
Fuse Online과 애플리케이션 통합
머리말
Red Hat Fuse는 아키텍처, 배포 및 툴을 선택할 수 있는 분산된 클라우드 네이티브 통합 솔루션입니다. Fuse Online은 Red Hat의 웹 기반 Fuse 배포판입니다. Syndesis 는 Fuse Online의 오픈 소스 프로젝트입니다. Fuse Online은 OpenShift Online, OpenShift Dedicated 및 OpenShift Container Platform에서 실행됩니다.
이 가이드에서는 Fuse Online의 웹 인터페이스를 사용하여 애플리케이션을 통합하는 데 필요한 정보와 지침을 제공합니다. 콘텐츠는 다음과 같이 구성됩니다.
샘플 통합을 생성하여 Fuse Online을 사용하는 방법에 대한 자세한 내용은 샘플 통합 튜토리얼을 참조하십시오.
지원을 받으려면 왼쪽 탐색 패널에서 Fuse Online에서 지원을 클릭하거나 오른쪽 상단에
 를 클릭한 다음 지원을 선택합니다.
를 클릭한 다음 지원을 선택합니다.
1장. Fuse Online의 상위 수준 개요
Fuse Online을 사용하면 애플리케이션 또는 서비스에서 데이터를 가져와서 필요한 경우 해당 데이터를 작동한 다음 데이터를 완전히 다른 애플리케이션 또는 서비스로 보낼 수 있습니다. 이 작업을 수행하기 위해 코딩이 필요하지 않습니다.
다음 주제에서는 Fuse Online에 대한 간략한 개요를 제공합니다.
1.1. Fuse Online의 작동 방식
Fuse Online에서는 코드를 작성하지 않고도 두 개 이상의 다른 애플리케이션 또는 서비스를 통합할 수 있는 웹 브라우저 인터페이스를 제공합니다. 또한 복잡한 사용 사례에 필요한 경우 코드를 도입할 수 있는 기능을 제공합니다.
Fuse Online을 사용하면 다양한 애플리케이션 간에 데이터를 전송할 수 있습니다. 예를 들어, 비즈니스 애널리스트는 Fuse Online을 사용하여 고객을 언급하고 Twitter에서 얻은 데이터를 활용하여 Cryostat 계정을 업데이트할 수 있는 정보를 캡처할 수 있습니다. 또 다른 예는 주식 거래 권장 사항을 만드는 서비스입니다. Fuse Online을 사용하여 관심 주식을 구매하거나 판매하기 위한 권장 사항을 캡처하고 해당 권장 사항을 주식 이전을 자동화하는 서비스로 전달할 수 있습니다.
간단한 통합을 생성하고 실행하려면 주요 단계는 다음과 같습니다.
- 통합할 각 애플리케이션에 대한 연결을 생성합니다.
연결 시작을 선택합니다. 이 연결은 다른 애플리케이션과 공유할 데이터가 포함된 애플리케이션에 연결됩니다.
또는 타이머 또는 HTTP 요청을 수락하는 Webhook와의 통합을 시작할 수 있습니다.
- 연결 완료를 선택합니다. 이 연결은 시작 연결에서 데이터를 수신하고 통합을 완료하는 애플리케이션에 대한 것입니다.
- 시작 연결의 데이터 필드를 완료 연결의 data 필드에 매핑합니다.
- 통합에 이름을 지정합니다.
- 게시 를 클릭하여 통합 실행을 시작합니다.
또 다른 종류의 통합은 API 공급자의 통합입니다. API 공급자 통합을 통해 REST API 클라이언트가 통합 실행을 트리거하는 명령을 호출할 수 있습니다. API 공급자 통합을 생성하고 실행하려면 OpenAPI 2.0 문서를 Fuse Online에 업로드합니다. 이 문서에서는 클라이언트가 호출할 수 있는 작업을 지정합니다. 각 작업에 대해 해당 작업을 실행하는 데이터 매퍼 또는 필터 단계와 같은 연결 및 단계의 흐름을 지정하고 구성합니다. 간단한 통합에는 하나의 기본 흐름이 있으며 API 공급자 통합에는 각 작업에 대한 기본 흐름이 있습니다.
Fuse Online 대시보드를 사용하면 통합을 모니터링하고 관리할 수 있습니다. 실행 중인 통합을 확인할 수 있으며 통합을 시작, 중지 및 편집할 수 있습니다.
1.2. Fuse Online의 대상
Fuse Online은 서로 다른 두 애플리케이션 간에 데이터를 공유하기 위해 코드를 작성하지 않으려는 금융, 인적 리소스 또는 마케팅과 같은 비즈니스 전문가를 위한 것입니다. 다양한 SaaS(Software-as-a-Service) 애플리케이션을 사용하면 비즈니스 요구 사항, 워크플로우 및 관련 데이터를 파악할 수 있습니다.
비즈니스 사용자는 Fuse Online을 사용하여 다음을 수행할 수 있습니다.
- 다른 사람이 알 수 없는 출처에서 가져온 경우, 귀사에 대해 언급하고, 이를 필터링하고, 새로운 연락처를 생성할 수 있는 정보를 캡처합니다.
- Cryostat 리드 업데이트를 확인한 다음 SQL 저장 프로시저를 실행하여 관련 데이터베이스를 최신 상태로 유지합니다.
- AMQ 브로커가 수신한 주문을 구독한 다음 사용자 정의 API를 사용하여 해당 주문에서 작동합니다.
- Amazon S3 버킷에서 데이터를 가져와 Dropbox 폴더에 추가합니다.
다음은 비즈니스 사용자가 코드를 작성하지 않고 수행할 수 있는 작업의 몇 가지 예입니다.
1.3. Fuse Online 사용의 이점
Fuse Online에는 다음과 같은 다양한 이점이 있습니다.
- 코드를 작성하지 않고 다양한 애플리케이션 또는 서비스의 데이터를 통합합니다.
- 퍼블릭 클라우드 또는 사이트의 OpenShift Container Platform에서 OpenShift Online에서 통합을 실행합니다.
- 시각적 데이터 매퍼를 사용하여 한 애플리케이션의 데이터 필드를 다른 애플리케이션의 데이터 필드에 매핑합니다.
- 오픈 소스 소프트웨어의 모든 이점을 활용합니다. 기능을 확장하고 인터페이스를 사용자 지정할 수 있습니다. Fuse Online에서 통합하려는 애플리케이션 또는 서비스에 대한 커넥터를 제공하지 않으면 개발자가 필요한 커넥터를 생성할 수 있습니다.
1.4. Fuse Online 구성에 대한 설명
Fuse Online을 사용하려면 커넥터, 연결, 작업, 단계 및 흐름을 사용하여 통합을 생성합니다. 이러한 각 구성을 기본적인 이해하도록 하는 것이 좋습니다.
각 Fuse Online 설치를 Fuse Online 환경이라고 합니다. Red Hat은 Fuse Online 환경을 설치하고 관리하는 경우 OpenShift Online 또는 OpenShift Dedicated에서 실행됩니다. Fuse Online 환경을 설치하고 관리할 때 일반적으로 OpenShift Container Platform에서 실행되지만 OpenShift Dedicated에서 실행할 수 있습니다.
통합
Fuse Online에는 간단한 통합 및 API 공급자 통합이 있습니다.
간단한 통합은 Fuse Online이 실행하는 일련의 정렬된 단계입니다. 이 세트에는 다음이 포함됩니다.
- 통합을 시작하기 위해 애플리케이션에 연결하는 단계입니다. 이 연결은 통합이 작동하는 초기 데이터를 제공합니다. 후속 연결은 추가 데이터를 제공할 수 있습니다.
- 애플리케이션에 연결하여 통합을 완료하는 단계입니다. 이 연결은 이전 단계에서 출력된 모든 데이터를 수신하고 통합을 완료합니다.
시작 및 완료 연결 사이의 애플리케이션에 연결하는 선택적 추가 단계입니다. 통합 단계 시퀀스의 추가 연결 위치에 따라 추가 연결은 다음 중 일부 또는 모두를 수행할 수 있습니다.
- 통합이 작동하도록 추가 데이터 제공
- 통합 데이터 처리
- 통합에 처리 결과를 출력
- 애플리케이션 연결 간 데이터에서 작동하는 선택적 단계입니다. 일반적으로 이전 연결의 데이터 필드를 다음 연결에 사용하는 데이터 필드에 매핑하는 단계가 있습니다.
API 공급자 통합은 OpenAPI 스키마를 제공한 REST API 서비스를 게시합니다. REST API 클라이언트의 호출은 API 공급자 통합 실행을 트리거합니다. 호출은 REST API에서 구현하는 모든 작업을 호출할 수 있습니다. 간단한 통합에는 하나의 기본 실행 흐름이 있지만 API 공급자 통합에는 각 작업에 대한 기본 흐름이 있습니다. 각 작업 흐름은 통합 생성 시 해당 작업의 흐름에 추가한 단계에 따라 애플리케이션에 연결하고 데이터를 처리합니다. 각 작업 흐름은 호출이 트리거된 통합 실행을 통해 클라이언트에 지정하는 응답을 반환하여 종료됩니다.
커넥터
Fuse Online에서는 커넥터 집합을 제공합니다. 커넥터는 데이터를 가져오거나 데이터를 보낼 특정 애플리케이션을 나타냅니다.A connector represents a specific application that you want to obtain data from or send data to. 각 커넥터는 특정 애플리케이션에 대한 연결을 생성하기 위한 템플릿입니다. 예를 들어 Cryostat 커넥터를 사용하여 Cryostat에 대한 연결을 생성합니다.
연결하려는 애플리케이션은 OAuth 프로토콜을 사용하여 사용자를 인증할 수 있습니다. 이 경우 해당 애플리케이션에 액세스할 수 있는 클라이언트로 Fuse Online 환경을 등록합니다. 등록은 해당 애플리케이션의 커넥터와 연결됩니다. OAuth를 사용하는 각 애플리케이션에 한 번만 특정 Fuse Online 환경을 등록해야 합니다. 등록은 해당 커넥터에서 생성한 각 연결까지 확장됩니다.
Fuse Online에서 필요한 커넥터를 제공하지 않으면 개발자가 필요한 커넥터를 생성할 수 있습니다.
연결
통합을 만들려면 먼저 데이터를 가져오거나 데이터를 보낼 각 애플리케이션 또는 서비스에 대한 연결을 만들어야 합니다.Before you can create an integration, you must create a connection to each application or service that you want to obtain data from or send data to. 연결을 생성하려면 커넥터를 선택하고 구성 정보를 추가합니다. 예를 들어 통합에서 AMQ 브로커에 연결하려면 AMQ 커넥터를 선택한 다음, 연결할 브로커와 연결에 사용할 계정을 식별하라는 프롬프트를 따라 연결을 생성합니다.
연결은 생성된 커넥터의 특정 인스턴스 중 하나입니다. 하나의 커넥터에서 여러 연결을 생성할 수 있습니다. 예를 들어 AMQ 커넥터를 사용하여 각 연결이 다른 브로커에 액세스하는 세 가지 AMQ 연결을 생성할 수 있습니다.
간단한 통합을 만들려면 연결을 선택하고 통합을 종료하는 연결, 추가 애플리케이션에 액세스하기 위한 하나 이상의 연결(선택 사항)을 선택합니다. API 공급자 통합을 생성하려면 각 작업 흐름에 하나 이상의 연결을 추가할 수 있습니다. 통합 및 작업 흐름의 개수는 동일한 연결을 사용할 수 있습니다. 특정 통합 또는 흐름은 동일한 연결을 두 번 이상 사용할 수 있습니다.
자세한 내용은 통합하려는 애플리케이션에 대한 연결 정보를 참조하십시오.
작업
통합에서 각 연결은 정확히 하나의 작업을 수행합니다. 통합을 만들 때 흐름에 추가할 연결을 선택한 다음 연결이 수행하는 작업을 선택합니다. 예를 들어, flow에 Cryostat 연결을 추가할 때, 이 작업을 포함하되 이에 국한되지 않는 일련의 작업 중에서 선택할 수 있으며,limit 계정을 만들고, Cryostat 계정을 업데이트하고, Cryostat 계정을 검색할 수 있습니다.
일부 작업에는 추가 구성이 필요하며 Fuse Online에서 이 정보를 입력하라는 메시지를 표시합니다.
단계
간단한 통합은 정렬된 일련의 단계입니다. API 공급자 통합에서 각 작업 흐름은 정렬된 단계 집합입니다.
각 단계는 데이터에 대해 작동합니다. 일부 단계는 Fuse Online 외부의 애플리케이션 또는 서비스에 연결된 동안 데이터에서 작동합니다. 이러한 단계는 연결입니다. 연결 간에 Fuse Online 데이터에서 작동하는 다른 단계가 있을 수 있습니다. 일반적으로 단계 세트에는 이전 연결에 사용된 데이터 필드를 흐름의 다음 연결에 사용되는 데이터 필드에 매핑하는 단계가 포함됩니다. 간단한 통합에서 시작 연결을 제외하고 각 단계는 이전 단계에서 수신하는 데이터에 대해 작동합니다.
연결 간 데이터 작업을 위해 Fuse Online에서는 다음에 대한 단계를 제공합니다.
- 한 애플리케이션의 데이터 필드를 다른 애플리케이션의 데이터 필드에 매핑합니다.
- 처리 중인 데이터가 정의한 기준을 충족하는 경우에만 통합이 계속되도록 데이터를 필터링합니다.
- 레코드 컬렉션을 개별 레코드로 분할하여 Fuse Online이 각 레코드에 대해 한 번 후속 단계를 반복적으로 실행합니다.
- Fuse Online이 컬렉션에 대해 한 번 후속 단계를 실행하도록 개별 레코드를 컬렉션에 집계합니다.
- Freemarker, Mustache 또는 Velocity 템플릿에 데이터를 삽입하여 동등하고 일관된 출력을 생성합니다.
- Fuse Online에서 자동으로 제공하는 기본 로깅 외에도 정보를 로깅합니다.
Fuse Online에 내장되지 않은 방식으로 연결 간에 데이터 작업을 수행하려면 사용자 지정 단계를 제공하는 확장을 업로드할 수 있습니다. Fuse Online 확장 개발을 참조하십시오.
흐름
흐름은 통합이 실행되는 정렬된 단계 집합입니다.
간단한 통합에는 하나의 기본 흐름이 있습니다. API 공급자 통합에는 REST API에서 정의하는 각 작업에 대한 기본 흐름이 있습니다. 각 작업의 기본 흐름은 해당 작업을 호출하는 호출을 처리하는 일련의 단계입니다.
기본 흐름에는 조건부 흐름이 있을 수 있습니다. 통합은 사용자가 지정하는 조건을 평가하여 연결된 흐름을 실행할지 여부를 결정합니다.
흐름에서는 각 단계가 이전 단계의 출력된 데이터에 대해 작동할 수 있습니다. 흐름에 필요한 단계를 확인하려면 통합 계획에 대한 고려 사항을 참조하십시오.
2장. 통합 생성 준비 방법
통합 생성을 위한 워크플로 계획 및 이해는 요구 사항에 맞는 통합을 생성하는 데 도움이 될 수 있습니다. 다음 주제에서는 통합을 생성할 준비를 위한 정보를 제공합니다.
2.1. 통합 계획 고려 사항
통합을 생성하기 전에 다음 질문을 고려하십시오.
통합 실행을 트리거하려면 어떻게 해야 합니까?
- 지정한 간격으로 실행을 트리거할 타이머를 설정하시겠습니까?
- HTTP 요청을 보내시겠습니까?
데이터를 가져오기 위해 애플리케이션에 연결하시겠습니까?
- 해당 애플리케이션에서 데이터를 가져오는 작업을 트리거하는 것은 무엇입니까? 예를 들어, Twitter에서 데이터를 가져와서 시작하는 통합은 Twitter 언급에서 트리거될 수 있습니다.
- 관심 있는 데이터 필드는 무엇입니까?
- Fuse Online에서 이 애플리케이션에 액세스하는 데 사용하는 인증 정보는 무엇입니까?
클라이언트가 작업에 대한 흐름 실행을 트리거하는 REST API 호출을 호출할 수 있도록 REST API 서비스를 게시하시겠습니까?
- 서비스에 대한 OpenAPI 스키마가 이미 정의되어 있습니까?
- 그렇지 않은 경우 서비스에서 어떤 작업을 정의합니까?
간단한 통합을 완료하려면 다음을 수행합니다.
- 데이터를 수신하거나 통합 로그에 정보를 전송하려는 애플리케이션이 있습니까?
- 애플리케이션에 데이터를 전송하는 경우 통합 작업은 어떻게 수행됩니까?
- 관심 있는 데이터 필드는 무엇입니까?
- Fuse Online에서 이 애플리케이션에 액세스하는 데 사용하는 인증 정보는 무엇입니까?
흐름의 단계에서는 다음과 같습니다.
다른 애플리케이션에 액세스해야 합니까? 액세스해야 하는 다른 모든 애플리케이션의 경우:
- 흐름은 어떤 애플리케이션에 연결되어야 합니까?
- 연결에 어떤 작업을 수행해야 합니까?
- 관심 있는 데이터 필드는 무엇입니까?
- 연결에서 이 애플리케이션에 연결하는 데 사용해야 하는 인증 정보는 무엇입니까?
흐름은 연결 간 데이터에서 작동해야 합니까? 예를 들면 다음과 같습니다.
- 흐름이 작동하는 데이터를 필터링해야합니까?
- 소스 애플리케이션과 대상 애플리케이션 간에 필드 이름이 다른가요? 이 경우 데이터 매핑이 필요합니다.
- 흐름은 컬렉션에서 작동합니까? 이 경우 흐름에서 데이터 매퍼를 사용하여 컬렉션을 처리하거나 흐름이 컬렉션을 개별 레코드로 분할해야 합니까? 흐름은 레코드를 컬렉션에 집계해야 합니까?
- 템플릿이 일관된 형식으로 데이터를 출력하는 데 도움이 됩니까?
- 처리 중인 메시지에 대한 정보를 통합 로그로 전송하시겠습니까?
- 흐름은 어떤 사용자 지정 방식으로 데이터에서 작동해야합니까?
- 통합 데이터의 내용에 따라 실행 흐름을 변경해야 합니까? 즉, 조건부 흐름이 필요합니까?
2.2. 간단한 통합을 생성하기 위한 일반 워크플로우
Fuse Online 콘솔에 로그인한 후 통합할 애플리케이션에 대한 연결 생성을 시작할 수 있습니다. 통합할 각 애플리케이션에 OAuth 프로토콜을 사용하는 경우 해당 애플리케이션의 클라이언트로 Fuse Online을 등록합니다. 다음을 포함하여 등록해야 하는 애플리케이션은 다음과 같습니다.
- Dropbox
- Google 애플리케이션 (Gmail, Cryostat, Cryostats)
- Salesforce
- SAP Concur
이러한 애플리케이션에 대한 등록 시 간단한 통합을 생성하는 워크플로우는 다음과 같습니다.
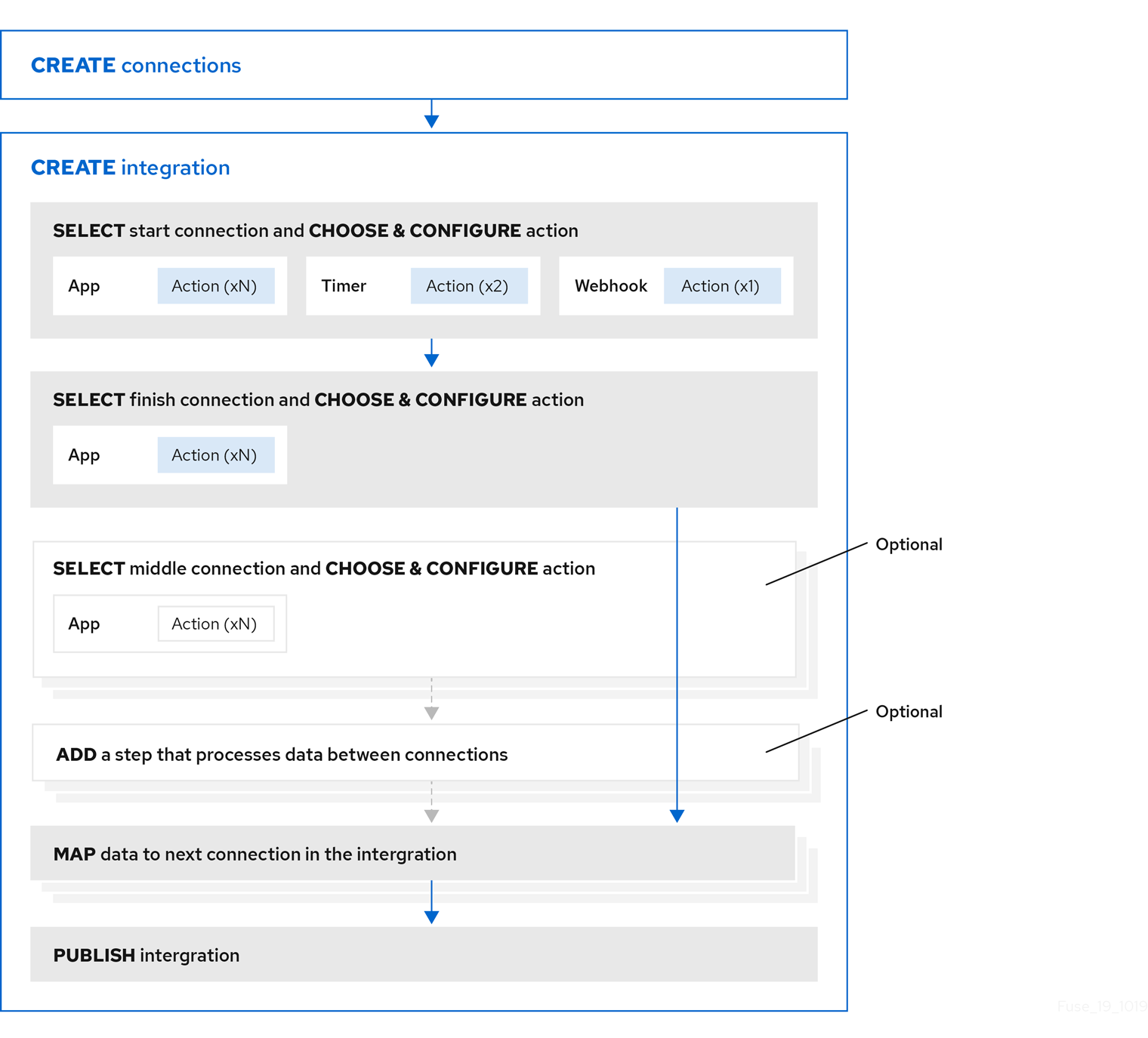
2.3. 데이터베이스 간단한 통합을 위한 Cryostat를 생성하기 위한 워크플로우의 예
Fuse Online을 사용하여 간단한 통합을 만드는 데 필요한 워크플로를 이해하는 가장 좋은 방법은 샘플 통합 튜토리얼에 따라 샘플 통합을 생성하는 것입니다.
다음 다이어그램에서는 데이터베이스 통합에 샘플 Cryostat를 생성하는 워크플로를 보여줍니다.
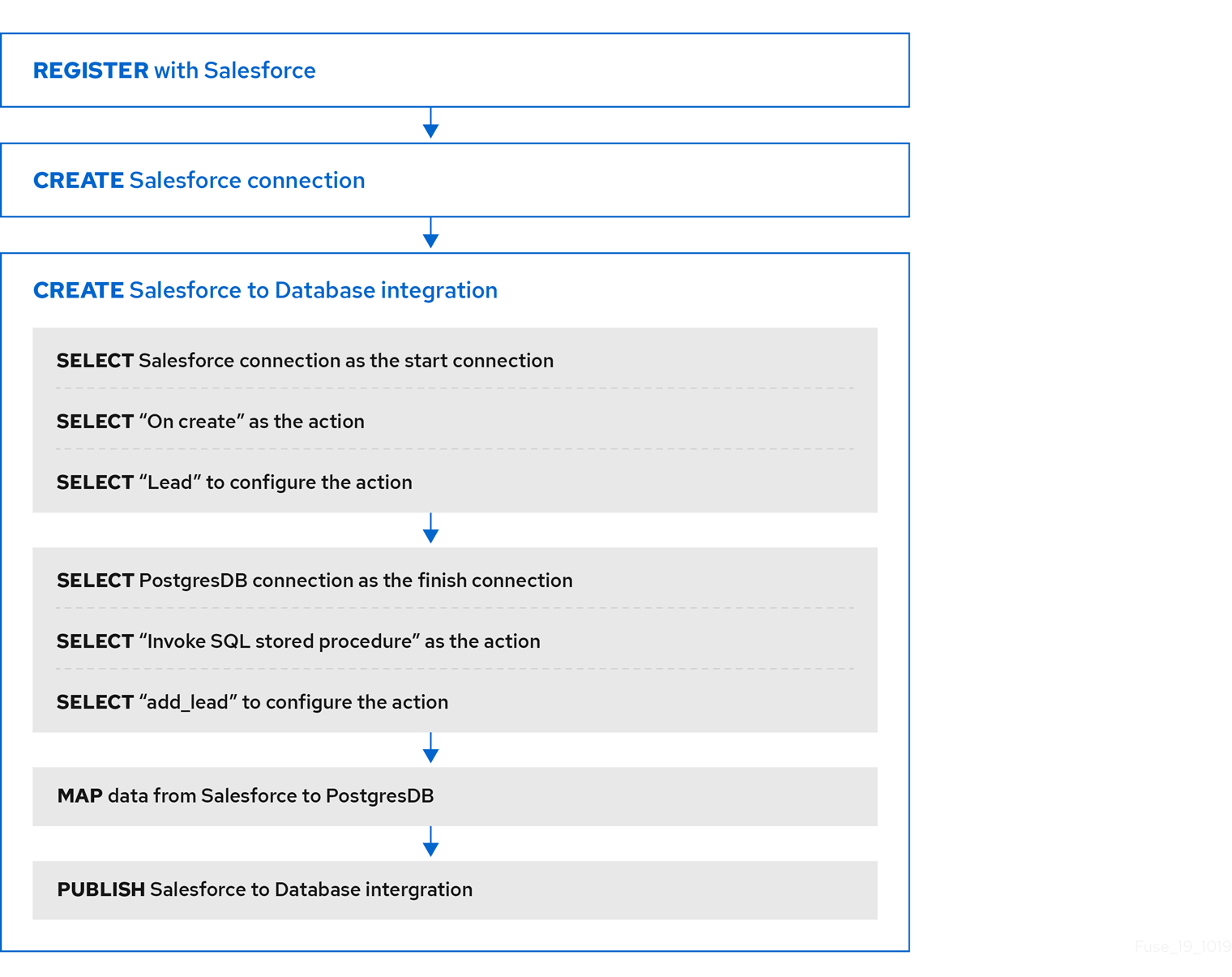
통합을 게시하면 통합을 실행할 준비가 되면 Fuse Online 대시보드에 통합 이름 옆에 Running 이 표시됩니다.
추가 리소스
3장. Fuse Online을 처음 사용할 때 고려해야 할 사항
OpenShift Online에서 Fuse Online에 액세스할 수 있도록 Red Hat은 링크를 제공합니다. 이 링크를 클릭하면 Red Hat OpenShift Online Log In 페이지가 표시되고 Red Hat 계정을 사용하여 로그인하라는 메시지가 표시됩니다. Fuse Online에서 OpenShift Online 계정으로 액세스 권한을 부여하도록 프롬프트를 로그인하십시오.
선택한 권한 허용을 클릭합니다. 이 작업은 한 번만 수행해야 합니다. 다음에 "Welcome to the Red Hat Fuse Online Evaluation" 이메일 메시지에 있는 Fuse Online 액세스 링크를 클릭하면 즉시 Fuse Online이 표시됩니다.
OpenShift Container Platform에서 Fuse Online을 사용하려면 OpenShift Container Platform에 온라인 설치 및 운영 체제 의 설치 지침을 따르십시오.
Red Hat은 다음 브라우저에서 Fuse Online 사용을 지원합니다.
- Chrome
- Firefox
4장. 통합할 애플리케이션에 대한 연결 정보
통합하려는 애플리케이션에 연결하려면 주요 단계는 다음과 같습니다.
- 통합할 각 애플리케이션 또는 서비스에 대한 연결을 생성합니다.
- 통합할 각 애플리케이션에 대한 연결이 있는 통합을 생성합니다.
연결을 생성하는 절차는 애플리케이션 또는 서비스에 따라 다릅니다. 특정 통합을 위해 각 종류의 연결을 생성하고 이를 구성하는 데 대한 세부 정보는 Fuse Online을 애플리케이션 및 서비스에 연결하는 것입니다.
다음 항목에서는 연결에 대한 일반적인 정보를 제공합니다.
4.1. Fuse Online에서 애플리케이션에 대한 연결 생성 정보
연결을 만들려면 연결하려는 애플리케이션의 커넥터를 선택한 다음 입력 필드에 값을 입력하여 해당 애플리케이션에 대한 연결을 구성합니다. 애플리케이션에 따라 다르게 제공해야 하는 구성 세부 정보입니다. 연결을 구성한 후 동일한 애플리케이션에 대한 다른 연결과 구별하는 데 도움이 되는 이름을 지정합니다. 선택적으로 연결에 대한 설명을 지정할 수 있습니다.
동일한 커넥터를 사용하여 해당 애플리케이션에 대한 여러 연결을 생성할 수 있습니다. 예를 들어 AMQ 커넥터를 사용하여 세 가지 다른 연결을 생성할 수 있습니다. 각 AMQ 연결은 다른 브로커를 지정할 수 있습니다.
예를 들면 다음과 같습니다.
4.2. 권한 부여를 위한 일반 절차
통합에서는 OAuth 프로토콜을 사용하여 액세스 요청을 인증하는 애플리케이션에 연결할 수 있습니다. 이렇게 하려면 해당 애플리케이션에 액세스하려면 Fuse Online 설치를 등록해야 합니다. 등록은 Fuse Online 설치의 모든 연결을 지정된 애플리케이션에 부여합니다. 예를 들어 Fuse Online 설치를 Cryostat에 등록하는 경우 Fuse Online 설치에 대한 모든 연결은 등록 시 동일한 Cryostat 클라이언트 ID와 동일한 Cryostat 클라이언트 시크릿을 사용합니다.
각 Fuse Online 환경에서 OAuth를 사용하는 각 애플리케이션에 대해 클라이언트로 Fuse Online의 등록은 하나만 필요합니다. 이 등록을 사용하면 여러 연결을 만들 수 있으며 각 연결은 다른 사용자 자격 증명을 사용할 수 있습니다.
연결하려는 각 OAuth 애플리케이션에 대해 특정 단계가 다르지만 등록은 항상 Fuse Online 환경에 클라이언트 ID와 클라이언트 시크릿을 제공합니다. 일부 애플리케이션은 클라이언트 ID 및 클라이언트 시크릿에 다른 레이블을 사용합니다. 예를 들어 Cryostat는 소비자 키와 소비자 시크릿을 생성합니다.
일부 OAuth 애플리케이션의 경우 Fuse Online은 등록에서 제공하는 클라이언트 ID 및 클라이언트 시크릿을 추가하기 위한 설정 페이지에서 항목을 제공합니다. 적용되는 애플리케이션을 확인하려면 Fuse Online의 왼쪽 패널에서 설정을 클릭합니다.
사전 요구 사항
- Fuse 온라인 설정 페이지에는 OAuth 프로토콜을 사용하여 액세스 권한을 부여하는 애플리케이션의 항목이 있습니다.
절차 개요
- Fuse Online OAuth 애플리케이션 관리 페이지에서 Fuse Online을 등록할 애플리케이션의 항목을 확장합니다. 클라이언트 ID 및 클라이언트 시크릿 필드가 표시됩니다.
-
OAuth 애플리케이션 관리 페이지 맨 위에
등록 중에 이 콜백 URL을 입력합니다. , 해당 URL을 클립보드에 복사합니다. - 다른 브라우저 탭에서 등록하려는 애플리케이션의 웹 사이트로 이동하여 클라이언트 ID와 시크릿을 가져오는 데 필요한 단계를 수행합니다. 다음 단계 중 하나를 사용하려면 Fuse Online 환경에 대한 콜백 URL을 입력해야 합니다. 두 번째 단계에서 클립보드에 복사한 URL을 붙여넣습니다.
- Fuse Online에서 설정 페이지에서 클라이언트 ID와 클라이언트 시크릿을 붙여넣고 설정을 저장합니다.
추가 리소스
설정 페이지에 항목이 있는 애플리케이션을 등록하는 예:
- Fuse Online Settings 페이지에 항목이 없는 애플리케이션에 등록하는 예: Dropbox 클라이언트로 Fuse Online 등록
- OAuth 프로토콜을 사용하는 애플리케이션에 액세스할 수 있는 사용자 지정 커넥터 사용 정보: 사용자 지정 커넥터에서 연결 생성 정보
4.3. 연결 검증 정보
Fuse Online에서 OAuth를 사용하는 애플리케이션에 액세스할 수 있는 권한을 얻은 후 해당 애플리케이션에 대한 하나 이상의 연결을 생성할 수 있습니다. OAuth 애플리케이션에 대한 연결을 생성하면 Fuse Online에서 유효성을 검증하여 권한 부여를 확인합니다. 언제든지 연결을 다시 검증하여 권한 부여가 여전히 있는지 확인할 수 있습니다.
일부 OAuth 애플리케이션은 만료 날짜가 있는 액세스 토큰을 부여합니다. 액세스 토큰이 만료되면 애플리케이션에 다시 연결하여 새 액세스 토큰을 가져올 수 있습니다.
OAuth를 사용하거나 OAuth 애플리케이션의 새 액세스 토큰을 가져오는 연결을 검증하려면 다음을 수행합니다.
- 왼쪽 패널에서 연결을 클릭합니다.
- 검증할 연결 또는 새 액세스 토큰을 가져올 연결을 클릭합니다.
- 연결 세부 정보 페이지에서 유효성 검사를 클릭하거나 다시 연결을 클릭합니다.
검증 또는 재연결이 실패하는 경우 애플리케이션/서비스 공급자로 확인하여 애플리케이션의 OAuth 키, ID, 토큰 또는 시크릿이 여전히 유효한지 확인합니다. 항목이 만료되었거나 취소되었을 수 있습니다.
OAuth 항목이 유효하지 않거나 만료되었거나 취소된 경우 새 값을 가져와 애플리케이션의 Fuse Online 설정에 붙여넣습니다. 연결이 검증되지 않은 애플리케이션을 등록하려면 Fuse Online 연결 및 애플리케이션 및 서비스 관련 지침을 참조하십시오. 업데이트된 설정을 사용하여 위의 지침에 따라 업데이트된 연결의 유효성을 검사합니다. 유효성 검사가 성공하고 이 연결을 사용하는 통합이 실행 중인 경우 통합을 다시 시작합니다. 통합을 다시 시작하려면 중지한 다음 시작합니다.
유효성 검사가 실패하고 다시 연결하는 데 실패하지만 서비스 공급자에서 모든 항목이 유효한 것으로 표시되면 Fuse Online 환경을 애플리케이션으로 다시 등록한 다음 연결을 다시 만듭니다. Fuse Online은 다시 생성할 때 연결을 검증합니다. 연결을 다시 생성하고 연결을 사용하는 통합이 있는 경우 통합을 편집하여 이전 연결을 삭제하고 새 연결을 추가해야 합니다. 통합이 실행 중인 경우 중지한 후 다시 시작해야 합니다.
4.4. 통합에 연결 추가 정보
간단한 통합 또는 작업 흐름에 연결을 추가하면 Fuse Online에서 애플리케이션에 연결할 때 연결이 수행할 수 있는 작업 목록을 표시합니다. 정확히 하나의 작업을 선택해야 합니다. 실행 중인 통합에서 각 연결은 선택한 작업만 수행합니다. 예를 들어, Twitter 연결을 통합의 시작 연결로 추가할 때 Twitter 처리를 언급하는 Twitter에서 Twitter를 모니터링하는 작업을 선택할 수 있습니다.
일부 작업을 선택하면 작업을 구성하는 하나 이상의 매개변수를 지정하라는 메시지가 표시됩니다. 예를 들어 Integration에 Cryostat 연결을 추가하고 On create 작업을 선택하면 리드 또는 연락처와 같이 사용자가 원하는 생성을 생성하는 오브젝트 유형을 표시해야 합니다.
4.5. 연결 정보를 보고 편집하는 방법
연결을 만든 후 Fuse Online에서 내부 식별자를 연결에 할당합니다. 이 식별자는 변경되지 않습니다. 연결의 이름, 설명 또는 구성 값을 변경하고 Fuse Online에서 동일한 연결로 인식할 수 있습니다.
연결에 대한 정보를 보고 편집하는 방법은 다음 두 가지가 있습니다.
- 왼쪽 패널에서 연결을 클릭한 다음 연결을 클릭하여 세부 정보를 확인합니다.
왼쪽 패널에서 통합을 클릭한 다음 통합을 보고 요약 페이지를 확인합니다. 통합 흐름 다이어그램에서 다음을 수행합니다.
- 간단한 통합을 위해 연결 아이콘을 클릭하여 해당 연결의 세부 정보를 확인합니다.
-
API 공급자 통합의 경우
 보기를 클릭하여 통합 작업 목록을 표시합니다. 세부 정보를 확인하려는 연결이 흐름에 포함된 작업을 클릭합니다.
보기를 클릭하여 통합 작업 목록을 표시합니다. 세부 정보를 확인하려는 연결이 흐름에 포함된 작업을 클릭합니다.
연결 세부 정보 페이지에서 편집하려는 연결에 대해 필드 옆에 있는
 를 클릭하여 해당 필드를 편집합니다. 또는 구성 필드 아래에 있는 일부 연결의 경우 편집 을 클릭하여 구성 값을 변경합니다. 값을 변경하는 경우 저장을 클릭합니다.
를 클릭하여 해당 필드를 편집합니다. 또는 구성 필드 아래에 있는 일부 연결의 경우 편집 을 클릭하여 구성 값을 변경합니다. 값을 변경하는 경우 저장을 클릭합니다.
실행 중인 통합에 사용되는 연결을 업데이트하는 경우 통합을 다시 게시해야 합니다.
OAuth 프로토콜을 사용하여 액세스 권한을 부여하는 애플리케이션의 경우 연결에 사용하는 로그인 인증 정보를 변경할 수 없습니다. 애플리케이션에 연결하고 다른 로그인 인증 정보를 사용하려면 새 연결을 생성해야 합니다.
4.6. 사용자 정의 커넥터에서 연결 생성 정보
사용자 지정 커넥터를 정의하는 확장을 업로드하면 사용자 정의 커넥터를 사용할 수 있습니다. Fuse Online 제공 커넥터를 사용하여 연결을 생성하는 것과 동일한 방식으로 사용자 지정 커넥터를 사용하여 연결을 생성합니다.
사용자 지정 커넥터는 OAuth 프로토콜을 사용하는 애플리케이션에 사용할 수 있습니다. 이러한 종류의 커넥터에서 연결을 생성하기 전에 커넥터가 제공되는 애플리케이션에 액세스하려면 Fuse Online 환경을 등록해야 합니다. 커넥터가 사용되는 애플리케이션의 인터페이스에서 이 작업을 수행합니다. Fuse Online 환경을 등록하는 방법에 대한 세부 정보는 애플리케이션마다 다릅니다.
예를 들어 사용자 지정 커넥터가 Cryostat에 대한 연결을 만드는 것이라고 가정합니다. Cryostat 내에서 새 애플리케이션을 생성하여 Fuse Online 환경을 등록해야 합니다. 등록은 Fuse Online의 경우 Cryostat 클라이언트 ID와 Fuse Online의 경우 클라이언트 시크릿 값을 제공합니다. Fuse Online 환경에 대한 연결에서는 이 두 값을 제공해야 합니다.
애플리케이션은 소비자 ID 또는 소비자 시크릿과 같은 이러한 값에 다른 이름을 사용할 수 있습니다.
Fuse Online 환경을 등록한 후 애플리케이션에 대한 연결을 만들 수 있습니다. 연결을 구성할 때 클라이언트 ID와 클라이언트 시크릿을 입력하기 위한 매개변수가 있어야 합니다. 이러한 매개변수를 사용할 수 없는 경우 확장 개발자와 통신하고 클라이언트 ID 및 클라이언트 시크릿을 지정할 수 있는 업데이트된 확장을 요청해야 합니다.
5장. 통합 생성
약간의 계획 및 준비 후 통합을 생성할 준비가 된 것입니다. Fuse Online 웹 인터페이스에서 통합 생성 을 클릭하면 Fuse Online에서 통합 생성 절차를 안내합니다.
사전 요구 사항
- 통합 계획 고려 사항
생성하려는 통합의 종류에 따라 다음을 수행합니다.
다음 항목에서는 통합을 생성하기 위한 정보와 지침을 제공합니다.
5.1. 통합 생성 준비
통합 생성 준비는 통합을 계획하기 위한 고려 사항에 나열된 질문에 대한 답변으로 시작됩니다. 통합 계획을 세우면 통합을 생성하기 전에 다음을 수행해야 합니다.
OAuth 프로토콜을 사용하기 위해 연결할 애플리케이션이 있는지 확인합니다. OAuth를 사용하는 각 애플리케이션에 대해 해당 애플리케이션에 액세스할 수 있는 클라이언트로 Fuse Online을 등록합니다. OAuth 프로토콜을 사용하는 애플리케이션은 다음과 같습니다.
