
AI Infrastructure automation with Ansible - Solution Guide
Table of Contents
- Background
- What this solution automates
- Solution Overview
- How to download these Collections
- AWS AMI Setup for RHEL AI
- Setting up the inventory
- Visualizing the workflow in Ansible Automation Platform
- Included playbooks
- Model selection and usage
- Pulling sample vars and playbook files
- Variable configuration
- Validating model deployment
- Final Notes
- Sources
Background
This solution article demonstrates how Ansible can automate the provisioning and configuration of AI infrastructure—specifically using Red Hat Enterprise Linux AI (RHEL AI) and InstructLab on AWS. It walks through how to set up infrastructure, serve models, and validate them using Ansible playbooks built with enterprise-ready content.
More broadly, deploying AI infrastructure involves provisioning compute resources, applying system configurations, installing model runtimes, and securing environments—all of which are ideal for automation. Ansible helps standardize and scale this process by:
- Automating infrastructure provisioning using cloud-native modules.
- Applying repeatable configurations to install and configure model servers (like InstructLab).
- Managing variables, playbooks, and roles as code—making automation shareable and auditable.
- Integrating with Ansible Automation Platform to operationalize deployments across teams and environments.
While this guide focuses on AWS, RHEL AI, and InstructLab, the same automation principles apply across public clouds, virtual machines, OpenShift clusters, and edge environments. Ansible collections for cloud, networking, operating systems, and AI runtimes enable teams to scale infrastructure for AI workloads reliably and consistently.
Important: Support for Ansible Lightspeed intelligent assistant
Once you have followed these instructions and validated that your LLM is running and serving inference requests, the LLM can serve as the foundational model for powering the Ansible Lightspeed intelligent assistant within Ansible Automation Platform (AAP), which currently requires a model hosted on your own infrastructure.
After the model backend is ready:
• Follow the Ansible Lightspeed documentation to configure and enable the Ansible Lightspeed intelligent assistant.
• In the Lightspeed settings, supply your hosted LLM’s API endpoint and token as required.
This integration enables you to leverage generative AI for Ansible Automation Platform while retaining full control over your LLM infrastructure. This is particularly useful for air-gapped, privacy-sensitive, or regulated environments where using public models is not ideal.
What does this solution automate?
This Ansible-based solution automates the key steps involved in setting up an AI-ready environment using RHEL AI and InstructLab on AWS. It includes:
- Provisioning infrastructure: Automatically launches EC2 instances, VPCs, subnets, and security groups using AWS modules in Ansible.
- Configuring the system: Sets up the RHEL AI instance with the required packages, configuration, and users.
- Serving an AI model: Deploys InstructLab, fetches a model, and launches an inference endpoint.
- Validation: Verifies that the model server is accessible and working using test prompts.
Together, these steps create a repeatable and auditable way to deploy AI infrastructure—from infrastructure provisioning to serving a model—using automation best practices. This automation can also be used to power the Ansible Lightspeed intelligent assistant by configuring Red Hat AI as a model provider and connecting Ansible Lightspeed to the hosted LLM.
Solution Overview
This solution guide helps Ansible Automation Platform (AAP) customers automate the deployment and configuration of RHEL AI on AWS using two key Ansible collections:
- Validated Collection: infra.ai – Provisions RHEL AI infrastructure.
- Certified Collection: redhat.ai – Configures and serves an AI model on a provisioned RHEL AI host using InstructLab.
Components
The solution leverages:
-
infra.ai for infrastructure provisioning:
- EC2 Instances
- VPC
- Subnets
- Security Groups
-
redhat.ai for model serving:
- InstructLab configuration
- Model deployment and validation
How to download these Collections
Before installing the collections, ensure your ansible.cfg file is configured to authenticate and pull content from automation hub.
Then install the collections directly from automation hub:
ansible-galaxy collection install infra.ai
ansible-galaxy collection install redhat.ai
Installing Ansible Collections – Documentation
AWS AMI Setup for RHEL AI
Provisioning requires an AMI ID for RHEL AI. Obtain it using one of these two methods:
Option 1: Subscribe via AWS Marketplace
- Visit Red Hat RHEL AI on AWS Marketplace.
- Subscribe to the RHEL AI AMI.
- Retrieve the AMI ID from your AWS Console in your selected region.
Option 2: Create Your Own AMI
- Install and configure RHEL AI manually on a supported base AWS image.
- Save your configured instance as an AMI.
- Note the AMI ID generated by AWS.
Pass the obtained AMI ID into your playbook using the variable:
rhelai_aws_rhelai_ami: ami-xxxxxxxxxxxxxxxxx
Setting up the inventory
After provisioning the AWS instance, you need to create or sync an inventory that targets your RHEL AI host. You can do this via the Ansible CLI or Ansible Automation Controller.
