
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
전원 관리 가이드
Red Hat Enterprise Linux 6에서 전력 소비 관리
엮음 1.0
초록
1장. 개요
1.1. 전원 관리의 중요성
- 전체 전력 소모 감소를 통한 비용 감소
- 서버와 컴퓨팅 센터의 발열 감소
- 냉각, 공간, 케이블, 발전기, 그리고 무정전 전원 공급장치(uninterruptible power supplies) 등의 2차 비용의 감소
- 랩탑의 배터리 수명 연장
- 더 적은 이산화탄소 배출
- 에너지 스타(Energy Star)와 같은 그린 IT와 관련된 정부 규제 또는 요구사항을 만족시킴
- 새로운 시스템에 대한 사내 가이드라인을 만족시킴
- 질문 최적화를 해야만 하는가?
- 질문 어느 정도까지 최적화할 필요가 있나?
- 질문 최적화가 시스템의 성능을 용납할 수 없을 정도로 떨어뜨리지는 않을 것인가?
- 질문 시스템 최적화를 위해 투자해야 하는 시간과 자원이 달성할 수 있는 이익을 상회하는가?
1.2. 전원 관리의 기본
Red Hat Enterprise Linux 5 커널은 각각의 CPU에 대한 주기적인 타이머를 사용합니다. 이 타이머로 인해서 CPU는 완전한 유휴상태로 들어갈 수 없습니다. 왜냐하면, CPU가 다른 프로세스가 실행중인지 여부와 관계 없이 각각의 타이머 이벤트(설정에 따라 몇 밀리초당 한 번씩 발생합니다)를 처리해야만 하기 때문입니다. 효과적인 전원 관리의 대부분은 이렇게 CPU가 깨어나야만 하는 주기를 줄이는 것과 관련이 있습니다.
이것은 움직이는 부품이 있는 장치(예: 하드디스크)의 경우 특별히 더 중요합니다. 또한 일부 애플리케이션은 사용하지 않는 장치를 "열린" 상태로 남겨두고는 합니다; 이러한 일이 발생하면, 커널은 그 장치가 사용중이라 가정하게 되어, 해당 장치를 전원 절약 상태로 전환할 수 없게 됩니다.
하지만, 많은 경우 이는 하드웨어와 BIOS 설정에 달려있습니다. 오래된 시스템의 구성요소들은 Red Hat Enterprise Linux 6에서 현재 지원할 수 있는 새로운 기능 중 일부를 지원하지 못하곤 합니다. 시스템에서 가장 최신의 공식 펌웨어를 사용하고 있는지 확인하시고, BIOS의 전원관리와 장치 설정 부분을 검토해서 전원관리 기능이 활성화 되도록 하십시오. 살펴봐야 하는 특성에는 다음과 같은 것들이 있습니다:
- SpeedStep
- PowerNow!
- Cool'n'Quiet
- ACPI (C state)
- Smart
향상된 설정과 전원 인터페이스(Advanced Configuration and Power Interface)(ACPI)를 제공하는 최근의 CPU들은 여러 다른 전원 상태를 제공합니다. 이러한 상태들에는:
- 슬립 (Sleep,C-states)
- 주파수 (Frequency, P-states)
- 열 출력(T-states 또는 "열 상태")
너무나 당연한 이야기이지만, 실제 전원을 절약하는 가장 좋은 방법은 시스템을 끄는 것입니다. 예를 들어 회사가 점심시간이나 퇴근시 컴퓨터를 끄도록 하여, "그린 IT" 정신에 입각한 사내 문화를 발전시킬 수도 있습니다. 또한 Red Hat Enterprise Linux 6에서 제공하는 가상화 기술을 활용해 몇몇 물리적인 서버를 한대의 큰 서버로 통합하여 이를 가상 서버로 사용할 수 도 있을 것입니다.
2장. 전원 관리 감사와 분석
2.1. 감사와 분석 개요
2.2. PowerTOP
yum install powertoppowertopincrease the VM dirty writeback time라고 되어있는 제안사항과 그 제안을 허용하기 위해서 눌러야 하는 키(W)를 확인해 보십시오.
C4가 C3보다 높음), 이것은 시스템이 CPU 활용도에 있어 얼마나 최적화 되어있는가를 보여주는 좋은 지표입니다. 목표를 시스템이 유휴상태에 있는 동안 CPU가 90% \ 또는 그 이상 최고의 C 또는 P 상태에 있는 것으로 잡아야 합니다.
<>사이에 목록이 표시됨), CPU를 깨우는 원인을 제공하는 특정 드라이버와 연관되어 있기도 합니다. 드라이버를 튜닝하기 위해서는 커널을 변경해야 하는 경우가 많고, 이는 이 문서의 범위를 벗어나는 것입니다. 하지만, 사용자 영역 프로세스가 CPU를 자주 깨우는 것은 더 쉽게 처리할 수 있습니다. 우선, 그 서비스나 프로그램이 이 시스템에서 실행될 필요가 있는지를 판단하십시오. 만약 필요가 없다면, 단순히 서비스를 비활성화 합니다. 서비스를 영구히 끄려면, 다음을 실행하십시오:
chkconfig 서비스이름 offps -awux | grep 콤포넌트이름strace -p 프로세스id
increase the VM dirty writeback time라는 제안과 그 제안을 받아들이기 위해 사용할 수 있는 W 키에 주의하십시오. 이 변경은 다음번 재시작 이전까지만 유효합니다. 이런 변경사항을 시스템에 영구히 적용하기 위해, PowerTOP은 최적화를 위해 실행해야 하는 정확한 명령을 표시합니다. 이 명령을 /etc/rc.local 파일에 선호하는 텍스트 에디터로 저장해서 시스템 시작시 해당 변경 사항이 적용되도록 하십시오.
