
仮想化
OpenShift Virtualization のインストール、使用方法、およびリリースノート
概要
第1章 概要
1.1. OpenShift Virtualization について
OpenShift Virtualization の機能およびサポート範囲について確認します。
1.1.1. OpenShift Virtualization の機能
OpenShift virtualization は OpenShift Container Platform のアドオンであり、仮想マシンのワークロードを実行し、このワークロードをコンテナーのワークロードと共に管理することを可能にします。
OpenShift Virtualization は、Kubernetes カスタムリソースにより新規オブジェクトを OpenShift Container Platform クラスターに追加し、仮想化タスクを有効にします。これらのタスクには、以下が含まれます。
- Linux および Windows 仮想マシン (VM) の作成と管理
- クラスター内で Pod と 仮想マシンのワークロードの同時実行
- 各種コンソールおよび CLI ツールの使用による仮想マシンへの接続
- 既存の仮想マシンのインポートおよびクローン作成
- ネットワークインターフェイスコントローラーおよび仮想マシンに割り当てられたストレージディスクの管理
- 仮想マシンのノード間でのライブマイグレーション
機能強化された Web コンソールは、これらの仮想化されたリソースを OpenShift Container Platform クラスターコンテナーおよびインフラストラクチャーと共に管理するためのグラフィカルポータルを提供します。
OpenShift Virtualization は、Red Hat OpenShift Data Foundation の機能とうまく連携するように設計およびテストされています。
OpenShift Data Foundation を使用して OpenShift Virtualization をデプロイする場合は、Windows 仮想マシンディスク用の専用ストレージクラスを作成する必要があります。詳細は 、Windows VM の ODF PersistentVolumes の最適化 を参照してください。
OpenShift Virtualization は、OVN-Kubernetes、OpenShift SDN、または 認定 OpenShift CNI プラグイン にリストされているその他の認定ネットワークプラグインのいずれかで使用できます。
Compliance Operator をインストールし、ocp4-moderate および ocp4-moderate-node プロファイル を使用してスキャンを実行することにより、OpenShift Virtualization クラスターのコンプライアンスの問題を確認できます。Compliance Operator は、NIST 認定ツール である OpenSCAP を使用して、セキュリティーポリシーをスキャンし、適用します。
1.1.1.1. OpenShift Virtualization サポートのクラスターバージョン
OpenShift Virtualization 4.14 は OpenShift Container Platform 4.14 クラスターで使用するためにサポートされます。Open Shift Virtualization の最新の z-stream リリースを使用するには、最初に Open Shift Container Platform の最新バージョンにアップグレードする必要があります。
1.1.2. 仮想マシンディスクのボリュームとアクセスモードについて
既知のストレージプロバイダーでストレージ API を使用する場合、ボリュームモードとアクセスモードは自動的に選択されます。ただし、ストレージプロファイルのないストレージクラスを使用する場合は、ボリュームとアクセスモードを設定する必要があります。
最良の結果を得るには、ReadWriteMany (RWX) アクセスモードと Block ボリュームモードを使用してください。これは、以下の理由により重要です。
-
ライブマイグレーションには
ReadWriteMany(RWX) アクセスモードが必要です。 Blockボリュームモードは、Filesystemボリュームモードよりもパフォーマンスが大幅に優れています。これは、Filesystemボリュームモードでは、ファイルシステムレイヤーやディスクイメージファイルなどを含め、より多くのストレージレイヤーが使用されるためです。仮想マシンのディスクストレージに、これらのレイヤーは必要ありません。たとえば、Red Hat OpenShift Data Foundation を使用する場合は、CephFS ボリュームよりも Ceph RBD ボリュームの方が推奨されます。
次の設定の仮想マシンをライブマイグレーションすることはできません。
-
ReadWriteOnce(RWO) アクセスモードのストレージボリューム - GPU などのパススルー機能
それらの仮想マシンの evictionStrategy フィールドを LiveMigrate に設定しないでください。
1.1.3. 単一ノードの Openshift の違い
OpenShift Virtualization は単一ノード OpenShift にインストールできます。
ただし、単一ノード OpenShift は次の機能をサポートしていないことに注意してください。
- 高可用性
- Pod の中断
- ライブマイグレーション
- エビクション戦略が設定されている仮想マシンまたはテンプレート
1.1.4. 関連情報
1.2. セキュリティーポリシー
OpenShift Virtualization のセキュリティーと認可について説明します。
主なポイント
-
OpenShift Virtualization は、Pod セキュリティーの現在のベストプラクティスを強制することを目的とした、
restrictedKubernetes pod security standards プロファイルに準拠しています。 - 仮想マシン (VM) のワークロードは、特権のない Pod として実行されます。
-
セキュリティーコンテキスト制約 (SCC) は、
kubevirt-controllerサービスアカウントに対して定義されます。 - OpenShift Virtualization コンポーネントの TLS 証明書は更新され、自動的にローテーションされます。
1.2.1. ワークロードのセキュリティーについて
デフォルトでは、OpenShift Virtualization の仮想マシン (VM) ワークロードは root 権限では実行されず、root 権限を必要とするサポート対象の OpenShift Virtualization 機能はありません。
仮想マシンごとに、virt-launcher Pod が libvirt のインスタンスを セッションモード で実行し、仮想マシンプロセスを管理します。セッションモードでは、libvirt デーモンは root 以外のユーザーアカウントとして実行され、同じユーザー識別子 (UID) で実行されているクライアントからの接続のみを許可します。したがって、仮想マシンは権限のない Pod として実行し、最小権限のセキュリティー原則に従います。
1.2.2. TLS 証明書
OpenShift Virtualization コンポーネントの TLS 証明書は更新され、自動的にローテーションされます。手動で更新する必要はありません。
自動更新スケジュール
TLS 証明書は自動的に削除され、以下のスケジュールに従って置き換えられます。
- KubeVirt 証明書は毎日更新されます。
- Containerized Data Importer controller (CDI) 証明書は、15 日ごとに更新されます。
- MAC プール証明書は毎年更新されます。
TLS 証明書の自動ローテーションはいずれの操作も中断しません。たとえば、以下の操作は中断せずに引き続き機能します。
- 移行
- イメージのアップロード
- VNC およびコンソールの接続
1.2.3. 認可
OpenShift Virtualization は、ロールベースのアクセス制御 (RBAC) を使用して、人間のユーザーとサービスアカウントの権限を定義します。サービスアカウントに定義された権限は、OpenShift Virtualization コンポーネントが実行できるアクションを制御します。
RBAC ロールを使用して、仮想化機能へのユーザーアクセスを管理することもできます。たとえば管理者は、仮想マシンの起動に必要な権限を提供する RBAC ロールを作成できます。管理者は、ロールを特定のユーザーにバインドすることでアクセスを制限できます。
1.2.3.1. OpenShift Virtualization のデフォルトのクラスターロール
クラスターロール集約を使用することで、OpenShift Virtualization はデフォルトの OpenShift Container Platform クラスターロールを拡張して、仮想化オブジェクトにアクセスするための権限を組み込みます。
表1.1 OpenShift Virtualization のクラスターロール
| デフォルトのクラスターロール | OpenShift Virtualization のクラスターロール | OpenShift Virtualization クラスターロールの説明 |
|---|---|---|
|
|
| クラスター内の OpenShift Virtualization リソースをすべて表示できるユーザー。ただし、リソースの作成、削除、変更、アクセスはできません。たとえば、ユーザーは仮想マシン (VM) が実行中であることを確認できますが、それをシャットダウンしたり、そのコンソールにアクセスしたりすることはできません。 |
|
|
| クラスター内のすべての OpenShift Virtualization リソースを変更できるユーザー。たとえば、ユーザーは仮想マシンの作成、VM コンソールへのアクセス、仮想マシンの削除を行えます。 |
|
|
|
リソースコレクションの削除を含め、すべての OpenShift Virtualization リソースに対する完全な権限を持つユーザー。このユーザーは、 |
1.2.3.2. OpenShift Virtualization のストレージ機能の RBAC ロール
cdi-operator および cdi-controller サービスアカウントを含む、次のパーミッションがコンテナー化データインポーター (CDI) に付与されます。
1.2.3.2.1. クラスター全体の RBAC のロール
表1.2 cdi.kubevirt.io API グループの集約されたクラスターロール
| CDI クラスターのロール | Resources | 動詞 |
|---|---|---|
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
表1.3 cdi-operator サービスアカウントのクラスター全体のロール
| API グループ | Resources | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
許可リスト: |
|
|
|
許可リスト: |
|
|
|
|
|
表1.4 cdi-controller サービスアカウントのクラスター全体のロール
| API グループ | Resources | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.2.3.2.2. namespace 付きの RBAC ロール
表1.5 cdi-operator サービスアカウントの namespace ロール
| API グループ | Resources | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表1.6 cdi-controller サービスアカウントの namespace ロール
| API グループ | Resources | 動詞 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.2.3.3. kubevirt-controller サービスアカウントの追加の SCC とパーミッション
SCC (Security Context Constraints) は Pod のパーミッションを制御します。これらのパーミッションには、コンテナーのコレクションである Pod が実行できるアクションおよびそれがアクセスできるリソース情報が含まれます。SCC を使用して、Pod がシステムに受け入れられるために必要な Pod の実行に関する条件の一覧を定義できます。
virt-controller は、クラスター内の仮想マシンの virt-launcher Pod を作成するクラスターコントローラーです。これらの Pod には、kubevirt-controller サービスアカウントによってパーミッションが付与されます。
kubevirt-controller サービスアカウントには追加の SCC および Linux 機能が付与され、これにより適切なパーミッションを持つ virt-launcher Pod を作成できます。これらの拡張パーミッションにより、仮想マシンは通常の Pod の範囲外の OpenShift Virtualization 機能を利用できます。
kubevirt-controller サービスアカウントには以下の SCC が付与されます。
-
scc.AllowHostDirVolumePlugin = true
これは、仮想マシンが hostpath ボリュームプラグインを使用することを可能にします。 -
scc.AllowPrivilegedContainer = false
これは、virt-launcher Pod が権限付きコンテナーとして実行されないようにします。 scc.AllowedCapabilities = []corev1.Capability{"SYS_NICE", "NET_BIND_SERVICE"}-
SYS_NICEを使用すると、CPU アフィニティーを設定できます。 -
NET_BIND_SERVICEは、DHCP および Slirp 操作を許可します。
-
kubevirt-controller の SCC および RBAC 定義の表示
oc ツールを使用して kubevirt-controller の SecurityContextConstraints 定義を表示できます。
$ oc get scc kubevirt-controller -o yaml
oc ツールを使用して kubevirt-controller クラスターロールの RBAC 定義を表示できます。
$ oc get clusterrole kubevirt-controller -o yaml
1.2.4. 関連情報
1.3. OpenShift Virtualization アーキテクチャー
Operator Lifecycle Manager (OLM) は、OpenShift Virtualization の各コンポーネントのオペレーター Pod をデプロイします。
-
コンピューティング:
virt-operator -
ストレージ:
cdi-operator -
ネットワーク:
cluster-network-addons-operator -
スケーリング:
ssp-operator -
テンプレート作成:
tekton-tasks-operator
OLM は、他のコンポーネントのデプロイ、設定、およびライフサイクルを担当する hyperconverged-cluster-operator Pod と、いくつかのヘルパー Pod (hco-webhook および hyperconverged-cluster-cli-download) もデプロイします。
すべての Operator Pod が正常にデプロイされたら、HyperConverged カスタム リソース (CR) を作成する必要があります。HyperConverged CR で設定された設定は、信頼できる唯一の情報源および OpenShift Virtualization のエントリーポイントとして機能し、CR の動作をガイドします。
HyperConverged CR は、調整ループ内の他のすべてのコンポーネントの Operator に対応する CR を作成します。その後、各 Operator は、デーモンセット、config map、および OpenShift Virtualization コントロールプレーン用の追加コンポーネントなどのリソースを作成します。たとえば、HyperConverged Operator (HCO) が KubeVirt CR を作成すると、OpenShift Virtualization Operator がそれを調整し、virt-controller、virt-handler、virt-api などの追加リソースを作成します。
OLM は Hostpath Provisioner (HPP) Operator をデプロイしますが、hostpath-provisioner CR を作成するまで機能しません。
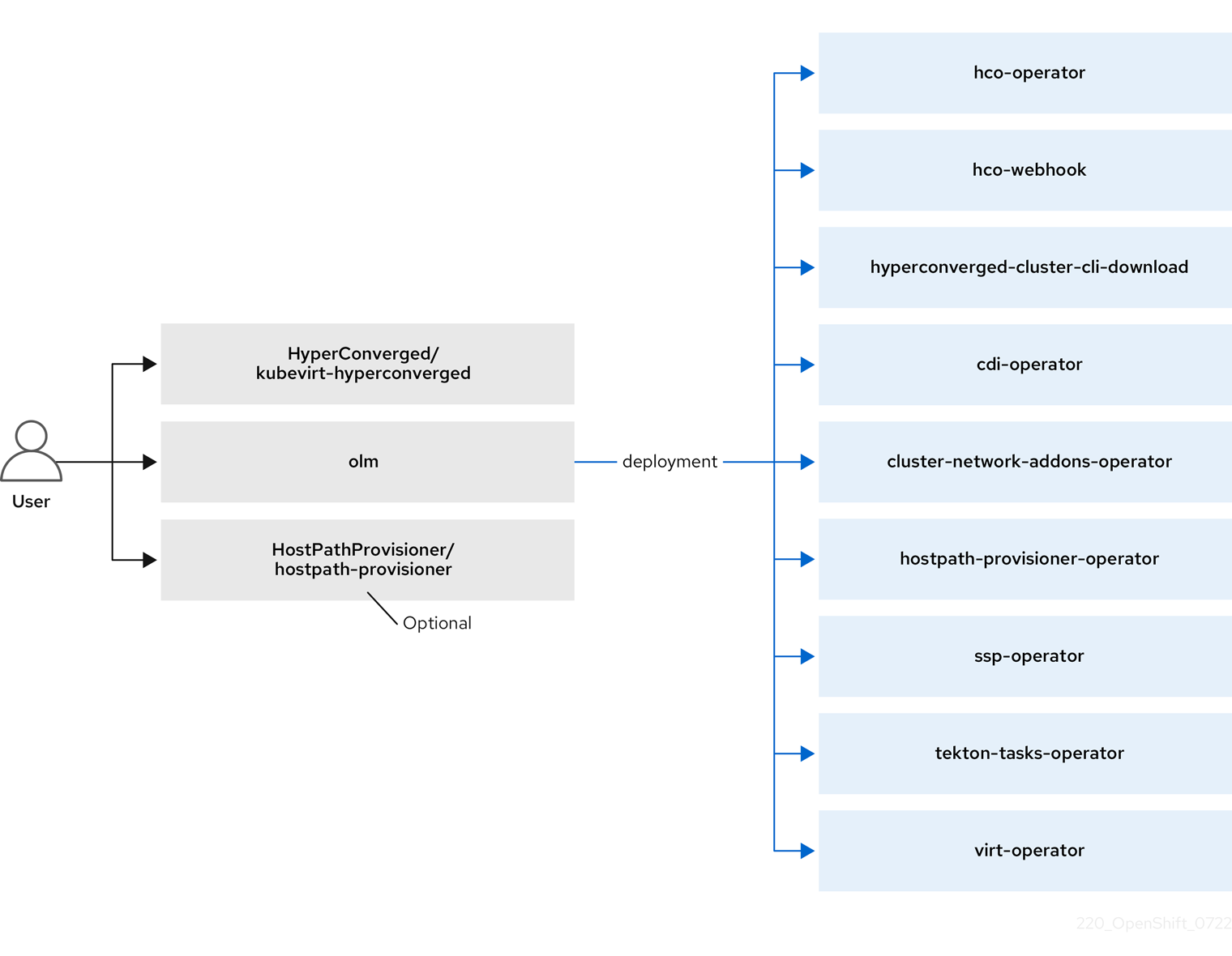
1.3.1. HyperConverged Operator (HCO) について
HCO (hco- operator) は、OpenShift Virtualization をデプロイおよび管理するための単一のエントリーポイントと、独自のデフォルトを持ついくつかのヘルパー Operator を提供します。また、これらの Operator のカスタム リソース (CR) も作成します。
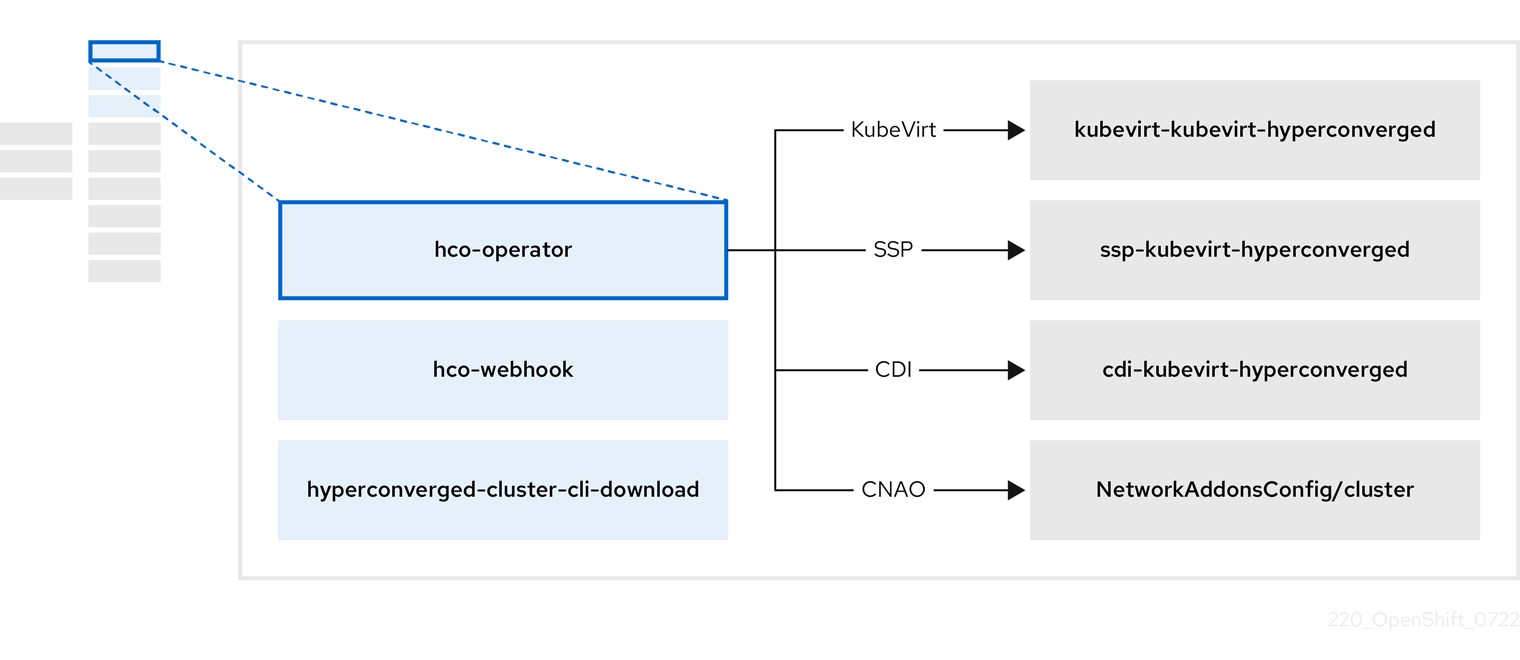
表1.7 HyperConverged Operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
|
|
|
|
クラスターから直接ダウンロードできるように、 |
|
| OpenShift Virtualization に必要なすべての Operator、CR、およびオブジェクトが含まれています。 |
|
| Scheduling, Scale, and Performance (SSP) CR。これは、HCO によって自動的に作成されます。 |
|
| Containerized Data Importer (CDI) CR。これは、HCO によって自動的に作成されます。 |
|
|
|
1.3.2. Containerized Data Importer (CDI) Operator について
CDI Operator cdi-operator は、CDI とその関連リソースを管理し、データボリュームを使用して仮想マシンイメージを永続ボリューム要求 (PVC) にインポートします。
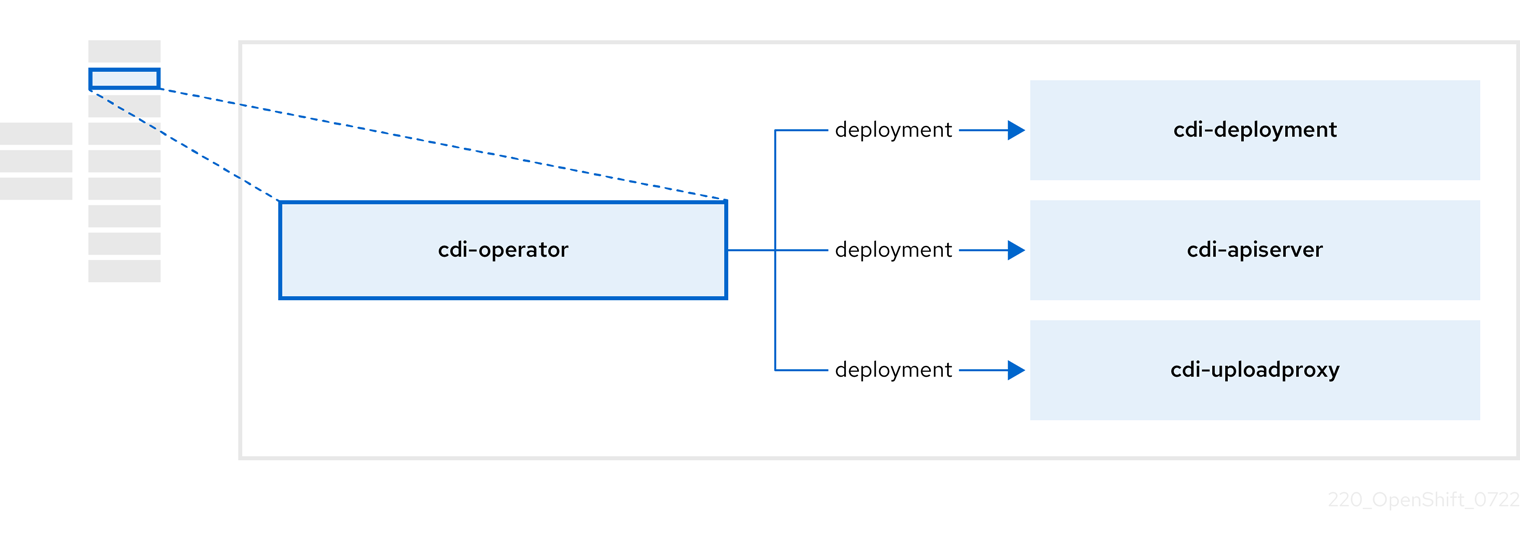
表1.8 CDI Operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
| 安全なアップロードトークンを発行して、VM ディスクを PVC にアップロードするための承認を管理します。 |
|
| 外部ディスクのアップロードトラフィックを適切なアップロードサーバー Pod に転送して、正しい PVC に書き込むことができるようにします。有効なアップロードトークンが必要です。 |
|
| データ ボリュームの作成時に仮想マシンイメージを PVC にインポートするヘルパー Pod。 |
1.3.3. Cluster Network Addons Operator について
Cluster Network Addons Operator (cluster-network-addons-operator) は、クラスターにネットワークコンポーネントをデプロイし、拡張ネットワーク機能の関連リソースを管理します。
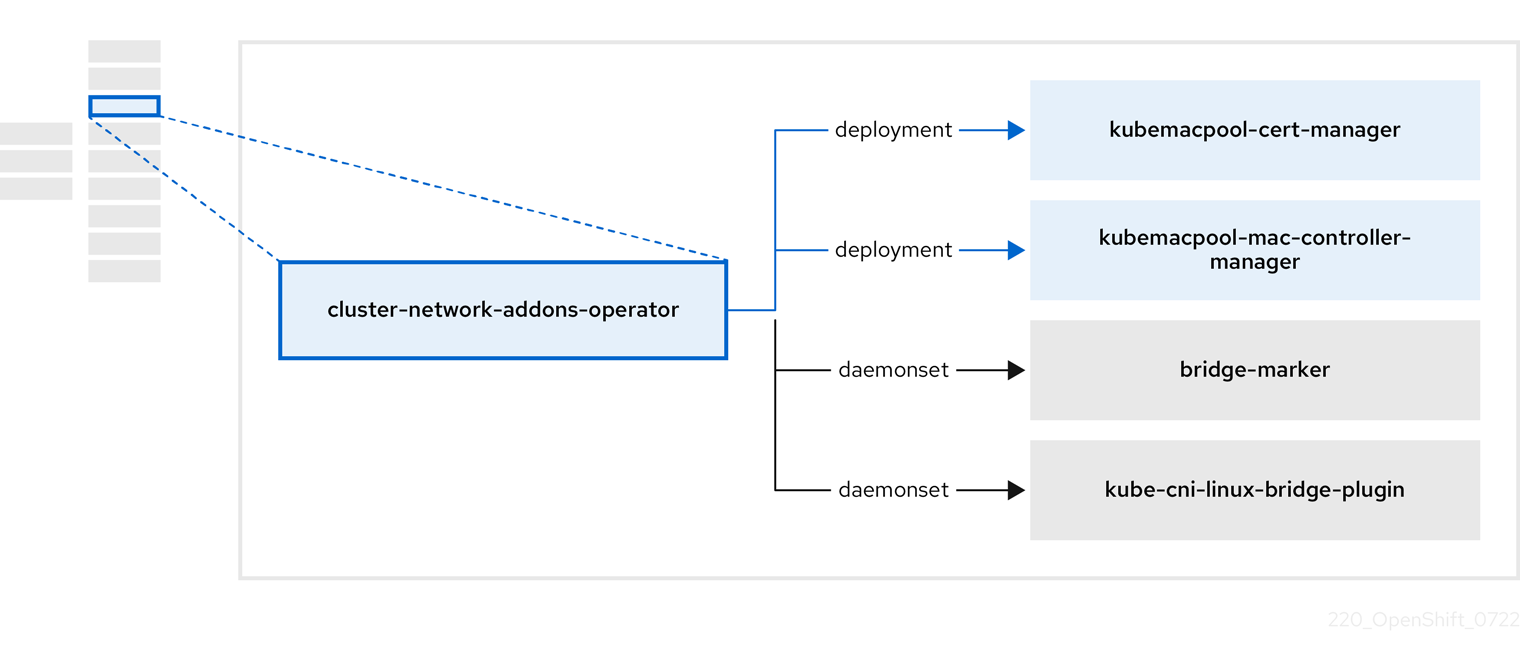
表1.9 Cluster Network Addons Operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
| Kubemacpool の Webhook の TLS 証明書を管理します。 |
|
| 仮想マシン (VM) ネットワークインターフェイス カード (NIC) の MAC アドレスプールサービスを提供します。 |
|
| ノードで使用可能なネットワークブリッジをノードリソースとしてマークします。 |
|
| クラスターノードに Container Network Interface (CNI) プラグインをインストールし、ネットワーク接続定義を介して Linux ブリッジに VM を接続できるようにします。 |
1.3.4. Hostpath Provisioner (HPP) Operator について
HPP オペレーター hostpath-provisioner-operator は、マルチノード HPP および関連リソースをデプロイおよび管理します。
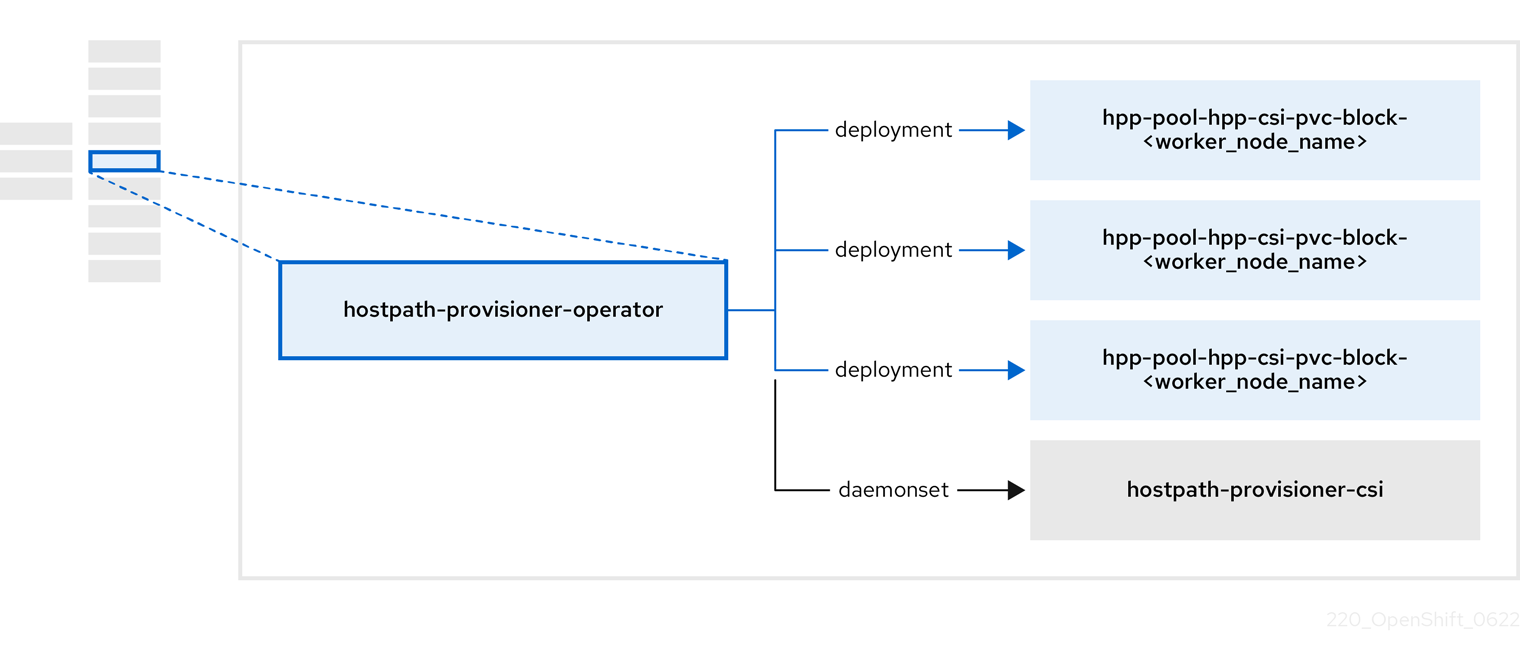
表1.10 HPP Operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
| HPP の実行が指定されている各ノードにワーカーを提供します。Pod は、指定されたバッキングストレージをノードにマウントします。 |
|
| HPP の Container Storage Interface (CSI) ドライバーインターフェイスを実装します。 |
|
| HPP のレガシードライバーインターフェイスを実装します。 |
1.3.5. Scheduling, Scale, and Performance (SSP) Operator について
SSP オペレーター ssp-operator は、共通テンプレート、関連するデフォルトのブートソース、パイプラインタスク、およびテンプレートバリデーターをデプロイします。
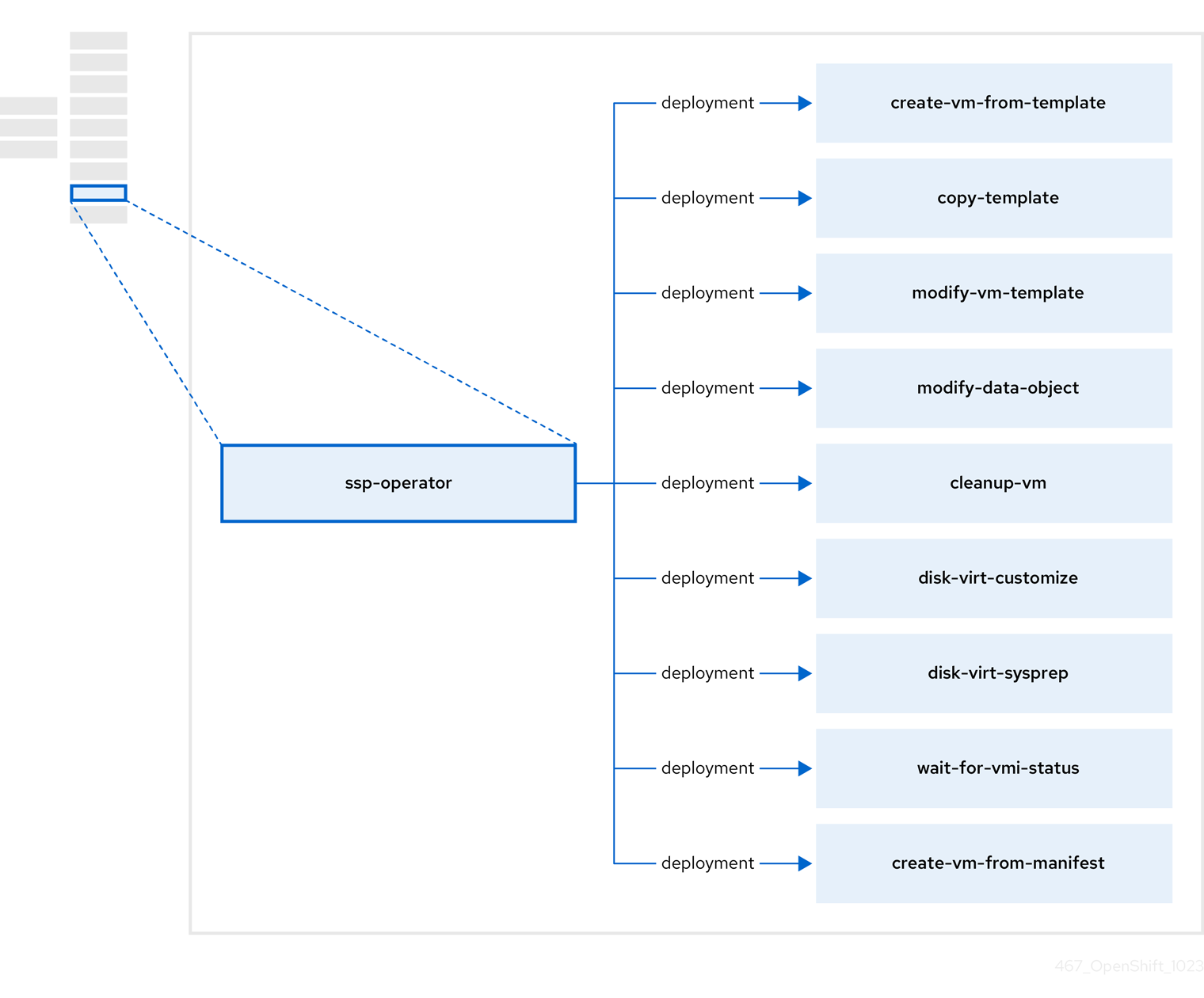
表1.11 SSP Operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
| テンプレートから仮想マシンを作成します。 |
|
| 仮想マシンテンプレートをコピーします。 |
|
| 仮想マシンテンプレートを作成または削除します。 |
|
| データボリュームまたはデータソースを作成または削除します。 |
|
| 仮想マシンでスクリプトまたはコマンドを実行し、後で仮想マシンを停止または削除します。 |
|
|
|
|
|
|
|
| 特定の仮想マシンインスタンス (VMI) ステータスを待機し、そのステータスに応じて失敗または成功します。 |
|
| マニフェストから仮想マシンを作成します。 |
1.3.6. OpenShift Virtualization Operator について
OpenShift Virtualization Operator virt-operator は、現在の仮想マシンワークロードを中断することなく OpenShift Virtualization をデプロイ、アップグレード、管理します。
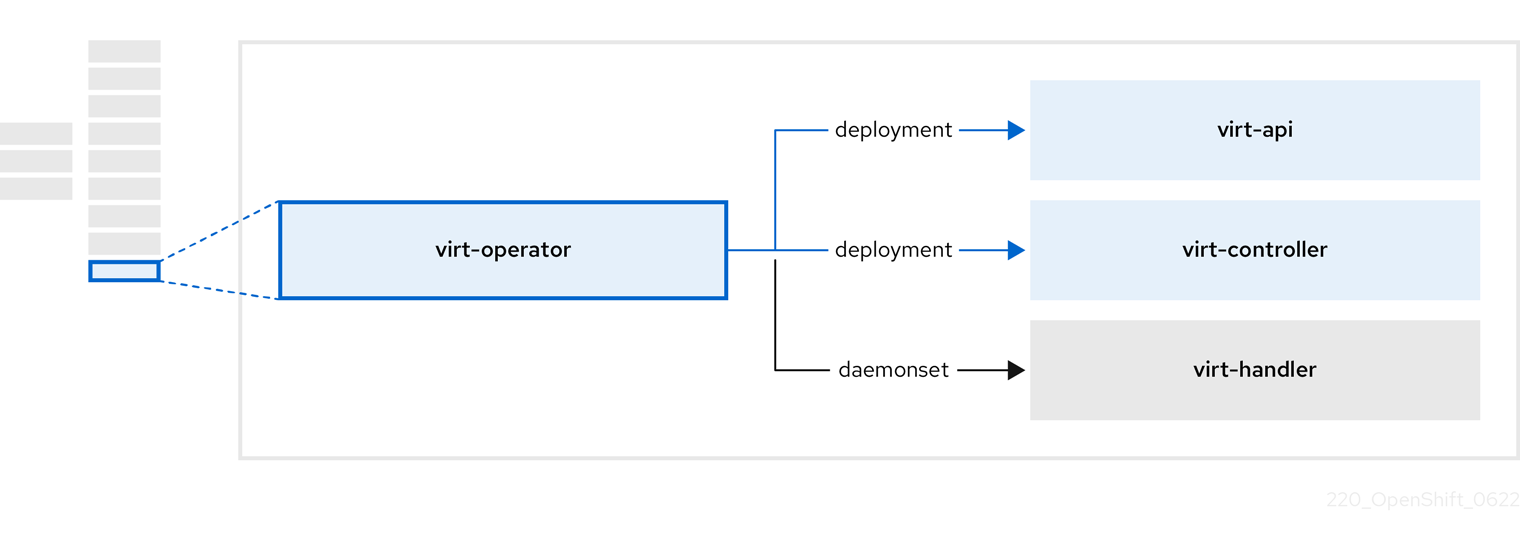
表1.12 virt-operator コンポーネント
| コンポーネント | 説明 |
|---|---|
|
| すべての仮想化関連フローのエントリーポイントとして機能する HTTP API サーバー。 |
|
|
新しい VM インスタンス オブジェクトの作成を監視し、対応する Pod を作成します。Pod がノードでスケジュールされると、 |
|
|
VM への変更を監視し、必要な操作を実行するように |
|
|
|
第2章 リリースノート
2.1. OpenShift Virtualization リリースノート
2.1.1. 多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ をご覧ください。
2.1.2. ドキュメントに関するフィードバックの提供
エラーを報告したり、ドキュメントを改善したりするには、Red Hat Jira アカウント にログインし、Jira issue を送信してください。
2.1.3. Red Hat OpenShift Virtualization について
Red Hat OpenShift Virtualization は、従来の仮想マシン (VM) をコンテナーと共に実行される OpenShift Container Platform に組み込み、それらをネイティブ Kubernetes オブジェクトとして管理することを可能にします。
OpenShift Virtualization は、
![]() アイコンで表されます。
アイコンで表されます。
OVN-Kubernetes または OpenShiftSDN のデフォルトの Container Network Interface (CNI) ネットワークプロバイダーのいずれかで OpenShift Virtualization を使用できます。
OpenShift Virtualization の機能 を参照してください。
OpenShift Virtualization のアーキテクチャーとデプロイメント の詳細を参照してください。
OpenShift Virtualization 用に クラスターを準備します。
2.1.3.1. OpenShift Virtualization サポートのクラスターバージョン
OpenShift Virtualization 4.14 は OpenShift Container Platform 4.14 クラスターで使用するためにサポートされます。Open Shift Virtualization の最新の z-stream リリースを使用するには、最初に Open Shift Container Platform の最新バージョンにアップグレードする必要があります。
2.1.3.2. サポート対象のゲストオペレーティングシステム
OpenShift Virtualization でサポートされているゲストオペレーティングシステムを確認するには、Red Hat OpenStack Platform、Red Hat Virtualization、OpenShift Virtualization、Red Hat Enterprise Linux with KVM の認定ゲストオペレーティングシステム を参照してください。
2.1.4. 新機能および変更された機能
OpenShift Virtualization は、Windows Server のワークロードを実行する Microsoft の Windows Server Virtualization Validation Program (SVVP) で認定されています。
SVVP の認定は以下に適用されます。
- Red Hat Enterprise Linux CoreOS ワーカー。Microsoft SVVP Catalog では、Red Hat OpenShift Container Platform 4 on RHEL CoreOS 9 という名前が付けられます。
- Intel および AMD CPU。
- OpenShift Virtualization でホストされたコントロールプレーンクラスターの作成は、以前はテクノロジープレビュー機能でしたが、現在は一般提供されています。詳細は、Red Hat Advanced Cluster Management (RHACM) ドキュメントの OpenShift Virtualization でのホストされたコントロールプレーンクラスターの管理 を参照してください。
Amazon Web Services (AWS) ベアメタル OpenShift Container Platform クラスター上で OpenShift Virtualization を使用することは、以前はテクノロジープレビューでしたが、現在は一般提供されています。
さらに、OpenShift Virtualization が Red Hat OpenShift Service on AWS の Classic クラスターでサポートされるようになりました。
詳細は、AWS ベアメタル上の OpenShift Virtualization を参照してください。
- NVIDIA GPU Operator を使用して GPU 対応仮想マシンのワーカーノードをプロビジョニングすることは、以前はテクノロジープレビューでしたが、現在は一般提供されています。詳細は、NVIDIA GPU Operator の設定 を参照してください。
- クラスター管理者は、OpenShift API for Data Protection (OADP) を使用して、OpenShift Virtualization で実行しているアプリケーションをバックアップおよび復元できます。
- Web コンソールを使用して、静的 の 認可された SSH キー をプロジェクトに追加できます。その後、キーはプロジェクト内で作成したすべての仮想マシンに追加されます。
-
OpenShift Virtualization は、仮想マシンの Persistent Volume Claims (PVC) を使用した、仮想 Trusted Platform Module (vTPM) デバイス状態の永続化をサポートするようになりました。
HyperConvergedカスタムリソース (CR) でvmStateStorageClass属性を設定することにより、PVC が使用する ストレージクラスを指定する 必要があります。
- RHEL 9 仮想マシンに対して 動的 SSH キーインジェクション を有効にできます。その後、実行時に認証された SSH キーを更新できます。
- ブートソースとして ボリュームスナップショットを有効化 できるようになりました。
ストレージプロファイルのアクセスモードとボリュームモードのフィールドには、次の追加の Containerized Storage Interface プロビジョナーに最適な値が自動的に入力されます。
- Dell PowerFlex
- Dell PowerMax
- Dell PowerScale
- Dell Unity
- Dell PowerStore
- Hitachi Virtual Storage Platform
- IBM Fusion Hyper-Converged Infrastructure
- IBM Fusion General Parallel File System
- IBM Fusion Software-Defined Storage
- IBM Fusion ブロックアレイ
- Hewlett Packard Enterprise 3PAR
- Hewlett Packard Enterprise Nimble
- Hewlett Packard Enterprise Alletra
- Hewlett Packard Enterprise Primera
- カスタムスケジューラー を使用して、ノード上の仮想マシンをスケジュールできます。
- データボリュームのガベージコレクションはデフォルトでは無効になっています。
- Web コンソールを使用して、静的 の 認可された SSH キー をプロジェクトに追加できます。その後、キーはプロジェクト内で作成したすべての仮想マシンに追加されます。
次の Runbook が変更されました。
-
SingleStackIPv6UnsupportedおよびVMStorageClassWarningが追加されました。 -
KubeMacPoolDownはKubemacpoolDownに名前が変更になりました。 -
KubevirtHyperconvergedClusterOperatorInstallationNotCompletedAlertはHCOInstallationIncompleteに名前が変更になりました。 -
KubevirtHyperconvergedClusterOperatorCRModificationはKubeVirtCRModifiedに名前が変更になりました。 -
KubevirtHyperconvergedClusterOperatorUSModificationはUnsupportedHCOModificationに名前が変更になりました。 -
SSPOperatorDownはSSPDownに名前が変更になりました。
-
2.1.4.1. クイックスタート
-
クイックスタートツアーは、複数の OpenShift Virtualization 機能で利用できます。ツアーを表示するには、OpenShift Virtualization コンソールのヘッダーのメニューバーにある Help アイコン ? をクリックし、Quick Starts を選択します。Filter フィールドに
virtualizationキーワードを入力して、利用可能なツアーをフィルターできます。
2.1.4.2. ネットワーク
- Web コンソールまたは CLI を使用して、仮想マシンを OVN-Kubernetes セカンダリーネットワーク に接続できます。
2.1.4.3. Web コンソール
- クラスター管理者は、OpenShift Virtualization Web コンソール で Red Hat Enterprise Linux (RHEL) 仮想マシンの自動サブスクリプションを有効にできるようになりました。
- 応答しない仮想マシンを アクションメニュー から強制停止できるようになりました。仮想マシンを強制停止するには、アクションメニューから Stop、Force stop の順に選択します。
- DataSources と Bootable volumes ページが ブート可能ボリューム ページ に統合され、これらの同様のリソースを 1 つの場所で管理できるようになりました。
- クラスター管理者は、Virtualization → Overview ページの Settings タブで テクノロジープレビュー 機能を有効または無効にできます。
- VM の VNC にアクセスするための 一時トークンを生成 できるようになりました。
2.1.5. 非推奨および削除された機能
2.1.5.1. 非推奨の機能
非推奨の機能は現在のリリースに含まれており、サポートされています。ただし、これらは今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
-
tekton-tasks-operatorは非推奨になり、Tekton タスクとサンプルパイプラインはssp-operatorによってデプロイされるようになりました。
-
copy-template、modify-vm-template、およびcreate-vm-from-templateタスクは非推奨になりました。
- OpenShift Virtualization メトリクスの多くが変更されているか、今後のバージョンで変更される予定です。これらの変更はカスタムダッシュボードに影響を与える可能性があります。詳細は、、OpenShift Virtualization 4.14 のメトリクスの変更 を参照してください。(BZ#2179660)
- Windows Server 2012 R2 テンプレートのサポートは廃止されました。
2.1.5.2. 削除された機能
削除された機能は、現在のリリースではサポートされません。
- 従来の HPP カスタムリソースと関連するストレージクラスのサポートは、すべての新しいデプロイメントで削除されました。OpenShift Virtualization 4.14 では、HPP Operator は Kubernetes Container Storage Interface (CSI) ドライバーを使用してローカルストレージを設定します。レガシー HPP カスタムリソースは、以前のバージョンの OpenShift Virtualization にインストールされていた場合にのみサポートされます。
-
virtctlクライアントを RPM としてインストールすることは、Red Hat Enterprise Linux (RHEL) 7 および RHEL 9 ではサポートされなくなりました。
2.1.6. テクノロジープレビューの機能
現在、今回のリリースに含まれる機能にはテクノロジープレビューのものがあります。これらの実験的機能は、実稼働環境での使用を目的としていません。これらの機能に関しては、Red Hat カスタマーポータルの以下のサポート範囲を参照してください。
- カスタマイズされたインスタンスタイプ と設定をインストールおよび編集して、ボリュームまたは PersistentVolumeClaim (PVC) から仮想マシンを作成できるようになりました。
- クラスター全体 の 仮想マシンエビクションストラテジー を設定できるようになりました。
- ブリッジネットワークインターフェイス を実行中の仮想マシン (VM) にホットプラグできます。ホットプラグとホットアンプラグは、OpenShift Virtualization 4.14 以降で作成された仮想マシンでのみサポートされます。
2.1.7. バグ修正
-
HyperConvergedカスタムリソース (CR) の 仲介デバイス設定 API が更新され、一貫性が向上しました。以前はmediatedDevicesTypesという名前であったフィールドは、nodeMediatedDeviceTypesフィールドに使用されている命名規則に合わせてmediatedDeviceTypesという名前になりました。(BZ#2054863)
-
Single Node OpenShift (SNO) クラスター上の共通テンプレートから作成された仮想マシンは、クラスターレベルのエビクションストラテジーが
Noneである場合にVMCannotBeEvictedアラートを表示しなくなりました。(BZ#2092412)
- Windows 11 仮想マシンが、FIPS モード で実行されているクラスター上で起動するようになりました。(BZ#2089301)
- さまざまなコンピュートノードが含まれる異種クラスターで、HyperV Reenlightenment が有効な仮想マシンを、タイムスタンプカウンター (TSC) スケーリングをサポートしていないノードまたは TSC の周波数が不適切なノードでスケジュールできます。(BZ#2151169)
-
異なる SELinux コンテキストを持つ 2 つの Pod を使用しても、
ocs-storagecluster-cephfsストレージクラスを持つ仮想マシンが移行に失敗しなくなりました。(BZ#2092271)
- クラスター上のノードを停止し、Node Health Check Operator を使用してノードを再起動した場合も、Multus への接続が維持されます。(OCPBUGS-8398)
-
バインディングモードが
WaitForFirstConsumerであるストレージの仮想マシンスナップショットを復元しても、復元された PVC がPending状態のままではなくなり、復元操作が続行されます。(BZ#2149654)
2.1.8. 既知の問題
Monitoring
Pod Disruption Budget (PDB) は、移行可能な仮想マシンイメージについての Pod の中断を防ぎます。PDB が Pod の中断を検出する場合、
openshift-monitoringはLiveMigrateエビクションストラテジーを使用する仮想マシンイメージに対して 60 分ごとにPodDisruptionBudgetAtLimitアラートを送信します。(BZ#2026733)- 回避策として、アラートをサイレンス にします。
ネットワーク
OpenShift Container Platform クラスターが OVN-Kubernetes をデフォルトの Container Network Interface (CNI) プロバイダーとして使用する場合、OVN-Kubernetes のホストネットワークトポロジーの変更により、Linux ブリッジまたはボンディングデバイスをホストのデフォルトインターフェイスに割り当てることはできません。(BZ#1885605)
- 回避策として、ホストに接続されたセカンダリーネットワークインターフェイスを使用するか、OpenShift SDN デフォルト CNI プロバイダーに切り替えることができます。
-
install-config.yamlファイルでnetworkType: OVNKubernetesオプションを使用している場合、仮想マシンに SSH 接続することはできません。(BZ#2165895)
- シングルスタックの IPv6 クラスターで OpenShift Virtualization は実行できません。(BZ#2193267)
ノード
-
OpenShift Virtualization をアンインストールしても、OpenShift Virtualization によって作成された
feature.node.kubevirt.ioノードラベルは削除されません。ラベルは手動で削除する必要があります。(CNV-22036)
Storage
場合によっては、複数の仮想マシンが読み取り/書き込みモードで同じ PVC をマウントできるため、データが破損する可能性があります。(BZ#1992753)
- 回避策として、複数の仮想マシンで読み取り/書き込みモードで単一の PVC を使用しないでください。
csi-cloneクローンストラテジーを使用して 100 台以上の仮想マシンのクローンを作成する場合、Ceph CSI はクローンをパージしない可能性があります。クローンの手動削除も失敗する可能性があります。(BZ#2055595)-
回避策として、
ceph-mgrを再起動して仮想マシンのクローンをパージすることができます。
-
回避策として、
AWS 上のストレージソリューションとして Portworx を使用し、仮想マシンのディスクイメージを作成する場合、ファイルシステムのオーバーヘッドが 2 回考慮されるため、作成されるイメージは予想よりも小さくなる可能性があります。(BZ#2237287)
- 回避策として、最初のプロビジョニングプロセスの完了後に永続ボリューム要求 (PVC) を手動で拡張して、利用可能なスペースを増やすことができます。
openshift-virtualization-os-imagesnamespace で提供された DataSource を使用して 1000 台を超える仮想マシンを同時にクローン作成する場合、一部の仮想マシンが実行状態に遷移しない可能性があります。(BZ#2216038)- 回避策として、仮想マシンを小さなバッチに分けてデプロイします。
- ホットプラグボリュームを追加または削除した後は、仮想マシンインスタンス (VMI) に対してライブマイグレーションを有効にできません。(BZ#2247593)
仮想化
OpenShift Virtualization は、Pod によって使用されるサービスアカウントトークンをその特定の Pod にリンクします。OpenShift Virtualization は、トークンが含まれるディスクイメージを作成してサービスアカウントボリュームを実装します。仮想マシンを移行すると、サービスアカウントボリュームが無効になります。(BZ#2037611)
- 回避策として、サービスアカウントではなくユーザーアカウントを使用してください。ユーザーアカウントトークンは特定の Pod にバインドされていないためです。
RHSA-2023:3722 アドバイザリーのリリースにより、FIPS 対応 RHEL 9 システム上の TLS 1.2 接続に、TLS
Extended Master Secret(EMS) エクステンション (RFC 7627) エクステンションが必須になりました。これは FIPS-140-3 要件に準拠しています。TLS 1.3 は影響を受けません。(BZ#2157951)EMS または TLS 1.3 をサポートしていないレガシー OpenSSL クライアントは、RHEL 9 で実行されている FIPS サーバーに接続できなくなりました。同様に、FIPS モードの RHEL 9 クライアントは、EMS なしでは TLS 1.2 のみをサポートするサーバーに接続できません。これは実際には、これらのクライアントが RHEL 6、RHEL 7、および RHEL 以外のレガシーオペレーティングシステム上のサーバーに接続できないことを意味します。これは、OpenSSL のレガシー 1.0.x バージョンが EMS または TLS 1.3 をサポートしていないためです。詳細は、TLS Extension "Extended Master Secret" enforced with Red Hat Enterprise Linux 9.2 を参照してください。
回避策として、レガシー OpenSSL クライアントを TLS 1.3 をサポートするバージョンにアップグレードし、FIPS モードで
最新のTLS セキュリティープロファイルタイプで TLS 1.3 を使用するように OpenShift Virtualization を設定します。
Web コンソール
OpenShift Virtualization をアップグレードせずに OpenShift Container Platform 4.13 を 4.14 にアップグレードすると、Web コンソールの Virtualization ページがクラッシュします。(OCPBUGS-22853)
OpenShift Virtualization Operator を手動で 4.14 にアップグレードするか、サブスクリプション承認ストラテジーを "Automatic" に設定する必要があります。
第3章 スタートガイド
3.1. OpenShift Virtualization の開始
基本的な環境をインストールして設定することにより、OpenShift Virtualization の特徴と機能を調べることができます。
クラスター設定手順には、cluster-admin 権限が必要です。
3.1.1. OpenShift Virtualization の計画とインストール
OpenShift Container Platform クラスターで OpenShift Virtualization を計画およびインストールします。
計画およびインストールのリソース
3.1.2. 仮想マシンの作成と管理
仮想マシンを作成します。
Red Hat テンプレートまたはインスタンスタイプを使用して仮想マシンを作成できます。
カスタムチューニング仕様のカスタムプロファイルはテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
仮想マシンを作成するには、コンテナーレジストリーまたは Web ページからカスタムイメージをインポートするか、ローカルマシンからイメージをアップロードするか、永続ボリューム要求 (PVC) を複製することによって実行できます。
仮想マシンをセカンダリーネットワークに接続します。
- Linux ブリッジネットワーク。
- オープン仮想ネットワーク (OVN)- Kubernetes セカンダリーネットワーク。
シングルルート I/O 仮想化 (SR-IOV) ネットワーク。
注記VM はデフォルトで Pod ネットワークに接続されます。
仮想マシンに接続します。
- 仮想マシンの シリアルコンソール または VNC コンソール に接続します。
- SSH を使用して仮想マシンに接続します。
- Windows 仮想マシンのデスクトップビューアーに接続します。
仮想マシンを管理します。
3.1.3. 次のステップ
3.2. virtctl および libguestfs CLI ツールの使用
virtctl コマンドラインツールを使用して、OpenShift Virtualization リソースを管理できます。
libguestfs コマンドラインツールを使用すると、仮想マシンのディスクイメージにアクセスして変更できます。libguestfs をデプロイするには、virtctl libguestfs コマンドを使用します。
3.2.1. virtctl のインストール
Red Hat Enterprise Linux (RHEL) 9、Linux、Windows、および MacOS オペレーティングシステムに virtctl をインストールするには、virtctl バイナリーファイルをダウンロードしてインストールします。
RHEL 8 に virtctl をインストールするには、OpenShift Virtualization リポジトリーを有効にしてから、kubevirt-virtctl パッケージをインストールします。
3.2.1.1. RHEL 9、Linux、Windows、 macOS への virtctl バイナリーのインストール
OpenShift Container Platform Web コンソールからオペレーティングシステムの virtctl バイナリーをダウンロードし、それをインストールできます。
手順
- Web コンソールの Virtualization → Overview ページに移動します。
-
Download virtctl リンクをクリックして、オペレーティングシステム用の
virtctlバイナリーをダウンロードします。 virtctlをインストールします。RHEL 9 およびその他の Linux オペレーティングシステムの場合:
アーカイブファイルを解凍します。
$ tar -xvf <virtctl-version-distribution.arch>.tar.gz
次のコマンドを実行して、
virtctlバイナリーを実行可能にします。$ chmod +x <path/virtctl-file-name>
virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
$ echo $PATH
KUBECONFIG環境変数を設定します。$ export KUBECONFIG=/home/<user>/clusters/current/auth/kubeconfig
Windows の場合:
- アーカイブファイルを解凍します。
-
展開したフォルダー階層に移動し、
virtctl実行可能ファイルをダブルクリックしてクライアントをインストールします。 virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
C:\> path
MacOS の場合:
- アーカイブファイルを解凍します。
virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。次のコマンドを実行して、パスを確認できます。
echo $PATH
3.2.1.2. RHEL 8 への virtctl RPM のインストール
OpenShift Virtualization リポジトリーを有効にし、kubevirt-virtctl パッケージをインストールすることで、Red Hat Enterprise Linux (RHEL) 8 に virtctl RPM をインストールできます。
前提条件
- クラスター内の各ホストは Red Hat Subscription Manager (RHSM) に登録されており、アクティブな OpenShift Container Platform サブスクリプションを持つ必要があります。
手順
subscription-managerCLI ツールを使用して次のコマンドを実行し、OpenShift Virtualization リポジトリーを有効にします。# subscription-manager repos --enable cnv-4.14-for-rhel-8-x86_64-rpms
次のコマンドを実行して、
kubevirt-virtctlパッケージをインストールします。# yum install kubevirt-virtctl
3.2.2. virtctl コマンド
virtctl クライアントは、OpenShift Virtualization リソースを管理するためのコマンドラインユーティリティーです。
特に指定がない限り、仮想マシンコマンドは仮想マシンインスタンスにも適用されます。
3.2.2.1. virtctl 情報コマンド
virtctl information コマンドを使用して、virtctl クライアントに関する情報を表示します。
表3.1 情報コマンド
| コマンド | 説明 |
|---|---|
|
|
|
|
|
|
|
| 特定のコマンドのオプションのリストを表示します。 |
|
|
任意の |
3.2.2.2. 仮想マシン情報コマンド
virtctl を使用すると、仮想マシンおよび仮想マシンインスタンス (VMI) に関する情報を表示できます。
表3.2 仮想マシン情報コマンド
| コマンド | 説明 |
|---|---|
|
| ゲストマシンで使用可能なファイルシステムを表示します。 |
|
| ゲストマシンのオペレーティングシステムに関する情報を表示します。 |
|
| ゲストマシンにログインしているユーザーを表示します。 |
3.2.2.3. 仮想マシン管理コマンド
virtctl 仮想マシン管理コマンドを使用して、仮想マシンおよび仮想マシンインスタンスを管理および移行します。
表3.3 仮想マシン管理コマンド
| コマンド | 説明 |
|---|---|
|
|
|
|
| 仮想マシンを開始します。 |
|
| 仮想マシンを一時停止状態で起動します。このオプションを使用すると、VNC コンソールからブートプロセスを中断できます。 |
|
| 仮想マシンを停止します。 |
|
| 仮想マシンを強制停止します。このオプションは、データの不整合またはデータ損失を引き起こす可能性があります。 |
|
| 仮想マシンを一時停止します。マシンの状態がメモリーに保持されます。 |
|
| 仮想マシンの一時停止を解除します。 |
|
| 仮想マシンを移行します。 |
|
| 仮想マシンの移行をキャンセルします。 |
|
| 仮想マシンを再起動します。 |
|
|
|
|
|
|
3.2.2.4. 仮想マシン接続コマンド
virtctl 接続コマンドを使用してポートを公開し、仮想マシンおよび仮想マシンインスタンスに接続します。
表3.4 仮想マシン接続コマンド
| コマンド | 説明 |
|---|---|
|
| 仮想マシンのシリアルコンソールに接続します。 |
|
| 仮想マシンの指定されたポートを転送するサービスを作成し、ノードの指定されたポートでサービスを公開します。
例: |
|
| マシンから仮想マシンにファイルをコピーします。このコマンドは、SSH キーペアの秘密キーを使用します。仮想マシンは公開キーを使用して設定する必要があります。 |
|
| 仮想マシンからマシンにファイルをコピーします。このコマンドは、SSH キーペアの秘密キーを使用します。仮想マシンは公開キーを使用して設定する必要があります。 |
|
| 仮想マシンとの SSH 接続を開きます。このコマンドは、SSH キーペアの秘密キーを使用します。仮想マシンは公開キーを使用して設定する必要があります。 |
|
| 仮想マシンの VNC コンソールに接続します。
|
|
| ポート番号を表示し、VNC 接続を介してビューアーを使用して手動で VM に接続します。 |
|
| ポートが利用可能な場合、その指定されたポートでプロキシーを実行するためにポート番号を指定します。 ポート番号が指定されていない場合、プロキシーはランダムポートで実行されます。 |
3.2.2.5. 仮想マシンエクスポートコマンド
virtctl vmexport コマンドを使用して、仮想マシン、仮想マシンスナップショット、または永続ボリューム要求 (PVC) からエクスポートされたボリュームを作成、ダウンロード、または削除できます。特定のマニフェストには、OpenShift Virtualization が使用できる形式でディスクイメージをインポートするためのエンドポイントへのアクセスを許可するヘッダーシークレットも含まれています。
表3.5 仮想マシンエクスポートコマンド
| コマンド | 説明 |
|---|---|
|
|
仮想マシン、仮想マシンスナップショット、または PVC からボリュームをエクスポートするには、
|
|
|
|
|
|
オプション:
|
|
|
|
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 仮想マシンサンプルの仮想マシンエクスポートを作成し、マニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 仮想マシンスナップショットの例の仮想マシンエクスポートを作成し、マニフェストを取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれています。 |
|
| 既存のエクスポートのマニフェストを json 形式で取得します。マニフェストにはヘッダーシークレットが含まれていません。 |
|
| 既存のエクスポートのマニフェストを取得します。マニフェストにはヘッダーシークレットが含まれており、指定されたファイルにそれを書き込みます。 |
3.2.2.6. 仮想マシンメモリーダンプコマンド
virtctl memory-dump コマンドを使用して、PVC に仮想マシンのメモリーダンプを出力できます。既存の PVC を指定するか、--create-claim フラグを使用して新しい PVC を作成できます。
前提条件
-
PVC ボリュームモードは
FileSystemである必要があります。 PVC は、メモリーダンプを格納するのに十分な大きさである必要があります。
PVC サイズを計算する式は
(VMMemorySize + 100Mi) * FileSystemOverheadです。ここで、100Miはメモリーダンプのオーバーヘッドです。次のコマンドを実行して、
HyperConvergedカスタムリソースでホットプラグフィーチャーゲートを有効にする必要があります。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "add", "path": "/spec/featureGates", \ "value": "HotplugVolumes"}]'
メモリーダンプのダウンロード
メモリーダンプをダウンロードするには、virtctl vmexport download コマンドを使用する必要があります。
$ virtctl vmexport download <vmexport_name> --vm|pvc=<object_name> \ --volume=<volume_name> --output=<output_file>
表3.6 仮想マシンメモリーダンプコマンド
| コマンド | 説明 |
|---|---|
|
|
仮想マシンのメモリーダンプを PVC に保存します。メモリーダンプのステータスは、 オプション:
|
|
|
同じ PVC で このコマンドは、以前のメモリーダンプを上書きします。 |
|
| メモリーダンプを削除します。 ターゲット PVC を変更する場合は、メモリーダンプを手動で削除する必要があります。
このコマンドは、 |
3.2.2.7. ホットプラグおよびホットアンプラグコマンド
virtctl を使用して、実行中の仮想マシンおよび仮想マシンインスタンス (VMI) にリソースを追加または削除します。
表3.7 ホットプラグおよびホットアンプラグコマンド
| コマンド | 説明 |
|---|---|
|
| データボリュームまたは永続ボリューム要求 (PVC) をホットプラグします。 オプション:
|
|
| 仮想ディスクをホットアンプラグします。 |
|
| Linux ブリッジネットワークインターフェイスをホットプラグします。 |
|
| Linux ブリッジネットワークインターフェイスをホットアンプラグします。 |
3.2.2.8. イメージアップロードコマンド
virtctl image-upload コマンドを使用して、VM イメージをデータボリュームにアップロードできます。
表3.8 イメージアップロードコマンド
| コマンド | 説明 |
|---|---|
|
| VM イメージを既存のデータボリュームにアップロードします。 |
|
| 指定された要求されたサイズの新しいデータボリュームに VM イメージをアップロードします。 |
3.2.3. virtctl を使用した libguestfs のデプロイ
virtctl guestfs コマンドを使用して、libguestfs-tools および永続ボリューム要求 (PVC) がアタッチされた対話型コンテナーをデプロイできます。
手順
libguestfs-toolsでコンテナーをデプロイして PVC をマウントし、シェルを割り当てるには、以下のコマンドを実行します。$ virtctl guestfs -n <namespace> <pvc_name> 1- 1
- PVC 名は必須の引数です。この引数を追加しないと、エラーメッセージが表示されます。
3.2.3.1. Libguestfs および virtctl guestfs コマンド
Libguestfs ツールは、仮想マシン (VM) のディスクイメージにアクセスして変更するのに役立ちます。libguestfs ツールを使用して、ゲスト内のファイルの表示および編集、仮想マシンのクローンおよびビルド、およびディスクのフォーマットおよびサイズ変更を実行できます。
virtctl guestfs コマンドおよびそのサブコマンドを使用して、PVC で仮想マシンディスクを変更して検査し、デバッグすることもできます。使用可能なサブコマンドの完全なリストを表示するには、コマンドラインで virt- と入力して Tab を押します。以下に例を示します。
| コマンド | 説明 |
|---|---|
|
| ターミナルでファイルを対話的に編集します。 |
|
| ゲストに ssh キーを挿入し、ログインを作成します。 |
|
| 仮想マシンによって使用されるディスク容量を確認します。 |
|
| 詳細のリストを含む出力ファイルを作成して、ゲストにインストールされたすべての RPM の詳細リストを参照してください。 |
|
|
ターミナルで |
|
| テンプレートとして使用する仮想マシンディスクイメージをシールします。 |
デフォルトでは、virtctl guestfs は、仮想ディスク管理に必要な項目を含めてセッションを作成します。ただし、動作をカスタマイズできるように、コマンドは複数のフラグオプションもサポートしています。
| フラグオプション | 説明 |
|---|---|
|
|
|
|
| 特定の namespace から PVC を使用します。
|
|
|
|
|
|
デフォルトでは、
クラスターに
設定されていない場合、 |
|
|
|
このコマンドは、PVC が別の Pod によって使用されているかどうかを確認します。使用されている場合には、エラーメッセージが表示されます。ただし、libguestfs-tools プロセスが開始されると、設定では同じ PVC を使用する新規 Pod を回避できません。同じ PVC にアクセスする仮想マシンを起動する前に、アクティブな virtctl guestfs Pod がないことを確認する必要があります。
virtctl guestfs コマンドは、インタラクティブな Pod に割り当てられている PVC 1 つだけを受け入れます。
3.3. Web コンソールの概要
OpenShift Container Platform Web コンソールの Virtualization セクションには、OpenShift Virtualization 環境を管理および監視するための以下のページが含まれています。
表3.9 Virtualization ページ
| ページ | 説明 |
|---|---|
| OpenShift Virtualization 環境を管理および監視します。 | |
| テンプレートのカタログから仮想マシンを作成します。 | |
| 仮想マシンを作成および管理します。 | |
| テンプレートを作成および管理します。 | |
| 仮想マシンのインスタンスタイプを作成および管理します。 | |
| 仮想マシンの設定を作成および管理します。 | |
| ブート可能ボリュームのデータソースを作成および管理します。 | |
| ワークロードの移行ポリシーを作成および管理します。 |
表3.10 キー
| アイコン | 説明 |
|---|---|
|
| Edit アイコン |
|
| Link アイコン |
3.3.1. Overview ページ
Overview ページには、リソース、メトリクス、移行の進行状況、およびクラスターレベルの設定が表示されます。
例3.1 Overview ページ
| 要素 | 説明 |
|---|---|
|
virtctl のダウンロード |
リソースを管理するには、 |
| リソース、使用率、アラート、およびステータス。 | |
| CPU、メモリー、およびストレージリソースのトップコンシューマー。 | |
| ライブマイグレーションのステータス。 | |
| Settings タブには Cluster タブと User タブが含まれています。 | |
| Settings → Cluster タブ | OpenShift Virtualization のバージョン、更新ステータス、ライブマイグレーション、テンプレートプロジェクト、プレビュー機能、ロードバランサーサービス設定。 |
| Settings → User タブ | 承認された SSH キー、ユーザー権限、ウェルカム情報の設定。 |
3.3.1.1. Overview タブ
Overview タブには、リソース、使用率、アラート、およびステータスが表示されます。
例3.2 Overview タブ
| 要素 | 説明 |
|---|---|
| Getting started resources カード |
|
| Memory タイル | 過去 7 日間の傾向を示すグラフを含むメモリー使用率。 |
| Storage タイル | 過去 7 日間の傾向を示すグラフを含むストレージ使用率。 |
| VirtualMachines タイル | 過去 7 日間の傾向を示すグラフを含む仮想マシンの数。 |
| vCPU usage タイル | 過去 7 日間の傾向を示すグラフを含む vCPU 使用率。 |
| VirtualMachine statuses タイル | ステータスごとにグループ化された仮想マシンの数。 |
| Alerts タイル | 重大度別にグループ化された OpenShift Virtualization アラート。 |
| VirtualMachines per resource グラフ | テンプレートとインスタンスタイプから作成された仮想マシンの数。 |
3.3.1.2. Top consumers タブ
Top consumers タブには、CPU、メモリー、およびストレージのトップコンシューマーが表示されます。
例3.3 Top consumers タブ
| 要素 | 説明 |
|---|---|
|
仮想化ダッシュボードを表示 | OpenShift Virtualization のトップコンシューマーを表示する Observe → Dashboards へのリンク。 |
| Time period リスト | 結果をフィルタリングする期間を選択します。 |
| Top consumers リスト | 結果をフィルタリングするトップコンシューマーの数を選択します。 |
| CPU チャート | CPU 使用率が最も高い仮想マシン。 |
| Memory チャート | メモリー使用量が最も多い仮想マシン。 |
| Memory swap traffic チャート | メモリースワップトラフィックが最も多い仮想マシン。 |
| vCPU wait チャート | vCPU 待機時間が最も長い仮想マシン。 |
| Storage throughput チャート | ストレージスループットの使用率が最も高い仮想マシン。 |
| Storage IOPS チャート | 1 秒あたりのストレージ入出力操作の使用率が最も高い仮想マシン。 |
3.3.1.3. Migrations タブ
Migrations タブには、仮想マシンの移行のステータスが表示されます。
例3.4 Migrations タブ
| 要素 | 説明 |
|---|---|
| Time period リスト | 仮想マシンの移行をフィルタリングする期間を選択します。 |
| VirtualMachineInstanceMigrations 情報 テーブル | 仮想マシンの移行のリスト。 |
3.3.1.4. Settings タブ
Settings タブには、クラスター全体の設定が表示されます。
例3.5 Settings タブのタブ
| タブ | 説明 |
|---|---|
| OpenShift Virtualization のバージョンと更新ステータス、ライブマイグレーション、テンプレートプロジェクト、プレビュー機能、ロードバランサーサービス設定。 | |
| 承認された SSH キー管理、ユーザー権限、ウェルカム情報設定。 |
3.3.1.4.1. クラスタータブ
Cluster タブには、OpenShift Virtualization のバージョンと更新ステータスが表示されます。Cluster タブでは、プレビュー機能、ライブマイグレーション、およびその他の設定を設定します。
例3.6 Cluster タブ
| 要素 | 説明 |
|---|---|
| インストール済みバージョン | OpenShift Virtualization バージョン |
| 更新ステータス | OpenShift 仮想化の更新ステータス。 |
| Channel | OpenShift 仮想化の更新チャネル。 |
| Preview features セクション | プレビュー機能 を管理するには、このセクションをデプロイメントします。 プレビュー機能はデフォルトで無効になっているため、運用環境では有効にしないでください。 |
| Live Migration セクション | このセクションを展開して、ライブマイグレーション設定を設定します。 |
| Live Migration → Max. migrations per cluster フィールド | クラスターごとのライブマイグレーションの最大数を選択します。 |
| Live Migration → Max. migrations per node フィールド | ノードごとのライブマイグレーションの最大数を選択します。 |
| Live Migration → Live migration network リスト | ライブマイグレーション専用のセカンダリーネットワークを選択します。 |
| 新しい RHEL VirtualMachines の自動サブスクリプション セクション | Red Hat Enterprise Linux (RHEL) 仮想マシンの自動サブスクリプションを有効にするには、このセクションをデプロイメントします。 この機能を有効にするには、クラスター管理者のパーミッション、組織 ID、およびアクティベーションキーが必要です。 |
| LoadBalancer セクション | このセクションを展開して、仮想マシンへの SSH アクセス用のロードバランサーサービスの作成を有効にします。 クラスターにはロードバランサーが設定されている必要があります。 |
| Template project セクション |
このセクションを展開して、Red Hat テンプレートのプロジェクトを選択します。デフォルトのプロジェクトは Red Hat テンプレートを複数のプロジェクトに保存するには、テンプレートを複製 し、複製したテンプレートのプロジェクトを選択します。 |
3.3.1.4.2. ユーザータブ
User タブでは、ユーザー権限を表示し、承認された SSH キーとウェルカム情報を管理します。
例3.7 User タブ
| 要素 | 説明 |
|---|---|
| Manage SSH keys セクション | このセクションを展開して、認可された SSH キーをプロジェクトに追加します。 キーは、選択したプロジェクトでその後作成するすべての仮想マシンに自動的に追加されます。 |
| Permissions セクション | このセクションをデプロイメントすると、クラスター全体のユーザー権限が表示されます。 |
| ようこそ情報 セクション | このセクションを展開すると、Welcome information ダイアログが表示または非表示になります。 |
3.3.2. Catalog ページ
Catalog ページのテンプレートまたはインスタンスタイプから仮想マシンを作成します。
例3.8 Catalog ページ
| 要素 | 説明 |
|---|---|
| 仮想マシンを作成するためのテンプレートのカタログを表示します。 | |
| 仮想マシンを作成するための起動可能なボリュームとインスタンスのタイプを表示します。 |
3.3.2.1. Template catalog タブ
Template catalog タブでテンプレートを選択して、仮想マシンを作成します。
例3.9 Template catalog タブ
| 要素 | 説明 |
|---|---|
| Template project リスト | Red Hat テンプレートが存在するプロジェクトを選択します。
デフォルトでは、Red Hat テンプレートは |
| All items|Default templates | All items をクリックして、使用可能なすべてのテンプレートを表示します。 |
| Boot source available チェックボックス | チェックボックスをオンにして、使用可能なブートソースを含むテンプレートを表示します。 |
| Operating system チェックボックス | チェックボックスをオンにして、選択したオペレーティングシステムのテンプレートを表示します。 |
| Workload チェックボックス | チェックボックスをオンにして、選択したワークロードを含むテンプレートを表示します。 |
| Search フィールド | テンプレートをキーワードで検索します。 |
| テンプレートタイル | テンプレートタイルをクリックして、テンプレートの詳細を表示し、仮想マシンを作成します。 |
3.3.2.2. InstanceTypes タブ
InstanceTypes タブのインスタンスタイプから仮想マシンを作成します。
インスタンスタイプからの仮想マシンの作成は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
| 要素 | 説明 |
|---|---|
| Volumes project フィールド |
ブート可能なボリュームが保存されているプロジェクト。デフォルトは |
| Add volume ボタン | クリックして新しいボリュームをアップロードするか、既存の永続ボリューム要求を使用します。 |
| Filter フィールド | オペレーティングシステムまたはリソースごとにブートソースをフィルタリングします。 |
| Search フィールド | ブートソースを名前で検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。 |
| ボリュームテーブル | 仮想マシンのブート可能ボリュームを選択します。 |
| Red Hat provided タブ | Red Hat が提供するインスタンスタイプを選択します。 |
| User provided タブ | InstanceType ページで作成したインスタンスタイプを選択します。 |
| VirtualMachine details ペイン | 仮想マシンの設定を表示します。 |
| Name フィールド | オプション: 仮想マシン名を入力します。 |
| SSH キーの名前 | 編集アイコンをクリックして公開 SSH キーを追加します。 |
| 作成後にこの VirtualMachine を開始する チェックボックス | 仮想マシンが自動的に起動しないようにするには、このチェックボックスをオフにします。 |
| Create VirtualMachine ボタン | 仮想マシンを作成します。 |
| YAML & CLI ボタン |
YAML 設定ファイルと、コマンドラインから仮想マシンを作成するための |
3.3.3. VirtualMachines ページ
VirtualMachines ページで仮想マシンを作成および管理します。
例3.10 VirtualMachines ページ
| 要素 | 説明 |
|---|---|
| Create ボタン | テンプレート、ボリューム、または YAML 設定ファイルから仮想マシンを作成します。 |
| Filter フィールド | ステータス、テンプレート、オペレーティングシステム、またはノードで仮想マシンをフィルタリングします。 |
| Search フィールド | 仮想マシンを名前またはラベルで検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| 仮想マシンテーブル | 仮想マシンのリスト。
仮想マシンの横にあるアクションメニュー
仮想マシンをクリックして、VirtualMachine details ページに移動します。 |
3.3.3.1. VirtualMachine details ページ
VirtualMachine details ページで仮想マシンを設定します。
例3.11 VirtualMachine details ページ
| 要素 | 説明 |
|---|---|
| Actions メニュー | Actions メニューをクリックして、Stop、Restart、Pause、Clone、Migrate、Copy SSH command、Edit labels、Edit annotations、または Delete を選択します。Stop を選択すると、、アクションメニューの Force stop が Stop に置き換わります。オペレーティングシステムが応答しなくなった場合は、Force stop を使用して即時シャットダウンを開始します。 |
| リソースの使用率、アラート、ディスク、およびデバイス。 | |
| 仮想マシンの詳細と設定。 | |
| メモリー、CPU、ストレージ、ネットワーク、移行のメトリクス。 | |
| 仮想マシンの YAML 設定ファイル。 | |
| Disks、Network interfaces、Scheduling、Environment、および Scripts タブが含まれます。 | |
| ディスク。 | |
| ネットワークインターフェイス。 | |
| 特定のノードで実行するように仮想マシンをスケジュールする | |
| 設定マップ、シークレット、およびサービスアカウントの管理。 | |
| Linux 仮想マシンの Cloud-init 設定、承認された SSH キーと動的キーインジェクション、Windows 仮想マシンの Sysprep 設定。 | |
| 仮想マシンのイベントストリーム。 | |
| コンソールセッション管理。 | |
| スナップショット管理 | |
| ステータス条件とボリュームスナップショットのステータス |
3.3.3.1.1. Overview タブ
Overview タブには、リソースの使用率、アラート、および設定情報が表示されます。
例3.12 Overview タブ
| 要素 | 説明 |
|---|---|
| Details タイル | 一般的な仮想マシン情報。 |
| Utilization タイル | CPU、Memory、Storage、および Network transfer グラフ。デフォルトでは、ネットワーク転送 は、すべてのネットワークの合計を表示します。特定のネットワークの内訳を表示するには、Breakdown by network をクリックします。 |
| Hardware devices タイル | GPU とホストデバイス。 |
| Alerts タイル | 重大度別にグループ化された OpenShift Virtualization アラート。 |
| Snapshots タイル |
Take snapshot |
| Network interfaces タイル | Network interfaces テーブル。 |
| Disks タイル | Disks テーブル。 |
3.3.3.1.2. Details タブ
Details タブで、仮想マシンに関する情報を表示し、ラベル、アノテーション、およびその他のメタデータを編集します。
例3.13 Details タブ
| 要素 | 説明 |
|---|---|
| YAML スイッチ | ON を設定して、YAML 設定ファイルでライブの変更を表示します。 |
| Name | 仮想マシン名 |
| Namespace | 仮想マシンの namespace またはプロジェクト。 |
| Labels | 編集アイコンをクリックして、ラベルを編集します。 |
| Annotations | 編集アイコンをクリックして、注釈を編集します。 |
| Description | 編集アイコンをクリックして、説明を入力します。 |
| Operating system | オペレーティングシステム名。 |
| CPU|Memory | 編集アイコンをクリックして、CPU|Memory 要求を編集します。仮想マシンを再起動して、変更を適用します。
CPU の数は、 |
| Machine type | Machine テーブル。 |
| Boot mode | 編集アイコンをクリックして、起動モードを編集します。仮想マシンを再起動して、変更を適用します。 |
| 一時停止モードで開始 | 編集アイコンをクリックして、この設定を有効にします。仮想マシンを再起動して、変更を適用します。 |
| テンプレート | 仮想マシンの作成に使用されるテンプレートの名前。 |
| Created at | 仮想マシンの作成日。 |
| Owner | 仮想マシンの所有者。 |
| ステータス | 仮想マシンのステータス。 |
| Pod |
|
| VirtualMachineInstance | 仮想マシンのインスタンス名。 |
| Boot order | 編集アイコンをクリックして、起動ソースを選択します。仮想マシンを再起動して、変更を適用します。 |
| IP アドレス | 仮想マシンの IP アドレス。 |
| Hostname | 仮想マシンのホスト名。仮想マシンを再起動して、変更を適用します。 |
| タイムゾーン | 仮想マシンのタイムゾーン。 |
| ノード | 仮想マシンが実行しているノード。 |
| Workload profile | 編集アイコンをクリックして、ワークロードプロファイルを編集します。 |
| SSH アクセス | これらの設定は Linux に適用されます。 |
| virtctl を使用している SSH |
コピーアイコンをクリックして、 |
| SSH サービスの種類 | SSH over LoadBalancer を選択します。 サービスを作成すると、SSH コマンドが表示されます。コピーアイコンをクリックして、コマンドをクリップボードにコピーします。 |
| GPU devices | 編集アイコンをクリックして、GPU デバイスを追加します。仮想マシンを再起動して、変更を適用します。 |
| Host devices | 編集アイコンをクリックして、ホストデバイスを追加します。仮想マシンを再起動して、変更を適用します。 |
| Headless mode | 編集アイコンをクリックしてヘッドレスモードを ON に設定し、VNC コンソールを無効にします。仮想マシンを再起動して、変更を適用します。 |
| サービス | QEMU ゲストエージェントがインストールされている場合は、サービスの一覧を表示します。 |
| アクティブなユーザー | QEMU ゲストエージェントがインストールされている場合、アクティブなユーザーのリストが表示されます。 |
3.3.3.1.3. Metrics タブ
Metrics タブには、メモリー、CPU、ストレージ、ネットワーク、および移行の使用率グラフが表示されます。
例3.14 Metrics タブ
| 要素 | 説明 |
|---|---|
| Time range リスト | 結果をフィルタリングする期間を選択します。 |
|
Virtualization ダッシュボード | 現在のプロジェクトの Workloads タブにリンクします。 |
| Utilization | Memory および CPU グラフ。 |
| Storage | Storage total read/write および Storage IOPS total read/write グラフ。 |
| Network | Network in、Network out、Network bandwidth、および Network interface グラフ。Network interface リストから All networks または特定のネットワークを選択します。 |
| Migration | Migration および KV data transfer rate グラフ。 |
3.3.3.1.4. YAML タブ
YAML タブで YAML ファイルを編集して、仮想マシンを設定します。
例3.15 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
3.3.3.1.5. Configuration タブ
Configuration タブで、スケジュール、ネットワークインターフェイス、ディスク、およびその他のオプションを設定します。
例3.16 Configuration タブ上のタブ
| 要素 | 説明 |
|---|---|
| YAML スイッチ | ON を設定して、YAML 設定ファイルでライブの変更を表示します。 |
| ディスク。 | |
| ネットワークインターフェイス。 | |
| スケジュールとリソースの要件。 | |
| 設定マップ、シークレット、およびサービスアカウント | |
| Cloud-init 設定、Linux 仮想マシンの承認済み SSH キー、Windows 仮想マシンの Sysprep アンサーファイル。 |
3.3.3.1.5.1. Disks タブ
ディスクは、Disks タブで管理します。
例3.17 Disks タブ
| 設定 | 説明 |
|---|---|
| Add disk ボタン | 仮想マシンにディスクを追加します。 |
| Filter フィールド | ディスクの種類でフィルタリングします。 |
| Search フィールド | ディスクを名前で検索します。 |
| Mount Windows drivers disk チェックボックス |
VirtIO ドライバーをインストールするために、 |
| Disks テーブル | 仮想マシンのディスクのリスト。
ディスクの横にある actions メニュー
|
| File systems テーブル | 仮想マシンのファイルシステムのリスト。 |
3.3.3.1.5.2. Network interfaces タブ
Network interfaces タブでネットワークインターフェイスを管理します。
例3.18 Network interfaces タブ
| 設定 | 説明 |
|---|---|
| Add network interface ボタン | 仮想マシンにネットワークインターフェイスを追加します。 |
| Filter フィールド | インターフェイスタイプでフィルタリングします。 |
| Search フィールド | 名前またはラベルでネットワークインターフェイスを検索します。 |
| Network interface テーブル | ネットワークインターフェイスのリスト。
ネットワークインターフェイスの横にある actions メニュー
|
3.3.3.1.5.3. Scheduling タブ
Scheduling タブで、特定のノードで実行されるように仮想マシンを設定します。
仮想マシンを再起動して変更を適用します。
例3.19 Scheduling タブ
| 設定 | 説明 |
|---|---|
| Node selector | 編集アイコンをクリックして、ラベルを追加し、適格なノードを指定します。 |
| 容認 | 編集アイコンをクリックして、許容範囲を追加し、適格なノードを指定します。 |
| アフィニティールール | 編集アイコンをクリックして、アフィニティールールを追加します。 |
| Descheduler スイッチ | Descheduler を有効または無効にします。Descheduler は、実行中の Pod をエビクトして、Pod をより適切なノードに再スケジュールできるようにします。 仮想マシンをライブマイグレーションできない場合、このフィールドは無効になります。 |
| 専用リソース | 編集アイコンをクリックして、Schedule this workload with dedicated resources (guaranteed policy) を選択します。 |
| エビクションストラテジー | 編集アイコンをクリックして、仮想マシンのエビクション戦略として LiveMigrate を選択します。 |
3.3.3.1.5.4. Environment タブ
Environment タブで設定マップ、シークレット、およびサービスアカウントを管理します。
例3.20 Environment タブ
| 要素 | 説明 |
|---|---|
|
Add Config Map, Secret or Service Account | リンクをクリックして、リソースリストから設定マップ、シークレット、またはサービスアカウントを選択します。 |
3.3.3.1.5.5. Scripts タブ
Scripts タブで、cloud-init 設定の管理、SSH キーの追加、または Windows 仮想マシン用の Sysprep の設定を行います。
仮想マシンを再起動して変更を適用します。
例3.21 Scripts タブ
| 要素 | 説明 |
|---|---|
| Cloud-init | 編集アイコンをクリックして、cloud-init 設定を編集します。 |
| 認可された SSH キー | 編集アイコンをクリックして、公開 SSH キーを Linux 仮想マシンに追加します。 キーは初回起動時に cloud-init データソースとして追加されます。 |
| Dynamic SSH key injection スイッチ | 動的公開 SSH キーインジェクションを有効にするには、Dynamic SSH key injection をオンに設定します。その後、実行時にキーを追加または取り消すことができます。 動的 SSH キーインジェクションは、Red Hat Enterprise Linux (RHEL) 9 でのみサポートされています。この設定を手動で無効にすると、仮想マシンは作成元のイメージの SSH キー設定を継承します。 |
| Sysprep |
編集アイコンをクリックして |
3.3.3.1.6. Events タブ
Events タブには、仮想マシンイベントのリストが表示されます。
3.3.3.1.7. Console タブ
Console タブで仮想マシンへのコンソールセッションを開くことができます。
例3.22 Console タブ
| 要素 | 説明 |
|---|---|
| Guest login credentials セクション |
Guest login credentials を展開して、 |
| Console リスト | VNC コンソール または Serial コンソール を選択します。 Windows 仮想マシンの場合は、Desktop viewer オプションが表示されます。同じネットワーク上のマシンに RDP クライアントをインストールする必要があります。 |
| Send key リスト | コンソールに送信するキーストロークの組み合わせを選択します。 |
| Disconnect ボタン | コンソール接続を切断します。 新しいコンソールセッションを開く場合は、コンソール接続を手動で切断する必要があります。それ以外の場合、最初のコンソールセッションは引き続きバックグラウンドで実行されます。 |
| Paste ボタン | 文字列をクリップボードから VNC コンソールに貼り付けます。 |
3.3.3.1.8. Snapshots タブ
Snapshots タブでスナップショットを作成し、スナップショットから仮想マシンを復元します。
例3.23 Snapshots タブ
| 要素 | 説明 |
|---|---|
| Take snapshot ボタン | スナップショットを作成します。 |
| Filter フィールド | スナップショットをステータスでフィルタリングします。 |
| Search フィールド | 名前またはラベルでスナップショットを検索します。 |
| Snapshot テーブル | スナップショットのリスト。 スナップショット名をクリックして、ラベルまたはアノテーションを編集します。
スナップショットの横にある actions メニュー
|
3.3.3.1.9. Diagnostics タブ
Diagnostics タブでステータス条件とボリュームスナップショットのステータスを表示します。
例3.24 Diagnostics タブ
| 要素 | 説明 |
|---|---|
| Status conditions テーブル | 仮想マシンに関して報告された状態のリストを表示します。 |
| Filter フィールド | ステータス条件をカテゴリーと条件でフィルタリングします。 |
| Search フィールド | ステータス条件を理由で検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。 |
| Volume snapshot status テーブル | ボリューム、スナップショットの有効化ステータス、および理由のリスト |
3.3.4. Templates ページ
VirtualMachine Templates ページで仮想マシンテンプレートを作成、編集、およびクローン作成します。
Red Hat テンプレートは編集できません。ただし、Red Hat テンプレートを複製して編集し、カスタムテンプレートを作成できます。
例3.25 VirtualMachine Templates ページ
| 要素 | 説明 |
|---|---|
| Create Template ボタン | YAML 設定ファイルを編集してテンプレートを作成します。 |
| Filter フィールド | テンプレートをタイプ、ブートソース、テンプレートプロバイダー、またはオペレーティングシステムでフィルタリングします。 |
| Search フィールド | 名前またはラベルでテンプレートを検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| 仮想マシンテンプレートテーブル | 仮想マシンテンプレートのリスト。
テンプレートの横にある actions メニュー
|
3.3.4.1. テンプレートの詳細ページ
Template details ページで、テンプレートの設定を表示し、カスタムテンプレートを編集します。
例3.26 Template details タブ
| 要素 | 説明 |
|---|---|
| YAML スイッチ | ON を設定して、YAML 設定ファイルでライブの変更を表示します。 |
| Actions メニュー | Actions メニューをクリックして、Edit、Clone、Edit boot source、Edit boot source reference の Edit labels の Edit annotations、または Delete を選択します。 |
| テンプレートの設定と設定。 | |
| YAML 設定ファイル。 | |
| スケジューリング設定。 | |
| ネットワークインターフェイス管理。 | |
| ディスク管理。 | |
| Cloud-init、SSH キー、および Sysprep の管理。 | |
| 名前とクラウドユーザーのパスワード管理。 |
3.3.4.1.1. Details タブ
Details タブでカスタムテンプレートを設定します。
例3.27 Details タブ
| 要素 | 説明 |
|---|---|
| Name | テンプレート名 |
| Namespace | テンプレートの namespace。 |
| Labels | 編集アイコンをクリックして、ラベルを編集します。 |
| Annotations | 編集アイコンをクリックして、注釈を編集します。 |
| Display name | 編集アイコンをクリックして、表示名を編集します。 |
| Description | 編集アイコンをクリックして、説明を入力します。 |
| Operating system | オペレーティングシステム名。 |
| CPU|Memory | 編集アイコンをクリックして、CPU|Memory 要求を編集します。
CPU の数は、 |
| Machine type | テンプレートマシンタイプ。 |
| Boot mode | 編集アイコンをクリックして、起動モードを編集します。 |
| Base template | このテンプレートの作成に使用されたベーステンプレートの名前。 |
| Created at | テンプレートの作成日。 |
| Owner | テンプレート所有者。 |
| Boot order | テンプレートの起動順序。 |
| Boot source | ブートソースの可用性。 |
| Provider | テンプレートプロバイダー |
| Support | テンプレートのサポートレベル。 |
| GPU devices | 編集アイコンをクリックして、GPU デバイスを追加します。 |
| Host devices | 編集アイコンをクリックして、ホストデバイスを追加します。 |
| Headless mode | 編集アイコンをクリックしてヘッドレスモードを ON に設定し、VNC コンソールを無効にします。 |
3.3.4.1.2. YAML タブ
YAML タブで YAML ファイルを編集して、カスタムテンプレートを設定します。
例3.28 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
3.3.4.1.3. Scheduling タブ
Scheduling タブでスケジュールを設定します。
例3.29 Scheduling タブ
| 設定 | 説明 |
|---|---|
| Node selector | 編集アイコンをクリックして、ラベルを追加し、適格なノードを指定します。 |
| 容認 | 編集アイコンをクリックして、許容範囲を追加し、適格なノードを指定します。 |
| アフィニティールール | 編集アイコンをクリックして、アフィニティールールを追加します。 |
| Descheduler スイッチ | Descheduler を有効または無効にします。Descheduler は、実行中の Pod をエビクトして、Pod をより適切なノードに再スケジュールできるようにします。 |
| 専用リソース | 編集アイコンをクリックして、Schedule this workload with dedicated resources (guaranteed policy) を選択します。 |
| エビクションストラテジー | 編集アイコンをクリックして、仮想マシンのエビクション戦略として LiveMigrate を選択します。 |
3.3.4.1.4. Network interfaces タブ
Network interfaces タブでネットワークインターフェイスを管理します。
例3.30 Network interfaces タブ
| 設定 | 説明 |
|---|---|
| Add network interface ボタン | テンプレートにネットワークインターフェイスを追加します。 |
| Filter フィールド | インターフェイスタイプでフィルタリングします。 |
| Search フィールド | 名前またはラベルでネットワークインターフェイスを検索します。 |
| Network interface テーブル | ネットワークインターフェイスのリスト。
ネットワークインターフェイスの横にある actions メニュー
|
3.3.4.1.5. Disks タブ
ディスクは、Disks タブで管理します。
例3.31 Disks タブ
| 設定 | 説明 |
|---|---|
| Add disk ボタン | テンプレートにディスクを追加します。 |
| Filter フィールド | ディスクの種類でフィルタリングします。 |
| Search フィールド | ディスクを名前で検索します。 |
| Disks テーブル | テンプレートディスクのリスト。
ディスクの横にある actions メニュー
|
3.3.4.1.6. Scripts タブ
Scripts タブで、cloud-init 設定、SSH キー、および Sysprep 応答ファイルを管理します。
例3.32 Scripts タブ
| 要素 | 説明 |
|---|---|
| Cloud-init | 編集アイコンをクリックして、cloud-init 設定を編集します。 |
| 認可された SSH キー | 編集アイコンをクリックして、新しいシークレットを作成するか、既存のシークレットを Linux 仮想マシンに割り当てます。 |
| Sysprep |
編集アイコンをクリックして |
3.3.4.1.7. パラメータータブ
パラメーター タブで、選択したテンプレート設定を編集します。
例3.33 Parameters タブ
| 要素 | 説明 |
|---|---|
| 名前 | このテンプレートから作成された仮想マシンの名前パラメーターを設定します。 |
| CLOUD_USER_PASSWORD | このテンプレートから作成された仮想マシンのクラウドユーザーパスワードパラメーターを設定します。 |
3.3.5. InstanceTypes ページ
InstanceTypes ページで仮想マシンインスタンスタイプを表示および管理します。
例3.34 VirtualMachineClusterInstancetypes ページ
| 要素 | 説明 |
|---|---|
| Create ボタン | YAML 設定ファイルを編集して、インスタンスタイプを作成します。 |
| Search フィールド | インスタンスタイプを名前またはラベルで検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| Instance types テーブル | インスタンスのリスト。
インスタンスタイプの横にあるアクションメニュー
|
インスタンスタイプをクリックして、VirtualMachineClusterInstancetypes details ページを表示します。
3.3.5.1. VirtualMachineClusterInstancetypes details ページ
VirtualMachineClusterInstancetypes details ページでインスタンスタイプを設定します。
例3.35 VirtualMachineClusterInstancetypes details ページ
| 要素 | 説明 |
|---|---|
| Details タブ | フォームを編集してインスタンスタイプを設定します。 |
| YAML タブ | YAML 設定ファイルを編集して、インスタンスタイプを設定します。 |
| Actions メニュー | Edit labels、Edit annotations、Edit VirtualMachineClusterInstancetype、または Delete VirtualMachineClusterInstancetype を選択します。 |
3.3.5.1.1. Details タブ
インスタンスタイプを設定するには、Details タブでフォームを編集します。
例3.36 Details タブ
| 要素 | 説明 |
|---|---|
| Name | VirtualMachineClusterInstancetype の名前。 |
| Labels | 編集アイコンをクリックして、ラベルを編集します。 |
| Annotations | 編集アイコンをクリックして、注釈を編集します。 |
| Created at | インスタンスタイプの作成日。 |
| Owner | インスタンスタイプの所有者。 |
3.3.5.1.2. YAML タブ
インスタンスタイプを設定するには、YAML タブで YAML ファイルを編集します。
例3.37 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
3.3.6. Preferences ページ
Preferences ページで仮想マシンの設定を表示および管理します。
例3.38 VirtualMachineClusterPreferences ページ
| 要素 | 説明 |
|---|---|
| Create ボタン | YAML 設定ファイルを編集して設定を作成します。 |
| Search フィールド | 名前またはラベルで設定を検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| Preferences テーブル | 設定のリスト。
設定の横にあるアクションメニュー
|
設定をクリックして、VirtualMachineClusterPreference details ページを表示します。
3.3.6.1. VirtualMachineClusterPreference details ページ
VirtualMachineClusterPreference details ページで設定を指定します。
例3.39 VirtualMachineClusterPreference details ページ
| 要素 | 説明 |
|---|---|
| Details タブ | フォームを編集して設定を指定します。 |
