
Stacking LVM volumes
Overview
Storage management is a complex task and LVM contributes to this complexity by offering flexibility how the volumes are stacked. We have seen incorrect usage of LVM many times and users are often neither aware of the possibilities, alternatives, nor system wide implications of particular storage stacks. This document offers guidelines how to stack devices and lists affected areas throughout the system. Though the article is written with Red Hat family of GNU/Linux distributions in mind (Red Hat Enterprise Linux, Fedora, CentOS), it equally applies to other GNU/Linux distributions.
The following diagram shows the layout of the storage stack. For each of its components, this article summarizes the best practices, known bugs and limitations, and potential rough edges (where upstream, in house, and third party testing needs focusing.) It does not include dm-era, dm-stats, and dm-verity, which are not currently supported by LVM.
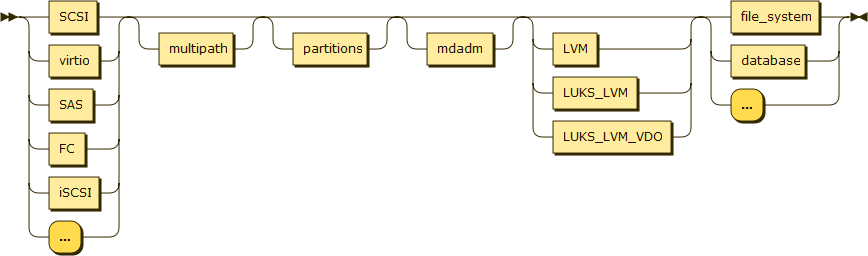
(local disk|SCSI|virtio|SAS|FC|iSCSI) [multipath] [partition table] [mdadm] LUKS, LVM and/or VDO (file system|database)
LVM stack
When using LVM alone, sometime we need Recursion - using a logical volume as physical volume:
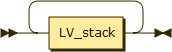
LVM and LUKS
When using LUKS, sometimes it is below LVM, sometime above, and sometimes in between, but never use one LUKS volume above another:

LVM, LUKS and VDO
When using VDO, sometimes it is below LVM, sometime above, and sometimes in between, but when used with LUKS it is always under VDO:
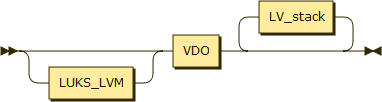
Table of Contents
- Implications on System
- Stack below Logical Volume
- VDO - Compression and Deduplication
- Logical volume stack
- Other parts
- Contribute
Implications on System
Stacking affects system boot and shutdown and stack activation/deactivation. Another important requirement is propagating device attributes to the upper levels of the stack and proper alignment of blocks across all levels of the stack.
In a cluster environment locking must ensure that the devices are always manipulated on the node which has them exclusively open. This is crucial for stacked devices which may have multiple top-level devices (thin-pool) to ensure that the pool and all thin-volumes are always exclusively open on one node only.
More detailed list of affected areas:
- activation/deactivation
- boot/shutdown with root file system on given stack
- shutdown with other mounted file system on given stack
- verify services start/stop in correct order
- verify volumes are properly activated by udev rules
- dracut
- generating new initramfs and reboot
- anaconda
- installing with stack present into new logical volume
- installing into new logical volume in existing volume group
- installing into existing logical volume
- kdump
- propagating attributes
- segment sizes and alignment
- discard
- pvmove
- pvmove is inserting a mirror inside stack
- vgsplit
- logical volumes are split correctly among the volume groups
- mirror and RAID specific operations
- split and merge leg of mirror and RAID logical volumes
- up and down converting mirror and RAID logical volumes
- event processing
- automatic resizing of snapshot and thin-pool data and metadata logical volumes
- automatic repair of missing legs in mirror and RAID logical volumes
- cluster
- operations on exclusively activated devices (anywhere in the stack) from another node
- performance
- no significant performance drop except than for old style snapshots
Stack below Logical Volume
The general rule is:
- Do striping, mirroring and/or encryption only once; i.e., do not try to mirror a RAIDn volume whether it is mdadm or LVM based.
- When redundancy and encryption is combined, use LUKS on top of mirrored data. Having the same data encrypted with multiple keys increases the surface for potential crypto analytic attack as well as consumes more CPU cycles.
iSCSI, FC, FCoE, AoE, virtio...
