
Chapter 40. Handling Network Partitions (Split Brain)
40.1. Network Partition Recovery
Network Partitions occur when a cluster breaks into two or more partitions. As a result, the nodes in each partition are unable to locate or communicate with nodes in the other partitions. This results in an unintentionally partitioned network.
In the event of a network partition in a distributed system like Red Hat JBoss Data Grid, the CAP (Brewer’s) theorem becomes relevant. The CAP theorem states that in the event of a Network Partition [P], a distributed system can provide either Consistency [C] or Availability [A] for the data, but not both.
By default, reads and writes are enabled on all nodes in JBoss Data Grid. During a network partition, the partitions continue to remain Available [A], at the cost of Consistency [C].
In JBoss Data Grid, a cache consists of data stored on a number of nodes. To prevent data loss if a node fails, JBoss Data Grid replicates a data item over multiple nodes. In distribution mode, this redundancy is configured using the owners configuration attribute, which specifies the number of replicas for each cache entry in the cache. As a result, as long as the number of nodes that have failed are less than the value of owners, JBoss Data Grid retains a copy of the lost data and can recover.
In JBoss Data Grid’s replication mode, however, owners is always equal to the number of nodes in the cache, because each node contains a copy of every data item in the cache in this mode.
In certain cases, a number of nodes greater than the value of owners can disappear from the cache. Two common reasons for this are:
- Split-Brain: Usually, as the result of a router crash, the cache is divided into two or more partitions. Each of the partitions operates independently of the other and each may contain different versions of the same data.
-
Sucessive Crashed Nodes: A number of nodes greater than the value of
ownerscrashes in succession for any reason. JBoss Data Grid is unable to properly balance the state between crashes, and the result is partial data loss.
The partition handling functionality described in this section determines what operations can be performed on a cache in the event of a split-brain scenario. JBoss Data Grid provides multiple partition handling strategies, which, in terms of the CAP theorem, determine whether availability or consistency is ensured. The provided strategies are listed in the table below:
Table 40.1. Parition Handling Strategies
| Strategy Name | Description | CAP |
|---|---|---|
|
| Allows entries on each partition to diverge, with conflicts resolved during merge. This is the default partition handling strategy in JBoss Data Grid. | Availability |
|
| If the partition does not have all owners for a given segment, both reads and writes are denied for all keys in that segment. | Consistency |
|
| Allows reads for a given key if it exists in this partition, but only allows writes if this partition contains all owners of a segment. | Availability |
40.2. Detecting and Recovering from a Split-Brain Problem
When a Split-Brain occurs in the data grid, each network partition installs its own JGroups view with nodes from other partitions removed. The partitions remain unaware of each other, therefore there is no way to determine how many partitions the network has split into. Red Hat JBoss Data Grid assumes the cache has unexpectedly split if one or more nodes disappear from the JGroups cache without sending an explicit leaving message, while in reality the cause can be physical (crashed switches, cable failure, etc.) to virtual (stop-the-world garbage collection).
This state is dangerous because each of the newly split partitions operates independently and can store conflicting updates for the same data entries.
A possible limitation is that if two partitions start as isolated partitions and do not merge, they can read and write inconsistent data. JBoss Data Grid does not identify such partitions as split partitions.
40.3. Partition Handling Strategies
JBoss Data Grid provides multiple partition handling strategies that can provide either data consistency or data availability. Application requirements should determine which strategy to use. For example, when data read from the system must be accurate, DENY_READ_WRITES may be the best choice, as it ensures data consistency.
40.3.1. ALLOW_READ_WRITES
When JBoss Data Grid is configured to use ALLOW_READ_WRITES, each partition continues to function as an independent cluster, with all partitions remaining in AVAILABLE mode. This means each partition may only see part of the data, and each partition could write conflicting updates to the cache. During a partition merge these conflicts are automatically resolved by utilising the ConflictManager and the configured EntryMergePolicy. The default partition handling strategy for JBoss Data Grid is ALLOW_READ_WRITES and the default merge policy is PREFERRED_ALWAYS. That is, if conflicts arise due to a split-brain scenario, upon merge, the preferredEntry cache entry will be used to resolve the conflict.