- Dropbox
- Google 애플리케이션 (Gmail, Cryostat, Cryostats)
- Salesforce
- SAP Concur
- 연결할 애플리케이션이 HTTP 기본 인증을 사용하는지 확인합니다. 이 기능을 수행하는 각 애플리케이션에 대해 해당 애플리케이션에 액세스하기 위한 사용자 이름과 암호를 식별합니다. 연결을 만들 때 이 정보를 제공해야 합니다.
- 통합할 각 애플리케이션에 대해 연결을 생성합니다.
추가 리소스
5.2. 통합 실행을 트리거하는 대안
통합을 생성할 때 통합의 첫 번째 단계는 통합 실행이 트리거되는 방식을 결정합니다. 통합의 첫 번째 단계는 다음 중 하나일 수 있습니다.
애플리케이션 또는 서비스에 연결합니다. 특정 애플리케이션 또는 서비스에 대한 연결을 구성합니다. 예:
- Twitter에 대한 연결은 사용자가 지정한 텍스트가 포함된 경우 간단한 통합 실행을 모니터링하고 간단한 통합 실행을 트리거할 수 있습니다.
- Cryostat에 대한 연결은 누구나 새로운 리드를 생성할 때 간단한 통합 실행을 트리거할 수 있습니다.
- AWS S3에 대한 연결은 주기적으로 특정 버킷을 폴링하고 버킷에 파일이 포함된 경우 간단한 통합 실행을 트리거할 수 있습니다.
-
타이머. Fuse Online은 사용자가 지정하는 간격으로 간단한 통합 실행을 트리거합니다. 이는 간단한 타이머 또는
cron작업일 수 있습니다. -
Webhook. 클라이언트는 Fuse Online에서 노출하는 HTTP 끝점에 HTTP
GET또는POST요청을 보낼 수 있습니다. 요청이 간단한 통합 실행을 트리거합니다. - API 공급자. API 공급자 통합은 REST API 서비스로 시작됩니다. 이 REST API 서비스는 API 공급자 통합을 생성할 때 제공하는 OpenAPI 2.0 문서에 의해 정의됩니다. API 공급자 통합을 게시한 후 Fuse Online은 OpenShift에 REST API 서비스를 배포합니다. 통합 엔드포인트에 대한 네트워크 액세스가 있는 모든 클라이언트는 통합 실행을 트리거할 수 있습니다.
5.3. 간단한 통합을 생성하기 위한 일반 절차
Fuse Online에서는 간단한 통합 생성 절차를 안내합니다. 시작 연결, 완료 연결, 중간 연결 및 기타 단계를 선택하라는 메시지를 표시합니다. 통합이 완료되면 실행 중이거나 나중에 게시하기 위해 저장할 수 있도록 게시할 수 있습니다.
API 공급자 통합을 생성하는 절차에 대한 자세한 내용은 6.3절. “API 공급자 통합 생성” 을 참조하십시오.
사전 요구 사항
- 통합 단계의 계획에 대한 계획이 있습니다.
- 이 통합에서 연결할 각 애플리케이션 또는 서비스에 대한 연결을 생성했습니다.
절차
- Fuse Online의 왼쪽 패널에서 통합을 클릭합니다.
- 오른쪽 상단에서 통합 생성 을 클릭합니다.
시작 연결을 선택하고 구성합니다.
- 연결 선택 페이지에서 통합을 시작하는 데 사용할 연결을 클릭합니다. 이 통합이 실행 중이면 Fuse Online에서 이 애플리케이션에 연결하여 통합 작업을 수행할 데이터를 가져옵니다.
- 작업 선택 페이지에서 이 연결을 수행할 작업을 선택합니다. 사용 가능한 작업은 각 연결에 따라 다릅니다.
- 작업을 구성하기 위한 페이지에서 필드에 값을 입력합니다.
- 연결에 데이터 유형 지정이 필요한 경우 Fuse Online에서 다음을 클릭하여 작업의 입력 및/또는 출력 유형을 지정할 수도 있습니다.
- 다음을 클릭하여 시작 연결을 추가합니다.
애플리케이션 연결 대신 시작 연결은 지정하는 간격에 따라 통합 실행을 트리거하는 타이머일 수 있으며 HTTP 요청을 수락하는 Webhook일 수 있습니다.
+ 시작 연결을 선택하고 구성한 후 Fuse Online에서 완료 연결을 선택하라는 메시지를 표시합니다.
완료 연결을 선택하고 구성합니다.
- 연결 선택 페이지에서 통합을 완료하는 데 사용할 연결을 클릭합니다. 이 통합이 실행 중이면 Fuse Online은 통합이 작동하는 데이터와 이 애플리케이션에 연결됩니다.
- 작업 선택 페이지에서 이 연결을 수행할 작업을 선택합니다. 사용 가능한 작업은 각 연결에 따라 다릅니다.
- 작업을 구성하기 위한 페이지에서 필드에 값을 입력합니다.
- 연결에 데이터 유형 지정이 필요한 경우 Fuse Online에서 다음을 클릭하여 작업의 입력 및/또는 출력 유형을 지정할 수도 있습니다.
- 다음을 클릭하여 완료 연결을 추가합니다.
애플리케이션 연결 대신 완료 연결은 통합이 처리된 메시지에 대한 통합 로그에 정보를 보낼 수 있습니다. 이렇게 하려면 Fuse Online에서 완료 연결을 선택하라는 메시지를 표시할 때 로그 를 선택합니다.
- 선택적으로 시작 연결과 finish 연결 사이에 하나 이상의 연결을 추가합니다. 각 연결에 대해 작업을 선택하고 필요한 구성 세부 정보를 입력합니다.
- 선택적으로 연결 간 통합 데이터에서 작동하는 하나 이상의 단계를 추가합니다. 연결 사이에 단계 추가를 참조하십시오.
-
통합 시각화에서
 아이콘을 찾습니다. 이러한 경고는 이 연결 전에 데이터 매퍼 단계가 필요함을 나타냅니다. 필요한 데이터 매퍼 단계를 추가합니다.
아이콘을 찾습니다. 이러한 경고는 이 연결 전에 데이터 매퍼 단계가 필요함을 나타냅니다. 필요한 데이터 매퍼 단계를 추가합니다.
- 통합에 필요한 모든 단계가 포함된 경우 통합 실행을 시작할지 여부에 따라 저장 또는 게시 를 클릭합니다.
- 이름 필드에 이 통합을 다른 통합과 구별하는 이름을 입력합니다.
- 선택적으로 Description 필드에 설명을 입력합니다. 예를 들어 이 통합이 수행하는 작업을 표시할 수 있습니다.
통합 실행을 시작할 준비가 되었으면 저장 및 게시 를 클릭합니다.
Fuse Online에는 통합 요약이 표시됩니다. Fuse Online이 게시 중임을 확인할 수 있습니다. 통합 상태가 Running 이 되는 데 다소 시간이 걸릴 수 있습니다.
통합을 게시하지 않으려면 저장을 클릭합니다. Fuse Online은 통합을 저장하고 흐름 시각화를 표시합니다. 계속 편집할 수 있습니다. 또는 페이지 상단의 이동 경로에서 통합을 클릭하여 통합 목록을 표시합니다. 저장했지만 통합을 게시하지 않은 경우 중지 가 통합 항목에 표시됩니다.
5.4. 통합 실행을 트리거하는 타이머 연결 추가
지정한 일정에 따라 통합 실행을 트리거하려면 간단한 통합 시작 연결로 타이머 연결을 추가합니다. 타이머 연결은 흐름의 중간이나 흐름의 끝에 있을 수 없습니다.
절차
- Fuse Online에서 왼쪽에 있는 통합을 클릭합니다.
- 오른쪽 상단에서 통합 생성 을 클릭합니다.
연결 선택 페이지에서 타이머 를 클릭합니다.
Fuse Online에서는 타이머 연결을 제공하므로 타이머 연결을 만들 필요가 없습니다.
작업 선택 페이지에서 Cron 또는 Simple 을 선택합니다.
-
cron타이머에는 통합 실행을 트리거하는 일정을 지정하는cron표현식이 필요합니다. -
간단한 타이머로 마침표와 해당 시간 단위를 지정하라는 메시지가 표시됩니다(예:
5초,1시간). 사용 가능한 단위는 밀리초, 초, 분, 시간, 일 수입니다.
-
-
추가하는 타이머 유형에 따라
cron표현식 또는 선택한 시간 단위가 있는 기간을 입력합니다. - 다음을 클릭하여 통합의 시작 연결로 타이머 연결을 추가합니다.
5.5. 데이터가 컬렉션에 있을 때의 통합 동작
경우에 따라 연결에서 동일한 유형의 여러 값을 포함하는 컬렉션을 반환합니다. 연결이 컬렉션을 반환하면 다음을 포함하여 여러 가지 방법으로 컬렉션에서 흐름이 작동할 수 있습니다.
- 컬렉션에 대해 각 단계를 한 번 실행합니다.
- 컬렉션의 각 요소에 대해 각 단계를 한 번 실행합니다.
- 컬렉션에 대해 일부 단계를 한 번 실행하고 컬렉션의 각 요소에 대해 한 번 다른 단계를 실행합니다.
흐름에서 컬렉션에 대해 작동하는 방법을 결정하려면 흐름이 연결되는 애플리케이션, 컬렉션을 처리할 수 있는지 여부 및 흐름에 달성하려는 애플리케이션을 알아야 합니다. 그런 다음 다음 항목의 정보를 사용하여 컬렉션을 처리하는 흐름에 단계를 추가할 수 있습니다.
5.5.1. 처리 컬렉션 정보
컬렉션을 처리하는 흐름이 가장 쉬운 방법은 데이터 매퍼를 사용하여 소스 컬렉션에 있는 필드를 대상 컬렉션에 있는 필드에 매핑하는 것입니다. 많은 흐름의 경우 이 모든 것이 필요합니다. 예를 들어 흐름은 데이터베이스에서 직원 레코드 컬렉션을 가져온 다음 해당 레코드를 제도에 삽입할 수 있습니다.For example, a flow might obtain a collection of employee records from a database and then insert those records into a font. 데이터베이스 연결과 Google의 연결 간에 데이터 매퍼 단계는 데이터베이스 필드를 Google Cryostat 필드에 매핑합니다. 소스와 대상은 모두 컬렉션이므로 Fuse Online에서 흐름을 실행할 때 Google 연결을 한 번 호출합니다. 이 호출에서 Fuse Online은 레코드를 반복하고 축소를 올바르게 채웁니다.
일부 흐름에서는 컬렉션을 개별 오브젝트로 분할해야 할 수 있습니다. 예를 들어 데이터베이스에 연결하고 특정 날짜 이전에 사용하지 않는 경우 할당된 시간이 손실되는 직원 컬렉션을 가져오는 흐름을 고려해 보십시오. 그런 다음 흐름은 각 직원에게 이메일 알림을 보내야 합니다. 이 흐름에서는 데이터베이스 연결 후 분할 단계를 추가합니다. 그런 다음 직원 레코드의 소스 필드를 message를 전송하는 GPO 연결의 대상 필드에 매핑하는 데이터 매퍼 단계를 추가합니다. Fuse Online에서 흐름을 실행할 때 데이터 매퍼 단계와 각 직원에 대해 한 번의 controlPlane 연결을 실행합니다.
흐름에서 컬렉션을 분할한 후 흐름이 컬렉션에 있는 각 요소에 대해 한 번 일부 단계를 실행한 후 컬렉션에서 흐름이 다시 작동하도록 합니다. 이전 단락의 예제를 고려하십시오. 각 직원에 게 메시지를 전송 한 후, 지금, you want to add a list of the employees who were notified to a picture. 이 시나리오에서는 GPO 연결 후 집계 단계를 추가하여 직원 이름 컬렉션을 생성합니다. 그런 다음 소스 컬렉션의 필드를 대상 Google Cryostat 연결의 필드에 매핑하는 데이터 매퍼 단계를 추가합니다. Fuse Online에서 흐름을 실행할 때 컬렉션에 대해 새 데이터 매퍼 단계와 Google의 연결을 한 번 실행합니다.
이러한 시나리오는 흐름에서 컬렉션을 처리하는 가장 일반적인 시나리오입니다. 그러나 훨씬 더 복잡한 처리도 가능합니다. 예를 들어 컬렉션의 요소가 자체 컬렉션인 경우 다른 분할 및 집계 단계 내부의 분할 및 집계 단계를 중첩할 수 있습니다.For example, when the elements in a collection are themselves collections, you can nest split and aggregate steps inside other split and aggregate steps.
5.5.2. 데이터 매퍼를 사용하여 컬렉션 처리
흐름에서 단계가 컬렉션을 출력하고 흐름에 있는 후속 연결이 컬렉션을 입력으로 예상하는 경우 데이터 매퍼를 사용하여 컬렉션을 처리할 방법을 지정할 수 있습니다.
단계가 컬렉션을 출력하면 흐름 시각화가 단계에 대한 세부 정보에 컬렉션을 표시합니다. 예를 들면 다음과 같습니다.
컬렉션을 제공하는 단계와 매핑이 필요한 단계 앞에 데이터 매퍼 단계를 추가합니다. 흐름에서 이 데이터 매퍼 단계는 흐름의 다른 단계에 따라 달라집니다. 다음 이미지는 소스 컬렉션 필드에서 대상 컬렉션 필드로의 매핑을 보여줍니다.
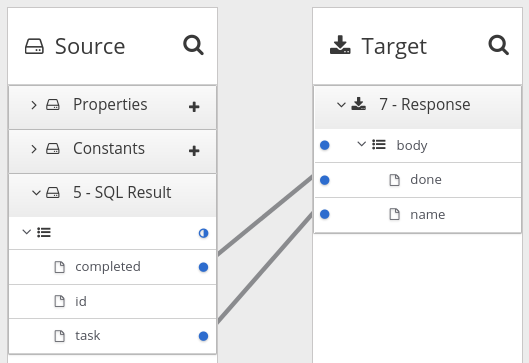
소스 및 대상 패널에서 데이터 매퍼는
![]() 를 표시하여 컬렉션을 나타냅니다. 소스 컬렉션 또는 대상 컬렉션에 기본 유형만 포함된 경우 필요하지 않기 때문에 데이터 매퍼는 컬렉션 필드를 표시하지 않습니다. 컬렉션에서 매핑하거나 컬렉션 자체에 매핑할 수 있습니다.
를 표시하여 컬렉션을 나타냅니다. 소스 컬렉션 또는 대상 컬렉션에 기본 유형만 포함된 경우 필요하지 않기 때문에 데이터 매퍼는 컬렉션 필드를 표시하지 않습니다. 컬렉션에서 매핑하거나 컬렉션 자체에 매핑할 수 있습니다.
컬렉션에 두 가지 유형의 기본 유형이 포함되거나 하나 이상의 복잡한 유형이 포함된 경우 데이터 매퍼에서 컬렉션의 하위 필드를 표시합니다. 각 필드에서 매핑할 수 있습니다. 그러나 또는 중첩된 컬렉션으로 매핑할 수 없습니다.
Fuse Online에서 흐름을 실행하면 소스 컬렉션 요소를 반복하여 대상 컬렉션 요소를 채웁니다. 하나 이상의 소스 컬렉션 필드를 대상 컬렉션 또는 대상 컬렉션 필드에 매핑하는 경우 대상 컬렉션 요소에는 매핑된 필드에 대한 값만 포함됩니다.
소스 컬렉션의 소스 컬렉션 또는 필드를 컬렉션에 없는 대상 필드에 매핑하는 경우 Fuse Online에서 흐름을 실행할 때 소스 컬렉션의 마지막 요소 값만 할당합니다. 컬렉션의 다른 요소는 해당 매핑 단계에서 무시됩니다. 그러나 후속 매핑 단계는 소스 컬렉션의 모든 요소에 액세스할 수 있습니다.
연결에서 JSON 또는 Java 문서에 정의된 컬렉션을 반환하는 경우 데이터 매퍼는 일반적으로 소스 문서를 컬렉션으로 처리할 수 있습니다.
5.5.3. 분할 단계 추가
흐름을 실행하는 동안 연결이 개체 컬렉션을 반환하면 Fuse Online은 컬렉션에 대해 한 번 후속 단계를 실행합니다. 컬렉션에 있는 각 오브젝트에 대해 후속 단계를 한 번 실행하려면 분할 단계를 추가합니다. 예를 들어 Google의 연결에서는 행 오브젝트 컬렉션을 반환합니다. 각 행에 대해 후속 단계를 한 번 실행하려면 Google recording 연결 후 분할 단계를 추가합니다.
분할 단계에 대한 입력이 항상 컬렉션인지 확인합니다. 분할 단계가 컬렉션 유형이 아닌 소스 문서를 가져오는 경우 단계는 각 공간에 입력을 분할합니다. 예를 들어, Fuse Online은 "Hello" 및 "world!"의 두 요소로 "Hello world!"를 분할하고 흐름의 다음 단계에 이 두 요소를 전달합니다. 특히 XML 데이터는 컬렉션 유형이 아닙니다.
사전 요구 사항
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 이미 있습니다.
- 흐름 시각화에서 원본 데이터를 가져오는 연결은 데이터가 (Collection)임을 나타냅니다.In the flow visualization, the connection that obtains the source data indicates that the data is a (Collection).
절차
-
흐름 시각화에서 분할 단계를 추가할 위치에서
 를 클릭합니다.
를 클릭합니다.
- 분할 을 클릭합니다. 이 단계에는 구성이 필요하지 않습니다.
- 다음을 클릭합니다.
추가 정보
일반적으로 데이터 매퍼 단계를 추가하기 전에 분할 단계와 집계 단계를 추가하려고 합니다. 이는 데이터가 컬렉션인지 또는 개별 개체가 매핑에 영향을 미치든 때문입니다. 데이터 매퍼 단계를 추가한 다음 분할 단계를 추가하는 경우 일반적으로 매핑을 다시 수행해야 합니다. 마찬가지로 분할 또는 집계 단계를 제거하는 경우 매핑을 다시 실행해야 합니다.
5.5.4. 집계 단계 추가
흐름에서 Fuse Online을 사용하여 개별 개체에서 컬렉션을 생성하려는 집계 단계를 추가합니다. 실행 중에 집계 단계 후 각 개체에 대해 후속 단계를 한 번 실행하지 않고 Fuse Online은 컬렉션에 대해 한 번 후속 단계를 실행합니다.
흐름에 집계 단계를 추가할지 여부를 결정할 때 흐름의 연결을 고려하십시오. 분할 단계 이후 각 후속 연결에 대해 Fuse Online은 흐름 데이터의 각 요소에 대해 한 번 해당 애플리케이션에 연결합니다. 일부 연결의 경우 여러 번 연결하는 것이 좋습니다.
사전 요구 사항
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 이미 있습니다.
- 이전 단계에서는 컬렉션을 개별 오브젝트로 나눕니다.
절차
-
흐름 시각화에서 흐름에 집계 단계를 추가하려면
를 클릭합니다.
- 집계 를 클릭합니다. 이 단계에는 구성이 필요하지 않습니다.
- 다음을 클릭합니다.
추가 정보
일반적으로 데이터 매퍼 단계를 추가하기 전에 분할 및 집계 단계를 추가하려고 합니다. 이는 데이터가 컬렉션인지 또는 개별 개체가 매핑에 영향을 미치든 때문입니다. 데이터 매퍼 단계를 추가한 다음 집계 단계를 추가하는 경우 일반적으로 매핑을 다시 수행해야 합니다. 마찬가지로 집계 단계를 제거하는 경우 매핑을 다시 수행해야 합니다.
5.5.5. 흐름에서 컬렉션을 처리하는 예
이 간단한 통합은 Fuse Online에서 제공되는 샘플 데이터베이스에서 작업 컬렉션을 가져옵니다. 흐름은 컬렉션을 개별 작업 오브젝트로 분할한 다음 이러한 오브젝트를 필터링하여 수행된 작업을 찾습니다. 그런 다음 흐름은 컬렉션의 완료된 작업을 집계하고, 해당 컬렉션의 필드를 제도의 필드에 매핑하고, 완료된 작업 목록을 document에 추가하여 완료합니다.
아래 절차에서는 이 간단한 통합을 생성하는 방법을 설명합니다.
사전 요구 사항
- Google connection을 생성했습니다.
- Google이 액세스하는 계정에는 데이터베이스 레코드를 수신하기 위한 정보 표시가 있습니다.
절차
- 통합 생성을 클릭합니다.
시작 연결을 추가합니다.
- 연결 선택 페이지에서 PostgresDB 를 클릭합니다.
- 작업 선택 페이지에서 Periodic SQL Invocation 을 선택합니다.
-
SQL 문 필드에
Select * fromdo를입력하고 Next 를 클릭합니다.
이 연결은 작업 오브젝트 컬렉션을 반환합니다.
완료 연결을 추가합니다.
- 연결 선택 페이지에서 Google Connect를 클릭합니다.
- 작업 선택 페이지에서 시트에 대한 앱 값을 선택합니다.
- SpreadsheetId 필드에 작업 목록을 추가하려면 프로젝트 ID를 입력합니다.
-
Range 필드에 값을 추가할 대상 열로
A:B를 입력합니다. 첫 번째 열인 A 는 작업 ID에 대한 것입니다. 두 번째 열인 B 는 작업 이름에 사용됩니다. - 주요 Cryostat 및 값 입력 옵션에 대한 기본값을 수락하고 Next 를 클릭합니다.
Google#159s 연결은 컬렉션의 각 요소를 제도에 추가하여 흐름을 완료합니다.
흐름에 분할 단계를 추가합니다.
- 흐름 시각화에서 더하기 기호를 클릭합니다.
- 분할 을 클릭합니다.
흐름이 분할 단계를 실행한 후 결과는 개별 작업 오브젝트 세트입니다. Fuse Online은 개별 작업 오브젝트에 대해 흐름의 후속 단계를 한 번 실행합니다.
흐름에 필터 단계를 추가합니다.
- 흐름 시각화에서 분할 단계 후 더하기 기호를 클릭합니다.
기본 필터 를 클릭하고 다음과 같이 필터를 구성합니다.
-
첫 번째 필드를 클릭하고 평가할 데이터가 포함된 필드의 이름인
completed를 선택합니다. - 두 번째 필드에서 완료된 필드 값이 충족되어야 하는 조건으로 선택합니다.
-
세 번째 필드에서 완료된 필드에 있어야 하는 값으로
1을 지정합니다.1은 작업이 완료되었음을 나타냅니다.
-
첫 번째 필드를 클릭하고 평가할 데이터가 포함된 필드의 이름인
- 다음을 클릭합니다.
실행 중에 흐름은 각 작업 오브젝트에 대해 필터 단계를 한 번 실행합니다. 결과는 개별 완료된 작업 오브젝트 세트입니다.
흐름에 집계 단계를 추가합니다.
- 흐름 시각화에서 필터 단계 후 더하기 기호를 클릭합니다.
- 집계 를 클릭합니다.
이제 결과 집합에는 각 완료된 작업의 요소가 포함된 하나의 컬렉션이 포함됩니다.
흐름에 데이터 매퍼 단계를 추가합니다.
- 흐름 시각화에서 집계 단계 후 더하기 기호를 클릭합니다.
데이터 매퍼 를 클릭하고 SQL 결과 소스 컬렉션의 다음 필드를 Google Cryostat 대상 컬렉션에 매핑합니다.
- ID A
- 작업 B
- Done 을 클릭합니다.
- 게시 를 클릭합니다.
결과
통합이 실행되면 1분마다 샘플 데이터베이스에서 작업을 얻은 다음 완료된 작업을 조각 모음의 첫 번째 시트에 추가합니다. 통합은 작업 ID를 첫 번째 열인 A 에 매핑하고 작업 이름을 두 번째 열인 B 에 매핑합니다.
5.6. 연결 간 단계 추가 정보
필수 사항은 아니지만 필요한 모든 연결을 기본 흐름에 추가한 다음 흐름을 실행하려는 처리에 따라 연결 사이에 추가 단계를 추가하는 것이 좋습니다. 흐름에서 각 단계는 이전 연결 및 이전 단계에서 얻은 데이터에서 작동합니다. 결과 데이터는 흐름의 다음 단계에서 사용할 수 있습니다.
종종 연결에서 수신되는 데이터 필드를 흐름의 다음 연결이 작동할 수 있는 데이터 필드에 매핑해야 합니다. 흐름에 대한 모든 연결을 추가한 후 흐름 시각화를 확인합니다. 입력 데이터에서 작동하기 전에 데이터 매핑이 필요한 각 연결에 대해 Fuse Online은
 을 표시합니다. 이 아이콘을 클릭하여 데이터 유형 Mismatch: Add a data mapper step before this connection to resolve the difference를 참조하십시오.
을 표시합니다. 이 아이콘을 클릭하여 데이터 유형 Mismatch: Add a data mapper step before this connection to resolve the difference를 참조하십시오.
메시지의 링크를 클릭하여 데이터 매퍼 단계를 추가하고 지정하는 Mapper 구성 페이지를 표시할 수 있습니다. 그러나 다른 필요한 단계를 추가한 다음 데이터 매퍼 단계를 마지막으로 추가하는 것이 좋습니다.
5.7. 실행 흐름을 결정하기 위해 통합 데이터 평가
흐름에서 조건부 흐름 단계는 사용자가 지정하는 조건에 대해 통합 데이터를 평가합니다.In a flow, a Conditional Flows step evaluates integration data against conditions that you specify. 지정된 각 조건에 대해 해당 조건과 연결된 흐름에 연결 및 기타 단계를 추가합니다. 실행 중에 조건부 흐름 단계는 들어오는 데이터를 평가하여 실행할 흐름을 결정합니다.
다음 주제에서는 세부 정보를 제공합니다.
5.7.1. 조건부 흐름 단계의 동작
통합 개발 중에 흐름에 조건부 흐름 단계를 추가하고 하나 이상의 조건을 정의할 수 있습니다. 각 조건에 대해 해당 조건과만 연결된 조건부 흐름에 단계를 추가합니다. 통합 실행 중에 이전 통합 단계가 조건 흐름 단계로 전달되는 각 메시지에 대해 Conditional Flows 단계는 조건을 지정하기 위해 Fuse Online 페이지에서 지정된 조건에 대해 메시지 콘텐츠를 평가합니다.
조건 흐름 단계에서 다음 동작 중 하나입니다.In a Conditional Flows step, the behavior is one of the following:
- true로 평가되는 첫 번째 조건의 경우 통합은 해당 조건과 연결된 조건부 흐름을 실행합니다.
- true로 평가되는 조건이 없고 기본 조건부 흐름이 있는 경우 통합은 해당 흐름을 실행합니다.
- 조건이 true로 평가되지 않고 기본 조건부 흐름이 없는 경우 통합에서 조건부 흐름을 실행하지 않습니다.
조건부 흐름을 실행하거나 조건이 true로 평가되지 않고 기본 조건부 흐름이 없는 후 통합은 기본 흐름의 다음 단계를 실행합니다.
5.7.2. 조건부 흐름 단계의 예
통합이 SQL 데이터베이스에 연결하여 각 직원이 PTO(Payment-Time-off)에 대한 정보를 얻을 수 있다고 가정합니다. 반환된 데이터는 다음을 나타냅니다.
- 일부 직원은 특정 날짜에 사용하지 않는 경우 PTO를 손실할 수 있습니다.
- 다른 직원은 이미 받은 것보다 더 많은 PTO를 사용했습니다.
- 나머지 직원은 시간 제한없이 사용할 수있는 PTO를 보유하고 있습니다.
조건 흐름 단계에서 이 예제 통합에서는 두 가지 조건, 각 조건에 대한 실행 흐름 및 기본 실행 흐름을 정의할 수 있습니다.In a Conditional Flows step, this example integration can define two conditions, an execution flow for each condition, and a default execution flow:
- PTO가 일부 숫자보다 크면 특정 날짜에 사용하지 않는 경우 일부 PTO가 손실될 수 있음을 나타냅니다. 이 조건이 true로 평가되면 통합은 영향을 받는 직원에게 이메일을 보내는 흐름을 실행합니다. 이메일에는 사용해야 하는 PTO 양과 사용해야 하는 날짜가 포함되어 있습니다.
- PTO가 음수인 경우 일부 PTO가 사용되었지만 취득되지 않았음을 나타냅니다. 이 조건이 true로 평가되면 통합은 영향을 받는 직원에게 이메일을 보내는 흐름을 실행합니다. 이메일에는 직원이 초과한 PTO의 양이 포함되어 있으며 직원이 PTO를 다시 누적하기 시작하는 날짜를 지정합니다.
- 두 조건 중 어느 것도 true로 평가되지 않으면 통합에서 기본 흐름을 실행합니다. 이 예제 통합은 PTO가 음수가 아니거나 지정된 숫자보다 큰 직원에 대해 기본 조건부 흐름을 실행합니다. 기본 흐름은 직원이 가지고 있는 PTO 양과 함께 해당 직원에게 이메일을 보냅니다.
5.7.3. 조건부 흐름 단계를 구성하는 일반 절차
조건 흐름 단계를 흐름에 추가한 후 단계를 구성하는 워크플로는 다음 이미지에 표시된 것과 같습니다.After you add a Conditional Flows step to a flow, the workflow for configuring the step is as shown in the following image:
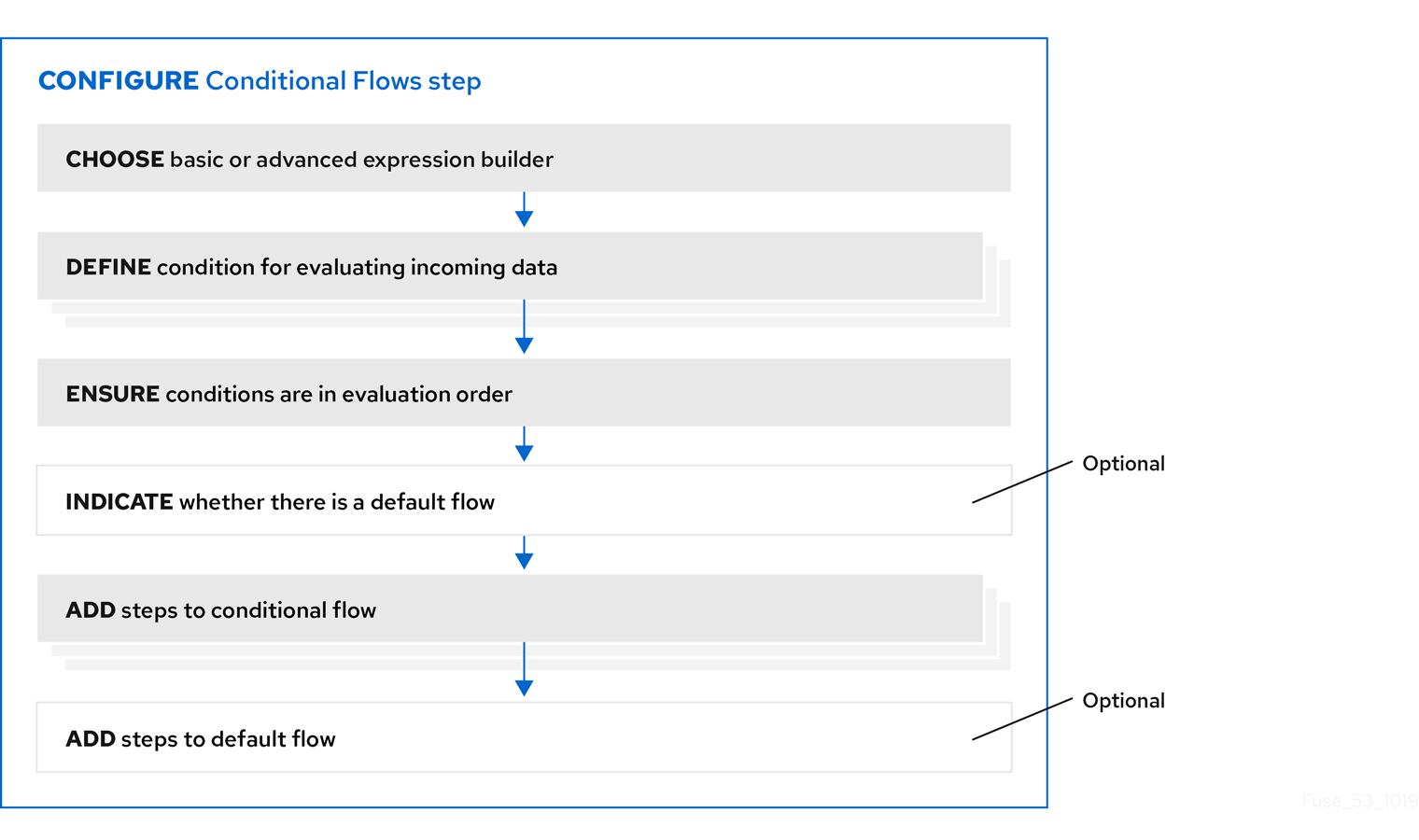
워크플로우에 대한 추가 정보
- 기본 표현식 빌더는 평가할 콘텐츠가 포함된 속성과 테스트할 조건과 값을 입력하라는 메시지를 표시합니다. 기본 표현식 빌더는 대부분의 조건부 흐름 단계에 적합합니다.
- 고급 표현식 빌더를 사용하면 Camel Simple Language에서 조건부 표현식을 지정할 수 있습니다.
- 모든 조건에 동일한 표현식 빌더를 사용해야 합니다. 즉, 조건부 흐름 단계를 구성하려면 기본 표현식 빌더 또는 고급 표현식 빌더를 사용해야 합니다. 둘 다 사용할 수 없습니다.
- 조건부 흐름에서는 조건 흐름 단계를 추가할 수 없습니다.
5.7.4. 기본 표현식 빌더를 사용하여 조건 지정
흐름에서 들어오는 데이터를 평가하여 통합의 실행 경로를 결정하려는 조건부 흐름 단계를 추가합니다. 여기에 설명된 절차는 기본 표현식 빌더를 사용하여 조건을 지정하는 방법을 보여줍니다.
사전 요구 사항
- 기본 흐름을 만들거나 편집하고 있습니다. 간단한 통합인 경우 시작 및 완료 연결이 추가되었습니다.
- 조건 흐름 단계에 대한 입력은 개별 메시지여야 합니다. 통합 시각화에서 이전 단계의 데이터 유형 표시 (Collection) 가 표시(Collection)인 경우 이전 단계 후 및 이 조건부 흐름 단계 앞에 분할 단계를 추가합니다.
- 통합이 조건 흐름 단계로 전달되는 메시지에 표시될 필드에 익숙합니다.
절차
-
통합 시각화에서 조건부 흐름 단계를 추가하려면
을 클릭합니다.
- 조건부 흐름을 클릭합니다.
- 기본 표현식 빌더 항목에서 Select 를 클릭합니다.
조건 흐름 구성 페이지에서 하나 이상의 조건을 정의합니다.
- 초기 When 필드를 클릭합니다.
- 속성 목록에서 조건 흐름 단계에서 평가할 콘텐츠가 포함된 속성을 클릭합니다.In the list of properties, click the property that contains the content that you want the Conditional Flows step to evaluate.
- 다음 필드에서 단계가 데이터를 평가하거나 다른 조건을 선택하는 조건으로 Contains 를 수락합니다. 이 필드에서 선택한 조건은 다음 필드에 입력하는 값에 대해 true로 평가되어야 합니다.
- 세 번째 필드에서 조건이 테스트되는 값을 지정합니다.
- 선택 사항: 다른 조건 추가 를 클릭하여 다른 조건을 지정합니다.
- 정의할 각 추가 조건에 대해 이 단계를 반복합니다.
- 선택 사항: 조건 오른쪽에 있는 위쪽 또는 아래쪽 화살표를 클릭하여 통합에서 정의된 조건을 평가하는 순서를 변경합니다.
선택 사항: 기본 조건부 흐름이 되도록 하려면 기본 흐름 실행을 클릭합니다.
실행 중에 지정한 조건이 true로 평가되지 않으면 통합에서 기본 조건 흐름을 실행합니다.If you select Execute default flow, during execution, if none of the conditions that you specified evaluates to true, the integration executes the default condition flow. 실행 중에 지정한 조건이 true로 평가되지 않으면 이 조건 흐름 단계를 따릅니다.If you do not select Execute default flow, during execution, if none of the conditions that you specified evaluates to true, the integration continues execution with the step that follows this Conditional Flows step.
- 다음을 클릭합니다.
- 선택 사항: Fuse Online에서 메시지를 표시하는 경우 출력 데이터 유형을 지정합니다. 이 조건부 흐름 단계에 속하는 모든 조건부 흐름에 는 동일한 출력 유형이 있어야 합니다.
다음을 클릭합니다.
Fuse Online은 흐름 시각화를 표시합니다. 추가하는 조건부 흐름 단계 아래에는 사용자가 지정한 각 조건에 대한 항목이 있으며 Conditional Flows 단계에 기본 흐름이 있음을 나타내는 경우 otherwise 기본 흐름에 대한 항목이 있습니다.Below the Conditional Flows step that you are adding, there is an entry for each condition that you specified, as well as an entry for an otherwise default flow if you indicated that the Conditional Flows step has a default flow.
다음 단계
각 조건에 대해 연결된 흐름에 단계를 추가합니다. 기본 흐름이 있는 경우 기본 흐름에 단계를 추가합니다.
추가 리소스
- 각 조건의 중간 필드에서 선택할 수 있는 조건에 대한 자세한 내용은 Camel Simple Language Operator 를 참조하십시오. matches 조건은 Simple Language regex Operator에 해당합니다.
- 기본 표현식 빌더를 사용하여 필요한 조건을 정의할 수 없는 경우 고급 표현식 빌더 사용을 참조하여 조건을 지정합니다.
5.7.5. 고급 표현식 빌더를 사용하여 조건 지정
흐름에서 들어오는 데이터를 평가하여 통합의 실행 경로를 결정하려는 조건부 흐름 단계를 추가합니다. 여기에서 설명하는 절차는 고급 표현식 빌더를 사용하여 Camel Simple Language에서 조건부 표현식을 지정하는 방법을 보여줍니다.
사전 요구 사항
- 기본 흐름을 만들거나 편집하고 있습니다. 간단한 통합인 경우 시작 및 완료 연결이 추가되었습니다.
- 조건 흐름 단계에 대한 입력은 개별 메시지여야 합니다. 통합 시각화에서 이전 단계의 데이터 유형 표시 (Collection) 를 표시하는 경우 분할 단계를 추가합니다.
- 통합이 조건 흐름 단계로 전달되는 메시지에 표시될 필드에 익숙합니다.
- Camel Simple Expression 언어에 익숙하거나 평가하려는 조건에 대한 표현식이 있습니다.
절차
-
통합 시각화에서 조건부 흐름 단계를 추가하려면
을 클릭합니다.
- 조건부 흐름을 클릭합니다.
- 고급 표현식 빌더 항목에서 Select 를 클릭합니다.
조건 흐름 구성 페이지에서 하나 이상의 조건을 정의합니다.
초기 When 필드에 Camel Simple Language 조건부 표현식을 입력합니다. 예를 들어, 다음 표현식은 메시지의 본문에
160보다 큰pto필드가 포함된 경우 true로 평가됩니다.${body.pto} > 160이 표현식이 true로 평가되면 통합에서 만들고 이 조건과 연결하는 조건부 흐름을 실행합니다.
참고식에서 조건 흐름 단계가 다음 종류의 흐름 중 하나에 있을 때 추가 속성 사양이 필요합니다.In an expression, an additional property specification is required when the Conditional Flows step is in one of the following kinds of flows:
- API 공급자 통합 작업 흐름
- Webhook 연결로 시작하는 간단한 통합
- 사용자 정의 REST API 연결로 시작하는 간단한 통합
이러한 흐름에서 Fuse Online은
본문속성 내에 실제 메시지 콘텐츠를 래핑합니다. 즉, Conditional Flows 단계에 대한 입력에는 실제 메시지 콘텐츠가 포함된 다른본문속성이 포함된 본문 속성이 포함됩니다.결과적으로 이러한 종류의 흐름 중 하나에 있는 조건부 흐름 단계에 있는 식에서 본문의 두 인스턴스를 지정해야 합니다.Consequently, in an expression that is in a Conditional Flows step that is in one of these kinds of flows, you must specify two instances ofbody. 예를 들어 입력 메시지의pto필드에 있는 콘텐츠를 평가한다고 가정합니다. 다음과 같이 표현식을 지정합니다.${body.body.pto} > 160- 선택 사항: 다른 조건 추가 를 클릭하고 이전 단계를 반복합니다. 정의할 각 추가 조건에 대해 이 작업을 수행합니다.
- 선택 사항: 조건 필드 오른쪽에 있는 위쪽 또는 아래쪽 화살표를 클릭하여 조건 흐름 단계가 정의된 조건을 평가하는 순서를 변경합니다.Change the order in which the Conditional Flows step evaluates the defined conditions by clicking the up or down arrow to the right of a condition field.
선택 사항: 기본 조건부 흐름이 되도록 하려면 기본 흐름 실행을 클릭합니다.
실행 중에 지정한 조건이 true로 평가되지 않으면 통합에서 기본 조건 흐름을 실행합니다.If you select Execute default flow, during execution, if none of the conditions that you specified evaluates to true, the integration executes the default condition flow. 실행 중에 지정한 조건이 true로 평가되지 않으면 이 조건 흐름 단계를 따릅니다.If you do not select Execute default flow, during execution, if none of the conditions that you specified evaluates to true, the integration continues execution with the step that follows this Conditional Flows step.
