
Introduction to storage performance analysis with PCP
この記事では、Performance Co-Pilot (PCP) を使用した基本的なストレージパフォーマンス分析タスクの概要とチュートリアルを紹介します。
はじめに
Performance Co-Pilot は、特にエンタープライズ環境での使用に適しているシステムレベルのパフォーマンスの監視および管理スイートです。PCP は、RHEL 6.6 以降、および他の多くのディストリビューション (F15 以降の Fedora、Debian、Ubuntu など) で同梱され、Red Hat によって完全にサポートされています。このオープンソースプロジェクトは、安定性があり、コミュニティーで積極的にメンテナンスおよび開発されています。詳細は、PCP のホームページ、GITHUB のプロジェクトページ および git リポジトリー を参照してください。

- メトリクスの範囲 - PCP は、Linux の /proc および /sys などの擬似ファイルシステムでエクスポートされたもの (プロセスごとのデータなど) をすべて取得します。 PCP は簡単に拡張でき、96 個のプラグインが利用可能です (最後のカウント時)。たとえば、Linux プラットフォーム、Oracle、mmv (Java/JVM 向け)、libvirt、コンテナーサポート、その他多くのプラグインがあり、リリースごとに新しいエージェントが追加されます。
- 名前空間およびメタデータ - PCP には統一された階層メトリクス名前空間があります。これには、データ型 (整数/文字列/ブロック/イベント)、セマンティクス (カウンター/インスタント/その他)、スケーリング単位 (時間/カウント/空間次元)、ヘルプテキストなど、すべてのメトリクスにメタデータが含まれます。一般的な監視ツールは、このメタデータを使用して、メトリクスデータの適切なスケーリング、フォーマット化、およびレート変換を行うことができ、これにより、多くの場合、カスタムの監視アプリケーションが必要なくなります。詳細は、pmrep(1)、pmchart(1) などのほか、その他のツールも参照してください。PCP には、sysstat、top などのレガシーツールに精通しているユーザー向けに、これらと同様の使い方をするフロントエンドツールが用意されています。詳細は、「How does Performance Co-Pilot (PCP) compare with sysstat」 および 「Side-by-side comparison of PCP tools with legacy tools」 を参照してください。
- 分散オペレーションおよびアーカイブ取得 - PCP には、セキュアな IPC チャンネルでライブデータをエクスポートして、オフサイト分析またはレトロスペクティブ分析のためにアーカイブを取得するログサービスもあります。PCP は基本的に、パフォーマンスデータ取得 (ライブまたはアーカイブ取得) をリプレイ (ライブローカル、ライブリモート、またはアーカイブリプレイ) から完全に分離させています。すべての PCP 監視ツールは、ライブ監視およびアーカイブリプレイの両方を実行でき、共通のコマンドラインオプションを共有します。詳細は、PCPINTRO(1) を参照してください。これにより、ユーザーはライブデータ (ローカルまたはリモートホスト) をクエリーしたり、必要とされる期間やサンプリング間隔がなんであれ、統計的低減に関する履歴データを詳しく検討します。また、PCP アーカイブは sosreport にも自動的に追加れされます。
- API - PCP は RHEL6.6 以降 RHEL に同梱されており、RHEL7、RHEL8、RHEL9 のすべてのバージョンに含まれています。新しいエージェントを開発するための、十分に文書化された安定したプラグインライブラリーやデータ取り込みライブラリー、および新しい監視ツールのためのライブラリーがあります。すべての API には、C、C++、Python、および Perl バインディングがあります。Go バインディングも利用できます (github での PCP レートの検索)。Web アプリケーション用の REST API と、PCP データを Grafana で視覚化できる grafana-pcp という名前のデータソースプラグインもあります。
- ツール - PCP は多種多様なツールを誇り、従来の sysstat ツール (iostat、pidstat、vmstat、mpstat、uptime、free、atop、numastat など) と互換性のある多くのコンソールツールのほか、データを詳しく調査してスクリプトを作成する多数の汎用ツールもあります。また、高度なインタラクティブ分析およびレポート生成を行う GUI ツールもあります。
- セキュリティー - PCP は、ローカルホスト限定 (UNIX ドメインのみで inet ドメインソケットなし)、または完全リモートに設定可能です。リモートアクセスに使用する場合、PCP サービスデーモンとライブラリーは、SSL で暗号化された IPC チャンネルを使用した証明書ベースの認証もサポートします。ファイアウォールを介したアクセスには、専用のプロキシーデーモンも使用できます。
- ドキュメント - PCP には、本 2 冊、多数のホワイトペーパー、HOWTO、KCS ソリューションおよび記事 (本記事もその 1 つ) を含む豊富なドキュメントがあります。詳細は、このページの下にある参考資料を参照してください。
- サポート - PCP は RHEL で完全にサポートされています。サポートケースを作成して Red Hat サポートのサポートを受けることができます。また、コミュニティーに直接問い合わせることも可能です。
ストレージ分析チュートリアル
小規模なサーバー (4 コア/4 ディスク/8G RAM) に PCP をインストールし、ロギングサービスを有効にして設定します。また、疑似ワークロードを設定し、数日間にわたってパフォーマンスログを取得します。次に、アーカイブログのリプレイモードでさまざまな PCP 監視ツールを使用して、基本的なストレージパフォーマンス分析タスクのデモを行います。
パフォーマンス統計を取得するようにサーバーを設定せずに、PCP 監視ツールについてのみ知りたい場合は、このチュートリアルで使用する PCP アーカイブをダウンロードして利用してください。
# wget https://fedorapeople.org/~nathans/archives/goody.tgz
# tar xf goody.tgz
アーカイブの tarball を解凍した後、後述の PCP の監視/分析環境の設定 に直接進むことができます。
サーバー環境の設定
クイックスタート - pcp-zeroconf パッケージをインストールします。
これにより、ほとんどのサーバーに適した標準の事前設定済みデプロイメントとして、PCP データ収集がインストール、設定、および有効化されます。
# dnf install pcp-zeroconf
詳細は、「Installing and using the pcp-zeroconf package for Performance Co-Pilot」 を参照してください。
pcp-zeroconf パッケージは、PCP ベースパッケージ、(pcp-system-tools パッケージ内の) 非 gui CLI ツール、最も一般的に必要で不可欠な PMDA エージェントを含む多数のパッケージ、および pcp-doc パッケージの man ページに依存関係があります。pcp-zeroconf パッケージのインストール後のスクリプトレットは、パフォーマンスデータを含む PCP アーカイブを取得するために、最も一般的な PCP サーバーデプロイメントを自動的に設定します。
カスタマイズされたインストールの詳細
追加のカスタマイズが必要な場合は、pcp-zeroconf の設定内容の他に、このタスク用に文書化された KCS ソリューションに従って PCP をインストールして設定します。これは、RHEL6.6 から RHEL8.x までのすべての RHEL サーバーに適用できます。パッケージは、主要なディストリビューション、Fedora、Debian、Ubuntu などでも入手できます。PCP は RHEL6.6 以降に正式に同梱されています。
- 「How do I install Performance Co-Pilot (PCP) on my RHEL server to capture performance logs」
