
8.4. Splitter
8.4.1. 개요
splitter 는 들어오는 메시지를 일련의 발신 메시지로 분할하는 라우터 유형입니다. 발신 메시지의 각 메시지에는 원본 메시지의 일부가 포함되어 있습니다. Apache Camel에서 그림 8.4. “Splitter 패턴” 에 표시된 splitter 패턴은 split() Java DSL 명령으로 구현됩니다.
그림 8.4. Splitter 패턴
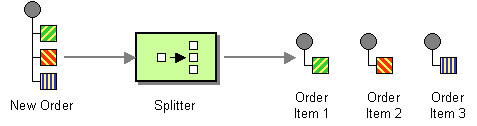
Apache Camel splitter는 다음과 같이 실제로 두 가지 패턴을 지원합니다.
- 단순 분할 기 Cryostat-반드기 패턴을 자체적으로 구현합니다.
- Splitter/aggregator kafka- Cryostat는 메시지 조각이 처리된 후 메시지의 조각이 다시 조합되도록 집계기 패턴과 함께 분할 패턴을 결합합니다.
splitter가 원본 메시지를 여러 부분으로 분리하기 전에 원본 메시지의 부분 복사본을 만듭니다. 단순 복사본에서는 원본 메시지의 헤더와 페이로드가 참조로만 복사됩니다. splitter는 결과 메시지 부분을 다른 끝점으로 라우팅하지 않지만 분할 메시지의 일부는 보조 라우팅을 받을 수 있습니다.
메시지 부분은 부분 복사본이므로 원래 메시지에 연결된 상태로 유지됩니다. 따라서 독립적으로 수정할 수 없습니다. 일련의 엔드포인트로 라우팅하기 전에 메시지 부분의 다른 사본에 사용자 지정 논리를 적용하려면 splitter 절에서 onPrepareRef DSL 옵션을 사용하여 원래 메시지의 깊은 복사본을 만들어야 합니다. 옵션 사용에 대한 자세한 내용은 “옵션” 을 참조하십시오.
8.4.2. Java DSL 예
다음 예제에서는 들어오는 메시지의 각 행을 별도의 발신 메시지로 변환하여 메시지를 분할하는 seda:a 에서 seda:b 로 경로를 정의합니다.
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.split(bodyAs(String.class).tokenize("\n"))
.to("seda:b");
}
};
splitter는 모든 표현식 언어를 사용할 수 있으므로 Cryostat, XQuery 또는 SQL과 같은 지원되는 스크립팅 언어를 사용하여 메시지를 분할할 수 있습니다( II 부. 라우팅 표현식 및 서술자 언어참조). 다음 예제에서는 들어오는 메시지에서 bar 요소를 추출하여 별도의 발신 메시지에 삽입합니다.
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file://some/directory")8.4.3. XML 구성 예
다음 예제에서는 Cryostat 스크립팅 언어를 사용하여 XML로 splitter 경로를 구성하는 방법을 보여줍니다.
<camelContext id="buildSplitter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="seda:b"/>
</split>
</route>
</camelContext>
XML DSL에서 tokenize 표현식을 사용하여 토큰을 사용하여 본문 또는 헤더를 분할할 수 있습니다. 여기서 tokenize 표현식은 tokenize 요소를 사용하여 정의됩니다. 다음 예에서 메시지 본문은 \n 구분 기호 문자를 사용하여 토큰화됩니다. 정규식 패턴을 사용하려면 tokenize 요소에서 regex=true 를 설정합니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<split>
<tokenize token="\n"/>
<to uri="mock:result"/>
</split>
</route>
</camelContext>8.4.4. 행 그룹으로 분할
큰 파일을 1000 줄의 청크로 분할하려면 Java DSL에서 다음과 같이 splitter 경로를 정의할 수 있습니다.
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");
tokenize 의 두 번째 인수는 단일 청크로 그룹화해야 하는 행 수를 지정합니다. streaming() 절에서는 splitter에서 한 번에 전체 파일을 읽지 않도록 지시합니다(파일이 클 경우 성능이 훨씬 향상됩니다).
다음과 같이 XML DSL에 동일한 경로를 정의할 수 있습니다.
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>
group 옵션을 사용하는 경우 출력은 항상 java.lang.String 유형입니다.
