
Red Hat Training
A Red Hat training course is available for RHEL 8
Despliegue de diferentes tipos de servidores
Guía para la implantación de diferentes tipos de servidores en Red Hat Enterprise Linux 8
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Capítulo 1. Configuración del servidor web Apache HTTP
1.1. Introducción al servidor web Apache HTTP
Un web server es un servicio de red que sirve contenidos a un cliente a través de la web. Normalmente se trata de páginas web, pero también se puede servir cualquier otro documento. Los servidores web también se conocen como servidores HTTP, ya que utilizan la dirección hypertext transport protocol (HTTP).
El Apache HTTP Server, httpd, es un servidor web de código abierto desarrollado por la Apache Software Foundation.
Si está actualizando desde una versión anterior de Red Hat Enterprise Linux, necesitará actualizar la configuración del servicio httpd en consecuencia. Esta sección revisa algunas de las nuevas características añadidas y le guía a través de la actualización de los archivos de configuración anteriores.
1.1.1. Cambios notables en el servidor HTTP Apache
El sitio web Apache HTTP Serverse ha actualizado de la versión 2.4.6 a la versión 2.4.37 entre RHEL 7 y RHEL 8. Esta versión actualizada incluye varias características nuevas, pero mantiene la compatibilidad con la versión RHEL 7 a nivel de configuración y de la interfaz binaria de aplicación (ABI) de los módulos externos.
Las nuevas características incluyen:
-
la compatibilidad con
HTTP/2la proporciona ahora el paquetemod_http2, que forma parte del módulohttpd. -
se admite la activación de sockets systemd. Consulte la página de manual
httpd.socket(8)para obtener más detalles.
Se han añadido varios módulos nuevos:
-
mod_proxy_hcheck- un módulo de comprobación de la salud del proxy -
mod_proxy_uwsgi- un proxy de la Interfaz del Servidor Web (WSGI) -
mod_proxy_fdpass- proporciona soporte para pasar el socket del cliente a otro proceso -
mod_cache_socache- una caché HTTP que utiliza, por ejemplo, memcache backend -
mod_md- un servicio de certificados SSL/TLS de protocolo ACME
-
Los siguientes módulos ahora se cargan por defecto:
-
mod_request -
mod_macro -
mod_watchdog
-
-
Se ha añadido un nuevo subpaquete,
httpd-filesystem, que contiene la disposición básica de los directorios para el Apache HTTP Server incluyendo los permisos correctos para los directorios. -
Se ha introducido el soporte de servicios instanciados,
httpd@.service. Consulte la página de manualhttpd.servicepara obtener más información.
-
Un nuevo
httpd-init.servicesustituye al%post scriptpara crear un par de claves autofirmadasmod_ssl.
-
El aprovisionamiento y la renovación automatizados de certificados TLS mediante el protocolo Automatic Certificate Management Environment (ACME) son ahora compatibles con el paquete
mod_md(para su uso con proveedores de certificados comoLet’s Encrypt). -
El sitio web Apache HTTP Server ahora soporta la carga de certificados TLS y claves privadas de tokens de seguridad de hardware directamente desde los módulos
PKCS#11. Como resultado, una configuración demod_sslpuede ahora utilizar URLs dePKCS#11para identificar la clave privada TLS y, opcionalmente, el certificado TLS en las directivasSSLCertificateKeyFileySSLCertificateFile. Ahora se admite una nueva directiva
ListenFreeen el archivo/etc/httpd/conf/httpd.conf.De forma similar a la directiva
Listen,ListenFreeproporciona información sobre las direcciones IP, los puertos o las combinaciones de dirección IP y puerto que escucha el servidor. Sin embargo, conListenFree, la opción de socketIP_FREEBINDestá habilitada por defecto. Por lo tanto, ahttpdse le permite enlazar con una dirección IP no local o con una dirección IP que aún no existe. Esto permite quehttpdescuche en un socket sin requerir que la interfaz de red subyacente o la dirección IP dinámica especificada estén activas en el momento en quehttpdintenta enlazarse a ella.Tenga en cuenta que la directiva
ListenFreesólo está disponible actualmente en RHEL 8.Para más detalles sobre
ListenFree, consulte la siguiente tabla:Tabla 1.1. Sintaxis, estado y módulos de la directiva ListenFree
Sintaxis Estado Módulos ListenFree [dirección IP:]número de puerto [protocolo]
MPM
evento, trabajador, prefork, mpm_winnt, mpm_netware, mpmt_os2
Otros cambios notables son:
Se han eliminado los siguientes módulos:
-
mod_file_cache mod_nssUtilice
mod_sslen su lugar. Para más detalles sobre la migración desdemod_nss, consulte Sección 1.10, “Exportación de una clave privada y de certificados de una base de datos NSS para utilizarlos en una configuración de servidor web Apache”.-
mod_perl
-
-
El tipo por defecto de la base de datos de autenticación DBM utilizada por el Apache HTTP Server en RHEL 8 se ha cambiado de
SDBMadb5. -
El módulo
mod_wsgipara el Apache HTTP Server ha sido actualizado a Python 3. Las aplicaciones WSGI ahora sólo son compatibles con Python 3, y deben ser migradas desde Python 2. El módulo de multiprocesamiento (MPM) configurado por defecto con el Apache HTTP Server ha cambiado de un modelo multiproceso y bifurcado (conocido como
prefork) a un modelo multihilo de alto rendimiento,event.Cualquier módulo de terceros que no sea seguro para los hilos debe ser reemplazado o eliminado. Para cambiar el MPM configurado, edite el archivo
/etc/httpd/conf.modules.d/00-mpm.conf. Consulte la página manhttpd.service(8)para obtener más información.- Los UID y GID mínimos permitidos para los usuarios por suEXEC son ahora 1000 y 500, respectivamente (antes 100 y 100).
-
El archivo
/etc/sysconfig/httpdya no es una interfaz compatible para establecer variables de entorno para el serviciohttpd. Se ha añadido la página manhttpd.service(8)para el servicio systemd. -
Al detener el servicio
httpdse utiliza ahora una "parada elegante" por defecto. -
El módulo
mod_auth_kerbha sido sustituido por el módulomod_auth_gssapi.
1.1.2. Actualización de la configuración
Para actualizar los archivos de configuración desde la Apache HTTP Server versión utilizada en Red Hat Enterprise Linux 7, elija una de las siguientes opciones:
-
Si se utiliza
/etc/sysconfig/httpdpara establecer variables de entorno, cree un archivo drop-in systemd en su lugar. - Si se utilizan módulos de terceros, asegúrese de que son compatibles con un MPM roscado.
- Si se utiliza suexec, asegúrese de que los identificadores de usuario y grupo cumplen los nuevos mínimos.
Puede comprobar la configuración en busca de posibles errores utilizando el siguiente comando:
# apachectl configtest Syntax OK
1.2. Los archivos de configuración de Apache
Cuando el servicio httpd se inicia, por defecto, lee la configuración de las ubicaciones que se enumeran en Tabla 1.2, “Los archivos de configuración del servicio httpd”.
Tabla 1.2. Los archivos de configuración del servicio httpd
| Ruta | Descripción |
|---|---|
|
| El archivo de configuración principal. |
|
| Un directorio auxiliar para los archivos de configuración que se incluyen en el archivo de configuración principal. |
|
| Un directorio auxiliar para los archivos de configuración que cargan los módulos dinámicos instalados y empaquetados en Red Hat Enterprise Linux. En la configuración por defecto, estos archivos de configuración se procesan primero. |
Aunque la configuración por defecto es adecuada para la mayoría de las situaciones, puede utilizar también otras opciones de configuración. Para que cualquier cambio surta efecto, reinicie primero el servidor web. Consulte Sección 1.3, “Gestión del servicio httpd” para obtener más información sobre cómo reiniciar el servicio httpd.
Para comprobar la configuración en busca de posibles errores, escriba lo siguiente en un prompt del shell:
# apachectl configtest Syntax OK
Para facilitar la recuperación de los errores, haga una copia del archivo original antes de editarlo.
1.3. Gestión del servicio httpd
Esta sección describe cómo iniciar, detener y reiniciar el servicio httpd.
Requisitos previos
- El servidor HTTP Apache está instalado.
Procedimiento
Para iniciar el servicio
httpd, introduzca:# systemctl start httpd
Para detener el servicio
httpd, introduzca:# systemctl stop httpd
Para reiniciar el servicio
httpd, introduzca:# systemctl restart httpd
1.4. Configuración de un servidor HTTP Apache de una sola instancia
Esta sección describe cómo configurar un servidor HTTP Apache de una sola instancia para servir contenido HTML estático.
Siga el procedimiento de esta sección si el servidor web debe proporcionar el mismo contenido para todos los dominios asociados al servidor. Si desea proporcionar un contenido diferente para diferentes dominios, configure hosts virtuales basados en nombres. Para más detalles, consulte Sección 1.5, “Configuración de hosts virtuales basados en nombres de Apache”.
Procedimiento
Instale el paquete
httpd:# yum install httpd
Abra el puerto TCP
80en el firewall local:# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
Habilite e inicie el servicio
httpd:# systemctl enable --now httpd
Opcional: Añada los archivos HTML al directorio
/var/www/html/.NotaAl añadir contenido a
/var/www/html/, los archivos y directorios deben ser legibles por el usuario bajo el cual se ejecutahttpdpor defecto. El propietario del contenido puede ser el usuariorooty el grupo de usuariosroot, u otro usuario o grupo a elección del administrador. Si el propietario del contenido es el usuariorooty el grupo de usuariosroot, los archivos deben poder ser leídos por otros usuarios. El contexto SELinux para todos los archivos y directorios debe serhttpd_sys_content_t, que se aplica por defecto a todo el contenido dentro del directorio/var/www.
Pasos de verificación
Conéctese con un navegador web para
http://server_IP_or_host_name/.Si el directorio
/var/www/html/está vacío o no contiene un archivoindex.htmloindex.htm, Apache muestra elRed Hat Enterprise Linux Test Page. Si/var/www/html/contiene archivos HTML con un nombre diferente, puede cargarlos introduciendo la URL de ese archivo, comohttp://server_IP_or_host_name/example.html.
Recursos adicionales
- Para más detalles sobre la configuración de Apache y la adaptación del servicio a su entorno, consulte el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
-
Para más detalles sobre el uso o el ajuste del servicio
httpdsystemd, consulte la página manhttpd.service(8).
1.5. Configuración de hosts virtuales basados en nombres de Apache
Los hosts virtuales basados en nombres permiten a Apache servir diferentes contenidos para diferentes dominios que se resuelven a la dirección IP del servidor.
El procedimiento en esta sección describe la configuración de un host virtual para el dominio example.com y example.net con directorios raíz de documentos separados. Ambos hosts virtuales sirven contenido HTML estático.
Requisitos previos
Los clientes y el servidor web resuelven el dominio
example.comyexample.neta la dirección IP del servidor web.Tenga en cuenta que debe añadir manualmente estas entradas a su servidor DNS.
Procedimiento
Instale el paquete
httpd:# yum install httpd
Edite el archivo
/etc/httpd/conf/httpd.conf:Añada la siguiente configuración de host virtual para el dominio
example.com:<VirtualHost *:80> DocumentRoot "/var/www/example.com/" ServerName example.com CustomLog /var/log/httpd/example.com_access.log combined ErrorLog /var/log/httpd/example.com_error.log </VirtualHost>Estos ajustes configuran lo siguiente:
-
Todos los ajustes de la directiva
<VirtualHost *:80>son específicos para este host virtual. -
DocumentRootestablece la ruta del contenido web del host virtual. ServerNameestablece los dominios para los que este host virtual sirve contenido.Para establecer varios dominios, añada el parámetro
ServerAliasa la configuración y especifique los dominios adicionales separados con un espacio en este parámetro.-
CustomLogestablece la ruta del registro de acceso del host virtual. ErrorLogestablece la ruta del registro de errores del host virtual.NotaApache utiliza el primer host virtual encontrado en la configuración también para las peticiones que no coinciden con ningún dominio establecido en los parámetros
ServerNameyServerAlias. Esto también incluye las peticiones enviadas a la dirección IP del servidor.
-
Todos los ajustes de la directiva
Añada una configuración de host virtual similar para el dominio
example.net:<VirtualHost *:80> DocumentRoot "/var/www/example.net/" ServerName example.net CustomLog /var/log/httpd/example.net_access.log combined ErrorLog /var/log/httpd/example.net_error.log </VirtualHost>Cree las raíces de los documentos para ambos hosts virtuales:
# mkdir /var/www/example.com/ # mkdir /var/www/example.net/
Si establece rutas en los parámetros de
DocumentRootque no están dentro de/var/www/, establezca el contextohttpd_sys_content_ten ambas raíces del documento:# semanage fcontext -a -t httpd_sys_content_t "/srv/example.com(/.*)?" # restorecon -Rv /srv/example.com/ # semanage fcontext -a -t httpd_sys_content_t "/srv/example.net(/.\*)?" # restorecon -Rv /srv/example.net/
Estos comandos establecen el contexto
httpd_sys_content_ten el directorio/srv/example.com/y/srv/example.net/.Tenga en cuenta que debe instalar el paquete
policycoreutils-python-utilspara ejecutar el comandorestorecon.Abra el puerto
80en el firewall local:# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
Habilite e inicie el servicio
httpd:# systemctl enable --now httpd
Pasos de verificación
Cree un archivo de ejemplo diferente en la raíz de documentos de cada host virtual:
# echo "vHost example.com" > /var/www/example.com/index.html # echo "vHost example.net" > /var/www/example.net/index.html
-
Utilice un navegador y conéctese a
http://example.com. El servidor web muestra el archivo de ejemplo del host virtualexample.com. -
Utilice un navegador y conéctese a
http://example.net. El servidor web muestra el archivo de ejemplo del host virtualexample.net.
Recursos adicionales
-
Para más detalles sobre la configuración de los hosts virtuales de Apache, consulte la documentación de
Virtual Hostsen el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
1.6. Configuración del cifrado TLS en un servidor HTTP Apache
Por defecto, Apache proporciona contenido a los clientes utilizando una conexión HTTP sin cifrar. Esta sección describe cómo habilitar el cifrado TLS y configurar las opciones más frecuentes relacionadas con el cifrado en un servidor HTTP Apache.
Requisitos previos
- El servidor HTTP Apache está instalado y funcionando.
1.6.1. Cómo añadir el cifrado TLS a un servidor HTTP Apache
Esta sección describe cómo activar el cifrado TLS en un servidor HTTP Apache para el dominio example.com.
Requisitos previos
- El servidor HTTP Apache está instalado y funcionando.
La clave privada se almacena en el archivo
/etc/pki/tls/private/example.com.key.Para obtener detalles sobre la creación de una clave privada y una solicitud de firma de certificado (CSR), así como para solicitar un certificado a una autoridad de certificación (CA), consulte la documentación de su CA. Como alternativa, si su CA admite el protocolo ACME, puede utilizar el módulo
mod_mdpara automatizar la recuperación y el aprovisionamiento de certificados TLS.-
El certificado TLS se almacena en el archivo
/etc/pki/tls/private/example.com.crt. Si utiliza una ruta diferente, adapte los pasos correspondientes del procedimiento. -
El certificado CA se almacena en el archivo
/etc/pki/tls/private/ca.crt. Si utiliza una ruta diferente, adapte los pasos correspondientes del procedimiento. - Los clientes y el servidor web resuelven el nombre de host del servidor a la dirección IP del servidor web.
Procedimiento
Instale el paquete
mod_ssl:# dnf install mod_ssl
Edite el archivo
/etc/httpd/conf.d/ssl.confy añada la siguiente configuración a la directiva<VirtualHost _default_:443>:Establezca el nombre del servidor:
Nombre del servidor example.comImportanteEl nombre del servidor debe coincidir con la entrada establecida en el campo
Common Namedel certificado.Opcional: Si el certificado contiene nombres de host adicionales en el campo
Subject Alt Names(SAN), puede configurarmod_sslpara que proporcione cifrado TLS también para estos nombres de host. Para configurarlo, añada el parámetroServerAliasescon los nombres correspondientes:ServidorAlias www.example.com server.example.com
Establezca las rutas de acceso a la clave privada, el certificado del servidor y el certificado de la CA:
SSLCertificateKeyFile "/etc/pki/tls/private/example.com.key" SSLCertificateFile "/etc/pki/tls/certs/example.com.crt" SSLCACertificateFile "/etc/pki/tls/certs/ca.crt"
Por razones de seguridad, configure que sólo el usuario
rootpueda acceder al archivo de la clave privada:# chown root:root /etc/pki/tls/private/example.com.key # chmod 600 /etc/pki/tls/private/example.com.key
AvisoSi los usuarios no autorizados accedieron a la clave privada, revoque el certificado, cree una nueva clave privada y solicite un nuevo certificado. En caso contrario, la conexión TLS deja de ser segura.
Abra el puerto
443en el firewall local:# firewall-cmd --permanent --add-port=443 # firewall-cmd --reload
Reinicie el servicio
httpd:# systemctl restart httpd
NotaSi protegió el archivo de clave privada con una contraseña, deberá introducirla cada vez que se inicie el servicio
httpd.
Pasos de verificación
-
Utilice un navegador y conéctese a
https://example.com.
Recursos adicionales
-
Para más detalles sobre la configuración de TLS, consulte la documentación de
SSL/TLS Encryptionen el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
1.6.2. Configuración de las versiones de protocolo TLS admitidas en un servidor HTTP Apache
Por defecto, el servidor HTTP Apache en RHEL 8 utiliza la política crypto de todo el sistema que define valores seguros por defecto, que además son compatibles con los navegadores recientes. Por ejemplo, la política DEFAULT define que sólo las versiones del protocolo TLSv1.2 y TLSv1.3 están habilitadas en apache.
Esta sección describe cómo configurar manualmente las versiones del protocolo TLS que soporta su servidor HTTP Apache. Siga el procedimiento si su entorno requiere habilitar sólo versiones específicas del protocolo TLS, por ejemplo:
-
Si su entorno requiere que los clientes también puedan utilizar el protocolo débil
TLS1(TLSv1.0) oTLS1.1. -
Si quiere configurar que Apache sólo soporte el protocolo
TLSv1.2oTLSv1.3.
Requisitos previos
- El cifrado TLS está habilitado en el servidor como se describe en Sección 1.6.1, “Cómo añadir el cifrado TLS a un servidor HTTP Apache”.
Procedimiento
Edite el archivo
/etc/httpd/conf/httpd.confy añada la siguiente configuración a la directiva<VirtualHost>para la que desea establecer la versión del protocolo TLS. Por ejemplo, para habilitar sólo el protocoloTLSv1.3:SSLProtocolo -Todo TLSv1.3
Reinicie el servicio
httpd:# systemctl restart httpd
Pasos de verificación
Utilice el siguiente comando para verificar que el servidor soporta
TLSv1.3:# openssl s_client -connect example.com:443 -tls1_3Utilice el siguiente comando para verificar que el servidor no soporta
TLSv1.2:# openssl s_client -connect example.com:443 -tls1_2Si el servidor no soporta el protocolo, el comando devuelve un error:
140111600609088:error:1409442E:Rutinas SSL:ssl3_read_bytes:versión del protocolo de alerta tlsv1:ssl/record/rec_layer_s3.c:1543:Número de alerta SSL 70
- Opcional: Repita el comando para otras versiones del protocolo TLS.
Recursos adicionales
-
Para más detalles sobre la política criptográfica a nivel de sistema, consulte la página man
update-crypto-policies(8)y Using system-wide cryptographic policies. -
Para más detalles sobre el parámetro
SSLProtocol, consulte la documentación demod_sslen el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
1.6.3. Cómo configurar los cifrados admitidos en un servidor HTTP Apache
Por defecto, el servidor HTTP Apache en RHEL 8 utiliza la política de cifrado de todo el sistema que define valores seguros por defecto, que también son compatibles con los navegadores recientes. Para ver la lista de cifrados que permite la política de cifrado de todo el sistema, consulte el archivo /etc/crypto-policies/back-ends/openssl.config.
Esta sección describe cómo configurar manualmente los cifrados que soporta su servidor HTTP Apache. Siga el procedimiento si su entorno requiere cifrados específicos.
Requisitos previos
- El cifrado TLS está habilitado en el servidor como se describe en Sección 1.6.1, “Cómo añadir el cifrado TLS a un servidor HTTP Apache”.
Procedimiento
Edite el archivo
/etc/httpd/conf/httpd.confy añada el parámetroSSLCipherSuitea la directiva<VirtualHost>para la que desea establecer los cifrados TLS:SSLCipherSuite \ "EECDH AESGCM:EDH AESGCM:AES256 EECDH:AES256 EDH:!SHA1:!SHA256"
Este ejemplo activa sólo los cifrados
EECDH AESGCM,EDH AESGCM,AES256 EECDH, yAES256 EDHy desactiva todos los cifrados que utilizan el código de autenticación de mensajes (MAC)SHA1ySHA256.Reinicie el servicio
httpd:# systemctl restart httpd
Pasos de verificación
Para mostrar la lista de cifrados que soporta el servidor HTTP Apache:
Instale el paquete
nmap:# yum install nmap
Utiliza la utilidad
nmappara mostrar los cifrados soportados:# nmap --script ssl-enum-ciphers -p 443 example.com ... PORT STATE SERVICE 443/tcp open https | ssl-enum-ciphers: | TLSv1.2: | ciphers: | TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (ecdh_x25519) - A | TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (dh 2048) - A | TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 (ecdh_x25519) - A ...
Recursos adicionales
-
Para más detalles sobre la política criptográfica a nivel de sistema, consulte la página man
update-crypto-policies(8)y Using system-wide cryptographic policies. -
Para más detalles sobre el parámetro
SSLCipherSuite, consulte la documentación demod_sslen el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
1.7. Configuración de la autenticación del certificado de cliente TLS
La autenticación de certificados de cliente permite a los administradores permitir que sólo los usuarios que se autentiquen utilizando un certificado puedan acceder a los recursos del servidor web. Esta sección describe cómo configurar la autenticación de certificados de cliente para el directorio /var/www/html/Example/.
Si el servidor HTTP Apache utiliza el protocolo TLS 1.3, algunos clientes requieren una configuración adicional. Por ejemplo, en Firefox, establezca el parámetro security.tls.enable_post_handshake_auth en el menú about:config a true. Para más detalles, consulte Transport Layer Security versión 1.3 en Red Hat Enterprise Linux 8.
Requisitos previos
- El cifrado TLS está habilitado en el servidor como se describe en Sección 1.6.1, “Cómo añadir el cifrado TLS a un servidor HTTP Apache”.
Procedimiento
Edite el archivo
/etc/httpd/conf/httpd.confy añada la siguiente configuración a la directiva<VirtualHost>para la que desea configurar la autenticación del cliente:<Directory "/var/www/html/Example/"> SSLVerifyClient require </Directory>
La configuración
SSLVerifyClient requiredefine que el servidor debe validar con éxito el certificado del cliente antes de que éste pueda acceder al contenido del directorio/var/www/html/Example/.Reinicie el servicio
httpd:# systemctl restart httpd
Pasos de verificación
Utilice la utilidad
curlpara acceder a la URLhttps://example.com/Example/sin autenticación de cliente:$ curl https://example.com/Example/ curl: (56) OpenSSL SSL_read: error:1409445C:SSL routines:ssl3_read_bytes:tlsv13 alert certificate required, errno 0El error indica que el servidor web requiere un certificado de autentificación del cliente.
Pase la clave privada y el certificado del cliente, así como el certificado de la CA a
curlpara acceder a la misma URL con autenticación de cliente:$ curl --cacert ca.crt --key client.key --cert client.crt https://example.com/Example/
Si la solicitud tiene éxito,
curlmuestra el archivoindex.htmlalmacenado en el directorio/var/www/html/Example/.
Recursos adicionales
-
Para más detalles sobre la autenticación de clientes, consulte la documentación de
mod_ssl Configuration How-Toen el manual de Apache. Para más detalles sobre la instalación del manual, consulte Sección 1.8, “Instalación del manual del servidor HTTP Apache”.
1.8. Instalación del manual del servidor HTTP Apache
Esta sección describe cómo instalar el manual del servidor HTTP Apache. Este manual proporciona una documentación detallada de, por ejemplo:
- Parámetros y directivas de configuración
- Ajuste del rendimiento
- Configuración de la autenticación
- Módulos
- Caché de contenidos
- Consejos de seguridad
- Configuración del cifrado TLS
Después de instalar el manual, puede visualizarlo mediante un navegador web.
Requisitos previos
- El servidor HTTP Apache está instalado y funcionando.
Procedimiento
Instale el paquete
httpd-manual:# yum install httpd-manual
Opcional: Por defecto, todos los clientes que se conectan al servidor HTTP Apache pueden mostrar el manual. Para restringir el acceso a un rango IP específico, como la subred
192.0.2.0/24, edite el archivo/etc/httpd/conf.d/manual.confy añada la configuraciónRequire ip 192.0.2.0/24a la directiva<Directory "/usr/share/httpd/manual">:<Directory "/usr/share/httpd/manual"> ... Require ip 192.0.2.0/24 ... </Directory>Reinicie el servicio
httpd:# systemctl restart httpd
Pasos de verificación
-
Para visualizar el manual del servidor HTTP Apache, conéctese con un navegador web a
http://host_name_or_IP_address/manual/
1.9. Trabajar con módulos
Al tratarse de una aplicación modular, el servicio httpd se distribuye junto con una serie de Dynamic Shared Objects (DSOs), que pueden cargarse o descargarse dinámicamente en tiempo de ejecución, según sea necesario. Estos módulos se encuentran en el directorio /usr/lib64/httpd/modules/.
1.9.1. Cargar un módulo
Para cargar un módulo DSO concreto, utilice la directiva LoadModule. Tenga en cuenta que los módulos proporcionados por un paquete independiente suelen tener su propio archivo de configuración en el directorio /etc/httpd/conf.modules.d/.
Ejemplo 1.1. Carga del DSO mod_ssl
LoadModule ssl_module modules/mod_ssl.so
Después de cargar el módulo, reinicie el servidor web para recargar la configuración. Consulte Sección 1.3, “Gestión del servicio httpd” para obtener más información sobre cómo reiniciar el servicio httpd.
1.9.2. Escribir un módulo
Para crear un nuevo módulo DSO, asegúrese de tener instalado el paquete httpd-devel. Para ello, introduzca el siguiente comando como root:
# yum install httpd-devel
Este paquete contiene los archivos de inclusión, los archivos de cabecera y la utilidad APache eXtenSion (apxs) necesarios para compilar un módulo.
Una vez escrito, puedes construir el módulo con el siguiente comando:
# apxs -i -a -c nombre_del_módulo.c
Si la compilación fue exitosa, debería poder cargar el módulo de la misma manera que cualquier otro módulo que se distribuya con el archivo Apache HTTP Server.
1.10. Exportación de una clave privada y de certificados de una base de datos NSS para utilizarlos en una configuración de servidor web Apache
RHEL 8 ya no proporciona el módulo mod_nss para el servidor web Apache y Red Hat recomienda utilizar el módulo mod_ssl. Si almacena su clave privada y sus certificados en una base de datos de Servicios de Seguridad de Red (NSS), por ejemplo, porque migró el servidor web de RHEL 7 a RHEL 8, siga este procedimiento para extraer la clave y los certificados en formato de Correo de Privacidad Mejorado (PEM). A continuación, puede utilizar los archivos en la configuración de mod_ssl como se describe en Sección 1.6, “Configuración del cifrado TLS en un servidor HTTP Apache”.
Este procedimiento asume que la base de datos NSS está almacenada en /etc/httpd/alias/ y que usted almacena la clave privada y los certificados exportados en el directorio /etc/pki/tls/.
Requisitos previos
- La clave privada, el certificado y el certificado de la autoridad de certificación (CA) se almacenan en una base de datos del NSS.
Procedimiento
Enumerar los certificados en la base de datos del NSS:
#
certutil -d /etc/httpd/alias/ -LCertificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI Example CA C,, Example Server Certificate u,u,uEn los próximos pasos necesitará los nombres de los certificados.
Para extraer la clave privada, debe exportar temporalmente la clave a un archivo PKCS #12:
Utilice el apodo del certificado asociado a la clave privada, para exportar la clave a un archivo PKCS #12:
#
pk12util -o /etc/pki/tls/private/export.p12 -d /etc/httpd/alias/ -n "Example Server Certificate"Enter password for PKCS12 file: password Re-enter password: password pk12util: PKCS12 EXPORT SUCCESSFULTenga en cuenta que debe establecer una contraseña en el archivo PKCS #12. Necesitará esta contraseña en el siguiente paso.
Exporte la clave privada del archivo PKCS #12:
#
openssl pkcs12 -in /etc/pki/tls/private/export.p12 -out /etc/pki/tls/private/server.key -nocerts -nodesEnter Import Password: password MAC verified OKEliminar el archivo temporal PKCS #12:
#
rm /etc/pki/tls/private/export.p12
Establezca los permisos en
/etc/pki/tls/private/server.keypara garantizar que sólo el usuariorootpueda acceder a este archivo:#
chown root:root /etc/pki/tls/private/server.key#chmod 0600 /etc/pki/tls/private/server.keyUtilice el apodo del certificado del servidor en la base de datos del NSS para exportar el certificado de la CA:
#
certutil -d /etc/httpd/alias/ -L -n "Example Server Certificate" -a -o /etc/pki/tls/certs/server.crtEstablezca los permisos en
/etc/pki/tls/certs/server.crtpara garantizar que sólo el usuariorootpueda acceder a este archivo:#
chown root:root /etc/pki/tls/certs/server.crt#chmod 0600 /etc/pki/tls/certs/server.crtUtilice el apodo del certificado CA en la base de datos NSS para exportar el certificado CA:
#
certutil -d /etc/httpd/alias/ -L -n "Example CA" -a -o /etc/pki/tls/certs/ca.crtSiga Sección 1.6, “Configuración del cifrado TLS en un servidor HTTP Apache” para configurar el servidor web Apache, y:
-
Ajuste el parámetro
SSLCertificateKeyFilea/etc/pki/tls/private/server.key. -
Ajuste el parámetro
SSLCertificateFilea/etc/pki/tls/certs/server.crt. -
Ajuste el parámetro
SSLCACertificateFilea/etc/pki/tls/certs/ca.crt.
