
在 OpenShift 中部署和升级 AMQ Streams
在 OpenShift Container Platform 上部署 AMQ Streams 2.3
摘要
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。有关更多详情,请参阅我们的首席技术官 Chris Wright 提供的消息。
第 1 章 部署概述
AMQ Streams 简化了在 OpenShift 集群中运行 Apache Kafka 的过程。
本指南提供有关部署和升级 AMQ Streams 的所有可用选项的信息,描述在 OpenShift 集群中运行 Apache Kafka 所需的部署顺序。
除了描述部署步骤外,指南还提供预部署前和部署后的说明,以准备和验证部署。本指南还介绍了用于引入指标的其他部署选项。
为 AMQ Streams 和 Kafka 升级提供了升级说明。
AMQ Streams 的设计设计可在所有类型的 OpenShift 集群上工作,无论从公共和私有云分布到本地部署,旨在开发。
1.1. 配置部署
本指南中的部署过程旨在帮助您设置部署的初始结构。设置结构后,您可以使用自定义资源根据您的具体需求来配置部署。部署过程使用 AMQ Streams 提供的示例安装文件。该流程强调了任何重要的配置注意事项,但它们并不描述所有可用的配置选项。
在部署 AMQ Streams 前,您可能想要查看 Kafka 组件可用的配置选项。如需有关配置选项的更多信息,请参阅在 OpenShift 中配置 AMQ Streams。
1.1.1. 保护 Kafka
在部署中,Cluster Operator 会自动为集群中的数据加密和身份验证设置 TLS 证书。
AMQ Streams 为 encryption, authentication 和 authorization 提供了额外的配置选项 :
- 通过 管理到 Kafka 的安全访问,在 Kafka 集群和客户端 间保护数据交换。
- 将您的部署配置为使用一个验证服务器来提供 OAuth 2.0 验证和OAuth 2.0 授权。
- 使用您自己的证书保护 Kafka 的安全。
1.1.2. 监控部署
AMQ Streams 支持额外的部署选项来监控您的部署。
- 使用您的 Kafka 集群部署 Prometheus 和 Grafana 来提取指标并监控 Kafka 组件。
- 通过使用 Kafka 集群部署 Kafka Exporter,提取与监控消费者 lag 相关的 额外指标。
- 通过设置分布式追踪功能来跟踪 消息端到端。
1.1.3. CPU 和内存资源限制和请求
默认情况下,AMQ Streams Cluster Operator 不会为其部署的任何操作对象指定 CPU 和内存资源的请求和限值。
对于 Kafka 等应用程序而言,有足够的资源是稳定的,并提供良好的性能。
您应该使用的资源大小正确取决于具体要求和用例。
您应该考虑配置 CPU 和内存资源。您可以为 AMQ Streams 自定义资源 中的每个容器设置资源请求和限值。
1.2. AMQ Streams 自定义资源
使用 AMQ Streams 将 Kafka 组件部署到 OpenShift 集群可以通过自定义资源的应用程序进行配置。自定义资源作为自定义资源定义 (CRD) 添加的 API 实例创建,以扩展 OpenShift 资源。
CRD 充当描述 OpenShift 集群中的自定义资源的配置说明,由 AMQ Streams 提供,用于部署中使用的每个 Kafka 组件,以及用户和主题。CRD 和自定义资源被定义为 YAML 文件。AMQ Streams 发行版提供了 YAML 文件示例。
CRD 还允许 AMQ Streams 资源从原生 OpenShift 功能中获益,如 CLI 访问和配置验证。
1.2.1. AMQ Streams 自定义资源示例
CRD 需要集群中的一次性安装来定义用于实例化和管理 AMQ Streams 特定资源的 schema。
在安装 CRD 中添加新的自定义资源类型后,您可以根据规格创建资源实例。
根据集群设置,安装通常需要集群管理员特权。
管理自定义资源的访问权限仅限于 AMQ Streams 管理员。如需更多信息,请参阅 设计 AMQ Streams 管理员。
在 OpenShift 集群中,CRD 定义了一个新的资源 kind,如 kind:Kafka。
Kubernetes API 服务器允许根据类型创建自定义资源,并通过 CRD 了解在添加到 OpenShift 时如何验证和存储自定义资源。
删除 CRD 时,该类型的自定义资源也会被删除。另外,自定义资源(如 pod 和 statefulsets)创建的资源也会被删除。
每个 AMQ Streams 特定的自定义资源符合为资源的类型的 CRD 定义的架构。AMQ Streams 组件的自定义资源具有通用配置属性,它们在 spec 下定义。
要了解 CRD 和自定义资源之间的关系,让我们来看一下 Kafka 主题的 CRD 示例。
Kafka 主题 CRD
apiVersion: kafka.strimzi.io/v1beta2 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta2 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- 主题 CRD 的元数据、其名称和用于标识 CRD 的标签。
- 2
- 此 CRD 的规格,包括组(域)名称、复数名称和支持的 schema 版本,在 URL 中用于访问该主题 API。其他名称用于在 CLI 中识别实例资源。例如,
oc get kafkatopic my-topic或oc get kafkatopics。 - 3
- shortname 可用于 CLI 命令。例如,
oc get kt可用作缩写而不是oc get kafkatopic。 - 4
- 对自定义资源使用
get命令时显示的信息。 - 5
- CRD 的当前状态,如资源的 schema 引用 中所述。
- 6
- OpenAPIV3Schema 验证为创建主题自定义资源提供验证。例如,一个主题需要至少一个分区和一个副本。
您可以识别 AMQ Streams 安装文件提供的 CRD YAML 文件,因为文件名包含一个索引号,后跟 'Crd'。
以下是 KafkaTopic 自定义资源的对应示例。
Kafka 主题自定义资源
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
自定义资源可以通过平台 CLI 应用到集群。创建自定义资源时,它会使用与 Kubernetes API 的内置资源相同的验证。
创建 KafkaTopic 自定义资源后,在 AMQ Streams 中创建 Topic Operator 会被通知和对应的 Kafka 主题。
1.3. 使用 Kafka Bridge 与 Kafka 集群连接
您可以使用 AMQ Streams Kafka Bridge API 来创建和管理消费者,并通过 HTTP 而不是原生 Kafka 协议来发送和接收记录。
当您设置 Kafka Bridge 时,您要配置对 Kafka 集群的 HTTP 访问。然后,您可以使用 Kafka Bridge 来生成和消费来自集群的消息,以及通过其 REST 接口执行其他操作。
其他资源
- 有关安装和使用 Kafka Bridge 的详情,请参考使用 AMQ Streams Kafka Bridge。
1.4. 文档约定
user-replaced 值
user-replaced 值(也称为 replaceables )在 italics 中带有 angle brackets (< >)。下划线(_)用于多词语值。如果值引用代码或命令,则使用 monospace。
例如,在以下代码中,您要将 < my_namespace& gt; 替换为命名空间的名称:
sed -i 's/namespace: .*/namespace: <my_namespace>/' install/cluster-operator/*RoleBinding*.yaml1.5. 其他资源
第 2 章 AMQ Streams 安装方法
您可以通过两种方式将 AMQ Streams 安装到 OpenShift 4.8 到 4.12 上。
| 安装方法 | Description |
|---|---|
|
从 AMQ Streams 软件下载页面,下载 Red Hat AMQ Streams 2.3 OpenShift 安装和示例文件。使用
您还可以使用
| |
| 使用 OperatorHub 中的 Red Hat Integration - AMQ Streams 将 AMQ Streams 部署到单一命名空间或所有命名空间中。 |
为了获得最大的灵活性,请选择安装工件方法。OperatorHub 方法提供了一个标准配置,可让您利用自动更新。
不支持使用 Helm 安装 AMQ Streams。
第 3 章 使用 AMQ Streams 部署的内容
为使用 AMQ Streams 分发的 OpenShift 提供了 Apache Kafka 组件。Kafka 组件通常作为集群运行,以实现高可用性。
使用 Kafka 组件的典型部署可能包括:
- 代理节点的 Kafka 集群
- 复制 ZooKeeper 实例的 zookeeper 集群
- 用于外部数据连接的 Kafka 连接 集群
- Kafka MirrorMaker 集群在二级集群中镜像 Kafka 集群
- Kafka Exporter 来提取额外的 Kafka 指标数据以进行监控。
- Kafka Bridge 为 Kafka 集群发出基于 HTTP 的请求
并非所有组件都是必须的,但最少需要 Kafka 和 ZooKeeper。有些组件可以在没有 Kafka 的情况下部署,如 MirrorMaker 或 Kafka Connect。
3.1. 部署顺序
如下为部署 OpenShift 集群所需的顺序:
- 部署 Cluster Operator 以管理 Kafka 集群
- 使用 ZooKeeper 集群部署 Kafka 集群,并在部署中包括 Topic Operator 和 User Operator
(可选)部署:
- 如果没有使用 Kafka 集群部署它们,请主题 Operator 和 User Operator 独立
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
- 用于监控指标的组件
Cluster Operator 为组件创建 OpenShift 资源,如 Deployment、Service 和 Pod 资源。OpenShift 资源的名称会附加在部署时为组件指定的名称。例如,名为 my-kafka-cluster 的 Kafka 集群有一个名为 my-kafka-cluster-kafka 的服务。
第 4 章 准备 AMQ Streams 部署
本节演示了如何为 AMQ Streams 部署做准备,具体描述:
要运行本指南中的命令,您的集群用户必须具有管理基于角色的访问控制(RBAC)和 CRD 的权限。
4.1. 部署先决条件
要部署 AMQ Streams,您需要以下内容:
OpenShift 4.8 到 4.12 集群。
AMQ Streams 基于 Strimzi 0.32.x。
-
已安装
oc命令行工具并配置为连接到正在运行的集群。
4.2. 下载 AMQ Streams 发行版本工件
要使用部署文件安装 AMQ Streams,请从 AMQ Streams 软件下载页面 下载文件。
AMQ Streams 发行工件包括示例 YAML 文件,可帮助您将 AMQ Streams 的组件部署到 OpenShift,执行常见操作并配置 Kafka 集群。
使用 oc 从下载的 ZIP 文件的 install/cluster-operator 文件夹部署 Cluster Operator。有关部署和配置 Cluster Operator 的更多信息,请参阅 第 6.2 节 “部署 Cluster Operator”。
另外,如果要使用由 AMQ Streams Cluster Operator 管理的 Kafka 集群,使用主题和用户 Operator 的独立安装,可以从 install/topic-operator 部署它们,并安装/user-operator 文件夹。
另外,AMQ Streams 容器镜像可以通过 Red Hat Ecosystem Catalog 提供。但是,我们建议您使用提供的 YAML 文件来部署 AMQ Streams。
4.3. 配置和部署文件示例
使用 AMQ Streams 提供的示例配置和部署文件来部署带有不同配置的 Kafka 组件,并监控您的部署。自定义资源的配置文件示例包含重要的属性和值,您可以使用您自己的部署的其他受支持配置属性进行扩展。
4.3.1. 文件位置示例
示例文件随 AMQ Streams 软件下载页面的 可下载版本工件提供。
您可以使用 oc 命令行工具下载并应用示例。在构建您自己的 Kafka 组件配置时,示例可以作为起点。
如果使用 Operator 安装 AMQ Streams,您仍然可以下载示例文件,并使用它们来上传配置。
4.3.2. AMQ Streams 提供的示例文件
发行工件包括 示例 目录,其中包含配置示例。
目录示例
examples ├── user 1 ├── topic 2 ├── security 3 │ ├── tls-auth │ ├── scram-sha-512-auth │ └── keycloak-authorization ├── mirror-maker 4 ├── metrics 5 ├── kafka 6 ├── cruise-control 7 ├── connect 8 └── bridge 9
- 1
KafkaUser自定义资源配置,由 User Operator 管理。- 2
KafkaTopic自定义资源配置,它由 Topic Operator 管理。- 3
- Kafka 组件的身份验证和授权配置。包括 TLS 和 SCRAM-SHA-512 身份验证配置示例。Red Hat Single Sign-On 示例包括
Kafka自定义资源配置和 Red Hat Single Sign-On realm 规格。您可以使用该示例尝试 Red Hat Single Sign-On 授权服务。还有一个启用了oauthauthentication 和keycloak授权指标的示例。 - 4
- 用于部署 Mirror Maker 的
Kafka自定义资源配置。包括复制策略和同步频率的示例配置。 - 5
- 指标配置,包括 Prometheus 安装和 Grafana 仪表板文件。
- 6
Kafka自定义资源配置,用于部署 Kafka。包含临时或持久单一或多节点部署配置示例。- 7
- 带有用于 Cruise Control 的部署配置的
Kafka自定义资源。包括KafkaRebalance自定义资源从 Cruise Control 生成优化器,并提供示例配置来使用默认或用户优化目标。 - 8
- 用于部署
Kafka Connect的 KafkaConnect 和KafkaConnector自定义资源配置。包括单一或多节点部署的示例配置。 - 9
- 部署
Kafka Bridge的 KafkaBridge 自定义资源配置。
其他资源
4.4. 将容器镜像推送到您自己的 registry
AMQ Streams 的容器镜像 Red Hat Ecosystem Catalog 提供。AMQ Streams 提供的安装 YAML 文件将直接 从红帽生态系统目录 拉取镜像。
如果您无法访问 红帽生态系统目录 或想要使用自己的容器存储库,请执行以下操作:
- 拉取此处列出 的所有容器镜像
- 将它们推送到您自己的 registry 中
- 更新安装 YAML 文件中的镜像名称
发行版本支持的每个 Kafka 版本均有单独的镜像。
| 容器镜像 | Namespace/Repository | Description |
|---|---|---|
| Kafka |
| 用于运行 Kafka 的 AMQ Streams 镜像,包括:
|
| Operator |
| 用于运行 Operator 的 AMQ Streams 镜像:
|
| Kafka Bridge |
| 用于运行 AMQ Streams Kafka Bridge 的 AMQ Streams 镜像 |
| AMQ Streams Drain Cleaner |
| 用于运行 AMQ Streams Drain Cleaner 的 AMQ Streams 镜像 |
4.5. 创建用于向容器镜像 registry 进行身份验证的 pull secret
AMQ Streams 提供的安装 YAML 文件直接 从红帽生态系统目录拉取容器镜像。如果 AMQ Streams 部署需要身份验证,请在 secret 中配置身份验证凭据并将其添加到安装 YAML 中。
通常不需要身份验证,但可能会在某些平台上请求。
先决条件
- 您需要红帽用户名和密码,或来自红帽 registry 服务帐户的登录详情。
您可以使用您的红帽订阅从 红帽客户门户网站 创建 registry 服务帐户。
流程
创建包含登录详情和从中拉取 AMQ Streams 镜像的容器 registry 的 pull secret:
oc create secret docker-registry <pull_secret_name> \ --docker-server=registry.redhat.io \ --docker-username=<user_name> \ --docker-password=<password> \ --docker-email=<email>添加您的用户名和密码。电子邮件地址是可选的。
编辑
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml部署文件,使用STRIMZI_IMAGE_PULL_SECRET环境变量指定 pull secret:apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-cluster-operator spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: # ... env: - name: STRIMZI_IMAGE_PULL_SECRETS value: "<pull_secret_name>" # ...该 secret 适用于 Cluster Operator 创建的所有 pod。
4.6. 设计 AMQ Streams 管理员
AMQ Streams 为部署配置提供自定义资源。默认情况下,查看、创建、编辑和删除这些资源的权限仅限于 OpenShift 集群管理员。AMQ Streams 提供了两个集群角色,可用于将这些权限分配给其他用户:
-
Strimzi-view允许用户查看和列出 AMQ Streams 资源。 -
Strimzi-admin允许用户创建、编辑或删除 AMQ Streams 资源。
安装这些角色时,它们会自动聚合(添加)默认 OpenShift 集群角色的权限。Strimzi-view 聚合到 view 角色,并将 strimzi-admin 聚合到 edit 和 admin 角色。由于聚合,您可能不需要为已经拥有类似权限的用户分配这些角色。
以下流程演示了如何分配 strimzi-admin 角色,允许非集群管理员管理 AMQ Streams 资源。
在部署了 Cluster Operator 后,系统管理员可以指定 AMQ Streams 管理员。
先决条件
- AMQ Streams 自定义资源定义(CRD)和基于角色的访问控制(RBAC)资源用于管理 CRD,已使用 Cluster Operator 部署。
流程
在 OpenShift 中创建
strimzi-view和strimzi-admin集群角色。oc create -f install/strimzi-admin
如果需要,分配提供需要他们的访问权限的角色。
oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2
第 5 章 使用 Web 控制台从 OperatorHub 安装 AMQ Streams
在 OpenShift Container Platform Web 控制台中,从 OperatorHub 安装 Red Hat Integration - AMQ Streams Operator。
本节中的步骤演示了如何:
5.1. 使用 Red Hat Integration Operator 安装 AMQ Streams Operator
Red Hat Integration operator (已弃用)允许您选择并安装管理 Red Hat Integration 组件的 Operator。如果您有一个多个 Red Hat Integration 订阅,您可以使用 Red Hat Integration operator 安装和更新 AMQ Streams operator,以及所有订阅的 Red Hat Integration 组件的 Operator。
与 AMQ Streams operator 一样,您可以使用 Operator Lifecycle Manager (OLM)在 OCP 控制台中的 OperatorHub 的 OpenShift Container Platform (OCP)集群中安装 Red Hat Integration operator。
Red Hat Integration Operator 已被弃用,并将在以后的版本中删除。它可从 OpenShift 4.6 中的 OperatorHub 向 4.10 提供。
其他资源
有关安装和使用 Red Hat Integration Operator 的更多信息,请参阅安装 Red Hat Integration Operator
5.2. 从 OperatorHub 安装 AMQ Streams Operator
您可以使用 OpenShift Container Platform Web 控制台中的 OperatorHub 安装并订阅 AMQ Streams Operator。
此流程描述了如何创建项目,并将 AMQ Streams Operator 安装到该项目中。项目是命名空间的表示。对于可管理性,最好使用命名空间来分隔功能。
确保使用正确的更新频道。如果您位于受支持的 OpenShift 版本,则默认 stable 频道安装 AMQ Streams 通常是安全的。但是,我们不推荐在 stable 频道中启用自动更新。自动升级将在升级前跳过所有必要的步骤。仅在特定于版本的频道中使用自动升级。
先决条件
-
使用具有
cluster-admin或strimzi-admin权限的账户访问 OpenShift Container Platform Web 控制台。
流程
在 OpenShift Web 控制台中进入到 Home > Projects 页面,再创建一个用于安装的项目(命名空间)。
在这个示例中,我们使用名为
amq-streams-kafka的项目。- 进入 Operators > OperatorHub 页面。
在 Filter by keyword 框中输入关键字以查找 Red Hat Integration - AMQ Streams operator。
operator 位于 Streaming 和 Messaging 目录中。
- 点 Red Hat Integration - AMQ Streams 显示 Operator 信息。
- 阅读有关 Operator 的信息,再点 Install。
在 Install Operator 页面中,从以下安装和更新选项中选择:
更新频道 :选择 Operator 的更新频道。
- (默认) stable 频道包含所有最新的更新和发行版本,包括主版本、次版本和微版本,这些版本被认为经过充分测试和稳定。
- amq-streams-X.x 频道包含主发行版本的次要和微版本更新,其中 X 是主版本的版本号。
- amq-streams-X.Y.x 频道包含次要发行本版本的微版本更新,其中 X 是主版本的版本号,Y 是次版本号。
Installation Mode :选择您创建的项目,以便在特定命名空间中安装 Operator。
您可以将 AMQ Streams Operator 安装到集群中的所有命名空间(默认选项)或特定命名空间。我们建议您将特定命名空间专用于 Kafka 集群和其他 AMQ Streams 组件。
- 更新批准 :默认情况下,AMQ Streams Operator 由 Operator Lifecycle Manager (OLM)自动升级到最新的 AMQ Streams 版本。另外,如果您希望手动批准将来的升级,请选择 Manual。如需更多信息,请参阅 OpenShift 文档中的 Operator 指南。
点 Install 将 Operator 安装到所选命名空间中。
AMQ Streams Operator 将 Cluster Operator、CRD 和基于角色的访问控制(RBAC)资源部署到所选命名空间中。
Operator 就绪可用后,进入 Operators > Installed Operators 来验证 Operator 是否已安装到所选命名空间中。
状态将显示为 Succeeded。
现在,您可以使用 AMQ Streams operator 部署 Kafka 组件,从 Kafka 集群开始。
如果您进入到 Workloads > Deployments,您可以查看 Cluster Operator 和 Entity Operator 的部署详情。Cluster Operator 的名称包含一个版本号:amq-streams-cluster-operator-<version>。使用 AMQ Streams 安装工件部署 Cluster Operator 时的名称不同。在本例中,名称是 strimzi-cluster-operator。
5.3. 使用 AMQ Streams operator 部署 Kafka 组件
在 Openshift 上安装时,AMQ Streams Operator 使 Kafka 组件可从用户界面安装。
以下 Kafka 组件可用于安装:
- Kafka
- Kafka Connect
- Kafka MirrorMaker
- Kafka MirrorMaker 2
- Kafka 主题
- Kafka 用户
- Kafka Bridge
- Kafka Connector
- Kafka Rebalance
您可以选择组件并创建实例。您至少创建一个 Kafka 实例。这个步骤描述了如何使用默认设置创建 Kafka 实例。您可以在执行安装前配置默认安装规格。
创建其他 Kafka 组件实例的过程相同。
先决条件
- AMQ Streams Operator 安装在 OpenShift 集群上。
流程
在 Web 控制台中导航到 Operators > Installed Operators 页面,然后点 Red Hat Integration - AMQ Streams 来显示 Operator 详情。
在 Provided APIs 中,您可以创建 Kafka 组件的实例。
点 Kafka 下的 Create instance 创建 Kafka 实例。
默认情况下,您将创建一个名为
my-cluster的 Kafka 集群,它有三个 Kafka 代理节点和三个 ZooKeeper 节点。集群使用临时存储。点 Create 开始安装 Kafka。
等待状态变为 Ready。
第 6 章 使用安装工件部署 AMQ Streams
为 AMQ Streams 部署准备了您的环境,您可以将 AMQ Streams 部署到 OpenShift 集群。使用随发行工件提供的安装文件。
AMQ Streams 基于 Strimzi 0.32.x。您可以将 AMQ Streams 2.3 部署到 OpenShift 4.8 到 4.12。
使用安装文件部署 AMQ Streams 的步骤如下:
- 部署 Cluster Operator
使用 Cluster Operator 部署以下内容:
另外,还可根据要求部署以下 Kafka 组件:
要运行本指南中的命令,OpenShift 用户必须有权管理基于角色的访问控制(RBAC)和 CRD。
6.1. 基本部署路径
您可以设置一个部署,AMQ Streams 在同一个命名空间中管理单个 Kafka 集群。您可以使用此配置进行开发或测试。或者,您可以在生产环境中使用 AMQ Streams 来管理不同命名空间中的很多 Kafka 集群。
任何 AMQ Streams 部署的第一个步骤都是使用 install/cluster-operator 文件安装 Cluster Operator。
单个命令应用 cluster-operator 文件夹中的所有安装文件: oc apply -f ./install/cluster-operator。
该命令设置能够创建和管理 Kafka 部署所需的所有内容,包括:
-
Cluster Operator (
部署、ConfigMap) -
AMQ Streams CRD (
CustomResourceDefinition) -
RBAC 资源(
ClusterRole、ClusterRoleBinding、RoleBinding) -
服务帐户(
ServiceAccount)
基本部署路径如下:
- 下载发行版工件
- 创建用于部署 Cluster Operator 的 OpenShift 命名空间
-
更新
install/cluster-operator文件,以使用为 Cluster Operator 创建的命名空间 - 安装 Cluster Operator 以监视一个、多个或所有命名空间
-
更新
- 创建 Kafka 集群
之后,您可以部署其他 Kafka 组件并设置部署的监控。
6.2. 部署 Cluster Operator
Cluster Operator 负责在 OpenShift 集群中部署和管理 Kafka 集群。
当 Cluster Operator 运行时,它会开始监视 Kafka 资源更新。
默认情况下,Cluster Operator 的单个副本会被部署。您可以使用领导选举机制添加副本,以便在出现问题时有其他 Cluster Operator 处于待机状态。如需更多信息,请参阅使用领导选举机制运行多个 Cluster Operator 副本。
6.2.1. 指定 Cluster Operator 监视的命名空间