8.4.5. 첫 번째 항목 건너뛰기
메시지의 첫 번째 항목을 건너뛰려면 skipFirst 옵션을 사용하면 됩니다.
Java DSL에서 tokenize 매개변수 true 에서 세 번째 옵션을 설정합니다.
from("direct:start")
// split by new line and group by 3, and skip the very first element
.split().tokenize("\n", 3, true).streaming()
.to("mock:group");다음과 같이 XML DSL에 동일한 경로를 정의할 수 있습니다.
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000" skipFirst="true" />
<to uri="activemq:queue:order"/>
</split>
</route>8.4.6. Splitter 응답
splitter에 들어오는 교환에 In Out 메시지 교환 패턴(즉, 응답이 예상)이 있는 경우 splitter는 메시지 슬롯의 응답 메시지로 원본 입력 메시지의 복사본을 반환합니다. 자체 집계 전략을 구현하여 이 기본 동작을 재정의할 수 있습니다.
8.4.7. 병렬 실행
결과적인 메시지 조각을 병렬로 실행하려는 경우 병렬 처리 옵션을 활성화하여 메시지 조각을 처리하도록 스레드 풀을 인스턴스화할 수 있습니다. 예를 들면 다음과 같습니다.
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
from("activemq:my.queue").split(xPathBuilder).parallelProcessing().to("activemq:my.parts");
병렬 분할기에서 사용되는 기본 ThreadPoolExecutor 를 사용자 지정할 수 있습니다. 예를 들어 다음과 같이 Java DSL에서 사용자 지정 executor를 지정할 수 있습니다.
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
from("activemq:my.queue")
.split(xPathBuilder)
.parallelProcessing()
.executorService(threadPoolExecutor)
.to("activemq:my.parts");다음과 같이 XML DSL에서 사용자 지정 executor를 지정할 수 있습니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:parallel-custom-pool"/>
<split executorServiceRef="threadPoolExecutor">
<xpath>/invoice/lineItems</xpath>
<to uri="mock:result"/>
</split>
</route>
</camelContext>
<bean id="threadPoolExecutor" class="java.util.concurrent.ThreadPoolExecutor">
<constructor-arg index="0" value="8"/>
<constructor-arg index="1" value="16"/>
<constructor-arg index="2" value="0"/>
<constructor-arg index="3" value="MILLISECONDS"/>
<constructor-arg index="4"><bean class="java.util.concurrent.LinkedBlockingQueue"/></constructor-arg>
</bean>8.4.8. 빈을 사용하여 분할 수행
splitter는 임의의 표현식을 사용하여 분할을 수행할 수 있으므로 method() 표현식을 호출하여 빈을 사용하여 분할을 수행할 수 있습니다. Cryostat는 java.util.Collection,java.util.Iterator 또는 배열과 같은 반복 가능한 값을 반환해야 합니다.
다음 경로는 my CryostatterBean -20 instances에서 메서드를 호출하는 method() 표현식을 정의합니다.
from("direct:body")
// here we use a POJO bean mySplitterBean to do the split of the payload
.split()
.method("mySplitterBean", "splitBody")
.to("mock:result");
from("direct:message")
// here we use a POJO bean mySplitterBean to do the split of the message
// with a certain header value
.split()
.method("mySplitterBean", "splitMessage")
.to("mock:result");
여기서 my CryostatterBean 은 다음과 같이 정의된 My CryostatterBean 클래스의 인스턴스입니다.
public class MySplitterBean {
/**
* The split body method returns something that is iteratable such as a java.util.List.
*
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<String> splitBody(String body) {
// since this is based on an unit test you can of couse
// use different logic for splitting as {router} have out
// of the box support for splitting a String based on comma
// but this is for show and tell, since this is java code
// you have the full power how you like to split your messages
List<String> answer = new ArrayList<String>();
String[] parts = body.split(",");
for (String part : parts) {
answer.add(part);
}
return answer;
}
/**
* The split message method returns something that is iteratable such as a java.util.List.
*
* @param header the header of the incoming message with the name user
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<Message> splitMessage(@Header(value = "user") String header, @Body String body) {
// we can leverage the Parameter Binding Annotations
// http://camel.apache.org/parameter-binding-annotations.html
// to access the message header and body at same time,
// then create the message that we want, splitter will
// take care rest of them.
