
운영 가이드
Red Hat Ceph Storage 운영 작업
초록
1장. Ceph Orchestrator 소개
스토리지 관리자는 Ceph Orchestrator를 Cephadm 유틸리티와 함께 사용하면 Red Hat Ceph Storage 클러스터에서 장치를 검색하고 서비스를 생성할 수 있습니다.
1.1. Ceph Orchestrator 사용
Red Hat Ceph Storage Orchestrators는 Red Hat Ceph Storage 클러스터와 Rook 및 Cephadm과 같은 배포 툴 간의 브리지 역할을 하는 관리자 모듈입니다. 또한 Ceph 명령줄 인터페이스 및 Ceph 대시보드와 통합됩니다.
다음은 Ceph Orchestrator의 워크플로우 다이어그램입니다.
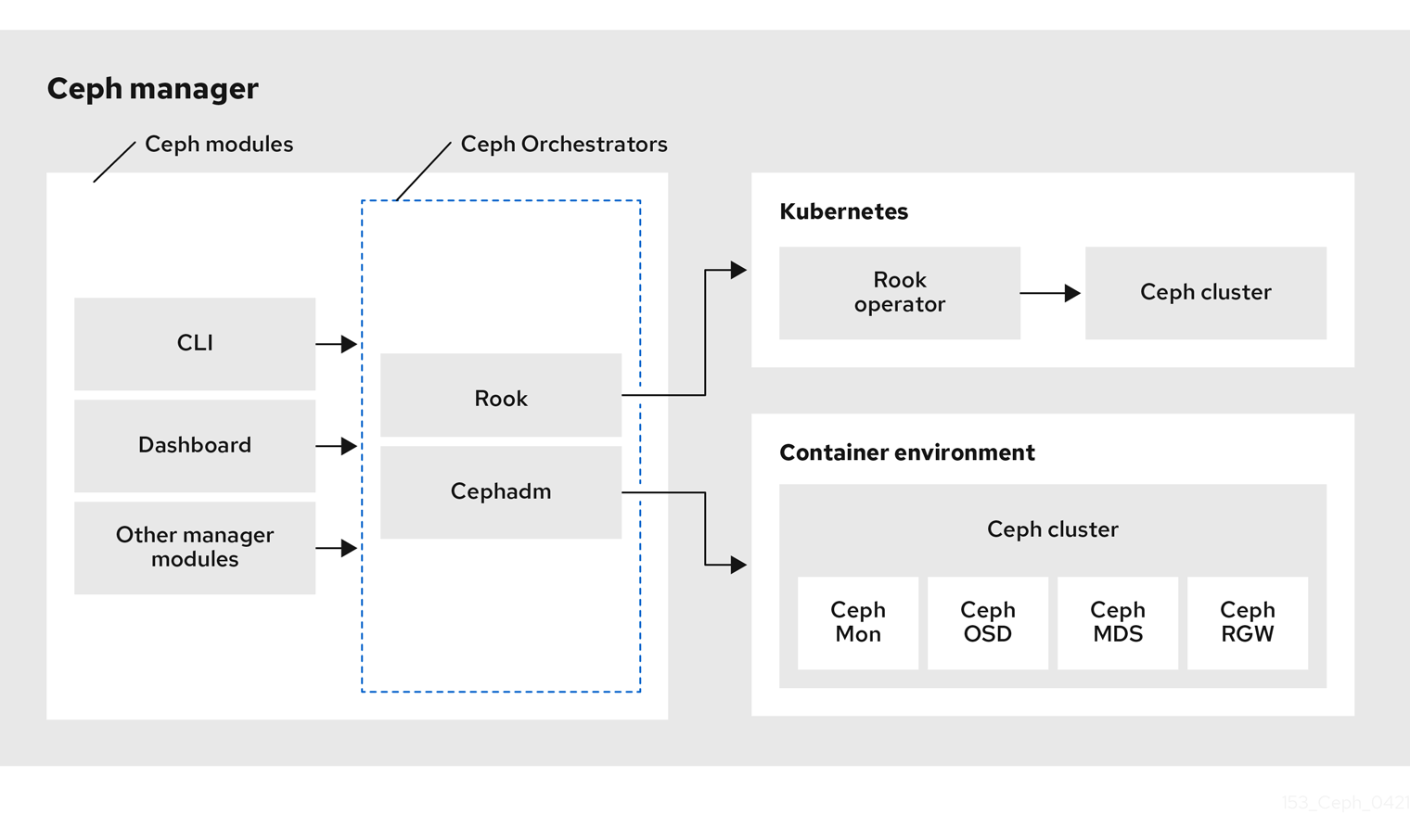
Red Hat Ceph Storage Orchestrators
Red Hat Ceph Storage Orchestrators에는 세 가지 주요 유형이 있습니다.
오케스트레이터 CLI : Orchestrators에서 사용되는 일반적인 API이며 구현할 수 있는 명령 세트를 포함합니다. 이러한 API는 외부 오케스트레이션 서비스를 사용하여
ceph-mgr모듈을 오케스트레이션하는 공통 CLI(명령줄 인터페이스)도 제공합니다. 다음은 Ceph Orchestrator와 함께 사용되는 nomenclature입니다.- host: Pod 이름, DNS 이름, 컨테이너 이름 또는 컨테이너 내부의 호스트 이름이 아닌 물리적 호스트의 호스트 이름입니다.
- 서비스 유형: nfs, mds, osd, mon, rgw, mgr과 같은 서비스 유형입니다.
- Service : 모니터 서비스, 관리자 서비스, OSD 서비스, Ceph Object Gateway 서비스 및 NFS 서비스와 같은 Ceph 스토리지 클러스터에서 제공하는 기능 서비스입니다.
- 데몬: Ceph Object Gateway 서비스와 같은 하나 이상의 호스트에서 배포한 서비스의 특정 인스턴스는 세 개의 다른 호스트에서 실행되는 다른 Ceph Object Gateway 데몬을 사용할 수 있습니다.
cephadm Orchestrator - Rook 또는 Ansible과 같은 외부 툴에 의존하지 않고 SSH 연결을 설정하고 명시적 관리 명령을 실행하여 클러스터의 노드를 관리하는 Ceph Orchestrator 모듈입니다. 이 모듈은 Day-one 및 day-two 작업을 위한 것입니다.
Cephadm Orchestrator를 사용하면 Ansible과 같은 배포 프레임워크를 활용하지 않고도 Ceph 스토리지 클러스터를 설치하는 것이 좋습니다. 이 개념은 관리자 데몬에 스토리지 장치의 인벤토리 생성, OSD 배포 및 교체 또는 Ceph 데몬 시작 및 중지와 같은 관리 작업을 수행하기 위해 클러스터의 모든 노드에 연결할 수 있는 SSH 구성 및 키에 대한 액세스 권한을 제공하는 것입니다. 또한 Cephadm Orchestrator는 공동 배치된 서비스의 독립적인 업그레이드를 위해
systemd에서 관리하는 컨테이너 이미지를 배포합니다.이 오케스트레이터는 Ceph Monitor 및 Ceph Manager를 실행하는 최소 클러스터를 부트스트랩하는 명령을 포함하여 현재 호스트에서 컨테이너 이미지 기반 서비스 배포를 관리하는 데 필요한 모든 작업을 캡슐화하는 툴도 강조 표시합니다.
Rook Orchestrator - Rook은 Kubernetes Rook Operator를 사용하여 Kubernetes 클러스터 내에서 실행되는 Ceph 스토리지 클러스터를 관리하는 오케스트레이션 툴입니다. rook 모듈은 Ceph Orchestrator 프레임워크와 Rook 간의 통합을 제공합니다. Rook은 Kubernetes용 오픈 소스 클라우드 네이티브 스토리지 운영자입니다.
Rook은 "operator" 모델을 따르며, 여기에서 CRD(사용자 정의 리소스 정의) 오브젝트가 Ceph 스토리지 클러스터 및 원하는 상태를 설명하는 Kubernetes에 정의되어 있으며, rook Operator 데몬은 현재 클러스터 상태를 원하는 상태와 비교하고 이를 통합하기 위한 단계를 수행하는 컨트롤 루프에서 실행되고 있습니다. Ceph의 원하는 상태를 설명하는 기본 오브젝트는 Ceph 스토리지 클러스터 CRD입니다. 여기에는 OSD에서 사용해야 하는 장치, 실행 중인 모니터 수 및 사용할 Ceph 버전에 대한 정보가 포함됩니다. Rook은 RBD 풀, CephFS 파일 시스템 등을 설명하는 여러 다른 CRD를 정의합니다.
Rook Orchestrator 모듈은
ceph-mgr데몬에서 실행되고 원하는 클러스터 상태를 설명하는 Kubernetes의 Ceph 스토리지 클러스터를 변경하여 Ceph 오케스트레이션 API를 구현하는 접착제 모듈입니다. Rook 클러스터의ceph-mgr데몬은 Kubernetes pod로 실행되므로 rook 모듈은 명시적 구성없이 Kubernetes API에 연결할 수 있습니다.
2장. Ceph Orchestrator를 사용한 서비스 관리
Red Hat Ceph Storage 클러스터를 설치한 후 스토리지 관리자는 Ceph Orchestrator를 사용하여 스토리지 클러스터의 서비스를 모니터링하고 관리할 수 있습니다. 서비스는 함께 구성된 데몬 그룹입니다.
이 섹션에서는 다음 관리 정보를 다룹니다.
2.1. Ceph Orchestrator 배치 사양
Ceph Orchestrator를 사용하여 osds,mons,mgrs ,mds, rgw 서비스를 배포할 수 있습니다. 배치 사양을 사용하여 서비스를 배포하는 것이 좋습니다. Ceph Orchestrator를 사용하여 서비스를 배포하기 위해 배치해야 하는 데몬 수와 위치를 알아야 합니다. 배치 사양은 명령줄 인수로 전달하거나 yaml 파일에서 서비스 사양으로 전달할 수 있습니다.
배치 사양을 사용하여 서비스를 배포하는 방법은 다음 두 가지가 있습니다.
명령줄 인터페이스에서 직접 배치 사양 사용. 예를 들어 호스트에 세 개의 모니터를 배포하려면 다음 명령을 실행하면
host01,host02,host03에 세 개의 모니터가 배포됩니다.예제
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
YAML 파일에서 배치 사양 사용. 예를 들어
node-exporter를 모든 호스트에 배포하려면yaml파일에서 다음을 지정할 수 있습니다.예제
service_type: node-exporter placement: host_pattern: '*' extra_entrypoint_args: - "--collector.textfile.directory=/var/lib/node_exporter/textfile_collector2"
2.2. 명령줄 인터페이스를 사용하여 Ceph 데몬 배포
Ceph Orchestrator를 사용하면 ceph orch 명령을 사용하여 Ceph Manager, Ceph Monitors, Ceph OSD, 모니터링 스택 등과 같은 데몬을 배포할 수 있습니다. 배치 사양은 Orchestrator 명령을 사용하여 --placement 인수로 전달됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트는 스토리지 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
다음 방법 중 하나를 사용하여 호스트에 데몬을 배포합니다.
방법 1: 데몬 수와 호스트 이름을 지정합니다.
구문
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
방법 2: 호스트에 레이블을 추가한 다음 라벨을 사용하여 데몬을 배포합니다.
호스트에 레이블을 추가합니다.
구문
ceph orch host label add HOSTNAME_1 LABEL
예제
[ceph: root@host01 /]# ceph orch host label add host01 mon
라벨을 사용하여 데몬을 배포합니다.
구문
ceph orch apply DAEMON_NAME label:LABEL
예제
ceph orch apply mon label:mon
방법 3: 호스트에 레이블을 추가하고
--placement인수를 사용하여 배포합니다.호스트에 레이블을 추가합니다.
구문
ceph orch host label add HOSTNAME_1 LABEL
예제
[ceph: root@host01 /]# ceph orch host label add host01 mon
라벨 배치 사양을 사용하여 데몬을 배포합니다.
구문
ceph orch apply DAEMON_NAME --placement="label:LABEL"
예제
ceph orch apply mon --placement="label:mon"
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME ceph orch ps --service_name=SERVICE_NAME
예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon [ceph: root@host01 /]# ceph orch ps --service_name=mon
추가 리소스
- Red Hat Ceph Storage 운영 가이드 의 Ceph Orchestrator 섹션을 사용하여 호스트 추가 섹션을 참조하십시오.
2.3. 명령줄 인터페이스를 사용하여 호스트 하위 세트에 Ceph 데몬 배포
--placement 옵션을 사용하여 호스트 하위 세트에 데몬을 배포할 수 있습니다. 데몬을 배포할 호스트 이름으로 배치 사양의 데몬 수를 지정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
Ceph 데몬을 배포할 호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
데몬을 배포합니다.
구문
ceph orch apply SERVICE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 _HOST_NAME_2 HOST_NAME_3"
예제
ceph orch apply mgr --placement="2 host01 host02 host03"
이 예에서는
mgr데몬은 두 호스트에만 배포됩니다.
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
추가 리소스
- Red Hat Ceph Storage 운영 가이드 의 Ceph Orchestrator 섹션을 사용하여 호스트 목록을 참조하십시오.
2.4. Ceph Orchestrator의 서비스 사양
서비스 사양은 Ceph 서비스를 배포하는 데 사용되는 서비스 속성 및 구성 설정을 지정하는 데이터 구조입니다. 다음은 서비스 사양을 지정하는 다중 문서 YAML 파일 cluster.yaml 의 예입니다.
예제
service_type: mon placement: host_pattern: "mon*" --- service_type: mgr placement: host_pattern: "mgr*" --- service_type: osd service_id: default_drive_group placement: host_pattern: "osd*" data_devices: all: true
다음 목록은 서비스 사양의 속성이 다음과 같이 정의되는 매개변수입니다.
service_type: 서비스 유형입니다.- mon, crash, mds, mgr, osd, rbd, rbd-mirror와 같은 Ceph 서비스.
- nfs 또는 rgw와 같은 Ceph 게이트웨이.
- Alertmanager, Prometheus, Grafana 또는 Node-exporter와 같은 모니터링 스택.
- 사용자 지정 컨테이너용 컨테이너입니다.
-
service_id: 서비스의 고유 이름입니다. -
placement: 데몬 배포 위치와 방법을 정의하는 데 사용됩니다. -
Unmanaged:true로 설정하면 Orchestrator는 이 서비스와 연결된 데몬을 배포하거나 제거하지 않습니다.
Orchestrators의 상태 비저장 서비스
상태 비저장 서비스는 상태 정보를 사용할 수 없는 서비스입니다. 예를 들어 rgw 서비스를 시작하려면 서비스를 시작하거나 실행하는 데 추가 정보가 필요하지 않습니다. rgw 서비스는 기능을 제공하기 위해 이 상태에 대한 정보를 생성하지 않습니다. rgw 서비스가 언제 시작되는지와 관계없이 상태는 동일합니다.
2.5. 데몬 자동 관리 비활성화
서비스 사양을 편집하고 다시 적용하지 않고도 Cephadm 서비스를 관리 또는 관리되지 않음 으로 표시할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
프로세스
다음 명령을 사용하여 서비스에 대해
Unmanaged를 설정합니다.구문
ceph orch set-unmanaged SERVICE_NAME예제
[root@host01 ~]# ceph orch set-unmanaged grafana
다음 명령을 사용하여 서비스에 대해
managed를 설정합니다.구문
ceph orch set-managed SERVICE_NAME예제
[root@host01 ~]# ceph orch set-managed mon
2.6. 서비스 사양을 사용하여 Ceph 데몬 배포
Ceph Orchestrator를 사용하면 YAML 파일의 서비스 사양을 사용하여 ceph Manager, Ceph Monitors, Ceph OSD, 모니터링 스택 등과 같은 데몬을 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
프로세스
yaml파일을 생성합니다.예제
[root@host01 ~]# touch mon.yaml
이 파일은 다음 두 가지 방법으로 구성할 수 있습니다.
배치 사양에 호스트 세부 정보를 포함하도록 파일을 편집합니다.
구문
service_type: SERVICE_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2
예제
service_type: mon placement: hosts: - host01 - host02 - host03배치 사양에 레이블 세부 정보를 포함하도록 파일을 편집합니다.
구문
service_type: SERVICE_NAME placement: label: "LABEL_1"
예제
service_type: mon placement: label: "mon"
선택 사항: 서비스를 배포하는 동안 CPU, CA 인증서 및 기타 파일과 같은 서비스 사양 파일에서 추가 컨테이너 인수를 사용할 수도 있습니다.
예제
extra_container_args: - "-v" - "/etc/pki/ca-trust/extracted:/etc/pki/ca-trust/extracted:ro" - "--security-opt" - "label=disable" - "cpus=2" - "--collector.textfile.directory=/var/lib/node_exporter/textfile_collector2"
참고Red Hat Ceph Storage는 추가 인수를 사용하여 Cephadm에서 배포한 node-exporter에서 추가 지표를 활성화할 수 있습니다.
YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/mon/
서비스 사양을 사용하여 Ceph 데몬을 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 mon]# ceph orch apply -i mon.yaml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
추가 리소스
- Red Hat Ceph Storage 운영 가이드 의 Ceph Orchestrator 섹션을 사용하여 호스트 목록을 참조하십시오.
2.7. 서비스 사양을 사용하여 Ceph 파일 시스템 미러링 데몬 배포
Ceph 파일 시스템(CephFS)은 CephFS 미러링 데몬(cephfs-mirror)을 사용하여 원격 CephFS 파일 시스템에 대한 스냅샷의 비동기 복제를 지원합니다. 스냅샷 동기화는 스냅샷 데이터를 원격 CephFS에 복사하고 이름이 동일한 원격 대상에 새 스냅샷을 생성합니다. Ceph Orchestrator를 사용하여 YAML 파일의 서비스 사양을 사용하여 cephfs-mirror 를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- CephFS가 생성되었습니다.
프로세스
yaml파일을 생성합니다.예제
[root@host01 ~]# touch mirror.yaml
다음을 포함하도록 파일을 편집합니다.
구문
service_type: cephfs-mirror service_name: SERVICE_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2 - HOST_NAME_3
예제
service_type: cephfs-mirror service_name: cephfs-mirror placement: hosts: - host01 - host02 - host03YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount mirror.yaml:/var/lib/ceph/mirror.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/
서비스 사양을 사용하여
cephfs-mirror데몬을 배포합니다.예제
[ceph: root@host01 /]# ceph orch apply -i mirror.yaml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=cephfs-mirror
추가 리소스
-
cephfs-mirror데몬에 대한 자세한 내용은 Ceph 파일 시스템 미러를 참조하십시오.
3장. Ceph Orchestrator를 사용한 호스트 관리
스토리지 관리자는 백엔드에서 Cephadm과 함께 Ceph Orchestrator를 사용하여 기존 Red Hat Ceph Storage 클러스터에서 호스트를 추가, 나열, 제거할 수 있습니다.
호스트에 레이블을 추가할 수도 있습니다. 레이블은 자유형이며 특정 의미가 없습니다. 각 호스트에는 여러 개의 레이블이 있을 수 있습니다. 예를 들어, 모니터링 데몬이 배포된 모든 호스트에 mon 레이블을 적용하고, 관리자 데몬이 배포된 모든 호스트의 경우 mgr, Ceph 개체 게이트웨이의 경우 rgw 를 적용합니다.
스토리지 클러스터의 모든 호스트에 레이블을 지정하면 각 호스트에서 실행되는 데몬을 빠르게 식별할 수 있으므로 시스템 관리 작업을 단순화하는 데 도움이 됩니다. 또한 Ceph Orchestrator 또는 YAML 파일을 사용하여 특정 호스트 레이블이 있는 호스트에서 데몬을 배포하거나 제거할 수 있습니다.
이 섹션에서는 다음 관리 작업에 대해 설명합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
-
새 호스트의 IP 주소는
/etc/hosts파일에서 업데이트해야 합니다.
3.1. Ceph Orchestrator를 사용하여 호스트 추가
백엔드에서 Ceph Orchestrator를 Cephadm과 함께 사용하여 기존 Red Hat Ceph Storage 클러스터에 호스트를 추가할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
- 노드를 CDN에 등록하고 서브스크립션을 연결합니다.
-
sudo 및 암호 없이
ssh를 사용하는 Ansible 사용자는 스토리지 클러스터의 모든 노드에 액세스할 수 있습니다.
프로세스
Ceph 관리 노드에서 Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
클러스터의 공개 SSH 키를 폴더에 추출합니다.
구문
ceph cephadm get-pub-key > ~/PATH예제
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pub
Ceph 클러스터의 공개 SSH 키를 새 호스트의 root 사용자의
authorized_keys파일에 복사합니다.구문
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2
예제
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02
Ansible 관리 노드에서 새 호스트를 Ansible 인벤토리 파일에 추가합니다. 파일의 기본 위치는
/usr/share/cephadm-ansible/hosts입니다. 다음 예제는 일반적인 인벤토리 파일의 구조를 보여줍니다.예제
host01 host02 host03 [admin] host00
참고이전에 새 호스트를 Ansible 인벤토리 파일에 추가하고 호스트에서 preflight 플레이북을 실행한 경우 6 단계로 건너뜁니다.
--limit옵션을 사용하여 preflight 플레이북을 실행합니다.구문
ansible-playbook -i INVENTORY_FILE cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit NEWHOST
예제
[ceph-admin@admin cephadm-ansible]$ ansible-playbook -i hosts cephadm-preflight.yml --extra-vars "ceph_origin=rhcs" --limit host02
preflight Playbook은 새 호스트에
podman,lvm2,chronyd,cephadm을 설치합니다. 설치가 완료되면cephadm은/usr/sbin/디렉터리에 있습니다.Ceph 관리 노드에서 Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
cephadm오케스트레이터를 사용하여 스토리지 클러스터에 호스트를 추가합니다.구문
ceph orch host add HOST_NAME IP_ADDRESS_OF_HOST [--label=LABEL_NAME_1,LABEL_NAME_2]
--label옵션은 선택 사항이며, 이는 호스트를 추가할 때 레이블을 추가합니다. 호스트에 여러 레이블을 추가할 수 있습니다.예제
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70 --labels=mon,mgr
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
추가 리소스
- Red Hat Ceph Storage 운영 가이드 의 Ceph Orchestrator 섹션을 사용하여 호스트 목록을 참조하십시오.
-
cephadm-preflight플레이북에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드 의 preflight 플레이북 실행 섹션을 참조하십시오. - Red Hat Ceph Storage 노드 등록 및 Red Hat Ceph Storage 설치 가이드의 서브스크립션 연결 섹션을 참조하십시오.
- Red Hat Ceph Storage 설치 가이드의 sudo 액세스 권한이 있는 Ansible 사용자 생성 섹션을 참조하십시오.
3.2. Ceph Orchestrator를 사용하여 여러 호스트 추가
Ceph Orchestrator를 사용하여 YAML 파일 형식의 서비스 사양을 사용하여 동시에 Red Hat Ceph Storage 클러스터에 여러 호스트를 추가할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
프로세스
hosts.yaml파일을 생성합니다.예제
[root@host01 ~]# touch hosts.yaml
다음 세부 정보를 포함하도록
hosts.yaml파일을 편집합니다.예제
service_type: host addr: host01 hostname: host01 labels: - mon - osd - mgr --- service_type: host addr: host02 hostname: host02 labels: - mon - osd - mgr --- service_type: host addr: host03 hostname: host03 labels: - mon - osd
YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount hosts.yaml:/var/lib/ceph/hosts.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/
서비스 사양을 사용하여 호스트를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 hosts]# ceph orch apply -i hosts.yaml
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
추가 리소스
- Red Hat Ceph Storage 운영 가이드 의 Ceph Orchestrator 섹션을 사용하여 호스트 목록을 참조하십시오.
3.3. Ceph Orchestrator를 사용하여 호스트 나열
Ceph Orchestrators를 사용하여 Ceph 클러스터의 호스트를 나열할 수 있습니다.
ceph orch host ls 명령의 출력에서 호스트 STATUS가 비어 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트는 스토리지 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
클러스터 호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
예상되는 호스트의 STATUS 가 비어 있음을 확인할 수 있습니다.
3.4. 호스트에 레이블 추가
Ceph Orchestrator를 사용하여 호스트에 레이블을 추가합니다. 레이블을 사용하여 데몬 배치를 지정할 수 있습니다.
레이블의 몇 가지 예는 호스트에 배포된 서비스를 기반으로 하는 mgr,mon, osd 입니다. 각 호스트에는 여러 개의 레이블이 있을 수 있습니다.
cephadm 에 특별한 의미가 있고 _ 로 시작하는 다음 호스트 레이블을 추가할 수도 있습니다.
-
_no_schedule: 이 레이블은cephadm이 호스트에 데몬을 예약하거나 배포하지 못하도록 합니다. Ceph 데몬이 이미 포함된 기존 호스트에 추가된 경우cephadm은 자동으로 제거되지 않은 OSD를 제외하고 해당 데몬을 다른 위치에서 이동합니다._no_schedule레이블을 사용하여 호스트를 추가하면 데몬이 배포되지 않습니다. 호스트가 제거되기 전에 데몬이 드레이닝되면 해당 호스트에_no_schedule레이블이 설정됩니다. -
_no_autotune_memory:이 레이블은 호스트에서 메모리를 자동 조정하지 않습니다. 해당 호스트에서 하나 이상의 데몬에 대해osd_memory_target_autotune옵션 또는 기타 유사한 옵션이 활성화된 경우에도 데몬 메모리가 튜닝되지 않습니다. -
_admin: 기본적으로_admin레이블은 스토리지 클러스터의 부트스트랩 호스트에 적용되며client.admin키는ceph orch 클라이언트 키링 {ls|set|rm}함수를 사용하여 해당 호스트에 배포되도록 설정됩니다. 일반적으로 이 레이블을 추가 호스트에 추가하면cephadm이/etc/ceph디렉터리에 구성 및 키링 파일을 배포합니다.
사전 요구 사항
- 설치 및 부트스트랩된 스토리지 클러스터입니다.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
- 호스트는 스토리지 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
호스트에 레이블을 추가합니다.
구문
ceph orch host label add HOSTNAME LABEL
예제
[ceph: root@host01 /]# ceph orch host label add host02 mon
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
3.5. 호스트에서 레이블 제거
Ceph 오케스트레이터를 사용하여 호스트에서 레이블을 제거할 수 있습니다.
사전 요구 사항
- 설치 및 부트스트랩된 스토리지 클러스터입니다.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
프로세스
cephadm쉘을 시작합니다.[root@host01 ~]# cephadm shell [ceph: root@host01 /]#
레이블을 제거합니다.
구문
ceph orch host label rm HOSTNAME LABEL
예제
[ceph: root@host01 /]# ceph orch host label rm host02 mon
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
3.6. Ceph Orchestrator를 사용하여 호스트 제거
Ceph Orchestrators로 Ceph 클러스터의 호스트를 제거할 수 있습니다. 모든 데몬은 작업이 완료될 때까지 데몬 또는 클러스터를 배포할 수 없도록 _no_schedule 레이블을 추가하는 drain 옵션으로 제거됩니다.
부트스트랩 호스트를 제거하는 경우 호스트를 제거하기 전에 관리자 인증 키와 구성 파일을 스토리지 클러스터의 다른 호스트에 복사해야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트는 스토리지 클러스터에 추가됩니다.
- 모든 서비스가 배포됩니다.
- Cephadm은 서비스를 제거해야 하는 노드에 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
호스트 세부 정보를 가져옵니다.
예제
[ceph: root@host01 /]# ceph orch host ls
호스트의 모든 데몬을 드레이닝합니다.
구문
ceph orch host drain HOSTNAME예제
[ceph: root@host01 /]# ceph orch host drain host02
_no_schedule레이블은 배포를 차단하는 호스트에 자동으로 적용됩니다.OSD 제거 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch osd rm status
OSD에 배치 그룹(PG)이 없는 경우 스토리지 클러스터에서 OSD가 해제되어 제거됩니다.
스토리지 클러스터에서 모든 데몬이 제거되었는지 확인합니다.
구문
ceph orch ps HOSTNAME예제
[ceph: root@host01 /]# ceph orch ps host02
호스트를 제거합니다.
구문
ceph orch host rm HOSTNAME예제
[ceph: root@host01 /]# ceph orch host rm host02
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 Ceph Orchestrator 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 Ceph Orchestrator 섹션을 참조하십시오.
3.7. Ceph Orchestrator를 사용하여 호스트를 유지 관리 모드에 배치
Ceph Orchestrator를 사용하여 호스트를 유지 관리 모드로 배치할 수 있습니다. ceph orch host maintenance enter 명령은 systemd 대상 을 중지하여 모든 Ceph 데몬이 호스트에서 중지되도록 합니다. 마찬가지로 ceph orch host maintenance exit 명령은 systemd 대상 을 재시작하고 Ceph 데몬은 자체적으로 다시 시작됩니다.
오케스트레이터는 호스트가 유지보수 모드에 배치될 때 다음 워크플로우를 채택합니다.
-
호스트를 제거해도
orch host ok-to-stop명령을 실행하여 데이터 가용성에 영향을 미치지 않는지 확인합니다. -
호스트에 Ceph OSD 데몬이 있는 경우
noout을 host 하위 트리에 적용하여 계획된 유지 관리 슬롯 중에 데이터 마이그레이션이 트리거되지 않도록 합니다. - Ceph 대상을 중지하여 모든 데몬을 중지합니다.
-
재부팅이 Ceph 서비스를 자동으로 시작하지 않도록 호스트에서
ceph 대상을 비활성화합니다.
유지 관리를 종료하면 위의 시퀀스가 되돌아갑니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 클러스터에 추가된 호스트입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
호스트를 유지 관리 모드로 배치하거나 유지 관리 모드에서 호스트를 배치할 수 있습니다.
호스트를 유지 관리 모드로 설정합니다.
구문
ceph orch host maintenance enter HOST_NAME [--force]예제
[ceph: root@host01 /]# ceph orch host maintenance enter host02 --force
--force플래그를 사용하면 경고를 바이패스할 수 있지만 경고를 바이패스할 수 없습니다.호스트를 유지 관리 모드에서 해제합니다.
구문
ceph orch host maintenance exit HOST_NAME예제
[ceph: root@host01 /]# ceph orch host maintenance exit host02
검증
호스트를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch host ls
4장. Ceph Orchestrator를 사용한 모니터 관리
스토리지 관리자는 배치 사양을 사용하여 추가 모니터를 배포하고, 서비스 사양을 사용하여 모니터를 추가하고, 서브넷 구성에 모니터를 추가하고, 특정 호스트에 모니터를 추가할 수 있습니다. 이 외에도 Ceph Orchestrator를 사용하여 모니터를 제거할 수 있습니다.
기본적으로 일반적인 Red Hat Ceph Storage 클러스터에는 서로 다른 호스트에 배포된 모니터 데몬이 3개 또는 5개입니다.
클러스터에 5개 이상의 노드가 있는 경우 5개의 모니터를 배포하는 것이 좋습니다.
Ceph가 OSP director와 함께 배포될 때 세 개의 모니터를 배포하는 것이 좋습니다.
Ceph는 클러스터가 증가할 때 모니터 데몬을 자동으로 배포하고 클러스터가 축소되면 모니터 데몬을 자동으로 확장합니다. 이러한 자동 증가 및 축소의 원활한 실행은 적절한 서브넷 구성에 따라 달라집니다.
모니터 노드 또는 전체 클러스터가 단일 서브넷에 있는 경우 클러스터에 새 호스트를 추가할 때 Cephadm에서 최대 5개의 모니터 데몬을 자동으로 추가합니다. cephadm 은 새 호스트에서 모니터 데몬을 자동으로 구성합니다. 새 호스트는 스토리지 클러스터의 부트스트랩 호스트와 동일한 서브넷에 있습니다.
cephadm 은 스토리지 클러스터 크기의 변경 사항에 맞게 모니터를 배포 및 확장할 수도 있습니다.
4.1. Ceph Monitors
Ceph Monitor는 스토리지 클러스터 맵의 마스터 복사본을 유지 관리하는 경량 프로세스입니다. 모든 Ceph 클라이언트는 Ceph 모니터에 연락하여 스토리지 클러스터 맵의 현재 사본을 검색하여 클라이언트가 풀에 바인딩하고 데이터를 읽고 쓸 수 있습니다.
Ceph Monitor는 Paxos 프로토콜의 변형을 사용하여 스토리지 클러스터 전체의 맵 및 기타 중요한 정보에 대한 합의를 설정합니다. Ceph는 Paxos의 특성으로 인해 쿼럼을 구축하기 위해 대부분의 모니터가 실행 중이어야 하므로 합의를 설정해야합니다.
Red Hat은 프로덕션 클러스터에 대한 지원을 받으려면 별도의 호스트에 3개 이상의 모니터가 필요합니다.