40.3.2. DENY_READ_WRITES
When DENY_READ_WRITES is configured, and JBoss Data Grid suspects one or more nodes are no longer accessible, each partition does not start a rebalance immediately, but first it checks whether it should enter degraded mode instead. To enter Degraded Mode, one of the following conditions must be true:
-
At least one segment has lost all its owners, which means that a number of nodes equal to or greater than the value of
ownershave left the JGroups view. - The partition does not contain a majority of nodes (greater than half) of the nodes from the latest stable topology. The stable topology is updated each time a rebalance operation successfully concludes and the coordinator determines that additional rebalancing is not required.
If neither of the conditions are met, the partition continues normal operations and JBoss Data Grid attempts to rebalance its nodes. If at least one of these conditions is met, at most one partition can remain in Available mode. Other partitions will enter Degraded Mode.
When a partition enters into Degraded Mode, it only allows read/write access to those entries for which all owners (copies) of the entry exist on nodes within the same partition. Read and write requests for an entry for which one or more of its owners (copies) exist on nodes that have disappeared from the partition are rejected with an AvailabilityException.
This guarantees partitions cannot write different values for the same key (cache is consistent), and also that one partition can not read keys that have been updated in the other partitions (no stale data).
40.3.2.1. Partition Recovery Example with DENY_READ_WRITE
In this example, a distributed cache is configured on a four node cluster with four data entries (k1, k2, k3 and k4). The parameter owners is set to 2, so the four data entries each have two copies in the cache.
Figure 40.1. Cache Before and After a Network Partition
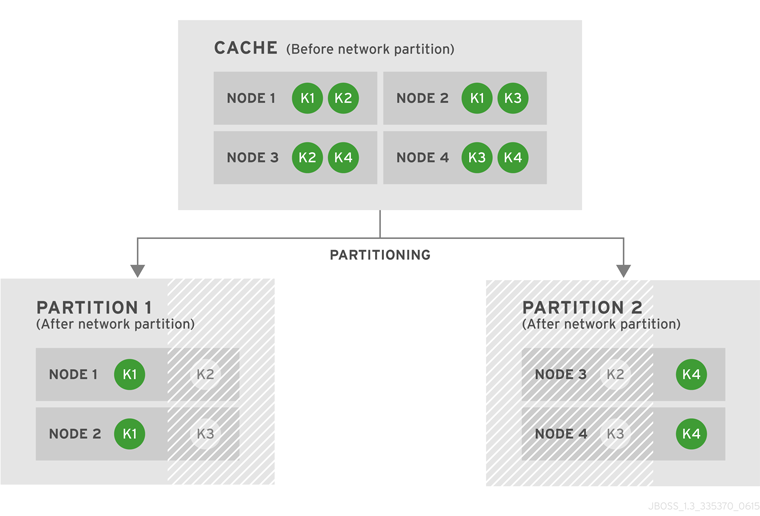
After the network partition occurs, Partitions 1 and 2 enter Degraded Mode (depicted in the diagram as grayed-out nodes). Within each partition, an entry will only be available for read or write operations if both its copies are in the same partition. In Partition 1, the data entry k1 is available for reads and writes because owners equals 2 and both copies of the entry remain in Partition 1. In Partition 2, k4 is available for reads and writes for the same reason. The entries k2 and k3 become unavailable in both partitions, as neither partition contains all copies of these entries. A new entry k5 can be written to a partition only if that partition were to own both copies of k5.
Figure 40.2. Cache After Partitions Are Merged
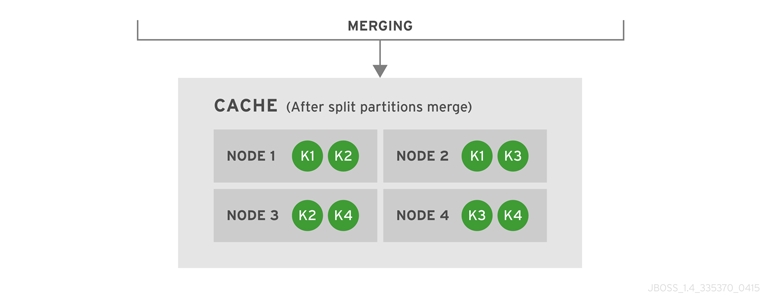
JBoss Data Grid subsequently merges the two split partitions into a single cache. No state transfer is required and the cache returns to Available Mode with four nodes and four data entries (k1, k2, k3 and k4).