Supported. These play no role in what is allowed on top of them.
- autoactivation during boot
Multipath
Supported. Plays no role in what is allowed above.
- filtering out duplicate devices
Multipath, when present, is always at the bottom of the stack (right above "physical" level - FC, iSCSI, SAS)
Network Bonding
Supported. For iSCSI/FCoE network bonding is an alternative to dm-multipath. Though dm-multipath is preferred, bonding is supported as well.
Partitions
Supported. Preferably left out with an exception in mixed environments.
- Partition + mdadm devices may be non-deterministic. When used, the partition should be below mdadm to protect mdadm headers at the end of device.
- Test GPT instead of MS DOS partition table.
It used to be recommended to use an 8e (LVM) partition to compensate for tools not identifying disks used by LVM. This may not be necessary any more in the GNU/Linux world, but this still applies in mixed environments particularly where block devices may be accessed by Windows machines to prevent them from treating such devices as free.
Recommendations:
- Do not partition logical volumes. (Logical volumes used by VMs will be partitioned during provisioning. These are not usually activated on the host.)
- Do not partition MDs.
- Avoid using multiple partitions on single device in one volume group. This is risky especially if you are using mirror or RAID volumes, as these are treated as independent devices.
Other Uses
Other use cases (out of scope) where partitions are still necessary are:
- removable (USB) devices, as these are likely to be used on machines that do now know about LVM
- boot partitions
- dual boot notebooks
mdadm RAID
Supported.
There are some MD features still not present in LVM RAID. Mdadm is there to stay.
LUKS
Supported. Whole physical volume encryption is preferred. Use per logical volume encryption with caution.
- Dracut: Check device is recognized and activated on boot. (Covered in Root file system.)
- Suspend [to disk] / Resume with encrypted swap.
- Check anaconda does handle the volume and creates bootable system.
Optional dm-crypt devices when present are either below physical volumes (encrypted disk or partitions) or above top-level logical volumes (encrypted file system). Encrypting the whole physical volume is safer, as it does not expose information about data layout.
NOTE: When redundancy is required place LUKS above MD RAID volumes as a rule. Physical volumes can sit on encrypted devices.
Known problems:
- LUKS and discard
Recursion: Physical volume on top of another logical volume
Supported, but not as a general rule. Use recursion when there is no other solution.
Known limitations (not considered bugs):
- There are known activation issues when the same volume group names and/or LVM or file system UUIDs are used, as is common in the case of snapshots of virtual machines images.
- Such a stacking creates a barrier when growing an inner logical volume which is limited by outer logical volumes.
- No cluster locking is supported when activating nested cluster volume groups on a non-cluster host.
The tools intended to work with such stacks must handle these problems themselves, for example by renaming volume groups or providing a way to ensure cluster volume groups are inactive in guests.
We recommend discussing any use cases involving recursion with LVM developers to check whether there is another way to support a required feature.
Known use cases
-
Mounting guest file systems in VM images based on logical volumes on the host.
Workaround: use another guest to work with the data. Keep in mind it poses a security risk to mount file systems from VMs on the host.
-
With VDO volumes it is best to have them in a LVM sandwich.
LVM below VDO can be used for RAID, Caching, or to aggregate space from multiple physical volumes.
LVM above VDO can be used for multiple linear volumes sharing same VDO device, thin data are another good candidate, and third user may want to cache the VDO volume, to avoid compression in some cases.
VDO - Compression and Deduplication
Supported.
VDO volumes are not integrated with LVM2 yet. Thus it may be desirable to use them with LVM below as well as above them.
Known problems:
- VDO volumes face similar problems as thin pools - due to "overprovisioning" where virtual size is larger than physical size, it may look like there is still space in the FS on top of VDO, while the physical space may be exhausted.
- As VDO is not integrated with LVM yet, free space must be monitored and extending physical size handled manually.
Stack below VDO
- Physical [multipth] [partition] [mdadm]
- LUKS over (1) - full disk encryption
- RAIDs, mirror, stripe, or linear LVs with optional cache above. Using LV below VDO has the usual benefits of LVM:
- extending of VDO volume,
- spanning VDO volume over multiple devices.