// *NOTE* this feature requires {router} version >= 1.6.1
List<Message> answer = new ArrayList<Message>();
String[] parts = header.split(",");
for (String part : parts) {
DefaultMessage message = new DefaultMessage();
message.setHeader("user", part);
message.setBody(body);
answer.add(message);
}
return answer;
}
}
Splitter EIP와 함께 CryostatIO Cryostatter 오브젝트를 사용하면 전체 콘텐츠를 메모리에 읽지 않도록 스트림 모드를 사용하여 큰 페이로드를 분할할 수 있습니다. 다음 예제에서는 classpath에서 로드된 매핑 파일을 사용하여 Cryostat IO Cryostatter 오브젝트를 설정하는 방법을 보여줍니다.
Camel 2.18의 새로운 클래스입니다. Camel 2.17에서는 사용할 수 없습니다.
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
// Following is a route that uses the beanio data format to format CSV data
// in Java objects:
from("direct:unmarshal")
// Here the message body is split to obtain a message for each row:
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");다음 예제에서는 오류 처리기를 추가합니다.
BeanIOSplitter splitter = new BeanIOSplitter();
splitter.setMapping("org/apache/camel/dataformat/beanio/mappings.xml");
splitter.setStreamName("employeeFile");
splitter.setBeanReaderErrorHandlerType(MyErrorHandler.class);
from("direct:unmarshal")
.split(splitter).streaming()
.to("log:line")
.to("mock:beanio-unmarshal");8.4.9. 속성 교환
다음 속성은 각 분할 교환에 대해 설정됩니다.
| 헤더 | type | description |
|---|---|---|
|
|
| Apache Camel 2.0: 분할되는 각 Exchange에 대해 증가되는 분할 카운터입니다. 카운터는 0부터 시작합니다. |
|
|
| Apache Camel 2.0: 분할된 총 교환 수입니다. 이 헤더는 스트림 기반 분할에는 적용되지 않습니다. |
|
|
| Apache Camel 2.4: 이 교환이 마지막인지 여부입니다. |
8.4.10. Splitter/aggregator 패턴
개별 조각 처리가 완료된 후 메시지 조각을 단일 교환으로 다시 집계하는 것이 일반적인 패턴입니다. 이 패턴을 지원하기 위해 split() DSL 명령을 사용하면 AggregationStrategy 오브젝트를 두 번째 인수로 제공할 수 있습니다.
8.4.11. Java DSL 예
다음 예제에서는 모든 메시지 조각이 처리된 후 사용자 정의 집계 전략을 사용하여 분할 메시지를 다시 가져오는 방법을 보여줍니다.
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message we want to send a single combined
// response back to the original caller, so we let this bean build it for us
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")8.4.12. 집계Strategy 구현
이전 경로에 사용되는 사용자 정의 집계 전략 MyOrderStrategy 는 다음과 같이 구현됩니다.
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* lose any message, we copy from the new to the old to preserve the
* order lines as long we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: " + orders);
LOG.debug("Aggregate new order: " + newLine);
// put orders together separating by semi colon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}8.4.13. 스트림 기반 처리
병렬 처리가 활성화되면 이론적으로 이전 메시지 조각이 이전 문서보다 먼저 집계할 수 있습니다. 즉, 메시지 조각이 순서대로 수집기에 도달할 수 있습니다. 기본적으로 분할자 구현은 메시지를 수집기로 전달하기 전에 메시지를 원래 순서로 다시 정렬하므로 이러한 상황이 발생하지 않습니다.
메시지 조각을 준비한 즉시 집계하려는 경우 다음과 같이 스트리밍 옵션을 활성화할 수 있습니다.
from("direct:streaming")
.split(body().tokenize(","), new MyOrderStrategy())
.parallelProcessing()
.streaming()
.to("activemq:my.parts")
.end()
.to("activemq:all.parts");다음과 같이 스트리밍에 사용할 사용자 지정 Cryostat를 제공할 수도 있습니다.
// Java
import static org.apache.camel.builder.ExpressionBuilder.beanExpression;
...
from("direct:streaming")
.split(beanExpression(new MyCustomIteratorFactory(), "iterator"))
.streaming().to("activemq:my.parts")Cryostat와 함께 스트리밍 모드를 사용할 수 없습니다. Cryostat에는 메모리에 전체 Cryostat XML 문서가 필요합니다.
