
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Handbuch zur Energieverwaltung
Verwaltung des Energieverbrauchs unter Red Hat Enterprise Linux 6
Ausgabe 1.0
Zusammenfassung
Kapitel 1. Überblick
1.1. Bedeutung von Energieverwaltung
- Reduzierung des Gesamt-Stromverbrauchs zur Kostensenkung
- Wärmereduzierung für Server und Rechenzentren
- verminderte Zweitkosten, inklusive Kühlung, Platz, Kabel, Generatoren und Uninterruptible Power Supplies (UPS)
- verlängerte Lebensdauer für Akkus für Laptops
- niedrigerer Kohlendioxid-Ausstoß
- Einhaltung von Regulierungen oder legalen Anforderungen in Bezug auf Green-IT seitens Regierungen, z.B. Energy Star
- Umsetzung von Unternehmens-Richtlinien für neue Systeme
- F: Muss ich optimieren?
- F: Wie viel muss ich optimieren?
- F: Reduziert die Optimierung die Systemleistung auf ein nicht akzeptables Level?
- F: Übertrifft der Aufwand bei der Optimierung hinsichtlich Zeit und Ressourcen die erzielten Gewinne?
1.2. Grundlagen zur Energieverwaltung
Der Red Hat Enterprise Linux 5 Kernel verwendete einen periodischen Taktgeber für jede CPU. Dieser Taktgeber verhindert, dass sich die CPU tatsächlich in den Leerlauf versetzt, da die CPU jede Anfrage des Taktgebers verarbeiten muss (was alle paar Millisekunden passieren würde, je nach Einstellung), unabhängig davon, ob irgendein Prozess lief oder nicht. Ein großer Teil effizienter Energieverwaltung umfasst die Reduzierung der Frequenz, bei der CPU-Wakeups initiiert werden.
Dies trifft besonders auf Geräte zu, die bewegliche Teile besitzen (z.B. Festplatten). Darüber hinaus halten einige Anwendungen die Verbindung zu einem nicht benutzten, jedoch aktivierten Gerät "open". Wenn dies passiert, nimmt der Kernel an, dass das Gerät in Gebrauch ist, was verhindert, dass das Gerät in einen Energiesparmodus versetzt wird.
In vielen Fällen hängt dies jedoch von moderner Hardware und einer korrekten BIOS-Konfiguration ab. Ältere Systemkomponenten unterstützen oft einige der neuen Features, die jetzt unter Red Hat Enterprise Linux 6 unterstützt werden, nicht. Stellen Sie sicher, dass Sie die aktuellste, offizielle Firmware für Ihre Systeme verwenden und dass die Energieverwaltungs-Features in den Abschnitten 'Energieverwaltung' oder 'Gerätekonfiguration' des BIOS aktiviert sind. Einige Features, auf die geachtet werden sollte, sind:
- SpeedStep
- PowerNow!
- Cool'n'Quiet
- ACPI (C-Zustand)
- Smart
Moderne CPUs liefern im Zusammenhang mit Advanced Configuration and Power Interface (ACPI) verschiedene Strom-Zustände. Die drei verschiedenen Zustände sind:
- Sleep (C-Zustände)
- Frequency (P-Zustände)
- Wärmeausgabe (T-Zustände oder "Thermal States")
So offensichtlich dies erscheinen mag - einer der besten Wege, um tatsächlich Strom zu sparen, ist das Abschalten eines Systems. Ihr Unternehmen kann beispielsweise eine Unternehmenskultur entwickeln, die auf dem Bewusstsein von "Green IT" ausgerichtet ist und eine Richtlinie zur Abschaltung von Maschinen während der Mittagspause oder nach Feierabend liefert. Sie können außerdem in Betracht ziehen, mehrere physikalische Server in einen größeren Server zusammenzufassen und mit Hilfe der Virtualisierungstechnologie, die wir mit Red Hat Enterprise Linux 6 ausliefern, zu virtualisieren.
Kapitel 2. Energieverwaltung - Auditing und Analyse
2.1. Überblick über Audit und Analyse
2.2. PowerTOP
yum install powertoppowertopdie VM Dirty Writeback-Zeit zu erhöhen, und die Tastaturbelegung (W), um den Vorschlag zu akzeptieren.
C4 höher ist, als C3). Gleichzeitig ist dies ein guter Indikator dafür, wie gut das System bezüglich der CPU-Verwendung abgestimmt ist. Ihr Ziel sollte ein Wert von 90% oder höher im höchsten C- oder P-Zustand sein, wenn das System sich im Leerlaufbetrieb befindet.
<> aufgelisteten Komponente), dann sind die Wakeups oft mit einem speziellen Treiber verknüpft, der sie auslöst. Das Abstimmen von Treibern erfordert für gewöhnlich Änderungen am Kernel, die über das Ausmaß dieses Dokuments hinausgehen. Userland-Prozesse, die Wakeups senden, können jedoch einfacher verwaltet werden. Identifizieren Sie zunächst, ob dieser Dienst oder diese Anwendung überhaupt auf diesem System laufen muss. Falls nicht, deaktivieren Sie diesen/sie einfach. Um einen Dienst permanent zu deaktivieren, führen Sie folgenden Befehl aus:
chkconfig servicename offps -awux | grep componentnamestrace -p processid
die VM Dirty Writeback-Zeit zu erhöhen, und die Tastaturbelegung (W), um den Vorschlag zu akzeptieren.
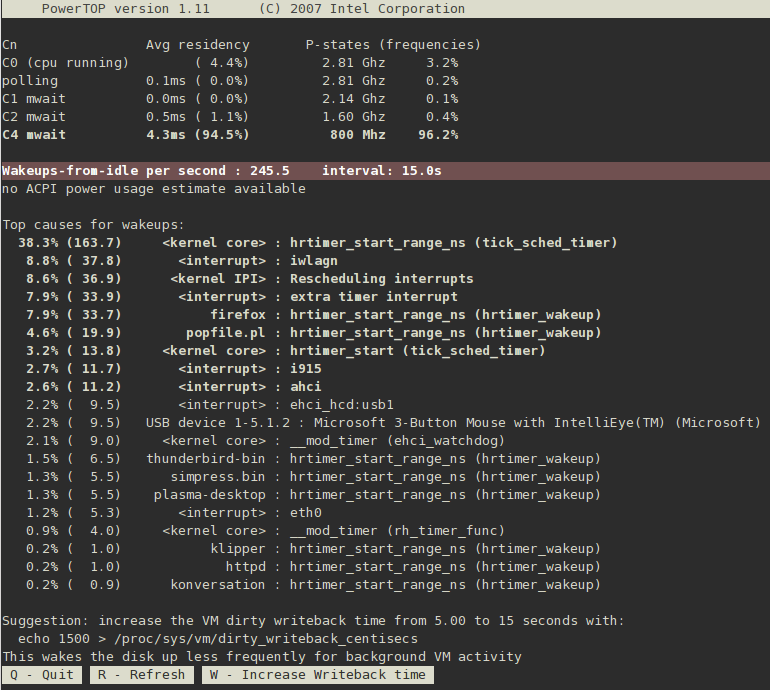
Abbildung 2.1. PowerTOP in Betrieb
2.3. Diskdevstat und netdevstat
yum install systemtap tuned-utils kernel-debuginfodiskdevstatnetdevstatdiskdevstat update_interval total_duration display_histogram
netdevstat update_interval total_duration display_histogram
- update_interval
- Die Zeit in Sekunden zwischen Aktualisierung der Anzeige. Standardwert:
5 - total_duration
- Die Zeit in Sekunden für den gesamten Durchlauf. Standardwert:
86400(1 Tag) - display_histogram
- Ein Flag zum Erstellen eines Histogramms aus allen gesammelten Daten am Ende eines Durchlaufs.
