
Chapter 1. Red Hat JBoss Data Grid
1.1. Red Hat JBoss Data Grid
Red Hat JBoss Data Grid is a distributed in-memory data grid, which provides the following capabilities:
- Schemaless key-value store – JBoss Data Grid is a NoSQL database that provides the flexibility to store different objects without a fixed data model.
- Grid-based data storage – JBoss Data Grid is designed to easily replicate data across multiple nodes.
- Elastic scaling – Adding and removing nodes is simple and non-disruptive.
- Multiple access protocols – It is easy to access the data grid using REST, Memcached, Hot Rod, or simple map-like API.
1.2. Supported Configurations
The set of supported features, configurations, and integrations for Red Hat JBoss Data Grid (current and past versions) are available at the Supported Configurations page at https://access.redhat.com/articles/115883.
1.3. Components and Versions
Red Hat JBoss Data Grid includes many components for Library and Remote Client-Server modes. A comprehensive (and up to date) list of components included in each of these usage modes and their versions is available in the Red Hat JBoss Data Grid Component Details page at https://access.redhat.com/articles/488833
1.4. Red Hat JBoss Data Grid Usage Modes
1.4.1. Red Hat JBoss Data Grid Usage Modes
Red Hat JBoss Data Grid offers two usage modes:
- Remote Client-Server mode
- Library mode
1.4.2. Remote Client-Server Mode
Remote Client-Server mode provides a managed, distributed, and clusterable data grid server. In Client-Server mode the server runs as a self-contained process, utilizing a container based on JBoss EAP, allowing client applications to remotely access the data grid server using Hot Rod, Memcached or REST client APIs.
All Red Hat JBoss Data Grid operations in Remote Client-Server mode are non-transactional. As a result, a number of features cannot be performed when running JBoss Data Grid in Remote Client-Server mode.
There are a number of benefits to running JBoss Data Grid in Remote Client-Server mode if Library mode features are not required. Remote Client-Server mode is client language agnostic, provided there is a client library for your chosen protocol. As a result, Remote Client-Server mode provides:
- easier scaling of the data grid.
- easier upgrades of the data grid without impact on client applications.
Run the following commands to start a standalone JBoss Data Grid instance in Remote Client-Server mode.
For Linux:
$JBOSS_HOME/bin/standalone.sh
For Windows:
$JBOSS_HOME\bin\standalone.bat
Run the following commands to start a managed domain JBoss Data Grid instance in Remote Client-Server mode.
For Linux:
$JBOSS_HOME/bin/domain.sh
For Windows:
$JBOSS_HOME\bin\domain.bat
1.4.3. Library Mode
Library mode allows building and deploying a custom runtime environment. The Library mode hosts a single data grid node in the applications process, with remote access to nodes hosted in other JVMs. Tested containers for Red Hat JBoss Data Grid Library mode includes Red Hat JBoss Enterprise Web Server 2.x and JBoss Enterprise Application Platform 7.x.
A number of features in JBoss Data Grid can be used in Library mode, but not in Remote Client-Server mode.
The following features require Library mode:
- transactions
- listeners and notifications
JBoss Data Grid can also be run as a standalone application in Java SE. Standalone mode is a supported alternative to running JBoss Data Grid in a container.
1.5. Red Hat JBoss Data Grid Benefits
Red Hat JBoss Data Grid provides the following benefits:
Benefits of JBoss Data Grid
- Performance
- Accessing objects from local memory is faster than accessing objects from remote data stores (such as a database). JBoss Data Grid provides an efficient way to store in-memory objects coming from a slower data source, resulting in faster performance than a remote data store. JBoss Data Grid also offers optimization for both clustered and non clustered caches to further improve performance.
- Consistency
- Storing data in a cache carries the inherent risk: at the time it is accessed, the data may be outdated (stale). To address this risk, JBoss Data Grid uses mechanisms such as cache invalidation and expiration to remove stale data entries from the cache. Additionally, JBoss Data Grid supports JTA, distributed (XA) and two-phase commit transactions along with transaction recovery and a version API to remove or replace data according to saved versions.
- Massive Heap and High Availability
- In JBoss Data Grid, applications no longer need to delegate the majority of their data lookup processes to a large single server database for performance benefits. JBoss Data Grid employs techniques such as replication and distribution to completely remove the bottleneck that exists in the majority of current enterprise applications.
