
1.4. Kubernetes Operator クラスターのライフサイクルの概要のマルチクラスターエンジン
Kubernetes Operator のマルチクラスターエンジンは、クラスターフリート管理を強化するソフトウェア Operator です。Kubernetes Operator のマルチクラスターエンジンは、クラウドおよびデータセンター全体の Red Hat OpenShift Container Platform および Kubernetes クラスターライフサイクル管理をサポートします。
以下のドキュメントを参照してください。
1.4.1. クラスターライフサイクルのアーキテクチャー
Kubernetes のマルチクラスターエンジンは、ハブクラスター と マネージドクラスター の 2 つの主なタイプのクラスターを使用します。
ハブクラスターは、マルチクラスターエンジンがインストールされたメインクラスターです。ハブクラスターを使用して他の Kubernetes クラスターの作成、管理、および監視を行うことができます。マネージドクラスターは、ハブクラスターが管理する Kubernetes クラスターです。ハブクラスターを使用していくつかのクラスターを作成できますが、ハブクラスターによって管理される既存のクラスターをインポートすることもできます。
Kubernetes Operator を使用してマネージドクラスターを作成する場合は、Hive リソースを含む Red Hat OpenShift Container Platform クラスターインストーラーを使用してクラスターが作成されます。OpenShift Container Platform インストーラーでクラスターのインストールプロセスについての詳細は、OpenShift Container Platform ドキュメントの OpenShift Container Platform インストールの概要 を参照してください。
次の図は、クラスター管理に使用する Kubernetes Operator 用のマルチクラスターエンジンと共にインストールされるコンポーネントを示しています。
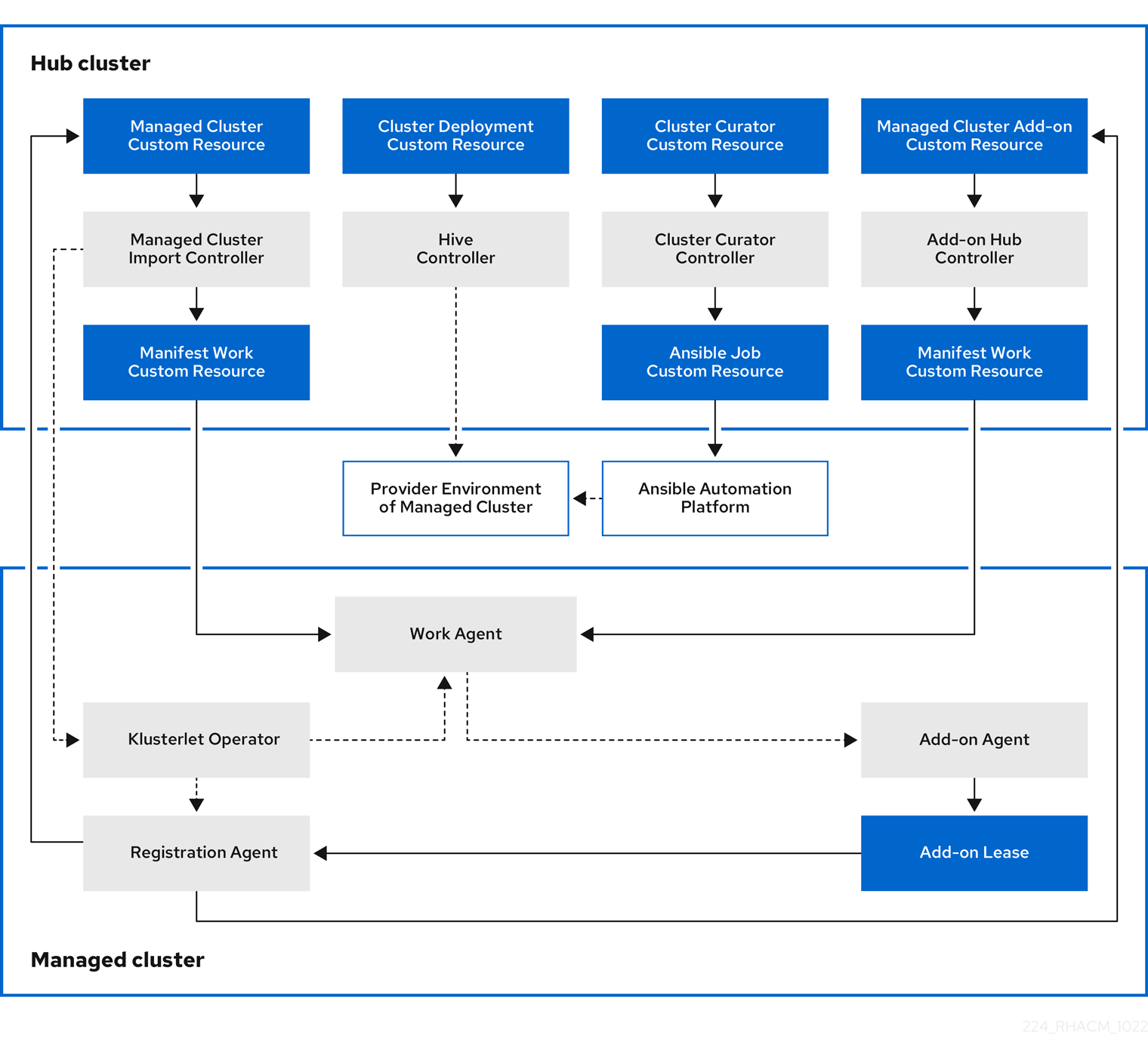
クラスターライフサイクル管理のアーキテクチャーのコンポーネントには、以下の項目が含まれます。
1.4.1.1. ハブクラスター
- マネージドクラスターのインポートコントローラー は、klusterlet Operator をマネージドクラスターにデプロイします。
- Hive コントローラー は、Kubernetes Operator 用のマルチクラスターエンジンを使用して作成したクラスターをプロビジョニングします。また、Hive コントローラーは、Kubernetes Operator 用のマルチクラスターエンジンによって作成されたマネージドクラスターを破棄します。
- クラスターキュレーターコントローラー は、マネージドクラスターの作成またはアップグレード時にクラスターインフラストラクチャー環境を設定するためのプレフックまたはポストフックとして Ansible ジョブを作成します。
- マネージドクラスターアドオンがハブクラスターで有効になると、その アドオンハブコントローラー がハブクラスターにデプロイされます。アドオンハブコントローラー は、アドオンエージェント をマネージドクラスターにデプロイします。
1.4.1.2. マネージドクラスター
- klusterlet Operator マネージドクラスターに登録およびワークコントローラーをデプロイします。
登録エージェント は、マネージドクラスターとマネージドクラスターアドオンをハブクラスターに登録します。登録エージェントは、管理対象クラスターと管理対象クラスターアドオンのステータスも維持します。次のアクセス許可が Clusterrole 内に自動的に作成され、マネージドクラスターがハブクラスターにアクセスできるようになります。
- エージェントは、ハブクラスターが管理する所有クラスターを取得または更新できます。
- エージェントが、ハブクラスターが管理する所有クラスターのステータスを更新できるようにします。
- エージェントが証明書をローテーションできるようにします。
-
エージェントが
coordination.k8s.ioリースをgetまたはupdateできるようにします。 -
エージェントがマネージドクラスターアドオンを
getできるようにします。 - エージェントがマネージドクラスターアドオンのステータスを更新できるようにします。
ワークエージェント マニフェストはマネージドクラスターで機能します。次のアクセス許可が Clusterrole 内に自動的に作成され、マネージドクラスターがハブクラスターにアクセスできるようになります。
- エージェントがハブクラスターにイベントを送信できるようにします。
-
エージェントが
manifestworksリソースをgetまたはupdateできるようにします。 -
エージェントが
manifestworksリソースのステータスを更新できるようにします。
- マネージドクラスターアドオンがハブクラスターのマネージドクラスター namespace に作成されると、そのハブコントローラーはマニフェスト作業を使用してそのエージェントデプロイリソースをマニフェストします。その後、作業エージェントはマニフェスト作業をマネージドクラスターに適用して、アドオンエージェントをデプロイします。
クラスターの追加と管理を続行するには、Kubernetes Operator クラスターライフサイクルのマルチクラスターエンジンの概要 を参照してください。
1.4.2. リリースイメージ
Kubernetes Operator 用のマルチクラスターエンジンを使用してプロバイダー上にクラスターを作成する場合は、新しいクラスターに使用するリリースイメージを指定する必要があります。リリースイメージでは、クラスターのビルドに使用する Red Hat OpenShift Container Platform のバージョンを指定します。
acm-hive-openshift-releases GitHub リポジトリーの YAML ファイルを使用して、リリースイメージを参照します。Red Hat Advanced Cluster Management はこれらのファイルを使用して、コンソールで利用可能なリリースイメージの一覧を作成します。これには、OpenShift Container Platform における最新の fast チャネルイメージが含まれます。コンソールには、OpenShift Container Platform の 3 つの最新バージョンの最新リリースイメージのみが表示されます。たとえば、コンソールオプションに以下のリリースイメージが表示される可能性があります。
- quay.io/openshift-release-dev/ocp-release:4.6.23-x86_64
- quay.io/openshift-release-dev/ocp-release:4.10.1-x86_64
注記: コンソールでクラスターの作成時に選択できるのは、visible: 'true' のラベルが付いたリリースイメージのみです。ClusterImageSet リソースのこのラベルの例は以下の内容で提供されます。
apiVersion: config.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.10.1-x86-64-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.10.1-x86_64
追加のリリースイメージは保管されますが、コンソールには表示されません。利用可能なすべてのリリースイメージを表示するには、CLI で kubectl get clusterimageset を実行します。最新のリリースイメージでクラスターを作成することが推奨されるため、コンソールには最新バージョンのみがあります。特定バージョンのクラスター作成が必要となる場合があります。そのため、古いバージョンが利用可能となっています。Red Hat Advanced Cluster Management はこれらのファイルを使用して、コンソールで利用可能なリリースイメージのリストを作成します。これには、OpenShift Container Platform における最新の fast チャネルイメージが含まれます。
リポジトリーには、clusterImageSets ディレクトリーと subscription ディレクトリーが含まれます。これらのディレクトリーは、リリースイメージの操作時に使用します。
clusterImageSets ディレクトリーには以下のディレクトリーが含まれます。
- Fast: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新バージョンを参照するファイルが含まれます。このフォルダー内のリリースイメージはテストされ、検証されており、サポートされます。
- Releases: 各 OpenShift Container Platform バージョン (stable、fast、および candidate チャネル) のリリースイメージをすべて参照するファイルが含まれます。注記: このリリースはすべてテストされ、安定していると判別されているわけではありません。
- Stable: サポート対象の各 OpenShift Container Platform バージョンのリリースイメージの内、最新の安定版 2 つを参照するファイルが含まれます。
注記: デフォルトでは、リリースイメージの現在のリストは 1 時間ごとに更新されます。製品をアップグレードした後、リストに製品の新しいバージョンの推奨リリースイメージバージョンが反映されるまでに最大 1 時間かかる場合があります。
独自の ClusterImageSets は以下の 3 つの方法でキュレートできます。
3 つの方法のいずれかの最初のステップは、最新の fast チャンネルイメージを自動的に更新する付属のサブスクリプションを無効にすることです。最新の fast の ClusterImageSets の自動キュレーションを無効にするには、multiclusterhub リソースでインストーラーパラメーターを使用します。spec.disableUpdateClusterImageSets パラメーターを true と false の間で切り替えることにより、Red Hat Advanced Cluster Management でインストールしたサブスクリプションが、それぞれ無効または有効になります。独自のイメージをキューレートする場合は、spec.disableUpdateClusterImageSets を true に設定してサブスクリプションを無効にします。
オプション 1: クラスターの作成時にコンソールで使用する特定の ClusterImageSet のイメージ参照を指定します。指定する新規エントリーはそれぞれ保持され、将来のすべてのクラスタープロビジョニングで利用できます。たとえば、エントリーは quay.io/openshift-release-dev/ocp-release:4.6.8-x86_64 のようになります。
オプション 2: GitHub リポジトリー acm-hive-openshift-releases から YAML ファイル ClusterImageSets を手動で作成し、適用します。
オプション 3: GitHub リポジトリー acm-hive-openshift-releases の README.md に従って、フォークした GitHub リポジトリーから ClusterImageSets の自動更新を有効にします。
subscription ディレクトリーには、リリースイメージの一覧がプルされる場所を指定するファイルが含まれます。
Red Hat Advanced Cluster Management のデフォルトのリリースイメージは、Quay.io デフォルトで提供されます。
イメージは、acm-hive-openshift-releases GitHub repository for release 2.5 のファイルで参照されます。
1.4.2.1. 別のアーキテクチャーにクラスターをデプロイするためのリリースイメージの作成
両方のアーキテクチャーのファイルを含むリリースイメージを手動で作成することで、ハブクラスターのアーキテクチャーとは異なるアーキテクチャーでクラスターを作成できます。
たとえば、ppc64le、aarch64、または s390x アーキテクチャーで実行されているハブクラスターから x86_64 クラスターを作成する必要があるとします。両方のファイルセットでリリースイメージを作成する場合に、新規のリリースイメージにより OpenShift Container Platform リリースレジストリーがマルチアーキテクチャーイメージマニフェストを提供できるので、クラスターの作成は成功します。
OpenShift Container Platform 4.11 以降は、デフォルトで複数のアーキテクチャーをサポートします。以下の clusterImageSet を使用してクラスターをプロビジョニングできます。
apiVersion: hive.openshift.io/v1
kind: ClusterImageSet
metadata:
labels:
channel: fast
visible: 'true'
name: img4.12.0-multi-appsub
spec:
releaseImage: quay.io/openshift-release-dev/ocp-release:4.12.0-multi複数のアーキテクチャーをサポートしない OpenShift Container Platform イメージのリリースイメージを作成するには、アーキテクチャータイプについて以下のような手順を実行します。
OpenShift Container Platform リリースレジストリー から、
x86_64、s390x、aarch64、およびppc64leリリースイメージを含む マニフェスト一覧 を作成します。以下のコマンド例を使用して、Quay リポジトリー から環境内の両方のアーキテクチャーのマニフェストリストをプルします。
podman pull quay.io/openshift-release-dev/ocp-release:4.10.1-x86_64 podman pull quay.io/openshift-release-dev/ocp-release:4.10.1-ppc64le podman pull quay.io/openshift-release-dev/ocp-release:4.10.1-s390x podman pull quay.io/openshift-release-dev/ocp-release:4.10.1-aarch64
イメージを管理するプライベートリポジトリーにログインします。
podman login <private-repo>
private-repoは、リポジトリーへのパスに置き換えます。環境に適用される以下のコマンドを実行して、リリースイメージマニフェストをプライベートリポジトリーに追加します。
podman push quay.io/openshift-release-dev/ocp-release:4.10.1-x86_64 <private-repo>/ocp-release:4.10.1-x86_64 podman push quay.io/openshift-release-dev/ocp-release:4.10.1-ppc64le <private-repo>/ocp-release:4.10.1-ppc64le podman push quay.io/openshift-release-dev/ocp-release:4.10.1-s390x <private-repo>/ocp-release:4.10.1-s390x podman push quay.io/openshift-release-dev/ocp-release:4.10.1-aarch64 <private-repo>/ocp-release:4.10.1-aarch64
private-repoは、リポジトリーへのパスに置き換えます。新規情報のマニフェストを作成します。
podman manifest create mymanifest
両方のリリースイメージへの参照をマニフェスト一覧に追加します。
podman manifest add mymanifest <private-repo>/ocp-release:4.10.1-x86_64 podman manifest add mymanifest <private-repo>/ocp-release:4.10.1-ppc64le podman manifest add mymanifest <private-repo>/ocp-release:4.10.1-s390x podman manifest add mymanifest <private-repo>/ocp-release:4.10.1-aarch64
private-repoは、リポジトリーへのパスに置き換えます。マニフェストリストの一覧を既存のマニフェストにマージします。
podman manifest push mymanifest docker://<private-repo>/ocp-release:4.10.1
private-repoは、リポジトリーへのパスに置き換えます。
ハブクラスターで、リポジトリーのマニフェストを参照するリリースイメージを作成します。
以下の例のような情報を含む YAML ファイルを作成します。
apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: labels: channel: fast visible: "true" name: img4.10.1-appsub spec: releaseImage: <private-repo>/ocp-release:4.10.1private-repoは、リポジトリーへのパスに置き換えます。ハブクラスターで以下のコマンドを実行し、変更を適用します。
oc apply -f <file-name>.yaml
file-nameを、先の手順で作成した YAML ファイルの名前に置き換えます。
- OpenShift Container Platform クラスターの作成時に新規リリースイメージを選択します。
- Red Hat Advanced Cluster Management コンソールを使用してマネージドクラスターをデプロイする場合は、クラスター作成のプロセス時に Architecture フィールドにマネージドクラスターのアーキテクチャーを指定します。
作成プロセスでは、マージされたリリースイメージを使用してクラスターを作成します。
1.4.2.2. 非接続時におけるリリースイメージのカスタム一覧の管理
ハブクラスターにインターネット接続がない場合は、リリースイメージのカスタムリストを管理しないといけない場合があります。クラスターの作成時に利用可能なリリースイメージのカスタムリストを作成します。非接続時に、利用可能なリリースイメージを管理するには、以下の手順を実行します。
- オンラインシステムを使用している場合は、GitHub リポジトリー acm-hive-openshift-releases に移動し、バージョン 2.5 で利用可能なクラスターイメージセットにアクセスします。
-
clusterImageSetsディレクトリーを、切断された Kubernetes Operator ハブクラスター用のマルチクラスターエンジンにアクセスできるシステムにコピーします。 管理対象クラスターに適合する次の手順を実行して、管理対象クラスターと切断されたリポジトリーの間にクラスターイメージセットを含むマッピングを追加します。
-
OpenShift Container Platform マネージドクラスターの場合は、
ImageContentSourcePolicyオブジェクトを使用してマッピングを完了する方法についての詳細は、イメージレジストリーリポジトリーのミラーリングの設定 を参照してください。 -
OpenShift Container Platform クラスターではないマネージドクラスターの場合は、
ManageClusterImageRegistryCRD を使用してイメージセットの場所を上書きします。マッピング用にクラスターを上書きする方法については、カスタム ManagedClusterImageRegistry CRD を使用したクラスターのインポート を参照してください。
-
OpenShift Container Platform マネージドクラスターの場合は、
-
clusterImageSetYAML を手作業で追加し、Red Hat Advanced Cluster Management for Kubernetes コンソールを使用してクラスターを作成する時に利用できるようにイメージの YAML ファイルを追加します。 残りの OpenShift Container Platform リリースイメージの
clusterImageSetYAML ファイルを、イメージの保存先の正しいオフラインリポジトリーを参照するように変更します。更新は次の例のようになります。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: img4.4.0-rc.6-x86-64 spec: releaseImage: IMAGE_REGISTRY_IPADDRESS_or_DNSNAME/REPO_PATH/ocp-release:4.4.0-rc.6-x86_64YAML ファイルで参照されているオフラインイメージレジストリーにイメージがロードされていることを確認します。
各 YAML ファイルに以下のコマンドを入力して、各
clusterImageSetsを作成します。oc create -f <clusterImageSet_FILE>
clusterImageSet_FILEを、クラスターイメージセットファイルの名前に置き換えます。以下は例になります。oc create -f img4.11.9-x86_64.yaml
追加するリソースごとにこのコマンドを実行すると、利用可能なリリースイメージの一覧が使用できるようになります。
- または Red Hat Advanced Cluster Management のクラスター作成のコンソールに直接イメージの URL を貼り付けることもできます。イメージ URL が存在しない場合は、イメージ URL を追加すると新しい clusterImageSets が作成されます。
- クラスターの作成時に、Red Hat Advanced Cluster Management コンソールで現在利用可能なリリースイメージの一覧を表示します。
1.4.3. インフラストラクチャー環境の作成
コンソールを使用してインフラストラクチャー環境を作成し、ホストを管理してそのホスト上にクラスターを作成できます。
インフラストラクチャー環境は、次の機能をサポートしています。
- クラスターのゼロタッチプロビジョニング: スクリプトを使用してクラスターをデプロイメントします。詳細は、Red Hat OpenShift Container Platform ドキュメントの 切断された環境での GitOps ZTP のインストール を参照してください。
- 遅延バインディング: 既存のクラスターにノードを追加します。インフラストラクチャー管理者はホストを起動でき、クラスター作成者は後でホストを既存のクラスターにバインドできます。遅延バインディングを使用する場合は、クラスター作成者がインフラストラクチャーにアクセスするのに管理者権限は必要ありません。
-
デュアルスタック: IPv4 と IPv6 の両方のアドレスを持つクラスターをデプロイします。デュアルスタックは、
OVN-Kubernetesネットワーク実装を使用して、複数のサブネットをサポートします。 - リモートワーカーノードの追加: リモートワーカーノードを作成して実行した後、クラスターに追加します。これにより、バックアップ目的で他の場所にノードを追加する柔軟性が提供されます。
- NMState を使用した静的 IP: NMState API を使用して、環境の静的 IP アドレスを定義します。
1.4.3.1. 前提条件
インフラストラクチャー環境を作成する前に、以下の前提条件を確認してください。
- OpenShift Container Platform をハブクラスターにデプロイする必要があります。
- クラスターを作成するために必要なイメージを取得するためのハブクラスターへのインターネットアクセス (接続済み)、あるいはインターネットへの接続がある内部またはミラーレジストリーへの接続 (非接続) がある。
- ハブクラスター上にある設定済みの Central Infrastructure Management (CIM) 機能のインスタンスがある。
- Bare Metal Operator をハブクラスターにインストールする必要がある。
- OpenShift Container Platform プルシークレット がある。詳細は、イメージプルシークレットの使用 を参照してください。
-
デフォルトで
~/.ssh/id_rsa.pubファイルに SSH キーがある。 - 設定済みのストレージクラスがある。
- 切断された環境のみ: OpenShift Container Platform のドキュメントで、ネットワーク遠端のクラスター の手順を完了します。
1.4.3.2. Central Infrastructure Management サービスの有効化
Central Infrastructure Management サービスは、Kubernetes 用のマルチクラスターエンジンで提供され、OpenShift Container Platform クラスターをデプロイします。CIM は、ハブクラスターで MultiClusterHub Operator を有効にするとデプロイされますが、有効にする必要があります。
CIM サービスを有効にするには、以下の手順を実行します。
重要: ハブクラスターが次のプラットフォームのいずれかにインストールされている場合のみ: ベアメタル、Red Hat OpenStack Platform、VMware vSphere、またはユーザープロビジョニングインフラストラクチャー (UPI) 方式を使用してインストールされ、プラットフォームが None の場合のみ、次の手順を実行します。ハブクラスターが他のプラットフォームにある場合は、この手順を省略します。
provisioningリソースを変更し、以下のコマンドを実行してベアメタル Operator がすべての namespace を監視できるようにします。oc patch provisioning provisioning-configuration --type merge -p '{"spec":{"watchAllNamespaces": true }}'非接続環境: では、インフラストラクチャー Operator と 同じ namespace に
ConfigMapを作成し、ミラーレジストリーのca-bundle.crtおよびregistries.confの値を指定します。ファイルのConfigMapは以下の例のようになります。apiVersion: v1 kind: ConfigMap metadata: name: <mirror-config> namespace: "<infrastructure-operator-namespace>" labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- certificate contents -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/multicluster-engine" mirror-by-digest-only = true [[registry.mirror]] location = "mirror.registry.com:5000/multicluster-engine"
1.4.3.2.1. AgentServiceConfig カスタムリソースの作成
以下の手順を実行して AgentServiceConfig カスタムリソースを作成します。
切断された環境のみ: 次の
YAMLコンテンツをagent_service_config.yamlファイルに保存し、必要に応じて値を置き換えます。apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: databaseStorage: accessModes: - ReadWriteOnce resources: requests: storage: <db_volume_size> filesystemStorage: accessModes: - ReadWriteOnce resources: requests: storage: <fs_volume_size> mirrorRegistryRef: name: <mirror_config> unauthenticatedRegistries: - <unauthenticated_registry> imageStorage: accessModes: - ReadWriteOnce resources: requests: storage: <img_volume_size> osImages: - openshiftVersion: "<ocp_version>" version: "<ocp_release_version>" url: "<iso_url>" cpuArchitecture: "x86_64"mirror_configは、ミラーレジストリー設定の詳細が含まれるConfigMapの名前に置き換えます。認証を必要としないミラーレジストリーを使用している場合は、オプションの
unauthenticated_registryパラメーターを含めます。このリストのエントリーは検証されず、プルシークレットにエントリーを含める必要はありません。-
接続環境の場合のみ: 次の
YAMLコンテンツをagent_service_config.yamlファイルに保存します。
apiVersion: agent-install.openshift.io/v1beta1
kind: AgentServiceConfig
metadata:
name: agent
spec:
databaseStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <db_volume_size>
filesystemStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <fs_volume_size>
imageStorage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: <img_volume_size>
+ db_volume_size は databaseStorage フィールドのボリュームサイズに置き換えます (例: 10Gi )。この値は、クラスターのデータベーステーブルやデータベースビューなどのファイルを格納するために割り当てられるストレージの量を指定します。クラスターが多い場合は、より高い値を使用する必要がある場合があります。
+ fs_volume_size は filesystemStorage フィールドのボリュームのサイズに置き換えます (例: クラスターごとに 200M、サポートされる OpenShift Container Platform バージョンごとに 2-3Gi)。必要な最小値は 100Gi です。この値は、クラスターのログ、マニフェスト、および kubeconfig ファイルを保存するために割り当てられるストレージのサイズを指定します。クラスターが多い場合は、より高い値を使用する必要がある場合があります。
+ img_volume_size を imageStorage フィールドのボリュームのサイズに置き換えます (例: オペレーティングシステムイメージごとに 2Gi)。最小サイズは 50Gi です。この値は、クラスターのイメージに割り当てられるストレージの量を指定します。実行中の Red Hat Enterprise Linux CoreOS の各インスタンスに 1 GB のイメージストレージを許可する必要があります。Red Hat Enterprise Linux CoreOS のクラスターおよびインスタンスが多数ある場合は、より高い値を使用する必要がある場合があります。