홀수의 모니터를 배포하는 것이 좋습니다. 홀수의 Ceph 모니터는 짝수의 모니터보다 실패에 대한 복원력이 높습니다. 예를 들어 2개의 모니터 배포에서 쿼럼을 유지하기 위해 Ceph는 3개의 모니터를 사용할 수 없습니다. 4개의 모니터가 1개, 하나의 실패, 5개의 모니터, 두 개의 실패가 있습니다. 이 때문에 홀수가 권장됩니다. 요약하면 Ceph는 대부분의 모니터를 실행하고 서로 통신할 수 있어야 하며 3개 중 3개, 4개 중 3개 등이어야 합니다.
멀티 노드 Ceph 스토리지 클러스터를 처음 배포하기 위해 모니터 3개가 필요하므로 모니터가 3개 이상 필요한 경우 한 번에 2개를 늘리십시오.
Ceph 모니터는 경량이므로 OpenStack 노드와 동일한 호스트에서 실행할 수 있습니다. 그러나 Red Hat은 별도의 호스트에서 모니터를 실행하는 것이 좋습니다.
Red Hat은 컨테이너화된 환경에서 Ceph 서비스 배치만 지원합니다.
스토리지 클러스터에서 모니터를 제거할 때 Ceph Monitor가 Paxos 프로토콜을 사용하여 마스터 스토리지 클러스터 맵에 대한 합의를 설정하는 것이 좋습니다. 쿼럼을 설정하려면 충분한 수의 Ceph 모니터가 있어야 합니다.
추가 리소스
- 지원되는 모든 Ceph 구성은 Red Hat Ceph Storage 지원 구성 지식베이스 문서를 참조하십시오.
4.2. 모니터 선택 전략 구성
모니터 선택 전략은 네트워크 분할을 식별하고 오류를 처리합니다. 선택 모니터 전략을 세 가지 모드로 구성할 수 있습니다.
-
클래식- 가장 낮은 순위의 모니터가 두 사이트 간의 선택 모듈을 기반으로 하는 기본 모드입니다. -
허용하지않음 - 이 모드를 사용하면 모니터를 허용하지 않음으로 표시할 수 있으며, 이 모드에서는 쿼럼에 참여하고 클라이언트를 서비스하지만 선택한 리더가 될 수 없습니다. 이를 통해 허용하지 않는 리더 목록에 모니터를 추가할 수 있습니다. 모니터가 허용되지 않는 목록에 있는 경우 항상 다른 모니터로 지연됩니다. -
연결- 이 모드는 주로 네트워크 불일치를 확인하는 데 사용됩니다. 각 모니터에서 피어에 대해 제공하는 활성 상태를 확인하고 가장 연결되고 신뢰할 수 있는 모니터를 리더가 되도록 선택하는 ping을 기반으로 연결 점수를 평가합니다. 이 모드는 네트워크 분할을 처리하도록 설계되었으며, 클러스터가 여러 데이터 센터 간에 확장되거나 영향을 받을 수 있는 경우 발생할 수 있습니다. 이 모드는 연결 점수 등급을 통합하고 모니터를 최상의 점수로 선택합니다. 특정 모니터가 리더가 되도록 하려면 특정 모니터가 목록의 첫 번째 모니터가0인 첫 번째 모니터가 되도록 선택 전략을 구성합니다.
다른 모드에서 기능이 필요하지 않는 한 클래식 모드를 사용하는 것이 좋습니다.
클러스터를 구성하기 전에 다음 명령에서 election_strategy 를 클래식,허용하지 않음 또는 연결을 변경합니다.
구문
ceph mon set election_strategy {classic|disallow|connectivity}
4.3. 명령줄 인터페이스를 사용하여 Ceph 모니터 데몬 배포
Ceph Orchestrator는 기본적으로 하나의 모니터 데몬을 배포합니다. 명령줄 인터페이스에서 배치 사양을 사용하여 추가 모니터 데몬을 배포할 수 있습니다. 다른 수의 모니터 데몬을 배포하려면 다른 수를 지정합니다. 모니터 데몬을 배포해야 하는 호스트를 지정하지 않으면 Ceph Orchestrator에서 호스트를 무작위로 선택하고 모니터 데몬을 배포합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
- Ceph 모니터 데몬을 배포하는 방법은 다음 네 가지가 있습니다.
방법 1
배치 사양을 사용하여 호스트에 모니터를 배포합니다.
참고--placement옵션을 사용하여 특정 호스트에 배포하는 것이 좋습니다.구문
ceph orch apply mon --placement="HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply mon --placement="host01 host02 host03"
참고명령에서 부트스트랩 노드를 첫 번째 노드로 포함해야 합니다.
중요ceph orch apply monreplaceses로 모니터를 개별적으로 추가하지 말고 모든 호스트에 모니터를 추가하지 않습니다. 예를 들어 다음 명령을 실행하는 경우 첫 번째 명령은host01에 모니터를 생성합니다. 그런 다음 두 번째 명령은 host1의 모니터를 대체하고host02에서 모니터를 생성합니다. 그런 다음 세 번째 명령은host02의 모니터를 대체하고host03에서 모니터를 생성합니다. 결국 세 번째 호스트에만 모니터가 있습니다.# ceph orch apply mon host01 # ceph orch apply mon host02 # ceph orch apply mon host03
방법 2
배치 사양을 사용하여 라벨이 있는 특정 호스트에 특정 모니터 수를 배포합니다.
호스트에 레이블을 추가합니다.
구문
ceph orch host label add HOSTNAME_1 LABEL
예제
[ceph: root@host01 /]# ceph orch host label add host01 mon
데몬을 배포합니다.
구문
ceph orch apply mon --placement="HOST_NAME_1:mon HOST_NAME_2:mon HOST_NAME_3:mon"
예제
[ceph: root@host01 /]# ceph orch apply mon --placement="host01:mon host02:mon host03:mon"
방법 3
배치 사양을 사용하여 특정 호스트에 특정 모니터 수를 배포합니다.
구문
ceph orch apply mon --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply mon --placement="3 host01 host02 host03"
방법 4
스토리지 클러스터의 호스트에 모니터 데몬을 임의로 배포합니다.
구문
ceph orch apply mon NUMBER_OF_DAEMONS예제
[ceph: root@host01 /]# ceph orch apply mon 3
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
4.4. 서비스 사양을 사용하여 Ceph 모니터 데몬 배포
Ceph Orchestrator는 기본적으로 하나의 모니터 데몬을 배포합니다. YAML 형식 파일과 같이 서비스 사양을 사용하여 추가 모니터 데몬을 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
mon.yaml파일을 생성합니다.예제
[root@host01 ~]# touch mon.yaml
다음 세부 정보를 포함하도록
mon.yaml파일을 편집합니다.구문
service_type: mon placement: hosts: - HOST_NAME_1 - HOST_NAME_2예제
service_type: mon placement: hosts: - host01 - host02YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount mon.yaml:/var/lib/ceph/mon/mon.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/mon/
모니터 데몬을 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 mon]# ceph orch apply -i mon.yaml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
4.5. Ceph Orchestrator를 사용하여 특정 네트워크에 모니터 데몬 배포
Ceph Orchestrator는 기본적으로 하나의 모니터 데몬을 배포합니다. 각 모니터의 IP 주소 또는 CIDR 네트워크를 명시적으로 지정하고 각 모니터가 배치되는 위치를 제어할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
자동화된 모니터 배포를 비활성화합니다.
예제
[ceph: root@host01 /]# ceph orch apply mon --unmanaged
특정 네트워크의 호스트에 모니터를 배포합니다.
구문
ceph orch daemon add mon HOST_NAME_1:IP_OR_NETWORK
예제
[ceph: root@host01 /]# ceph orch daemon add mon host03:10.1.2.123
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
4.6. Ceph Orchestrator를 사용하여 모니터 데몬 제거
호스트에서 모니터 데몬을 제거하려면 다른 호스트에 모니터 데몬을 다시 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 호스트에 배포된 하나 이상의 모니터 데몬.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
ceph orch apply명령을 실행하여 필요한 모니터 데몬을 배포합니다.구문
ceph orch apply mon “NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3”
host02에서 모니터 데몬을 제거하려면 다른 호스트에 모니터를 재배포할 수 있습니다.예제
[ceph: root@host01 /]# ceph orch apply mon “2 host01 host03”
검증
호스트,daemon 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mon
4.7. 비정상 스토리지 클러스터에서 Ceph Monitor 제거
비정상 스토리지 클러스터에서 ceph-mon 데몬을 제거할 수 있습니다. 비정상 스토리지 클러스터는 배치 그룹이 active + clean 상태가 아닌 영구적으로 있는 클러스터입니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph Monitor 노드에 대한 루트 수준 액세스.
- 하나 이상의 Ceph Monitor 노드를 실행합니다.
프로세스
남아 있는 모니터를 식별하고 호스트에 로그인합니다.
구문
ssh root@MONITOR_ID예제
[root@admin ~]# ssh root@host00
각 Ceph Monitor 호스트에 로그인하고 모든 Ceph 모니터를 중지합니다.
구문
cephadm unit --name DAEMON_NAME.HOSTNAME stop
예제
[root@host00 ~]# cephadm unit --name mon.host00 stop
확장된 데몬 유지 관리에 적합한 환경을 설정하고 데몬을 대화형으로 실행하려면 다음을 수행합니다.
구문
cephadm shell --name DAEMON_NAME.HOSTNAME
예제
[root@host00 ~]# cephadm shell --name mon.host00
monmap파일의 사본을 추출합니다.구문
ceph-mon -i HOSTNAME --extract-monmap TEMP_PATH
예제
[ceph: root@host00 /]# ceph-mon -i host01 --extract-monmap /tmp/monmap 2022-01-05T11:13:24.440+0000 7f7603bd1700 -1 wrote monmap to /tmp/monmap
비활성화되지 않은 Ceph 모니터를 제거합니다.
구문
monmaptool TEMPORARY_PATH --rm HOSTNAME
예제
[ceph: root@host00 /]# monmaptool /tmp/monmap --rm host01
제거된 모니터가 있는 남아 있는 모니터 맵을 Ceph 모니터에 삽입합니다.
구문
ceph-mon -i HOSTNAME --inject-monmap TEMP_PATH
예제
[ceph: root@host00 /]# ceph-mon -i host00 --inject-monmap /tmp/monmap
남아 있는 모니터만 시작합니다.
구문
cephadm unit --name DAEMON_NAME.HOSTNAME start
예제
[root@host00 ~]# cephadm unit --name mon.host00 start
모니터가 쿼럼을 형성하는지 확인합니다.
예제
[ceph: root@host00 /]# ceph -s
-
선택 사항: 제거된 Ceph Monitor의 데이터 디렉토리를
/var/lib/ceph/CLUSTER_FSID/mon.HOSTNAME디렉터리에 보관합니다.
5장. Ceph Orchestrator를 사용한 관리자 관리
스토리지 관리자는 Ceph Orchestrator를 사용하여 추가 관리자 데몬을 배포할 수 있습니다. cephadm 은 부트스트랩 프로세스 중에 부트스트랩 노드에 관리자 데몬을 자동으로 설치합니다.
일반적으로 동일한 수준의 가용성을 달성하려면 Ceph Monitor 데몬을 실행하는 각 호스트에 Ceph Manager를 설정해야 합니다.
기본적으로 ceph-mgr 인스턴스가 먼저 제공되는 것은 Ceph 모니터에 의해 활성화되며 다른 인스턴스는 대기 관리자입니다. ceph-mgr 데몬 사이에 쿼럼이 없어야 합니다.
활성 데몬이 mon mgr 비컨 유예보다 더 많은 모니터에 비컨 을 보내는 데 실패하면 대기 상태로 교체됩니다.
장애 조치를 사전 시도하려면 ceph mgr fail MANAGER_NAME 명령으로 ceph-mgr 데몬을 실패로 명시적으로 표시할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
5.1. Ceph Orchestrator를 사용하여 관리자 데몬 배포
Ceph Orchestrator는 기본적으로 두 개의 Manager 데몬을 배포합니다. 명령줄 인터페이스에서 배치 사양을 사용하여 추가 관리자 데몬을 배포할 수 있습니다. 다른 수의 Manager 데몬을 배포하려면 다른 수를 지정합니다. Manager 데몬을 배포해야 하는 호스트를 지정하지 않으면 Ceph Orchestrator에서 호스트를 무작위로 선택하고 Manager 데몬을 배포합니다.
배포마다 배포마다 3개 이상의 Ceph Manager가 있는지 확인합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
- 관리자 데몬은 다음 두 가지 방법으로 배포할 수 있습니다.
방법 1
특정 호스트 세트에 배치 사양을 사용하여 관리자 데몬을 배포합니다.
참고--placement옵션을 사용하여 특정 호스트에 배포하는 것이 좋습니다.구문
ceph orch apply mgr --placement=" HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply mgr --placement="host01 host02 host03"
방법 2
스토리지 클러스터의 호스트에 관리자 데몬을 임의로 배포합니다.
구문
ceph orch apply mgr NUMBER_OF_DAEMONS예제
[ceph: root@host01 /]# ceph orch apply mgr 3
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgr
5.2. Ceph Orchestrator를 사용하여 관리자 데몬 제거
호스트에서 관리자 데몬을 제거하려면 다른 호스트에 데몬을 다시 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 호스트에 배포된 하나 이상의 관리자 데몬.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
ceph orch apply명령을 실행하여 필요한 관리자 데몬을 재배포합니다.구문
ceph orch apply mgr "NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_3"
host02에서 관리자 데몬을 제거하려면 다른 호스트에 manager 데몬을 재배포할 수 있습니다.예제
[ceph: root@host01 /]# ceph orch apply mgr "2 host01 host03"
검증
호스트,daemon 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mgr
추가 리소스
5.3. Ceph Manager 모듈 사용
ceph mgr module ls 명령을 사용하여 사용 가능한 모듈과 현재 활성화된 모듈을 확인합니다.
ceph mgr 모듈을 사용하여 모듈을 활성화하거나 비활성화하면 MODULE 명령 또는 ceph mgr 모듈이 각각 MODULE 명령을 비활성화합니다.
모듈이 활성화되면 활성 ceph-mgr 데몬이 로드되어 실행합니다. HTTP 서버와 같은 서비스를 제공하는 모듈의 경우 모듈은 로드될 때 해당 주소를 게시할 수 있습니다. 이러한 모듈의 주소를 보려면 ceph mgr services 명령을 실행합니다.
일부 모듈은 대기 ceph-mgr 데몬과 활성 데몬에서 실행되는 특수 대기 모드를 구현할 수도 있습니다. 이를 통해 클라이언트가 대기 모드에 연결을 시도하는 경우 서비스를 제공하여 클라이언트를 활성 데몬으로 리디렉션할 수 있습니다.
다음은 dashboard 모듈을 활성화하는 예입니다.
[ceph: root@host01 /]# ceph mgr module enable dashboard
[ceph: root@host01 /]# ceph mgr module ls
MODULE
balancer on (always on)
crash on (always on)
devicehealth on (always on)
orchestrator on (always on)
pg_autoscaler on (always on)
progress on (always on)
rbd_support on (always on)
status on (always on)
telemetry on (always on)
volumes on (always on)
cephadm on
dashboard on
iostat on
nfs on
prometheus on
restful on
alerts -
diskprediction_local -
influx -
insights -
k8sevents -
localpool -
mds_autoscaler -
mirroring -
osd_perf_query -
osd_support -
rgw -
rook -
selftest -
snap_schedule -
stats -
telegraf -
test_orchestrator -
zabbix -
[ceph: root@host01 /]# ceph mgr services
{
"dashboard": "http://myserver.com:7789/",
"restful": "https://myserver.com:8789/"
}
클러스터가 처음 시작될 때 mgr_initial_modules 설정을 사용하여 활성화할 모듈을 재정의합니다. 그러나 이 설정은 클러스터의 나머지 수명 동안 무시됩니다. 부트 스트랩에만 사용합니다. 예를 들어 모니터 데몬을 처음 시작하기 전에 다음과 같은 섹션을 ceph.conf 파일에 추가할 수 있습니다.
[mon]
mgr initial modules = dashboard balancer모듈이 주석 행 후크를 구현하는 경우 일반 Ceph 명령으로 명령에 액세스할 수 있으며 Ceph는 모듈 명령을 표준 CLI 인터페이스에 자동으로 통합하고 모듈에 적절하게 라우팅합니다.
[ceph: root@host01 /]# ceph <command | help>
위의 명령과 함께 다음 구성 매개변수를 사용할 수 있습니다.
표 5.1. 구성 매개변수
| 설정 | 설명 | 유형 | 기본 |
|---|---|---|---|
|
| 에서 모듈 로드 경로입니다. | 문자열 |
|
|
| 데몬 데이터를 로드하는 경로(예: 인증) | 문자열 |
|
|
| 관리자 비컨과 기타 주기적 검사 사이의 시간(초)입니다. | 정수 |
|
|
| 마지막 비컨 이후 관리자가 실패한 것으로 간주해야 하는 기간이 얼마나 됩니까. | 정수 |
|
5.4. Ceph Manager balancer 모듈 사용
밸런서는 자동으로 또는 숙련된 방식으로 분산 배포를 수행하기 위해 OSD에서 배치 그룹(PG) 배치를 최적화하는 Ceph Manager(ceph-mgr)용 모듈입니다.
현재 balancer 모듈은 비활성화할 수 없습니다. 구성을 사용자 지정하도록만 해제할 수 있습니다.
모드
현재 두 가지 지원되는 밸런서 모드가 있습니다.
crush-compat: CRUSH 호환 모드는 Ceph Luminous에 도입된 compat
weight-set기능을 사용하여 CRUSH 계층 구조의 장치에 대한 대체 가중치 세트를 관리합니다. 일반 가중치는 장치에 저장하려는 대상 데이터 양을 반영하도록 장치의 크기로 설정되어야 합니다. 그런 다음 밸런서는 가능한 한 가깝게 대상 배포와 일치하는 배포를 달성하기 위해weight-set값을 최적화하여 작은 증분으로 조정하거나 축소합니다. PG 배치는 의사 임의 프로세스이므로 배치에는 자연적인 변형이 있습니다. 가중치를 최적화함으로써 밸런서는 이러한 자연적 변형을 수행합니다.이 모드는 이전 클라이언트와 완전히 호환됩니다. OSDMap 및 CRUSH 맵이 이전 클라이언트와 공유되면 밸런서는 최적화된 가중치를 실제 가중치로 제공합니다.
이 모드의 기본 제한은 계층 구조의 하위 트리가 모든 OSD를 공유하는 경우 다양한 배치 규칙으로 여러 CRUSH 계층 구조를 처리할 수 없다는 것입니다. 이 구성을 사용하면 공유 OSD에서 공간 사용률을 관리하기가 어렵기 때문에 일반적으로 사용하지 않는 것이 좋습니다. 따라서 이 제한은 일반적으로 문제가 아닙니다.
upmap: Luminous를 사용하여 시작하여 OSDMap은 일반 CRUSH 배치 계산에 예외적으로 개별 OSD에 대한 명시적 매핑을 저장할 수 있습니다. 이러한
upmap항목은 PG 매핑에 대한 세분화된 제어를 제공합니다. 이 CRUSH 모드는 분산 배포를 수행하기 위해 개별 PG의 배치를 최적화합니다. 대부분의 경우 이 배포는 균등하게 분배되지 않을 수 있으므로 각 OSD +/-1 PG에 동일한 수의 PG가 있는 "perfect"입니다.중요이 기능을 사용하려면 다음 명령을 사용하여 고급 또는 이후 클라이언트만 지원해야 함을 클러스터에 알려야 합니다.
[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminous
기존 클라이언트 또는 데몬이 모니터에 연결되어 있으면 이 명령이 실패합니다.
알려진 문제로 인해 커널 CephFS 클라이언트는 자신을 jewel 클라이언트로 보고합니다. 이 문제를 해결하려면
--yes-i-really-mean-it플래그를 사용합니다.[ceph: root@host01 /]# ceph osd set-require-min-compat-client luminous --yes-i-really-mean-it
다음과 함께 사용 중인 클라이언트 버전을 확인할 수 있습니다.
[ceph: root@host01 /]# ceph features
5.4.1. 용량 밸런서를 사용하여 Red Hat Ceph 클러스터 밸런싱
용량 밸런서를 사용하여 Red Hat Ceph 스토리지 클러스터의 균형을 조정합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
프로세스
balancer 모듈이 활성화되어 있는지 확인합니다.
예제
[ceph: root@host01 /]# ceph mgr module enable balancer
balancer 모듈을 활성화합니다.
예제
[ceph: root@host01 /]# ceph balancer on
모드를 변경하려면 다음 명령을 사용합니다. 기본 모드는
upmap입니다.예제
[ceph: root@host01 /]# ceph balancer mode crush-compat
또는
예제
[ceph: root@host01 /]# ceph balancer mode upmap
밸런서의 현재 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph balancer status
자동 밸런싱
기본적으로 balancer 모듈을 켜면 자동 밸런싱이 사용됩니다.
예제
[ceph: root@host01 /]# ceph balancer on
다음을 사용하여 밸런서를 다시 끌 수 있습니다.
예제
[ceph: root@host01 /]# ceph balancer off
이렇게 하면 이전 클라이언트와 이전 버전과 호환되는 crush-compat 모드를 사용하며 OSD가 동일하게 활용되도록 시간이 지남에 따라 데이터 배포를 약간 변경합니다.
제한
OSD가 실패하고 시스템이 아직 복구되지 않은 경우 클러스터의 성능이 저하된 경우 PG 배포에 대한 조정이 이루어지지 않습니다.
클러스터가 정상이면 밸런서는 변경 사항을 제한하여 잘못 배치되거나 이동해야 하는 PG의 백분율이 기본적으로 임계값의 5% 미만입니다. 이 백분율은 target_max_misplaced_ratio 설정을 사용하여 조정할 수 있습니다. 예를 들어 임계값을 7%로 늘리려면 다음을 수행합니다.
예제
[ceph: root@host01 /]# ceph config-key set mgr target_max_misplaced_ratio .07
자동 밸런싱의 경우:
- 자동 밸런서 실행 사이에 유휴 상태로 전환될 시간(초)을 설정합니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/sleep_interval 60
- HHMM 형식으로 자동 밸런싱을 시작하도록 시간을 설정합니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_time 0000
- HHMM 형식의 자동 밸런싱을 완료하도록 시간을 설정합니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_time 2359
-
이번 주 또는 이후 날짜로 자동 밸런싱을 제한합니다. crontab과 동일한 규칙을 사용하며
0은 일요일,1은 월요일 등입니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/begin_weekday 0
-
이 요일 또는 이전 날짜로 자동 밸런싱을 제한합니다. 이 명령은 crontab과 동일한 규칙을 사용하며
0은 일요일,1은 월요일 등입니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/end_weekday 6
-
자동 분산이 제한된 풀 ID를 정의합니다. 기본값은 빈 문자열이므로 모든 풀이 균형을 유지합니다.
ceph osd pool ls detail명령을 사용하여 숫자 풀 ID를 가져올 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/balancer/pool_ids 1,2,3
검증된 최적화
밸런서 작업은 다음과 같은 몇 가지 단계로 나뉩니다.
-
계획을만듭니다. -
현재 PG 배포를 위해 또는
계획을실행한 후 발생할 PG 배포를 위해 데이터 배포의 품질을 평가합니다. 계획을실행합니다.현재 배포를 평가하고 점수화하려면 다음을 수행합니다.
예제
[ceph: root@host01 /]# ceph balancer eval
단일 풀의 배포를 평가하려면 다음을 수행합니다.
구문
ceph balancer eval POOL_NAME예제
[ceph: root@host01 /]# ceph balancer eval rbd
평가에 대한 자세한 내용을 보려면 다음을 수행합니다.
예제
[ceph: root@host01 /]# ceph balancer eval-verbose ...
현재 구성된 모드를 사용하여 계획을 생성하려면 다음을 수행합니다.
구문
ceph balancer optimize PLAN_NAMEPLAN_NAME 을 사용자 지정 계획 이름으로 바꿉니다.
예제
[ceph: root@host01 /]# ceph balancer optimize rbd_123
계획의 내용을 보려면 다음을 수행합니다.
구문
ceph balancer show PLAN_NAME예제
[ceph: root@host01 /]# ceph balancer show rbd_123
이전 계획을 삭제하려면 다음을 수행합니다.
구문
ceph balancer rm PLAN_NAME예제
[ceph: root@host01 /]# ceph balancer rm rbd_123
현재 기록된 계획을 보려면 status 명령을 사용합니다.
[ceph: root@host01 /]# ceph balancer status
계획을 실행한 후 생성되는 배포의 품질을 계산하려면 다음을 수행합니다.
구문
ceph balancer eval PLAN_NAME예제
[ceph: root@host01 /]# ceph balancer eval rbd_123
계획을 실행하려면 다음을 수행합니다.
구문
ceph balancer execute PLAN_NAME예제
[ceph: root@host01 /]# ceph balancer execute rbd_123
참고배포를 개선할 것으로 예상되는 경우에만 계획을 실행합니다. 계획이 실행되면 계획이 삭제됩니다.
5.4.2. 읽기 밸런서를 사용하여 Red Hat Ceph 클러스터 밸런싱 [기술 프리뷰]
Read Balancer는 Red Hat Ceph Storage 7.0에만 기술 프리뷰 기능입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있으며 Red Hat은 해당 기능을 프로덕션용으로 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. 자세한 내용은 Red Hat 기술 프리뷰 기능에 대한 지원 범위를 참조하십시오.
균형이 맞지 않는 기본 OSD가 있는 경우 osdmaptool 에 빌드된 오프라인 Cryostat로 업데이트할 수 있습니다.
최상의 결과를 보장하기 위해 읽기 밸런서를 실행하기 전에 용량 밸런서를 실행하는 것이 좋습니다.
읽기 밸런서를 사용하여 클러스터의 균형을 조정하려면 절차의 단계를 따르십시오.
사전 요구 사항
- 실행 중이고 용량 균형을 이루는 Red Hat Ceph Storage 클러스터입니다.
최상의 결과를 보장하기 위해 읽기 밸런서를 실행하기 전에 용량 밸런서를 실행하여 각 OSD의 용량을 균형 있게 조정하는 것이 좋습니다. 다음 단계를 실행하여 용량의 균형을 조정합니다.
osdmap의 최신 사본을 가져옵니다.
[ceph: root@host01 /]# ceph osd getmap -o map
upmap 밸런서를 실행합니다.
[ceph: root@host01 /]# ospmaptool map –upmap out.txt
file out.txt에는 제안된 솔루션이 포함되어 있습니다.
이 절차의 명령은 클러스터에 변경 사항을 적용하기 위해 실행되는 일반 Ceph CLI 명령입니다.
out.txt 파일에 권장 사항이 있는 경우 다음 명령을 실행합니다.
[ceph: root@host01 /]# source out.txt
자세한 내용은 Balancing IBM Ceph cluster using capacity balancer에서 참조하십시오.
프로세스
각 풀에 사용할 수 있는
read_balance_score를 확인합니다.[ceph: root@host01 /]# ceph osd pool ls detail
read_balance_score가 1보다 큰 경우 풀에서 기본 OSD의 균형이 해제되었습니다.동종 클러스터의 경우 최적의 점수는 [Ceil{( PGs/Number of OSDs)}/( PGs/Number of OSDs)]/[ ( PGs/Number of OSDs)/(CPU 수의 PGs/Number)]입니다. 예를 들어 32개의 PG와 10개의 OSD가 있는 풀이 있는 경우 ( PGs/Number of OSDs) = 32/10 = 3.2입니다. 따라서 모든 장치가 동일한 경우 최적 점수는 4/3.2 = 1.25인 최적 점수가 3.2의 경우 ( PG/Number of OSDs)로 나뉩니다. 64 PG가 있는 동일한 시스템에 다른 풀이 있는 경우 최적의 점수는 7/6.4 =1.09375입니다.
출력 예:
$ ceph osd pool ls detail pool 1 '.mgr' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 17 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 3.00 pool 2 'cephfs.a.meta' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 autoscale_mode on last_change 55 lfor 0/0/25 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs read_balance_score 1.50 pool 3 'cephfs.a.data' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode on last_change 27 lfor 0/0/25 flags hashpspool,bulk stripe_width 0 application cephfs read_balance_score 1.31
osdmap의 최신 사본을 가져옵니다.[ceph: root@host01 /]# ceph osd getmap -o om
출력 예:
got osdmap epoch 56
Cryostat를 실행합니다.
file
out.txt에는 제안된 솔루션이 포함되어 있습니다.[ceph: root@host01 /]# osdmaptool om --read out.txt --read-pool _POOL_NAME_ [--vstart]
출력 예:
$ osdmaptool om --read out.txt --read-pool cephfs.a.meta ./bin/osdmaptool: osdmap file 'om' writing upmap command output to: out.txt ---------- BEFORE ------------ osd.0 | primary affinity: 1 | number of prims: 4 osd.1 | primary affinity: 1 | number of prims: 8 osd.2 | primary affinity: 1 | number of prims: 4 read_balance_score of 'cephfs.a.meta': 1.5 ---------- AFTER ------------ osd.0 | primary affinity: 1 | number of prims: 5 osd.1 | primary affinity: 1 | number of prims: 6 osd.2 | primary affinity: 1 | number of prims: 5 read_balance_score of 'cephfs.a.meta': 1.13 num changes: 2
file
out.txt에는 제안된 솔루션이 포함되어 있습니다.이 절차의 명령은 클러스터에 변경 사항을 적용하기 위해 실행되는 일반 Ceph CLI 명령입니다. vstart 클러스터에서 작업하는 경우 CLI 명령이
./bin/ 접두사로 포맷되도록--vstart매개변수를 전달할 수 있습니다.[ceph: root@host01 /]# source out.txt
출력 예:
$ cat out.txt ceph osd pg-upmap-primary 2.3 0 ceph osd pg-upmap-primary 2.4 2 $ source out.txt change primary for pg 2.3 to osd.0 change primary for pg 2.4 to osd.2
참고ceph osd pg-upmap-primary명령을 처음 실행하는 경우 다음과 같이 경고가 표시될 수 있습니다.Error EPERM: min_compat_client luminous < reef, which is required for pg-upmap-primary. Try 'ceph osd set-require-min-compat-client reef' before using the new interface
이 경우 권장 명령
ceph osd set-require-min-compat-client reef를 실행하고 클러스터의 min-compact-client를 조정합니다.
배치 그룹(PG) 수가 변경되거나 클러스터에서 OSD가 추가되거나 제거된 경우 이러한 작업이 풀에 읽기 밸런서 효과에 상당한 영향을 미칠 수 있으므로 점수를 다시 확인하고 밸런서를 다시 실행하는 것이 좋습니다.
5.5. Ceph Manager 경고 모듈 사용
Ceph Manager 경고 모듈을 사용하여 이메일로 Red Hat Ceph Storage 클러스터 상태에 대한 간단한 경고 메시지를 보낼 수 있습니다.
이 모듈은 강력한 모니터링 솔루션이 아닙니다. Ceph 클러스터 자체의 일부로 실행된다는 사실은 ceph-mgr 데몬 실패로 인해 경고가 전송되지 않도록 근본적으로 제한됩니다. 그러나 이 모듈은 기존 모니터링 인프라가 없는 환경에 존재하는 독립 실행형 클러스터에 유용할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph Monitor 노드에 대한 루트 수준 액세스.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
alerts 모듈을 활성화합니다.
예제
[ceph: root@host01 /]# ceph mgr module enable alerts
alerts 모듈이 활성화되었는지 확인합니다.
예제
[ceph: root@host01 /]# ceph mgr module ls | more { "always_on_modules": [ "balancer", "crash", "devicehealth", "orchestrator", "pg_autoscaler", "progress", "rbd_support", "status", "telemetry", "volumes" ], "enabled_modules": [ "alerts", "cephadm", "dashboard", "iostat", "nfs", "prometheus", "restful" ]SMTP(Simple Mail Transfer Protocol)를 구성합니다.
구문
ceph config set mgr mgr/alerts/smtp_host SMTP_SERVER ceph config set mgr mgr/alerts/smtp_destination RECEIVER_EMAIL_ADDRESS ceph config set mgr mgr/alerts/smtp_sender SENDER_EMAIL_ADDRESS
예제
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_host smtp.example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_destination example@example.com [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_sender example2@example.com
선택 사항: 기본적으로 alerts 모듈은 SSL 및 포트 465를 사용합니다.
구문
ceph config set mgr mgr/alerts/smtp_port PORT_NUMBER예제
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_port 587
경고를 구성하는 동안
smtp_ssl매개변수를 설정하지 마십시오.SMTP 서버에 인증합니다.
구문
ceph config set mgr mgr/alerts/smtp_user USERNAME ceph config set mgr mgr/alerts/smtp_password PASSWORD
예제
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_user admin1234 [ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_password admin1234
선택 사항: 기본적으로 이름에 따라 SMTP는
Ceph입니다.이를 변경하려면smtp_from_name매개변수를 설정합니다.구문
ceph config set mgr mgr/alerts/smtp_from_name CLUSTER_NAME예제
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/smtp_from_name 'Ceph Cluster Test'
선택 사항: 기본적으로 alerts 모듈은 1분마다 스토리지 클러스터의 상태를 확인하고 클러스터 상태가 변경될 때 메시지를 보냅니다. 빈도를 변경하려면
interval매개변수를 설정합니다.구문
ceph config set mgr mgr/alerts/interval INTERVAL예제
[ceph: root@host01 /]# ceph config set mgr mgr/alerts/interval "5m"
이 예에서 간격은 5분으로 설정됩니다.