標準の pmcd サービスおよび pmlogger サービスを有効にし、デフォルトのログ記録間隔を調整して 30 秒から 5 秒に短縮します。
- 「How can I change the default logging interval used by Performance Co-Pilot (PCP)?」
pcp-atop(1) および他の PCP 監視ツールを使用して後でリプレイできるように、30 秒間隔でプロセスごとのメトリクスのロギングを有効にします。この手順は、I/O パフォーマンス分析に必ずしも必要ではありませんが、アクティブになっているプロセス、I/O を行っているプロセス、そしてその他のシステムリソースを使用しているプロセスを確認する際に便利な場合があります。
- 「How can I customize the Performance Co-Pilot logging configuration」
この設定では、1 日あたりおよそ 0.5 GB を取得し、標準の PCP ロギングディレクトリー (/var/log/pcp) 配下にある PCP アーカイブのログにこれを保存します。新しいバージョンの sos(1) では、このディレクトリー (存在する場合) は、標準の sosreport に含まれます。古いバージョンの sos(1) を使用している場合は、お客様は gzip 形式で圧縮された tar ファイルを手動で作成し、これをケースにアップロードすることができます。
- 「How do I gather performance data logs to upload to my support case using Performance Co-Pilot (PCP)」
疑似ワークロードの設定
以下のチュートリアルでは、crontab エントリーから「疑似」ワークロードをデプロイし、毎日午後 8 時に約 2 時間実行されるバックアップをシミュレートしています。これにより、ストレージに対して毎日読み取り専用の重い負荷をかけることで、監視ツールのデモを行うことができます。この KCS の記事は公開されているため、お客様の実際のデータを使用することはできません。そこで、疑似ワークロードを使用しています。お客様の一般的なケースでは、「毎晩 I/O 待機が長く、サーバーのパフォーマンスが低下し、それが原因でローカルサーバーや他のタイムゾーンのマシンでアプリケーションのパフォーマンスが低下する」といった苦情が考えられます。
#
# cat /etc/cron.d/fakebackups
# Fake workload - every day at 8pm, pretend to run backups of /home
0 20 * * * root dd if=/dev/mapper/vg-home bs=1M of=/dev/null >/dev/null 2>&1
PCP の監視/分析環境の設定
ワークステーションに (少なくとも) pcp-system-tools パッケージをインストールします。 また、pmchart チャートツール用の pcp-gui および pcp-doc をインストールします。man ページも必要になります。これらのパッケージはサーバー上では必要ありません。監視ツールは、分析に使用する予定のシステムでのみ必要です。PCP は移植可能で、データ取得とリプレイを完全に分離している前方/後方バージョンの互換性があるため、対象のサーバーでパフォーマンスログを取得してから、PCP 監視ツールがインストールされている任意のシステムで後で分析することができます。これは、ライブ監視のほか、以前に取得されたログからのレトロスペクティブ分析にも適用されます。
# dnf -y install pcp-system-tools pcp-doc
しばらく待ってから PCP アーカイブを調べる
PCP pmlogger サービスが数時間または数日実行された後、もしくは対象のパフォーマンスの問題が再現された後、作成されたログをケースにアップロードしたり、ワークステーションにコピーしたりすることができます。
- 「How do I gather performance data logs to upload to my support case using Performance Co-Pilot (PCP)」
PCP アーカイブはしっかりと圧縮されるので、毎日のログローテーションスクリプトは、ディスクスペースを最小限に抑えるために、これを自動的に実行することに注意してください。詳細は、pmlogger_daily(1) の man ページを参照してください。 解凍されると、疑似カスタマーサーバーのログはサブディレクトリーに保存され、ホストごとに 1 つずつログが記録されます。単純なケースでは、1 つのホストのみのログが記録されます。この場合、ホストの名前は goody で、ログは /var/log/pcp/pmlogger/goody にあります。ログを 2 日間記録すると、ディレクトリーには以下のファイルが含まれます。
# ls -hl /var/log/pcp/pmlogger/goody
total 1.4G
-rw-r--r-- 1 pcp pcp 472M Jul 19 12:48 20160718.12.38.0
-rw-r--r-- 1 pcp pcp 86K Jul 19 12:48 20160718.12.38.index
-rw-r--r-- 1 pcp pcp 3.2M Jul 19 12:47 20160718.12.38.meta
-rw-r--r-- 1 pcp pcp 474M Jul 20 13:04 20160719.12.55.0
-rw-r--r-- 1 pcp pcp 86K Jul 20 13:05 20160719.12.55.index
-rw-r--r-- 1 pcp pcp 9.2M Jul 20 13:01 20160719.12.55.meta
-rw-r--r-- 1 pcp pcp 418M Jul 21 10:18 20160720.13.25.0
-rw-r--r-- 1 pcp pcp 74K Jul 21 10:18 20160720.13.25.index
-rw-r--r-- 1 pcp pcp 4.2M Jul 21 10:15 20160720.13.25.meta
-rw-r--r-- 1 pcp pcp 216 Jul 20 13:25 Latest
-rw-r--r-- 1 pcp pcp 11K Jul 20 13:25 pmlogger.log
-rw-r--r-- 1 pcp pcp 11K Jul 20 13:05 pmlogger.log.prior
この例では、アーカイブファイルはすでに解凍されており、以下のチュートリアルで使用する準備が整っていることに留意してください。PCP は透過的なアーカイブ解凍に対応しているため、厳密には解凍する必要はありません。ただし、明らかな理由によりアーカイブがすでに解凍されている場合は、ツールはより速く動作します。
PCP ログは、system(1) タイマーの制御下にある pmlogger_daily(1) サービスにより、毎日ロールオーバーされます。各アーカイブのベースネームには、アーカイブを作成した日時が YYMMDD.HH.MM の形式で使われ、一時インデックス (.index)、メタデータ (.meta)、および 1 つ以上のデータボリューム (.0、`.1' など) の少なくとも 3 つのファイルで構成されます。上記の一覧では、7 月 18 日、19 日、20 日に日次ログが記録されていることが確認できます。PCP アーカイブ名が監視ツールの引数として指定される場合は、アーカイブのベースネームのみを指定する必要があることに注意してください。PCP クライアントツールは、ディレクトリー名を指定するだけで、特定のホストのすべてのアーカイブをリプレイすることもできます。
pmdumplog -L コマンドを使用して、時間の範囲を決定するアーカイブラベルを調べることができます。以下に例を示します。
# cd /var/log/pcp/pmlogger/goody
# pmdumplog -L 20160718.12.38
Log Label (Log Format Version 2)
Performance metrics from host goody
commencing Mon Jul 18 12:38:49.106 2016
ending Tue Jul 19 12:48:44.134 2016
Archive timezone: AEST-10
PID for pmlogger: 12976
pmlogger/goody ディレクトリーのその他のファイルは、以下のとおりです。