Massive Heap and High Availability Example
In a sample grid with 16 blade servers, each node has 2 GB storage space dedicated for a replicated cache. In this case, all the data in the grid is copies of the 2 GB data. In contrast, using a distributed grid (assuming the requirement of one copy per data item, resulting in the capacity of the overall heap being divided by two) the resulting memory backed virtual heap contains 16 GB data. This data can now be effectively accessed from anywhere in the grid. In case of a server failure, the grid promptly creates new copies of the lost data and places them on operational servers in the grid.
- Scalability
A significant benefit of a distributed data grid over a replicated clustered cache is that a data grid is scalable in terms of both capacity and performance. Adding a node to JBoss Data Grid increases throughput and capacity for the entire grid. JBoss Data Grid uses a consistent hashing algorithm that limits the impact of adding or removing a node to a subset of the nodes instead of every node in the grid.
Due to the even distribution of data in JBoss Data Grid, the only upper limit for the size of the grid is the group communication on the network. The network’s group communication is minimal and restricted only to the discovery of new nodes. Nodes are permitted by all data access patterns to communicate directly via peer-to-peer connections, facilitating further improved scalability. JBoss Data Grid clusters can be scaled up or down in real time without requiring an infrastructure restart. The result of the real time application of changes in scaling policies results in an exceptionally flexible environment.
- Data Distribution
JBoss Data Grid uses consistent hash algorithms to determine the locations for keys in clusters. Benefits associated with consistent hashing include:
- cost effectiveness.
- speed.
deterministic location of keys with no requirements for further metadata or network traffic.
Data distribution ensures that sufficient copies exist within the cluster to provide durability and fault tolerance, while not an abundance of copies, which would reduce the environment’s scalability.
- Persistence
-
JBoss Data Grid exposes a
CacheStoreinterface and several high-performance implementations, including the JDBC Cache stores and file system based cache stores. Cache stores can be used to populate the cache when it starts and to ensure that the relevant data remains safe from corruption. The cache store also overflows data to the disk when required to prevent running out of memory. - Language bindings
- JBoss Data Grid supports both the popular Memcached protocol, with existing clients for a large number of popular programming languages, as well as an optimized JBoss Data Grid specific protocol called Hot Rod. As a result, instead of being restricted to Java, JBoss Data Grid can be used for any major website or application. Additionally, remote caches can be accessed using the HTTP protocol via a RESTful API.
- Management
- In a grid environment of several hundred or more servers, management is an important feature. JBoss Operations Network, the enterprise network management software, is the best tool to manage multiple JBoss Data Grid instances. JBoss Operations Network’s features allow easy and effective monitoring of the Cache Manager and cache instances.
- Remote Data Grids
- Rather than scale up the entire application server architecture to scale up your data grid, JBoss Data Grid provides a Remote Client-Server mode which allows the data grid infrastructure to be upgraded independently from the application server architecture. Additionally, the data grid server can be assigned different resources than the application server and also allow independent data grid upgrades and application redeployment within the data grid.
1.6. Red Hat JBoss Data Grid and Infinispan
Red Hat JBoss Data Grid is based on Infinispan, the open source community version of the data grid software. Infinispan uses code, designs, and ideas from JBoss Cache that are tried and tested under load in production deployments. For this reason, the initial release of JBoss Data Grid is version 6.0 to reflect integration of proven software.
The following table lists the correlation between JBoss Data Grid and Infinispan versions.
Table 1.1. JBoss Data Grid and Infinispan Versioning
| JBoss Data Grid Version | Infinispan Version |
|---|---|
| JBoss Data Grid 6.0.0 | Infinispan 5.1.5 |
| JBoss Data Grid 6.0.1 | Infinispan 5.1.7 |
| JBoss Data Grid 6.1.0 | Infinispan 5.2.4 |
| JBoss Data Grid 6.2.0 | Infinispan 6.0.1 |
| JBoss Data Grid 6.3.0 | Infinispan 6.1.0 |
| JBoss Data Grid 6.3.1 | Infinispan 6.1.1 |
| JBoss Data Grid 6.4.0 | Infinispan 6.2.0 |
| JBoss Data Grid 6.4.1 | Infinispan 6.2.1 |
| JBoss Data Grid 6.5.0 | Infinispan 6.3.0 |
| JBoss Data Grid 6.5.1 | Infinispan 6.3.1 |
| JBoss Data Grid 6.6.0 | Infinispan 6.4.0 |
| JBoss Data Grid 7.0.0 | Infinispan 8.3.0 |
| JBoss Data Grid 7.1.0 | Infinispan 8.4.0 |
| JBoss Data Grid 7.2.0 | Infinispan 8.5.0 |
As of Red Hat JBoss Data Grid 6.2.0, JBoss Data Grid versions do no do not directly correspond to Infinispan versions. In the preceding table, some Infinispan versions listed for JBoss Data Grid 6.3.0 and later are internal to Red Hat and might not be publicly available.