선택 사항: 즉시 경고를 보냅니다.
예제
[ceph: root@host01 /]# ceph alerts send
추가 리소스
- Ceph 상태 메시지에 대한 자세한 내용은 Red Hat Ceph Storage 문제 해결 가이드에서 Ceph 클러스터 의 상태 메시지 섹션을 참조하십시오.
5.6. Ceph manager 크래시 모듈 사용
Ceph manager 크래시 모듈을 사용하면 데몬 크래시 덤프에 대한 정보를 수집하여 추가 분석을 위해 Red Hat Ceph Storage 클러스터에 저장할 수 있습니다.
기본적으로 데몬 크래시 덤프는 /var/lib/ceph/crash 에 덤프됩니다. 옵션 크래시 dir 을 사용하여 구성할 수 있습니다. 크래시 디렉터리는 시간, 날짜 및 무작위로 생성된 UUID에 따라 이름이 지정되며 동일한 crash_id 가 있는 메타데이터 파일 메타 및 최근 로그 파일을 포함합니다.
ceph-crash.service 를 사용하여 이러한 충돌을 자동으로 제출하고 Ceph 모니터에 유지할 수 있습니다. ceph-crash.service 는 crashdump 디렉터리를 감시하고 ceph 크래시 게시물 로 업로드합니다.
RECENT_CRASH heath 메시지는 Ceph 클러스터에서 가장 일반적인 상태 메시지 중 하나입니다. 이 상태 메시지는 최근에 하나 이상의 Ceph 데몬이 충돌했으며 충돌은 아직 관리자가 보관하거나 승인하지 않았음을 의미합니다. 이는 소프트웨어 버그, 디스크 오류와 같은 하드웨어 문제 또는 다른 문제를 나타낼 수 있습니다. 옵션 mgr/crash/warn_recent_interval 은 기본적으로 2주인 최근의 의미의 기간을 제어합니다. 다음 명령을 실행하여 경고를 비활성화할 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set mgr/crash/warn_recent_interval 0
mgr/crash/retain_interval 옵션은 충돌 보고서를 자동으로 제거하기 전에 유지하려는 기간을 제어합니다. 이 옵션의 기본값은 1년입니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
프로세스
crash 모듈이 활성화되었는지 확인합니다.
예제
[ceph: root@host01 /]# ceph mgr module ls | more { "always_on_modules": [ "balancer", "crash", "devicehealth", "orchestrator_cli", "progress", "rbd_support", "status", "volumes" ], "enabled_modules": [ "dashboard", "pg_autoscaler", "prometheus" ]크래시 덤프 저장: 메타데이터 파일은 크래시 디렉터리에
메타로 저장된 JSON Blob입니다. stdin에서 읽는 ceph command-i -옵션을 호출할 수 있습니다.예제
[ceph: root@host01 /]# ceph crash post -i meta
모든 신규 및 아카이브된 크래시 정보의 타임스탬프 또는 UUID 충돌 ID를 나열합니다.
예제
[ceph: root@host01 /]# ceph crash ls
모든 새로운 충돌 정보의 타임스탬프 또는 UUID 충돌 ID를 나열합니다.
예제
[ceph: root@host01 /]# ceph crash ls-new
모든 새로운 충돌 정보의 타임스탬프 또는 UUID 충돌 ID를 나열합니다.
예제
[ceph: root@host01 /]# ceph crash ls-new
저장된 충돌 정보의 요약을 기간별로 그룹화합니다.
예제
[ceph: root@host01 /]# ceph crash stat 8 crashes recorded 8 older than 1 days old: 2022-05-20T08:30:14.533316Z_4ea88673-8db6-4959-a8c6-0eea22d305c2 2022-05-20T08:30:14.590789Z_30a8bb92-2147-4e0f-a58b-a12c2c73d4f5 2022-05-20T08:34:42.278648Z_6a91a778-bce6-4ef3-a3fb-84c4276c8297 2022-05-20T08:34:42.801268Z_e5f25c74-c381-46b1-bee3-63d891f9fc2d 2022-05-20T08:34:42.803141Z_96adfc59-be3a-4a38-9981-e71ad3d55e47 2022-05-20T08:34:42.830416Z_e45ed474-550c-44b3-b9bb-283e3f4cc1fe 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d 2022-05-24T19:58:44.315282Z_1847afbc-f8a9-45da-94e8-5aef0738954e
저장된 충돌의 세부 정보를 확인합니다.
구문
ceph crash info CRASH_ID예제
[ceph: root@host01 /]# ceph crash info 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d { "assert_condition": "session_map.sessions.empty()", "assert_file": "/builddir/build/BUILD/ceph-16.1.0-486-g324d7073/src/mon/Monitor.cc", "assert_func": "virtual Monitor::~Monitor()", "assert_line": 287, "assert_msg": "/builddir/build/BUILD/ceph-16.1.0-486-g324d7073/src/mon/Monitor.cc: In function 'virtual Monitor::~Monitor()' thread 7f67a1aeb700 time 2022-05-24T19:58:42.545485+0000\n/builddir/build/BUILD/ceph-16.1.0-486-g324d7073/src/mon/Monitor.cc: 287: FAILED ceph_assert(session_map.sessions.empty())\n", "assert_thread_name": "ceph-mon", "backtrace": [ "/lib64/libpthread.so.0(+0x12b30) [0x7f679678bb30]", "gsignal()", "abort()", "(ceph::__ceph_assert_fail(char const*, char const*, int, char const*)+0x1a9) [0x7f6798c8d37b]", "/usr/lib64/ceph/libceph-common.so.2(+0x276544) [0x7f6798c8d544]", "(Monitor::~Monitor()+0xe30) [0x561152ed3c80]", "(Monitor::~Monitor()+0xd) [0x561152ed3cdd]", "main()", "__libc_start_main()", "_start()" ], "ceph_version": "16.2.8-65.el8cp", "crash_id": "2022-07-06T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d", "entity_name": "mon.ceph-adm4", "os_id": "rhel", "os_name": "Red Hat Enterprise Linux", "os_version": "8.5 (Ootpa)", "os_version_id": "8.5", "process_name": "ceph-mon", "stack_sig": "957c21d558d0cba4cee9e8aaf9227b3b1b09738b8a4d2c9f4dc26d9233b0d511", "timestamp": "2022-07-06T19:58:42.549073Z", "utsname_hostname": "host02", "utsname_machine": "x86_64", "utsname_release": "4.18.0-240.15.1.el8_3.x86_64", "utsname_sysname": "Linux", "utsname_version": "#1 SMP Wed Jul 06 03:12:15 EDT 2022" }KEEP 일보다 저장된 충돌 제거: 여기에서 KEEP 는 정수여야 합니다.
구문
ceph crash prune KEEP예제
[ceph: root@host01 /]# ceph crash prune 60
더 이상
RECENT_CRASH상태 점검으로 간주되지 않고크래시 ls-new 출력에 표시되지 않도록 크래시보고서를 보관합니다.충돌 ls에 나타납니다.구문
ceph crash archive CRASH_ID예제
[ceph: root@host01 /]# ceph crash archive 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
모든 충돌 보고서를 보관합니다.
예제
[ceph: root@host01 /]# ceph crash archive-all
크래시 덤프 제거:
구문
ceph crash rm CRASH_ID예제
[ceph: root@host01 /]# ceph crash rm 2022-05-24T19:58:42.549073Z_b2382865-ea89-4be2-b46f-9a59af7b7a2d
추가 리소스
- Ceph 상태 메시지에 대한 자세한 내용은 Red Hat Ceph Storage 문제 해결 가이드에서 Ceph 클러스터 의 상태 메시지 섹션을 참조하십시오.
5.7. Telemetry 모듈
Telemetry 모듈은 스토리지 클러스터에 대한 데이터를 전송하여 Ceph 사용 방법과 작업 중에 발생하는 문제를 이해하는 데 도움이 됩니다. 데이터는 공용 대시보드에 시각화되어 보고되는 클러스터 수, 총 용량 및 OSD 수, 버전 배포 추세에 대한 요약 통계를 확인합니다.
채널
원격 분석 보고서는 각각 다른 유형의 정보를 가진 다양한 채널로 나뉩니다. Telemetry가 활성화되면 개별 채널을 켜거나 끌 수 있습니다.
다음은 4개의 다른 채널입니다.
Basic- 기본값은on입니다. 이 채널은 다음 정보를 포함하는 클러스터에 대한 기본 정보를 제공합니다.- 클러스터의 용량입니다.
- 모니터, 관리자, OSD, MDSs, 오브젝트 게이트웨이 또는 기타 데몬의 수입니다.
- 현재 사용 중인 소프트웨어 버전입니다.
- RADOS 풀 및 Ceph 파일 시스템의 수 및 유형입니다.
- 기본값(값이 아님)에서 변경된 구성 옵션의 이름입니다.
crash- 기본값은on입니다. 이 채널은 다음 정보를 포함하는 데몬 충돌에 대한 정보를 제공합니다.- 데몬 유형입니다.
- 데몬의 버전입니다.
- 운영 체제, OS 배포 및 커널 버전입니다.
- Ceph 코드에서 크래시가 발생한 위치를 식별하는 스택 추적입니다.
-
device- 기본값은입니다. 이 채널은 익명화된 SMART 메트릭을 포함하는 장치 메트릭에 대한 정보를 제공합니다. -
idENT - 기본값은OFF입니다. 이 채널은 클러스터 설명과 같은 클러스터에 대한 사용자 제공 식별 정보 및 연락처 이메일 주소를 제공합니다. perf- 기본값은OFF입니다. 이 채널은 클러스터의 다양한 성능 지표를 제공하며, 이는 다음에 사용할 수 있습니다.- 전체 클러스터 상태를 표시합니다.
- 워크로드 패턴을 식별합니다.
- 대기 시간, 제한, 메모리 관리 및 기타 유사한 문제에 대한 문제를 해결합니다.
- 데몬을 통해 클러스터 성능을 모니터링합니다.
보고된 데이터에는 풀 이름, 오브젝트 이름, 오브젝트 콘텐츠, 호스트 이름 또는 장치 일련 번호와 같은 중요한 데이터가 포함되어 있지 않습니다.
클러스터 배포 방법, Ceph 버전, 호스트 배포 및 Ceph 사용 방식을 보다 잘 이해하는 데 도움이 되는 기타 매개 변수에 대한 카운터 및 통계가 포함되어 있습니다.
데이터는 안전하며 https://telemetry.ceph.com 로 전송됩니다.
Telemetry 활성화
채널을 활성화하기 전에 Telemetry가 켜져 있는지 확인합니다.
Telemetry를 활성화합니다.
ceph telemetry on
채널 활성화 및 비활성화
개별 채널을 활성화 또는 비활성화합니다.
ceph telemetry enable channel basic ceph telemetry enable channel crash ceph telemetry enable channel device ceph telemetry enable channel ident ceph telemetry enable channel perf ceph telemetry disable channel basic ceph telemetry disable channel crash ceph telemetry disable channel device ceph telemetry disable channel ident ceph telemetry disable channel perf
여러 채널을 활성화하거나 비활성화합니다.
ceph telemetry enable channel basic crash device ident perf ceph telemetry disable channel basic crash device ident perf
모든 채널을 함께 활성화 또는 비활성화합니다.
ceph telemetry enable channel all ceph telemetry disable channel all
샘플 보고서
언제든지 보고된 데이터를 검토하려면 샘플 보고서를 생성합니다.
ceph telemetry show
Telemetry가
꺼져있는 경우 샘플 보고서를 미리 봅니다.ceph telemetry preview
수백 개의 OSD 이상이 있는 스토리지 클러스터에 대한 샘플 보고서를 생성하는 데 시간이 오래 걸립니다.
개인 정보를 보호하기 위해 장치 보고서가 별도로 생성되고 호스트 이름 및 장치 일련 번호와 같은 데이터는 익명화됩니다. 장치 Telemetry는 다른 끝점으로 전송되며 장치 데이터를 특정 클러스터와 연결하지 않습니다. 장치 보고서를 보려면 다음 명령을 실행합니다.
ceph telemetry show-device
Telemetry가
꺼져있는 경우 샘플 장치 보고서를 미리 봅니다.ceph telemetry preview-device
: :
에Telemetry가 있는 두 보고서의 단일 출력을 가져옵니다.ceph telemetry show-all
Telemetry
off가 포함된 두 보고서의 단일 출력을 가져옵니다.ceph telemetry preview-all
채널별 샘플 보고서를 생성합니다.
구문
ceph telemetry show CHANNEL_NAME채널별 샘플 보고서의 프리뷰를 생성합니다.
구문
ceph telemetry preview CHANNEL_NAME
컬렉션
컬렉션은 채널 내에서 수집되는 데이터의 다양한 측면입니다.
컬렉션을 나열합니다.
ceph telemetry collection ls
등록된 컬렉션과 사용 가능한 새 컬렉션 간의 차이점을 참조하십시오.
ceph telemetry diff
최신 컬렉션에 등록합니다.
구문
ceph telemetry on ceph telemetry enable channel CHANNEL_NAME
간격
모듈은 기본적으로 24시간마다 새 보고서를 컴파일하고 보냅니다.
간격을 조정합니다.
구문
ceph config set mgr mgr/telemetry/interval INTERVAL예제
[ceph: root@host01 /]# ceph config set mgr mgr/telemetry/interval 72
이 예제에서는 3일(72시간)마다 보고서가 생성됩니다.
상태
현재 구성을 확인합니다.
ceph telemetry status
Telemetry 수동 전송
임시로 Telemetry 데이터를 보냅니다.
ceph telemetry send
Telemetry가 비활성화된 경우
ceph telemetry send명령에--license sharing-1-0을 추가합니다.
프록시를 통해 Telemetry 전송
클러스터가 구성된 Telemetry 끝점에 직접 연결할 수 없는 경우 HTTP/HTTPs 프록시 서버를 구성할 수 있습니다.
구문
ceph config set mgr mgr/telemetry/proxy PROXY_URL예제
[ceph: root@host01 /]# ceph config set mgr mgr/telemetry/proxy https://10.0.0.1:8080
user pass를 명령에 포함할 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/telemetry/proxy https://10.0.0.1:8080
연락처 및 설명
선택 사항: 보고서에 연락처 및 설명을 추가합니다.
구문
ceph config set mgr mgr/telemetry/contact '_CONTACT_NAME_' ceph config set mgr mgr/telemetry/description '_DESCRIPTION_' ceph config set mgr mgr/telemetry/channel_ident true
예제
[ceph: root@host01 /]# ceph config set mgr mgr/telemetry/contact 'John Doe <john.doe@example.com>' [ceph: root@host01 /]# ceph config set mgr mgr/telemetry/description 'My first Ceph cluster' [ceph: root@host01 /]# ceph config set mgr mgr/telemetry/channel_ident true
ident플래그가 활성화되면 해당 세부 정보가 리더보드에 표시되지 않습니다.
Leaderboard
공용 대시보드의 리더 보드에 참여하십시오.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/telemetry/leaderboard true
leaderboard에는 스토리지 클러스터에 대한 기본 정보가 표시됩니다. 이 보드에는 총 스토리지 용량과 OSD 수가 포함됩니다.
Telemetry 비활성화
언제든지 Telemetry를 비활성화합니다.
예제
ceph telemetry off
6장. Ceph Orchestrator를 사용하여 OSD 관리
스토리지 관리자는 Ceph Orchestrators를 사용하여 Red Hat Ceph Storage 클러스터의 OSD를 관리할 수 있습니다.
6.1. Ceph OSD
Red Hat Ceph Storage 클러스터가 가동되어 실행되면 런타임 시 스토리지 클러스터에 OSD를 추가할 수 있습니다.
Ceph OSD는 일반적으로 하나의 스토리지 드라이브와 노드 내의 관련 저널을 위한 하나의 ceph-osd 데몬으로 구성됩니다. 노드에 스토리지 드라이브가 여러 개 있는 경우 각 드라이브에 대해 하나의 ceph-osd 데몬을 매핑합니다.
Red Hat은 클러스터의 용량을 정기적으로 확인하여 스토리지 용량의 상단에 도달하고 있는지 확인하는 것이 좋습니다. 스토리지 클러스터가 거의 전체 비율에 도달하면 하나 이상의 OSD를 추가하여 스토리지 클러스터의 용량을 확장합니다.
Red Hat Ceph Storage 클러스터의 크기를 줄이거나 하드웨어를 교체하려는 경우 런타임 시 OSD도 제거할 수 있습니다. 노드에 스토리지 드라이브가 여러 개 있는 경우 해당 드라이브의 ceph-osd 데몬 중 하나를 제거해야 할 수도 있습니다. 일반적으로 스토리지 클러스터의 용량을 확인하여 용량의 상단에 도달하고 있는지 확인하는 것이 좋습니다. 스토리지 클러스터가 거의 전체 비율에 있지 않은 OSD를 제거해야 합니다.
OSD를 추가하기 전에 스토리지 클러스터가 전체 비율에 도달하도록 허용하지 마십시오. 스토리지 클러스터가 거의 전체 비율에 도달한 후 발생하는 OSD 오류로 인해 스토리지 클러스터가 전체 비율을 초과할 수 있습니다. Ceph 블록은 스토리지 용량 문제를 해결할 때까지 데이터를 보호하기 위해 쓰기 액세스 권한을 차단합니다. 먼저 전체 비율에 미치는 영향을 고려하지 않고 OSD를 제거하지 마십시오.
6.2. Ceph OSD 노드 구성
Ceph OSD와 지원 하드웨어를 OSD를 사용할 풀의 스토리지 전략과 유사하게 구성합니다. Ceph는 일관된 성능 프로파일을 위해 풀 전체에서 균일한 하드웨어를 선호합니다. 최상의 성능을 위해 동일한 유형 또는 크기의 드라이브가 있는 CRUSH 계층 구조를 고려하십시오.
다른 크기의 드라이브를 추가하는 경우 그에 따라 가중치를 조정합니다. CRUSH 맵에 OSD를 추가할 때 새 OSD의 가중치를 고려하십시오. 하드 드라이브 용량은 연간 약 40% 증가하므로 최신 OSD 노드에는 스토리지 클러스터의 이전 노드보다 더 큰 하드 드라이브가 있을 수 있습니다. 즉, 가중치가 클 수 있습니다.
새 설치를 수행하기 전에 설치 가이드의 Red Hat Ceph Storage 설치 요구 사항 장을 참조하십시오.
6.3. OSD 메모리 자동 튜닝
OSD 데몬은 osd_memory_target 구성 옵션을 기반으로 메모리 사용을 조정합니다. osd_memory_target 옵션은 시스템에서 사용 가능한 RAM에 따라 OSD 메모리를 설정합니다.
Red Hat Ceph Storage가 다른 서비스와 메모리를 공유하지 않는 전용 노드에 배포된 경우 cephadm 은 총 RAM 양 및 배포된 OSD 수에 따라 자동으로 OSD 소비를 조정합니다.
기본적으로 osd_memory_target_autotune 매개변수는 Red Hat Ceph Storage 클러스터에서 true 로 설정됩니다.
구문
ceph config set osd osd_memory_target_autotune true
cephadm 은 mgr/cephadm/autotune_memory_target_ratio 로 시작합니다. 기본값은 시스템의 총 RAM으로, 비 자동 조정되지 않은 데몬에서 사용하는 메모리를 제거하고 osd_memory_target_autotune 이 false인 OSD로 나눕니다.
osd_memory_target 매개변수는 다음과 같이 계산됩니다.
구문
osd_memory_target = TOTAL_RAM_OF_THE_OSD * (1048576) * (autotune_memory_target_ratio) / NUMBER_OF_OSDS_IN_THE_OSD_NODE - (SPACE_ALLOCATED_FOR_OTHER_DAEMONS)
SPACE_ALLOCATED_FOR_OTHER_DAEMONS 는 선택적으로 다음 데몬 공간 할당을 포함할 수 있습니다.
- Alertmanager: 1GB
- Grafana: 1GB
- Ceph Manager: 4GB
- Ceph 모니터: 2GB
- node-exporter: 1GB
- Prometheus: 1GB
예를 들어 노드에 24개의 OSD가 있고 251GB RAM 공간이 있는 경우 osd_memory_target 은 7860684936 입니다.
최종 대상은 옵션을 사용하여 구성 데이터베이스에 반영됩니다. MEM LIMIT 열의 ceph orch ps 출력에서 각 데몬에서 사용하는 제한 및 현재 메모리를 볼 수 있습니다.
osd_memory_target_autotune true 의 기본 설정은 컴퓨팅 및 Ceph 스토리지 서비스가 배치되는 하이퍼 컨버지드 인프라에 적합하지 않습니다. 하이퍼컨버지드 인프라에서 autotune_memory_target_ratio 를 0.2 로 설정하여 Ceph의 메모리 사용량을 줄일 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set mgr mgr/cephadm/autotune_memory_target_ratio 0.2
스토리지 클러스터에서 OSD의 특정 메모리 대상을 수동으로 설정할 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 7860684936
스토리지 클러스터에서 OSD 호스트의 특정 메모리 대상을 수동으로 설정할 수 있습니다.
구문
ceph config set osd/host:HOSTNAME osd_memory_target TARGET_BYTES
예제
[ceph: root@host01 /]# ceph config set osd/host:host01 osd_memory_target 1000000000
osd_memory_target_autotune 을 활성화하면 기존 수동 OSD 메모리 대상 설정을 덮어씁니다. osd_memory_target_autotune 옵션 또는 기타 유사한 옵션이 활성화된 경우에도 데몬 메모리가 튜닝되지 않도록 하려면 호스트에서 _no_autotune_memory 레이블을 설정합니다.
구문
ceph orch host label add HOSTNAME _no_autotune_memory
autotune 옵션을 비활성화하고 특정 메모리 대상을 설정하여 OSD를 메모리 자동 튜닝에서 제외할 수 있습니다.
예제
[ceph: root@host01 /]# ceph config set osd.123 osd_memory_target_autotune false [ceph: root@host01 /]# ceph config set osd.123 osd_memory_target 16G
6.4. Ceph OSD 배포를 위한 장치 나열
Ceph Orchestrator를 사용하여 OSD를 배포하기 전에 사용 가능한 장치 목록을 확인할 수 있습니다. 명령은 Cephadm에서 검색할 수 있는 장치 목록을 인쇄하는 데 사용됩니다. 다음 조건이 모두 충족되면 스토리지 장치를 사용할 수 있는 것으로 간주됩니다.
- 장치에 파티션이 없어야 합니다.
- 장치에 LVM 상태가 없어야 합니다.
- 장치를 마운트해서는 안 됩니다.
- 장치에 파일 시스템을 포함할 수 없습니다.
- 장치에 Ceph BlueStore OSD가 포함되어 있지 않아야 합니다.
- 장치는 5GB보다 커야 합니다.
Ceph는 사용할 수 없는 장치에 OSD를 프로비저닝하지 않습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자 및 모니터 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 배포할 사용 가능한 장치를 나열합니다.
구문
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
예제
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
--wide옵션을 사용하면 장치가 OSD로 사용할 수 없는 이유를 포함하여 장치와 관련된 모든 세부 정보를 제공합니다. 이 옵션은 NVMe 장치를 지원하지 않습니다.선택 사항:
ceph orch 장치 ls의 출력에서 Health,Ident 및 Fault 필드를 활성화하려면 다음 명령을 실행합니다.참고이러한 필드는
libstoragemgmt라이브러리에서 지원하며 현재 SCSI, SAS 및 SATA 장치를 지원합니다.Cephadm 쉘 외부의 root 사용자로
libstoragemgmt라이브러리와의 하드웨어 호환성을 확인하여 서비스에 대한 계획되지 않은 중단을 방지합니다.예제
[root@host01 ~]# cephadm shell lsmcli ldl
출력에 각 SCSI VPD 0x83 ID를 사용하여 Health Status 가 good로 표시됩니다.
참고이 정보를 얻지 못하면 필드를 활성화하면 장치의 비정상적인 동작이 발생할 수 있습니다.
Cephadm 쉘로 다시 로그인하고
libstoragemgmt지원을 활성화합니다.예제
[root@host01 ~]# cephadm shell [ceph: root@host01 /]# ceph config set mgr mgr/cephadm/device_enhanced_scan true
이 기능이 활성화되면
ceph orch device ls는 Health 필드의 출력을 good로 제공합니다.
검증
장치를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch device ls
6.5. Ceph OSD 배포를 위한 zapping 장치
OSD를 배포하기 전에 사용 가능한 장치 목록을 확인해야 합니다. 장치에 사용 가능한 공간이 없는 경우 zapping하여 장치의 데이터를 지울 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자 및 모니터 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 배포할 사용 가능한 장치를 나열합니다.
구문
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
예제
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
장치의 데이터를 지웁니다.
구문
ceph orch device zap HOSTNAME FILE_PATH --force
예제
[ceph: root@host01 /]# ceph orch device zap host02 /dev/sdb --force
검증
장치에서 공간을 사용할 수 있는지 확인합니다.
예제
[ceph: root@host01 /]# ceph orch device ls
Available 아래에 있는 필드가 Yes 임을 확인할 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 Ceph OSD 배포 목록 섹션을 참조하십시오.
6.6. 사용 가능한 모든 장치에 Ceph OSD 배포
사용 가능한 모든 장치에 모든 OSDS를 배포할 수 있습니다. cephadm을 사용하면 Ceph Orchestrator가 사용 가능하고 사용되지 않는 스토리지 장치에 OSD를 검색하고 배포할 수 있습니다.
사용 가능한 모든 장치를 배포하려면 관리되지 않는 매개 변수 없이 명령을 실행한 다음, 향후 OSD를 생성하지 못하도록 매개 변수를 사용하여 명령을 다시 실행합니다.
일반적으로 --all-available-devices 가 포함된 OSD 배포는 소규모 클러스터에 사용됩니다. 대규모 클러스터의 경우 OSD 사양 파일을 사용합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자 및 모니터 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 배포할 사용 가능한 장치를 나열합니다.
구문
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
예제
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
사용 가능한 모든 장치에 OSD를 배포합니다.
예제
[ceph: root@host01 /]# ceph orch apply osd --all-available-devices
ceph orch apply의 영향은 영속적입니다. 즉 Orchestrator가 장치를 자동으로 찾아 클러스터에 추가하고 새 OSD를 생성합니다. 이는 다음 조건에서 수행됩니다.- 새 디스크 또는 드라이브가 시스템에 추가됩니다.
- 기존 디스크 또는 드라이브가 zapped입니다.
OSD가 제거되고 장치가 zapped됩니다.
--unmanaged매개변수를 사용하여 사용 가능한 모든 장치에서 OSD 자동 생성을 비활성화할 수 있습니다.예제
[ceph: root@host01 /]# ceph orch apply osd --all-available-devices --unmanaged=true
--unmanaged매개변수를true로 설정하면 OSD 생성이 비활성화되고 새 OSD 서비스를 적용하는 경우 변경 사항도 발생하지 않습니다.참고ceph orch 데몬 add명령은 새 OSD를 생성하지만 OSD 서비스를 추가하지 않습니다.
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
노드 및 장치의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
추가 리소스
- Red Hat Ceph Storage Operations Guide의 Ceph OSD 배포 목록 섹션을 참조하십시오.
6.7. 특정 장치 및 호스트에 Ceph OSD 배포
Ceph Orchestrator를 사용하여 특정 장치 및 호스트에 모든 Ceph OSD를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자 및 모니터 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 배포할 사용 가능한 장치를 나열합니다.
구문
ceph orch device ls [--hostname=HOSTNAME_1 HOSTNAME_2] [--wide] [--refresh]
예제
[ceph: root@host01 /]# ceph orch device ls --wide --refresh
특정 장치 및 호스트에 OSD를 배포합니다.
구문
ceph orch daemon add osd HOSTNAME:DEVICE_PATH
예제
[ceph: root@host01 /]# ceph orch daemon add osd host02:/dev/sdb
LVM 계층 없이 원시 물리적 장치에 ODS를 배포하려면
--method raw옵션을 사용합니다.구문
ceph orch daemon add osd --method raw HOSTNAME:DEVICE_PATH
예제
[ceph: root@host01 /]# ceph orch daemon add osd --method raw host02:/dev/sdb
참고DB 또는 WAL 장치가 별도의 경우 블록 대 DB 또는 WAL 장치의 비율은 1:1 이어야합니다.
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls osd
노드 및 장치의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --service_name=SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch ps --service_name=osd
추가 리소스
- Red Hat Ceph Storage Operations Guide의 Ceph OSD 배포 목록 섹션을 참조하십시오.
6.8. OSD 배포를 위한 고급 서비스 사양 및 필터
OSD 유형의 서비스 사양은 디스크 속성을 사용하여 클러스터 레이아웃을 설명하는 방법입니다. 장치 이름 및 경로의 세부 사항을 파악하지 않고도 필요한 구성으로 OSD로 전환해야 하는 디스크를 Ceph에 알리는 추상적인 방법을 사용자에게 제공합니다. 각 장치와 각 호스트에 대해 yaml 파일 또는 json 파일을 정의합니다.
OSD 사양의 일반 설정
- service_type: 'osd': OSDS를 생성하려면 필수입니다.
- service_id: 원하는 서비스 이름 또는 ID를 사용합니다. OSD 세트는 사양 파일을 사용하여 생성됩니다. 이 이름은 모든 OSD를 함께 관리하고 Orchestrator 서비스를 나타내는 데 사용됩니다.
placement: OSD를 배포해야 하는 호스트를 정의하는 데 사용됩니다.
다음 옵션에서 사용할 수 있습니다.
- host_pattern: '*' - 호스트를 선택하는 데 사용되는 호스트 이름 패턴입니다.
- label: 'osd_host' - OSD를 배포해야 하는 호스트에서 사용되는 레이블입니다.
- hosts: 'host01', 'host02' - OSD를 배포해야 하는 호스트 이름의 명시적 목록입니다.
장치 선택: OSD가 생성되는 장치입니다. 이를 통해 OSD를 다른 장치와 분리할 수 있습니다. 다음 세 가지 구성 요소가 있는 BlueStore OSD만 생성할 수 있습니다.
- OSD data: 모든 OSD 데이터를 포함합니다.
- WAL: BlueStore 내부 저널 또는 쓰기 로그
- DB: BlueStore 내부 메타데이터
- data_devices: OSD를 배포할 장치를 정의합니다. 이 경우 OSD는 배치된 스키마로 생성됩니다. 필터를 사용하여 장치 및 폴더를 선택할 수 있습니다.
- wal_devices: WAL OSD에 사용되는 장치를 정의합니다. 필터를 사용하여 장치 및 폴더를 선택할 수 있습니다.
- db_devices: DB OSD의 장치를 정의합니다. 필터를 사용하여 장치 및 폴더를 선택할 수 있습니다.
-
encrypted:
True또는False로 설정할 수 있는 OSD에 대한 정보를 암호화하는 선택적 매개변수입니다. - Unmanaged: 기본적으로 False로 설정된 선택적 매개변수입니다. Orchestrator가 OSD 서비스를 관리하지 않으려면 True로 설정할 수 있습니다.
- block_wal_size: 사용자 정의 값(바이트)입니다.
- block_db_size: 사용자 정의 값(바이트)입니다.
- osds_per_device: 장치당 두 개 이상의 OSD를 배포하기 위한 사용자 정의 값입니다.
-
메서드: OSD가 LVM 계층으로 생성되었는지 여부를 지정하는 선택적 매개변수입니다. LVM 계층을 포함하지 않는 원시 물리적 장치에서 OSD를 생성하려면
raw로 설정합니다. DB 또는 WAL 장치가 별도의 경우 블록 대 DB 또는 WAL 장치의 비율은 1:1 이어야합니다.
장치 지정을 위한 필터
필터는 data_devices,wal_devices 및 db_devices 매개변수와 함께 사용됩니다.
| 필터의 이름 | 설명 | 구문 | 예제 |
| 모델 |
특정 디스크를 대상으로 합니다. | Model: DISK_MODEL_NAME | 모델: MC-55-44-XZ |
| vendor | 대상 특정 디스크 | vendor: DISK_VENDOR_NAME | 공급 업체: 벤더 Cs |
| 크기 사양 | 정확한 크기의 디스크 포함 | 크기: EXACT | 크기: '10G' |
| 크기 사양 | 범위 내에 있는 디스크 크기 포함 | 크기: LOW:HIGH | 크기: '10G:40G' |
| 크기 사양 | 크기보다 작거나 같은 디스크 포함 | 크기 :HIGH | 크기: ':10G' |
| 크기 사양 | 크기와 같거나 큰 디스크 포함 | 크기: LOW: | 크기: '40G:' |
| rotational | 디스크의 rotational 속성입니다. 1 rotational인 모든 디스크와 일치하고 0은 순환되지 않은 모든 디스크와 일치합니다. rotational =0인 경우 OSD는 SSD 또는 NVME로 구성됩니다. rotational=1인 경우 OSD는 HDD로 구성됩니다. | rotational: 0 또는 1 | rotational: 0 |
| All | 사용 가능한 모든 디스크 고려 | 모두: true | 모두: true |
| Limiter | 유효한 필터를 지정했지만 일치하는 디스크의 양을 제한하려면 'limit' 지시문을 사용할 수 있습니다. 마지막 수단으로만 사용해야 합니다. | 제한: NUMBER | 제한: 2 |
동일한 호스트에 배치되지 않은 구성 요소가 있는 OSD를 생성하려면 사용되는 다양한 유형의 장치를 지정해야 하며 장치가 동일한 호스트에 있어야 합니다.
