
Red Hat Training
A Red Hat training course is available for RHEL 8
Implantação de diferentes tipos de servidores
Um guia para a implantação de diferentes tipos de servidores no Red Hat Enterprise Linux 8
Resumo
Tornando o código aberto mais inclusivo
A Red Hat tem o compromisso de substituir a linguagem problemática em nosso código, documentação e propriedades da web. Estamos começando com estes quatro termos: master, slave, blacklist e whitelist. Por causa da enormidade deste esforço, estas mudanças serão implementadas gradualmente ao longo de vários lançamentos futuros. Para mais detalhes, veja a mensagem de nosso CTO Chris Wright.
Fornecendo feedback sobre a documentação da Red Hat
Agradecemos sua contribuição em nossa documentação. Por favor, diga-nos como podemos melhorá-la. Para fazer isso:
Para comentários simples sobre passagens específicas:
- Certifique-se de que você está visualizando a documentação no formato Multi-page HTML. Além disso, certifique-se de ver o botão Feedback no canto superior direito do documento.
- Use o cursor do mouse para destacar a parte do texto que você deseja comentar.
- Clique no pop-up Add Feedback que aparece abaixo do texto destacado.
- Siga as instruções apresentadas.
Para enviar comentários mais complexos, crie um bilhete Bugzilla:
- Ir para o site da Bugzilla.
- Como Componente, use Documentation.
- Preencha o campo Description com sua sugestão de melhoria. Inclua um link para a(s) parte(s) relevante(s) da documentação.
- Clique em Submit Bug.
Capítulo 1. Configurando o servidor web Apache HTTP
1.1. Introdução ao servidor web Apache HTTP
Um web server é um serviço de rede que serve conteúdo para um cliente através da web. Isso normalmente significa páginas web, mas quaisquer outros documentos também podem ser ser servidos. Os servidores web também são conhecidos como servidores HTTP, pois utilizam o hypertext transport protocol (HTTP).
O Apache HTTP ServerA Apache Software Foundation, httpd, é um servidor web de código aberto desenvolvido pela Apache Software Foundation.
Se você estiver atualizando a partir de um lançamento anterior do Red Hat Enterprise Linux, você precisará atualizar a configuração do serviço httpd de acordo. Esta seção revisa alguns dos recursos recém-adicionados e o orienta através da atualização dos arquivos de configuração anteriores.
1.1.1. Mudanças notáveis no Servidor HTTP Apache
O Apache HTTP ServerEsta versão atualizada inclui várias características novas, mas mantém compatibilidade com a versão RHEL 7 no nível de configuração e Interface Binária de Aplicação (ABI) dos módulos externos.
As novas características incluem:
-
HTTP/2agora é fornecido pelo pacotemod_http2, que faz parte do módulohttpd. -
é suportada a ativação do soquete systemd. Consulte a página de manual
httpd.socket(8)para mais detalhes.
Múltiplos novos módulos foram adicionados:
-
mod_proxy_hcheck- um módulo de verificação de saúde por procuração -
mod_proxy_uwsgi- um proxy de interface Web Server Gateway (WSGI) -
mod_proxy_fdpass- fornece suporte para a passagem do soquete do cliente para outro processo -
mod_cache_socache- um cache HTTP usando, por exemplo, o backend memcache -
mod_md- um serviço de certificado do protocolo ACME SSL/TLS
-
Os seguintes módulos agora são carregados por padrão:
-
mod_request -
mod_macro -
mod_watchdog
-
-
Um novo subpacote,
httpd-filesystem, foi adicionado, que contém o layout básico do diretório para o Apache HTTP Server incluindo as permissões corretas para os diretórios. -
O suporte de serviço instantâneo,
httpd@.servicefoi introduzido. Veja a página de manualhttpd.servicepara mais informações.
-
Um novo
httpd-init.servicesubstitui o%post scriptpara criar um par de chaves autoassinadomod_ssl.
-
O provisionamento e renovação automatizada de certificados TLS usando o protocolo ACME (Automatic Certificate Management Environment) é agora suportado com o pacote
mod_md(para uso com provedores de certificados comoLet’s Encrypt). -
O Apache HTTP Server agora suporta o carregamento de certificados TLS e chaves privadas a partir de tokens de segurança de hardware diretamente dos módulos
PKCS#11. Como resultado, uma configuraçãomod_sslpode agora usarPKCS#11URLs para identificar a chave privada do TLS e, opcionalmente, o certificado TLS nas diretivasSSLCertificateKeyFileeSSLCertificateFile. Uma nova diretiva
ListenFreeno arquivo/etc/httpd/conf/httpd.confé agora suportada.De forma similar à diretiva
Listen,ListenFreefornece informações sobre endereços IP, portas ou endereços IP - e combinações de portas que o servidor ouve. Entretanto, comListenFree, a opção de soqueteIP_FREEBINDé ativada por padrão. Assim,httpdé permitido vincular a um endereço IP não local ou a um endereço IP que ainda não existe. Isto permite quehttpdescute em um socket sem exigir que a interface de rede subjacente ou o endereço IP dinâmico especificado esteja em alta no momento em quehttpdestiver tentando ligar-se a ele.Note que a diretiva
ListenFreeestá atualmente disponível apenas na RHEL 8.Para mais detalhes em
ListenFree, consulte a tabela a seguir:Tabela 1.1. Sintaxe, status e módulos da diretriz ListenFree
Sintaxe Status Módulos ListenFree [IP-address:]número de porta [protocolo]
MPM
evento, trabalhador, prefork, mpm_winnt, mpm_netware, mpmt_os2
Outras mudanças notáveis incluem:
Os seguintes módulos foram removidos:
-
mod_file_cache mod_nssUse
mod_sslcomo um substituto. Para detalhes sobre a migração demod_nss, veja Seção 1.10, “Exportar uma chave privada e certificados de um banco de dados NSS para utilizá-los na configuração de um servidor web Apache”.-
mod_perl
-
-
O tipo padrão do banco de dados de autenticação DBM utilizado pelo Apache HTTP Server no RHEL 8 foi alterado de
SDBMparadb5. -
O módulo
mod_wsgipara o Apache HTTP Server foi atualizado para Python 3. As aplicações WSGI agora são suportadas somente com Python 3, e devem ser migradas a partir de Python 2. O módulo multi-processamento (MPM) configurado por padrão com o Apache HTTP Server mudou de um modelo multi-processo, bifurcado (conhecido como
prefork) para um modelo multi-rosca de alto desempenho,event.Qualquer módulo de terceiros que não seja seguro para a rosca precisa ser substituído ou removido. Para alterar o MPM configurado, edite o arquivo
/etc/httpd/conf.modules.d/00-mpm.conf. Consulte a página de manualhttpd.service(8)para mais informações.- Os mínimos UID e GID permitidos aos usuários pelo suEXEC são agora 1000 e 500, respectivamente (anteriormente 100 e 100).
-
O arquivo
/etc/sysconfig/httpdnão é mais uma interface suportada para definir variáveis de ambiente para o serviçohttpd. A página de manualhttpd.service(8)foi adicionada para o serviço systemd. -
A interrupção do serviço
httpdagora usa uma "parada graciosa" por padrão. -
O módulo
mod_auth_kerbfoi substituído pelo módulomod_auth_gssapi.
1.1.2. Atualização da configuração
Para atualizar os arquivos de configuração do Apache HTTP Server usada no Red Hat Enterprise Linux 7, escolha uma das seguintes opções:
-
Se
/etc/sysconfig/httpdfor usado para definir variáveis de ambiente, crie um arquivo drop-in do sistema em seu lugar. - Se algum módulo de terceiros for utilizado, certifique-se de que seja compatível com um MPM rosqueado.
- Se for utilizado suexec, garantir que as identificações de usuário e grupo atendam aos novos mínimos.
Você pode verificar a configuração para possíveis erros usando o seguinte comando:
# apachectl configtest Syntax OK
1.2. Os arquivos de configuração do Apache
Quando o serviço httpd é iniciado, por padrão, ele lê a configuração de locais que estão listados em Tabela 1.2, “Os arquivos de configuração do serviço httpd”.
Tabela 1.2. Os arquivos de configuração do serviço httpd
| Caminho | Descrição |
|---|---|
|
| O arquivo principal de configuração. |
|
| Um diretório auxiliar para os arquivos de configuração que estão incluídos no arquivo de configuração principal. |
|
| Um diretório auxiliar para arquivos de configuração que carregam os módulos dinâmicos instalados no Red Hat Enterprise Linux. Na configuração default, estes arquivos de configuração são processados primeiro. |
Embora, a configuração padrão seja adequada para a maioria das situações, você pode usar também outras opções de configuração. Para que qualquer mudança tenha efeito, reinicie o servidor web primeiro. Veja Seção 1.3, “Gerenciando o serviço httpd” para mais informações sobre como reiniciar o serviço httpd.
Para verificar a configuração para possíveis erros, digite o seguinte em uma janela de comandos:
# apachectl configtest Syntax OK
Para facilitar a recuperação de erros, faça uma cópia do arquivo original antes de editá-lo.
1.3. Gerenciando o serviço httpd
Esta seção descreve a quente para iniciar, parar e reiniciar o serviço httpd.
Pré-requisitos
- O Servidor HTTP Apache está instalado.
Procedimento
Para iniciar o serviço
httpd, entre:# systemctl start httpd
Para interromper o serviço
httpd, entre:# systemctl stop httpd
Para reiniciar o serviço
httpd, entre:# systemctl restart httpd
1.4. Configuração de um Servidor HTTP Apache de uma única instância
Esta seção descreve como configurar um Servidor HTTP Apache de uma única instância para servir conteúdo HTML estático.
Siga o procedimento desta seção se o servidor web deve fornecer o mesmo conteúdo para todos os domínios associados com o servidor. Se você quiser fornecer conteúdo diferente para domínios diferentes, estabeleça hosts virtuais baseados em nomes. Para detalhes, veja Seção 1.5, “Configuração de hosts virtuais baseados no nome Apache”.
Procedimento
Instale o pacote
httpd:# yum instalar httpd
Abra a porta TCP
80no firewall local:# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
Habilite e inicie o serviço
httpd:# systemctl enable --now httpd
Opcional: Adicionar arquivos HTML ao diretório
/var/www/html/.NotaAo adicionar conteúdo a
/var/www/html/, arquivos e diretórios devem ser legíveis pelo usuário, sob o qualhttpdé executado por padrão. O proprietário do conteúdo pode ser o usuárioroote o grupo de usuáriosroot, ou outro usuário ou grupo da escolha do administrador. Se o proprietário do conteúdo for o usuárioroote o grupo de usuáriosroot, os arquivos devem ser legíveis por outros usuários. O contexto SELinux para todos os arquivos e diretórios deve serhttpd_sys_content_t, que é aplicado por padrão a todo o conteúdo dentro do diretório/var/www.
Etapas de verificação
Conecte-se com um navegador da web para
http://server_IP_or_host_name/.Se o diretório
/var/www/html/estiver vazio ou não contiver um arquivoindex.htmlouindex.htm, o Apache exibe oRed Hat Enterprise Linux Test Page. Se/var/www/html/contém arquivos HTML com um nome diferente, você pode carregá-los inserindo a URL para esse arquivo, como por exemplohttp://server_IP_or_host_name/example.html.
Recursos adicionais
- Para maiores detalhes sobre como configurar o Apache e adaptar o serviço ao seu ambiente, consulte o manual do Apache. Para obter detalhes sobre a instalação do manual, consulte Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
-
Para detalhes sobre o uso ou ajuste do serviço
httpdsystemd, consulte a página de manualhttpd.service(8).
1.5. Configuração de hosts virtuais baseados no nome Apache
Os hosts virtuais baseados em nomes permitem que o Apache sirva diferentes conteúdos para diferentes domínios que resolvam para o endereço IP do servidor.
O procedimento nesta seção descreve a criação de um host virtual para o domínio example.com e example.net com diretórios raiz de documentos separados. Ambos os hosts virtuais servem conteúdo HTML estático.
Pré-requisitos
Os clientes e o servidor web resolvem o domínio
example.comeexample.netpara o endereço IP do servidor web.Observe que você deve adicionar manualmente estas entradas ao seu servidor DNS.
Procedimento
Instale o pacote
httpd:# yum instalar httpd
Edite o arquivo
/etc/httpd/conf/httpd.conf:Anexe a seguinte configuração de host virtual para o domínio
example.com:<VirtualHost *:80> DocumentRoot "/var/www/example.com/" ServerName example.com CustomLog /var/log/httpd/example.com_access.log combined ErrorLog /var/log/httpd/example.com_error.log </VirtualHost>Estas configurações configuram o seguinte:
-
Todas as configurações da diretiva
<VirtualHost *:80>são específicas para este host virtual. -
DocumentRootestabelece o caminho para o conteúdo da web do host virtual. ServerNamedefine os domínios para os quais este host virtual serve de conteúdo.Para definir vários domínios, adicione o parâmetro
ServerAliasà configuração e especifique os domínios adicionais separados com um espaço neste parâmetro.-
CustomLogdefine o caminho para o log de acesso do host virtual. ErrorLogdefine o caminho para o registro de erros do host virtual.NotaO Apache utiliza o primeiro host virtual encontrado na configuração também para solicitações que não correspondem a nenhum domínio definido nos parâmetros
ServerNameeServerAlias. Isto também inclui pedidos enviados para o endereço IP do servidor.
-
Todas as configurações da diretiva
Anexar uma configuração similar de host virtual para o domínio
example.net:<VirtualHost *:80> DocumentRoot "/var/www/example.net/" ServerName example.net CustomLog /var/log/httpd/example.net_access.log combined ErrorLog /var/log/httpd/example.net_error.log </VirtualHost>Criar as raízes dos documentos para ambos os anfitriões virtuais:
# mkdir /var/www/example.com/ # mkdir /var/www/example.net/
Se você definir caminhos nos parâmetros
DocumentRootque não estão dentro de/var/www/, defina o contextohttpd_sys_content_tem ambas as raízes do documento:# semanage fcontext -a -t httpd_sys_content_t "/srv/example.com(/.*)?" # restorecon -Rv /srv/example.com/ # semanage fcontext -a -t httpd_sys_content_t "/srv/example.net(/.\*)?" # restorecon -Rv /srv/example.net/
Estes comandos definem o contexto
httpd_sys_content_tno diretório/srv/example.com/e/srv/example.net/.Note que você deve instalar o pacote
policycoreutils-python-utilspara executar o comandorestorecon.Abra a porta
80no firewall local:# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
Habilite e inicie o serviço
httpd:# systemctl enable --now httpd
Etapas de verificação
Criar um arquivo de exemplo diferente em cada raiz de documento do host virtual:
# echo "vHost example.com" > /var/www/example.com/index.html # echo "vHost example.net" > /var/www/example.net/index.html
-
Use um navegador e conecte-se a
http://example.com. O servidor web mostra o arquivo de exemplo do host virtualexample.com. -
Use um navegador e conecte-se a
http://example.net. O servidor web mostra o arquivo de exemplo do host virtualexample.net.
Recursos adicionais
-
Para mais detalhes sobre a configuração dos hosts virtuais Apache, consulte a documentação
Virtual Hostsno manual Apache. Para detalhes sobre a instalação do manual, veja Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
1.6. Configurando a criptografia TLS em um servidor Apache HTTP
Por padrão, o Apache fornece conteúdo aos clientes usando uma conexão HTTP não criptografada. Esta seção descreve como habilitar a criptografia TLS e configurar as configurações freqüentemente usadas relacionadas à criptografia em um Servidor HTTP Apache.
Pré-requisitos
- O Servidor HTTP Apache está instalado e funcionando.
1.6.1. Adicionando criptografia TLS a um Servidor HTTP Apache
Esta seção descreve como ativar a criptografia TLS em um Servidor HTTP Apache para o domínio example.com.
Pré-requisitos
- O Servidor HTTP Apache está instalado e funcionando.
A chave privada é armazenada no arquivo
/etc/pki/tls/private/example.com.key.Para detalhes sobre a criação de uma chave privada e pedido de assinatura de certificado (CSR), bem como sobre como solicitar um certificado a uma autoridade certificadora (CA), consulte a documentação de sua CA. Alternativamente, se sua CA suporta o protocolo ACME, você pode usar o módulo
mod_mdpara automatizar a recuperação e o provisionamento de certificados TLS.-
O certificado do TLS é armazenado no arquivo
/etc/pki/tls/private/example.com.crt. Se você usar um caminho diferente, adapte as etapas correspondentes do procedimento. -
O certificado da CA é armazenado no arquivo
/etc/pki/tls/private/ca.crt. Se você usar um caminho diferente, adapte as etapas correspondentes do procedimento. - Os clientes e o servidor web resolvem o nome do anfitrião do servidor para o endereço IP do servidor web.
Procedimento
Instale o pacote
mod_ssl:# dnf install mod_ssl
Edite o arquivo
/etc/httpd/conf.d/ssl.confe adicione as seguintes configurações à diretiva<VirtualHost _default_:443>:Defina o nome do servidor:
ServerName example.comImportanteO nome do servidor deve corresponder à entrada definida no campo
Common Namedo certificado.Opcional: Se o certificado contiver nomes de host adicionais no campo
Subject Alt Names(SAN), você pode configurarmod_sslpara fornecer criptografia TLS também para esses nomes de host. Para configurar isto, adicione o parâmetroServerAliasescom os nomes correspondentes:ServerAlias www.example.com server.example.com
Defina os caminhos para a chave privada, o certificado do servidor e o certificado da CA:
SSLCertificateKeyFile "/etc/pki/tls/private/example.com.key" SSLCertificateFile "/etc/pki/tls/certs/example.com.crt" SSLCACertificateFile "/etc/pki/tls/certs/ca.crt"
Por razões de segurança, configure que somente o usuário
rootpossa acessar o arquivo de chave privada:# chown root:root /etc/pki/tls/private/example.com.key # chmod 600 /etc/pki/tls/private/example.com.key
AtençãoSe a chave privada foi acessada por usuários não autorizados, revogar o certificado, criar uma nova chave privada e solicitar um novo certificado. Caso contrário, a conexão TLS não é mais segura.
Abra a porta
443no firewall local:# firewall-cmd --permanent --add-port=443 # firewall-cmd --reload
Reinicie o serviço
httpd:# systemctl restart httpd
NotaSe você protegeu o arquivo de chave privada com uma senha, você deve digitar esta senha toda vez que o serviço
httpdfor iniciado.
Etapas de verificação
-
Use um navegador e conecte-se a
https://example.com.
Recursos adicionais
-
Para mais detalhes sobre a configuração do TLS, consulte a documentação
SSL/TLS Encryptionno manual do Apache. Para detalhes sobre a instalação do manual, veja Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
1.6.2. Configuração das versões do protocolo TLS suportadas em um Servidor HTTP Apache
Por padrão, o Servidor HTTP Apache no RHEL 8 utiliza a política de criptografia de todo o sistema que define valores seguros padrão, que também são compatíveis com navegadores recentes. Por exemplo, a política DEFAULT define que somente as versões do protocolo TLSv1.2 e TLSv1.3 são habilitadas no Apache.
Esta seção descreve como configurar manualmente quais versões do protocolo TLS seu Servidor HTTP Apache suporta. Siga o procedimento se seu ambiente exigir que somente versões específicas do protocolo TLS sejam habilitadas, por exemplo:
-
Se seu ambiente exige que os clientes também possam utilizar o fraco protocolo
TLS1(TLSv1.0) ouTLS1.1. -
Se você quiser configurar que o Apache suporta apenas o protocolo
TLSv1.2ouTLSv1.3.
Pré-requisitos
- A criptografia TLS está habilitada no servidor, conforme descrito em Seção 1.6.1, “Adicionando criptografia TLS a um Servidor HTTP Apache”.
Procedimento
Edite o arquivo
/etc/httpd/conf/httpd.conf, e adicione a seguinte configuração à diretiva<VirtualHost>para a qual você deseja definir a versão do protocolo TLS. Por exemplo, para habilitar somente o protocoloTLSv1.3:SSLProtocol -Todos os TLSv1.3
Reinicie o serviço
httpd:# systemctl restart httpd
Etapas de verificação
Use o seguinte comando para verificar se o servidor suporta
TLSv1.3:# openssl s_client -connect example.com:443 -tls1_3Use o seguinte comando para verificar se o servidor não suporta
TLSv1.2:# openssl s_client -connect example.com:443 -tls1_2Se o servidor não suportar o protocolo, o comando retorna um erro:
140111600609088:error:1409442E:SSL routines:ssl3_read_bytes:tlsv1 alert protocol version:ssl/record/rec_layer_s3.c:1543:SSL alert number 70
- Opcional: Repetir o comando para outras versões do protocolo TLS.
Recursos adicionais
-
Para mais detalhes sobre a política de criptografia do sistema, consulte a página de manual
update-crypto-policies(8)e Utilizando políticas criptográficas de todo o sistema. -
Para mais detalhes sobre o parâmetro
SSLProtocol, consulte a documentaçãomod_sslno manual do Apache. Para obter detalhes sobre a instalação do manual, consulte Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
1.6.3. Configurando as cifras suportadas em um Servidor HTTP Apache
Por padrão, o Servidor HTTP Apache no RHEL 8 utiliza a política de criptografia de todo o sistema que define valores seguros padrão, que também são compatíveis com navegadores recentes. Para a lista de cifras que a criptografia em todo o sistema permite, veja o arquivo /etc/crypto-policies/back-ends/openssl.config.
Esta seção descreve como configurar manualmente quais cifras seu Servidor HTTP Apache suporta. Siga o procedimento se seu ambiente exigir cifras específicas.
Pré-requisitos
- A criptografia TLS está habilitada no servidor, conforme descrito em Seção 1.6.1, “Adicionando criptografia TLS a um Servidor HTTP Apache”.
Procedimento
Edite o arquivo
/etc/httpd/conf/httpd.conf, e adicione o parâmetroSSLCipherSuiteà diretiva<VirtualHost>para a qual você deseja definir as cifras TLS:SSLCipherSuite "EECDH AESGCM:EDH AESGCM:AES256 EECDH:AES256 EDH:!SHA1:!SHA256"
Este exemplo permite apenas as cifras
EECDH AESGCM,EDH AESGCM,AES256 EECDHeAES256 EDHe desativa todas as cifras que utilizam o código de autenticação de mensagens (MAC)SHA1eSHA256.Reinicie o serviço
httpd:# systemctl restart httpd
Etapas de verificação
Para exibir a lista de cifras que o Servidor HTTP Apache suporta:
Instale o pacote
nmap:nmap # yum instalar nmap
Use o utilitário
nmappara exibir as cifras suportadas:# nmap --script ssl-enum-ciphers -p 443 example.com ... PORT STATE SERVICE 443/tcp open https | ssl-enum-ciphers: | TLSv1.2: | ciphers: | TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (ecdh_x25519) - A | TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (dh 2048) - A | TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 (ecdh_x25519) - A ...
Recursos adicionais
-
Para mais detalhes sobre a política de criptografia do sistema, consulte a página de manual
update-crypto-policies(8)e Utilizando políticas criptográficas de todo o sistema. -
Para mais detalhes sobre o parâmetro
SSLCipherSuite, consulte a documentaçãomod_sslno manual do Apache. Para obter detalhes sobre a instalação do manual, consulte Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
1.7. Configuração da autenticação do certificado do cliente TLS
A autenticação do certificado do cliente permite aos administradores permitir que somente usuários que se autenticam usando um certificado acessem recursos no servidor web. Esta seção descreve como configurar a autenticação de certificado de cliente para o diretório /var/www/html/Example/.
Se o Servidor HTTP Apache utiliza o protocolo TLS 1.3, certos clientes requerem configuração adicional. Por exemplo, no Firefox, defina o parâmetro security.tls.enable_post_handshake_auth no menu about:config para true. Para mais detalhes, veja Transport Layer Security versão 1.3 no Red Hat Enterprise Linux 8.
Pré-requisitos
- A criptografia TLS está habilitada no servidor, conforme descrito em Seção 1.6.1, “Adicionando criptografia TLS a um Servidor HTTP Apache”.
Procedimento
Edite o arquivo
/etc/httpd/conf/httpd.confe adicione as seguintes configurações à diretiva<VirtualHost>para a qual você deseja configurar a autenticação do cliente:<Directory "/var/www/html/Example/"> SSLVerifyClient require </Directory>
A configuração
SSLVerifyClient requiredefine que o servidor deve validar com sucesso o certificado do cliente antes que o cliente possa acessar o conteúdo no diretório/var/www/html/Example/.Reinicie o serviço
httpd:# systemctl restart httpd
Etapas de verificação
Use o utilitário
curlpara acessar a URLhttps://example.com/Example/sem autenticação do cliente:$ curl https://example.com/Example/ curl: (56) OpenSSL SSL_read: error:1409445C:SSL routines:ssl3_read_bytes:tlsv13 alert certificate required, errno 0O erro indica que o servidor web requer uma autenticação de certificado de cliente.
Passe a chave privada e o certificado do cliente, assim como o certificado da CA para
curlpara acessar a mesma URL com a autenticação do cliente:$ enrolado --cacert ca.crt --key client.key --cert client.crt https://example.com/Example/
Se a solicitação for bem sucedida,
curlexibe o arquivoindex.htmlarmazenado no diretório/var/www/html/Example/.
Recursos adicionais
-
Para mais detalhes sobre autenticação de clientes, consulte a documentação
mod_ssl Configuration How-Tono manual Apache. Para detalhes sobre a instalação do manual, veja Seção 1.8, “Instalando o manual do Servidor HTTP Apache”.
1.8. Instalando o manual do Servidor HTTP Apache
Esta seção descreve como instalar o manual do Servidor HTTP Apache. Este manual fornece uma documentação detalhada de, por exemplo:
- Parâmetros de configuração e diretrizes
- Sintonia de desempenho
- Configurações de autenticação
- Módulos
- Caching de conteúdo
- Dicas de segurança
- Configurando a criptografia TLS
Após instalar o manual, você pode exibi-lo usando um navegador web.
Pré-requisitos
- O Servidor HTTP Apache está instalado e funcionando.
Procedimento
Instale o pacote
httpd-manual:# yum instalar httpd-manual
Opcional: Por padrão, todos os clientes conectados ao Servidor HTTP Apache podem exibir o manual. Para restringir o acesso a uma faixa IP específica, como a sub-rede
192.0.2.0/24, edite o arquivo/etc/httpd/conf.d/manual.confe adicione a configuraçãoRequire ip 192.0.2.0/24à diretiva<Directory "/usr/share/httpd/manual">:<Directory "/usr/share/httpd/manual"> ... Require ip 192.0.2.0/24 ... </Directory>Reinicie o serviço
httpd:# systemctl restart httpd
Etapas de verificação
-
Para exibir o manual do Servidor HTTP Apache, conecte-se com um navegador da web para
http://host_name_or_IP_address/manual/
1.9. Trabalhando com módulos
Sendo uma aplicação modular, o serviço httpd é distribuído juntamente com um número de Dynamic Shared Objects (DSOs), que pode ser carregado ou descarregado dinamicamente em tempo de execução, conforme necessário. Estes módulos estão localizados no diretório /usr/lib64/httpd/modules/.
1.9.1. Carregamento de um módulo
Para carregar um determinado módulo DSO, use a diretiva LoadModule. Observe que os módulos fornecidos por um pacote separado freqüentemente têm seu próprio arquivo de configuração no diretório /etc/httpd/conf.modules.d/.
Exemplo 1.1. Carregando o mod_ssl DSO
LoadModule ssl_module ssl_module modules/mod_ssl.so
Depois de carregar o módulo, reinicie o servidor web para recarregar a configuração. Veja Seção 1.3, “Gerenciando o serviço httpd” para mais informações sobre como reiniciar o serviço httpd.
1.9.2. Escrever um módulo
Para criar um novo módulo DSO, certifique-se de ter o pacote httpd-devel instalado. Para fazer isso, digite o seguinte comando como root:
# yum instalar httpd-devel
Este pacote contém os arquivos de inclusão, os arquivos de cabeçalho, e os arquivos de APache eXtenSion (apxs) utilidade necessária para a compilação de um módulo.
Uma vez escrito, você pode construir o módulo com o seguinte comando:
# Apxs -i -a -c_nome_do_módulo.c
Se a construção foi bem sucedida, você deve ser capaz de carregar o módulo da mesma forma que qualquer outro módulo que é distribuído com o Apache HTTP Server.
1.10. Exportar uma chave privada e certificados de um banco de dados NSS para utilizá-los na configuração de um servidor web Apache
A RHEL 8 não fornece mais o módulo mod_nss para o servidor web Apache, e a Red Hat recomenda o uso do módulo mod_ssl. Se você armazenar sua chave privada e certificados em um banco de dados de Serviços de Segurança de Rede (NSS), por exemplo, porque você migrou o servidor web do RHEL 7 para o RHEL 8, siga este procedimento para extrair a chave e os certificados no formato Privacy Enhanced Mail (PEM). Você pode então utilizar os arquivos na configuração mod_ssl, conforme descrito em Seção 1.6, “Configurando a criptografia TLS em um servidor Apache HTTP”.
