
RHEL 7.5+ Guidelines for Configuring SAP NetWeaver (A)SCS/ERS ENSA1 with Standalone Resources
IMPORTANT NOTICES:
- The guidelines outlined below are only valid for Red Hat Enterprise Linux 7.5+, which is currently during its Extended Life Phase.
- These guidelines should not be used for new installations and, when requiring assistance from Technical Support for current installations only, a valid Extended Life-cycle Support Add-On is essential.
- For any existing RHEL 7.5+ setup, Red Hat recommends customers to considering upgrading to RHEL 8 or migrating to RHEL 9.
- For guidelines on how to set up a RHEL HA Add-On based cluster for managing SAP NetWeaver Standalone Enqueue Server 1 (ENSA1) on RHEL 8, please use the version of the documentation available in the RHEL 8 for SAP Solutions product documentation: Configuring HA clusters to manage SAP NetWeaver or SAP S/4HANA Application server instances using the RHEL HA Add-On.
- For guidelines on how to set up a RHEL HA Add-On based cluster for managing SAP NetWeaver Standalone Enqueue Server 1 (ENSA1) on RHEL 9, please use the version of the documentation available in the RHEL 9 for SAP Solutions product documentation: Configuring HA clusters to manage SAP NetWeaver or SAP S/4HANA Application server instances using the RHEL HA Add-On.
Contents
- 1. Overview
- 2. Requirements
- 3. Install SAP NetWeaver
- 3.1. Configuration options used in this document
- 3.2. Prepare hosts
- 3.3. Install NetWeaver
- 3.4. Post Installation
- 3.4.1. (A)SCS profile modification
- 3.4.2. ERS profile modification
- 3.4.3. Update the
/usr/sap/sapservicesfile - 3.4.4. Create mount points for ASCS and ERS on the failover node
- 3.4.5. Manual Testing Instance on Other Node
- 3.4.6. Check SAP HostAgent on all nodes
- 3.4.7. Install permanent SAP license keys
- 4. Install Pacemaker
- 4.1. Configure general cluster properties
- 4.2. Install
resource-agents-sapon all cluster nodes - 4.3. Configure cluster resources for shared filesystems
- 4.4. Configure ASCS resource group
- 4.5. Configure ERS resource group
- 4.6. Create constraints
- 4.7. Configure Primary Application Server group (PAS)
- 4.8. Configure Additional Application Server group (AAS)
- 4.8.1. Create Virtual IP address for AAS instance
- 4.8.2. Configure
LVMandFilesystemcluster resources in AAS resource group - 4.8.3. Configure constraints for AAS resource group
- 4.8.4. Configure AAS
SAPInstancecluster resource - 4.8.5. Configure constraint for PAS and AAS
SAPInstancecluster resources - 4.8.6. Update the
/usr/sap/sapservicesfile
- 5. Test the cluster configuration
- 5.1. Check the constraints
- 5.2. Failover ASCS due to node crashs
- 5.3. ERS moves to the previously failed node
- 6. Enable cluster to auto-start after reboot
- 7. Optional - Enable SAP HAlib for Management by Outside Tools
- 8. Multi-SID Support
1. Overview
1.1. Introduction
SAP NetWeaver-based systems (like SAP ERP, SAP CRM, ...) play an important role in business processes, thus it's critical for SAP NetWeaver-based systems to be highly available. The underlying idea of Clustering is a fairly simple one: Not a single large machine bears all of the load and risk; but rather one or more machines automatically drop in as an instant full replacement for the service or the machine that has failed. In the best case, this replacement process causes no interruption to the systems' users.
1.2. Audience
This document is intended for SAP and Red Hat certified or trained administrators and consultants who already have experience setting up high available solutions using the RHEL HA add-on or other clustering solutions. Access to both SAP Service Marketplace and Red Hat Customer Portal is required to be able to download software and additional documentation.
Red Hat Consulting is highly recommend to set up the cluster and customize the solution to meet customers' data center requirements, that are normally more complex than the solution presented in this document.
1.3. Concepts
This document describes how to set up a two-node-cluster solution that conforms to the guidelines for high availability that have been established by both SAP and Red Hat. It is based on SAP NetWeaver on top of Red Hat Enterprise Linux 7.5 or newer, with RHEL HA Add-on. The reference architecture described in this document is under the tests of SAP High Availability Interface certification NW-HA-CLU 7.50. This document will be updated after the certification is obtained.
At application tier, the lock table of the enqueue server is the most critical piece. To protect it, SAP has developed the “Enqueue Replication Server” (ERS) which maintains a backup copy of the lock table. While the (A)SCS is running on node1, the ERS always needs to maintain a copy of the current enqueue table on node2. When the system needs to failover the (A)SCS to node2, it first starts on node2, and then shuts down the ERS, taking over its' shared memory segment and thereby acquiring an up-to-date enqueue table, thus the replicated enqueue table becomes the new primary enqueue table. ERS will start on node1 when it becomes available. To further clarify, in case there is an issue with the (A)SCS instance, for the Standalone Enqueue Server (ENSA1), it is required that the (A)SCS instance "follows” the ERS instance. That is, an HA cluster has to start the (A)SCS instance on the host where the ERS instance is currently running. Until the host where the (A)SCS instance was running has been fenced, it can be noticed that both instances stay running on that same node. When the HA cluster node where the (A)SCS instance was previously running is back online, the HA cluster should move the ERS instance to that HA cluster node so that Enqueue Replication can resume.
Required by the SAP HA-Interface certification, this document focuses on the high availability of (A)SCS and ERS, both are controlled by the cluster software. In normal mode, cluster ensures that ERS and (A)SCS always run on different nodes. In the event of failover, the (A)SCS needs to “follow” the ERS. (A)SCS needs to switch to the node where ERS is running. Cluster has to ensure that the ERS is already running when (A)SCS starts up, because (A)SCS needs to take over the replicated enqueue table from ERS.