- 다음을 클릭합니다.
- 선택 사항: Fuse Online에서 메시지를 표시하는 경우 출력 데이터 유형을 지정합니다. 이 조건부 흐름 단계에 속하는 모든 조건부 흐름에 는 동일한 출력 유형이 있어야 합니다.
다음을 클릭합니다.
Fuse Online은 흐름 시각화를 표시합니다. 추가하는 조건부 흐름 단계 아래에는 사용자가 지정한 각 조건에 대한 항목이 있으며 Conditional Flows 단계에 기본 흐름이 있음을 나타내는 경우 otherwise 기본 흐름에 대한 항목이 있습니다.Below the Conditional Flows step that you are adding, there is an entry for each condition that you specified, as well as an entry for an otherwise default flow if you indicated that the Conditional Flows step has a default flow.
다음 단계
각 조건에 대해 연결된 흐름에 단계를 추가합니다. 기본 흐름이 있는 경우 기본 흐름에 단계를 추가합니다.
추가 리소스
5.7.6. 조건부 흐름에 단계 추가
조건 흐름 단계에서 조건을 정의한 후 각 조건에 대해 해당 조건과 연결된 흐름에 단계를 추가합니다.In a Conditional Flows step, after you define conditions, for each condition, add steps to the flow that is associated with that condition. 실행 중에 조건 흐름 단계가 조건을 true로 평가하면 해당 조건과 연결된 흐름을 실행합니다.During execution, when the Conditional Flows step evaluates a condition as true, it executes the flow that is associated with that condition.
사전 요구 사항
- 이 조건부 흐름 단계에 대한 조건을 정의했습니다.
- 통합이 이 조건 흐름 단계로 전달되는 메시지에 있을 필드에 대해 잘 알고 있습니다.
- 조건부 흐름에 추가할 각 연결을 생성했습니다.
절차
통합 시각화에서 추가하려는 흐름의 조건에 대해 흐름 열기를 클릭합니다.In the integration visualization, for the condition whose flow you want to add to, click Open Flow.
Fuse Online은 페이지 상단에 해당 조건을 표시합니다. 조건부 흐름 시각화는 모든 조건부 흐름에 있는 흐름 시작 및 흐름 종료 단계를 보여줍니다.
-
흐름 시각화에서 이 조건부 흐름에 단계를 추가할
를 클릭합니다.
추가할 단계를 클릭합니다. 기본 흐름에 추가할 수 있는 연결 또는 단계를 추가할 수 있습니다.
흐름 시작 단계의 출력은 이 조건 흐름 단계 이전의 기본 흐름 단계의 출력과 항상 동일합니다. 예를 들어 필터 단계 또는 데이터 매퍼 단계를 이 조건부 흐름에 추가하는 경우 사용 가능한 필드는 기본 흐름에서 사용할 수 있는 필드와 동일합니다.
- 필요에 따라 단계를 구성합니다.
- 이 조건부 흐름에 추가할 각 단계에 대해 이전 세 명령을 반복합니다.
- 페이지 상단의 흐름 필드에서 아래쪽을 클릭하고 기본 흐름으로 돌아가 이 조건부 흐름을 저장하고 기본 흐름을 표시하는 기본 흐름을 클릭합니다.At the top of the page, in the Flow field, click the down carat and click Back to primary flow, which saves this conditional flow and displays the primary flow.
- 추가할 각 조건부 흐름에 대해 이 절차를 반복합니다.
결과
기본 흐름에는 조건 흐름 단계에서 정의한 각 조건에 대한 조건부 흐름이 있습니다. 기본 실행 흐름 옵션을 선택한 경우 기본 흐름에도 기본 조건 흐름이 있습니다.
실행 중에 조건부 흐름 단계는 true로 평가되는 첫 번째 조건과 연결된 조건부 흐름을 실행합니다.During execution, the Conditional Flows step executes the conditional flow that is associated with the first condition that evaluates to true. 그런 다음 통합은 조건 흐름 단계를 따르는 단계를 실행합니다.
조건이 true로 평가되지 않으면 Conditional Flows 단계가 기본 조건 흐름을 실행합니다. 그런 다음 통합은 조건 흐름 단계를 따르는 단계를 실행합니다.
다음 두 항목이 모두 true인 경우:
- 조건이 true로 평가되지 않습니다.
- 기본 조건부 흐름은 없습니다.
그런 다음 통합은 조건 흐름 단계를 따르는 단계를 실행합니다.
5.8. 데이터 매퍼 단계 추가
거의 모든 통합에는 데이터 매핑이 필요합니다. 데이터 매퍼 단계는 이전 연결의 데이터 필드와 기타 단계를 흐름의 다음 연결이 작동할 수 있는 데이터 필드에 매핑합니다. 예를 들어 통합 데이터에 Name 필드가 포함되어 있고 흐름의 다음 연결에 CustomerName 필드가 있다고 가정합니다. 소스 이름 필드를 대상 Customer 필드에 매핑해야 합니다.
Name
데이터 매퍼는 이전 통합 단계에서 제공할 수 있는 가장 큰 소스 필드 세트를 표시합니다. 그러나 모든 연결이 표시된 각 소스 필드에 데이터를 제공하는 것은 아닙니다. 예를 들어 타사 애플리케이션을 변경하면 특정 필드에 데이터 제공을 중단할 수 있습니다. 통합을 만들 때 데이터 매핑이 예상대로 작동하지 않는 경우 매핑하려는 소스 필드에 예상 데이터가 포함되어 있는지 확인합니다.
사전 요구 사항
흐름을 만들거나 편집하고 있습니다.
절차
-
데이터 매퍼 단계를 추가할 흐름 시각화에서
을 클릭합니다.
- 데이터 매퍼( Data Mapper )를 클릭하여 데이터 매퍼 캔버스의 소스 및 대상 필드를 표시합니다.
다음 단계
다음 연결에 대한 통합 데이터 매핑을 참조하십시오.
5.9. 기본 필터 단계 추가
흐름에 단계를 추가하여 흐름이 작동하는 데이터를 필터링할 수 있습니다. 필터 단계에서 Fuse Online은 데이터를 검사하고 콘텐츠가 정의한 기준을 충족하는 경우에만 계속됩니다. 예를 들어, Twitter에서 데이터를 가져오는 흐름에서 "Red Hat"이 포함된 notify에서만 작동하여 계속 실행하도록 지정할 수 있습니다.
사전 요구 사항
- 흐름에는 필요한 모든 연결이 포함됩니다.
- 흐름을 만들거나 편집하고 있습니다.
절차
-
필터 단계를 추가할 흐름 시각화에서
을 클릭합니다.
- 기본 필터 를 클릭합니다.
Configure Basic Filter step 페이지에서 들어오는 데이터가 일치하는 경우에만 Continue 를 클릭합니다.
- 정의된 모든 규칙을 충족해야 하는 기본값을 수락합니다.
- 또는 다음 중 하나를 선택하여 하나의 규칙만 충족되어야 함을 나타냅니다.
필터 규칙을 정의합니다.
속성 이름 필드에 필터를 평가할 콘텐츠가 포함된 필드 이름을 입력하거나 선택합니다. 예를 들어, 단계로 들어오는 데이터가 Twitter 처리를 언급하는 토론장으로 구성되어 있다고 가정합니다. 다른 사람이 특정 콘텐츠를 포함하는 경우에만 계속 실행하려고 합니다. chunk은
텍스트라는 필드에 있으므로 속성 이름 필드에 값으로텍스트를 입력하거나 선택합니다.속성 이름은 다음과 같은 방법으로 정의할 수 있습니다.
- 입력을 시작합니다. 필드에는 팝업 상자에 가능한 완료 목록을 제공하는 typeahead 기능이 있습니다. 상자에서 올바른 하나를 선택합니다.
- 필드를 클릭합니다. 사용 가능한 속성 목록이 포함된 드롭다운 상자가 표시됩니다. 목록에서 관심 항목을 선택합니다.
- Operator 필드의 드롭다운 상자에서 Operator를 선택합니다. 기본값은 Contains 입니다. 실행을 계속하려면 이 필드에서 선택한 조건이 Key words 필드에 입력한 값에 대해 true로 평가되어야 합니다.
- 키워드 필드에 필터링할 값을 입력합니다. 예를 들어 기본 Contains 연산자를 수락하고 들어오는 텍스트가 특정 제품을 언급하는 경우에만 통합 실행을 계속하려는 경우를 가정해 보겠습니다. 여기에서 제품 이름을 입력합니다.
필요한 경우 + Add another rule 을 클릭하고 다른 규칙을 정의합니다.
규칙 항목의 오른쪽 상단에 있는 휴지통 아이콘을 클릭하여 규칙을 삭제할 수 있습니다.
- 필터 단계가 완료되면 Done 을 클릭하여 흐름에 추가합니다.
추가 리소스
- Operator 및 평가할 텍스트 지정 예에 대한 자세한 내용은 Camel Simple Language Operator 를 참조하십시오. 기본 필터 단계와 일치하는 연산자는 Simple Language regex Operator에 해당합니다.
- 기본 필터 단계에서 필요한 필터를 정의할 수 없는 경우 고급 필터 단계 추가 를 참조하십시오.
5.10. 고급 필터 단계 추가
필터 단계에서 Fuse Online은 데이터를 검사하고 콘텐츠가 정의한 기준을 충족하는 경우에만 흐름을 계속 실행합니다. 기본 필터 단계에서 필요한 정확한 필터를 정의하지 않으면 고급 필터 단계를 추가합니다.
사전 요구 사항
- 흐름에는 필요한 모든 연결이 포함됩니다.
- 흐름을 만들거나 편집하고 있습니다.
- Camel Simple Language에 익숙하거나 필터 표현식이 제공되었습니다.
절차
-
흐름 시각화에서 흐름에 고급 필터 단계를 추가하려면
을 클릭합니다.
- 고급 필터 를 클릭합니다.
편집 상자에서 Camel Simple Language 를 사용하여 필터 표현식을 지정합니다. 예를 들어 메시지 헤더의
type필드가위젯으로 설정된 경우 다음 표현식은 true로 평가됩니다.${in.header.type} == 'widget'다음 예에서는 메시지의 본문에
제목필드가 포함된 경우 표현식이 true로 평가됩니다.${in.body.title}- 다음을 클릭하여 고급 필터 단계를 흐름에 추가합니다.
일부 종류의 흐름에 대한 추가 속성 사양
식에서 고급 필터 단계가 다음 종류의 흐름 중 하나에 있는 경우 추가 속성 사양이 필요합니다.
- API 공급자 통합 작업 흐름
- Webhook 연결로 시작하는 간단한 통합
- 사용자 정의 REST API 연결로 시작하는 간단한 통합
이러한 흐름에서 Fuse Online은 본문 속성 내에 실제 메시지 콘텐츠를 래핑합니다. 즉, 고급 필터에 대한 입력에는 실제 메시지 콘텐츠가 포함된 다른 본문 속성이 포함된 본문 속성이 포함됩니다. 결과적으로 이러한 종류의 흐름 중 하나에 있는 고급 필터 표현식에서 본문 의 두 인스턴스를 지정해야 합니다. 예를 들어 입력 메시지의 완료된 필드에 있는 콘텐츠를 평가한다고 가정합니다. 다음과 같이 표현식을 지정합니다.
${body.body.completed} = 15.11. 템플릿 단계 추가
흐름에서 템플릿 단계는 소스의 데이터를 가져와 Fuse Online에 업로드하는 템플릿에 정의된 형식으로 삽입합니다. 템플릿 단계의 이점은 사용자가 지정하는 일관된 형식으로 데이터 출력을 제공하는 것입니다.
템플릿에서 자리 표시자를 정의하고 정적 텍스트를 지정합니다. 흐름을 생성할 때 템플릿 단계를 추가하고 소스 필드를 템플릿 자리 표시자에 매핑한 다음 템플릿 콘텐츠를 흐름의 다음 단계에 매핑합니다. Fuse Online에서 흐름을 실행할 때 매핑된 소스 필드에 있는 값을 템플릿 인스턴스에 삽입하고 그 결과를 흐름의 다음 단계에서 사용할 수 있도록 합니다.
흐름에 템플릿 단계가 포함된 경우 해당 흐름의 유일한 템플릿 단계가 포함됩니다. 그러나 흐름에서 두 개 이상의 템플릿 단계가 허용됩니다.
Fuse Online에서는 다음과 같은 유형의 템플릿을 지원합니다. Freemarker,Mustache,Velocity.
사전 요구 사항
- 흐름을 만들거나 편집해야 합니다.
- 간단한 통합을 생성하는 경우 이미 시작 및 연결을 완료해야 합니다.
절차
-
흐름 시각화에서 템플릿 단계를 추가할
를 클릭합니다.
- 템플릿을 클릭합니다. 템플릿 업로드 페이지가 열립니다.
- Freemarker, Mustache 또는 Velocity 템플릿 유형을 지정합니다.
템플릿을 정의하려면 다음 중 하나를 수행합니다.
- 템플릿 파일 또는 템플릿을 생성하기 위해 수정할 텍스트가 포함된 파일을 템플릿 편집기로 드래그 앤 드롭합니다.
- 찾아보기를 클릭하여 업로드 한 후 파일로 이동한 후 업로드합니다.
- 템플릿 편집기에서 입력을 시작하여 템플릿을 정의합니다.
-
템플릿 편집기에서 템플릿이 Fuse Online에서 사용하는 데 유효한지 확인합니다. 유효한 템플릿의 예는 이 절차 뒤에 있습니다. Fuse Online은 구문 오류가 포함된 행 왼쪽에
 를 표시합니다. 구문 오류 표시 위에 마우스를 가져가면 오류 해결 방법에 대한 힌트가 표시됩니다.
를 표시합니다. 구문 오류 표시 위에 마우스를 가져가면 오류 해결 방법에 대한 힌트가 표시됩니다.
Done 을 클릭하여 템플릿 단계를 흐름에 추가합니다.
Done 버튼이 활성화되어 있지 않으면 수정해야 하는 구문 오류가 하나 이상 있습니다.
템플릿 단계에 대한 입력은 JSON 오브젝트의 형식이어야 합니다. 따라서 템플릿 단계 앞에 데이터 매핑 단계를 추가해야 합니다.
템플릿 단계 앞에 데이터 매퍼 단계를 추가하려면 다음을 수행합니다.
-
흐름 시각화에서 방금 추가한 템플릿 단계 바로 앞에 있는
를 클릭합니다.
- 데이터 매퍼 를 클릭합니다.
데이터 매퍼에서 소스 필드를 각 템플릿 자리 표시자 필드에 매핑합니다.
예를 들어 이 절차 이후의 예제 템플릿을 사용하여 소스 필드를 각 템플릿 필드에 매핑합니다.
-
time -
name -
text
-
- 오른쪽 상단에서 Done 을 클릭하여 데이터 매퍼 단계를 흐름에 추가합니다.
템플릿 단계의 출력은 항상 JSON 오브젝트입니다. 따라서 템플릿 단계 후에 데이터 매퍼 단계를 추가해야 합니다.
-
흐름 시각화에서 방금 추가한 템플릿 단계 바로 앞에 있는
템플릿 단계 뒤에 데이터 매퍼 단계를 추가하려면 다음을 수행합니다.
-
흐름 시각화에서 방금 추가한 템플릿 단계 직후에 있는
를 클릭합니다.
- 데이터 매퍼 를 클릭합니다.
- 데이터 매퍼에서 소스 필드를 템플릿에 삽입한 결과가 항상 포함된 템플릿의 메시지 필드를 대상 필드에 매핑합니다. 예를 들어, localhost 연결이 흐름 옆에 있고 템플릿 단계의 결과를Registry 메시지의 콘텐츠로 전송하려는 경우를 가정해 보겠습니다. 이렇게 하려면 메시지 소스 필드를 텍스트 대상 필드에 매핑합니다.
- 오른쪽 상단에서 Done 을 클릭합니다.
-
흐름 시각화에서 방금 추가한 템플릿 단계 직후에 있는
템플릿의 예
Mustache 템플릿의 예:
At {{time}}, {{name}} tweeted:
{{text}}Freemarker 및 Velocity는 이 예제 템플릿을 지원합니다.
At ${time}, ${name} tweeted:
${text}속도에서는 다음 예와 같이 중괄호가 없는 구문도 지원합니다.
At $time, $name tweeted: $text
자리 표시자는 . (period)를 포함할 수 없습니다.
추가 리소스
매핑 필드에 대한 자세한 내용은 다음 연결의 필드에 통합 데이터 매핑을 참조하십시오.
5.12. 사용자 정의 단계 추가
Fuse Online에서 흐름에 필요한 단계를 제공하지 않는 경우 개발자는 확장에 하나 이상의 사용자 지정 단계를 정의할 수 있습니다. 사용자 지정 단계는 흐름의 연결 간 데이터에서 작동합니다.
기본 제공 단계를 추가하는 것과 동일한 방식으로 흐름에 사용자 지정 단계를 추가합니다. 간단한 통합을 위해 시작 및 완료 연결을 선택하고 필요에 따라 다른 연결을 추가한 다음 단계를 추가합니다. API 공급자 통합의 경우 흐름이 사용자 지정 단계를 실행하는 작업을 선택하고 필요에 따라 흐름에 연결을 추가한 다음 다른 단계를 추가합니다. 단계를 추가하면 Fuse Online은 흐름의 이전 단계에서 수신하는 데이터에 대해 작동합니다.
사전 요구 사항
- 사용자 지정 단계 확장을 Fuse Online에 업로드했습니다. 사용자 지정 기능을 사용할 수 있도록 설정을 참조하십시오.
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 이미 있습니다.
절차
-
워크플로우 시각화에서 사용자 정의 단계를 추가하려는 경우
을 클릭합니다.
추가할 사용자 지정 단계를 클릭합니다.
사용 가능한 단계에는 Fuse Online 환경에 업로드된 확장에 정의된 사용자 지정 단계가 포함되어 있습니다.
- 단계를 수행하는 데 필요한 모든 정보를 입력하라는 메시지에 응답합니다. 이 정보는 사용자 정의 단계마다 다릅니다.
6장. REST API 호출에 의해 트리거되는 통합 생성
필요에 따라 통합 실행을 트리거하려면 사용자가 제공하는 REST API 설명 문서로 통합을 시작합니다. 이러한 방식으로 시작하는 통합을 API 공급자 통합 이라고 합니다. API 공급자 통합을 통해 REST API 클라이언트가 통합 실행을 트리거하는 명령을 호출할 수 있습니다.
Fuse Online에서 API 공급자 통합을 게시하면 통합 엔드포인트에 대한 네트워크 액세스 권한이 있는 모든 클라이언트에서 통합 실행을 트리거할 수 있습니다.
OpenShift Container Platform 온사이트에서 Fuse Online을 사용하는 경우 관리자는 Fuse Online 서버를 구성하여 Red Hat 3scale API를 검색할 수 있습니다. 기본적으로 Fuse Online은 3scale과 함께 사용할 API 공급자 통합의 API 서비스 정의에 주석을 달지만 자동 3scale 검색을 위해 해당 API를 노출하지 않습니다. 3scale 검색이 없으면 액세스 제어가 없습니다. 3scale 검색을 사용하면 액세스 정책을 설정하고, 제어를 중앙 집중화하고, API 공급자 통합 API의 고가용성을 제공할 수 있습니다. 자세한 내용은 Red Hat 3scale 설명서 페이지에서 사용할 수 있는 API 게이트웨이 설명서를 참조하십시오.
API의 3scale 검색을 활성화하려면 Fuse Online 구성 도 참조하십시오.
다음 주제에서는 API 공급자 통합을 생성하기 위한 정보와 지침을 제공합니다.
API 공급자 통합을 생성, 게시 및 테스트하는 방법을 보여주는 동영상은 https://youtu.be/sox8SSqJ0zQ 을 참조하십시오.
6.1. API 공급자 통합을 생성하기 위한 이점, 개요 및 워크플로우
API 공급자 통합은 REST API 서비스로 시작됩니다. 이 REST API 서비스는 API 공급자 통합을 생성할 때 제공하는 OpenAPI 2.0 문서에 의해 정의됩니다. API 공급자 통합을 게시한 후 Fuse Online은 OpenShift에 REST API 서비스를 배포합니다. API 공급자 통합의 이점은 REST API 클라이언트가 통합 실행을 트리거하는 호출을 호출할 수 있다는 점입니다.
여러 실행 흐름
API 공급자 통합에는 흐름이라는 여러 실행 경로가 있습니다. OpenAPI 문서에서 정의하는 각 작업에는 자체 흐름이 있습니다. Fuse Online에서는 OpenAPI 문서에서 정의한 각 작업에 대해 해당 작업의 실행 흐름에 연결 및 기타 단계를 추가합니다. 이러한 단계는 특정 작업에 필요한 대로 데이터를 처리합니다.
실행 흐름 예
예를 들어 Fuse Online에서 사용할 수 있는 REST API 서비스를 호출하는 인적 리소스 애플리케이션을 고려해 보십시오. 호출이 새 작업자를 추가하는 작업을 호출한다고 가정합니다. 이 호출을 처리하는 작업 흐름은 다음을 수행할 수 있습니다.
- 새 직원 장비에 대한 비용 보고서를 생성하는 애플리케이션에 연결합니다.
- SQL 데이터베이스에 연결하여 새 장비 설정을 위한 내부 티켓을 추가합니다.
- Google 메일에 연결하여 방향 정보를 제공하는 새 직원에게 메시지를 보냅니다.
실행을 트리거하는 방법
다음을 포함하여 통합 실행을 트리거하는 REST API를 호출하는 방법에는 여러 가지가 있습니다.
- 데이터 입력을 사용하고 호출을 생성하는 웹 브라우저 페이지입니다.
-
curl유틸리티와 같이 REST API를 명시적으로 호출하는 애플리케이션입니다. - REST API를 호출하는 기타 API(예: Webhook)
흐름을 편집하는 방법
각 작업에 대해 다음을 통해 해당 흐름을 편집할 수 있습니다.
- 데이터를 처리해야 하는 애플리케이션에 대한 연결 추가.
- 분할, 집계 및 데이터 매핑 단계를 포함한 연결 간 단계 추가
- 연결 오류 메시지를 매핑하여 HTTP 응답의 코드를 반환하여 흐름을 완료합니다. 응답은 통합 실행을 트리거한 호출을 호출한 애플리케이션으로 이동합니다.
API 공급자 통합을 생성하기 위한 워크플로우
API 공급자 통합을 생성하기 위한 일반 워크플로우는 다음 다이어그램에 표시되어 있습니다.
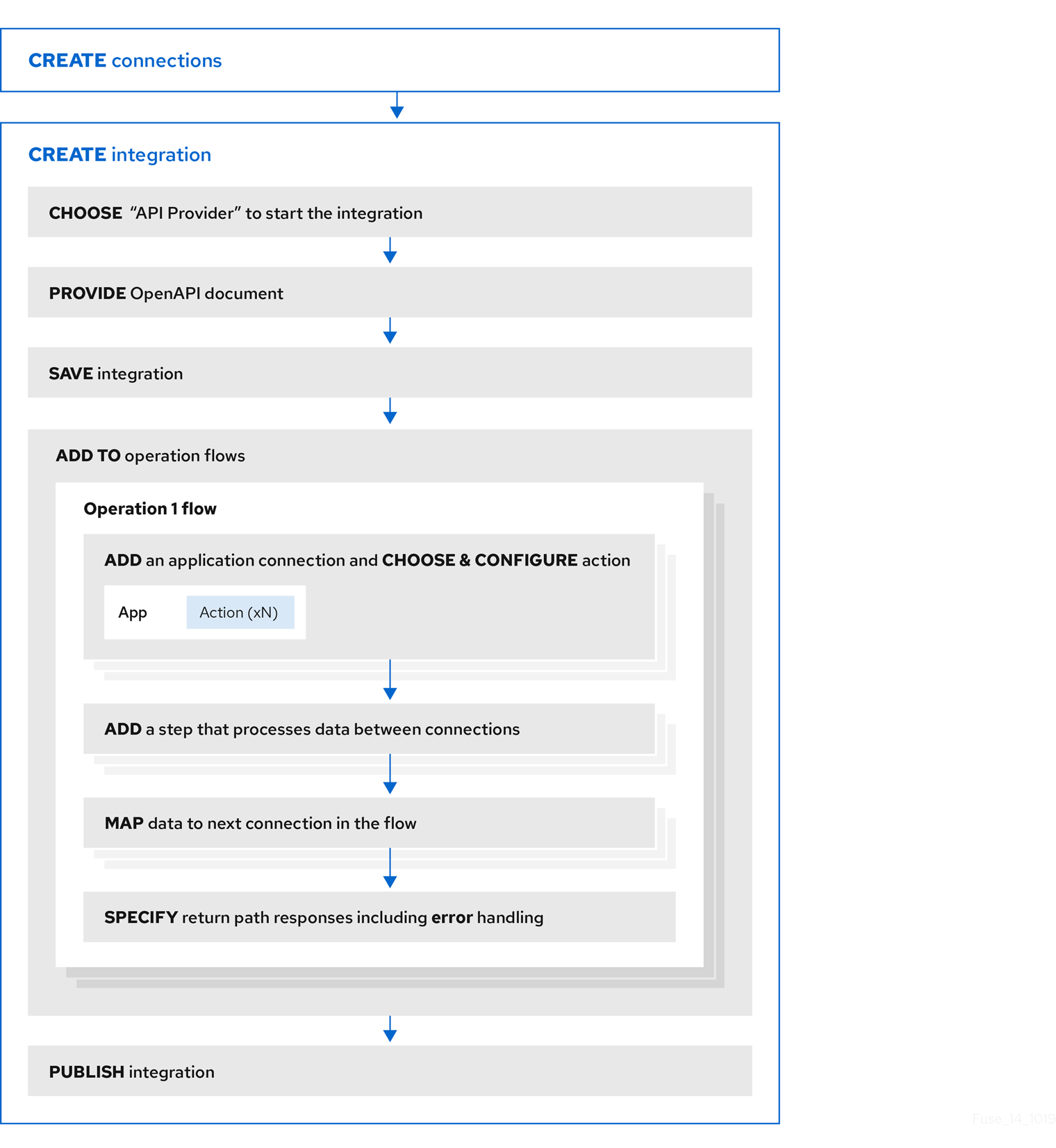
API 공급자 통합 게시
API 공급자 통합을 게시한 후 통합 요약 페이지에서 Fuse Online에 REST API 서비스의 외부 URL이 표시됩니다. 이 외부 URL은 클라이언트가 REST API 서비스를 호출하는 데 사용하는 기본 URL입니다.
API 공급자 통합 테스트
API 공급자 통합의 흐름을 테스트하기 위해 curl 유틸리티를 사용하면 됩니다. 예를 들어 다음 curl 명령은 ID로 Get Task에 대한 흐름 실행을 트리거한다고 가정합니다. HTTP GET 명령은 기본 요청이므로 GET 을 지정할 필요가 없습니다. URL의 마지막 부분은 가져올 작업의 ID를 지정합니다.
curl -k https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/todo/1
6.2. OpenAPI 작업이 API 공급자 통합 흐름과 관련된 방법
API 공급자 통합의 OpenAPI 문서는 REST API 클라이언트가 호출할 수 있는 작업을 정의합니다. 각 OpenAPI 작업에는 자체 API 공급자 통합 흐름이 있습니다. 결과적으로 각 작업에는 자체 REST API 서비스 URL도 있을 수 있습니다. 각 URL은 API 서비스의 기본 URL에 의해 정의되며, 선택적으로 하위 경로에 의해 정의됩니다. REST API 호출은 해당 작업의 흐름 실행을 트리거하는 작업의 URL을 지정합니다.
OpenAPI 문서는 REST API 서비스 URL에 대한 호출에 지정할 수 있는 HTTP 동사(예: GET,POST,DELETE 등)를 결정합니다. API 공급자 URL에 대한 호출의 예는 API 공급자 빠른 시작 예제를 시도하는 방법에 있습니다.
또한 OpenAPI 문서에는 작업이 반환할 수 있는 가능한 HTTP 상태 코드가 결정됩니다. 작업의 반환 경로는 OpenAPI 문서에서 정의한 응답만 처리할 수 있습니다. 예를 들어 ID를 기반으로 오브젝트를 삭제하는 작업은 다음과 같은 가능한 응답을 정의할 수 있습니다.
"responses": {
"204": {
"description": "Task deleted"
},
"404": {
"description": "No Record found with this ID"
},
"500": {
"description": "Server Error"
}
}API 공급자 통합 예
다음 다이어그램은 사용자에 대한 데이터를 처리하는 API 공급자 통합을 보여줍니다. 외부 REST API 클라이언트는 API 공급자 통합에서 배포한 REST API URL을 호출합니다. URL을 호출하면 하나의 REST 작업에 대한 흐름 실행이 트리거됩니다. 이 API 공급자 통합에는 3개의 흐름이 있습니다. 각 흐름은 Fuse Online에서 사용할 수 있는 모든 연결 또는 단계를 사용할 수 있습니다. REST API는 흐름과 함께 하나의 Fuse Online API 공급자 통합으로, 하나의 OpenShift Pod에 배포됩니다.
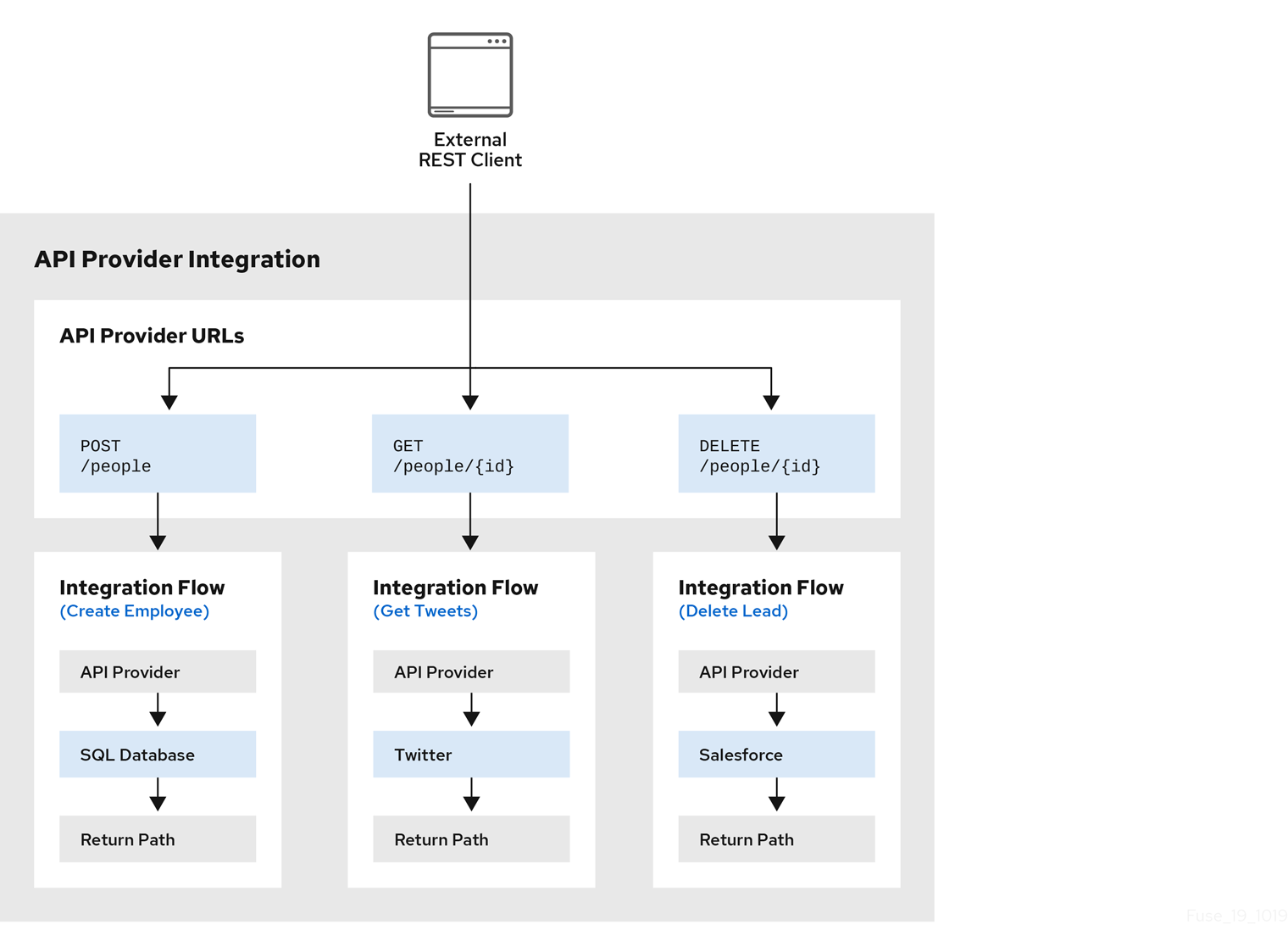
API 공급자 통합을 생성하는 동안 OpenAPI 문서 편집
API 공급자 통합을 위해 OpenAPI 2.0 문서를 지정한 후 API 작업의 실행 흐름을 정의하는 동안 필요에 따라 문서를 업데이트할 수 있습니다. 이렇게 하려면 API 공급자 통합을 편집 중인 페이지의 오른쪽 상단에 있는 API 정의 보기/ 편집을 클릭합니다. 그러면 API Cryostat 편집기에 OpenAPI 문서가 표시됩니다. 문서를 편집하고 저장하여 Fuse Online에 반영된 내용을 변경합니다.
OpenAPI 문서를 편집하는 동안 고려 사항:
동기화에 대한
operationId속성API window 편집기의 OpenAPI 문서 버전과 Fuse Online 통합 편집기의 OpenAPI 문서 버전 간의 동기화는 문서에 정의된 각 작업에 할당된 고유한
operationId속성에 따라 달라집니다. 각 작업에 특정operationId속성 값을 할당하거나 Fuse Online에서 자동으로 생성하는 작업을 사용할 수 있습니다.요청 및 응답 정의
각 작업의 정의에서 작업의 요청 및 응답을 정의하는 JSON 스키마를 제공할 수 있습니다. Fuse Online에서는 JSON 스키마를 사용합니다.
- 작업의 입력 및 출력 데이터 셰이프를 기반으로 합니다.
- 데이터 매퍼의 작업 필드를 표시하려면 다음을 수행합니다.
순환 스키마 참조 없음
API 공급자 통합 작업의 JSON 스키마에는 사이클 스키마 참조가 있을 수 없습니다. 예를 들어 요청 또는 응답 본문을 지정하는 JSON 스키마는 전체로 참조하거나 중간 JSON 스키마를 통해 자체의 일부를 참조할 수 없습니다.
6.3. API 공급자 통합 생성
API 공급자 통합을 생성하려면 통합에서 수행할 수 있는 작업을 정의하는 OpenAPI 문서(.json,.yaml 또는 .yml 파일)를 제공합니다. Fuse Online은 각 작업에 대한 실행 흐름을 생성합니다. 각 작업의 흐름을 편집하여 해당 작업의 요구 사항에 따라 통합 데이터를 처리하는 연결 및 단계를 추가합니다.
사전 요구 사항
통합이 수행하려는 REST API 작업에 대해 OpenAPI 문서를 제공하거나 정의할 수 있습니다.
실험하려면 API 공급자 빠른 시작 의 OpenAPI 문서인
task-api.json파일의 원시 버전을 다운로드합니다. Fuse Online에서 OpenAPI 문서를 제공하라는 메시지가 표시되면 이 파일을 업로드할 수 있습니다. 또는 https://raw.githubusercontent.com/syndesisio/syndesis-quickstarts/1.8/api-provider/task-api.json 인 rawtask-api.json파일의 URL을 지정할 수 있습니다.- 각 OpenAPI 작업에 대한 흐름 계획이 있습니다.
- 작업 흐름에 추가할 각 애플리케이션 또는 서비스에 대한 연결을 생성했습니다.
절차
- Fuse Online의 왼쪽 탐색 패널에서 통합을 클릭합니다.
- 오른쪽 상단에서 통합 생성 을 클릭합니다.
- 연결 선택 페이지에서 API 공급자 를 클릭합니다.
API 호출 페이지와의 통합 시작에서 다음을 수행합니다.
- REST API 작업을 정의하는 OpenAPI 2.0 문서가 있는 경우 OpenAPI 문서를 업로드합니다.
- OpenAPI 2.0 문서를 정의해야 하는 경우 만들기 를 선택합니다.
다음을 클릭합니다.
문서를 업로드한 경우 문서를 검토하거나 편집합니다.
- 검토/편집 을 클릭하여 API Splunk 편집기를 엽니다.
- 필요에 따라 검토하고 편집합니다.
- 오른쪽 상단에서 저장 또는 취소 를 클릭하여 편집기를 종료합니다.
- 다음을 클릭합니다.
문서를 작성하는 경우 Fuse Online이 열리는 API developers editor에서 다음을 수행하십시오.
- OpenAPI 문서를 정의합니다.
- 오른쪽 상단에서 저장을 클릭하여 편집기를 닫습니다.
- 다음을 클릭합니다.
API 편집기 사용에 대한 자세한 내용은 API Creator 를 사용한 API 정의 설계 및 개발을 참조하십시오.
결과
Fuse Online에는 OpenAPI 문서에서 정의한 작업 목록이 표시됩니다.
다음 단계
각 작업에 대해 해당 작업을 실행하는 흐름을 정의합니다.
6.4. API 공급자 통합을 위한 작업 흐름 정의
REST API 서비스를 정의하는 OpenAPI 문서는 서비스에서 수행할 수 있는 작업을 정의합니다. API 공급자 통합을 생성한 후 각 작업에 대한 흐름을 편집할 수 있습니다.
각 작업에는 정확히 하나의 흐름이 있습니다. 작업 흐름에서는 다른 애플리케이션 및 서비스에 대한 연결과 연결 간 데이터에서 작동하는 단계를 추가할 수 있습니다.
작업 흐름을 추가하면 API 공급자 통합이 기반으로 하는 OpenAPI 문서를 업데이트해야 할 수 있습니다. 이렇게 하려면 API 공급자 통합을 편집 중인 페이지의 오른쪽 상단에 있는 API 정의 보기/ 편집을 클릭합니다. API Creator 편집기에 문서가 표시됩니다. OpenAPI 정의에서는 각 작업에 고유한 operationId 속성이 있는 한 API Splunk 및 Fuse Online에 업데이트를 저장하면 API 공급자 통합의 흐름 정의를 동기화하여 업데이트를 수행할 수 있습니다.
사전 요구 사항
- API 공급자 통합을 생성하고 이름을 부여하여 저장했습니다.
- 작업 흐름에 연결하려는 각 애플리케이션 또는 서비스에 대한 연결을 생성했습니다. 자세한 내용은 연결 생성에 대한 정보를 참조하십시오.
- Fuse Online에서는 API에서 정의하는 작업 목록을 표시합니다.
절차
- 작업 목록 페이지에서 편집하려는 작업의 흐름 만들기를 클릭합니다.In the Operations list page, for the operation whose flow you want to edit, click Create flow.
이 흐름에 추가할 각 연결에 대해 다음을 수행합니다.
- 흐름 시각화에서 더하기 기호를 클릭하여 해당 위치에 연결을 추가합니다.
- 추가할 연결을 클릭합니다.
- 이 연결을 수행할 작업을 선택합니다.
- 레이블이 지정된 필드에 데이터를 입력하여 작업을 구성합니다.
- 다음을 클릭합니다.
계속하기 전에 원하는 모든 연결을 흐름에 추가합니다.
이 작업 흐름에서 연결 간 데이터를 처리하려면 다음을 수행합니다.
- 흐름 시각화에서 단계를 추가할 더하기 기호를 클릭합니다.
- 추가할 단계를 클릭합니다.
- 레이블이 지정된 필드에 데이터를 입력하여 단계를 구성합니다.
다음을 클릭합니다.
자세한 내용은 연결 간 단계 추가 를 참조하십시오.
연결 간에 데이터를 처리하는 다른 단계를 추가하려면 이 명령의 하위 집합을 반복합니다.
다음 연결의 필드에 데이터를 매핑합니다.
-
흐름 시각화에서
아이콘이 일치하지 않는 데이터 유형을 확인하여 들어오는 데이터를 처리할 수 없음을 나타냅니다. 여기에 데이터 매퍼 단계를 추가해야 합니다.
흐름 시각화의 각 데이터 불일치 아이콘에 대해:
- 해당 단계 직전에 있는 더하기 기호를 클릭합니다.
- 데이터 매퍼 를 클릭합니다.
- 필요한 매핑을 정의합니다. 자세한 내용은 다음 연결의 필드에 통합 데이터 매핑을 참조하십시오.
- Done 을 클릭하여 데이터 매퍼 단계를 흐름에 추가합니다.
-
흐름 시각화에서
흐름 시각화에서 제공된 API 반환 경로 단계에서 구성을 클릭합니다.
모든 API 공급자 통합은 작업 흐름 실행을 트리거한 REST API 호출자에 대한 응답을 전송하여 각 작업 흐름을 완료합니다. 응답에는 작업의 흐름을 완료하는 Provided API 반환 경로 단계에 대해 구성하는 반환 코드 중 하나가 포함됩니다. 다음과 같이 반환 경로 단계를 구성합니다.