Data consistency can be at risk from the time (t1) when the cache physically split to the time (t2) when JBoss Data Grid detects the connectivity change and changes the state of the partitions:
- Transactional writes that were in progress at t1 when the split physically occurred may be rolled back on some of the owners. This can result in inconsistency between the copies (after the partitions rejoin) of an entry that is affected by such a write. However, transactional writes that started after t1 will fail as expected.
- If the write is non-transactional, then during this time window, a value written only in a minor partition (due to physical split and because the partition has not yet been Degraded) can be lost when partitions rejoin, if this minor partition receives state from a primary (Available) partition upon rejoin. If the partition does not receive state upon rejoin (i.e. all partitions are degraded), then the value is not lost, but an inconsistency can remain.
- There is also a possibility of a stale read in a minor partition during this transition period, as an entry is still Available until the minor partition enters Degraded state.
When partitions merge after a network partition has occurred:
- If one of the partitions was Available during the network partition, then the joining partition(s) are wiped out and state transfer occurs from the Available (primary) partition to the joining nodes.
- If all joining partitions were Degraded during the Split Brain, then no state transfer occurs during the merge. The combined cache is then Available only if the merging partitions contain a simple majority of the members in the latest stable topology (one with the highest topology ID) and has at least an owner for each segment (i.e. keys are not lost).
Between the time (t1) when partitions begin merging to the time (t2) when the merge is complete, nodes reconnect through a series of merge events. During this time window, it is possible that a node can be reported as having temporarily left the cluster. For a Transactional cache, if during this window between t1 and t2, such a node is executing a transaction that spans other nodes, then this transaction may not execute on the remote node, but still succeed on the originating node. The result is a potential stale value for affected entries on a node that did not commit this transaction.
After t2, once the merge has completed on all nodes, this situation will not occur for subsequent transactions. However, an inconsistency introduced on entries that were affected by a transaction in progress during the time window between t1 and t2 is not resolved until these entries are subsequently updated or deleted. Until then, a read on such impacted entries can potentially return the stale value.
40.3.3. ALLOW_READS
Partitions are handled in the same manner as DENY_READ_WRITES, except that when a partition is in DEGRADED mode read operations on a partially owned key will not throw an AvailabilityException.
40.4. Detecting and Recovering from Successive Node Failures
Nodes can leave a cluster for reasons other than network failures. For example, a process might stop running or the JVM pauses due to Garbage Collection (GC). However, Red Hat JBoss Data Grid cannot detect these different causes. When a node leaves the JGroups cluster abruptly, JBoss Data Grid handles it as a network failure.
If only one node leaves a cluster and there are backup owners (numOwners) then:
- The cluster remains available.
- JBoss Data Grid attempts to create new replicas of the lost data.
If multiple nodes leave a cluster, it is possible that unrecoverable data loss can occur. For example, additional nodes crash while JBoss Data Grid is attempting to create replicas of data that were lost during a previous node crash. In this case, all copies of data for some entries might no longer be available on any node in the cluster.
Either the DENY_READ_WRITES or ALLOW_READS partition handling strategy causes JBoss Data Grid to enter DEGRADED mode when it detects one or more nodes are no longer available. These strategies help prevent unrecoverable data loss even if a Split-Brain has not occurred.
Data loss can also occur when nodes are shut down in rapid succession, or not gracefully, if those nodes are all owners for data that was stored on those nodes only.
When you shut down nodes gracefully, JBoss Data Grid knows that the nodes cannot come back. However, the cluster does not track how each node leaves the cluster. As a result, the cache still enters DEGRADED mode as if those nodes had crashed.
When nodes crash or are shut down in rapid succession, it is not possible for the cluster to recover its state unless you stop it and then repopulate the data from an external source when you restart the cluster. For this reason, you should configure the numOwners parameter so that there is an adequate number of data copies to prevent data loss from successive node failures.
Alternatively, if you can tolerate some data loss, you can force JBoss Data Grid into AVAILABLE mode from DEGRADED mode using the Cache JMX MBean. See Cache JMX MBean.
Likewise, the AdvancedCache interface lets you read and change the cache availability. See The AdvancedCache Interface in the Developer Guide.
40.5. Conflict Manager
The most basic function of the conflict manager is to allow the retrieval of all stored replica values for a given key. This provides the opportunity to process a stream of cache entries whose stored replicas have conflicting values. By using implementations of the EntryMergePolicy interface it is possible for conflicts to be resolved automatically.
