
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
2장. 네트워크 구성 참조
네트워크 구성은 고성능 Red Hat Ceph Storage 클러스터를 구축하는 데 중요합니다. Ceph 스토리지 클러스터는 Ceph 클라이언트를 대신하여 라우팅 또는 디스패치를 수행하지 않습니다. 대신 Ceph 클라이언트는 Ceph OSD 데몬에 직접 요청합니다. Ceph OSD는 Ceph 클라이언트를 대신하여 데이터 복제를 수행합니다. 즉, 복제 및 기타 요인으로 Ceph 스토리지 클러스터 네트워크에 추가 로드가 발생합니다.
모든 Ceph 클러스터에서는 공용 네트워크를 사용해야 합니다. 그러나 클러스터(내부) 네트워크를 지정하지 않으면 Ceph는 단일 공용 네트워크를 가정합니다. Ceph는 공용 네트워크로만 작동할 수 있지만 대규모 클러스터에서는 두 번째 "클러스터" 네트워크를 통해 성능이 크게 향상됩니다.
다음 두 개의 네트워크를 사용하여 Ceph 스토리지 클러스터를 실행하는 것이 좋습니다.
- 공용 네트워크
- 클러스터 네트워크입니다.
두 개의 네트워크를 지원하려면 각 Ceph 노드에 NIC(네트워크 인터페이스 카드)가 두 개 이상 있어야 합니다.
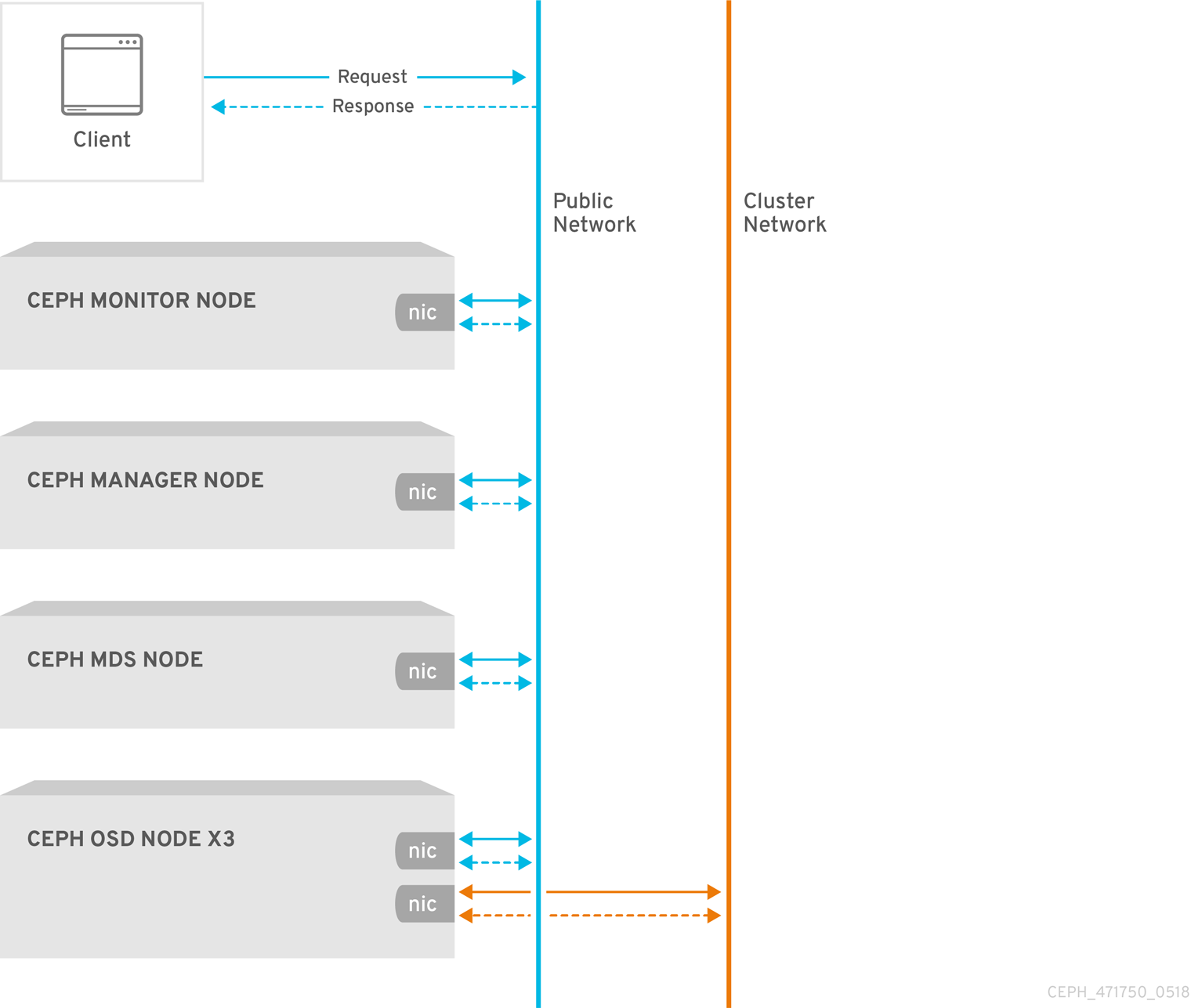
두 개의 별도 네트워크를 운영해야 하는 몇 가지 이유가 있습니다.