-
Ajuste el parámetro
Recursos adicionales
-
La página de manual
certutil(1) -
La página de manual
pk12util(1) -
La página de manual
pkcs12(1ssl)
1.11. Recursos adicionales
-
httpd(8)- La página del manual del serviciohttpdque contiene la lista completa de sus opciones de línea de comandos. -
httpd.service(8)- La página del manual del archivo de la unidadhttpd.service, que describe cómo personalizar y mejorar el servicio. -
httpd.conf(5)- La página del manual de configuración dehttpd, que describe la estructura y la ubicación de los archivos de configuración dehttpd. -
apachectl(8)- La página del manual de la Apache HTTP Server Interfaz de control.
Capítulo 2. Instalación y configuración de NGINX
NGINX es un servidor de alto rendimiento y modular que puede utilizar, por ejemplo, como:
- Servidor web
- Proxy inverso
- Equilibrador de carga
Esta sección describe cómo NGINX en estos escenarios.
2.1. Instalación y preparación de NGINX
Red Hat utiliza Application Streams para proporcionar diferentes versiones de NGINX. Esta sección describe cómo:
- Seleccione un flujo e instale NGINX
- Abra los puertos necesarios en el cortafuegos
-
Habilitar e iniciar el servicio
nginx
Utilizando la configuración por defecto, NGINX se ejecuta como un servidor web en el puerto 80 y proporciona contenido desde el directorio /usr/share/nginx/html/.
Requisitos previos
- RHEL 8 está instalado.
- El host está suscrito al Portal del Cliente de Red Hat.
-
El servicio
firewalldestá activado e iniciado.
Procedimiento
Muestra los flujos de módulos NGINX disponibles:
#
yum module list nginxRed Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary nginx 1.14 [d] common [d] nginx webserver nginx 1.16 common [d] nginx webserver ... Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalledSi desea instalar un flujo diferente al predeterminado, seleccione el flujo:
#
yum module enable nginx:stream_versionInstale el paquete
nginx:#
yum install nginxAbra los puertos en los que NGINX debe prestar su servicio en el cortafuegos. Por ejemplo, para abrir los puertos por defecto para HTTP (puerto 80) y HTTPS (puerto 443) en
firewalld, introduzca:#
firewall-cmd --permanent --add-port={80/tcp,443/tcp}#firewall-cmd --reloadHabilite el servicio
nginxpara que se inicie automáticamente al arrancar el sistema:#
systemctl enable nginxOpcionalmente, inicie el servicio
nginx:#
systemctl start nginxSi no desea utilizar la configuración por defecto, sáltese este paso y configure NGINX como corresponda antes de iniciar el servicio.
Pasos de verificación
Utilice la utilidad
yumpara verificar que el paquetenginxestá instalado:#
yum list installed nginxInstalled Packages nginx.x86_64 1:1.14.1-9.module+el8.0.0+4108+af250afe @rhel-8-for-x86_64-appstream-rpmsAsegúrese de que los puertos en los que NGINX debe prestar su servicio están abiertos en el firewalld:
#
firewall-cmd --list-ports80/tcp 443/tcpCompruebe que el servicio
nginxestá activado:#
systemctl is-enabled nginxenabled
Recursos adicionales
- Para más detalles sobre el Gestor de Suscripciones, consulte la guía Uso y configuración del Gestor de Suscripciones.
- Para obtener más detalles sobre los flujos de aplicaciones, los módulos y la instalación de paquetes, consulte la guía Instalación, gestión y eliminación de componentes del espacio de usuario.
- Para más detalles sobre la configuración de los cortafuegos, consulte la guía sobre la seguridad de las redes.
2.2. Configurar NGINX como un servidor web que proporciona diferentes contenidos para diferentes dominios
Por defecto, NGINX actúa como un servidor web que proporciona el mismo contenido a los clientes para todos los nombres de dominio asociados a las direcciones IP del servidor. Este procedimiento explica cómo configurar NGINX:
-
Para servir peticiones al dominio
example.comcon contenido del directorio/var/www/example.com/ -
Para servir peticiones al dominio
example.netcon contenido del directorio/var/www/example.net/ -
Servir todas las demás solicitudes, por ejemplo, a la dirección IP del servidor o a otros dominios asociados a la dirección IP del servidor, con contenido del directorio
/usr/share/nginx/html/
Requisitos previos
- NGINX se instala como se describe en Sección 2.1, “Instalación y preparación de NGINX”.
Los clientes y el servidor web resuelven el dominio
example.comyexample.neta la dirección IP del servidor web.Tenga en cuenta que debe añadir manualmente estas entradas a su servidor DNS.
Procedimiento
Edite el archivo
/etc/nginx/nginx.conf:Por defecto, el archivo
/etc/nginx/nginx.confya contiene una configuración de tipo catch-all. Si ha eliminado esta parte de la configuración, vuelva a añadir el siguiente bloqueserveral bloquehttpdel archivo/etc/nginx/nginx.conf:server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /usr/share/nginx/html; }Estos ajustes configuran lo siguiente:
-
La directiva
listendefine qué dirección IP y qué puertos escucha el servicio. En este caso, NGINX escucha en el puerto80en todas las direcciones IPv4 e IPv6. El parámetrodefault_serverindica que NGINX utiliza este bloqueserverpor defecto para las peticiones que coincidan con las direcciones IP y los puertos. -
El parámetro
server_namedefine los nombres de host de los que es responsable este bloqueserver. Establecerserver_namea_configura a NGINX para aceptar cualquier nombre de host para este bloqueserver. -
La directiva
rootestablece la ruta del contenido web para este bloqueserver.
-
La directiva
Añade un bloque similar
serverpara el dominioexample.comal bloquehttp:server { server_name example.com; root /var/www/example.com/; access_log /var/log/nginx/example.com/access.log; error_log /var/log/nginx/example.com/error.log; }-
La directiva
access_logdefine un archivo de registro de acceso independiente para este dominio. -
La directiva
error_logdefine un archivo de registro de errores separado para este dominio.
-
La directiva
Añade un bloque similar
serverpara el dominioexample.netal bloquehttp:server { server_name example.net; root /var/www/example.net/; access_log /var/log/nginx/example.net/access.log; error_log /var/log/nginx/example.net/error.log; }
Cree los directorios raíz de ambos dominios:
#
mkdir -p /var/www/example.com/#mkdir -p /var/www/example.net/Establezca el contexto
httpd_sys_content_ten ambos directorios raíz:#
semanage fcontext -a -t httpd_sys_content_t "/var/www/example.com(/.*)?"#restorecon -Rv /var/www/example.com/#semanage fcontext -a -t httpd_sys_content_t "/var/www/example.net(/.\*)?"#restorecon -Rv /var/www/example.net/Estos comandos establecen el contexto
httpd_sys_content_ten los directorios/var/www/example.com/y/var/www/example.net/.Tenga en cuenta que debe instalar el paquete
policycoreutils-python-utilspara ejecutar los comandos derestorecon.Cree los directorios de registro para ambos dominios:
#
mkdir /var/log/nginx/example.com/#mkdir /var/log/nginx/example.net/Reinicie el servicio
nginx:#
systemctl restart nginx
Pasos de verificación
Cree un archivo de ejemplo diferente en la raíz de documentos de cada host virtual:
#
echo "Content for example.com" > /var/www/example.com/index.html#echo "Content for example.net" > /var/www/example.net/index.html#echo "Catch All content" > /usr/share/nginx/html/index.html-
Utilice un navegador y conéctese a
http://example.com. El servidor web muestra el contenido de ejemplo del archivo/var/www/example.com/index.html. -
Utilice un navegador y conéctese a
http://example.net. El servidor web muestra el contenido de ejemplo del archivo/var/www/example.net/index.html. -
Utilice un navegador y conéctese a
http://IP_address_of_the_server. El servidor web muestra el contenido de ejemplo del archivo/usr/share/nginx/html/index.html.
2.3. Añadir encriptación TLS a un servidor web NGINX
Esta sección describe cómo habilitar el cifrado TLS en un servidor web NGINX para el dominio example.com.
Requisitos previos
- NGINX se instala como se describe en Sección 2.1, “Instalación y preparación de NGINX”.
La clave privada se almacena en el archivo
/etc/pki/tls/private/example.com.key.Para obtener detalles sobre la creación de una clave privada y una solicitud de firma de certificado (CSR), así como para solicitar un certificado a una autoridad de certificación (CA), consulte la documentación de su CA.
-
El certificado TLS se almacena en el archivo
/etc/pki/tls/certs/example.com.crt. Si utiliza una ruta diferente, adapte los pasos correspondientes del procedimiento. - El certificado de la CA se ha añadido al archivo de certificados TLS del servidor.
- Los clientes y el servidor web resuelven el nombre de host del servidor a la dirección IP del servidor web.
-
El puerto
443está abierto en el firewall local.
Procedimiento
Edite el archivo
/etc/nginx/nginx.confy añada el siguiente bloqueserveral bloquehttpen la configuración:server { listen 443 ssl; server_name example.com; root /usr/share/nginx/html; ssl_certificate /etc/pki/tls/certs/example.com.crt; ssl_certificate_key /etc/pki/tls/private/example.com.key; }Por razones de seguridad, configure que sólo el usuario
rootpueda acceder al archivo de la clave privada:#
chown root:root /etc/pki/tls/private/example.com.key#chmod 600 /etc/pki/tls/private/example.com.keyAvisoSi los usuarios no autorizados accedieron a la clave privada, revoque el certificado, cree una nueva clave privada y solicite un nuevo certificado. En caso contrario, la conexión TLS deja de ser segura.
Reinicie el servicio
nginx:#
systemctl restart nginx
Pasos de verificación
-
Utilice un navegador y conéctese a
https://example.com
2.4. Configurar NGINX como proxy inverso para el tráfico HTTP
Puede configurar el servidor web NGINX para que actúe como proxy inverso para el tráfico HTTP. Por ejemplo, puede utilizar esta funcionalidad para reenviar las peticiones a un subdirectorio específico en un servidor remoto. Desde la perspectiva del cliente, éste carga el contenido del host al que accede. Sin embargo, NGINX carga el contenido real del servidor remoto y lo reenvía al cliente.
Este procedimiento explica cómo reenviar el tráfico al directorio /example del servidor web a la URL https://example.com.
Requisitos previos
- NGINX se instala como se describe en Sección 2.1, “Instalación y preparación de NGINX”.
- Opcional: El cifrado TLS está activado en el proxy inverso.
Procedimiento
Edite el archivo
/etc/nginx/nginx.confy añada la siguiente configuración al bloqueserverque debe proporcionar el proxy inverso:location /example { proxy_pass https://example.com; }El bloque
locationdefine que NGINX pase todas las peticiones en el directorio/exampleahttps://example.com.Establezca el parámetro booleano
httpd_can_network_connectSELinux en1para configurar que SELinux permita a NGINX reenviar el tráfico:#
setsebool -P httpd_can_network_connect 1Reinicie el servicio
nginx:#
systemctl restart nginx
Pasos de verificación
-
Utilice un navegador y conéctese a
http://host_name/exampley se muestra el contenido dehttps://example.com.
2.5. Configuración de NGINX como equilibrador de carga HTTP
Puede utilizar la función de proxy inverso de NGINX para equilibrar la carga del tráfico. Este procedimiento describe cómo configurar NGINX como un equilibrador de carga HTTP que envía las peticiones a diferentes servidores, basándose en cuál de ellos tiene el menor número de conexiones activas. Si ambos servidores no están disponibles, el procedimiento también define un tercer host por razones de fallback.
Requisitos previos
- NGINX se instala como se describe en Sección 2.1, “Instalación y preparación de NGINX”.
Procedimiento
Edite el archivo
/etc/nginx/nginx.confy añada la siguiente configuración:http { upstream backend { least_conn; server server1.example.com; server server2.example.com; server server3.example.com backup; } server { location / { proxy_pass http://backend; } } }La directiva
least_connen el grupo de hosts llamadobackenddefine que NGINX envíe las peticiones aserver1.example.comoserver2.example.com, dependiendo del host que tenga el menor número de conexiones activas. NGINX utilizaserver3.example.comsolo como respaldo en caso de que los otros dos hosts no estén disponibles.Con la directiva
proxy_passestablecida enhttp://backend, NGINX actúa como un proxy inverso y utiliza el grupo de hostsbackendpara distribuir las peticiones basándose en la configuración de este grupo.En lugar del método de equilibrio de carga
least_conn, puede especificar:- No hay método para utilizar round robin y distribuir las peticiones de manera uniforme entre los servidores.
-
ip_hashpara enviar solicitudes de una dirección de cliente al mismo servidor basándose en un hash calculado a partir de los tres primeros octetos de la dirección IPv4 o de la dirección IPv6 completa del cliente. -
hashpara determinar el servidor basándose en una clave definida por el usuario, que puede ser una cadena, una variable o una combinación de ambas. El parámetroconsistentconfigura que NGINX distribuya las peticiones entre todos los servidores basándose en el valor de la clave hash definida por el usuario. -
randompara enviar solicitudes a un servidor seleccionado al azar.
Reinicie el servicio
nginx:#
systemctl restart nginx
2.6. Recursos adicionales
- Para la documentación oficial de NGINX consulte https://nginx.org/en/docs/. Tenga en cuenta que Red Hat no mantiene esta documentación y que podría no funcionar con la versión de NGINX que tiene instalada.
Capítulo 3. Uso de Samba como servidor
Samba implementa el protocolo Server Message Block (SMB) en Red Hat Enterprise Linux. El protocolo SMB se utiliza para acceder a los recursos de un servidor, como archivos compartidos e impresoras compartidas. Además, Samba implementa el protocolo DCE RPC (Distributed Computing Environment Remote Procedure Call) utilizado por Microsoft Windows.
Puedes ejecutar Samba como:
- Un miembro del dominio de Active Directory (AD) o NT4
- Un servidor independiente
Un controlador de dominio primario (PDC) o un controlador de dominio de respaldo (BDC) de NT4
NotaRed Hat soporta los modos PDC y BDC sólo en instalaciones existentes con versiones de Windows que soportan dominios NT4. Red Hat recomienda no configurar un nuevo dominio Samba NT4, porque los sistemas operativos de Microsoft posteriores a Windows 7 y Windows Server 2008 R2 no admiten dominios NT4.
Red Hat no soporta la ejecución de Samba como controlador de dominio (DC) de AD.
Independientemente del modo de instalación, puede compartir opcionalmente directorios e impresoras. Esto permite a Samba actuar como un servidor de archivos e impresiones.
3.1. Entender los diferentes servicios y modos de Samba
Esta sección describe los diferentes servicios incluidos en Samba y los diferentes modos que puede configurar.
3.1.1. Los servicios de Samba
Samba proporciona los siguientes servicios:
smbdEste servicio proporciona servicios de compartición e impresión de archivos utilizando el protocolo SMB. Además, el servicio es responsable del bloqueo de recursos y de la autenticación de los usuarios que se conectan. El servicio
smbsystemdinicia y detiene el demoniosmbd.Para utilizar el servicio
smbd, instale el paquetesamba.nmbdEste servicio proporciona la resolución de nombres de host e IP utilizando el protocolo NetBIOS sobre IPv4. Además de la resolución de nombres, el servicio
nmbdpermite navegar por la red SMB para localizar dominios, grupos de trabajo, hosts, archivos compartidos e impresoras. Para ello, el servicio comunica esta información directamente al cliente emisor o la reenvía a un navegador local o principal. El servicionmbsystemdinicia y detiene el demonionmbd.Tenga en cuenta que las redes SMB modernas utilizan DNS para resolver los clientes y las direcciones IP.
Para utilizar el servicio
nmbd, instale el paquetesamba.winbinddEste servicio proporciona una interfaz para que el conmutador de servicio de nombres (NSS) utilice usuarios y grupos de dominio AD o NT4 en el sistema local. Esto permite, por ejemplo, que los usuarios del dominio se autentiquen en servicios alojados en un servidor Samba o en otros servicios locales. El servicio
winbindsystemdinicia y detiene el demoniowinbindd.Si configura Samba como miembro del dominio,
winbindddebe iniciarse antes que el serviciosmbd. De lo contrario, los usuarios y grupos del dominio no están disponibles para el sistema local..Para utilizar el servicio
winbindd, instale el paquetesamba-winbind.ImportanteRed Hat sólo soporta la ejecución de Samba como servidor con el servicio
winbinddpara proporcionar usuarios y grupos de dominio al sistema local. Debido a ciertas limitaciones, tales como la falta de soporte de la lista de control de acceso (ACL) de Windows y de la recuperación de NT LAN Manager (NTLM), SSSD no es compatible.
3.1.2. Los servicios de seguridad de Samba
El parámetro security en la sección [global] del archivo /etc/samba/smb.conf gestiona cómo Samba autentifica a los usuarios que se conectan al servicio. Dependiendo del modo en el que se instale Samba, el parámetro debe establecerse con valores diferentes:
- En un miembro del dominio AD, establezca
security = ads En este modo, Samba utiliza Kerberos para autenticar a los usuarios de AD.
Para más detalles sobre la configuración de Samba como miembro del dominio, consulte Sección 3.5, “Configuración de Samba como servidor miembro del dominio AD”.
- En un servidor independiente, configure
security = user En este modo, Samba utiliza una base de datos local para autenticar a los usuarios que se conectan.
Para más detalles sobre la configuración de Samba como servidor independiente, consulte Sección 3.3, “Configuración de Samba como servidor independiente”.
- En un PDC o BDC NT4, configure
security = user - En este modo, Samba autentifica a los usuarios en una base de datos local o LDAP.
- En un miembro del dominio NT4, configure
security = domain En este modo, Samba autentifica a los usuarios que se conectan a un PDC o BDC de NT4. No se puede utilizar este modo en los miembros del dominio AD.
Para más detalles sobre la configuración de Samba como miembro del dominio, consulte Sección 3.5, “Configuración de Samba como servidor miembro del dominio AD”.
Recursos adicionales
-
Consulte la descripción del parámetro
securityen la página de manualsmb.conf(5).
3.1.3. Escenarios cuando los servicios de Samba y las utilidades de cliente de Samba cargan y recargan su configuración
A continuación se describe cuándo los servicios y utilidades de Samba cargan y recargan su configuración:
Los servicios de Samba recargan su configuración:
- Automáticamente cada 3 minutos
-
A petición manual, por ejemplo, cuando se ejecuta el comando
smbcontrol all reload-config.
- Las utilidades de los clientes de Samba leen su configuración sólo cuando usted las inicia.
Tenga en cuenta que ciertos parámetros, como security, requieren un reinicio del servicio smb para que surta efecto y no basta con una recarga.
Recursos adicionales
-
La sección
How configuration changes are applieden la página mansmb.conf(5) -
Las páginas de manual
smbd(8),nmbd(8), ywinbindd(8)
3.1.4. Editar la configuración de Samba de forma guardada
Los servicios Samba recargan automáticamente su configuración cada 3 minutos. Este procedimiento describe cómo editar la configuración de Samba de forma que se evite que los servicios recarguen los cambios antes de que usted haya verificado la configuración mediante la utilidad testparm.
Requisitos previos
- Samba está instalado.
Procedimiento
Cree una copia del archivo
/etc/samba/smb.conf:#
cp /etc/samba/smb.conf /etc/samba/samba.conf.copy- Edite el archivo copiado y realice los cambios deseados.
Verifique la configuración en el
/etc/samba/samba.conf.copyarchivo:#
testparm -s /etc/samba/samba.conf.copySi
testparminforma de errores, arréglelos y vuelva a ejecutar el comando.Anule el archivo
/etc/samba/smb.confcon la nueva configuración:#
mv /etc/samba/samba.conf.copy /etc/samba/smb.confEspere a que los servicios Samba recarguen automáticamente su configuración o recargue manualmente la configuración:
#
smbcontrol all reload-config
3.2. Verificación de la configuración de Samba
Red Hat recomienda que verifique la configuración de Samba cada vez que actualice el archivo /etc/samba/smb.conf. Esta sección proporciona detalles al respecto.
3.2.1. Verificación del archivo smb.conf mediante la utilidad testparm
La utilidad testparm verifica que la configuración de Samba en el archivo /etc/samba/smb.conf es correcta. La utilidad detecta parámetros y valores no válidos, pero también configuraciones incorrectas, como por ejemplo para el mapeo de ID. Si testparm no informa de ningún problema, los servicios Samba cargarán con éxito el archivo /etc/samba/smb.conf. Tenga en cuenta que testparm no puede verificar que los servicios configurados estarán disponibles o funcionarán como se espera.
Red Hat recomienda verificar el archivo /etc/samba/smb.conf utilizando testparm después de cada modificación de este archivo.
Requisitos previos
- Has instalado Samba.
-
El archivo
/etc/samba/smb.confsale.
Procedimiento
Ejecute la utilidad
testparmcomo el usuarioroot:#
testparmLoad smb config files from /etc/samba/smb.conf rlimit_max: increasing rlimit_max (1024) to minimum Windows limit (16384) Unknown parameter encountered: "log levell" Processing section "[example_share]" Loaded services file OK. ERROR: The idmap range for the domain * (tdb) overlaps with the range of DOMAIN (ad)! Server role: ROLE_DOMAIN_MEMBER Press enter to see a dump of your service definitions # Global parameters [global] ... [example_share] ...La salida del ejemplo anterior informa de un parámetro inexistente y de una configuración incorrecta del mapeo de ID.
-
Si
testparminforma de parámetros o valores incorrectos, o de otros errores en la configuración, solucione el problema y vuelva a ejecutar la utilidad.
3.3. Configuración de Samba como servidor independiente
Puede configurar Samba como un servidor que no es miembro de un dominio. En este modo de instalación, Samba autentifica a los usuarios en una base de datos local en lugar de en un DC central. Además, puede habilitar el acceso de invitados para permitir que los usuarios se conecten a uno o varios servicios sin autenticación.
3.3.1. Establecimiento de la configuración del servidor independiente
Esta sección describe cómo establecer la configuración del servidor para un servidor autónomo Samba.
Procedimiento
Instale el paquete
samba:#
yum install sambaEdite el archivo
/etc/samba/smb.confy establezca los siguientes parámetros:[global] workgroup = Example-WG netbios name = Server security = user log file = /var/log/samba/%m.log log level = 1
Esta configuración define un servidor independiente llamado
Serverdentro del grupo de trabajoExample-WG. Además, esta configuración permite el registro en un nivel mínimo (1) y los archivos de registro se almacenarán en el directorio/var/log/samba/. Samba expandirá la macro%men el parámetrolog fileal nombre NetBIOS de los clientes conectados. Esto permite archivos de registro individuales para cada cliente.Opcionalmente, configure el uso compartido de archivos o impresoras. Ver:
Verifique el archivo
/etc/samba/smb.conf:#
testparmSi configura recursos compartidos que requieren autenticación, cree las cuentas de usuario.
Para más detalles, consulte Sección 3.3.2, “Creación y habilitación de cuentas de usuario locales”.
Abra los puertos necesarios y recargue la configuración del cortafuegos mediante la utilidad
firewall-cmd:#
firewall-cmd --permanent --add-port={139/tcp,445/tcp}#firewall-cmd --reloadHabilite e inicie el servicio
smb:#
systemctl enable --now smb
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el procedimiento, consulte las descripciones de los parámetros en la página man
smb.conf(5).
3.3.2. Creación y habilitación de cuentas de usuario locales
Para permitir que los usuarios se autentiquen cuando se conectan a un recurso compartido, debe crear las cuentas en el host Samba tanto en el sistema operativo como en la base de datos de Samba. Samba requiere la cuenta del sistema operativo para validar las listas de control de acceso (ACL) en los objetos del sistema de archivos y la cuenta de Samba para autenticar a los usuarios que se conectan.
Si utiliza la configuración por defecto passdb backend = tdbsam, Samba almacena las cuentas de usuario en la base de datos /var/lib/samba/private/passdb.tdb.
El procedimiento de esta sección describe cómo crear un usuario local de Samba llamado example.
Requisitos previos
- Samba se instala configurado como un servidor independiente.
Procedimiento
Crear la cuenta del sistema operativo:
#
useradd -M -s /sbin/nologin exampleEste comando añade la cuenta
examplesin crear un directorio de inicio. Si la cuenta sólo se utiliza para autenticarse en Samba, asigne el comando/sbin/nologincomo shell para evitar que la cuenta se registre localmente.Establezca una contraseña a la cuenta del sistema operativo para habilitarla:
#
passwd exampleEnter new UNIX password:passwordRetype new UNIX password:passwordpasswd: password updated successfullySamba no utiliza la contraseña establecida en la cuenta del sistema operativo para autenticarse. Sin embargo, es necesario establecer una contraseña para habilitar la cuenta. Si una cuenta está deshabilitada, Samba deniega el acceso si este usuario se conecta.
Añade el usuario a la base de datos Samba y establece una contraseña para la cuenta:
#
smbpasswd -a exampleNew SMB password:passwordRetype new SMB password:passwordAdded user example.Utilice esta contraseña para autenticarse cuando utilice esta cuenta para conectarse a un recurso compartido de Samba.
Habilitar la cuenta Samba:
#
smbpasswd -e exampleEnabled user example.
3.4. Comprender y configurar la asignación de ID de Samba
Los dominios de Windows distinguen a los usuarios y grupos mediante identificadores de seguridad (SID) únicos. Sin embargo, Linux requiere UIDs y GIDs únicos para cada usuario y grupo. Si ejecuta Samba como miembro de un dominio, el servicio winbindd es responsable de proporcionar información sobre los usuarios y grupos del dominio al sistema operativo.
Para que el servicio winbindd proporcione a Linux identificadores únicos para usuarios y grupos, debe configurar la asignación de identificadores en el archivo /etc/samba/smb.conf para:
- La base de datos local (dominio por defecto)
- El dominio AD o NT4 del que es miembro el servidor Samba
- Cada dominio de confianza desde el que los usuarios deben poder acceder a los recursos de este servidor Samba
Samba proporciona diferentes back ends de mapeo de ID para configuraciones específicas. Los back ends más utilizados son:
| Parte trasera | Caso de uso |
|---|---|
|
|
El dominio por defecto |
|
| Sólo dominios AD |
|
| Dominios AD y NT4 |
|
|
AD, NT4 y el dominio por defecto |
3.4.1. Planificación de rangos de ID de Samba
Independientemente de si almacena los UIDs y GIDs de Linux en AD o si configura Samba para generarlos, cada configuración de dominio requiere un rango de IDs único que no debe solaparse con ninguno de los otros dominios.
Si se establecen rangos de ID que se solapan, Samba no funciona correctamente.
Ejemplo 3.1. Rangos de identificación únicos
A continuación se muestran los rangos de asignación de ID no superpuestos para los dominios por defecto (*), AD-DOM, y el TRUST-DOM.
[global] ... idmap config * : backend = tdb idmap config * : range = 10000-999999 idmap config AD-DOM:backend = rid idmap config AD-DOM:range = 2000000-2999999 idmap config TRUST-DOM:backend = rid idmap config TRUST-DOM:range = 4000000-4999999
Sólo puede asignar un rango por dominio. Por lo tanto, deje suficiente espacio entre los rangos de los dominios. Esto le permite ampliar el rango más adelante si su dominio crece.
Si más adelante asigna un rango diferente a un dominio, se perderá la propiedad de los archivos y directorios creados previamente por estos usuarios y grupos.
3.4.2. The * default domain
En un entorno de dominio, se añade una configuración de asignación de ID para cada uno de los siguientes elementos:
- El dominio al que pertenece el servidor Samba
- Cada dominio de confianza que debe poder acceder al servidor Samba
Sin embargo, para todos los demás objetos, Samba asigna IDs del dominio por defecto. Esto incluye:
- Usuarios y grupos locales de Samba
-
Cuentas y grupos incorporados a Samba, como
BUILTIN\Administrators
Debe configurar el dominio por defecto como se describe en esta sección para que Samba funcione correctamente.
El back end del dominio por defecto debe ser escribible para almacenar permanentemente los IDs asignados.
Para el dominio por defecto, puede utilizar uno de los siguientes back ends:
tdbCuando configure el dominio por defecto para utilizar el back end
tdb, establezca un rango de ID lo suficientemente grande como para incluir los objetos que se crearán en el futuro y que no forman parte de una configuración de asignación de ID de dominio definida.Por ejemplo, establezca lo siguiente en la sección
[global]del archivo/etc/samba/smb.conf:idmap config * : backend = tdb idmap config * : range = 10000-999999
Para más detalles, consulte Sección 3.4.3, “Utilizar el back end de mapeo de ID de tdb”.
autoridCuando se configura el dominio por defecto para utilizar el back end
autorid, añadir configuraciones adicionales de mapeo de ID para los dominios es opcional.Por ejemplo, establezca lo siguiente en la sección
[global]del archivo/etc/samba/smb.conf:idmap config * : backend = autorid idmap config * : range = 10000-999999
Para más detalles, consulte Sección 3.4.6, “Utilizar el back end de mapeo de autorid ID”.
3.4.3. Utilizar el back end de mapeo de ID de tdb
El servicio winbindd utiliza por defecto el back-end de mapeo de ID de escritura tdb para almacenar las tablas de mapeo de Identificador de Seguridad (SID), UID y GID. Esto incluye a los usuarios locales, los grupos y los directores incorporados.
Utilice este back end sólo para el dominio por defecto *. Por ejemplo:
idmap config * : backend = tdb idmap config * : range = 10000-999999
Recursos adicionales
3.4.4. Utilización del back end de mapeo de ID de anuncios
Esta sección describe cómo configurar un miembro de Samba AD para utilizar el back end de mapeo de IDs ad.
El back end de mapeo de ID de ad implementa una API de sólo lectura para leer la información de cuentas y grupos de AD. Esto proporciona los siguientes beneficios:
- Todas las configuraciones de usuarios y grupos se almacenan de forma centralizada en AD.
- Los ID de usuario y grupo son consistentes en todos los servidores Samba que utilizan este back end.
- Las identificaciones no se almacenan en una base de datos local que pueda corromperse, y por lo tanto no se pueden perder las titularidades de los archivos.
El back-end de asignación de ID ad no es compatible con los dominios de Active Directory con confianzas unidireccionales. Si configura un miembro del dominio en un Directorio Activo con confianzas unidireccionales, utilice en su lugar uno de los siguientes back-ends de asignación de ID: tdb, rid, o autorid.
