
9.5.4. Replicated Caches With Each Cache Having Its Own Store
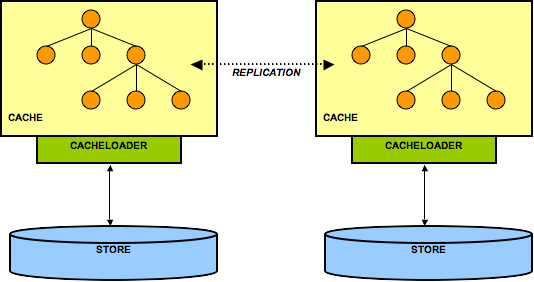
Figure 9.4. 2 nodes each having its own back end store
Here, each node has its own datastore. Modifications to the cache are (a) replicated across the cluster and (b) persisted using the cache loader. This means that all datastores have exactly the same state. When replicating changes synchronously and in a transaction, the two-phase commit protocol takes care that all modifications are replicated and persisted in each datastore, or none is replicated and persisted (atomic updates).
Note that JBoss Cache is not an XA Resource, that means it does not implement recovery. When used with a transaction manager that supports recovery, this functionality is not available.
The challenge here is state transfer: when a new node starts it needs to do the following:
- Tell the coordinator (oldest node in a cluster) to send it the state. This is always a full state transfer, overwriting any state that may already be present.
- The coordinator then needs to wait until all in-flight transactions have completed. During this time, it will not allow for new transactions to be started.
- Then the coordinator asks its cache loader for the entire state using
loadEntireState(). It then sends back that state to the new node. - The new node then tells its cache loader to store that state in its store, overwriting the old state. This is the
CacheLoader.storeEntireState()method - As an option, the transient (in-memory) state can be transferred as well during the state transfer.
- The new node now has the same state in its back end store as everyone else in the cluster, and modifications received from other nodes will now be persisted using the local cache loader.