- 성능: Ceph OSD는 Ceph 클라이언트의 데이터 복제를 처리합니다. Ceph OSD가 데이터를 두 번 이상 복제하면 Ceph OSD 간 네트워크 로드가 Ceph 클라이언트와 Ceph 스토리지 클러스터 간의 네트워크 로드를 쉽게 분리할 수 있습니다. 이로 인해 대기 시간이 도입되고 성능 문제가 발생할 수 있습니다. 복구 및 재조정으로 공용 네트워크에 상당한 대기 시간이 발생할 수도 있습니다.
-
보안: 대부분의 사람들은 일반적으로 대중이지만 일부 행위자는 서비스 거부 (DoS) 공격으로 알려진 것에 참여할 것입니다. Ceph OSD 간 트래픽이 중단되면 피어링이 실패할 수 있으며 배치 그룹이 더 이상
활성 + 클린상태가 반영되지 않을 수 있으므로 사용자가 데이터를 읽고 쓰는 것을 방지할 수 있습니다. 이러한 유형의 공격을 차단하는 가장 좋은 방법은 인터넷에 직접 연결되지 않는 완전히 분리된 클러스터 네트워크를 유지하는 것입니다.
2.1. 네트워크 설정
네트워크 구성 설정이 필요하지 않습니다. Ceph 데몬을 실행하는 모든 호스트에 공용 네트워크가 구성되어 있다고 가정하면 Ceph에서 공용 네트워크로 작동할 수 있습니다. 그러나 Ceph를 사용하면 공용 네트워크에 대한 여러 IP 네트워크 및 서브넷 마스크를 포함하여 훨씬 더 구체적인 기준을 설정할 수 있습니다. OSD 하트비트, 오브젝트 복제 및 복구 트래픽을 처리하기 위해 별도의 클러스터 네트워크를 설정할 수도 있습니다.
구성에 설정한 IP 주소를 공용 방향 IP 주소 네트워크 클라이언트가 서비스에 액세스하는 데 사용할 수 있는 IP 주소를 혼동하지 마십시오. 일반적인 내부 IP 네트워크는 종종 192.168.0.0 또는 10.0.0.0 입니다.
공용 또는 클러스터 네트워크에 대해 두 개 이상의 IP 주소와 서브넷 마스크를 지정하는 경우 네트워크 내의 서브넷이 서로 라우팅할 수 있어야 합니다. 필요한 경우 IP 테이블에 각 IP 주소/subnet을 포함하고 이를 위해 포트를 열어야 합니다.
Ceph는 서브넷에 대한 CIDR 표기법을 사용합니다(예: 10.0.0.0/24).
네트워크를 구성하면 클러스터를 다시 시작하거나 각 데몬을 다시 시작할 수 있습니다. Ceph 데몬이 동적으로 바인딩되므로 네트워크 구성을 변경하는 경우 전체 클러스터를 즉시 재시작할 필요가 없습니다.