- LUKS over (3) - especially when using RAIDs.
LVs not suitable as backing devices:
- thin volumes - at the moment it is not possible to take a consistent snapshot of active VDO volume (same as with LUKS volumes on top of thin-volumes.)
- old snapshots, or volumes with snapshots - same as above with severe performance hit on top of that.
Using VDO as a backing device
When using VDO as a PV, there are few devices where it fits perfectly:
- under tdata (data device of thin pool):
- This may be the best fit - it will deduplicate additional redundancies among multiple thin volumes and compression will further reduce the amount of data.
- Risks: Resize! dmeventd will not be able to handle resizing of tdata on VDO device - so ensure there is enough free space in the VG and on the VDO device.
- under multiple linear volumes:
- VDO itself does not allow multiple volumes, so to have multiple devices sharing one VDO as a backing device use this option.
VDO also fits under e.g. multiple snapshots, when LVs are sharing data.
In cases where compression or deduplication happens to be bottleneck, one may want to use cache with corig on top of VDO, and using faster drive for cdata.
Devices not suitable to use on top of VDO
- never use LUKS on top of VDO - encrypted data do neither compress nor deduplicate.
- never use VDO under cache or thin metadata - these are pseudo-random and do not deduplicate well.
- RAID, stripe, or mirror volumes:
- RAID1 and mirror will duplicate data, so having VDO as mirror/RAID1 legs would mean more duplicit work,
- stripe and RAID0 will distribute data among multiple disks, so VDO would find less duplicates,
- and RAID{4,5,6} will both increase amount of data written and distribute data among multiple disks.
Logical volume stack
Older versions of LVM offered only a limited number of possibilities while more recent versions introduced new targets with many more combinations.
- Older versions:
- (Linear | Stripe | RAID | Mirror) | [Snapshot]
- Recent versions:
- Pool and cache data or metadata on any of above except for snapshots and mirrors.
Thin snapshots of any of above except for snapshots.
Cache the top-level logical volume (except for unsupported mirrors and snapshots, and planned thin and cache volumes) or cache thin-pool's data.
Old style snapshots
Old style snapshot - terminal stop. Nothing is supported on top of them.
Limited support, for only short term snapshots (for example, to create backups). For long term and especially for large changes, use thin-snapshots.
Mirror or RAID or both?
Mirror continues to be supported in existing use cases.
Due to existing issues we are not extending support for devices stacked on top of mirrors.
Currently there are these indispensable uses of mirrors:
- Shared activation in cluster. RAID can not be activated in shared mode in cluster.
- pvmove using mirrors internally.
The need to support both targets will be reevaluated in the future.
Mirror with stripes
You can use mirrors with stripes (lvcreate -m N -i M) but this creates a mirror of stripes, which is suboptimal as the whole stripe is considered lost in the case ofa failed drive. Use RAID10 instead if possible.
Thin snapshot vs. old snapshots
Limit old snapshots to a minimum - a short term snapshot to copy and delete should be the only supported case. Poor performance with huge or many snapshots is a known limitation. Use thin snapshots if you need large long term or many snapshots.
Remember to enable monitoring and thresholds for extending full snapshots and/or pools.
One difference between snapshots and thin-snapshots with external origin is that the snapshots do not change origin at all, while creating thin-snapshot converts the origin into a thin-volume with external origin. Currently there is no way back to pure origin while keeping data written to origin after conversion.
Another difference between snapshots and thin-snapshots with external origina is that once a snapshot becomes full and is not extended in time it is marked invalid, but the origin logical volume remains fully functional. Once the thin pool gets full, it can be configured to return an error or to queue the writes, but in the case of timed out operations this may lead to data corruption. See lvmthin(7) man page for details.