- 기본 응답 의 경우 반환 코드 필드에서 Fuse Online에서 표시하는 기본 응답을 수락하거나 다운을 클릭하고 스크롤을 클릭하여 원하는 기본 응답을 선택합니다. 흐름은 작업 흐름 실행 시 구성된 오류 응답 중 하나를 반환하지 않으면 이 응답을 보냅니다. 일반적으로 기본 응답 반환 코드는 성공적인 작업을 나타냅니다.
오류 처리 에서 반환된 메시지의 본문에 오류 메시지를 포함할지 여부를 나타냅니다.
개발 중에 일반적으로 오류 메시지를 반환하려고 합니다. 그러나 프로덕션에서는 민감한 정보 또는 독점 정보가 포함된 경우 오류 메시지를 숨기고자 할 수 있습니다. 오류 메시지는
responseCode,category,message요소가 포함된 JSON 형식의 문자열입니다. 예를 들면 다음과 같습니다.{ responseCode: 404, category: "SQL_ENTITY_NOT_FOUND_ERROR", message: "SQL SELECT did not SELECT any records" }오류 응답 코드 에서 는 Fuse Online에서 흐름의 연결이 반환될 수 있는 각 오류에 대한 항목을 표시합니다. 각 오류에 대해 200 All is good default return code 또는 click to select another HTTP status return code를 수락합니다.
선택할 수 있는 반환 코드는 OpenAPI 문서가 이 흐름이 실행되는 작업에 대해 정의하는 반환 코드입니다. Fuse Online에서 필요한 반환 코드를 표시하지 않으면 OpenAPI 문서를 편집하여 추가할 수 있습니다.
이렇게 하려면 오른쪽 상단에서 API 정의 보기/편집 을 클릭합니다. 필요에 따라 OpenAPI 문서를 편집합니다. 완료되면 OpenAPI 문서를 저장합니다. Fuse Online에서 Provided API 반환 경로 편집으로 돌아가고 저장한 모든 변경 사항을 반영합니다.
- 다음을 클릭하여 반환 경로 구성을 완료합니다.
이 흐름에 필요한 모든 연결 및 단계가 있고 데이터 불일치 아이콘이 없거나 더 이상 흐름을 편집하지 않으려면 다음 중 하나를 수행하십시오.
- 오른쪽 상단에 있는 통합 실행을 시작하려면 게시 를 클릭합니다. 이렇게 하면 통합을 빌드하고, REST API 서비스를 OpenShift에 배포하고, 통합을 실행할 수 있도록 합니다. 작업의 흐름 또는 작업 흐름을 편집할 때마다 통합을 게시할 수 있습니다.
- 작업 목록을 오른쪽 상단에 표시하려면 저장을 클릭합니다.
다른 작업의 흐름을 편집하려면 이 절차를 반복합니다.
API 공급자 통합 테스트
다음 플랫폼 중 하나에서 실행되는 API 공급자 통합을 테스트합니다.
- OpenShift Online
- OpenShift Dedicated
- API 검색이 비활성화된 경우 OpenShiftContainer Platform
curl유틸리티를 사용하여 통합이 예상대로 작동하는지 확인할 수 있습니다.curl명령에서 API 공급자 통합을 게시한 후 Fuse Online이 표시하는 외부 URL을 지정합니다. 이 작업의 예는 예제 API 공급자 빠른 시작 통합 테스트를 참조하십시오.API 검색을 지정할 때 OpenShift Container Platform에서 실행되는 API공급자 통합 테스트
OCP 관리자가
OPENSHIFT_MANAGEMENT_URL_FOR3SCALE환경 변수를 설정할 수 있습니다. 이 환경 변수가 설정되면 Red Hat 3scale이 API 공급자 통합을 게시합니다. 즉 3scale이 통합 API에 대한 액세스를 제어합니다. 통합을 테스트하려면 3scale 대시보드를 열어 통합의 URL을 가져옵니다.Red Hat 3scale이 통합 API에 대한 액세스를 제어하지 않으려면 검색을 비활성화할 수 있습니다. 통합 요약 페이지를 확인하여 Fuse Online에서 이 작업을 수행합니다. 이 페이지에서 검색 비활성화 를 클릭합니다. Fuse Online에서 통합을 다시 게시하고 통합 실행을 호출하기 위한 외부 URL을 제공합니다.
각 API 공급자 통합에 대해 검색을 활성화하거나 비활성화할 수 있습니다.
6.5. 예제 API 공급자 빠른 시작 통합 가져오기 및 게시
Fuse Online에서는 Fuse Online 환경으로 가져올 수 있는 빠른 시작 API 공급자를 제공합니다. 이 빠른 시작에는 작업 관리 API를 위한 OpenAPI 문서가 포함되어 있습니다. 빠른 시작 통합을 가져온 후 흐름을 검사한 다음 통합을 게시할 수 있습니다. 아래에 설명된 절차를 완료하면 TaskAPI 통합이 실행 중이며 실행될 준비가 된 것입니다.
API 공급자 빠른 시작 기능을 사용하면 API 공급자 통합을 구성, 게시 및 테스트하는 방법을 빠르게 확인할 수 있습니다. 그러나 이는 API 공급자 통합이 얼마나 유용할 수 있는지에 대한 실제 사례가 아닙니다. 실제 예제의 경우 이미 Fuse Online을 사용하여 몇 가지 간단한 통합을 게시한다고 가정합니다. 이러한 통합 실행을 트리거하기 위해 OpenAPI 문서를 정의할 수 있습니다. 이를 위해 각 OpenAPI 작업의 흐름을 편집하여 이미 게시한 간단한 통합과 거의 동일합니다.
사전 요구 사항
- Fuse Online은 브라우저에서 열려 있습니다.
절차
TaskAPI 빠른 시작 통합을 가져옵니다.
-
https://github.com/syndesisio/syndesis-quickstarts/tree/1.8/api-provider 로 이동하여
TaskAPI-export.zip을 다운로드합니다. - Fuse Online의 왼쪽 탐색 패널에서 통합을 클릭합니다.
- 오른쪽 상단에서 가져오기 를 클릭합니다.
-
다운로드한
TaskAPI-export.zip파일을 가져오기 페이지로 끕니다. Fuse Online은 파일을 가져왔음을 나타냅니다. - 왼쪽 탐색 패널에서 통합을 클릭하여 방금 가져온 TaskAPI 통합에 대한 항목을 확인합니다. 항목은 구성이 필요함을 나타내지만 이 통합은 게시할 준비가 되어 있습니다.
-
https://github.com/syndesisio/syndesis-quickstarts/tree/1.8/api-provider 로 이동하여
-
TaskAPI 항목에서
 를 클릭한 다음 편집을 클릭하여 이 API에서 제공하는 작업 목록을 표시합니다.
를 클릭한 다음 편집을 클릭하여 이 API에서 제공하는 작업 목록을 표시합니다.
각 작업의 흐름을 검사하려면 다음을 수행합니다.
흐름 만들기 버튼을 클릭하여 해당 흐름에 대한 시각화를 표시합니다.
각 흐름에는 이미 데이터베이스 연결, 하나 이상의 데이터 매퍼 단계 및 흐름을 완료하는 Provided API 반환 단계가 있습니다.
- Invoke SQL 단계의 구성을 클릭하여 연결이 실행되는 SQL 문을 확인합니다. 그런 다음 취소 를 클릭하여 해당 작업의 시각화 흐름으로 돌아갑니다.
- 데이터 매퍼 단계의 경우 Configure (구성)를 클릭하여 매핑을 확인합니다. 그런 다음 취소 를 클릭하여 시각화로 돌아갑니다.
- 모든 작업 흐름의 마지막 단계인 Provided API return Path 단계의 경우 Configure 를 클릭하여 작업이 호출자에게 보낼 수 있는 HTTP 반환 코드를 확인합니다. 취소 를 클릭하여 시각화로 돌아갑니다.
- 하나의 작업 흐름을 검사한 후 Integrations> TaskAPI> Operation 드롭다운 메뉴를 클릭한 다음 다른 작업을 선택합니다.
- 이 단계의 하위 집합을 반복하여 각 흐름을 검사합니다.
흐름을 검사한 후 게시 를 클릭하고 원하는 경우 통합 이름을 편집한 다음 저장 및 게시 를 클릭합니다.
Fuse Online은 이 통합에 대한 요약 페이지를 표시하고 통합을 어셈블, 빌드, 배포 및 시작할 때 게시 진행 상황을 표시합니다.
TaskAPI 통합 요약 페이지에 실행 중이 표시되면 Fuse Online에 Task API 서비스의 외부 URL이 표시됩니다. 다음과 같습니다.
https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/여기에서 Fuse Online을 사용하면 Task API 서비스를 사용할 수 있습니다. REST API 호출은 이 기본 URL로 시작하는 URL을 지정합니다.
OpenShift Container Platform에서 Fuse Online을 사용하는 경우 외부 URL이 통합 요약 페이지에 없는 경우 관리자는
OPENSHIFT_MANAGEMENT_URL_FOR3SCALE환경 변수를 설정했습니다. 이 환경 변수가 설정되면 Red Hat 3scale이 API 공급자 통합을 게시합니다. 즉 3scale이 통합 API에 대한 액세스를 제어합니다. 통합을 테스트하려면 3scale 대시보드를 열어 통합의 URL을 가져옵니다.Red Hat 3scale이 통합 API에 대한 액세스를 제어하지 않으려면 검색을 비활성화할 수 있습니다. 통합 요약 페이지를 확인하여 Fuse Online에서 이 작업을 수행합니다. 이 페이지에서 검색 비활성화 를 클릭합니다. Fuse Online에서 통합을 다시 게시하고 통합 실행을 호출하기 위한 외부 URL을 제공합니다.
각 API 공급자 통합에 대해 검색을 활성화하거나 비활성화할 수 있습니다.
6.6. 예제 API 공급자 빠른 시작 통합 테스트
Fuse Online TaskAPI 빠른 시작 통합이 실행 중인 경우 HTTP 요청을 Task API 서비스에 보내는 curl 유틸리티 명령을 호출할 수 있습니다. HTTP 요청을 지정하는 방법은 호출이 트리거하는 흐름을 결정합니다.
사전 요구 사항
- Fuse Online은 TaskAPI 통합이 실행 중 임을 나타냅니다.
- Fuse Online 환경이 OCP에서 실행 중인 경우 Fuse Online은 API를 3scale에 노출하거나 검색을 비활성화하도록 구성되지 않았습니다.
절차
- Fuse Online의 왼쪽 탐색 패널에서 통합을 클릭합니다.
- TaskAPI 통합 항목에서 보기를 클릭하여 통합 요약을 표시합니다.
- 통합의 외부 URL을 복사합니다.
터미널에서 다음과 같은 명령을 호출하여 통합의 외부 URL을
externalURL환경 변수에 할당합니다. 이 샘플 명령의 URL을 복사한 URL로 교체해야 합니다.export externalURL="https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api"
새 작업 생성 작업 의 흐름 실행을 트리거하는
curl명령을 호출합니다.curl -k --header "Content-Type: application/json" --request POST --data '{ "task":"my new task!"}' $externalURL/todo-
-k를 사용하면 안전하지 않은 것으로 간주되는 서버 연결에 대해curl을 진행하고 작동할 수 있습니다. -
--header는 명령이 JSON 형식 데이터를 전송하고 있음을 나타냅니다. -
--request는 데이터를 저장하는 HTTPPOST명령을 지정합니다. -
--data는 저장할 JSON 형식 콘텐츠를 지정합니다. 이 예에서 콘텐츠는{ "task":"my 새 작업!"}입니다. $externalURL/todo는 호출할 URL입니다.이 명령은 HTTP
POST요청을 Task API 서비스로 전송하여 Create new task operation's flow의 실행을 트리거합니다. 흐름 실행은 샘플 데이터베이스에 새 작업을 추가하고 다음과 같은 메시지를 반환하여 수행 한 내용을 표시합니다.
{"completed":false,"id":1,"task":"my new task!"}-
ID 작업으로 Fetch 작업 의 흐름 실행을 트리거하는
curl명령을 호출합니다.curl -k $externalURL/todo/1
작업을 가져오려면
curl명령은 URL만 지정해야 합니다. HTTPGET명령은 기본 요청입니다. URL의 마지막 부분은 가져올 작업의 ID를 지정합니다.ID 작업에 대한 Delete 작업 의 흐름 실행을 트리거하는
curl명령을 호출합니다.curl -k -X DELETE $externalURL/todo/1
이 명령은 ID로 작업을 가져온 명령과 동일한 URL을 사용하여 HTTP
DELETE명령을 호출합니다.
7장. HTTP 요청(Webhook)에 의해 트리거되는 통합 생성
Fuse Online에서 노출하는 HTTP 끝점으로 HTTP GET 또는 POST 요청을 전송하여 간단한 통합 실행을 트리거할 수 있습니다. 다음 주제에서는 세부 정보를 제공합니다.
7.1. Fuse Online Webhook 사용 절차
HTTP GET 또는 POST 요청과의 통합 실행을 트리거하려면 다음을 수행해야 합니다.
-
GET또는POST요청을 Fuse Online에 보낼지 여부를 결정합니다. - 이 요청을 처리하기 위해 통합을 계획하십시오.
통합을 완료하는 연결을 생성합니다.
Fuse Online은 시작 연결로 사용하는 Webhook 연결을 제공합니다.
- 통합에 추가할 다른 연결을 만듭니다.
통합을 생성합니다.
- Webhook 연결을 시작 연결로 추가합니다.
완료 연결을 추가한 다음 통합에 필요한 기타 연결을 추가합니다. 완료 연결 및 중간 연결은 통합 실행을 트리거하는 HTTP 요청을 처리합니다. 목표를 달성하는 데 가장 적합한 HTTP 요청을 선택하고 지정해야 합니다. 다음 사항에 유의하십시오.
- 가져올 데이터가 들어 있거나 업데이트할 데이터가 포함된 애플리케이션에 연결을 추가합니다.
-
GET요청은 key/value 매개변수의 사양으로 제한됩니다. -
POST요청은 XML 또는 JSON 인스턴스와 같은 임의의 본문을 제공할 수 있습니다. -
Fuse Online은 HTTP 상태 헤더만 반환하고 데이터를 반환하지 않습니다. 결과적으로
GET요청에 의해 트리거되고 데이터를 가져오는 대신 데이터를 업데이트하는 통합을 정의할 수 있습니다. 마찬가지로POST요청에 의해 트리거되고 데이터를 업데이트하는 대신 데이터를 가져오는 통합을 정의할 수 있습니다.
Webhook 연결 후 데이터 매퍼 단계를 추가합니다.
GET요청의 경우 HTTP 요청의 매개 변수 필드를 다음 연결의 데이터 필드에 매핑합니다.POST요청의 경우 JSON 인스턴스, JSON 스키마, XML 인스턴스 또는 XML 스키마를 전달하여 요청에 출력 데이터 모양을 지정할 수 있습니다. 그렇지 않은 경우 Webhook 연결을 통합 시작 연결로 추가할 때 Fuse Online에서 출력 데이터 유형을 지정하라는 메시지를 표시합니다. 그렇지 않은 경우 기본 Webhook 연결 출력 데이터 유형은 JSON 형식으로 되어 있습니다.- 통합에 필요한 다른 단계를 추가합니다.
- 통합을 게시하고 실행 중이 될 때까지 기다립니다.
- 통합 요약 페이지로 이동하여 Fuse Online에서 제공하는 외부 URL을 복사합니다.
-
이 외부 URL을 수정하여
GET또는POST요청을 구성합니다. -
HTTP
GET또는POST요청을 Fuse Online으로 전송하는 애플리케이션을 구현합니다.
7.2. HTTP 요청이 트리거할 수 있는 통합 생성
HTTP GET 또는 POST 요청과의 통합 실행을 트리거하려면 Webhook 연결을 통합 시작 연결로 추가합니다.
절차
- 왼쪽의 Fuse Online 패널에서 통합을 클릭합니다.
- 통합 생성을 클릭합니다.
- 연결 선택 페이지에서 Webhook 연결을 클릭합니다.
작업 선택 페이지에서 다음 Webhook 작업을 선택합니다.
Webhook 구성 페이지에서 Fuse Online은 이 통합을 위해 Fuse Online에서 생성하는 Webhook 토큰을 표시합니다.
HTTP 요청을 생성할 때 이 토큰은 URL의 마지막 부분입니다. 이 통합을 게시하고 실행 중인 후 Fuse Online에 이 토큰이 있는 Fuse Online 외부 URL이 표시됩니다.
- 다음을 클릭합니다.
출력 데이터 유형 지정 페이지에서 다음을 수행합니다.
- 유형 선택 필드를 클릭하고 JSON 스키마 를 선택합니다.
- 정의 필드에 HTTP 요청에 있는 매개변수의 데이터 유형을 정의하는 JSON 스키마를 붙여넣습니다. 요청 매개변수를 지정하려면 JSON 스키마 정보를 참조하십시오.
- 데이터 유형 이름 필드에서 이 데이터 유형의 이름을 지정합니다. 이 값은 선택 사항이지만 이름을 지정하면 데이터 매퍼 소스 목록에 표시되어 필드를 보다 쉽게 매핑할 수 있습니다.
- 선택적으로 데이터 유형 설명 필드에 이 데이터 유형을 구분하는 데 도움이 되는 몇 가지 정보를 제공합니다.
- 다음을 클릭합니다.
- 통합에 완료 연결을 추가합니다.
- 필요한 다른 연결을 추가합니다.
- 필요한 다른 단계를 추가합니다.
- 시작 연결 직후 데이터 매퍼 단계를 추가합니다.
- 게시 를 클릭하고 통합 이름을 지정하고 선택적으로 설명을 지정한 다음 저장 및 게시 를 클릭합니다.
7.3. Fuse Online에서 HTTP 요청을 처리하는 방법
HTTP GET 또는 POST 요청을 지정하여 간단한 통합 실행을 트리거할 수 있습니다. GET 요청은 일반적으로 데이터를 가져오고 POST 요청이 일반적으로 데이터를 업데이트하지만 두 요청 중 하나를 사용하여 두 작업 중 하나를 수행하는 통합을 트리거할 수 있습니다. 요청의 모든 매개변수는 통합에 있는 다음 연결에서 데이터 필드에 매핑할 수 있습니다. 자세한 내용은 요청 매개변수를 지정하는 JSON 스키마 정보를 참조하십시오.
Webhook 연결은 수신하는 데이터만 통합에서 다음 연결로 전달합니다. Fuse Online에서 HTTP 요청을 수신하면 다음과 같습니다.
-
요청자에게 HTTP 상태 헤더를 반환합니다. 요청이 성공적으로 통합 실행을 트리거하면 Fuse Online 반환 코드는
201입니다. 요청이 통합 실행을 트리거하지 못하면 Fuse Online 반환 코드는5xx입니다. - 다른 데이터를 요청자에게 반환하지 않습니다. 즉, 상태 헤더를 포함하는 응답의 HTTP 본문에 데이터가 없습니다.
- 요청의 데이터를 통합의 다음 연결로 전달합니다.
즉, GET 요청에 의해 트리거되고 데이터를 가져오는 대신 데이터를 업데이트하는 간단한 통합을 정의할 수 있습니다. 마찬가지로 POST 요청에 의해 트리거되고 데이터를 업데이트하는 대신 데이터를 가져오는 간단한 통합을 정의할 수 있습니다.
7.4. Fuse Online Webhook를 호출하는 HTTP 클라이언트에 대한 지침
HTTP 요청을 Fuse Online으로 전송하는 클라이언트를 구현하면 구현해야 합니다.
-
Fuse 온라인 제공 외부 URL에 추가하여
GET또는POST요청을 수행하는 URL을 구성합니다. -
URL 요청에서 데이터 유형이
io:syndesis:webhookJSON 스키마를 준수하는 HTTP 헤더 및 쿼리 매개변수 값을 지정합니다. 요청 매개변수를 지정하려면 JSON 스키마 정보를 참조하십시오. 헤더 및 쿼리 매개변수가 이 데이터 유형 사양을 준수하는 경우 매개변수 필드를 통합에서 처리할 수 있는 필드에 매핑할 수 있습니다. -
요청이 성공하면
201의 반환된 성공 코드를 처리합니다. -
요청이 실패하면 HTTP
5xx오류 코드를 처리합니다. - Fuse Online의 다른 응답이 예상되지 않습니다. 즉, 요청을 보내는 것은 반환 코드 이외의 요청 클라이언트로 직접 데이터를 반환하지 않습니다.
7.5. 요청 매개변수를 지정하기 위한 JSON 스키마 정보
통합에서는 일반적으로 HTTP 요청의 헤더 및 쿼리 매개변수를 통합의 다음 연결이 처리할 수 있는 데이터 필드에 매핑합니다. 이를 위해 통합에 Webhook 연결을 추가할 때 다음 구조가 있는 JSON 스키마에 출력 데이터 유형을 지정합니다.
{
"$schema": "http://json-schema.org/schema#",
"id": "io:syndesis:webhook",
"type": "object",
"properties": {
"parameters": {
"type": "object",
"properties": { 1
}
},
"body": {
"type": "object",
"properties": { 2
}
}
}
}필요한 데이터 구조를 HTTP 요청에 대한 JSON 인스턴스에서 추가하려면 다음을 수행합니다.
HTTP 클라이언트가 보내는 모든 데이터는 통합에서 사용할 수 있지만 Webhook 연결의 데이터 셰이프가 이 JSON 스키마를 준수하는 경우 매핑에 매개변수 및 본문 콘텐츠를 사용할 수 있습니다.
예를 들어 HTTP 요청을 지정하는 방법을 참조하십시오.
7.6. HTTP 요청을 지정하는 방법
다음 예제에서는 Fuse Online Webhook에 대한 HTTP 요청을 지정하는 방법을 보여줍니다.
HTTP 본문만 포함하는 POST 요청의 Webhook 예
Webhook 연결로 시작된 통합을 고려한 다음 Fuse Online 제공 데이터베이스의 Todo 테이블에 행을 만듭니다.

이 통합을 생성하는 동안 Webhook 시작 연결을 추가할 때 이 콘텐츠가 있는 JSON 인스턴스로 출력 데이터 유형을 지정합니다. {"todo":"text"}:
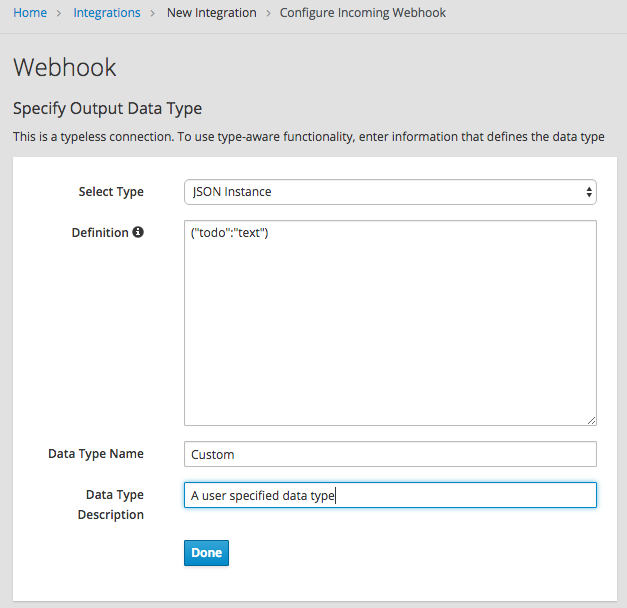
PostgresDB 연결을 완료 연결로 추가하면 Invoke SQL 작업을 선택하고 이 SQL 문을 지정합니다.
TODO (TASK) 값 (:#TASK)을 삽입합니다.
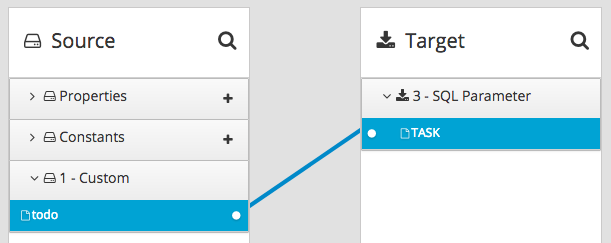
데이터베이스 연결을 추가한 후 매핑 단계를 추가합니다.
통합을 저장하고 게시합니다. 실행 중인 경우 Fuse Online에서 제공하는 외부 URL을 복사할 수 있습니다.
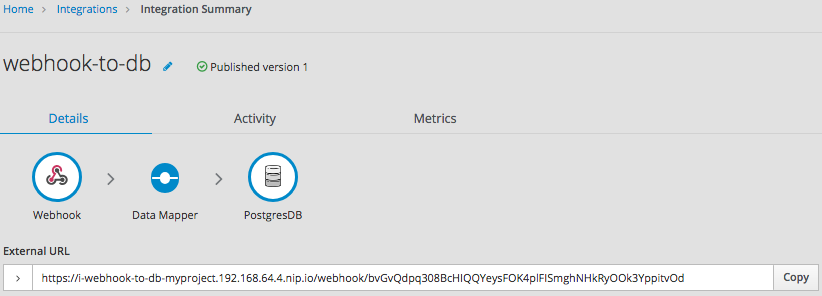
외부 URL의 일부를 이해하려면 다음 샘플 URL을 고려하십시오.
https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
| 현재의 | 설명 |
|---|---|
|
| Fuse Online에서는 항상 이 값을 URL 시작 부분에 삽입합니다. |
|
| 통합의 이름입니다. |
|
| 통합을 실행 중인 포드가 포함된 OpenShift 네임스페이스입니다. |
|
| OpenShift용으로 구성된 DNS 도메인입니다. Webhook를 제공하는 Fuse Online 환경이 표시됩니다. |
|
| 각 Webhook 연결 URL에 표시됩니다. |
|
| 통합에 Webhook 연결을 추가할 때 Fuse Online에서 제공하는 Webhook 연결 토큰입니다. 토큰은 URL을 식별하기가 어려워서 다른 사람이 요청을 보내지 못하도록 한다는 점에서 보안을 제공하는 임의의 문자열입니다. 요청에서는 Fuse Online에서 제공하는 토큰을 지정하거나 자체적으로 정의할 수 있습니다. 자신을 정의하는 경우 추측하기가 어려운지 확인하십시오. |
외부 URL에서 볼 수 있듯이 Fuse Online은 통합 이름, OpenShift 네임스페이스 이름 및 OpenShift DNS 도메인에서 호스트 이름을 구성합니다. Fuse Online에서는 불법 문자를 제거하고 공백을 하이픈으로 변환합니다. 샘플 외부 URL에서 호스트 이름입니다.
https://i-webhook-to-db-myproject.192.168.64.4.nip.io
curl 을 사용하여 Webhook를 호출하려면 다음과 같이 명령을 지정합니다.
curl -H 'Content-Type: application/json' -d '{"todo":"from webhook"}' https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
-
H옵션은 HTTPContent-Type헤더를 지정합니다. -
d옵션은 기본적으로 HTTP 메서드를POST로 설정합니다.
이 명령을 실행하면 통합을 트리거합니다. 데이터베이스 완료 연결은 새 작업을 tasks 테이블에 삽입합니다. 이를 보려면 https://todo-myproject.192.168.64.4.nip.io 에서 업데이트를 클릭하면 Webhook에서 새 작업으로 표시되는 Todo 앱을 표시합니다.
쿼리 매개변수를 사용한 POST 요청의 예
이 예제에서는 이전 예와 동일한 통합을 고려하십시오.
그러나 이 예제에서는 이 콘텐츠로 JSON 스키마를 지정하여 Webhook 연결 출력 데이터 유형을 정의합니다.
{
"type": "object",
"definitions": {},
"$schema": "http://json-schema.org/draft-07/schema#",
"id": "io:syndesis:webhook",
"properties": {
"parameters": {
"type": "object",
"properties": {
"source": {
"type": "string"
},
"status": {
"type": "string"
}
}
},
"body": {
"type": "object",
"properties": {
"company": {
"type": "string"
},
"email": {
"type": "string"
},
"phone": {
"type": "string"
}
}
}
}
}이 JSON 스키마에서 다음을 수행합니다.
-
id는io.syndesis.webhook로 설정해야 합니다. -
parameters섹션에서는 HTTP 쿼리 매개변수를 지정해야 합니다. -
본문섹션은 본문 내용을 지정해야 하며 필요한 만큼 복잡할 수 있습니다. 예를 들어 중첩 속성 및 배열을 정의할 수 있습니다.For example, it can define nested properties as well as arrays.
그러면 Webhook 커넥터가 통합의 다음 단계를 위해 콘텐츠를 준비하는 데 필요한 정보가 제공됩니다.
curl 을 사용하여 HTTP 요청을 보내려면 다음과 같은 명령을 호출합니다.
curl -h 'Content-Type: application/json' -d '{"company":"Gadgets","email":" ","phone":"+1-202-555-0152"}'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=newmailto:sales@gadgets.com
Webhook 연결이 이 요청을 수신하면 다음과 같은 JSON 인스턴스가 생성됩니다.
{
"parameters": {
"source": "web",
"status": "new"
},
"body": {
"company": "Gadgets",
"email": "sales@gadgets.com",
"phone": "+1-202-555-0152"
}
}이 내부 JSON 인스턴스는 다음 매핑을 활성화합니다.
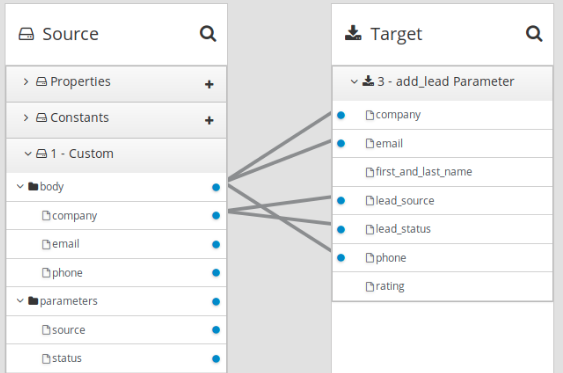
GET이 있는 Webhook 예
입력 데이터를 제공하지 않는 GET 요청과의 통합을 트리거하려면 '{}' 정의를 사용하여 Webhook 연결 출력 데이터 모양을 JSON 인스턴스로 지정합니다. 그런 다음 쿼리 매개변수를 지정하지 않는 다음 curl 명령을 호출할 수 있습니다.
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg'
이전 POST 예제를 변경하여 쿼리 매개변수로 GET 요청을 보낼 수 있지만 본문은 전송할 수 없습니다. 다음과 같이 Webhook 연결 출력 데이터 모양을 정의를 사용하여 JSON 스키마로 지정합니다.
{
"type": "object",
"definitions": {},
"$schema": "http://json-schema.org/draft-07/schema#",
"id": "io:syndesis:webhook",
"properties": {
"parameters": {
"type": "object",
"properties": {
"source": {
"type": "string"
},
"status": {
"type": "string"
}
}
}
}
}
GET 요청을 보내는 curl 명령은 다음과 같습니다.
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=new'`
8장. 다음 연결을 위해 통합 데이터를 필드에 매핑
대부분의 흐름에서는 이미 수집되었거나 처리된 데이터 필드를 흐름의 다음 연결이 처리할 수 있는 데이터 필드에 매핑해야 합니다. Fuse Online에서는 이러한 작업을 수행하는 데 도움이 되는 데이터 매퍼를 제공합니다. 흐름에서 데이터 필드를 매핑해야 하는 각 시점에서 데이터 매퍼 단계를 추가합니다.
데이터 매퍼는 이전 통합 단계에서 제공할 수 있는 가장 큰 소스 필드 세트를 표시합니다. 그러나 모든 연결이 표시된 각 소스 필드에 데이터를 제공하는 것은 아닙니다. 예를 들어 타사 애플리케이션을 변경하면 특정 필드에 데이터 제공을 중단할 수 있습니다. 통합을 만들 때 데이터 매핑이 예상대로 작동하지 않는 경우 매핑하려는 소스 필드에 예상 데이터가 포함되어 있는지 확인합니다.
매핑 데이터 필드에 대한 세부 사항은 다음 항목에 있습니다.
- 8.1절. “데이터 매핑이 필요한 위치 확인”
- 8.2절. “매핑할 데이터 필드 검색”
- 8.3절. “하나의 소스 필드를 하나의 대상 필드에 매핑”
- 8.4절. “필드를 결합하거나 분리할 때 누락되거나 원하지 않는 데이터의 예”
- 8.5절. “여러 소스 필드를 하나의 대상 필드에 결합”
- 8.6절. “하나의 소스 필드를 여러 대상 필드로 분리”
- 8.7절. “데이터 매퍼를 사용하여 컬렉션 처리”
- 8.8절. “컬렉션과 수집되지 않은 매핑 정보”
- 8.9절. “소스 또는 대상 데이터 변환”
- 8.10절. “매핑에 조건 적용”
- 8.11절. “단계에서 매핑 보기”
- 8.12절. “사용 가능한 변환에 대한 설명”
- 8.13절. “하나의 대상 필드에 매핑하기 전에 여러 소스 값의 변환 정보”
- 8.14절. “데이터 매핑 문제 해결”
8.1. 데이터 매핑이 필요한 위치 확인
Fuse Online은 경고 아이콘을 표시하여 흐름에 데이터 매핑이 필요한 위치를 나타냅니다.
사전 요구 사항
- 흐름을 만들거나 편집하고 있습니다.
- 흐름에는 필요한 모든 연결이 포함됩니다.
절차
-
흐름 시각화에서
아이콘을 찾습니다.
- 아이콘을 클릭하여 데이터 유형 Mismatch 알림을 확인합니다.
- 메시지에서 데이터 매퍼를 표시하는 데이터 매핑 단계 추가 를 클릭합니다.
8.2. 매핑할 데이터 필드 검색
비교적 몇 단계가 있는 흐름에서는 데이터 필드를 쉽고 직관적으로 매핑할 수 있습니다. 데이터 매퍼 사용 방법에 대한 몇 가지 배경이 있는 경우 더 복잡한 흐름 또는 대규모 데이터 필드를 처리하는 흐름에서 source에서 대상으로 하는 매핑이 더 쉽습니다.
데이터 매퍼는 데이터 필드의 두 열을 표시합니다.
- 소스 는 흐름의 모든 이전 단계에서 얻거나 처리되는 데이터 필드 목록입니다.
- target 은 흐름의 다음 연결이 예상되고 처리할 수 있는 데이터 필드 목록입니다.
매핑할 데이터 필드를 빠르게 찾으려면 다음 중 하나를 수행할 수 있습니다.
이를 검색합니다.
소스 패널과 대상 패널에는 각각 맨 위에 검색 필드가 있습니다. 검색 필드가 표시되지 않으면 소스 또는 대상 패널의 오른쪽 상단에 있는
 를 클릭합니다.
를 클릭합니다.
매핑할 필드의 이름을 입력합니다.
이렇게 하려면 Mapper 구성 페이지의 오른쪽 상단에서 더하기 기호를 클릭하여 매핑 세부 정보 패널을 표시합니다. Sources 섹션에 소스 필드의 이름을 입력합니다. 대상 섹션에서 매핑할 필드의 이름을 입력합니다.
폴더를 확장하고 축소하여 표시되는 필드를 제한합니다.
특정 단계에서 사용 가능한 데이터 필드를 보려면 해당 단계에 대한 폴더를 확장합니다.
흐름에 대한 단계를 추가하면 Fuse Online 수를 다시 작성하여 Fuse Online이 단계를 처리하는 순서를 나타냅니다. 데이터 매퍼 단계를 추가하면 소스 패널과 대상 패널의 폴더 레이블에 단계 번호가 표시됩니다.
폴더 레이블은 해당 단계에서 출력하는 데이터 유형의 이름도 표시합니다. Twitter, Cryostat 및 SQL과 같은 애플리케이션에 대한 연결은 자체 데이터 유형을 정의합니다. Amazon S3, AMQ, AMQP, Dropbox 및 FTP/SFTP와 같은 애플리케이션에 연결하려면 흐름에 대한 연결을 추가하고 연결이 수행하는 작업을 선택할 때 연결의 입력 및/또는 출력 유형을 정의합니다. 데이터 유형을 지정하면 유형에 이름도 지정합니다. 지정한 유형 이름은 데이터 매퍼에서 폴더 이름으로 표시됩니다. 데이터 유형을 선언할 때 설명을 지정한 경우 매퍼의 단계 폴더를 마우스로 가리킬 때 유형 설명이 표시됩니다.
8.3. 하나의 소스 필드를 하나의 대상 필드에 매핑
기본 매핑 동작은 하나의 소스 필드를 하나의 대상 필드에 매핑합니다. 예를 들어 이름 필드를 Customer 필드에 매핑합니다.
Name
절차
소스 패널에서 매핑할 데이터 필드를 클릭합니다.
제공하는 데이터 필드를 보려면 단계를 확장해야 할 수 있습니다.
소스 필드가 여러 개인 경우
를 클릭하고 검색 필드에 데이터 필드의 이름을 입력하여 관심 있는 필드를 검색할 수 있습니다.
대상 패널에서 매핑할 데이터 필드를 클릭합니다.
데이터 매퍼는 방금 선택한 두 필드를 연결하는 행을 표시합니다.
선택적으로 데이터 매핑 결과를 미리 봅니다. 이 기능은 매핑에 변환을 추가하거나 매핑에 형식 변환이 필요할 때 유용합니다.
-
데이터 매퍼 오른쪽 상단에서
 를 클릭하고 매핑 프리뷰 표시를 선택하여 소스 필드에 텍스트 입력 필드와 대상 필드에 읽기 전용 결과 필드를 표시합니다.
를 클릭하고 매핑 프리뷰 표시를 선택하여 소스 필드에 텍스트 입력 필드와 대상 필드에 읽기 전용 결과 필드를 표시합니다.
- 소스 필드의 데이터 입력 필드에 텍스트를 입력합니다.
- 대상 필드의 읽기 전용 필드에 매핑 결과를 표시하려면 이 텍스트 상자 외부의 위치를 클릭합니다.
- 필요한 경우 변환 결과를 보려면 매핑 세부 정보 패널에서 변환을 추가합니다.
-
을 다시 클릭하고 매핑 프리뷰 표시를 선택하여 프리뷰 필드를 숨깁니다.
-
데이터 매퍼 오른쪽 상단에서
필요한 경우 매핑이 정의되었는지 확인하려면 오른쪽 상단에
 를 클릭하여 정의된 매핑을 표시합니다.
를 클릭하여 정의된 매핑을 표시합니다.
이 뷰에서 데이터 매핑 결과를 미리 볼 수도 있습니다. 프리뷰 필드가 표시되지 않으면
을 클릭하고 매핑 프리뷰 표시를 선택합니다. 이전 단계에서 설명한 대로 데이터를 입력합니다. 정의된 매핑 테이블에는 선택한 매핑에만 대한 프리뷰 필드가 표시됩니다. 다른 매핑에 대한 프리뷰 필드를 보려면 선택합니다.
를 다시 클릭하여 데이터 필드 패널을 표시합니다.
- 오른쪽 상단에서 Done 을 클릭하여 데이터 매퍼 단계를 통합에 추가합니다.
대체 절차
다음은 단일 소스 필드를 단일 대상 필드에 매핑하는 또 다른 방법입니다.
- Configure Mapper 페이지의 오른쪽 상단에 있는 더하기 기호를 클릭하여 매핑 세부 정보 패널을 표시합니다.
- Sources 섹션에 소스 필드의 이름을 입력합니다.
- 작업 섹션에서 기본 맵 작업을 수락합니다.
- 대상 섹션에 매핑할 필드의 이름을 입력하고 Enter 를 클릭합니다.
문제 해결 팁
데이터 매퍼는 이전 통합 단계에서 제공할 수 있는 가장 큰 소스 필드 세트를 표시합니다. 그러나 모든 연결이 표시된 각 소스 필드에 데이터를 제공하는 것은 아닙니다. 예를 들어 타사 애플리케이션을 변경하면 특정 필드에 데이터 제공을 중단할 수 있습니다. 통합을 만들 때 데이터 매핑이 예상대로 작동하지 않는 경우 매핑하려는 소스 필드에 예상 데이터가 포함되어 있는지 확인합니다.
8.4. 필드를 결합하거나 분리할 때 누락되거나 원하지 않는 데이터의 예
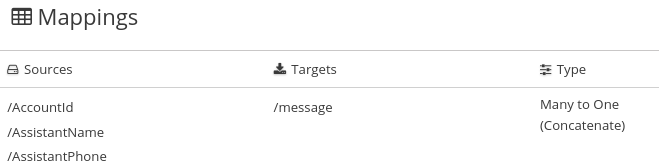
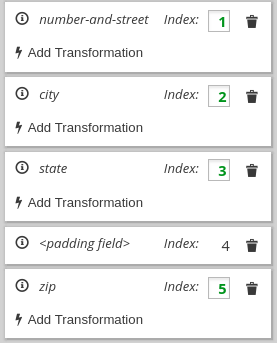
데이터 매핑에서는 소스 또는 대상 필드에 복합 데이터가 포함된 경우 누락되거나 원하지 않는 데이터를 식별해야 할 수 있습니다. 예를 들어 다음 형식의 long_address 필드를 고려하십시오.
개인 정보 보호 정책
long_address 필드를 숫자,Street,city,state 및 zip 에 대한 개별 필드로 분리하려고 가정하겠습니다. 이렇게 하려면 소스 필드로 long_address 를 선택한 다음 대상 필드를 선택합니다. 그런 다음 원하지 않는 소스 필드의 부분에 대한 위치에 패딩 필드를 추가합니다. 이 예에서 원하지 않는 부분은 새우주 ,zip+4 및 국가 입니다.
