
比较 Red Hat Insights 清单中的系统配置和基准
使用偏移服务比较和基准进行系统分析
摘要
第 1 章 使用 Insights for Red Hat Enterprise Linux 清单中的比较来执行偏移分析
偏移服务允许您将一个系统的系统配置与 Insights for Red Hat Enterprise Linux 清单中的其他系统进行比较。您还可以随着时间的推移比较系统配置,以跟踪和分析更改。另外,您可以设置参考点并将其与所有系统状态进行比较。您可以使用其中任何一个比较来对系统在不同时间点上进行故障排除。
在不同系统间比较配置时,您可以过滤配置集事实和系统标签以突出显示匹配的配置,或者查看它们的不同位置。您还可以看到哪些系统丢失或不正确的信息。
您还可以定义和管理基准。您可以使用 Insights for Red Hat Enterprise Linux 清单中的定义基准来比较基准和系统配置。另外,您可以生成您要比较的系统和基准的逗号分隔列表(CSV)或 JavaScript Object Notation (JSON)输出。
1.1. 偏移服务用户的用户访问
在访问 Red Hat Insights for Red Hat Enterprise Linux 应用程序中的某些功能前,您必须具有正确的权限,在 Red Hat Hybrid Cloud Console > Settings 图标 > Identity & Access Management > User Access > Groups 授予。机构管理员或 用户访问权限管理员必须 作为成员添加到具有所需角色的 User Access 组中。
默认情况下,Red Hat Hybrid Cloud Console 上的用户访问已预先配置了 Drift 分析管理员角色 (所有访问)和 Drift viewer 角色(只读访问权限)。如果您的组织决定预定义的角色提供权限不足,则用户访问权限 管理员可以配置自定义角色,以提供用户所需的特定权限。
本章中的以下部分描述了偏移服务用户的每个预定义角色。
改为 User Access 需要由机构管理员在您的红帽帐户中执行,或者由一个是 User Access 组的成员,并带有 User Access administrator 角色的用户执行。
1.1.1. 偏移分析管理员角色
Drift 分析管理员角色 是 Default admin access 组中的一个预定义角色。在默认配置中,具有 Drift 分析管理员角色 的组的成员可以对偏移资源执行任何操作。
如果之前修改了 Default access 组,则这些更改不会应用到它。如果您在 2022 年 10 月前配置了组,则任何不是机构管理员的用户都会将 Drift analysis administrator 替换为 Drift viewer 角色。
1.1.2. drift viewer 角色
Drift viewer 角色是 Default admin access 组中的一个预定义角色。您帐户中的所有 Insights for Red Hat Enterprise Linux 用户都是 Default access 组的成员。Drift viewer 角色提供只读访问权限。如果您的组织确定 Drift viewer 角色的默认配置是不做的,则 User Access 管理员可以创建 具有所需特定权限的自定义角色。
如果之前修改了 Default access 组,则这些更改不会应用到它。如果您在 2022 年 10 月前配置了组,则任何不是机构管理员的用户都会将 Drift analysis administrator 替换为 Drift viewer 角色。
第 2 章 访问 Drift 服务
drift 服务是 Red Hat Insights for Red Hat Enterprise Linux 的一部分。使用 Red Hat Hybrid Cloud Console 访问此服务。
基准是一组系统必须维护的标准配置。配置是 name:value 对的集合。您可以创建对,也可以从现有系统配置复制它们。
先决条件
- 在将 Insights 客户端上传到偏移服务之前,必须在系统中安装并运行 Insights 客户端。
流程
进入 Operations > Drift > compare 页面。compare 屏幕将打开。
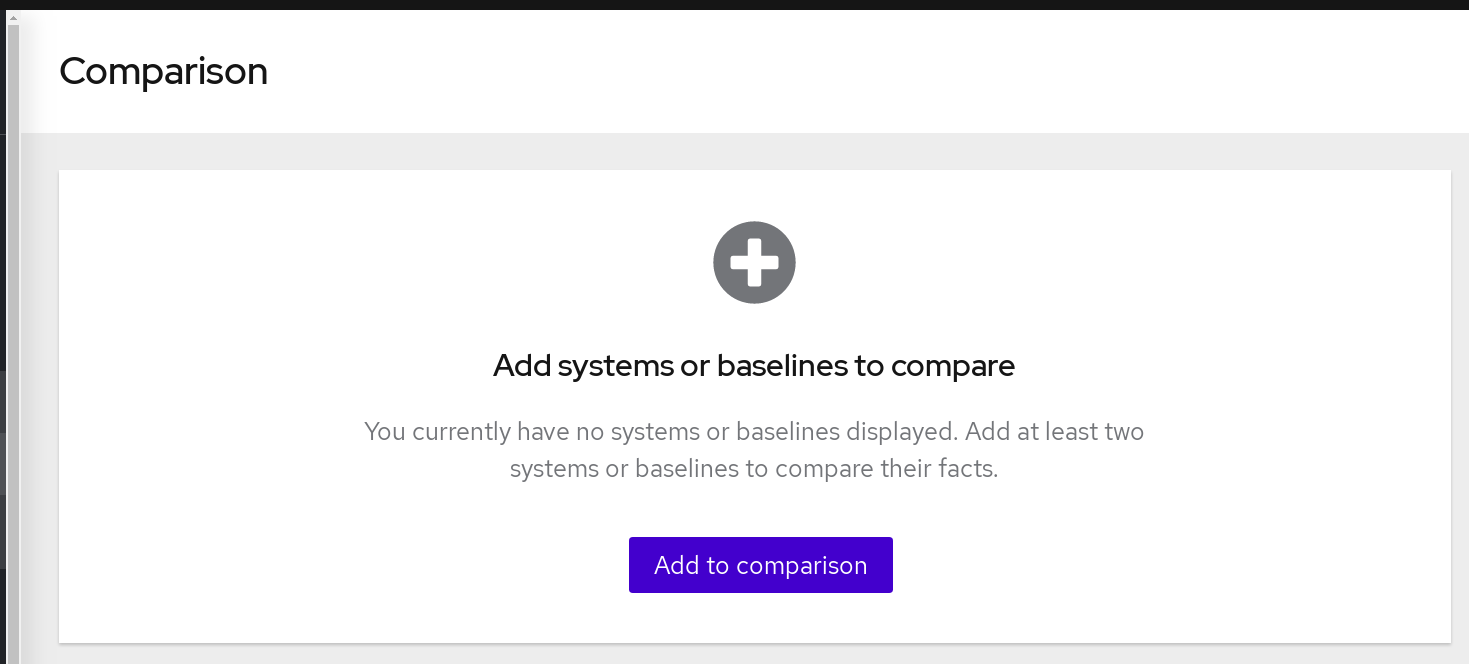
单击 Add to compare。此时会打开 Add to compare 屏幕。
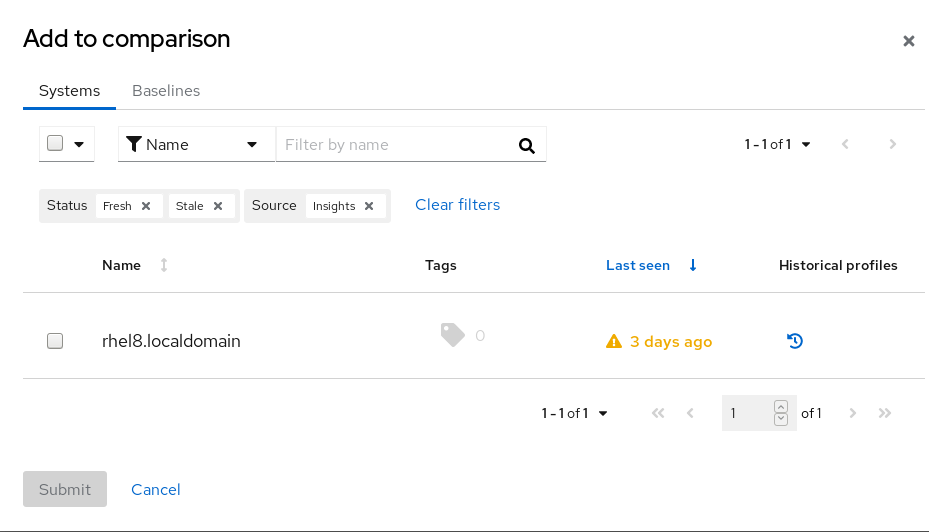
- 在 Systems 选项卡中,添加您要比较的系统。此屏幕还列出 Insights for Red Hat Enterprise Linux 清单中已存在的基准。
在 Baselines 选项卡中,使用
name:value表单创建基准,或者从现有的基准中复制并粘贴基准。此屏幕还列出 Insights for Red Hat Enterprise Linux 清单中已存在的基准。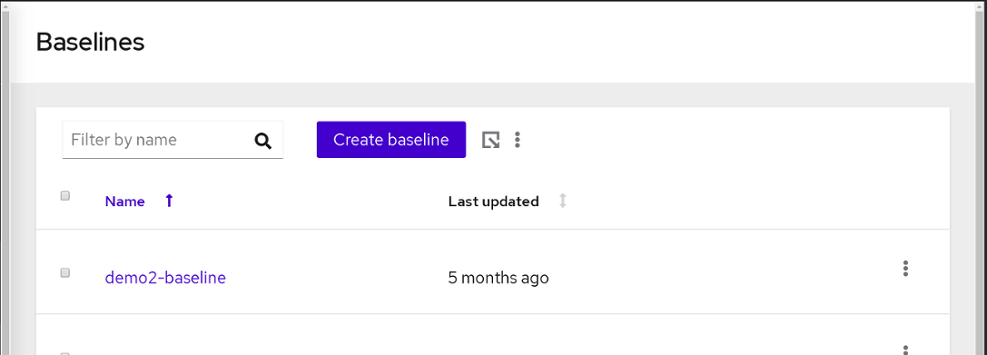