The concept described above is known as Standalone Enqueue Server 1 (ENSA1), available in ABAP 1709 or older. For Standalone Enqueue Server 2 (ENSA2) which is now the default installation in ABAP 1809 or newer, check Configure SAP S/4HANA ASCS/ERS with Standalone Enqueue Server 2 (ENSA2) in Pacemaker
1.4. Resources: Standalone vs. Master/Slave
There are two approaches to configure (A)SCS and ERS resources in Pacemaker: Master/Slave and Standalone. Master/Slave approach has already been supported in all RHEL 7 minor releases. Standalone approach is supported in RHEL 7.5 or newer.
In any new deployment, Standalone is recommended for the following reasons:
- it meets the requirements of the current SAP HA Interface Certification
- it is compatible with the new Standalone Enqueue Server 2 (ENSA2) configuration
- (A)SCS/ERS instances can be started and stopped independently
- (A)SCS/ERS instance directories can be managed as part of the cluster
This article outlines the configuration procedure of the SAPInstance Standalone approach. If you need information or support about the old SAPInstance Master/Slave approach on RHEL 7 only, please open a support case to discuss it with our Red Hat representatives
1.5. Support Policies
See: Support Policies for RHEL High Availability Clusters - Management of SAP NetWeaver in a Cluster
2. Requirements
2.1 Subscription
It’s important to keep the subscription, kernel, and patch level identical on both nodes.
Please follow this kbase article to subscribe your systems to the Update Service for RHEL for SAP Solutions.
2.2. Pacemaker Resource Agents
- RHEL for SAP Solutions 7.5 or newer.
2.3. SAP NetWeaver High-Availability Architecture
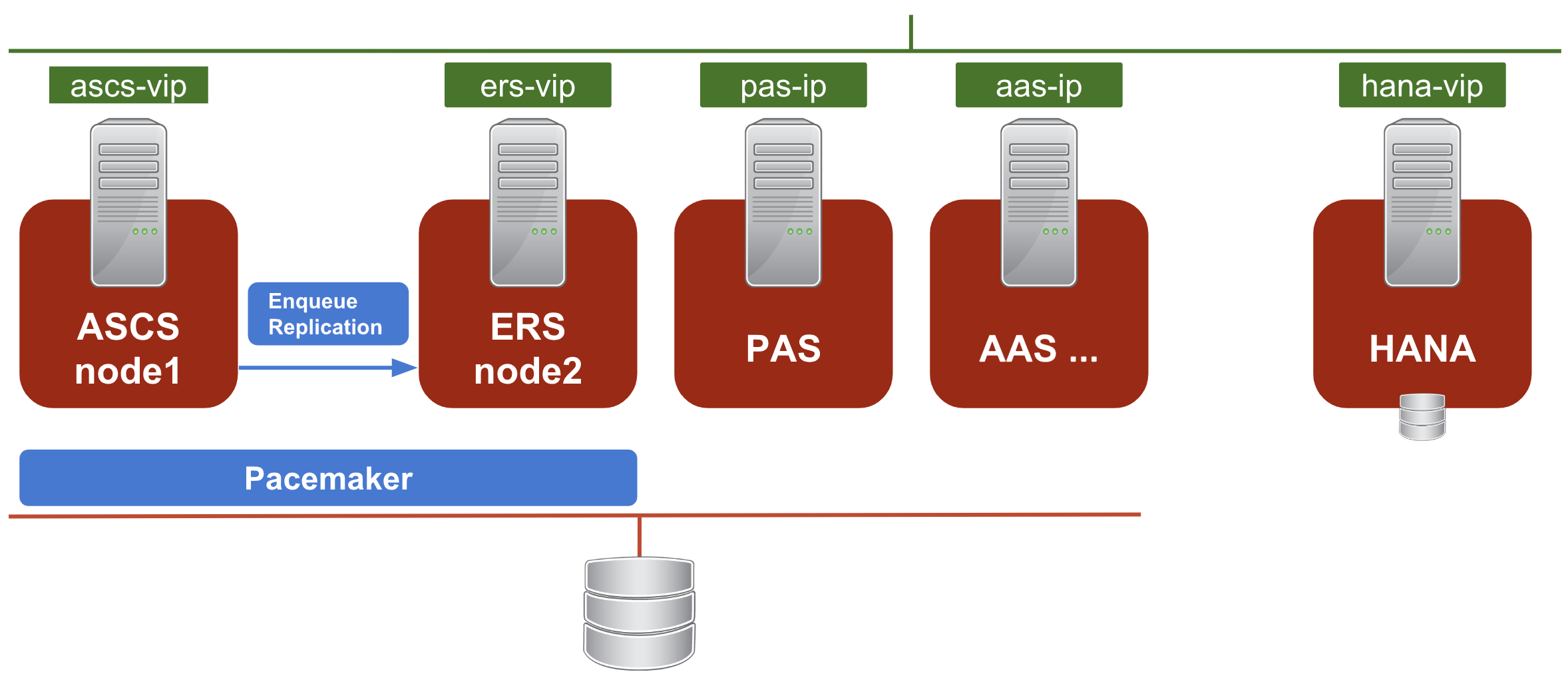
A typical setup for SAP NetWeaver High-Availability consists of 3 distinctive components:
- SAP NetWeaver ASCS/ERS cluster resources
- SAP NetWeaver application servers - Primary application server (PAS) and additional application servers (AAS)
- Database: SAP HANA or Oracle/DB2/ASE/MaxDB
This article focuses on the configuration of SAP NetWeaver ASCS and ERS in a pacemaker cluster. As the best practice, we recommend to install Application Servers and Database on separate nodes outside of the two-node cluster designated for (A)SCS and ERS.