El back end del anuncio lee los siguientes atributos del AD:
| Nombre del atributo AD | Tipo de objeto | Asignado a |
|---|---|---|
|
| Usuario y grupo | Nombre de usuario o de grupo, según el objeto |
|
| Usuario | ID de usuario (UID) |
|
| Grupo | ID de grupo (GID) |
|
| Usuario | Ruta de acceso al shell del usuario |
|
| Usuario | Ruta de acceso al directorio principal del usuario |
|
| Usuario | ID del grupo primario |
[a]
Samba sólo lee este atributo si se establece idmap config DOMAIN:unix_nss_info = yes.
[b]
Samba sólo lee este atributo si se establece idmap config DOMAIN:unix_primary_group = yes.
| ||
Requisitos previos
-
Tanto los usuarios como los grupos deben tener IDs únicos establecidos en AD, y los IDs deben estar dentro del rango configurado en el archivo
/etc/samba/smb.conf. Los objetos cuyos IDs estén fuera del rango no estarán disponibles en el servidor Samba. - Los usuarios y grupos deben tener todos los atributos requeridos en AD. Si faltan los atributos requeridos, el usuario o grupo no estará disponible en el servidor Samba. Los atributos requeridos dependen de su configuración. Requisitos previos
- Has instalado Samba.
-
La configuración de Samba, excepto la asignación de ID, existe en el archivo
/etc/samba/smb.conf.
Procedimiento
Edite la sección
[global]en el archivo/etc/samba/smb.conf:Añada una configuración de asignación de ID para el dominio por defecto (
*) si no existe. Por ejemplo:idmap config * : backend = tdb idmap config * : range = 10000-999999Habilite el back end de asignación de ID de
adpara el dominio de AD:idmap config DOMAIN: backend = adEstablezca el rango de IDs que se asigna a los usuarios y grupos en el dominio AD. Por ejemplo:
idmap config DOMAIN: rango = 2000000-2999999
ImportanteEl rango no debe solaparse con ninguna otra configuración de dominio en este servidor. Además, el rango debe ser lo suficientemente grande como para incluir todos los IDs asignados en el futuro. Para más detalles, consulte Sección 3.4.1, “Planificación de rangos de ID de Samba”.
Establezca que Samba utilice el esquema RFC 2307 cuando lea los atributos de AD:
idmap config DOMAIN: schema_mode = rfc2307Para permitir que Samba lea el shell de inicio de sesión y la ruta de acceso al directorio personal de los usuarios desde el atributo AD correspondiente, establezca:
idmap config DOMAIN: unix_nss_info = yesComo alternativa, puede establecer una ruta de directorio principal y un shell de inicio de sesión uniformes para todo el dominio que se apliquen a todos los usuarios. Por ejemplo:
template shell = /bin/bash template homedir = /home/%U
Por defecto, Samba utiliza el atributo
primaryGroupIDde un objeto de usuario como grupo principal del usuario en Linux. Como alternativa, puede configurar Samba para que utilice el valor establecido en el atributogidNumberen su lugar:idmap config DOMAIN: unix_primary_group = yes
Verifique el archivo
/etc/samba/smb.conf:#
testparmRecarga la configuración de Samba:
#
smbcontrol all reload-config
Recursos adicionales
- Sección 3.4.2, “The * default domain”
-
Para más detalles sobre los parámetros utilizados en el procedimiento, consulte las páginas de manual
smb.conf(5)yidmap_ad(8). -
Para más detalles sobre la sustitución de variables, consulte la sección
VARIABLE SUBSTITUTIONSen la página de manualsmb.conf(5).
3.4.5. Utilización del back end de asignación de ID de crestas
Esta sección describe cómo configurar un miembro del dominio Samba para utilizar el back end de mapeo de IDs rid.
Samba puede utilizar el identificador relativo (RID) de un SID de Windows para generar un ID en Red Hat Enterprise Linux.
El RID es la última parte de un SID. Por ejemplo, si el SID de un usuario es S-1-5-21-5421822485-1151247151-421485315-30014, entonces 30014 es el RID correspondiente.
El back end de mapeo de ID de rid implementa una API de sólo lectura para calcular la información de cuentas y grupos basada en un esquema de mapeo algorítmico para dominios AD y NT4. Cuando configure el back end, debe establecer el RID más bajo y el más alto en el idmap config DOMAIN : range parámetro. Samba no mapeará usuarios o grupos con un RID inferior o superior al establecido en este parámetro.
Como back end de sólo lectura, rid no puede asignar nuevos IDs, como por ejemplo para los grupos de BUILTIN. Por lo tanto, no utilice este back end para el dominio por defecto *.
Ventajas de utilizar el back end de rid
- Todos los usuarios y grupos del dominio que tienen un RID dentro del rango configurado están automáticamente disponibles en el miembro del dominio.
- No es necesario asignar manualmente IDs, directorios de inicio y shells de inicio de sesión.
Inconvenientes de utilizar el back end de rid
- Todos los usuarios del dominio tienen asignados el mismo shell de inicio de sesión y el mismo directorio personal. Sin embargo, se pueden utilizar variables.
-
Los ID de usuario y grupo sólo son iguales entre los miembros del dominio Samba si todos utilizan el back end
ridcon la misma configuración de rango de ID. - No se puede excluir a usuarios o grupos individuales de estar disponibles en el miembro del dominio. Sólo se excluyen los usuarios y grupos fuera del rango configurado.
-
Según las fórmulas que utiliza el servicio
winbinddpara calcular los ID, pueden producirse duplicados en entornos multidominio si los objetos de diferentes dominios tienen el mismo RID.
Requisitos previos
- Has instalado Samba.
-
La configuración de Samba, excepto la asignación de ID, existe en el archivo
/etc/samba/smb.conf.
Procedimiento
Edite la sección
[global]en el archivo/etc/samba/smb.conf:Añada una configuración de asignación de ID para el dominio por defecto (
*) si no existe. Por ejemplo:idmap config * : backend = tdb idmap config * : range = 10000-999999Habilite el back end de asignación de ID de
ridpara el dominio:idmap config DOMAIN: backend = ridEstablezca un rango lo suficientemente grande como para incluir todos los RID que se asignarán en el futuro. Por ejemplo:
idmap config DOMAIN: rango = 2000000-2999999
Samba ignora a los usuarios y grupos cuyos RIDs en este dominio no están dentro del rango.
ImportanteEl rango no debe solaparse con ninguna otra configuración de dominio en este servidor. Para más detalles, consulte Sección 3.4.1, “Planificación de rangos de ID de Samba”.
Establezca una ruta de acceso al shell y al directorio principal que se asignará a todos los usuarios asignados. Por ejemplo:
template shell = /bin/bash template homedir = /home/%U
Verifique el archivo
/etc/samba/smb.conf:#
testparmRecarga la configuración de Samba:
#
smbcontrol all reload-configRecursos adicionales
- Sección 3.4.2, “The * default domain”
-
Para más detalles sobre la sustitución de variables, consulte la sección
VARIABLE SUBSTITUTIONSen la página de manualsmb.conf(5). -
Para más detalles sobre cómo Samba calcula el ID local a partir de un RID, consulte la página man
idmap_rid(8).
3.4.6. Utilizar el back end de mapeo de autorid ID
Esta sección describe cómo configurar un miembro del dominio Samba para utilizar el back end de mapeo de IDs autorid.
El back end autorid funciona de forma similar al back end de mapeo de ID rid, pero puede asignar automáticamente IDs para diferentes dominios. Esto le permite utilizar el back end autorid en las siguientes situaciones:
-
Sólo para el dominio por defecto
* -
Para el dominio por defecto
*y los dominios adicionales, sin necesidad de crear configuraciones de asignación de ID para cada uno de los dominios adicionales - Sólo para dominios específicos
Si utiliza autorid para el dominio por defecto, añadir la configuración de asignación de ID adicional para los dominios es opcional.
Partes de esta sección fueron adoptadas de la documentación de idmap config autorid publicada en el Wiki de Samba. Licencia: CC BY 4.0. Autores y colaboradores: Ver la pestaña de historia en la página de la Wiki.
Ventajas de utilizar el back end de autorid
- Todos los usuarios y grupos del dominio cuyo UID y GID calculados están dentro del rango configurado están automáticamente disponibles en el miembro del dominio.
- No es necesario asignar manualmente IDs, directorios de inicio y shells de inicio de sesión.
- No se duplican los ID, aunque varios objetos en un entorno multidominio tengan el mismo RID.
Inconvenientes
- Los ID de usuario y de grupo no son los mismos en todos los miembros del dominio Samba.
- Todos los usuarios del dominio tienen asignados el mismo shell de inicio de sesión y el mismo directorio personal. Sin embargo, se pueden utilizar variables.
- No se puede excluir a usuarios o grupos individuales de estar disponibles en el miembro del dominio. Sólo se excluyen los usuarios y grupos cuyo UID o GID calculado está fuera del rango configurado.
Requisitos previos
- Has instalado Samba.
-
La configuración de Samba, excepto la asignación de ID, existe en el archivo
/etc/samba/smb.conf.
Procedimiento
Edite la sección
[global]en el archivo/etc/samba/smb.conf:Habilite el back end de mapeo de ID de
autoridpara el dominio por defecto*:idmap config * : backend = autorid
Establezca un rango lo suficientemente grande como para asignar IDs para todos los objetos existentes y futuros. Por ejemplo:
idmap config * : range = 10000-999999Samba ignora a los usuarios y grupos cuyos IDs calculados en este dominio no están dentro del rango.
AvisoDespués de establecer el rango y de que Samba comience a utilizarlo, sólo puede aumentar el límite superior del rango. Cualquier otro cambio en el rango puede dar lugar a nuevas asignaciones de ID, y por lo tanto a la pérdida de la propiedad de los archivos.
Opcionalmente, establezca un tamaño de rango. Por ejemplo:
idmap config * : rangesize = 200000Samba assigns this number of continuous IDs for each domain’s object until all IDs from the range set in the
idmap config * : rangeparameter are taken.Establezca una ruta de acceso al shell y al directorio principal que se asignará a todos los usuarios asignados. Por ejemplo:
template shell = /bin/bash template homedir = /home/%U
Opcionalmente, añada una configuración adicional de mapeo de ID para los dominios. Si no hay ninguna configuración para un dominio individual, Samba calcula el ID utilizando la configuración del back-end
autoriden el dominio por defecto previamente configurado*.ImportanteSi se configuran extremos posteriores adicionales para dominios individuales, los rangos para toda la configuración de mapeo de ID no deben superponerse. Para más detalles, consulte Sección 3.4.1, “Planificación de rangos de ID de Samba”.
Verifique el archivo
/etc/samba/smb.conf:#
testparmRecarga la configuración de Samba:
#
smbcontrol all reload-config
Recursos adicionales
-
Para obtener detalles sobre cómo el back end calculó los IDs, consulte la sección
THE MAPPING FORMULASen la página manidmap_autorid(8). -
Para más detalles sobre el uso del parámetro
idmap configrangesize, consulte la descripción del parámetrorangesizeen la página de manualidmap_autorid(8). -
Para más detalles sobre la sustitución de variables, consulte la sección
VARIABLE SUBSTITUTIONSen la página de manualsmb.conf(5).
3.5. Configuración de Samba como servidor miembro del dominio AD
Si está ejecutando un dominio AD o NT4, utilice Samba para añadir su servidor Red Hat Enterprise Linux como miembro del dominio para obtener lo siguiente:
- Acceder a los recursos del dominio en otros miembros del dominio
-
Autenticar a los usuarios del dominio en los servicios locales, como
sshd - Compartir directorios e impresoras alojados en el servidor para actuar como servidor de archivos e impresión
3.5.1. Unir un sistema RHEL a un dominio AD
Esta sección describe cómo unir un sistema Red Hat Enterprise Linux a un dominio AD utilizando realmd para configurar Samba Winbind.
Procedimiento
Si su AD requiere el tipo de cifrado RC4 obsoleto para la autenticación Kerberos, habilite el soporte para estos cifrados en RHEL:
#
update-crypto-policies --set DEFAULT:AD-SUPPORTInstale los siguientes paquetes:
#
yum install realmd oddjob-mkhomedir oddjob samba-winbind-clients \ samba-winbind samba-common-tools samba-winbind-krb5-locatorPara compartir directorios o impresoras en el miembro del dominio, instale el paquete
samba:#
yum install sambaRealice una copia de seguridad del archivo de configuración de Samba existente en
/etc/samba/smb.conf:#
mv /etc/samba/smb.conf /etc/samba/smb.conf.bakÚnase al dominio. Por ejemplo, para unirse a un dominio llamado
ad.example.com:#
realm join --membership-software=samba --client-software=winbind ad.example.comUtilizando el comando anterior, la utilidad
realmautomáticamente:-
Crea un archivo
/etc/samba/smb.confpara un miembro del dominioad.example.com -
Añade el módulo
winbindpara la búsqueda de usuarios y grupos en el archivo/etc/nsswitch.conf -
Actualiza los archivos de configuración del Pluggable Authentication Module (PAM) en el directorio
/etc/pam.d/ -
Inicia el servicio
winbindy permite que el servicio se inicie al arrancar el sistema
-
Crea un archivo
-
Opcionalmente, establezca un back end de mapeo de ID alternativo o ajustes de mapeo de ID personalizados en el archivo
/etc/samba/smb.conf. Para más detalles, consulte Sección 3.4, “Comprender y configurar la asignación de ID de Samba”. Compruebe que el servicio
winbindestá en funcionamiento:#
systemctl status winbind... Active: active (running) since Tue 2018-11-06 19:10:40 CET; 15s agoImportantePara que Samba pueda consultar la información de los usuarios y grupos del dominio, el servicio
winbinddebe estar funcionando antes de iniciarsmb.Si ha instalado el paquete
sambapara compartir directorios e impresoras, active e inicie el serviciosmb:#
systemctl enable --now smb-
Opcionalmente, si está autenticando inicios de sesión locales en Active Directory, habilite el complemento
winbind_krb5_localauth. Véase Sección 3.5.2, “Uso del complemento de autorización local para MIT Kerberos”.
Pasos de verificación
Muestra los detalles de un usuario AD, como la cuenta de administrador AD en el dominio AD:
#
getent passwd "AD\administrator"AD\administrator:*:10000:10000::/home/administrator@AD:/bin/bashConsultar los miembros del grupo de usuarios del dominio en el dominio AD:
#
getent group "AD\Domain Users"AD\domain users:x:10000:user1,user2Opcionalmente, verifique que puede utilizar los usuarios y grupos del dominio cuando establezca los permisos de los archivos y directorios. Por ejemplo, para establecer el propietario del archivo
/srv/samba/example.txtcomoAD\administratory el grupo comoAD\Domain Users:#
chown "AD\administrator":"AD\Domain Users" /srv/samba/example.txtVerifique que la autenticación Kerberos funciona como se espera:
En el miembro del dominio AD, obtenga un ticket para la entidad de crédito
administrator@AD.EXAMPLE.COM:#
kinit administrator@AD.EXAMPLE.COMMuestra el ticket de Kerberos en caché:
#
klistTicket cache: KCM:0 Default principal: administrator@AD.EXAMPLE.COM Valid starting Expires Service principal 01.11.2018 10:00:00 01.11.2018 20:00:00 krbtgt/AD.EXAMPLE.COM@AD.EXAMPLE.COM renew until 08.11.2018 05:00:00
Muestra los dominios disponibles:
#
wbinfo --all-domainsBUILTIN SAMBA-SERVER AD
Recursos adicionales
- Si no desea utilizar los cifrados RC4 obsoletos, puede activar el tipo de cifrado AES en AD. Consulte Sección 3.6.2, “Habilitación del tipo de cifrado AES en Active Directory mediante un GPO”. Tenga en cuenta que esto puede tener un impacto en otros servicios de su AD.
-
Para más detalles sobre la utilidad
realm, consulte la página de manualrealm(8).
3.5.2. Uso del complemento de autorización local para MIT Kerberos
El servicio winbind proporciona usuarios de Active Directory al miembro del dominio. En determinadas situaciones, los administradores desean permitir que los usuarios del dominio se autentiquen en servicios locales, como un servidor SSH, que se ejecutan en el miembro del dominio. Si utiliza Kerberos para autenticar a los usuarios del dominio, habilite el complemento winbind_krb5_localauth para asignar correctamente los principales de Kerberos a las cuentas de Active Directory a través del servicio winbind.
Por ejemplo, si el atributo sAMAccountName de un usuario de Active Directory está configurado como EXAMPLE y el usuario intenta iniciar sesión con el nombre de usuario en minúsculas, Kerberos devuelve el nombre de usuario en mayúsculas. Como consecuencia, las entradas no coinciden y la autenticación falla.
Utilizando el complemento winbind_krb5_localauth, los nombres de las cuentas se asignan correctamente. Tenga en cuenta que esto sólo se aplica a la autenticación GSSAPI y no para obtener el ticket inicial de concesión (TGT).
Requisitos previos
- Samba está configurado como miembro de un Directorio Activo.
- Red Hat Enterprise Linux autentifica los intentos de inicio de sesión contra Active Directory.
-
El servicio
winbindestá funcionando.
Procedimiento
Edite el archivo /etc/krb5.conf y añada la siguiente sección:
[plugins]
localauth = {
module = winbind:/usr/lib64/samba/krb5/winbind_krb5_localauth.so
enable_only = winbind
}Recursos adicionales
-
Consulte la página de manual
winbind_krb5_localauth(8).
3.6. Configuración de Samba en un miembro del dominio IdM
Esta sección describe cómo configurar Samba en un host que está unido a un dominio de Red Hat Identity Management (IdM). Los usuarios de IdM y también, si están disponibles, de los dominios de confianza de Active Directory (AD), pueden acceder a los recursos compartidos y a los servicios de impresión proporcionados por Samba.
El uso de Samba en un miembro del dominio IdM es una característica de Technology Preview no soportada y contiene ciertas limitaciones. Por ejemplo, debido a que los controladores de confianza de IdM no admiten el servicio de catálogo global, los hosts de Windows inscritos en AD no pueden encontrar usuarios y grupos de IdM en Windows. Además, los controladores de confianza de IdM no admiten la resolución de grupos de IdM mediante los protocolos Distributed Computing Environment / Remote Procedure Calls (DCE/RPC). Como consecuencia, los usuarios de AD sólo pueden acceder a los recursos compartidos e impresoras de Samba desde los clientes de IdM.
Se anima a los clientes que despliegan Samba en los miembros del dominio IdM a que proporcionen sus comentarios a Red Hat.
Requisitos previos
- El host se une como cliente al dominio IdM.
- Tanto los servidores de IdM como el cliente deben ejecutarse en RHEL 8.1 o posterior.
3.6.1. Preparación del dominio IdM para instalar Samba en los miembros del dominio
Antes de establecer una confianza con AD y si desea configurar Samba en un cliente IdM, debe preparar el dominio IdM mediante la utilidad ipa-adtrust-install en un servidor IdM. Sin embargo, aunque se den ambas situaciones, debe ejecutar ipa-adtrust-install sólo una vez en un maestro de IdM.
Requisitos previos
- El IdM está instalado.
Procedimiento
Instale los paquetes necesarios:
[root@ipaserver ~]#
yum install ipa-server ipa-server-trust-ad samba-clientAutenticarse como usuario administrativo de IdM:
[root@ipaserver ~]#
kinit adminEjecute la utilidad
ipa-adtrust-install:[root@ipaserver ~]#
ipa-adtrust-installLos registros de servicio DNS se crean automáticamente si IdM se ha instalado con un servidor DNS integrado.
Si IdM se instaló sin un servidor DNS integrado,
ipa-adtrust-installimprime una lista de registros de servicio que deben añadirse manualmente al DNS antes de poder continuar.El script le indica que el
/etc/samba/smb.confya existe y será reescrito:WARNING: The smb.conf already exists. Running ipa-adtrust-install will break your existing Samba configuration. Do you wish to continue? [no]:
yesEl script le pide que configure el complemento
slapi-nis, un complemento de compatibilidad que permite a los clientes de Linux más antiguos trabajar con usuarios de confianza:Do you want to enable support for trusted domains in Schema Compatibility plugin? This will allow clients older than SSSD 1.9 and non-Linux clients to work with trusted users. Enable trusted domains support in slapi-nis? [no]:
yesCuando se le solicite, introduzca el nombre NetBIOS del dominio IdM o pulse Enter para aceptar el nombre propuesto:
Trust is configured but no NetBIOS domain name found, setting it now. Enter the NetBIOS name for the IPA domain. Only up to 15 uppercase ASCII letters, digits and dashes are allowed. Example: EXAMPLE. NetBIOS domain name [IDM]:
Se le pide que ejecute la tarea de generación de SID para crear un SID para cualquier usuario existente:
¿Desea ejecutar la tarea ipa-sidgen? [no]
yesCuando el directorio se instala por primera vez, existe al menos un usuario (el administrador de IdM) y como esta es una tarea que consume muchos recursos, si tienes un número elevado de usuarios, puedes ejecutarla en otro momento.
(Optional) Por defecto, el rango de puertos RPC dinámicos está definido como
49152-65535para Windows Server 2008 y posteriores. Si necesita definir un rango de puertos RPC dinámicos diferente para su entorno, configure Samba para utilizar puertos diferentes y abra esos puertos en la configuración de su cortafuegos. El siguiente ejemplo establece el rango de puertos en55000-65000.[root@ipaserver ~]#
net conf setparm global 'rpc server dynamic port range' 55000-65000[root@ipaserver ~]#firewall-cmd --add-port=55000-65000/tcp[root@ipaserver ~]#firewall-cmd --runtime-to-permanentReinicie el servicio
ipa:[root@ipaserver ~]#
ipactl restartUtilice la utilidad
smbclientpara verificar que Samba responde a la autenticación Kerberos desde el lado de IdM:[root@ipaserver ~]#
smbclient -L server.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- IPC$ IPC IPC Service (Samba 4.12.3) ...
3.6.2. Habilitación del tipo de cifrado AES en Active Directory mediante un GPO
Esta sección describe cómo habilitar el tipo de cifrado AES en Active Directory (AD) mediante un objeto de política de grupo (GPO). Algunas características de RHEL 8, como la ejecución de un servidor Samba en un cliente IdM, requieren este tipo de cifrado.
Tenga en cuenta que RHEL 8 no soporta los tipos de cifrado débil DES y RC4.
Requisitos previos
- Usted está conectado a AD como un usuario que puede editar las políticas de grupo.
-
El
Group Policy Management Consoleestá instalado en el ordenador.
Procedimiento
-
Abra la página web
Group Policy Management Console. -
Haga clic con el botón derecho del ratón en
Default Domain Policy, y seleccioneEdit. Se abre la páginaGroup Policy Management Editor. -
Navegue hasta
Computer Configuration→Policies→Windows Settings→Security Settings→Local Policies→Security Options. -
Haga doble clic en la política
Network security: Configure encryption types allowed for Kerberos. -
Seleccione
AES256_HMAC_SHA1y, opcionalmente,Future encryption types. - Haga clic en .
-
Cierre la página
Group Policy Management Editor. -
Repita los pasos para el
Default Domain Controller Policy. Espere a que los controladores de dominio (DC) de Windows apliquen la política de grupo automáticamente. Como alternativa, para aplicar la GPO manualmente en un DC, introduzca el siguiente comando utilizando una cuenta que tenga permisos de administrador:
C:\N>
gpupdate /force /target:computer
3.6.3. Instalación y configuración de un servidor Samba en un cliente IdM
Esta sección describe cómo instalar y configurar Samba en un cliente inscrito en un dominio IdM.
Requisitos previos
- Tanto los servidores de IdM como el cliente deben ejecutarse en RHEL 8.1 o posterior.
- El dominio IdM se prepara como se describe en Sección 3.6.1, “Preparación del dominio IdM para instalar Samba en los miembros del dominio”.
- Si IdM tiene una confianza configurada con AD, habilite el tipo de cifrado AES para Kerberos. Por ejemplo, utilice un objeto de política de grupo (GPO) para habilitar el tipo de cifrado AES. Para obtener más información, consulte Sección 3.6.2, “Habilitación del tipo de cifrado AES en Active Directory mediante un GPO”.
Procedimiento
Instale el paquete
ipa-client-samba:[root@idm_client]#
yum install ipa-client-sambaUtilice la utilidad
ipa-client-sambapara preparar el cliente y crear una configuración inicial de Samba:[root@idm_client]#
ipa-client-sambaSearching for IPA server... IPA server: DNS discovery Chosen IPA master: idm_server.idm.example.com SMB principal to be created: cifs/idm_client.idm.example.com@IDM.EXAMPLE.COM NetBIOS name to be used: IDM_CLIENT Discovered domains to use: Domain name: idm.example.com NetBIOS name: IDM SID: S-1-5-21-525930803-952335037-206501584 ID range: 212000000 - 212199999 Domain name: ad.example.com NetBIOS name: AD SID: None ID range: 1918400000 - 1918599999 Continue to configure the system with these values? [no]: yes Samba domain member is configured. Please check configuration at /etc/samba/smb.conf and start smb and winbind servicesPor defecto,
ipa-client-sambaañade automáticamente la sección[homes]al archivo/etc/samba/smb.confque comparte dinámicamente el directorio personal de un usuario cuando éste se conecta. Si los usuarios no tienen directorios personales en este servidor, o si no desea compartirlos, elimine las siguientes líneas de/etc/samba/smb.conf:[homes] read only = noCompartir directorios e impresoras. Para más detalles, consulte:
Abra los puertos necesarios para un cliente Samba en el firewall local:
[root@idm_client]#
firewall-cmd --permanent --add-service=samba-client[root@idm_client]#firewall-cmd --reloadHabilite e inicie los servicios
smbywinbind:[root@idm_client]#
systemctl enable --now smb winbind
Pasos de verificación
Ejecute los siguientes pasos de verificación en otro miembro del dominio IdM que tenga instalado el paquete samba-client:
Autenticar y obtener un ticket de Kerberos:
$
kinit example_userEnumerar los recursos compartidos en el servidor Samba utilizando la autenticación Kerberos:
$
smbclient -L idm_client.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.12.3) ...
Recursos adicionales
-
Para obtener detalles sobre los pasos que
ipa-client-sambarealiza durante la configuración, consulte la página de manualipa-client-samba(1).
3.6.4. Añadir manualmente una configuración de asignación de ID si IdM confía en un nuevo dominio
Samba requiere una configuración de asignación de ID para cada dominio desde el que los usuarios acceden a los recursos. En un servidor Samba existente que se ejecuta en un cliente IdM, debe añadir manualmente una configuración de asignación de ID después de que el administrador haya añadido una nueva confianza a un dominio de Active Directory (AD).
Requisitos previos
- Has configurado Samba en un cliente IdM. Después, se añadió una nueva confianza a IdM.
- Los tipos de cifrado DES y RC4 para Kerberos deben estar desactivados en el dominio AD de confianza. Por razones de seguridad, RHEL 8 no admite estos tipos de cifrado débil.
Procedimiento
Autenticar usando el keytab del host:
[root@idm_client]#
kinit -kUtilice el comando
ipa idrange-findpara mostrar tanto el ID base como el tamaño del rango de ID del nuevo dominio. Por ejemplo, el siguiente comando muestra los valores del dominioad.example.com:[root@idm_client]#
ipa idrange-find --name="AD.EXAMPLE.COM_id_range" --raw--------------- 1 range matched --------------- cn: AD.EXAMPLE.COM_id_range ipabaseid: 1918400000 ipaidrangesize: 200000 ipabaserid: 0 ipanttrusteddomainsid: S-1-5-21-968346183-862388825-1738313271 iparangetype: ipa-ad-trust ---------------------------- Number of entries returned 1 ----------------------------Los valores de los atributos
ipabaseidyipaidrangesizeson necesarios en los siguientes pasos.Para calcular el ID utilizable más alto, utilice la siguiente fórmula:
rango_máximo = ipabaseid ipaidrangesize - 1
Con los valores del paso anterior, el mayor ID utilizable para el dominio
ad.example.comes1918599999(1918400000 200000 - 1).Edite el archivo
/etc/samba/smb.confy añada la configuración de la asignación de ID para el dominio en la sección[global]:idmap config AD : range = 1918400000 - 1918599999 idmap config AD : backend = sss
Especifique el valor del atributo
ipabaseidcomo el más bajo y el valor calculado del paso anterior como el valor más alto del rango.Reinicie los servicios
smbywinbind:[root@idm_client]#
systemctl restart smb winbind
Pasos de verificación
Autentifíquese como usuario del nuevo dominio y obtenga un ticket Kerberos:
$
kinit example_userEnumerar los recursos compartidos en el servidor Samba utilizando la autenticación Kerberos:
$
smbclient -L idm_client.idm.example.com -klp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.12.3) ...
3.6.5. Recursos adicionales
-
Para obtener más detalles sobre cómo unir RHEL 8 a un dominio IdM, consulte la sección
Installing an Identity Management clientsección de la guíaInstalling Identity Management.
3.13. Configuración de Samba para clientes de macOS
El módulo Samba del sistema de archivos virtual (VFS) fruit proporciona una mayor compatibilidad con los clientes de bloque de mensajes de servidor (SMB) de Apple.
3.15. Configuración de Samba como servidor de impresión
Si configura Samba como servidor de impresión, los clientes de su red pueden utilizar Samba para imprimir. Además, los clientes de Windows pueden, si están configurados, descargar el controlador desde el servidor Samba.
Partes de esta sección han sido adoptadas de la documentación de Configuración de Samba como servidor de impresión publicada en el Wiki de Samba. Licencia: CC BY 4.0. Autores y colaboradores: Ver la pestaña de historia en la página de la Wiki.
Requisitos previos
Samba se ha configurado en uno de los siguientes modos:
3.15.1. El servicio Samba spoolssd
El servicio Samba spoolssd está integrado en el servicio smbd. Habilite spoolssd en la configuración de Samba para aumentar significativamente el rendimiento en los servidores de impresión con un elevado número de trabajos o impresoras.
Sin spoolssd, Samba bifurca el proceso smbd e inicializa la caché printcap para cada trabajo de impresión. En el caso de un gran número de impresoras, el servicio smbd puede dejar de responder durante varios segundos mientras se inicializa la caché. El servicio spoolssd permite iniciar procesos smbd preforkados que están procesando trabajos de impresión sin ningún retraso. El proceso principal spoolssd smbd utiliza una cantidad baja de memoria, y bifurca y termina los procesos hijos.
El siguiente procedimiento explica cómo activar el servicio spoolssd.