- 点 Submit 以添加您的系统或基准。
第 3 章 使用系统事实比较 Insights 清单中的系统
使用系统事实来创建有关您的系统的有用信息,或者提供系统之间的比较。分析 Insights for Red Hat Enterprise Linux 清单中组件的事实可让您在特定时间查看您的系统或多个系统。您还可以随着时间的推移创建系统比较,以了解和分析系统的更改。
3.1. 创建并添加到比较
完成以下步骤,在 Insights for Red Hat Enterprise Linux 清单中创建或添加比较。
先决条件
- 必须在系统上安装并运行 Insights 客户端。
有关如何安装 Insights 客户端并将您的系统注册到 Insights for Red Hat Enterprise Linux 的步骤,请参阅 Red Hat Insights for Red Hat Enterprise Linux,入门说明。
流程
进入 Operations > Drift > compare 页面。compare 屏幕将打开。
单击 Add to compare。此时会打开 Add to compare 屏幕。
- 在 Systems 选项卡中,您可以添加您要比较的任何系统。此屏幕还列出 Insights for Red Hat Enterprise Linux 清单中已存在的基准。
在 Baselines 选项卡中,您可以创建基准。此屏幕还列出 Insights for Red Hat Enterprise Linux 清单中已存在的基准。
- 点 Submit 添加您的系统或基准进行比较。
- 在任何时候,您可以通过单击 比较屏幕顶部附近的 Add to compare 按钮来添加更多系统。
- 同样,您可以通过单击各个系统名称右上角的 X 符号来删除特定的系统。
-
您可以点位于顶部的选项菜单
 来删除所有系统。
来删除所有系统。
- 点 Clear all compares 再次启动。
第 4 章 检查和管理基准
基准是一组系统必须维护的标准配置。配置是一组 name:value 对,您可以从现有系统配置中创建或复制。
您可以管理系统配置文件基准定义。您可以通过更改事实的值来编辑基准,也可以删除事实。您可以使用偏移用户界面创建、复制、编辑、删除和导出基准。
您还可以使用基准 API 创建和管理基准。有关如何使用 REST API 查询并编辑基准的信息,请参阅 Red Hat Insights for Red Hat Enterprise Linux API 文档。
4.1. 创建新基准
您可以使用几种方法创建基准:
- 创建一个新的基准
- 复制现有基准
- 复制现有系统
- 复制历史系统配置集
4.1.1. 创建全新的基准
从头开始创建基准。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
点 Create baseline。Create baseline 屏幕将打开。
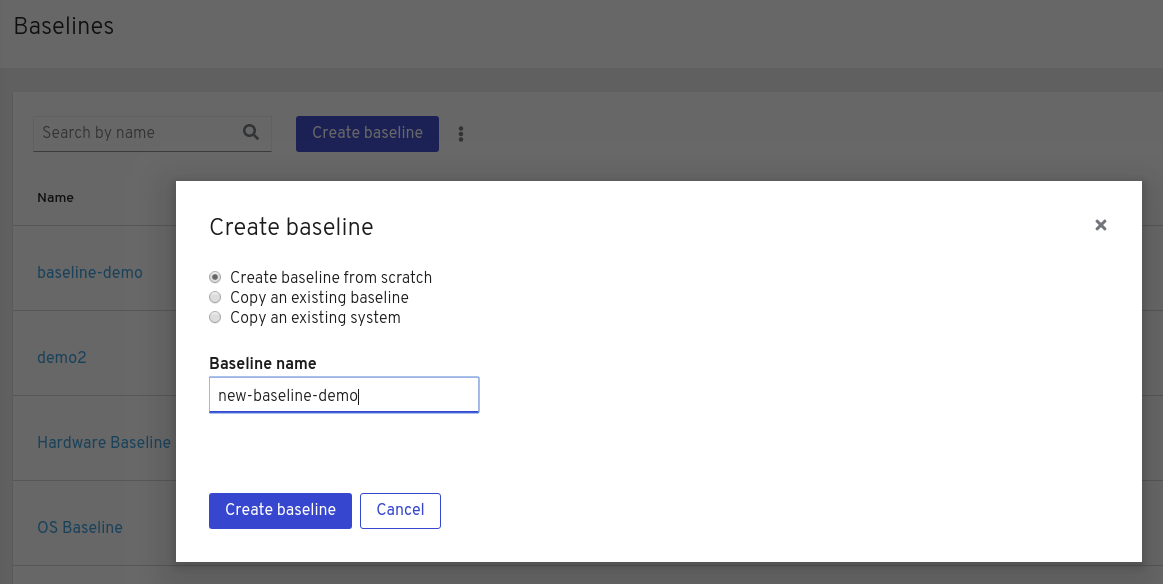
- 选择 Create baseline from scratch。
- 在 Baseline name 字段中输入您要创建的基准的名称。
- 点 Create baseline。这会打开新基线的编辑界面。
- 单击 Add fact 或 category。新基线的 Add 事实 屏幕将打开。
- 如果这是您要添加子事实的类别(父事实),请选择 This is a category only the Category name。点击 Save。
- 否则,输入 Fact name 和 Value,然后点 Save。
要在类别下添加子事实,点类别旁边的 Options 菜单
,然后选择 Add sub fact。您还可以使用 More Options 菜单来编辑或删除类别。
注意所有执行的更改都会被自动保存。
- 添加所有事实和子事实及其值后,进入 Operations > Drift > Baselines 来查看和管理您创建的基准。
4.1.2. 复制现有基准以创建新基准
您可以复制现有的基准来创建新基准。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
- 点 Create baseline。Create baseline 屏幕将打开。
- 选择 Copy an existing baseline or historical profile。
- 在 Baseline name 字段中,为新基准输入一个名称。
- 从现有基准列表中,选择您要复制的基准,然后单击 Create baseline。打开的屏幕会填充所有事实,并填充了新创建的基准。
-
使用事实旁的 More Options 菜单
来编辑或删除该事实。
- 若要添加新事实或类别,请单击 Add fact 或 category。您还可以为类别添加值。