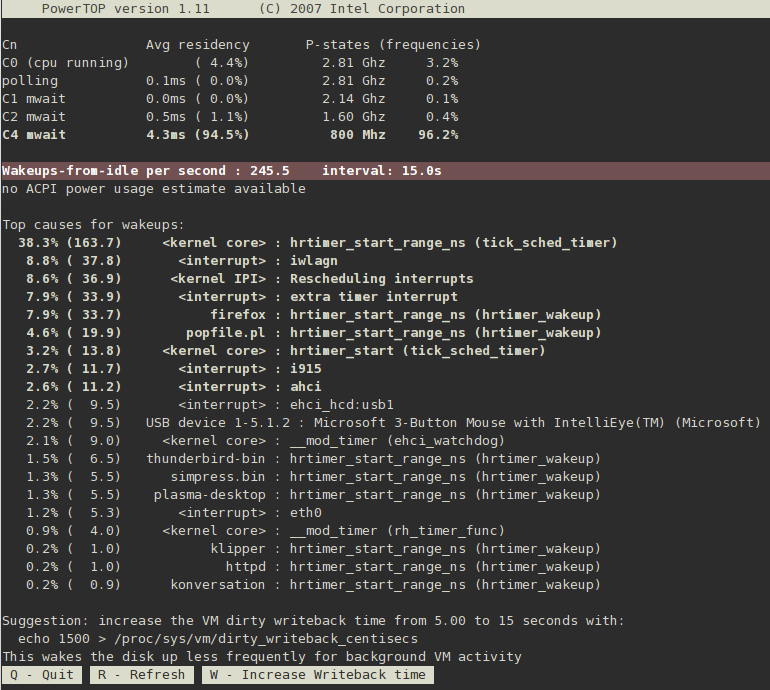
그림 2.1. 동작중인 PowerTOP
2.3. Diskdevstat과 netdevstat
yum install systemtap tuned-utils kernel-debuginfodiskdevstatnetdevstatdiskdevstat 업데이트_주기 전체_시간 히스토그램_표시
netdevstat 업데이트_주기 전체_시간 히스토그램_표시
- 업데이트_주기
- 각 화면 업데이트 사이의 시간(단위:초). 기본값:
5 - 전체_시간
- 모니터링을 할 전체 시간(단위:초). 기본값:
86400(하루) - 히스토그램_표시
- 실행이 끝날 때 수집한 전체 데이터를 히스토그램으로 보여줄지 여부
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 15494 0 sda1 0 0.000 0.000 0.000 758 0.000 0.012 0.000 0logwatch 15520 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15549 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15585 0 sda1 0 0.000 0.000 0.000 108 0.001 0.002 0.000 perl 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 15429 0 sda1 0 0.000 0.000 0.000 62 0.009 0.009 0.000 crond 15379 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15473 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15415 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15433 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15425 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15375 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15477 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15469 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15419 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15481 0 sda1 0 0.000 0.000 0.000 61 0.000 0.001 0.000 crond 15355 0 sda1 0 0.000 0.000 0.000 37 0.000 0.014 0.001 laptop_mode 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd 15575 0 sda1 0 0.000 0.000 0.000 16 0.000 0.000 0.000 cat 15581 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15582 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15579 0 sda1 0 0.000 0.000 0.000 12 0.000 0.001 0.000 perl 15580 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 12 0.000 0.170 0.014 sh 15584 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15548 0 sda1 0 0.000 0.000 0.000 12 0.001 0.014 0.001 perl 15577 0 sda1 0 0.000 0.000 0.000 12 0.001 0.003 0.000 perl 15519 0 sda1 0 0.000 0.000 0.000 12 0.001 0.005 0.000 perl 15578 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15583 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15547 0 sda1 0 0.000 0.000 0.000 11 0.000 0.002 0.000 perl 15576 0 sda1 0 0.000 0.000 0.000 11 0.001 0.001 0.000 perl 15518 0 sda1 0 0.000 0.000 0.000 11 0.000 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 10 0.053 0.053 0.005 lm_lid.sh
- PID
- 프로그램의 프로세스 ID
- UID
- 실행중인 프로그램의 사용자 ID
- DEV
- I/O가 일어난 장치
- WRITE_CNT
- 쓰기 동작 횟수
- WRITE_MIN
- 연속된 두 쓰기 동작 사이의 최소 간격(초)
- WRITE_MAX
- 연속된 두 쓰기 동작 사이의 최대 간격(초)
- WRITE_AVG
- 두 연속된 쓰기 동작 사이의 평균 간격(초)
- READ_CNT
- 전체 읽기 동작 횟수
- READ_MIN
- 두 연속된 읽기 동작 사이의 최소 간격(초)
- READ_MAX
- 두 연속된 읽기 동작 사이의 최대 간격(초)
- READ_AVG
- 두 연속된 읽기 동작 사이의 평균 시간(초)
- COMMAND
- 프로세스의 이름
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd
WRITE_CNT가 0보다 큽니다. 이는 이들이 측정하는 동안 어떤 데이터를 기록했다는 것을 의미합니다. 이들 중에서 plasma는 상당히 큰 차이로 가장 나쁜 결과를 보여줍니다: 그것은 가장 많은 쓰기 동작을 수행했고, 또한 쓰기 동작 사이의 평균 시간도 가장 짧습니다. Plasma는 따라서 여러분이 에너지를 낭비하는 프로그램에 대해 우려하고 있다면 검사해야할 가장 좋은 대상이 됩니다.
strace -p 2789strace의 출력에는 45초마다 반복되는 패턴이 있습니다. 그것은 사용자의 KDE 아이콘 캐시 파일을 쓰기위해 연 직후 그 파일을 닫는 것입니다. 이것은 파일 메타정보 부분(특히 마지막 변경 시간 정보)이 바뀌었기 때문에 하드 디스크에 물리적인 쓰기를 야기합니다. 최종 수정본에서는 아이콘이 실제 업데이트 되지 않은 경우 이러한 불필요한 시스템 콜이 일어나지 않도록 변경되었습니다.
2.4. 배터리 수명 도구 키트
-a 옵션으로 시작해서 데스크탑 컴퓨터의 성능에 대해서도 보고할 수 있습니다.
office 부하는 텍스트를 쓰고, 수정하는 작업을 하고, 동일한 일을 스프레드시트에서도 합니다. BLTK와 PowerTOP등의 분석/감사 도구를 함께 수행함으로써, 수행한 최적화가 유휴시간 뿐 아니라 컴퓨터를 활동적으로 사용하는 경우에도 효과가 있는지를 테스트할수 있습니다. 서로 다른 설정에서도 동일한 부하량을 발생시킬 수 있기 때문에, 서로 다른 설정하에서의 결과를 비교해 볼 수 있습니다.
yum install bltkbltk workload 옵션들idle 작업부하를 120초간 실행하려면 다음과 같이 합니다:
bltk -I -T 120-I,--idle- 시스템이 유휴상태입니다. 다른 작업부하와 비교를 위한 기준으로 사용됩니다
-R,--reader- 문서를 읽는 작업을 시뮬레이션합니다(디폴트로, Firefox를 사용합니다)
-P,--player- CD나 DVD 드라이브에서 멀티미디어 파일을 보는 것을 시뮬레이션합니다(디폴트로, mplayer를 사용합니다)
-O,--office- OpenOffice.org 스위트를 사용해 문서를 편집하는 것을 시뮬레이션합니다
-a,--ac-ignore- 교류 전원이 있는지 여부를 무시합니다(데스크탑에서 사용시 필요)
-T 시간(초),--time 시간(초)- 테스트를 얼마동안 실행할지를 초단위로 정합니다; 이 옵션을
idle작업부하와 함께 사용하십시오 -F 파일이름,--file 파일이름- 특정 부하를 위해 사용할 파일을 지정합니다. 예를 들자면
player부하가 CD나 DVD 드라이브를 읽는 대신 사용할 파일이 되겠습니다. -W 어플리케이션,--prog 어플리케이션- 특정 작업부하에서 사용할 어플리케이션을 지정합니다. 예를 들자면
reader작업부하에서 Firefox 대신 사용할 브라우저가 되겠습니다.
bltk 매뉴얼(man) 페이지를 참조하십시오.
/etc/bltk.conf 설정 파일에 지정된 디렉터리에 보고서를 저장합니다. 디폴트는 ~/.bltk/작업부하.results.숫자/ 입니다. 예를 들어 ~/.bltk/reader.results.002/ 디렉터리는 reader 작업부하를 가지고 수행한 3번째 테스트의 결과가 저장되어 있습니다(첫번째 테스트에는 번호가 붙지 않습니다). 결과는 몇 개의 텍스트 파일에 나뉘어 있습니다. 이러한 결과를 읽기 쉬운 형식으로 축약하려면, 다음을 실행하십시오:
bltk_report 결과_디렉터리_경로Report라는 텍스트파일에 저장될 것입니다. 이 결과를 터미널에서 보려면, -o 옵션을 사용하십시오:
bltk_report -o 결과_디렉터리_경로2.5. Tuned와 ktune
yum install tuned/etc/tuned.conf에는 몇 가지 예제 설정 파일이 저장되며, 디폴트 프로파일이 활성화됩니다.
service tuned startchkconfig tuned on-d,--daemon- tuned를 데몬으로 실행합니다.