+ ocp_version は、インストールする OpenShift Container Platform バージョンに置き換えます。
+ ocp_release_version は、特定のインストールバージョン (例: 49.83.2021032516400) に置き換えます。
+ iso_url は、ISO URL に置き換えます (例:https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/rhcos-4.10.3-x86_64-live.x86_64.iso)。他の値は https://mirror.openshift.com/pub/openshift-v4/x86_64/dependencies/rhcos/4.10/4.10.3/ にあります。
次のコマンドを実行して、
AgentServiceConfigカスタムリソースを作成します。oc create -f agent_service_config.yaml
出力は次の例のような内容になります。
agentserviceconfig.agent-install.openshift.io/agent created
CIM サービスが設定されました。assisted-service と assisted-image-service デプロイメントをチェックして、Pod の準備ができ、実行されていることを確認して、正常性を検証できます。
1.4.3.2.2. プロビジョニングカスタムリソース (CR) を手動で作成する
次のコマンドを使用して、プロビジョニング CR を手動で作成し、サービスの自動プロビジョニングを有効にします。
oc create -f provisioning-configuration.yaml
CR は次のサンプルのようになります。
apiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: name: provisioning-configuration spec: provisioningNetwork: Disabled watchAllNamespaces: true
1.4.3.2.3. Amazon Web Services での中央インフラストラクチャー管理の有効化
Amazon Web Services でハブクラスターを実行していて、CIM サービスを有効にする場合は、CIM を有効 にした後に次の追加手順を実行します。
ハブにログインしていることを確認し、次のコマンドを実行して、
assisted-image-serviceで設定された一意のドメインを見つけます。oc get routes --all-namespaces | grep assisted-image-service
ドメインは
assisted-image-service-multicluster-engine.apps.<yourdomain>.comのようになります。ハブにログインしていることを確認し、
NLBtypeパラメーターを使用して一意のドメインで新しいIngressControllerを作成します。以下の例を参照してください。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: ingress-controller-with-nlb namespace: openshift-ingress-operator spec: domain: nlb-apps.<domain>.com routeSelector: matchLabels: router-type: nlb endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB-
nlb-apps.<domain>.comの<domain>を<yourdomain>に置き換えて、IngressControllerのdomainパラメーターに<yourdomain>を追加します。 次のコマンドを使用して、新しい
IngressControllerを適用します。oc apply -f ingresscontroller.yaml
次の手順を実行して、新しい
IngressControllerのspec.domainパラメーターの値が既存の IngressController と競合していないことを確認します。次のコマンドを実行して、すべての
IngressControllerを一覧表示します。oc get ingresscontroller -n openshift-ingress-operator
先ほど作成した
ingress-controller-with-nlbを除く各IngressControllersで次のコマンドを実行します。oc edit ingresscontroller <name> -n openshift-ingress-operator
spec.domainレポートが見つからない場合は、nlb-apps.<domain>.comを除く、クラスターで公開されているすべてのルートに一致するデフォルトドメインを追加します。spec.domainレポートが提供されている場合は、指定された範囲からnlb-apps.<domain>.comルートが除外されていることを確認してください。
次のコマンドを実行して、
assisted-image-serviceルートを編集し、nlb-appsの場所を使用します。oc edit route assisted-image-service -n <namespace>
次の行を
assisted-image-serviceルートに追加します。metadata: labels: router-type: nlb name: assisted-image-serviceassisted-image-serviceルートで、spec.hostの URL 値を見つけます。URL は次の例のようになります。assisted-image-service-multicluster-engine.apps.<yourdomain>.com-
URL 内の
appsをnlb-appsに置き換えて、新しいIngressControllerで設定されたドメインと一致させます。
Amazon Web Services で CIM サービスが有効になっていることを確認するには、次の手順を実行します。
次のコマンドを実行して、Pod が正常であることを確認します。
oc get pods -n multicluster-engine | grep assist
-
新しいインフラストラクチャー環境を作成し、ダウンロード URL が新しい
nlb-appsURL を使用していることを確認します。
1.4.3.3. コンソールを使用したインフラストラクチャー環境の作成
コンソールからインフラストラクチャー環境を作成するには、次の手順を実行します。
- ナビゲーションメニューから、Infrastructure > Host inventory に移動し、Create infrastructure environment をクリックします。
お使いのインフラストラクチャー環境設定に以下の情報を追加します。
- 名前: インフラストラクチャー環境の一意の名前。
- ネットワークの種類: インフラストラクチャー環境に追加できるホストの種類を指定します。ベアメタルホストを使用している場合には、静的 IP オプションのみを使用できます。
- Location: ホストの地理的な場所を指定します。地理的な場所を使用すると、クラスターの作成時に、クラスター上のデータの保存場所を簡単に判断できます。
- Labels: インフラストラクチャー環境にラベルを追加できる任意のフィールド。これにより、検索がかんたんになり、特徴がよく似た他の環境とグループ化できます。ネットワークタイプと場所に対して行った選択は、自動的にラベルのリストに追加されます。
- プルシークレット: OpenShift Container Platform リソースへのアクセスを可能にする OpenShift Container Platform プルシークレット。
-
SSH 公開鍵: ホストとのセキュアな通信を可能にする SSH キー。これは通常
~/.ssh/id_rsa.pubファイルにあります。 すべてのクラスターでプロキシー設定を有効にする必要がある場合は、有効にする設定を選択します。この設定は、以下の情報を入力する必要があります。
- HTTP Proxy URL: 検出サービスへのアクセス時に使用する必要のある URL。
-
HTTPS Proxy URL: 検出サービスへのアクセス時に使用する必要のあるセキュアなプロキシー URL。
httpsはまだサポートされていないため、形式はhttpである必要があります。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。
ホストをインフラストラクチャー環境に追加して、続行できるようになりました。
インフラストラクチャー環境にアクセスするには、コンソールで Infrastructure > Host inventory を選択します。一覧からインフラストラクチャー環境を選択し、そのインフラストラクチャー環境の詳細とホストを表示します。
1.4.4. クラスターの作成
Kubernetes Operator 用のマルチクラスターエンジンを使用して、複数のクラウドプロバイダー間で Red Hat OpenShift Container Platform クラスターを作成する方法を学びます。
Kubernetes Operator 用のマルチクラスターエンジンは、OpenShift Container Platform で提供される Hive Operator を使用して、オンプレミスクラスターおよびホスティングされたコントロールプレーンを除くすべてのプロバイダーのクラスターをプロビジョニングします。オンプレミスクラスターをプロビジョニングする場合、Kubernetes Operator 用のマルチクラスターエンジンは、OpenShift Container Platform で提供される Central Infrastructure Management (CIM) および Assisted Installer 機能を使用します。ホステッドコントロールプレーンのホステッドクラスターは、HyperShift Operator を使用してプロビジョニングされます。
1.4.4.1. CLI を使用したクラスターの作成
Kubernetes のマルチクラスターエンジンは、内部 Hive コンポーネントを使用して Red Hat OpenShift Container Platform クラスターを作成します。クラスターの作成方法については、以下の情報を参照してください。
1.4.4.1.1. 前提条件
クラスターを作成する前に、clusterImageSets リポジトリーのクローンを作成し、ハブクラスターに適用する必要があります。以下の手順を参照してください。
次のコマンドを実行してクローンを作成します。
git clone https://github.com/stolostron/acm-hive-openshift-releases.git cd acm-hive-openshift-releases git checkout origin/release-2.6
次のコマンドを実行して、ハブクラスターに適用します。
find clusterImageSets/fast -type d -exec oc apply -f {} \; 2> /dev/null
クラスターを作成するときに、Red Hat OpenShift Container Platform リリースイメージを選択します。
1.4.4.1.2. ClusterDeployment を使用してクラスターを作成する
ClusterDeployment は、Hive カスタムリソースです。個々のクラスターを作成する方法については、次のドキュメントを参照してください。
Using Hive のドキュメントに従って、ClusterDeployment カスタムリソースを作成します。
1.4.4.1.3. ClusterPool を使用してクラスターを作成
ClusterPool は、複数のクラスターを作成するために使用される Hive カスタムリソースでもあります。ClusterPool API を使用してクラスターを作成します。
Cluster Pools のドキュメントに従って、クラスターをプロビジョニングします。
1.4.4.2. クラスター作成時の追加のマニフェストの設定
追加の Kubernetes リソースマニフェストは、クラスター作成のインストールプロセス中に設定できます。これは、ネットワークの設定やロードバランサーの設定など、シナリオの追加マニフェストを設定する必要がある場合に役立ちます。
クラスターを作成する前に、追加のリソースマニフェストが含まれる ConfigMap を指定する ClusterDeployment リソースへの参照を追加する必要があります。
注記: ClusterDeployment リソースと ConfigMap は同じ namespace にある必要があります。以下の例で、どのような内容かを紹介しています。
リソースマニフェストを含む ConfigMap
ConfigMapリソースが別のマニフェストが含まれるConfigMap。リソースマニフェストのConfigMapには、data.<resource_name>\.yamlパターンに追加されたリソース設定が指定されたキーを複数含めることができます。kind: ConfigMap apiVersion: v1 metadata: name: <my-baremetal-cluster-install-manifests> namespace: <mynamespace> data: 99_metal3-config.yaml: | kind: ConfigMap apiVersion: v1 metadata: name: metal3-config namespace: openshift-machine-api data: http_port: "6180" provisioning_interface: "enp1s0" provisioning_ip: "172.00.0.3/24" dhcp_range: "172.00.0.10,172.00.0.100" deploy_kernel_url: "http://172.00.0.3:6180/images/ironic-python-agent.kernel" deploy_ramdisk_url: "http://172.00.0.3:6180/images/ironic-python-agent.initramfs" ironic_endpoint: "http://172.00.0.3:6385/v1/" ironic_inspector_endpoint: "http://172.00.0.3:5150/v1/" cache_url: "http://192.168.111.1/images" rhcos_image_url: "https://releases-art-rhcos.svc.ci.openshift.org/art/storage/releases/rhcos-4.3/43.81.201911192044.0/x86_64/rhcos-43.81.201911192044.0-openstack.x86_64.qcow2.gz"リソースマニフェスト
ConfigMapが参照される ClusterDeploymentリソースマニフェスト
ConfigMapはspec.provisioning.manifestsConfigMapRefで参照されます。apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <my-baremetal-cluster> namespace: <mynamespace> annotations: hive.openshift.io/try-install-once: "true" spec: baseDomain: test.example.com clusterName: <my-baremetal-cluster> controlPlaneConfig: servingCertificates: {} platform: baremetal: libvirtSSHPrivateKeySecretRef: name: provisioning-host-ssh-private-key provisioning: installConfigSecretRef: name: <my-baremetal-cluster-install-config> sshPrivateKeySecretRef: name: <my-baremetal-hosts-ssh-private-key> manifestsConfigMapRef: name: <my-baremetal-cluster-install-manifests> imageSetRef: name: <my-clusterimageset> sshKnownHosts: - "10.1.8.90 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXvVVVKUYVkuyvkuygkuyTCYTytfkufTYAAAAIbmlzdHAyNTYAAABBBKWjJRzeUVuZs4yxSy4eu45xiANFIIbwE3e1aPzGD58x/NX7Yf+S8eFKq4RrsfSaK2hVJyJjvVIhUsU9z2sBJP8=" pullSecretRef: name: <my-baremetal-cluster-pull-secret>
1.4.4.3. Amazon Web Services でのクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンを使用して、Amazon Web Services (AWS) に Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの AWS へのインストール でプロセスの詳細を確認してください。
1.4.4.3.1. 前提条件
AWS でクラスターを作成する前に、以下の前提条件を確認してください。
- Kubernetes Operator ハブクラスター用にデプロイされたマルチクラスターエンジンがある。
- Amazon Web Services で Kubernetes クラスターを作成できるように、Kubernetes Operator ハブクラスター用のマルチクラスターエンジンにインターネットアクセスが必要です。
- AWS 認証情報がある。詳細は、Amazon Web Services の認証情報の作成 を参照してください。
- AWS で設定されたドメインがある。ドメインの設定方法は、AWS アカウントの設定 を参照してください。
- ユーザー名、パスワード、アクセスキー ID およびシークレットアクセスキーなど、Amazon Web Services (AWS) のログイン認証情報がある。Understanding and Getting Your Security Credentials を参照してください。
- OpenShift Container Platform イメージのプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注意: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、Kubernetes Operator 用のマルチクラスターエンジンのコンソールで、クラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.4.4.3.2. コンソールを使用したクラスターの作成
コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は、Amazon Web Services の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.3.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
AWS アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。この名前はクラスターのホスト名で使用されます。詳細は、AWS アカウントの設定 を参照してください。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
- アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- ゾーン: コントロールプレーンプールを実行する場所を指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: コントロールプレーンノードのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ルートストレージ: クラスターに割り当てるルートストレージの量を指定します。
ワーカープールにワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。オプションの情報には以下のフィールドが含まれます。
- ゾーン: ワーカープールを実行する場所を指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: ワーカープールのインスタンスタイプを指定します。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
- ノード数: ワーカープールのノード数を指定します。ワーカープールを定義する場合にこの設定は必須です。
- ルートストレージ: ワーカープールに割り当てるルートストレージの量を指定します。ワーカープールを定義する場合にこの設定は必須です。
クラスターにはネットワークの詳細が必要であり、IPv6 を使用するには複数のネットワークが必要です。Add network をクリックして、追加のネットワークを追加できます。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツを指定します。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに install-config.yaml ファイルの内容を表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.4. Microsoft Azure でのクラスターの作成
Kubernetes Operator コンソール用のマルチクラスターエンジンを使用して、Red Hat OpenShift Container Platform クラスターを Microsoft Azure または Microsoft Azure Government にデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの Azure へのインストール でプロセスの詳細を確認してください。
1.4.4.4.1. 前提条件
Azure でクラスターを作成する前に、以下の前提条件を確認してください。
- Kubernetes Operator ハブクラスター用にデプロイされたマルチクラスターエンジンがある。
- Azure または Azure Government で Kubernetes クラスターを作成できるように、Kubernetes Operator ハブクラスター用のマルチクラスターエンジンにインターネットアクセスが必要です。
- Azure 認証情報がある。詳細は、Microsoft Azure の認証情報の作成 を参照してください。
- Azure または Azure Government に設定済みドメインがある。ドメイン設定の方法は、Configuring a custom domain name for an Azure cloud service を参照してください。
- ユーザー名とパスワードなどの Azure ログイン認証情報がある。Microsoft Azure Portal を参照してください。
-
clientId、clientSecretおよびtenantIdなどの Azure サービスプリンシパルがある。azure.microsoft.com を参照してください。 - OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注意: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、Kubernetes Operator 用のマルチクラスターエンジンのコンソールで、クラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.4.4.4.2. コンソールを使用したクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は、詳細について Microsoft Azure の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.4.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
Azure アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Configuring a custom domain name for an Azure cloud service を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。この情報には、次のオプションフィールドが含まれます。
- リージョン: ノードプールを実行するリージョンを指定します。より分散されているコントロールプレーンノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- コントロールプレーンプールのインスタンスタイプおよびルートストレージの割り当て (必須)。インスタンスの作成後にインスタンスのタイプやサイズを変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- ゾーン: ワーカープールを実行することを指定します。より分散されているノードグループでは、リージョンで複数のゾーンを選択できます。ゾーンが近くにある場合はパフォーマンスの速度が向上しますが、ゾーンの距離が離れると、より分散されます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスとバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツ。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.5. Google Cloud Platform でのクラスターの作成
Google Cloud Platform (GCP) で Red Hat OpenShift Container Platform クラスターを作成する手順に従います。GCP の詳細については、Google Cloud Platform を参照してください。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの GCP のインストール でプロセスの詳細を確認してください。
1.4.4.5.1. 前提条件
GCP でクラスターを作成する前に、次の前提条件を確認してください。
- Kubernetes Operator ハブクラスター用にデプロイされたマルチクラスターエンジンがある。
- Kubernetes Operator ハブクラスター用のマルチクラスターエンジンが GCP 上に Kubernetes クラスターを作成できるようにするには、インターネットアクセスが必要です。
- GCP 認証情報がある。詳細は、Google Cloud Platform の認証情報の作成 を参照してください。
- GCP に設定済みのドメインがある。ドメインの設定方法は、Setting up a custom domain を参照してください。
- ユーザー名とパスワードを含む GCP ログイン認証情報がある。
- OpenShift Container Platform イメージのプルシークレットがある。イメージプルシークレットの使用 を参照してください。
注意: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、Kubernetes Operator 用のマルチクラスターエンジンのコンソールで、クラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.4.4.5.2. コンソールを使用したクラスターの作成
Kubernetes Operator コンソール用のマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は、Google Cloud Platform の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。GCP クラスターの命名に適用される制限がいくつかあります。この制限には、名前を goog で開始しないことや、名前に google に類似する文字および数字のグループが含まれないことなどがあります。制限の完全な一覧は、Bucket naming guidelines を参照してください。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.5.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
選択した GCP アカウントの認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Setting up a custom domain を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
- リージョン: コントロールプレーンプールを実行するリージョンを指定します。リージョンが近くにある場合はパフォーマンスの速度が向上しますが、リージョンの距離が離れると、より分散されます。
- アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
- ノード数: ワーカープールを定義するときに必要な設定です。
ネットワークの詳細が必要であり、IPv6 アドレスを使用するには複数のネットワークが必要です。Add network をクリックして、追加のネットワークを追加できます。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスとバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツ。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに install-config.yaml ファイルの内容を表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.6. VMware vSphere でのクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンを使用して、Red Hat OpenShift Container Platform クラスターを VMware vSphere にデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの vSphere のインストール でプロセスの詳細を確認してください。
1.4.4.6.1. 前提条件
vSphere でクラスターを作成する前に、次の前提条件を確認してください。