2.1.1. 공용 네트워크
공용 네트워크를 구성하려면 Ceph 구성 파일의 [global] 섹션에 다음 옵션을 추가합니다.
[global]
...
public_network = <public-network/netmask>
공용 네트워크 구성을 사용하면 공용 네트워크의 IP 주소 및 서브넷을 구체적으로 정의할 수 있습니다. 특정 데몬에 대한 공용 설정을 재정의할 수 있습니다.
addr 설정을 사용하여 고정 IP 주소를 할당하거나 공용 네트워크
- public_network
- 설명
-
공용(front-side) 네트워크의 IP 주소 및 넷마스크(예:journal )
입니다.[global]에 설정합니다. 쉼표로 구분된 서브넷을 지정할 수 있습니다. - 유형
-
<ip-address>/<netmask> [, <ip-address>/<netmask>] - 필수 항목
- 없음
- 기본값
- 해당 없음
- public_addr
- 설명
- 공용(전면) 네트워크의 IP 주소입니다. 각 데몬에 대해 설정됩니다.
- 유형
- IP 주소
- 필수 항목
- 없음
- 기본값
- 해당 없음
2.1.2. 클러스터 네트워크
클러스터 네트워크를 선언하면 OSD는 클러스터 네트워크를 통해 하트비트, 오브젝트 복제 및 복구 트래픽을 라우팅합니다. 이는 단일 네트워크를 사용하는 것과 비교하여 성능을 향상시킬 수 있습니다. 클러스터 네트워크를 구성하려면 Ceph 구성 파일의 [global] 섹션에 다음 옵션을 추가합니다.
[global]
...
cluster_network = <cluster-network/netmask>보안을 강화하기 위해 공용 네트워크 또는 인터넷에서 클러스터 네트워크에 연결할 수 없는 것이 좋습니다.
클러스터 네트워크 구성을 사용하면 클러스터 네트워크를 선언하고 클러스터 네트워크의 IP 주소 및 서브넷을 구체적으로 정의할 수 있습니다. 특정 OSD 데몬의 클러스터 애드온 설정을 사용하여 고정 IP 주소를 할당하거나 설정을 덮어쓸 수 있습니다.
클러스터 네트워크
- cluster_network
- 설명
-
클러스터 네트워크의 IP 주소 및 넷마스크(예:
10.0.0.0/24)입니다.[global]에 설정합니다. 쉼표로 구분된 서브넷을 지정할 수 있습니다. - 유형
-
<ip-address>/<netmask> [, <ip-address>/<netmask>] - 필수 항목
- 없음
- 기본값
- 해당 없음
- cluster_addr
- 설명
- 클러스터 네트워크의 IP 주소입니다. 각 데몬에 대해 설정됩니다.
- 유형
- address
- 필수 항목
- 없음
- 기본값
- 해당 없음
2.1.3. MTU 값 확인 및 구성
최대 전송 단위(MTU) 값은 링크 계층에서 전송되는 가장 큰 패킷의 크기(바이트)입니다. 기본 MTU 값은 1500바이트입니다. Red Hat은 Red Hat Ceph Storage 클러스터에서 MTU 값 9000바이트의 점보 프레임을 사용하는 것이 좋습니다.
Red Hat Ceph Storage는 공용 네트워크와 클러스터 네트워크 모두에 대해 통신 경로의 모든 네트워킹 장치에 걸쳐 동일한 MTU 값이 필요합니다. 프로덕션에서 Red Hat Ceph Storage 클러스터를 사용하기 전에 MTU 값이 환경의 모든 노드 및 네트워킹 장비에서 같은지 확인합니다.
본딩 네트워크 인터페이스를 함께 사용하는 경우 MTU 값은 결합된 인터페이스에서만 설정해야 합니다. 새로운 MTU 값은 본딩 장치에서 기본 네트워크 장치로 전파됩니다.
사전 요구 사항
- 노드에 대한 루트 수준 액세스.
절차
현재 MTU 값을 확인합니다.
예제
[root@mon ~]# ip link list 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: enp22s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000이 예에서 네트워크 인터페이스는
enp22s0f0이며 MTU 값은1500입니다.MTU 값을 온라인으로 일시적으로 변경하려면 다음을 수행합니다.
