
Show Table of Contents
4.2. クラスターのタスク
4.2.1. 新規クラスターの作成
データセンターには複数のクラスターが属することができます。また、クラスターには複数のホストが属することが可能です。クラスター内のホストは同じ CPU タイプ (Intel あるいは AMD) である必要があります。CPU タイプを確実に最適化するには、クラスターを作成する前にホストを作成しておくことをお勧めします。ただしホストの設定は、 ボタンを使用して後で行うことができます。
手順4.1 新規クラスターの作成
- クラスター リソースタブを選択します。
- をクリックします。
- ドロップダウンメニューからクラスターが属する データセンター を選択します。
- クラスターの 名前 と 説明 を入力します。
- 管理ネットワーク ドロップダウンリストでネットワークを選択して、管理ネットワークのロールを割り当てます。
- ドロップダウンリストから CPU アーキテクチャー と CPU タイプ を選択します。CPU のプロセッサーファミリーが、クラスターにアタッチするホストの最小限必要な CPU タイプに適合していることが重要です。この条件が満たされない場合には、ホストは稼働しません。
注記
Intel および AMD のいずれの CPU タイプでも、CPU モデルは最も古いものから最も新しいものに論理的な順序でリストされます。クラスターに異なる複数の CPU モデルが含まれている場合には、最も古い CPU モデルを選択してください。各 CPU モデルについての詳しい情報は、https://access.redhat.com/solutions/634853 を参照してください。 - ドロップダウンリストからクラスターの 互換バージョン を選択します。
- クラスターに仮想マシンホストまたは Gluster 対応ノードを事前設定するかどうかに応じて、Virt サービスを有効にする または Gluster サービスを有効にする のいずれかのラジオボタンを選択します。Gluster サービスを有効にしたクラスターには、Red Hat Virtualization Host (RHVH) を追加することはできない点に注意してください。
- オプションで、仮想マシンのメンテナンスを行う理由の設定を有効にする のチェックボックスを選択して、Manager から仮想マシンをシャットダウンする際の理由フィールド (オプション) を有効にして、管理者によりメンテナンスの説明を提示できるようにします。
- オプションで、ホストのメンテナンスを行う理由の設定を有効にする のチェックボックスを選択して、Manager からホストをメンテナンスモードに切り替える際の理由フィールド (オプション) を有効にして、管理者がメンテナンスの説明を提示できるようにします。
- /dev/random source (Linux 提供のデバイス) または /dev/hwrng source (外部のハードウェアデバイス) のチェックボックスを選択して、クラスター内の全ホストが使用する乱数ジェネレーターデバイスを指定します。
- 最適化 タブをクリックし、クラスターのメモリーページ共有の閾値を選択します。またオプションで、クラスターのホストで CPU スレッド処理とメモリーバルーニングを有効化します。
- クラスターに対して仮想マシンの移行ポリシーを定義するには 移行ポリシー タブをクリックします。
- スケジューリングポリシー タブをクリックして、そのクラスター内のホストのスケジューリングポリシーの設定、スケジューラーの最適化の設定、信頼済みサービスの有効化、HA 予約の有効化、カスタムのシリアル番号ポリシーの指定などをオプションで設定します。
- オプションとして、グローバルの SPICE プロキシー (該当する場合) を上書きするには、コンソール タブをクリックして、そのクラスター内のホストのSPICE プロキシーのアドレスを指定します。
- フェンシングポリシー タブをクリックして、クラスター内のフェンシングを有効化/無効化して、フェンシングオプションを選択します。
- をクリックしてクラスターを作成すると、新規クラスター - ガイド ウィンドウが開きます。
- 新規クラスター - ガイド ウィンドウでは、データセンターに設定する必要のあるエンティティーが表示されます。これらのエンティティーを設定するか、 ボタンを押して後ほど設定を行います。設定を再開するにはクラスターを選択し、 ボタンを押してください。
新規クラスターが仮想化環境に追加されました。
4.2.2. 新規クラスターおよびクラスターの編集ウィンドウの設定とコントロール
4.2.2.1. クラスターの全般設定