- pmlogger.log - pmlogger サービスのログです。これは、どのメトリクスがどのようなログ間隔で記録されているのかを詳細に説明しています。メトリクスのさまざまなグループをさまざまなレートでログに記録できます。疑似カスタマーサイトでは、ほとんどのデータを 5 秒間隔で、プロセスごとのデータを 30 秒間隔でログに記録しています。pmlogger.log ファイルは、1 日あたりのおおよそのロギングデータボリュームも提供します。これは、ロギング間隔を設定する際や /var ファイルシステムの容量を計画する際に役に立ちます。
タイムゾーンおよび -z フラグ (重要)
上記の pmdumplog -L の一覧では、サーバーのタイムゾーンがログラベルのヘッダーに表示されます。監視ツールを使用して PCP アーカイブをリプレイする場合、デフォルトのレポートタイムゾーンは、監視ツールが実行されているホストのローカルタイムゾーンになります。これは、多くの PCP 監視ツールで、複数のアーカイブのリプレイを可能にするためです。これらのアーカイブは、世界中のさまざまなタイムゾーンのホストで取得された可能性があります。実際にお客様のサイトからアーカイブをリプレイする場合は通常、お客様のタイムゾーンに注目しますが、これは自身のタイムゾーンと異なることが多いです。ローカルのタイムゾーンではなくサーバーのタイムゾーンを使用する場合 (双方が異なる場合) は、使用している監視ツールで -z フラグを使用します。これにより、最適な分析結果をお客様に報告することができ、syslog などのログで報告されるタイムスタンプが正しく相関されます。また、-Z zone フラグを使用すると、使用するレポートタイムゾーンを zone に指定することもできます (例: -Z EDT、-Z PST、-Z UTC など)。一般的には、-z フラグを常に使用する必要があります (おそらくデフォルトにすべきです)。
pmlogextract を使用して複数のアーカイブを 1 つにマージする
監視ツールを使用して、特定の短い期間を調べる前に、サマリーや概要を知るために数日または数週間のパフォーマンスデータを調査したいと思うことが多々あるでしょう。これは、pmlogextract ツールを使用して、複数のアーカイブを 1 つの大きなアーカイブにマージすることで簡単に実現できます。この大きなアーカイブは、監視ツールに -a フラグを渡して使用することができます。
- 「How can I merge multiple PCP archives into one for a system level performance analysis covering multiple days or weeks」
以下に例を示します。
# pwd
/var/log/pcp/pmlogger/goody
# pmlogextract *.0 ../myarchive
# pmdumplog -L ../myarchive
Log Label (Log Format Version 2)
Performance metrics from host goody
commencing Mon Jul 18 12:38:49.106 2016
ending Thu Jul 21 08:13:12.404 2016
Archive timezone: AEST-10
PID for pmlogger: 22379
ご覧のように、myarchive の期間は数日間にわたっています。上記のツールを使用すれば、数日間のデータを確認してから、特定の短い期間を調べることができるため、この機能は非常に便利です。pmlogextract ツールは、必要に応じて特定のメトリクスのみを抽出することもできます。詳細は、man ページを参照してください。また、新しいバージョンの PCP (pcp-3.11.2 以降) では、-a フラグを複数回指定でき、ツールはアーカイブを「オンザフライ」で透過的にマージすることに留意してください。さらに、前述のように、-a フラグの引数は、複数のアーカイブを含むディレクトリー名にすることができます。これは、「オンザフライ」でのマージに特に便利ですが、同じディレクトリー内のすべてのアーカイブは 1 つのホスト専用でなければならない点に注意してください。
複数日にわたるパフォーマンス概要に pmchart を使用する
myarchive を使用して、PCP 監視ツールでパフォーマンスサマリーをレポートできるようになりました。たとえば、3 日間の CPU 使用量を調べ、過剰な I/O Wait 時間 (I/O を保留しているアイドル時間) があるかどうかを確認します。
# pmchart -z -a myarchive -t 10m -O-0 -s 400 -v 400 -geometry 800x450 -c CPU -c Loadavg
つまり、サンプリング間隔は 10 分間 (-t 10m) で、間隔は 400 (-s 400 -v 400) であることから、期間は (10 x 400 / 60) = 66 時間 (3 日間弱) になります。ここでは、サーバーのタイムゾーン (-z)、アーカイブの終わりまでのオフセット (-O-0 - これは -O と負のゼロで、アーカイブの 終わりまで ゼロ秒を意味します)、800x450 のウィンドウサイズを使用し、2 つの pmchart「views」(-c CPU -c Loadavg) をプリロードしました。

毎晩午後 8 時に負荷の平均値が明らかに急上昇し、I/O の待機時間が長くなっていることがわかります (上部の CPU チャートの水色の部分)。この簡単な例では、イメージをケースにアップロードして、毎晩午後 8 時に実行しているアプリケーションについてお客様に尋ねることができます。
テキストベースの出力に pmrep を使用する
# pmrep -z -a myarchive -t 10m -p -S'@19:45' -s 20 kernel.all.load kernel.all.cpu.{user,sys,wait.total} disk.all.total_bytes
k.a.load k.a.load k.a.load k.a.c.user k.a.c.sys k.a.c.w.total d.a.total_bytes
1 minute 5 minute 15 minut
util util util Kbyte/s
19:45:00 0.010 0.020 0.050 N/A N/A N/A N/A
19:55:00 0.010 0.020 0.050 0.012 0.004 0.009 12.507
20:05:00 1.100 0.690 0.330 0.016 0.055 0.292 44104.872
20:15:00 1.010 0.990 0.670 0.012 0.088 0.754 79864.410
20:25:00 1.050 1.060 0.860 0.012 0.074 0.908 66039.610
20:35:00 1.060 1.070 0.960 0.015 0.074 0.913 63837.190
20:45:00 1.310 1.160 1.020 0.012 0.070 0.792 62741.337
20:55:00 1.000 1.030 1.030 0.012 0.070 0.792 61975.538
21:05:00 1.000 1.060 1.060 0.016 0.071 0.882 60047.950
21:15:00 1.000 1.020 1.050 0.013 0.065 0.907 56705.562
21:25:00 1.000 1.020 1.050 0.012 0.060 0.907 52059.462
21:35:00 1.030 1.040 1.050 0.016 0.057 0.921 46970.013
21:45:00 1.020 1.110 1.090 0.012 0.047 0.960 41684.985
21:55:00 0.130 0.680 0.920 0.013 0.035 0.769 29428.372
22:05:00 0.000 0.130 0.510 0.016 0.007 0.013 25.687
22:15:00 0.000 0.020 0.270 0.012 0.004 0.010 13.060
22:25:00 0.000 0.010 0.150 0.014 0.006 0.012 44.713
22:35:00 0.000 0.010 0.080 0.017 0.008 0.010 17.532
22:45:00 0.030 0.030 0.050 0.012 0.004 0.010 13.690