Cluster Operator 会监视部署 Kafka 资源的命名空间中的更新。部署 Cluster Operator 时,您可以指定要监视的命名空间。您可以指定以下命名空间:
Cluster Operator 可以监控 OpenShift 集群中的一个、多个或所有命名空间。Topic Operator 和 User Operator 会监视单一命名空间中的 KafkaTopic 和 KafkaUser 资源。如需更多信息,请参阅 使用 AMQ Streams operator 观察命名空间。
Cluster Operator 监视以下资源的更改:
-
Kafka集群的 Kafka。 -
Kafka Connect集群的 KafkaConnect。 -
用于在 Kafka Connect 集群中创建和管理连接器的
KafkaConnector。 -
Kafka MirrorMaker实例的 KafkaMirrorMaker。 -
KafkaMirrorMaker2用于 Kafka MirrorMaker 2.0 实例。 -
Kafka Bridge实例的 KafkaBridge。 -
KafkaRebalance用于 Cruise Control 优化请求。
当在 OpenShift 集群中创建这些资源时,Operator 会从资源获取集群描述,并通过创建必要的 OpenShift 资源(如 StatefulSets、Service 和 ConfigMap)来开始为资源创建新集群。
每次更新 Kafka 资源时,Operator 都会对组成资源的 OpenShift 资源执行对应的更新。
资源可以修补或删除,然后重新创建资源以便让该资源显示集群状态。此操作可能会导致滚动更新造成服务中断。
删除资源时,操作器会取消部署集群并删除所有相关的 OpenShift 资源。
6.2.2. 部署 Cluster Operator 以观察单个命名空间
此流程演示了如何部署 Cluster Operator 来监控 OpenShift 集群中的单个命名空间中的 AMQ Streams 资源。
先决条件
-
您需要具有权限的帐户来创建和管理
CustomResourceDefinition和 RBAC (ClusterRole、RoleBinding)资源。
流程
编辑 AMQ Streams 安装文件,以使用 Cluster Operator 将要安装到的命名空间。
例如,在此流程中,Cluster Operator 安装到命名空间
my-cluster-operator-namespace中。在 Linux 上,使用:
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
在 MacOS 上,使用:
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
部署 Cluster Operator:
oc create -f install/cluster-operator -n my-cluster-operator-namespace
检查部署的状态:
oc get deployments -n my-cluster-operator-namespace
输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.2.3. 部署 Cluster Operator 以观察多个命名空间
此流程演示了如何部署 Cluster Operator 来监控 OpenShift 集群中的多个命名空间之间的 AMQ Streams 资源。
先决条件
-
您需要具有权限的帐户来创建和管理
CustomResourceDefinition和 RBAC (ClusterRole、RoleBinding)资源。
流程
编辑 AMQ Streams 安装文件,以使用 Cluster Operator 将要安装到的命名空间。
例如,在此流程中,Cluster Operator 安装到命名空间
my-cluster-operator-namespace中。在 Linux 上,使用:
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
在 MacOS 上,使用:
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
编辑
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml文件,以添加 Cluster Operator 将监视到STRIMZI_NAMESPACE环境变量的所有命名空间列表。例如,在此流程中,Cluster Operator 将监控命名空间
watched-namespace-1、watched-namespace-2、watched-namespace-3。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel8-operator:2.3.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: watched-namespace-1,watched-namespace-2,watched-namespace-3对于每个命名空间,安装
RoleBindings。在这个示例中,将这些命令的
watched-namespace替换为在前一步中列出的命名空间,为watched-namespace-1,watched-namespace-2,watched-namespace-3重复这个操作:oc create -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n <watched_namespace> oc create -f install/cluster-operator/023-RoleBinding-strimzi-cluster-operator.yaml -n <watched_namespace> oc create -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n <watched_namespace>
部署 Cluster Operator:
oc create -f install/cluster-operator -n my-cluster-operator-namespace
检查部署的状态:
oc get deployments -n my-cluster-operator-namespace
输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.2.4. 部署 Cluster Operator 以监视所有命名空间
此流程演示了如何部署 Cluster Operator,以便在 OpenShift 集群的所有命名空间中监视 AMQ Streams 资源。
在这种模式中运行时,Cluster Operator 会自动管理创建的任何新命名空间中的集群。
先决条件
-
您需要具有权限的帐户来创建和管理
CustomResourceDefinition和 RBAC (ClusterRole、RoleBinding)资源。
流程
编辑 AMQ Streams 安装文件,以使用 Cluster Operator 将要安装到的命名空间。
例如,在此流程中,Cluster Operator 安装到命名空间
my-cluster-operator-namespace中。在 Linux 上,使用:
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
在 MacOS 上,使用:
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
编辑
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml文件,将STRIMZI_NAMESPACE环境变量的值设置为*。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: # ... serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel8-operator:2.3.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: "*" # ...创建
ClusterRoleBindings,为 Cluster Operator 的所有命名空间授予集群范围的访问权限。oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-watched --clusterrole=strimzi-cluster-operator-watched --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator
将 Cluster Operator 部署到您的 OpenShift 集群。
oc create -f install/cluster-operator -n my-cluster-operator-namespace
检查部署的状态:
oc get deployments -n my-cluster-operator-namespace
输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.3. 部署 Kafka
要使用 Cluster Operator 管理 Kafka 集群,您必须将其部署为 Kafka 资源。AMQ Streams 提供示例部署文件来执行此操作。您可以使用这些文件同时部署主题 Operator 和 User Operator。
部署 Cluster Operator 后,使用 Kafka 资源来部署以下组件:
安装 Kafka 时,AMQ Streams 还会安装 ZooKeeper 集群,并添加与 ZooKeeper 连接 Kafka 所需的配置。
如果您还没有将 Kafka 集群部署为 Kafka 资源,则无法使用 Cluster Operator 来管理它。这适用于在 OpenShift 外部运行的 Kafka 集群。但是,您可以将 Topic Operator 和 User Operator 与 AMQ Streams 管理的 Kafka 集群一起使用,方法是将其部署为独立组件。您还可以在不由 AMQ Streams 管理的 Kafka 集群中部署并使用其他 Kafka 组件。
6.3.1. 部署 Kafka 集群
此流程演示了如何使用 Cluster Operator 将 Kafka 集群部署到 OpenShift 集群。
部署使用 YAML 文件来提供创建 Kafka 资源的规格。
AMQ Streams 提供了以下 可用于创建 Kafka 集群的示例文件:
kafka-persistent.yaml- 使用三个 ZooKeeper 和三个 Kafka 节点部署持久集群。
kafka-jbod.yaml- 使用三个 ZooKeeper 和三个 Kafka 节点(每个都使用多个持久性卷)部署持久集群。
kafka-persistent-single.yaml- 使用单个 ZooKeeper 节点和单个 Kafka 节点部署持久集群。
kafka-ephemeral.yaml- 使用三个 ZooKeeper 和三个 Kafka 节点部署临时集群。
kafka-ephemeral-single.yaml- 使用三个 ZooKeeper 节点和一个 Kafka 节点部署临时集群。
在此过程中,我们使用示例进行 临时和 持久 Kafka 集群部署。
- 临时集群
-
通常,一个临时(或临时) Kafka 集群适合开发和测试目的,不适用于生产环境。此部署使用
emptyDir卷来存储代理信息(对于 ZooKeeper)和主题或分区(用于 Kafka)。使用emptyDir卷意味着其内容严格与 pod 生命周期相关,并在 pod 发生故障时删除。 - 持久性集群
持久性 Kafka 集群使用持久性卷来存储 ZooKeeper 和 Kafka 数据。使用
PersistentVolumeClaim来获取PersistentVolume,使其独立于PersistentVolume的实际类型。PersistentVolumeClaim可以使用StorageClass来触发自动卷置备。如果没有指定StorageClass,OpenShift 将尝试使用默认的StorageClass。以下示例显示了一些常见持久性卷类型:
- 如果您的 OpenShift 集群在 Amazon AWS 上运行,OpenShift 可以置备 Amazon EBS 卷
- 如果 OpenShift 集群在 Microsoft Azure 上运行,OpenShift 可以置备 Azure Disk Storage 卷
- 如果 OpenShift 集群在 Google Cloud 上运行,OpenShift 可以置备 Persistent Disk 卷
- 如果 OpenShift 集群在裸机上运行,OpenShift 可以置备本地持久性卷
示例 YAML 文件指定支持的最新 Kafka 版本,以及其支持的日志消息格式版本和 inter-broker 协议版本的配置。Kafka config 的 inter.broker.protocol.version 属性必须是指定的 Kafka 版本 (spec.kafka.version) 支持的版本。属性表示 Kafka 集群中使用的 Kafka 协议版本。
从 Kafka 3.0.0,当 inter.broker.protocol.version 设置为 3.0 或更高版本时,logging.message.format.version 选项会被忽略,不需要设置。
升级 Kafka 时需要对 inter.broker.protocol.version 的更新。
示例集群默认命名为 my-cluster。集群名称由资源名称定义,在部署集群后无法更改。要在部署集群前更改集群名称,请编辑相关 YAML 文件中的 Kafka 资源的 Kafka.metadata.name 属性。
默认集群名称和指定的 Kafka 版本
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.3.1
#...
config:
#...
log.message.format.version: "3.3"
inter.broker.protocol.version: "3.3"
# ...
流程
创建和部署临时或持久的集群。
创建和部署临时集群:
oc apply -f examples/kafka/kafka-ephemeral.yaml
创建和部署持久集群:
oc apply -f examples/kafka/kafka-persistent.yaml
检查部署的状态:
oc get pods -n <my_cluster_operator_namespace>输出显示了 pod 名称和就绪度
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 my-cluster-kafka-0 1/1 Running 0 my-cluster-kafka-1 1/1 Running 0 my-cluster-kafka-2 1/1 Running 0 my-cluster-zookeeper-0 1/1 Running 0 my-cluster-zookeeper-1 1/1 Running 0 my-cluster-zookeeper-2 1/1 Running 0
my-cluster是 Kafka 集群的名称。使用默认部署,您要安装一个 Entity Operator 集群、3 Kafka pod 和 3 ZooKeeper pod。
READY显示 ready/expected 的副本数量。当STATUS显示为Running时,部署成功。
其他资源
6.3.2. 使用 Cluster Operator 部署 Topic Operator
此流程描述了如何使用 Cluster Operator 部署主题 Operator。
您可以配置 Kafka 资源的 entityOperator 属性,使其包含 topicOperator。默认情况下,Topic Operator 会监视 Cluster Operator 部署的 Kafka 集群命名空间中的 KafkaTopic 资源。您还可以使用 Topic Operator spec 中的 watchedNamespace 指定一个命名空间。单个主题 Operator 可以监视单个命名空间。只应一个命名空间监视一个主题 Operator。
如果您使用 AMQ Streams 将多个 Kafka 集群部署到同一命名空间中,请只将一个 Kafka 集群启用 Topic Operator,或使用 watchedNamespace 属性来配置主题 Operator 以观察其他命名空间。
如果要将 topics Operator 与由 AMQ Streams 管理的 Kafka 集群一起使用,则必须将 Topic Operator 部署为独立组件。
有关配置 entityOperator 和 topicOperator 属性的更多信息,请参阅配置 Entity Operator。
流程
编辑
Kafka资源的entityOperator属性,使其包含topicOperator:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}使用
EntityTopicOperatorSpecschema reference 中所述的属性配置 Topic Operatorspec。如果您希望所有属性使用它们的默认值,请使用空对象(
{})。创建或更新资源:
oc apply -f <kafka_configuration_file>检查部署的状态:
oc get pods -n <my_cluster_operator_namespace>输出显示了 pod 名称和就绪度
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 # ...
my-cluster是 Kafka 集群的名称。READY显示 ready/expected 的副本数量。当STATUS显示为Running时,部署成功。
6.3.3. 使用 Cluster Operator 部署 User Operator
此流程描述了如何使用 Cluster Operator 部署 User Operator。
您可以配置 Kafka 资源的 entityOperator 属性,使其包含 userOperator。默认情况下,User Operator 会监视 Kafka 集群部署命名空间中的 KafkaUser 资源。您还可以使用 User Operator spec 中的 watchedNamespace 指定命名空间。单个用户 Operator 可以监视单个命名空间。只应该只监视一个用户 Operator 的命名空间。
如果要将 User Operator 与 AMQ Streams 管理的 Kafka 集群一起使用,则必须将 User Operator 部署为独立组件。
有关配置 entityOperator 和 userOperator 属性的更多信息,请参阅配置 Entity Operator。
流程
编辑
Kafka资源的entityOperator属性,使其包含userOperator:apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}使用
EntityUserOperatorSpecschema reference 中所述的属性配置 User Operatorspec。如果您希望所有属性使用它们的默认值,请使用空对象(
{})。创建或更新资源:
oc apply -f <kafka_configuration_file>检查部署的状态:
oc get pods -n <my_cluster_operator_namespace>输出显示了 pod 名称和就绪度
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 # ...
my-cluster是 Kafka 集群的名称。READY显示 ready/expected 的副本数量。当STATUS显示为Running时,部署成功。
6.4. 部署 Kafka 连接
Kafka Connect 是一个在 Apache Kafka 和外部系统之间传输数据的工具。
在 AMQ Streams 中,Kafka Connect 以分布式模式部署。Kafka Connect 也可以在独立模式下工作,但AMQ Streams 不支持它。
使用 连接器 的概念,Kafka Connect 提供了一个框架,可将大量数据移入和移出 Kafka 集群,同时保持可伸缩性和可靠性。
Kafka Connect 通常用于将 Kafka 与外部数据库和存储及消息传递系统集成。
Cluster Operator 管理使用 KafkaConnector 资源部署的 Kafka Connect 集群,以及利用 KafkaConnector 资源创建的连接器。
以下流程描述了如何部署 Kafka Connect 并为流传输数据设置连接器:
术语 连接器 可互换使用,表示在 Kafka Connect 集群或连接器类中运行的连接器实例。在本指南中,当从上下文中明确的含义时,会使用 连接器。
6.4.1. 部署 Kafka 连接到 OpenShift 集群
此流程演示了如何使用 Cluster Operator 将 Kafka Connect 集群部署到 OpenShift 集群。
Kafka Connect 集群作为 Deployment 实施,它带有可配置的节点(也称为 worker),将连接器的工作负载作为 任务 分发,以便消息流高度可扩展和可靠性。
部署使用 YAML 文件来提供规格来创建 KafkaConnect 资源。
AMQ Streams 提供示例配置文件。在此过程中,我们使用以下示例文件:
-
examples/connect/kafka-connect.yaml
流程
将 Kafka 连接到您的 OpenShift 集群。使用 example
/connect/kafka-connect.yaml文件部署 Kafka Connect。oc apply -f examples/connect/kafka-connect.yaml
检查部署的状态:
oc get deployments -n <my_cluster_operator_namespace>输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE my-connect-cluster-connect 1/1 1 1
my-connect-cluster是 Kafka Connect 集群的名称。READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
其他资源
6.4.2. 多个实例的 Kafka 连接配置
如果您运行多个 Kafka Connect 实例,您必须更改以下配置属性 的默认配置 :
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: connect-cluster 1
offset.storage.topic: connect-cluster-offsets 2
config.storage.topic: connect-cluster-configs 3
status.storage.topic: connect-cluster-status 4
# ...
# ...
这三个主题的值对于具有相同 组.id 的所有 Kafka 连接实例必须相同。
除非更改默认设置,否则每个 Kafka 连接实例都使用相同的值部署连接到同一 Kafka 集群。这是因为所有实例都联合在集群中运行,并使用相同的主题。
如果多个 Kafka Connect 集群尝试使用相同主题,则 Kafka Connect 将无法按预期工作,并生成错误。
如果要运行多个 Kafka Connect 实例,请更改每个实例的这些属性值。
6.4.3. 使用连接器插件扩展 Kafka 连接
Kafka Connect 使用连接器实例来与其他系统集成以流传输数据。连接器可以是以下类型之一:
- 将数据推送到 Kafka 的源连接器
- 从 Kafka 中提取数据的接收器连接器
本节中的步骤描述了如何通过以下方法添加连接器:
您可以使用 Kafka Connect REST API 或 KafkaConnector 自定义资源 直接为连接器创建配置。
您可以使用自己的连接器,或尝试示例 FileStreamSourceConnector 和 FileStreamSinkConnector 连接器,以便将基于文件的数据移入和移出 Kafka 集群。有关将示例文件连接器部署为 KafkaConnector 资源的详情,请参考 第 6.4.4.2 节 “部署 KafkaConnector 资源示例”。
在 Apache Kafka 3.1.0 之前,AMQ Streams 容器镜像用于 Kafka Connect,包括示例文件连接器。从 Apache Kafka 3.1.1 和 3.2.0,这些连接器将不再包含,且必须像任何连接器一样部署。
6.4.3.1. 使用 AMQ Streams 自动创建新容器镜像
此流程演示了如何配置 Kafka Connect,以便 AMQ Streams 会自动构建带有额外连接器的新容器镜像。您可以使用 KafkaConnect 自定义资源的 .spec.build.plugins 属性来定义连接器插件。AMQ Streams 将自动下载并添加到新容器镜像中。容器被推送到 .spec.build.output 中指定的容器仓库,并在 Kafka Connect 部署中自动使用。
先决条件
- 必须部署 Cluster Operator。
- 容器 registry。
您需要提供自己的容器 registry,以便镜像可以推送到、存储和拉取(pull)镜像。AMQ Streams 支持私有容器 registry 和公共 registry,如 Quay 或 Docker Hub。
流程
通过在
.spec.build.output中指定容器 registry 和 .spec.build.plugins 中的其他连接器来配置KafkaConnect自定义资源:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: 1 #... build: output: 2 type: docker image: my-registry.io/my-org/my-connect-cluster:latest pushSecret: my-registry-credentials plugins: 3 - name: debezium-postgres-connector artifacts: - type: tgz url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.3.1.Final/debezium-connector-postgres-1.3.1.Final-plugin.tar.gz sha512sum: 962a12151bdf9a5a30627eebac739955a4fd95a08d373b86bdcea2b4d0c27dd6e1edd5cb548045e115e33a9e69b1b2a352bee24df035a0447cb820077af00c03 - name: camel-telegram artifacts: - type: tgz url: https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-telegram-kafka-connector/0.7.0/camel-telegram-kafka-connector-0.7.0-package.tar.gz sha512sum: a9b1ac63e3284bea7836d7d24d84208c49cdf5600070e6bd1535de654f6920b74ad950d51733e8020bf4187870699819f54ef5859c7846ee4081507f48873479 #...
创建或更新资源:
$ oc apply -f KAFKA-CONNECT-CONFIG-FILE- 等待新容器镜像构建,然后部署 Kafka Connect 集群。
- 使用 Kafka Connect REST API 或 KafkaConnector 自定义资源使用您添加的连接器插件。
其他资源
如需了解更多信息,请参阅使用 Strimzi 指南:
6.4.3.2. 从 Kafka Connect 基础镜像创建 Docker 镜像
此流程演示了如何创建自定义镜像并将其添加到 /opt/kafka/plugins 目录中。
您可以使用 红帽生态系统目录 上的 Kafka 容器镜像作为基础镜像,通过其他连接器插件创建您自己的自定义镜像。
在启动时,Kafka Connect 的 AMQ Streams 版本加载 /opt/kafka/plugins 目录中包含的任何第三方连接器插件。
流程
使用
registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0作为基础镜像创建新Dockerfile:FROM registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001插件文件示例
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md
注意这个示例为 MongoDB、MySQL 和 PostgreSQL 使用 Debezium 连接器。在 Kafka Connect 中运行的 Debezium 与任何其他 Kafka Connect 任务相同。
- 构建容器镜像。
- 将自定义镜像推送到容器 registry。
指向新的容器镜像。
您可以:
编辑
KafkaConnect自定义资源的KafkaConnect.spec.image属性。如果设置,此属性会覆盖 Cluster Operator 中的
STRIMZI_KAFKA_CONNECT_IMAGES变量。apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: 1 #... image: my-new-container-image 2 config: 3 #...