-c,--conffile- 예를 들자면,
--conffile=/etc/tuned2.conf과 같이, 지정한 이름과 경로에 있는 설정 파일을 사용합니다. 디폴트는/etc/tuned.conf입니다. -D,--debug- 가장 높은 로깅(logging) 수준을 사용합니다.
2.5.1. tuned.conf 파일
tuned.conf 파일은 tuned의 설정을 저장하고 있습니다. 디폴트로 이 파일은 /etc/tuned.conf입니다. 다른 위치나 이름으로 지정하려면, tuned.conf를 --conffile 옵션을 사용해 실행하면 됩니다.
[main]라는 섹션이 들어가 있어야만 합니다. 이 파일은 또한 각각의 플러그인에 대한 섹션을 포함할 수 있습니다.
[main] 섹션은 다음과 같은 옵션을 포함합니다:
interval- tuned가 시스템을 모니터하고 튜닝해야 하는 주기를 초단위로 지정합니다. 기본값은
10입니다. verbose- 자세한 메시지를 출력할지를 정합니다. 기본값은
False입니다. logging- 로깅할 메시지의 최소 우선순위를 지정합니다. 지정 가능한 값은 우선순위가 높은 것부터 다음과 같습니다:
critical,error,warning,info,debug. 기본값은info입니다. logging_disable- 로깅할 메시지의 최대 우선순위를 지정합니다; 여기 지정된 우선순위값 이하의 메시지는 로깅하지 않습니다. 지정 가능한 값은 우선순위가 높은 것부터 다음과 같습니다:
critical,error,warning,info,debug. 기본값은info입니다.
[CPUTuning]. 각각의 플러그인에 자신만의 옵션을 지정할 수 있지만, 다음 옵션들은 모든 플러그인에 사용 가능합니다:
enabled- 이 플러그인을 사용할지 여부를 지정합니다. 디폴트 값은
True입니다. verbose- 자세한 출력을 표시할지 여부를 지정합니다. 만약 특정 플로그인에 대해 설정하지 않는다면,
[main]에서 지정된 값에 따르게 됩니다. logging- 로깅할 메시지의 최소 우선순위를 지정합니다. 특정 플로그인에 대해 지정하지 않았다면,
[main]에서 지정한 값을 따릅니다.
[main] interval=10 pidfile=/var/run/tuned.pid logging=info logging_disable=notset # Disk monitoring section [DiskMonitor] enabled=True logging=debug # Disk tuning section [DiskTuning] enabled=True hdparm=False alpm=False logging=debug # Net monitoring section [NetMonitor] enabled=True logging=debug # Net tuning section [NetTuning] enabled=True logging=debug # CPU monitoring section [CPUMonitor] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True # CPU tuning section [CPUTuning] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True
2.5.2. Tuned-adm
tuned-adm listtuned-adm activetuned-adm profile profile_nametuned-adm profile server-powersavetuned-adm offdefault 프로파일이 활성화될 것입니다. Red Hat Enterprise Linux 6는 또한 다음과 같은 미리 정의된 프로파일을 제공합니다.
- default
- 디폴트 전원절약 프로파일. 이는 사용 가능한 프로파일 중 전원 절약에 가장 적은 영향을 끼치는 것입니다. 오직 tuned의 CPU와 디스크 플러그인만을 사용합니다.
- desktop-powersave
- 데스크탑 시스템을 위한 전원 절약 프로파일입니다. SATA 호스트 아답터에 대해서 ALPM 전원 절약을 사용하며(3.6절. “적극적 연결 전원 관리(Aggressive Link Power Management)”를 참조), tuned의 CPU, 이더넷, 디스크 플러그인도 함께 사용합니다.
- server-powersave
- 서버 시스템을 위한 전원 절약 프로파일입니다. SATA 호스트 아답터에 대해서 ALPM 전원 절약을 사용하며, HAL(hal-disable-polling 매뉴얼 페이지 참조)을 통한 CD-ROM 폴링을 금지하고, tuned의 CPU와 디스크 플러그인을 사용합니다.
- laptop-ac-powersave
- AC전원에서 동작하는 랩탑을 위해 중간정도의 전원 절약을 제공하는 프로파일입니다. SATA 호스트 아답터를 위한 ALPM 전원 절약을 사용하고, WiFi 전원 절약과, tuned의 CPU, 이더넷, 디스크 플러그인을 사용합니다.
- laptop-battery-powersave
- 배터리로 작동하는 랩탑을 위해 많은 전원 절약을 제공하는 프로파일입니다. 이전에 설명한 프로파일에서 제공하는 모든 전원 절약 방법을 사용하는 것은 물론이고, CPU를 덜 깨우는 시스템을 위한 멀티 코어 전원 절약 스케줄러를 사용하며, 요구불 조정기를 사용도록 설정하고, AC97 오디오 전원 절약도 활성화합니다. 이 프로파일을 사용하면 배터리로 동작하는 랩탑 뿐만 아니고 다른 모든 종류의 시스템에서도 최대로 전원 절약을 하게 됩니다. 이 프로파일을 사용하는 경우의 단점은 성능에 눈에 띄는 영향을 끼친다는 것입니다. 특히 디스크와 네트워크 I/O의 응답 지연 면에서 그렇습니다.
- throughput-performance
- 서버를 위한 전형적인 처리속도 성능에 비중을 둔 튜닝 프로파일입니다. tuned와 ktune 전원 절약 방법을 사용하지 않도록 하며, sysctl 설정을 디스크와 네트워크 I/O의 처리속도(throughput) 성능을 향상시키도록 활성화합니다. 또한 deadline scheduler로 스케줄러를 변경합니다.
- latency-performance
- 서버를 위한 응답 시간에 비중을 둔 전형적인 튜닝 프로파일. tuned와 ktune 전원 절약 메커니즘을 상용 금지하고, 네트워크 I/O의 응답 지연을 향상시키기 위해 sysctl 설정을 활성화합니다.
/etc/tune-profiles 서브디렉터리에 저장됩니다. 따라서 /etc/tune-profiles/desktop-powersave는 해당 프로파일에 필요한 모든 파일을 포함하게 됩니다. 각각의 프로파일 디렉터리는 최대 4개의 파일을 포함합니다:
tuned.conf- 이 프로파일을 위해 활성화될 tuned의 설정 파일
sysctl.ktune- ktune가 사용할 sysctl 설정 파일. 파일의 포맷은
/etc/sysconfig/sysctl과 동일합니다(sysctl와 sysctl.conf 매뉴얼 페이지 참조). ktune.sysconfig- ktune 자체에 대한 설정 파일. 보통
/etc/sysconfig/ktune입니다. ktune.sh- ktune에 의해 사용되는 init-스타일의 셀 스크립트로 시스템 부팅시 시스템을 튜닝하기 위해 사용되는 구체적인 명령들을 담고 있습니다.
laptop-battery-powersave 프로파일에는 매우 풍부한 튜닝 예제가 들어가 있으므로, 유용한 시작점이 될 수 있습니다. 전체 디렉터리를 다음과 같이 통째로 복사하십시오:
cp -a /etc/tune-profiles/laptop-battery-powersave/ /etc/tune-profiles/myprofile# Disable HAL polling of CDROMS # for i in /dev/scd*; do hal-disable-polling --device $i; done > /dev/null 2>&1
2.6. DeviceKit-power 및 devkit-power
devkit-power 명령과 다음 옵션을 사용하여 명령행 도구에 액세스할 수 있습니다:
--enumerate,-e- 시스템의 각 전원 장치에 대한 객체 경로를 표시합니다. 예:
/org/freedesktop/DeviceKit/power/devices/line_power_AC/org/freedesktop/UPower/DeviceKit/power/battery_BAT0 --dump,-d- 시스템의 모든 전원 장치에 대한 매개 변수를 표시합니다.