원치 않는 부분을 식별하려면 부품의 순서를 알아야 합니다. 순서는 복합 필드의 콘텐츠 각 부분에 대한 인덱스를 나타냅니다. 예를 들어, long_address 필드에는 8개의 정렬된 부분이 있습니다. 1에서 시작하여 각 부분의 인덱스는 다음과 같습니다.
| 1 | 숫자 |
| 2 | Street |
| 3 | 하우스키지 |
| 4 | 도시 |
| 5 | 상태 |
| 6 | zip |
| 7 | zip+4 |
| 8 | 국가 |
데이터 매퍼에서는 기숙사 ,zip+4 및 country 를 식별하기 위해 인덱스 3, 7 및 8에 패딩 필드를 추가합니다. 하나의 대상 필드에 여러 소스 필드 조합을 참조하십시오.
이제 숫자,Street,city, state ,state 에 대한 소스 필드를 결합하고 long_address 대상 필드에 압축 하려고한다고 가정합니다. 또한, 기숙사 ,zip+4 및 국가에 대한 콘텐츠를 제공할 소스 필드가 없다고 가정합니다. 데이터 매퍼에서는 이러한 필드를 누락된 것으로 식별해야 합니다. 다시 말하지만 인덱스 3, 7 및 8에 패딩 필드를 추가합니다. 하나의 소스 필드를 여러 대상 필드로 분리를 참조하십시오.
8.5. 여러 소스 필드를 하나의 대상 필드에 결합
데이터 매퍼 단계에서는 여러 소스 필드를 하나의 복합 대상 필드로 결합할 수 있습니다. 예를 들어 FirstName 및 LastName 필드를 CustomerName 필드에 매핑할 수 있습니다.
사전 요구 사항
대상 필드의 경우 이 복합 필드의 각 부분에 있는 콘텐츠 유형, 콘텐츠의 각 부분의 순서 및 인덱스, 공간 또는 쉼표와 같은 부분 간의 구분자를 알아야 합니다. 누락되거나 원하지 않는 데이터의 예를 참조하십시오.
절차
- 대상 패널에서 둘 이상의 소스 필드를 매핑할 필드를 클릭합니다.
Sources 패널에서 대상 필드에 매핑할 필드가 포함된 필드가 있는 경우 해당 컨테이너 필드를 클릭하여 포함된 모든 필드를 대상 필드에 매핑합니다.
각 소스 필드를 개별적으로 선택하려면 대상 필드에 결합할 첫 번째 필드를 클릭합니다. 대상 필드에 결합할 다른 각 필드에 대해 해당 필드 위에 마우스를 올리고 CTRL-Mouse1 ( MacOS에서CMD-Mouse 1)을 누릅니다.
완료되면 각 소스 필드에서 대상 필드로의 행이 표시되어야 합니다.
매핑 세부 정보 패널의 Sources 에서 데이터 매퍼는 기본 멀티플리티 변환을 표시하며, 이는 Concatenate 입니다. 이는 매핑 실행이 선택한 소스 필드의 값에 통합 변환을 적용하고 연결된 값을 선택한 대상 필드에 매핑함을 나타냅니다.
참고여러 소스 값에 적용할 수 있는 다른 변환에 대한 자세한 내용은 여러 소스 값에 대한 변환정보를 참조하십시오.
Sources 에도 선택한 소스 필드마다 항목이 있습니다.
매핑 세부 정보 패널에서 다음과 같이 매핑을 구성합니다.
- Sources 에서 Delimiter 필드에서 데이터 매퍼가 서로 다른 소스 필드의 콘텐츠 간에 대상 필드에 삽입하는 문자를 수락하거나 선택합니다. 기본값은 공백입니다.
- 선택 사항: 각 소스 필드 항목에서 Add Cryostat를 클릭하여 대상 필드에 매핑되기 전에 변환을 소스 필드 값에 적용할 수 있습니다.
Sources 에서 선택한 소스 필드의 항목 순서를 확인합니다. 항목은 복합 대상 필드의 해당 콘텐츠와 동일한 순서로 있어야 합니다.
항목이 올바른 순서가 아닌 경우 소스 필드 항목을 드래그 앤 드롭하여 동일한 순서를 달성합니다. 데이터 매퍼는 새 순서를 반영하도록 인덱스 번호를 자동으로 업데이트합니다.
복합 대상 필드의 각 부분에 소스 필드를 매핑한 경우 다음 단계를 건너뜁니다.
대상 필드에서 해당 데이터와 동일한 인덱스가 없는 각 소스 필드 항목에 대해 인덱스를 동일하게 편집합니다. 각 소스 필드 항목에는 대상 필드의 해당 데이터와 동일한 인덱스가 있어야 합니다. 데이터 매퍼는 누락된 데이터를 표시하는 데 필요에 따라 패딩 필드를 자동으로 추가합니다.
실수로 너무 많은 패딩 필드를 생성하는 경우 각 추가 패딩 필드에서 trash-can 아이콘을 클릭하여 삭제합니다.
- 선택 사항: 대상 에서 추가 를 클릭하여 콘텐츠를 대상 필드에 매핑한 다음 변환을 적용합니다.
선택적으로 데이터 매핑 결과를 미리 봅니다.
-
데이터 매퍼 오른쪽 상단에서
를 클릭하고 매핑 프리뷰 표시를 선택하여 현재 선택한 매핑의 각 소스 필드에 텍스트 입력 필드와 현재 선택한 매핑의 대상 필드에 읽기 전용 결과 필드를 표시합니다.
소스 데이터 입력 필드에 텍스트를 입력합니다. 텍스트 상자 외부를 클릭하여 대상 필드의 읽기 전용 필드에 매핑 결과를 표시합니다.
소스 필드를 다시 정렬하거나 매핑에 변환을 추가하면 대상 필드의 결과 필드가 이를 반영합니다. 데이터 매퍼가 오류를 감지하면 매핑 세부 정보 패널 상단에 정보 메시지를 표시합니다.
-
을 다시 클릭하고 매핑 프리뷰 표시를 선택하여 프리뷰 필드를 숨깁니다.
미리 보기 필드를 다시 표시하면 해당 필드에 입력한 데이터는 그대로 있으며 데이터 매퍼를 종료할 때까지 그대로 유지됩니다.
-
데이터 매퍼 오른쪽 상단에서
매핑이 올바르게 정의되었는지 확인하려면 오른쪽 상단에
를 클릭하여 이 단계에 정의된 매핑을 표시합니다. 두 개 이상의 소스 필드의 값을 하나의 대상 필드에 결합하는 매핑은
 과 같습니다.
과 같습니다.
이 보기에서 매핑 결과를 미리 볼 수도 있습니다.
를 클릭하고 매핑 프리뷰 표시를 선택하고 이전 단계에서 설명하는 대로 텍스트를 입력합니다. 선택한 매핑에만 미리 보기 필드가 표시됩니다. 표에서 다른 매핑을 클릭하여 미리 보기 필드를 확인합니다.
추가 리소스
패딩 필드를 추가하는 예: 하나의 소스 필드를 여러 대상 필드에 분리합니다.
이 예제는 일대다 매핑의 경우이지만 원칙은 동일합니다.
8.6. 하나의 소스 필드를 여러 대상 필드로 분리
데이터 매퍼 단계에서는 복합 소스 필드를 여러 대상 필드로 분리할 수 있습니다. 예를 들어 Name 필드를 FirstName 및 LastName 필드에 매핑합니다.
사전 요구 사항
소스 필드의 경우 이 복합 필드의 각 부분에 있는 콘텐츠 유형, 콘텐츠의 각 부분의 순서 및 인덱스, 공간 또는 쉼표와 같은 부분 간의 구분자를 알아야 합니다. 누락되거나 원하지 않는 데이터의 예를 참조하십시오.
절차
- 소스 패널에서 분리할 콘텐츠가 있는 필드를 클릭합니다.
- 대상 패널에서 소스 필드 데이터를 분리할 첫 번째 필드를 클릭합니다.
대상 패널에서 소스 필드의 일부 데이터를 포함하려는 각 추가 대상 필드에 대해 필드 위에 마우스를 올리고 CTRL-Mouse1 ( MacOS에서CMD-Mouse 1)을 눌러 선택합니다.
대상 필드 선택을 완료하면 선택한 각 대상 필드로의 소스 필드에서 행이 표시되어야 합니다.
매핑 세부 정보 패널에서 다음을 수행합니다.
- 소스 아래에서 데이터 매퍼 는 분할 을 표시하여 매핑 실행이 소스 필드 값을 분할하고 여러 대상 필드에 매핑함을 나타냅니다.
- 대상 아래에는 선택한 각 대상 필드에 대한 항목이 있습니다.
매핑 세부 정보 패널에서 다음과 같이 매핑을 구성합니다.
- Sources 에서 Delimiter 필드에서 source 필드에서 source 필드 값을 분리할 위치를 나타내는 문자를 수락하거나 선택합니다. 기본값은 공백입니다.
- 선택 사항: 대상 필드에 매핑되기 전에 소스 필드 값에 변환을 적용하려면 Add Cryostat를 클릭합니다.
대상 에서 선택한 대상 필드의 항목 순서를 확인합니다. 항목은 복합 소스 필드의 해당 콘텐츠와 동일한 순서로 있어야 합니다. 소스 필드에서 콘텐츠 중 하나 이상의 부분에 대한 대상 필드를 지정하지 않았는지 여부는 중요하지 않습니다.
항목이 올바른 순서가 아닌 경우 대상 필드 항목을 드래그 앤 드롭하여 동일한 순서를 달성합니다. 데이터 매퍼는 새 순서를 반영하도록 인덱스 번호를 자동으로 업데이트합니다.
복합 소스 필드의 각 부분을 대상 필드에 매핑한 경우 다음 단계로 건너뜁니다.
소스 필드에 필요하지 않은 데이터가 포함된 경우 Mapping Details 패널에서 소스 필드에 해당 데이터와 동일한 인덱스가 없는 각 대상 필드의 인덱스를 편집합니다. 각 대상 필드 항목에는 해당 데이터가 소스 필드에 있는 것과 동일한 인덱스가 있어야 합니다. 데이터 매퍼는 원하지 않는 데이터를 나타내기 위해 필요에 따라 패딩 필드를 자동으로 추가합니다.
이 절차의 끝에 있는 예제를 참조하십시오.
- 선택 사항: Add Cryo stat를 클릭하여 콘텐츠를 대상 필드에 매핑한 다음 변환을 적용합니다.
선택 사항: 데이터 매핑 결과를 미리 봅니다.
-
데이터 매퍼 오른쪽 상단에서
를 클릭하고 매핑 프리뷰 표시를 선택하여 소스 필드에 텍스트 입력 필드와 각 대상 필드에 읽기 전용 결과 필드를 표시합니다.
소스 필드의 데이터 입력 필드에 텍스트를 입력합니다. 필드의 부분 사이에 구분 기호 문자를 입력해야 합니다. 텍스트 상자 외부를 클릭하여 대상 필드의 읽기 전용 필드에 매핑 결과를 표시합니다.
대상 필드를 다시 정렬하거나 대상 필드에 변환을 추가하면 대상 필드의 결과 필드가 이를 반영합니다. 데이터 매퍼가 오류를 감지하면 매핑 세부 정보 패널 상단에 정보 메시지를 표시합니다.
-
을 다시 클릭하고 매핑 프리뷰 표시를 선택하여 프리뷰 필드를 숨깁니다.
미리 보기 필드를 다시 표시하면 해당 필드에 입력한 데이터는 그대로 있으며 데이터 매퍼를 종료할 때까지 그대로 유지됩니다.
-
데이터 매퍼 오른쪽 상단에서
매핑이 올바르게 정의되었는지 확인하려면
를 클릭하여 이 단계에 정의된 매핑을 표시합니다. 소스 필드의 값을 여러 대상 필드로 분리하는 매핑은
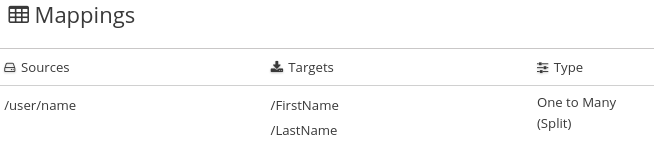 과 같습니다.
과 같습니다.
이 보기에서 매핑 결과를 미리 볼 수도 있습니다.
를 클릭하고 매핑 프리뷰 표시를 선택하고 이전 단계에서 설명하는 대로 텍스트를 입력합니다. 선택한 매핑에만 미리 보기 필드가 표시됩니다. 표에서 다른 매핑을 클릭하여 미리 보기 필드를 확인합니다.
하나의 필드를 여러 필드로 분리하는 예
소스 데이터에 하나의 주소 필드가 포함되어 있으며 쉼표를 사용하여 콘텐츠 부분을 구분합니다. 예를 들면 다음과 같습니다.
77 Hill Street, Brooklyn, New York, United States, 12345, 6789
주소 필드에서 콘텐츠 부분에는 다음과 같은 인덱스가 있습니다.
| 콘텐츠 | 인덱스 |
|---|---|
| 번호 및 거리 | 1 |
| 도시 | 2 |
| 상태 | 3 |
| 국가 | 4 |
| zip 코드 | 5 |
| Zip+4 | 6 |
이제 대상 데이터에 주소에 대한 4 개의 필드가 있다고 가정합니다.
number-and-street city state zip
매핑을 정의하려면 다음을 수행합니다.
- 소스 필드를 선택합니다.
- 매핑 세부 정보 패널의 소스 섹션에서 구분 기호(이 예제의 쉼표)를 선택합니다.
- 4개의 대상 필드를 선택합니다.
이렇게 하면 대상 의 세부 정보 매핑 패널에 선택한 각 대상 필드에 대한 항목이 있습니다. 예를 들면 다음과 같습니다.
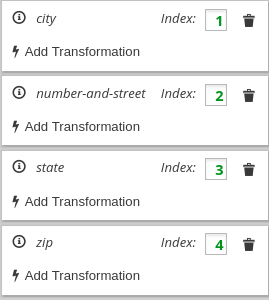 .
.
데이터 매퍼는 알파벳순으로 데이터 매퍼에 표시되는 순서대로 대상 항목을 표시합니다. 소스 필드에서 순서를 미러링하도록 이 순서를 변경해야 합니다. 이 예에서 source 필드에는 도시 콘텐츠 앞에 있는 number-and-street 콘텐츠가 포함되어 있습니다. 대상 항목의 순서를 수정하려면 도시 인덱스 필드를 2 로 편집하거나 number-and-street 항목 뒤에 있도록 시 항목을 드래그합니다. 결과는 다음과 같습니다.
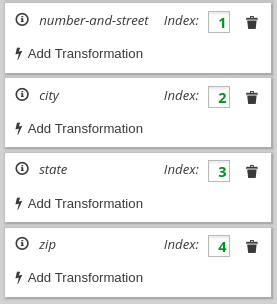 .
.
대상 필드 항목에서 인덱스 번호는 이 대상 필드에 매핑될 소스 필드의 부분을 나타냅니다. 올바른 대상 필드 값을 달성하려면 인덱스 값을 변경해야 합니다. 각 대상 필드를 고려하십시오.
-
number-and-street- 소스 필드에서 숫자 및 스트리트 콘텐츠에는 1의 인덱스가 있습니다. 인덱스 1 소스를number-and-street대상 필드에 매핑하는 것이 맞습니다. 이 대상 항목에는 변경이 필요하지 않습니다. -
city- 소스 필드에서 도시 콘텐츠에는 인덱스가 2입니다. 이 대상 항목도 그대로 적합합니다. -
State- 소스 필드에서 상태 콘텐츠에는 인덱스가 3입니다. 이 대상 항목도 그대로 적합합니다. -
zip- 소스 필드에서 zip 코드 콘텐츠에는 인덱스가 5입니다. 대상 필드 인덱스 4가 잘못되었습니다. 이를 변경하지 않으면 실행 중에 소스 필드의 국가 부분이zip대상 필드에 매핑됩니다. 인덱스를 5로 변경해야 합니다. 이는 인덱스 5 소스 콘텐츠를zip대상 필드에 매핑하도록 데이터 매퍼에 지시합니다. 인덱스를 변경하면 데이터 매퍼에서 인덱스가 4인 패딩 필드를 추가합니다. 결과는 다음과 같습니다.
 .
.
이제 이 매핑이 완료되었습니다. 소스 필드에는 인덱스 6(zip+4)에 추가 콘텐츠가 있지만 대상에 데이터가 필요하지 않으며 수행할 필요가 없습니다.
8.7. 데이터 매퍼를 사용하여 컬렉션 처리
흐름에서 단계가 컬렉션을 출력하고 흐름에 있는 후속 연결이 컬렉션을 입력으로 예상하는 경우 데이터 매퍼를 사용하여 컬렉션을 처리할 방법을 지정할 수 있습니다.
단계가 컬렉션을 출력하면 흐름 시각화가 단계에 대한 세부 정보에 컬렉션을 표시합니다. 예를 들면 다음과 같습니다.
컬렉션을 제공하는 단계와 매핑이 필요한 단계 앞에 데이터 매퍼 단계를 추가합니다. 흐름에서 이 데이터 매퍼 단계는 흐름의 다른 단계에 따라 달라집니다. 다음 이미지는 소스 컬렉션 필드에서 대상 컬렉션 필드로의 매핑을 보여줍니다.
소스 및 대상 패널에서 데이터 매퍼는
![]() 를 표시하여 컬렉션을 나타냅니다. 소스 컬렉션 또는 대상 컬렉션에 기본 유형만 포함된 경우 필요하지 않기 때문에 데이터 매퍼는 컬렉션 필드를 표시하지 않습니다. 컬렉션에서 매핑하거나 컬렉션 자체에 매핑할 수 있습니다.
를 표시하여 컬렉션을 나타냅니다. 소스 컬렉션 또는 대상 컬렉션에 기본 유형만 포함된 경우 필요하지 않기 때문에 데이터 매퍼는 컬렉션 필드를 표시하지 않습니다. 컬렉션에서 매핑하거나 컬렉션 자체에 매핑할 수 있습니다.
컬렉션에 두 가지 유형의 기본 유형이 포함되거나 하나 이상의 복잡한 유형이 포함된 경우 데이터 매퍼에서 컬렉션의 하위 필드를 표시합니다. 각 필드에서 매핑할 수 있습니다. 그러나 또는 중첩된 컬렉션으로 매핑할 수 없습니다.
Fuse Online에서 흐름을 실행하면 소스 컬렉션 요소를 반복하여 대상 컬렉션 요소를 채웁니다. 하나 이상의 소스 컬렉션 필드를 대상 컬렉션 또는 대상 컬렉션 필드에 매핑하는 경우 대상 컬렉션 요소에는 매핑된 필드에 대한 값만 포함됩니다.
소스 컬렉션의 소스 컬렉션 또는 필드를 컬렉션에 없는 대상 필드에 매핑하는 경우 Fuse Online에서 흐름을 실행할 때 소스 컬렉션의 마지막 요소 값만 할당합니다. 컬렉션의 다른 요소는 해당 매핑 단계에서 무시됩니다. 그러나 후속 매핑 단계는 소스 컬렉션의 모든 요소에 액세스할 수 있습니다.
연결에서 JSON 또는 Java 문서에 정의된 컬렉션을 반환하는 경우 데이터 매퍼는 일반적으로 소스 문서를 컬렉션으로 처리할 수 있습니다.
8.8. 컬렉션과 수집되지 않은 매핑 정보
데이터 매퍼 소스 및 대상 패널에서 다음을 수행합니다.
-
 컬렉션을 나타냅니다. 컬렉션에 하나의 기본 유형이 포함된 경우 또는 컬렉션에서 직접 매핑할 수 있습니다. 컬렉션에 두 개 이상의 다른 유형이 포함된 경우 데이터 매퍼는 컬렉션의 하위 필드를 표시하고 컬렉션의 필드에 매핑할 수 있습니다.
컬렉션을 나타냅니다. 컬렉션에 하나의 기본 유형이 포함된 경우 또는 컬렉션에서 직접 매핑할 수 있습니다. 컬렉션에 두 개 이상의 다른 유형이 포함된 경우 데이터 매퍼는 컬렉션의 하위 필드를 표시하고 컬렉션의 필드에 매핑할 수 있습니다.
-
 복잡한 유형의 확장 가능한 컨테이너를 나타냅니다. 복잡한 유형에는 다양한 유형의 여러 필드가 포함되어 있습니다. 복잡한 형식의 필드는 배열과 같은 컬렉션 형식일 수 있습니다.A field in a complex type can be a type that is a collection, such as an array. 복잡한 유형의 컨테이너 자체를 매핑할 수 없습니다. 복잡한 유형에 있는 필드만 매핑할 수 있습니다.
복잡한 유형의 확장 가능한 컨테이너를 나타냅니다. 복잡한 유형에는 다양한 유형의 여러 필드가 포함되어 있습니다. 복잡한 형식의 필드는 배열과 같은 컬렉션 형식일 수 있습니다.A field in a complex type can be a type that is a collection, such as an array. 복잡한 유형의 컨테이너 자체를 매핑할 수 없습니다. 복잡한 유형에 있는 필드만 매핑할 수 있습니다.
데이터 매퍼의 오른쪽 상단에 있는 (COMPLEX), STRING, INTEGER 와 같은 데이터 유형 표시를 전환하려면
을 클릭하고 유형 표시를 클릭합니다.
수집이 아닌(many-to-one) 매핑
컬렉션 필드에서 수집되지 않은 필드에 매핑하면 데이터 매퍼는 다대일 매핑을 인식합니다. 기본 동작은 데이터 매퍼가 소스 컬렉션 또는 소스 컬렉션 필드에 Concatenate 변환을 적용한다는 것입니다. 기본 구분 기호는 공백입니다. 예를 들어 이 소스 컬렉션을 고려해 보십시오.
- 첫 번째 요소에서 city 필드의 값은 Boston 입니다.
- 두 번째 요소에서, 시 필드의 값은 파키스탄 입니다.
- 세 번째 요소에서는 시 필드의 값은 Cryo stat 입니다.
실행하는 동안 데이터 매퍼는 대상 필드를 으로 채웁니다.
보스 파키스 파키스탄
다른 변환을 적용하여 이 기본 동작을 변경할 수 있습니다. 예를 들어 선택한 요소에서만 매핑하려면 항목 변환을 소스에 적용하고 인덱스를 지정합니다. 소스 컬렉션의 첫 번째 요소에 있는 값을 매핑하려면 인덱스에 0 을 지정합니다.
소스 컬렉션에 매핑되지 않은 필드가 포함된 경우 해당 필드는 흐름에 있는 후속 단계에서 계속 사용할 수 있습니다.
수집이 아닌 (일대 다대다) 매핑
수집이 아닌 소스 필드에서 대상 컬렉션 또는 컬렉션 요소에 있는 대상 필드에 매핑하면 데이터 매퍼는 일대다 매핑을 인식합니다. 기본 동작은 데이터 매퍼가 공백을 구분 기호로 사용하고 소스 값을 여러 값으로 분할하여 분할 변환을 적용한다는 것입니다. 실행 중에 데이터 매퍼는 각 분할 값을 대상 컬렉션의 자체 요소에 삽입합니다. 예를 들어 소스 필드가 4개의 값으로 분할되면 대상 컬렉션에는 4개의 요소가 포함됩니다.
이번 릴리스에서는 분할 변환이 일대다 매핑에 적용할 수 있는 유일한 변환입니다.
예를 들어 수집이 아닌 도시 소스 필드에 다음이 포함된 경우를 살펴보겠습니다.
보스 파키스 파키스탄
이 소스 필드를 대상 컬렉션 또는 컬렉션에 있는 대상 필드에 매핑할 수 있습니다. 실행되는 동안 데이터 매퍼는 city 필드의 값을 공간 구분 기호로 분할합니다. 결과는 세 개의 요소를 포함하는 컬렉션입니다. 첫 번째 요소에서 city 필드의 값은 보스턴 입니다. 두 번째 요소에서, 시 필드의 값은 파키스탄 입니다. 세 번째 요소에서는 시 필드의 값은 Cryo stat 입니다.
8.9. 소스 또는 대상 데이터 변환
데이터 매퍼에서는 매핑을 정의한 후 매핑의 모든 필드를 변환할 수 있습니다. data 필드 변환은 데이터를 저장하는 방법을 정의합니다. 예를 들어 데이터 값의 첫 번째 문자가 대문자인지 확인하기 위해 conversion을 지정할 수 있습니다.
절차
- 필드를 매핑합니다. 이는 일대일 매핑, 조합 매핑 또는 분리 매핑일 수 있습니다.
- 매핑 세부 정보 패널의 소스 또는 대상 아래의 변환하려는 필드의 상자에서 휴지통을 가리키는 화살표를 클릭합니다. 그러면 데이터 매퍼에서 수행할 변환을 선택할 수 있는 필드가 표시됩니다.
- 변환 목록을 표시하려면 이 필드를 클릭합니다.
- 수행할 변환을 클릭합니다.
- 변환에 입력 매개변수가 필요한 경우 적절한 입력 필드에 지정합니다.
- 다른 변환을 추가하려면 휴지통을 가리키는 화살표를 다시 클릭 할 수 있습니다.
추가 리소스
8.10. 매핑에 조건 적용
일부 통합에서는 매핑에 조건부 처리를 추가하는 것이 유용합니다. 예를 들어 소스 zip 코드 필드를 대상 zip 코드 필드에 매핑한다고 가정합니다. 소스 zip 코드 필드가 비어 있으면 대상 필드를 99999 로 채울 수 있습니다. 이렇게 하려면 zip 코드 소스 필드를 테스트하여 비어 있는지 확인하는 표현식을 지정하고, 비어 있으면 zip 코드 대상 필드에 99999 를 삽입합니다.
매핑에 조건을 적용하는 것은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
데이터 매퍼는 Microsoft excel 표현식과 유사하지만 모든 Microsoft excel 표현식 구문을 지원하지는 않는 표현식을 지원합니다. 이번 릴리스에서는 조건부 표현식에서 컬렉션 필드를 참조할 수 없습니다. 이는 향후 릴리스에서 변경될 것으로 예상됩니다.
각 매핑에 대해 0 또는 하나의 조건을 정의할 수 있습니다.
다음 절차에서는 매핑에 조건을 적용하여 시작됩니다. 매핑 및 조건으로 작업할 때 가장 편리한 순서대로 필요한 단계를 수행할 수 있습니다.
사전 요구 사항
- 데이터 매퍼 단계에서 필드를 매핑하고 있습니다.
- MicrosoftExcel 식에 익숙하거나 매핑에 적용할 조건부 식을 사용합니다.
절차
데이터 유형이 아직 표시되지 않은 경우
을 클릭한 다음 유형 표시 를 클릭하여 표시합니다.
이는 조건을 지정하기 위한 요구 사항은 아니지만 데이터 유형을 확인하는 것이 도움이 됩니다.
조건을 적용할 매핑을 생성하거나 현재 선택한 매핑이 조건을 적용할 매핑인지 확인합니다. 예를 들어 다음 매핑을 고려하십시오.
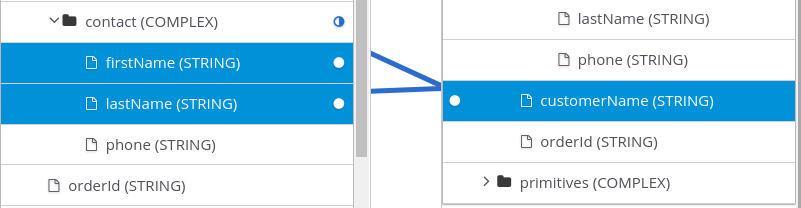
오른쪽 상단에서
 을 클릭하여 조건부 표현식 입력 필드를 표시합니다.
을 클릭하여 조건부 표현식 입력 필드를 표시합니다.
표현식 필드에서 데이터 매퍼는 현재 매핑에서 소스 필드의 이름을 자동으로 표시합니다. 예를 들면 다음과 같습니다.

표현식 입력 필드에서 소스 필드의 순서는 매핑을 만들 때 선택한 순서입니다. 기본 매핑 동작은 데이터 매퍼가 대상 필드에 결과를 삽입하기 위해 이 필드의 필드 값을 연결하므로 중요합니다. 이 예에서는 이 매핑을 생성하기 위해
lastName이 먼저 선택되고firstName이 선택됩니다.표현식 입력 필드를 편집하여 데이터 매퍼가 매핑에 적용할 조건부 표현식을 지정합니다. 지원되는 조건부 표현식에 대한 자세한 내용은 다음 절차를 따르십시오.
표현식을 지정하면 다음을 수행할 수 있습니다.
-
@을 입력하고 필드 이름을 입력하려면 시작합니다. 데이터 매퍼는 입력한 것과 일치하는 필드 목록을 표시합니다. 표현식에서 지정할 필드를 선택합니다. 매핑 캔버스에서 표현식 입력 필드로 필드를 드래그합니다.
식에 필드 이름을 추가하면 데이터 매퍼에서 해당 필드를 매핑에 추가합니다. 예를 들어 다음 조건부 표현식을 고려하십시오.

실행하는 동안 데이터 매퍼에서
lastName필드가 비어 있다고 판단하면firstName필드만 대상customerName필드에 매핑됩니다.lastName필드에 값이 포함된 경우 데이터 매퍼는 소스orderId및전화필드의 값을 연결하고customerName필드에 결과를 삽입합니다. (이 예제에서는 논리가 작동하는 방식을 보여 주지만lastName필드에 값이 있을 때 데이터 매퍼가 간단히 매핑을 수행하고 다른 값을 대상에 매핑하지 않도록 하기 때문에 유용한 예는 아닐 수 있습니다.)이 예제에서는 표현식을 입력한 후 데이터 매핑은 다음과 같습니다.

조건부 표현식에서 표현식이 적용되는 매핑에 있는 필드 이름을 제거하면 데이터 매퍼가 매핑에서 해당 필드를 제거합니다. 즉, 매핑의 모든 필드 이름은 조건식에 있어야 합니다.
-
-
매핑 프리뷰 필드가 아직 표시되지 않은 경우
을 클릭한 다음 매핑 프리뷰 를 표시하여 표시합니다.
- 소스 프리뷰 입력 필드에 샘플 데이터를 입력하여 대상 필드 또는 대상 필드가 올바른 값을 가져오도록 합니다.
선택적으로 매핑에 있는 하나 이상의 소스 또는 대상 필드에 변환을 적용합니다.
- 매핑 세부 정보 패널에서 변환을 적용할 필드를 찾습니다.
- 바로 아래를 클릭하고 추가를 클릭합니다.
- 데이터 매퍼에서 수행할 변환을 클릭합니다.
- 필요한 경우 입력 매개 변수를 지정합니다.
예를 들어 이 절차에 표시된 것과 동일한 매핑 세부 정보 패널에서는
Uppercase변환을firstName필드에 적용할 수 있습니다.firstName필드의 프리뷰 입력 필드에 데이터를 입력하여 테스트할 수 있습니다.- 필요한 경우 조건부 표현식을 편집하여 원하는 결과를 얻습니다.
조건부 표현식에서 지원되는 함수
ISEMPTY(source-field-name1 [+ source-field-name2])ISEMPTY()함수의 결과는 부울 값입니다. 조건을 적용할 매핑의 소스 필드의 이름인 하나 이상의 인수를 지정합니다. 지정된 source 필드가 비어 있으면ISEMPTY()함수가 true를 반환합니다.선택적으로 추가 필드가 포함된 +(concatenation) Operator를 추가합니다. 예를 들면 다음과 같습니다.
ISEMPTY(lastName + firstName)이 표현식은
lastName및firstName필드가 모두 비어 있으면 true로 평가됩니다.종종
ISEMPTY()함수는IF()함수의 첫 번째 인수입니다.IF(boolean-expression, then, else)부울-표현이 true로 평가되면 데이터 매퍼는 다음을 반환합니다.부울-표현이 false로 평가되면 데이터 매퍼는다른값을 반환합니다. 세 가지 인수가 모두 필요합니다. 마지막 인수는 null일 수 있습니다. 즉,boolean-expression이 false로 평가될 때 아무것도 매핑되지 않습니다.예를 들어 대상
customerName필드에lastName및firstName소스 필드를 결합하는 매핑을 고려하십시오. 이 조건부 표현식을 지정할 수 있습니다.IF (ISEMPTY(lastName), firstName, lastName + ',' + firstName )실행하는 동안 데이터 매퍼는
lastName필드를 평가합니다.-
lastName필드가 비어 있으면ISEMPTY(lastName)가 true를 반환하면 데이터 매퍼는firstName값만 대상customerName필드에 삽입합니다. lastName필드에 값이 포함된 경우ISEMPTY(lastName)는 false를 반환하고 데이터 매퍼는lastName값을 매핑한 다음 쉼표를 사용한 다음firstName값을 대상customerName필드에 매핑합니다.이제 이 표현식의 세 번째 인수가 null인 경우 동작을 고려하십시오.
IF (ISEMPTY(lastName), firstName, null )실행하는 동안 데이터 매퍼는
lastName필드를 평가합니다.-
이전 예에서와 같이
lastName필드가 비어 있으면ISEMPTY(lastName)에서 true를 반환하는 경우 데이터 매퍼는firstName값만 대상customerName필드에 삽입합니다. -
그러나 세 번째 인수가 null인 경우
lastName필드에 값이 포함된 경우ISEMPTY(lastName)에서 false를 반환하면 데이터 매퍼가 대상customerName필드에 아무것도 매핑하지 않습니다.
-
표 8.1. 조건부 표현식에서 지원되는 연산자
| Operator | 설명 |
|
| 숫자 값 또는 연결 문자열 값을 추가합니다. |
|
| 다른 숫자 값에서 숫자 값을 뺀 값입니다. |
|
| 숫자 값을 곱합니다. |
|
| 숫자 값을 나눕니다. |
|
| 왼쪽 피연산자와 오른쪽 피연산자가 모두 true이면 true를 반환합니다.true if both the left and right operands are true. 각 피연산자는 부울 값을 반환해야 합니다. |
|
| 왼쪽 피연산자가 true이면 true이거나 오른쪽 피연산자가 true이면 true를 반환합니다.true if the left operand is true, or if the right operand is true. 각 피연산자는 부울 값을 반환해야 합니다. |
|
| 해당 없음 |
|
| 왼쪽 숫자 피연산자가 오른쪽 숫자 피연산자보다 큰 경우 true를 반환합니다. |
|
< | 왼쪽 숫자 피연산자가 오른쪽 숫자 피연산자보다 작은 경우 true를 반환합니다. |
|
| 왼쪽 피연산자와 오른쪽 피연산자가 동일한 경우 true를 반환합니다. |
8.11. 단계에서 매핑 보기
데이터 매퍼 단계를 추가하거나 편집하는 동안 이 단계에서 이미 정의된 매핑을 볼 수 있습니다. 이를 통해 올바른 매핑이 있는지 확인할 수 있습니다.
사전 요구 사항
- 통합을 생성하거나 편집하고 있습니다.
- 데이터 매퍼 단계를 추가하고 있습니다. 즉, 데이터 매퍼가 표시됩니다.
절차
-
오른쪽 상단에서
을 클릭합니다.
-
매핑 목록을 제거하고 소스 및 대상 필드를 다시 표시하려면
를 다시 클릭합니다.
8.12. 사용 가능한 변환에 대한 설명
다음 표에서는 사용 가능한 변환을 설명합니다. 날짜 및 숫자 유형은 일반적으로 이러한 개념의 다양한 형태를 나타냅니다. 즉, number는 정수,long,double 을 포함합니다. 날짜는 예를 들어 날짜 ,시간, ZonedDateTime 이 포함됩니다.Date includes, for example, ,date, timeZonedDateTime.
| 변환 | 입력 유형 | 출력 유형 | 매개변수(* = 필수) | 설명 |
|---|---|---|---|---|
|
| 숫자 | 숫자 | 없음 | 숫자의 절대 값을 반환합니다. |
|
| date | date |
| 날짜를 추가합니다. 기본값은 0일입니다. |
|
| date | date |
| 날짜에 초를 추가합니다. 기본값은 0초입니다. |
|
| string | string | string | 문자열 끝에 문자열을 추가합니다. 기본값은 아무것도 추가하지 않는 것입니다. |
|
| string | string | 없음 | 공백을 제거하고 소문자를 만들고 각 후속 단어의 첫 번째 문자를 대문자로 변환하여 구문으로 변환합니다. |
|
| string | string | 없음 | 문자열에서 첫 번째 문자를 대문자로 지정합니다. |
|
| 숫자 | 숫자 | 없음 | 숫자의 정수를 반환합니다. |
|
| Any | 부울 |
| 필드에 지정된 값이 포함된 경우 true를 반환합니다. |
|
| 숫자 | 숫자 |
|
영역을 다른 단위로 나타내는 숫자를 변환합니다. |
|
| 숫자 | 숫자 |
|
거리를 다른 단위로 나타내는 숫자를 변환합니다. |
|
| 숫자 | 숫자 |
|
수를 다른 단위로 나타내는 숫자를 변환합니다. |
|
| 숫자 | 숫자 |
|
볼륨을 다른 단위로 표시하는 숫자를 변환합니다. |
|
| date | 숫자 | 없음 | 날짜에 해당하는 요일(1~7까지)을 반환합니다. |
|
| date | 숫자 | 없음 | 날짜에 해당하는 일 (1~366)을 반환합니다. |
|
| string | 부울 |
|
문자열이 지정된 문자열로 끝나고 케이스가 두 |
|
| Any | 부울 |
|
입력 필드가 지정된 |
|
| string | string | 없음 | 파일 이름을 나타내는 문자열에서 점 없이 파일 확장자를 반환합니다. |
|
| 숫자 | 숫자 | 없음 | 숫자의 전체 숫자 플로어를 반환합니다. |
|
| Any | string |
|
|
|
|
문자열 | 숫자 |
|
매개 변수 문자열의 첫 번째 문자인 입력 문자열에 있는 문자의 인덱스를 반환합니다. 매개 변수 문자열을 찾을 수 없는 경우 |
|
| Any | 부울 | 없음 | 필드가 null인 경우 true를 반환합니다. |
|
|
문자열 | 숫자 |
|
매개 변수 문자열의 마지막 문자인 입력 문자열에 있는 문자의 인덱스를 반환합니다. 매개 변수 문자열을 찾을 수 없는 경우 |
|
| Any | 숫자 | 없음 |
필드의 길이를 반환하거나 필드가 null인 경우 |
|
| string | string | 없음 | 문자열을 소문자로 변환합니다. |
|
| string | string | 없음 | 연속 공백 문자를 단일 공백으로 바꾸고 문자열에서 선행 및 후행 공백을 트리로 바꿉니다. |
|
| string | string |
|
문자열 시작 부분에 |
|
| string | string |
|
문자열 끝에 |
|
| string | string |
|
|
|
| string | string |
|
문자열에서 제공된 일치하는 문자열의 모든 항목을 제공된 |
|
| string | string |
|
문자열에서 지정된 |
|
| 숫자 | 숫자 | 없음 | 숫자의 반올림된 정수를 반환합니다. |
|
| string | string | 없음 | 각 공백, 콜론(:), 밑줄(_), 더하기(+) 및 등호(=)를 하이픈(-)으로 바꿉니다. |
|
| string | string | 없음 | 각 공백, 콜론(:), 하이픈(-), 더하기(+) 및 등호(=)를 밑줄(_)으로 바꿉니다. |
|
| string | 부울 |
| 문자열이 지정된 문자열로 시작하는 경우(대소문자 포함) true를 반환합니다. |
|
| string | string |
|
지정된 포함 된 startIndex에서 지정된 배타적인 endIndex로 문자열 세그먼트를 검색합니다.Retrieves a segment of a string from the specified inclusive |
|
| string | string |
|
지정된 전용 |
|
| string | string |
|
제공된 전용 |
|
| string | string | 없음 | 문자열에서 선행 공백 및 후행 공백을 건너뜁니다.Twm leading and trailing whitespace from a string. |
|
| string | string | 없음 | 문자열에서 선행 공백을 검색합니다. |
|
| string | string | 없음 | 문자열에서 공백을 반올림합니다. |
|
| string | string | 없음 | 문자열을 대문자로 변환합니다. |
8.13. 하나의 대상 필드에 매핑하기 전에 여러 소스 값의 변환 정보
여러 소스 필드 또는 컬렉션과 같은 여러 값을 포함하는 소스 필드의 값에 적용할 수 있는 몇 가지 변환이 있습니다. 데이터 매퍼는 변환 결과를 대상 필드에 삽입합니다. 다음 표에서는 이러한 다중 복제 변환을 설명합니다.
| Multiplicity 변환 | 설명 |
|---|---|
| add | 숫자 소스 값을 추가하고 대상 필드에 합계를 삽입합니다. 선택한 소스 필드 또는 선택한 컬렉션의 값은 숫자여야 합니다. |
| 평균 | 숫자 소스 값의 평균을 계산하고 대상 필드에 결과를 삽입합니다. 선택한 소스 필드 또는 선택한 컬렉션의 값은 숫자여야 합니다. |
| 연결 | 소스 값을 조인하고 대상 필드에 결과를 삽입합니다. 공백을 구분 기호로 허용하거나 다른 문자를 지정할 수 있습니다. 데이터 매퍼는 소스 값 간의 대상 필드에 이 문자를 삽입합니다. 이 변환의 일반적인 용도는 CustomerName과 같은 여러 소스 필드 값(예: Customer Name )을 대상 필드(예: Customer Name )로 결합하는 것입니다. |
| 포함 | 소스 값을 평가하여 값에 지정된 매개 변수 값이 포함되어 있는지 확인합니다. 소스 값에 지정된 매개변수 값이 포함된 경우 데이터 매퍼는 대상 필드에 true 를 삽입합니다. 소스 값에 매개 변수 값이 없는 경우 데이터 매퍼는 대상 필드에 false 를 삽입합니다. 예를 들어 특정 고객과 관련된 활동을 추적하려는 경우를 예로 들 수 있습니다. 각 컬렉션 멤버에 고객 정보가 포함된 소스 컬렉션 필드를 선택할 수 있습니다. Value 매개변수의 경우 특정 이메일 주소를 지정합니다. 데이터 매퍼가 컬렉션에서 지정된 이메일 주소를 찾으면 대상 필드에 true 를 삽입합니다. |
| 수량 | 대상 필드에 소스 값 수를 삽입합니다. 소스 필드가 컬렉션인 경우 유용합니다. 데이터 매퍼는 대상 필드에 컬렉션의 크기를 삽입합니다. 예를 들어 항목 개체의 컬렉션인 주문 소스 필드를 선택했다고 가정합니다. 개수 변환 적용은 대상 필드에 순서에 있는 항목 수를 삽입합니다. 다른 예로 개별 소스 필드 4를 선택하면 데이터 매퍼는 대상 필드에 4 를 삽입합니다. |
| 분할 |
첫 번째 소스 값을 두 번째 소스 값으로 분할하고 대상 필드에 결과를 삽입합니다. 두 소스 값이 더 있는 경우 실행은 계속 결과를 다음 수로 나눕니다. 예를 들어 |
| 형식 | 지정한 템플릿의 자리 표시자를 선택한 소스 필드의 값으로 교체합니다. 데이터 매퍼는 대상 필드에 결과 문자열을 삽입합니다. 예를 들어 세 가지 소스 필드를 선택했다고 가정합니다.