或者
-
在
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml文件中,编辑STRIMZI_KAFKA_CONNECT_IMAGES变量以指向新容器镜像,然后重新安装 Cluster Operator。
6.4.4. 创建和管理连接器
当您为连接器插件创建容器镜像时,您需要在 Kafka Connect 集群中创建一个连接器实例。然后,您可以配置、监控和管理正在运行的连接器实例。
连接器是特定 连接器类 的实例,知道如何在消息中与相关外部系统通信。连接器适用于许多外部系统,也可以自行创建。
您可以创建 源和 接收器连接 器类型。
- 源连接器
- 源连接器是一个运行时实体,用于从外部系统获取数据并将其作为消息传送给 Kafka。
- sink 连接器
- sink 连接器是一个运行时实体,用于从 Kafka 主题获取信息并将其传送到外部系统。
6.4.4.1. 用于创建和管理连接器的 API
AMQ Streams 提供两个 API 用于创建和管理连接器:
-
KafkaConnector自定义资源(称为 KafkaConnectors) - Kafka Connect REST API
使用 API,您可以:
- 检查连接器实例的状态
- 重新配置正在运行的连接器
- 为连接器实例增加或减少连接器任务数量
- 重启连接器
- 重启连接器任务,包括失败的任务
- 暂停连接器实例
- 恢复之前暂停的连接器实例
- 删除连接器实例
KafkaConnector 自定义资源
KafkaConnectors 允许您以 OpenShift 原生的方式创建和管理 Kafka Connect 的连接器实例,因此不需要 HTTP 客户端,如 cURL。与其他 Kafka 资源一样,您可以在部署到 OpenShift 集群的 KafkaConnector YAML 文件中声明一个连接器所需的状态,以创建连接器实例。KafkaConnector 资源必须部署到它们所链接的 Kafka Connect 集群相同的命名空间中。
您可以通过更新对应的 KafkaConnector 资源来管理正在运行的连接器实例,然后应用更新。您可以通过删除其对应的 KafkaConnector 来删除连接器。
为确保与 AMQ Streams 早期版本的兼容性,KafkaConnectors 会被默认禁用。要为 Kafka Connect 集群启用 KafkaConnectors,您可以在 KafkaConnect 资源中将 strimzi.io/use-connector-resources 注解设置为 true。具体步骤请参阅 配置 Kafka 连接。
当启用 KafkaConnectors 时,Cluster Operator 会开始监视它们。它更新正在运行的连接器实例的配置,以匹配其 KafkaConnectors 中定义的配置。
AMQ Streams 提供了一个 KafkaConnector 配置文件示例,您可以使用它 创建和管理 FileStreamSourceConnector 和 FileStreamSinkConnector。
Kafka Connect API
Kafka Connect REST API 支持的操作在 Apache Kafka Connect API 文档中 描述。
使用 Kafka Connect API 从 Kafka Connect API 切换到使用 KafkaConnectors
您可以使用 Kafka Connect API 从 使用 Kafka Connect API 来管理您的连接器。要进行切换,请按所示的顺序进行以下操作:
-
使用配置部署
KafkaConnector资源,以创建您的连接器实例。 -
通过将
strimzi.io/use-connector-resources注解设置为true,在 Kafka Connect 配置中启用 KafkaConnectors。
如果您在创建资源前启用 KafkaConnectors,您将删除所有连接器。
要使用 Kafka Connectors 从 Kafka Connect API 切换到,首先删除在 Kafka Connect 配置中启用 KafkaConnectors 的注解。否则,Cluster Operator 会恢复使用 Kafka Connect REST API 进行的手动更改。
6.4.4.2. 部署 KafkaConnector 资源示例
KafkaConnector 资源提供了一种 OpenShift 原生的方法来管理 Cluster Operator 连接器。AMQ Streams 提供示例配置文件。在此过程中,我们使用 example /connect/source-connector.yaml 文件创建以下连接器实例作为 KafkaConnector 资源:
-
一个
FileStreamSourceConnector实例,从 Kafka 许可证文件(源)读取每行,并将数据作为信息写入单个 Kafka 主题。 -
一个
FileStreamSinkConnector实例,从 Kafka 主题读取信息并将信息写入临时文件(sink)。
另外,您可以使用 example /connect/kafka-connect-build.yaml 文件使用文件连接器构建新的 Kafka Connect 镜像。
在 Apache Kafka 3.1.0 之前,Apache Kafka 中包含示例文件连接器插件。从 Apache Kafka 的 3.1.1 和 3.2.0 版本开始,需要将示例作为任何其他连接器添加到插件路径中。如需了解更多详细信息,请参阅使用连接器插件扩展 Kafka 连接。
在生产环境中,您可以使用所需的 Kafka 连接连接器准备容器镜像,如 第 6.4.3 节 “使用连接器插件扩展 Kafka 连接” 所述。
FileStreamSourceConnector 和 FileStreamSinkConnector 作为示例提供。在容器内运行这些连接器,因为这里描述不太可能适合于生产用例。
先决条件
- Kafka Connect 部署
- KafkaConnectors 在 Kafka Connect 部署中启用
- Cluster Operator 正在运行
流程
编辑 example
/connect/source-connector.yaml文件:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector 1 labels: strimzi.io/cluster: my-connect-cluster 2 spec: class: org.apache.kafka.connect.file.FileStreamSourceConnector 3 tasksMax: 2 4 config: 5 file: "/opt/kafka/LICENSE" 6 topic: my-topic 7 # ...
在 OpenShift 集群中创建源
KafkaConnector:oc apply -f examples/connect/source-connector.yaml
创建
示例/连接/sink-connector.yaml文件:touch examples/connect/sink-connector.yaml
将以下 YAML 粘贴到
sink-connector.yaml文件中:apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-sink-connector labels: strimzi.io/cluster: my-connect spec: class: org.apache.kafka.connect.file.FileStreamSinkConnector 1 tasksMax: 2 config: 2 file: "/tmp/my-file" 3 topics: my-topic 4在 OpenShift 集群中创建 sink
KafkaConnector:oc apply -f examples/connect/sink-connector.yaml
检查是否创建了连接器资源:
oc get kctr --selector strimzi.io/cluster=MY-CONNECT-CLUSTER -o name my-source-connector my-sink-connector将 MY-CONNECT-CLUSTER 替换为您的 Kafka Connect 集群。
在容器中执行
kafka-console-consumer.sh来读取源连接器写入主题的消息:oc exec MY-CLUSTER-kafka-0 -i -t -- bin/kafka-console-consumer.sh --bootstrap-server MY-CLUSTER-kafka-bootstrap.NAMESPACE.svc:9092 --topic my-topic --from-beginning
源和接收器连接器配置选项
连接器配置在 KafkaConnector 资源的 spec.config 属性中定义。
FileStreamSourceConnector 和 FileStreamSinkConnector 类支持与 Kafka Connect REST API 相同的配置选项。其他连接器支持不同的配置选项。
表 6.1. FileStreamSource connector 类的配置选项
| 名称 | 类型 | 默认值 | Description |
|---|---|---|---|
|
| 字符串 | null | 源文件,以便将消息写入到.如果没有指定,则使用标准输入。 |
|
| list | null | 将数据发布至的 Kafka 主题。 |
表 6.2. FileStreamSinkConnector 类的配置选项
| 名称 | 类型 | 默认值 | Description |
|---|---|---|---|
|
| 字符串 | null | 要写入消息的目标文件。如果未指定,则使用标准输出。 |
|
| list | null | 从中读取数据的一个或多个 Kafka 主题。 |
|
| 字符串 | null | 与一个或多个 Kafka 主题匹配的正则表达式来读取数据。 |
6.4.4.3. 执行 Kafka 连接器重启
此流程描述了如何使用 OpenShift 注解手动触发 Kafka 连接器重启。
先决条件
- Cluster Operator 正在运行。
流程
查找控制您要重启的 Kafka 连接器的
KafkaConnector自定义资源的名称:oc get KafkaConnector
要重启连接器,请在 OpenShift 中注解
KafkaConnector资源。例如,使用oc annotate:oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart=true等待下一次协调发生(默认为两分钟)。
只要协调过程检测到注解,则 Kafka 连接器会被重启。当 Kafka Connect 接受重启请求时,注解会从
KafkaConnector自定义资源中删除。
6.4.4.4. 执行 Kafka 连接器任务重启
此流程描述了如何使用 OpenShift 注解手动触发 Kafka 连接器任务重启。
先决条件
- Cluster Operator 正在运行。
流程
查找控制您要重启的 Kafka 连接器任务的
KafkaConnector自定义资源的名称:oc get KafkaConnector
查找要从
KafkaConnector自定义资源重启的任务 ID。任务 ID 是非负的整数,从 0 开始。oc describe KafkaConnector KAFKACONNECTOR-NAME要重启 connector 任务,请在 OpenShift 中注解
KafkaConnector资源。例如,使用oc annotate重启任务 0:oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart-task=0等待下一次协调发生(默认为两分钟)。
只要协调过程检测到注解,则 Kafka 连接器任务会被重启。当 Kafka Connect 接受重启请求时,注解会从
KafkaConnector自定义资源中删除。
6.4.4.5. 公开 Kafka Connect API
使用 Kafka Connect REST API 作为使用 KafkaConnector 资源管理连接器的替代选择。Kafka Connect REST API 作为一个运行在 <connect_cluster_name>-connect-api:8083 的服务其中 <connect_cluster_name> 是 Kafka Connect 集群的名称。服务在创建 Kafka Connect 实例时创建。
strimzi.io/use-connector-resources 注解可启用 KafkaConnectors。如果您将注解应用到 KafkaConnect 资源配置,则需要将其删除以使用 Kafka Connect API。否则,Cluster Operator 会恢复使用 Kafka Connect REST API 进行的手动更改。
您可以将连接器配置添加为 JSON 对象。
添加连接器配置的 curl 请求示例
curl -X POST \
http://my-connect-cluster-connect-api:8083/connectors \
-H 'Content-Type: application/json' \
-d '{ "name": "my-source-connector",
"config":
{
"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector",
"file": "/opt/kafka/LICENSE",
"topic":"my-topic",
"tasksMax": "4",
"type": "source"
}
}'
API 只能在 OpenShift 集群内访问。如果要让 Kafka Connect API 可以被 OpenShift 集群外运行的应用程序访问,您可以通过创建以下功能来手动公开:
-
LoadBalancer或NodePort类型服务 -
Ingress资源 - OpenShift 路由
连接是不安全的,因此建议进行外部访问。
如果您决定创建服务,请使用 < connect_cluster_name> -connect-api 服务 选择器的 标签来配置服务要路由流量的 pod:
服务的选择器配置
# ... selector: strimzi.io/cluster: my-connect-cluster 1 strimzi.io/kind: KafkaConnect strimzi.io/name: my-connect-cluster-connect 2 #...
您还必须创建一个允许来自外部客户端的 HTTP 请求的 NetworkPolicy。
允许请求 Kafka Connect API 的 NetworkPolicy 示例
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-custom-connect-network-policy
spec:
ingress:
- from:
- podSelector: 1
matchLabels:
app: my-connector-manager
ports:
- port: 8083
protocol: TCP
podSelector:
matchLabels:
strimzi.io/cluster: my-connect-cluster
strimzi.io/kind: KafkaConnect
strimzi.io/name: my-connect-cluster-connect
policyTypes:
- Ingress
- 1
- 允许连接到 API 的 pod 标签。
要在集群外部添加连接器配置,请使用 curl 命令中公开 API 的资源的 URL。
6.4.4.6. 限制对 Kafka Connect API 的访问
仅将对 Kafka Connect API 的访问限制为可信用户,以防止未经授权的操作和潜在的安全问题。Kafka Connect API 提供了大量更改连接器配置的功能,这有助于采取安全措施。有权访问 Kafka Connect API 的人员可能会获得管理员可能假设的敏感信息是安全的。
Kafka Connect REST API 可以被经过身份验证访问 OpenShift 集群的任何人访问,并知道端点 URL,其中包括主机名/IP 地址和端口号。
例如,假设机构使用 Kafka Connect 集群和连接器将客户数据库的敏感数据流传输到中央数据库。管理员使用配置供应商插件存储与连接到客户数据库和中央数据库相关的敏感信息,如数据库连接详情和身份验证凭据。配置提供程序保护此敏感信息无法向未授权用户公开。但是,有权访问 Kafka Connect API 的用户仍然可以获得对客户数据库的访问权限,而无需经过管理员的批准。他们可以通过设置一个假的数据库并将连接器配置为连接它。然后,他们可以修改连接器配置以指向客户数据库,但不是将数据发送到中央数据库,而是将其发送到假的数据库。通过将连接器配置为连接到假的数据库,可以截获连接到客户端数据库的登录详情和凭证,即使它们被安全地存储在配置提供程序中。
如果您使用 KafkaConnector 自定义资源,默认情况下,OpenShift RBAC 规则只允许 OpenShift 集群管理员更改连接器。您还可以指定非集群管理员来管理 AMQ Streams 资源。在 Kafka Connect 配置中启用 KafkaConnector 资源后,Cluster Operator 会恢复使用 Kafka Connect REST API 所做的更改。如果您不使用 KafkaConnector 资源,默认的 RBAC 规则不会限制对 Kafka Connect API 的访问。如果要使用 OpenShift RBAC 限制对 Kafka Connect REST API 的直接访问,则需要启用和使用 KafkaConnector 资源。
为了提高安全性,我们建议为 Kafka Connect API 配置以下属性:
connector.client.config.override.policy将
connector.client.config.override.policy属性设置为None(默认)以防止连接器配置覆盖 Kafka Connect 配置及其使用的用户和制作者。指定连接器覆盖策略的配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" spec: # ... config: connector.client.config.override.policy: None # ...
6.5. 部署 Kafka MirrorMaker
Cluster Operator 部署一个或多个 Kafka MirrorMaker 副本,以便在 Kafka 集群间复制数据。此过程称为镜像(mirror),以避免与 Kafka 分区复制概念混淆。MirrorMaker 使用来自源集群的消息,并将这些消息重新发布到目标集群。
6.5.1. 将 Kafka MirrorMaker 部署到 OpenShift 集群
此流程演示了如何使用 Cluster Operator 将 Kafka MirrorMaker 集群部署到 OpenShift 集群。
部署使用 YAML 文件来提供规范来创建 KafkaMirrorMaker 或 KafkaMirrorMaker2 资源,具体取决于部署的 MirrorMaker 版本。
在 Apache Kafka 3.0.0 中已弃用 Kafka MirrorMaker 1 (正如文档中的 imagesMaker),并将在 Apache Kafka 4.0.0 中删除。因此,在 AMQ Streams 中还已弃用了用于部署 Kafka MirrorMaker 1 的 KafkaMirrorMaker 自定义资源。当使用 Apache Kafka 4.0.0 时,KafkaMirrorMaker 资源将从 AMQ Streams 中删除。作为替代方法,在 IdentityReplicationPolicy 中使用 KafkaMirrorMaker2 自定义资源。
AMQ Streams 提供示例配置文件。在此过程中,我们使用以下示例文件:
-
examples/mirror-maker/kafka-mirror-maker.yaml -
examples/mirror-maker/kafka-mirror-maker-2.yaml
流程
将 Kafka MirrorMaker 部署到 OpenShift 集群:
对于 MirrorMaker:
oc apply -f examples/mirror-maker/kafka-mirror-maker.yaml
对于 MirrorMaker 2.0:
oc apply -f examples/mirror-maker/kafka-mirror-maker-2.yaml
检查部署的状态:
oc get deployments -n <my_cluster_operator_namespace>输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE my-mirror-maker-mirror-maker 1/1 1 1 my-mm2-cluster-mirrormaker2 1/1 1 1
my-mirror-maker是 Kafka MirrorMaker 集群的名称。my-mm2-cluster是 Kafka MirrorMaker 2.0 集群的名称。READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.6. 部署 Kafka Bridge
Cluster Operator 部署一个或多个 Kafka 网桥副本,以通过 HTTP API 在 Kafka 集群和客户端之间发送数据。
6.6.1. 在 OpenShift 集群中部署 Kafka Bridge
此流程演示了如何使用 Cluster Operator 将 Kafka Bridge 集群部署到 OpenShift 集群。
部署使用 YAML 文件来提供规格来创建 KafkaBridge 资源。
AMQ Streams 提供示例配置文件。在此过程中,我们使用以下示例文件:
-
examples/bridge/kafka-bridge.yaml
流程
将 Kafka Bridge 部署到 OpenShift 集群:
oc apply -f examples/bridge/kafka-bridge.yaml
检查部署的状态:
oc get deployments -n <my_cluster_operator_namespace>输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE my-bridge-bridge 1/1 1 1
my-bridge是 Kafka Bridge 集群的名称。READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.6.2. 将 Kafka Bridge 服务公开给本地机器中
使用端口转发将 AMQ Streams Kafka Bridge 服务公开给 http://localhost:8080 上的本地机器。
端口转发仅适用于开发和测试目的。
流程
列出 OpenShift 集群中 pod 的名称:
oc get pods -o name pod/kafka-consumer # ... pod/my-bridge-bridge-7cbd55496b-nclrt
连接到端口
8080上的 Kafka Bridge pod:oc port-forward pod/my-bridge-bridge-7cbd55496b-nclrt 8080:8080 &
注意如果本地机器上的端口 8080 已使用,请使用其他 HTTP 端口,如
8008。
API 请求现在从本地机器的端口 8080 转发到 Kafka Bridge pod 的端口 8080。
6.6.3. 在 OpenShift 之外访问 Kafka Bridge
部署后,AMQ Streams Kafka Bridge 只能由同一 OpenShift 集群中运行的应用程序访问。这些应用程序使用 < ;kafka_bridge_name> -bridge-service 服务来访问 API。
如果要让 Kafka Bridge 可以被 OpenShift 集群外运行的应用程序访问,您可以通过创建以下功能来手动公开:
-
LoadBalancer或NodePort类型服务 -
Ingress资源 - OpenShift 路由
如果您决定创建服务,请使用 < kafka_bridge_name> -bridge-service 服务 选择器 中的标签来配置服务要路由流量的 pod:
# ...
selector:
strimzi.io/cluster: kafka-bridge-name 1
strimzi.io/kind: KafkaBridge
#...- 1
- OpenShift 集群中的 Kafka Bridge 自定义资源的名称。
6.7. AMQ Streams operator 的替代独立部署选项
您可以对 Topic Operator 和 User Operator 执行独立部署。如果您使用不由 Cluster Operator 管理的 Kafka 集群,请考虑对这些 Operator 的独立部署。
您将操作器部署到 OpenShift。Kafka 可以在 OpenShift 外部运行。例如,您可以使用 Kafka 作为受管服务。您可以调整独立 Operator 的部署配置以匹配 Kafka 集群的地址。
6.7.1. 部署独立主题 Operator
此流程演示了如何将主题 Operator 部署为主题管理的独立组件。您可以将独立主题 Operator 与不由 Cluster Operator 管理的 Kafka 集群一起使用。
独立部署可以与任何 Kafka 集群操作。
独立部署文件随 AMQ Streams 提供。使用 05-Deployment-strimzi-topic-operator.yaml 部署文件来部署主题 Operator。添加或设置在 Kafka 集群建立连接所需的环境变量。
Topic Operator 会监视单个命名空间中的 KafkaTopic 资源。您可以在主题 Operator 配置中指定要监视的命名空间,以及到 Kafka 集群的连接。单个主题 Operator 可以监视单个命名空间。只应一个命名空间监视一个主题 Operator。如果要使用多个主题 Operator,请将每个主题配置为监视不同的命名空间。这样,您可以在多个 Kafka 集群中使用主题 Operator。
先决条件
您正在运行一个 Kafka 集群,以便主题 Operator 要连接。
只要独立主题 Operator 配置了连接,因此 Kafka 集群可以在裸机环境、虚拟机或受管云应用程序服务上运行。
流程
编辑
install/topic-operator/05-Deployment-strimzi-topic-operator.yaml独立部署文件中的env属性。独立主题 Operator 部署配置示例
apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-topic-operator labels: app: strimzi spec: # ... template: # ... spec: # ... containers: - name: strimzi-topic-operator # ... env: - name: STRIMZI_NAMESPACE 1 valueFrom: fieldRef: fieldPath: metadata.namespace - name: STRIMZI_KAFKA_BOOTSTRAP_SERVERS 2 value: my-kafka-bootstrap-address:9092 - name: STRIMZI_RESOURCE_LABELS 3 value: "strimzi.io/cluster=my-cluster" - name: STRIMZI_ZOOKEEPER_CONNECT 4 value: my-cluster-zookeeper-client:2181 - name: STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS 5 value: "18000" - name: STRIMZI_FULL_RECONCILIATION_INTERVAL_MS 6 value: "120000" - name: STRIMZI_TOPIC_METADATA_MAX_ATTEMPTS 7 value: "6" - name: STRIMZI_LOG_LEVEL 8 value: INFO - name: STRIMZI_TLS_ENABLED 9 value: "false" - name: STRIMZI_JAVA_OPTS 10 value: "-Xmx=512M -Xms=256M" - name: STRIMZI_JAVA_SYSTEM_PROPERTIES 11 value: "-Djavax.net.debug=verbose -DpropertyName=value" - name: STRIMZI_PUBLIC_CA 12 value: "false" - name: STRIMZI_TLS_AUTH_ENABLED 13 value: "false" - name: STRIMZI_SASL_ENABLED 14 value: "false" - name: STRIMZI_SASL_USERNAME 15 value: "admin" - name: STRIMZI_SASL_PASSWORD 16 value: "password" - name: STRIMZI_SASL_MECHANISM 17 value: "scram-sha-512" - name: STRIMZI_SECURITY_PROTOCOL 18 value: "SSL"- 1
- 用于监视
KafkaTopic资源的 topics Operator 的 OpenShift 命名空间。指定 Kafka 集群的命名空间。 - 2
- 用于发现并连接到 Kafka 集群中所有代理的 bootstrap 代理地址的主机和端口对。在服务器停机时,使用逗号分隔列表来指定两个或三个代理地址。
- 3
- 用于标识由 Topic Operator 管理的
KafkaTopic资源的标签。这不一定是 Kafka 集群的名称。它可以是分配给KafkaTopic资源的标签。如果部署多个主题 Operator,则每个标签必须是唯一的。也就是说,操作员无法管理相同的资源。 - 4
- 连接到 ZooKeeper 集群的地址和端口对。这必须与 Kafka 集群使用的相同 ZooKeeper 集群。
- 5
- ZooKeeper 会话超时,以毫秒为单位。默认值为
18000(18 秒)。 - 6
- 定期协调之间的间隔(以毫秒为单位)。默认值为
120000(2 分钟)。 - 7
- 从 Kafka 获取主题元数据时的尝试次数。每次尝试之间的时间都定义为 exponential backoff。由于分区或副本数,请考虑增加这个值。默认值为
6次尝试。 - 8
- 打印日志记录消息的级别。您可以将级别设为
ERROR、WARNING、INFO、DEBUG或TRACE。 - 9
- 启用 TLS 支持与 Kafka 代理的加密通信。
- 10
- (可选)JVM 运行 Topic Operator 使用的 Java 选项。
- 11
- (可选)为 Topic Operator 设置的调试(
-D)选项。 - 12
- (可选)如果通过
STRIMZI_TLS_ENABLED启用 TLS,则跳过信任存储证书的生成。如果启用了此环境变量,代理必须使用公共可信证书颁发机构作为其 TLS 证书。默认值为false。 - 13
- (可选)为 mTLS 验证生成密钥存储证书。把它设置为
false会禁用使用 mTLS 到 Kafka 代理的客户端身份验证。默认值是true。 - 14
- (可选)连接到 Kafka 代理时支持客户端身份验证的 SASL。默认值为
false。 - 15
- (可选)用于客户端身份验证的 SASL 用户名。仅在通过
STRIMZI_SASL_ENABLED启用 SASL 时强制强制。 - 16
- (可选)客户端身份验证的 SASL 密码。仅在通过
STRIMZI_SASL_ENABLED启用 SASL 时强制强制。 - 17
- (可选)客户端身份验证的 SASL 机制。仅在通过
STRIMZI_SASL_ENABLED启用 SASL 时强制强制。您可以将值设为plain、scram-sha-256或scram-sha-512。 - 18
- (可选)用于与 Kafka 代理通信的安全协议。默认值为 "PLAINTEXT"。您可以将值设为
PLAINTEXT、SSL、SASL_PLAINTEXT或SASL_SSL。
-
如果要连接到使用公共证书颁发机构中的证书的 Kafka 代理,请将
STRIMZI_PUBLI_CA设置为true。将此属性设置为true,例如,如果您使用 Amazon AWS MSK 服务。 如果您使用
STRIMZI_TLS_ENABLED环境变量启用 mTLS,请指定用于验证到 Kafka 集群连接的密钥存储和信任存储。mTLS 配置示例
# .... env: - name: STRIMZI_TRUSTSTORE_LOCATION 1 value: "/path/to/truststore.p12" - name: STRIMZI_TRUSTSTORE_PASSWORD 2 value: "TRUSTSTORE-PASSWORD" - name: STRIMZI_KEYSTORE_LOCATION 3 value: "/path/to/keystore.p12" - name: STRIMZI_KEYSTORE_PASSWORD 4 value: "KEYSTORE-PASSWORD" # ...