Este procedimento assume que o banco de dados do NSS é armazenado em /etc/httpd/alias/ e que você armazena a chave privada exportada e os certificados no diretório /etc/pki/tls/.
Pré-requisitos
- A chave privada, o certificado e o certificado da autoridade certificadora (CA) são armazenados em um banco de dados do NSS.
Procedimento
Liste os certificados no banco de dados do NSS:
#
certutil -d /etc/httpd/alias/ -LCertificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI Example CA C,, Example Server Certificate u,u,uVocê precisa dos apelidos dos certificados nas próximas etapas.
Para extrair a chave privada, você deve exportar temporariamente a chave para um arquivo PKCS #12:
Use o apelido do certificado associado à chave privada, para exportar a chave para um arquivo PKCS #12:
#
pk12util -o /etc/pki/tls/private/export.p12 -d /etc/httpd/alias/ -n "Example Server Certificate"Enter password for PKCS12 file: password Re-enter password: password pk12util: PKCS12 EXPORT SUCCESSFULObserve que você deve definir uma senha no arquivo PKCS #12. Você precisa desta senha na próxima etapa.
Exportar a chave privada do arquivo PKCS #12:
#
openssl pkcs12 -in /etc/pki/tls/private/export.p12 -out /etc/pki/tls/private/server.key -nocerts -nodesEnter Import Password: password MAC verified OKApagar o arquivo temporário PKCS #12:
#
rm /etc/pki/tls/private/export.p12
Defina as permissões em
/etc/pki/tls/private/server.keypara garantir que somente o usuáriorootpossa acessar este arquivo:#
chown root:root /etc/pki/tls/private/server.key#chmod 0600 /etc/pki/tls/private/server.keyUse o apelido do certificado do servidor no banco de dados do NSS para exportar o certificado CA:
#
certutil -d /etc/httpd/alias/ -L -n "Example Server Certificate" -a -o /etc/pki/tls/certs/server.crtDefina as permissões em
/etc/pki/tls/certs/server.crtpara garantir que somente o usuáriorootpossa acessar este arquivo:#
chown root:root /etc/pki/tls/certs/server.crt#chmod 0600 /etc/pki/tls/certs/server.crtUse o apelido do certificado CA no banco de dados do NSS para exportar o certificado CA:
#
certutil -d /etc/httpd/alias/ -L -n "Example CA" -a -o /etc/pki/tls/certs/ca.crtSiga Seção 1.6, “Configurando a criptografia TLS em um servidor Apache HTTP” para configurar o servidor web Apache, e:
-
Ajustar o parâmetro
SSLCertificateKeyFilepara/etc/pki/tls/private/server.key. -
Ajustar o parâmetro
SSLCertificateFilepara/etc/pki/tls/certs/server.crt. -
Ajustar o parâmetro
SSLCACertificateFilepara/etc/pki/tls/certs/ca.crt.
-
Ajustar o parâmetro
Recursos adicionais
-
A página do homem
certutil(1) -
A página do homem
pk12util(1) -
A página do homem
pkcs12(1ssl)
1.11. Recursos adicionais
-
httpd(8)- A página do manual do serviçohttpdcontendo a lista completa de suas opções de linha de comando. -
httpd.service(8)- A página do manual do arquivo da unidadehttpd.service, descrevendo como personalizar e melhorar o serviço. -
httpd.conf(5)- A página de manual de configuraçãohttpd, descrevendo a estrutura e localização dos arquivos de configuraçãohttpd. -
apachectl(8)- A página do manual para o Apache HTTP Server Interface de controle.
Capítulo 2. Instalação e configuração do NGINX
NGINX é um servidor modular e de alto desempenho que você pode usar, por exemplo, como um:
- Servidor Web
- Proxy reverso
- Balanceador de carga
Esta seção descreve como fazer o NGINX nestes cenários.
2.1. Instalando e preparando o NGINX
A Red Hat usa os fluxos de aplicação para fornecer diferentes versões do NGINX. Esta seção descreve como fazê-lo:
- Selecione um fluxo e instale o NGINX
- Abrir as portas necessárias no firewall
-
Habilitar e iniciar o serviço
nginx
Usando a configuração padrão, NGINX roda como um servidor web na porta 80 e fornece conteúdo do diretório /usr/share/nginx/html/.
Pré-requisitos
- O RHEL 8 está instalado.
- O anfitrião está inscrito no Portal do Cliente da Red Hat.
-
O serviço
firewalldestá habilitado e foi iniciado.
Procedimento
Mostrar os fluxos de módulos NGINX disponíveis:
#
yum module list nginxRed Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary nginx 1.14 [d] common [d] nginx webserver nginx 1.16 common [d] nginx webserver ... Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalledSe você quiser instalar um fluxo diferente do padrão, selecione o fluxo:
#
yum module enable nginx:stream_versionInstale o pacote
nginx:#
yum install nginxAbra as portas nas quais a NGINX deve fornecer seu serviço no firewall. Por exemplo, para abrir as portas padrão para HTTP (porta 80) e HTTPS (porta 443) em
firewalld, entre:#
firewall-cmd --permanent --add-port={80/tcp,443/tcp}#firewall-cmd --reloadHabilitar o serviço
nginxpara iniciar automaticamente quando o sistema inicializar:#
systemctl enable nginxOpcionalmente, inicie o serviço
nginx:#
systemctl start nginxSe você não quiser usar a configuração padrão, pule esta etapa e configure o NGINX de acordo antes de iniciar o serviço.
Etapas de verificação
Use o utilitário
yumpara verificar se o pacotenginxestá instalado:#
yum list installed nginxInstalled Packages nginx.x86_64 1:1.14.1-9.module+el8.0.0+4108+af250afe @rhel-8-for-x86_64-appstream-rpmsAssegurar que os portos nos quais a NGINX deve prestar seu serviço sejam abertos na firewalld:
#
firewall-cmd --list-ports80/tcp 443/tcpVerifique se o serviço
nginxestá habilitado:#
systemctl is-enabled nginxenabled
Recursos adicionais
- Para obter detalhes sobre o Gerenciador de Assinaturas, consulte o guia de Uso e Configuração do Gerenciador de Assinaturas.
- Para mais detalhes sobre Fluxos de Aplicação, módulos e instalação de pacotes, consulte o guia Instalação, gerenciamento e remoção de componentes de espaço do usuário.
- Para obter detalhes sobre a configuração de firewalls, consulte o guia Securing networks guide.
2.2. Configuração do NGINX como um servidor web que fornece diferentes conteúdos para diferentes domínios
Por padrão, NGINX atua como um servidor web que fornece o mesmo conteúdo aos clientes para todos os nomes de domínio associados com os endereços IP do servidor. Este procedimento explica como configurar o NGINX:
-
Para atender aos pedidos ao domínio
example.comcom conteúdo do diretório/var/www/example.com/ -
Para atender aos pedidos ao domínio
example.netcom conteúdo do diretório/var/www/example.net/ -
Para atender todas as outras solicitações, por exemplo, para o endereço IP do servidor ou para outros domínios associados com o endereço IP do servidor, com conteúdo do diretório
/usr/share/nginx/html/
Pré-requisitos
- O NGINX é instalado como descrito em Seção 2.1, “Instalando e preparando o NGINX”.
Os clientes e o servidor web resolvem o domínio
example.comeexample.netpara o endereço IP do servidor web.Observe que você deve adicionar manualmente estas entradas ao seu servidor DNS.
Procedimento
Edite o arquivo
/etc/nginx/nginx.conf:Por padrão, o arquivo
/etc/nginx/nginx.confjá contém uma configuração "catch-all". Se você eliminou esta parte da configuração, readicione o seguinte blocoserverao blocohttpno arquivo/etc/nginx/nginx.conf:server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /usr/share/nginx/html; }Estas configurações configuram o seguinte:
-
A diretiva
listendefine o endereço IP e as portas que o serviço escuta. Neste caso, NGINX escuta na porta80tanto em todos os endereços IPv4 como IPv6. O parâmetrodefault_serverindica que o NGINX usa este blocoservercomo padrão para solicitações correspondentes aos endereços IP e portas. -
O parâmetro
server_namedefine os nomes dos anfitriões pelos quais este blocoserveré responsável. O parâmetroserver_namepara_configura o NGINX para aceitar qualquer nome de host para este blocoserver. -
A diretiva
rootestabelece o caminho para o conteúdo da web para este blocoserver.
-
A diretiva
Acrescentar um bloco similar
serverpara o domínioexample.comao blocohttp:server { server_name example.com; root /var/www/example.com/; access_log /var/log/nginx/example.com/access.log; error_log /var/log/nginx/example.com/error.log; }-
A diretiva
access_logdefine um arquivo de log de acesso separado para este domínio. -
A diretiva
error_logdefine um arquivo de registro de erros separado para este domínio.
-
A diretiva
Acrescentar um bloco similar
serverpara o domínioexample.netao blocohttp:server { server_name example.net; root /var/www/example.net/; access_log /var/log/nginx/example.net/access.log; error_log /var/log/nginx/example.net/error.log; }
Criar os diretórios raiz para ambos os domínios:
#
mkdir -p /var/www/example.com/#mkdir -p /var/www/example.net/Configurar o contexto
httpd_sys_content_tem ambos os diretórios raiz:#
semanage fcontext -a -t httpd_sys_content_t "/var/www/example.com(/.*)?"#restorecon -Rv /var/www/example.com/#semanage fcontext -a -t httpd_sys_content_t "/var/www/example.net(/.\*)?"#restorecon -Rv /var/www/example.net/Estes comandos definem o contexto
httpd_sys_content_tnos diretórios/var/www/example.com/e/var/www/example.net/.Note que você deve instalar o pacote
policycoreutils-python-utilspara executar os comandosrestorecon.Criar os diretórios de log para os dois domínios:
#
mkdir /var/log/nginx/example.com/#mkdir /var/log/nginx/example.net/Reinicie o serviço
nginx:#
systemctl restart nginx
Etapas de verificação
Criar um arquivo de exemplo diferente em cada raiz de documento do host virtual:
#
echo "Content for example.com" > /var/www/example.com/index.html#echo "Content for example.net" > /var/www/example.net/index.html#echo "Catch All content" > /usr/share/nginx/html/index.html-
Use um navegador e conecte-se a
http://example.com. O servidor web mostra o conteúdo do exemplo do arquivo/var/www/example.com/index.html. -
Use um navegador e conecte-se a
http://example.net. O servidor web mostra o conteúdo do exemplo do arquivo/var/www/example.net/index.html. -
Use um navegador e conecte-se a
http://IP_address_of_the_server. O servidor web mostra o conteúdo do exemplo do arquivo/usr/share/nginx/html/index.html.
2.3. Adicionando a criptografia TLS a um servidor web NGINX
Esta seção descreve como habilitar a criptografia TLS em um servidor web NGINX para o domínio example.com.
Pré-requisitos
- O NGINX é instalado como descrito em Seção 2.1, “Instalando e preparando o NGINX”.
A chave privada é armazenada no arquivo
/etc/pki/tls/private/example.com.key.Para detalhes sobre a criação de uma chave privada e pedido de assinatura de certificado (CSR), bem como sobre como solicitar um certificado de uma autoridade certificadora (CA), consulte a documentação de sua CA.
-
O certificado do TLS é armazenado no arquivo
/etc/pki/tls/certs/example.com.crt. Se você usar um caminho diferente, adapte as etapas correspondentes do procedimento. - O certificado CA foi anexado ao arquivo do certificado TLS do servidor.
- Os clientes e o servidor web resolvem o nome do anfitrião do servidor para o endereço IP do servidor web.
-
A porta
443está aberta no firewall local.
Procedimento
Edite o arquivo
/etc/nginx/nginx.confe adicione o seguinte blocoserverao blocohttpna configuração:server { listen 443 ssl; server_name example.com; root /usr/share/nginx/html; ssl_certificate /etc/pki/tls/certs/example.com.crt; ssl_certificate_key /etc/pki/tls/private/example.com.key; }Por razões de segurança, configure que somente o usuário
rootpossa acessar o arquivo de chave privada:#
chown root:root /etc/pki/tls/private/example.com.key#chmod 600 /etc/pki/tls/private/example.com.keyAtençãoSe a chave privada foi acessada por usuários não autorizados, revogar o certificado, criar uma nova chave privada e solicitar um novo certificado. Caso contrário, a conexão TLS não é mais segura.
Reinicie o serviço
nginx:#
systemctl restart nginx
Etapas de verificação
-
Use um navegador e conecte-se a
https://example.com
2.4. Configuração do NGINX como proxy reverso para o tráfego HTTP
Você pode configurar o servidor web NGINX para atuar como um proxy reverso para o tráfego HTTP. Por exemplo, você pode usar esta funcionalidade para encaminhar solicitações para um subdiretório específico em um servidor remoto. Do ponto de vista do cliente, o cliente carrega o conteúdo a partir do host ao qual acessa. Entretanto, NGINX carrega o conteúdo real do servidor remoto e o encaminha para o cliente.
Este procedimento explica como encaminhar o tráfego para o diretório /example no servidor web para a URL https://example.com.
Pré-requisitos
- O NGINX é instalado como descrito em Seção 2.1, “Instalando e preparando o NGINX”.
- Opcional: A criptografia TLS é habilitada no proxy reverso.
Procedimento
Edite o arquivo
/etc/nginx/nginx.confe adicione as seguintes configurações ao blocoserverque deve fornecer o proxy reverso:location /example { proxy_pass https://example.com; }O bloco
locationdefine que a NGINX passa todas as solicitações no diretório/exampleparahttps://example.com.Defina o parâmetro booleano
httpd_can_network_connectSELinux para1para configurar que o SELinux permite que o NGINX encaminhe o tráfego:#
setsebool -P httpd_can_network_connect 1Reinicie o serviço
nginx:#
systemctl restart nginx
Etapas de verificação
-
Use um navegador e conecte-se a
http://host_name/examplee o conteúdo dehttps://example.comé mostrado.
2.5. Configurando o NGINX como um balanceador de carga HTTP
Você pode usar o recurso de proxy reverso NGINX para balancear o tráfego de carga. Este procedimento descreve como configurar o NGINX como um balanceador de carga HTTP que envia solicitações para diferentes servidores, com base em qual deles tem o menor número de conexões ativas. Se os dois servidores não estiverem disponíveis, o procedimento também define um terceiro host por razões de fallback.
Pré-requisitos
- O NGINX é instalado como descrito em Seção 2.1, “Instalando e preparando o NGINX”.
Procedimento
Edite o arquivo
/etc/nginx/nginx.confe adicione as seguintes configurações:http { upstream backend { least_conn; server server1.example.com; server server2.example.com; server server3.example.com backup; } server { location / { proxy_pass http://backend; } } }A diretiva
least_conndo grupo anfitriãobackenddefine que a NGINX envia solicitações paraserver1.example.comouserver2.example.com, dependendo de qual anfitrião tem o menor número de conexões ativas. NGINX usaserver3.example.comapenas como backup caso os outros dois hospedeiros não estejam disponíveis.Com a diretiva
proxy_passdefinida parahttp://backend, NGINX atua como um proxy reverso e usa o grupo anfitriãobackendpara distribuir solicitações com base nas configurações deste grupo.Em vez do método de balanceamento de carga
least_conn, você pode especificar:- Nenhum método para usar round robin e distribuir os pedidos uniformemente entre os servidores.
-
ip_hashpara enviar solicitações de um endereço de cliente para o mesmo servidor com base em um hash calculado a partir dos três primeiros octetos do endereço IPv4 ou de todo o endereço IPv6 do cliente. -
hashpara determinar o servidor com base em uma chave definida pelo usuário, que pode ser uma string, uma variável ou uma combinação de ambas. O parâmetroconsistentconfigura que o NGINX distribui as solicitações por todos os servidores com base no valor da chave definida pelo usuário. -
randompara enviar solicitações para um servidor selecionado aleatoriamente.
Reinicie o serviço
nginx:#
systemctl restart nginx
2.6. Recursos adicionais
- Para a documentação oficial do NGINX, ver https://nginx.org/en/docs/. Note que a Red Hat não mantém esta documentação e que ela pode não funcionar com a versão do NGINX que você instalou.
Capítulo 3. Usando Samba como um servidor
O Samba implementa o protocolo Server Message Block (SMB) no Red Hat Enterprise Linux. O protocolo SMB é usado para acessar recursos em um servidor, tais como compartilhamento de arquivos e impressoras compartilhadas. Além disso, o Samba implementa o protocolo de Chamada de Procedimento Remoto de Ambiente de Computação Distribuída (DCE RPC) usado pelo Microsoft Windows.
Você pode administrar o Samba como:
- Um membro do Active Directory (AD) ou do domínio NT4
- Um servidor autônomo
Um controlador de domínio primário NT4 (PDC) ou controlador de domínio de backup (BDC)
NotaA Red Hat suporta os modos PDC e BDC somente em instalações existentes com versões Windows que suportam os domínios NT4. A Red Hat recomenda não configurar um novo domínio Samba NT4, porque os sistemas operacionais Microsoft mais recentes que Windows 7 e Windows Server 2008 R2 não suportam os domínios NT4.
A Red Hat não suporta executar o Samba como controlador de domínio AD (DC).
Independentemente do modo de instalação, você pode opcionalmente compartilhar diretórios e impressoras. Isto permite que Samba atue como servidor de arquivos e impressão.
3.1. Entendendo os diferentes serviços e modos de Samba
Esta seção descreve os diferentes serviços incluídos no Samba e os diferentes modos que você pode configurar.
3.1.1. Os serviços de Samba
O Samba oferece os seguintes serviços:
smbdEste serviço oferece serviços de compartilhamento de arquivos e impressão usando o protocolo SMB. Além disso, o serviço é responsável pelo bloqueio de recursos e pela autenticação da conexão dos usuários. O serviço
smbsystemdinicia e pára o daemonsmbd.Para utilizar o serviço
smbd, instale o pacotesamba.nmbdEste serviço fornece nome do host e resolução IP usando o protocolo NetBIOS sobre IPv4. Além da resolução do nome, o serviço
nmbdpermite a navegação na rede SMB para localizar domínios, grupos de trabalho, hosts, compartilhamento de arquivos e impressoras. Para isso, o serviço ou reporta essas informações diretamente ao cliente de transmissão ou as encaminha a um navegador local ou mestre. O serviçonmbsystemdinicia e pára o daemonnmbd.Observe que as modernas redes SMB utilizam o DNS para resolver clientes e endereços IP.
Para utilizar o serviço
nmbd, instale o pacotesamba.winbinddEste serviço fornece uma interface para o Name Service Switch (NSS) para usar usuários e grupos de domínios AD ou NT4 no sistema local. Isto permite, por exemplo, que usuários de domínio se autentiquem em serviços hospedados em um servidor Samba ou em outros serviços locais. O serviço
winbindsystemdinicia e pára o daemonwinbindd.Se você configurar o Samba como um membro do domínio,
winbindddeve ser iniciado antes do serviçosmbd. Caso contrário, os usuários e grupos de domínio não estão disponíveis para o sistema local.Para utilizar o serviço
winbindd, instale o pacotesamba-winbind.ImportanteA Red Hat só suporta rodar Samba como servidor com o serviço
winbinddpara fornecer usuários e grupos de domínio para o sistema local. Devido a certas limitações, como a falta de suporte à lista de controle de acesso do Windows (ACL) e falha do NT LAN Manager (NTLM), o SSSD não é suportado.
3.1.2. Os serviços de segurança do Samba
O parâmetro security na seção [global] do arquivo /etc/samba/smb.conf gerencia como o Samba autentica os usuários que estão se conectando ao serviço. Dependendo do modo de instalação do Samba, o parâmetro deve ser definido para valores diferentes:
- Em um membro de domínio AD, conjunto
security = ads Neste modo, Samba usa o Kerberos para autenticar usuários AD.
Para detalhes sobre como configurar o Samba como membro do domínio, veja Seção 3.5, “Configurando o Samba como um servidor membro do domínio AD”.
- Em um servidor autônomo, conjunto
security = user Neste modo, Samba usa um banco de dados local para autenticar os usuários conectados.
Para detalhes sobre como configurar o Samba como um servidor autônomo, veja Seção 3.3, “Configurando o Samba como um servidor autônomo”.
- Em um NT4 PDC ou BDC, conjunto
security = user - Neste modo, o Samba autentica os usuários a um banco de dados local ou LDAP.
- Em um membro de domínio NT4, conjunto
security = domain Neste modo, o Samba autentica a conexão dos usuários a um NT4 PDC ou BDC. Você não pode usar este modo em membros do domínio AD.
Para detalhes sobre como configurar o Samba como membro do domínio, veja Seção 3.5, “Configurando o Samba como um servidor membro do domínio AD”.
Recursos adicionais
-
Veja a descrição do parâmetro
securityna página de manualsmb.conf(5).
3.1.3. Cenários quando os serviços Samba e as utilidades dos clientes Samba carregam e recarregam sua configuração
O seguinte descreve quando os serviços e utilitários Samba carregam e recarregam sua configuração:
Os serviços de Samba recarregam sua configuração:
- Automaticamente a cada 3 minutos
-
A pedido manual, por exemplo, quando você executa o comando
smbcontrol all reload-config.
- As utilidades do cliente Samba só lêem sua configuração quando você as inicia.
Note que certos parâmetros, tais como security requerem um reinício do serviço smb para entrar em vigor e uma recarga não é suficiente.
Recursos adicionais
-
A seção
How configuration changes are appliedna página de manualsmb.conf(5) -
As páginas de manual
smbd(8),nmbd(8), ewinbindd(8)
3.1.4. Editando a configuração do Samba de uma forma segura
Os serviços de Samba recarregam automaticamente sua configuração a cada 3 minutos. Este procedimento descreve como editar a configuração do Samba de forma a evitar que os serviços recarreguem as mudanças antes que você tenha verificado a configuração usando o utilitário testparm.
Pré-requisitos
- O Samba está instalado.
Procedimento
Crie uma cópia do arquivo
/etc/samba/smb.conf:#
cp /etc/samba/smb.conf /etc/samba/samba.conf.copy- Edite o arquivo copiado e faça as alterações desejadas.
Verificar a configuração no
/etc/samba/samba.conf.copyarquivo:#
testparm -s /etc/samba/samba.conf.copySe
testparmreportar erros, conserte-os e execute o comando novamente.Anular o arquivo
/etc/samba/smb.confcom a nova configuração:#
mv /etc/samba/samba.conf.copy /etc/samba/smb.confAguarde até que os serviços Samba recarreguem automaticamente sua configuração ou recarreguem manualmente a configuração:
#
smbcontrol all reload-config
3.2. Verificando a configuração do Samba
A Red Hat recomenda que você verifique a configuração do Samba cada vez que atualizar o arquivo /etc/samba/smb.conf. Esta seção fornece detalhes sobre isso.
3.2.1. Verificação do arquivo smb.conf usando o utilitário testparm
O utilitário testparm verifica se a configuração do Samba no arquivo /etc/samba/smb.conf está correta. O utilitário detecta parâmetros e valores inválidos, mas também configurações incorretas, tais como para o mapeamento de identificação. Se testparm não relatar nenhum problema, os serviços do Samba carregarão com sucesso o arquivo /etc/samba/smb.conf. Note que testparm não pode verificar se os serviços configurados estarão disponíveis ou funcionarão como esperado.
A Red Hat recomenda que você verifique o arquivo /etc/samba/smb.conf usando testparm após cada modificação deste arquivo.
Pré-requisitos
- Você instalou o Samba.
-
O arquivo
/etc/samba/smb.confsai.
Procedimento
Execute o utilitário
testparmcomo o usuárioroot:#
testparmLoad smb config files from /etc/samba/smb.conf rlimit_max: increasing rlimit_max (1024) to minimum Windows limit (16384) Unknown parameter encountered: "log levell" Processing section "[example_share]" Loaded services file OK. ERROR: The idmap range for the domain * (tdb) overlaps with the range of DOMAIN (ad)! Server role: ROLE_DOMAIN_MEMBER Press enter to see a dump of your service definitions # Global parameters [global] ... [example_share] ...O exemplo anterior informa um parâmetro inexistente e uma configuração de mapeamento de identificação incorreta.
-
Se
testparmrelatar parâmetros incorretos, valores ou outros erros na configuração, conserte o problema e execute novamente o utilitário.
3.3. Configurando o Samba como um servidor autônomo
Você pode configurar o Samba como um servidor que não é membro de um domínio. Neste modo de instalação, o Samba autentica os usuários a um banco de dados local ao invés de a um CD central. Além disso, você pode permitir o acesso de visitantes para permitir que os usuários se conectem a um ou vários serviços sem autenticação.
3.3.1. Configurando a configuração do servidor para o servidor autônomo
Esta seção descreve como configurar a configuração do servidor para um servidor autônomo Samba.
Procedimento
Instale o pacote
samba:#
yum install sambaEdite o arquivo
/etc/samba/smb.confe defina os seguintes parâmetros:[global] workgroup = Example-WG netbios name = Server security = user log file = /var/log/samba/%m.log log level = 1
Esta configuração define um servidor autônomo chamado
Serverdentro do grupo de trabalhoExample-WG. Além disso, esta configuração permite o logon em um nível mínimo (1) e os arquivos de log serão armazenados no diretório/var/log/samba/. Samba expandirá a macro%mno parâmetrolog filepara o nome NetBIOS de conexão de clientes. Isto permite arquivos de log individuais para cada cliente.Opcionalmente, configure o compartilhamento de arquivos ou impressoras. Veja:
Verifique o arquivo
/etc/samba/smb.conf:#
testparmSe você configurar ações que requerem autenticação, crie as contas de usuário.
Para maiores detalhes, ver Seção 3.3.2, “Criação e habilitação de contas de usuário locais”.
Abra as portas necessárias e recarregue a configuração do firewall, usando o utilitário
firewall-cmd:#
firewall-cmd --permanent --add-port={139/tcp,445/tcp}#firewall-cmd --reloadHabilite e inicie o serviço
smb:#
systemctl enable --now smb
Recursos adicionais
-
Para mais detalhes sobre os parâmetros utilizados no procedimento, veja as descrições dos parâmetros na página de manual
smb.conf(5).
3.3.2. Criação e habilitação de contas de usuário locais
Para que os usuários possam autenticar quando se conectam a uma ação, é necessário criar as contas no host Samba tanto no sistema operacional quanto no banco de dados Samba. O Samba requer a conta do sistema operacional para validar as Listas de Controle de Acesso (ACL) nos objetos do sistema de arquivos e a conta Samba para autenticar os usuários conectados.
Se você usar a configuração padrão passdb backend = tdbsam, Samba armazena as contas de usuário no banco de dados /var/lib/samba/private/passdb.tdb.
O procedimento nesta seção descreve como criar um usuário Samba local chamado example.
Pré-requisitos
- O Samba é instalado configurado como um servidor autônomo.
Procedimento
Criar a conta do sistema operacional:
#
useradd -M -s /sbin/nologin exampleEste comando adiciona a conta
examplesem criar um diretório home. Se a conta for usada apenas para autenticar no Samba, atribua o comando/sbin/nologincomo shell para evitar que a conta entre no sistema local.Defina uma senha para a conta do sistema operacional para habilitá-la:
#
passwd exampleEnter new UNIX password:passwordRetype new UNIX password:passwordpasswd: password updated successfullySamba não usa a senha definida na conta do sistema operacional para autenticar. Entretanto, é necessário definir uma senha para habilitar a conta. Se uma conta for desativada, o Samba negará o acesso se este usuário se conectar.
Adicione o usuário ao banco de dados do Samba e defina uma senha para a conta:
#
smbpasswd -a exampleNew SMB password:passwordRetype new SMB password:passwordAdded user example.Use esta senha para autenticar ao usar esta conta para se conectar a uma ação Samba.
Habilitar a conta Samba:
#
smbpasswd -e exampleEnabled user example.
3.4. Entendendo e configurando o mapeamento do Samba ID
Os domínios Windows distinguem usuários e grupos por Identificadores de Segurança (SID) exclusivos. Entretanto, o Linux requer UIDs e GIDs únicos para cada usuário e grupo. Se você executar Samba como membro do domínio, o serviço winbindd é responsável por fornecer informações sobre usuários e grupos de domínios para o sistema operacional.
Para habilitar o serviço winbindd a fornecer identificações únicas para usuários e grupos ao Linux, você deve configurar o mapeamento de identificação no arquivo /etc/samba/smb.conf para:
- O banco de dados local (domínio padrão)
- O domínio AD ou NT4 do qual o servidor Samba é membro
- Cada domínio confiável do qual os usuários devem ser capazes de acessar recursos neste servidor Samba
O Samba fornece diferentes back ends de mapeamento de identificação para configurações específicas. Os back ends mais freqüentemente utilizados são:
| Voltar ao final | Estojo de uso |
|---|---|
|
|
O domínio padrão |
|
| Somente domínios AD |
|
| Domínios AD e NT4 |
|
|
AD, NT4, e o domínio padrão |
3.4.1. Planejamento de gamas de identificação Samba
Independentemente de você armazenar os UIDs e GIDs Linux no AD ou se você configurar o Samba para gerá-los, cada configuração de domínio requer uma faixa de ID única que não deve se sobrepor a nenhum dos outros domínios.