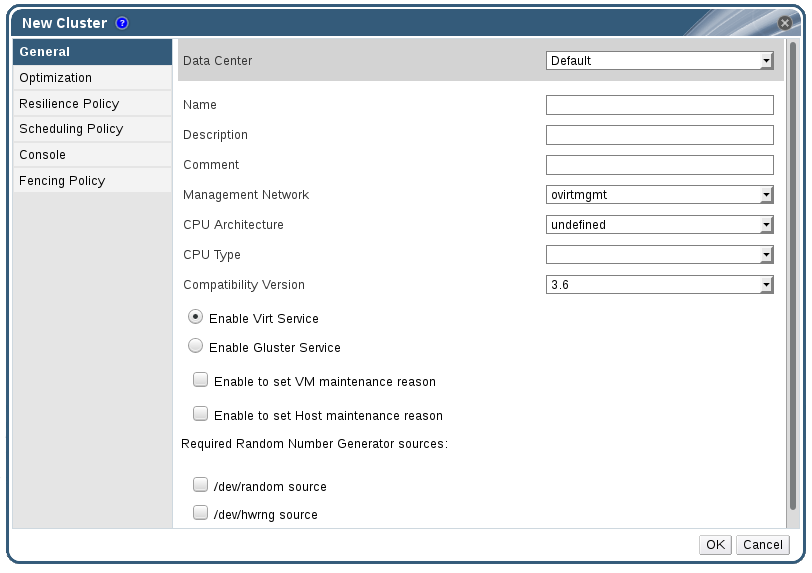
以下の表には、新規クラスター および クラスターの編集 ウィンドウ内の 全般 タブの設定についての説明をまとめています。OK をクリックすると、無効な値が入力されている箇所はオレンジ色の枠で囲まれ、そのままでは変更が確定されないようになっています。また、フィールドプロンプトには、期待値または期待値の範囲が表示されます。
表4.1 クラスターの全般設定
フィールド | 説明/アクション |
|---|---|
データセンター | クラスターが所属するデータセンター。このデータセンターは、クラスターを追加する前に作成しておく必要があります。 |
名前 | クラスターの名前。このテキストフィールドは最長で 40 文字に制限されており、アルファベットの大文字/小文字、数字、ハイフン、アンダースコアを任意に組み合わせた一意名にする必要があります。 |
説明 / コメント | クラスターの説明または補注。これらのフィールドへの入力は推奨されますが、必須ではありません。 |
管理ネットワーク | 管理ネットワークロールに割り当てられる論理ネットワーク。デフォルトでは ovirtmgmt です。既存のクラスターの管理ネットワークは、詳細ペインの 論理ネットワーク タブの ボタンを押して変更するのが唯一の方法です。 |
| CPU アーキテクチャー | クラスターの CPU アーキテクチャー。選択する CPU アーキテクチャーによって、異なる CPU タイプが利用できます。
|
CPU タイプ | クラスターの CPU タイプ。以下のいずれかを選択します。
|
互換バージョン | Red Hat Virtualization のバージョン。以下のいずれかを選択します。
|
Virt サービスを有効にする | このラジオボタンを選択した場合に、そのクラスター内のホストは仮想マシンの実行に使用されます。 |
Gluster サービスを有効にする | このラジオボタンを選択した場合に、そのクラスター内のホストは Red Hat Gluster Storage Server のノードとして使用され、仮想マシンは実行しません。このオプションが有効化されているクラスターには、Red Hat Virtualization Host を追加することはできません。 |
既存の Gluster 設定をインポート | このチェックボックスは、Gluster サービスを有効にする のラジオボタンが選択されている場合にのみ表示されます。このオプションにより、既存の Gluster 対応クラスターおよびそのクラスターにアタッチされた全ホストを Red Hat Virtualization Manager にインポートすることができます。 次のオプションは、インポートするクラスター内の各ホストに必要となります。
|
| 仮想マシンのメンテナンスを行う理由の設定を有効にする | このチェックボックスを選択した場合には、Manager を使用してクラスター内の仮想マシンをシャットダウンする際に、オプションの理由のフィールドが表示され、メンテナンスの理由を入力することができます。この理由は、ログに表示され、また仮想マシンの電源が再度オンになると表示されます。 |
| ホストのメンテナンスを行う理由の設定を有効にする | このチェックボックスが選択されている場合には、Manager からクラスター内のホストをメンテナンスモードに切り替えると、オプションの理由のフィールドが表示されます。これにより、メンテナンスの理由を入力することが可能となります。この理由は、ログに表示され、またホストを再度アクティブにすると表示されます。 |
| 必要な乱数ジェネレーターのソース: | 以下のチェックボックスのいずれかを選択する場合は、クラスター内の全ホストでそのデバイスが利用可能である必要があります。この設定により、乱数ジェネレーターデバイスからエントロピーを仮想マシンに渡すことができるようになります。
|
4.2.2.2. 最適化の設定
メモリーページ共有により、仮想マシンは他の仮想マシンで未使用のメモリーを活用することで、割り当てられたメモリーを最大 200% 利用することができます。このプロセスは、Red Hat Virtualization 環境にある仮想マシンが同時にフル稼働しておらず、未使用のメモリーを特定の仮想マシンに一時的に割り当てることができるという前提に基づいています。
CPU スレッド処理により、ホストは、そのホストのコア数を上回るプロセッサーコア合計数で仮想マシンを実行することができます。この機能は、CPU を集中的に使用しないワークロードに有用で、より多くの仮想マシンを実行可能にすることにより、ハードウェア要件を軽減できます。またこれにより、特にゲストのコア数がホストのコアよりも多く、ホストのスレッド数よりも少ない場合に、この機能がなければ不可能な CPU トポロジーで仮想マシンを実行できます。