部署主题 Operator。
oc create -f install/topic-operator
检查部署的状态:
oc get deployments
输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE strimzi-topic-operator 1/1 1 1
READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
6.7.2. 部署独立用户 Operator
此流程演示了如何将 User Operator 部署为用户管理的独立组件。您可以将单机 User Operator 用于不由 Cluster Operator 管理的 Kafka 集群。
独立部署可以与任何 Kafka 集群操作。
独立部署文件随 AMQ Streams 提供。使用 05-Deployment-strimzi-user-operator.yaml 部署文件来部署 User Operator。添加或设置在 Kafka 集群建立连接所需的环境变量。
User Operator 会监视单一命名空间中的 KafkaUser 资源。您可以在 User Operator 配置中指定要监视的命名空间,以及到 Kafka 集群的连接。单个用户 Operator 可以监视单个命名空间。只应该只监视一个用户 Operator 的命名空间。如果要使用多个用户 Operator,请将每个用户配置为监视不同的命名空间。这样,您可以在多个 Kafka 集群中使用 User Operator。
先决条件
您正在运行一个 Kafka 集群,供 User Operator 连接。
只要为连接正确配置了独立用户 Operator,则 Kafka 集群可以在裸机环境、虚拟机或受管云应用程序服务上运行。
流程
编辑
install/user-operator/05-Deployment-strimzi-user-operator.yaml独立部署文件中的以下env属性。独立用户 Operator 部署配置示例
apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-user-operator labels: app: strimzi spec: # ... template: # ... spec: # ... containers: - name: strimzi-user-operator # ... env: - name: STRIMZI_NAMESPACE 1 valueFrom: fieldRef: fieldPath: metadata.namespace - name: STRIMZI_KAFKA_BOOTSTRAP_SERVERS 2 value: my-kafka-bootstrap-address:9092 - name: STRIMZI_CA_CERT_NAME 3 value: my-cluster-clients-ca-cert - name: STRIMZI_CA_KEY_NAME 4 value: my-cluster-clients-ca - name: STRIMZI_LABELS 5 value: "strimzi.io/cluster=my-cluster" - name: STRIMZI_FULL_RECONCILIATION_INTERVAL_MS 6 value: "120000" - name: STRIMZI_WORK_QUEUE_SIZE 7 value: 10000 - name: STRIMZI_CONTROLLER_THREAD_POOL_SIZE 8 value: 10 - name: STRIMZI_LOG_LEVEL 9 value: INFO - name: STRIMZI_GC_LOG_ENABLED 10 value: "true" - name: STRIMZI_CA_VALIDITY 11 value: "365" - name: STRIMZI_CA_RENEWAL 12 value: "30" - name: STRIMZI_JAVA_OPTS 13 value: "-Xmx=512M -Xms=256M" - name: STRIMZI_JAVA_SYSTEM_PROPERTIES 14 value: "-Djavax.net.debug=verbose -DpropertyName=value" - name: STRIMZI_SECRET_PREFIX 15 value: "kafka-" - name: STRIMZI_ACLS_ADMIN_API_SUPPORTED 16 value: "true" - name: STRIMZI_MAINTENANCE_TIME_WINDOWS 17 value: '* * 8-10 * * ?;* * 14-15 * * ?' - name: STRIMZI_KAFKA_ADMIN_CLIENT_CONFIGURATION 18 value: | default.api.timeout.ms=120000 request.timeout.ms=60000- 1
- 用于监视
KafkaUser资源的 User Operator 的 OpenShift 命名空间。只能指定一个命名空间。 - 2
- 用于发现并连接到 Kafka 集群中所有代理的 bootstrap 代理地址的主机和端口对。在服务器停机时,使用逗号分隔列表来指定两个或三个代理地址。
- 3
- 包含为 mTLS 身份验证签名新用户证书的证书颁发机构(
ca.crt)值的 OpenShiftSecret。 - 4
- 包含为 mTLS 身份验证签名新用户证书的证书颁发机构(
ca.key)值的 OpenShiftSecret。 - 5
- 用于标识由 User Operator 管理的
KafkaUser资源的标签。这不一定是 Kafka 集群的名称。它可以是分配给KafkaUser资源的标签。如果部署多个用户 Operator,则每个标签必须是唯一的。也就是说,操作员无法管理相同的资源。 - 6
- 定期协调之间的间隔(以毫秒为单位)。默认值为
120000(2 分钟)。 - 7
- 控制器事件队列的大小。队列的大小应至少与您希望 User Operator 操作的用户的最大影响大小相同。默认值为
1024。 - 8
- 用于协调用户的 worker 池的大小。较大的池可能需要更多资源,但它也会处理更多的
KafkaUser资源。默认值为50。 - 9
- 打印日志记录消息的级别。您可以将级别设为
ERROR、WARNING、INFO、DEBUG或TRACE。 - 10
- 启用垃圾回收(GC)日志记录。默认值是
true。 - 11
- 证书颁发机构的有效性周期。默认值为
365天。 - 12
- 证书颁发机构的续订期限。续订周期从当前证书的过期日期向后兼容。默认为
30天,可在旧证书过期之前启动证书续订。 - 13
- (可选)运行 User Operator 的 JVM 使用的 Java 选项
- 14
- (可选)为 User Operator 设置的调试(
-D)选项 - 15
- (可选) 用于 User Operator 创建的 OpenShift secret 的名称的前缀。
- 16
- (可选)指示 Kafka 集群是否支持使用 Kafka Admin API 管理授权 ACL 规则。当设置为
false时,User Operator 将拒绝具有simple授权 ACL 规则的所有资源。这有助于避免 Kafka 集群日志中不必要的异常。默认值是true。 - 17
- (可选)Semi-colon 分离的 Cron 表达式列表,用于定义过期用户证书的维护时间窗口。
- 18
- (可选)用来以属性格式配置 User Operator 使用的 Kafka Admin 客户端的配置选项。
如果使用 mTLS 连接到 Kafka 集群,请指定用于验证连接的 secret。否则,转到下一步。
mTLS 配置示例
# .... env: - name: STRIMZI_CLUSTER_CA_CERT_SECRET_NAME 1 value: my-cluster-cluster-ca-cert - name: STRIMZI_EO_KEY_SECRET_NAME 2 value: my-cluster-entity-operator-certs # ..."
部署 User Operator。
oc create -f install/user-operator
检查部署的状态:
oc get deployments
输出显示了部署名称和就绪状态
NAME READY UP-TO-DATE AVAILABLE strimzi-user-operator 1/1 1 1
READY显示 ready/expected 的副本数量。当AVAILABLE输出显示为1时,部署成功。
第 7 章 设置 Kafka 集群的客户端访问权限
部署 AMQ Streams 后,本节中的步骤解释了如何:
- 部署示例制作者和使用者客户端,您可以使用它来验证部署
使用监听程序设置对 Kafka 集群的客户端访问权限
为 OpenShift 外部的客户端设置对 Kafka 集群的访问权限的步骤比较复杂,需要熟悉 Kafka 组件配置流程。
7.1. 部署示例客户端
此流程演示了如何部署使用您创建的 Kafka 集群来发送和接收消息的示例制作者和使用者客户端。
先决条件
- Kafka 集群可用于客户端。
流程
部署 Kafka producer。
oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic
- 在运行制作者的控制台中键入一条消息。
- 按 Enter 来发送邮件。
部署 Kafka 使用者。
oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginning
- 确认您在使用者控制台中看到传入的信息。
7.2. 使用监听程序设置对 Kafka 集群的客户端访问
使用 Kafka 集群的地址,您可以提供对同一 OpenShift 集群中的客户端的访问权限;或提供对不同 OpenShift 命名空间或 OpenShift 之外的客户端的外部访问权限。此流程演示了如何配置从 OpenShift 外部或从另一个 OpenShift 集群配置对 Kafka 集群的客户端访问。
Kafka 侦听器提供访问。支持以下监听程序类型:
-
在同一 OpenShift 集群内连接的
内部 -
使用 OpenShift
Route和默认 HAProxy 路由器的路由 -
LoadBalancer使用负载均衡器服务 -
NodePort使用 OpenShift 节点上的端口 -
Ingress使用 OpenShift Ingress 和 Ingress NGINX Controller for Kubernetes -
cluster-ip使用 per-brokerClusterIP服务公开 Kafka
所选的类型取决于您的要求,以及您的环境和基础架构。例如,负载均衡器可能不适用于某些基础架构,如裸机,节点端口提供了更好的选项。
在这个流程中:
-
为 Kafka 集群配置外部监听程序,启用 TLS 加密和 mTLS 身份验证,以及 Kafka
简单授权。 -
为客户端创建
KafkaUser,使用 mTLS 验证和为简单授权定义的访问控制列表(ACL)创建。
您可以将监听程序配置为使用 mutual tls、scram-sha-512 或 oauth 身份验证。mTLS 始终使用加密,但在使用 SCRAM-SHA-512 和 OAuth 2.0 身份验证时,也建议加密。
您可以为 Kafka 代理配置简单的、oauth、opa 或 自定义 授权。启用后,授权将应用到所有启用的监听程序。
当您配置 KafkaUser 身份验证和授权机制时,请确保它们与对等的 Kafka 配置匹配:
-
KafkaUser.spec.authentication匹配Kafka.spec.kafka.listeners[*].authentication -
KafkaUser.spec.authorization匹配Kafka.spec.kafka.authorization
您应该至少有一个监听程序支持您要用于 KafkaUser 的身份验证。
Kafka 用户和 Kafka 代理之间的身份验证取决于每个验证设置。例如,如果 Kafka 配置中还没有启用,则无法使用 mTLS 验证用户。
AMQ Streams operator 会自动完成配置过程,并创建身份验证所需的证书:
- Cluster Operator 创建监听程序并设置集群和客户端证书颁发机构(CA)证书,以便通过 Kafka 集群启用身份验证。
- User Operator 根据所选的身份验证类型创建代表客户端和用于客户端身份验证的安全凭证的用户。
您可以将证书添加到客户端配置中。
在这一流程中,会使用 Cluster Operator 生成的 CA 证书,但您可以 通过安装自己的证书 来替换它们。您还可以将监听程序 配置为使用由外部 CA (证书颁发机构)管理的 Kafka 侦听器证书。
证书以 PEM (.crt)和 PKCS #12 (.p12)格式提供。这个过程使用 PEM 证书。将 PEM 证书用于 X.509 格式使用证书的客户端。
对于同一 OpenShift 集群和命名空间中的内部客户端,您可以在 pod 规格中挂载集群 CA 证书。如需更多信息,请参阅配置内部客户端以信任集群 CA。
先决条件
- Kafka 集群可供 OpenShift 集群外部运行的客户端进行连接
- Cluster Operator 和 User Operator 在集群中运行
流程
使用 Kafka 侦听器配置 Kafka 集群。
- 定义通过监听程序访问 Kafka 代理所需的身份验证。
在 Kafka 代理上启用授权。
监听程序配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster namespace: myproject spec: kafka: # ... listeners: 1 - name: external 2 port: 9094 3 type: <listener_type> 4 tls: true 5 authentication: type: tls 6 configuration: 7 #... authorization: 8 type: simple superUsers: - super-user-name 9 # ...- 1
- 有关启用外部监听器的配置选项,请参考 Generic Kafka 侦听器 schema。
- 2
- 用于标识监听程序的名称。必须在 Kafka 集群中唯一。
- 3
- Kafka 内监听器使用的端口号。端口号必须在给定的 Kafka 集群中唯一。允许的端口号为 9092 及更高版本,除了端口 9404 和 9999 除外,后者已用于 Prometheus 和 JMX。根据监听程序类型,端口号可能与连接 Kafka 客户端的端口号不同。
- 4
- 将外部监听程序类型指定为
路由、loadbalancer、nodeport或ingress。内部监听程序被指定为internal或cluster-ip。 - 5
- 必需。监听器上的 TLS 加密。对于
route和ingress类型监听程序,它必须设置为true。对于 mTLS 身份验证,也使用authentication属性。 - 6
- 侦听器上的客户端身份验证机制。对于使用 mTLS 的服务器和客户端身份验证,请指定
tls: true和authentication.type: tls。 - 7
- (可选)根据监听程序类型的要求,您可以指定额外的 监听程序配置。
- 8
- 授权指定为
simple,它使用AclAuthorizerKafka 插件。 - 9
- (可选)Super 用户可以访问所有代理,无论 ACL 中定义的任何访问限制如何。
警告OpenShift Route 地址由 Kafka 集群的名称、侦听器的名称以及在其中创建的命名空间的名称组成。例如,
my-cluster-kafka-listener1-bootstrap-myproject(CLUSTER-NAME-kafka-LISTENER-NAME-bootstrap-NAMESPACE)。如果您使用路由监听程序类型,请注意地址的整个长度不超过 63 个字符的最大值。
创建或更新
Kafka资源。oc apply -f <kafka_configuration_file>Kafka 集群使用 mTLS 身份验证配置有 Kafka 代理监听程序。
为每个 Kafka 代理 pod 创建服务。
创建服务作为连接到 Kafka 集群的 bootstrap 地址。
一个服务也作为外部 bootstrap 地址为到 Kafka 集群的外部连接创建,使用
nodeport监听器。在 secret <cluster
_name> -cluster-ca-cert 中也创建了用于验证 kafka 代理身份的集群CA 证书。注意如果您在使用外部监听程序时扩展 Kafka 集群,可能会触发所有 Kafka 代理的滚动更新。这取决于配置。
检索您用来从
Kafka资源状态访问 Kafka 集群的 bootstrap 地址。oc get kafka <kafka_cluster_name> -o=jsonpath='{.status.listeners[?(@.name=="<listener_name>")].bootstrapServers}{"\n"}'
例如:
oc get kafka my-cluster -o=jsonpath='{.status.listeners[?(@.name=="external")].bootstrapServers}{"\n"}'使用 Kafka 客户端中的 bootstrap 地址连接到 Kafka 集群。
创建或修改代表需要访问 Kafka 集群的客户端的用户。
-
指定与
Kafka监听器相同的验证类型。 指定用于
简单授权的授权 ACL。用户配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster 1 spec: authentication: type: tls 2 authorization: type: simple acls: 3 - resource: type: topic name: my-topic patternType: literal operations: - Describe - Read - resource: type: group name: my-group patternType: literal operations: - Read
-
指定与
创建或修改
KafkaUser资源。oc apply -f USER-CONFIG-FILE创建用户,以及名称与
KafkaUser资源的名称相同的 secret。secret 包含用于 mTLS 验证的公钥和私钥。secret 示例
apiVersion: v1 kind: Secret metadata: name: my-user labels: strimzi.io/kind: KafkaUser strimzi.io/cluster: my-cluster type: Opaque data: ca.crt: <public_key> # Public key of the clients CA user.crt: <user_certificate> # Public key of the user user.key: <user_private_key> # Private key of the user user.p12: <store> # PKCS #12 store for user certificates and keys user.password: <password_for_store> # Protects the PKCS #12 store从 Kafka 集群的 <
cluster_name>-cluster-ca-certsecret 中提取集群 CA 证书。oc get secret <cluster_name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt从 <
user_name> secret 中提取用户 CA 证书。oc get secret <user_name> -o jsonpath='{.data.user\.crt}' | base64 -d > user.crt从 <
user_name> secret 中提取用户的私钥。oc get secret <user_name> -o jsonpath='{.data.user\.key}' | base64 -d > user.key使用用于连接 Kafka 集群的 bootstrap 地址主机名和端口配置客户端:
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "<hostname>:<port>");使用 truststore 凭证配置客户端,以验证 Kafka 集群的身份。
指定公共集群 CA 证书。
信任存储配置示例
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL"); props.put(SslConfigs.SSL_TRUSTSTORE_TYPE_CONFIG, "PEM"); props.put(SslConfigs.SSL_TRUSTSTORE_CERTIFICATES_CONFIG, "<ca.crt_file_content>");SSL 是用于 mTLS 验证的指定安全协议。为 TLS 的 SCRAM-SHA-512 身份验证指定
SASL_SSL。PEM 是 truststore 的文件格式。使用密钥存储凭证配置您的客户端,以在连接到 Kafka 集群时验证用户。
指定公共证书和私钥。
密钥存储配置示例
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL"); props.put(SslConfigs.SSL_KEYSTORE_TYPE_CONFIG, "PEM"); props.put(SslConfigs.SSL_KEYSTORE_CERTIFICATE_CHAIN_CONFIG, "<user.crt_file_content>"); props.put(SslConfigs.SSL_KEYSTORE_KEY_CONFIG, "<user.key_file_content>");
将密钥存储证书和私钥直接添加到配置中。将 作为单行格式添加。在
BEGIN CERTIFICATE和END CERTIFICATE分隔符之间,以换行符(\n)开头。结束原始证书中的每一行也带有\n。密钥存储配置示例
props.put(SslConfigs.SSL_KEYSTORE_CERTIFICATE_CHAIN_CONFIG, "-----BEGIN CERTIFICATE----- \n<user_certificate_content_line_1>\n<user_certificate_content_line_n>\n-----END CERTIFICATE---"); props.put(SslConfigs.SSL_KEYSTORE_KEY_CONFIG, "----BEGIN PRIVATE KEY-----\n<user_key_content_line_1>\n<user_key_content_line_n>\n-----END PRIVATE KEY-----");
其他资源
- 侦听器身份验证选项
- Kafka 授权选项
- 如果您使用的是授权服务器,您可以使用基于令牌的 OAuth 2.0 身份验证和 OAuth 2.0 授权。
第 8 章 为 AMQ Streams 设置指标和仪表板
您可以使用 Prometheus 和 Grafana 监控 AMQ Streams 部署。
您可以通过查看仪表板上的密钥指标并设置在特定条件下触发的警报来监控 AMQ Streams 部署。对于 AMQ Streams 的每个组件,指标数据都可用。
您还可以收集特定于 oauth 身份验证和 opa 或 keycloak 授权的指标。您可以通过在 Kafka 资源的监听程序配置中将 enableMetrics 属性设置为 true。例如,在 spec.kafka.listeners.authentication 和 spec.kafka.authorization 中将 enableMetrics 设置为 true。同样,您可以在 KafkaBridge,KafkaConnect, 和 KafkaMirrorMaker 2oauth 身份验证的指标。
为提供指标数据,AMQ Streams 使用 Prometheus 规则和 Grafana 仪表板。
当为 AMQ Streams 组件配置一组规则时,Prometheus 会消耗集群中运行的 pod 中的关键指标。然后,Grafana 会在仪表板中视觉化这些指标。AMQ Streams 包括 Grafana 仪表板示例,您可以自定义以适合您的部署。
AMQ Streams 为用户定义的项目(一个 OpenShift 功能)使用监控 来简化 Prometheus 设置过程。
根据您的要求,您可以:
使用 Prometheus 和 Grafana 设置,您可以使用 AMQ Streams 提供的示例 Grafana 仪表板进行监控。
另外,您可以通过设置 分布式追踪功能,将部署配置为跟踪消息端到端。
AMQ Streams 为 Prometheus 和 Grafana 提供示例安装文件。您可以在尝试监控 AMQ Streams 时将这些文件用作起点。要获得进一步的支持,请尝试与 Prometheus 和 Grafana 开发人员社区互动。
支持指标和监控工具的文档
如需有关指标和监控工具的更多信息,请参阅支持文档:
- Prometheus
- Prometheus 配置
- Kafka Exporter
- Grafana Labs
- Apache Kafka Monitoring 描述了 Apache Kafka 公开的 JMX 指标
- zookeeper JMX 描述了 Apache ZooKeeper 公开的 JMX 指标
8.1. 使用 Kafka 导出器监控消费者
Kafka Exporter 是一个开源项目,用于增强对 Apache Kafka 代理和客户端的监控。您可以配置 Kafka 资源,以使用 Kafka 集群部署 Kafka 导出器。Kafka Exporter 从与偏移、消费者组、消费者群和主题相关的 Kafka 代理中提取额外的指标数据。例如,使用指标数据来帮助识别缓慢的消费者。lag 数据作为 Prometheus 指标公开,然后可在 Grafana 中进行分析。
Kafka Exporter 从 __consumer_offsets 主题中读取,该主题存储了消费者组的提交偏移信息。要使 Kafka 导出器能够正常工作,需要使用使用者组。
Kafka Exporter 的 Grafana 仪表板是 AMQ Streams 提供的很多 Grafana 仪表板 之一。
Kafka Exporter 只提供与消费者 lag 和 consumer offsets 相关的其他指标。对于常规 Kafka 指标,您必须在 Kafka 代理 中配置 Prometheus 指标。
消费者滞后表示消息的速度与消息的消耗的差别。具体来说,给定使用者组的使用者 lag 指示分区中最后一条消息之间的延时,以及当前由该使用者获取的消息之间的延迟。
lag 反映了与分区日志末尾相关的使用者偏移位置。
生产者和消费者偏移量之间
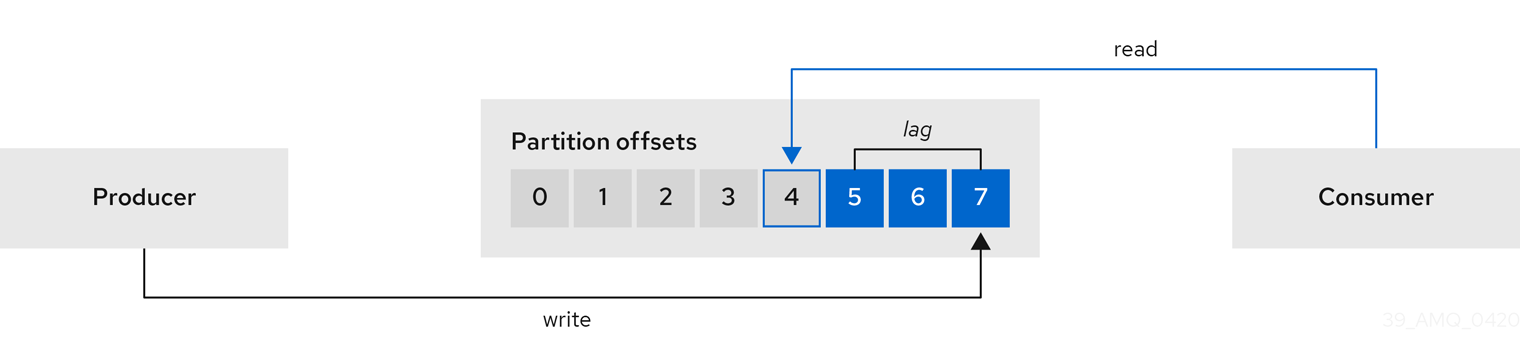
这种区别有时被称为制作者偏移和使用者偏移之间的 delta :在 Kafka 代理主题分区中读取和写入位置。
假设主题流 100 条消息。生产偏移(主题分区头)和最后的偏移量之间是 1000 条消息的 lag 表示 10 秒的延迟。
监控消费者的重要性
对于依赖于实时数据的处理的应用程序,监控消费者来判断其是否不会变得太大。整个过程越好,流程从实时处理目标中得到的增长。
例如,消费者滞后可能是消耗太多的旧数据(这些数据尚未被清除)或出现计划外的关闭。
减少消费 lag
使用 Grafana 图表来分析 lag,并检查是否对受影响的消费者组产生影响。例如,如果对 Kafka 代理进行了调整以减少滞后,仪表板将显示 Lag by consumer group 图表下降,Messages consumed per minute 图表增加。
减少 lag 的典型操作包括:
- 通过添加新消费者扩展消费者
- 为在主题中保留消息的保留时间
- 增加更多磁盘容量以增加消息缓冲区
减少消费者 lag 的操作取决于底层基础架构和 AMQ Streams 的支持。例如,分发的消费者不太可能从其磁盘缓存中获取请求的服务从代理服务。在某些情况下,在消费者发现之前,自动丢弃消息可能可以接受。
8.2. 监控控制操作
Cruise Control 监控 Kafka 代理,以跟踪代理、主题和分区的利用率。Cruise Control 提供一组用于监控其自身性能的指标。
Cruise Control metrics reporter 从 Kafka 代理收集原始指标数据。数据会被生成给由 Cruise Control 自动创建的主题。指标 用于为 Kafka 集群生成优化探测。
可以利用 Cruise Control 指标进行实时监控。例如,您可以使用 Cruise Control 指标来监控正在运行的重新平衡操作的状态,或者提供操作性能中检测到的任何异常情况的警报。
您可以通过在 Cruise Control 配置中启用 Prometheus JMX Exporter 来公开控制指标。
有关可用 Cruise 控制指标的完整列表,这些指标称为 sensors,请参见 Cruise Control 文档。
8.2.1. 公开 Cruise 控制指标
如果要公开基于 Cruise Control 操作的指标,请配置 Kafka 资源 来部署 Cruise Control 并在部署中启用 Prometheus 指标。您可以使用您自己的配置,或使用 AMQ Streams 提供的 kafka-cruise-control-metrics.yaml 文件示例。
您可以将配置添加到 Kafka 资源中 CruiseControl 属性的 metricsConfig 中。该配置可让 Prometheus JMX Exporter 通过 HTTP 端点公开控制指标。HTTP 端点由 Prometheus 服务器提取。
Cruise Control 的指标配置示例
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
Spec:
# ...
cruiseControl:
# ...
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: cruise-control-metrics
key: metrics-config.yml
---
kind: ConfigMap
apiVersion: v1
metadata:
name: cruise-control-metrics
labels:
app: strimzi
data:
metrics-config.yml: |
# metrics configuration...
8.2.2. 查看 Cruise Control 指标
公开 Cruise Control 指标后,您可以使用 Prometheus 或其他合适的监控系统查看指标数据的信息。AMQ Streams 提供了一个 Grafana 仪表板示例,用于显示 Cruise Control 指标的视觉化。仪表板是名为 strimzi-cruise-control.json 的 JSON 文件。公开的指标在启用 Grafana 仪表板时提供 监控数据。
8.2.2.1. 监控均衡的分数
断路器控制指标包括均衡的分数。Balancedness 是指在 Kafka 集群中平均分配工作负载的方式。
平衡器分数(均衡器分数)的 Cruise Control 指标可能与 KafkaRebalance 资源中的平衡分数不同。Cruise Control 使用可能与 KafkaRebalance 资源中使用的 default.goals 不同的 anomaly.detection.goals 计算每个分数。anomaly.detection.goals 在 Kafka 自定义资源的 spec.cruiseControl.config 中指定。
刷新 KafkaRebalance 资源获取优化提议。如果适用以下条件之一,则会获取最新的缓存的优化方案:
-
KafkaRebalance
目标与Kafka资源default.goals部分配置的目标匹配 -
未指定 KafkaRebalance
目标
否则,Cruise Control 会根据 KafkaRebalance 目标生成一个新的优化建议。如果使用每个刷新生成新提议,这可能会影响性能监控。
8.2.2.2. 异常检测上的警报
Cruise Control 的 omaly detector 提供了阻止生成优化目标(如代理故障)的条件的指标数据。如果需要更多可见性,您可以使用 anomaly detector 提供的指标来设置警报并发出通知。您可以设置 Cruise Control 的 anomaly notifier,以通过指定的通知频道根据这些指标路由警报。另外,您可以设置 Prometheus 来提取 anomaly detector 提供的指标数据,并生成警报。然后,Prometheus Alertmanager 可以路由 Prometheus 生成的警报。
Cruise Control 文档 提供有关 AnomalyDetector 指标和 anomaly notifier 的信息。
8.3. 指标文件示例
您可以在 AMQ Streams 提供的示例配置文件中找到 Grafana 仪表板和其他指标配置文件示例。
AMQ Streams 提供的指标文件示例
metrics ├── grafana-dashboards 1 │ ├── strimzi-cruise-control.json │ ├── strimzi-kafka-bridge.json │ ├── strimzi-kafka-connect.json │ ├── strimzi-kafka-exporter.json │ ├── strimzi-kafka-mirror-maker-2.json │ ├── strimzi-kafka.json │ ├── strimzi-operators.json │ └── strimzi-zookeeper.json ├── grafana-install │ └── grafana.yaml 2 ├── prometheus-additional-properties │ └── prometheus-additional.yaml 3 ├── prometheus-alertmanager-config │ └── alert-manager-config.yaml 4 ├── prometheus-install │ ├── alert-manager.yaml 5 │ ├── prometheus-rules.yaml 6 │ ├── prometheus.yaml 7 │ ├── strimzi-pod-monitor.yaml 8 ├── kafka-bridge-metrics.yaml 9 ├── kafka-connect-metrics.yaml 10 ├── kafka-cruise-control-metrics.yaml 11 ├── kafka-metrics.yaml 12 └── kafka-mirror-maker-2-metrics.yaml 13
- 1
- 不同 AMQ Streams 组件的 Grafana 仪表板示例。
- 2
- Grafana 镜像的安装文件。
- 3
- 额外的配置,用于提取 CPU、内存和磁盘卷使用量的指标,直接来自于节点上的 OpenShift cAdvisor 代理和 kubelet。
- 4
- 用于通过 Alertmanager 发送通知的 hook 定义。
- 5
- 用于部署和配置 Alertmanager 的资源。
- 6
- 用于 Prometheus Alertmanager 的警报规则示例(与 Prometheus 一起部署)。
- 7
- Prometheus 镜像的安装资源文件。
- 8
- PodMonitor 定义由 Prometheus Operator 转换为作业,以便 Prometheus 服务器直接从 pod 中提取指标数据。
- 9
- 启用指标的 Kafka Bridge 资源。
- 10
- 为 Kafka 连接定义 Prometheus JMX Exporter 重新标记规则的指标配置。
- 11
- 为 Cruise 控制定义 Prometheus JMX Exporter 重新标记规则的指标配置。
- 12
- 为 Kafka 和 ZooKeeper 定义 Prometheus JMX Exporter 重新标记规则的指标配置。
- 13
- 为 Kafka Mirror Maker 2.0 定义 Prometheus JMX Exporter 重新标记规则的指标配置。
8.3.1. Prometheus 指标配置示例
AMQ Streams 使用 Prometheus JMX Exporter 来通过 HTTP 端点公开指标,端点可由 Prometheus 服务器提取。
Grafana 仪表板依赖于 Prometheus JMX Exporter 重新标记规则,这些规则在自定义资源配置中为 AMQ Streams 组件定义。
标签是一个名称值对。重新标记是指动态编写标签的过程。例如,标签的值可以从 Kafka 服务器和客户端名称派生而来。
AMQ Streams 提供示例自定义资源配置 YAML 文件,并带有重新标记规则。在部署 Prometheus 指标配置时,您可以部署示例自定义资源,或将指标配置复制到您自己的自定义资源定义中。
表 8.1. 带有指标配置的自定义资源示例
| 组件 | 自定义资源 | YAML 文件示例 |
|---|---|---|
| Kafka 和 ZooKeeper |
|
|
| Kafka Connect |
|
|
| Kafka MirrorMaker 2.0 |
|
|
| Kafka Bridge |
|
|
| Sything Control |
|
|
8.3.2. 警报通知的 Prometheus 规则示例
警报通知的 Prometheus 规则示例提供 AMQ Streams 提供的示例 指标配置文件。规则在 prometheus-rules.yaml 文件中的示例中指定,用于 Prometheus 部署。
警报规则提供有关指标中观察到的特定条件的通知。规则在 Prometheus 服务器上声明,但 Prometheus Alertmanager 负责警报通知。
Prometheus 警报规则使用 PromQL 表达式来持续评估的条件。
当警报表达式变为 true 时,满足条件,Prometheus 服务器会将警报数据发送到 Alertmanager。Alertmanager 然后使用为其部署配置的通信方法发送通知。
有关警报规则定义的一般点:
-
for属性与规则搭配使用,以确定在触发警报前必须保留条件的时间。 -
一个 tick 是一个基本的 ZooKeeper 时间单元,单位为毫秒,使用
Kafka.spec.zookeeper.config的tickTime参数进行测量和配置。例如,如果 ZooKeepertickTime=3000, 3 个 ticks (3 x 3000)等于 9000 毫秒。 -
ZookeeperRunningOutOfSpace指标和警报的可用性取决于所使用的 OpenShift 配置和存储实施。某些平台的存储实施可能无法提供指标提供警报所需的可用空间的信息。
Alertmanager 可以配置为使用电子邮件、聊天消息或其他通知方法。根据您的需要调整示例规则的默认配置。
8.3.2.1. 更改规则示例
prometheus-rules.yaml 文件包含以下组件的示例规则:
- Kafka
- ZooKeeper
- Entity Operator
- Kafka Connect
- Kafka Bridge
- MirrorMaker
- Kafka Exporter
文件中提供了每个示例规则的描述。
8.3.3. Grafana 仪表板示例
如果部署 Prometheus 以提供指标,您可以使用 AMQ Streams 提供的示例 Grafana 仪表板来监控 AMQ Streams 组件。
示例仪表板在 example /metrics/grafana-dashboards 目录中作为 JSON 文件提供。
所有仪表板都提供 JVM 指标,以及组件相关的指标。例如,AMQ Streams 操作器的 Grafana 仪表板提供有关它们正在处理的协调或自定义资源数量的信息。
示例仪表板没有显示 Kafka 支持的所有指标。仪表板会填充一组用于监控的代表指标。
表 8.2. Grafana 仪表板文件示例
| 组件 | JSON 文件示例 |
|---|---|
| AMQ Streams operator |
|
| Kafka |
|
| ZooKeeper |
|
| Kafka Connect |
|
| Kafka MirrorMaker 2.0 |
|
| Kafka Bridge |
|
| Sything Control |
|
| Kafka Exporter |
|
当 Kafka Exporter 没有可用于 Kafka Exporter 时,因为集群中没有流量,Kafka Exporter Grafana 仪表板将显示 N/A 的数字字段和 No data to show for graphs。
8.4. 部署 Prometheus 指标配置
部署 Prometheus 指标配置,以便将 Prometheus 与 AMQ Streams 搭配使用。使用 metricsConfig 属性来启用和配置 Prometheus 指标。
您可以使用您自己的配置或者 AMQ Streams 提供的示例自定义资源配置文件。
-
kafka-metrics.yaml -
kafka-connect-metrics.yaml -
kafka-mirror-maker-2-metrics.yaml -
kafka-bridge-metrics.yaml -
kafka-cruise-control-metrics.yaml
示例配置文件具有重新标记规则以及启用 Prometheus 指标所需的配置。Prometheus 从目标 HTTP 端点中提取指标。示例文件是尝试使用 AMQ Streams 尝试 Prometheus 的好方法。
要应用重新标记规则和指标配置,请执行以下操作之一:
- 将示例配置复制到您自己的自定义资源
- 使用指标配置部署自定义资源
如果要包含 Kafka Exporter 指标,请在 Kafka 资源中添加 kafkaExporter 配置。
Kafka Exporter 只提供与消费者 lag 和 consumer offsets 相关的其他指标。对于常规 Kafka 指标,您必须在 Kafka 代理 中配置 Prometheus 指标。
此流程演示了如何在 Kafka 资源中部署 Prometheus 指标配置。将示例文件用于其他资源时,该进程是相同的。
流程
使用 Prometheus 配置部署示例自定义资源。
例如,对于应用
kafka-metrics.yaml文件的每个Kafka资源。部署示例配置
oc apply -f kafka-metrics.yaml
另外,您可以将
kafka-metrics.yaml中的示例配置复制到您自己的Kafka资源。复制示例配置
oc edit kafka <kafka-configuration-file>复制
metricsConfig属性及其对Kafka资源引用的ConfigMap。Kafka 的指标配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... metricsConfig: 1 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: kafka-metrics key: kafka-metrics-config.yml --- kind: ConfigMap 2 apiVersion: v1 metadata: name: kafka-metrics labels: app: strimzi data: kafka-metrics-config.yml: | # metrics configuration...注意对于 Kafka Bridge,您可以指定
enableMetrics属性,并将其设置为true。apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: # ... bootstrapServers: my-cluster-kafka:9092 http: # ... enableMetrics: true # ...要部署 Kafka Exporter,请添加
kafkaExporter配置。kafkaExporter配置只在Kafka资源中指定。部署 Kafka 导出器配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: # ... kafkaExporter: image: my-registry.io/my-org/my-exporter-cluster:latest 1 groupRegex: ".*" 2 topicRegex: ".*" 3 resources: 4 requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi logging: debug 5 enableSaramaLogging: true 6 template: 7 pod: metadata: labels: label1: value1 imagePullSecrets: - name: my-docker-credentials securityContext: runAsUser: 1000001 fsGroup: 0 terminationGracePeriodSeconds: 120 readinessProbe: 8 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: 9 initialDelaySeconds: 15 timeoutSeconds: 5 # ...