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 15494 0 sda1 0 0.000 0.000 0.000 758 0.000 0.012 0.000 0logwatch 15520 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15549 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15585 0 sda1 0 0.000 0.000 0.000 108 0.001 0.002 0.000 perl 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 15429 0 sda1 0 0.000 0.000 0.000 62 0.009 0.009 0.000 crond 15379 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15473 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15415 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15433 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15425 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15375 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15477 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15469 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15419 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15481 0 sda1 0 0.000 0.000 0.000 61 0.000 0.001 0.000 crond 15355 0 sda1 0 0.000 0.000 0.000 37 0.000 0.014 0.001 laptop_mode 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd 15575 0 sda1 0 0.000 0.000 0.000 16 0.000 0.000 0.000 cat 15581 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15582 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15579 0 sda1 0 0.000 0.000 0.000 12 0.000 0.001 0.000 perl 15580 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 12 0.000 0.170 0.014 sh 15584 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15548 0 sda1 0 0.000 0.000 0.000 12 0.001 0.014 0.001 perl 15577 0 sda1 0 0.000 0.000 0.000 12 0.001 0.003 0.000 perl 15519 0 sda1 0 0.000 0.000 0.000 12 0.001 0.005 0.000 perl 15578 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15583 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15547 0 sda1 0 0.000 0.000 0.000 11 0.000 0.002 0.000 perl 15576 0 sda1 0 0.000 0.000 0.000 11 0.001 0.001 0.000 perl 15518 0 sda1 0 0.000 0.000 0.000 11 0.000 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 10 0.053 0.053 0.005 lm_lid.sh
- PID
- Die Prozess-ID der Anwendung
- UID
- Die Benutzer-ID, unter welcher die Anwendungen laufen
- DEV
- Das Gerät auf welchem der I/O stattfand
- WRITE_CNT
- Die Gesamtanzahl der Schreiboperationen
- WRITE_MIN
- Die niedrigste Zeit, für zwei aufeinander folgende Schreibprozesse (in Sekunden)
- WRITE_MAX
- Die maximale Zeit, für zwei aufeinander folgende Schreibprozesse (in Sekunden)
- WRITE_AVG
- Die durchschnittliche Zeit, für zwei aufeinander folgende Schreibprozesse (in Sekunden)
- READ_CNT
- Die Gesamtanzahl für Lese-Operationen
- READ_MIN
- Die niedrigste Zeit, für zwei aufeinander folgende Leseprozesse (in Sekunden)
- READ_MAX
- Die maximale Zeit, für zwei aufeinander folgende Leseprozesse (in Sekunden)
- READ_AVG
- Die durchschnittliche Zeit, für zwei aufeinander folgende Leseprozesse (in Sekunden)
- COMMAND
- Der Name des Prozesses
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd
WRITE_CNT größer als 0, was bedeutet, dass sie eine Form von Schreibprozess während des Meßvorgangs durchgeführt haben. Von diesen war plasma bei weitem schlimmste Missetäter: es führte die meisten Schreiboperationen durch und natürlich war die durchschnittliche Zeit zwischen den Schreiboperationen die niedrigste. Aus diesem Grund wäre Plasma der beste Kandidat für Nachforschungen, wenn Sie sich Gedanken zu strom-ineffizienten Anwendungen machen würden.
strace -p 2789strace ein sich alle 45 Sekunden wiederholendes Muster, welches die KDE-Symbol Cache-Datei des Benutzers zum Schreiben öffnete, gefolgt von einem unmittelbaren Schließen der Datei. Daraus ergab sich ein notwendiges physikalisches Schreiben auf die Festplatte, da sich die Meta-Informationen der Datei (speziell der Änderungszeit) geändert hatten. Die abschließende Behebung war das Vermeiden dieser unnötigen Aufrufe, wenn keine Aktualisierungen an den Symbolen aufgetreten waren.
2.4. Battery Life Tool Kit
-a gestartet wird.
office-Workload beispielsweise einen Text, korrigiert den Inhalt und wiederholt den Vorgang für eine Tabellenkalkulation. Wenn Sie BLTK in Kombination mit PowerTOP oder jedem anderen Auditing- oder Analyse-Werkzeug ausführen, können Sie testen, ob die von Ihnen durchgeführten Optimierungen eine Auswirkung haben, wenn die Maschine aktiv benutzt wird, anstatt nur im Leerlauf zu sein. Da Sie den exakt selben Workload mehrere Male für verschiedene Einstellungen ausführen können, können Sie die Ergebnisse für verschiedene Einstellungen vergleichen.
yum install bltkbltk workload optionsidle-Workload für 120 Sekunden auszuführen:
bltk -I -T 120-I,--idle- Das System befindet sich im Leerlauf und kann als Vergleichsbasis für anderen Workloads herangezogen werden
-R,--reader- simuliert das Lesen von Dokumenten (standardmäßig mit Firefox)
-P,--player- simuliert das Ansehen von multimedialen Dateien von einem CD- oder DVD-Laufwerk (standardmäßig mit mplayer)
-O,--office- simuliert das Bearbeiten von Dokumenten mit der OpenOffice.org-Suite
-a,--ac-ignore- ignoriert, ob AC-Strom zur Verfügung steht (wird bei Desktop-Gebrauch benötigt)
-T number_of_seconds,--time number_of_seconds- die Dauer (in Sekunden), wie lange der Test laufen soll. Verwenden Sie diese Option mit
idle-Workload -F filename,--file filename- bestimmt eine Datei, die mir einem bestimmten Workload verwendet werden soll, z.B. einer Datei für den
player-Workload, die abgespielt werden soll, anstatt auf das CD- oder DVD-Laufwerk zuzugreifen -W application,--prog application- definiert eine Anwendung, die mit einem bestimmten Workload verwendet werden soll, z.B. einem anderen Browser als Firefox für den
reader-Workload
bltk-Handbuchseite für weitere Details.
/etc/bltk.conf definierten Verzeichnis — standardmäßig ~/.bltk/workload.results.number/. So beinhaltet das Verzeichnis ~/.bltk/reader.results.002/ beispielsweise das Ergebnis des dritten Tests mit dem reader-Workload (der erste Test wird nicht gezählt). Das Ergebnis wird über mehrere Textdateien verteilt. Um diese Ergebnisse in ein leicht zu lesendes Format zusammenzufassen, führen Sie Folgendes aus:
bltk_report path_to_results_directoryReport im Ergebnis-Verzeichnis. Um die Ergebnisse alternativ in einem Terminal anzusehen, verwenden Sie die Option -o:
bltk_report -o path_to_results_directory2.5. Tuned und ktune
yum install tuned/etc/tuned.conf eingerichtet und das Standardprofil aktiviert.
service tuned startchkconfig tuned on-d,--daemon- tuned als Daemon starten, anstatt es im Vordergrund laufen zu lassen.