Below is the architecture diagram of the example installation:
2.4. SAPInstance resource agent
SAPInstance is a pacemaker resource agent used for both ASCS and ERS resources. All operations of the SAPInstance resource agent are done by using the SAP start service framework sapstartsrv.
2.5. Storage requirements
The directories used by the SAP installation that is managed by the cluster must be setup according to the guidelines provided by SAP. See SAP Directories for more information.
2.5.1. Instance Specific Directories
For the (A)SCS, ERS and any other application server instance that is managed by the cluster the instance specific directory must be created on a separate SAN LUN or NFS export that can be mounted by the cluster as a local directory on the node where an instance is supposed to be running. For example:
- (A)SCS:
/usr/sap/<SAPSID>/ASCS<Ins#> - ERS:
/usr/sap/<SAPSID>/ERS<Ins#> - App Server:
/usr/sap/<SAPSID>/D<Ins#>
When using SAN LUNs for the instance specific directories customers must use HA-LVM to ensure that the instance directories can only be mounted on one node at a time.
With the exception of NFS, using a shared filesystem (for example GFS2) to host all the instance specific directories and make them available on all cluster nodes at the same time is not supported.
When using NFS exports for the instance specific directories, if the directories are created on the same directory tree on an NFS file server, such as Azure NetApp Files (ANF) or Amazon EFS, the option force_unmount=safe must be used when configuring the Filesystem resource. This option will ensure that the cluster only stops the processes running on the specific NFS export instead of stopping all processes running on the directory tree where the exports hve been created (see During failover of a pacemaker resources, a Filesystem resource kills processes not using the filesystem for more information).
2.5.2. Shared Directories
The following shared directories must be available on all cluster nodes managing SAP instances
/sapmnt
/usr/sap/trans
The /sapmnt directory must also be accessible on all other servers that are running services that are part of the SAP system (for example the servers hosting the DB instances or servers hosting additional application servers not managed by the cluster).
To share the /sapmnt and /usr/sap/trans directories between all the servers hosting services of the same SAP system either one of the following methods can be used:
- using an external NFS server (as documented in Support Policies for RHEL High Availability Clusters - Management of Highly Available Filesystem Mounts using the same host as an NFS server and as an NFS Client that mounts the same NFS exports ("loopback mounts") from this NFS server at the same time is not supported)
- using the GFS2 filesystem (this requires all nodes to have Resilient Storage Add-on subscriptions)
- using the glusterfs filesystem (check the additional notes in article Can glusterfs be used for the SAP NetWeaver shared filesystems?)
The shared directories can either be statically mounted via /etc/fstab or the mounts can be managed by the cluster (in this case it must be ensured that the cluster mounts the /sapmnt directory on the cluster nodes before attempting to start any SAP instances by setting up appropriate constraints).
3. Install SAP NetWeaver
3.1. Configuration options used in this document
Below are configuration options that will be used for instances in this document:
Two nodes will be running the ASCS/ERS instances in pacemaker:
1st node hostname: node1
2nd node hostname: node2
SID: RH2
ASCS Instance number: 20
ASCS virtual hostname: rhascs
ERS Instance number: 29
ERS virtual hostname: rhers
Outside the two-node cluster:
PAS Instance number: 21
AAS Instance number: 22
HANA database:
SID: RH0
HANA Instance number: 00
HANA virtual hostname: rhdb
3.2. Prepare hosts
Before starting installation ensure that:
- Install RHEL for SAP Solutions 7.x
- Register system to RHN or Satellite, enable RHEL for SAP Applications channel, or Update Services (E4S) channel
- Enable High Availability Add-on channel
- Shared storage and filesystems are present at correct mount points
- Virtual IP addresses used by instances are present and reachable
- Hostnames that will be used by instances can be resolved to IP addresses and back
- Installation medias are available
- System is configured according to the recommendation for running SAP NetWeaver
- Red Hat Enterprise Linux 7.x: Installation and Upgrade - SAP Note 2002167
- Red Hat Enterprise Linux 8.x: Installation and Configuration - SAP Note 2772999
3.3. Install NetWeaver
Using software provisioning manager (SWPM) install instances in the following order:
- ASCS instance
- ERS instance
- DB instance
- PAS instance
- AAS instances
3.3.1. Install ASCS on node1
The following file systems should be mounted on node1, where ASCS will be installed:
/usr/sap/RH2/ASCS20
/usr/sap/RH2/SYS
/usr/sap/trans
/sapmnt
Virtual IP for rhascs should be enabled on node1.
Run the installer:
[root@node1]# ./sapinst SAPINST_USE_HOSTNAME=rhascs
Select High-Availability System option.
3.3.2. Install ERS on node2
The following file systems should be mounted on node2, where ERS will be installed:
/usr/sap/RH2/ERS29
/usr/sap/RH2/SYS
/usr/sap/trans
/sapmnt
Virtual IP for rhers should be enabled on node2.
Run the installer:
[root@node2]# ./sapinst SAPINST_USE_HOSTNAME=rhers
Select High-Availability System option.

3.3.3. SAP HANA
In the example, SAP HANA will be using the following configuration. You can also use other supported database.
SAP HANA SID: RH0
SAP HANA Instance number: 00
SAP HANA should be installed on separate host. Optionally, Automated HANA System Replication can be installed in another pacemaker cluster by following document SAP HANA system replication in pacemaker cluster.
Run the installer on the HANA host:
[root]# ./sapinst SAPINST_USE_HOSTNAME=rhdb
3.3.4. Install Application Servers
The following file systems should be mounted on the host to run the Application Server instance. If you have multiple application servers, install each one on corresponding host:
/usr/sap/RH2/D<Ins#>
/usr/sap/RH2/SYS
/usr/sap/trans
/sapmnt
Run the installer:
[root]# ./sapinst
Select High-Availability System option.
3.4. Post Installation
3.4.1. (A)SCS profile modification
(A)SCS instance requires following modification in profile to prevent automatic restart of enqueue server as it will be managed by cluster. To apply the change run the following command at your ASCS profile /sapmnt/RH2/profile/RH2_ASCS20_rhascs.