| YAML タブ | YAML 設定ファイルを編集して設定を指定します。 |
| Actions メニュー | Edit labels、Edit annotations、Edit VirtualMachineClusterPreference、または Delete VirtualMachineClusterPreference を選択します。 |
3.3.6.1.1. Details タブ
Details タブでフォームを編集して設定を指定します。
例3.40 Details タブ
| 要素 | 説明 |
|---|---|
| Name | VirtualMachineClusterPreference の名前。 |
| Labels | 編集アイコンをクリックして、ラベルを編集します。 |
| Annotations | 編集アイコンをクリックして、注釈を編集します。 |
| Created at | 設定の作成日。 |
| Owner | 設定の所有者。 |
3.3.6.1.2. YAML タブ
設定タイプを設定するには、YAML タブで YAML ファイルを編集します。
例3.41 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
3.3.7. Bootable volumes ページ
Bootable volumes ページで、使用可能なブート可能ボリュームを表示および管理します。
例3.42 Bootable volumes ページ
| 要素 | 説明 |
|---|---|
| Add volume ボタン | フォームに入力するか、YAML 設定ファイルを編集して、ブート可能ボリュームを追加します。 |
| Filter フィールド | ブート可能ボリュームをオペレーティングシステムとリソースタイプでフィルタリングします。 |
| Search フィールド | ブート可能ボリュームを名前またはラベルで検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| ブート可能ボリュームテーブル | ブート可能なボリュームのリスト。
ブート可能ボリュームの横にあるアクションメニュー
|
ブート可能ボリュームをクリックして、PersistentVolumeClaim details ページを表示します。
3.3.7.1. PersistentVolumeClaim details ページ
PersistentVolumeClaim details ページでブート可能ボリュームの永続ボリューム要求 (PVC) を設定します。
例3.43 PersistentVolumeClaim details ページ
| 要素 | 説明 |
|---|---|
| Details タブ | フォームを編集して PVC を設定します。 |
| YAML タブ | YAML 設定ファイルを編集して PVC を設定します。 |
| Events タブ | Events タブには、PVC イベントのリストが表示されます。 |
| VolumeSnapshots タブ | VolumeSnapshots タブには、ボリュームスナップショットのリストが表示されます。 |
| Actions メニュー | Expand PVC、Create snapshot、Clone PVC、Edit labels、Edit annotations、Edit PersistentVolumeClaim、または Delete PersistentVolumeClaim を選択します。 |
3.3.7.1.1. Details タブ
Details タブのフォームを編集して、ブート可能ボリュームの永続ボリューム要求 (PVC) を設定します。
例3.44 Details タブ
| 要素 | 説明 |
|---|---|
| Name | PVC の名前。 |
| Namespace | PVC の namespace。 |
| Labels | 編集アイコンをクリックして、ラベルを編集します。 |
| Annotations | 編集アイコンをクリックして、注釈を編集します。 |
| Created at | PVC の作成日。 |
| Owner | PVC の所有者。 |
| ステータス | PVC のステータス (Bound など)。 |
| Requested capacity | PVC の要求された容量。 |
| 容量 | PVC の容量。 |
| Used | PVC の使用済み領域。 |
| アクセスモード | PVC のアクセスモード。 |
| ボリュームモード | PVC のボリュームモード。 |
| StorageClasses | PVC のストレージクラス。 |
| PersistentVolumes | PVC に関連付けられた永続ボリューム。 |
| 条件 表 | PVC のステータスを表示します。 |
3.3.7.1.2. YAML タブ
ブート可能ボリュームの永続ボリューム要求を設定するには、YAML タブで YAML ファイルを編集します。
例3.45 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
3.3.8. MigrationPolicies ページ
MigrationPolicies ページでワークロードの移行ポリシーを管理します。
例3.46 MigrationPolicies ページ
| 要素 | 説明 |
|---|---|
| 移行ポリシーの作成 | フォームに設定とラベルを入力するか、YAML ファイルを編集して、移行ポリシーを作成します。 |
| Search フィールド | 名前またはラベルで移行ポリシーを検索します。 |
| Manage columns アイコン | テーブルに表示する列を最大 9 つ選択します。Namespace 列は、Projects リストから All Projects が選択されている場合にのみ表示されます。 |
| MigrationPolicies テーブル | 移行ポリシーのリスト。
移行ポリシーの横にあるアクションメニュー
|
移行ポリシーをクリックして、MigrationPolicy details ページを表示します。
3.3.8.1. MigrationPolicy details ページ
移行ポリシーは、MigrationPolicy details ページで設定します。
例3.47 MigrationPolicy details ページ
| 要素 | 説明 |
|---|---|
| Details タブ | フォームを編集して移行ポリシーを設定します。 |
| YAML タブ | YAML 設定ファイルを編集して、移行ポリシーを設定します。 |
| Actions メニュー | Edit または Delete を選択します。 |
3.3.8.1.1. Details タブ
Details タブでカスタムテンプレートを設定します。
例3.48 Details タブ
| 要素 | 説明 |
|---|---|
| Name | 移行ポリシー名。 |
| Description | 移行ポリシーの説明。 |
| 設定 | 編集アイコンをクリックして、移行ポリシー設定を更新します。 |
| 移行ごとの帯域幅 |
移行ごとの帯域幅要求。帯域幅を無制限にするには、値を |
| 自動収束 | 自動収束が有効になっている場合は、移行を確実に成功させるために、仮想マシンのパフォーマンスと可用性が低下する可能性があります。 |
| ポストコピー | ポストコピーポリシー。 |
| 完了タイムアウト | 秒単位の完了タイムアウト値。 |
| プロジェクトラベル | Edit をクリックして、プロジェクトラベルを編集します。 |
| VirtualMachine のラベル | Edit をクリックして仮想マシンのラベルを編集します。 |
3.3.8.1.2. YAML タブ
移行ポリシーを設定するには、YAML タブで YAML ファイルを編集します。
例3.49 YAML タブ
| 要素 | 説明 |
|---|---|
| Save ボタン | 変更を YAML ファイルに保存します。 |
| Reload ボタン | 変更を破棄し、YAML ファイルをリロードします。 |
| Cancel ボタン | YAML タブを終了します。 |
| Download ボタン | YAML ファイルをローカルマシンにダウンロードします。 |
第4章 インストール
4.1. OpenShift Virtualization のクラスターの準備
OpenShift Virtualization をインストールする前にこのセクションを確認して、クラスターが要件を満たしていることを確認してください。
- インストール方法の考慮事項
- ユーザープロビジョニング、インストーラープロビジョニング、またはアシステッドインストーラーなど、任意のインストール方法を使用して、OpenShift Container Platform をデプロイできます。ただし、インストール方法とクラスタートポロジーは、スナップショットや ライブマイグレーション などの OpenShift Virtualization 機能に影響を与える可能性があります。
- Red Hat OpenShift Data Foundation
- Red Hat OpenShift Data Foundation を使用して OpenShift Virtualization をデプロイする場合は、Windows 仮想マシンディスク用の専用ストレージクラスを作成する必要があります。詳細は 、Windows VM の ODF PersistentVolumes の最適化 を参照してください。
- IPv6
- シングルスタックの IPv6 クラスターで OpenShift Virtualization は実行できません。
FIPS モード
クラスターを FIPS モード でインストールする場合、OpenShift Virtualization に追加の設定は必要ありません。
4.1.1. サポート対象のプラットフォーム
OpenShift Virtualization では、以下のプラットフォームを使用できます。
- オンプレミスのベアメタルサーバー。OpenShift 仮想化のためのベアメタルクラスターの計画 を参照してください。
IBM Cloud® ベアメタルサーバー。Deploy OpenShift Virtualization on IBM Cloud® Bare Metal nodes を参照してください。
重要IBM Cloud® ベアメタルサーバーへの OpenShift Virtualization のインストールは、テクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
他のクラウドプロバイダーが提供するベアメタルインスタンスまたはサーバーはサポートされていません。
4.1.1.1. AWS ベアメタル上の OpenShift Virtualization
OpenShift Virtualization は、Amazon Web Services (AWS) ベアメタル OpenShift Container Platform クラスターで実行できます。
OpenShift Virtualization は、AWS ベアメタルクラスターと同じ設定要件を持つ Red Hat OpenShift Service on AWS (ROSA) Classic クラスターでもサポートされています。
クラスターを設定する前に、サポート対象の機能と制限に関する以下の要約を確認してください。
- インストール
installer-provisioned infrastructure を使用してクラスターをインストールできます。その際に、
install-config.yamlファイルを編集してワーカーノードのベアメタルインスタンスタイプを確実に指定してください。たとえば、x86_64 アーキテクチャーをベースとするマシンのc5n.metalタイプの値を使用できます。詳細は、AWS へのインストールに関する OpenShift Container Platform ドキュメントを参照してください。
- 仮想マシン (VM) へのアクセス
-
virtctlCLI ツールまたは OpenShift Container Platform Web コンソールを使用して仮想マシンにアクセスする方法に変更はありません。 NodePortまたはLoadBalancerサービスを使用して、仮想マシンを公開できます。- OpenShift Container Platform は AWS でロードバランサーを自動的に作成し、そのライフサイクルを管理するため、ロードバランサーのアプローチが推奨されます。また、セキュリティーグループはロードバランサー用にも作成され、アノテーションを使用して既存のセキュリティーグループをアタッチできます。サービスを削除すると、OpenShift Container Platform はロードバランサーとそれに関連付けられたリソースを削除します。
- ネットワーク
- Single Root I/O Virtualization (SR-IOV) またはブリッジ Container Network Interface (CNI) ネットワーク (仮想 LAN (VLAN) を含む) は使用できません。アプリケーションにフラットレイヤー 2 ネットワークが必要な場合や、IP プールを制御する必要がある場合は、OVN-Kubernetes セカンダリーオーバーレイネットワークを使用することを検討してください。
- ストレージ
基盤となるプラットフォームとの連携がストレージベンダーによって認定されている任意のストレージソリューションを使用できます。
重要AWS ベアメタルクラスターと ROSA クラスターでは、サポートされているストレージソリューションが異なる場合があります。ストレージベンダーにサポートを確認してください。
- Amazon Elastic File System (EFS) および Amazon Elastic Block Store (EBS) は、パフォーマンスと機能が限定されるため、OpenShift Virtualization での使用は推奨されません。代わりに共有ストレージを使用してください。
4.1.2. ハードウェアとオペレーティングシステムの要件
OpenShift Virtualization の次のハードウェアおよびオペレーティングシステム要件を確認してください。
4.1.2.1. CPU の要件
Red Hat Enterprise Linux (RHEL) 9 でサポート。
サポートされている CPU の Red Hat Ecosystem Catalog を参照してください。
注記ワーカーノードの CPU が異なる場合は、CPU ごとに機能が異なるため、ライブマイグレーションが失敗する可能性があります。この問題は、ワーカーノードに適切な容量の CPU が搭載されていることを確認し、仮想マシンのノードアフィニティールールを設定することで軽減できます。
詳細は、必要なノードアフィニティールールの設定 を参照してください。
- AMD および Intel 64 ビットアーキテクチャー (x86-64-v2) のサポート。
- Intel 64 または AMD64 CPU 拡張機能のサポート。
- Intel VT または AMD-V ハードウェア仮想化拡張機能が有効化されている。
- NX (実行なし) フラグが有効。
4.1.2.2. オペレーティングシステム要件
ワーカーノードにインストールされた Red Hat Enterprise Linux CoreOS (RHCOS)。
詳細は、RHCOS について を参照してください。
注記RHEL ワーカー ノードはサポートされていません。
4.1.2.3. ストレージ要件
- OpenShift Container Platform によるサポート。Optimizing storage を参照してください。
- デフォルトの OpenShift Virtualization または OpenShift Container Platform ストレージクラスを作成する必要があります。これは、仮想マシンワークロード固有のストレージニーズに対応し、最適化されたパフォーマンス、信頼性、ユーザーエクスペリエンスを提供することを目的としています。OpenShift Virtualization と OpenShift Container Platform の両方にデフォルトのストレージクラスが存在する場合、仮想マシンディスクの作成時には OpenShift Virtualization のクラスが優先されます。
クラスターのデフォルトのストレージクラスを指定する必要があります。デフォルトストレージクラスの管理 を参照してください。デフォルトのストレージクラスプロビジョナーが ReadWriteMany (RWX) アクセスモード をサポートしている場合は、最適なパフォーマンスを得るために、関連する永続ボリュームに RWX モードを使用してください。
ストレージプロビジョナーがスナップショットをサポートしている場合は、デフォルトのストレージクラスに関連付けられた VolumeSnapshotClass オブジェクトが必要です。
4.1.2.3.1. 仮想マシンディスクのボリュームとアクセスモードについて
既知のストレージプロバイダーでストレージ API を使用する場合、ボリュームモードとアクセスモードは自動的に選択されます。ただし、ストレージプロファイルのないストレージクラスを使用する場合は、ボリュームとアクセスモードを設定する必要があります。
最良の結果を得るには、ReadWriteMany (RWX) アクセスモードと Block ボリュームモードを使用してください。これは、以下の理由により重要です。
-
ライブマイグレーションには
ReadWriteMany(RWX) アクセスモードが必要です。 Blockボリュームモードは、Filesystemボリュームモードよりもパフォーマンスが大幅に優れています。これは、Filesystemボリュームモードでは、ファイルシステムレイヤーやディスクイメージファイルなどを含め、より多くのストレージレイヤーが使用されるためです。仮想マシンのディスクストレージに、これらのレイヤーは必要ありません。たとえば、Red Hat OpenShift Data Foundation を使用する場合は、CephFS ボリュームよりも Ceph RBD ボリュームの方が推奨されます。
次の設定の仮想マシンをライブマイグレーションすることはできません。
-
ReadWriteOnce(RWO) アクセスモードのストレージボリューム - GPU などのパススルー機能
それらの仮想マシンの evictionStrategy フィールドを LiveMigrate に設定しないでください。
4.1.3. ライブマイグレーションの要件
-
ReadWriteMany(RWX) アクセスモードの共有ストレージ 十分な RAM およびネットワーク帯域幅
注記ライブマイグレーションを引き起こすノードドレインをサポートするために、クラスター内に十分なメモリーリクエスト容量があることを確認する必要があります。以下の計算を使用して、必要な予備のメモリーを把握できます。
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)
クラスターで 並行して実行できるデフォルトの移行数 は 5 です。
- 仮想マシンがホストモデルの CPU を使用する場合、ノードは仮想マシンのホストモデルの CPU をサポートする必要があります。
- ライブマイグレーション 専用の Multus ネットワーク を強く推奨します。専用ネットワークは、移行中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
4.1.4. 物理リソースのオーバーヘッド要件
OpenShift Virtualization は OpenShift Container Platform のアドオンであり、クラスターの計画時に考慮する必要のある追加のオーバーヘッドを強要します。各クラスターマシンは、OpenShift Container Platform の要件に加えて、以下のオーバーヘッドの要件を満たす必要があります。クラスター内の物理リソースを過剰にサブスクライブすると、パフォーマンスに影響する可能性があります。
本書に記載されている数は、Red Hat のテスト方法およびセットアップに基づいています。これらの数は、独自のセットアップおよび環境に応じて異なります。
メモリーのオーバーヘッド
以下の式を使用して、OpenShift Virtualization のメモリーオーバーヘッドの値を計算します。
クラスターメモリーのオーバーヘッド
Memory overhead per infrastructure node ≈ 150 MiB
Memory overhead per worker node ≈ 360 MiB
さらに、OpenShift Virtualization 環境リソースには、すべてのインフラストラクチャーノードに分散される合計 2179 MiB の RAM が必要です。
仮想マシンのメモリーオーバーヘッド
Memory overhead per virtual machine ≈ (1.002 × requested memory) \
+ 218 MiB \ 1
+ 8 MiB × (number of vCPUs) \ 2
+ 16 MiB × (number of graphics devices) \ 3
+ (additional memory overhead) 4
- 1
virt-launcherPod で実行されるプロセスに必要です。- 2
- 仮想マシンが要求する仮想 CPU の数。
- 3
- 仮想マシンが要求する仮想グラフィックスカードの数。
- 4
- 追加のメモリーオーバーヘッド:
- お使いの環境に Single Root I/O Virtualization (SR-IOV) ネットワークデバイスまたは Graphics Processing Unit (GPU) が含まれる場合、それぞれのデバイスに 1 GiB の追加のメモリーオーバーヘッドを割り当てます。
- Secure Encrypted Virtualization (SEV) が有効な場合は、256 MiB を追加します。
- Trusted Platform Module (TPM) が有効な場合は、53 MiB を追加します。
CPU オーバーヘッド
以下の式を使用して、OpenShift Virtualization のクラスタープロセッサーのオーバーヘッド要件を計算します。仮想マシンごとの CPU オーバーヘッドは、個々の設定によって異なります。
クラスターの CPU オーバーヘッド
CPU overhead for infrastructure nodes ≈ 4 cores
OpenShift Virtualization は、ロギング、ルーティング、およびモニタリングなどのクラスターレベルのサービスの全体的な使用率を増加させます。このワークロードに対応するには、インフラストラクチャーコンポーネントをホストするノードに、4 つの追加コア (4000 ミリコア) の容量があり、これがそれらのノード間に分散されていることを確認します。
CPU overhead for worker nodes ≈ 2 cores + CPU overhead per virtual machine
仮想マシンをホストする各ワーカーノードには、仮想マシンのワークロードに必要な CPU に加えて、OpenShift Virtualization 管理ワークロード用に 2 つの追加コア (2000 ミリコア) の容量が必要です。
仮想マシンの CPU オーバーヘッド
専用の CPU が要求される場合は、仮想マシン 1 台につき CPU 1 つとなり、クラスターの CPU オーバーヘッド要件に影響が出てきます。それ以外の場合は、仮想マシンに必要な CPU の数に関する特別なルールはありません。
ストレージのオーバーヘッド
以下のガイドラインを使用して、OpenShift Virtualization 環境のストレージオーバーヘッド要件を見積もります。
クラスターストレージオーバーヘッド
Aggregated storage overhead per node ≈ 10 GiB
10 GiB は、OpenShift Virtualization のインストール時にクラスター内の各ノードについてのディスク上のストレージの予想される影響に相当します。
仮想マシンのストレージオーバーヘッド
仮想マシンごとのストレージオーバーヘッドは、仮想マシン内のリソース割り当ての特定の要求により異なります。この要求は、クラスター内の別の場所でホストされるノードまたはストレージリソースの一時ストレージに対するものである可能性があります。OpenShift Virtualization は現在、実行中のコンテナー自体に追加の一時ストレージを割り当てていません。
例
クラスター管理者が、クラスター内の 10 台の (それぞれ 1 GiB の RAM と 2 つの vCPU の) 仮想マシンをホストする予定の場合、クラスター全体で影響を受けるメモリーは 11.68 GiB になります。クラスターの各ノードについて予想されるディスク上のストレージの影響は 10 GiB で示され、仮想マシンのワークロードをホストするワーカーノードについての CPU の影響は最小 2 コアで示されます。
4.1.5. 単一ノードの Openshift の違い
OpenShift Virtualization は単一ノード OpenShift にインストールできます。
ただし、単一ノード OpenShift は次の機能をサポートしていないことに注意してください。
- 高可用性
- Pod の中断
- ライブマイグレーション
- エビクション戦略が設定されている仮想マシンまたはテンプレート
4.1.6. オブジェクトの最大値
クラスターを計画するときは、次のテスト済みオブジェクトの最大数を考慮する必要があります。
4.1.7. クラスターの高可用性オプション
クラスターには、次の高可用性 (HA) オプションのいずれかを設定できます。
インストーラーによってプロビジョニングされたインフラストラクチャー (IPI) の 自動高可用性は、マシンヘルスチェック をデプロイすることで利用できます。
注記インストーラーによってプロビジョニングされたインフラストラクチャーを使用し、適切に設定された
MachineHealthCheckリソースを使用してインストールされた OpenShift Container Platform クラスターでは、ノードがマシンヘルスチェックに失敗し、クラスターで使用できなくなった場合、そのノードはリサイクルされます。障害が発生したノードで実行された仮想マシンでは、一連の条件によって次に起こる動作が変わります。潜在的な結果と、実行戦略がそれらの結果にどのように影響するかに関する詳細は、戦略の実行 を参照してください。-
IPI と非 IPI の両方の自動高可用性は、OpenShift Container Platform クラスターで Node Health Check Operator を使用して
NodeHealthCheckコントローラーをデプロイすることで利用できます。コントローラーは異常なノードを特定し、Self Node Remediation Operator や Fence Agents Remediation Operator などの修復プロバイダーを使用して異常なノードを修復します。ノードの修復、フェンシング、メンテナンスについて、詳しくは Red Hat OpenShift のワークロードの可用性 を参照してください。 モニタリングシステムまたは有資格者を使用してノードの可用性をモニターすることにより、あらゆるプラットフォームの高可用性を利用できます。ノードが失われた場合は、これをシャットダウンして
oc delete node <lost_node>を実行します。注記外部モニタリングシステムまたは資格のある人材によるノードの正常性の監視が行われない場合、仮想マシンは高可用性を失います。
4.2. OpenShift virtualization のインストール
OpenShift Virtualization をインストールし、仮想化機能を OpenShift Container Platform クラスターに追加します。
インターネット接続のない制限された環境に OpenShift Virtualization をインストールする場合は、制限されたネットワーク用に Operator Lifecycle Manager (OLM) を設定 する必要があります。
インターネット接続が制限されている場合は、OLM でプロキシーサポートを設定して OperatorHub にアクセスできます。
4.2.1. OpenShift Virtualization Operator のインストール
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、OpenShift Virtualization Operator をインストールします。
4.2.1.1. Web コンソールを使用した OpenShift Virtualization Operator のインストール
OpenShift Container Platform Web コンソールを使用して、OpenShift Virtualization Operator をデプロイできます。
前提条件
- OpenShift Container Platform 4.14 をクラスターにインストールしていること。
-
cluster-adminパーミッションを持つユーザーとして OpenShift Container Platform Web コンソールにログインすること。
手順
- Administrator パースペクティブから、Operators → OperatorHub をクリックします。
- Filter by keyword に Virtualization と入力します。
- Red Hat ソースラベルが示されている OpenShift Virtualization Operator タイルを選択します。
- Operator についての情報を確認してから、Install をクリックします。
Install Operator ページで以下を行います。
- 選択可能な Update Channel オプションの一覧から stable を選択します。これにより、OpenShift Container Platform バージョンと互換性がある OpenShift Virtualization のバージョンをインストールすることができます。
インストールされた namespace の場合、Operator recommended namespace オプションが選択されていることを確認します。これにより、Operator が必須の
openshift-cnvnamespace にインストールされます。この namespace は存在しない場合は、自動的に作成されます。警告OpenShift Virtualization Operator を
openshift-cnv以外の namespace にインストールしようとすると、インストールが失敗します。Approval Strategy の場合に、stable 更新チャネルで新しいバージョンが利用可能になったときに OpenShift Virtualization が自動更新されるように、デフォルト値である Automaticを選択することを強く推奨します。
Manual 承認ストラテジーを選択することは可能ですが、クラスターのサポート容易性および機能に対応するリスクが高いため、推奨できません。これらのリスクを完全に理解していて、Automatic を使用できない場合のみ、Manual を選択してください。
警告OpenShift Virtualization は対応する OpenShift Container Platform バージョンで使用される場合にのみサポートされるため、OpenShift Virtualization が更新されないと、クラスターがサポートされなくなる可能性があります。
-
Install をクリックし、Operator を
openshift-cnvnamespace で利用可能にします。 - Operator が正常にインストールされたら、Create HyperConverged をクリックします。
- オプション: OpenShift Virtualization コンポーネントの Infra および Workloads ノード配置オプションを設定します。
- Create をクリックして OpenShift Virtualization を起動します。
検証
- Workloads → Pods ページに移動して、OpenShift Virtualization Pod がすべて Running 状態になるまでこれらの Pod をモニターします。すべての Pod で Running 状態が表示された後に、OpenShift Virtualization を使用できます。
4.2.1.2. コマンドラインを使用した OpenShift Virtualization Operator のインストール
OpenShift Virtualization カタログをサブスクライブし、クラスターにマニフェストを適用して OpenShift Virtualization Operator をインストールします。
4.2.1.2.1. CLI を使用した OpenShift Virtualization カタログのサブスクライブ
OpenShift Virtualization をインストールする前に、OpenShift Virtualization カタログにサブスクライブする必要があります。サブスクライブにより、openshift-cnv namespace に OpenShift Virtualization Operator へのアクセスが付与されます。
単一マニフェストをクラスターに適用して Namespace、OperatorGroup、および Subscription オブジェクトをサブスクライブし、設定します。
前提条件
- OpenShift Container Platform 4.14 をクラスターにインストールしていること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下のマニフェストを含む YAML ファイルを作成します。
apiVersion: v1 kind: Namespace metadata: name: openshift-cnv --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: kubevirt-hyperconverged-group namespace: openshift-cnv spec: targetNamespaces: - openshift-cnv --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: hco-operatorhub namespace: openshift-cnv spec: source: redhat-operators sourceNamespace: openshift-marketplace name: kubevirt-hyperconverged startingCSV: kubevirt-hyperconverged-operator.v4.14.5 channel: "stable" 1- 1
stableチャネルを使用することで、OpenShift Container Platform バージョンと互換性のある OpenShift Virtualization のバージョンをインストールすることができます。
以下のコマンドを実行して、OpenShift Virtualization に必要な
Namespace、OperatorGroup、およびSubscriptionオブジェクトを作成します。$ oc apply -f <file name>.yaml
YAML ファイルで、証明書のローテーションパラメーターを設定 できます。
4.2.1.2.2. CLI を使用した OpenShift Virtualization Operator のデプロイ
oc CLI を使用して OpenShift Virtualization Operator をデプロイすることができます。
前提条件
-
openshift-cnvnamespace の OpenShift Virtualization カタログへのサブスクリプション。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下のマニフェストを含む YAML ファイルを作成します。
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec:
以下のコマンドを実行して OpenShift Virtualization Operator をデプロイします。
$ oc apply -f <file_name>.yaml
検証
openshift-cnvnamespace の Cluster Service Version (CSV) のPHASEを監視して、OpenShift Virtualization が正常にデプロイされたことを確認します。以下のコマンドを実行します。$ watch oc get csv -n openshift-cnv
以下の出力は、デプロイメントに成功したかどうかを表示します。
出力例
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.14.5 OpenShift Virtualization 4.14.5 Succeeded
4.2.2. 次のステップ
- ホストパスプロビジョナー は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。仮想マシンのローカルストレージを設定する必要がある場合、まずホストパスプロビジョナーを有効にする必要があります。
4.3. OpenShift Virtualization のアンインストール
Web コンソールまたはコマンドラインインターフェイス (CLI) を使用して OpenShift Virtualization をアンインストールし、OpenShift Virtualization ワークロード、Operator、およびそのリソースを削除します。
4.3.1. Web コンソールを使用した OpenShift Virtualization のアンインストール
Web コンソール を使用して OpenShift Virtualization をアンインストールし、以下のタスクを実行します。
まず、すべての 仮想マシン と 仮想マシンインスタンス を削除する必要があります。
ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
4.3.1.1. HyperConverged カスタムリソースの削除
OpenShift Virtualization をアンインストールするには、最初に HyperConverged カスタムリソース (CR) を削除します。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Operators → Installed Operators ページに移動します。
- OpenShift Virtualization Operator を選択します。
- OpenShift Virtualization Deployment タブをクリックします。
-
kubevirt-hyperconvergedの横にある Options メニュー をクリックし、Delete HyperConverged を選択します。
をクリックし、Delete HyperConverged を選択します。
- 確認ウィンドウで Delete をクリックします。
4.3.1.2. Web コンソールの使用によるクラスターからの Operator の削除
クラスター管理者は Web コンソールを使用して、選択した namespace からインストールされた Operator を削除できます。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスター Web コンソールにアクセスできる。
手順
- Operators → Installed Operators ページに移動します。
- スクロールするか、キーワードを Filter by name フィールドに入力して、削除する Operator を見つけます。次に、それをクリックします。
Operator Details ページの右側で、Actions 一覧から Uninstall Operator を選択します。
Uninstall Operator? ダイアログボックスが表示されます。
Uninstall を選択し、Operator、Operator デプロイメント、および Pod を削除します。このアクションの後には、Operator は実行を停止し、更新を受信しなくなります。
注記このアクションは、カスタムリソース定義 (CRD) およびカスタムリソース (CR) など、Operator が管理するリソースは削除されません。Web コンソールおよび継続して実行されるクラスター外のリソースによって有効にされるダッシュボードおよびナビゲーションアイテムには、手動でのクリーンアップが必要になる場合があります。Operator のアンインストール後にこれらを削除するには、Operator CRD を手動で削除する必要があります。
4.3.1.3. Web コンソールを使用した namespace の削除
OpenShift Container Platform Web コンソールを使用して namespace を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Administration → Namespaces に移動します。
- namespace の一覧で削除する必要のある namespace を見つけます。
-
namespace の一覧の右端で、Options メニュー
から Delete Namespace を選択します。
- Delete Namespace ペインが表示されたら、フィールドから削除する namespace の名前を入力します。
- Delete をクリックします。
4.3.1.4. OpenShift Virtualization カスタムリソース定義の削除
Web コンソールを使用して、OpenShift Virtualization カスタムリソース定義 (CRD) を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Administration → CustomResourceDefinitions に移動します。
-
Label フィルターを選択し、Search フィールドに
operators.coreos.com/kubevirt-hyperconverged.openshift-cnvと入力して OpenShift Virtualization CRD を表示します。 -
各 CRD の横にある Options メニュー
をクリックし、Delete CustomResourceDefinition の削除を選択します。
4.3.2. CLI を使用した OpenShift Virtualization のアンインストール
OpenShift CLI (oc) を使用して OpenShift Virtualization をアンインストールできます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - すべての仮想マシンと仮想マシンインスタンスを削除した。ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
手順
HyperConvergedカスタムリソースを削除します。$ oc delete HyperConverged kubevirt-hyperconverged -n openshift-cnv
OpenShift Virtualization Operator サブスクリプションを削除します。
$ oc delete subscription kubevirt-hyperconverged -n openshift-cnv
OpenShift Virtualization
ClusterServiceVersionリソースを削除します。$ oc delete csv -n openshift-cnv -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
OpenShift Virtualization namespace を削除します。
$ oc delete namespace openshift-cnv
dry-runオプションを指定してoc delete crdコマンドを実行し、OpenShift Virtualization カスタムリソース定義 (CRD) を一覧表示します。$ oc delete crd --dry-run=client -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
出力例
customresourcedefinition.apiextensions.k8s.io "cdis.cdi.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hostpathprovisioners.hostpathprovisioner.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hyperconvergeds.hco.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "kubevirts.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "networkaddonsconfigs.networkaddonsoperator.network.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "ssps.ssp.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "tektontasks.tektontasks.kubevirt.io" deleted (dry run)
dry-runオプションを指定せずにoc delete crdコマンドを実行して、CRD を削除します。$ oc delete crd -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
関連情報
第5章 インストール後の設定
5.1. インストール後の設定
通常、次の手順は OpenShift Virtualization のインストール後に実行されます。環境に関連するコンポーネントを設定できます。
- OpenShift Virtualization Operator、ワークロード、およびコントローラーのノード配置ルール
- Kubernetes NMState および SR-IOV Operator のインストール
- 仮想マシンへの外部アクセスのための Linux ブリッジネットワークの設定
- ライブマイグレーション用の専用セカンダリーネットワークの設定
- SR-IOV ネットワークの設定
- OpenShift Container Platform Web コンソールを使用したロードバランサーサービスの作成の有効化
- Container Storage Interface (CSI) のデフォルトのストレージクラスの定義
- ホストパスプロビジョナー (HPP) を使用したローカルストレージの設定
5.2. OpenShift Virtualization コンポーネントのノードの指定
ベアメタルノード上の仮想マシンのデフォルトのスケジューリングは適切です。任意で、ノードの配置ルールを設定して、OpenShift Virtualization Operator、ワークロード、およびコントローラーをデプロイするノードを指定できます。
OpenShift Virtualization のインストール後に一部のコンポーネントに対してノード配置ルールを設定できますが、ワークロードに対してノード配置ルールを設定する場合は仮想マシンが存在できません。
5.2.1. OpenShift Virtualization コンポーネントのノード配置ルールについて
ノード配置ルールは次のタスクに使用できます。
- 仮想マシンは、仮想化ワークロードを対象としたノードにのみデプロイしてください。
- Operator はインフラストラクチャーノードにのみデプロイメントします。
- ワークロード間の分離を維持します。
オブジェクトに応じて、以下のルールタイプを 1 つ以上使用できます。
nodeSelector- Pod は、キーと値のペアまたはこのフィールドで指定したペアを使用してラベルが付けられたノードに Pod をスケジュールできます。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinity- より表現的な構文を使用して、ノードと Pod に一致するルールを設定できます。アフィニティーを使用すると、ルールの適用方法に追加のニュアンスを持たせることができます。たとえば、ルールが要件ではなく設定であると指定できます。ルールが優先の場合、ルールが満たされていない場合でも Pod はスケジュールされます。
tolerations- 一致するテイントを持つノードで Pod をスケジュールできます。テイントがノードに適用される場合、そのノードはテイントを容認する Pod のみを受け入れます。
5.2.2. ノード配置ルールの適用
コマンドラインを使用して Subscription、HyperConverged、または HostPathProvisioner オブジェクトを編集することで、ノード配置ルールを適用できます。
前提条件
-
ocCLI ツールがインストールされている。 - クラスター管理者の権限でログインしています。
手順
次のコマンドを実行して、デフォルトのエディターでオブジェクトを編集します。
$ oc edit <resource_type> <resource_name> -n {CNVNamespace}- 変更を適用するためにファイルを保存します。
5.2.3. ノード配置ルールの例
Subscription、HyperConverged、または HostPathProvisioner オブジェクトを編集することで、OpenShift Virtualization コンポーネントのノード配置ルールを指定できます。
5.2.3.1. サブスクリプションオブジェクトノード配置ルールの例
OLM が OpenShift Virtualization Operator をデプロイするノードを指定するには、OpenShift Virtualization のインストール時に Subscription オブジェクトを編集します。
現時点では、Web コンソールを使用して Subscription オブジェクトのノードの配置ルールを設定することはできません。
Subscription オブジェクトは、affinity ノードの配置ルールをサポートしていません。
nodeSelector ルールを使用した Subscription オブジェクトの例
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.14.5
channel: "stable"
config:
nodeSelector:
example.io/example-infra-key: example-infra-value 1
- 1
- OLM は、
example.io/example-infra-key = example-infra-valueというラベルのノードに OpenShift Virtualization Operator をデプロイします。
tolerations ルールを備えた Subscription オブジェクトの例
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.14.5
channel: "stable"
config:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization" 1
effect: "NoSchedule"
- 1
- OLM は、
key = virtualization:NoScheduleテイントというラベルの付いたノードに OpenShift Virtualization Operator をデプロイします。一致する容認のある Pod のみがこれらのノードにスケジュールされます。
5.2.3.2. HyperConverged オブジェクトノード配置ルールの例
OpenShift Virtualization がそのコンポーネントをデプロイするノードを指定するには、OpenShift Virtualization のインストール時に作成する HyperConverged カスタムリソース (CR) ファイルに nodePlacement オブジェクトを編集できます。
nodeSelector ルールを使用した HyperConverged オブジェクトの例
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
nodeSelector:
example.io/example-infra-key: example-infra-value 1
workloads:
nodePlacement:
nodeSelector:
example.io/example-workloads-key: example-workloads-value 2
affinity ルールを使用した HyperConverged オブジェクトの例
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-infra-key
operator: In
values:
- example-infra-value 1
workloads:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-workloads-key 2
operator: In
values:
- example-workloads-value
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: example.io/num-cpus
operator: Gt
values:
- 8 3
tolerations ルールを備えた HyperConverged オブジェクトの例
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
workloads:
nodePlacement:
tolerations: 1
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"
- 1
- OpenShift Virtualization コンポーネント用に予約されたノードには、
key = virtualization:NoScheduleテイントのラベルが付けられます。許容範囲が一致する Pod のみが予約済みノードでスケジュールされます。
5.2.3.3. HostPathProvisioner オブジェクトノード配置ルールの例
HostPathProvisioner オブジェクトは、直接編集することも、Web コンソールを使用して編集することもできます。
ホストパスプロビジョナーと OpenShift Virtualization コンポーネントを同じノード上でスケジュールする必要があります。スケジュールしない場合は、ホストパスプロビジョナーを使用する仮想化 Pod を実行できません。仮想マシンを実行することはできません。
ホストパスプロビジョナー (HPP) ストレージクラスを使用して仮想マシン (VM) をデプロイした後、ノードセレクターを使用して同じノードからホストパスプロビジョナー Pod を削除できます。ただし、少なくともその特定のノードについては、まずその変更を元に戻し、仮想マシンを削除しようとする前に Pod が実行されるのを待つ必要があります。
ノード配置ルールを設定するには、ホストパスプロビジョナーのインストール時に作成する HostPathProvisioner オブジェクトの spec.workload フィールドに nodeSelector、affinity、または tolerations を指定します。
nodeSelector ルールを使用した HostPathProvisioner オブジェクトの例
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "</path/to/backing/directory>"
useNamingPrefix: false
workload:
nodeSelector:
example.io/example-workloads-key: example-workloads-value 1
- 1
- ワークロードは、
example.io/example-workloads-key = example-workloads-valueというラベルの付いたノードに配置されます。
5.2.4. 関連情報
5.3. インストール後のネットワーク設定
デフォルトでは、OpenShift Virtualization は単一の内部 Pod ネットワークとともにインストールされます。
OpenShift Virtualization をインストールした後、ネットワーク Operator をインストールし、追加のネットワークを設定できます。
5.3.1. ネットワーキングオペレーターのインストール
仮想マシンへのライブマイグレーションまたは外部アクセス用に Linux ブリッジネットワークを設定するには、Kubernetes NMState Operator をインストールする必要があります。インストール手順については、Web コンソールを使用した Kubernetes NMState Operator のインストール を参照してください。
SR-IOV Operator をインストールして、SR-IOV ネットワークデバイスとネットワークアタッチメントを管理できます。インストール手順については、SR-IOV Network Operator のインストール を参照してください。
MetalLB Operator を追加すると、クラスター上の MetalLB インスタンスのライフサイクルを管理できます。インストール手順については、Web コンソールを使用した OperatorHub からの MetalLB Operator のインストール を参照してください。
5.3.2. Linux ブリッジネットワークの設定
Kubernetes NMState Operator をインストールした後、仮想マシンへのライブマイグレーションまたは外部アクセス用に Linux ブリッジネットワークを設定できます。
5.3.2.1. Linux ブリッジ NNCP の作成
Linux ブリッジネットワークの NodeNetworkConfigurationPolicy (NNCP) マニフェストを作成できます。
前提条件
- Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicyマニフェストを作成します。この例には、独自の情報で置き換える必要のあるサンプルの値が含まれます。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy 1 spec: desiredState: interfaces: - name: br1 2 description: Linux bridge with eth1 as a port 3 type: linux-bridge 4 state: up 5 ipv4: enabled: false 6 bridge: options: stp: enabled: false 7 port: - name: eth1 8
5.3.2.2. Web コンソールを使用した Linux ブリッジ NAD の作成
OpenShift Container Platform Web コンソールを使用して、ネットワーク接続定義 (NAD) を作成して、Pod および仮想マシンに layer-2 ネットワークを提供できます。
Linux ブリッジ ネットワーク接続定義は、仮想マシンを VLAN に接続するための最も効率的な方法です。
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
手順
- Web コンソールで、Networking → NetworkAttachmentDefinitions をクリックします。
Create Network Attachment Definition をクリックします。
注記ネットワーク接続定義は Pod または仮想マシンと同じ namespace にある必要があります。
- 一意の Name およびオプションの Description を入力します。
- Network Type リストから CNV Linux bridge を選択します。
- Bridge Name フィールドにブリッジの名前を入力します。
- オプション: リソースに VLAN ID が設定されている場合、 VLAN Tag Number フィールドに ID 番号を入力します。
- オプション: MAC Spoof Check を選択して、MAC スプーフ フィルタリングを有効にします。この機能により、Pod を終了するための MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。
- Create をクリックします。
次のステップ
5.3.3. ライブマイグレーション用のネットワークの設定
Linux ブリッジネットワークを設定した後、ライブマイグレーション用の専用ネットワークを設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
5.3.3.1. ライブマイグレーション用の専用セカンダリーネットワークの設定
ライブマイグレーション用に専用のセカンダリーネットワークを設定するには、まず CLI を使用してブリッジネットワーク接続定義 (NAD) を作成する必要があります。次に、NetworkAttachmentDefinition オブジェクトの名前を HyperConverged カスタムリソース (CR) に追加します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - 各ノードには少なくとも 2 つのネットワークインターフェイスカード (NIC) があります。
- ライブマイグレーション用の NIC は同じ VLAN に接続されます。
手順
次の例に従って、
NetworkAttachmentDefinitionマニフェストを作成します。設定ファイルのサンプル
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: my-secondary-network 1 namespace: openshift-cnv 2 spec: config: '{ "cniVersion": "0.3.1", "name": "migration-bridge", "type": "macvlan", "master": "eth1", 3 "mode": "bridge", "ipam": { "type": "whereabouts", 4 "range": "10.200.5.0/24" 5 } }'
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
NetworkAttachmentDefinitionオブジェクトの名前をHyperConvergedCR のspec.liveMigrationConfigスタンザに追加します。HyperConvergedマニフェストの例apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: liveMigrationConfig: completionTimeoutPerGiB: 800 network: <network> 1 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150 # ...- 1
- ライブマイグレーションに使用される Multus
NetworkAttachmentDefinitionオブジェクトの名前を指定します。
-
変更を保存し、エディターを終了します。
virt-handlerPod が再起動し、セカンダリーネットワークに接続されます。
検証
仮想マシンが実行されるノードがメンテナンスモードに切り替えられると、仮想マシンは自動的にクラスター内の別のノードに移行します。仮想マシンインスタンス (VMI) メタデータのターゲット IP アドレスを確認して、デフォルトの Pod ネットワークではなく、セカンダリーネットワーク上で移行が発生したことを確認できます。
$ oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'
5.3.3.2. Web コンソールを使用して専用ネットワークを選択する
OpenShift Container Platform Web コンソールを使用して、ライブマイグレーション用の専用ネットワークを選択できます。
前提条件
- ライブマイグレーション用に Multus ネットワークが設定されている。
手順
- OpenShift Container Platform Web コンソールで Virtualization > Overview に移動します。
- Settings タブをクリックし、Live migration をクリックします。
- Live migration network リストからネットワークを選択します。
5.3.4. SR-IOV ネットワークの設定
SR-IOV Operator をインストールした後、SR-IOV ネットワークを設定できます。
5.3.4.1. SR-IOV ネットワークデバイスの設定
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io CustomResourceDefinition を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。
設定の変更が適用されるまでに数分かかる場合があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - SR-IOV Network Operator がインストールされている。
- ドレイン (解放) されたノードからエビクトされたワークロードを処理するために、クラスター内に利用可能な十分なノードがあること。
- SR-IOV ネットワークデバイス設定についてコントロールプレーンノードを選択していないこと。
手順
SriovNetworkNodePolicyオブジェクトを作成してから、YAML を<name>-sriov-node-network.yamlファイルに保存します。<name>をこの設定の名前に置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" 4 priority: <priority> 5 mtu: <mtu> 6 numVfs: <num> 7 nicSelector: 8 vendor: "<vendor_code>" 9 deviceID: "<device_id>" 10 pfNames: ["<pf_name>", ...] 11 rootDevices: ["<pci_bus_id>", "..."] 12 deviceType: vfio-pci 13 isRdma: false 14
- 1
- CR オブジェクトの名前を指定します。
- 2
- SR-IOV Operator がインストールされている namespace を指定します。
- 3
- SR-IOV デバイスプラグインのリソース名を指定します。1 つのリソース名に複数の
SriovNetworkNodePolicyオブジェクトを作成できます。 - 4
- 設定するノードを選択するノードセレクターを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。
- 5
- オプション:
0から99までの整数値を指定します。数値が小さいほど優先度が高くなります。したがって、10は99よりも優先度が高くなります。デフォルト値は99です。 - 6
- オプション: 仮想機能 (VF) の最大転送単位 (MTU) の値を指定します。MTU の最大値は NIC モデルによって異なります。
- 7
- SR-IOV 物理ネットワークデバイス用に作成する仮想機能 (VF) の数を指定します。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 8
nicSelectorマッピングは、Operator が設定するイーサネットデバイスを選択します。すべてのパラメーターの値を指定する必要はありません。意図せずにイーサネットデバイスを選択する可能性を最低限に抑えるために、イーサネットアダプターを正確に特定できるようにすることが推奨されます。rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesとrootDevicesの両方を同時に指定する場合、それらが同一のデバイスをポイントすることを確認します。- 9
- オプション: SR-IOV ネットワークデバイスのベンダー 16 進コードを指定します。許可される値は
8086または15b3のいずれかのみになります。 - 10
- オプション: SR-IOV ネットワークデバイスのデバイス 16 進コードを指定します。許可される値は
158b、1015、1017のみになります。 - 11
- オプション: このパラメーターは、1 つ以上のイーサネットデバイスの物理機能 (PF) 名の配列を受け入れます。
- 12
- このパラメーターは、イーサネットデバイスの物理機能についての 1 つ以上の PCI バスアドレスの配列を受け入れます。以下の形式でアドレスを指定します:
0000:02:00.1 - 13
- OpenShift Virtualization の仮想機能には、
vfio-pciドライバータイプが必要です。 - 14
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを指定します。Mellanox カードの場合、
isRdmaをfalseに設定します。デフォルト値はfalseです。
注記isRDMAフラグがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。-
オプション: SR-IOV 対応のクラスターノードにまだラベルが付いていない場合は、
SriovNetworkNodePolicy.Spec.NodeSelectorでラベルを付けます。ノードのラベル付けについて、詳しくはノードのラベルを更新する方法についてを参照してください。 SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f <name>-sriov-node-network.yaml
ここで、
<name>はこの設定の名前を指定します。設定の更新が適用された後に、
sriov-network-operatornamespace のすべての Pod がRunningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
次のステップ
5.3.5. Web コンソールを使用したロードバランサーサービスの作成の有効化
OpenShift Container Platform Web コンソールを使用して、仮想マシン (VM) のロードバランサーサービスの作成を有効にすることができます。
前提条件
- クラスターのロードバランサーが設定されました。
-
cluster-adminロールを持つユーザーとしてログインしている。
手順
- Virtualization → Overview に移動します。
- Settings タブで、Cluster をクリックします。
- LoadBalancer service をデプロイメントし、Enable the creation of LoadBalancer services for SSH connections to VirtualMachines を選択します。
5.4. インストール後のストレージ設定
次のストレージ設定タスクは必須です。
- クラスターの デフォルトのストレージクラス を設定する必要があります。そうしないと、クラスターは自動ブートソース更新を受信できません。
- ストレージプロバイダーが CDI によって認識されない場合は、storage profiles を設定する必要があります。ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。
オプション: ホストパスプロビジョナー (HPP) を使用して、ローカルストレージを設定できます。
Containerized Data Importer (CDI)、データボリューム、自動ブートソース更新の設定など、その他のオプションについては、ストレージ設定の概要 を参照してください。
5.4.1. HPP を使用したローカルストレージの設定
OpenShift Virtualization Operator のインストール時に、Hostpath Provisioner (HPP) Operator は自動的にインストールされます。HPP Operator は HPP プロビジョナーを作成します。
HPP は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。HPP を使用するには、HPP カスタムリソース (CR) を作成する必要があります。
HPP ストレージプールは、オペレーティングシステムと同じパーティションにあってはなりません。そうしないと、ストレージプールがオペレーティングシステムパーティションをいっぱいにする可能性があります。オペレーティングシステムのパーティションがいっぱいになると、パフォーマンスに影響が生じたり、ノードが不安定になったり使用できなくなったりする可能性があります。
5.4.1.1. storagePools スタンザを使用した CSI ドライバーのストレージクラスの作成
ホストパスプロビジョナー (HPP) を使用するには、コンテナーストレージインターフェイス (CSI) ドライバーに関連するストレージクラスを作成する必要があります。
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
手順
storageclass_csi.yamlファイルを作成して、ストレージクラスを定義します。apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: hostpath-csi provisioner: kubevirt.io.hostpath-provisioner reclaimPolicy: Delete 1 volumeBindingMode: WaitForFirstConsumer 2 parameters: storagePool: my-storage-pool 3
- 1
reclaimPolicyには、DeleteおよびRetainの 2 つの値があります。値を指定しない場合、デフォルト値はDeleteです。- 2
volumeBindingModeパラメーターは、動的プロビジョニングとボリュームのバインディングが実行されるタイミングを決定します。WaitForFirstConsumerを指定して、永続ボリューム要求 (PVC) を使用する Pod が作成されるまで PV のバインディングおよびプロビジョニングを遅延させます。これにより、PV が Pod のスケジュール要件を満たすようになります。- 3
- HPP CR で定義されているストレージプールの名前を指定します。
- ファイルを保存して終了します。
次のコマンドを実行して、
StorageClassオブジェクトを作成します。$ oc create -f storageclass_csi.yaml
第6章 更新
6.1. OpenShift Virtualization の更新
Operator Lifecycle Manager(OLM) が OpenShift Virtualization の z-stream およびマイナーバージョンの更新を提供する方法を確認します。
6.1.1. RHEL 9 上の OpenShift Virtualization
OpenShift Virtualization 4.14 は、Red Hat Enterprise Linux (RHEL) 9 をベースにしています。標準の OpenShift Virtualization 更新手順に従って、RHEL 8 をベースとするバージョンから OpenShift Virtualization 4.14 に更新できます。追加の手順は必要ありません。
以前のバージョンと同様に、実行中のワークロードを中断することなく更新を実行できます。OpenShift Virtualization 4.14 では、RHEL 8 ノードから RHEL 9 ノードへのライブマイグレーションがサポートされています。
6.1.1.1. RHEL 9 マシンタイプ
OpenShift Virtualization に含まれるすべての仮想マシンテンプレートは、デフォルトで RHEL 9 マシンタイプ machineType: pc-q35-rhel9.<y>.0 を使用するようになりました。この場合の <y> は RHEL 9 の最新のマイナーバージョンに対応する 1 桁の数字です。たとえば、RHEL 9.2 の場合は pc-q35-rhel9.2.0 の値が使用されます。
OpenShift Virtualization を更新しても、既存仮想マシンの machineType 値は変更されません。これらの仮想マシンは、引き続き更新前と同様に機能します。RHEL 9 での改良を反映するために、オプションで仮想マシンのマシンタイプを変更できます。
仮想マシンの machineType 値を変更する前に、仮想マシンをシャットダウンする必要があります。
6.1.2. OpenShift Virtualization の更新について
- Operator Lifecycle Manager(OLM) は OpenShift Virtualization Operator のライフサイクルを管理します。OpenShift Container Platform のインストール時にデプロイされる Marketplace Operator により、クラスターで外部 Operator が利用できるようになります。
- OLM は、OpenShift Virtualization の z-stream およびマイナーバージョンの更新を提供します。OpenShift Container Platform を次のマイナーバージョンに更新すると、マイナーバージョンの更新が利用可能になります。OpenShift Container Platform を最初に更新しない限り、OpenShift Virtualization を次のマイナーバージョンに更新できません。
- OpenShift Virtualization サブスクリプションは、stable という名前の単一の更新チャネルを使用します。stable チャネルでは、OpenShift Virtualization および OpenShift Container Platform バージョンとの互換性が確保されます。
サブスクリプションの承認ストラテジーが Automatic に設定されている場合に、更新プロセスは、Operator の新規バージョンが stable チャネルで利用可能になるとすぐに開始します。サポート可能な環境を確保するために、自動 承認ストラテジーを使用することを強く推奨します。OpenShift Virtualization の各マイナーバージョンは、対応する OpenShift Container Platform バージョンを実行する場合にのみサポートされます。たとえば、OpenShift Virtualization 4.14 は OpenShift Container Platform 4.14 で実行する必要があります。
- クラスターのサポート容易性および機能が損なわれるリスクがあるので、Manual 承認ストラテジーを選択することは可能ですが、推奨していません。Manual 承認ストラテジーでは、保留中のすべての更新を手動で承認する必要があります。OpenShift Container Platform および OpenShift Virtualization の更新の同期が取れていない場合には、クラスターはサポートされなくなります。
- 更新の完了までにかかる時間は、ネットワーク接続によって異なります。ほとんどの自動更新は 15 分以内に完了します。
- Open Shift Virtualization を更新しても、ネットワーク接続が中断されることはありません。
- データボリュームおよびその関連付けられた永続ボリューム要求 (PVC) は更新時に保持されます。
ホストパスプロビジョナーストレージを使用する仮想マシンを実行している場合、それらをライブマイグレーションすることはできず、Open Shift Container Platform クラスターの更新をブロックする可能性があります。
回避策として、仮想マシンを再設定し、クラスターの更新時にそれらの電源を自動的にオフになるようにできます。evictionStrategy: LiveMigrate フィールドを削除し、runStrategy フィールドを Always に設定します。
6.1.2.1. ワークロードの更新について
OpenShift Virtualization を更新すると、ライブマイグレーションをサポートしている場合には libvirt、virt-launcher、および qemu などの仮想マシンのワークロードが自動的に更新されます。
各仮想マシンには、仮想マシンインスタンス (VMI) を実行する virt-launcher Pod があります。virt-launcher Pod は、仮想マシン (VM) のプロセスを管理するために使用される libvirt のインスタンスを実行します。
HyperConverged カスタムリソース (CR) の spec.workloadUpdateStrategy スタンザを編集して、ワークロードの更新方法を設定できます。ワークロードの更新方法として、LiveMigrate と Evict の 2 つが利用可能です。
Evictメソッドは VMI Pod をシャットダウンするため、デフォルトではLiveMigrate更新ストラテジーのみが有効になっています。
LiveMigrateが有効な唯一の更新ストラテジーである場合:
- ライブマイグレーションをサポートする VMI は更新プロセス時に移行されます。VM ゲストは、更新されたコンポーネントが有効になっている新しい Pod に移動します。
ライブマイグレーションをサポートしない VMI は中断または更新されません。
-
VMI に
LiveMigrateエビクションストラテジーがあるが、ライブマイグレーションをサポートしていない場合、VMI は更新されません。
-
VMI に
LiveMigrateとEvictの両方を有効にした場合:
-
ライブマイグレーションをサポートする VMI は、
LiveMigrate更新ストラテジーを使用します。 -
ライブマイグレーションをサポートしない VMI は、
Evict更新ストラテジーを使用します。VMI がrunStrategy: Alwaysに設定されたVirtualMachineオブジェクトによって制御される場合、新規の VMI は、更新されたコンポーネントを使用して新規 Pod に作成されます。
移行の試行とタイムアウト
ワークロードを更新するときに、Pod が次の期間Pending状態の場合、ライブマイグレーションは失敗します。
- 5 分間
-
Pod が
Unschedulableであるために保留中の場合。 - 15 分
- 何らかの理由で Pod が保留状態のままになっている場合。
VMI が移行に失敗すると、 virt-controllerは VMI の移行を再試行します。すべての移行可能な VMI が新しいvirt-launcher Pod で実行されるまで、このプロセスが繰り返されます。ただし、VMI が不適切に設定されている場合、これらの試行は無限に繰り返される可能性があります。
各試行は、移行オブジェクトに対応します。直近の 5 回の試行のみがバッファーに保持されます。これにより、デバッグ用の情報を保持しながら、移行オブジェクトがシステムに蓄積されるのを防ぎます。
6.1.2.2. EUS から EUS への更新について
4.10 および 4.12 を含む OpenShift Container Platform の偶数番号のマイナーバージョンはすべて、Extended Update Support (EUS) バージョンです。ただし、Kubernetes の設計ではシリアルマイナーバージョンの更新が義務付けられているため、ある EUS バージョンから次の EUS バージョンに直接更新することはできません。
ソース EUS バージョンから次の奇数番号のマイナーバージョンに更新した後、更新パス上にあるそのマイナーバージョンのすべての z-stream リリースに OpenShift Virtualization を順次更新する必要があります。適用可能な最新の z-stream バージョンにアップグレードしたら、OpenShift Container Platform をターゲットの EUS マイナーバージョンに更新できます。
OpenShift Container Platform の更新が成功すると、対応する OpenShift Virtualization の更新が利用可能になります。OpenShift Virtualization をターゲットの EUS バージョンに更新できるようになりました。
6.1.2.2.1. 更新の準備中
EUS から EUS への更新を開始する前に、次のことを行う必要があります。
- EUS から EUS への更新を開始する前に、ワーカーノードのマシン設定プールを一時停止して、ワーカーが 2 回再起動されないようにします。
- 更新プロセスを開始する前に、ワークロードの自動更新を無効にします。これは、ターゲットの EUS バージョンに更新するまで、OpenShift Virtualization が仮想マシン (VM) を移行または削除しないようにするためです。
デフォルトでは、OpenShift Virtualization Operator を更新すると、OpenShift Virtualization は virt-launcher Pod などのワークロードを自動的に更新します。この動作は、HyperConverged カスタムリソースの spec.workloadUpdateStrategy スタンザで設定できます。
EUS から EUS への更新の実行 の詳細を参照してください。
6.1.3. EUS から EUS への更新中のワークロード更新の防止
ある Extended Update Support (EUS) バージョンから次のバージョンに更新する場合、自動ワークロード更新を手動で無効にして、更新プロセス中に OpenShift Virtualization がワークロードを移行または削除しないようにする必要があります。
前提条件
- OpenShift Container Platform の EUS バージョンを実行しており、次の EUS バージョンに更新したい。その間、奇数番号のバージョンにまだ更新していません。
- EUS から EUS への更新を実行するための準備を読み、OpenShift Container Platform クラスターに関連する警告と要件を学習しました。
- OpenShift Container Platform ドキュメントの指示に従って、ワーカーノードのマシン設定プールを一時停止しました。
- デフォルトの 自動 承認ストラテジーを使用することを推奨します。手動 承認ストラテジーを使用する場合、Web コンソールですべての保留中の更新を承認する必要があります。詳細については、保留中のオペレーターの更新を手動で承認するセクションを参照してください。
手順
次のコマンドを実行して、現在の
workloadUpdateMethods設定をバックアップします。$ WORKLOAD_UPDATE_METHODS=$(oc get kv kubevirt-kubevirt-hyperconverged \ -n openshift-cnv -o jsonpath='{.spec.workloadUpdateStrategy.workloadUpdateMethods}')次のコマンドを実行して、すべてのワークロード更新方法をオフにします。
$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op":"replace","path":"/spec/workloadUpdateStrategy/workloadUpdateMethods", "value":[]}]'出力例
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched
続行する前に、
HyperConvergedOperator がアップグレード可能であることを確認してください。次のコマンドを入力して、出力をモニターします。$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.conditions"
例6.1 出力例
[ { "lastTransitionTime": "2022-12-09T16:29:11Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "ReconcileComplete" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "Available" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "False", "type": "Progressing" }, { "lastTransitionTime": "2022-12-09T16:39:11Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "False", "type": "Degraded" }, { "lastTransitionTime": "2022-12-09T20:30:10Z", "message": "Reconcile completed successfully", "observedGeneration": 3, "reason": "ReconcileCompleted", "status": "True", "type": "Upgradeable" 1 } ]- 1
- OpenShift Virtualization Operator のステータスは
Upgradeableです。
クラスターをソース EUS バージョンから OpenShift Container Platform の次のマイナーバージョンに手動で更新します。
$ oc adm upgrade
検証
次のコマンドを実行して、現在のバージョンを確認します。
$ oc get clusterversion
注記OpenShift Container Platform を次のバージョンに更新することは、OpenShift Virtualization を更新するための前提条件です。詳細は、OpenShift Container Platform ドキュメントのクラスターの更新セクションを参照してください。
OpenShift Virtualization を更新します。
- デフォルトの 自動 承認ストラテジーでは、OpenShift Container Platform を更新した後、OpenShift Virtualization は対応するバージョンに自動的に更新します。
- 手動 承認ストラテジーを使用する場合は、Web コンソールを使用して保留中の更新を承認します。
次のコマンドを実行して、OpenShift Virtualization の更新をモニターします。
$ oc get csv -n openshift-cnv
- OpenShift Virtualization を非 EUS マイナーバージョンで使用可能なすべての z-stream バージョンに更新し、前の手順で示したコマンドを実行して各更新を監視します。
以下のコマンドを実行して、OpenShift Virtualization が非 EUS バージョンの最新の z-stream リリースに正常に更新されたことを確認します。
$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.versions"
出力例
[ { "name": "operator", "version": "4.14.5" } ]次の更新を実行する前に、
HyperConvergedOperator がUpgradeableステータスになるまで待ちます。次のコマンドを入力して、出力をモニターします。$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o json | jq ".status.conditions"
- OpenShift Container Platform をターゲットの EUS バージョンに更新します。
クラスターのバージョンを確認して、更新が成功したことを確認します。
$ oc get clusterversion
OpenShift Virtualization をターゲットの EUS バージョンに更新します。
- デフォルトの 自動 承認ストラテジーでは、OpenShift Container Platform を更新した後、OpenShift Virtualization は対応するバージョンに自動的に更新します。
- 手動 承認ストラテジーを使用する場合は、Web コンソールを使用して保留中の更新を承認します。
次のコマンドを実行して、OpenShift Virtualization の更新をモニターします。
$ oc get csv -n openshift-cnv
VERSIONフィールドがターゲットの EUS バージョンと一致し、PHASEフィールドがSucceededになると、更新が完了します。バックアップしたワークロードの更新方法の設定を復元します。
$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv --type json -p \ "[{\"op\":\"add\",\"path\":\"/spec/workloadUpdateStrategy/workloadUpdateMethods\", \"value\":$WORKLOAD_UPDATE_METHODS}]"出力例
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched
検証
次のコマンドを実行して、VM 移行のステータスを確認します。
$ oc get vmim -A
次のステップ
- ワーカーノードのマシン設定プールの一時停止を解除できるようになりました。
6.1.4. ワークロードの更新方法の設定
HyperConvergedカスタムリソース (CR) を編集することにより、ワークロードの更新方法を設定できます。
前提条件
ライブマイグレーションを更新方法として使用するには、まずクラスターでライブマイグレーションを有効にする必要があります。
注記VirtualMachineInstanceCR にevictionStrategy: LiveMigrateが含まれており、仮想マシンインスタンス (VMI) がライブマイグレーションをサポートしない場合には、VMI は更新されません。
手順
デフォルトエディターで
HyperConvergedCR を作成するには、以下のコマンドを実行します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
HyperConvergedCR のworkloadUpdateStrategyスタンザを編集します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: workloadUpdateStrategy: workloadUpdateMethods: 1 - LiveMigrate 2 - Evict 3 batchEvictionSize: 10 4 batchEvictionInterval: "1m0s" 5 # ...- 1
- ワークロードの自動更新を実行するのに使用できるメソッド。設定可能な値は
LiveMigrateおよびEvictです。上記の例のように両方のオプションを有効にした場合に、ライブマイグレーションをサポートする VMI にはLiveMigrateを、ライブマイグレーションをサポートしない VMI にはEvictを、更新に使用します。ワークロードの自動更新を無効にするには、workloadUpdateStrategyスタンザを削除するか、workloadUpdateMethods: []を設定して配列を空のままにします。 - 2
- 中断を最小限に抑えた更新メソッド。ライブマイグレーションをサポートする VMI は、仮想マシン (VM) ゲストを更新されたコンポーネントが有効なっている新規 Pod に移行することで更新されます。
LiveMigrateがリストされている唯一のワークロード更新メソッドである場合には、ライブマイグレーションをサポートしない VMI は中断または更新されません。 - 3
- アップグレード時に VMI Pod をシャットダウンする破壊的な方法。
Evictは、ライブマイグレーションがクラスターで有効でない場合に利用可能な唯一の更新方法です。VMI がrunStrategy: Alwaysに設定されたVirtualMachineオブジェクトによって制御される場合には、新規の VMI は、更新されたコンポーネントを使用して新規 Pod に作成されます。 - 4
Evictメソッドを使用して一度に強制的に更新できる VMI の数。これは、LiveMigrateメソッドには適用されません。- 5
- 次のワークロードバッチをエビクトするまで待機する間隔。これは、
LiveMigrateメソッドには適用されません。
注記HyperConvergedCR のspec.liveMigrationConfigスタンザを編集することにより、ライブマイグレーションの制限とタイムアウトを設定できます。- 変更を適用するには、エディターを保存し、終了します。
6.1.5. 保留中の Operator 更新の承認
6.1.5.1. 保留中の Operator 更新の手動による承認
インストールされた Operator のサブスクリプションの承認ストラテジーが Manual に設定されている場合、新規の更新が現在の更新チャネルにリリースされると、インストールを開始する前に更新を手動で承認する必要があります。
前提条件
- Operator Lifecycle Manager (OLM) を使用して以前にインストールされている Operator。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Operators → Installed Operators に移動します。
- 更新が保留中の Operator は Upgrade available のステータスを表示します。更新する Operator の名前をクリックします。
- Subscription タブをクリックします。承認が必要な更新は、Upgrade status の横に表示されます。たとえば、1 requires approval が表示される可能性があります。
- 1 requires approval をクリックしてから、Preview Install Plan をクリックします。
- 更新に利用可能なリソースとして一覧表示されているリソースを確認します。問題がなければ、Approve をクリックします。
- Operators → Installed Operators ページに戻り、更新の進捗をモニターします。完了時に、ステータスは Succeeded および Up to date に変更されます。
6.1.6. 更新ステータスの監視
6.1.6.1. OpenShift Virtualization アップグレードステータスのモニタリング
OpenShift Virtualization Operator のアップグレードのステータスをモニターするには、クラスターサービスバージョン (CSV) PHASE を監視します。Web コンソールを使用するか、ここに提供されているコマンドを実行して CSV の状態をモニターすることもできます。
PHASE および状態の値は利用可能な情報に基づく近似値になります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにログインすること。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行します。
$ oc get csv -n openshift-cnv
出力を確認し、
PHASEフィールドをチェックします。以下に例を示します。出力例
VERSION REPLACES PHASE 4.9.0 kubevirt-hyperconverged-operator.v4.8.2 Installing 4.9.0 kubevirt-hyperconverged-operator.v4.9.0 Replacing
オプション: 以下のコマンドを実行して、すべての OpenShift Virtualization コンポーネントの状態の集約されたステータスをモニターします。
$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv \ -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}'アップグレードが成功すると、以下の出力が得られます。
出力例
ReconcileComplete True Reconcile completed successfully Available True Reconcile completed successfully Progressing False Reconcile completed successfully Degraded False Reconcile completed successfully Upgradeable True Reconcile completed successfully
6.1.6.2. 以前の OpenShift Virtualization ワークロードの表示
CLI を使用して、以前のワークロードのリストを表示できます。
クラスターに以前の仮想化 Pod がある場合には、OutdatedVirtualMachineInstanceWorkloads アラートが実行されます。
手順
以前の仮想マシンインスタンス (VMI) の一覧を表示するには、以下のコマンドを実行します。
$ oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespaces
ワークロードの更新を設定して、VMI が自動的に更新されるようにします。
6.1.7. 関連情報
第7章 仮想マシン
7.1. Red Hat イメージからの仮想マシンの作成
7.1.1. Red Hat イメージからの仮想マシン作成の概要
Red Hat イメージは ゴールデンイメージ です。これらは、安全なレジストリー内のコンテナーディスクとして公開されます。Containerized Data Importer (CDI) は、コンテナーディスクをポーリングしてクラスターにインポートし、スナップショットまたは永続ボリュームクレーム (PVC) として openshift-virtualization-os-images プロジェクトに保存します。
Red Hat イメージは自動的に更新されます。これらのイメージの自動更新を無効にして再度有効にすることができます。Red Hat ブートソースの更新の管理 を参照してください。
クラスター管理者は、OpenShift Virtualization Web コンソール で Red Hat Enterprise Linux (RHEL) 仮想マシンの自動サブスクリプションを有効にできるようになりました。
次のいずれかの方法を使用して、Red Hat が提供するオペレーティングシステムイメージから仮想マシンを作成できます。
デフォルトの openshift-* namespace に仮想マシンを作成しないでください。代わりに、openshift 接頭辞なしの新規 namespace を作成するか、既存 namespace を使用します。
7.1.1.1. ゴールデンイメージについて
ゴールデンイメージは、新しい仮想マシンをデプロイメントするためのリソースとして使用できる、仮想マシンの事前設定されたスナップショットです。たとえば、ゴールデンイメージを使用すると、同じシステム環境を一貫してプロビジョニングし、システムをより迅速かつ効率的にデプロイメントできます。
7.1.1.1.1. ゴールデンイメージはどのように機能しますか?