以下の表には、新規クラスター および クラスターの編集 ウィンドウの 最適化 タブの設定についての説明をまとめています。
表4.2 最適化の設定
フィールド | 説明/アクション |
|---|---|
メモリーの最適化 |
|
CPU スレッド | スレッドをコアとしてカウント のチェックボックスを選択すると、ホストのコア数を上回るプロセッサーコア合計数の仮想マシンを実行することができます。 公開されたホストのスレッドは、コアとして扱われ、仮想マシンに活用することができます。たとえば、1 コアあたり 2 スレッドの 24 コアシステム (合計 48 スレッド) は、それぞれ最大 48 コアの仮想マシンを実行することができ、ホスト CPU の負荷を算出するアルゴリズムは、2 倍の利用可能コアに対して負荷を比較します。 |
メモリーバルーン | メモリーバルーンの最適化を有効にする のチェックボックスを選択すると、このクラスター内のホストで実行されている仮想マシンのメモリーのオーバーコミットが有効になります。このオプションが設定されると、Memory Overcommit Manager (MOM) が可能な箇所で可能な場合にバルーニングを開始します。各仮想マシンに確保されているメモリーのサイズが上限となります。 バルーンを稼働させるには、バルーンデバイスと適切なドライバーが必要です。バルーンデバイスは、特に削除していない限り、各仮想マシンに含まれます。このクラスター内の各ホストは、ステータスが Up に切り替わった時点でバルーンポリシーの更新を受信します。必要な場合には、ホスト上でステータスを変更せずにバルーンポリシーを手動で更新することができます。「クラスター内のホスト上での MOM ポリシーの更新」を参照してください。 シナリオによっては、バルーニングが KSM と競合する可能性があることを認識しておくことが重要です。そのような場合には、MOM がバルーンサイズの調整を試みて、競合を最小限に抑えます。また、一部のシナリオでは、バルーニングによって、仮想マシンでパフォーマンスが十分最適化されない可能性があります。バルーニングの最適化は、慎重に使用することを推奨します。 |
KSM コントロール | KSM を有効化 のチェックボックスを選択すると、MOM が有効になり、必要な場合に、CPU を犠牲にしてもメモリーを節約することでより高いメリットが得られる場合に Kernel Same-page Merging (KSM) を実行します。 |
4.2.2.3. 移行ポリシーの設定
移行ポリシーは、ホストに問題が発生した場合に、仮想マシンをライブマイグレーションする条件を定義します。これらの条件には、移行中の仮想マシンのダウンタイム、ネットワーク帯域幅、仮想マシンの優先順位付けなどが含まれます。
表4.3 移行ポリシー
ポリシー | 説明 |
|---|---|
Legacy | バージョン 3.6 のレガシーの動作。 vdsm.conf の設定内容がそのまま優先されて適用されます。ゲストエージェントのフックメカニズムは無効になります。 |
Minimal downtime | 一般的な状況での仮想マシンの移行が可能です。仮想マシンのダウンタイムは長時間にならないはずです。仮想マシンが長時間経過した後に収束されない場合は移行が中断されます (最大 500 ミリ秒の QEMU の繰り返し回数により異なります)。ゲストエージェントのフックメカニズムは有効になります。 |
Suspend workload if needed | 仮想マシンが高負荷のワークロードを実行している場合など、多くの状況で仮想マシンを移行できます。仮想マシンのダウンタイムはさらに長時間にわたる可能性があります。ワークロードが過剰な場合には、移行が中断されてしまう可能性があります。ゲストエージェントのフックメカニズムは有効になります。 |
帯域幅の設定は、
表4.4 帯域幅
ポリシー | 説明 |
|---|---|
Auto | 帯域幅は、データセンターの ホストネットワーク QoS の 速度の上限 [Mbps] 設定からコピーされます。速度の上限が定義されていない場合には、ネットワークインターフェースの送受信の最低リンクスピードとして算出されます。速度の上限が定義されておらず、リンクスピードが取得できない場合には、送信ホストのローカル VDSM の設定により決まります。 |
Hypervisor default | 帯域幅は、送信元のホストのローカル VDSM 設定で制御されます。 |