要使 Kafka 导出器能够正常工作,需要使用使用者组。
8.5. 在 OpenShift 中查看 Kafka 指标和仪表板
当 AMQ Streams 部署到 OpenShift Container Platform 时,通过 监控用户定义的项目提供指标数据。此 OpenShift 功能允许开发人员访问单独的 Prometheus 实例来监控其自己的项目(如 Kafka 项目)。
如果启用了对用户定义的项目的监控,openshift-user-workload-monitoring 项目包含以下组件:
- Prometheus Operator
- Prometheus 实例(由 Prometheus Operator 自动部署)
- Thanos Ruler 实例
AMQ Streams 使用这些组件来消耗指标。
集群管理员必须为用户定义的项目启用监控,然后授予开发人员和其他用户权限来监控其自己的项目中的应用程序。
Grafana 部署
您可以将 Grafana 实例部署到包含 Kafka 集群的项目中。然后,可以使用 Grafana 仪表板示例来视觉化 Grafana 用户界面中 AMQ Streams 的 Prometheus 指标。
openshift-monitoring 项目为核心平台组件提供监控。不要在 OpenShift Container Platform 4.x 上使用 Prometheus 和 Grafana 组件来为 AMQ Streams 配置监控。
流程概述
要在 OpenShift Container Platform 中设置 AMQ Streams 监控,请按照以下步骤执行:
8.5.1. 先决条件
- 已使用示例 YAML 文件 部署了 Prometheus 指标配置。
-
启用了 对用户定义的项目的监控。集群管理员已在 OpenShift 集群中创建了
cluster-monitoring-config配置映射。 -
集群管理员已为您分配了
monitoring-rules-edit或monitoring-edit角色。
有关创建 cluster-monitoring-config 配置映射并授予用户监控用户定义的项目的权限的更多信息,请参阅 OpenShift Container Platform Monitoring。
8.5.2. 其他资源
- OpenShift Container Platform Monitoring
8.5.3. 部署 Prometheus 资源
使用 Prometheus 获取 Kafka 集群中的监控数据。
您可以使用自己的 Prometheus 部署,或使用 AMQ Streams 提供的示例指标配置文件 部署 Prometheus。要使用示例文件,您需要配置和部署 PodMonitor 资源。PodMonitor 直接从 Apache Kafka、ZooKeeper、Operator、Kafka Bridge 和 Cruise Control 的 pod 中提取数据。
然后,您要为 Alertmanager 部署示例警报规则。
先决条件
- 正在运行的 Kafka 集群。
- 检查 AMQ Streams 提供的示例警报规则。
流程
检查是否启用了对用户定义的项目的监控:
oc get pods -n openshift-user-workload-monitoring
如果启用,则返回监控组件的 Pod。例如:
NAME READY STATUS RESTARTS AGE prometheus-operator-5cc59f9bc6-kgcq8 1/1 Running 0 25s prometheus-user-workload-0 5/5 Running 1 14s prometheus-user-workload-1 5/5 Running 1 14s thanos-ruler-user-workload-0 3/3 Running 0 14s thanos-ruler-user-workload-1 3/3 Running 0 14s
如果没有返回 pod,则禁用对用户定义的项目的监控。请参阅 第 8.5 节 “在 OpenShift 中查看 Kafka 指标和仪表板” 中的先决条件。
在 example
/metrics/prometheus-install/strimzi-pod-monitor.yaml中定义多个PodMonitor资源。对于每个
PodMonitor资源,编辑spec.namespaceSelector.matchNames属性:apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: name: cluster-operator-metrics labels: app: strimzi spec: selector: matchLabels: strimzi.io/kind: cluster-operator namespaceSelector: matchNames: - <project-name> 1 podMetricsEndpoints: - path: /metrics port: http # ...- 1
- 要从中提取指标的 Pod 的项目,如
Kafka。
将
strimzi-pod-monitor.yaml文件部署到运行 Kafka 集群的项目:oc apply -f strimzi-pod-monitor.yaml -n MY-PROJECT将示例 Prometheus 规则部署到同一个项目中:
oc apply -f prometheus-rules.yaml -n MY-PROJECT
8.5.4. 为 Grafana 创建服务帐户
AMQ Streams 的 Grafana 实例需要使用为 cluster-monitoring-view 角色的服务帐户运行。
如果您使用 Grafana 呈现用于监控指标,请创建一个服务帐户。
先决条件
流程
为 Grafana 创建
ServiceAccount。此处的资源名为grafana-serviceaccount。apiVersion: v1 kind: ServiceAccount metadata: name: grafana-serviceaccount labels: app: strimzi将
ServiceAccount部署到包含 Kafka 集群的项目:oc apply -f GRAFANA-SERVICEACCOUNT -n MY-PROJECT
创建一个
ClusterRoleBinding资源,它将cluster-monitoring-view角色分配给 GrafanaServiceAccount。此处的资源名为grafana-cluster-monitoring-binding。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: grafana-cluster-monitoring-binding labels: app: strimzi subjects: - kind: ServiceAccount name: grafana-serviceaccount namespace: <my-project> 1 roleRef: kind: ClusterRole name: cluster-monitoring-view apiGroup: rbac.authorization.k8s.io- 1
- 项目的名称。
将
ClusterRoleBinding部署到包含 Kafka 集群的项目:oc apply -f <grafana-cluster-monitoring-binding> -n <my-project>
8.5.5. 使用 Prometheus 数据源部署 Grafana
将 Grafana 部署到 present Prometheus 指标。Grafana 应用程序需要配置 OpenShift Container Platform 监控堆栈。
OpenShift Container Platform 在 openshift-monitoring 项目中包含一个 Thanos Querier 实例。Thanos Querier 用于聚合平台指标。
要使用所需的平台指标,您的 Grafana 实例需要一个可连接到 Thanos Querier 的 Prometheus 数据源。要配置这个连接,您可以创建一个配置映射来进行身份验证,使用令牌到与 Thanos Querier 一起运行的 oauth-proxy sidecar。datasource.yaml 文件被用作配置映射的来源。
最后,您要使用挂载为卷的配置映射部署 Grafana 应用程序到包含 Kafka 集群的项目。
流程
获取 Grafana
ServiceAccount的访问令牌:oc serviceaccounts get-token grafana-serviceaccount -n MY-PROJECT复制访问令牌以在下一步中使用。
创建包含 Grafana 的 Thanos Querier 配置的
datasource.yaml文件。按照所示,将访问令牌粘贴到
httpHeaderValue1属性中。apiVersion: 1 datasources: - name: Prometheus type: prometheus url: https://thanos-querier.openshift-monitoring.svc.cluster.local:9091 access: proxy basicAuth: false withCredentials: false isDefault: true jsonData: timeInterval: 5s tlsSkipVerify: true httpHeaderName1: "Authorization" secureJsonData: httpHeaderValue1: "Bearer ${GRAFANA-ACCESS-TOKEN}" 1 editable: true- 1
GRAFANA-ACCESS-TOKEN:GrafanaServiceAccount的访问令牌值。
从 Datasource
.yaml文件中创建一个名为grafana-config的配置映射:oc create configmap grafana-config --from-file=datasource.yaml -n MY-PROJECT创建由
Deployment和Service组成的 Grafana 应用程序。grafana-config配置映射作为数据源配置的卷挂载。apiVersion: apps/v1 kind: Deployment metadata: name: grafana labels: app: strimzi spec: replicas: 1 selector: matchLabels: name: grafana template: metadata: labels: name: grafana spec: serviceAccountName: grafana-serviceaccount containers: - name: grafana image: grafana/grafana:9.3.1 ports: - name: grafana containerPort: 3000 protocol: TCP volumeMounts: - name: grafana-data mountPath: /var/lib/grafana - name: grafana-logs mountPath: /var/log/grafana - name: grafana-config mountPath: /etc/grafana/provisioning/datasources/datasource.yaml readOnly: true subPath: datasource.yaml readinessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 15 periodSeconds: 20 volumes: - name: grafana-data emptyDir: {} - name: grafana-logs emptyDir: {} - name: grafana-config configMap: name: grafana-config --- apiVersion: v1 kind: Service metadata: name: grafana labels: app: strimzi spec: ports: - name: grafana port: 3000 targetPort: 3000 protocol: TCP selector: name: grafana type: ClusterIP将 Grafana 应用程序部署到包含 Kafka 集群的项目中:
oc apply -f <grafana-application> -n <my-project>
8.5.6. 创建到 Grafana 服务的路由
您可以通过公开 Grafana 服务的路由访问 Grafana 用户界面。
流程
创建到
grafana服务的边缘路由:oc create route edge <my-grafana-route> --service=grafana --namespace=KAFKA-NAMESPACE
8.5.7. 导入 Grafana 仪表板示例
使用 Grafana 在可自定义仪表板上提供 Prometheus 指标的视觉化。
AMQ Streams 以 JSON 格式为 Grafana 提供示例仪表板配置文件。
-
examples/metrics/grafana-dashboards
此流程使用 Grafana 仪表板示例。
示例仪表板是监控密钥指标的良好起点,但它们不会显示 Kafka 支持的所有指标。您可以修改示例仪表板,或根据您的基础架构添加其他指标。
流程
获取到 Grafana 服务的路由详情。例如:
oc get routes NAME HOST/PORT PATH SERVICES MY-GRAFANA-ROUTE MY-GRAFANA-ROUTE-amq-streams.net grafana
- 在 Web 浏览器中,使用 Route 主机和端口的 URL 访问 Grafana 登录屏幕。
输入您的用户名和密码,然后点 Log In。
默认的 Grafana 用户名和密码都是
admin。第一次登录后,您可以更改密码。- 在 Configuration > Data Sources 中,检查是否已创建 Prometheus 数据源。数据源是在 第 8.5.5 节 “使用 Prometheus 数据源部署 Grafana” 中创建。
- 单击 + 图标,然后单击 Import。
-
在
example/metrics/grafana-dashboards中,复制要导入的仪表板的 JSON。 - 将 JSON 粘贴到文本框中,然后点 Load。
- 为其他 Grafana 仪表板重复步骤 5-7。
从 Dashboards 主页中查看导入的 Grafana 仪表板。
第 9 章 分布式追踪简介
分布式追踪跟踪分布式系统中应用程序之间的事务进度。在微服务架构中,跟踪服务间的事务进度。trace 数据可用于监控应用程序性能和调查目标系统和最终用户应用程序的问题。
在 AMQ Streams 中,追踪有助于对消息的端到端跟踪:从源系统到 Kafka,然后从 Kafka 到目标系统和应用程序。分布式追踪在 Grafana 仪表板中补充指标监控以及组件日志记录器。
以下 Kafka 组件内置了对追踪的支持:
- MirrorMaker 将来自源集群的信息追踪到目标集群
- Kafka 连接到由 Kafka Connect 使用和生成的 trace 信息
- Kafka Bridge 用来跟踪 Kafka 和 HTTP 客户端应用程序之间的信息
Kafka 代理不支持追踪。
您可以通过其自定义资源为这些组件启用和配置追踪。您可以使用 spec.template 属性添加追踪配置。
您可以使用 spec.tracing.type 属性指定追踪类型来启用追踪:
opentelemetry-
指定
type: opentelemetry以使用 OpenTelemetry。默认情况下,OpenTelemetry 使用 OTLP (OpenTelemetry Protocol)导出器和端点来获取追踪数据。您可以指定 OpenTelemetry 支持的其他追踪系统,包括 Jaeger tracing。要做到这一点,您可以在追踪配置中更改 OpenTelemetry exporter 和端点。 jaeger-
指定
type:jaeger以使用 OpenTracing 和 Jaeger 客户端来获取 trace 数据。
支持 type: jaeger tracing 已被弃用。Jaeger 客户端现已停用,OpenTracing 项目存档。因此,我们不能保证其对将来的 Kafka 版本的支持。如果可能,我们将保持对 type: jaeger tracing 的支持,直到 2023 年 6 月为止。请尽快迁移到 OpenTelemetry。
9.1. 跟踪选项
使用 OpenTelemetry 或 OpenTracing (已弃用) Jaeger 追踪系统。
OpenTelemetry 和 OpenTracing 提供独立于追踪或监控系统的 API 规格。
您可以使用 API 检测应用程序代码进行追踪。
- 检测的应用程序会在 分布式系统中为单个请求生成跟踪。
- trace 由 范围 组成,它们定义一段时间内的特定工作单元。
Jaeger 是基于微服务的分布式系统的追踪系统。
- Jaeger 实现追踪 API,并为工具提供客户端库。
- Jaeger 用户界面允许您查询、过滤和分析追踪数据。
Jaeger 用户界面显示简单的查询

9.2. 用于追踪的环境变量
在为 Kafka 组件启用追踪或为 Kafka 客户端初始化 tracer 时,请使用环境变量。
跟踪环境变量可能会发生变化。有关最新信息,请参阅 OpenTelemetry 文档 和 OpenTracing 文档。
下表描述了用于设置 tracer 的关键环境变量。
表 9.1. OpenTelemetry 环境变量
| 属性 | 必需 | Description |
|---|---|---|
|
| 是 | OpenTelemetry 的 Jaeger tracing 服务的名称。 |
|
| 是 | 用于追踪的 exporter。 |
|
| 是 |
用于追踪的 exporter。默认设置为 |
表 9.2. OpenTracing 环境变量
| 属性 | 必需 | Description |
|---|---|---|
|
| 是 | Jaeger tracer 服务的名称。 |
|
| 否 |
通过 User Datagram Protocol (UDP)与 |
|
| 否 |
用于通过 UDP 与 |
9.3. 设置分布式追踪
通过在自定义资源中指定追踪类型,在 Kafka 组件中启用分布式追踪。Kafka 客户端中的工具追踪器,用于端到端跟踪信息。
要设置分布式追踪,请按照以下步骤执行:
- 为 MirrorMaker、Kafka Connect 和 Kafka Bridge 启用追踪
为客户端设置追踪:
使用 tracers 检测客户端:
9.3.1. 先决条件
在设置分布式追踪前,请确保 Jaeger 后端组件已部署到 OpenShift 集群。我们建议使用 Jaeger operator 在 OpenShift 集群上部署 Jaeger。
有关部署说明,请参阅 Jaeger 文档。
为 AMQ Streams 以外的应用程序和系统设置追踪不在此内容范围内。
9.3.2. 在 MirrorMaker、Kafka Connect 和 Kafka Bridge 资源中启用追踪
MirrorMaker、MirrorMaker 2.0、Kafka Connect 和 AMQ Streams Kafka Bridge 支持分布式追踪。配置组件的自定义资源,以指定和启用 tracer 服务。
在资源中启用追踪会触发以下事件:
- 拦截器类在组件的集成使用者和生产者中更新。
- 对于 MirrorMaker、MirrorMaker 2.0 和 Kafka Connect,追踪代理根据资源中定义的追踪配置初始化 tracer。
- 对于 Kafka Bridge,基于资源中定义的追踪配置 tracer 由 Kafka Bridge 本身初始化。
您可以启用使用 OpenTelemetry 或 OpenTracing 的追踪。
MirrorMaker 和 MirrorMaker 2.0 中的追踪
对于 MirrorMaker 和 MirrorMaker 2.0,信息会根据源集群追踪到目标集群。trace 数据记录输入并离开 MirrorMaker 或 MirrorMaker 2.0 组件的消息。
Kafka Connect 中的追踪
对于 Kafka Connect,只有 Kafka Connect 生成并消耗的消息才会被追踪。要跟踪 Kafka Connect 和外部系统之间发送的消息,您必须在连接器中配置这些系统的追踪。
在 Kafka Bridge 中的追踪
对于 Kafka Bridge,Kafka Bridge 生成并消耗的消息会被追踪。另外还会跟踪来自客户端应用程序来发送和接收通过 Kafka Bridge 的信息的 HTTP 请求。要具有端到端追踪,您必须在 HTTP 客户端中配置追踪。
流程
为每个 KafkaMirrorMaker、KafkaMirrorMaker2、KafkaConnect 和 KafkaBridge 资源执行这些步骤。
在
spec.template属性中配置 tracer 服务。- 使用 追踪环境变量 作为模板配置属性。
-
对于 OpenTelemetry,将
spec.tracing.type属性设置为opentelemetry。 -
对于 OpenTracing,将
spec.tracing.type属性设置为jaeger。
使用 OpenTelemetry 的 Kafka Connect 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...使用 OpenTelemetry 的 MirrorMaker 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: #... template: mirrorMakerContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...使用 OpenTelemetry 的 MirrorMaker 2.0 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...使用 OpenTelemetry 的 Kafka Bridge 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: #... template: bridgeContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...使用 OpenTracing 进行 Kafka Connect 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... template: connectContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...使用 OpenTracing 的 MirrorMaker 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: #... template: mirrorMakerContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...使用 OpenTracing 的 MirrorMaker 2.0 的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...使用 OpenTracing 的 Kafka 网桥的追踪配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: #... template: bridgeContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...创建或更新资源:
oc apply -f <resource_configuration_file>
9.3.3. 为 Kafka 客户端初始化追踪
初始化 tracer,然后检测您的客户端应用程序以进行分布式追踪。您可以检测 Kafka producer 和使用者客户端,以及 Kafka Streams API 应用程序。您可以初始化 OpenTracing 或 OpenTelemetry 的 tracer。
使用一组 追踪环境变量 配置和初始化 tracer。
流程
在每个客户端应用程序中添加 tracer 的依赖项:
将 Maven 依赖项添加到客户端应用程序的
pom.xml文件中:OpenTelemetry 的依赖项
<dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-sdk-extension-autoconfigure</artifactId> <version>1.18.0-alpha</version> </dependency> <dependency> <groupId>io.opentelemetry.instrumentation</groupId> <artifactId>opentelemetry-kafka-clients-{OpenTelemetryKafkaClient}</artifactId> <version>1.18.0-alpha</version> </dependency> <dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-exporter-jaeger</artifactId> <version>1.18.0</version> </dependency>OpenTracing 的依赖项
<dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.15</version> </dependency>- 使用追踪环境变量定义 tracer 的配置。
创建一个 tracer,它使用环境变量初始化:
为 OpenTelemetry 创建 tracer
OpenTelemetry ot = GlobalOpenTelemetry.get();
为 OpenTracing 创建追踪器
Tracer tracer = Configuration.fromEnv().getTracer();
将 tracer 注册为全局 tracer:
GlobalTracer.register(tracer);
检测您的客户端:
9.3.4. 提取制作者和消费者以进行追踪
在 Kafka 生产者和消费者中启用追踪的检测应用程序代码。使用 decorator 模式或拦截器工具您的 Java producer 和消费者应用程序代码进行追踪。然后,您可以在从主题生成或检索信息时记录跟踪。
OpenTelemetry 和 OpenTracing 检测项目提供支持生产者和消费者工具的类。
- decorator 工具
- 对于 decorator 检测,请创建修改的制作者或消费者实例以进行追踪。decorator 工具与 OpenTelemetry 和 OpenTracing 的不同。
- 拦截器工具
- 要进行拦截器检测,请将追踪功能添加到使用者或制作者配置中。拦截器工具与 OpenTelemetry 和 OpenTracing 相同。
先决条件
您已为 客户端 初始化追踪。
您可以通过在项目中添加追踪 JAR 作为依赖项来启用制作者和使用者应用。
流程
在各个制作者和消费者应用的应用代码中执行这些步骤。使用 decorator 模式或拦截器(拦截器)检测您的客户端应用程序代码。
要使用 decorator 模式,请创建修改后的制作者或消费者实例来发送或接收消息。
您传递了原始
KafkaProducer或KafkaConsumer类。OpenTelemetry 的 decorator 检测示例
// Producer instance Producer < String, String > op = new KafkaProducer < > ( configs, new StringSerializer(), new StringSerializer() ); Producer < String, String > producer = tracing.wrap(op); KafkaTracing tracing = KafkaTracing.create(GlobalOpenTelemetry.get()); producer.send(...); //consumer instance Consumer<String, String> oc = new KafkaConsumer<>( configs, new StringDeserializer(), new StringDeserializer() ); Consumer<String, String> consumer = tracing.wrap(oc); consumer.subscribe(Collections.singleton("mytopic")); ConsumerRecords<Integer, String> records = consumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);OpenTracing 的 decorator 检测示例
//producer instance KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer, tracer); TracingKafkaProducer.send(...) //consumer instance KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer, tracer); tracingConsumer.subscribe(Collections.singletonList("mytopic")); ConsumerRecords<Integer, String> records = tracingConsumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);要使用拦截器,请在制作者或消费者配置中设置拦截器类。
您以通常的方式使用
KafkaProducer和KafkaConsumer类。TracingProducerInterceptor和TracingConsumerInterceptorinterceptor 类负责追踪功能。使用拦截器的制作者配置示例
senderProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); producer.send(...);使用拦截器的使用者配置示例
consumerProps.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName()); KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); consumer.subscribe(Collections.singletonList("messages")); ConsumerRecords<Integer, String> records = consumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
9.3.5. 用于追踪的 Kafka Streams 应用程序
在 Kafka Streams API 应用程序中启用追踪的检测应用程序代码。使用 decorator 模式或拦截器检测您的 Kafka Streams API 应用程序进行追踪。然后,您可以在从主题生成或检索信息时记录跟踪。
- decorator 工具
-
对于 decorator 工具,为追踪创建修改后的 Kafka Streams 实例。OpenTracing 工具项目提供
TracingKafkaClientSupplier类,它支持 Kafka 流的检测。您可以创建一个TracingKafkaClientSupplier供应商接口的嵌套实例,它为 Kafka Streams 提供追踪工具。对于 OpenTelemetry,此过程相同,但您需要创建一个自定义TracingKafkaClientSupplier类以提供支持。 - 拦截器工具
- 要进行拦截器检测,请将追踪功能添加到 Kafka Streams producer 和消费者配置中。
先决条件
您已为 客户端 初始化追踪。
您可以通过在项目中添加追踪 JAR 作为依赖项来启用 Kafka Streams 应用程序中的检测。
-
要使用 OpenTelemetry 检测 Kafka Streams,您需要编写自定义
TracingKafkaClientSupplier。 自定义
TracingKafkaClientSupplier可以扩展 Kafka 的DefaultKafkaClientSupplier,覆盖生成者和消费者创建方法,将实例嵌套与遥测相关的代码。自定义
TracingKafkaClientSupplier示例private class TracingKafkaClientSupplier extends DefaultKafkaClientSupplier { @Override public Producer<byte[], byte[]> getProducer(Map<String, Object> config) { KafkaTelemetry telemetry = KafkaTelemetry.create(GlobalOpenTelemetry.get()); return telemetry.wrap(super.getProducer(config)); } @Override public Consumer<byte[], byte[]> getConsumer(Map<String, Object> config) { KafkaTelemetry telemetry = KafkaTelemetry.create(GlobalOpenTelemetry.get()); return telemetry.wrap(super.getConsumer(config)); } @Override public Consumer<byte[], byte[]> getRestoreConsumer(Map<String, Object> config) { return this.getConsumer(config); } @Override public Consumer<byte[], byte[]> getGlobalConsumer(Map<String, Object> config) { return this.getConsumer(config); } }
流程
为每个 Kafka Streams API 应用程序执行这些步骤。
要使用 decorator 模式,请创建一个
TracingKafkaClientSupplier供应商接口实例,然后向KafkaStreams提供供应商接口。decorator 工具示例
KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer); KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();
要使用拦截器,请在 Kafka Streams producer 和消费者配置中设置拦截器类。
TracingProducerInterceptor和TracingConsumerInterceptorinterceptor 类负责追踪功能。使用拦截器的制作者和使用者配置示例
props.put(StreamsConfig.PRODUCER_PREFIX + ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); props.put(StreamsConfig.CONSUMER_PREFIX + ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName());
9.3.6. 介绍不同的 OpenTelemetry 追踪系统
除了默认的 Jaeger 系统,您可以指定 OpenTelemetry 支持的其他追踪系统。您可以通过在 AMQ Streams 提供的 Kafka 镜像中添加所需的工件。还必须设置任何必要的实施特定环境变量。然后,您可以使用 OTEL_TRACES_EXPORTER 环境变量启用新的追踪实施。
此流程演示了如何实施 Zipkin tracing。
流程
将追踪工件添加到 AMQ Streams Kafka 镜像的
/opt/kafka/libs/目录中。您可以使用 红帽生态系统目录 上的 Kafka 容器镜像作为创建新自定义镜像的基础镜像。
Zipkin 的 OpenTelemetry 构件
io.opentelemetry:opentelemetry-exporter-zipkin
为新的追踪实施设置追踪器和端点。
Zikpin tracer 配置示例
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-zipkin-service - name: OTEL_EXPORTER_ZIPKIN_ENDPOINT value: http://zipkin-exporter-host-name:9411/api/v2/spans 1 - name: OTEL_TRACES_EXPORTER value: zipkin 2 tracing: type: opentelemetry #...
