
OpenShift에서 AMQ Streams 배포 및 업그레이드
OpenShift Container Platform에 AMQ Streams 2.3 배포
초록
보다 포괄적 수용을 위한 오픈 소스 용어 교체
Red Hat은 코드, 문서, 웹 속성에서 문제가 있는 용어를 교체하기 위해 최선을 다하고 있습니다. 먼저 마스터(master), 슬레이브(slave), 블랙리스트(blacklist), 화이트리스트(whitelist) 등 네 가지 용어를 교체하고 있습니다. 이러한 변경 작업은 작업 범위가 크므로 향후 여러 릴리스에 걸쳐 점차 구현할 예정입니다. 자세한 내용은 CTO Chris Wright의 메시지를 참조하십시오.
1장. 배포 개요
AMQ Streams는 OpenShift 클러스터에서 Apache Kafka를 실행하는 프로세스를 간소화합니다.
이 가이드에서는 AMQ Streams 배포 및 업그레이드에 사용할 수 있는 모든 옵션과 OpenShift 클러스터에서 Apache Kafka를 실행하는 데 필요한 배포 순서를 설명합니다.
배포 단계에 대한 설명뿐만 아니라 이 가이드에서는 사전 및 배포 후 지침을 제공하여 배포를 준비하고 검증합니다. 이 가이드에서는 메트릭을 도입하기 위한 추가 배포 옵션도 설명합니다.
AMQ Streams 및 Kafka 업그레이드에 대한 업그레이드 지침이 제공됩니다.
AMQ Streams는 공용 및 프라이빗 클라우드에서 개발을 위해 의도된 로컬 배포에 관계없이 배포와 관계없이 모든 유형의 OpenShift 클러스터에서 작동하도록 설계되었습니다.
1.1. 배포 구성
이 가이드의 배포 절차는 배포의 초기 구조를 설정하는 데 도움이 되도록 고안되어 있습니다. 구조를 설정한 후 사용자 정의 리소스를 사용하여 정확한 요구에 맞게 배포를 구성할 수 있습니다. 배포 절차에서는 AMQ Streams와 함께 제공되는 설치 파일 예제를 사용합니다. 이 절차에서는 중요한 구성 고려 사항을 강조하지만 사용 가능한 모든 구성 옵션을 설명하지는 않습니다.
AMQ Streams를 배포하기 전에 Kafka 구성 요소에 사용할 수 있는 구성 옵션을 검토할 수 있습니다. 구성 옵션에 대한 자세한 내용은 OpenShift에서 AMQ Streams 구성을 참조하십시오.
1.1.1. Securing Kafka
배포 시 Cluster Operator는 클러스터 내의 데이터 암호화 및 인증에 필요한 TLS 인증서를 자동으로 설정합니다.
AMQ Streams는 암호화,인증 및 권한 부여 에 대한 추가 구성 옵션을 제공합니다.
- Kafka에 대한 보안 액세스를 관리하여 Kafka 클러스터와 클라이언트 간 데이터 교환을 보호합니다.
- OAuth 2.0 인증 및 OAuth 2.0 권한 부여를 제공하도록 권한 부여 서버를 사용하도록 배포를 구성합니다.
- 자체 인증서를 사용하여 Kafka를 보호합니다.
1.1.2. 배포 모니터링
AMQ Streams는 배포를 모니터링할 수 있는 추가 배포 옵션을 지원합니다.
- Kafka 클러스터와 함께 Prometheus 및 Grafana를 배포하여 메트릭을 추출하고 Kafka 구성 요소를 모니터링합니다.
- Kafka 클러스터와 함께 Kafka Exporter를 배포하여 특히 소비자 지연 모니터링과 관련된 추가 메트릭을 추출합니다.
- 분산 추적을 설정하여 메시지 엔드 투 엔드 추적을 추적합니다.
1.1.3. CPU 및 메모리 리소스 제한 및 요청
기본적으로 AMQ Streams Cluster Operator는 배포하는 피연산자의 CPU 및 메모리 리소스에 대한 요청 및 제한을 지정하지 않습니다.
Kafka와 같은 애플리케이션이 안정적이고 우수한 성능을 제공하려면 충분한 리소스를 보유하는 것이 중요합니다.
사용해야 하는 적절한 리소스 양은 특정 요구 사항 및 사용 사례에 따라 다릅니다.
CPU 및 메모리 리소스를 구성하는 것을 고려해야 합니다. AMQ Streams 사용자 정의 리소스에서 각 컨테이너에 대한 리소스 요청 및 제한을 설정할 수 있습니다.
1.2. AMQ Streams 사용자 정의 리소스
AMQ Streams를 사용하여 OpenShift 클러스터에 Kafka 구성 요소를 배포하는 것은 사용자 정의 리소스 애플리케이션을 통해 구성할 수 있습니다. 사용자 정의 리소스는 OpenShift 리소스를 확장하기 위해 CRD(Custom Resource Definitions)에서 추가한 API 인스턴스로 생성됩니다.
CRD는 OpenShift 클러스터의 사용자 정의 리소스를 설명하는 구성 지침 역할을 하며, 배포에 사용된 각 Kafka 구성 요소에 대해 AMQ Streams와 사용자 및 주제를 제공합니다. CRD 및 사용자 정의 리소스는 YAML 파일로 정의됩니다. YAML 파일의 예는 AMQ Streams 배포와 함께 제공됩니다.
또한 CRD를 사용하면 AMQ Streams 리소스가 CLI 접근성 및 구성 검증과 같은 기본 OpenShift 기능을 활용할 수 있습니다.
1.2.1. AMQ Streams 사용자 정의 리소스 예
CRD에는 AMQ Streams 관련 리소스를 인스턴스화하고 관리하는 데 사용되는 스키마를 정의하기 위해 클러스터에 일회성 설치가 필요합니다.
CRD를 설치하여 새 사용자 정의 리소스 유형을 클러스터에 추가한 후 사양을 기반으로 리소스 인스턴스를 생성할 수 있습니다.
클러스터 설정에 따라 설치에 따라 일반적으로 클러스터 관리자 권한이 필요합니다.
사용자 정의 리소스 관리에 대한 액세스는 AMQ Streams 관리자에게 제한됩니다. 자세한 내용은 AMQ Streams 관리자 지정을 참조하십시오.
CRD는 OpenShift 클러스터 내에서 와 같은 새로운 종류의 리소스를 정의합니다.
kind:Kafka
Kubernetes API 서버를 사용하면 유형을 기반으로 사용자 정의 리소스를 생성할 수 있으며 OpenShift 클러스터에 추가할 때 사용자 정의 리소스의 유효성을 검사하고 저장하는 방법을 CRD에서 이해할 수 있습니다.
CRD가 삭제되면 해당 유형의 사용자 정의 리소스도 삭제됩니다. 또한 Pod 및 statefulsets와 같은 사용자 정의 리소스에서 생성한 리소스도 삭제됩니다.
각 AMQ Streams별 사용자 정의 리소스는 리소스 종류의 CRD에서 정의한 스키마를 준수합니다. AMQ Streams 구성 요소에 대한 사용자 정의 리소스에는 사양에 정의된 공통 구성 속성이 있습니다.
CRD와 사용자 정의 리소스 간의 관계를 이해하기 위해 Kafka 항목에 대한 CRD 샘플을 살펴보겠습니다.
Kafka topic CRD
apiVersion: kafka.strimzi.io/v1beta2 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta2 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- CRD 주제 CRD의 메타데이터, CRD를 식별하는 라벨 및 이름입니다.
- 2
- 그룹(domain) 이름, 복수형 이름 및 지원되는 스키마 버전을 포함하여 주제의 API에 액세스하는 URL에 사용되는 이 CRD의 사양입니다. 다른 이름은 CLI에서 인스턴스 리소스를 식별하는 데 사용됩니다. 예를 들어
oc get kafkatopic my-topic또는oc get kafkatopics. - 3
- 단축은 CLI 명령에서 사용할 수 있습니다. 예를 들어
oc get kt는oc get kafkatopic대신 약어로 사용할 수 있습니다. - 4
- 사용자 정의 리소스에서
get명령을 사용할 때 제공되는 정보입니다. - 5
- 리소스의 스키마 참조에 설명된 대로 CRD의 현재 상태입니다.
- 6
- OpenAPIV3Schema 검증은 주제 사용자 정의 리소스의 생성에 대한 검증을 제공합니다. 예를 들어 항목에는 하나 이상의 파티션과 복제본이 필요합니다.
파일 이름에 인덱스 번호와 'Crd'가 포함되어 있기 때문에 AMQ Streams 설치 파일과 함께 제공되는 CRD YAML 파일을 확인할 수 있습니다.
다음은 KafkaTopic 사용자 정의 리소스의 예입니다.
Kafka 주제 사용자 정의 리소스
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
- 1
kind및apiVersion은 사용자 정의 리소스가 인스턴스인 CRD를 식별합니다.- 2
- 주제 또는 사용자가 속하는
Kafka클러스터의 이름을 정의하는KafkaTopic및KafkaUser리소스에만 적용되는 레이블입니다. - 3
- 사양은 주제의 파티션 및 복제본 수와 주제 자체에 대한 구성 매개 변수를 보여줍니다. 이 예에서는 메시지가 항목에 남아 있고 로그의 세그먼트 파일 크기가 지정됩니다.
- 4
KafkaTopic리소스의 상태 상태입니다.lastTransitionTime에서유형조건이Ready로 변경되었습니다.
사용자 정의 리소스는 플랫폼 CLI를 통해 클러스터에 적용할 수 있습니다. 사용자 정의 리소스가 생성되면 Kubernetes API의 기본 제공 리소스와 동일한 검증을 사용합니다.
KafkaTopic 사용자 정의 리소스가 생성되면 Topic Operator에 알림을 받고 해당 Kafka 항목이 AMQ Streams에서 생성됩니다.
1.3. Kafka 브리지를 사용하여 Kafka 클러스터 연결
AMQ Streams Kafka Bridge API를 사용하여 소비자를 생성 및 관리하고 기본 Kafka 프로토콜이 아닌 HTTP를 통해 레코드를 전송 및 수신할 수 있습니다.
Kafka 브리지를 설정하면 Kafka 클러스터에 대한 HTTP 액세스를 구성합니다. 그런 다음 Kafka Bridge를 사용하여 클러스터에서 메시지를 생성 및 사용하고 REST 인터페이스를 통해 다른 작업을 수행할 수 있습니다.
추가 리소스
- Kafka 브리지 설치 및 사용에 대한 자세한 내용은 AMQ Streams Kafka Bridge 사용을 참조하십시오.
1.4. 문서 관련
사용자 대체 값
대체 가능 값이라고도 하는 사용자 대체 값은 이진수에 빙각 대괄호(< >)로 표시됩니다. 밑줄( _ )은 여러 단어 값에 사용됩니다. 값이 코드 또는 명령을 참조하는 경우 monospace 도 사용됩니다.
예를 들어 다음 코드에서 < my_namespace>를 네임스페이스 이름으로 교체하려고 합니다.
sed -i 's/namespace: .*/namespace: <my_namespace>/' install/cluster-operator/*RoleBinding*.yaml1.5. 추가 리소스
2장. AMQ Streams 설치 방법
다음 두 가지 방법으로 OpenShift 4.8에서 4.12에 AMQ Streams를 설치할 수 있습니다.
| 설치 방법 | 설명 |
|---|---|
|
AMQ Streams 소프트웨어 다운로드 페이지에서 Red Hat AMQ Streams 2.3 OpenShift 설치 및 예제 파일을 다운로드합니다.
| |
| OperatorHub에서 Red Hat Integration - AMQ Streams 를 사용하여 단일 네임스페이스 또는 모든 네임스페이스에 AMQ Streams를 배포합니다. |
유연성을 극대화하려면 설치 아티팩트 방법을 선택합니다. OperatorHub 방법은 표준 구성을 제공하며 자동 업데이트를 활용할 수 있습니다.
Helm을 사용한 AMQ Streams 설치는 지원되지 않습니다.
3장. AMQ Streams로 배포 대상
Apache Kafka 구성 요소는 AMQ Streams 배포를 사용하여 OpenShift에 배포할 수 있도록 제공됩니다. Kafka 구성 요소는 일반적으로 가용성을 위해 클러스터로 실행됩니다.
Kafka 구성 요소를 통합하는 일반적인 배포에는 다음이 포함될 수 있습니다.
- 브로커 노드의 Kafka 클러스터
- 복제된 ZooKeeper 인스턴스의 zookeeper 클러스터
- 외부 데이터 연결을 위한 Kafka Connect 클러스터
- 보조 클러스터에서 Kafka 클러스터를 미러링할 Kafka MirrorMaker 클러스터
- 모니터링을 위한 추가 Kafka 메트릭 데이터를 추출하기 위한 Kafka 내보내기
- Kafka 클러스터에 대한 HTTP 기반 요청 생성
이러한 구성 요소가 모두 필수는 아니지만 Kafka 및 ZooKeeper가 최소한 필요합니다. 일부 구성 요소는 MirrorMaker 또는 Kafka Connect와 같은 Kafka 없이 배포할 수 있습니다.
3.1. 배포 순서
OpenShift 클러스터에 필요한 배포 순서는 다음과 같습니다.
- Kafka 클러스터를 관리하기 위해 Cluster Operator 배포
- ZooKeeper 클러스터를 사용하여 Kafka 클러스터를 배포하고 배포에 Topic Operator 및 User Operator를 포함합니다.
선택적으로 다음을 배포합니다.
- Kafka 클러스터와 함께 배포하지 않은 경우 Topic Operator 및 User Operator 독립 실행형
- Kafka Connect
- Kafka MirrorMaker
- Kafka 브리지
- 메트릭 모니터링을 위한 구성 요소
Cluster Operator는 Deployment,Service 및 Pod 리소스와 같은 구성 요소에 대해 OpenShift 리소스를 생성합니다. OpenShift 리소스의 이름에는 배포 시 구성 요소에 지정된 이름이 추가됩니다. 예를 들어 my-kafka-cluster 라는 Kafka 클러스터에는 my-kafka-cluster-kafka 라는 서비스가 있습니다.
4장. AMQ Streams 배포 준비
이 섹션에서는 다음을 설명하는 AMQ Streams 배포를 준비하는 방법을 보여줍니다.
이 가이드에서 명령을 실행하려면 클러스터 사용자에게 RBAC(역할 기반 액세스 제어) 및 CRD를 관리할 수 있는 권한이 있어야 합니다.
4.1. 배포 사전 요구 사항
AMQ Streams를 배포하려면 다음이 필요합니다.
OpenShift 4.8 - 4.12 클러스터.
AMQ Streams는 Strimzi 0.32.x를 기반으로 합니다.
-
oc명령줄 툴이 설치되고 실행 중인 클러스터에 연결하도록 구성되어 있습니다.
4.2. AMQ Streams 릴리스 아티팩트 다운로드
배포 파일을 사용하여 AMQ Streams를 설치하려면 AMQ Streams 소프트웨어 다운로드 페이지에서 파일을 다운로드하여 추출합니다.
AMQ Streams 릴리스 아티팩트에는 OpenShift에 AMQ Streams의 구성 요소를 배포하고, 공통 작업을 수행하고, Kafka 클러스터를 구성하는 데 도움이 되는 샘플 YAML 파일이 포함되어 있습니다.
oc 를 사용하여 다운로드한 ZIP 파일의 install/cluster-operator 폴더에 Cluster Operator를 배포합니다. Cluster Operator 배포 및 구성에 대한 자세한 내용은 6.2절. “Cluster Operator 배포” 을 참조하십시오.
또한 AMQ Streams Cluster Operator에서 관리하지 않는 Kafka 클러스터에서 Topic 및 User Operator의 독립 실행형 설치를 사용하려면 install/topic-operator 및 install/user-operator 폴더에서 해당 Operator를 배포할 수 있습니다.
또한 AMQ Streams 컨테이너 이미지는 Red Hat Ecosystem Catalog 를 통해 사용할 수 있습니다. 그러나 AMQ Streams를 배포하기 위해 제공된 YAML 파일을 사용하는 것이 좋습니다.
4.3. 구성 및 배포 파일의 예
AMQ Streams와 함께 제공되는 구성 및 배포 파일을 사용하여 다양한 구성으로 Kafka 구성 요소를 배포하고 배포를 모니터링합니다. 사용자 지정 리소스에 대한 구성 파일의 예제에는 중요한 속성 및 값이 포함되어 있으며, 자체 배포에 대해 지원되는 추가 구성 속성으로 확장할 수 있습니다.
4.3.1. 파일 위치 예
예제 파일은 AMQ Streams 소프트웨어 다운로드 페이지에서 다운로드할 수 있는 릴리스 아티팩트를 통해 제공됩니다.
oc 명령줄 툴을 사용하여 예제를 다운로드하여 적용할 수 있습니다. 이 예제에서는 배포에 대한 자체 Kafka 구성 요소 구성을 빌드할 때 시작점으로 사용될 수 있습니다.
Operator를 사용하여 AMQ Streams를 설치한 경우에도 예제 파일을 다운로드하여 구성을 업로드할 수 있습니다.
4.3.2. AMQ Streams와 함께 제공되는 파일 예
릴리스 아티팩트에는 구성 예제가 포함된 examples 디렉터리가 포함되어 있습니다.
디렉터리 예
examples ├── user 1 ├── topic 2 ├── security 3 │ ├── tls-auth │ ├── scram-sha-512-auth │ └── keycloak-authorization ├── mirror-maker 4 ├── metrics 5 ├── kafka 6 ├── cruise-control 7 ├── connect 8 └── bridge 9
- 1
- User Operator가 관리하는
KafkaUser사용자 정의 리소스 구성 - 2
- Topic Operator에서 관리하는
KafkaTopic사용자 정의 리소스 구성 - 3
- Kafka 구성 요소에 대한 인증 및 권한 부여 구성 TLS 및 SCRAM-SHA-512 인증에 대한 구성 예를 포함합니다. Red Hat Single Sign-On 예제에는
Kafka사용자 정의 리소스 구성 및 Red Hat Single Sign-On 영역 사양이 포함되어 있습니다. 이 예제를 사용하여 Red Hat Single Sign-On 권한 부여 서비스를 사용해 볼 수 있습니다. 활성화된oauth인증 및keycloak권한 부여 지표가 있는 예도 있습니다. - 4
- MirrorECDHE 배포를 위한
Kafka사용자 정의 리소스 구성 복제 정책 및 동기화 빈도에 대한 구성 예제가 포함되어 있습니다. - 5
- Prometheus 설치 및 Grafana 대시보드 파일을 포함한 지표 구성
- 6
Kafka배포에 대한 Kafka 사용자 지정 리소스 구성 임시 또는 영구 단일 또는 다중 노드 배포를 위한 구성 예를 포함합니다.- 7
- Cruise Control에 대한 배포 구성이 있는
Kafka사용자 지정 리소스KafkaRebalance사용자 정의 리소스를 포함하여 Cruise Control에서 최적화 제안을 생성하고 기본 또는 사용자 최적화 목표를 사용하는 예제 구성을 포함합니다. - 8
KafkaConnect및KafkaConnector사용자 정의 리소스 구성: Kafka Connect 배포용. 단일 또는 다중 노드 배포를 위한 구성 예시가 포함되어 있습니다.- 9
Kafka 브리지배포를 위한 KafkaBridge 사용자 정의 리소스 구성
추가 리소스
4.4. 자체 레지스트리로 컨테이너 이미지 푸시
AMQ Streams의 컨테이너 이미지는 Red Hat Ecosystem Catalog 에서 사용할 수 있습니다. AMQ Streams에서 제공하는 설치 YAML 파일은 Red Hat Ecosystem Catalog 에서 직접 이미지를 가져옵니다.
Red Hat Ecosystem Catalog 에 액세스할 수 없거나 자체 컨테이너 리포지토리를 사용하려는 경우 다음을 수행하십시오.
- 여기에 나열된 모든 컨테이너 이미지를 가져옵니다.
- 사용자 고유의 레지스트리로 푸시
- 설치 YAML 파일에서 이미지 이름을 업데이트
릴리스에 지원되는 각 Kafka 버전에는 별도의 이미지가 있습니다.
| 컨테이너 이미지 | namespace/Repository | 설명 |
|---|---|---|
| Kafka |
| Kafka를 실행하기 위한 AMQ Streams 이미지 (예:
|
| Operator |
| Operator 실행을 위한 AMQ Streams 이미지:
|
| Kafka 브리지 |
| AMQ Streams Kafka 브리지 실행을 위한 AMQ Streams 이미지 |
| AMQ Streams DrainCleaner |
| AMQ Streams Drain cleaner 실행을 위한 AMQ Streams 이미지 |
4.5. 컨테이너 이미지 레지스트리에 인증할 풀 시크릿 생성
AMQ Streams에서 제공하는 설치 YAML 파일은 Red Hat Ecosystem Catalog 에서 직접 컨테이너 이미지를 가져옵니다. AMQ Streams 배포에 인증이 필요한 경우 시크릿에서 인증 자격 증명을 구성하고 설치 YAML에 추가합니다.
인증은 일반적으로 필요하지 않지만 특정 플랫폼에서 요청할 수 있습니다.
사전 요구 사항
- Red Hat 사용자 이름 및 암호 또는 Red Hat 레지스트리 서비스 계정의 로그인 정보가 필요합니다.
Red Hat 서브스크립션을 사용하여 Red Hat 고객 포털에서 레지스트리 서비스 계정을 생성할 수 있습니다.
절차
로그인 세부 정보와 AMQ Streams 이미지를 가져오는 컨테이너 레지스트리가 포함된 풀 시크릿을 생성합니다.
oc create secret docker-registry <pull_secret_name> \ --docker-server=registry.redhat.io \ --docker-username=<user_name> \ --docker-password=<password> \ --docker-email=<email>사용자 이름 및 암호를 추가합니다. 이메일 주소는 선택 사항입니다.
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml배포 파일을 편집하여STRIMZI_IMAGE_PULL_SECRET환경 변수를 사용하여 풀 시크릿을 지정합니다.apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-cluster-operator spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: # ... env: - name: STRIMZI_IMAGE_PULL_SECRETS value: "<pull_secret_name>" # ...보안은 Cluster Operator가 생성한 모든 Pod에 적용됩니다.
4.6. AMQ Streams 관리자 지정
AMQ Streams는 배포 구성을 위한 사용자 정의 리소스를 제공합니다. 기본적으로 이러한 리소스를 보고, 생성, 편집 및 삭제하는 권한은 OpenShift 클러스터 관리자에게 제한됩니다. AMQ Streams는 이러한 권한을 다른 사용자에게 할당하는 데 사용할 수 있는 두 개의 클러스터 역할을 제공합니다.
-
Strimzi-view를 사용하면 AMQ Streams 리소스를 보고 나열할 수 있습니다. -
Strimzi-admin을 사용하면 AMQ Streams 리소스를 생성, 편집 또는 삭제할 수도 있습니다.
이러한 역할을 설치하면 기본 OpenShift 클러스터 역할에 이러한 권한을 자동으로 집계(추가)합니다. Strimzi-view 는 view 역할로 집계하고, strimzi-admin 은 edit 및 admin 역할에 대해 집계합니다. 집계로 인해 이미 유사한 권한이 있는 사용자에게 이러한 역할을 할당할 필요가 없습니다.
다음 절차에서는 비 클러스터 관리자가 AMQ Streams 리소스를 관리할 수 있는 strimzi-admin 역할을 할당하는 방법을 보여줍니다.
시스템 관리자는 Cluster Operator를 배포한 후 AMQ Streams 관리자를 지정할 수 있습니다.
사전 요구 사항
- CRD를 관리하기 위한 AMQ Streams CRD(Custom Resource Definitions) 및 RBAC(역할 기반 액세스 제어) 리소스가 Cluster Operator와 함께 배포되었습니다.
절차
OpenShift에서
strimzi-view및strimzi-admin클러스터 역할을 만듭니다.oc create -f install/strimzi-admin
필요한 경우 사용자에게 액세스 권한을 제공하는 역할을 할당합니다.
oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2
5장. 웹 콘솔을 사용하여 OperatorHub에서 AMQ Streams 설치
OpenShift Container Platform 웹 콘솔의 OperatorHub에서 Red Hat Integration - AMQ Streams operator를 설치합니다.
이 섹션의 절차에서는 다음을 수행하는 방법을 보여줍니다.
5.1. Red Hat Integration Operator를 사용하여 AMQ Streams Operator 설치
Red Hat Integration Operator(더 이상 사용되지 않음)를 사용하면 Red Hat Integration 구성 요소를 관리하는 Operator를 선택하고 설치할 수 있습니다. Red Hat Integration 서브스크립션이 두 개 이상인 경우 Red Hat Integration Operator를 사용하여 AMQ Streams Operator 및 모든 서브스크립션된 Red Hat Integration 구성 요소에 대한 Operator를 설치 및 업데이트할 수 있습니다.
AMQ Streams Operator와 마찬가지로 OLM(Operator Lifecycle Manager)을 사용하여 OCP 콘솔의 OperatorHub에서 OpenShift Container Platform(OCP) 클러스터에 Red Hat Integration Operator를 설치할 수 있습니다.
Red Hat Integration Operator는 더 이상 사용되지 않으며 향후 제거될 예정입니다. OpenShift 4.6의 OperatorHub에서 4.10으로 사용할 수 있습니다.
추가 리소스
Red Hat Integration Operator 설치 및 사용에 대한 자세한 내용은 Installing the Red Hat Integration Operator를 참조하십시오.
5.2. OperatorHub에서 AMQ Streams Operator 설치
OpenShift Container Platform 웹 콘솔에서 OperatorHub를 사용하여 AMQ Streams Operator를 설치하고 구독할 수 있습니다.
다음 절차에서는 프로젝트를 생성하고 해당 프로젝트에 AMQ Streams Operator를 설치하는 방법을 설명합니다. 프로젝트는 네임스페이스를 나타냅니다. 관리 효율성을 위해 네임스페이스를 사용하여 함수를 분리하는 것이 좋습니다.
적절한 업데이트 채널을 사용하고 있는지 확인하십시오. 지원되는 OpenShift 버전에 있는 경우 기본 stable 채널에서 AMQ Streams를 설치하는 것이 일반적으로 안전합니다. 그러나 stable 채널에서 자동 업데이트를 활성화하는 것은 권장되지 않습니다. 자동 업그레이드는 업그레이드하기 전에 필요한 단계를 건너뜁니다. 버전별 채널에서만 자동 업그레이드를 사용합니다.
사전 요구 사항
-
cluster-admin또는strimzi-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 웹 콘솔에 액세스합니다.
절차
OpenShift 웹 콘솔에서 홈 > 프로젝트 페이지로 이동하여 설치에 사용할 프로젝트(네임스페이스)를 생성합니다.
이 예제에서는
amq-streams-kafka라는 프로젝트를 사용합니다.- Operators > OperatorHub 페이지로 이동합니다.
Red Hat Integration - AMQ Streams Operator를 찾으려면 키워드로 스크롤하거나 키워드로 필터링 상자에 입력하여 Red Hat Integration - AMQ Streams Operator를 찾습니다.
Operator는 Streaming & Messaging 카테고리에 있습니다.
- Red Hat Integration - AMQ Streams 를 클릭하여 Operator 정보를 표시합니다.
- Operator에 대한 정보를 읽고 설치를 클릭합니다.
Operator 설치 페이지에서 다음 설치 및 업데이트 옵션 중에서 선택합니다.
Update Channel: Operator의 업데이트 채널을 선택합니다.
- (기본값) stable 채널에는 메이저, 마이너 및 마이크로 릴리스를 포함하여 모든 최신 업데이트 및 릴리스가 포함되어 있으며 이는 테스트되고 안정적인 것으로 간주됩니다.
- amq-streams-X.x 채널에는 주요 릴리스의 마이너 릴리스 및 마이크로 릴리스 업데이트가 포함되어 있습니다. 여기서 X 는 주요 릴리스 버전 번호입니다.
- amq-streams-X.Y.x 채널에는 마이너 릴리스의 마이크로 릴리스 업데이트가 포함되어 있습니다. 여기서 X 는 주요 릴리스 버전 번호이고 Y 는 마이너 릴리스 버전 번호입니다.
설치 모드: 특정 네임스페이스에 Operator를 설치하기 위해 생성한 프로젝트를 선택합니다.
AMQ Streams Operator를 클러스터의 모든 네임스페이스(기본 옵션) 또는 특정 네임스페이스에 설치할 수 있습니다. Kafka 클러스터 및 기타 AMQ Streams 구성 요소에 특정 네임스페이스를 전용으로 지정하는 것이 좋습니다.
- 업데이트 승인: 기본적으로 AMQ Streams Operator는 OLM(Operator Lifecycle Manager)에 의해 최신 AMQ Streams 버전으로 자동으로 업그레이드됩니다. 필요한 경우 향후 업그레이드를 수동으로 승인하려면 수동 을 선택합니다. 자세한 내용은 OpenShift 설명서 의 Operator 가이드를 참조하십시오.
Install 을 클릭하여 선택한 네임스페이스에 Operator를 설치합니다.
AMQ Streams Operator는 Cluster Operator, CRD, RBAC(역할 기반 액세스 제어) 리소스를 선택한 네임스페이스에 배포합니다.
Operator를 사용할 준비가 되면 Operator > 설치된 Operator 로 이동하여 Operator가 선택한 네임스페이스에 설치되었는지 확인합니다.
상태가 성공으로 표시됩니다.
이제 AMQ Streams Operator를 사용하여 Kafka 클러스터부터 Kafka 구성 요소를 배포할 수 있습니다.
워크로드 > 배포로 이동하는 경우 Cluster Operator 및 Entity Operator에 대한 배포 세부 정보를 확인할 수 있습니다. Cluster Operator의 이름에는 amq-streams-cluster-operator-<version> 이라는 버전 번호가 포함됩니다. AMQ Streams 설치 아티팩트를 사용하여 Cluster Operator를 배포할 때 이름은 다릅니다. 이 경우 이름은 strimzi-cluster-operator 입니다.