添加或编辑事实及其值后,进入 Operations > Drift > Baselines 页面,以查看和管理您创建的基准。
根据对事实行为的典型预期,偏移服务会向可能需要注意的事实向用户发出警报。如果预期不同,或者它们不重要,则它不会标记相互不同的事实。它仅标记可能导致问题的重要区别或相似点。
然后,您可以将这些例外解决到典型的事实行为。
4.1.3. 复制现有系统以创建新基准
您可以复制现有系统来创建新基准。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
- 点 Create baseline。Create baseline 屏幕将打开。
- 选择 Copy an existing system。
- 在 Baseline name 字段中,为新基准输入一个名称。
- 从现有系统列表中,选择包含您要复制基准的系统,然后单击 Create baseline。打开的屏幕会填充所有事实,并填充了新创建的基准。
-
要删除现有事实,请使用 More options 菜单
。此菜单位于蓝色 添加事实或类别 按钮的右侧。
- 若要添加新事实或类别,请单击 Add fact 或 category。您还可以向类别添加子事实。
根据对事实行为的典型预期,偏移服务会向可能需要注意的事实向用户发出警报。如果预期不同,或者它们不重要,则它不会标记相互不同的事实。它仅标记可能导致问题的重要区别或相似点。然后,您可以将这些例外解决到典型的事实行为。
添加或编辑事实、子事实及其值后,您可以导航到 → 来查看和管理您创建的基准。
4.1.4. 复制历史系统配置集以创建新基准
您可以复制历史系统配置集来创建新基准。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
- 点 Create baseline。Create baseline 屏幕将打开。
- 选择 Copy an existing system or historical profile。
- 在 Baseline name 字段中,为新基准输入一个名称。
- 在现有系统中,选择具有您要复制基准的系统。
-
在 Historical profile 列中,点 Historical 配置集图标
 。
。
-
在下拉菜单中,根据日期和时间选择您要复制的配置集。进行选择后,drift 会在
Name列中显示所选配置集的时间戳。如果您更改了您,并希望选择不同的历史配置集,点配置集时间戳旁边的X,然后选择不同的历史配置集。 -
当您满足您要复制的特定配置集时,点
Create baseline。此时会打开一个屏幕,其中包含新创建的基准,并填充所有事实。 -
要编辑或删除现有事实,请使用事实旁的 More Options 菜单
。
- 若要添加新事实或类别,请单击 Add fact 或 category。您还可以为事实添加一个值。
添加或编辑事实及其值后,进入 Operations > Drift > Baselines 来查看和管理您创建的基准。
根据对事实行为的典型预期,偏移服务会向可能需要注意的事实向用户发出警报。如果差别是预期或不重要,则它不会标记相互不同的事实。它仅标记可能导致问题的重要区别或相似点。然后,您可以将这些例外处理到基准中典型的事实行为。
4.2. 编辑或删除基准
您可以重命名基准并更改、添加或删除事实、类别和子事实。
4.2.1. 编辑基准
流程
- 要编辑基准,请点击包含基准名称的行末尾的 More options 图标。这会打开 Edit 屏幕。
- 点 Add fact 或 category 为基准添加事实或类别。此时会打开 Add fact 屏幕。
- 如果这是要添加子事实的类别(父事实),请选择 This is a category only the Category name。点击 Save。
- 要编辑事实,请选择您要编辑的项目,然后点击 More options 菜单上的 Edit fact,它位于包含事实的行的右侧。这会打开 Edit fact 屏幕。
- 更改名称或值,然后点 Save。
- 要删除事实或类别,请选择您要删除的项目,再单击 More options 菜单上的 Delete fact,位于包含该事实的行的右侧。
- 对于事实类别,点 More options 菜单,它位于包含事实类别的行右侧。
- 单击 Add sub fact、Edit category 或 Delete category。此时会打开对应的屏幕。输入或编辑请求的信息,然后单击保存。
4.2.2. 删除基准
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
-
使用下拉菜单选择您要删除的基准(或基准)。当您做出选择时,
 字段表示您选择的基准数。
字段表示您选择的基准数。
-
要删除列表中的基准,请点击屏幕顶部的 More options 菜单
上的 Delete。此时会打开一个警报,提醒删除基准无法撤消。如果您仍然希望继续,请单击 Delete baseline。
4.3. 系统配置与基准的比较