Custom | ユーザーが定義します (Mbps)。 |
耐障害性ポリシーは、移行時に仮想マシンをどのように優先順位付けするかを定義します。
表4.5 耐障害性ポリシー設定
フィールド | 説明/アクション |
|---|---|
仮想マシンを移行する | 定義した優先度の順に、すべての仮想マシンを移行します。 |
高可用性の仮想マシンのみを移行する | 高可用性の仮想マシンのみ移行し、他のホストが過負荷状態になるのを防ぎます。 |
仮想マシンを移行しない | 仮想マシンが移行されないようにします。 |
追加のプロパティー は、Legacy の移行ポリシーにのみ適用されます。
表4.6 追加のプロパティ
プロパティー | 説明 |
|---|---|
移行の自動収束 | 仮想マシンのライブマイグレーション中に自動収束を使用するかどうかを設定することができます。ワークロードが大きくサイズの大きい仮想マシンは、ライブマイグレーション中に到達する転送速度よりも早くメモリーをダーティーな状態にして、移行を収束できないようにする可能性があります。QEMU の自動収束機能は、仮想マシンの移行を強制的に収束することができます。収束されていない場合には、QEMU が自動的に検出して、仮想マシン上の vCPU の使用率を制限します。デフォルトでは、自動収束はグローバルレベルで無効化されています。
|
移行時の圧縮の有効化 | このオプションでは、仮想マシンのライブマイグレーション中に移行の圧縮を使用するかどうかを設定することができます。この機能は、Xor Binary Zero Run-Length-Encoding を使用して、仮想マシンのダウンタイムおよび、メモリーの書き込みの多いワークロードを実行する仮想マシンやメモリー更新パターンがスパースなアプリケーションの合計ライブマイグレーション時間を減らします。デフォルトでは、移行の圧縮はグローバルレベルで無効化されています。
|
4.2.2.4. スケジューリングポリシーの設定
スケジューリングポリシーにより、利用可能なホスト間で仮想マシンの使用率や配分を指定することができます。クラスター内のホスト間で、自動的に負荷を分散できるようにするには、スケジューリングポリシーを定義します。
既存のクラスターにスケジューリングポリシーを追加するには、クラスター タブで ボタンをクリックして、スケジューリングポリシー のタブを選択します。
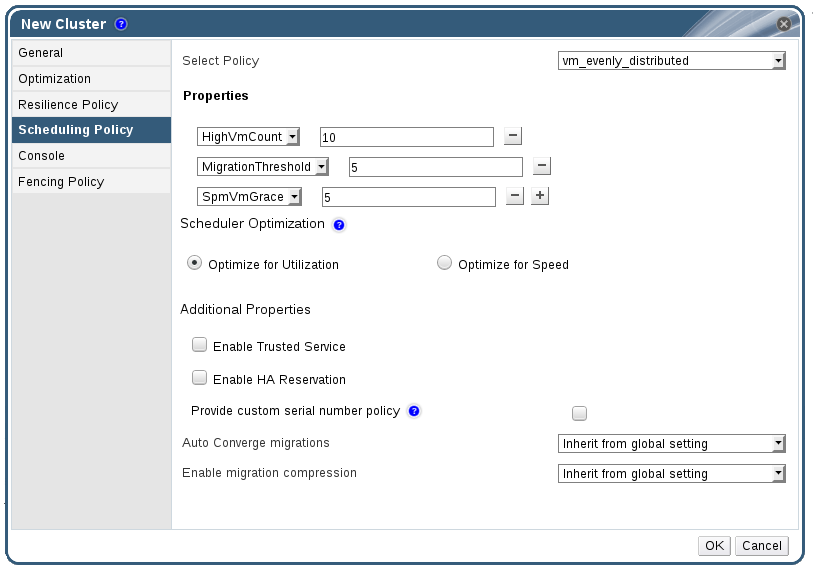
以下の表には、スケジューリングポリシー タブの設定についての説明をまとめています。
表4.7 スケジューリングポリシータブのプロパティー
フィールド | 説明/アクション |
|---|---|
ポリシーを選択 | ドロップダウンリストからポリシーを選択します。
|
プロパティー | 以下のプロパティーは、選択したポリシーに応じて表示され、必要に応じて編集することができます。
|
スケジューラーの最適化 | ホストの加重/順序のスケジューリングを最適化します。
|
信頼済みサービスを有効にする | OpenAttestation サーバーとの統合を有効にします。この設定を有効にする前に、 engine-config ツールを使用して OpenAttestation サーバーの詳細を入力します。詳しくは、「信頼済みコンピュートプール」を参照してください。 |
HA 予約を有効にする | Manager による高可用性仮想マシン用のクラスターキャパシティーのモニタリングを有効にします。Manager は、既存のホストで予期しないエラーが発生した場合に、高可用性に指定されている仮想マシンを移行するための適切なキャパシティーをクラスター内で確保します。 |
カスタムのシリアル番号ポリシーを指定する | このチェックボックスを選択すると、クラスター内の仮想マシンのシリアル番号ポリシーを指定することができます。以下のいずれかのオプションを選択してください。
|
移行の自動収束 | このオプションは、クラスター内の仮想マシンのライブマイグレーション中に自動収束を使用するかどうかを設定することができます。ワークロードが大きくサイズの大きい仮想マシンは、ライブマイグレーション中に到達する転送率よりも早くメモリーをダーティーな状態にして、移行を収束できないようにする可能性があります。QEMU の自動収束機能は、仮想マシンの移行を強制的に収束させることができます。QEMU は収束されていないことを自動検出し、仮想マシンで vCPU のスロットルを減らします。デフォルトでは、自動収束はグローバルレベルで無効化されています。
|