5.3. AMQ Streams Operator를 사용하여 Kafka 구성 요소 배포
Openshift에 설치하는 경우 AMQ Streams Operator를 사용하면 사용자 인터페이스에서 Kafka 구성 요소를 설치할 수 있습니다.
다음 Kafka 구성 요소를 설치에 사용할 수 있습니다.
- Kafka
- Kafka Connect
- Kafka MirrorMaker
- Kafka MirrorMaker 2
- Kafka Topic
- Kafka 사용자
- Kafka 브리지
- Kafka Connector
- Kafka 리밸런스
구성 요소를 선택하고 인스턴스를 만듭니다. 최소한 Kafka 인스턴스를 생성합니다. 다음 절차에서는 기본 설정을 사용하여 Kafka 인스턴스를 생성하는 방법을 설명합니다. 설치를 수행하기 전에 기본 설치 사양을 구성할 수 있습니다.
프로세스는 다른 Kafka 구성 요소의 인스턴스를 생성하는 것과 동일합니다.
사전 요구 사항
- AMQ Streams Operator 가 OpenShift 클러스터에 설치되어 있습니다.
절차
웹 콘솔에서 Operator > 설치된 Operator 페이지로 이동하여 Red Hat Integration - AMQ Streams 를 클릭하여 Operator 세부 정보를 표시합니다.
제공된 API 에서 Kafka 구성 요소의 인스턴스를 생성할 수 있습니다.
Kafka 에서 인스턴스 생성을 클릭하여 Kafka 인스턴스를 생성합니다.
기본적으로 세 개의 Kafka 브로커 노드와 3 개의 ZooKeeper 노드가 있는
my-cluster라는 Kafka 클러스터를 생성합니다. 클러스터는 임시 스토리지를 사용합니다.생성을 클릭하여 Kafka 설치를 시작합니다.
상태가 Ready 로 변경될 때까지 기다립니다.
6장. 설치 아티팩트를 사용하여 AMQ Streams 배포
AMQ Streams 배포를 위한 환경을 준비하면 OpenShift 클러스터에 AMQ Streams 를 배포할 수 있습니다. 릴리스 아티팩트와 함께 제공되는 설치 파일을 사용합니다.
AMQ Streams는 Strimzi 0.32.x를 기반으로 합니다. OpenShift 4.8에 AMQ Streams 2.3을 4.12에 배포할 수 있습니다.
설치 파일을 사용하여 AMQ Streams를 배포하는 단계는 다음과 같습니다.
- Cluster Operator 배포
Cluster Operator를 사용하여 다음을 배포합니다.
선택적으로 요구 사항에 따라 다음 Kafka 구성 요소를 배포합니다.
이 가이드에서 명령을 실행하려면 OpenShift 사용자에게 RBAC(역할 기반 액세스 제어) 및 CRD를 관리할 수 있는 권한이 있어야 합니다.
6.1. 기본 배포 경로
AMQ Streams가 동일한 네임스페이스에서 단일 Kafka 클러스터를 관리하는 배포를 설정할 수 있습니다. 개발 또는 테스트에 이 구성을 사용할 수 있습니다. 또는 프로덕션 환경에서 AMQ Streams를 사용하여 다른 네임스페이스의 여러 Kafka 클러스터를 관리할 수 있습니다.
AMQ Streams 배포의 첫 번째 단계는 install/cluster-operator 파일을 사용하여 Cluster Operator를 설치하는 것입니다.
단일 명령은 cluster-operator 폴더의 모든 설치 파일을 적용합니다. oc apply -f ./install/cluster-operator.
이 명령은 다음을 포함하여 Kafka 배포를 생성하고 관리하는 데 필요한 모든 것을 설정합니다.
-
Cluster Operator (
배포,ConfigMap) -
AMQ Streams CRD(
CustomResourceDefinition) -
RBAC 리소스(
ClusterRole,ClusterRoleBinding,RoleBinding) -
서비스 계정(
ServiceAccount)
기본 배포 경로는 다음과 같습니다.
- 릴리스 아티팩트 다운로드
- Cluster Operator를 배포할 OpenShift 네임스페이스 생성
-
Cluster Operator에 생성된 네임스페이스를 사용하도록
install/cluster-operator파일을 업데이트합니다. - Cluster Operator를 설치하여 하나, 여러 개 또는 모든 네임스페이스를 조사합니다.
-
Cluster Operator에 생성된 네임스페이스를 사용하도록
- Kafka 클러스터 생성
그 후 다른 Kafka 구성 요소를 배포하고 배포 모니터링을 설정할 수 있습니다.
6.2. Cluster Operator 배포
Cluster Operator는 OpenShift 클러스터 내에서 Kafka 클러스터를 배포하고 관리합니다.
Cluster Operator가 실행 중이면 Kafka 리소스의 업데이트를 감시하기 시작합니다.
기본적으로 Cluster Operator의 단일 복제본이 배포됩니다. 중단 시 추가 Cluster Operator가 제공되도록 리더 선택으로 복제본을 추가할 수 있습니다. 자세한 내용은 리더 선택을 사용하여 여러 Cluster Operator 복제본 실행을 참조하십시오.
6.2.1. Cluster Operator에서 감시하는 네임스페이스 지정
Cluster Operator는 Kafka 리소스가 배포되는 네임스페이스의 업데이트를 감시합니다. Cluster Operator를 배포할 때 조사할 네임스페이스를 지정합니다. 다음 네임스페이스를 지정할 수 있습니다.
Cluster Operator는 OpenShift 클러스터에서 하나, 여러 개 또는 모든 네임스페이스를 조사할 수 있습니다. Topic Operator 및 User Operator는 단일 네임스페이스에서 KafkaTopic 및 KafkaUser 리소스를 조사합니다. 자세한 내용은 AMQ Streams Operator를 사용하여 네임스페이스 감시를 참조하십시오.
Cluster Operator는 다음 리소스에 대한 변경 사항을 감시합니다.
-
Kafka클러스터의 Kafka입니다. -
Kafka Connect클러스터의 KafkaConnect. -
Kafka Connect 클러스터에서 커넥터를 생성하고 관리하기 위한
KafkaConnector. -
Kafka MirrorMaker인스턴스인 KafkaMirrorMaker입니다. -
Kafka MirrorMaker 2.0 인스턴스인
KafkaMirrorMaker2입니다. -
Kafka 브리지인스턴스용 KafkaBridge. -
Cruise Control 최적화 요청에 대한
KafkaRebalance
OpenShift 클러스터에 이러한 리소스 중 하나가 생성되면 Operator가 리소스에서 클러스터 설명을 가져오고 StatefulSets, Services 및 ConfigMaps와 같은 필요한 OpenShift 리소스를 생성하여 리소스에 대한 새 클러스터 생성을 시작합니다.
Kafka 리소스가 업데이트될 때마다 Operator는 리소스에 대한 클러스터를 구성하는 OpenShift 리소스에서 해당 업데이트를 수행합니다.
리소스를 패치하거나 삭제한 다음 다시 생성하여 리소스의 클러스터를 원하는 클러스터 상태를 반영합니다. 이 작업으로 인해 서비스 중단으로 이어질 수 있는 롤링 업데이트가 발생할 수 있습니다.
리소스가 삭제되면 Operator는 클러스터 배포를 취소하고 관련된 모든 OpenShift 리소스를 삭제합니다.
6.2.2. 단일 네임스페이스를 조사하기 위해 Cluster Operator 배포
다음 절차에서는 OpenShift 클러스터의 단일 네임스페이스에서 AMQ Streams 리소스를 조사하기 위해 Cluster Operator를 배포하는 방법을 설명합니다.
사전 요구 사항
-
CustomResourceDefinition및 RBAC(ClusterRole,RoleBinding) 리소스를 생성하고 관리하려면 권한이 있는 계정이 필요합니다.
절차
AMQ Streams 설치 파일을 편집하여 Cluster Operator가 설치될 네임스페이스를 사용합니다.
예를 들어 이 절차에서는 Cluster Operator가
my-cluster-operator-namespace네임스페이스에 설치됩니다.Linux에서 다음을 사용합니다.
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
MacOS에서 다음을 사용합니다.
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
Cluster Operator를 배포합니다.
oc create -f install/cluster-operator -n my-cluster-operator-namespace
배포 상태를 확인합니다.
oc get deployments -n my-cluster-operator-namespace
출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
6.2.3. 여러 네임스페이스를 조사하기 위해 Cluster Operator 배포
다음 절차에서는 Cluster Operator를 배포하여 OpenShift 클러스터의 여러 네임스페이스에서 AMQ Streams 리소스를 조사하는 방법을 설명합니다.
사전 요구 사항
-
CustomResourceDefinition및 RBAC(ClusterRole,RoleBinding) 리소스를 생성하고 관리하려면 권한이 있는 계정이 필요합니다.
절차
AMQ Streams 설치 파일을 편집하여 Cluster Operator가 설치될 네임스페이스를 사용합니다.
예를 들어 이 절차에서는 Cluster Operator가
my-cluster-operator-namespace네임스페이스에 설치됩니다.Linux에서 다음을 사용합니다.
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
MacOS에서 다음을 사용합니다.
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml파일을 편집하여 Cluster Operator가STRIMZI_NAMESPACE환경 변수를 조사하는 모든 네임스페이스 목록을 추가합니다.예를 들어, 이 절차에서 Cluster Operator는
watched-namespace-1네임스페이스,watched-namespace-2,watched-namespace-3을 확인합니다.apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel8-operator:2.3.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: watched-namespace-1,watched-namespace-2,watched-namespace-3나열된 각 네임스페이스에 대해
RoleBindings를 설치합니다.이 예제에서는 이 명령에서
watched-namespace를 이전 단계에 나열된 네임스페이스로 교체하고watched-namespace-1,watched-namespace-2,watched-namespace-3에 대해 반복합니다.oc create -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n <watched_namespace> oc create -f install/cluster-operator/023-RoleBinding-strimzi-cluster-operator.yaml -n <watched_namespace> oc create -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n <watched_namespace>
Cluster Operator를 배포합니다.
oc create -f install/cluster-operator -n my-cluster-operator-namespace
배포 상태를 확인합니다.
oc get deployments -n my-cluster-operator-namespace
출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
6.2.4. 모든 네임스페이스를 조사하기 위해 Cluster Operator 배포
다음 절차에서는 OpenShift 클러스터의 모든 네임스페이스에서 AMQ Streams 리소스를 조사하기 위해 Cluster Operator를 배포하는 방법을 설명합니다.
이 모드에서 실행하면 Cluster Operator가 생성된 새 네임스페이스의 클러스터를 자동으로 관리합니다.
사전 요구 사항
-
CustomResourceDefinition및 RBAC(ClusterRole,RoleBinding) 리소스를 생성하고 관리하려면 권한이 있는 계정이 필요합니다.
절차
AMQ Streams 설치 파일을 편집하여 Cluster Operator가 설치될 네임스페이스를 사용합니다.
예를 들어 이 절차에서는 Cluster Operator가
my-cluster-operator-namespace네임스페이스에 설치됩니다.Linux에서 다음을 사용합니다.
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
MacOS에서 다음을 사용합니다.
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml파일을 편집하여STRIMZI_NAMESPACE환경 변수 값을*로 설정합니다.apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: # ... serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel8-operator:2.3.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: "*" # ...모든 네임스페이스에 대한 클러스터 전체 액세스 권한을 Cluster Operator에 부여하는
ClusterRoleBindings를 생성합니다.oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-watched --clusterrole=strimzi-cluster-operator-watched --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator
OpenShift 클러스터에 Cluster Operator를 배포합니다.
oc create -f install/cluster-operator -n my-cluster-operator-namespace
배포 상태를 확인합니다.
oc get deployments -n my-cluster-operator-namespace
출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE strimzi-cluster-operator 1/1 1 1
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
6.3. Kafka 배포
Cluster Operator를 사용하여 Kafka 클러스터를 관리할 수 있으려면 Kafka 리소스로 배포해야 합니다. AMQ Streams는 이 작업을 수행할 배포 파일 예를 제공합니다. 이러한 파일을 사용하여 Topic Operator 및 User Operator를 동시에 배포할 수 있습니다.
Cluster Operator를 배포한 후 Kafka 리소스를 사용하여 다음 구성 요소를 배포합니다.
Kafka를 설치할 때 AMQ Streams는 ZooKeeper 클러스터를 설치하고, Kafka를 ZooKeeper와 연결하는 데 필요한 구성을 추가합니다.
Kafka 클러스터를 Kafka 리소스로 배포하지 않은 경우 Cluster Operator를 사용하여 관리할 수 없습니다. 이는 예를 들어 OpenShift 외부에서 실행되는 Kafka 클러스터에 적용됩니다. 그러나 독립 실행형 구성 요소로 배포하여 AMQ Streams에서 관리하지 않는 Kafka 클러스터와 함께 Topic Operator 및 User Operator를 사용할 수 있습니다. AMQ Streams에서 관리하지 않는 Kafka 클러스터와 함께 다른 Kafka 구성 요소를 배포하고 사용할 수도 있습니다.
6.3.1. Kafka 클러스터 배포
다음 절차에서는 Cluster Operator를 사용하여 Kafka 클러스터를 OpenShift 클러스터에 배포하는 방법을 설명합니다.
배포에서는 YAML 파일을 사용하여 Kafka 리소스를 생성하는 사양을 제공합니다.
AMQ Streams는 Kafka 클러스터를 생성하는 데 사용할 수 있는 다음 예제 파일을 제공합니다.
kafka-persistent.yaml- 3개의 ZooKeeper 및 3개의 Kafka 노드로 영구 클러스터를 배포합니다.
kafka-jbod.yaml- 3개의 ZooKeeper 및 3개의 Kafka 노드로 영구 클러스터를 배포합니다(각각 여러 영구 볼륨을 사용).
kafka-persistent-single.yaml- 단일 ZooKeeper 노드와 단일 Kafka 노드로 영구 클러스터를 배포합니다.
kafka-ephemeral.yaml- 3개의 ZooKeeper 및 3개의 Kafka 노드로 임시 클러스터를 배포합니다.
kafka-ephemeral-single.yaml- 3개의 ZooKeeper 노드와 단일 Kafka 노드로 임시 클러스터를 배포합니다.
이 절차에서는 임시 및 영구 Kafka 클러스터 배포에 대한 예제를 사용합니다.
- 임시 클러스터
-
일반적으로 임시(또는 임시) Kafka 클러스터는 프로덕션이 아닌 개발 및 테스트 목적으로 적합합니다. 이 배포에서는 브로커 정보(축소용) 및 주제 또는 파티션( Kafka용)을 저장하는 데
emptyDir볼륨을 사용합니다.emptyDir볼륨을 사용하면 콘텐츠가 Pod 라이프 사이클과 엄격하게 관련되어 있으며 Pod가 중단되면 삭제됩니다. - 영구 클러스터
영구 Kafka 클러스터는 영구 볼륨을 사용하여 ZooKeeper 및 Kafka 데이터를 저장합니다.
PersistentVolume은PersistentVolumeClaim을 사용하여 실제 유형의PersistentVolume과 독립적되도록 합니다.PersistentVolumeClaim은StorageClass를 사용하여 자동 볼륨 프로비저닝을 트리거할 수 있습니다.StorageClass를 지정하지 않으면 OpenShift에서 기본StorageClass를 사용하려고 합니다.다음 예제에서는 몇 가지 일반적인 유형의 영구 볼륨을 보여줍니다.
- OpenShift 클러스터가 Amazon AWS에서 실행되는 경우 OpenShift는 Amazon EBS 볼륨을 프로비저닝할 수 있습니다.
- OpenShift 클러스터가 Microsoft Azure에서 실행되는 경우 OpenShift는 Azure Disk Storage 볼륨을 프로비저닝할 수 있습니다.
- OpenShift 클러스터가 Google Cloud에서 실행되는 경우 OpenShift는 영구 디스크 볼륨을 프로비저닝할 수 있습니다.
- OpenShift 클러스터가 베어 메탈에서 실행되는 경우 OpenShift는 로컬 영구 볼륨을 프로비저닝할 수 있습니다.
예제 YAML 파일은 지원되는 최신 Kafka 버전을 지정하고 지원되는 로그 메시지 형식 버전 및broker 간 프로토콜 버전에 대한 구성을 지정합니다. Kafka 구성에 대한 inter.broker.protocol.version 속성은 지정된 Kafka 버전 (spec.kafka.version)에서 지원하는 버전이어야합니다. 속성은 Kafka 클러스터에서 사용되는 Kafka 프로토콜 버전을 나타냅니다.
Kafka 3.0.0에서 inter.broker.protocol.version 이 3.0 이상으로 설정되면 log.message.format.version 옵션이 무시되고 설정할 필요가 없습니다.
Kafka를 업그레이드 할 때 inter.broker.protocol.version 에 대한 업데이트가 필요합니다.
예제 클러스터의 이름은 기본적으로 my-cluster 로 지정됩니다. 클러스터 이름은 리소스 이름으로 정의되며 클러스터를 배포한 후에는 변경할 수 없습니다. 클러스터를 배포하기 전에 클러스터 이름을 변경하려면 관련 YAML 파일에서 Kafka 리소스의 Kafka.metadata.name 속성을 편집합니다.
기본 클러스터 이름 및 지정된 Kafka 버전
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.3.1
#...
config:
#...
log.message.format.version: "3.3"
inter.broker.protocol.version: "3.3"
# ...
사전 요구 사항
절차
임시 또는 영구 클러스터를 생성하고 배포합니다.
임시 클러스터를 생성하고 배포하려면 다음을 수행합니다.
oc apply -f examples/kafka/kafka-ephemeral.yaml
영구 클러스터를 생성하고 배포하려면 다음을 수행합니다.
oc apply -f examples/kafka/kafka-persistent.yaml
배포 상태를 확인합니다.
oc get pods -n <my_cluster_operator_namespace>출력에는 Pod 이름과 준비 상태가 표시됩니다.
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 my-cluster-kafka-0 1/1 Running 0 my-cluster-kafka-1 1/1 Running 0 my-cluster-kafka-2 1/1 Running 0 my-cluster-zookeeper-0 1/1 Running 0 my-cluster-zookeeper-1 1/1 Running 0 my-cluster-zookeeper-2 1/1 Running 0
my-cluster는 Kafka 클러스터의 이름입니다.기본 배포를 사용하면 Entity Operator 클러스터, Kafka Pod 3개 및 3 ZooKeeper Pod를 설치합니다.
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.STATUS가Running으로 표시되면 배포가 성공적으로 수행됩니다.
추가 리소스
6.3.2. Cluster Operator를 사용하여 Topic Operator 배포
다음 절차에서는 Cluster Operator를 사용하여 Topic Operator를 배포하는 방법을 설명합니다.
topicOperator 를 포함하도록 Kafka 리소스의 entityOperator 속성을 구성합니다. 기본적으로 Topic Operator는 Cluster Operator가 배포한 Kafka 클러스터의 네임스페이스에서 KafkaTopic 리소스를 감시합니다. 주제 Operator 사양에서 watchedNamespace 를 사용하여 네임스페이스를 지정할 수도 있습니다. 단일 Topic Operator는 단일 네임스페이스를 조사할 수 있습니다. 하나의 네임스페이스는 하나의 Topic Operator에서만 조사해야 합니다.
AMQ Streams를 사용하여 여러 Kafka 클러스터를 동일한 네임스페이스에 배포하는 경우 하나의 Kafka 클러스터에 대해서만 Topic Operator를 활성화하거나 watchedNamespace 속성을 사용하여 다른 네임스페이스를 조사하도록 Topic Operator를 구성합니다.
AMQ Streams에서 관리하지 않는 Kafka 클러스터에서 Topic Operator를 사용하려면 Topic Operator를 독립 실행형 구성 요소로 배포 해야 합니다.
entityOperator 및 topicOperator 속성 구성에 대한 자세한 내용은 Entity Operator 구성을 참조하십시오.
사전 요구 사항
절차
topicOperator를 포함하도록Kafka리소스의entityOperator속성을 편집합니다.apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}EntityTopicOperatorSpec스키마 참조에 설명된 속성을 사용하여 Topic Operator사양을 구성합니다.모든 속성이 기본값을 사용하려면 빈 오브젝트(
{})를 사용합니다.리소스를 생성하거나 업데이트합니다.
oc apply -f <kafka_configuration_file>배포 상태를 확인합니다.
oc get pods -n <my_cluster_operator_namespace>출력에 Pod 이름과 준비 상태가 표시됩니다.
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 # ...
my-cluster는 Kafka 클러스터의 이름입니다.READY에는 준비되거나 예상된 복제본 수가 표시됩니다.STATUS가Running으로 표시되면 배포가 성공적으로 수행됩니다.
6.3.3. Cluster Operator를 사용하여 User Operator 배포
다음 절차에서는 Cluster Operator를 사용하여 User Operator를 배포하는 방법을 설명합니다.
userOperator 를 포함하도록 Kafka 리소스의 entityOperator 속성을 구성합니다. 기본적으로 User Operator는 Kafka 클러스터 배포의 네임스페이스에서 KafkaUser 리소스를 감시합니다. User Operator 사양에서 watchedNamespace 를 사용하여 네임스페이스를 지정할 수도 있습니다. 단일 User Operator는 단일 네임스페이스를 조사할 수 있습니다. 하나의 네임스페이스는 User Operator 한 개만 조사해야 합니다.
AMQ Streams에서 관리하지 않는 Kafka 클러스터에서 User Operator를 사용하려면 User Operator를 독립 실행형 구성 요소로 배포 해야 합니다.
entityOperator 및 userOperator 속성 구성에 대한 자세한 내용은 Entity Operator 구성을 참조하십시오.
사전 요구 사항
절차
userOperator를 포함하도록Kafka리소스의entityOperator속성을 편집합니다.apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}EntityUserOperatorSpec스키마 참조에 설명된 속성을 사용하여 User Operator사양을 구성합니다.모든 속성이 기본값을 사용하려면 빈 오브젝트(
{})를 사용합니다.리소스를 생성하거나 업데이트합니다.
oc apply -f <kafka_configuration_file>배포 상태를 확인합니다.
oc get pods -n <my_cluster_operator_namespace>출력에 Pod 이름과 준비 상태가 표시됩니다.
NAME READY STATUS RESTARTS my-cluster-entity-operator 3/3 Running 0 # ...
my-cluster는 Kafka 클러스터의 이름입니다.READY에는 준비되거나 예상된 복제본 수가 표시됩니다.STATUS가Running으로 표시되면 배포가 성공적으로 수행됩니다.
6.4. Kafka Connect 배포
Kafka Connect 는 Apache Kafka와 외부 시스템 간에 데이터를 스트리밍하는 툴입니다.
AMQ Streams에서 Kafka Connect는 분산 모드로 배포됩니다. Kafka Connect는 독립 실행형 모드에서도 작동할 수 있지만 AMQ Streams에서는 지원되지 않습니다.
커넥터 의 개념을 사용하여 Kafka Connect는 확장성과 신뢰성을 유지하면서 Kafka 클러스터 내외로 대량의 데이터를 이동하기 위한 프레임워크를 제공합니다.
Kafka Connect는 일반적으로 Kafka를 외부 데이터베이스 및 스토리지 및 메시징 시스템과 통합하는 데 사용됩니다.
Cluster Operator는 KafkaConnector 리소스를 사용하여 생성된 KafkaConnect 리소스 및 커넥터를 사용하여 배포된 Kafka Connect 클러스터를 관리합니다.
다음 절차에서는 Kafka Connect를 배포하고 스트리밍 데이터를 위한 커넥터를 설정하는 방법을 보여줍니다.
커넥터 라는 용어는 Kafka Connect 클러스터 또는 커넥터 클래스 내에서 실행되는 커넥터 인스턴스를 의미합니다. 이 가이드에서 커넥터 라는 용어는 컨텍스트에서 의미가 명확해질 때 사용됩니다.
6.4.1. OpenShift 클러스터에 Kafka Connect 배포
다음 절차에서는 Cluster Operator를 사용하여 Kafka Connect 클러스터를 OpenShift 클러스터에 배포하는 방법을 설명합니다.
Kafka Connect 클러스터는 연결의 워크로드를 작업으로 배포 하는 구성 가능한 수의 노드( 작업자라고도 함)를 사용한 배포로 구현되므로 메시지 흐름이 확장성이 높고 신뢰할 수 있습니다.
배포에서는 YAML 파일을 사용하여 사양을 제공하여 KafkaConnect 리소스를 생성합니다.
AMQ Streams는 구성 파일 예제 를 제공합니다. 이 절차에서는 다음 예제 파일을 사용합니다.
-
examples/connect/kafka-connect.yaml
절차
OpenShift 클러스터에 Kafka Connect를 배포합니다.
examples/connect/kafka-connect.yaml파일을 사용하여 Kafka Connect를 배포합니다.oc apply -f examples/connect/kafka-connect.yaml
배포 상태를 확인합니다.
oc get deployments -n <my_cluster_operator_namespace>출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE my-connect-cluster-connect 1/1 1 1
my-connect-cluster는 Kafka Connect 클러스터의 이름입니다.READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
추가 리소스
6.4.2. 여러 인스턴스에 대한 Kafka Connect 구성
Kafka Connect의 여러 인스턴스를 실행하는 경우 다음 구성 속성의 기본 구성을 변경해야 합니다.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: connect-cluster 1
offset.storage.topic: connect-cluster-offsets 2
config.storage.topic: connect-cluster-configs 3
status.storage.topic: connect-cluster-status 4
# ...
# ...
세 항목의 값은 동일한 group.id 가 있는 모든 Kafka Connect 인스턴스에 대해 동일해야 합니다.
기본 설정을 변경하지 않으면 동일한 Kafka 클러스터에 연결하는 각 Kafka Connect 인스턴스가 동일한 값으로 배포됩니다. 실제로 모든 인스턴스가 클러스터에서 실행되고 동일한 주제를 사용하도록 연결된 것입니다.
여러 Kafka Connect 클러스터가 동일한 주제를 사용하려고 하면 Kafka Connect가 예상대로 작동하지 않고 오류를 생성합니다.
여러 Kafka Connect 인스턴스를 실행하려면 각 인스턴스에 대해 이러한 속성의 값을 변경합니다.
6.4.3. 커넥터 플러그인을 사용하여 Kafka Connect 확장
Kafka Connect는 커넥터 인스턴스를 사용하여 다른 시스템과 통합하여 데이터를 스트리밍합니다. 커넥터는 다음 유형 중 하나일 수 있습니다.
- Kafka로 데이터를 푸시하는 소스 커넥터
- Kafka에서 데이터를 추출하는 싱크 커넥터
이 섹션의 절차에서는 다음 중 하나를 수행하여 커넥터를 추가하는 방법을 설명합니다.
Kafka Connect REST API 또는 KafkaConnector 사용자 정의 리소스를 사용하여 직접 커넥터 에 대한 구성을 생성합니다.
사용자 고유의 커넥터를 사용하거나 파일 기반 데이터를 Kafka 클러스터 내외로 이동하기 위한ECDHE SourceConnector 및ECDHE Sink Connector 커넥터 예제를 시도할 수 있습니다. 예제 파일 커넥터를 KafkaConnector 리소스로 배포하는 방법에 대한 자세한 내용은 6.4.4.2절. “KafkaConnector 리소스 예 배포” 을 참조하십시오.
Apache Kafka 3.1.0까지 Kafka Connect의 AMQ Streams 컨테이너 이미지에 예제 파일 커넥터가 포함되어 있습니다. Apache Kafka 3.1.1 및 3.2.0에서 이러한 커넥터는 더 이상 포함되지 않으며 커넥터와 같이 배포해야 합니다.
6.4.3.1. AMQ Streams를 사용하여 자동으로 새 컨테이너 이미지 생성
다음 절차에서는 AMQ Streams가 추가 커넥터를 사용하여 새 컨테이너 이미지를 자동으로 빌드하도록 Kafka Connect를 구성하는 방법을 설명합니다. KafkaConnect 사용자 정의 리소스의 .spec.build.plugins 속성을 사용하여 커넥터 플러그인을 정의합니다. AMQ Streams는 커넥터 플러그인을 자동으로 다운로드하여 새 컨테이너 이미지에 추가합니다. 컨테이너는 .spec.build.output 에 지정된 컨테이너 리포지토리로 푸시되고 Kafka Connect 배포에 자동으로 사용됩니다.
사전 요구 사항
- Cluster Operator를 배포해야 합니다.
- 컨테이너 레지스트리.
이미지를 푸시, 저장 및 가져올 수 있는 자체 컨테이너 레지스트리를 제공해야 합니다. AMQ Streams는 프라이빗 컨테이너 레지스트리 및 Quay 또는 Docker Hub 와 같은 공개 레지스트리를 지원합니다.
절차
.spec.build.output에서 컨테이너 레지스트리를 지정하고.spec.build.plugins에서 추가 커넥터를 지정하여KafkaConnect사용자 정의 리소스를 구성합니다.apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: 1 #... build: output: 2 type: docker image: my-registry.io/my-org/my-connect-cluster:latest pushSecret: my-registry-credentials plugins: 3 - name: debezium-postgres-connector artifacts: - type: tgz url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.3.1.Final/debezium-connector-postgres-1.3.1.Final-plugin.tar.gz sha512sum: 962a12151bdf9a5a30627eebac739955a4fd95a08d373b86bdcea2b4d0c27dd6e1edd5cb548045e115e33a9e69b1b2a352bee24df035a0447cb820077af00c03 - name: camel-telegram artifacts: - type: tgz url: https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-telegram-kafka-connector/0.7.0/camel-telegram-kafka-connector-0.7.0-package.tar.gz sha512sum: a9b1ac63e3284bea7836d7d24d84208c49cdf5600070e6bd1535de654f6920b74ad950d51733e8020bf4187870699819f54ef5859c7846ee4081507f48873479 #...
리소스를 생성하거나 업데이트합니다.
$ oc apply -f KAFKA-CONNECT-CONFIG-FILE- 새 컨테이너 이미지가 빌드될 때까지 기다린 후 Kafka Connect 클러스터가 배포될 때까지 기다립니다.
- Kafka Connect REST API 또는 KafkaConnector 사용자 정의 리소스를 사용하여 사용자가 추가한 커넥터 플러그인을 사용합니다.