-c,--conffile- eine Konfigurationsdatei mit dem angegeben Namen und Pfad verwenden, z.B.
--conffile=/etc/tuned2.conf. Der Standard ist/etc/tuned.conf. -D,--debug- die höchste Log-Stufe verwenden.
2.5.1. Die Datei tuned.conf.
tuned.conf beinhaltet Konfigurationseinstellungen für tuned. Standardmäßig befindet sie sich unter /etc/tuned.conf, aber Sie können einen anderen Namen und Ort angeben, indem Sie tuned mit der Option --conffile starten.
[main] beinhalten, der die allgemeinen Parameter für tuned definiert. Die Datei umfasst dann einen Abschnitt pro Plugin.
[main] enthält die folgenden Optionen:
interval- das Intervall in Sekunden, in dem tuned das System überwachen und abstimmen soll. Der Standardwert ist
10. verbose- gibt an, ob die Ausgabe umfangreich sein soll. Der Standardwert ist
False. logging- gibt die unterste Priorität für Meldungen an, die protokolliert werden sollen. In abfallender Reihenfolge sind die folgenden Werte gültig:
critical,error,warning,infounddebug. Der Standardwert istinfo. logging_disable- gibt die oberste Priorität für Meldungen an, die protokolliert werden sollen. Jede Meldung mit dieser Priorität oder niedriger wird nicht protokolliert. In aufsteigender Reihenfolge sind die folgenden Werte gültig:
critical,error,warning,infounddebug. Der Wertnotsetdeaktiviert diese Option.
[CPUTuning]. Jedes Plugin kann seine eigenen Optionen besitzen, Folgendes trifft jedoch auf alle Plugins zu:
enabled- gibt an, ob das Plugin aktiviert ist, oder nicht. Der Standardwert ist
True. verbose- gibt an, ob die Ausgabe umfangreich sein soll. Falls nicht für dieses Plugin gesetzt, wird der Wert von
[main]übernommen. logging- gibt die unterste Priorität für Meldungen an, die protokolliert werden sollen. Falls nicht für dieses Plugin gesetzt, wird der Wert von
[main]übernommen.
[main] interval=10 pidfile=/var/run/tuned.pid logging=info logging_disable=notset # Disk monitoring section [DiskMonitor] enabled=True logging=debug # Disk tuning section [DiskTuning] enabled=True hdparm=False alpm=False logging=debug # Net monitoring section [NetMonitor] enabled=True logging=debug # Net tuning section [NetTuning] enabled=True logging=debug # CPU monitoring section [CPUMonitor] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True # CPU tuning section [CPUTuning] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True
2.5.2. Tuned-adm
tuned-adm einfach auswählen können. Sie können jedoch Profile auch selbst erstellen, modifizieren oder löschen.
tuned-adm listtuned-adm activetuned-adm profile profile_nametuned-adm profile server-powersavetuned-adm offdefault aktiviert. Daneben umfasst Red Hat Enterprise Linux 6 auch die folgenden vordefinierten Profile:
- default
- das standardmäßige Stromspar-Profil. Es hat von allen verfügbaren Profilen die geringste Auswirkung auf das Stromsparen und aktiviert lediglich CPU- und Platten-Plugins von tuned.
- desktop-powersave
- ein Stromspar-Profil, das auf Desktop-Systeme ausgerichtet ist. Aktiviert ALPM-Stromsparen für SATA-Host-Adapter (siehe Abschnitt 3.6, »Aggressive Link Power Management«), sowie die Plugins des tuned für CPU, Ethernet und Festplatte.
- server-powersave
- ein Stromspar-Profil, das auf Server-Systeme ausgerichtet ist. Aktiviert ALPM-Stromsparen für SATA-Host-Adapter, deaktiviert das Abfragen von CD-ROM via HAL (siehe hal-disable-polling-Handbuchseite) und aktiviert die CPU- und Festplatten-Plugins des tuned.
- laptop-ac-powersave
- ein Stromspar-Profil mit mittlerer Auswirkung, ausgerichtet auf Laptops im Strombetrieb. Aktiviert ALPM-Stromsparen für SATA-Host-Adapter, Wi-Fi-Stromsparen, sowie die CPU-, Ethernet- und Festplatten-Plugins des tuned.
- laptop-battery-powersave
- ein Stromspar-Profil mit großer Auswirkung, das auf Laptops im Batteriebetrieb ausgerichtet ist. Es aktiviert alle Stromspar-Mechanismen der vorherigen Profile und aktiviert zusätzlich noch den Mehrkern-Stromspar-Scheduler für niedrige Wakeup-Systeme und stellt sicher, dass der Ondemand-Governor, sowie AC97 Audio-Stromsparen aktiviert sind. Sie können dieses Profil verwenden, um die maximale Menge an Strom auf jeglicher Art von System zu sparen, nicht nur Laptops im Batteriebetrieb.
- throughput-performance
- ein Server-Profil für typisches Anpassen der Durchsatz-Leistung. Es deaktiviert die tuned und ktune Stromspar-Mechanismen, aktiviert sysctl-Einstellungen, die die Durchsatz-Leistung Ihrer Festplatten- und Netzwerk-I/O verbessern und wechselt zum Deadline Scheduler.
- latency-performance
- ein Server-Profil für typisches Anpassen der Latenz-Leistung. Es deaktiviert die tuned und ktune Stromspar-Mechanismen und aktiviert sysctl-Einstellungen, die die Latenz-Leistung ihrer Netzwerk-I/O verbessern.
/etc/tune-profiles abgelegt. /etc/tune-profiles/desktop-powersave umfasst somit alle notwendigen Dateien und Einstellungen für dieses Profil. Jedes dieser Verzeichnisse enthält bis zu vier Dateien:
tuned.conf- die Konfiguration des Tuned-Dienstes, die für dieses Profil aktiv sein soll.
sysctl.ktune- die von ktune verwendeten sysctl-Einstellungen. Das Format ist identisch mit der Datei
/etc/sysconfig/sysctl(siehe sysctl und sysctl.conf Handbuchseiten). ktune.sysconfig- die Konfigurationsdatei von ktune selber, üblicherweise
/etc/sysconfig/ktune. ktune.sh- ein Shell-Skript im Stil von init, welches vom ktune-Dienst verwendet wird und mit Hilfe dessen spezielle Befehle während des Systemstarts zum Anpassen des Systems ausgeführt werden können.
laptop-battery-powersave beinhaltet bereits ein umfangreiches Set an Anpassungen und ist somit ein nützlicher Ausgangspunkt. Kopieren Sie einfach das gesamte Verzeichnis zu dem neuen Profilnamen, wie folgt:
cp -a /etc/tune-profiles/laptop-battery-powersave/ /etc/tune-profiles/myprofile# Disable HAL polling of CDROMS # for i in /dev/scd*; do hal-disable-polling --device $i; done > /dev/null 2>&1
2.6. DeviceKit-power und devkit-power
devkit-power und den folgenden Optionen auf die Kommandozeilen-Werkzeuge zugreifen:
--enumerate,-e- zeigt einen Objektpfad für jedes Energiegerät auf dem System an, z.B.:
/org/freedesktop/DeviceKit/power/devices/line_power_AC/org/freedesktop/UPower/DeviceKit/power/battery_BAT0 --dump,-d- zeigt die Parameter für alle Energiegeräte auf dem System an.