Se você definir intervalos de identificação sobrepostos, o Samba não funciona corretamente.
Exemplo 3.1. Faixas de identificação exclusivas
A seguir são mostradas as faixas de mapeamento de identificação não sobrepostas para os domínios padrão (*), AD-DOM, e os domínios TRUST-DOM.
[global] ... idmap config * : backend = tdb idmap config * : range = 10000-999999 idmap config AD-DOM:backend = rid idmap config AD-DOM:range = 2000000-2999999 idmap config TRUST-DOM:backend = rid idmap config TRUST-DOM:range = 4000000-4999999
Você só pode atribuir uma faixa por domínio. Portanto, deixe espaço suficiente entre as faixas de domínios. Isto permite que você amplie a faixa mais tarde se seu domínio crescer.
Se posteriormente você atribuir uma faixa diferente a um domínio, a propriedade de arquivos e diretórios previamente criados por esses usuários e grupos será perdida.
3.4.2. The * default domain
Em um ambiente de domínio, você adiciona uma configuração de mapeamento de identificação para cada um dos seguintes itens:
- O domínio do servidor Samba é um membro do
- Cada domínio de confiança que deve ser capaz de acessar o servidor Samba
Entretanto, para todos os outros objetos, o Samba atribui IDs do domínio padrão. Isto inclui:
- Usuários e grupos locais de Samba
-
Contas e grupos incorporados no Samba, tais como
BUILTIN\Administrators
Você deve configurar o domínio padrão conforme descrito nesta seção para permitir que o Samba funcione corretamente.
O back end padrão do domínio deve ser gravável para armazenar permanentemente as identificações atribuídas.
Para o domínio padrão, você pode usar um dos seguintes back ends:
tdbQuando você configurar o domínio padrão para usar o back end
tdb, defina uma faixa de ID que seja grande o suficiente para incluir objetos que serão criados no futuro e que não façam parte de uma configuração definida de mapeamento de ID de domínio.Por exemplo, defina o seguinte na seção
[global]no arquivo/etc/samba/smb.conf:idmap config * : backend = tdb idmap config * : range = 10000-999999
Para mais detalhes, veja Seção 3.4.3, “Usando o tdb ID mapeamento back end”.
autoridQuando você configura o domínio padrão para usar o back end
autorid, a adição de configurações adicionais de mapeamento de ID para domínios é opcional.Por exemplo, defina o seguinte na seção
[global]no arquivo/etc/samba/smb.conf:idmap config * : backend = autorid idmap config * : range = 10000-999999
Para mais detalhes, veja Seção 3.4.6, “Usando o mapeamento de identificação autorídica back end”.
3.4.3. Usando o tdb ID mapeamento back end
O serviço winbindd usa o mapeamento de identificação por default tdb para armazenar as tabelas de mapeamento Security Identifier (SID), UID, e GID. Isto inclui usuários locais, grupos e principais incorporados.
Use este back end somente para o domínio padrão *. Por exemplo:
idmap config * : backend = tdb idmap config * : range = 10000-999999
Recursos adicionais
3.4.4. Usando o mapeamento de identificação do anúncio back end
Esta seção descreve como configurar um membro do Samba AD para usar o back end de mapeamento de ID ad.
O ad ID mapping back end implementa uma API somente leitura para ler as informações de conta e grupo do AD. Isto proporciona os seguintes benefícios:
- Todas as configurações de usuário e grupo são armazenadas centralmente em AD.
- As identificações de usuários e grupos são consistentes em todos os servidores Samba que utilizam este back end.
- As IDs não são armazenadas em um banco de dados local que pode corromper e, portanto, a propriedade dos arquivos não pode ser perdida.
O ad ID mapping back end não suporta domínios Active Directory com trusts unidirecionais. Se você configurar um membro do domínio em um Active Directory com trusts unidirecionais, use ao invés de um dos seguintes back ends de mapeamento de ID: tdb, rid, ou autorid.
A parte traseira do anúncio lê os seguintes atributos do AD:
| Nome do atributo AD | Tipo de objeto | Mapeado para |
|---|---|---|
|
| Usuário e grupo | Nome do usuário ou do grupo, dependendo do objeto |
|
| Usuário | ID do usuário (UID) |
|
| Grupo | ID do grupo (GID) |
|
| Usuário | Caminho para a casca do usuário |
|
| Usuário | Caminho para o diretório pessoal do usuário |
|
| Usuário | ID do grupo primário |
[a]
O Samba só lê este atributo se você definir idmap config DOMAIN:unix_nss_info = yes.
[b]
O Samba só lê este atributo se você definir idmap config DOMAIN:unix_primary_group = yes.
| ||
Pré-requisitos
-
Tanto os usuários quanto os grupos devem ter IDs únicos definidos no AD, e as IDs devem estar dentro do intervalo configurado no arquivo
/etc/samba/smb.conf. Objetos cujos IDs estão fora do intervalo não estarão disponíveis no servidor Samba. - Os usuários e grupos devem ter todos os atributos necessários definidos no AD. Se faltarem atributos requeridos, o usuário ou grupo não estará disponível no servidor Samba. Os atributos requeridos dependem de sua configuração. Pré-requisitos
- Você instalou o Samba.
-
A configuração do Samba, exceto o mapeamento de ID, existe no arquivo
/etc/samba/smb.conf.
Procedimento
Edite a seção
[global]no arquivo/etc/samba/smb.conf:Adicione uma configuração de mapeamento de identificação para o domínio padrão (
*) se ele não existir. Por exemplo:idmap config * : backend = tdb idmap config * : range = 10000-999999Habilite o back end do mapeamento de ID
adpara o domínio AD:idmap config DOMAIN: backend = adDefina a gama de IDs que é atribuída aos usuários e grupos no domínio AD. Por exemplo:
idmap config DOMAIN: intervalo = 2000000-2999999
ImportanteA faixa não deve se sobrepor a nenhuma outra configuração de domínio neste servidor. Além disso, o intervalo deve ser definido suficientemente grande para incluir todas as IDs atribuídas no futuro. Para mais detalhes, veja Seção 3.4.1, “Planejamento de gamas de identificação Samba”.
Defina que o Samba usa o esquema RFC 2307 ao ler os atributos do AD:
idmap config DOMAIN: schema_mode = rfc2307Para permitir que o Samba leia a shell de login e o caminho para o diretório home do usuário a partir do atributo AD correspondente, definido:
idmap config DOMAIN: unix_nss_info = simAlternativamente, você pode definir um caminho uniforme de diretório home e shell de login em todo o domínio que é aplicado a todos os usuários. Por exemplo:
template shell = /bin/bash template homedir = /home/%U
Por padrão, Samba usa o atributo
primaryGroupIDde um objeto de usuário como o grupo primário do usuário no Linux. Alternativamente, você pode configurar o Samba para usar o valor definido no atributogidNumber:idmap config DOMAIN: unix_primary_group = sim
Verifique o arquivo
/etc/samba/smb.conf:#
testparmRecarregar a configuração do Samba:
#
smbcontrol all reload-config
Recursos adicionais
- Seção 3.4.2, “The * default domain”
-
Para mais detalhes sobre os parâmetros utilizados no procedimento, consulte as páginas de manual
smb.conf(5)eidmap_ad(8). -
Para obter detalhes sobre substituição de variáveis, consulte a seção
VARIABLE SUBSTITUTIONSna página de manualsmb.conf(5).
3.4.5. Usando o mapeamento de identificação do rid back end
Esta seção descreve como configurar um membro do domínio Samba para usar o back end do mapeamento de ID rid.
O Samba pode usar o identificador relativo (RID) de um SID do Windows para gerar um ID no Red Hat Enterprise Linux.
O RID é a última parte de um SID. Por exemplo, se o SID de um usuário é S-1-5-21-5421822485-1151247151-421485315-30014, então 30014 é o RID correspondente.
O back end de mapeamento de ID rid implementa uma API somente leitura para calcular informações de contas e grupos com base em um esquema de mapeamento algorítmico para domínios AD e NT4. Quando você configura o back end, você deve definir o RID mais baixo e o mais alto no idmap config DOMAIN : range parâmetro. O Samba não mapeará usuários ou grupos com um RID menor ou maior do que o definido neste parâmetro.
Como back end só de leitura, rid não pode atribuir novas identificações, como para os grupos BUILTIN. Portanto, não utilize este back end para o domínio padrão *.
Benefícios de usar a parte traseira do carro
- Todos os usuários e grupos de domínio que têm um RID dentro do intervalo configurado estão automaticamente disponíveis no membro do domínio.
- Não é necessário atribuir manualmente IDs, diretórios residenciais e shells de login.
Problemas de usar a parte traseira do carro
- Todos os usuários de domínio recebem a mesma shell de login e diretório pessoal atribuídos. Entretanto, você pode usar variáveis.
-
Os IDs de usuários e grupos só são os mesmos entre os membros do domínio Samba se todos usarem o back end
ridcom as mesmas configurações de faixa de ID. - Você não pode excluir que usuários individuais ou grupos estejam disponíveis no membro do domínio. Somente usuários e grupos fora da faixa configurada são excluídos.
-
Com base nas fórmulas que o serviço
winbinddusa para calcular as IDs, podem ocorrer IDs duplicadas em ambientes de vários domínios se objetos em domínios diferentes tiverem o mesmo RID.
Pré-requisitos
- Você instalou o Samba.
-
A configuração do Samba, exceto o mapeamento de ID, existe no arquivo
/etc/samba/smb.conf.
Procedimento
Edite a seção
[global]no arquivo/etc/samba/smb.conf:Adicione uma configuração de mapeamento de identificação para o domínio padrão (
*) se ele não existir. Por exemplo:idmap config * : backend = tdb idmap config * : range = 10000-999999Habilite o back end do mapeamento de ID
ridpara o domínio:idmap config DOMAIN: backend = ridDefina uma faixa que seja suficientemente grande para incluir todos os RIDs que serão designados no futuro. Por exemplo:
idmap config DOMAIN: intervalo = 2000000-2999999
O Samba ignora usuários e grupos cujos RIDs neste domínio não estão dentro do alcance.
ImportanteA faixa não deve se sobrepor a nenhuma outra configuração de domínio neste servidor. Para mais detalhes, veja Seção 3.4.1, “Planejamento de gamas de identificação Samba”.
Defina um caminho de shell e diretório home que será atribuído a todos os usuários mapeados. Por exemplo:
template shell = /bin/bash template homedir = /home/%U
Verifique o arquivo
/etc/samba/smb.conf:#
testparmRecarregar a configuração do Samba:
#
smbcontrol all reload-configRecursos adicionais
- Seção 3.4.2, “The * default domain”
-
Para obter detalhes sobre substituição de variáveis, consulte a seção
VARIABLE SUBSTITUTIONSna página de manualsmb.conf(5). -
Para detalhes, como Samba calcula a identificação local a partir de um RID, consulte a página de manual
idmap_rid(8).
3.4.6. Usando o mapeamento de identificação autorídica back end
Esta seção descreve como configurar um membro do domínio Samba para usar o back end do mapeamento de ID autorid.
O back end autorid funciona similar ao back end de mapeamento de ID rid, mas pode atribuir automaticamente IDs para diferentes domínios. Isto permite utilizar o back end autorid nas seguintes situações:
-
Somente para o domínio padrão
* -
Para o domínio padrão
*e domínios adicionais, sem a necessidade de criar configurações de mapeamento de ID para cada um dos domínios adicionais - Somente para domínios específicos
Se você usar autorid para o domínio padrão, a adição de configuração adicional de mapeamento de ID para domínios é opcional.
Partes desta seção foram adotadas a partir da documentação autoridada do idmap config publicada no Samba Wiki. Licença: CC BY 4.0. Autores e colaboradores: Veja a aba histórico na página Wiki.
Benefícios de utilizar o back end do autorid
- Todos os usuários e grupos de domínio cujos UID e GID calculados estão dentro do intervalo configurado estão automaticamente disponíveis no membro do domínio.
- Não é necessário atribuir manualmente IDs, diretórios residenciais e shells de login.
- Nenhuma identificação duplicada, mesmo que vários objetos em um ambiente de vários domínios tenham o mesmo RID.
Drawbacks
- Os IDs de usuário e de grupo não são os mesmos entre os membros do domínio Samba.
- Todos os usuários de domínio recebem a mesma shell de login e diretório pessoal atribuídos. Entretanto, você pode usar variáveis.
- Você não pode excluir que usuários individuais ou grupos estejam disponíveis no membro do domínio. Somente usuários e grupos cujo UID ou GID calculado esteja fora da faixa configurada são excluídos.
Pré-requisitos
- Você instalou o Samba.
-
A configuração do Samba, exceto o mapeamento de ID, existe no arquivo
/etc/samba/smb.conf.
Procedimento
Edite a seção
[global]no arquivo/etc/samba/smb.conf:Habilite o back end do mapeamento de ID
autoridpara o domínio padrão*:idmap config * : backend = autorid
Defina um intervalo suficientemente grande para atribuir identificações para todos os objetos existentes e futuros. Por exemplo:
idmap config * : range = 10000-999999O Samba ignora usuários e grupos cujos IDs calculados neste domínio não estão dentro do intervalo.
AtençãoApós definir a faixa e o Samba começar a usá-la, você só pode aumentar o limite superior da faixa. Qualquer outra mudança no intervalo pode resultar em novas atribuições de ID e, portanto, na perda da propriedade dos arquivos.
Opcionalmente, defina um tamanho de faixa. Por exemplo, o tamanho da gama:
idmap config * : rangesize = 200000Samba assigns this number of continuous IDs for each domain’s object until all IDs from the range set in the
idmap config * : rangeparameter are taken.Defina um caminho de shell e diretório home que será atribuído a todos os usuários mapeados. Por exemplo:
template shell = /bin/bash template homedir = /home/%U
Opcionalmente, adicione configuração adicional de mapeamento de identificação para domínios. Se nenhuma configuração para um domínio individual estiver disponível, Samba calcula o ID usando as configurações do back end
autoridno domínio padrão*previamente configurado.ImportanteSe você configurar back ends adicionais para domínios individuais, os intervalos para todas as configurações de mapeamento de identificação não devem se sobrepor. Para mais detalhes, veja Seção 3.4.1, “Planejamento de gamas de identificação Samba”.
Verifique o arquivo
/etc/samba/smb.conf:#
testparmRecarregar a configuração do Samba:
#
smbcontrol all reload-config
Recursos adicionais
-
Para detalhes sobre como o back end calculou os IDs, consulte a seção
THE MAPPING FORMULASna página de manualidmap_autorid(8). -
Para obter detalhes sobre o uso do parâmetro
idmap configrangesize, consulte a descrição do parâmetrorangesizena página de manualidmap_autorid(8). -
Para obter detalhes sobre substituição de variáveis, consulte a seção
VARIABLE SUBSTITUTIONSna página de manualsmb.conf(5).
3.5. Configurando o Samba como um servidor membro do domínio AD
Se você estiver rodando um domínio AD ou NT4, use Samba para adicionar seu servidor Red Hat Enterprise Linux como membro ao domínio para ganhar o seguinte:
- Acessar recursos de domínio em outros membros do domínio
-
Autenticar usuários de domínio para serviços locais, tais como
sshd - Compartilhar diretórios e impressoras hospedadas no servidor para atuar como um servidor de arquivos e impressão
3.5.1. Juntando um sistema RHEL a um domínio AD
Esta seção descreve como unir um sistema Red Hat Enterprise Linux a um domínio AD, usando realmd para configurar o Samba Winbind.
Procedimento
Se seu AD requer o tipo de criptografia RC4 obsoleto para autenticação Kerberos, habilite o suporte para estas cifras na RHEL:
#
update-crypto-policies --set DEFAULT:AD-SUPPORTInstale os seguintes pacotes:
#
yum install realmd oddjob-mkhomedir oddjob samba-winbind-clients \ samba-winbind samba-common-tools samba-winbind-krb5-locatorPara compartilhar diretórios ou impressoras no membro do domínio, instale o pacote
samba:#
yum install sambaFaça o backup do arquivo de configuração existente
/etc/samba/smb.confSamba:#
mv /etc/samba/smb.conf /etc/samba/smb.conf.bakJunte-se ao domínio. Por exemplo, para ingressar em um domínio chamado
ad.example.com:#
realm join --membership-software=samba --client-software=winbind ad.example.comUsando o comando anterior, o utilitário
realmautomaticamente:-
Cria um arquivo
/etc/samba/smb.confpara uma associação no domínioad.example.com -
Adiciona o módulo
winbindpara pesquisas de usuários e grupos ao arquivo/etc/nsswitch.conf -
Atualiza os arquivos de configuração do Módulo de Autenticação Pluggável (PAM) no diretório
/etc/pam.d/ -
Inicia o serviço
winbinde permite que o serviço seja iniciado quando o sistema inicia
-
Cria um arquivo
-
Opcionalmente, defina um mapeamento alternativo de identificação no back end ou configurações personalizadas de mapeamento de identificação no arquivo
/etc/samba/smb.conf. Para detalhes, veja Seção 3.4, “Entendendo e configurando o mapeamento do Samba ID”. Verifique se o serviço
winbindestá funcionando:#
systemctl status winbind... Active: active (running) since Tue 2018-11-06 19:10:40 CET; 15s agoImportantePara que o Samba possa consultar informações de usuários e grupos de domínio, o serviço
winbinddeve estar em execução antes de você iniciarsmb.Se você instalou o pacote
sambapara compartilhar diretórios e impressoras, ative e inicie o serviçosmb:#
systemctl enable --now smb-
Opcionalmente, se você estiver autenticando os logins locais no Active Directory, ative o plug-in
winbind_krb5_localauth. Veja Seção 3.5.2, “Usando o plug-in de autorização local para o MIT Kerberos”.
Etapas de verificação
Exibir os detalhes de um usuário AD, tais como a conta do administrador AD no domínio AD:
#
getent passwd "AD\administrator"AD\administrator:*:10000:10000::/home/administrator@AD:/bin/bashConsultar os membros do grupo de usuários do domínio no domínio AD:
#
getent group "AD\Domain Users"AD\domain users:x:10000:user1,user2Opcionalmente, verifique se você pode utilizar usuários e grupos de domínio quando definir permissões em arquivos e diretórios. Por exemplo, para definir o proprietário do arquivo
/srv/samba/example.txtparaAD\administratore o grupo paraAD\Domain Users:#
chown "AD\administrator":"AD\Domain Users" /srv/samba/example.txtVerificar se a autenticação Kerberos funciona como esperado:
No membro do domínio AD, obtenha um ticket para o principal
administrator@AD.EXAMPLE.COM:#
kinit administrator@AD.EXAMPLE.COMExibir o bilhete Kerberos em cache:
#
klistTicket cache: KCM:0 Default principal: administrator@AD.EXAMPLE.COM Valid starting Expires Service principal 01.11.2018 10:00:00 01.11.2018 20:00:00 krbtgt/AD.EXAMPLE.COM@AD.EXAMPLE.COM renew until 08.11.2018 05:00:00
Mostrar os domínios disponíveis:
#
wbinfo --all-domainsBUILTIN SAMBA-SERVER AD
Recursos adicionais
- Se você não quiser usar as cifras RC4 depreciadas, você pode habilitar o tipo de criptografia AES em AD. Veja Seção 3.6.2, “Habilitando o tipo de criptografia AES no Active Directory usando um GPO”. Note que isto pode ter um impacto em outros serviços em seu AD.
-
Para mais detalhes sobre a utilidade
realm, consulte a página de manualrealm(8).
3.5.2. Usando o plug-in de autorização local para o MIT Kerberos
O serviço winbind fornece aos usuários do Active Directory para o membro do domínio. Em certas situações, os administradores querem permitir que os usuários do domínio se autentiquem nos serviços locais, como um servidor SSH, que estão rodando no membro do domínio. Ao usar Kerberos para autenticar os usuários do domínio, habilite o plug-in winbind_krb5_localauth para mapear corretamente os diretores do Kerberos para as contas do Active Directory através do serviço winbind.
Por exemplo, se o atributo sAMAccountName de um usuário do Active Directory estiver configurado para EXAMPLE e o usuário tentar logar com o nome de usuário em minúsculas, Kerberos retorna o nome de usuário em maiúsculas. Como conseqüência, as entradas não correspondem a uma autenticação falha.
Usando o plug-in winbind_krb5_localauth, os nomes das contas são mapeados corretamente. Note que isto só se aplica à autenticação GSSAPI e não para a obtenção do bilhete inicial de concessão do bilhete (TGT).
Pré-requisitos
- O Samba é configurado como membro de um Active Directory.
- O Red Hat Enterprise Linux autentica as tentativas de login contra o Active Directory.
-
O serviço
winbindestá funcionando.
Procedimento
Edite o arquivo /etc/krb5.conf e adicione a seguinte seção:
[plugins]
localauth = {
module = winbind:/usr/lib64/samba/krb5/winbind_krb5_localauth.so
enable_only = winbind
}Recursos adicionais
-
Veja a página de manual
winbind_krb5_localauth(8).
3.6. Estabelecimento do Samba em um membro do domínio IdM
Esta seção descreve como configurar o Samba em um host que é unido a um domínio da Red Hat Identity Management (IdM). Os usuários do IdM e também, se disponíveis, dos domínios confiáveis do Active Directory (AD), podem acessar ações e serviços de impressão fornecidos pelo Samba.
O uso do Samba em um membro do domínio IdM é um recurso de Pré-visualização Tecnológica não suportado e contém certas limitações. Por exemplo, devido aos controladores de confiança IdM que não suportam o serviço de Catálogo Global, os hosts do Windows registrados no AD não conseguem encontrar usuários e grupos IdM no Windows. Além disso, os controladores de confiança IdM não suportam a resolução de grupos IdM usando os protocolos Ambiente de Computação Distribuída / Chamadas de Procedimento Remoto (DCE/RPC). Como conseqüência, os usuários AD só podem acessar os compartilhamentos e impressoras Samba dos clientes IdM.
Os clientes que implantam Samba nos membros do domínio IdM são encorajados a fornecer feedback à Red Hat.
Pré-requisitos
- O host é unido como um cliente ao domínio IdM.
- Tanto os servidores da IdM quanto o cliente devem rodar no RHEL 8.1 ou posterior.
3.6.1. Preparando o domínio IdM para instalar o Samba nos membros do domínio
Antes de estabelecer uma confiança com AD e se você quiser configurar o Samba em um cliente IdM, você deve preparar o domínio IdM usando o utilitário ipa-adtrust-install em um servidor IdM. Entretanto, mesmo que ambas as situações se apliquem, você deve rodar ipa-adtrust-install apenas uma vez em um master IdM.
Pré-requisitos
- O IdM está instalado.
Procedimento
Instalar os pacotes necessários:
[root@ipaserver ~]#
yum install ipa-server ipa-server-trust-ad samba-clientAutenticar como usuário administrativo da IdM:
[root@ipaserver ~]#
kinit adminExecute o utilitário
ipa-adtrust-install:[root@ipaserver ~]#
ipa-adtrust-installOs registros do serviço DNS são criados automaticamente se a IdM foi instalada com um servidor DNS integrado.
Se o IdM foi instalado sem um servidor DNS integrado,
ipa-adtrust-installimprime uma lista de registros de serviços que devem ser adicionados manualmente ao DNS antes que você possa continuar.O roteiro lhe pede que o
/etc/samba/smb.confjá existe e será reescrito:WARNING: The smb.conf already exists. Running ipa-adtrust-install will break your existing Samba configuration. Do you wish to continue? [no]:
yesO script solicita que você configure o plug-in
slapi-nis, um plug-in de compatibilidade que permite que clientes Linux mais antigos trabalhem com usuários confiáveis:Do you want to enable support for trusted domains in Schema Compatibility plugin? This will allow clients older than SSSD 1.9 and non-Linux clients to work with trusted users. Enable trusted domains support in slapi-nis? [no]:
yesQuando solicitado, digite o nome NetBIOS para o domínio IdM ou pressione Enter para aceitar o nome sugerido:
Trust is configured but no NetBIOS domain name found, setting it now. Enter the NetBIOS name for the IPA domain. Only up to 15 uppercase ASCII letters, digits and dashes are allowed. Example: EXAMPLE. NetBIOS domain name [IDM]:
Você é solicitado a executar a tarefa da geração SID para criar um SID para qualquer usuário existente:
Você quer executar a tarefa ipa-sidgen? [não]
yesQuando o diretório é instalado pela primeira vez, pelo menos um usuário (o administrador do IdM) existe e como esta é uma tarefa de recursos intensivos, se você tiver um alto número de usuários, você pode executá-la em outro momento.
(Optional) Por padrão, a faixa de portas Dynamic RPC é definida como
49152-65535para Windows Server 2008 e posteriores. Se você precisar definir uma faixa de portas Dynamic RPC diferente para seu ambiente, configure o Samba para usar diferentes portas e abra essas portas em suas configurações de firewall. O exemplo a seguir define o intervalo de portas para55000-65000.[root@ipaserver ~]#
net conf setparm global 'rpc server dynamic port range' 55000-65000[root@ipaserver ~]#firewall-cmd --add-port=55000-65000/tcp[root@ipaserver ~]#firewall-cmd --runtime-to-permanentReinicie o serviço
ipa:[root@ipaserver ~]#
ipactl restartUse o utilitário
smbclientpara verificar se o Samba responde à autenticação Kerberos pelo lado do IdM:[root@ipaserver ~]#
smbclient -L server.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- IPC$ IPC IPC Service (Samba 4.12.3) ...
3.6.2. Habilitando o tipo de criptografia AES no Active Directory usando um GPO
Esta seção descreve como ativar o tipo de criptografia AES no Active Directory (AD) usando um objeto de política de grupo (GPO). Certas características no RHEL 8, como a execução de um servidor Samba em um cliente IdM, requerem este tipo de criptografia.
Observe que a RHEL 8 não suporta os tipos fracos de criptografia DES e RC4.
Pré-requisitos
- Você está logado no AD como um usuário que pode editar políticas de grupo.
-
O
Group Policy Management Consoleestá instalado no computador.
Procedimento
-
Abra o
Group Policy Management Console. -
Clique com o botão direito do mouse
Default Domain Policy, e selecioneEdit. OGroup Policy Management Editorabre. -
Navegue para
Computer ConfigurationSecurity OptionsPolicies→Windows Settings→Security SettingsLocal Policies→ → → . -
Clique duas vezes na política
Network security: Configure encryption types allowed for Kerberos. -
Selecione
AES256_HMAC_SHA1e, opcionalmente,Future encryption types. - Clique .
-
Feche o
Group Policy Management Editor. -
Repita os passos para o
Default Domain Controller Policy. Esperar até que os controladores de domínio Windows (DC) aplicassem automaticamente a política de grupo. Alternativamente, para aplicar o GPO manualmente em um CD, digite o seguinte comando usando uma conta que tenha permissões de administrador:
C:|>
gpupdate /force /target:computer
3.6.3. Instalação e configuração de um servidor Samba em um cliente IdM
Esta seção descreve como instalar e configurar o Samba em um cliente registrado em um domínio IdM.
Pré-requisitos
- Tanto os servidores da IdM quanto o cliente devem rodar no RHEL 8.1 ou posterior.
- O domínio IdM é preparado como descrito em Seção 3.6.1, “Preparando o domínio IdM para instalar o Samba nos membros do domínio”.
- Se a IdM tiver uma confiança configurada com AD, habilite o tipo de criptografia AES para Kerberos. Por exemplo, use um objeto de política de grupo (GPO) para habilitar o tipo de criptografia AES. Para detalhes, veja Seção 3.6.2, “Habilitando o tipo de criptografia AES no Active Directory usando um GPO”.
Procedimento
Instale o pacote
ipa-client-samba:[root@idm_client]#
yum install ipa-client-sambaUse o utilitário
ipa-client-sambapara preparar o cliente e criar uma configuração inicial do Samba:[root@idm_client]#
ipa-client-sambaSearching for IPA server... IPA server: DNS discovery Chosen IPA master: idm_server.idm.example.com SMB principal to be created: cifs/idm_client.idm.example.com@IDM.EXAMPLE.COM NetBIOS name to be used: IDM_CLIENT Discovered domains to use: Domain name: idm.example.com NetBIOS name: IDM SID: S-1-5-21-525930803-952335037-206501584 ID range: 212000000 - 212199999 Domain name: ad.example.com NetBIOS name: AD SID: None ID range: 1918400000 - 1918599999 Continue to configure the system with these values? [no]: yes Samba domain member is configured. Please check configuration at /etc/samba/smb.conf and start smb and winbind servicesPor padrão,
ipa-client-sambaadiciona automaticamente a seção[homes]ao arquivo/etc/samba/smb.confque compartilha dinamicamente o diretório home de um usuário quando este se conecta. Se os usuários não tiverem diretórios home neste servidor, ou se não quiserem compartilhá-los, remova as seguintes linhas do/etc/samba/smb.conf:[homes] read only = noCompartilhar diretórios e impressoras. Para detalhes, veja:
Abra as portas necessárias para um cliente Samba no firewall local:
[root@idm_client]#
firewall-cmd --permanent --add-service=samba-client[root@idm_client]#firewall-cmd --reloadHabilitar e iniciar os serviços
smbewinbind:[root@idm_client]#
systemctl enable --now smb winbind
Etapas de verificação
Execute os seguintes passos de verificação em um membro diferente do domínio IdM que tenha o pacote samba-client instalado:
Autenticar e obter um ingresso Kerberos para a concessão de bilhetes:
$
kinit example_userListe as ações no servidor Samba usando autenticação Kerberos:
$
smbclient -L idm_client.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.12.3) ...