추가 리소스
다음에 대한 자세한 내용은 Strimzi 사용 가이드를 참조하십시오.
6.4.3.2. Kafka Connect 기본 이미지에서 Docker 이미지 생성
다음 절차에서는 사용자 지정 이미지를 생성하고 이를 /opt/kafka/plugins 디렉터리에 추가하는 방법을 설명합니다.
Red Hat Ecosystem Catalog 의 Kafka 컨테이너 이미지를 기본 이미지로 사용하여 추가 커넥터 플러그인으로 자체 사용자 지정 이미지를 생성할 수 있습니다.
시작 시 Kafka Connect의 AMQ Streams 버전은 /opt/kafka/plugins 디렉터리에 포함된 타사 커넥터 플러그인을 로드합니다.
사전 요구 사항
절차
registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0을 기본 이미지로 사용하여 새Dockerfile을 생성합니다.FROM registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001플러그인 파일 예
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md
참고이 예에서는 MongoDB, MySQL, PostgreSQL에 Debezium 커넥터를 사용합니다. Kafka Connect에서 실행 중인 Debezium은 다른 Kafka Connect 작업과 동일합니다.
- 컨테이너 이미지를 빌드합니다.
- 사용자 정의 이미지를 컨테이너 레지스트리로 내보냅니다.
새 컨테이너 이미지를 가리킵니다.
다음 중 하나를 수행할 수 있습니다.
KafkaConnect사용자 정의 리소스의KafkaConnect.spec.image속성을 편집합니다.설정된 경우 이 속성은 Cluster Operator의
STRIMZI_KAFKA_CONNECT_IMAGES변수를 덮어씁니다.apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: 1 #... image: my-new-container-image 2 config: 3 #...
또는
-
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml파일에서STRIMZI_KAFKA_CONNECT_IMAGES변수를 편집하여 새 컨테이너 이미지를 가리키는 다음 Cluster Operator를 다시 설치합니다.
6.4.4. 커넥터 생성 및 관리
커넥터 플러그인의 컨테이너 이미지를 생성한 경우 Kafka Connect 클러스터에서 커넥터 인스턴스를 생성해야 합니다. 그런 다음 실행 중인 커넥터 인스턴스를 구성, 모니터링 및 관리할 수 있습니다.
커넥터는 메시지 측면에서 관련 외부 시스템과 통신하는 방법을 알고 있는 특정 커넥터 클래스의 인스턴스입니다. 커넥터는 여러 외부 시스템에서 사용할 수 있거나 직접 만들 수 있습니다.
커넥터의 소스 및 싱크 유형을 생성할 수 있습니다.
- 소스 커넥터
- 소스 커넥터는 외부 시스템에서 데이터를 가져와서 메시지로 Kafka에 제공하는 런타임 엔티티입니다.
- 싱크 커넥터
- 싱크 커넥터는 Kafka 주제에서 메시지를 가져와서 외부 시스템에 제공하는 런타임 엔티티입니다.
6.4.4.1. 커넥터 생성 및 관리를 위한 API
AMQ Streams는 커넥터를 생성하고 관리하기 위해 두 가지 API를 제공합니다.
-
KafkaConnector사용자 정의 리소스 ( KafkaConnectors로 참조) - Kafka Connect REST API
API를 사용하면 다음을 수행할 수 있습니다.
- 커넥터 인스턴스의 상태 확인
- 실행 중인 커넥터 재구성
- 커넥터 인스턴스의 커넥터 작업 수를 늘리거나 줄입니다.
- 커넥터 재시작
- 실패한 작업을 포함한 커넥터 작업 재시작
- 커넥터 인스턴스 일시 중지
- 이전에 일시 중지된 커넥터 인스턴스 재시작
- 커넥터 인스턴스 삭제
KafkaConnector 사용자 정의 리소스
KafkaConnectors를 사용하면 OpenShift 네이티브 방식으로 Kafka Connect에 대한 커넥터 인스턴스를 생성하고 관리할 수 있으므로 cURL과 같은 HTTP 클라이언트가 필요하지 않습니다. 다른 Kafka 리소스와 마찬가지로 OpenShift 클러스터에 배포된 KafkaConnector YAML 파일에서 커넥터의 원하는 상태를 선언하여 커넥터 인스턴스를 생성합니다. KafkaConnector 리소스를 연결하는 Kafka Connect 클러스터와 동일한 네임스페이스에 배포해야 합니다.
해당 KafkaConnector 리소스를 업데이트한 다음 업데이트를 적용하여 실행 중인 커넥터 인스턴스를 관리합니다. 해당 KafkaConnector 를 삭제하여 커넥터를 제거합니다.
이전 AMQ Streams 버전과의 호환성을 보장하기 위해 KafkaConnectors는 기본적으로 비활성화되어 있습니다. Kafka Connect 클러스터의 KafkaConnectors를 활성화하려면 KafkaConnect 리소스에서 strimzi.io/use-connector-resources 주석을 true 로 설정합니다. 자세한 내용은 Kafka Connect 구성을 참조하십시오.
KafkaConnectors가 활성화되면 Cluster Operator에서 감시하기 시작합니다. KafkaConnectors에 정의된 구성과 일치하도록 실행 중인 커넥터 인스턴스의 구성을 업데이트합니다.
AMQ Streams는 examples KafkaConnector 구성 파일을 제공하며, 이 파일을 사용하여 ScanSetting Source Connector 및ECDHE SinkConnector를 생성하고 관리할 수 있습니다.
KafkaConnector 리소스에 주석 을 달아 커넥터를 다시 시작하거나 커넥터 작업을 다시 시작할 수 있습니다.
Kafka Connect API
Kafka Connect REST API에서 지원하는 작업은 Apache Kafka Connect API 설명서에 설명되어 있습니다.
Kafka Connect API를 사용하여 KafkaConnectors 사용으로 전환
Kafka Connect API를 사용하여 KafkaConnectors를 사용하여 커넥터를 관리할 수 있습니다. 전환하려면 표시된 순서대로 다음을 수행합니다.
-
구성과 함께
KafkaConnector리소스를 배포하여 커넥터 인스턴스를 생성합니다. -
strimzi.io/use-connector-resources주석을true로 설정하여 Kafka Connect 구성에서 KafkaConnectors를 활성화합니다.
리소스를 생성하기 전에 KafkaConnectors를 활성화하면 모든 커넥터를 삭제합니다.
KafkaConnectors를 Kafka Connect API를 사용하도록 전환하려면 먼저 Kafka Connect 구성에서 KafkaConnectors를 활성화하는 주석을 제거합니다. 그렇지 않으면 Kafka Connect REST API를 직접 사용하여 수행한 수동 변경 사항을 Cluster Operator에 의해 되돌립니다.
6.4.4.2. KafkaConnector 리소스 예 배포
KafkaConnector 리소스는 Cluster Operator의 커넥터 관리에 OpenShift 네이티브 접근 방식을 제공합니다. AMQ Streams는 구성 파일 예제 를 제공합니다. 이 절차에서는 examples/connect/source-connector.yaml 파일을 사용하여 KafkaConnector 리소스로 다음 커넥터 인스턴스를 생성합니다.
-
Kafka 라이센스 파일(소스)에서 각 행을 읽고 해당 데이터를 단일 Kafka 항목에 메시지로 기록하는 instance입니다.
-
Kafka 주제에서 메시지를 읽고 메시지를 임시 파일(스케크)에 쓰는 instance입니다.
또는 examples/connect/kafka-connect-build.yaml 파일을 사용하여 파일 커넥터로 새 Kafka Connect 이미지를 빌드할 수 있습니다.
Apache Kafka 3.1.0까지 예제 파일 커넥터 플러그인이 Apache Kafka에 포함되었습니다. Apache Kafka의 3.1.1 및 3.2.0 릴리스부터 다른 커넥터로 플러그인 경로에 예제를 추가해야 합니다. 자세한 내용은 커넥터 플러그인을 사용하여 Kafka Connect 확장을 참조하십시오.
프로덕션 환경에서는 6.4.3절. “커넥터 플러그인을 사용하여 Kafka Connect 확장” 에 설명된 대로 필요한 Kafka Connect 커넥터를 사용하여 컨테이너 이미지를 준비합니다.
ScanSetting SourceConnector 및 ScanSettingSinkConnector 는 예제로 제공됩니다. 여기에 설명된 대로 컨테이너에서 이러한 커넥터를 실행하는 것은 프로덕션 사용 사례에 적합하지 않을 수 있습니다.
사전 요구 사항
- Kafka Connect 배포
- KafkaConnectors는 Kafka Connect 배포에서 활성화됩니다.
- Cluster Operator가 실행 중입니다.
절차
examples/connect/source-connector.yaml파일을 편집합니다.apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-source-connector 1 labels: strimzi.io/cluster: my-connect-cluster 2 spec: class: org.apache.kafka.connect.file.FileStreamSourceConnector 3 tasksMax: 2 4 config: 5 file: "/opt/kafka/LICENSE" 6 topic: my-topic 7 # ...
- 1
- 커넥터의 이름으로 사용되는
KafkaConnector리소스의 이름입니다. OpenShift 리소스에 유효한 이름을 사용합니다. - 2
- Kafka Connect 클러스터의 이름이 에서 커넥터 인스턴스를 생성합니다. 커넥터를 연결하는 Kafka Connect 클러스터와 동일한 네임스페이스에 배포해야 합니다.
- 3
- 커넥터 클래스의 전체 이름 또는 별칭입니다. Kafka Connect 클러스터에서 사용하는 이미지에 있어야 합니다.
- 4
- 커넥터가 생성할 수 있는
최대 Kafka Connect Task수입니다. - 5
- 커넥터 구성은 키-값 쌍으로 설정됩니다.
- 6
- 이 예제 소스 커넥터 구성은
/opt/kafka/LICENSE파일에서 데이터를 읽습니다. - 7
- 소스 데이터를 게시하는 Kafka 주제입니다.
OpenShift 클러스터에서 소스
KafkaConnector를 생성합니다.oc apply -f examples/connect/source-connector.yaml
examples/connect/sink-connector.yaml파일을 생성합니다.touch examples/connect/sink-connector.yaml
다음 YAML을
sink-connector.yaml파일에 붙여넣습니다.apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: my-sink-connector labels: strimzi.io/cluster: my-connect spec: class: org.apache.kafka.connect.file.FileStreamSinkConnector 1 tasksMax: 2 config: 2 file: "/tmp/my-file" 3 topics: my-topic 4OpenShift 클러스터에 싱크
KafkaConnector를 생성합니다.oc apply -f examples/connect/sink-connector.yaml
커넥터 리소스가 생성되었는지 확인합니다.
oc get kctr --selector strimzi.io/cluster=MY-CONNECT-CLUSTER -o name my-source-connector my-sink-connectorMY-CONNECT-CLUSTER 를 Kafka Connect 클러스터로 교체합니다.
컨테이너에서
kafka-console-consumer.sh를 실행하여 소스 커넥터가 항목에 기록된 메시지를 읽습니다.oc exec MY-CLUSTER-kafka-0 -i -t -- bin/kafka-console-consumer.sh --bootstrap-server MY-CLUSTER-kafka-bootstrap.NAMESPACE.svc:9092 --topic my-topic --from-beginning
소스 및 싱크 커넥터 구성 옵션
커넥터 구성은 KafkaConnector 리소스의 spec.config 속성에 정의되어 있습니다.
ECDHE SourceConnector 및 ECDHESinkConnector 클래스는 Kafka Connect REST API와 동일한 구성 옵션을 지원합니다. 기타 커넥터는 다양한 구성 옵션을 지원합니다.
표 6.1. 10.0.0.1 Source 커넥터 클래스에 대한 구성 옵션
| 이름 | 유형 | 기본값 | 설명 |
|---|---|---|---|
|
| 문자열 | null | 메시지를 작성할 소스 파일입니다. 지정하지 않으면 표준 입력이 사용됩니다. |
|
| list | null | 데이터를 게시하는 Kafka 주제입니다. |
표 6.2. ScanSetting SinkConnector 클래스에 대한 구성 옵션
| 이름 | 유형 | 기본값 | 설명 |
|---|---|---|---|
|
| 문자열 | null | 메시지를 작성할 대상 파일입니다. 지정하지 않으면 표준 출력이 사용됩니다. |
|
| list | null | 데이터를 읽을 하나 이상의 Kafka 주제입니다. |
|
| 문자열 | null | 데이터를 읽을 하나 이상의 Kafka 주제와 일치하는 정규식입니다. |
6.4.4.3. Kafka 커넥터를 다시 시작 수행
다음 절차에서는 OpenShift 주석을 사용하여 Kafka 커넥터의 재시작을 수동으로 트리거하는 방법을 설명합니다.
사전 요구 사항
- Cluster Operator가 실행 중입니다.
절차
재시작하려는 Kafka 커넥터를 제어하는
KafkaConnector사용자 정의 리소스의 이름을 찾습니다.oc get KafkaConnector
커넥터를 다시 시작하려면 OpenShift에서
KafkaConnector리소스에 주석을 답니다. 예를 들어oc annotate:oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart=true다음 조정이 수행될 때까지 기다립니다(기본적으로 2분 마다).
조정 프로세스에서 주석이 감지된 한 Kafka 커넥터가 재시작됩니다. Kafka Connect에서 재시작 요청을 수락하면 주석이
KafkaConnector사용자 정의 리소스에서 제거됩니다.
6.4.4.4. Kafka 커넥터 작업 재시작 수행
다음 절차에서는 OpenShift 주석을 사용하여 Kafka 커넥터 작업 재시작을 수동으로 트리거하는 방법을 설명합니다.
사전 요구 사항
- Cluster Operator가 실행 중입니다.
절차
재시작하려는 Kafka 커넥터 작업을 제어하는
KafkaConnector사용자 정의 리소스의 이름을 찾습니다.oc get KafkaConnector
KafkaConnector사용자 정의 리소스에서 재시작할 작업의 ID를 찾습니다. 작업 ID는 0부터 시작하는 음수가 아닌 정수입니다.oc describe KafkaConnector KAFKACONNECTOR-NAME커넥터 작업을 다시 시작하려면 OpenShift에서
KafkaConnector리소스에 주석을 답니다. 예를 들어oc annotate를 사용하여 작업 0을 다시 시작합니다.oc annotate KafkaConnector KAFKACONNECTOR-NAME strimzi.io/restart-task=0다음 조정이 수행될 때까지 기다립니다(기본적으로 2분 마다).
조정 프로세스에서 주석을 탐지한 경우 Kafka 커넥터 작업이 재시작됩니다. Kafka Connect에서 재시작 요청을 수락하면 주석이
KafkaConnector사용자 정의 리소스에서 제거됩니다.
6.4.4.5. Kafka Connect API 노출
KafkaConnector 리소스를 사용하여 커넥터를 관리하는 대신 Kafka Connect REST API를 사용합니다. Kafka Connect REST API는 < connect_cluster_name> -connect-api:8083 에서 실행되는 서비스로 사용할 수 있습니다. 여기서 < connect_cluster_name >은 Kafka Connect 클러스터의 이름입니다. 이 서비스는 Kafka Connect 인스턴스를 생성할 때 생성됩니다.
strimzi.io/use-connector-resources 주석은 KafkaConnectors를 활성화합니다. KafkaConnect 리소스 구성에 주석을 적용한 경우 Kafka Connect API를 사용하려면 해당 주석을 제거해야 합니다. 그렇지 않으면 Kafka Connect REST API를 직접 사용하여 수행한 수동 변경 사항을 Cluster Operator에 의해 되돌립니다.
커넥터 구성을 JSON 오브젝트로 추가할 수 있습니다.
커넥터 구성 추가에 대한 curl 요청의 예
curl -X POST \
http://my-connect-cluster-connect-api:8083/connectors \
-H 'Content-Type: application/json' \
-d '{ "name": "my-source-connector",
"config":
{
"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector",
"file": "/opt/kafka/LICENSE",
"topic":"my-topic",
"tasksMax": "4",
"type": "source"
}
}'
API는 OpenShift 클러스터 내에서만 액세스할 수 있습니다. OpenShift 클러스터 외부에서 실행되는 애플리케이션에서 Kafka Connect API에 액세스하도록 하려면 다음 기능 중 하나를 생성하여 수동으로 노출할 수 있습니다.
-
LoadBalancer또는NodePort유형 서비스 -
Ingress리소스 - OpenShift 경로
연결이 안전하지 않으므로 외부 액세스를 권장합니다.
서비스를 생성하기로 결정하는 경우 < connect_cluster_name> -connect-api 서비스의 선택기 에서 레이블을 사용하여 서비스에서 트래픽을 라우팅할 Pod를 구성합니다.
서비스에 대한 선택기 구성
# ... selector: strimzi.io/cluster: my-connect-cluster 1 strimzi.io/kind: KafkaConnect strimzi.io/name: my-connect-cluster-connect 2 #...
외부 클라이언트의 HTTP 요청을 허용하는 NetworkPolicy 도 생성해야 합니다.
Kafka Connect API에 대한 요청을 허용하는 NetworkPolicy의 예
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-custom-connect-network-policy
spec:
ingress:
- from:
- podSelector: 1
matchLabels:
app: my-connector-manager
ports:
- port: 8083
protocol: TCP
podSelector:
matchLabels:
strimzi.io/cluster: my-connect-cluster
strimzi.io/kind: KafkaConnect
strimzi.io/name: my-connect-cluster-connect
policyTypes:
- Ingress
- 1
- API에 연결할 수 있는 Pod의 레이블입니다.
클러스터 외부에 커넥터 구성을 추가하려면 curl 명령에서 API를 노출하는 리소스의 URL을 사용합니다.
6.4.4.6. Kafka Connect API에 대한 액세스 제한
인증되지 않은 작업 및 잠재적 보안 문제를 방지하기 위해 Kafka Connect API에 대한 액세스를 신뢰할 수 있는 사용자에게만 제한하는 것이 중요합니다. Kafka Connect API는 커넥터 구성을 변경하기 위한 광범위한 기능을 제공하므로 보안 예방 조치를 취하는 것이 더 중요합니다. Kafka Connect API에 액세스할 수 있는 사용자는 관리자가 안전한 것으로 가정할 수 있는 중요한 정보를 얻을 수 있습니다.
Kafka Connect REST API는 OpenShift 클러스터에 대한 인증 액세스 권한이 있고 호스트 이름/IP 주소 및 포트 번호를 포함하는 끝점 URL을 알고 있는 모든 사용자가 액세스할 수 있습니다.
예를 들어 조직이 Kafka Connect 클러스터 및 커넥터를 사용하여 중요한 데이터를 고객 데이터베이스에서 중앙 데이터베이스로 스트리밍한다고 가정합니다. 관리자는 구성 공급자 플러그인을 사용하여 고객 데이터베이스 연결 및 중앙 데이터베이스(예: 데이터베이스 연결 세부 정보 및 인증 자격 증명)와 관련된 중요한 정보를 저장합니다. 구성 공급자는 이 민감한 정보가 인증되지 않은 사용자에게 노출되는 것을 보호합니다. 그러나 Kafka Connect API에 액세스할 수 있는 사용자는 관리자의 동의 없이 고객 데이터베이스에 계속 액세스할 수 있습니다. 이는 페이크 데이터베이스를 설정하고 연결하도록 커넥터를 구성하여 수행할 수 있습니다. 그런 다음 고객 데이터베이스를 가리키도록 커넥터 구성을 수정하지만 데이터를 중앙 데이터베이스로 보내는 대신 페이크 데이터베이스로 전송합니다. 페이크 데이터베이스에 연결하도록 커넥터를 구성하면 구성 공급자에 안전하게 저장된 경우에도 고객 데이터베이스에 연결하는 데 필요한 로그인 세부 정보와 인증 정보가 가로채집니다.
KafkaConnector 사용자 정의 리소스를 사용하는 경우 기본적으로 OpenShift RBAC 규칙에서는 OpenShift 클러스터 관리자만 커넥터를 변경할 수 있습니다. AMQ Streams 리소스를 관리하기 위해 비 클러스터 관리자를 지정할 수도 있습니다. Kafka Connect 구성에서 KafkaConnector 리소스를 활성화하면 Kafka Connect REST API를 사용하여 직접 변경한 사항이 Cluster Operator에 의해 되돌아갑니다. KafkaConnector 리소스를 사용하지 않는 경우 기본 RBAC 규칙은 Kafka Connect API에 대한 액세스를 제한하지 않습니다. OpenShift RBAC를 사용하여 Kafka Connect REST API에 대한 직접 액세스를 제한하려면 KafkaConnector 리소스를 활성화하고 사용해야 합니다.
보안을 개선하기 위해 Kafka Connect API에 대해 다음 속성을 구성하는 것이 좋습니다.
connector.client.config.override.policyconnector.client.config.override.policy속성을None(기본값)으로 설정하여 커넥터 구성이 Kafka Connect 구성 및 사용하는 소비자 및 생산자를 덮어쓰지 않도록 합니다.커넥터 덮어쓰기 정책 지정 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" spec: # ... config: connector.client.config.override.policy: None # ...
6.5. Kafka MirrorMaker 배포
Cluster Operator는 하나 이상의 Kafka MirrorMaker 복제본을 배포하여 Kafka 클러스터 간에 데이터를 복제합니다. Kafka 파티션 복제 개념과 혼동하지 않도록 이 프로세스를 미러링이라고 합니다. MirrorMaker는 소스 클러스터의 메시지를 사용하여 해당 메시지를 대상 클러스터에 다시 게시합니다.
6.5.1. OpenShift 클러스터에 Kafka MirrorMaker 배포
다음 절차에서는 Cluster Operator를 사용하여 Kafka MirrorMaker 클러스터를 OpenShift 클러스터에 배포하는 방법을 설명합니다.
배포에서는 YAML 파일을 사용하여 배포된 MirrorMaker 버전에 따라 KafkaMirrorMaker 또는 KafkaMirrorMaker2 리소스를 생성합니다.
Kafka MirrorMaker 1(문서의 MirrorMaker 라고도 함)은 Apache Kafka 3.0.0에서 더 이상 사용되지 않으며 Apache Kafka 4.0.0에서 제거됩니다. 결과적으로 Kafka MirrorMaker 1을 배포하는 데 사용되는 KafkaMirrorMaker 사용자 정의 리소스도 AMQ Streams에서 더 이상 사용되지 않습니다. Apache Kafka 4.0.0을 채택하면 KafkaMirrorMaker 리소스가 AMQ Streams에서 제거됩니다. 대체 방법으로 KafkaMirrorMaker2 사용자 정의 리소스를 IdentityReplicationPolicy 와 함께 사용합니다.
AMQ Streams는 구성 파일 예제 를 제공합니다. 이 절차에서는 다음 예제 파일을 사용합니다.
-
examples/mirror-maker/kafka-mirror-maker.yaml -
examples/mirror-maker/kafka-mirror-maker-2.yaml
사전 요구 사항
절차
Kafka MirrorMaker를 OpenShift 클러스터에 배포합니다.
MirrorMaker의 경우:
oc apply -f examples/mirror-maker/kafka-mirror-maker.yaml
MirrorMaker 2.0의 경우:
oc apply -f examples/mirror-maker/kafka-mirror-maker-2.yaml
배포 상태를 확인합니다.
oc get deployments -n <my_cluster_operator_namespace>출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE my-mirror-maker-mirror-maker 1/1 1 1 my-mm2-cluster-mirrormaker2 1/1 1 1
my-mirror-maker는 Kafka MirrorMaker 클러스터의 이름입니다.my-mm2-cluster는 Kafka MirrorMaker 2.0 클러스터의 이름입니다.READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
추가 리소스
6.6. Kafka 브리지 배포
Cluster Operator는 하나 이상의 Kafka 브리지 복제본을 배포하여 HTTP API를 통해 Kafka 클러스터와 클라이언트 간에 데이터를 보냅니다.
6.6.1. OpenShift 클러스터에 Kafka 브리지 배포
다음 절차에서는 Cluster Operator를 사용하여 Kafka Bridge 클러스터를 OpenShift 클러스터에 배포하는 방법을 설명합니다.
배포에서는 YAML 파일을 사용하여 사양을 제공하여 KafkaBridge 리소스를 생성합니다.
AMQ Streams는 구성 파일 예제 를 제공합니다. 이 절차에서는 다음 예제 파일을 사용합니다.
-
examples/bridge/kafka-bridge.yaml
사전 요구 사항
절차
OpenShift 클러스터에 Kafka 브리지를 배포합니다.
oc apply -f examples/bridge/kafka-bridge.yaml
배포 상태를 확인합니다.
oc get deployments -n <my_cluster_operator_namespace>출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE my-bridge-bridge 1/1 1 1
my-bridge는 Kafka 브리지 클러스터의 이름입니다.READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
6.6.2. Kafka 브리지 서비스를 로컬 머신에 노출
포트 전달을 사용하여 http://localhost:8080 의 로컬 머신에 AMQ Streams Kafka Bridge 서비스를 노출합니다.
포트 전달은 개발 및 테스트 목적으로만 적합합니다.
절차
OpenShift 클러스터에 있는 포드 이름을 나열합니다.
oc get pods -o name pod/kafka-consumer # ... pod/my-bridge-bridge-7cbd55496b-nclrt
포트
8080의 Kafka 브리지 Pod에 연결합니다.oc port-forward pod/my-bridge-bridge-7cbd55496b-nclrt 8080:8080 &
참고로컬 시스템의 8080 포트가 이미 사용 중인 경우
8008과 같은 대체 HTTP 포트를 사용합니다.
이제 API 요청이 로컬 시스템의 포트 8080에서 Kafka 브리지 Pod의 포트 8080으로 전달됩니다.
6.6.3. OpenShift 외부에서 Kafka 브릿지 액세스
배포 후 AMQ Streams Kafka Bridge는 동일한 OpenShift 클러스터에서 실행되는 애플리케이션에서만 액세스할 수 있습니다. 이러한 애플리케이션은 < ;kafka_bridge_name> -bridge-service 서비스를 사용하여 API에 액세스합니다.
OpenShift 클러스터 외부에서 실행되는 애플리케이션에 Kafka Bridge에 액세스하도록 하려면 다음 기능 중 하나를 생성하여 수동으로 노출할 수 있습니다.
-
LoadBalancer또는NodePort유형 서비스 -
Ingress리소스 - OpenShift 경로
서비스를 생성하기로 결정하는 경우 < kafka_bridge_name> -bridge-service 서비스의 선택기 에서 레이블을 사용하여 서비스에서 트래픽을 라우팅할 Pod를 구성합니다.
# ...
selector:
strimzi.io/cluster: kafka-bridge-name 1
strimzi.io/kind: KafkaBridge
#...- 1
- OpenShift 클러스터에서 Kafka 브리지 사용자 정의 리소스의 이름입니다.
6.7. AMQ Streams Operator의 다른 독립 실행형 배포 옵션
Topic Operator 및 User Operator의 독립 실행형 배포를 수행할 수 있습니다. Cluster Operator에서 관리하지 않는 Kafka 클러스터를 사용하는 경우 이러한 Operator의 독립 실행형 배포를 고려하십시오.
OpenShift에 Operator를 배포합니다. Kafka는 OpenShift 외부에서 실행할 수 있습니다. 예를 들어 Kafka를 관리 서비스로 사용할 수 있습니다. Kafka 클러스터의 주소와 일치하도록 독립 실행형 Operator의 배포 구성을 조정합니다.
6.7.1. 독립 실행형 주제 Operator 배포
다음 절차에서는 주제 관리를 위해 Topic Operator를 독립 실행형 구성 요소로 배포하는 방법을 설명합니다. Cluster Operator에서 관리하지 않는 Kafka 클러스터에서 독립 실행형 Topic Operator를 사용할 수 있습니다.
독립 실행형 배포는 모든 Kafka 클러스터에서 작동할 수 있습니다.
독립 실행형 배포 파일은 AMQ Streams에서 제공됩니다. 05-Deployment-strimzi-topic-operator.yaml 배포 파일을 사용하여 Topic Operator를 배포합니다. Kafka 클러스터에 연결하는 데 필요한 환경 변수를 추가하거나 설정합니다.
주제 Operator는 단일 네임스페이스에서 KafkaTopic 리소스를 감시합니다. Topic Operator 구성에서 조사할 네임스페이스와 Kafka 클러스터에 대한 연결을 지정합니다. 단일 Topic Operator는 단일 네임스페이스를 조사할 수 있습니다. 하나의 네임스페이스는 하나의 Topic Operator에서만 조사해야 합니다. 둘 이상의 Topic Operator를 사용하려면 각 네임스페이스를 모니터링하도록 구성합니다. 이렇게 하면 여러 Kafka 클러스터가 있는 Topic Operator를 사용할 수 있습니다.
사전 요구 사항
Topic Operator가 연결할 Kafka 클러스터를 실행하고 있습니다.
독립 실행형 Topic Operator가 연결에 맞게 올바르게 구성된 경우 Kafka 클러스터는 베어 메탈 환경, 가상 머신 또는 관리형 클라우드 애플리케이션 서비스에서 실행될 수 있습니다.