40.5.1. Detecting Conflicts
The conflict manager detects conflicts by comparing each of the stored values for a given key. The result of the .equals method on the stored values is used to determine whether all values are equal. If all values are equal then no conflicts exist for the key, otherwise a conflict has occurred. Note that null values are returned if no entry exists on a given node. JBoss Data Grid indicates a conflict has occurred if both a null and non-null value exist for a given key.
40.5.2. Merge Policies
If a conflict between one or more replicas of a given CacheEntry exists, a conflict resolution algorithm can be used to resolve it. JBoss Data Grid provides the EntryMergePolicy interface for this purpose. This interface consists of a single method, merge, whose returned CacheEntry is used as the resolved entry for a given key. When a non-null CacheEntry is returned, this entry’s value is put to all replicas in the cache. However, when the merge implementation returns a null value, all replicas associated with the conflicting key are removed from the cache.
The merge method takes two parameters, preferredEntry, and otherEntries. In the context of a partition merge, the preferredEntry is the CacheEntry associated with the partition whose coordinator is conducting the merge (or if multiple entries exist in this partition, it is the primary replica). However, in all other contexts, the preferredEntry is the primary replica. The second parameter, otherEntries, is a list of all other entries associated with the key for which a conflict was detected.
EntryMergePolicy::merge is only called when a conflict has been detected, it is not called if all CacheEntrys are the same.
The following table describes the merge policies that JBoss Data Grid provides:
Table 40.2. Merge Policies
| Policy | Description | Possible Risks |
|---|---|---|
|
| Do not attempt to resolve conflicts on merge. This is the default merge policy. | Nodes drop segments if they no longer own the segments. This can lead to the loss of segments. |
|
|
Always use the |
Even the |
|
|
Use the | This policy could restore deleted entries. |
|
| Always remove the key and value from the cache when a conflict is detected. | This policy results in the loss of all entries that are modified concurrently and have different values. |
Along with the implementations of the EntryMergePolicy interface that JBoss Data Grid provides, you can also create custom implementations. See Creating Custom Merge Policies.
40.6. Split Brain Timing: Detecting a Split
When using the FD_ALL protocol a given node becomes suspected after the following amount of milliseconds have passed:
FD_ALL.timeout + FD_ALL.interval + VERIFY_SUSPECT.timeout + GMS.view_ack_collection_timeout
40.7. Split Brain Timing: Recovering From a Split
After a split occurs JBoss Data Grid will merge the partitions back, and the maximum time to detect a merge after the network partition is healed is:
3.1 * MERGE3.max_interval
In some cases multiple merges will occur after a split so that the cluster may contain all available partitions. In this case, where multiple merges occur, time should be allowed for all of these to complete, and as there may be as many as three merges occurring sequentially the total delay should be no more than the following:
10 * MERGE3.max_interval
40.7.1. Considerations with Garbage Collection
A Java Virtual Machine (JVM) provides the runtime environment for Red Hat JBoss Data Grid. Garbage Collection (GC) in the JVM can cause splits and impact the behavior of the conflict manager.
It is important to monitor GC when you deploy JBoss Data Grid so that "stop-the-world" suspension of the JVM does not negatively impact performance of your cluster.
Long GC times can increase the amount of time it takes JBoss Data Grid to detect and recover from splits. In some cases, GC can cause JBoss Data Grid to exceed the maximum time to detect a split.
Additionally, when merging partitions after a split, JBoss Data Grid attempts to confirm all nodes are present in the cluster. Because no timeout or upper bound applies to the response time from nodes, the operation to merge the cluster view can be delayed. This can result from network issues as well as long GC times.
Another scenario in which GC can impact performance through partition handling is when GC suspends the JVM, causing one or more nodes to leave the cluster. When this occurs, and suspended nodes resume after GC completes, the nodes can have out of date or conflicting cluster topologies.
If the merge policy is configured to detect conflicts, JBoss Data Grid attempts to resolve conflicts before merging the nodes. However the merge policy is enforced only if more than one node in the cluster is suspended due to GC. In cases where JBoss Data Grid detects a single suspended node, it clears the out of date topology without attempting to resolve conflicts. JBoss Data Grid then rebalances the nodes after the merge completes.