Option 1: CLI-Based Inventory
Create a static inventory file locally with the instance IP and SSH credentials:
[rhelai_servers]
<instance_ip> ansible_user=cloud-user ansible_ssh_private_key_file=~/.ssh/your_private_key.pem
Use this inventory when running the playbook manually:
ansible-playbook -i inventory.ini ilab.yml
Option 2: Inventory sync in Ansible Automation Platform
For workflows within Ansible Automation Platform, configure a dynamic inventory source:
- Go to Automation Execution -> Infrastructure -> Inventories.
- Add a new inventory and open it.
- Navigate to Sources tab and Add a new source of type Amazon EC2.
- Provide the correct AWS credentials.
- Apply filters or tags (e.g.,
Environment: RHEL-AI) to scope the hosts. - Sync the inventory. The resulting host group (e.g.,
rhelai_servers) will be used in your job templates.
This dynamic inventory sync ensures your infrastructure is always up to date and aligns well with controller workflows.
✅ Tip: Use dynamic inventory sync in AAP to scale automation and keep environments consistent.
Visualizing the workflow in Ansible Automation Platform
You can also orchestrate this automation through Ansible Automation Controller by creating a workflow template. The example below shows a simple two-step workflow:
- Provision RHEL AI – Launches an EC2 instance with the required network, security groups, and AMI.
- Configure InstructLab – Connects to the provisioned instance and installs InstructLab along with the model-serving components.
This visual representation can help teams manage hand-offs between infrastructure and AI platform configuration, enforce approvals or triggers, and re-use this workflow across environments.
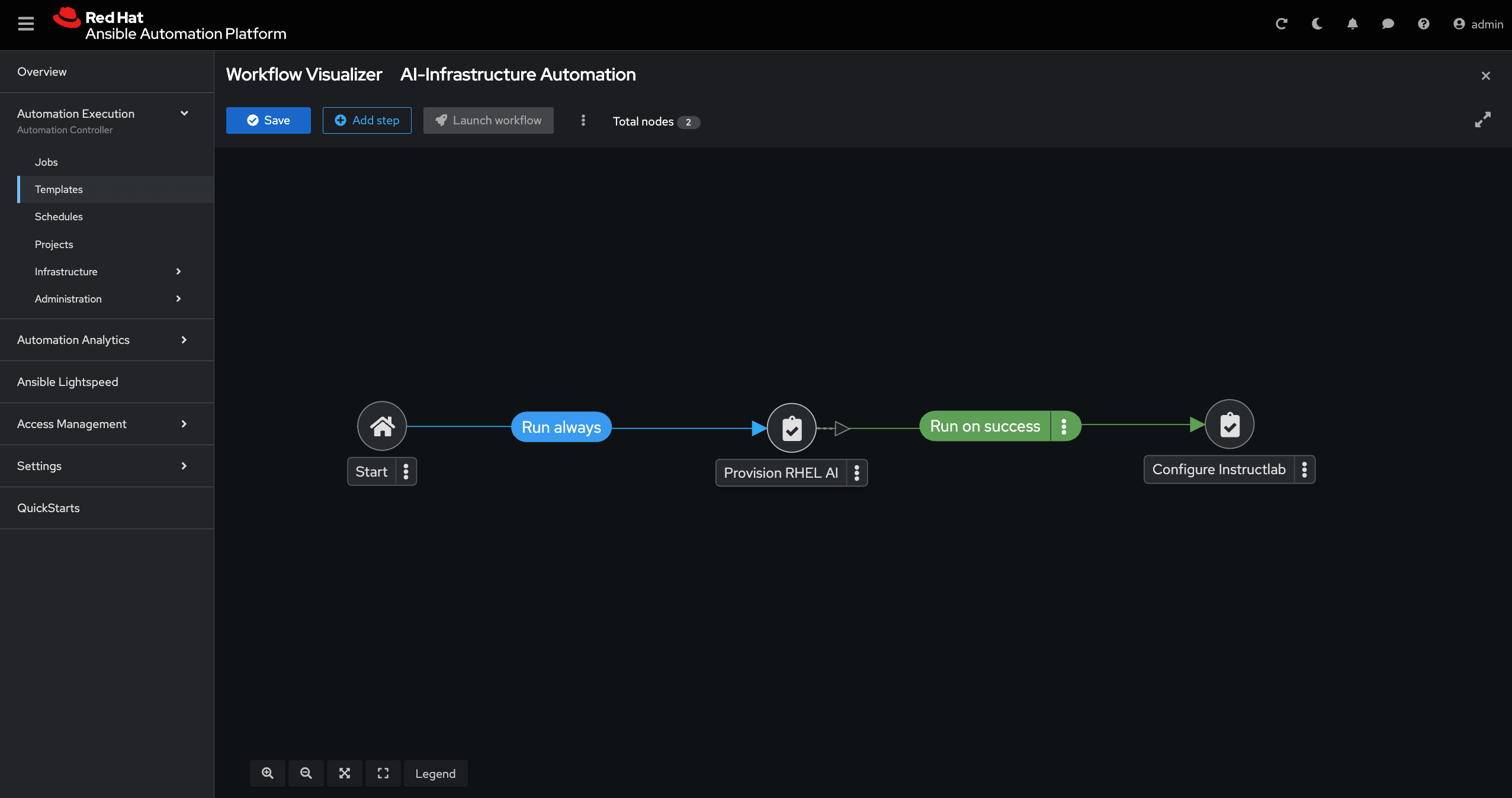
Included playbooks
1. provision.yml (infra.ai)
This playbook automates infrastructure provisioning:
- Sets up AWS credentials.