절차
install/topic-operator/05-Deployment-strimzi-topic-operator.yaml독립 실행형 배포 파일에서env속성을 편집합니다.독립 실행형 주제 Operator 배포 구성의 예
apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-topic-operator labels: app: strimzi spec: # ... template: # ... spec: # ... containers: - name: strimzi-topic-operator # ... env: - name: STRIMZI_NAMESPACE 1 valueFrom: fieldRef: fieldPath: metadata.namespace - name: STRIMZI_KAFKA_BOOTSTRAP_SERVERS 2 value: my-kafka-bootstrap-address:9092 - name: STRIMZI_RESOURCE_LABELS 3 value: "strimzi.io/cluster=my-cluster" - name: STRIMZI_ZOOKEEPER_CONNECT 4 value: my-cluster-zookeeper-client:2181 - name: STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS 5 value: "18000" - name: STRIMZI_FULL_RECONCILIATION_INTERVAL_MS 6 value: "120000" - name: STRIMZI_TOPIC_METADATA_MAX_ATTEMPTS 7 value: "6" - name: STRIMZI_LOG_LEVEL 8 value: INFO - name: STRIMZI_TLS_ENABLED 9 value: "false" - name: STRIMZI_JAVA_OPTS 10 value: "-Xmx=512M -Xms=256M" - name: STRIMZI_JAVA_SYSTEM_PROPERTIES 11 value: "-Djavax.net.debug=verbose -DpropertyName=value" - name: STRIMZI_PUBLIC_CA 12 value: "false" - name: STRIMZI_TLS_AUTH_ENABLED 13 value: "false" - name: STRIMZI_SASL_ENABLED 14 value: "false" - name: STRIMZI_SASL_USERNAME 15 value: "admin" - name: STRIMZI_SASL_PASSWORD 16 value: "password" - name: STRIMZI_SASL_MECHANISM 17 value: "scram-sha-512" - name: STRIMZI_SECURITY_PROTOCOL 18 value: "SSL"- 1
KafkaTopic리소스를 조사할 Topic Operator의 OpenShift 네임스페이스입니다. Kafka 클러스터의 네임스페이스를 지정합니다.- 2
- Kafka 클러스터의 모든 브로커를 검색하고 연결하는 부트스트랩 브로커 주소의 호스트 및 포트 쌍입니다. 서버가 중단된 경우 쉼표로 구분된 목록을 사용하여 두 개 또는 세 개의 브로커 주소를 지정합니다.
- 3
- Topic Operator에서 관리하는
KafkaTopic리소스를 식별하는 레이블입니다. Kafka 클러스터의 이름이 될 필요는 없습니다.KafkaTopic리소스에 할당된 레이블일 수 있습니다. 둘 이상의 Topic Operator를 배포하는 경우 레이블은 각각에 대해 고유해야 합니다. 즉, Operator는 동일한 리소스를 관리할 수 없습니다. - 4
- ZooKeeper 클러스터에 연결할 주소의 호스트 및 포트 쌍입니다. Kafka 클러스터가 사용 중인 것과 동일한 ZooKeeper 클러스터여야 합니다.
- 5
- ZooKeeper 세션 시간 초과(밀리초)입니다. 기본값은
18000(18초)입니다. - 6
- 정기적인 조정 간격(밀리초)입니다. 기본값은
120000(2분)입니다. - 7
- Kafka에서 주제 메타데이터를 가져오는 시도 횟수입니다. 각 시도 사이의 시간은 지수 백오프로 정의됩니다. 파티션 또는 복제본 수로 인해 주제 생성에 시간이 더 걸리면 이 값을 늘리는 것이 좋습니다. 기본값은
6번 시도입니다. - 8
- 로깅 메시지를 출력하는 수준입니다. 수준을
ERROR,WARNING,INFO,DEBUG,TRACE로 설정할 수 있습니다. - 9
- Kafka 브로커와의 암호화된 통신에 대한 TLS 지원을 활성화합니다.
- 10
- (선택 사항) Topic Operator를 실행하는 JVM에서 사용하는 Java 옵션입니다.
- 11
- (선택 사항) Topic Operator에 설정된 디버깅(
-D) 옵션입니다. - 12
- (선택 사항) TLS가
STRIMZI_TLS_ENABLED를 통해 활성화되는 경우 신뢰 저장소 인증서 생성에 영향을 미칩니다. 이 환경 변수가 활성화된 경우 브로커는 TLS 인증서에 신뢰할 수 있는 공개 인증 기관을 사용해야 합니다. 기본값은false입니다. - 13
- (선택 사항) mTLS 인증을 위한 키 저장소 인증서를 생성합니다. 이 값을
false로 설정하면 mTLS를 사용하여 Kafka 브로커에 대한 클라이언트 인증이 비활성화됩니다. 기본값은true입니다. - 14
- (선택 사항) Kafka 브로커에 연결할 때 클라이언트 인증에 대해 SASL 지원을 활성화합니다. 기본값은
false입니다. - 15
- (선택 사항) 클라이언트 인증을 위한 SASL 사용자 이름입니다.
STRIMZI_SASL_ENABLED를 통해 SASL이 활성화된 경우에만 필수 항목입니다. - 16
- (선택 사항) 클라이언트 인증을 위한 SASL 암호입니다.
STRIMZI_SASL_ENABLED를 통해 SASL이 활성화된 경우에만 필수 항목입니다. - 17
- (선택 사항) 클라이언트 인증을 위한 SASL 메커니즘입니다.
STRIMZI_SASL_ENABLED를 통해 SASL이 활성화된 경우에만 필수 항목입니다. 값을plain,scram-sha-256또는scram-sha-512로 설정할 수 있습니다. - 18
- (선택 사항) Kafka 브로커와의 통신에 사용되는 보안 프로토콜입니다. 기본값은 "PLAINTEXT"입니다. 이 값을
PLAINTEXT,SSL,SASL_PLAINTEXT,SASL_SSL로 설정할 수 있습니다.
-
공개 인증 기관의 인증서를 사용하는 Kafka 브로커에 연결하려면
STRIMZI_ECDHELIC_CA를true로 설정합니다. 이 속성을true로 설정합니다(예: Amazon AWS MSK 서비스를 사용하는 경우). STRIMZI_TLS_ENABLED환경 변수를 사용하여 mTLS를 활성화하면 Kafka 클러스터에 대한 연결을 인증하는 데 사용되는 키 저장소 및 신뢰 저장소를 지정합니다.mTLS 구성의 예
# .... env: - name: STRIMZI_TRUSTSTORE_LOCATION 1 value: "/path/to/truststore.p12" - name: STRIMZI_TRUSTSTORE_PASSWORD 2 value: "TRUSTSTORE-PASSWORD" - name: STRIMZI_KEYSTORE_LOCATION 3 value: "/path/to/keystore.p12" - name: STRIMZI_KEYSTORE_PASSWORD 4 value: "KEYSTORE-PASSWORD" # ...
Topic Operator를 배포합니다.
oc create -f install/topic-operator
배포 상태를 확인합니다.
oc get deployments
출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE strimzi-topic-operator 1/1 1 1
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
6.7.2. 독립 실행형 사용자 Operator 배포
다음 절차에서는 사용자 관리를 위한 독립 실행형 구성 요소로 User Operator를 배포하는 방법을 설명합니다. Cluster Operator에서 관리하지 않는 Kafka 클러스터와 함께 독립 실행형 User Operator를 사용할 수 있습니다.
독립 실행형 배포는 모든 Kafka 클러스터에서 작동할 수 있습니다.
독립 실행형 배포 파일은 AMQ Streams에서 제공됩니다. 05-Deployment-strimzi-user-operator.yaml 배포 파일을 사용하여 User Operator를 배포합니다. Kafka 클러스터에 연결하는 데 필요한 환경 변수를 추가하거나 설정합니다.
User Operator는 단일 네임스페이스에서 KafkaUser 리소스를 감시합니다. User Operator 구성에서 조사할 네임스페이스와 Kafka 클러스터에 대한 연결을 지정합니다. 단일 User Operator는 단일 네임스페이스를 조사할 수 있습니다. 하나의 네임스페이스는 User Operator 한 개만 조사해야 합니다. User Operator를 두 개 이상 사용하려면 각각 다른 네임스페이스를 조사하도록 구성합니다. 이렇게 하면 여러 Kafka 클러스터가 있는 User Operator를 사용할 수 있습니다.
사전 요구 사항
User Operator가 연결할 Kafka 클러스터를 실행하고 있습니다.
독립 실행형 User Operator가 연결에 맞게 올바르게 구성된 경우 Kafka 클러스터는 베어 메탈 환경, 가상 머신 또는 관리형 클라우드 애플리케이션 서비스에서 실행될 수 있습니다.
절차
install/user-operator/05-Deployment-strimzi-user-operator.yaml독립 실행형 배포 파일에서 다음env속성을 편집합니다.독립 실행형 User Operator 배포 구성 예
apiVersion: apps/v1 kind: Deployment metadata: name: strimzi-user-operator labels: app: strimzi spec: # ... template: # ... spec: # ... containers: - name: strimzi-user-operator # ... env: - name: STRIMZI_NAMESPACE 1 valueFrom: fieldRef: fieldPath: metadata.namespace - name: STRIMZI_KAFKA_BOOTSTRAP_SERVERS 2 value: my-kafka-bootstrap-address:9092 - name: STRIMZI_CA_CERT_NAME 3 value: my-cluster-clients-ca-cert - name: STRIMZI_CA_KEY_NAME 4 value: my-cluster-clients-ca - name: STRIMZI_LABELS 5 value: "strimzi.io/cluster=my-cluster" - name: STRIMZI_FULL_RECONCILIATION_INTERVAL_MS 6 value: "120000" - name: STRIMZI_WORK_QUEUE_SIZE 7 value: 10000 - name: STRIMZI_CONTROLLER_THREAD_POOL_SIZE 8 value: 10 - name: STRIMZI_LOG_LEVEL 9 value: INFO - name: STRIMZI_GC_LOG_ENABLED 10 value: "true" - name: STRIMZI_CA_VALIDITY 11 value: "365" - name: STRIMZI_CA_RENEWAL 12 value: "30" - name: STRIMZI_JAVA_OPTS 13 value: "-Xmx=512M -Xms=256M" - name: STRIMZI_JAVA_SYSTEM_PROPERTIES 14 value: "-Djavax.net.debug=verbose -DpropertyName=value" - name: STRIMZI_SECRET_PREFIX 15 value: "kafka-" - name: STRIMZI_ACLS_ADMIN_API_SUPPORTED 16 value: "true" - name: STRIMZI_MAINTENANCE_TIME_WINDOWS 17 value: '* * 8-10 * * ?;* * 14-15 * * ?' - name: STRIMZI_KAFKA_ADMIN_CLIENT_CONFIGURATION 18 value: | default.api.timeout.ms=120000 request.timeout.ms=60000- 1
KafkaUser리소스를 조사할 User Operator의 OpenShift 네임스페이스입니다. 하나의 네임스페이스만 지정할 수 있습니다.- 2
- Kafka 클러스터의 모든 브로커를 검색하고 연결하는 부트스트랩 브로커 주소의 호스트 및 포트 쌍입니다. 서버가 중단된 경우 쉼표로 구분된 목록을 사용하여 두 개 또는 세 개의 브로커 주소를 지정합니다.
- 3
- mTLS 인증을 위해 새 사용자 인증서에 서명하는 인증 기관의 공개 키(
ca.crt) 값이 포함된 OpenShiftSecret - 4
- mTLS 인증을 위해 새 사용자 인증서에 서명하는 인증 기관의 개인 키(
ca.key) 값이 포함된 OpenShiftSecret. - 5
- User Operator가 관리하는
KafkaUser리소스를 식별하는 레이블입니다. Kafka 클러스터의 이름이 될 필요는 없습니다.KafkaUser리소스에 할당된 레이블일 수 있습니다. 둘 이상의 User Operator를 배포하는 경우 레이블은 각각에 대해 고유해야 합니다. 즉, Operator는 동일한 리소스를 관리할 수 없습니다. - 6
- 정기적인 조정 간격(밀리초)입니다. 기본값은
120000(2분)입니다. - 7
- 컨트롤러 이벤트 큐의 크기입니다. 대기열 크기는 User Operator가 작동할 것으로 예상되는 최대 사용자 수만큼 커야 합니다. 기본값은
1024입니다. - 8
- 사용자 조정을 위한 작업자 풀의 크기입니다. 더 큰 풀에는 더 많은 리소스가 필요할 수 있지만 더 많은
KafkaUser리소스를 처리할 수도 있습니다. 기본값은50입니다. - 9
- 로깅 메시지를 출력하는 수준입니다. 수준을
ERROR,WARNING,INFO,DEBUG,TRACE로 설정할 수 있습니다. - 10
- 가비지 컬렉션(GC) 로깅을 활성화합니다. 기본값은
true입니다. - 11
- 인증 기관의 유효 기간입니다. 기본값은
365일입니다. - 12
- 인증 기관의 갱신 기간입니다. 갱신 기간은 현재 인증서의 만료 날짜에서 역으로 측정됩니다. 기본값은 이전 인증서가 만료되기 전에 인증서 갱신을 시작하는
30일입니다. - 13
- (선택 사항) User Operator를 실행하는 JVM에서 사용하는 Java 옵션입니다.
- 14
- (선택 사항) User Operator에 설정된 디버깅(
-D) 옵션 - 15
- (선택 사항) User Operator가 생성한 OpenShift 시크릿의 이름에 대한 접두사입니다.
- 16
- (선택 사항) Kafka 클러스터가 Kafka Admin API를 사용하여 권한 부여 ACL 규칙 관리를 지원하는지 여부를 나타냅니다.
false로 설정하면 User Operator는간단한권한 부여 ACL 규칙이 있는 모든 리소스를 거부합니다. 이는 Kafka 클러스터 로그에서 불필요한 예외를 방지하는 데 도움이 됩니다. 기본값은true입니다. - 17
- (선택 사항) 만료 사용자 인증서가 갱신되는 동안 유지 관리 시간 창을 정의하는 Cron 표현식의 반 연속으로 구분된 목록입니다.
- 18
- (선택 사항) User Operator가 속성 형식으로 사용하는 Kafka 관리자 클라이언트를 구성하기 위한 구성 옵션입니다.
Kafka 클러스터에 연결하는 데 mTLS를 사용하는 경우 연결을 인증하는 데 사용되는 시크릿을 지정합니다. 그렇지 않으면 다음 단계로 이동합니다.
mTLS 구성의 예
# .... env: - name: STRIMZI_CLUSTER_CA_CERT_SECRET_NAME 1 value: my-cluster-cluster-ca-cert - name: STRIMZI_EO_KEY_SECRET_NAME 2 value: my-cluster-entity-operator-certs # ..."
User Operator를 배포합니다.
oc create -f install/user-operator
배포 상태를 확인합니다.
oc get deployments
출력에 배포 이름과 준비 상태가 표시됩니다.
NAME READY UP-TO-DATE AVAILABLE strimzi-user-operator 1/1 1 1
READY에는 준비되거나 예상된 복제본 수가 표시됩니다.AVAILABLE출력에1이 표시되면 배포가 성공적으로 수행됩니다.
7장. Kafka 클러스터에 대한 클라이언트 액세스 설정
AMQ Streams를 배포한 후 이 섹션의 절차에서는 다음을 수행하는 방법을 설명합니다.
- 배포를 확인하는 데 사용할 수 있는 생산자 및 소비자 클라이언트 예제를 배포합니다.
리스너를 사용하여 Kafka 클러스터에 대한 클라이언트 액세스 설정
OpenShift 외부의 클라이언트의 Kafka 클러스터에 대한 액세스를 설정하는 단계는 더 복잡하며 Kafka 구성 요소 구성 절차에 대해 숙지해야 합니다.
7.1. 예제 클라이언트 배포
다음 절차에서는 생성한 Kafka 클러스터를 사용하여 메시지를 보내고 수신하는 예제 생산자 및 소비자 클라이언트를 배포하는 방법을 설명합니다.
사전 요구 사항
- Kafka 클러스터는 클라이언트에서 사용할 수 있습니다.
절차
Kafka 생산자를 배포합니다.
oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic
- 생산자가 실행 중인 콘솔에 메시지를 입력합니다.
- Enter 를 눌러 메시지를 보냅니다.
Kafka 소비자를 배포합니다.
oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginning
- 소비자 콘솔에 들어오는 메시지가 표시되는지 확인합니다.
7.2. 리스너를 사용하여 Kafka 클러스터에 클라이언트 액세스 설정
Kafka 클러스터의 주소를 사용하여 동일한 OpenShift 클러스터의 클라이언트에 대한 액세스를 제공하거나 다른 OpenShift 네임스페이스 또는 OpenShift 외부의 클라이언트에 대한 외부 액세스를 제공할 수 있습니다. 다음 절차에서는 OpenShift 외부 또는 다른 OpenShift 클러스터에서 Kafka 클러스터에 대한 클라이언트 액세스를 구성하는 방법을 설명합니다.
Kafka 리스너는 액세스를 제공합니다. 다음 리스너 유형이 지원됩니다.
-
내부와 동일한 OpenShift 클러스터 내에서 연결 -
OpenShift
경로 -
LoadBalancer를 사용하여 로드 밸런서 서비스를 사용 -
OpenShift
노드에서 포트를사용하는 NodePort -
OpenShift Ingress 및 Kubernetes용 Ingress NGINX Controller를 사용하기 위한Ingress
-
broker별
ClusterIP서비스를 사용하여 Kafka를 노출하는cluster-ip
선택한 유형은 요구 사항 및 환경 및 인프라에 따라 다릅니다. 예를 들어 노드 포트가 더 나은 옵션을 제공하는 베어 메탈과 같은 특정 인프라에는 로드 밸런서가 적합하지 않을 수 있습니다.
이 절차에서는 다음을 수행합니다.
-
외부 리스너는 TLS 암호화 및 mTLS 인증 및 Kafka
간단한인증이 활성화된 Kafka 클러스터에 대해 구성됩니다. -
KafkaUser는 mTLS 인증 및간단한권한 부여를 위해 정의된 ACL(액세스 제어 목록)을 사용하여 클라이언트에 대해 생성됩니다.
상호 tls,scram-sha-512 또는 oauth 인증을 사용하도록 리스너를 구성할 수 있습니다. mTLS는 항상 암호화를 사용하지만 SCRAM-SHA-512 및 OAuth 2.0 인증을 사용할 때 암호화를 사용하는 것이 좋습니다.
Kafka 브로커에 대해 간단한,oauth,opa 또는 사용자 정의 인증을 구성할 수 있습니다. 활성화되면 권한 부여가 활성화된 모든 리스너에 적용됩니다.
KafkaUser 인증 및 권한 부여 메커니즘을 구성할 때 동등한 Kafka 구성과 일치하는지 확인합니다.
-
KafkaUser.spec.authentication은Kafka.spec.kafka.listeners[*].authentication과 일치합니다. -
KafkaUser.spec.authorization과Kafka.spec.kafka.authorization과 일치
KafkaUser 에 사용하려는 인증을 지원하는 리스너가 하나 이상 있어야 합니다.
Kafka 사용자와 Kafka 브로커 간의 인증은 각각에 대한 인증 설정에 따라 다릅니다. 예를 들어 Kafka 구성에서 활성화되지 않은 경우 mTLS로 사용자를 인증할 수 없습니다.
AMQ Streams Operator는 구성 프로세스를 자동화하고 인증에 필요한 인증서를 생성합니다.
- Cluster Operator는 리스너를 생성하고 클러스터 및 클라이언트 CA(인증 기관) 인증서를 설정하여 Kafka 클러스터와의 인증을 활성화합니다.
- User Operator는 선택한 인증 유형을 기반으로 클라이언트 및 클라이언트 인증에 사용되는 보안 자격 증명을 나타내는 사용자를 생성합니다.
클라이언트 구성에 인증서를 추가합니다.
이 절차에서는 Cluster Operator에서 생성한 CA 인증서가 사용되지만 자체 인증서를 설치하여 교체할 수 있습니다. 외부 CA(인증 기관)에서 관리하는 Kafka 리스너 인증서를 사용하도록 리스너를 구성할 수도 있습니다.
인증서는 PEM(.crt) 및 PKCS #12(.p12) 형식으로 사용할 수 있습니다. 이 절차에서는 PEM 인증서를 사용합니다. X.509 형식의 인증서를 사용하는 클라이언트와 PEM 인증서를 사용합니다.
동일한 OpenShift 클러스터 및 네임스페이스의 내부 클라이언트의 경우 Pod 사양에 클러스터 CA 인증서를 마운트할 수 있습니다. 자세한 내용은 클러스터 CA를 신뢰하도록 내부 클라이언트 구성을 참조하십시오.
사전 요구 사항
- Kafka 클러스터는 OpenShift 클러스터 외부에서 실행되는 클라이언트에서 연결할 수 있습니다.
- Cluster Operator 및 User Operator가 클러스터에서 실행 중입니다.
절차
Kafka 리스너를 사용하여 Kafka 클러스터를 구성합니다.
- 리스너를 통해 Kafka 브로커에 액세스하는 데 필요한 인증을 정의합니다.
Kafka 브로커에서 인증을 활성화합니다.
리스너 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster namespace: myproject spec: kafka: # ... listeners: 1 - name: external 2 port: 9094 3 type: <listener_type> 4 tls: true 5 authentication: type: tls 6 configuration: 7 #... authorization: 8 type: simple superUsers: - super-user-name 9 # ...- 1
- 외부 리스너를 활성화하기 위한 구성 옵션은 일반 Kafka 리스너 스키마 참조에 설명되어 있습니다.
- 2
- 리스너를 식별할 이름입니다. Kafka 클러스터 내에서 고유해야 합니다.
- 3
- Kafka 내부의 리스너에서 사용하는 포트 번호입니다. 포트 번호는 지정된 Kafka 클러스터 내에서 고유해야 합니다. 허용되는 포트 번호는 9092이고 포트 9404 및 9999를 제외하고 이미 Prometheus 및 10.0.0.1에 사용됩니다. 리스너 유형에 따라 포트 번호가 Kafka 클라이언트를 연결하는 포트 번호와 동일하지 않을 수 있습니다.
- 4
- 외부 리스너 유형은
경로, 로드 밸런서,노드포트수신으로 지정됩니다. 내부 리스너는내부또는cluster-ip로 지정됩니다. - 5
- 필수 항목입니다. 리스너의 TLS 암호화입니다.
route및ingress유형 리스너의 경우true로 설정해야 합니다. mTLS 인증의 경우인증속성도 사용합니다. - 6
- 리스너의 클라이언트 인증 메커니즘. mTLS를 사용한 서버 및 클라이언트 인증의 경우
tls: true및authentication.type: tls를 지정합니다. - 7
- (선택 사항) 리스너 유형의 요구 사항에 따라 추가 리스너 구성을 지정할 수 있습니다.
- 8
- 권한 부여는
AclAuthorizerKafka 플러그인을 사용하는단순로 지정됩니다. - 9
- (선택 사항) 슈퍼 사용자는 ACL에 정의된 액세스 제한에 관계없이 모든 브로커에 액세스할 수 있습니다.
주의OpenShift 경로 주소는 Kafka 클러스터의 이름, 리스너의 이름 및 생성된 네임스페이스의 이름으로 구성됩니다. 예를 들면
my-cluster-kafka-listener1-bootstrap-myproject(CLUSTER-NAME-kafka-LISTENER-NAME -bootstrap-NAMESPACE)입니다.경로리스너 유형을 사용하는 경우 주소의 전체 길이가 최대 63자 제한을 초과하지 않도록 주의하십시오.
Kafka리소스를 생성하거나 업데이트합니다.oc apply -f <kafka_configuration_file>Kafka 클러스터는 mTLS 인증을 사용하는 Kafka 브로커 리스너로 구성됩니다.
각 Kafka 브로커 Pod에 대해 서비스가 생성됩니다.
Kafka 클러스터 연결에 필요한 부트스트랩 주소로 사용되는 서비스가 생성됩니다.
또한
nodeport리스너를 사용하여 Kafka 클러스터에 외부 연결을 위해 외부 부트스트랩 주소로 서비스가 생성됩니다.kafka 브로커의 ID를 확인하는 클러스터 CA 인증서도 시크릿 <
cluster_name> -cluster-ca-cert에 생성됩니다.참고외부 리스너를 사용하는 동안 Kafka 클러스터를 스케일링하는 경우 모든 Kafka 브로커의 롤링 업데이트가 트리거될 수 있습니다. 구성에 따라 달라집니다.
Kafka리소스의 상태에서 Kafka 클러스터에 액세스하는 데 사용할 수 있는 부트스트랩 주소를 검색합니다.oc get kafka <kafka_cluster_name> -o=jsonpath='{.status.listeners[?(@.name=="<listener_name>")].bootstrapServers}{"\n"}'
예를 들면 다음과 같습니다.
oc get kafka my-cluster -o=jsonpath='{.status.listeners[?(@.name=="external")].bootstrapServers}{"\n"}'Kafka 클라이언트에서 부트스트랩 주소를 사용하여 Kafka 클러스터에 연결합니다.
Kafka 클러스터에 액세스해야 하는 클라이언트를 나타내는 사용자를 생성하거나 수정합니다.
-
Kafka리스너와 동일한 인증 유형을 지정합니다. 간단한권한 부여를 위한 권한 부여 ACL을 지정합니다.사용자 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster 1 spec: authentication: type: tls 2 authorization: type: simple acls: 3 - resource: type: topic name: my-topic patternType: literal operations: - Describe - Read - resource: type: group name: my-group patternType: literal operations: - Read
-
KafkaUser리소스를 생성하거나 수정합니다.oc apply -f USER-CONFIG-FILE사용자는
KafkaUser리소스와 동일한 이름의 시크릿과 함께 생성됩니다. 보안에는 mTLS 인증을 위한 공개 및 개인 키가 포함됩니다.보안 예
apiVersion: v1 kind: Secret metadata: name: my-user labels: strimzi.io/kind: KafkaUser strimzi.io/cluster: my-cluster type: Opaque data: ca.crt: <public_key> # Public key of the clients CA user.crt: <user_certificate> # Public key of the user user.key: <user_private_key> # Private key of the user user.p12: <store> # PKCS #12 store for user certificates and keys user.password: <password_for_store> # Protects the PKCS #12 storeKafka 클러스터의 <
cluster_name> -cluster-ca-cert시크릿에서 클러스터 CA 인증서를 추출합니다.oc get secret <cluster_name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt<user
_name> 시크릿에서 사용자 CA 인증서를추출합니다.oc get secret <user_name> -o jsonpath='{.data.user\.crt}' | base64 -d > user.crt<user
_name> 시크릿에서 사용자의 개인 키를추출합니다.oc get secret <user_name> -o jsonpath='{.data.user\.key}' | base64 -d > user.keyKafka 클러스터에 연결하기 위해 부트스트랩 주소 호스트 이름 및 포트를 사용하여 클라이언트를 구성합니다.
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "<hostname>:<port>");Kafka 클러스터의 ID를 확인하도록 신뢰 저장소 자격 증명으로 클라이언트를 구성합니다.
공용 클러스터 CA 인증서를 지정합니다.
신뢰 저장소 구성 예
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL"); props.put(SslConfigs.SSL_TRUSTSTORE_TYPE_CONFIG, "PEM"); props.put(SslConfigs.SSL_TRUSTSTORE_CERTIFICATES_CONFIG, "<ca.crt_file_content>");SSL은 mTLS 인증에 대해 지정된 보안 프로토콜입니다. TLS를 통해 SCRAM-SHA-512 인증에 대해
SASL_SSL을 지정합니다. PEM은 신뢰 저장소의 파일 형식입니다.Kafka 클러스터에 연결할 때 사용자를 확인하도록 키 저장소 자격 증명으로 클라이언트를 구성합니다.
공개 인증서 및 개인 키를 지정합니다.
키 저장소 구성 예
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL"); props.put(SslConfigs.SSL_KEYSTORE_TYPE_CONFIG, "PEM"); props.put(SslConfigs.SSL_KEYSTORE_CERTIFICATE_CHAIN_CONFIG, "<user.crt_file_content>"); props.put(SslConfigs.SSL_KEYSTORE_KEY_CONFIG, "<user.key_file_content>");
키 저장소 인증서와 개인 키를 구성에 직접 추가합니다. 를 단일 줄 형식으로 추가합니다.
BEGINCERTIFICATE와ENDCERTIFICATE 구분자 사이에 줄 바꿈 문자(\n)로 시작합니다.\n을 사용하여 원래 인증서에서 각 행을 종료합니다.키 저장소 구성 예
props.put(SslConfigs.SSL_KEYSTORE_CERTIFICATE_CHAIN_CONFIG, "-----BEGIN CERTIFICATE----- \n<user_certificate_content_line_1>\n<user_certificate_content_line_n>\n-----END CERTIFICATE---"); props.put(SslConfigs.SSL_KEYSTORE_KEY_CONFIG, "----BEGIN PRIVATE KEY-----\n<user_key_content_line_1>\n<user_key_content_line_n>\n-----END PRIVATE KEY-----");
추가 리소스
- 리스너 인증 옵션
- Kafka 인증 옵션
- 권한 부여 서버를 사용하는 경우 토큰 기반 OAuth 2.0 인증 및 OAuth 2.0 권한 부여 를 사용할 수 있습니다.
8장. AMQ Streams에 대한 메트릭 및 대시보드 설정
Prometheus 및 Grafana를 사용하여 AMQ Streams 배포를 모니터링할 수 있습니다.
대시보드의 주요 메트릭을 보고 특정 조건에서 트리거되는 경고를 설정하여 AMQ Streams 배포를 모니터링할 수 있습니다. 메트릭은 AMQ Streams의 각 구성 요소에서 사용할 수 있습니다.
oauth 인증 및 opa 또는 keycloak 권한 부여와 관련된 메트릭을 수집할 수도 있습니다. Kafka 리소스의 리스너 구성에서 enableMetrics 속성을 true 로 설정하여 이 작업을 수행합니다. 예를 들어 spec.kafka.listeners.authentication 및 spec.kafka.authorization 에서 enableMetrics 를 true 로 설정합니다. 마찬가지로 KafkaBridge,KafkaConnect, KafkaMirrorMaker , KafkaMirrorMaker 2oauth 인증에 대한 지표를 활성화할 수 있습니다.
지표 정보를 제공하기 위해 AMQ Streams는 Prometheus 규칙 및 Grafana 대시보드를 사용합니다.
AMQ Streams의 각 구성 요소에 대한 규칙 세트로 구성된 경우 Prometheus는 클러스터에서 실행 중인 Pod의 주요 메트릭을 사용합니다. 그런 다음 Grafana는 대시보드에서 해당 지표를 시각화합니다. AMQ Streams에는 배포에 맞게 사용자 지정할 수 있는 Grafana 대시보드 예제가 포함되어 있습니다.
AMQ Streams는 사용자 정의 프로젝트(OpenShift 기능) 모니터링을 사용하여 Prometheus 설정 프로세스를 단순화합니다.
요구 사항에 따라 다음을 수행할 수 있습니다.
Prometheus 및 Grafana가 설정된 경우 모니터링을 위해 AMQ Streams에서 제공하는 Grafana 대시보드 예제를 사용할 수 있습니다.