--wakeups,-w- zeigt die CPU-Wakeups auf dem System an.
--monitor,-m- überwacht das System auf Änderungen an den Energiegeräten, z.B. dem Anschließen/Entfernen einer Stromquelle oder dem Entleeren einer Batterie. Drücken Sie Strg+C, um die Überwachung des Systems zu beenden.
--monitor-detail- überwacht das System auf Änderungen an den Energiegeräten, z.B. dem Anschließen/Entfernen einer Stromquelle oder dem Entleeren einer Batterie. Die Option
--monitor-detailliefert mehr Details, als die Option--monitor. Drücken Sie Strg+C, um die Überwachung des Systems zu beenden. --show-info object_path,-i object_path- zeigt alle Informationen an, die für einen speziellen Objektpfad zur Verfügung stehen. Um beispielsweise Informationen über eine Batterie auf Ihrem System abzurufen, welche durch den Pfad
/org/freedesktop/UPower/DeviceKit/power/battery_BAT0dargestellt wird, führen Sie Folgendes aus:devkit-power -i /org/freedesktop/UPower/DeviceKit/power/battery_BAT0
2.7. GNOME Power Manager
- Im Netzbetrieb
- Im Batteriebetrieb
- Allgemein
2.8. Andere Auditing-Mittel
- vmstat
- vmstat liefert Ihnen detaillierte Informationen zu Prozessen, Speicher, Paging, Block-I/O, Traps und CPU-Aktivität. Verwenden Sie es, um einen genaueren Überblick zu bekommen, was das System insgesamt tut und wo es beschäftigt ist.
- iostat
- iostat ist ähnlich wie vmstat, allerdings nur für I/O auf Blockgeräten. Es liefert außerdem eine detailliertere Ausgabe und Statistiken.
- blktrace
- blktrace ist ein sehr detailliertes Block-I/O-Trace-Programm. Es unterteilt Informationen in einzelne Blöcke, die mit Anwendungen verknüpft sind. Es ist sehr nützlich in Kombination mit diskdevstat.
Kapitel 3. Zentrale Infrastruktur und Mechanismen
3.1. CPU-Leerlauf-Zustände
- C0
- der Betriebs- oder Lauf-Zustand. In diesem Zustand arbeitet die CPU und befindet sich überhaupt nicht im Leerzustand.
- C1, Halt
- ein Zustand, in dem der Prozessor keinerlei Anweisungen ausführt, sich jedoch in keinem Niedrigstrom-Zustand befindet. Die CPU kann mit der Verarbeitung von Prozessen fast ohne Verzögerung fortfahren. Alle Prozessoren, die C-Zustände bieten, müssen diesen Zustand unterstützen. Pentium 4 Prozessoren unterstützen einen verbesserten C1-Zustand, genannt C1E, der tatsächlich ein Zustand für niedrigeren Stromverbrauch ist.
- C2, Stop-Clock
- ein Zustand, bei dem die Taktrate für diesen Prozessor eingefroren wird, der komplette Zustand für dessen Register und Cache jedoch behalten wird, so dass beim erneuten Start der Taktrate, die Verarbeitung von Prozessen fortfahren kann. Dies ist ein optionaler Zustand.
- C3, Sleep
- ein Zustand, in dem der Prozessor tatsächlich in einen Schlafzustand versetzt wird und der Cache nicht beibehalten werden muss. Das Aufwachen aus diesem Zustand dauert aus diesem Grund deutlich länger, als aus C2. Auch dies ist ein optionaler Zustand.
3.2. CPUfreq-Governors verwenden
3.2.1. CPUfreq Regler-Typen
Der Performanz-Regler zwingt die CPU, die höchstmögliche Taktfrequenz zu verwenden. Diese Frequenz wird statisch festgesetzt und ändert sich nicht. Aus diesem Grund bietet dieser Regler keine Stromsparvorteile. Es ist nur für Zeitspannen mit hoher Workload geeignet und auch nur dann, wenn sich die CPU kaum (oder nie) im Leerlauf befindet.
Im Gegensatz dazu zwingt der Powersave-Regler die CPU, die geringstmögliche Taktfrequenz zu verwenden. Aus diesem Grund bietet dieser spezielle Regler maximale Stromsparvorteile, allerdings auf Kosten der geringsten CPU-Performanz.
Der Ondemand-Regler ist ein dynamischer Regler, der es der CPU ermöglicht, maximale Taktfrequenz zu erreichen, wenn die Systemauslastung hoch ist, sowie die minimale Taktfrequenz, wenn sich das System im Leerlauf befindet. Während dies dem System ermöglicht, den Stromverbrauch entsprechend in Bezug auf die System-Auslastung anzupassen, geschieht dies zu Lasten der Latenz zwischen dem Hin- und Herschalten von Frequenzen. Aus diesem Grund kann Latenz jeglichen durch den Ondemand-Regler offerierten Nutzen bei der Performanz bzw. dem Stromsparen außer Kraft setzen, wenn das System zu oft zwischen Leerlauf und großen Workloads hin- und herwechselt.
Der Userspace-Regler ermöglicht es Userspace-Programmen (oder jeglichen Prozessen, die als Root ausgeführt werden), die Frequenz zu bestimmen. Dieser Regler wird normalerweise in Zusammenhang mit dem cpuspeed-Daemon verwendet. Von allen Reglern ist der Userspace-Regler derjenige, der am meisten angepasst werden kann. Abhängig davon, wie er konfiguriert ist, kann er die beste Balance zwischen Performanz und Verbrauch für Ihr System bieten.
Wie der Ondemand-Regler passt der Conservative-Regler auch die Taktfrequenz, abhängig vom Gebrauch (wie der Ondemand-Regler). Während der Ondemand-Regler dies jedoch in einer aggressiveren Art und Weise tut (d.h. vom Maximalwert zum Minimalwert und zurück), wechselt der Conservative-Regler mehr schrittweise zwischen Frequenzen hin- und her.
Anmerkung
cron-Jobs aktivieren. Dies erlaubt es Ihnen, spezielle Regler automatisch während speziellen Tageszeiten zu bestimmen. Daher können Sie einen Regler mit niedriger Frequenz während Leerlaufzeiten (z.B. nach Büroschluß) definieren und zu einem Regler mit höherer Frequenz während Zeiten mit hohem Workload wechseln.