8.4.14. XML로 스트림 기반 처리
들어오는 메시지가 매우 큰 XML 파일인 경우 스트리밍 모드에서 tokenize XML 하위 명령을 사용하여 메시지를 가장 효율적으로 처리할 수 있습니다.
예를 들어 순서 요소 시퀀스가 포함된 큰 XML 파일이 있는 경우 다음과 같은 경로를 사용하여 파일을 주문 요소로 분할할 수 있습니다.
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");XML에서 다음과 같은 경로를 정의하여 동일한 작업을 수행할 수 있습니다.
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>토큰 요소의 enclosing (ancestor) 요소 중 하나에 정의된 네임스페이스에 액세스해야 하는 경우가 많습니다. 네임스페이스 정의를 상속하려는 요소를 지정함으로써 ancestor 요소 중 하나에서 네임스페이스 정의를 토큰 요소로 복사할 수 있습니다.
Java DSL에서 ancestor 요소를 tokenize XML 의 두 번째 인수로 지정합니다. 예를 들어, enclosing orders 요소에서 네임스페이스 정의를 상속하려면 다음을 수행합니다.
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");
XML DSL에서 inheritNamespaceTagName 특성을 사용하여 ancestor 요소를 지정합니다. 예를 들면 다음과 같습니다.
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order"
xml="true"
inheritNamespaceTagName="orders"/>
<to uri="activemq:queue:order"/>
</split>
</route>8.4.15. 옵션
분할 DSL 명령은 다음 옵션을 지원합니다.
| 이름 | 기본값 | 설명 |
|
| 하위 메시지의 응답을 8.4절. “Splitter” 에서 보내는 단일 메시지로 어셈블하는 데 사용되는 집계Strategy 를 나타냅니다. 기본적으로 사용되는 항목에 대해서는 아래 분할자 반환의 제목 섹션 을 참조하십시오. | |
|
|
이 옵션을 사용하면 Cryostat를 | |
|
|
|
이 옵션은 Cryostat를 |
|
|
| 이 옵션을 사용하면 하위 메시지 처리가 동시에 수행됩니다. 호출자 스레드는 계속 진행하기 전에 모든 하위 메시지가 완전히 처리될 때까지 대기합니다. |
|
|
|
활성화하면 |
|
| 병렬 처리에 사용할 사용자 지정 스레드 풀을 나타냅니다.Indicates to a custom Thread Pool to be used for parallel processing. 이 옵션을 설정하면 병렬 처리가 자동으로 표시되고 해당 옵션도 활성화할 필요가 없습니다. | |
|
|
| Camel 2.2: 예외가 발생한 경우 즉시 처리를 중지해야 하는지의 여부입니다. disable인 경우 Camel은 실패했는지에 관계없이 하위 메시지를 계속 분할하고 처리합니다. 이를 처리하는 방법을 완전히 제어하는 AggregationStrategy 클래스에서 예외를 처리할 수 있습니다. |
|
|
| Camel이 활성화된 경우 Camel은 스트리밍 방식으로 분할되므로 입력 메시지를 청크로 분할합니다. 이렇게 하면 메모리 오버헤드가 줄어듭니다. 예를 들어 큰 메시지를 분할하는 경우 스트리밍을 활성화하는 것이 좋습니다. 스트리밍이 활성화되면 하위 메시지 응답이 순서대로 집계됩니다(예: 반환 순서에 따라). 비활성화된 경우 Camel은 분할된 위치와 동일한 순서로 하위 메시지 응답을 처리합니다. |
|
|
Camel 2.5: 밀리 초 단위로 지정된 총 타임아웃을 설정합니다. 8.3절. “수신자 목록” 에서 지정된 기간 내에 모든 응답을 분할하고 처리할 수 없는 경우 시간 초과 트리거와 8.4절. “Splitter” 가 중단되고 계속됩니다. AggregationStrategy 를 제공하면 | |
|
| Camel 2.8: 처리되기 전에 교환의 하위 메시지를 준비하기 위해 사용자 지정 프로세서를 참조합니다. 이를 통해 필요한 경우 메시지 페이로드를 깊이 복제하는 등 사용자 지정 논리를 수행할 수 있습니다. | |
|
|
| Camel 2.8: 작업 단위를 공유해야 하는지 여부입니다. 자세한 내용은 아래를 참조하십시오. |