또한 분산 추적을 설정하여 메시지를 엔드투엔드로 추적하도록 배포를 구성할 수 있습니다.
AMQ Streams는 Prometheus 및 Grafana의 설치 파일 예를 제공합니다. AMQ Streams 모니터링을 시도할 때 이러한 파일을 시작점으로 사용할 수 있습니다. 추가 지원을 받으려면 Prometheus 및 Grafana 개발자 커뮤니티에 참여해 보십시오.
메트릭 및 모니터링 툴에 대한 지원 문서
메트릭 및 모니터링 툴에 대한 자세한 내용은 지원 문서를 참조하십시오.
- Prometheus
- Prometheus 구성
- Kafka Exporter
- Grafana Labs
- Apache Kafka 모니터링은 Apache Kafka 에서 노출하는 CloudEvent 메트릭에 대해 설명합니다.
- zookeeperer에서 Apache ZooKeeper 에 의해 노출되는 CloudEvent 메트릭에 대해 설명합니다.
8.1. Kafka 내보내기로 소비자 지연 모니터링
Kafka 내보내기 는 Apache Kafka 브로커 및 클라이언트의 모니터링을 개선하는 오픈 소스 프로젝트입니다. Kafka 클러스터와 함께 Kafka 내보내기를 배포하도록 Kafka 리소스를 구성할 수 있습니다. Kafka Exporter는 오프셋, 소비자 그룹, 소비자 지연 및 주제와 관련된 Kafka 브로커에서 추가 지표 데이터를 추출합니다. 예를 들어 지표 데이터가 느린 소비자를 식별하는 데 사용됩니다. 지연 데이터는 Prometheus 지표로 노출되며 분석을 위해 Grafana에 표시될 수 있습니다.
Kafka Exporter는 소비자 그룹에 대해 커밋된 오프셋에 대한 정보를 저장하는 __consumer_offsets 주제에서 읽습니다. Kafka 내보내기가 제대로 작동하려면 소비자 그룹을 사용 중이어야 합니다.
Kafka Exporter의 Grafana 대시보드는 AMQ Streams에서 제공하는 여러 가지 Grafana 대시보드 중 하나입니다.
Kafka Exporter는 소비자 지연 및 소비자 오프셋과 관련된 추가 메트릭만 제공합니다. 일반 Kafka 메트릭의 경우 Kafka 브로커 에서 Prometheus 지표를 구성해야 합니다.
소비자 지연은 프로덕션 속도 및 메시지 소비 속도의 차이를 나타냅니다. 특히 지정된 소비자 그룹의 소비자 지연은 파티션의 마지막 메시지와 해당 소비자가 현재 선택 중인 메시지 간의 지연을 나타냅니다.
지연은 파티션 로그의 끝과 관련하여 소비자 오프셋의 위치를 반영합니다.
생산자와 소비자 오프셋 간의 소비자 지연
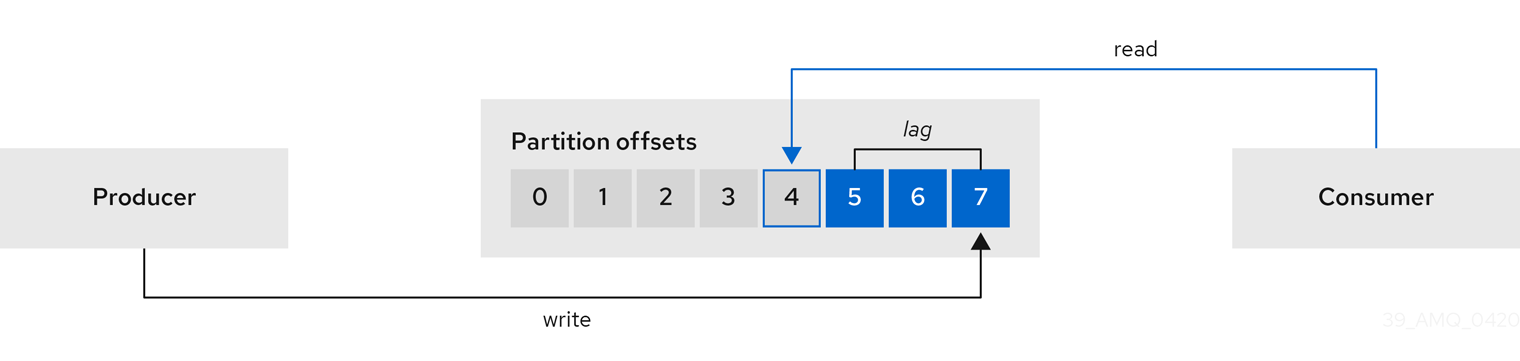
이러한 차이점은 생산자 오프셋과 소비자 오프셋 간의 CloudEvent라고 합니다. Kafka 브로커 주제 파티션의 읽기 및 쓰기 위치입니다.
주제가 100개의 메시지 1초를 스트리밍한다고 가정합니다. 생산자 오프셋(주제 파티션 헤드)과 소비자가 읽은 마지막 오프셋 사이에 1000개의 메시지 지연은 10초 지연을 의미합니다.
소비자 지연 모니터링의 중요성
(near) 실시간 데이터 처리에 의존하는 애플리케이션의 경우 소비자 지연을 모니터링하여 너무 크지 않은지 확인하는 것이 중요합니다. 지연이 클수록 프로세스가 실시간 처리 목표에서 더 많이 이동합니다.
예를 들어 소비자 지연은 제거되지 않은 오래된 데이터를 너무 많이 소비하거나 계획되지 않은 종료를 통해 소비한 결과일 수 있습니다.
소비자 지연 감소
Grafana 차트를 사용하여 지연을 분석하고 작업을 줄이는 작업이 영향을 받는 소비자 그룹에 영향을 미치는지 확인합니다. 예를 들어 Kafka 브로커가 지연을 줄이기 위해 조정되면 대시보드에 소비자 그룹 차트가 내려가고 분별 차트가 소비되는 메시지가 표시됩니다.
지연을 줄이기 위한 일반적인 작업은 다음과 같습니다.
- 새 소비자를 추가하여 확장 소비자 그룹
- 메시지에 대한 보존 시간이 항목에 남아 있게 늘립니다.Increase the retention time for a message to remain in a topic.
- 메시지 버퍼를 늘리기 위한 디스크 용량 추가
소비자 지연을 줄이기 위한 조치는 기본 인프라에 따라 다르며 AMQ Streams가 지원하는 사용 사례에 따라 다릅니다. 예를 들어 지연된 소비자는 브로커가 디스크 캐시에서 가져오기 요청을 처리할 수 있다는 이점이 적습니다. 그리고 특정 경우에는 소비자가 캡처될 때까지 메시지를 자동으로 삭제하는 것이 허용될 수 있습니다.
8.2. Cruise Control 작업 모니터링
cruise Control은 브로커, 주제 및 파티션의 사용률을 추적하기 위해 Kafka 브로커를 모니터링합니다. Cruise Control은 자체 성능을 모니터링하기 위한 일련의 메트릭도 제공합니다.
Cruise Control 지표 보고자는 Kafka 브로커에서 원시 메트릭 데이터를 수집합니다. 데이터는 Cruise Control에 의해 자동으로 생성되는 항목에 생성됩니다. 메트릭은 Kafka 클러스터에 대한 최적화 제안을 생성하는 데 사용됩니다.
Cruise Control 작업 실시간 모니터링에 대해 Cruise Control 메트릭을 사용할 수 있습니다. 예를 들어 Cruise Control 메트릭을 사용하여 실행 중인 재조정 작업의 상태를 모니터링하거나 작업 성능에서 감지된 모든 이상 사항에 대한 경고를 제공할 수 있습니다.
Cruise Control 구성에서 PrometheusECDHE Exporter 를 활성화하여 Cruise Control 메트릭을 노출합니다.
센서로 알려진 사용 가능한 Cruise Control 지표의 전체 목록은 Cruise Control 문서를 참조하십시오.
8.2.1. Cruise Control 지표 노출
Cruise Control 작업에 지표를 노출하려면 Cruise Control을 배포하고 배포에 Prometheus 지표를 활성화하도록 Kafka 리소스를 구성합니다. 자체 구성을 사용하거나 AMQ Streams에서 제공하는 kafka-cruise-control-metrics.yaml 파일 예제를 사용할 수 있습니다.
Kafka 리소스에서 CruiseControl 속성의 metricsConfig 에 구성을 추가합니다. 이 구성을 사용하면 Prometheus>-< Exporter 에서 HTTP 끝점을 통해 Cruise Control 지표를 노출할 수 있습니다. HTTP 끝점은 Prometheus 서버에서 스크랩합니다.
Cruise Control의 메트릭 구성 예
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
Spec:
# ...
cruiseControl:
# ...
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: cruise-control-metrics
key: metrics-config.yml
---
kind: ConfigMap
apiVersion: v1
metadata:
name: cruise-control-metrics
labels:
app: strimzi
data:
metrics-config.yml: |
# metrics configuration...
8.2.2. Cruise Control 지표 보기
Cruise Control 메트릭을 노출하면 Prometheus 또는 다른 적절한 모니터링 시스템을 사용하여 메트릭 데이터에 대한 정보를 볼 수 있습니다. AMQ Streams는 Cruise Control 지표의 시각화를 표시하는 Grafana 대시보드 예제 를 제공합니다. 대시보드는 strimzi-cruise-control.json 이라는 JSON 파일입니다. Grafana 대시보드를 활성화할 때 노출된 지표는 모니터링 데이터를 제공합니다.
8.2.2.1. 균형 점수 모니터링
크루즈 컨트롤 메트릭에는 균형 점수가 포함됩니다. Balancedness는 Kafka 클러스터에 워크로드를 균등하게 분산하는 방법에 대한 척도입니다.
균형 점수(balanceness-score)에 대한 크루즈 컨트롤 메트릭은 KafkaRebalance 리소스의 balancedness 점수와 다를 수 있습니다. cruise Control은 KafkaRebalance 리소스에 사용되는 default .goals를 사용하여 각 점수를 계산합니다. oma .goals 와 동일하지 않을 수 있는omaly.detectionly.detection.goals 는 Kafka 사용자 정의 리소스의 spec.cruiseControl.config 에 지정됩니다.
KafkaRebalance 리소스를 새로 고침하면 최적화 제안을 가져옵니다. 다음 조건 중 하나가 적용되는 경우 최신 캐시된 최적화 제안을 가져옵니다.
-
KafkaRebalance
목표는Kafka리소스의default.goals섹션에 구성된 값과 일치합니다. -
KafkaRebalance
목표는지정되지 않습니다.
그렇지 않으면 Cruise Control은 KafkaRebalance 목표를 기반으로 새로운 최적화 제안을 생성합니다. 새로 고침할 때마다 새 제안이 생성되는 경우 성능 모니터링에 영향을 미칠 수 있습니다.
8.2.2.2. 이상 탐지에 대한 경고
크루즈 컨트롤의 이상성 탐지 는 브로커 실패와 같은 최적화 목표 생성을 차단하는 조건에 대한 메트릭 데이터를 제공합니다. 더 많은 가시성을 원한다면 anomaly detect에서 제공하는 메트릭을 사용하여 경고를 설정하고 알림을 보낼 수 있습니다. Cruise Control의 변명 도를 설정하여 지정된 알림 채널을 통해 이러한 메트릭을 기반으로 경고를 라우팅할 수 있습니다. 또는 이상 탐지기에서 제공하는 지표 데이터를 스크랩하고 경고를 생성하도록 Prometheus를 설정할 수 있습니다. 그런 다음 Prometheus Alertmanager는 Prometheus에서 생성한 경고를 라우팅할 수 있습니다.
Cruise Control 문서는 AnomalyDetector 메트릭 및 이상적으로 알림기에 대한 정보를 제공합니다.
8.3. 메트릭 파일 예
AMQ Streams에서 제공하는 예제 구성 파일에서 Grafana 대시보드 및 기타 메트릭 구성 파일 예제 를 찾을 수 있습니다.
AMQ Streams와 함께 제공되는 메트릭 파일의 예
metrics ├── grafana-dashboards 1 │ ├── strimzi-cruise-control.json │ ├── strimzi-kafka-bridge.json │ ├── strimzi-kafka-connect.json │ ├── strimzi-kafka-exporter.json │ ├── strimzi-kafka-mirror-maker-2.json │ ├── strimzi-kafka.json │ ├── strimzi-operators.json │ └── strimzi-zookeeper.json ├── grafana-install │ └── grafana.yaml 2 ├── prometheus-additional-properties │ └── prometheus-additional.yaml 3 ├── prometheus-alertmanager-config │ └── alert-manager-config.yaml 4 ├── prometheus-install │ ├── alert-manager.yaml 5 │ ├── prometheus-rules.yaml 6 │ ├── prometheus.yaml 7 │ ├── strimzi-pod-monitor.yaml 8 ├── kafka-bridge-metrics.yaml 9 ├── kafka-connect-metrics.yaml 10 ├── kafka-cruise-control-metrics.yaml 11 ├── kafka-metrics.yaml 12 └── kafka-mirror-maker-2-metrics.yaml 13
- 1
- 다른 AMQ Streams 구성 요소의 Grafana 대시보드의 예.
- 2
- Grafana 이미지의 설치 파일입니다.
- 3
- 노드의 OpenShift cAdvisor 에이전트 및 kubelet에서 직접 제공되는 CPU, 메모리, 디스크 볼륨 사용량에 대한 메트릭을 스크랩하는 추가 구성입니다.
- 4
- Alertmanager를 통해 알림을 전송하기 위한 후크 정의.
- 5
- Alertmanager 배포 및 구성을 위한 리소스입니다.
- 6
- Prometheus Alertmanager와 함께 사용할 경고 규칙 예(Prometheus와 함께 배포됨).
- 7
- Prometheus 이미지의 설치 리소스 파일
- 8
- Prometheus Operator에서 변환한 PodMonitor 정의는 Pod에서 직접 메트릭 데이터를 스크랩할 수 있도록 Prometheus 서버의 작업으로 변환됩니다.
- 9
- 지표가 활성화된 Kafka 브리지 리소스
- 10
- Kafka Connect에 대한 Prometheus>-< Exporter 재지정 규칙을 정의하는 지표 구성입니다.
- 11
- Cruise Control에 대한 Prometheus ScanSetting Exporter 재지정 규칙을 정의하는 지표 구성입니다.
- 12
- Prometheus ScanSetting Exporter를 정의하는 지표 구성에서는 Kafka 및 ZooKeeper에 대한 재지정 규칙 재지정 규칙입니다.
- 13
- Kafka MirrorECDHE 2.0에 대한 Prometheus ScanSetting Exporter 재레이블 규칙을 정의하는 지표 구성입니다.
8.3.1. Prometheus 지표 구성의 예
AMQ Streams는 Prometheus>-< Exporter 를 사용하여 HTTP 끝점을 통해 지표를 노출합니다. 이 값은 Prometheus 서버에서 스크랩할 수 있습니다.
Grafana 대시보드는 사용자 정의 리소스 구성에서 AMQ Streams 구성 요소에 대해 정의된 Prometheus>-< Exporter 재레이블 규칙을 사용합니다.
레이블은 이름-값 쌍입니다. 레이블 재레이블은 레이블을 동적으로 작성하는 프로세스입니다. 예를 들어 레이블 값은 Kafka 서버 이름 및 클라이언트 ID에서 파생될 수 있습니다.
AMQ Streams는 사용자 정의 리소스 구성 YAML 파일의 예와 레이블 지정 규칙을 제공합니다. Prometheus 지표 구성을 배포할 때 사용자 정의 리소스 예제를 배포하거나 자체 사용자 정의 리소스 정의에 메트릭 구성을 복사할 수 있습니다.
표 8.1. 메트릭 구성이 있는 사용자 정의 리소스의 예
| 구성 요소 | 사용자 정의 리소스 | YAML 파일 예 |
|---|---|---|
| Kafka 및 ZooKeeper |
|
|
| Kafka Connect |
|
|
| Kafka MirrorMaker 2.0 |
|
|
| Kafka 브리지 |
|
|
| 크루즈 컨트롤 |
|
|
8.3.2. 경고 알림에 대한 Prometheus 규칙 예
경고 알림에 대한 Prometheus 규칙의 예는 AMQ Streams에서 제공하는 지표 구성 파일 예제와 함께 제공됩니다. 규칙은 Prometheus 배포에서 사용하기 위해 예제 prometheus-rules.yaml 파일에 지정됩니다.
경고 규칙은 메트릭에서 관찰되는 특정 조건에 대한 알림을 제공합니다. 규칙은 Prometheus 서버에 선언되지만 Prometheus Alertmanager는 경고 알림을 담당합니다.
Prometheus 경고 규칙은 지속적으로 평가되는 PromQL 표현식을 사용하여 조건을 설명합니다.
경고 표현식이 true가 되면 조건이 충족되고 Prometheus 서버는 경고 데이터를 Alertmanager로 보냅니다. 그런 다음 Alertmanager는 배포에 대해 구성된 통신 방법을 사용하여 알림을 보냅니다.
경고 규칙 정의에 대한 일반 지점:
-
for속성을 규칙과 함께 사용하여 경고가 트리거되기 전에 조건이 지속되는 기간을 결정합니다. -
눈금은 기본 ZooKeeper 시간 단위이며, 밀리초 단위로 측정되고
Kafka.spec.zookeeper.config의tickTime매개변수를 사용하여 구성됩니다. 예를 들어, ZooKeepertickTime=3000인 경우 3 눈금 (3 x 3000)이 9000밀리초와 같습니다. -
ZookeeperRunningOutOfSpace및 경고의 가용성은 사용된 OpenShift 구성 및 스토리지 구현에 따라 달라집니다. 특정 플랫폼에 대한 스토리지 구현은 메트릭이 경고를 제공하는 데 필요한 사용 가능한 공간에 대한 정보를 제공하지 못할 수 있습니다.
Alertmanager는 이메일, 채팅 메시지 또는 기타 알림 방법을 사용하도록 구성할 수 있습니다. 특정 요구에 따라 예제 규칙의 기본 구성을 조정합니다.
8.3.2.1. 규칙 변경 예
prometheus-rules.yaml 파일에는 다음 구성 요소에 대한 예제 규칙이 포함되어 있습니다.
- Kafka
- ZooKeeper
- 엔터티 Operator
- Kafka Connect
- Kafka 브리지
- MirrorMaker
- Kafka Exporter
각 예제 규칙에 대한 설명은 파일에서 제공됩니다.
8.3.3. Grafana 대시보드 예
메트릭을 제공하기 위해 Prometheus를 배포하는 경우 AMQ Streams와 함께 제공되는 Grafana 대시보드 예제를 사용하여 AMQ Streams 구성 요소를 모니터링할 수 있습니다.
예제 대시보드는 examples/metrics/grafana-dashboards 디렉터리에서 JSON 파일로 제공됩니다.
모든 대시보드는 JVM 메트릭과 구성 요소에 대한 지표를 제공합니다. 예를 들어, AMQ Streams Operator의 Grafana 대시보드는 처리하는 조정 또는 사용자 정의 리소스의 수에 대한 정보를 제공합니다.
예제 대시보드는 Kafka에서 지원하는 모든 메트릭을 표시하지 않습니다. 대시보드는 모니터링을 위한 대표 지표 세트로 채워집니다.
표 8.2. Grafana 대시보드 파일의 예
| 구성 요소 | JSON 파일 예 |
|---|---|
| AMQ Streams Operator |
|
| Kafka |
|
| ZooKeeper |
|
| Kafka Connect |
|
| Kafka MirrorMaker 2.0 |
|
| Kafka 브리지 |
|
| 크루즈 컨트롤 |
|
| Kafka Exporter |
|
Kafka Exporter에 메트릭을 사용할 수 없는 경우 아직 클러스터에 트래픽이 없기 때문에 Kafka Exporter Grafana 대시보드에 숫자 필드에 대한 N/A 가 표시되고 그래프에 대한 데이터 없음이 표시됩니다.
8.4. Prometheus 지표 구성 배포
AMQ Streams와 함께 Prometheus를 사용하도록 Prometheus 지표 구성을 배포합니다. metricsConfig 속성을 사용하여 Prometheus 지표를 활성화하고 구성합니다.
자체 구성 또는 AMQ Streams와 함께 제공되는 사용자 정의 리소스 구성 파일 예제 를 사용할 수 있습니다.
-
kafka-metrics.yaml -
kafka-connect-metrics.yaml -
kafka-mirror-maker-2-metrics.yaml -
kafka-bridge-metrics.yaml -
kafka-cruise-control-metrics.yaml
예제 구성 파일에는 Prometheus 지표를 활성화하는 데 필요한 규칙 및 구성의 레이블이 다시 지정되었습니다. Prometheus는 대상 HTTP 끝점에서 메트릭을 스크랩합니다. 예제 파일은 AMQ Streams를 사용하여 Prometheus를 시도할 수 있는 좋은 방법입니다.
재레이블 규칙 및 메트릭 구성을 적용하려면 다음 중 하나를 수행하십시오.
- 사용자 정의 리소스에 예제 구성을 복사
- 메트릭 구성을 사용하여 사용자 정의 리소스 배포
Kafka Exporter 메트릭을 포함하려면 Kafka 리소스에 kafkaExporter 구성을 추가합니다.
Kafka Exporter는 소비자 지연 및 소비자 오프셋과 관련된 추가 메트릭만 제공합니다. 일반 Kafka 메트릭의 경우 Kafka 브로커 에서 Prometheus 지표를 구성해야 합니다.
다음 절차에서는 Kafka 리소스에 Prometheus 지표 구성을 배포하는 방법을 설명합니다. 다른 리소스에 예제 파일을 사용할 때 프로세스는 동일합니다.
절차
Prometheus 구성을 사용하여 예제 사용자 정의 리소스를 배포합니다.
예를 들어 각
Kafka리소스에 대해kafka-metrics.yaml파일을 적용합니다.예제 구성 배포
oc apply -f kafka-metrics.yaml
또는
kafka-metrics.yaml의 예제 구성을 자체Kafka리소스에 복사할 수 있습니다.예제 구성 복사
oc edit kafka <kafka-configuration-file>metricsConfig속성 및Kafka리소스에 참조하는ConfigMap을 복사합니다.Kafka의 메트릭 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: kafka: # ... metricsConfig: 1 type: jmxPrometheusExporter valueFrom: configMapKeyRef: name: kafka-metrics key: kafka-metrics-config.yml --- kind: ConfigMap 2 apiVersion: v1 metadata: name: kafka-metrics labels: app: strimzi data: kafka-metrics-config.yml: | # metrics configuration...참고Kafka Bridge의 경우
enableMetrics속성을 지정하고true로 설정합니다.apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: # ... bootstrapServers: my-cluster-kafka:9092 http: # ... enableMetrics: true # ...Kafka Exporter를 배포하려면
kafkaExporter구성을 추가합니다.kafkaExporter구성은Kafka리소스에만 지정됩니다.Kafka Exporter를 배포하기 위한 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-cluster spec: # ... kafkaExporter: image: my-registry.io/my-org/my-exporter-cluster:latest 1 groupRegex: ".*" 2 topicRegex: ".*" 3 resources: 4 requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi logging: debug 5 enableSaramaLogging: true 6 template: 7 pod: metadata: labels: label1: value1 imagePullSecrets: - name: my-docker-credentials securityContext: runAsUser: 1000001 fsGroup: 0 terminationGracePeriodSeconds: 120 readinessProbe: 8 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: 9 initialDelaySeconds: 15 timeoutSeconds: 5 # ...
Kafka 내보내기가 제대로 작동하려면 소비자 그룹을 사용 중이어야 합니다.
8.5. OpenShift에서 Kafka 메트릭 및 대시보드 보기
AMQ Streams가 OpenShift Container Platform에 배포되면 사용자 정의 프로젝트에 대한 모니터링을 통해 메트릭이 제공됩니다. 이 OpenShift 기능을 통해 개발자는 자체 프로젝트(예: Kafka 프로젝트)를 모니터링하기 위해 별도의 Prometheus 인스턴스에 액세스할 수 있습니다.
사용자 정의 프로젝트에 대한 모니터링이 활성화된 경우 openshift-user-workload-monitoring 프로젝트에는 다음 구성 요소가 포함됩니다.
- Prometheus Operator
- Prometheus 인스턴스(매개 Prometheus Operator가 자동으로 배포)
- Thanos Ruler 인스턴스
AMQ Streams는 이러한 구성 요소를 사용하여 메트릭을 사용합니다.
클러스터 관리자는 사용자 정의 프로젝트에 대한 모니터링을 활성화한 다음 개발자 및 기타 사용자에게 자체 프로젝트 내에서 애플리케이션을 모니터링할 수 있는 권한을 부여해야 합니다.
Grafana 배포
Kafka 클러스터가 포함된 프로젝트에 Grafana 인스턴스를 배포할 수 있습니다. 그런 다음 Grafana 대시보드 예제를 사용하여 Grafana 사용자 인터페이스에서 AMQ Streams에 대한 Prometheus 지표를 시각화할 수 있습니다.
openshift-monitoring 프로젝트는 코어 플랫폼 구성 요소에 대한 모니터링을 제공합니다. 이 프로젝트에서 Prometheus 및 Grafana 구성 요소를 사용하여 OpenShift Container Platform 4.x에서 AMQ Streams에 대한 모니터링을 구성하지 마십시오.
절차 개요
OpenShift Container Platform에서 AMQ Streams 모니터링을 설정하려면 다음 절차를 순서대로 따르십시오.
8.5.1. 사전 요구 사항
- 예제 YAML 파일을 사용하여 Prometheus 지표 구성을 배포 했습니다.
-
사용자 정의 프로젝트에 대한 모니터링 이 활성화됩니다. 클러스터 관리자가 OpenShift 클러스터에
cluster-monitoring-config구성 맵을 생성했습니다. -
클러스터 관리자에게
monitoring-rules-edit또는monitoring-edit역할이 할당되었습니다.
cluster-monitoring-config 구성 맵을 생성하고 사용자 정의 프로젝트를 모니터링할 수 있는 권한을 사용자에게 부여하는 방법에 대한 자세한 내용은 OpenShift Container Platform 모니터링을 참조하십시오. https://access.redhat.com/documentation/en-us/openshift_container_platform/4.11/html/monitoring/index
8.5.2. 추가 리소스
- OpenShift Container Platform 모니터링
8.5.3. Prometheus 리소스 배포
Prometheus를 사용하여 Kafka 클러스터에서 모니터링 데이터를 가져옵니다.
자체 Prometheus 배포를 사용하거나 AMQ Streams에서 제공하는 예제 메트릭 구성 파일을 사용하여 Prometheus를 배포할 수 있습니다. 예제 파일을 사용하려면 PodMonitor 리소스를 구성하고 배포합니다. PodMonitors 는 Apache Kafka, ZooKeeper, Operator, Kafka Bridge 및 Cruise Control에 대한 Pod에서 직접 데이터를 스크랩합니다.
그런 다음 Alertmanager에 대한 경고 규칙 예제를 배포합니다.
사전 요구 사항
- 실행 중인 Kafka 클러스터입니다.
- AMQ Streams와 함께 제공되는 경고 규칙 예를 확인합니다.
절차
사용자 정의 프로젝트에 대한 모니터링이 활성화되어 있는지 확인합니다.
oc get pods -n openshift-user-workload-monitoring
활성화된 경우 모니터링 구성 요소의 Pod가 반환됩니다. 예를 들면 다음과 같습니다.
NAME READY STATUS RESTARTS AGE prometheus-operator-5cc59f9bc6-kgcq8 1/1 Running 0 25s prometheus-user-workload-0 5/5 Running 1 14s prometheus-user-workload-1 5/5 Running 1 14s thanos-ruler-user-workload-0 3/3 Running 0 14s thanos-ruler-user-workload-1 3/3 Running 0 14s
Pod가 반환되지 않으면 사용자 정의 프로젝트에 대한 모니터링이 비활성화됩니다. 8.5절. “OpenShift에서 Kafka 메트릭 및 대시보드 보기” 의 사전 요구 사항을 참조하십시오.
여러
PodMonitor리소스는examples/metrics/prometheus-install/strimzi-pod-monitor.yaml에 정의됩니다.각
PodMonitor리소스에 대해spec.namespaceSelector.matchNames속성을 편집합니다.apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: name: cluster-operator-metrics labels: app: strimzi spec: selector: matchLabels: strimzi.io/kind: cluster-operator namespaceSelector: matchNames: - <project-name> 1 podMetricsEndpoints: - path: /metrics port: http # ...- 1
Kafka와 같이 메트릭을 스크랩할 Pod가 실행 중인 프로젝트입니다.
Kafka 클러스터가 실행 중인 프로젝트에
strimzi-pod-monitor.yaml파일을 배포합니다.oc apply -f strimzi-pod-monitor.yaml -n MY-PROJECT동일한 프로젝트에 예제 Prometheus 규칙을 배포합니다.
oc apply -f prometheus-rules.yaml -n MY-PROJECT
8.5.4. Grafana의 서비스 계정 생성
AMQ Streams의 Grafana 인스턴스는 cluster-monitoring-view 역할이 할당된 서비스 계정으로 실행해야 합니다.
모니터링을 위한 메트릭을 제공하기 위해 Grafana를 사용하는 경우 서비스 계정을 생성합니다.
사전 요구 사항
절차
Grafana의
ServiceAccount를 생성합니다. 여기에서 리소스의 이름은grafana-serviceaccount입니다.apiVersion: v1 kind: ServiceAccount metadata: name: grafana-serviceaccount labels: app: strimziKafka 클러스터가 포함된 프로젝트에
ServiceAccount를 배포합니다.oc apply -f GRAFANA-SERVICEACCOUNT -n MY-PROJECT
cluster-monitoring-view역할을 GrafanaServiceAccount에 할당하는ClusterRoleBinding리소스를 생성합니다. 여기에서 리소스의 이름은grafana-cluster-monitoring-binding입니다.apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: grafana-cluster-monitoring-binding labels: app: strimzi subjects: - kind: ServiceAccount name: grafana-serviceaccount namespace: <my-project> 1 roleRef: kind: ClusterRole name: cluster-monitoring-view apiGroup: rbac.authorization.k8s.io- 1
- 프로젝트 이름입니다.