40.8. Configuring Partition Handling
Unless the cache is distributed or replicated, partition handling configuration is ignored. The default partition handling strategy is ALLOW_READ_WRITES and the default EntryMergePolicy is MergePolicies::NONE.
40.8.1. Example Configurations
Declarative Configuration (Library Mode)
Enable partition handling declaratively as follows:
<distributed-cache name="distributed_cache"
l1-lifespan="20000">
<partition-handling when-split="DENY_READ_WRITES" merge-policy="REMOVE_ALL"/>
</distributed-cache>Declarative Configuration (Remote Client-server Mode)
Enable partition handling declaratively in remote client-server mode by using the following configuration:
<subsystem xmlns="urn:infinispan:server:core:8.5" default-cache-container="clustered">
<cache-container name="clustered" default-cache="default" statistics="true">
<distributed-cache name="default" >
<partition-handling when-split="DENY_READ_WRITES" merge-policy="REMOVE_ALL"/>
<locking isolation="READ_COMMITTED" acquire-timeout="30000"
concurrency-level="1000" striping="false"/>
</distributed-cache>
</cache-container>
</subsystem>A programmatic configuration example of partition handling is included in the Developer Guide.
40.8.2. Configuration of Partition Handling Between Releases
If you migrate the configuration from a previous release, there are specific changes that apply to partition handling.
In JBoss Data Grid 7.1 and earlier, you could disable or enable partition handling. Either option provides specific functionality that is limited to a subset of what you can now configure in JBoss Data Grid.
40.8.2.1. No Partition Handling Configuration or Partition Handling Disabled
If the partition-handling element is not specified in the configuration or if the configuration is as follows:
<partition-handling enabled="false">
Then it is equivalent to the following configuration:
<partition-handling when-split="ALLOW_READ_WRITES" merge-policy="NONE"/>
This configuration enables the conflict manager. If you do not want to enable the conflict manager, set the merge policy to PREFERRED_ALWAYS.
40.8.2.2. Partition Handling Enabled
<partition-handling enabled="true">
The preceding configuration from JBoss Data Grid 7.1 and earlier is equivalent to the following configuration:
<partition-handling when-split="DENY_READ_WRITES" merge-policy="NONE"/>
This configuration enables partition handling with similar behavior to JBoss Data Grid 7.1 and earlier. No merge policy is necessary because different data cannot be written to copies of the entry on different nodes given that the DENY_READ_WRITES strategy is configured.
To find out more about merge policies in JBoss Data Grid 7.2, see Merge Policies.
40.9. Creating Custom Merge Policies
A custom merge policy is an implementation of the EntryMergePolicy interface such as the following:
public class CustomMergePolicy implements EntryMergePolicy<String, String> {
@Override
public CacheEntry<String, String> merge(CacheEntry<String, String> preferredEntry, List<CacheEntry<String, String>> otherEntries) {
// decide which entry should be used
return the_solved_CacheEntry;
}
To use custom merge policies in Remote Client-Server Mode, you must package the implementation class files to JBoss Data Grid in a JAR file that contains the following file:
META-INF/services/org.infinispan.conflict.EntryMergePolicy
This file must provide the fully qualified class name of the EntryMergePolicy implementation.
In Library Mode, you should ensure that the custom merge policy is on the classpath.
Data Interoperability with Custom Merge Policies
When using JBoss Data Grid in Remote Client-Server Mode, custom merge policies that exchange data with the cache must be able to handle data interoperability. JBoss Data Grid stores cache entries in a marshalled format and returns key/value pairs to custom merge policies as byte arrays.
To handle cache entries in a marshalled format, custom merge policies must be able to perform marshalling. Alternatively you can configure the media type for data in the cache so that JBoss Data Grid converts between storage formats.
In cases where your custom merge policy depends on metadata associated with cache entries only, you do not need to configure your merge policy to handle marshalling.
For more information, see the following sections in the Developer Guide:
40.9.1. Specifying Custom Merge Policies
You can declaratively configure custom merge policies as follows:
<distributed-cache name="the-default-cache"> <partition-handling when-split="DENY_READ_WRITES" merge-policy="org.example.CustomMergePolicy"/> </distributed-cache>
Alternatively, you can programmatically configure custom merge policies as follows:
ConfigurationBuilder dcc = new ConfigurationBuilder();
dcc.clustering().partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());