您可以将系统配置与一个或多个基准进行比较,以识别环境中的差异并执行偏移分析。
流程
- 进入 Operations > Drift > compare 页面。compare 屏幕将打开。
- 点 Add systems 或 baselines。
- 在 Systems 选项卡中,从列表中选择一个或多个系统。或者,您也可以按名称搜索系统,然后选择系统。
- 在 Baselines 选项卡中,从列表中选择一个或多个基准。或者,您也可以按名称搜索基准,然后选择基准。
- 点 Submit。
可选流程
比较结果也可以根据基准事实过滤。此功能允许您在创建比较时专注于最重要的数据。
- 单击 Fact Name 下拉菜单,然后选择 Fact type。
- 接下来,单击 Show 下拉菜单,然后选中 Baseline facts only 旁边的框。
在任何时候,您可以通过单击已添加的系统右侧的 Add System 按钮来添加更多系统和基准。
要从比较中删除特定的系统或基准,请单击各个系统或基准名称面板右上角的 X 符号。
要从比较中删除所有系统和基准,请点击位于屏幕顶部的 Options 菜单
中的 Clear all compares。
您可以根据需要查看显示的比较结果,并根据事实名称、比较状态和类别过滤。要将结果和任何当前选择(如过滤器)导出到以逗号分隔的值(CSV)或 JavaScript Object Notation (JSON)文件,请在 Options 菜单中点 Export as CSV 或 Export as JSON。
4.4. 导出基准
您可以将所有系统基准或单独的基准事实或类别导出到以逗号分隔的值(CSV)或 JavaScript Object Notation (JSON)文件中。然后您可以在外部分析它们。如果您将任何搜索过滤器应用到您要导出的基准,则会在下载的 CSV 或 JSON 文件中保留过滤器。
4.4.1. 导出单个基准、事实和类别
您可以将单个基准导出到 CSV 或 JSON 文件。您还可以使用相同的流程导出单个事实或类别。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
- 从列表中选择一个基准。
- 点 baseline 的 More options 菜单,然后选择 Edit。Edit 屏幕会出现。
-
点 Export 图标(
 )并选择 Export to CSV 或 Export to JSON。
)并选择 Export to CSV 或 Export to JSON。
4.4.2. 导出所有系统基准
您可以将所有系统基准导出到以逗号分隔的值(CSV)或 JavaScript Object Notation (JSON)文件中。
流程
- 进入 Operations > Drift > Baselines 页面。Baselines 屏幕将打开。
-
点 Create baseline 按钮旁边的 Export 图标(
)。
- 选择 Export to CSV 或 Export to JSON。
第 5 章 比较使用系统事实
系统事实是重要的组件,可帮助您了解系统比较。检查它们会显示有关 Insights for Red Hat Enterprise Linux 系统清单中的性能和更改的详细信息。系统事实还提醒您,了解其状态为未知的系统组件,以及识别需要注意的系统部分。
5.1. 系统事实与角色进行比较
根据观察到的事实值比较状态可帮助您管理系统。偏移服务标识其行为与预期和状态未知的事实不同。它还会提醒您需要注意的事实。
drift 服务以不同的颜色显示观察到的事实值。
红色图标表示您应该检查的问题。

绿色图标表示预期的状态或值。

在黑色中显示的状态带有问号图标,表示事实的预期状态未知。

某些事实是特定于系统的,被视为唯一。如果值等于给定比较,其状态将以红色标记。例如,如果 fqdn 和 IP 地址的事实以红色标记,则需要注意力。
对于所有比较的系统,偏移服务需要其他事实,如 last_boot_time。对于此类事实,它不会突出显示区别。该服务将比较状态标记为 unknown (没有建议)。
5.2. 如何将事实用于比较
根据观察到的事实值比较状态,提供管理系统的指导。偏移服务识别其行为与预期不同、状态为未知的事实,并将用户通知给需要注意的事实。
5.3. 使用用户界面(UI)过滤系统事实。
您可以以多种方式过滤系统事实:
- 通过事实比较状态
- 按事实名称
- 按事实类别.
5.3.1. 选择要比较的系统
流程
- 进入 Operations > Drift > compare 页面。compare 屏幕将打开。
- 在比较屏幕上,点 Add systems or baselines。
- 在 Add to compare 屏幕中,选择 Systems 选项卡来查看在 Insights for Red Hat Enterprise Linux 清单中检查的系统。
在 Name 列中,选中两个或更多个系统的复选框,然后单击 Submit。比较屏幕将打开,显示系统中事实的状态。
比较结果也可以根据基准事实过滤。此功能允许您在创建比较时专注于最重要的数据。