22:55:00 0.000 0.010 0.050 0.012 0.005 0.009 14.037
上記のコマンドでは、pmrep を使用して、更新間隔が 10 分 (-t 10m)、サンプルが 20 (-s 20)、開始時間が 19 時 45 分 (-S@19:45) のタイムスタンプ (-p) を表示しました。また、負荷平均 (kernel.all.load)、ユーザーとシステムの待機 CPU 測定 (kernel.all.cpu.{user,sys,wait.total}、およびディスクスループットの合計 (disk.all.total_bytes) も表示しました。 ここでは、pmchart グラフにおける最初の I/O の急増が 7 月 18 日の午後 8 ごろに発生し、約 2 時間続いたことを示しています。
ストレージパフォーマンス分析に pmiostat を使用する
pmiostat ツールは、PCP アーカイブログをリプレイできる CLI ツールです。これは、pcp-iostat とも呼ばれます。pmiostatレポートは、sysstat(1) の同名のものと非常によく似ていますが、多くの点でより強力です。
以下は、上記の pmrep の使用状況と同様の例になります。同じアーカイブで pmiostat を使用していますが、7 月 19 日に発生した 2 回目の I/O の急増を選択し、sda ディスクのレポートのみを要求しました (正規表現パターンとして -R sda$ を使用)。
# pmiostat -z -a myarchive -x t -t 10m -S'@Jul 19 19:55:00' -s 10 -P0 -R 'sda$'
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 20:05:00 2016 sda 0 0 0 2 0 5 2.7 0.0 7 8 7 1
Tue Jul 19 20:15:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 10 4 1
Tue Jul 19 20:25:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 20:35:00 2016 sda 1 0 419 2 53299 4 126.8 1.6 4 4 26 81
Tue Jul 19 20:45:00 2016 sda 0 0 32 1 4108 3 121.5 0.1 4 4 6 8
Tue Jul 19 20:55:00 2016 sda 0 0 0 2 0 4 2.4 0.0 6 14 6 1
Tue Jul 19 21:05:00 2016 sda 0 0 0 2 0 5 2.5 0.0 5 11 5 1
Tue Jul 19 21:15:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 21:25:00 2016 sda 0 0 0 2 0 4 2.4 0.0 6 15 6 1
Tue Jul 19 21:35:00 2016 sda 0 0 0 1 0 3 2.2 0.0 5 0 5 1
上記のレポートの列は以下のとおりです。
| 列名 | 説明 |
|---|---|
| rrqm/s | /O スケジューラーによってマージされた読み取りリクエストの、集計期間内における 1 秒あたりの平均回数です。 |
| wrqm/s | 集計期間内に I/O スケジューラーによってマージされた書き込みリクエストの、1 秒あたりの平均回数です。 |
| r/s | 集計期間内にデバイスによって完了した、1 秒あたりの読み取りリクエスト数 (マージ後) です。 |
| w/s | 集計期間内にデバイスによって完了した、1 秒あたりの書き込みリクエスト数 (マージ後) です。 |
| rkB/s | 集計期間内にデバイスから読み取られたデータの平均量 (キロバイト/秒) です。 |
| wkB/s | 集計期間内にデバイスに書き込まれたデータの平均量 (キロバイト/秒) です。 |
| avgrq-sz | 集計期間内中にデバイスに対して行われた読み取りと書き込みの両方における平均 I/O 要求サイズをキロバイト単位で表したものです。 |
| avgqu-sz | 集計期間内にデバイスに対して行われた読み取りおよび書き込みリクエストの平均キュー長です。 |
| await | 集計期間内に、読み取りおよび書き込み要求がデバイスにキューイング (および処理) された平均時間 (ミリ秒) です。 |
| r_await | 集計期間内に、読み取りリクエストがデバイスにキューイング (および処理) された平均時間 (ミリ秒) です。 |
| w_await | 集計期間内に、書き込みリクエストがデバイスにキューイング (および処理) された平均時間 (ミリ秒) です。 |
| %util | 報告期間中に、デバイスがリクエストの処理にビジー状態であった時間の割合です。 値が 100% の場合はデバイスの飽和状態を示します。 |
どのようなデバイスマッパーボリュームを持っているか確認してください。
# pminfo -a myarchive -f hinv.map.dmname
hinv.map.dmname
inst [0 or "vg-swap"] value "dm-0"
inst [1 or "vg-root"] value "dm-1"
inst [3 or "vg-libvirt"] value "dm-2"
inst [5 or "vg-home"] value "dm-3"
inst [7 or "docker-253:1-4720837-pool"] value "dm-4"
inst [273 or "docker-253:1-4720837-bd20b3551af42d2a0a6a3ed96cccea0fd59938b70e57a967937d642354e04859"] value "dm-5"
inst [274 or "docker-253:1-4720837-b4aca4676507814fcbd56f81f3b68175e0d675d67bbbe371d16d1e5b7d95594e"] value "dm-6"
hinv.map.dmname メトリクスは、永続的な LVM 論理ボリューム名を一覧表示するだけでなく、カーネルが使用する現在の dm-X 名にマッピングする場合にも非常に便利です。後者は永続的ではないので、再起動の際や、デバイスが削除されて新しいデバイスが作成される際にも変更される可能性があります (これについては以下で詳しく説明します)。
pmiostat では、-x dm フラグはデバイスマッパーの統計を調べるように指示します。では、-x dm を使用して論理ボリュームの統計を確認しましょう。-R フラグを使用して、vg- で始まる論理ボリューム名のみを含めます。つまり、Docker ボリュームを 除外 します。
# pmiostat -z -a myarchive -x t -x dm -t 10m -S'@Jul 19 19:55:00' -s 5 -P0 -R'vg-*'
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 20:05:00 2016 vg-home 0 0 347 0 44025 0 126.8 1.0 3 3 0 50
Tue Jul 19 20:05:00 2016 vg-libvirt 0 0 0 2 0 5 2.6 0.0 7 8 7 1
Tue Jul 19 20:05:00 2016 vg-root 0 0 0 2 5 12 9.7 0.1 70 33 74 2
Tue Jul 19 20:05:00 2016 vg-swap 0 0 0 0 0 0 4.1 0.0 25 25 0 0
Tue Jul 19 20:15:00 2016 vg-home 0 0 631 0 79965 0 126.7 1.9 3 3 0 100
Tue Jul 19 20:15:00 2016 vg-libvirt 0 0 0 1 0 3 2.0 0.0 4 10 4 1
Tue Jul 19 20:15:00 2016 vg-root 0 0 0 1 4 10 10.6 0.1 66 41 73 3
Tue Jul 19 20:15:00 2016 vg-swap 0 0 0 0 0 0 4.0 0.0 68 68 0 0
Tue Jul 19 20:25:00 2016 vg-home 0 0 522 0 65960 0 126.4 2.0 4 4 0 100