ゴールデンイメージは、リファレンスマシンまたは仮想マシンにオペレーティングシステムとソフトウェアアプリケーションをインストールして設定することによって作成されます。これには、システムのセットアップ、必要なドライバーのインストール、パッチと更新の適用、特定のオプションと環境設定の設定が含まれます。
ゴールデンイメージは、作成後、複数のクラスターに複製してデプロイできるテンプレートまたはイメージファイルとして保存されます。ゴールデンイメージは、メンテナーによって定期的に更新されて、必要なソフトウェア更新とパッチが組み込まれるため、イメージが最新かつ安全な状態に保たれ、新しく作成された仮想マシンはこの更新されたイメージに基づいています。
7.1.1.1.2. Red Hat のゴールデンイメージの実装
Red Hat は、Red Hat Enterprise Linux (RHEL) のバージョンのレジストリー内のコンテナーディスクとしてゴールデンイメージを公開します。コンテナーディスクは、コンテナーイメージレジストリーにコンテナーイメージとして保存される仮想マシンイメージです。公開されたイメージは、OpenShift Virtualization のインストール後に、接続されたクラスターで自動的に使用できるようになります。イメージがクラスター内で使用可能になると、仮想マシンの作成に使用できるようになります。
7.1.1.2. 仮想マシンブートソースについて
仮想マシンは、仮想マシン定義と、データボリュームによってバックアップされる 1 つ以上のディスクで構成されます。仮想マシンテンプレートを使用すると、事前定義された仕様を使用して仮想マシンを作成できます。
すべてのテンプレートにはブートソースが必要です。ブートソースは、設定されたドライバーを含む完全に設定されたディスクイメージです。各テンプレートには、ブートソースへのポインターを含む仮想マシン定義が含まれています。各ブートソースには、事前に定義された名前および namespace があります。オペレーティングシステムによっては、ブートソースは自動的に提供されます。これが提供されない場合、管理者はカスタムブートソースを準備する必要があります。
提供されたブート ソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されるブートソースの場合、永続ボリュームクレーム (PVC) とボリュームスナップショットはクラスターのデフォルトストレージクラスで作成されます。設定後に別のデフォルトストレージクラスを選択した場合は、以前のデフォルトストレージクラスで設定されたクラスター namespace 内の既存のブートソースを削除する必要があります。
7.1.2. テンプレートからの仮想マシンの作成
OpenShift Container Platform Web コンソールを使用して、Red Hat テンプレートから仮想マシン (VM) を作成できます。
7.1.2.1. 仮想マシンテンプレートについて
- ブートソース
利用可能なブートソースを持つテンプレートを使用すると、仮想マシンの作成を効率化できます。ブートソースを含むテンプレートには、カスタムラベルがない場合、Available boot source ラベルが付けられます。
ブートソースのないテンプレートには、Boot source required というラベルが付けられます。カスタムイメージからの仮想マシンの作成 を参照してください。
- カスタマイズ
仮想マシンを起動する前に、ディスクソースと仮想マシンパラメーターをカスタマイズできます。
- ディスクソース設定の詳細は、ストレージボリュームタイプ と ストレージフィールド を参照してください。
- 仮想マシン設定の詳細は、Overview、YAML、および Configuration タブのドキュメントを参照してください。
すべてのラベルとアノテーションとともに仮想マシンテンプレートをコピーすると、新しいバージョンの Scheduling、Scale、and Performance (SSP) Operator がデプロイされたときに、そのバージョンのテンプレートが非推奨に指定されます。この指定は削除できます。Web コンソールを使用した仮想マシンテンプレートのカスタマイズ 参照してください。
- シングルノード OpenShift
-
ストレージの動作の違いにより、一部のテンプレートはシングルノード OpenShift と互換性がありません。互換性を確保するには、データボリュームまたはストレージプロファイルを使用するテンプレートまたは仮想マシンに
evictionStrategyフィールドを設定しないでください。
7.1.2.2. テンプレートから仮想マシンを作成する
OpenShift Container Platform Web コンソールを使用して、使用可能なブートソースを持つテンプレートから仮想マシンを作成できます。
オプション:仮想マシンを起動する前に、データソース、cloud-init、SSH キーなどのテンプレートまたは仮想マシンパラメーターをカスタマイズできます。
手順
- Web コンソールで Virtualization → Catalog に移動します。
利用可能なブートソース をクリックして、テンプレートをブートソースでフィルタリングします。
カタログにはデフォルトのテンプレートが表示されます。All Items をクリックして、フィルターに使用できるすべてのテンプレートを表示します。
- テンプレートタイルをクリックして詳細を表示します。
仮想マシンの Quick create VirtualMachine をクリックして、テンプレートから VM を作成します。
オプション: テンプレートまたは仮想マシンパラメーターをカスタマイズします。
- Customize VirtualMachineを クリックします。
- Storage または Optional parameters をデプロイメントして、データソース設定を編集します。
VirtualMachine パラメーターのカスタマイズ をクリックします。
Customize and create VirtualMachine ペインには、Overview、YAML、Scheduling、Environment、Network interfaces、Disks、Scripts、および Metadata タブが表示されます。
- 仮想マシンの起動前に設定する必要があるパラメーター (cloud-init や静的 SSH キーなど) を編集します。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、プロビジョニングステータスが表示されます。
7.1.2.2.1. ストレージボリュームタイプ
表7.1 ストレージボリュームタイプ
| タイプ | 説明 |
|---|---|
| ephemeral | ネットワークボリュームを読み取り専用のバッキングストアとして使用するローカルの copy-on-write (COW) イメージ。バッキングボリュームは PersistentVolumeClaim である必要があります。一時イメージは仮想マシンの起動時に作成され、すべての書き込みをローカルに保存します。一時イメージは、仮想マシンの停止、再起動または削除時に破棄されます。バッキングボリューム (PVC) はいずれの方法でも変更されません。 |
| persistentVolumeClaim | 利用可能な PV を仮想マシンに割り当てます。PV の割り当てにより、仮想マシンデータのセッション間での永続化が可能になります。 CDI を使用して既存の仮想マシンディスクを PVC にインポートし、PVC を仮想マシンインスタンスに割り当てる方法は、既存の仮想マシンを OpenShift Container Platform にインポートするための推奨される方法です。ディスクを PVC 内で使用できるようにするためのいくつかの要件があります。 |
| dataVolume |
データボリュームは、インポート、クローンまたはアップロード操作で仮想マシンディスクの準備プロセスを管理することによって
|
| cloudInitNoCloud | 参照される cloud-init NoCloud データソースが含まれるディスクを割り当て、ユーザーデータおよびメタデータを仮想マシンに提供します。cloud-init インストールは仮想マシンディスク内で必要になります。 |
| containerDisk | コンテナーイメージレジストリーに保存される、仮想マシンディスクなどのイメージを参照します。イメージはレジストリーからプルされ、仮想マシンの起動時にディスクとして仮想マシンに割り当てられます。
RAW および QCOW2 形式のみがコンテナーイメージレジストリーのサポートされるディスクタイプです。QCOW2 は、縮小されたイメージサイズの場合に推奨されます。 注記
|
| emptyDisk | 仮想マシンインターフェイスのライフサイクルに関連付けられるスパースの QCOW2 ディスクを追加で作成します。データは仮想マシンのゲストによって実行される再起動後も存続しますが、仮想マシンが Web コンソールから停止または再起動する場合には破棄されます。空のディスクは、アプリケーションの依存関係および一時ディスクの一時ファイルシステムの制限を上回るデータを保存するために使用されます。 ディスク 容量 サイズも指定する必要があります。 |
7.1.2.2.2. ストレージフィールド
| フィールド | 説明 |
|---|---|
| 空白 (PVC の作成) | 空のディスクを作成します。 |
| URL を使用したインポート (PVC の作成) | URL (HTTP または HTTPS エンドポイント) を介してコンテンツをインポートします。 |
| 既存 PVC の使用 | クラスターですでに利用可能な PVC を使用します。 |
| 既存の PVC のクローン作成 (PVC の作成) | クラスターで利用可能な既存の PVC を選択し、このクローンを作成します。 |
| レジストリーを使用したインポート (PVC の作成) | コンテナーレジストリーを使用してコンテンツをインポートします。 |
| コンテナー (一時的) | クラスターからアクセスできるレジストリーにあるコンテナーからコンテンツをアップロードします。コンテナーディスクは、CD-ROM や一時的な仮想マシンなどの読み取り専用ファイルシステムにのみ使用する必要があります。 |
| Name |
ディスクの名前。この名前には、小文字 ( |
| Size | ディスクのサイズ (GiB 単位)。 |
| タイプ | ディスクのタイプ。例: Disk または CD-ROM |
| Interface | ディスクデバイスのタイプ。サポートされるインターフェイスは、virtIO、SATA、および SCSI です。 |
| Storage Class | ディスクの作成に使用されるストレージクラス。 |
ストレージの詳細設定
以下のストレージの詳細設定はオプションであり、Blank、Import via URLURL、および Clone existing PVC ディスクで利用できます。
これらのパラメーターを指定しない場合、システムはデフォルトのストレージプロファイル値を使用します。
| パラメーター | オプション | パラメーターの説明 |
|---|---|---|
| ボリュームモード | Filesystem | ファイルシステムベースのボリュームで仮想ディスクを保存します。 |
| Block |
ブロックボリュームで仮想ディスクを直接保存します。基礎となるストレージがサポートしている場合は、 | |
| アクセスモード | ReadWriteOnce (RWO) | ボリュームは単一ノードで読み取り/書き込みとしてマウントできます。 |
| ReadWriteMany (RWX) | ボリュームは、一度に多くのノードで読み取り/書き込みとしてマウントできます。 注記 このモードはライブマイグレーションに必要です。 |
7.1.2.2.3. Web コンソールを使用した仮想マシンテンプレートのカスタマイズ
仮想マシンを起動する前に、データソース、cloud-init、SSH キーなど、仮想マシンまたはテンプレートのパラメーターを変更することで、既存の仮想マシン (VM) テンプレートをカスタマイズできます。テンプレートをコピーし、すべてのラベルとアノテーションを含めてテンプレートをカスタマイズすると、新しいバージョンの Scheduling、Scale、and Performance (SSP) Operator がデプロイされたときに、カスタマイズしたテンプレートが非推奨に指定されます。
この非推奨の指定は、カスタマイズしたテンプレートから削除できます。
手順
- Web コンソールで Virtualization → Templates に移動します。
- 仮想マシンテンプレートのリストから、非推奨とマークされているテンプレートをクリックします。
- Labels の近くにある鉛筆アイコンの横にある Edit をクリックします。
次の 2 つのラベルを削除します。
-
template.kubevirt.io/type: "base" -
template.kubevirt.io/version: "version"
-
- Save をクリックします。
- 既存の Annotations の数の横にある鉛筆アイコンをクリックします。
次のアノテーションを削除します。
-
template.kubevirt.io/deprecated
-
- Save をクリックします。
7.1.3. インスタンスタイプからの仮想マシンの作成
OpenShift Container Platform Web コンソールを使用して、インスタンスタイプから仮想マシン (VM) を作成できます。
インスタンスタイプからの仮想マシンの作成は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
7.1.3.1. インスタンスタイプからの仮想マシンの作成
OpenShift Container Platform Web コンソールを使用して、インスタンスタイプから仮想マシンを作成できます。
手順
- Web コンソールで、Virtualization → Catalog に移動し、InstanceTypes タブをクリックします。
起動可能なボリュームを選択します。
注記ボリュームテーブルには、
instancetype.kubevirt.io/default-preferenceラベルを持つopenshift-virtualization-os-imagesnamespace 内のボリュームのみがリストされます。- インスタンスタイプのタイルをクリックし、ワークロードに適した設定を選択します。
- 公開 SSH キーをまだプロジェクトに追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- 公開 SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
7.1.4. コマンドラインからの仮想マシンの作成
VirtualMachine マニフェストを編集または作成することで、コマンドラインから仮想マシン (VM) を作成できます。
7.1.4.1. VirtualMachine マニフェストからの仮想マシンの作成
VirtualMachine マニフェストから仮想マシンを作成できます。
手順
仮想マシンの
VirtualMachineマニフェストを編集します。次の例では、Red Hat Enterprise Linux (RHEL) 仮想マシンを設定します。例7.1 RHEL 仮想マシンのマニフェストの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: app: <vm_name> 1 name: <vm_name> spec: dataVolumeTemplates: - apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <vm_name> spec: sourceRef: kind: DataSource name: rhel9 2 namespace: openshift-virtualization-os-images storage: resources: requests: storage: 30Gi running: false template: metadata: labels: kubevirt.io/domain: <vm_name> spec: domain: cpu: cores: 1 sockets: 2 threads: 1 devices: disks: - disk: bus: virtio name: rootdisk - disk: bus: virtio name: cloudinitdisk interfaces: - masquerade: {} name: default rng: {} features: smm: enabled: true firmware: bootloader: efi: {} resources: requests: memory: 8Gi evictionStrategy: LiveMigrate networks: - name: default pod: {} volumes: - dataVolume: name: <vm_name> name: rootdisk - cloudInitNoCloud: userData: |- #cloud-config user: cloud-user password: '<password>' 3 chpasswd: { expire: False } name: cloudinitdiskマニフェストファイルを使用して仮想マシンを作成します。
$ oc create -f <vm_manifest_file>.yaml
オプション: 仮想マシンを起動します。
$ virtctl start <vm_name> -n <namespace>
7.2. カスタムイメージからの仮想マシンの作成
7.2.1. カスタムイメージからの仮想マシン作成の概要
次のいずれかの方法を使用して、カスタムオペレーティングシステムイメージから仮想マシンを作成できます。
レジストリーからイメージをコンテナーディスクとしてインポートします。
オプション: コンテナーディスクの自動更新を有効にすることができます。詳細は、ブートソースの自動更新の管理 を参照してください。
- Web ページからイメージをインポートします。
- ローカルマシンからイメージをアップロードします。
- イメージを含む Persistent Volume Claim (PVC) のクローンを作成します。
Containerized Data Importer (CDI) は、データボリュームを使用してイメージを PVC にインポートします。OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、PVC を仮想マシンに追加します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
Windows 仮想マシンにも VirtIO ドライバー をインストールする必要があります。
QEMU ゲストエージェントは Red Hat イメージに含まれています。
7.2.2. コンテナーディスクを使用した仮想マシンの作成
オペレーティングシステムイメージから構築されたコンテナーディスクを使用して、仮想マシンを作成できます。
コンテナーディスクの自動更新を有効にすることができます。詳細は、ブートソースの自動更新の管理 を参照してください。
コンテナーディスクが大きい場合は、I/O トラフィックが増加し、ワーカーノードが使用できなくなる可能性があります。この問題を解決するには、次のタスクを実行できます。
次の手順を実行して、コンテナーディスクから仮想マシンを作成します。
- オペレーティングシステムイメージをコンテナーディスクに構築し、それをコンテナーレジストリーにアップロードします。
- コンテナーレジストリーに TLS がない場合は、レジストリーの TLS を無効にするように環境を設定します。
- Web コンソール または コマンドライン を使用して、コンテナーディスクをディスクソースとして使用する仮想マシンを作成します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
7.2.2.1. コンテナーディスクの構築とアップロード
仮想マシンイメージをコンテナーディスクに構築し、レジストリーにアップロードできます。
コンテナーディスクのサイズは、コンテナーディスクがホストされているレジストリーの最大レイヤーサイズによって制限されます。
Red Hat Quay の場合、Red Hat Quay の初回デプロイ時に作成される YAML 設定ファイルを編集して、最大レイヤーサイズを変更できます。
前提条件
-
podmanがインストールされている必要があります。 - QCOW2 または RAW イメージファイルが必要です。
手順
Dockerfile を作成して、仮想マシンイメージをコンテナーイメージにビルドします。仮想マシンイメージは、UID
107を持つ QEMU によって所有され、コンテナー内の/disk/ディレクトリーに配置される必要があります。次に、/disk/ディレクトリーのパーミッションは0440に設定する必要があります。以下の例では、Red Hat Universal Base Image (UBI) を使用して最初の段階でこれらの設定変更を処理し、2 番目の段階で最小の
scratchイメージを使用して結果を保存します。$ cat > Dockerfile << EOF FROM registry.access.redhat.com/ubi8/ubi:latest AS builder ADD --chown=107:107 <vm_image>.qcow2 /disk/ \1 RUN chmod 0440 /disk/* FROM scratch COPY --from=builder /disk/* /disk/ EOF- 1
<vm_image>は、QCOW2 または RAW 形式のイメージです。リモートイメージを使用する場合は、<vm_image>.qcow2を完全な URL に置き換えます。
コンテナーをビルドし、これにタグ付けします。
$ podman build -t <registry>/<container_disk_name>:latest .
コンテナーイメージをレジストリーにプッシュします。
$ podman push <registry>/<container_disk_name>:latest
7.2.2.2. コンテナーレジストリーの TLS を無効にする
HyperConverged カスタムリソースの insecureRegistries フィールドを編集して、1 つ以上のコンテナーレジストリーの TLS(トランスポート層セキュリティー) を無効にできます。
前提条件
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
セキュアでないレジストリーのリストを
spec.storageImport.insecureRegistriesフィールドに追加します。HyperConvergedカスタムリソースの例apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: storageImport: insecureRegistries: 1 - "private-registry-example-1:5000" - "private-registry-example-2:5000"- 1
- このリストのサンプルを、有効なレジストリーホスト名に置き換えます。
7.2.2.3. Web コンソールを使用してコンテナーディスクから仮想マシンを作成する
OpenShift Container Platform Web コンソールを使用してコンテナーレジストリーからコンテナーディスクをインポートすることで、仮想マシンを作成できます。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachineを クリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから Registry (creates PVC) を選択します。
-
コンテナーイメージの URL を入力します。例:
https://mirror.arizona.edu/fedora/linux/releases/38/Cloud/x86_64/images/Fedora-Cloud-Base-38-1.6.x86_64.qcow2 - ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.2.2.4. コマンドラインを使用したコンテナーディスクからの仮想マシンの作成
コマンドラインを使用して、コンテナーディスクから仮想マシンを作成できます。
仮想マシンが作成されると、コンテナーディスクを含むデータボリュームが永続ストレージにインポートされます。
前提条件
- コンテナーディスクを含むコンテナーレジストリーへのアクセス認証情報が必要です。
手順
コンテナーレジストリーで認証が必要な場合は、認証情報を指定して
Secretマニフェストを作成し、data-source-secret.yamlファイルとして保存します。apiVersion: v1 kind: Secret metadata: name: data-source-secret labels: app: containerized-data-importer type: Opaque data: accessKeyId: "" 1 secretKey: "" 2次のコマンドを実行して
Secretマニフェストを取得します。$ oc apply -f data-source-secret.yaml
仮想マシンが自己署名証明書またはシステム CA バンドルによって署名されていない証明書を使用するサーバーと通信する必要がある場合は、仮想マシンと同じ namespace に config map を作成します。
$ oc create configmap tls-certs 1 --from-file=</path/to/file/ca.pem> 2
VirtualMachineマニフェストを編集し、vm-fedora-datavolume.yamlファイルとして保存します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume name: vm-fedora-datavolume 1 spec: dataVolumeTemplates: - metadata: creationTimestamp: null name: fedora-dv 2 spec: storage: resources: requests: storage: 10Gi 3 storageClassName: <storage_class> 4 source: registry: url: "docker://kubevirt/fedora-cloud-container-disk-demo:latest" 5 secretRef: data-source-secret 6 certConfigMap: tls-certs 7 status: {} running: true template: metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume spec: domain: devices: disks: - disk: bus: virtio name: datavolumedisk1 machine: type: "" resources: requests: memory: 1.5Gi terminationGracePeriodSeconds: 180 volumes: - dataVolume: name: fedora-dv name: datavolumedisk1 status: {}次のコマンドを実行して VM を作成します。
$ oc create -f vm-fedora-datavolume.yaml
oc createコマンドは、データボリュームと仮想マシンを作成します。CDI コントローラーは適切なアノテーションを使用して基礎となる PVC を作成し、インポートプロセスが開始されます。インポートが完了すると、データボリュームのステータスがSucceededに変わります。仮想マシンを起動できます。データボリュームのプロビジョニングはバックグランドで実行されるため、これをプロセスをモニターする必要はありません。
検証
インポーター Pod は、指定された URL からコンテナーディスクをダウンロードし、プロビジョニングされた永続ボリュームに保存します。以下のコマンドを実行してインポーター Pod のステータスを確認します。
$ oc get pods
次のコマンドを実行して、ステータスが
Succeededになるまでデータボリュームを監視します。$ oc describe dv fedora-dv 1- 1
VirtualMachineマニフェストで定義したデータボリューム名を指定します。
プロビジョニングが完了し、シリアルコンソールにアクセスして仮想マシンが起動したことを確認します。
$ virtctl console vm-fedora-datavolume
7.2.3. Web ページからイメージをインポートして仮想マシンを作成する
Web ページからオペレーティングシステムイメージをインポートすることで、仮想マシンを作成できます。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
7.2.3.1. Web コンソールを使用して Web ページ上のイメージから仮想マシンを作成する
OpenShift Container Platform Web コンソールを使用して Web ページからイメージをインポートすることで、仮想マシンを作成できます。
前提条件
- イメージを含む Web ページにアクセスできる。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachineを クリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから URL (creates PVC) を選択します。
-
イメージの URL を入力します。例:
https://access.redhat.com/downloads/content/69/ver=/rhel---7/7.9/x86_64/product-software -
コンテナーイメージの URL を入力します。例:
https://mirror.arizona.edu/fedora/linux/releases/38/Cloud/x86_64/images/Fedora-Cloud-Base-38-1.6.x86_64.qcow2 - ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.2.3.2. コマンドラインを使用して Web ページ上のイメージから仮想マシンを作成する
コマンドラインを使用して、Web ページ上のイメージから仮想マシンを作成できます。
仮想マシンが作成されると、イメージを含むデータボリュームが永続ストレージにインポートされます。
前提条件
- イメージを含む Web ページへのアクセス認証情報が必要です。
手順
Web ページで認証が必要な場合は、認証情報を指定して
Secretマニフェストを作成し、data-source-secret.yamlファイルとして保存します。apiVersion: v1 kind: Secret metadata: name: data-source-secret labels: app: containerized-data-importer type: Opaque data: accessKeyId: "" 1 secretKey: "" 2次のコマンドを実行して
Secretマニフェストを取得します。$ oc apply -f data-source-secret.yaml
仮想マシンが自己署名証明書またはシステム CA バンドルによって署名されていない証明書を使用するサーバーと通信する必要がある場合は、仮想マシンと同じ namespace に config map を作成します。
$ oc create configmap tls-certs 1 --from-file=</path/to/file/ca.pem> 2
VirtualMachineマニフェストを編集し、vm-fedora-datavolume.yamlファイルとして保存します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume name: vm-fedora-datavolume 1 spec: dataVolumeTemplates: - metadata: creationTimestamp: null name: fedora-dv 2 spec: storage: resources: requests: storage: 10Gi 3 storageClassName: <storage_class> 4 source: http: url: "https://mirror.arizona.edu/fedora/linux/releases/35/Cloud/x86_64/images/Fedora-Cloud-Base-35-1.2.x86_64.qcow2" 5 registry: url: "docker://kubevirt/fedora-cloud-container-disk-demo:latest" 6 secretRef: data-source-secret 7 certConfigMap: tls-certs 8 status: {} running: true template: metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume spec: domain: devices: disks: - disk: bus: virtio name: datavolumedisk1 machine: type: "" resources: requests: memory: 1.5Gi terminationGracePeriodSeconds: 180 volumes: - dataVolume: name: fedora-dv name: datavolumedisk1 status: {}次のコマンドを実行して VM を作成します。
$ oc create -f vm-fedora-datavolume.yaml
oc createコマンドは、データボリュームと仮想マシンを作成します。CDI コントローラーは適切なアノテーションを使用して基礎となる PVC を作成し、インポートプロセスが開始されます。インポートが完了すると、データボリュームのステータスがSucceededに変わります。仮想マシンを起動できます。データボリュームのプロビジョニングはバックグランドで実行されるため、これをプロセスをモニターする必要はありません。
検証
インポーター Pod は、指定された URL からイメージをダウンロードし、プロビジョニングされた永続ボリュームに保存します。以下のコマンドを実行してインポーター Pod のステータスを確認します。
$ oc get pods
次のコマンドを実行して、ステータスが
Succeededになるまでデータボリュームを監視します。$ oc describe dv fedora-dv 1- 1
VirtualMachineマニフェストで定義したデータボリューム名を指定します。
プロビジョニングが完了し、シリアルコンソールにアクセスして仮想マシンが起動したことを確認します。
$ virtctl console vm-fedora-datavolume
7.2.4. イメージをアップロードして仮想マシンを作成する
ローカルマシンからオペレーティングシステムイメージをアップロードすることで、仮想マシンを作成できます。
Windows イメージを PVC にアップロードすることで、Windows仮想マシンを作成できます。次に、仮想マシンの作成時に PVC のクローンを作成します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
Windows 仮想マシンにも VirtIO ドライバー をインストールする必要があります。
7.2.4.1. Web コンソールを使用して、アップロードされたイメージから仮想マシンを作成する
OpenShift Container Platform Web コンソールを使用して、アップロードされたオペレーティングシステムイメージから仮想マシンを作成できます。
前提条件
-
IMG、ISO、またはQCOW2イメージファイルが必要です。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachineを クリックします。
- Customize template parameters ページで、Storage を展開し、Disk source リストから Upload (Upload a new file to a PVC) を選択します。
- ローカルマシン上のイメージを参照し、ディスクサイズを設定します。
- Customize VirtualMachineを クリックします。
- Create VirtualMachine をクリックします。
7.2.4.2. Windows 仮想マシンの作成
Windows 仮想マシンを作成するには、Windows イメージを永続ボリューム要求 (PVC) にアップロードし、OpenShift Container Platform Web コンソールを使用して仮想マシンを作成するときに PVC のクローンを作成します。
前提条件
- Windows Media Creation Tool を使用して Windows インストール DVD または USB が作成されている。Microsoft ドキュメントの Windows 10 インストールメディアの作成 を参照してください。
-
autounattend.xmlアンサーファイルを作成しました。Microsoft ドキュメントの アンサーファイル (unattend.xml) を参照してください。
手順
Windows イメージを新しい PVC としてアップロードします。
- Web コンソールで Storage → PersistentVolumeClaims に移動します。
- Create PersistentVolumeClaim → With Data upload form をクリックします。
- Windows イメージを参照して選択します。
PVC 名を入力し、ストレージクラスとサイズを選択して、Upload をクリックします。
Windows イメージは PVC にアップロードされます。
アップロードされた PVC のクローンを作成して、新しい仮想マシンを設定します。
- Virtualization → Catalog に移動します。
- Windows テンプレートタイルを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから Clone (clone PVC) を選択します。
- PVC プロジェクト、Windows イメージ PVC、およびディスクサイズを選択します。
アンサーファイルを仮想マシンに適用します。
- VirtualMachine パラメーターのカスタマイズ をクリックします。
- Scripts タブの Sysprep セクションで、Edit をクリックします。
-
autounattend.xml応答ファイルを参照し、Save をクリックします。
仮想マシンの実行戦略を設定します。
- 仮想マシンがすぐに起動しないように、Start this VirtualMachine after creation をオフにします。
- Create VirtualMachine をクリックします。
-
YAML タブで、
running:falseをrunStrategy: RerunOnFailureに置き換え、Save をクリックします。
オプションメニュー
をクリックして Start を選択します。
仮想マシンは、
autounattend.xmlアンサーファイルを含むsysprepディスクから起動します。
7.2.4.2.1. Windows 仮想マシンイメージの一般化
Windows オペレーティングシステムイメージを一般化して、イメージを使用して新しい仮想マシンを作成する前に、システム固有の設定データをすべて削除できます。
仮想マシンを一般化する前に、Windows の無人インストール後にsysprepツールが応答ファイルを検出できないことを確認する必要があります。
前提条件
- QEMU ゲストエージェントがインストールされた実行中の Windows 仮想マシン。
手順
- OpenShift Container Platform コンソールで、Virtualization → VirtualMachines をクリックします。
- Windows 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration → Disks をクリックします。
-
sysprepディスクの横にある Options メニュー
をクリックし、Detach を選択します。
- Detach をクリックします。
-
sysprepツールによる検出を回避するために、C:\Windows\Panther\unattend.xmlの名前を変更します。 次のコマンドを実行して、
sysprepプログラムを開始します。%WINDIR%\System32\Sysprep\sysprep.exe /generalize /shutdown /oobe /mode:vm
-
sysprepツールが完了すると、Windows 仮想マシンがシャットダウンします。これで、仮想マシンのディスクイメージを Windows 仮想マシンのインストールイメージとして使用できるようになりました。
これで、仮想マシンを特殊化できます。
7.2.4.2.2. Windows 仮想マシンイメージの特殊化
Windows 仮想マシンを特殊化すると、一般化された Windows イメージから VM にコンピューター固有の情報が設定されます。
前提条件
- 一般化された Windows ディスクイメージが必要です。
-
unattend.xml応答ファイルを作成する必要があります。詳細は、Microsoft のドキュメント を参照してください。
手順
- OpenShift Container Platform コンソールで、Virtualization → Catalog をクリックします。
- Windows テンプレートを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから PVC (clone PVC) を選択します。
- 一般化された Windows イメージの PVC プロジェクトと PVC 名を選択します。
- VirtualMachine パラメーターのカスタマイズ をクリックします。
- Scripts タブをクリックします。
-
Sysprep セクションで、Edit をクリックし、
unattend.xml応答ファイルを参照して、Save をクリックします。 - Create VirtualMachine をクリックします。
Windows は初回起動時に、unattend.xml 応答ファイルを使用して VM を特殊化します。これで、仮想マシンを使用する準備が整いました。
Windows仮想マシンを作成するための関連情報
7.2.4.3. コマンドラインを使用して、アップロードされたイメージから仮想マシンを作成する
virtctl コマンドラインツールを使用して、オペレーティングシステムイメージをアップロードできます。既存のデータボリュームを使用することも、イメージ用に新しいデータボリュームを作成することもできます。
前提条件
-
ISO、IMG、またはQCOW2オペレーティングシステムイメージファイルがある。 -
最高のパフォーマンスを得るには、virt-sparsify ツールまたは
xzユーティリティーまたはgzipユーティリティーを使用してイメージファイルを圧縮しておく。 -
virtctlがインストールされている。 - クライアントマシンが OpenShift Container Platform ルーターの証明書を信頼するように設定されていること。
手順
virtctl image-uploadコマンドを実行してイメージをアップロードします。$ virtctl image-upload dv <datavolume_name> \ 1 --size=<datavolume_size> \ 2 --image-path=</path/to/image> \ 3
注記-
新規データボリュームを作成する必要がない場合は、
--sizeパラメーターを省略し、--no-createフラグを含めます。 - ディスクイメージを PVC にアップロードする場合、PVC サイズは圧縮されていない仮想ディスクのサイズよりも大きくなければなりません。
-
HTTPS を使用したセキュアでないサーバー接続を許可するには、
--insecureパラメーターを使用します。--insecureフラグを使用する際に、アップロードエンドポイントの信頼性は検証 されない 点に注意してください。
-
新規データボリュームを作成する必要がない場合は、
オプション: データボリュームが作成されたことを確認するには、以下のコマンドを実行してすべてのデータボリュームを表示します。
$ oc get dvs
7.2.5. PVC のクローン作成による仮想マシンの作成
カスタムイメージを使用して既存の Persistent Volume Claim (PVC) のクローンを作成することで、仮想マシンを作成できます。
PVC のクローンを作成するには、ソース PVC を参照するデータボリュームを作成します。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェント をインストールする必要があります。
7.2.5.1. Web コンソールを使用した PVC からの仮想マシンの作成
OpenShift Container Platform Web コンソールを使用して Web ページからイメージをインポートすることで、仮想マシンを作成できます。OpenShift Container Platform Web コンソールを使用して Persistent Volume Claim (PVC) のクローンを作成することにより、仮想マシンを作成できます。
前提条件
- イメージを含む Web ページにアクセスできる。
- ソース PVC を含む namespace にアクセスできる。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- 使用可能なブートソースのないテンプレートタイルをクリックします。
- Customize VirtualMachineを クリックします。
- テンプレートパラメーターのカスタマイズ ページで、Storage を展開し、Disk source リストから PVC (clone PVC) を選択します。
-
イメージの URL を入力します。例:
https://access.redhat.com/downloads/content/69/ver=/rhel---7/7.9/x86_64/product-software -
コンテナーイメージの URL を入力します。例:
https://mirror.arizona.edu/fedora/linux/releases/38/Cloud/x86_64/images/Fedora-Cloud-Base-38-1.6.x86_64.qcow2 - PVC プロジェクトと PVC 名を選択します。
- ディスクサイズを設定します。
- Next をクリックします。
- Create VirtualMachine をクリックします。
7.2.5.2. コマンドラインを使用した PVC からの仮想マシンの作成
コマンドラインを使用して既存の仮想マシンの Persistent Volume Claim (PVC) のクローンを作成することで、仮想マシンを作成できます。
次のオプションのいずれかを使用して、PVC のクローンを作成できます。
PVC を新しいデータボリュームに複製します。
この方法では、ライフサイクルが元の仮想マシンから独立したデータボリュームが作成されます。元の仮想マシンを削除しても、新しいデータボリュームやそれに関連付けられた PVC には影響しません。
dataVolumeTemplatesスタンザを含むVirtualMachineマニフェストを作成して、PVC を複製します。この方法では、ライフサイクルが元の仮想マシンに依存するデータボリュームが作成されます。元の仮想マシンを削除すると、クローン作成されたデータボリュームとそれに関連付けられた PVC も削除されます。
7.2.5.2.1. データボリュームへの PVC のクローン作成
コマンドラインを使用して、既存の仮想マシンディスクの Persistent Volume Claim (PVC) のクローンをデータボリュームに作成できます。
元のソース PVC を参照するデータボリュームを作成します。新しいデータボリュームのライフサイクルは、元の仮想マシンから独立しています。元の仮想マシンを削除しても、新しいデータボリュームやそれに関連付けられた PVC には影響しません。
異なるボリュームモード間のクローン作成は、ソース PV とターゲット PV が kubevirt コンテンツタイプに属している限り、ブロック永続ボリューム (PV) からファイルシステム PV へのクローン作成など、ホスト支援型クローン作成でサポートされます。
スマートクローン作成は、スナップショットを使用して PVC のクローンを作成するため、ホスト支援型クローン作成よりも高速かつ効率的です。スマートクローン作成は、Red Hat OpenShift Data Foundation など、スナップショットをサポートするストレージプロバイダーによってサポートされています。
異なるボリュームモード間のクローン作成は、スマートクローン作成ではサポートされていません。
前提条件
- ソース PVC を含む仮想マシンの電源をオフにする必要があります。
- PVC を別の namespace に複製する場合は、ターゲットの namespace にリソースを作成するパーミッションが必要です。
スマートクローン作成の追加の前提条件:
- ストレージプロバイダーはスナップショットをサポートする必要がある。
- ソース PVC とターゲット PVC には、同じストレージプロバイダーとボリュームモードがある必要があります。
次の例に示すように、
VolumeSnapshotClassオブジェクトのdriverキーの値は、StorageClassオブジェクトのprovisionerキーの値と一致する必要があります。VolumeSnapshotClassオブジェクトの例kind: VolumeSnapshotClass apiVersion: snapshot.storage.k8s.io/v1 driver: openshift-storage.rbd.csi.ceph.com # ...
StorageClassオブジェクトの例kind: StorageClass apiVersion: storage.k8s.io/v1 # ... provisioner: openshift-storage.rbd.csi.ceph.com
手順
次の例に示すように、
DataVolumeマニフェストを作成します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <datavolume> 1 spec: source: pvc: namespace: "<source_namespace>" 2 name: "<my_vm_disk>" 3 storage: {}
以下のコマンドを実行してデータボリュームを作成します。
$ oc create -f <datavolume>.yaml
注記データ量により、PVC が準備される前に仮想マシンが起動できなくなります。PVC のクローン作成中に、新しいデータボリュームを参照する仮想マシンを作成できます。
7.2.5.2.2. データボリュームテンプレートを使用したクローン PVC からの仮想マシンの作成
データボリュームテンプレートを使用して、既存の仮想マシンの Persistent Volume Claim (PVC) のクローンを作成する仮想マシンを作成できます。
この方法では、ライフサイクルが元の仮想マシンに依存するデータボリュームが作成されます。元の仮想マシンを削除すると、クローン作成されたデータボリュームとそれに関連付けられた PVC も削除されます。
前提条件
- ソース PVC を含む仮想マシンの電源をオフにする必要があります。
手順
次の例に示すように、
VirtualMachineマニフェストを作成します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-dv-clone name: vm-dv-clone 1 spec: running: false template: metadata: labels: kubevirt.io/vm: vm-dv-clone spec: domain: devices: disks: - disk: bus: virtio name: root-disk resources: requests: memory: 64M volumes: - dataVolume: name: favorite-clone name: root-disk dataVolumeTemplates: - metadata: name: favorite-clone spec: storage: accessModes: - ReadWriteOnce resources: requests: storage: 2Gi source: pvc: namespace: <source_namespace> 2 name: "<source_pvc>" 3PVC のクローンが作成されたデータボリュームで仮想マシンを作成します。
$ oc create -f <vm-clone-datavolumetemplate>.yaml
7.2.6. QEMU ゲストエージェントと VirtIO ドライバーのインストール
QEMU ゲストエージェントは、仮想マシンで実行され、仮想マシン、ユーザー、ファイルシステム、およびセカンダリーネットワークに関する情報をホストに渡すデーモンです。
Red Hat が提供していないオペレーティングシステムイメージから作成された仮想マシンには、QEMU ゲストエージェントをインストールする必要があります。
7.2.6.1. QEMU ゲストエージェントのインストール
7.2.6.1.1. Linux 仮想マシンへの QEMU ゲストエージェントのインストール
qemu-guest-agent は広範な使用が可能で、Red Hat Enterprise Linux (RHEL) 仮想マシン (VM) においてデフォルトで使用できます。このエージェントをインストールし、サービスを起動します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
手順
- コンソールまたは SSH を使用して仮想マシンにログインします。
次のコマンドを実行して、QEMU ゲストエージェントをインストールします。
$ yum install -y qemu-guest-agent
サービスに永続性があることを確認し、これを起動します。
$ systemctl enable --now qemu-guest-agent
検証
次のコマンドを実行して、
AgentConnectedが VM 仕様にリストされていることを確認します。$ oc get vm <vm_name>
7.2.6.1.2. Windows 仮想マシンへの QEMU ゲストエージェントのインストール
Windows 仮想マシンの場合には、QEMU ゲストエージェントは VirtIO ドライバーに含まれます。ドライバーは、Windows のインストール中または既存の Windows仮想マシンにインストールできます。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
手順
-
Windows Guest Operating Systemで、File Explorer を使用して、
virtio-winCD ドライブのguest-agentディレクトリーに移動します。 -
qemu-ga-x86_64.msiインストーラーを実行します。
検証
次のコマンドを実行して、ネットワークサービスのリストを取得します。
$ net start
-
出力に
QEMU Guest Agentが含まれていることを確認します。
7.2.6.2. Windows 仮想マシンへの VirtIO ドライバーのインストール
VirtIO ドライバーは、Microsoft Windows 仮想マシンが OpenShift Virtualization で実行されるために必要な準仮想化デバイスドライバーです。ドライバーは残りのイメージと同梱されるされるため、個別にダウンロードする必要はありません。
container-native-virtualization/virtio-win コンテナーディスクは、ドライバーのインストールを有効にするために SATA CD ドライブとして仮想マシンに割り当てられる必要があります。VirtIO ドライバーは、Windows のインストール中にインストールすることも、既存の Windows インストールに追加することもできます。
ドライバーのインストール後に、container-native-virtualization/virtio-win コンテナーディスクは仮想マシンから削除できます。
表7.2 サポートされているドライバー
| ドライバー名 | ハードウェア ID | 説明 |
|---|---|---|
| viostor |
VEN_1AF4&DEV_1001 | ブロックドライバー。Other devices グループの SCSI Controller としてラベル付けされる場合があります。 |
| viorng |
VEN_1AF4&DEV_1005 | エントロピーソースドライバー。Other devices グループの PCI Device としてラベル付けされる場合があります。 |
| NetKVM |
VEN_1AF4&DEV_1000 | ネットワークドライバー。Other devices グループの Ethernet Controller としてラベル付けされる場合があります。VirtIO NIC が設定されている場合にのみ利用できます。 |
7.2.6.2.1. インストール中に VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする
必要な Windows ドライバーをインストールするには、VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする必要があります。これは、仮想マシンの作成時に実行できます。
手順
- テンプレートから Windows 仮想マシンを作成する場合は、Customize VirtualMachine をクリックします。
- Mount Windows drivers disk を選択します。
- Customize VirtualMachine parameters をクリックします。
- Create VirtualMachine をクリックします。
仮想マシンの作成後、virtio-win SATA CD ディスクが 仮想マシンにアタッチされます。
7.2.6.2.2. VirtIO コンテナーディスクを既存の Windows 仮想マシンにアタッチする
必要な Windows ドライバーをインストールするには、VirtIO コンテナーディスクを Windows 仮想マシンにアタッチする必要があります。これは既存の仮想マシンに対して実行できます。
手順
- 既存の Windows 仮想マシンに移動し、Actions → Stop をクリックします。
- VM Details → Configuration → Disks に移動し、Add disk をクリックします。
-
コンテナーソースから
windows-driver-diskを追加し、Type を CD-ROM に設定して、Interface を SATA に設定します。 - Save をクリックします。
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
7.2.6.2.3. Windows インストール時の VirtIO ドライバーのインストール
仮想マシンに Windows をインストールする際に VirtIO ドライバーをインストールできます。
この手順では、Windows インストールの汎用的なアプローチを使用しますが、インストール方法は Windows のバージョンごとに異なる可能性があります。インストールする Windows のバージョンについてのドキュメントを参照してください。
前提条件
-
virtioドライバーを含むストレージデバイスを仮想マシンに接続している。
手順
-
Windows オペレーティングシステムでは、
File Explorerを 使用してvirtio-winCD ドライブに移動します。 ドライブをダブルクリックして、仮想マシンに適切なインストーラーを実行します。
64 ビット vCPU の場合は、
virtio-win-gt-x64インストーラーを選択します。32 ビット vCPU はサポート対象外になりました。- オプション: インストーラーの Custom Setup 手順で、インストールするデバイスドライバーを選択します。デフォルトでは、推奨ドライバーセットが選択されています。
- インストールが完了したら、Finish を選択します。
- 仮想マシンを再起動します。
検証
-
PC でシステムディスクを開きます。通常は
(C:)です。 - Program Files → Virtio-Win に移動します。
Virtio-Win ディレクトリーが存在し、各ドライバーのサブディレクトリーが含まれていればインストールは成功です。
7.2.6.2.4. 既存の Windows 仮想マシン上の SATA CD ドライブから VirtIO ドライバーのインストール
VirtIO ドライバーは、SATA CD ドライブから既存の Windows 仮想マシンにインストールできます。
この手順では、ドライバーを Windows に追加するための汎用的なアプローチを使用しています。特定のインストール手順については、お使いの Windows バージョンについてのインストールドキュメントを参照してください。
前提条件
- virtio ドライバーを含むストレージデバイスは、SATA CD ドライブとして仮想マシンに接続する必要があります。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows ユーザーセッションにログインします。
Device Manager を開き、Other devices を拡張して、Unknown device をリスト表示します。
- Device Properties を開いて、不明なデバイスを特定します。
- デバイスを右クリックし、Properties を選択します。
- Details タブをクリックし、Property リストで Hardware Ids を選択します。
- Hardware Ids の Value をサポートされる VirtIO ドライバーと比較します。
- デバイスを右クリックし、Update Driver Software を選択します。
- Browse my computer for driver software をクリックし、VirtIO ドライバーが置かれている割り当て済みの SATA CD ドライブの場所に移動します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- Next をクリックしてドライバーをインストールします。
- 必要なすべての VirtIO ドライバーに対してこのプロセスを繰り返します。
- ドライバーのインストール後に、Close をクリックしてウィンドウを閉じます。
- 仮想マシンを再起動してドライバーのインストールを完了します。
7.2.6.2.5. SATA CD ドライブとして追加されたコンテナーディスクからの VirtIO ドライバーのインストール
Windows 仮想マシンに SATA CD ドライブとして追加するコンテナーディスクから VirtIO ドライバーをインストールできます。
コンテナーディスクがクラスター内に存在しない場合、コンテナーディスクは Red Hat レジストリーからダウンロードされるため、Red Hat エコシステムカタログ からの container-native-virtualization/virtio-win コンテナーディスクのダウンロードは必須ではありません。ただし、ダウンロードするとインストール時間が短縮されます。
前提条件
-
制限された環境では、Red Hat レジストリー、またはダウンロードされた
container-native-virtualization/virtio-winコンテナーディスクにアクセスできる必要があります。
手順
VirtualMachineマニフェストを編集して、container-native-virtualization/virtio-winコンテナーディスクを CD ドライブとして追加します。# ... spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 2 1 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 1
- OpenShift Virtualization は、
VirtualMachineマニフェストで定義された順序で仮想マシンディスクを起動します。container-native-virtualization/virtio-winコンテナーディスクの前に起動する他の仮想マシンディスクを定義するか、オプションのbootOrderパラメーターを使用して仮想マシンが正しいディスクから起動するようにすることができます。ディスクのブート順序を設定する場合は、他のディスクのブート順序も設定する必要があります。
変更を適用します。
仮想マシンを実行していない場合は、次のコマンドを実行します。
$ virtctl start <vm> -n <namespace>
仮想マシンが実行中の場合は、仮想マシンを再起動するか、次のコマンドを実行します。
$ oc apply -f <vm.yaml>
- 仮想マシンが起動したら、SATA CD ドライブから VirtIO ドライバーをインストールします。
7.2.6.3. VirtIO ドライバーの更新
7.2.6.3.1. Windows 仮想マシンでの VirtIO ドライバーの更新
Windows Update サービスを使用して、Windows 仮想マシン上の virtio ドライバーを更新します。
前提条件
- クラスターはインターネットに接続されている必要があります。切断されたクラスターは Windows Update サービスにアクセスできません。
手順
- Windows ゲストオペレーティングシステムで、Windows キーをクリックし、Settings を選択します。
- Windows Update → Advanced Options → Optional Updates に移動します。
- Red Hat, Inc. からのすべての更新をインストールします。
- 仮想マシンを再起動します。
検証
- Windows 仮想マシンで、Device Manager に移動します。
- デバイスを選択します。
- Driver タブを選択します。
-
Driver Details をクリックし、
virtioドライバーの詳細に正しいバージョンが表示されていることを確認します。
7.3. 仮想マシンコンソールへの接続
次のコンソールに接続して、実行中の仮想マシンにアクセスできます。
7.3.1. VNC コンソールへの接続
OpenShift Container Platform Web コンソールまたは virtctl コマンドラインツールを使用して、仮想マシンの VNC コンソールに接続できます。
7.3.1.1. Web コンソールを使用した VNC コンソールへの接続
OpenShift Container Platform Web コンソールを使用して、仮想マシンの VNC コンソールに接続できます。
vGPU が仲介デバイスとして割り当てられている Windows仮想マシンに接続すると、デフォルトの表示と vGPU 表示を切り替えることができます。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
オプション: Windows 仮想マシンの vGPU 表示に切り替えるには、Send key リストから Ctl + Alt + 2 を選択します。
- デフォルトの表示に戻すには、Send key リストから Ctl + Alt + 1 を選択します。
- コンソールセッションを終了するには、コンソールペインの外側をクリックし、Disconnect をクリックします。
7.3.1.2. virtctl を使用した VNC コンソールへの接続
virtctl コマンドラインツールを使用して、実行中の仮想マシンの VNC コンソールに接続できます。
SSH 接続経由でリモートマシン上で virtctl vnc コマンドを実行する場合は、-X フラグまたは -Y フラグを指定して ssh コマンドを実行して、X セッションをローカルマシンに転送する必要があります。
前提条件
-
virt-viewerパッケージをインストールする必要があります。
手順
次のコマンドを実行して、コンソールセッションを開始します。
$ virtctl vnc <vm_name>
接続に失敗した場合は、次のコマンドを実行してトラブルシューティング情報を収集します。
$ virtctl vnc <vm_name> -v 4
7.3.1.3. VNC コンソールの一時トークンの生成
Kubernetes API が仮想マシン (VM) の VNC にアクセスするための一時的な認証ベアラートークンを生成します。
Kubernetes は、curl コマンドを変更することで、ベアラートークンの代わりにクライアント証明書を使用した認証もサポートします。
前提条件
-
OpenShift Virtualization 4.14 以降および
ssp-operator4.14 以降の仮想マシンを実行している。
手順
HyperConverged (
HCO) カスタムリソース (CR) の機能ゲートを有効にします。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv --type json -p '[{"op": "replace", "path": "/spec/featureGates/deployVmConsoleProxy", "value": true}]'次のコマンドを実行してトークンを生成します。
$ curl --header "Authorization: Bearer ${TOKEN}" \ "https://api.<cluster_fqdn>/apis/token.kubevirt.io/v1alpha1/namespaces/<namespace>/virtualmachines/<vm_name>/vnc?duration=<duration>" 1- 1
- 期間は時間と分で指定でき、最小期間は 10 分です。例:
5h30m。このパラメーターが設定されていない場合、トークンはデフォルトで 10 分間有効です。
出力サンプル
{ "token": "eyJhb..." }オプション: 出力で提供されたトークンを使用して変数を作成します。
$ export VNC_TOKEN="<token>"
これで、トークンを使用して、仮想マシンの VNC コンソールにアクセスできるようになります。
検証
次のコマンドを実行してクラスターにログインします。
$ oc login --token ${VNC_TOKEN}次のコマンドを実行し、
virtctlを使用して、仮想マシンの VNC コンソールへのアクセスをテストします。$ virtctl vnc <vm_name> -n <namespace>
7.3.2. シリアルコンソールへの接続
OpenShift Container Platform Web コンソールまたは virtctl コマンドラインツールを使用して、仮想マシンのシリアルコンソールに接続できます。
単一の仮想マシンに対する同時 VNC 接続の実行は、現在サポートされていません。
7.3.2.1. Web コンソールを使用したシリアルコンソールへの接続
OpenShift Container Platform Web コンソールを使用して、仮想マシンのシリアルコンソールに接続できます。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
- Disconnect をクリックして、VNC コンソールセッションを終了します。それ以外の場合、VNC コンソールセッションは引き続きバックグラウンドで実行されます。
- コンソールリストから Serial console を選択します。
- コンソールセッションを終了するには、コンソールペインの外側をクリックし、Disconnect をクリックします。
7.3.2.2. virtctl を使用したシリアルコンソールへの接続
virtctl コマンドラインツールを使用して、実行中の仮想マシンのシリアルコンソールに接続できます。
手順
次のコマンドを実行して、コンソールセッションを開始します。
$ virtctl console <vm_name>
-
Ctrl+]を押してコンソールセッションを終了します。
7.3.3. デスクトップビューアーに接続する
デスクトップビューアーとリモートデスクトッププロトコル (RDP) を使用して、Windows 仮想マシンに接続できます。
7.3.3.1. Web コンソールを使用したデスクトップビューアーへの接続
OpenShift Container Platform Web コンソールを使用して、Windows 仮想マシンのデスクトップビューアーに接続できます。
前提条件
- QEMU ゲストエージェントが Windows 仮想マシンにインストールされている。
- RDP クライアントがインストールされている。
手順
- Virtualization → VirtualMachines ページで仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールセッションが自動的に開始します。
- Disconnect をクリックして、VNC コンソールセッションを終了します。それ以外の場合、VNC コンソールセッションは引き続きバックグラウンドで実行されます。
- コンソールのリストから Desktop viewer を選択します。
- RDP サービスの作成 をクリックして、RDP サービス ダイアログを開きます。
- Expose RDP Service を選択し、Save をクリックしてノードポートサービスを作成します。
-
Launch Remote Desktop をクリックして
.rdpファイルをダウンロードし、デスクトップビューアーを起動します。
7.4. 仮想マシンへの SSH アクセスの設定
次の方法を使用して、仮想マシンへの SSH アクセスを設定できます。
SSH キーペアを作成し、公開キーを仮想マシンに追加し、秘密キーを使用して
virtctl sshコマンドを実行して仮想マシンに接続します。cloud-init データソースを使用して設定できるゲストオペレーティングシステムを使用して、実行時または最初の起動時に Red Hat Enterprise Linux (RHEL) 9 仮想マシンに公開 SSH キーを追加できます。
virtctl port-fowardコマンドを.ssh/configファイルに追加し、OpenSSH を使用して仮想マシンに接続します。サービスを作成し、そのサービスを仮想マシンに関連付け、サービスによって公開されている IP アドレスとポートに接続します。
セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、DHCP によって割り当てられた IP アドレスに接続します。
7.4.1. アクセス設定の考慮事項
仮想マシンへのアクセスを設定する各方法には、トラフィックの負荷とクライアントの要件に応じて利点と制限があります。
サービスは優れたパフォーマンスを提供するため、クラスターの外部からアクセスされるアプリケーションに推奨されます。
内部クラスターネットワークがトラフィック負荷を処理できない場合は、セカンダリーネットワークを設定できます。
virtctl sshおよびvirtctl port-forwardingコマンド- 設定が簡単。
- 仮想マシンのトラブルシューティングに推奨されます。
-
Ansible を使用した仮想マシンの自動設定には、
virtctl port-forwardingが推奨されます。 - 動的公開 SSH キーを使用して、Ansible で仮想マシンをプロビジョニングできます。
- API サーバーに負担がかかるため、Rsync やリモートデスクトッププロトコルなどの高トラフィックのアプリケーションには推奨されません。
- API サーバーはトラフィック負荷を処理できる必要があります。
- クライアントは API サーバーにアクセスできる必要があります。
- クライアントはクラスターへのアクセス認証情報を持っている必要があります。
- クラスター IP サービス
- 内部クラスターネットワークはトラフィック負荷を処理できる必要があります。
- クライアントは内部クラスター IP アドレスにアクセスできる必要があります。
- ノードポートサービス
- 内部クラスターネットワークはトラフィック負荷を処理できる必要があります。
- クライアントは少なくとも 1 つのノードにアクセスできる必要があります。
- ロードバランサーサービス
- ロードバランサーを設定する必要があります。
- 各ノードは、1 つ以上のロードバランサーサービスのトラフィック負荷を処理できなければなりません。
- セカンダリーネットワーク
- トラフィックが内部クラスターネットワークを経由しないため、優れたパフォーマンスが得られます。
- ネットワークトポロジーへの柔軟なアプローチを可能にします。
- 仮想マシンはセカンダリーネットワークに直接公開されるため、ゲストオペレーティングシステムは適切なセキュリティーを備えて設定する必要があります。仮想マシンが侵害されると、侵入者がセカンダリーネットワークにアクセスする可能性があります。
7.4.2. virtctl ssh の使用
virtctl ssh コマンドを実行することで、公開 SSH キーを仮想マシンに追加し、仮想マシンに接続できます。
この方法の設定は簡単です。ただし、API サーバーに負担がかかるため、トラフィック負荷が高い場合には推奨されません。
7.4.2.1. 静的および動的 SSH キー管理について
公開 SSH キーは、最初の起動時に静的に、または実行時に動的に仮想マシンに追加できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
静的 SSH キー管理
cloud-init データソースを使用して、設定をサポートするゲストオペレーティングシステムを備えた仮想マシンに静的に管理された SSH キーを追加できます。キーは、最初の起動時に仮想マシンに追加されます。
次のいずれかの方法を使用してキーを追加できます。
- Web コンソールまたはコマンドラインを使用して単一の仮想マシンを作成する場合は、その仮想マシンにキーを追加します。
- Web コンソールを使用してプロジェクトにキーを追加します。その後、このプロジェクトで作成した仮想マシンにキーが自動的に追加されます。
ユースケース
- 仮想マシン所有者は、新しく作成したすべての仮想マシンを 1 つのキーでプロビジョニングできます。
動的な SSH キー管理
Red Hat Enterprise Linux (RHEL) 9 がインストールされている仮想マシンに対して動的 SSH キー管理を有効にすることができます。その後、実行時にキーを更新できます。キーは、Red Hat ブートソースとともにインストールされる QEMU ゲストエージェントによって追加されます。
セキュリティー上の理由から、動的キー管理を無効にできます。その後、仮想マシンは作成元のイメージのキー管理設定を継承します。
ユースケース
-
仮想マシンへのアクセスの付与または取り消し: クラスター管理者は、namespace 内のすべての仮想マシンに適用される
Secretオブジェクトに個々のユーザーのキーを追加または削除することで、リモート仮想マシンアクセスを付与または取り消すことができます。 - ユーザーアクセス: 作成および管理するすべての仮想マシンにアクセス認証情報を追加できます。
Ansible プロビジョニング:
- 運用チームのメンバーは、Ansible プロビジョニングに使用されるすべてのキーを含む 1 つのシークレットを作成できます。
- 仮想マシン所有者は、仮想マシンを作成し、Ansible プロビジョニングに使用されるキーをアタッチできます。
キーのローテーション:
- クラスター管理者は、namespace 内の仮想マシンによって使用される Ansible プロビジョナーキーをローテーションできます。
- ワークロード所有者は、管理する仮想マシンのキーをローテーションできます。
7.4.2.2. 静的キー管理
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して仮想マシンを作成するときに、静的に管理される公開 SSH キーを追加できます。このキーは、仮想マシンが初めて起動するときに、cloud-init データソースとして追加されます。
OpenShift Container Platform Web コンソールを使用してキーをプロジェクトに追加することもできます。その後、このキーはプロジェクトで作成した仮想マシンに自動的に追加されます。
7.4.2.2.1. テンプレートから仮想マシンを作成するときにキーを追加する
OpenShift Container Platform Web コンソールを使用して仮想マシンを作成するときに、静的に管理される公開 SSH キーを追加できます。キーは、最初の起動時に cloud-init データソースとして仮想マシンに追加されます。このメソッドは、cloud-init ユーザーデータには影響しません。
オプション: プロジェクトにキーを追加できます。その後、このキーはプロジェクトで作成した仮想マシンに自動的に追加されます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
- Web コンソールで Virtualization → Catalog に移動します。
テンプレートタイルをクリックします。
ゲストオペレーティングシステムは、cloud-init データソースからの設定をサポートする必要があります。
- Customize VirtualMachineを クリックします。
- Next をクリックします。
- Scripts タブをクリックします。
公開 SSH キーをまだプロジェクトに追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、仮想マシン作成の進行状況が表示されます。
検証
Configuration タブの Scripts タブをクリックします。
シークレット名は Authorized SSH key セクションに表示されます。
7.4.2.2.2. インスタンスタイプから仮想マシンを作成する場合のキーの追加
OpenShift Container Platform Web コンソールを使用して、インスタンスタイプから仮想マシンを作成できます。OpenShift Container Platform Web コンソールを使用してインスタンスタイプから仮想マシンを作成するときに、静的に管理される SSH キーを追加できます。キーは、最初の起動時に cloud-init データソースとして仮想マシンに追加されます。このメソッドは、cloud-init ユーザーデータには影響しません。
手順
- Web コンソールで、Virtualization → Catalog に移動し、InstanceTypes タブをクリックします。
起動可能なボリュームを選択します。
注記ボリュームテーブルには、
instancetype.kubevirt.io/default-preferenceラベルを持つopenshift-virtualization-os-imagesnamespace 内のボリュームのみがリストされます。- インスタンスタイプのタイルをクリックし、ワークロードに適した設定を選択します。
- 公開 SSH キーをまだプロジェクトに追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- 公開 SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
7.4.2.2.3. コマンドラインを使用して仮想マシンを作成するときにキーを追加する
コマンドラインを使用して仮想マシンを作成するときに、静的に管理される公開 SSH キーを追加できます。キーは最初の起動時に仮想マシンに追加されます。
キーは、cloud-init データソースとして仮想マシンに追加されます。このメソッドは、cloud-init ユーザーデータ内のアプリケーションデータからアクセス認証情報を分離します。このメソッドは、cloud-init ユーザーデータには影響しません。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
VirtualMachineオブジェクトとSecretオブジェクトのマニフェストファイルを作成します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: dataVolumeTemplates: - apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: example-vm-disk spec: sourceRef: kind: DataSource name: rhel9 namespace: openshift-virtualization-os-images storage: resources: requests: storage: 30Gi running: false template: metadata: labels: kubevirt.io/domain: example-vm spec: domain: cpu: cores: 1 sockets: 2 threads: 1 devices: disks: - disk: bus: virtio name: rootdisk - disk: bus: virtio name: cloudinitdisk interfaces: - masquerade: {} name: default rng: {} features: smm: enabled: true firmware: bootloader: efi: {} resources: requests: memory: 8Gi evictionStrategy: LiveMigrate networks: - name: default pod: {} volumes: - dataVolume: name: example-volume name: example-vm-disk - cloudInitConfigDrive: <.> userData: |- #cloud-config user: cloud-user password: <password> chpasswd: { expire: False } name: cloudinitdisk accessCredentials: - sshPublicKey: propagationMethod: configDrive: {} source: secret: secretName: authorized-keys <.> --- apiVersion: v1 kind: Secret metadata: name: authorized-keys data: key: | MIIEpQIBAAKCAQEAulqb/Y... <.><.> 設定ドライブを作成するには、
cloudInitConfigDriveを指定します。<.>Secretオブジェクト名を指定します。<.> 公開 SSH キーを貼り付けます。VirtualMachineオブジェクトとSecretオブジェクトを作成します。$ oc create -f <manifest_file>.yaml
仮想マシンを起動します。
$ virtctl start vm example-vm -n example-namespace
検証
仮想マシン設定を取得します。
$ oc describe vm example-vm -n example-namespace
出力例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: template: spec: accessCredentials: - sshPublicKey: propagationMethod: configDrive: {} source: secret: secretName: authorized-keys # ...