3.2.2. CPUfreq-Einrichtung
Prozedur 3.1. So wird ein CPUfreq-Treiber hinzugefügt
- Verwenden Sie den folgenden Befehl, um anzuzeigen, welche CPUfreq-Treiber für Ihr System zur Verfügung stehen:
ls /lib/modules/[kernel version]/kernel/arch/[architecture]/kernel/cpu/cpufreq/ - Verwenden Sie den Befehl
modprobe, um den entsprechenden CPUfreq-Treiber hinzuzufügen.modprobe [CPUfreq driver]Stellen Sie sicher, dass Sie den.koDatei-Suffix entfernen, wenn Sie den oben aufgeführten Befehl verwenden.Wichtig
Wählen Sie bei der Auswahl eines entsprechenden CPUfreq-Treibers immeracpi-cpufreqvorp4-clockmod. Auch wenn die Verwendung desp4-clockmod-Treibers die Taktfrequenz einer CPU verringert, reduziert es nicht die Spannung. Im Gegensatz dazu verringertacpi-cpufreqdie Spannung zusammen mit der CPU-Taktfrequenz. Dies ermöglicht einen geringeren Stromverbrauch und Wärmeabgabe für jedes Teil, was allerdings zu Lasten der Performanz geht. - Sobald der CPUfreq-Treiber eingerichtet ist, können Sie sich ansehen, welchen Governor das System derzeit verwendet:
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
cat /sys/devices/system/cpu/[cpu ID]/cpufreq/scaling_available_governorsmodprobe, um die notwendigen Kernel-Module hinzuzufügen, die den spezifischen CPUfreq-Governor, den Sie verwenden möchten, aktivieren. Diese Kernel-Module stehen unter /lib/modules/[kernel version]/kernel/drivers/cpufreq/ zur Verfügung.
Prozedur 3.2. Aktivierung eines CPUfreq-Governors
- Verwenden Sie den Befehl
modprobe, um den Governor, den Sie verwenden möchten, zu aktivieren. Falls beispielsweise derondemand-Governor nicht für Ihre CPU zur Verfügung steht, verwenden Sie den folgenden Befehl:modprobe cpufreq_ondemand - Sobald ein Governor für Ihre CPU als verfügbar aufgelistet ist, können Sie ihn mit dem folgenden Befehl aktivieren:
echo [governor] > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
3.2.3. CPUfreq-Richtlinie und Geschwindigkeit abstimmen
/sys/devices/system/cpu/[cpu ID]/cpufreq/ verwenden. Diese tunables sind:
cpuinfo_min_freq— Zeigt die verfügbare minimale Betriebsfrequenz der CPU (in KHz) an.cpuinfo_max_freq— Zeigt die verfügbare maximale Betriebsfrequenz der CPU (in KHz) an.scaling_driver— Zeigt an, welcher CPUfreq-Treiber zur Einstellung der Frequenz auf dieser CPU verwendet wird.scaling_available_governors— Zeigt die im Rahmen dieses Kernels verfügbaren CPUfreq-Governors an. Falls Sie einen CPUfreq-Governors verwenden möchten, der nicht in dieser Datei aufgeführt ist, werfen Sie einen Blick auf Prozedur 3.2, »Aktivierung eines CPUfreq-Governors« in Abschnitt 3.2.2, »CPUfreq-Einrichtung« für Anweisungen, wie Sie dies tun können.scaling_governor— Zeigt an, welcher CPUfreq-Governor derzeit verwendet wird. Um einen anderen Governor zu verwenden, führen Sie einfachecho [governor] > /sys/devices/system/cpu/[cpu ID]/cpufreq/scaling_governoraus (siehe Prozedur 3.2, »Aktivierung eines CPUfreq-Governors« in Abschnitt 3.2.2, »CPUfreq-Einrichtung« für weitere Informationen).cpuinfo_cur_freq— Zeigt die aktuelle Geschwindigkeit der CPU (in KHz) an.scaling_available_frequencies— Listet verfügbare Frequenzen für die CPU (in KHz) auf.scaling_min_frequndscaling_max_freq— Setzt die policy limits der CPU (in KHz).affected_cpus— Listet CPUs auf, die Software zur Frequenzkoordination benötigen.scaling_setspeed— Wird verwendet, um die Taktrate der CPU zu ändern (in KHz). Sie können nur eine Rate im Rahmen der Richtlinien-Limits der CPU (gemäßscaling_min_frequndscaling_max_freq) setzen.
cat [tunable]. Um beispielsweise die aktuelle Geschwindigkeit der cpu0 (in KHz) anzusehen:
cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq.
echo [value] > /sys/devices/system/cpu/[cpu ID]/cpufreq/[tunable]. Um beispielsweise die Minimal-Taktrate der cpu0 auf 360 KHz zu setzen, verwenden Sie:
echo 360000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
3.3. Suspend (Ruhezustand) und Resume
3.4. Tickless-Kernel
3.5. Active-State Power Management
- default
- setzt Strom-Zustände der PCIe-Verknüpfung auf den von der Firmware des Systems (z.B. BIOS) definierten Standard. Dies ist der standardmäßige Zustand für ASPM.
- powersave
- stellt ASPM so ein, dass Strom gespart wird, wann immer möglich und unabhängig von Einbußen bei der Performanz.
- performance
- deaktiviert ASPM, damit es PCIe-Verknüpfungen möglich ist, mit der maximalen Performanz zu operieren.
/sys/module/pcie_aspm/parameters/policy gesetzt, können aber auch zum Zeitpunkt des Systemstarts mit dem pcie_aspm Kernel-Parameter angegeben werden, wobei pcie_aspm=off ASPM deaktiviert und pcie_aspm=force ASPM aktiviert, sogar auf Geräten, die kein ASPM unterstützen.
Warnung
pcie_aspm=force gesetzt wird, kann Hardware, die kein ASPM unterstützt, dazu führen, dass das System nicht mehr reagiert. Stellen Sie sicher, dass alle PCIe-Hardware auf dem System ASPM unterstützt, bevor Sie pcie_aspm=force setzen.
3.6. Aggressive Link Power Management
Dieser Modus setzt die Verknüpfung auf den untersten Strom-Status (SLUMBER), wenn keine I/O auf der Platte vorhanden sind. Dieser Modus ist dann geeignet, wenn längere Leerlaufzeiten erwartet werden.
Dieser Modus setzt die Verknüpfung auf den zweitniedrigsten Strom-Status (PARTIAL), wenn keine I/O auf der Platte stattfindet. Dieser Modus wurde konzipiert, um Übergänge bei den Verknüpfungen von Strom-Status (z.B. in Zeiten von sporadischen, größeren I/O und I/O im Leerlauf) mit geringstmöglichen Auswirkungen auf die Leistung zu ermöglichen.
medium_power ermöglicht die Verknüpfung von Übergängen zwischen PARTIAL und "ACTIVE" (ohne Stromeinsparung) Zuständen, abhängig von der Auslastung. Beachten Sie, dass es nicht immer möglich ist, eine Verknüpfung direkt von PARTIAL zu SLUMBER und umgekehrt zu erstellen. In diesem Fall kann der jeweilige Strom-Status nicht in den anderen übergehen, ohne zunächst in den ACTIVE-Status zu wechseln.
ALPM ist deaktiviert. Die Verknüpfung geht in keinen Niedrigstrom-Zustand über, wenn es keine I/O auf der Platte gibt.
/sys/class/scsi_host/host*/link_power_management_policy existiert. Schreiben Sie einfach die in diesem Abschnitt beschriebenen Werte in diese Dateien, um die Einstellungen zu ändern oder betrachten Sie die Dateien zur Überprüfung der aktuellen Einstellungen.