- OpenShift Container Platform バージョン 4.6 以降にデプロイされたハブクラスターが必要です。
- ハブクラスターが vSphere に Kubernetes クラスターを作成できるようにするには、ハブクラスターにインターネットアクセスが必要です。
- vSphere 認証情報がある。詳細は、VMware vSphere の認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
デプロイする VMware インスタンスについて、以下の情報がある。
- API および Ingress インスタンスに必要な静的 IP アドレス
以下の DNS レコード。
-
静的 API VIP を指す
api.<cluster_name>.<base_domain> -
Ingress VIP の静的 IP アドレスを指す
*.apps.<cluster_name>.<base_domain>
-
静的 API VIP を指す
注記: VMware vSphere または Red Hat OpenStack Platform プロバイダーと切断されたインストールを使用してクラスターを作成する場合、ミラーレジストリーにアクセスするために証明書が必要であれば、切断されたインストールの設定セクション で認証情報の Additional trust bundle フィールドに証明書を入力する必要があります。クラスター作成コンソールエディターで入力することはできません。
1.4.4.6.2. コンソールを使用したクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は、認証情報の作成の詳細について、VMware vSphere の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.6.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
vSphere アカウントで設定した、選択した認証情報に関連付けられているベースドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は Installing a cluster on vSphere with customizations を参照してください。値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細については、リリースイメージ を参照してください。
注記: OpenShift Container Platform バージョン 4.5.x 以降のリリースイメージのみがサポートされます。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。この情報には、Architecture フィールドが含まれます。次のフィールドの説明を表示します。
- アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。この情報には、ソケットあたりのコア数、CPU、Memory_min MB、GiB 単位の _Disk サイズ、および ノード数 が含まれます。
ネットワーク情報が必要です。IPv6 を使用するには、複数のネットワークが必要です。必要なネットワーク情報の一部は、次のフィールドに含まれています。
- vSphere ネットワーク名: VMware vSphere ネットワーク名を指定します。
API VIP: 内部 API 通信に使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリストを提供します。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツを指定します。
Disconnected installation をクリックして、切断されたインストールイメージを定義できます。VMware vSphere プロバイダーを使用してクラスターを作成し、切断されたインストールを行う場合、ミラーレジストリーにアクセスするために証明書が必要な場合は、切断されたインストールの設定セクションの認証情報の 追加の信頼バンドル フィールドに証明書を入力する必要があります。その証明書をクラスター作成コンソールエディターに入力すると、無視されます。
Add automation template をクリックしてテンプレートを作成できます。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.7. Red Hat OpenStack Platform でのクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンを使用して、Red Hat OpenStack Platform に Red Hat OpenShift Container Platform クラスターをデプロイできます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターの作成について不明な点がある場合は、OpenShift Container Platform ドキュメントの OpenStack のインストール でプロセスの詳細を確認してください。
1.4.4.7.1. 前提条件
Red Hat OpenStack Platform でクラスターを作成する前に、以下の前提条件を確認してください。
- OpenShift Container Platform バージョン 4.6 以降にデプロイされたハブクラスターが必要です。
- ハブクラスターが Red Hat OpenStack Platform で Kubernetes クラスターを作成できるようにするには、ハブクラスターにインターネットアクセスが必要です。
- Red Hat OpenStack Platform の認証情報がある。詳細は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
- OpenShift Container Platform イメージプルシークレットがある。イメージプルシークレットの使用 を参照してください。
デプロイする Red Hat OpenStack Platform インスタンスについての以下の情報がある。
-
コントロールプレーンとワーカーインスタンスのフレーバー名 (例:
m1.xlarge) - Floating IP アドレスを提供する外部ネットワークのネットワーク名
- API および Ingress インスタンスに必要な静的 IP アドレス
以下の DNS レコード。
-
API の Floating IP アドレスを指す
api.<cluster_name>.<base_domain> -
Ingreess の Floating IP アドレスを指す
*.apps.<cluster_name>.<base_domain>
-
API の Floating IP アドレスを指す
-
コントロールプレーンとワーカーインスタンスのフレーバー名 (例:
1.4.4.7.2. コンソールを使用したクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は、Red Hat OpenStack Platform の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。名前には 15 文字以上指定できません。値は、認証情報の要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.7.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
Red Hat OpenStack Platform アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は、上書きすると変更できます。詳細は、Red Hat OpenStack Platform ドキュメントの ドメインの管理 を参照してください。この名前はクラスターのホスト名で使用されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。OpenShift Container Platform バージョン 4.6.x 以降のリリースイメージのみがサポートされます。
ノードプールには、コントロールプレーンプールとワーカープールが含まれます。コントロールプレーンノードは、クラスターアクティビティーの管理を共有します。情報には以下のフィールドが含まれます。
- (オプション) アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
- コントロールプレーンプールのインスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
ワーカープールに 1 つまたは複数のワーカーノードを作成し、クラスターのコンテナーワークロードを実行できます。ワーカーノードは、1 つのワーカープールに属することも、複数のワーカープールに分散させることもできます。ワーカーノードが指定されていない場合は、コントロールプレーンノードもワーカーノードとして機能します。情報には以下のフィールドが含まれます。
- インスタンスタイプ: インスタンスのタイプとサイズは、作成後に変更できます。
- ノード数: ワーカープールのノード数を指定します。ワーカープールを定義する場合にこの設定は必須です。
クラスターにはネットワークの詳細が必要です。IPv4 ネットワーク用に 1 つ以上のネットワークの値を指定する必要があります。IPv6 ネットワークの場合は、複数のネットワークを定義する必要があります。
Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリストを定義します。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツを指定します。
Disconnected installation をクリックして、切断されたインストールイメージを定義できます。Red Hat OpenStack Platform プロバイダーを使用してクラスターを作成し、切断されたインストールを行う場合、ミラーレジストリーにアクセスするために証明書が必要な場合は、切断されたインストールの設定セクション の認証情報の 追加の信頼バンドル フィールドに証明書を入力する必要があります。.その証明書をクラスター作成コンソールエディターに入力すると、無視されます。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
内部認証局 (CA) を使用するクラスターを作成する場合、以下の手順を実行してクラスターの YAML ファイルをカスタマイズする必要があります。
レビューステップで YAML スイッチをオンにし、CA 証明書バンドルを使用してリストの上部に
Secretオブジェクトを挿入します。注記: Red Hat OpenStack Platform 環境が複数の機関によって署名された証明書を使用してサービスを提供する場合、バンドルには、必要なすべてのエンドポイントを検証するための証明書を含める必要があります。ocp3という名前のクラスターの追加は以下の例のようになります。apiVersion: v1 kind: Secret type: Opaque metadata: name: ocp3-openstack-trust namespace: ocp3 stringData: ca.crt: | -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <Base64 certificate contents here> -----END CERTIFICATE----以下の例のように、Hive
ClusterDeploymentオブジェクトを変更して、spec.platform.openstackにcertificatesSecretRefの値を指定します。platform: openstack: certificatesSecretRef: name: ocp3-openstack-trust credentialsSecretRef: name: ocp3-openstack-creds cloud: openstack上記の例では、
clouds.yamlファイルのクラウド名がopenstackであることを前提としています。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.8. Red Hat Virtualization でのクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンを使用して、Red Hat Virtualization 上に Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターを作成する場合、作成プロセスでは、Hive リソースを使用して OpenShift Container Platform インストーラーを使用します。この手順の完了後にクラスターを作成する場合、このプロセスの詳細について、OpenShift Container Platform ドキュメントの RHV へのインストール を参照してください。
1.4.4.8.1. 前提条件
Red Hat Virtualization でクラスターを作成する前に、以下の前提条件を確認してください。
- Kubernetes Operator ハブクラスター用にデプロイされたマルチクラスターエンジンがある。
- Red Hat Virtualization で Kubernetes クラスターを作成できるように、Kubernetes Operator ハブクラスター用のマルチクラスターエンジンにインターネットアクセスが必要です。
- Red Hat Virtualization の認証情報がある。詳細は、Red Hat Virtualization の認証情報の作成 を参照してください。
- oVirt Engine 仮想マシンに設定されたドメインおよび仮想マシンプロキシーがある。ドメインの設定方法は、Red Hat OpenShift Container Platform ドキュメントの RHV へのインストール を参照してください。
- Red Hat Virtualization のログイン認証情報 (Red Hat カスタマーポータルのユーザー名およびパスワードを含む) がある。
- OpenShift Container Platform イメージプルシークレットがある。Pull secret からプルシークレットをダウンロードします。プルシークレットの詳細は、イメージプルシークレットの使用 を参照してください。
注意: クラウドプロバイダーでクラウドプロバイダーのアクセスキーを変更する場合は、Kubernetes Operator 用のマルチクラスターエンジンのコンソールで、クラウドプロバイダーの対応する認証情報を手動で更新する必要もあります。これは、マネージドクラスターがホストされ、マネージドクラスターの削除を試みるクラウドプロバイダーで認証情報の有効期限が切れる場合に必要です。
1.4.4.8.2. コンソールを使用したクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
認証情報を作成する必要がある場合は Red Hat Virtualization の認証情報の作成 を参照してください。
クラスターの名前はクラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
1.4.4.8.3. クラスターを既存のクラスターセットに追加する
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
Red Hat Virtualization アカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値を上書きして変更できます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
コントロールプレーンプールのコア、ソケット、メモリー、およびディスクサイズの数など、ノードプールの情報。3 つのコントロールプレーンノードは、クラスターアクティビティーの管理を共有します。この情報には、Architecture フィールドが含まれます。次のフィールドの説明を表示します。
- アーキテクチャー: マネージドクラスターのアーキテクチャータイプがハブクラスターのアーキテクチャーと同じでない場合は、プール内のマシンの命令セットアーキテクチャーの値を入力します。有効な値は amd64、ppc64le、s390x、および arm64 です。
ワーカープール情報には、ワーカープールのプール名、コア数、メモリー割り当て、ディスクサイズ割り当て、およびノード数が必要です。ワーカープール内のワーカーノードは単一のワーカープールに配置するか、複数のワーカープールに分散できます。
事前設定された oVirt 環境には、以下のネットワークの詳細が必要です。
- oVirt ネットワーク名
API VIP: 内部 API 通信に使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。-
ネットワークタイプ: デフォルト値は
OpenShiftSDNです。IPv6 を使用するには、OVNKubernetes の設定は必須です。 -
クラスターネットワーク CIDR: これは、Pod IP アドレスに使用できる IP アドレスの数およびリストです。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.128.0.0/14です。 -
ネットワークホストの接頭辞: 各ノードのサブネット接頭辞の長さを設定します。デフォルト値は
23です。 -
サービスネットワーク CIDR: サービスの IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
172.30.0.0/16です。 マシン CIDR: OpenShift Container Platform ホストで使用される IP アドレスのブロックを指定します。このブロックは他のネットワークブロックと重複できません。デフォルト値は
10.0.0.0/16です。Add network をクリックして、追加のネットワークを追加できます。IPv6 アドレスを使用している場合は、複数のネットワークが必要です。
認証情報で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL を指定します。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL を指定します。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリストを提供します。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツを指定します。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML スイッチをクリックして On にすると、パネルに install-config.yaml ファイルの内容が表示されます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注記: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Kubernetes Operator のマルチクラスターエンジンの管理下に自動的に設定されます。
1.4.4.9. オンプレミス環境でのクラスターの作成
コンソールを使用して、オンプレミスの Red Hat OpenShift Container Platform クラスターを作成できます。非推奨となったベアメタルプロセスの代わりに、このプロセスを使用してください。
この手順を使用すると、VMware vSphere、Red Hat OpenStack、Red Hat Virtualization Platform、およびベアメタル環境で、単一ノード OpenShift (SNO) クラスター、マルチノードクラスター、およびコンパクトな 3 ノードクラスターを作成できます。
Red Hat OpenShift Container Platform で利用できる機能であるゼロタッチプロビジョニング機能を使用して、エッジリソース上に複数の単一ノード OpenShift クラスターをプロビジョニングすることもできます。詳細は、OpenShift Container Platform ドキュメントの 非接続環境でのスケールでの分散ユニットのデプロイ を参照してください。
1.4.4.9.1. 前提条件
オンプレミス環境にクラスターを作成する前に、以下の前提条件を確認してください。
- ハブクラスターが OpenShift Container Platform バージョン 4.9 以降にデプロイされている。
- 設定済みホストのホストインベントリーを備えた設定済みインフラストラクチャー環境が必要です。
- クラスターの作成に必要なイメージを取得するには、ハブクラスターのインターネットアクセス (接続)、またはインターネットへの接続 (切断) を持つ内部またはミラーレジストリーへの接続が必要です。
- オンプレミス認証情報が設定されている。
- OpenShift Container Platform イメージプルシークレットがある。詳細については、イメージプルシークレットの使用 を参照してください。
1.4.4.9.2. コンソールを使用したクラスターの作成
コンソールからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster をクリックし、コンソールの手順を実行します。
- クラスターのタイプとして Host inventory を選択します。
支援インストールでは、次のオプションを使用できます。
- 既存の検出されたホストを使用する: 既存のホストインベントリーにあるホストのリストからホストを選択します。
- 新規ホストの検出: 既存のインフラストラクチャー環境にないホストを検出します。インフラストラクチャー環境にあるものを使用するのではなく、独自のホストを検出します。
認証情報を作成する必要がある場合は オンプレミス環境の認証情報の作成 を参照してください。
クラスターの名前は、クラスターのホスト名で使用されます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
プロバイダーアカウントで設定した、選択した認証情報に関連付けられているベース DNS ドメインがすでに存在する場合、その値がフィールドに入力されます。値は上書きすると変更できますが、この設定はクラスターの作成後には変更できません。プロバイダーのベースドメインは、Red Hat OpenShift Container Platform クラスターコンポーネントへのルートの作成に使用されます。これは、クラスタープロバイダーの DNS で Start of Authority (SOA) レコードとして設定されます。
OpenShift version は、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。使用するバージョンが利用可能な場合は、イメージの一覧からイメージを選択できます。標準イメージ以外のイメージを使用する場合は、使用するイメージの URL を入力できます。リリースイメージの詳細は、リリースイメージ を参照してください。
4.9 以降の OpenShift バージョンを選択すると、Install single node OpenShift (SNO) を選択するオプションが表示されます。シングルノード OpenShift クラスターには、コントロールプレーンサービスとユーザーワークロードをホストするシングルノードが含まれます。単一ノード OpenShift クラスターの作成後にノードを追加する方法の詳細は、インフラストラクチャー環境へのホストのスケーリング を参照してください。
クラスターをシングルノード OpenShift クラスターにする場合は、シングルノード OpenShift オプションを選択します。以下の手順を実行することで、単一ノードの OpenShift クラスターにワーカーを追加できます。
- コンソールから、Infrastructure > Clusters に移動し、作成したクラスターまたはアクセスするクラスターの名前を選択します。
- Actions > Add hosts を選択して、ワーカーを追加します。
注記: シングルノード OpenShift コントロールプレーンには 8 つの CPU コアが必要ですが、マルチノードコントロールプレーンクラスターのコントロールプレーンノードには 4 つの CPU コアしか必要ありません。
クラスターを確認して保存すると、クラスターはドラフトクラスターとして保存されます。Clusters ページでクラスター名を選択すると、作成プロセスを閉じてプロセスを終了することができます。
既存のホストを使用している場合は、ホストを独自に選択するか、自動的に選択するかどうかを選択します。ホストの数は、選択したノード数に基づいています。たとえば、SNO クラスターではホストが 1 つだけ必要ですが、標準の 3 ノードクラスターには 3 つのホストが必要です。
このクラスターの要件を満たす利用可能なホストの場所は、ホストの場所 のリストに表示されます。ホストと高可用性設定の分散については、複数の場所を選択します。
既存のインフラストラクチャー環境がない新規ホストを検出する場合には、手順 4 から始まる インフラストラクチャー環境にホストをスケーリング してホストを定義します。
ホストがバインドされ、検証に合格したら、以下の IP アドレスを追加してクラスターのネットワーク情報を入力します。
API VIP: 内部 API 通信に使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
api.が正しく解決されるようにします。Ingress VIP: Ingress トラフィックに使用する IP アドレスを指定します。
注記: 値は、要件セクションに記載されている DNS レコードの作成に使用した名前と一致させる必要があります。指定しない場合は、DNS を事前設定して
test.apps.が正しく解決されるようにします。
Clusters ナビゲーションページで、インストールのステータスを表示できます。
1.4.4.10. ホステッドクラスターの作成 (テクノロジープレビュー)
Kubernetes Operator コンソール用のマルチクラスターエンジンを使用して、Red Hat OpenShift Container Platform がホストするクラスターを作成できます。
1.4.4.10.1. 前提条件
ホスト型クラスターを作成する前に、次の前提条件を確認してください。
- OpenShift Container Platform バージョン 4.6 以降で、Kubernetes Operator ハブクラスター用にデプロイされたマルチクラスターエンジンが必要です。
- Kubernetes Operator ハブクラスター用のマルチクラスターエンジン (接続済み)のインターネットアクセス、またはクラスターの作成に必要なイメージを取得するために、インターネットへの接続 (切断済み) を持つ内部レジストリーまたはミラーレジストリーへの接続が必要です。
- ホストされたコントロールプレーン Operator を有効にする必要があります。詳細については、ホスティングされたコントロールプレーンクラスターの使用 を参照してください。
- OpenShift Container Platform イメージプルシークレットがある。詳細については、イメージプルシークレットの使用 を参照してください。
ホストが検出されたインフラストラクチャー環境が必要です。
注意: インベントリーのホストと切断されたインストールを使用してクラスターを作成する場合は、切断されたインストールの設定 セクションの認証情報にすべての設定を保存する必要があります。クラスター作成コンソールエディターで入力することはできません。
1.4.4.10.2. ホストされたクラスターの作成
Kubernetes Operator コンソールのマルチクラスターエンジンからクラスターを作成するには、Infrastructure > Clusters に移動します。Clusters ページで、Create cluster > Host inventory > Hosted をクリックし、コンソールで手順を完了します。
注記: この手順では、クラスターを作成します。既存のクラスターをインポートする場合には、ハブクラスターへのターゲットマネージドクラスターのインポート の手順を参照してください。
重要: クラスターを作成すると、Kubernetes Operator コントローラー用のマルチクラスターエンジンによって、クラスターとそのリソースの名前空間が作成されます。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
ヒント: YAML: On を選択すると、コンソールに情報を入力する際にコンテンツの更新が表示されます。
クラスターを既存のクラスターセットに追加する場合は、そのクラスターセットで追加できる適切なパーミッションが必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin 権限があるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットがない場合には、クラスター管理者に連絡して、任意のクラスターセットへの clusterset-admin 権限を受け取ってください。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
このリリースイメージで、クラスターの作成に使用される OpenShift Container Platform イメージのバージョンを特定します。ホストされたクラスターは、提供されたリリースイメージのいずれかを使用する必要があります。
インフラストラクチャー環境で提供されるプロキシー情報は、プロキシーフィールドに自動的に追加されます。情報をそのまま使用することも、上書きすることも、プロキシーを有効にする場合に情報を追加することもできます。次のリストには、プロキシーの作成に必要な情報が含まれています。
-
HTTP プロキシー URL:
HTTPトラフィックのプロキシーとして使用する URL。 -
HTTPS プロキシー URL:
HTTPSトラフィックに使用するセキュアなプロキシー URL。値の指定がない場合は、HTTP Proxy URLと同じ値がHTTPおよびHTTPSの両方に使用されます。 -
プロキシードメインなし: プロキシーをバイパスする必要のあるドメインのコンマ区切りリスト。ドメイン名をピリオド (
.) で開始し、そのドメインにあるすべてのサブドメインを組み込みます。アステリスク (*) を追加し、すべての宛先のプロキシーをバイパスします。 - 追加のトランスとバンドル: ミラーレジストリーへのアクセスに必要な証明書ファイルのコンテンツ。
クラスターを作成する前に情報を確認し、必要に応じてカスタマイズする場合は、YAML: On を選択して、パネルに YAML コンテンツを表示できます。更新がある場合は、カスタム設定で YAML ファイルを編集できます。
注意: クラスターのインポートには、クラスターの詳細で提示された kubectl コマンドを実行する必要はありません。クラスターを作成すると、Red Hat Advanced Cluster Management で管理されるように自動的に設定されません。
1.4.4.11. プロキシー環境でのクラスターの作成
ハブクラスターがプロキシーサーバー経由で接続されている場合は、Red Hat OpenShift Container Platform クラスターを作成できます。
クラスターの作成を成功させるには、以下のいずれかの状況が true である必要があります。