- 单击 Fact Name 下拉菜单,然后选择 Fact type。
- 接下来,单击 Show 下拉菜单,然后选中 Baseline facts only 旁边的框。
5.3.2. 按比较状态过滤
流程
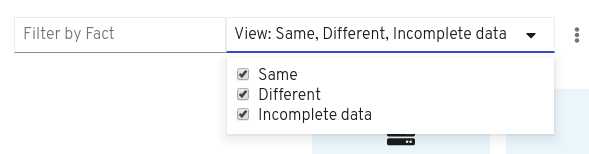
点 View 下拉列表并选择
- 等同于 仅显示相同值的事实,
- 不同的 仅显示不同事实,或者
用于 仅显示信息不完整的事实。
您可以选择 Same, Different, 和Incomplete data 状态的组合,可以根据需要清除选择。当您第一次添加系统进行比较时,会默认选择所有三个选项。
5.3.3. 根据事实名称过滤
流程
在顶部的搜索框中输入您的第一个事实名称。
例如,输入
kernel-
要查看所有软件包,请在搜索框中输入
installed_packages。 要添加额外的事实名称,请在搜索框中输入事实名称,然后按 Enter。
您可以根据过滤器需要添加任意数量的事实名称。
5.3.4. 根据事实(fact)类别过滤
流程
在搜索框中输入您的第一个事实类别,以根据该类别比较系统。
示例包括
installed_packages,installed_services,kernel_modules,network_interfaces,yum_repos,cpu_flags, 和enabled_services。要添加额外的事实类别,在搜索框中输入类别名称,并按 Enter 键。
您可以根据需要添加过滤器所需的事实类别。
5.3.5. 使用 UI 对系统事实进行排序
您可以在 UI 中按字母顺序对系统事实进行排序。
流程
要在升序和按字母顺序切换排序,请点击 Fact 旁边的箭头(
 )。
)。
默认情况下,系统事实列表以升序的形式出现。
5.3.6. 按比较状态对事实进行排序
您还可以根据比较状态对系统事实 进行排序。
流程
要按状态切换到排序,请点击 State 旁边的箭头(
 ) ()。
) ()。
如果您的搜索过滤器应用到系统事实列表,搜索过滤器也会应用到列表。
5.3.7. 示例和屏幕截图
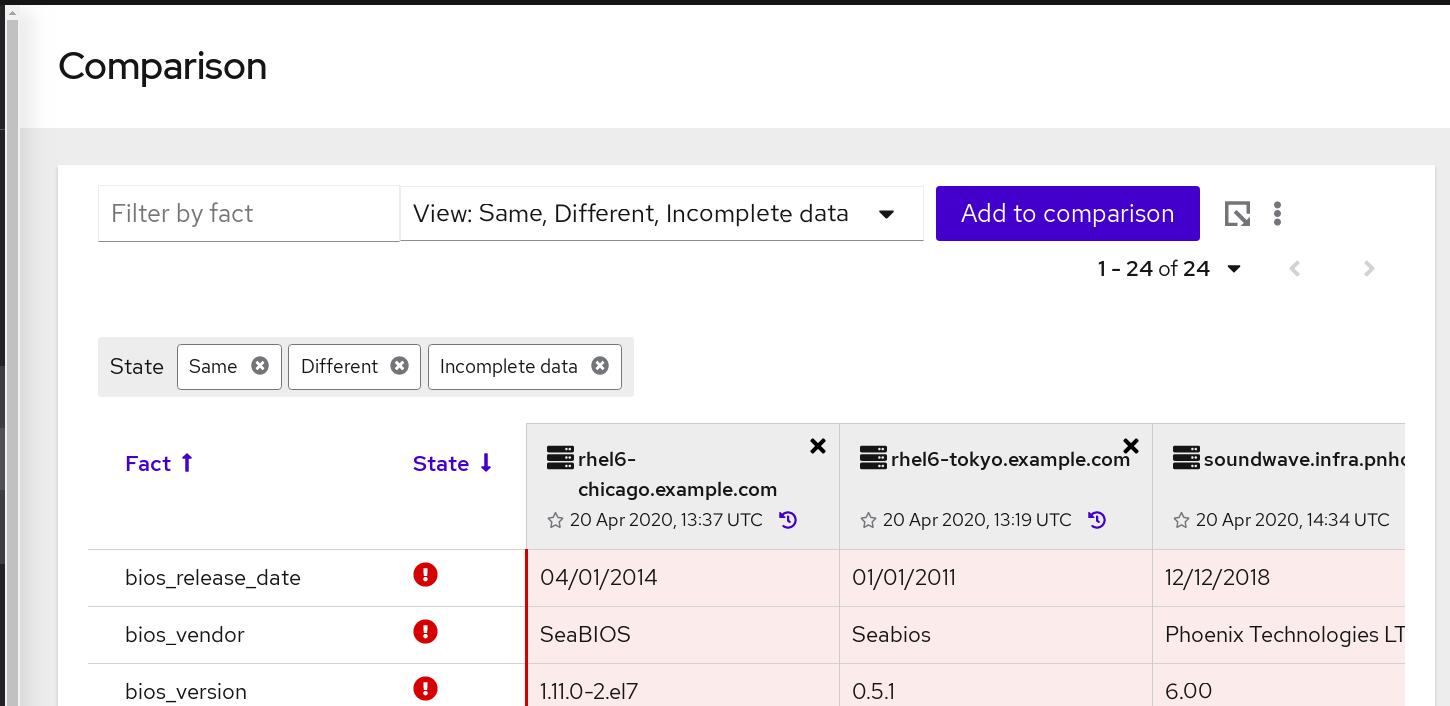
在以下示例屏幕中,您可以看到根据事实过滤的系统比较数据,其中显示系统间的差别。有些事实(如 fqdn )应该会因每个系统而异,但安装的软件包应该保持不变。随着时间的推移,一些软件包已在系统 1 上升级,但未在系统 2 和系统 3 上升级。要查看这些更改,请展开 installed_packages 的事实类别。
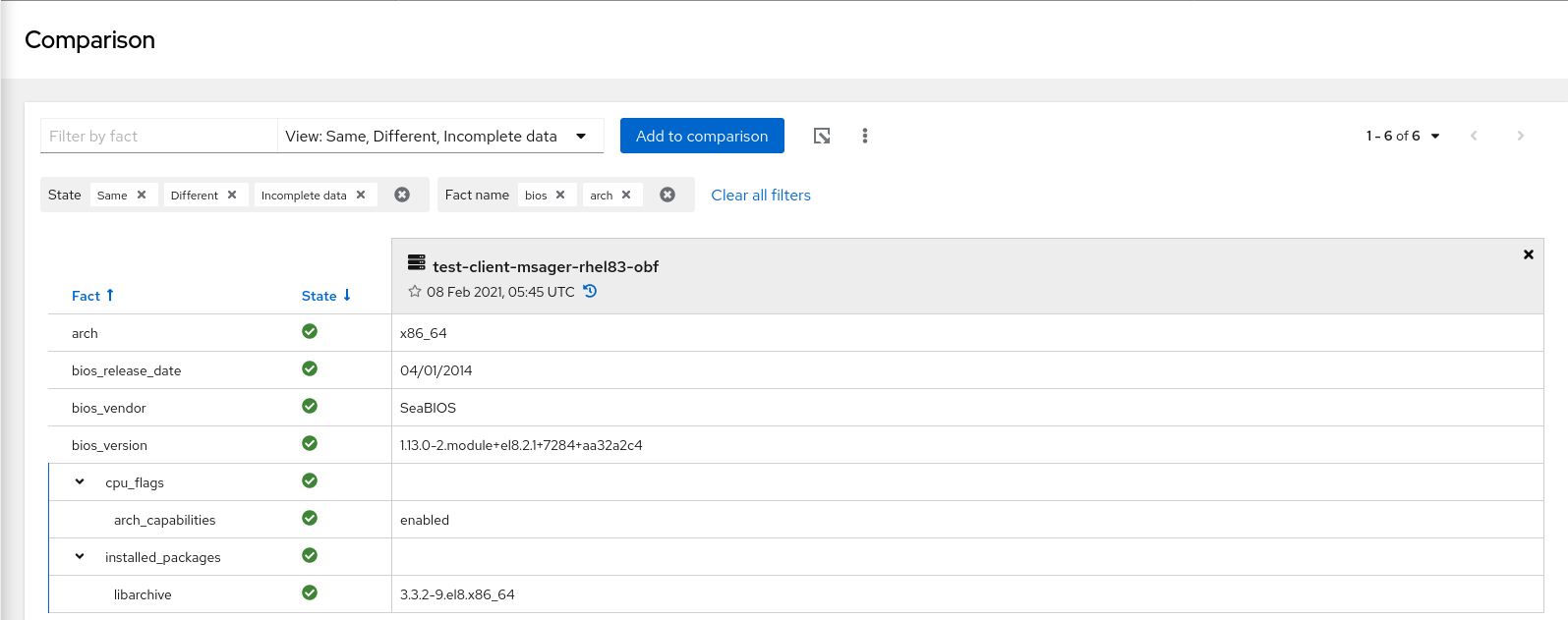
要锁定事实上的多个过滤器,请在文本框中键入事实名称并按 Enter。这个功能由"OR"操作器驱动,允许您过滤出与您选择的任何事实不匹配的任何内容。
在以下示例中,过滤过的事实列表仅显示与 bios 或 arch 匹配的名称的事实。
5.4. 使用 URL 参数过滤系统事实
drift 服务启用多事实过滤,允许您创建自定义比较。您可以通过几种方法过滤系统事实:
- 通过事实比较状态
- 按事实名称,或者
- 根据事实 (fact) 类别
5.4.1. 通过编辑 URL 排序
要加快过滤,您可以编辑 URL 参数。以下示例显示了示例 URL 及其参数。参数的数量与以下参数描述中的编号项目对应。
[package]insights/drift/?baseline_ids=<baseline-id>&system_ids=<system-id>&hsp_ids=<hsp-id>&reference_id=<reference-id>&filter[name]=bios,arch&filter[state]=same,different,incomplete_data&sort=state,fact
参数
-
[package]insights/drift/ -
[package]? -
[package]baseline_ids=<baseline-id>&system_ids=<system-id>&hsp_ids=<hsp-id> -
[package]&reference_id=<reference-id> -
[package]&filter[name]=bios,arch -
[package]&filter[state]=same,different,incomplete_data -
[package]&sort=-state,fact -
[package]&filter[show]=baseline
参数描述
如果需要,您可以手动输入这些参数,但 UI 中所做的更改会自动填充到此参数列表。
- App 服务: 这反映了您使用的 Red Hat Enterprise Linux 的 Red Hat Insights。这个示例在 Red Hat Insights for Red Hat Enterprise Linux 上使用 drift 服务。
- 搜索参数 :此字符告诉您要在下面的参数中搜索偏移。