移行時の圧縮の有効化 | このオプションでは、クラスター内の仮想マシンのライブマイグレーション中に移行の圧縮を使用するかどうかを設定することができます。この機能は、Xor Binary Zero Run-Length-Encoding を使用して、仮想マシンのダウンタイムおよび、メモリーの書き込みの多いワークロードを実行する仮想マシンやメモリー更新パターンがスパースなアプリケーションの合計ライブマイグレーション時間を減らします。デフォルトでは、移行の圧縮はグローバルレベルで無効化されています。
|
ホストの空きメモリーが 20% 未満に下がると、
mom.Controllers.Balloon - INFO Ballooning guest:half1 from 1096400 to 1991580 のようなバルーニングコマンドが /var/log/vdsm/mom.log にログ記録されます。/var/log/vdsm/mom.log は、Memory Overcommit Manager のログファイルです。 4.2.2.5. クラスターのコンソール設定
以下の表には、新規クラスター および クラスターの編集 ウィンドウの コンソール タブの設定についての説明をまとめています。
表4.8 コンソールの設定
フィールド | 説明/アクション |
|---|---|
クラスターの SPICE プロキシーを定義 | グローバル設定で定義されている SPICE プロキシーの上書きを有効にするには、このチェックボックスを選択します。この機能は、ハイパーバイザーが属するネットワークの外部からユーザーが接続する場合 (例: ユーザーポータルからの接続) に有用です。 |
SPICE プロキシーアドレスを上書き | SPICE クライアントが仮想マシンに接続するのに使用するプロキシー。このアドレスは、以下の形式で指定する必要があります。 protocol://[host]:[port] |
4.2.2.6. フェンシングポリシーの設定
以下の表には、新規クラスター および クラスターの編集 ウィンドウの フェンシングポリシー タブの設定についての説明をまとめています。
表4.9 フェンシングポリシーの設定
| フィールド | 説明/アクション |
|---|---|
| フェンシングを有効にする | クラスターでフェンシングを有効にします。フェンシングはデフォルトで有効化されていますが、必要に応じて無効にすることができます。たとえば、一時的なネットワークの問題が発生している場合、または発生することが予想される場合に、診断またはメンテナンスの作業が完了するまでの間、管理者はフェンシングを無効にすることができます。フェンシングが無効になると、応答なしの状態のホストで実行されている高可用性の仮想マシンは、別のホストでは再起動されなくなる点に注意してください。 |
| ホストがストレージの有効なリースを持っている場合はフェンシングをスキップ | このチェックボックスを選択した場合には、ステータスが Non Responsive で、かつストレージにまだ接続されているクラスター内のホストはフェンシングされません。 |
| クラスターの接続性に問題がある場合はフェンシングをスキップ | このチェックボックスを選択すると、クラスター内で接続の問題が発生しているホストの割合が定義済みの 閾値 以上となった場合にフェンシングが一時的に無効となります。閾値 の値はドロップダウンリストから選択します。設定可能な値は、25、50、 75、100 です。 |
4.2.3. リソースの編集
概要
リソースのプロパティーを編集します。
手順4.2 リソースの編集
- リソースタブ、ツリーモード、または検索機能を使用して、結果一覧に表示された候補の中から対象のリソースを選択します。
- をクリックして 編集 ウィンドウを開きます。
- 必要なプロパティーを変更して をクリックします。
結果
新規プロパティーがリソースに保存されました。プロパティーフィールドが無効の場合には、編集 ウィンドウは閉じません。 4.2.4. クラスター内のホストに負荷および電源管理のポリシーを設定する手順
evenly_distributed および power_saving のスケジューリングポリシーでは、許容可能なメモリーおよび CPU 使用率の値と、どの時点で仮想マシンがホスト間で移行される必要があるかを指定することができます。vm_evenly_distributed スケジューリングポリシーは、仮想マシンの数に基づいて、ホスト間で仮想マシンを均等に配分します。クラスター内のホスト間における自動負荷分散を有効にするスケジューリングポリシーを定義します。各スケジューリングポリシーに関する詳しい説明は、「スケジューリングポリシーの設定」を参照してください。
手順4.3 ホストに負荷および電源管理のポリシーを設定する手順