Recursos adicionais
-
Para detalhes sobre quais passos
ipa-client-sambaexecuta durante a configuração, consulte a página de manualipa-client-samba(1).
3.6.4. Adicionar manualmente uma configuração de mapeamento de ID se a IdM confia em um novo domínio
O Samba requer uma configuração de mapeamento de identificação para cada domínio a partir do qual os usuários acessam recursos. Em um servidor Samba existente rodando em um cliente IdM, você deve adicionar manualmente uma configuração de mapeamento de ID após o administrador ter adicionado uma nova confiança a um domínio Active Directory (AD).
Pré-requisitos
- Você configurou o Samba em um cliente da IdM. Posteriormente, uma nova confiança foi adicionada à IdM.
- Os tipos de criptografia DES e RC4 para Kerberos devem ser desativados no domínio AD confiável. Por razões de segurança, a RHEL 8 não suporta esses tipos fracos de criptografia.
Procedimento
Autenticar usando o keytab do host:
[root@idm_client]#
kinit -kUse o comando
ipa idrange-findpara exibir tanto o ID base quanto o tamanho da faixa de ID do novo domínio. Por exemplo, o comando a seguir exibe os valores para o domínioad.example.com:[root@idm_client]#
ipa idrange-find --name="AD.EXAMPLE.COM_id_range" --raw--------------- 1 range matched --------------- cn: AD.EXAMPLE.COM_id_range ipabaseid: 1918400000 ipaidrangesize: 200000 ipabaserid: 0 ipanttrusteddomainsid: S-1-5-21-968346183-862388825-1738313271 iparangetype: ipa-ad-trust ---------------------------- Number of entries returned 1 ----------------------------Você precisa dos valores dos atributos
ipabaseideipaidrangesizenos próximos passos.Para calcular a maior identificação utilizável, use a seguinte fórmula:
alcance_máximo = ipabaseid ipaidrangesize - 1
Com os valores da etapa anterior, o ID mais alto utilizável para o domínio
ad.example.comé1918599999(1918400000 200000 - 1).Edite o arquivo
/etc/samba/smb.conf, e adicione a configuração do mapeamento de identificação do domínio à seção[global]:idmap config AD : range = 1918400000 - 1918599999 idmap config AD : backend = sss
Especificar o valor do atributo
ipabaseidcomo o valor mais baixo e o valor computado da etapa anterior como o valor mais alto do intervalo.Reinicie os serviços
smbewinbind:[root@idm_client]#
systemctl restart smb winbind
Etapas de verificação
Autenticar como usuário do novo domínio e obter um ticket de concessão de Kerberos:
$
kinit example_userListe as ações no servidor Samba usando autenticação Kerberos:
$
smbclient -L idm_client.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.12.3) ...
3.6.5. Recursos adicionais
-
Para detalhes sobre como unir a RHEL 8 a um domínio IdM, veja o
Installing an Identity Management clientno guiaInstalling Identity Management.
3.13. Configuração de Samba para clientes MacOS
O módulo Samba do sistema de arquivo virtual (VFS) fruit oferece maior compatibilidade com os clientes Apple server message block (SMB).
3.15. Configurando o Samba como servidor de impressão
Se você configurar o Samba como um servidor de impressão, os clientes em sua rede podem usar o Samba para imprimir. Além disso, os clientes Windows podem, se configurados, baixar o driver do servidor Samba.
Partes desta seção foram adotadas a partir da documentação de Criação do Samba como um Servidor de Impressão publicada no Samba Wiki. Licença: CC BY 4.0. Autores e colaboradores: Veja a guia Histórico na página Wiki.
Pré-requisitos
O Samba foi criado em uma das seguintes modalidades:
3.15.1. O serviço Samba spoolssd
O Samba spoolssd é um serviço que está integrado ao serviço smbd. Habilite spoolssd na configuração do Samba para aumentar significativamente o desempenho em servidores de impressão com um alto número de trabalhos ou impressoras.
Sem spoolssd, Samba forca o processo smbd e inicializa o cache printcap para cada trabalho de impressão. No caso de um grande número de impressoras, o serviço smbd pode ficar sem resposta por vários segundos enquanto o cache é inicializado. O serviço spoolssd permite iniciar os processos smbd pré-fabricados que estão processando os trabalhos de impressão sem qualquer atraso. O processo principal spoolssd smbd usa uma quantidade baixa de memória, e forca e encerra processos infantis.
O procedimento a seguir explica como habilitar o serviço spoolssd.
Procedimento
Edite a seção
[global]no arquivo/etc/samba/smb.conf:Adicione os seguintes parâmetros:
rpc_server:spoolss = external rpc_daemon:spoolssd = fork
Opcionalmente, você pode definir os seguintes parâmetros:
Parâmetro Padrão Descrição spoolssd:prefork_min_children5
Número mínimo de processos infantis
spoolssd:prefork_max_children25
Número máximo de processos infantis
spoolssd:prefork_spawn_rate5
O Samba forca o número de novos processos infantis estabelecidos neste parâmetro, até o valor estabelecido em
spoolssd:prefork_max_children, se uma nova conexão for estabelecidaspoolssd:prefork_max_allowed_clients100
Número de clientes, um processo infantil serve
spoolssd:prefork_child_min_life60
Duração mínima de um processo infantil em segundos. 60 segundos é o mínimo.
Verifique o arquivo
/etc/samba/smb.conf:#
testparmReinicie o serviço
smb:#
systemctl restart smbDepois de reiniciar o serviço, Samba inicia automaticamente
smbdprocessos infantis:#
ps axf... 30903 smbd 30912 \_ smbd 30913 \_ smbd 30914 \_ smbd 30915 \_ smbd ...
3.15.2. Permitindo suporte a servidores de impressão no Samba
Esta seção explica como habilitar o suporte do servidor de impressão no Samba.
Procedimento
No servidor Samba, configure o CUPS e adicione a impressora ao back end do CUPS. Para detalhes sobre a configuração de impressoras no CUPS; veja a documentação fornecida no console web do CUPS (https://print_server_host_name:631/help) no servidor de impressão.
NotaO Samba só pode encaminhar os trabalhos de impressão para o CUPS se o CUPS estiver instalado localmente no servidor de impressão do Samba.
Edite o arquivo
/etc/samba/smb.conf:Se você quiser ativar o serviço
spoolssd, adicione os seguintes parâmetros à seção[global]:rpc_server:spoolss = external rpc_daemon:spoolssd = fork
Para configurar o back end de impressão, adicione a seção
[printers]:[printers] comment = All Printers path = /var/tmp/ printable = yes create mask = 0600ImportanteO nome da ação
[printers]é codificado e não pode ser alterado.
Verifique o arquivo
/etc/samba/smb.conf:#
testparmAbra as portas necessárias e recarregue a configuração do firewall usando o utilitário
firewall-cmd:#
firewall-cmd --permanent --add-service=samba#firewall-cmd --reloadReinicie o serviço
smb:#
systemctl restart smb
Após reiniciar o serviço, Samba compartilha automaticamente todas as impressoras que estão configuradas no back end do CUPS. Se você quiser compartilhar manualmente apenas impressoras específicas, veja Seção 3.15.3, “Compartilhamento manual de impressoras específicas”.
3.15.3. Compartilhamento manual de impressoras específicas
Se você configurou o Samba como um servidor de impressão, por padrão, o Samba compartilha todas as impressoras que estão configuradas no back end do CUPS. O procedimento a seguir explica como compartilhar apenas impressoras específicas.
Pré-requisitos
- O Samba é configurado como um servidor de impressão
Procedimento
Edite o arquivo
/etc/samba/smb.conf:Na seção
[global], desabilite o compartilhamento automático da impressora através da configuração:impressoras de carga = não
Adicione uma seção para cada impressora que você deseja compartilhar. Por exemplo, para compartilhar a impressora chamada
exampleno back end do CUPS comoExample-Printerno Samba, adicione a seguinte seção:[Example-Printer] path = /var/tmp/ printable = yes printer name = exampleVocê não precisa de diretórios de bobinas individuais para cada impressora. Você pode definir o mesmo diretório de spool no parâmetro
pathpara a impressora, como você definiu na seção[printers].
Verifique o arquivo
/etc/samba/smb.conf:#
testparmRecarregar a configuração do Samba:
#
smbcontrol all reload-config
3.16. Configuração de downloads automáticos de drivers de impressão para clientes Windows em servidores de impressão Samba
Se você estiver executando um servidor de impressão Samba para clientes Windows, você pode carregar drivers e pré-configurar impressoras. Se um usuário se conectar a uma impressora, o Windows automaticamente faz o download e instala o driver localmente no cliente. O usuário não necessita de permissões de administrador local para a instalação. Além disso, o Windows aplica configurações de driver pré-configuradas, tais como o número de bandejas.
Partes desta seção foram adotadas a partir da documentação de Configuração de Driver de Impressora Automática Downloads para Clientes Windows, publicada no Samba Wiki. Licença: CC BY 4.0. Autores e colaboradores: Veja a guia Histórico na página Wiki.
Pré-requisitos
- O Samba é configurado como um servidor de impressão
3.16.1. Informações básicas sobre drivers de impressora
Esta seção fornece informações gerais sobre os drivers da impressora.
Versão do modelo de driver suportado
Samba suporta apenas o modelo de driver de impressora versão 3 que é suportado no Windows 2000 e posteriores, e no Windows Server 2000 e posteriores. Samba não suporta o modelo de driver versão 4, introduzido no Windows 8 e no Windows Server 2012. Entretanto, estas e versões posteriores do Windows também suportam os drivers da versão 3.
Motoristas conscientes das embalagens
O Samba não suporta motoristas sensíveis às embalagens.
Preparando um driver de impressão para ser carregado
Antes que você possa carregar um driver para um servidor de impressão Samba:
- Desembalar o motorista se ele for fornecido em um formato comprimido.
Alguns drivers requerem iniciar um aplicativo de configuração que instala o driver localmente em um host Windows. Em certas situações, o instalador extrai os arquivos individuais para a pasta temporária do sistema operacional durante as execuções de configuração. Para usar os arquivos do driver para fazer upload:
- Inicie o instalador.
- Copiar os arquivos da pasta temporária para um novo local.
- Cancele a instalação.
Solicite ao fabricante de sua impressora drivers que suportem o upload para um servidor de impressão.
Fornecendo drivers de 32 e 64 bits para uma impressora a um cliente
Para fornecer o driver para uma impressora tanto para clientes Windows de 32 e 64 bits, você deve carregar um driver com exatamente o mesmo nome para ambas as arquiteturas. Por exemplo, se você estiver fazendo o upload do driver de 32 bits chamado Example PostScript e do driver de 64 bits chamado Example PostScript (v1.0), os nomes não correspondem. Consequentemente, você só pode atribuir um dos drivers a uma impressora e o driver não estará disponível para ambas as arquiteturas.
3.16.2. Permitindo aos usuários carregar e pré-configurar drivers
Para ser capaz de carregar e pré-configurar drivers de impressora, um usuário ou um grupo precisa ter o privilégio SePrintOperatorPrivilege concedido. Um usuário deve ser adicionado ao grupo printadmin. O Red Hat Enterprise Linux cria automaticamente este grupo quando você instala o pacote samba. O grupo printadmin recebe o GID de sistema dinâmico mais baixo disponível que é inferior a 1000.
Procedimento
Por exemplo, para conceder o privilégio
SePrintOperatorPrivilegeao grupoprintadmin:#
net rpc rights grant "printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"Enter DOMAIN\administrator's password: Successfully granted rights.NotaEm um ambiente de domínio, conceder
SePrintOperatorPrivilegea um grupo de domínio. Isto permite administrar centralmente o privilégio, atualizando a filiação de um usuário a um grupo de usuários.Para listar todos os usuários e grupos tendo
SePrintOperatorPrivilegeconcedido:#
net rpc rights list privileges SePrintOperatorPrivilege -U "DOMAIN\administrator"Enter administrator's password: SePrintOperatorPrivilege: BUILTIN\Administrators DOMAIN\printadmin
3.16.4. Criação de um GPO para permitir que os clientes confiem no servidor de impressão Samba
Por razões de segurança, os sistemas operacionais Windows recentes impedem que os clientes baixem drivers de impressora que não sejam sensíveis ao pacote a partir de um servidor não confiável. Se seu servidor de impressão é membro de um AD, você pode criar um Objeto de Política de Grupo (GPO) em seu domínio para confiar no servidor Samba.
Pré-requisitos
- O servidor de impressão Samba é membro de um domínio AD.
- O computador Windows que você está usando para criar o GPO deve ter as Ferramentas de Administração do Servidor Remoto do Windows (RSAT) instaladas. Para obter detalhes, consulte a documentação do Windows.
Procedimento
-
Entre em um computador Windows usando uma conta que é permitida para editar políticas de grupo, como o usuário do domínio AD
Administrator. -
Abra o
Group Policy Management Console. Clique com o botão direito do mouse em seu domínio AD e selecione
Create a GPO in this domain, and Link it here.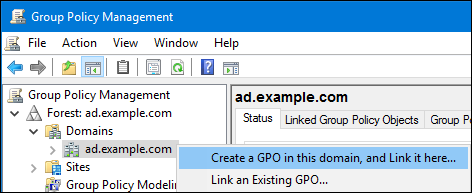
-
Digite um nome para o GPO, tal como
Legacy Printer Driver Policye clique emOK. O novo GPO será exibido sob a entrada do domínio. -
Clique com o botão direito do mouse no GPO recém-criado e selecione
Editpara abrir oGroup Policy Management Editor. Navegue para → → → .

No lado direito da janela, clique duas vezes em
Point and Print Restrictionpara editar a política:Habilite a política e defina as seguintes opções:
-
Selecione
Users can only point and print to these serverse digite o nome de domínio totalmente qualificado (FQDN) do servidor de impressão Samba no campo próximo a esta opção. Em ambas as caixas de seleção em
Security Prompts, selecioneDo not show warning or elevation prompt.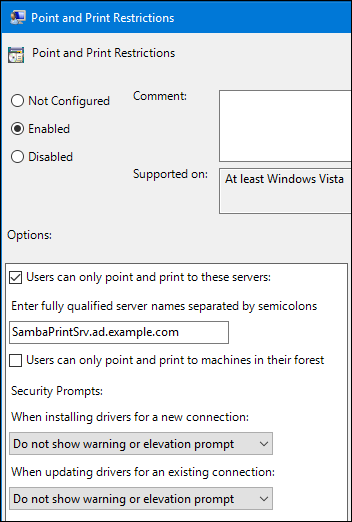
-
Selecione
- Clique OK.
Clique duas vezes em
Package Point and Print - Approved serverspara editar a política:-
Ative a política e clique no botão
Show. Entre na FQDN do servidor de impressão Samba.

-
Feche tanto o
Show Contentsquanto a janela de propriedades da apólice clicando emOK.
-
Ative a política e clique no botão
-
Feche o
Group Policy Management Editor. -
Feche o
Group Policy Management Console.
Depois que os membros do domínio Windows aplicaram a política de grupo, os drivers da impressora são automaticamente baixados do servidor Samba quando um usuário se conecta a uma impressora.
Recursos adicionais
- Para mais detalhes sobre o uso de políticas de grupo, consulte a documentação do Windows.
3.16.5. Carregamento de drivers e pré-configuração de impressoras
Use o aplicativo Print Management em um cliente Windows para carregar drivers e pré-configurar impressoras hospedadas no servidor de impressão Samba. Para mais detalhes, consulte a documentação do Windows.
3.17. Ajustando o desempenho de um servidor de Samba
Este capítulo descreve que configurações podem melhorar o desempenho do Samba em determinadas situações, e que configurações podem ter um impacto negativo no desempenho.
Partes desta seção foram adotadas a partir da documentação Performance Tuning publicada no Samba Wiki. Licença: CC BY 4.0. Autores e colaboradores: Veja a guia Histórico na página Wiki.
Pré-requisitos
- O Samba é configurado como um servidor de arquivos ou de impressão
3.17.1. Definição da versão do protocolo SMB
Cada nova versão SMB acrescenta características e melhora o desempenho do protocolo. Os recentes sistemas operacionais Windows e Windows Server sempre suportam a última versão do protocolo. Se o Samba também usa a versão mais recente do protocolo, os clientes Windows conectados ao Samba se beneficiam das melhorias de desempenho. No Samba, o valor padrão do protocolo máximo do servidor é definido para a última versão estável do protocolo SMB suportada.
Para ter sempre a última versão estável do protocolo SMB habilitada, não defina o parâmetro server max protocol. Se você definir o parâmetro manualmente, será necessário modificar a configuração com cada nova versão do protocolo SMB, para ter a última versão do protocolo ativada.
O procedimento seguinte explica como utilizar o valor padrão no parâmetro server max protocol.
Procedimento
-
Remover o parâmetro
server max protocolda seção[global]no arquivo/etc/samba/smb.conf. Recarregar a configuração do Samba
#
smbcontrol all reload-config
3.17.3. Configurações que podem ter um impacto negativo no desempenho
Por default, o kernel do Red Hat Enterprise Linux está sintonizado para alto desempenho da rede. Por exemplo, o kernel usa um mecanismo de sintonia automática para tamanhos de buffer. A configuração do parâmetro socket options no arquivo /etc/samba/smb.conf substitui estas configurações do kernel. Como resultado, a configuração deste parâmetro diminui o desempenho da rede Samba na maioria dos casos.
Para utilizar as configurações otimizadas do Kernel, remova o parâmetro socket options da seção [global] no site /etc/samba/smb.conf.
3.18. Configuração do Samba para ser compatível com clientes que requerem uma versão SMB menor que a padrão
O Samba usa um valor padrão razoável e seguro para a versão de bloco mínimo de mensagens do servidor (SMB) que ele suporta. No entanto, se você tiver clientes que requerem uma versão SMB mais antiga, você pode configurar o Samba para suportar isso.
3.18.1. Definição da versão mínima do protocolo SMB suportada por um servidor Samba
No Samba, o parâmetro server min protocol no arquivo /etc/samba/smb.conf define a versão do protocolo de bloco mínimo de mensagens do servidor (SMB) que o servidor Samba suporta. Esta seção descreve como alterar a versão mínima do protocolo SMB.
Por padrão, o Samba no RHEL 8.2 e posteriores suporta apenas as versões SMB2 e de protocolo mais recente. A Red Hat recomenda não usar o protocolo SMB1 depreciado. Entretanto, se seu ambiente exigir SMB1, você pode definir manualmente o parâmetro server min protocol para NT1 para reativar o SMB1.
Pré-requisitos
- O Samba é instalado e configurado.
Procedimento
Editar o arquivo
/etc/samba/smb.conf, adicionar o parâmetroserver min protocol, e definir o parâmetro para a versão mínima do protocolo SMB que o servidor deve suportar. Por exemplo, para definir a versão mínima do protocolo SMB paraSMB3, adicione:server min protocol = SMB3
Reinicie o serviço
smb:#
systemctl restart smb
Recursos adicionais
-
Para uma lista de versões de protocolo você pode definir no parâmetro
server min protocol, veja a descrição do parâmetroserver max protocolna página de manualsmb.conf(5).
3.19. Utilitários de linha de comando Samba freqüentemente utilizados
Este capítulo descreve os comandos freqüentemente utilizados quando se trabalha com um servidor Samba.
3.19.1. Usando os anúncios net join e os comandos net rpc join
Usando o sub-comando join do utilitário net, você pode unir o Samba a um domínio AD ou NT4. Para ingressar no domínio, você deve criar o arquivo /etc/samba/smb.conf manualmente, e opcionalmente atualizar configurações adicionais, como o PAM.
A Red Hat recomenda o uso do utilitário realm para ingressar em um domínio. O utilitário realm atualiza automaticamente todos os arquivos de configuração envolvidos.
Procedimento
Criar manualmente o arquivo
/etc/samba/smb.confcom as seguintes configurações:Para um membro de domínio AD:
[global] workgroup = domain_name security = ads passdb backend = tdbsam realm = AD_REALM
Para um membro de domínio NT4:
[global] workgroup = domain_name security = user passdb backend = tdbsam
-
Adicione uma configuração de mapeamento de ID para o domínio padrão
*e para o domínio que você deseja se juntar à seção[global] no arquivo/etc/samba/smb.conf. Verifique o arquivo
/etc/samba/smb.conf:#
testparmJunte-se ao domínio como administrador do domínio:
Para ingressar em um domínio AD:
#
net ads join -U "DOMAIN\administrator"Para aderir a um domínio NT4:
#
net rpc join -U "DOMAIN\administrator"
Anexar a fonte
winbindà entrada no banco de dadospasswdegroupno arquivo/etc/nsswitch.conf:passwd: files
winbindgroup: fileswinbindHabilite e inicie o serviço
winbind:#
systemctl enable --now winbindOpcionalmente, configure o PAM usando o utilitário
authselect.Para detalhes, consulte a página de manual
authselect(8).Opcionalmente para ambientes AD, configure o cliente Kerberos.
Para detalhes, consulte a documentação de seu cliente Kerberos.
3.19.2. Usando o comando net rpc rights
No Windows, você pode atribuir privilégios a contas e grupos para realizar operações especiais, tais como configurar ACLs em um compartilhamento ou carregar drivers de impressora. Em um servidor Samba, você pode usar o comando net rpc rights para gerenciar os privilégios.
Privilégios de listagem que você pode definir
Para listar todos os privilégios disponíveis e seus proprietários, use o comando net rpc rights list. Por exemplo:
# net rpc rights list -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
SeMachineAccountPrivilege Add machines to domain
SeTakeOwnershipPrivilege Take ownership of files or other objects
SeBackupPrivilege Back up files and directories
SeRestorePrivilege Restore files and directories
SeRemoteShutdownPrivilege Force shutdown from a remote system
SePrintOperatorPrivilege Manage printers
SeAddUsersPrivilege Add users and groups to the domain
SeDiskOperatorPrivilege Manage disk shares
SeSecurityPrivilege System securityConcessão de privilégios
Para conceder um privilégio a uma conta ou grupo, use o comando net rpc rights grant.
Por exemplo, conceder o privilégio de SePrintOperatorPrivilege ao DOMAIN\printadmin grupo:
# net rpc rights grant "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
Successfully granted rights.Revogação de privilégios
Para revogar um privilégio de uma conta ou grupo, use o comando net rpc rights revoke.
Por exemplo, para revogar o privilégio de SePrintOperatorPrivilege do DOMAIN\printadmin grupo:
# net rpc rights remoke "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
Successfully revoked rights.3.19.4. Usando o comando de usuário da rede
O comando net user permite realizar as seguintes ações em um AD DC ou NT4 PDC:
- Liste todas as contas de usuário
- Adicionar usuários
- Remover Usuários
Especificar um método de conexão, como ads para domínios AD ou rpc para domínios NT4, só é necessário quando você lista contas de usuário de domínio. Outros subcomandos relacionados ao usuário podem auto-detectar o método de conexão.
Passe o -U user_name ao comando para especificar um usuário que tem permissão para executar a ação solicitada.
Listagem de contas de usuário de domínio
Para listar todos os usuários em um domínio AD:
# net ads user -U "DOMAIN\administrator"Para listar todos os usuários em um domínio NT4:
# net rpc user -U "DOMAIN\administrator"Adicionando uma conta de usuário ao domínio
Em um membro do domínio Samba, você pode usar o comando net user add para adicionar uma conta de usuário ao domínio.
Por exemplo, adicione a conta user ao domínio:
Adicione a conta:
#
net user add user password -U "DOMAIN\administrator"User user addedOpcionalmente, use o shell de chamada de procedimento remoto (RPC) para habilitar a conta no AD DC ou NT4 PDC. Por exemplo:
#
net rpc shell -U DOMAIN\administrator -S DC_or_PDC_nameTalking to domain DOMAIN (S-1-5-21-1424831554-512457234-5642315751) net rpc>user edit disabled user: noSet user's disabled flag from [yes] to [no] net rpc>exit
Eliminação de uma conta de usuário do domínio
Em um membro do domínio Samba, você pode usar o comando net user delete para remover uma conta de usuário do domínio.
Por exemplo, para remover a conta user do domínio:
# net user delete user -U "DOMAIN\administrator"
User user deleted3.19.5. Usando a utilidade rpcclient
O utilitário rpcclient permite executar manualmente as funções de Chamada de Procedimento Remoto Microsoft (MS-RPC) do lado do cliente em um servidor SMB local ou remoto. No entanto, a maioria das funcionalidades são integradas em utilitários separados fornecidos pelo Samba. Use rpcclient apenas para testar as funções do MS-PRC.
Pré-requisitos
-
O pacote
samba-clientestá instalado.
Exemplos
Por exemplo, você pode usar o utilitário rpcclient para:
Gerenciar o subsistema de spool de impressão (SPOOLSS).
Exemplo 3.7. Atribuição de um driver a uma impressora
#
rpcclient server_name -U "DOMAIN\administrator" -c 'setdriver "printer_name" "driver_name"'Enter DOMAIN\administrators password: Successfully set printer_name to driver driver_name.Recuperar informações sobre um servidor SMB.
Exemplo 3.8. Listagem de todas as ações de arquivos e impressoras compartilhadas
#
rpcclient server_name -U "DOMAIN\administrator" -c 'netshareenum'Enter DOMAIN\administrators password: netname: Example_Share remark: path: C:\srv\samba\example_share\ password: netname: Example_Printer remark: path: C:\var\spool\samba\ password:Realizar ações utilizando o protocolo Security Account Manager Remote (SAMR).
Exemplo 3.9. Listagem de usuários em um servidor SMB
#
rpcclient server_name -U "DOMAIN\administrator" -c 'enumdomusers'Enter DOMAIN\administrators password: user:[user1] rid:[0x3e8] user:[user2] rid:[0x3e9]Se você executar o comando contra um servidor autônomo ou um membro do domínio, ele lista os usuários no banco de dados local. Executando o comando contra um AD DC ou NT4 PDC lista os usuários do domínio.
Recursos adicionais
Para uma lista completa dos subcomandos suportados, consulte a seção COMMANDS na página de manual rpcclient(1).
3.19.6. Usando a aplicação samba-regedit
Algumas configurações, tais como configurações de impressora, são armazenadas no registro no servidor Samba. Você pode usar o aplicativo ncurses baseado em samba-regedit para editar o registro de um servidor Samba.
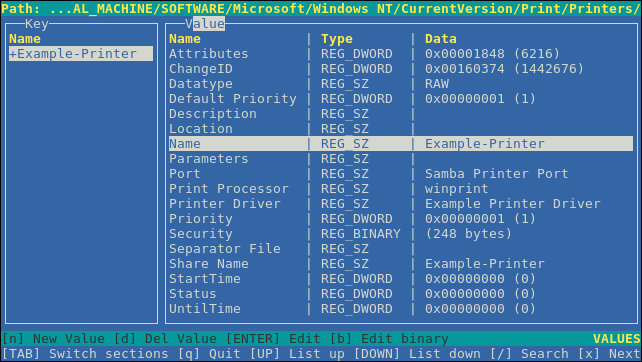
Pré-requisitos
-
O pacote
samba-clientestá instalado.
Procedimento
Para iniciar o pedido, entre:
# samba-regedit
Use as seguintes chaves:
- Cursor para cima e cursor para baixo: Navegue através da árvore de registro e dos valores.
- Entre: Abre uma chave ou edita um valor.
-
Tab: Alternância entre o painel
KeyeValue. - Ctrl+C: Encerra a aplicação.
3.19.7. Usando o utilitário smbcontrol
O utilitário smbcontrol permite que você envie mensagens de comando para smbd, nmbd, winbindd, ou todos estes serviços. Estas mensagens de controle instruem o serviço, por exemplo, a recarregar sua configuração.
O procedimento nesta seção mostra como recarregar a configuração dos serviços smbd, nmbd, winbindd enviando o tipo de mensagem reload-config para o destino all.
Pré-requisitos
-
O pacote
samba-common-toolsestá instalado.
Procedimento
# smbcontrol all reload-config
Recursos adicionais
Para mais detalhes e uma lista dos tipos de mensagens de comando disponíveis, consulte a página de manual smbcontrol(1).
3.19.8. Usando a utilidade smbpasswd
O utilitário smbpasswd gerencia contas de usuários e senhas no banco de dados local do Samba.
Pré-requisitos
-
O pacote
samba-common-toolsestá instalado.