시간 형식 변환 및 템플릿 매개변수에서 지정할 수 있습니다.
대상 필드에서 결과는 다음과 같습니다. 오전 8:00, aslan sayinged: ROAR! 이는 Java 및 C와 같은 프로그래밍 언어에서 사용할 수 있는 메커니즘과 유사합니다. |
| 항목 위치 | 선택한 소스 필드의 경우 데이터 매퍼는 사용자가 지정하는 인덱스에서 값을 찾고 대상 필드에 해당 값을 삽입합니다. 소스 필드는 컬렉션 또는 구분 기호가 있는 여러 값을 포함하는 필드여야 합니다. 예를 들어 선택한 소스 필드가 고객 이메일 주소 컬렉션입니다. Item At 변환 을 선택한 후 Index 매개변수 필드에서 0을 지정합니다. 데이터 매퍼는 target 필드에 인덱스 0에 있는 첫 번째 이메일 주소를 삽입합니다. |
| 최대 | 소스 값을 평가하고 대상 필드에 가장 높은 값을 삽입합니다. 소스 값은 숫자여야 합니다. |
| 최소 | 소스 값을 평가하고 대상 필드에 가장 낮은 값을 삽입합니다. 소스 값은 숫자여야 합니다. |
| 곱 |
첫 번째 소스 값을 두 번째 소스 값으로 멀티플링하고 대상 필드에 결과를 삽입합니다. 두 소스 값이 더 있는 경우 실행은 계속 결과에 다음 수를 곱합니다. 예를 들어 |
| 뺀 값 |
첫 번째 소스 값에서 두 번째 소스 값을 뺀 후 대상 필드에 결과를 삽입합니다. 두 소스 값이 더 있는 경우 실행은 이전 결과에서 다음 수를 뺀 것입니다. 예를 들어 |
8.14. 데이터 매핑 문제 해결
이미 매핑된 필드에 영향을 미치는 데이터 모양 변경으로 인해 데이터 매퍼가 문서를 로드하지 못할 수 있습니다. 이 경우 영향을 받는 필드를 매핑하는 데이터 매퍼 단계를 편집하려고 하면 데이터 매퍼에서 소스 및 대상 패널을 표시할 수 없습니다. 대신 문서를 로드하거나 찾을 수 없음을 나타내는 오류가 표시됩니다. 오류 메시지는 다음 메시지 중 하나와 같습니다.
-
데이터 매퍼 UI 초기화 오류: '-La_rwMD_ggphAW6nE9o': undefined 문서를 로드할 수 없습니다 -
las:json:-LaX4LMC1CfVJYp3JXM6에서 매핑된 필드 'last_name'에 대한 문서를 찾을 수 없습니다
이 데이터 매퍼 단계를 삭제하고 업데이트된 필드를 매핑하는 새 데이터 매퍼 단계로 교체해야 합니다.
매핑된 필드를 데이터 모양을 변경하려면 항상 매핑을 다시 실행해야 하지만 데이터 매퍼 단계를 삭제하고 제거할 필요는 없습니다. 예를 들어 XML 인스턴스가 입력 데이터 모양을 지정하고 요소의 이름을 변경하는 경우 데이터 매퍼는 이전 필드 이름에 있는 매핑을 제거합니다.For example, if an XML instance specifies an input data shape and you change the name of an element, the data mapper removes the mapping that was to/from the old field name. 업데이트된 이름으로 필드에 매핑하기만 하면 됩니다.
매핑된 필드의 데이터 모양을 다음과 같은 방법으로 변경할 수 있습니다.
API 공급자 통합에서는 흐름을 편집하는 동안 작업을 정의하는 OpenAPI 문서를 편집합니다.
작업 응답의 데이터 모양을 변경하면 항상 데이터 매퍼가 문서를 로드할 수 없게 됩니다.
흐름에서는 이러한 종류의 연결 중 하나에 대한 입력 데이터 유형 및/또는 출력 데이터 유형을 편집합니다.
- Amazon S3
- AMQ
- AMQP
- Dropbox
- FTP/SFTP
- HTTP/HTTPS
- Kafka
- IRC
- MQTT
9장. 통합 관리
일반적인 설정은 Fuse Online 개발 환경, Fuse Online 테스트 환경 및 Fuse Online 배포 환경을 사용하는 것입니다. 이를 위해 Fuse Online에서는 하나의 Fuse Online 환경에서 통합을 내보낸 다음 다른 Fuse Online 환경으로 통합할 수 있는 기능을 제공합니다. 구체적으로 명시하지 않는 한 통합을 관리하기 위한 정보 및 절차는 각 유형의 Fuse Online 환경에서 동일합니다.
다음 항목에서는 통합을 관리하는 데 도움이 되는 정보를 제공합니다.
9.1. 통합 라이프사이클 처리 정보
통합을 생성하고 게시한 후 통합 기능을 업데이트할 수 있습니다. 게시된 통합 초안을 편집한 다음 실행 중인 버전을 업데이트된 버전으로 교체할 수 있습니다. 이를 용이하게 하기 위해 각 통합을 위해 Fuse Online은 여러 버전과 각 버전의 상태를 유지 관리합니다. 통합 버전 및 상태를 이해하면 통합을 관리하는 데 도움이 됩니다.
통합 버전 설명
각 Fuse Online 환경에서 각 통합에는 여러 버전이 있을 수 있습니다. 여러 통합 버전을 지원하면 다음과 같은 몇 가지 이점이 있습니다.
- 제대로 작동하지 않는 버전을 게시하는 경우 올바른 버전의 통합으로 돌아갈 수 있습니다. 이렇게 하려면 잘못된 버전을 중지하고 원하는 방식으로 실행되는 버전을 시작합니다.
- 요구 사항 또는 도구가 변경되면 통합을 점진적으로 업데이트할 수 있습니다. 새 통합을 생성할 필요가 없습니다.
Fuse Online에서는 새 버전의 통합을 실행할 때마다 새 버전 번호를 할당합니다. 예를 들어, twitter를 Cryostat 샘플 통합에 게시한다고 가정해 보겠습니다. 실행 후 다른 계정을 사용하여 Twitter에 연결하도록 통합을 업데이트합니다. 그런 다음 업데이트된 통합을 게시합니다. Fuse Online은 실행 중인 통합 버전을 중지하고 증가된 버전 번호와 업데이트된 버전의 통합을 게시합니다.
실행 중인 초기 통합은 버전 1입니다. 현재 실행 중인 업데이트된 통합은 버전 2입니다. 예를 들어 버전 2를 편집하여 Cryostat에 연결하는 데 다른 계정을 사용하고 해당 버전을 게시하면 통합의 버전 3이 됩니다.
정확히 하나의 통합 버전이 있을 수 있습니다. Fuse Online에는 통합 초안 버전에 대한 정의가 있지만 이 통합 버전을 실행하지는 않습니다. 통합 버전 초안에는 숫자가 없습니다. 통합을 편집하면 통합 초안을 업데이트하고 있습니다.
Fuse Online에서는 통합의 요약 페이지에서 통합 버전 목록을 볼 수 있습니다. 이 페이지를 보려면 왼쪽 탐색 패널에서 통합을 클릭합니다. 관심 있는 통합 항목에서 보기를 클릭합니다.
통합 상태 설명
Fuse Online에서 통합 버전 목록에서 각 항목은 다음 버전 중 하나인 해당 버전의 상태를 나타냅니다.
| 상태 | 설명 |
| 실행 중 | 실행 중인 버전이 실행 중입니다. 서비스 중입니다. 하나의 통합 버전만 실행할 수 있습니다. 즉, 한 번에 하나의 버전만 Running 상태가 될 수 있습니다. |
| 중지됨 | 중지된 버전이 실행되고 있지 않습니다. 통합 초안은 Stopped 상태입니다. 한 번에 실행된 각 통합이 Stopped 상태입니다. 이 통합 버전이 Running 상태에 없는 경우 중지된 버전을 시작할 수 있습니다. |
| 보류 중 | 보류 중인 버전이 전환 중입니다. Fuse Online은 이 버전의 통합을 시작하거나 이 통합 버전을 중지하지만 통합은 아직 실행 중이거나 중지되지 않습니다. |
| 오류 |
Error 상태에 있는 통합 버전에서는 시작하는 동안 또는 실행 중에 OpenShift 오류가 발생했습니다. 시작 또는 실행이 중단된 오류입니다. 이 경우 올바르게 실행된 이전 통합 버전을 시작합니다. 또는 기술 지원에 문의하십시오. 이렇게 하려면 오른쪽 상단에 있는 Fuse Online 페이지에서
|
9.2. 서비스에 통합 및 중단
통합을 생성한 후 초안으로 저장하거나 게시하여 실행을 시작할 수 있습니다. 통합을 게시하면 Fuse Online에서 필요한 리소스를 어셈블하고, 통합 런타임을 빌드하고, 통합을 실행할 OpenShift 포드를 배포한 다음 통합 실행을 시작합니다.
언제든지 버튼을 클릭하여 통합 실행을 중지할 수 있습니다. 통합을 다시 시작하려는 경우 Fuse Online에는 이미 필요한 사항이 있으므로 처음 실행하는 데 게시한 시간보다 시간이 단축되었습니다.
처음으로 통합 버전을 시작하는 프로세스를 통합 게시라고 합니다. 다음 주제에서는 세부 정보를 제공합니다.
9.2.1. 게시 통합 정보
처음으로 통합 버전을 실행하려면 이를 게시합니다. 통합 빌드를 게시하고 통합 런타임을 배포합니다. 통합이 실행되기 시작합니다. 통합을 게시한 후 중지한 후 다시 시작할 수 있습니다. 한 번에 하나의 통합 버전을 실행할 수 있습니다.
게시 대안
통합을 처음 실행하려면 다음 중 하나를 수행하여 게시합니다.
- 오른쪽 상단에 있는 통합을 만들거나 편집하는 절차가 끝나면 게시 를 클릭합니다.
통합 버전을 게시합니다.
- 왼쪽 Fuse Online 패널에서 통합을 클릭합니다.
-
통합 목록에서 초안 항목 오른쪽에 있는
를 클릭하고 게시 를 선택합니다.
게시 진행 상황 정보
Fuse Online에서는 여러 단계가 있는 게시 프로세스의 진행 상황을 표시합니다.
- 어셈블링은 통합을 빌드하는 데 필요한 Pod 리소스를 생성합니다.
- 구축하면 통합을 배포할 준비가 되었습니다.
- 배포 는 통합을 실행할 Pod의 배포를 기다립니다.
- Pod가 통합 실행을 시작할 때까지 기다립니다.
- 배포됨 은 통합이 실행 중임을 나타냅니다.
시작 중에 로그 보기를 클릭하여 시작 정보를 제공하는 OpenShift 로그를 표시할 수 있습니다.
게시 후 통합 상태
통합 게시가 완료되면 통합 이름 옆에 Running 상태가 표시됩니다. Pod가 통합을 실행하고 있습니다.
9.2.2. 통합 중지
각 통합에는 실행 중인 정확히 하나의 버전이 있을 수 있습니다. 실행 중인 버전이 Running 상태입니다. 언제든지 통합 실행을 중지할 수 있습니다.
사전 요구 사항
중지하려는 통합은 Running 상태입니다.
절차
- 왼쪽 Fuse Online 패널에서 통합을 클릭합니다.
- 통합 목록에서 실행을 중지하려는 통합 항목을 식별합니다. 항목은 이 통합이 Running 이라는 것을 보여줍니다.
-
이 통합 항목의 맨 오른쪽에 있는
을 클릭하고 중지 를 선택합니다.
결과
Fuse Online은 통합 실행을 중지합니다. 중지한 다음 중지 는 통합 목록의 통합 항목에 나타납니다.
9.2.3. 통합 시작
통합을 처음 시작할 때 Fuse Online에서 통합을 실행하기 전에 통합 런타임을 빌드해야 하므로 프로세스를 통합 게시라고 합니다. 언제든지 통합 실행을 중지하고 다시 시작할 수 있습니다.
사전 요구 사항
시작하려는 통합은 Stopped 상태입니다.
절차
- 왼쪽 탐색 패널에서 통합을 클릭합니다.
-
통합 목록에서 시작하려는 통합 항목 오른쪽에 있는
을 클릭합니다.
- 시작을 선택합니다.
결과
Fuse Online에서 통합 버전의 상태로 Starting 을 표시한 다음 통합 버전이 다시 실행되면 Running 을 표시합니다.
9.2.4. 이전 통합 버전 다시 시작
원하는 방식으로 작동하지 않는 통합을 게시할 수 있습니다. 이 경우 잘못된 버전을 중지하고 이전에 게시한 버전과 올바르게 실행되는 버전으로 교체할 수 있습니다.
사전 요구 사항
- 통합 버전이 실행 중이지만 중지하려고 합니다.
- 다른 버전의 통합이 있고 해당 버전을 실행하려고 합니다.
절차
- 왼쪽 패널에서 통합을 클릭하여 이 환경의 통합 목록을 표시합니다.
- 이전 버전을 게시할 통합 항목을 클릭합니다. Fuse Online에는 통합 버전 목록이 표시됩니다.
-
실행 중인 버전의 항목에서 맨 오른쪽에 있는
를 클릭하고 중지 를 선택합니다.
- OK 를 클릭하여 이 버전 실행을 중지할지 확인합니다.
- 페이지 상단에 있는 통합 이름 오른쪽에 Stopped 가 표시될 때까지 기다립니다.
이전 버전을 그대로 게시하려면 다음 단계로 건너뜁니다. 또는 이전 버전을 게시하기 전에 다음을 업데이트할 수 있습니다.
-
업데이트하려는 통합 버전의 항목에서 맨 오른쪽에 있는
를 클릭하고 Draft 교체를 선택합니다.
- 필요에 따라 통합을 업데이트합니다.
- 업데이트가 완료되면 오른쪽 상단에서 게시를 클릭한 다음 게시 를 클릭하여 확인합니다. 이 작업은 다음 두 단계의 공간을 차지합니다.
-
업데이트하려는 통합 버전의 항목에서 맨 오른쪽에 있는
-
이전 버전을 그대로 게시하려면 맨 오른쪽에 있는 통합 버전의 통합 버전 항목에서
을 클릭하고 시작을 선택합니다.
- Start 를 클릭하여 이 버전의 통합을 시작할지 확인합니다.
결과
Fuse Online은 통합을 시작하는데, 이는 몇 분 정도 걸립니다. 통합이 실행되면 실행 버전 n 이 통합 이름의 오른쪽에 나타납니다.
9.3. 통합 실행에 대한 로깅 정보
통합 실행을 위해 흐름의 각 단계에 대해 Fuse Online에서는 다음과 같은 활동 정보를 제공합니다.
- 단계가 실행된 날짜 및 시간
- 단계를 실행하는 데 걸린 시간
- 실행이 성공했는지 여부
- 실행이 성공하지 못한 경우 오류 메시지
Fuse Online에서 이 정보를 보려면 통합 요약을 표시한 다음 활동 탭을 클릭합니다.
통합 실행에 대한 자세한 정보를 얻으려면 통합 흐름에 로그 단계를 추가하여 통합 프로세스에서 처리하는 메시지에 대한 정보를 기록할 수 있습니다. 통합이 수신하는 각 메시지에 대해 로그 단계는 다음 중 하나 이상을 제공할 수 있습니다.
- 메시지의 헤더를 포함하여 메시지에 대한 메타데이터를 제공하는 메시지의 컨텍스트입니다.
- 메시지의 본문으로, 메시지의 내용을 제공합니다.
- 명시적으로 또는 Apache Camel Simple 언어 표현식의 평가를 통해 지정하는 텍스트입니다.
이전 릴리스에서 사용 가능한 로그 연결은 더 이상 통합에 추가할 수 없습니다. 로그 연결 대신 로그 단계를 추가합니다.
사전 요구 사항
- 흐름을 만들거나 편집하는 동안 Fuse Online에서 통합에 추가하라는 메시지가 표시됩니다. 또는 Fuse Online에서 완료 연결을 선택하라는 메시지가 표시됩니다.
절차
- 흐름 시각화에서 로그 단계를 추가할 더하기 기호를 클릭합니다. Fuse Online에서 완료 연결을 선택하라는 메시지가 표시되면 이 단계를 건너뜁니다.
- 로그 를 클릭합니다.
로그 구성 단계 페이지에서 로깅할 콘텐츠를 선택합니다. Custom text 를 선택한 경우 텍스트 입력 필드에 다음 중 하나를 입력합니다.
- 기록하려는 텍스트
- Camel Simple 언어 표현식
표현식을 입력하면 Fuse Online에서 표현식을 확인하고 결과 텍스트를 기록합니다.
- 로그 단계 구성이 완료되면 다음을 클릭하여 흐름에 단계를 추가합니다.
다음 단계
흐름이 완료되면 통합을 게시하여 새 로그 단계에서 출력 표시가 시작됩니다.
추가 리소스
로그 단계가 실행된 흐름이 실행된 후 로그 단계의 출력이 통합의 활동 탭에 표시됩니다. 통합 활동 정보 보기를 참조하십시오.
9.4. 통합 모니터링
Fuse Online에서는 통합 실행을 모니터링할 수 있는 다양한 방법을 제공합니다. 다음 내용을 참조하십시오.
9.4.1. 통합 내역 보기
Fuse Online은 각 통합 버전을 유지 관리합니다. 각 통합 버전 목록을 볼 수 있습니다.
절차
- 왼쪽 패널에서 통합을 클릭하여 사용자 환경에 통합 목록을 표시합니다.
- 표시하려는 버전이 있는 통합 항목 오른쪽에 있는 보기 를 클릭합니다.
결과
표시되는 페이지에서 기록 섹션에 통합 버전이 나열됩니다.
 아이콘은 현재 버전(최근의 성공적으로 실행 중인 버전)을 식별합니다. 각 버전에 대해 마지막으로 시작된 날짜도 확인할 수 있습니다.
아이콘은 현재 버전(최근의 성공적으로 실행 중인 버전)을 식별합니다. 각 버전에 대해 마지막으로 시작된 날짜도 확인할 수 있습니다.
특정 버전을 편집, 시작 또는 중지하려면 버전 항목 오른쪽에 있는
를 클릭합니다. 수행할 작업을 선택합니다.
9.4.2. 통합 활동에 대한 정보 보기
Fuse Online에서는 통합 실행을 위한 활동 정보를 제공합니다. 이 정보는 통합 로그의 일부입니다. 흐름의 각 단계에서 Fuse Online에서는 다음을 제공합니다.
- 단계가 실행된 날짜 및 시간
- 단계를 실행하는 데 걸린 시간
- 실행이 성공했는지 여부
- 실행이 성공하지 못한 경우 오류 메시지
언제든지 이 정보를 볼 수 있습니다.
사전 요구 사항
- 활동 정보를 확인하려는 통합이 실행 중이거나 있었습니다.
- 이러한 통합은 적어도 한 번 실행되었습니다.
절차
- 왼쪽 패널에서 통합을 클릭합니다.
- 활동 정보를 볼 통합 항목 오른쪽에 있는 보기를 클릭합니다.
- 통합 요약 페이지에서 활동 탭을 클릭합니다.
- 선택적으로 날짜 및/또는 키워드 필터를 입력하여 나열된 실행을 제한합니다.
- 활동 정보를 볼 통합 실행을 클릭합니다.
추가 리소스
- 두 단계 간에 추가 정보를 얻으려면 통합에 로그 단계를 추가할 수 있습니다. 로그 단계는 수신하는 각 메시지에 대한 정보를 제공하고 사용자가 지정하는 사용자 지정 텍스트를 제공할 수 있습니다. 로그 단계를 추가하면 활동 정보를 볼 통합 실행을 확장할 때 통합 단계 중 하나로 표시됩니다. 다른 단계에 대한 Fuse Online 정보를 보는 것과 동일한 방식으로 로그 단계에 대한 Fuse Online 정보를 볼 수 있습니다. 통합 실행에 대한 로깅 정보를 참조하십시오.
9.4.3. 특정 통합에 대한 메트릭 보기
Fuse Online에서는 각 통합에 대해 다음과 같은 메트릭을 제공합니다.
- Total Errors 는 지난 30일 동안 이 통합 실행이 발생한 런타임 오류 수를 나타냅니다.
- last Processed 는 이 통합이 메시지를 처리한 최신 날짜와 시간을 표시합니다. 메시지가 성공적으로 처리되었거나 오류가 있을 수 있습니다.
- Total Messages 는 지난 30일 동안 이 통합을 실행하는 모든 메시지 수입니다. 여기에는 메시지 실패가 포함됩니다.
- uptime 은 이 통합이 시작된 시점과 오류 없이 실행된 기간을 나타냅니다.
사전 요구 사항
메트릭을 확인하려는 통합이 실행 중이거나 실행 중입니다.
절차
- 왼쪽 패널에서 통합을 클릭합니다.
- 메트릭을 볼 통합 항목 오른쪽에 있는 보기 를 클릭합니다.
- 통합 요약 페이지에서 Metrics 를 클릭합니다.
9.4.4. Fuse Online 환경에 대한 메트릭 보기
Fuse Online 환경에 대한 메트릭은 Fuse Online 홈 페이지에 표시됩니다.
절차
왼쪽 패널에서 홈 을 클릭합니다.
결과
Fuse Online에서는 5초마다 다음 메트릭을 업데이트합니다.
- 이 환경에 정의된 통합 수와 실행 중인 통합 수, 중지된 통합 수, 보류 중인 통합 수입니다. Fuse Online은 통합을 중지하거나 대기 중인 상태로 시작합니다. 빨간색 크로스는 실행 중이지만 실행을 중단한 오류가 발생한 모든 통합을 나타냅니다.
- 이 환경에 정의된 연결 수입니다.
- 지난 30일 동안 이 환경에서 통합으로 처리된 총 메시지 수입니다. 여기에는 더 이상 실행되지 않거나 이 환경에서 삭제되었을 수 있는 통합으로 처리된 메시지가 포함됩니다.
- uptime은 실행 중인 통합이 하나 이상 있는 기간을 나타냅니다. 가동 시간이 시작된 날짜와 시간도 표시됩니다.
9.5. 통합 테스트
통합을 생성하고 Fuse Online 개발 환경에서 올바르게 실행되고 있으면 다른 Fuse Online 환경에서 테스트하려는 경우가 있습니다.
사전 요구 사항
- Fuse Online 개발 환경과 Fuse Online 테스트 환경이 있습니다.
- Fuse Online 개발 환경에서 올바르게 실행되고 있는 통합이 있습니다.
절차
- 다른 환경에 통합을 복사하는 방법을 알아보십시오.
- 개발 환경에서 통합을 내보냅니다. 통합 내보내기를 참조하십시오.
- 통합을 테스트 환경으로 가져옵니다. 통합 가져오기를 참조하십시오.
9.6. 통합 실행 문제 해결 팁
통합이 중지되면 해당 활동 및 기록 세부 정보를 확인합니다. 통합 활동 정보 보기 및 통합 기록 보기를 참조하십시오.
OAuth를 사용하는 애플리케이션에 대한 연결의 경우 애플리케이션의 액세스 토큰이 만료되었음을 나타내는 오류 메시지가 표시될 수 있습니다. 경우에 따라 덜 명시적 403 - Access denied 메시지가 표시될 수 있습니다. 메시지의 정보는 통합이 연결 중인 애플리케이션에 따라 달라집니다. 이 경우 애플리케이션에 다시 연결한 다음 통합을 다시 게시하십시오.
- 왼쪽 패널에서 통합을 클릭합니다.
- 통합 목록에서 실행 중지된 통합 항목 오른쪽에 있는 보기 를 클릭합니다.
통합의 요약 페이지에서 흐름 시각화에서 다시 연결할 애플리케이션의 아이콘을 클릭합니다.In the integration's summary page, in the flow visualization, click the icon for the application that you want to reconnect to.
API 공급자 통합인 경우 통합 요약 페이지에서 흐름 아이콘을 클릭하여 작업 목록을 표시합니다. 그런 다음 경로에 실패한 연결이 포함된 작업을 클릭한 다음 작업의 경로 시각화에서 실패한 연결을 클릭합니다.
- 연결 세부 정보 페이지에서 다시 연결을 클릭합니다.
해당 애플리케이션의 OAuth 워크플로 프롬프트에 응답합니다.
Fuse Online에서 애플리케이션에 대한 액세스 권한이 있음을 나타내는 메시지를 표시합니다. 일부 애플리케이션의 경우 몇 초가 소요되지만 다른 애플리케이션에는 시간이 더 오래 걸릴 수 있습니다.
- 애플리케이션에 다시 연결한 후 통합을 시작합니다.
재연결이 성공하지 못하면 다음을 시도합니다.
- Fuse Online을 애플리케이션 클라이언트로 다시 등록합니다. 권한 부여를 위한 일반 절차를 참조하십시오.
- 새 연결을 만듭니다.
이전 연결을 사용한 각 통합을 편집합니다.
- 이전 연결을 제거합니다.
- 새 연결로 바꿉니다.
- 업데이트된 각 통합을 게시합니다.
9.7. 통합 업데이트
통합을 생성한 후 단계를 추가, 편집 또는 제거하기 위해 이를 업데이트해야 할 수 있습니다.
사전 요구 사항
Fuse Online 환경에는 업데이트하려는 통합 버전이 있습니다.
절차
- 왼쪽 Fuse Online 패널에서 통합을 클릭합니다.
- 통합 목록에서 업데이트할 통합에 대한 보기를 클릭합니다.
통합 요약 페이지의 오른쪽 상단에 있는 통합 편집을 클릭합니다.
간단한 통합인 경우 Fuse Online에서 통합 흐름을 표시합니다. API 공급자 통합인 경우 Fuse Online에 작업 목록이 표시됩니다. 특정 작업의 흐름을 업데이트하려면 해당 작업 오른쪽에 있는 흐름 생성 또는 흐름 편집을 클릭하여 흐름을 표시합니다.
필요에 따라 흐름을 업데이트합니다.
- 단계를 추가하려면 흐름 시각화에서 단계를 추가할 위치에 있는 더하기 기호를 클릭합니다. 그런 다음 추가할 단계를 나타내는 카드를 클릭합니다.
-
단계를 삭제하려면 흐름 시각화에서 삭제하려는 단계에서
 를 클릭합니다.
를 클릭합니다.
- 단계 구성을 변경하려면 흐름 시각화에서 업데이트할 단계에서 구성 을 클릭합니다. 구성 페이지에서 필요에 따라 매개변수 설정을 업데이트합니다.
9.8. 통합 삭제
통합을 삭제한 후에도 Fuse Online은 여전히 통합 기록을 유지합니다. 삭제된 통합 버전을 가져오는 경우 Fuse Online은 삭제된 통합 기록을 가져온 통합과 연결합니다.
절차
- 왼쪽 Fuse Online 패널에서 통합을 클릭합니다.
-
통합 목록에서 삭제하려는 통합 항목 오른쪽에 있는
를 클릭하고 삭제 를 선택합니다.
- 팝업에서 OK 를 클릭하여 통합을 삭제할지 확인합니다.
9.9. 다른 환경에 통합 복사
개발, 스테이징 및 프로덕션 환경 전체에서 통합을 실행하려면 통합을 내보내고 가져올 수 있습니다. 환경은 모두 단일 OpenShift 클러스터에 있거나 여러 OpenShift 클러스터에 분산될 수 있습니다.
여기에 설명된 절차에서는 Fuse Online 콘솔에서 통합을 내보내고 가져오도록 지시합니다.
OpenShift Container Platform 온사이트에서 Fuse Online을 실행하는 경우 특정 통합을 내보내고 가져와야 하는 CI/CD(Continuous Integration/Continuous Deployment) 파이프라인이 있을 수 있습니다. 이 작업에 대한 자세한 내용은 외부 툴을 사용하여 CI/CD의 통합을 내보내거나 가져오기 를 참조하십시오.
다음 항목을 참조하십시오.
9.9.1. 통합 복사 정보
각 Fuse Online 설치는 통합을 내보낼 수 있는 환경입니다. 통합 내보내기는 다른 Fuse Online 환경에서 통합을 다시 생성하는 데 필요한 정보가 포함된 zip 파일을 다운로드합니다.
환경에서 각 통합에는 하나의 Draft 버전만 있을 수 있습니다.
통합 가져오기 결과는 다음에 따라 다릅니다.
- 이전에 통합을 가져왔는지 여부
- 통합에서 사용하는 연결을 이전에 가져왔는지 여부
Fuse Online에서는 각 통합 및 각 연결에 내부 식별자를 사용하여 해당 ID를 가져오는 환경에 이미 있는지 확인합니다. 통합 또는 연결의 이름을 변경하면 Fuse Online에서 이름이 다른 통합 또는 연결로 인식합니다.
다음 표에서는 통합 가져오기의 가능한 결과를 설명합니다.
| 가져오기 환경에서 다음을 수행합니다. | 가져오기 작업에서 수행하는 작업: |
|---|---|
| 이전에는 통합을 가져오지 않았습니다. | 통합을 생성합니다. 통합은 Draft 상태에 있습니다. |
| 이전에 통합을 가져왔습니다. | Fuse Online에서 통합을 업데이트합니다. 업데이트된 통합은 Draft 상태입니다. 이 통합의 Draft 버전이 있는 경우 손실됩니다. |
| 가져온 통합에서는 가져오기 작업 전에 환경에 없는 연결을 사용합니다. | Fuse Online에서는 보안을 제외하고 동일한 설정이 있는 연결을 생성합니다. 각각의 새 연결을 검토해야 합니다. 새 환경에 대한 연결이 완전히 구성되지 않은 경우 누락된 설정을 추가해야 합니다. 예를 들어 이 Fuse Online 환경을 이 연결에 액세스하는 애플리케이션의 클라이언트로 등록하여 시크릿 설정을 가져와야 할 수 있습니다. |
9.9.2. 통합 내보내기
Fuse Online에서 통합을 내보낼 때 zip 파일을 로컬 다운로드 폴더에 다운로드합니다. 이 zip 파일에는 다른 Fuse Online 환경에서 통합을 다시 생성하는 데 필요한 정보가 포함되어 있습니다.
통합 내보내기는 통합 백업을 수행하는 방법이기도 합니다. 그러나 Fuse Online은 통합 버전을 유지 관리하므로 백업 사본에는 통합을 내보낼 필요가 없습니다.
절차
- Fuse Online의 왼쪽 패널에서 통합을 클릭합니다.
- 통합 목록에서 내보낼 통합 항목을 식별합니다.
-
항목 오른쪽에 있는
을 클릭하고 내보내기 를 선택합니다.
다음 단계
다른 Fuse Online 환경으로 통합을 가져오려면 해당 환경을 열고 내보낸 zip 파일을 가져옵니다.
9.9.3. 통합 가져오기
Fuse Online 환경에서는 다른 Fuse Online 환경에서 내보낸 통합을 가져올 수 있습니다. 통합을 내보내면 통합을 가져오기 위해 업로드하는 zip 파일이 다운로드됩니다.
사전 요구 사항
- 다른 Fuse Online 환경에서 내보낸 통합이 포함된 zip 파일이 있습니다.
절차
- 통합을 가져올 Fuse Online 환경을 엽니다.
- 왼쪽 패널에서 통합을 클릭합니다.
- 오른쪽 상단에서 가져오기 를 클릭합니다.
내보낸 통합 zip 파일을 하나 이상 드래그 앤 드롭하거나 내보낸 통합이 포함된 zip 파일로 이동하여 선택합니다.
Fuse Online에서 파일을 가져오고 가져올 때 메시지를 표시합니다.
- 왼쪽 패널에서 통합을 클릭합니다.
- 통합 목록에서 방금 가져온 통합 항목에서 보기를 클릭합니다.
- 통합 요약에서 구성이 필요한 알림이 있는 경우 오른쪽 상단에서 통합 편집을 클릭합니다.
구성이 필요한 각 연결에 대해 다음을 수행합니다.
- Configure 버튼을 클릭하여 세부 정보를 표시합니다.
- 필요에 따라 연결 세부 정보를 입력하거나 변경합니다. 이 페이지의 모든 필드가 올바르며 보안 구성만 필요할 수 있습니다.
- 다음을 클릭합니다.
왼쪽 패널에서 설정을 클릭합니다.
설정 페이지에는 OAuth 프로토콜을 사용하는 애플리케이션의 항목이 표시됩니다.
구성이 필요하고 OAuth 프로토콜을 사용하는 애플리케이션에 액세스하는 각 연결에 대해 Fuse Online 환경을 애플리케이션에 등록합니다. 각 애플리케이션에 따라 단계가 달라집니다. 적절한 주제를 참조하십시오.
- 왼쪽 패널에서 연결을 클릭하고 구성이 필요한 연결이 더 이상 없는지 확인합니다.
- 왼쪽 패널에서 통합을 클릭합니다. 통합 목록에서 가져온 통합에는 항목의 왼쪽 상단에 녹색 일각형이 있습니다.
-
통합 목록에서 가져온 통합 항목 오른쪽에 있는
를 클릭하고 편집을 선택합니다.
- 오른쪽 상단에서 저장을 클릭하거나 가져온 통합 실행을 시작하려면 게시 를 클릭합니다. 초안으로 통합을 저장하거나 통합을 게시하는지 여부에 관계없이 Fuse Online은 통합을 업데이트하여 업데이트된 연결을 사용합니다.
10장. Fuse Online 사용자 정의
Fuse Online에서는 일반적인 애플리케이션 및 서비스에 연결하는 데 사용할 수 있는 다양한 커넥터를 제공합니다. 또한 일반적인 방법으로 데이터를 처리하기 위한 여러 가지 기본 제공 단계가 있습니다. 그러나 Fuse Online에서 필요한 기능을 제공하지 않는 경우 요구 사항에 대해 개발자와 상의하십시오. 숙련된 개발자는 다음 중 하나를 제공하여 통합을 사용자 지정할 수 있습니다.
Fuse Online에서 REST API 클라이언트용 커넥터를 만드는 데 사용할 수 있는 OpenAPI 문서입니다.
이 스키마를 Fuse Online 및 Fuse Online에 업로드하면 스키마에 따라 커넥터가 생성됩니다. 그런 다음 커넥터를 사용하여 통합에 추가할 수 있는 연결을 만듭니다. 예를 들어 많은 소매 웹 사이트에서는 개발자가 OpenAPI 문서에서 캡처할 수 있는 REST API 클라이언트 인터페이스를 제공합니다.
REST API 서비스를 정의하는 OpenAPI 문서입니다.
이 스키마를 Fuse Online에 업로드합니다. Fuse Online을 사용하면 API 서비스를 사용할 수 있으며 API 호출을 위한 URL을 제공합니다. 이를 통해 API 호출을 사용하여 통합 실행을 트리거할 수 있습니다.
Fuse Online 확장을 구현하는
JAR파일입니다. 확장은 다음 중 하나일 수 있습니다.- 연결 간 통합 데이터에서 작동하는 하나 이상의 단계
- 애플리케이션 또는 서비스에 대한 커넥터
전용 SQL 데이터베이스에 대한 JDBC 드라이버와 같은 라이브러리 리소스
이
JAR파일을 Fuse Online 및 Fuse Online에 업로드하면 확장 프로그램에서 제공하는 사용자 지정 기능을 사용할 수 있습니다.
자세한 내용은 다음 항목을 참조하십시오.
10.1. REST API 클라이언트 커넥터 개발
Fuse Online은 HTTP(Hypertext Transfer Protocol)를 지원하는 REST API(Representational State Transfer Application Programming Interface)용 커넥터를 생성할 수 있습니다. 이를 위해 Fuse Online에는 연결하려는 REST API를 설명하는 유효한 OpenAPI 2.0 문서가 필요합니다. API 서비스 공급자가 OpenAPI 문서를 사용할 수 없도록 하는 경우 숙련된 개발자가 OpenAPI 문서를 생성해야 합니다.
다음 항목에서는 REST API 커넥터 개발을 위한 정보와 지침을 제공합니다.
10.1.1. REST API 클라이언트 커넥터에 대한 요구사항
OpenAPI 스키마를 Fuse Online에 업로드한 후 REST API에 대한 커넥터를 사용할 수 있게 됩니다. 커넥터를 선택하여 REST API 클라이언트 연결을 생성할 수 있습니다. 그런 다음 새 통합을 생성하고 REST API 클라이언트 연결을 추가하거나 기존 통합을 편집하여 REST API 클라이언트 연결을 추가할 수 있습니다.
Fuse Online 커넥터는 OAuth 2.0, HTTP 기본 인증 및 API 키를 지원합니다. REST API에 대한 액세스에 TLS(Transport Layer Security)가 필요한 경우 API는 인식된 CA(인증 기관)에서 발급한 유효한 인증서를 사용해야 합니다.
OAuth를 사용하는 REST API에는 클라이언트 콜백 URL을 입력으로 사용하는 권한 부여 URL이 있어야 합니다. Fuse Online에서 커넥터를 생성한 후 커넥터를 사용하여 연결을 만들기 전에 해당 URL을 방문하여 Fuse Online 환경을 REST API 클라이언트로 등록해야 합니다. 이렇게 하면 Fuse Online 환경이 REST API에 액세스할 수 있습니다. 등록 과정의 일환으로 Fuse Online 콜백 URL을 제공합니다. 이 작업에 대한 자세한 내용은 Fuse Online을 REST API 클라이언트로 등록하여 애플리케이션 및 서비스에 Fuse Online 연결 에서 설명합니다.
OAuth를 사용하는 REST API의 경우 Fuse Online은 권한 부여를 받기 위한 인증 코드 권한 부여 흐름만 지원합니다. OAuth 보안Definitions 오브젝트에서 커넥터를 생성하기 위해 업로드하는 OpenAPI 문서에서 flow 속성을 accessCode 로 설정해야 합니다. 예를 들면 다음과 같습니다.
securityDefinitions:
OauthSecurity:
type: oauth2
flow: accessCode
authorizationUrl: 'https://oauth.simple.api/authorization'
tokenUrl: 'https://oauth.simple.api/token'
암시적,암호 또는 애플리케이션 흐름을 설정할 수 없습니다.
REST API 클라이언트 커넥터의 OpenAPI 스키마에는 사이클 스키마 참조가 있을 수 없습니다. 예를 들어 요청 또는 응답 본문을 지정하는 JSON 스키마는 자체적으로 전체로 참조하거나 여러 중간 스키마를 통해 자체의 일부를 참조할 수 없습니다.
Fuse Online은 HTTP 2.0 프로토콜을 지원하는 REST API용 커넥터를 생성할 수 없습니다.
10.1.2. REST API 클라이언트 커넥터를 위한 OpenAPI 스키마에 대한 지침
Fuse Online에서 REST API 클라이언트 커넥터를 생성할 때 OpenAPI 문서의 각 리소스 작업을 연결 작업에 매핑합니다. 작업 이름 및 작업 설명은 OpenAPI 문서의 문서에서 제공합니다.
OpenAPI 문서에서 제공하는 자세한 내용은 Fuse Online에서 API에 연결할 때 더 많은 지원을 제공할 수 있습니다. 예를 들어 API 정의는 요청 및 응답에 대한 데이터 유형을 선언할 필요가 없습니다. 유형 선언 없이 Fuse Online은 해당 연결 작업을 유형 없이 정의합니다. 그러나 통합에서는 유형 없는 작업을 수행하는 API 연결 직후 또는 직후 데이터 매핑 단계를 추가할 수 없습니다.