3.7. Relatime Drive Access Optimization
atime bezeichnet und seine Wartung erfordert eine beständige Serie von Schreiboperationen auf das Speichergerät. Diese Schreiboperationen beschäftigen Speichergeräte und ihre Verknüpfungen permanent und sorgen dafür, dass Sie angeschaltet bleiben. Da nur wenige Anwendungen von den atime-Daten tatsächlich Gebrauch machen, verschwendet diese Aktivität auf Speichergeräten Strom. Bezeichnenderweise würde das Schreiben auf das Speichergerät auch dann stattfinden, wenn die Datei nicht vom Speichergerät, sondern aus dem Cache gelesen würde. Der Linux-Kernel unterstützt seit einiger Zeit eine noatime-Option für mount und schreibt daher keine atime-Daten auf Dateisysteme, die mit dieser Option eingehängt sind. Das simple Deaktivieren dieses Features ist jedoch problematisch, da einige Anwendungen auf atime-Daten angewiesen sind und fehlschlagen, wenn diese nicht zur Verfügung stehen.
relatime. Relatime speichert die atime-Daten, allerdings nicht für jedes Mal, bei dem auf eine Datei zugegriffen wird. Wird diese Option aktiviert, werden atime-Daten nur dann auf die Platte geschrieben, wenn die Datei seit der letzten Aktualisierung der atime-Daten modifiziert wurde (mtime), oder wenn der letzte Zugriff auf die Datei eine bestimmte Länge überschreitet (standardmäßig ein Tag).
relatime aktiviert eingehängt. Um dieses Feature auf einem gesamten System zu unterdrücken, verwenden Sie den Boot-Parameter default_relatime=0. Falls relatime standardmäßig auf einem System aktiviert ist, können Sie es für jedes beliebige Dateisystem unterdrücken, indem Sie dieses Dateisystem mit der Option norelatime einhängen. Zu guter Letzt, um die vorgegebene Dauer, bis ein System die atime-Daten einer Datei aktualisiert, zu ändern, verwenden Sie den Boot-Parameter relatime_interval=, welcher die Frist in Sekunden angibt. Der Standardwert ist 86400.
3.8. Power-Capping
"Dynamic Power Capping" ist ein Feature, dass auf ausgewählten ProLiant- und BladeSystem-Servern zur Verfügung steht und das es Systemadministratoren ermöglicht, den Stromverbrauch eines Servers oder einer Gruppe von Servern nach oben zu begrenzen. Die Begrenzung ist ein definitives Limit, welches der Server nicht überschreitet, unabhängig von seiner aktuellen Workload. Die Begrenzung tritt nur dann in Kraft, wenn der Server sein Stromverbrauch-Limit erreicht. An dieser Stelle passt ein Management-Prozessor CPU P-Zustände und Taktdrosselung zur Einschränkung des Stromverbrauchs an.
/dev/hpilo/dXccbN abzufragen. Weiterhin umfasst der Kernel eine Erweiterung der hwmon sysfs Schnittstelle zur Unterstützung von Power-Capping-Features, sowie einen hwmon-Treiber für ACPI 4.0 Stromzähler, welcher die sysfs-Schnittstelle verwenden. Insgesamt ermöglichen diese Features Betriebssystemen und User-Space-Werkzeuge, den Wert auszulesen, der für die Power-Cap konfiguriert ist, sowie den aktuellen Stromverbrauch des Systems.
Intel Node Manager verhängt eine Power-Cap für Systeme und verwendet dabei P-Zustände und T-Zustände eines Prozessors zur Einschränkung der CPU-Performanz und somit des Stromverbrauchs. Durch das Umsetzen einer Energieverwaltungsrichtlinie können Administratoren Systeme so konfigurieren, dass diese weniger Strom während Zeiten, an denen die Systemauslastung niedrig ist (z.B. in der Nacht oder an Wochenenden), verbrauchen.
3.9. Erweiterte Grafik-Energieverwaltung
Low-voltage differential signalling (LVDS) ist ein System zur Übertragung von elektronischen Signalen über Kupferkabel. Eine bedeutende Umsetzung dieses Systems ist das Senden von Pixel-Informationen an liquid crystal display (LCD) Bildschirme in Notebook-Computern. Alle Bildschirme besitzen eine Wiederholungsrate — die Rate, in der sie neue Daten von einem Grafik-Controller erhalten und ein Bild auf dem Bildschirm erzeugen. Üblicherweise erhält der Bildschirm aktualisierte Daten 60 Mal pro Sekunde (eine Frequenz von 60 Hz). Wenn ein Bildschirm und ein Grafik-Controller via LVDS verbunden sind, verbraucht das LVDS-System Strom bei jedem Wiederholungszyklus. Im Leerlaufbetrieb kann die Wiederholungsrate vieler LCD-Bildschirme ohne spürbare Änderung auf 30 Hz reduziert werden (im Gegensatz zu cathode ray tube (CRT) Monitore, wo eine Reduzierung der Wiederholungsrate ein charakteristisches Flimmern verursacht). Der im von Red Hat Enterprise Linux 6 verwendeten Kernel-Treiber für Intel Grafikadapter führt dies downclocking automatisch durch und spart dabei ca. 0.5 W im Leerlaufbetrieb des Bildschirms ein.
Synchronous Dynamic Random Access Memory (SDRAM) — wie es für Videospeicher in Grafikadaptern verwendet wird — wird tausendmal pro Sekunde neu aufgeladen, so dass die individuellen Speicherzellen die in ihnen gespeicherten Daten beibehalten können. Neben der Hauptfunktion, den Datenfluß in und aus dem Speicher heraus zu verwalten, ist der Speicher-Controller normalerweise verantwortlich für die Initiierung dieser Refresh-Zyklen. SDRAM besitzt jedoch auch einen self-refresh-Modus. In diesem Modus verwendet der Speicher einen internen Taktgeber, um seine eigenen Refresh-Zyklen zu generieren. Dies gestattet dem System, den Speicher-Controller herunterzufahren, ohne die Daten, die sich gerade im Speicher befinden, zu gefährden. Der in Red Hat Enterprise Linux 6 verwendete Kernel kann Speicher "self-refresh" in Intel Grafikadaptern initiieren, wenn sich diese im Leerlauf befinden. Dies spart in etwa 0.8 W.
Typische Graphical Processing Units (GPUs) beinhalten interne Taktgeber, die verschiedene Teile ihrer internen Schaltkreise verwalten. Der in Red Hat Enterprise Linux 6 verwendete Kernel kann die Frequenz einiger interner Taktgeber in Intel und ATI GPUs reduzieren. Die Verringerung der Anzahl der Zyklen, die GPU-Komponenten in einer vorgegebenen Zeitspanne durchlaufen, spart den Strom, den sie ansonsten in Zyklen verbraucht hätten, in denen Sie keine Leistung erbracht hätten. Der Kernel reduziert die Geschwindigkeit dieser Taktgeber automatisch, wenn sich die GPU im Leerlauf befindet und erhöht sie entsprechend, wenn die GPU-Aktivität steigt. Die Reduzierung von GPU-Taktgeber-Zyklen kann bis zu 5 W einsparen.
Die Intel und ATI Grafiktreiber in Red Hat Enterprise Linux 6 können ermitteln, wenn kein Monitor an einen Adapter angeschlossen ist und somit die GPU komplett deaktivieren. Dieses Feature ist besonders bedeutend für Server, an die keine Monitore regulär angeschlossen sind.