[root]# sed -i -e 's/Restart_Program_01/Start_Program_01/' /sapmnt/RH2/profile/RH2_ASCS20_rhascs
3.4.2. ERS profile modification
ERS instance requires following modification in profile to prevent automatic restart as it will be managed by cluster. To apply the change run the following command at your ERS profile /sapmnt/RH2/profile/RH2_ERS29_rhers.
[root]# sed -i -e 's/Restart_Program_00/Start_Program_00/' /sapmnt/RH2/profile/RH2_ERS29_rhers
3.4.3. Update the /usr/sap/sapservices file
On both node1 and node2, make sure following two lines are commented out in /usr/sap/sapservices file:
#LD_LIBRARY_PATH=/usr/sap/RH2/ASCS20/exe:$LD_LIBRARY_PATH; export LD_LIBRARY_PATH; /usr/sap/RH2/ASCS20/exe/sapstartsrv pf=/usr/sap/RH2/SYS/profile/RH2_ASCS20_rhascs -D -u rh2adm
#LD_LIBRARY_PATH=/usr/sap/RH2/ERS29/exe:$LD_LIBRARY_PATH; export LD_LIBRARY_PATH; /usr/sap/RH2/ERS29/exe/sapstartsrv pf=/usr/sap/RH2/ERS29/profile/RH2_ERS29_rhers -D -u rh2adm
3.4.4. Create mount points for ASCS and ERS on the failover node
[root@node1 ~]# mkdir /usr/sap/RH2/ERS29
[root@node1 ~]# chown rh2adm:sapsys /usr/sap/RH2/ERS29
[root@node2 ~]# mkdir /usr/sap/RH2/ASCS20
[root@node2 ~]# chown rh2adm:sapsys /usr/sap/RH2/ASCS20
3.4.5. Manual Testing Instance on Other Node
Stop ASCS and ERS instances. Move the instance specific directory to the other node:
[root@node1 ~]# umount /usr/sap/RH2/ASCS20
[root@node2 ~]# mount /usr/sap/RH2/ASCS20
[root@node2 ~]# umount /usr/sap/RH2/ERS29
[root@node1 ~]# mount /usr/sap/RH2/ERS29
Manually start ASCS and ERS instances on other cluster node, then manually stop them, respectively.
3.4.6. Check SAP HostAgent on all nodes
On all nodes check if SAP HostAgent has the same version and meets the minimum version requirement:
[root]# /usr/sap/hostctrl/exe/saphostexec -version
To upgrade/install SAP HostAgent, follow SAP note 1031096.
3.4.7. Install permanent SAP license keys
SAP hardware key determination in the high-availability scenario has been improved. It might be necessary to install several SAP license keys based on the hardware key of each cluster node. Please see SAP Note 1178686 - Linux: Alternative method to generate a SAP hardware key for more information.
4. Install Pacemaker
Please refer to the following documentation to first set up a pacemaker cluster.
Please make sure to follow the guidelines in Support Policies for RHEL High Availability Clusters - General Requirements for Fencing/STONITH for the fencing/STONITH setup. Information about the fencing/STONITH agents supported for different platforms are available at Cluster Platforms and Architectures.
This guide will assume that following things are working properly:
- Pacemaker cluster is configured according to documentation and has proper and working fencing
- Enqueue replication between the (A)SCS and ERS instances has been manually tested as explained in Setting up Enqueue Replication Server fail over
- The nodes are subscribed to the required channels as explained in RHEL for SAP Repositories and How to Enable Them
4.1. Configure general cluster properties
To avoid unnecessary failovers of the resources during initial testing and post production, set the following default values for the resource-stickiness and migration-threshold parameters. Note that defaults do not apply to resources which override them with their own defined values.
[root]# pcs resource defaults resource-stickiness=1
[root]# pcs resource defaults migration-threshold=3
Notes:
1. It is sufficient to run the commands above on one node of the cluster.
2. The command resource-stickiness=1 will encourage the resource to stay running where it is, while migration-threshold=3 will cause the resource to move to a new node after 3 failures. 3 is generally sufficient in preventing the resource from prematurely failing over to another node. This also ensures that the resource failover time stays within a controllable limit.
4.2. Install resource-agents-sap on all cluster nodes
[root]# yum install resource-agents-sap
4.3. Configure cluster resources for shared filesystems
Configure shared filesystem to provide following mount points on all of cluster nodes.
/sapmnt
/usr/sap/trans
/usr/sap/RH2/SYS
4.3.1. Configure shared filesystems managed by the cluster
The cloned Filesystem cluster resource can be used to mount the shares from external NFS server on all cluster nodes as shown below.
NOTE: The '--clone' option works in RHEL 7.
For RHEL 7
[root]# pcs resource create rh2_fs_sapmnt Filesystem device='<NFS_Server>:<sapmnt_nfs_share>' directory='/sapmnt' fstype='nfs' --clone interleave=true
[root]# pcs resource create rh2_fs_sap_trans Filesystem device='<NFS_Server>:<sap_trans_nfs_share>' directory='/usr/sap/trans' fstype='nfs' --clone interleave=true
[root]# pcs resource create rh2_fs_sap_sys Filesystem device='<NFS_Server>:<rh2_sys_nfs_share>' directory='/usr/sap/RH2/SYS' fstype='nfs' --clone interleave=true
4.3.2. Configure shared filesystems managed outside of cluster
In case that shared filesystems will NOT be managed by cluster, it must be ensured that they are available before the pacemaker service is started.
In RHEL 7 due to systemd parallelization you must ensure that shared filesystems are started in resource-agents-deps target. More details on this can be found in documentation section 9.6. Configuring Startup Order for Resource Dependencies not Managed by Pacemaker (Red Hat Enterprise Linux 7.4 and later).