7.4.2.3. 動的なキー管理
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、仮想マシンの動的キーインジェクションを有効にできます。その後、実行時にキーを更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
動的キーインジェクションを無効にすると、仮想マシンは作成元のイメージのキー管理方法を継承します。
7.4.2.3.1. テンプレートから仮想マシンを作成するときに動的キーインジェクションを有効にする
OpenShift Container Platform Web コンソールを使用してテンプレートから仮想マシンを作成するときに、動的パブリック SSH キーインジェクションを有効にすることができます。その後、実行時にキーを更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
キーは、RHEL 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
- Web コンソールで Virtualization → Catalog に移動します。
- Red Hat Enterprise Linux 9 VM タイルをクリックします。
- Customize VirtualMachineを クリックします。
- Next をクリックします。
- Scripts タブをクリックします。
公開 SSH キーをまだプロジェクトに追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Dynamic SSH key injection をオンに設定します。
- Save をクリックします。
Create VirtualMachine をクリックします。
VirtualMachine details ページには、仮想マシン作成の進行状況が表示されます。
検証
Configuration タブの Scripts タブをクリックします。
シークレット名は Authorized SSH key セクションに表示されます。
7.4.2.3.2. インスタンスタイプから仮想マシンを作成するときに動的キーインジェクションを有効にする
OpenShift Container Platform Web コンソールを使用して、インスタンスタイプから仮想マシンを作成できます。OpenShift Container Platform Web コンソールを使用してインスタンスタイプから仮想マシンを作成するときに、動的 SSH キーインジェクションを有効にできます。その後、実行時にキーを追加または取り消すことができます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
キーは、RHEL 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
手順
- Web コンソールで、Virtualization → Catalog に移動し、InstanceTypes タブをクリックします。
起動可能なボリュームを選択します。
注記ボリュームテーブルには、
instancetype.kubevirt.io/default-preferenceラベルを持つopenshift-virtualization-os-imagesnamespace 内のボリュームのみがリストされます。- インスタンスタイプのタイルをクリックし、ワークロードに適した設定を選択します。
- Red Hat Enterprise Linux 9 VM タイルをクリックします。
- 公開 SSH キーをまだプロジェクトに追加していない場合は、VirtualMachine details セクションの Authorized SSH key の横にある編集アイコンをクリックします。
以下のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- 公開 SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Save をクリックします。
- VirtualMachine details セクションで Dynamic SSH key injection をオンに設定します。
- オプション: View YAML & CLI をクリックして YAML ファイルを表示します。CLI をクリックして CLI コマンドを表示します。YAML ファイルの内容または CLI コマンドをダウンロードまたはコピーすることもできます。
- Create VirtualMachine をクリックします。
仮想マシンの作成後、VirtualMachine details ページでステータスを監視できます。
7.4.2.3.3. Web コンソールを使用した動的 SSH キーインジェクションの有効化
OpenShift Container Platform Web コンソールを使用して、仮想マシンの動的キーインジェクションを有効にできます。その後、実行時に公開 SSH キーを更新できます。
キーは、Red Hat Enterprise Linux (RHEL) 9 とともにインストールされる QEMU ゲストエージェントによって仮想マシンに追加されます。
前提条件
- ゲスト OS は RHEL 9 です。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration タブで、Scripts をクリックします。
公開 SSH キーをまだプロジェクトに追加していない場合は、Authorized SSH key の横にある編集アイコンをクリックし、次のオプションのいずれかを選択します。
- Use existing: シークレットリストからシークレットを選択します。
Add new:
- SSH キーファイルを参照するか、ファイルをキーフィールドに貼り付けます。
- シークレット名を入力します。
- オプション: Automatically apply this key to any new VirtualMachine you create in this project を選択します。
- Dynamic SSH key injection をオンに設定します。
- Save をクリックします。
7.4.2.3.4. コマンドラインを使用して動的キーインジェクションを有効にする
コマンドラインを使用して、仮想マシンの動的キーインジェクションを有効にすることができます。その後、実行時に公開 SSH キーを更新できます。
Red Hat Enterprise Linux (RHEL) 9 のみが動的キーインジェクションをサポートしています。
キーは QEMU ゲストエージェントによって仮想マシンに追加され、RHEL 9 とともに自動的にインストールされます。
前提条件
-
ssh-keygenコマンドを実行して、SSH 鍵ペアを生成しました。
手順
VirtualMachineオブジェクトとSecretオブジェクトのマニフェストファイルを作成します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: dataVolumeTemplates: - apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: example-vm-disk spec: sourceRef: kind: DataSource name: rhel9 namespace: openshift-virtualization-os-images storage: resources: requests: storage: 30Gi running: false template: metadata: labels: kubevirt.io/domain: example-vm spec: domain: cpu: cores: 1 sockets: 2 threads: 1 devices: disks: - disk: bus: virtio name: rootdisk - disk: bus: virtio name: cloudinitdisk interfaces: - masquerade: {} name: default rng: {} features: smm: enabled: true firmware: bootloader: efi: {} resources: requests: memory: 8Gi evictionStrategy: LiveMigrate networks: - name: default pod: {} volumes: - dataVolume: name: example-volume name: example-vm-disk - cloudInitConfigDrive: <.> userData: |- #cloud-config user: cloud-user password: <password> chpasswd: { expire: False } runcmd: - [ setsebool, -P, virt_qemu_ga_manage_ssh, on ] name: cloudinitdisk accessCredentials: - sshPublicKey: propagationMethod: qemuGuestAgent: users: ["user1","user2","fedora"] <.> source: secret: secretName: authorized-keys <.> --- apiVersion: v1 kind: Secret metadata: name: authorized-keys data: key: | MIIEpQIBAAKCAQEAulqb/Y... <.><.> 設定ドライブを作成するには、
cloudInitConfigDriveを指定します。<.> ユーザー名を指定します。<.>Secretオブジェクト名を指定します。<.> 公開 SSH キーを貼り付けます。VirtualMachineオブジェクトとSecretオブジェクトを作成します。$ oc create -f <manifest_file>.yaml
仮想マシンを起動します。
$ virtctl start vm example-vm -n example-namespace
検証
仮想マシン設定を取得します。
$ oc describe vm example-vm -n example-namespace
出力例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: template: spec: accessCredentials: - sshPublicKey: propagationMethod: qemuGuestAgent: users: ["user1","user2","fedora"] source: secret: secretName: authorized-keys # ...
7.4.2.4. virtctl ssh コマンドの使用
virtcl ssh コマンドを使用して、実行中の仮想マシンにアクセスできます。
前提条件
-
virtctlコマンドラインツールがインストールされました。 - 公開 SSH キーを仮想マシンに追加しました。
- SSH クライアントがインストールされています。
-
virtctlツールがインストールされている環境には、仮想マシンへのアクセスに必要なクラスターパーミッションがある。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
virtctl sshコマンドを実行します。$ virtctl -n <namespace> ssh <username>@example-vm -i <ssh_key> 1- 1
- namespace、ユーザー名、SSH 秘密キーを指定します。デフォルトの SSH キーの場所は
/home/user/.sshです。キーを別の場所に保存する場合は、パスを指定する必要があります。
例
$ virtctl -n my-namespace ssh cloud-user@example-vm -i my-key
VirtualMachines ページ の仮想マシンの横にあるオプション
メニューから、Copy SSH command を選択すると、Web コンソールで virtctl ssh コマンドをコピーできます。
7.4.3. virtctl port-forward コマンドの使用
ローカルの OpenSSH クライアントと virtctl port-forward コマンドを使用して、実行中の仮想マシン (VM) に接続できます。Ansible でこの方法を使用すると、VM の設定を自動化できます。
ポート転送トラフィックはコントロールプレーン経由で送信されるため、この方法はトラフィックの少ないアプリケーションに推奨されます。ただし、API サーバーに負荷が大きいため、Rsync や Remote Desktop Protocol などのトラフィックの高いアプリケーションには推奨されません。
前提条件
-
virtctlクライアントをインストールしている。 - アクセスする仮想マシンが実行されている。
-
virtctlツールがインストールされている環境には、仮想マシンへのアクセスに必要なクラスターパーミッションがある。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
以下のテキストをクライアントマシンの
~/.ssh/configファイルに追加します。Host vm/* ProxyCommand virtctl port-forward --stdio=true %h %p
次のコマンドを実行して、仮想マシンに接続します。
$ ssh <user>@vm/<vm_name>.<namespace>
7.4.4. SSH アクセス用のサービスを使用する
仮想マシンのサービスを作成し、サービスによって公開される IP アドレスとポートに接続できます。
サービスは優れたパフォーマンスを提供するため、クラスターの外部またはクラスター内からアクセスされるアプリケーションに推奨されます。受信トラフィックはファイアウォールによって保護されます。
クラスターネットワークがトラフィック負荷を処理できない場合は、仮想マシンアクセスにセカンダリーネットワークを使用することを検討してください。
7.4.4.1. サービスについて
Kubernetes サービスは一連の Pod で実行されているアプリケーションへのクライアントのネットワークアクセスを公開します。サービスは抽象化、負荷分散を提供し、タイプ NodePort と LoadBalancer の場合は外部世界への露出を提供します。
- ClusterIP
-
内部 IP アドレスでサービスを公開し、クラスター内の他のアプリケーションに DNS 名として公開します。1 つのサービスを複数の仮想マシンにマッピングできます。クライアントがサービスに接続しようとすると、クライアントのリクエストは使用可能なバックエンド間で負荷分散されます。
ClusterIPはデフォルトのサービスタイプです。 - NodePort
-
クラスター内の選択した各ノードの同じポートでサービスを公開します。
NodePortは、ノード自体がクライアントから外部にアクセスできる限り、クラスターの外部からポートにアクセスできるようにします。 - LoadBalancer
- 現在のクラウド(サポートされている場合)に外部ロードバランサーを作成し、固定の外部 IP アドレスをサービスに割り当てます。
オンプレミスクラスターの場合、MetalLB Operator をデプロイすることで負荷分散サービスを設定できます。
7.4.4.2. サービスの作成
OpenShift Container Platform Web コンソール、virtctl コマンドラインツール、または YAML ファイルを使用して、仮想マシンを公開するサービスを作成できます。
7.4.4.2.1. Web コンソールを使用したロードバランサーサービスの作成の有効化
OpenShift Container Platform Web コンソールを使用して、仮想マシン (VM) のロードバランサーサービスの作成を有効にすることができます。
前提条件
- クラスターのロードバランサーが設定されました。
-
cluster-adminロールを持つユーザーとしてログインしている。
手順
- Virtualization → Overview に移動します。
- Settings タブで、Cluster をクリックします。
- LoadBalancer service をデプロイメントし、Enable the creation of LoadBalancer services for SSH connections to VirtualMachines を選択します。
7.4.4.2.2. Web コンソールを使用したサービスの作成
OpenShift Container Platform Web コンソールを使用して、仮想マシンのノードポートまたはロードバランサーサービスを作成できます。
前提条件
- ロードバランサーまたはノードポートをサポートするようにクラスターネットワークが設定されている。
- ロードバランサーサービスを作成するためにロードバランサーサービスの作成が有効化されている。
手順
- VirtualMachines に移動し、仮想マシンを選択して、VirtualMachine details ページを表示します。
- Details タブで、SSH service type リストから SSH over LoadBalancer を選択します。
-
オプション: コピーアイコンをクリックして、
SSHコマンドをクリップボードにコピーします。
検証
- Details タブの Services ペインをチェックして、新しいサービスを表示します。
7.4.4.2.3. virtctl を使用したサービスの作成
virtctl コマンドラインツールを使用して、仮想マシンのサービスを作成できます。
前提条件
-
virtctlコマンドラインツールがインストールされました。 - サービスをサポートするようにクラスターネットワークを設定しました。
-
virtctlをインストールした環境には、仮想マシンにアクセスするために必要なクラスター権限があります。たとえば、oc loginを実行するか、KUBECONFIG環境変数を設定します。
手順
次のコマンドを実行してサービスを作成します。
$ virtctl expose vm <vm_name> --name <service_name> --type <service_type> --port <port> 1- 1
ClusterIP、NodePort、またはLoadBalancerサービスタイプを指定します。
例
$ virtctl expose vm example-vm --name example-service --type NodePort --port 22
検証
以下のコマンドを実行してサービスを確認します。
$ oc get service
次のステップ
virtctl を使用してサービスを作成した後、VirtualMachine マニフェストの spec.template.metadata.labels スタンザに special: key を追加する必要があります。コマンドラインを使用したサービスの作成 を参照してください。
7.4.4.2.4. コマンドラインを使用したサービスの作成
コマンドラインを使用して、サービスを作成し、それを仮想マシンに関連付けることができます。
前提条件
- サービスをサポートするようにクラスターネットワークを設定しました。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: running: false template: metadata: labels: special: key 1 # ...- 1
special: keyをspec.template.metadata.labelsスタンザに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: キーラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。apiVersion: v1 kind: Service metadata: name: example-service namespace: example-namespace spec: # ... selector: special: key 1 type: NodePort 2 ports: 3 protocol: TCP port: 80 targetPort: 9376 nodePort: 30000-
サービスマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
$ oc create -f example-service.yaml
- 仮想マシンを再起動して変更を適用します。
検証
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。$ oc get service -n example-namespace
7.4.4.3. SSH を使用してサービスによって公開される仮想マシンに接続する
SSH を使用して、サービスによって公開されている仮想マシンに接続できます。
前提条件
- 仮想マシンを公開するサービスを作成しました。
- SSH クライアントがインストールされています。
- クラスターにログインしている。
手順
次のコマンドを実行して仮想マシンにアクセスします。
$ ssh <user_name>@<ip_address> -p <port> 1- 1
- クラスター IP サービスの場合はクラスター IP、ノードポートサービスの場合はノード IP、またはロードバランサーサービスの場合は外部 IP アドレスを指定します。
7.4.5. SSH アクセスにセカンダリーネットワークを使用する
SSH を使用して、セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、DHCP によって割り当てられた IP アドレスに接続できます。
セカンダリーネットワークは、トラフィックがクラスターネットワークスタックによって処理されないため、優れたパフォーマンスを提供します。ただし、仮想マシンはセカンダリーネットワークに直接公開されており、ファイアウォールによって保護されません。仮想マシンが侵害されると、侵入者がセカンダリーネットワークにアクセスする可能性があります。この方法を使用する場合は、仮想マシンのオペレーティングシステム内で適切なセキュリティーを設定する必要があります。
ネットワークオプションの詳細はOpenShift Virtualization Tuning & Scaling Guide の Multus および SR-IOV ドキュメントを参照してください。
前提条件
- Linux ブリッジ や SR-IOV などのセカンダリーネットワークを設定しました。
-
Linux ブリッジネットワーク のネットワークアタッチメント定義を作成したか、
SriovNetworkオブジェクトの作成時に SR-IOV ネットワークオペレータが ネットワークアタッチメント定義 を作成しました。
7.4.5.1. Web コンソールを使用した仮想マシンネットワークインターフェイスの設定
OpenShift Container Platform Web コンソールを使用して、仮想マシンのネットワークインターフェイスを設定できます。
前提条件
- ネットワークのネットワーク接続定義を作成しました。
手順
- Virtualization → VirtualMachines に移動します。
- 仮想マシンをクリックして、VirtualMachine details ページを表示します。
- Configuration タブで、Network interfaces タブをクリックします。
- Add network interface をクリックします。
- インターフェイス名を入力し、Network リストからネットワーク接続定義を選択します。
- Save をクリックします。
- 仮想マシンを再起動して変更を適用します。
7.4.5.2. SSH を使用したセカンダリーネットワークに接続された仮想マシンへの接続
SSH を使用して、セカンダリーネットワークに接続されている仮想マシンに接続できます。
前提条件
- DHCP サーバーを使用して仮想マシンをセカンダリーネットワークに接続しました。
- SSH クライアントがインストールされています。
手順
次のコマンドを実行して、仮想マシンの IP アドレスを取得します。
$ oc describe vm <vm_name> -n <namespace>
出力例
# ... Interfaces: Interface Name: eth0 Ip Address: 10.244.0.37/24 Ip Addresses: 10.244.0.37/24 fe80::858:aff:fef4:25/64 Mac: 0a:58:0a:f4:00:25 Name: default # ...次のコマンドを実行して、仮想マシンに接続します。
$ ssh <user_name>@<ip_address> -i <ssh_key>
例
$ ssh cloud-user@10.244.0.37 -i ~/.ssh/id_rsa_cloud-user
7.5. 仮想マシンの編集
OpenShift Container Platform Web コンソールを使用して、仮想マシン設定を更新できます。YAML ファイル または VirtualMachine の詳細 ページ を更新できます。
コマンドラインを使用して仮想マシンを編集することもできます。
7.5.1. コマンドラインを使用した仮想マシンの編集
コマンドラインを使用して仮想マシンを編集できます。
前提条件
-
ocCLI をインストールした。
手順
次のコマンドを実行して、仮想マシンの設定を取得します。
$ oc edit vm <vm_name>
- YAML 設定を編集します。
実行中の仮想マシンを編集する場合は、以下のいずれかを実行する必要があります。
- 仮想マシンを再起動します。
新規の設定を有効にするために、以下のコマンドを実行します。
$ oc apply vm <vm_name> -n <namespace>
7.5.2. 仮想マシンへのディスクの追加
OpenShift Container Platform Web コンソールを使用して、仮想ディスクを仮想マシンに追加できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Disks タブで、Add disk をクリックします。
Source、Name、Size、Type、Interface、および Storage Class を指定します。
- オプション: 空のディスクソースを使用し、データボリュームの作成時に最大の書き込みパフォーマンスが必要な場合に、事前割り当てを有効にできます。そのためには、Enable preallocation チェックボックスをオンにします。
-
オプション: Apply optimized StorageProfile settings をクリアして、仮想ディスクの Volume Mode と Access Mode を変更できます。これらのパラメーターを指定しない場合、システムは
kubevirt-storage-class-defaultsconfig map のデフォルト値を使用します。
- Add をクリックします。
仮想マシンが実行中の場合は、仮想マシンを再起動して変更を適用する必要があります。
7.5.2.1. ストレージフィールド
| フィールド | 説明 |
|---|---|
| 空白 (PVC の作成) | 空のディスクを作成します。 |
| URL を使用したインポート (PVC の作成) | URL (HTTP または HTTPS エンドポイント) を介してコンテンツをインポートします。 |
| 既存 PVC の使用 | クラスターですでに利用可能な PVC を使用します。 |
| 既存の PVC のクローン作成 (PVC の作成) | クラスターで利用可能な既存の PVC を選択し、このクローンを作成します。 |
| レジストリーを使用したインポート (PVC の作成) | コンテナーレジストリーを使用してコンテンツをインポートします。 |
| コンテナー (一時的) | クラスターからアクセスできるレジストリーにあるコンテナーからコンテンツをアップロードします。コンテナーディスクは、CD-ROM や一時的な仮想マシンなどの読み取り専用ファイルシステムにのみ使用する必要があります。 |
| Name |
ディスクの名前。この名前には、小文字 ( |
| Size | ディスクのサイズ (GiB 単位)。 |
| タイプ | ディスクのタイプ。例: Disk または CD-ROM |
| Interface | ディスクデバイスのタイプ。サポートされるインターフェイスは、virtIO、SATA、および SCSI です。 |
| Storage Class | ディスクの作成に使用されるストレージクラス。 |
ストレージの詳細設定
以下のストレージの詳細設定はオプションであり、Blank、Import via URLURL、および Clone existing PVC ディスクで利用できます。
これらのパラメーターを指定しない場合、システムはデフォルトのストレージプロファイル値を使用します。
| パラメーター | オプション | パラメーターの説明 |
|---|---|---|
| ボリュームモード | Filesystem | ファイルシステムベースのボリュームで仮想ディスクを保存します。 |
| Block |
ブロックボリュームで仮想ディスクを直接保存します。基礎となるストレージがサポートしている場合は、 | |
| アクセスモード | ReadWriteOnce (RWO) | ボリュームは単一ノードで読み取り/書き込みとしてマウントできます。 |
| ReadWriteMany (RWX) | ボリュームは、一度に多くのノードで読み取り/書き込みとしてマウントできます。 注記 このモードはライブマイグレーションに必要です。 |
7.5.3. シークレット、設定マップ、またはサービスアカウントの仮想マシンへの追加
OpenShift Container Platform Web コンソールを使用して、シークレット、設定マップ、またはサービスアカウントを仮想マシンに追加します。
これらのリソースは、ディスクとして仮想マシンに追加されます。他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントします。
仮想マシンが実行中の場合、仮想マシンを再起動するまで、変更は有効になりません。新しく追加されたリソースは、ページの上部で保留中の変更としてマークされます。
前提条件
- 追加するシークレット、設定マップ、またはサービスアカウントは、ターゲット仮想マシンと同じ namespace に存在する必要がある。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration → Environment をクリックします。
- Add Config Map, Secret or Service Account をクリックします。
- Select a resource をクリックし、リストから resource を選択します。6 文字のシリアル番号が、選択したリソースについて自動的に生成されます。
- オプション: Reload をクリックして、環境を最後に保存した状態に戻します。
- Save をクリックします。
検証
- VirtualMachine details ページで、Configuration → Disks をクリックし、リソースがディスクのリストに表示されていることを確認します。
- Actions → Restart をクリックして、仮想マシンを再起動します。
他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントできるようになりました。
config map、シークレット、サービスアカウントの追加リソース
7.6. ブート順序の編集
Web コンソールまたは CLI を使用して、ブート順序リストの値を更新できます。
Virtual Machine Overview ページの Boot Order で、以下を実行できます。
- ディスクまたはネットワークインターフェイスコントローラー (NIC) を選択し、これをブート順序のリストに追加します。
- ブート順序の一覧でディスクまたは NIC の順序を編集します。
- ブート順序のリストからディスクまたは NIC を削除して、起動可能なソースのインベントリーに戻します。
7.6.1. Web コンソールでのブート順序リストへの項目の追加
Web コンソールを使用して、ブート順序リストに項目を追加します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。YAML 設定が存在しない場合や、これがブート順序リストの初回作成時の場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
- Add Source をクリックして、仮想マシンのブート可能なディスクまたはネットワークインターフェイスコントローラー (NIC) を選択します。
- 追加のディスクまたは NIC をブート順序一覧に追加します。
- Save をクリックします。
仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
7.6.2. Web コンソールでのブート順序リストの編集
Web コンソールで起動順序リストを編集します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
ブート順序リストで項目を移動するのに適した方法を選択します。
- スクリーンリーダーを使用しない場合、移動する項目の横にある矢印アイコンにカーソルを合わせ、項目を上下にドラッグし、選択した場所にドロップします。
- スクリーンリーダーを使用する場合は、上矢印キーまたは下矢印を押して、ブート順序リストで項目を移動します。次に Tab キーを押して、選択した場所に項目をドロップします。
- Save をクリックします。
仮想マシンが実行されている場合、ブート順序の変更は仮想マシンが再起動されるまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
7.6.3. YAML 設定ファイルでのブート順序リストの編集
CLI を使用して、YAML 設定ファイルのブート順序のリストを編集します。
手順
以下のコマンドを実行して、仮想マシンの YAML 設定ファイルを開きます。
$ oc edit vm <vm_name> -n <namespace>
YAML ファイルを編集し、ディスクまたはネットワークインターフェイスコントローラー (NIC) に関連付けられたブート順序の値を変更します。以下に例を示します。
disks: - bootOrder: 1 1 disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk - cdrom: bus: virtio name: cd-drive-1 interfaces: - boot Order: 2 2 macAddress: '02:96:c4:00:00' masquerade: {} name: default
- YAML ファイルを保存します。
7.6.4. Web コンソールでのブート順序リストからの項目の削除
Web コンソールを使用して、ブート順序のリストから項目を削除します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
-
項目の横にある Remove アイコン
 をクリックします。この項目はブート順序のリストから削除され、利用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
をクリックします。この項目はブート順序のリストから削除され、利用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
7.7. 仮想マシンの削除
Web コンソールまたは oc コマンドラインインターフェイスを使用して、仮想マシンを削除できます。
7.7.1. Web コンソールの使用による仮想マシンの削除
仮想マシンを削除すると、仮想マシンはクラスターから永続的に削除されます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
仮想マシンの横にある Options メニュー
をクリックし、Delete を選択します。
または、仮想マシン名をクリックして VirtualMachine details ページを開き、Actions → Delete をクリックします。
- オプション: With grace period を選択するか、Delete disks をクリアします。
- Delete をクリックして、仮想マシンを完全に削除します。
7.7.2. CLI の使用による仮想マシンの削除
oc コマンドラインインターフェイス (CLI) を使用して仮想マシンを削除できます。oc クライアントを使用すると、複数の仮想マシンでアクションを実行できます。
前提条件
- 削除する仮想マシンの名前を特定すること。
手順
以下のコマンドを実行し、仮想マシンを削除します。
$ oc delete vm <vm_name>
注記このコマンドは、現在のプロジェクト内の VM のみを削除します。削除する仮想マシンが別のプロジェクトまたは namespace にある場合は、
-n <project_name>オプションを指定します。
7.8. 仮想マシンのエクスポート
仮想マシンを別のクラスターにインポートしたり、フォレンジック目的でボリュームを分析したりするために、仮想マシン (VM) とそれに関連付けられたディスクをエクスポートできます。
コマンドラインインターフェイスを使用して、VirtualMachineExport カスタムリソース (CR) を作成します。
または、virtctl vmexport コマンド を使用して VirtualMachineExport CR を作成し、エクスポートされたボリュームをダウンロードすることもできます。
7.8.1. VirtualMachineExport カスタムリソースの作成
VirtualMachineExport カスタムリソース (CR) を作成して、次のオブジェクトをエクスポートできます。
- 仮想マシン (VM): 指定された仮想マシンの永続ボリューム要求 (PVC) をエクスポートします。
-
VM スナップショット:
VirtualMachineSnapshotCR に含まれる PVC をエクスポートします。 -
PVC: PVC をエクスポートします。PVC が
virt-launcherPod などの別の Pod で使用されている場合、エクスポートは PVC が使用されなくなるまでPending状態のままになります。
VirtualMachineExport CR は、エクスポートされたボリュームの内部および外部リンクを作成します。内部リンクはクラスター内で有効です。外部リンクには、Ingress または Route を使用してアクセスできます。
エクスポートサーバーは、次のファイル形式をサポートしています。
-
raw: raw ディスクイメージファイル。 -
gzip: 圧縮されたディスクイメージファイル。 -
dir: PVC ディレクトリーとファイル。 -
tar.gz: 圧縮された PVC ファイル。
前提条件
- 仮想マシンをエクスポートするには、仮想マシンをシャットダウンする必要があります。
手順
次の例に従って
VirtualMachineExportマニフェストを作成し、VirtualMachine、VirtualMachineSnapshot、またはPersistentVolumeClaimCR からボリュームをエクスポートし、example-export.yamlとして保存します。VirtualMachineExportの例apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export spec: source: apiGroup: "kubevirt.io" 1 kind: VirtualMachine 2 name: example-vm ttlDuration: 1h 3VirtualMachineExportCR を作成します。$ oc create -f example-export.yaml
VirtualMachineExportCR を取得します。$ oc get vmexport example-export -o yaml
エクスポートされたボリュームの内部および外部リンクは、
statusスタンザに表示されます。出力例
apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export namespace: example spec: source: apiGroup: "" kind: PersistentVolumeClaim name: example-pvc tokenSecretRef: example-token status: conditions: - lastProbeTime: null lastTransitionTime: "2022-06-21T14:10:09Z" reason: podReady status: "True" type: Ready - lastProbeTime: null lastTransitionTime: "2022-06-21T14:09:02Z" reason: pvcBound status: "True" type: PVCReady links: external: 1 cert: |- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- volumes: - formats: - format: raw url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/volumes/example-disk/disk.img - format: gzip url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/volumes/example-disk/disk.img.gz name: example-disk internal: 2 cert: |- -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- volumes: - formats: - format: raw url: https://virt-export-example-export.example.svc/volumes/example-disk/disk.img - format: gzip url: https://virt-export-example-export.example.svc/volumes/example-disk/disk.img.gz name: example-disk phase: Ready serviceName: virt-export-example-export
7.8.2. エクスポートされた仮想マシンマニフェストへのアクセス
仮想マシン (VM) またはスナップショットをエクスポートすると、エクスポートサーバーから VirtualMachine マニフェストと関連情報を取得できます。
前提条件
VirtualMachineExportカスタムリソース (CR) を作成して、仮想マシンまたは VM スナップショットをエクスポートしている。注記spec.source.kind: PersistentVolumeClaimパラメーターを持つVirtualMachineExportオブジェクトは、仮想マシンマニフェストを生成しません。
手順
マニフェストにアクセスするには、まず証明書をソースクラスターからターゲットクラスターにコピーする必要があります。
- ソースクラスターにログインします。
次のコマンドを実行して、証明書を
cacert.crtファイルに保存します。$ oc get vmexport <export_name> -o jsonpath={.status.links.external.cert} > cacert.crt 1- 1
<export_name>を、VirtualMachineExportオブジェクトのmetadata.name値に置き換えます。
-
cacert.crtファイルをターゲットクラスターにコピーします。
次のコマンドを実行して、ソースクラスター内のトークンをデコードし、
token_decodeファイルに保存します。$ oc get secret export-token-<export_name> -o jsonpath={.data.token} | base64 --decode > token_decode 1- 1
<export_name>を、VirtualMachineExportオブジェクトのmetadata.name値に置き換えます。
-
token_decodeファイルをターゲットクラスターにコピーします。 次のコマンドを実行して、
VirtualMachineExportカスタムリソースを取得します。$ oc get vmexport <export_name> -o yaml
status.linksスタンザを確認します。このスタンザはexternalセクションとinternalセクションに分かれています。各セクション内のmanifests.urlフィールドに注意してください。出力例
apiVersion: export.kubevirt.io/v1alpha1 kind: VirtualMachineExport metadata: name: example-export spec: source: apiGroup: "kubevirt.io" kind: VirtualMachine name: example-vm tokenSecretRef: example-token status: #... links: external: #... manifests: - type: all url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/all 1 - type: auth-header-secret url: https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret 2 internal: #... manifests: - type: all url: https://virt-export-export-pvc.default.svc/internal/manifests/all 3 - type: auth-header-secret url: https://virt-export-export-pvc.default.svc/internal/manifests/secret phase: Ready serviceName: virt-export-example-export- 1
VirtualMachineマニフェスト、存在する場合はData Volumeマニフェスト、外部 URL のイングレスまたはルートの公開証明書を含むConfigMapマニフェストが含まれます。- 2
- Containerized Data Importer (CDI) と互換性のあるヘッダーを含むシークレットが含まれます。ヘッダーには、エクスポートトークンのテキストバージョンが含まれています。
- 3
VirtualMachineマニフェスト、存在する場合はData Volumeマニフェスト、および内部 URL のエクスポートサーバーの証明書を含むConfigMapマニフェストが含まれます。
- ターゲットクラスターにログインします。
次のコマンドを実行して
Secretマニフェストを取得します。$ curl --cacert cacert.crt <secret_manifest_url> -H \ 1 "x-kubevirt-export-token:token_decode" -H \ 2 "Accept:application/yaml"
以下に例を示します。
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/secret -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"
次のコマンドを実行して、
ConfigMapマニフェストやVirtualMachineマニフェストなどのtype: allマニフェストを取得します。$ curl --cacert cacert.crt <all_manifest_url> -H \ 1 "x-kubevirt-export-token:token_decode" -H \ 2 "Accept:application/yaml"
以下に例を示します。
$ curl --cacert cacert.crt https://vmexport-proxy.test.net/api/export.kubevirt.io/v1alpha1/namespaces/example/virtualmachineexports/example-export/external/manifests/all -H "x-kubevirt-export-token:token_decode" -H "Accept:application/yaml"
次のステップ
-
エクスポートしたマニフェストを使用して、ターゲットクラスター上に
ConfigMapオブジェクトとVirtualMachineオブジェクトを作成できます。
7.9. 仮想マシンインスタンスの管理
OpenShift Virtualization 環境の外部で独立して作成されたスタンドアロン仮想マシンインスタンス (VMI) がある場合、Web コンソールを使用するか、コマンドラインインターフェイス (CLI) から oc または virtctl コマンドを使用してそれらを管理できます。
virtctl コマンドは、oc コマンドよりも多くの仮想化オプションを提供します。たとえば、virtctl を使用して仮想マシンを一時停止したり、ポートを公開したりできます。
7.9.1. 仮想マシンインスタンスについて
仮想マシンインスタンス (VMI) は、実行中の仮想マシンを表します。VMI が仮想マシンまたは別のオブジェクトによって所有されている場合、Web コンソールで、または oc コマンドラインインターフェイス (CLI) を使用し、所有者を通してこれを管理します。
スタンドアロンの VMI は、自動化または CLI で他の方法により、スクリプトを使用して独立して作成され、起動します。お使いの環境では、OpenShift Virtualization 環境外で開発され、起動されたスタンドアロンの VMI が存在する可能性があります。CLI を使用すると、引き続きそれらのスタンドアロン VMI を管理できます。スタンドアロン VMI に関連付けられた特定のタスクに Web コンソールを使用することもできます。
- スタンドアロン VMI とそれらの詳細をリスト表示します。
- スタンドアロン VMI のラベルとアノテーションを編集します。
- スタンドアロン VMI を削除します。
仮想マシンを削除する際に、関連付けられた VMI は自動的に削除されます。仮想マシンまたは他のオブジェクトによって所有されていないため、スタンドアロン VMI を直接削除します。
OpenShift Virtualization をアンインストールする前に、CLI または Web コンソールを使用してスタンドアロンの VMI のリストを表示します。次に、未処理の VMI を削除します。
7.9.2. CLI を使用した仮想マシンインスタンスのリスト表示
oc コマンドラインインターフェイス (CLI) を使用して、スタンドアロンおよび仮想マシンによって所有されている VMI を含むすべての仮想マシンのリストを表示できます。
手順
以下のコマンドを実行して、すべての VMI のリストを表示します。
$ oc get vmis -A
7.9.3. Web コンソールを使用したスタンドアロン仮想マシンインスタンスのリスト表示
Web コンソールを使用して、仮想マシンによって所有されていないクラスター内のスタンドアロンの仮想マシンインスタンス (VMI) のリストを表示できます。
仮想マシンまたは他のオブジェクトが所有する VMI は、Web コンソールには表示されません。Web コンソールは、スタンドアロンの VMI のみを表示します。クラスター内のすべての VMI をリスト表示するには、CLI を使用する必要があります。
手順
サイドメニューから Virtualization → VirtualMachines をクリックします。
スタンドアロン VMI は、名前の横にある濃い色のバッジで識別できます。
7.9.4. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの編集
Web コンソールを使用して、スタンドアロン仮想マシンインスタンスのアノテーションおよびラベルを編集できます。他のフィールドは編集できません。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- スタンドアロン VMI を選択して、VirtualMachineInstance details ページを開きます。
- Details タブで、Annotations または Labels の横にある鉛筆アイコンをクリックします。
- 関連する変更を加え、Save をクリックします。
7.9.5. CLI を使用したスタンドアロン仮想マシンインスタンスの削除
oc コマンドラインインターフェイス (CLI) を使用してスタンドアロン仮想マシンインスタンス (VMI) を削除できます。
前提条件
- 削除する必要のある VMI の名前を特定すること。
手順
以下のコマンドを実行して VMI を削除します。
$ oc delete vmi <vmi_name>
7.9.6. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの削除
Web コンソールからスタンドアロン仮想マシンインスタンス (VMI) を削除します。
手順
- Open Shift Container Platform Web コンソールで、サイドメニューからVirtualization → VirtualMachinesをクリックします。
- Actions → Delete VirtualMachineInstance をクリックします。
- 確認のポップアップウィンドウで、Delete をクリックし、スタンドアロン VMI を永続的に削除します。
7.10. 仮想マシンの状態の制御
Web コンソールから仮想マシンを停止し、起動し、再起動し、一時停止を解除することができます。
virtctl を使用して仮想マシンの状態を管理し、CLI から他のアクションを実行できます。たとえば、virtctl を使用して仮想マシンを強制停止したり、ポートを公開したりできます。
7.10.1. 仮想マシンの起動
Web コンソールから仮想マシンを起動できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 起動する仮想マシンが含まれる行を見つけます。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対して操作を実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Start VirtualMachine をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを起動する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Start をクリックします。
URL ソースからプロビジョニングされる仮想マシンの初回起動時に、OpenShift Virtualization が URL エンドポイントからコンテナーをインポートする間、仮想マシンの状態は Importing になります。このプロセスは、イメージのサイズによって数分の時間がかかる可能性があります。
7.10.2. 仮想マシンの停止
Web コンソールから仮想マシンを停止できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 停止する仮想マシンが含まれる行を見つけます。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対して操作を実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Stop VirtualMachine をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを停止する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Stop をクリックします。
7.10.3. 仮想マシンの再起動
Web コンソールから実行中の仮想マシンを再起動できます。
エラーを回避するには、ステータスが Importing の仮想マシンは再起動しないでください。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 再起動する仮想マシンが含まれる行を見つけます。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対して操作を実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Restart をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを再起動する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Restart をクリックします。
7.10.4. 仮想マシンの一時停止
Web コンソールから仮想マシンを一時停止できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 一時停止する仮想マシンが含まれている行を見つけます。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対して操作を実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Pause VirtualMachine をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを一時停止する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Pause をクリックします。
7.10.5. 仮想マシンの一時停止の解除
Web コンソールから仮想マシンの一時停止を解除できます。
前提条件
- 1 つ以上の仮想マシンのステータスが Paused である必要がある。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 一時停止を解除する仮想マシンが含まれる行を見つけます。
ユースケースに応じて適切なメニューに移動します。
このページに留まり、複数の仮想マシンに対して操作を実行するには、次の手順を実行します。
-
行の右端にある Options メニュー
をクリックして、Unpause VirtualMachine をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンの一時停止を解除する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Unpause をクリックします。
7.11. 仮想 Trusted Platform Module デバイスの使用
VirtualMachine (VM) または VirtualMachineInstance (VMI) マニフェストを編集して、仮想 Trusted Platform Module (vTPM) デバイスを新規または既存の仮想マシンに追加します。
7.11.1. vTPM デバイスについて
仮想トラステッドプラットフォームモジュール (vTPM) デバイスは、物理トラステッドプラットフォームモジュール (TPM) ハードウェアチップのように機能します。
vTPM デバイスはどのオペレーティングシステムでも使用できますが、Windows 11 をインストールまたは起動するには TPM チップが必要です。vTPM デバイスを使用すると、Windows 11 イメージから作成された VM を物理 TPM チップなしで機能させることができます。
vTPM を有効にしないと、ノードに TPM デバイスがある場合でも、VM は TPM デバイスを認識しません。
また、vTPM デバイスは、物理ハードウェアを使用せずにシークレットを保存することで仮想マシンを保護します。OpenShift Virtualization は、仮想マシンの Persistent Volume Claims (PVC) を使用して、vTPM デバイス状態の永続化をサポートします。HyperConverged カスタムリソース (CR) で vmStateStorageClass 属性を設定することにより、PVC が使用するストレージクラスを指定する必要があります。
kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: vmStateStorageClass: <storage_class_name> # ...
ストレージクラスは Filesystem タイプであり、ReadWriteMany (RWX) アクセスモードをサポートしている必要があります。
7.11.2. 仮想マシンへの vTPM デバイスの追加
仮想トラステッドプラットフォームモジュール (vTPM) デバイスを仮想マシン (VM) に追加すると、物理 TPM デバイスなしで Windows 11 イメージから作成された仮想マシンを実行できます。vTPM デバイスには、その仮想マシンのシークレットも保存されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
ReadWriteMany(RWX) アクセスモードをサポートするFilesystemタイプのストレージクラスを使用するように Persistent Volume Claim (PVC) を設定しました。これは、仮想マシンの再起動後も vTPM デバイスデータを維持するために必要です。
手順
次のコマンドを実行して、仮想マシン設定を更新します。
$ oc edit vm <vm_name> -n <namespace>
仮想マシン仕様を編集して vTPM デバイスを追加します。以下に例を示します。
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: template: spec: domain: devices: tpm: 1 persistent: true 2 # ...- 変更を適用するには、エディターを保存し、終了します。
- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
7.12. OpenShift Pipelines を使用した仮想マシンの管理
Red Hat OpenShift Pipelines は、開発者が独自のコンテナーで CI/CD パイプラインの各ステップを設計および実行できるようにする、Kubernetes ネイティブの CI/CD フレームワークです。
Scheduling、Scale、and Performance (SSP) Operator は、OpenShift Virtualization を OpenShift Pipelines と統合します。SSP Operator には、次のことを可能にするタスクとサンプルパイプラインが含まれています。
- 仮想マシン (VM)、永続ボリューム要求 (PVC)、およびデータボリュームの作成と管理
- 仮想マシンでコマンドを実行する
-
libguestfsツールを使用してディスクイメージを操作する
Red Hat OpenShift Pipelines を使用した仮想マシンの管理は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
7.12.1. 前提条件
-
cluster-admin権限を使用して OpenShift Container Platform クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - OpenShift Pipelines CLI がインストールされている。
7.12.2. Scheduling, Scale, and Performance (SSP) リソースのデプロイ
SSP Operator のサンプル Tekton Tasks と Pipelines は、OpenShift Virtualization をインストールするときにデフォルトではデプロイされません。SSP Operator の Tekton リソースをデプロイするには、HyperConverged カスタムリソース (CR) で deployTektonTaskResources 機能ゲートを有効にします。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.featureGates.deployTektonTaskResourcesフィールドをtrueに設定します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: kubevirt-hyperconverged spec: tektonPipelinesNamespace: <user_namespace> 1 featureGates: deployTektonTaskResources: true 2 # ...
注記後でフィーチャーゲートを無効にしても、タスクとサンプルパイプラインは引き続き使用できます。
- 変更を保存し、エディターを終了します。
7.12.3. SSP Operator によってサポートされる仮想マシンのタスク
次の表は、SSP Operator の一部として含まれるタスクを示しています。
表7.3 SSP Operator によってサポートされる仮想マシンのタスク
| タスク | 説明 |
|---|---|
|
|
提供されたマニフェストから、または |
|
| テンプレートからの仮想マシンの作成 |
|
| 仮想マシンテンプレートをコピーします。 |
|
| 仮想マシンテンプレートを変更します。 |
|
| データボリュームまたはデータソースを作成または削除します。 |
|
| 仮想マシンでスクリプトまたはコマンドを実行し、後で仮想マシンを停止または削除します。 |
|
|
|
|
|
|
|
| 仮想マシンインスタンスの特定のステータスを待機し、ステータスに基づいて失敗または成功します。 |
パイプラインでの仮想マシンの作成では、非推奨になったテンプレートベースのタスクではなく、ClusterInstanceType と ClusterPreference が使用されるようになりました。create-vm-from-template、copy-template、および edit-vm-template コマンドは引き続き使用できますが、デフォルトのパイプラインタスクでは使用されません。
7.12.4. パイプラインの例
SSP Operator には、次の Pipeline マニフェストの例が含まれています。サンプルパイプラインは、Web コンソールまたは CLI を使用して実行できます。
複数バージョンの Windows が必要な場合は、複数のインストーラーパイプラインを実行する必要がある可能性があります。複数のインストーラーパイプラインを実行する場合、それぞれに autounattend config map やベースイメージ名などの一意のパラメーターが必要です。たとえば、Windows 10 および Windows 11 または Windows Server 2022 イメージが必要な場合は、Windows efi インストーラーパイプラインと Windows bios インストーラーパイプラインの両方を実行する必要があります。一方で、Windows 11 および Windows Server 2022 イメージが必要な場合、実行する必要があるのは Windows efi インストーラーパイプラインのみです。
- Windows EFI インストーラーパイプライン
- このパイプラインは、Windows 11 または Windows Server 2022 を Windows インストールイメージ (ISO ファイル) から新しいデータボリュームにインストールします。インストールプロセスの実行には、カスタムアンサーファイルが使用されます。
- Windows BIOS インストーラーパイプライン
- このパイプラインは、Windows 10 を Windows インストールイメージ (ISO ファイル) から新しいデータボリュームにインストールします。インストールプロセスの実行には、カスタムアンサーファイルが使用されます。
- Windows カスタマイズパイプライン
- このパイプラインは、基本的な Windows 10、11、または Windows Server 2022 インストールのデータボリュームを複製し、Microsoft SQL Server Express または Microsoft Visual Studio Code をインストールすることでカスタマイズして、新しいイメージとテンプレートを作成します。
サンプルパイプラインでは、OpenShift Container Platform によって事前定義され、Microsoft ISO ファイルに適した sysprep を含む config map ファイルを使用します。さまざまな Windows エディションに関連する ISO ファイルの場合は、システム固有の sysprep 定義を使用して新しい config map ファイルを作成することが必要になる場合があります。
7.12.4.1. Web コンソールを使用してサンプルパイプラインを実行する
サンプルパイプラインは、Web コンソールの Pipelines メニューから実行できます。
手順
- サイドメニューの Pipelines → Pipelines をクリックします。
- パイプラインを選択して、Pipeline details ページを開きます。
- Actions リストから、Start を選択します。Start Pipeline ダイアログが表示されます。
- パラメーターのデフォルト値を保持し、Start をクリックしてパイプラインを実行します。Details タブでは、各タスクの進行状況が追跡され、パイプラインのステータスが表示されます。
7.12.4.2. CLI を使用してサンプルパイプラインを実行する
PipelineRun リソースを使用して、サンプルパイプラインを実行します。PipelineRun オブジェクトは、パイプラインの実行中のインスタンスです。これは、クラスター上の特定の入力、出力、および実行パラメーターで実行されるパイプラインをインスタンス化します。また、パイプライン内のタスクごとに TaskRun オブジェクトを作成します。
手順
Windows 10 インストーラーパイプラインを実行するには、次の
PipelineRunマニフェストを作成します。apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: generateName: windows10-installer-run- labels: pipelinerun: windows10-installer-run spec: params: - name: winImageDownloadURL value: <link_to_windows_10_iso> 1 pipelineRef: name: windows10-installer taskRunSpecs: - pipelineTaskName: copy-template taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template taskServiceAccountName: modify-vm-template-task - pipelineTaskName: create-vm-from-template taskServiceAccountName: create-vm-from-template-task - pipelineTaskName: wait-for-vmi-status taskServiceAccountName: wait-for-vmi-status-task - pipelineTaskName: create-base-dv taskServiceAccountName: modify-data-object-task - pipelineTaskName: cleanup-vm taskServiceAccountName: cleanup-vm-task status: {}- 1
- Windows 10 64 ビット ISO ファイルの URL を指定します。製品の言語は英語 (米国) でなければなりません。
PipelineRunマニフェストを適用します。$ oc apply -f windows10-installer-run.yaml
Windows 10 カスタマイズパイプラインを実行するには、次の
PipelineRunマニフェストを作成します。apiVersion: tekton.dev/v1beta1 kind: PipelineRun metadata: generateName: windows10-customize-run- labels: pipelinerun: windows10-customize-run spec: params: - name: allowReplaceGoldenTemplate value: true - name: allowReplaceCustomizationTemplate value: true pipelineRef: name: windows10-customize taskRunSpecs: - pipelineTaskName: copy-template-customize taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template-customize taskServiceAccountName: modify-vm-template-task - pipelineTaskName: create-vm-from-template taskServiceAccountName: create-vm-from-template-task - pipelineTaskName: wait-for-vmi-status taskServiceAccountName: wait-for-vmi-status-task - pipelineTaskName: create-base-dv taskServiceAccountName: modify-data-object-task - pipelineTaskName: cleanup-vm taskServiceAccountName: cleanup-vm-task - pipelineTaskName: copy-template-golden taskServiceAccountName: copy-template-task - pipelineTaskName: modify-vm-template-golden taskServiceAccountName: modify-vm-template-task status: {}PipelineRunマニフェストを適用します。$ oc apply -f windows10-customize-run.yaml
7.12.5. 関連情報
7.13. 高度な仮想マシン管理
7.13.1. 仮想マシンのリソースクォータの使用
仮想マシンのリソースクォータの作成および管理
7.13.1.1. 仮想マシンのリソースクォータ制限の設定
リクエストのみを使用するリソースクォータは、仮想マシン (VM) で自動的に機能します。リソースクォータで制限を使用する場合は、VM に手動でリソース制限を設定する必要があります。リソース制限は、リソース要求より少なくとも 100 MiB 大きくする必要があります。
手順
VirtualMachineマニフェストを編集して、VM の制限を設定します。以下に例を示します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: with-limits spec: running: false template: spec: domain: # ... resources: requests: memory: 128Mi limits: memory: 256Mi 1- 1
- この設定がサポートされるのは、
limits.memory値がrequests.memory値より少なくとも100Mi大きいためです。
-
VirtualMachineマニフェストを保存します。
7.13.1.2. 関連情報
7.13.2. 仮想マシンのノードの指定
ノードの配置ルールを使用して、仮想マシン (VM) を特定のノードに配置することができます。
7.13.2.1. 仮想マシンのノード配置について
仮想マシン (VM) が適切なノードで実行されるようにするには、ノードの配置ルールを設定できます。以下の場合にこれを行うことができます。
- 仮想マシンが複数ある。フォールトトレランスを確保するために、これらを異なるノードで実行する必要がある。
- 2 つの相互間のネットワークトラフィックの多い chatty VM がある。冗長なノード間のルーティングを回避するには、仮想マシンを同じノードで実行します。
- 仮想マシンには、利用可能なすべてのノードにない特定のハードウェア機能が必要です。
- 機能をノードに追加する Pod があり、それらの機能を使用できるように仮想マシンをそのノードに配置する必要があります。
仮想マシンの配置は、ワークロードの既存のノードの配置ルールに基づきます。ワークロードがコンポーネントレベルの特定のノードから除外される場合、仮想マシンはそれらのノードに配置できません。
以下のルールタイプは、VirtualMachine マニフェストの spec フィールドで使用できます。
nodeSelector- 仮想マシンは、キーと値のペアまたはこのフィールドで指定したペアを使用してラベルが付けられたノードに Pod をスケジュールできます。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinity-
より表現的な構文を使用して、ノードと仮想マシンに一致するルールを設定できます。たとえば、ルールがハード要件ではなく基本設定になるように指定し、ルールの条件が満たされない場合も仮想マシンがスケジュールされるようにすることができます。Pod のアフィニティー、Pod の非アフィニティー、およびノードのアフィニティーは仮想マシンの配置でサポートされます。Pod のアフィニティーは仮想マシンに対して動作します。
VirtualMachineワークロードタイプはPodオブジェクトに基づくためです。 tolerations一致するテイントを持つノードで仮想マシンをスケジュールできます。テイントがノードに適用される場合、そのノードはテイントを容認する仮想マシンのみを受け入れます。
注記アフィニティールールは、スケジューリング時にのみ適用されます。OpenShift Container Platform は、制約を満たさなくなった場合に実行中のワークロードを再スケジューリングしません。
7.13.2.2. ノード配置の例
以下の YAML スニペットの例では、nodePlacement、affinity、および tolerations フィールドを使用して仮想マシンのノード配置をカスタマイズします。
7.13.2.2.1. 例: nodeSelector を使用した仮想マシンノードの配置
この例では、仮想マシンに example-key-1 = example-value-1 および example-key-2 = example-value-2 ラベルの両方が含まれるメタデータのあるノードが必要です。
この説明に該当するノードがない場合、仮想マシンはスケジュールされません。
仮想マシンマニフェストの例
metadata:
name: example-vm-node-selector
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
nodeSelector:
example-key-1: example-value-1
example-key-2: example-value-2
# ...
7.13.2.2.2. 例: Pod のアフィニティーおよび Pod の非アフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example-key-1 = example-value-1 を持つ実行中の Pod のあるノードでスケジュールされる必要があります。このようなノードで実行中の Pod がない場合、仮想マシンはスケジュールされません。
可能な場合に限り、仮想マシンはラベル example-key-2 = example-value-2 を持つ Pod のあるノードではスケジュールされません。ただし、すべての候補となるノードにこのラベルを持つ Pod がある場合、スケジューラーはこの制約を無視します。
仮想マシンマニフェストの例
metadata:
name: example-vm-pod-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: 1
- labelSelector:
matchExpressions:
- key: example-key-1
operator: In
values:
- example-value-1
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution: 2
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: example-key-2
operator: In
values:
- example-value-2
topologyKey: kubernetes.io/hostname
# ...
7.13.2.2.3. 例: ノードのアフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example.io/example-key = example-value-1 またはラベル example.io/example-key = example-value-2 を持つノードでスケジュールされる必要があります。この制約は、ラベルのいずれかがノードに存在する場合に満たされます。いずれのラベルも存在しない場合、仮想マシンはスケジュールされません。
可能な場合、スケジューラーはラベル example-node-label-key = example-node-label-value を持つノードを回避します。ただし、すべての候補となるノードにこのラベルがある場合、スケジューラーはこの制約を無視します。
仮想マシンマニフェストの例
metadata:
name: example-vm-node-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: 1
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-key
operator: In
values:
- example-value-1
- example-value-2
preferredDuringSchedulingIgnoredDuringExecution: 2
- weight: 1
preference:
matchExpressions:
- key: example-node-label-key
operator: In
values:
- example-node-label-value
# ...
7.13.2.2.4. 例: 容認 (toleration) を使用した仮想マシンノードの配置
この例では、仮想マシン用に予約されるノードには、すでに key=virtualization:NoSchedule テイントのラベルが付けられています。この仮想マシンには一致する tolerations があるため、これをテイントが付けられたノードにスケジュールできます。
テイントを容認する仮想マシンは、そのテイントを持つノードにスケジュールする必要はありません。
仮想マシンマニフェストの例
metadata:
name: example-vm-tolerations
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"
# ...
7.13.2.3. 関連情報
7.13.3. 証明書ローテーションの設定
証明書ローテーションパラメーターを設定して、既存の証明書を置き換えます。
7.13.3.1. 証明書ローテーションの設定
これは、Web コンソールでの OpenShift Virtualization のインストール時に、または HyperConverged カスタムリソース (CR) でインストール後に実行することができます。
手順
以下のコマンドを実行して
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
以下の例のように
spec.certConfigフィールドを編集します。システムのオーバーロードを避けるには、すべての値が 10 分以上であることを確認します。golangParseDuration形式 に準拠する文字列として、すべての値を表現します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: certConfig: ca: duration: 48h0m0s renewBefore: 24h0m0s 1 server: duration: 24h0m0s 2 renewBefore: 12h0m0s 3- YAML ファイルをクラスターに適用します。
7.13.3.2. 証明書ローテーションパラメーターのトラブルシューティング
1 つ以上の certConfig 値を削除すると、デフォルト値が以下のいずれかの条件と競合する場合を除き、デフォルト値に戻ります。
-
ca.renewBeforeの値はca.durationの値以下である必要があります。 -
server.durationの値はca.durationの値以下である必要があります。 -
server.renewBeforeの値はserver.durationの値以下である必要があります。
デフォルト値がこれらの条件と競合すると、エラーが発生します。
以下の例で server.duration 値を削除すると、デフォルト値の 24h0m0s は ca.duration の値よりも大きくなり、指定された条件と競合します。
例
certConfig:
ca:
duration: 4h0m0s
renewBefore: 1h0m0s
server:
duration: 4h0m0s
renewBefore: 4h0m0s
これにより、以下のエラーメッセージが表示されます。
error: hyperconvergeds.hco.kubevirt.io "kubevirt-hyperconverged" could not be patched: admission webhook "validate-hco.kubevirt.io" denied the request: spec.certConfig: ca.duration is smaller than server.duration
エラーメッセージには、最初の競合のみが記載されます。続行する前に、すべての certConfig の値を確認します。
7.13.4. デフォルトの CPU モデルの設定
HyperConverged カスタムリソース (CR) の defaultCPUModel 設定を使用して、クラスター全体のデフォルト CPU モデルを定義します。
仮想マシン (VM) の CPU モデルは、仮想マシンおよびクラスター内の CPU モデルの可用性によって異なります。
仮想マシンに定義された CPU モデルがない場合:
-
defaultCPUModelは、クラスター全体のレベルで定義された CPU モデルを使用して自動的に設定されます。
-
仮想マシンとクラスターの両方に CPU モデルが定義されている場合:
- 仮想マシンの CPU モデルが優先されます。
仮想マシンにもクラスターにも CPU モデルが定義されていない場合:
- ホストモデルは、ホストレベルで定義された CPU モデルを使用して自動的に設定されます。
7.13.4.1. デフォルトの CPU モデルの設定
HyperConverged カスタムリソース (CR) を更新して、defaultCPUModel を設定します。OpenShift Virtualization の実行中に、defaultCPUModel を変更できます。
defaultCPUModel では、大文字と小文字が区別されます。
前提条件
- OpenShift CLI (oc) のインストール。
手順
以下のコマンドを実行して
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
CR に
defaultCPUModelフィールドを追加し、値をクラスター内に存在する CPU モデルの名前に設定します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: defaultCPUModel: "EPYC"
- YAML ファイルをクラスターに適用します。
7.13.5. 仮想マシンに UEFI モードを使用する
Unified Extensible Firmware Interface (UEFI) モードで仮想マシン (VM) を起動できます。
7.13.5.1. 仮想マシンの UEFI モードについて
レガシー BIOS などの Unified Extensible Firmware Interface (UEFI) は、コンピューターの起動時にハードウェアコンポーネントやオペレーティングシステムのイメージファイルを初期化します。UEFI は BIOS よりも最新の機能とカスタマイズオプションをサポートするため、起動時間を短縮できます。
これは、.efi 拡張子を持つファイルに初期化と起動に関する情報をすべて保存します。このファイルは、EFI System Partition (ESP) と呼ばれる特別なパーティションに保管されます。ESP には、コンピューターにインストールされるオペレーティングシステムのブートローダープログラムも含まれます。
7.13.5.2. UEFI モードでの仮想マシンの起動
VirtualMachine マニフェストを編集して、UEFI モードで起動するように仮想マシンを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストファイルを編集または作成します。spec.firmware.bootloaderスタンザを使用して、UEFI モードを設定します。セキュアブートがアクティブな状態の UEFI モードでのブート
apiversion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: special: vm-secureboot name: vm-secureboot spec: template: metadata: labels: special: vm-secureboot spec: domain: devices: disks: - disk: bus: virtio name: containerdisk features: acpi: {} smm: enabled: true 1 firmware: bootloader: efi: secureBoot: true 2 # ...以下のコマンドを実行して、マニフェストをクラスターに適用します。
$ oc create -f <file_name>.yaml
7.13.6. 仮想マシンの PXE ブートの設定
PXE ブートまたはネットワークブートは OpenShift Virtualization で利用できます。ネットワークブートにより、ローカルに割り当てられたストレージデバイスなしにコンピューターを起動し、オペレーティングシステムまたは他のプログラムを起動し、ロードすることができます。たとえば、これにより、新規ホストのデプロイ時に PXE サーバーから必要な OS イメージを選択できます。
7.13.6.1. 前提条件
- Linux ブリッジが 接続されていること。
- PXE サーバーがブリッジとして同じ VLAN に接続されていること。
7.13.6.2. MAC アドレスを指定した PXE ブート
まず、管理者は PXE ネットワークの NetworkAttachmentDefinition オブジェクトを作成し、ネットワーク経由でクライアントを起動できます。次に、仮想マシンインスタンスの設定ファイルでネットワーク接続定義を参照して仮想マシンインスタンスを起動します。また PXE サーバーで必要な場合には、仮想マシンインスタンスの設定ファイルで MAC アドレスを指定することもできます。
前提条件
- Linux ブリッジが接続されていること。
- PXE サーバーがブリッジとして同じ VLAN に接続されていること。
手順
クラスターに PXE ネットワークを設定します。
PXE ネットワーク
pxe-net-confのネットワーク接続定義ファイルを作成します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: pxe-net-conf spec: config: '{ "cniVersion": "0.3.1", "name": "pxe-net-conf", "plugins": [ { "type": "cnv-bridge", "bridge": "br1", "vlan": 1 1 }, { "type": "cnv-tuning" 2 } ] }'注記仮想マシンインスタンスは、必要な VLAN のアクセスポートでブリッジ
br1に割り当てられます。
直前の手順で作成したファイルを使用してネットワーク接続定義を作成します。
$ oc create -f pxe-net-conf.yaml
仮想マシンインスタンス設定ファイルを、インターフェイスおよびネットワークの詳細を含めるように編集します。
PXE サーバーで必要な場合には、ネットワークおよび MAC アドレスを指定します。MAC アドレスが指定されていない場合、値は自動的に割り当てられます。
bootOrderが1に設定されており、インターフェイスが最初に起動することを確認します。この例では、インターフェイスは<pxe-net>というネットワークに接続されています。interfaces: - masquerade: {} name: default - bridge: {} name: pxe-net macAddress: de:00:00:00:00:de bootOrder: 1注記複数のインターフェイスおよびディスクのブートの順序はグローバル順序になります。
オペレーティングシステムのプロビジョニング後に起動が適切に実行されるよう、ブートデバイス番号をディスクに割り当てます。
ディスク
bootOrderの値を2に設定します。devices: disks: - disk: bus: virtio name: containerdisk bootOrder: 2直前に作成されたネットワーク接続定義に接続されるネットワークを指定します。このシナリオでは、
<pxe-net>は<pxe-net-conf>というネットワーク接続定義に接続されます。networks: - name: default pod: {} - name: pxe-net multus: networkName: pxe-net-conf
仮想マシンインスタンスを作成します。
$ oc create -f vmi-pxe-boot.yaml
出力例
virtualmachineinstance.kubevirt.io "vmi-pxe-boot" created
仮想マシンインスタンスの実行を待機します。
$ oc get vmi vmi-pxe-boot -o yaml | grep -i phase phase: Running
VNC を使用して仮想マシンインスタンスを表示します。
$ virtctl vnc vmi-pxe-boot
- ブート画面で、PXE ブートが正常に実行されていることを確認します。
仮想マシンインスタンスにログインします。
$ virtctl console vmi-pxe-boot
検証
仮想マシンのインターフェイスおよび MAC アドレスを確認し、ブリッジに接続されたインターフェイスに MAC アドレスが指定されていることを確認します。この場合、PXE ブートには IP アドレスなしに
eth1を使用しています。他のインターフェイスeth0は OpenShift Container Platform から IP アドレスを取得しています。$ ip addr
出力例
... 3. eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether de:00:00:00:00:de brd ff:ff:ff:ff:ff:ff
7.13.6.3. OpenShift Virtualization ネットワークの用語集
以下の用語は、OpenShift Virtualization ドキュメント全体で使用されています。
- Container Network Interface (CNI)
- コンテナーのネットワーク接続に重点を置く Cloud Native Computing Foundation プロジェクト。OpenShift Virtualization は CNI プラグインを使用して基本的な Kubernetes ネットワーク機能を強化します。
- Multus
- 複数の CNI の存在を可能にし、Pod または仮想マシンが必要なインターフェイスを使用できるようにする "メタ" CNI プラグイン。
- カスタムリソース定義 (CRD、Custom Resource Definition)
- カスタムリソースの定義を可能にする Kubernetes API リソース、または CRD API リソースを使用して定義されるオブジェクト。
- ネットワーク接続定義 (NAD)
- Multus プロジェクトによって導入された CRD。Pod、仮想マシン、および仮想マシンインスタンスを 1 つ以上のネットワークに接続できるようにします。
- ノードネットワーク設定ポリシー (NNCP)
-
nmstate プロジェクトによって導入された CRD。ノード上で要求されるネットワーク設定を表します。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。
7.13.7. 仮想マシンでの Huge Page の使用
Huge Page は、クラスター内の仮想マシンのバッキングメモリーとして使用できます。
7.13.7.1. 前提条件
7.13.7.2. Huge Page の機能
メモリーは Page と呼ばれるブロックで管理されます。多くのシステムでは、1 ページは 4Ki です。メモリー 1Mi は 256 ページに、メモリー 1Gi は 256,000 ページに相当します。CPU には、内蔵のメモリー管理ユニットがあり、ハードウェアでこのようなページリストを管理します。トランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffer) は、仮想から物理へのページマッピングの小規模なハードウェアキャッシュのことです。ハードウェアの指示で渡された仮想アドレスが TLB にあれば、マッピングをすばやく決定できます。そうでない場合には、TLB ミスが発生し、システムは速度が遅く、ソフトウェアベースのアドレス変換にフォールバックされ、パフォーマンスの問題が発生します。TLB のサイズは固定されているので、TLB ミスの発生率を減らすには Page サイズを大きくする必要があります。
Huge Page とは、4Ki より大きいメモリーページのことです。x86_64 アーキテクチャーでは、2Mi と 1Gi の 2 つが一般的な Huge Page サイズです。別のアーキテクチャーではサイズは異なります。Huge Page を使用するには、アプリケーションが認識できるようにコードを書き込む必要があります。Transparent Huge Pages (THP) は、アプリケーションによる認識なしに、Huge Page の管理を自動化しようとしますが、制約があります。特に、ページサイズは 2Mi に制限されます。THP では、THP のデフラグが原因で、メモリー使用率が高くなり、断片化が起こり、パフォーマンスの低下につながり、メモリーページがロックされてしまう可能性があります。このような理由から、アプリケーションは THP ではなく、事前割り当て済みの Huge Page を使用するように設計 (また推奨) される場合があります。
OpenShift Virtualization では、事前に割り当てられた Huge Page を使用できるように仮想マシンを設定できます。
7.13.7.3. 仮想マシンの Huge Page の設定
memory.hugepages.pageSize および resources.requests.memory パラメーターを仮想マシン設定に組み込み、仮想マシンを事前に割り当てられた Huge Page を使用するように設定できます。
メモリー要求はページサイズ別に分ける必要があります。たとえば、ページサイズ 1Gi の場合に 500Mi メモリーを要求することはできません。
ホストおよびゲスト OS のメモリーレイアウトには関連性がありません。仮想マシンマニフェストで要求される Huge Page が QEMU に適用されます。ゲスト内の Huge Page は、仮想マシンインスタンスの利用可能なメモリー量に基づいてのみ設定できます。
実行中の仮想マシンを編集する場合は、変更を有効にするために仮想マシンを再起動する必要があります。
前提条件
- ノードには、事前に割り当てられた Huge Page が設定されている必要がある。
手順
仮想マシン設定で、
resources.requests.memoryおよびmemory.hugepages.pageSizeパラメーターをspec.domainに追加します。以下の設定スニペットは、ページサイズが1Giの合計4Giメモリーを要求する仮想マシンについてのものです。kind: VirtualMachine # ... spec: domain: resources: requests: memory: "4Gi" 1 memory: hugepages: pageSize: "1Gi" 2 # ...仮想マシン設定を適用します。
$ oc apply -f <virtual_machine>.yaml
7.13.8. 仮想マシン用の専用リソースの有効化
パフォーマンスを向上させるために、CPU などのノードリソースを仮想マシン専用に確保できます。
7.13.8.1. 専用リソースについて
仮想マシンの専用リソースを有効にする場合、仮想マシンのワークロードは他のプロセスで使用されない CPU でスケジュールされます。専用リソースを使用することで、仮想マシンのパフォーマンスとレイテンシーの予測の精度を向上させることができます。
7.13.8.2. 前提条件
-
CPU マネージャー がノードに設定されている必要があります。仮想マシンのワークロードをスケジュールする前に、ノードに
cpumanager = trueラベルが設定されていることを確認する。 - 仮想マシンの電源がオフになっている。
7.13.8.3. 仮想マシンの専用リソースの有効化
Details タブで、仮想マシンの専用リソースを有効にすることができます。Red Hat テンプレートから作成された仮想マシンは、専用のリソースで設定できます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Configuration → Scheduling タブで、Dedicated Resources の横にある編集アイコンをクリックします。
- Schedule this workload with dedicated resources (guaranteed policy) を選択します。
- Save をクリックします。
7.13.9. 仮想マシンのスケジュール
仮想マシンの CPU モデルとポリシー属性が、ノードがサポートする CPU モデルおよびポリシー属性との互換性について一致することを確認して、ノードで仮想マシン (VM) をスケジュールできます。
7.13.9.1. ポリシー属性
仮想マシン (VM) をスケジュールするには、ポリシー属性と、仮想マシンがノードでスケジュールされる際の互換性について一致する CPU 機能を指定します。仮想マシンに指定されるポリシー属性は、その仮想マシンをノードにスケジュールする方法を決定します。
| ポリシー属性 | 説明 |
|---|---|
| force | 仮想マシンは強制的にノードでスケジュールされます。これは、ホストの CPU が仮想マシンの CPU に対応していない場合でも該当します。 |
| require | 仮想マシンが特定の CPU モデルおよび機能仕様で設定されていない場合に仮想マシンに適用されるデフォルトのポリシー。このデフォルトポリシー属性または他のポリシー属性のいずれかを持つ CPU ノードの検出をサポートするようにノードが設定されていない場合、仮想マシンはそのノードでスケジュールされません。ホストの CPU が仮想マシンの CPU をサポートしているか、ハイパーバイザーが対応している CPU モデルをエミュレートできる必要があります。 |
| optional | 仮想マシンがホストの物理マシンの CPU でサポートされている場合は、仮想マシンがノードに追加されます。 |
| disable | 仮想マシンは CPU ノードの検出機能と共にスケジュールすることはできません。 |
| forbid | この機能がホストの CPU でサポートされ、CPU ノード検出が有効になっている場合でも、仮想マシンはスケジュールされません。 |
7.13.9.2. ポリシー属性および CPU 機能の設定
それぞれの仮想マシン (VM) にポリシー属性および CPU 機能を設定して、これがポリシーおよび機能に従ってノードでスケジュールされるようにすることができます。設定する CPU 機能は、ホストの CPU によってサポートされ、またはハイパーバイザーがエミュレートされることを確認するために検証されます。
7.13.9.3. サポートされている CPU モデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルを設定して、CPU モデルがサポートされるノードにこれをスケジュールできます。
手順
仮想マシン設定ファイルの
domain仕様を編集します。以下の例は、VM 向けに定義された特定の CPU モデルを示しています。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: Conroe 1- 1
- VM の CPU モデル。
7.13.9.4. ホストモデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルが host-model に設定されている場合、仮想マシンはスケジュールされているノードの CPU モデルを継承します。
手順
仮想マシン設定ファイルの
domain仕様を編集します。以下の例は、仮想マシン (VM) に指定されるhost-modelを示しています。apiVersion: kubevirt/v1alpha3 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: host-model 1- 1
- スケジュールされるノードの CPU モデルを継承する仮想マシン。
7.13.9.5. カスタムスケジューラーを使用した仮想マシンのスケジュール設定
カスタムスケジューラーを使用して、ノード上の仮想マシンをスケジュールできます。
前提条件
- セカンダリースケジューラーがクラスター用に設定されています。
手順
VirtualMachineマニフェストを編集して、カスタムスケジューラーを仮想マシン設定に追加します。以下に例を示します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-fedora spec: running: true template: spec: schedulerName: my-scheduler 1 domain: devices: disks: - name: containerdisk disk: bus: virtio # ...- 1
- カスタムスケジューラーの名前。
schedulerName値が既存のスケジューラーと一致しない場合、virt-launcherPod は、指定されたスケジューラーが見つかるまでPending状態のままになります。
検証
virt-launcherPod イベントをチェックして、仮想マシンがVirtualMachineマニフェストで指定されたカスタムスケジューラーを使用していることを確認します。次のコマンドを入力して、クラスター内の Pod のリストを表示します。
$ oc get pods
出力例
NAME READY STATUS RESTARTS AGE virt-launcher-vm-fedora-dpc87 2/2 Running 0 24m
次のコマンドを実行して Pod イベントを表示します。
$ oc describe pod virt-launcher-vm-fedora-dpc87
出力の
Fromフィールドの値により、スケジューラー名がVirtualMachineマニフェストで指定されたカスタムスケジューラーと一致することが検証されます。出力例
[...] Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 21m my-scheduler Successfully assigned default/virt-launcher-vm-fedora-dpc87 to node01 [...]
関連情報
7.13.10. PCI パススルーの設定
PCI (Peripheral Component Interconnect) パススルー機能を使用すると、仮想マシンからハードウェアデバイスにアクセスし、管理できます。PCI パススルーが設定されると、PCI デバイスはゲストオペレーティングシステムに物理的に接続されているかのように機能します。
クラスター管理者は、oc コマンドラインインターフェイス (CLI) を使用して、クラスターでの使用が許可されているホストデバイスを公開および管理できます。
7.13.10.1. GPU パススルー用のノードの準備
GPU パススルー用に指定したワーカーノードに GPU オペランドがデプロイされないようにすることができます。
7.13.10.1.1. NVIDIA GPU オペランドがノードにデプロイメントされないようにする
クラスター内で NVIDIA GPU Operator を使用する場合は、GPU または vGPU オペランド用に設定したくないノードに nvidia.com/gpu.deploy.operands=false ラベルを適用できます。このラベルは、GPU または vGPU オペランドを設定する Pod の作成を防止し、Pod がすでに存在する場合は終了します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、ノードのラベルを付けます。
$ oc label node <node_name> nvidia.com/gpu.deploy.operands=false 1- 1
<node_name>を、NVIDIA GPU オペランドをインストールしないノードの名前に置き換えます。
検証
次のコマンドを実行して、ラベルがノードに追加されたことを確認します。
$ oc describe node <node_name>
オプション: GPU オペランドが以前にノードにデプロイされていた場合は、それらの削除を確認します。
次のコマンドを実行して、
nvidia-gpu-operatornamespace 内の Pod のステータスを確認します。$ oc get pods -n nvidia-gpu-operator
出力例
NAME READY STATUS RESTARTS AGE gpu-operator-59469b8c5c-hw9wj 1/1 Running 0 8d nvidia-sandbox-validator-7hx98 1/1 Running 0 8d nvidia-sandbox-validator-hdb7p 1/1 Running 0 8d nvidia-sandbox-validator-kxwj7 1/1 Terminating 0 9d nvidia-vfio-manager-7w9fs 1/1 Running 0 8d nvidia-vfio-manager-866pz 1/1 Running 0 8d nvidia-vfio-manager-zqtck 1/1 Terminating 0 9d
Terminationステータスの Pod が削除されるまで、Pod のステータスを監視します。$ oc get pods -n nvidia-gpu-operator
出力例
NAME READY STATUS RESTARTS AGE gpu-operator-59469b8c5c-hw9wj 1/1 Running 0 8d nvidia-sandbox-validator-7hx98 1/1 Running 0 8d nvidia-sandbox-validator-hdb7p 1/1 Running 0 8d nvidia-vfio-manager-7w9fs 1/1 Running 0 8d nvidia-vfio-manager-866pz 1/1 Running 0 8d
7.13.10.2. PCI パススルー用のホストデバイスの準備
7.13.10.2.1. PCI パススルー用ホストデバイスの準備について
CLI を使用して PCI パススルー用にホストデバイスを準備するには、MachineConfig オブジェクトを作成し、カーネル引数を追加して、Input-Output Memory Management Unit (IOMMU) を有効にします。PCI デバイスを Virtual Function I/O (VFIO) ドライバーにバインドしてから、HyperConverged カスタムリソース (CR) の permittedHostDevices フィールドを編集してクラスター内で公開します。OpenShift Virtualization Operator を最初にインストールする場合、permittedHostDevices のリストは空になります。
CLI を使用してクラスターから PCI ホストデバイスを削除するには、HyperConverged CR から PCI デバイス情報を削除します。
7.13.10.2.2. IOMMU ドライバーを有効にするためのカーネル引数の追加
カーネルで IOMMU ドライバーを有効にするには、MachineConfig オブジェクトを作成し、カーネル引数を追加します。
前提条件
- クラスター管理者パーミッションがある。
- CPU ハードウェアは Intel または AMD です。
- BIOS で Directed I/O 拡張機能または AMD IOMMU 用の Intel Virtualization Technology を有効にしました。
手順
カーネル引数を識別する
MachineConfigオブジェクトを作成します。以下の例は、Intel CPU のカーネル引数を示しています。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker 1 name: 100-worker-iommu 2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on 3 # ...新規
MachineConfigオブジェクトを作成します。$ oc create -f 100-worker-kernel-arg-iommu.yaml
検証
新規
MachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig
7.13.10.2.3. PCI デバイスの VFIO ドライバーへのバインディング
PCI デバイスを VFIO (Virtual Function I/O) ドライバーにバインドするには、各デバイスから vendor-ID および device-ID の値を取得し、これらの値でリストを作成します。リストを MachineConfig オブジェクトに追加します。MachineConfig Operator は、PCI デバイスを持つノードで /etc/modprobe.d/vfio.conf を生成し、PCI デバイスを VFIO ドライバーにバインドします。
前提条件
- カーネル引数を CPU の IOMMU を有効にするために追加している。
手順
lspciコマンドを実行して、PCI デバイスのvendor-IDおよびdevice-IDを取得します。$ lspci -nnv | grep -i nvidia
出力例
02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)
Butane 設定ファイル
100-worker-vfiopci.buを作成し、PCI デバイスを VFIO ドライバーにバインドします。注記Butane の詳細は、Butane を使用したマシン設定の作成を参照してください。
例
variant: openshift version: 4.14.0 metadata: name: 100-worker-vfiopci labels: machineconfiguration.openshift.io/role: worker 1 storage: files: - path: /etc/modprobe.d/vfio.conf mode: 0644 overwrite: true contents: inline: | options vfio-pci ids=10de:1eb8 2 - path: /etc/modules-load.d/vfio-pci.conf 3 mode: 0644 overwrite: true contents: inline: vfio-pciButane を使用して、ワーカーノードに配信される設定を含む
MachineConfigオブジェクトファイル (100-worker-vfiopci.yaml) を生成します。$ butane 100-worker-vfiopci.bu -o 100-worker-vfiopci.yaml
MachineConfigオブジェクトをワーカーノードに適用します。$ oc apply -f 100-worker-vfiopci.yaml
MachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig
出力例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 00-worker d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 100-worker-iommu 3.2.0 30s 100-worker-vfiopci-configuration 3.2.0 30s
検証
VFIO ドライバーがロードされていることを確認します。
$ lspci -nnk -d 10de:
この出力では、VFIO ドライバーが使用されていることを確認します。
出力例
04:00.0 3D controller [0302]: NVIDIA Corporation GP102GL [Tesla P40] [10de:1eb8] (rev a1) Subsystem: NVIDIA Corporation Device [10de:1eb8] Kernel driver in use: vfio-pci Kernel modules: nouveau
7.13.10.2.4. CLI を使用したクラスターでの PCI ホストデバイスの公開
クラスターで PCI ホストデバイスを公開するには、PCI デバイスの詳細を HyperConverged カスタムリソース (CR) の spec.permittedHostDevices.pciHostDevices 配列に追加します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
PCI デバイス情報を
spec.permittedHostDevices.pciHostDevices配列に追加します。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices: 1 pciHostDevices: 2 - pciDeviceSelector: "10DE:1DB6" 3 resourceName: "nvidia.com/GV100GL_Tesla_V100" 4 - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" - pciDeviceSelector: "8086:6F54" resourceName: "intel.com/qat" externalResourceProvider: true 5 # ...
