
Replacing devices
실패한 장치를 안전하게 교체하기 위한 명령
초록
머리말
배포 유형에 따라 다음 절차 중 하나를 선택하여 스토리지 장치를 교체할 수 있습니다.
AWS에 배포된 동적으로 생성된 스토리지 클러스터의 경우 다음을 참조하십시오.
- VMware에 배포된 동적 스토리지 클러스터의 경우 참조하십시오. 2.1절. “VMware 사용자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체”
- Microsoft Azure에 배포된 동적으로 생성된 스토리지 클러스터의 경우 참조하십시오. 3.1절. “Azure 설치 관리자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체”
로컬 스토리지 장치를 사용하여 배포된 스토리지 클러스터의 경우 다음을 참조하십시오.
OpenShift Container Storage는 이기종 OSD 크기를 지원하지 않습니다.
1장. AWS에 배포된 동적으로 프로비저닝된 OpenShift Container Storage
1.1. AWS 사용자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체
AWS 사용자 프로비저닝 인프라에서 동적으로 생성된 스토리지 클러스터에서 장치를 교체해야 하는 경우 스토리지 노드를 교체해야 합니다. 노드 교체 방법에 대한 자세한 내용은 다음을 참조하십시오.
1.2. AWS 설치 관리자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체
AWS 설치 관리자 프로비저닝 인프라에서 동적으로 생성된 스토리지 클러스터에서 장치를 교체해야 하는 경우 스토리지 노드를 교체해야 합니다. 노드 교체 방법에 대한 자세한 내용은 다음을 참조하십시오.
2장. 동적으로 프로비저닝된 OpenShift Container Storage는 VMware에 배포
2.1. VMware 사용자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체
VMware 인프라에 동적으로 배포되는 OpenShift Container Storage에서 하나 이상의 VMI(가상 머신 디스크)를 교체해야 하는 경우 이 절차를 사용하십시오. 이 절차에서는 새 볼륨에서 새 PVC(영구 볼륨 클레임)를 생성하고 이전 오브젝트 스토리지 장치(OSD)를 제거하는 데 도움이 됩니다.
절차
교체해야 하는 OSD와 OSD가 예약된 OpenShift Container Platform 노드를 식별합니다.
$ oc get -n openshift-storage pods -l app=rook-ceph-osd -o wide
출력 예:
rook-ceph-osd-0-6d77d6c7c6-m8xj6 0/1 CrashLoopBackOff 0 24h 10.129.0.16 compute-2 <none> <none> rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 24h 10.128.2.24 compute-0 <none> <none> rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 24h 10.130.0.18 compute-1 <none> <none>
이 예에서는
rook-ceph-osd-0-6d77d6c7c6-m8xj6을 교체해야 하며,compute-2는 OSD가 예약된 OpenShift Container Platform 노드입니다.참고교체할 OSD가 정상이면 Pod 상태가
Running이 됩니다.OSD를 교체할 OSD 배포를 축소합니다.
# osd_id_to_remove=0 # oc scale -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove} --replicas=0여기서
osd_id_to_remove는rook-ceph-osd접두사 바로 직후 포드 이름에 있는 정수입니다. 이 예에서 배포 이름은rook-ceph-osd-0입니다.출력 예:
deployment.extensions/rook-ceph-osd-0 scaled
rook-ceph-osd포드가 종료되었는지 확인합니다.# oc get -n openshift-storage pods -l ceph-osd-id=${osd_id_to_remove}출력 예:
No resources found.
참고rook-ceph-osdPod가종료상태인 경우force옵션을 사용하여 Pod를 삭제합니다.# oc delete pod rook-ceph-osd-0-6d77d6c7c6-m8xj6 --force --grace-period=0
출력 예:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "rook-ceph-osd-0-6d77d6c7c6-m8xj6" force deleted
새 OSD를 추가할 수 있도록 클러스터에서 이전 OSD를 제거합니다.