Procedimiento
Edite la sección
[global]en el archivo/etc/samba/smb.conf:Añade los siguientes parámetros:
rpc_server:spoolss = external rpc_daemon:spoolssd = fork
Opcionalmente, puede establecer los siguientes parámetros:
Parámetro Por defecto Descripción spoolssd:prefork_min_children5
Número mínimo de procesos hijos
spoolssd:prefork_max_children25
Número máximo de procesos hijos
spoolssd:prefork_spawn_rate5
Samba bifurca el número de nuevos procesos hijos establecidos en este parámetro, hasta el valor establecido en
spoolssd:prefork_max_children, si se establece una nueva conexiónspoolssd:prefork_max_allowed_clients100
Número de clientes a los que sirve un proceso infantil
spoolssd:prefork_child_min_life60
Duración mínima de un proceso hijo en segundos. 60 segundos es el mínimo.
Verifique el archivo
/etc/samba/smb.conf:#
testparmReinicie el servicio
smb:#
systemctl restart smbDespués de reiniciar el servicio, Samba inicia automáticamente los procesos hijos de
smbd:#
ps axf... 30903 smbd 30912 \_ smbd 30913 \_ smbd 30914 \_ smbd 30915 \_ smbd ...
3.15.2. Activación del soporte del servidor de impresión en Samba
Esta sección explica cómo habilitar el soporte del servidor de impresión en Samba.
Procedimiento
En el servidor Samba, configure CUPS y añada la impresora al back end de CUPS. Para más detalles sobre la configuración de impresoras en CUPS; consulte la documentación proporcionada en la consola web de CUPS (https://print_server_host_name:631/help) en el servidor de impresión.
NotaSamba sólo puede reenviar los trabajos de impresión a CUPS si éste está instalado localmente en el servidor de impresión Samba.
Edite el archivo
/etc/samba/smb.conf:Si desea activar el servicio
spoolssd, añada los siguientes parámetros a la sección[global]:rpc_server:spoolss = external rpc_daemon:spoolssd = fork
Para configurar el back end de impresión, añada la sección
[printers]:[printers] comment = All Printers path = /var/tmp/ printable = yes create mask = 0600ImportanteEl nombre de la acción de
[printers]está codificado y no se puede cambiar.
Verifique el archivo
/etc/samba/smb.conf:#
testparmAbra los puertos necesarios y recargue la configuración del cortafuegos mediante la utilidad
firewall-cmd:#
firewall-cmd --permanent --add-service=samba#firewall-cmd --reloadReinicie el servicio
smb:#
systemctl restart smb
Después de reiniciar el servicio, Samba comparte automáticamente todas las impresoras que están configuradas en el back-end de CUPS. Si desea compartir manualmente sólo impresoras específicas, consulte Sección 3.15.3, “Compartir manualmente impresoras específicas”.
3.15.3. Compartir manualmente impresoras específicas
Si ha configurado Samba como servidor de impresión, por defecto, Samba comparte todas las impresoras que están configuradas en el back-end de CUPS. El siguiente procedimiento explica cómo compartir sólo impresoras específicas.
Requisitos previos
- Samba está configurado como servidor de impresión
Procedimiento
Edite el archivo
/etc/samba/smb.conf:En la sección
[global], desactive el uso compartido automático de la impresora mediante la configuración:cargar impresoras = no
Añade una sección para cada impresora que quieras compartir. Por ejemplo, para compartir la impresora llamada
exampleen el back end de CUPS comoExample-Printeren Samba, añada la siguiente sección:[Example-Printer] path = /var/tmp/ printable = yes printer name = exampleNo necesita directorios de spool individuales para cada impresora. Puede establecer el mismo directorio de spool en el parámetro
pathpara la impresora que estableció en la sección[printers].
Verifique el archivo
/etc/samba/smb.conf:#
testparmRecarga la configuración de Samba:
#
smbcontrol all reload-config
3.16. Configuración de descargas automáticas de controladores de impresora para clientes de Windows en servidores de impresión Samba
Si está ejecutando un servidor de impresión Samba para clientes de Windows, puede cargar los controladores y preconfigurar las impresoras. Si un usuario se conecta a una impresora, Windows descarga e instala automáticamente el controlador de forma local en el cliente. El usuario no necesita permisos de administrador local para la instalación. Además, Windows aplica los ajustes preconfigurados del controlador, como el número de bandejas.
Partes de esta sección fueron adoptadas de la documentación Configuración de la descarga automática de controladores de impresora para clientes de Windows publicada en el Wiki de Samba. Licencia: CC BY 4.0. Autores y colaboradores: Ver la pestaña de historia en la página de la Wiki.
Requisitos previos
- Samba está configurado como servidor de impresión
3.16.1. Información básica sobre los controladores de impresora
Esta sección proporciona información general sobre los controladores de la impresora.
Versión del modelo de controlador compatible
Samba sólo es compatible con el modelo de controlador de impresora versión 3 que se admite en Windows 2000 y posteriores, y Windows Server 2000 y posteriores. Samba no es compatible con la versión 4 del controlador, introducida en Windows 8 y Windows Server 2012. Sin embargo, estas versiones de Windows y las posteriores también son compatibles con los controladores de la versión 3.
Controladores compatibles con los paquetes
Samba no es compatible con los controladores de paquetes.
Preparación de un controlador de impresora para ser cargado
Antes de poder cargar un controlador en un servidor de impresión Samba:
- Descomprimir el controlador si se proporciona en un formato comprimido.
Algunos controladores requieren el inicio de una aplicación de configuración que instala el controlador localmente en un host de Windows. En ciertas situaciones, el instalador extrae los archivos individuales en la carpeta temporal del sistema operativo durante la ejecución de la instalación. Para utilizar los archivos del controlador para la carga:
- Inicie el instalador.
- Copie los archivos de la carpeta temporal a una nueva ubicación.
- Cancelar la instalación.
Pregunte al fabricante de su impresora por los controladores que admiten la carga en un servidor de impresión.
Suministro de controladores de 32 y 64 bits para una impresora a un cliente
Para proporcionar el controlador de una impresora para clientes de Windows de 32 y 64 bits, debe cargar un controlador con exactamente el mismo nombre para ambas arquitecturas. Por ejemplo, si carga el controlador de 32 bits denominado Example PostScript y el de 64 bits denominado Example PostScript (v1.0), los nombres no coinciden. En consecuencia, sólo podrá asignar uno de los controladores a una impresora y el controlador no estará disponible para ambas arquitecturas.
3.16.2. Permitir a los usuarios cargar y preconfigurar los controladores
Para poder cargar y preconfigurar los controladores de impresora, un usuario o un grupo debe tener concedido el privilegio SePrintOperatorPrivilege. Un usuario debe ser agregado al grupo printadmin. Red Hat Enterprise Linux crea automáticamente este grupo cuando se instala el paquete samba. Al grupo printadmin se le asigna el GID de sistema dinámico más bajo disponible que sea inferior a 1000.
Procedimiento
Por ejemplo, para conceder el privilegio
SePrintOperatorPrivilegeal grupoprintadmin:#
net rpc rights grant "printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"Enter DOMAIN\administrator's password: Successfully granted rights.NotaEn un entorno de dominio, conceda
SePrintOperatorPrivilegea un grupo de dominio. Esto le permite gestionar de forma centralizada el privilegio mediante la actualización de la pertenencia a un grupo de usuarios.Para listar todos los usuarios y grupos que tienen
SePrintOperatorPrivilegeconcedido:#
net rpc rights list privileges SePrintOperatorPrivilege -U "DOMAIN\administrator"Enter administrator's password: SePrintOperatorPrivilege: BUILTIN\Administrators DOMAIN\printadmin
3.16.4. Creación de un GPO para que los clientes confíen en el servidor de impresión Samba
Por razones de seguridad, los sistemas operativos Windows más recientes impiden que los clientes descarguen controladores de impresora no compatibles con el paquete desde un servidor no fiable. Si su servidor de impresión es miembro de un AD, puede crear un objeto de directiva de grupo (GPO) en su dominio para confiar en el servidor Samba.
Requisitos previos
- El servidor de impresión Samba es miembro de un dominio AD.
- El ordenador con Windows que utilice para crear el GPO debe tener instaladas las Herramientas de Administración Remota de Servidores de Windows (RSAT). Para más detalles, consulte la documentación de Windows.
Procedimiento
-
Inicie sesión en un equipo Windows con una cuenta que tenga permiso para editar las políticas de grupo, como el usuario del dominio AD
Administrator. -
Abra la página web
Group Policy Management Console. Haga clic con el botón derecho del ratón en su dominio AD y seleccione
Create a GPO in this domain, and Link it here.
-
Introduzca un nombre para el GPO, como
Legacy Printer Driver Policyy haga clic enOK. El nuevo GPO aparecerá bajo la entrada del dominio. -
Haga clic con el botón derecho del ratón en el GPO recién creado y seleccione
Editpara abrir la páginaGroup Policy Management Editor. Navegue hasta → → → .
En la parte derecha de la ventana, haga doble clic en
Point and Print Restrictionpara editar la política:Habilite la política y configure las siguientes opciones:
-
Seleccione
Users can only point and print to these serverse introduzca el nombre de dominio completo (FQDN) del servidor de impresión Samba en el campo situado junto a esta opción. En las dos casillas de
Security Prompts, seleccioneDo not show warning or elevation prompt.
-
Seleccione
- Haga clic en Aceptar.
Haga doble clic en
Package Point and Print - Approved serverspara editar la política:-
Habilite la política y haga clic en el botón
Show. Introduzca el FQDN del servidor de impresión Samba.
-
Cierre tanto la ventana
Show Contentscomo la de propiedades de la política haciendo clic enOK.
-
Habilite la política y haga clic en el botón
-
Cierre la página
Group Policy Management Editor. -
Cierre la página
Group Policy Management Console.
Después de que los miembros del dominio de Windows aplicaran la política de grupo, los controladores de impresora se descargan automáticamente del servidor Samba cuando un usuario se conecta a una impresora.
Recursos adicionales
- Para más detalles sobre el uso de las políticas de grupo, consulte la documentación de Windows.
3.16.5. Carga de controladores y preconfiguración de impresoras
Utilice la aplicación Print Management en un cliente Windows para cargar los controladores y preconfigurar las impresoras alojadas en el servidor de impresión Samba. Para más detalles, consulte la documentación de Windows.
3.17. Ajuste del rendimiento de un servidor Samba
Este capítulo describe qué ajustes pueden mejorar el rendimiento de Samba en ciertas situaciones, y qué ajustes pueden tener un impacto negativo en el rendimiento.
Partes de esta sección han sido adoptadas de la documentación de Performance Tuning publicada en el Wiki de Samba. Licencia: CC BY 4.0. Autores y colaboradores: Ver la pestaña de historia en la página de la Wiki.
Requisitos previos
- Samba se configura como servidor de archivos o de impresión
3.17.1. Configuración de la versión del protocolo SMB
Cada nueva versión de SMB añade funciones y mejora el rendimiento del protocolo. Los recientes sistemas operativos Windows y Windows Server siempre admiten la última versión del protocolo. Si Samba también utiliza la última versión del protocolo, los clientes de Windows que se conectan a Samba se benefician de las mejoras de rendimiento. En Samba, el valor por defecto del protocolo máximo del servidor se establece en la última versión estable del protocolo SMB soportada.
Para tener siempre habilitada la última versión estable del protocolo SMB, no configure el parámetro server max protocol. Si establece el parámetro manualmente, tendrá que modificar la configuración con cada nueva versión del protocolo SMB, para tener habilitada la última versión del protocolo.
El siguiente procedimiento explica cómo utilizar el valor por defecto en el parámetro server max protocol.
Procedimiento
-
Eliminar el parámetro
server max protocolde la sección[global]en el archivo/etc/samba/smb.conf. Recargar la configuración de Samba
#
smbcontrol all reload-config
3.17.3. Ajustes que pueden tener un impacto negativo en el rendimiento
Por defecto, el kernel de Red Hat Enterprise Linux está ajustado para un alto rendimiento de la red. Por ejemplo, el kernel utiliza un mecanismo de auto-ajuste para los tamaños de búfer. El ajuste del parámetro socket options en el archivo /etc/samba/smb.conf anula estos ajustes del kernel. Como resultado, el establecimiento de este parámetro disminuye el rendimiento de la red Samba en la mayoría de los casos.
Para utilizar la configuración optimizada del Kernel, elimine el parámetro socket options de la sección [global] en el sitio web /etc/samba/smb.conf.
3.18. Configurar Samba para que sea compatible con clientes que requieren una versión de SMB inferior a la predeterminada
Samba utiliza un valor razonable y seguro por defecto para la versión mínima de bloque de mensajes de servidor (SMB) que soporta. Sin embargo, si tiene clientes que requieren una versión SMB más antigua, puede configurar Samba para que la soporte.
3.18.1. Establecer la versión mínima del protocolo SMB soportada por un servidor Samba
En Samba, el parámetro server min protocol en el archivo /etc/samba/smb.conf define la versión mínima del protocolo de bloque de mensajes del servidor (SMB) que soporta el servidor Samba. Esta sección describe cómo cambiar la versión mínima del protocolo SMB.
Por defecto, Samba en RHEL 8.2 y posteriores sólo soporta el protocolo SMB2 y versiones más recientes. Red Hat recomienda no utilizar el protocolo obsoleto SMB1. Sin embargo, si su entorno requiere SMB1, puede establecer manualmente el parámetro server min protocol a NT1 para volver a habilitar SMB1.
Requisitos previos
- Samba está instalado y configurado.
Procedimiento
Edite el archivo
/etc/samba/smb.conf, añada el parámetroserver min protocoly establezca el parámetro a la versión mínima del protocolo SMB que el servidor debe soportar. Por ejemplo, para establecer la versión mínima del protocolo SMB enSMB3, añada:protocolo mínimo del servidor = SMB3
Reinicie el servicio
smb:#
systemctl restart smb
Recursos adicionales
-
Para obtener una lista de las versiones de protocolo que puede establecer en el parámetro
server min protocol, consulte la descripción del parámetroserver max protocolen la página de manualsmb.conf(5).
3.19. Utilidades de línea de comandos de Samba de uso frecuente
En este capítulo se describen los comandos más utilizados cuando se trabaja con un servidor Samba.
3.19.1. Uso de los comandos net ads join y net rpc join
Utilizando el subcomando join de la utilidad net, puede unir Samba a un dominio AD o NT4. Para unirse al dominio, debe crear el archivo /etc/samba/smb.conf manualmente y, opcionalmente, actualizar las configuraciones adicionales, como PAM.
Red Hat recomienda utilizar la utilidad realm para unirse a un dominio. La utilidad realm actualiza automáticamente todos los archivos de configuración involucrados.
Procedimiento
Cree manualmente el archivo
/etc/samba/smb.confcon la siguiente configuración:Para un miembro del dominio AD:
[global] workgroup = domain_name security = ads passdb backend = tdbsam realm = AD_REALM
Para un miembro del dominio NT4:
[global] workgroup = domain_name security = user passdb backend = tdbsam
-
Añada una configuración de asignación de ID para el dominio por defecto
*y para el dominio al que desea unirse a la sección[global] en el archivo/etc/samba/smb.conf. Verifique el archivo
/etc/samba/smb.conf:#
testparmÚnase al dominio como administrador del mismo:
Para unirse a un dominio AD:
#
net ads join -U "DOMAIN\administrator"Para unirse a un dominio NT4:
#
net rpc join -U "DOMAIN\administrator"
Añada la fuente
winbinda la entrada de la base de datospasswdygroupen el archivo/etc/nsswitch.conf:passwd: files
winbindgroup: fileswinbindHabilite e inicie el servicio
winbind:#
systemctl enable --now winbindOpcionalmente, configure PAM utilizando la utilidad
authselect.Para más detalles, consulte la página man
authselect(8).Opcionalmente para entornos AD, configure el cliente Kerberos.
Para más detalles, consulte la documentación de su cliente Kerberos.
3.19.2. Uso del comando net rpc rights
En Windows, puede asignar privilegios a cuentas y grupos para realizar operaciones especiales, como establecer ACL en un recurso compartido o cargar controladores de impresora. En un servidor Samba, puede utilizar el comando net rpc rights para gestionar los privilegios.
Los privilegios de la lista se pueden establecer
Para enumerar todos los privilegios disponibles y sus propietarios, utilice el comando net rpc rights list. Por ejemplo:
# net rpc rights list -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
SeMachineAccountPrivilege Add machines to domain
SeTakeOwnershipPrivilege Take ownership of files or other objects
SeBackupPrivilege Back up files and directories
SeRestorePrivilege Restore files and directories
SeRemoteShutdownPrivilege Force shutdown from a remote system
SePrintOperatorPrivilege Manage printers
SeAddUsersPrivilege Add users and groups to the domain
SeDiskOperatorPrivilege Manage disk shares
SeSecurityPrivilege System securityConcesión de privilegios
Para conceder un privilegio a una cuenta o grupo, utilice el comando net rpc rights grant.
Por ejemplo, conceda el privilegio SePrintOperatorPrivilege al grupo DOMAIN\printadmin grupo:
# net rpc rights grant "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
Successfully granted rights.Revocación de privilegios
Para revocar un privilegio de una cuenta o grupo, utilice el comando net rpc rights revoke.
Por ejemplo, para revocar el privilegio SePrintOperatorPrivilege del DOMAIN\printadmin grupo:
# net rpc rights remoke "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator"
Enter DOMAIN\administrator's password:
Successfully revoked rights.3.19.4. Uso del comando net user
El comando net user le permite realizar las siguientes acciones en un DC de AD o un PDC de NT4:
- Lista de todas las cuentas de usuario
- Añadir usuarios
- Eliminar usuarios
Especificar un método de conexión, como ads para dominios AD o rpc para dominios NT4, sólo es necesario cuando se listan cuentas de usuario de dominio. Otros subcomandos relacionados con los usuarios pueden autodetectar el método de conexión.
Pase el parámetro -U user_name al comando para especificar un usuario que esté autorizado a realizar la acción solicitada.
Listado de cuentas de usuario del dominio
Para listar todos los usuarios de un dominio AD:
# net ads user -U "DOMAIN\administrator"Para listar todos los usuarios de un dominio NT4:
# net rpc user -U "DOMAIN\administrator"Añadir una cuenta de usuario al dominio
En un miembro del dominio Samba, puede utilizar el comando net user add para añadir una cuenta de usuario al dominio.
Por ejemplo, añada la cuenta user al dominio:
Añade la cuenta:
#
net user add user password -U "DOMAIN\administrator"User user addedOpcionalmente, utilice el shell de llamada a procedimiento remoto (RPC) para habilitar la cuenta en el DC de AD o en el PDC de NT4. Por ejemplo:
#
net rpc shell -U DOMAIN\administrator -S DC_or_PDC_nameTalking to domain DOMAIN (S-1-5-21-1424831554-512457234-5642315751) net rpc>user edit disabled user: noSet user's disabled flag from [yes] to [no] net rpc>exit
Eliminar una cuenta de usuario del dominio
En un miembro del dominio Samba, puede utilizar el comando net user delete para eliminar una cuenta de usuario del dominio.
Por ejemplo, para eliminar la cuenta user del dominio:
# net user delete user -U "DOMAIN\administrator"
User user deleted3.19.5. Uso de la utilidad rpcclient
La utilidad rpcclient permite ejecutar manualmente las funciones de Microsoft Remote Procedure Call (MS-RPC) del lado del cliente en un servidor SMB local o remoto. Sin embargo, la mayoría de las funciones están integradas en utilidades separadas proporcionadas por Samba. Utilice rpcclient sólo para probar las funciones MS-RPC.
Requisitos previos
-
El paquete
samba-clientestá instalado.
Ejemplos
Por ejemplo, puede utilizar la utilidad rpcclient para:
Gestionar el subsistema de carrete de la impresora (SPOOLSS).
Ejemplo 3.7. Asignación de un controlador a una impresora
#
rpcclient server_name -U "DOMAIN\administrator" -c 'setdriver "printer_name" "driver_name"'Enter DOMAIN\administrators password: Successfully set printer_name to driver driver_name.Recuperar información sobre un servidor SMB.
Ejemplo 3.8. Listado de todos los archivos compartidos e impresoras compartidas
#
rpcclient server_name -U "DOMAIN\administrator" -c 'netshareenum'Enter DOMAIN\administrators password: netname: Example_Share remark: path: C:\srv\samba\example_share\ password: netname: Example_Printer remark: path: C:\var\spool\samba\ password:Realizar acciones mediante el protocolo Security Account Manager Remote (SAMR).
Ejemplo 3.9. Listado de usuarios en un servidor SMB
#
rpcclient server_name -U "DOMAIN\administrator" -c 'enumdomusers'Enter DOMAIN\administrators password: user:[user1] rid:[0x3e8] user:[user2] rid:[0x3e9]Si ejecuta el comando contra un servidor independiente o un miembro del dominio, se enumeran los usuarios de la base de datos local. Si ejecuta el comando contra un DC de AD o un PDC de NT4, se enumeran los usuarios del dominio.
Recursos adicionales
Para obtener una lista completa de los subcomandos admitidos, consulte la sección COMMANDS en la página de manual rpcclient(1).
3.19.6. Uso de la aplicación samba-regedit
Algunos ajustes, como la configuración de las impresoras, se almacenan en el registro del servidor Samba. Puede utilizar la aplicación samba-regedit basada en ncurses para editar el registro de un servidor Samba.
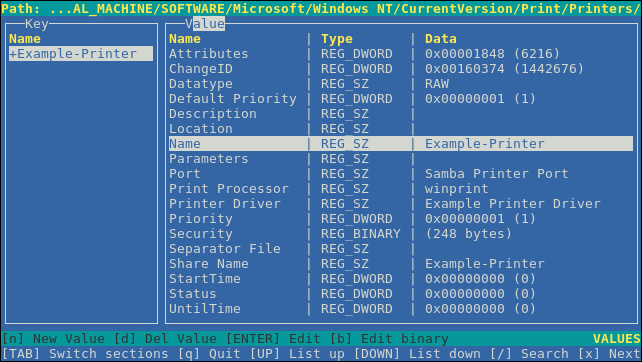
Requisitos previos
-
El paquete
samba-clientestá instalado.
Procedimiento
Para iniciar la aplicación, introduzca:
# samba-regedit
Utilice las siguientes teclas:
- Cursor arriba y cursor abajo: Navegar por el árbol del registro y los valores.
- Introducir: Abre una tecla o edita un valor.
-
Pestaña: Cambia entre el panel
KeyyValue. - Ctrl+C: Cierra la aplicación.
3.19.7. Uso de la utilidad smbcontrol
La utilidad smbcontrol le permite enviar mensajes de control a los servicios smbd, nmbd, winbindd, o a todos ellos. Estos mensajes de control ordenan al servicio, por ejemplo, que recargue su configuración.
El procedimiento de esta sección muestra cómo recargar la configuración de los servicios smbd, nmbd, winbindd enviando el tipo de mensaje reload-config al destino all.
Requisitos previos
-
El paquete
samba-common-toolsestá instalado.
Procedimiento
# smbcontrol all reload-config
Recursos adicionales
Para más detalles y una lista de los tipos de mensajes de comando disponibles, consulte la página de manual smbcontrol(1).
3.19.8. Uso de la utilidad smbpasswd
La utilidad smbpasswd gestiona las cuentas de usuario y las contraseñas en la base de datos local de Samba.
Requisitos previos
-
El paquete
samba-common-toolsestá instalado.
Procedimiento
Si ejecuta el comando como usuario,
smbpasswdcambia la contraseña de Samba del usuario que ejecuta el comando. Por ejemplo:[user@server ~]$
smbpasswdNew SMB password: password Retype new SMB password: passwordSi ejecuta
smbpasswdcomo usuario deroot, puede utilizar la utilidad, por ejemplo, paraCrear un nuevo usuario:
[root@server ~]#
smbpasswd -a user_nameNew SMB password:password` Retype new SMB password: [command]password` Added user user_name.NotaAntes de poder añadir un usuario a la base de datos Samba, debe crear la cuenta en el sistema operativo local. Consulte la sección Añadir un nuevo usuario desde la línea de comandos en la guía Configurar los ajustes básicos del sistema.
Habilitar un usuario de Samba:
[root@server ~]#
smbpasswd -e user_nameEnabled user user_name.Desactivar un usuario de Samba:
[root@server ~]#
smbpasswd -x user_nameDisabled user ser_nameEliminar un usuario:
[root@server ~]#
smbpasswd -x user_nameDeleted user user_name.
Recursos adicionales
Para más detalles, consulte la página de manual smbpasswd(8).
3.19.9. Uso de la utilidad smbstatus
La utilidad smbstatus informa sobre:
-
Conexiones por PID de cada demonio
smbdal servidor Samba. Este informe incluye el nombre de usuario, el grupo principal, la versión del protocolo SMB, el cifrado y la información de firma. -
Conexiones por recurso compartido Samba. Este informe incluye el PID del demonio
smbd, la IP de la máquina que se conecta, la marca de tiempo cuando se estableció la conexión, el cifrado y la información de firma. - Una lista de archivos bloqueados. Las entradas del informe incluyen más detalles, como los tipos de bloqueo oportunista (oplock)
Requisitos previos
-
El paquete
sambaestá instalado. -
El servicio
smbdestá funcionando.
Procedimiento
# smbstatus
Samba version 4.12.3
PID Username Group Machine Protocol Version Encryption Signing
....-------------------------------------------------------------------------------------------------------------------------
963 DOMAIN\administrator DOMAIN\domain users client-pc (ipv4:192.0.2.1:57786) SMB3_02 - AES-128-CMAC
Service pid Machine Connected at Encryption Signing:
....---------------------------------------------------------------------------
example 969 192.0.2.1 Thu Nov 1 10:00:00 2018 CEST - AES-128-CMAC
Locked files:
Pid Uid DenyMode Access R/W Oplock SharePath Name Time
....--------------------------------------------------------------------------------------------------------
969 10000 DENY_WRITE 0x120089 RDONLY LEASE(RWH) /srv/samba/example file.txt Thu Nov 1 10:00:00 2018
Recursos adicionales
Para más detalles, consulte la página de manual smbstatus(1).
3.19.10. Uso de la utilidad smbtar
La utilidad smbtar hace una copia de seguridad del contenido de un recurso compartido SMB o de un subdirectorio del mismo y almacena el contenido en un archivo tar. Como alternativa, puede escribir el contenido en un dispositivo de cinta.
Requisitos previos
-
El paquete
samba-clientestá instalado.
Procedimiento
Utilice el siguiente comando para hacer una copia de seguridad del contenido del directorio
demoen el recurso compartido//server/example/y almacenar el contenido en el archivo/root/example.tar:#
smbtar -s server -x example -u user_name -p password -t /root/example.tar
Recursos adicionales
Para más detalles, consulte la página de manual smbtar(1).
3.19.11. Uso de la utilidad wbinfo
La utilidad wbinfo consulta y devuelve la información creada y utilizada por el servicio winbindd.
Requisitos previos
-
El paquete
samba-winbind-clientsestá instalado.
Procedimiento
Puede utilizar wbinfo, por ejemplo, para:
Lista de usuarios del dominio:
#
wbinfo -uAD\administrator AD\guest ...Lista de grupos de dominios:
#
wbinfo -gAD\domain computers AD\domain admins AD\domain users ...Muestra el SID de un usuario:
#
wbinfo --name-to-sid="AD\administrator"S-1-5-21-1762709870-351891212-3141221786-500 SID_USER (1)Muestra información sobre dominios y fideicomisos:
#
wbinfo --trusted-domains --verboseDomain Name DNS Domain Trust Type Transitive In Out BUILTIN None Yes Yes Yes server None Yes Yes Yes DOMAIN1 domain1.example.com None Yes Yes Yes DOMAIN2 domain2.example.com External No Yes Yes
Recursos adicionales
Para más detalles, consulte la página de manual wbinfo(1).
Capítulo 5. Asegurar NFS
Para minimizar los riesgos de seguridad de NFS y proteger los datos en el servidor, tenga en cuenta las siguientes secciones cuando exporte sistemas de archivos NFS en un servidor o los monte en un cliente.
5.1. Seguridad NFS con AUTH_SYS y controles de exportación
NFS ofrece las siguientes opciones tradicionales para controlar el acceso a los archivos exportados:
- El servidor restringe qué hosts pueden montar qué sistemas de archivos, ya sea por dirección IP o por nombre de host.
-
El servidor aplica los permisos del sistema de archivos para los usuarios de los clientes NFS de la misma manera que lo hace para los usuarios locales. Tradicionalmente, NFS hace esto utilizando el mensaje de llamada
AUTH_SYS(también llamadoAUTH_UNIX), que depende de que el cliente indique el UID y el GID del usuario. Ten en cuenta que esto significa que un cliente malicioso o mal configurado podría fácilmente equivocarse y permitir a un usuario el acceso a archivos que no debería.
Para limitar los riesgos potenciales, los administradores a menudo limitan el acceso a sólo lectura o aplastan los permisos de usuario a un ID de usuario y grupo común. Lamentablemente, estas soluciones impiden que el recurso compartido NFS se utilice de la forma prevista originalmente.
Además, si un atacante se hace con el control del servidor DNS utilizado por el sistema que exporta el sistema de archivos NFS, puede apuntar el sistema asociado a un determinado nombre de host o nombre de dominio completo a una máquina no autorizada. En este punto, la máquina no autorizada is el sistema permitido para montar el recurso compartido NFS, porque no se intercambia información de nombre de usuario o contraseña para proporcionar seguridad adicional para el montaje NFS.
Los comodines deben utilizarse con moderación al exportar directorios a través de NFS, ya que es posible que el alcance del comodín abarque más sistemas de los previstos.
Recursos adicionales
-
Para asegurar NFS y
rpcbind, utilice, por ejemplo,nftablesyfirewalld. Para obtener detalles sobre la configuración de estos marcos, consulte las páginas de manualnft(8)yfirewalld-cmd(1).
5.2. Seguridad NFS con AUTH_GSS
Todas las versiones de NFS soportan RPCSEC_GSS y el mecanismo Kerberos.
A diferencia de AUTH_SYS, con el mecanismo RPCSEC_GSS Kerberos, el servidor no depende del cliente para representar correctamente qué usuario está accediendo al archivo. En su lugar, se utiliza la criptografía para autenticar a los usuarios en el servidor, lo que evita que un cliente malicioso se haga pasar por un usuario sin tener las credenciales Kerberos de ese usuario. El uso del mecanismo RPCSEC_GSS Kerberos es la forma más directa de asegurar los montajes porque después de configurar Kerberos, no se necesita ninguna configuración adicional.