4.4. Configure ASCS resource group
4.4.1. Create resource for virtual IP address
# pcs resource create rh2_vip_ascs20 IPaddr2 ip=192.168.200.101 --group rh2_ASCS20_group
4.4.2. Create resource for ASCS filesystem.
Below is the example of creating resource for NFS filesystem
# pcs resource create rh2_fs_ascs20 Filesystem device='<NFS_Server>:<rh2_ascs20_nfs_share>' directory=/usr/sap/RH2/ASCS20 fstype=nfs force_unmount=safe --group rh2_ASCS20_group \
op start interval=0 timeout=60 \
op stop interval=0 timeout=120 \
op monitor interval=200 timeout=40
Below is the example of creating resources for HA-LVM filesystem
# pcs resource create rh2_fs_ascs20_lvm LVM volgrpname='<ascs_volume_group>' exclusive=true --group rh2_ASCS20_group
# pcs resource create rh2_fs_ascs20 Filesystem device='/dev/mapper/<ascs_logical_volume>' directory=/usr/sap/RH2/ASCS20 fstype=ext4 --group rh2_ASCS20_group
4.4.3. Create resource for ASCS instance
# pcs resource create rh2_ascs20 SAPInstance InstanceName="RH2_ASCS20_rhascs" START_PROFILE=/sapmnt/RH2/profile/RH2_ASCS20_rhascs AUTOMATIC_RECOVER=false meta resource-stickiness=5000 migration-threshold=1 failure-timeout=60 --group rh2_ASCS20_group \
op monitor interval=20 on-fail=restart timeout=60 \
op start interval=0 timeout=600 \
op stop interval=0 timeout=600
Note: meta resource-stickiness=5000 is here to balance out the failover constraint with ERS so the resource stays on the node where it started and doesn't migrate around cluster uncontrollably. migration-threshold=1 ensures that ASCS failover to another node when issue is detected instead of restarting on same node.
Add a resource stickiness to the group to ensure that the ASCS will stay on a node if possible:
# pcs resource meta rh2_ASCS20_group resource-stickiness=3000
4.5. Configure ERS resource group
4.5.1. Create resource for virtual IP address
# pcs resource create rh2_vip_ers29 IPaddr2 ip=192.168.200.102 --group rh2_ERS29_group
4.5.2. Create resource for ERS filesystem
Below is the example of creating resource for NFS filesystem
# pcs resource create rh2_fs_ers29 Filesystem device='<NFS_Server>:<rh2_ers29_nfs_share>' directory=/usr/sap/RH2/ERS29 fstype=nfs force_unmount=safe --group rh2_ERS29_group \
op start interval=0 timeout=60 \
op stop interval=0 timeout=120 \
op monitor interval=200 timeout=40
Below is the example of creating resources for HA-LVM filesystem
# pcs resource create rh2_fs_ers29_lvm LVM volgrpname='<ers_volume_group>' exclusive=true --group rh2_ERS29_group
# pcs resource create rh2_fs_ers29 Filesystem device='/dev/mapper/<ers_logical_volume>' directory=/usr/sap/RH2/ERS29 fstype=ext4 --group rh2_ERS29_group
4.5.3. Create resource for ERS instance
Create the ERS instance cluster resource. Note: IS_ERS=true attribute is mandatory for ENSA1 deployments. More information about IS_ERS can be found in How does the IS_ERS attribute work on a SAP NetWeaver cluster with Standalone Enqueue Server (ENSA1 and ENSA2)?.
# pcs resource create rh2_ers29 SAPInstance InstanceName="RH2_ERS29_rhers" START_PROFILE=/sapmnt/RH2/profile/RH2_ERS29_rhers AUTOMATIC_RECOVER=false IS_ERS=true --group rh2_ERS29_group \
op monitor interval=20 on-fail=restart timeout=60 \
op start interval=0 timeout=600 \
op stop interval=0 timeout=600
4.6. Create constraints
4.6.1. Create colocation constraint for ASCS and ERS resource groups
Resource groups rh2_ASCS20_group and rh2_ERS29_group should try to avoid running on same node. Order of groups matters.
# pcs constraint colocation add rh2_ERS29_group with rh2_ASCS20_group -5000
4.6.2. Create location constraint for ASCS resource
ASCS20 instance rh2_ascs20 prefers to run on node where ERS was running before when failover is happening
# pcs constraint location rh2_ascs20 rule score=2000 runs_ers_RH2 eq 1
4.6.3. Create order constraint for ASCS and ERS resource groups
Prefer to start rh2_ASCS20_group before the rh2_ERS29_group (optionally)
# pcs constraint order start rh2_ASCS20_group then stop rh2_ERS29_group symmetrical=false kind=Optional
4.6.4. Create order constraint for /sapmnt resource managed by cluster
If the shared filesystem /sapmnt is managed by cluster, then following constraints ensures that resource groups with ASCS and ERS SAPInstance resource are started only once the filesystem is available.
# pcs constraint order rh2_fs_sapmnt-clone then rh2_ASCS20_group
# pcs constraint order rh2_fs_sapmnt-clone then rh2_ERS29_group
4.7. Configure Primary Application Server group (PAS) (Optional)
Below is example of configuring resource group rh2_PAS_D01_group containing the Primary Application Server (PAS) instance rh2_pas_d01 managed by SAPInstance resource agent.
4.7.1. Create Virtual IP address for PAS instance
To create the virtual IP address that will be part of the rh2_PAS_D01_group use the command below.
[root]# pcs resource create rh2_vip_pas_d01 IPaddr2 ip=192.168.0.16 --group rh2_PAS_D01_group
To verify that resource got created in new group rh2_PAS_D01_group the output from pcs status command should look like below.
[root]# pcs status
...
Resource Group: rh2_PAS_D01_group
rh1_vip_pas_d01 (ocf::heartbeat:IPaddr2): Started node1
...
