
1.2. 障害復旧
プライマリーハブクラスターに障害が発生した場合、管理者はパッシブハブクラスターを選択してマネージドクラスターを引き継ぎます。以下のイメージでは、管理者は ハブクラスター N を新しいプライマリーハブクラスターとして使用するように決めます。
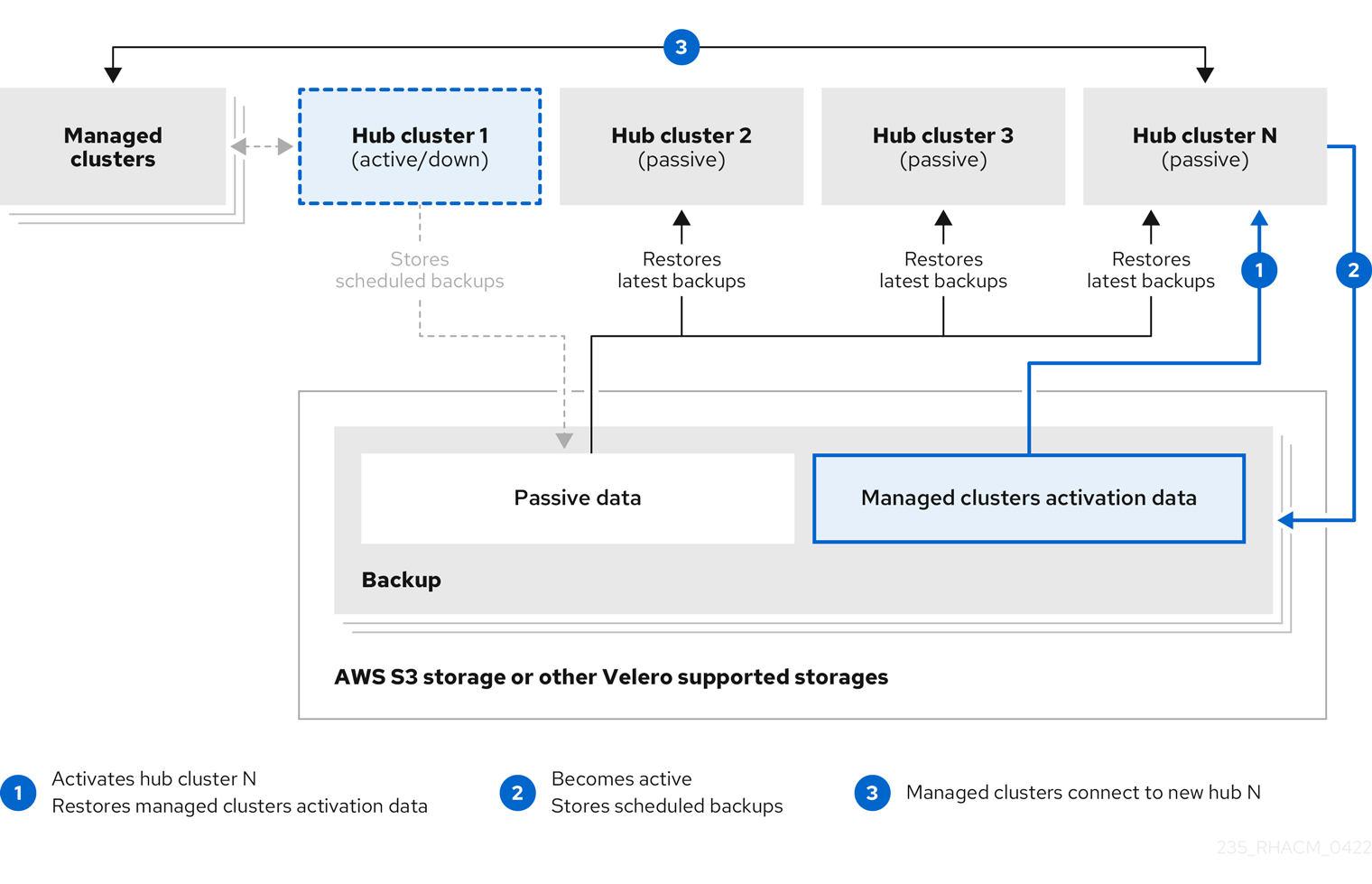
ハブクラスター N は、マネージドクラスターのアクティブ化データを復元します。この時点で、マネージドクラスターは、ハブクラスター N に接続されます。管理者は、BackupSchedule.cluster.open-cluster-management.io リソースを作成し、最初のプライマリーハブクラスターと同じストレージの場所にバックアップを保存することにより、新しいプライマリーハブクラスターである ハブクラスター N のバックアップをアクティブ化します。
その他のパッシブハブクラスターはすべて、新しいプライマリーハブクラスターで作成したバックアップデータを使用してパッシブデータを復元するようになりました。ハブクラスター N がプライマリーハブクラスターとなり、クラスターの管理とデータのバックアップを行います。
注記:
- 前の図のプロセス 1 は自動化されていません。これは、プライマリーハブクラスターに障害が発生して交換する必要があるかどうか、ハブクラスターとマネージドクラスターの間にネットワーク通信エラーがあるかどうかを管理者が判断する必要があるためです。また、管理者は、どのパッシブハブクラスターがプライマリーハブクラスターになるかを決定します。Ansible ジョブとのポリシー統合は、バックアップポリシーがバックアップエラーを報告したときに Ansible ジョブを実行することで、このステップを自動化するのに役立ちます。
- 前の図のプロセス 2 は手動です。管理者が新しいプライマリーハブクラスターからバックアップを作成しない場合、cron ジョブとしてアクティブに実行されているバックアップを使用して、管理者に通知されます。