Procedimento
Se você executar o comando como usuário,
smbpasswdmuda a senha Samba do usuário que executa o comando. Por exemplo:[user@server ~]$
smbpasswdNew SMB password: password Retype new SMB password: passwordSe você executar
smbpasswdcomo o usuárioroot, você pode usar o utilitário, por exemplo, para:Criar um novo usuário:
[root@server ~]#
smbpasswd -a user_nameNew SMB password:password` Retype new SMB password: [command]password` Added user user_name.NotaAntes de poder adicionar um usuário ao banco de dados Samba, você deve criar a conta no sistema operacional local. Veja a seção Adicionar um novo usuário a partir da linha de comando no guia Configuração de configurações básicas do sistema.
Habilitar um usuário de Samba:
[root@server ~]#
smbpasswd -e user_nameEnabled user user_name.Desativar um usuário de Samba:
[root@server ~]#
smbpasswd -x user_nameDisabled user ser_nameExcluir um usuário:
[root@server ~]#
smbpasswd -x user_nameDeleted user user_name.
Recursos adicionais
Para mais detalhes, consulte a página de manual smbpasswd(8).
3.19.9. Usando o utilitário smbstatus
O site smbstatus apresenta relatórios de utilidade pública:
-
Conexões por PID de cada daemon
smbdpara o servidor Samba. Este relatório inclui o nome do usuário, grupo primário, versão do protocolo SMB, criptografia e informações de assinatura. -
Conexões por ação Samba. Este relatório inclui o PID do daemon
smbd, o IP da máquina de conexão, o carimbo de tempo quando a conexão foi estabelecida, a criptografia e as informações de assinatura. - Uma lista de arquivos trancados. As entradas do relatório incluem mais detalhes, tais como os tipos de fechadura oportunista (oplock)
Pré-requisitos
-
O pacote
sambaestá instalado. -
O serviço
smbdestá funcionando.
Procedimento
# smbstatus
Samba version 4.12.3
PID Username Group Machine Protocol Version Encryption Signing
....-------------------------------------------------------------------------------------------------------------------------
963 DOMAIN\administrator DOMAIN\domain users client-pc (ipv4:192.0.2.1:57786) SMB3_02 - AES-128-CMAC
Service pid Machine Connected at Encryption Signing:
....---------------------------------------------------------------------------
example 969 192.0.2.1 Thu Nov 1 10:00:00 2018 CEST - AES-128-CMAC
Locked files:
Pid Uid DenyMode Access R/W Oplock SharePath Name Time
....--------------------------------------------------------------------------------------------------------
969 10000 DENY_WRITE 0x120089 RDONLY LEASE(RWH) /srv/samba/example file.txt Thu Nov 1 10:00:00 2018
Recursos adicionais
Para mais detalhes, consulte a página de manual smbstatus(1).
3.19.10. Usando a utilidade smbtar
O utilitário smbtar faz backup do conteúdo de um compartilhamento SMB ou de um subdiretório do mesmo e armazena o conteúdo em um arquivo tar. Alternativamente, você pode escrever o conteúdo em um dispositivo de fita.
Pré-requisitos
-
O pacote
samba-clientestá instalado.
Procedimento
Use o seguinte comando para fazer o backup do conteúdo do diretório
demono diretório//server/example/compartilhar e armazenar o conteúdo no arquivo/root/example.tar:#
smbtar -s server -x example -u user_name -p password -t /root/example.tar
Recursos adicionais
Para mais detalhes, consulte a página de manual smbtar(1).
3.19.11. Usando o utilitário wbinfo
O serviço wbinfo consulta e devolve informações criadas e utilizadas pelo serviço winbindd.
Pré-requisitos
-
O pacote
samba-winbind-clientsestá instalado.
Procedimento
Você pode usar wbinfo, por exemplo, para:
Liste os usuários do domínio:
#
wbinfo -uAD\administrator AD\guest ...Listar grupos de domínio:
#
wbinfo -gAD\domain computers AD\domain admins AD\domain users ...Exibir o SID de um usuário:
#
wbinfo --name-to-sid="AD\administrator"S-1-5-21-1762709870-351891212-3141221786-500 SID_USER (1)Mostrar informações sobre domínios e trusts:
#
wbinfo --trusted-domains --verboseDomain Name DNS Domain Trust Type Transitive In Out BUILTIN None Yes Yes Yes server None Yes Yes Yes DOMAIN1 domain1.example.com None Yes Yes Yes DOMAIN2 domain2.example.com External No Yes Yes
Recursos adicionais
Para mais detalhes, consulte a página de manual wbinfo(1).
Capítulo 5. Segurança do NFS
Para minimizar os riscos de segurança NFS e proteger os dados no servidor, considere as seguintes seções ao exportar sistemas de arquivos NFS em um servidor ou montá-los em um cliente.
5.1. Segurança NFS com AUTH_SYS e controles de exportação
A NFS oferece as seguintes opções tradicionais para controlar o acesso aos arquivos exportados:
- O servidor restringe quais hosts estão autorizados a montar quais sistemas de arquivo por endereço IP ou pelo nome do host.
-
O servidor aplica as permissões do sistema de arquivos para usuários em clientes NFS da mesma forma que o faz para usuários locais. Tradicionalmente, o NFS faz isto usando a mensagem de chamada
AUTH_SYS(também chamadaAUTH_UNIX), que depende do cliente para declarar a UID e GIDs do usuário. Esteja ciente de que isto significa que um cliente malicioso ou mal configurado pode facilmente errar isto e permitir que um usuário tenha acesso a arquivos que não deveria.
Para limitar os riscos potenciais, os administradores muitas vezes limitam o acesso a permissões de usuário somente leitura ou de esmagamento a um usuário comum e a uma identificação de grupo. Infelizmente, estas soluções impedem que o compartilhamento NFS seja utilizado da forma originalmente pretendida.
Além disso, se um atacante ganhar o controle do servidor DNS utilizado pelo sistema de exportação do sistema de arquivos NFS, ele pode apontar o sistema associado a um determinado nome de máquina ou nome de domínio totalmente qualificado para uma máquina não autorizada. Neste ponto, a máquina não autorizada is o sistema permite a montagem do compartilhamento NFS, porque nenhuma informação de nome de usuário ou senha é trocada para fornecer segurança adicional para a montagem do NFS.
Os curingas devem ser usados com parcimônia na exportação de diretórios através do NFS, pois é possível que o escopo do curinga englobe mais sistemas do que o pretendido.
Recursos adicionais
-
Para garantir o NFS e
rpcbind, utilize, por exemplo,nftablesefirewalld. Para detalhes sobre a configuração dessas estruturas, consulte as páginas de manualnft(8)efirewalld-cmd(1).
5.2. Segurança NFS com AUTH_GSS
Todas as versões do suporte NFS RPCSEC_GSS e o mecanismo Kerberos.
Ao contrário do AUTH_SYS, com o mecanismo RPCSEC_GSS Kerberos, o servidor não depende do cliente para representar corretamente qual usuário está acessando o arquivo. Em vez disso, a criptografia é usada para autenticar usuários no servidor, o que impede que um cliente malicioso imite um usuário sem ter as credenciais Kerberos desse usuário. O uso do mecanismo Kerberos RPCSEC_GSS é a maneira mais simples de garantir montagens porque, após configurar o Kerberos, não é necessária nenhuma configuração adicional.
5.3. Configuração de um servidor e cliente NFS para usar o Kerberos
Kerberos é um sistema de autenticação de rede que permite que clientes e servidores se autentiquem uns aos outros usando criptografia simétrica e um terceiro de confiança, o KDC. A Red Hat recomenda o uso do Gerenciamento de Identidade (IdM) para a configuração do Kerberos.
Pré-requisitos
-
O Centro de Distribuição de Chaves Kerberos (
KDC) está instalado e configurado.
Procedimento
-
Criar o
nfs/hostname.domain@REALMprincipal no lado do servidor NFS. -
Criar o
host/hostname.domain@REALMprincipal tanto do lado do servidor como do lado do cliente. - Adicione as chaves correspondentes às fichas-chave para o cliente e o servidor.
-
Criar o
No lado do servidor, use a opção
sec=para habilitar os sabores de segurança desejados. Para habilitar todos os sabores de segurança, bem como as montagens não criptográficas:/exportar *(seg=sys:krb5:krb5i:krb5p)
Os sabores de segurança válidos para usar com a opção
sec=são:-
sys: sem proteção criptográfica, o padrão -
krb5: somente autenticação -
krb5i: proteção da integridade -
krb5p: proteção de privacidade
-
No lado do cliente, adicionar
sec=krb5(ousec=krb5i, ousec=krb5p, dependendo da configuração) às opções de montagem:# mount -o sec=krb5 server:/exportar /mnt
Recursos adicionais
- Se você precisar escrever arquivos como raiz no compartilhamento NFS protegido por Kerberos e manter a propriedade raiz nesses arquivos, veja https://access.redhat.com/articles/4040141. Note que esta configuração não é recomendada.
- Para mais informações sobre a configuração do NFS, consulte as páginas de manual exports(5) e nfs(5).
5.4. Opções de segurança NFSv4
O NFSv4 inclui suporte ACL baseado no modelo Microsoft Windows NT, não no modelo POSIX, devido às características do modelo Microsoft Windows NT e sua ampla implementação.
Outra importante característica de segurança do NFSv4 é a remoção do uso do protocolo MOUNT para montagem de sistemas de arquivos. O protocolo MOUNT apresentou um risco de segurança devido à forma como o protocolo processava o arquivo.
5.5. Permissões de arquivo em exportações NFS montadas
Uma vez que o sistema de arquivo NFS é montado como leitura ou leitura e escrita por um host remoto, a única proteção que cada arquivo compartilhado tem é suas permissões. Se dois usuários que compartilham o mesmo valor de ID de usuário montarem o mesmo sistema de arquivo NFS em sistemas clientes diferentes, eles podem modificar os arquivos um do outro. Além disso, qualquer pessoa logada como root no sistema cliente pode usar o comando su - para acessar qualquer arquivo com o compartilhamento NFS.
Por default, as listas de controle de acesso (ACLs) são suportadas pelo NFS sob o Red Hat Enterprise Linux. A Red Hat recomenda manter este recurso ativado.
Por padrão, a NFS usa root squashing ao exportar um sistema de arquivo. Isto define o ID de usuário de qualquer pessoa que acesse o compartilhamento do NFS como usuário root em sua máquina local para nobody. O esmagamento de raízes é controlado pela opção padrão root_squash; para mais informações sobre esta opção, veja Seção 4.6, “Configuração do servidor NFS”.
Ao exportar uma ação da NFS como somente leitura, considere o uso da opção all_squash. Esta opção faz com que cada usuário que acesse o sistema de arquivo exportado pegue o ID de usuário do usuário nobody.
Capítulo 6. Habilitando layouts pNFS SCSI em NFS
É possível configurar o servidor e cliente NFS para usar o layout pNFS SCSI para acessar dados. pNFS SCSI é benéfico em casos de uso que envolvam acesso a um arquivo de um único cliente de duração mais longa.
Pré-requisitos
- Tanto o cliente quanto o servidor devem ser capazes de enviar comandos SCSI para o mesmo dispositivo de bloco. Ou seja, o dispositivo de bloco deve estar em um barramento SCSI compartilhado.
- O dispositivo de bloco deve conter um sistema de arquivo XFS.
- O dispositivo SCSI deve suportar as Reservas Persistentes SCSI, conforme descrito na especificação dos Comandos Primários SCSI-3.
6.1. A tecnologia pNFS
A arquitetura pNFS melhora a escalabilidade do NFS. Quando um servidor implementa o pNFS, o cliente é capaz de acessar dados através de múltiplos servidores simultaneamente. Isto pode levar a melhorias de desempenho.
o pNFS suporta os seguintes protocolos ou layouts de armazenamento no RHEL:
- Arquivos
- Flexfiles
- SCSI
6.2. layouts do pNFS SCSI
O layout SCSI se baseia no trabalho de layouts de blocos pNFS. O layout é definido através dos dispositivos SCSI. Ele contém uma série sequencial de blocos de tamanho fixo como unidades lógicas (LUs) que devem ser capazes de suportar reservas persistentes SCSI. Os dispositivos LU são identificados por sua identificação de dispositivos SCSI.
pNFS SCSI tem um bom desempenho em casos de uso que envolvem acesso de um único cliente a um arquivo com duração mais longa. Um exemplo pode ser um servidor de e-mail ou uma máquina virtual que abrigue um cluster.
Operações entre o cliente e o servidor
Quando um cliente NFS lê de um arquivo ou escreve para ele, o cliente realiza uma operação em LAYOUTGET. O servidor responde com a localização do arquivo no dispositivo SCSI. O cliente pode precisar realizar uma operação adicional de GETDEVICEINFO para determinar qual dispositivo SCSI usar. Se estas operações funcionarem corretamente, o cliente pode emitir solicitações de E/S diretamente para o dispositivo SCSI em vez de enviar READ e WRITE operações para o servidor.
Erros ou contendas entre os clientes podem fazer com que o servidor relembre os layouts ou não os emita para os clientes. Nesses casos, os clientes voltam a emitir operações em READ e WRITE para o servidor em vez de enviar pedidos de E/S diretamente para o dispositivo SCSI.
Para monitorar as operações, ver Seção 6.7, “Monitoramento da funcionalidade dos layouts SCSI do pNFS”.
Reservas de dispositivos
pNFS SCSI lida com as vedações através da atribuição de reservas. Antes de o servidor emitir layouts para os clientes, ele reserva o dispositivo SCSI para garantir que somente clientes registrados possam acessar o dispositivo. Se um cliente pode emitir comandos para esse dispositivo SCSI mas não está registrado com o dispositivo, muitas operações do cliente nesse dispositivo falham. Por exemplo, o comando blkid no cliente não mostra a UUID do sistema de arquivos XFS se o servidor não tiver dado um layout para aquele dispositivo ao cliente.
O servidor não remove sua própria reserva persistente. Isto protege os dados dentro do sistema de arquivos no dispositivo através de reinicializações de clientes e servidores. A fim de redirecionar o dispositivo SCSI, talvez seja necessário remover manualmente a reserva persistente no servidor NFS.
6.3. Verificação de um dispositivo SCSI compatível com o pNFS
Este procedimento verifica se um dispositivo SCSI suporta o layout pNFS SCSI.
Pré-requisitos
Instale o pacote
sg3_utils:# yum instalar sg3_utils
Procedimento
Tanto no servidor quanto no cliente, verifique o suporte adequado do dispositivo SCSI:
# sg_persist --in --reportar-capacidades --verbose path-to-scsi-deviceCertifique-se de que o bit Persist Through Power Loss Active (
PTPL_A) esteja definido.Exemplo 6.1. Um dispositivo SCSI que suporta o pNFS SCSI
A seguir, um exemplo de saída
sg_persistpara um dispositivo SCSI que suporta o pNFS SCSI. O relatório de bitPTPL_Ainforma1.inquiry cdb: 12 00 00 00 24 00 Persistent Reservation In cmd: 5e 02 00 00 00 00 00 20 00 00 LIO-ORG block11 4.0 Peripheral device type: disk Report capabilities response: Compatible Reservation Handling(CRH): 1 Specify Initiator Ports Capable(SIP_C): 1 All Target Ports Capable(ATP_C): 1 Persist Through Power Loss Capable(PTPL_C): 1 Type Mask Valid(TMV): 1 Allow Commands: 1 Persist Through Power Loss Active(PTPL_A): 1 Support indicated in Type mask: Write Exclusive, all registrants: 1 Exclusive Access, registrants only: 1 Write Exclusive, registrants only: 1 Exclusive Access: 1 Write Exclusive: 1 Exclusive Access, all registrants: 1
Recursos adicionais
-
A página do homem
sg_persist(8)
6.4. Configurando o pNFS SCSI no servidor
Este procedimento configura um servidor NFS para exportar um layout SCSI pNFS.
Procedimento
- No servidor, monte o sistema de arquivos XFS criado no dispositivo SCSI.
Configurar o servidor NFS para exportar a versão NFS 4.1 ou superior. Configurar a seguinte opção na seção
[nfsd]do arquivo/etc/nfs.conf:[nfsd] vers4.1=y
Configurar o servidor NFS para exportar o sistema de arquivos XFS sobre o NFS com a opção
pnfs:Exemplo 6.2. Uma entrada em /etc/exportação para exportar pNFS SCSI
A seguinte entrada no arquivo de configuração
/etc/exportsexporta o sistema de arquivo montado em/exported/directory/para o clienteallowed.example.comcomo um layout pNFS SCSI:/exportado/diretório permitido.example.com(pnfs)
Recursos adicionais
- Para mais informações sobre a configuração de um servidor NFS, veja Capítulo 4, Exportação de ações da NFS.
6.5. Instalação do pNFS SCSI no cliente
Este procedimento configura um cliente NFS para montar um layout SCSI pNFS.
Pré-requisitos
- O servidor NFS é configurado para exportar um sistema de arquivos XFS sobre pNFS SCSI. Veja Seção 6.4, “Configurando o pNFS SCSI no servidor”.
Procedimento
No cliente, monte o sistema de arquivos XFS exportado usando o NFS versão 4.1 ou superior:
# montagem -t nfs -o nfsvers=4,1 host:/remote/export /local/directory
Não montar o sistema de arquivo XFS diretamente sem NFS.
Recursos adicionais
- Para mais informações sobre montagem de ações NFS, veja Montagem de ações NFS.
6.6. Liberação da reserva do pNFS SCSI no servidor
Este procedimento libera a reserva persistente que um servidor NFS mantém em um dispositivo SCSI. Isto permite que você possa redirecionar o dispositivo SCSI quando não precisar mais exportar o SCSI pNFS.
Você deve remover a reserva do servidor. Ela não pode ser removida de um Nexus de TI diferente.
Pré-requisitos
Instale o pacote
sg3_utils:# yum instalar sg3_utils
Procedimento
Consultar uma reserva existente no servidor:
# sg_persist --ler-reserva path-to-scsi-deviceExemplo 6.3. Consultar uma reserva em /dev/sda
# sg_persist --read-reservation /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk PR generation=0x8, Reservation follows: Key=0x100000000000000 scope: LU_SCOPE, type: Exclusive Access, registrants onlyRemover o registro existente no servidor:
# sg_persist --out \ --release \ --param-rk=reservation-key \ --prout-type=6 \ path-to-scsi-deviceExemplo 6.4. Removendo uma reserva em /dev/sda
# sg_persist --out \ --release \ --param-rk=0x100000000000000 \ --prout-type=6 \ /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk
Recursos adicionais
-
A página do homem
sg_persist(8)
6.7. Monitoramento da funcionalidade dos layouts SCSI do pNFS
Você pode monitorar se o cliente pNFS e o servidor trocam operações pNFS SCSI adequadas ou se elas recaem em operações NFS regulares.
Pré-requisitos
- Um cliente e servidor pNFS SCSI são configurados.
6.7.1. Verificação das operações pNFS SCSI a partir do servidor usando o nfsstat
Este procedimento utiliza o utilitário nfsstat para monitorar as operações SCSI do pNFS a partir do servidor.
Procedimento
Monitorar as operações atendidas a partir do servidor:
# watch --differences \ "nfsstat --server | egrep --after-context=1 read\|write\|layout" Every 2.0s: nfsstat --server | egrep --after-context=1 read\|write\|layout putrootfh read readdir readlink remove rename 2 0% 0 0% 1 0% 0 0% 0 0% 0 0% -- setcltidconf verify write rellockowner bc_ctl bind_conn 0 0% 0 0% 0 0% 0 0% 0 0% 0 0% -- getdevlist layoutcommit layoutget layoutreturn secinfononam sequence 0 0% 29 1% 49 1% 5 0% 0 0% 2435 86%O cliente e o servidor utilizam operações pNFS SCSI quando:
-
Os balcões
layoutget,layoutreturn, elayoutcommitincrementam. Isto significa que o servidor está servindo layouts. -
O servidor
readewritenão incrementam os balcões. Isto significa que os clientes estão realizando solicitações de E/S diretamente para os dispositivos SCSI.
-
Os balcões
6.7.2. Verificação das operações pNFS SCSI por parte do cliente utilizando montarias
Este procedimento utiliza o arquivo /proc/self/mountstats para monitorar as operações pNFS SCSI do cliente.
Procedimento
Liste os contadores por operação de montagem:
# cat /proc/self/mountstats \ | awk /scsi_lun_0/,/^$/ \ | egrep device\|READ\|WRITE\|LAYOUT device 192.168.122.73:/exports/scsi_lun_0 mounted on /mnt/rhel7/scsi_lun_0 with fstype nfs4 statvers=1.1 nfsv4: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x803,acl=0x3,sessions,pnfs=LAYOUT_SCSI READ: 0 0 0 0 0 0 0 0 WRITE: 0 0 0 0 0 0 0 0 READLINK: 0 0 0 0 0 0 0 0 READDIR: 0 0 0 0 0 0 0 0 LAYOUTGET: 49 49 0 11172 9604 2 19448 19454 LAYOUTCOMMIT: 28 28 0 7776 4808 0 24719 24722 LAYOUTRETURN: 0 0 0 0 0 0 0 0 LAYOUTSTATS: 0 0 0 0 0 0 0 0Nos resultados:
-
As estatísticas
LAYOUTindicam solicitações onde o cliente e o servidor utilizam operações SCSI pNFS. -
As estatísticas
READeWRITEindicam solicitações onde o cliente e o servidor retornam às operações NFS.
-
As estatísticas
Capítulo 7. Configuração do servidor proxy de cache Squid
O Squid é um servidor proxy que armazena o conteúdo para reduzir a largura de banda e carregar páginas da web mais rapidamente. Este capítulo descreve como configurar o Squid como um proxy para o protocolo HTTP, HTTPS e FTP, assim como autenticação e restrição de acesso.
7.1. Configurando o Squid como um proxy de cache sem autenticação
Esta seção descreve uma configuração básica do Squid como um proxy de cache sem autenticação. O procedimento limita o acesso ao proxy com base em faixas de IP.
Pré-requisitos
-
O procedimento pressupõe que o arquivo
/etc/squid/squid.confé o fornecido pelo pacotesquid. Se você editou este arquivo antes, remova o arquivo e reinstale o pacote.
Procedimento
Instale o pacote
squid:# yum instalar lula
Edite o arquivo
/etc/squid/squid.conf:Adaptar as listas de controle de acesso (ACL) do site
localnetpara corresponder aos intervalos de IP que devem ser permitidos para usar o proxy:acl localnet src 192.0.2.0/24 acl localnet 2001:db8:1::/64
Por padrão, o arquivo
/etc/squid/squid.confcontém a regrahttp_access allow localnetque permite utilizar o proxy de todas as faixas de IP especificadas emlocalnetACLs. Note que você deve especificar todas aslocalnetACLs antes da regrahttp_access allow localnet.ImportanteRemova todas as entradas existentes no site
acl localnetque não correspondem ao seu ambiente.A seguinte ACL existe na configuração padrão e define
443como uma porta que usa o protocolo HTTPS:acl Porta SSL_port 443
Se os usuários devem ser capazes de usar o protocolo HTTPS também em outras portas, acrescente uma ACL para cada uma dessas portas:
acl Porta SSL_ports port_numberAtualizar a lista de regras
acl Safe_portspara configurar com quais portas a Squid pode estabelecer uma conexão. Por exemplo, para configurar que os clientes que utilizam o proxy só podem acessar recursos nas portas 21 (FTP), 80 (HTTP) e 443 (HTTPS), mantenha apenas as seguintes declaraçõesacl Safe_portsna configuração:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por padrão, a configuração contém a regra
http_access deny !Safe_portsque define a negação de acesso às portas que não estão definidas emSafe_portsACLs.Configure o tipo de cache, o caminho para o diretório de cache, o tamanho do cache e outras configurações específicas do tipo de cache no parâmetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Com estas configurações:
-
A lula usa o tipo de cache
ufs. -
A Squid armazena seu cache no diretório
/var/spool/squid/. -
O cache cresce até
10000MB. -
A Squid cria subdiretórios de nível 1 em
16no diretório/var/spool/squid/. A Squid cria subdiretórios
256em cada diretório de nível 1.Se você não definir uma diretiva
cache_dir, a Squid armazena o cache na memória.
-
A lula usa o tipo de cache
Se você definir um diretório de cache diferente de
/var/spool/squid/no parâmetrocache_dir:Criar o diretório do cache:
# mkdir -p path_to_cache_directoryConfigurar as permissões para o diretório do cache:
# chown squid:lula path_to_cache_directorySe você executar o SELinux no modo
enforcing, defina o contextosquid_cache_tpara o diretório do cache:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Se o utilitário
semanagenão estiver disponível em seu sistema, instale o pacotepolicycoreutils-python-utils.
Abra a porta
3128no firewall:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie o serviço
squid:# systemctl habilita --agora lula
Etapas de verificação
Para verificar se o proxy funciona corretamente, baixe uma página da web usando o utilitário curl:
# curl -O -L"https://www.redhat.com/index.html" -x"proxy.example.com:3128"
Se curl não exibir nenhum erro e o arquivo index.html tiver sido baixado para o diretório atual, o proxy funciona.
7.2. Configurando o Squid como um proxy de cache com autenticação LDAP
Esta seção descreve uma configuração básica do Squid como um proxy de cache que usa LDAP para autenticar usuários. O procedimento configura que somente os usuários autenticados podem usar o proxy.
Pré-requisitos
-
O procedimento pressupõe que o arquivo
/etc/squid/squid.confé o fornecido pelo pacotesquid. Se você editou este arquivo antes, remova o arquivo e reinstale o pacote. -
Um usuário de serviço, como o
uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com, existe no diretório LDAP. A Squid usa esta conta apenas para procurar o usuário que se autentica. Se o usuário autenticador existir, Squid se vincula como este usuário ao diretório para verificar a autenticação.
Procedimento
Instale o pacote
squid:# yum instalar lula
Edite o arquivo
/etc/squid/squid.conf:Para configurar o utilitário helper
basic_ldap_auth, adicione a seguinte entrada de configuração ao topo do site/etc/squid/squid.conf:auth_param basic program /usr/lib64/squid/basic_ldap_auth -bcn=users,cn=accounts,dc=example,dc=com" -D "uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f "(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389
A seguir descrevemos os parâmetros passados para o utilitário helper
basic_ldap_authno exemplo acima:-
-B base_DNdefine a base de busca LDAP. -
-D proxy_service_user_DNdefine o nome distinto (DN) da conta que a Squid usa para procurar o usuário que se autentica no diretório. -
-W path_to_password_filedefine o caminho para o arquivo que contém a senha do usuário do serviço de proxy. O uso de um arquivo de senha impede que a senha seja visível na lista de processos do sistema operacional. -f LDAP_filterespecifica o filtro de busca LDAP. O Squid substitui a variável%spelo nome de usuário fornecido pelo usuário que se autentica.O filtro
(&(objectClass=person)(uid=%s))no exemplo define que o nome do usuário deve corresponder ao valor definido no atributouide que a entrada do diretório contém a classe de objetoperson.-ZZfaz cumprir uma conexão criptografada por TLS sobre o protocolo LDAP usando o comandoSTARTTLS. Omitir o-ZZnas seguintes situações:- O servidor LDAP não suporta conexões criptografadas.
- A porta especificada no URL utiliza o protocolo LDAPS.
- O parâmetro -H LDAP_URL especifica o protocolo, o nome do host ou endereço IP, e a porta do servidor LDAP no formato URL.
-
Adicione a seguinte ACL e regra para configurar que o Squid permite que somente usuários autenticados possam usar o proxy:
acl ldap-auth proxy_auth REQUIRED http_access allow ldap-auth
ImportanteEspecifique estas configurações antes da regra
http_access denytodas.Remover a seguinte regra para desativar a autenticação por proxy a partir de faixas IP especificadas em
localnetACLs:http_access permite rede local
A seguinte ACL existe na configuração padrão e define
443como uma porta que usa o protocolo HTTPS:acl Porta SSL_port 443
Se os usuários devem ser capazes de usar o protocolo HTTPS também em outras portas, acrescente uma ACL para cada uma dessas portas:
acl SSL_port porto_número_de_porta
Atualizar a lista de regras
acl Safe_portspara configurar com quais portas a Squid pode estabelecer uma conexão. Por exemplo, para configurar que os clientes que utilizam o proxy só podem acessar recursos nas portas 21 (FTP), 80 (HTTP) e 443 (HTTPS), mantenha apenas as seguintes declaraçõesacl Safe_portsna configuração:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por padrão, a configuração contém a regra
http_access deny !Safe_portsque define a negação de acesso a portos que não estão definidos emSafe_ports ACLs.Configure o tipo de cache, o caminho para o diretório de cache, o tamanho do cache e outras configurações específicas do tipo de cache no parâmetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Com estas configurações:
-
A lula usa o tipo de cache
ufs. -
A Squid armazena seu cache no diretório
/var/spool/squid/. -
O cache cresce até
10000MB. -
A Squid cria subdiretórios de nível 1 em
16no diretório/var/spool/squid/. A Squid cria subdiretórios
256em cada diretório de nível 1.Se você não definir uma diretiva
cache_dir, a Squid armazena o cache na memória.