구문
ip link set dev NET_INTERFACE mtu NEW_MTU_VALUE
예제
[root@mon ~]# ip link set dev enp22s0f0 mtu 9000
MTU 값을 영구적으로 변경하려면 다음을 수행합니다.
해당 특정 네트워크 인터페이스에 대한 네트워크 구성 파일을 편집하기 위해 을 엽니다.
구문
vim /etc/sysconfig/network-scripts/ifcfg-NET_INTERFACE예제
[root@mon ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp22s0f0
새 줄에서
MTU=9000옵션을 추가합니다.예제
NAME="enp22s0f0" DEVICE="enp22s0f0" MTU=9000 1 ONBOOT=yes NETBOOT=yes UUID="a8c1f1e5-bd62-48ef-9f29-416a102581b2" IPV6INIT=yes BOOTPROTO=dhcp TYPE=Ethernetnetwork 서비스를 다시 시작하십시오.
예제
[root@mon ~]# systemctl restart network
추가 리소스
- 자세한 내용은 Red Hat Enterprise Linux 7의 네트워킹 가이드 를 참조하십시오.
2.1.4. messaging
Makefile은 Ceph 네트워크 계층 구현입니다. Red Hat은 두 가지 장애 조치 유형을 지원합니다.
-
simple -
async
RHCS 2 및 이전 버전에서 simple 는 기본 래커 유형입니다. RHCS 3에서 async 는 기본 래지어 유형입니다. messenger 유형을 변경하려면 Ceph 구성 파일의 [global] 섹션에 ms_type 구성 설정을 지정합니다.
Red Hat은 비동기 선지의 경우 posix 전송 유형을 지원하지만 현재 rdma 또는 dpdk 를 지원하지 않습니다. 기본적으로 RHCS 3의 ms_type 설정은 async+posix 를 반영해야 합니다. 여기서 async 는 선지자 유형이며 posix 는 전송 유형입니다.
About SimpleMessenger
SimpleMessenger 구현에서는 소켓당 두 개의 스레드가 있는 TCP 소켓을 사용합니다. Ceph는 각 논리 세션을 연결과 연결합니다. 파이프는 각 메시지의 입력 및 출력을 포함하여 연결을 처리합니다. SimpleMessenger 는 posix 전송 유형에 효과적이지만 rdma 또는 dpdk 와 같은 다른 전송 유형에는 효과적이지 않습니다. 결과적으로 AsyncMessenger 는 RHCS 3 이상 릴리스의 기본 래커 유형입니다.
AsyncMessenger 정보
RHCS 3의 경우 AsyncMessenger 구현에서는 연결에 고정된 크기의 스레드 풀과 함께 TCP 소켓을 사용합니다. 이 풀은 가장 많은 복제본 또는 삭제 코드 청크 수와 같아야 합니다. CPU 수가 낮거나 서버당 OSD 수가 많아 성능이 저하되는 경우 스레드 수를 더 낮은 값으로 설정할 수 있습니다.
Red Hat은 현재 rdma 또는 dpdk 와 같은 다른 전송 유형을 지원하지 않습니다.
Makefile 유형 설정
- ms_type
- 설명
-
네트워크 전송 계층의 잘못된 유형. Red Hat은
posix의미를 사용하여간단하고비동기 - 유형
- 문자열.
- 필수 항목
- 아니요.
- 기본값
-
async+posix
- ms_public_type
- 설명
-
공용 네트워크의 네트워크 전송 계층을 위한 선지자 유형입니다.
ms_type과 동일하게 작동하지만 공용 또는 전면 네트워크에만 적용됩니다. 이 설정을 사용하면 Ceph에서 공용 또는 프런트 엔드 및 클러스터 또는 백 측 네트워크에 다른 래커 유형을 사용할 수 있습니다. - 유형
- 문자열.
- 필수 항목
- 아니요.
- 기본값
- 없음.
- ms_cluster_type
- 설명
-
클러스터 네트워크의 네트워크 전송 계층에 대한 잘못된 전송 유형입니다.
ms_type과 동일하게 작동하지만 클러스터 또는 백엔드 네트워크에만 적용됩니다. 이 설정을 사용하면 Ceph에서 공용 또는 프런트 엔드 및 클러스터 또는 백 측 네트워크에 다른 래커 유형을 사용할 수 있습니다. - 유형
- 문자열.