이전
ocs-osd-removal작업을 삭제합니다.$ oc delete -n openshift-storage job ocs-osd-removal-${osd_id_to_remove}출력 예:
job.batch "ocs-osd-removal-0" deleted
openshift-storage프로젝트로 변경합니다.$ oc project openshift-storage
클러스터에서 이전 OSD를 제거합니다.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_IDS=${osd_id_to_remove} |oc create -n openshift-storage -f -주의이 단계에서는 OSD가 클러스터에서 완전히 제거됩니다.
osd_id_to_remove의 올바른 값이 제공되는지 확인합니다.
ocs-osd-removalPod의 상태를 확인하여 OSD가 성공적으로 제거되었는지 확인합니다.완료된상태로 OSD 제거 작업이 성공했는지 확인합니다.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage참고ocs-osd-removal이 실패하고 Pod가 예상Completed상태가 아닌 경우 Pod 로그에서 추가 디버깅을 확인합니다. 예:# oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1설치 시 암호화가 활성화된 경우 해당 OpenShift Container Storage 노드에서 제거된 OSD 장치에서
dm매핑을 제거합니다.-crypt관리 장치-mapperocs-osd-removal-jobPod 로그에서 교체된 OSD의 PVC 이름을 가져옵니다.$ oc logs -l job-name=ocs-osd-removal-job -n openshift-storage --tail=-1 |egrep -i ‘pvc|deviceset’
예:
2021-05-12 14:31:34.666000 I | cephosd: removing the OSD PVC "ocs-deviceset-xxxx-xxx-xxx-xxx"
단계 #1에서 식별된 각 노드에 대해 다음을 수행합니다.
스토리지 노드의 호스트에
디버그Pod 및chroot를 생성합니다.$ oc debug node/<node name> $ chroot /host
이전 단계에서 확인한 PVC 이름을 기반으로 관련 장치 이름을 찾습니다.
sh-4.4# dmsetup ls| grep <pvc name> ocs-deviceset-xxx-xxx-xxx-xxx-block-dmcrypt (253:0)
매핑된 장치를 제거합니다.
$ cryptsetup luksClose --debug --verbose ocs-deviceset-xxx-xxx-xxx-xxx-block-dmcrypt
참고충분하지 않은 권한으로 인해 위 명령이 중단되는 경우 다음 명령을 실행합니다.
-
CTRL+Z를 눌러 위의 명령을 종료합니다. 정지된 프로세스의 PID를 찾습니다.
$ ps -ef | grep crypt
kill명령을 사용하여 프로세스를 종료합니다.$ kill -9 <PID>
장치 이름이 제거되었는지 확인합니다.
$ dmsetup ls
-
ocs-osd-removal작업을 삭제합니다.# oc delete -n openshift-storage job ocs-osd-removal-${osd_id_to_remove}출력 예:
job.batch "ocs-osd-removal-0" deleted
검증 단계
새 OSD가 실행되고 있는지 확인합니다.
# oc get -n openshift-storage pods -l app=rook-ceph-osd
출력 예:
rook-ceph-osd-0-5f7f4747d4-snshw 1/1 Running 0 4m47s rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 1d20h rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 1d20h
Bound상태에 있는 새 PVC가 생성되었는지 확인합니다.# oc get -n openshift-storage pvc
출력 예:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-0-0-2s6w4 Bound pvc-7c9bcaf7-de68-40e1-95f9-0b0d7c0ae2fc 512Gi RWO thin 5m ocs-deviceset-1-0-q8fwh Bound pvc-9e7e00cb-6b33-402e-9dc5-b8df4fd9010f 512Gi RWO thin 1d20h ocs-deviceset-2-0-9v8lq Bound pvc-38cdfcee-ea7e-42a5-a6e1-aaa6d4924291 512Gi RWO thin 1d20h
(선택 사항) 클러스터에서 데이터 암호화가 활성화된 경우 새 OSD 장치가 암호화되었는지 확인합니다.
새 OSD 포드가 실행 중인 노드를 식별합니다.