Tue Jul 19 20:25:00 2016 vg-libvirt 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 20:25:00 2016 vg-root 0 0 1 1 28 12 14.7 0.2 56 30 77 5
Tue Jul 19 20:25:00 2016 vg-swap 0 0 0 0 0 0 4.0 0.0 59 59 0 0
Tue Jul 19 20:35:00 2016 vg-home 0 0 501 0 63784 0 127.3 2.0 4 4 0 100
Tue Jul 19 20:35:00 2016 vg-libvirt 0 0 0 2 0 4 2.5 0.0 28 37 28 3
Tue Jul 19 20:35:00 2016 vg-root 0 0 1 2 12 12 11.3 0.1 55 34 62 2
Tue Jul 19 20:35:00 2016 vg-swap 0 0 0 0 0 0 4.0 0.0 33 33 0 0
Tue Jul 19 20:45:00 2016 vg-home 0 0 485 0 61965 0 127.8 2.0 4 4 0 100
Tue Jul 19 20:45:00 2016 vg-libvirt 0 0 0 1 0 3 2.2 0.0 7 12 7 1
Tue Jul 19 20:45:00 2016 vg-root 0 0 0 1 4 10 11.6 0.0 15 17 15 1
Tue Jul 19 20:45:00 2016 vg-swap 0 0 0 0 0 0 4.0 0.0 13 13 0 0
したがって、疑似ワークロードでは、vg-home LVM 論理ボリュームにすべてのトラフィックがあり、他のものは比較的アイドル状態になっているように見えます。-R フラグのみを使用して、そのボリュームを拡大してみましょう。
# pmiostat -z -a myarchive -x t -x dm -t 10m -S'@Jul 19 19:45:00' -s 15 -P0 -R'vg-home'
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 19:55:00 2016 vg-home 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:05:00 2016 vg-home 0 0 347 0 44025 0 126.8 1.0 3 3 0 50
Tue Jul 19 20:15:00 2016 vg-home 0 0 631 0 79965 0 126.7 1.9 3 3 0 100
Tue Jul 19 20:25:00 2016 vg-home 0 0 522 0 65960 0 126.4 2.0 4 4 0 100
Tue Jul 19 20:35:00 2016 vg-home 0 0 501 0 63784 0 127.3 2.0 4 4 0 100
Tue Jul 19 20:45:00 2016 vg-home 0 0 485 0 61965 0 127.8 2.0 4 4 0 100
Tue Jul 19 20:55:00 2016 vg-home 0 0 479 0 61362 0 128.0 1.9 4 4 0 100
Tue Jul 19 21:05:00 2016 vg-home 0 0 467 0 59751 0 128.0 2.0 4 4 0 100
Tue Jul 19 21:15:00 2016 vg-home 0 0 440 0 56380 0 128.0 2.0 4 4 0 100
Tue Jul 19 21:25:00 2016 vg-home 0 0 405 0 51875 0 128.0 2.0 5 5 0 100
Tue Jul 19 21:35:00 2016 vg-home 0 0 367 0 46996 0 128.0 2.0 5 5 0 100
Tue Jul 19 21:45:00 2016 vg-home 0 0 326 0 41727 0 128.0 2.0 6 6 0 100
Tue Jul 19 21:55:00 2016 vg-home 0 0 242 0 31030 0 128.0 1.7 7 7 0 85
Tue Jul 19 22:05:00 2016 vg-home 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 22:15:00 2016 vg-home 0 0 0 0 0 0 0.0 0.0 0 0 0 0
sosreport を確認すると、vg ボリュームグループは以下の physvols を使用しています。
#
# pvs
PV VG Fmt Attr PSize PFree
/dev/sda1 vg lvm2 a-- 232.88g 0
/dev/sdb2 vg lvm2 a-- 230.88g 0
/dev/sdc vg lvm2 a-- 232.88g 0
現在、PV を LV にマッピングするための PCP メトリクスはないことに注意してください。もしあれば便利でしょう。同様に、デバイスマッパーマルチパスの代替パスを一覧表示するためのマッピングメトリクスはありません。これも、もしあれば便利でしょう。このようなメトリクス (例: hinv.map.multipath) は、scsi デバイスパスを WWID にマップします。これは、マルチパス環境内での多対 1 のマッピングになります。
それでは、pmiostat を使用してこれらの個々の scsi デバイスを確認しましょう。
# pmiostat -z -a myarchive -x t -t 10m -S'@Jul 19 19:45:00' -s 10 -P0 -R'sd[abc]'
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 19:55:00 2016 sda 0 0 0 1 0 3 2.0 0.0 5 0 5 1
Tue Jul 19 19:55:00 2016 sdb 0 0 0 1 1 10 10.8 0.0 8 12 7 1
Tue Jul 19 19:55:00 2016 sdc 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:05:00 2016 sda 0 0 0 2 0 5 2.7 0.0 7 8 7 1
Tue Jul 19 20:05:00 2016 sdb 0 0 347 1 44030 12 126.4 1.1 3 3 78 50
Tue Jul 19 20:05:00 2016 sdc 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:15:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 10 4 1
Tue Jul 19 20:15:00 2016 sdb 1 0 630 1 79970 10 126.7 2.0 3 3 66 100
Tue Jul 19 20:15:00 2016 sdc 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:25:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 20:25:00 2016 sdb 1 0 522 1 65988 12 126.2 2.1 4 4 77 100
Tue Jul 19 20:25:00 2016 sdc 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:35:00 2016 sda 1 0 419 2 53299 4 126.8 1.6 4 4 26 81
Tue Jul 19 20:35:00 2016 sdb 0 0 82 1 10496 12 125.5 0.5 6 5 69 19
Tue Jul 19 20:35:00 2016 sdc 0 0 0 0 0 0 0.0 0.0 0 0 0 0
Tue Jul 19 20:45:00 2016 sda 0 0 32 1 4108 3 121.5 0.1 4 4 6 8
Tue Jul 19 20:45:00 2016 sdb 0 0 0 1 4 10 12.8 0.0 17 16 17 1
Tue Jul 19 20:45:00 2016 sdc 0 0 452 0 57858 0 127.9 1.8 4 4 0 93
Tue Jul 19 20:55:00 2016 sda 0 0 0 2 0 4 2.4 0.0 6 14 6 1