4.7.2. Configure LVM and Filesystem cluster resources in PAS resource group
First LVM cluster resource is added then followed by Filesystem cluster resource. LVM shared by cluster is expected to be configured as described in the article What is a Highly Available LVM (HA-LVM) configuration and how do I implement it?.
[root]# pcs resource create rh2_lvm_pas_d01 LVM volgrpname=vg_d01 exclusive=true --group rh2_PAS_D01_group
[root]# pcs resource create rh2_fs_pas_d01 Filesystem device=/dev/vg_d01/lv_d01 directory=/usr/sap/RH2/D01 fstype=xfs --group rh2_PAS_D01_group
Verify that resources were added to rh2_PAS_D01_group resource group and started as shown below.
[root]# pcs status
...
Resource Group: rh2_PAS_D01_group
rh2_vip_pas_d01 (ocf::heartbeat:IPaddr2): Started node1
rh2_lvm_pas_d01 (ocf::heartbeat:LVM): Started node1
rh2_fs_pas_d01 (ocf::heartbeat:Filesystem): Started node1
...
4.7.3. Configure constraints for PAS resource group
PAS requires the ASCS and database instance to be running before it can start properly. Below are example commands on how to setup constraints to achieve this for various databases that can be used by SAP Netweaver.
4.7.3.1. Deployments with rh2_SAPDatabase_group group
For configurations that has one cluster resource group that will start all resources needed by database. In example here the SAPDatabase resource agent is used to manage the database and is part of the the database group rh2_SAPDatabase_group. Commands below will create constraints that will start the whole rh2_PAS_D01_group only once the ASCS instance was promoted and when the database group rh2_SAPDatabase_group is running.
[root]# pcs constraint order rh2_SAPDatabase_group then rh2_PAS_D01_group kind=Optional symmetrical=false
[root]# pcs constraint order start rh2_ASCS20_group then rh2_PAS_D01_group kind=Optional symmetrical=false
After executing the commands verify that the constraints were added properly.
[root]# pcs constraint
Ordering Constraints:
...
start rh2_SAPDatabase_group then start rh2_PAS_group (kind:Optional) (non-symmetrical)
start rh2_ASCS20_group then start rh2_PAS_group (kind:Optional) (non-symmetrical)
...
4.7.3.2. Deployments with SAP HANA with System Replication as database
When using SAP HANA database that is configured for system replication (SR) that is managed by cluster, the following constraints will ensure that whole rh2_PAS_D01_group will start only once the ASCS instance was promoted and when the SAP HANA SAPHana_RH2_02-master was promoted.
[root]# pcs constraint order promote SAPHana_RH2_02-master then rh2_PAS_D01_group Kind=Optional symmetrical=false
[root]# pcs constraint order start rh2_ASCS20_group then rh2_PAS_D01_group Kind=Optional symmetrical=false
After executing the commands verify that the constraints were added properly.
[root]# pcs constraint
Ordering Constraints:
...
promote SAPHana_RH2_02-master then start rh2_PAS_group (kind:Optional) (non-symmetrical)
start rh2_ASCS20_group then start rh2_PAS_group (kind:Optional) (non-symmetrical)
...
4.7.4. Configure PAS SAPInstance cluster resource
To run the PAS instance the same SAPInstance resource agents as for (A)SCS/ERS instance is used. The PAS instance is compared to (A)SCS/ERS a simple instance and requires less attributes to be configured. Check the command below for example on how to create a PAS instance for 'D01' instance and place it at the end of the rh2_PAS_D01_group resource group.
[root]# pcs resource create rh2_pas_d01 SAPInstance InstanceName="RH2_D01_rh1-pas" DIR_PROFILE=/sapmnt/RH2/profile START_PROFILE=/sapmnt/RH2/profile/RH2_D01_rh1-pas --group rh2_PAS_D01_group
Verify the configuration of the PAS SAPInstance resource using command below.
[root]# pcs resource show rh2_pas_d01
Resource: rh2_pas_d01 (class=ocf provider=heartbeat type=SAPInstance)
Attributes: DIR_PROFILE=/sapmnt/RH2/profile InstanceName=RH2_D01_rh1-pas START_PROFILE=/sapmnt/RH2/profile/RH2_D01_rh2-pas
Operations: demote interval=0s timeout=320 (rh2_pas_d01-demote-interval-0s)
monitor interval=120 timeout=60 (rh2_pas_d01-monitor-interval-120)
monitor interval=121 role=Slave timeout=60 (rh2_pas_d01-monitor-interval-121)
monitor interval=119 role=Master timeout=60 (rh2_pas_d01-monitor-interval-119)
promote interval=0s timeout=320 (rh2_pas_d01-promote-interval-0s)
start interval=0s timeout=180 (rh2_pas_d01-start-interval-0s)
stop interval=0s timeout=240 (rh2_pas_d01-stop-interval-0s)
4.8. Configure Additional Application Server group (AAS)(Optional)
Below is example of configuring resource group rh2_AAS_D02_group containing the Additional Application Server (AAS) instance rh2_aas_d02 managed by SAPInstance resource agent.
4.8.1. Create Virtual IP address for AAS instance
To create the virtual IP address that will be part of the rh2_AAS_D02_group use the command below.
[root]# pcs resource create rh2_vip_aas_d02 IPaddr2 ip=192.168.0.17 --group rh2_AAS_D02_group
To verify that resource got created in new group rh2_AAS_D02_group the output from pcs status command should look like below.
[root]# pcs status
...
Resource Group: rh2_AAS_D02_group
rh2_vip_aas_d02 (ocf::heartbeat:IPaddr2): Started node1
...
4.8.2. Configure LVM and Filesystem cluster resources in AAS resource group
First LVM cluster resource is added then followed by Filesystem cluster resource. LVM shared by cluster is expected to be configured as described in the article What is a Highly Available LVM (HA-LVM) configuration and how do I implement it?.