5.3. Configuración de un servidor y un cliente NFS para utilizar Kerberos
Kerberos es un sistema de autenticación de red que permite a los clientes y a los servidores autenticarse entre sí mediante el uso de encriptación simétrica y una tercera parte de confianza, el KDC. Red Hat recomienda utilizar Identity Management (IdM) para configurar Kerberos.
Requisitos previos
-
El Centro de Distribución de Claves Kerberos (
KDC) está instalado y configurado.
Procedimiento
-
Cree la
nfs/hostname.domain@REALMprincipal en el lado del servidor NFS. -
Cree la
host/hostname.domain@REALMprincipal tanto en el lado del servidor como en el del cliente. - Añade las claves correspondientes a los keytabs del cliente y del servidor.
-
Cree la
En el lado del servidor, utilice la opción
sec=para habilitar los tipos de seguridad deseados. Para habilitar todos los tipos de seguridad, así como los montajes no criptográficos:/export *(sec=sys:krb5:krb5i:krb5p)
Los sabores de seguridad válidos para usar con la opción
sec=son:-
sys: sin protección criptográfica, por defecto -
krb5: sólo autenticación -
krb5i: protección de la integridad -
krb5p: protección de la intimidad
-
En el lado del cliente, añada
sec=krb5(osec=krb5i, osec=krb5p, dependiendo de la configuración) a las opciones de montaje:# mount -o sec=krb5 server:/export /mnt
Recursos adicionales
- Si necesita escribir archivos como root en el recurso compartido NFS protegido por Kerberos y mantener la propiedad de root sobre estos archivos, consulte https://access.redhat.com/articles/4040141. Tenga en cuenta que esta configuración no se recomienda.
- Para más información sobre la configuración de NFS, consulte las páginas de manual exports(5) y nfs(5).
5.4. Opciones de seguridad de NFSv4
NFSv4 incluye soporte ACL basado en el modelo de Microsoft Windows NT, no en el modelo POSIX, debido a las características del modelo de Microsoft Windows NT y a su amplia implantación.
Otra característica de seguridad importante de NFSv4 es la eliminación del uso del protocolo MOUNT para montar sistemas de archivos. El protocolo MOUNT presentaba un riesgo de seguridad debido a la forma en que el protocolo procesaba los manejadores de archivos.
5.5. Permisos de archivos en exportaciones NFS montadas
Una vez que el sistema de archivos NFS es montado como lectura o lectura y escritura por un host remoto, la única protección que tiene cada archivo compartido son sus permisos. Si dos usuarios que comparten el mismo valor de ID de usuario montan el mismo sistema de archivos NFS en diferentes sistemas cliente, pueden modificar los archivos del otro. Además, cualquier persona que haya iniciado sesión como root en el sistema cliente puede utilizar el comando su - para acceder a cualquier archivo con el recurso compartido NFS.
Por defecto, las listas de control de acceso (ACLs) son soportadas por NFS bajo Red Hat Enterprise Linux. Red Hat recomienda mantener esta característica habilitada.
Por defecto, NFS utiliza root squashing al exportar un sistema de archivos. Esto establece el ID de usuario de cualquiera que acceda al recurso compartido NFS como usuario root en su máquina local en nobody. El aplastamiento de la raíz se controla con la opción por defecto root_squash; para más información sobre esta opción, consulte Sección 4.6, “Configuración del servidor NFS”.
Al exportar un recurso compartido NFS como de sólo lectura, considere el uso de la opción all_squash. Esta opción hace que todos los usuarios que accedan al sistema de archivos exportado tomen el ID del usuario de nobody.
Capítulo 6. Habilitación de disposiciones SCSI pNFS en NFS
Puede configurar el servidor y el cliente NFS para que utilicen la disposición SCSI pNFS para acceder a los datos. SCSI pNFS es beneficioso en los casos de uso que implican un acceso de larga duración de un solo cliente a un archivo.
Requisitos previos
- Tanto el cliente como el servidor deben poder enviar comandos SCSI al mismo dispositivo de bloque. Es decir, el dispositivo de bloque debe estar en un bus SCSI compartido.
- El dispositivo de bloque debe contener un sistema de archivos XFS.
- El dispositivo SCSI debe ser compatible con las reservas persistentes SCSI, como se describe en la especificación de comandos primarios SCSI-3.
6.1. La tecnología pNFS
La arquitectura pNFS mejora la escalabilidad de NFS. Cuando un servidor implementa pNFS, el cliente puede acceder a los datos a través de varios servidores de forma simultánea. Esto puede suponer una mejora del rendimiento.
pNFS admite los siguientes protocolos o disposiciones de almacenamiento en RHEL:
- Archivos
- Flexfiles
- SCSI
6.2. disposiciones SCSI pNFS
El diseño SCSI se basa en el trabajo de los diseños de bloques pNFS. La disposición se define a través de los dispositivos SCSI. Contiene una serie secuencial de bloques de tamaño fijo como unidades lógicas (LUs) que deben ser capaces de soportar reservas persistentes SCSI. Los dispositivos LU se identifican por su identificación de dispositivo SCSI.
pNFS SCSI funciona bien en casos de uso que implican el acceso de un solo cliente de larga duración a un archivo. Un ejemplo podría ser un servidor de correo o una máquina virtual que albergue un clúster.
Operaciones entre el cliente y el servidor
Cuando un cliente NFS lee de un archivo o escribe en él, el cliente realiza una operación LAYOUTGET. El servidor responde con la ubicación del archivo en el dispositivo SCSI. Es posible que el cliente tenga que realizar una operación adicional de GETDEVICEINFO para determinar qué dispositivo SCSI debe utilizar. Si estas operaciones funcionan correctamente, el cliente puede emitir peticiones de E/S directamente al dispositivo SCSI en lugar de enviar las operaciones READ y WRITE al servidor.
Los errores o la contención entre clientes pueden hacer que el servidor recupere los diseños o no los emita a los clientes. En esos casos, los clientes vuelven a emitir READ y WRITE operaciones al servidor en lugar de enviar solicitudes de E/S directamente al dispositivo SCSI.
Para supervisar las operaciones, consulte Sección 6.7, “Supervisión de la funcionalidad de los diseños SCSI de PNFS”.
Reservas de dispositivos
pNFS SCSI maneja el cercado a través de la asignación de reservas. Antes de que el servidor emita distribuciones a los clientes, reserva el dispositivo SCSI para garantizar que sólo los clientes registrados puedan acceder al dispositivo. Si un cliente puede emitir comandos a ese dispositivo SCSI pero no está registrado en el dispositivo, muchas operaciones del cliente en ese dispositivo fallan. Por ejemplo, el comando blkid en el cliente falla al mostrar el UUID del sistema de archivos XFS si el servidor no ha dado una distribución para ese dispositivo al cliente.
El servidor no elimina su propia reserva persistente. Esto protege los datos dentro del sistema de archivos del dispositivo a través de los reinicios de los clientes y servidores. Para reutilizar el dispositivo SCSI, es posible que tenga que eliminar manualmente la reserva persistente en el servidor NFS.
6.3. Comprobación de un dispositivo SCSI compatible con pNFS
Este procedimiento comprueba si un dispositivo SCSI es compatible con la disposición SCSI pNFS.
Requisitos previos
Instale el paquete
sg3_utils:# yum install sg3_utils
Procedimiento
Tanto en el servidor como en el cliente, compruebe que el dispositivo SCSI es compatible:
sg_persist --in --report-capabilities --verbose path-to-scsi-deviceAsegúrese de que el bit Persist Through Power Loss Active (
PTPL_A) está activado.Ejemplo 6.1. Un dispositivo SCSI compatible con SCSI pNFS
El siguiente es un ejemplo de la salida de
sg_persistpara un dispositivo SCSI que soporta pNFS SCSI. El bitPTPL_Ainforma de1.inquiry cdb: 12 00 00 00 24 00 Persistent Reservation In cmd: 5e 02 00 00 00 00 00 20 00 00 LIO-ORG block11 4.0 Peripheral device type: disk Report capabilities response: Compatible Reservation Handling(CRH): 1 Specify Initiator Ports Capable(SIP_C): 1 All Target Ports Capable(ATP_C): 1 Persist Through Power Loss Capable(PTPL_C): 1 Type Mask Valid(TMV): 1 Allow Commands: 1 Persist Through Power Loss Active(PTPL_A): 1 Support indicated in Type mask: Write Exclusive, all registrants: 1 Exclusive Access, registrants only: 1 Write Exclusive, registrants only: 1 Exclusive Access: 1 Write Exclusive: 1 Exclusive Access, all registrants: 1
Recursos adicionales
-
La página de manual
sg_persist(8)
6.4. Configuración de pNFS SCSI en el servidor
Este procedimiento configura un servidor NFS para exportar una disposición SCSI pNFS.
Procedimiento
- En el servidor, monte el sistema de archivos XFS creado en el dispositivo SCSI.
Configure el servidor NFS para exportar la versión 4.1 o superior de NFS. Establezca la siguiente opción en la sección
[nfsd]del archivo/etc/nfs.conf:[nfsd] vers4.1=y
Configure el servidor NFS para exportar el sistema de archivos XFS a través de NFS con la opción
pnfs:Ejemplo 6.2. Una entrada en /etc/exports para exportar pNFS SCSI
La siguiente entrada en el archivo de configuración
/etc/exportsexporta el sistema de archivos montado en/exported/directory/al clienteallowed.example.comcomo una disposición SCSI pNFS:/exportado/directorio permitido.ejemplo.com(pnfs)
Recursos adicionales
- Para más información sobre la configuración de un servidor NFS, consulte Capítulo 4, Exportación de recursos compartidos NFS.
6.5. Configuración de pNFS SCSI en el cliente
Este procedimiento configura un cliente NFS para montar una disposición SCSI pNFS.
Requisitos previos
- El servidor NFS está configurado para exportar un sistema de archivos XFS sobre SCSI pNFS. Véase Sección 6.4, “Configuración de pNFS SCSI en el servidor”.
Procedimiento
En el cliente, monte el sistema de archivos XFS exportado utilizando la versión 4.1 o superior de NFS:
# mount -t nfs -o nfsvers=4.1 host:/remote/export /local/directory
No monte el sistema de archivos XFS directamente sin NFS.
Recursos adicionales
- Para obtener más información sobre el montaje de recursos compartidos NFS, consulte Montaje de recursos compartidos NFS.
6.6. Liberación de la reserva SCSI pNFS en el servidor
Este procedimiento libera la reserva persistente que un servidor NFS mantiene en un dispositivo SCSI. Esto le permite reutilizar el dispositivo SCSI cuando ya no necesite exportar pNFS SCSI.
Debe eliminar la reserva del servidor. No se puede eliminar de otro IT Nexus.
Requisitos previos
Instale el paquete
sg3_utils:# yum install sg3_utils
Procedimiento
Consultar una reserva existente en el servidor:
# sg_persist --read-reservation path-to-scsi-deviceEjemplo 6.3. Consulta de una reserva en /dev/sda
# sg_persist --read-reservation /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk PR generation=0x8, Reservation follows: Key=0x100000000000000 scope: LU_SCOPE, type: Exclusive Access, registrants onlyEliminar el registro existente en el servidor:
# sg_persist --out \ --release \ --param-rk=reservation-key \ --prout-type=6 \ path-to-scsi-deviceEjemplo 6.4. Eliminación de una reserva en /dev/sda
# sg_persist --out \ --release \ --param-rk=0x100000000000000 \ --prout-type=6 \ /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk
Recursos adicionales
-
La página de manual
sg_persist(8)
6.7. Supervisión de la funcionalidad de los diseños SCSI de PNFS
Puede supervisar si el cliente y el servidor pNFS intercambian operaciones SCSI pNFS adecuadas o si recurren a operaciones NFS normales.
Requisitos previos
- Un cliente y un servidor SCSI pNFS están configurados.
6.7.1. Comprobación de las operaciones SCSI pNFS desde el servidor mediante nfsstat
Este procedimiento utiliza la utilidad nfsstat para supervisar las operaciones SCSI de pNFS desde el servidor.
Procedimiento
Supervisar las operaciones atendidas desde el servidor:
# watch --differences \ "nfsstat --server | egrep --after-context=1 read\|write\|layout" Every 2.0s: nfsstat --server | egrep --after-context=1 read\|write\|layout putrootfh read readdir readlink remove rename 2 0% 0 0% 1 0% 0 0% 0 0% 0 0% -- setcltidconf verify write rellockowner bc_ctl bind_conn 0 0% 0 0% 0 0% 0 0% 0 0% 0 0% -- getdevlist layoutcommit layoutget layoutreturn secinfononam sequence 0 0% 29 1% 49 1% 5 0% 0 0% 2435 86%El cliente y el servidor utilizan operaciones SCSI pNFS cuando:
-
Los contadores
layoutget,layoutreturn, ylayoutcommitse incrementan. Esto significa que el servidor está sirviendo diseños. -
Los contadores del servidor
readywriteno se incrementan. Esto significa que los clientes están realizando peticiones de E/S directamente a los dispositivos SCSI.
-
Los contadores
6.7.2. Comprobación de las operaciones SCSI de pNFS desde el cliente mediante mountstats
Este procedimiento utiliza el archivo /proc/self/mountstats para supervisar las operaciones SCSI de pNFS desde el cliente.
Procedimiento
Enumerar los contadores de operaciones por monte:
# cat /proc/self/mountstats \ | awk /scsi_lun_0/,/^$/ \ | egrep device\|READ\|WRITE\|LAYOUT device 192.168.122.73:/exports/scsi_lun_0 mounted on /mnt/rhel7/scsi_lun_0 with fstype nfs4 statvers=1.1 nfsv4: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x803,acl=0x3,sessions,pnfs=LAYOUT_SCSI READ: 0 0 0 0 0 0 0 0 WRITE: 0 0 0 0 0 0 0 0 READLINK: 0 0 0 0 0 0 0 0 READDIR: 0 0 0 0 0 0 0 0 LAYOUTGET: 49 49 0 11172 9604 2 19448 19454 LAYOUTCOMMIT: 28 28 0 7776 4808 0 24719 24722 LAYOUTRETURN: 0 0 0 0 0 0 0 0 LAYOUTSTATS: 0 0 0 0 0 0 0 0En los resultados:
-
Las estadísticas de
LAYOUTindican las peticiones en las que el cliente y el servidor utilizan operaciones SCSI pNFS. -
Las estadísticas
READyWRITEindican las solicitudes en las que el cliente y el servidor vuelven a las operaciones NFS.
-
Las estadísticas de
Capítulo 7. Configuración del servidor proxy de caché Squid
Squid es un servidor proxy que almacena en caché el contenido para reducir el ancho de banda y cargar las páginas web más rápidamente. Este capítulo describe cómo configurar Squid como proxy para el protocolo HTTP, HTTPS y FTP, así como la autenticación y la restricción de acceso.
7.1. Configuración de Squid como proxy de caché sin autenticación
Esta sección describe una configuración básica de Squid como proxy de caché sin autenticación. El procedimiento limita el acceso al proxy basándose en rangos de IP.
Requisitos previos
-
El procedimiento asume que el archivo
/etc/squid/squid.confes el proporcionado por el paquetesquid. Si ha editado este archivo anteriormente, elimine el archivo y vuelva a instalar el paquete.
Procedimiento
Instale el paquete
squid:# yum install squid
Edite el archivo
/etc/squid/squid.conf:Adapte las listas de control de acceso (ACL) de
localnetpara que coincidan con los rangos de IP a los que se debe permitir el uso del proxy:acl localnet src 192.0.2.0/24 acl localnet 2001:db8:1::/64
Por defecto, el archivo
/etc/squid/squid.confcontiene la reglahttp_access allow localnetque permite utilizar el proxy desde todos los rangos de IP especificados en las ACLslocalnet. Tenga en cuenta que debe especificar todas las ACL delocalnetantes de la regla dehttp_access allow localnet.ImportanteElimine todas las entradas existentes en
acl localnetque no coincidan con su entorno.La siguiente ACL existe en la configuración por defecto y define
443como un puerto que utiliza el protocolo HTTPS:acl puertos_SSL puerto 443
Si los usuarios deben poder utilizar el protocolo HTTPS también en otros puertos, añada una ACL para cada uno de estos puertos:
acl Puerto SSL port_numberActualice la lista de reglas de
acl Safe_portspara configurar a qué puertos puede establecer una conexión Squid. Por ejemplo, para configurar que los clientes que utilicen el proxy sólo puedan acceder a los recursos del puerto 21 (FTP), 80 (HTTP) y 443 (HTTPS), mantenga sólo las siguientes declaraciones deacl Safe_portsen la configuración:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por defecto, la configuración contiene la regla
http_access deny !Safe_portsque define la denegación de acceso a los puertos que no están definidos en las ACL deSafe_ports.Configure el tipo de caché, la ruta del directorio de la caché, el tamaño de la caché y otros ajustes específicos del tipo de caché en el parámetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Con estos ajustes:
-
Squid utiliza el tipo de caché
ufs. -
Squid almacena su caché en el directorio
/var/spool/squid/. -
El caché crece hasta
10000MB. -
Squid crea
16subdirectorios de nivel 1 en el directorio/var/spool/squid/. Squid crea subdirectorios
256en cada directorio de nivel 1.Si no se establece una directiva
cache_dir, Squid almacena la caché en la memoria.
-
Squid utiliza el tipo de caché
Si establece un directorio de caché diferente a
/var/spool/squid/en el parámetrocache_dir:Crear el directorio de la caché:
# mkdir -p path_to_cache_directoryConfigure los permisos para el directorio de la caché:
# chown squid:squid path_to_cache_directorySi ejecuta SELinux en modo
enforcing, establezca el contextosquid_cache_tpara el directorio de la caché:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Si la utilidad
semanageno está disponible en su sistema, instale el paquetepolicycoreutils-python-utils.
Abra el puerto
3128en el cortafuegos:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie el servicio
squid:# systemctl enable --now squid
Pasos de verificación
Para comprobar que el proxy funciona correctamente, descargue una página web utilizando la utilidad curl:
# curl -O -L "https://www.redhat.com/index.html" -x "proxy.example.com:3128"
Si curl no muestra ningún error y el archivo index.html se ha descargado en el directorio actual, el proxy funciona.
7.2. Configuración de Squid como proxy de caché con autenticación LDAP
Esta sección describe una configuración básica de Squid como proxy de caché que utiliza LDAP para autenticar a los usuarios. El procedimiento configura que sólo los usuarios autenticados puedan utilizar el proxy.
Requisitos previos
-
El procedimiento asume que el archivo
/etc/squid/squid.confes el proporcionado por el paquetesquid. Si ha editado este archivo anteriormente, elimine el archivo y vuelva a instalar el paquete. -
Un usuario de servicio, como
uid=proxy_user,cn=users,cn=accounts,dc=example,dc=comexiste en el directorio LDAP. Squid utiliza esta cuenta sólo para buscar al usuario autentificador. Si el usuario de autenticación existe, Squid se vincula como este usuario al directorio para verificar la autenticación.
Procedimiento
Instale el paquete
squid:# yum install squid
Edite el archivo
/etc/squid/squid.conf:Para configurar la utilidad de ayuda
basic_ldap_auth, añada la siguiente entrada de configuración en la parte superior de/etc/squid/squid.conf:auth_param programa básico /usr/lib64/squid/basic_ldap_auth -b "cn=users,cn=accounts,dc=example,dc=com" -D "uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f "(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389
A continuación se describen los parámetros pasados a la utilidad de ayuda
basic_ldap_authen el ejemplo anterior:-
-B base_DNestablece la base de búsqueda LDAP. -
-D proxy_service_user_DNestablece el nombre distinguido (DN) de la cuenta que Squid utiliza para buscar al usuario autentificado en el directorio. -
-W path_to_password_fileestablece la ruta del archivo que contiene la contraseña del usuario del servicio proxy. El uso de un archivo de contraseña evita que la contraseña sea visible en la lista de procesos del sistema operativo. -f LDAP_filterespecifica el filtro de búsqueda LDAP. Squid sustituye la variable%spor el nombre de usuario proporcionado por el usuario autentificador.El filtro
(&(objectClass=person)(uid=%s))del ejemplo define que el nombre de usuario debe coincidir con el valor establecido en el atributouidy que la entrada del directorio contiene la clase de objetoperson.-ZZimpone una conexión cifrada por TLS sobre el protocolo LDAP mediante el comandoSTARTTLS. Omita el-ZZen las siguientes situaciones:- El servidor LDAP no admite conexiones cifradas.
- El puerto especificado en la URL utiliza el protocolo LDAPS.
- El parámetro -H LDAP_URL especifica el protocolo, el nombre del host o la dirección IP y el puerto del servidor LDAP en formato URL.
-
Añade la siguiente ACL y regla para configurar que Squid sólo permita a los usuarios autentificados utilizar el proxy:
acl ldap-auth proxy_auth REQUIRED http_access allow ldap-auth
ImportanteEspecifique estos ajustes antes de la regla
http_access denyall.Elimine la siguiente regla para desactivar la omisión de la autenticación del proxy desde los rangos de IP especificados en las ACL de
localnet:http_access allow localnet
La siguiente ACL existe en la configuración por defecto y define
443como un puerto que utiliza el protocolo HTTPS:acl puertos_SSL puerto 443
Si los usuarios deben poder utilizar el protocolo HTTPS también en otros puertos, añada una ACL para cada uno de estos puertos:
acl puerto_SSL número_de_puerto
Actualice la lista de reglas de
acl Safe_portspara configurar a qué puertos puede establecer una conexión Squid. Por ejemplo, para configurar que los clientes que utilicen el proxy sólo puedan acceder a los recursos del puerto 21 (FTP), 80 (HTTP) y 443 (HTTPS), mantenga sólo las siguientes declaraciones deacl Safe_portsen la configuración:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por defecto, la configuración contiene la regla
http_access deny !Safe_portsque define la denegación de acceso a los puertos que no están definidos enSafe_ports ACLs.Configure el tipo de caché, la ruta del directorio de la caché, el tamaño de la caché y otros ajustes específicos del tipo de caché en el parámetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Con estos ajustes:
-
Squid utiliza el tipo de caché
ufs. -
Squid almacena su caché en el directorio
/var/spool/squid/. -
El caché crece hasta
10000MB. -
Squid crea
16subdirectorios de nivel 1 en el directorio/var/spool/squid/. Squid crea subdirectorios
256en cada directorio de nivel 1.Si no se establece una directiva
cache_dir, Squid almacena la caché en la memoria.
-
Squid utiliza el tipo de caché
Si establece un directorio de caché diferente a
/var/spool/squid/en el parámetrocache_dir:Crear el directorio de la caché:
# mkdir -p path_to_cache_directoryConfigure los permisos para el directorio de la caché:
# chown squid:squid path_to_cache_directorySi ejecuta SELinux en modo
enforcing, establezca el contextosquid_cache_tpara el directorio de la caché:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Si la utilidad
semanageno está disponible en su sistema, instale el paquetepolicycoreutils-python-utils.
Guarde la contraseña del usuario del servicio LDAP en el archivo
/etc/squid/ldap_password, y establezca los permisos adecuados para el archivo:# echo "password" > /etc/squid/ldap_password # chown root:squid /etc/squid/ldap_password # chmod 640 /etc/squid/ldap_passwordAbra el puerto
3128en el cortafuegos:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie el servicio
squid:# systemctl enable --now squid
Pasos de verificación
Para comprobar que el proxy funciona correctamente, descargue una página web utilizando la utilidad curl:
# curl -O -L "https://www.redhat.com/index.html" -x "user_name:password@proxy.example.com:3128"
Si curl no muestra ningún error y el archivo index.html se ha descargado en el directorio actual, el proxy funciona.
Pasos para la resolución de problemas
Para verificar que la utilidad de ayuda funciona correctamente:
Inicie manualmente la utilidad de ayuda con la misma configuración que utilizó en el parámetro
auth_param:# /usr/lib64/squid/basic_ldap_auth -b "cn=users,cn=accounts,dc=example,dc=com" -D "uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f "(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389
Introduzca un nombre de usuario y una contraseña válidos, y pulse Intro:
user_name password
Si la utilidad de ayuda devuelve
OK, la autenticación tuvo éxito.
7.3. Configuración de Squid como proxy de caché con autenticación kerberos
Esta sección describe una configuración básica de Squid como proxy de caché que autentifica a los usuarios en un Directorio Activo (AD) utilizando Kerberos. El procedimiento configura que sólo los usuarios autenticados pueden utilizar el proxy.
Requisitos previos
-
El procedimiento asume que el archivo
/etc/squid/squid.confes el proporcionado por el paquetesquid. Si ha editado este archivo anteriormente, elimine el archivo y vuelva a instalar el paquete. -
El servidor en el que desea instalar Squid es un miembro del dominio AD. Para más detalles, consulte Configuración de Samba como miembro del dominio en la documentación de Red Hat Enterprise Linux 8
Deploying different types of servers.
Procedimiento
Instale los siguientes paquetes:
yum install squid krb5-workstation
Autenticarse como administrador del dominio AD:
# kinit administrator@AD.EXAMPLE.COMCree un keytab para Squid y almacénelo en el archivo
/etc/squid/HTTP.keytab:# export KRB5_KTNAME=FILE:/etc/squid/HTTP.keytab # net ads keytab CREATE -U administrator
Añade la entidad de crédito del servicio
HTTPal keytab:# net ads keytab ADD HTTP -U administrador
Establezca el propietario del archivo keytab al usuario
squid:# chown squid /etc/squid/HTTP.keytab
Opcionalmente, verifique que el archivo keytab contiene el principal de servicio
HTTPpara el nombre de dominio completamente calificado (FQDN) del servidor proxy:# klist -k /etc/squid/HTTP.keytab Keytab name: FILE:/etc/squid/HTTP.keytab KVNO Principal ---- --------------------------------------------------- ... 2 HTTP/proxy.ad.example.com@AD.EXAMPLE.COM ...
Edite el archivo
/etc/squid/squid.conf:Para configurar la utilidad de ayuda
negotiate_kerberos_auth, añada la siguiente entrada de configuración en la parte superior de/etc/squid/squid.conf:auth_param negotiate program /usr/lib64/squid/negotiate_kerberos_auth -k /etc/squid/HTTP.keytab -s HTTP/proxy.ad.example.com@AD.EXAMPLE.COM
A continuación se describen los parámetros pasados a la utilidad de ayuda
negotiate_kerberos_authen el ejemplo anterior:-
-k fileestablece la ruta de acceso al archivo de tabulación de claves. Tenga en cuenta que el usuario squid debe tener permisos de lectura en este archivo. -s HTTP/host_name@kerberos_realmestablece el principal de Kerberos que utiliza Squid.Opcionalmente, puede activar el registro pasando uno o ambos de los siguientes parámetros a la utilidad de ayuda:
-
-iregistra mensajes informativos, como el usuario que se autentifica. -dactiva el registro de depuración.Squid registra la información de depuración de la utilidad de ayuda en el archivo
/var/log/squid/cache.log.
-
Añade la siguiente ACL y regla para configurar que Squid sólo permita a los usuarios autentificados utilizar el proxy:
acl kerb-auth proxy_auth REQUIRED http_access allow kerb-auth
ImportanteEspecifique estos ajustes antes de la regla
http_access deny all.Elimine la siguiente regla para desactivar la omisión de la autenticación del proxy desde los rangos de IP especificados en las ACL de
localnet:http_access allow localnet
La siguiente ACL existe en la configuración por defecto y define
443como un puerto que utiliza el protocolo HTTPS:acl puertos_SSL puerto 443
Si los usuarios deben poder utilizar el protocolo HTTPS también en otros puertos, añada una ACL para cada uno de estos puertos:
acl Puerto SSL port_numberActualice la lista de reglas de
acl Safe_portspara configurar a qué puertos puede establecer una conexión Squid. Por ejemplo, para configurar que los clientes que utilicen el proxy sólo puedan acceder a los recursos del puerto 21 (FTP), 80 (HTTP) y 443 (HTTPS), mantenga sólo las siguientes declaraciones deacl Safe_portsen la configuración:acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
Por defecto, la configuración contiene la regla
http_access deny !Safe_portsque define la denegación de acceso a los puertos que no están definidos en las ACL deSafe_ports.Configure el tipo de caché, la ruta del directorio de la caché, el tamaño de la caché y otros ajustes específicos del tipo de caché en el parámetro
cache_dir:cache_dir ufs /var/spool/squid 10000 16 256
Con estos ajustes:
-
Squid utiliza el tipo de caché
ufs. -
Squid almacena su caché en el directorio
/var/spool/squid/. -
El caché crece hasta
10000MB. -
Squid crea
16subdirectorios de nivel 1 en el directorio/var/spool/squid/. Squid crea subdirectorios
256en cada directorio de nivel 1.Si no se establece una directiva
cache_dir, Squid almacena la caché en la memoria.
-
Squid utiliza el tipo de caché
Si establece un directorio de caché diferente a
/var/spool/squid/en el parámetrocache_dir:Crear el directorio de la caché:
# mkdir -p path_to_cache_directoryConfigure los permisos para el directorio de la caché:
# chown squid:squid path_to_cache_directorySi ejecuta SELinux en modo
enforcing, establezca el contextosquid_cache_tpara el directorio de la caché:# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
Si la utilidad
semanageno está disponible en su sistema, instale el paquetepolicycoreutils-python-utils.
Abra el puerto
3128en el cortafuegos:# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
Habilite e inicie el servicio
squid:# systemctl enable --now squid
Pasos de verificación
Para comprobar que el proxy funciona correctamente, descargue una página web utilizando la utilidad curl:
# curl -O -L "https://www.redhat.com/index.html" --proxy-negotiate -u : -x "proxy.ad.example.com:3128"
Si curl no muestra ningún error y el archivo index.html existe en el directorio actual, el proxy funciona.
Pasos para la resolución de problemas
Para probar manualmente la autenticación Kerberos:
Obtenga un ticket Kerberos para la cuenta AD:
# kinit user@AD.EXAMPLE.COMOpcionalmente, mostrar el billete:
# klist
Utilice la utilidad
negotiate_kerberos_auth_testpara probar la autenticación:# /usr/lib64/squid/negotiate_kerberos_auth_test proxy.ad.example.comSi la utilidad de ayuda devuelve un token, la autenticación tuvo éxito:
Ficha: YIIFTAYGKwYBBQUCoIIFqDC...