- 필수 항목
- 아니요.
- 기본값
- 없음.
2.1.5. AsyncMessenger 설정
- ms_async_transport_type
- 설명
-
AsyncMessenger에서 사용하는 전송 유형입니다. Red Hat은posix설정을 지원하지만 현재dpdk또는rdma설정은 지원하지 않습니다. POSIX는 표준 TCP/IP 네트워킹을 사용하며 이는 기본값입니다. 다른 전송 유형은 실험적이며 지원되지 않습니다. - 유형
- 문자열
- 필수 항목
- 없음
- 기본값
-
POSIX
- ms_async_op_threads
- 설명
-
각
AsyncMessenger인스턴스에서 사용하는 초기 작업자 스레드 수입니다. 이 구성 설정은 복제본 수 또는 삭제 코드 청크 수와 동일하지만 CPU 코어 수가 낮거나 단일 서버의 OSD 수가 높은 경우 더 낮게 설정할 수 있습니다. - 유형
- 64비트 서명되지 않은 Integer
- 필수 항목
- 없음
- 기본값
-
3
- ms_async_max_op_threads
- 설명
-
각
AsyncMessenger인스턴스에서 사용하는 최대 작업자 스레드 수입니다. OSD 호스트에 CPU 수가 제한된 경우 더 낮은 값으로 설정하고 Ceph가 CPU를 사용하지 않는 경우 증가시킵니다. - 유형
- 64비트 서명되지 않은 Integer
- 필수 항목
- 없음
- 기본값
-
5
- ms_async_set_affinity
- 설명
-
AsyncMessenger작업자를 특정 CPU 코어에 바인딩하려면true로 설정합니다. - 유형
- 부울
- 필수 항목
- 없음
- 기본값
-
true
- ms_async_affinity_cores
- 설명
-
ms_async_set_affinity가true인 경우 이 문자열은AsyncMessenger작업자가 CPU 코어에 바인딩되는 방법을 지정합니다. 예를 들어0,2는 작업자 #1 및 #2를 CPU 코어 #0 및 #2에 각각 바인딩합니다. 참고: 유사성을 수동으로 설정할 때 물리적 CPU 코어보다 느리기 때문에 하이퍼 스레딩 또는 유사한 기술의 효과로 생성된 가상 CPU에 작업자를 할당하지 않도록 해야 합니다. - 유형
- 문자열
- 필수 항목
- 없음
- 기본값
-
(비어 있음)
- ms_async_send_inline
- 설명
-
AsyncMessenger스레드에서 대기 및 전송 대신 해당 스레드를 생성한 스레드에서 직접 메시지를 보냅니다. 이 옵션은 많은 CPU 코어가 있는 시스템의 성능을 줄이는 것으로 알려져 있으므로 기본적으로 비활성화되어 있습니다. - 유형
- 부울
- 필수 항목
- 없음
- 기본값
-
false
2.1.6. 바인딩
바인딩 설정은 Ceph OSD 데몬이 사용하는 기본 포트 범위를 설정합니다. 기본 범위는 6800:7100 입니다. 방화벽 구성이 구성된 포트 범위를 사용할 수 있는지 확인합니다.
Ceph 데몬을 활성화하여 IPv6 주소에 바인딩할 수도 있습니다.
- ms_bind_port_min
- 설명
- OSD 데몬이 바인딩할 최소 포트 번호입니다.
- 유형
- 32비트 정수
- 기본값
-
6800 - 필수 항목
- 없음
- ms_bind_port_max
- 설명
- OSD 데몬이 바인딩할 최대 포트 번호입니다.
- 유형
- 32비트 정수
- 기본값
-
7300 - 필수 항목
- 아니요.
- ms_bind_ipv6
- 설명
- Ceph 데몬이 IPv6 주소에 바인딩되도록 합니다.
- 유형
- 부울
- 기본값
-
false - 필수 항목
- 없음
2.1.7. 호스트
Ceph 구성 파일에 하나 이상의 모니터가 있어야 하며, 각 모니터에는 mon addr 설정이 포함됩니다. Ceph 구성 파일에서 선언된 각 모니터, 메타데이터 서버, OSD 아래에 호스트 설정이 필요합니다.