OSD 배포에 사용되는 장치는 libstoragemgmt 에서 지원해야 합니다.
추가 리소스
- Red Hat Ceph Storage Operations Guide의 고급 사양 섹션을 사용하여 Ceph OSD 배포 섹션을 참조하십시오.
-
libstoragemgmt에 대한 자세한 내용은 Red Hat Ceph Storage Operations Guide의 Ceph OSD 배포 목록 섹션을 참조하십시오.
6.9. 고급 서비스 사양을 사용하여 Ceph OSD 배포
OSD 유형의 서비스 사양은 디스크 속성을 사용하여 클러스터 레이아웃을 설명하는 방법입니다. 장치 이름 및 경로의 세부 사항을 파악하지 않고도 필요한 구성으로 OSD로 전환해야 하는 디스크를 Ceph에 알리는 추상적인 방법을 사용자에게 제공합니다.
yaml 파일 또는 json 파일을 정의하여 각 장치 및 각 호스트에 대해 OSD를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자 및 모니터 데몬이 배포됩니다.
프로세스
모니터 노드에서
osd_spec.yaml파일을 생성합니다.예제
[root@host01 ~]# touch osd_spec.yaml
다음 세부 정보를 포함하도록
osd_spec.yaml파일을 편집합니다.구문
service_type: osd service_id: SERVICE_ID placement: host_pattern: '*' # optional data_devices: # optional model: DISK_MODEL_NAME # optional paths: - /DEVICE_PATH osds_per_device: NUMBER_OF_DEVICES # optional db_devices: # optional size: # optional all: true # optional paths: - /DEVICE_PATH encrypted: true
간단한 시나리오: 이러한 경우 모든 노드에 동일한 설정이 있습니다.
예제
service_type: osd service_id: osd_spec_default placement: host_pattern: '*' data_devices: all: true paths: - /dev/sdb encrypted: true
예제
service_type: osd service_id: osd_spec_default placement: host_pattern: '*' data_devices: size: '80G' db_devices: size: '40G:' paths: - /dev/sdc
간단한 시나리오: 이 경우 모든 노드는 LVM 계층 없이 원시 모드에서 생성된 OSD 장치와 동일한 설정을 갖습니다.
예제
service_type: osd service_id: all-available-devices encrypted: "true" method: raw placement: host_pattern: "*" data_devices: all: "true"
고급 시나리오: 이 경우 전용 DB 또는 WAL 장치로 할당된 두 개의 SSD가 있는
data_devices를 모든 HDD를 사용하여 원하는 레이아웃을 생성합니다. 나머지 SSD는 NVMEs 공급업체가 전용 DB 또는 WAL 장치로 할당된data_devices입니다.예제
service_type: osd service_id: osd_spec_hdd placement: host_pattern: '*' data_devices: rotational: 0 db_devices: model: Model-name limit: 2 --- service_type: osd service_id: osd_spec_ssd placement: host_pattern: '*' data_devices: model: Model-name db_devices: vendor: Vendor-name
비균일 노드가 있는 고급 시나리오: host_pattern 키에 따라 다른 OSD 사양을 다른 호스트에 적용합니다.
예제
service_type: osd service_id: osd_spec_node_one_to_five placement: host_pattern: 'node[1-5]' data_devices: rotational: 1 db_devices: rotational: 0 --- service_type: osd service_id: osd_spec_six_to_ten placement: host_pattern: 'node[6-10]' data_devices: model: Model-name db_devices: model: Model-name
전용 WAL 및 DB 장치가 있는 고급 시나리오:
예제
service_type: osd service_id: osd_using_paths placement: hosts: - host01 - host02 data_devices: paths: - /dev/sdb db_devices: paths: - /dev/sdc wal_devices: paths: - /dev/sdd장치당 여러 OSD가 있는 고급 시나리오:
예제
service_type: osd service_id: multiple_osds placement: hosts: - host01 - host02 osds_per_device: 4 data_devices: paths: - /dev/sdb미리 생성된 볼륨의 경우 다음 세부 정보를 포함하도록
osd_spec.yaml파일을 편집합니다.구문
service_type: osd service_id: SERVICE_ID placement: hosts: - HOSTNAME data_devices: # optional model: DISK_MODEL_NAME # optional paths: - /DEVICE_PATH db_devices: # optional size: # optional all: true # optional paths: - /DEVICE_PATH
예제
service_type: osd service_id: osd_spec placement: hosts: - machine1 data_devices: paths: - /dev/vg_hdd/lv_hdd db_devices: paths: - /dev/vg_nvme/lv_nvmeID로 OSD의 경우 다음 세부 정보를 포함하도록
osd_spec.yaml파일을 편집합니다.참고이 구성은 Red Hat Ceph Storage 5.3z1 이상 릴리스에 적용할 수 있습니다. 이전 릴리스에서는 사전 생성된 lvm을 사용합니다.
구문
service_type: osd service_id: OSD_BY_ID_HOSTNAME placement: hosts: - HOSTNAME data_devices: # optional model: DISK_MODEL_NAME # optional paths: - /DEVICE_PATH db_devices: # optional size: # optional all: true # optional paths: - /DEVICE_PATH
예제
service_type: osd service_id: osd_by_id_host01 placement: hosts: - host01 data_devices: paths: - /dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_drive-scsi0-0-0-5 db_devices: paths: - /dev/disk/by-id/nvme-nvme.1b36-31323334-51454d55204e564d65204374726c-00000001경로별로 OSD의 경우 다음 세부 정보를 포함하도록
osd_spec.yaml파일을 편집합니다.참고이 구성은 Red Hat Ceph Storage 5.3z1 이상 릴리스에 적용할 수 있습니다. 이전 릴리스에서는 사전 생성된 lvm을 사용합니다.
구문
service_type: osd service_id: OSD_BY_PATH_HOSTNAME placement: hosts: - HOSTNAME data_devices: # optional model: DISK_MODEL_NAME # optional paths: - /DEVICE_PATH db_devices: # optional size: # optional all: true # optional paths: - /DEVICE_PATH
예제
service_type: osd service_id: osd_by_path_host01 placement: hosts: - host01 data_devices: paths: - /dev/disk/by-path/pci-0000:0d:00.0-scsi-0:0:0:4 db_devices: paths: - /dev/disk/by-path/pci-0000:00:02.0-nvme-1
YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount osd_spec.yaml:/var/lib/ceph/osd/osd_spec.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/osd/
OSD를 배포하기 전에 예행 실행을 수행합니다.
참고이 단계에서는 데몬을 배포하지 않고 배포 프리뷰를 제공합니다.
예제
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yaml --dry-run
서비스 사양을 사용하여 OSD를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yml예제
[ceph: root@host01 osd]# ceph orch apply -i osd_spec.yaml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls osd
노드 및 장치의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
추가 리소스
- Red Hat Ceph Storage Operations Guide 의 OSD 배포 섹션은 고급 서비스 사양 및 필터 를 참조하십시오.
6.10. Ceph Orchestrator를 사용하여 OSD 데몬 제거
Cephadm을 사용하여 클러스터에서 OSD를 제거할 수 있습니다.
클러스터에서 OSD를 제거하려면 다음 두 단계가 필요합니다.
- 클러스터에서 모든 배치 그룹(PG)을 비웁니다.
- 클러스터에서 PG가 없는 OSD를 제거합니다.
--zap 옵션은 볼륨 그룹, 논리 볼륨 및 LVM 메타데이터를 제거했습니다.
OSD를 제거한 후 OSD를 다시 사용할 수 있게 되면 기존 drivegroup 사양과 일치하는 경우 cephadm' 이 자동으로 이러한 드라이브에 더 많은 OSD를 배포하려고 할 수 있습니다. 사양으로 제거 중인 OSD를 배포하고 제거 후 드라이브에 새 OSD를 배포하지 않으려면 제거 전에 drivegroup 사양을 수정합니다. OSD를 배포하는 동안 --all-available-devices 옵션을 사용한 경우 unmanaged: true 를 설정하여 새 드라이브를 전혀 선택하지 않도록 합니다. 기타 배포의 경우 사양을 수정합니다. 자세한 내용은 고급 서비스 사양을 사용하여 Ceph OSD 배포를 참조하십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- Ceph Monitor, Ceph Manager 및 Ceph OSD 데몬은 스토리지 클러스터에 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 제거해야 하는 장치 및 노드를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
OSD를 제거합니다.
구문
ceph orch osd rm OSD_ID [--replace] [--force] --zap예제
[ceph: root@host01 /]# ceph orch osd rm 0 --zap
참고--replace와 같은 옵션 없이 스토리지 클러스터에서 OSD를 제거하면 스토리지 클러스터에서 장치가 완전히 제거됩니다. OSD 배포에 동일한 장치를 사용하려면 먼저 장치 zap을 스토리지 클러스터에 추가해야 합니다.선택 사항: 특정 노드에서 여러 OSD를 제거하려면 다음 명령을 실행합니다.
구문
ceph orch osd rm OSD_ID OSD_ID --zap
예제
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zap
OSD 제거 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch osd rm status OSD HOST STATE PGS REPLACE FORCE ZAP DRAIN STARTED AT 9 host01 done, waiting for purge 0 False False True 2023-06-06 17:50:50.525690 10 host03 done, waiting for purge 0 False False True 2023-06-06 17:49:38.731533 11 host02 done, waiting for purge 0 False False True 2023-06-06 17:48:36.641105
OSD에 PG가 남아 있지 않으면 클러스터에서 해제되고 제거됩니다.
검증
Ceph OSD가 제거된 장치 및 노드의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 사용 가능한 모든 장치에 Ceph OSD 배포 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 특정 장치 및 호스트에 Ceph OSD 배포 섹션을 참조하십시오.
- 장치의 공간 지우기에 대한 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph OSD 배포 Zapping devices 섹션을 참조하십시오.
6.11. Ceph Orchestrator를 사용하여 OSD 교체
디스크가 실패하면 물리적 스토리지 장치를 교체하고 동일한 OSD ID를 재사용하여 CRUSH 맵을 재구성할 필요가 없습니다.
--replace 옵션을 사용하여 클러스터의 OSD를 교체할 수 있습니다.
단일 OSD를 교체하려면 특정 장치 및 호스트에 Ceph OSD 배포를 참조하십시오. 사용 가능한 모든 장치에 OSD를 배포하려면 사용 가능한 모든 장치에 Ceph OSD 배포를 참조하십시오.
이 옵션은 ceph orch rm 명령을 사용하여 OSD ID를 유지합니다. OSD는 CRUSH 계층에서 영구적으로 제거되지 않지만 삭제 플래그가 할당됩니다. 이 플래그는 다음 OSD 배포에서 재사용할 수 있는 OSD ID를 결정하는 데 사용됩니다. 삭제된 플래그는 다음 OSD 배포에서 재사용되는 OSD ID를 결정하는 데 사용됩니다.
rm 명령과 유사하게 클러스터에서 OSD를 교체하려면 다음 두 단계가 필요합니다.
- 클러스터에서 모든 배치 그룹(PG)을 비웁니다.
- 클러스터에서 PG가 없는 OSD 제거.
배포에 OSD 사양을 사용하는 경우 새로 추가된 디스크에 교체된 항목의 OSD ID가 할당됩니다.
OSD를 제거한 후 드라이브가 다시 사용 가능하게 되면 OSD가 다시 사용 가능하게 되면 기존 drivegroup 사양과 일치하는 경우 cephadm 에서 이러한 드라이브에 더 많은 OSD를 자동으로 배포할 수 있습니다. 사양으로 제거 중인 OSD를 배포하고 제거 후 드라이브에 새 OSD를 배포하지 않으려면 제거 전에 drivegroup 사양을 수정합니다. OSD를 배포하는 동안 --all-available-devices 옵션을 사용한 경우 unmanaged: true 를 설정하여 새 드라이브를 전혀 선택하지 않도록 합니다. 기타 배포의 경우 사양을 수정합니다. 자세한 내용은 고급 서비스 사양을 사용하여 Ceph OSD 배포를 참조하십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모니터, 관리자 및 OSD 데몬은 스토리지 클러스터에 배포됩니다.
- 제거된 OSD를 대체하는 새 OSD는 OSD가 제거된 동일한 호스트에서 생성해야 합니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
향후 참조를 위해 OSD 구성 매핑을 덤프하고 저장해야 합니다.
예제
[ceph: root@node /]# ceph osd metadata -f plain | grep device_paths "device_paths": "sde=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:1,sdi=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:1", "device_paths": "sde=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:1,sdf=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:1", "device_paths": "sdd=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:2,sdg=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:2", "device_paths": "sdd=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:2,sdh=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:2", "device_paths": "sdd=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:2,sdk=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:2", "device_paths": "sdc=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:3,sdl=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:3", "device_paths": "sdc=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:3,sdj=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:3", "device_paths": "sdc=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:0:0:3,sdm=/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:3", [.. output omitted ..]
OSD를 교체해야 하는 장치 및 노드를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
OSD를 교체합니다.
중요스토리지 클러스터에
health_warn또는 기타 오류가 연결된 경우 OSD를 교체하기 전에 오류를 확인하고 수정하여 데이터 손실을 방지합니다.구문
ceph orch osd rm OSD_ID --replace [--force]스토리지 클러스터에 지속적인 작업이 있는 경우
--force옵션을 사용할 수 있습니다.예제
[ceph: root@host01 /]# ceph orch osd rm 0 --replace
OSD 교체 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch osd rm status
오케스트레이터를 중지하여 기존 OSD 사양을 적용합니다.
예제
[ceph: root@node /]# ceph orch pause [ceph: root@node /]# ceph orch status Backend: cephadm Available: Yes Paused: Yes
제거된 OSD 장치를 zap합니다.
예제
[ceph: root@node /]# ceph orch device zap node.example.com /dev/sdi --force zap successful for /dev/sdi on node.example.com [ceph: root@node /]# ceph orch device zap node.example.com /dev/sdf --force zap successful for /dev/sdf on node.example.com
일시 중지 모드에서 Orcestrator를 다시 시작
예제
[ceph: root@node /]# ceph orch resume
OSD 교체 상태를 확인합니다.
예제
[ceph: root@node /]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.77112 root default -3 0.77112 host node 0 hdd 0.09639 osd.0 up 1.00000 1.00000 1 hdd 0.09639 osd.1 up 1.00000 1.00000 2 hdd 0.09639 osd.2 up 1.00000 1.00000 3 hdd 0.09639 osd.3 up 1.00000 1.00000 4 hdd 0.09639 osd.4 up 1.00000 1.00000 5 hdd 0.09639 osd.5 up 1.00000 1.00000 6 hdd 0.09639 osd.6 up 1.00000 1.00000 7 hdd 0.09639 osd.7 up 1.00000 1.00000 [.. output omitted ..]
검증
Ceph OSD가 교체되는 장치 및 노드의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
동일한 호스트에서 실행 중인 것과 동일한 ID가 있는 OSD를 확인할 수 있습니다.
새로 배포된 OSD의
db_device가 교체된db_device인지 확인합니다.예제
[ceph: root@host01 /]# ceph osd metadata 0 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1", [ceph: root@host01 /]# ceph osd metadata 1 | grep bluefs_db_devices "bluefs_db_devices": "nvme0n1",
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 사용 가능한 모든 장치에 Ceph OSD 배포 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 특정 장치 및 호스트에 Ceph OSD 배포 섹션을 참조하십시오.
6.12. OSD를 사전 생성된 LVM으로 교체
ceph-volume lvm zap 명령을 사용하여 OSD를 삭제한 후 디렉터리가 없는 경우 OSD를 OSd 서비스 사양 파일로 미리 생성된 LVM으로 교체할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- OSD 실패
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD를 제거합니다.
구문
ceph orch osd rm OSD_ID [--replace]예제
[ceph: root@host01 /]# ceph orch osd rm 8 --replace Scheduled OSD(s) for removal
OSD가 삭제되었는지 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.32297 root default -9 0.05177 host host10 3 hdd 0.01520 osd.3 up 1.00000 1.00000 13 hdd 0.02489 osd.13 up 1.00000 1.00000 17 hdd 0.01169 osd.17 up 1.00000 1.00000 -13 0.05177 host host11 2 hdd 0.01520 osd.2 up 1.00000 1.00000 15 hdd 0.02489 osd.15 up 1.00000 1.00000 19 hdd 0.01169 osd.19 up 1.00000 1.00000 -7 0.05835 host host12 20 hdd 0.01459 osd.20 up 1.00000 1.00000 21 hdd 0.01459 osd.21 up 1.00000 1.00000 22 hdd 0.01459 osd.22 up 1.00000 1.00000 23 hdd 0.01459 osd.23 up 1.00000 1.00000 -5 0.03827 host host04 1 hdd 0.01169 osd.1 up 1.00000 1.00000 6 hdd 0.01129 osd.6 up 1.00000 1.00000 7 hdd 0.00749 osd.7 up 1.00000 1.00000 9 hdd 0.00780 osd.9 up 1.00000 1.00000 -3 0.03816 host host05 0 hdd 0.01169 osd.0 up 1.00000 1.00000 8 hdd 0.01129 osd.8 destroyed 0 1.00000 12 hdd 0.00749 osd.12 up 1.00000 1.00000 16 hdd 0.00769 osd.16 up 1.00000 1.00000 -15 0.04237 host host06 5 hdd 0.01239 osd.5 up 1.00000 1.00000 10 hdd 0.01540 osd.10 up 1.00000 1.00000 11 hdd 0.01459 osd.11 up 1.00000 1.00000 -11 0.04227 host host07 4 hdd 0.01239 osd.4 up 1.00000 1.00000 14 hdd 0.01529 osd.14 up 1.00000 1.00000 18 hdd 0.01459 osd.18 up 1.00000 1.00000
zap 및
ceph-volume명령을 사용하여 OSD를 제거합니다.구문
ceph-volume lvm zap --osd-id OSD_ID예제
[ceph: root@host01 /]# ceph-volume lvm zap --osd-id 8 Zapping: /dev/vg1/data-lv2 Closing encrypted path /dev/mapper/l4D6ql-Prji-IzH4-dfhF-xzuf-5ETl-jNRcXC Running command: /usr/sbin/cryptsetup remove /dev/mapper/l4D6ql-Prji-IzH4-dfhF-xzuf-5ETl-jNRcXC Running command: /usr/bin/dd if=/dev/zero of=/dev/vg1/data-lv2 bs=1M count=10 conv=fsync stderr: 10+0 records in 10+0 records out stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.034742 s, 302 MB/s Zapping successful for OSD: 8
OSD 토폴로지를 확인합니다.
예제
[ceph: root@host01 /]# ceph-volume lvm list
특정 OSD 토폴로지에 해당하는 사양 파일을 사용하여 OSD를 다시 생성합니다.
예제
[ceph: root@host01 /]# cat osd.yml service_type: osd service_id: osd_service placement: hosts: - host03 data_devices: paths: - /dev/vg1/data-lv2 db_devices: paths: - /dev/vg1/db-lv1
업데이트된 사양 파일을 적용합니다.
예제
[ceph: root@host01 /]# ceph orch apply -i osd.yml Scheduled osd.osd_service update...
OSD가 다시 있는지 확인합니다.
예제
[ceph: root@host01 /]# ceph -s [ceph: root@host01 /]# ceph osd tree
6.13. 공동 배치되지 않은 시나리오에서 OSD 교체
중복되지 않은 시나리오에서 OSD가 실패하면 WAL/DB 장치를 교체할 수 있습니다. 절차는 DB 및 WAL 장치에 대해 동일합니다. DB 장치용 db_devices 아래의 경로 와 WAL 장치의 wal_devices 아래의 경로를 편집해야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 데몬은 결합되지 않습니다.
- OSD 실패
프로세스
클러스터의 장치를 확인합니다.
예제
[root@host01 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─rhel-root 253:0 0 17G 0 lvm / └─rhel-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 10G 0 disk └─ceph--5726d3e9--4fdb--4eda--b56a--3e0df88d663f-osd--block--3ceb89ec--87ef--46b4--99c6--2a56bac09ff0 253:2 0 10G 0 lvm sdc 8:32 0 10G 0 disk └─ceph--d7c9ab50--f5c0--4be0--a8fd--e0313115f65c-osd--block--37c370df--1263--487f--a476--08e28bdbcd3c 253:4 0 10G 0 lvm sdd 8:48 0 10G 0 disk ├─ceph--1774f992--44f9--4e78--be7b--b403057cf5c3-osd--db--31b20150--4cbc--4c2c--9c8f--6f624f3bfd89 253:7 0 2.5G 0 lvm └─ceph--1774f992--44f9--4e78--be7b--b403057cf5c3-osd--db--1bee5101--dbab--4155--a02c--e5a747d38a56 253:9 0 2.5G 0 lvm sde 8:64 0 10G 0 disk sdf 8:80 0 10G 0 disk └─ceph--412ee99b--4303--4199--930a--0d976e1599a2-osd--block--3a99af02--7c73--4236--9879--1fad1fe6203d 253:6 0 10G 0 lvm sdg 8:96 0 10G 0 disk └─ceph--316ca066--aeb6--46e1--8c57--f12f279467b4-osd--block--58475365--51e7--42f2--9681--e0c921947ae6 253:8 0 10G 0 lvm sdh 8:112 0 10G 0 disk ├─ceph--d7064874--66cb--4a77--a7c2--8aa0b0125c3c-osd--db--0dfe6eca--ba58--438a--9510--d96e6814d853 253:3 0 5G 0 lvm └─ceph--d7064874--66cb--4a77--a7c2--8aa0b0125c3c-osd--db--26b70c30--8817--45de--8843--4c0932ad2429 253:5 0 5G 0 lvm sr0
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD 및 해당 DB 장치를 식별합니다.
예제
[ceph: root@host01 /]# ceph-volume lvm list /dev/sdh ====== osd.2 ======= [db] /dev/ceph-d7064874-66cb-4a77-a7c2-8aa0b0125c3c/osd-db-0dfe6eca-ba58-438a-9510-d96e6814d853 block device /dev/ceph-5726d3e9-4fdb-4eda-b56a-3e0df88d663f/osd-block-3ceb89ec-87ef-46b4-99c6-2a56bac09ff0 block uuid GkWLoo-f0jd-Apj2-Zmwj-ce0h-OY6J-UuW8aD cephx lockbox secret cluster fsid fa0bd9dc-e4c4-11ed-8db4-001a4a00046e cluster name ceph crush device class db device /dev/ceph-d7064874-66cb-4a77-a7c2-8aa0b0125c3c/osd-db-0dfe6eca-ba58-438a-9510-d96e6814d853 db uuid 6gSPoc-L39h-afN3-rDl6-kozT-AX9S-XR20xM encrypted 0 osd fsid 3ceb89ec-87ef-46b4-99c6-2a56bac09ff0 osd id 2 osdspec affinity non-colocated type db vdo 0 devices /dev/sdh ====== osd.5 ======= [db] /dev/ceph-d7064874-66cb-4a77-a7c2-8aa0b0125c3c/osd-db-26b70c30-8817-45de-8843-4c0932ad2429 block device /dev/ceph-d7c9ab50-f5c0-4be0-a8fd-e0313115f65c/osd-block-37c370df-1263-487f-a476-08e28bdbcd3c block uuid Eay3I7-fcz5-AWvp-kRcI-mJaH-n03V-Zr0wmJ cephx lockbox secret cluster fsid fa0bd9dc-e4c4-11ed-8db4-001a4a00046e cluster name ceph crush device class db device /dev/ceph-d7064874-66cb-4a77-a7c2-8aa0b0125c3c/osd-db-26b70c30-8817-45de-8843-4c0932ad2429 db uuid mwSohP-u72r-DHcT-BPka-piwA-lSwx-w24N0M encrypted 0 osd fsid 37c370df-1263-487f-a476-08e28bdbcd3c osd id 5 osdspec affinity non-colocated type db vdo 0 devices /dev/sdhosds.yaml파일에서관리되지 않는매개변수를true로 설정하고, 기타cephadm은 OSD를 재배포합니다.예제
[ceph: root@host01 /]# cat osds.yml service_type: osd service_id: non-colocated unmanaged: true placement: host_pattern: 'ceph*' data_devices: paths: - /dev/sdb - /dev/sdc - /dev/sdf - /dev/sdg db_devices: paths: - /dev/sdd - /dev/sdh
업데이트된 사양 파일을 적용합니다.
예제
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...
상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch ls NAME PORTS RUNNING REFRESHED AGE PLACEMENT alertmanager ?:9093,9094 1/1 9m ago 4d count:1 crash 3/4 4d ago 4d * grafana ?:3000 1/1 9m ago 4d count:1 mgr 1/2 4d ago 4d count:2 mon 3/5 4d ago 4d count:5 node-exporter ?:9100 3/4 4d ago 4d * osd.non-colocated 8 4d ago 5s <unmanaged> prometheus ?:9095 1/1 9m ago 4d count:1
OSD를 제거합니다. OSD ID를 유지하려면
--zap옵션을 사용하여 백엔드 서비스와--replace옵션을 제거해야 합니다.예제
[ceph: root@host01 /]# ceph orch osd rm 2 5 --zap --replace Scheduled OSD(s) for removal
상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd df tree | egrep -i "ID|host02|osd.2|osd.5" ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME -5 0.04877 - 55 GiB 15 GiB 4.1 MiB 0 B 60 MiB 40 GiB 27.27 1.17 - host02 2 hdd 0.01219 1.00000 15 GiB 5.0 GiB 996 KiB 0 B 15 MiB 10 GiB 33.33 1.43 0 destroyed osd.2 5 hdd 0.01219 1.00000 15 GiB 5.0 GiB 1.0 MiB 0 B 15 MiB 10 GiB 33.33 1.43 0 destroyed osd.5
osds.yaml사양 파일을 편집하여관리되지 않는매개변수를false로 변경하고 장치가 물리적으로 교체된 후 변경된 경우 DB 장치의 경로를 바꿉니다.예제
[ceph: root@host01 /]# cat osds.yml service_type: osd service_id: non-colocated unmanaged: false placement: host_pattern: 'ceph01*' data_devices: paths: - /dev/sdb - /dev/sdc - /dev/sdf - /dev/sdg db_devices: paths: - /dev/sdd - /dev/sde
위의 예에서
/dev/sdh는/dev/sde로 교체됩니다.중요동일한 호스트 사양 파일을 사용하여 단일 OSD 노드에서 결함이 있는 DB 장치를 교체하는 경우, OSD 노드만 지정하도록
host_pattern옵션을 수정하면 배포가 실패하고 다른 호스트에서 새 DB 장치를 찾을 수 없습니다.사양 파일을
--dry-run옵션으로 다시 적용하여 새 DB 장치를 사용하여 OSD를 배포해야 합니다.예제
[ceph: root@host01 /]# ceph orch apply -i osds.yml --dry-run WARNING! Dry-Runs are snapshots of a certain point in time and are bound to the current inventory setup. If any of these conditions change, the preview will be invalid. Please make sure to have a minimal timeframe between planning and applying the specs. #################### SERVICESPEC PREVIEWS #################### +---------+------+--------+-------------+ |SERVICE |NAME |ADD_TO |REMOVE_FROM | +---------+------+--------+-------------+ +---------+------+--------+-------------+ ################ OSDSPEC PREVIEWS ################ +---------+-------+-------+----------+----------+-----+ |SERVICE |NAME |HOST |DATA |DB |WAL | +---------+-------+-------+----------+----------+-----+ |osd |non-colocated |host02 |/dev/sdb |/dev/sde |- | |osd |non-colocated |host02 |/dev/sdc |/dev/sde |- | +---------+-------+-------+----------+----------+-----+
사양 파일을 적용합니다.
예제
[ceph: root@host01 /]# ceph orch apply -i osds.yml Scheduled osd.non-colocated update...
OSD가 재배포되었는지 확인합니다.
예제
[ceph: root@host01 /]# ceph osd df tree | egrep -i "ID|host02|osd.2|osd.5" ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS TYPE NAME -5 0.04877 - 55 GiB 15 GiB 4.5 MiB 0 B 60 MiB 40 GiB 27.27 1.17 - host host02 2 hdd 0.01219 1.00000 15 GiB 5.0 GiB 1.1 MiB 0 B 15 MiB 10 GiB 33.33 1.43 0 up osd.2 5 hdd 0.01219 1.00000 15 GiB 5.0 GiB 1.1 MiB 0 B 15 MiB 10 GiB 33.33 1.43 0 up osd.5
검증
OSDS가 재배포되는 OSD 호스트에서 새 DB 장치에 있는지 확인합니다.
예제
[ceph: root@host01 /]# ceph-volume lvm list /dev/sde ====== osd.2 ======= [db] /dev/ceph-15ce813a-8a4c-46d9-ad99-7e0845baf15e/osd-db-1998a02e-5e67-42a9-b057-e02c22bbf461 block device /dev/ceph-a4afcb78-c804-4daf-b78f-3c7ad1ed0379/osd-block-564b3d2f-0f85-4289-899a-9f98a2641979 block uuid ITPVPa-CCQ5-BbFa-FZCn-FeYt-c5N4-ssdU41 cephx lockbox secret cluster fsid fa0bd9dc-e4c4-11ed-8db4-001a4a00046e cluster name ceph crush device class db device /dev/ceph-15ce813a-8a4c-46d9-ad99-7e0845baf15e/osd-db-1998a02e-5e67-42a9-b057-e02c22bbf461 db uuid HF1bYb-fTK7-0dcB-CHzW-xvNn-dCym-KKdU5e encrypted 0 osd fsid 564b3d2f-0f85-4289-899a-9f98a2641979 osd id 2 osdspec affinity non-colocated type db vdo 0 devices /dev/sde ====== osd.5 ======= [db] /dev/ceph-15ce813a-8a4c-46d9-ad99-7e0845baf15e/osd-db-6c154191-846d-4e63-8c57-fc4b99e182bd block device /dev/ceph-b37c8310-77f9-4163-964b-f17b4c29c537/osd-block-b42a4f1f-8e19-4416-a874-6ff5d305d97f block uuid 0LuPoz-ao7S-UL2t-BDIs-C9pl-ct8J-xh5ep4 cephx lockbox secret cluster fsid fa0bd9dc-e4c4-11ed-8db4-001a4a00046e cluster name ceph crush device class db device /dev/ceph-15ce813a-8a4c-46d9-ad99-7e0845baf15e/osd-db-6c154191-846d-4e63-8c57-fc4b99e182bd db uuid SvmXms-iWkj-MTG7-VnJj-r5Mo-Moiw-MsbqVD encrypted 0 osd fsid b42a4f1f-8e19-4416-a874-6ff5d305d97f osd id 5 osdspec affinity non-colocated type db vdo 0 devices /dev/sde
6.14. Ceph Orchestrator를 사용하여 OSD 제거 중지
제거를 위해 대기열에 있는 OSD만 제거할 수 있습니다. OSD의 초기 상태가 재설정되고 제거 대기열에서 제거됩니다.
OSD가 제거 프로세스에 있는 경우 프로세스를 중지할 수 없습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모니터, 관리자 및 OSD 데몬이 클러스터에 배포됩니다.
- 시작된 OSD 프로세스를 제거합니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
OSD가 제거되도록 시작된 장치 및 노드를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
대기 중인 OSD의 제거를 중지합니다.
구문
ceph orch osd rm stop OSD_ID예제
[ceph: root@host01 /]# ceph orch osd rm stop 0
OSD 제거 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch osd rm status
검증
제거를 위해 Ceph OSD가 대기열에 있는 장치 및 노드의 세부 정보를 확인합니다.
예제
[ceph: root@host01 /]# ceph osd tree
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 Ceph Orchestrator 섹션을 사용하여 OSD 데몬 제거를 참조하십시오.
6.15. Ceph Orchestrator를 사용하여 OSD 활성화
호스트의 운영 체제가 다시 설치된 경우 클러스터에서 OSD를 활성화할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모니터, 관리자 및 OSD 데몬은 스토리지 클러스터에 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
호스트의 운영 체제가 다시 설치되면 OSD를 활성화합니다.
구문
ceph cephadm osd activate HOSTNAME예제
[ceph: root@host01 /]# ceph cephadm osd activate host03
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --service_name=SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch ps --service_name=osd
6.16. 데이터 마이그레이션 관찰
CRUSH 맵에 OSD를 추가하거나 제거하면 배치 그룹을 새 OSD 또는 기존 OSD로 마이그레이션하여 Ceph에서 데이터 재조정을 시작합니다. ceph-w 명령을 사용하여 데이터 마이그레이션을 확인할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- OSD를 최근에 추가 또는 제거했습니다.