7.4. Configuración de una lista de denegación de dominio en Squid
Con frecuencia, los administradores quieren bloquear el acceso a dominios específicos. Esta sección describe cómo configurar una lista de denegación de dominio en Squid.
Requisitos previos
- Squid está configurado y los usuarios pueden utilizar el proxy.
Procedimiento
Edite el archivo
/etc/squid/squid.confy añada la siguiente configuración:acl domain_deny_list dstdomain "/etc/squid/domain_deny_list.txt" http_access deny all domain_deny_list
ImportanteAñada estas entradas antes de la primera declaración
http_access allowque permite el acceso a los usuarios o clientes.Cree el archivo
/etc/squid/domain_deny_list.txty añada los dominios que desea bloquear. Por ejemplo, para bloquear el acceso aexample.comincluyendo subdominios y para bloquearexample.net, añada:.example.com example.net
ImportanteSi ha hecho referencia al archivo
/etc/squid/domain_deny_list.txten la configuración de Squid, este archivo no debe estar vacío. Si el archivo está vacío, Squid falla al iniciarse.Reinicie el servicio
squid:# systemctl restart squid
7.5. Configurar el servicio Squid para que escuche en un puerto o dirección IP específicos
Por defecto, el servicio proxy Squid escucha en el puerto 3128 en todas las interfaces de red. Esta sección describe cómo cambiar el puerto y configurar Squid para que escuche en una dirección IP específica.
Requisitos previos
-
El paquete
squidestá instalado.
Procedimiento
Edite el archivo
/etc/squid/squid.conf:Para establecer el puerto en el que escucha el servicio Squid, establezca el número de puerto en el parámetro
http_port. Por ejemplo, para establecer el puerto en8080, establezca:puerto_http 8080
Para configurar en qué dirección IP escucha el servicio Squid, establezca la dirección IP y el número de puerto en el parámetro
http_port. Por ejemplo, para configurar que Squid escuche sólo en la dirección IP192.0.2.1en el puerto3128, establezca:puerto_http 192.0.2.1:3128
Añade múltiples parámetros de
http_portal archivo de configuración para configurar que Squid escuche en múltiples puertos y direcciones IP:http_port 192.0.2.1:3128 http_port 192.0.2.1:8080
Si ha configurado que Squid utilice un puerto diferente al predeterminado (
3128):Abre el puerto en el firewall:
# firewall-cmd --permanent --add-port=port_number/tcp # firewall-cmd --reloadSi ejecuta SELinux en modo de aplicación, asigne el puerto a la definición del tipo de puerto
squid_port_t:# semanage port -a -t squid_port_t -p tcp port_numberSi la utilidad
semanageno está disponible en su sistema, instale el paquetepolicycoreutils-python-utils.
Reinicie el servicio
squid:# systemctl restart squid
7.6. Recursos adicionales
-
Consulte el archivo
usr/share/doc/squid-<version>/squid.conf.documentedpara obtener una lista de todos los parámetros de configuración que puede establecer en el archivo/etc/squid/squid.confjunto con una descripción detallada.
Capítulo 8. Servidores de bases de datos
8.1. Introducción a los servidores de bases de datos
Un servidor de base de datos es un dispositivo de hardware que tiene una cierta cantidad de memoria principal, y una aplicación de base de datos (DB) instalada. Esta aplicación de base de datos proporciona servicios como medio para escribir los datos almacenados en la memoria principal, que suele ser pequeña y costosa, en archivos de base de datos (DB). Estos servicios se prestan a múltiples clientes en una red. Puede haber tantos servidores de BD como lo permita la memoria principal y el almacenamiento de una máquina.
Red Hat Enterprise Linux 8 proporciona las siguientes aplicaciones de bases de datos:
- MariaDB 10.3
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - disponible desde RHEL 8.1.1
8.2. Uso de MariaDB
8.2.1. Introducción a MariaDB
El servidor MariaDB es un servidor de bases de datos de código abierto rápido y robusto que se basa en la tecnología MySQL.
MariaDB es una base de datos relacional que convierte los datos en información estructurada y proporciona una interfaz SQL para acceder a los datos. Incluye múltiples motores de almacenamiento y complementos, así como funciones de sistema de información geográfica (GIS) y de notación de objetos de JavaScript (JSON).
Esta sección describe cómo instalar el servidor MariaDB en Instalación de MariaDB o cómo migrar desde la versión por defecto de Red Hat Enterprise Linux 7, MariaDB 5.5, a la versión por defecto de Red Hat Enterprise Linux 8, MariaDB 10.3, en Migración a MariaDB 10.3, y también cómo hacer una copia de seguridad de los datos de MariaDB. Realizar una copia de seguridad de los datos es uno de los prerrequisitos para la migración de MariaDB.
8.2.2. Instalación de MariaDB
Para instalar MariaDB, siga este procedimiento:
Asegúrese de que todos los paquetes necesarios para el servidor MariaDB están disponibles en el sistema mediante la instalación del módulo
mariadbutilizando un flujo específico:# yum module install mariadb:10.3/server
Inicie el servicio
mariadb:# systemctl start mariadb.service
Habilitar el servicio
mariadbpara que se inicie en el arranque:# systemctl enable mariadb.service
Tenga en cuenta que los servidores de bases de datos MariaDB y MySQL no pueden instalarse en paralelo en Red Hat Enterprise Linux 8.0 debido a que los paquetes RPM entran en conflicto. La instalación paralela de componentes es posible en Red Hat Software Collections para Red Hat Enterprise Linux 6 y Red Hat Enterprise Linux 7. En Red Hat Enterprise Linux 8, se pueden utilizar diferentes versiones de servidores de bases de datos en contenedores.
8.2.2.1. Mejora de la seguridad de la instalación de MariaDB
Para mejorar la seguridad al instalar MariaDB, ejecute el siguiente comando.
El comando lanza un script totalmente interactivo, que solicita cada paso del proceso.
# mysql_secure_installation
El script permite mejorar la seguridad de las siguientes maneras:
- Establecer una contraseña para las cuentas root
- Eliminación de usuarios anónimos
- No permitir los inicios de sesión remotos (fuera del host local) de root
8.2.3. Configuración de MariaDB
8.2.3.1. Configurar el servidor MariaDB para la red
Para configurar el servidor MariaDB para su conexión en red, utilice la sección [mysqld] del archivo /etc/my.cnf.d/mariadb-server.cnf, donde puede establecer las siguientes directivas de configuración:
bind-addressBind-address es la dirección en la que escuchará el servidor.
Las opciones posibles son: un nombre de host, una dirección IPv4 o una dirección IPv6.
skip-networkingLos valores posibles son:
0 - para escuchar a todos los clientes
1 - para escuchar sólo a los clientes locales
portEl puerto en el que MariaDB escucha las conexiones TCP/IP.
8.2.4. Copia de seguridad de los datos de MariaDB
Hay dos formas principales de hacer una copia de seguridad de los datos de una base de datos MariaDB:
- Copia de seguridad lógica
- Copia de seguridad física
Logical backup consiste en las sentencias SQL necesarias para restaurar los datos. Este tipo de copia de seguridad exporta la información y los registros en archivos de texto plano.
La principal ventaja de la copia de seguridad lógica sobre la física es la portabilidad y la flexibilidad. Los datos se pueden restaurar en otras configuraciones de hardware, versiones de MariaDB o sistema de gestión de bases de datos (DBMS), lo que no es posible con las copias de seguridad físicas.
Tenga en cuenta que la copia de seguridad lógica se puede realizar si el mariadb.service está en funcionamiento. La copia de seguridad lógica no incluye los archivos de registro y configuración.
Physical backup consiste en copias de archivos y directorios que almacenan el contenido.
La copia de seguridad física tiene las siguientes ventajas en comparación con la copia de seguridad lógica:
- La salida es más compacta.
- La copia de seguridad es de menor tamaño.
- La copia de seguridad y la restauración son más rápidas.
- La copia de seguridad incluye archivos de registro y de configuración.
Tenga en cuenta que la copia de seguridad física debe realizarse cuando el mariadb.service no está en funcionamiento o todas las tablas de la base de datos están bloqueadas para evitar cambios durante la copia de seguridad.
Puede utilizar uno de los siguientes enfoques de copia de seguridad de MariaDB para hacer una copia de seguridad de los datos de una base de datos MariaDB:
- Copia de seguridad lógica con mysqldump
- Copia de seguridad física en línea con la herramienta Mariabackup
- Copia de seguridad del sistema de archivos
- La replicación como solución de copia de seguridad
8.2.4.1. Realizando una copia de seguridad lógica con mysqldump
El cliente mysqldump es una utilidad de copia de seguridad, que puede utilizarse para volcar una base de datos o una colección de bases de datos con el fin de realizar una copia de seguridad o transferirla a otro servidor de bases de datos. La salida de mysqldump suele consistir en sentencias SQL para recrear la estructura de las tablas del servidor, rellenarlas con datos, o ambas cosas. Como alternativa, mysqldump también puede generar archivos en otros formatos, incluyendo CSV u otros formatos de texto delimitados, y XML.
Para realizar la mysqldump copia de seguridad, puede utilizar una de las siguientes opciones:
- Copia de seguridad de una base de datos seleccionada
- Copia de seguridad de un subconjunto de tablas de una base de datos
- Copia de seguridad de varias bases de datos
- Haga una copia de seguridad de todas las bases de datos
8.2.4.1.1. Copia de seguridad de una base de datos completa con mysqldump
Procedimiento
Para hacer una copia de seguridad de una base de datos completa, ejecute
# mysqldump [options] db_name > backup-file.sql
8.2.4.1.2. Uso de mysqldump para hacer una copia de seguridad de un conjunto de tablas de una base de datos
Procedimiento
Para hacer una copia de seguridad de un subconjunto de tablas de una base de datos, añada una lista de las tablas elegidas al final del comando
mysqldump:# mysqldump [opciones] db_name [tbl_name ...]
8.2.4.1.3. Usando mysqldump para cargar el archivo de volcado de nuevo en un servidor
Procedimiento
Para cargar el archivo de volcado de nuevo en un servidor, utilice cualquiera de estas opciones:
# mysql db_name < backup-file.sql
# mysql -e \ "source /path-to-backup/backup-file.sql" db_name
8.2.4.1.4. Usando mysqldump para copiar datos entre dos bases de datos
Procedimiento
Para rellenar las bases de datos copiando los datos de un servidor MariaDB a otro, ejecute
# mysqldump --opt db_name | mysql --host=remote_host -C db_name
8.2.4.1.5. Volcado de múltiples bases de datos con mysqldump
Procedimiento
Para volcar varias bases de datos a la vez, ejecute
# mysqldump [opciones] --bases de datos db_nombre1 [db_nombre2 ...] > mis_bases_de_datos.sql
8.2.4.1.6. Volcado de todas las bases de datos con mysqldump
Procedimiento
Para volcar todas las bases de datos, ejecute
# mysqldump [options] --all-databases > all_databases.sql
8.2.4.1.7. Revisando las opciones de mysqldump
Procedimiento
Para ver una lista de las opciones que soporta mysqldump, ejecute
$ mysqldump --help
8.2.4.1.8. Recursos adicionales
Para más información sobre la copia de seguridad lógica con mysqldumpconsulte la documentación de MariaDB.
8.2.4.2. Realización de una copia de seguridad física en línea con la herramienta Mariabackup
Mariabackup es una herramienta basada en la tecnología Percona XtraBackup, que permite realizar copias de seguridad físicas en línea de tablas InnoDB, Aria y MyISAM.
Mariabackup, proporcionado por el paquete mariadb-backup del repositorio de AppStream, admite la capacidad de realizar copias de seguridad completas para el servidor MariaDB, que incluye datos cifrados y comprimidos.
Requisitos previos
El paquete
mariadb-backupestá instalado en el sistema:# yum install mariadb-backup
Mariabackup necesita que se le proporcionen las credenciales del usuario con el que se ejecutará la copia de seguridad. Puede proporcionar las credenciales en la línea de comandos, como se muestra en el procedimiento, o mediante un archivo de configuración antes de aplicar el procedimiento. Para establecer las credenciales utilizando el archivo de configuración, primero cree el archivo (por ejemplo,
/etc/my.cnf.d/mariabackup.cnf), y luego añada las siguientes líneas en la sección[xtrabackup]o[mysqld]del nuevo archivo:[xtrabackup] user=myuser password=mypassword
ImportanteMariabackup no lee las opciones de la sección
[mariadb]de los archivos de configuración. Si se especifica un directorio de datos no predeterminado en un servidor MariaDB, debe especificar este directorio en las secciones[xtrabackup]o[mysqld]de los archivos de configuración, para que Mariabackup sea capaz de encontrar el directorio de datos.Para especificar dicho directorio de datos, incluya la siguiente línea en las secciones
[xtrabackup]o[mysqld]de los archivos de configuración de MariaDB:datadir=/var/miadatadir
NotaLos usuarios de Mariabackup deben tener los privilegios
RELOAD,LOCK TABLES, yREPLICATION CLIENTpara poder trabajar con la copia de seguridad.
Para crear una copia de seguridad de una base de datos con Mariabackuputilice el siguiente procedimiento:
Procedimiento
Ejecute el siguiente comando:
$ mariabackup --backup --target-dir <backup_directory> --user <backup_user> --password <backup_passwd>
La opción
target-dirdefine el directorio donde se almacenan los archivos de la copia de seguridad. Si desea realizar una copia de seguridad completa, el directorio de destino debe estar vacío o no existir.Las opciones
userypasswordpermiten configurar el nombre de usuario y la contraseña. No utilice estas opciones si ya ha configurado el nombre de usuario y la contraseña en el archivo de configuración como se describe en los requisitos previos.
Recursos adicionales
Para más información sobre cómo realizar copias de seguridad con Mariabackupvea Copia de seguridad completa y restauración con Mariabackup.
8.2.4.3. Restauración de datos con la herramienta Mariabackup
Una vez finalizada la copia de seguridad, puedes restaurar los datos de la misma utilizando el comando mariabackup con una de las siguientes opciones:
-
--copy-back -
--move-back
La opción --copy-back permite mantener los archivos originales de la copia de seguridad. La opción --move-back mueve los archivos de copia de seguridad al directorio de datos, y elimina los archivos de copia de seguridad originales.
Requisitos previos
Asegúrese de que el servicio
mariadbno está funcionando:# systemctl stop mariadb.service
- Asegúrese de que el directorio de datos está vacío.
8.2.4.3.1. Restauración de datos con Mariabackup conservando los archivos de copia de seguridad
Para restaurar los datos manteniendo los archivos originales de la copia de seguridad, utilice el siguiente procedimiento.
Procedimiento
Ejecute el comando
mariabackupcon la opción--copy-back:$ mariabackup --copy-back --target-dir=/var/mariadb/backup/
Arregla los permisos de los archivos.
Al restaurar una base de datos, Mariabackup conserva los privilegios de archivo y directorio de la copia de seguridad. Sin embargo, Mariabackup escribe los archivos en el disco como el usuario y el grupo que restaura la base de datos. En consecuencia, después de restaurar una copia de seguridad, es posible que tenga que ajustar el propietario del directorio de datos para que coincida con el usuario y el grupo del servidor MariaDB, normalmente
mysqlpara ambos.Por ejemplo, para cambiar recursivamente la propiedad de los archivos al usuario y grupo
mysql:# chown -R mysql:mysql /var/lib/mysql/
Inicie el servicio
mariadb:# systemctl start mariadb.service
8.2.4.3.2. Restauración de datos con Mariabackup mientras se eliminan los archivos de copia de seguridad
Para restaurar los datos, y no conservar los archivos originales de la copia de seguridad, utilice el siguiente procedimiento.
Procedimiento
Ejecute el comando
mariabackupcon la opción--move-back:$ mariabackup --move-back --target-dir=/var/mariadb/backup/
Arregla los permisos de los archivos.
Al restaurar una base de datos, Mariabackup conserva los privilegios de archivo y directorio de la copia de seguridad. Sin embargo, Mariabackup escribe los archivos en el disco como el usuario y el grupo que restaura la base de datos. En consecuencia, después de restaurar una copia de seguridad, es posible que tenga que ajustar el propietario del directorio de datos para que coincida con el usuario y el grupo del servidor MariaDB, normalmente
mysqlpara ambos.Por ejemplo, para cambiar recursivamente la propiedad de los archivos al usuario y grupo
mysql:# chown -R mysql:mysql /var/lib/mysql/
Inicie el servicio
mariadb:# systemctl start mariadb.service
8.2.4.3.3. Recursos adicionales
Para más información, consulte Copia de seguridad y restauración completa con Mariabackup.
8.2.4.4. Realizar una copia de seguridad del sistema de archivos
Para crear una copia de seguridad del sistema de archivos de MariaDB, cambie al usuario root y copie el contenido del directorio de datos MariaDB a la ubicación de la copia de seguridad.
Para hacer una copia de seguridad también de la configuración actual o de los archivos de registro, utilice los pasos opcionales del siguiente procedimiento.
Procedimiento
Detenga el servicio
mariadb:# systemctl stop mariadb.service
Copie los archivos de datos en la ubicación requerida:
# cp -r /var/lib/mysql /ubicación de la copia de seguridad
Opcionalmente, copie los archivos de configuración en la ubicación requerida:
# cp -r /etc/mi.cnf /etc/mi.cnf.d /backup-location/configuration
Opcionalmente, copie los archivos de registro en la ubicación requerida:
# cp /var/log/mariadb/* /backup-location/logs
Inicie el servicio
mariadb:# systemctl start mariadb.service
8.2.4.5. Introducción a la replicación como solución de copia de seguridad
La replicación es una solución de copia de seguridad alternativa para los servidores maestros. Si un servidor maestro se replica a un servidor esclavo, las copias de seguridad pueden ejecutarse en el esclavo sin ningún impacto en el maestro. El maestro puede seguir funcionando mientras se apaga el esclavo y se hace una copia de seguridad de los datos desde él.
La replicación en sí misma no es una solución de copia de seguridad suficiente. La replicación protege a los servidores maestros contra los fallos de hardware, pero no garantiza la protección contra la pérdida de datos. Se recomienda utilizar cualquier otra solución de copia de seguridad en el esclavo de replicación junto con este método.
Recursos adicionales
Para más información sobre la replicación como solución de copia de seguridad, consulte la documentación de MariaDB.
8.2.5. Migración a MariaDB 10.3
Red Hat Enterprise Linux 7 contiene MariaDB 5.5 como implementación por defecto de un servidor de la familia de bases de datos MySQL. Las versiones posteriores del servidor de bases de datos MariaDB están disponibles como Software Collections para Red Hat Enterprise Linux 6 y Red Hat Enterprise Linux 7. Red Hat Enterprise Linux 8 proporciona MariaDB 10.3 y MySQL 8.0.
8.2.5.1. Diferencias notables entre las versiones RHEL 7 y RHEL 8 de MariaDB
Los cambios más importantes entre MariaDB 5.5 y MariaDB 10.3 son los siguientes:
- MariaDB Galera Cluster, un clúster multimaster síncrono, es una parte estándar de MariaDB desde 10.1.
- El motor de almacenamiento ARCHIVE ya no está habilitado por defecto, y es necesario habilitar el complemento específicamente.
- El motor de almacenamiento de BLACKHOLE ya no está habilitado por defecto, y es necesario habilitar el complemento específicamente.
Se utiliza InnoDB como motor de almacenamiento por defecto en lugar de XtraDB, que se utilizaba en MariaDB 10.1 y versiones anteriores.
Para más detalles, consulte ¿Por qué MariaDB 10.2 utiliza InnoDB en lugar de XtraDB?
-
Los nuevos paquetes
mariadb-connector-cproporcionan una biblioteca cliente común para MySQL y MariaDB. Esta biblioteca es utilizable con cualquier versión de los servidores de bases de datos MySQL y MariaDB. Como resultado, el usuario es capaz de conectar una compilación de una aplicación a cualquiera de los servidores MySQL y MariaDB distribuidos con Red Hat Enterprise Linux 8.
Para migrar de MariaDB 5.5 a MariaDB 10.3, es necesario realizar varios cambios de configuración como se describe en Sección 8.2.5.2, “Cambios de configuración”.
8.2.5.2. Cambios de configuración
La ruta de migración recomendada de MariaDB 5.5 a MariaDB 10.3 es actualizar primero a MariaDB 10.0, y luego actualizar una versión sucesivamente.
La principal ventaja de actualizar una por una las versiones es una mejor adaptación de la base de datos, tanto de los datos como de la configuración a los cambios. La actualización termina en la misma versión principal que está disponible en RHEL 8 (MariaDB 10.3), lo que reduce significativamente los cambios de configuración u otros problemas.
Para más información sobre los cambios de configuración al migrar de MariaDB 5.5 a MariaDB 10.0, consulte Migración a MariaDB 10. 0 en la documentación de Red Hat Software Collections.
La migración a las siguientes versiones sucesivas de MariaDB y los cambios de configuración necesarios se describen en estos documentos:
- Migración a MariaDB 10.1 en la documentación de Red Hat Software Collections.
- Migración a MariaDB 10.2 en la documentación de Red Hat Software Collections.
- Migración a MariaDB 10.3 en la documentación de Red Hat Software Collections.
La migración directamente de MariaDB 5.5 a MariaDB 10.3 también es posible, pero debe realizar todos los cambios de configuración que se requieren por las diferencias descritas en los documentos de migración anteriores.
8.2.5.3. Actualización en el lugar utilizando la herramienta mysql_upgrade
Para migrar los archivos de la base de datos a Red Hat Enterprise Linux 8, los usuarios de MariaDB en Red Hat Enterprise Linux 7 necesitan realizar la actualización in situ utilizando la herramienta mysql_upgrade. La herramienta mysql_upgrade es proporcionada por el subpaquete mariadb-server-utils, que se instala como una dependencia del paquete mariadb-server.
Para realizar una actualización in situ, debe copiar los archivos de datos binarios al directorio de datos /var/lib/mysql/ en el sistema Red Hat Enterprise Linux 8 y utilizar la herramienta mysql_upgrade.
Puede utilizar este método para migrar datos de:
- La versión de Red Hat Enterprise Linux 7 de MariaDB 5.5
Las versiones de Red Hat Software Collections de:
- MariaDB 5.5 (ya no es compatible)
- MariaDB 10.0 (ya no es compatible)
- MariaDB 10.1 (ya no es compatible)
- MariaDB 10.2
Tenga en cuenta que se recomienda actualizar a MariaDB 10.2 por una versión sucesivamente. Consulte los respectivos capítulos de migración en las Notas de la versión de Red Hat Software Collections.
Si está actualizando desde la versión de Red Hat Enterprise Linux 7 de MariaDB, los datos de origen se almacenan en el directorio /var/lib/mysql/. En el caso de las versiones de Red Hat Software Collections de MariaDB, el directorio de datos fuente es /var/opt/rh/<collection_name>/lib/mysql/ (con la excepción de mariadb55, que utiliza el directorio de datos /opt/rh/mariadb55/root/var/lib/mysql/ ).
Antes de realizar la actualización, haga una copia de seguridad de todos sus datos almacenados en las bases de datos de MariaDB.
Para realizar la actualización in situ, cambie al usuario root y utilice el siguiente procedimiento:
Asegúrese de que el paquete
mariadb-serverestá instalado en el sistema Red Hat Enterprise Linux 8:# yum install mariadb-server
Asegúrese de que el demonio mariadb no se está ejecutando en ninguno de los sistemas de origen y destino en el momento de copiar los datos:
# systemctl stop mariadb.service
-
Copie los datos de la ubicación de origen al directorio
/var/lib/mysql/en el sistema de destino de Red Hat Enterprise Linux 8. Establezca los permisos adecuados y el contexto SELinux para los archivos copiados en el sistema de destino:
# restorecon -vr /var/lib/mysql
Inicie el servidor MariaDB en el sistema de destino:
# systemctl start mariadb.service
Ejecute el comando
mysql_upgradepara comprobar y reparar las tablas internas:# systemctl mysql_upgrade
-
Una vez completada la actualización, asegúrese de que todos los archivos de configuración dentro del directorio
/etc/my.cnf.d/incluyan sólo opciones válidas para MariaDB 10.3.
Existen ciertos riesgos y problemas conocidos relacionados con la actualización in situ. Por ejemplo, es posible que algunas consultas no funcionen o que se ejecuten en un orden diferente al de antes de la actualización. Para más información sobre estos riesgos y problemas, y para información general sobre la actualización in situ, consulte las Notas de la versión de MariaDB 10.3.
8.2.6. Replicar MariaDB con Galera
Esta sección describe cómo replicar una base de datos MariaDB utilizando la solución Galera.
8.2.6.1. Introducción al clúster MariaDB Galera
La replicación de Galera se basa en la creación de un multimaster síncrono MariaDB Galera Cluster compuesto por varios servidores MariaDB.
La interfaz entre la replicación de Galera y una base de datos MariaDB está definida por la API de replicación de conjuntos de escritura (wsrep API).
Las principales características de MariaDB Galera Cluster son:
- Replicación sincrónica
- Topología multimaster activa-activa
- Leer y escribir en cualquier nodo del clúster
- Control automático de los miembros, los nodos que fallan se retiran del clúster
- Unión automática de nodos
- Replicación paralela a nivel de filas
- Conexiones directas de clientes (los usuarios pueden conectarse a los nodos del clúster y trabajar con los nodos directamente mientras se ejecuta la replicación)
La replicación sincrónica significa que un servidor replica una transacción en el momento de la confirmación, transmitiendo el conjunto de escritura asociado a la transacción a todos los nodos del clúster. El cliente (aplicación de usuario) se conecta directamente al sistema de gestión de bases de datos (DBMS), y experimenta un comportamiento similar al de MariaDB nativo.
La replicación sincrónica garantiza que un cambio ocurrido en un nodo del clúster ocurra en otros nodos del clúster al mismo tiempo.
Por lo tanto, la replicación sincrónica tiene las siguientes ventajas sobre la asincrónica:
- No hay retraso en la propagación de los cambios entre los nodos de cluster particulares
- Todos los nodos del clúster son siempre coherentes
- Los últimos cambios no se pierden si uno de los nodos del clúster se bloquea
- Las transacciones en todos los nodos del clúster se ejecutan en paralelo
- Causalidad en toda la agrupación
Recursos adicionales
Para obtener información más detallada, consulte la documentación de la corriente ascendente:
8.2.6.2. Componentes para construir el clúster MariaDB Galera
Para poder construir MariaDB Galera Cluster, los siguientes paquetes deben estar instalados en su sistema:
-
mariadb-server-galera -
mariadb-server -
galera
El paquete mariadb-server-galera contiene archivos de apoyo y scripts para MariaDB Galera Cluster.
MariaDB upstream parchea el paquete mariadb-server para incluir la API de replicación de conjuntos de escritura (wsrep API). Esta API proporciona la interfaz entre la replicación de Galera y MariaDB.
MariaDB upstream también parchea el paquete galera para añadir soporte completo para MariaDB. El paquete galera contiene la herramienta Galera Replication Library y la Galera Arbitrator. Galera Replication Library proporciona toda la funcionalidad de replicación. Galera Arbitrator puede utilizarse como miembro del clúster que participa en la votación en los escenarios de cerebro dividido. Sin embargo, Galera Arbitrator no puede participar en la replicación real.
Recursos adicionales
Para obtener información más detallada, consulte la documentación de la corriente ascendente:
8.2.6.3. Despliegue del clúster MariaDB Galera
Requisitos previos
Todo el software necesario para construir MariaDB Galera Cluster debe estar instalado en el sistema. Para asegurarse de ello, instale el perfil
galeradel módulomariadb:10.3:# yum module install mariadb:10.3/galera
Como resultado, se instalan los siguientes paquetes:
-
mariadb-server-galera -
mariadb-server galeraEl paquete
mariadb-server-galeratiene como dependencia los paquetesmariadb-serverygalera.Para más información sobre los componentes para construir MariaDB Galera Cluster, consulte Sección 8.2.6.2, “Componentes para construir el clúster MariaDB Galera”.
-
La configuración de replicación del servidor MariaDB debe actualizarse antes de añadir el sistema a un clúster por primera vez.
La configuración por defecto se incluye en el archivo
/etc/my.cnf.d/galera.cnf.Antes de desplegar MariaDB Galera Cluster, configure la opción
wsrep_cluster_addressen el archivo/etc/my.cnf.d/galera.cnfen todos los nodos para que comience con la siguiente cadena:gcomm://
Para el nodo inicial, es posible establecer
wsrep_cluster_addresscomo una lista vacía:wsrep_cluster_address="gcomm://\_"
Para todos los demás nodos, configure
wsrep_cluster_addresspara incluir una dirección a cualquier nodo que ya forme parte del clúster en ejecución. Por ejemplo:wsrep_cluster_address="gcomm://10.0.0.10"
Para obtener más información sobre cómo establecer la dirección del clúster de Galera, consulte Dirección del clúster de Galera.
Procedimiento
Arranca el primer nodo de un nuevo cluster ejecutando el siguiente wrapper en ese nodo:
$ galera_new_cluster
Esta envoltura asegura que el demonio del servidor MariaDB (
mysqld) se ejecuta con la opción--wsrep-new-cluster. Esta opción proporciona la información de que no hay un cluster existente al que conectarse. Por lo tanto, el nodo crea un nuevo UUID para identificar el nuevo cluster.NotaEl servicio
mariadbsoporta un método systemd para interactuar con múltiples procesos del servidor MariaDB. Por lo tanto, en casos con múltiples servidores MariaDB en ejecución, puede arrancar una instancia específica especificando el nombre de la instancia como sufijo:$ galera_new_cluster mariadb@node1Conecte otros nodos al clúster ejecutando el siguiente comando en cada uno de los nodos:
# systemctl start mariadb
Como resultado, el nodo se conecta al clúster y se sincroniza con el estado del clúster.
Recursos adicionales
Para más información, vea Cómo empezar con MariaDB Galera Cluster.
8.2.6.4. Añadir un nuevo nodo al clúster MariaDB Galera
Para añadir un nuevo nodo a MariaDB Galera Cluster, utilice el siguiente procedimiento.
Tenga en cuenta que también puede utilizar este procedimiento para reconectar un nodo ya existente.