Tue Jul 19 20:55:00 2016 sdb 0 0 0 1 3 10 12.1 0.0 24 21 24 1
Tue Jul 19 20:55:00 2016 sdc 0 0 479 0 61362 0 128.0 1.9 4 4 0 100
Tue Jul 19 21:05:00 2016 sda 0 0 0 2 0 5 2.5 0.0 5 11 5 1
Tue Jul 19 21:05:00 2016 sdb 0 0 0 1 7 12 10.5 0.1 34 20 38 1
Tue Jul 19 21:05:00 2016 sdc 0 0 467 0 59751 0 128.0 2.0 4 4 0 100
Tue Jul 19 21:15:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 21:15:00 2016 sdb 0 0 0 1 2 10 12.0 0.0 19 15 19 1
Tue Jul 19 21:15:00 2016 sdc 0 0 440 0 56380 0 128.0 2.0 4 4 0 100
Tue Jul 19 21:25:00 2016 sda 0 0 0 2 0 4 2.4 0.0 6 15 6 1
Tue Jul 19 21:25:00 2016 sdb 0 0 4 1 150 11 32.4 0.0 9 3 31 1
Tue Jul 19 21:25:00 2016 sdc 0 0 405 0 51875 0 128.0 2.0 5 5 0 100
vg ボリュームグループの physvols は線形で、vg-home ボリュームグループを構成する 3 つの physvols の読み取りで疑似ワークロードが進行するにつれて、sdb、sda、sdcの順にトラフィックがビジーになることに注意してください。代わりにストライプがある場合、3 つのデバイスすべてで同時にトラフィックが発生します。pmchart を使用して、これをより明確に視覚化できます。以下に例を示します。
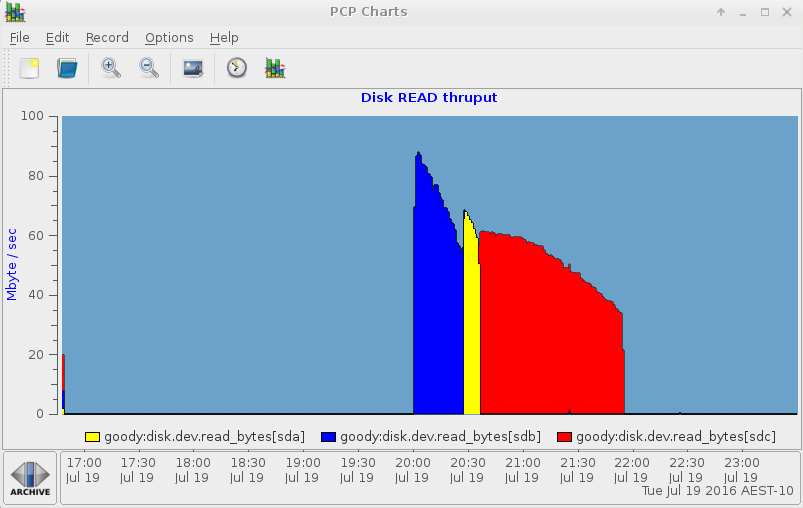
以下は、pmchart IOSTAT ビューです。
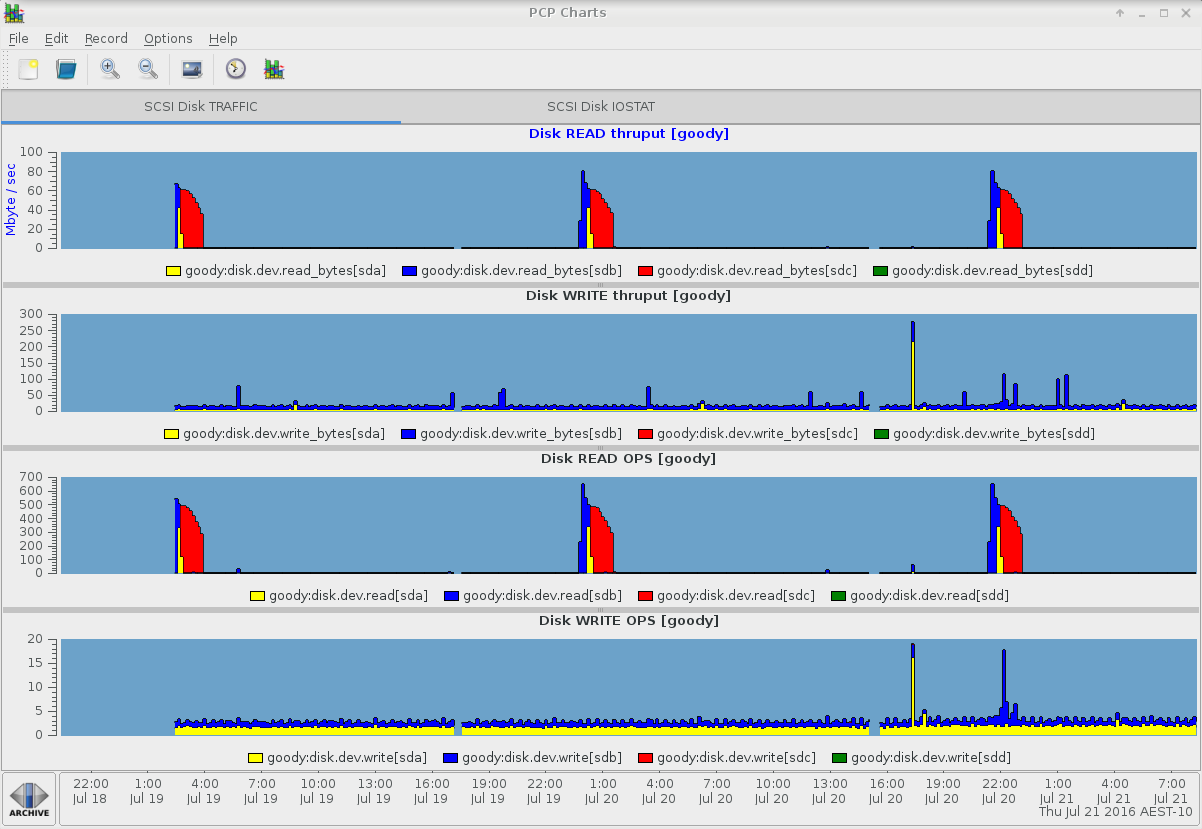
他の iostat 列を表示する他の pmchart タブは以下のとおりです。
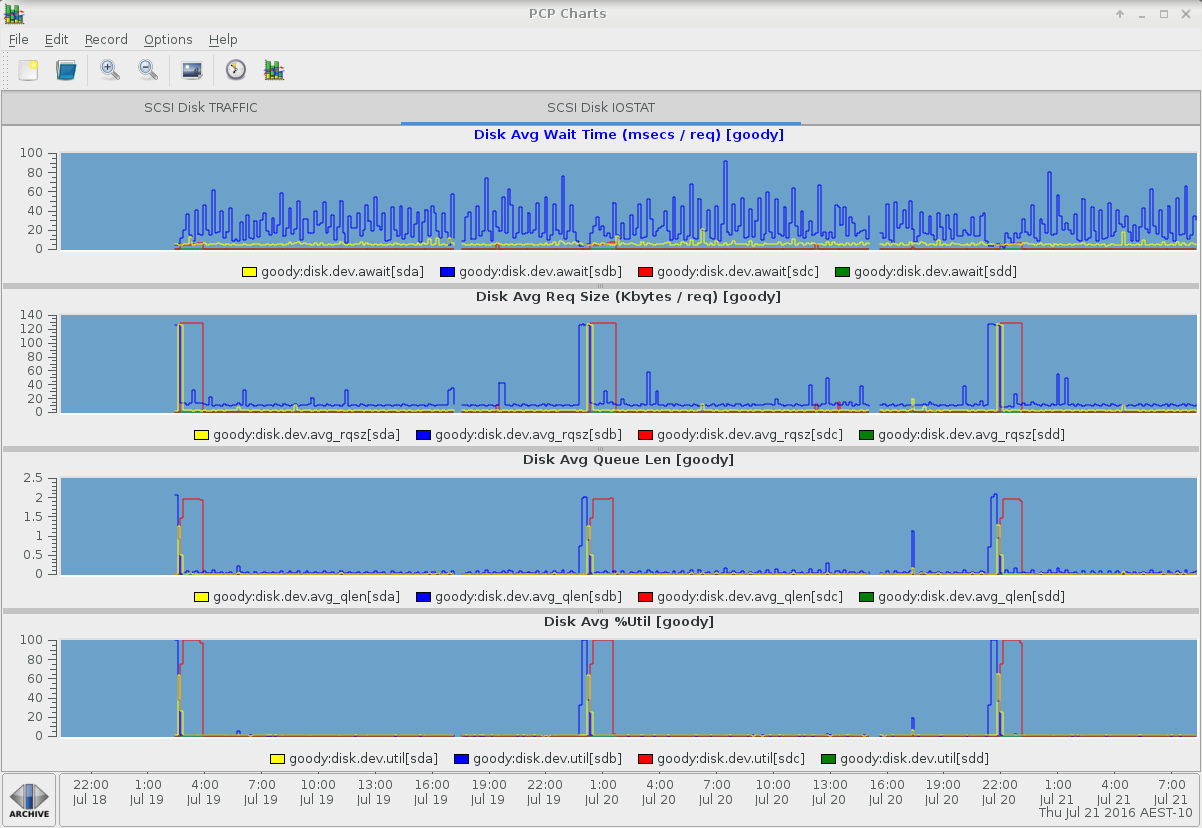
pmiostat - デバイスの選択と集計演算子
pmiostat (バージョン 3.11.2 以降) では、便利な機能として、コマンドラインオプションの -R regex および -G sum|avg|min|max が追加されました。正規表現は、利用可能なデバイスのサブセットを選択します (sd デバイス、または -x dm フラグが指定されている場合は device-mapper 論理デバイスのいずれか)。選択したデバイスのみが報告されます。以下に例を示します。
# pmiostat -z -a myarchive -x t -t 10m -S'@Jul 19 19:45:00' -s 4 -P0 -R'sd[ab]$'
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 19:55:00 2016 sda 0 0 0 1 0 3 2.0 0.0 5 0 5 1
Tue Jul 19 19:55:00 2016 sdb 0 0 0 1 1 10 10.8 0.0 8 12 7 1
Tue Jul 19 20:05:00 2016 sda 0 0 0 2 0 5 2.7 0.0 7 8 7 1
Tue Jul 19 20:05:00 2016 sdb 0 0 347 1 44030 12 126.4 1.1 3 3 78 50
Tue Jul 19 20:15:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 10 4 1
Tue Jul 19 20:15:00 2016 sdb 1 0 630 1 79970 10 126.7 2.0 3 3 66 100
Tue Jul 19 20:25:00 2016 sda 0 0 0 1 0 3 2.0 0.0 4 0 4 1
Tue Jul 19 20:25:00 2016 sdb 1 0 522 1 65988 12 126.2 2.1 4 4 77 100
拡張正規表現は、末尾の $ で固定する必要があることに注意してください。そうしないと、sdaa、sdab などに一致させることになります。
-G フラグを使用すると、-R フラグで指定された正規表現に一致するデバイス、または -R が指定されていない場合はデフォルトですべてのデバイスで、統計を集約することができます。たとえば、hinv.map.scsi メトリクスをクエリーすることで、HBTL scsi-id を確認することができます。以下に例を示します。
# pminfo -a myarchive -f hinv.map.scsi
hinv.map.scsi
inst [0 or "scsi0:0:0:0 Direct-Access"] value "sda"
inst [1 or "scsi1:0:0:0 Direct-Access"] value "sdb"
inst [2 or "scsi2:0:0:0 Direct-Access"] value "sdc"
inst [3 or "scsi3:0:0:0 Direct-Access"] value "sdd"
また、sda と sdb の統計の総計を計算したい場合があるとします (たとえば、同じターゲットへの代替パス、または同じ PCI バス上の代替パスである可能性があるため、そのトラフィックの総計に関心がある場合など)。
# pmiostat -z -a myarchive -x t -t 10m -S'@Jul 19 19:45:00' -s 4 -P0 -R'sd[ab]$' -Gsum
# Timestamp Device rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await %util
Tue Jul 19 19:55:00 2016 sum(sd[ab]$) 0 1 0 2 1 13 12.8 0.0 12 12 12 1
Tue Jul 19 20:05:00 2016 sum(sd[ab]$) 0 1 347 3 44030 17 129.1 1.1 10 11 85 51
Tue Jul 19 20:15:00 2016 sum(sd[ab]$) 1 0 630 2 79970 13 128.7 2.0 7 13 70 101
Tue Jul 19 20:25:00 2016 sum(sd[ab]$) 1 1 522 3 65988 15 128.2 2.1 8 4 80 101
デバイス名の列は、提供される正規表現パターンとして報告されるようになり、-Gsum フラグを使用している場合でも、%util 列は常に平均化されることに注意してください。
dm-XX から論理ボリューム名へのマッピング
内部的には、カーネルはデバイスマッパーデバイスを動的に割り当て、それらに dm-XX という名前を付けます。マッピングは動的で、再起動後も変更でき、特定のデバイスマッパーデバイス名を再利用できます (削除してから新しいデバイスを作成する場合)。カーネル syslog メッセージは通常、LVM が使用する永続的な論理デバイス名ではなく、dm-XX 名を報告します。したがって、カーネルメッセージで使用される動的な名前と LVM の永続的な名前を相互に関連付けることは、特に困難な作業となります。幸いなことに、PCP は hinv.map.dmname メトリクスをサポートしており、他のメトリクスと同様に pmrep レポートで使用することができます。マッピングの例を以下に示します。
# pminfo -a myarchive -f hinv.map.dmname
hinv.map.dmname
inst [0 or "vg-swap"] value "dm-0"
inst [1 or "vg-root"] value "dm-1"
inst [3 or "vg-libvirt"] value "dm-2"
inst [5 or "vg-home"] value "dm-3"
inst [7 or "docker-253:1-4720837-pool"] value "dm-4"