프로세스
데이터 마이그레이션을 관찰하려면 다음을 수행합니다.
예제
[ceph: root@host01 /]# ceph -w
-
배치 그룹 상태가
active+clean에서active, 일부 성능이 저하된 오브젝트,마이그레이션이 완료되면 마지막으로active+clean으로 변경되는지 확인합니다. -
유틸리티를 종료하려면
Ctrl + C를 누릅니다.
6.17. 배치 그룹 다시 계산
배치 그룹(PG)은 사용 가능한 OSD에 풀 데이터 풀의 분배를 정의합니다. 배치 그룹은 사용할 지정된 중복 알고리즘에 따라 빌드됩니다. 3방향 복제의 경우 중복성은 3개의 다른 OSD를 사용하도록 정의됩니다. 삭제 코드 풀의 경우 사용할 OSD 수는 청크 수로 정의됩니다.
풀을 정의할 때 배치 그룹 수는 사용 가능한 모든 OSD에 걸쳐 데이터가 분배되는 세분성 등급을 정의합니다. 용량이 클수록 용량 부하의 동등성이 향상될 수 있습니다. 그러나 데이터 재구성의 경우 배치 그룹을 처리하는 것도 중요하므로 먼저 이 번호를 신중하게 선택하는 것이 중요합니다. 계산을 지원하기 위해 민첩한 환경을 생성하는 데 툴을 사용할 수 있습니다.
스토리지 클러스터의 수명 동안 풀은 처음에 예상되는 제한 이상으로 증가할 수 있습니다. 드라이브 수가 증가함에 따라 재 계산이 권장됩니다. OSD당 배치 그룹 수는 약 100개여야 합니다. 스토리지 클러스터에 OSD를 더 추가하면 OSD당 PG 수가 시간이 지남에 따라 줄어듭니다. 처음에 120 드라이브를 스토리지 클러스터에서 시작하고 풀의 pg_num 을 4000으로 설정하면 OSD당 100개의 PG가 3개씩 복제됩니다. 시간이 지남에 따라 OSD 수의 10배로 증가할 때 OSD당 PG 수가 10개로 제한됩니다. OSD당 적은 수의 PG는 균등하게 분산된 용량을 사용하는 경향이 있기 때문에 풀당 PG를 조정하는 것이 좋습니다.
배치 그룹 수 조정은 온라인으로 수행할 수 있습니다. 재 계산은 PG 번호의 재 계산 일뿐만 아니라 데이터 재배치가 수반되며 이는 긴 프로세스가 될 것입니다. 그러나 데이터 가용성은 언제든지 유지됩니다.
실패한 OSD에서 모든 PG를 재구성하는 것은 한 번에 시작되므로 OSD당 매우 많은 수의 PG를 사용하지 않도록 해야 합니다. 적시에 재구성을 수행하려면 많은 IOPS가 필요하며 사용할 수 없습니다. 이로 인해 깊이 있는 I/O 대기열과 높은 대기 시간이 발생하고 스토리지 클러스터를 사용할 수 없게 되거나 복구 시간이 길어집니다.
추가 리소스
- 지정된 사용 사례로 값을 계산하려면 PG 계산기 를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Strategies Guide 의 Erasure Code Pools 장을 참조하십시오.
7장. Ceph Orchestrator를 사용한 모니터링 스택 관리
스토리지 관리자는 백엔드에서 Ceph Orchestrator를 Cephadm과 함께 사용하여 모니터링 및 경고 스택을 배포할 수 있습니다. 모니터링 스택은 Prometheus, Prometheus 내보내기, Prometheus Alertmanager 및 Grafana로 구성됩니다. 사용자는 YAML 구성 파일에서 Cephadm으로 이러한 서비스를 정의하거나 명령줄 인터페이스를 사용하여 배포할 수 있어야 합니다. 동일한 유형의 여러 서비스가 배포되면 고가용성 설정이 배포됩니다. 노드 내보내기는 이 규칙에 대한 예외입니다.
Red Hat Ceph Storage는 Prometheus, Grafana, Alertmanager 및 node-exporter와 같은 모니터링 서비스를 배포하기 위한 사용자 정의 이미지를 지원하지 않습니다.
Cephadm을 사용하여 다음 모니터링 서비스를 배포할 수 있습니다.
Prometheus는 모니터링 및 경고 툴킷입니다. Prometheus 내보내기에서 제공하는 데이터를 수집하고 사전 정의된 임계값에 도달한 경우 사전 구성된 경고를 실행합니다. Prometheus manager 모듈은
ceph-mgr의 컬렉션 지점에서 Ceph 성능 카운터에 전달할 Prometheus 내보내기를 제공합니다.데몬을 제공하는 지표와 같은 스크랩 대상을 포함한 Prometheus 구성은 Cephadm에 의해 자동으로 설정됩니다. cephadm 은 또한 기본 경고 목록(예: 상태 오류, 10% OSD 다운 또는 pgs 비활성)을 배포합니다.
- Alertmanager는 Prometheus 서버에서 보낸 경고를 처리합니다. 이 명령은 경고를 중복, 그룹화하고 올바른 수신자에게 라우팅합니다. 기본적으로 Ceph 대시보드는 수신자로 자동으로 구성됩니다. Alertmanager는 Prometheus 서버에서 보낸 경고를 처리합니다. Alertmanager를 사용하여 경고를 음소거할 수 있지만 Ceph 대시보드를 사용하여 음소거를 관리할 수도 있습니다.
Grafana는 시각화 및 경고 소프트웨어입니다. Grafana의 경고 기능은 이 모니터링 스택에서 사용되지 않습니다. 경고의 경우 Alertmanager가 사용됩니다.
기본적으로 Grafana로의 트래픽은 TLS를 사용하여 암호화됩니다. 자체 TLS 인증서를 제공하거나 자체 서명된 인증서를 사용할 수 있습니다. Grafana를 배포하기 전에 사용자 정의 인증서를 구성하지 않은 경우 자체 서명된 인증서가 자동으로 생성되어 Grafana에 대해 구성됩니다. Grafana에 대한 사용자 정의 인증서는 다음 명령을 사용하여 구성할 수 있습니다.
구문
ceph config-key set mgr/cephadm/HOSTNAME/grafana_key -i PRESENT_WORKING_DIRECTORY/key.pem ceph config-key set mgr/cephadm/HOSTNAME/grafana_crt -i PRESENT_WORKING_DIRECTORY/certificate.pem
노드 내보내기는 설치된 노드에 대한 데이터를 제공하는 Prometheus의 내보내기입니다. 모든 노드에 노드 내보내기를 설치하는 것이 좋습니다. 이 작업은 node-exporter 서비스 유형의 monitoring.yml 파일을 사용하여 수행할 수 있습니다.
7.1. Ceph Orchestrator를 사용하여 모니터링 스택 배포
모니터링 스택은 Prometheus, Prometheus 내보내기, Prometheus Alertmanager, Grafana 및 Ceph Exporter로 구성됩니다. Ceph 대시보드는 이러한 구성 요소를 사용하여 클러스터 사용량 및 성능에 대한 자세한 지표를 저장하고 시각화합니다.
YAML 파일 형식의 서비스 사양을 사용하여 모니터링 스택을 배포할 수 있습니다. 모든 모니터링 서비스에는 yml 파일에 설정된 에 바인딩되는 네트워크 및 포트가 있을 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
프로세스
Ceph Manager 데몬에서 prometheus 모듈을 활성화합니다. 이렇게 하면 Prometheus가 읽을 수 있도록 내부 Ceph 지표가 노출됩니다.
예제
[ceph: root@host01 /]# ceph mgr module enable prometheus
중요Prometheus가 배포되기 전에 이 명령이 실행되었는지 확인합니다. 배포 전에 명령이 실행되지 않은 경우 구성을 업데이트하려면 Prometheus를 재배포해야 합니다.
ceph orch redeploy prometheus
다음 디렉터리로 이동합니다.
구문
cd /var/lib/ceph/DAEMON_PATH/예제
[ceph: root@host01 mds/]# cd /var/lib/ceph/monitoring/
참고디렉터리
모니터링이없으면 생성합니다.monitoring.yml파일을 생성합니다.예제
[ceph: root@host01 monitoring]# touch monitoring.yml
다음 예와 유사한 콘텐츠로 사양 파일을 편집합니다.
예제
service_type: prometheus service_name: prometheus placement: hosts: - host01 networks: - 192.169.142.0/24 --- service_type: node-exporter --- service_type: alertmanager service_name: alertmanager placement: hosts: - host01 networks: - 192.169.142.0/24 --- service_type: grafana service_name: grafana placement: hosts: - host01 networks: - 192.169.142.0/24 --- service_type: ceph-exporter
참고모니터링 스택 구성 요소
alertmanager,prometheus,grafana가 동일한 호스트에 배포되었는지 확인합니다.node-exporter및ceph-exporter구성 요소를 모든 호스트에 배포해야 합니다.모니터링 서비스를 적용합니다.
예제
[ceph: root@host01 monitoring]# ceph orch apply -i monitoring.yml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --service_name=SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch ps --service_name=prometheus
Prometheus, Grafana 및 Ceph 대시보드는 서로 통신하도록 자동으로 구성되므로 Ceph 대시보드에서 Grafana 통합이 완전히 작동합니다.
7.2. Ceph Orchestrator를 사용하여 모니터링 스택 제거
ceph orch rm 명령을 사용하여 모니터링 스택을 제거할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
ceph orch rm명령을 사용하여 모니터링 스택을 제거합니다.구문
ceph orch rm SERVICE_NAME --force예제
[ceph: root@host01 /]# ceph orch rm grafana [ceph: root@host01 /]# ceph orch rm prometheus [ceph: root@host01 /]# ceph orch rm node-exporter [ceph: root@host01 /]# ceph orch rm ceph-exporter [ceph: root@host01 /]# ceph orch rm alertmanager [ceph: root@host01 /]# ceph mgr module disable prometheus
프로세스 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph orch status
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps
예제
[ceph: root@host01 /]# ceph orch ps
추가 리소스
8장. 기본 Red Hat Ceph Storage 클라이언트 설정
스토리지 관리자는 스토리지 클러스터와 상호 작용하기 위해 기본 구성으로 클라이언트 시스템을 설정해야 합니다. 대부분의 클라이언트 시스템에는 ceph-common 패키지 및 해당 종속 항목만 설치됩니다. 기본 ceph 및 rados 명령과 mount.ceph 및 rbd 와 같은 기타 명령을 제공합니다.
8.1. 클라이언트 시스템에서 파일 설정 구성
일반적으로 클라이언트 시스템에는 완전한 스토리지 클러스터 멤버보다 작은 구성 파일이 필요합니다. Ceph 모니터에 도달하기 위해 클라이언트에 세부 정보를 제공할 수 있는 최소 구성 파일을 생성할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 액세스입니다.
프로세스
파일을 설정하려는 노드에서
/etc폴더에 디렉터리ceph를 생성합니다.예제
[root@host01 ~]# mkdir /etc/ceph/
/etc/ceph디렉터리로 이동합니다.예제
[root@host01 ~]# cd /etc/ceph/
ceph디렉터리에 구성 파일을 생성합니다.예제
[root@host01 ceph]# ceph config generate-minimal-conf # minimal ceph.conf for 417b1d7a-a0e6-11eb-b940-001a4a000740 [global] fsid = 417b1d7a-a0e6-11eb-b940-001a4a000740 mon_host = [v2:10.74.249.41:3300/0,v1:10.74.249.41:6789/0]
이 파일의 내용은
/etc/ceph/ceph.conf경로에 설치해야 합니다. 이 구성 파일을 사용하여 Ceph 모니터에 연결할 수 있습니다.
8.2. 클라이언트 시스템에서 인증 키 설정
대부분의 Ceph 클러스터는 인증이 활성화된 상태에서 실행되며, 클라이언트는 클러스터 시스템과 통신하기 위해 키가 필요합니다. 클라이언트에 세부 정보를 제공하여 Ceph 모니터에 연결할 수 있는 인증 키를 생성할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 액세스입니다.
프로세스
인증 키를 설정할 노드에서
/etc폴더에ceph디렉터리를 생성합니다.예제
[root@host01 ~]# mkdir /etc/ceph/
ceph 디렉터리의
/etc/디렉터리로 이동합니다.ceph예제
[root@host01 ~]# cd /etc/ceph/
클라이언트의 인증 키를 생성합니다.
구문
ceph auth get-or-create client.CLIENT_NAME -o /etc/ceph/NAME_OF_THE_FILE
예제
[root@host01 ceph]# ceph auth get-or-create client.fs -o /etc/ceph/ceph.keyring
ceph.keyring파일의 출력을 확인합니다.예제
[root@host01 ceph]# cat ceph.keyring [client.fs] key = AQAvoH5gkUCsExAATz3xCBLd4n6B6jRv+Z7CVQ==
결과 출력은 인증 키 파일(예:
/etc/ceph/ceph.keyring)에 배치해야 합니다.
9장. Ceph Orchestrator를 사용하여 MDS 서비스 관리
스토리지 관리자는 백엔드에서 Cephadm과 함께 Ceph Orchestrator를 사용하여 MDS 서비스를 배포할 수 있습니다. 기본적으로 Ceph 파일 시스템(CephFS)은 활성 MDS 데몬을 하나만 사용합니다. 그러나 많은 클라이언트가 있는 시스템은 여러 활성 MDS 데몬의 이점을 활용할 수 있습니다.
이 섹션에서는 다음 관리 작업에 대해 설명합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
9.1. 명령줄 인터페이스를 사용하여 MDS 서비스 배포
Ceph Orchestrator를 사용하여 명령줄 인터페이스의 배치 사양을 사용하여 Metadata Server(MDS) 서비스를 배포할 수 있습니다. Ceph 파일 시스템(CephFS)에는 하나 이상의 MDS가 필요합니다.
Ceph 파일 시스템(CephFS) 데이터 및 CephFS 메타데이터에 대해 하나 이상의 풀이 있는지 확인합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
- 배치 사양을 사용하여 MDS 데몬을 배포하는 방법은 다음 두 가지가 있습니다.
방법 1
ceph fs 볼륨을사용하여 MDS 데몬을 생성합니다. 이렇게 하면 CephFS와 연결된 CephFS 볼륨 및 풀이 생성되고 호스트에서 MDS 서비스도 시작됩니다.구문
ceph fs volume create FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
참고기본적으로 이 명령에 대해 복제된 풀이 생성됩니다.
예제
[ceph: root@host01 /]# ceph fs volume create test --placement="2 host01 host02"
방법 2
pool, CephFS를 생성한 다음 배치 사양을 사용하여 MDS 서비스를 배포합니다.
CephFS의 풀을 생성합니다.
구문
ceph osd pool create DATA_POOL [PG_NUM] ceph osd pool create METADATA_POOL [PG_NUM]
예제
[ceph: root@host01 /]# ceph osd pool create cephfs_data 64 [ceph: root@host01 /]# ceph osd pool create cephfs_metadata 64
일반적으로 메타데이터 풀은 일반적으로 데이터 풀보다 오브젝트 수가 훨씬 적기 때문에 보수적인 수의 PG(배치 그룹)로 시작할 수 있습니다. 필요한 경우 PG 수를 늘릴 수 있습니다. 풀 크기는 64개의 PG에서 512 PG 사이입니다. 데이터 풀의 크기는 파일 시스템에서 예상되는 파일의 수 및 크기에 비례합니다.
중요메타데이터 풀의 경우 다음을 사용하십시오.
- 이 풀에 대한 데이터가 손실되어 전체 파일 시스템에 액세스할 수 없기 때문에 복제 수준이 높습니다.
- 클라이언트에서 파일 시스템 작업의 관찰된 대기 시간에 직접적인 영향을 미치기 때문에 SSD(Solid-State Drive) 디스크와 같은 대기 시간이 짧은 스토리지입니다.
데이터 풀 및 메타데이터 풀에 대한 파일 시스템을 생성합니다.
구문
ceph fs new FILESYSTEM_NAME METADATA_POOL DATA_POOL
예제
[ceph: root@host01 /]# ceph fs new test cephfs_metadata cephfs_data
ceph orch apply명령을 사용하여 MDS 서비스를 배포합니다.구문
ceph orch apply mds FILESYSTEM_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply mds test --placement="2 host01 host02"
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
CephFS 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph fs ls [ceph: root@host01 /]# ceph fs status
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mds
추가 리소스
- Ceph 파일 시스템(CephFS) 생성에 대한 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드를 참조하십시오.
- 풀 값을 설정하는 방법에 대한 자세한 내용은 풀에서 배치 그룹 수 설정을 참조하십시오.
9.2. 서비스 사양을 사용하여 MDS 서비스 배포
Ceph Orchestrator를 사용하여 서비스 사양을 사용하여 MDS 서비스를 배포할 수 있습니다.
Ceph 파일 시스템(CephFS) 데이터 및 CephFS 메타데이터에 대해 하나 이상의 풀이 있는지 확인합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
프로세스
mds.yaml파일을 생성합니다.예제
[root@host01 ~]# touch mds.yaml
다음 세부 정보를 포함하도록
mds.yaml파일을 편집합니다.구문
service_type: mds service_id: FILESYSTEM_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2 - HOST_NAME_3
예제
service_type: mds service_id: fs_name placement: hosts: - host01 - host02
YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount mds.yaml:/var/lib/ceph/mds/mds.yaml
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/mds/
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
다음 디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/mds/
서비스 사양을 사용하여 MDS 서비스를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 mds]# ceph orch apply -i mds.yaml
MDS 서비스가 배포 및 작동되면 CephFS를 생성합니다.
구문
ceph fs new CEPHFS_NAME METADATA_POOL DATA_POOL
예제
[ceph: root@host01 /]# ceph fs new test metadata_pool data_pool
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=mds
9.3. Ceph Orchestrator를 사용하여 MDS 서비스 제거
ceph orch rm 명령을 사용하여 서비스를 제거할 수 있습니다. 또는 파일 시스템 및 관련 풀을 제거할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 호스트에 배포된 하나 이상의 MDS 데몬.
프로세스
- 클러스터에서 MDS 데몬을 제거하는 방법은 다음 두 가지가 있습니다.
방법 1
CephFS 볼륨, 관련 풀 및 서비스를 제거합니다.
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
설정 매개변수
mon_allow_pool_delete를true로 설정합니다.예제
[ceph: root@host01 /]# ceph config set mon mon_allow_pool_delete true
파일 시스템을 제거합니다.
구문
ceph fs volume rm FILESYSTEM_NAME --yes-i-really-mean-it예제
[ceph: root@host01 /]# ceph fs volume rm cephfs-new --yes-i-really-mean-it
이 명령은 파일 시스템, 해당 데이터 및 메타데이터 풀을 제거합니다. 활성화된
ceph-mgrOrchestrator 모듈을 사용하여 MDS도 제거하려고 합니다.
방법 2
ceph orch rm명령을 사용하여 전체 클러스터에서 MDS 서비스를 제거합니다.서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
서비스 제거
구문
ceph orch rm SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch rm mds.test
검증
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps
예제
[ceph: root@host01 /]# ceph orch ps
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 명령줄 인터페이스를 사용하여 MDS 서비스 배포를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 서비스 사양을 사용하여 MDS 서비스 배포를 참조하십시오.
10장. Ceph Orchestrator를 사용하여 Ceph 개체 게이트웨이 관리
스토리지 관리자는 명령줄 인터페이스를 사용하거나 서비스 사양을 사용하여 Ceph 개체 게이트웨이를 배포할 수 있습니다.
다중 사이트 오브젝트 게이트웨이를 구성하고 Ceph Orchestrator를 사용하여 Ceph 오브젝트 게이트웨이를 제거할 수도 있습니다.
cephadm 은 Ceph 개체 게이트웨이를 다중 사이트 배포에서 단일 클러스터 배포 또는 특정 영역 및 영역을 관리하는 데몬으로 배포합니다.
Cephadm을 사용하면 ceph.conf 또는 명령줄 대신 monitor 구성 데이터베이스를 사용하여 오브젝트 게이트웨이 데몬이 구성됩니다. 해당 구성이 client.rgw 섹션에 없는 경우 오브젝트 게이트웨이 데몬이 기본 설정으로 시작되어 포트 80 에 바인딩됩니다.
.default.rgw.buckets.index 풀은 Ceph Object Gateway에서 버킷이 생성된 후에만 생성되는 반면 .default.rgw.buckets.data 풀은 버킷에 업로드된 후 생성됩니다.
이 섹션에서는 다음 관리 작업에 대해 설명합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 모든 관리자, 모니터 및 OSD는 스토리지 클러스터에 배포됩니다.
10.1. 명령줄 인터페이스를 사용하여 Ceph Object Gateway 배포
Ceph Orchestrator를 사용하여 명령줄 인터페이스에서 ceph orch 명령을 사용하여 Ceph Object Gateway를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
- Ceph 개체 게이트웨이 데몬은 다음과 같은 세 가지 방법으로 배포할 수 있습니다.
방법 1
영역, 영역 그룹, 영역을 생성한 다음 호스트 이름으로 배치 사양을 사용합니다.
영역을 생성합니다.
구문
radosgw-admin realm create --rgw-realm=REALM_NAME --default예제
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --default
영역 그룹을 생성합니다.
구문
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --master --default예제
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
영역을 생성합니다.
구문
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME --rgw-zone=ZONE_NAME --master --default
예제
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=test_zone --master --default
변경 사항을 커밋합니다.
구문
radosgw-admin period update --rgw-realm=REALM_NAME --commit예제
[ceph: root@host01 /]# radosgw-admin period update --rgw-realm=test_realm --commit
ceph orch apply명령을 실행합니다.구문
ceph orch apply rgw NAME [--realm=REALM_NAME] [--zone=ZONE_NAME] --placement="NUMBER_OF_DAEMONS [HOST_NAME_1 HOST_NAME_2]"
예제
[ceph: root@host01 /]# ceph orch apply rgw test --realm=test_realm --zone=test_zone --placement="2 host01 host02"
방법 2
임의의 서비스 이름을 사용하여 단일 클러스터 배포를 위해 두 개의 Ceph Object Gateway 데몬을 배포합니다.
구문
ceph orch apply rgw SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch apply rgw foo
방법 3
레이블이 지정된 호스트 세트에서 임의의 서비스 이름을 사용합니다.
구문
ceph orch host label add HOST_NAME_1 LABEL_NAME ceph orch host label add HOSTNAME_2 LABEL_NAME ceph orch apply rgw SERVICE_NAME --placement="label:LABEL_NAME count-per-host:NUMBER_OF_DAEMONS" --port=8000
참고NUMBER_OF_DAEMONS 는 각 호스트에 배포된 Ceph 개체 게이트웨이 수를 제어합니다. 추가 비용이 발생하지 않고 최고 성능을 달성하려면 이 값을 2로 설정합니다.
예제
[ceph: root@host01 /]# ceph orch host label add host01 rgw # the 'rgw' label can be anything [ceph: root@host01 /]# ceph orch host label add host02 rgw [ceph: root@host01 /]# ceph orch apply rgw foo --placement="2 label:rgw" --port=8000
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgw
10.2. 서비스 사양을 사용하여 Ceph Object Gateway 배포
기본 또는 사용자 지정 영역, 영역 및 영역 그룹과 함께 서비스 사양을 사용하여 Ceph Object Gateway를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 부트 스트랩된 호스트에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
프로세스
root 사용자로 사양 파일을 생성합니다.
예제
[root@host01 ~]# touch radosgw.yml
기본 영역, 영역, 영역 그룹에 대한 다음 세부 정보를 포함하도록
radosgw.yml파일을 편집합니다.구문
service_type: rgw service_id: REALM_NAME.ZONE_NAME placement: hosts: - HOST_NAME_1 - HOST_NAME_2 count_per_host: NUMBER_OF_DAEMONS spec: rgw_realm: REALM_NAME rgw_zone: ZONE_NAME rgw_frontend_port: FRONT_END_PORT networks: - NETWORK_CIDR # Ceph Object Gateway service binds to a specific network
참고NUMBER_OF_DAEMONS 는 각 호스트에 배포된 Ceph Object Gateway 수를 제어합니다. 추가 비용이 발생하지 않고 최고 성능을 달성하려면 이 값을 2로 설정합니다.
예제
service_type: rgw service_id: default placement: hosts: - host01 - host02 - host03 count_per_host: 2 spec: rgw_realm: default rgw_zone: default rgw_frontend_port: 1234 networks: - 192.169.142.0/24
선택 사항: 사용자 지정 영역, 영역 및 영역 그룹의 경우 리소스를 생성한 다음
radosgw.yml파일을 생성합니다.사용자 지정 영역, 영역 및 영역 그룹을 생성합니다.
예제
[root@host01 ~]# radosgw-admin realm create --rgw-realm=test_realm [root@host01 ~]# radosgw-admin zonegroup create --rgw-zonegroup=test_zonegroup [root@host01 ~]# radosgw-admin zone create --rgw-zonegroup=test_zonegroup --rgw-zone=test_zone [root@host01 ~]# radosgw-admin period update --rgw-realm=test_realm --commit
다음 세부 정보를 사용하여
radosgw.yml파일을 생성합니다.예제
service_type: rgw service_id: test_realm.test_zone placement: hosts: - host01 - host02 - host03 count_per_host: 2 spec: rgw_realm: test_realm rgw_zone: test_zone rgw_frontend_port: 1234 networks: - 192.169.142.0/24
radosgw.yml파일을 컨테이너의 디렉터리에 마운트합니다.예제
[root@host01 ~]# cephadm shell --mount radosgw.yml:/var/lib/ceph/radosgw/radosgw.yml
참고쉘을 종료할 때마다 데몬을 배포하기 전에 컨테이너에 파일을 마운트해야 합니다.
서비스 사양을 사용하여 Ceph Object Gateway를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yml예제
[ceph: root@host01 /]# ceph orch apply -i radosgw.yml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=rgw
10.3. Ceph Orchestrator를 사용하여 다중 사이트 Ceph Object Gateway 배포
Ceph Orchestrator는 Ceph Object Gateway에 대한 다중 사이트 구성 옵션을 지원합니다.
각 오브젝트 게이트웨이가 활성-활성 영역 구성에서 작동하도록 구성하여 기본이 아닌 영역에 쓰기를 허용할 수 있습니다. 다중 사이트 구성은 영역이라는 컨테이너 내에 저장됩니다.
영역은 영역 그룹, 영역 및 기간을 저장합니다. rgw 데몬은 별도의 동기화 에이전트가 필요하지 않은 동기화를 처리하므로 active-active 구성으로 작동합니다.
CLI(명령줄 인터페이스)를 사용하여 다중 사이트 영역을 배포할 수도 있습니다.
다음 구성에서는 두 개 이상의 Red Hat Ceph Storage 클러스터가 지리적으로 별도의 위치에 있다고 가정합니다. 그러나 구성은 동일한 사이트에서도 작동합니다.
사전 요구 사항
- 두 개 이상의 실행 중인 Red Hat Ceph Storage 클러스터
- 각 Red Hat Ceph Storage 클러스터에 하나씩 두 개 이상의 Ceph Object Gateway 인스턴스.
- 모든 노드에 대한 루트 수준 액세스.
- 노드 또는 컨테이너가 스토리지 클러스터에 추가됩니다.
- 모든 Ceph Manager, Monitor 및 OSD 데몬이 배포됩니다.
프로세스
cephadm쉘에서 기본 영역을 구성합니다.영역을 생성합니다.
구문
radosgw-admin realm create --rgw-realm=REALM_NAME --default예제
[ceph: root@host01 /]# radosgw-admin realm create --rgw-realm=test_realm --default
스토리지 클러스터에 단일 영역이 있는 경우
--default플래그를 지정합니다.기본 영역 그룹을 생성합니다.
구문
radosgw-admin zonegroup create --rgw-zonegroup=ZONE_GROUP_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --master --default
예제
[ceph: root@host01 /]# radosgw-admin zonegroup create --rgw-zonegroup=us --endpoints=http://rgw1:80 --master --default
기본 영역을 생성합니다.
구문
radosgw-admin zone create --rgw-zonegroup=PRIMARY_ZONE_GROUP_NAME --rgw-zone=PRIMARY_ZONE_NAME --endpoints=http://RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY
예제
[ceph: root@host01 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-1 --endpoints=http://rgw1:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
선택 사항: 기본 영역, 영역 그룹 및 관련 풀을 삭제합니다.
중요데이터를 저장하기 위해 기본 영역 및 영역 그룹을 사용하는 경우 기본 영역 및 해당 풀을 삭제하지 마십시오. 또한 기본 영역 그룹을 제거하면 시스템 사용자가 삭제됩니다.
기본영역 및 zonegroup에서 이전 데이터에 액세스하려면radosgw-admin명령에서--rgw-zone default및--rgw-zonegroup 기본값을 사용합니다.예제
[ceph: root@host01 /]# radosgw-admin zonegroup delete --rgw-zonegroup=default [ceph: root@host01 /]# ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-it [ceph: root@host01 /]# ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it [ceph: root@host01 /]# ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-it [ceph: root@host01 /]# ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-it [ceph: root@host01 /]# ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-it
시스템 사용자를 생성합니다.
구문
radosgw-admin user create --uid=USER_NAME --display-name="USER_NAME" --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY --system
예제
[ceph: root@host01 /]# radosgw-admin user create --uid=zone.user --display-name="Zone user" --system
access_key및secret_key를 기록합니다.기본 영역에 액세스 키와 시스템 키를 추가합니다.
구문
radosgw-admin zone modify --rgw-zone=PRIMARY_ZONE_NAME --access-key=ACCESS_KEY --secret=SECRET_KEY
예제
[ceph: root@host01 /]# radosgw-admin zone modify --rgw-zone=us-east-1 --access-key=NE48APYCAODEPLKBCZVQ--secret=u24GHQWRE3yxxNBnFBzjM4jn14mFIckQ4EKL6LoW
변경 사항을 커밋합니다.
구문
radosgw-admin period update --commit
예제
[ceph: root@host01 /]# radosgw-admin period update --commit
cephadm쉘 외부에서 스토리지 클러스터 및 프로세스의FSID를 가져옵니다.예제
[root@host01 ~]# systemctl list-units | grep ceph
Ceph Object Gateway 데몬을 시작합니다.
구문
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAME
예제
[root@host01 ~]# systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.service [root@host01 ~]# systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-1.host01.ahdtsw.service
Cephadm 쉘에서 보조 영역을 구성합니다.
호스트에서 기본 영역 구성을 가져옵니다.
구문
radosgw-admin realm pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEY
예제
[ceph: root@host04 /]# radosgw-admin realm pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
호스트에서 기본 기간 구성을 가져옵니다.
구문
radosgw-admin period pull --url=URL_TO_PRIMARY_ZONE_GATEWAY --access-key=ACCESS_KEY --secret-key=SECRET_KEY
예제
[ceph: root@host04 /]# radosgw-admin period pull --url=http://10.74.249.26:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ
보조 영역을 구성합니다.
구문
radosgw-admin zone create --rgw-zonegroup=ZONE_GROUP_NAME \ --rgw-zone=SECONDARY_ZONE_NAME --endpoints=http://RGW_SECONDARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 \ --access-key=SYSTEM_ACCESS_KEY --secret=SYSTEM_SECRET_KEY \ --endpoints=http://FQDN:80 \ [--read-only]
예제
[ceph: root@host04 /]# radosgw-admin zone create --rgw-zonegroup=us --rgw-zone=us-east-2 --endpoints=http://rgw2:80 --access-key=LIPEYZJLTWXRKXS9LPJC --secret-key=IsAje0AVDNXNw48LjMAimpCpI7VaxJYSnfD0FFKQ --endpoints=http://rgw.example.com:80
선택 사항: 기본 영역을 삭제합니다.
중요데이터를 저장하기 위해 기본 영역 및 영역 그룹을 사용하는 경우 기본 영역 및 해당 풀을 삭제하지 마십시오.
기본영역 및 zonegroup에서 이전 데이터에 액세스하려면radosgw-admin명령에서--rgw-zone default및--rgw-zonegroup 기본값을 사용합니다.예제
[ceph: root@host04 /]# radosgw-admin zone rm --rgw-zone=default [ceph: root@host04 /]# ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.data.root default.rgw.data.root --yes-i-really-really-mean-it [ceph: root@host04 /]# ceph osd pool rm default.rgw.gc default.rgw.gc --yes-i-really-really-mean-it
Ceph 구성 데이터베이스를 업데이트합니다.
구문
ceph config set SERVICE_NAME rgw_zone SECONDARY_ZONE_NAME
예제
[ceph: root@host04 /]# ceph config set rgw rgw_zone us-east-2
변경 사항을 커밋합니다.
구문
radosgw-admin period update --commit
예제
[ceph: root@host04 /]# radosgw-admin period update --commit
Cephadm 쉘 외부에서 스토리지 클러스터 및 프로세스의 FSID를 가져옵니다.