--wakeups,-w- 시스템의 CPU wakeups를 표시합니다.
--monitor,-m- AC 전원 연결 및 연결 해제 또는 배터리 부족과 같은 전원 장치의 변화에 대해 시스템을 모니터링합니다. 시스템 모니터링을 중지하려면 Ctrl+C를 누릅니다.
--monitor-detail- AC 전원 연결 및 연결 해제 또는 배터리 부족과 같은 전원 장치의 변화에 대해 시스템을 모니터링합니다.
--monitor-detail옵션은--monitor옵션 보다 더 자세한 정보를 제공합니다. 시스템 모니터링을 중지하려면 Ctrl+C를 누릅니다. --show-info object_path,-i object_path- 특정 객체 경로에 대해 사용 가능한 모든 정보를 표시합니다. 예를 들어, 객체 경로
/org/freedesktop/UPower/DeviceKit/power/battery_BAT0로 표시되는 시스템 배터리에 대한 정보를 검색하려면 다음을 수행합니다:devkit-power -i /org/freedesktop/UPower/DeviceKit/power/battery_BAT0
2.7. GNOME Power Manager
- AC 전원으로 동작
- 배터리로 동작
- 일반
2.8. 감사를 위한 다른 방법
- vmstat
- vmstat은 프로세스, 메모리, 페이징, 블럭 I/O, 트랩, 그리고 CPU 활동에 대한 상세 정보를 제공합니다. 시스템이 전체적으로 어떤 일을 하고, 어느 부분에서 바쁜지 자세히 살펴보기 위해 이를 사용하십시오.
- iostat
- iostat은 vmstat와 비슷하지만, 블럭 장치에 대한 I/O 정보만 제공합니다. 이는 또한 더 자세한 출력과 통계를 제공합니다.
- blktrace
- blktrace은 아주 자세한 블럭 I/O 추적 프로그램입니다. 이는 프로그램과 관련된 매 블럭에 대한 정보에 이르기까지 자세한 정보를 제공합니다. diskdevstat와 함께 사용하면 매우 유용합니다.
3장. 핵심 인프라와 기법
3.1. CPU 유휴 상태
- C0
- 동작중 또는 실행중인 상태. 이 상태에서 CPU는 동작중이며 전혀 쉬는 일이 없습니다.
- C1, 중단
- 프로세서가 명령어를 실행하지는 않고 있지만, 전형적인 저전력 상태에 있지는 않은 상태. CPU는 실제적으로 거의 지연 없이 명령어 처리를 계속 할 수 있습니다. C-상태를 지원하는 모든 프로세서들은 이 상태를 제공해야만 합니다. Pentium 4 프로세서들은 C1E라 불리는 실제로는 저전력소모 상태인 확장된 상태를 제공합니다.
- C2, 클럭-중단
- 프로세서의 클럭이 중단되지만, 레지스터와 캐시의 생태는 온전히 유지됩니다. 따라서 클럭만 재개하면 즉시 처리를 시작할 수 있습니다. 이 상태는 옵션입니다.
- C3, 슬립
- 프로세서가 슬립 상태로 들어가서 캐시를 최신 상태로 유지하지 못하는 상태입니다. 이로 인해 이 상태에서 깨어나는 것은 C2 상태에서 깨어나는 것보다 훨씬 시간이 걸립니다. 이 상태도 옵션입니다.
3.2. CPUfreq 조정기 사용하기
3.2.1. CPUfreq 조정기 유형
성능 조정기(Performance governor)는 CPU가 가능한 한 최고의 클럭 주파수를 사용하도록 합니다. 이 주파수는 정적으로 설정될 것이며, 변하지 않을 것입니다. 따라서, 이 조정기는 전원 절약을 제공하지 않습니다. 이러한 조정기는 오직 부하가 많은 시간에 적합하며, 그런 경우 중에도 CPU가 거의(혹은 전혀) 유휴상태로 가지 않는 경우에 적합합니다.
반대로, 전원절약 조정기는 CPU가 가능한 가장 낮은 클럭 주파수를 사용하도록 합니다. 이 주파수는 정적으로 설정될 것이며, 변하지 않을 것입니다. 이 조정기는 전력 소모를 최고로 줄지만, 그 댓가로 CPU 성능은 가장 낮아집니다.
요구불(Ondemand) 조정기는 CPU가 시스템의 부하가 높을 때는 최고 클럭 주파수로 동작하고, 시스템이 유휴상태일 때는 CPU가 최저 주파수로 돌도록 하는 조정기입니다. 이렇게 하면 전력 소비를 시스템의 부하에 따라 적절히 조정할 수 있지만, 그 댓가로 주파수 변경에 따른 지연시간이 발생합니다. 만약 시스템이 유휴상태와 고부하 상태를 자주 오가는 경우라면, 이러한 변경 지연시간이 요구불 조정기가 제공하는 성능/전력 절약에 따르는 이익을 상쇄할 수 있습니다.
사용자 공간(Userspace) 조정기는 사용자 공간의 프로그램(또는 root로 실행중인 프로세스)이 주파수를 지정하도록 합니다. 이 조정기는 일반적으로 cpuspeed 데몬과 함께 사용합니다. 모든 조정기 중에서, 사용자 공간 조정기가 가장 사용자 설정이 자유로운 것입니다; 또한, 어떻게 설정되느냐에 따라서 시스템에 있어 성능과 전력 소모 간의 균형을 가장 잘 맞춰줄 수 있습니다.
요구불 조정기와 마찬가지로, 보수적 조정기 또한 클럭 주파수를 사용량(요구불 조정기의 경우와 같음)에 따라 조정합니다. 하지만, 요구불 조정기가 더 적극적인 방식으로 주파수를 조정하는 반면(즉, 최대에서 최소, 최소에서 최대로 변경함), 보수적 조정기는 주파수를 좀 더 점진적으로 변경합니다.
참고
cron 명령을 사용해 조정기를 활성화할 수 있습니다. 그것은 특정 조정기를 하루 중 특정 시간대에 지정할 수 있게 해 줍니다. 유휴 시간대(예: 일과시간 후)에 낮은 주파수의 조정기를 지정하고, 업무 부하가 큰 시간대에는 주파수가 높은 조정기로 돌아가도록 지정할 수 있습니다.