- Kubernetes Operator には、作成しているマネージドクラスターとのプライベートネットワーク接続がありますが、Red Hat Advanced Cluster Management とマネージドクラスターはプロキシーを使用してインターネットにアクセスします。
- マネージドクラスターはインフラストラクチャープロバイダーにありますが、ファイアウォールポートを使用することでマネージドクラスターからハブクラスターへの通信を有効にします。
プロキシーで設定されたクラスターを作成するには、以下の手順を実行します。
以下の情報を
install-config.yamlファイルに追加して、ハブクラスターに cluster-wide-proxy 設定を指定します。apiVersion: v1 kind: Proxy baseDomain: <domain> proxy: httpProxy: http://<username>:<password>@<proxy.example.com>:<port> httpsProxy: https://<username>:<password>@<proxy.example.com>:<port> noProxy: <wildcard-of-domain>,<provisioning-network/CIDR>,<BMC-address-range/CIDR>
usernameは、プロキシーサーバーのユーザー名に置き換えます。passwordは、プロキシーサーバーへのアクセス時に使用するパスワードに置き換えます。proxy.example.comは、プロキシーサーバーのパスに置き換えます。portは、プロキシーサーバーとの通信ポートに置き換えます。wildcard-of-domainは、プロキシーをバイパスするドメインのエントリーに置き換えます。provisioning-network/CIDRは、プロビジョニングネットワークの IP アドレスと割り当てられた IP アドレスの数 (CIDR 表記) に置き換えます。BMC-address-range/CIDRは、BMC アドレスおよびアドレス数 (CIDR 表記) に置き換えます。以前の値を追加すると、設定はクラスターに適用されます。
- クラスターの作成手順を実行してクラスターをプロビジョニングします。クラスターの作成 を参照してプロバイダーを選択します。
注: install-config YAML は、クラスターをデプロイする場合にのみ使用できます。クラスターをデプロイした後、install-config.yaml に加えた新しい変更は適用されません。導入後に設定を更新するには、ポリシーを作成する必要があります。詳細は、Pod ポリシー を参照してください。
1.4.4.11.1. 既存のクラスターアドオンでクラスター全体のプロキシーを有効にする
クラスター namespace で KlusterletAddonConfig を設定して、ハブクラスターが管理する Red Hat OpenShift Container Platform クラスターのすべての klusterlet アドオン Pod にプロキシー環境変数を追加できます。
KlusterletAddonConfig が 3 つの環境変数を klusterlet アドオンの Pod に追加するように設定するには、以下の手順を実行します。
-
プロキシーを追加する必要のあるクラスターの namespace にある
KlusterletAddonConfigファイルを開きます。 ファイルの
.spec.proxyConfigセクションを編集して、以下の例のようにします。spec proxyConfig: httpProxy: "<proxy_not_secure>" httpsProxy: "<proxy_secure>" noProxy: "<no_proxy>"proxy_not_secureは、http要求のプロキシーサーバーのアドレスに置き換えます。(例:http://192.168.123.145:3128)。proxy_secureは、https要求のプロキシーサーバーのアドレスに置き換えます。例:https://192.168.123.145:3128no_proxyは、トラフィックがプロキシー経由でルーティングされない IP アドレス、ホスト名、およびドメイン名のコンマ区切りのリストに置き換えます。(例:.cluster.local,.svc,10.128.0.0/14,example.com)。spec.proxyConfigは任意のセクションです。OpenShift Container Platform クラスターがハブクラスターでクラスターワイドプロキシーを設定して作成されている場合は、以下の条件が満たされると、クラスターワイドプロキシー設定値が環境変数として klusterlet アドオンの Pod に追加されます。-
addonセクションの.spec.policyController.proxyPolicyが有効になり、OCPGlobalProxyに設定されます。 .spec.applicationManager.proxyPolocyが有効になり、CustomProxyに設定されます。注記:
addonセクションのproxyPolicyのデフォルト値はDisabledです。以下の例を参照してください。
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: clusterName namespace: clusterName spec: proxyConfig: httpProxy: http://pxuser:12345@10.0.81.15:3128 httpsProxy: http://pxuser:12345@10.0.81.15:3128 noProxy: .cluster.local,.svc,10.128.0.0/14, example.com applicationManager: enabled: true proxyPolicy: CustomProxy policyController: enabled: true proxyPolicy: OCPGlobalProxy searchCollector: enabled: true proxyPolicy: Disabled certPolicyController: enabled: true proxyPolicy: Disabled iamPolicyController: enabled: true proxyPolicy: Disabled
-
重要: グローバルプロキシー設定は、アラートの転送には影響しません。クラスター全体のプロキシーを使用して Red Hat Advanced Cluster Management ハブクラスターのアラート転送を設定する場合は、その詳細について アラートの転送 を参照してください。
1.4.5. 作成されたクラスターの休止 (テクノロジープレビュー)
リソースを節約するために、Kubernetes Operator 用のマルチクラスターエンジンを使用して作成されたクラスターを休止状態にすることができます。休止状態のクラスターに必要となるリソースは、実行中のものより少なくなるので、クラスターを休止状態にしたり、休止状態を解除したりすることで、プロバイダーのコストを削減できる可能性があります。この機能は、次の環境で Kubernetes Operator 用のマルチクラスターエンジンによって作成されたクラスターにのみ適用されます。
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
1.4.5.1. コンソールを使用したクラスターの休止
コンソールを使用して、Kubernetes Operator 用のマルチクラスターエンジンによって作成されたクラスターを休止状態にするには、次の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。Manage clusters タブが選択されていることを確認します。
- そのクラスターの Options メニューから Hibernate cluster を選択します。注記: Hibernate cluster オプションが利用できない場合には、クラスターを休止状態にすることはできません。これは、クラスターがインポートされ、Kubernetes Operator のマルチクラスターエンジンによって作成されていない場合に発生する可能性があります。
Clusters ページのクラスターのステータスは、プロセスが完了すると Hibernating になります。
ヒント: Clusters ページで休止するするクラスターを選択し、Actions > Hibernate cluster を選択して、複数のクラスターを休止できます。
選択したクラスターが休止状態になりました。
1.4.5.2. CLI を使用したクラスターの休止
CLI を使用して、Kubernetes Operator 用のマルチクラスターエンジンによって作成されたクラスターを休止状態にするには、次の手順を実行します。
以下のコマンドを入力して、休止するクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値はHibernatingに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yaml
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターを休止するプロセスが完了すると、クラスターのタイプの値は
type=Hibernatingになります。
選択したクラスターが休止状態になりました。
1.4.5.3. コンソールを使用して休止中のクラスターの通常操作を再開する手順
コンソールを使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters を選択します。Manage clusters タブが選択されていることを確認します。
- 再開するクラスターの Options メニューから Resume cluster を選択します。
プロセスを完了すると、Clusters ページのクラスターのステータスは Ready になります。
ヒント: Clusters ページで、再開するクラスターを選択し、Actions > Resume cluster の順に選択して、複数のクラスターを再開できます。
選択したクラスターで通常の操作が再開されました。
1.4.5.4. CLI を使用して休止中のクラスターの通常操作を再開する手順
CLI を使用して、休止中のクラスターの通常操作を再開するには、以下の手順を実行します。
以下のコマンドを入力してクラスターの設定を編集します。
oc edit clusterdeployment <name-of-cluster> -n <namespace-of-cluster>
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。-
spec.powerStateの値をRunningに変更します。 以下のコマンドを実行して、クラスターのステータスを表示します。
oc get clusterdeployment <name-of-cluster> -n <namespace-of-cluster> -o yaml
name-of-clusterは、休止するクラスター名に置き換えます。namespace-of-clusterは、休止するクラスターの namespace に置き換えます。クラスターの再開プロセスが完了すると、クラスターのタイプの値は
type=Runningになります。
選択したクラスターで通常の操作が再開されました。
1.4.6. ハブクラスターへのターゲットのマネージドクラスターのインポート
別の Kubernetes クラウドプロバイダーからクラスターをインポートできます。インポート後、対象のクラスターは、Kubernetes Operator ハブクラスターのマルチクラスターエンジンのマネージドクラスターになります。指定されていない場合は、ハブクラスターとターゲットのマネージドクラスターにアクセスできる場所で、インポートタスクを実行します。
ハブクラスターは 他 のハブクラスターの管理はできず、自己管理のみが可能です。ハブクラスターは、自動的にインポートして自己管理できるように設定されています。ハブクラスターは手動でインポートする必要はありません。
ただし、ハブクラスターを削除して、もう一度インポートする場合は、local-cluster:true ラベルを追加する必要があります。
コンソールまたは CLI からのマネージドクラスターの設定は、以下の手順から選択します。
必要なユーザータイプまたはアクセスレベル: クラスター管理者
1.4.6.1. コンソールを使用した既存クラスターのインポート
Kubernetes Operator 用のマルチクラスターエンジンをインストールすると、クラスターをインポートして管理できるようになります。コンソールと CLI の両方からインポートできます。
コンソールからインポートするには、以下の手順に従います。この手順では、認証用にターミナルが必要です。
1.4.6.1.1. 前提条件
- デプロイされたハブクラスターが必要です。ベアメタルクラスターをインポートする場合には、ハブクラスターを Red Hat OpenShift Container Platform バージョン 4.8 以降にインストールする必要があります。
- 管理するクラスターとインターネット接続が必要である。
-
kubectlをインストールしておく必要がある。kubectlのインストール手順は、Kubernetes ドキュメント の Install and Set Up kubectl を参照してください。 -
Base64コマンドラインツールが必要である。 注意: OpenShift Container Platform によって作成されていないクラスターをインポートする場合は、
multiclusterhub.spec.imagePullSecretを定義する必要があります。このシークレットは、Kubernetes Operator 用のマルチクラスターエンジンがインストールされたときに作成される可能性があります。新しいシークレットを作成する必要がある場合は、次の手順を実行します。
- cloud.redhat.com から Kubernetes プルシークレットをダウンロードします。
- プルシークレットをハブクラスターの namespace に追加します。
次のコマンドを実行して、
open-cluster-managementnamespace に新しいシークレットを作成します。oc create secret generic pull-secret -n <open-cluster-management> --from-file=.dockerconfigjson=<path-to-pull-secret> --type=kubernetes.io/dockerconfigjson
open-cluster-managementをハブクラスターの namespace の名前に置き換えます。ハブクラスターのデフォルトの名前空間はopen-cluster-managementです。path-to-pull-secretを、ダウンロードしたプルシークレットへのパスに置き換えます。シークレットは、インポート時にマネージドクラスターに自動的にコピーされます。
プルシークレットの詳細は、イメージプルシークレットの使用 または サービスアカウントの理解と作成 を参照してください。
このシークレットを定義する方法の詳細については、カスタムイメージプルシークレット を参照してください。
-
インポートするクラスターでエージェントが削除されていることを確認します。エラーを避けるために、
open-cluster-management-agentおよびopen-cluster-management-agent-addonnamespace を削除する必要があります。 Red Hat OpenShift Dedicated 環境にインポートする場合には、以下の注意点を参照してください。
- ハブクラスターを Red Hat OpenShift Dedicated 環境にデプロイしている必要があります。
-
Red Hat OpenShift Dedicated のデフォルトパーミッションは dedicated-admin ですが、namespace を作成するためのパーミッションがすべて含まれているわけではありません。Kubernetes Operator 用のマルチクラスターエンジンを使用してクラスターをインポートおよび管理するには、
cluster-adminアクセス権が必要です。
- インポートしたクラスターで自動化を有効にする場合は、Red Hat Ansible Automation Platform が必要です。
必要なユーザータイプまたはアクセスレベル: クラスター管理者
1.4.6.1.2. クラスターのインポート
利用可能なクラウドプロバイダーごとに、コンソールから既存のクラスターをインポートできます。
注記: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、自動的にインポートおよび自己管理するように設定されるため、ハブクラスターを手動でインポートして自己管理する必要はありません。
デフォルトでは、namespace がクラスター名と namespace に使用されますが、これは変更できます。
重要: クラスターを作成すると、コントローラーはクラスターとそのリソースの名前空間を作成します。その名前空間には、そのクラスターインスタンスのリソースのみを含めるようにしてください。クラスターを破棄すると、名前空間とその中のすべてのリソースが削除されます。
マネージドクラスターはすべて、マネージドクラスターセットに関連付けられている必要があります。マネージドクラスターを ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
別のクラスターセットに追加する場合は、そのクラスターセットに対する cluster-admin 権限が必要です。クラスターの作成時に cluster-admin 権限がない場合に、clusterset-admin パーミッションがあるクラスターセットを選択する必要があります。指定されたクラスターセットに対して適切なパーミッションがないと、クラスターの作成に失敗します。選択するクラスターセットが存在しない場合は、クラスター管理者に連絡して、クラスターセットへの clusterset-admin パーミッションを受け取ってください。
Red Hat OpenShift Dedicated クラスターをインポートし、vendor=OpenShiftDedicated のラベルを追加してベンダーが指定されないようにする場合、または vendor=auto-detect のラベルを追加する場合は、managed-by=platform ラベルがクラスターに自動的に追加されます。この追加ラベルを使用して、クラスターを Red Hat OpenShift Dedicated クラスターとして識別し、Red Hat OpenShift Dedicated クラスターをグループとして取得できます。
次のリストは、クラスターをインポートする方法を指定する インポートモード で使用可能なオプションを示しています。
- インポートコマンドを手動で実行する: Red Hat Ansible Automation Platform テンプレートを含む情報をコンソールに入力して送信したら、提供されたコマンドをターゲットクラスターで実行してクラスターをインポートします。Ansible Automation Platform ジョブを作成して実行するには、OperatorHub から Red Hat Ansible Automation Platform Resource Operator をインストールする必要があります。インポートコマンドを手動で実行するための追加手順 を続行します。
既存のクラスターのサーバー URL および API トークンを入力する: インポートするクラスターの サーバー URL および API トークンを指定します。
クラスターのアップグレード時に実行する Red Hat Ansible Automation Platform テンプレートを指定できます。Ansible Automation Platform ジョブを作成して実行するには、OperatorHub から Red Hat Ansible Automation Platform Resource Operator をインストールする必要があります。
クラスター API アドレスを設定する場合は、オプション: クラスター API アドレスを設定する の手順を完了します。
kubeconfigファイルを提供します。インポートするクラスターのkubeconfigファイルの内容をコピーして貼り付けます。クラスターのアップグレード時に実行する Red Hat Ansible Automation Platform テンプレートを指定できます。Ansible Automation Platform ジョブを作成して実行するには、OperatorHub から Red Hat Ansible Automation Platform Resource Operator をインストールする必要があります。
クラスター API アドレスを設定する場合は、オプション: クラスター API アドレスを設定する の手順に進みます。
1.4.6.1.2.1. インポートコマンドを手動で実行するための追加手順
指定されたコマンドをターゲットクラスターで実行して、クラスターをインポートします。
クラスターの詳細および自動化情報を送信したら、Copy command を選択して、生成されたコマンドおよびトークンをクリップボードにコピーします。
重要: コマンドには、インポートした各クラスターにコピーされるプルシークレット情報が含まれます。インポートしたクラスターにアクセスできるユーザーであれば誰でも、プルシークレット情報を表示することもできます。https://cloud.redhat.com/ で 2 つ目のプルシークレットを作成することを検討するか、サービスアカウントを作成して個人の認証情報を保護してください。
- インポートするマネージドクラスターにログインします。
Red Hat OpenShift Dedicated 環境の場合のみ、次の手順を実行します (Red Hat OpenShift Dedicated 環境を使用していない場合は、手順 3 に進みます)。
-
マネージドクラスターで
open-cluster-management-agentおよびopen-cluster-managementnamespace またはプロジェクトを作成します。 - OpenShift Container Platform カタログで klusterlet Operator を検索します。
作成した
open-cluster-managementnamespace またはプロジェクトにインストールします。重要:
open-cluster-management-agentnamespace に Operator をインストールしないでください。以下の手順を実行して、import コマンドからブートストラップシークレットをデプロイメントします。
import コマンドを生成します。
- コンソールナビゲーションから Infrastructure > Clusters を選択します。
- Add a cluster > Import an existing cluster を選択します。
- クラスター情報を追加し、Save import and generate code を選択します。
- import コマンドをコピーします。
-
import-commandという名前で作成したファイルに、import コマンドを貼り付けます。 以下のコマンドを実行して、新しいファイルにコンテンツを挿入します。
cat import-command | awk '{split($0,a,"&&"); print a[3]}' | awk '{split($0,a,"|"); print a[1]}' | sed -e "s/^ echo //" | base64 -d-
出力で
bootstrap-hub-kubeconfigという名前のシークレットを見つけ、コピーします。 -
シークレットをマネージドクラスターの
open-cluster-management-agentnamespace に適用します。 インストールした Operator の例を使用して klusterlet リソースを作成します。clusterName は、インポート中に設定されたクラスター名と同じ名前に変更する必要があります。
注記:
managedclusterリソースがハブに正しく登録されると、2 つの klusterlet Operator がインストールされます。klusterlet Operator の 1 つはopen-cluster-managementnamespace に、もう 1 つはopen-cluster-management-agentnamespace にあります。Operator が複数あっても klusterlet の機能には影響はありません。
-
マネージドクラスターで
Red Hat OpenShift Dedicated 環境に含まれていないクラスターのインポート: 以下の手順を実行します。
-
必要な場合は、マネージドクラスターの
kubectlコマンドを設定します。 -
マネージドクラスターに
open-cluster-management-agent-addonをデプロイするには、コピーしたトークンでコマンドを実行します。
-
必要な場合は、マネージドクラスターの
View cluster をクリックして Overview ページのクラスターの概要を表示します。
クラスターがインポートされると、クラスターの Cluster details ページで進行状況を表示できます。
クラスター API アドレスを設定する場合は、オプション: クラスター API アドレスを設定する の手順に進みます。
1.4.6.1.2.2. オプション: クラスター API アドレスを設定する
oc get managedcluster コマンドを実行する際に、テーブルに表示される URL を設定して、クラスターの詳細ページにある Cluster API アドレス を任意で設定できます。
-
cluster-adminパーミッションがある ID でハブクラスターにログインします。 -
ターゲットのマネージドクラスターの
kubectlを設定します。 以下のコマンドを入力して、インポートしているクラスターのマネージドクラスターエントリーを編集します。
oc edit managedcluster <cluster-name>
cluster-nameは、マネージドクラスターの名前に置き換えます。以下の例のように、YAML ファイルの
ManagedCluster仕様にmanageClusterClientConfigsセクションを追加します。spec: hubAcceptsClient: true managedClusterClientConfigs: - url: https://multicloud-console.apps.new-managed.dev.redhat.com
URL の値を、インポートするマネージドクラスターへの外部アクセスを提供する URL に置き換えます。
1.4.6.1.3. インポートされたクラスターの削除
以下の手順を実行して、インポートされたクラスターと、マネージドクラスターで作成された open-cluster-management-agent-addon を削除します。
Clusters ページで、Actions > Detach cluster をクリックしてマネージメントからクラスターを削除します。
注記: local-cluster という名前のハブクラスターをデタッチしようとする場合は、デフォルトの disableHubSelfManagement 設定が false である点に注意してください。この設定が原因で、ハブクラスターがデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
disableHubSelfManagement の値を true に指定して、自動的にインポートされないように、ハブクラスターの値を変更できます。詳細は、disableHubSelfManagement トピックを参照してください。
1.4.6.2. CLI を使用したマネージドクラスターのインポート
Kubernetes Operator 用のマルチクラスターエンジンをインストールしたら、Red Hat OpenShift Container Platform CLI を使用して管理するクラスターをインポートする準備が整います。インポートしているクラスターの kubeconfig ファイルを使用してクラスターをインポートするか、インポートしているクラスターで import コマンドを手動で実行できます。どちらの手順も文書化されています。
重要: ハブクラスターは別のハブクラスターを管理できません。ハブクラスターは、自動でインポートおよび自己管理するように設定されます。ハブクラスターは、手動でインポートして自己管理する必要はありません。ただし、ハブクラスターを削除して、もう一度インポートする場合は、local-cluster:true ラベルを追加する必要があります。
1.4.6.2.1. 前提条件
- デプロイされたハブクラスターが必要です。ベアメタルクラスターをインポートする場合は、ハブクラスターを Red Hat OpenShift Container Platform バージョン 4.6 以降にインストールする必要があります。
- インターネットに接続できる、管理する別のクラスターが必要です。
-
ocコマンドを実行するには、Red Hat OpenShift Container Platform の CLI バージョン 4.6 以降が必要である。Red Hat OpenShift Container Platform CLI (oc) のインストールおよび設定の詳細は、Getting started with the OpenShift CLI を参照してください。コンソールから CLI ツールのインストールファイルをダウンロードします。 -
Kubernetes CLI (
kubectl) をインストールする必要がある。kubectlのインストール手順は、Kubernetes ドキュメント の Install and Set Up kubectl を参照してください。 -
OpenShift Container Platform によって作成されていないクラスターをインポートする場合は、
multiclusterhub.spec.imagePullSecretを定義する必要があります。このシークレットは、Kubernetes Operator 用のマルチクラスターエンジンがインストールされたときに作成された可能性があります。このシークレットを定義する方法の詳細については、カスタムイメージプルシークレット を参照してください。
1.4.6.2.2. サポートされているアーキテクチャー
- Linux (x86_64, s390x, ppc64le)
- MacOS
1.4.6.2.3. インポートの準備
以下のコマンドを実行して ハブクラスター にログインします。
oc login
ハブクラスターで次のコマンドを実行して、プロジェクトおよび namespace を作成します。
CLUSTER_NAMEで定義したクラスター名は、YAML ファイルおよびコマンドでクラスターの namespace としても使用します。oc new-project ${CLUSTER_NAME}重要:
cluster.open-cluster-management.io/managedClusterラベルは、マネージドクラスターの namespace に対して自動的に追加および削除されます。マネージドクラスターに手動で追加したり、クラスターから削除したりしないでください。以下の内容例で