inst [273 or "docker-253:1-4720837-bd20b3551af42d2a0a6a3ed96cccea0fd59938b70e57a967937d642354e04859"] value "dm-5"
inst [274 or "docker-253:1-4720837-b4aca4676507814fcbd56f81f3b68175e0d675d67bbbe371d16d1e5b7d95594e"] value "dm-6"
pmrep - その他の例
pmrep を使用する場合、hinv.map.dmname は自身の列にリストすることができます。以下に例を示します。
# pmrep -a myarchive -X "Device Name" -z -g -t 10m -p -f%c -S'@19:45' -s 5 -i 'vg-.*' hinv.map.dmname disk.dm.read_bytes disk.dm.write_bytes
[ 1] - hinv.map.dmname["vg-swap"] - none
[ 1] - hinv.map.dmname["vg-root"] - none
[ 1] - hinv.map.dmname["vg-libvirt"] - none
[ 1] - hinv.map.dmname["vg-home"] - none
[ 2] - disk.dm.read_bytes["vg-swap"] - Kbyte/s
[ 2] - disk.dm.read_bytes["vg-root"] - Kbyte/s
[ 2] - disk.dm.read_bytes["vg-libvirt"] - Kbyte/s
[ 2] - disk.dm.read_bytes["vg-home"] - Kbyte/s
[ 3] - disk.dm.write_bytes["vg-swap"] - Kbyte/s
[ 3] - disk.dm.write_bytes["vg-root"] - Kbyte/s
[ 3] - disk.dm.write_bytes["vg-libvirt"] - Kbyte/s
[ 3] - disk.dm.write_bytes["vg-home"] - Kbyte/s
1 2 3
Mon Jul 18 19:45:00 2016 vg-swap dm-0 N/A N/A
Mon Jul 18 19:45:00 2016 vg-root dm-1 N/A N/A
Mon Jul 18 19:45:00 2016 vg-libvirt dm-2 N/A N/A
Mon Jul 18 19:45:00 2016 vg-home dm-3 N/A N/A
Mon Jul 18 19:55:00 2016 vg-swap dm-0 0.187 0.000
Mon Jul 18 19:55:00 2016 vg-root dm-1 0.000 9.617
Mon Jul 18 19:55:00 2016 vg-libvirt dm-2 0.000 2.703
Mon Jul 18 19:55:00 2016 vg-home dm-3 0.000 0.000
Mon Jul 18 20:05:00 2016 vg-swap dm-0 0.500 0.000
Mon Jul 18 20:05:00 2016 vg-root dm-1 5.037 11.875
Mon Jul 18 20:05:00 2016 vg-libvirt dm-2 0.020 5.337
Mon Jul 18 20:05:00 2016 vg-home dm-3 44082.53 0.000
Mon Jul 18 20:15:00 2016 vg-swap dm-0 0.240 0.000
Mon Jul 18 20:15:00 2016 vg-root dm-1 8.888 9.778
Mon Jul 18 20:15:00 2016 vg-libvirt dm-2 0.007 3.007
Mon Jul 18 20:15:00 2016 vg-home dm-3 79842.49 0.000
Mon Jul 18 20:25:00 2016 vg-swap dm-0 0.190 0.000
Mon Jul 18 20:25:00 2016 vg-root dm-1 31.063 11.827
Mon Jul 18 20:25:00 2016 vg-libvirt dm-2 0.013 3.093
Mon Jul 18 20:25:00 2016 vg-home dm-3 65993.43 0.000
上記では、"Device Name" という見出しの付いた -X フラグを使用して、レポートを転置 (列と行の入れ替え) していることに注意してください。-g フラグを使用して、メインレポートの前に各列の見出しの詳細を一覧表示しました。タイムスタンプがアーカイブのタイムゾーンになるように -z フラグを指定し、デフォルトの省略バージョンではなく、完全な ctime(3) タイムスタンプが必要であることを指定するために -f%c を指定しました。 また、-i フラグを使用して、レポートを vg-.* に一致するインスタンスのみに制限しました。そして最後に、dm-X 名と永続的な LV 名の両方を別々の列としてレポートに含めました。
pmrep のもう 1 つの非常に便利な機能は、事前設定されたレポート列です。これらは pmrep.conf で定義されています (通常は /etc/pcp/pmrep/pmrep.conf にあります)。たとえば、事前設定された :vmstat レポートを追加の列と組み合わせて、以下のようにディスクトラフィックの合計を表示できます。
# pmrep -a myarchive -z -t 10m -p -S'@19:45' -s 5 disk.all.total_bytes :vmstat
d.a.total_bytes r b swpd free buff cache si so bi bo in cs us sy id wa st
19:45:00 N/A 1 0 1460764 1261236 1968296 3504052 N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A
19:55:00 13 1 0 1460664 1255956 1969544 3507748 0 0 0 12 283 387 0 0 99 0 0
20:05:00 44105 2 0 1460448 51976 6138692 540784 0 0 44088 18 848 1260 0 1 90 7 0
20:15:00 79864 1 1 1460300 51196 6229432 451360 0 0 79851 12 1336 1901 0 2 78 18 0
20:25:00 66040 1 2 1460180 50864 6226808 453452 0 0 66024 15 1333 1656 0 2 74 22 0
:vmstat 仕様の前に : が付いていることに注意してください。pmrep.conf に多数の事前に定義されたレポート設定エントリーがあります。確認してください。man ページの pmrep(1) で説明されているように、独自に定義することもできます。
非補間モード
デフォルトでは、すべての PCP 監視ツールは補間メカニズムを使用しており、レポート間隔が基本的なネイティブサンプリング間隔と異なることを許容します。利用方法の詳細については、PCPIntro(1) を参照してください。補間を使用しない場合もあります。たとえば、blktrace(1) のデータと pmiostat のデータを相関させる場合、タイムスタンプを完全に一致させる必要があります。補間を無効にするには、pmrep または pmiostat で -u フラグを使用します。
-u フラグは -t フラグと互換性がないことに注意してください。補間を使用しない場合、サンプリング間隔は変更できません。つまり、データが最初に記録された基本となるサンプリング間隔と常に同じになります。
プロセスごとの I/O を報告するツール
pcp-atop(1) コマンドを使用して、プロセスごとの I/O 統計や、その他の豊富なシステムレベルのパフォーマンスデータを調べることができます。すべての PCP ツールと同様に、pcp-atop は適切な pmlogconf 設定が有効になっている場合に、アーカイブをリプレイできます。上記を参照してください。プロセスごとの I/O 分析には、pcp -a ARCHIVE atop -d フラグを使用します。また、特に proc データが存在する場合は、大規模なアーカイブで atop を実行すると非常に時間がかかるため、かなり長いサンプリング間隔を指定する必要があるでしょう。オプションは、多数あります。プロセス I/O の場合、-d フラグが最も便利です。