3.10. RFKill
/dev/rfkill, welches den aktuellen Zustand aller Sender auf dem System beinhaltet. Für jedes Gerät ist der aktuelle RFKill-Zustand in sysfs registriert. Zusätzlich liefert RFKill uevents für jede Zustandsänderung bei einem RFKill-aktivierten Gerät.
rfkill list, um eine Liste von Geräten zu erhalten, welches jeweils mit einer Index-Nummer verknüpft ist, beginnend mit 0. Sie können diese Index-Nummer verwenden, um rfkill darüber zu informieren, ob ein Gerät geblockt oder entblockt werden soll. Zum Beispiel:
rfkill block 0rfkill block wifirfkill block allrfkill unblock anstatt rfkill block aus, um Geräte zu entblockieren. Um eine komplette Liste von Geräte-Kategorien, die rfkill blockieren kann, zu erhalten, führen Sie rfkill help aus.
3.11. Optimierungen im User Space
Red Hat Enterprise Linux 6 verwendet einen Tickless Kernel (siehe Abschnitt 3.4, »Tickless-Kernel«), der es den CPUs ermöglicht, länger in einem tieferen Leerlauf-Zustand zu verbleiben. Allerdings ist der Timer Tick nicht die einzige Quelle für exzessive CPU-Wakeups und Funktionsaufrufe von Anwendungen können die CPU auch daran hindern, in Leerlauf-Zustände zu wechseln oder in diesen zu verbleiben. Unnötige Funktionsaufrufe wurden in über 50 Anwendungen reduziert.
Input oder Output (IO) auf Speichergeräten und Netzwerkschnittstellen zwingen Geräte zum Stromverbrauch. In Speicher- und Netzwerkgeräten, die im Leerlauf reduzierte Stromzustände unterstützen (z.B. ALPM oder ASPM), kann dieser Datenfluss verhindern, dass das Gerät in einen Leerlauf-Zustand versetzt wird oder in diesem verbleibt. Auch kann es verhindern, dass Festplatten die Drehzahl reduzieren, wenn Sie nicht mehr verwendet werden. Exzessive und unnötige Anforderungen an Speicher wurden in mehreren Anwendungen minimiert. Speziell in solchen, die verhinderten, dass Festplatten die Drehzahl reduzieren.
Dienste, die automatisch starten, unabhängig davon, ob sie benötigt werden, oder nicht, bergen ein großes Potential bei der Verschwendung von Systemressourcen. Dienste sollten stattdessen wann immer möglich standardmäßig "aus" oder "auf Anfrage" sein. So wurde beispielsweise bisher der BlueZ-Dienst, der Bluetooth-Unterstützung aktiviert, automatisch beim Systemstart aktiviert, unabhängig davon, ob Bluetooth-Hardware vorhanden war, oder nicht. Das BlueZ initscript überprüft nun, ob Bluetooth-Hardware auf dem System vorhanden ist, bevor es den Dienst startet.
Kapitel 4. Anwendungsfälle
4.1. Beispiel — Server
Ein Webserver benötigt Netzwerk- und Platten-I/O. Abhängig von der externen Verbindungsgeschwindigkeit könnten 100 Mbit/s ausreichen. Falls die Maschine eher statische Seiten anbietet, ist die CPU-Performanz ggf. nicht so wichtig. Optionen bei der Energieverwaltung könnten daher sein:
- keine Platten- oder Netzwerk-Plugins für tuned.
- ALPM angeschaltet.
ondemand-Governor angeschaltet.- Netzwerkkarte auf 100 Mbit/s limitiert.
Ein Rechen-Server benötigt hauptsächlich CPU. Optionen bei der Energieverwaltung können sein:
- abhängig von den Jobs und wo die Datenspeicherung stattfindet, Platten- oder Netzwerk-Plugins für tuned oder für Batch-Modus-Systeme, voll aktiver tuned.
- abhängig von der Verwendung evtl. der
performance-Governor.
Ein Mailserver benötigt überwiegend I/O und CPU. Optionen bei der Energieverwaltung können sein:
ondemand-Governor angeschaltet, da die letzten paar Prozent der CPU-Performanz nicht wichtig sind.- keine Platten- oder Netzwerk-Plugins für tuned.
- Netzwerkgeschwindigkeit sollte nicht beschränkt werden, da Mail oft intern verschickt wird und somit aus einem 1 Gbit/s oder einem 10 Gbit/s-Link Nutzen ziehen kann.
Die Anforderungen für Datei-Server ähneln denen für Mailserver, aber abhängig von dem verwendeten Protokoll, benötigen sie ggf. mehr CPU-Performanz. Samba-basierte Server benötigen üblicherweise mehr CPU als NFS und NFS üblicherweise mehr als iSCSI. Nichtsdestrotrotz sollten Sie in der Lage sein, den ondemand-Governor zu verwenden.
Ein Verzeichnis-Server besitzt üblicherweise geringere Anforderungen für Platten-I/O, besonders wenn er mit genügend RAM ausgestattet ist. Netzwerk-Latenz ist wichtig, Netzwerk-I/O dagegen nicht so. Sie können erwägen, die Netzwerk-Latenz mit einer geringeren Link-Geschwindigkeit abzustimmen, sollten dies jedoch sorgfältig in Ihrem jeweiligen Netzwerk testen.
4.2. Beispiel — Laptop
- Konfigurieren Sie das System-BIOS so, dass sämtliche nicht verwendete Hardware deaktiviert ist. Beispielsweise Parallel- oder Serielle-Ports, Kartenleser, Webcams, Wi-Fi und Bluetooth, um nur ein paar mögliche Kandidaten zu nennen.
- Dimmen Sie die Anzeige in dunkleren Umgebungen, in denen Sie keine volle Beleuchtung zum Lesen des Bildschirms benötigen. Verwenden Sie + → auf dem GNOME-Desktop, +++ → auf dem KDE-Desktop; oder gnome-power-manager oder xbacklight auf der Kommandozeile; oder die Funktionstasten auf Ihrem Laptop.
- Verwenden Sie das Profil
laptop-battery-powersavevon tuned-adm, um eine ganze Reihe an Stromsparmechanismen einzustellen. Beachten Sie, dass die Leistung und Latenz für die Festplatte und die Netzwerkschnittstelle davon betroffen sind.