-
A lula usa o tipo de cache
Se você definir um diretório de cache diferente de
/var/spool/squid/no parâmetrocache_dir:Criar o diretório do cache:
# mkdir -p path_to_cache_directoryConfigurar as permissões para o diretório do cache:
# chown squid:lula path_to_cache_directorySe você executar o SELinux no modo
enforcing, defina o contextosquid_cache_tpara o diretório do cache:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Se o utilitário
semanagenão estiver disponível em seu sistema, instale o pacotepolicycoreutils-python-utils.
Armazene a senha do usuário do serviço LDAP no arquivo
/etc/squid/ldap_password, e defina as permissões apropriadas para o arquivo:# echo "password" > /etc/squid/ldap_password # chown root:squid /etc/squid/ldap_password # chmod 640 /etc/squid/ldap_passwordAbra a porta
3128no firewall:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie o serviço
squid:# systemctl habilita --agora lula
Etapas de verificação
Para verificar se o proxy funciona corretamente, baixe uma página da web usando o utilitário curl:
# curl -O -L"https://www.redhat.com/index.html" -x"user_name:password@proxy.example.com:3128"
Se o curl não exibir nenhum erro e o arquivo index.html tiver sido baixado para o diretório atual, o proxy funciona.
Passos para a solução de problemas
Para verificar se o utilitário auxiliar funciona corretamente:
Inicie manualmente o utilitário auxiliar com as mesmas configurações que você usou no parâmetro
auth_param:/usr/lib64/squid/basic_ldap_auth -bcn=users,cn=accounts,dc=example,dc=com" -Duid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f"(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389
Digite um nome de usuário e senha válidos, e pressione Enter:
user_name password
Se o utilitário auxiliar retornar
OK, a autenticação será bem sucedida.
7.3. Configurando o Squid como um proxy de cache com autenticação de kerberos
Esta seção descreve uma configuração básica do Squid como um proxy de cache que autentica os usuários a um Active Directory (AD) usando Kerberos. O procedimento configura que somente usuários autenticados podem usar o proxy.
Pré-requisitos
-
O procedimento pressupõe que o arquivo
/etc/squid/squid.confé o fornecido pelo pacotesquid. Se você editou este arquivo antes, remova o arquivo e reinstale o pacote. -
O servidor no qual você deseja instalar o Squid é um membro do domínio AD. Para detalhes, veja Configurando o Samba como membro do domínio na documentação do Red Hat Enterprise Linux 8
Deploying different types of servers.
Procedimento
Instale os seguintes pacotes:
yum instalar estação de trabalho squid krb5
Autenticar como administrador do domínio AD:
# parente administrador@AD.EXAMPLE.COMCrie uma tabela de chaves para o Squid e armazene-a no arquivo
/etc/squid/HTTP.keytab:# export KRB5_KTNAME=FILE:/etc/squid/HTTP.keytab # net ads keytab CREATE -U administrator
Acrescente o principal serviço
HTTPao keytab:# net ads keytab ADD HTTP -U administrador
Defina o proprietário do arquivo keytab para o usuário do
squid:# chown squid /etc/squid/HTTP.keytab
Opcionalmente, verifique se o arquivo keytab contém o principal do serviço
HTTPpara o nome de domínio totalmente qualificado (FQDN) do servidor proxy:# klist -k /etc/squid/HTTP.keytab Keytab name: FILE:/etc/squid/HTTP.keytab KVNO Principal ---- --------------------------------------------------- ... 2 HTTP/proxy.ad.example.com@AD.EXAMPLE.COM ...
Edite o arquivo
/etc/squid/squid.conf:Para configurar o utilitário helper
negotiate_kerberos_auth, adicione a seguinte entrada de configuração ao topo do site/etc/squid/squid.conf:auth_param negociar programa /usr/lib64/squid/negociar_kerberos_auth -k /etc/squid/HTTP.keytab -s HTTP/proxy.ad.example.com@AD.EXAMPLE.COM
A seguir descrevemos os parâmetros passados para o utilitário helper
negotiate_kerberos_authno exemplo acima:-
-k filedefine o caminho para o arquivo da aba chave. Note que o usuário da lula deve ter permissões de leitura neste arquivo. -s HTTP/host_name@kerberos_realmdefine o Kerberos principal que a Lula usa.Opcionalmente, você pode habilitar o registro passando um ou ambos os parâmetros a seguir para o utilitário auxiliar:
-
-iregistra mensagens informativas, como o usuário que se autentica. -dpermite o registro de depuração.O Squid registra as informações de depuração do utilitário auxiliar no arquivo
/var/log/squid/cache.log.
-
Adicione a seguinte ACL e regra para configurar que o Squid permite que somente usuários autenticados possam usar o proxy:
acl kerb-auth proxy_auth REQUIRED http_access allow kerb-auth
ImportanteEspecifique estas configurações antes da regra
http_access deny all.Remover a seguinte regra para desativar a autenticação por proxy a partir de faixas IP especificadas em
localnetACLs:http_access permite rede local
A seguinte ACL existe na configuração padrão e define
443como uma porta que usa o protocolo HTTPS:acl Porta SSL_port 443
Se os usuários devem ser capazes de usar o protocolo HTTPS também em outras portas, acrescente uma ACL para cada uma dessas portas:
acl Porta SSL_ports port_numberAtualizar a lista de regras
acl Safe_portspara configurar com quais portas a Squid pode estabelecer uma conexão. Por exemplo, para configurar que os clientes que utilizam o proxy só podem acessar recursos nas portas 21 (FTP), 80 (HTTP) e 443 (HTTPS), mantenha apenas as seguintes declaraçõesacl Safe_portsna configuração:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por padrão, a configuração contém a regra
http_access deny !Safe_portsque define a negação de acesso às portas que não estão definidas emSafe_portsACLs.Configure o tipo de cache, o caminho para o diretório de cache, o tamanho do cache e outras configurações específicas do tipo de cache no parâmetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Com estas configurações:
-
A lula usa o tipo de cache
ufs. -
A Squid armazena seu cache no diretório
/var/spool/squid/. -
O cache cresce até
10000MB. -
A Squid cria subdiretórios de nível 1 em
16no diretório/var/spool/squid/. A Squid cria subdiretórios
256em cada diretório de nível 1.Se você não definir uma diretiva
cache_dir, a Squid armazena o cache na memória.
-
A lula usa o tipo de cache
Se você definir um diretório de cache diferente de
/var/spool/squid/no parâmetrocache_dir:Criar o diretório do cache:
# mkdir -p path_to_cache_directoryConfigurar as permissões para o diretório do cache:
# chown squid:lula path_to_cache_directorySe você executar o SELinux no modo
enforcing, defina o contextosquid_cache_tpara o diretório do cache:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Se o utilitário
semanagenão estiver disponível em seu sistema, instale o pacotepolicycoreutils-python-utils.
Abra a porta
3128no firewall:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie o serviço
squid:# systemctl habilita --agora lula
Etapas de verificação
Para verificar se o proxy funciona corretamente, baixe uma página da web usando o utilitário curl:
# curl -O -L"https://www.redhat.com/index.html" --proxy-negotiate -u : -x"proxy.ad.example.com:3128"
Se curl não exibir nenhum erro e o arquivo index.html existir no diretório atual, o proxy funciona.
Passos para a solução de problemas
Para testar manualmente a autenticação Kerberos:
Obter um bilhete Kerberos para a conta AD:
# parente usuário@AD.EXAMPLE.COMOpcionalmente, exibir o bilhete:
# klist
Use o utilitário
negotiate_kerberos_auth_testpara testar a autenticação:/usr/lib64/squid/negociar_kerberos_auth_test proxy.ad.example.comSe o utilitário auxiliar devolver um token, a autenticação foi bem sucedida:
Token: YIIFtAYGKwYBBQUCoIIFqDC...
7.4. Configuração de uma lista de negação de domínio em Squid
Freqüentemente, os administradores querem bloquear o acesso a domínios específicos. Esta seção descreve como configurar uma lista de negação de domínio no Squid.
Pré-requisitos
- O Squid é configurado, e os usuários podem usar o proxy.
Procedimento
Edite o arquivo
/etc/squid/squid.confe adicione as seguintes configurações:acl domain_deny_list dstdomain "/etc/squid/domain_deny_list.txt" http_access deny all domain_deny_list
ImportanteAdicione estas entradas antes da primeira declaração em
http_access allowque permite o acesso a usuários ou clientes.Crie o arquivo
/etc/squid/domain_deny_list.txte adicione os domínios que você deseja bloquear. Por exemplo, para bloquear o acesso aexample.comincluindo subdomínios e para bloquearexample.net, adicione:.example.com example.net
ImportanteSe você se referiu ao arquivo
/etc/squid/domain_deny_list.txtna configuração da lula, este arquivo não deve estar vazio. Se o arquivo estiver vazio, o Squid não inicia.Reinicie o serviço
squid:# systemctl restart squid
7.5. Configuração do serviço Squid para ouvir em uma porta específica ou endereço IP
Por padrão, o serviço de proxy Squid ouve na porta 3128 em todas as interfaces de rede. Esta seção descreve como mudar a porta e configurar o Squid para escutar em um endereço IP específico.
Pré-requisitos
-
O pacote
squidestá instalado.
Procedimento
Edite o arquivo
/etc/squid/squid.conf:Para definir a porta na qual o serviço Squid ouve, defina o número da porta no parâmetro
http_port. Por exemplo, para definir a porta para8080, defina o número da porta:http_port 8080
Para configurar em qual endereço IP o serviço Squid ouve, defina o endereço IP e o número da porta no parâmetro
http_port. Por exemplo, para configurar que o Squid escuta somente no endereço IP192.0.2.1na porta3128, defina o endereço IP e o número da porta no parâmetro :http_port 192.0.2.1:3128
Adicione vários parâmetros
http_portao arquivo de configuração para configurar que o Squid escute em múltiplas portas e endereços IP:http_port 192.0.2.1:3128 http_port 192.0.2.1:8080
Se você configurou que o Squid usa uma porta diferente como padrão (
3128):Abra a porta no firewall:
# firewall-cmd --permanent --add-port=port_number/tcp # firewall-cmd --reloadSe você executar o SELinux em modo de aplicação, atribua a porta para a definição do tipo de porta
squid_port_t:# porto semanage -a -t lula_port_t -p tcp port_numberSe o utilitário
semanagenão estiver disponível em seu sistema, instale o pacotepolicycoreutils-python-utils.
Reinicie o serviço
squid:# systemctl restart squid
7.6. Recursos adicionais
-
Consulte o arquivo
usr/share/doc/squid-<version>/squid.conf.documentedpara obter uma lista de todos os parâmetros de configuração que você pode definir no arquivo/etc/squid/squid.conf, juntamente com uma descrição detalhada.
Capítulo 8. Servidores de banco de dados
8.1. Introdução aos servidores de banco de dados
Um servidor de banco de dados é um dispositivo de hardware que tem uma certa quantidade de memória principal, e um aplicativo de banco de dados (DB) instalado. Esta aplicação DB fornece serviços como um meio de escrever os dados em cache da memória principal, que normalmente é pequena e cara, para arquivos DB (banco de dados). Estes serviços são fornecidos a vários clientes em uma rede. Pode haver tantos servidores de banco de dados quanto a memória principal de uma máquina e o armazenamento permitem.
O Red Hat Enterprise Linux 8 fornece as seguintes aplicações de banco de dados:
- MariaDB 10.3
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - disponível desde RHEL 8.1.1
8.2. Usando o MariaDB
8.2.1. Começando com a MariaDB
O servidor MariaDB é um servidor de banco de dados de código aberto, rápido e robusto, baseado na tecnologia MySQL.
MariaDB é um banco de dados relacional que converte dados em informações estruturadas e fornece uma interface SQL para acesso aos dados. Inclui múltiplos mecanismos de armazenamento e plug-ins, bem como recursos de sistema de informação geográfica (GIS) e JavaScript Object Notation (JSON).
Esta seção descreve como instalar o servidor MariaDB na instalação do MariaDB ou como migrar da versão default do Red Hat Enterprise Linux 7, MariaDB 5.5, para a versão default do Red Hat Enterprise Linux 8, MariaDB 10.3, na migração para o MariaDB 10.3, e também como fazer o backup dos dados do MariaDB. A realização de backup de dados é um dos pré-requisitos para a migração para o MariaDB.
8.2.2. Instalando o MariaDB
Para instalar MariaDB, siga este procedimento:
Certifique-se de que todos os pacotes necessários para o servidor MariaDB estejam disponíveis no sistema, instalando o módulo
mariadbusando um fluxo específico:# yum module install mariadb:10.3/server
Iniciar o serviço
mariadb:# systemctl start mariadb.service
Habilite o serviço
mariadbpara começar na inicialização:# systemctl habilita o mariadb.service
Note que os servidores de banco de dados MariaDB e MySQL não podem ser instalados em paralelo no Red Hat Enterprise Linux 8.0 devido a pacotes RPM conflitantes. A instalação paralela de componentes é possível no Red Hat Software Collections para Red Hat Enterprise Linux 6 e Red Hat Enterprise Linux 7. No Red Hat Enterprise Linux 8, diferentes versões de servidores de banco de dados podem ser usadas em containers.
8.2.2.1. Melhorando a segurança da instalação do MariaDB
Para melhorar a segurança ao instalar MariaDB, execute o seguinte comando.
O comando lança um roteiro totalmente interativo, que solicita cada etapa do processo.
# mysql_secure_installation
O roteiro permite melhorar a segurança das seguintes maneiras:
- Definir uma senha para as contas raiz
- Remoção de usuários anônimos
- Proibição de logins remotos (fora do host local)
8.2.3. Configuração do MariaDB
8.2.3.1. Configuração do servidor MariaDB para rede
Para configurar o servidor MariaDB para a rede, use a seção [mysqld] do arquivo /etc/my.cnf.d/mariadb-server.cnf, onde você pode definir as seguintes diretrizes de configuração:
bind-addressBind-address é o endereço no qual o servidor irá escutar.
As opções possíveis são: um nome de host, um endereço IPv4, ou um endereço IPv6.
skip-networkingOs valores possíveis são:
0 - ouvir para todos os clientes
1 - ouvir apenas os clientes locais
portA porta na qual MariaDB ouve as conexões TCP/IP.
8.2.4. Cópia de segurança dos dados da MariaDB
Há duas formas principais de fazer backup de dados de um banco de dados MariaDB:
- Backup lógico
- Apoio físico
Logical backup consiste das instruções SQL necessárias para restaurar os dados. Este tipo de backup exporta informações e registros em arquivos de texto simples.
A principal vantagem do backup lógico em relação ao backup físico é a portabilidade e a flexibilidade. Os dados podem ser restaurados em outras configurações de hardware, versões MariaDB ou Sistema de Gerenciamento de Banco de Dados (SGBD), o que não é possível com backups físicos.
Note que o backup lógico pode ser realizado se o mariadb.service estiver em execução. O backup lógico não inclui arquivos de log e configuração.
Physical backup consiste de cópias de arquivos e diretórios que armazenam o conteúdo.
O backup físico tem as seguintes vantagens em comparação com o backup lógico:
- A saída é mais compacta.
- O Backup é menor em tamanho.
- O backup e a restauração são mais rápidos.
- O backup inclui arquivos de log e configuração.
Observe que o backup físico deve ser realizado quando o mariadb.service não estiver rodando ou quando todas as tabelas do banco de dados estiverem bloqueadas para evitar alterações durante o backup.
Você pode usar uma das seguintes abordagens de backup MariaDB para fazer o backup dos dados de um banco de dados MariaDB:
- Backup lógico com mysqldump
- Backup físico on-line usando a ferramenta Mariabackup
- Backup do sistema de arquivos
- Replicação como uma solução de backup
8.2.4.1. Realização de backup lógico com mysqldump
O mysqldump cliente é um utilitário de backup, que pode ser usado para despejar um banco de dados ou uma coleção de bancos de dados com o propósito de um backup ou transferência para outro servidor de banco de dados. A saída de mysqldump normalmente consiste em instruções SQL para recriar a estrutura da tabela do servidor, preenchê-la com dados, ou ambos. Alternativamente, mysqldump também pode gerar arquivos em outros formatos, incluindo CSV ou outros formatos de texto delimitados, e XML.
Para realizar o mysqldump backup, você pode usar uma das seguintes opções:
- Cópia de segurança de um banco de dados selecionado
- Cópia de segurança de um subconjunto de tabelas de um banco de dados
- Cópia de segurança de múltiplos bancos de dados
- Cópia de segurança de todos os bancos de dados
8.2.4.1.1. Cópia de segurança de todo um banco de dados com mysqldump
Procedimento
Para fazer o backup de todo um banco de dados, execute:
# mysqldump [opções] db_name > backup-file.sql
8.2.4.1.2. Usando o mysqldump para fazer o backup de um conjunto de tabelas de um banco de dados
Procedimento
Para fazer backup de um subconjunto de tabelas de um banco de dados, adicione uma lista das tabelas escolhidas ao final do comando
mysqldump:# mysqldump [opções] db_name [tbl_name ...]
8.2.4.1.3. Usando o mysqldump para carregar o arquivo dump de volta para um servidor
Procedimento
Para carregar o arquivo de descarga de volta para um servidor, use um destes dois:
# mysql db_name < arquivo de backup.sql
# mysql -e "fonte /path-to-backup/backup-file.sql" db_name
8.2.4.1.4. Usando o mysqldump para copiar dados entre dois bancos de dados
Procedimento
Para preencher bancos de dados copiando dados de um servidor MariaDB para outro, execute:
# mysqldump --opt db_name | mysql --host=host_remote_host -C db_name
8.2.4.1.5. Descarga de múltiplos bancos de dados com mysqldump
Procedimento
Para despejar vários bancos de dados de uma só vez, execute:
# mysqldump [opções] --databases db_name1 [db_name2 ...] > my_databases.sql
8.2.4.1.6. Largando todos os bancos de dados com mysqldump
Procedimento
Para descarregar todos os bancos de dados, correr:
# mysqldump [opções] -- todas_bases de dados > all_databases.sql
8.2.4.1.7. Revendo as opções do mysqldump
Procedimento
Para ver uma lista das opções que o mysqldump suporta, execute:
$ mysqldump --ajuda
8.2.4.1.8. Recursos adicionais
Para mais informações sobre backup lógico com mysqldumpver a documentação do MariaDB.
8.2.4.2. Realização de backup físico on-line usando a ferramenta Mariabackup
Mariabackup é uma ferramenta baseada na tecnologia Percona XtraBackup, que permite realizar backups físicos on-line das mesas InnoDB, Aria e MyISAM.
MariabackupO pacote mariadb-backup, fornecido pelo repositório AppStream, suporta a capacidade total de backup para o servidor MariaDB, que inclui dados criptografados e comprimidos.
Pré-requisitos
O pacote
mariadb-backupestá instalado no sistema:# yum instalar mariadb-backup
Mariabackup precisa ser fornecido com credenciais para o usuário pelas quais o backup será executado. O usuário pode fornecer as credenciais na linha de comando, como mostrado no procedimento, ou por um arquivo de configuração antes de aplicar o procedimento. Para definir as credenciais usando o arquivo de configuração, primeiro crie o arquivo (por exemplo,
/etc/my.cnf.d/mariabackup.cnf), e depois adicione as seguintes linhas na seção[xtrabackup]ou[mysqld]do novo arquivo:[xtrabackup] user=myuser password=mypassword
ImportanteMariabackup não lê opções na seção
[mariadb]dos arquivos de configuração. Se um diretório de dados não-padrão for especificado em um servidor MariaDB, você deve especificar este diretório nas seções[xtrabackup]ou[mysqld]dos arquivos de configuração, de modo que Mariabackup é capaz de encontrar o diretório de dados.Para especificar tal diretório de dados, inclua a seguinte linha nas seções
[xtrabackup]ou[mysqld]dos arquivos de configuração MariaDB:datadir=/var/mycustomdatadir
NotaUsuários de Mariabackup devem ter os privilégios
RELOAD,LOCK TABLES, eREPLICATION CLIENTpara poder trabalhar com o backup.
Para criar um backup de um banco de dados usando MariabackupUse o procedimento a seguir:
Procedimento
Execute o seguinte comando:
mariabackup --backup --target-dir <backup_directory> --user <backup_user> --password <backup_passwd>
A opção
target-dirdefine o diretório onde os arquivos de backup são armazenados. Se você quiser realizar um backup completo, o diretório de destino deve estar vazio ou não existir.As opções
userepasswordpermitem que você configure o nome de usuário e a senha. Não utilize estas opções se você já configurou o nome de usuário e a senha no arquivo de configuração como descrito em pré-requisitos.
Recursos adicionais
Para mais informações sobre a realização de backups com Mariabackupver Full Backup e Restore com Mariabackup.
8.2.4.3. Restaurando dados usando a ferramenta Mariabackup
Quando o backup estiver completo, você pode restaurar os dados do backup usando o comando mariabackup com uma das seguintes opções:
-
--copy-back -
--move-back
A opção --copy-back permite que você mantenha os arquivos de backup originais. A opção --move-back move os arquivos de backup para o diretório de dados, e remove os arquivos de backup originais.
Pré-requisitos
Certifique-se de que o serviço
mariadbnão esteja funcionando:# systemctl stop mariadb.service
- Certifique-se de que o diretório de dados esteja vazio.
8.2.4.3.1. Restaurando os dados com Mariabackup enquanto mantém os arquivos de backup
Para restaurar os dados, mantendo os arquivos de backup originais, use o seguinte procedimento.
Procedimento
Execute o comando
mariabackupcom a opção--copy-back:$ mariabackup --copy-back --target-dir=/var/mariadb/backup/
Consertar as permissões dos arquivos.
Ao restaurar um banco de dados, Mariabackup preserva o arquivo e os privilégios de diretório do backup. No entanto, Mariabackup grava os arquivos em disco como o usuário e grupo restaurando o banco de dados. Consequentemente, após restaurar um backup, pode ser necessário ajustar o proprietário do diretório de dados para corresponder o usuário e o grupo para o servidor MariaDB, tipicamente
mysqlpara ambos.Por exemplo, para mudar recursivamente a propriedade dos arquivos para o usuário e grupo
mysql:# chown -R mysql:mysql /var/lib/mysql/
Iniciar o serviço
mariadb:# systemctl start mariadb.service
8.2.4.3.2. Restaurando os dados com Mariabackup e removendo os arquivos de backup
Para restaurar os dados, e não manter os arquivos de backup originais, use o seguinte procedimento.
Procedimento
Execute o comando
mariabackupcom a opção--move-back:$ mariabackup --move-back --target-dir=/var/mariadb/backup/
Consertar as permissões dos arquivos.
Ao restaurar um banco de dados, Mariabackup preserva o arquivo e os privilégios de diretório do backup. No entanto, Mariabackup grava os arquivos em disco como o usuário e grupo restaurando o banco de dados. Consequentemente, após restaurar um backup, pode ser necessário ajustar o proprietário do diretório de dados para corresponder o usuário e o grupo para o servidor MariaDB, tipicamente
mysqlpara ambos.Por exemplo, para mudar recursivamente a propriedade dos arquivos para o usuário e grupo
mysql:# chown -R mysql:mysql /var/lib/mysql/
Iniciar o serviço
mariadb:# systemctl start mariadb.service
8.2.4.3.3. Recursos adicionais
Para mais informações, veja Full Backup e Restore com Mariabackup.
8.2.4.4. Realização de backup do sistema de arquivos
Para criar um backup do sistema de arquivos de dados MariaDB, mude para o usuário root e copie o conteúdo do diretório de dados MariaDB para seu local de backup.
Para fazer backup também de sua configuração atual ou dos arquivos de log, use as etapas opcionais do procedimento a seguir.
Procedimento
Pare o serviço
mariadb:# systemctl stop mariadb.service
Copiar os arquivos de dados para o local desejado:
# cp -r /var/lib/mysql /backup-location
Opcionalmente, copie os arquivos de configuração para o local desejado:
# cp -r /etc/my.cnf /etc/my.cnf.d /backup-location/configuration
Opcionalmente, copie os arquivos de registro para o local desejado:
# cp /var/log/mariadb/* /backup-location/logs
Iniciar o serviço
mariadb:# systemctl start mariadb.service
8.2.4.5. Introdução à replicação como uma solução de backup
A replicação é uma solução alternativa de backup para servidores mestre. Se um servidor mestre se replicar para um servidor escravo, os backups podem ser executados no escravo sem qualquer impacto sobre o mestre. O master ainda pode rodar enquanto você desliga o escravo, e fazer backup dos dados dele.
A replicação em si não é uma solução de backup suficiente. A replicação protege os servidores mestre contra falhas de hardware, mas não garante proteção contra perda de dados. É recomendado que você utilize qualquer outra solução de backup no escravo da replicação junto com este método.
Recursos adicionais
Para mais informações sobre replicação como solução de backup, consulte a documentação da MariaDB.
8.2.5. Migrando para MariaDB 10.3
O Red Hat Enterprise Linux 7 contém MariaDB 5.5 como a implementação default de um servidor da família de bancos de dados MySQL. Versões posteriores do servidor de banco de dados MariaDB estão disponíveis como Coleções de Software para o Red Hat Enterprise Linux 6 e Red Hat Enterprise Linux 7. O Red Hat Enterprise Linux 8 fornece MariaDB 10.3 e MySQL 8.0.
8.2.5.1. Notáveis diferenças entre as versões RHEL 7 e RHEL 8 do MariaDB
As mudanças mais importantes entre MariaDB 5.5 e MariaDB 10.3 são as seguintes:
- MariaDB O Galera Cluster, um cluster síncrono multi-mestre, é uma parte padrão do MariaDB desde 10.1.
- O motor de armazenamento ARCHIVE não é mais ativado por padrão, e o plug-in precisa ser especificamente ativado.
- O motor de armazenamento BLACKHOLE não é mais ativado por padrão, e o plug-in precisa ser especificamente ativado.
O InnoDB é usado como o mecanismo de armazenamento padrão em vez do XtraDB, que foi usado em MariaDB 10.1 e em versões anteriores.
Para mais detalhes, veja Por que MariaDB 10.2 usa InnoDB em vez de XtraDB?
-
Os novos pacotes
mariadb-connector-cfornecem uma biblioteca comum de clientes para MySQL e MariaDB. Esta biblioteca é utilizável com qualquer versão dos servidores de banco de dados MySQL e MariaDB. Como resultado, o usuário é capaz de conectar um build de uma aplicação a qualquer um dos servidores MySQL e MariaDB distribuídos com o Red Hat Enterprise Linux 8.
Para migrar de MariaDB 5.5 para MariaDB 10.3, você precisa realizar múltiplas mudanças de configuração, conforme descrito em Seção 8.2.5.2, “Mudanças de configuração”.
8.2.5.2. Mudanças de configuração
O caminho de migração recomendado de MariaDB 5.5 para MariaDB 10.3 é primeiro atualizar para MariaDB 10.0, e depois atualizar por uma versão sucessivamente.
A principal vantagem de atualizar uma a uma versão é uma melhor adaptação do banco de dados, incluindo tanto os dados quanto a configuração às mudanças. A atualização termina na mesma versão principal que está disponível no RHEL 8 (MariaDB 10.3), o que reduz significativamente as mudanças de configuração ou outras questões.
Para mais informações sobre mudanças de configuração ao migrar de MariaDB 5.5 para MariaDB 10.0, veja Migrar para MariaDB 10.0 na documentação da Red Hat Software Collections.
A migração para as seguintes versões sucessivas de MariaDB e as mudanças de configuração necessárias estão descritas nestes documentos:
- Migrando para MariaDB 10.1 na documentação da Red Hat Software Collections.
- Migrando para MariaDB 10.2 na documentação da Red Hat Software Collections.
- Migrando para MariaDB 10.3 na documentação da Red Hat Software Collections.
A migração diretamente de MariaDB 5.5 para MariaDB 10.3 também é possível, mas você deve realizar todas as mudanças de configuração que são requeridas pelas diferenças descritas nos documentos de migração acima.
8.2.5.3. Atualização no local usando a ferramenta mysql_upgrade
Para migrar os arquivos do banco de dados para o Red Hat Enterprise Linux 8, os usuários do MariaDB no Red Hat Enterprise Linux 7 precisam realizar a atualização no local usando a ferramenta mysql_upgrade. A ferramenta mysql_upgrade é fornecida pelo subpacote mariadb-server-utils, que é instalado como uma dependência do pacote mariadb-server.
Para realizar uma atualização no local, você precisa copiar arquivos de dados binários para o diretório de dados /var/lib/mysql/ no sistema Red Hat Enterprise Linux 8 e usar a ferramenta mysql_upgrade.
Você pode usar este método para migrar dados de:
- A versão 7 do Red Hat Enterprise Linux 7 do MariaDB 5.5
As versões da Red Hat Software Collections de:
- MariaDB 5.5 (não mais suportado)
- MariaDB 10.0 (não mais suportado)
- MariaDB 10.1 (não mais suportado)
- MariaDB 10.2
Note que é recomendado atualizar para MariaDB 10.2 por uma versão sucessivamente. Veja os respectivos capítulos de Migração nas Notas de Lançamento das Coleções de Software da Red Hat.