# pcp atop --help
Usage: pcp-atop [-flags] [interval [samples]]
or
Usage: pcp-atop -w file [-S] [-a] [interval [samples]]
pcp-atop -r file [-b hh:mm] [-e hh:mm] [-flags]
generic flags:
-a show or log all processes (i.s.o. active processes only)
-R calculate proportional set size (PSS) per process
-P generate parseable output for specified label(s)
-L alternate line length (default 80) in case of non-screen output
-f show fixed number of lines with system statistics
-F suppress sorting of system resources
-G suppress exited processes in output
-l show limited number of lines for certain resources
-y show individual threads
-1 show average-per-second i.s.o. total values
-x no colors in case of high occupation
-g show general process-info (default)
-m show memory-related process-info
-d show disk-related process-info
-n show network-related process-info
-s show scheduling-related process-info
-v show various process-info (ppid, user/group, date/time)
-c show command line per process
-o show own defined process-info
-u show cumulated process-info per user
-p show cumulated process-info per program (i.e. same name)
-C sort processes in order of cpu-consumption (default)
-M sort processes in order of memory-consumption
-D sort processes in order of disk-activity
-N sort processes in order of network-activity
-A sort processes in order of most active resource (auto mode)
specific flags for raw logfiles:
-w write raw data to PCP archive folio
-r read raw data from PCP archive folio
-S finish pcp-atop automatically before midnight (i.s.o. #samples)
-b begin showing data from specified time
-e finish showing data after specified time
interval: number of seconds (minimum 0)
samples: number of intervals (minimum 1)
ブロックされたプロセスの検索
I/O パフォーマンス分析で一般的なタスクの 1 つに、ブロックされたタスク、すなわち「D」状態のプロセスまたは UN 割り込み不可能スリープがあります。proc.runq.runnable および proc.runq.blocked プロセスカウントをプロットすることにより、pmchart で簡単に確認できます。以下に例を示します。
# pmchart -z -a myarchive -t 10m -O-0 -s 400 -v 400 -geometry 800x450 -c CPU
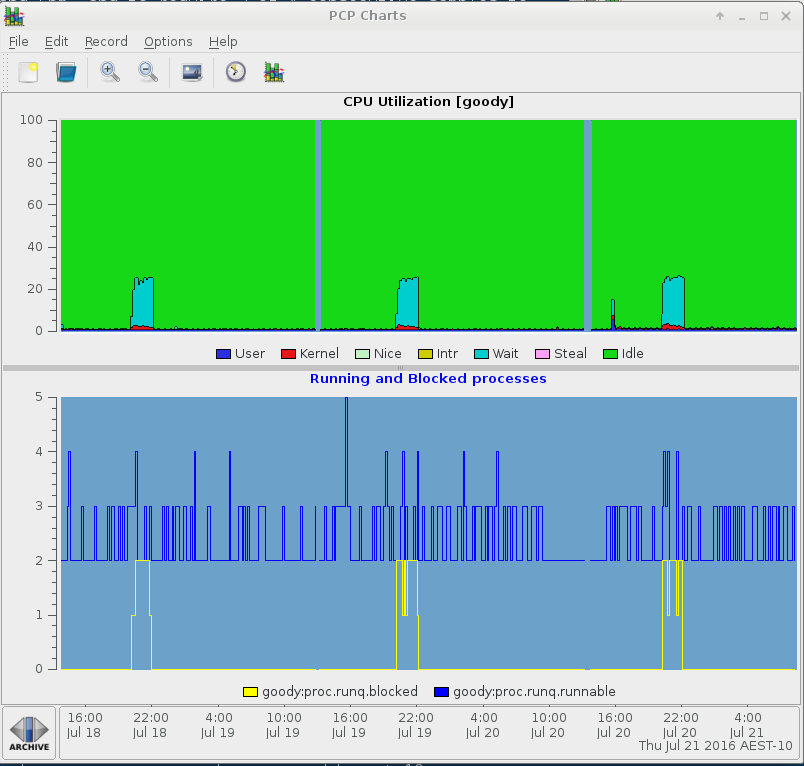
特定のプロセスを監視するには、pmrep ツールおよび pcp-pidstat ツールなどを使用することもできます。現在、pcp-pidstat ツールは、ブロックされたプロセスを検出および監視する機能を追加するように開発されています。
参考資料
ナレッジベースの記事およびソリューション
- 「PCP (Performance Co-Pilot) に関するナレッジ、チュートリアル、およびホワイトペーパー」
- 「PCP Data Sheet」
- 「How do I install Performance Co-Pilot (PCP) on my RHEL server to capture performance logs」
- 「What are all the Performance Co-Pilot (PCP) RPM packages in RHEL?」
- 「How to use Performance Co-Pilot」
- 「How do I gather performance data logs to upload to my support case using Performance Co-Pilot (PCP)」
- 「How can I merge multiple PCP archives into one for a system level performance analysis covering multiple days or weeks」
- 「How can I use Performance Co-Pilot (PCP) to capture a "once-off" performance data archive log for a specific interval of time」
- 「How is Performance Co-Pilot (PCP) designed and structured?」
- 「What are the typical Performance Co-Pilot (PCP) deployment strategies?」
- 「How can I customize the Performance Co-Pilot logging configuration」
- 「How can I change the default logging interval used by Performance Co-Pilot (PCP)?」
- 「Is Red Hat planning to include PCP (Performance Co-Pilot) in RHEL?」
- 「How do I configure a firewall on a RHEL server to allow remote monitoring with Performance Co-Pilot (PCP)?」
- 「How does Performance Co-Pilot (PCP) compare with sysstat」
- 「Side-by-side comparison of PCP tools with legacy tools」
- 「How to use a non-default PMDA with PCP?」
- 「pmiostat fails to replay a PCP archive log created on a RHEL6 system」
- 「Overview of Additional Performance Tuning Utilities in Red Hat Enterprise Linux 7」
- 「Interactive web interface for Performance Co-Pilot」
- 「How can I convert a collectl archive into a Performance Co-Pilot (PCP) archive?」
Comments