- 系统/基线/历史配置文件的 ID: 它们是系统、基准和历史配置文件的 ID。在第一个 ? 符号后,每个符号都以 & 符号开头,以及相应的参数类型(baseline_ids、system_ids 或 hsp_ids)。
- 用作参考的系统/基线/历史配置文件的 ID:这是系统 ID、基准或历史系统配置文件,用作所有其他事实比较的引用。reference-id 必须在其中一个参数中指定(baseline_ids、system_ids 或 hsp_ids)。如果没有指定,则参数不会设置比较引用。
-
事实名称过滤器: 此事实名称过滤器采用格式
&filter[name]=fact。例如:&filter[name]=bios,arch要指定多个事实,请使用逗号分隔它们,且没有空格。 -
State 过滤器: 这些过滤器采用类似于事实名称过滤器的格式,但使用
&filter[state]。filter[state]的有效值为:same,different, 和incomplete_data。要指定多个事实,请使用逗号分隔它们,且没有空格。 -
表排序: 此参数使用表单
&sort=state。要指定多个事实,请使用逗号分隔它们,且没有空格。要按降序排序,请添加减号(-);例如&sort=-fact。如果没有减号,则按升序进行排序。要省略状态排序("no sort"),请省略参数中的状态排序。您不能省略事实排序。如果您没有为事实排序指定值,则排序默认为升序。
5.5. 排序系统事实
您可以像使用用户界面(UI)或编辑 URL 参数对系统事实进行排序。
使用 UI 排序
您可以在 UI 中按字母顺序对系统事实进行排序。点 Fact (
)旁的箭头在升序和降序间切换。请注意,事实默认以升序显示。您还可以根据比较状态对系统事实 进行排序。点 State (
)旁边的箭头按状态切换到排序。
排序可与任何应用的过滤器结合使用。也就是说,如果您过滤了安装的软件包或按比较状态查看事实,则过滤的数据可以按字母顺序排序或比较状态。
通过编辑 URL 排序
可以通过编辑 URL 参数来加快排序。检查以下 URL 以了解有关如何使用此功能的说明:
[package]insights/drift/?baseline_ids=<baseline-id>&system_ids=<system-id>&hsp_ids=<hsp-id>&reference_id=<reference-id>&filter[name]=bios,arch&filter[state]=same,different,incomplete_data&sort=state,fact
参数
-
[package]insights/drift/ -
[package]? -
[package]baseline_ids=<baseline-id>&system_ids=<system-id>&hsp_ids=<hsp-id> -
[package]&reference_id=<reference-id> -
[package]&filter[name]=bios,arch -
[package]&filter[state]=same,different,incomplete_data -
[package]&sort=-state,fact
如何使用参数
- 应用服务: 这反映了您使用的应用程序服务。在这种情况下,Red Hat Insights for Red Hat Enterprise Linux 的偏移。
- 搜索参数 :此字符告诉您要在下面的参数中搜索偏移。
- 系统/基线/历史配置文件的 ID: 它们是系统、基准和历史配置文件的 ID。在第一个 ? 符号后,每个符号都以 & 符号开头,以及相应的参数类型(baseline_ids、system_ids 或 hsp_ids)。
- 用作参考的系统/基线/历史配置文件的 ID: 这是系统 ID、基准或历史系统配置文件,用作比较所有其他事实的参考。reference-id 必须在其中一个参数中指定(baseline_ids、system_ids 或 hsp_ids)。如果没有指定,则不会为比较设置引用。
- 事实名称过滤器: 以 & 符号和 filter[name] 开始。应用的每个事实名称过滤器都会在 = 符号后面添加,并用逗号分隔,无空格。
- State 过滤器: 与事实名称过滤器相同,但前面带有 filter[state]。filter[state] 的有效值为: same, different 和 incomplete_data。可以通过使用逗号和空格分离来指定多个值。
- 表排序:按 & 符号处理,state 和/或事实在 sort= 后添加,并用逗号分开。如果 state 或 fact 前面带有 - 符号,则按降序排列;否则,它按升序排序。状态排序具有没有任何排序的功能。在这种情况下,状态不会在 url 参数中添加。另一方面,在另一方面进行排序(如果关闭)将默认为升序。
这些参数可以手动输入,但在 UI 中进行更改时,其主要功能是自动填充。
5.6. 使用模糊的值进行比较
Insights 客户端提供 IP 地址模糊处理和主机名模糊处理。