예제
[root@host04 ~]# systemctl list-units | grep ceph
Ceph Object Gateway 데몬을 시작합니다.
구문
systemctl start ceph-FSID@DAEMON_NAME systemctl enable ceph-FSID@DAEMON_NAME
예제
[root@host04 ~]# systemctl start ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service [root@host04 ~]# systemctl enable ceph-62a081a6-88aa-11eb-a367-001a4a000672@rgw.test_realm.us-east-2.host04.ahdtsw.service
선택 사항: 배치 사양을 사용하여 다중 사이트 Ceph Object Gateway를 배포합니다.
구문
ceph orch apply rgw NAME --realm=REALM_NAME --zone=PRIMARY_ZONE_NAME --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2"
예제
[ceph: root@host04 /]# ceph orch apply rgw east --realm=test_realm --zone=us-east-1 --placement="2 host01 host02"
검증
동기화 상태를 확인하여 배포를 확인합니다.
예제
[ceph: root@host04 /]# radosgw-admin sync status
10.4. Ceph Orchestrator를 사용하여 Ceph Object Gateway 제거
ceph orch rm 명령을 사용하여 Ceph 개체 게이트웨이 데몬을 제거할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 호스트에 배포된 하나 이상의 Ceph 오브젝트 게이트웨이 데몬입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
서비스를 제거합니다.
구문
ceph orch rm SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch rm rgw.test_realm.test_zone_bb
검증
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps
예제
[ceph: root@host01 /]# ceph orch ps
11장. Ceph Orchestrator(제한된 가용성)를 사용하여 NFS-Ganesha 게이트웨이 관리
스토리지 관리자는 백엔드에서 Cephadm과 함께 Orchestrator를 사용하여 NFS-Ganesha 게이트웨이를 배포할 수 있습니다. cephadm 은 사전 정의된 RADOS 풀 및 선택적 네임스페이스를 사용하여 NFS Ganesha를 배포합니다.
이 기술은 제한된 가용성입니다. 자세한 내용은 더 이상 사용되지 않는 기능 장을 참조하십시오.
Red Hat은 NFS v4.0 이상 프로토콜을 통해서만 CephFS 내보내기를 지원합니다.
이 섹션에서는 다음 관리 작업에 대해 설명합니다.
- Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 생성.
- 명령줄 인터페이스를 사용하여 NFS-Ganesha 게이트웨이를 배포합니다.
- 서비스 사양을 사용하여 NFS-Ganesha 게이트웨이 배포.
- CephFS/NFS 서비스에 대한 HA 구현.
- Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 업데이트.
- Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 정보 보기.
- Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 로그 가져오기.
- Ceph Orchestrator 를 사용하여 사용자 지정 NFS-Ganesha 구성 설정.
- Ceph Orchestrator 를 사용하여 사용자 지정 NFS-Ganesha 구성 재설정.
- Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 삭제.
- Ceph Orchestrator를 사용하여 NFS Ganesha 게이트웨이 제거.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
11.1. Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 생성
Ceph Orchestrator의 mgr/nfs 모듈을 사용하여 NFS-Ganesha 클러스터를 생성할 수 있습니다. 이 모듈은 백엔드에서 Cephadm을 사용하여 NFS 클러스터를 배포합니다.
이렇게 하면 모든 NFS-Ganesha 데몬에 대한 공통 복구 풀, clusterid 를 기반으로 하는 새 사용자, 공통 NFS-Ganesha 구성 RADOS 오브젝트가 생성됩니다.
각 데몬에 대해 새 사용자와 공통 구성이 풀에 생성됩니다. 모든 클러스터에 클러스터 이름과 관련하여 다른 네임스페이스가 있지만 동일한 복구 풀을 사용합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
mgr/nfs모듈을 활성화합니다.예제
[ceph: root@host01 /]# ceph mgr module enable nfs
클러스터를 생성합니다.
구문
ceph nfs cluster create CLUSTER_NAME ["HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"]
CLUSTER_NAME 은 임의의 문자열이며 HOST_NAME_1 은 NFS-Ganesha 데몬을 배포할 호스트를 나타내는 선택적 문자열입니다.
예제
[ceph: root@host01 /]# ceph nfs cluster create nfsganesha "host01 host02" NFS Cluster Created Successful
그러면
host01및host02에 하나의 데몬이 포함된 NFS_Ganesha 클러스터nfsganesha가 생성됩니다.
검증
클러스터 세부 정보를 나열합니다.
예제
[ceph: root@host01 /]# ceph nfs cluster ls
NFS-Ganesha 클러스터 정보를 표시합니다.
구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info nfsganesha
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 파일 시스템 가이드의 NFS 프로토콜을 통해 Ceph 파일 시스템네임스페이스 내보내기 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 서비스 사양을 사용하여 Ceph 데몬 배포를 참조하십시오.
11.2. 명령줄 인터페이스를 사용하여 NFS-Ganesha 게이트웨이 배포
백엔드에서 Ceph Orchestrator를 Cephadm과 함께 사용하여 배치 사양을 사용하여 NFS-Ganesha 게이트웨이를 배포할 수 있습니다. 이 경우 RADOS 풀을 생성하고 게이트웨이를 배포하기 전에 네임스페이스를 생성해야 합니다.
Red Hat은 NFS v4.0 이상 프로토콜을 통해서만 CephFS 내보내기를 지원합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
RADOS 풀 네임스페이스를 생성하고 애플리케이션을 활성화합니다. RBD 풀의 경우 RBD를 활성화합니다.
구문
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME freeform/rgw/rbd/cephfs/nfs rbd pool init -p POOL_NAME
예제
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha nfs [ceph: root@host01 /]# rbd pool init -p nfs-ganesha
명령줄 인터페이스에서 배치 사양을 사용하여 NFS-Ganesha 게이트웨이를 배포합니다.
구문
ceph orch apply nfs SERVICE_ID --placement="NUMBER_OF_DAEMONS HOST_NAME_1 HOST_NAME_2 HOST_NAME_3"
예제
[ceph: root@host01 /]# ceph orch apply nfs foo --placement="2 host01 host02"
이렇게 하면
host01및host02에 하나의 데몬이 포함된 NFS-Ganesha 클러스터nfsganesha가 배포됩니다.
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 명령줄 인터페이스를 사용하여 Ceph 데몬 배포를 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 블록 장치 가이드의 블록 장치풀 생성 섹션을 참조하십시오.
11.3. 서비스 사양을 사용하여 NFS-Ganesha 게이트웨이 배포
백엔드에서 Ceph Orchestrator를 Cephadm과 함께 사용하여 서비스 사양을 사용하여 NFS-Ganesha 게이트웨이를 배포할 수 있습니다. 이 경우 RADOS 풀을 생성하고 게이트웨이를 배포하기 전에 네임스페이스를 생성해야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
프로세스
nfs.yaml파일을 생성합니다.예제
[root@host01 ~]# touch nfs.yaml
nfs.yaml 사양 파일을 편집합니다.
구문
service_type: nfs service_id: SERVICE_ID placement: hosts: - HOST_NAME_1 - HOST_NAME_2
예제
# cat nfs.yaml service_type: nfs service_id: foo placement: hosts: - host01 - host02선택 사항:
ganesha.yaml사양 파일에enable_nlm: true를 추가하여 NLM에서 NFS 프로토콜 v3 지원에 대한 잠금을 지원할 수 있습니다.구문
service_type: nfs service_id: SERVICE_ID placement: hosts: - HOST_NAME_1 - HOST_NAME_2 spec: enable_nlm: true
예제
# cat ganesha.yaml service_type: nfs service_id: foo placement: hosts: - host01 - host02 spec: enable_nlm: true
YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yaml
RADOS 풀, 네임스페이스를 생성하고 RBD를 활성화합니다.
구문
ceph osd pool create POOL_NAME ceph osd pool application enable POOL_NAME rbd rbd pool init -p POOL_NAME
예제
[ceph: root@host01 /]# ceph osd pool create nfs-ganesha [ceph: root@host01 /]# ceph osd pool application enable nfs-ganesha rbd [ceph: root@host01 /]# rbd pool init -p nfs-ganesha
디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/
서비스 사양을 사용하여 NFS-Ganesha 게이트웨이를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 블록 장치 가이드의 블록 장치풀 생성 섹션을 참조하십시오.
11.4. CephFS/NFS 서비스용 HA 구현(기술 프리뷰)
HA(고가용성) 프런트 엔드, 가상 IP 및 로드 밸런서를 사용하여 NFS를 배포할 수 있습니다. --ingress 플래그를 사용하고 가상 IP 주소를 지정하면 됩니다. 이렇게 하면 keepalived 및 haproxy 의 조합을 배포하고 NFS 서비스에 고가용성 NFS 프런트 엔드를 제공합니다.
--ingress 플래그를 사용하여 클러스터를 생성하면 NFS 서버에 부하 분산 및 고가용성을 제공하기 위해 수신 서비스가 추가로 배포됩니다. 가상 IP는 모든 NFS 클라이언트가 마운트에 사용할 수 있는 알려진 안정적인 NFS 엔드포인트를 제공하는 데 사용됩니다. Ceph는 가상 IP의 NFS 트래픽을 적절한 백엔드 NFS 서버로 리디렉션하는 세부 정보를 처리하고 실패할 때 NFS 서버를 재배포합니다.
기존 서비스에 대한 수신 서비스를 배포하면 다음을 수행할 수 있습니다.
- NFS 서버에 액세스하는 데 사용할 수 있는 안정적인 가상 IP입니다.
- 여러 NFS 게이트웨이에 부하를 분산합니다.
- 호스트 장애 발생 시 호스트 간 페일오버.
CephFS/NFS용 HA는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있으며 Red Hat은 해당 기능을 프로덕션용으로 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. 자세한 내용은 Red Hat 기술 프리뷰 기능에 대한 지원 범위를 참조하십시오.
수신 서비스가 NFS 클러스터 앞에 배포되면 백엔드 NFS-ganesha 서버에서 클라이언트의 IP 주소가 아닌 haproxy의 IP 주소를 확인합니다. 결과적으로 IP 주소를 기반으로 클라이언트 액세스를 제한하는 경우 NFS 내보내기에 대한 액세스 제한이 예상대로 작동하지 않습니다.
클라이언트를 제공하는 활성 NFS 서버가 다운되면 활성 NFS 서버를 교체하고 NFS 클러스터가 다시 활성화될 때까지 클라이언트의 I/O가 중단됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
- NFS 모듈이 활성화되었는지 확인합니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
--ingress플래그를 사용하여 NFS 클러스터를 생성합니다.구문
ceph nfs cluster create CLUSTER_ID [PLACEMENT] [--port PORT_NUMBER] [--ingress --virtual-ip IP_ADDRESS/CIDR_PREFIX]
- CLUSTER_ID 를 NFS Ganesha 클러스터의 이름을 지정할 고유한 문자열로 바꿉니다.
- PLACEMENT 를 배포할 NFS 서버 수와 NFS Ganesha 데몬 컨테이너를 배포하려는 호스트 또는 호스트로 교체합니다.
--portPORT_NUMBER 플래그를 사용하여 기본 포트인 12049 이외의 포트에 NFS를 배포합니다.참고수신 모드에서는 고가용성 프록시가 포트 2049를 사용하고 NFS 서비스는 12049에 배포됩니다.
-
--virtual-ip플래그와 결합된--ingress플래그는 고가용성 프런트 엔드(가상 IP 및 로드 밸런서)를 사용하여 NFS를 배포합니다. --virtual-ipIP_ADDRESS 를 IP 주소로 교체하여 모든 클라이언트가 NFS 내보내기를 마운트하는 데 사용할 수 있는 알려진 안정적인 NFS 끝점을 제공합니다.--virtual-ip에는 CIDR 접두사 길이를 포함해야 합니다. 가상 IP는 일반적으로 동일한 서브넷에 기존 IP가 있는 첫 번째 식별된 네트워크 인터페이스에서 구성됩니다.참고NFS 서비스에 할당하는 호스트 수는 배포하도록 요청하는 활성 NFS 서버 수보다 커야 합니다.
placement: count매개 변수로 지정됩니다. 아래 예제에서는 하나의 활성 NFS 서버가 요청되고 두 개의 호스트가 할당됩니다.예제
[ceph: root@host01 /]# ceph nfs cluster create mycephnfs "1 host02 host03" --ingress --virtual-ip 10.10.128.75/22
참고NFS 데몬 및 수신 서비스의 배포는 비동기적이며 서비스가 완전히 시작되기 전에 명령이 반환될 수 있습니다.
서비스가 성공적으로 시작되었는지 확인합니다.
구문
ceph orch ls --service_name=nfs.CLUSTER_ID ceph orch ls --service_name=ingress.nfs.CLUSTER_ID
예제
[ceph: root@host01 /]# ceph orch ls --service_name=nfs.mycephnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT nfs.mycephnfs ?:12049 2/2 0s ago 20s host02;host03 [ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.mycephnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.mycephnfs 10.10.128.75:2049,9049 4/4 46s ago 73s count:2
검증
IP 끝점, 개별 NFS 데몬의 IP,
Ingress 서비스의 가상 IP를확인합니다.구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info mycephnfs { "mycephnfs": { "virtual_ip": "10.10.128.75", "backend": [ { "hostname": "host02", "ip": "10.10.128.69", "port": 12049 }, { "hostname": "host03", "ip": "10.10.128.70", "port": 12049 } ], "port": 2049, "monitor_port": 9049 } }호스트 및 프로세스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ps | grep nfs haproxy.nfs.cephnfs.host01.rftylv host01 *:2049,9000 running (11m) 10m ago 11m 23.2M - 2.2.19-7ea3822 5e6a41d77b38 f8cc61dc827e haproxy.nfs.cephnfs.host02.zhtded host02 *:2049,9000 running (11m) 53s ago 11m 21.3M - 2.2.19-7ea3822 5e6a41d77b38 4cad324e0e23 keepalived.nfs.cephnfs.host01.zktmsk host01 running (11m) 10m ago 11m 2349k - 2.1.5 18fa163ab18f 66bf39784993 keepalived.nfs.cephnfs.host02.vyycvp host02 running (11m) 53s ago 11m 2349k - 2.1.5 18fa163ab18f 1ecc95a568b4 nfs.cephnfs.0.0.host02.fescmw host02 *:12049 running (14m) 3m ago 14m 76.9M - 3.5 cef6e7959b0a bb0e4ee9484e nfs.cephnfs.1.0.host03.avaddf host03 *:12049 running (14m) 3m ago 14m 74.3M - 3.5 cef6e7959b0a ea02c0c50749
11.5. HA용 독립 실행형 CephFS/NFS 클러스터 업그레이드
스토리지 관리자는 기존 NFS 서비스에 Ingress 서비스를 배포하여 독립 실행형 스토리지 클러스터를 HA(고가용성) 클러스터로 업그레이드할 수 있습니다.
사전 요구 사항
- 기존 NFS 서비스가 있는 실행 중인 Red Hat Ceph Storage 클러스터입니다.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
- NFS 모듈이 활성화되었는지 확인합니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
기존 NFS 클러스터를 나열합니다.
예제
[ceph: root@host01 /]# ceph nfs cluster ls mynfs
참고하나의 노드에서 독립 실행형 NFS 클러스터가 생성된 경우 HA의 두 개 이상의 노드로 늘려야 합니다. NFS 서비스를 늘리려면
nfs.yaml파일을 편집하고 동일한 포트 번호로 배치를 늘립니다.NFS 서비스에 할당하는 호스트 수는 배포하도록 요청하는 활성 NFS 서버 수보다 커야 합니다.
placement: count매개 변수로 지정됩니다.구문
service_type: nfs service_id: SERVICE_ID placement: hosts: - HOST_NAME_1 - HOST_NAME_2 count: COUNT spec: port: PORT_NUMBER
예제
service_type: nfs service_id: mynfs placement: hosts: - host02 - host03 count: 1 spec: port: 12345이 예에서 기존 NFS 서비스는 포트
12345에서 실행 중이며 동일한 포트가 있는 NFS 클러스터에 추가 노드가 추가됩니다.nfs.yaml서비스 사양 변경 사항을 적용하여 두 개의 노드 NFS 서비스로 업그레이드합니다.예제
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
기존 NFS 클러스터 ID로
ingress.yaml사양 파일을 편집합니다.구문
service_type: SERVICE_TYPE service_id: SERVICE_ID placement: count: PLACEMENT spec: backend_service: SERVICE_ID_BACKEND 1 frontend_port: FRONTEND_PORT monitor_port: MONITOR_PORT 2 virtual_ip: VIRTUAL_IP_WITH_CIDR
예제
service_type: ingress service_id: nfs.mynfs placement: count: 2 spec: backend_service: nfs.mynfs frontend_port: 2049 monitor_port: 9000 virtual_ip: 10.10.128.75/22
수신 서비스를 배포합니다.
예제
[ceph: root@host01 /]# ceph orch apply -i ingress.yaml
참고NFS 데몬 및 수신 서비스의 배포는 비동기적이며 서비스가 완전히 시작되기 전에 명령이 반환될 수 있습니다.
수신 서비스가 성공적으로 시작되었는지 확인합니다.
구문
ceph orch ls --service_name=ingress.nfs.CLUSTER_ID예제
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.mynfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.mynfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2
검증
IP 끝점, 개별 NFS 데몬의 IP,
Ingress 서비스의 가상 IP를확인합니다.구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info mynfs { "mynfs": { "virtual_ip": "10.10.128.75", "backend": [ { "hostname": "host02", "ip": "10.10.128.69", "port": 12049 }, { "hostname": "host03", "ip": "10.10.128.70", "port": 12049 } ], "port": 2049, "monitor_port": 9049 } }호스트 및 프로세스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ps | grep nfs haproxy.nfs.mynfs.host01.ruyyhq host01 *:2049,9000 running (27m) 6m ago 34m 9.85M - 2.2.19-7ea3822 5e6a41d77b38 328d27b3f706 haproxy.nfs.mynfs.host02.ctrhha host02 *:2049,9000 running (34m) 6m ago 34m 4944k - 2.2.19-7ea3822 5e6a41d77b38 4f4440dbfde9 keepalived.nfs.mynfs.host01.fqgjxd host01 running (27m) 6m ago 34m 31.2M - 2.1.5 18fa163ab18f 0e22b2b101df keepalived.nfs.mynfs.host02.fqzkxb host02 running (34m) 6m ago 34m 17.5M - 2.1.5 18fa163ab18f c1e3cc074cf8 nfs.mynfs.0.0.host02.emoaut host02 *:12345 running (37m) 6m ago 37m 82.7M - 3.5 91322de4f795 2d00faaa2ae5 nfs.mynfs.1.0.host03.nsxcfd host03 *:12345 running (37m) 6m ago 37m 81.1M - 3.5 91322de4f795 d4bda4074f17
11.6. 사양 파일을 사용하여 CephFS/NFS용 HA 배포
먼저 NFS 서비스를 배포한 다음 동일한 NFS 서비스에 Ingress 를 배포하여 사양 파일을 사용하여 CephFS/NFS의 HA를 배포할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor, OSD 데몬이 배포됩니다.
- NFS 모듈이 활성화되었는지 확인합니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
NFS 모듈이 활성화되었는지 확인합니다.
예제
[ceph: root@host01 /]# ceph mgr module ls | more
Cephadm 쉘을 종료하고
nfs.yaml파일을 생성합니다.예제
[root@host01 ~]# touch nfs.yaml
다음 세부 정보를 포함하도록
nfs.yaml파일을 편집합니다.구문
service_type: nfs service_id: SERVICE_ID placement: hosts: - HOST_NAME_1 - HOST_NAME_2 count: COUNT spec: port: PORT_NUMBER
참고NFS 서비스에 할당하는 호스트 수는 배포하도록 요청하는 활성 NFS 서버 수보다 커야 합니다.
placement: count매개 변수로 지정됩니다.예제
service_type: nfs service_id: cephfsnfs placement: hosts: - host02 - host03 count: 1 spec: port: 12345이 예에서 서버는 host02 및 host03에서 기본 포트
2049대신12345의 기본 포트에서 실행됩니다.YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yaml
Cephadm 쉘에 로그인하고 디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/
서비스 사양을 사용하여 NFS 서비스를 배포합니다.
구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 ceph]# ceph orch apply -i nfs.yaml
참고NFS 서비스의 배포는 비동기적이며 서비스가 완전히 시작되기 전에 명령이 반환될 수 있습니다.
NFS 서비스가 성공적으로 시작되었는지 확인합니다.
구문
ceph orch ls --service_name=nfs.CLUSTER_ID예제
[ceph: root@host01 /]# ceph orch ls --service_name=nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT nfs.cephfsnfs ?:12345 2/2 3m ago 13m host02;host03
Cephadm 쉘에서 종료하고
ingress.yaml파일을 생성합니다.예제
[root@host01 ~]# touch ingress.yaml
다음 세부 정보를 포함하도록
ingress.yaml파일을 편집합니다.구문
service_type: SERVICE_TYPE service_id: SERVICE_ID placement: count: PLACEMENT spec: backend_service: SERVICE_ID_BACKEND frontend_port: FRONTEND_PORT monitor_port: MONITOR_PORT virtual_ip: VIRTUAL_IP_WITH_CIDR
예제
service_type: ingress service_id: nfs.cephfsnfs placement: count: 2 spec: backend_service: nfs.cephfsnfs frontend_port: 2049 monitor_port: 9000 virtual_ip: 10.10.128.75/22
참고이 예제에서
placement: count: 2는keepalived및haproxy서비스를 임의의 노드에 배포합니다.keepalived및haproxy를 배포할 노드를 지정하려면placement: hosts옵션을 사용합니다.예제
service_type: ingress service_id: nfs.cephfsnfs placement: hosts: - host02 - host03YAML 파일을 컨테이너의 디렉터리에 마운트합니다.
예제
[root@host01 ~]# cephadm shell --mount ingress.yaml:/var/lib/ceph/ingress.yaml
Cephadm 쉘에 로그인하고 디렉터리로 이동합니다.
예제
[ceph: root@host01 /]# cd /var/lib/ceph/
서비스 사양을 사용하여
수신서비스를 배포합니다.구문
ceph orch apply -i FILE_NAME.yaml예제
[ceph: root@host01 ceph]# ceph orch apply -i ingress.yaml
수신 서비스가 성공적으로 시작되었는지 확인합니다.
구문
ceph orch ls --service_name=ingress.nfs.CLUSTER_ID예제
[ceph: root@host01 /]# ceph orch ls --service_name=ingress.nfs.cephfsnfs NAME PORTS RUNNING REFRESHED AGE PLACEMENT ingress.nfs.cephfsnfs 10.10.128.75:2049,9000 4/4 4m ago 22m count:2
검증
IP 끝점, 개별 NFS 데몬의 IP,
Ingress 서비스의 가상 IP를확인합니다.구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info cephfsnfs { "cephfsnfs": { "virtual_ip": "10.10.128.75", "backend": [ { "hostname": "host02", "ip": "10.10.128.69", "port": 12345 }, { "hostname": "host03", "ip": "10.10.128.70", "port": 12345 } ], "port": 2049, "monitor_port": 9049 } }호스트 및 프로세스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ps | grep nfs haproxy.nfs.cephfsnfs.host01.ruyyhq host01 *:2049,9000 running (27m) 6m ago 34m 9.85M - 2.2.19-7ea3822 5e6a41d77b38 328d27b3f706 haproxy.nfs.cephfsnfs.host02.ctrhha host02 *:2049,9000 running (34m) 6m ago 34m 4944k - 2.2.19-7ea3822 5e6a41d77b38 4f4440dbfde9 keepalived.nfs.cephfsnfs.host01.fqgjxd host01 running (27m) 6m ago 34m 31.2M - 2.1.5 18fa163ab18f 0e22b2b101df keepalived.nfs.cephfsnfs.host02.fqzkxb host02 running (34m) 6m ago 34m 17.5M - 2.1.5 18fa163ab18f c1e3cc074cf8 nfs.cephfsnfs.0.0.host02.emoaut host02 *:12345 running (37m) 6m ago 37m 82.7M - 3.5 91322de4f795 2d00faaa2ae5 nfs.cephfsnfs.1.0.host03.nsxcfd host03 *:12345 running (37m) 6m ago 37m 81.1M - 3.5 91322de4f795 d4bda4074f17
11.7. Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 업데이트
백엔드에서 Cephadm과 Ceph Orchestrator를 사용하여 호스트의 데몬 배치를 변경하여 NFS-Ganesha 클러스터를 업데이트할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
-
mgr/nfs모듈을 사용하여 생성된 NFS-Ganesha 클러스터입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
클러스터를 업데이트합니다.
구문
ceph orch apply nfs CLUSTER_NAME ["HOST_NAME_1,HOST_NAME_2,HOST_NAME_3"]
CLUSTER_NAME 은 임의의 문자열이며 HOST_NAME_1 은 배포된 NFS-Ganesha 데몬을 업데이트할 호스트를 나타내는 선택적 문자열입니다.
예제
[ceph: root@host01 /]# ceph orch apply nfs nfsganesha "host02"
이렇게 하면
host02에서nfsganesha클러스터가 업데이트됩니다.
검증
클러스터 세부 정보를 나열합니다.
예제
[ceph: root@host01 /]# ceph nfs cluster ls
NFS-Ganesha 클러스터 정보를 표시합니다.
구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info nfsganesha
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME
예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 NFS-Ganesha 클러스터 생성 섹션을 참조하십시오.
11.8. Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 정보 보기
Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터의 정보를 볼 수 있습니다. 포트, IP 주소 및 클러스터가 생성된 호스트의 이름을 사용하여 모든 NFS Ganesha 클러스터 또는 특정 클러스터에 대한 정보를 가져올 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
-
mgr/nfs모듈을 사용하여 생성된 NFS-Ganesha 클러스터입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
NFS-Ganesha 클러스터 정보를 확인합니다.
구문
ceph nfs cluster info CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster info nfsganesha { "nfsganesha": [ { "hostname": "host02", "ip": [ "10.10.128.70" ], "port": 2049 } ] }
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 NFS-Ganesha 클러스터 생성 섹션을 참조하십시오.
11.9. Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 로그 가져오기
Ceph Orchestrator를 사용하면 NFS-Ganesha 클러스터 로그를 가져올 수 있습니다. 서비스가 배포된 노드에 있어야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- cephadm 은 NFS가 배포된 노드에 설치됩니다.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
-
mgr/nfs모듈을 사용하여 생성된 NFS-Ganesha 클러스터입니다.
프로세스
root 사용자로 스토리지 클러스터의 FSID 를 가져옵니다.
예제
[root@host03 ~]# cephadm ls
FSID 와 서비스 이름을 복사합니다.
로그를 가져옵니다.
구문
cephadm logs --fsid FSID --name SERVICE_NAME
예제
[root@host03 ~]# cephadm logs --fsid 499829b4-832f-11eb-8d6d-001a4a000635 --name nfs.foo.host03
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide의 배치 사양 섹션을 사용하여 Ceph 데몬 배포를 참조하십시오.
11.10. Ceph Orchestrator를 사용하여 사용자 지정 NFS-Ganesha 구성 설정
NFS-Ganesha 클러스터는 기본 구성 블록에 정의되어 있습니다. Ceph Orchestrator를 사용하면 구성을 사용자 지정할 수 있으며 기본 구성 블록보다 우선합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
-
mgr/nfs모듈을 사용하여 생성된 NFS-Ganesha 클러스터입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
다음은 NFS-Ganesha 클러스터의 기본 구성의 예입니다.
예제
# {{ cephadm_managed }} NFS_CORE_PARAM { Enable_NLM = false; Enable_RQUOTA = false; Protocols = 4; } MDCACHE { Dir_Chunk = 0; } EXPORT_DEFAULTS { Attr_Expiration_Time = 0; } NFSv4 { Delegations = false; RecoveryBackend = 'rados_cluster'; Minor_Versions = 1, 2; } RADOS_KV { UserId = "{{ user }}"; nodeid = "{{ nodeid}}"; pool = "{{ pool }}"; namespace = "{{ namespace }}"; } RADOS_URLS { UserId = "{{ user }}"; watch_url = "{{ url }}"; } RGW { cluster = "ceph"; name = "client.{{ rgw_user }}"; } %url {{ url }}NFS-Ganesha 클러스터 구성을 사용자 지정합니다. 다음은 구성을 사용자 정의하는 두 가지 예입니다.
로그 수준을 변경합니다.
예제
LOG { COMPONENTS { ALL = FULL_DEBUG; } }사용자 정의 내보내기 블록을 추가합니다.
사용자를 생성합니다.
참고FSAL 블록에 지정된 사용자에게 NFS-Ganesha 데몬이 Ceph 클러스터에 액세스할 수 있는 적절한 제한이 있어야 합니다.
구문
ceph auth get-or-create client.USER_ID mon 'allow r' osd 'allow rw pool=.nfs namespace=NFS_CLUSTER_NAME, allow rw tag cephfs data=FS_NAME' mds 'allow rw path=EXPORT_PATH'
예제
[ceph: root@host01 /]# ceph auth get-or-create client.f64f341c-655d-11eb-8778-fa163e914bcc mon 'allow r' osd 'allow rw pool=.nfs namespace=nfs_cluster_name, allow rw tag cephfs data=fs_name' mds 'allow rw path=export_path'
다음 디렉터리로 이동합니다.
구문
cd /var/lib/ceph/DAEMON_PATH/예제
[ceph: root@host01 /]# cd /var/lib/ceph/nfs/
nfs디렉터리가 없는 경우 경로에 디렉터리를 생성합니다.새 구성 파일을 생성합니다.
구문
touch PATH_TO_CONFIG_FILE예제
[ceph: root@host01 nfs]# touch nfs-ganesha.conf
사용자 지정 내보내기 블록을 추가하여 구성 파일을 편집합니다. 단일 내보내기를 생성하고 Ceph NFS 내보내기 인터페이스에서 관리합니다.
구문
EXPORT { Export_Id = NUMERICAL_ID; Transports = TCP; Path = PATH_WITHIN_CEPHFS; Pseudo = BINDING; Protocols = 4; Access_Type = PERMISSIONS; Attr_Expiration_Time = 0; Squash = None; FSAL { Name = CEPH; Filesystem = "FILE_SYSTEM_NAME"; User_Id = "USER_NAME"; Secret_Access_Key = "USER_SECRET_KEY"; } }예제
EXPORT { Export_Id = 100; Transports = TCP; Path = /; Pseudo = /ceph/; Protocols = 4; Access_Type = RW; Attr_Expiration_Time = 0; Squash = None; FSAL { Name = CEPH; Filesystem = "filesystem name"; User_Id = "user id"; Secret_Access_Key = "secret key"; } }
클러스터의 새 구성을 적용합니다.
구문
ceph nfs cluster config set CLUSTER_NAME -i PATH_TO_CONFIG_FILE
예제
[ceph: root@host01 nfs]# ceph nfs cluster config set nfs-ganesha -i /var/lib/ceph/nfs/nfs-ganesha.conf
또한 사용자 지정 구성에 대한 서비스를 다시 시작합니다.
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
사용자 지정 구성을 확인합니다.
구문
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -
예제
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 사용자 지정 NFS-Ganesha 구성 재설정 섹션을 참조하십시오.
11.11. Ceph Orchestrator를 사용하여 사용자 정의 NFS-Ganesha 구성 재설정
Ceph Orchestrator를 사용하여 사용자 정의 구성을 기본 구성으로 재설정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
-
mgr/nfs모듈을 사용하여 배포된 NFS-Ganesha. - 사용자 정의 NFS 클러스터 구성이 설정됨
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
NFS-Ganesha 구성을 재설정합니다.
구문
ceph nfs cluster config reset CLUSTER_NAME예제
[ceph: root@host01 /]# ceph nfs cluster config reset nfs-cephfs
검증
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps --daemon_type=DAEMON_NAME예제
[ceph: root@host01 /]# ceph orch ps --daemon_type=nfs
사용자 정의 구성이 삭제되었는지 확인합니다.
구문
/bin/rados -p POOL_NAME -N CLUSTER_NAME get userconf-nfs.CLUSTER_NAME -
예제
[ceph: root@host01 /]# /bin/rados -p nfs-ganesha -N nfsganesha get userconf-nfs.nfsganesha -
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 NFS-Ganesha 클러스터 생성 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 사용자 지정 NFS-Ganesha 구성 설정을 참조하십시오.
11.12. Ceph Orchestrator를 사용하여 NFS-Ganesha 클러스터 삭제
백엔드에서 Ceph Orchestrator를 Cephadm과 함께 사용하여 NFS-Ganesha 클러스터를 삭제할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 호스트가 클러스터에 추가됩니다.
- 모든 manager, monitor 및 OSD 데몬이 배포됩니다.
-
mgr/nfs모듈을 사용하여 생성된 NFS-Ganesha 클러스터입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
클러스터를 삭제합니다.
구문
ceph nfs cluster rm CLUSTER_NAMECLUSTER_NAME 은 임의의 문자열입니다.