- リソースタブ、ツリーモード、または検索機能を使用して、結果一覧に表示された候補の中から対象のクラスターを選択します。
- クリックすると、クラスターの編集 ウィンドウが表示されます。
- 以下のポリシーのいずれかを選択します。
- none
- vm_evenly_distributed
- HighVmCount フィールドには、各ホストで実行可能な仮想マシンの最大数を設定します。
- MigrationThreshold フィールドには、使用率が最も高いホスト上の仮想マシン数と使用率が最も低いホスト上の仮想マシン数の差異を定義します。
- SpmVmGrace フィールドには、SPM ホスト上で確保する仮想マシン用のスロット数を定義します。
- evenly_distributed
- CpuOverCommitDurationMinutes フィールドには、スケジューリングポリシーが対応するまでに、ホストが所定の使用率外で CPU 負荷を実行できる時間 (分単位) を設定します。
- HighUtilization フィールドには、他のホストへの仮想マシン移行を開始する CPU 使用率を入力します。
- MinFreeMemoryForUnderUtilized には、仮想マシンが他のホストへの移行を開始する、必要な空きメモリー容量の最小値を MB 単位でを入力します。
- MaxFreeMemoryForOverUtilized には、仮想マシンが他のホストへの移行を開始する、必要な最大空きメモリー容量を MB 単位でを入力します。
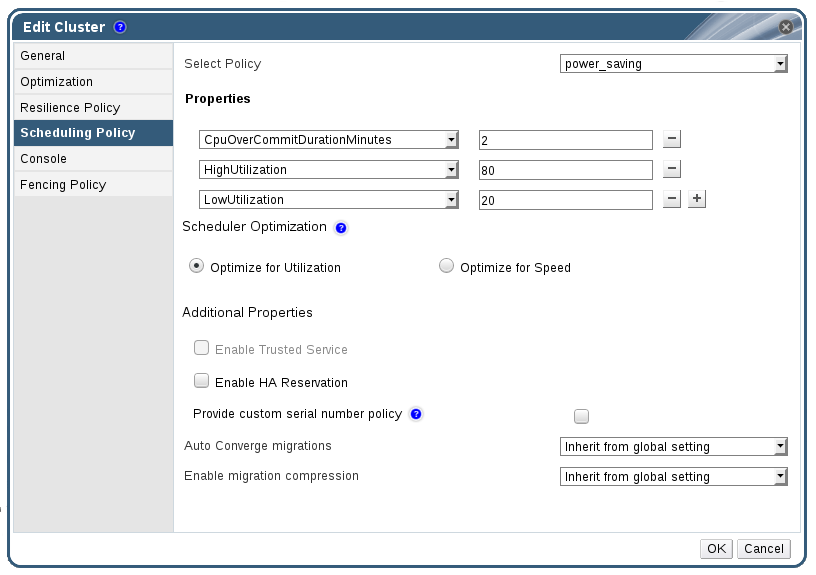
- power_saving
- CpuOverCommitDurationMinutes フィールドには、スケジューリングポリシーが対応するまでに、ホストが所定の使用率外で CPU 負荷を実行できる時間 (分単位) を設定します。
- LowUtilization フィールドには、ホストが十分に活用されていないと見なされる CPU 使用率の下限を入力します。
- HighUtilization フィールドには、他のホストへの仮想マシン移行を開始する CPU 使用率を入力します。
- MinFreeMemoryForUnderUtilized には、仮想マシンが他のホストへの移行を開始する、必要な空きメモリー容量の最小値を MB 単位でを入力します。
- MaxFreeMemoryForOverUtilized には、仮想マシンが他のホストへの移行を開始する、必要な最大空きメモリー容量を MB 単位でを入力します。
- クラスターの スケジューラーの最適化 には、以下のいずれかを選択します。
- 使用率で最適化 を選択すると、スケジューリングに加重モジュールが含まれ、最適の選択が可能となります。
- スピードで最適化 を選択すると、保留中の要求が 10 件以上ある場合には、ホストの重み付けをスキップします。
engine-configツールを使用してサーバーの詳細を設定済みで、OpenAttestation サーバーを使用してホストを検証する場合は、信頼済みサービスを有効にする のチェックボックスを選択します。- オプションとして、Manager による高可用性仮想マシン用のクラスターキャパシティーのモニタリングを有効にするには、HA 予約を有効にする のチェックボックスにチェックを入れます。
- オプションとして、クラスター内の仮想マシンのシリアル番号ポリシーを指定するには、カスタムのシリアル番号ポリシーを指定する チェックボックスにチェックを入れて、以下のオプションのいずれかを選択します。
- ホストの UUID を仮想マシンのシリアル番号として設定するには、Host ID を選択します。
- 仮想マシンの UUID を仮想マシンのシリアル番号として設定するには、Vm ID を選択します。
- カスタムのシリアル番号を指定するには、カスタムのシリアル番号 を選択します。
- をクリックします。
4.2.5. クラスター内のホスト上での MOM ポリシーの更新
Memory Overcommit Manager は、ホストでメモリーバルーンと KSM の機能を処理します。これらの機能をクラスターレベルで変更した場合には、その設定がホストに渡されるのは、ホストの再起動後か、ホストがメンテナンスモードから Up のステータスに切り替わった後のみです。ただし、必要な場合には、ホストが Up の状態の時に MOM ポリシーを同期することによって、重要な変更をホストに即時に適用することができます。以下の手順は、各ホストで個別に実行する必要があります。
手順4.4 ホスト上での MOM ポリシーの同期
