles peuvent être appliquées indépendamment de celles du microcode hardware, mais ne prendront effet que lorsque le firmware du processeur aura été mis à jour.
Tuned
Les nouveaux noyaux L1TF fournissent des contrôles qui permettent à l'utilisateur de désactiver l'Hyper-Threading soit au moment de l'exécution, soit lors de l'amorçage du noyau. Si l'une de ces deux méthodes est utilisée et que le système exécute l'un des quatre profils syntonisés (tuned) suivants :
cpu-partitioning
realtime
realtime-virtual-host
realtime-virtual-guest
alors une mise à jour syntonisée (tuned) sera nécessaire. Ceci n'affecte que RHEL 7.4z et 7.5z. Une mise à jour n'est pas nécessaire si Hyper-Threading est désactivé dans le BIOS.
Comments