Se você estiver atualizando a partir da versão do Red Hat Enterprise Linux 7 de MariaDB, os dados de origem serão armazenados no diretório /var/lib/mysql/. No caso das versões da Red Hat Software Collections de MariaDB, o diretório de dados fonte é /var/opt/rh/<collection_name>/lib/mysql/ (com exceção do mariadb55, que usa o diretório de dados /opt/rh/mariadb55/root/var/lib/mysql/ ).
Antes de realizar a atualização, faça o backup de todos os seus dados armazenados nos bancos de dados MariaDB.
Para realizar a atualização no local, mude para o usuário root, e use o seguinte procedimento:
Certifique-se de que o pacote
mariadb-serveresteja instalado no sistema Red Hat Enterprise Linux 8:# yum instalar mariadb-server
Certifique-se de que o daemon mariadb não esteja funcionando em nenhum dos sistemas de origem e destino no momento da cópia dos dados:
# systemctl stop mariadb.service
-
Copie os dados do local de origem para o diretório
/var/lib/mysql/no sistema alvo do Red Hat Enterprise Linux 8. Defina as permissões apropriadas e o contexto SELinux para arquivos copiados no sistema de destino:
# restorecon -vr /vr /var/lib/mysql
Inicie o servidor MariaDB no sistema alvo:
# systemctl start mariadb.service
Execute o comando
mysql_upgradepara verificar e reparar as tabelas internas:# systemctl mysql_upgrade
-
Quando a atualização estiver concluída, certifique-se de que todos os arquivos de configuração dentro do diretório
/etc/my.cnf.d/incluam apenas opções válidas para MariaDB 10.3.
Existem certos riscos e problemas conhecidos relacionados à atualização no local. Por exemplo, algumas consultas podem não funcionar ou elas serão executadas em ordem diferente do que antes da atualização. Para mais informações sobre estes riscos e problemas, e para informações gerais sobre atualização no local, consulte as Notas de Lançamento do MariaDB 10.3.
8.2.6. Replicando a MariaDB com a Galera
Esta seção descreve como replicar um banco de dados MariaDB usando a solução Galera.
8.2.6.1. Introdução ao MariaDB Galera Cluster
A replicação Galera é baseada na criação de um multi-mestre síncrono MariaDB Galera Cluster que consiste em vários servidores MariaDB.
A interface entre a replicação Galera e um banco de dados MariaDB é definida pela API de replicação write set (wsrep API).
As principais características do MariaDB Galera Cluster são:
- Replicação síncrona
- Topologia multi-mestre ativa e ativa
- Ler e escrever em qualquer nó de cluster
- Controle automático de filiação, queda de nós falhados do cluster
- Junção automática de nódulos
- Replicação paralela em nível de linha
- Conexões diretas do cliente (Os usuários podem conectar-se aos nós de cluster e trabalhar com os nós diretamente enquanto a replicação é executada)
A replicação síncrona significa que um servidor replica uma transação no momento do compromisso, transmitindo o conjunto de gravação associado à transação para cada nó do cluster. O cliente (aplicação do usuário) se conecta diretamente ao Sistema de Gerenciamento de Banco de Dados (SGBD), e experimenta um comportamento semelhante ao da nativa MariaDB.
A replicação síncrona garante que uma mudança que aconteceu em um nó do cluster acontece em outros nós do cluster ao mesmo tempo.
Portanto, a replicação síncrona tem as seguintes vantagens em relação à replicação assíncrona:
- Sem atraso na propagação das mudanças entre determinados nós de agrupamento
- Todos os nós de agrupamento são sempre consistentes
- As últimas mudanças não se perdem se um dos nós de agrupamento cair
- As transações em todos os nós de cluster são executadas em paralelo
- Causalidade em todo o conjunto
Recursos adicionais
Para obter informações mais detalhadas, consulte a documentação a montante:
8.2.6.2. Componentes para construir o Aglomerado MariaDB Galera
Para poder construir MariaDB Galera Cluster, os seguintes pacotes devem ser instalados em seu sistema:
-
mariadb-server-galera -
mariadb-server -
galera
O pacote mariadb-server-galera contém arquivos de suporte e scripts para MariaDB Galera Cluster.
O MariaDB remende o pacote mariadb-server para incluir o API de replicação de escrita (wsrep API). Esta API fornece a interface entre a replicação Galera e o MariaDB.
MariaDB a montante também remende o pacote galera para adicionar suporte total para MariaDB. O pacote galera contém o Galera Replication Library e a ferramenta Galera Arbitrator. Galera Replication Library fornece toda a funcionalidade de replicação. Galera Arbitrator pode ser usado como um membro do cluster que participa da votação em cenários de cérebro dividido. Entretanto, Galera Arbitrator não pode participar da replicação propriamente dita.
Recursos adicionais
Para informações mais detalhadas, consulte a documentação a montante:
8.2.6.3. Implantação do Aglomerado MariaDB Galera
Pré-requisitos
Todo o software necessário para construir MariaDB Galera Cluster deve ser instalado no sistema. Para garantir isso, instale o perfil
galerado módulomariadb:10.3:# yum module install mariadb:10.3/galera
Como resultado, são instalados os seguintes pacotes:
-
mariadb-server-galera -
mariadb-server galeraO pacote
mariadb-server-galerapuxa os pacotesmariadb-serveregaleracomo sua dependência.Para mais informações sobre componentes a serem construídos MariaDB Galera Cluster, veja Seção 8.2.6.2, “Componentes para construir o Aglomerado MariaDB Galera”.
-
A configuração da replicação do servidor MariaDB deve ser atualizada antes que o sistema seja adicionado a um cluster pela primeira vez.
A configuração padrão é enviada no arquivo
/etc/my.cnf.d/galera.cnf.Antes de implantar MariaDB Galera Cluster, defina a opção
wsrep_cluster_addressno arquivo/etc/my.cnf.d/galera.cnfem todos os nós para começar com a seguinte seqüência:gcomm://
Para o nó inicial, é possível definir
wsrep_cluster_addresscomo uma lista vazia:wsrep_cluster_address="gcomm:///"
Para todos os outros nós, definir
wsrep_cluster_addresspara incluir um endereço para qualquer nó que já faça parte do cluster em funcionamento. Por exemplo:wsrep_cluster_address="gcomm://10.0.0.10"
Para mais informações sobre como definir o endereço do Galera Cluster, veja Galera Cluster Address.
Procedimento
Atrapalhe um primeiro nó de um novo agrupamento executando o seguinte invólucro nesse nó:
$ galera_new_cluster
Esta embalagem garante que o daemon do servidor MariaDB (
mysqld) funcione com a opção--wsrep-new-cluster. Esta opção fornece a informação de que não há nenhum cluster existente para se conectar. Portanto, o nó cria uma nova UUID para identificar o novo cluster.NotaO serviço
mariadbsuporta um método de sistema para interagir com múltiplos processos de servidores MariaDB. Portanto, em casos com múltiplos servidores MariaDB em execução, você pode iniciar uma instância específica especificando o nome da instância como um sufixo:$ galera_new_cluster mariadb@node1Conecte outros nós ao cluster executando o seguinte comando em cada um dos nós:
# systemctl start mariadb
Como resultado, o nó se conecta ao agrupamento, e se sincroniza com o estado do agrupamento.
Recursos adicionais
Para mais informações, veja Começando com o MariaDB Galera Cluster.
8.2.6.4. Adicionando um novo nó ao MariaDB Galera Cluster
Para adicionar um novo nó a MariaDB Galera Cluster, use o seguinte procedimento.
Note que você pode usar este procedimento também para reconectar um nó já existente.
Procedimento
No nó específico, fornecer um endereço para um ou mais membros do cluster existente na opção
wsrep_cluster_addressdentro da seção[mariadb]do arquivo de configuração/etc/my.cnf.d/galera.cnf:[mariadb] wsrep_cluster_address="gcomm://192.168.0.1"Quando um novo nó se conecta a um dos nós de cluster existentes, ele é capaz de ver todos os nós do cluster.
No entanto, de preferência, liste todos os nós do agrupamento em
wsrep_cluster_address.Como resultado, qualquer nó pode se unir a um cluster conectando-se a qualquer outro nó de cluster, mesmo que um ou mais nós de cluster estejam em baixo. Quando todos os membros concordam com a adesão, o estado do aglomerado é alterado. Se o estado do novo nó for diferente do do agrupamento, ele solicita ou uma Transferência Estatal Incremental (IST) ou uma Transferência Estatal Instantânea (SST) para se tornar consistente com os outros nós.
Recursos adicionais
- Para mais informações, veja Começando com o MariaDB Galera Cluster.
- Para informações detalhadas sobre as Transferências de Instantâneos Estaduais (SSTs), veja Introdução às Transferências de Instantâneos Estaduais (SSTs).
8.2.6.5. Reiniciando o Aglomerado MariaDB Galera
Se você fecha todos os nós ao mesmo tempo, você termina o cluster, e o cluster em funcionamento não existe mais. Entretanto, os dados do cluster ainda existem.
Para reiniciar o agrupamento, inicialize um primeiro nó como descrito em Seção 8.2.6.3, “Implantação do Aglomerado MariaDB Galera”.
Se o cluster não for inicializado, e mysqld no primeiro nó for iniciado apenas com o comando systemctl start mariadb, o nó tenta se conectar a pelo menos um dos nós listados na opção wsrep_cluster_address no arquivo /etc/my.cnf.d/galera.cnf. Se nenhum nó estiver em execução no momento, o reinício falha.
Recursos adicionais
Para mais informações, veja Começando com o MariaDB Galera Cluster.
8.3. Usando PostgreSQL
8.3.1. Começando com o PostgreSQL
O servidor PostgreSQL é um servidor de banco de dados open source robusto e altamente extensível baseado na linguagem SQL. Ele fornece um sistema de banco de dados objeto-relacional, que permite gerenciar extensos conjuntos de dados e um alto número de usuários simultâneos. Por estas razões, os servidores PostgreSQL podem ser utilizados em clusters para gerenciar grandes quantidades de dados.
O servidor PostgreSQL inclui recursos para garantir a integridade dos dados, construir ambientes tolerantes a falhas ou construir aplicações. Ele permite estender um banco de dados com tipos de dados próprios do usuário, funções personalizadas ou código de diferentes linguagens de programação sem a necessidade de recompilar o banco de dados.
Esta seção descreve como instalar PostgreSQL na Instalação do PostgreSQL ou como migrar para uma versão diferente de PostgreSQL na Migração para uma versão RHEL 8 do PostgreSQL. Um dos pré-requisitos da migração é realizar um backup de dados.
8.3.2. Instalando o PostgreSQL
No RHEL 8, o servidor PostgreSQL está disponível em várias versões, cada uma fornecida por um fluxo separado:
- PostgreSQL 10 - o fluxo padrão
- PostgreSQL 9.6
- PostgreSQL 12 - disponível desde RHEL 8.1.1
Por projeto, é impossível instalar mais de uma versão (fluxo) do mesmo módulo em paralelo. Portanto, é necessário escolher apenas um dos fluxos disponíveis no módulo postgresql. A instalação paralela de componentes é possível no Red Hat Software Collections para RHEL 7 e RHEL 6. No RHEL 8, diferentes versões de servidores de banco de dados podem ser usadas em containers.
Para instalar PostgreSQL:
Habilite o fluxo (versão) que você deseja instalar:
# módulo yum permite postgresql:stream
Substitua stream pela versão selecionada do servidor PostgreSQL.
Você pode omitir esta etapa se quiser usar o fluxo padrão, que fornece PostgreSQL 10.
Certifique-se de que o pacote
postgresql-server, disponível no repositório AppStream, esteja instalado no servidor necessário:# yum instalar postgresql-server
Inicializar o diretório de dados
pós-configuração --initdb
Iniciar o serviço
postgresql:# systemctl start postgresql.service
Habilite o serviço
postgresqlpara começar na inicialização:# systemctl habilita o serviço postgresql.service
Para informações sobre o uso de fluxos de módulos, consulte Instalação, gerenciamento e remoção de componentes de espaço do usuário.
Se você quiser atualizar de um fluxo anterior postgresql dentro do RHEL 8, siga os dois procedimentos descritos em Mudança para um fluxo posterior e em Seção 8.3.5, “Migrando para uma versão RHEL 8 do PostgreSQL”.
8.3.3. Configurando o PostgreSQL
Para alterar a configuração do PostgreSQL, utilize o arquivo /var/lib/pgsql/data/postgresql.conf. Em seguida, reinicie o serviço postgresql para que as mudanças se tornem efetivas:
systemctl restart postgresql.service
Além de /var/lib/pgsql/data/postgresql.conf, existem outros arquivos para alterar a configuração PostgreSQL:
-
postgresql.auto.conf -
pg_ident.conf -
pg_hba.conf
O arquivo postgresql.auto.conf contém as configurações básicas PostgreSQL, de forma semelhante a /var/lib/pgsql/data/postgresql.conf. Entretanto, este arquivo está sob o controle do servidor. Ele é editado pelas consultas do ALTER SYSTEM, e não pode ser editado manualmente.
O arquivo pg_ident.conf é usado para mapear as identidades dos usuários a partir de mecanismos de autenticação externos para as identidades de usuários postgresql.
O arquivo pg_hba.conf é usado para configurar permissões detalhadas de usuário para bancos de dados PostgreSQL.
8.3.3.1. Inicialização de um cluster de banco de dados
Em um banco de dados PostgreSQL, todos os dados são armazenados em um único diretório, que é chamado de cluster de banco de dados. Você pode escolher onde armazenar seus dados, mas a Red Hat recomenda que os dados sejam armazenados no diretório default /var/lib/pgsql/data.
Para inicializar este diretório de dados, execute:
pós-configuração --initdb
8.3.4. Cópia de segurança dos dados PostgreSQL
Para fazer o backup dos dados PostgreSQL, use uma das seguintes abordagens:
- Lixeira SQL
- Backup em nível de sistema de arquivos
- Arquivamento contínuo
8.3.4.1. Backing up de dados PostgreSQL com um dump SQL
8.3.4.1.1. Execução de um despejo SQL
O método SQL dump é baseado na geração de um arquivo com comandos SQL. Quando este arquivo é carregado de volta ao servidor de banco de dados, ele recria o banco de dados no mesmo estado em que se encontrava no momento da descarga. O despejo SQL é garantido pelo método pg_dump que é uma aplicação do cliente PostgreSQL. O uso básico do comando pg_dump é tal que o comando escreve seu resultado na saída padrão:
pg_dump dbname > dumpfile
O arquivo SQL resultante pode ser em formato de texto ou em outros formatos diferentes, o que permite o paralelismo e um controle mais detalhado da restauração de objetos.
Você pode realizar o dump SQL a partir de qualquer host remoto que tenha acesso ao banco de dados. O pg_dump não opera com permissões especiais, mas deve ter acesso lido a todas as tabelas que você deseja fazer backup. Para fazer o backup de todo o banco de dados, você deve executá-lo como um superusuário do banco de dados.
Para especificar qual servidor de banco de dados pg_dump entrará em contato, use as seguintes opções de linha de comando:
A opção
-hpara definir o anfitrião.O anfitrião padrão é o anfitrião local ou o que é especificado pela variável de ambiente
PGHOST.A opção
-ppara definir o porto.A porta padrão é indicada pela variável de ambiente
PGPORTou pela variável compilada por padrão.
Note que pg_dump despeja apenas um único banco de dados. Ele não descarta informações sobre papéis ou espaços de tabela porque tais informações são de todo o cluster.
Para fazer backup de cada banco de dados em um determinado cluster e para preservar dados em todo o cluster, tais como definições de funções e espaço de tabela, use o comando pg_dumpall:
pg_dumpall > arquivo dump
8.3.4.1.2. Restauração de banco de dados a partir de um dump SQL
Para restaurar um banco de dados a partir de uma lixeira SQL:
Criar um novo banco de dados (dbname):
criadob
dbnameCertifique-se de que todos os usuários que possuem objetos ou receberam permissões sobre objetos no banco de dados despejados já existam.
Se tais usuários não existirem, a restauração não consegue recriar os objetos com a propriedade e as permissões originais.
Execute o psql para restaurar um arquivo de texto criado pelo pg_dump utilidade:
psql dbname < dumpfile
onde dumpfile é a saída do comando pg_dump.
Se você quiser restaurar uma lixeira de arquivos sem texto, use o utilitário pg_restore:
pg_restore non-plain-text-file
8.3.4.1.2.1. Restaurando um banco de dados em outro servidor
O despejo de um banco de dados diretamente de um servidor para outro é possível porque pg_dump e psql pode escrever e ler a partir de tubos.
Para descarregar um banco de dados de um servidor para outro, execute:
pg_dump -h host1 dbname | psql -h host2 dbname
8.3.4.1.2.2. Manuseio de erros SQL durante a restauração
Por padrão, psql continua a ser executado se ocorrer um erro SQL. Conseqüentemente, o banco de dados é restaurado apenas parcialmente.
Se você quiser mudar este comportamento padrão, use uma das seguintes abordagens:
Faça psql sair com um status de saída de 3 se ocorrer um erro SQL, definindo a variável
ON_ERROR_STOP:psql --set ON_ERROR_STOP=onome dbname < dumpfile
Especificar que toda a lixeira é restaurada como uma única transação para que a restauração seja totalmente concluída ou cancelada usando
psqlcom uma das seguintes opções:psql -1
ou
psql --transação única
Note que ao utilizar esta abordagem, mesmo um erro menor pode cancelar uma operação de restauração que já tenha funcionado por muitas horas.
8.3.4.1.3. Vantagens e desvantagens de uma lixeira SQL
Uma lixeira SQL tem as seguintes vantagens em comparação com outros métodos de backup PostgreSQL:
- Um dump SQL é o único método de backup PostgreSQL que não é específico para uma versão de servidor. A saída do pg_dump pode ser recarregado em versões posteriores de PostgreSQL, o que não é possível para backups em nível de sistema de arquivos ou arquivamento contínuo.
- Um dump SQL é o único método que funciona ao transferir um banco de dados para uma arquitetura de máquina diferente, como ir de um servidor de 32 bits para um de 64 bits.
- Um lixão SQL fornece lixões internamente consistentes. Um depósito de lixo representa um instantâneo do banco de dados no momento em que o pg_dump começou a funcionar.
- O pg_dump não bloqueia outras operações no banco de dados quando ele está em funcionamento.
Uma desvantagem de um despejo SQL é que leva mais tempo em comparação com o backup em nível de sistema de arquivos.
8.3.4.1.4. Recursos adicionais
Para mais informações sobre o dump SQL, consulte a Documentação do PostgreSQL.
8.3.4.2. Cópia de segurança dos dados PostgreSQL com um backup em nível de sistema de arquivos
8.3.4.2.1. Execução de um backup em nível de sistema de arquivos
Para realizar um backup em nível de sistema de arquivos, você precisa copiar os arquivos que o PostgreSQL usa para armazenar os dados no banco de dados em outro local:
- Escolha a localização de um cluster de banco de dados e inicialize este cluster como descrito em Seção 8.3.3.1, “Inicialização de um cluster de banco de dados”.
Interromper o serviço pósgresql:
# systemctl stop postgresql.service
Use qualquer método para fazer um backup do sistema de arquivos, por exemplo:
tar -cf backup.tar /var/lib/pgsql/dados
Iniciar o serviço postgresql:
# systemctl start postgresql.service
8.3.4.2.2. Vantagens e desvantagens de um backup em nível de sistema de arquivos
Um backup em nível de sistema de arquivos tem a seguinte vantagem em comparação com outros métodos de backup PostgreSQL:
- O backup no nível do sistema de arquivos é geralmente mais rápido que o dump SQL.
O backup em nível de sistema de arquivos tem as seguintes desvantagens em comparação com outros métodos de backup PostgreSQL:
- O backup é específico da arquitetura e o Red Hat Enterprise Linux 7 específico. Ele só pode ser usado como backup para retornar ao Red Hat Enterprise Linux 7 se a atualização não foi bem sucedida, mas não pode ser usado com PostgreSQL 10.0.
- O servidor do banco de dados deve ser desligado antes do backup dos dados e antes da restauração dos dados também.
- O backup e restauração de certos arquivos ou tabelas individuais é impossível. Os backups do sistema de arquivos só funcionam para um backup completo e restauração de todo um cluster de banco de dados.
8.3.4.2.3. Abordagens alternativas para backup em nível de sistema de arquivos
Abordagens alternativas para o backup do sistema de arquivos incluem:
- Um instantâneo consistente do diretório de dados
- A utilidade rsync
8.3.4.2.4. Recursos adicionais
Para mais informações sobre o backup em nível de sistema de arquivos, consulte a Documentação do PostgreSQL.
8.3.4.3. Cópia de segurança dos dados PostgreSQL através de arquivamento contínuo
8.3.4.3.1. Introdução ao arquivamento contínuo
PostgreSQL registra todas as alterações feitas nos arquivos de dados do banco de dados em um arquivo de log de gravação prévia (WAL) que está disponível no subdiretório pg_wal/ do diretório de dados do cluster. Este registro é destinado principalmente para uma recuperação de falhas. Após uma falha, as entradas do log feitas desde o último ponto de verificação podem ser usadas para restaurar a consistência do banco de dados.
O método de arquivamento contínuo, também conhecido como online backup, combina os arquivos WAL com um backup em nível de sistema de arquivos. Se uma recuperação de banco de dados for necessária, você pode restaurar o banco de dados a partir do backup do sistema de arquivos e, em seguida, reproduzir o log do backup dos arquivos WAL para trazer o sistema para o estado atual.
Para este método de backup, você precisa de uma seqüência contínua de arquivos WAL arquivados que se estenda pelo menos até a hora de início de seu backup.
Se você quiser começar a usar o método de arquivamento contínuo de backup, certifique-se de configurar e testar seu procedimento para arquivar arquivos WAL antes de fazer seu primeiro backup básico.
Você não pode usar pg_dump e pg_dumpall despejos como parte de uma solução de backup de arquivamento contínuo. Estas lixeiras produzem backups lógicos, não backups de nível de sistema de arquivo. Como tal, eles não contêm informações suficientes para serem usadas por uma repetição WAL.
8.3.4.3.2. Execução de backup de arquivamento contínuo
Para realizar um backup do banco de dados e restaurar usando o método de arquivamento contínuo, siga estes passos:
8.3.4.3.2.1. Fazendo um backup básico
Para realizar um backup de base, use o pg_basebackup que pode criar um backup básico na forma de arquivos individuais ou de um arquivo tar.
Para utilizar o backup de base, é necessário manter todos os arquivos do segmento WAL gerados durante e após o backup do sistema de arquivos. O processo de backup básico cria um arquivo de histórico de backup que é armazenado na área de arquivo WAL e é nomeado após o primeiro arquivo de segmento WAL que você precisa para o backup do sistema de arquivos. Quando você tiver arquivado com segurança o backup do sistema de arquivos e os arquivos de segmentos WAL usados durante o backup, que são especificados no arquivo de histórico de backup, você pode excluir todos os segmentos WAL arquivados com nomes numericamente menos, porque eles não são mais necessários para recuperar o backup do sistema de arquivos. Entretanto, considere manter vários conjuntos de backup para ter certeza de que você pode recuperar seus dados.
O arquivo de histórico de backup é um pequeno arquivo de texto, que contém a cadeia de etiquetas que você deu a pg_basebackupos horários de início e fim, e os segmentos WAL do backup. Se você usou a cadeia de etiquetas para identificar o arquivo de despejo associado, então o arquivo de histórico arquivado é suficiente para lhe dizer qual arquivo de despejo restaurar.
Com o método de arquivamento contínuo, você precisa manter todos os arquivos WAL arquivados de volta à sua última base de backup. Portanto, a freqüência ideal de backups de base depende:
- O volume de armazenamento disponível para arquivos WAL arquivados.
A duração máxima possível da recuperação de dados em situações em que a recuperação é necessária.
Em casos com longo período desde o último backup, o sistema reproduz mais segmentos WAL, e a recuperação, portanto, leva mais tempo.
Para mais informações sobre como fazer um backup básico, consulte a Documentação do PostgreSQL.
8.3.4.3.2.2. Restaurando o banco de dados usando um arquivo de backup contínuo
Para restaurar um banco de dados usando um backup contínuo:
Pare o servidor:
# systemctl stop postgresql.service
Copiar os dados necessários para um local temporário.
De preferência, copie todo o diretório de dados do cluster e quaisquer tablespaces. Note que isto requer espaço livre suficiente em seu sistema para manter duas cópias de seu banco de dados existente.
Se você não tiver espaço suficiente, salve o conteúdo do diretório
pg_waldo cluster, que pode conter logs que não foram arquivados antes da queda do sistema.- Remova todos os arquivos e subdiretórios existentes sob o diretório de dados do cluster e sob os diretórios raiz de quaisquer tablespaces que você estiver usando.
Restaure os arquivos do banco de dados a partir do backup de seu sistema de arquivos.
Certifique-se disso:
-
Os arquivos são restaurados com a propriedade correta (o usuário do sistema de banco de dados, não
root) - Os arquivos são restaurados com as permissões corretas
-
Os links simbólicos no subdiretório
pg_tblspc/foram restaurados corretamente
-
Os arquivos são restaurados com a propriedade correta (o usuário do sistema de banco de dados, não
Remover quaisquer arquivos presentes no subdiretório
pg_wal/Estes arquivos resultaram do backup do sistema de arquivos e são, portanto, obsoletos. Se você não arquivou
pg_wal/, recrie-o com as devidas permissões.-
Copie os arquivos não arquivados do segmento WAL que você salvou no passo 2 em
pg_wal/se houver tais arquivos. -
Criar o arquivo de comando de recuperação
recovery.confno diretório de dados do cluster. Inicie o servidor:
# systemctl start postgresql.service
O servidor entrará no modo de recuperação e procederá à leitura dos arquivos WAL arquivados de que necessita.
Se a recuperação for encerrada devido a um erro externo, o servidor pode simplesmente ser reiniciado e ele continuará a recuperação. Quando o processo de recuperação é concluído, o servidor renomeia
recovery.confpararecovery.donepara evitar a reentrada acidental no modo de recuperação mais tarde, quando o servidor inicia as operações normais do banco de dados.Verifique o conteúdo do banco de dados para ter certeza de que o banco de dados se recuperou para o estado exigido.
Se o banco de dados não tiver se recuperado para o estado exigido, volte ao passo 1. Se o banco de dados se recuperou para o estado exigido, permita que os usuários se conectem restaurando o arquivo
pg_hba.confpara o estado normal.
Para mais informações sobre a restauração usando o backup contínuo, consulte a Documentação do PostgreSQL.
8.3.4.3.3. Vantagens e desvantagens do arquivamento contínuo
O arquivamento contínuo tem as seguintes vantagens em comparação com outros métodos de backup PostgreSQL:
-
Com o método de backup contínuo, é possível usar um backup do sistema de arquivos que não é totalmente consistente porque qualquer inconsistência interna no backup é corrigida pela reprodução do log. Um instantâneo do sistema de arquivo não é necessário;
tarou uma ferramenta de arquivamento similar é suficiente. - O backup contínuo pode ser alcançado continuando a arquivar os arquivos WAL porque a seqüência de arquivos WAL para a reprodução do log pode ser indefinidamente longa. Isto é particularmente valioso para grandes bancos de dados.
- O backup contínuo suporta a recuperação point-in-time. Não é necessário repetir as entradas WAL até o final. A repetição pode ser interrompida em qualquer ponto e o banco de dados pode ser restaurado ao seu estado a qualquer momento desde que o backup base foi feito.
- Se a série de arquivos WAL estiver continuamente disponível para outra máquina que tenha sido carregada com o mesmo arquivo de backup básico, é possível restaurar a outra máquina com uma cópia quase atual do banco de dados em qualquer ponto.
O arquivamento contínuo tem as seguintes desvantagens em comparação com outros métodos de backup PostgreSQL:
- O método de backup contínuo suporta apenas a restauração de um cluster de banco de dados inteiro, não de um subconjunto.
- O backup contínuo requer um extenso armazenamento de arquivos.
8.3.4.3.4. Recursos adicionais
Para mais informações sobre o método de arquivamento contínuo, consulte a Documentação do PostgreSQL.
8.3.5. Migrando para uma versão RHEL 8 do PostgreSQL
O Red Hat Enterprise Linux 7 contém PostgreSQL 9.2 como a versão default do servidor PostgreSQL. Além disso, várias versões do PostgreSQL são fornecidas como Coleções de Software para RHEL 7 e RHEL 6.
O Red Hat Enterprise Linux 8 fornece PostgreSQL 10 (o fluxo padrão postgresql ), PostgreSQL 9.6 e PostgreSQL 12.
Os usuários do PostgreSQL no Red Hat Enterprise Linux podem usar dois caminhos de migração para os arquivos do banco de dados:
Use de preferência o método de atualização rápida, que é mais rápido do que o processo de despejo e restauração.
No entanto, em certos casos, a atualização rápida não funciona, e você só pode usar o processo de despejo e restauração. Tais casos incluem:
- Atualizações de arquitetura cruzada
-
Sistemas que utilizam as extensões
plpythonouplpython2. Note que o repositório AppStream RHEL 8 inclui apenas o pacotepostgresql-plpython3, não o pacotepostgresql-plpython2. - O upgrade rápido não é suportado para migração das versões da Red Hat Software Collections de PostgreSQL.