managed-cluster.yamlという名前のファイルを作成します。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: ${CLUSTER_NAME} labels: cloud: auto-detect vendor: auto-detect spec: hubAcceptsClient: truecloudおよびvendorの値をauto-detectする場合、Red Hat Advanced Cluster Management はインポートしているクラスターからクラウドおよびベンダータイプを自動的に検出します。オプションで、auto-detectの値をクラスターのクラウドおよびベンダーの値に置き換えることができます。以下の例を参照してください。cloud: Amazon vendor: OpenShift
以下のコマンドを入力して、YAML ファイルを
ManagedClusterリソースに適用します。oc apply -f managed-cluster.yaml
次に、以下のいずれかの手順を実行してクラスターをインポートします。
1.4.6.2.4. 自動インポートシークレットを使用したクラスターのインポート
自動インポートシークレットでインポートするには、クラスターの kubeconfig ファイルを参照するか、クラスターの kube API サーバーおよびトークンのペアのいずれかの参照を含むシークレットを作成する必要があります。
-
インポートしているクラスターの
kubeconfigファイルまたは kube API サーバーおよびトークンを取得します。kubeconfigファイルまたは kube API サーバーおよびトークンの場所を特定する方法については、Kubernetes クラスターのドキュメントを参照してください。 ${CLUSTER_NAME} namespace に
auto-import-secret.yamlファイルを作成します。以下のテンプレートのようなコンテンツが含まれる
auto-import-secret.yamlという名前の YAML ファイルを作成します。apiVersion: v1 kind: Secret metadata: name: auto-import-secret namespace: <cluster_name> stringData: autoImportRetry: "5" # If you are using the kubeconfig file, add the following value for the kubeconfig file # that has the current context set to the cluster to import: kubeconfig: |- <kubeconfig_file> # If you are using the token/server pair, add the following two values instead of # the kubeconfig file: token: <Token to access the cluster> server: <cluster_api_url> type: Opaque
次のコマンドを使用して、${CLUSTER_NAME} 名前空間の YAML ファイルを適用します。
oc apply -f auto-import-secret.yaml
注記: デフォルトでは、自動インポートシークレットは 1 回使用され、インポートプロセスの完了時に削除されます。自動インポートシークレットを保持する場合は、
managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secretをシークレットに追加します。これを追加するには、以下のコマンドを実行します。
oc -n <cluster_name> annotate secrets auto-import-secret managedcluster-import-controller.open-cluster-management.io/keeping-auto-import-secret=""
インポートしたクラスターのステータス (
JOINEDおよびAVAILABLE) を確認します。ハブクラスターから以下のコマンドを実行します。oc get managedcluster ${CLUSTER_NAME}マネージドクラスターで次のコマンドを実行して、マネージドクラスターにログインします。
oc login
次のコマンドを実行して、インポートするクラスターの Pod ステータスを検証します。
oc get pod -n open-cluster-management-agent
次 に、klusterlet アドオンのインポート の手順を実行し ます。アドオンのインポートは、クラスターのインポートプロセス全体を完了するために必要な手順です。
1.4.6.2.5. 手動コマンドを使用したクラスターのインポート
重要: import コマンドには、インポートした各クラスターにコピーされるプルシークレット情報が含まれます。インポートしたクラスターにアクセスできるユーザーであれば誰でも、プルシークレット情報を表示することもできます。
以下のコマンドを実行して、ハブクラスターでインポートコントローラーによって生成された
klusterlet-crd.yamlファイルを取得します。oc get secret ${CLUSTER_NAME}-import -n ${CLUSTER_NAME} -o jsonpath={.data.crds\\.yaml} | base64 --decode > klusterlet-crd.yaml以下のコマンドを実行して、ハブクラスターにインポートコントローラーによって生成された
import.yamlファイルを取得します。oc get secret ${CLUSTER_NAME}-import -n ${CLUSTER_NAME} -o jsonpath={.data.import\\.yaml} | base64 --decode > import.yamlインポートするクラスターで次の手順を実行します。
次のコマンドを入力して、インポートするマネージドクラスターにログインします。
oc login
以下のコマンドを実行して、手順 1 で生成した
klusterlet-crd.yamlを適用します。oc apply -f klusterlet-crd.yaml
以下のコマンドを実行して、以前に生成した
import.yamlファイルを適用します。oc apply -f import.yaml
インポートしているクラスターの
JOINEDおよびAVAILABLEのステータスを検証します。ハブクラスターから以下のコマンドを実行します。oc get managedcluster ${CLUSTER_NAME}
次 に、klusterlet アドオンのインポート の手順を実行し ます。アドオンのインポートは、クラスターのインポートプロセス全体を完了するために必要な手順です。
1.4.6.2.6. klusterlet アドオンのインポート
以下の手順を実行して、klusterlet アドオン設定ファイルを作成および適用できます。
以下の例のような YAML ファイルを作成します。
apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: true-
ファイルは
klusterlet-addon-config.yamlとして保存します。 以下のコマンドを実行して YAML を適用します。
oc apply -f klusterlet-addon-config.yaml
ManagedCluster-Import-Controller は
${CLUSTER_NAME}-importという名前のシークレットを生成します。${CLUSTER_NAME}-importシークレットには、import.yamlが含まれており、このファイルをユーザーがマネージドクラスターに適用して klusterlet をインストールします。アドオンは、インポートするクラスターの
AVAILABLEの後にインストールされます。次のコマンドを実行して、インポートするクラスター上のアドオンの Pod ステータスを検証します。
oc get pod -n open-cluster-management-agent-addon
1.4.6.2.7. CLI でのインポートされたクラスターの削除
クラスターを削除するには、以下のコマンドを実行します。
oc delete managedcluster ${CLUSTER_NAME}
cluster_name は、クラスターの名前に置き換えます。
これでクラスターが削除されます。
1.4.6.3. カスタム ManagedClusterImageRegistry CRD を使用したクラスターのインポート
インポートするマネージドクラスターのイメージレジストリーをオーバーライドする必要がある場合があります。この方法は、ManagedClusterImageRegistry カスタムリソース定義 (CRD) を作成して実行できます。
ManagedClusterImageRegistry CRD は namespace スコープのリソースです。
ManagedClusterImageRegistry CRD は、配置が選択するマネージドクラスターのセットを指定しますが、カスタムイメージレジストリーとは異なるイメージが必要になります。マネージドクラスターが新規イメージで更新されると、識別用に各マネージドクラスターに、open-cluster-management.io/image-registry=<namespace>.<managedClusterImageRegistryName> のラベルが追加されます。
以下の例は、ManagedClusterImageRegistry CRD を示しています。
apiVersion: imageregistry.open-cluster-management.io/v1alpha1
kind: ManagedClusterImageRegistry
metadata:
name: <imageRegistryName>
namespace: <namespace>
spec:
placementRef:
group: cluster.open-cluster-management.io
resource: placements
name: <placementName>
pullSecret:
name: <pullSecretName>
registries:
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
- mirror: <mirrored-image-registry-address>
source: <image-registry-address>
spec セクション:
-
placementNameは、マネージドクラスターセットを選択する同じ namespace の Placement 名に置き換えます。 -
pullSecretNameは、カスタムイメージレジストリーからイメージをプルするために使用されるプルシークレットの名前に置き換えます。 ソースおよびミラーレジストリーのそれぞれの値をリスト表示します。mirrored-image-registry-addressおよびimage-registry-addressは、レジストリーの各ミラーおよびソース値に置き換えます。例 1:
registry.redhat.io/rhacm2という名前のソースイメージレジストリーをlocalhost:5000/rhacm2に、registry.redhat.io/multicluster-engineをlocalhost:5000/multicluster-engineに置き換えるには、以下の例を使用します。registries: - mirror: localhost:5000/rhacm2/ source: registry.redhat.io/rhacm2 - mirror: localhost:5000/multicluster-engine source: registry.redhat.io/multicluster-engine例 2: ソースイメージ
registry.redhat.io/rhacm2/registration-rhel8-operatorをlocalhost:5000/rhacm2-registration-rhel8-operatorに置き換えるには、以下の例を使用します。registries: - mirror: localhost:5000/rhacm2-registration-rhel8-operator source: registry.redhat.io/rhacm2/registration-rhel8-operator
1.4.6.3.1. ManagedClusterImageRegistry CRD を使用したクラスターのインポート
ManagedClusterImageRegistry CRD でクラスターをインポートするには、以下の手順を実行します。
クラスターをインポートする必要のある namespace にプルシークレットを作成します。これらの手順では、これは
myNamespaceです。$ kubectl create secret docker-registry myPullSecret \ --docker-server=<your-registry-server> \ --docker-username=<my-name> \ --docker-password=<my-password>
作成した namespace に Placement を作成します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: myPlacement namespace: myNamespace spec: clusterSets: - myClusterSet tolerations: - key: "cluster.open-cluster-management.io/unreachable" operator: Exists注記: Placement がクラスターを選択できるようにするには、Toleration を
unreachableに指定する必要があります。ManagedClusterSetリソースを作成し、これを namespace にバインドします。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSet metadata: name: myClusterSet --- apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSetBinding metadata: name: myClusterSet namespace: myNamespace spec: clusterSet: myClusterSet
namespace に
ManagedClusterImageRegistryCRD を作成します。apiVersion: imageregistry.open-cluster-management.io/v1alpha1 kind: ManagedClusterImageRegistry metadata: name: myImageRegistry namespace: myNamespace spec: placementRef: group: cluster.open-cluster-management.io resource: placements name: myPlacement pullSecret: name: myPullSecret registry: myRegistryAddress- コンソールからマネージドクラスターをインポートし、マネージドクラスターセットに追加します。
-
open-cluster-management.io/image-registry=myNamespace.myImageRegistryラベルをマネージドクラスターに追加した後に、マネージドクラスターで import コマンドをコピーして実行します。
1.4.7. マネージメントからのクラスターの削除
Kubernetes Operator 用のマルチクラスターエンジンで作成された OpenShift Container Platform クラスターを管理から削除する場合は、それを デタッチ または 破壊 できます。クラスターをデタッチするとマネージメントから削除されますが、完全には削除されません。管理する場合には、もう一度インポートし直すことができます。このオプションは、クラスターが Ready 状態にある場合にだけ利用できます。
次の手順により、次のいずれかの状況でクラスターが管理から削除されます。
- すでにクラスターを削除しており、削除したクラスターを Red Hat Advanced Cluster Management から削除したいと考えています。
- クラスターを管理から削除したいが、クラスターを削除していない。
重要:
- クラスターを破棄すると、マネージメントから削除され、クラスターのコンポーネントが削除されます。
マネージドクラスターを切り離すと、関連するネームスペースが自動的に削除されます。この名前空間にカスタムリソースを配置しないでください。
1.4.7.1. コンソールを使用したクラスターの削除
ナビゲーションメニューから、Infrastructure > Clusters に移動し、管理から削除するクラスターの横にあるオプションメニューから Destroy cluster または Detach cluster を選択します。
+ ヒント: 複数のクラスターをデタッチまたは破棄するには、デタッチまたは破棄するクラスターのチェックボックスを選択して、Detach または Destroy を選択します。
注記: local-cluster と呼ばれる管理対象時にハブクラスターをデタッチしようとすると、disableHubSelfManagement のデフォルト設定が false かどうかを確認してください。この設定が原因で、ハブクラスターはデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。
プロセスが終了するのを待たずにハブクラスターを再インポートするには、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
ネットワーク接続時のオンラインインストール で説明されているように、disableHubSelfManagement の値を true に変更して、自動的にインポートされないようにハブクラスターの値を変更できます。
1.4.7.2. コマンドラインを使用したクラスターの削除
ハブクラスターのコマンドラインを使用してマネージドクラスターをデタッチするには、以下のコマンドを実行します。
oc delete managedcluster $CLUSTER_NAME
デタッチ後にマネージドクラスターを削除するには、次のコマンドを実行します。
oc delete clusterdeployment <CLUSTER_NAME> -n $CLUSTER_NAME
注記: local-cluster という名前のハブクラスターをデタッチしようとする場合は、デフォルトの disableHubSelfManagement 設定が false である点に注意してください。この設定が原因で、ハブクラスターがデタッチされると、自身を再インポートして管理し、MultiClusterHub コントローラーが調整されます。ハブクラスターがデタッチプロセスを完了して再インポートするのに時間がかかる場合があります。プロセスが終了するのを待たずにハブクラスターを再インポートする場合は、以下のコマンドを実行して multiclusterhub-operator Pod を再起動して、再インポートの時間を短縮できます。
oc delete po -n open-cluster-management `oc get pod -n open-cluster-management | grep multiclusterhub-operator| cut -d' ' -f1`
ネットワーク接続時のオンラインインストール で説明されているように、disableHubSelfManagement の値を true に変更して、自動的にインポートされないようにハブクラスターの値を変更できます。
1.4.7.3. クラスター削除後の残りのリソースの削除
削除したマネージドクラスターにリソースが残っている場合は、残りのすべてのコンポーネントを削除するための追加の手順が必要になります。これらの追加手順が必要な場合には、以下の例が含まれます。
-
マネージドクラスターは、完全に作成される前にデタッチされ、
klusterletなどのコンポーネントはマネージドクラスターに残ります。 - マネージドクラスターをデタッチする前に、クラスターを管理していたハブが失われたり、破棄されているため、ハブからマネージドクラスターをデタッチする方法はありません。
- マネージドクラスターは、デタッチ時にオンライン状態ではありませんでした。
これらの状況の 1 つがマネージドクラスターのデタッチの試行に該当する場合は、マネージドクラスターから削除できないリソースがいくつかあります。マネージドクラスターをデタッチするには、以下の手順を実行します。
-
ocコマンドラインインターフェイスが設定されていることを確認してください。 また、マネージドクラスターに
KUBECONFIGが設定されていることを確認してください。oc get ns | grep open-cluster-management-agentを実行すると、2 つの namespace が表示されるはずです。open-cluster-management-agent Active 10m open-cluster-management-agent-addon Active 10m
次のコマンドを実行して、残りのリソースを削除します。
oc delete namespaces open-cluster-management-agent open-cluster-management-agent-addon --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc delete crds --wait=false oc get crds | grep open-cluster-management.io | awk '{print $1}' | xargs oc patch crds --type=merge -p '{"metadata":{"finalizers": []}}'次のコマンドを実行して、namespaces と開いているすべてのクラスター管理
crdsの両方が削除されていることを確認します。oc get crds | grep open-cluster-management.io | awk '{print $1}' oc get ns | grep open-cluster-management-agent
1.4.7.4. クラスターの削除後の etcd データベースのデフラグ
マネージドクラスターが多数ある場合は、ハブクラスターの etcd データベースのサイズに影響を与える可能性があります。OpenShift Container Platform 4.8 では、マネージドクラスターを削除すると、ハブクラスターの etcd データベースのサイズは自動的に縮小されません。シナリオによっては、etcd データベースは領域不足になる可能性があります。etcdserver: mvcc: database space exceeded のエラーが表示されます。このエラーを修正するには、データベース履歴を圧縮し、etcd データベースのデフラグを実行して etcd データベースのサイズを縮小します。
注記: OpenShift Container Platform バージョン 4.9 以降では、etcd Operator はディスクを自動的にデフラグし、etcd 履歴を圧縮します。手動による介入は必要ありません。以下の手順は、OpenShift Container Platform 4.8 以前のバージョン向けです。
以下の手順を実行して、ハブクラスターで etcd 履歴を圧縮し、ハブクラスターで etcd データベースをデフラグします。
1.4.7.4.1. 前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
1.4.7.4.2. 手順
etcd履歴を圧縮します。次に、
etcdメンバーへのリモートシェルセッションを開きます。$ oc rsh -n openshift-etcd etcd-control-plane-0.example.com etcdctl endpoint status --cluster -w table
以下のコマンドを実行して
etcd履歴を圧縮します。sh-4.4#etcdctl compact $(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9]*' -m1)
出力例
$ compacted revision 158774421
-
Defragmenting
etcddata で説明されているように、etcdデータベースを デフラグし、NOSPACEアラームを消去します。
1.4.8. マネージドクラスターのスケーリング
作成したクラスターについては、仮想マシンのサイズやノード数など、マネージドクラスターの仕様をカスタマイズおよびサイズ変更できます。以下のオプションを参照してください。
1.4.8.1. MachinePool を使用したスケーリング (テクノロジープレビュー)
作成したクラスターについては、仮想マシンのサイズやノード数など、マネージドクラスターの仕様をカスタマイズおよびサイズ変更できます。
テクノロジープレビュー: コンソールを使用した MachinePool スケーリングはプレビューステータスですが、MachinePool リソースは完全にサポートされています。
-
MachinePoolリソースの使用は、ベアメタルクラスターではサポートされていない機能です。 -
MachinePoolリソースは、ハブクラスター上の Kubernetes リソースで、MachineSetリソースをマネージドクラスターでグループ化します。 -
MachinePoolリソースは、ゾーンの設定、インスタンスタイプ、ルートストレージなど、マシンリソースのセットを均一に設定します。 -
MachinePoolでは、マネージドクラスターで、必要なノード数を手動で設定したり、ノードの自動スケーリングを設定したりするのに役立ちます。
1.4.8.1.1. 自動スケーリング
自動スケーリングを設定すると、トラフィックが少ない場合にリソースをスケールダウンし、多くのリソースが必要な場合に十分にリソースを確保できるようにスケールアップするなど、必要に応じてクラスターに柔軟性を持たせることができます。
1.4.8.1.1.1. 自動スケーリングの有効化
コンソールを使用して
MachinePoolリソースで自動スケーリングを有効にするには、以下の手順を実行します。- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- ターゲットクラスターの名前をクリックし、Machine pools タブを選択します。
- マシンプールページのターゲットマシンプールの Options メニューから Enable autoscale を選択します。
マシンセットレプリカの最小数および最大数を選択します。マシンセットレプリカは、クラスターのノードに直接マップします。
Scale をクリックした後、変更がコンソールに反映されるまでに数分かかる場合があります。Machine pools タブの通知がある場合は、View machines をクリックしてスケーリング操作のステータスを表示できます。
コマンドラインを使用して
MachinePoolリソースで自動スケーリングを有効にするには、以下の手順を実行します。以下のコマンドを実行して、マシンプールのリストを表示します。
oc get machinepools -n <managed-cluster-namespace>
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>
name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML ファイルから
spec.replicasフィールドを削除します。 -
spec.autoscaling.minReplicas設定およびspec.autoscaling.maxReplicasフィールドをリソース YAML に追加します。 -
レプリカの最小数を
minReplicas設定に追加します。 -
レプリカの最大数を
maxReplicas設定に追加します。 - ファイルを保存して変更を送信します。
マシンプールの自動スケーリングが有効になりました。
1.4.8.1.1.2. 自動スケーリングの無効化
コンソールまたはコマンドラインを使用して自動スケーリングを無効にできます。
コンソールを使用して自動スケーリングを無効にするには、次の手順を実行します。
- ナビゲーションで、Infrastructure > Clusters を選択します。
- ターゲットクラスターの名前をクリックし、Machine pools タブを選択します。
- マシンプールページから、ターゲットマシンプールの Options メニューから autoscale を無効にします。
必要なマシンセットのレプリカ数を選択します。マシンセットのレプリカは、クラスター上のノードを直接マップします。
Scale をクリックした後、表示されるまでに数分かかる場合があります。Machine pools タブの通知で View machines をクリックすると、スケーリングの状態を表示できます。
コマンドラインを使用して自動スケーリングを無効にするには、以下の手順を実行します。
以下のコマンドを実行して、マシンプールのリストを表示します。
oc get machinepools -n <managed-cluster-namespace>
managed-cluster-namespaceは、ターゲットのマネージドクラスターの namespace に置き換えます。以下のコマンドを入力してマシンプールの YAML ファイルを編集します。
oc edit machinepool <name-of-MachinePool-resource> -n <namespace-of-managed-cluster>
name-of-MachinePool-resourceは、MachinePoolリソースの名前に置き換えます。namespace-of-managed-clusterは、マネージドクラスターの namespace 名に置き換えます。-
YAML ファイルから
spec.autoscalingフィールドを削除します。 -
spec.replicasフィールドをリソース YAML に追加します。 -
replicasの設定にレプリカ数を追加します。 - ファイルを保存して変更を送信します。
1.4.8.2. Scaling hosts to an infrastructure environment
コンソールを使用して、ホストをインフラストラクチャー環境に追加できます。ホストを追加すると、クラスターの作成時に設定済みホストを簡単に選択できます。
以下の手順を実行して、新規スポットを追加します。
- ナビゲーションから、Infrastructure > Host inventory を選択します。
- ホストを追加するホストインベントリーを選択して、設定を表示します。
- ホスト タブを選択して、その環境にすでに追加されているホスト、またはホストを追加するホストを表示します。利用可能なホストが表に表示されるまでに数分かかる場合があります。
- Using a Discovery ISO、With BMC form、または By Uploading a YAML を選択して、ホストの情報を入力します。
Using a Discovery ISO オプションを選択した場合は、次の手順を実行します。
- コンソールで提供されるコマンドをコピーして ISO をダウンロードするか、Download Discovery ISO を選択します。
- ブート可能なデバイスで以下のコマンドを実行し、各ホストを起動します。
- セキュリティーを強化する場合は、検出された各ホストに対して Approve host を選択します。この追加手順では、ISO ファイルが変更されたり、アクセス権のないユーザーにより実行された場合に備えて保護します。