- mon_addr
- 설명
-
클라이언트가 Ceph 모니터에 연결하는 데 사용할 수 있는 <
hostname>:<port> 항목 목록입니다. 설정하지 않는 경우 Ceph 검색[mon.*]섹션. - 유형
- 문자열
- 필수 항목
- 없음
- 기본값
- 해당 없음
- host
- 설명
-
호스트 이름입니다. 특정 데몬 인스턴스에 대해 이 설정을 사용합니다(예:
[osd.0]). - 유형
- 문자열
- 필수 항목
- 예. 데몬 인스턴스의 경우
- 기본값
-
localhost
localhost 를 사용하지 마십시오. 호스트 이름을 얻으려면 hostname -s 명령을 실행하고 정규화된 도메인 이름이 아닌 첫 번째 기간 동안 호스트 이름을 사용합니다.
사용자를 위한 호스트 이름을 검색하는 타사 배포 시스템을 사용할 때 호스트의 값을 지정하지 마십시오.
2.1.8. TCP
Ceph는 기본적으로 TCP 버퍼링을 비활성화합니다.
- ms_tcp_nodelay
- 설명
-
Ceph는
ms_tcp_nodelay를 활성화하여 각 요청이 즉시 전송됩니다(기고 없음). Nagle의 알고리즘을 비활성화하면 네트워크 트래픽이 증가하여 혼잡을 초래할 수 있습니다. 많은 수의 작은 패킷이 발생하는 경우ms_tcp_nodelay를 비활성화하여 비활성화하면 일반적으로 대기 시간이 증가한다는 점에 유의하십시오. - 유형
- 부울
- 필수 항목
- 없음
- 기본값
-
true
- ms_tcp_rcvbuf
- 설명
- 네트워크 연결 수신 끝에 있는 소켓 버퍼의 크기입니다. 기본적으로 비활성화합니다.
- 유형
- 32비트 정수
- 필수 항목
- 없음
- 기본값
-
0
- ms_tcp_read_timeout
- 설명
-
클라이언트 또는 데몬에서 다른 Ceph 데몬을 요청하고 사용되지 않는 연결을 삭제하지 않는 경우
tcp 읽기 타임아웃은 지정된 수의 초 후에 연결을 유휴 상태로 정의합니다. - 유형
- 서명되지 않은 64비트 정수
- 필수 항목
- 없음
- 기본값
-
90015분.
2.1.9. 방화벽
기본적으로 데몬은 6800:7100 범위 내의 포트에 바인딩됩니다. 이 범위는 재량에 따라 구성할 수 있습니다. 방화벽을 구성하기 전에 기본 방화벽 구성을 확인합니다. 이 범위는 재량에 따라 구성할 수 있습니다.
sudo iptables -L
firewalld 데몬의 경우 root 로 다음 명령을 실행합니다.
# firewall-cmd --list-all-zones
일부 Linux 배포에는 모든 네트워크 인터페이스에서 SSH를 제외한 모든 인바운드 요청을 거부하는 규칙이 포함되어 있습니다. 예를 들어 다음과 같습니다.
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
2.1.9.1. 모니터 방화벽
Ceph 모니터는 기본적으로 포트 6789 에서 수신 대기합니다. 또한 Ceph 모니터는 항상 공용 네트워크에서 작동합니다. 아래 예제를 사용하여 규칙을 추가할 때 < iface >를 공용 네트워크 인터페이스(예: eth0,eth1 등)로 바꾸고 < ip-address >를 공용 네트워크의 IP 주소로, < net mask >를 공용 네트워크의 넷마스크로 바꿉니다.
sudo iptables -A INPUT -i <iface> -p tcp -s <ip-address>/<netmask> --dport 6789 -j ACCEPT
firewalld 데몬의 경우 root 로 다음 명령을 실행합니다.
# firewall-cmd --zone=public --add-port=6789/tcp # firewall-cmd --zone=public --add-port=6789/tcp --permanent
2.1.9.2. OSD 방화벽
기본적으로 Ceph OSD는 포트 6800에서 시작되는 Ceph 노드에서 사용 가능한 첫 번째 포트에 바인딩됩니다. 호스트에서 실행되는 각 OSD마다 포트 6800에서 시작하는 포트 3개를 열어야 합니다.