Kafka 클러스터가 포함된 프로젝트에
ClusterRoleBinding을 배포합니다.oc apply -f <grafana-cluster-monitoring-binding> -n <my-project>
8.5.5. Prometheus 데이터 소스를 사용하여 Grafana 배포
Prometheus 지표를 제공하도록 Grafana를 배포합니다. Grafana 애플리케이션에는 OpenShift Container Platform 모니터링 스택에 대한 구성이 필요합니다.
OpenShift Container Platform에는 openshift-monitoring 프로젝트에 Thanos Querier 인스턴스가 포함되어 있습니다. Thanos Querier는 플랫폼 지표를 집계하는 데 사용됩니다.
필요한 플랫폼 지표를 사용하려면 Grafana 인스턴스에 Thanos Querier에 연결할 수 있는 Prometheus 데이터 소스가 필요합니다. 이 연결을 구성하려면 토큰을 사용하여 Thanos Querier와 함께 실행되는 oauth-proxy 사이드카에 대해 인증하는 구성 맵을 생성합니다. datasource.yaml 파일은 구성 맵의 소스로 사용됩니다.
마지막으로 Kafka 클러스터가 포함된 프로젝트에 볼륨으로 마운트된 구성 맵을 사용하여 Grafana 애플리케이션을 배포합니다.
사전 요구 사항
절차
Grafana
ServiceAccount의 액세스 토큰을 가져옵니다.oc serviceaccounts get-token grafana-serviceaccount -n MY-PROJECT다음 단계에서 사용할 액세스 토큰을 복사합니다.
Grafana에 대한 Thanos Querier 구성이 포함된
datasource.yaml파일을 생성합니다.표시된 대로 액세스 토큰을
httpHeaderValue1속성에 붙여넣습니다.apiVersion: 1 datasources: - name: Prometheus type: prometheus url: https://thanos-querier.openshift-monitoring.svc.cluster.local:9091 access: proxy basicAuth: false withCredentials: false isDefault: true jsonData: timeInterval: 5s tlsSkipVerify: true httpHeaderName1: "Authorization" secureJsonData: httpHeaderValue1: "Bearer ${GRAFANA-ACCESS-TOKEN}" 1 editable: true- 1
GRAFANA-ACCESS-TOKEN: GrafanaServiceAccount에 대한 액세스 토큰의 값입니다.
datasource.yaml파일에서grafana-config라는 구성 맵을 생성합니다.oc create configmap grafana-config --from-file=datasource.yaml -n MY-PROJECT배포및 서비스로 구성된 Grafana 애플리케이션을 생성합니다.grafana-config구성 맵은 데이터 소스 구성을 위한 볼륨으로 마운트됩니다.apiVersion: apps/v1 kind: Deployment metadata: name: grafana labels: app: strimzi spec: replicas: 1 selector: matchLabels: name: grafana template: metadata: labels: name: grafana spec: serviceAccountName: grafana-serviceaccount containers: - name: grafana image: grafana/grafana:9.3.1 ports: - name: grafana containerPort: 3000 protocol: TCP volumeMounts: - name: grafana-data mountPath: /var/lib/grafana - name: grafana-logs mountPath: /var/log/grafana - name: grafana-config mountPath: /etc/grafana/provisioning/datasources/datasource.yaml readOnly: true subPath: datasource.yaml readinessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 15 periodSeconds: 20 volumes: - name: grafana-data emptyDir: {} - name: grafana-logs emptyDir: {} - name: grafana-config configMap: name: grafana-config --- apiVersion: v1 kind: Service metadata: name: grafana labels: app: strimzi spec: ports: - name: grafana port: 3000 targetPort: 3000 protocol: TCP selector: name: grafana type: ClusterIPKafka 클러스터가 포함된 프로젝트에 Grafana 애플리케이션을 배포합니다.
oc apply -f <grafana-application> -n <my-project>
8.5.6. Grafana 서비스에 대한 경로 생성
Grafana 서비스를 노출하는 경로를 통해 Grafana 사용자 인터페이스에 액세스할 수 있습니다.
절차
grafana서비스에 대한 엣지 경로를 생성합니다.oc create route edge <my-grafana-route> --service=grafana --namespace=KAFKA-NAMESPACE
8.5.7. Grafana 대시보드 예제 가져오기
Grafana를 사용하여 사용자 정의 대시보드에서 Prometheus 지표의 시각화를 제공합니다.
AMQ Streams는 JSON 형식의 Grafana에 대한 대시보드 구성 파일의 예를 제공합니다.
-
examples/metrics/grafana-dashboards
이 절차에서는 예제 Grafana 대시보드를 사용합니다.
예제 대시보드는 주요 메트릭을 모니터링하는 데 적합하지만 Kafka에서 지원하는 모든 메트릭을 표시하지는 않습니다. 인프라에 따라 예제 대시보드를 수정하거나 다른 메트릭을 추가할 수 있습니다.
사전 요구 사항
절차
Grafana 서비스에 대한 경로 세부 정보를 가져옵니다. 예를 들면 다음과 같습니다.
oc get routes NAME HOST/PORT PATH SERVICES MY-GRAFANA-ROUTE MY-GRAFANA-ROUTE-amq-streams.net grafana
- 웹 브라우저에서 경로 호스트 및 포트의 URL을 사용하여 Grafana 로그인 화면에 액세스합니다.
사용자 이름과 암호를 입력한 다음 로그인을 클릭합니다.
기본 Grafana 사용자 이름과 암호는 모두
admin입니다. 처음 로그인하면 암호를 변경할 수 있습니다.- 구성 > 데이터 소스에서 Prometheus 데이터 소스가 생성되었는지 확인합니다. 데이터 소스는 8.5.5절. “Prometheus 데이터 소스를 사용하여 Grafana 배포” 에서 생성되었습니다.
- + 아이콘을 클릭한 다음 가져오기 를 클릭합니다.
-
examples/metrics/grafana-dashboards에서 가져올 대시보드의 JSON을 복사합니다. - JSON을 텍스트 상자에 붙여넣고 Load 를 클릭합니다.
- Grafana 대시보드 예제에 대해 5-7단계를 반복합니다.
가져온 Grafana 대시보드는 대시보드 홈 페이지에서 볼 수 있습니다.
9장. 분산 추적 소개
분산 추적은 분산 시스템의 애플리케이션 간 트랜잭션 진행 상황을 추적합니다. 마이크로 서비스 아키텍처에서 추적은 서비스 간 트랜잭션 진행 상황을 추적합니다. 추적 데이터는 애플리케이션 성능을 모니터링하고 대상 시스템 및 최종 사용자 애플리케이션 관련 문제를 조사하는 데 유용합니다.
AMQ Streams에서 추적을 사용하면 소스 시스템에서 Kafka로의 메시지 엔드 투 엔드 추적을 용이하게 하고 Kafka에서 시스템 및 애플리케이션을 대상으로 지정할 수 있습니다. 분산 추적은 Grafana 대시보드의 메트릭 모니터링과 구성 요소 로거를 보완합니다.
추적 지원은 다음 Kafka 구성 요소에 빌드됩니다.
- 소스 클러스터에서 대상 클러스터로 메시지를 추적할 MirrorMaker
- Kafka Connect에서 사용하고 생성한 메시지를 추적하기 위한 Kafka Connect
- Kafka 및 HTTP 클라이언트 애플리케이션 간 메시지 추적을 위한 Kafka Bridge
Kafka 브로커에서는 추적이 지원되지 않습니다.
사용자 정의 리소스를 통해 이러한 구성 요소의 추적을 활성화하고 구성합니다. spec.template 속성을 사용하여 추적 구성을 추가합니다.
spec.tracing.type 속성을 사용하여 추적 유형을 지정하여 추적을 활성화합니다.
OpenTelemetry-
type: opentelemetry를 지정하여 OpenTelemetry를 사용합니다. 기본적으로 OpenTelemetry는 OTLP (OpenTelemetry Protocol) 내보내기 및 끝점을 사용하여 추적 데이터를 가져옵니다. Jaeger 추적을 포함하여 OpenTelemetry에서 지원하는 다른 추적 시스템을 지정할 수 있습니다. 이를 위해 추적 구성에서 OpenTelemetry 내보내기 및 끝점을 변경합니다. jaeger-
OpenTracing 및 Jaeger 클라이언트를 사용하여 추적 데이터를 가져오려면
type:jaeger를 지정합니다.
type: jaeger tracing에 대한 지원은 더 이상 사용되지 않습니다. 이제 Jaeger 클라이언트가 사용 중지되고 OpenTracing 프로젝트가 아카이브됩니다. 따라서 향후 Kafka 버전에 대한 지원을 보장할 수 없습니다. 가능한 경우 type: jaeger 추적은 2023년 6월까지 유지 관리하고 나중에 삭제합니다. 최대한 빨리 OpenTelemetry로 마이그레이션하십시오.
9.1. 추적 옵션
Jaeger 추적 시스템과 함께 OpenTelemetry 또는 OpenTracing (더 이상 사용되지 않음)을 사용합니다.
OpenTelemetry 및 OpenTracing은 추적 또는 모니터링 시스템과 독립적 인 API 사양을 제공합니다.
API를 사용하여 추적을 위한 애플리케이션 코드를 계측합니다.
- 계측된 애플리케이션은 분산 시스템에서 개별 요청에 대한 추적을 생성합니다.
- 추적은 시간 경과에 따른 특정 작업 단위를 정의하는 기간으로 구성됩니다.
Jaeger는 마이크로 서비스 기반 분산 시스템의 추적 시스템입니다.
- Jaeger는 추적 API를 구현하고 조정을 위한 클라이언트 라이브러리를 제공합니다.
- Jaeger 사용자 인터페이스를 사용하면 추적 데이터를 쿼리, 필터링 및 분석할 수 있습니다.
간단한 쿼리를 보여주는 Jaeger 사용자 인터페이스

9.2. 추적을 위한 환경 변수
Kafka 구성 요소에 대한 추적을 활성화하거나 Kafka 클라이언트의 추적기를 초기화하는 경우 환경 변수를 사용합니다.
환경 변수 추적은 변경될 수 있습니다. 최신 정보는 OpenTelemetry 문서 및 OpenTracing 설명서 를 참조하십시오.
다음 표에서는 추적 프로그램을 설정하기 위한 주요 환경 변수에 대해 설명합니다.
표 9.1. OpenTelemetry 환경 변수
| 속성 | 필수 항목 | 설명 |
|---|---|---|
|
| 제공됨 | OpenTelemetry의 Jaeger 추적 서비스의 이름입니다. |
|
| 제공됨 | 추적에 사용되는 내보내기입니다. |
|
| 제공됨 |
추적에 사용되는 내보내기입니다. 기본적으로 |
표 9.2. OpenTracing 환경 변수
| 속성 | 필수 항목 | 설명 |
|---|---|---|
|
| 제공됨 | Jaeger 추적 프로그램의 이름입니다. |
|
| 없음 |
UDP(User Datagram Protocol)를 통해 |
|
| 없음 |
UDP를 통해 |
9.3. 분산 추적 설정
사용자 정의 리소스에서 추적 유형을 지정하여 Kafka 구성 요소에서 분산 추적을 활성화합니다. 메시지의 엔드 투 엔드 추적을 위해 Kafka 클라이언트의 계측 추적기입니다.
분산 추적을 설정하려면 다음 절차를 순서대로 수행합니다.
- MirrorMaker, Kafka Connect 및 Kafka Bridge에 대한 추적 활성화
클라이언트의 추적을 설정합니다.
추적기를 사용하여 클라이언트 장치:
9.3.1. 사전 요구 사항
분산 추적을 설정하기 전에 Jaeger 백엔드 구성 요소가 OpenShift 클러스터에 배포되었는지 확인합니다. OpenShift 클러스터에 Jaeger를 배포하는 데 Jaeger Operator를 사용하는 것이 좋습니다.
배포 지침은 Jaeger 문서를 참조하십시오.
AMQ Streams 이외의 애플리케이션 및 시스템의 추적 설정은 이 콘텐츠의 범위를 벗어납니다.
9.3.2. MirrorMaker, Kafka Connect 및 Kafka Bridge 리소스에서 추적 활성화
MirrorMaker, MirrorMaker 2.0, Kafka Connect 및 AMQ Streams Kafka Bridge에서 분산 추적이 지원됩니다. 추적기 서비스를 지정하고 활성화하도록 구성 요소의 사용자 정의 리소스를 구성합니다.
리소스에서 추적을 활성화하면 다음 이벤트가 트리거됩니다.
- 인터셉터 클래스는 구성 요소의 통합 소비자 및 생산자에서 업데이트됩니다.
- MirrorMaker, MirrorMaker 2.0 및 Kafka Connect의 경우 추적 에이전트는 리소스에 정의된 추적 구성을 기반으로 추적기를 초기화합니다.
- Kafka 브리지의 경우 리소스에 정의된 추적 구성을 기반으로 하는 추적자는 Kafka 브리지 자체에서 초기화합니다.
OpenTelemetry 또는 OpenTracing을 사용하는 추적을 활성화할 수 있습니다.
MirrorMaker 및 MirrorMaker 2.0에서 추적
MirrorMaker 및 MirrorMaker 2.0의 경우 메시지가 소스 클러스터에서 대상 클러스터로 추적됩니다. 추적 데이터는 MirrorMaker 또는 MirrorMaker 2.0 구성 요소를 입력하고 나가는 메시지를 기록합니다.
Kafka Connect에서 추적
Kafka Connect의 경우 Kafka Connect에서 생성하고 사용하는 메시지만 추적됩니다. Kafka Connect와 외부 시스템 간에 전송된 메시지를 추적하려면 해당 시스템의 커넥터에서 추적을 구성해야 합니다.
Kafka 브리지의 추적
Kafka 브리지의 경우 Kafka 브리지에서 생성 및 사용하는 메시지가 추적됩니다. Kafka 브리지를 통해 메시지를 보내고 받을 클라이언트 애플리케이션에서 들어오는 HTTP 요청도 추적됩니다. 엔드 투 엔드 추적을 유지하려면 HTTP 클라이언트에서 추적을 구성해야 합니다.
절차
각 KafkaMirrorMaker,KafkaMirrorMaker2,KafkaConnect 및 KafkaBridge 리소스에 대해 다음 단계를 수행합니다.
spec.template속성에서 tracer 서비스를 구성합니다.- 추적 환경 변수를 템플릿 구성 속성으로 사용합니다.
-
OpenTelemetry의 경우
spec.tracing.type속성을opentelemetry로 설정합니다. -
OpenTracing의 경우
spec.tracing.type속성을jaeger로 설정합니다.
OpenTelemetry를 사용하는 Kafka Connect의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...OpenTelemetry를 사용하는 MirrorMaker의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: #... template: mirrorMakerContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...OpenTelemetry를 사용한 MirrorMaker 2.0의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...OpenTelemetry를 사용하는 Kafka 브리지의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: #... template: bridgeContainer: env: - name: OTEL_SERVICE_NAME value: my-otel-service - name: OTEL_EXPORTER_JAEGER_ENDPOINT value: "http://jaeger-host:14250" tracing: type: opentelemetry #...OpenTracing을 사용하는 Kafka Connect의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... template: connectContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...OpenTracing을 사용하는 MirrorMaker의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: #... template: mirrorMakerContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...OpenTracing을 사용하는 MirrorMaker 2.0의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...OpenTracing을 사용하는 Kafka 브리지의 추적 구성 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaBridge metadata: name: my-bridge spec: #... template: bridgeContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...리소스를 생성하거나 업데이트합니다.
oc apply -f <resource_configuration_file>
9.3.3. Kafka 클라이언트의 추적 초기화
추적기를 초기화한 다음 분산 추적을 위해 클라이언트 애플리케이션을 계측합니다. Kafka 생산자 및 소비자 클라이언트 및 Kafka Streams API 애플리케이션을 조정할 수 있습니다. OpenTracing 또는 OpenTelemetry에 대해 추적기를 초기화할 수 있습니다.
추적 환경 변수 세트를 사용하여 추적 프로그램을 구성하고 초기화합니다.
절차
각 클라이언트 애플리케이션에서 추적기에 대한 종속성을 추가합니다.
클라이언트 애플리케이션의
pom.xml파일에 Maven 종속성을 추가합니다.OpenTelemetry의 종속 항목
<dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-sdk-extension-autoconfigure</artifactId> <version>1.18.0-alpha</version> </dependency> <dependency> <groupId>io.opentelemetry.instrumentation</groupId> <artifactId>opentelemetry-kafka-clients-{OpenTelemetryKafkaClient}</artifactId> <version>1.18.0-alpha</version> </dependency> <dependency> <groupId>io.opentelemetry</groupId> <artifactId>opentelemetry-exporter-jaeger</artifactId> <version>1.18.0</version> </dependency>OpenTracing의 종속 항목
<dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.15</version> </dependency>- 추적 환경 변수를 사용하여 추적 프로그램의 구성을 정의합니다.
환경 변수를 사용하여 초기화되는 추적기를 생성합니다.
OpenTelemetry용 추적기 생성
OpenTelemetry ot = GlobalOpenTelemetry.get();
OpenTracing용 추적기 생성
Tracer tracer = Configuration.fromEnv().getTracer();
추적기를 글로벌 추적기로 등록합니다.
GlobalTracer.register(tracer);
클라이언트 사용 방법:
9.3.4. 추적을 위한 생산자 및 소비자 측정
Kafka 생산자 및 소비자에서 추적할 수 있는 장치 애플리케이션 코드를 제공합니다. 데코레이터 패턴 또는 인터셉터를 사용하여 추적을 위해 Java 생산자 및 소비자 애플리케이션 코드를 계측합니다. 그런 다음 메시지가 생성되거나 주제에서 검색될 때 추적을 기록할 수 있습니다.
OpenTelemetry 및 OpenTracing 계측 프로젝트는 생산자와 소비자의 계측을 지원하는 클래스를 제공합니다.
- 데코레이터 장치
- 데코레이터 계측의 경우 추적을 위한 수정된 생산자 또는 소비자 인스턴스를 생성합니다. 데코레이터 장치는 OpenTelemetry 및 OpenTracing과는 다릅니다.
- 인터셉터 계측
- 인터셉터 계측의 경우 소비자 또는 생산자 구성에 추적 기능을 추가합니다. 인터셉터 계측은 OpenTelemetry 및 OpenTracing의 경우 동일합니다.
사전 요구 사항
추적 JAR를 프로젝트에 종속 항목으로 추가하여 생산자 및 소비자 애플리케이션에서 계측을 활성화합니다.
절차
각 생산자 및 소비자 애플리케이션의 애플리케이션 코드에서 다음 단계를 수행합니다. 데코레이터 패턴 또는 인터셉터를 사용하여 클라이언트 애플리케이션 코드를 계측합니다.
데코레이터 패턴을 사용하려면 수정된 생산자 또는 소비자 인스턴스를 생성하여 메시지를 보내거나 받습니다.
원래
KafkaProducer또는KafkaConsumer클래스를 전달합니다.OpenTelemetry를 위한 데코레이터의 예
// Producer instance Producer < String, String > op = new KafkaProducer < > ( configs, new StringSerializer(), new StringSerializer() ); Producer < String, String > producer = tracing.wrap(op); KafkaTracing tracing = KafkaTracing.create(GlobalOpenTelemetry.get()); producer.send(...); //consumer instance Consumer<String, String> oc = new KafkaConsumer<>( configs, new StringDeserializer(), new StringDeserializer() ); Consumer<String, String> consumer = tracing.wrap(oc); consumer.subscribe(Collections.singleton("mytopic")); ConsumerRecords<Integer, String> records = consumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);OpenTracing을 위한 데코레이터 계측 예
//producer instance KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer, tracer); TracingKafkaProducer.send(...) //consumer instance KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer, tracer); tracingConsumer.subscribe(Collections.singletonList("mytopic")); ConsumerRecords<Integer, String> records = tracingConsumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);인터셉터를 사용하려면 생산자 또는 소비자 구성에서 인터셉터 클래스를 설정합니다.
일반적인 방법으로
KafkaProducer및KafkaConsumer클래스를 사용합니다.TracingProducerInterceptor및TracingConsumerInterceptor클래스는 추적 기능을 처리합니다.인터셉터를 사용한 생산자 구성 예
senderProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); producer.send(...);인터셉터를 사용하는 소비자 구성 예
consumerProps.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName()); KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); consumer.subscribe(Collections.singletonList("messages")); ConsumerRecords<Integer, String> records = consumer.poll(1000); ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
9.3.5. 추적을 위한 Kafka Streams 애플리케이션 조정
Kafka Streams API 애플리케이션에서 추적을 활성화하는 장치 애플리케이션 코드입니다. 데코레이터 패턴 또는 인터셉터를 사용하여 추적을 위해 Kafka Streams API 애플리케이션을 조정합니다. 그런 다음 메시지가 생성되거나 주제에서 검색될 때 추적을 기록할 수 있습니다.
- 데코레이터 장치
-
데코레이터 계측의 경우 추적을 위해 수정된 Kafka Streams 인스턴스를 생성합니다. OpenTracing 계측 프로젝트는 Kafka Streams 계측을 지원하는
TracingKafkaClientSupplier클래스를 제공합니다. Kafka Streams에 추적을 제공하는TracingKafkaClientSupplier공급업체 인터페이스의 래핑된 인스턴스를 생성합니다. OpenTelemetry의 경우 프로세스는 동일하지만 지원을 제공하기 위해 사용자 정의TracingKafkaClientSupplier클래스를 생성해야 합니다. - 인터셉터 계측
- 인터셉터 계측의 경우 Kafka Streams 생산자 및 소비자 구성에 추적 기능을 추가합니다.
사전 요구 사항
추적 JAR를 프로젝트에 종속 항목으로 추가하여 Kafka Streams 애플리케이션에서 계측을 활성화합니다.
-
OpenTelemetry를 사용하여 Kafka Streams를 측정하려면 사용자 지정
TracingKafkaClientSupplier를 작성해야 합니다. 사용자 정의
TracingKafkaClientSupplier는 Kafka의DefaultKafkaClientSupplier를 확장하여 생산자 및 소비자 생성 방법을 재정의하여 Telemetry 관련 코드로 인스턴스를 래핑할 수 있습니다.사용자 정의
TracingKafkaClientSupplier의 예private class TracingKafkaClientSupplier extends DefaultKafkaClientSupplier { @Override public Producer<byte[], byte[]> getProducer(Map<String, Object> config) { KafkaTelemetry telemetry = KafkaTelemetry.create(GlobalOpenTelemetry.get()); return telemetry.wrap(super.getProducer(config)); } @Override public Consumer<byte[], byte[]> getConsumer(Map<String, Object> config) { KafkaTelemetry telemetry = KafkaTelemetry.create(GlobalOpenTelemetry.get()); return telemetry.wrap(super.getConsumer(config)); } @Override public Consumer<byte[], byte[]> getRestoreConsumer(Map<String, Object> config) { return this.getConsumer(config); } @Override public Consumer<byte[], byte[]> getGlobalConsumer(Map<String, Object> config) { return this.getConsumer(config); } }
절차
각 Kafka Streams API 애플리케이션에 대해 다음 단계를 수행합니다.
데코레이터 패턴을 사용하려면
TracingKafkaClientSupplier공급업체 인터페이스 인스턴스를 생성한 다음KafkaStreams에 공급업체 인터페이스를 제공합니다.데코레이터 장치 예
KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer); KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();
인터셉터를 사용하려면 Kafka Streams 생산자 및 소비자 구성에서 인터셉터 클래스를 설정합니다.
TracingProducerInterceptor및TracingConsumerInterceptor클래스는 추적 기능을 처리합니다.인터셉터를 사용한 생산자 및 소비자 구성의 예
props.put(StreamsConfig.PRODUCER_PREFIX + ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); props.put(StreamsConfig.CONSUMER_PREFIX + ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName());
9.3.6. 다른 OpenTelemetry 추적 시스템 소개
기본 Jaeger 시스템 대신 OpenTelemetry에서 지원하는 다른 추적 시스템을 지정할 수 있습니다. AMQ Streams와 함께 제공되는 Kafka 이미지에 필요한 아티팩트를 추가하여 이 작업을 수행합니다. 필요한 구현 특정 환경 변수도 설정해야 합니다. 그런 다음 OTEL_TRACES_EXPORTER 환경 변수를 사용하여 새 추적 구현을 활성화합니다.
다음 절차에서는 Zipkin 추적을 구현하는 방법을 설명합니다.
절차
AMQ Streams Kafka 이미지의
/opt/kafka/libs/디렉터리에 추적 아티팩트를 추가합니다.Red Hat Ecosystem Catalog 에서 Kafka 컨테이너 이미지를 기본 이미지로 사용하여 새 사용자 지정 이미지를 생성할 수 있습니다.
Zipkin에 대한 OpenTelemetry 아티팩트
io.opentelemetry:opentelemetry-exporter-zipkin
새 추적 구현에 대한 추적 내보내기 및 끝점을 설정합니다.
Zikpin tracer 구성의 예
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: OTEL_SERVICE_NAME value: my-zipkin-service - name: OTEL_EXPORTER_ZIPKIN_ENDPOINT value: http://zipkin-exporter-host-name:9411/api/v2/spans 1 - name: OTEL_TRACES_EXPORTER value: zipkin 2 tracing: type: opentelemetry #...
9.3.7. 사용자 정의 범위 이름
추적 범위는 작업 이름, 시작 시간 및 기간이 있는 Jaeger의 논리 작업 단위입니다. 기간에는 이름이 기본 제공되지만, 사용하는 Kafka 클라이언트 계측에서 사용자 지정 범위 이름을 지정할 수 있습니다.
사용자 지정 범위 이름을 지정하는 것은 선택 사항이며 생산자 및 소비자 클라이언트 계측에서 데코레이터 패턴을 사용하는 경우에만 적용됩니다. ???
9.3.7.1. OpenTelemetry의 기간 이름 지정
사용자 지정 기간 이름은 OpenTelemetry를 사용하여 직접 지정할 수 없습니다. 대신 클라이언트 애플리케이션에 코드를 추가하여 범위 이름을 검색하여 추가 태그 및 속성을 추출합니다.
속성을 추출하기 위한 코드 예
//Defines attribute extraction for a producer
private static class ProducerAttribExtractor implements AttributesExtractor < ProducerRecord < ? , ? > , Void > {
@Override
public void onStart(AttributesBuilder attributes, ProducerRecord < ? , ? > producerRecord) {
set(attributes, AttributeKey.stringKey("prod_start"), "prod1");
}
@Override
public void onEnd(AttributesBuilder attributes, ProducerRecord < ? , ? > producerRecord, @Nullable Void unused, @Nullable Throwable error) {
set(attributes, AttributeKey.stringKey("prod_end"), "prod2");
}
}
//Defines attribute extraction for a consumer
private static class ConsumerAttribExtractor implements AttributesExtractor < ConsumerRecord < ? , ? > , Void > {
@Override
public void onStart(AttributesBuilder attributes, ConsumerRecord < ? , ? > producerRecord) {
set(attributes, AttributeKey.stringKey("con_start"), "con1");
}
@Override
public void onEnd(AttributesBuilder attributes, ConsumerRecord < ? , ? > producerRecord, @Nullable Void unused, @Nullable Throwable error) {
set(attributes, AttributeKey.stringKey("con_end"), "con2");
}
}
//Extracts the attributes
public static void main(String[] args) throws Exception {
Map < String, Object > configs = new HashMap < > (Collections.singletonMap(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"));
System.setProperty("otel.traces.exporter", "jaeger");
System.setProperty("otel.service.name", "myapp1");
KafkaTracing tracing = KafkaTracing.newBuilder(GlobalOpenTelemetry.get())
.addProducerAttributesExtractors(new ProducerAttribExtractor())
.addConsumerAttributesExtractors(new ConsumerAttribExtractor())
.build();
9.3.7.2. OpenTracing의 범위 이름 지정
OpenTracing에 대한 사용자 지정 범위 이름을 지정하려면 생산자와 소비자를 계측할 때 BiFunction 오브젝트를 추가 인수로 전달합니다.
기본 제공 이름에 대한 자세한 내용은 OpenTracing Apache Kafka 클라이언트 계측에서 클라이언트 애플리케이션 코드를 계측 하기 위해 사용자 지정 범위 이름을 지정합니다.
10장. AMQ Streams 업그레이드
AMQ Streams를 버전 2.3으로 업그레이드하여 새로운 기능 및 개선 사항, 성능 개선 사항 및 보안 옵션을 활용할 수 있습니다.
업그레이드의 일부로 Kafka를 지원되는 최신 버전으로 업그레이드합니다. 각 Kafka 릴리스에는 AMQ Streams 배포에 새로운 기능, 개선 사항 및 버그 수정이 포함되어 있습니다.
최신 버전에 문제가 발생하면 AMQ Streams를 이전 버전으로 다운그레이드 할 수 있습니다.
AMQ Streams의 릴리스 버전은 AMQ Streams 소프트웨어 다운로드 페이지에서 사용할 수 있습니다.
다운타임 및 가용성 업그레이드
고가용성을 위해 주제를 구성하는 경우 AMQ Streams 업그레이드로 인해 해당 주제의 데이터를 게시 및 읽는 소비자 및 생산자의 다운타임이 발생하지 않습니다. 고가용성 주제는 최소 3가지 이상의 복제 요인과 브로커에 균등하게 분산된 파티션이 있습니다.
AMQ Streams를 업그레이드하면 프로세스의 다른 단계에서 모든 브로커가 다시 시작되는 롤링 업데이트를 트리거합니다. 롤링 업데이트 중에 일부 브로커가 온라인 상태가 아닌 전체 클러스터 가용성이 일시적으로 줄어듭니다. 클러스터 가용성이 감소하면 브로커 오류가 발생할 가능성이 증가하여 메시지가 손실될 수 있습니다.
10.1. AMQ Streams 업그레이드 경로
두 가지 업그레이드 경로가 가능합니다.
- 증분 업그레이드
- 이전 마이너 버전에서 AMQ Streams를 버전 2.3으로 업그레이드
- 다중 버전 업그레이드
단일 업그레이드 내에서 이전 버전에서 버전 2.3으로 AMQ Streams 업그레이드( 하나 이상의 중간 버전 생략).