예제
[ceph: root@host01 /]# ceph nfs cluster rm nfsganesha NFS Cluster Deleted Successfully
참고delete옵션은 더 이상 사용되지 않으며rm을 사용하여 NFS 클러스터를 삭제해야 합니다.
검증
클러스터 세부 정보를 나열합니다.
예제
[ceph: root@host01 /]# ceph nfs cluster ls
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage File System 가이드의 NFS 프로토콜을 통해 Ceph파일 시스템 네임스페이스 내보내기 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage Operations Guide 의 Ceph Orchestrator 섹션을 사용하여 NFS-Ganesha 클러스터 생성 섹션을 참조하십시오.
11.13. Ceph Orchestrator를 사용하여 NFS-Ganesha 게이트웨이 제거
ceph orch rm 명령을 사용하여 NFS-Ganesha 게이트웨이를 제거할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 노드에 대한 루트 수준 액세스.
- 호스트가 클러스터에 추가됩니다.
- 호스트에 배포된 하나 이상의 NFS-Ganesha 게이트웨이입니다.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
서비스를 나열합니다.
예제
[ceph: root@host01 /]# ceph orch ls
서비스를 제거합니다.
구문
ceph orch rm SERVICE_NAME예제
[ceph: root@host01 /]# ceph orch rm nfs.foo
검증
호스트, 데몬 및 프로세스를 나열합니다.
구문
ceph orch ps
예제
[ceph: root@host01 /]# ceph orch ps
추가 리소스
11.14. Kerberos 통합
Kerberos는 서버에 사용자를 인증하고 신뢰할 수 없는 네트워크 전체에서 사용자를 인증하는 중앙 집중식 인증 서버를 제공하는 컴퓨터 네트워크 보안 프로토콜입니다. Kerberos 인증에서는 서버 및 데이터베이스가 클라이언트 인증에 사용됩니다.
11.14.1. KDC 설정(필요에 따라)
Kerberos는 네트워크의 각 사용자 및 서비스가 주체인 KDC(Key Distribution Center)라는 타사 신뢰할 수 있는 서버로 실행됩니다. KDC는 모든 클라이언트(사용자 주체, 서비스 주체)에 대한 정보를 보유하고 있으므로 보안을 유지해야 합니다. Kerberos 설정에서 KDC는 단일 장애 지점이므로 하나의 마스터 KDC 및 여러 개의 슬레이브 KDC를 사용하는 것이 좋습니다.
사전 요구 사항
/etc/hosts 파일에서 다음 변경 사항이 완료되었는지 확인합니다. 필요한 경우 도메인 이름을 추가합니다.
[root@chost ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.208.97 ceph-node1-installer.ibm.com ceph-node1-installer 10.0.210.243 ceph-node2.ibm.com ceph-node2 10.0.208.63 ceph-node3.ibm.com ceph-node3 10.0.210.222 ceph-node4.ibm.com ceph-node4 10.0.210.235 ceph-node5.ibm.com ceph-node5 10.0.209.87 ceph-node6.ibm.com ceph-node6 10.0.208.89 ceph-node7.ibm.com ceph-node7
설정의 모든 관련 노드(Ceph 클러스터 및 모든 NFS 클라이언트 노드의 모든 노드)에 대해 도메인 이름이 있는지 확인합니다.
프로세스
다음 단계에 따라 KDC를 설치하고 구성합니다. KDC가 이미 설치되어 구성된 경우 이 부분을 건너뜁니다.
KDC를 설정할 시스템에 필요한 RPM이 설치되어 있는지 확인합니다.
[root@host ~]# rpm -qa | grep krb5 krb5-libs-1.20.1-9.el9_2.x86_64 krb5-pkinit-1.20.1-9.el9_2.x86_64 krb5-server-1.20.1-9.el9_2.x86_64 krb5-server-ldap-1.20.1-9.el9_2.x86_64 krb5-devel-1.20.1-9.el9_2.x86_64 krb5-workstation-1.20.1-9.el9_2.x86_64
참고- Kerberos REALM 이름에 따라 도메인 이름을 사용하는 것이 좋습니다. 예를 들어, Cryostat - PUNE.IBM.COM, Admin principal - admin/admin.
- 설치된 구성 파일을 편집하여 새 KDC를 반영합니다. KDC는 IP 주소 또는 DNS 이름으로 제공할 수 있습니다.
krb5.conf파일을 업데이트합니다.참고krb5.conf파일의kdc및admin_serverIP를 사용하여 모든 영역(default_realm및domain_realm)을 업데이트해야 합니다.[root@host ~]# cat /etc/krb5.conf # To opt out of the system crypto-policies configuration of krb5, remove the # symlink at /etc/krb5.conf.d/crypto-policies which will not be recreated. includedir /etc/krb5.conf.d/ [logging] default = [FILE:/var/log/krb5libs.log](file:///var/log/krb5libs.log) kdc = [FILE:/var/log/krb5kdc.log](file:///var/log/krb5kdc.log) admin_server = [FILE:/var/log/kadmind.log](file:///var/log/kadmind.log) [libdefaults] dns_lookup_realm = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true rdns = false pkinit_anchors = [FILE:/etc/pki/tls/certs/ca-bundle.crt](file:///etc/pki/tls/certs/ca-bundle.crt) spake_preauth_groups = edwards25519 dns_canonicalize_hostname = fallback qualify_shortname = "" default_realm = PUNE.IBM.COM default_ccache_name = KEYRING:persistent:%{uid} [realms] PUNE.IBM.COM = { kdc = 10.0.210.222:88 admin_server = 10.0.210.222:749 } [domain_realm] .redhat.com = PUNE.IBM.COM redhat.com = PUNE.IBM.COMkrb5.conf파일을 업데이트합니다.참고kdc.conf파일에서 영역을 업데이트해야 합니다.[root@host ~]# cat /var/kerberos/krb5kdc/kdc.conf [kdcdefaults] kdc_ports = 88 kdc_tcp_ports = 88 spake_preauth_kdc_challenge = edwards25519 [realms] PUNE.IBM.COM = { master_key_type = aes256-cts-hmac-sha384-192 acl_file = /var/kerberos/krb5kdc/kadm5.acl dict_file = /usr/share/dict/words default_principal_flags = +preauth admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab supported_enctypes = aes256-cts-hmac-sha384-192:normal aes128-cts-hmac-sha256-128:normal aes256-cts-hmac-sha1-96:normal aes128-cts-hmac-sha1-96:normal camellia256-cts-cmac:normal camellia128-cts-cmac:normal arcfour-hmac-md5:normal # Supported encryption types for FIPS mode: #supported_enctypes = aes256-cts-hmac-sha384-192:normal aes128-cts-hmac-sha256-128:normal }kdb5_util:을 사용하여 KDC 데이터베이스를 생성합니다.참고DNS또는/etc/hosts를 통해 호스트 이름을 확인할 수 있는지 확인합니다.[root@host ~]# kdb5_util create -s -r [PUNE.IBM.COM](http://pune.ibm.com/) Initializing database '/var/kerberos/krb5kdc/principal' for realm 'PUNE.IBM.COM', master key name 'K/M@PUNE.IBM.COM' You will be prompted for the database Master Password. It is important that you NOT FORGET this password. Enter KDC database master key: Re-enter KDC database master key to verify:
ACL 파일에 관리자를 추가합니다.
[root@host ~]# cat /var/kerberos/krb5kdc/kadm5.acl */admin@PUNE.IBM.COM *
출력은 관리자 인스턴스의 PUNE.IBM.COM 영역에 있는 모든 주체에 모든 관리 권한이 있음을 나타냅니다.
Kerberos 데이터베이스에 관리자를 추가합니다.
[root@host ~]# kadmin.local Authenticating as principal root/admin@PUNE.IBM.COM with password. kadmin.local: addprinc admin/admin@PUNE.IBM.COM No policy specified for admin/admin@PUNE.IBM.COM; defaulting to no policy Enter password for principal "admin/admin@PUNE.IBM.COM": Re-enter password for principal "admin/admin@PUNE.IBM.COM": Principal "admin/admin@PUNE.IBM.COM" created. kadmin.local:
kdc및kadmind:을 시작합니다.# krb5kdc # kadmind
검증
kdc및kadmind가 올바르게 실행되고 있는지 확인합니다.# ps -eaf | grep krb root 27836 1 0 07:35 ? 00:00:00 krb5kdc root 27846 13956 0 07:35 pts/8 00:00:00 grep --color=auto krb # ps -eaf | grep kad root 27841 1 0 07:35 ? 00:00:00 kadmind root 27851 13956 0 07:36 pts/8 00:00:00 grep --color=auto kad
설정이 올바른지 확인합니다.
[root@host ~]# kinit admin/admin Password for admin/admin@PUNE.IBM.COM: [root@ceph-mani-o7fdxp-node4 ~]# klist Ticket cache: KCM:0 Default principal: admin/admin@PUNE.IBM.COM Valid starting Expires Service principal 10/25/23 06:37:08 10/26/23 06:37:01 krbtgt/PUNE.IBM.COM@PUNE.IBM.COM renew until 10/25/23 06:37:08
11.14.2. Kerberos 클라이언트 설정
Kerberos 클라이언트 시스템은 KDC와 동기화할 수 있어야 합니다. NTP를 사용하여 KDC 및 클라이언트를 동기화해야 합니다. 5분 이상의 시간 차이로 인해 Kerberos 인증 오류가 발생하고 클럭 스큐 오류가 발생합니다. 이 단계는 NFS Ganesha 컨테이너가 실행될 호스트인 NFS 클라이언트와 같은 Kerberos 인증에 참여할 모든 시스템의 사전 요구 사항입니다.
프로세스
필요한 RPM 확인
[root@host ~]# rpm -qa | grep krb5 krb5-libs-1.20.1-9.el9_2.x86_64 krb5-pkinit-1.20.1-9.el9_2.x86_64 krb5-workstation-1.20.1-9.el9_2.x86_64
KDC 서버의 것과 유사한
krb5.conf파일을 업데이트합니다.[root@host ~]# cat /etc/krb5.conf # To opt out of the system crypto-policies configuration of krb5, remove the # symlink at /etc/krb5.conf.d/crypto-policies which will not be recreated. includedir /etc/krb5.conf.d/ [logging] default = [FILE:/var/log/krb5libs.log](file:///var/log/krb5libs.log) kdc = [FILE:/var/log/krb5kdc.log](file:///var/log/krb5kdc.log) admin_server = [FILE:/var/log/kadmind.log](file:///var/log/kadmind.log) [libdefaults] dns_lookup_realm = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true rdns = false pkinit_anchors = [FILE:/etc/pki/tls/certs/ca-bundle.crt](file:///etc/pki/tls/certs/ca-bundle.crt) spake_preauth_groups = edwards25519 dns_canonicalize_hostname = fallback qualify_shortname = "" default_realm = PUNE.IBM.COM default_ccache_name = KEYRING:persistent:%{uid} [realms] PUNE.IBM.COM = { kdc = 10.0.210.222:88 admin_server = 10.0.210.222:749 } [domain_realm] .IBM.com = PUNE.IBM.COM IBM.com = PUNE.IBM.COM
검증
클라이언트 설정을 확인합니다.
[root@host ~]# kinit admin/admin Password for admin/admin@PUNE.IBM.COM: [root@ceph-mani-o7fdxp-node5 ~]# klist Ticket cache: KCM:0 Default principal: admin/admin@PUNE.IBM.COM Valid starting Expires Service principal 10/25/23 08:49:12 10/26/23 08:49:08 krbtgt/PUNE.IBM.COM@PUNE.IBM.COM renew until 10/25/23 08:49:12
11.14.3. NFS별 Kerberos 설정
NFS 서버와 클라이언트 모두에 대한 서비스 주체를 생성해야 합니다. 각 키는 키탭 파일에 저장됩니다. 이러한 주체는 GSS_RPCSEC에 필요한 초기 보안 컨텍스트를 설정해야 합니다. 이러한 서비스 주체는 nfs/@REALM과 같은 형식을 갖습니다. /etc/krb5.conf 파일을 작업 시스템에서 Ceph 노드로 복사할 수 있습니다.
프로세스
해당 호스트에 대한 서비스 주체를 생성합니다.
[root@host ~]# kinit admin/admin Password for admin/admin@PUNE.IBM.COM: [root@host ~]# kadmin Authenticating as principal admin/admin@PUNE.IBM.COM with password. Password for admin/admin@PUNE.IBM.COM: kadmin: addprinc -randkey nfs/<hostname>.ibm.com No policy specified for nfs/<hostname>.ibm.com@PUNE.IBM.COM; defaulting to no policy Principal "nfs/<hostname>.ibm.com@PUNE.IBM.COM" created.
키탭 파일에 키를 추가합니다.
참고이 단계에서는 이미 NFS 서버에 있고 kadmin 인터페이스를 사용합니다. 여기에서 키탭 작업은 NFS 서버의 키탭에 반영됩니다.
kadmin: ktadd nfs/<hostname>.ibm.com Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type aes256-cts-hmac-sha384-192 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type aes128-cts-hmac-sha256-128 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type aes256-cts-hmac-sha1-96 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type aes128-cts-hmac-sha1-96 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type camellia256-cts-cmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type camellia128-cts-cmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com with kvno 2, encryption type arcfour-hmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). kadmin:
- NFS Ganesha 컨테이너가 실행 중인 모든 Ceph 노드와 모든 NFS 클라이언트에서 1단계와 2단계를 실행합니다.
11.14.4. NFS Ganesha 컨테이너 설정
다음 단계에 따라 Ceph 환경에서 NFS Ganesha 설정을 구성합니다.
프로세스
기존 NFS Ganesha 컨테이너 구성을 검색합니다.
[ceph: root@host /]# ceph orch ls --service-type nfs --export service_type: nfs service_id: c_ganesha service_name: nfs.c_ganesha placement: hosts: - host1 - host2 - host3 spec: port: 2049
/etc/krb5.conf및 /etc/krb5.keytab파일을 호스트에서 컨테이너로 전달하도록 컨테이너 구성을 수정합니다. 이러한 파일을 런타임 시 NFS Ganesha에서 참조하여 들어오는 서비스 티켓을 검증하고 Ganesha와 NFS 클라이언트(krb5p) 간의 통신을 보호합니다.[root@host ~]# cat nfs.yaml service_type: nfs service_id: c_ganesha service_name: nfs.c_ganesha placement: hosts: - host1 - host2 - host3 spec: port: 2049 extra_container_args: - "-v" - "/etc/krb5.keytab:/etc/krb5.keytab:ro" - "-v" - "/etc/krb5.conf:/etc/krb5.conf:ro"
cephadm 쉘 내에서 수정된 nfs.yaml 파일을 사용할 수 있도록 합니다.
[root@host ~]# cephadm shell --mount nfs.yaml:/var/lib/ceph/nfs.yaml Inferring fsid ff1c1498-73ec-11ee-af38-fa163e9a17fd Inferring config /var/lib/ceph/ff1c1498-73ec-11ee-af38-fa163e9a17fd/mon.ceph-msaini-qp49z7-node1-installer/config Using ceph image with id 'fada497f9c5f' and tag 'ceph-7.0-rhel-9-containers-candidate-73711-20231018030025' created on 2023-10-18 03:03:39 +0000 UTC registry-proxy.engineering.ibm.com/rh-osbs/rhceph@sha256:e66e5dd79d021f3204a183f5dbe4537d0c0e4b466df3b2cc4d50cc79c0f34d75
파일에 필요한 변경 사항이 있는지 확인합니다.
[ceph: root@host /]# cat /var/lib/ceph/nfs.yaml service_type: nfs service_id: c_ganesha service_name: nfs.c_ganesha placement: hosts: - host1 - host2 - host3 spec: port: 2049 extra_container_args: - "-v" - "/etc/krb5.keytab:/etc/krb5.keytab:ro" - "-v" - "/etc/krb5.conf:/etc/krb5.conf:ro"
NFS Ganesha 컨테이너에 필요한 변경 사항을 적용하고 컨테이너를 재배포합니다.
[ceph: root@host /]# ceph orch apply -i /var/lib/ceph/nfs.yaml Scheduled nfs.c_ganesha update... [ceph: root@ceph-msaini-qp49z7-node1-installer /]# ceph orch redeploy nfs.c_ganesha Scheduled to redeploy nfs.c_ganesha.1.0.ceph-msaini-qp49z7-node1-installer.sxzuts on host 'ceph-msaini-qp49z7-node1-installer' Scheduled to redeploy nfs.c_ganesha.2.0.ceph-msaini-qp49z7-node2.psuvki on host 'ceph-msaini-qp49z7-node2' Scheduled to redeploy nfs.c_ganesha.0.0.ceph-msaini-qp49z7-node3.qizzvk on host 'ceph-msaini-qp49z7-node3'
재배포된 서비스에 필요한 변경 사항이 있는지 확인합니다.
[ceph: root@host /]# ceph orch ls --service-type nfs --export service_type: nfs service_id: c_ganesha service_name: nfs.c_ganesha placement: hosts: - ceph-msaini-qp49z7-node1-installer - ceph-msaini-qp49z7-node2 - ceph-msaini-qp49z7-node3 extra_container_args: - -v - /etc/krb5.keytab:/etc/krb5.keytab:ro - -v - /etc/krb5.conf:/etc/krb5.conf:ro spec: port: 2049
krb5* (krb5, krb5i, krb5p)보안 플레이버를 갖도록 내보내기 정의를 수정합니다.참고위의 설정을 완료한 후 이러한 내보내기를 생성할 수 있습니다.
[ceph: root@host /]# ceph nfs export info c_ganesha /exp1 { "access_type": "RW", "clients": [], "cluster_id": "c_ganesha", "export_id": 1, "fsal": { "fs_name": "fs1", "name": "CEPH", "user_id": "nfs.c_ganesha.1" }, "path": "/volumes/_nogroup/exp1/81f9a67e-ddf1-4b5a-9fe0-d87effc7ca16", "protocols": [ 4 ], "pseudo": "/exp1", "sectype": [ "krb5" ], "security_label": true, "squash": "none", "transports": [ "TCP" ] }
11.14.5. NFS 클라이언트 측 작업
다음은 NFS 클라이언트가 수행할 수 있는 몇 가지 작업입니다.
프로세스
서비스 주체를 생성합니다.
kadmin: addprinc -randkey nfs/<hostname>.ibm.com@PUNE.IBM.COM No policy specified for nfs/<hostname>.ibm.com@PUNE.IBM.COM; defaulting to no policy Principal "nfs/<hostname>.ibm.com@PUNE.IBM.COM" created. kadmin: ktadd nfs/<hostname>.ibm.com@PUNE.IBM.COM Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type aes256-cts-hmac-sha384-192 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type aes128-cts-hmac-sha256-128 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type aes256-cts-hmac-sha1-96 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type aes128-cts-hmac-sha1-96 added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type camellia256-cts-cmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type camellia128-cts-cmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab). Entry for principal nfs/<hostname>.ibm.com@PUNE.IBM.COM with kvno 2, encryption type arcfour-hmac added to keytab [FILE:/etc/krb5.keytab](file:///etc/krb5.keytab).
rpc.gssd서비스를 다시 시작하여 수정된 키탭 파일을 적용합니다.# systemctl restart rpc-gssd
NFS 내보내기를 마운트합니다.
구문
[root@host ~]# mount -t nfs -o vers=4.1,port=2049 <IP>:/<export_name> >mount_point>
예제
mount -t nfs -o vers=4.1,port=2049 10.8.128.233:/ganesha /mnt/test/
- 사용자를 생성합니다. NFS 내보내기가 마운트되면 일반 사용자가 마운트된 내보내기에서 작업하는 데 사용됩니다. 이러한 일반 사용자(일반적으로 시스템의 로컬 사용자 또는 LDAP/AD와 같은 중앙 집중식 시스템의 사용자)는 Kerberos 설정의 일부여야 합니다. 설정 유형에 따라 KDC에도 로컬 사용자를 생성해야 합니다.
11.14.6. 설정 검증
다음 단계에 따라 설정을 검증합니다.
프로세스
Kerberos 티켓을 사용하지 않고 일반 사용자로 내보내기에 액세스합니다.
[user@host ~]$ klist klist: Credentials cache 'KCM:1001' not found [user@host ~]$ cd /mnt -bash: cd: /mnt: Permission denied
Kerberos 티켓을 사용하여 일반 사용자로 내보내기에 액세스합니다.
[user@host ~]$ kinit sachin Password for user@PUNE.IBM.COM: [user@host ~]$ klist Ticket cache: KCM:1001 Default principal: user@PUNE.IBM.COM Valid starting Expires Service principal 10/27/23 12:57:21 10/28/23 12:57:17 krbtgt/PUNE.IBM.COM@PUNE.IBM.COM renew until 10/27/23 12:57:21 [user@host ~]$ cd /mnt [user@host mnt]$ klist Ticket cache: KCM:1001 Default principal: user@PUNE.IBM.COM Valid starting Expires Service principal 10/27/23 12:57:21 10/28/23 12:57:17 krbtgt/PUNE.IBM.COM@PUNE.IBM.COM renew until 10/27/23 12:57:21 10/27/23 12:57:28 10/28/23 12:57:17 nfs/ceph-msaini-qp49z7-node1-installer.ibm.com@ renew until 10/27/23 12:57:21 Ticket server: nfs/ceph-msaini-qp49z7-node1-installer.ibm.com@PUNE.IBM.COM
참고: nfs/ 서비스 티켓은 클라이언트에서 확인할 수 있습니다.
12장. SNMP 트랩 구성
스토리지 관리자는 Red Hat Ceph Storage 클러스터에서 간단한 네트워크 관리 프로토콜(SNMP) 게이트웨이를 배포하고 구성하여 Prometheus Alertmanager에서 경고를 수신하고 SNMP 트랩으로 클러스터에 라우팅할 수 있습니다.
12.1. 간단한 네트워크 관리 프로토콜
SNMP(Simple Network Management Protocol)는 다양한 하드웨어 및 소프트웨어 플랫폼에서 분산 시스템 및 장치를 모니터링하기 위해 가장 널리 사용되는 오픈 프로토콜 중 하나입니다. Ceph의 SNMP 통합은 Prometheus Alertmanager 클러스터에서 게이트웨이 데몬으로 경고를 전달하는 데 중점을 둡니다. 게이트웨이 데몬은 경고를 SNMP 알림으로 변환하고 지정된 SNMP 관리 플랫폼으로 보냅니다. 게이트웨이 데몬은 snmp_notifier_project 에서 제공되며, SNMP V2c 및 V3에서 인증 및 암호화를 지원합니다.
Red Hat Ceph Storage SNMP 게이트웨이 서비스는 기본적으로 하나의 게이트웨이 인스턴스를 배포합니다. 배치 정보를 제공하여 이를 늘릴 수 있습니다. 그러나 SNMP 게이트웨이 데몬을 여러 개 활성화하면 SNMP 관리 플랫폼에서 동일한 이벤트에 대해 여러 알림을 수신합니다.
SNMP 트랩은 경고 메시지이며 Prometheus Alertmanager는 이러한 경고를 SNMP 알림기로 전송한 다음 지정된 경고 라벨에서 OID(오브젝트 식별자)를 찾습니다. 각 SNMP 트랩에는 고유한 ID가 있으므로 업데이트된 상태의 추가 트랩을 지정된 SNMP 폴링기로 보낼 수 있습니다. SNMP는 모든 상태 경고가 특정 SNMP 트랩을 생성하도록 Ceph 상태 점검으로 후크합니다.
올바르게 작동하고 장치 상태에 대한 정보를 모니터링하기 위해 SNMP는 여러 구성 요소를 사용합니다. SNMP를 만드는 세 가지 주요 구성 요소가 있습니다.
- SNMP Manager- 관리 스테이션이라고도 하는 SNMP 관리자는 네트워크 모니터링 플랫폼을 실행하는 컴퓨터입니다. SNMP 지원 장치를 폴링하고 해당 장치에서 데이터를 검색하는 작업이 있는 플랫폼입니다. SNMP Manager는 에이전트에서 응답을 수신하고 에이전트의 비동기 이벤트를 승인합니다.
- SNMP 에이전트 - SNMP 에이전트는 관리할 시스템에서 실행되고 시스템의 message database를 포함하는 프로그램입니다. 이는 대역폭 및 디스크 공간과 같은 데이터를 수집하고 집계하여 관리 정보 베이스(MIB)로 보냅니다.
- 관리 정보 기반(MIB) - SNMP 에이전트에 포함된 구성 요소입니다. SNMP 관리자는 이를 데이터베이스로 사용하고 에이전트에게 특정 정보에 대한 액세스를 요청합니다. 이 정보는 네트워크 관리 시스템(NMS)에 필요합니다. NMS는 에이전트를 폴링하여 이러한 파일에서 정보를 가져온 다음 사용자가 볼 수 있는 그래프로 변환하고 표시됩니다. MIB에는 네트워크 장치에 의해 결정된 통계 및 제어 값이 포함되어 있습니다.
- SNMP 장치
다음 SNMP 버전은 게이트웨이 구현에 대해 호환 및 지원됩니다.
- V2c - 인증 없이 커뮤니티 문자열을 사용하며 외부 공격에 취약합니다.
- V3 authNoPriv - 암호화 없이 사용자 이름과 암호 인증을 사용합니다.
- V3 authPriv - SNMP 관리 플랫폼에 대한 암호화를 사용하여 사용자 이름 및 암호 인증을 사용합니다.
SNMP 트랩을 사용하는 경우 SNMP에 내재된 취약점을 최소화하고 권한이 없는 사용자로부터 네트워크를 보호하려면 버전 번호에 대한 올바른 보안 구성이 있는지 확인합니다.
12.2. snmptrapd구성
snmptrapd 데몬에는 snmp-gateway 서비스를 생성할 때 지정해야 하는 auth 설정이 포함되어 있으므로 snmp-gateway (SNMP) 대상을 배포하기 전에 간단한 네트워크 관리 프로토콜(SNMP) 대상을 구성하는 것이 중요합니다.
SNMP 게이트웨이 기능은 Prometheus 스택에서 생성된 경고를 SNMP 관리 플랫폼에 노출하는 수단을 제공합니다. snmptrapd 툴을 기반으로 SNMP 트랩을 대상에 구성할 수 있습니다. 이 도구를 사용하면 하나 이상의 SNMP 트랩 리스너를 설정할 수 있습니다.
다음 매개변수는 구성에 중요합니다.
-
engine-id는 장치의 고유 식별자이며 SNMPV3 게이트웨이에 필요합니다. Red Hat은 이 매개변수에는 '8000C53F_CLUSTER_FSID_WITHOUT_DASHES_'를 사용하는 것이 좋습니다. -
snmp-community. SNMP_COMMUNITY_FOR_SNMPV2 매개변수인 snmp-community는 SNMPV2c 게이트웨이의 경우public입니다. -
AUTH_PROTOCOL 인
auth-protocol은 SNMPV3 게이트웨이의 경우 필수이며 기본적으로SHA입니다. -
PRIVACY_PROTOCOL 인
privacy-protocol은 SNMPV3 게이트웨이의 경우 필수입니다. - PRIVACY_PASSWORD 는 암호화가 있는 SNMPV3 게이트웨이의 경우 필수입니다.
- SNMP_V3_AUTH_USER_NAME 은 사용자 이름이며 SNMPV3 게이트웨이의 경우 필수입니다.
- SNMP_V3_AUTH_PASSWORD 는 암호이며 SNMPV3 게이트웨이의 경우 필수입니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
-
Red Hat Enterprise Linux 시스템에
firewalld를 설치합니다.
프로세스
SNMP 관리 호스트에서 SNMP 패키지를 설치합니다.
예제
[root@host01 ~]# dnf install -y net-snmp-utils net-snmp
SNMP의 포트 162를 열어 경고를 수신합니다.
예제
[root@host01 ~]# firewall-cmd --zone=public --add-port=162/udp [root@host01 ~]# firewall-cmd --zone=public --add-port=162/udp --permanent
SNMP 알림을 이해하고 대상 호스트에서 SNMP 지원을 강화하기 위해 관리 정보 베이스(MIB)를 구현합니다. 기본 리포지토리에서 원시 파일을 복사합니다. https://github.com/ceph/ceph/blob/master/monitoring/snmp/CEPH-MIB.txt
예제
[root@host01 ~]# curl -o CEPH_MIB.txt -L https://raw.githubusercontent.com/ceph/ceph/master/monitoring/snmp/CEPH-MIB.txt [root@host01 ~]# scp CEPH_MIB.txt root@host02:/usr/share/snmp/mibs
snmptrapd디렉토리를 생성합니다.예제
[root@host01 ~]# mkdir /root/snmptrapd/
SNMP 버전을 기반으로 각 프로토콜에 대한
snmptrapd디렉터리에 구성 파일을 생성합니다.구문
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x_ENGINE_ID_ SNMPV3_AUTH_USER_NAME AUTH_PROTOCOL SNMP_V3_AUTH_PASSWORD PRIVACY_PROTOCOL PRIVACY_PASSWORD authuser log,execute SNMP_V3_AUTH_USER_NAME authCommunity log,execute,net SNMP_COMMUNITY_FOR_SNMPV2
SNMPV2c의 경우 다음과 같이
snmptrapd_public.conf파일을 만듭니다.예제
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n authCommunity log,execute,net public
여기에
공용설정은snmp-gateway서비스를 배포할 때 사용되는snmp_community설정과 일치해야 합니다.인증이 있는 SNMPV3의 경우 다음과 같이
snmptrapd_auth.conf파일을 생성합니다.예제
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword authuser log,execute myuser
0x8000C53Ff64f341c655d11eb8778fa163e914bcc문자열은engine_id이고myuser및mypassword는 인증 정보입니다. 암호 보안은SHA알고리즘에 의해 정의됩니다.snmp-gateway데몬 배포 설정에 해당합니다.예제
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword
SNMPV3 인증 및 암호화의 경우 다음과 같이
snmptrapd_authpriv.conf파일을 생성합니다.예제
format2 %V\n% Agent Address: %A \n Agent Hostname: %B \n Date: %H - %J - %K - %L - %M - %Y \n Enterprise OID: %N \n Trap Type: %W \n Trap Sub-Type: %q \n Community/Infosec Context: %P \n Uptime: %T \n Description: %W \n PDU Attribute/Value Pair Array:\n%v \n -------------- \n createuser -e 0x8000C53Ff64f341c655d11eb8778fa163e914bcc myuser SHA mypassword DES mysecret authuser log,execute myuser
0x8000C53Ff64f341c655d11eb8778fa163e914bcc문자열은engine_id이고myuser및mypassword는 인증 정보입니다. 암호 보안은SHA알고리즘에 의해 정의되며DES는 개인 정보 암호화 유형입니다.snmp-gateway데몬 배포 설정에 해당합니다.예제
snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecret
SNMP 관리 호스트에서 데몬을 실행합니다.
구문
/usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/CONFIGURATION_FILE -Of -Lo :162예제
[root@host01 ~]# /usr/sbin/snmptrapd -M /usr/share/snmp/mibs -m CEPH-MIB.txt -f -C -c /root/snmptrapd/snmptrapd_auth.conf -Of -Lo :162
스토리지 클러스터에서 경고가 트리거되면 SNMP 관리 호스트의 출력을 모니터링할 수 있습니다. SNMP 트랩과MIB에 의해 디코딩된 트랩을 확인합니다.
예제
NET-SNMP version 5.8 Agent Address: 0.0.0.0 Agent Hostname: <UNKNOWN> Date: 15 - 5 - 12 - 8 - 10 - 4461391 Enterprise OID: . Trap Type: Cold Start Trap Sub-Type: 0 Community/Infosec Context: TRAP2, SNMP v3, user myuser, context Uptime: 0 Description: Cold Start PDU Attribute/Value Pair Array: .iso.org.dod.internet.mgmt.mib-2.1.3.0 = Timeticks: (292276100) 3 days, 19:52:41.00 .iso.org.dod.internet.snmpV2.snmpModules.1.1.4.1.0 = OID: .iso.org.dod.internet.private.enterprises.ceph.cephCluster.cephNotifications.prometheus.promMgr.promMgrPrometheusInactive .iso.org.dod.internet.private.enterprises.ceph.cephCluster.cephNotifications.prometheus.promMgr.promMgrPrometheusInactive.1 = STRING: "1.3.6.1.4.1.50495.1.2.1.6.2[alertname=CephMgrPrometheusModuleInactive]" .iso.org.dod.internet.private.enterprises.ceph.cephCluster.cephNotifications.prometheus.promMgr.promMgrPrometheusInactive.2 = STRING: "critical" .iso.org.dod.internet.private.enterprises.ceph.cephCluster.cephNotifications.prometheus.promMgr.promMgrPrometheusInactive.3 = STRING: "Status: critical - Alert: CephMgrPrometheusModuleInactive Summary: Ceph's mgr/prometheus module is not available Description: The mgr/prometheus module at 10.70.39.243:9283 is unreachable. This could mean that the module has been disabled or the mgr itself is down. Without the mgr/prometheus module metrics and alerts will no longer function. Open a shell to ceph and use 'ceph -s' to determine whether the mgr is active. If the mgr is not active, restart it, otherwise you can check the mgr/prometheus module is loaded with 'ceph mgr module ls' and if it's not listed as enabled, enable it with 'ceph mgr module enable prometheus'"
위 예제에서는 Prometheus 모듈이 비활성화된 후 경고가 생성됩니다.