3.2.2. CPUfreq 설정
절차 3.1. CPUfreq 드라이버를 추가하는 방법
- 다음 명령을 실행해서 시스템에 사용 가능한 CPUfreq 드라이버를 확인하십시오:
ls /lib/modules/[커널 버전]/kernel/arch/[아키텍쳐]/kernel/cpu/cpufreq/ - 거기에서,
modprobe를 사용해 적절한 CPUfreq 드라이버를 추가하십시오.modprobe [CPUfreq 드라이버]위의 명령을 사용할 때,.ko파일 확장자를 빼고 입력하셔야 합니다. - CPUfreq 드라이버가 설정된 다음, 어떤 조정기를 시스템에서 현재 사용중인지를 다음과 같이 알아 볼 수 있습니다:
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
cat /sys/devices/system/cpu/[cpu ID]/cpufreq/scaling_available_governorsmodprobe를 실행해 사용하고자 하는 특정 CPUfreq 조정기를 활성화하는 데 필요한 커널 모듈을 추가하십시오. 이러한 커널 모듈은 /lib/modules/[커널 버전]/kernel/drivers/cpufreq/에 있습니다.
3.2.3. CPUfreq 정책과 속도 튜닝하기
/sys/devices/system/cpu/[cpu ID]/cpufreq/에 있는 값을 조정해서 각각의 CPU의 속도를 더 세밀하게 튜닝할 수 있습니다. 이러한 값들은 다음과 같습니다:
cpuinfo_min_freq— CPU가 동작 가능한 최소 운용 주파수를 표시합니다. (KHz 단위)cpuinfo_max_freq— CPU가 동작 가능한 최대 운용 주파수를 표시합니다. (KHz 단위)scaling_driver— CPU의 주파수를 설정하기 위해서 사용되는 CPUfreq 드라이버.scaling_available_governors— 이 커널에서 사용 가능한 CPUfreq 조정기를 보여줌. 만약 이 파일에 없는 CPUfreq 조정기를 사용하고 싶다면, 3.2.2절. “CPUfreq 설정”에 있는 3.2.2절. “CPUfreq 설정”을 참조하시면 방법을 알 수 있습니다.scaling_governor— 현재 사용중인 CPUfreq 조정기를 표시합니다. 다른 조정기를 사용하려면, 단순히echo [governor] > /sys/devices/system/cpu/[cpu ID]/cpufreq/scaling_governor를 사용하십시오. 자세한 내용은 3.2.2절. “CPUfreq 설정”에서 절차 3.2. “CPUfreq 조정기 활성화하기”를 참조하십시오.cpuinfo_cur_freq— 현재의 CPU 속도(KHz)scaling_available_frequencies— 해당 CPU에 설정 가능한 주파수들(KHz단위)scaling_min_freq와scaling_max_freq— 해당 CPU의 정책 한계(policy limits)를 KHz로 지정.affected_cpus— 주파소 조정 소프트웨어를 필요로 하는 CPU의 목록.scaling_setspeed— CPU의 클럭 속도를 변경하는 데 사용됨(KHz). 해당 CPU의 정책 한계 내의 속도만 설정할 수 있습니다(scaling_min_freq와scaling_max_freq와 마찬 가지임).
cat [tunable]를 사용합니다. 예를 들어 현재 cpu0의 속도를 Khz로 보려면, 다음과 같이 합니다:
cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq.
echo [value] > /sys/devices/system/cpu/[cpu ID]/cpufreq/[tunable]를 사용합니다. 예를 들어, cpu0의 최저 클럭 속도를 360 Khz로 설정하려면 다음과 같이 합니다:
echo 360000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
3.3. 전원 절약모드와 재개
3.4. 틱없는 커널
3.5. 활성 상태 전원 관리(Active-State Power Management)
- default
- PICe 연결의 전원 상태를 시스템의 펌웨어(예: BIOS)에 지정된 디폴트 상태로 설정합니다. 이는 ASPM의 디폴트 상태입니다.
- powersave
- ASPM을 성능 감소를 감수하고라도 가능한 한 전력을 덜 소비하도록 설정합니다.
- performance
- ASPM을 비활성화해서 PCIe 연결이 최대 성능을 발휘하도록 합니다.
/sys/module/pcie_aspm/parameters/policy에 설정되어 있습니다. 하지만 시스템 부팅시 pcie_aspm 커널 매개변수를 사용해 설정할 수도 있습니다. pcie_aspm=off이라고 하면 ASPM을 비활성화하며, pcie_aspm=force는 ASPM을, 심지어는 ASPM을 지원하지 않는 장치에 대해서 까지, 활성화합니다.
주의
pcie_aspm=force를 설정하면, ASPM을 지원하지 않는 하드웨어로 인해 시스템이 멈출 수 있습니다. pcie_aspm=force를 지정하기 전에, 시스템의 모든 PCIe 하드웨어가 ASPM을 지원하는지 확인하십시오.
3.6. 적극적 연결 전원 관리(Aggressive Link Power Management)
이 모드는 디스크 I/O가 없을 때, 연결을 두 번째로 낮은 전원 상태(PARTIAL)로 설정합니다. 이 모드는 가능한 한 성능에 적은 영향을 끼치면서, 연결의 전원 상태를 전환하기 위해 설계되었습니다(예를 들어 간헐적으로 많은 I/O와 유휴 I/O가 일어나는 경우).
medium_power 모드에서는 연결이 부하에 따라 PARTIAL과 최대 전원(즉, "ACTIVE") 상태 사이를 오갈 수 있습니다. 연결의 전원 상태가 PARTIAL에서 SLUMBER로 직접 바뀌거나, 그 반대로 직접 바뀔 수 없다는 것에 주의하십시오; 두 경우 모두 ACTIVE 상태로 일단 전환된 다음에, 다른 상태로 변경될 수 있습니다.
/sys/class/scsi_host/host*/link_power_management_policy 파일이 있는지를 봐야 합니다. 설정을 변경하려면 여기서 설명한 값을 이 파일에 기록하고, 현재 설정을 검토하려면 이 파일을 표시해보면 됩니다.
3.7. 실시간 드라이브 액세스 최적화
atime라 불리며, 이를 유지하기 위해서는 저장소에 계속해서 데이터를 기록할 필요가 있습니다. 이렇게 데이터를 기록하는 것으로 인해 저장소와 그 연결의 상태를 사용중으로, 전원을 계속 켜진 상태로 유지하게 됩니다. atime 데이터를 사용하는 어플리케이션이 별로 많지 않기 때문에, 이렇게 저장소 장치가 동작하면 전력을 낭비하게 됩니다. 특히, 심지어는 파일을 저장소에서 읽지 않고 캐시에서 읽은 경우에도 저장소에 기록하는 작업이 이뤄져야 합니다. 때때로 Linux 커널은 mount시 noatime 옵션을 지원하기도 합니다. 이 옵션과 함께 마운트된 경우에는 atime 데이터를 파일 시스템에 기록하지 않습니다. 하지만, 이렇게 무작정 해당 기능을 꺼버리는 것은 atime에 의존하는 몇몇 어플리케이션이 있고, 그것들에게 오류가 발생하게 되므로, 문제가 될 수 있습니다.
relatime라 불리는 대안을 지원합니다. relatime은 atime 데이터를 유지하지만, 파일 액세스가 있을 때 마다 하지는 않습니다. 이 옵션을 활성화시키면, atime 데이터가 파일의 최종 업데이트 날짜(mtime)와 같고 그 이후 파일이 변경된 경우거나, 파일의 최종 액세스 시간이 현재로부터 일정 시간 이전(디폴트는 하루)인 경우에만 디스크에 기록됩니다.
relatime 옵션이 활성화된 상태로 마운트됩니다. 이 기능을 전체 시스템에서 사용하지 않으려면, 부트 매개변수로 default_relatime=0를 지정하십시오. 만약 relatime이 디폴트로 시스템에서 활성화되어 있고, 특정 파일시스템에서 그 기능을 사용하고 싶지 않은 경우 norelatime 옵션으로 파일시스템을 마운트하면 됩니다. 마지막으로, 시스템이 파일의 atime 데이터를 업데이트하기 전에 디폴트 시간을 변경하려면, relatime_interval= 부트 매개변수를 사용해서, 시간을 초 단위로 지정합니다. 기본값은 86400입니다.