Matrix
The following table summarizes supported cases of stacker (or layered) volumes where a logical volume of a given type (Y) plays a certain role (X) in another logical volume. This also includes VDO volumes, which are not integrated with LVM yet, but the matrix view is suitable to display supported combinations.
| X/Y | X/Linear | X/Stripe | X/Mirror | X/RAIDn | X/Thin Volume | X/Old Snapshot | X/Cache Volume | X/VDO Volume |
|---|---|---|---|---|---|---|---|---|
| Pool Meta/Y | OK | OK | - | Preferred | - | - | - | bad |
| Pool Data/Y | OK | OK | - | OK | - | - | OK ! | OK |
| Ext.Origin for Thin Snapshot/Y | OK | OK | OK | OK | OK | - | - | OK |
| Origin for Old Snapshot/Y | OK | OK | OK | OK | OK | - | - | OK |
| Cache Data/Y | OK | OK | - | OK | - | - | - | avoid |
| Cache Meta/Y | OK | OK | - | OK | - | - | - | bad |
| Cache Origin/Y | OK | OK | - | OK | MAYBE | - | TODO | OK |
| VDO/Y | OK | OK | OK | OK | - | - | OK | bad |
Legend
X/Y: logical volume of type Y has a role X in another logical volume.
- Working:
- works and supported by Red Hat (OK)
- works and supported but discouraged (avoid)
- works and support is planned (WIP)
- works but is unsupported feature (bad)
- Not working:
- does not work but support is planned (TODO)
- does not work, undecided (MAYBE)
- does not work and no plans to support (-)
- Known issues (!)
Pool metadata on X
Data safety and speed are important for pool metadata. Use linear or RAID1 on your fastest drives.
- Corrupted metadata volume may result in losing all data, not only a few files.
- This is a relatively small volume but is frequently accessed.
How to create and manage thin pools on top of another logical volume is covered in lvmthin(7) man page.
Pool metadata on Liner/Stripe
Supported. This is a normal use-case if there is just 1 disk. Volume with redundancy is strongly recommended.
Pool metadata on Mirror
Unsupported. For details see Bug 919604 - thinpool stacked on mirror volume fails to recover from device failure.
Pool metadata on RAIDn
RAID1 Recommended.
Since speed is equally as important as safety, RAID1 and maybe RAID10 are the only two RAID levels which make sense to use. The benefits of using RAID10 were not measured.
Also, the size of metadata is limited to 16GiB so saving few gigabytes by using e.g. RAID6 at the cost of performance is not a good decision.
How to create and manage thin pools on top of another logical volume is covered in lvmthin(7) man page.
Pool metadata on thin-volume
Unsupported.
Pool metadata on old snapshot
Unsupported.
Pool metadata on cache logical volume
Unsupported.
Pool Data on X
It is just data. Handle it as such. But remember that thin snapshots offer no redundancy, so losing a sector shared among multiple snapshots will result in losing the data held by the lost sector in all of them.
Pool data on Linear/Stripe
Supported. This is a normal/typical use case.
Pool data on Mirror
Unsupported. For details see Bug 919604 - thinpool stacked on mirror volume fails to recover from device failure.
Pool data on RAIDn
Supported.
Pool data on thin-volume
Unsupported. May be reconsidered if there are interesting use cases.
Use case: use pool with large chunks for thin provisioning on the bottom and pool with smaller chunks for snapshots at the top. This could be implemented as a pool with larger chunks for base images and creating their thin snapshots in second pool with smaller chunks.
Pool data on old-style snapshot
Unsupported.
Pool data on cache logical volume
Supported. (v2.02.125)
Known Issues:
- Resizing cache volumes is currently not working. Pool could not be extended in case it gets full.
- It is impossible to convert cache volume backing the pool back to uncached. You would have to resort to metadata editing.
Thin with Ext. origin of type X
Thin with Ext. origin of type Linear/Stripe
Supported.
Thin with Ext. origin of type Mirror/RAID
Supported. Be careful not to lose redundancy when thin data itself is not mirrored, as any writes to the original logical volume would be lost on failure of physical volume with thin data.
Thin with Ext. origin of type thin-volume
Supported. (Unlimited depth except when creating circular dependencies among thin pools.)
Thin with Ext. origin of type old-style snapshot
Unsupported.
Thin with Ext. origin of type cache logical volume
Unsupported.
Old snapshot of logical volume of type X
Limited support, for only short term snapshots (for example, to create backups). For long term and especially for large changes, use thin-snapshots.
Advantages over thin snapshots:
- Smaller chunk sizes are allowed. This comes at a price and poor write performance of snapshots is a known problem.
- Possibility to limit its size. Limiting size of thin snapshots is possible only if there is exactly one snapshot in the thin pool used.