Procedimiento
En el nodo concreto, proporcione una dirección a uno o más miembros del clúster existentes en la opción
wsrep_cluster_addressdentro de la sección[mariadb]del archivo de configuración/etc/my.cnf.d/galera.cnf:[mariadb] wsrep_cluster_address="gcomm://192.168.0.1"Cuando un nuevo nodo se conecta a uno de los nodos existentes del clúster, puede ver todos los nodos del clúster.
Sin embargo, es preferible enumerar todos los nodos del clúster en
wsrep_cluster_address.Como resultado, cualquier nodo puede unirse a un clúster conectándose a cualquier otro nodo del clúster, incluso si uno o más nodos del clúster están caídos. Cuando todos los miembros están de acuerdo con la adhesión, se cambia el estado del clúster. Si el estado del nuevo nodo es diferente al del clúster, solicita una Transferencia de Estado Incremental (IST) o una Transferencia de Estado Instantánea (SST) para ser coherente con los demás nodos.
Recursos adicionales
- Para más información, vea Cómo empezar con MariaDB Galera Cluster.
- Para obtener información detallada sobre las transferencias instantáneas de estado (SST), consulte Introducción a las transferencias instantáneas de estado.
8.2.6.5. Reinicio del clúster MariaDB Galera
Si se apagan todos los nodos al mismo tiempo, se termina el clúster, y el clúster en funcionamiento deja de existir. Sin embargo, los datos del clúster siguen existiendo.
Para reiniciar el clúster, inicie un primer nodo como se describe en Sección 8.2.6.3, “Despliegue del clúster MariaDB Galera”.
Si el cluster no está arrancado, y mysqld en el primer nodo se inicia sólo con el comando systemctl start mariadb, el nodo intenta conectarse al menos a uno de los nodos listados en la opción wsrep_cluster_address del archivo /etc/my.cnf.d/galera.cnf. Si no hay ningún nodo en funcionamiento, el reinicio falla.
Recursos adicionales
Para más información, vea Cómo empezar con MariaDB Galera Cluster.
8.3. Uso de PostgreSQL
8.3.1. Introducción a PostgreSQL
El servidor PostgreSQL es un servidor de bases de datos de código abierto, robusto y altamente extensible, basado en el lenguaje SQL. Proporciona un sistema de base de datos relacional con objetos, que permite gestionar amplios conjuntos de datos y un elevado número de usuarios simultáneos. Por estas razones, los servidores PostgreSQL pueden utilizarse en clusters para gestionar grandes cantidades de datos.
El servidor PostgreSQL incluye funciones para garantizar la integridad de los datos, construir entornos tolerantes a fallos o crear aplicaciones. Permite ampliar una base de datos con tipos de datos propios del usuario, funciones personalizadas o código de diferentes lenguajes de programación sin necesidad de recompilar la base de datos.
Esta sección describe cómo instalar PostgreSQL en Instalación de PostgreSQL o cómo migrar a una versión diferente de PostgreSQL en Migración a una versión RHEL 8 de PostgreSQL. Uno de los requisitos previos a la migración es realizar una copia de seguridad de los datos.
8.3.2. Instalación de PostgreSQL
En RHEL 8, el servidor PostgreSQL está disponible en varias versiones, cada una de ellas proporcionada por una corriente independiente:
- PostgreSQL 10 - el flujo por defecto
- PostgreSQL 9.6
- PostgreSQL 12 - disponible desde RHEL 8.1.1
Por diseño, es imposible instalar más de una versión (stream) del mismo módulo en paralelo. Por lo tanto, debe elegir sólo uno de los flujos disponibles del módulo postgresql. La instalación paralela de componentes es posible en Red Hat Software Collections para RHEL 7 y RHEL 6. En RHEL 8, se pueden utilizar diferentes versiones de servidores de bases de datos en contenedores.
Para instalar PostgreSQL:
Habilite el flujo (versión) que desea instalar:
# yum module enable postgresql:stream
Sustituya stream por la versión seleccionada del servidor PostgreSQL.
Puede omitir este paso si desea utilizar el flujo por defecto, que proporciona PostgreSQL 10.
Asegúrese de que el paquete
postgresql-server, disponible en el repositorio de AppStream, está instalado en el servidor requerido:# yum install postgresql-server
Inicializar el directorio de datos
postgresql-setup --initdb
Inicie el servicio
postgresql:# systemctl start postgresql.service
Habilitar el servicio
postgresqlpara que se inicie en el arranque:# systemctl enable postgresql.service
Para obtener información sobre el uso de flujos de módulos, consulte Instalación, gestión y eliminación de componentes del espacio de usuario.
Si desea actualizar desde un flujo anterior de postgresql dentro de RHEL 8, siga los dos procedimientos descritos en Cambiar a un flujo posterior y en Sección 8.3.5, “Migración a la versión RHEL 8 de PostgreSQL”.
8.3.3. Configuración de PostgreSQL
Para cambiar la configuración de PostgreSQL, utilice el archivo /var/lib/pgsql/data/postgresql.conf. Después, reinicie el servicio postgresql para que los cambios se hagan efectivos:
systemctl restart postgresql.service
Aparte de /var/lib/pgsql/data/postgresql.conf, existen otros archivos para cambiar la configuración de PostgreSQL:
-
postgresql.auto.conf -
pg_ident.conf -
pg_hba.conf
El archivo postgresql.auto.conf contiene los ajustes básicos de PostgreSQL de forma similar a /var/lib/pgsql/data/postgresql.conf. Sin embargo, este archivo está bajo el control del servidor. Es editado por las consultas de ALTER SYSTEM, y no puede ser editado manualmente.
El archivo pg_ident.conf se utiliza para mapear las identidades de usuario de los mecanismos de autenticación externos en las identidades de usuario de postgresql.
El archivo pg_hba.conf se utiliza para configurar los permisos detallados de los usuarios para las bases de datos PostgreSQL.
8.3.3.1. Inicialización de un clúster de bases de datos
En una base de datos PostgreSQL, todos los datos se almacenan en un único directorio, que se denomina clúster de base de datos. Usted puede elegir dónde almacenar sus datos, pero Red Hat recomienda almacenar los datos en el directorio por defecto /var/lib/pgsql/data.
Para inicializar este directorio de datos, ejecute
postgresql-setup --initdb
8.3.4. Copia de seguridad de los datos de PostgreSQL
Para hacer una copia de seguridad de los datos de PostgreSQL, utilice uno de los siguientes métodos:
- Volcado SQL
- Copia de seguridad a nivel de sistema de archivos
- Archivo continuo
8.3.4.1. Copia de seguridad de los datos de PostgreSQL con un volcado SQL
8.3.4.1.1. Realización de un volcado SQL
El método de volcado SQL se basa en la generación de un archivo con comandos SQL. Cuando este archivo se vuelve a cargar en el servidor de la base de datos, recrea la base de datos en el mismo estado en el que se encontraba en el momento del volcado. El volcado de SQL está garantizado por la utilidad pg_dump que es una aplicación cliente de PostgreSQL. El uso básico del comando pg_dump es tal que el comando escribe su resultado en la salida estándar:
pg_dump dbname > dumpfile
El archivo SQL resultante puede estar en formato de texto o en otros formatos diferentes, lo que permite el paralelismo y un control más detallado de la restauración de objetos.
Puede realizar el volcado SQL desde cualquier host remoto que tenga acceso a la base de datos. La utilidad pg_dump utilidad no opera con permisos especiales, pero debe tener un acceso de lectura a todas las tablas de las que quiera hacer una copia de seguridad. Para realizar una copia de seguridad de toda la base de datos, debe ejecutarla como superusuario de la base de datos.
Para especificar con qué servidor de bases de datos pg_dump contactará, utilice las siguientes opciones de la línea de comandos:
La opción
-hpara definir el host.El host por defecto es el local o el especificado por la variable de entorno
PGHOST.La opción
-ppara definir el puerto.El puerto por defecto está indicado por la variable de entorno
PGPORTo por el puerto por defecto compilado.
Tenga en cuenta que pg_dump vuelca sólo una base de datos. No vuelca la información sobre los roles o los tablespaces porque dicha información se refiere a todo el clúster.
Para hacer una copia de seguridad de cada base de datos de un clúster determinado y conservar los datos de todo el clúster, como las definiciones de roles y espacios de tablas, utilice el comando pg_dumpall:
pg_dumpall > dumpfile
8.3.4.1.2. Restauración de la base de datos a partir de un volcado SQL
Para restaurar una base de datos a partir de un volcado SQL:
Crear una nueva base de datos (dbname):
creadob
dbnameAsegúrese de que todos los usuarios que poseen objetos o a los que se les concedieron permisos sobre objetos en la base de datos volcada ya existen.
Si estos usuarios no existen, la restauración no consigue recrear los objetos con la propiedad y los permisos originales.
Ejecute la psql utilidad para restaurar un volcado de archivos de texto creado por la pg_dump utilidad:
psql dbname < dumpfile
donde dumpfile es la salida del comando pg_dump.
Si desea restaurar un volcado de archivos que no sean de texto, utilice la utilidad pg_restore:
pg_restore archivo de texto no plano
8.3.4.1.2.1. Restaurar una base de datos en otro servidor
El volcado de una base de datos directamente de un servidor a otro es posible porque pg_dump y psql pueden escribir en y leer de tuberías.
Para volcar una base de datos de un servidor a otro, ejecute
pg_dump -h host1 dbname | psql -h host2 dbname
8.3.4.1.2.2. Manejo de errores SQL durante la restauración
Por defecto, psql continúa ejecutándose si se produce un error SQL. En consecuencia, la base de datos se restaura sólo parcialmente.
Si quiere cambiar este comportamiento por defecto, utilice uno de los siguientes métodos:
Haga que psql salga con un estado de salida de 3 si se produce un error SQL estableciendo la variable
ON_ERROR_STOP:psql --set ON_ERROR_STOP=on dbname < dumpfile
Especifique que todo el volcado se restaura como una única transacción para que la restauración se complete o se cancele por completo utilizando
psqlcon una de las siguientes opciones:psql -1
o
psql --single-transaction
Tenga en cuenta que cuando se utiliza este enfoque, incluso un error menor puede cancelar una operación de restauración que ya se ha ejecutado durante muchas horas.
8.3.4.1.3. Ventajas y desventajas de un volcado SQL
Un volcado de SQL tiene las siguientes ventajas en comparación con otros métodos de copia de seguridad de PostgreSQL:
- Un volcado SQL es el único método de copia de seguridad de PostgreSQL que no es específico de la versión del servidor. La salida de la utilidad pg_dump puede recargarse en versiones posteriores de PostgreSQL, lo que no es posible para las copias de seguridad a nivel de sistema de archivos o el archivado continuo.
- Un volcado de SQL es el único método que funciona cuando se transfiere una base de datos a una arquitectura de máquina diferente, como pasar de un servidor de 32 bits a uno de 64 bits.
- Un volcado SQL proporciona volcados internamente consistentes. Un volcado representa una instantánea de la base de datos en el momento en que pg_dump comenzó a ejecutarse.
- La utilidad pg_dump utilidad no bloquea otras operaciones en la base de datos cuando se está ejecutando.
Una desventaja de un volcado de SQL es que lleva más tiempo en comparación con la copia de seguridad a nivel de sistema de archivos.
8.3.4.1.4. Recursos adicionales
Para más información sobre el volcado de SQL, consulte la documentación de PostgreSQL.
8.3.4.2. Copia de seguridad de los datos de PostgreSQL con una copia de seguridad a nivel de sistema de archivos
8.3.4.2.1. Realización de una copia de seguridad a nivel de sistema de archivos
Para realizar una copia de seguridad a nivel de sistema de archivos, es necesario copiar los archivos que PostgreSQL utiliza para almacenar los datos de la base de datos en otra ubicación:
- Elija la ubicación de un clúster de base de datos e inicialice este clúster como se describe en Sección 8.3.3.1, “Inicialización de un clúster de bases de datos”.
Detenga el servicio postgresql:
# systemctl stop postgresql.service
Utilice cualquier método para hacer una copia de seguridad del sistema de archivos, por ejemplo:
tar -cf backup.tar /var/lib/pgsql/data
Inicie el servicio postgresql:
# systemctl start postgresql.service
8.3.4.2.2. Ventajas y desventajas de una copia de seguridad a nivel de sistema de archivos
Una copia de seguridad a nivel de sistema de archivos tiene la siguiente ventaja en comparación con otros métodos de copia de seguridad de PostgreSQL:
- La copia de seguridad a nivel de sistema de archivos suele ser más rápida que el volcado de SQL.
La copia de seguridad a nivel de sistema de archivos tiene las siguientes desventajas en comparación con otros métodos de copia de seguridad de PostgreSQL:
- La copia de seguridad es específica de la arquitectura y de Red Hat Enterprise Linux 7. Sólo se puede utilizar como copia de seguridad para volver a Red Hat Enterprise Linux 7 si la actualización no fue exitosa, pero no se puede utilizar con PostgreSQL 10.0.
- El servidor de la base de datos debe apagarse antes de la copia de seguridad de los datos y también antes de la restauración de los mismos.
- La copia de seguridad y restauración de ciertos archivos o tablas individuales es imposible. Las copias de seguridad del sistema de archivos sólo funcionan para una copia de seguridad y restauración completa de un clúster de bases de datos.
8.3.4.2.3. Enfoques alternativos a la copia de seguridad a nivel de sistema de archivos
Los enfoques alternativos a la copia de seguridad del sistema de archivos incluyen:
- Una instantánea coherente del directorio de datos
- La utilidad rsync
8.3.4.2.4. Recursos adicionales
Para más información sobre la copia de seguridad a nivel de sistema de archivos, consulte la documentación de PostgreSQL.
8.3.4.3. Copia de seguridad de los datos de PostgreSQL mediante archivo continuo
8.3.4.3.1. Introducción al archivo continuo
PostgreSQL registra todos los cambios realizados en los archivos de datos de la base de datos en un archivo de registro de escritura (WAL) que está disponible en el subdirectorio pg_wal/ del directorio de datos del clúster. Este registro está pensado principalmente para la recuperación de un fallo. Después de una caída, las entradas del registro realizadas desde el último punto de control pueden utilizarse para restaurar la consistencia de la base de datos.
El método de archivo continuo, también conocido como online backup, combina los archivos WAL con una copia de seguridad a nivel del sistema de archivos. Si se necesita una recuperación de la base de datos, se puede restaurar la base de datos a partir de la copia de seguridad del sistema de archivos y, a continuación, reproducir el registro de los archivos WAL respaldados para llevar el sistema al estado actual.
Para este método de copia de seguridad, se necesita una secuencia continua de archivos WAL archivados que se remonte al menos a la hora de inicio de la copia de seguridad.
Si quiere empezar a utilizar el método de copia de seguridad de archivo continuo, asegúrese de configurar y probar su procedimiento para archivar los archivos WAL antes de realizar su primera copia de seguridad base.
No se puede utilizar pg_dump y pg_dumpall como parte de una solución de copia de seguridad de archivo continuo. Estos volcados producen copias de seguridad lógicas, no copias de seguridad a nivel de sistema de archivos. Como tal, no contienen suficiente información para ser utilizada por una repetición de WAL.
8.3.4.3.2. Realización de copias de seguridad de archivo continuo
Para realizar una copia de seguridad y restauración de la base de datos utilizando el método de archivo continuo, siga estos pasos:
8.3.4.3.2.1. Hacer una copia de seguridad de la base
Para realizar una copia de seguridad base, utilice la herramienta pg_basebackup que puede crear una copia de seguridad base en forma de archivos individuales o de un archivo tar.
Para utilizar la copia de seguridad básica, es necesario conservar todos los archivos de segmentos WAL generados durante y después de la copia de seguridad del sistema de archivos. El proceso de copia de seguridad básica crea un archivo de historial de copias de seguridad que se almacena en el área de archivo WAL y recibe el nombre del primer archivo de segmentos WAL que se necesita para la copia de seguridad del sistema de archivos. Cuando haya archivado de forma segura la copia de seguridad del sistema de archivos y los archivos de segmentos WAL utilizados durante la copia de seguridad, que se especifican en el archivo de historial de copias de seguridad, puede eliminar todos los segmentos WAL archivados con nombres numéricamente menores porque ya no son necesarios para recuperar la copia de seguridad del sistema de archivos. Sin embargo, considere la posibilidad de mantener varios conjuntos de copias de seguridad para estar seguro de que puede recuperar sus datos.
El archivo del historial de la copia de seguridad es un pequeño archivo de texto, que contiene la cadena de etiquetas que le diste a pg_basebackupla hora de inicio y de finalización, y los segmentos WAL de la copia de seguridad. Si utilizó la cadena de etiquetas para identificar el archivo de volcado asociado, entonces el archivo de historial archivado es suficiente para indicarle qué archivo de volcado debe restaurar.
Con el método de archivo continuo, es necesario mantener todos los archivos WAL archivados hasta la última copia de seguridad base. Por lo tanto, la frecuencia ideal de las copias de seguridad base depende de:
- El volumen de almacenamiento disponible para los archivos WAL archivados.
La duración máxima posible de la recuperación de datos en situaciones en las que es necesaria la recuperación.
En los casos en los que ha transcurrido un largo periodo desde la última copia de seguridad, el sistema vuelve a reproducir más segmentos WAL, por lo que la recuperación tarda más tiempo.
Para más información sobre cómo hacer una copia de seguridad de la base, consulte la documentación de PostgreSQL.
8.3.4.3.2.2. Restauración de la base de datos mediante una copia de seguridad de archivo continuo
Para restaurar una base de datos utilizando una copia de seguridad continua:
Detener el servidor:
# systemctl stop postgresql.service
Copie los datos necesarios en una ubicación temporal.
Preferiblemente, copie todo el directorio de datos del clúster y cualquier tablespace. Tenga en cuenta que esto requiere suficiente espacio libre en su sistema para mantener dos copias de su base de datos existente.
Si no tiene suficiente espacio, guarde el contenido del directorio
pg_waldel clúster, que puede contener registros que no fueron archivados antes de que el sistema se cayera.- Elimine todos los archivos y subdirectorios existentes en el directorio de datos del clúster y en los directorios raíz de los tablespaces que esté utilizando.
Restaurar los archivos de la base de datos desde la copia de seguridad del sistema de archivos.
Asegúrate de que:
-
Los archivos se restauran con la propiedad correcta (el usuario del sistema de la base de datos, no
root) - Los archivos se restauran con los permisos correctos
-
Los enlaces simbólicos en el subdirectorio
pg_tblspc/se han restaurado correctamente
-
Los archivos se restauran con la propiedad correcta (el usuario del sistema de la base de datos, no
Eliminar los archivos presentes en el subdirectorio
pg_wal/Estos archivos proceden de la copia de seguridad del sistema de archivos y, por tanto, son obsoletos. Si no archivó
pg_wal/, vuelva a crearlo con los permisos adecuados.-
Copie los archivos de segmentos de WAL no archivados que guardó en el paso 2 en
pg_wal/, si es que existen tales archivos. -
Cree el archivo de comandos de recuperación
recovery.confen el directorio de datos del clúster. Inicie el servidor:
# systemctl start postgresql.service
El servidor entrará en el modo de recuperación y procederá a leer los ficheros WAL archivados que necesite.
Si la recuperación se interrumpe debido a un error externo, basta con reiniciar el servidor para que continúe la recuperación. Cuando el proceso de recuperación finaliza, el servidor cambia el nombre de
recovery.confarecovery.donepara evitar que se vuelva a entrar accidentalmente en el modo de recuperación más adelante, cuando el servidor inicie las operaciones normales de la base de datos.Compruebe el contenido de la base de datos para asegurarse de que la base de datos se ha recuperado en el estado requerido.
Si la base de datos no se ha recuperado en el estado requerido, vuelva al paso 1. Si la base de datos se ha recuperado en el estado requerido, permita que los usuarios se conecten restaurando el archivo
pg_hba.confa la normalidad.
Para obtener más información sobre la restauración mediante la copia de seguridad continua, consulte la documentación de PostgreSQL.
8.3.4.3.3. Ventajas y desventajas del archivo continuo
El archivo continuo tiene las siguientes ventajas en comparación con otros métodos de copia de seguridad de PostgreSQL:
-
Con el método de copia de seguridad continua, es posible utilizar una copia de seguridad del sistema de archivos que no sea totalmente consistente porque cualquier inconsistencia interna en la copia de seguridad es corregida por la repetición del registro. No se necesita una instantánea del sistema de archivos; basta con
taro una herramienta de archivo similar. - Se puede conseguir una copia de seguridad continua si se siguen archivando los archivos WAL, ya que la secuencia de archivos WAL para la repetición del registro puede ser indefinidamente larga. Esto es especialmente valioso para las grandes bases de datos.
- La copia de seguridad continua admite la recuperación puntual. No es necesario reproducir las entradas WAL hasta el final. La reproducción puede detenerse en cualquier punto y la base de datos puede restaurarse a su estado en cualquier momento desde que se tomó la copia de seguridad base.
- Si la serie de archivos WAL está continuamente disponible para otra máquina que ha sido cargada con el mismo archivo de copia de seguridad base, es posible restaurar la otra máquina con una copia casi actual de la base de datos en cualquier momento.
El archivo continuo tiene las siguientes desventajas en comparación con otros métodos de copia de seguridad de PostgreSQL:
- El método de copia de seguridad continua sólo admite la restauración de todo un clúster de bases de datos, no de un subconjunto.
- Las copias de seguridad continuas requieren un amplio almacenamiento de archivos.
8.3.4.3.4. Recursos adicionales
Para más información sobre el método de archivo continuo, consulte la documentación de PostgreSQL.
8.3.5. Migración a la versión RHEL 8 de PostgreSQL
Red Hat Enterprise Linux 7 contiene PostgreSQL 9.2 como versión por defecto del servidor PostgreSQL. Además, se proporcionan varias versiones de PostgreSQL como Software Collections para RHEL 7 y RHEL 6.
Red Hat Enterprise Linux 8 proporciona PostgreSQL 10 (el flujo por defecto postgresql ), PostgreSQL 9.6, y PostgreSQL 12.
Los usuarios de PostgreSQL en Red Hat Enterprise Linux pueden utilizar dos rutas de migración para los archivos de la base de datos:
Utilice preferentemente el método de actualización rápida, que es más rápido que el proceso de volcado y restauración.
Sin embargo, en ciertos casos, la actualización rápida no funciona, y sólo se puede utilizar el proceso de volcado y restauración. Estos casos incluyen:
- Actualizaciones entre arquitecturas
-
Sistemas que utilizan las extensiones
plpythonoplpython2. Tenga en cuenta que el repositorio de RHEL 8 AppStream sólo incluye el paquetepostgresql-plpython3, no el paquetepostgresql-plpython2. - La actualización rápida no es compatible con la migración desde las versiones de Red Hat Software Collections de PostgreSQL.
Como requisito previo a la migración a una versión posterior de PostgreSQL, haga una copia de seguridad de todas sus bases de datos de PostgreSQL.
El volcado de las bases de datos y la realización de copias de seguridad de los archivos SQL es una parte necesaria del proceso de volcado y restauración. Sin embargo, se recomienda hacerlo también si se realiza la actualización rápida.
Antes de migrar a una versión posterior de PostgreSQL, consulte las notas de compatibilidad de la versión de PostgreSQL a la que desea migrar, así como de todas las versiones de PostgreSQL omitidas entre la que está migrando y la versión de destino.
8.3.5.1. Actualización rápida con la herramienta pg_upgrade
Durante una actualización rápida, es necesario copiar los archivos de datos binarios en el directorio /var/lib/pgsql/data/ y utilizar la herramienta pg_upgrade.
Puede utilizar este método para migrar datos:
- De la versión del sistema RHEL 7 de PostgreSQL 9.2 a la versión RHEL 8 de PostgreSQL 10
- De la versión RHEL 8 de PostgreSQL 10 a la versión RHEL 8 de PostgreSQL 12
Si desea actualizar desde un flujo anterior de postgresql dentro de RHEL 8, siga el procedimiento descrito en Cambio a un flujo posterior y luego migre sus datos de PostgreSQL.
Para migrar entre otras combinaciones de versiones de PostgreSQL dentro de RHEL, y para la migración desde las versiones de Red Hat Software Collections de PostgreSQL a RHEL, utilice Dump and restore upgrade.
Antes de realizar la actualización, haga una copia de seguridad de todos sus datos almacenados en las bases de datos de PostgreSQL.
Por defecto, todos los datos se almacenan en el directorio /var/lib/pgsql/data/ en los sistemas RHEL 7 y RHEL 8.
El siguiente procedimiento describe la migración de la versión del sistema RHEL 7 de Postgreql 9.2 a una versión RHEL 8 de PostgreSQL.
Para realizar una actualización rápida:
En el sistema RHEL 8, active el flujo (versión) al que desea migrar:
# yum module enable postgresql:stream
Sustituya stream por la versión seleccionada del servidor PostgreSQL.
Puede omitir este paso si desea utilizar el flujo por defecto, que proporciona PostgreSQL 10.
En el sistema RHEL 8, instale los paquetes
postgresql-serverypostgresql-upgrade:# yum install postgresql-server postgresql-upgrade
Opcionalmente, si ha utilizado algún módulo de servidor PostgreSQL en RHEL 7, instálelo también en el sistema RHEL 8 en dos versiones, compiladas tanto contra PostgreSQL 9.2 (instalado como paquete
postgresql-upgrade) como contra la versión de destino de PostgreSQL (instalado como paquetepostgresql-server). Si necesita compilar un módulo de servidor PostgreSQL de terceros, constrúyalo tanto contra los paquetespostgresql-develcomopostgresql-upgrade-devel.Compruebe los siguientes elementos:
-
Configuración básica: En el sistema RHEL 8, compruebe si su servidor utiliza el directorio por defecto
/var/lib/pgsql/datay si la base de datos está correctamente inicializada y habilitada. Además, los archivos de datos deben almacenarse en la misma ruta mencionada en el archivo/usr/lib/systemd/system/postgresql.service. - servidoresPostgreSQL: Su sistema puede ejecutar varios servidores PostgreSQL. Asegúrese de que los directorios de datos de todos estos servidores se manejan de forma independiente.
-
módulos del servidorPostgreSQL: Asegúrese de que los módulos del servidor PostgreSQL que utilizó en RHEL 7 están instalados también en su sistema RHEL 8. Tenga en cuenta que los complementos se instalan en el directorio
/usr/lib64/pgsql/(o en el directorio/usr/lib/pgsql/en los sistemas de 32 bits).
-
Configuración básica: En el sistema RHEL 8, compruebe si su servidor utiliza el directorio por defecto
Asegúrese de que el servicio
postgresqlno se está ejecutando en ninguno de los sistemas de origen y destino en el momento de copiar los datos.# systemctl stop postgresql.service
-
Copie los archivos de la base de datos desde la ubicación de origen al directorio
/var/lib/pgsql/data/en el sistema RHEL 8. Realice el proceso de actualización ejecutando el siguiente comando como usuario de PostgreSQL:
$ /bin/postgresql-setup --upgrade
Esto lanza el proceso
pg_upgradeen segundo plano.En caso de fallo,
postgresql-setupproporciona un mensaje de error informativo.Copie la configuración anterior de
/var/lib/pgsql/data-oldal nuevo clúster.Tenga en cuenta que la actualización rápida no reutiliza la configuración anterior en la pila de datos más nueva y la configuración se genera desde cero. Si quieres combinar la configuración antigua y la nueva manualmente, utiliza los archivos *.conf en los directorios de datos.
Inicie el nuevo servidor PostgreSQL:
# systemctl start postgresql.service
Ejecute el script
analyze_new_cluster.shque se encuentra en el directorio principal PostgreSQL:su postgres -c '~/analyze_new_cluster.sh'
Si quieres que el nuevo servidor PostgreSQL se inicie automáticamente al arrancar, ejecuta:
# systemctl enable postgresql.service
8.3.5.2. Actualización de volcado y restauración
Cuando se utiliza la actualización de volcado y restauración, es necesario volcar el contenido de todas las bases de datos en un archivo de volcado de archivos SQL.
Tenga en cuenta que la actualización de volcado y restauración es más lenta que el método de actualización rápida y puede requerir alguna corrección manual en el archivo SQL generado.
Puede utilizar este método para migrar datos de:
- La versión del sistema Red Hat Enterprise Linux 7 de PostgreSQL 9.2
- Cualquier versión anterior de Red Hat Enterprise Linux 8 de PostgreSQL
Una versión anterior o igual de PostgreSQL de Red Hat Software Collections:
- PostgreSQL 9.2 (ya no es compatible)
- PostgreSQL 9.4 (ya no es compatible)
- PostgreSQL 9.6
- PostgreSQL 10
- PostgreSQL 12
En los sistemas Red Hat Enterprise Linux 7 y Red Hat Enterprise Linux 8, los datos de PostgreSQL se almacenan por defecto en el directorio /var/lib/pgsql/data/. En el caso de las versiones de Red Hat Software Collections de PostgreSQL, el directorio de datos por defecto es /var/opt/rh/collection_name/lib/pgsql/data/ (con la excepción de postgresql92, que utiliza el directorio /opt/rh/postgresql92/root/var/lib/pgsql/data/ ).
Si desea actualizar desde un flujo anterior de postgresql dentro de RHEL 8, siga el procedimiento descrito en Cambio a un flujo posterior y luego migre sus datos de PostgreSQL.
Para realizar la actualización de volcado y restauración, cambie el usuario a root.
El siguiente procedimiento describe la migración de la versión del sistema RHEL 7 de Postgreql 9.2 a una versión RHEL 8 de PostgreSQL.
En su sistema RHEL 7, inicie el servidor PostgreSQL 9.2:
# systemctl start postgresql.service
En el sistema RHEL 7, vuelque el contenido de todas las bases de datos en el archivo
pgdump_file.sql:su - postgres -c \ "pg_dumpall > ~/pgdump_file.sql"
Asegúrese de que las bases de datos se han volcado correctamente:
su - postgres -c 'less \ "$HOME/pgdump_file.sql"'
Como resultado, se muestra la ruta del archivo sql volcado:
/var/lib/pgsql/pgdump_file.sql.En el sistema RHEL 8, active el flujo (versión) al que desea migrar:
# yum module enable postgresql:stream
Sustituya stream por la versión seleccionada del servidor PostgreSQL.
Puede omitir este paso si desea utilizar el flujo por defecto, que proporciona PostgreSQL 10.