注記上記のスニペットの例は、
nvidia.com/GV100GL_Tesla_V100およびnvidia.com/TU104GL_Tesla_T4という名前の 2 つの PCI ホストデバイスが、HyperConvergedCR の許可されたホストデバイスの一覧に追加されたことを示しています。これらのデバイスは、OpenShift Virtualization と動作することがテストおよび検証されています。- 変更を保存し、エディターを終了します。
検証
以下のコマンドを実行して、PCI ホストデバイスがノードに追加されたことを確認します。この出力例は、各デバイスが
nvidia.com/GV100GL_Tesla_V100、nvidia.com/TU104GL_Tesla_T4、およびintel.com/qatのリソース名にそれぞれ関連付けられたデバイスが 1 つあることを示しています。$ oc describe node <node_name>
出力例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250
7.13.10.2.5. CLI を使用したクラスターからの PCI ホストデバイスの削除
クラスターから PCI ホストデバイスを削除するには、HyperConverged カスタムリソース (CR) からそのデバイスの情報を削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
適切なデバイスの
pciDeviceSelector、resourceName、およびexternalResourceProvider(該当する場合) のフィールドを削除して、spec.permittedHostDevices.pciHostDevices配列から PCI デバイス情報を削除します。この例では、intel.com/qatリソースが削除されました。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices: pciHostDevices: - pciDeviceSelector: "10DE:1DB6" resourceName: "nvidia.com/GV100GL_Tesla_V100" - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" # ...- 変更を保存し、エディターを終了します。
検証
以下のコマンドを実行して、PCI ホストデバイスがノードから削除されたことを確認します。この出力例は、
intel.com/qatリソース名に関連付けられているデバイスがゼロであることを示しています。$ oc describe node <node_name>
出力例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250
7.13.10.3. PCI パススルー用の仮想マシンの設定
PCI デバイスがクラスターに追加された後に、それらを仮想マシンに割り当てることができます。PCI デバイスが仮想マシンに物理的に接続されているかのような状態で利用できるようになりました。
7.13.10.3.1. PCI デバイスの仮想マシンへの割り当て
PCI デバイスがクラスターで利用可能な場合、これを仮想マシンに割り当て、PCI パススルーを有効にすることができます。
手順
PCI デバイスをホストデバイスとして仮想マシンに割り当てます。
例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: hostDevices: - deviceName: nvidia.com/TU104GL_Tesla_T4 1 name: hostdevices1- 1
- クラスターでホストデバイスとして許可される PCI デバイスの名前。仮想マシンがこのホストデバイスにアクセスできます。
検証
以下のコマンドを使用して、ホストデバイスが仮想マシンから利用可能であることを確認します。
$ lspci -nnk | grep NVIDIA
出力例
$ 02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)
7.13.10.4. 関連情報
7.13.11. 仮想 GPU の設定
グラフィックスプロセッシングユニット (GPU) カードがある場合、OpenShift Virtualization は仮想マシンに割り当てることができる仮想 GPU (vGPU) を自動的に作成できます。
7.13.11.1. OpenShift Virtualization での仮想 GPU の使用について
一部のグラフィックス処理ユニット (GPU) カードは、仮想 GPU (vGPU) の作成をサポートしています。管理者がHyperConvergedカスタムリソース (CR) で設定の詳細を提供すると、Open Shift Virtualization は仮想 GPU およびその他の仲介デバイスを自動的に作成できます。この自動化は、大規模なクラスターで特に役立ちます。
機能とサポートの詳細については、ハードウェアベンダーのドキュメントを参照してください。
- 仲介デバイス
- 1 つまたは複数の仮想デバイスに分割された物理デバイス。仮想 GPU は、仲介デバイス (mdev) の一種です。物理 GPU のパフォーマンスが、仮想デバイス間で分割されます。仲介デバイスを 1 つまたは複数の仮想マシン (VM) に割り当てることができますが、ゲストの数は GPU と互換性がある必要があります。一部の GPU は複数のゲストをサポートしていません。
7.13.11.2. 仲介デバイス用のホストの準備
仲介デバイスを設定する前に、入出力メモリー管理ユニット (IOMMU) ドライバーを有効にする必要があります。
7.13.11.2.1. IOMMU ドライバーを有効にするためのカーネル引数の追加
カーネルで IOMMU ドライバーを有効にするには、MachineConfig オブジェクトを作成し、カーネル引数を追加します。
前提条件
- クラスター管理者パーミッションがある。
- CPU ハードウェアは Intel または AMD です。
- BIOS で Directed I/O 拡張機能または AMD IOMMU 用の Intel Virtualization Technology を有効にしました。
手順
カーネル引数を識別する
MachineConfigオブジェクトを作成します。以下の例は、Intel CPU のカーネル引数を示しています。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker 1 name: 100-worker-iommu 2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on 3 # ...新規
MachineConfigオブジェクトを作成します。$ oc create -f 100-worker-kernel-arg-iommu.yaml
検証
新規
MachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig
7.13.11.3. NVIDIA GPU Operator の設定
NVIDIA GPU Operator を使用して、OpenShift Virtualization で GPU 高速化仮想マシンを実行するためのワーカーノードをプロビジョニングできます。
NVIDIA GPU Operator は、NVIDIA によってのみサポートされています。詳細は、Red Hat ナレッジベースの Obtaining Support from NVIDIA を参照してください。
7.13.11.3.1. NVIDIA GPU Operator の使用について
NVIDIA GPU Operator と OpenShift Virtualization を使用すると、GPU 対応の仮想マシンを実行するためのワーカーノードを迅速にプロビジョニングできます。NVIDIA GPU Operator は、OpenShift Container Platform クラスター内の NVIDIA GPU リソースを管理し、GPU ワークロード用にノードを準備するときに必要なタスクを自動化します。
アプリケーションワークロードを GPU リソースにデプロイする前に、コンピューティングユニファイドデバイスアーキテクチャー (CUDA)、Kubernetes デバイスプラグイン、コンテナーランタイム、および自動ノードラベル付けや監視などのその他の機能を有効にする NVIDIA ドライバーなどのコンポーネントをインストールする必要があります。これらのタスクを自動化することで、インフラストラクチャーの GPU 容量を迅速に拡張できます。NVIDIA GPU Operator は、複雑な人工知能および機械学習 (AI/ML) ワークロードのプロビジョニングを特に容易にします。
7.13.11.3.2. 仲介デバイスを設定するためのオプション
NVIDIA GPU Operator を使用すると、仲介デバイスを設定するには 2 つの方法があります。Red Hat がテストする方法では、OpenShift Virtualization 機能を使用して仲介デバイスをスケジュールしますが、NVIDIA の方法では GPU Operator のみを使用します。
- NVIDIA GPU Operator を使用した仲介デバイスの設定
- この方法では、NVIDIA GPU Operator のみを使用して仲介デバイスを設定します。この方法を使用するには、NVIDIA ドキュメントの NVIDIA GPU Operator with OpenShift Virtualization を参照してください。
- OpenShift Virtualization を使用した仲介デバイスの設定
この方法は Red Hat によってテストされており、OpenShift Virtualization の機能を使用して仲介デバイスを設定します。この場合、NVIDIA GPU Operator は、NVIDIA vGPU Manager でドライバーをインストールするためにのみ使用されます。GPU Operator は仲介デバイスを設定しません。
OpenShift 仮想化方式を使用する場合でも、NVIDIA ドキュメント に従って GPU Operator を設定します。ただし、この方法は次の点で NVIDIA ドキュメントとは異なります。
HyperConvergedカスタムリソース (CR) のデフォルトのdisableMDEVConfiguration: false設定を上書きしないでください。重要NVIDIA ドキュメント の説明に従ってこの機能ゲートを設定すると、OpenShift Virtualization が仲介デバイスを設定できなくなります。
次の例と一致するように
ClusterPolicyマニフェストを設定する必要があります。マニフェストの例
kind: ClusterPolicy apiVersion: nvidia.com/v1 metadata: name: gpu-cluster-policy spec: operator: defaultRuntime: crio use_ocp_driver_toolkit: true initContainer: {} sandboxWorkloads: enabled: true defaultWorkload: vm-vgpu driver: enabled: false 1 dcgmExporter: {} dcgm: enabled: true daemonsets: {} devicePlugin: {} gfd: {} migManager: enabled: true nodeStatusExporter: enabled: true mig: strategy: single toolkit: enabled: true validator: plugin: env: - name: WITH_WORKLOAD value: "true" vgpuManager: enabled: true 2 repository: <vgpu_container_registry> 3 image: <vgpu_image_name> version: nvidia-vgpu-manager vgpuDeviceManager: enabled: false 4 config: name: vgpu-devices-config default: default sandboxDevicePlugin: enabled: false 5 vfioManager: enabled: false 6- 1
- この値を
falseに設定します。仮想マシンには必要ありません。 - 2
- この値を
trueに設定します。仮想マシンで vGPU を使用する場合に必要です。 - 3
<vgpu_container_registry>をレジストリー値に置き換えます。- 4
- この値を
falseに設定すると、OpenShift Virtualization が NVIDIA GPU Operator の代わりに仲介デバイスを設定できるようになります。 - 5
- vGPU デバイスの検出と kubelet へのアドバタイズを防止するには、この値を
falseに設定します。 - 6
vfio-pciドライバーがロードされないようにするには、この値をfalseに設定します。代わりに、OpenShift Virtualization のドキュメントに従って PCI パススルーを設定します。
関連情報
7.13.11.4. 仮想 GPU がノードに割り当てられる方法
物理デバイスごとに、OpenShift Virtualization は以下の値を設定します。
- 1 つの mdev タイプ。
-
選択した
mdevタイプのインスタンスの最大数。
クラスターのアーキテクチャーは、デバイスの作成およびノードへの割り当て方法に影響します。
- ノードごとに複数のカードを持つ大規模なクラスター
同様の仮想 GPU タイプに対応する複数のカードを持つノードでは、関連するデバイス種別がラウンドロビン方式で作成されます。以下に例を示します。
# ... mediatedDevicesConfiguration: mediatedDeviceTypes: - nvidia-222 - nvidia-228 - nvidia-105 - nvidia-108 # ...
このシナリオでは、各ノードに以下の仮想 GPU 種別に対応するカードが 2 つあります。
nvidia-105 # ... nvidia-108 nvidia-217 nvidia-299 # ...
各ノードで、OpenShift Virtualization は以下の vGPU を作成します。
- 最初のカード上に nvidia-105 タイプの 16 の仮想 GPU
- 2 番目のカード上に nvidia-108 タイプの 2 つの仮想 GPU
- 1 つのノードに、要求された複数の仮想 GPU タイプをサポートするカードが 1 つある
OpenShift Virtualization は、
mediatedDeviceTypes一覧の最初のサポートされるタイプを使用します。たとえば、ノードカードのカードは
nvidia-223とnvidia-224をサポートします。次のmediatedDeviceTypesリストが設定されています。# ... mediatedDevicesConfiguration: mediatedDeviceTypes: - nvidia-22 - nvidia-223 - nvidia-224 # ...
この例では、OpenShift Virtualization は
nvidia-223タイプを使用します。
7.13.11.5. 仲介されたデバイスの管理
仲介されたデバイスを仮想マシンに割り当てる前に、デバイスを作成してクラスターに公開する必要があります。仲介されたデバイスを再設定および削除することもできます。
7.13.11.5.1. 仲介デバイスの作成および公開
管理者は、HyperConverged カスタムリソース (CR) を編集することで、仲介デバイスを作成し、クラスターに公開できます。
前提条件
- 入出力メモリー管理ユニット (IOMMU) ドライバーを有効にしました。
ハードウェアベンダーがドライバーを提供している場合は、仲介デバイスを作成するノードにドライバーをインストールしている。
- NVIDIA カードを使用する場合は、NVIDIAGRID ドライバーをインストールしている。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
例7.2 仲介デバイスが設定された設定ファイルの例
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: mediatedDeviceTypes: - nvidia-231 nodeMediatedDeviceTypes: - mediatedDeviceTypes: - nvidia-233 nodeSelector: kubernetes.io/hostname: node-11.redhat.com permittedHostDevices: mediatedDevices: - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q - mdevNameSelector: GRID T4-8Q resourceName: nvidia.com/GRID_T4-8Q # ...仲介デバイスを
spec.mediatedDevicesConfigurationスタンザに追加して作成します。YAML スニペットの例
# ... spec: mediatedDevicesConfiguration: mediatedDeviceTypes: 1 - <device_type> nodeMediatedDeviceTypes: 2 - mediatedDeviceTypes: 3 - <device_type> nodeSelector: 4 <node_selector_key>: <node_selector_value> # ...重要OpenShift Virtualization 4.14 より前では、
mediatedDeviceTypesフィールドの名前はmediatedDevicesTypesでした。仲介デバイスを設定するときは、必ず正しいフィールド名を使用してください。クラスターに公開するデバイスの名前セレクターとリソース名の値を特定します。次のステップで、これらの値を
HyperConvergedCR に追加します。次のコマンドを実行して、
resourceName値を見つけます。$ oc get $NODE -o json \ | jq '.status.allocatable \ | with_entries(select(.key | startswith("nvidia.com/"))) \ | with_entries(select(.value != "0"))'/sys/bus/pci/devices/<slot>:<bus>:<domain>.<function>/mdev_supported_types/<type>/nameの内容を表示してmdevNameSelector値を見つけ、システムの正しい値に置き換えます。たとえば、
nvidia-231タイプの name ファイルには、セレクター文字列GRID T4-2Qが含まれます。GRID T4-2QをmdevNameSelector値として使用することで、ノードはnvidia-231タイプを使用できます。
mdevNameSelectorとresourceNameの値をHyperConvergedCR のspec.permittedHostDevices.mediatedDevicesスタンザに追加することで、仲介されたデバイスをクラスターに公開します。YAML スニペットの例
# ... permittedHostDevices: mediatedDevices: - mdevNameSelector: GRID T4-2Q 1 resourceName: nvidia.com/GRID_T4-2Q 2 # ...- 変更を保存し、エディターを終了します。
検証
オプション: 次のコマンドを実行して、デバイスが特定のノードに追加されたことを確認します。
$ oc describe node <node_name>
7.13.11.5.2. 仲介デバイスの変更および削除について
仲介されたデバイスは、いくつかの方法で再設定または削除できます。
-
HyperConvergedCR を編集し、mediatedDevicesTypesスタンザの内容を変更します。 -
nodeMediatedDeviceTypesノードセレクターに一致するノードラベルを変更します。 HyperConvergedCR のspec.mediatedDevicesConfigurationおよびspec.permittedHostDevicesスタンザからデバイス情報を削除します。注記spec.permittedHostDevicesスタンザからデバイス情報を削除したが、spec.mediatedDevicesConfigurationスタンザからは削除しなかった場合、同じノードで新規の仲介デバイスタイプを作成することはできません。仲介デバイスを適切に削除するには、両方のスタンザからデバイス情報を削除します。
7.13.11.5.3. 仲介されたデバイスをクラスターから削除する
クラスターから仲介デバイスを削除するには、HyperConverged カスタムリソース (CR) からそのデバイスの情報を削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
HyperConvergedCR のspec.mediatedDevicesConfigurationおよびspec.permittedHostDevicesスタンザからデバイス情報を削除します。両方のエントリーを削除すると、後で同じノードで新しい仲介デバイスタイプを作成できます。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: mediatedDeviceTypes: 1 - nvidia-231 permittedHostDevices: mediatedDevices: 2 - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q- 変更を保存し、エディターを終了します。
7.13.11.6. 仲介デバイスの使用
仲介デバイスを 1 つ以上の仮想マシンに割り当てることができます。
7.13.11.6.1. CLI を使用した仮想マシンへの vGPU の割り当て
仮想 GPU (vGPU) などの仲介デバイスを仮想マシンに割り当てます。
前提条件
-
仲介デバイスが
HyperConvergedカスタムリソースで設定されている。 - 仮想マシンが停止しています。
手順
VirtualMachineマニフェストのspec.domain.devices.gpusスタンザを編集して、仲介デバイスを仮想マシン (VM) に割り当てます。仮想マシンマニフェストの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: gpus: - deviceName: nvidia.com/TU104GL_Tesla_T4 1 name: gpu1 2 - deviceName: nvidia.com/GRID_T4-2Q name: gpu2
検証
デバイスが仮想マシンで利用できることを確認するには、
<device_name>をVirtualMachineマニフェストのdeviceNameの値に置き換えて以下のコマンドを実行します。$ lspci -nnk | grep <device_name>
7.13.11.6.2. Web コンソールを使用した仮想マシンへの vGPU の割り当て
OpenShift Container Platform Web コンソールを使用して、仮想 GPU を仮想マシンに割り当てることができます。
カスタマイズされたテンプレートまたは YAML ファイルから作成された仮想マシンに、ハードウェアデバイスを追加できます。特定のオペレーティングシステム用に事前に提供されているブートソーステンプレートにデバイスを追加することはできません。
前提条件
vGPU は、クラスター内の仲介デバイスとして設定されます。
- クラスターに接続されているデバイスを表示するには、サイドメニューから Compute → Hardware Devices をクリックします。
- 仮想マシンが停止しています。
手順
- Open Shift Container Platform Web コンソールで、サイドメニューからVirtualization → VirtualMachinesをクリックします。
- デバイスを割り当てる仮想マシンを選択します。
- Details タブで、GPU devices をクリックします。
- Add GPU device をクリックします。
- Name フィールドに識別値を入力します。
- Device name リストから、仮想マシンに追加するデバイスを選択します。
- Save をクリックします。
検証
-
デバイスが仮想マシンに追加されたことを確認するには、YAML タブをクリックし、
VirtualMachine設定を確認します。仲介されたデバイスはspec.domain.devicesスタンザに追加されます。
7.13.11.7. 関連情報
7.13.12. 仮想マシンでの Descheduler エビクションの有効化
Descheduler を使用して Pod を削除し、Pod をより適切なノードに再スケジュールできます。Pod が仮想マシンの場合、Pod の削除により、仮想マシンが別のノードにライブマイグレーションされます。
仮想マシンの Descheduler エビクションはテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
7.13.12.1. Descheduler プロファイル
テクノロジープレビューの DevPreviewLongLifecycle プロファイルを使用して、仮想マシンで Descheduler を有効にします。これは、現在 OpenShift Virtualization で利用可能な唯一の Descheduler プロファイルです。適切なスケジューリングを確保するには、予想される負荷に応じた CPU およびメモリー要求で仮想マシンを作成します。
DevPreviewLongLifecycleこのプロファイルは、ノード間のリソース使用率のバランスを取り、以下のストラテジーを有効にします。
-
RemovePodsHavingTooManyRestarts: コンテナーが何度も再起動された Pod、およびすべてのコンテナー (Init コンテナーを含む) の再起動の合計が 100 を超える Pod を削除します。仮想マシンのゲストオペレーティングシステムを再起動しても、この数は増えません。 LowNodeUtilization: 使用率の低いノードがある場合に、使用率の高いノードから Pod をエビクトします。エビクトされた Pod の宛先ノードはスケジューラーによって決定されます。- ノードは、使用率がすべてのしきい値 (CPU、メモリー、Pod の数) について 20% 未満の場合に使用率が低いと見なされます。
- ノードは、使用率がすべてのしきい値 (CPU、メモリー、Pod の数) について 50% を超える場合に過剰に使用されていると見なされます。
-
7.13.12.2. Descheduler のインストール
Descheduler はデフォルトで利用できません。Descheduler を有効にするには、Kube Descheduler Operator を OperatorHub からインストールし、1 つ以上の Descheduler プロファイルを有効にする必要があります。
デフォルトで、Descheduler は予測モードで実行されます。つまり、これは Pod エビクションのみをシミュレートします。Pod エビクションを実行するには、Descheduler のモードを automatic に変更する必要があります。
クラスターでホストされたコントロールプレーンを有効にしている場合は、カスタム優先度のしきい値を設定して、ホストされたコントロールプレーンの namespace の Pod が削除される可能性を下げます。ホストされたコントロールプレーンの優先度クラスの中で優先度値が最も低い (100000000) ため、優先度しきい値クラス名を hypershift-control-plane に設定します。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform にログインしている。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
- OpenShift Container Platform Web コンソールにログインします。
Kube Descheduler Operator に必要な namespace を作成します。
- Administration → Namespaces に移動し、Create Namespace をクリックします。
-
Name フィールドに
openshift-kube-descheduler-operatorを入力し、Labels フィールドにopenshift.io/cluster-monitoring=trueを入力して Descheduler メトリックを有効にし、Create をクリックします。
Kube Descheduler Operator をインストールします。
- Operators → OperatorHub に移動します。
- Kube Descheduler Operator をフィルターボックスに入力します。
- Kube Descheduler Operator を選択し、Install をクリックします。
- Install Operator ページで、A specific namespace on the cluster を選択します。ドロップダウンメニューから openshift-kube-descheduler-operator を選択します。
- Update Channel および Approval Strategy の値を必要な値に調整します。
- Install をクリックします。
Descheduler インスタンスを作成します。
- Operators → Installed Operators ページから、 Kube Descheduler Operator をクリックします。
- Kube Descheduler タブを選択し、Create KubeDescheduler をクリックします。
必要に応じて設定を編集します。
- エビクションをシミュレーションせずに Pod をエビクトするには、Mode フィールドを Automatic に変更します。
Profiles セクションを展開し、
DevPreviewLongLifecycleを選択します。AffinityAndTaintsプロファイルがデフォルトで有効になっています。重要OpenShift Virtualization で現在利用できるプロファイルは
DevPreviewLongLifecycleのみです。
また、後で OpenShift CLI (oc) を使用して、Descheduler のプロファイルおよび設定を設定することもできます。
7.13.12.3. 仮想マシン (VM) での Descheduler エビクションの有効化
Descheduler のインストール後に、アノテーションを VirtualMachine カスタムリソース (CR) に追加して Descheduler エビクションを仮想マシンで有効にできます。
前提条件
-
Descheduler を OpenShift Container Platform Web コンソールまたは OpenShift CLI (
oc) にインストールしている。 - 仮想マシンが実行されていないことを確認します。
手順
仮想マシンを起動する前に、
Descheduler.alpha.kubernetes.io/evictアノテーションをVirtualMachineCR に追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: template: metadata: annotations: descheduler.alpha.kubernetes.io/evict: "true"インストール時に Web コンソールで
DevPreviewLongLifecycleプロファイルをまだ設定していない場合は、KubeDeschedulerオブジェクトのspec.profileセクションにDevPreviewLongLifecycleを指定します。apiVersion: operator.openshift.io/v1 kind: KubeDescheduler metadata: name: cluster namespace: openshift-kube-descheduler-operator spec: deschedulingIntervalSeconds: 3600 profiles: - DevPreviewLongLifecycle mode: Predictive 1- 1
- デフォルトでは、Descheduler は Pod をエビクトしません。Pod をエビクトするには、
modeをAutomaticに設定します。
Descheduler が仮想マシンで有効になりました。
7.13.12.4. 関連情報
7.13.13. 仮想マシンの高可用性について
障害が発生したノードを手動で削除して仮想マシンフェイルオーバーをトリガーするか、修復ノードを設定することによって、仮想マシンの高可用性を有効にすることができます。
障害が発生したノードを手動で削除する
ノードに障害が発生し、マシンヘルスチェックがクラスターにデプロイされていない場合、runStrategy: Always が設定された仮想マシン (VM) は正常なノードに自動的に移動しません。仮想マシンのフェイルオーバーをトリガーするには、Node オブジェクトを手動で削除する必要があります。
障害が発生したノードを削除して仮想マシンのフェイルオーバーをトリガーする を参照してください。
修復ノードの設定
OperatorHub から Self Node Remediation Operator をインストールし、マシンの健全性チェックまたはノード修復チェックを有効にすることで、修復ノードを設定できます。
ノードの修復、フェンシング、メンテナンスについて、詳しくは Red Hat OpenShift のワークロードの可用性 を参照してください。
7.13.14. 仮想マシンのコントロールプレーンのチューニング
OpenShift Virtualization は、コントロールプレーンレベルで次のチューニングオプションを提供します。
-
highBurstプロファイルは、固定QPSとburstレートを使用して、1 つのバッチで数百の仮想マシンを作成します。 - ワークロードの種類に基づいた移行設定の調整
7.13.14.1. ハイバーストプロファイルの設定
highBurst プロファイルを使用して、1 つのクラスター内に多数の仮想マシンを作成および維持します。
手順
次のパッチを適用して、
highBurstチューニングポリシープロファイルを有効にします。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type=json -p='[{"op": "add", "path": "/spec/tuningPolicy", \ "value": "highBurst"}]'
検証
次のコマンドを実行して、
highBurstチューニングポリシープロファイルが有効になっていることを確認します。$ oc get kubevirt.kubevirt.io/kubevirt-kubevirt-hyperconverged \ -n openshift-cnv -o go-template --template='{{range $config, \ $value := .spec.configuration}} {{if eq $config "apiConfiguration" \ "webhookConfiguration" "controllerConfiguration" "handlerConfiguration"}} \ {{"\n"}} {{$config}} = {{$value}} {{end}} {{end}} {{"\n"}}
7.13.15. コンピュートリソースの割り当て
OpenShift Virtualization では、仮想マシン (VM) に割り当てられたコンピュートリソースは、Guaranteed CPU またはタイムスライスされた CPU シェアのいずれかによってサポートされます。
Guaranteed CPU (CPU 予約とも呼ばれる) は、CPU コアまたはスレッドを特定のワークロード専用にし、他のワークロードでは使用できなくなります。Guaranteed CPU を仮想マシンに割り当てると、仮想マシンは予約された物理 CPU に単独でアクセスできるようになります。仮想マシンの専用リソースを有効化 し、Guaranteed CPU を使用します。
タイムスライス CPU は、共有物理 CPU 上の時間のスライスを各ワークロード専用にします。スライスのサイズは、仮想マシンの作成中、または仮想マシンがオフラインのときに指定できます。デフォルトでは、各 vCPU は 100 ミリ秒、つまり 1/10 秒の物理 CPU 時間を受け取ります。
CPU 予約のタイプは、インスタンスのタイプまたは仮想マシン設定によって異なります。
7.13.15.1. CPU リソースのオーバーコミット
タイムスライシングにより、複数の仮想 CPU (vCPU) が 1 つの物理 CPU を共有できます。これは CPU オーバーコミットメント として知られています。Guaranteed 仮想マシンをオーバーコミットすることはできません。
CPU を仮想マシンに割り当てるときに、パフォーマンスよりも仮想マシン密度を優先するように CPU オーバーコミットメントを設定します。vCPU の CPU オーバーコミットメントが高くなると、より多くの仮想マシンが特定のノードに適合します。
7.13.15.2. CPU 割り当て率の設定
CPU 割り当て率は、vCPU を物理 CPU のタイムスライスにマッピングすることにより、オーバーコミットメントの程度を指定します。
たとえば、10:1 のマッピングまたは比率は、タイムスライスを使用して、10 個の仮想 CPU を 1 個の物理 CPU にマッピングします。
各物理 CPU にマップされる vCPU のデフォルトの数を変更するには、HyperConverged CR で vmiCPUAllocationRatio 値を設定します。Pod CPU リクエストは、vCPU の数に CPU 割り当て率の逆数を乗算して計算されます。たとえば、vmiCPUAllocationRatio が 10 に設定されている場合、OpenShift Virtualization はその仮想マシンの Pod 上で 10 分の 1 少ない CPU を要求します。
手順
HyperConverged CR で vmiCPUAllocationRatio 値を設定して、ノードの CPU 割り当て率を定義します。
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
vmiCPUAllocationRatioを設定します。... spec: resourceRequirements: vmiCPUAllocationRatio: 1 1 # ...- 1
vmiCPUAllocationRatioが1に設定されている場合、Pod に対して最大量の vCPU が要求されます。
7.13.15.3. 関連情報
7.14. 仮想マシンディスク
7.14.1. 仮想マシンディスクのホットプラグ
仮想マシン (VM) または仮想マシンインスタンス (VMI) を停止することなく、仮想ディスクを追加または削除できます。
データボリュームおよび永続ボリューム要求 (PVC) のみをホットプラグおよびホットアンプラグできます。コンテナーディスクのホットプラグおよびホットアンプラグはできません。
ホットプラグされたディスクは、再起動後も仮想マシンに残ります。仮想マシンからディスクを削除するには、ディスクを切断する必要があります。
ホットプラグされたディスクを永続的に作成して、仮想マシンに永続的にマウントできます。
各仮想マシンには virtio-scsi コントローラーがあり、ホットプラグされたディスクが SCSI バスを使用できるようになります。virtio-scsi コントローラーは、パフォーマンス上の利点を維持しながら、virtio の制限を克服します。スケーラビリティが高く、400 万台を超えるディスクのホットプラグをサポートします。
通常の virtio はスケーラブルではないため、ホットプラグされたディスクには使用できません。各 virtio ディスクは、仮想マシン内の限られた PCI Express (PCIe) スロットの 1 つを使用します。PCIe スロットは他のデバイスでも使用されるため、事前に予約する必要があります。したがって、スロットはオンデマンドで利用できない場合があります。
7.14.1.1. Web コンソールを使用したディスクのホットプラグとホットアンプラグ
OpenShift Container Platform Web コンソールを使用して、仮想マシンの実行中にディスクを仮想マシンに接続することで、ディスクをホットプラグできます。
ホットプラグされたディスクは、プラグを抜くまで仮想マシンに接続されたままになります。
ホットプラグされたディスクを永続的に作成して、仮想マシンに永続的にマウントできます。
前提条件
- ホットプラグに使用できるデータボリュームまたは永続ボリュームクレーム (PVC) が必要です。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 実行中の仮想マシンを選択して、その詳細を表示します。
- VirtualMachine details ページで、Configuration → Disks をクリックします。
ホットプラグされたディスクを追加します。
- ディスクの追加をクリックします。
- Add disk (hot plugged) ウィンドウで、Source リストからディスクを選択し、Save をクリックします。
オプション: ホットプラグされたディスクを取り外します。
-
ディスクの横にあるオプションメニュー
をクリックし、Detach を選択します。
- Detach をクリックします。
-
ディスクの横にあるオプションメニュー
オプション: ホットプラグされたディスクを永続的にします。
-
ディスクの横にあるオプションメニュー
をクリックし、Make persistent を選択します。
- 仮想マシンを再起動して変更を適用します。
-
ディスクの横にあるオプションメニュー
7.14.1.2. コマンドラインを使用したディスクのホットプラグとホットアンプラグ
コマンドラインを使用して、仮想マシンの実行中にディスクのホットプラグおよびホットアンプラグを行うことができます。
ホットプラグされたディスクを永続的に作成して、仮想マシンに永続的にマウントできます。
前提条件
- ホットプラグ用に 1 つ以上のデータボリュームまたは永続ボリューム要求 (PVC) が利用可能である必要があります。
手順
次のコマンドを実行して、ディスクをホットプラグします。
$ virtctl addvolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC> \ [--persist] [--serial=<label-name>]
-
オプションの
--persistフラグを使用して、ホットプラグされたディスクを、永続的にマウントされた仮想ディスクとして仮想マシン仕様に追加します。仮想ディスクを永続的にマウントするために、仮想マシンを停止、再開または再起動します。--persistフラグを指定しても、仮想ディスクをホットプラグしたり、ホットアンプラグしたりできなくなります。--persistフラグは仮想マシンに適用され、仮想マシンインスタンスには適用されません。 -
オプションの
--serialフラグを使用すると、選択した英数字の文字列ラベルを追加できます。これは、ゲスト仮想マシンでホットプラグされたディスクを特定するのに役立ちます。このオプションを指定しない場合、ラベルはデフォルトでホットプラグされたデータボリュームまたは PVC の名前に設定されます。
-
オプションの
次のコマンドを実行して、ディスクをホットアンプラグします。
$ virtctl removevolume <virtual-machine|virtual-machine-instance> \ --volume-name=<datavolume|PVC>
7.14.2. 仮想マシンディスクの拡張
ディスクの Persistent Volume Claim (PVC) を拡張することで、仮想マシンディスクのサイズを増やすことができます。
ストレージプロバイダーがボリューム拡張をサポートしていない場合は、空のデータボリュームを追加することで、仮想マシンの利用可能な仮想ストレージを拡張できます。
仮想マシンディスクのサイズを減らすことはできません。
7.14.2.1. 仮想マシンディスク PVC の拡張
ディスクの Persistent Volume Claim (PVC) を拡張することで、仮想マシンディスクのサイズを増やすことができます。
PVC がファイルシステムボリュームモードを使用する場合、ディスクイメージファイルは、ファイルシステムのオーバーヘッド用にスペースを確保しながら、利用可能なサイズまで拡張されます。
手順
拡張する必要のある仮想マシンディスクの
PersistentVolumeClaimマニフェストを編集します。$ oc edit pvc <pvc_name>
ディスクサイズを更新します。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: vm-disk-expand spec: accessModes: - ReadWriteMany resources: requests: storage: 3Gi 1 # ...- 1
- 新しいディスクサイズを指定します。
7.14.2.2. 空のデータボリュームを追加して利用可能な仮想ストレージを拡張する
空のデータボリュームを追加することで、仮想マシンの利用可能なストレージを拡張できます。
前提条件
- 少なくとも 1 つの永続ボリュームが必要です。
手順
次の例に示すように、
DataVolumeマニフェストを作成します。DataVolumeマニフェストの例apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: blank-image-datavolume spec: source: blank: {} storage: resources: requests: storage: <2Gi> 1 storageClassName: "<storage_class>" 2以下のコマンドを実行してデータボリュームを作成します。
$ oc create -f <blank-image-datavolume>.yaml
データボリューム用の関連情報
第8章 ネットワーク
8.1. ネットワークの概要
OpenShift Virtualization は、カスタムリソースおよびプラグインを使用して高度なネットワーク機能を提供します。仮想マシン (VM) は、OpenShift Container Platform のネットワークおよびエコシステムと統合されています。
8.1.1. OpenShift Virtualization ネットワークの用語集
以下の用語は、OpenShift Virtualization ドキュメント全体で使用されています。
- Container Network Interface (CNI)
- コンテナーのネットワーク接続に重点を置く Cloud Native Computing Foundation プロジェクト。OpenShift Virtualization は CNI プラグインを使用して基本的な Kubernetes ネットワーク機能を強化します。
- Multus
- 複数の CNI の存在を可能にし、Pod または仮想マシンが必要なインターフェイスを使用できるようにする "メタ" CNI プラグイン。
- カスタムリソース定義 (CRD、Custom Resource Definition)
- カスタムリソースの定義を可能にする Kubernetes API リソース、または CRD API リソースを使用して定義されるオブジェクト。
- ネットワーク接続定義 (NAD)
- Multus プロジェクトによって導入された CRD。Pod、仮想マシン、および仮想マシンインスタンスを 1 つ以上のネットワークに接続できるようにします。
- ノードネットワーク設定ポリシー (NNCP)
-
nmstate プロジェクトによって導入された CRD。ノード上で要求されるネットワーク設定を表します。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。
8.1.2. デフォルトの Pod ネットワークの使用
- 仮想マシンをデフォルトの Pod ネットワークに接続する
- 各仮想マシンは、デフォルトの内部 Pod ネットワークにデフォルトで接続されます。仮想マシン仕様を編集することで、ネットワークインターフェイスを追加または削除できます。
- 仮想マシンをサービスとして公開する
-
Serviceオブジェクトを作成することで、クラスター内またはクラスター外に仮想マシンを公開できます。オンプレミスクラスターの場合、MetalLB Operator を使用して負荷分散サービスを設定できます。MetalLB Operator は、OpenShift Container Platform Web コンソールまたは CLI を使用して インストール できます。
8.1.3. 仮想マシンのセカンダリーネットワークインターフェイスの設定
- Linux ブリッジ ネットワークへの仮想マシンの割り当て
Kubernetes NMState Operator をインストール して、 セカンダリーネットワークの Linux ブリッジ、VLAN、およびボンディングを設定します。
次の手順を実行すると、Linux ブリッジネットワークを作成し、そのネットワークに仮想マシンを接続できます。
-
NodeNetworkConfigurationPolicyカスタムリソース定義 (CRD) を作成して、Linux ブリッジネットワークデバイスを設定 します。 -
NetworkAttachmentDefinitionCRD を作成して、Linux ブリッジネットワークを設定 します。 - 仮想マシン設定にネットワークの詳細を追加して、仮想マシンを Linux ブリッジネットワークに接続 します。
-
- 仮想マシンの SR-IOV ネットワークへの接続
高帯域幅または低レイテンシーを必要とするアプリケーション向けに、ベアメタルまたは Red Hat OpenStack Platform (RHOSP) インフラストラクチャーにインストールされた OpenShift Container Platform クラスター上の追加ネットワークで、Single Root I/O Virtualization (SR-IOV) ネットワークデバイスを使用できます。
SR-IOV ネットワークデバイスとネットワーク接続を管理するには、クラスターに SR-IOV Network Operator をインストール する必要があります。
次の手順を実行すると、仮想マシンを SR-IOV ネットワークに接続できます。
-
SriovNetworkNodePolicyCRD を作成して、SR-IOV ネットワークデバイスを設定 します。 -
SriovNetworkオブジェクトを作成して、SR-IOV ネットワークを設定 します。 - 仮想マシン設定にネットワークの詳細を追加して、仮想マシンを SR-IOV ブリッジネットワークに接続 します。
-
- OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
仮想マシンは Open Virtual Network (OVN)-Kubernetes セカンダリーネットワークに接続できます。OVN-Kubernetes セカンダリーネットワークを設定し、そのネットワークに仮想マシンを接続するには、次の手順を実行します。
-
NetworkAttachmentDefinitionCRD を作成して、OVN-Kubernetes セカンダリーネットワークを設定 します。 - ネットワークの詳細を仮想マシン仕様に追加して、仮想マシンを OVN-Kubernetes セカンダリーネットワークに接続 します。
-
- ホットプラグ対応のセカンダリーネットワークインターフェイス
- 仮想マシンを停止せずに、セカンダリーネットワークインターフェイスを追加または削除できます。OpenShift Virtualization は、VirtIO デバイスドライバーを使用する Linux ブリッジインターフェイスのホットプラグとホットアンプラグをサポートしています。
- SR-IOV での DPDK の使用
- データプレーン開発キット (DPDK) は、高速パケット処理のためのライブラリーとドライバーのセットを提供します。SR-IOV ネットワーク上で DPDK ワークロードを実行するようにクラスターと仮想マシンを設定できます。
- ライブマイグレーション用の専用ネットワークの設定
- ライブマイグレーション専用の Multus ネットワーク を設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
- クラスター FQDN を使用した仮想マシンへのアクセス
- 完全修飾ドメイン名 (FQDN) を使用して、クラスターの外部からセカンダリーネットワークインターフェイスに接続されている仮想マシンにアクセスできます。
- IP アドレスの設定と表示
- 仮想マシンを作成するときに、セカンダリーネットワークインターフェイスの IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。仮想マシンの IP アドレスは、OpenShift Container Platform Web コンソールまたはコマンドラインを使用して表示できます。ネットワーク情報は QEMU ゲストエージェントによって収集されます。
8.1.4. OpenShift Service Mesh との統合
- 仮想マシンのサービスメッシュへの接続
- OpenShift Virtualization は OpenShift Service Mesh と統合されています。Pod と仮想マシン間のトラフィックを監視、視覚化、制御できます。
8.1.5. MAC アドレスプールの管理
- ネットワークインターフェイスの MAC アドレスプールの管理
- KubeMacPool コンポーネントは、共有 MAC アドレスプールから仮想マシンネットワークインターフェイスの MAC アドレスを割り当てます。これにより、各ネットワークインターフェイスに一意の MAC アドレスが確実に割り当てられます。その仮想マシンから作成された仮想マシンインスタンスは、再起動後も割り当てられた MAC アドレスを保持します。
8.1.6. SSH アクセスの設定
- 仮想マシンへの SSH アクセスの設定
次の方法を使用して、仮想マシンへの SSH アクセスを設定できます。
SSH キーペアを作成し、公開キーを仮想マシンに追加し、秘密キーを使用して
virtctl sshコマンドを実行して仮想マシンに接続します。cloud-init データソースを使用して設定できるゲストオペレーティングシステムを使用して、実行時または最初の起動時に Red Hat Enterprise Linux (RHEL) 9 仮想マシンに公開 SSH キーを追加できます。
virtctl port-fowardコマンドを.ssh/configファイルに追加し、OpenSSH を使用して仮想マシンに接続します。サービスを作成し、そのサービスを仮想マシンに関連付け、サービスによって公開されている IP アドレスとポートに接続します。
セカンダリーネットワークを設定し、仮想マシンをセカンダリーネットワークインターフェイスに接続し、割り当てられた IP アドレスに接続します。
8.2. 仮想マシンをデフォルトの Pod ネットワークに接続する
masquerade バインディングモードを使用するようにネットワークインターフェイスを設定することで、仮想マシンをデフォルトの内部 Pod ネットワークに接続できます。
ネットワークインターフェイスを通過してデフォルトの Pod ネットワークに到達するトラフィックは、ライブマイグレーション中に中断されます。
8.2.1. コマンドラインでのマスカレードモードの設定
マスカレードモードを使用し、仮想マシンの送信トラフィックを Pod IP アドレスの背後で非表示にすることができます。マスカレードモードは、ネットワークアドレス変換 (NAT) を使用して仮想マシンを Linux ブリッジ経由で Pod ネットワークバックエンドに接続します。
仮想マシンの設定ファイルを編集して、マスカレードモードを有効にし、トラフィックが仮想マシンに到達できるようにします。
前提条件
- 仮想マシンは、IPv4 アドレスを取得するために DHCP を使用できるように設定される必要がある。
手順
仮想マシン設定ファイルの
interfaces仕様を編集します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: template: spec: domain: devices: interfaces: - name: default masquerade: {} 1 ports: 2 - port: 80 # ... networks: - name: default pod: {}注記ポート 49152 および 49153 は libvirt プラットフォームで使用するために予約され、これらのポートへの他のすべての受信トラフィックは破棄されます。
仮想マシンを作成します。
$ oc create -f <vm-name>.yaml
8.2.2. デュアルスタック (IPv4 および IPv6) でのマスカレードモードの設定
cloud-init を使用して、新規仮想マシン (VM) を、デフォルトの Pod ネットワークで IPv6 と IPv4 の両方を使用するように設定できます。
仮想マシン インスタンス設定の Network.pod.vmIPv6NetworkCIDR フィールドは、VM の静的 IPv6 アドレスとゲートウェイ IP アドレスを決定します。これらは IPv6 トラフィックを仮想マシンにルーティングするために virt-launcher Pod で使用され、外部では使用されません。Network.pod.vmIPv6NetworkCIDR フィールドは、Classless Inter-Domain Routing (CIDR) 表記で IPv6 アドレス ブロックを指定します。デフォルト値は fd10:0:2::2/120 です。この値は、ネットワーク要件に基づいて編集できます。
仮想マシンが実行されている場合、仮想マシンの送受信トラフィックは、virt-launcher Pod の IPv4 アドレスと固有の IPv6 アドレスの両方にルーティングされます。次に、virt-launcher Pod は IPv4 トラフィックを仮想マシンの DHCP アドレスにルーティングし、IPv6 トラフィックを仮想マシンの静的に設定された IPv6 アドレスにルーティングします。
前提条件
- OpenShift Container Platform クラスターは、デュアルスタック用に設定された OVN-Kubernetes Container Network Interface (CNI) ネットワークプラグインを使用する必要があります。
手順
新規の仮想マシン設定では、
masqueradeを指定したインターフェイスを追加し、cloud-init を使用して IPv6 アドレスとデフォルトゲートウェイを設定します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm-ipv6 spec: template: spec: domain: devices: interfaces: - name: default masquerade: {} 1 ports: - port: 80 2 # ... networks: - name: default pod: {} volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth0: dhcp4: true addresses: [ fd10:0:2::2/120 ] 3 gateway6: fd10:0:2::1 4namespace で仮想マシンインスタンスを作成します。
$ oc create -f example-vm-ipv6.yaml
検証
- IPv6 が設定されていることを確認するには、仮想マシンを起動し、仮想マシンインスタンスのインターフェイスステータスを表示して、これに IPv6 アドレスがあることを確認します。
$ oc get vmi <vmi-name> -o jsonpath="{.status.interfaces[*].ipAddresses}"8.2.3. ジャンボフレームのサポートについて
OVN-Kubernetes CNI プラグインを使用すると、デフォルトの Pod ネットワークに接続されている 2 つの仮想マシン (VM) 間でフラグメント化されていないジャンボフレームパケットを送信できます。ジャンボフレームの最大伝送単位 (MTU) 値は 1500 バイトを超えています。
VM は、クラスター管理者が設定したクラスターネットワークの MTU 値を、次のいずれかの方法で自動的に取得します。
-
libvirt: ゲスト OS に VirtIO ドライバーの最新バージョンがあり、エミュレーションされたデバイスの Peripheral Component Interconnect (PCI) 設定レジスターを介して着信データを解釈できる場合。 - DHCP: ゲスト DHCP クライアントが DHCP サーバーの応答から MTU 値を読み取ることができる場合。
VirtIO ドライバーを持たない Windows VM の場合、netsh または同様のツールを使用して MTU を手動で設定する必要があります。これは、Windows DHCP クライアントが MTU 値を読み取らないためです。
8.2.4. 関連情報
8.3. サービスを使用して仮想マシンを公開する
Service オブジェクトを作成して、クラスター内またはクラスターの外部に仮想マシンを公開することができます。
8.3.1. サービスについて
Kubernetes サービスは一連の Pod で実行されているアプリケーションへのクライアントのネットワークアクセスを公開します。サービスは抽象化、負荷分散を提供し、タイプ NodePort と LoadBalancer の場合は外部世界への露出を提供します。
- ClusterIP
-
内部 IP アドレスでサービスを公開し、クラスター内の他のアプリケーションに DNS 名として公開します。1 つのサービスを複数の仮想マシンにマッピングできます。クライアントがサービスに接続しようとすると、クライアントのリクエストは使用可能なバックエンド間で負荷分散されます。
ClusterIPはデフォルトのサービスタイプです。 - NodePort
-
クラスター内の選択した各ノードの同じポートでサービスを公開します。
NodePortは、ノード自体がクライアントから外部にアクセスできる限り、クラスターの外部からポートにアクセスできるようにします。 - LoadBalancer
- 現在のクラウド(サポートされている場合)に外部ロードバランサーを作成し、固定の外部 IP アドレスをサービスに割り当てます。
オンプレミスクラスターの場合、MetalLB Operator をデプロイすることで負荷分散サービスを設定できます。
8.3.2. デュアルスタックサポート
IPv4 および IPv6 のデュアルスタックネットワークがクラスターに対して有効にされている場合、Service オブジェクトに spec.ipFamilyPolicy および spec.ipFamilies フィールドを定義して、IPv4、IPv6、またはそれら両方を使用するサービスを作成できます。
spec.ipFamilyPolicy フィールドは以下の値のいずれかに設定できます。
- SingleStack
- コントロールプレーンは、最初に設定されたサービスクラスターの IP 範囲に基づいて、サービスのクラスター IP アドレスを割り当てます。
- PreferDualStack
- コントロールプレーンは、デュアルスタックが設定されたクラスターのサービス用に IPv4 および IPv6 クラスター IP アドレスの両方を割り当てます。
- RequireDualStack
-
このオプションは、デュアルスタックネットワークが有効にされていないクラスターの場合には失敗します。デュアルスタックが設定されたクラスターの場合、その値が
PreferDualStackに設定されている場合と同じになります。コントロールプレーンは、IPv4 アドレスと IPv6 アドレス範囲の両方からクラスター IP アドレスを割り当てます。
単一スタックに使用する IP ファミリーや、デュアルスタック用の IP ファミリーの順序は、spec.ipFamilies を以下のアレイ値のいずれかに設定して定義できます。
-
[IPv4] -
[IPv6] -
[IPv4, IPv6] -
[IPv6, IPv4]
8.3.3. コマンドラインを使用したサービスの作成
コマンドラインを使用して、サービスを作成し、それを仮想マシンに関連付けることができます。
前提条件
- サービスをサポートするようにクラスターネットワークを設定しました。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: running: false template: metadata: labels: special: key 1 # ...- 1
special: keyをspec.template.metadata.labelsスタンザに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: キーラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。apiVersion: v1 kind: Service metadata: name: example-service namespace: example-namespace spec: # ... selector: special: key 1 type: NodePort 2 ports: 3 protocol: TCP port: 80 targetPort: 9376 nodePort: 30000-
サービスマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
$ oc create -f example-service.yaml
- 仮想マシンを再起動して変更を適用します。
検証
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。$ oc get service -n example-namespace
8.3.4. 関連情報
8.4. Linux ブリッジ ネットワークへの仮想マシンの割り当て
デフォルトでは、OpenShift Virtualization は単一の内部 Pod ネットワークとともにインストールされます。
次の手順を実行すると、Linux ブリッジネットワークを作成し、そのネットワークに仮想マシンを接続できます。
- Linux ブリッジノードネットワーク設定ポリシー (NNCP) を作成します。
- Web コンソール または コマンドライン を使用して、Linux ブリッジネットワークアタッチメント定義 (NAD) を作成します。
- Web コンソール または コマンドライン を使用して、NAD を認識するように仮想マシンを設定します。
8.4.1. Linux ブリッジ NNCP の作成
Linux ブリッジネットワークの NodeNetworkConfigurationPolicy (NNCP) マニフェストを作成できます。
前提条件
- Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicyマニフェストを作成します。この例には、独自の情報で置き換える必要のあるサンプルの値が含まれます。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy 1 spec: desiredState: interfaces: - name: br1 2 description: Linux bridge with eth1 as a port 3 type: linux-bridge 4 state: up 5 ipv4: enabled: false 6 bridge: options: stp: enabled: false 7 port: - name: eth1 8
8.4.2. Linux ブリッジ NAD の作成
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、Linux ブリッジネットワーク接続定義 (NAD) を作成できます。
8.4.2.1. Web コンソールを使用した Linux ブリッジ NAD の作成
OpenShift Container Platform Web コンソールを使用して、ネットワーク接続定義 (NAD) を作成して、Pod および仮想マシンに layer-2 ネットワークを提供できます。
Linux ブリッジ ネットワーク接続定義は、仮想マシンを VLAN に接続するための最も効率的な方法です。
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
手順
- Web コンソールで、Networking → NetworkAttachmentDefinitions をクリックします。
Create Network Attachment Definition をクリックします。
注記ネットワーク接続定義は Pod または仮想マシンと同じ namespace にある必要があります。
- 一意の Name およびオプションの Description を入力します。
- Network Type リストから CNV Linux bridge を選択します。
- Bridge Name フィールドにブリッジの名前を入力します。
- オプション: リソースに VLAN ID が設定されている場合、 VLAN Tag Number フィールドに ID 番号を入力します。
- オプション: MAC Spoof Check を選択して、MAC スプーフ フィルタリングを有効にします。この機能により、Pod を終了するための MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。
- Create をクリックします。
8.4.2.2. コマンドラインを使用した Linux ブリッジ NAD の作成
コマンドラインを使用してネットワークアタッチメント定義 (NAD) を作成し、Pod および仮想マシンに layer-2 ネットワークを提供できます。
NAD と仮想マシンは同じ namespace に存在する必要があります。
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
前提条件
-
MAC スプーフィングチェックを有効にするには、ノードが nftables をサポートして、
nftバイナリーがデプロイされている必要があります。
手順
次の例のように、仮想マシンを
NetworkAttachmentDefinition設定に追加します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: bridge-network 1 annotations: k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/bridge-interface 2 spec: config: '{ "cniVersion": "0.3.1", "name": "bridge-network", 3 "type": "cnv-bridge", 4 "bridge": "bridge-interface", 5 "macspoofchk": true, 6 "vlan": 100, 7 "preserveDefaultVlan": false 8 }'
- 1
NetworkAttachmentDefinitionオブジェクトの名前。- 2
- オプション: ノード選択のアノテーションのキーと値のペア。
bridge-interfaceは一部のノードに設定されるブリッジの名前に一致する必要があります。このアノテーションをネットワーク接続定義に追加する場合、仮想マシンインスタンスはbridge-interfaceブリッジが接続されているノードでのみ実行されます。 - 3
- 設定の名前。設定名をネットワーク接続定義の
name値に一致させることが推奨されます。 - 4
- このネットワーク接続定義のネットワークを提供する Container Network Interface (CNI) プラグインの実際の名前。異なる CNI を使用するのでない限り、このフィールドは変更しないでください。
- 5
- ノードに設定される Linux ブリッジの名前。
- 6
- オプション:MAC スプーフィングチェックを有効にする。
trueに設定すると、Pod またはゲストインターフェイスの MAC アドレスを変更できません。この属性は、Pod からの MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。 - 7
- オプション: VLAN タグ。ノードのネットワーク設定ポリシーでは、追加の VLAN 設定は必要ありません。
- 8
- オプション: 仮想マシンがデフォルト VLAN 経由でブリッジに接続するかどうかを示します。デフォルト値は
trueです。
注記Linux ブリッジ ネットワーク接続定義は、仮想マシンを VLAN に接続するための最も効率的な方法です。
ネットワーク接続定義を作成します。
$ oc create -f network-attachment-definition.yaml 1- 1
- ここで、
network-attachment-definition.yamlはネットワーク接続定義マニフェストのファイル名です。
検証
次のコマンドを実行して、ネットワーク接続定義が作成されたことを確認します。
$ oc get network-attachment-definition bridge-network
8.4.3. 仮想マシンネットワークインターフェイスの設定
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、仮想マシンネットワークインターフェイスを設定できます。
8.4.3.1. Web コンソールを使用した仮想マシンネットワークインターフェイスの設定
OpenShift Container Platform Web コンソールを使用して、仮想マシンのネットワークインターフェイスを設定できます。
前提条件
- ネットワークのネットワーク接続定義を作成しました。
手順
- Virtualization → VirtualMachines に移動します。
- 仮想マシンをクリックして、VirtualMachine details ページを表示します。
- Configuration タブで、Network interfaces タブをクリックします。
- Add network interface をクリックします。
- インターフェイス名を入力し、Network リストからネットワーク接続定義を選択します。
- Save をクリックします。
- 仮想マシンを再起動して変更を適用します。
ネットワークフィールド
| Name | 説明 |
|---|---|
| Name | ネットワークインターフェイスコントローラーの名前。 |
| モデル | ネットワークインターフェイスコントローラーのモデルを示します。サポートされる値は e1000e および virtio です。 |
| Network | 利用可能なネットワーク接続定義のリスト。 |
| タイプ | 利用可能なバインディングメソッドの一覧。ネットワークインターフェイスに適したバインド方法を選択します。
|
| MAC Address | ネットワークインターフェイスコントローラーの MAC アドレス。MAC アドレスが指定されていない場合、これは自動的に割り当てられます。 |
8.4.3.2. コマンドラインを使用した仮想マシンネットワークインターフェイスの設定
コマンドラインを使用して、ブリッジネットワークの仮想マシンネットワークインターフェイスを設定できます。
前提条件
- 設定を編集する前に仮想マシンをシャットダウンします。実行中の仮想マシンを編集する場合は、変更を有効にするために仮想マシンを再起動する必要があります。
手順
次の例のように、ブリッジインターフェイスとネットワークアタッチメント定義を仮想マシン設定に追加します。
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: template: spec: domain: devices: interfaces: - masquerade: {} name: default - bridge: {} name: bridge-net 1 # ... networks: - name: default pod: {} - name: bridge-net 2 multus: networkName: a-bridge-network 3設定を適用します。
$ oc apply -f example-vm.yaml
- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
8.5. 仮想マシンの SR-IOV ネットワークへの接続
次の手順を実行して、仮想マシン (VM) を Single Root I/O Virtualization (SR-IOV) ネットワークに接続できます。
8.5.1. SR-IOV ネットワークデバイスの設定
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io CustomResourceDefinition を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。
設定の変更が適用されるまでに数分かかる場合があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - SR-IOV Network Operator がインストールされている。
- ドレイン (解放) されたノードからエビクトされたワークロードを処理するために、クラスター内に利用可能な十分なノードがあること。
- SR-IOV ネットワークデバイス設定についてコントロールプレーンノードを選択していないこと。
手順
SriovNetworkNodePolicyオブジェクトを作成してから、YAML を<name>-sriov-node-network.yamlファイルに保存します。<name>をこの設定の名前に置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" 4 priority: <priority> 5 mtu: <mtu> 6 numVfs: <num> 7 nicSelector: 8 vendor: "<vendor_code>" 9 deviceID: "<device_id>" 10 pfNames: ["<pf_name>", ...] 11 rootDevices: ["<pci_bus_id>", "..."] 12 deviceType: vfio-pci 13 isRdma: false 14
- 1
- CR オブジェクトの名前を指定します。
- 2
- SR-IOV Operator がインストールされている namespace を指定します。
- 3
- SR-IOV デバイスプラグインのリソース名を指定します。1 つのリソース名に複数の
SriovNetworkNodePolicyオブジェクトを作成できます。 - 4
- 設定するノードを選択するノードセレクターを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。
- 5
- オプション:
0から99までの整数値を指定します。数値が小さいほど優先度が高くなります。したがって、10は99よりも優先度が高くなります。デフォルト値は99です。 - 6
- オプション: 仮想機能 (VF) の最大転送単位 (MTU) の値を指定します。MTU の最大値は NIC モデルによって異なります。
- 7
- SR-IOV 物理ネットワークデバイス用に作成する仮想機能 (VF) の数を指定します。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 8
nicSelectorマッピングは、Operator が設定するイーサネットデバイスを選択します。すべてのパラメーターの値を指定する必要はありません。意図せずにイーサネットデバイスを選択する可能性を最低限に抑えるために、イーサネットアダプターを正確に特定できるようにすることが推奨されます。rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesとrootDevicesの両方を同時に指定する場合、それらが同一のデバイスをポイントすることを確認します。- 9
- オプション: SR-IOV ネットワークデバイスのベンダー 16 進コードを指定します。許可される値は
8086または15b3のいずれかのみになります。 - 10
- オプション: SR-IOV ネットワークデバイスのデバイス 16 進コードを指定します。許可される値は
158b、1015、1017のみになります。 - 11
- オプション: このパラメーターは、1 つ以上のイーサネットデバイスの物理機能 (PF) 名の配列を受け入れます。
- 12
- このパラメーターは、イーサネットデバイスの物理機能についての 1 つ以上の PCI バスアドレスの配列を受け入れます。以下の形式でアドレスを指定します:
0000:02:00.1 - 13
- OpenShift Virtualization の仮想機能には、
vfio-pciドライバータイプが必要です。 - 14
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを指定します。Mellanox カードの場合、
isRdmaをfalseに設定します。デフォルト値はfalseです。
注記isRDMAフラグがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。-
オプション: SR-IOV 対応のクラスターノードにまだラベルが付いていない場合は、
SriovNetworkNodePolicy.Spec.NodeSelectorでラベルを付けます。ノードのラベル付けについて、詳しくはノードのラベルを更新する方法についてを参照してください。 SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f <name>-sriov-node-network.yaml
ここで、
<name>はこの設定の名前を指定します。設定の更新が適用された後に、
sriov-network-operatornamespace のすべての Pod がRunningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
8.5.2. SR-IOV の追加ネットワークの設定
SriovNetwork オブジェクト を作成して、SR-IOV ハードウェアを使用する追加のネットワークを設定できます。
SriovNetwork オブジェクトの作成時に、SR-IOV Network Operator は NetworkAttachmentDefinition オブジェクトを自動的に作成します。
SriovNetwork オブジェクトが running 状態の Pod または仮想マシンに割り当てられている場合、これを変更したり、削除したりしないでください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
-
以下の
SriovNetworkオブジェクトを作成してから、YAML を<name>-sriov-network.yamlファイルに保存します。<name>を、この追加ネットワークの名前に置き換えます。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 networkNamespace: <target_namespace> 4 vlan: <vlan> 5 spoofChk: "<spoof_check>" 6 linkState: <link_state> 7 maxTxRate: <max_tx_rate> 8 minTxRate: <min_rx_rate> 9 vlanQoS: <vlan_qos> 10 trust: "<trust_vf>" 11 capabilities: <capabilities> 12
- 1
<name>をオブジェクトの名前に置き換えます。SR-IOV Network Operator は、同じ名前を持つNetworkAttachmentDefinitionオブジェクトを作成します。- 2
- SR-IOV ネットワーク Operator がインストールされている namespace を指定します。
- 3
<sriov_resource_name>を、この追加ネットワークの SR-IOV ハードウェアを定義するSriovNetworkNodePolicyオブジェクトの.spec.resourceNameパラメーターの値に置き換えます。- 4
<target_namespace>を SriovNetwork のターゲット namespace に置き換えます。ターゲット namespace の Pod または仮想マシンのみを SriovNetwork に割り当てることができます。- 5
- オプション:
<vlan>を、追加ネットワークの仮想 LAN (VLAN) ID に置き換えます。整数値は0から4095である必要があります。デフォルト値は0です。 - 6
- オプション:
<spoof_check>を VF の spoof check モードに置き換えます。許可される値は、文字列の"on"および"off"です。重要指定する値を引用符で囲む必要があります。そうしないと、CR は SR-IOV ネットワーク Operator によって拒否されます。
- 7
- オプション:
<link_state>を仮想機能 (VF) のリンクの状態に置き換えます。許可される値は、enable、disable、およびautoです。 - 8
- オプション:
<max_tx_rate>を VF の最大伝送レート (Mbps) に置き換えます。 - 9
- オプション:
<min_tx_rate>を VF の最小伝送レート (Mbps) に置き換えます。この値は、常に最大伝送レート以下である必要があります。注記Intel NIC は
minTxRateパラメーターをサポートしません。詳細は、BZ#1772847 を参照してください。 - 10
- オプション:
<vlan_qos>を VF の IEEE 802.1p 優先レベルに置き換えます。デフォルト値は0です。 - 11
- オプション:
<trust_vf>を VF の信頼モードに置き換えます。許可される値は、文字列の"on"および"off"です。重要指定する値を引用符で囲む必要があります。そうしないと、CR は SR-IOV ネットワーク Operator によって拒否されます。
- 12
- オプション:
<capabilities>を、このネットワークに設定する機能に置き換えます。
オブジェクトを作成するには、以下のコマンドを入力します。
<name>を、この追加ネットワークの名前に置き換えます。$ oc create -f <name>-sriov-network.yaml
オプション: 以下のコマンドを実行して、直前の手順で作成した
SriovNetworkオブジェクトに関連付けられたNetworkAttachmentDefinitionオブジェクトが存在することを確認するには、以下のコマンドを入力します。<namespace>を、SriovNetworkオブジェクト で指定した namespace に置き換えます。$ oc get net-attach-def -n <namespace>
8.5.3. 仮想マシンの SR-IOV ネットワークへの接続
仮想マシンの設定にネットワークの詳細を含めることで、仮想マシンを SR-IOV ネットワークに接続することができます。
手順
次の例のように、SR-IOV ネットワークの詳細を仮想マシン設定の
spec.domain.devices.interfacesスタンザとspec.networksスタンザに追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: domain: devices: interfaces: - name: default masquerade: {} - name: nic1 1 sriov: {} networks: - name: default pod: {} - name: nic1 2 multus: networkName: sriov-network 3 # ...仮想マシン設定を適用します。
$ oc apply -f <vm_sriov>.yaml 1- 1
- 仮想マシン YAML ファイルの名前。
8.5.4. 関連情報
8.6. SR-IOV での DPDK の使用
データプレーン開発キット (DPDK) は、高速パケット処理のためのライブラリーとドライバーのセットを提供します。
SR-IOV ネットワーク上で DPDK ワークロードを実行するようにクラスターと仮想マシンを設定できます。
DPDK ワークロードの実行はテクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
8.6.1. DPDK ワークロード用のクラスター設定
ネットワークパフォーマンスを向上させるために、Data Plane Development Kit (DPDK) ワークロードを実行するように OpenShift Container Platform クラスターを設定できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできます。 -
OpenShift CLI (
oc) がインストールされている。 - SR-IOV Network Operator がインストールされている。
- Node Tuning Operator がインストールされている。
手順
- コンピュートノードトポロジーのマッピングを実行し、DPDK アプリケーション用に分離する Non-Uniform Memory Access (NUMA) CPUと、オペレーティングシステム (OS) 用に予約する NUMA CPU を決定します。
コンピュートノードのサブセットにカスタムロール (例:
worker-dpdk) のラベルを追加します。$ oc label node <node_name> node-role.kubernetes.io/worker-dpdk=""
spec.machineConfigSelectorオブジェクトにworker-dpdkラベルを含む新しいMachineConfigPoolマニフェストを作成します。MachineConfigPoolマニフェストの例apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-dpdk labels: machineconfiguration.openshift.io/role: worker-dpdk spec: machineConfigSelector: matchExpressions: - key: machineconfiguration.openshift.io/role operator: In values: - worker - worker-dpdk nodeSelector: matchLabels: node-role.kubernetes.io/worker-dpdk: ""前の手順で作成したラベル付きノードとマシン設定プールに適用する
PerformanceProfileマニフェストを作成します。パフォーマンスプロファイルは、DPDK アプリケーション用に分離された CPU とハウスキーピング用に予約された CPU を指定します。PerformanceProfileマニフェストの例apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: profile-1 spec: cpu: isolated: 4-39,44-79 reserved: 0-3,40-43 globallyDisableIrqLoadBalancing: true hugepages: defaultHugepagesSize: 1G pages: - count: 8 node: 0 size: 1G net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-dpdk: "" numa: topologyPolicy: single-numa-node注記MachineConfigPoolマニフェストとPerformanceProfileマニフェストを適用すると、コンピュートノードが自動的に再起動します。PerformanceProfileオブジェクトのstatus.runtimeClassフィールドから、生成されたRuntimeClassリソースの名前を取得します。$ oc get performanceprofiles.performance.openshift.io profile-1 -o=jsonpath='{.status.runtimeClass}{"\n"}'HyperConvergedカスタムリソース (CR) を編集して、以前に取得したRuntimeClass名をvirt-launcherPod のデフォルトのコンテナーランタイムクラスとして設定します。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type='json' -p='[{"op": "add", "path": "/spec/defaultRuntimeClass", "value":"<runtimeclass-name>"}]'注記HyperConvergedCR を編集すると、変更の適用後に作成されるすべての仮想マシンに影響するグローバル設定が変更されます。spec.deviceTypeフィールドをvfio-pciに設定してSriovNetworkNodePolicyオブジェクトを作成します。SriovNetworkNodePolicyマニフェストの例apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policy-1 namespace: openshift-sriov-network-operator spec: resourceName: intel_nics_dpdk deviceType: vfio-pci mtu: 9000 numVfs: 4 priority: 99 nicSelector: vendor: "8086" deviceID: "1572" pfNames: - eno3 rootDevices: - "0000:19:00.2" nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true"
8.6.2. DPDK ワークロード用のプロジェクト設定
SR-IOV ハードウェアで DPDK ワークロードを実行するプロジェクトを設定できます。
前提条件
- DPDK ワークロードを実行するようにクラスターが設定されている。
手順
DPDK アプリケーションの namespace を作成します。
$ oc create ns dpdk-checkup-ns
SriovNetworkNodePolicyオブジェクトを参照するSriovNetworkオブジェクトを作成します。SriovNetworkオブジェクトの作成時に、SR-IOV Network Operator はNetworkAttachmentDefinitionオブジェクトを自動的に作成します。SriovNetworkマニフェストの例apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: dpdk-sriovnetwork namespace: openshift-sriov-network-operator spec: ipam: | { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [{ "dst": "0.0.0.0/0" }], "gateway": "10.56.217.1" } networkNamespace: dpdk-checkup-ns 1 resourceName: intel_nics_dpdk 2 spoofChk: "off" trust: "on" vlan: 1019- オプション: 仮想マシンレイテンシーチェックアップを実行して、ネットワークが適切に設定されていることを確認します。
- オプション: DPDK チェックアップを実行して、namespace が DPDK ワークロード用に準備できているか確認します。
8.6.3. DPDK ワークロード用の仮想マシン設定
仮想マシン (VM) 上で Data Packet Development Kit (DPDK) ワークロードを実行すると、レイテンシーの短縮とスループットが向上し、ユーザー空間でのパケット処理を高速化できます。DPDK は、ハードウェアベースの I/O 共有に SR-IOV ネットワークを使用します。
前提条件
- DPDK ワークロードを実行するようにクラスターが設定されている。
- 仮想マシンを実行するプロジェクトを作成し、設定している。
手順
VirtualMachineマニフェストを編集して、SR-IOV ネットワークインターフェイス、CPU トポロジー、CRI-O アノテーション、Huge Page に関する情報を格納します。VirtualMachineマニフェストの例apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: rhel-dpdk-vm spec: running: true template: metadata: annotations: cpu-load-balancing.crio.io: disable 1 cpu-quota.crio.io: disable 2 irq-load-balancing.crio.io: disable 3 spec: domain: cpu: sockets: 1 4 cores: 5 5 threads: 2 dedicatedCpuPlacement: true isolateEmulatorThread: true interfaces: - masquerade: {} name: default - model: virtio name: nic-east pciAddress: '0000:07:00.0' sriov: {} networkInterfaceMultiqueue: true rng: {} memory: hugepages: pageSize: 1Gi 6 guest: 8Gi networks: - name: default pod: {} - multus: networkName: dpdk-net 7 name: nic-east # ...- 1
- このアノテーションは、コンテナーが使用する CPU に対するロードバランシングが無効であることを示します。
- 2
- このアノテーションは、コンテナーが使用する CPU に対する CPU クォータが無効であることを示します。
- 3
- このアノテーションは、コンテナーが使用する CPU に対する Interrupt Request (IRQ) のロードバランシングが無効であることを示します。
- 4
- 仮想マシン内のソケットの数。同じ Non-Uniform Memory Access (NUMA) ノードから CPU をスケジュールするには、このフィールドを
1に設定する必要があります。 - 5
- 仮想マシン内のコアの数。値は
1以上とします。この例では、仮想マシンは 5 個のハイパースレッドか 10 個の CPU でスケジュールされています。 - 6
- Huge Page のサイズ。x86-64 アーキテクチャーの有効な値は 1Gi と 2Mi です。この例は、サイズが 1Gi の 8 個の Huge Page に対する要求です。
- 7
- SR-IOV
NetworkAttachmentDefinitionオブジェクトの名前。
- エディターを保存し、終了します。
VirtualMachineマニフェストを適用します。$ oc apply -f <file_name>.yaml
ゲストオペレーティングシステムを設定します。次の例は、RHEL 8 OS の設定手順を示しています。
GRUB ブートローダーコマンドラインインターフェイスを使用して、Huge Page を設定します。次の例では、1G の Huge Page を 8 個指定しています。
$ grubby --update-kernel=ALL --args="default_hugepagesz=1GB hugepagesz=1G hugepages=8"
TuneD アプリケーションで
cpu-partitioningプロファイルを使用して低レイテンシーチューニングを実現するには、次のコマンドを実行します。$ dnf install -y tuned-profiles-cpu-partitioning
$ echo isolated_cores=2-9 > /etc/tuned/cpu-partitioning-variables.conf
最初の 2 つの CPU (0 と 1) はハウスキーピングタスク用に確保され、残りは DPDK アプリケーション用に分離されます。
$ tuned-adm profile cpu-partitioning
driverctlデバイスドライバー制御ユーティリティーを使用して、SR-IOV NIC ドライバーをオーバーライドします。$ dnf install -y driverctl
$ driverctl set-override 0000:07:00.0 vfio-pci
- 仮想マシンを再起動して変更を適用します。
8.7. OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
仮想マシンを Open Virtual Network (OVN)-Kubernetes セカンダリーネットワークに接続できます。OVN-Kubernetes Container Network Interface (CNI) プラグインは、 Geneve (Generic Network Virtualization Encapsulation) プロトコルを使用してノード間にオーバーレイネットワークを作成します。
OpenShift Virtualization は現在、フラットレイヤー 2 トポロジーをサポートしています。このトポロジーは、クラスター全体の論理スイッチによってワークロードを接続します。このオーバーレイネットワークを使用すると、追加の物理ネットワークインフラストラクチャーを設定することなく、さまざまなノード上の仮想マシンを接続できます。
OVN-Kubernetes セカンダリーネットワークを設定し、そのネットワークに仮想マシンを接続するには、次の手順を実行します。
8.7.1. OVN-Kubernetes NAD の作成
OpenShift Container Platform Web コンソールまたは CLI を使用して、OVN-Kubernetes フラットレイヤー 2 ネットワーク接続定義 (NAD) を作成できます。
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
8.7.1.1. CLI を使用したフラットレイヤ 2 トポロジー用の NAD の作成
Pod をレイヤー 2 オーバーレイネットワークに接続する方法を説明するネットワーク接続定義 (NAD) を作成できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
NetworkAttachmentDefinitionオブジェクトを作成します。apiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: name: l2-network namespace: my-namespace spec: config: |2 { "cniVersion": "0.3.1", 1 "name": "my-namespace-l2-network", 2 "type": "ovn-k8s-cni-overlay", 3 "topology":"layer2", 4 "mtu": 1300, 5 "netAttachDefName": "my-namespace/l2-network" 6 }- 1
- CNI 仕様のバージョン。必要な値は
0.3.1です。 - 2
- ネットワークの名前。この属性には namespace がありません。たとえば、
l2-networkという名前のネットワークを、2 つの異なる namespace に存在する 2 つの異なるNetworkAttachmentDefinitionオブジェクトから参照させることができます。この機能は、異なる namespace の仮想マシンを接続する場合に役立ちます。 - 3
- 設定する CNI プラグインの名前。必要な値は
ovn-k8s-cni-overlayです。 - 4
- ネットワークのトポロジー設定。必要な値は
layer2です。 - 5
- オプション: 最大伝送単位 (MTU) の値。デフォルト値はカーネルによって自動的に設定されます。
- 6
NetworkAttachmentDefinitionオブジェクトのmetadataスタンザ内のnamespaceおよびnameフィールドの値。
注記上記の例では、サブネットを定義せずにクラスター全体のオーバーレイを設定します。これは、ネットワークを実装する論理スイッチがレイヤー 2 通信のみを提供することを意味します。仮想マシンの作成時に、静的 IP アドレスを設定するか、動的 IP アドレス用にネットワーク上に DHCP サーバーをデプロイすることによって、IP アドレスを設定する必要があります。
マニフェストを適用します。
$ oc apply -f <filename>.yaml
8.7.2. OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
OpenShift Container Platform Web コンソールまたは CLI を使用して、仮想マシンを OVN-Kubernetes セカンダリーネットワークインターフェイスに接続できます。
8.7.2.1. CLI を使用した OVN-Kubernetes セカンダリーネットワークへの仮想マシンの接続
仮想マシン設定にネットワークの詳細を含めることで、仮想マシンを OVN-Kubernetes セカンダリーネットワークに接続できます。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次の例のように、
VirtualMachineマニフェストを編集して OVN-Kubernetes セカンダリーネットワークインターフェイスの詳細を追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-server spec: running: true template: spec: domain: devices: interfaces: - name: default masquerade: {} - name: secondary 1 bridge: {} resources: requests: memory: 1024Mi networks: - name: default pod: {} - name: secondary 2 multus: networkName: l2-network 3 # ...VirtualMachineマニフェストを適用します。$ oc apply -f <filename>.yaml
- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
8.7.3. 関連情報
8.8. ホットプラグ対応のセカンダリーネットワークインターフェイス
仮想マシンを停止せずに、セカンダリーネットワークインターフェイスを追加または削除できます。OpenShift Virtualization は、VirtIO デバイスドライバーを使用する Linux ブリッジインターフェイスのホットプラグとホットアンプラグをサポートしています。
ブリッジネットワークインターフェイスのホットプラグおよびホットアンプラグは、テクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
8.8.1. VirtIO の制限事項
各 VirtIO インターフェイスは、仮想マシン内の限られたペリフェラル接続インターフェイス (PCI) スロットの 1 つを使用します。合計 32 個のスロットが利用可能です。PCI スロットは他のデバイスでも使用され、事前に予約する必要があるため、オンデマンドでスロットを利用できない場合があります。OpenShift Virtualization は、ホットプラグインターフェイス用に最大 4 つのスロットを予約します。これには、接続されている既存のネットワークインターフェイスが含まれます。たとえば、仮想マシンにプラグインされた既存のインターフェイスが 2 つある場合は、さらに 2 つのネットワークインターフェイスをホットプラグできます。
ホットプラグに使用できる実際のスロット数もマシンのタイプによって異なります。たとえば、q35 マシンタイプのデフォルトの PCI トポロジーは、1 台の追加 PCIe デバイスのホットプラグをサポートしています。PCI トポロジーとホットプラグのサポートの詳細は、libvirt のドキュメント を参照してください。
インターフェイスをホットプラグした後に仮想マシンを再起動すると、そのインターフェイスは標準ネットワークインターフェイスの一部になります。
8.8.2. CLI を使用したブリッジネットワークインターフェイスのホットプラグ
仮想マシンの実行中に、ブリッジネットワークインターフェイスを仮想マシンにホットプラグします。
前提条件
- ネットワークアタッチメント定義は、仮想マシンと同じ namespace で設定されます。
-
virtctlツールがインストールされています。
手順
ネットワークインターフェイスをホットプラグする仮想マシンが実行していない場合は、次のコマンドを使用して仮想マシンを起動します。
$ virtctl start <vm_name> -n <namespace>
次のコマンドを使用して、新しいネットワークインターフェイスを実行中の仮想マシンにホットプラグします。
virtctl addinterfaceコマンドは、新しいネットワークインターフェイスを仮想マシンおよび仮想マシンインスタンス仕様に追加しますが、実行中の仮想マシンには接続しません。$ virtctl addinterface <vm_name> --network-attachment-definition-name <net_attach_def_name> --name <interface_name>
ここでは、以下のようになります。
- <vm_name>
-
VirtualMachineオブジェクトの名前を指定します。 - <net_attach_def_name>
-
NetworkAttachmentDefinitionオブジェクトの名前を指定します。 - <interface_name>
- 新しいネットワークインターフェイスの名前を指定します。
実行中の仮想マシンにネットワークインターフェイスを接続するには、次のコマンドを使用して仮想マシンをライブマイグレーションします。
$ virtctl migrate <vm_name>
検証
次のコマンドを使用して、仮想マシンのライブマイグレーションが成功したことを確認します。
$ oc get VirtualMachineInstanceMigration -w
出力例
NAME PHASE VMI kubevirt-migrate-vm-lj62q Scheduling vm-fedora kubevirt-migrate-vm-lj62q Scheduled vm-fedora kubevirt-migrate-vm-lj62q PreparingTarget vm-fedora kubevirt-migrate-vm-lj62q TargetReady vm-fedora kubevirt-migrate-vm-lj62q Running vm-fedora kubevirt-migrate-vm-lj62q Succeeded vm-fedora
VMI ステータスをチェックして、新しいインターフェイスが仮想マシンに追加されていることを確認します。
$ oc get vmi vm-fedora -ojsonpath="{ @.status.interfaces }"出力例
[ { "infoSource": "domain, guest-agent", "interfaceName": "eth0", "ipAddress": "10.130.0.195", "ipAddresses": [ "10.130.0.195", "fd02:0:0:3::43c" ], "mac": "52:54:00:0e:ab:25", "name": "default", "queueCount": 1 }, { "infoSource": "domain, guest-agent, multus-status", "interfaceName": "eth1", "mac": "02:d8:b8:00:00:2a", "name": "bridge-interface", 1 "queueCount": 1 } ]- 1
- ホットプラグされたインターフェイスが VMI ステータスに表示されます。
8.8.3. CLI を使用したブリッジネットワークインターフェイスのホットアンプラグ
実行中の仮想マシンからブリッジネットワークインターフェイスを削除できます。
前提条件
- 仮想マシンが実行している必要があります。
- 仮想マシンは、OpenShift Virtualization 4.14 以降を実行しているクラスター上に作成する必要があります。
- 仮想マシンにはブリッジネットワークインターフェイスが接続されている必要があります。
手順
次のコマンドを実行して、ブリッジネットワークインターフェイスをホットアンプラグします。
virtctl removeinterfaceコマンドはゲストからネットワークインターフェイスを切り離しますが、インターフェイスは Pod 内にまだ存在します。$ virtctl removeinterface <vm_name> --name <interface_name>
仮想マシンを移行して、Pod からインターフェイスを削除します。
$ virtctl migrate <vm_name>
8.8.4. 関連情報
8.9. 仮想マシンのサービスメッシュへの接続
OpenShift Virtualization が OpenShift Service Mesh に統合されるようになりました。IPv4 を使用してデフォルトの Pod ネットワークで仮想マシンのワークロードを実行する Pod 間のトラフィックのモニター、可視化、制御が可能です。
8.9.1. サービスメッシュへの仮想マシンの追加
仮想マシン (VM) ワークロードをサービスメッシュに追加するには、sidecar.istio.io/inject アノテーションを true に設定して、仮想マシン設定ファイルでサイドカーコンテナーの自動挿入を有効にします。次に、仮想マシンをサービスとして公開し、メッシュでアプリケーションを表示します。
ポートの競合を回避するには、Istio サイドカープロキシーが使用するポートを使用しないでください。これには、ポート 15000、15001、15006、15008、15020、15021、および 15090 が含まれます。
前提条件
- Service Mesh Operators がインストールされました。
- Service Mesh コントロールプレーンを作成しました。
- 仮想マシンプロジェクトを Service Mesh メンバーロールに追加しました。
手順
仮想マシン設定ファイルを編集し、
sidecar.istio.io/inject: "true"アノテーションを追加します。設定ファイルのサンプル
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-istio name: vm-istio spec: runStrategy: Always template: metadata: labels: kubevirt.io/vm: vm-istio app: vm-istio 1 annotations: sidecar.istio.io/inject: "true" 2 spec: domain: devices: interfaces: - name: default masquerade: {} 3 disks: - disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk resources: requests: memory: 1024M networks: - name: default pod: {} terminationGracePeriodSeconds: 180 volumes: - containerDisk: image: registry:5000/kubevirt/fedora-cloud-container-disk-demo:devel name: containerdisk仮想マシン設定を適用します。
$ oc apply -f <vm_name>.yaml 1- 1
- 仮想マシン YAML ファイルの名前。
Serviceオブジェクトを作成し、仮想マシンをサービスメッシュに公開します。apiVersion: v1 kind: Service metadata: name: vm-istio spec: selector: app: vm-istio 1 ports: - port: 8080 name: http protocol: TCP- 1
- サービスの対象となる Pod セットを判別するサービスセレクターです。この属性は、仮想マシン設定ファイルの
spec.metadata.labelsフィールドに対応します。上記の例では、vm-istioという名前のServiceオブジェクトは、ラベルがapp=vm-istioの Pod の TCP ポート 8080 をターゲットにします。
サービスを作成します。
$ oc create -f <service_name>.yaml 1- 1
- サービス YAML ファイルの名前。
8.9.2. 関連情報
8.10. ライブマイグレーション用の専用ネットワークの設定
ライブマイグレーション専用の Multus ネットワーク を設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
8.10.1. ライブマイグレーション用の専用セカンダリーネットワークの設定
ライブマイグレーション用に専用のセカンダリーネットワークを設定するには、まず CLI を使用してブリッジネットワーク接続定義 (NAD) を作成する必要があります。次に、NetworkAttachmentDefinition オブジェクトの名前を HyperConverged カスタムリソース (CR) に追加します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - 各ノードには少なくとも 2 つのネットワークインターフェイスカード (NIC) があります。
- ライブマイグレーション用の NIC は同じ VLAN に接続されます。
手順
次の例に従って、
NetworkAttachmentDefinitionマニフェストを作成します。設定ファイルのサンプル
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: my-secondary-network 1 namespace: openshift-cnv 2 spec: config: '{ "cniVersion": "0.3.1", "name": "migration-bridge", "type": "macvlan", "master": "eth1", 3 "mode": "bridge", "ipam": { "type": "whereabouts", 4 "range": "10.200.5.0/24" 5 } }'
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
NetworkAttachmentDefinitionオブジェクトの名前をHyperConvergedCR のspec.liveMigrationConfigスタンザに追加します。HyperConvergedマニフェストの例apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: liveMigrationConfig: completionTimeoutPerGiB: 800 network: <network> 1 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150 # ...- 1
- ライブマイグレーションに使用される Multus
NetworkAttachmentDefinitionオブジェクトの名前を指定します。
-
変更を保存し、エディターを終了します。
virt-handlerPod が再起動し、セカンダリーネットワークに接続されます。
検証
仮想マシンが実行されるノードがメンテナンスモードに切り替えられると、仮想マシンは自動的にクラスター内の別のノードに移行します。仮想マシンインスタンス (VMI) メタデータのターゲット IP アドレスを確認して、デフォルトの Pod ネットワークではなく、セカンダリーネットワーク上で移行が発生したことを確認できます。
$ oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'
8.10.2. Web コンソールを使用して専用ネットワークを選択する
OpenShift Container Platform Web コンソールを使用して、ライブマイグレーション用の専用ネットワークを選択できます。
前提条件
- ライブマイグレーション用に Multus ネットワークが設定されている。
手順
- OpenShift Container Platform Web コンソールで Virtualization > Overview に移動します。
- Settings タブをクリックし、Live migration をクリックします。
- Live migration network リストからネットワークを選択します。
8.10.3. 関連情報
8.11. IP アドレスの設定と表示
仮想マシンを作成するときに IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。
仮想マシンの IP アドレスは、OpenShift Container Platform Web コンソールまたはコマンドラインを使用して表示できます。ネットワーク情報は QEMU ゲストエージェントによって収集されます。
8.11.1. 仮想マシンの IP アドレスの設定
Web コンソールまたはコマンドラインを使用して仮想マシンを作成するときに、静的 IP アドレスを設定できます。
コマンドラインを使用して仮想マシンを作成するときに、動的 IP アドレスを設定できます。
IP アドレスは、cloud-init でプロビジョニングされます。
8.11.1.1. コマンドラインを使用して仮想マシンを作成するときに IP アドレスを設定する
仮想マシンを作成するときに、静的または動的 IP アドレスを設定できます。IP アドレスは、cloud-init でプロビジョニングされます。
VM が Pod ネットワークに接続されている場合、更新しない限り、Pod ネットワークインターフェイスがデフォルトルートになります。
前提条件
- 仮想マシンはセカンダリーネットワークに接続されている。
- 仮想マシンの動的 IP を設定するために、セカンダリーネットワーク上で使用できる DHCP サーバーがある。
手順
仮想マシン設定の
spec.template.spec.volumes.cloudInitNoCloud.networkDataスタンザを編集します。動的 IP アドレスを設定するには、インターフェイス名を指定し、DHCP を有効にします。
kind: VirtualMachine spec: # ... template: # ... spec: volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1: 1 dhcp4: true- 1
- インターフェイス名を指定します。
静的 IP を設定するには、インターフェイス名と IP アドレスを指定します。
kind: VirtualMachine spec: # ... template: # ... spec: volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1: 1 addresses: - 10.10.10.14/24 2
8.11.2. 仮想マシンの IP アドレスの表示
仮想マシンの IP アドレスは、OpenShift Container Platform Web コンソールまたはコマンドラインを使用して表示できます。
ネットワーク情報は QEMU ゲストエージェントによって収集されます。
8.11.2.1. Web コンソールを使用した仮想マシンの IP アドレスの表示
OpenShift Container Platform Web コンソールを使用して、仮想マシンの IP アドレスを表示できます。
セカンダリーネットワークインターフェイスの IP アドレスを表示するには、仮想マシンに QEMU ゲストエージェントをインストールする必要があります。Pod ネットワークインターフェイスには QEMU ゲストエージェントは必要ありません。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックして IP アドレスを表示します。
8.11.2.2. コマンドラインを使用した仮想マシンの IP アドレスの表示
コマンドラインを使用して、仮想マシンの IP アドレスを表示できます。
セカンダリーネットワークインターフェイスの IP アドレスを表示するには、仮想マシンに QEMU ゲストエージェントをインストールする必要があります。Pod ネットワークインターフェイスには QEMU ゲストエージェントは必要ありません。
手順
次のコマンドを実行して、仮想マシンインスタンスの設定を取得します。
$ oc describe vmi <vmi_name>
出力例
# ... Interfaces: Interface Name: eth0 Ip Address: 10.244.0.37/24 Ip Addresses: 10.244.0.37/24 fe80::858:aff:fef4:25/64 Mac: 0a:58:0a:f4:00:25 Name: default Interface Name: v2 Ip Address: 1.1.1.7/24 Ip Addresses: 1.1.1.7/24 fe80::f4d9:70ff:fe13:9089/64 Mac: f6:d9:70:13:90:89 Interface Name: v1 Ip Address: 1.1.1.1/24 Ip Addresses: 1.1.1.1/24 1.1.1.2/24 1.1.1.4/24 2001:de7:0:f101::1/64 2001:db8:0:f101::1/64 fe80::1420:84ff:fe10:17aa/64 Mac: 16:20:84:10:17:aa
8.11.3. 関連情報
8.12. クラスター FQDN を使用した仮想マシンへのアクセス
クラスターの完全修飾ドメイン名 (FQDN) を使用して、クラスターの外部からセカンダリーネットワークインターフェイスに接続されている仮想マシン (VM) にアクセスできます。
クラスター FQDN を使用した VM へのアクセスは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
8.12.1. セカンダリーネットワーク用の DNS サーバーの設定
Cluster Network Addons Operator (CNAO) は、HyperConverged カスタムリソース (CR) で deployKubeSecondaryDNS 機能ゲートを有効にすると、ドメインネームサーバー (DNS) サーバーと監視コンポーネントをデプロイします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスターのロードバランサーを設定しました。
-
cluster-adminパーミッションを使用してクラスターにログインしました。
手順
次の例に従って
oc exposeコマンドを実行して、クラスターの外部に DNS サーバーを公開するロードバランサーサービスを作成します。$ oc expose -n openshift-cnv deployment/secondary-dns --name=dns-lb \ --type=LoadBalancer --port=53 --target-port=5353 --protocol='UDP'
次のコマンドを実行して、外部 IP アドレスを取得します。
$ oc get service -n openshift-cnv
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dns-lb LoadBalancer 172.30.27.5 10.46.41.94 53:31829/TCP 5s
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
次の例に従って、DNS サーバーと監視コンポーネントを有効にします。
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: featureGates: deployKubeSecondaryDNS: true kubeSecondaryDNSNameServerIP: "10.46.41.94" 1 # ...- 1
- ロードバランサーサービスによって公開される外部 IP アドレスを指定します。
- ファイルを保存して、エディターを終了します。
次のコマンドを実行して、クラスターの FQDN を取得します。
$ oc get dnses.config.openshift.io cluster -o jsonpath='{.spec.baseDomain}'出力例
openshift.example.com
次のいずれかの方法を使用して、DNS サーバーを指定します。
ローカルマシンの
resolv.confファイルにkubeSecondaryDNSNameServerIP値を追加します。注記resolv.confファイルを編集すると、既存の DNS 設定が上書きされます。kubeSecondaryDNSNameServerIP値とクラスター FQDN をエンタープライズ DNS サーバーレコードに追加します。以下に例を示します。vm.<FQDN>. IN NS ns.vm.<FQDN>.