3.8. 전원 캡핑(Power Capping)
동적 전력 캡핑은 몇몇 ProLiant와 BladeSystem 서버에서 사용 가능한 특징으로, 시스템 관리자가 서버 또는 서버의 그룹에 대한 전력 사용량을 제한할 수 있는 기능입니다. 캡은 부하량과 관계 없이 서버가 넘어설 수 없는 확고한 한계입니다. 캡은 서버가 전원 사용 제한량에 도달가기 전까지는 효력을 나타내지 않습니다. 전력 제한량에 도달하면, 관리 프로세서가 CPU P-상태와 클럭 임계치를 조정해서 소비되는 전력을 제한합니다.
/dev/hpilo/dXccbN에 있는 관리 프로세서에 질의할 수 있습니다. 커널은 또한 전원 캡핑을 지원하기 위한 hwmon sysfs 인터페이스의 확장을 포함합니다. 또한, sysfs 인터페이스를 사용하는 hwmon ACPI 4.0 전력계 드라이버도 제공합니다. 이런 특징들이 한데 어우러져서, 운영 체제와 사용자-영역의 도구를 사용해 전원 캡핑을 위해서 설정된 값을 읽고, 현재 시스템의 전력 소비량을 측정할 수 있도록 해 줍니다.
인텔 노드 관리자는 시스템에 전력 사용량 제한을 겁니다. 이는 프로세서의 P-상태와 T-상태를 활용해 CPU의 성능을 제약함으로써, 전력 소비를 제한하는 것입니다. 전원 관리 정책을 결정함으로써, 관리자는 밤이나 주말과 같이 시스템이 시스템 부하가 적은 경우, 더 작은 전력을 소비할 수 있도록 할 수 있습니다.
3.9. 향상된 그래픽 전원 관리
저전압 차등 신호(Low-voltage differential signalling)(LVDS)는 구리선으로 전기 신호를 전달하는 시스템입니다. 이 시스템의 중요한 응용은 픽셀 정보를 노트북의 액정 디스플레이(liquid crystal display)(LCD) 화면에 전달하는 것입니다. 모든 디스플레이는 갱신 비율(refresh rate), 즉 그래픽 컨트롤러에서 새 데이터를 받아와서 화면에 그 이미지를 다시 그려주는 초당 횟수가 있습니다. 전형적인 LCD는 보통 1초에 60번 데이터를 새로 받아서 그려줍니다(주파수로 60 Hz). 화면과 그래픽 컨트롤러가 LVDS로 연결되어 있을 때, LVDS 시스템이 매 갱신 주기마다 전력을 소비합니다. 대부분의 LCD 화면의 갱신 비율을 유휴시간에 30 Hz까지 사용자에게 눈에 띄는 효과를 미치지 않으면서 떨어뜨릴 수 있습니다(갱신 비율을 감소시키면 깜빡임을 야기하는 음극선관(cathode ray tube)(CRT) 모니터와는 다릅니다). Red Hat Enterprise Linux 6에 포함된 인텔 그래픽 아답터 드라이버는 이러한 클럭낮추기(downclocking)를 자동으로 수행해서, 화면이 유휴상태일 때 소비전력을 0.5 W 근처로 낯출 수 있습니다.
그래픽 아답터에 쓰이는 동기화된 동적 랜덤 액세스 메모리(Synchronous dynamic random access memory)(SDRAM)은 개별 메모리 셀에 저장된 데이터를 유지하기 위해 1초에 수천번 갱신됩니다. 원래의 기능인 메모리에서 데이터를 가져오고, 메모리에 데이터를 쓰는 작업 이외에, 이 갱신작업을 시작하는 것도 메모리 컨트롤러의 책임입니다. 하지만, SDRAM은 또한 처전력 자체 갱신 모드를 제공합니다. 이 모드에서, 메모리는 자기 자신의 갱신 주기를 만들기 위해 내부 타이머를 활용합니다. 이에 따라 시스템은 메모리 컨트롤러를 메모리에 저장된 데이터를 잃지 않으면서도 중단시킬 수 있습니다. Red Hat Enterprise Linux 6에 사용된 커널은 유휴시 인텔 그래픽 아답터의 메모리 자체 갱신을 활성화 시켜서, 0.8 W 가까운 전력을 절약할 수 있습니다.
전형적인 그래픽 처리 유니트(GPU)는 내부 회로의 여러 부분을 관장하는 내부 클럭을 포함합니다. Red Hat Enterprise Linux 6에 사용된 커널은 인텔과 ATI GPU 중 일부의 내부 클럭 주파수를 낮출 수 있습니다. 어떤 주어진 시간 동안 GPU 구성요소가 수행하는 작업의 사이클을 줄이는 것을 통해 GPU가 수행하지 않아도 될 사이클에서 소모하는 전력을 줄일 수 있습니다. 커널은 자동으로 GPU가 유휴상태일 때 이러한 클럭의 속도를 줄이며, GPU의 활동이 늘어나면 클럭을 다시 높여줍니다. GPU 클럭을 줄임으로써 최대 5 W의 전력을 절약할 수 있습니다.
Red Hat Enterprise Linux 6의 인텔과 ATI 그래픽 드라이버는 어답터에 모니터가 연결되지 않은 경우를 감지해서, 그런 경우 GPU를 완전히 꺼줍니다. 이 기능은 특별히 보통 모니터를 연결해 놓지 않는 서버들의 경우 매우 중요합니다.
3.10. RFKill
/dev/rfkill에 위치하며, 그 안에는 시스템의 모든 전파 송수신 장치의 상태정보가 포함되어 있습니다. 각각의 장치는 현재의 RFKill 상태를 sysfs에 등록해 둡니다. 추가적으로, RFKill이 활성화되어 있는 장치의 상태가 변화되면 RFKill은 uevents 이벤트를 발생시킵니다.
rfkill list를 사용해 장치의 목록을 얻습니다. 각각의 장치는, 0번 부터, 연관된 인덱스 번호를 부여받습니다. 이 인덱스 번호를 사용해 rfkill에 어떤 장치를 블럭하거나 블럭을 해제해도록 지정할 수 있습니다. 예를 들면:
rfkill block 0rfkill block wifirfkill block allrfkill block 대신 rfkill unblock를 사용합니다. rfkill이 블럭할 수 있는 장치들의 종류를 확인하려면 rfkill help를 실행하십시오.