[root]# pcs resource create rh2_lvm_aas_d02 LVM volgrpname=vg_d02 exclusive=true --group rh2_AAS_D02_group
[root]# pcs resource create rh2_fs_aas_d02 Filesystem device=/dev/vg_d02/lv_d02 directory=/usr/sap/RH2/D02 fstype=xfs --group rh1_AAS_D02_group
Verify that resources were added to rh1_AAS_D02_group resource group and started as shown below.
[root]# pcs status
...
Resource Group: rh1_AAS_D02_group
rh2_vip_aas_d02 (ocf::heartbeat:IPaddr2): Started node1
rh2_lvm_aas_d02 (ocf::heartbeat:LVM): Started node1
rh2_fs_aas_d02 (ocf::heartbeat:Filesystem): Started node1
...
4.8.3. Configure constraints for AAS resource group
AAS also requires the ASCS and database instance to be running before it can start properly. Below are example commands on how to setup constraints to achieve this for various databases that can be used by SAP Netweaver.
4.8.3.1. Deployments with rh2_SAPDatabase_group group
For configurations that has one cluster resource group that will start all resources needed by database. In example here the SAPDatabase resource agent is used to manage the database and is part of the the database group rh2_SAPDatabase_group. Commands below will create constraints that will start the whole rh2_AAS_D02_group only once the ASCS instance was promoted and when the database group rh2_SAPDatabase_group is running.
[root]# pcs constraint order rh2_SAPDatabase_group then rh2_AAS_D02_group kind=Optional symmetrical=false
[root]# pcs constraint order start rh2_ASCS20_group then rh1_AAS_D02_group kind=Optional symmetrical=false
After executing the commands verify that the constraints were added properly.
[root]# pcs constraint
Ordering Constraints:
...
start rh2_SAPDatabase_group then start rh2_AAS_group (kind:Optional) (non-symmetrical)
start rh2_ASCS20_group then start rh2_AAS_group (kind:Optional) (non-symmetrical)
...
4.8.3.2. Deployments with SAP HANA with SR as database
When using SAP HANA database that is configured for system replication (SR) that is managed by cluster, the following constraints will ensure that whole rh2_PAS_D01_group will start only once the ASCS instance was promoted and when the SAP HANA SAPHana_RH2_02-master was promoted.
[root]# pcs constraint order promote SAPHana_RH2_02-master then rh2_AAS_D02_group symmetrical=false
[root]# pcs constraint order start rh2_ASCS20_group then rh2_AAS_D02_group
After executing the commands verify that the constraints were added properly.
[root]# pcs constraint
Ordering Constraints:
...
promote SAPHana_RH2_02-master then start rh2_AAS_group (kind:Optional) (non-symmetrical)
start rh2_ASCS20_group then start rh2_AAS_group (kind:Optional) (non-symmetrical)
...
Important Note: Please note that when the parameters kind=Optional and symmetrical=false are set, then failover of the ASCS and HANA Database will not cause a restart of PAS and/or AAS Instance but during the Initial startup if the associated ASCS and/or the Database Instance fails to start, then cluster can still attempt to start the PAS and AAS instances which inturn will also fail.
4.8.4. Configure AAS SAPInstance cluster resource
To run the AAS instance also, the same SAPInstance resource agents as for (A)SCS/ERS instance is used. The AAS instance is, compared to (A)SCS/ERS, a simple instance and requires less attributes to be configured. Check the command below for example on how to create a AAS instance for 'D02' instance and place it at the end of the rh2_AAS_D02_group resource group.
[root]# pcs resource create rh2_aas_d02 SAPInstance InstanceName="RH2_D02_rh2-aas" DIR_PROFILE=/sapmnt/RH2/profile START_PROFILE=/sapmnt/RH2/profile/RH2_D02_rh2-aas --group rh2_AAS_D02_group
Verify the configuration of the AAS SAPInstance resource using command below.
[root]# pcs resource show rh2_aas_d02
Resource: rh2_aas_d02 (class=ocf provider=heartbeat type=SAPInstance)
Attributes: DIR_PROFILE=/sapmnt/RH2/profile InstanceName=RH2_D02_rh2-aas START_PROFILE=/sapmnt/RH2/profile/RH2_D02_rh2-aas
Operations: demote interval=0s timeout=320 (rh2_aas_d02-demote-interval-0s)
monitor interval=120 timeout=60 (rh2_aas_d02-monitor-interval-120)
monitor interval=121 role=Slave timeout=60 (rh2_aas_d02-monitor-interval-121)
monitor interval=119 role=Master timeout=60 (rh2_aas_d02-monitor-interval-119)
promote interval=0s timeout=320 (rh2_aas_d02-promote-interval-0s)
start interval=0s timeout=180 (rh2_aas_d02-start-interval-0s)
stop interval=0s timeout=240 (rh2_aas_d02-stop-interval-0s)
4.8.5. Configure constraint for PAS and AAS SAPInstance cluster resources
To ensure that PAS and AAS instances do not run on the same nodes whenever both nodes are running you can add a negative colocation constraint with the command below:
[root]# pcs constraint colocation add rh2_AAS_D02_group with rh2_PAS_D01_group score=-1000
Verify the constraint set:
[root]# pcs constraint colocation
Colocation Constraints:
rh2_AAS_D02_group with rh2_PAS_D01_group (score:-1000)
The score of -1000 is to ensure that if only 1 node is available then the AAS instance will continue to run on the other node. In such situation if you would like to keep the AAS instance down then you can use the score=-INFINITY which will enforce this condition.
4.8.6. Update the /usr/sap/sapservices file
On both nodes update the /usr/sap/sapservices file by commenting out the following 2 lines.
...........