-
localhostに指定されたホスト名を一意の名前に変更します。
With BMC form オプションを選択した場合は、次の手順を実行します。
注記: ホストを追加する BMC オプションは、ハブクラスターのプラットフォームがベアメタル、Red Hat OpenStack Platform、VMware vSphere、またはユーザープロビジョニングのインフラストラクチャー (UPI) メソッドを使用してインストールされており、プラットフォームが
Noneである場合にのみ使用できます。- ホストの BMC の接続詳細を追加します。
ホストの追加 を選択して、ブートプロセスを開始します。ホストは、検出 ISO イメージを使用して自動的に起動され、起動時にホストのリストに追加されます。
BMC オプションを使用してホストを追加すると、ホストは自動的に承認されます。
By uploading a YAML オプションを選択した場合は、次の手順を実行します。
注意: YAML オプションを使用すると、複数のホストを同時にアップロードできます。
- Download template を選択して、提供された YAML に入力します。
- Upload を選択し、完成した YAML テンプレートに移動して、複数のホストを追加します。
このインフラストラクチャー環境にオンプレミスクラスターを作成できるようになりました。クラスターの作成の詳細については、オンプレミス環境でのクラスターの作成 を参照してください。
1.4.8.2.1. CIM でデプロイされた既存の OpenShift Container Platform クラスターへのノードの追加
CIM を使用してデプロイされた既存の OpenShift Container Platform クラスターにさらにノードを追加するには、前の手順を完了してから、新しい Agent カスタムリソース定義を agentSelector パラメーターに追加して ClusterDeployment カスタムリソースに関連付けます。
1.4.9. クラスタープロキシーアドオンの使用
一部の環境では、マネージドクラスターはファイアウォールの背後にあり、ハブクラスターから直接アクセスすることはできません。アクセスを取得するには、プロキシーアドオンを設定してマネージドクラスターの kube-apiserver にアクセスし、よりセキュアな接続を提供できます。
必要なアクセス: 編集
ハブクラスターとマネージドクラスターのクラスタープロキシーアドオンを設定するには、次の手順を実行します。
次の手順を実行してマネージドクラスター
kube-apiserverにアクセスするようにkubeconfigファイルを設定します。マネージドクラスターに有効なアクセストークンを指定します。
注記: サービスアカウントの対応するトークンを使用できます。デフォルトの namespace にあるデフォルトのサービスアカウントを使用することもできます。
次のコマンドを実行して、マネージドクラスターの
kubeconfigファイルをエクスポートします。export KUBECONFIG=<managed-cluster-kubeconfig>
次のコマンドを実行して、Pod へのアクセス権があるロールをサービスアカウントに追加します。
oc create role -n default test-role --verb=list,get --resource=pods oc create rolebinding -n default test-rolebinding --serviceaccount=default:default --role=test-role
次のコマンドを実行して、サービスアカウントトークンのシークレットを見つけます。
oc get secret -n default | grep <default-token>
default-tokenは、シークレット名に置き換えます。次のコマンドを実行して、トークンをコピーします。
export MANAGED_CLUSTER_TOKEN=$(kubectl -n default get secret <default-token> -o jsonpath={.data.token} | base64 -d)default-tokenは、シークレット名に置き換えます。
Red Hat Advanced Cluster Management ハブクラスターで
kubeconfigファイルを設定します。次のコマンドを実行して、ハブクラスター上の現在の
kubeconfigファイルをエクスポートします。oc config view --minify --raw=true > cluster-proxy.kubeconfig
エディターで
serverファイルを変更します。この例では、sedの使用時にコマンドを使用します。OSX を使用している場合は、alias sed=gsedを実行します。export TARGET_MANAGED_CLUSTER=<managed-cluster-name> export NEW_SERVER=https://$(oc get route -n multicluster-engine cluster-proxy-addon-user -o=jsonpath='{.spec.host}')/$TARGET_MANAGED_CLUSTER sed -i'' -e '/server:/c\ server: '"$NEW_SERVER"'' cluster-proxy.kubeconfig export CADATA=$(oc get configmap -n openshift-service-ca kube-root-ca.crt -o=go-template='{{index .data "ca.crt"}}' | base64) sed -i'' -e '/certificate-authority-data:/c\ certificate-authority-data: '"$CADATA"'' cluster-proxy.kubeconfigcluster1は、アクセスするマネージドクラスター名に置き換えます。次のコマンドを入力して、元のユーザー認証情報を削除します。
sed -i'' -e '/client-certificate-data/d' cluster-proxy.kubeconfig sed -i'' -e '/client-key-data/d' cluster-proxy.kubeconfig sed -i'' -e '/token/d' cluster-proxy.kubeconfig
サービスアカウントのトークンを追加します。
sed -i'' -e '$a\ token: '"$MANAGED_CLUSTER_TOKEN"'' cluster-proxy.kubeconfig
次のコマンドを実行して、ターゲットマネージドクラスターのターゲット namespace にあるすべての Pod をリスト表示します。
oc get pods --kubeconfig=cluster-proxy.kubeconfig -n <default>
defaultnamespace は、使用する namespace に置き換えます。マネージドクラスター上の他のサービスにアクセスします。この機能は、マネージドクラスターが Red Hat OpenShift Container Platform クラスターの場合に利用できます。サービスは
service-serving-certificateを使用してサーバー証明書を生成する必要があります。マネージドクラスターから、以下のサービスアカウントトークンを使用します。
export PROMETHEUS_TOKEN=$(kubectl get secret -n openshift-monitoring $(kubectl get serviceaccount -n openshift-monitoring prometheus-k8s -o=jsonpath='{.secrets[0].name}') -o=jsonpath='{.data.token}' | base64 -d)
ハブクラスターから、以下のコマンドを実行して認証局をファイルに変換します。
oc get configmap kube-root-ca.crt -o=jsonpath='{.data.ca\.crt}' > hub-ca.crt
1.4.10. 特定のクラスター管理ロールの設定
Kubernetes Operator 用のマルチクラスターエンジンをインストールすると、デフォルトの設定により、ハブクラスターで cluster-admin ロールが提供されます。このパーミッションを使用すると、ハブクラスターでマネージドクラスターを作成、管理、およびインポートできます。状況によっては、ハブクラスターのすべてのマネージドクラスターへのアクセスを提供するのではなく、ハブクラスターが管理する特定のマネージドクラスターへのアクセスを制限する必要がある場合があります。
クラスターロールを定義し、ユーザーまたはグループに適用することで、特定のマネージドクラスターへのアクセスを制限できます。ロールを設定して適用するには、以下の手順を実行します。
以下の内容を含む YAML ファイルを作成してクラスターロールを定義します。
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <clusterrole-name> rules: - apiGroups: - cluster.open-cluster-management.io resources: - managedclusters resourceNames: - <managed-cluster-name> verbs: - get - list - watch - update - delete - deletecollection - patch - apiGroups: - cluster.open-cluster-management.io resources: - managedclusters verbs: - create - apiGroups: - "" resources: - namespaces resourceNames: - <managed-cluster-name> verbs: - create - get - list - watch - update - delete - deletecollection - patch - apiGroups: - register.open-cluster-management.io resources: - managedclusters/accept resourceNames: - <managed-cluster-name> verbs: - update
clusterrole-nameは、作成するクラスターロールの名前に置き換えます。managed-cluster-nameは、ユーザーにアクセスを許可するマネージドクラスターの名前に置き換えます。以下のコマンドを入力して
clusterrole定義を適用します。oc apply -f <filename>
filenameを、先の手順で作成した YAML ファイルの名前に置き換えます。以下のコマンドを入力して、
clusterroleを指定されたユーザーまたはグループにバインドします。oc adm policy add-cluster-role-to-user <clusterrole-name> <username>
clusterrole-nameを、直前の手順で適用したクラスターロールの名前に置き換えます。usernameを、クラスターロールをバインドするユーザー名に置き換えます。
1.4.11. クラスターラベルの管理
クラスターにラベルを追加してグループリソースを選択します。詳細は、Labels and Selectors を参照してください。
クラスターの新規ラベルの追加、既存ラベルの削除、既存ラベルの編集が可能です。
ラベルを管理するには、Infrastructure > Clusters に移動し、Clusters の表でクラスターを見つけます。クラスターの Options メニューを使用して Edit labels を選択します。
新しいラベルを追加するには、Edit labels ダイアログボックスにラベルを入力します。エントリーは
Key=Valueの形式である必要があります。複数のラベルを追加する場合は、Enterキーを押すか、コンマを追加するか、ラベル間にスペースを追加して、ラベルを区切ります。Save をクリックしてからでないと、ラベルは保存されません。
- 既存のラベルを削除するには、リストから削除するラベルの Remove アイコンをクリックします。
-
既存のラベルを更新する場合は、同じキーに別の値を使用して、新規ラベルを追加すると、新しい値にキーを再割り当てすることができます。たとえば、
Key=Valueを変更するには、Key=NewValueを入力してKeyの値を更新します。
ヒント: クラスターの詳細ページからクラスターラベルを編集することもできます。ナビゲーションメニューから Infrastructure > Clusters をクリックします。Clusters ページで、クラスターの名前をクリックしてクラスターの詳細ページにアクセスします。Labels セクションの Edit アイコンをクリックします。Edit labels ダイアログボックスが表示されます。
1.4.12. マネージドクラスターで実行する Ansible Tower タスクの設定
Kubernetes Operator 用のマルチクラスターエンジンは Ansible Tower 自動化と統合されているため、クラスターの作成またはアップグレードの前または後に発生するプリフックおよびポストフックの AnsibleJob インスタンスを作成できます。クラスター破棄の prehook および posthook ジョブの設定やクラスターのスケールアクションはサポートされません。
必要なアクセス権限: クラスターの管理者
1.4.12.1. 前提条件
クラスターで Ansible テンプレートを実行するには、次の前提条件を満たす必要があります。
- OpenShift Container Platform 4.6 以降
- Ansible Automation Platform Resource Operator をインストールして、Ansible ジョブを Git サブスクリプションのライフサイクルに接続している。AnsibleJob を使用した Ansible Tower ジョブの実行時に最善の結果を得るには、実行時に Ansible Tower ジョブテンプレートが冪等でなければなりません。Ansible Automation Platform Resource Operator は、Red Hat OpenShift Container Platform OperatorHub ページから検索できます。
Ansible Tower 自動化のインストールおよび設定に関する詳細は、Ansible Tower タスクの設定 を参照してください。
1.4.12.2. コンソールでを使用したクラスターでの実行用の AnsibleJob テンプレート設定
クラスターの作成時、クラスターのインポート時、またはクラスターの作成後に、クラスターに使用する Ansible ジョブテンプレートを指定できます。
クラスターの作成時またはインポート時にテンプレートを指定するには、Automation の手順でクラスターに適用する Ansible テンプレートを選択します。Ansible テンプレートがない場合は、Add automation template をクリックして作成します。
クラスターの作成後にテンプレートを指定するには、既存のクラスターのアクションメニューで Update automation template をクリックします。Update automation template オプションを使用して、既存の自動化テンプレートを更新することもできます。
1.4.12.3. AnsibleJob テンプレートの作成
クラスターのインストールまたはアップグレードで Ansible ジョブを開始するには、ジョブ実行のタイミングを指定する Ansible ジョブテンプレートを作成する必要があります。これらは、クラスターのインストールまたはアップグレード前後に実行するように設定できます。
テンプレートの作成時に Ansible テンプレートの実行に関する詳細を指定するには、コンソールで以下の手順を実行します。
- ナビゲーションから Infrastructure > Automation を選択します。
状況に適したパスを選択します。
- 新規テンプレートを作成する場合には、Create Ansible template をクリックして手順 3 に進みます。
- 既存のテンプレートを変更する場合は、変更するテンプレートの Options メニューの Edit template をクリックして、手順 5 に進みます。
- 一意のテンプレート名を入力します。名前には小文字の英数字またはハイフン (-) を指定してください。
新規テンプレートの認証情報を選択します。Ansible 認証情報を Ansible テンプレートにリンクするには、以下の手順を実行します。
- ナビゲーションから Automation を選択します。認証情報にリンクされていないテンプレートの一覧内のテンプレートには、テンプレートを既存の認証情報にリンクするために使用できるリンク 認証情報へのリンク アイコンが含まれています。テンプレートと同じ namespace の認証情報のみが表示されます。
- 選択できる認証情報がない場合や、既存の認証情報を使用しない場合は、リンクするテンプレートの Options メニューから Edit template を選択します。
- 認証情報を作成する場合は、Add credential をクリックして、Ansible Automation Platform の認証情報の作成 の手順を行います。
- テンプレートと同じ namespace に認証情報を作成したら、テンプレートの編集時に Ansible Automation Platform credential フィールドで認証情報を選択します。
- クラスターをインストールする前に Ansible ジョブを開始する場合は、Pre-install Ansible job templates セクションで Add an Ansible job template を選択します。
prehook および posthook Ansible ジョブを選択するか、名前を入力して、クラスターのインストールまたはアップグレードに追加します。
注記: Ansible job template name は、Ansible Tower の Ansible ジョブの名前と一致している必要があります。
- 必要に応じて、Ansible ジョブをドラッグして、順番を変更します。
- Post-install Ansible job templates セクション、Pre-upgrade Ansible job templates セクション、および Post-upgrade Ansible job templates セクションで、クラスターがインストール後に開始する Ansible ジョブテンプレートに対して、手順 5-7 を繰り返します。
Ansible テンプレートは、指定のアクションが起こるタイミングで、このテンプレートを指定するクラスターで実行するように設定されます。
1.4.12.4. Ansible ジョブのステータスの表示
実行中の Ansible ジョブのステータスを表示して、起動し、正常に実行されていることを確認できます。実行中の Ansible ジョブの現在のステータスを表示するには、以下の手順を実行します。
- メニューで、Infrastructure > Clusters を選択して、Clusters ページにアクセスします。
- クラスターの名前を選択して、その詳細を表示します。
クラスター情報で Ansible ジョブの最後の実行ステータスを表示します。エントリーには、以下のステータスの 1 つが表示されます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
Failedと表示されます。 アップグレード prehook または posthook ジョブが失敗すると、アップグレードに失敗した Distribution フィールドに警告が表示されます。
ヒント: クラスターの prehook または posthook が失敗した場合は、Clusters ページからアップグレードを再試行できます。
-
インストール prehook または posthook ジョブが失敗すると、クラスターのステータスは
1.4.13. ManagedClusterSets の作成および管理
ManagedClusterSet は、マネージドクラスターのグループです。マネージドクラスターセットでは、グループ内の全マネージドクラスターに対するアクセス権を管理できます。ManagedClusterSetBinding リソースを作成して ManagedClusterSet リソースを namespace にバインドすることもできます。
各マネージドクラスターは、マネージドクラスターセットのメンバーである必要があります。ハブクラスターをインストールすると、default と呼ばれるデフォルトの ManagedClusterSet リソースが作成されます。マネージドクラスターセットに特に割り当てられていないマネージドクラスターはすべて、デフォルト のマネージドクラスターセットに自動的に割り当てられます。デフォルトのマネージドクラスターセットを常に利用可能にするには、デフォルト のマネージドクラスターセットを削除したり、更新したりできません。
注意: マネージドクラスターセットに明確に追加されていないクラスタープールは、デフォルトの ManagedClusterSet リソースに追加されません。マネージドクラスターがクラスタープールから要求された後、マネージドクラスターはデフォルトの ManagedClusterSet に追加されます。
1.4.13.1. Global ManagedClusterSet
マネージドクラスターを作成すると、管理を容易にするために次のものが自動的に作成されます。
-
globalと呼ばれるManagedClusterSet。 -
open-cluster-management-global-setという namespace。 globalと呼ばれるManagedClusterSetBindingは、globalManagedClusterSetをopen-cluster-management-global-setnamespace にバインドします。重要:
globalマネージドクラスターセットを削除、更新、または編集することはできません。globalマネージドクラスターセットには、すべてのマネージドクラスターが含まれます。以下の例を参照してください。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSetBinding metadata: name: global namespace: open-cluster-management-global-set spec: clusterSet: global
マネージドクラスターセットの更新の詳細については、以下を参照してください。
1.4.13.2. ManagedClusterSet の作成
マネージドクラスターセットにマネージドクラスターをグループ化して、マネージドクラスターでのユーザーのアクセス権限を制限できます。
必要なアクセス権限: クラスターの管理者
ManagedClusterSet は、クラスタースコープのリソースであるため、ManagedClusterSet の作成先となるクラスターで管理者権限が必要です。マネージドクラスターは、複数の ManagedClusterSet に追加できません。マネージドクラスターセットは、Kubernetes Operator コンソール用のマルチクラスターエンジンまたはコマンドラインインターフェイスから作成できます。
1.4.13.2.1. コンソールを使用した ManagedClusterSet の作成
コンソールを使用して、マネージドクラスターセットを作成するには、以下の手順を実行します。
- メインコンソールナビゲーションで Infrastructure > Clusters を選択し、Cluster sets タブが選択されていることを確認します。
- Create cluster set を選択し、クラスターセットの名前を入力します。
1.4.13.2.2. コマンドラインを使用した ManagedClusterSet の作成
コマンドラインを使用して yaml ファイルに以下のマネージドクラスターセットの定義を追加し、マネージドクラスターセットを作成します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSet metadata: name: <clusterset1>
clusterset1 はマネージドクラスターセットの名前に置き換えます。
1.4.13.3. ManagedClusterSet に対するユーザーまたはグループのロールベースのアクセス制御パーミッションの割り当て
ハブクラスターに設定したアイデンティティープロバイダーが提供するクラスターセットに、ユーザーまたはグループを割り当てることができます。
必要なアクセス権限: クラスターの管理者
ManagedClusterSet API が提供する RBAC パーミッションにはレベルが 3 つあります。
クラスターセット
admin- マネージドクラスターセットに割り当てられた、すべてのクラスターおよびクラスタープールリソースに対する完全なアクセス権限。
- クラスターの作成、クラスターのインポート、クラスタープールの作成権限。パーミッションは、マネージドクラスターセットの作成時に設定したマネージドクラスターに割り当てる必要があります。
クラスターセット
bind-
ManagedClusterSetBindingを作成してクラスターセットを namespace にバインドするアクセス許可。ユーザーまたはグループには、ターゲット namespace でManagedClusterSetBindingを作成する権限も必要です。 - マネージドクラスターセットに割り当てられた、すべてのクラスターおよびクラスタープールリソースに対する読み取り専用の権限。
- クラスターの作成、クラスターのインポート、またはクラスタープールの作成を実行する権限なし。
-
クラスターセット
view- マネージドクラスターセットに割り当てられた、すべてのクラスターおよびクラスタープールリソースに対する読み取り専用の権限。
- クラスターの作成、クラスターのインポート、またはクラスタープールの作成を実行する権限なし。
注意: グローバルクラスターセットにクラスターセット admin 権限を適用することはできません。
コンソールからマネージドクラスターセットにユーザーまたはグループを割り当てるには、次の手順を実行します。
- コンソールのメインナビゲーションメニューで、Infrastructure > Clusters を選択します。
- Cluster sets タブを選択します。
- ターゲットクラスターセットを選択します。
- Access management タブを選択します。
- Add user or group を選択します。
- アクセス権を割り当てるユーザーまたはグループを検索して選択します。
- Cluster set admin または Cluster set view ロールを選択して、選択したユーザーまたはグループに付与します。ロールの権限の詳細については、ロールの概要 を参照してください。
- Add を選択して変更を送信します。
テーブルにユーザーまたはグループが表示されます。全マネージドクラスターセットリソースのパーミッションの割り当てがユーザーまたはグループに伝播されるまでに数秒かかる場合があります。
ロールベースのアクションの詳細については、ロールベースのアクセス制御 を参照してください。
配置情報については、配置での ManagedClusterSets の使用 を参照してください。
1.4.13.3.1. ManagedClusterSetBinding リソースの作成
ManagedClusterSetBinding リソースを作成して ManagedClusterSet リソースを namespace にバインドします。同じ namespace で作成されたアプリケーションおよびポリシーがアクセスできるのは、バインドされたマネージドクラスターセットリソースに含まれるマネージドクラスターだけです。
namespace へのアクセスパーミッションは、その namespace にバインドされるマネージドクラスターセットに自動的に適用されます。マネージドクラスターセットがバインドされる namespace へのアクセス権限がある場合は、その namespace にバインドされているマネージドクラスターセットにアクセス権限が自動的に付与されます。ただし、マネージドクラスターセットへのアクセス権限のみがある場合は、対象の namespace にある他のマネージドクラスターセットにアクセスする権限は自動的に割り当てられません。マネージドクラスターセットが表示されない場合は、表示に必要なパーミッションがない可能性があります。
コンソールまたはコマンドラインを使用してマネージドクラスターセットバインディングを作成できます。
1.4.13.3.1.1. コンソールを使用した ManagedClusterSetBinding の作成
コンソールを使用して ManagedClusterSetBinding を作成するには、以下の手順を実行します。
- メインナビゲーションで Infrastructure > Clusters を選択し、Cluster sets タブを選択します。
- バインディングを作成するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Edit namespace bindings を選択します。
- Edit namespace bindings ページで、ドロップダウンメニューからクラスターセットをバインドする namespace を選択します。このクラスターセットにバインディングされている既存の namespace は選択してあります。
1.4.13.3.1.2. コマンドラインを使用した ManagedClusterSetBinding の作成
コマンドラインを使用してマネージドクラスターセットバインディングを作成するには、以下の手順を実行します。
yamlファイルにManagedClusterSetBindingリソースを作成します。クラスターセットバインディングの作成時には、クラスターセットバインディング名と、バインドするマネージドクラスターセット名を一致させる必要があります。ManagedClusterSetBindingリソースは、以下の情報のようになります。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: ManagedClusterSetBinding metadata: namespace: project1 name: clusterset1 spec: clusterSet: clusterset1
ターゲットのマネージドクラスターセットでのバインド権限を割り当てておく必要があります。以下の
ClusterRoleリソースの例を確認してください。この例には、ユーザーがclusterset1にバインドできるように、複数のルールが含まれています。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/bind"] resourceNames: ["clusterset1"] verbs: ["create"]
1.4.13.4. クラスターの ManagedClusterSet への追加
ManagedClusterSet の作成後に、1 つ以上のマネージドクラスターを追加する必要があります。コンソールまたはコマンドラインのいずれかを使用して、マネージドクラスターをマネージドクラスターセットに追加できます。
1.4.13.4.1. コンソールを使用したクラスターの ManagedClusterSet への追加