ns.vm.<FQDN>. IN A 10.46.41.94
8.12.2. クラスター FQDN を使用したセカンダリーネットワーク上の仮想マシンへの接続
クラスターの完全修飾ドメイン名 (FQDN) を使用して、セカンダリーネットワークインターフェイスに接続された実行中の仮想マシンにアクセスできます。
前提条件
- QEMU ゲストエージェントを仮想マシンにインストールしました。
- 仮想マシンの IP アドレスはパブリックです。
- セカンダリーネットワーク用の DNS サーバーを設定しました。
- クラスターの完全修飾ドメイン名 (FQDN) を取得しました。
手順
次のコマンドを実行して、仮想マシン設定からネットワークインターフェイス名を取得します。
$ oc get vm -n <namespace> <vm_name> -o yaml
出力例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm namespace: example-namespace spec: running: true template: spec: domain: devices: interfaces: - bridge: {} name: example-nic # ... networks: - multus: networkName: bridge-conf name: example-nic 1- 1
- ネットワークインターフェイスの名前を書き留めます。
sshコマンドを使用して仮想マシンに接続します。$ ssh <user_name>@<interface_name>.<vm_name>.<namespace>.vm.<cluster_fqdn>
8.12.3. 関連情報
8.13. ネットワークインターフェイスの MAC アドレスプールの管理
KubeMacPool コンポーネントは、共有 MAC アドレスプールから仮想マシンネットワークインターフェイスの MAC アドレスを割り当てます。これにより、各ネットワークインターフェイスに一意の MAC アドレスが確実に割り当てられます。
その仮想マシンから作成された仮想マシンインスタンスは、再起動後も割り当てられた MAC アドレスを保持します。
KubeMacPool は、仮想マシンから独立して作成される仮想マシンインスタンスを処理しません。
8.13.1. コマンドラインを使用した KubeMacPool の管理
コマンドラインを使用して、KubeMacPool を無効にしたり、再度有効にしたりできます。
KubeMacPool はデフォルトで有効になっています。
手順
2 つの namespace で KubeMacPool を無効にするには、次のコマンドを実行します。
$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io=ignore
2 つの namespace で KubeMacPool を再度有効にするには、次のコマンドを実行します。
$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io-
第9章 ストレージ
9.1. ストレージ設定の概要
デフォルトのストレージクラス、ストレージプロファイル、Containerized Data Importer (CDI)、データボリューム、および自動ブートソース更新を設定できます。
9.1.1. ストレージ
次のストレージ設定タスクは必須です。
- デフォルトのストレージクラスを設定する
- クラスターのデフォルトのストレージクラスを設定する必要があります。そうしないと、クラスターは自動ブートソース更新を受信できません。
- ストレージプロファイルを設定する
- ストレージプロバイダーが CDI によって認識されない場合は、ストレージプロファイルを設定する必要があります。ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。
次のストレージ設定タスクはオプションです。
- ファイルシステムのオーバーヘッドのために追加の PVC スペースを予約する
- デフォルトでは、ファイルシステム PVC の 5.5% がオーバーヘッド用に予約されており、その分仮想マシンディスクに使用できるスペースが減少します。別のオーバーヘッド値を設定できます。
- ホストパスプロビジョナーを使用してローカルストレージを設定する
- ホストパスプロビジョナー (HPP) を使用して、仮想マシンのローカルストレージを設定できます。OpenShift Virtualization Operator をインストールすると、HPP Operator が自動的にインストールされます。
- namespace 間でデータボリュームのクローンを作成するためのユーザー権限を設定する
- RBAC ロールを設定して、ユーザーが namespace 間でデータボリュームのクローンを作成できるようにすることができます。
9.1.2. コンテナー化されたデータインポーター
次の Containerized Data Importer (CDI) 設定タスクを実行できます。
- namespace のリソース要求制限をオーバーライドする
- CPU およびメモリーリソースの制限を受ける namespace に仮想マシンディスクをインポート、アップロード、およびクローン作成するように CDI を設定できます。
- CDI スクラッチスペースを設定する
- CDI では、仮想マシンイメージのインポートやアップロードなどの一部の操作を完了するためにスクラッチスペース (一時ストレージ) が必要です。このプロセスで、CDI は、宛先データボリューム (DV) をサポートする PVC のサイズと同じサイズのスクラッチ領域 PVC をプロビジョニングします。
9.1.3. データボリューム
次のデータボリューム設定タスクを実行できます。
- データボリュームの事前割り当てを有効にする
- CDI は、データボリュームの作成時の書き込みパフォーマンスを向上させるために、ディスク領域を事前に割り当てることができます。特定のデータボリュームの事前割り当てを有効にできます。
- データボリュームのアノテーションを管理する
- データボリュームアノテーションを使用して Pod の動作を管理できます。1 つ以上のアノテーションをデータボリュームに追加してから、作成されたインポーター Pod に伝播できます。
9.1.4. ブートソースの更新
次のブートソース更新設定タスクを実行できます。
- ブートソースの自動更新を管理する
- ブートソースにより、ユーザーは仮想マシン (VM) をよりアクセスしやすく効率的に作成できるようになります。ブートソースの自動更新が有効になっている場合、CDI はイメージをインポート、ポーリング、更新して、新しい仮想マシン用にクローンを作成できるようにします。デフォルトでは、CDI は Red Hat ブートソースを自動的に更新します。次に、カスタムブートソースの自動更新を有効にできます。
9.2. ストレージプロファイルの設定
ストレージプロバイダーが Containerized Data Importer (CDI) によって認識されない場合は、ストレージプロファイルを設定する必要があります。
ストレージプロファイルは、関連付けられたストレージクラスに基づいて推奨されるストレージ設定を提供します。ストレージクラスごとにストレージクラスが割り当てられます。
認識されたストレージタイプの場合、CDI は PVC の作成を最適化する値を提供します。ただし、ストレージプロファイルをカスタマイズする場合は、ストレージクラスの自動設定を行うことができます。
Red Hat OpenShift Data Foundation で OpenShift Virtualization を使用する場合は、仮想マシンディスクの作成時に RBD ブロックモードの Persistent Volume Claim (PVC) を指定します。RBD ブロックモードボリュームは、Ceph FS または RBD ファイルシステムモード PVC よりも効率が高く、優れたパフォーマンスを提供します。
RBD ブロックモードの PVC を指定するには、'ocs-storagecluster-ceph-rbd' ストレージクラスおよび VolumeMode: Block を使用します。
9.2.1. ストレージプロファイルのカスタマイズ
プロビジョナーのストレージクラスの StorageProfile オブジェクトを編集してデフォルトパラメーターを指定できます。これらのデフォルトパラメーターは、DataVolume オブジェクトで設定されていない場合にのみ永続ボリューム要求 (PVC) に適用されます。
ストレージプロファイルの空の status セクションは、ストレージプロビジョナーが Containerized Data Interface (CDI) によって認識されないことを示します。CDI で認識されないストレージプロビジョナーがある場合、ストレージプロファイルをカスタマイズする必要があります。この場合、管理者はストレージプロファイルに適切な値を設定し、割り当てが正常に実行されるようにします。
データボリュームを作成し、YAML 属性を省略し、これらの属性がストレージプロファイルで定義されていない場合は、要求されたストレージは割り当てられず、基礎となる永続ボリューム要求 (PVC) は作成されません。
前提条件
- 計画した設定がストレージクラスとそのプロバイダーでサポートされていることを確認してください。ストレージプロファイルに互換性のない設定を指定すると、ボリュームのプロビジョニングに失敗します。
手順
ストレージプロファイルを編集します。この例では、プロビジョナーは CDI によって認識されません。
$ oc edit storageprofile <storage_class>
ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: {} status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>ストレージプロファイルに必要な属性値を指定します。
ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: claimPropertySets: - accessModes: - ReadWriteOnce 1 volumeMode: Filesystem 2 status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>変更を保存した後、選択した値がストレージプロファイルの
status要素に表示されます。
9.2.1.1. ストレージプロファイルを使用したデフォルトのクローンストラテジーの設定
ストレージプロファイルを使用してストレージクラスのデフォルトクローンメソッドを設定し、クローンストラテジー を作成できます。ストレージベンダーが特定のクローン作成方法のみをサポートする場合などに、クローンストラテジーを設定すると便利です。また、リソースの使用の制限やパフォーマンスの最大化を実現する手法を選択することもできます。
クローン作成ストラテジーは、ストレージプロファイルの cloneStrategy 属性を以下の値のいずれかに設定して指定できます。
-
snapshotが設定されている場合、デフォルトでスナップショットが使用されます。このクローン作成ストラテジーは、一時的なボリュームスナップショットを使用してボリュームのクローンを作成します。ストレージプロビジョナーは、Container Storage Interface (CSI) スナップショットをサポートする必要があります。 -
copyは、ソース Pod とターゲット Pod を使用して、ソースボリュームからターゲットボリュームにデータをコピーします。ホスト支援型でのクローン作成は、最も効率的な方法です。 -
csi-cloneは、CSI クローン API を使用して、中間ボリュームスナップショットを使用せずに、既存のボリュームのクローンを効率的に作成します。ストレージプロファイルが定義されていない場合にデフォルトで使用されるsnapshotまたはcopyとは異なり、CSI ボリュームのクローンは、プロビジョナーのストレージクラスのStorageProfileオブジェクトに指定した場合にだけ使用されます。
YAML spec セクションのデフォルトの claimPropertySets を変更せずに、CLI でクローンストラテジーを設定することもできます。
ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1
kind: StorageProfile
metadata:
name: <provisioner_class>
# ...
spec:
claimPropertySets:
- accessModes:
- ReadWriteOnce 1
volumeMode:
Filesystem 2
cloneStrategy: csi-clone 3
status:
provisioner: <provisioner>
storageClass: <provisioner_class>
9.3. ブートソースの自動更新の管理
次のブートソースの自動更新を管理できます。
ブートソースにより、ユーザーは仮想マシン (VM) をよりアクセスしやすく効率的に作成できるようになります。ブートソースの自動更新が有効になっている場合、コンテナー化データインポーター (CDI) はイメージをインポート、ポーリング、更新して、新しい仮想マシン用にクローンを作成できるようにします。デフォルトでは、CDI は Red Hat ブートソースを自動的に更新します。
9.3.1. Red Hat ブートソースの更新の管理
EnableCommonBootImageImport 機能ゲートを無効にすることで、システム定義のすべてのブートソースの自動更新をオプトアウトできます。この機能ゲートを無効にすると、すべての DataImportCron オブジェクトが削除されます。この場合、オペレーティングシステムイメージを保存する以前にインポートされたブートソースオブジェクトは削除されませんが、管理者はこれらのオブジェクトを手動で削除できます。
EnableCommonBootImageImport 機能ゲートが無効になると、DataSource オブジェクトがリセットされ、元のブートソースを指さなくなります。管理者は、DataSource オブジェクトの永続ボリューム要求 (PVC) またはボリュームスナップショットを新規作成し、それにオペレーティングシステムイメージを追加することで、ブートソースを手動で提供できます。
9.3.1.1. すべてのシステム定義のブートソースの自動更新の管理
ブートソースの自動インポートと更新を無効にすると、リソースの使用量が削減される可能性があります。切断された環境では、ブートソースの自動更新を無効にすると、CDIDataImportCronOutdated アラートがログをいっぱいにするのを防ぎます。
すべてのシステム定義のブートソースの自動更新を無効にするには、値を false に設定して、enableCommonBootImageImport 機能ゲートをオフにします。この値を true に設定すると、機能ゲートが再度有効になり、自動更新が再びオンになります。
カスタムブートソースは、この設定の影響を受けません。
手順
HyperConvergedカスタムリソース (CR) を編集して、ブートソースの自動更新の機能ゲートを切り替えます。ブートソースの自動更新を無効にするには、
HyperConvergedCR のspec.featureGates.enableCommonBootImageImportフィールドをfalseに設定します。以下に例を示します。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/featureGates/enableCommonBootImageImport", \ "value": false}]'ブートソースの自動更新を再び有効にするには、
HyperConvergedCR のspec.featureGates.enableCommonBootImageImportフィールドをtrueに設定します。以下に例を示します。$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": \ "/spec/featureGates/enableCommonBootImageImport", \ "value": true}]'
9.3.2. カスタムブートソースの更新の管理
OpenShift Virtualization によって提供されていない カスタム ブートソースは、機能ゲートによって制御されません。HyperConverged カスタムリソース (CR) を編集して、それらを個別に管理する必要があります。
ストレージクラスを設定する必要があります。そうしないと、クラスターはカスタムブートソースの自動更新を受信できません。詳細は、ストレージクラスの定義 を参照してください。
9.3.2.1. カスタムブートソース更新用のストレージクラスの設定
HyperConverged カスタムリソース (CR) を編集することで、デフォルトのストレージクラスをオーバーライドできます。
ブートソースは、デフォルトのストレージクラスを使用してストレージから作成されます。クラスターにデフォルトのストレージクラスがない場合は、カスタムブートソースの自動更新を設定する前に、デフォルトのストレージクラスを定義する必要があります。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
storageClassNameフィールドに値を入力して、新しいストレージクラスを定義します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: rhel8-image-cron spec: template: spec: storageClassName: <new_storage_class> 1 schedule: "0 */12 * * *" 2 managedDataSource: <data_source> 3 # ...For the custom image to be detected as an available boot source, the value of the `spec.dataVolumeTemplates.spec.sourceRef.name` parameter in the VM template must match this value.
現在のデフォルトのストレージクラスから
storageclass.kubernetes.io/is-default-classアノテーションを削除します。次のコマンドを実行して、現在のデフォルトのストレージクラスの名前を取得します。
$ oc get storageclass
出力例
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE csi-manila-ceph manila.csi.openstack.org Delete Immediate false 11d hostpath-csi-basic (default) kubevirt.io.hostpath-provisioner Delete WaitForFirstConsumer false 11d 1- 1
- この例では、現在のデフォルトのストレージクラスの名前は
hostpath-csi-basicです。
次のコマンドを実行して、現在のデフォルトのストレージクラスからアノテーションを削除します。
$ oc patch storageclass <current_default_storage_class> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}' 1- 1
<current_default_storage_class>をデフォルトのストレージクラスのstorageClassName値に置き換えます。
次のコマンドを実行して、新しいストレージクラスをデフォルトとして設定します。
$ oc patch storageclass <new_storage_class> -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' 1- 1
<new_storage_class>をHyperConvergedCR に追加したstorageClassName値に置き換えます。
9.3.2.2. カスタムブートソースの自動更新を有効にする
OpenShift Virtualization は、デフォルトでシステム定義のブートソースを自動的に更新しますが、カスタムブートソースは自動的に更新しません。HyperConverged カスタムリソース (CR) を編集して、自動更新を手動で有効にする必要があります。
前提条件
- クラスターにはデフォルトのストレージクラスがあります。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
適切なテンプレートおよびブートソースを
dataImportCronTemplatesセクションで追加して、HyperConvergedCR を編集します。以下に例を示します。カスタムリソースの例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: centos7-image-cron annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" 1 spec: schedule: "0 */12 * * *" 2 template: spec: source: registry: 3 url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 10Gi managedDataSource: centos7 4 retentionPolicy: "None" 5- 1
- このアノテーションは、
volumeBindingModeがWaitForFirstConsumerに設定されたストレージクラスに必要です。 - 2
- cron 形式で指定されるジョブのスケジュール。
- 3
- レジストリーソースからデータボリュームを作成するのに使用します。
nodedocker キャッシュに基づくデフォルトのnodepullMethodではなく、デフォルトのpodpullMethodを使用します。nodedocker キャッシュはレジストリーイメージがContainer.Imageで利用可能な場合に便利ですが、CDI インポーターはこれにアクセスすることは許可されていません。 - 4
- 利用可能なブートソースとして検出するカスタムイメージの場合、イメージの
managedDataSourceの名前が、仮想マシンテンプレート YAML ファイルのspec.dataVolumeTemplates.spec.sourceRef.nameにあるテンプレートのDataSourceの名前に一致する必要があります。 - 5
- cron ジョブが削除されたときにデータボリュームおよびデータソースを保持するには、
Allを使用します。cron ジョブが削除されたときにデータボリュームおよびデータソースを削除するには、Noneを使用します。
- ファイルを保存します。
9.3.2.3. ボリュームスナップショットのブートソースを有効にする
オペレーティングシステムのベースイメージを保存するストレージクラスに関連付けられた StorageProfile のパラメーターを設定して、ボリュームスナップショットのブートソースを有効にします。DataImportCron は、元々 PVC ソースのみを維持するように設計されていましたが、特定のストレージタイプでは VolumeSnapshot ソースの方が PVC ソースよりも拡張性に優れています。
ストレージプロファイルでは、単一のスナップショットからクローンを作成する場合により適切に拡張できることが証明されているボリュームスナップショットを使用してください。
前提条件
- オペレーティングシステムイメージを含むボリュームスナップショットにアクセスできる。
- ストレージはスナップショットをサポートしている。
手順
次のコマンドを実行して、ブートソースのプロビジョニングに使用されるストレージクラスに対応するストレージプロファイルオブジェクトを開きます。
$ oc edit storageprofile <storage_class>
-
StorageProfileのdataImportCronSourceFormat仕様を確認して、仮想マシンがデフォルトで PVC またはボリュームスナップショットを使用しているか確認します。 必要に応じて、
dataImportCronSourceFormat仕様をsnapshotに更新して、ストレージプロファイルを編集します。ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: # ... spec: dataImportCronSourceFormat: snapshot
検証
ブートソースのプロビジョニングに使用されるストレージクラスに対応するストレージプロファイルオブジェクトを開きます。
$ oc get storageprofile <storage_class> -oyaml
-
StorageProfileのdataImportCronSourceFormat仕様が 'snapshot' に設定されていること、およびDataImportCronが指すDataSourceオブジェクトがボリュームスナップショットを参照していることを確認します。
これで、これらのブートソースを使用して仮想マシンを作成できるようになりました。
9.3.3. 単一ブートソースの自動更新を無効にする
HyperConverged カスタムリソース (CR) を編集することで、カスタムブートソースかシステム定義ブートソースかに関係なく、個々のブートソースの自動更新を無効にできます。
手順
以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.dataImportCronTemplatesフィールドを編集して、個々のブートソースの自動更新を無効にします。- カスタムブートソース
-
spec.dataImportCronTemplatesフィールドからブートソースを削除します。カスタムブートソースの自動更新はデフォルトで無効になっています。
-
- システム定義のブートソース
ブートソースを
spec.dataImportCronTemplatesに追加します。注記システム定義のブートソースの自動更新はデフォルトで有効になっていますが、これらのブートソースは追加しない限り CR にリストされません。
dataimportcrontemplate.kubevirt.io/enableアノテーションの値を'false'に設定します。以下に例を示します。
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: annotations: dataimportcrontemplate.kubevirt.io/enable: 'false' name: rhel8-image-cron # ...
- ファイルを保存します。
9.3.4. ブートソースのステータスの確認
HyperConverged カスタムリソース (CR) を表示することで、ブートソースがシステム定義であるかカスタムであるかを判断できます。
手順
次のコマンドを実行して、
HyperConvergedCR の内容を表示します。$ oc get hyperconverged kubevirt-hyperconverged -n openshift-cnv -o yaml
出力例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: # ... status: # ... dataImportCronTemplates: - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: centos-7-image-cron spec: garbageCollect: Outdated managedDataSource: centos7 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 30Gi status: {} status: commonTemplate: true 1 # ... - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: user-defined-dic spec: garbageCollect: Outdated managedDataSource: user-defined-centos-stream8 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: pullMethod: node url: docker://quay.io/containerdisks/centos-stream:8 storage: resources: requests: storage: 30Gi status: {} status: {} 2 # ...status.dataImportCronTemplates.statusフィールドを確認して、ブートソースのステータスを確認します。-
フィールドに
commonTemplate: trueが含まれている場合、それはシステム定義のブートソースです。 -
status.dataImportCronTemplates.statusフィールドの値が{}の場合、それはカスタムブートソースです。
-
フィールドに
9.4. ファイルシステムオーバーヘッドの PVC 領域の確保
Filesystem ボリュームモードを使用する永続ボリューム要求 (PVC) に仮想マシンディスクを追加する場合は、仮想マシンディスクおよびファイルシステムのオーバーヘッド (メタデータなど) 用に十分なスペースが PVC 上にあることを確認する必要があります。
デフォルトでは、OpenShift Virtualization は PVC 領域の 5.5% をオーバーヘッド用に予約し、その分、仮想マシンディスクに使用できる領域を縮小します。
HCO オブジェクトを編集して、別のオーバーヘッド値を設定できます。値はグローバルに変更でき、特定のストレージクラスの値を指定できます。
9.4.1. デフォルトのファイルシステムオーバーヘッド値の上書き
HCO オブジェクトの spec.filesystemOverhead 属性を編集することで、OpenShift Virtualization がファイルシステムオーバーヘッド用に予約する永続ボリューム要求 (PVC) 領域の量を変更します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
HCOオブジェクトを編集用に開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.filesystemOverheadフィールドを編集して、選択した値でデータを設定します。# ... spec: filesystemOverhead: global: "<new_global_value>" 1 storageClass: <storage_class_name>: "<new_value_for_this_storage_class>" 2-
エディターを保存して終了し、
HCOオブジェクトを更新します。
検証
次のいずれかのコマンドを実行して、
CDIConfigステータスを表示し、変更を確認します。一般的に
CDIConfigへの変更を確認するには以下を実行します。$ oc get cdiconfig -o yaml
CDIConfig に対する特定の変更を表示するには以下を実行します。$ oc get cdiconfig -o jsonpath='{.items..status.filesystemOverhead}'
9.5. ホストパスプロビジョナーを使用したローカルストレージの設定
ホストパスプロビジョナー (HPP) を使用して、仮想マシンのローカルストレージを設定できます。
OpenShift Virtualization Operator のインストール時に、Hostpath Provisioner Operator は自動的にインストールされます。HPP は、Hostpath Provisioner Operator によって作成される OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。HPP を使用するには、基本ストレージプールを使用して HPP カスタムリソース (CR) を作成します。
9.5.1. 基本ストレージ プールを使用したホストパスプロビジョナーの作成
storagePools スタンザを使用して HPP カスタムリソース (CR) を作成することにより、基本ストレージプールを使用してホストパスプロビジョナー (HPP) を設定します。ストレージプールは、CSI ドライバーが使用する名前とパスを指定します。
オペレーティングシステムと同じパーティションにストレージプールを作成しないでください。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。
手順
次の例のように、
storagePoolsスタンザを含むhpp_cr.yamlファイルを作成します。apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools: 1 - name: any_name path: "/var/myvolumes" 2 workload: nodeSelector: kubernetes.io/os: linux
- ファイルを保存して終了します。
次のコマンドを実行して HPP を作成します。
$ oc create -f hpp_cr.yaml
9.5.1.1. ストレージクラスの作成について
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
ホストパスプロビジョナー (HPP) を使用するには、storagePools スタンザで CSI ドライバーの関連付けられたストレージクラスを作成する必要があります。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
9.5.1.2. storagePools スタンザを使用した CSI ドライバーのストレージクラスの作成
ホストパスプロビジョナー (HPP) を使用するには、コンテナーストレージインターフェイス (CSI) ドライバーに関連するストレージクラスを作成する必要があります。
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
手順
storageclass_csi.yamlファイルを作成して、ストレージクラスを定義します。apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: hostpath-csi provisioner: kubevirt.io.hostpath-provisioner reclaimPolicy: Delete 1 volumeBindingMode: WaitForFirstConsumer 2 parameters: storagePool: my-storage-pool 3
- 1
reclaimPolicyには、DeleteおよびRetainの 2 つの値があります。値を指定しない場合、デフォルト値はDeleteです。- 2
volumeBindingModeパラメーターは、動的プロビジョニングとボリュームのバインディングが実行されるタイミングを決定します。WaitForFirstConsumerを指定して、永続ボリューム要求 (PVC) を使用する Pod が作成されるまで PV のバインディングおよびプロビジョニングを遅延させます。これにより、PV が Pod のスケジュール要件を満たすようになります。- 3
- HPP CR で定義されているストレージプールの名前を指定します。
- ファイルを保存して終了します。
次のコマンドを実行して、
StorageClassオブジェクトを作成します。$ oc create -f storageclass_csi.yaml
9.5.2. PVC テンプレートで作成されたストレージプールについて
単一の大きな永続ボリューム (PV) がある場合は、ホストパスプロビジョナー (HPP) カスタムリソース (CR) で PVC テンプレートを定義することにより、ストレージプールを作成できます。
PVC テンプレートで作成されたストレージプールには、複数の HPP ボリュームを含めることができます。PV を小さなボリュームに分割すると、データ割り当ての柔軟性が向上します。
PVC テンプレートは、PersistentVolumeClaim オブジェクトの spec スタンザに基づいています。
PersistentVolumeClaim オブジェクトの例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iso-pvc
spec:
volumeMode: Block 1
storageClassName: my-storage-class
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
- 1
- この値は、ブロックボリュームモードの PV にのみ必要です。
HPP CR の pvcTemplate 仕様を使用してストレージプールを定義します。Operator は、HPP CSI ドライバーを含む各ノードの pvcTemplate 仕様から PVC を作成します。PVC テンプレートから作成される PVC は単一の大きな PV を消費するため、HPP は小規模な動的ボリュームを作成できます。
基本的なストレージプールを、PVC テンプレートから作成されたストレージプールと組み合わせることができます。
9.5.2.1. PVC テンプレートを使用したストレージプールの作成
HPP カスタムリソース (CR) で PVC テンプレートを指定することにより、複数のホストパスプロビジョナー (HPP) ボリューム用のストレージプールを作成できます。
オペレーティングシステムと同じパーティションにストレージプールを作成しないでください。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。
手順
次の例に従って、
storagePoolsスタンザで永続ボリューム (PVC) テンプレートを指定する HPP CR のhpp_pvc_template_pool.yamlファイルを作成します。apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools: 1 - name: my-storage-pool path: "/var/myvolumes" 2 pvcTemplate: volumeMode: Block 3 storageClassName: my-storage-class 4 accessModes: - ReadWriteOnce resources: requests: storage: 5Gi 5 workload: nodeSelector: kubernetes.io/os: linux
- 1
storagePoolsスタンザは、基本ストレージプールと PVC テンプレートストレージプールの両方を含むことができるアレイです。- 2
- このノードパスの下にストレージプールディレクトリーを指定します。
- 3
- オプション:
volumeModeパラメーターは、プロビジョニングされたボリューム形式と一致する限り、BlockまたはFilesystemのいずれかにすることができます。値が指定されていない場合、デフォルトはFilesystemです。volumeModeがBlockの場合、Pod をマウントする前にブロックボリュームに XFS ファイルシステムが作成されます。 - 4
storageClassNameパラメーターを省略すると、デフォルトのストレージクラスを使用して PVC を作成します。storageClassNameを省略する場合、HPP ストレージクラスがデフォルトのストレージクラスではないことを確認してください。- 5
- 静的または動的にプロビジョニングされるストレージを指定できます。いずれの場合も、要求されたストレージサイズが仮想的に分割する必要のあるボリュームに対して適切になるようにしてください。そうしないと、PVC を大規模な PV にバインドすることができません。使用しているストレージクラスが動的にプロビジョニングされるストレージを使用する場合、典型的な要求のサイズに一致する割り当てサイズを選択します。
- ファイルを保存して終了します。
次のコマンドを実行して、ストレージ プールを使用して HPP を作成します。
$ oc create -f hpp_pvc_template_pool.yaml
9.6. 複数の namespace 間でデータボリュームをクローン作成するためのユーザーパーミッションの有効化
namespace には相互に分離する性質があるため、ユーザーはデフォルトでは namespace をまたがってリソースのクローンを作成することができません。
ユーザーが仮想マシンのクローンを別の namespace に作成できるようにするには、cluster-admin ロールを持つユーザーが新規のクラスターロールを作成する必要があります。このクラスターロールをユーザーにバインドし、それらのユーザーが仮想マシンのクローンを宛先 namespace に対して作成できるようにします。
9.6.1. データボリュームのクローン作成のための RBAC リソースの作成
datavolumes リソースのすべてのアクションのパーミッションを有効にする新規のくスターロールを作成します。
前提条件
- クラスター管理者権限がある。
手順
ClusterRoleマニフェストを作成します。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <datavolume-cloner> 1 rules: - apiGroups: ["cdi.kubevirt.io"] resources: ["datavolumes/source"] verbs: ["*"]- 1
- クラスターロールの一意の名前。
クラスターにクラスターロールを作成します。
$ oc create -f <datavolume-cloner.yaml> 1- 1
- 直前の手順で作成された
ClusterRoleマニフェストのファイル名です。
移行元および宛先 namespace の両方に適用される
RoleBindingマニフェストを作成し、直前の手順で作成したクラスターロールを参照します。apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <allow-clone-to-user> 1 namespace: <Source namespace> 2 subjects: - kind: ServiceAccount name: default namespace: <Destination namespace> 3 roleRef: kind: ClusterRole name: datavolume-cloner 4 apiGroup: rbac.authorization.k8s.io
クラスターにロールバインディングを作成します。
$ oc create -f <datavolume-cloner.yaml> 1- 1
- 直前の手順で作成された
RoleBindingマニフェストのファイル名です。
9.7. CPU およびメモリークォータをオーバーライドするための CDI の設定
Containerized Data Importer (CDI) を設定して、CPU およびメモリーリソースの制限が適用される namespace に仮想マシンディスクをインポートし、アップロードし、そのクローンを作成できるようになりました。
9.7.1. namespace の CPU およびメモリークォータについて
ResourceQuota オブジェクトで定義される リソースクォータ は、その namespace 内のリソースが消費できるコンピュートリソースの全体量を制限する制限を namespace に課します。
HyperConverged カスタムリソース (CR) は、Containerized Data Importer (CDI) のユーザー設定を定義します。CPU とメモリーの要求値と制限値は、デフォルト値の 0 に設定されています。これにより、コンピュートリソース要件を指定しない CDI によって作成される Pod にデフォルト値が付与され、クォータで制限される namespace での実行が許可されます。
9.7.2. CPU およびメモリーのデフォルトの上書き
HyperConverged カスタムリソース (CR) に spec.resourceRequirements.storageWorkloads スタンザを追加して、CPU およびメモリー要求のデフォルト設定とユースケースの制限を変更します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.resourceRequirements.storageWorkloadsスタンザを CR に追加し、ユースケースに基づいて値を設定します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: resourceRequirements: storageWorkloads: limits: cpu: "500m" memory: "2Gi" requests: cpu: "250m" memory: "1Gi"-
エディターを保存して終了し、
HyperConvergedCR を更新します。
9.7.3. 関連情報
9.8. CDI のスクラッチ領域の用意
9.8.1. スクラッチ領域について
Containerized Data Importer (CDI) では、仮想マシンイメージのインポートやアップロードなどの、一部の操作を実行するためにスクラッチ領域 (一時ストレージ) が必要になります。このプロセスで、CDI は、宛先データボリューム (DV) をサポートする PVC のサイズと同じサイズのスクラッチ領域 PVC をプロビジョニングします。スクラッチ領域 PVC は操作の完了または中止後に削除されます。
HyperConverged カスタムリソースの spec.scratchSpaceStorageClass フィールドで、スクラッチ領域 PVC をバインドするために使用されるストレージクラスを定義できます。
定義されたストレージクラスがクラスターのストレージクラスに一致しない場合、クラスターに定義されたデフォルトのストレージクラス が使用されます。クラスターで定義されたデフォルトのストレージクラスがない場合、元の DV または PVC のプロビジョニングに使用されるストレージクラスが使用されます。
CDI では、元のデータボリュームをサポートする PVC の種類を問わず、file ボリュームモードが設定されているスクラッチ領域が必要です。元の PVC が block ボリュームモードでサポートされる場合、 file ボリュームモード PVC をプロビジョニングできるストレージクラスを定義する必要があります。
手動プロビジョニング
ストレージクラスがない場合、CDI はイメージのサイズ要件に一致するプロジェクトの PVC を使用します。これらの要件に一致する PVC がない場合、CDI インポート Pod は適切な PVC が利用可能になるまで、またはタイムアウト機能が Pod を強制終了するまで Pending 状態になります。
9.8.2. スクラッチ領域を必要とする CDI 操作
| タイプ | 理由 |
|---|---|
| レジストリーのインポート | CDI はイメージをスクラッチ領域にダウンロードし、イメージファイルを見つけるためにレイヤーを抽出する必要があります。その後、raw ディスクに変換するためにイメージファイルが QEMU-img に渡されます。 |
| イメージのアップロード | QEMU-IMG は STDIN の入力を受け入れません。代わりに、アップロードするイメージは、変換のために QEMU-IMG に渡される前にスクラッチ領域に保存されます。 |
| アーカイブされたイメージの HTTP インポート | QEMU-IMG は、CDI がサポートするアーカイブ形式の処理方法を認識しません。イメージが QEMU-IMG に渡される前にアーカイブは解除され、スクラッチ領域に保存されます。 |
| 認証されたイメージの HTTP インポート | QEMU-IMG が認証を適切に処理しません。イメージが QEMU-IMG に渡される前にスクラッチ領域に保存され、認証されます。 |
| カスタム証明書の HTTP インポート | QEMU-IMG は HTTPS エンドポイントのカスタム証明書を適切に処理しません。代わりに CDI は、ファイルを QEMU-IMG に渡す前にイメージをスクラッチ領域にダウンロードします。 |
9.8.3. ストレージクラスの定義
spec.scratchSpaceStorageClass フィールドを HyperConverged カスタムリソース (CR) に追加することにより、スクラッチ領域を割り当てる際に、Containerized Data Importer (CDI) が使用するストレージクラスを定義できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.scratchSpaceStorageClassフィールドを CR に追加し、値をクラスターに存在するストレージクラスの名前に設定します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: scratchSpaceStorageClass: "<storage_class>" 1- 1
- ストレージクラスを指定しない場合、CDI は設定されている永続ボリューム要求 (PVC) のストレージクラスを使用します。
-
デフォルトのエディターを保存して終了し、
HyperConvergedCR を更新します。
9.8.4. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.8.5. 関連情報
9.9. データボリュームの事前割り当ての使用
Containerized Data Importer は、データボリュームの作成時に書き込みパフォーマンスを向上させるために、ディスク領域を事前に割り当てることができます。
特定のデータボリュームの事前割り当てを有効にできます。
9.9.1. 事前割り当てについて
Containerized Data Importer (CDI) は、データボリュームに QEMU 事前割り当てモードを使用し、書き込みパフォーマンスを向上できます。操作のインポートおよびアップロードには、事前割り当てモードを使用できます。また、空のデータボリュームを作成する際にも使用できます。
事前割り当てが有効化されている場合、CDI は基礎となるファイルシステムおよびデバイスタイプに応じて、より適切な事前割り当て方法を使用します。
fallocate-
ファイルシステムがこれをサポートする場合、CDI は
posix_fallocate関数を使用して領域を事前に割り当てるためにオペレーティングシステムのfallocate呼び出しを使用します。これは、ブロックを割り当て、それらを未初期化としてマークします。 full-
fallocateモードを使用できない場合は、基礎となるストレージにデータを書き込むことで、fullモードがイメージの領域を割り当てます。ストレージの場所によっては、空の割り当て領域がすべてゼロになる場合があります。
9.9.2. データボリュームの事前割り当ての有効化
データボリュームマニフェストに spec.preallocation フィールドを含めることにより、特定のデータボリュームの事前割り当てを有効にできます。Web コンソールで、または OpenShift CLI (oc) を使用して、事前割り当てモードを有効化することができます。
事前割り当てモードは、すべての CDI ソースタイプでサポートされます。
手順
データボリュームマニフェストの
spec.preallocationフィールドを指定します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: preallocated-datavolume spec: source: 1 registry: url: <image_url> 2 storage: resources: requests: storage: 1Gi # ...
9.10. データボリュームアノテーションの管理
データボリューム (DV) アノテーションを使用して Pod の動作を管理できます。1 つ以上のアノテーションをデータボリュームに追加してから、作成されたインポーター Pod に伝播できます。
9.10.1. 例: データボリュームアノテーション
以下の例は、インポーター Pod が使用するネットワークを制御するためにデータボリューム (DV) アノテーションを設定する方法を示しています。v1.multus-cni.io/default-network: bridge-network アノテーションにより、Pod は bridge-network という名前の multus ネットワークをデフォルトネットワークとして使用します。インポーター Pod にクラスターからのデフォルトネットワークとセカンダリー multus ネットワークの両方を使用させる必要がある場合は、k8s.v1.cni.cncf.io/networks: <network_name> アノテーションを使用します。
Multus ネットワークアノテーションの例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: datavolume-example
annotations:
v1.multus-cni.io/default-network: bridge-network 1
# ...
- 1
- Multus ネットワークアノテーション
第10章 ライブマイグレーション
10.1. ライブマイグレーションについて
ライブマイグレーションは、仮想ワークロードに支障を与えることなく、実行中の仮想マシンをクラスター内の別のノードに移行するプロセスです。デフォルトでは、ライブマイグレーショントラフィックは Transport Layer Security (TLS) を使用して暗号化されます。
10.1.1. ライブマイグレーションの要件
ライブマイグレーションには次の要件があります。
-
クラスターには、
ReadWriteMany(RWX) アクセスモードの共有ストレージが必要です。 クラスターには十分な RAM とネットワーク帯域幅が必要です。
注記ライブマイグレーションを引き起こすノードドレインをサポートするために、クラスター内に十分なメモリーリクエスト容量があることを確認する必要があります。以下の計算を使用して、必要な予備のメモリーを把握できます。
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)
クラスターで並行して実行できるデフォルトの移行数は 5 です。
- 仮想マシンがホストモデル CPU を使用する場合、ノードはその CPU をサポートする必要があります。
- ライブマイグレーション用に 専用の Multus ネットワークを設定すること を強く推奨します。専用ネットワークは、移行中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
10.1.2. 一般的なライブマイグレーションタスク
次のライブマイグレーションタスクを実行できます。
10.1.3. 関連情報
10.2. ライブマイグレーションの設定
ライブマイグレーション設定を行い、移行プロセスがクラスターに負荷を与えないようにすることができます。
ライブマイグレーションポリシーを設定して、さまざまな移行設定を仮想マシンのグループに適用できます。
10.2.1. ライブマイグレーション設定
次のライブマイグレーション設定を設定できます。
10.2.1.1. ライブマイグレーションの制限およびタイムアウトの設定
openshift-cnv namespace にある HyperConverged カスタムリソース (CR) を更新して、クラスターのライブマイグレーションの制限およびタイムアウトを設定します。
手順
HyperConvergedCR を編集し、必要なライブマイグレーションパラメーターを追加します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: liveMigrationConfig: bandwidthPerMigration: 64Mi 1 completionTimeoutPerGiB: 800 2 parallelMigrationsPerCluster: 5 3 parallelOutboundMigrationsPerNode: 2 4 progressTimeout: 150 5- 1
- 各マイグレーションの帯域幅制限。値は 1 秒あたりのバイト数です。たとえば、値
2048Miは 2048 MiB/s を意味します。デフォルト:0(無制限)。 - 2
- 移行がこの時間内に終了しない場合 (単位はメモリーの GiB あたりの秒数)、移行は取り消されます。たとえば、6 GiB メモリーを搭載した仮想マシンは、4800 秒以内に移行が完了しないとタイムアウトになります。
Migration MethodがBlockMigrationの場合、移行するディスクのサイズは計算に含められます。 - 3
- クラスターで並行して実行される移行の数。デフォルトは
5です。 - 4
- ノードごとのアウトバウンドの移行の最大数。デフォルトは
2です。 - 5
- メモリーのコピーの進捗がこの時間内 (秒単位) に見られない場合に、移行は取り消されます。デフォルトは
150です。
キー/値のペアを削除し、ファイルを保存して、spec.liveMigrationConfig フィールドのデフォルト値を復元できます。たとえば、progressTimeout: <value> を削除してデフォルトの progressTimeout: 150 を復元します。
10.2.2. ライブマイグレーションポリシー
ライブマイグレーションポリシーを作成して、仮想マシンまたはプロジェクトラベルによって定義された仮想マシンのグループにさまざまな移行設定を適用できます。
Web コンソール を使用してライブマイグレーションポリシーを作成できます。
10.2.2.1. コマンドラインを使用したライブマイグレーションポリシーの作成
コマンドラインを使用してライブマイグレーションポリシーを作成できます。ライブマイグレーションポリシーは、ラベルの任意の組み合わせを使用して、選択した仮想マシンに適用されます。
-
size、os、gpuなどの仮想マシンラベル -
priority、bandwidth、またはhpc-workloadなどのプロジェクトラベル
ポリシーを特定の仮想マシングループに適用するには、仮想マシングループのすべてのラベルがポリシーのラベルと一致する必要があります。
複数のライブマイグレーションポリシーが仮想マシンに適用される場合は、一致するラベルの数が最も多いポリシーが優先されます。
複数のポリシーがこの基準を満たす場合、ポリシーは一致するラベルキーのアルファベット順に並べ替えられ、その順序の最初のポリシーが優先されます。
手順
次の例のように
MigrationPolicyオブジェクトを作成します。apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy metadata: name: <migration_policy> spec: selectors: namespaceSelector: 1 hpc-workloads: "True" xyz-workloads-type: "" virtualMachineInstanceSelector: 2 workload-type: "db" operating-system: ""次のコマンドを実行して、移行ポリシーを作成します。
$ oc create migrationpolicy -f <migration_policy>.yaml
10.2.3. 関連情報
10.3. ライブマイグレーションの開始とキャンセル
OpenShift Container Platform Web コンソール または コマンドライン を使用して、仮想マシンの別のノードへのライブマイグレーションを開始できます。
ライブマイグレーションは、Web コンソール または コマンドライン を使用してキャンセルできます。仮想マシンは元のノードに残ります。
virtctl migrate <vm_name> コマンドおよび virtctl migrate-cancel <vm_name> コマンドを使用して、ライブマイグレーションを開始およびキャンセルすることもできます。
10.3.1. ライブマイグレーションの開始
10.3.1.1. Web コンソールを使用したライブマイグレーションの開始
OpenShift Container Platform Web コンソールを使用して、実行中の仮想マシンをクラスター内の別のノードにライブマイグレーションできます。
Migrate アクションはすべてのユーザーに表示されますが、ライブマイグレーションを開始できるのはクラスター管理者のみです。
前提条件
- 仮想マシンは移行可能である必要があります。
- 仮想マシンがホストモデル CPU で設定されている場合、クラスターにはその CPU モデルをサポートする利用可能なノードが必要です。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
-
仮想マシンの横にあるオプションメニュー
から 移行 を選択します。
- Migrate をクリックします。
10.3.1.2. コマンドラインを使用してライブマイグレーションを開始する
コマンドラインを使用して仮想マシンの VirtualMachineInstanceMigration オブジェクトを作成することで、実行中の仮想マシンのライブマイグレーションを開始できます。
手順
移行する仮想マシンの
VirtualMachineInstanceMigrationマニフェストを作成します。apiVersion: kubevirt.io/v1 kind: VirtualMachineInstanceMigration metadata: name: <migration_name> spec: vmiName: <vm_name>
以下のコマンドを実行してオブジェクトを作成します。
$ oc create -f <migration_name>.yaml
VirtualMachineInstanceMigrationオブジェクトは、仮想マシンのライブマイグレーションをトリガーします。このオブジェクトは、手動で削除されない場合、仮想マシンインスタンスが実行中である限りクラスターに存在します。
検証
次のコマンドを実行して、仮想マシンのステータスを取得します。
$ oc describe vmi <vm_name> -n <namespace>
出力例
# ... Status: Conditions: Last Probe Time: <nil> Last Transition Time: <nil> Status: True Type: LiveMigratable Migration Method: LiveMigration Migration State: Completed: true End Timestamp: 2018-12-24T06:19:42Z Migration UID: d78c8962-0743-11e9-a540-fa163e0c69f1 Source Node: node2.example.com Start Timestamp: 2018-12-24T06:19:35Z Target Node: node1.example.com Target Node Address: 10.9.0.18:43891 Target Node Domain Detected: true
10.3.2. ライブマイグレーションのキャンセル
10.3.2.1. Web コンソールを使用したライブマイグレーションのキャンセル
OpenShift Container Platform Web コンソールを使用して、仮想マシンのライブマイグレーションをキャンセルできます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
-
仮想マシンの横にある オプションメニュー
で Cancel Migration を選択します。
10.3.2.2. コマンドラインを使用したライブマイグレーションのキャンセル
移行に関連付けられた VirtualMachineInstanceMigration オブジェクトを削除して、仮想マシンのライブマイグレーションを取り消します。
手順
ライブマイグレーションをトリガーした
VirtualMachineInstanceMigrationオブジェクトを削除します。 この例では、migration-jobが使用されています。$ oc delete vmim migration-job
10.3.3. 関連情報
第11章 ノード
11.1. ノードのメンテナンス
oc adm ユーティリティーまたは NodeMaintenance カスタムリソース (CR) を使用してノードをメンテナンスモードにすることができます。
node-maintenance-operator (NMO) は OpenShift Virtualization に同梱されなくなりました。これは、OpenShift Container Platform Web コンソールの OperatorHub から、または OpenShift CLI (oc) を使用して、スタンドアロン Operator としてデプロイされます。
ノードの修復、フェンシング、メンテナンスについて、詳しくは Red Hat OpenShift のワークロードの可用性 を参照してください。
仮想マシンでは、共有 ReadWriteMany (RWX) アクセスモードを持つ永続ボリューム要求 (PVC) のライブマイグレーションが必要です。
Node Maintenance Operator は、新規または削除された NodeMaintenance CR をモニタリングします。新規の NodeMaintenance CR が検出されると、新規ワークロードはスケジュールされず、ノードは残りのクラスターから遮断されます。エビクトできるすべての Pod はノードからエビクトされます。NodeMaintenance CR が削除されると、CR で参照されるノードは新規ワークロードで利用可能になります。
ノードのメンテナンスタスクに NodeMaintenance CR を使用すると、標準の OpenShift Container Platform カスタムリソース処理を使用して oc adm cordon および oc adm drain コマンドの場合と同じ結果が得られます。
11.1.1. エビクションストラテジー
ノードをメンテナンス状態にすると、そのノードはスケジュール不能としてマークされ、そこからすべての仮想マシンと Pod が排出されます。
仮想マシンまたはクラスターに対してエビクション戦略を設定できます。
- 仮想マシンエビクションストラテジー
仮想マシンの
LiveMigrateエビクションストラテジーは、ノードがメンテナンス状態になるか、ドレイン (解放) される場合に仮想マシンインスタンスが中断されないようにします。このエビクション戦略を持つ VMI は、別のノードにライブマイグレーションされます。Web コンソール または コマンドライン を使用して、仮想マシンのエビクション戦略を設定できます。
重要デフォルトのエビクション戦略は
LiveMigrateです。LiveMigrateエビクション戦略を使用する移行不可能な仮想マシンは、仮想マシンがノードからエビクションされないため、ノードのドレインを妨げたり、インフラストラクチャーのアップグレードをブロックしたりする可能性があります。この状況では、仮想マシンを手動でシャットダウンしない限り、移行はPendingまたはScheduling中の状態のままになります。移行不可能な仮想マシンのエビクション戦略を、アップグレードをブロックしない
LiveMigrateIfPossibleに設定するか、移行すべきでない仮想マシンの場合はNoneに設定する必要があります。
- クラスターエビクション戦略
- ワークロードの継続性またはインフラストラクチャーのアップグレードを優先するために、クラスターのエビクション戦略を設定できます。
クラスターエビクション戦略の設定はテクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
表11.1 クラスターのエビクション戦略
| エビクションストラテジー | 説明 | ワークフローを中断する | アップグレードをブロックする |
|---|---|---|---|
|
| アップグレードよりもワークロードの継続性を優先します。 | No | はい 2 |
|
| ワークロードの継続性よりもアップグレードを優先して、環境が確実に更新されるようにします。 | Yes | No |
|
| エビクション戦略を使用せずに仮想マシンをシャットダウンします。 | Yes | No |
- マルチノードクラスターのデフォルトのエビクション戦略。
- 仮想マシンがアップグレードをブロックする場合は、仮想マシンを手動でシャットダウンする必要があります。
- シングルノード OpenShift のデフォルトのエビクション戦略。
11.1.1.1. コマンドラインを使用した仮想マシンエビクション戦略の設定
コマンドラインを使用して、仮想マシンのエビクション戦略を設定できます。
デフォルトのエビクション戦略は LiveMigrate です。LiveMigrate エビクション戦略を使用する移行不可能な仮想マシンは、仮想マシンがノードからエビクションされないため、ノードのドレインを妨げたり、インフラストラクチャーのアップグレードをブロックしたりする可能性があります。この状況では、仮想マシンを手動でシャットダウンしない限り、移行は Pending または Scheduling 中の状態のままになります。
移行不可能な仮想マシンのエビクション戦略を、アップグレードをブロックしない LiveMigrateIfPossible に設定するか、移行すべきでない仮想マシンの場合は None に設定する必要があります。
手順
次のコマンドを実行して、
VirtualMachineリソースを編集します。$ oc edit vm <vm_name> -n <namespace>
エビクション戦略の例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: <vm_name> spec: template: spec: evictionStrategy: LiveMigrateIfPossible 1 # ...- 1
- エビクション戦略を指定します。デフォルト値は
LiveMigrateです。
仮想マシンを再起動して変更を適用します。
$ virtctl restart <vm_name> -n <namespace>
11.1.1.2. コマンドラインを使用したクラスターエビクション戦略の設定
コマンドラインを使用して、クラスターのエビクション戦略を設定できます。
クラスターエビクション戦略の設定はテクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
手順
次のコマンドを実行して、
hyperconvergedリソースを編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
次の例に示すように、クラスターのエビクション戦略を設定します。
クラスターエビクション戦略の例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: evictionStrategy: LiveMigrate # ...
11.1.2. 戦略を実行する
spec.running: true で設定された仮想マシンはすぐに再起動されます。spec.runStrategy キーを使用すると、特定の条件下で仮想マシンがどのように動作するかを決定するための柔軟性が高まります。
spec.runStrategy キーと spec.running キーは相互に排他的です。いずれか 1 つだけを使用できます。
両方のキーを含む仮想マシン設定は無効です。
11.1.2.1. 戦略を実行する
spec.runStrategy キーには 4 つの値があります。
Always-
仮想マシンインスタンス (VMI) は、仮想マシンが別のノードに作成されるときに常に存在します。元の VMI が何らかの理由で停止した場合、新しい VMI が作成されます。これは、
running: trueと同じ動作です。 RerunOnFailure- 以前のインスタンスに障害が発生した場合、VMI は別のノードで再作成されます。仮想マシンがシャットダウンされた場合など、仮想マシンが正常に停止した場合、インスタンスは再作成されません。
Manual-
VMI 状態は、virtctl クライアントコマンドの
start、stop、およびrestartを使用して手動で制御します。仮想マシンは自動的には再起動されません。 Halted-
仮想マシンの作成時には VMI は存在しません。これは、
running: falseと同じ動作です。
virtctl start、stop、および restart コマンドのさまざまな組み合わせは、実行戦略に影響します。
次の表では、仮想マシンの状態間の遷移について説明します。最初の列は、仮想マシンの初期実行戦略を示します。残りの列には、virtctl コマンドと、そのコマンドの実行後の新しい実行戦略が表示されます。
表11.2 virtctl コマンドの前後でストラテジーを実行する
| 初期実行戦略 | Start | Stop | Restart |
|---|---|---|---|
| Always | - | Halted | Always |
| RerunOnFailure | - | Halted | RerunOnFailure |
| Manual | Manual | Manual | Manual |
| Halted | Always | - | - |
インストーラーによってプロビジョニングされたインフラストラクチャーを使用してインストールされたクラスター内のノードがマシンの健全性チェックに失敗して使用できない場合は、runStrategy: Always または runStrategy: RerunOnFailure を持つ仮想マシンが新しいノードで再スケジュールされます。
11.1.2.2. コマンドラインを使用した仮想マシン実行戦略の設定
コマンドラインを使用して、仮想マシンの実行戦略を設定できます。
spec.runStrategy キーと spec.running キーは相互に排他的です。両方のキーの値を含む仮想マシン設定は無効です。
手順
次のコマンドを実行して、
VirtualMachineリソースを編集します。$ oc edit vm <vm_name> -n <namespace>
実行戦略の例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: runStrategy: Always # ...