3.11. 사용자 공간에서의 최적화
Red Hat Enterprise Linux 6는 틱 없는 커널(tickless kernel)을 사용합니다(3.4절. “틱없는 커널” 참조). 이는 CPU가 더 깊은 유휴 상태에 더 오래 있도록 해 줍니다. 하지만, 타이머 틱(timer tick)만이 과도하게 CPU를 깨우는 원인은 아니며, 어플리케이션에서 함수를 호출하는 것도, CPU가 유휴 상태에 들어가거나, 그 상태에 남아있지 못하는 원인이 됩니다. 불필요한 함수 호출을 50개 이상의 어플리케이션에서 감소시켰습니다.
저장소 장치와 네트워크 인터페이스에 대한 입출력(IO)이 있으면 장치들이 전력을 소비하게 됩니다. 유휴시 저전력 상태를 가질 수 있는 저장소와 네트워크 장치(예: ALPM이나 ASPM)에서, 이러한 트래픽은 해당 장치가 유휴 상태에 들어가거나 남아있는 것을 막게 되며, 하드 드라이브가 사용중이 아닐 때 회전수를 감소시키지 못하게 됩니다. 저장소에 대한 불필요하거나 과도한 요청을 몇몇 어플리케이션에서 최소화 시켰습니다. 특히, 하드 드라이브를 계속 돌게 만드는 몇몇 어플리케이션들을 수정했습니다.
사용 여부와 관계 없이 자동으로 시작되는 서비스들은 시스템 자원을 낭비할 가능성이 매우 큽니다. 대신, 서비스들은 가능한 한 디폴트로 "미사용"이거나 "요청시 사용"으로 설정되야 합니다. 예를 들어 Bluetooth를 지원하는 BlueZ 서비스는 예전에는 Bluetooth 장치의 존재 여부와 관계 없이 자동으로 시스템 시작시 실행되었습니다. 이제는 BlueZ initscript가 Bluetooth 장치가 시스템에 있는지를 서비스 시작 전에 검사하도록 변경되었습니다.
4장. 사용 사례
4.1. 예 — 서버
웹서버는 네트워크와 디스크 I/O를 필요로 합니다. 위부 연결 속도에 따라서 100 Mbit/s가 충분할 수도 있습니다. 만약 기계가 대부분 정적인 페이지를 서비스한다면, CPU 성능은 그리 중요하지 않을 수도 있습니다. 따라서 전원 관리 선택 사항은 다음을 포함할 수 있을 것입니다:
- tuned에 대해 디스크/네트워크 플러그인을 제외합니다.
- ALPM을 켭니다.
ondemand조정기를 켭니다.- 네트워크 카드를 100 Mbit/s로 제한합니다.
계산 서버는 주로 CPU를 필요로 합니다. 전원 관리 선택은 다음과 같이 할 수 있습니다:
- 수행하려는 작업과 데이터를 저장하는 장소에 따라서, tuned에 대해 디스크나 네트워크 플로그인을 사용합니다. 배치 모드 시스템의 경우 tuned를 완전히 활성화 합니다.
- 활용도에 따라서, 아마도
performance조정기를 사용해야 할 것입니다.
메일서버는 주로 디스크 I/O와 CPU를 필요로 합니다. 전원 관리는 다음과 같을 수 있습니다:
ondemand조정기를 켭니다. 왜냐하면 마지막 몇 %의 CPU 성능을 더 발휘하는 것이 중요하지는 않기 때문입니다.- tuned에 대해 디스크/네트워크 플러그인을 제외합니다.
- 네트워크 속도를 제한하지 않아야 할 것입니다. 왜냐하면 메일은 때로 내부용으로 쓰이며, 이런 경우 1 Gbit/s나 10 Gbit/s 연결의 잇점을 살릴 수 있을 것이기 때문입니다.
파일서버는 메일서버와 유사한 요구사항을 필요로 합니다. 하지만, 사용할 프로토콜에 따라서, 더 많은 CPU성능을 필요로 할 수도 있습니다. 보통 삼바 기반의 서버가 NFS에 비해 더 많은 CPU 성능을 필요로 합니다. 또한 NFS는 보통 iSCSI보다 더 많은 CPU 성능을 필요로 합니다. 그럼에도 불구하고, ondemand 조정기를 사용할 수 있을 것입니다.
보통 디렉토리 서버는 디스크 I/O에 대한 필요성이 적습니다. 이는 특히 RAM이 많은 경우 더 그렇습니다. 네트워크 응답 시간이 더 중요하지만, 네트워크 I/O는 덜 중요합니다. 사용자는 더 낮은 전송 속도에서 네트워크 응답 속도에 대한 튜닝을 진행하는 것을 검토할 수 있을 것입니다. 하지만, 사용하는 특정 네트워크에 따라서 매우 조심스럽게 테스트해야만 합니다.
4.2. 예 — 랩탑
- 시스템 BIOS에서 사용하지 않는 모든 하드웨어를 비활성화 시킵니다. 예를 들어, 병렬포트나 직렬포트, 카드리더, 웹캠, WiFi, 블루투스등이 가능한 대상이 될 수 있습니다.
- 화면을 편안히 보기 위해 최고 밝기가 필요하지 않은 경우라면, 화면 밝기를 가능한 한 어둡게 합니다. GNOME 데스크탑의 + → 를 사용하거나, KDE 데스크탑의 +++ → 을 사용하거나, 명령행에서 xbacklight을 사용하면 됩니다; 또는 랩탑의 기능키를 사용합니다.
- tuned-adm의
laptop-battery-powersave프로파일을 사용해 전체 에너지 절약 메카니즘을 활성화합니다. 성능과 하드디스크/네트워크의 응답시간이 영향받을 수 있다는 것을 명심하십시오.
ondemand조정기를 사용합니다(Red Hat Enterprise Linux 6에서는 디폴트)- 랩탑 모드를 활성화합니다(
laptop-battery-powersave프로파일의 일부):echo 5 > /proc/sys/vm/laptop_mode - 디스크 플러시 시간 간격을 늘립니다(
laptop-battery-powersave프로파일의 일부):echo 1500 > /proc/sys/vm/dirty_writeback_centisecs - nmi 와치독을 비활성화합니다(
laptop-battery-powersave프로파일의 일부):echo 0 > /proc/sys/kernel/nmi_watchdog - AC97 오디오 전원 절약을 활성화(Red Hat Enterprise Linux 6에서는 디폴트로 활성화됨):
echo Y > /sys/module/snd_ac97_codec/parameters/power_save - 멀티코어 전원절약을 활성화(
laptop-battery-powersave프로파일의 일부):echo 1 > /sys/devices/system/cpu/sched_mc_power_savings - USB 자동 중단(auto-suspend을 활성화:
for i in /sys/bus/usb/devices/*/power/autosuspend; do echo 1 > $i; doneUSB 자동 중단이 모든 USB 장치에서 잘 동작하는 것은 아님을 알아두십시오. - ALPM 최소 전력 설정 활성화(
laptop-battery-powersave프로파일의 일부):echo min_power > /sys/class/scsi_host/host*/link_power_management_policy - relatime을 사용해 파일시스템 마운트(Red Hat Enterprise Linux 6에서는 디폴트):
mount -o remount,relatime mountpoint - 하드드라이브의 최대 전원 절약 모드를 활성화(
laptop-battery-powersave프로파일의 일부):hdparm -B 1 -S 200 /dev/sd* - CD-ROM 폴링 금지(
laptop-battery-powersave프로파일의 일부):hal-disable-polling --device /dev/scd* - 화면 밝기를
50또는 그 이하로 감소시키기. 예:xbacklight -set 50 - 유휴시 화면의 DPMS를 활성화:
xset +dpms; xset dpms 0 0 300 - Wi-Fi 전력 수준을 낮춤(
laptop-battery-powersave프로파일의 일부):for i in /sys/bus/pci/devices/*/power_level ; do echo 5 > $i ; done - Wi-Fi를 사용하지 않음:
echo 1 > /sys/bus/pci/devices/*/rf_kill - 유선 네트워크 속도를 100 Mbit/s로 제한함(
laptop-battery-powersave프로파일의 일부):ethtool -s eth0 advertise 0x0F
부록 A. 개발자를 위한 팁
- 쓰레드의 사용.