コンソールを使用してクラスターをマネージドクラスターに追加するには、以下の手順を実行します。
- マネージドクラスターセットを作成している場合は、Manage resource assignments を選択して、Manage resource assignments ページに直接移動します。この手順のステップ 6 に進みます。
- クラスターがすでに存在する場合は、メインのナビゲーションで Infrastructure > Clusters を選択してクラスターページにアクセスします。
- Cluster sets タブを選択して、利用可能なクラスターセットを表示します。
- マネージドクラスターセットに追加するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Manage resource assignments を選択します。
- Manage resource assignments ページで、クラスターセットに追加するリソースのチェックボックスを選択します。
- Review を選択して変更を確認します。
Save を選択して変更を保存します。
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合は、マネージドクラスター両方で RBAC パーミッションの設定が必要です。
1.4.13.4.2. コマンドラインを使用した ManagedClusterSet へのクラスターの追加
コマンドラインを使用してクラスターをマネージドクラスターに追加するには、以下の手順を実行します。
managedclustersets/joinの仮想サブリソースに作成できるように、RBACClusterRoleエントリーが追加されていることを確認します。このパーミッションがない場合は、マネージドクラスターをManagedClusterSetに割り当てることはできません。このエントリーが存在しない場合は、
yamlファイルに追加します。サンプルエントリーは以下の内容のようになります。kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: clusterrole1 rules: - apiGroups: ["cluster.open-cluster-management.io"] resources: ["managedclustersets/join"] resourceNames: ["<clusterset1>"] verbs: ["create"]clusterset1はManagedClusterSetの名前に置き換えます。注記: マネージドクラスターを別の
ManagedClusterSetに移動する場合には、マネージドクラスターセット両方でパーミッションの設定が必要です。yamlファイルでマネージドクラスターの定義を検索します。ラベルの追加先のマネージドクラスター定義のセクションは、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true
この例では、
cluster1はマネージドクラスターの名前です。ManagedClusterSetの名前をcluster.open-cluster-management.io/clusterset: clusterset1形式で指定してラベルを追加します。コードは以下の例のようになります。
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 labels: cluster.open-cluster-management.io/clusterset: clusterset1 spec: hubAcceptsClient: trueこの例では、
cluster1は、clusterset1のマネージドクラスターセット名に追加するクラスターです。注記: マネージドクラスターが削除済みのマネージドクラスターセットにこれまでに割り当てられていた場合は、すでに存在しないクラスターが指定されたマネージドクラスターセットがマネージドクラスターに設定されている可能性があります。その場合は、名前を新しい名前に置き換えます。
1.4.13.5. Placement での ManagedClusterSets の使用
Placement リソースは、namespace レベルのリソースで、placement namespace にバインドされる ManagedClusterSets から ManagedClusters セットを選択するルールを定義します。
必要なアクセス権限: クラスター管理者またはクラスターセット管理者。
1.4.13.5.1. 配置の概要
マネージドクラスターを使用した配置がどのように機能するかについては、次の情報を参照してください。
-
Kubernetes クラスターは、cluster スコープの
ManagedClustersとしてハブクラスターに登録されます。 -
managedclusterは、クラスタースコープのManagedClusterSetsに編成されます。 -
ManagedClusterSetsはワークロード namespace にバインドされます。 -
namespace スコープの
Placementsは、ManagedClusterSetsの一部を指定して、ManagedClusters候補の作業セットを選択します。 Placementsは、ラベルと要求セレクターを使用して作業セットから選択します。重要:
Placementでは、placement namespace にManagedClusterSetがバインドされていない場合、ManagedClusterは選択されません。-
ManagedClustersの配置は、テイントおよび容認 (Toleration) を使用して制御できます。詳細は、Taint と Toleration を使用したマネージドクラスターの配置 を参照してください。
Placement 仕様には以下のフィールドが含まれます。
ClusterSetsは、ManagedClustersの選択元のManagedClusterSetsを表します。-
指定されていない場合は、Placement namespace にバインドされる
ManagedClusterSetsからManagedClustersが選択されます。 -
指定されている場合は、
ManagedClustersがこのセットの交差部分から選択され、ManagedClusterSetsは Placement namespace にバインドされます。
-
指定されていない場合は、Placement namespace にバインドされる
NumberOfClustersは、配置要件を満たすManagedClustersの中から選択する数を表します。指定されていない場合は、配置要件を満たすすべての
ManagedClustersが選択されます。-
Predicatesは、ラベルおよび要求セレクターでManagedClustersを選択する述語のスライスを表します。述語は ORed です。 prioritizerPolicyは優先順位のポリシーを表します。モードはExact、Additive、または""のいずれかになります。ここで""はデフォルトでAdditiveになります。-
Additiveモードでは、設定値が特に指定されていない Prioritizer はデフォルト設定で有効になっています。現在のデフォルト設定では、Steady と Balance の重みは 1 で、他の Prioritizer は 0 になります。デフォルトの設定は、今後変更される可能性があるので、優先順位が変更される可能性があります。Additiveモードでは、すべての Prioritizer を設定する必要はありません。 -
Exactモードでは、設定値で特に指定されていない Prioritizer の重みがゼロになります。Exactモードでは、必要な Prioritizer の完全なセットを入力する必要がありますが、リリースごとに動作が変わることはありません。
-
設定とは、Prioritizer の設定を表します。scoreCoordinate は prioritizer およびスコアソースの設定を表します。
-
typeは prioritizer スコアのタイプを定義します。タイプはBuiltIn、AddOn、または" "です。" "のデフォルトはBuiltInです。タイプがBuiltInの場合、prioritizer 名を指定する必要があります。タイプがAddOnの場合、AddOnでスコアソースを設定する必要があります。 builtinは、BuiltIn prioritizer の名前を定義します。以下のリストには、有効なBuiltInの prioritizer 名が含まれます。- Balance: クラスター間の決定を分散します。
- Steady: 既存の意思決定が安定していることを確認します。
- ResourceAllocatableCPU & ResourceAllocatableMemory: 割り当て可能なリソースに基づいてクラスターを分類します。
addOnはリソース名およびスコア名を定義します。AddOnPlacementScoreは、アドオンスコアを記述するために導入されました。詳細は Extensible scheduling を参照してください。-
resourceNameはAddOnPlacementScoreのリソース名を定義します。Placement prioritizer は、この名前でAddOnPlacementScoreカスタムリソースを選択します。 -
scoreNameはAddOnPlacementScore内でスコア名を定義します。AddOnPlacementScoreには、スコア名とスコア値のリストが含まれます。scoreName: prioritizer で使用されるスコアを指定します。
-
-
-
weightは Prioritizer の重みを定義します。値は [-10,10] の範囲に指定する必要があります。それぞれの prioritizer は、[-100, 100] の範囲でクラスターの整数スコアを計算します。クラスターの最後のスコアは、以下の式sum(weight * prioritizer_score)で決定されます。重みが大きい場合は、Prioritizer はクラスターの選択で重みの高いものを受け取ることを意味し、一方、重みが 0 の場合は Prioritizer が無効であることを示します。負の重みは、最後に選択されたものであることを示します。
注記: configurations.name ファイルは v1beta1 で削除され、scoreCoordinate.builtIn ファイルに置き換えられる予定です。name と scoreCoordinate.builtIn の両方が定義されている場合には、scoreCoordinate.builtIn の値を使用して選択を決定します。
1.4.13.5.2. 配置の例
namespace に ManagedClusterSetBinding を作成して、その namespace に ManagedClusterSet を最低でも 1 つバインドする必要があります。注記: managedclustersets/bind の仮想サブリソースの CREATE に対してロールベースのアクセスが必要です。以下の例を参照してください。
labelSelectorでManagedClustersを選択します。以下の例では、labelSelectorはラベルvendor: OpenShiftのクラスターだけに一致します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShiftclaimSelectorでManagedClustersを選択します。以下の例では、claimSelectorはregion.open-cluster-management.ioがus-west-1のクラスターだけに一致します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1clusterSetsからManagedClustersを選択します。以下の例では、claimSelectorはclusterSets:clusterset1clusterset2だけに一致します。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement3 namespace: ns1 spec: clusterSets: - clusterset1 - clusterset2 predicates: - requiredClusterSelector: claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1任意の数の
ManagedClustersを選択します。以下の例は、numberOfClustersが3の場合です。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement4 namespace: ns1 spec: numberOfClusters: 3 predicates: - requiredClusterSelector: labelSelector: matchLabels: vendor: OpenShift claimSelector: matchExpressions: - key: region.open-cluster-management.io operator: In values: - us-west-1割り当て可能なメモリーが最大のクラスターを選択します。
注記: Kubernetes Node Allocatable と同様に、allocatable は、各クラスターの Pod で利用可能なコンピュートリソースの量として定義されます。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement6 namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableMemory割り当て可能な CPU およびメモリーが最大のクラスターを選択し、配置がリソースの変更に厳密に対応するように設定します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement7 namespace: ns1 spec: numberOfClusters: 1 prioritizerPolicy: configurations: - scoreCoordinate: builtIn: ResourceAllocatableCPU weight: 2 - scoreCoordinate: builtIn: ResourceAllocatableMemory weight: 2最大割り当て可能なメモリーと最大のアドオンスコアの cpu 比率を持つ 2 つのクラスターを選択し、配置の決定を固定します。
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement8 namespace: ns1 spec: numberOfClusters: 2 prioritizerPolicy: mode: Exact configurations: - scoreCoordinate: builtIn: ResourceAllocatableMemory - scoreCoordinate: builtIn: Steady weight: 3 - scoreCoordinate: type: AddOn addOn: resourceName: default scoreName: cpuratio
1.4.13.5.3. 配置のデシジョン
ラベルが cluster.open-cluster-management.io/placement={placement name} の PlacementDecisions が 1 つまたは複数作成され、Placement で選択された ManagedClusters を表します。
ManagedCluster が選択され、PlacementDecision に追加されると、この Placement を使用するコンポーネントは、ManagedCluster でワークロードを適用する可能性があります。ManagedCluster が選択されなくなり、PlacementDecisions から削除されると、この ManagedCluster に適用されるワークロードも随時削除する必要があります。
以下の PlacementDecision の例を参照してください。
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: PlacementDecision
metadata:
labels:
cluster.open-cluster-management.io/placement: placement1
name: placement1-kbc7q
namespace: ns1
ownerReferences:
- apiVersion: cluster.open-cluster-management.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: Placement
name: placement1
uid: 05441cf6-2543-4ecc-8389-1079b42fe63e
status:
decisions:
- clusterName: cluster1
reason: ''
- clusterName: cluster2
reason: ''
- clusterName: cluster3
reason: ''1.4.13.5.4. アドオンのステータス
デプロイ先のアドオンのステータスに合わせて、配置用のマネージドクラスターを選択できます。たとえば、クラスターで有効になっている特定のアドオンがある場合にのみ、配置のマネージドクラスターを選択します。
これは、アドオンのラベルと、必要に応じてそのステータスを指定して実行できます。クラスターでアドオンが有効になっている場合、ラベルは ManagedCluster リソースで自動的に作成されます。アドオンが無効になると、ラベルは自動的に削除されます。
各アドオンは、feature.open-cluster-management.io/addon-<addon_name>=<status_of_addon> の形式でラベルで表現します。
addon_name は、選択するマネージドクラスターで有効にする必要があるアドオンの名前に置き換えます。
status_of_addon は、クラスターが選択されている場合にアドオンに指定すべきステータスに置き換えます。status_of_addon の使用可能な値は以下のリストのとおりです。
-
Available: アドオンが有効で利用可能である。 -
unhealthy: アドオンは有効になっているが、リースは継続的に更新されない。 -
unreachable: アドオンは有効になっているが、リースが見つからない。これは、マネージドクラスターがオフライン時にも発生する可能性があります。
たとえば、利用可能な application-manager アドオンは、以下を読み取るマネージドクラスターのラベルで表されます。
feature.open-cluster-management.io/addon-application-manager: available
アドオンおよびそれらのステータスに基づいて配置を作成する以下の例を参照してください。
以下の YAML コンテンツを追加して、
application-managerを有効化したマネージドクラスターすべてを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: Exists以下の YAML コンテンツを追加して、
application-managerがavailableのステータスで有効化されているすべてのマネージドクラスターを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement2 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchLabels: "feature.open-cluster-management.io/addon-application-manager": "available"以下の YAML コンテンツを追加して、
application-managerが無効にされているマネージドクラスターすべてを含む配置を作成できます。apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement3 namespace: ns1 spec: predicates: - requiredClusterSelector: labelSelector: matchExpressions: - key: feature.open-cluster-management.io/addon-application-manager operator: DoesNotExist
1.4.13.5.5. 拡張可能なスケジューリング
配置リソースベースのスケジューリングでは、マネージドクラスターのスコアを計算するために、prioritizer が MananagedCluster リソースで提供されるデフォルト値よりも多くのデータを必要とする場合があります。たとえば、モニタリングシステム経由で取得されるクラスターの CPU またはメモリー使用量データに基づいてクラスターをスケジュールします。
API AddOnPlacementScore は、カスタムのスコアをもとにスケジューリングする拡張可能な方法をサポートします。
-
placement.yamlファイルにスコアを指定して、クラスターを選択できます。 -
スコアプロバイダーとして、サードパーティーのコントローラーをハブクラスターまたはマネージドクラスターのいずれかで実行して、
AddOnPlacementScoreのライフサイクルを維持し、スコアを更新することができます。
詳細は、open-cluster-management リポジトリーの 配置拡張可能なスケジューリングの拡張機能 を参照してください。
1.4.13.6. テイントおよび容認 (Toleration) を使用したマネージドクラスターの配置
テイントおよび容認 (Toleration) を使用して、マネージドクラスターまたはマネージドクラスターセットの配置を制御できます。Taint と Toleration は、特定の placement でマネージドクラスターが選択されないようにする方法を提供します。この制御は、特定のマネージドクラスターが一部の placement に含まれないようにする場合に役立ちます。Taint をマネージドクラスターに、Toleration を placement に追加できます。Taint と Toleration が一致しない場合は、マネージドクラスターはその placement には選択されません。
1.4.13.6.1. マネージドクラスターへの Taint の追加
Taint はマネージドクラスターのプロパティーで指定され、 placement がマネージドクラスターまたはマネージドクラスターのセットを除外できます。以下の例のようなコマンドを入力して、Taint をマネージドクラスターに追加できます。
kubectl taint ManagedCluster <managed_cluster_name> key=value:NoSelect
Taint の仕様には以下のフィールドが含まれます。
-
(必須) key: クラスターに適用される Taint キー。この値は、その placement に追加される基準を満たすように、マネージドクラスターの Toleration の値と一致させる必要があります。この値は確認できます。たとえば、この値は
barまたはfoo.example.com/barです。 -
(オプション) Value: Taint キーのTaint値。この値は、その placement に追加される基準を満たすように、マネージドクラスターの Toleration の値と一致させる必要があります。たとえば、この値は
valueとすることができます。 (必須) Effect: Taint を許容しない placement における Taint の効果、または placement の Taint と Toleration が一致しないときに何が起こるか。effect の値は、以下のいずれかの値である必要があります。
-
NoSelect: placement は、この Taint を許容しない限り、クラスターを選択できません。Taint の設定前に placement でクラスターが選択された場合は、クラスターは placement の決定から削除されます。 -
NoSelectIfNew: スケジューラーは、クラスターが新しい場合にそのクラスターを選択できません。プレイスメントは、Taint を許容し、すでにクラスター決定にそのクラスターがある場合にのみ、そのクラスターを選択することができます。
-
-
(必須)
TimeAdded: Taint を追加した時間。この値は自動的に設定されます。
1.4.13.6.2. マネージドクラスターのステータスを反映させる組み込み Taint の特定
マネージドクラスターにアクセスできない場合には、クラスターを placement に追加しないでください。以下の Taint は、アクセスできないマネージドクラスターに自動的に追加されます。
cluster.open-cluster-management.io/unavailable: この Taint は、ステータスがFalseのManagedClusterConditionAvailableの条件がある場合にマネージドクラスターに追加されます。Taint にはNoSelectと同じ効果があり、空の値を指定すると、利用不可のクラスターがスケジュールされないようにできます。この Taint の例は、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unavailable timeAdded: '2022-02-21T08:11:54Z'cluster.open-cluster-management.io/unreachable-ManagedClusterConditionAvailableの条件のステータスがUnknownであるか、条件がない場合に、この Taint はマネージドクラスターに追加されます。この Taint にはNoSelectと同じ効果があり、空の値を指定すると、到達不可のクラスターがスケジュールされないようにできます。この Taint の例は、以下の内容のようになります。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: cluster.open-cluster-management.io/unreachable timeAdded: '2022-02-21T08:11:06Z'
1.4.13.6.3. Toleration の placement への追加
Toleration は placement に適用され、 placement の Toleration と Taint が同じでないマネージドクラスターを placement から除外できます。Toleration の仕様には以下のフィールドが含まれます。
- (任意) Key: キーは placement ができるように Taint キーに一致します。
- (任意) Value: toleration の値は、 placement を許可する Toleration の Taint の値と一致する必要があります。
(任意) Operator: 演算子はキーと値の関係を表します。有効な演算子は
equalとexistsです。デフォルト値はequalです。Toleration は、キーが同じ場合、効果が同じ場合、さらび演算子が以下の値のいずれかである場合に、Taint にマッチします。-
equal: Operator はequalで、値は Taint および Toleration と同じになります。 -
exists: 値のワイルドカード。これにより、 placement は特定のカテゴリーのすべての Taint を許容できます。
-
-
(任意) Effect: 一致する Taint の効果。空のままにすると、すべての Taint の効果と一致します。指定可能な値は、
NoSelectまたはNoSelectIfNewです。 -
(任意) TolerationSeconds: マネージドクラスターを新しい placement に移動する前に、Taint を許容する時間の長さ (秒単位) です。effect 値が
NoSelectまたはPreferNoSelectでない場合は、このフィールドは無視されます。デフォルト値はnilで、時間制限がないことを示します。TolerationSecondsのカウント開始時刻は、クラスターのスケジュール時刻やTolerationSeconds加算時刻の値ではなく、自動的に Taint のTimeAddedの値として記載されます。
以下の例は、Taint が含まれるクラスターを許容する Toleration を設定する方法を示しています。
この例のマネージドクラスターの Taint:
apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: cluster1 spec: hubAcceptsClient: true taints: - effect: NoSelect key: gpu value: "true" timeAdded: '2022-02-21T08:11:06Z'Taint を許容できる placement の Toleration
apiVersion: cluster.open-cluster-management.io/v1beta1 kind: Placement metadata: name: placement1 namespace: default spec: tolerations: - key: gpu value: "true" operator: EqualToleration の定義例では、
key: gpuとvalue: "true"が一致するため、placement でcluster1を選択できます。
注記: マネージドクラスターは、Taint の Toleration が含まれる placement に置かれる保証はありません。他の placement に同じ Toleration が含まれる場合には、マネージドクラスターはそれらの placement のいずれかに置かれる可能性があります。
1.4.13.6.4. 一時的な Toleration の指定
TolerationSeconds の値は、Toleration が Taint を許容する期間を指定します。この一時的な Toleration は、マネージドクラスターがオフラインで、このクラスターにデプロイされているアプリケーションを、許容時間中に別のマネージドクラスターに転送できる場合に役立ちます。
たとえば、以下の Taint を持つマネージドクラスターに到達できなくなります。
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
name: cluster1
spec:
hubAcceptsClient: true
taints:
- effect: NoSelect
key: cluster.open-cluster-management.io/unreachable
timeAdded: '2022-02-21T08:11:06Z'
以下の例のように、TolerationSeconds の値で placement を定義すると、ワークロードは 5 分後に利用可能な別のマネージドクラスターに転送されます。
apiVersion: cluster.open-cluster-management.io/v1alpha1
kind: Placement
metadata:
name: demo4
namespace: demo1
spec:
tolerations:
- key: cluster.open-cluster-management.io/unreachable
operator: Exists
tolerationSeconds: 300