이를 위한 한 가지 방법은 OpenAPI 문서에 더 많은 정보를 추가하는 것입니다. API 연결을 수행할 작업에 매핑할 OpenAPI 리소스 작업을 식별합니다. OpenAPI 문서에서 각 작업의 요청 및 응답 유형을 지정하는 YAML 또는 JSON 스키마가 있는지 확인합니다.
스키마를 업로드한 후 Fuse Online은 OpenAPI 문서를 기반으로 API를 설계하기 위한 시각적 편집기인 API desktop에서 검토하고 편집할 수 있는 기회를 제공합니다. 세부 정보를 추가하고, 업데이트를 저장하고, Fuse Online은 업데이트를 통합하는 API 클라이언트 커넥터를 생성합니다. Fuse Online에서 클라이언트 커넥터를 생성한 후에는 더 이상 OpenAPI 문서를 편집할 수 없습니다. 변경 사항을 구현하려면 새 클라이언트 커넥터를 생성해야 합니다.
API에 대한 OpenAPI 문서가 application/json 콘텐츠 유형 및 application/xml 콘텐츠 유형에 대한 지원을 선언하는 경우 커넥터는 JSON 형식을 사용합니다. OpenAPI 문서에서 application/json 및 application/xml 을 모두 정의하는 매개변수를 사용하거나 생성하는 경우 커넥터는 JSON 형식을 사용합니다.
10.1.3. 매개변수에서 클라이언트 인증 정보 제공
Fuse Online에서 OAuth2 애플리케이션에 액세스 권한을 가져오려고 하면 HTTP 기본 인증을 사용하여 클라이언트 자격 증명을 제공합니다. 필요한 경우 Fuse Online에서 HTTP 기본 인증을 사용하는 대신 클라이언트 자격 증명을 매개 변수로 전달하도록 이 기본 동작을 변경할 수 있습니다. OAuth 액세스 토큰을 가져오는 데 사용되는 tokenUrl 끝점 사용에 영향을 미칩니다.
Fuse Online에서 클라이언트 자격 증명을 매개 변수로 전달하도록 지정하려면 OpenAPI 문서의 securityDefinitions 섹션에서 true 로 설정된 x-authorize-using-parameters 공급업체 확장을 추가합니다. 아래 예제에서 마지막 줄은 x-authorize-using-parameters 를 지정합니다.
securityDefinitions:
concur_oauth2:
type: 'oauth2'
flow: 'accessCode'
authorizationUrl: 'https://example.com/oauth/authorize'
tokenUrl: 'https://example.com/oauth/token'
scopes:
LIST: Access List API
x-authorize-using-parameters: true
x-authorize-using-parameters 벤더 확장의 설정은 true 또는 false 입니다.
-
true는 클라이언트 자격 증명이 매개 변수에 있음을 나타냅니다. -
false(기본값)는 Fuse Online이 HTTP 기본 인증을 사용하여 클라이언트 자격 증명을 제공한다는 것을 나타냅니다.
10.1.4. 액세스 토큰 자동 새로 고침
액세스 토큰의 만료 날짜가 있는 경우 토큰이 만료될 때 해당 토큰을 사용하여 애플리케이션 중지에 성공적으로 연결하는 Fuse Online 통합입니다. 새 액세스 토큰을 얻으려면 애플리케이션에 다시 연결하거나 애플리케이션에 다시 등록해야 합니다.
필요한 경우 Fuse Online에서 다음 상황에서 새 액세스 토큰을 자동으로 요청하도록 이 기본 동작을 변경할 수 있습니다.
- 만료 날짜에 도달한 경우
- 지정한 HTTP 응답 상태 코드가 수신되는 경우
Fuse Online에서 OpenAPI 문서의 securityDefinitions 섹션에서 자동으로 새 액세스 토큰을 가져오도록 지정하려면 x-refresh-token-retry-statuses 벤더 확장을 추가합니다. 이 확장의 설정은 HTTP 응답 상태 코드를 지정하는 쉼표로 구분된 목록입니다. 액세스 토큰의 만료 날짜에 도달하거나 Fuse Online에서 OAuth2 공급자로부터 메시지를 수신하고 메시지에 이러한 응답 상태 코드 중 하나가 있는 경우 Fuse Online에서 새 액세스 토큰을 자동으로 가져오려고 합니다. 아래 예제에서 마지막 줄은 x-refresh-token-retry-statuses 를 지정합니다.
securityDefinitions:
concur_oauth2:
type: 'oauth2'
flow: 'accessCode'
authorizationUrl: 'https://example.com/oauth/authorize'
tokenUrl: 'https://example.com/oauth/token'
scopes:
LIST: Access List API
x-refresh-token-retry-statuses: 401,402,403경우에 따라 API 작업이 실패하고 해당 실패의 부작용은 액세스 토큰을 새로 고치는 것입니다. 이 경우 새 액세스 토큰을 얻는 경우에도 API 작업이 계속 실패합니다. 즉, Fuse Online은 새 액세스 토큰을 수신한 후 실패한 API 작업을 재시도하지 않습니다.
10.2. REST API 클라이언트 커넥터 추가 및 관리
Fuse Online에서는 OpenAPI 문서에서 REST API 클라이언트 커넥터를 생성할 수 있습니다. OpenAPI 문서의 콘텐츠에 대한 자세한 내용은 REST API 클라이언트 커넥터 개발을 참조하십시오.
다음 항목에서는 REST API 클라이언트 커넥터를 추가 및 관리하기 위한 정보와 지침을 제공합니다.
REST API 클라이언트 커넥터를 생성한 후 해당 커넥터 사용에 대한 자세한 내용은 Fuse Online을 애플리케이션 및 서비스에 연결, REST API에 연결을 참조하십시오.
10.2.1. REST API 클라이언트 커넥터 생성
OpenAPI 문서를 업로드하여 Fuse Online에서 REST API 클라이언트 커넥터를 생성할 수 있습니다.
사전 요구 사항
Fuse Online에서 생성할 커넥터에 대한 OpenAPI 문서가 있습니다.
절차
- Fuse Online 탐색 패널에서 사용자 지정 > API 클라이언트 커넥터 를 클릭합니다. 이미 사용 가능한 API 클라이언트 커넥터는 여기에 나열되어 있습니다.
- API 커넥터 만들기를 클릭합니다.
Create API Client Connector 페이지에서 다음 중 하나를 수행합니다.
- 점선 상자를 클릭하고 업로드할 OpenAPI 파일을 선택합니다.
- URL 사용을 선택하고 입력 필드에 OpenAPI 문서의 URL을 붙여넣습니다.
다음을 클릭합니다. 잘못된 콘텐츠가 있거나 누락된 콘텐츠가 있는 경우 Fuse Online에서 수정해야 하는 사항에 대한 정보를 표시합니다. 다른 OpenAPI 파일을 선택하여 업로드하거나 취소 를 클릭하고 OpenAPI 파일을 수정하고 업데이트된 파일을 업로드합니다.
스키마가 유효한 경우 Fuse Online에서 커넥터가 제공하는 작업에 대한 요약을 표시합니다. 여기에는 작업 정의에 대한 오류 및 경고가 포함될 수 있습니다.
작업 요약에 만족하는 경우 다음을 클릭합니다.
또는 OpenAPI 문서를 수정하려면 오른쪽 하단에서 검토/편집 을 클릭하여 API Splunk 편집기를 엽니다. 필요에 따라 스키마를 업데이트합니다. 오른쪽 상단에서 저장을 클릭하여 새 API 클라이언트 커넥터에 업데이트를 통합합니다. 그런 다음 다음을 클릭하여 API 클라이언트 커넥터를 계속 생성합니다.
API 편집기 사용에 대한 자세한 내용은 API Creator 를 사용한 API 정의 설계 및 개발을 참조하십시오.
OpenAPI 문서의 URL을 제공하는 경우 Fuse Online에서 업로드할 수 있지만 편집을 위해 열 수는 없습니다. 일반적으로 이는 파일 호스트의 설정으로 인해 발생합니다. 편집을 위해 스키마를 열려면 Fuse Online에서 파일 호스트에 다음이 필요합니다.
-
httpsURL입니다.httpURL이 작동하지 않습니다. - 활성화된 CORS.
-
API의 보안 요구 사항을 나타냅니다. Fuse Online은 OpenAPI 정의를 읽고 API의 보안 요구 사항을 충족하도록 커넥터를 구성하는 데 필요한 정보를 확인합니다. Fuse Online에서는 다음 중 하나를 표시할 수 있습니다.
- 보안 없음
- HTTP 기본 인증 - API 서비스에서 HTTP 기본 인증을 사용하는 경우 이 확인란을 선택합니다. 나중에 이 커넥터를 사용하여 연결을 생성할 때 Fuse Online에서 사용자 이름과 암호를 입력하라는 메시지를 표시합니다.
OAuth 2.0 - Fuse Online 프롬프트를 입력합니다.
- 권한 부여 URL 은 Fuse Online을 API의 클라이언트로 등록하는 위치입니다. 등록은 Fuse Online에서 API에 액세스할 수 있도록 권한을 부여합니다. Fuse Online을 REST API 클라이언트로 등록하여 Fuse Online에 애플리케이션 및 서비스 연결을 참조하십시오. API의 OpenAPI 문서 또는 기타 문서는 이 URL을 지정해야 합니다. 그렇지 않은 경우 이 URL을 받으려면 서비스 공급자에게 문의해야 합니다.
- OAuth 인증에는 액세스 토큰 URL 이 필요합니다. 다시 한 번 OpenAPI 문서 또는 API의 다른 문서에서 이 URL을 제공해야 합니다. 그렇지 않은 경우 서비스 공급자에게 문의해야 합니다.
- API 키 - API 서비스에 API 키가 필요한 경우 Fuse Online에서 커넥터를 생성하는 데 필요한 정보를 입력하라는 메시지를 표시합니다. 프롬프트는 OpenAPI 정의를 기반으로 합니다. 예를 들어 API 키가 메시지 헤더 또는 쿼리 매개변수에 있는지 여부를 지정해야 할 수 있습니다. OpenAPI 정의에서 API 키 보안과 다른 보안 유형을 지정하는 경우 확인란을 선택하여 이 커넥터를 기반으로 하는 연결에서 API 키 보안을 사용하도록 지정합니다. 나중에 이 커넥터를 사용하여 연결을 생성할 때 Fuse Online에서 API 키 값을 입력하라는 메시지를 표시합니다.
다음을 클릭합니다. Fuse Online은 OpenAPI 문서에 표시된 대로 커넥터의 이름, 설명, 호스트 및 기본 URL을 표시합니다. 이 커넥터에서 생성하는 연결의 경우,
-
Fuse Online은 호스트 및 기본 URL 값을 연결하여 연결 끝점을 정의합니다. 예를 들어 호스트가
https://example.com이고 기본 URL이/api/v1인 경우 연결 끝점은https://example.com/api/v1입니다. - Fuse Online은 OpenAPI 문서를 데이터 매핑 단계에 적용합니다. OpenAPI 문서가 두 개 이상의 스키마를 지원하는 경우 Fuse Online에서는 TLS(HTTPS) 스키마를 사용합니다.
-
Fuse Online은 호스트 및 기본 URL 값을 연결하여 연결 끝점을 정의합니다. 예를 들어 호스트가
- 커넥터 세부 정보를 검토하고 선택적으로 커넥터의 아이콘을 업로드합니다. 아이콘을 업로드하지 않으면 Fuse Online에서 하나의 아이콘을 생성합니다. 나중에 아이콘을 업로드할 수 있습니다. Fuse Online에 통합 흐름이 표시되면 해당 커넥터에서 생성된 연결을 나타내는 커넥터의 아이콘이 표시됩니다.
OpenAPI 파일에서 얻은 값을 재정의하려면 변경할 필드 값을 편집합니다.
중요Fuse Online에서 커넥터를 생성한 후에는 변경할 수 없습니다. 변경 사항을 적용하려면 Fuse Online에서 새 커넥터를 만들거나 동일한 스키마를 업로드한 다음 API 편집기에서 편집할 수 있도록 업데이트된 OpenAPI 문서를 업로드해야 합니다. 그런 다음 새 API 클라이언트 커넥터를 생성하는 프로세스를 계속합니다.
- 커넥터 세부 정보에 만족하는 경우 API 커넥터 만들기 를 클릭합니다. Fuse Online은 다른 커넥터와 함께 새 커넥터를 표시합니다.
다음 단계
새 API 커넥터 사용에 대한 자세한 내용은 Fuse Online을 애플리케이션 및 서비스에 연결, REST API에 연결을 참조하십시오.
10.2.2. 새 API 클라이언트 커넥터를 생성하여 API 클라이언트 커넥터 업데이트
API 클라이언트 커넥터를 만든 OpenAPI 문서에 대한 업데이트가 있고 API 클라이언트 커넥터가 이러한 업데이트를 사용하려면 새 API 클라이언트 커넥터를 생성해야 합니다. API 클라이언트 커넥터를 직접 업데이트할 수 없습니다. 새 API 클라이언트 커넥터를 생성한 후 이를 사용하여 새 연결을 만든 다음, 오래된 커넥터에서 생성된 연결을 사용하는 각 통합을 편집합니다.
사전 요구 사항
다음 중 하나를 수행할 준비가 되어 있습니다.
- 업데이트된 OpenAPI 문서를 업로드합니다.
- 최신 스키마를 다시 업로드하고 API Splunk에서 업데이트합니다.
절차
업데이트된 OpenAPI 문서를 기반으로 새 API 클라이언트 커넥터를 생성합니다. 이전 커넥터와 새 커넥터를 쉽게 구분하기 위해 커넥터 이름 또는 커넥터 설명에 버전 번호를 지정할 수 있습니다.
REST API 클라이언트 커넥터 생성 을 참조하십시오.
- 새 커넥터에서 새 연결을 만듭니다. 다시 말하지만 이전 커넥터에서 생성된 연결과 새 커넥터에서 생성된 연결을 쉽게 구분할 수 있어야 합니다. 연결 이름 또는 연결 설명의 버전 번호가 도움이 됩니다.
- 이전 연결을 제거하고 새 연결을 추가하여 이전 커넥터에서 생성된 연결을 사용하는 각 통합을 편집합니다.
- 업데이트된 각 통합을 게시합니다.
- 권장 사항이지만 필수는 아님: 이전 커넥터 및 이전 연결을 삭제합니다.
10.2.3. API 클라이언트 커넥터 삭제
해당 커넥터에서 생성된 연결이 있고 이 연결이 통합에서 사용되는 커넥터는 삭제할 수 없습니다. API 클라이언트 커넥터를 삭제한 후에는 해당 커넥터에서 생성된 연결을 사용할 수 없습니다.
절차
- 왼쪽 패널에서 사용자 지정 > API 클라이언트 커넥터 를 클릭합니다.
- 삭제할 커넥터 이름 오른쪽에 있는 경우 삭제를 클릭합니다.
- 확인 팝업에서 커넥터를 삭제하려는 경우 삭제 를 클릭합니다.
10.3. Fuse Online 확장 개발
Fuse Online에서 통합을 생성하는 데 필요한 기능을 제공하지 않으면 전문가 개발자가 필요한 동작을 제공하는 확장을 코딩할 수 있습니다. 통합 확장 리포지토리 https://github.com/syndesisio/syndesis-extensions 에는 확장의 예가 포함되어 있습니다.
비즈니스 통합자는 확장을 코딩하는 개발자와 요구 사항을 공유합니다. 개발자는 확장자가 포함된 .jar 파일을 제공합니다. 비즈니스 통합자는 Fuse Online에서 .jar 파일을 업로드하여 사용자 지정 커넥터, 사용자 지정 단계 또는 Fuse Online에서 사용할 수 있는 라이브러리 리소스를 만듭니다.
Red Hat Developer Studio의 Fuse Tooling 플러그인은 단계 확장 또는 커넥터 확장을 개발하는 데 도움이 되는 마법사를 제공합니다. Developer Studio에서 단계 확장 또는 커넥터 확장을 개발하도록 선택하는 경우 또는 다른 IDE에서 개인 기본 설정의 문제입니다. Developer Studio 플러그인 사용에 대한 자세한 내용은 Fuse Online 통합을 위한 확장 개발을 참조하십시오.
이 문서에서는 다음 항목에서는 절차를 간략하게 설명하고 요구 사항을 설명하고 선택한 IDE에서 확장 기능을 개발하기 위한 추가 예제를 제공합니다.
- 10.3.1절. “확장 개발을 위한 일반 절차”
- 10.3.2절. “확장 종류에 대한 설명”
- 10.3.3절. “확장 콘텐츠 및 구조 개요”
- 10.3.4절. “확장 정의 JSON 파일의 요구 사항”
- 10.3.5절. “사용자 인터페이스 속성에 대한 설명”
- 10.3.6절. “확장을 지원하는 Maven 플러그인에 대한 설명”
- 10.3.7절. “확장에서 데이터 도형을 지정하는 방법”
- 10.3.8절. “단계 확장 개발의 예”
- 10.3.9절. “커넥터 확장 개발 예”
- 10.3.10절. “라이브러리 확장을 개발하는 방법”
- 10.3.11절. “JDBC 드라이버 라이브러리 확장 생성”
10.3.1. 확장 개발을 위한 일반 절차
확장 기능을 개발하기 전에 수행해야 하는 작업에 익숙해집니다.
사전 요구 사항
통합 Pod는 플랫 클래스 경로를 사용하여 Java 프로세스에서 실행됩니다. 버전 충돌을 방지하려면 확장이 사용하는 종속 항목이 다음 모든 출처에서 가져온 자료 청구(BOM)와 일치하는지 확인합니다.
-
org.springframework.boot:spring-boot-dependencies:$SPRING_BOOT_VERSION -
org.apache.camel:camel-spring-boot-dependencies:$CAMEL_VERSION -
io.syndesis.integration:integration-bom:$SYNDESIS_VERSION
가져온 BOM의 일부가 아닌 추가 종속성이 있는 경우 다음을 수행해야 합니다.
-
lib디렉터리에 있는 확장 JAR 파일에 패키징합니다. -
확장의 JSON 설명자 파일의
dependencies속성에서 생략합니다.
절차
- 확장 기능을 이해해야 하는 작업을 파악합니다. 비즈니스 동료에게 문의하여 기능 요구 사항을 파악하십시오.
- 단계 확장, 커넥터 확장 또는 라이브러리 확장을 개발해야 하는지 여부를 결정합니다.
- 확장을 개발할 Maven 프로젝트를 설정합니다.
단계 확장을 개발하는 경우:
-
Camel 경로로 구현할지 또는 Syndesis
StepAPI를 사용하여 구현할지 여부를 결정합니다. Syndesis API에 대한 정보는 http://javadoc.io/doc/io.syndesis.extension/extension-api. -
확장 기능을 Camel 경로로 구현하도록 선택하는 경우 XML 조각,
RouteBuilder클래스 또는 Cryostat를 구현할지 여부를 결정합니다. -
Maven 프로젝트에서
schemaVersion, 확장이름,extensionId등과 같은 필수 메타데이터를 지정합니다.
-
Camel 경로로 구현할지 또는 Syndesis
- 기능을 구현하는 클래스를 코딩합니다.
-
프로젝트의
pom.xml파일에 종속 항목을 추가합니다. 커넥터 및 라이브러리 확장 및 XML에서 구현하는 단계 확장의 경우 확장을 정의하는 JSON 파일을 생성합니다.
Java에서 구현하는 단계 확장의 경우 Maven은 Maven 프로젝트에서 해당 데이터 구조 값을 지정할 때 JSON 확장 정의 파일을 생성할 수 있습니다.
- Maven을 실행하여 확장자를 빌드하고 확장 프로그램의 JAR 파일을 생성합니다.
- JAR 파일을 Fuse Online 개발 환경에 업로드하여 확장을 테스트합니다.
- Fuse Online 프로덕션 환경에 업로드한 비즈니스 동료에게 확장을 패키지하는 JAR 파일을 제공합니다. JAR 파일을 제공할 때 비즈니스 동료에게 Fuse Online 웹 인터페이스에 표시되는 것 이상으로 정보가 필요한 구성 설정에 대해 알려주십시오.
10.3.2. 확장 종류에 대한 설명
확장은 다음 중 하나를 정의합니다.
- 연결 간 통합 데이터에서 작동하는 하나 이상의 사용자 지정 단계입니다. 각 사용자 지정 단계는 하나의 작업을 수행합니다. 이는 단계 확장입니다.
- 통합 런타임에서 사용하는 라이브러리 리소스입니다. 예를 들어 라이브러리 확장은 Oracle과 같은 전용 SQL 데이터베이스에 연결하기 위한 JDBC 드라이버를 제공할 수 있습니다.
통합할 특정 애플리케이션 또는 서비스에 대한 연결을 생성하기 위한 단일 사용자 정의 커넥터입니다. 이는 커넥터 확장입니다.
참고Fuse Online에서는 OpenAPI 문서를 사용하여 REST API 클라이언트용 커넥터를 만들 수 있습니다. REST API 클라이언트 커넥터 개발을 참조하십시오.
비즈니스 통합자는 확장을 코딩하는 개발자와 요구 사항을 공유합니다. 개발자는 확장자가 포함된 .jar 파일을 제공합니다. 비즈니스 통합자는 Fuse Online에서 .jar 파일을 업로드하여 사용자 지정 커넥터, 사용자 지정 단계 또는 Fuse Online에서 사용할 수 있는 라이브러리 리소스를 만듭니다.
Fuse Online에 업로드하는 확장자 .jar 파일에는 항상 하나의 확장자가 포함되어 있습니다.
연결 간 데이터에서 작동하는 단계를 제공하는 확장을 업로드하고 사용하는 예는 AMQ to REST API 샘플 통합 튜토리얼을 참조하십시오.
10.3.3. 확장 콘텐츠 및 구조 개요
확장은 .jar 파일에 패키지로 제공되는 클래스, 종속 항목 및 리소스의 컬렉션입니다.
Fuse Online에서는 Spring Boot를 사용하여 확장을 로드합니다. 따라서 Spring Boot의 실행 가능한 JAR 형식에 따라 확장을 패키징해야 합니다. 예를 들어 ZipEntry.STORED() 메서드를 사용하여 중첩된 JAR 파일을 저장해야 합니다.
확장자를 패키지하는 .jar 파일의 구조는 다음과 같습니다.
extension.jar | +- META-INF | | | +- syndesis | | | +- syndesis-extension-definition.json 1 | +- mycompany | | | +-project | | | +-YourClasses.class 2 | +- lib 3 | +-dependency1.jar | +-dependency2.jar
10.3.4. 확장 정의 JSON 파일의 요구 사항
각 확장에는 이름, 설명, 지원되는 동작 및 종속 항목과 같은 데이터 구조의 값을 지정하여 확장을 정의하는 .json 파일이 있어야 합니다. 다음 표는 각 확장 유형에 대해 Maven이 확장 정의 JSON 파일을 생성할 수 있는지 여부와 필요한 데이터 구조를 나타냅니다.
| 확장 유형 | Maven에서 확장 정의를 생성할 수 있음 | 필수 데이터 structure |
|---|---|---|
| Java의 단계 확장 | 제공됨 |
|
| XML의 단계 확장 | 없음 |
|
| 커넥터 확장 | 없음 |
|
| 라이브러리 확장 | 없음 |
|
* 종속 항목의 사양은 엄격하게 요구되지는 않지만 실제로는 거의 항상 지정해야 하는 종속성이 있습니다.
일반적으로 확장 정의 파일에는 다음과 같은 레이아웃이 있습니다.
{
"schemaVersion": "v1",
"name": "",
"description": "",
"version": "",
"extensionId": "",
"extensionType": "",
"properties": {
},
"actions": [
],
"dependencies": [
],
}- schemaVersion 은 확장 정의 스키마의 버전을 정의합니다. 내부적으로 Syndesis는 schemaVersion 을 사용하여 확장 확장 정의를 내부 모델에 매핑하는 방법을 결정합니다. 이를 통해 이전 버전의 Syndesis에 대해 개발된 확장 기능을 최신 버전의 Syndesis에 배포할 수 있습니다.
- 확장의 이름입니다.Is the name of the extension. Fuse Online에 확장을 업로드할 때 이 이름이 표시됩니다.
- 설명은 지정할 유용한 정보입니다. Fuse Online은 이 값을 사용하지 않습니다.
- 버전은 확장 업데이트를 구분하는 데 도움이 되는 편의를 위한 것입니다. Fuse Online은 이 값을 사용하지 않습니다.
- extensionId 는 확장에 대한 고유한 ID를 정의합니다. 이는 최소한 통합 환경에서 고유해야 합니다.
extensionType 은 확장이 제공하는 통합에 해당합니다. Syndesis 버전 1.3부터 다음과 같은 확장 유형이 지원됩니다.
-
단계 -
커넥터 -
라이브러리
-
커넥터 확장의 최상위 수준에 있는 속성이 필요합니다. Fuse Online 사용자가 커넥터를 선택하여 연결을 만들 때 표시되는 Fuse Online을 제어합니다. 이 속성 개체에는 연결을 만들기 위한 각 폼 컨트롤의 속성 세트가 포함되어 있습니다.This
propertiesobject contains a set of properties for each form control for creating a connection. 예를 들면 다음과 같습니다."myControlName": { "deprecated": true|false, "description": "", "displayName": "", "group": "", "kind": "", "label": "", "required": true|false, "secret": true|false, "javaType": "", "type": "", "defaultValue": "", "enum": { } }커넥터 확장에서 중첩된
속성오브젝트는 연결 작업을 구성하기 위한 HTML 양식 제어를 정의합니다. 단계 확장에서 작업 개체에는 속성 개체가 포함되어 있습니다.In step extensions, theactionsobject contains apropertiesobject.properties오브젝트는 단계 구성을 위한 각 양식 컨트롤의 속성 세트를 정의합니다. 사용자 인터페이스 속성에 대한 설명도 참조하십시오.작업은 커넥터가 수행할 수 있는 작업 또는 연결 간 단계에서 수행할 수 있는 작업을 정의합니다. 커넥터 및 단계 확장만 지정한 작업을 사용합니다. 작업 사양의 형식은 다음과 같습니다.
{ "id": "", "name": "", "description": "", "actionType": "step|connector", "descriptor": { } }- ID 는 작업의 고유 ID입니다. 이는 최소한 통합 환경 내에서 고유해야 합니다.
- name 은 Fuse Online에 표시되는 작업 이름입니다. 통합자는 이 값을 연결 동작의 이름 또는 연결 간 통합 데이터에서 작동하는 단계의 이름으로 확인합니다.
- 설명은 Fuse Online에 표시되는 동작 설명입니다. 이 필드를 사용하여 통합자가 해당 작업이 수행하는 작업을 이해하는 데 도움이 됩니다.
- actionType 은 연결이 연결인지 또는 연결 간 단계에서 작업을 수행할지 여부를 나타냅니다.
-
설명자 는
kind,entrypoint,inputDataType,outputDatatype등과 같은 중첩 특성을 지정합니다.
종속성 은 이 확장에서 Fuse Online이 제공하는 데 필요한 리소스를 정의합니다.
종속성을 다음과 같이 정의합니다.
{ "type": "MAVEN", "id" : "org.apache.camel:camel-telegram:jar:2.21.0" }- type 은 종속성의 유형을 나타냅니다. MAVEN 을 지정합니다. (다른 유형은 나중에 지원될 것으로 예상됩니다.)
- ID 는 Maven GAV인 Maven 종속성의 ID입니다.
10.3.5. 사용자 인터페이스 속성에 대한 설명
커넥터 확장 및 단계 확장에서는 확장자 정의 JSON 파일 또는 Java 클래스 파일에서 사용자 인터페이스 속성을 지정합니다. 이러한 속성 설정은 Fuse Online 사용자가 연결을 만들거나, 연결 작업을 구성하거나, 확장 프로그램에서 제공하는 단계를 구성할 때 Fuse Online이 표시되는 HTML 양식 컨트롤을 정의합니다.
Fuse Online 콘솔의 확장 사용자 인터페이스에 표시할 각 양식 컨트롤의 속성을 지정해야 합니다. 각 폼 컨트롤에 대해 임의의 순서로 일부 또는 모든 속성을 지정합니다.For each form control, specify some or all properties in any order.
사용자 인터페이스 속성 사양의 예
IRC 커넥터의 일부인 JSON 파일에서 최상위 속성 오브젝트는 Fuse Online 사용자가 IRC 커넥터를 선택하여 연결을 생성한 후 표시되는 HTML 양식 컨트롤을 정의합니다. 세 가지 양식 제어에 대한 속성 정의에는 hostname,password, port 세 가지 유형이 있습니다.
"properties": {
"hostname": {
"description": "IRC Server hostname",
"displayName": "Hostname",
"labelHint": "Hostname of the IRC server to connect to",
"order": "1",
"required": true,
"secret": false,
"type": "string"
},
"password": {
"description": "IRC Server password",
"displayName": "Password",
"labelHint": "Required if IRC server requires it to join",
"order": "3",
"required": false,
"secret": true,
"type": "string"
},
"port": {
"description": "IRC Server port",
"displayName": "Port",
"labelHint": "Port of the IRC server to connect to",
"order": "2",
"required": true,
"secret": false,
"tags": [],
"type": "int"
}
},이러한 속성 사양을 기반으로 Fuse Online 사용자가 IRC 커넥터를 선택할 때 Fuse Online에 다음과 같은 대화 상자가 표시됩니다. 사용자가 두 개의 필수 필드에 값을 입력하고 Next 를 클릭하면 Fuse Online에서 Fuse Online 사용자가 입력하는 값으로 구성된 IRC 연결을 생성합니다.
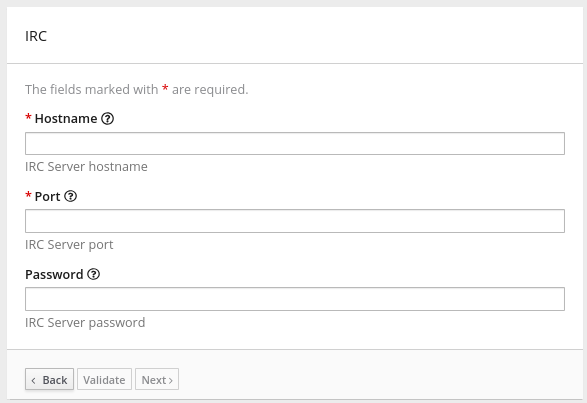
확장 정의 JSON 파일의 속성 오브젝트 정보
커넥터 확장에서 다음을 수행합니다.
-
최상위
속성개체가 필요합니다. Fuse Online 사용자가 커넥터를 선택하여 연결을 만들 때 표시되는 Fuse Online을 제어합니다. 이 속성 개체에는 연결을 만들기 위한 각 폼 컨트롤의 속성 세트가 포함되어 있습니다.Thispropertiesobject contains a set of properties for each form control for creating a connection. -
actions오브젝트에는 각 작업에 대한속성개체가 있습니다. 이러한속성 개체 각각에는 해당 작업을 구성하기 위한 각 양식 컨트롤의 속성 세트가 있습니다.
단계 확장에서 actions 오브젝트에는 속성 개체가 포함되어 있습니다. properties 오브젝트는 단계 구성을 위한 각 양식 컨트롤의 속성 세트를 정의합니다. JSON 계층 구조는 다음과 같습니다.
"actions": [
{
...
"propertyDefinitionSteps": [
{
...
"properties":
{
"control-ONE": {
"type": "string",
"displayName": "Topic Name",
"order": "2",
...,
}
"control-TWO": {
"type": "boolean",
"displayName": "Urgent",
"order": "3",
...
}
"control-THREE": {
"type": "textarea",
"displayName": "Comment",
"order": "1",
...,
}
} } ]Java 파일의 사용자 인터페이스 속성 정보
Java 파일에서 사용자 인터페이스 양식 제어를 정의하려면 연결, 작업 또는 단계의 사용자 구성을 정의하는 각 클래스 파일에서 io.syndesis.extension.api.annotations.ConfigurationProperty 를 가져옵니다. Fuse Online 콘솔이 표시할 각 양식 제어에 대해 @ConfigurationProperty 주석 뒤에 속성 목록을 지정합니다. 지정할 수 있는 속성에 대한 자세한 내용은 이 섹션의 끝에 있는 사용자 인터페이스 속성 참조 테이블을 참조하십시오.
다음 코드에서는 하나의 양식 컨트롤에 대한 속성 정의를 보여줍니다. 이 코드는 RouteBuilder 를 사용하여 Camel 경로를 개발하는 예입니다.
public class LogAction extends RouteBuilder {
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")다음 코드에서는 두 개의 컨트롤에 대한 속성 정의를 보여줍니다. 이 코드는 Syndesis Step API 사용 예의 예입니다.
@Action(id = "split", name = "Split", description = "Split your exchange")
public class SplitAction implements Step {
@ConfigurationProperty(
name = "language",
displayName = "Language",
description = "The language used for the expression")
private String language;
@ConfigurationProperty(
name = "expression",
displayName = "Expression",
description = "The expression used to split the exchange
private String language;제어 양식 입력 유형에 대한 설명
각 HTML 양식 컨트롤의 속성 집합에서 type 속성은 Fuse Online에서 표시하는 폼 컨트롤의 입력 유형을 정의합니다. HTML 양식 입력 유형에 대한 자세한 내용은 https://www.w3schools.com/html/html_form_input_types.asp 을 참조하십시오.
다음 표에는 Fuse Online 양식 제어에 사용 가능한 입력 유형이 나열되어 있습니다. 컨트롤의 속성 집합에서 알 수 없는 유형 값을 지정하면 Fuse Online에서 한 줄의 텍스트를 허용하는 입력 필드를 표시합니다. 기본값은 "type": "text" 입니다.
속성 유형 값 | HTML | Fuse Online 디스플레이 |
|---|---|---|
|
|
| 사용자가 선택할 수 있거나 선택할 수 없는 확인란입니다. |
|
|
Fuse Online 사용자가 시간 단위(밀리초, 초, 분, 시간 또는 일)를 선택할 수 있는 사용자 지정 컨트롤입니다. 또한 사용자가 번호를 입력하고 Fuse Online은 밀리초를 반환합니다. 예: | |
|
|
| 이 필드는 Fuse Online 콘솔에 표시되지 않습니다. 다른 속성을 사용하여 이 필드와 연결된 데이터(예: 어떤 종류의 텍스트 데이터)를 지정할 수 있습니다. Fuse Online 사용자는 이 데이터를 보거나 수정할 수 없지만 사용자가 Fuse Online 페이지에 대해 View Source 를 선택하면 숨겨진 필드가 소스 화면에 표시됩니다. 따라서 보안 목적으로 숨겨진 필드를 사용하지 마십시오. |
|
|
| 번호를 허용하는 입력 필드입니다. |
|
|
| Fuse Online에서 사용자가 입력한 문자를 마스킹하는 입력 필드(일반적으로 별표)입니다. |
|
|
< |
폼 컨트롤의 enum 속성에서 지정하는 각 레이블/값 쌍에 대한 항목이 포함된 드롭다운 목록입니다.A drop-down list with an entry for each label/value pair that you specify in the form control's |
|
|
| 한 줄의 텍스트를 허용하는 입력 필드입니다. |
|
|
| 텍스트 영역 요소가 사용됨 |
컨트롤 양식 사용자 인터페이스 속성에 대한 설명
커넥터 또는 단계 확장에서는 Fuse Online 콘솔에 표시되는 각 HTML 양식 컨트롤에 대해 다음 표에 설명된 속성 중 하나 이상을 지정할 수 있습니다. HTML 양식 입력 유형에 대한 자세한 내용은 https://www.w3schools.com/html/html_form_input_types.asp 을 참조하십시오.
| 속성 이름 | 유형 | 설명 |
|---|---|---|
|
| string | Fuse Online에서 표시하는 양식 컨트롤의 종류를 제어합니다. 자세한 내용은 이전 표를 참조하십시오. |
|
| 숫자 |
|
|
| string |
설정하면 값이 form 컨트롤 요소의 HTML |
|
| array |
|
|
|
속성의 값에 따라 달라집니다.Depending according to the value of the |
Fuse Online은 처음에 양식 필드에 이 값을 표시합니다. |
|
| string | 설정된 경우 Fuse Online은 양식 제어 아래에 이 값을 표시합니다. 일반적으로 이 메시지는 제어에 대한 짧고 유용한 메시지입니다. |
|
| string | Fuse Online에서 이 값을 표시합니다. |
|
| array |
설정된 경우 Fuse Online은 |
|
| string |
설정하면 표시 이름 옆에 |
|
| 숫자 |
|
|
| 숫자 |
|
|
| 부울 |
|
|
| 숫자 |
Fuse Online 콘솔의 제어 순서를 결정합니다. Fuse Online에서는 오름차순, 즉 |
|
| string | 설정된 경우 Fuse Online은 사용자가 예상 입력을 이해하는 데 도움이 되도록 입력 필드에 이 값을 hazed font에 표시합니다. |
|
| 부울 |
|
|
| 숫자 |
형식 속성 값이 |
|
| 부울 |
지정된 경우, Fuse Online은 아직 설정이 아닌 경우 컨트롤의 |
10.3.6. 확장을 지원하는 Maven 플러그인에 대한 설명
extension-maven-plugin 은 확장을 유효한 Spring Boot 모듈로 패키징하여 확장 개발을 지원합니다. Java에서 구현하는 단계 확장의 경우 이 플러그인은 확장 정의 JSON 파일을 생성할 수 있습니다.
Maven 프로젝트의 pom.xml 파일에 다음 플러그인 선언을 추가합니다.
<plugin>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-maven-plugin</artifactId>
<version>${syndesis.version}</version>
<executions>
<execution>
<goals>
<goal>generate-metadata</goal>
<goal>repackage-extension</goal>
</goals>
</execution>
</executions>
</plugin>
extension-maven-plugin 은 다음 목표를 정의합니다.
generate-metadata 는 다음과 같이 생성된 JAR 파일에 있을 JSON 확장 정의 파일을 생성합니다.
Maven은
META-INF/syndesis/syndesis-extension-definition.json파일에 있는 데이터 구조 사양으로 시작합니다.XML로 코딩하는 경우 확장 정의 JSON 파일을 직접 정의해야 하며 필요한 모든 데이터 구조를 지정해야 합니다.
커넥터 또는 라이브러리 확장을 개발하는 경우 확장 정의 JSON 파일을 직접 정의해야 하며 필요한 모든 데이터 구조를 지정해야 합니다.
Java에서 단계 확장을 개발하는 경우 다음을 수행할 수 있습니다.
- 확장자 정의 JSON 파일을 직접 생성합니다.
- Java 코드에서 필요한 모든 데이터 구조를 정의하는 주석을 지정합니다. 확장 정의 JSON 파일을 생성하지 않습니다.
- 확장 정의 JSON 파일을 생성하고 일부 데이터 구조를 지정합니다.
- Java에서 개발하는 단계 확장의 경우 Maven은 코드 주석에서 누락된 사양을 가져옵니다.
-
Maven은 제공된 범위와
extension-bom을 통해 관리되는 종속성을 지정하는 종속 항목 목록을 추가합니다.
확장을 다시 패키징 하여 패키지합니다.
-
확장을 통해 관리되지 않는 종속성 및 관련 전달 종속성은생성된 JAR의lib폴더에 있습니다. -
라이브러리 확장의 경우 범위가 생성된 JAR의
lib폴더에 있는 종속 항목입니다.
-
예를 들어 Maven 프로젝트에 다음 pom.xml 파일이 있다고 가정합니다.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.company</groupId>
<artifactId>my-extension</artifactId>
<version>1.0.0</version>
<name>MyExtension</name>
<description>A Sample Extension</description>
<packaging>jar</packaging>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-bom</artifactId>
<version>1.3.10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-api</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.github.lalyos</groupId>
<artifactId>jfiglet</artifactId>
<version>0.0.8</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-maven-plugin</artifactId>
<version>1.3.10</version>
<executions>
<execution>
<goals>
<goal>generate-metadata</goal>
<goal>repackage-extension</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
이 pom.xml 파일을 기반으로 생성된 확장 정의 JSON 파일은 다음과 같습니다.
{
"name": "MyExtension",
"description": "A Sample Extension",
"extensionId": "com.company:my-extension",
"version": "1.0.0",
"dependencies": [ {
"type": "MAVEN",
"id": "io.syndesis.extension:extension-api:jar:1.3.10"
} ],
"extensionType": "Libraries",
"schemaVersion": "v1"
}생성된 아카이브에는 이 구조와 콘텐츠가 있습니다.
my-extension-1.0.0.jar
|
+- lib
| |
| + jfiglet-0.0.8.jar
|
+- META-INF
|
+- MANIFEST.MF
|
+- syndesis
|
+- syndesis-extension-definition.json10.3.7. 확장에서 데이터 도형을 지정하는 방법
데이터 셰이프는 데이터 매퍼에서 사용할 데이터 유형 메타데이터를 보유합니다.A data shape holds data type metadata for use by the data mapper. 데이터 매퍼는 이 메타데이터를 데이터 매퍼 사용자 인터페이스에서 소스 및 대상 데이터 필드를 표시하는 데 사용하는 내부 문서로 변환합니다. 커넥터 또는 사용자 지정 단계에 대한 확장 정의 JSON 파일에서 각 작업 사양은 입력 데이터 도형(inputDataShape) 및 출력 데이터 도형(outputDataShape)을 정의합니다.
확장을 개발할 때는 데이터 매퍼가 소스 및 대상 필드를 올바르게 처리하고 표시할 수 있는 데이터 셰이프 속성을 지정해야 합니다. 다음 데이터 셰이프 속성은 데이터 매퍼 동작에 영향을 미칩니다.