예를 들어 AMQ Streams 1.8에서 AMQ Streams 2.3으로 직접 업그레이드할 수 있습니다.
10.1.1. 지원되는 Kafka 버전
AMQ Streams 업그레이드 프로세스를 시작하기 전에 업그레이드할 Kafka 버전을 결정합니다. AMQ Streams 지원 구성에서 지원되는 Kafka 버전을 검토할 수 있습니다.
- Kafka 3.3.1은 프로덕션 용도로 지원됩니다.
- Kafka 3.2.3은 AMQ Streams 2.3으로 업그레이드할 때만 지원됩니다.
사용 중인 AMQ Streams 버전에서 지원하는 Kafka 버전만 사용할 수 있습니다. AMQ Streams 버전에서 지원하는 경우 더 높은 Kafka 버전으로 업그레이드할 수 있습니다. 경우에 따라 이전에 지원되는 Kafka 버전으로 다운그레이드할 수도 있습니다.
10.1.2. 1.7 이전 AMQ Streams 버전에서 업그레이드
버전 1.7 이전 버전에서 AMQ Streams의 최신 버전으로 업그레이드하는 경우 다음을 수행하십시오.
- 표준 시퀀스에 따라 AMQ Streams를 버전 1.7으로 업그레이드합니다.
-
AMQ Streams 1.8과 함께 제공되는 Red Hat AMQ Streams API 변환 툴을 사용하여 AMQ Streams 사용자 정의 리소스를
v1beta2로 변환합니다. 다음 중 하나를 수행합니다.
-
AMQ Streams 1.8로 업그레이드(
ControlPlaneListener기능 게이트가 기본적으로 비활성화되어 있는 경우) -
ControlPlaneListener기능 게이트가 비활성화되어 있는 AMQ Streams 2.0 또는 2.2(ControlPlaneListener기능 게이트가 기본적으로 활성화되어 있는 위치)로 업그레이드
-
AMQ Streams 1.8로 업그레이드(
-
ControlPlaneListener기능 게이트를 활성화합니다. - 표준 시퀀스에 따라 AMQ Streams 2.3으로 업그레이드합니다.
AMQ Streams 사용자 정의 리소스는 릴리스 1.7에서 v1beta2 API 버전을 사용하기 시작했습니다. AMQ Streams 1.8 이상으로 업그레이드하기 전에 CRD 및 사용자 정의 리소스를 변환해야 합니다. API 변환 툴 사용에 대한 자세한 내용은 AMQ Streams 1.7 업그레이드 설명서 를 참조하십시오.
버전 1.7로 처음 업그레이드하는 대신 버전 1.7에서 사용자 지정 리소스를 설치한 다음 리소스를 변환할 수 있습니다.
이제 AMQ Streams에서 ControlPlaneListener 기능이 영구적으로 활성화됩니다. 비활성화된 AMQ Streams 버전으로 업그레이드한 다음 Cluster Operator 구성에서 STRIMZI_FEATURE_GATES 환경 변수를 사용하여 활성화해야 합니다.
ControlPlaneListener 기능 게이트 비활성화
env:
- name: STRIMZI_FEATURE_GATES
value: -ControlPlaneListener
ControlPlaneListener 기능 게이트 활성화
env:
- name: STRIMZI_FEATURE_GATES
value: +ControlPlaneListener
10.2. 필수 업그레이드 순서
다운타임 없이 브로커 및 클라이언트를 업그레이드하려면 AMQ Streams 업그레이드 절차를 순서대로 완료해야 합니다.
OpenShift 클러스터 버전이 지원되는지 확인합니다.
AMQ Streams 2.3은 OpenShift 4.8에서 4.12로 지원됩니다.
다운타임을 최소화하여 OpenShift를 업그레이드 할 수 있습니다.
- Cluster Operator 업그레이드.
- 모든 Kafka 브로커 및 클라이언트 애플리케이션을 지원되는 최신 Kafka 버전으로 업그레이드 합니다.
- 선택 사항: 소비자 및 Kafka Streams 애플리케이션을 업그레이드하여 파티션 재조정에 증분 협업 재조정 프로토콜을 사용합니다.
10.3. 다운타임을 최소화하여 OpenShift 업그레이드
OpenShift를 업그레이드하는 경우 OpenShift 업그레이드 설명서를 참조하여 업그레이드 경로와 노드를 올바르게 업그레이드하는 단계를 확인합니다. OpenShift를 업그레이드하기 전에 사용 중인 AMQ Streams 버전에 지원되는 버전을 확인하십시오.
업그레이드를 수행할 때 Kafka 클러스터를 계속 사용할 수 있어야 합니다.
다음 전략 중 하나를 사용할 수 있습니다.
- Pod 중단 예산 구성
다음 방법 중 하나로 Pod를 롤링합니다.
- AMQ Streams Drain cleaner 사용
- Pod에 주석을 수동으로 적용하여
Pod를 롤오버하는 방법 중 하나를 사용하기 전에 Pod 중단 예산을 구성해야 합니다.
Kafka가 작동 상태를 유지하려면 고가용성을 위해 주제도 복제해야 합니다. 이를 위해 최소 3개의 복제 요소와 최소 동기화 복제본 수를 복제 요인보다 작은 1개로 지정하는 주제 구성이 필요합니다.
고가용성을 위해 복제된 Kafka 주제
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 1
replicas: 3
config:
# ...
min.insync.replicas: 2
# ...
고가용성 환경에서 Cluster Operator는 다운타임이 발생하지 않도록 업그레이드 프로세스 중 항목에 대해 최소 수의 동기화 복제본을 유지 관리합니다.
10.3.1. AMQ Streams Drain cleaner를 사용하여 Pod 롤링
AMQ Streams DrainCleaner 툴을 사용하여 업그레이드 중에 노드를 제거할 수 있습니다. AMQ Streams DrainCleaner는 롤링 업데이트 Pod 주석으로 Pod에 주석을 답니다. 그러면 제거된 Pod의 롤링 업데이트를 수행하도록 Cluster Operator에 알립니다.
Pod 중단 예산을 사용하면 지정된 시간에 지정된 수의 Pod만 사용할 수 없습니다. Kafka 브로커 Pod의 계획된 유지 관리 기간 동안 Pod 중단 예산은 Kafka가 고가용성 환경에서 계속 실행되도록 합니다.
Kafka 구성 요소에 대한 템플릿 사용자 지정을 사용하여 Pod 중단 예산을 지정합니다. 기본적으로 Pod 중단 예산을 사용하면 지정된 시간에 단일 Pod만 사용할 수 없습니다.
이렇게 하려면 maxUnavailable 을 0 (zero)으로 설정합니다. 최대 Pod 중단 예산을 0으로 줄이면 자발적으로 중단되는 것이 방지되므로 Pod를 수동으로 제거해야 합니다.
Pod 중단 예산 지정
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: myproject
spec:
kafka:
# ...
template:
podDisruptionBudget:
maxUnavailable: 0
# ...
10.3.2. 주제를 사용 가능한 상태로 유지하면서 Pod 수동 롤링
업그레이드하는 동안 Cluster Operator를 통해 Pod 수동 롤링 업데이트를 트리거할 수 있습니다. Pod 리소스를 사용하여 롤링 업데이트를 통해 새 Pod로 리소스의 Pod를 재시작합니다. AMQ Streams DrainCleaner를 사용하는 것과 마찬가지로 Pod 중단 예산에 대해 maxUnavailable 값을 0으로 설정해야 합니다.
드레인해야 하는 Pod를 확인해야 합니다. 그런 다음 Pod 주석을 추가하여 업데이트합니다.
여기에서 주석은 Kafka 브로커를 업데이트합니다.
Kafka 브로커 Pod에서 수동 롤링 업데이트 수행
oc annotate pod <cluster_name>-kafka-<index> strimzi.io/manual-rolling-update=true
< ;cluster_name& gt;을 클러스터 이름으로 교체합니다. Kafka 브로커 Pod의 이름은 < cluster-name> -kafka- <index >입니다. 여기서 < index >는 0에서 시작하여 총 복제본 수에서 1을 뺀 값입니다. 예: my-cluster-kafka-0.
10.4. Cluster Operator 업그레이드
동일한 방법을 사용하여 초기 배포 방법과 동일한 방법으로 Cluster Operator를 업그레이드합니다.
- 설치 파일 사용
- 설치 YAML 파일을 사용하여 Cluster Operator를 배포한 경우 설치 파일을 사용하여 Cluster Operator 업그레이드에 설명된 대로 Operator 설치 파일을 수정하여 업그레이드를 수행합니다.
- OperatorHub 사용
OperatorHub에서 AMQ Streams를 배포한 경우 OLM(Operator Lifecycle Manager)을 사용하여 AMQ Streams Operator의 업데이트 채널을 새 AMQ Streams 버전으로 변경합니다.
채널을 업데이트하면 선택한 업그레이드 전략에 따라 다음 유형의 업그레이드 중 하나가 시작됩니다.
- 자동 업그레이드가 시작됩니다.
- 설치를 시작하기 전에 승인이 필요한 수동 업그레이드
참고stable 채널에 가입하면 채널을 변경하지 않고 자동 업데이트를 받을 수 있습니다. 그러나 자동 업데이트 활성화는 사전 설치 업그레이드 단계가 누락될 가능성이 있기 때문에 권장되지 않습니다. 버전별 채널에서만 자동 업그레이드를 사용합니다.
OperatorHub를 사용하여 Operator 업그레이드에 대한 자세한 내용은 설치된 Operator(OpenShift 문서) 업그레이드를 참조하십시오.
10.4.1. Cluster Operator 업그레이드에서 Kafka 버전 오류를 반환합니다.
Cluster Operator를 업그레이드하고 지원되지 않는 Kafka 버전 오류를 가져오는 경우 Kafka 클러스터 배포에는 새 Operator 버전에서 지원하지 않는 이전 Kafka 버전이 있습니다. 이 오류는 모든 설치 방법에 적용됩니다.
이 오류가 발생하면 Kafka를 지원되는 Kafka 버전으로 업그레이드합니다. Kafka 리소스의 spec.kafka.version 을 지원되는 버전으로 변경합니다.
oc 를 사용하여 Kafka 리소스의 상태에서 이와 같은 오류 메시지를 확인할 수 있습니다.
Kafka 상태 확인 오류 확인
oc get kafka <kafka_cluster_name> -n <namespace> -o jsonpath='{.status.conditions}'
< kafka_cluster_name >을 Kafka 클러스터의 이름으로 바꾸고 < namespace >를 Pod가 실행 중인 OpenShift 네임스페이스로 바꿉니다.
10.4.2. OperatorHub를 사용하여 AMQ Streams 1.7 또는 이전 버전에서 업그레이드
OperatorHub를 사용하여 AMQ Streams 1.7 또는 이전 버전에서 업그레이드하는 경우 필요한 작업
Red Hat Integration - AMQ Streams Operator 를 버전 2.3으로 업그레이드하기 전에 다음 사항을 변경해야 합니다.
-
사용자 정의 리소스 및 CRD를
v1beta2로 변환 -
ControlPlaneListener기능 게이트가 비활성화된 AMQ Streams 버전으로 업그레이드
이러한 요구 사항은 10.1.2절. “1.7 이전 AMQ Streams 버전에서 업그레이드” 에 설명되어 있습니다.
AMQ Streams 1.7 이상에서 업그레이드하는 경우 다음을 수행하십시오.
- AMQ Streams 1.7로 업그레이드
- AMQ Streams 1.8과 함께 제공되는 Red Hat AMQ Streams API 변환 툴 을 다운로드합니다.
사용자 정의 리소스 및 CRD를
v1beta2로 변환합니다.자세한 내용은 AMQ Streams 1.7 업그레이드 설명서를 참조하십시오.
- OperatorHub에서 Red Hat Integration - AMQ Streams Operator 의 1.7 버전을 삭제합니다.
또한 Red Hat Integration - AMQ Streams Operator 의 2.3 버전을 삭제합니다.
존재하지 않는 경우 다음 단계로 이동합니다.
AMQ Streams Operator에 대한 승인 전략이 자동으로 설정된 경우 Operator의 2.3 버전이 클러스터에 이미 있을 수 있습니다. 사용자 정의 리소스 및 CRD를 릴리스 전에
v1beta2API 버전으로 변환 하지 않은 경우 Operator에서 관리하는 사용자 정의 리소스 및 CRD는 이전 API 버전을 사용합니다. 결과적으로 2.3 Operator가 Pending 상태로 설정되어 있습니다. 이 경우 Red Hat Integration - AMQ Streams Operator 버전 및 1.7 버전을 삭제해야 합니다.두 Operator를 모두 삭제하면 새 Operator 버전이 설치될 때까지 조정이 일시 중지됩니다. 사용자 정의 리소스에 대한 변경 사항이 지연되지 않도록 다음 단계를 즉시 수행합니다.
OperatorHub에서 다음 중 하나를 수행합니다.
-
Red Hat Integration - AMQ Streams Operator 의 버전 1.8로 업그레이드 -
AMQ Streams 기능게이트는 기본적으로 비활성화되어 있습니다. -
Red Hat Integration - AMQ Streams Operator 의 버전 2.0 또는 2.2로 업그레이드 - AMQ Streams Operator(기본적으로
ControlPlaneListener기능 게이트가 활성화된 경우)ControlPlaneListener기능 게이트가 비활성화되어 있습니다.
-
Red Hat Integration - AMQ Streams Operator 의 버전 1.8로 업그레이드 -
Red Hat Integration - AMQ Streams Operator 버전 2.3으로 즉시 업그레이드
설치된 2.3 Operator는 클러스터를 감시하고 롤링 업데이트를 수행합니다. 이 프로세스 중에 클러스터 성능이 일시적으로 저하될 수 있습니다.
10.4.3. 설치 파일을 사용하여 Cluster Operator 업그레이드
다음 절차에서는 AMQ Streams 2.3을 사용하도록 Cluster Operator 배포를 업그레이드하는 방법을 설명합니다.
설치 YAML 파일을 사용하여 Cluster Operator를 배포한 경우 다음 절차를 따르십시오.
Cluster Operator에서 관리하는 Kafka 클러스터의 가용성은 업그레이드 작업의 영향을 받지 않습니다.
해당 버전으로 업그레이드하는 방법에 대한 자세한 내용은 특정 버전의 AMQ Streams를 지원하는 설명서를 참조하십시오.
사전 요구 사항
- 기존 Cluster Operator 배포를 사용할 수 있습니다.
- AMQ Streams 2.3 릴리스 아티팩트를 다운로드 했습니다.
절차
-
기존 Cluster Operator 리소스(
/install/cluster-operator디렉터리)에 대한 구성 변경 사항을 기록해 두십시오. 새로운 Cluster Operator 버전에서 모든 변경 사항을 덮어씁니다. - AMQ Streams 버전 2.3에 사용할 수 있는 지원되는 구성 옵션을 반영하도록 사용자 정의 리소스를 업데이트합니다.
Cluster Operator를 업데이트합니다.
Cluster Operator가 실행 중인 네임스페이스에 따라 새 Cluster Operator 버전의 설치 파일을 수정합니다.
Linux에서 다음을 사용합니다.
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
MacOS에서 다음을 사용합니다.
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
-
기존 Cluster Operator
Deployment에서 하나 이상의 환경 변수를 수정한 경우install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml파일을 편집하여 해당 환경 변수를 사용합니다.
업데이트된 구성이 있는 경우 나머지 설치 리소스와 함께 배포합니다.
oc replace -f install/cluster-operator
롤링 업데이트가 완료될 때까지 기다립니다.
새 Operator 버전에서 업그레이드할 Kafka 버전을 더 이상 지원하지 않는 경우 Cluster Operator는 해당 버전이 지원되지 않는 경우 오류 메시지를 반환합니다. 그렇지 않으면 오류 메시지가 반환되지 않습니다.
오류 메시지가 반환되면 새 Cluster Operator 버전에서 지원하는 Kafka 버전으로 업그레이드합니다.
-
Kafka사용자 정의 리소스를 편집합니다. -
spec.kafka.version속성을 지원되는 Kafka 버전으로 변경합니다.
-
- 오류 메시지가 반환되지 않으면 다음 단계로 이동합니다. 나중에 Kafka 버전을 업그레이드합니다.
Kafka Pod의 이미지를 가져와서 업그레이드가 성공했는지 확인합니다.
oc get pods my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'이미지 태그는 새 Operator 버전을 표시합니다. 예를 들면 다음과 같습니다.
registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0
Cluster Operator가 버전 2.3으로 업그레이드되었지만 관리하는 클러스터에서 실행되는 Kafka 버전은 변경되지 않습니다.
Cluster Operator 업그레이드 후 Kafka 업그레이드를 수행해야 합니다.
10.5. Kafka 업그레이드
Cluster Operator를 2.3으로 업그레이드한 다음 다음 단계는 모든 Kafka 브로커를 지원되는 최신 Kafka 버전으로 업그레이드하는 것입니다.
Kafka 브로커의 롤링 업데이트를 통해 Kafka 업그레이드는 Cluster Operator에서 수행합니다.
Cluster Operator는 Kafka 클러스터 구성을 기반으로 롤링 업데이트를 시작합니다.
Kafka.spec.kafka.config 에…이 포함된 경우 | Cluster Operator가…을 시작합니다. |
|---|---|
|
|
단일 롤링 업데이트 업데이트 후 |
|
| 롤링 업데이트 2개 |
|
| 롤링 업데이트 2개 |
Kafka 3.0.0에서 inter.broker.protocol.version 이 3.0 이상으로 설정되면 log.message.format.version 옵션이 무시되고 설정할 필요가 없습니다. 브로커의 log.message.format.version 속성과 토픽에 대한 message.format.version 속성은 더 이상 사용되지 않으며 Kafka의 향후 릴리스에서 제거됩니다.
Kafka 업그레이드의 일부로 Cluster Operator는 ZooKeeper에 대한 롤링 업데이트를 시작합니다.
- 단일 롤링 업데이트는 ZooKeeper 버전이 변경되지 않은 경우에도 발생합니다.
- 새로운 버전의 Kafka에 새로운 ZooKeeper 버전이 필요한 경우 추가 롤링 업데이트가 수행됩니다.
10.5.1. Kafka 버전
Kafka의 로그 메시지 형식 버전 및broker 간 프로토콜 버전은 각각 메시지에 추가된 로그 형식 버전 및 클러스터에 사용된 Kafka 프로토콜 버전을 지정합니다. 올바른 버전을 사용하려면 업그레이드 프로세스에는 기존 Kafka 브로커를 구성하고 클라이언트 애플리케이션(소유자 및 생산자)에 대한 코드를 변경해야 합니다.
다음 표는 Kafka 버전의 차이점을 보여줍니다.
표 10.1. Kafka 버전 차이점
| Kafka 버전 | inter-broker 프로토콜 버전 | 로그 메시지 형식 버전 | zookeeper 버전 |
|---|---|---|---|
| 3.2.0 | 3.2 | 3.2 | 3.6.3 |
| 3.2.1 | 3.2 | 3.2 | 3.6.3 |
| 3.2.3 | 3.2 | 3.2 | 3.6.3 |
| 3.3.1 | 3.3 | 3.3 | 3.6.3 |
inter-broker 프로토콜 버전
Kafka에서broker 간 통신에 사용되는 네트워크 프로토콜을 인스턴스 간 프로토콜 이라고 합니다. Kafka의 각 버전에는broker 간 프로토콜의 호환 버전이 있습니다. 프로토콜의 마이너 버전은 일반적으로 이전 표에 표시된 Kafka의 마이너 버전과 일치하도록 증가합니다.
inter-broker 프로토콜 버전은 Kafka 리소스에서 cluster wide을 설정합니다. 이를 변경하려면 Kafka.spec.kafka.config 에서 inter.broker.protocol.version 속성을 편집합니다.
로그 메시지 형식 버전
생산자가 Kafka 브로커에 메시지를 보내면 특정 형식을 사용하여 메시지가 인코딩됩니다. 형식은 Kafka 릴리스 간에 변경될 수 있으므로 메시지는 인코딩된 메시지 형식의 버전을 지정합니다.
특정 메시지 형식 버전을 설정하는 데 사용되는 속성은 다음과 같습니다.
-
topic의
message.format.version속성 -
Kafka 브로커의
log.message.format.version속성
Kafka 3.0.0에서 메시지 형식 버전 값은 inter.broker.protocol.version 과 일치하는 것으로 간주되며 설정할 필요가 없습니다. 값은 사용된 Kafka 버전을 반영합니다.
Kafka 3.0.0 이상으로 업그레이드할 때 inter.broker.protocol.version 을 업데이트할 때 이러한 설정을 제거할 수 있습니다. 그렇지 않으면 업그레이드할 Kafka 버전에 따라 메시지 형식 버전을 설정합니다.
항목에 대한 message.format.version 의 기본값은 Kafka 브로커에 설정된 log.message.format.version 에 의해 정의됩니다. 주제 구성을 수정하여 topic.version of a topic를 수동으로 설정할 수 있습니다.
10.5.2. 클라이언트 업그레이드 전략
클라이언트 애플리케이션 업그레이드( Kafka Connect 커넥터 포함)에 대한 올바른 방법은 특정 상황에 따라 달라집니다.
애플리케이션 사용에서는 이해할 수 있는 메시지 형식으로 메시지를 수신해야 합니다. 다음 두 가지 방법 중 하나로 이 문제를 방지할 수 있습니다.
- 생산자를 업그레이드하기 전에 항목에 대한 모든 소비자를 업그레이드합니다.
- 브로커를 다운-일치하는 이전 형식으로 메시지를 되돌리도록 합니다.
브로커 다운-conversion을 사용하면 브로커에 추가 로드가 발생하므로 장기간에 걸쳐 모든 주제의 다운 컨버전에 의존하는 것이 이상적이지 않습니다. 브로커가 최적으로 수행되려면 메시지 변환이 중단되어서는 안 됩니다.
broker down-conversion은 다음 두 가지 방법으로 구성됩니다.
-
topic-level
message.format.version은 단일 항목에 대해 구성합니다. -
broker-level
log.message.format.version은 topic-levelmessage.format.version이 구성되지 않은 항목의 기본값입니다.
브로커는 소비자에게 메시지를 수신할 때가 아니라 생산자에서 메시지를 수신할 때 다운버전을 수행하기 때문에 새 버전의 항목에 게시된 메시지가 소비자에게 표시됩니다.
클라이언트를 업그레이드하는 데 사용할 수 있는 일반적인 전략은 다음과 같습니다. 클라이언트 애플리케이션을 업그레이드하기 위한 다른 전략도 가능합니다.
Kafka 3.0.0 이상으로 업그레이드할 때 각 전략에 설명된 단계는 약간 변경됩니다. Kafka 3.0.0에서 메시지 형식 버전 값은 inter.broker.protocol.version 과 일치하는 것으로 간주되며 설정할 필요가 없습니다.
브로커 수준 소비자 첫 번째 전략
- 모든 사용 애플리케이션을 업그레이드합니다.
-
broker-level
log.message.format.version을 새 버전으로 변경합니다. - 모든 생성 애플리케이션을 업그레이드합니다.
이 전략은 간단하며 브로커의 다운스버전을 피할 수 있습니다. 그러나 조직의 모든 소비자는 조정된 방식으로 업그레이드할 수 있으며 소비자와 생산자 둘 다의 애플리케이션에는 작동하지 않는 것으로 가정합니다. 업그레이드된 클라이언트에 문제가 있는 경우 이전 소비자 버전으로 되돌릴 수 없도록 메시지 로그에 새 형식 메시지가 추가될 수도 있습니다.
주제 수준 소비자 첫 번째 전략
각 주제의 경우:
- 모든 사용 애플리케이션을 업그레이드합니다.
-
topic-level
message.format.version을 새 버전으로 변경합니다. - 모든 생성 애플리케이션을 업그레이드합니다.
이 전략은 모든 브로커의 다운-conversion을 피하고, 주제별로 진행할 수 있음을 의미합니다. 소비자와 동일한 주제의 생산자 모두에 해당하는 애플리케이션은 작동하지 않습니다. 다시 말해 업그레이드된 클라이언트에 문제가 있는 경우 새 형식 메시지가 메시지 로그에 추가될 수 있다는 위험이 있습니다.
주제 수준 소비자 첫 번째 전략 다운 변환
각 주제의 경우:
-
topic-level
message.format.version을 이전 버전으로 변경합니다(또는 broker-levellog.message.format.version). - 모든 소비 및 생성 애플리케이션을 업그레이드합니다.
- 업그레이드된 애플리케이션이 제대로 작동하는지 확인합니다.
-
topic-level
message.format.version을 새 버전으로 변경합니다.
이 전략에는 브로커의 다운-conversion이 필요하지만 한 번에 하나의 주제 (또는 소규모 주제 그룹)에만 필요하므로 브로커의 부하가 최소화됩니다. 또한 소비자와 동일한 주제의 생산자 모두에 해당하는 애플리케이션에도 작동합니다. 이 방법을 사용하면 새 메시지 형식 버전을 사용하기 전에 업그레이드된 생산자와 소비자가 제대로 작동하는지 확인합니다.
이 접근 방식의 주요 단점은 많은 주제와 애플리케이션이 있는 클러스터에서 관리하기가 복잡할 수 있다는 것입니다.
또한 여러 전략을 적용할 수 있습니다. 예를 들어 처음 몇 개의 애플리케이션과 주제별로 "분위원별 소비자" 전략을 먼저 사용할 수 있습니다. 이것이 다른 것으로 입증되면 더 효율적인 전략을 대신 사용할 수 있는 것으로 간주할 수 있습니다.
10.5.3. Kafka 버전 및 이미지 매핑
Kafka를 업그레이드할 때 STRIMZI_KAFKA_IMAGES 환경 변수 및 Kafka.spec.kafka.version 속성에 대한 설정을 고려하십시오.
-
각
Kafka리소스는Kafka.spec.kafka.version을 사용하여 구성할 수 있습니다. Cluster Operator의
STRIMZI_KAFKA_IMAGES환경 변수는 Kafka 버전과 해당 버전이 지정된Kafka리소스에서 요청할 때 사용할 이미지 간 매핑을 제공합니다.-
Kafka.spec.kafka.image가 구성되지 않은 경우 지정된 버전의 기본 이미지가 사용됩니다. -
Kafka.spec.kafka.image가 구성된 경우 기본 이미지가 재정의됩니다.
-
Cluster Operator는 이미지에 실제로 예상 버전의 Kafka 브로커가 포함되어 있는지 확인할 수 없습니다. 지정된 이미지가 지정된 Kafka 버전에 해당하는지 확인합니다.
10.5.4. Kafka 브로커 및 클라이언트 애플리케이션 업그레이드
AMQ Streams Kafka 클러스터를 지원되는 최신 Kafka 버전 및 broker 간 프로토콜 버전으로 업그레이드합니다.
또한 클라이언트 업그레이드를 위한 전략을 선택해야 합니다. Kafka 클라이언트는 이 절차의 6단계에서 업그레이드됩니다.
사전 요구 사항
- Cluster Operator가 실행 중입니다.
-
AMQ Streams Kafka 클러스터를 업그레이드하기 전에 Kafka 리소스의
Kafka.spec.kafka.config속성에 새Kafka버전에서 지원되지 않는 설정 옵션이 포함되어 있지 않은지 확인합니다.
절차
Kafka 클러스터 구성을 업데이트합니다.
oc edit kafka <my_cluster>구성된 경우
inter.broker.protocol.version및log.message.format.version속성이 현재 버전으로 설정되어 있는지 확인합니다.예를 들어 Kafka 버전 3.2.3에서 3.3.1로 업그레이드하는 경우 현재 버전은 3.2입니다.
kind: Kafka spec: # ... kafka: version: 3.2.3 config: log.message.format.version: "3.2" inter.broker.protocol.version: "3.2" # ...log.message.format.version및inter.broker.protocol.version이 구성되지 않은 경우 AMQ Streams는 다음 단계에서 Kafka 버전으로 업데이트한 후 이러한 버전을 현재 기본값으로 자동으로 업데이트합니다.참고log.message.format.version및inter.broker.protocol.version의 값은 해당 값이 부동 소수점 숫자로 해석되지 않도록 문자열이어야 합니다.Kafka.spec.kafka.version을 변경하여 새 Kafka 버전을 지정합니다. 현재 Kafka 버전의 기본값으로log.message.format.version및inter.broker.protocol.version을 그대로 둡니다.참고kafka.version을 변경하면 클러스터의 모든 브로커가 새 브로커 바이너리를 사용하도록 업그레이드됩니다. 이 프로세스 중에 일부 브로커는 이전 바이너리를 사용하고 다른 브로커는 이미 새 바이너리로 업그레이드 중입니다. 현재 설정을 변경하지 않고inter.broker.protocol.version을 남겨 두면 브로커가 업그레이드 중에 서로 계속 통신할 수 있습니다.예를 들어 Kafka 3.2.3에서 3.3.1로 업그레이드하는 경우 다음을 수행합니다.
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 1 config: log.message.format.version: "3.2" 2 inter.broker.protocol.version: "3.2" 3 # ...주의새 Kafka 버전의
inter.broker.protocol.version이 변경되면 Kafka를 다운그레이드할 수 없습니다. The inter-broker protocol version determines the schemas used for persistent metadata stored by the broker, including messages written to__consumer_offsets. 다운그레이드된 클러스터는 메시지를 이해할 수 없습니다.Kafka 클러스터의 이미지가 Kafka 사용자 정의 리소스인
Kafka.spec.kafka.에 정의된 경우 새 Kafka 버전이 있는 컨테이너 이미지를 가리키도록 이미지를 업데이트합니다.image편집기를 저장하고 종료한 다음 롤링 업데이트가 완료될 때까지 기다립니다.
Pod 상태 전환을 확인하여 롤링 업데이트의 진행 상황을 확인합니다.
oc get pods my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'롤링 업데이트를 통해 각 Pod가 새 Kafka 버전에 브로커 바이너리를 사용하고 있는지 확인합니다.