- Creates a key pair.
- Provisions networking (VPC, Subnets, Security Groups).
- Launches EC2 instance with RHEL AI AMI.
2. ilab.yml (redhat.ai)
This playbook configures and serves your AI model:
- Installs and configures InstructLab.
- Downloads the required AI model.
- Starts and validates the model server.
These playbooks work sequentially to provision infrastructure and serve an AI model quickly and efficiently.
Model selection and usage
This solution uses a Red Hat-supported large language model (LLM) designed specifically for inference serving. The model is automatically downloaded and served using the redhat.ai collection as part of the InstructLab configuration process.
Red Hat AI provides a variety of validated and optimized models for different purposes such as fine-tuning, training, or serving. You can explore the list of supported models in the Red Hat Enterprise Linux AI documentation – Supported LLMs.
For this solution, the focus is on inference—deploying a model to serve responses to user queries. You can specify the model using the following variable in your configuration:
- name: Download model
redhat.ai.ilab_model_download:
name: granite-8b-lab-v1
release: latest
registry_url: docker://registry.redhat.io
registry_namespace: rhelai1
registry_username: "{{ my_registry_username }}"
registry_password: "{{ my_registry_password }}"
Pulling sample vars and playbook files
You can obtain the sample_vars.yml, provision.yml, and ilab.yml files directly from their respective collections:
These files are typically available in the installed collections directory:
~/.ansible/collections/ansible_collections/infra/ai/playbooks/~/.ansible/collections/ansible_collections/redhat/ai/playbooks/
Variable configuration
All required variables for these playbooks are pre-defined in sample_vars.yml. Ensure this file is correctly populated to match your specific setup.
Validating model deployment
Once your model is deployed and the inference server is running, you can validate that it is operational using either a curl command or the redhat.ai.completion module available in the redhat.ai Ansible content collection.
Option 1: Using curl
Send a sample inference request:
curl -X POST http://<instance_ip>:<port>/v1/completions
-H 'Content-Type: application/json'
-H 'Authorization: Bearer <TOKEN>'
-d '{
"model": "/home/cloud-user/.cache/instructlab/models/granite-8b-lab-v1",
"prompt": "What is the capital of France?",
"max_tokens": 10
}'
Option 2: Using Ansible
You can also use the redhat.ai.completion module to send a prompt to the model directly from a playbook:
- name: Ask model a question
hosts: localhost
gather_facts: false
tasks:
- name: Ask model a question
redhat.ai.completion:
base_url: "http://{{ rhelai_host }}:{{ rhelai_port }}"
validate_certs: false
token: "{{ rhelai_api_token }}"
prompt: "What is the capital of France?"
model_path: "/home/cloud-user/.cache/instructlab/models/granite-8b-lab-v1"
This method is useful when testing from within an automated workflow or integrating into a larger playbook.
Final Notes
- This solution offers a scalable foundation for automating AI infrastructure provisioning and model serving using Ansible Automation Platform.
- While the current setup focuses on RHEL AI deployments on AWS, the approach is extensible to other public clouds (Azure, GCP) and platforms like OpenShift.
- The validated (
infra.ai) and certified (redhat.ai) collections used here are maintained by Red Hat and provide a reliable starting point for both experimentation and production. - Customers can customize these playbooks to fit their organization’s infrastructure policies, integrate them into CI/CD pipelines, or use them within Automation Controller for governance and reuse.
- As Red Hat AI evolves, this automation will help ensure consistency, reduce manual effort, and streamline Day 0 to Day 2 operations for AI model serving.
We recommend checking for updates to these collections regularly on Automation Hub for the latest features and improvements.
Comments