
31.9. 避免侦听队列锁争用
队列锁争用可能会导致数据包丢弃和更高的 CPU 使用用率,因此导致更高的延迟。您可以通过调整应用程序并使用传输数据包转向,来避免接收(RX)和传输(TX)队列上的队列锁争用。
31.9.1. 避免 RX 队列锁争用:SO_REUSEPORT 和 SO_REUSEPORT_BPF 套接字选项
在多核系统上,如果应用程序使用 SO_REUSEPORT 或 SO_REUSEPORT_BPF 套接字选项打开端口,则您可以提高多线程网络服务器应用程序的性能。如果应用程序不使用其中一个套接字选项,则所有线程都会被强制共享一个套接字来接收传入流量。使用一个套接字会导致:
- 接收缓冲区上的重大竞争,这可能会导致数据包丢弃和更高的 CPU 使用率。
- CPU 使用率显著增加
- 可能的数据包丢弃
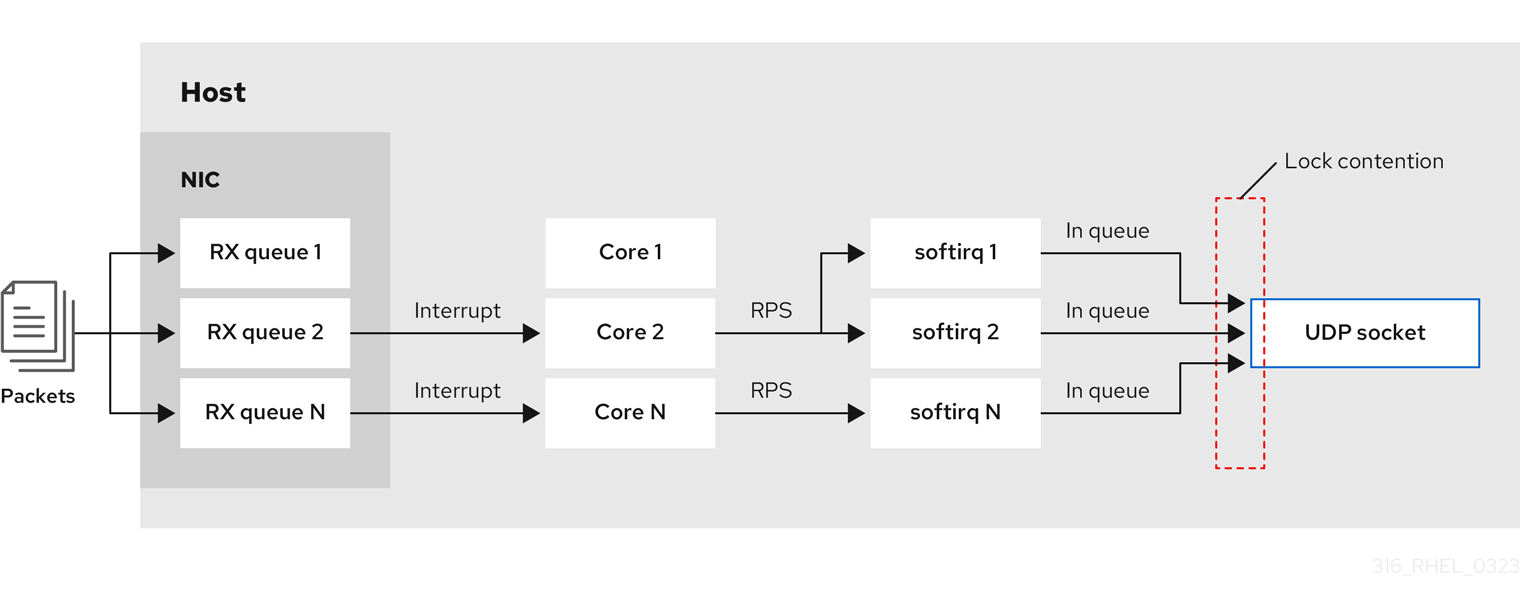
使用 SO_REUSEPORT 或 SO_REUSEPORT_BPF 套接字选项,一个主机上的多个套接字可以绑定到同一端口:

Red Hat Enterprise Linux 提供了一个如何在内核源中使用 SO_REUSEPORT 套接字选项的代码示例。要访问代码示例:
启用
rhel-9-for-x86_64-baseos-debug-rpms存储库:# subscription-manager repos --enable rhel-9-for-x86_64-baseos-debug-rpms安装
kernel-debuginfo-common-x86_64软件包:# dnf install kernel-debuginfo-common-x86_64-
代码示例现在在
/usr/src/debug/kernel-<version>/linux-<version>/tools/testing/selftests/net/reuseport_bpf_cpu.c文件中。
其他资源
-
socket (7)手册页 -
/usr/src/debug/kernel-<version>/linux-<version>/tools/testing/selftests/net/reuseport_bpf_cpu.c
31.9.2. 避免 TX 队列锁争用:传输数据包转向
在具有支持多个队列的网络接口控制器(NIC)的主机中,传输数据包转向(XPS)将传出网络数据包的处理分发到多个队列。这可让多个 CPU 处理传出的网络流量,并避免传输队列锁争用,因此避免了数据包丢弃。
某些驱动程序,如 ixgbe、i40e 和 mlx5 会自动配置 XPS。要识别驱动程序是否支持此功能,请参阅 NIC 驱动程序的文档。请参考您的 NIC 驱动程序文档来识别驱动程序是否支持此功能。如果驱动程序不支持 XPS 自动调整,您可以手动将 CPU 核分配给传输队列。
Red Hat Enterprise Linux 没有提供一个将传输队列永久分配给 CPU 内核的选项。在脚本中使用命令,并在系统启动时运行它。
先决条件
- NIC 支持多个队列。
-
numactl软件包已安装。
流程
显示可用队列的数量:
# ethtool -l enp1s0 Channel parameters for enp1s0: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 1
Pre-set maximums部分显示队列的总数,Current hardware settings显示当前分配给接收、传输、其他或组合队列的队列数。可选:如果您在特定通道上需要队列,请相应地分配它们。例如,要将 4 个队列分配给
Combined通道,请输入:# ethtool -L enp1s0 combined 4显示 NIC 被分配给了哪个 Non-Uniform Memory Access (NUMA)节点:
# cat /sys/class/net/enp1s0/device/numa_node 0如果文件未找到,或者命令返回
-1, 则主机不是 NUMA 系统。如果主机是 NUMA 系统,显示哪些 CPU 分配给了哪个 NUMA 节点:
# lscpu | grep NUMA NUMA node(s): 2 NUMA node0 CPU(s): 0-3 NUMA node1 CPU(s): 4-7在上例中,NIC 有 4 个队列,NIC 被分配给了 NUMA 节点 0。此节点使用 CPU 核 0-3。因此,将每个传输队列映射到 CPU 核 0-3 中的一个:
# echo 1 > /sys/class/net/enp1s0/queues/tx-0/xps_cpus # echo 2 > /sys/class/net/enp1s0/queues/tx-1/xps_cpus # echo 4 > /sys/class/net/enp1s0/queues/tx-2/xps_cpus # echo 8 > /sys/class/net/enp1s0/queues/tx-3/xps_cpus
如果 CPU 核数和传输(TX)队列相同,请使用 1 对 1 映射,以避免 TX 队列上任何类型的争用。否则,如果您在同一 TX 队列上映射了多个 CPU,则不同 CPU 上的传输操作将导致 TX 队列锁争用,并对传输吞吐量造成负面影响。
请注意,您必须将包含 CPU 核号的位图传给队列。使用以下命令计算位图:
# printf %x $((1 << <core_number> ))
验证
识别发送流量的服务的进程 ID (PID):
# pidof <process_name> 12345 98765
将 PID 固定到使用 XPS 的核:
# numactl -C 0-3 12345 98765在进程发送流量时监控
requeues计数:# tc -s qdisc qdisc fq_codel 0: dev enp10s0u1 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64 Sent 125728849 bytes 1067587 pkt (dropped 0, overlimits 0 requeues 30) backlog 0b 0p requeues 30 ...
如果
requeues计数不再以明显的速率增加,则 TX 队列锁争用不再发生。
其他资源
-
/usr/share/doc/kernel-doc-_<version>/Documentation/networking/scaling.rst
31.9.3. 在具有高 UDP 流量的服务器上禁用 Generic Receive Offload 功能
使用高速度 UDP 批量传输的应用程序应该在 UDP 套接字上启用和使用 UDP Generic Receive Offload (GRO)。但是,如果满足以下条件,您可以禁用 GRO 来提高吞吐量:
- 应用程序不支持 GRO,此功能无法添加。
与 TCP 吞吐量无关。
警告禁用 GRO 可显著减少 TCP 流量的接收吞吐量。因此,不要在与 TCP 性能相关的主机上禁用 GRO。
先决条件
- 主机主要处理 UDP 流量。
- 应用程序不使用 GRO。
- 主机不使用 UDP 隧道协议,如 VXLAN。
- 主机不运行虚拟机(VM)或容器。
流程
可选:显示 NetworkManager 连接配置文件:
# nmcli connection show NAME UUID TYPE DEVICE example f2f33f29-bb5c-3a07-9069-be72eaec3ecf ethernet enp1s0
在连接配置文件中禁用 GRO 支持:
# nmcli connection modify example ethtool.feature-gro off重新激活连接配置文件:
# nmcli connection up example
验证
验证 GRO 是否已禁用:
# ethtool -k enp1s0 | grep generic-receive-offload generic-receive-offload: off- 监控服务器上的吞吐量。如果设置对主机上的其他应用程序有负面影响,则在 NetworkManager 配置文件中重新启用 GRO。