----マネージドクラスターに到達できなくなると、アプリケーションが 5 分間別のマネージドクラスターに移動されます。
1.4.13.7. ManagedClusterSet からのマネージドクラスターの削除
マネージドクラスターセットからマネージドクラスターを削除して別のマネージドクラスターセットに移動するか、セットの管理設定から削除する必要がある場合があります。コンソールまたはコマンドラインインターフェイスを使用して、マネージドクラスターセットからマネージドクラスターを削除できます。
注記: マネージドクラスターはすべて、マネージドクラスターセットに割り当てる必要があります。ManagedClusterSet からマネージドクラスターを削除して、別の ManagedClusterSet に割り当てない場合は、デフォルト のマネージドクラスターセットに自動的に追加されます。
1.4.13.7.1. コンソールを使用した ManagedClusterSet からのマネージドクラスターの削除
コンソールを使用してマネージドクラスターセットからクラスターを削除するには、次の手順を実行します。
- Infrastructure > Clusters をクリックし、Cluster sets タブが選択されていることを確認します。
- マネージドクラスターセットから削除するクラスターセットの名前を選択し、クラスターセットの詳細を表示します。
- Actions > Manage resource assignments を選択します。
Manage resource assignments ページで、クラスターセットから削除するリソースのチェックボックスをオフにします。
この手順では、すでにクラスターセットのメンバーであるリソースを削除します。マネージドクラスターの詳細を表示して、リソースがすでにクラスターセットのメンバーであるかどうかを確認できます。
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合には、マネージドクラスターセット両方で RBAC パーミッションの設定が必要です。
1.4.13.7.2. コマンドラインを使用した ManagedClusterSet からのクラスターの削除
マネージドクラスターセットからマネージドクラスターを削除するには、以下の手順を実行します。
以下のコマンドを実行して、マネージドクラスターセットでマネージドクラスターのリストを表示します。
oc get managedclusters -l cluster.open-cluster-management.io/clusterset=<clusterset1>
clusterset1はマネージドクラスターセットの名前を置き換えます。- 削除するクラスターのエントリーを見つけます。
削除するクラスターの
yamlエントリーからラベルを削除します。ラベルの例については、以下のコードを参照してください。labels: cluster.open-cluster-management.io/clusterset: clusterset1
注記: マネージドクラスターを別のマネージドクラスターセットに移動する場合には、マネージドクラスターセット両方で RBAC パーミッションの設定が必要です。
1.4.14. クラスタープールの管理 (テクノロジープレビュー)
クラスタープールは、Red Hat OpenShift Container Platform クラスターにオンデマンドで、スケーリングする場合に、迅速かつコスト効果を高く保ちながら、アクセスできるようにします。クラスタープールは、Amazon Web Services、Google Cloud Platform または Microsoft Azure で設定可能な数多くの OpenShift Container Platform クラスターをプロビジョニングします。このプールは、開発、継続統合、および実稼働のシナリオにおいてクラスター環境を提供したり、置き換えたりする場合に特に便利です。実行を継続するクラスターの数を指定して、すぐに要求できるようにすることができます。残りのクラスターは休止状態に保たれるため、数分以内に再開して要求できます。
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスター要求が作成されると、その要求にプールは実行中のクラスターを割り当てます。実行中のクラスターがない場合は、休止状態のクラスターを再開してクラスターを提供するか、新規クラスターをプロビジョニングします。クラスタープールは自動的に新しいクラスターを作成し、休止状態のクラスターを再開して、プール内で利用可能な実行中のクラスターの指定サイズおよび数を維持します。
クラスタープールを作成する手順は、クラスターの作成手順と似ています。クラスタープールのクラスターは、すぐ使用するために作成されるわけではありません。
1.4.14.1. クラスタープールの作成
クラスタープールを作成する手順は、クラスターの作成手順と似ています。クラスタープールのクラスターは、すぐ使用するために作成されるわけではありません。
必要なアクセス権限: 管理者
1.4.14.1.1. 前提条件
クラスタープールを作成する前に、次の前提条件を参照してください。
- Kubernetes Operator ハブクラスター用のマルチクラスターエンジンをデプロイする必要があります。
- プロバイダー環境で Kubernetes クラスターを作成できるように、Kubernetes Operator ハブクラスター用のマルチクラスターエンジンにインターネットアクセスが必要です。
- AWS、GCP、または Microsoft Azure プロバイダーのクレデンシャルが必要です。詳細は、認証情報の管理の概要 を参照してください。
- プロバイダー環境で設定済みのドメインが必要です。ドメインの設定方法は、プロバイダーのドキュメントを参照してください。
- プロバイダーのログイン認証情報が必要です。
- OpenShift Container Platform イメージプルシークレットが必要です。イメージプルシークレットの使用 を参照してください。
注意: この手順でクラスタープールを追加すると、プールからクラスターを要求するときに、Kubernetes Operator のマルチクラスターエンジンによって管理されるクラスターが自動的にインポートされるように設定されます。クラスター要求で管理用に、要求されたクラスターを自動的にインポートしないようにクラスタープールを作成する場合には、clusterClaim 理 s−すを以下ののテーションに追加します。
kind: ClusterClaim
metadata:
annotations:
cluster.open-cluster-management.io/createmanagedcluster: "false"
文字列であることを示すには、"false" という単語を引用符で囲む必要があります。
1.4.14.1.2. クラスタープールを作成する
クラスタープールを作成するには、ナビゲーションメニューで Infrastructure > Clusters を選択します。Cluster pools タブには、アクセス可能なクラスタープールがリスト表示されます。Create cluster pool を選択し、コンソールの手順を実行します。
クラスタープールに使用するインフラストラクチャー認証情報がない場合は、Add credential を選択して作成できます。
リストから既存の namespace を選択するか、作成する新規 namespace の名前を入力します。クラスタープールは、クラスターと同じ namespace に配置する必要はありません。
クラスターセットでクラスタープールを作成すると、クラスタープールの追加先の namespace の clusterset admin パーミッションがある全ユーザーに、namespace admin パーミッションが適用されます。同様に、namespace view パーミッションは clusterset view パーミッションのあるユーザーに適用されます。
クラスタープールの RBAC ロールを使用して、既存クラスターセットのロール割り当てを共有する場合は、クラスターセット名を選択します。クラスタープールのクラスターセットは、クラスタープールの作成時にのみ設定できます。クラスタープールの作成後には、クラスタープールまたはクラスタープールのクラスターセットの関連付けを変更できません。クラスタープールから要求したクラスターは、クラスタープールと同じクラスターセットに自動的に追加されます。
注記: cluster admin の権限がない場合は、クラスターセットを選択する必要があります。この状況でクラスターセットの名前が含まれない場合は、禁止エラーで、クラスターセットの作成要求が拒否されます。選択できるクラスターセットがない場合は、クラスター管理者に連絡してクラスターセットを作成し、clusterset admin 権限を付与してもらいます。
cluster pool size は、クラスタープールにプロビジョニングするクラスターの数を指定し、クラスタープールの実行回数は、プールが実行を継続し、すぐに使用できるように要求できるクラスターの数を指定します。
この手順は、クラスターを作成する手順と非常に似ています。
プロバイダーに必要な固有の情報は、以下を参照してください。
1.4.14.2. クラスタープールからのクラスターの要求
ClusterClaim リソースは、クラスタープールからクラスターをチェックアウトするために使用されます。クラスターの稼働中で、クラスタープールで準備できると、要求が完了します。クラスタープールは、クラスタープールに指定された要件を維持するために、クラスタープールに新しい実行中およびハイバネートされたクラスターを自動的に作成します。
注記: クラスタープールから要求されたクラスターが不要になり、破棄されると、リソースは削除されます。クラスターはクラスタープールに戻りません。
必要なアクセス権限: 管理者
1.4.14.2.1. 前提条件
クラスタープールからクラスターを要求する前に、以下を利用意する必要があります。
利用可能なクラスターのある/ないクラスタープール。クラスタープールに利用可能なクラスターがある場合、利用可能なクラスターが要求されます。クラスタープールに利用可能なクラスターがない場合は、要求を満たすためにクラスターが作成されます。クラスタープールの作成方法については、クラスタープールの作成 を参照してください。
1.4.14.2.2. クラスタープールからのクラスターの要求
クラスター要求の作成時に、クラスタープールから新規クラスターを要求します。クラスターが利用可能になると、クラスターはプールからチェックアウトされます。自動インポートを無効にしていない限り、要求されたクラスターはマネージドクラスターの 1 つとして自動的にインポートされます。
以下の手順を実行してクラスターを要求します。
- ナビゲーションメニューから Infrastructure > Clusters をクリックし、Cluster pools タブを選択します。
- クラスターを要求するクラスタープールの名前を見つけ、Claim cluster を選択します。
クラスターが利用可能な場合には、クラスターが要求され、マネージドクラスター タブにすぐに表示されます。利用可能なクラスターがない場合は、休止状態のクラスターの再開や、新しいクラスターのプロビジョニングに数分かかる場合があります。この間、要求のステータスは pending です。クラスタープールをデプロイメントして、保留中の要求を表示または削除します。
要求されたクラスターは、クラスタープールにあった時に関連付けられたクラスターセットに所属します。要求時には、要求したクラスターのクラスターセットは変更できません。
1.4.14.3. クラスタープールリリースイメージの更新
クラスタープールのクラスターが一定期間、休止状態のままになると、クラスターの Red Hat OpenShift Container Platform リリースイメージがバックレベルになる可能性があります。このような場合は、クラスタープールにあるクラスターのリリースイメージのバージョンをアップグレードしてください。
必要なアクセス: 編集
クラスタープールにあるクラスターの OpenShift Container Platform リリースイメージを更新するには、以下の手順を実行します。
注記: この手順では、クラスタープールですでに要求されているクラスタープールからクラスターを更新しません。この手順を完了すると、リリースイメージの更新は、クラスタープールに関連する次のクラスターにのみ適用されます。
- この手順でリリースイメージを更新した後にクラスタープールによって作成されたクラスター。
- クラスタープールで休止状態になっているクラスター。古いリリースイメージを持つ既存の休止状態のクラスターは破棄され、新しいリリースイメージを持つ新しいクラスターがそれらを置き換えます。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- クラスタープール の表で、更新するクラスタープールの名前を見つけます。
- 表の Cluster pools の Options メニューをクリックし、Update release image を選択します。
- このクラスタープールから今後、クラスターの作成に使用する新規リリースイメージを選択します。
クラスタープールのリリースイメージが更新されました。
ヒント: アクション 1 つで複数のクラスターのリリースイメージを更新するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールのリリースイメージを更新します。
1.4.14.4. Scaling cluster pools (Technology Preview)
クラスタープールのクラスター数は、クラスタープールサイズのクラスター数を増やしたり、減らしたりして変更できます。
必要なアクセス権限: クラスターの管理者
クラスタープールのクラスター数を変更するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
- 変更するクラスタープールの Options メニューで、Scale cluster pool を選択します。
- プールサイズの値を変更します。
- オプションで、実行中のクラスターの数を更新して、要求時にすぐに利用可能なクラスター数を増減できます。
クラスタープールは、新しい値を反映するようにスケーリングされます。
1.4.14.5. クラスタープールの破棄
クラスタープールを作成し、不要になった場合は、そのクラスタープールを破棄できます。クラスタープールを破棄する時に、要求されていない休止状態のクラスターはすべて破棄され、そのリソースは解放されます。
必要なアクセス権限: クラスターの管理者
クラスタープールを破棄するには、以下の手順を実行します。
- ナビゲーションメニューから infrastructure > Clusters をクリックします。
- Cluster pools タブを選択します。
削除するクラスタープールの Options メニューで、Destroy cluster pool を選択します。クラスタープールで要求されていないクラスターは破棄されます。すべてのリソースが削除されるまでに時間がかかる場合があります。また、クラスタープールは、すべてのリソースが削除されるまでコンソールに表示されたままになります。
ClusterPool が含まれる namespace は削除されません。namespace を削除すると、これらのクラスターの ClusterClaim リソースは同じ namespace で作成されるため、ClusterPool から要求されたクラスターがすべて破棄されます。
ヒント: アクション 1 つで複数のクラスタープールを破棄するには、各クラスタープールのボックスを選択して Actions メニューを使用し、選択したクラスタープールを破棄します。
1.4.15. ClusterClaims
ClusterClaim は、マネージドクラスター上のカスタムリソース定義 (CRD) です。ClusterClaim は、マネージドクラスターが要求する情報の一部を表します。以下の例は、YAML ファイルで特定される要求を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: ClusterClaim metadata: name: id.openshift.io spec: value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
次の表は、Kubernetes Operator 用のマルチクラスターエンジンが管理するクラスター上にある可能性がある、定義済みの ClusterClaims を示しています。
| 要求名 | 予約 | 変更可能 | 説明 |
|---|---|---|---|
|
| true | false | アップストリームの提案で定義された ClusterID |
|
| true | true | Kubernetes バージョン |
|
| true | false | AWS、GCE、Equinix Metal など、マネージドクラスターが稼働しているプラットフォーム |
|
| true | false | OpenShift、Anthos、EKS、および GKE などの製品名 |
|
| false | false | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform 外部 ID |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる管理コンソールの URL |
|
| false | true | OpenShift Container Platform クラスターでのみ利用できる OpenShift Container Platform バージョン |
マネージドクラスターで以前の要求が削除されるか、更新されると、自動的に復元またはロールバックされます。
マネージドクラスターがハブに参加すると、マネージドクラスターで作成された ClusterClaim は、ハブの ManagedCluster リソースのステータスと同期されます。ClusterClaims のマネージドクラスターは、以下の例のようになります。
apiVersion: cluster.open-cluster-management.io/v1
kind: ManagedCluster
metadata:
labels:
cloud: Amazon
clusterID: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
installer.name: multiclusterhub
installer.namespace: open-cluster-management
name: cluster1
vendor: OpenShift
name: cluster1
spec:
hubAcceptsClient: true
leaseDurationSeconds: 60
status:
allocatable:
cpu: '15'
memory: 65257Mi
capacity:
cpu: '18'
memory: 72001Mi
clusterClaims:
- name: id.k8s.io
value: cluster1
- name: kubeversion.open-cluster-management.io
value: v1.18.3+6c42de8
- name: platform.open-cluster-management.io
value: AWS
- name: product.open-cluster-management.io
value: OpenShift
- name: id.openshift.io
value: 95f91f25-d7a2-4fc3-9237-2ef633d8451c
- name: consoleurl.openshift.io
value: 'https://console-openshift-console.apps.xxxx.dev04.red-chesterfield.com'
- name: version.openshift.io
value: '4.5'
conditions:
- lastTransitionTime: '2020-10-26T07:08:49Z'
message: Accepted by hub cluster admin
reason: HubClusterAdminAccepted
status: 'True'
type: HubAcceptedManagedCluster
- lastTransitionTime: '2020-10-26T07:09:18Z'
message: Managed cluster joined
reason: ManagedClusterJoined
status: 'True'
type: ManagedClusterJoined
- lastTransitionTime: '2020-10-30T07:20:20Z'
message: Managed cluster is available
reason: ManagedClusterAvailable
status: 'True'
type: ManagedClusterConditionAvailable
version:
kubernetes: v1.18.3+6c42de81.4.15.1. 既存の ClusterClaim の表示
kubectl コマンドを使用して、マネージドクラスターに適用される ClusterClaim をリスト表示できます。これは、ClusterClaim をエラーメッセージと比較する場合に便利です。
注記: clusterclaims.cluster.open-cluster-management.io のリソースに list の権限があることを確認します。
以下のコマンドを実行して、マネージドクラスターにある既存の ClusterClaim のリストを表示します。
kubectl get clusterclaims.cluster.open-cluster-management.io
1.4.15.2. カスタム ClusterClaims の作成
ClusterClaim は、マネージドクラスターでカスタム名を使用して作成できるため、簡単に識別できます。カスタム ClusterClaim は、ハブクラスターの ManagedCluster リソースのステータスと同期されます。以下のコンテンツでは、カスタマイズされた ClusterClaim の定義例を示しています。
apiVersion: cluster.open-cluster-management.io/v1alpha1 kind: ClusterClaim metadata: name: <custom_claim_name> spec: value: <custom_claim_value>
spec.value フィールドの最大長は 1024 です。ClusterClaim を作成するには clusterclaims.cluster.open-cluster-management.io リソースの create パーミッションが必要です。
1.4.16. ManagedServiceAccount アドオンの有効化 (テクノロジープレビュー)
Kubernetes Operator 用のマルチクラスターエンジンをインストールすると、ManagedServiceAccount アドオンはデフォルトで無効になります。このコンポーネントを有効にすると、マネージドクラスターでサービスアカウントを作成または削除できます。
必要なアクセス権限: 編集
ManagedServiceAccount カスタムリソースがハブクラスターの <managed_cluster> namespace に作成されると、ServiceAccount がマネージドクラスターに作成されます。
TokenRequest は、マネージドクラスターの ServiceAccount を使用して、マネージドクラスターの Kubernetes API サーバーに対して行われます。トークンは、ハブクラスターの <target_managed_cluster> namespace の Secret に保存されます。
注記 トークンは期限切れになり、ローテーションされる可能性があります。トークンリクエストの詳細については、TokenRequest を参照してください。
1.4.16.1. 前提条件
- お使いの環境に Red Hat OpenShift Container Platform バージョン 4.11 以降をインストールし、コマンドラインインターフェイス (CLI) でログインしている。
- Kubernetes Operator 用のマルチクラスターエンジンがインストールされている。
1.4.16.2. ManagedServiceAccount の有効化
ハブクラスターとマネージドクラスターの Managed-ServiceAccount アドオンを有効にするには、次の手順を実行します。
-
ハブクラスターで
ManagedServiceAccountアドオンを有効にします。詳細は、詳細設定 を参照してください。 ManagedServiceAccountアドオンをデプロイし、それをターゲットのマネージドクラスターに適用します。次の YAML ファイルを作成し、target_managed_clusterをManaged-ServiceAccountアドオンを適用するマネージドクラスターの名前に置き換えます。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: managed-serviceaccount namespace: <target_managed_cluster> spec: installNamespace: open-cluster-management-agent-addon
次のコマンドを実行して、ファイルを適用します。
oc apply -f -
これで、マネージドクラスターの
Managed-ServiceAccountプラグインが有効になりました。ManagedServiceAccountを設定するには、次の手順を参照してください。次の YAML ソースを使用して
ManagedServiceAccountカスタムリソースを作成します。apiVersion: authentication.open-cluster-management.io/v1alpha1 kind: ManagedServiceAccount metadata: name: <managed_serviceaccount_name> namespace: <target_managed_cluster> spec: rotation: {}-
managed_serviceaccount_nameをManagedServiceAccountの名前に置き換えます。 -
target_managed_clusterを、ManagedServiceAccountを適用するマネージドクラスターの名前に置き換えます。
-
確認するには、
ManagedServiceAccountオブジェクトのステータスでtokenSecretRef属性を表示して、シークレット名と namespace を見つけます。アカウントとクラスター名を使用して次のコマンドを実行します。oc get managedserviceaccount <managed_serviceaccount_name> -n <target_managed_cluster> -o yaml
マネージドクラスターで作成された
ServiceAccountに接続されている取得されたトークンを含むSecretを表示します。以下のコマンドを実行します。oc get secret <managed_serviceaccount_name> -n <target_managed_cluster> -o yaml
1.4.17. クラスターのアップグレード
Kubernetes Operator コンソール用マルチクラスターエンジンで管理する Red Hat OpenShift Container Platform クラスターを作成したら、Kubernetes Operator コンソール用マルチクラスターエンジンを使用して、それらのクラスターを、マネージドクラスターが使用するバージョンチャネルで利用可能な最新のマイナーバージョンにアップグレードできます。
オンライン環境では、Red Hat Advanced Cluster Management コンソールでアップグレードが必要なクラスターごとに送信される通知を使用して、更新が自動識別されます。
注記:
メジャーバージョンへのアップグレードには、そのバージョンへのアップグレードの前提条件をすべて満たしていることを確認する必要があります。コンソールでクラスターをアップグレードする前に、マネージドクラスターのバージョンチャネルを更新する必要があります。
マネージドクラスターでバージョンチャネルを更新すると、Kubernetes Operator コンソールのマルチクラスターエンジンに、アップグレードに使用できる最新バージョンが表示されます。
このアップグレードの手法は、ステータスが Ready の OpenShift Container Platform のマネージドクラスタークラスターでだけ使用できます。
重要: Red Hat OpenShift Kubernetes Service マネージドクラスターまたは OpenShift Container Platform マネージドクラスターを Red Hat OpenShift Dedicated で Kubernetes Operator コンソール用のマルチクラスターエンジンを使用してアップグレードすることはできません。
オンライン環境でクラスターをアップグレードするには、以下の手順を実行します。
- ナビゲーションメニューから Infrastructure > Clusters に移動します。アップグレードが利用可能な場合には、Distribution version の列に表示されます。
- アップグレードする Ready 状態のクラスターを選択します。クラスターはコンソールを使用してアップグレードされる OpenShift Container Platform クラスターである必要があります。
- Upgrade を選択します。
- 各クラスターの新しいバージョンを選択します。
- Upgrade を選択します。
クラスターのアップグレードに失敗すると、Operator は通常アップグレードを数回再試行し、停止し、コンポーネントに問題があるステータスを報告します。場合によっては、アップグレードプロセスは、プロセスの完了を繰り返し試行します。アップグレードに失敗した後にクラスターを以前のバージョンにロールバックすることはサポートされていません。クラスターのアップグレードに失敗した場合は、Red Hat サポートにお問い合わせください。
1.4.17.1. チャネルの選択
Red Hat Advanced Cluster Management コンソールを使用して、OpenShift Container Platform バージョン 4.6 以降でクラスターのアップグレードのチャネルを選択できます。チャネルを選択すると、エラータバージョン (4.8.1> 4.8.2> 4.8.3 など) とリリースバージョン (4.8> 4.9 など) の両方で使用できるクラスターアップグレードが自動的に通知されます。
クラスターのチャネルを選択するには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ナビゲーションで Infrastructure > Clusters に移動します。
- 変更するクラスターの名前を選択して、Cluster details ページを表示します。クラスターに別のチャネルが利用可能な場合は、編集アイコンが Channel フィールドに表示されます。
- 編集アイコンをクリックして、フィールドの設定を変更します。
- New channel フィールドでチャネルを選択します。
利用可能なチャネル更新のリマインダーは、クラスターの Cluster details ページで見つけることができます。