11.1.3. ベアメタルノードのメンテナンス
OpenShift Container Platform をベアメタルインフラストラクチャーにデプロイする場合、クラウドインフラストラクチャーにデプロイする場合と比較すると、追加で考慮する必要のある点があります。クラスターノードが一時的とみなされるクラウド環境とは異なり、ベアメタルノードを再プロビジョニングするには、メンテナンスタスクにより多くの時間と作業が必要になります。
致命的なカーネルエラーが発生したり、NIC カードのハードウェア障害が発生する場合などにベアメタルノードに障害が発生した場合には、障害のあるノードが修復または置き換えられている間に、障害が発生したノード上のワークロードをクラスターの別の場所で再起動する必要があります。ノードのメンテナンスモードにより、クラスター管理者はノードの電源を正常に停止し、ワークロードをクラスターの他の部分に移動させ、ワークロードが中断されないようにします。詳細な進捗とノードのステータスについての詳細は、メンテナンス時に提供されます。
11.1.4. 関連情報
11.2. 古い CPU モデルのノードラベルの管理
VM CPU モデルおよびポリシーがノードでサポートされている限り、ノードで仮想マシン (VM) をスケジュールできます。
11.2.1. 古い CPU モデルのノードラベリングについて
OpenShift Virtualization Operator は、古い CPU モデルの事前定義されたリストを使用して、ノードがスケジュールされた仮想マシンの有効な CPU モデルのみをサポートするようにします。
デフォルトでは、以下の CPU モデルはノード用に生成されたラベルのリストから削除されます。
例11.1 古い CPU モデル
"486" Conroe athlon core2duo coreduo kvm32 kvm64 n270 pentium pentium2 pentium3 pentiumpro phenom qemu32 qemu64
この事前定義された一覧は HyperConverged CR には表示されません。このリストから CPU モデルを 削除 できませんが、HyperConverged CR の spec.obsoleteCPUs.cpuModels フィールドを編集してリストに追加することはできます。
11.2.2. CPU 機能のノードのラベル付けについて
反復処理により、最小 CPU モデルのベース CPU 機能は、ノード用に生成されたラベルのリストから削除されます。
以下に例を示します。
-
環境には、
PenrynとHaswellという 2 つのサポートされる CPU モデルが含まれる可能性があります。 PenrynがminCPUの CPU モデルとして指定される場合、Penrynのベース CPU の各機能はHaswellによってサポートされる CPU 機能のリストと比較されます。例11.2
Penrynでサポートされる CPU 機能apic clflush cmov cx16 cx8 de fpu fxsr lahf_lm lm mca mce mmx msr mtrr nx pae pat pge pni pse pse36 sep sse sse2 sse4.1 ssse3 syscall tsc
例11.3
Haswellでサポートされる CPU 機能aes apic avx avx2 bmi1 bmi2 clflush cmov cx16 cx8 de erms fma fpu fsgsbase fxsr hle invpcid lahf_lm lm mca mce mmx movbe msr mtrr nx pae pat pcid pclmuldq pge pni popcnt pse pse36 rdtscp rtm sep smep sse sse2 sse4.1 sse4.2 ssse3 syscall tsc tsc-deadline x2apic xsave
PenrynとHaswellの両方が特定の CPU 機能をサポートする場合、その機能にラベルは作成されません。ラベルは、Haswellでのみサポートされ、Penrynではサポートされていない CPU 機能用に生成されます。例11.4 反復後に CPU 機能用に作成されるノードラベル
aes avx avx2 bmi1 bmi2 erms fma fsgsbase hle invpcid movbe pcid pclmuldq popcnt rdtscp rtm sse4.2 tsc-deadline x2apic xsave
11.2.3. 古い CPU モデルの設定
HyperConverged カスタムリソース (CR) を編集して、古い CPU モデルのリストを設定できます。
手順
古い CPU モデルを
obsoleteCPUs配列で指定して、HyperConvergedカスタムリソースを編集します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: obsoleteCPUs: cpuModels: 1 - "<obsolete_cpu_1>" - "<obsolete_cpu_2>" minCPUModel: "<minimum_cpu_model>" 2
11.3. ノードの調整の防止
skip-node アノテーションを使用して、node-labeller がノードを調整できないようにします。
11.3.1. skip-node アノテーションの使用
node-labeller でノードを省略するには、oc CLI を使用してそのノードにアノテーションを付けます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、スキップするノードにアノテーションを付けます。
$ oc annotate node <node_name> node-labeller.kubevirt.io/skip-node=true 1- 1
<node_name>は、スキップする関連ノードの名前に置き換えます。
調整は、ノードアノテーションが削除されるか、false に設定された後に、次のサイクルで再開されます。
11.3.2. 関連情報
11.4. 障害が発生したノードを削除して仮想マシンのフェイルオーバーをトリガーする
ノードに障害が発生し、マシンヘルスチェック がクラスターにデプロイされていない場合、runStrategy: Always が設定された仮想マシン (VM) は正常なノードに自動的に移動しません。仮想マシンのフェイルオーバーをトリガーするには、Node オブジェクトを手動で削除する必要があります。
インストーラーによってプロビジョニングされたインフラストラクチャー を使用してクラスターをインストールし、マシンのヘルスチェックを適切に設定した場合、次のイベントが発生します。
- 障害が発生したノードは自動的に再利用されます。
-
runStrategyがAlwaysまたはRerunOnFailureに設定された仮想マシンは正常なノードで自動的にスケジュールされます。
11.4.1. 前提条件
-
仮想マシンが実行されていたノードに
NotReady状態 が設定されている。 -
障害のあるノードで実行されていた仮想マシンでは、
runStrategyがAlwaysに設定されている。 -
OpenShift CLI (
oc) がインストールされている。
11.4.2. ベアメタルクラスターからのノードの削除
CLI を使用してノードを削除する場合、ノードオブジェクトは Kubernetes で削除されますが、ノード自体にある Pod は削除されません。レプリケーションコントローラーで管理されないベア Pod は、OpenShift Container Platform からはアクセスできなくなります。レプリケーションコントローラーで管理されるベア Pod は、他の利用可能なノードに再スケジュールされます。ローカルのマニフェスト Pod は削除する必要があります。
手順
以下の手順を実行して、ベアメタルで実行されている OpenShift Container Platform クラスターからノードを削除します。
ノードにスケジュール対象外 (unschedulable) のマークを付けます。
$ oc adm cordon <node_name>
ノード上のすべての Pod をドレイン (解放) します。
$ oc adm drain <node_name> --force=true
このステップは、ノードがオフラインまたは応答しない場合に失敗する可能性があります。ノードが応答しない場合でも、共有ストレージに書き込むワークロードを実行している可能性があります。データの破損を防ぐには、続行する前に物理ハードウェアの電源を切ります。
クラスターからノードを削除します。
$ oc delete node <node_name>
ノードオブジェクトはクラスターから削除されていますが、これは再起動後や kubelet サービスが再起動される場合にクラスターに再び参加することができます。ノードとそのすべてのデータを永続的に削除するには、ノードの使用を停止 する必要があります。
- 物理ハードウェアを電源を切っている場合は、ノードがクラスターに再度加わるように、そのハードウェアを再びオンに切り替えます。
11.4.3. 仮想マシンのフェイルオーバーの確認
すべてのリソースが正常でないノードで終了すると、移行した仮想マシンのそれぞれについて、新しい仮想マシンインスタンス (VMI) が正常なノードに自動的に作成されます。VMI が作成されていることを確認するには、oc CLI を使用してすべての VMI を表示します。
11.4.3.1. CLI を使用した仮想マシンインスタンスのリスト表示
oc コマンドラインインターフェイス (CLI) を使用して、スタンドアロンおよび仮想マシンによって所有されている VMI を含むすべての仮想マシンのリストを表示できます。
手順
以下のコマンドを実行して、すべての VMI のリストを表示します。
$ oc get vmis -A
第12章 Monitoring
12.1. モニタリングの概要
次のツールを使用して、クラスターと仮想マシン (VM) の正常性を監視できます。
- OpenShift Virtualization 仮想マシンの健全性ステータスのモニタリング
- OpenShift Container Platform Web コンソールの Home → Overview ページに移動して、Web コンソールで OpenShift Virtualization 環境の全体的な健全性を表示します。Status カードには、アラートと条件に基づいて OpenShift Virtualization の全体的な健全性が表示されます。
- OpenShift Container Platform クラスター診断フレームワーク
OpenShift Container Platform クラスター診断フレームワークを使用してクラスターに対する自動テストを実行し、以下の状態を確認します。
- セカンダリーネットワークインターフェイスに接続された 2 つの 仮想マシン間のネットワーク接続とレイテンシー
- パケット損失ゼロで Data Plane Development Kit (DPDK) ワークロードを実行する仮想マシン
- 仮想リソースの Prometheus クエリー
- vCPU、ネットワーク、ストレージ、およびゲストメモリースワッピングの使用状況とライブマイグレーションの進行状況をクエリーします。
- VM カスタムメトリクス
-
内部 VM メトリクスとプロセスを公開するように、
node-exporterサービスを設定します。 - VM ヘルスチェック
- レディネス、ライブネス、ゲストエージェントの ping プローブ、および VM のウォッチドッグを設定します。
- ランブック
- OpenShift Container Platform Web コンソールで OpenShift Virtualization アラート をトリガーする問題を診断して解決します。
12.2. OpenShift Virtualization クラスター検査フレームワーク
OpenShift Virtualization には、クラスターのメンテナンスとトラブルシューティングに使用できる以下の定義済みのチェックアップが含まれています。
- 遅延チェック
- ネットワーク接続を確認し、セカンダリーネットワークインターフェイスに接続されている 2 つの仮想マシン間の遅延を測定します。
- DPDK チェックアップ
- ノードが Data Plane Development Kit (DPDK) ワークロードを使用して仮想マシンをパケット損失なしで実行できることを検証します。
OpenShift Virtualization クラスター検査フレームワークはテクノロジープレビューのみの機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
12.2.1. OpenShift Virtualization クラスター検査フレームワークについて
チェックアップは、特定のクラスター機能が期待どおりに機能するかどうかを確認できる自動テストワークロードです。クラスター検査フレームワークは、ネイティブの Kubernetes リソースを使用して、チェックアップを設定および実行します。
事前定義されたチェックアップを使用することで、クラスター管理者はクラスターの保守性を向上させ、予期しない動作をトラブルシューティングし、エラーを最小限に抑え、時間を節約できます。また、チェックアップの結果を確認し、専門家と共有してさらに分析することもできます。ベンダーは、提供する機能やサービスのチェックアップを作成して公開し、顧客環境が正しく設定されていることを確認できます。
既存の namespace で事前定義されたチェックアップを実行するには、チェックアップ用のサービスアカウントの設定、サービスアカウント用の Role および RoleBinding オブジェクトの作成、チェックアップのパーミッションの有効化、入力 config map とチェックアップジョブの作成が含まれます。チェックアップは複数回実行できます。
以下が常に必要になります。
- チェックアップイメージを適用する前に、信頼できるソースからのものであることを確認します。
-
RoleおよびRoleBindingオブジェクトを作成する前に、チェックアップパーミッションを確認してください。
12.2.1.1. 遅延チェックの実行
定義済みのチェックアップを使用して、ネットワーク接続を確認し、セカンダリーネットワークインターフェイスに接続されている 2 つの仮想マシン (VM) 間の待機時間を測定します。レイテンシーチェックアップでは ping ユーティリティーを使用します。
次の手順でレイテンシーチェックアップを実行します。
- サービスアカウント、ロール、ロールバインディングを作成して、レイテンシーチェックアップへのクラスターアクセス権を提供します。
- config map を作成し、チェックアップを実行して結果を保存するための入力を行います。
- チェックアップを実行するジョブを作成します。
- config map で結果を確認します。
- オプション: チェックアップを再実行するには、既存の config map とジョブを削除し、新しい config map とジョブを作成します。
- 完了したら、レイテンシーチェックアップリソースを削除します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスターには少なくとも 2 つのワーカーノードがあります。
- namespace のネットワーク接続定義を設定しました。
手順
レイテンシーチェックアップ用の
ServiceAccount、Role、RoleBindingマニフェストを作成します。例12.1 ロールマニフェストファイルの例
--- apiVersion: v1 kind: ServiceAccount metadata: name: vm-latency-checkup-sa --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kubevirt-vm-latency-checker rules: - apiGroups: ["kubevirt.io"] resources: ["virtualmachineinstances"] verbs: ["get", "create", "delete"] - apiGroups: ["subresources.kubevirt.io"] resources: ["virtualmachineinstances/console"] verbs: ["get"] - apiGroups: ["k8s.cni.cncf.io"] resources: ["network-attachment-definitions"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubevirt-vm-latency-checker subjects: - kind: ServiceAccount name: vm-latency-checkup-sa roleRef: kind: Role name: kubevirt-vm-latency-checker apiGroup: rbac.authorization.k8s.io --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kiagnose-configmap-access rules: - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: ["get", "update"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kiagnose-configmap-access subjects: - kind: ServiceAccount name: vm-latency-checkup-sa roleRef: kind: Role name: kiagnose-configmap-access apiGroup: rbac.authorization.k8s.io
ServiceAccount、Role、RoleBindingマニフェストを適用します。$ oc apply -n <target_namespace> -f <latency_sa_roles_rolebinding>.yaml 1- 1
<target_namespace>は、チェックアップを実行する namespace です。これは、NetworkAttachmentDefinitionオブジェクトが存在する既存の namespace である必要があります。
チェックアップの入力パラメーターを含む
ConfigMapマニフェストを作成します。入力 config map の例
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup-config data: spec.timeout: 5m spec.param.networkAttachmentDefinitionNamespace: <target_namespace> spec.param.networkAttachmentDefinitionName: "blue-network" 1 spec.param.maxDesiredLatencyMilliseconds: "10" 2 spec.param.sampleDurationSeconds: "5" 3 spec.param.sourceNode: "worker1" 4 spec.param.targetNode: "worker2" 5
ターゲット namespace に config map マニフェストを適用します。
$ oc apply -n <target_namespace> -f <latency_config_map>.yaml
チェックアップを実行する
Jobマニフェストを作成します。ジョブマニフェストの例
apiVersion: batch/v1 kind: Job metadata: name: kubevirt-vm-latency-checkup spec: backoffLimit: 0 template: spec: serviceAccountName: vm-latency-checkup-sa restartPolicy: Never containers: - name: vm-latency-checkup image: registry.redhat.io/container-native-virtualization/vm-network-latency-checkup-rhel9:v4.14.0 securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] runAsNonRoot: true seccompProfile: type: "RuntimeDefault" env: - name: CONFIGMAP_NAMESPACE value: <target_namespace> - name: CONFIGMAP_NAME value: kubevirt-vm-latency-checkup-config - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uidJobマニフェストを適用します。$ oc apply -n <target_namespace> -f <latency_job>.yaml
ジョブが完了するまで待ちます。
$ oc wait job kubevirt-vm-latency-checkup -n <target_namespace> --for condition=complete --timeout 6m
以下のコマンドを実行して、レイテンシーチェックアップの結果を確認します。測定された最大レイテンシーが
spec.param.maxDesiredLatencyMilliseconds属性の値よりも大きい場合、チェックアップは失敗し、エラーが返されます。$ oc get configmap kubevirt-vm-latency-checkup-config -n <target_namespace> -o yaml
出力 config map の例 (成功)
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup-config namespace: <target_namespace> data: spec.timeout: 5m spec.param.networkAttachmentDefinitionNamespace: <target_namespace> spec.param.networkAttachmentDefinitionName: "blue-network" spec.param.maxDesiredLatencyMilliseconds: "10" spec.param.sampleDurationSeconds: "5" spec.param.sourceNode: "worker1" spec.param.targetNode: "worker2" status.succeeded: "true" status.failureReason: "" status.completionTimestamp: "2022-01-01T09:00:00Z" status.startTimestamp: "2022-01-01T09:00:07Z" status.result.avgLatencyNanoSec: "177000" status.result.maxLatencyNanoSec: "244000" 1 status.result.measurementDurationSec: "5" status.result.minLatencyNanoSec: "135000" status.result.sourceNode: "worker1" status.result.targetNode: "worker2"- 1
- 測定された最大レイテンシー (ナノ秒)。
オプション: チェックアップが失敗した場合に詳細なジョブログを表示するには、次のコマンドを使用します。
$ oc logs job.batch/kubevirt-vm-latency-checkup -n <target_namespace>
以下のコマンドを実行して、以前に作成したジョブおよび config map を削除します。
$ oc delete job -n <target_namespace> kubevirt-vm-latency-checkup
$ oc delete config-map -n <target_namespace> kubevirt-vm-latency-checkup-config
オプション: 別のチェックアップを実行する予定がない場合は、ロールマニフェストを削除します。
$ oc delete -f <latency_sa_roles_rolebinding>.yaml
12.2.1.2. DPDK チェックアップ
事前定義されたチェックアップを使用して、OpenShift Container Platform クラスターノードが Data Plane Development Kit (DPDK) ワークロードがある仮想マシン (VM) をパケット損失ゼロで実行できるか確認します。DPDK チェックアップは、トラフィックジェネレーターと、テスト DPDK アプリケーションを実行している仮想マシン間でトラフィックを実行します。
次の手順で DPDK チェックアップを実行します。
- DPDK チェック用のサービスアカウント、ロール、およびロールバインディングを作成します。
- config map を作成し、チェックアップを実行して結果を保存するための入力を行います。
- チェックアップを実行するジョブを作成します。
- config map で結果を確認します。
- オプション: チェックアップを再実行するには、既存の config map とジョブを削除し、新しい config map とジョブを作成します。
- 完了したら、DPDK チェックリソースを削除します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスターは DPDK アプリケーションを実行するように設定されています。
- プロジェクトは DPDK アプリケーションを実行するように設定されています。
手順
DPDK チェック用の
ServiceAccount、Role、およびRoleBindingマニフェストを作成します。例12.2 サービスアカウント、ロール、ロールバインディングマニフェストファイルの例
--- apiVersion: v1 kind: ServiceAccount metadata: name: dpdk-checkup-sa --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kiagnose-configmap-access rules: - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: [ "get", "update" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kiagnose-configmap-access subjects: - kind: ServiceAccount name: dpdk-checkup-sa roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kiagnose-configmap-access --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: kubevirt-dpdk-checker rules: - apiGroups: [ "kubevirt.io" ] resources: [ "virtualmachineinstances" ] verbs: [ "create", "get", "delete" ] - apiGroups: [ "subresources.kubevirt.io" ] resources: [ "virtualmachineinstances/console" ] verbs: [ "get" ] - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: [ "create", "delete" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubevirt-dpdk-checker subjects: - kind: ServiceAccount name: dpdk-checkup-sa roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubevirt-dpdk-checkerServiceAccount、Role、RoleBindingマニフェストを適用します。$ oc apply -n <target_namespace> -f <dpdk_sa_roles_rolebinding>.yaml
チェックアップの入力パラメーターを含む
ConfigMapマニフェストを作成します。入力 config map の例
apiVersion: v1 kind: ConfigMap metadata: name: dpdk-checkup-config data: spec.timeout: 10m spec.param.networkAttachmentDefinitionName: <network_name> 1 spec.param.trafficGenContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-traffic-gen:v0.2.0 2 spec.param.vmUnderTestContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-vm:v0.2.0" 3
ターゲット namespace に
ConfigMapマニフェストを適用します。$ oc apply -n <target_namespace> -f <dpdk_config_map>.yaml
チェックアップを実行する
Jobマニフェストを作成します。ジョブマニフェストの例
apiVersion: batch/v1 kind: Job metadata: name: dpdk-checkup spec: backoffLimit: 0 template: spec: serviceAccountName: dpdk-checkup-sa restartPolicy: Never containers: - name: dpdk-checkup image: registry.redhat.io/container-native-virtualization/kubevirt-dpdk-checkup-rhel9:v4.14.0 imagePullPolicy: Always securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] runAsNonRoot: true seccompProfile: type: "RuntimeDefault" env: - name: CONFIGMAP_NAMESPACE value: <target-namespace> - name: CONFIGMAP_NAME value: dpdk-checkup-config - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uidJobマニフェストを適用します。$ oc apply -n <target_namespace> -f <dpdk_job>.yaml
ジョブが完了するまで待ちます。
$ oc wait job dpdk-checkup -n <target_namespace> --for condition=complete --timeout 10m
次のコマンドを実行して、チェックアップの結果を確認します。
$ oc get configmap dpdk-checkup-config -n <target_namespace> -o yaml
出力 config map の例 (成功)
apiVersion: v1 kind: ConfigMap metadata: name: dpdk-checkup-config data: spec.timeout: 10m spec.param.NetworkAttachmentDefinitionName: "dpdk-network-1" spec.param.trafficGenContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-traffic-gen:v0.2.0" spec.param.vmUnderTestContainerDiskImage: "quay.io/kiagnose/kubevirt-dpdk-checkup-vm:v0.2.0" status.succeeded: "true" 1 status.failureReason: "" 2 status.startTimestamp: "2023-07-31T13:14:38Z" 3 status.completionTimestamp: "2023-07-31T13:19:41Z" 4 status.result.trafficGenSentPackets: "480000000" 5 status.result.trafficGenOutputErrorPackets: "0" 6 status.result.trafficGenInputErrorPackets: "0" 7 status.result.trafficGenActualNodeName: worker-dpdk1 8 status.result.vmUnderTestActualNodeName: worker-dpdk2 9 status.result.vmUnderTestReceivedPackets: "480000000" 10 status.result.vmUnderTestRxDroppedPackets: "0" 11 status.result.vmUnderTestTxDroppedPackets: "0" 12
- 1
- チェックが成功したか (
true)、失敗したか (false) を指定します。 - 2
- チェックが失敗した場合の失敗の理由。
- 3
- チェックが開始された時刻 (RFC 3339 時刻形式)。
- 4
- 検査が完了した時刻 (RFC 3339 時刻形式)。
- 5
- トラフィックジェネレーターから送信されたパケットの数。
- 6
- トラフィックジェネレーターから送信されたエラーパケットの数。
- 7
- トラフィックジェネレーターが受信したエラーパケットの数。
- 8
- トラフィックジェネレーター仮想マシンがスケジュールされたノード。
- 9
- テスト対象の仮想マシンがスケジュールされたノード。
- 10
- テスト対象の仮想マシンで受信したパケットの数。
- 11
- DPDK アプリケーションによって破棄された入力トラフィックパケット。
- 12
- DPDK アプリケーションから破棄された出力トラフィックパケット。
以下のコマンドを実行して、以前に作成したジョブおよび config map を削除します。
$ oc delete job -n <target_namespace> dpdk-checkup
$ oc delete config-map -n <target_namespace> dpdk-checkup-config
オプション: 別のチェックアップを実行する予定がない場合は、
ServiceAccount、role、roleBindingマニフェストを削除します。$ oc delete -f <dpdk_sa_roles_rolebinding>.yaml
12.2.1.2.1. DPDK チェックアップ config map パラメーター
次の表は、クラスター DPDK 準備状況チェックを実行するときに、入力 ConfigMap マニフェストの data スタンザに設定できる必須パラメーターとオプションパラメーターを示しています。
表12.1 DPDK チェックアップ config map の入力パラメーター
| パラメーター | 説明 | 必須かどうか |
|---|---|---|
|
| チェックアップが失敗するまでの時間 (分単位)。 | True |
|
|
接続されている SR-IOV NIC の | True |
|
|
トラフィックジェネレーターのコンテナーディスクイメージ。デフォルト値は | False |
|
| トラフィックジェネレーター仮想マシンがスケジュールされるノード。DPDK トラフィックを許可するようにノードを設定する必要があります。 | False |
|
| 1 秒あたりのパケット数 (キロ (k) または 100 万 (m) 単位)。デフォルト値は 8m です。 | False |
|
|
テスト対象の仮想マシンのコンテナーディスクイメージ。デフォルト値は | False |
|
| テスト対象の仮想マシンがスケジュールされるノード。DPDK トラフィックを許可するようにノードを設定する必要があります。 | False |
|
| トラフィックジェネレーターが実行される期間 (分単位)。デフォルト値は 5 分です。 | False |
|
| SR-IOV NIC の最大帯域幅。デフォルト値は 10Gbps です。 | False |
|
|
| False |
12.2.1.2.2. RHEL 仮想マシン用コンテナーディスクイメージのビルド
カスタムの Red Hat Enterprise Linux (RHEL) 8 OS イメージを qcow2 形式でビルドし、それを使用してコンテナーディスクイメージを作成できます。クラスターからアクセス可能なレジストリーにコンテナーディスクイメージを保存し、DPDK チェック config map の spec.param.vmContainerDiskImage 属性でイメージの場所を指定できます。
コンテナーディスクイメージをビルドするには、Image Builder 仮想マシン (VM) を作成する必要があります。Image Builder 仮想マシン は、カスタム RHEL イメージのビルドに使用できる RHEL 8 仮想マシンです。
前提条件
-
Image Builder 仮想マシンは RHEL 8.7 を実行でき、
/varディレクトリーに少なくとも 2 つの CPU コア、4 GiB RAM、20 GB の空き領域がある。 -
Image Builder ツールとその CLI (
composer-cli) が仮想マシンにインストールされている。 virt-customizeツールがインストールされている。# dnf install libguestfs-tools
-
Podman CLI ツール (
podman) がインストールされている。
手順
RHEL 8.7 イメージをビルドできることを確認します。
# composer-cli distros list
注記非 root として
composer-cliコマンドを実行するには、ユーザーをweldrまたはrootグループに追加します。# usermod -a -G weldr user
$ newgrp weldr
次のコマンドを入力して、インストールするパッケージ、カーネルのカスタマイズ、起動時に無効化するサービスを含むイメージブループリントファイルを TOML 形式で作成します。
$ cat << EOF > dpdk-vm.toml name = "dpdk_image" description = "Image to use with the DPDK checkup" version = "0.0.1" distro = "rhel-87" [[packages]] name = "dpdk" [[packages]] name = "dpdk-tools" [[packages]] name = "driverctl" [[packages]] name = "tuned-profiles-cpu-partitioning" [customizations.kernel] append = "default_hugepagesz=1GB hugepagesz=1G hugepages=8 isolcpus=2-7" [customizations.services] disabled = ["NetworkManager-wait-online", "sshd"] EOF
次のコマンドを実行して、ブループリントファイルを Image Builder ツールにプッシュします。
# composer-cli blueprints push dpdk-vm.toml
ブループリント名と出力ファイル形式を指定して、システムイメージを生成します。作成プロセスを開始すると、イメージのユニバーサル一意識別子 (UUID) が表示されます。
# composer-cli compose start dpdk_image qcow2
作成プロセスが完了するまで待ちます。作成ステータスが
FINISHEDになると次のステップに進めます。# composer-cli compose status
次のコマンドを入力し、UUID を指定して
qcow2イメージファイルをダウンロードします。# composer-cli compose image <UUID>
次のコマンドを実行して、カスタマイズスクリプトを作成します。
$ cat <<EOF >customize-vm echo isolated_cores=2-7 > /etc/tuned/cpu-partitioning-variables.conf tuned-adm profile cpu-partitioning echo "options vfio enable_unsafe_noiommu_mode=1" > /etc/modprobe.d/vfio-noiommu.conf EOF
$ cat <<EOF >first-boot driverctl set-override 0000:06:00.0 vfio-pci driverctl set-override 0000:07:00.0 vfio-pci mkdir /mnt/huge mount /mnt/huge --source nodev -t hugetlbfs -o pagesize=1GB EOF
virt-customizeツールを使用して、Image Builder ツールによって生成されたイメージをカスタマイズします。$ virt-customize -a <UUID>.qcow2 --run=customize-vm --firstboot=first-boot --selinux-relabel
コンテナーディスクイメージのビルドに必要なすべてのコマンドを含む Dockerfile を作成するには、次のコマンドを入力します。
$ cat << EOF > Dockerfile FROM scratch COPY <uuid>-disk.qcow2 /disk/ EOF
ここでは、以下のようになります。
- <uuid>-disk.qcow2
-
カスタムイメージの名前を
qcow2形式で指定します。
次のコマンドを実行し、コンテナーをビルドしてタグを追加します。
$ podman build . -t dpdk-rhel:latest
次のコマンドを実行して、クラスターからアクセスできるレジストリーにコンテナーディスクイメージをプッシュします。
$ podman push dpdk-rhel:latest
-
DPDK チェックアップ config map の
spec.param.vmContainerDiskImage属性で、コンテナーディスクイメージへのリンクを指定します。
12.2.2. 関連情報
12.3. 仮想リソースの Prometheus クエリー
OpenShift Virtualization は、vCPU、ネットワーク、ストレージ、ゲストメモリースワッピングなどのクラスターインフラストラクチャーリソースの消費を監視するために使用できるメトリックを提供します。メトリクスを使用して、ライブマイグレーションのステータスを照会することもできます。
12.3.1. 前提条件
-
vCPU メトリックを使用するには、
schedstats=enableカーネル引数をMachineConfigオブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。詳細は、ノードへのカーネル引数の追加 を参照してください。 - ゲストメモリースワップクエリーがデータを返すには、仮想ゲストでメモリースワップを有効にする必要があります。
12.3.2. メトリクスのクエリー
OpenShift Container Platform モニタリングダッシュボードでは、Prometheus のクエリー言語 (PromQL) クエリーを実行し、プロットに可視化されるメトリクスを検査できます。この機能により、クラスターの状態と、モニターしているユーザー定義のワークロードに関する情報が提供されます。
クラスター管理者は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトのメトリックをクエリーできます。
開発者として、メトリクスのクエリー時にプロジェクト名を指定する必要があります。選択したプロジェクトのメトリクスを表示するには、必要な権限が必要です。
12.3.2.1. クラスター管理者としてのすべてのプロジェクトのメトリックのクエリー
クラスター管理者またはすべてのプロジェクトの表示権限を持つユーザーとして、メトリック UI ですべてのデフォルト OpenShift Container Platform およびユーザー定義プロジェクトのメトリックにアクセスできます。
前提条件
-
cluster-adminクラスターロールまたはすべてのプロジェクトの表示権限を持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブから、Observe → Metrics を選択します。
1 つ以上のクエリーを追加するには、次のいずれかを実行します。
オプション 説明 カスタムクエリーを作成します。
Prometheus Query Language (PromQL) クエリーを Expression フィールドに追加します。
PromQL 式を入力すると、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数、メトリクス、ラベル、および時間トークンが含まれます。キーボードの矢印を使用して提案された項目のいずれかを選択し、Enter を押して項目を式に追加できます。また、マウスポインターを推奨項目の上に移動して、その項目の簡単な説明を表示することもできます。
複数のクエリーを追加します。
クエリーの追加 を選択します。
既存のクエリーを複製します。
オプションメニューを選択します
クエリーの横にある Duplicate query を選択します。
クエリーの実行を無効にします。
オプションメニューを選択します
クエリーの横にある Disable query を選択します。
作成したクエリーを実行するには、Run queries を選択します。クエリーからのメトリクスはプロットで可視化されます。クエリーが無効な場合は、UI にエラーメッセージが表示されます。
注記大量のデータで動作するクエリーは、時系列グラフの描画時にタイムアウトするか、ブラウザーをオーバーロードする可能性があります。これを回避するには、Hide graph を選択し、メトリクステーブルのみを使用してクエリーを調整します。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
注記デフォルトでは、クエリーテーブルに、すべてのメトリクスとその現在の値をリスト表示する拡張ビューが表示されます。˅ を選択すると、クエリーの拡張ビューを最小にすることができます。
- オプション: ページ URL には、実行したクエリーが含まれます。このクエリーのセットを再度使用できるようにするには、この URL を保存します。
視覚化されたメトリクスを調べます。最初に、有効な全クエリーの全メトリクスがプロットに表示されます。次のいずれかを実行して、表示するメトリクスを選択できます。
オプション 説明 クエリーからすべてのメトリクスを非表示にします。
オプションメニューをクリックします
クエリーを選択し、Hide all series をクリックします。
特定のメトリクスを非表示にします。
クエリーテーブルに移動し、メトリクス名の近くにある色付きの四角形をクリックします。
プロットを拡大し、時間範囲を変更します。
次のいずれかになります。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
時間範囲をリセットします。
Reset zoom を選択します。
特定の時点でのすべてのクエリーの出力を表示します。
その時点でプロット上にマウスカーソルを置きます。クエリーの出力はポップアップに表示されます。
プロットを非表示にします。
Hide graph を選択します。
12.3.2.2. 開発者が行うユーザー定義プロジェクトのメトリクスのクエリー
ユーザー定義のプロジェクトのメトリクスには、開発者またはプロジェクトの表示権限を持つユーザーとしてアクセスできます。
Developer パースペクティブには、選択したプロジェクトの事前に定義された CPU、メモリー、帯域幅、およびネットワークパケットのクエリーが含まれます。また、プロジェクトの CPU、メモリー、帯域幅、ネットワークパケット、およびアプリケーションメトリクスについてカスタム Prometheus Query Language (PromQL) クエリーを実行することもできます。
開発者は Developer パースペクティブのみを使用でき、Administrator パースペクティブは使用できません。開発者は、1 度に 1 つのプロジェクトのメトリクスのみをクエリーできます。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示権限を持つユーザーとしてクラスターへのアクセスがある。
- ユーザー定義プロジェクトのモニタリングを有効にしている。
- ユーザー定義プロジェクトにサービスをデプロイしている。
-
サービスのモニター方法を定義するために、サービスの
ServiceMonitorカスタムリソース定義 (CRD) を作成している。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブから、Observe → Metrics を選択します。
- Project: 一覧でメトリクスで表示するプロジェクトを選択します。
Select query 一覧からクエリーを選択するか、Show PromQL を選択して、選択したクエリーに基づいてカスタム PromQL クエリーを作成します。クエリーからのメトリクスはプロットで可視化されます。
注記Developer パースペクティブでは、1 度に 1 つのクエリーのみを実行できます。
次のいずれかを実行して、視覚化されたメトリクスを調べます。
オプション 説明 プロットを拡大し、時間範囲を変更します。
次のいずれかになります。
- プロットを水平にクリックし、ドラッグして、時間範囲を視覚的に選択します。
- 左上隅のメニューを使用して、時間範囲を選択します。
時間範囲をリセットします。
Reset zoom を選択します。
特定の時点でのすべてのクエリーの出力を表示します。
その時点でプロット上にマウスカーソルを置きます。クエリーの出力はポップアップに表示されます。
12.3.3. 仮想化メトリクス
以下のメトリクスの記述には、Prometheus Query Language (PromQL) クエリーのサンプルが含まれます。これらのメトリクスは API ではなく、バージョン間で変更される可能性があります。
以下の例では、期間を指定する topk クエリーを使用します。その期間中に仮想マシンが削除された場合でも、クエリーの出力に依然として表示されます。
12.3.3.1. vCPU メトリック
以下のクエリーは、入出力 I/O) を待機している仮想マシンを特定します。
kubevirt_vmi_vcpu_wait_seconds- 仮想マシンの vCPU の待機時間 (秒単位) を返します。タイプ: カウンター。
0 より大きい値は、vCPU は実行する用意ができているが、ホストスケジューラーがこれをまだ実行できないことを意味します。実行できない場合には I/O に問題があることを示しています。
vCPU メトリックをクエリーするには、最初に schedstats=enable カーネル引数を MachineConfig オブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。
vCPU 待機時間クエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_vcpu_wait_seconds[6m]))) > 0 1
- 1
- このクエリーは、6 分間の任意の全タイミングで I/O を待機する上位 3 の仮想マシンを返します。
12.3.3.2. ネットワークメトリック
以下のクエリーは、ネットワークを飽和状態にしている仮想マシンを特定できます。
kubevirt_vmi_network_receive_bytes_total- 仮想マシンのネットワークで受信したトラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
kubevirt_vmi_network_transmit_bytes_total- 仮想マシンのネットワーク上で送信されるトラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
ネットワークトラフィッククエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_network_receive_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_network_transmit_bytes_total[6m]))) > 0 1
- 1
- このクエリーは、6 分間の任意のタイミングで最大のネットワークトラフィックを送信する上位 3 の仮想マシンを返します。
12.3.3.3. ストレージメトリクス
12.3.3.3.1. ストレージ関連のトラフィック
以下のクエリーは、大量のデータを書き込んでいる仮想マシンを特定できます。
kubevirt_vmi_storage_read_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックの合計量 (バイト単位) を返します。タイプ: カウンター。
kubevirt_vmi_storage_write_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックのストレージ書き込みの合計量 (バイト単位) を返します。タイプ: カウンター。
ストレージ関連のトラフィッククエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_write_traffic_bytes_total[6m]))) > 0 1
- 1
- 上記のクエリーは、6 分間の任意のタイミングで最も大きなストレージトラフィックを送信する上位 3 の仮想マシンを返します。
12.3.3.3.2. ストレージスナップショットデータ
kubevirt_vmsnapshot_disks_restored_from_source_total- ソース仮想マシンから復元された仮想マシンディスクの総数を返します。タイプ: ゲージ。
kubevirt_vmsnapshot_disks_restored_from_source_bytes- ソース仮想マシンから復元された容量をバイト単位で返します。タイプ: ゲージ。
ストレージスナップショットデータクエリーの例
kubevirt_vmsnapshot_disks_restored_from_source_total{vm_name="simple-vm", vm_namespace="default"} 1
- 1
- このクエリーは、ソース仮想マシンから復元された仮想マシンディスクの総数を返します。
kubevirt_vmsnapshot_disks_restored_from_source_bytes{vm_name="simple-vm", vm_namespace="default"} 1- 1
- このクエリーは、ソース仮想マシンから復元された容量をバイト単位で返します。
12.3.3.3.3. I/O パフォーマンス
以下のクエリーで、ストレージデバイスの I/O パフォーマンスを判別できます。
kubevirt_vmi_storage_iops_read_total- 仮想マシンが実行している 1 秒あたりの書き込み I/O 操作の量を返します。タイプ: カウンター。
kubevirt_vmi_storage_iops_write_total- 仮想マシンが実行している 1 秒あたりの読み取り I/O 操作の量を返します。タイプ: カウンター。
I/O パフォーマンスクエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_read_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_write_total[6m]))) > 0 1
- 1
- 上記のクエリーは、6 分間の任意のタイミングで最も大きな I/O 操作を実行している上位 3 の仮想マシンを返します。
12.3.3.4. ゲストメモリーのスワップメトリクス
以下のクエリーにより、メモリースワップを最も多く実行しているスワップ対応ゲストを特定できます。
kubevirt_vmi_memory_swap_in_traffic_bytes_total- 仮想ゲストがスワップされているメモリーの合計量 (バイト単位) を返します。タイプ: ゲージ。
kubevirt_vmi_memory_swap_out_traffic_bytes_total- 仮想ゲストがスワップアウトされているメモリーの合計量 (バイト単位) を返します。タイプ: ゲージ。
メモリースワップクエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_in_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_out_traffic_bytes_total[6m]))) > 0 1
- 1
- 上記のクエリーは、6 分間の任意のタイミングでゲストが最も大きなメモリースワップを実行している上位 3 の仮想マシンを返します。
メモリースワップは、仮想マシンがメモリー不足の状態にあることを示します。仮想マシンのメモリー割り当てを増やすと、この問題を軽減できます。
12.3.3.5. ライブマイグレーションのメトリクス
次のメトリックをクエリーして、ライブマイグレーションのステータスを表示できます。
kubevirt_migrate_vmi_data_processed_bytes- 新しい仮想マシン (VM) に移行されたゲストオペレーティングシステムデータの量。タイプ: ゲージ。
kubevirt_migrate_vmi_data_remaining_bytes- 移行されていないゲストオペレーティングシステムデータの量。タイプ: ゲージ。
kubevirt_migrate_vmi_dirty_memory_rate_bytes- ゲスト OS でメモリーがダーティーになる速度。ダーティメモリーとは、変更されたがまだディスクに書き込まれていないデータです。タイプ: ゲージ。
kubevirt_migrate_vmi_pending_count- 保留中の移行の数。タイプ: ゲージ。
kubevirt_migrate_vmi_scheduling_count- スケジュール移行の数。タイプ: ゲージ。
kubevirt_migrate_vmi_running_count- 実行中の移行の数。タイプ: ゲージ。
kubevirt_migrate_vmi_succeeded- 正常に完了した移行の数。タイプ: ゲージ。
kubevirt_migrate_vmi_failed- 失敗した移行の数。タイプ: ゲージ。
12.3.4. 関連情報
12.4. 仮想マシンのカスタムメトリクスの公開
OpenShift Container Platform には、コアプラットフォームコンポーネントのモニタリングを提供する事前に設定され、事前にインストールされた自己更新型のモニタリングスタックが含まれます。このモニタリングスタックは、Prometheus モニタリングシステムをベースにしています。Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。
OpenShift Container Platform モニタリングスタックの使用のほかに、CLI を使用してユーザー定義プロジェクトのモニタリングを有効にし、node-exporter サービスで仮想マシン用に公開されるカスタムメトリックをクエリーできます。
12.4.1. ノードエクスポーターサービスの設定
node-exporter エージェントは、メトリクスを収集するクラスター内のすべての仮想マシンにデプロイされます。node-exporter エージェントをサービスとして設定し、仮想マシンに関連付けられた内部メトリクスおよびプロセスを公開します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 -
cluster-monitoring-configConfigMapオブジェクトをopenshift-monitoringプロジェクトに作成する。 -
enableUserWorkloadをtrueに設定して、user-workload-monitoring-configConfigMapオブジェクトをopenshift-user-workload-monitoringプロジェクトに設定する。
手順
ServiceYAML ファイルを作成します。以下の例では、このファイルはnode-exporter-service.yamlという名前です。kind: Service apiVersion: v1 metadata: name: node-exporter-service 1 namespace: dynamation 2 labels: servicetype: metrics 3 spec: ports: - name: exmet 4 protocol: TCP port: 9100 5 targetPort: 9100 6 type: ClusterIP selector: monitor: metrics 7
- 1
- 仮想マシンからメトリクスを公開する node-exporter サービス。
- 2
- サービスが作成される namespace。
- 3
- サービスのラベル。
ServiceMonitorはこのラベルを使用してこのサービスを照会します。 - 4
ClusterIPサービスのポート 9100 でメトリクスを公開するポートに指定された名前。- 5
- リクエストをリッスンするために
node-exporter-serviceによって使用されるターゲットポート。 - 6
monitorラベルが設定された仮想マシンの TCP ポート番号。- 7
- 仮想マシンの Pod を照会するために使用されるラベル。この例では、ラベル
monitorのある仮想マシンの Pod と、metricsの値がマッチします。
node-exporter サービスを作成します。
$ oc create -f node-exporter-service.yaml
12.4.2. ノードエクスポーターサービスが設定された仮想マシンの設定
node-exporter ファイルを仮想マシンにダウンロードします。次に、仮想マシンの起動時に node-exporter サービスを実行する systemd サービスを作成します。
前提条件
-
コンポーネントの Pod は
openshift-user-workload-monitoringプロジェクトで実行されます。 -
このユーザー定義プロジェクトをモニターする必要のあるユーザーに
monitoring-editロールを付与します。
手順
- 仮想マシンにログインします。
node-exporterファイルのバージョンに適用されるディレクトリーパスを使用して、node-exporterファイルを仮想マシンにダウンロードします。$ wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
実行ファイルを展開して、
/usr/binディレクトリーに配置します。$ sudo tar xvf node_exporter-1.3.1.linux-amd64.tar.gz \ --directory /usr/bin --strip 1 "*/node_exporter"ディレクトリーのパス
/etc/systemd/systemにnode_exporter.serviceファイルを作成します。このsystemdサービスファイルは、仮想マシンの再起動時に node-exporter サービスを実行します。[Unit] Description=Prometheus Metrics Exporter After=network.target StartLimitIntervalSec=0 [Service] Type=simple Restart=always RestartSec=1 User=root ExecStart=/usr/bin/node_exporter [Install] WantedBy=multi-user.target
systemdサービスを有効にし、起動します。$ sudo systemctl enable node_exporter.service $ sudo systemctl start node_exporter.service
検証
node-exporter エージェントが仮想マシンからのメトリクスを報告していることを確認します。
$ curl http://localhost:9100/metrics
出力例
go_gc_duration_seconds{quantile="0"} 1.5244e-05 go_gc_duration_seconds{quantile="0.25"} 3.0449e-05 go_gc_duration_seconds{quantile="0.5"} 3.7913e-05
12.4.3. 仮想マシンのカスタムモニタリングラベルの作成
単一サービスから複数の仮想マシンに対するクエリーを有効にするには、仮想マシンの YAML ファイルにカスタムラベルを追加します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - 仮想マシンを停止および再起動するための Web コンソールへのアクセス権限がある。
手順
仮想マシン設定ファイルの
templatespec を編集します。この例では、ラベルmonitorの値がmetricsになります。spec: template: metadata: labels: monitor: metrics-
仮想マシンを停止して再起動し、
monitorラベルに指定されたラベル名を持つ新しい Pod を作成します。
12.4.3.1. メトリクスを取得するための node-exporter サービスのクエリー
仮想マシンのメトリクスは、/metrics の正規名の下に HTTP サービスエンドポイント経由で公開されます。メトリクスのクエリー時に、Prometheus は仮想マシンによって公開されるメトリクスエンドポイントからメトリクスを直接収集し、これらのメトリクスを確認用に表示します。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
サービスの namespace を指定して、HTTP サービスエンドポイントを取得します。
$ oc get service -n <namespace> <node-exporter-service>
node-exporter サービスの利用可能なすべてのメトリクスを一覧表示するには、
metricsリソースをクエリーします。$ curl http://<172.30.226.162:9100>/metrics | grep -vE "^#|^$"
出力例
node_arp_entries{device="eth0"} 1 node_boot_time_seconds 1.643153218e+09 node_context_switches_total 4.4938158e+07 node_cooling_device_cur_state{name="0",type="Processor"} 0 node_cooling_device_max_state{name="0",type="Processor"} 0 node_cpu_guest_seconds_total{cpu="0",mode="nice"} 0 node_cpu_guest_seconds_total{cpu="0",mode="user"} 0 node_cpu_seconds_total{cpu="0",mode="idle"} 1.10586485e+06 node_cpu_seconds_total{cpu="0",mode="iowait"} 37.61 node_cpu_seconds_total{cpu="0",mode="irq"} 233.91 node_cpu_seconds_total{cpu="0",mode="nice"} 551.47 node_cpu_seconds_total{cpu="0",mode="softirq"} 87.3 node_cpu_seconds_total{cpu="0",mode="steal"} 86.12 node_cpu_seconds_total{cpu="0",mode="system"} 464.15 node_cpu_seconds_total{cpu="0",mode="user"} 1075.2 node_disk_discard_time_seconds_total{device="vda"} 0 node_disk_discard_time_seconds_total{device="vdb"} 0 node_disk_discarded_sectors_total{device="vda"} 0 node_disk_discarded_sectors_total{device="vdb"} 0 node_disk_discards_completed_total{device="vda"} 0 node_disk_discards_completed_total{device="vdb"} 0 node_disk_discards_merged_total{device="vda"} 0 node_disk_discards_merged_total{device="vdb"} 0 node_disk_info{device="vda",major="252",minor="0"} 1 node_disk_info{device="vdb",major="252",minor="16"} 1 node_disk_io_now{device="vda"} 0 node_disk_io_now{device="vdb"} 0 node_disk_io_time_seconds_total{device="vda"} 174 node_disk_io_time_seconds_total{device="vdb"} 0.054 node_disk_io_time_weighted_seconds_total{device="vda"} 259.79200000000003 node_disk_io_time_weighted_seconds_total{device="vdb"} 0.039 node_disk_read_bytes_total{device="vda"} 3.71867136e+08 node_disk_read_bytes_total{device="vdb"} 366592 node_disk_read_time_seconds_total{device="vda"} 19.128 node_disk_read_time_seconds_total{device="vdb"} 0.039 node_disk_reads_completed_total{device="vda"} 5619 node_disk_reads_completed_total{device="vdb"} 96 node_disk_reads_merged_total{device="vda"} 5 node_disk_reads_merged_total{device="vdb"} 0 node_disk_write_time_seconds_total{device="vda"} 240.66400000000002 node_disk_write_time_seconds_total{device="vdb"} 0 node_disk_writes_completed_total{device="vda"} 71584 node_disk_writes_completed_total{device="vdb"} 0 node_disk_writes_merged_total{device="vda"} 19761 node_disk_writes_merged_total{device="vdb"} 0 node_disk_written_bytes_total{device="vda"} 2.007924224e+09 node_disk_written_bytes_total{device="vdb"} 0
12.4.4. ノードエクスポーターサービスの ServiceMonitor リソースの作成
Prometheus クライアントライブラリーを使用し、/metrics エンドポイントからメトリクスを収集して、node-exporter サービスが公開するメトリクスにアクセスし、表示できます。ServiceMonitor カスタムリソース定義 (CRD) を使用して、ノードエクスポーターサービスをモニターします。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
ServiceMonitorリソース設定の YAML ファイルを作成します。この例では、サービスモニターはラベルmetricsが指定されたサービスとマッチし、30 秒ごとにexmetポートをクエリーします。apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: node-exporter-metrics-monitor name: node-exporter-metrics-monitor 1 namespace: dynamation 2 spec: endpoints: - interval: 30s 3 port: exmet 4 scheme: http selector: matchLabels: servicetype: metricsnode-exporter サービスの
ServiceMonitor設定を作成します。$ oc create -f node-exporter-metrics-monitor.yaml
12.4.4.1. クラスター外のノードエクスポーターサービスへのアクセス
クラスター外の node-exporter サービスにアクセスし、公開されるメトリクスを表示できます。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
node-exporter サービスを公開します。
$ oc expose service -n <namespace> <node_exporter_service_name>
ルートの FQDN(完全修飾ドメイン名) を取得します。
$ oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.host
出力例
NAME DNS node-exporter-service node-exporter-service-dynamation.apps.cluster.example.org
curlコマンドを使用して、node-exporter サービスのメトリクスを表示します。$ curl -s http://node-exporter-service-dynamation.apps.cluster.example.org/metrics
出力例
go_gc_duration_seconds{quantile="0"} 1.5382e-05 go_gc_duration_seconds{quantile="0.25"} 3.1163e-05 go_gc_duration_seconds{quantile="0.5"} 3.8546e-05 go_gc_duration_seconds{quantile="0.75"} 4.9139e-05 go_gc_duration_seconds{quantile="1"} 0.000189423
12.4.5. 関連情報
12.5. 仮想マシンのヘルスチェック
VirtualMachine リソースで readiness プローブと liveness プローブを定義することにより、仮想マシン (VM) のヘルスチェックを設定できます。
12.5.1. readiness および liveness プローブについて
readiness プローブと liveness プローブを使用して、異常な仮想マシン (VM) を検出および処理します。VM の仕様に 1 つ以上のプローブを含めて、準備ができていない VM にトラフィックが到達しないようにし、VM が応答しなくなったときに新しい VM が作成されるようにすることができます。
readiness プローブ は、VM がサービス要求を受け入れることができるかどうかを判断します。プローブが失敗すると、VM は、準備状態になるまで、利用可能なエンドポイントのリストから削除されます。
liveness プローブ は、VM が応答しているかどうかを判断します。プローブが失敗すると、VM は削除され、応答性を復元するために、新しい VM が作成されます。
VirtualMachine オブジェクトの spec.readinessProbe フィールドと spec.livenessProbe フィールドを設定することで、readiness プローブと liveness プローブを設定できます。これらのフィールドは、以下のテストをサポートします。
- HTTP GET
- プローブは、Web フックを使用して VM の正常性を判断します。このテストは、HTTP の応答コードが 200 から 399 までの値の場合に正常と見なされます。完全に初期化されている場合に、HTTP ステータスコードを返すアプリケーションで HTTP GET テストを使用できます。
- TCP ソケット
- プローブは、VM へのソケットを開こうとします。プローブが接続を確立できる場合のみ、VM は正常であると見なされます。TCP ソケットテストは、初期化が完了するまでリスニングを開始しないアプリケーションで使用できます。
- ゲストエージェントの ping
-
プローブは、
guest-pingコマンドを使用して、QEMU ゲストエージェントが仮想マシンで実行されているかどうかを判断します。
12.5.1.1. HTTP readiness プローブの定義
仮想マシン (VM) 設定の spec.readinessProbe.httpGet フィールドを設定して、HTTP readiness プローブを定義します。
手順
VM 設定ファイルに readiness プローブの詳細を含めます。
HTTP GET テストを使用した readiness プローブの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: annotations: name: fedora-vm namespace: example-namespace # ... spec: template: spec: readinessProbe: httpGet: 1 port: 1500 2 path: /healthz 3 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 120 4 periodSeconds: 20 5 timeoutSeconds: 10 6 failureThreshold: 3 7 successThreshold: 3 8 # ...- 1
- VM に接続するために実行する HTTP GET 要求。
- 2
- プローブがクエリーする VM のポート。上記の例では、プローブはポート 1500 をクエリーします。
- 3
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの /healthz パスのハンドラーが成功コードを返した場合、VM は正常であると見なされます。ハンドラーが失敗コードを返した場合、VM は使用可能なエンドポイントのリストから削除されます。
- 4
- VM が起動してから準備プローブが開始されるまでの時間 (秒単位)。
- 5
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 6
- プローブがタイムアウトになり、VM が失敗したと見なされるまでの非アクティブな秒数。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。 - 7
- プローブが失敗できる回数。デフォルトは 3 です。指定された試行回数になると、Pod には
Unreadyというマークが付けられます。 - 8
- 成功とみなされるまでにプローブが失敗後に成功を報告する必要のある回数。デフォルトでは 1 回です。
次のコマンドを実行して VM を作成します。
$ oc create -f <file_name>.yaml
12.5.1.2. TCP readiness プローブの定義
仮想マシン (VM) 設定の spec.readinessProbe.tcpSocket フィールドを設定して、TCP readiness プローブを定義します。
手順
TCP readiness プローブの詳細を VM 設定ファイルに追加します。
TCP ソケットテストを含む readiness プローブの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: annotations: name: fedora-vm namespace: example-namespace # ... spec: template: spec: readinessProbe: initialDelaySeconds: 120 1 periodSeconds: 20 2 tcpSocket: 3 port: 1500 4 timeoutSeconds: 10 5 # ...次のコマンドを実行して VM を作成します。
$ oc create -f <file_name>.yaml
12.5.1.3. HTTP liveness プローブの定義
仮想マシン (VM) 設定の spec.livenessProbe.httpGet フィールドを設定して、HTTP liveness プローブを定義します。readiness プローブと同様に、liveness プローブの HTTP および TCP テストの両方を定義できます。この手順では、HTTP GET テストを使用して liveness プローブのサンプルを設定します。
手順
VM 設定ファイルに HTTP liveness プローブの詳細を含めます。
HTTP GET テストを使用した liveness プローブの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: annotations: name: fedora-vm namespace: example-namespace # ... spec: template: spec: livenessProbe: initialDelaySeconds: 120 1 periodSeconds: 20 2 httpGet: 3 port: 1500 4 path: /healthz 5 httpHeaders: - name: Custom-Header value: Awesome timeoutSeconds: 10 6 # ...- 1
- VM が起動してから liveness プローブが開始されるまでの時間 (秒単位)。
- 2
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 3
- VM に接続するために実行する HTTP GET 要求。
- 4
- プローブがクエリーする VM のポート。上記の例では、プローブはポート 1500 をクエリーします。VM は、cloud-init を介してポート 1500 に最小限の HTTP サーバーをインストールして実行します。
- 5
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの
/healthzパスのハンドラーが成功コードを返した場合、VM は正常であると見なされます。ハンドラーが失敗コードを返した場合、VM は削除され、新しい VM が作成されます。 - 6
- プローブがタイムアウトになり、VM が失敗したと見なされるまでの非アクティブな秒数。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。
次のコマンドを実行して VM を作成します。
$ oc create -f <file_name>.yaml
12.5.2. ウォッチドッグの定義
次の手順を実行して、ゲスト OS の正常性を監視するウォッチドッグを定義できます。
- 仮想マシン (VM) のウォッチドッグデバイスを設定します。
- ゲストにウォッチドッグエージェントをインストールします。
ウォッチドッグデバイスはエージェントを監視し、ゲストオペレーティングシステムが応答しない場合、次のいずれかのアクションを実行します。
-
poweroff: VM の電源がすぐにオフになります。spec.runningがtrueに設定されているか、spec.runStrategyがmanualに設定されていない場合、VM は再起動します。 reset: VM はその場で再起動し、ゲストオペレーティングシステムは反応できません。注記再起動時間が原因で liveness プローブがタイムアウトする場合があります。クラスターレベルの保護が liveness プローブの失敗を検出すると、VM が強制的に再スケジュールされ、再起動時間が長くなる可能性があります。
-
shutdown: すべてのサービスを停止することで、VM の電源を正常にオフにします。
ウォッチドッグは、Windows VM では使用できません。
12.5.2.1. 仮想マシンのウォッチドッグデバイスの設定
仮想マシン (VM) のウォッチドッグデバイスを設定するとします。
前提条件
-
VM には、
i6300esbウォッチドッグデバイスのカーネルサポートが必要です。Red Hat Enterprise Linux(RHEL) イメージが、i6300esbをサポートしている。
手順
次の内容で
YAMLファイルを作成します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog name: <vm-name> spec: running: false template: metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog spec: domain: devices: watchdog: name: <watchdog> i6300esb: action: "poweroff" 1 # ...- 1
poweroff、reset、またはshutdownを指定します。
上記の例では、電源オフアクションを使用して、RHEL8 VM で
i6300esbウォッチドッグデバイスを設定し、デバイスを/dev/watchdogとして公開します。このデバイスは、ウォッチドッグバイナリーで使用できるようになりました。
以下のコマンドを実行して、YAML ファイルをクラスターに適用します。
$ oc apply -f <file_name>.yaml
この手順は、ウォッチドッグ機能をテストするためにのみ提供されており、実稼働マシンでは実行しないでください。
以下のコマンドを実行して、VM がウォッチドッグデバイスに接続されていることを確認します。
$ lspci | grep watchdog -i
以下のコマンドのいずれかを実行して、ウォッチドッグがアクティブであることを確認します。
カーネルパニックをトリガーします。
# echo c > /proc/sysrq-trigger
ウォッチドッグサービスを停止します。
# pkill -9 watchdog
12.5.2.2. ゲストへのウォッチドッグエージェントのインストール
ゲストにウォッチドッグエージェントをインストールし、watchdog サービスを開始します。
手順
- root ユーザーとして仮想マシンにログインします。
watchdogドッグパッケージとその依存関係をインストールします。# yum install watchdog
/etc/watchdog.confファイルの次の行のコメントを外し、変更を保存します。#watchdog-device = /dev/watchdog
起動時に
watchdogサービスを開始できるようにします。# systemctl enable --now watchdog.service
12.5.3. ゲストエージェントの ping プローブの定義
仮想マシン (VM) 設定の spec.readinessProbe.guestAgentPing フィールドを設定して、ゲストエージェント ping プローブを定義します。
ゲストエージェント ping プローブは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
前提条件
- 仮想マシンに QEMU ゲストエージェントをインストールして有効にする必要があります。
手順
VM 設定ファイルにゲストエージェント ping プローブの詳細を含めます。以下に例を示します。
ゲストエージェント ping プローブの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: annotations: name: fedora-vm namespace: example-namespace # ... spec: template: spec: readinessProbe: guestAgentPing: {} 1 initialDelaySeconds: 120 2 periodSeconds: 20 3 timeoutSeconds: 10 4 failureThreshold: 3 5 successThreshold: 3 6 # ...- 1
- VM に接続するためのゲストエージェント ping プローブ。
- 2
- オプション: VM が起動してからゲストエージェントプローブが開始されるまでの時間 (秒単位)。
- 3
- オプション: プローブを実行する間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 4
- オプション: プローブがタイムアウトになり、VM が失敗したと見なされるまでの非アクティブの秒数。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。 - 5
- オプション: プローブが失敗できる回数。デフォルトは 3 です。指定された試行回数になると、Pod には
Unreadyというマークが付けられます。 - 6
- オプション: 成功とみなされるまでにプローブが失敗後に成功を報告する必要のある回数。デフォルトでは 1 回です。
次のコマンドを実行して VM を作成します。
$ oc create -f <file_name>.yaml
12.5.4. 関連情報
12.6. OpenShift Virtualization ランブック
これらのランブックの手順を使用して、OpenShift Virtualization アラート をトリガーする問題を診断および解決できます。
OpenShift Virtualization アラートは、Web コンソールの Virtualization → Overview → Overview タブ に表示されます。
12.6.1. CDIDataImportCronOutdated
意味
このアラートは、DataImportCron が最新のディスクイメージバージョンをポーリングまたはインポートできない場合に発生します。
DataImportCron は、ディスクイメージをポーリングして最新バージョンをチェックし、イメージを永続ボリュームクレーム (PVC) としてインポートします。このプロセスにより、PVC が確実に最新バージョンに更新され、仮想マシン (VM) の信頼できるクローンソースまたはゴールデンイメージとして使用できるようになります。
ゴールデンイメージの場合、latest はディストリビューションの最新のオペレーティングシステムを参照します。他のディスクイメージの場合、latest は利用可能なイメージの最新のハッシュを参照します。
影響
古いディスクイメージから仮想マシンが作成される場合があります。
クローン作成に使用できるソース PVC がないため、仮想マシンの起動に失敗する場合があります。
診断
クラスターのデフォルトストレージクラスを確認します。
$ oc get sc
出力には、デフォルトのストレージクラスの名前の横に
(default)が付いたストレージクラスが表示されます。DataImportCronがゴールデンイメージをポーリングしてインポートするには、クラスターまたはDataImportCron仕様でデフォルトのストレージクラスを設定する必要があります。ストレージクラスが定義されていない場合、DataVolume コントローラーは PVC の作成に失敗し、次のイベントが表示されます:DataVolume.storage spec is missing accessMode and no storageClass to choose profile。DataImportCronnamespace と名前を取得します。$ oc get dataimportcron -A -o json | jq -r '.items[] | \ select(.status.conditions[] | select(.type == "UpToDate" and \ .status == "False")) | .metadata.namespace + "/" + .metadata.name'
クラスターでデフォルトのストレージクラスが定義されていない場合は、
DataImportCron仕様でデフォルトのストレージクラスをチェックします。$ oc get dataimportcron <dataimportcron> -o yaml | \ grep -B 5 storageClassName
出力例
url: docker://.../cdi-func-test-tinycore storage: resources: requests: storage: 5Gi storageClassName: rook-ceph-blockDataImportCronオブジェクトに関連付けられたDataVolumeの名前を取得します。$ oc -n <namespace> get dataimportcron <dataimportcron> -o json | \ jq .status.lastImportedPVC.name
DataVolumeログでエラーメッセージを確認します。$ oc -n <namespace> get dv <datavolume> -o yaml
CDI_NAMESPACE環境変数を設定します。$ export CDI_NAMESPACE="$(oc get deployment -A | \ grep cdi-operator | awk '{print $1}')"cdi-deploymentログでエラーメッセージを確認します。$ oc logs -n $CDI_NAMESPACE deployment/cdi-deployment
軽減策
-
クラスターまたは
DataImportCron仕様でデフォルトのストレージクラスを設定し、ゴールデンイメージをポーリングしてインポートします。更新された Containerized Data Importer (CDI) は、数秒以内に問題を解決します。 -
問題が解決しない場合は、影響を受ける
DataImportCronオブジェクトに関連付けられているデータボリュームを削除します。CDI は、デフォルトのストレージクラスでデータボリュームを再作成します。 クラスターが制限されたネットワーク環境にインストールされている場合は、自動更新をオプトアウトするために
enableCommonBootImageImportフィーチャーゲートを無効にします。$ oc patch hco kubevirt-hyperconverged -n $CDI_NAMESPACE --type json \ -p '[{"op": "replace", "path": \ "/spec/featureGates/enableCommonBootImageImport", "value": false}]'
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.2. CDIDataVolumeUnusualRestartCount
意味
このアラートは、DataVolume オブジェクトが 3 回以上再起動した場合に発生します。
影響
データボリュームは、永続ボリューム要求での仮想マシンディスクのインポートと作成を担当します。データボリュームの再起動が 3 回を超えると、これらの操作が成功する可能性は低くなります。問題を診断して解決する必要があります。
診断
3 回以上再起動した Containerized Data Importer (CDI) Pod を検索します。
$ oc get pods --all-namespaces -l app=containerized-data-importer \ -o=jsonpath='{range .items[?(@.status.containerStatuses[0].restartCount>3)]}{.metadata.name}{"/"}{.metadata.namespace}{"\n"}'Pod の詳細を取得します。
$ oc -n <namespace> describe pods <pod>
Pod のログでエラーメッセージをチェックします。
$ oc -n <namespace> logs <pod>
軽減策
データボリュームを削除し、問題を解決して、新しいデータボリュームを作成します。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.3. CDINotReady
意味
このアラートは、Containerized Data Importer (CDI) がデグレード状態にある場合に発生します。
- 進行中でない
- 使用不可
影響
CDI は使用できないため、ユーザーは CDI のデータボリュームを使用して永続ボリュームクレーム (PVC) に仮想マシンディスクをビルドできません。CDI コンポーネントの準備ができておらず、準備完了状態への進行が停止しました。
診断
CDI_NAMESPACE環境変数を設定します。$ export CDI_NAMESPACE="$(oc get deployment -A | \ grep cdi-operator | awk '{print $1}')"準備ができていないコンポーネントの CDI デプロイメントをチェックします。
$ oc -n $CDI_NAMESPACE get deploy -l cdi.kubevirt.io
失敗した Pod の詳細をチェックします。
$ oc -n $CDI_NAMESPACE describe pods <pod>
失敗した Pod のログをチェックします。
$ oc -n $CDI_NAMESPACE logs <pod>
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.4. CDIOperatorDown
意味
このアラートは、Containerized Data Importer (CDI) Operator がダウンしたときに発生します。CDI Operator は、データボリュームや永続ボリューム要求 (PVC) コントローラーなどの CDI インフラストラクチャーコンポーネントをデプロイおよび管理します。これらのコントローラーは、ユーザーが PVC 上に仮想マシンディスクをビルドするのに役立ちます。
影響
CDI コンポーネントがデプロイに失敗するか、必要な状態を維持できない可能性があります。CDI のインストールが正しく機能しない可能性があります。
診断
CDI_NAMESPACE環境変数を設定します。$ export CDI_NAMESPACE="$(oc get deployment -A | grep cdi-operator | \ awk '{print $1}')"cdi-operatorPod が現在実行されているかどうかを確認します。$ oc -n $CDI_NAMESPACE get pods -l name=cdi-operator
cdi-operatorPod の詳細を取得します。$ oc -n $CDI_NAMESPACE describe pods -l name=cdi-operator
cdi-operatorPod のログでエラーをチェックします。$ oc -n $CDI_NAMESPACE logs -l name=cdi-operator
軽減策
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.5. CDIStorageProfilesIncomplete
意味
このアラートは、Containerized Data Importer (CDI) ストレージプロファイルが不完全な場合に発生します。
ストレージプロファイルが不完全な場合、CDI は、仮想マシン (VM) ディスクの作成に必要な volumeMode や accessModes などの永続ボリューム要求 (PVC) フィールドを推測できません。
影響
CDI は PVC 上に仮想マシンディスクを作成できません。
診断
不完全なストレージプロファイルを特定します。
$ oc get storageprofile <storage_class>
軽減策
次の例のように、不足しているストレージプロファイル情報を追加します。
$ oc patch storageprofile <storage_class> --type=merge -p '{"spec": {"claimPropertySets": [{"accessModes": ["ReadWriteOnce"], "volumeMode": "Filesystem"}]}}'
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.6. CnaoDown
意味
このアラートは、Cluster Network Addons Operator (CNAO) がダウンしたときに発生します。CNAO は、追加のネットワークコンポーネントをクラスターの上にデプロイします。
影響
CNAO が実行されていない場合、クラスターは仮想マシンコンポーネントへの変更を調整できません。その結果、変更が有効にならない場合があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get deployment -A | \ grep cluster-network-addons-operator | awk '{print $1}')"cluster-network-addons-operatorPod のステータスをチェックします。$ oc -n $NAMESPACE get pods -l name=cluster-network-addons-operator
cluster-network-addons-operatorログでエラーメッセージをチェックします。$ oc -n $NAMESPACE logs -l name=cluster-network-addons-operator
cluster-network-addons-operatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pods -l name=cluster-network-addons-operator
軽減策
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.7. HCOInstallationIncomplete
意味
このアラートは、HyperConverged Cluster Operator (HCO) が HyperConverged カスタムリソース (CR) なしで 1 時間以上実行された場合に発生します。
このアラートには次の原因があります。
-
インストールプロセス中に HCO をインストールしましたが、
HyperConvergedCR を作成していません。 -
アンインストールプロセス中に、HCO をアンインストールする前に
HyperConvergedCR を削除しましたが、HCO はまだ実行されています。
軽減策
軽減策は、HCO をインストールするかアンインストールするかによって異なります。
HyperConvergedCR をデフォルト値で作成して、インストールを完了します。$ cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: hco-operatorgroup namespace: kubevirt-hyperconverged spec: {} EOF- HCO をアンインストールします。アンインストールプロセスが引き続き実行される場合は、アラートをキャンセルするためにその問題を解決する必要があります。
12.6.8. HPPNotReady
意味
このアラートは、ホストパスプロビジョナー (HPP) のインストールが劣化状態にある場合に発生します。
HPP は、ホストパスボリュームを動的にプロビジョニングして、永続ボリューム要求 (PVC) 用のストレージを提供します。
影響
HPP は使用できません。そのコンポーネントは準備ができておらず、準備完了状態に向かって進んでいません。
診断
HPP_NAMESPACE環境変数を設定します。$ export HPP_NAMESPACE="$(oc get deployment -A | \ grep hostpath-provisioner-operator | awk '{print $1}')"現在準備が整っていない HPP コンポーネントを確認します。
$ oc -n $HPP_NAMESPACE get all -l k8s-app=hostpath-provisioner
失敗した Pod の詳細を取得します。
$ oc -n $HPP_NAMESPACE describe pods <pod>
失敗した Pod のログをチェックします。
$ oc -n $HPP_NAMESPACE logs <pod>
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.9. HPPOperatorDown
意味
このアラートは、ホストパスプロビジョナー (HPP) オペレーターがダウンしたときに発生します。
HPP Operator は、ホストパスボリュームをプロビジョニングするデーモンセットなど、HPP インフラストラクチャーコンポーネントをデプロイおよび管理します。
影響
HPP コンポーネントがデプロイに失敗するか、必要な状態のままになる可能性があります。その結果、HPP のインストールがクラスターで正しく機能しない可能性があります。
診断
HPP_NAMESPACE環境変数を設定します。$ HPP_NAMESPACE="$(oc get deployment -A | grep \ hostpath-provisioner-operator | awk '{print $1}')"hostpath-provisioner-operatorPod が現在実行中かどうかをチェックします。$ oc -n $HPP_NAMESPACE get pods -l name=hostpath-provisioner-operator
hostpath-provisioner-operatorPod の詳細を取得します。$ oc -n $HPP_NAMESPACE describe pods -l name=hostpath-provisioner-operator
hostpath-provisioner-operatorPod のログでエラーをチェックします。$ oc -n $HPP_NAMESPACE logs -l name=hostpath-provisioner-operator
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.10. HPPSharingPoolPathWithOS
意味
このアラートは、ホストパスプロビジョナー (HPP) がファイルシステムを kubelet やオペレーティングシステム (OS) などの他の重要なコンポーネントと共有している場合に発生します。
HPP は、ホストパスボリュームを動的にプロビジョニングして、永続ボリューム要求 (PVC) 用のストレージを提供します。
影響
共有ホストパスプールは、ノードのディスクに圧力をかけます。ノードのパフォーマンスと安定性が低下している可能性があります。
診断
HPP_NAMESPACE環境変数を設定します。$ export HPP_NAMESPACE="$(oc get deployment -A | \ grep hostpath-provisioner-operator | awk '{print $1}')"hostpath-provisioner-csiデーモンセット Pod のステータスを取得します。$ oc -n $HPP_NAMESPACE get pods | grep hostpath-provisioner-csi
hostpath-provisioner-csiログを確認して、共有プールとパスを特定します。$ oc -n $HPP_NAMESPACE logs <csi_daemonset> -c hostpath-provisioner
出力例
I0208 15:21:03.769731 1 utils.go:221] pool (<legacy, csi-data-dir>/csi), shares path with OS which can lead to node disk pressure
軽減策
診断セクションで取得したデータを使用して、プールパスが OS と共有されないようにします。具体的な手順は、ノードやその他の状況によって異なります。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.11. KubemacpoolDown
意味
KubeMacPool がダウンしています。KubeMacPool は、MAC アドレスの割り当てと MAC アドレスの競合の防止を担当します。
影響
KubeMacPool がダウンしている場合、VirtualMachine オブジェクトを作成できません。
診断
KMP_NAMESPACE環境変数を設定します。$ export KMP_NAMESPACE="$(oc get pod -A --no-headers -l \ control-plane=mac-controller-manager | awk '{print $1}')"KMP_NAME環境変数を設定します。$ export KMP_NAME="$(oc get pod -A --no-headers -l \ control-plane=mac-controller-manager | awk '{print $2}')"KubeMacPool-managerPod の詳細を取得します。$ oc describe pod -n $KMP_NAMESPACE $KMP_NAME
KubeMacPool-managerログでエラーメッセージを確認します。$ oc logs -n $KMP_NAMESPACE $KMP_NAME
軽減策
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.12. KubeMacPoolDuplicateMacsFound
意味
このアラートは、KubeMacPool が重複した MAC アドレスを検出したときに発生します。
KubeMacPool は、MAC アドレスの割り当てと MAC アドレスの競合の防止を担当します。KubeMacPool が起動すると、クラスターをスキャンして、管理された namespace 内の仮想マシン (VM) の MAC アドレスを探します。
影響
同じ LAN で MAC アドレスが重複していると、ネットワークの問題が発生する可能性があります。
診断
namespace と
kubemacpool-mac-controllerPod の名前を取得します。$ oc get pod -A -l control-plane=mac-controller-manager --no-headers \ -o custom-columns=":metadata.namespace,:metadata.name"
kubemacpool-mac-controllerログから重複する MAC アドレスを取得します。$ oc logs -n <namespace> <kubemacpool_mac_controller> | \ grep "already allocated"
出力例
mac address 02:00:ff:ff:ff:ff already allocated to vm/kubemacpool-test/testvm, br1, conflict with: vm/kubemacpool-test/testvm2, br1
軽減策
- 仮想マシンを更新して、重複する MAC アドレスを削除します。
kubemacpool-mac-controllerPod を再起動します。$ oc delete pod -n <namespace> <kubemacpool_mac_controller>
12.6.13. KubeVirtComponentExceedsRequestedCPU
意味
このアラートは、コンポーネントの CPU 使用率が要求された制限を超えたときに発生します。
影響
CPU リソースの使用率が最適ではなく、ノードが過負荷になっている可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
コンポーネントの CPU リクエスト制限を確認します。
$ oc -n $NAMESPACE get deployment <component> -o yaml | grep requests: -A 2
PromQL クエリーを使用して、実際の CPU 使用率を確認します。
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate {namespace="$NAMESPACE",container="<component>"}
詳細については、Prometheus のドキュメント を参照してください。
軽減策
HCO カスタムリソースの CPU リクエスト制限を更新します。
12.6.14. KubeVirtComponentExceedsRequestedMemory
意味
このアラートは、コンポーネントのメモリー使用率が要求された制限を超えたときに発生します。
影響
メモリーリソースの使用が最適化されておらず、ノードが過負荷になっている可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
コンポーネントのメモリー要求制限を確認します。
$ oc -n $NAMESPACE get deployment <component> -o yaml | \ grep requests: -A 2
PromQL クエリーを使用して、実際のメモリー使用率を確認します。
container_memory_usage_bytes{namespace="$NAMESPACE",container="<component>"}
詳細については、Prometheus のドキュメント を参照してください。
軽減策
HCO カスタムリソースのメモリー要求制限を更新します。
12.6.15. KubeVirtCRModified
意味
このアラートは、HyperConverged Cluster Operator (HCO) のオペランドが HCO 以外の誰かまたは何かによって変更されたときに発生します。
HCO は、OpenShift Virtualization とそのサポートオペレーターを独自の方法で設定し、予期しない変更があった場合にそのオペランドを上書きします。ユーザーは、オペランドを直接変更してはなりません。HyperConverged カスタムリソースは、設定の信頼できる情報源です。
影響
オペランドを手動で変更すると、クラスター設定が変動し、不安定になる可能性があります。
診断
アラートの詳細で
component_nameの値を確認して、変更されているオペランドの種類 (kubevirt) とオペランド名 (kubevirt-kubevirt-hyperconverged) を特定します。Labels alertname=KubevirtHyperconvergedClusterOperatorCRModification component_name=kubevirt/kubevirt-kubevirt-hyperconverged severity=warning
軽減策
HCO オペランドを直接変更しないでください。HyperConverged オブジェクトを使用してクラスターを設定します。
オペランドが手動で変更されていない場合、アラートは 10 分後に自動的に解決されます。
12.6.16. KubeVirtDeprecatedAPIRequested
意味
このアラートは、非推奨の KubeVirt API が使用されている場合に発生します。
影響
将来のリリースで API が削除されるとリクエストが失敗するため、非推奨の API の使用は推奨されません。
診断
次の例のように、アラートの Description セクションと Summary セクションを確認して、非推奨の API を特定します。
Description
非推奨の virtualmachines.kubevirt.io/v1alpha3 API へのリクエストが検出されました。Summary
過去 10 分間に 2 つのリクエストが検出されました。
軽減策
完全にサポートされている API を使用します。非推奨の API が使用されていない場合、アラートは 10 分後に自動的に解決されます。
12.6.17. KubeVirtNoAvailableNodesToRunVMs
意味
このアラートは、クラスター内のノード CPU が仮想化をサポートしていない場合、または仮想化拡張機能が有効になっていない場合に発生します。
影響
仮想マシンを実行するには、ノードが仮想化をサポートし、BIOS で仮想化機能が有効になっている必要があります。
診断
ノードでハードウェア仮想化がサポートされているかどうかを確認します。
$ oc get nodes -o json|jq '.items[]|{"name": .metadata.name, "kvm": .status.allocatable["devices.kubevirt.io/kvm"]}'出力例
{ "name": "shift-vwpsz-master-0", "kvm": null } { "name": "shift-vwpsz-master-1", "kvm": null } { "name": "shift-vwpsz-master-2", "kvm": null } { "name": "shift-vwpsz-worker-8bxkp", "kvm": "1k" } { "name": "shift-vwpsz-worker-ctgmc", "kvm": "1k" } { "name": "shift-vwpsz-worker-gl5zl", "kvm": "1k" }"kvm": nullまたは"kvm": 0のノードは仮想化拡張機能をサポートしません。"kvm": "1k"のノードは仮想化拡張機能をサポートします。
軽減策
ハードウェアおよび CPU 仮想化拡張機能がすべてのノードで有効になっていること、およびノードに正しくラベルが付けられていることを確認してください。
詳細は、OpenShift Virtualization reports no nodes are available, cannot start VMs を参照してください。
問題を解決できない場合は、カスタマーポータル にログインし、サポートケースをオープンしてください。
12.6.18. KubevirtVmHighMemoryUsage
意味
このアラートは、仮想マシン (VM) をホストするコンテナーの空きメモリーが 20 MB 未満の場合に発生します。
影響
コンテナーのメモリー制限を超えると、コンテナー内で実行されている仮想マシンはランタイムによって終了されます。
診断
virt-launcherPod の詳細を取得します。$ oc get pod <virt-launcher> -o yaml
virt-launcherPod でメモリー使用率が多いcomputeコンテナープロセスを特定します。$ oc exec -it <virt-launcher> -c compute -- top
軽減策
次の例のように、
VirtualMachine仕様のメモリー制限を増やします。spec: running: false template: metadata: labels: kubevirt.io/vm: vm-name spec: domain: resources: limits: memory: 200Mi requests: memory: 128Mi
12.6.19. KubeVirtVMIExcessiveMigrations
意味
このアラートは、仮想マシンインスタンス (VMI) のライブマイグレーションが 24 時間に 12 回を超えた場合に発生します。
この移行率は、アップグレード中でも異常に高くなっています。このアラートは、ネットワークの中断やリソース不足など、クラスターインフラストラクチャーの問題を示している可能性があります。
影響
頻繁に移行する仮想マシン (VM) では、移行中にメモリーページフォールトが発生するため、パフォーマンスが低下する可能性があります。
診断
ワーカーノードに十分なリソースがあることを確認します。
$ oc get nodes -l node-role.kubernetes.io/worker= -o json | \ jq .items[].status.allocatable
出力例
{ "cpu": "3500m", "devices.kubevirt.io/kvm": "1k", "devices.kubevirt.io/sev": "0", "devices.kubevirt.io/tun": "1k", "devices.kubevirt.io/vhost-net": "1k", "ephemeral-storage": "38161122446", "hugepages-1Gi": "0", "hugepages-2Mi": "0", "memory": "7000128Ki", "pods": "250" }ワーカーノードのステータスを確認します。
$ oc get nodes -l node-role.kubernetes.io/worker= -o json | \ jq .items[].status.conditions
出力例
{ "lastHeartbeatTime": "2022-05-26T07:36:01Z", "lastTransitionTime": "2022-05-23T08:12:02Z", "message": "kubelet has sufficient memory available", "reason": "KubeletHasSufficientMemory", "status": "False", "type": "MemoryPressure" }, { "lastHeartbeatTime": "2022-05-26T07:36:01Z", "lastTransitionTime": "2022-05-23T08:12:02Z", "message": "kubelet has no disk pressure", "reason": "KubeletHasNoDiskPressure", "status": "False", "type": "DiskPressure" }, { "lastHeartbeatTime": "2022-05-26T07:36:01Z", "lastTransitionTime": "2022-05-23T08:12:02Z", "message": "kubelet has sufficient PID available", "reason": "KubeletHasSufficientPID", "status": "False", "type": "PIDPressure" }, { "lastHeartbeatTime": "2022-05-26T07:36:01Z", "lastTransitionTime": "2022-05-23T08:24:15Z", "message": "kubelet is posting ready status", "reason": "KubeletReady", "status": "True", "type": "Ready" }ワーカーノードにログインし、
kubeletサービスが実行されていることを確認します。$ systemctl status kubelet
kubeletジャーナルログでエラーメッセージを確認します。$ journalctl -r -u kubelet
軽減策
VM ワークロードを中断することなく実行するのに十分なリソース (CPU、メモリー、ディスク) がワーカーノードにあることを確認します。
問題が解決しない場合は、根本原因を特定して問題を解決してください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.20. LowKVMNodesCount
意味
このアラートは、クラスター内の 2 つ未満のノードに KVM リソースがある場合に発生します。
影響
クラスターには、ライブマイグレーション用の KVM リソースを備えた少なくとも 2 つのノードが必要です。
どのノードにも KVM リソースがない場合、仮想マシンをスケジュールまたは実行することはできません。
診断
KVM リソースを持つノードを特定します。
$ oc get nodes -o jsonpath='{.items[*].status.allocatable}' | \ grep devices.kubevirt.io/kvm
軽減策
KVM リソースのないノードに KVM をインストールします。
12.6.21. LowReadyVirtControllersCount
意味
このアラートは、1 つ以上の virt-controller Pod が実行されているが、これらの Pod が過去 5 分間 Ready 状態になかった場合に発生します。
virt-controller デバイスは、仮想マシンインスタンス (VMI) のカスタムリソース定義 (CRD) をモニターし、関連する Pod を管理します。デバイスは VMI の Pod を作成し、そのライフサイクルを管理します。このデバイスは、クラスター全体の仮想化機能にとって重要です。
影響
このアラートは、クラスターレベルの障害が発生する可能性があることを示します。新しい VMI の起動や既存の VMI のシャットダウンなど、VM のライフサイクル管理に関連するアクションは失敗します。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-controllerデバイスが利用可能であることを確認します。$ oc get deployment -n $NAMESPACE virt-controller \ -o jsonpath='{.status.readyReplicas}'virt-controllerデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-controller -o yaml
virt-controllerデプロイメントの詳細を取得して、Pod のクラッシュやイメージのプルの失敗などのステータス条件を確認します。$ oc -n $NAMESPACE describe deploy virt-controller
ノードに問題が発生していないか確認してください。たとえば、
NotReady状態にある可能性があります。$ oc get nodes
軽減策
このアラートには、次のような複数の原因が考えられます。
- クラスターのメモリーが不足しています。
- ノードがダウンしています。
- API サーバーが過負荷になっています。たとえば、スケジューラーの負荷が高く、完全には使用できない場合があります。
- ネットワークの問題があります。
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.22. LowReadyVirtOperatorsCount
意味
このアラートは、1 つ以上の virt-operator Pod が実行されているときに発生しますが、これらの Pod はいずれも過去 10 分間 Ready 状態ではありません。
virt-operator は、クラスターで開始する最初の Operator です。virt-operator デプロイメントには、2 つの virt-operator Pod のデフォルトのレプリカがあります。
その主な責任には、次のものが含まれます。
- クラスターのインストール、ライブ更新、およびライブアップグレード
-
virt-controller、virt-handler、virt-launcherなどの最上位コントローラーのライフサイクルをモニターし、それらの調整を管理する - 証明書のローテーションやインフラストラクチャー管理など、特定のクラスター全体のタスク
影響
クラスターレベルの障害が発生する可能性があります。証明書のローテーション、アップグレード、およびコントローラーの調整などの重要なクラスター全体の管理機能は利用できなくなる可能性があります。このような状態でも、NoReadyVirtOperator アラートがトリガーされます。
virt-operator には、クラスター内の仮想マシンに対する直接の責任はありません。したがって、一時的に利用できなくても仮想マシンのワークロードに大きな影響はありません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operatorデプロイメントの名前を取得します。$ oc -n $NAMESPACE get deploy virt-operator -o yaml
virt-operatorデプロイメントの詳細を取得します。$ oc -n $NAMESPACE describe deploy virt-operator
NotReady状態などのノードの問題をチェックします。$ oc get nodes
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.23. LowVirtAPICount
意味
このアラートは、スケジューリングに少なくとも 2 つのノードが使用可能であるにもかかわらず、60 分間に使用可能な virt-api Pod が 1 つしか検出されない場合に発生します。
影響
virt-api Pod が単一障害点になるため、ノードの削除中に API 呼び出しの停止が発生する可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
使用可能な
virt-apiPod の数を確認します。$ oc get deployment -n $NAMESPACE virt-api \ -o jsonpath='{.status.readyReplicas}'エラー条件について、
virt-apiデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-api -o yaml
NotReady状態のノードなどの問題がないかノードを確認します。$ oc get nodes
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.24. LowVirtControllersCount
意味
このアラートは、検出された virt-controller Pod の数が少ない場合に発生します。高可用性を確保するには、少なくとも 1 つの virt-controller Pod が利用可能である必要があります。レプリカのデフォルト数は、2 です。
virt-controller デバイスは、仮想マシンインスタンス (VMI) のカスタムリソース定義 (CRD) をモニターし、関連する Pod を管理します。デバイスは VMI の Pod を作成し、Pod のライフサイクルを管理します。このデバイスは、クラスター全体の仮想化機能にとって重要です。
影響
OpenShift Virtualization の応答性に悪影響が及ぶ可能性があります。たとえば、特定のリクエストが見逃される場合があります。
さらに、別の virt-launcher インスタンスが予期せず終了した場合、OpenShift Virtualization が完全に応答しなくなる可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
実行
中の virt-controllerPod が利用可能であることを確認します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-controller
virt-launcherログでエラーメッセージを確認します。$ oc -n $NAMESPACE logs <virt-launcher>
virt-launcherPod の詳細を取得して、予期しない終了やNotReady状態などのステータス条件を確認します。$ oc -n $NAMESPACE describe pod/<virt-launcher>
軽減策
このアラートには、次のようなさまざまな原因が考えられます。
- クラスターに十分なメモリーがない
- ノードがダウンしている
- API サーバーが過負荷になっています。たとえば、スケジューラーの負荷が高く、完全には使用できない場合があります。
- ネットワークの問題
根本原因を特定し、可能であれば修正します。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.25. LowVirtOperatorCount
意味
このアラートは、Ready 状態の virt-operator Pod が 1 つだけ過去 60 分間実行されている場合に発生します。
virt-operator は、クラスターで開始する最初の Operator です。その主な責任には、次のものが含まれます。
- クラスターのインストール、ライブ更新、およびライブアップグレード
-
virt-controller、virt-handler、virt-launcherなどの最上位コントローラーのライフサイクルをモニターし、それらの調整を管理する - 証明書のローテーションやインフラストラクチャー管理など、特定のクラスター全体のタスク
影響
virt-operator は、デプロイメントに高可用性 (HA) を提供できません。HA には、Ready 状態の virt-operator Pod が 2 つ以上必要です。デフォルトのデプロイは 2 つの Pod です。
virt-operator には、クラスター内の仮想マシンに対する直接の責任はありません。したがって、可用性の低下が VM のワークロードに大きな影響を与えることはありません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operator Podの状態を確認します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator
影響を受ける
virt-operatorPod のログを確認します。$ oc -n $NAMESPACE logs <virt-operator>
影響を受ける
virt-operatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pod <virt-operator>
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.26. NetworkAddonsConfigNotReady
意味
このアラートは、Cluster Network Addons Operator (CNAO) の NetworkAddonsConfig カスタムリソース (CR) の準備ができていない場合に発生します。
CNAO は、追加のネットワークコンポーネントをクラスターにデプロイします。このアラートは、デプロイメントされたコンポーネントのいずれかの準備ができていないことを示します。
影響
ネットワーク機能が影響を受けます。
診断
NetworkAddonsConfigCR のステータス条件をチェックして、準備ができていないデプロイメントまたはデーモンセットを特定します。$ oc get networkaddonsconfig \ -o custom-columns="":.status.conditions[*].message
出力例
DaemonSet "cluster-network-addons/macvtap-cni" update is being processed...