- 클라이언트 및 모니터(공용 네트워크)에 대해 이야기하는 것입니다.
- 데이터를 다른 OSD(클러스터 네트워크)로 전송하기 위한 것입니다.
- 하트비트 패킷(클러스터 네트워크)을 전송하는 것입니다.
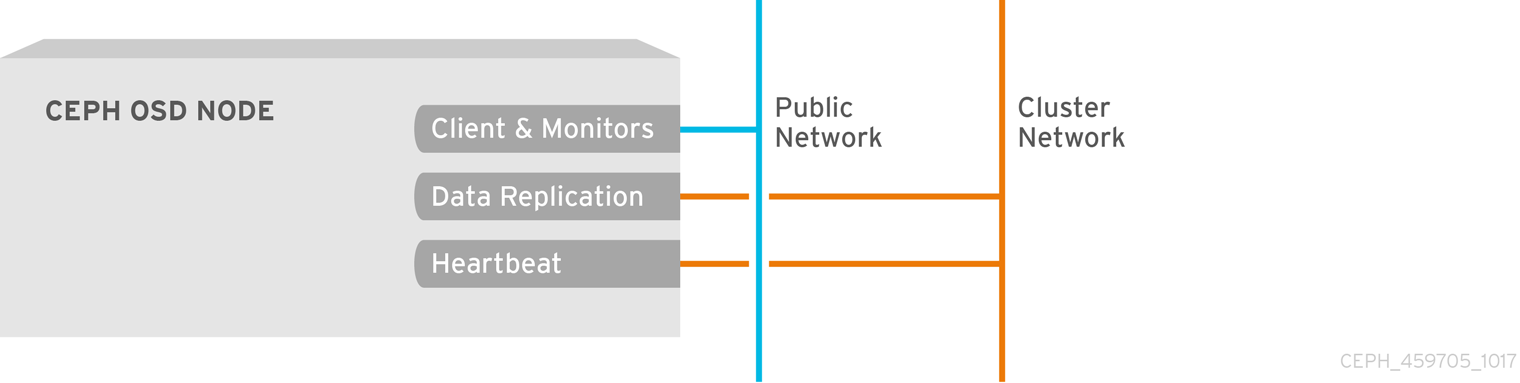
포트는 노드별입니다. 그러나 프로세스가 다시 시작되고 바인딩된 포트가 릴리스되지 않는 경우 Ceph 노드에서 실행되는 Ceph 데몬에 필요한 포트 수보다 많은 포트를 열어야 할 수 있습니다. 다시 시작한 데몬이 새 포트에 바인딩되도록 포트를 해제하지 않고 데몬이 실패하는 경우 몇 가지 추가 포트를 여는 것이 좋습니다. 또한 각 OSD 호스트에서 6800:7300 의 포트 범위를 여는 것이 좋습니다.
별도의 공용 네트워크와 클러스터 네트워크를 설정하는 경우 클라이언트가 공용 네트워크를 사용하여 연결되고 기타 Ceph OSD 데몬이 클러스터 네트워크를 사용하여 연결되므로 공용 네트워크와 클러스터 네트워크에 대한 규칙을 추가해야 합니다.
아래 예제를 사용하여 규칙을 추가할 때 < iface >를 네트워크 인터페이스(예: eth0 또는 eth1), '<ip-address >를 IP 주소로, < netmask >을 공용 또는 클러스터 네트워크의 넷마스크로 바꿉니다. 예를 들어 다음과 같습니다.
sudo iptables -A INPUT -i <iface> -m multiport -p tcp -s <ip-address>/<netmask> --dports 6800:6810 -j ACCEPT
firewalld 데몬의 경우 root 로 다음 명령을 실행합니다.
# firewall-cmd --zone=public --add-port=6800-6810/tcp # firewall-cmd --zone=public --add-port=6800-6810/tcp --permanent
클러스터 네트워크를 다른 영역에 배치하면 해당 영역 내의 포트를 적절하게 엽니다.