-
kind -
type -
사양 -
name -
description
kind 속성 정보
데이터 셰이프 종류 속성은 DataShapeKinds 열거로 표시됩니다. kind 속성에 가능한 값은 다음과 같습니다.
Java는 데이터 유형이 Java 클래스로 표시됨을 나타냅니다.type속성에 정규화된 클래스 이름을 지정하여"kind": "java"선언을 따릅니다. 예를 들면 다음과 같습니다."outputDataShape": { "kind": "java", "type": "org.apache.camel.component.telegram.model.IncomingMessage" },JSON-schema는 데이터 유형이 JSON 스키마로 표시됨을 나타냅니다.kind가json-schema로 설정된 경우 JSON 스키마를 데이터 셰이프의specification속성 값으로 지정합니다. 예를 들면 다음과 같습니다."inputDataShape": { "description": "Person data", "kind": "json-schema", "name": "Person", "specification": "{\"$schema\":\"http://json-schema.org/draft-04/schema#\",\"title\":\"Person\",\"type\":\"object\",\"properties\":{\"firstName\":{...}}}" }SAP Concur 커넥터의 코드에는 JSON 스키마로 지정된 데이터 도형의 예가 포함되어 있습니다.
JSON-instance는 데이터 유형이 JSON 인스턴스로 표시됨을 나타냅니다.kind가json-instance로 설정된 경우 JSON 인스턴스를 데이터 셰이프의specification속성 값으로 지정합니다. 예를 들면 다음과 같습니다."inputDataShape": { "description": "Person data", "kind": "json-instance", "name": "Person", "specification": "{\"firstName\":\"John\",...}" }XML-schema는 데이터 유형이 XML 스키마로 표시됨을 나타냅니다.kind가xml-schema로 설정된 경우 XML 스키마를 데이터 셰이프의specification속성 값으로 지정합니다. 예를 들면 다음과 같습니다."inputDataShape": { "description": "Person data", "kind": "xml-schema", "name": "Person", "specification": "<?xml version=\"1.0\" encoding=\"UTF-8\" ?><xs:schema xmlns:xs=\"http://www.w3.org/2001/XMLSchema\">...</xs:schema>" }XML-instance는 데이터 유형이 XML 인스턴스로 표시됨을 나타냅니다.kind가xml-instance로 설정된 경우 XML 인스턴스를 데이터 셰이프의specification속성 값으로 지정합니다. 예를 들면 다음과 같습니다."inputDataShape": { "description": "Person data", "kind": "xml-instance", "name": "Person", "specification": "<?xml version=\"1.0\" encoding=\"UTF-8\" ?><Person><firstName>Jane</firstName></Person>" }any는 데이터 유형이 구조화되지 않음을 나타냅니다. 예를 들어 바이트 배열 또는 무료 형식 텍스트일 수 있습니다. 데이터 매퍼는종류속성이임의의로 설정된 경우 데이터 모양을 무시합니다. 즉, 데이터는 데이터 매퍼에 표시되지 않으므로 이 데이터에 또는 이 데이터에 필드를 매핑할 수 없습니다.그러나 사용자 지정 커넥터의 경우
kind속성이 로 설정된경우사용자 지정 커넥터에서 만든 연결을 구성할 때 Fuse Online에서 입력 및/또는 출력 데이터 유형을 지정하라는 메시지를 표시합니다. 이는 통합에 연결을 추가할 때 발생합니다. 데이터 셰이프 스키마의 종류, 지정한 스키마 종류에 대한 적절한 문서 및 데이터 유형의 이름을 지정할 수 있습니다.-
none은 데이터 유형이 없음을 나타냅니다. 입력 데이터 셰이프의 경우 연결 또는 단계가 데이터를 읽지 않음을 나타냅니다. 출력 데이터 셰이프의 경우 연결 또는 단계가 데이터를 수정하지 않음을 나타냅니다.For an output data shape, this indicates that the connection or step does not modify data. 예를 들어 입력 메시지 본문이 출력 메시지 본문으로 전송되는 경우kind속성을none으로 설정하면 데이터가 전달됨을 나타냅니다. 데이터 매퍼는kind가none으로 설정된 경우 데이터 셰이프를 무시합니다. 즉, 데이터는 데이터 매퍼에 표시되지 않으므로 이 데이터에 또는 이 데이터에 필드를 매핑할 수 없습니다.
유형 속성 정보
kind 속성 값이 java 이면 "kind": "java" 선언 뒤에 정규화된 Java 클래스 이름을 지정하는 형식 선언이 옵니다. 예를 들면 다음과 같습니다.
"outputDataShape": {
"kind": "java",
"type": "org.apache.camel.component.telegram.model.IncomingMessage"
},
kind 속성이 java 이외의 것으로 설정되면 type 속성에 대한 모든 설정이 무시됩니다.
사양 속성 정보
kind 속성 설정은 다음 표에 표시된 대로 specification 속성의 설정을 결정합니다.
kind 속성 설정 | 사양 속성 설정 |
|---|---|
|
| Java 검사 결과
Java에서 작성하는 각 확장에 대해
미리 알림으로 Java로 작성된 단계 확장을 위해 |
|
| 실제 JSON 스키마 문서. 이 설정은 문서에 대한 참조일 수 없으며 JSON 스키마는 참조를 통해 다른 JSON 스키마 문서를 가리킬 수 없습니다. |
|
| 예제 데이터가 포함된 실제 JSON 문서입니다. 데이터 매퍼는 예제 데이터에서 데이터 유형을 파생합니다. 이 설정은 문서에 대한 참조일 수 없습니다. |
|
| 실제 XML 스키마 문서. 이 설정은 문서에 대한 참조일 수 없으며 XML 스키마는 참조를 통해 다른 XML 스키마 문서를 가리킬 수 없습니다. |
|
| 실제 XML 인스턴스 문서. 이 설정은 문서에 대한 참조일 수 없습니다. |
|
|
|
|
|
|
name 속성 정보
data shape name 속성은 사람이 읽을 수 있는 데이터 유형의 이름을 지정합니다. 데이터 매퍼는 이 이름을 사용자 인터페이스에 데이터 필드의 레이블로 표시합니다. 다음 이미지에서 twitter focus tion은 이름 속성의 값을 볼 수 있는 예입니다.
이 이름은 Fuse Online 흐름 시각화의 데이터 유형 지표에도 나타납니다.
description 속성 정보
데이터 셰이프 설명 속성은 커서가 데이터 매퍼 사용자 인터페이스에서 데이터 유형 이름을 가리킬 때 툴팁으로 표시되는 텍스트를 지정합니다.
10.3.8. 단계 확장 개발의 예
단계 확장은 하나 이상의 사용자 지정 단계를 구현합니다. 각 사용자 지정 단계는 연결 간 통합 데이터를 처리하기 위한 하나의 작업을 구현합니다. 다음 예제에서는 단계 확장을 개발하는 대안을 보여줍니다.
Syndesis는 syndesis-extension-plugin 과 함께 사용할 수 있는 사용자 지정 Java 주석을 제공합니다. Java에서 단계 확장 또는 커넥터 확장을 구현하는 경우 Maven을 활성화하여 확장 정의 JSON 파일에 작업 정의를 추가할 수 있는 주석을 지정할 수 있습니다. 주석 처리를 활성화하려면 Maven 프로젝트에 다음 종속성을 추가합니다.
<dependency> <groupId>io.syndesis.extension</groupId> <artifactId>extension-annotation-processor</artifactId> <optional>true</optional> </dependency>
Spring Boot는 Camel 컨텍스트에 빈을 삽입하는 통합 런타임이므로 표준 Spring Boot 사례를 따라야 합니다. 예를 들어 자동 구성 클래스를 생성하고 여기에 빈을 생성합니다. 그러나 기본 동작은 확장 코드에 패키지 스캔이 적용되지 않는다는 것입니다. 따라서 단계 확장자에 META-INF/spring.factories 파일을 생성하고 채워야 합니다.
10.3.8.1. XML 조각을 사용하여 Camel 경로를 개발하는 예
사용자 지정 단계를 개발하려면 직접 와 같은 입력이 있는 Camel 경로인 XML 조각으로 작업을 구현할 수 있습니다. Syndesis 런타임은 다른 Camel 경로를 호출하는 것과 동일한 방식으로 이 경로를 호출합니다.
예를 들어 선택적 접두사를 사용하여 메시지 본문을 기록하는 단계를 생성한다고 가정합니다. 다음 XML은 이 작업을 수행하는 Camel 경로를 정의합니다.
<?xml version="1.0" encoding="UTF-8"?>
<routes xmlns="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://camel.apache.org/schema/spring
http://camel.apache.org/schema/spring/camel-spring.xsd">
<route id="log-body-with-prefix">
<from uri="direct:log"/>
<choice>
<when>
<simple>${header.prefix} != ''</simple>
<log message="${header.prefix} ${body}"/>
</when>
<otherwise>
<log message="Output ${body}"/>
</otherwise>
</choice>
</route>
</routes>
XML로 확장을 개발할 때는 확장자 정의 JSON 파일을 직접 생성해야 합니다. 이 XML 조각의 경우 src/main/resources/META-INF/syndesis/syndesis-extension-definition.json 파일은 다음과 같이 작업을 정의할 수 있습니다.
{
"actionType": "step",
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"resource": "classpath:log-body-action.xml", 3
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 4
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string"
}
}
} ]
}
}- 1
- 작업 유형은
ENDPOINT로 설정됩니다. 런타임은 Camel 엔드포인트를 호출하여 이 사용자 지정 단계에서 제공하는 작업을 실행합니다. - 2
- 호출할 Camel 끝점은
direct:log입니다. 경로의from사양입니다. - 3
- XML 조각의 위치입니다.
- 4
- 이러한 속성은 이 사용자 지정 단계에서 정의한 작업이 통합 단계에 이 단계를 추가하는 통합업체에 노출되는 속성입니다. Fuse Online에서는 사용자 인터페이스에서 지정하는 각 값이 속성 이름과 동일한 메시지 헤더에 매핑됩니다. 이 예제에서 통합자는 로그 접두사 표시 이름이 있는 하나의 입력 필드를 볼 수 있습니다. 자세한 내용은 사용자 인터페이스 속성에 대한 설명을 참조하십시오.
Syndesis는 전체 Camel XML 구성을 지원하지 않습니다. Syndesis는 <routes> 태그만 지원합니다.
10.3.8.2. RouteBuilder를 사용하여 Camel 경로 개발 예
RouteBuilder 클래스를 지원하는 Camel 경로로 작업을 개발하여 사용자 정의 단계를 구현할 수 있습니다. 이러한 경로에는 직접 과 같은 입력이 있습니다. Syndesis는 다른 Camel 경로를 호출하는 것과 동일한 방식으로 이 경로를 호출합니다.
선택적 접두사를 사용하여 메시지 본문을 기록하는 단계를 생성하는 예제를 구현하려면 다음과 같이 작성할 수 있습니다.
import org.apache.camel.builder.RouteBuilder; import io.syndesis.extension.api.annotations.Action; import io.syndesis.extension.api.annotations.ConfigurationProperty; @Action( 1 id = "log-body-with-prefix", name = "Log body with prefix", description = "A simple body log with a prefix", entrypoint = "direct:log") public class LogAction extends RouteBuilder { @ConfigurationProperty( 2 name = "prefix", description = "The Log body prefix message", displayName = "Log Prefix", type = "string") private String prefix; @Override public void configure() throws Exception { from("direct::start") 3 .choice() .when(simple("${header.prefix} != ''")) .log("${header.prefix} ${body}") .otherwise() .log("Output ${body}") .endChoice(); } }
- 1
@Action주석은 작업 정의를 나타냅니다.- 2
@ConfigurationProperty주석은 사용자 인터페이스 양식 제어의 정의를 나타냅니다. 자세한 내용은 사용자 인터페이스 속성 설명을 참조하십시오.- 3
- 이것이 action implementation입니다.
이 Java 코드는 Syndesis 주석을 사용합니다. 즉, extension-maven-plugin 이 작업 정의를 자동으로 생성할 수 있습니다. 확장 정의 JSON 파일에서 작업 정의는 다음과 같습니다.
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"resource": "class:io.syndesis.extension.log.LogAction", 3
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 4
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 작업 유형은
ENDPOINT입니다. 런타임은 Camel 엔드포인트를 호출하여 이 단계에서 구현하는 작업을 실행합니다. - 2
- 호출할 Camel 끝점입니다. 경로의
from사양입니다. - 3
RoutesBuilder를 구현하는 클래스입니다.- 4
- 이러한 속성은 이 사용자 지정 단계에서 정의한 작업이 통합 단계에 이 단계를 추가하는 통합업체에 노출되는 속성입니다. Fuse Online에서는 사용자 인터페이스에서 지정하는 각 값이 속성 이름과 동일한 메시지 헤더에 매핑됩니다. 이 예제에서 통합자는 로그 접두사 표시 이름이 있는 하나의 입력 필드를 볼 수 있습니다. 자세한 내용은 사용자 인터페이스 속성에 대한 설명을 참조하십시오.
10.3.8.3. RouteBuilder 및 Spring Boot를 사용하여 Camel 경로를 개발하는 예
RouteBuilder 클래스 및 Spring Boot를 지원하는 Camel 경로로 작업을 개발하여 사용자 정의 단계를 구현할 수 있습니다. 이 예에서 Spring Boot는 Camel 컨텍스트에서 RouteBuilder 오브젝트를 등록하는 기능입니다. Syndesis는 다른 Camel 경로를 호출하는 것과 동일한 방식으로 이 경로를 호출합니다.
선택적 접두사를 사용하여 메시지 본문을 기록하는 단계를 생성하는 예제를 구현하려면 다음과 같이 작성할 수 있습니다.
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ActionsConfiguration {
@Action( 1
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix",
entrypoint = "direct:log")
@ConfigurationProperty( 2
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
@Bean 3
public RouteBuilder logBodyWithprefix() {
return new RouteBuilder() {
@Override
public void configure() throws Exception {
from("direct::start") 4
.choice()
.when(simple("${header.prefix} != ''"))
.log("${header.prefix} ${body}")
.otherwise()
.log("Output ${body}")
.endChoice();
}
};
}
}- 1
@Action주석은 작업 정의를 나타냅니다.- 2
@ConfigurationProperty주석은 사용자 인터페이스 양식 제어의 정의를 나타냅니다. 자세한 내용은 사용자 인터페이스 속성 설명을 참조하십시오.- 3
RouteBuilder오브젝트를 8080으로 등록합니다.- 4
- 이것이 action implementation입니다.
이 Java 코드는 Syndesis 주석을 사용합니다. 즉, extension-maven-plugin 이 작업 정의를 자동으로 생성할 수 있습니다. 확장 정의 JSON 파일에서 작업 정의는 다음과 같습니다.
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 3
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 작업 유형은
ENDPOINT입니다. 런타임은 Camel 엔드포인트를 호출하여 이 단계에서 구현하는 작업을 실행합니다. - 2
- 호출할 Camel 끝점입니다. 경로의
from사양입니다. - 3
- 이러한 속성은 이 사용자 지정 단계에서 정의한 작업이 통합 단계에 이 단계를 추가하는 통합업체에 노출되는 속성입니다. Fuse Online에서는 사용자 인터페이스에서 지정하는 각 값이 속성 이름과 동일한 메시지 헤더에 매핑됩니다. 이 예제에서 통합자는 로그 접두사 표시 이름이 있는 하나의 입력 필드를 볼 수 있습니다. 자세한 내용은 사용자 인터페이스 속성에 대한 설명을 참조하십시오.
Spring Boot로 구성 클래스를 검색할 수 있도록 하려면 META-INF/spring.factories 라는 파일에 나열해야 합니다. 예를 들면 다음과 같습니다.
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.company.ActionsConfiguration
Spring Boot를 사용하면 결국 구성 클래스에 등록한 모든 Cryostat를 Camel 컨텍스트에 사용할 수 있습니다. 자세한 내용은 자체 자동 구성 생성에 대한 Spring Boot 설명서를 참조하십시오.
10.3.8.4. Camel 빈 사용 예
Camel 8080 프로세서로 작업을 개발하여 사용자 지정 단계를 구현할 수 있습니다. 선택적 접두사를 사용하여 메시지 본문을 기록하는 단계를 생성하는 예제를 구현하려면 다음과 같이 작성할 수 있습니다.
import org.apache.camel.Body;
import org.apache.camel.Handler;
import org.apache.camel.Header;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
@Action(
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix")
public class LogAction {
private static final Logger LOGGER = LoggerFactory.getLogger(LogAction.class);
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
private String prefix;
@Handler 1
public void process(@Header("prefix") String prefix, @Body Object body) {
if (prefix == null) {
LOGGER.info("Output {}", body);
} else {
LOGGER.info("{} {}", prefix, body);
}
}
}- 1
- 작업을 구현하는 함수입니다.
이 Java 코드는 Syndesis 주석을 사용합니다. 즉, extension-maven-plugin 이 작업 정의를 자동으로 생성할 수 있습니다. 확장 정의 JSON 파일에서 작업 정의는 다음과 같습니다.
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "BEAN", 1
"entrypoint": "io.syndesis.extension.log.LogAction::process", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": {
"prefix": { 3
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 작업 유형은
BEAN입니다. 런타임은 이 사용자 지정 단계에서 작업을 실행하기 위해 Camel 8080 프로세서를 호출합니다. - 2
- 호출할 Camel 빈입니다.
- 3
- 이러한 속성은 이 사용자 지정 단계에서 정의한 작업이 통합 단계에 이 단계를 추가하는 통합업체에 노출되는 속성입니다. Fuse Online에서는 사용자 인터페이스에서 지정하는 각 값이 속성 이름과 동일한 메시지 헤더에 매핑됩니다. 이 예제에서 통합자는 로그 접두사 표시 이름이 있는 하나의 입력 필드를 볼 수 있습니다. 자세한 내용은 사용자 인터페이스 속성에 대한 설명을 참조하십시오.
빈을 사용하면 교환 헤더에서 사용자 속성을 검색하는 대신 사용자 속성을 빈에 삽입하는 것이 편리할 수 있습니다. 이렇게 하려면 삽입하려는 속성에 대한 getter 및 setter 메서드를 구현합니다. 작업 구현은 다음과 같습니다.
import org.apache.camel.Body;
import org.apache.camel.Handler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
@Action(
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix")
public class LogAction {
private static final Logger LOGGER = LoggerFactory.getLogger(LogAction.class);
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
private String prefix;
public void setPrefix(String prefix) { 1
this.prefix = prefix;
}
public String getPrefix() { 2
return prefix;
}
@Handler
public void process(@Body Object body) {
if (this.prefix == null) {
LOGGER.info("Output {}", body);
} else {
LOGGER.info("{} {}", this.prefix, body);
}
}
}10.3.8.5. 통합 단계 API 사용 예
통합 단계 API를 사용하여 사용자 지정 단계를 구현할 수 있습니다. 이를 통해 런타임 경로 생성과 상호 작용할 수 있습니다. ProcessorDefinition 클래스에서 제공하는 모든 메서드를 사용할 수 있으며 더 복잡한 경로를 생성할 수 있습니다. Syndesis API에 대한 정보는 http://javadoc.io/doc/io.syndesis.extension/extension-api.
다음은 통합 단계 API를 사용하여 분할 작업을 구현하는 단계 확장의 예입니다.
import java.util.Map;
import java.util.Optional;
import io.syndesis.extension.api.Step;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
import org.apache.camel.CamelContext;
import org.apache.camel.model.ProcessorDefinition;
import org.apache.camel.util.ObjectHelper;
import org.apache.camel.Expression;
import org.apache.camel.builder.Builder;
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.processor.aggregate.UseOriginalAggregationStrategy;
import org.apache.camel.spi.Language;
@Action(id = "split", name = "Split", description = "Split your exchange")
public class SplitAction implements Step {
@ConfigurationProperty(
name = "language",
displayName = "Language",
description = "The language used for the expression")
private String language;
@ConfigurationProperty(
name = "expression",
displayName = "Expression",
description = "The expression used to split the exchange")
private String expression;
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
public String getExpression() {
return expression;
}
public void setExpression(String expression) {
this.expression = expression;
}
@Override
public Optional<ProcessorDefinition> configure(
CamelContext context,
ProcessorDefinition route,
Map<String, Object> parameters) { 1
String languageName = language;
String expressionDefinition = expression;
if (ObjectHelper.isEmpty(languageName) && ObjectHelper.isEmpty(expressionDefinition)) {
route = route.split(Builder.body());
} else if (ObjectHelper.isNotEmpty(expressionDefinition)) {
if (ObjectHelper.isEmpty(languageName)) {
languageName = "simple";
}
final Language splitLanguage = context.resolveLanguage(languageName);
final Expression splitExpression = splitLanguage.createExpression(expressionDefinition);
final AggregationStrategy aggreationStrategy = new UseOriginalAggregationStrategy(null, false);
route = route.split(splitExpression).aggregationStrategy(aggreationStrategy);
}
return Optional.of(route);
}
}- 1
- 이는 사용자 지정 단계가 수행하는 작업의 구현입니다.
이 Java 코드는 Syndesis 주석을 사용합니다. 즉, extension-maven-plugin 이 작업 정의를 자동으로 생성할 수 있습니다. 확장 정의 JSON 파일에서 작업 정의는 다음과 같습니다.
{
"id": "split",
"name": "Split",
"description": "Split your exchange",
"descriptor": {
"kind": "STEP", 1
"entrypoint": "io.syndesis.extension.split.SplitAction", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": {
"language": {
"componentProperty": false,
"deprecated": false,
"description": "The language used for the expression",
"displayName": "Language",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
},
"expression": {
"componentProperty": false,
"deprecated": false,
"description": "The expression used to split the exchange",
"displayName": "Expression",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"tags": [],
"actionType": "step"
}추가 리소스
사용자 인터페이스 속성에 대한 자세한 내용은 사용자 인터페이스 속성에 대한 설명을 참조하십시오.
10.3.9. 커넥터 확장 개발 예
Fuse Online에서 통합에서 연결하려는 애플리케이션 또는 서비스에 대한 커넥터를 제공하지 않는 경우 숙련된 개발자는 Fuse Online에 새 커넥터를 제공하는 확장을 코딩할 수 있습니다. 이 문서에서는 커넥터 확장 개발을 위한 소개를 제공합니다. 커넥터 개발에 대한 자세한 내용은 Syndesis 커뮤니티 사이트에서 통합 커넥터 개발을 참조하십시오.
커넥터 확장의 경우 Java 코드에서 확장자 정의 JSON 파일을 자동으로 생성할 수 없습니다.
커넥터는 기본적으로 Camel 구성 요소의 프록시입니다. 커넥터는 기본 구성 요소를 구성하고 확장 정의 및 Fuse Online 웹 인터페이스에서 수집하는 사용자 제공 옵션에 따라 끝점을 생성합니다.
커넥터 확장 정의는 다음과 같은 추가 데이터 구조를 사용하여 단계 확장에 필요한 확장 정의를 확장합니다.
componentScheme커넥터가 사용하는 Camel 구성 요소를 정의합니다. 커넥터 또는 작업에 대해
componentScheme을 설정할 수 있습니다. 커넥터와 작업에 대해componentScheme을 설정하면 작업에 대한 설정이 우선합니다.connectorCustomizersComponentProxyCustomizer 클래스를 구현하는 클래스 목록을 지정합니다. 각 클래스는 커넥터의 동작을 사용자 지정합니다. 예를 들어 클래스는 기본 구성 요소/endpoint에 적용되기 전에 속성을 조작하거나 클래스가 사전/post 엔드포인트 논리를 추가할 수 있습니다. 각 클래스에 대해 구현의 전체 클래스 이름을 지정합니다(예:
com.mycomponent.MyCustomizer). 동작 및 커넥터에 대해connectorCustomizers를 설정할 수 있습니다. 설정되어 있는 내용에 따라 Fuse Online은 커넥터에 사용자 지정기를 먼저 적용한 다음 작업에 적용됩니다.connectorFactory기본 구성 요소/endpoint를 생성 및/또는 구성하는 ComponentProxyFactory 클래스를 구현하는 클래스를 정의합니다. 구현의 전체 클래스 이름을 지정합니다. 커넥터 또는 작업에 대해
connectorFactory를 설정할 수 있습니다. 작업이 우선합니다.
Customizer 예
다음 사용자 지정기 예제에서는 개별 옵션에서 DataSource를 설정합니다.The following customizer example sets up a DataSource from individual options:
public class DataSourceCustomizer implements ComponentProxyCustomizer, CamelContextAware {
private final static Logger LOGGER = LoggerFactory.getLogger(DataSourceCustomizer.class);
private CamelContext camelContext;
@Override
public void setCamelContext(CamelContext camelContext) { 1
this.camelContext = camelContext;
}
@Override
public CamelContext getCamelContext() { 2
return this.camelContext;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
if (!options.containsKey("dataSource")) {
if (options.containsKey("user") && options.containsKey("password") && options.containsKey("url")) {
try {
BasicDataSource ds = new BasicDataSource();
consumeOption(camelContext, options, "user", String.class, ds::setUsername); 3
consumeOption(camelContext, options, "password", String.class, ds::setPassword); 4
consumeOption(camelContext, options, "url", String.class, ds::setUrl); 5
options.put("dataSource", ds);
} catch (@SuppressWarnings("PMD.AvoidCatchingGenericException") Exception e) {
throw new IllegalArgumentException(e);
}
} else {
LOGGER.debug("Not enough information provided to set-up the DataSource");
}
}
}
}속성 삽입의 예
customizer가 Java 8080 규칙을 준수하면 이전 예제의 이 버전에 표시된 것처럼 속성을 삽입할 수도 있습니다.
public class DataSourceCustomizer implements ComponentProxyCustomizer, CamelContextAware {
private final static Logger LOGGER = LoggerFactory.getLogger(DataSourceCustomizer.class);
private CamelContext camelContext;
private String userName;
private String password;
private String url;
@Override
public void setCamelContext(CamelContext camelContext) { 1
this.camelContext = camelContext;
}
@Override
public CamelContext getCamelContext() { 2
return this.camelContext;
}
public void setUserName(String userName) { 3
this.userName = userName;
}
public String getUserName() { 4
return this.userName;
}
public void setPassword(String password) { 5
this.password = password;
}
public String getPassword() { 6
return this.password;
}
public void setUrl(String url) { 7
this.url = url;
}
public String getUrl() { 8
return this.url;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
if (!options.containsKey("dataSource")) {
if (userName != null && password != null && url != null) {
try {
BasicDataSource ds = new BasicDataSource();
ds.setUserName(userName);
ds.setPassword(password);
ds.setUrl(url);
options.put("dataSource", ds);
} catch (@SuppressWarnings("PMD.AvoidCatchingGenericException") Exception e) {
throw new IllegalArgumentException(e);
}
} else {
LOGGER.debug("Not enough information provided to set-up the DataSource");
}
}
}
}사용자 지정기를 사용하여 논리 전/후 구성
이 예와 같이 사용자 지정기를 사용하여 논리 전/후를 구성할 수 있습니다.
public class AWSS3DeleteObjectCustomizer implements ComponentProxyCustomizer {
private String filenameKey;
public void setFilenameKey(String filenameKey) {
this.filenameKey = filenameKey;
}
public String getFilenameKey() {
return this.filenameKey;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
component.setBeforeProducer(this::beforeProducer);
}
public void beforeProducer(final Exchange exchange) throws IOException {
exchange.getIn().setHeader(S3Constants.S3_OPERATION, S3Operations.deleteObject);
if (filenameKey != null) {
exchange.getIn().setHeader(S3Constants.KEY, filenameKey);
}
}
}ComponentProxyComponent동작 사용자 정의
ComponentProxyFactory 클래스는 기본 구성 요소/endpoint를 생성 및/또는 구성합니다. ComponentProxyFactory 가 생성하는 ComponentProxyComponent 개체의 동작을 사용자 지정하려면 다음 메서드를 재정의할 수 있습니다.
createDelegateComponent()Syndesis는 프록시가 시작될 때 이 메서드를 호출하고, 결국
componentScheme옵션으로 정의된 스키마를 사용하여 구성 요소의 전용 인스턴스를 생성하는 데 사용됩니다.이 메서드의 기본 동작은 커넥터/작업 옵션이 구성 요소 수준에서 적용되는지 확인하는 것입니다. 엔드포인트에서 동일한 옵션을 적용할 수 없는 경우에만 이 방법은 사용자 지정 구성 요소 인스턴스를 생성하고 해당 옵션에 따라 구성합니다.
configureDelegateComponent()Syndesis는 위임된 구성 요소 인스턴스의 추가 동작을 구성하기 위해 사용자 지정 구성 요소 인스턴스가 생성된 경우에만 이 메서드를 호출합니다.
createDelegateEndpoint()Syndesis는 프록시가 끝점을 생성할 때 이 메서드를 호출하고 Camel 카탈로그 기능을 사용하여 기본적으로 엔드포인트를 생성합니다.
configureDelegateEndpoint()위임된 엔드포인트가 생성되면 Syndesis는 이 메서드를 호출하여 위임된 끝점 인스턴스의 추가 동작을 구성합니다. 예를 들면 다음과 같습니다.
public class IrcComponentProxyFactory implements ComponentProxyFactory { @Override public ComponentProxyComponent newInstance(String componentId, String componentScheme) { return new ComponentProxyComponent(componentId, componentScheme) { @Override protected void configureDelegateEndpoint(ComponentDefinition definition, Endpoint endpoint, Map<String, Object> options) throws Exception { if (!(endpoint instanceof IrcEndpoint)) { throw new IllegalStateException("Endpoint should be of type IrcEndpoint"); } final IrcEndpoint ircEndpoint = (IrcEndpoint)endpoint; final String channels = (String)options.remove("channels"); if (ObjectHelper.isNotEmpty(channels)) { ircEndpoint.getConfiguration().setChannel( Arrays.asList(channels.split(",")) ); } } }; } }
10.3.10. 라이브러리 확장을 개발하는 방법
라이브러리 확장은 런타임 시 통합에 필요한 리소스를 제공합니다. 라이브러리 확장은 Fuse Online에 단계 또는 커넥터를 제공하지 않습니다.
라이브러리 확장에 대한 지원이 증가하고 있습니다. 이번 릴리스에서는 Fuse Online 웹 인터페이스에서 다음을 수행합니다.
- 통합을 생성할 때 통합에 포함되어야 하는 라이브러리 확장을 선택할 수 없습니다.
-
통합에 데이터베이스 연결을 추가하면 Fuse Online에서
jdbc-driver태그가 있는 모든 확장 기능을 통합 런타임에 추가합니다.
라이브러리 확장에서는 작업을 정의하지 않습니다. 라이브러리 확장에 대한 샘플 정의는 다음과 같습니다.
{
"schemaVersion" : "v1",
"name" : "Example JDBC Driver Library",
"description" : "Syndesis Extension for adding a custom JDBC Driver",
"extensionId" : "io.syndesis.extensions:syndesis-library-jdbc-driver",
"version" : "1.0.0",
"tags" : [ "jdbc-driver" ],
"extensionType" : "Libraries"
}작업 부족 외에도 라이브러리 확장의 구조는 단계 또는 커넥터 확장의 구조와 동일합니다.
라이브러리 확장을 생성하는 Maven 프로젝트에서 Maven 리포지토리에서 사용할 수 없는 종속성을 추가하려면 시스템 종속성을 지정합니다. 예를 들면 다음과 같습니다.
<dependency>
<groupId>com.company</groupId>
<artifactId>jdbc-driver</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/jdbc-driver-1.0.jar</systemPath>
</dependency>10.3.11. JDBC 드라이버 라이브러리 확장 생성
Apache Derby, MySQL 및 PostgreSQL 이외의 SQL 데이터베이스에 연결하려면 연결하려는 데이터베이스에 대한 JDBC 드라이버를 래핑하는 라이브러리 확장을 생성할 수 있습니다. 이 확장을 Fuse Online에 업로드한 후 Fuse 온라인 제공 데이터베이스 커넥터는 드라이버에 액세스하여 독점 데이터베이스에 대한 연결을 검증하고 생성할 수 있습니다. 특정 데이터베이스에 대한 새 커넥터를 생성하지 않습니다.
Syndesis 오픈 소스 커뮤니티는 JDBC 드라이버를 래핑하는 확장을 생성하기 위한 프로젝트를 제공합니다.
하나의 드라이버를 확장에서만 패키지합니다. 이렇게 하면 특정 데이터베이스를 관리하는 과정의 일부로 확장을 더 쉽게 관리할 수 있습니다. 그러나 두 개 이상의 드라이버를 래핑하는 라이브러리 확장을 생성할 수 있습니다.
사전 요구 사항
Syndesis 프로젝트를 사용하려면 GitHub 계정이 있어야 합니다.
절차
다음 중 하나를 수행하여 연결하려는 데이터베이스에 대해 JDBC 드라이버에 대한 액세스를 확인하십시오.
- 드라이버가 Maven 리포지토리에 있는지 확인합니다.
- 드라이버를 다운로드합니다.
- 브라우저 탭에서 https://github.com/syndesisio/syndesis-extensions로 이동합니다.
-
syndesis-extensions리포지토리를 GitHub 계정에 분기합니다. - 포크에서 로컬 복제본을 생성합니다.
syndesis-extensions복제본에서 다음을 수행합니다.-
드라이버가 Maven 리포지토리에 없는 경우 드라이버를
syndesis-jdbc-driver/lib폴더에 복사합니다. syndesis- Cryostat-jdbc-driver/pom.xml파일을 편집합니다.-
Name요소의 값을 이 확장에 대해 선택한 이름으로 업데이트합니다. -
Description요소의 값을 업데이트하여 이 확장에 대한 유용한 정보를 제공합니다. -
드라이버를
syndesis-jdbc-driver/lib로 복사한 경우pom.xml의systemPath가 해당 드라이버 파일을 가리키는지 확인합니다. 필요한 경우 드라이버에 따라 적절한 값을 반영하도록groupId,artifactId및version을 변경합니다. -
드라이버가 Maven 리포지토리에 있는 경우 해당 Maven 종속성에 대한 참조가
pom.xml파일에 있는지 확인합니다. -
pom.xml파일의 나머지 내용을 검사하고 필요에 따라 관련 메타데이터를 변경합니다.
-
-
./mvnw -pl :syndesis-jdbc-driver clean 패키지를실행하여 확장을 빌드합니다.
-
드라이버가 Maven 리포지토리에 없는 경우 드라이버를
생성된 .jar 파일은 syndesis-jdbc-driver/target 폴더에 있습니다. Fuse Online에 업로드할 이 .jar 파일을 제공합니다.
Fuse Online에서는 통합해야 하는 라이브러리 확장을 선택할 수 있는 방법이 아직 제공되지 않습니다. 통합에 데이터베이스 연결을 추가하면 Fuse Online에서 jdbc-driver 태그가 있는 모든 확장 기능을 통합 런타임에 추가합니다. 이는 향후 릴리스에서 개선될 것으로 예상됩니다.
10.4. 확장 기능 추가 및 관리
확장을 통해 Fuse Online에 사용자 지정을 추가하여 원하는 방식으로 애플리케이션을 통합할 수 있습니다. 확장 프로그램에서 제공된 사용자 지정 사용을 시작한 후 해당 사용자 지정을 사용하는 통합을 식별할 수 있습니다. 이 기능은 확장 기능을 업데이트하거나 삭제하기 전에 수행하는 데 유용합니다.
다음 주제에서는 세부 정보를 제공합니다.
10.4.1. 사용자 정의 기능 사용 가능
통합에서 사용자 지정 기능을 사용하려면 확장을 Fuse Online에 업로드합니다.
사전 요구 사항
-
개발자는 Fuse Online 확장자가 포함된
.jar파일을 제공했습니다.
절차
- 왼쪽 Fuse Online 패널에서 사용자 지정 > 확장을 클릭합니다.
- 확장 가져오기 를 클릭합니다.
업로드할 확장자가 포함된
.jar파일을 드래그 앤 드롭하거나 선택합니다.Fuse Online에서는 파일에 확장자가 포함되어 있는지 즉시 검증하려고 합니다. 문제가 있는 경우 Fuse Online에서 오류에 대한 메시지를 표시합니다. 확장 개발자와 조정하여 업데이트된
.jar파일을 가져와야 하며 업로드를 시도할 수 있습니다.확장 세부 정보를 검토합니다.
Fuse Online에서 파일을 검증한 후 확장자 이름, ID, 설명, 유형을 추출하여 표시합니다. 유형은 확장이 사용자 지정 커넥터를 정의하는지 또는 연결 간 데이터에서 작동하기 위한 하나 이상의 사용자 지정 단계 또는 독점 데이터베이스의 JDBC 드라이버를 정의하는지 여부를 나타냅니다. JDBC 드라이버를 제공하는 확장을 라이브러리 확장이라고 합니다.
커넥터 확장의 경우 Fuse Online은 이 사용자 지정 커넥터에서 생성된 연결에 사용할 수 있는 작업을 표시합니다. 확장 시 개발자는 Fuse Online에서 이 커넥터에서 만든 애플리케이션 연결을 나타내는 데 사용할 수 있는 아이콘을 제공했을 수 있습니다. 확장 세부 정보 페이지에는 이 아이콘이 표시되지 않지만 사용자 정의 커넥터에서 연결을 만들 때 표시됩니다. 확장 개발자가 확장에 아이콘을 제공하지 않은 경우 Fuse Online에서 아이콘을 생성합니다.
단계 확장을 위해 Fuse Online은 확장이 정의하는 각 사용자 지정 단계의 이름을 표시합니다.
라이브러리 확장의 경우 이 확장에 이전에 업로드한 JDBC 드라이버의 최신 버전이 포함된 경우 classpath에서 이전 버전을 제거해야 합니다. classpath에 이 드라이버의 버전이 하나만 있고 업로드 중인 최신 드라이버에 대한 참조가 있는지 확인합니다. 실행 중이고 이전 드라이버를 기반으로 연결을 사용하는 통합에는 영향을 미치지 않습니다. 생성하는 새 연결은 새 드라이버를 사용합니다. 이전 드라이버로 생성된 연결이 있는 통합을 시작하면 Fuse Online에서 대신 새 드라이버를 자동으로 사용합니다.
- 확장 가져오기 를 클릭합니다. Fuse Online을 사용하면 사용자 정의 커넥터 또는 사용자 정의 단계를 사용할 수 있으며 확장 프로그램의 세부 정보 페이지가 표시됩니다.
10.4.2. 확장을 사용하는 통합 식별
확장을 업데이트하거나 삭제하기 전에 해당 확장에서 제공하는 사용자 정의를 사용하는 통합을 식별해야 합니다.
절차
- 왼쪽 Fuse Online 패널에서 사용자 지정 > 확장을 클릭합니다.
- 확장 기능 목록에서 업데이트 또는 삭제하려는 확장 항목을 찾아 세부 정보 버튼을 클릭합니다.
결과
Fuse Online에는 확장 프로그램에서 제공하는 사용자 지정을 사용하는 통합 목록을 포함하여 확장 기능에 대한 세부 정보가 표시됩니다.
10.4.3. 확장 업데이트
개발자가 확장을 업데이트하면 업데이트된 .jar 파일을 업로드하여 통합에 업데이트를 구현할 수 있습니다.
사전 요구 사항
개발자는 이전에 업로드한 확장자에 대해 업데이트된 .jar 파일을 제공했습니다.
절차
- Fuse Online의 왼쪽 패널에서 사용자 지정 > 확장을 클릭합니다.
- 업데이트할 확장 항목의 오른쪽에 있는 업데이트를 클릭합니다.
-
점선 상자를 클릭하여 로 이동하여 업데이트된
.jar파일을 선택한 후 열기 를 클릭합니다. - 확장 세부 정보가 올바른지 확인하고 확장 가져오기 를 클릭합니다.
- 업데이트된 확장의 세부 정보 페이지에서 확장에 정의된 커넥터 또는 사용자 지정 단계를 사용하는 통합을 결정합니다.
사용자 지정 커넥터를 사용하는 각 통합 업데이트 또는 업데이트된 확장의 사용자 지정 단계를 사용하는 각 통합을 업데이트하는 데 필요한 사항을 정확히 알아야 합니다. 최소한 업데이트된 확장에 정의된 사용자 지정을 사용하는 각 통합을 다시 게시해야 합니다.
사용자 지정에 대한 구성 세부 정보를 변경하거나 추가하도록 통합을 편집해야 하는 경우도 있습니다. 통합을 업데이트하는 방법을 이해하려면 확장 개발자와 통신해야 합니다.
10.4.4. 확장 프로그램 삭제
실행 중인 통합에서 해당 확장으로 제공되는 단계를 사용하거나 해당 확장에서 제공한 커넥터에서 생성된 연결을 사용하는 경우에도 확장을 삭제할 수 있습니다. 확장을 삭제한 후에는 해당 확장에서 제공한 사용자 지정을 사용하는 통합을 시작할 수 없습니다.
절차
- 왼쪽 Fuse Online 패널에서 사용자 지정 > 확장을 클릭합니다.
- 확장 목록에서 삭제할 확장 항목을 찾아 항목 오른쪽에 표시되는 삭제 를 클릭합니다.
결과
사용자가 삭제한 확장에서 제공하는 사용자 지정을 사용하는 중지되거나 통합 초안이 있을 수 있습니다. 이러한 통합 중 하나를 실행하려면 통합을 편집하여 사용자 지정을 제거해야 합니다.