1.7. Red Hat JBoss Data Grid Cache Architecture
Figure 1.1. Red Hat JBoss Data Grid Cache Architecture
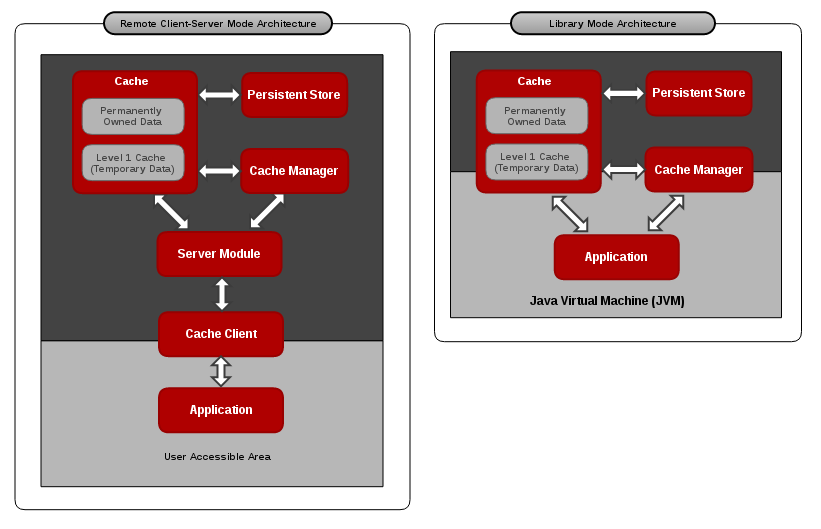
Red Hat JBoss Data Grid’s cache infrastructure depicts the individual elements and their interaction with each other in each JBoss Data Grid Usage Mode (Library and Remote Client-Server). For clarity, each cache architecture diagram is separated into two parts:
- Elements that a user cannot directly interact with are depicted within a dark grey box in the diagram. In Remote Client-Server mode, this includes Persistent Store, Cache, Cache Manager, L1 Cache, and Server Module. In Library mode, user cannot directly interact with Persistent Store and L1 Cache.
- Elements that a user can interact directly with are depicted in a light grey box in the diagram. In Remote Client-Server mode, this includes the Application and the Cache Client. In Library mode, users are allowed to interact with the Cache and Cache Manager, as well as the Application.
Cache Architecture Elements
JBoss Data Grid’s cache architecture includes the following elements:
- The Persistent Store is an optional component. It can permanently store the cached entries for restoration after a data grid shutdown.
- The Level 1 Cache (or L1 Cache) stores remote cache entries after they are initially accessed, preventing unnecessary remote fetch operations for each subsequent use of the same entries.
- The Cache Manager controls the life cycle of Cache instances and can store and retrieve them when required.
- The Cache is the main component for storage and retrieval of the key-value entries.
Library and Remote Client-Server Mode Architecture
In Library mode, the Application (user code) can interact with the Cache and Cache Manager components directly. In this case the Application resides in the same Java Virtual Machine (JVM) and can call Cache and Cache Manager Java API methods directly.
In Remote Client-Server mode, the Application does not directly interact with the cache. Additionally, the Application usually resides in a different JVM, on different physical host, or does not need to be a Java Application. In this case, the Application uses a Cache Client that communicates with a remote JBoss Data Grid Server over the network using one of the supported protocols such as Memcached, Hot Rod, or REST. The appropriate server module handles the communication on the server side. When a request is sent to the server remotely, it translates the protocol back to the concrete operations performed on the cache component to store and retrieve data.
1.8. Red Hat JBoss Data Grid APIs
Red Hat JBoss Data Grid provides the following programmable APIs:
- Cache
- Batching
- Grouping
- Persistence (formerly CacheStore)
- ConfigurationBuilder
- Externalizable
- Notification (also known as the Listener API because it deals with Notifications and Listeners)
JBoss Data Grid offers the following APIs to interact with the data grid in Remote Client-Server mode:
- The Asynchronous API (can only be used in conjunction with the Hot Rod Client in Remote Client-Server Mode)
- The REST Interface
- The Memcached Interface
The Hot Rod Interface
- The RemoteCache API