- クラスター タブをクリックして、対象のホストが属するクラスターを選択します。
- 詳細ペインの ホスト タブをクリックして、MOM ポリシーを更新する必要のあるホストを選択します。
- をクリックします。
この操作を実行すると、ホストをメンテナンスモードに切り替えてから Up のステータスに戻す必要なく、ホスト上の MOM ポリシーが更新されます。
4.2.6. CPU プロファイル
CPU プロファイルは、クラスター内の仮想マシンが、その仮想マシンを実行するホストで利用できる最大処理能力を定義します。この値は、そのホストで利用可能な総処理能力に対するパーセンテージで指定します。CPU プロファイルは、データセンター下で定義されている CPU プロファイルに基づいて作成されますが、クラスター内の全仮想マシンには自動的に適用されないので、有効にするには個別の仮想マシンに手動で割り当てる必要があります。
4.2.6.1. CPU プロファイルの作成
CPU プロファイルを作成します。以下の手順は、クラスターの属するデータセンター下で CPU QoS エントリーが 1 つ以上定義済みであることを前提としています。
手順4.5 CPU プロファイルの作成
- クラスター リソースタブをクリックしてクラスターを選択します。
- 詳細ペインで CPU プロファイル のサブタブをクリックします。
- をクリックします。
- 名前 フィールドに CPU プロファイルの名前を入力します。
- 説明 フィールドに CPU プロファイルの説明を入力します。
- QoS 一覧から CPU プロファイルに適用する QoS を選択します。
- をクリックします。
CPU プロファイルが作成されました。この CPU プロファイルは、そのクラスター内の仮想マシンに適用することができます。
4.2.6.2. CPU プロファイルの削除
Red Hat Virtualization 環境から既存の CPU プロファイルを削除します。
手順4.6 CPU プロファイルの削除
- クラスター リソースタブをクリックしてクラスターを選択します。
- 詳細ペインで CPU プロファイル のサブタブをクリックします。
- 削除する CPU プロファイルを選択します。
- をクリックします。
- をクリックします。
CPU プロファイルが削除され、その CPU プロファイルは使用できなくなりました。CPU プロファイルが仮想マシンに割り当てられていた場合は、その仮想マシンには
default CPU プロファイルが自動的に割り当てられます。 4.2.7. 既存の Red Hat Gluster Storage クラスターのインポート
Red Hat Gluster Storage クラスターおよびそのクラスターに属する全ホストを Red Hat Virtualization Manager にインポートすることができます。
クラスター内のホストの IP アドレスやホスト名、パスワードなどの情報を提供する際には、SSH 経由で、そのホスト上で
gluster peer status コマンドを実行すると、そのクラスターに属するホストの一覧が表示されます。各ホストのフィンガープリントは手動で確認して、パスワードを提供する必要があります。クラスター内のいずれかのホストが停止しているか、または到達不可な時には、クラスターをインポートすることはできません。新たにインポートされたホストには、VDSM はインストールされていないので、インポートした後には、ブートストラップスクリプトにより必要な VDSM パッケージがすべてホストにインストールされ、ホストが再起動されます。
手順4.7 Red Hat Virtualization Manager への既存の Red Hat Gluster Storage クラスターのインポート
- クラスター リソースタブを選択すると、結果一覧に全クラスターが表示されます。
- 次に ボタンをクリックして、新規クラスター ウィンドウを開きます。
- ドロップダウンメニューからクラスターが属する データセンター を選択します。
- クラスターの 名前 と 説明 を入力します。
- Gluster サービスを有効にする のラジオボタンと 既存の Gluster 設定をインポート のチェックボックスを選択します。既存の Gluster 設定をインポート のフィールドは、Gluster サービスを有効にする のラジオボタンを選択した場合のみに表示されます。
- アドレス フィールドに、クラスター内の任意のサーバーのホスト名または IP アドレスを入力します。ホストの フィンガープリント が表示され、正しいホストに接続していることを確認します。ホストが到達不可の場合、またはネットワークエラーが発生している場合には、フィンガープリント フィールドに フィンガープリントの取得でエラーが発生しました というエラーメッセージが表示されます。