클라이언트 업그레이드를 위한 선택한 전략에 따라 모든 클라이언트 애플리케이션을 업그레이드하여 새 버전의 클라이언트 바이너리를 사용합니다.
필요한 경우 Kafka Connect 및 MirrorMaker의
version속성을 Kafka의 새 버전으로 설정합니다.-
Kafka Connect의 경우
KafkaConnect.spec.version을 업데이트합니다. -
MirrorMaker의 경우
KafkaMirrorMaker.spec.version을 업데이트합니다. -
MirrorMaker 2.0의 경우
KafkaMirrorMaker2.spec.version을 업데이트합니다.
-
Kafka Connect의 경우
구성된 경우 새
inter.broker.protocol.version버전을 사용하도록 Kafka 리소스를 업데이트합니다. 그렇지 않으면 9 단계로 이동합니다.예를 들어 Kafka 3.3.1로 업그레이드하는 경우 다음을 수행합니다.
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 config: log.message.format.version: "3.2" inter.broker.protocol.version: "3.3" # ...- Cluster Operator가 클러스터를 업데이트할 때까지 기다립니다.
구성된 경우 새
log.message.format.version버전을 사용하도록 Kafka 리소스를 업데이트합니다. 그렇지 않으면 10 단계로 이동합니다.예를 들어 Kafka 3.3.1로 업그레이드하는 경우 다음을 수행합니다.
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.3.1 config: log.message.format.version: "3.3" inter.broker.protocol.version: "3.3" # ...중요Kafka 3.0.0에서
inter.broker.protocol.version이3.0이상으로 설정되면log.message.format.version옵션이 무시되고 설정할 필요가 없습니다.Cluster Operator가 클러스터를 업데이트할 때까지 기다립니다.
- Kafka 클러스터 및 클라이언트는 이제 새 Kafka 버전을 사용합니다.
- 브로커는 inter-broker 프로토콜 버전과 Kafka의 새 버전의 메시지 형식 버전을 사용하여 메시지를 전송하도록 구성됩니다.
필요한 경우 Kafka 업그레이드 후 증분 협력 재조정 프로토콜을 사용하도록 소비자를 업그레이드 할 수 있습니다.
10.6. 소비자를 협업 재조정으로 업그레이드
Kafka 소비자 및 Kafka Streams 애플리케이션을 업그레이드하여 기본 성능 재조정 프로토콜 대신 파티션 재조정에 증분 협업 재조정 프로토콜을 사용할 수 있습니다. 새 프로토콜은 Kafka 2.4.0에 추가되었습니다.
소비자는 파티션 할당을 협력적인 리밸런스(cooperative rebalance)로 유지하고, 균형 잡힌 클러스터를 달성하는 데 필요한 경우 프로세스의 마지막에만 파티션 할당을 취소합니다. 이렇게 하면 소비자 그룹 또는 Kafka Streams 애플리케이션의 사용할 수 없게 됩니다.
증분 협업 재조정 프로토콜로 업그레이드하는 것은 선택 사항입니다. eager rebalance 프로토콜은 계속 지원됩니다.
사전 요구 사항
절차
증분 협업 재조정 프로토콜을 사용하도록 Kafka 소비자를 업그레이드하려면 다음을 수행합니다.
-
Kafka 클라이언트
.jar파일을 새 버전으로 교체합니다. -
소비자 구성에서
파티션.assignment.strategy에cooperative-sticky를 추가합니다. 예를 들어범위전략이 설정된 경우 구성을cooperative-sticky로 변경합니다. - 그룹의 각 소비자를 차례로 재시작하고 사용자가 다시 시작한 후 그룹에 다시 참여할 때까지 기다립니다.
-
소비자 구성에서 이전
partition.assignment.strategy를 제거하여 그룹의 각 소비자를 재구성하고cooperative-sticky전략만 남습니다. - 그룹의 각 소비자를 차례로 재시작하고 사용자가 다시 시작한 후 그룹에 다시 참여할 때까지 기다립니다.
증분 공동 조정 프로토콜을 사용하도록 Kafka Streams 애플리케이션을 업그레이드하려면 다음을 수행합니다.
-
Kafka Streams
.jar파일을 새 버전으로 교체합니다. -
Kafka Streams 구성에서
upgrade.from구성 매개변수를 업그레이드 중인 Kafka 버전(예: 2.3)으로 설정합니다. - 각 스트림 프로세서(노드)를 차례로 다시 시작합니다.
-
Kafka Streams 구성에서
upgrade.from구성 매개변수를 제거합니다. - 그룹의 각 소비자를 차례로 다시 시작합니다.
11장. AMQ Streams 다운그레이드
업그레이드한 AMQ Streams 버전에 문제가 발생하면 이전 버전으로 설치를 되돌릴 수 있습니다.
YAML 설치 파일을 사용하여 AMQ Streams를 설치한 경우 이전 릴리스의 YAML 설치 파일을 사용하여 다음 다운그레이드 절차를 수행할 수 있습니다.
이전 AMQ Streams 버전이 사용 중인 Kafka 버전을 지원하지 않는 경우 메시지에 추가된 로그 메시지 형식 버전이 일치하는 경우 Kafka를 다운그레이드할 수도 있습니다.
다른 설치 방법을 사용하여 AMQ Streams를 배포한 경우 지원되는 방법을 사용하여 AMQ Streams 다운그레이드를 줄입니다. 여기에 제공된 지침을 사용하지 마십시오. 예를 들어 OLM(Operator Lifecycle Manager)을 사용하여 AMQ Streams를 설치한 경우 배포 채널을 이전 버전의 AMQ Streams로 변경하여 다운그레이드할 수 있습니다.
11.1. Cluster Operator를 이전 버전으로 다운그레이드
AMQ Streams에 문제가 발생하면 설치를 되돌릴 수 있습니다.
다음 절차에서는 Cluster Operator 배포를 이전 버전으로 다운그레이드하는 방법을 설명합니다.
사전 요구 사항
- 기존 Cluster Operator 배포를 사용할 수 있습니다.
- 이전 버전의 설치 파일을 다운로드 했습니다.
절차
-
기존 Cluster Operator 리소스(
/install/cluster-operator디렉터리)에 대한 구성 변경 사항을 기록해 두십시오. 이전 버전의 Cluster Operator에서 모든 변경 사항을 덮어씁니다. - 사용자 정의 리소스를 복원하여 다운그레이드 중인 AMQ Streams 버전에 지원되는 구성 옵션을 반영합니다.
Cluster Operator를 업데이트합니다.
Cluster Operator가 실행 중인 네임스페이스에 따라 이전 버전의 설치 파일을 수정합니다.
Linux에서 다음을 사용합니다.
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
MacOS에서 다음을 사용합니다.
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml
-
기존 Cluster Operator
Deployment에서 하나 이상의 환경 변수를 수정한 경우install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml파일을 편집하여 해당 환경 변수를 사용합니다.
업데이트된 구성이 있는 경우 나머지 설치 리소스와 함께 배포합니다.
oc replace -f install/cluster-operator
롤링 업데이트가 완료될 때까지 기다립니다.
Kafka Pod의 이미지를 가져와서 다운그레이드에 성공했는지 확인합니다.
oc get pod my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'이미지 태그는 새 AMQ Streams 버전과 Kafka 버전을 표시합니다. 예를 들어
NEW-STRIMZI-VERSION-kafka-CURRENT-KAFKA-VERSION입니다.
Cluster Operator가 이전 버전으로 다운그레이드되었습니다.
11.2. Kafka 다운그레이드
Kafka 버전 다운그레이드는 Cluster Operator에서 수행합니다.
11.2.1. 다운그레이드에 대한 Kafka 버전 호환성
Kafka 다운그레이드는 호환 현재 및 대상 Kafka 버전 및 메시지가 기록된 상태에 따라 달라집니다.
해당 버전이 해당 클러스터에서 사용된 inter.broker.protocol.version 설정을 지원하지 않는 경우 이전 Kafka 버전으로 되돌리거나 최신 log.message.format.version 을 사용하는 메시지 로그에 메시지가 추가되었습니다.
inter.broker.protocol.version 은 __consumer_offsets 에 기록된 메시지의 스키마와 같이 브로커가 저장한 영구 메타데이터에 사용되는 스키마를 결정합니다. 클러스터에서 이전에 사용된 inter.broker.protocol.version 을 이해하지 못하는 Kafka 버전으로 다운그레이드하면 브로커에서 이해할 수 없는 데이터가 발생합니다.
Kafka의 대상 다운그레이드 버전에는 다음을 수행합니다.
-
현재 버전과 동일한
log.message.format.version과 동일한 경우 브로커의 단일 롤링 재시작을 수행하여 Cluster Operator가 다운그레이드됩니다. 다른
log.message.format.version, downgrading은 실행중인 클러스터에 항상log.message.format.version이 downgraded 버전에서 사용하는 버전으로 설정된 경우에만 가능합니다. 일반적으로log.message.format.version이 변경되기 전에 업그레이드 절차가 중단된 경우에만 해당합니다. 이 경우 다운그레이드에는 다음이 필요합니다.- 두 버전의 interbroker 프로토콜이 다른 경우 브로커의 롤링 재시작 두 개
- 동일한 경우 단일 롤링 재시작
새 버전이 log.message.format.version 의 기본값을 사용하는 경우를 포함하여 이전 버전에서 지원하지 않는 log.message.format.version 을 사용한 경우 다운그레이딩이 불가능합니다. 예를 들어 log.message.format.version 이 변경되지 않았기 때문에 이 리소스는 Kafka 버전 3.2.3으로 다운그레이드될 수 있습니다.
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
spec:
# ...
kafka:
version: 3.3.1
config:
log.message.format.version: "3.2"
# ...
log.message.format.version 을 "3.3" 에 설정하거나 값이 없는 경우 다운그레이드가 3.3의 3.3.1 브로커에 대한 기본값을 가져오도록 할 수 없습니다.
Kafka 3.0.0에서 inter.broker.protocol.version 이 3.0 이상으로 설정되면 log.message.format.version 옵션이 무시되고 설정할 필요가 없습니다.
11.2.2. Kafka 브로커 및 클라이언트 애플리케이션 다운그레이드
AMQ Streams Kafka 클러스터를 3.3.1에서 3.2.3으로 다운그레이드하는 등 더 낮은 Kafka 버전으로 다운그레이드합니다.
사전 요구 사항
- Cluster Operator가 실행 중입니다.
AMQ Streams Kafka 클러스터를 다운그레이드하기 전에
Kafka리소스에 대해 다음을 확인합니다.- 중요: Kafka 버전의 호환성.
-
Kafka.spec.kafka.config에는 다운그레이드된 Kafka 버전에서 지원하지 않는 옵션이 포함되어 있지 않습니다. Kafka.spec.kafka.config에는log.message.format.version및inter.broker.protocol.version이 있습니다. 이 버전은 다운그레이드된 Kafka 버전에서 지원합니다.Kafka 3.0.0에서
inter.broker.protocol.version이3.0이상으로 설정되면log.message.format.version옵션이 무시되고 설정할 필요가 없습니다.
절차
Kafka 클러스터 구성을 업데이트합니다.
oc edit kafka KAFKA-CONFIGURATION-FILEKafka.spec.kafka.version을 변경하여 이전 버전을 지정합니다.예를 들어 Kafka 3.3.1에서 3.2.3으로 다운그레이드하는 경우:
apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka spec: # ... kafka: version: 3.2.3 1 config: log.message.format.version: "3.2" 2 inter.broker.protocol.version: "3.2" 3 # ...참고log.message.format.version및inter.broker.protocol.version의 값은 해당 값이 부동 소수점 숫자로 해석되지 않도록 문자열이어야 합니다.Kafka 버전의 이미지가 Cluster Operator의
STRIMZI_KAFKA_IMAGES에 정의된 이미지와 다른 경우Kafka.spec.kafka.image를 업데이트합니다.편집기를 저장하고 종료한 다음 롤링 업데이트가 완료될 때까지 기다립니다.
로그 또는 Pod 상태 전환을 확인하여 업데이트를 확인합니다.
oc logs -f CLUSTER-OPERATOR-POD-NAME | grep -E "Kafka version downgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"oc get pod -w
INFO수준 메시지가 있는지 Cluster Operator 로그를 확인합니다.Reconciliation #NUM(watch) Kafka(NAMESPACE/NAME): Kafka version downgrade from FROM-VERSION to TO-VERSION, phase 1 of 1 completed
이전 버전의 클라이언트 바이너리를 사용하도록 모든 클라이언트 애플리케이션(소유자)을 다운그레이드합니다.
Kafka 클러스터 및 클라이언트는 이제 이전 Kafka 버전을 사용합니다.
주제 메타데이터 스토리지에 ZooKeeper를 사용하는 1.7 이전의 AMQ Streams 버전으로 되돌리는 경우 Kafka 클러스터에서 내부 주제 저장소 주제를 삭제합니다.
oc run kafka-admin -ti --image=registry.redhat.io/amq7/amq-streams-kafka-33-rhel8:2.3.0 --rm=true --restart=Never -- ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic __strimzi-topic-operator-kstreams-topic-store-changelog --delete && ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --topic __strimzi_store_topic --delete
추가 리소스
12장. Kafka 재시작에 대한 정보 검색
Cluster Operator는 OpenShift 클러스터에서 Kafka Pod를 다시 시작한 후 Pod가 재시작되는 이유를 설명하는 Pod의 네임스페이스로 OpenShift 이벤트를 내보냅니다. 클러스터 동작을 이해하는 데 도움이 필요한 경우 명령줄에서 재시작 이벤트를 확인할 수 있습니다.
Prometheus와 같은 메트릭 수집 툴을 사용하여 재시작 이벤트를 내보내고 모니터링할 수 있습니다. 출력을 적절한 형식으로 내보낼 수 있는 이벤트 내보내기와 함께 메트릭 툴을 사용합니다.
12.1. 재시작 이벤트의 이유
Cluster Operator는 특정 이유로 재시작 이벤트를 시작합니다. 재시작 이벤트에 대한 정보를 가져와서 이유를 확인할 수 있습니다.
지정된 이유는 Pod 생성 및 관리에 StrimziPodSet 또는 StatefulSet 리소스를 사용 중인지 여부에 따라 달라집니다.
표 12.1. 재시작 이유
| StrimziPodSet | StatefulSet | 설명 |
|---|---|---|
| CaCertHasOldGeneration | CaCertHasOldGeneration | Pod는 여전히 이전 CA로 서명된 서버 인증서를 사용하고 있으므로 인증서 업데이트의 일부로 다시 시작해야 합니다. |
| CaCertRemoved | CaCertRemoved | 만료된 CA 인증서가 제거되었으며 Pod가 현재 인증서와 함께 실행되도록 다시 시작됩니다. |
| CaCertRenewed | CaCertRenewed | CA 인증서가 갱신되었으며 Pod가 업데이트된 인증서와 함께 실행되도록 다시 시작됩니다. |
| ClientCaCertKeyReplaced | ClientCaCertKeyReplaced | 클라이언트 CA 인증서에 서명하는 데 사용된 키가 교체되었으며 CA 갱신 프로세스의 일부로 Pod가 다시 시작됩니다. |
| ClusterCaCertKeyReplaced | ClusterCaCertKeyReplaced | 클러스터의 CA 인증서에 서명하는 데 사용된 키가 교체되었으며 CA 갱신 프로세스의 일부로 Pod가 재시작됩니다. |
| ConfigChangeRequiresRestart | ConfigChangeRequiresRestart | 일부 Kafka 구성 속성은 동적으로 변경되지만 다른 값은 브로커를 다시 시작해야 합니다. |
| CustomListenerCaCertChanged | CustomListenerCaCertChanged | Kafka 네트워크 리스너를 보호하는 데 사용되는 CA 인증서가 변경되었으며 이를 사용하도록 Pod가 다시 시작됩니다. |
| FileSystemResizeNeeded | FileSystemResizeNeeded | 파일 시스템 크기가 증가하고 이를 적용하려면 다시 시작해야 합니다. |
| KafkaCertificatesChanged | KafkaCertificatesChanged | Kafka 브로커가 사용하는 하나 이상의 TLS 인증서가 업데이트되었으며 이를 사용하려면 재시작이 필요합니다. |
| ManualRollingUpdate | ManualRollingUpdate |
재시작을 트리거하기 위해 Pod 또는 |
| PodForceRestartOnError | PodForceRestartOnError | Pod를 다시 시작하여 수정해야 하는 오류가 발생했습니다. |
| PodHasOldRevision | JbodVolumesChanged |
Kafka 볼륨에서 디스크가 추가 또는 제거되었으며 변경 사항을 적용하려면 재시작이 필요합니다. |
| PodHasOldRevision | PodHasOldGeneration |
Pod가 의 멤버인 |
| PodStuck | PodStuck | Pod는 여전히 보류 중이며 예약되지 않았거나 예약할 수 없으므로 Operator에서 Pod를 마지막 시도에서 재시작했습니다. |
| PodUnresponsive | PodUnresponsive | AMQ Streams는 Pod에 연결할 수 없어 브로커가 올바르게 시작되지 않음을 나타낼 수 있으므로 Operator에서 문제를 해결하려고 시도합니다. |
12.2. 이벤트 필터 재시작
명령줄에서 재시작 이벤트를 확인할 때 OpenShift 이벤트 필드에서 필터링할 필드 선택기 를 지정할 수 있습니다.
필드 선택기로 이벤트를 필터링하는 경우 다음 필드 를 사용할 수 있습니다.
regardingObject.kind-
다시 시작한 오브젝트와 재시작 이벤트의 경우 kind는 항상
Pod입니다. regarding.namespace- Pod가 속한 네임스페이스입니다.
regardingObject.name-
Pod의 이름입니다(예:
strimzi-cluster-kafka-0). regardingObject.uid- Pod의 고유 ID입니다.
reason-
pod가 재시작된 이유(예:
JbodVolumesChanged). reportingController-
보고 구성 요소는 항상 AMQ Streams 재시작 이벤트용으로
strimzi.io/cluster-operator입니다. source-
Source는reportingController의 이전 버전입니다. 보고 구성 요소는 항상 AMQ Streams 재시작 이벤트용으로strimzi.io/cluster-operator입니다. type-
Warning또는Normal인 이벤트 유형입니다. AMQ Streams 재시작 이벤트의 경우 유형은Normal입니다.
이전 버전의 OpenShift에서는 접두사를 사용하는 필드에 대신 involvedObject 접두사가 사용될 수 있습니다. reportingController 는 이전에 reportingComponent 라고 했습니다.
12.3. Kafka 재시작 확인
oc 명령을 사용하여 Cluster Operator에서 시작한 재시작 이벤트를 나열합니다. reportingController 또는 소스 이벤트 필드를 사용하여 Cluster Operator를 보고 구성 요소로 설정하여 Cluster Operator에서 내보내는 재시작 이벤트를 필터링합니다.
사전 요구 사항
- Cluster Operator가 OpenShift 클러스터에서 실행 중입니다.
절차
Cluster Operator가 내보내는 모든 재시작 이벤트를 가져옵니다.
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator
반환된 이벤트 표시 예
LAST SEEN TYPE REASON OBJECT MESSAGE 2m Normal CaCertRenewed pod/strimzi-cluster-kafka-0 CA certificate renewed 58m Normal PodForceRestartOnError pod/strimzi-cluster-kafka-1 Pod needs to be forcibly restarted due to an error 5m47s Normal ManualRollingUpdate pod/strimzi-cluster-kafka-2 Pod was manually annotated to be rolled
반환된 이벤트를 제한하기 위해
이유또는 기타필드 선택기옵션을 지정할 수도 있습니다.여기에는 구체적인 이유가 추가되었습니다.
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator,reason=PodForceRestartOnError
YAML과 같은 출력 형식을 사용하여 하나 이상의 이벤트에 대한 자세한 정보를 반환합니다.
oc -n kafka get events --field-selector reportingController=strimzi.io/cluster-operator,reason=PodForceRestartOnError -o yaml
자세한 이벤트 출력 예
apiVersion: v1 items: - action: StrimziInitiatedPodRestart apiVersion: v1 eventTime: "2022-05-13T00:22:34.168086Z" firstTimestamp: null involvedObject: kind: Pod name: strimzi-cluster-kafka-1 namespace: kafka kind: Event lastTimestamp: null message: Pod needs to be forcibly restarted due to an error metadata: creationTimestamp: "2022-05-13T00:22:34Z" generateName: strimzi-event name: strimzi-eventwppk6 namespace: kafka resourceVersion: "432961" uid: 29fcdb9e-f2cf-4c95-a165-a5efcd48edfc reason: PodForceRestartOnError reportingController: strimzi.io/cluster-operator reportingInstance: strimzi-cluster-operator-6458cfb4c6-6bpdp source: {} type: Normal kind: List metadata: resourceVersion: "" selfLink: ""
다음 필드는 더 이상 사용되지 않으므로 이러한 이벤트에는 채워지지 않습니다.
-
firstTimestamp -
lastTimestamp -
source
13장. AMQ Streams 설치 제거
OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OperatorHub에서 OpenShift 4.8에서 4.12로 AMQ Streams를 설치 제거할 수 있습니다.
AMQ Streams를 설치하는 데 사용한 것과 동일한 방법을 사용합니다.
AMQ Streams를 설치 제거할 때 배포용으로 특별히 생성된 리소스를 식별하고 AMQ Streams 리소스에서 참조해야 합니다.
이러한 리소스는 다음과 같습니다.
- 보안(사용자 정의 CA 및 인증서, Kafka Connect 시크릿 및 기타 Kafka 시크릿)
-
로깅
ConfigMaps(외부유형의 경우)
Kafka , ,Kafka ConnectKafkaMirrorMaker 또는 KafkaBridge 구성에서 참조하는 리소스입니다.
CustomResourceDefinitions 를 삭제하면 해당 사용자 정의 리소스(Kafka,KafkaConnect,KafkaMirrorMaker 또는 KafkaBridge)와 해당 리소스에 종속된 리소스(Deployments, StatefulSets 및 기타 종속 리소스)의 가비지 컬렉션이 생성됩니다.
13.1. 웹 콘솔을 사용하여 OperatorHub에서 AMQ Streams 설치 제거
다음 절차에서는 OperatorHub에서 AMQ Streams를 제거하고 배포와 관련된 리소스를 제거하는 방법을 설명합니다.
콘솔에서 단계를 수행하거나 대체 CLI 명령을 사용할 수 있습니다.
사전 요구 사항
-
cluster-admin또는strimzi-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 웹 콘솔에 액세스합니다. 삭제할 리소스를 식별했습니다.
다음
ocCLI 명령을 사용하여 리소스를 찾고 AMQ Streams를 제거할 때 해당 리소스가 제거되었는지 확인할 수도 있습니다.AMQ Streams 배포와 관련된 리소스를 찾는 명령
oc get <resource_type> --all-namespaces | grep <kafka_cluster_name>
& lt;resource_type >을 검사 중인 리소스 유형(예:
secret또는configmap)으로 바꿉니다.
절차
- OpenShift 웹 콘솔에서 Operator > 설치된 Operator로 이동합니다.
설치된 Red Hat Integration - AMQ Streams operator의 경우 옵션 아이콘(세 개의 수직점)을 선택하고 Uninstall Operator 를 클릭합니다.
Operator는 설치된 Operator에서 제거됩니다.
- 홈 > 프로젝트로 이동하여 AMQ Streams 및 Kafka 구성 요소를 설치한 프로젝트를 선택합니다.
인벤토리 아래의 옵션을 클릭하여 관련 리소스를 삭제합니다.
리소스는 다음과 같습니다.
- 배포
- StatefulSets
- Pods
- 서비스
- ConfigMaps
- 보안
작은 정보검색을 사용하여 Kafka 클러스터의 이름으로 시작하는 관련 리소스를 찾습니다. 워크로드에서 리소스를 찾을 수도 있습니다.
대체 CLI 명령
CLI 명령을 사용하여 OperatorHub에서 AMQ Streams를 제거할 수 있습니다.
AMQ Streams 서브스크립션을 삭제합니다.
oc delete subscription amq-streams -n openshift-operators
CSV(클러스터 서비스 버전)를 삭제합니다.
oc delete csv amqstreams.<version> -n openshift-operators관련 CRD를 제거합니다.
oc get crd -l app=strimzi -o name | xargs oc delete
13.2. CLI를 사용하여 AMQ Streams 설치 제거
다음 절차에서는 oc 명령줄 툴을 사용하여 AMQ Streams를 제거하고 배포와 관련된 리소스를 제거하는 방법을 설명합니다.
사전 요구 사항
-
cluster-admin또는strimzi-admin권한이 있는 계정을 사용하여 OpenShift 클러스터에 액세스할 수 있습니다. 삭제할 리소스를 식별했습니다.
다음
ocCLI 명령을 사용하여 리소스를 찾고 AMQ Streams를 제거할 때 해당 리소스가 제거되었는지 확인할 수도 있습니다.AMQ Streams 배포와 관련된 리소스를 찾는 명령
oc get <resource_type> --all-namespaces | grep <kafka_cluster_name>
& lt;resource_type >을 검사 중인 리소스 유형(예:
secret또는configmap)으로 바꿉니다.
절차
Cluster Operator
배포, 관련CustomResourceDefinitions,RBAC리소스를 삭제합니다.Cluster Operator를 배포하는 데 사용되는 설치 파일을 지정합니다.
oc delete -f install/cluster-operator
사전 요구 사항에서 식별한 리소스를 삭제합니다.
oc delete <resource_type> <resource_name> -n <namespace>
& lt;resource_type >을 삭제한 리소스 유형으로 바꾸고 < resource_name >을 리소스 이름으로 바꿉니다.
시크릿 삭제 예
oc delete secret my-cluster-clients-ca -n my-project
14장. AMQ Streams에서 미터링 사용
OpenShift에서 사용할 수 있는 미터링 툴을 사용하여 다양한 데이터 소스에서 미터링 보고서를 생성할 수 있습니다. 클러스터 관리자는 미터링을 사용하여 클러스터에서 발생하는 상황을 분석할 수 있습니다. 자체적으로 작성하거나 사전 정의된 SQL 쿼리를 사용하여 사용 가능한 다양한 데이터 소스에서 데이터를 처리하는 방법을 정의할 수 있습니다. Prometheus를 기본 데이터 소스로 사용하여 Pod, 네임스페이스 및 대부분의 기타 OpenShift 리소스에 대한 보고서를 생성할 수 있습니다.
OpenShift Metering Operator를 사용하여 설치된 AMQ Streams 구성 요소를 분석하여 Red Hat 서브스크립션을 준수하는지 여부를 확인할 수도 있습니다.
AMQ Streams에서 미터링을 사용하려면 먼저 OpenShift Container Platform에 Metering Operator 를 설치하고 구성해야 합니다.
14.1. 미터링 리소스
미터링에는 많은 리소스가 있으며, 기능 미터링을 보고하는 기능과 함께 미터링 배포 및 설치를 관리하는 데 사용할 수 있습니다. 미터링은 다음 CRD를 사용하여 관리합니다.
표 14.1. 미터링 리소스
| 이름 | 설명 |
|---|---|
|
| 배포에 대해 미터링 스택을 구성합니다. 미터링 스택을 구성하는 각 구성 요소를 제어하기 위한 사용자 정의 및 구성 옵션이 포함되어 있습니다. |
|
| 사용할 쿼리, 쿼리를 실행할 빈도 및 결과를 저장할 위치를 제어합니다. |
|
|
|
|
| ReportQueries 및 Reports에서 사용할 수 있는 데이터를 제어합니다. 미터링 내에서 사용할 수 있도록 다양한 데이터베이스에 대한 액세스를 구성할 수 있습니다. |
14.2. AMQ Streams의 미터링 라벨
다음 표에는 AMQ Streams 인프라 구성 요소 및 통합의 미터링 라벨이 나열되어 있습니다.
표 14.2. 미터링 라벨
| 레이블 | 가능한 값 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 인프라
|
| 애플리케이션
| |
|
|
|
예
인프라 예(인프라 구성 요소가 entity-operator임)
com.company=Red_Hat rht.prod_name=Red_Hat_Application_Foundations rht.prod_ver=2023.Q1 rht.comp=AMQ_Streams rht.comp_ver=2.3 rht.subcomp=entity-operator rht.comp_t=infrastructure
애플리케이션 예(통합 배포 이름이 kafka-bridge임)
com.company=Red_Hat rht.prod_name=Red_Hat_Application_Foundations rht.prod_ver=2023.Q1 rht.comp=AMQ_Streams rht.comp_ver=2.3 rht.subcomp=kafka-bridge rht.comp_t=application
부록 A. 서브스크립션 사용
AMQ Streams는 소프트웨어 서브스크립션을 통해 제공됩니다. 서브스크립션을 관리하려면 Red Hat 고객 포털에서 계정에 액세스하십시오.
귀하의 계정에 액세스
- access.redhat.com 으로 이동합니다.
- 아직 계정이 없는 경우 계정을 생성합니다.
- 계정에 로그인합니다.
서브스크립션 활성화
- access.redhat.com 으로 이동합니다.
- 내 서브스크립션으로 이동합니다.
- 서브스크립션을 활성화하여 16자리 활성화 번호를 입력합니다.
Zip 및 Tar 파일 다운로드
zip 또는 tar 파일에 액세스하려면 고객 포털을 사용하여 다운로드할 관련 파일을 찾습니다. RPM 패키지를 사용하는 경우에는 이 단계가 필요하지 않습니다.
- 브라우저를 열고 access.redhat.com/downloads 에서 Red Hat 고객 포털 제품 다운로드 페이지에 로그인합니다.
- INTEGRAT ION 및 AUTOMATION 카테고리에서 Apache Kafka의 AMQ Streams 를 찾습니다.
- 원하는 AMQ Streams 제품을 선택합니다. Software Download 페이지가 열립니다.
- 구성 요소에 대한 다운로드 링크를 클릭합니다.
DNF로 패키지 설치
패키지 및 모든 패키지 종속 항목을 설치하려면 다음을 사용합니다.
dnf install <package_name>로컬 디렉터리에서 이전에 다운로드한 패키지를 설치하려면 다음을 사용합니다.
dnf install <path_to_download_package>2023-04-06에 최종 업데이트된 문서