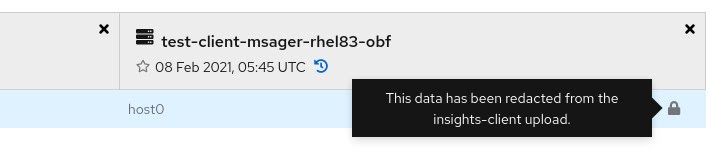
如果您的一个事实值已被修改来保护敏感信息,则偏移会通知您您的比较包含隐藏(模糊)数据。
模糊处理的事实值显示以下特征:
- 值 cell 被灰掉。
- 锁定图标会出现在灰掉的单元中,以及指出值已被重新处理的工具提示。
工具提示会出现在"状态"图标中,用于描述行为"incomplete data"状态的原因。
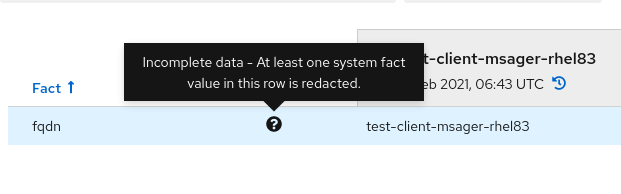
如果比较中的其中一个值被重做,则该事实比较的状态会显示"完成数据"。
其他资源
- 有关设置客户端数据模糊的更多信息,请参阅 Red Hat Insights 的客户端配置指南。
5.7. 了解多值事实
多值事实提供了更详细的信息,以帮助对系统问题进行故障排除。例如,偏移存储给定软件包名称的所有已安装版本的列表。这会导致软件包可以使用多值事实。清单和偏移 API 也为事实提供多个值。
以下示例显示了有两个内核软件包的系统。通过多值事实支持,可以查看一个系统上两个软件包的值。
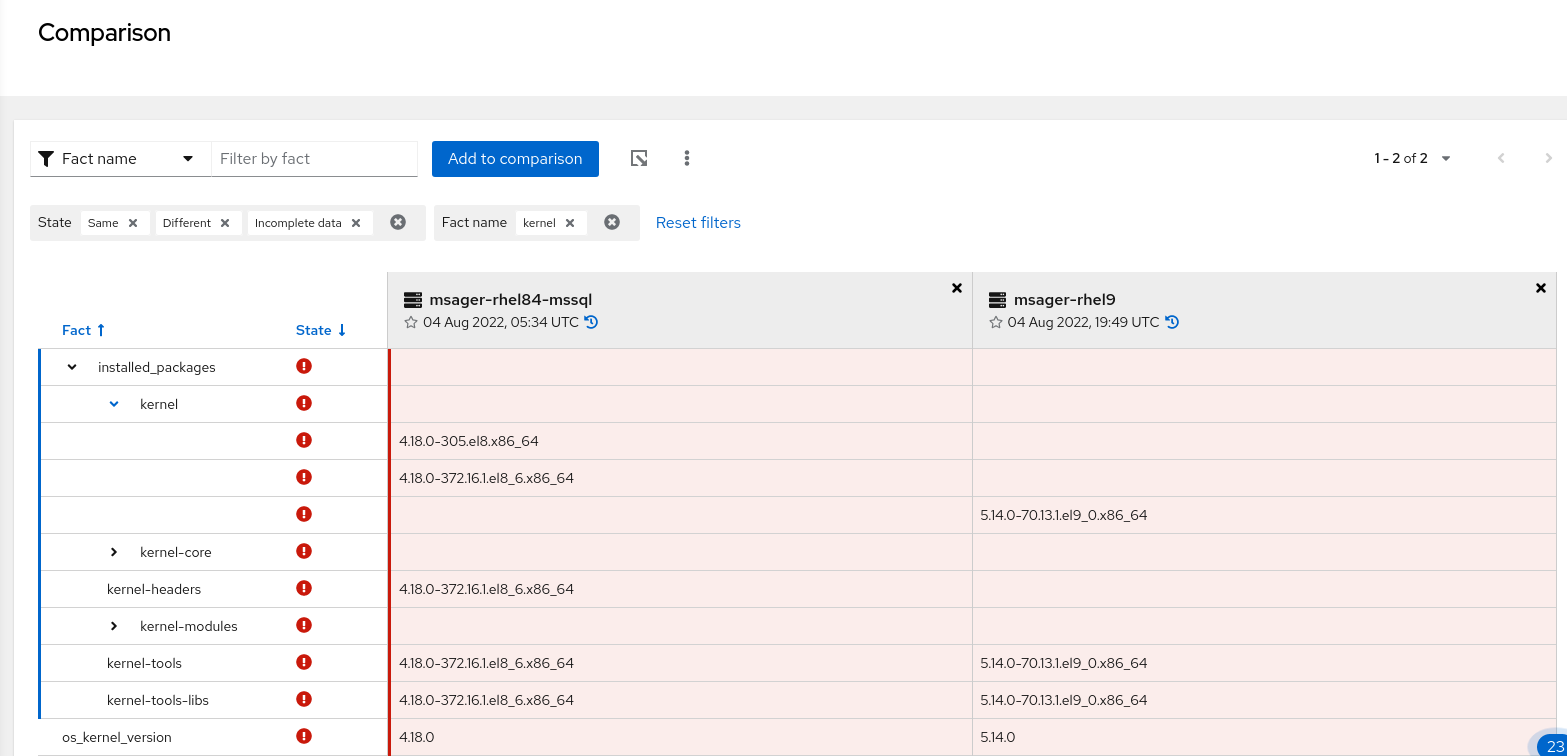
通过这种增强的详细程度,您可以在执行分析时正确评估并比较所有已安装的版本。
以下示例显示了包含为两个架构编译的软件包的系统。它具有 i686 和 x86_64 架构的 glibc 软件包。
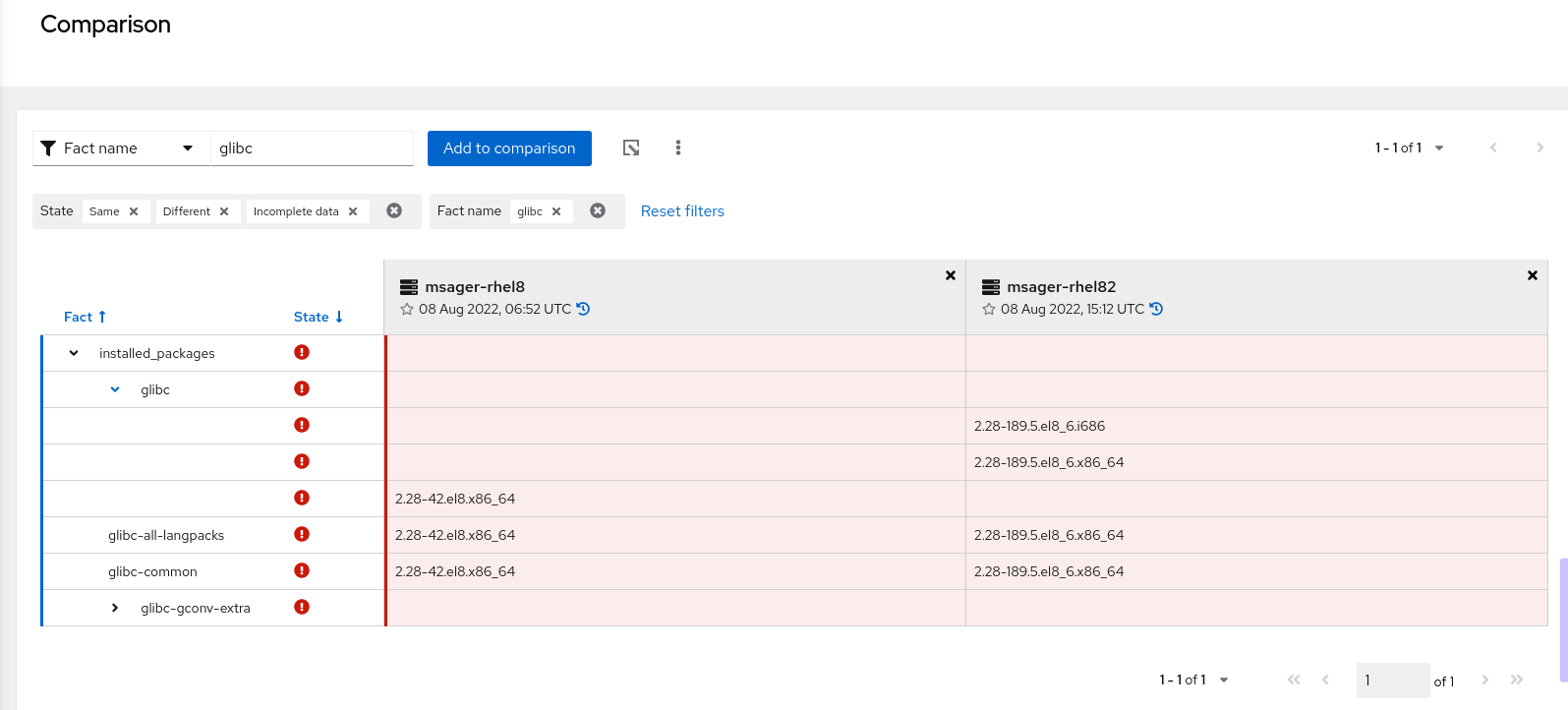
其他资源
- 有关清单和偏移 API 中的多个值的更多信息,请参阅 Red Hat Insights for Red Hat Enterprise Linux API 文档: https://access.redhat.com/documentation/zh-cn/red_hat_insights/1-latest/html/system_comparison_api_documentation/[系统比较 API 文档。
5.8. 使用多事实过滤
使用多事实过滤来为您的系统创建自定义比较。您可以根据特定事实和标签组过滤您的比较查询。
您可以使用多事实过滤来:
- 在 fact name 字段中有多个输入。
- 避免在多个过滤器之间重新交换。
- 排除不相关的事实。
- 比较与特定问题相关的事实,以改进故障排除。
- 与其他管理员或同事共享比较。
5.9. 可用事实及其功能
下表列出了您可以在系统比较中使用的系统事实。
表 5.1. 系统事实
| 事实名称 | 描述 | 值示例 |
|---|---|---|
|
| 带有 Ansible 相关事实列表的 flavor | controller_version,值为 4.0.0 |
|
| 系统架构 |
|
|
|
BIOS 发行日期;通常为 | 01/01/2011 |
|
| BIOS 供应商名称 | LENOVO |
|
| BIOS 版本 | 1.17.0 |
|
|
云供应商。值为 |
|
|
| 每个插槽的 CPU 内核数 | 2 |
|
|
带有 CPU 标记列表的 category。每个名称都是 CPU 标记(例如: |
|
|
|
带有启用的服务列表的 flavor。类别中的每个名称都是服务名称(例如: |
|
|
| 系统完全限定域名 | system1.example.com |
|
|
系统基础架构;常见的值是 |
|
|
|
基础架构厂商;常见值为 |
|
|
| 安装的 RPM 软件包列表。这是一个类别。 |
|
|
|
带有已安装服务列表的 flavor。类别中的每个名称都是服务名称(例如: |
|
|
|
内核模块列表。类别中的每个名称都是内核模块(例如: |
|
|
|
|
|
|
| 带有 MSSQL 相关事实列表的类别 | mssql_version,值为 15.0.4153.1 |
|
| 与网络接口相关的事实列表。 | |
|
每个接口都有六个事实: | ||
|
每个接口(例如: | ||
|
与大多数网络接口事实进行比较,以确保它们在系统间相等。但是,会检查 | ||
|
| CPU 总数 |
|
|
| 插槽总数 |
|
|
| 内核版本 |
|
|
| 内核版本 |
|
|
| 正在运行的进程列表。事实名称是进程的名称,值是实例数。 |
|
|
| SAP 实例号 |
|
|
| SAP 系统 ID (SID) |
|
|
| 指明系统上是否安装了 SAP 的布尔值字段 |
|
|
| SAP 版本号 |
|
|
| 表示系统已注册到 Satellite 服务器的布尔值字段。 |
|
|
| 当前 SELinux 模式 |
|
|
| 在配置文件中设置的 SELinux 模式 |
|
|
| 以人类可读形式的系统内存总量 |
|
|
|
来自命令 |
|
|
|
yum 存储库列表。存储库名称添加到事实的开头。每个存储库都有相关的事实 |
|
第 6 章 比较系统和系统配置集
您可以将系统相互比较,与配置文件以及参考点进行比较。当您选择您要比较的所有系统后,您可以使用比较页面来比较系统的事实。