- サーバーの root パスワード を入力し、OK をクリックします。
- ホストの追加 ウィンドウが開き、クラスターに属するホストの一覧が表示されます。
- 各ホストの 名前 と root パスワード を入力します。
- 全ホストで同じパスワードを使用する場合は、共通のパスワードを使用 のチェックボックスを選択し、表示されているテキストフィールドにパスワードを入力します。をクリックし、入力したパスワードを全ホストに設定します。フィンガープリントが有効であることを確認した上で をクリックし、変更を送信します。
ホストをインポートした後に、ブートストラップスクリプトにより、必要な VDSM パッケージがすべてホストにインストールされました。既存の Red Hat Gluster Storage クラスターが Red Hat Virtualization Manager に正常にインポートされました。
4.2.8. ホストの追加ウィンドウの設定
ホストの追加 ウィンドウでは、Gluster 対応クラスターの一部としてインポートするホストの詳細を指定することができます。このウィンドウは、新規クラスター ウィンドウの Gluster サービスを有効にする のチェックボックスを選択して、必要なホストの詳細を指定した後に表示されます。
表4.10 Gluster ホスト追加の設定
| フィールド | 説明 |
|---|---|
| 共通のパスワードを使用 | クラスター内の全ホストに同じパスワードを使用するには、このチェックボックスにチェックを入れます。パスワード フィールドにパスワードを入力して、適用 ボタンをクリックすると、そのパスワードが全ホストに設定されます。 |
| 名前 | ホスト名を入力します。 |
| ホスト名/IP アドレス | このフィールドには、新規クラスター ウィンドウで指定したホストの完全修飾ドメイン名または IP アドレスが自動的に入力されます。 |
| root パスワード | ホストごとに異なる root パスワードを使用する場合には、このフィールドにパスワードを入力します。このフィールドにより、クラスター内の全ホストに対して指定した共通パスワードが上書きされます。 |
| フィンガープリント | ホストのフィンガープリントが表示され、正しいホストに接続することを確認します。このフィールドには、新規クラスター ウィンドウで指定したホストのフィンガープリントが自動的に入力されます。 |
4.2.9. クラスターの削除
概要
削除前にクラスターからすべてのホストを移動します。 注記
Default クラスターには Blank テンプレートが含まれているため削除することはできません。ただし、Default クラスターの名前を変更し、新規データセンターに追加することはできます。
手順4.8 クラスターの削除
- リソースタブ、ツリーモード、または検索機能を使用して、結果一覧に表示された候補の中から対象のクラスターを選択します。
- クラスター内にホストがないことを確認します。
- をクリックすると クラスターの削除 の確認ウィンドウが開きます。
- をクリックします。
結果
クラスターが削除されました。 4.2.10. クラスターの互換バージョンの変更
Red Hat Virtualization のクラスターには互換バージョンがあります。クラスターの互換バージョンは、そのクラスター内の全ホストがサポートする Red Hat Virtualization の機能を示します。クラスターの互換バージョンは、そのクラスター内で最も機能性の低いホストのバージョンに応じて設定されます。
注記
クラスターの互換バージョンを変更するには、まず、クラスター内の全ホストを更新して、必要な互換性レベルをサポートするレベルにする必要があります。
手順4.9 クラスターの互換バージョンの変更
- 管理ポータルで クラスター タブをクリックします。
- 表示された一覧の中から、変更するクラスターを選択します。
- をクリックします。
- 互換バージョン を必要な値に変更します。
- をクリックして、クラスターの互換バージョンを変更 の確認ウィンドウを開きます。
- をクリックして確定します。
クラスターの互換バージョンが更新されました。データセンター内の全クラスターの互換バージョンの更新が済むと、データセンター自体の互換バージョンも変更することができます。
重要
互換バージョンをアップグレードすると、そのデータセンターに属しているストレージドメインもすべてアップグレードされます。
Comments