9.3.7. 自定义范围名称
追踪 span 是 Jaeger 中的逻辑工作单元,包括操作名称、开始时间和持续时间。span 具有内置名称,但您可以在使用 Kafka 客户端工具中指定自定义 span 名称。
指定自定义范围名称是可选的,只有在生成者和消费者客户端检测或 Kafka Streams 检测中使用 decorator 模式时才适用。
9.3.7.1. 为 OpenTelemetry 指定 span 名称
无法使用 OpenTelemetry 直接指定自定义 span 名称。相反,您可以通过向客户端应用程序添加代码来获取 span 名称,以提取其他标签和属性。
提取属性的代码示例
//Defines attribute extraction for a producer
private static class ProducerAttribExtractor implements AttributesExtractor < ProducerRecord < ? , ? > , Void > {
@Override
public void onStart(AttributesBuilder attributes, ProducerRecord < ? , ? > producerRecord) {
set(attributes, AttributeKey.stringKey("prod_start"), "prod1");
}
@Override
public void onEnd(AttributesBuilder attributes, ProducerRecord < ? , ? > producerRecord, @Nullable Void unused, @Nullable Throwable error) {
set(attributes, AttributeKey.stringKey("prod_end"), "prod2");
}
}
//Defines attribute extraction for a consumer
private static class ConsumerAttribExtractor implements AttributesExtractor < ConsumerRecord < ? , ? > , Void > {
@Override
public void onStart(AttributesBuilder attributes, ConsumerRecord < ? , ? > producerRecord) {
set(attributes, AttributeKey.stringKey("con_start"), "con1");
}
@Override
public void onEnd(AttributesBuilder attributes, ConsumerRecord < ? , ? > producerRecord, @Nullable Void unused, @Nullable Throwable error) {
set(attributes, AttributeKey.stringKey("con_end"), "con2");
}
}
//Extracts the attributes
public static void main(String[] args) throws Exception {
Map < String, Object > configs = new HashMap < > (Collections.singletonMap(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"));
System.setProperty("otel.traces.exporter", "jaeger");
System.setProperty("otel.service.name", "myapp1");
KafkaTracing tracing = KafkaTracing.newBuilder(GlobalOpenTelemetry.get())
.addProducerAttributesExtractors(new ProducerAttribExtractor())
.addConsumerAttributesExtractors(new ConsumerAttribExtractor())
.build();
9.3.7.2. 为 OpenTracing 指定范围名称
要为 OpenTracing 指定自定义范围名称,请在检测生产者和消费者时将 BiFunction 对象作为参数传递。
有关内置名称和指定自定义范围名称以检测客户端应用代码的更多信息,请参阅 OpenTracing Apache Kafka 客户端检测。
第 10 章 升级 AMQ Streams
AMQ Streams 可以升级至 2.3 版本,以充分利用新功能、改进性能以及安全性选项。
作为升级的一部分,您需要将 Kafka 升级到最新支持的版本。每个 Kafka 版本都会为 AMQ Streams 部署引入了新功能、改进和程序错误修复。
如果您遇到与 新版本相关的问题,AMQ Streams 可以降级到 以前的版本。
发布的 AMQ Streams 版本可从 AMQ Streams 软件下载页面获得。
升级停机时间和可用性
如果为高可用性配置了主题,升级 AMQ Streams 不应该导致消费者和制作者发布和从这些主题发布和读取数据的生产时间。高可用性主题在代理中平均分布至少 3 个和分区的复制因素。
升级 AMQ Streams 会触发滚动更新,所有代理都会在进程的不同阶段重启。在滚动更新过程中,并非所有代理都在线,因此会临时减少 集群总体可用性。集群可用性的缩减会增加代理失败会导致信息丢失的几率。
10.1. AMQ Streams 升级路径
可以使用两个升级路径。
- 增量升级
- 将 AMQ Streams 从以前的次版本升级到 2.3 版本。
- 多版本升级
在单个升级中,将 AMQ Streams 从旧版本升级到 2.3 (skipping一个或多个中间版本)。
例如,从 AMQ Streams 1.8 直接升级到 AMQ Streams 2.3。
10.1.1. 支持的 Kafka 版本
决定在启动 AMQ Streams 升级过程前要升级到的 Kafka 版本。您可以在 AMQ Streams 支持的配置 中查看支持的 Kafka 版本。
- 对于生产环境,支持 Kafka 3.3.1。
- Kafka 3.2.3 仅支持升级到 AMQ Streams 2.3。
只能使用您要使用的 AMQ Streams 版本支持的 Kafka 版本。只要您的 AMQ Streams 版本支持,就可以升级到一个更高的 Kafka 版本。在某些情况下,您还可以降级以前的 Kafka 版本。
10.1.2. 从 1.7 之前的 AMQ Streams 版本升级
如果要从 1.7 版本之前的版本升级到 AMQ Streams 的最新版本,请执行以下操作:
- 按照标准序列 将 AMQ Streams 升级到 1.7。
-
使用 AMQ Streams 1.8 提供的 Red Hat AMQ Streams API Conversion Tool 将 AMQ Streams 自定义资源转换为
v1beta2。 执行以下操作之一:
-
升级到 AMQ Streams 1.8 (其中
ControlPlaneListener功能被默认禁用)。 -
升级到 AMQ Streams 2.0 或 2.2 (其中
ControlPlaneListener功能门被默认启用),并禁用ControlPlaneListener功能门。
-
升级到 AMQ Streams 1.8 (其中
-
启用
ControlPlaneListener功能门。 - 按照标准序列 升级到 AMQ Streams 2.3。
AMQ Streams 自定义资源使用 1.7 中的 v1beta2 API 版本启动。在升级到 AMQ Streams 1.8 或更新版本 前,必须转换 CRD 和自定义资源。有关使用 API 转换工具的详情,请查看 AMQ Streams 1.7 升级文档。
作为第一个升级到 1.7 版本的替代选择,您可以从版本 1.7 中安装自定义资源,然后转换资源。
ControlPlaneListener 功能现在在 AMQ Streams 中永久启用。您必须升级到一个禁用的 AMQ Streams 版本,然后使用 Cluster Operator 配置中的 STRIMZI_FEATURE_GATES 环境变量启用。
禁用 ControlPlaneListener 功能门
env:
- name: STRIMZI_FEATURE_GATES
value: -ControlPlaneListener
启用 ControlPlaneListener 功能门
env:
- name: STRIMZI_FEATURE_GATES
value: +ControlPlaneListener
10.2. 所需的升级序列
要在不停机的情况下升级代理和客户端,您必须 按照以下顺序完成 AMQ Streams 升级过程:
确保您的 OpenShift 集群版本被支持。
OpenShift 4.8 到 4.12 支持 AMQ Streams 2.3。
您可以以 最短停机时间升级 OpenShift。
- 升级 Cluster Operator。
- 将所有 Kafka 代理和客户端应用程序 升级到最新支持的 Kafka 版本。
- 可选:升级使用者和 Kafka Streams 应用程序 ,以使用 增量合作重新平衡 协议 进行分区重新平衡。
10.3. 在短短停机时间的情况下升级 OpenShift
如果要升级 OpenShift,请参阅 OpenShift 升级文档,以检查升级路径和正确升级节点的步骤。在升级 OpenShift 前 ,请检查您的 AMQ Streams 版本的支持版本。
在执行升级时,您需要将 Kafka 集群保持可用。
您可以使用以下策略之一:
- 配置 pod 中断预算
使用以下方法之一滚动 pod:
- 使用 AMQ Streams Drain Cleaner
- 通过将注解应用到 pod 手动
在使用其中一种方法推出 pod 前,您必须配置 pod 中断预算。
要使 Kafka 保持正常运行,还必须复制主题以实现高可用性。这要求主题配置指定至少 3 个复制因素,最小同步副本的数量为复制因素的数量减 1。
Kafka 主题复制以实现高可用性
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 3
config:
# ...
min.insync.replicas: 2
# ...
在高可用性环境中,Cluster Operator 会在升级过程中维护最少数量的非同步副本,以便不会停机。
10.3.1. 使用 AMQ Streams Drain Cleaner 滚动 pod
您可以使用 AMQ Streams Drain Cleaner 工具在升级过程中驱除节点。AMQ Streams Drain Cleaner 使用滚动更新 pod 注解注解 pod。这会通知 Cluster Operator 执行被驱除的 pod 的滚动更新。
pod 中断预算只允许指定数量的 pod 在给定时间不可用。在计划维护 Kafka 代理 pod 的过程中,pod 中断预算可确保 Kafka 在高可用性的环境中继续运行。
您可以使用对 Kafka 组件的 模板 自定义来指定 pod 中断预算。默认情况下,pod 中断预算只允许一个 pod 在给定时间不可用。
要做到这一点,您要将 maxUnavailable 设置为 0 ( 零)。减少最大 pod 中断预算为零可防止自愿中断,因此必须手动驱除 pod。
指定 pod 中断预算
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: myproject
spec:
kafka:
# ...
template:
podDisruptionBudget:
maxUnavailable: 0
# ...
10.3.2. 手动滚动 pod,同时保持主题可用
在升级过程中,您可以通过 Cluster Operator 手动滚动更新 pod。使用 Pod 资源,滚动使用新 pod 来更新资源 pod。与使用 AMQ Streams Drain Cleaner 一样,对于 pod 中断预算,您需要将 maxUnavailable 值设置为零。
您需要监视需要排空的 pod。然后,添加一个 pod 注解来进行更新。
此处,注解会更新 Kafka 代理。
对 Kafka 代理 pod 执行手动滚动更新
oc annotate pod <cluster_name>-kafka-<index> strimzi.io/manual-rolling-update=true
将 & lt;cluster_name > 替换为集群的名称。Kafka 代理 pod 的名称为 & lt;cluster-name> -kafka-<index & gt;,其中 <index> 从零开始,结尾是 replicas减一总数。例如,my-cluster-kafka-0。
10.4. 升级 Cluster Operator
使用相同的方法,将 Cluster Operator 升级为初始部署方法。
- 使用安装文件
- 如果您使用安装 YAML 文件部署了 Cluster Operator,通过修改 Operator 安装文件来执行升级,如使用安装文件 升级 Cluster Operator 所述。
- 使用 OperatorHub
如果您从 OperatorHub 部署 AMQ Streams,请使用 Operator Lifecycle Manager (OLM)将 AMQ Streams Operator 的更新频道改为一个新的 AMQ Streams 版本。
更新频道会根据您选择的升级策略启动以下类型的升级之一:
- 启动自动升级
- 在安装开始前需要批准的手动升级
注意如果您订阅了 stable 频道,您可以在不更改频道的情况下获得自动更新。但是,不建议启用自动更新,因为缺少任何预安装升级步骤。仅在特定于版本的频道中使用自动升级。
如需有关使用 OperatorHub 升级 Operator 的更多信息,请参阅升级安装的 Operator (OpenShift 文档)。
10.4.1. 升级 Cluster Operator 会返回 Kafka 版本错误
如果升级 Cluster Operator 并收到 不受支持的 Kafka 版本 错误,则 Kafka 集群部署有一个旧的 Kafka 版本,它不受新 operator 版本的支持。这个错误适用于所有安装方法。
如果发生这个错误,将 Kafka 升级到受支持的 Kafka 版本。将 Kafka 资源中的 spec.kafka.version 更改为支持的版本。
您可以使用 oc 检查错误信息,如包括在 Kafka 资源的 status 中的信息。
检查 Kafka 状态中的错误
oc get kafka <kafka_cluster_name> -n <namespace> -o jsonpath='{.status.conditions}'
将 <kafka_cluster_name > 替换为 Kafka 集群的名称,& lt;namespace > 替换为运行 pod 的 OpenShift 命名空间。
10.4.2. 使用 OperatorHub 从 AMQ Streams 1.7 或更早版本升级
从 AMQ Streams 1.7 或更早版本使用 OperatorHub 进行的操作
在将 Red Hat Integration - AMQ Streams Operator 升级到 2.3 之前,您需要进行以下更改:
-
将自定义资源和 CRD 转换为
v1beta2 -
升级到禁用
ControlPlaneListener功能门的 AMQ Streams 版本
这些要求在 第 10.1.2 节 “从 1.7 之前的 AMQ Streams 版本升级” 中进行了描述。
如果您要从 AMQ Streams 1.7 或更早版本升级,请执行以下操作:
- 升级到 AMQ Streams 1.7。
- 下载由 AMQ Streams 1.8 提供的 Red Hat AMQ Streams API Conversion Tool。
将自定义资源和 CRD 转换为
v1beta2。如需更多信息,请参阅 AMQ Streams 1.7 升级文档。
- 在 OperatorHub 中,删除 Red Hat Integration - AMQ Streams Operator 版本 1.7。
如果存在,请删除 Red Hat Integration - AMQ Streams Operator 的版本 2.3。
如果不存在,请转到下一步。
如果 AMQ Streams Operator 的批准策略被设置为 Automatic,则集群中可能已存在 operator 版本 2.3。如果您没有将 自定义资源和 CRD 转换为
v1beta2API 版本,Operator 管理的自定义资源和 CRD 将使用旧的 API 版本。因此,2.3 Operator 处于 Pending 状态。在这种情况下,您需要删除 Red Hat Integration - AMQ Streams Operator 和 1.7 版本 2.3 版本。如果删除了这两个 Operator,协调会暂停,直到安装了新的 operator 版本。立即按照以下步骤操作,以便对自定义资源的任何更改都不会延迟。
在 OperatorHub 中,执行以下操作之一:
-
升级到 Red Hat Integration 版本 1.8 - AMQ Streams Operator (其中
ControlPlaneListener功能门被默认禁用)。 -
升级至 Red Hat Integration 的版本 2.0 或 2.2 - AMQ Streams Operator (默认为启用
ControlPlaneListener功能门),且禁用了ControlPlaneListener功能门。
-
升级到 Red Hat Integration 版本 1.8 - AMQ Streams Operator (其中
马上升级到 Red Hat Integration 的 2.3 版本 - AMQ Streams Operator。
安装的 2.3 operator 开始监视集群并执行滚动更新。您可能会注意到这个过程中集群性能的临时降低。
10.4.3. 使用安装文件升级 Cluster Operator
这个步骤描述了如何升级 Cluster Operator 部署以使用 AMQ Streams 2.3。
如果使用安装 YAML 文件部署 Cluster Operator,请按照以下步骤操作。
由 Cluster Operator 管理的 Kafka 集群可用性不受升级操作的影响。
有关如何升级到该版本的信息,请参阅支持 AMQ Streams 特定版本的文档。
先决条件
- 提供了现有 Cluster Operator 部署。
- 您已 下载了 AMQ Streams 2.3 的发行工件。
流程
-
记录对现有 Cluster Operator 资源(在
/install/cluster-operator目录中)所做的任何配置更改。Cluster Operator 的新版本 将覆盖 任何更改。 - 更新您的自定义资源,以反映 AMQ Streams 版本 2.3 可用的受支持配置选项。
更新 Cluster Operator。
根据 Cluster Operator 在其中运行的命名空间,为新的 Cluster Operator 版本修改安装文件。
在 Linux 上,使用:
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
在 MacOS 上,使用:
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
-
如果您在现有 Cluster Operator
Deployment中修改了一个或多个环境变量,请编辑install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml文件来使用这些环境变量。
当您有更新的配置时,将其与其它安装资源一起部署:
oc replace -f install/cluster-operator
等待滚动更新完成。
如果新 Operator 版本不再支持从中升级的 Kafka 版本,Cluster Operator 会返回一条错误消息,表示不支持该版本。否则,不会返回任何错误消息。
如果返回错误消息,升级到新 Cluster Operator 版本支持的 Kafka 版本:
-
编辑
Kafka自定义资源。 -
将
spec.kafka.version属性改为受支持的 Kafka 版本。
-
编辑
- 如果未 返回错误消息,请转到下一步。稍后您将升级 Kafka 版本。
获取 Kafka pod 的镜像,以确保升级成功:
oc get pods my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'镜像标签显示新的 Operator 版本。例如:
registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0
Cluster Operator 升级到 2.3 版本,但其管理的集群中运行的 Kafka 版本没有改变。
在 Cluster Operator 升级后,您必须执行 Kafka 升级。
10.5. 升级 Kafka
将 Cluster Operator 升级到 2.3 后,下一步是将所有 Kafka 代理升级到最新支持的 Kafka 版本。
Kafka 升级由 Cluster Operator 通过滚动更新 Kafka 代理执行。
Cluster Operator 根据 Kafka 集群配置启动滚动更新。
如果 Kafka.spec.kafka.config 包含… | Cluster Operator 启动… |
|---|---|
|
|
单个滚动更新。在更新后,必须手动更新 |
|
| 两个滚动更新。 |
|
不配置 | 两个滚动更新。 |
从 Kafka 3.0.0,当 inter.broker.protocol.version 设置为 3.0 或更高版本时,logging.message.format.version 选项会被忽略,不需要设置。代理的 log.message.format.version 属性和主题的 message.format.version 属性已弃用,并将在以后的发行版本中删除。
作为 Kafka 升级的一部分,Cluster Operator 会启动 ZooKeeper 的滚动更新。
- 即使 ZooKeeper 版本没有改变,也会进行单个滚动更新。
- 如果新版本的 Kafka 需要新的 ZooKeeper 版本,则会出现额外的滚动更新。
10.5.1. Kafka 版本
Kafka 的日志消息格式版本和 inter-broker 协议版本分别指定,附加到消息的日志格式版本以及集群中使用的 Kafka 协议版本。为确保使用了正确的版本,升级过程涉及对现有 Kafka 代理和客户端应用程序(使用者和生产者)进行配置更改。
下表显示了 Kafka 版本之间的区别:
表 10.1. Kafka 版本的不同
| Kafka 版本 | Inter-broker 协议版本 | 日志消息格式版本 | zookeeper 版本 |
|---|---|---|---|
| 3.2.0 | 3.2 | 3.2 | 3.6.3 |
| 3.2.1 | 3.2 | 3.2 | 3.6.3 |
| 3.2.3 | 3.2 | 3.2 | 3.6.3 |
| 3.3.1 | 3.3 | 3.3 | 3.6.3 |
Inter-broker 协议版本
在 Kafka 中,用于交集通信的网络协议称为 inter-broker 协议。Kafka 的每个版本都有了一个内部代理协议的兼容版本。协议的次要版本通常会增加以匹配 Kafka 的次版本,如上表中所示。
在 Kafka 资源中设置了 cluster wide 的 inter-broker 协议版本。要更改它,您可以编辑 Kafka.spec.kafka.config 中的 inter.broker.protocol.version 属性。
日志消息格式版本
当制作者向 Kafka 代理发送消息时,该消息会使用特定的格式进行编码。在 Kafka 发行版本间可能会更改格式,因此信息会指定它们采用哪一种消息格式版本。
用来设置特定消息格式版本的属性如下:
-
主题的
message.format.version属性 -
Kafka 代理的
log.message.format.version属性
从 Kafka 3.0.0,消息格式版本值被假定为与 inter.broker.protocol.version 匹配,且不需要设置。这些值反映了使用的 Kafka 版本。
当升级到 Kafka 3.0.0 或更高版本时,您可以在更新 inter.broker.protocol.version 时删除这些设置。否则,根据您要升级到的 Kafka 版本设置消息格式版本。
由在 Kafka 代理中设置的 log.message.format.version 定义的 message.format.version 的默认值。您可以通过修改主题配置来手动设置主题的 message.format.version。
10.5.2. 升级客户端的策略
升级客户端应用程序(包括 Kafka Connect 连接器)的正确方法取决于您的具体情况。
消耗应用程序需要以消息格式接收它们所了解的消息。您可以以两种方式之一来确保这种情况:
- 在升级任何生产者 之前,先升级 主题的所有消费者。
- 通过将代理关闭至旧格式。
使用 broker down-conversion 在代理中放入额外的负载,因此对于较长的时间段内,它并不能依赖于 down-conversion 来处理所有主题。对于执行优化的代理,不应完全降低转换消息。
代理 down-conversion 可以通过两种方式配置:
-
topic-level
message.format.version为单个主题进行配置。 -
broker-level
log.message.format.version是没有配置 topic 级别消息.format.version的主题的默认设置。
向主题发布的新版本格式的消息对消费者可见,因为代理在从生产者接收消息时而不是向消费者接收消息时执行 down-conversion。
您可以用来升级客户端的常见策略如下所述。也可以升级客户端应用程序的其他策略。
当升级到 Kafka 3.0.0 或更高版本时,每个策略中所述的步骤都会稍有不同。从 Kafka 3.0.0,消息格式版本值被假定为与 inter.broker.protocol.version 匹配,且不需要设置。
代理级消费者第一个策略
- 升级所有消耗的应用程序。
-
将 broker-level
log.message.format.version更改为新版本。 - 升级所有生产应用程序。
这个策略非常简单,并避免任何代理 down-conversion。但是,它假定您组织中的所有消费者都能以协调的方式升级,并且不适用于使用者和制作者的应用程序。如果升级的客户端存在问题,新的格式信息可能会添加到消息日志中,因此您无法恢复到以前的消费者版本。
主题级消费者优先策略
对于每个主题:
- 升级所有消耗的应用程序。
-
将 topic-level
message.format.version更改为新版本。 - 升级所有生产应用程序。
此策略可避免任何代理 down-conversion,意味着您可以按主题进行主题。它不适用于同一主题的使用者和生产者。同样,如果升级的客户端出现问题,新的格式信息可能会添加到消息日志中。
使用转换进行"主题级消费者"优先策略
对于每个主题:
-
将 topic-level
message.format.version改为旧版本(或依赖主题 defaulting to the broker-levellog.message.format.version)。 - 升级所有消耗和生产应用程序。
- 验证升级的应用程序是否正常工作。
-
将 topic-level
message.format.version更改为新版本。
这个策略需要 broker down-conversion,但代理的负载会被最小化,因为它只需要单个主题(或小组主题)。它还适用于同一主题的使用者和生产者。这种方法可确保升级的制作者和使用者在提交使用新消息格式版本之前正常工作。
这种方法的主要缺点是,在具有许多主题和应用程序的集群中管理可能比较复杂。
也可以应用多个策略。例如,对于前几个应用程序和主题用户首先可以使用 "per-topic 用户,可以使用 down conversion"策略。经证实成功了另外一个成功时,可以考虑使用更有效的策略。
10.5.3. Kafka 版本和镜像映射
在升级 Kafka 时,请考虑 STRIMZI_KAFKA_IMAGES 环境变量和 Kafka.spec.kafka.version 属性的设置。
-
每个
Kafka资源都可使用Kafka.spec.kafka.version配置。 Cluster Operator 的
STRIMZI_KAFKA_IMAGES环境变量提供在给定 Kafka 资源中请求该版本时使用的Kafka版本和镜像之间的映射。-
如果没有配置
Kafka.spec.kafka.image,则会使用给定版本的默认镜像。 -
如果配置了
Kafka.spec.kafka.image,则默认镜像会被覆盖。
-
如果没有配置
Cluster Operator 无法验证镜像是否实际包含预期版本的 Kafka 代理。请小心操作,以确保指定的镜像与给定的 Kafka 版本对应。
10.5.4. 升级 Kafka 代理和客户端应用程序
将 AMQ Streams Kafka 集群升级到最新的支持的 Kafka 版本和 inter-broker 协议版本。
您还应选择 升级客户端 的策略。Kafka 客户端在此流程的第 6 步升级。
先决条件
- Cluster Operator 已启动并在运行。
-
在升级 AMQ Streams Kafka 集群前,请检查
Kafka资源的Kafka.spec.kafka.config属性不包含新的 Kafka 版本不支持的配置选项。
流程
更新 Kafka 集群配置:
oc edit kafka <my_cluster>如果配置,请检查
inter.broker.protocol.version和log.message.format.version属性是否已设置为 当前版本。例如,如果从 Kafka 版本 3.2.3 升级到 3.3.1,则当前版本为 3.2:
kind: Kafka spec: # ... kafka: version: 3.2.3 config: log.message.format.version: "3.2" inter.broker.protocol.version: "3.2" # ...如果没有配置
log.message.format.version和inter.broker.protocol.version,AMQ Streams 会在下一步升级到 Kafka 版本后自动将这些版本更新为当前默认值。注意log.message.format.version和inter.broker.protocol.version的值必须是字符串,以防止它们被解释为浮点号。更改
Kafka.spec.kafka.version以指定新的 Kafka 版本;将log.message.format.version和inter.broker.protocol.version保留为 当前 Kafka 版本的默认值。注意更改
kafka.version可确保将使用新的代理二进制文件升级集群中的所有代理。在此过程中,一些代理使用旧的二进制文件,而其他代理已升级到新的二进制文件。在当前设置中保持inter.broker.protocol.version的 inter.broker.protocol.version 可确保代理可以在升级期间继续相互通信。例如,如果从 Kafka 3.2.3 升级到 3.3.1:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 1 config: log.message.format.version: "3.2" 2 inter.broker.protocol.version: "3.2" 3 # ...警告如果新 Kafka 版本有
inter.broker.protocol.version的变化,则无法降级 Kafka。inter-broker 协议版本决定了用于代理存储的持久性元数据的 schema,包括写入__consumer_offsets的消息。降级的集群将无法了解信息。如果在 Kafka 自定义资源中定义了 Kafka 集群的镜像,在
Kafka.spec.kafka.image中,更新image以指向新的 Kafka 版本的容器镜像。请参阅 Kafka 版本和镜像映射
保存并退出编辑器,然后等待滚动更新完成。
通过观察 pod 状态转换来检查滚动更新的进度:
oc get pods my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'滚动更新可确保每个 pod 都对 Kafka 的新版本使用 broker 二进制文件。
根据您选择的 策略来升级客户端,将所有客户端应用升级到使用客户端二进制文件的新版本。
如果需要,将 Kafka Connect 和 MirrorMaker
的版本属性设置为 Kafka 的新版本:-
对于 Kafka Connect,更新
KafkaConnect.spec.version。 -
对于 MirrorMaker,更新
KafkaMirrorMaker.spec.version。 -
对于 MirrorMaker 2.0,更新
KafkaMirrorMaker2.spec.version。
-
对于 Kafka Connect,更新
如果配置,更新 Kafka 资源以使用新的
inter.broker.protocol.version版本。否则,请转到第 9 步。例如,如果升级到 Kafka 3.3.1:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 config: log.message.format.version: "3.2" inter.broker.protocol.version: "3.3" # ...- 等待 Cluster Operator 更新集群。
如果配置,更新 Kafka 资源以使用新的
log.message.format.version版本。否则,转至第 10 步。例如,如果升级到 Kafka 3.3.1:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 config: log.message.format.version: "3.3" inter.broker.protocol.version: "3.3" # ...重要从 Kafka 3.0.0,当
inter.broker.protocol.version设置为3.0或更高版本时,logging.message.format.version选项会被忽略,不需要设置。等待 Cluster Operator 更新集群。
- Kafka 集群和客户端现在使用新的 Kafka 版本。
- 代理被配置为使用新版本的 Kafka 的 inter-broker 协议版本和消息格式版本来发送消息。
如果需要,在 Kafka 升级后,您可以升级 用户以使用增量合作重新平衡协议。
10.6. 将消费者升级到合作重新平衡
您可以升级 Kafka 使用者和 Kafka Streams 应用程序,以使用 增量合作重新平衡 协议进行分区重新平衡,而不是默认的 预先重新平衡 协议。在 Kafka 2.4.0 中添加新协议。
消费者将分区分配保持在协作重新平衡中,并仅在需要实现均衡的集群时在进程结束时撤销它们。这可减少消费者组或 Kafka Streams 应用程序不可用。
升级到增量协作协议是可选的。仍然在支持预先重新平衡协议。
先决条件
- 您已将 Kafka 代理和客户端应用程序升级到 Kafka 3.3.1。
流程
要升级 Kafka 消费者以使用增量合作重新平衡协议:
-
将 Kafka 客户端
.jar文件替换为新版本。 -
在消费者配置中,将
cooperative-sticky附加到partition.assignment.strategy。例如,如果设置了范围策略,请将配置更改为范围,合作-sticky。 - 依次重启组中的每个消费者,等待用户在每次重启后重新加入组。
-
通过从消费者配置中删除之前
的分区.assignment.strategy来重新配置组中的每个消费者,仅让合作策略成为一个合作策略。 - 依次重启组中的每个消费者,等待用户在每次重启后重新加入组。
要升级 Kafka Streams 应用程序,请使用增量重新平衡协议:
-
将 Kafka Streams
.jar文件替换为新版本。 -
在 Kafka Streams 配置中,将
upgrade.from配置参数设置为您要从升级的 Kafka 版本(如 2.3)。 - 依次重启每个流处理器(节点)。
-
从 Kafka Streams 配置中删除
upgrade.from配置参数。 - 依次重新启动组中的每个消费者。
第 11 章 降级 AMQ Streams
如果您遇到升级到 AMQ Streams 版本的问题,您可以将安装恢复到以前的版本。
如果使用 YAML 安装文件来安装 AMQ Streams,您可以使用上一个发行版本中的 YAML 安装文件执行以下降级步骤:
如果之前的 AMQ Streams 版本不支持您使用的 Kafka 版本,则只要附加到消息的日志消息格式版本,您也可以降级 Kafka。
如果您使用其他安装方法部署 AMQ Streams,请使用受支持的方法降级 AMQ Streams。请勿使用此处提供的降级说明。例如,如果您使用 Operator Lifecycle Manager (OLM)安装了 AMQ Streams,可以通过将部署频道改为更早版本的 AMQ Streams 来降级。
11.1. 将 Cluster Operator 降级到以前的版本
如果您在使用 AMQ Streams 时遇到问题,您可以恢复安装。
这个步骤描述了如何将 Cluster Operator 部署降级到以前的版本。
先决条件
- 提供了现有 Cluster Operator 部署。
- 您已 下载了上一版本 的安装文件。
流程
-
记录对现有 Cluster Operator 资源(在
/install/cluster-operator目录中)所做的任何配置更改。所有 更改都会被 Cluster Operator 的早期版本覆盖。 - 恢复您的自定义资源,以反映可用于 AMQ Streams 版本的受支持配置选项,以降级到。
更新 Cluster Operator。
根据 Cluster Operator 在其中运行的命名空间,为之前的版本修改安装文件。
在 Linux 上,使用:
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
在 MacOS 上,使用:
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
-
如果您在现有 Cluster Operator
Deployment中修改了一个或多个环境变量,请编辑install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml文件来使用这些环境变量。
当您有更新的配置时,将其与其它安装资源一起部署:
oc replace -f install/cluster-operator
等待滚动更新完成。
获取 Kafka pod 的镜像,以确保降级成功:
oc get pod my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'镜像标签显示新的 AMQ Streams 版本,后跟 Kafka 版本。例如,
NEW-STRIMZI-VERSION-kafka-CURRENT-KAFKA-VERSION。
Cluster Operator 已降级为之前的版本。
11.2. 降级 Kafka
Kafka 版本降级由 Cluster Operator 执行。
11.2.1. 降级的 Kafka 版本兼容性
Kafka 降级依赖于兼容当前和目标 Kafka 版本,以及记录信息的状态。
如果该版本不支持该集群中 已使用的 inter.broker.protocol.version 设置,或者消息添加到使用较新的 log.message.format.version 的消息日志中,则无法恢复到之前的 Kafka 版本。
inter.broker.protocol.version 决定用于代理存储持久元数据的 schema,如写入 __consumer_offsets 的消息的 schema。如果您降级到不了解前已在集群中使用的 inter.broker.protocol.version 的 Kafka 版本,则该代理将遇到它无法理解的数据。
如果目标降级版本 Kafka 具有:
-
与当前版本 相同的
log.message.format.version,通过执行代理的单一滚动重启来降级 Cluster Operator。 一个不同的
log.message.format.version,只有运行的集群始终有log.message.format.version设置为降级版本使用的版本时,才可以下载。在更改log.message.format.version之前,升级过程才会被终止。在这种情况下,降级需要:- 如果两个版本的 interbroker 协议不同,则代理的两个滚动重启
- 如果滚动重启相同
如果新版本使用了之前版本 不支持的 log.message.format.version,则无法降级,包括在使用 log.message.format.version 的默认值时。例如,这个资源可以降级到 Kafka 版本 3.2.3,因为 log.message.format.version 还没有改变:
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
spec:
# ...
kafka:
version: 3.3.1
config:
log.message.format.version: "3.2"
# ...
如果 log.message.format.version 设置为 "3.3" 或没有值,则参数会为一个 3.3 代理 3.3.1 使用默认值,这会导致降级无法进行。
从 Kafka 3.0.0,当 inter.broker.protocol.version 设置为 3.0 或更高版本时,logging.message.format.version 选项会被忽略,不需要设置。
11.2.2. 降级 Kafka 代理和客户端应用程序
将 AMQ Streams Kafka 集群降级为 Kafka 的较低(以前)版本,如从 3.3.1 降级到 3.2.3。
先决条件
- Cluster Operator 已启动并在运行。
在降级 AMQ Streams Kafka 集群前,检查以下
Kafka资源:- 重要信息 : Kafka 版本的兼容性
-
Kafka.spec.kafka.config不包含将 Kafka 版本降级到的 Kafka 版本不支持的选项。 Kafka.spec.kafka.config有一个log.message.format.version和inter.broker.protocol.version,被降级到的 Kafka 版本支持。从 Kafka 3.0.0,当
inter.broker.protocol.version设置为3.0或更高版本时,logging.message.format.version选项会被忽略,不需要设置。
流程
更新 Kafka 集群配置。
oc edit kafka KAFKA-CONFIGURATION-FILE更改
Kafka.spec.kafka.version以指定上一个版本。例如,如果从 Kafka 3.3.1 降级到 3.2.3:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.2.3 1 config: log.message.format.version: "3.2" 2 inter.broker.protocol.version: "3.2" 3 # ...注意log.message.format.version和inter.broker.protocol.version的值必须是字符串,以防止它们被解释为浮点号。如果 Kafka 版本的镜像与 Cluster Operator 的
STRIMZI_KAFKA_IMAGES中定义的镜像不同,请更新Kafka.spec.kafka.image。保存并退出编辑器,然后等待滚动更新完成。
检查日志中的更新,或者查看 pod 状态转换:
oc logs -f CLUSTER-OPERATOR-POD-NAME | grep -E "Kafka version downgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"oc get pod -w
检查 Cluster Operator 日志中的
INFO级别信息:Reconciliation #NUM(watch) Kafka(NAMESPACE/NAME): Kafka version downgrade from FROM-VERSION to TO-VERSION, phase 1 of 1 completed
降级所有客户端应用程序(使用者),以使用之前版本的客户端二进制文件。
Kafka 集群和客户端现在使用之前的 Kafka 版本。
如果您恢复到 1.7 之前的 AMQ Streams 版本,该版本使用 ZooKeeper 作为存储主题元数据,请删除 Kafka 集群的内部主题存储主题。
oc run kafka-admin -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic __strimzi-topic-operator-kstreams-topic-store-changelog --delete && ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic __strimzi_store_topic --delete
其他资源
第 12 章 查找 Kafka 重启的信息
在 Cluster Operator 在 OpenShift 集群中重启 Kafka pod 后,它会将 OpenShift 事件发送到 pod 的命名空间中,解释为什么 pod 重启的原因。有关了解集群行为的帮助,您可以从命令行检查重启事件。
您可以使用 Prometheus 等指标收集工具导出和监控重启事件。将指标工具与事件导出导出为合适的格式 的事件 导出。
12.1. 重启事件的原因
Cluster Operator 根据具体原因启动重启事件。您可以通过获取重启事件的信息来检查原因。
给出的原因取决于您使用 StrimziPodSet 或 StatefulSet 资源来创建和管理 pod。
表 12.1. 重启原因
| StrimziPodSet | StatefulSet | Description |
|---|---|---|
| CaCertHasOldGeneration | CaCertHasOldGeneration | pod 仍然使用与旧 CA 签名的服务器证书,因此需要在证书更新过程中重启。 |
| CaCertRemoved | CaCertRemoved | 已删除过期的 CA 证书,pod 被重启以使用当前证书运行。 |
| CaCertRenewed | CaCertRenewed | CA 证书已被更新,pod 被重启以使用更新的证书运行。 |
| ClientCaCertKeyReplaced | ClientCaCertKeyReplaced | 用于为客户端 CA 证书签名的密钥已被替换,pod 被作为 CA 续订过程的一部分重启。 |
| ClusterCaCertKeyReplaced | ClusterCaCertKeyReplaced | 现在,用来为集群 CA 证书签名的密钥已被替换,pod 正在作为 CA 续订过程的一部分重启。 |
| ConfigChangeRequiresRestart | ConfigChangeRequiresRestart | 有些 Kafka 配置属性会被动态更改,但其他配置属性需要重启代理。 |
| CustomListenerCaCertChanged | CustomListenerCaCertChanged | 用于保护 Kafka 网络监听器的 CA 证书已更改,pod 被重启来使用它。 |
| FileSystemResizeNeeded | FileSystemResizeNeeded | 文件系统大小已增加,需要重启才能应用它。 |
| KafkaCertificatesChanged | KafkaCertificatesChanged | Kafka 代理使用的一个或多个 TLS 证书已更新,需要使用它们重启。 |
| ManualRollingUpdate | ManualRollingUpdate |
注解了 pod 的用户,或 |
| PodForceRestartOnError | PodForceRestartOnError | 发生一个错误,需要 pod 重启来改正。 |
| PodHasOldRevision | JbodVolumesChanged |
在 Kafka 卷中添加或删除磁盘,需要重启来应用更改。使用 |
| PodHasOldRevision | PodHasOldGeneration |
|
| PodStuck | PodStuck | pod 仍然处于待处理状态,且没有调度或无法调度,因此 Operator 会以最终尝试运行 Pod 来重启 pod。 |
| PodUnresponsive | PodUnresponsive | AMQ Streams 无法连接到 pod,它可指示代理无法正确启动,因此 Operator 会在尝试解决这个问题时重启它。 |
12.2. 重启事件过滤器
从命令行检查重启事件时,您可以指定一个 field-selector 来过滤 OpenShift 事件字段。
在使用 field-selector 过滤事件时,可以使用以下字段。
regardingObject.kind-
重启的对象以及重启事件的对象始终是
Pod。 regarding.namespace- pod 所属的命名空间。
regardingObject.name-
pod 的名称,如
strimzi-cluster-kafka-0。 regardingObject.uid- pod 的唯一 ID。
reason-
pod 重启的原因,如
JbodVolumesChanged。 reportingController-
报告组件始终为 AMQ Streams 重启事件的
strimzi.io/cluster-operator。 source-
Source是最新版本的reportingController。报告组件始终为 AMQ Streams 重启事件的strimzi.io/cluster-operator。 type-
事件类型,即
Warning或Normal。对于 AMQ Streams 重启事件,类型为Normal。
在较旧版本的 OpenShift 中,使用有关 前缀的字段可能会改用 involvedObject 前缀。reportingController 之前被称为 reportingComponent。
12.3. 检查 Kafka 重启
使用 oc 命令列出 Cluster Operator 启动的重启事件。使用 reportingController 或 源 事件字段将 Cluster Operator 设置为报告组件来过滤 Cluster Operator 发出的重启事件。
先决条件
- Cluster Operator 在 OpenShift 集群中运行。
流程
获取 Cluster Operator 发出的所有重启事件:
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator
显示返回的事件示例
LAST SEEN TYPE REASON OBJECT MESSAGE 2m Normal CaCertRenewed pod/strimzi-cluster-kafka-0 CA certificate renewed 58m Normal PodForceRestartOnError pod/strimzi-cluster-kafka-1 Pod needs to be forcibly restarted due to an error 5m47s Normal ManualRollingUpdate pod/strimzi-cluster-kafka-2 Pod was manually annotated to be rolled
您还可以指定
原因或其他字段选择器选项,以限制返回的事件。这里添加了具体原因:
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator,reason=PodForceRestartOnError
使用 YAML 等输出格式返回有关一个或多个事件的更多详细信息。
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator,reason=PodForceRestartOnError -o yaml
显示详细的事件输出示例
apiVersion: v1 items: - action: StrimziInitiatedPodRestart apiVersion: v1 eventTime: "2022-05-13T00:22:34.168086Z" firstTimestamp: null involvedObject: kind: Pod name: strimzi-cluster-kafka-1 namespace: kafka kind: Event lastTimestamp: null message: Pod needs to be forcibly restarted due to an error metadata: creationTimestamp: "2022-05-13T00:22:34Z" generateName: strimzi-event name: strimzi-eventwppk6 namespace: kafka resourceVersion: "432961" uid: 29fcdb9e-f2cf-4c95-a165-a5efcd48edfc reason: PodForceRestartOnError reportingController: strimzi.io/cluster-operator reportingInstance: strimzi-cluster-operator-6458cfb4c6-6bpdp source: {} type: Normal kind: List metadata: resourceVersion: "" selfLink: ""
以下字段已弃用,因此不会为这些事件填充它们:
-
firstTimestamp -
lastTimestamp -
source
第 13 章 卸载 AMQ Streams
您可以使用 OpenShift Container Platform Web 控制台或 CLI 从 OperatorHub 卸载 OpenShift 4.8 上的 AMQ Streams 到 4.12。
使用您用于安装 AMQ Streams 的相同方法。
卸载 AMQ Streams 时,您需要识别专门为部署创建的资源,并从 AMQ Streams 资源引用。
此类资源包括:
- secret (客户 CA 和证书、Kafka 连接 secret 和其他 Kafka secret)
-
日志记录
ConfigMap(类型为外部)
这些资源由 Kafka、KafkaConnect、KafkaMirrorMaker 或 KafkaBridge 配置引用。
删除 CustomResourceDefinitions 会导致对应自定义资源的垃圾回收(Kafka、KafkaConnect、KafkaMirrorMaker、或 KafkaBridge)以及依赖它们的资源(Deployment、StatefulSet 和其他依赖资源)。
13.1. 使用 Web 控制台从 OperatorHub 卸载 AMQ Streams
此流程描述了如何从 OperatorHub 卸载 AMQ Streams,并删除与部署相关的资源。
您可以在控制台中执行这些步骤,也可以使用替代的 CLI 命令。
先决条件
-
使用具有
cluster-admin或strimzi-admin权限的账户访问 OpenShift Container Platform Web 控制台。 您已找出要删除的资源。
您可以使用以下
ocCLI 命令查找资源,并在卸载 AMQ Streams 时验证它们是否已被删除。查找与 AMQ Streams 部署相关的资源的命令
oc get <resource_type> --all-namespaces | grep <kafka_cluster_name>
将 <resource_type > 替换为您要检查的资源类型,如
secret或configmap。
流程
- 在 OpenShift Web 控制台中导航至 Operators > Installed Operators。
对于已安装的 Red Hat Integration - AMQ Streams operator,选择选项图标(三个垂直点),然后点击 Uninstall Operator。
Operator 从 Installed Operators 中删除。
- 进入 Home > Projects 并选择您安装 AMQ Streams 和 Kafka 组件的项目。
点 Inventory 下的选项删除相关资源。
资源包括以下内容:
- 部署
- StatefulSets
- Pods
- 服务
- ConfigMaps
- Secrets
提示使用搜索查找以 Kafka 集群名称开头的相关资源。您还可以在 Workloads 下找到资源。
其它CLI命令
您可以使用 CLI 命令从 OperatorHub 卸载 AMQ Streams。
删除 AMQ Streams 订阅。
oc delete subscription amq-streams -n openshift-operators
删除集群服务版本(CSV)。
oc delete csv amqstreams.<version> -n openshift-operators删除相关的 CRD。
oc get crd -l app=strimzi -o name | xargs oc delete
13.2. 使用 CLI 卸载 AMQ Streams
此流程描述了如何使用 oc 命令行工具卸载 AMQ Streams 并删除与部署相关的资源。
先决条件
-
使用具有
cluster-admin或strimzi-admin权限的账户访问 OpenShift 集群。 您已找出要删除的资源。
您可以使用以下
ocCLI 命令查找资源,并在卸载 AMQ Streams 时验证它们是否已被删除。查找与 AMQ Streams 部署相关的资源的命令
oc get <resource_type> --all-namespaces | grep <kafka_cluster_name>
将 <resource_type > 替换为您要检查的资源类型,如
secret或configmap。
流程
删除 Cluster Operator
Deployment、相关的CustomResourceDefinitions和RBAC资源。指定用于部署 Cluster Operator 的安装文件。
oc delete -f install/cluster-operator
删除您在先决条件中创建的资源。
oc delete <resource_type> <resource_name> -n <namespace>
将 <resource_type > 替换为您要删除的资源类型,将 <resource_name > 替换为资源的名称。
删除 secret 示例
oc delete secret my-cluster-clients-ca -n my-project
第 14 章 在 AMQ Streams 上使用 Metering
您可以使用 OpenShift 上可用的 Metering 工具从不同的数据源生成 metering 报告。作为集群管理员,您可使用 Metering 来分析集群中的情况。您可以自行编写报告,也可以使用预定义的 SQL 查询来定义如何处理来自现有不同数据源的数据。使用 Prometheus 作为默认数据源,您可以生成 Pod、命名空间以及大多数其他 OpenShift 资源的报告。
您还可以使用 OpenShift Metering operator 来分析已安装的 AMQ Streams 组件,以确定您是否遵循红帽订阅。
要将 metering 与 AMQ Streams 搭配使用,您必须首先在 OpenShift Container Platform 上安装和配置 Metering Operator。
14.1. Metering 资源
Metering 具有很多资源,可用于管理 Metering 的部署与安装以及 Metering 提供的报告功能。Metering 使用以下 CRD 管理:
表 14.1. Metering 资源
| 名称 | Description |
|---|---|
|
| 为部署配置 metering 堆栈。包含用于控制 metering 堆栈各个组件的自定义和配置选项。 |
|
| 控制要使用的查询、查询运行时间、运行频率以及查询结果的存储位置。 |
|
|
包含用于对 |
|
| 控制 ReportQueries 和 Reports 可用数据。支持配置 metering 中使用的不同数据库的访问权限。 |
14.2. AMQ Streams 的 Metering 标签
下表列出了 AMQ Streams 基础架构组件和集成的 metering 标签。
表 14.2. Metering Labels
| 标签 | 可能的值 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 基础架构
|
| Application(应用程序)
| |
|
|
|
例子
基础架构示例(基础架构组件是 entity-operator)
com.company=Red_Hat rht.prod_name=Red_Hat_Application_Foundations rht.prod_ver=2023.Q1 rht.comp=AMQ_Streams rht.comp_ver=2.3 rht.subcomp=entity-operator rht.comp_t=infrastructure
应用程序示例(其中集成部署名称为 kafka-bridge)
com.company=Red_Hat rht.prod_name=Red_Hat_Application_Foundations rht.prod_ver=2023.Q1 rht.comp=AMQ_Streams rht.comp_ver=2.3 rht.subcomp=kafka-bridge rht.comp_t=application
附录 A. 使用您的订阅
AMQ Streams 通过软件订阅提供。要管理您的订阅,请访问红帽客户门户中的帐户。
访问您的帐户
- 转至 access.redhat.com。
- 如果您还没有帐户,请创建一个帐户。
- 登录到您的帐户。
激活订阅
- 转至 access.redhat.com。
- 导航到 My Subscriptions。
- 导航到 激活订阅 并输入您的 16 位激活号。
下载 Zip 和 Tar 文件
要访问 zip 或 tar 文件,请使用客户门户网站查找下载的相关文件。如果您使用 RPM 软件包,则不需要这一步。
- 打开浏览器并登录红帽客户门户网站 产品下载页面,网址为 access.redhat.com/downloads。
- 在 INTEGRATION AND AUTOMATION 目录中找到 AMQ Streams for Apache Kafka 项。
- 选择所需的 AMQ Streams 产品。此时会打开 Software Downloads 页面。
- 单击组件的 Download 链接。
使用 DNF 安装软件包
要安装软件包以及所有软件包的依赖软件包,请使用:
dnf install <package_name>要从本地目录中安装之前下载的软件包,请使用:
dnf install <path_to_download_package>更新于 2023-04-06