- den
ondemand-Governor verwenden (standardmäßig unter Red Hat Enterprise Linux 6 aktiviert) - Laptop-Modus aktivieren (Teil des
laptop-battery-powersave-Profils):echo 5 > /proc/sys/vm/laptop_mode - Flush-Zeit auf Platte erhöhen (Teil des
laptop-battery-powersave-Profils):echo 1500 > /proc/sys/vm/dirty_writeback_centisecs - NMI-Watchdog deaktivieren (Teil des
laptop-battery-powersave-Profils):echo 0 > /proc/sys/kernel/nmi_watchdog - AC97 Audio-Energiesparen aktivieren (standardmäßig unter Red Hat Enterprise Linux 6 aktiviert):
echo Y > /sys/module/snd_ac97_codec/parameters/power_save - Multi-Core Stromsparen aktivieren (Teil des
laptop-battery-powersave-Profils):echo 1 > /sys/devices/system/cpu/sched_mc_power_savings - USB auto-suspend aktivieren:
for i in /sys/bus/usb/devices/*/power/autosuspend; do echo 1 > $i; doneBeachten Sie, dass USB auto-suspend nicht mit allen USB-Geräten korrekt funktioniert. - minimale Stromeinstellungen für ALPM aktivieren (Teil des
laptop-battery-powersave-Profils):echo min_power > /sys/class/scsi_host/host*/link_power_management_policy - Dateisystem unter Verwendung von relatime einhängen (Standard in Red Hat Enterprise Linux 6):
mount -o remount,relatime mountpoint - den besten Modus für das Stromsparen für Festplatten aktivieren (Teil des
laptop-battery-powersave-Profils):hdparm -B 1 -S 200 /dev/sd* - CD-ROM-Abfrage deaktivieren (Teil des
laptop-battery-powersave-Profils):hal-disable-polling --device /dev/scd* - Bildschirmhelligkeit auf
50oder weniger reduzieren, z.B.:xbacklight -set 50 - DPMS für Bildschirme im Leerlaufbetrieb aktivieren:
xset +dpms; xset dpms 0 0 300 - Wi-Fi Strom-Level reduzerien (Teil des
laptop-battery-powersave-Profils):for i in /sys/bus/pci/devices/*/power_level ; do echo 5 > $i ; done - Wi-Fi deaktivieren:
echo 1 > /sys/bus/pci/devices/*/rf_kill - Kabel-Netzwerk auf 100 Mbit/s limitieren (Teil des
laptop-battery-powersave-Profils):>
ethtool -s eth0 advertise 0x0F
Anhang A. Tipps für Entwickler
- das Verwenden von Threads.
- unnötige und ineffiziente CPU-Wake-Ups. Falls Sie den Ruhezustand beenden müssen, machen Sie alles gleichzeitig (race to idle) und so schnell wie möglich.
- unnötiges Verwenden von
[f]sync(). - unnötiges aktives Abfragen (polling) oder das Verwenden von kurzen, regelmäßigen Timeouts (stattdessen auf Ereignisse reagieren).
- ineffektives Verwenden von Wake-Ups.
- ineffizienter Zugriff auf Platten. Verwenden Sie große Puffer, um häufigen Zugriff auf die Platte zu vermeiden. Schreiben Sie jeweils einen großen Block.
- ineffiziente Verwendung von Timer. Gruppieren Sie Timer über Anwendungen (oder sogar Systemen) verteilt, falls möglich.
- exzessive I/O. Stromverbrauch oder Speichergebrauch (inklusive Speicherlecks)
- Durchführen unnötiger Berechnungen.
A.1. Das Verwenden von Threads
Python verwendet Global Lock Interpreter[1], so dass Threading nur für größere I/O-Operationen profitabel ist. Unladen-swallow [2] ist eine schnellere Python-Implementierung, mit der Sie ggf. Ihren Code optimieren können.
Perl-Threads wurden ursprünglich für Systeme ohne Forking geschaffen (wie beispielsweise Systeme mit 32-Bit Windows-Betriebssystemen). Bei Perl-Threads werden Daten für jeden einzelnen Thread kopiert (Copy On Write). Daten werden standardmäßig nicht gemeinsam genutzt, da Benutzer in der Lage sein sollten, das Level an Daten-Sharing zu bestimmen. Das Modul threads::shared muss für Daten-Sharing eingebunden sein. Daten werden jedoch nicht nur dann kopiert (Copy On Write), sondern das Modul erstellt auch eng verknüpfte Variablen für die Daten, was noch mehr Zeit kostet und noch langsamer ist [3].
C-Threads nutzen den Speicher gemeinsam, jeder Thread besitzt seinen eigenen Stapel (stack) und der Kernel muss keine neuen Dateideskriptoren erstellen und neuen Speicherplatz zuweisen. C kann wirklich die Unterstützung von mehreren CPUs für mehrere Threads nutzen. Um daher die Performanz Ihrer Threads zu maximieren, verwenden Sie eine höhere Sprache wie C oder C++. Falls Sie eine Skripting-Sprache verwenden, ziehen Sie das Schreiben eines C-Bindings in Betracht. Benutzen Sie Profilers zur Identifizierung von schlecht funktionierenden Teilen in Ihrem Code [4].
A.2. Wake-ups
int fd;
fd = inotify_init();
int wd;
/* checking modification of a file - writing into */
wd = inotify_add_watch(fd, "./myConfig", IN_MODIFY);
if (wd < 0) {
inotify_cant_be_used();
switching_back_to_previous_checking();
}
...
fd_set rdfs;
struct timeval tv;
int retval;
FD_ZERO(&rdfs);
FD_SET(0, &rdfs);
tv.tv_sec = 5;
value = select(1, &rdfs, NULL, NULL, &tv);
if (value == -1)
perror(select);
else {
do_some_stuff();
}
.../proc/sys/fs/inotify/max_user_watches abgerufen werden und obwohl sie geändert werden kann, wird dies nicht empfohlen. Darüber hinaus, falls inotify fehlschlägt, muss der Code auf eine andere Check-Methode zurückgreifen, was üblicherweise bedeutet, dass #if #define oft im Quellcode vorkommt.
A.3. Fsync
Fsync ist für seinen I/O-intensiven Betrieb bekannt, aber das ist nur die halbe Wahrheit. Werfen Sie beispielsweise einen Blick auf Theodore Ts'o's Artikel Don't fear the fsync! [5] und die dazugehörige Diskussion.
fsync auf und aufgrund der Einstellungen des Dateisystems (hauptsächlich ext3 mit data-ordered Modus) entstand eine hohe Latenz bei Inaktivität. Dies konnte lange dauern (bis zu 30 Sekunden), wenn ein andere Prozess eine große Datei zur selben Zeit kopierte.
fsync überhaupt nicht benutzt wurde, traten Probleme mit dem Wechsel zum ext4-Dateisystem auf. Ext3 war auf data-ordered Modus gesetzt, der den Speicher alle paar Sekunden löschte und auf Platte speicherte. Mit ext4 jedoch und laptop_mode, wurde das Intervall zwischen Speicherungen länger und Daten konnten verloren gehen, wenn das System unerwartet ausgeschaltet wurde. Auch wenn ext4 nun gepatcht ist, müssen wir das Design unserer Anwendungen nach wie vor vorsichtig überdenken und fsync verwenden, wo es angebracht ist.
/* open and read configuration file e.g. ~/.kde/myconfig */
fd = open("./kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
close(fd);open("/.kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
fd = open("/.kde/myconfig.suffix", O_WRONLY|O_TRUNC|O_CREAT);
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
fsync; /* paranoia - optional */
...
close(fd);
rename("/.kde/myconfig", "/.kde/myconfig~"); /* paranoia - optional */
rename("/.kde/myconfig.suffix", "/.kde/myconfig");Anhang B. Revisionsverlauf
| Versionsgeschichte | |||
|---|---|---|---|
| Version 1.0-7.400 | 2013-10-31 | ||
| |||
| Version 1.0-7 | 2012-07-18 | ||
| |||
| Version 1.0-2 | Fri Oct 22 2010 | ||
| |||
| Version 1.0-1 | Thu Oct 7 2010 | ||
| |||
| Version 1.0-0 | Thu Oct 7 2010 | ||
| |||