- Origin remains writable.
Old snapshot of Linear/Stripe
Supported.
Old snapshot of mirror logical volume
Supported.
Old snapshot of RAID logical volume
Supported (snapshot when creating backup from the data). It is unlikely one would want to use old style snapshot (without redundancy) for long term use.
Old snapshot of old snapshots
Unsupported.
Old snapshot of cache logical volume
Unsupported.
Q: Old snapshot of Pool data and metadata for backup?
post 7.0
Cache Pool metadata on X
Data safety and speed are important for metadata. Use RAID1 on your fastest drives.
When using writeback losing data or metadata volume may result in corrupted data on cached logical volume.
This is a relatively small volume but it is frequently accessed.
How to create and manage cache pools on top of another logical volume is covered in lvmcache(7) man page.
Cache Pool metadata on Liner/Stripe
Supported. This is a normal use-case if there is just 1 disk. Volume with redundancy is recommended especially for writeback caching.
Cache Pool metadata on Mirror
Unsupported.
Cache Pool metadata on RAID1
Recommended.
Since speed is equally as important as safety, RAID1 and maybe RAID10 are the only two RAID levels which make sense to use. The benefits of using RAID10 were not measured.
Also, the size of metadata is limited to 16GiB so saving few gigabytes by using e.g. RAID6 at the cost of performance is not a good decision.
Cache Pool metadata on thin-volume
Unsupported.
Cache Pool metadata on old snapshot
Unsupported.
Cache Pool metadata on cache logical volume
Unsupported.
Cache Pool Data on X
It is just data. Handle it as such.
How to create and manage cache pools on top of another logical volume is covered in lvmcache(7) man page.
Cache Pool data on Linear/Stripe
Supported - normal/typical use case
Cache Pool data on Mirror
Unsupported.
Cache Pool data on RAIDn
Supported. Preferred RAID1 or RAID10. Other RAID levels would slow the cache down.
Cache Pool data on thin-volume
Unsupported.
Cache Pool data on old-style snapshot
Unsupported.
Cache Pool data on cache logical volume
Unsupported.
Caching logical volume of type X
Known Issues
- Cache logical volumes can not be resized.
Caching logical volume of type Linear/Stripe
Supported.
Caching logical volume of type Mirror
Unsupported.
Caching logical volume of type RAID
Supported. When data integrity is preferred over speed avoid writeback and in the case of metadata corruption there is a high probability of data corruption. In the case of broken data or metadata drive, there is no automatic uncaching implemented, so if availability is important, use mirroring.
Caching logical volume of type thin-volume
Unsupported.
Caching logical volume of type old-style snapshot
Unsupported.
Caching logical volume of type Cache logical volume
Unsupported. Multi-tier cache planned in the future.
Other parts
File system
Supported. LVM provides regular block devices and any supported filesystem is supported on top of logical volumes.
- alignment of blocks
Clusters
Exclusive activation is allowed where a fully cluster-aware target is not available. Anything not working should be considered a bug.
Sharing volumes is limited to linear/stripe and mirror targets.
/boot
Unsupported in RHEL7. Boot on logical volume will not be a supported feature although it is known to work with linear and mirrored logical volumes.
This needs to be tested with RAID1. Avoid other types even if working as these were not tested at all.
Root File System (/)
Goal: all supported stacks should work for the root file system. Anything not working should be considered a bug.
- Check if anaconda can build the stack and/or it can be built using kickstart.
- Check dracut handles boot (and shutdown) properly.
- Check corner cases:
- lost leg of mirror or RAID volume,
- extending full logical volume when thin-volume or old style snapshot is used,
- thin_check(8) failing on activation.
Installation
- Check how installer handles creating stack - GUI/TUI/kickstart.
- Check how installer handles an existing stack on the drives:
- reusing existing logical volumes, with or without formatting,
- wiping the logical volumes and reusing space,
- keeping logical volumes and using them (reusing in case of home)
- keeping other logical volumes untouched (for example, created snapshots of old home partition).
Credits
Thanks to all who contributed comments and other advice, especially to (in alphabetical order) Jon Brassow, Tom Coughlan, Zdenek Kabelac, Alasdair G. Kergon.
Comments