コンポーネントの Pod でエラーをチェックします。
$ oc -n cluster-network-addons get daemonset <pod> -o yaml
コンポーネントのログをチェックします。
$ oc -n cluster-network-addons logs <pod>
コンポーネントの詳細でエラー状態をチェックします。
$ oc -n cluster-network-addons describe <pod>
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.27. NoLeadingVirtOperator
意味
このアラートは、virt-operator Pod が Ready 状態であるにも関わらず、リーダーリースを持つ virt-operator Pod が 10 分間検出されない場合に発生します。このアラートは、使用できるリーダー Pod がないことを示しています。
virt-operator は、クラスターで開始する最初の Operator です。その主な責任には、次のものが含まれます。
- クラスターのインストール、ライブ 更新、およびライブアップグレード
-
virt-controller、virt-handler、virt-launcherなどの最上位コントローラーのライフサイクルをモニターし、それらの調整を管理する - 証明書のローテーションやインフラストラクチャー管理など、特定のクラスター全体のタスク
virt-operator デプロイメントには、2 つの Pod のデフォルトのレプリカがあり、1 つの Pod がリーダーリースを保持しています。
影響
このアラートは、クラスターレベルでの障害を示します。その結果、証明書のローテーション、アップグレード、コントローラーの調整など、重要なクラスター全体の管理機能が利用できなくなる可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A -o \ custom-columns="":.metadata.namespace)"
virt-operator Podのステータスを取得します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator
virt-operatorPod のログを確認して、リーダーのステータスをチェックします。$ oc -n $NAMESPACE logs | grep lead
リーダー Pod の例:
{"component":"virt-operator","level":"info","msg":"Attempting to acquire leader status","pos":"application.go:400","timestamp":"2021-11-30T12:15:18.635387Z"} I1130 12:15:18.635452 1 leaderelection.go:243] attempting to acquire leader lease <namespace>/virt-operator... I1130 12:15:19.216582 1 leaderelection.go:253] successfully acquired lease <namespace>/virt-operator {"component":"virt-operator","level":"info","msg":"Started leading", "pos":"application.go:385","timestamp":"2021-11-30T12:15:19.216836Z"}リーダー以外の Pod の例:
{"component":"virt-operator","level":"info","msg":"Attempting to acquire leader status","pos":"application.go:400","timestamp":"2021-11-30T12:15:20.533696Z"} I1130 12:15:20.533792 1 leaderelection.go:243] attempting to acquire leader lease <namespace>/virt-operator...影響を受ける
virt-operatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pod <virt-operator>
軽減策
診断手順で得られた情報に基づいて、根本原因を見つけて問題を解決してください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.28. NoReadyVirtController
意味
このアラートは、使用可能な virt-controller デバイスが 5 分間検出されなかった場合に発生します。
virt-controller デバイスは、仮想マシンインスタンス (VMI) のカスタムリソース定義を監視し、関連する Pod を管理します。デバイスは VMI の Pod を作成し、Pod のライフサイクルを管理します。
したがって、virt-controller デバイスは、すべてのクラスター全体の仮想化機能にとって重要です。
影響
仮想マシンライフサイクル管理に関連するアクションはすべて失敗します。これには特に、新しい VMI の起動または既存の VMI のシャットダウンが含まれます。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-controllerデバイスの数を検証します。$ oc get deployment -n $NAMESPACE virt-controller \ -o jsonpath='{.status.readyReplicas}'virt-controllerデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-controller -o yaml
virt-controllerデプロイメントの詳細を取得して、Pod のクラッシュやイメージのプルの失敗などのステータス条件をチェックします。$ oc -n $NAMESPACE describe deploy virt-controller
virt-controller Podの詳細を取得します。$ get pods -n $NAMESPACE | grep virt-controller
virt-controllerPod のログでエラーメッセージをチェックします。$ oc logs -n $NAMESPACE <virt-controller>
NotReady状態などの問題がないかノードをチェックします。$ oc get nodes
軽減策
診断手順で得られた情報に基づいて、根本原因を見つけて問題を解決してください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.29. NoReadyVirtOperator
意味
このアラートは、Ready 状態の virt-operator Pod が 10 分間検出されなかった場合に発生します。
virt-operator は、クラスターで開始する最初の Operator です。その主な責任には、次のものが含まれます。
- クラスターのインストール、ライブ更新、およびライブアップグレード
-
virt-controller、virt-handler、virt-launcherなどの最上位コントローラーのライフサイクルを監視し、それらの調整を管理する - 証明書のローテーションやインフラストラクチャー管理など、特定のクラスター全体のタスク
デフォルトのデプロイメントは 2 つの virt-operator Pod です。
影響
このアラートは、クラスターレベルの障害を示します。証明書のローテーション、アップグレード、コントローラーの調整などの重要なクラスター管理機能が利用できない場合があります。
virt-operator には、クラスター内の仮想マシンに対する直接の責任はありません。したがって、一時的に利用できなくてもワークロードに大きな影響はありません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operatorデプロイメントの名前を取得します。$ oc -n $NAMESPACE get deploy virt-operator -o yaml
virt-operatorデプロイメントの説明を生成します。$ oc -n $NAMESPACE describe deploy virt-operator
NotReady状態などのノードの問題をチェックします。$ oc get nodes
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.30. OrphanedVirtualMachineInstances
意味
このアラートは、仮想マシンインスタンス (VMI) または virt-launcher Pod が、実行中の virt-handler Pod を持たないノードで実行されている場合に発生します。このような VMI は orphaned と呼ばれます。
影響
孤立した VMI は管理できません。
診断
virt-handler Podのステータスを確認して、それらが実行されているノードを表示します。$ oc get pods --all-namespaces -o wide -l kubevirt.io=virt-handler
VMI のステータスを確認して、実行中の
virt-handlerPod を持たないノードで実行されている VMI を特定します。$ oc get vmis --all-namespaces
virt-handlerデーモンのステータスを確認します。$ oc get daemonset virt-handler --all-namespaces
出力例
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE ... virt-handler 2 2 2 2 2 ...
Desired、Ready、およびAvailable列に同じ値が含まれている場合、デーモンセットは正常であると見なされます。virt-handlerデーモンセットが正常でない場合は、virt-handlerデーモンセットで Pod のデプロイの問題を確認します。$ oc get daemonset virt-handler --all-namespaces -o yaml | jq .status
ノードの
NotReadyステータスなどの問題を確認します。$ oc get nodes
ワークロード配置ポリシーについては、
KubeVirtカスタムリソース (CR) のspec.workloadsスタンザを確認してください。$ oc get kubevirt kubevirt --all-namespaces -o yaml
軽減策
ワークロード配置ポリシーが設定されている場合は、VMI を持つノードをポリシーに追加します。
ノードからの virt-handler Pod の削除の考えられる原因には、ノードのテイントと容認、または Pod のスケジューリングルールの変更が含まれます。
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.31. OutdatedVirtualMachineInstanceWorkloads
意味
このアラートは、OpenShift Virtualization コントロールプレーンが更新されてから 24 時間後に、古い virt-launcher Pod で実行中の仮想マシンインスタンス (VMI) が検出されたときに発生します。
影響
古い VMI は、新しい OpenShift Virtualization 機能にアクセスできない可能性があります。
古い VMI は、virt-launcher Pod の更新に関連するセキュリティー修正を受け取りません。
診断
古い VMI を特定します。
$ oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespaces
KubeVirtカスタムリソース (CR) をチェックして、workloadUpdateMethodsがworkloadUpdateStrategyスタンザで設定されているかどうかを確認します。$ oc get kubevirt --all-namespaces -o yaml
古い VMI をそれぞれチェックして、ライブマイグレーション可能かどうかを判断します。
$ oc get vmi <vmi> -o yaml
出力例
apiVersion: kubevirt.io/v1 kind: VirtualMachineInstance # ... status: conditions: - lastProbeTime: null lastTransitionTime: null message: cannot migrate VMI which does not use masquerade to connect to the pod network reason: InterfaceNotLiveMigratable status: "False" type: LiveMigratable
軽減策
ワークロードの自動更新の設定
HyperConverged CR を更新して、ワークロードの自動更新を有効にします。
ライブマイグレーション不可能な VMI に関連付けられた VM の停止
VMI がライブマイグレーション可能でなく、対応する
VirtualMachineオブジェクトにrunStrategy: alwaysが設定されている場合、仮想マシン (VM) を手動で停止することにより VMI を更新することができます。$ virctl stop --namespace <namespace> <vm>
新しい VMI は、更新された virt-launcher Pod ですぐにスピンアップし、停止した VMI を置き換えます。これは、再起動アクションに相当します。
ライブマイグレーション可能 な VM を手動で停止することは破壊的であり、ワークロードが中断されるため推奨できません。
ライブ移行可能な VMI の移行
VMI がライブマイグレーション可能な場合は、実行中の特定の VMI を対象とする VirtualMachineInstanceMigration オブジェクトを作成することで更新できます。VMI は、更新された virt-launcher Pod に移行されます。
VirtualMachineInstanceMigrationマニフェストを作成し、migration.yamlとして保存します。apiVersion: kubevirt.io/v1 kind: VirtualMachineInstanceMigration metadata: name: <migration_name> namespace: <namespace> spec: vmiName: <vmi_name>
移行をトリガーする
VirtualMachineInstanceMigrationオブジェクトを作成します。$ oc create -f migration.yaml
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.32. SingleStackIPv6Unsupported
意味
このアラートは、シングルスタック IPv6 クラスターに OpenShift Virtualization をインストールすると発生します。
影響
仮想マシンを作成することはできません。
診断
次のコマンドを実行して、クラスターのネットワーク設定を確認します。
$ oc get network.config cluster -o yaml
出力には、クラスターネットワークの IPv6 CIDR のみが表示されます。
出力例
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: clusterNetwork: - cidr: fd02::/48 hostPrefix: 64
軽減策
OpenShift Virtualization をシングルスタック IPv4 クラスターまたはデュアルスタック IPv4/IPv6 クラスターにインストールします。
12.6.33. SSPCommonTemplatesModificationReverted
意味
このアラートは、Scheduling、Scale、and Performance (SSP) Operator が調整手順の一環として共通テンプレートへの変更を元に戻すときに発生します。
SSP Operator は、共通テンプレートおよびテンプレートバリデーターをデプロイし、調整します。ユーザーまたはスクリプトが共通テンプレートを変更すると、その変更は SSP オペレーターによって元に戻されます。
影響
共通テンプレートへの変更は上書きされます。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | \ awk '{print $1}')"変更が元に戻されたテンプレートの
ssp-operatorログを確認します。$ oc -n $NAMESPACE logs --tail=-1 -l control-plane=ssp-operator | \ grep 'common template' -C 3
軽減策
変更の原因を特定して解決するようにしてください。
テンプレート自体ではなく、テンプレートのコピーのみを変更するようにしてください。
12.6.34. SSPDown
意味
このアラートは、すべての Scheduling、Scale and Performance (SSP) Operator Pod がダウンしたときに発生します。
SSP オペレーターは、共通テンプレートとテンプレートバリデーターのデプロイと調整を担当します。
影響
依存コンポーネントがデプロイされていない可能性があります。コンポーネントの変更は調整されない場合があります。その結果、共通テンプレートおよび/またはテンプレートバリデーターが失敗した場合、更新またはリセットされない可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | \ awk '{print $1}')"ssp-operator Podのステータスをチェックします。$ oc -n $NAMESPACE get pods -l control-plane=ssp-operator
ssp-operator Podの詳細を取得します。$ oc -n $NAMESPACE describe pods -l control-plane=ssp-operator
ssp-operatorログでエラーメッセージをチェックします。$ oc -n $NAMESPACE logs --tail=-1 -l control-plane=ssp-operator
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.35. SSPFailingToReconcile
意味
このアラートは、SSP Operator が実行されているにもかかわらず、Scheduling、Scale and Performance (SSP) Operator の調整サイクルが繰り返し失敗した場合に発生します。
SSP オペレーターは、共通テンプレートとテンプレートバリデーターのデプロイと調整を担当します。
影響
依存コンポーネントがデプロイされていない可能性があります。コンポーネントの変更は調整されない場合があります。その結果、共通テンプレートまたはテンプレートバリデーターが失敗した場合、更新またはリセットされない可能性があります。
診断
NAMESPACE環境変数をエクスポートします。$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | \ awk '{print $1}')"ssp-operator Podの詳細を取得します。$ oc -n $NAMESPACE describe pods -l control-plane=ssp-operator
ssp-operatorログでエラーをチェックします。$ oc -n $NAMESPACE logs --tail=-1 -l control-plane=ssp-operator
virt-template-validatorPod のステータスを取得します。$ oc -n $NAMESPACE get pods -l name=virt-template-validator
virt-template-validatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pods -l name=virt-template-validator
virt-template-validatorログでエラーをチェックします。$ oc -n $NAMESPACE logs --tail=-1 -l name=virt-template-validator
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.36. SSPHighRateRejectedVms
意味
このアラートは、ユーザーまたはスクリプトが無効な設定を使用して多数の仮想マシン (VM) を作成または変更しようとすると発生します。
影響
VM は作成または変更されません。その結果、環境が期待どおりに動作しない可能性があります。
診断
NAMESPACE環境変数をエクスポートします。$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | \ awk '{print $1}')"virt-template-validatorログで、原因を示す可能性のあるエラーをチェックします。$ oc -n $NAMESPACE logs --tail=-1 -l name=virt-template-validator
出力例
{"component":"kubevirt-template-validator","level":"info","msg":"evalution summary for ubuntu-3166wmdbbfkroku0:\nminimal-required-memory applied: FAIL, value 1073741824 is lower than minimum [2147483648]\n\nsucceeded=false", "pos":"admission.go:25","timestamp":"2021-09-28T17:59:10.934470Z"}
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.37. SSPTemplateValidatorDown
意味
このアラートは、すべての Template Validator Pod がダウンしたときに発生します。
Template Validator は、仮想マシン (VM) をチェックして、テンプレートに違反していないことを確認します。
影響
VM はテンプレートに対して検証されません。その結果、それぞれのワークロードに一致しない仕様で仮想マシンが作成される可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | \ awk '{print $1}')"virt-template-validatorPod のステータスを取得します。$ oc -n $NAMESPACE get pods -l name=virt-template-validator
virt-template-validatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pods -l name=virt-template-validator
virt-template-validatorログでエラーメッセージをチェックします。$ oc -n $NAMESPACE logs --tail=-1 -l name=virt-template-validator
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.38. UnsupportedHCOModification
意味
このアラートは、JSON パッチアノテーションを使用して HyperConverged Cluster Operator (HCO) のオペランドを変更したときに発生します。
HCO は、OpenShift Virtualization とそのサポートオペレーターを独自の方法で設定し、予期しない変更があった場合にそのオペランドを上書きします。ユーザーは、オペランドを直接変更してはなりません。
ただし、変更が必要であり、HCO API でサポートされていない場合は、JSON パッチアノテーションを使用して HCO に強制的にオペレーターに変更を設定させることができます。これらの変更は、調整プロセス中に HCO によって元に戻されません。
影響
JSON パッチアノテーションを誤って使用すると、予期しない結果が生じたり、環境が不安定になったりする可能性があります。
コンポーネントのカスタムリソースの構造が変更される可能性があるため、JSON パッチアノテーションを使用してシステムをアップグレードすることは危険です。
診断
JSON パッチアノテーションを特定するには、アラートの詳細で
annotation_nameを確認します。Labels alertname=KubevirtHyperconvergedClusterOperatorUSModification annotation_name=kubevirt.kubevirt.io/jsonpatch severity=info
軽減策
オペランドを変更するには、HCO API を使用することを推奨します。ただし、JSON パッチアノテーションを使用しないと変更できない場合は、注意して進めてください。
潜在的な問題を回避するために、アップグレード前に JSON パッチアノテーションを削除します。
12.6.39. VirtAPIDown
意味
このアラートは、すべての API サーバー Pod がダウンしたときに発生します。
影響
OpenShift Virtualization オブジェクトは API 呼び出しを送信できません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-apiPod のステータスを確認します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-api
virt-apiデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-api -o yaml
Pod のクラッシュやイメージのプルの失敗などの問題について、
virt-apiデプロイメントの詳細を確認します。$ oc -n $NAMESPACE describe deploy virt-api
NotReady状態のノードなどの問題をチェックします。$ oc get nodes
軽減策
根本原因の特定と問題の解決を試みてください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.40. VirtApiRESTErrorsBurst
意味
過去 5 分間に virt-api Pod で REST 呼び出しの 80% 以上が失敗しました。
影響
virt-api への REST 呼び出しの失敗率が非常に高いと、API 呼び出しの応答と実行が遅くなり、API 呼び出しが完全に無視される可能性があります。
ただし、現在実行中の仮想マシンのワークロードが影響を受ける可能性はほとんどありません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
デプロイメントの
virt-apiPod のリストを取得します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-api
virt-apiログでエラーメッセージをチェックします。$ oc logs -n $NAMESPACE <virt-api>
virt-apiPod の詳細を取得します。$ oc describe -n $NAMESPACE <virt-api>
ノードに問題が発生していないか確認してください。たとえば、
NotReady状態にある可能性があります。$ oc get nodes
virt-apiデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-api -o yaml
virt-apiデプロイメントの詳細を取得します。$ oc -n $NAMESPACE describe deploy virt-api
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.41. VirtApiRESTErrorsHigh
意味
過去 60 分間に virt-api Pod で 5% 以上の REST 呼び出しが失敗しました。
影響
virt-api への REST 呼び出しの失敗率が高いと、API 呼び出しの応答と実行が遅くなる可能性があります。
ただし、現在実行中の仮想マシンのワークロードが影響を受ける可能性はほとんどありません。
診断
NAMESPACE環境変数を次のように設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-apiPod のステータスを確認します。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-api
virt-apiログをチェックします。$ oc logs -n $NAMESPACE <virt-api>
virt-apiPod の詳細を取得します。$ oc describe -n $NAMESPACE <virt-api>
ノードに問題が発生していないか確認してください。たとえば、
NotReady状態にある可能性があります。$ oc get nodes
virt-apiデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-api -o yaml
virt-apiデプロイメントの詳細を取得します。$ oc -n $NAMESPACE describe deploy virt-api
軽減策
診断手順で得られた情報に基づいて、根本原因の特定と問題の解決を試みます。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.42. VirtControllerDown
意味
実行 中の virt-controller Pod が 5 分間検出されませんでした。
影響
仮想マシン (VM) のライフサイクル管理に関連するアクションはすべて失敗します。これには特に、新しい仮想マシンインスタンス (VMI) の起動や既存の VMI のシャットダウンが含まれます。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-controllerデプロイメントのステータスを確認します。$ oc get deployment -n $NAMESPACE virt-controller -o yaml
virt-controllerPod のログを確認します。$ oc get logs <virt-controller>
軽減策
このアラートには、次のようなさまざまな原因が考えられます。
- ノードリソースの枯渇
- クラスターに十分なメモリーがない
- ノードがダウンしている
- API サーバーが過負荷になっています。たとえば、スケジューラーの負荷が高く、完全には使用できない場合があります。
- ネットワークの問題
根本原因を特定し、可能であれば修正します。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.43. VirtControllerRESTErrorsBurst
意味
過去 5 分間で、virt-controller Pod の REST 呼び出しの 80% 以上が失敗しました。
virt-controller が API サーバーへの接続を完全に失った可能性があります。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-controllerPod が API サーバーに到達できない。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
ステータスの更新は反映されず、移行などのアクションは実行できません。ただし、実行中のワークロードは影響を受けません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
使用可能な
virt-controllerPod を一覧表示します。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-controller
API サーバーに接続するときのエラーメッセージについては、
virt-controllerログを確認します。$ oc logs -n $NAMESPACE <virt-controller>
軽減策
virt-controllerPod が API サーバーに接続できない場合は、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-controller>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.44. VirtControllerRESTErrorsHigh
意味
過去 60 分間に virt-controller で REST 呼び出しの 5% 以上が失敗しました。
これはおそらく、virt-controller が API サーバーへの接続を部分的に失ったためです。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-controllerPod が API サーバーに到達できない。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
仮想マシンの起動や移行、スケジューリングなどのノード関連のアクションが遅れます。実行中のワークロードは影響を受けませんが、現在のステータスのレポートが遅れる可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
使用可能な
virt-controllerPod を一覧表示します。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-controller
API サーバーに接続するときのエラーメッセージについては、
virt-controllerログを確認します。$ oc logs -n $NAMESPACE <virt-controller>
軽減策
virt-controllerPod が API サーバーに接続できない場合は、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-controller>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.45. VirtHandlerDaemonSetRolloutFailing
意味
virt-handler デーモンセットは、15 分後に 1 つ以上のワーカーノードにデプロイできませんでした。
影響
このアラートは警告です。すべての virt-handler デーモンセットがデプロイに失敗したことを示すわけではありません。したがって、クラスターが過負荷にならない限り、仮想マシンの通常のライフサイクルは影響を受けません。
診断
実行中の virt-handler Pod を持たないワーカーノードを特定します。
NAMESPACE環境変数をエクスポートします。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-handlerPod のステータスを確認して、デプロイされていない Pod を特定します。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-handler
virt-handlerPod のワーカーノードの名前を取得します。$ oc -n $NAMESPACE get pod <virt-handler> -o jsonpath='{.spec.nodeName}'
軽減策
リソースが不足しているために virt-handler Pod のデプロイに失敗した場合は、影響を受けるワーカーノード上の他の Pod を削除できます。
12.6.46. VirtHandlerRESTErrorsBurst
意味
過去 5 分間に virt-handler で REST 呼び出しの 80% 以上が失敗しました。このアラートは通常、virt-handler Pod が API サーバーに接続できないことを示します。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-handlerPod が API サーバーに到達できません。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
ステータスの更新は反映されず、移行などのノード関連のアクションは失敗します。ただし、影響を受けるノードで実行中のワークロードは影響を受けません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-handlerPod のステータスをチェックします。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-handler
API サーバーに接続するときのエラーメッセージについては、
virt-handlerログを確認します。$ oc logs -n $NAMESPACE <virt-handler>
軽減策
virt-handlerが API サーバーに接続できない場合、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-handler>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.47. VirtHandlerRESTErrorsHigh
意味
過去 60 分間に、REST 呼び出しの 5% 以上が virt-handler で失敗しました。このアラートは通常、virt-handler Pod が API サーバーへの接続を部分的に失ったことを示します。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-handlerPod が API サーバーに到達できません。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
ワークロードの開始や移行などのノード関連のアクションは、virt-handler が実行されているノードで遅延します。実行中のワークロードは影響を受けませんが、現在のステータスのレポートが遅れる可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-handlerPod のステータスをチェックします。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-handler
API サーバーに接続するときのエラーメッセージについては、
virt-handlerログを確認します。$ oc logs -n $NAMESPACE <virt-handler>
軽減策
virt-handlerが API サーバーに接続できない場合、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-handler>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.48. VirtOperatorDown
意味
このアラートは、Running 状態の virt-operator Pod が 10 分間検出されなかった場合に発生します。
virt-operator は、クラスターで開始する最初の Operator です。その主な責任には、次のものが含まれます。
- クラスターのインストール、ライブ更新、およびライブアップグレード
-
virt-controller、virt-handler、virt-launcherなどの最上位コントローラーのライフサイクルを監視し、それらの調整を管理する - 証明書のローテーションやインフラストラクチャー管理など、特定のクラスター全体のタスク
virt-operator デプロイメントには、2 つの Pod のデフォルトレプリカが設定されます。
影響
このアラートは、クラスターレベルでの障害を示します。証明書のローテーション、アップグレード、コントローラーの調整など、重要なクラスター全体の管理機能が利用できない場合があります。
virt-operator には、クラスター内の仮想マシンに対する直接の責任はありません。したがって、一時的に利用できなくても仮想マシンのワークロードに大きな影響はありません。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operatorデプロイメントのステータスを確認します。$ oc -n $NAMESPACE get deploy virt-operator -o yaml
virt-operatorデプロイメントの詳細を取得します。$ oc -n $NAMESPACE describe deploy virt-operator
virt-operator Podのステータスをチェックします。$ oc get pods -n $NAMESPACE -l=kubevirt.io=virt-operator
NotReady状態などのノードの問題をチェックします。$ oc get nodes
軽減策
診断手順で得られた情報に基づいて、根本原因を見つけて問題を解決してください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.49. VirtOperatorRESTErrorsBurst
意味
このアラートは、virt-operator Pod の REST 呼び出しの 80% 以上が過去 5 分間に失敗した場合に発生します。これは通常、virt-operator Pod が API サーバーに接続できないことを示しています。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-operatorPod が API サーバーに到達できない。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
アップグレードやコントローラーの調整などのクラスターレベルのアクションは利用できない場合があります。
ただし、仮想マシン (VM) や VM インスタンス (VMI) などのワークロードは影響を受けない可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operator Podのステータスをチェックします。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator
API サーバーに接続するときのエラーメッセージについては、
virt-operatorログを確認します。$ oc -n $NAMESPACE logs <virt-operator>
virt-operatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pod <virt-operator>
軽減策
virt-operatorが API サーバーに接続できない場合、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-operator>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.50. VirtOperatorRESTErrorsHigh
意味
このアラートは、過去 60 分間に virt-operator Pod で 5% を超える REST 呼び出しが失敗した場合に発生します。これは通常、virt-operator Pod が API サーバーに接続できないことを示しています。
このエラーは、多くの場合、次のいずれかの問題が原因で発生します。
- API サーバーが過負荷になっているため、タイムアウトが発生します。これに該当するかどうかを確認するには、API サーバーのメトリクスを確認し、その応答時間と全体的な呼び出しを表示します。
-
virt-operatorPod が API サーバーに到達できない。これは通常、ノードの DNS の問題とネットワーク接続の問題が原因で発生します。
影響
アップグレードやコントローラーの調整などのクラスターレベルのアクションが遅れる場合があります。
ただし、仮想マシン (VM) や VM インスタンス (VMI) などのワークロードは影響を受けない可能性があります。
診断
NAMESPACE環境変数を設定します。$ export NAMESPACE="$(oc get kubevirt -A \ -o custom-columns="":.metadata.namespace)"
virt-operator Podのステータスをチェックします。$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator
API サーバーに接続するときのエラーメッセージについては、
virt-operatorログを確認します。$ oc -n $NAMESPACE logs <virt-operator>
virt-operatorPod の詳細を取得します。$ oc -n $NAMESPACE describe pod <virt-operator>
軽減策
virt-operatorが API サーバーに接続できない場合、Pod を削除して強制的に再起動します。$ oc delete -n $NAMESPACE <virt-operator>
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
12.6.51. VMCannotBeEvicted
意味
このアラートは、仮想マシン (VM) のエビクションストラテジーが LiveMigration に設定されているが、仮想マシンが移行可能でない場合に発生します。
影響
移行不可能な仮想マシンは、ノードの削除を妨げます。この状態は、ノードのドレインや更新などの操作に影響します。
診断
VMI 設定をチェックして、
evictionStrategyの値がLiveMigrateであるかどうかを判断します。$ oc get vmis -o yaml
LIVE-MIGRATABLE列のFalseステータスを確認して、移行できない VMI を特定します。$ oc get vmis -o wide
VMI の詳細を取得し、
spec.conditionsをチェックして問題を特定します。$ oc get vmi <vmi> -o yaml
出力例
status: conditions: - lastProbeTime: null lastTransitionTime: null message: cannot migrate VMI which does not use masquerade to connect to the pod network reason: InterfaceNotLiveMigratable status: "False" type: LiveMigratable
軽減策
VMI の evictionStrategy を シャットダウン するように設定するか、VMI の移行を妨げている問題を解決します。
12.6.52. VMStorageClassWarning
意味
このアラートは、ストレージクラスが正しく設定されていない場合に発生します。システム全体で共有されるダミーページは、異なるプロセスまたはスレッド間でデータの書き込みと読み取りが行われるときに CRC エラーを引き起こします。
影響
CRC エラーが多数発生すると、クラスターのパフォーマンスが大幅に低下する可能性があります。
診断
- Web コンソールで Observe → Metrics に移動します。
次の PromQL クエリーを実行して、ストレージクラスが正しく設定されていない仮想マシンのリストを取得します。
kubevirt_ssp_vm_rbd_volume{rxbounce_enabled="false", volume_mode="Block"} == 1出力には、
rxbounce_enabledのないストレージクラスを使用する仮想マシンのリストが表示されます。出力例
kubevirt_ssp_vm_rbd_volume{name="testvmi-gwgdqp22k7", namespace="test_ns", pv_name="testvmi-gwgdqp22k7", rxbounce_enabled="false", volume_mode="Block"} 1次のコマンドを実行して、ストレージクラス名を取得します。
$ oc get pv <pv_name> -o=jsonpath='{.spec.storageClassName}'
軽減策
krbd:rxbounce マップオプションを使用して、デフォルトの OpenShift Virtualization ストレージクラスを作成します。詳細は 、Windows VM の ODF PersistentVolumes の最適化 を参照してください。
問題を解決できない場合は、カスタマーポータル にログインしてサポートケースを開き、診断手順で収集したアーティファクトを添付してください。
第13章 サポート
13.1. サポートの概要
以下のツールを使用して、環境に関するデータを収集し、クラスターと仮想マシン (VM) の状態を監視し、OpenShift 仮想化リソースのトラブルシューティングを行うことができます。
13.1.1. Web コンソール
OpenShift Container Platform Web コンソールには、クラスターと OpenShift Virtualization コンポーネントおよびリソースのリソース使用量、アラート、イベント、および傾向が表示されます。
表13.1 監視とトラブルシューティングのための Web コンソールページ
| ページ | 説明 |
|---|---|
| Overview ページ | クラスターの詳細、ステータス、アラート、インベントリー、およびリソースの使用状況 |
| Virtualization → Overview タブ | OpenShift 仮想化のリソース、使用状況、アラート、およびステータス |
| Virtualization → Top consumers タブ | CPU、メモリー、およびストレージの上位コンシューマー |
| Virtualization → Migrations タブ | ライブマイグレーションの進捗 |
| VirtualMachines → VirtualMachine → VirtualMachine details → Metrics タブ | VM リソースの使用状況、ストレージ、ネットワーク、および移行 |
| VirtualMachines → VirtualMachine → VirtualMachine details → Events タブ | VM イベントリスト |
| VirtualMachines → VirtualMachine → VirtualMachine details → Diagnostics タブ | 仮想マシンのステータス条件とボリュームスナップショットのステータス |
13.1.2. Red Hat サポート用のデータ収集
Red Hat サポートに サポートケース を送信する際、デバッグ情報を提供すると役立ちます。次の手順を実行して、デバッグ情報を収集できます。
- 環境に関するデータの収集
-
Prometheus および Alertmanager を設定し、OpenShift Container Platform および OpenShift Virtualization の
must-gatherデータを収集します。 - VM に関するデータの収集
-
must-gatherデータとメモリーダンプを VM から収集します。
- OpenShift 仮想化のための
must-gatherツール -
must-gatherツールを設定および使用します。
13.1.3. トラブルシューティング
OpenShift Virtualization コンポーネントと VM のトラブルシューティングを行い、Web コンソールでアラートをトリガーする問題を解決します。
- イベント
- VM、namespace、およびリソースの重要なライフサイクル情報を表示します。
- ログ
- OpenShift Virtualization コンポーネントおよび VM のログを表示および設定します。
- データボリュームのトラブルシューティング
- 条件とイベントを分析して、データボリュームのトラブルシューティングを行います。
13.2. Red Hat サポート用のデータ収集
Red Hat サポートに サポートケース を送信する際、以下のツールを使用して OpenShift Container Platform および OpenShift Virtualization のデバッグ情報を提供すると役立ちます。
- must-gather ツール
-
must-gatherツールは、リソース定義やサービスログなどの診断情報を収集します。 - Prometheus
- Prometheus は Time Series を使用するデータベースであり、メトリクスのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Alertmanager
- Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
OpenShift Container Platform モニタリングスタックの詳細については、OpenShift Container Platform モニタリングについて を参照してください。
13.2.1. 環境に関するデータの収集
環境に関するデータを収集すると、根本原因の分析および特定に必要な時間が最小限に抑えられます。
前提条件
- Prometheus メトリックデータの保持期間を最低 7 日間に設定 します。
- クラスターの外部で表示および永続化できるように、Alertmanager を設定して、関連するアラートをキャプチャーし、アラート通知を専用のメールボックスに送信 します。
- 影響を受けるノードおよび仮想マシンの正確な数を記録する。
手順
13.2.2. 仮想マシンに関するデータの収集
仮想マシン (VM) の誤動作に関するデータを収集することで、根本原因の分析および特定に必要な時間を最小限に抑えることができます。
前提条件
- Linux VM: 最新の QEMU ゲストエージェントをインストール します。
Windows 仮想マシン:
- Windows パッチ更新の詳細を記録します。
- 最新の VirtIO ドライバーをインストール します。
- 最新の QEMU ゲストエージェントをインストール します。
- Remote Desktop Protocol (RDP) が有効になっている場合は、デスクトップビューアー を使用して接続し、接続ソフトウェアに問題があるかどうかを確認します。
手順
-
/usr/bin/gatherスクリプトを使用して、VM の必須収集データを収集 します。 - VM を再起動する 前 に、クラッシュした VM のスクリーンショットを収集します。
- 修復を試みる 前 に、VM からメモリーダンプを収集 します。
- 誤動作している仮想マシンに共通する要因を記録します。たとえば、仮想マシンには同じホストまたはネットワークがあります。
13.2.3. OpenShift Virtualization の must-gather ツールの使用
OpenShift Virtualization イメージで must-gather コマンドを実行することにより、OpenShift Virtualization リソースに関するデータを収集できます。
デフォルトのデータ収集には、次のリソースに関する情報が含まれています。
- 子オブジェクトを含む OpenShift Virtualization Operator namespace
- すべての OpenShift Virtualization カスタムリソース定義 (CRD)
- 仮想マシンを含むすべての namespace
- 基本的な仮想マシン定義
現在、インスタンスタイプの情報はデフォルトでは収集されません。ただし、オプションでコマンドを実行して収集することもできます。
手順
以下のコマンドを実行して、OpenShift Virtualization に関するデータを収集します。
$ oc adm must-gather --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \ -- /usr/bin/gather
13.2.3.1. must-gather ツールオプション
次のオプションに対して、スクリプトおよび環境変数の組み合わせを指定できます。
- namespace から詳細な仮想マシン (VM) 情報の収集する
- 特定の仮想マシンに関する詳細情報の収集
- image、image-stream、および image-stream-tags 情報の収集
-
must-gatherツールが使用する並列プロセスの最大数の制限
13.2.3.1.1. パラメーター
環境変数
互換性のあるスクリプトの環境変数を指定できます。
NS=<namespace_name>-
指定した namespace から
virt-launcherPod の詳細を含む仮想マシン情報を収集します。VirtualMachineおよびVirtualMachineInstanceCR データはすべての namespace で収集されます。 VM=<vm_name>-
特定の仮想マシンに関する詳細を収集します。このオプションを使用するには、
NS環境変数を使用して namespace も指定する必要があります。 PROS=<number_of_processes>must-gatherツールが使用する並列処理の最大数を変更します。デフォルト値は5です。重要並列処理が多すぎると、パフォーマンスの問題が発生する可能性があります。並列処理の最大数を増やすことは推奨されません。
スクリプト
各スクリプトは、特定の環境変数の組み合わせとのみ互換性があります。
/usr/bin/gather-
デフォルトの
must-gatherスクリプトを使用します。すべての namespace からクラスターデータが収集され、基本的な仮想マシン情報のみが含まれます。このスクリプトは、PROS変数とのみ互換性があります。 /usr/bin/gather --vms_details-
OpenShift Virtualization リソースに属する VM ログファイル、VM 定義、コントロールプレーンログ、および namespace を収集します。namespace の指定には、その子オブジェクトが含まれます。namespace または仮想マシンを指定せずにこのパラメーターを使用する場合、
must-gatherツールはクラスター内のすべての仮想マシンについてこのデータを収集します。このスクリプトはすべての環境変数と互換性がありますが、VM変数を使用する場合は namespace を指定する必要があります。 /usr/bin/gather --images-
image、image-stream、および image-stream-tags カスタムリソース情報を収集します。このスクリプトは、
PROS変数とのみ互換性があります。 /usr/bin/gather --instancetypes- インスタンスタイプの情報を収集します。この情報は現在、デフォルトでは収集されません。ただし、オプションで収集することもできます。
13.2.3.1.2. 使用方法および例
環境変数はオプションです。スクリプトは、単独で実行することも、1 つ以上の互換性のある環境変数を使用して実行することもできます。
表13.2 互換性のあるパラメーター
| スクリプト | 互換性のある環境変数 |
|---|---|
|
|
* |
|
|
* namespace の場合:
* 仮想マシンの場合:
* |
|
|
* |
構文
$ oc adm must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \ -- <environment_variable_1> <environment_variable_2> <script_name>
デフォルトのデータ収集の並列プロセス
デフォルトでは、5 つのプロセスを並行して実行します。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \
-- PROS=5 /usr/bin/gather 1- 1
- デフォルトを変更することで、並列プロセスの数を変更できます。
詳細な仮想マシン情報
次のコマンドは、mynamespace namespace にある my-vm 仮想マシンの詳細な仮想マシン情報を収集します。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \
-- NS=mynamespace VM=my-vm /usr/bin/gather --vms_details 1- 1
VM環境変数を使用する場合、NS環境変数は必須です。
image、image-stream、および image-stream-tags 情報
以下のコマンドは、クラスターからイメージ、image-stream、および image-stream-tags 情報を収集します。
$ oc adm must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \ /usr/bin/gather --images
インスタンスタイプの情報
次のコマンドは、クラスターからインスタンスタイプ情報を収集します。
$ oc adm must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel9:v4.14.5 \ /usr/bin/gather --instancetypes
13.3. トラブルシューティング
OpenShift Virtualization は、仮想マシンと仮想化コンポーネントのトラブルシューティングに使用するツールとログを提供します。
OpenShift Virtualization コンポーネントのトラブルシューティングは、Web コンソールで提供されるツール または oc CLI ツールを使用して実行できます。
13.3.1. イベント
OpenShift Container Platform イベント は重要なライフサイクル情報の記録であり、仮想マシン、namespace、リソース問題のモニタリングおよびトラブルシューティングに役立ちます。
13.3.2. ログ
トラブルシューティングのために、次のログを確認できます。
13.3.2.1. Web コンソールを使用した仮想マシンログの表示
OpenShift Container Platform Web コンソールで仮想マシンのログを表示できます。
手順
- Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブで、Pod 名をクリックして Pod details ページを開きます。
- Logs タブをクリックして、ログを表示します。
13.3.2.2. OpenShift Virtualization Pod のログ表示
oc CLI ツールを使用して、OpenShift Virtualization Pod のログを表示できます。
HyperConverged カスタムリソース (CR) を編集することで、ログの詳細レベルを設定できます。
13.3.2.2.1. CLI を使用した OpenShift Virtualization Pod ログの表示
oc CLI ツールを使用して、OpenShift Virtualization Pod のログを表示できます。
手順
以下のコマンドを実行して、OpenShift Virtualization の namespace 内の Pod のリストを表示します。
$ oc get pods -n openshift-cnv
例13.1 出力例
NAME READY STATUS RESTARTS AGE disks-images-provider-7gqbc 1/1 Running 0 32m disks-images-provider-vg4kx 1/1 Running 0 32m virt-api-57fcc4497b-7qfmc 1/1 Running 0 31m virt-api-57fcc4497b-tx9nc 1/1 Running 0 31m virt-controller-76c784655f-7fp6m 1/1 Running 0 30m virt-controller-76c784655f-f4pbd 1/1 Running 0 30m virt-handler-2m86x 1/1 Running 0 30m virt-handler-9qs6z 1/1 Running 0 30m virt-operator-7ccfdbf65f-q5snk 1/1 Running 0 32m virt-operator-7ccfdbf65f-vllz8 1/1 Running 0 32m
Pod ログを表示するには、次のコマンドを実行します。
$ oc logs -n openshift-cnv <pod_name>
注記Pod の起動に失敗した場合は、
--previousオプションを使用して、最後の試行からのログを表示できます。ログ出力をリアルタイムで監視するには、
-fオプションを使用します。例13.2 出力例
{"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373695Z"} {"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373726Z"} {"component":"virt-handler","level":"info","msg":"setting rate limiter to 5 QPS and 10 Burst","pos":"virt-handler.go:462","timestamp":"2022-04-17T08:58:37.373782Z"} {"component":"virt-handler","level":"info","msg":"CPU features of a minimum baseline CPU model: map[apic:true clflush:true cmov:true cx16:true cx8:true de:true fpu:true fxsr:true lahf_lm:true lm:true mca:true mce:true mmx:true msr:true mtrr:true nx:true pae:true pat:true pge:true pni:true pse:true pse36:true sep:true sse:true sse2:true sse4.1:true ssse3:true syscall:true tsc:true]","pos":"cpu_plugin.go:96","timestamp":"2022-04-17T08:58:37.390221Z"} {"component":"virt-handler","level":"warning","msg":"host model mode is expected to contain only one model","pos":"cpu_plugin.go:103","timestamp":"2022-04-17T08:58:37.390263Z"} {"component":"virt-handler","level":"info","msg":"node-labeller is running","pos":"node_labeller.go:94","timestamp":"2022-04-17T08:58:37.391011Z"}
13.3.2.2.2. OpenShift Virtualization Pod ログの詳細レベルの設定
HyperConverged カスタムリソース (CR) を編集することで、OpenShift Virtualization Pod ログの詳細レベルを設定できます。
手順
特定のコンポーネントのログの詳細度を設定するには、次のコマンドを実行して、デフォルトのテキストエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv
spec.logVerbosityConfigスタンザを編集して、1 つ以上のコンポーネントのログレベルを設定します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: logVerbosityConfig: kubevirt: virtAPI: 5 1 virtController: 4 virtHandler: 3 virtLauncher: 2 virtOperator: 6- 1
- ログの詳細度の値は
1 ~ 9の範囲の整数である必要があり、数値が大きいほど詳細なログであることを示します。この例では、virtAPIコンポーネントのログは、優先度が5以上の場合に公開されます。
- エディターを保存して終了し、変更を適用します。
13.3.2.2.3. 一般的なエラーメッセージ
以下のエラーメッセージが OpenShift Virtualization ログに表示される場合があります。
ErrImagePullまたはImagePullBackOff- デプロイメント設定が正しくないか、参照されているイメージに問題があることを示します。
13.3.2.3. LokiStack を使用した OpenShift Virtualization 集約ログの表示
Web コンソールで LokiStack を使用すると、OpenShift Virtualization Pod およびコンテナーの集約ログを表示できます。
前提条件
- LokiStack をデプロイしている。
手順
- Web コンソールで Observe → Logs に移動します。
-
ログタイプのリストから、
virt-launcherPod ログの場合は application を選択し、OpenShift Virtualization コントロールプレーン Pod およびコンテナーの場合は infrastructure を選択します。 - Show Query をクリックしてクエリーフィールドを表示します。
- クエリーフィールドに LogQL クエリーを入力し、Run Query をクリックしてフィルタリングされたログを表示します。
13.3.2.3.1. OpenShift Virtualization LogQL クエリー
Web コンソールの Observe → Logs ページで Loki Query Language (LogQL) クエリーを実行することで、OpenShift Virtualization コンポーネントの集約ログを表示およびフィルタリングできます。
デフォルトのログタイプは infrastructure です。virt-launcher のログタイプは application です。
オプション: 行フィルター式を使用して、文字列または正規表現の追加や除外を行えます。
クエリーが多数のログに一致する場合、クエリーがタイムアウトになる可能性があります。
表13.3 OpenShift Virtualization LogQL クエリーの例
| コンポーネント | LogQL クエリー |
|---|---|
| すべて |
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="storage"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="deployment"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="network"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="compute"
|
|
|
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|kubernetes_labels_app_kubernetes_io_component="schedule"
|
| Container |
{log_type=~".+",kubernetes_container_name=~"<container>|<container>"} 1
|json|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|
|
| このクエリーを実行する前に、ログタイプのリストから application を選択する必要があります。 {log_type=~".+", kubernetes_container_name="compute"}|json
|!= "custom-ga-command" 1
|
行フィルター式を使用して、文字列や正規表現を追加または除外するようにログ行をフィルタリングできます。
表13.4 行フィルター式
| 行フィルター式 | 説明 |
|---|---|
|
| ログ行に文字列が含まれています |
|
| ログ行に文字列は含まれていません |
|
| ログ行に正規表現が含まれています |
|
| ログ行に正規表現は含まれていません |
行フィルター式の例
{log_type=~".+"}|json
|kubernetes_labels_app_kubernetes_io_part_of="hyperconverged-cluster"
|= "error" != "timeout"
LokiStack および LogQL の関連情報
- ログストレージについて
- Lokistack のデプロイ
- Grafana ドキュメントの LogQL log queries
13.3.3. データボリュームのトラブルシューティング
DataVolume オブジェクトの Conditions および Events セクションを確認して、問題を分析および解決できます。
13.3.3.1. データボリュームの条件とイベントについて
コマンドによって生成された Conditions および Events セクションの出力を調べることで、データボリュームの問題を診断できます。
$ oc describe dv <DataVolume>
Conditions セクションには、次の Types が表示されます。
-
Bound -
running -
Ready
Events セクションでは、以下の追加情報を提供します。
-
イベントの
Type -
ロギングの
Reason -
イベントの
Source -
追加の診断情報が含まれる
Message
oc describe からの出力には常に Events が含まれるとは限りません。
Status、Reason、または Message が変化すると、イベントが生成されます。状態およびイベントはどちらもデータボリュームの状態の変更に対応します。
たとえば、インポート操作中に URL のスペルを誤ると、インポートにより 404 メッセージが生成されます。メッセージの変更により、理由と共にイベントが生成されます。Conditions セクションの出力も更新されます。
13.3.3.2. データボリュームの状態とイベントの分析
describe コマンドで生成される Conditions セクションおよび Events セクションを検査することにより、永続ボリューム要求 (PVC) に関連してデータボリュームの状態を判別します。また、操作がアクティブに実行されているか、または完了しているかどうかを判断します。また、データボリュームのステータスについての特定の詳細、およびどのように現在の状態になったかについての情報を提供するメッセージを受信する可能性があります。
状態の組み合わせは多数あります。それぞれは一意のコンテキストで評価される必要があります。
各種の組み合わせの例を以下に示します。
Bound- この例では、正常にバインドされた PVC が表示されます。TypeはBoundであるため、StatusはTrueになります。PVC がバインドされていない場合、StatusはFalseになります。PVC がバインドされると、PVC がバインドされていることを示すイベントが生成されます。この場合、
ReasonはBoundで、StatusはTrueです。Messageはデータボリュームを所有する PVC を示します。EventsセクションのMessageでは、PVC がバインドされている期間 (Age) およびどのリソース (From) によってバインドされているか、datavolume-controllerに関する詳細が提供されます。出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T03:58:24Z Last Transition Time: 2020-07-15T03:58:24Z Message: PVC win10-rootdisk Bound Reason: Bound Status: True Type: Bound ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Bound 24s datavolume-controller PVC example-dv BoundRunning- この場合、TypeがRunningで、StatusがFalseであることに注意してください。これは、試行された操作が失敗する原因となったイベントが発生し、Status がTrueからFalseに変化したことを示しています。ただし、
ReasonがCompletedであり、MessageフィールドにはImport Completeが表示されることに注意してください。Eventsセクションには、ReasonおよびMessageに失敗した操作に関する追加のトラブルシューティング情報が含まれます。この例では、Eventsセクションの最初のWarningに一覧表示されるMessageに、404によって接続できないことが示唆されます。この情報から、インポート操作が実行されており、データボリュームにアクセスしようとしている他の操作に対して競合が生じることを想定できます。
出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Message: Import Complete Reason: Completed Status: False Type: Running ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Error 12s (x2 over 14s) datavolume-controller Unable to connect to http data source: expected status code 200, got 404. Status: 404 Not FoundReady:TypeがReadyであり、StatusがTrueの場合、以下の例のようにデータボリュームは使用可能な状態になります。データボリュームが使用可能な状態にない場合、StatusはFalseになります。出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Status: True Type: Ready
第14章 バックアップおよび復元
14.1. 仮想マシンスナップショットを使用したバックアップと復元
スナップショットを使用して、仮想マシンをバックアップおよび復元できます。スナップショットは、次のストレージプロバイダーによってサポートされています。
- Red Hat OpenShift Data Foundation
- Kubernetes Volume Snapshot API をサポートする Container Storage Interface (CSI) ドライバーを使用するその他のクラウドストレージプロバイダー
オンラインスナップショットのデフォルト期限は 5 分 (5m) で、必要に応じて変更できます。
オンラインスナップショットは、ホットプラグされた仮想ディスクを持つ仮想マシンでサポートされます。ただし、仮想マシンの仕様に含まれていないホットプラグされたディスクは、スナップショットに含まれません。
最も整合性の高いオンライン (実行状態) 仮想マシンのスナップショットを作成する際、QEMU ゲストエージェントがオペレーティングシステムに含まれていない場合はインストールします。QEMU ゲストエージェントは、デフォルトの Red Hat テンプレートに含まれています。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
14.1.1. スナップショット
スナップショット は、特定の時点における仮想マシン (VM) の状態およびデータを表します。スナップショットを使用して、バックアップおよび障害復旧のために既存の仮想マシンを (スナップショットで表される) 以前の状態に復元したり、以前の開発バージョンに迅速にロールバックしたりできます。
仮想マシンのスナップショットは、電源がオフ (停止状態) またはオン (実行状態) の仮想マシンから作成されます。
実行中の仮想マシンのスナップショットを作成する場合には、コントローラーは QEMU ゲストエージェントがインストールされ、実行中であることを確認します。そのような場合には、スナップショットの作成前に仮想マシンファイルシステムをフリーズして、スナップショットの作成後にファイルシステムをロールアウトします。
スナップショットは、仮想マシンに割り当てられた各 Container Storage Interface (CSI) ボリュームのコピーと、仮想マシンの仕様およびメタデータのコピーを保存します。スナップショットは作成後に変更できません。
次のスナップショットアクションを実行できます。
- 新規 SCC の作成
- 特定の仮想マシンに割り当てられているすべてのスナップショットのリスト表示
- スナップショットからの仮想マシンの復元
- 既存の仮想マシンスナップショットの削除
仮想マシンスナップショットコントローラーとカスタムリソース
仮想マシンスナップショット機能では、スナップショットを管理するためのカスタムリソース定義 (CRD) として定義される 3 つの新しい API オブジェクトが導入されています。
-
VirtualMachineSnapshot: スナップショットを作成するユーザー要求を表します。これには、仮想マシンの現在の状態に関する情報が含まれます。 -
VirtualMachineSnapshotContent: クラスター上のプロビジョニングされたリソース (スナップショット) を表します。これは、仮想マシンのスナップショットコントローラーによって作成され、仮想マシンの復元に必要なすべてのリソースへの参照が含まれます。 -
VirtualMachineRestore: スナップショットから仮想マシンを復元するユーザー要求を表します。
仮想マシンスナップショットコントローラーは、1 対 1 のマッピングで、VirtualMachineSnapshotContent オブジェクトを、この作成に使用した VirtualMachineSnapshot オブジェクトにバインドします。
14.1.2. スナップショットの作成
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、仮想マシンのスナップショットを作成できます。
14.1.2.1. Web コンソールを使用したスナップショットを作成する
OpenShift Container Platform Web コンソールを使用して、仮想マシンのスナップショットを作成できます。
仮想マシンスナップショットには、以下の要件を満たすディスクが含まれます。
- データボリュームまたは永続ボリュームの要求のいずれか
- Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスに属している必要があります。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
-
仮想マシンが実行中の場合は、オプションメニュー
をクリックし、Stop を選択して電源を切ります。
- Snapshots タブをクリックしてから Take Snapshot をクリックします。
- スナップショット名を入力します。
- Disks included in this Snapshot を拡張し、スナップショットに組み込むストレージボリュームを表示します。
- 仮想マシンにスナップショットに含めることができないディスクがあり、続行する場合は、I am aware of this warning and wish to proceed を選択します。
- Save をクリックします。
14.1.2.2. コマンドラインを使用したスナップショットの作成
VirtualMachineSnapshot オブジェクトを作成し、オフラインまたはオンラインの仮想マシンの仮想マシン (VM) スナップショットを作成できます。
前提条件
- 永続ボリューム要求 (PVC) が Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスにあることを確認する。
-
OpenShift CLI (
oc) がインストールされている。 - オプション: スナップショットを作成する仮想マシンの電源を切ること。
手順
次の例のように、YAML ファイルを作成して、新しい
VirtualMachineSnapshotの名前とソース仮想マシンの名前を指定するVirtualMachineSnapshotオブジェクトを定義します。apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineSnapshot metadata: name: <snapshot_name> spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: <vm_name>VirtualMachineSnapshotオブジェクトを作成します。$ oc create -f <snapshot_name>.yaml
スナップコントローラーは
VirtualMachineSnapshotContentオブジェクトを作成し、これをVirtualMachineSnapshotにバインドし、VirtualMachineSnapshotオブジェクトのstatusおよびreadyToUseフィールドを更新します。オプション: オンラインスナップショットを作成している場合は、
waitコマンドを使用して、スナップショットのステータスを監視できます。以下のコマンドを入力します。
$ oc wait <vm_name> <snapshot_name> --for condition=Ready
スナップショットのステータスを確認します。
-
InProgress: オンラインスナップショットの操作が進行中です。 -
Succeeded: オンラインスナップショット操作が正常に完了しました。 Failed: オンラインスナップショットの操作に失敗しました。注記オンラインスナップショットのデフォルト期限は 5 分 (
5m) です。スナップショットが 5 分後に正常に完了しない場合には、ステータスがfailedに設定されます。その後、ファイルシステムと仮想マシンのフリーズが解除され、失敗したスナップショットイメージが削除されるまで、ステータスはfailedのままになります。デフォルトの期限を変更するには、仮想マシンスナップショット仕様に
FailureDeadline属性を追加して、スナップショット操作がタイムアウトするまでの時間を分単位 (m) または秒単位 (s) で指定します。期限を指定しない場合は、
0を指定できますが、仮想マシンが応答しなくなる可能性があるため、通常は推奨していません。mまたはsなどの時間の単位を指定しない場合、デフォルトは秒 (s) です。
-
検証
VirtualMachineSnapshotオブジェクトが作成され、VirtualMachineSnapshotContentにバインドされていることと、readyToUseフラグがtrueに設定されていることを確認します。$ oc describe vmsnapshot <snapshot_name>
出力例
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineSnapshot metadata: creationTimestamp: "2020-09-30T14:41:51Z" finalizers: - snapshot.kubevirt.io/vmsnapshot-protection generation: 5 name: mysnap namespace: default resourceVersion: "3897" selfLink: /apis/snapshot.kubevirt.io/v1alpha1/namespaces/default/virtualmachinesnapshots/my-vmsnapshot uid: 28eedf08-5d6a-42c1-969c-2eda58e2a78d spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm status: conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "False" 1 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "True" 2 type: Ready creationTime: "2020-09-30T14:42:03Z" readyToUse: true 3 sourceUID: 355897f3-73a0-4ec4-83d3-3c2df9486f4f virtualMachineSnapshotContentName: vmsnapshot-content-28eedf08-5d6a-42c1-969c-2eda58e2a78d 4-
VirtualMachineSnapshotContentリソースのspec:volumeBackupsプロパティーをチェックし、予想される PVC がスナップショットに含まれることを確認します。
14.1.3. スナップショット指示を使用したオンラインスナップショットの検証
スナップショットの表示は、オンライン仮想マシン (VM) スナップショット操作に関するコンテキスト情報です。オフラインの仮想マシン (VM) スナップショット操作では、指示は利用できません。イベントは、オンラインスナップショット作成の詳説する際に役立ちます。
前提条件
- オンライン仮想マシンスナップショットを作成しようとしている必要があります。
手順
次のいずれかの操作を実行して、スナップショット指示からの出力を表示します。
-
コマンドラインを使用して、
VirtualMachineSnapshotオブジェクト YAML のstatusスタンザのインジケーター出力を表示します。 - Web コンソールの Snapshot details 画面で、VirtualMachineSnapshot → Status をクリックします。
-
コマンドラインを使用して、
status.indicationsパラメーターの値を表示して、オンラインの仮想マシンスナップショットのステータスを確認します。-
Onlineは、オンラインスナップショットの作成中に仮想マシンが実行されていたことを示します。 -
GuestAgentは、オンラインスナップショットの作成中に QEMU ゲストエージェントが実行されていたことを示します。 -
NoGuestAgentは、オンラインスナップショットの作成中に QEMU ゲストエージェントが実行されていなかったことを示します。QEMU ゲストエージェントがインストールされていないか、実行されていないか、別のエラーが原因で、QEMU ゲストエージェントを使用してファイルシステムをフリーズしてフリーズを解除できませんでした。
-
14.1.4. スナップショットからの仮想マシンの復元
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、スナップショットから仮想マシンを復元できます。
14.1.4.1. Web コンソールを使用したスナップショットからの仮想マシンの復元
OpenShift Container Platform Web コンソールのスナップショットで表される以前の設定に仮想マシンを復元できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
-
仮想マシンが実行中の場合は、オプションメニュー
をクリックし、Stop を選択して電源を切ります。
- Snapshots タブをクリックして、仮想マシンに関連付けられたスナップショットのリストを表示します。
- スナップショットを選択して、Snapshot Details 画面を開きます。
-
オプションメニュー
をクリックし、Restore VirtualMachineSnapshot を選択します。
- Restore をクリックします。
14.1.4.2. コマンドラインを使用したスナップショットからの仮想マシンの復元
コマンドラインを使用して、既存の仮想マシンを以前の設定に復元できます。オフラインの仮想マシンスナップショットからしか復元できません。
前提条件
- 復元する仮想マシンの電源を切ります。
手順
次の例のように、復元する仮想マシンの名前およびソースとして使用されるスナップショットの名前を指定する
VirtualMachineRestoreオブジェクトを定義するために YAML ファイルを作成します。apiVersion: snapshot.kubevirt.io/v1beta1 kind: VirtualMachineRestore metadata: name: <vm_restore> spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: <vm_name> virtualMachineSnapshotName: <snapshot_name>VirtualMachineRestoreオブジェクトを作成します。$ oc create -f <vm_restore>.yaml
スナップショットコントローラーは、
VirtualMachineRestoreオブジェクトのステータスフィールドを更新し、既存の仮想マシン設定をスナップショットのコンテンツに置き換えます。
検証
仮想マシンがスナップショットで表される以前の状態に復元されていること、および
completeフラグがtrueに設定されていることを確認します。$ oc get vmrestore <vm_restore>
出力例
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineRestore metadata: creationTimestamp: "2020-09-30T14:46:27Z" generation: 5 name: my-vmrestore namespace: default ownerReferences: - apiVersion: kubevirt.io/v1 blockOwnerDeletion: true controller: true kind: VirtualMachine name: my-vm uid: 355897f3-73a0-4ec4-83d3-3c2df9486f4f resourceVersion: "5512" selfLink: /apis/snapshot.kubevirt.io/v1alpha1/namespaces/default/virtualmachinerestores/my-vmrestore uid: 71c679a8-136e-46b0-b9b5-f57175a6a041 spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm virtualMachineSnapshotName: my-vmsnapshot status: complete: true 1 conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "False" 2 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "True" 3 type: Ready deletedDataVolumes: - test-dv1 restoreTime: "2020-09-30T14:46:28Z" restores: - dataVolumeName: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 persistentVolumeClaim: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 volumeName: datavolumedisk1 volumeSnapshotName: vmsnapshot-28eedf08-5d6a-42c1-969c-2eda58e2a78d-volume-datavolumedisk1
14.1.5. スナップショットの削除
OpenShift Container Platform Web コンソールまたはコマンドラインを使用して、仮想マシンのスナップショットを削除できます。
14.1.5.1. Web コンソールを使用してスナップショットを削除する
Web コンソールを使用して既存の仮想マシンスナップショットを削除できます。
手順
- Web コンソールで Virtualization → VirtualMachines に移動します。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Snapshots タブをクリックして、仮想マシンに関連付けられたスナップショットのリストを表示します。
-
スナップショットの横にあるオプションメニュー
をクリックし、Delete VirtualMachineSnapshot を選択します。
- Delete をクリックします。
14.1.5.2. CLI での仮想マシンのスナップショットの削除
適切な VirtualMachineSnapshot オブジェクトを削除して、既存の仮想マシン (VM) スナップショットを削除できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineSnapshotオブジェクトを削除します。$ oc delete vmsnapshot <snapshot_name>
スナップショットコントローラーは、
VirtualMachineSnapshotを、関連付けられたVirtualMachineSnapshotContentオブジェクトと共に削除します。
検証
スナップショットが削除され、この仮想マシンに割り当てられていないことを確認します。
$ oc get vmsnapshot
14.1.6. 関連情報
14.2. OADP のインストールおよび設定
クラスター管理者は、OADP Operator をインストールして、OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.12 をインストールします。
バックアップストレージプロバイダーのデフォルトの Secret を作成し、Data Protection Application をインストールします。
14.2.1. OADP Operator のインストール
Operator Lifecycle Manager (OLM) を使用して、OpenShift Container Platform 4.14 に OpenShift API for Data Protection (OADP) オペレーターをインストールします。
OADP Operator は Velero 1.12 をインストールします。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- Filter by keyword フィールドを使用して、OADP Operator を検索します。
- OADP Operator を選択し、Install をクリックします。
-
Install をクリックして、
openshift-adpプロジェクトに Operator をインストールします。 - Operators → Installed Operators をクリックして、インストールを確認します。
14.2.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
Multicloud Object Gateway または MinIO などの AWS S3 互換オブジェクトストレージを、バックアップの場所として指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
ファイルシステムバックアップ (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
14.2.2.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップの場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用してデフォルト名前で Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
-
オブジェクトストレージ用の
credentials-veleroファイルを適切な形式で作成する必要があります。
手順
デフォルト名で
Secretを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
14.2.3. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
14.2.3.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: # ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
14.2.3.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: # ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 # ...
14.2.3.2.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADP
このコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txt
バックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>
このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
14.2.4. Data Protection Application 1.2 以前のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする必要がある。
- オブジェクトストレージをバックアップ場所として設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。注記Velero は、OADP namespace に
velero-repo-credentialsという名前のシークレットを作成します。これには、デフォルトのバックアップリポジトリーパスワードが含まれます。バックアップリポジトリーを対象とした最初のバックアップを実行する 前 に、base64 としてエンコードされた独自のパスワードを使用してシークレットを更新できます。更新するキーの値はData[repository-password]です。DPA を作成した後、バックアップリポジトリーを対象としたバックアップを初めて実行するときに、Velero はシークレットが
velero-repo-credentialsのバックアップリポジトリーを作成します。これには、デフォルトのパスワードまたは置き換えたパスワードが含まれます。最初のバックアップの 後 にシークレットパスワードを更新すると、新しいパスワードがvelero-repo-credentialsのパスワードと一致しなくなり、Velero は古いバックアップに接続できなくなります。
-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - kubevirt 1 - gcp 2 - csi 3 - openshift 4 resourceTimeout: 10m 5 restic: enable: true 6 podConfig: nodeSelector: <node_selector> 7 backupLocations: - velero: provider: gcp 8 default: true credential: key: cloud name: <default_secret> 9 objectStorage: bucket: <bucket_name> 10 prefix: <prefix> 11- 1
kubevirtプラグインは OpenShift Virtualization に必須です。- 2
- バックアッププロバイダーのプラグインがある場合には、それを指定します (例:
gcp)。 - 3
- CSI スナップショットを使用して PV をバックアップするには、
csiプラグインが必須です。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 4
openshiftプラグインは必須です。- 5
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 6
- Restic インストールを無効にする場合は、この値を
falseに設定します。Restic はデーモンセットをデプロイします。これは、Restic Pod が各動作ノードで実行していることを意味します。OADP バージョン 1.2 以降では、spec.defaultVolumesToFsBackup: trueをBackupCR に追加することで、バックアップ用に Restic を設定できます。OADP バージョン 1.1 では、spec.defaultVolumesToRestic: trueをBackupCR に追加します。 - 7
- Restic を使用できるノードを指定します。デフォルトでは、Restic はすべてのノードで実行されます。
- 8
- バックアッププロバイダーを指定します。
- 9
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 10
- バックアップの保存場所としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 11
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp
出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、バックアップの保存場所を確認し、
PHASEがAvailableであることを確認します。$ oc get backupStorageLocation -n openshift-adp
出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
-
PHASEがAvailableになっていることを確認します。
14.2.5. Data Protection Application 1.3 のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする必要がある。
- オブジェクトストレージをバックアップ場所として設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 -
スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。
注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp 1 spec: configuration: velero: defaultPlugins: - kubevirt 2 - gcp 3 - csi 4 - openshift 5 resourceTimeout: 10m 6 nodeAgent: 7 enable: true 8 uploaderType: kopia 9 podConfig: nodeSelector: <node_selector> 10 backupLocations: - velero: provider: gcp 11 default: true credential: key: cloud name: <default_secret> 12 objectStorage: bucket: <bucket_name> 13 prefix: <prefix> 14
- 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
kubevirtプラグインは OpenShift Virtualization に必須です。- 3
- バックアッププロバイダーのプラグインがある場合には、それを指定します (例:
gcp)。 - 4
- CSI スナップショットを使用して PV をバックアップするには、
csiプラグインが必須です。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 5
openshiftプラグインは必須です。- 6
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 7
- 管理要求をサーバーにルーティングする管理エージェント。
- 8
nodeAgentを有効にしてファイルシステムバックアップを実行する場合は、この値をtrueに設定します。- 9
- 組み込み DataMover を使用するには、アップローダーとして
kopiaと入力します。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。ファイルシステムバックアップを設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 10
- Kopia が利用可能なノードを指定します。デフォルトでは、Kopia はすべてのノードで実行されます。
- 11
- バックアッププロバイダーを指定します。
- 12
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 13
- バックアップの保存場所としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 14
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp
出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、バックアップの保存場所を確認し、
PHASEがAvailableであることを確認します。$ oc get backupStorageLocation -n openshift-adp
出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
-
PHASEがAvailableになっていることを確認します。
14.2.5.1. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csiデフォルトプラグインを追加します。
14.2.6. OADP のアンインストール
OpenShift API for Data Protection (OADP) をアンインストールするには、OADP Operator を削除します。詳細は、クラスターからの演算子の削除 を参照してください。
14.3. 仮想マシンのバックアップと復元
OpenShift API for Data Protection (OADP) を使用して、仮想マシンをバックアップおよび復元します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- ストレージプロバイダーの指示に従って OADP Operator をインストールします。
-
kubevirtおよびopenshiftプラグイン を使用して データ保護アプリケーション をインストールします。 -
Backupカスタムリソース (CR) を作成して、仮想マシンをバックアップします。 -
RestoreCR を作成し、BackupCR を復元します。
14.3.1. 関連情報
14.4. 仮想マシンのバックアップ
OpenShift Virtualization の OADP は、テクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
OpenShift API for Data Protection (OADP) の Backup カスタムリソース (CR) を作成して、仮想マシン (VM) をバックアップします。
Backup CR は以下のアクションを実行します。
- Multicloud Object Gateway、Noobaa、または Minio などの S3 互換オブジェクトストレージにアーカイブファイルを作成して、OpenShift Virtualization リソースをバックアップします。
以下のオプションのいずれかを使用して、仮想マシンディスクをバックアップします。
- Ceph RBD または Ceph FS などの CSI 対応クラウドストレージ上の Container Storage Interface (CSI) スナップショット。
- オブジェクトストレージでの ファイルシステムバックアップ (Kopia または Restic) を使用したアプリケーションのバックアップ。
OADP はバックアップフックを提供し、バックアップ操作の前に仮想マシンのファイルシステムをフリーズし、バックアップの完了時にフリーズを解除します。
kubevirt-controller は、バックアップ操作の前後に Velero が virt-freezer バイナリーを実行できるようにするアノテーションで virt-launcher Pod を作成します。
freeze および unfreeze API は、仮想マシンスナップショット API のサブリソースです。詳細は、仮想マシンのスナップショットについてを参照してください。
フック をBackup CR に追加して、バックアップ操作の前後に特定の仮想マシンでコマンドを実行できます。
Backup CR の代わりに Schedule CR を作成することにより、バックアップをスケジュールします。
14.4.1. バックアップ CR の作成
Backup カスタムリソース (CR) を作成して、Kubernetes イメージ、内部イメージ、および永続ボリューム (PV) をバックアップします。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 バックアップ場所の前提条件:
- Velero 用に S3 オブジェクトストレージを設定する必要があります。
-
DataProtectionApplicationCR でバックアップの場所を設定する必要があります。
スナップショットの場所の前提条件:
- クラウドプロバイダーには、ネイティブスナップショット API が必要であるか、Container Storage Interface (CSI) スナップショットをサポートしている必要があります。
-
CSI スナップショットの場合、CSI ドライバーを登録するために
VolumeSnapshotClassCR を作成する必要があります。 -
DataProtectionApplicationCR でボリュームの場所を設定する必要があります。
手順
次のコマンドを入力して、
backupStorageLocationsCR を取得します。$ oc get backupStorageLocations -n openshift-adp
出力例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m
次の例のように、
BackupCR を作成します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace> 1 includedResources: [] 2 excludedResources: [] 3 storageLocation: <velero-sample-1> 4 ttl: 720h0m0s labelSelector: 5 matchLabels: app=<label_1> app=<label_2> app=<label_3> orLabelSelectors: 6 - matchLabels: app=<label_1> app=<label_2> app=<label_3>- 1
- バックアップする namespace の配列を指定します。
- 2
- オプション: バックアップに含めるリソースの配列を指定します。リソースは、ショートカット (Pods は po など) または完全修飾の場合があります。指定しない場合、すべてのリソースが含まれます。
- 3
- オプション: バックアップから除外するリソースの配列を指定します。リソースは、ショートカット (Pods は po など) または完全修飾の場合があります。
- 4
backupStorageLocationsCR の名前を指定します。- 5
- 指定したラベルを すべて 持つバックアップリソースの {key,value} ペアのマップ。
- 6
- 指定したラベルを 1 つ以上 持つバックアップリソースの {key,value} ペアのマップ。
BackupCR のステータスがCompletedしたことを確認します。$ oc get backup -n openshift-adp <backup> -o jsonpath='{.status.phase}'
14.4.1.1. CSI スナップショットを使用した永続ボリュームのバックアップ
Backup CR を作成する前に、クラウドストレージの VolumeSnapshotClass カスタムリソース (CR) を編集して、Container Storage Interface (CSI) スナップショットを使用して永続ボリュームをバックアップします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
-
DataProtectionApplicationCR で CSI を有効にする必要があります。
手順
metadata.labels.velero.io/csi-volumesnapshot-class: "true"のキー: 値ペアをVolumeSnapshotClassCR に追加します。設定ファイルのサンプル
apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true" 1 annotations: snapshot.storage.kubernetes.io/is-default-class: true 2 driver: <csi_driver> deletionPolicy: <deletion_policy_type> 3
次のステップ
-
これで、
BackupCR を作成できます。
14.4.1.2. Restic を使用したアプリケーションのバックアップ
Backup カスタムリソース (CR) を編集して、Restic を使用して Kubernetes リソース、内部イメージ、および永続ボリュームをバックアップします。
DataProtectionApplication CR でスナップショットの場所を指定する必要はありません。
Restic は、hostPath ボリュームのバックアップをサポートしません。詳細は、追加の Restic 制限事項 を参照してください。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR でspec.configuration.restic.enableをfalseに設定して、デフォルトの Restic インストールを無効にしていない。 -
DataProtectionApplicationCR がReady状態である。
手順
次の例のように、
BackupCR を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToFsBackup: true 1 ...- 1
- OADP バージョン 1.2 以降では、
defaultVolumesToFsBackup: true設定をspecブロック内に追加します。OADP バージョン 1.1 では、defaultVolumesToRestic: trueを追加します。
14.4.1.3. バックアップフックの作成
Backup カスタムリソース (CR) を編集して、Pod 内のコンテナーでコマンドを実行するためのバックアップフックを作成します。
プレ フックは、Pod のバックアップが作成される前に実行します。ポスト フックはバックアップ後に実行します。
手順
次の例のように、
BackupCR のspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace> 1 excludedNamespaces: 2 - <namespace> includedResources: - pods 3 excludedResources: [] 4 labelSelector: 5 matchLabels: app: velero component: server pre: 6 - exec: container: <container> 7 command: - /bin/uname 8 - -a onError: Fail 9 timeout: 30s 10 post: 11 ...- 1
- オプション: フックが適用される namespace を指定できます。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 2
- オプション: フックが適用されない namespace を指定できます。
- 3
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 4
- オプション: フックが適用されないリソースを指定できます。
- 5
- オプション: このフックは、ラベルに一致するオブジェクトにのみ適用されます。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 6
- バックアップの前に実行するフックの配列。
- 7
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 8
- これは、追加される init コンテナーのエントリーポイントです。
- 9
- エラー処理に許可される値は、
FailとContinueです。デフォルトはFailです。 - 10
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 11
- このブロックでは、バックアップ後に実行するフックの配列を、バックアップ前のフックと同じパラメーターで定義します。
14.4.2. 関連情報
14.5. 仮想マシンの復元
Restore CR を作成して、OpenShift API for Data Protection (OADP) のBackup カスタムリソース (CR) を復元します。
フック を Restore CR に追加して、アプリケーションコンテナーの起動前に init コンテナーでコマンドを実行するか、アプリケーションコンテナー自体でコマンドを実行することができます。
14.5.1. 復元 CR の作成
Restore CR を作成して、Backup カスタムリソース (CR) を復元します。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 -
Velero
BackupCR がある。 - 永続ボリューム (PV) の容量は、バックアップ時に要求されたサイズと一致する必要があります。必要に応じて、要求されたサイズを調整します。
手順
次の例のように、
RestoreCR を作成します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup> 1 includedResources: [] 2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true 3
- 1
BackupCR の名前- 2
- オプション: 復元プロセスに含めるリソースの配列を指定します。リソースは、ショートカット (
Podsはpoなど) または完全修飾の場合があります。指定しない場合、すべてのリソースが含まれます。 - 3
- オプション:
RestorePVsパラメーターをfalseに設定すると、コンテナーストレージインターフェイス (CSI) スナップショットのVolumeSnapshotから、またはVolumeSnaphshotLocationが設定されている場合はネイティブスナップショットからのPersistentVolumesの復元をオフにすることができます。
次のコマンドを入力して、
RestoreCR のステータスがCompletedであることを確認します。$ oc get restore -n openshift-adp <restore> -o jsonpath='{.status.phase}'次のコマンドを入力して、バックアップリソースが復元されたことを確認します。
$ oc get all -n <namespace> 1- 1
- バックアップした namespace。
ボリュームを使用して
DeploymentConfigを復元する場合、または復元後のフックを使用する場合は、次のコマンドを入力してdc-post-restore.shクリーンアップスクリプトを実行します。$ bash dc-restic-post-restore.sh -> dc-post-restore.sh
注記復元プロセス中に、OADP Velero プラグインは
DeploymentConfigオブジェクトをスケールダウンし、Pod をスタンドアロン Pod として復元します。これは、クラスターが復元されたDeploymentConfigPod を復元時にすぐに削除することを防ぎ、復元フックと復元後のフックが復元された Pod 上でアクションを完了できるようにするために行われます。以下に示すクリーンアップスクリプトは、これらの切断された Pod を削除し、DeploymentConfigオブジェクトを適切な数のレプリカにスケールアップします。例14.1
dc-restic-post-restore.sh → dc-post-restore.shクリーンアップスクリプト#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } OADP_NAMESPACE=${OADP_NAMESPACE:=openshift-adp} if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo using OADP Namespace $OADP_NAMESPACE echo restore: $1 label=$(label_name $1) echo label: $label echo Deleting disconnected restore pods oc delete pods -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
14.5.1.1. 復元フックの作成
Restore カスタムリソース (CR) を編集して、Pod 内のコンテナーでコマンドを実行する復元フックを作成します。
2 種類の復元フックを作成できます。
initフックは、init コンテナーを Pod に追加して、アプリケーションコンテナーが起動する前にセットアップタスクを実行します。Restic バックアップを復元する場合は、復元フック init コンテナーの前に
restic-waitinit コンテナーが追加されます。-
execフックは、復元された Pod のコンテナーでコマンドまたはスクリプトを実行します。
手順
次の例のように、
Restore CRのspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace> 1 excludedNamespaces: - <namespace> includedResources: - pods 2 excludedResources: [] labelSelector: 3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout: 4 - exec: container: <container> 5 command: - /bin/bash 6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m 7 execTimeout: 1m 8 onError: Continue 9- 1
- オプション: フックが適用される namespace の配列。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 2
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 3
- オプション: このフックは、ラベルセレクターに一致するオブジェクトにのみ適用されます。
- 4
- オプション: Timeout は、
initContainersが完了するまで Velero が待機する最大時間を指定します。 - 5
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 6
- これは、追加される init コンテナーのエントリーポイントです。
- 7
- オプション: コンテナーの準備が整うまでの待機時間。これは、コンテナーが起動して同じコンテナー内の先行するフックが完了するのに十分な長さである必要があります。設定されていない場合、復元プロセスの待機時間は無期限になります。
- 8
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 9
- エラー処理に許可される値は、
FailおよびContinueです。-
Continue: コマンドの失敗のみがログに記録されます。 -
Fail: Pod 内のコンテナーで復元フックが実行されなくなりました。RestoreCR のステータスはPartiallyFailedになります。
-