#LD_LIBRARY_PATH=/usr/sap/RH2/D01/exe:$LD_LIBRARY_PATH; export LD_LIBRARY_PATH; /usr/sap/RH2/D01/exe/sapstartsrv pf=/usr/sap/RH2/SYS/profile/RH2_D01_rh2pas -D -u rh2adm
#LD_LIBRARY_PATH=/usr/sap/RH2/D02/exe:$LD_LIBRARY_PATH; export LD_LIBRARY_PATH; /usr/sap/RH2/D02/exe/sapstartsrv pf=/usr/sap/RH2/SYS/profile/RH2_D02_rh2aas -D -u rh2adm
As cluster is managing the instances now, the above entries are no longer required.
5. Test the cluster configuration
5.1. Check the constraints
# pcs constraint
Location Constraints:
Resource: rh2_ascs20
Constraint: location-rh2_ascs20
Rule: score=2000
Expression: runs_ers_RH2 eq 1
Ordering Constraints:
start rh2_ASCS20_group then stop rh2_ERS29_group (kind:Optional) (non-symmetrical)
Colocation Constraints:
rh2_ERS29_group with rh2_ASCS20_group (score:-5000)
Ticket Constraints:
5.2. Failover ASCS due to node crash
Before the crash, ASCS is running on node1 while ERS running on node2.
# pcs status
...
Resource Group: rh2_ASCS20_group
rh2_vip_ascs20 (ocf::heartbeat:IPaddr2): Started node1
rh2_fs_ascs20 (ocf::heartbeat:Filesystem): Started node1
rh2_ascs20 (ocf::heartbeat:SAPInstance): Started node1
Resource Group: rh2_ERS29_group
rh2_vip_ers29 (ocf::heartbeat:IPaddr2): Started node2
rh2_fs_ers29 (ocf::heartbeat:Filesystem): Started node2
rh2_ers29 (ocf::heartbeat:SAPInstance): Started node2
...
On node2, run the following command to monitor the status changes in the cluster:
[root@node2 ~]# crm_mon -Arf
Crash node1 by running the following command. Please note that connection to node1 will be lost after the command.
[root@node1 ~]# echo c > /proc/sysrq-trigger
On node2, monitor the failover process. After failover, cluster should be in such state, with ASCS and ERS both on node2.
[root@node2 ~]# pcs status
...
Resource Group: rh2_ASCS20_group
rh2_fs_ascs20 (ocf::heartbeat:Filesystem): Started node2
rh2_ascs20 (ocf::heartbeat:SAPInstance): Started node2
rh2_vip_ascs20 (ocf::heartbeat:IPaddr2): Started node2
Resource Group: rh2_ERS29_group
rh2_fs_ers29 (ocf::heartbeat:Filesystem): Started node2
rh2_vip_ers29 (ocf::heartbeat:IPaddr2): Started node2
rh2_ers29 (ocf::heartbeat:SAPInstance): Started node2
...
5.3. ERS moves to the previously failed node
Bring node1 back online, and start the cluster on node1:
[root@node1 ~]# pcs cluster start
ERS should move to node1, while ASCS remaining on node2. Wait for ERS to finish the migration, and at the end the cluster should be in such state:
[root@node1 ~]# pcs status
...
Resource Group: rh2_ASCS20_group
rh2_fs_ascs20 (ocf::heartbeat:Filesystem): Started node2
rh2_ascs20 (ocf::heartbeat:SAPInstance): Started node2
rh2_vip_ascs20 (ocf::heartbeat:IPaddr2): Started node2
Resource Group: rh2_ERS29_group
rh2_fs_ers29 (ocf::heartbeat:Filesystem): Started node1
rh2_vip_ers29 (ocf::heartbeat:IPaddr2): Started node1
rh2_ers29 (ocf::heartbeat:SAPInstance): Started node1
...
6. Enable cluster to auto-start after reboot
The cluster is not yet enabled to auto-start after reboot. System admin needs to manually start the cluster after the node is fenced and rebooted.
After testing the previous section, when everything works fine, enable the cluster to auto-start after reboot.
# pcs cluster enable --all
Note: in some situations it can be beneficial not to have the cluster auto-start after a node has been rebooted. For example, if there is an issue with a filesystem that is required by a cluster resource, and the filesystem needs to be repaired first before it can be used again, having the cluster auto-start but then fail because the filesystem doesn't work can cause even more trouble.
Now please rerun the tests in previous section to make sure that cluster still works fine. Please note that in section 5.3., there is no need to run command pcs cluster start after a node is rebooted. Cluster should automatically start after reboot.
7. Optional - Enable SAP HAlib for Management by Outside Tools
When a system admin controls a SAP instance that is running inside the pacemaker cluster, either manually or using tools such as SAP Management Console (MC/MMC), the change needs to be done through the HA interface that's provided by the HA cluster software. SAP Start Service sapstartsrv controls the SAP instances, and needs to be configured to communicate with the pacemaker cluster software through the HA interface.
Please follow the kbase article to configure the HAlib: How to configure SAP HAlib for SAPInstance resources?
8. Multi-SID Support
The setup described in this document can also be used to manage the (A)SCS/ERS instances for multiple SAP environments (Multi-SID) within the same cluster. Below are some of the considerations:
8.1. Prerequisites
8.1.1. Unique SID and Instance Number
To avoid conflict, each pair of (A)SCS/ERS instances must use a different SID and each instance must use a unique Instance Number, even if they belong to different SID.
8.1.2. Sizing
Each cluster node must meet the SAP requirements for sizing to support the multiple instances.
8.1.3. Shared File Systems
Since shared file systems can be managed either by the cluster or outside the cluster, if you want to simplify the cluster management, you can choose to configure shared file systems managed outside of cluster, as documented in section 4.5.2.
8.2. Installation
For each (A)SCS/ERS pair please repeat all the steps documented in sections 4.6, 4.7 and 4.8 above.
Each (A)SCS/ERS pair will failover independently following the configuration rules.
Comments