En el sistema RHEL 8, instale el paquete
postgresql-server:# yum install postgresql-server
Opcionalmente, si ha utilizado algún módulo de servidor PostgreSQL en RHEL 7, instálelo también en el sistema RHEL 8. Si necesita compilar un módulo de servidor PostgreSQL de un tercero, constrúyalo con el paquete
postgresql-devel.En el sistema RHEL 8, inicialice el directorio de datos para el nuevo servidor PostgreSQL:
# postgresql-setup --initdb
En el sistema RHEL 8, copie el
pgdump_file.sqlen el directorio principal PostgreSQL y compruebe que el archivo se ha copiado correctamente:su - postgres -c 'test -e \ "$HOME/pgdump_file.sql" && echo exists'
Copie los archivos de configuración del sistema RHEL 7:
su - postgres -c 'ls -1 $PGDATA/*.conf'
Los archivos de configuración que deben copiarse son:
-
/var/lib/pgsql/data/pg_hba.conf -
/var/lib/pgsql/data/pg_ident.conf -
/var/lib/pgsql/data/postgresql.conf
-
En el sistema RHEL 8, inicie el nuevo servidor PostgreSQL:
# systemctl start postgresql.service
En el sistema RHEL 8, importe los datos del archivo sql volcado:
su - postgres -c 'psql -f ~/pgdump_file.sql postgres'
Cuando se actualice desde una versión de Red Hat Software Collections de PostgreSQL, ajuste los comandos para incluir scl enable collection_name.. Por ejemplo, para volcar los datos de la Colección de Software rh-postgresql96, utilice el siguiente comando:
su - postgres -c 'scl enable rh-postgresql96 \ "pg_dumpall > ~/pgdump_file.sql"'
Capítulo 9. Configuración de la impresión
La impresión en Red Hat Enterprise Linux 8 se basa en el sistema de impresión común de Unix (CUPS).
Esta documentación describe cómo configurar una máquina para que pueda funcionar como servidor CUPS.
9.1. Activación del servicio de copas
Esta sección describe cómo activar el servicio cups en su sistema.
Requisitos previos
El paquete
cups, que está disponible en el repositorio de Appstream, debe estar instalado en tu sistema:# yum install cups
Procedimiento
Inicie el servicio
cups:# systemctl start cups
Configure el servicio
cupspara que se inicie automáticamente en el momento del arranque:# systemctl enable cups
Opcionalmente, compruebe el estado del servicio
cups:$ systemctl status cups
9.2. Herramientas de configuración de la impresión
Para realizar diversas tareas relacionadas con la impresión, puede elegir una de las siguientes herramientas:
- CUPS web user interface (UI)
- GNOME Control center
La herramienta de configuración Print Settings herramienta de configuración, que se utilizaba en Red Hat Enterprise Linux 7, ya no está disponible.
Entre las tareas que puedes realizar con estas herramientas se encuentran:
- Añadir y configurar una nueva impresora
- Mantener la configuración de la impresora
- Gestión de las clases de impresoras
Tenga en cuenta que esta documentación sólo cubre la impresión en CUPS web user interface (UI). Si quiere imprimir con GNOME Control centernecesita tener una GUI disponible. Para más información sobre la impresión con GNOME Control centervea Manejo de la impresión a partir de GNOME.
9.3. Acceso y configuración de la interfaz web de CUPS
Esta sección describe el acceso a la CUPS web user interface) (web UI) y la configuración para poder gestionar la impresión a través de esta interfaz.
Procedimiento
Para acceder a la página web CUPS web UI:
Permita que el servidor CUPS escuche las conexiones de la red estableciendo
Port 631en el archivo/etc/cups/cupsd.conf:#Listen localhost:631 Port 631
AvisoAl habilitar el servidor CUPS para que escuche en el puerto 631 se abre este puerto para cualquier dirección accesible por el servidor. Por lo tanto, utilice esta configuración sólo en redes locales que sean inalcanzables desde una red externa. Si un servidor necesita ser accesible desde una red externa, pero quiere abrir el puerto 631 sólo para su red local, configure lo siguiente en el archivo
/etc/cups/cupsd.conf:#Listen <server_local_IP_address>:631, donde <server_local_IP_address> es una dirección IP inalcanzable desde una red externa, pero está disponible para las máquinas locales.Permita que su sistema acceda al servidor CUPS incluyendo lo siguiente en el archivo
/etc/cups/cupsd.conf:<Location /> Allow from <your_ip_address> Order allow,deny </Location>
donde <your_ip_address> es la dirección IP real de su sistema. También puede utilizar expresiones regulares para las subredes.
AvisoLa configuración de CUPS ofrece la directiva
Allow from allen las etiquetas <Location>, pero Red Hat no recomienda usarla, a menos que quiera abrir CUPS a la red externa de Internet, o si el servidor está en una red privada. La configuraciónAllow from allpermite el acceso a todos los usuarios que puedan conectarse al servidor a través del puerto 631. Si establece la directivaPorten 631, y el servidor es accesible desde una red externa, cualquier persona en Internet puede acceder al servicio CUPS en su sistema.Reinicie el servicio cups.service:
# systemctl restart cups
Abra su navegador y vaya a
http://<IP_address_of_the_CUPS_server>:631/.
Ya están disponibles todos los menús, excepto el de
Administration.Si hace clic en el menú
Administration, recibirá el mensaje Forbidden:
Para adquirir el acceso al menú
Administration, siga las instrucciones de Sección 9.3.1, “Adquirir acceso de administración a la interfaz web de CUPS”.
9.3.1. Adquirir acceso de administración a la interfaz web de CUPS
Esta sección describe cómo adquirir acceso de administración al CUPS web UI.
Procedimiento
Para poder acceder al menú
Administationen el CUPS web UIincluya lo siguiente en el archivo/etc/cups/cupsd.conf:<Location /admin> Allow from <your_ip_address> Order allow,deny </Location>
NotaSustituya
<your_ip_address>por la dirección IP real de su sistema.Para poder acceder a los archivos de configuración en el CUPS web UIincluya lo siguiente en el archivo
/etc/cups/cupsd.conf:<Location /admin/conf> AuthType Default Require user @SYSTEM Allow from <your_ip_address> Order allow,deny </Location>
NotaSustituya
<your_ip_address>por la dirección IP real de su sistema.Para poder acceder a los archivos de registro en el CUPS web UIincluya lo siguiente en el archivo
/etc/cups/cupsd.conf:<Location /admin/log> AuthType Default Require user @SYSTEM Allow from <your_ip_address> Order allow,deny </Location>
NotaSustituya
<your_ip_address>por la dirección IP real de su sistema.Para especificar el uso de la encriptación para las peticiones autenticadas en el CUPS web UIincluya
DefaultEncryptionen el archivo/etc/cups/cupsd.conf:Encriptación por defecto IfRequested
Con esta configuración, recibirá una ventana de autenticación para introducir el nombre de usuario de un usuario autorizado a añadir impresoras cuando intente acceder al menú
Administration. Sin embargo, también hay otras opciones cómo configurarDefaultEncryption. Para más detalles, consulte la página man decupsd.conf.Reinicie el servicio
cups:# systemctl restart cups
AvisoSi no reinicia el servicio
cups, los cambios en/etc/cups/cupsd.confno se aplicarán. Por lo tanto, no podrá obtener acceso de administración al servicio CUPS web UI.
Recursos adicionales
-
Para más información sobre cómo configurar un servidor CUPS utilizando el archivo
/etc/cups/cupsd.conf, consulte la página de manualcupsd.conf.
9.4. Añadir una impresora en la interfaz web de CUPS
Esta sección describe cómo añadir una nueva impresora utilizando la opción CUPS web user interface.
Requisitos previos
- Usted ha adquirido el acceso de administración al CUPS web UI como se describe en Sección 9.3.1, “Adquirir acceso de administración a la interfaz web de CUPS”.
Procedimiento
- Inicie el CUPS web UI como se describe en Sección 9.3, “Acceso y configuración de la interfaz web de CUPS”
Ir a
Adding Printers and Classes-Add printer
Autenticación por nombre de usuario y contraseña:
 Importante
ImportantePara poder añadir una nueva impresora mediante el botón CUPS web UIdebe autenticarse como uno de los siguientes usuarios:
- Superusuario
-
Cualquier usuario con el acceso de administración proporcionado por el comando
sudo(usuarios listados en/etc/sudoers) -
Cualquier usuario perteneciente al grupo
printadminen/etc/group
Si hay una impresora local conectada, o CUPS encuentra una impresora de red disponible, seleccione la impresora. Si no hay ninguna impresora local ni de red disponible, seleccione uno de los tipos de impresora de
Other Network Printers, por ejemplo APP Socket/HP Jet direct, introduzca la dirección IP de la impresora y haga clic enContinue.
Si ha seleccionado, por ejemplo, APP Socket/HP Jet direct como se muestra arriba, introduzca la dirección IP de la impresora y, a continuación, haga clic en
Continue.
Puede añadir más detalles sobre la nueva impresora, como el nombre, la descripción y la ubicación. Para configurar una impresora para que se comparta en la red, utilice
Share This Printercomo se muestra a continuación.
Seleccione el fabricante de la impresora y haga clic en
Continue.
También puede proporcionar un archivo de descripción de impresora postscript (PPD) que se utilizará como controlador para la impresora, haciendo clic en
Browse…en la parte inferior.Seleccione el modelo de la impresora y, a continuación, haga clic en
Add Printer.
Una vez añadida la impresora, la siguiente ventana permite establecer las opciones de impresión por defecto.
Tras hacer clic en Set Default Options, recibirá una confirmación de que la nueva impresora se ha añadido correctamente.

9.5. Configurar una impresora en la interfaz web de CUPS
Esta sección describe cómo configurar una nueva impresora, y cómo mantener la configuración de una impresora utilizando el CUPS web UI.
Requisitos previos
- Usted ha adquirido el acceso de administración al CUPS web UI como se describe en Sección 9.3.1, “Adquirir acceso de administración a la interfaz web de CUPS”.
Procedimiento
Haga clic en el menú
Printerspara ver las impresoras disponibles que puede configurar.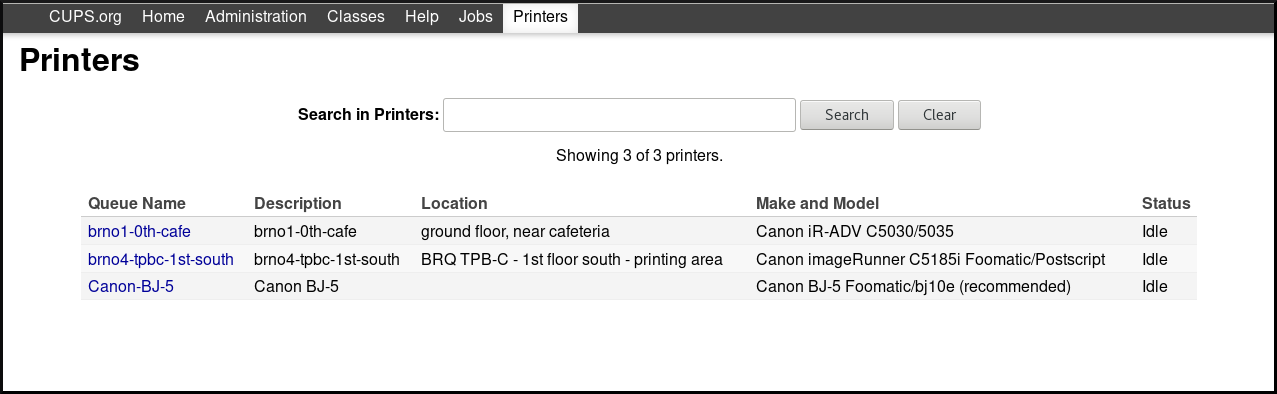
Elija una impresora que desee configurar.
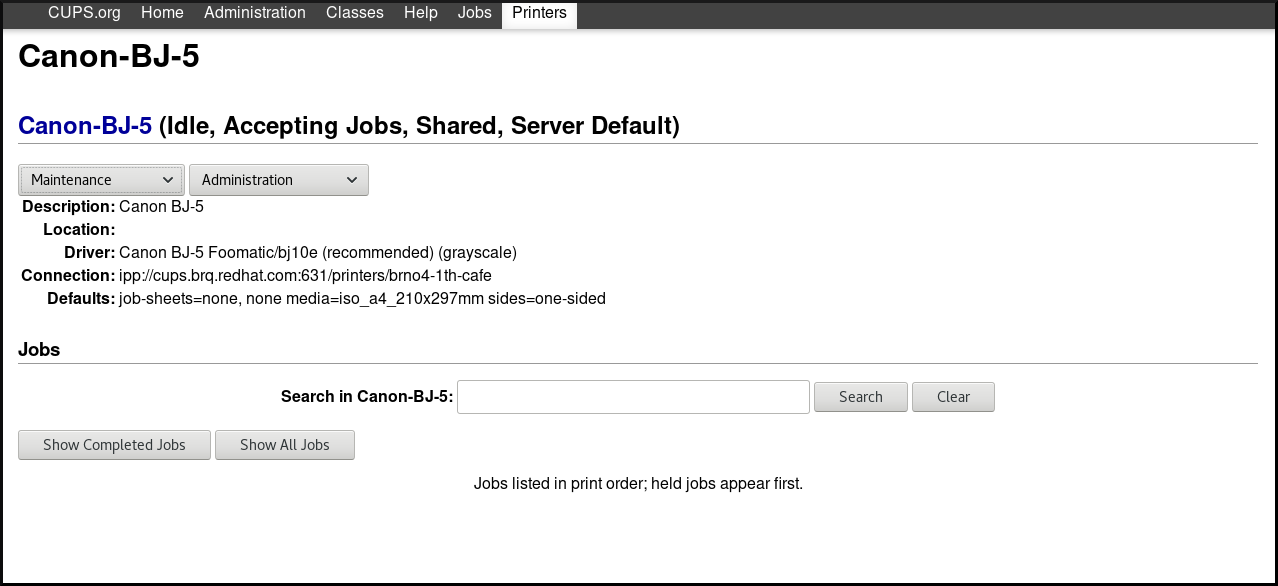
Realice la tarea seleccionada utilizando uno de los menús disponibles:
Vaya a
Maintenancepara las tareas de mantenimiento.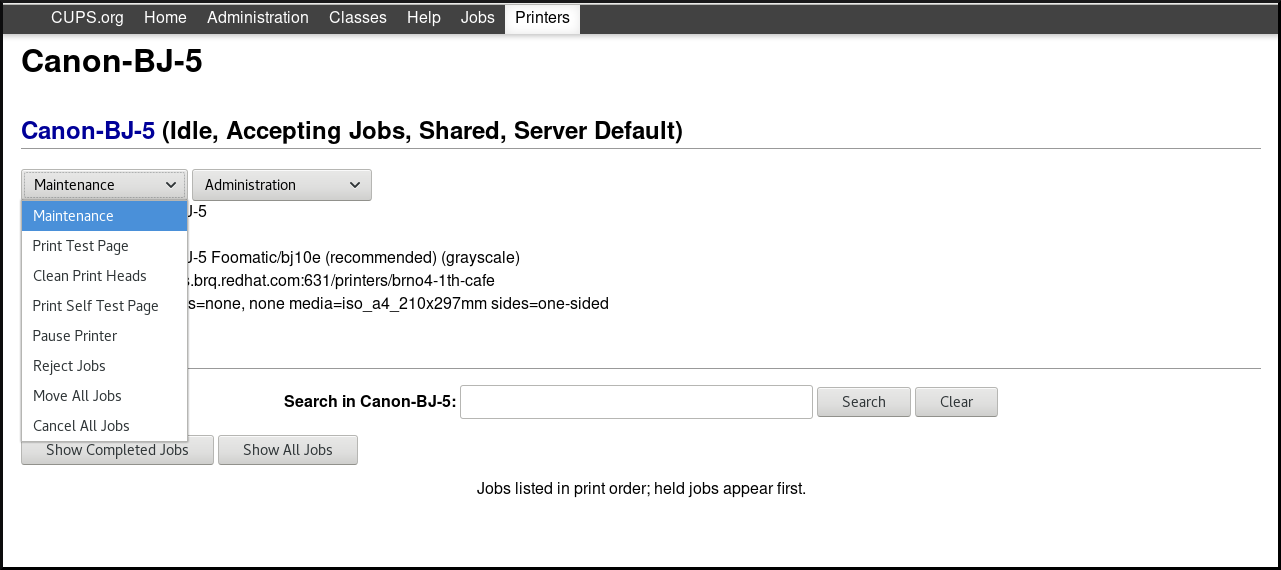
Vaya a
Administrationpara las tareas de administración.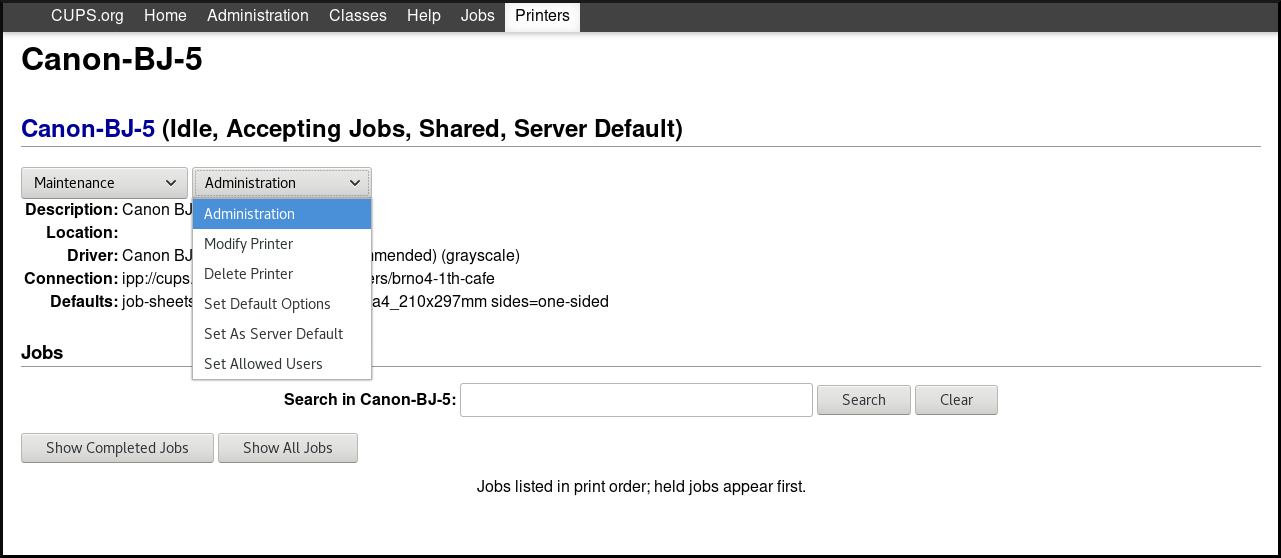
-
También puede comprobar los trabajos de impresión completados o todos los trabajos de impresión activos haciendo clic en los botones
Show Completed JobsoShow All Jobs.
9.6. Impresión de una página de prueba mediante la interfaz web de CUPS
Esta sección describe cómo imprimir una página de prueba para asegurarse de que la impresora funciona correctamente.
Es posible que desee imprimir una página de prueba si se cumple una de las siguientes condiciones.
- Se ha instalado una impresora.
- Se ha modificado la configuración de una impresora.
Requisitos previos
Usted ha adquirido el acceso de administración al CUPS web UI como se describe en Sección 9.3.1, “Adquirir acceso de administración a la interfaz web de CUPS”.
Procedimiento
Vaya al menú
Printersy haga clic enMaintenance→Print Test Page.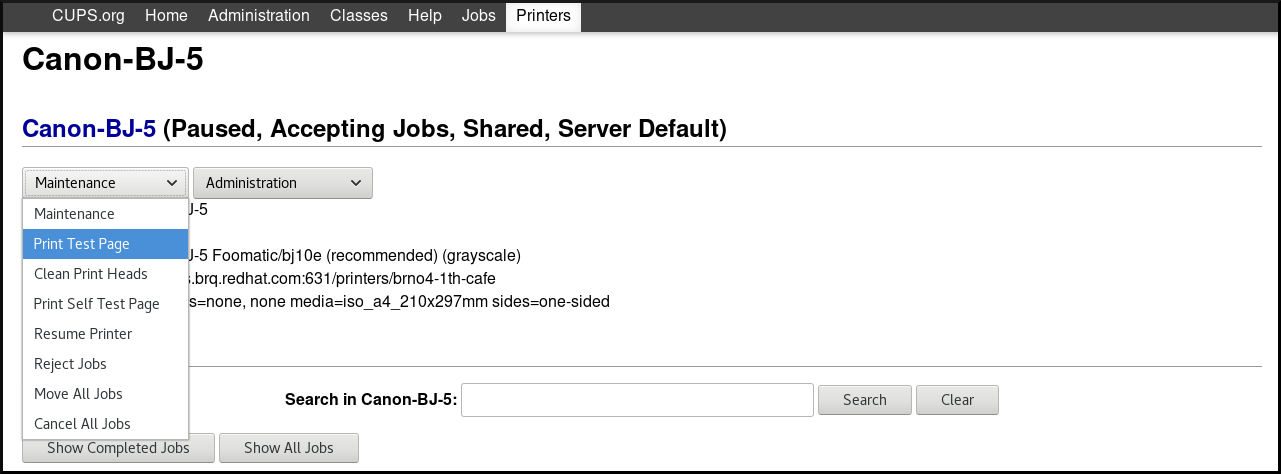
9.7. Configuración de las opciones de impresión mediante la interfaz web de CUPS
Esta sección describe cómo configurar las opciones de impresión más comunes, como el tamaño y el tipo de soporte, la calidad de impresión o el modo de color, en el CUPS web UI.
Requisitos previos
Usted ha adquirido el acceso de administración al CUPS web UI como se describe en Sección 9.3.1, “Adquirir acceso de administración a la interfaz web de CUPS”.
Procedimiento
Vaya al menú
Administrationy haga clic enMaintenance→Set Default Options.
Configure las opciones de impresión.
9.8. Instalación de certificados para un servidor de impresión
Para instalar certificados para un servidor de impresión, puede elegir una de las siguientes opciones:
- Instalación automática mediante un certificado autofirmado
- Instalación manual utilizando un certificado y una clave privada generados por una Autoridad de Certificación
Requisitos previos
Para el demonio cupsd en el servidor:
Establezca la siguiente directiva en el archivo
/etc/cups/cupsd.conf:Encryption RequiredReinicie el servicio de tazas:
$ sudo systemctl restart cups
Automatic installation using a self-signed certificate
Con esta opción, CUPS genera el certificado y la clave automáticamente.
El certificado autofirmado no proporciona una seguridad tan fuerte como los certificados generados por las Autoridades de Certificación de Gestión de Identidades (IdM), Directorio Activo (AD) o Red Hat Certificate System (RHCS), pero puede ser utilizado para servidores de impresión ubicados dentro de una red local segura.
Procedimiento
Para acceder a la interfaz web de CUPS, abra su navegador y vaya a
https://<server>:631donde <server> es la dirección IP o el nombre del servidor.
NotaCuando CUPS se conecta a un sistema por primera vez, el navegador muestra una advertencia acerca de que el certificado autofirmado es un riesgo potencial para la seguridad.
Para confirmar que es seguro proceder, haga clic en
Advanced….
Haga clic en
Accept the Risk and Continue.
CUPS comienza ahora a utilizar el certificado autogenerado y la clave.
Cuando accede a la interfaz web de CUPS después de la instalación automática, el navegador muestra un icono de advertencia en la barra de direcciones. Esto se debe a que ha añadido la excepción de seguridad confirmando la advertencia de riesgo de seguridad. Si desea eliminar este icono de advertencia de forma permanente, realice la instalación manual con un certificado y una clave privada generados por una Autoridad de Certificación.
Manual installation using a certificate and a private key generated by a Certification Authority
Para los servidores de impresión situados en una red pública o para eliminar permanentemente la advertencia en el navegador, importe el certificado y la clave manualmente.
Requisitos previos
- Tiene archivos de certificados y claves privadas generados por IdM, AD o por las Autoridades de Certificación RHCS.
Procedimiento
-
Copie los archivos
.crty.keyen el directorio/etc/cups/ssldel sistema en el que desea utilizar la interfaz web de CUPS. Cambie el nombre de los archivos copiados a
<hostname>.crty<hostname>.key.Sustituya <hostname> por el nombre del sistema al que desea conectar la interfaz web de CUPS.
Establezca los siguientes permisos para los archivos renombrados:
-
# chmod 644 /etc/cups/ssl/<hostname>.crt -
# chmod 644 /etc/cups/ssl/<hostname>.key -
# chown root:root /etc/cups/ssl/<hostname>.crt -
# chown root:root /etc/cups/ssl/<hostname>.key
-
Reinicie el servicio de tazas:
-
# systemctl restart cupsd
-
9.9. Uso de Samba para imprimir en un servidor de impresión de Windows con autenticación Kerberos
Con la envoltura samba-krb5-printing, los usuarios de Active Directory (AD) que han iniciado sesión en Red Hat Enterprise Linux pueden autenticarse en Active Directory (AD) utilizando Kerberos y luego imprimir en un servidor de impresión CUPS local que reenvía el trabajo de impresión a un servidor de impresión Windows.
El beneficio de esta configuración es que el administrador de CUPS en Red Hat Enterprise Linux no necesita almacenar un nombre de usuario y contraseña fijos en la configuración. CUPS se autentifica en AD con el ticket Kerberos del usuario que envía el trabajo de impresión.
Esta sección describe cómo configurar CUPS para este escenario.
Red Hat sólo soporta el envío de trabajos de impresión a CUPS desde su sistema local, y no para volver a compartir una impresora en un servidor de impresión Samba.
Requisitos previos
- La impresora que desea añadir a la instancia local de CUPS está compartida en un servidor de impresión de AD.
- Usted se unió al host de Red Hat Enterprise Linux como miembro del AD. Para más detalles, consulte Sección 3.5.1, “Unir un sistema RHEL a un dominio AD”.
-
CUPS está instalado en Red Hat Enterprise Linux y el servicio
cupsestá funcionando. Para más detalles, consulte Sección 9.1, “Activación del servicio de copas”. -
El archivo PostScript Printer Description (PPD) de la impresora se almacena en el directorio
/usr/share/cups/model/.
Procedimiento
Instale los paquetes
samba-krb5-printing,samba-client, ykrb5-workstation:# yum install samba-krb5-printing samba-client krb5-workstation
Opcional: Autenticarse como administrador de dominio y mostrar la lista de impresoras que se comparten en el servidor de impresión de Windows:
# kinit administrator@AD_KERBEROS_REALM # smbclient -L win_print_srv.ad.example.com -k Sharename Type Comment --------- ---- ------- ... Example Printer Example ...
Opcional: Muestra la lista de modelos CUPS para identificar el nombre PPD de su impresora:
lpinfo -m ... samsung.ppd Samsung M267x 287x Series PXL ...Necesitará el nombre del archivo PPD cuando añada la impresora en el siguiente paso.
Añade la impresora a CUPS:
# lpadmin -p "example_printer" -v smb://win_print_srv.ad.example.com/Example -m samsung.ppd -o auth-info-required=negotiate -E
El comando utiliza las siguientes opciones:
-
-p printer_nameestablece el nombre de la impresora en CUPS. -
-v URI_to_Windows_printerestablece el URI de la impresora de Windows. Utilice el siguiente formatosmb://host_name/printer_share_name. -
-m PPD_fileestablece el archivo PPD que utiliza la impresora. -
-o auth-info-required=negotiateconfigura CUPS para que utilice la autenticación Kerberos cuando reenvíe los trabajos de impresión al servidor remoto. -
-Ehabilita la impresora y CUPS acepta trabajos para la impresora.
-
Pasos de verificación
- Inicie sesión en el host de Red Hat Enterprise Linux como usuario de dominio de AD.
Autenticarse como un usuario del dominio AD:
# kinit domain_user_name@AD_KERBEROS_REALM
Imprime un archivo en la impresora que has añadido al servidor de impresión local CUPS:
# lp -d example_printer file
9.10. Trabajar con los registros de CUPS
9.10.1. Tipos de registros CUPS
CUPS proporciona tres tipos diferentes de registros:
- Registro de errores - Almacena mensajes de error, advertencias y mensajes de depuración.
- Registro de acceso - Almacena mensajes sobre el número de veces que se ha accedido a los clientes CUPS y a la interfaz web.
- Registro de páginas - Almacena mensajes sobre el número total de páginas impresas para cada trabajo de impresión.
En Red Hat Enterprise Linux 8, los tres tipos se registran de forma centralizada en systemd-journald junto con los registros de otros programas.
En Red Hat Enterprise Linux 8, los registros ya no se almacenan en archivos específicos dentro del directorio /var/log/cups, que se utilizaba en Red Hat Enterprise Linux 7.
9.10.2. Acceso a los registros de CUPS
Esta sección describe cómo acceder:
- Todos los registros de CUPS
- Registros de CUPS para un trabajo de impresión específico
- Registros CUPS en un plazo determinado
9.10.2.1. Acceso a todos los registros de CUPS
Procedimiento
- Filtrar los registros de CUPS desde systemd-journald:
$ journalctl -u cups
9.10.2.2. Acceso a los registros de CUPS para un trabajo de impresión específico
Procedimiento
- Filtrar los registros de un trabajo de impresión específico:
$ journalctl -u cups JID=N
Donde N es el número de un trabajo de impresión.
9.10.2.3. Acceder a los registros de CUPS por un periodo de tiempo específico
Procedimiento
- Filtra los registros dentro del marco de tiempo especificado:
$ journalctl -u cups --since=YYY-MM-DD --until=YYY-MM-DD
Donde YYYY es el año, MM es el mes y DD es el día.
9.10.3. Configuración de la ubicación del registro de CUPS
Esta sección describe cómo configurar la ubicación de los registros de CUPS.
En Red Hat Enterprise Linux 8, los registros de CUPS se registran por defecto en systemd-journald, lo que se asegura mediante la siguiente configuración por defecto en el archivo /etc/cups/cups-files.conf:
ErrorLog syslog
Red Hat recomienda mantener la ubicación por defecto de los registros de CUPS.
Si desea enviar los registros a una ubicación diferente, debe cambiar la configuración en el archivo /etc/cups/cups-files.conf de la siguiente manera:
ErrorLog <su_ubicación_requerida>
Si cambia la ubicación por defecto del registro de CUPS, puede experimentar un comportamiento inesperado o problemas con SELinux.
contexto: configuración-impresión
contexto: Desplegando-diferentes-tipos-de-servidores