추가 리소스
- Red Hat Ceph Storage Operations Guide 의 Deploying the SNMP gateway 섹션을 참조하십시오.
12.3. SNMP 게이트웨이 배포
SNMPV2c 또는 SNMPV3을 사용하여 간단한 네트워크 관리 프로토콜(SNMP) 게이트웨이를 배포할 수 있습니다. SNMP 게이트웨이를 배포하는 방법은 다음 두 가지가 있습니다.
- 자격 증명 파일을 생성합니다.
- 모든 세부 정보를 사용하여 하나의 서비스 구성 yaml 파일을 생성합니다.
다음 매개변수를 사용하여 버전에 따라 SNMP 게이트웨이를 배포할 수 있습니다.
-
service_type은snmp-gateway입니다. -
service_name은 사용자 정의 문자열입니다. -
개수는 스토리지 클러스터에 배포할 SNMP 게이트웨이 수입니다. -
snmp_destination매개변수는 hostname:port 형식이어야 합니다. -
engine-id는 장치의 고유 식별자이며 SNMPV3 게이트웨이에 필요합니다. Red Hat은 이 매개변수에는 '8000C53F_CLUSTER_FSID_WITHOUT_DASHES_'를 사용할 것을 권장합니다. -
snmp_community매개변수는 SNMPV2c 게이트웨이의 경우공용입니다. -
auth-protocol은 SNMPV3 게이트웨이의 경우 필수이며 기본적으로SHA입니다. -
인증 및 암호화를 사용하는 SNMPV3 게이트웨이의 경우
개인 정보 프로토콜이필요합니다. -
포트는 기본적으로
9464입니다. -
시크릿과 암호를 오케스트레이터에 전달하려면
-i FILENAME을 제공해야 합니다.
SNMP 게이트웨이 서비스가 배포되거나 업데이트되면 Prometheus Alertmanager 구성이 자동으로 업데이트되어 추가 처리를 위해 objectidentifier가 있는 경고를 SNMP 게이트웨이 데몬으로 전달합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
-
SNMP 관리 호스트인 대상 호스트에서
snmptrapd구성.
프로세스
Cephadm 쉘에 로그인합니다.
예제
[root@host01 ~]# cephadm shell
SNMP 게이트웨이를 배포해야 하는 호스트의 레이블을 생성합니다.
구문
ceph orch host label add HOSTNAME snmp-gateway예제
[ceph: root@host01 /]# ceph orch host label add host02 snmp-gateway
SNMP 버전을 기반으로 인증 정보 파일 또는 서비스 구성 파일을 생성합니다.
SNMPV2c의 경우 다음과 같이 파일을 생성합니다.
예제
[ceph: root@host01 /]# cat snmp_creds.yml snmp_community: public
또는
예제
[ceph: root@host01 /]# cat snmp-gateway.yml service_type: snmp-gateway service_name: snmp-gateway placement: count: 1 spec: credentials: snmp_community: public port: 9464 snmp_destination: 192.168.122.73:162 snmp_version: V2c인증이 있는 SNMPV3의 경우 다음과 같이 파일을 생성합니다.
예제
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword
또는
예제
[ceph: root@host01 /]# cat snmp-gateway.yml service_type: snmp-gateway service_name: snmp-gateway placement: count: 1 spec: credentials: snmp_v3_auth_password: mypassword snmp_v3_auth_username: myuser engine_id: 8000C53Ff64f341c655d11eb8778fa163e914bcc port: 9464 snmp_destination: 192.168.122.1:162 snmp_version: V3인증 및 암호화가 있는 SNMPV3의 경우 다음과 같이 파일을 생성합니다.
예제
[ceph: root@host01 /]# cat snmp_creds.yml snmp_v3_auth_username: myuser snmp_v3_auth_password: mypassword snmp_v3_priv_password: mysecret
또는
예제
[ceph: root@host01 /]# cat snmp-gateway.yml service_type: snmp-gateway service_name: snmp-gateway placement: count: 1 spec: credentials: snmp_v3_auth_password: mypassword snmp_v3_auth_username: myuser snmp_v3_priv_password: mysecret engine_id: 8000C53Ff64f341c655d11eb8778fa163e914bcc port: 9464 snmp_destination: 192.168.122.1:162 snmp_version: V3
ceph orch명령을 실행합니다.구문
ceph orch apply snmp-gateway --snmp_version=V2c_OR_V3 --destination=SNMP_DESTINATION [--port=PORT_NUMBER]\ [--engine-id=8000C53F_CLUSTER_FSID_WITHOUT_DASHES_] [--auth-protocol=MDS_OR_SHA] [--privacy_protocol=DES_OR_AES] -i FILENAME
또는
구문
ceph orch apply -i FILENAME.ymlSNMPV2c의 경우
snmp_creds파일을 사용하여snmp-version을V2c로 사용하여ceph orch명령을 실행합니다.예제
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V2c --destination=192.168.122.73:162 --port=9464 -i snmp_creds.yml
인증이 있는 SNMPV3의 경우
snmp_creds파일을 사용하는 SNMPV3의 경우snmp-version을V3및engine-id로 사용하여ceph orch명령을 실행합니다.예제
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 -i snmp_creds.yml
인증 및 암호화가 있는 SNMPV3의 경우
snmp_creds파일을 사용하여snmp-version을V3,privacy-protocol,engine-id로 사용하여ceph orch명령을 실행합니다.예제
[ceph: root@host01 /]# ceph orch apply snmp-gateway --snmp-version=V3 --engine-id=8000C53Ff64f341c655d11eb8778fa163e914bcc--destination=192.168.122.73:162 --privacy-protocol=AES -i snmp_creds.yml
또는
snmp-gateway파일을 사용하여 모든 SNMP 버전의 경우 다음 명령을 실행합니다.예제
[ceph: root@host01 /]# ceph orch apply -i snmp-gateway.yml
추가 리소스
- Red Hat Ceph Storage Operations Guide 의 Configuring 'snmptrapd' 섹션을 참조하십시오.
13장. 노드 장애 처리
스토리지 관리자는 스토리지 클러스터 내에서 전체 노드가 실패하고 노드 오류를 처리하는 것은 디스크 오류를 처리하는 것과 유사합니다. 노드에 장애가 발생하면 하나의 디스크에 대해서만 Ceph 복구 배치 그룹(PG) 대신 해당 노드 내의 디스크의 모든 PG를 복구해야 합니다. Ceph는 OSD가 모두 중단되었음을 감지하고 자동 복구라는 복구 프로세스를 자동으로 시작합니다.
노드 장애 시나리오는 세 가지가 있습니다.
- 실패한 노드의 root 및 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
- 운영 체제를 다시 설치하고 실패한 노드에서 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
- 운영 체제를 다시 설치하고 모든 새 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
각 노드 교체 시나리오에 대한 수준 워크플로의 경우 노드 교체를 위한 link:https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/7/html-single/operations_guide/#ops_workflow-for replacing-a-node[Workflow for replacing a node]를 참조하십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 실패한 노드
13.1. 노드를 추가하거나 제거하기 전에 고려 사항
Ceph의 뛰어난 기능 중 하나는 런타임 시 Ceph OSD 노드를 추가하거나 제거하는 기능입니다. 즉, 스토리지 클러스터를 중단하지 않고도 스토리지 클러스터 용량의 크기를 조정하거나 하드웨어를 교체할 수 있습니다.
스토리지 클러스터가 성능이 저하된 상태에서 Ceph 클라이언트에 서비스를 제공할 수 있는 기능도 운영상의 이점을 제공합니다. 예를 들어, 초과 시간이나 주말 작업하지 않고 일반 업무 시간 동안 하드웨어를 추가하거나 제거하거나 교체할 수 있습니다. 그러나 Ceph OSD 노드를 추가 및 제거하면 성능에 큰 영향을 미칠 수 있습니다.
Ceph OSD 노드를 추가하거나 제거하기 전에 스토리지 클러스터 성능에 미치는 영향을 고려하십시오.
- 스토리지 클러스터 용량을 확장하거나 줄이는지 여부에 관계없이 Ceph OSD 노드를 추가하거나 제거하면 스토리지 클러스터 재조정으로 백필이 발생합니다. 이러한 재조정 기간 동안 Ceph는 추가 리소스를 사용하므로 스토리지 클러스터 성능에 영향을 미칠 수 있습니다.
- 프로덕션 Ceph 스토리지 클러스터에서 Ceph OSD 노드에는 특정 유형의 스토리지 전략을 용이하게 하는 특정 하드웨어 구성이 있습니다.
- Ceph OSD 노드는 CRUSH 계층 구조의 일부이므로 노드 추가 또는 제거의 성능에 미치는 영향은 일반적으로 CRUSH 규칙 세트를 사용하는 풀의 성능에 영향을 미칩니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Storage Strategies Guide 를 참조하십시오.
13.2. 노드 교체를 위한 워크플로우
노드 장애 시나리오는 세 가지가 있습니다. 노드를 교체할 때 각 시나리오에 대해 이러한 상위 수준 워크플로를 사용합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 실패한 노드
13.2.1. 실패한 노드의 root 및 Ceph OSD 디스크를 사용하여 노드 교체
실패한 노드의 root 및 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
프로세스
백필을 비활성화합니다.
구문
ceph osd set noout ceph osd set noscrub ceph osd set nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
- 기존 노드에서 디스크를 가져와 새 노드에 노드를 추가합니다.
백필을 활성화합니다.
구문
ceph osd unset noout ceph osd unset noscrub ceph osd unset nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrub
13.2.2. 운영 체제를 다시 설치하고 실패한 노드에서 Ceph OSD 디스크를 사용하여 노드 교체
운영 체제를 다시 설치하고 오류가 발생한 노드의 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
프로세스
백필을 비활성화합니다.
구문
ceph osd set noout ceph osd set noscrub ceph osd set nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
Ceph 구성의 백업을 만듭니다.
구문
cp /etc/ceph/ceph.conf /PATH_TO_BACKUP_LOCATION/ceph.conf예제
[ceph: root@host01 /]# cp /etc/ceph/ceph.conf /some/backup/location/ceph.conf
- 노드를 교체하고 실패한 노드의 Ceph OSD 디스크를 추가합니다.
디스크를 JBOD로 구성합니다.
참고이 작업은 스토리지 관리자가 수행해야 합니다.
운영 체제를 설치합니다. 운영 체제 요구 사항에 대한 자세한 내용은 Red Hat Ceph Storage의 운영 체제 요구 사항을 참조하십시오. 운영 체제 설치에 대한 자세한 내용은 Red Hat Enterprise Linux 제품 설명서를 참조하십시오.
참고이 작업은 시스템 관리자가 수행해야 합니다.
Ceph 구성을 복원합니다.
구문
cp /PATH_TO_BACKUP_LOCATION/ceph.conf /etc/ceph/ceph.conf예제
[ceph: root@host01 /]# cp /some/backup/location/ceph.conf /etc/ceph/ceph.conf
- Ceph Orchestrator 명령을 사용하여 새 노드를 스토리지 클러스터에 추가합니다. Ceph 데몬은 해당 노드에 자동으로 배치됩니다. 자세한 내용은 Ceph OSD 노드 추가를 참조하십시오.
백필을 활성화합니다.
구문
ceph osd unset noout ceph osd unset noscrub ceph osd unset nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrub
13.2.3. 운영 체제를 다시 설치하고 모든 새 Ceph OSD 디스크를 사용하여 노드 교체
운영 체제를 다시 설치하고 모든 새 Ceph OSD 디스크를 사용하여 노드를 교체합니다.
프로세스
백필을 비활성화합니다.
구문
ceph osd set noout ceph osd set noscrub ceph osd set nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
- 스토리지 클러스터에서 실패한 노드의 모든 OSD를 제거합니다. 자세한 내용은 Ceph OSD 노드 제거를 참조하십시오.
Ceph 구성의 백업을 만듭니다.
구문
cp /etc/ceph/ceph.conf /PATH_TO_BACKUP_LOCATION/ceph.conf예제
[ceph: root@host01 /]# cp /etc/ceph/ceph.conf /some/backup/location/ceph.conf
- 노드를 교체하고 실패한 노드의 Ceph OSD 디스크를 추가합니다.
디스크를 JBOD로 구성합니다.
참고이 작업은 스토리지 관리자가 수행해야 합니다.
운영 체제를 설치합니다. 운영 체제 요구 사항에 대한 자세한 내용은 Red Hat Ceph Storage의 운영 체제 요구 사항을 참조하십시오. 운영 체제 설치에 대한 자세한 내용은 Red Hat Enterprise Linux 제품 설명서를 참조하십시오.
참고이 작업은 시스템 관리자가 수행해야 합니다.
- Ceph Orchestrator 명령을 사용하여 새 노드를 스토리지 클러스터에 추가합니다. Ceph 데몬은 해당 노드에 자동으로 배치됩니다. 자세한 내용은 Ceph OSD 노드 추가를 참조하십시오.
백필을 활성화합니다.
구문
ceph osd unset noout ceph osd unset noscrub ceph osd unset nodeep-scrub
예제
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrub
13.3. 성능 고려 사항
다음 요인은 일반적으로 Ceph OSD 노드를 추가하거나 제거할 때 스토리지 클러스터 성능에 영향을 미칩니다.
- Ceph 클라이언트는 I/O 인터페이스에 로드를 Ceph에 배치합니다. 즉, 클라이언트는 풀에 로드를 배치합니다. 풀은 CRUSH 규칙 세트에 매핑됩니다. 기본 CRUSH 계층 구조를 사용하면 Ceph에서 장애 도메인에 데이터를 배치할 수 있습니다. 기본 Ceph OSD 노드에 클라이언트 로드가 높은 풀이 포함된 경우 클라이언트 로드가 복구 시간에 큰 영향을 미치고 성능을 저하시킬 수 있습니다. 쓰기 작업에는 지속성을 위해 데이터 복제가 필요하므로 특히 쓰기 집약적인 클라이언트 로드는 스토리지 클러스터 복구 시간이 증가할 수 있습니다.
- 일반적으로 추가 또는 제거하는 용량은 스토리지 클러스터 복구 시간에 영향을 미칩니다. 또한 추가 또는 삭제하려는 노드의 스토리지 밀도도 복구 시간에 영향을 미칠 수 있습니다. 예를 들어 36 OSD가 있는 노드는 일반적으로 12개의 OSD가 있는 노드보다 복구하는 데 시간이 오래 걸립니다.
-
노드를 제거할 때
전체 비율 또는 전체 비율에도달하지 않도록 충분한 예비 용량이 있는지확인해야합니다. 스토리지 클러스터가전체 비율에도달하면 Ceph는 데이터 손실을 방지하기 위해 쓰기 작업을 일시 중지합니다. - Ceph OSD 노드는 하나 이상의 Ceph CRUSH 계층 구조에 매핑되며 계층 구조는 하나 이상의 풀에 매핑됩니다. CRUSH 규칙 세트를 사용하는 각 풀은 Ceph OSD 노드를 추가하거나 제거할 때 성능에 영향을 미칩니다.
-
복제 풀은 더 많은 네트워크 대역폭을 사용하여 데이터의 깊은 복사본을 복제하는 경향이 있지만 삭제 코딩 풀은 더 많은 CPU를 사용하여
k+m코딩 청크를 계산하는 경향이 있습니다. 데이터의 복사본이 존재할수록 스토리지 클러스터를 복구하는 데 시간이 오래 걸립니다. 예를 들어, 더 큰 풀 또는k+m청크 수가 많은 풀은 동일한 데이터의 복사본이 적은 복제 풀보다 복구하는 데 시간이 더 오래 걸립니다. - 드라이브, 컨트롤러 및 네트워크 인터페이스 카드에는 모두 복구 시간에 영향을 줄 수 있는 처리량 특성이 있습니다. 일반적으로 10Gbps 및 SSD와 같은 처리량이 높은 노드는 처리량이 낮은 노드(예: 1Gbps 및 SATA 드라이브)보다 빠르게 복구됩니다.
13.4. 노드 추가 또는 제거를 위한 권장 사항
Red Hat은 노드 내에서 한 번에 하나의 OSD를 추가하거나 제거하고 다음 OSD로 진행하기 전에 스토리지 클러스터를 복구할 것을 권장합니다. 이를 통해 스토리지 클러스터 성능에 미치는 영향을 최소화할 수 있습니다. 노드가 실패하면 한 번에 하나의 OSD가 아닌 한 번에 전체 노드를 변경해야 할 수 있습니다.
OSD를 제거하려면 다음을 수행합니다.
OSD를 추가하려면 다음을 수행합니다.
Ceph OSD 노드를 추가하거나 제거할 때 다른 진행 중인 프로세스가 스토리지 클러스터 성능에도 영향을 미치는지 고려하십시오. 클라이언트 I/O에 미치는 영향을 줄이기 위해 Red Hat은 다음을 권장합니다.
용량 계산
Ceph OSD 노드를 제거하기 전에 전체 비율에 도달하지 않고 스토리지 클러스터가 모든 OSD의 콘텐츠를 백필할 수 있는지 확인합니다. 전체 비율에 도달하면 스토리지 클러스터가 쓰기 작업을 거부합니다.
임시로 스크럽 비활성화
스크럽은 스토리지 클러스터 데이터의 지속성을 보장하는 데 중요하지만 리소스 집약적입니다. Ceph OSD 노드를 추가하거나 제거하기 전에 스크럽 및 딥스크럽을 비활성화하고 계속하기 전에 현재 스크럽 작업이 완료되도록 합니다.
ceph osd set noscrub ceph osd set nodeep-scrub
Ceph OSD 노드를 추가하거나 제거하고 스토리지 클러스터가 active+clean 상태로 반환되면 noscrub 및 nodeep-scrub 설정을 설정 해제합니다.
ceph osd unset noscrub ceph osd unset nodeep-scrub
백필 및 복구 제한
데이터 지속성이 합리적인 경우 성능이 저하된 상태에서 작동하는 데 문제가 없습니다. 예를 들어 osd_pool_default_size = 3 및 osd_pool_default_min_size = 2 로 스토리지 클러스터를 작동할 수 있습니다. 가능한 빨리 복구 시간을 위해 스토리지 클러스터를 조정할 수 있지만 이렇게 하면 Ceph 클라이언트 I/O 성능에 큰 영향을 미칩니다. 가장 높은 Ceph 클라이언트 I/O 성능을 유지하려면 백필 및 복구 작업을 제한하고 더 오래 걸릴 수 있습니다.
osd_max_backfills = 1 osd_recovery_max_active = 1 osd_recovery_op_priority = 1
sleep 및 delay 매개변수(예: osd_recovery_sleep )를 설정할 수도 있습니다.
배치 그룹 수 증가
마지막으로 스토리지 클러스터 크기를 확장하는 경우 배치 그룹 수를 늘려야 할 수 있습니다. 배치 그룹 수를 확장해야 하는 경우 배치 그룹 수를 늘리는 것이 좋습니다. 배치 그룹 수를 상당한 양만큼 늘리면 성능이 상당히 저하됩니다.
13.5. Ceph OSD 노드 추가
Red Hat Ceph Storage 클러스터의 용량을 확장하려면 OSD 노드를 추가할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 네트워크 연결이 있는 프로비저닝된 노드.
프로세스
- 스토리지 클러스터의 다른 노드가 짧은 호스트 이름으로 새 노드에 연결할 수 있는지 확인합니다.
임시로 스크럽을 비활성화합니다.
예제
[ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
백필 및 복구 기능을 제한합니다.
구문
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]
예제
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1
클러스터의 공개 SSH 키를 폴더에 추출합니다.
구문
ceph cephadm get-pub-key > ~/PATH예제
[ceph: root@host01 /]# ceph cephadm get-pub-key > ~/ceph.pub
ceph 클러스터의 공개 SSH 키를 새 호스트의 root 사용자의
authorized_keys파일에 복사합니다.구문
ssh-copy-id -f -i ~/PATH root@HOST_NAME_2
예제
[ceph: root@host01 /]# ssh-copy-id -f -i ~/ceph.pub root@host02
CRUSH 맵에 새 노드를 추가합니다.
구문
ceph orch host add NODE_NAME IP_ADDRESS
예제
[ceph: root@host01 /]# ceph orch host add host02 10.10.128.70
노드의 각 디스크의 OSD를 스토리지 클러스터에 추가합니다.
Red Hat Ceph Storage 클러스터에 OSD 노드를 추가할 때 한 번에 하나의 OSD 데몬을 추가하고 다음 OSD로 진행하기 전에 클러스터를 active+clean 상태로 복구할 것을 권장합니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 구성 가이드의 런타임 시 특정 구성설정 섹션을 참조하십시오.
- CRUSH 계층 구조의 적절한 위치에 노드를 배치하는 방법에 대한 자세한 내용은 Red Hat Ceph Storage Storage Strategies 가이드 의 버킷 추가 및 버킷 이동 섹션을 참조하십시오.
13.6. Ceph OSD 노드 제거
스토리지 클러스터의 용량을 줄이려면 OSD 노드를 제거합니다.
Ceph OSD 노드를 제거하기 전에 전체 비율에 도달하지 않고 스토리지 클러스터가 모든 OSD의 콘텐츠를 백필할 수 있는지 확인합니다. 전체 비율에 도달하면 스토리지 클러스터가 쓰기 작업을 거부합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
프로세스
스토리지 클러스터의 용량을 확인합니다.
구문
ceph df rados df ceph osd df
임시로 스크럽을 비활성화합니다.
구문
ceph osd set noscrub ceph osd set nodeep-scrub
백필 및 복구 기능을 제한합니다.
구문
ceph tell DAEMON_TYPE.* injectargs --OPTION_NAME VALUE [--OPTION_NAME VALUE]
예제
[ceph: root@host01 /]# ceph tell osd.* injectargs --osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-op-priority 1
스토리지 클러스터에서 노드의 각 OSD를 제거합니다.
Ceph Orchestrator를 사용하여 OSD 데몬 제거.
중요스토리지 클러스터에서 OSD 노드를 제거할 때 Red Hat은 노드 내에서 한 번에 하나의 OSD를 제거하고 다음 OSD를 제거하기 전에 클러스터가
active+clean상태로 복구되도록 하는 것이 좋습니다.OSD를 제거한 후 스토리지 클러스터가
거의 전체 비율에도달하지 않는지 확인합니다.구문
ceph -s ceph df
- 노드의 모든 OSD가 스토리지 클러스터에서 제거될 때까지 이 단계를 반복합니다.
모든 OSD가 제거되면 호스트를 제거하십시오.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 구성 가이드의 런타임 시 특정 구성 설정 섹션을 참조하십시오.
13.7. 노드 오류 시뮬레이션
하드 노드 오류를 시뮬레이션하려면 노드의 전원을 끄고 운영 체제를 다시 설치합니다.
사전 요구 사항
- 정상 실행 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
프로세스
스토리지 클러스터의 용량을 확인하여 노드 제거의 영향을 파악합니다.
예제
[ceph: root@host01 /]# ceph df [ceph: root@host01 /]# rados df [ceph: root@host01 /]# ceph osd df
필요한 경우 복구 및 백필을 비활성화합니다.
예제
[ceph: root@host01 /]# ceph osd set noout [ceph: root@host01 /]# ceph osd set noscrub [ceph: root@host01 /]# ceph osd set nodeep-scrub
- 노드를 종료합니다.
호스트 이름을 변경하는 경우 CRUSH 맵에서 노드를 삭제합니다.
예제
[ceph: root@host01 /]# ceph osd crush rm host03
스토리지 클러스터의 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph -s
- 노드에 운영 체제를 다시 설치합니다.
새 노드를 추가합니다.
필요한 경우 복구 및 백필을 활성화합니다.
예제
[ceph: root@host01 /]# ceph osd unset noout [ceph: root@host01 /]# ceph osd unset noscrub [ceph: root@host01 /]# ceph osd unset nodeep-scrub
Ceph 상태를 확인합니다.
예제
[ceph: root@host01 /]# ceph -s
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드를 참조하십시오.
14장. 데이터 센터 실패 처리
스토리지 관리자는 데이터 센터 실패를 방지하기 위해 예방 조치를 취할 수 있습니다. 이러한 예방 조치에는 다음이 포함됩니다.
- 데이터 센터 인프라 구성.
- CRUSH 맵 계층 구조 내에서 장애 도메인 설정.
- 도메인 내에서 장애 노드 지정.
사전 요구 사항
- 정상 실행 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 루트 수준 액세스.
14.1. 데이터 센터 오류 방지
데이터 센터 인프라 구성
확장 클러스터 내의 각 데이터 센터에는 로컬 기능 및 종속성을 반영하기 위해 다른 스토리지 클러스터 구성이 있을 수 있습니다. 데이터 보존을 위해 데이터 센터 간 복제를 설정합니다. 하나의 데이터 센터가 실패하면 스토리지 클러스터의 다른 데이터 센터에 데이터 사본이 포함됩니다.
CRUSH 맵 계층 구조 내에서 장애 도메인 설정
장애 조치(failover) 또는 장애 조치(failover) 도메인은 스토리지 클러스터 내에서 도메인의 중복 사본입니다. 활성 도메인이 실패하면 실패 도메인이 활성 도메인이 됩니다.
기본적으로 CRUSH 맵은 플랫 계층 구조 내의 스토리지 클러스터의 모든 노드를 나열합니다. 그러나 최상의 결과를 얻으려면 CRUSH 맵에 논리 계층 구조를 생성합니다. 계층 구조는 각 노드가 속한 도메인과 장애 도메인을 포함하여 스토리지 클러스터 내의 해당 도메인 간의 관계를 지정합니다. 계층 내에서 각 도메인의 실패 도메인을 정의하면 스토리지 클러스터의 안정성이 향상됩니다.
여러 데이터 센터가 포함된 스토리지 클러스터를 계획할 때 CRUSH 맵 계층 구조에 노드를 배치하여 한 데이터 센터가 다운되면 나머지 스토리지 클러스터가 가동되고 실행 중이 되도록 합니다.
도메인 내의 장애 노드 지정
스토리지 클러스터 내에서 데이터에 3방향 복제를 사용하려면 실패 도메인 내의 노드의 위치를 고려하십시오. 데이터 센터 내에서 중단이 발생하면 일부 데이터가 하나의 사본에만 존재할 수 있습니다. 이 시나리오가 발생하면 다음 두 가지 옵션이 있습니다.
- 표준 설정으로 데이터를 읽기 전용 상태로 둡니다.
- 중단 기간 동안 하나의 사본만 있습니다.
표준 설정에서 및 노드 전체의 데이터 배치의 무작위성 때문에 모든 데이터에 영향을 미치지는 않지만 일부 데이터에는 하나의 복사만 있을 수 있으며 스토리지 클러스터는 읽기 전용 모드로 되돌아갑니다. 그러나 일부 데이터가 하나의 사본에만 있는 경우 스토리지 클러스터는 읽기 전용 모드로 되돌아갑니다.
14.2. 데이터 센터 실패 처리
Red Hat Ceph Storage는 확장 클러스터의 데이터 센터 중 하나 손실과 같은 인프라에 심각한 오류를 견딜 수 있습니다. 표준 오브젝트 저장소 사용 사례의 경우 세 개의 데이터 센터 모두를 구성하는 작업은 둘 사이의 복제 설정을 사용하여 독립적으로 수행할 수 있습니다. 이 시나리오에서는 각 데이터 센터의 스토리지 클러스터 구성이 로컬 기능 및 종속 항목을 반영하여 다를 수 있습니다.
배치 계층 구조의 논리 구조를 고려해야 합니다. 인프라 내의 장애 도메인의 계층적 구조를 반영하여 적절한 CRUSH 맵을 사용할 수 있습니다. 논리 계층 정의를 사용하면 표준 계층 정의를 사용하는 것보다 스토리지 클러스터의 안정성이 향상됩니다. 실패 도메인은 CRUSH 맵에 정의되어 있습니다. 기본 CRUSH 맵에는 플랫 계층 구조의 모든 노드가 포함되어 있습니다. 확장 클러스터와 같은 3개의 데이터 센터 환경에서 하나의 데이터 센터가 중단될 수 있는 방식으로 노드 배치를 관리해야 하지만 스토리지 클러스터는 계속 가동되고 실행됩니다. 노드에 3방향 복제를 사용할 때 노드에서 상주하는 오류 도메인을 고려하십시오.
아래 예제에서 결과 맵은 6개의 OSD 노드가 있는 스토리지 클러스터의 초기 설정에서 파생됩니다. 이 예에서 모든 노드에는 디스크가 하나만 있고 따라서 하나의 OSD가 있습니다. 모든 노드는 계층 트리의 표준 루트 인 기본 루트 아래에 정렬됩니다. 두 개의 OSD에 가중치가 할당되므로 이러한 OSD는 다른 OSD보다 적은 데이터 청크를 수신합니다. 이러한 노드는 나중에 초기 OSD 디스크보다 큰 디스크에서 도입되었습니다. 이는 노드 그룹 장애를 견딜 수 있도록 데이터 배치에 영향을 미치지 않습니다.
예제
[ceph: root@host01 /]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -1 0.33554 root default -2 0.04779 host host03 0 0.04779 osd.0 up 1.00000 1.00000 -3 0.04779 host host02 1 0.04779 osd.1 up 1.00000 1.00000 -4 0.04779 host host01 2 0.04779 osd.2 up 1.00000 1.00000 -5 0.04779 host host04 3 0.04779 osd.3 up 1.00000 1.00000 -6 0.07219 host host06 4 0.07219 osd.4 up 0.79999 1.00000 -7 0.07219 host host05 5 0.07219 osd.5 up 0.79999 1.00000
논리 계층 정의를 사용하여 노드를 동일한 데이터 센터로 그룹화하면 데이터 배치 성숙도가 달성될 수 있습니다. 가능한 루트 정의 유형,데이터 센터,랙,행 및 호스트 를 사용하면 세 개의 데이터 센터 확장 클러스터에 대한 장애 도메인을 반영할 수 있습니다.
- host01 및 host02 노드는 데이터 센터 1(DC1)에 있습니다.
- host03 및 host05 노드는 데이터 센터 2(DC2)에 있습니다.
- host04 및 host06 노드는 데이터 센터 3 (DC3)에 있습니다.
- 모든 데이터 센터가 동일한 구조(allDC)에 속합니다.
호스트의 모든 OSD는 호스트 정의에 속하므로 변경할 필요가 없습니다. 다음을 통해 스토리지 클러스터 런타임 중에 다른 모든 할당을 조정할 수 있습니다.
다음 명령을 사용하여 버킷 구조를 정의합니다.
ceph osd crush add-bucket allDC root ceph osd crush add-bucket DC1 datacenter ceph osd crush add-bucket DC2 datacenter ceph osd crush add-bucket DC3 datacenter
CRUSH 맵을 수정하여 이 구조 내에서 노드를 적절한 위치로 이동합니다.
ceph osd crush move DC1 root=allDC ceph osd crush move DC2 root=allDC ceph osd crush move DC3 root=allDC ceph osd crush move host01 datacenter=DC1 ceph osd crush move host02 datacenter=DC1 ceph osd crush move host03 datacenter=DC2 ceph osd crush move host05 datacenter=DC2 ceph osd crush move host04 datacenter=DC3 ceph osd crush move host06 datacenter=DC3
이 구조 내에서 새 호스트와 새 디스크도 추가할 수 있습니다. 계층 구조의 올바른 위치에 OSD를 배치하면 CRUSH 알고리즘은 구조 내의 다른 장애 도메인에 중복 조각을 배치하도록 변경됩니다.
위 예제에서는 다음을 생성합니다.
예제
[ceph: root@host01 /]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -8 6.00000 root allDC -9 2.00000 datacenter DC1 -4 1.00000 host host01 2 1.00000 osd.2 up 1.00000 1.00000 -3 1.00000 host host02 1 1.00000 osd.1 up 1.00000 1.00000 -10 2.00000 datacenter DC2 -2 1.00000 host host03 0 1.00000 osd.0 up 1.00000 1.00000 -7 1.00000 host host05 5 1.00000 osd.5 up 0.79999 1.00000 -11 2.00000 datacenter DC3 -6 1.00000 host host06 4 1.00000 osd.4 up 0.79999 1.00000 -5 1.00000 host host04 3 1.00000 osd.3 up 1.00000 1.00000 -1 0 root default
위의 목록에는 osd 트리를 표시하여 결과 CRUSH 맵이 표시됩니다. 쉽게 볼 수 있는 방법은 호스트가 데이터 센터에 속하고 모든 데이터 센터가 동일한 최상위 구조에 속하지만 위치를 명확하게 구분하는 것입니다.
맵에 따라 적절한 위치에 데이터를 배치하는 것은 정상 클러스터 내에서만 제대로 작동합니다. 일부 OSD를 사용할 수 없는 경우 Misplacement가 발생할 수 있습니다. 이러한 오류는 가능한 한 자동으로 수정될 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Storage Strategies Guide의 CRUSH 관리 장을 참조하십시오.