6.1. 将系统与参考点进行比较
在某些情况下,您可能想要将所有系统与单个引用点进行比较,而不是相互比较所有的系统,或者将它们作为组进行比较。例如,您可能需要将所有系统与基准进行比较,以便根据这个基准计算所有系统。您还可以将系统与时间戳的配置文件进行比较,以了解更改的位置和的时间。
您可能还希望反转比较。例如,您可能希望将所有配置集与最新配置集进行比较,而不是将配置集与旧时间戳进行比较。这种比较可让您识别与引用点分开的更改。
6.1.1. 将系统与单一参考点进行比较
您可以将多个系统或所有系统与单一的参考点进行比较。
流程
-
在比较屏幕中,点系统标头中的星号图标(
 )。
)。
drift 服务将您选择的每个系统与参考系统中的事实值进行比较。参考值显示在第一位置列中,列标题以蓝色突出显示。
事实值以红色突出显示的每个差别显示。
在扩展事实来查看详情前,具有多个值的事实类别不会突出显示。当您这样做时,drift 会显示以红色突出显示的特定事实详情。
6.2. 使用系统配置集的历史记录
每次提交系统以进行比较时,配置集中的提交检查并使用时间戳进行标记。通过检查不同的配置集版本,您可以随着时间的推移查看系统。
在 Choose systems 屏幕中,如果系统标记为时间戳
![]() 图标,您可以直接打开该系统。否则,在比较系统前添加您要比较的系统。
图标,您可以直接打开该系统。否则,在比较系统前添加您要比较的系统。
6.3. 导出系统比较输出
drift 服务允许您将系统比较输出(包括任何当前选择(如过滤器)导出到以逗号分隔的值(CSV)文件或 JavaScript 对象表示法(JSON)文件。然后,您可以使用您选择的工具打开 CSV 或 JSON 文件,以比较导出的事实并分析系统中的差异。
导出的 CSV 或 JSON 报告会在系统比较输出中保留所有当前选择,包括任何应用的过滤器。要查看嵌套事实类别(如 installed_packages)中的所有事实,请在将系统比较输出导出到报告前扩展所有嵌套事实类别。
流程
-
在两个或多个系统的比较输出屏幕上,点 Export 图标
,然后选择 Export as CSV,或 Export as JSON。
- 使用您选择的工具打开 CSV 或 JSON 文件,以便您可以轻松比较导出的事实并分析系统中的差异。
6.3.1. 将系统比较输出导出到 CSV 或 JSON 文件
您可以将您的系统配置集输出以及您使用的过滤器导出到以逗号分隔的值(CSV)或 JavaScript Object Notation (JSON)文件中。过滤器突出显示您的系统配置文件中的区别和不完整数据。您可以使用这些信息来研究与您的系统相关的特征,并排除您发现的所有问题。
流程
-
在两个或多个系统比较输出中,点 Export 图标
,然后选择 Export to CSV 或 Export to JSON。
第 7 章 为偏移事件启用通知和集成
7.1. 启用通知和集成
您可以在 Red Hat Hybrid Cloud Console 上启用通知服务,以便在偏移服务检测到问题并生成警报时发送通知。使用通知服务可自由地检查 Red Hat Insights for Red Hat Enterprise Linux 仪表板 是否有警报。
例如,您可以将通知服务配置为在偏移服务检测到基准更改时自动发送电子邮件消息,或者发送偏移服务每天生成的所有警报的电子邮件摘要。
除了发送电子邮件信息外,您还可以将通知服务配置为以其他方式发送事件数据:
- 使用经过身份验证的客户端查询 Red Hat Insights API 获取事件数据
- 使用 Webhook 将事件发送到接受入站请求的第三方应用程序
- 将通知与 Splunk 等应用程序集成,以将偏移事件路由到应用程序仪表板
启用通知服务需要三个主要步骤:
- 首先,机构管理员会创建一个具有 Notifications 管理员角色的用户访问权限组,然后将帐户成员添加到组中。
- 接下来,通知管理员为通知服务中的事件设置行为组。行为组指定每个通知的交付方法。例如,行为组可以指定电子邮件通知是否发送到所有用户,或者只向机构管理员发送。
- 最后,从事件接收电子邮件通知的用户必须设置其用户首选项,以便他们为每个事件接收单独的电子邮件。
其他资源
有关如何为偏移警报设置通知的更多信息,请参阅 在 Red Hat Hybrid Cloud Console 上配置通知,并将 Red Hat Hybrid Cloud Console 与第三方应用程序集成。
对红帽文档提供反馈
我们非常感谢并对我们文档的反馈进行优先排序。提供尽可能多的详细信息,以便快速解决您的请求。
先决条件
- 已登陆到红帽客户门户网站。
流程
要提供反馈,请执行以下步骤:
- 点击以下链接: Create Issue
- 在 Summary 文本框中描述问题或功能增强。
- 在 Description 文本框中提供有关问题或请求的增强的详细信息。
- 在 Reporter 文本框中键入您的名称。
- 点 Create 按钮。
此操作会创建一个文档票据,并将其路由到适当的文档团队。感谢您花时间来提供反馈。