Como pré-requisito para a migração para uma versão posterior de PostgreSQL, faça backup de todos os seus bancos de dados PostgreSQL.
O despejo dos bancos de dados e a realização de backup dos arquivos SQL é uma parte necessária do processo de despejo e restauração. No entanto, é recomendável que você o faça também se estiver realizando a atualização rápida.
Antes de migrar para uma versão posterior de PostgreSQL, veja as notas de compatibilidade a montante para a versão de PostgreSQL para a qual você deseja migrar, assim como para todas as versões ignoradas PostgreSQL entre a versão de onde você está migrando e a versão de destino.
8.3.5.1. Atualização rápida usando a ferramenta pg_upgrade
Durante uma rápida atualização, você precisa copiar arquivos de dados binários para o diretório /var/lib/pgsql/data/ e usar a ferramenta pg_upgrade.
Você pode usar este método para a migração de dados:
- Desde a versão do sistema RHEL 7 de PostgreSQL 9.2 até a versão RHEL 8 de PostgreSQL 10
- Desde a versão RHEL 8 de PostgreSQL 10 até a versão RHEL 8 de PostgreSQL 12
Se você quiser atualizar de um fluxo postgresql anterior dentro do RHEL 8, siga o procedimento descrito em Mudança para um fluxo posterior e depois migre seus dados PostgreSQL.
Para migração entre outras combinações de versões PostgreSQL dentro da RHEL, e para migração das versões da Red Hat Software Collections de PostgreSQL para a RHEL, use Dump e restore upgrade.
Antes de realizar a atualização, faça o backup de todos os seus dados armazenados nos bancos de dados PostgreSQL.
Por padrão, todos os dados são armazenados no diretório /var/lib/pgsql/data/ tanto no sistema RHEL 7 quanto no RHEL 8.
O seguinte procedimento descreve a migração da versão do sistema RHEL 7 de Postgreql 9.2 para uma versão RHEL 8 de PostgreSQL.
Para realizar uma rápida atualização:
No sistema RHEL 8, habilite o fluxo (versão) para o qual você deseja migrar:
# módulo yum permite postgresql:stream
Substitua stream pela versão selecionada do servidor PostgreSQL.
Você pode omitir esta etapa se quiser usar o fluxo padrão, que fornece PostgreSQL 10.
No sistema RHEL 8, instale os pacotes
postgresql-serverepostgresql-upgrade:# yum instalar postgresql-server postgresql-upgrade
Opcionalmente, se você usou algum módulo do servidor PostgreSQL no RHEL 7, instale-o também no sistema RHEL 8 em duas versões, compiladas contra PostgreSQL 9.2 (instalado como o pacote
postgresql-upgrade) e a versão alvo de PostgreSQL (instalado como o pacotepostgresql-server). Se você precisar compilar um módulo de servidor PostgreSQL de terceiros, compile-o tanto contra os pacotespostgresql-develepostgresql-upgrade-devel.Verifique os seguintes itens:
-
Configuração básica: No sistema RHEL 8, verifique se seu servidor usa o diretório padrão
/var/lib/pgsql/datae se o banco de dados está corretamente inicializado e habilitado. Além disso, os arquivos de dados devem ser armazenados no mesmo caminho mencionado no arquivo/usr/lib/systemd/system/postgresql.service. - PostgreSQL servidores: Seu sistema pode rodar vários servidores PostgreSQL. Certifique-se de que os diretórios de dados de todos esses servidores sejam tratados de forma independente.
-
PostgreSQL módulos do servidor: Certifique-se de que os módulos do servidor PostgreSQL que você usou no RHEL 7 também estejam instalados em seu sistema RHEL 8. Observe que os plug-ins estão instalados no diretório
/usr/lib64/pgsql/(ou no diretório/usr/lib/pgsql/em sistemas de 32 bits).
-
Configuração básica: No sistema RHEL 8, verifique se seu servidor usa o diretório padrão
Certifique-se de que o serviço
postgresqlnão esteja funcionando em nenhum dos sistemas fonte e alvo no momento da cópia dos dados.# systemctl stop postgresql.service
-
Copie os arquivos do banco de dados do local de origem para o diretório
/var/lib/pgsql/data/no sistema RHEL 8. Execute o processo de atualização executando o seguinte comando como usuário do PostgreSQL:
$ /bin/postgresql-setup --upgrade
Isto lança o processo
pg_upgradecomo pano de fundo.Em caso de falha,
postgresql-setupfornece uma mensagem de erro informativa.Copie a configuração anterior de
/var/lib/pgsql/data-oldpara o novo cluster.Observe que a atualização rápida não reutiliza a configuração anterior na pilha de dados mais recente e a configuração é gerada do zero. Se você quiser combinar manualmente as configurações antiga e nova, use os arquivos *.conf nos diretórios de dados.
Inicie o novo servidor PostgreSQL:
# systemctl start postgresql.service
Execute o script
analyze_new_cluster.shlocalizado no diretório home PostgreSQL:su postgres -c '~/analyze_new_cluster.sh
Se você quiser que o novo servidor PostgreSQL seja iniciado automaticamente na inicialização, execute:
# systemctl habilita o serviço postgresql.service
8.3.5.2. Despejar e restaurar atualização
Ao usar o dump e restaurar a atualização, você precisa despejar todo o conteúdo do banco de dados em um arquivo SQL dump.
Observe que a atualização de despejo e restauração é mais lenta do que o método de atualização rápida e pode requerer alguma correção manual no arquivo SQL gerado.
Você pode usar este método para migrar dados de:
- A versão do sistema Red Hat Enterprise Linux 7 do PostgreSQL 9.2
- Qualquer versão anterior do Red Hat Enterprise Linux 8 de PostgreSQL
Uma versão anterior ou igual de PostgreSQL da Red Hat Software Collections:
- PostgreSQL 9.2 (não mais suportado)
- PostgreSQL 9.4 (não mais suportado)
- PostgreSQL 9.6
- PostgreSQL 10
- PostgreSQL 12
Nos sistemas Red Hat Enterprise Linux 7 e Red Hat Enterprise Linux 8, PostgreSQL os dados são armazenados no diretório /var/lib/pgsql/data/ por default. No caso das versões do Red Hat Software Collections de PostgreSQL, o diretório de dados default é /var/opt/rh/collection_name/lib/pgsql/data/ (com exceção de postgresql92, que usa o diretório /opt/rh/postgresql92/root/var/lib/pgsql/data/ ).
Se você quiser atualizar de um fluxo postgresql anterior dentro do RHEL 8, siga o procedimento descrito em Mudança para um fluxo posterior e depois migre seus dados PostgreSQL.
Para executar o despejo e restaurar a atualização, mude o usuário para root.
O seguinte procedimento descreve a migração da versão do sistema RHEL 7 de Postgreql 9.2 para uma versão RHEL 8 de PostgreSQL.
Em seu sistema RHEL 7, inicie o servidor PostgreSQL 9.2:
# systemctl start postgresql.service
No sistema RHEL 7, despeje todo o conteúdo do banco de dados no arquivo
pgdump_file.sql:su - postgres -c "pg_dumpall > ~/pgdump_file.sql"
Certifique-se de que os bancos de dados foram despejados corretamente:
su - postgres -c 'menos "$HOME/pgdump_file.sql
Como resultado, o caminho para o arquivo sql despejado é exibido:
/var/lib/pgsql/pgdump_file.sql.No sistema RHEL 8, habilite o fluxo (versão) para o qual você deseja migrar:
# módulo yum permite postgresql:stream
Substitua stream pela versão selecionada do servidor PostgreSQL.
Você pode omitir esta etapa se quiser usar o fluxo padrão, que fornece PostgreSQL 10.
No sistema RHEL 8, instale o pacote
postgresql-server:# yum instalar postgresql-server
Opcionalmente, se você usou algum módulo do servidor PostgreSQL no RHEL 7, instale-o também no sistema RHEL 8. Se você precisar compilar um módulo de servidor PostgreSQL de terceiros, construa-o contra o pacote
postgresql-devel.No sistema RHEL 8, inicialize o diretório de dados para o novo servidor PostgreSQL:
# pós-configuração --initdb
No sistema RHEL 8, copie o
pgdump_file.sqlpara o diretório home PostgreSQL, e verifique se o arquivo foi copiado corretamente:su - postgres -c 'teste -e "$HOME/pgdump_file.sql" && echo existe'
Copiar os arquivos de configuração do sistema RHEL 7:
su - postgres -c 'ls -1 $PGDATA/*.conf
Os arquivos de configuração a serem copiados são:
-
/var/lib/pgsql/data/pg_hba.conf -
/var/lib/pgsql/data/pg_ident.conf -
/var/lib/pgsql/data/postgresql.conf
-
No sistema RHEL 8, inicie o novo servidor PostgreSQL:
# systemctl start postgresql.service
No sistema RHEL 8, importar dados do arquivo sql despejado:
su - postgres -c 'psql -f ~/pgdump_file.sql postgres
Ao atualizar a partir de uma versão da Red Hat Software Collections de PostgreSQL, ajuste os comandos para incluir scl enable collection_name. Por exemplo, para descarregar dados da Coleção de Software rh-postgresql96, use o seguinte comando:
su - postgres -c 'scl enable rh-postgresql96 "pg_dumpall > ~/pgdump_file.sql\i}"
Capítulo 9. Configurando a impressão
A impressão no Red Hat Enterprise Linux 8 é baseada no Common Unix Printing System (CUPS).
Esta documentação descreve como configurar uma máquina para poder operar como um servidor CUPS.
9.1. Ativando o serviço de copos
Esta seção descreve como ativar o serviço cups em seu sistema.
Pré-requisitos
O pacote
cups, que está disponível no repositório Appstream, deve ser instalado em seu sistema:# yum instalar copos
Procedimento
Iniciar o serviço
cups:# systemctl start cups
Configurar o serviço
cupspara ser iniciado automaticamente no momento da inicialização:# systemctl habilita os copos
Opcionalmente, verifique o status do serviço
cups:copos de status systemctl $
9.2. Ferramentas de configuração de impressão
Para realizar várias tarefas relacionadas à impressão, você pode escolher uma das seguintes ferramentas:
- CUPS web user interface (UI)
- GNOME Control center
O Print Settings ferramenta de configuração, que foi usada no Red Hat Enterprise Linux 7, não está mais disponível.
As tarefas que você pode realizar utilizando estas ferramentas incluem
- Acréscimo e configuração de uma nova impressora
- Manutenção da configuração da impressora
- Gestão de classes de impressoras
Note que esta documentação cobre apenas a impressão em CUPS web user interface (UI). Se você quiser imprimir usando GNOME Control centeré preciso ter uma GUI disponível. Para mais informações sobre impressão usando GNOME Control centerver Manuseio de impressão a partir da utilização do GNOME.
9.3. Acesso e configuração da UI web CUPS
Esta seção descreve o acesso ao CUPS web user interface) (web UI) e sua configuração para poder gerenciar a impressão através desta interface.
Procedimento
Para acessar o CUPS web UI:
Permita que o servidor CUPS escute as conexões da rede, configurando
Port 631no arquivo/etc/cups/cupsd.conf:#Listen localhost:631 Port 631
AtençãoPermitir que o servidor CUPS escute na porta 631 abre esta porta para qualquer endereço acessível pelo servidor. Portanto, use esta configuração somente em redes locais que não sejam acessíveis a partir de uma rede externa. Se um servidor precisa ser acessível a partir de uma rede externa, mas você deseja abrir a porta 631 somente para sua rede local, configure o seguinte no arquivo
/etc/cups/cupsd.conf:#Listen <server_local_IP_address>:631, onde <server_local_IP_address> é um endereço IP inalcançável de uma rede externa, mas está disponível para máquinas locais.Permita que seu sistema tenha acesso ao servidor CUPS, incluindo o seguinte no arquivo
/etc/cups/cupsd.conf:<Location /> Allow from <your_ip_address> Order allow,deny </Location>
onde <your_ip_address> é o verdadeiro endereço IP do seu sistema. Você também pode usar expressões regulares para sub-redes.
AtençãoA configuração do CUPS oferece a diretiva
Allow from allnas tags <Location>, mas a Red Hat não recomenda seu uso, a menos que você queira abrir o CUPS para a rede externa da Internet, ou se o servidor estiver em uma rede privada. A configuraçãoAllow from allpermite o acesso de todos os usuários que podem se conectar ao servidor através da porta 631. Se você configurar a diretivaPortpara 631, e o servidor for acessível de uma rede externa, qualquer pessoa na Internet pode acessar o serviço CUPS em seu sistema.Reinicie o serviço de copos:
# systemctl restart cups
Abra seu navegador, e vá para
http://<IP_address_of_the_CUPS_server>:631/.
Todos os menus, exceto o menu
Administration, já estão disponíveis.Se você clicar no menu
Administration, você receberá a mensagem Forbidden:
Para adquirir o acesso ao menu
Administration, siga as instruções em Seção 9.3.1, “Adquirir acesso da administração à UI web CUPS”.
9.3.1. Adquirir acesso da administração à UI web CUPS
Esta seção descreve como adquirir o acesso da administração ao CUPS web UI.
Procedimento
Para poder acessar o menu
Administationno CUPS web UIincluir o seguinte no arquivo/etc/cups/cupsd.conf:<Location /admin> Allow from <your_ip_address> Order allow,deny </Location>
NotaSubstitua
<your_ip_address>pelo verdadeiro endereço IP do seu sistema.Para poder ter acesso aos arquivos de configuração no CUPS web UIincluir o seguinte no arquivo
/etc/cups/cupsd.conf:<Location /admin/conf> AuthType Default Require user @SYSTEM Allow from <your_ip_address> Order allow,deny </Location>
NotaSubstitua
<your_ip_address>pelo verdadeiro endereço IP do seu sistema.Para poder ter acesso aos arquivos de log no CUPS web UIincluir o seguinte no arquivo
/etc/cups/cupsd.conf:<Location /admin/log> AuthType Default Require user @SYSTEM Allow from <your_ip_address> Order allow,deny </Location>
NotaSubstitua
<your_ip_address>pelo verdadeiro endereço IP do seu sistema.Para especificar o uso de criptografia para pedidos autenticados no CUPS web UIincluir
DefaultEncryptionno arquivo/etc/cups/cupsd.conf:DefaultEncryption IfRequested
Com esta configuração, você receberá uma janela de autenticação para inserir o nome de usuário de um usuário autorizado a adicionar impressoras quando você tentar acessar o menu
Administration. No entanto, há também outras opções para definirDefaultEncryption. Para mais detalhes, consulte a página de manualcupsd.conf.Reinicie o serviço
cups:# systemctl restart cups
AtençãoSe você não reiniciar o serviço
cups, as mudanças em/etc/cups/cupsd.confnão serão aplicadas. Conseqüentemente, você não poderá obter acesso administrativo ao serviço CUPS web UI.
Recursos adicionais
-
Para mais informações sobre como configurar um servidor CUPS usando o arquivo
/etc/cups/cupsd.conf, consulte a página de manualcupsd.conf.
9.4. Adicionando uma impressora na CUPS web UI
Esta seção descreve como adicionar uma nova impressora usando o CUPS web user interface.
Pré-requisitos
- Você adquiriu o acesso da administração ao CUPS web UI como descrito em Seção 9.3.1, “Adquirir acesso da administração à UI web CUPS”.
Procedimento
- Comece o CUPS web UI como descrito em Seção 9.3, “Acesso e configuração da UI web CUPS”
Ir para
Adding Printers and Classes-Add printer
Autenticar por nome de usuário e senha:
 Importante
ImportantePara poder adicionar uma nova impressora usando o CUPS web UIé necessário autenticar como um dos seguintes usuários:
- Superusuário
-
Qualquer usuário com o acesso administrativo fornecido pelo comando
sudo(usuários listados em/etc/sudoers) -
Qualquer usuário pertencente ao grupo
printadminem/etc/group
Se uma impressora local estiver conectada, ou se a CUPS encontrar uma impressora em rede disponível, selecione a impressora. Se nem a impressora local nem a impressora em rede estiverem disponíveis, selecione um dos tipos de impressora a partir de
Other Network Printers, por exemplo APP Socket/HP Jet direct, digite o endereço IP da impressora e depois clique emContinue.
Se você selecionou, por exemplo, APP Socket/HP Jet direct como mostrado acima, digite o endereço IP da impressora, e depois clique em
Continue.
Você pode adicionar mais detalhes sobre a nova impressora, tais como o nome, descrição e localização. Para configurar uma impressora a ser compartilhada através da rede, use
Share This Printercomo mostrado abaixo.
Selecione o fabricante da impressora e, em seguida, clique em
Continue.
Alternativamente, você também pode fornecer um arquivo de descrição da impressora (PPD) para ser usado como um driver para a impressora, clicando em
Browse…na parte inferior.Selecione o modelo da impressora e, em seguida, clique em
Add Printer.
Após a impressora ter sido adicionada, a janela seguinte permite que você defina as opções de impressão padrão.

Após clicar em Set Default Options, você receberá uma confirmação de que a nova impressora foi adicionada com sucesso.

9.5. Configuração de uma impressora na CUPS web UI
Esta seção descreve como configurar uma nova impressora, e como manter uma configuração de uma impressora usando o CUPS web UI.
Pré-requisitos
- Você adquiriu o acesso da administração ao CUPS web UI como descrito em Seção 9.3.1, “Adquirir acesso da administração à UI web CUPS”.
Procedimento
Clique no menu
Printerspara ver as impressoras disponíveis que você pode configurar.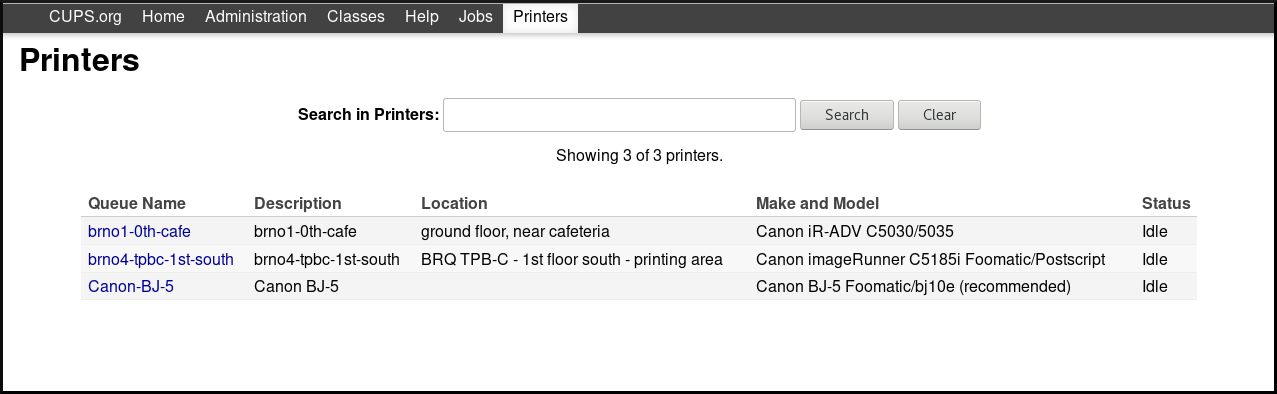
Escolha uma impressora que você deseja configurar.

Realize sua tarefa selecionada utilizando um dos menus disponíveis:
Ir para
Maintenancepara tarefas de manutenção.
Acesse
Administrationpara tarefas administrativas.
-
Você também pode verificar os trabalhos de impressão concluídos ou todos os trabalhos de impressão ativos, clicando nos botões
Show Completed JobsouShow All Jobs.
9.6. Impressão de uma página de teste utilizando a UI web CUPS
Esta seção descreve como imprimir uma página de teste para certificar-se de que a impressora funciona corretamente.
Você pode querer imprimir uma página de teste se uma das condições abaixo for atendida.
- Foi montada uma impressora.
- A configuração de uma impressora foi alterada.
Pré-requisitos
Você adquiriu o acesso da administração ao CUPS web UI como descrito em Seção 9.3.1, “Adquirir acesso da administração à UI web CUPS”.
Procedimento
Vá ao menu
Printers, e clique emMaintenance→Print Test Page.
9.7. Configuração das opções de impressão usando a interface web CUPS
Esta seção descreve como definir opções de impressão comuns, tais como o tamanho e tipo de mídia, qualidade de impressão ou o modo de cor, no CUPS web UI.
Pré-requisitos
Você adquiriu o acesso da administração ao CUPS web UI como descrito em Seção 9.3.1, “Adquirir acesso da administração à UI web CUPS”.
Procedimento
Vá ao menu
Administration, e clique emMaintenance→Set Default Options.
Defina as opções de impressão.
9.8. Instalação de certificados para um servidor de impressão
Para instalar certificados para um servidor de impressão, você pode escolher uma das seguintes opções:
- Instalação automática usando um certificado autoassinado
- Instalação manual usando um certificado e uma chave privada gerada por uma Autoridade de Certificação
Pré-requisitos
Para o daemon cupsd no servidor:
Defina a seguinte diretiva no arquivo
/etc/cups/cupsd.confpara:Encryption RequiredReinicie o serviço de copos:
$ sudo systemctl restart cups
Automatic installation using a self-signed certificate
Com esta opção, o CUPS gera o certificado e a chave automaticamente.
O certificado autoassinado não oferece segurança tão forte quanto os certificados gerados pelas Autoridades de Certificação do Gerenciamento de Identidade (IdM), Active Directory (AD) ou Red Hat Certificate System (RHCS), mas pode ser usado para servidores de impressão localizados dentro de uma rede local segura.
Procedimento
Para acessar a CUPS Web UI, abra seu navegador e vá para
https://<server>:631onde <server> é o endereço IP do servidor ou o nome do host do servidor.
NotaQuando o CUPS se conecta a um sistema pela primeira vez, o navegador mostra um aviso de que o certificado autoassinado é um risco potencial de segurança.
Para confirmar que é seguro prosseguir, clique em
Advanced….
Clique em
Accept the Risk and Continue.
O CUPS agora começa a usar o certificado autogerado e a chave.
Quando você acessa o CUPS Web UI após a instalação automática, o navegador exibe um ícone de aviso na barra de endereço. Isto porque você adicionou a exceção de segurança ao confirmar o aviso de risco de segurança. Se você quiser remover este ícone de aviso permanentemente, execute a instalação manual com um certificado e uma chave privada gerada por uma Autoridade de Certificação.
Manual installation using a certificate and a private key generated by a Certification Authority
Para servidores de impressão localizados dentro de uma rede pública ou para remover permanentemente o aviso no navegador, importar o certificado e a chave manualmente.
Pré-requisitos
- Você tem arquivos de certificados e chaves privadas gerados pela IdM, AD, ou pelas Autoridades de Certificação RHCS.
Procedimento
-
Copie os arquivos
.crte.keypara o diretório/etc/cups/ssldo sistema no qual você deseja usar a interface Web CUPS. Renomeie os arquivos copiados para
<hostname>.crte<hostname>.key.Substitua <hostname> pelo nome do host do sistema ao qual você deseja conectar a CUPS Web UI.
Defina as seguintes permissões para os arquivos renomeados:
-
# chmod 644 /etc/cups/ssl/<hostname>.crt -
# chmod 644 /etc/cups/ssl/<hostname>.key -
# chown root:root /etc/cups/ssl/<hostname>.crt -
# chown root:root /etc/cups/ssl/<hostname>.key
-
Reinicie o serviço de copos:
-
# systemctl restart cupsd
-
9.9. Usando Samba para imprimir para um servidor de impressão Windows com autenticação Kerberos
Com o wrapper samba-krb5-printing, os usuários do Active Directory (AD) que estão logados no Red Hat Enterprise Linux podem autenticar-se no Active Directory (AD) usando Kerberos e depois imprimir para um servidor de impressão CUPS local que encaminha o trabalho de impressão para um servidor de impressão Windows.
O benefício desta configuração é que o administrador do CUPS no Red Hat Enterprise Linux não precisa armazenar um nome de usuário e senha fixos na configuração. O CUPS se autentica ao AD com o bilhete Kerberos do usuário que envia o trabalho de impressão.
Esta seção descreve como configurar o CUPS para este cenário.
A Red Hat só suporta o envio de trabalhos de impressão para o CUPS a partir de seu sistema local, e não para compartilhar novamente uma impressora em um servidor de impressão Samba.
Pré-requisitos
- A impressora que você deseja adicionar à instância local CUPS é compartilhada em um servidor de impressão AD.
- Você se juntou ao anfitrião do Red Hat Enterprise Linux como membro do AD. Para detalhes, veja Seção 3.5.1, “Juntando um sistema RHEL a um domínio AD”.
-
O CUPS está instalado no Red Hat Enterprise Linux e o serviço
cupsestá em execução. Para detalhes, veja Seção 9.1, “Ativando o serviço de copos”. -
O arquivo PostScript Printer Description (PPD) para a impressora é armazenado no diretório
/usr/share/cups/model/.
Procedimento
Instale os pacotes
samba-krb5-printing,samba-client, ekrb5-workstation:# yum instalar samba-krb5-impressão samba-cliente samba-cliente krb5-workstation
Opcional: Autenticar como administrador do domínio e exibir a lista de impressoras que são compartilhadas no servidor de impressão do Windows:
# kinit administrator@AD_KERBEROS_REALM # smbclient -L win_print_srv.ad.example.com -k Sharename Type Comment --------- ---- ------- ... Example Printer Example ...
Opcional: Exibir a lista de modelos CUPS para identificar o nome do PPD de sua impressora:
lpinfo -m ... samsung.ppd Samsung M267x 287x Series PXL ...Você requer o nome do arquivo PPD ao adicionar a impressora na próxima etapa.
Adicione a impressora ao CUPS:
# lpadmin -p "example_printer" -v smb://win_print_srv.ad.example.com/Example -m samsung.ppd -o auth-info-required=negociar -E
O comando usa as seguintes opções:
-
-p printer_namedefine o nome da impressora no CUPS. -
-v URI_to_Windows_printerdefine o URI para a impressora Windows. Use o seguinte formatosmb://host_name/printer_share_name. -
-m PPD_filedefine o arquivo PPD que a impressora utiliza. -
-o auth-info-required=negotiateconfigura o CUPS para usar a autenticação Kerberos ao encaminhar os trabalhos de impressão para o servidor remoto. -
-Ehabilita a impressora e a CUPS aceita trabalhos para a impressora.
-
Etapas de verificação
- Acesse o host do Red Hat Enterprise Linux como usuário do domínio AD.
Autenticar como usuário do domínio AD:
# kinit domain_user_name@AD_KERBEROS_REALM
Imprima um arquivo para a impressora que você adicionou ao servidor de impressão local CUPS:
# lp -d example_printer file
9.10. Trabalhando com logs CUPS
9.10.1. Tipos de logs CUPS
A CUPS fornece três tipos diferentes de troncos:
- Log de erros - Armazena mensagens de erro, avisos e mensagens de debugging.
- Log de acesso - Armazena mensagens sobre quantas vezes os clientes CUPS e a interface web foram acessados.
- Log de páginas - Armazena mensagens sobre o número total de páginas impressas para cada trabalho de impressão.
No Red Hat Enterprise Linux 8, todos os três tipos são registrados centralmente em systemd-journald junto com os logs de outros programas.
No Red Hat Enterprise Linux 8, os logs não são mais armazenados em arquivos específicos dentro do diretório /var/log/cups, que foi usado no Red Hat Enterprise Linux 7.
9.10.2. Acesso aos logs do CUPS
Esta seção descreve como acessar:
- Todos os logs CUPS
- CUPS logs para um trabalho de impressão específico
- Registros CUPS dentro de um período de tempo específico
9.10.2.1. Acesso a todos os logs CUPS
Procedimento
- Filtrar os logs CUPS do sistema-jornald:
copos de $ journalctl -u
9.10.2.2. Acesso aos logs CUPS para um trabalho de impressão específico
Procedimento
- Logs de filtro para um trabalho de impressão específico:
$ journalctl -u cups JID=N
Onde N é um número de um trabalho de impressão.
9.10.2.3. Acesso aos logs CUPS por período de tempo específico
Procedimento
- Registros de filtro dentro do prazo especificado:
$ journalctl -u cups --since=YYYYY-MM-DD -- até=YYYYY-MM-DD
Onde YYYY é ano, MM é mês e DD é dia.
9.10.3. Configuração da localização do log CUPS
Esta seção descreve como configurar a localização dos logs do CUPS.
No Red Hat Enterprise Linux 8, os logs do CUPS estão, por default, logados em systemd-journald, o que é garantido pela seguinte configuração default no arquivo /etc/cups/cups-files.conf:
ErroLog syslog
A Red Hat recomenda manter a localização padrão dos logs do CUPS.
Se você quiser enviar os logs para um local diferente, você precisa alterar as configurações no arquivo /etc/cups/cups-files.conf da seguinte forma:
ErrorLog <seu_lugar_requerido_de_localização>
Se você mudar a localização padrão do log CUPS, você pode ter um comportamento inesperado ou problemas com o SELinux.
contexto: configuração-impressão
contexto: Implantação de diferentes tipos de servidores