- 불필요한 CPU 깨우기를 야기하며, 깨어난 CPU를 효율적으로 활용하지 못하는 것. 만약 CPU를 깨워야만 한다면, 해야할 일 전체를 깨어난 CPU에서 한꺼번에 가능한 한 빨리 수행하십시오(race to idle, 역주: CPU 절전기능이 뛰어나기 때문에 CPU가 깨어있을 때는 최대한 빠른 속도로 필요한 작업을 수행하고, 유휴상태로 남는 시간을 최대한 늘려야 전력 소모를 최소화할 수 있다는 것).
[f]sync()를 불필요하게 사용하는 것.- 불필요한 액티브 폴링 또는, 짧게 주기적으로 타임아웃을 사용하는 것. (대신 이벤트에 반응하도록 수정하십시오).
- 깨어난 CPU를 효율적으로 사용하지 않는 것.
- 비효율적인 디스크 액세스. 잦은 디스크 액세스를 방지하기 위해 커다란 버퍼를 사용하십시오. 한번에 커다란 블럭을 쓰도록 하십시오.
- 비효율적인 타이머 사용. 가능한 한 어플리케이션 사이에(가능한 한 시스템 전반에 걸쳐서도) 타이머를 그룹화하도록 하십시오.
- 과도학 I/O, 전력 소모, 또는 메모리 사용(메모리 누수 포함)
- 불필요한 계산 수행.
A.1. 쓰레드의 사용
Python은 전역 잠금 인터프리터(Global Lock Interpreter)[1]를 사용하며, 이에 따라 쓰레드를 사용하는 것은 오직 커다란 I/O 연산에서만 이득이 있습니다. Unladen-swallow[2]가 코드를 최적화하는 데 사용할 수 있는 더 빠른 파이썬 구현입니다.
펄 쓰레드는 원래 fork를 하지 않는 시스템(32비트 Windows 운영체제 등)에서 동작하는 프로그램을 위해 만들어졌습니다. 펄 쓰레드에서 데이터는 모든 개별 쓰레드에 복사됩니다(쓰기시 복사,Copy On Write). 사용자들이 데이터 공유의 수준을 결정할 수 있기 때문에, 데이터는 기본적으로 공유되지 않습니다. 데이터를 공유하기 위해서는 threads::shared 모듈을 포함시켜야 합니다. 하지만, 그렇게 할 경우 데이터가 (쓰기시 복사에 의해) 복사될 뿐아니라, 공유 모듈에 의해서 해당 데이터와 연계된 변수도 만들어집니다. 이 작업은 더 시간이 걸리고 더 느립니다.[3]
C 쓰레드는 메모리를 공유하고, 개별 쓰레드마다 자신만의 스택이 있습니다. 또한 커널은 쓰레드에 대해 새로운 파일 디스크립터를 할당하거나 새로운 메모리 공간을 할당할 필요가 없습니다. C는 실제로 더 많은 쓰레드에 대해 더 많은 CPU지원을 활용할 수 있습니다. 따라서 쓰레드의 성능을 최고로 끌어올리기 위해, C나 C++과 같은 저수준 언어를 사용하십시오. 만약 스크립트 언어를 사용한다면, C 바인딩(binding)을 작성하는 것을 고려해 보십시오. 프로파일러(profiler)를 사용해 코드에서 성능이 낮은 부분을 판별하십시오.[4]
A.2. 디스크 동작
int fd;
fd = inotify_init();
int wd;
/* checking modification of a file - writing into */
wd = inotify_add_watch(fd, "./myConfig", IN_MODIFY);
if (wd < 0) {
inotify_cant_be_used();
switching_back_to_previous_checking();
}
...
fd_set rdfs;
struct timeval tv;
int retval;
FD_ZERO(&rdfs);
FD_SET(0, &rdfs);
tv.tv_sec = 5;
value = select(1, &rdfs, NULL, NULL, &tv);
if (value == -1)
perror(select);
else {
do_some_stuff();
}
.../proc/sys/fs/inotify/max_user_watches에서 찾을 수 있으며, 변경할 수 있긴 하지만, 변경을 권장하지는 않습니다. 더구나, /proc/sys/fs/inotify/max_user_watches가 제공되지 않는 경우, 코드는 다른 체크 방법으로 복구를 시도해야 하며, 이는 보통 소스 코드의 여러 부분에 #if #define가 나타나는 것을 의미합니다.
A.3. Fsync
Fsync는 I/O 비용이 많이 드는 시스템 콜로 알려져 있습니다. 하지만 항상 그런것은 아닙니다. 예를 들어 Theodore Ts'o의 글 Don't fear the fsync! [5]과 그에 따르는 토론을 살펴보십시오.
fsync를 부르고, 파일 시스템 설정(주로 ext3에 데이터 정렬 모드)에 따라서는, 아무 일이 일어자니 않더라도 응답 시간이 매우 길었습니다. 만약 다른 프로세스가 동시에 큰 파일을 복사하고 있는 중이라면 이 작업에 아주 긴 시간(최대 30초까지)이 걸릴 수도 있습니다.
fsync를 전혀 사용하지 않는 다른 경우에도 ext4 파일 시스템으로 변경하자 문제가 발생했습니다. Ext3은 데이터-정렬 모드 (data-ordered mode)로 설정되어, 몇초마다 메모리를 플러시해서 디스크에 저장했습니다. 하지만 ext4에서는 랩톱 모드 (laptop_mode)로 설정되어 저장 간격이 더 길어졌고, 시스템이 중간에 예기치 않게 꺼지면 데이터가 손실될 수 있었습니다. 이제 ext4가 패치가 되었지만, 여전히 프로그램을 설계할 때 fsync를 적절히 사용하도록 주의를 기울여야만 합니다.
/* open and read configuration file e.g. ~/.kde/myconfig */
fd = open("./kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
close(fd);open("/.kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
fd = open("/.kde/myconfig.suffix", O_WRONLY|O_TRUNC|O_CREAT);
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
fsync; /* paranoia - optional */
...
close(fd);
rename("/.kde/myconfig", "/.kde/myconfig~"); /* paranoia - optional */
rename("/.kde/myconfig.suffix", "/.kde/myconfig");부록 B. 개정 내역
| 고친 과정 | |||
|---|---|---|---|
| 고침 1.0-10.400 | 2013-10-31 | ||
| |||
| 고침 1.0-10 | 2012-07-18 | ||
| |||
| 고침 1.0-2 | Fri Oct 22 2010 | ||
| |||
| 고침 1.0-1 | Thu Oct 7 2010 | ||
| |||
| 고침 1.0-0 | Thu Oct 7 2010 | ||
| |||