$ oc get -o=custom-columns=NODE:.spec.nodeName pod/<OSD pod name>
예:
oc get -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqm
이전 단계에서 확인한 각 노드에서 다음을 수행합니다.
디버그 Pod를 생성하고 선택한 호스트에 대한 chroot 환경을 엽니다.
$ oc debug node/<node name> $ chroot /host
"lsblk"를 실행하고
ocs-deviceset이름 옆에 "crypt" 키워드를 확인합니다.$ lsblk
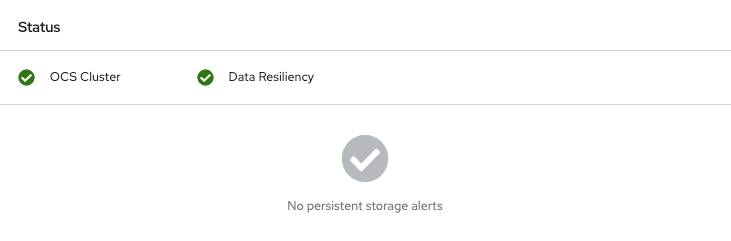
OpenShift 웹 콘솔에 로그인하고 스토리지 대시보드를 확인합니다.
그림 2.1. 장치 교체 후 OpenShift Container Platform 스토리지 대시보드의 OSD 상태
3장. Microsoft Azure에 배포된 동적으로 프로비저닝된 OpenShift Container Storage
3.1. Azure 설치 관리자 프로비저닝 인프라에서 운영 또는 실패한 스토리지 장치 교체
Azure 설치 관리자 프로비저닝 인프라에서 동적으로 생성된 스토리지 클러스터에서 장치를 교체해야 하는 경우 스토리지 노드를 교체해야 합니다. 노드 교체 방법에 대한 자세한 내용은 다음을 참조하십시오.
4장. 로컬 스토리지 장치를 사용하여 배포된 OpenShift Container Storage
4.1. Amazon EC2 인프라에서 실패한 스토리지 장치 교체
Amazon EC2(스토리지 최적화 I3) 인프라에서 스토리지 장치를 교체해야 하는 경우 스토리지 노드를 교체해야 합니다. 노드를 교체하는 방법에 대한 자세한 내용은 Amazon EC2 인프라에 오류가 발생한 스토리지 노드 교체를 참조하십시오.
4.2. 사용자 인터페이스를 사용하여 VMware 및 베어 메탈 인프라에서 실패한 스토리지 장치 교체
I/O 오류로 인해 실패한 스토리지 장치를 교체하려면 이 절차를 사용하십시오. 클러스터 또는 영구 스토리지 대시보드, 노드 페이지 또는 알림에서 실패한 스토리지 장치 교체를 시작할 수 있습니다.
그러나 오류가 디스크를 제거한 경우 로컬 스토리지 장치 섹션에서 지원하는 클러스터에서 운영 또는 실패한 스토리지 장치 교체에 설명된 명령줄 단계를 사용하여 OSD(오브젝트 스토리지 장치 )를 교체해야 합니다.
암호화된 클러스터의 경우 사용자 인터페이스에서 실패한 장치를 교체하는 것은 지원되지 않습니다. 명령줄 인터페이스의 장치를 교체하려면 로컬 스토리지 장치 섹션에서 지원하는 클러스터에 운영 또는 실패한 스토리지 장치 교체 장에 있는 단계를 따르십시오.
사전 요구 사항
- 교체 중인 노드에 유사한 인프라, 리소스 및 디스크로 대체 노드를 구성하는 것이 좋습니다.
- 이전 버전에서 OpenShift Container Storage 4.6으로 업그레이드하는 경우 사용자 인터페이스에서 실패한 장치 교체를 활성화하려면 스토리지 클러스터에 주석을 추가하십시오. 주석 추가 를 참조하십시오.
-
이전 버전에서 OpenShift Container Storage 4.6으로 업그레이드하는 경우 업그레이드 후 프로시저를 따라
LocalVolumeDiscovery오브젝트를 생성해야 합니다. 자세한 내용은 업데이트 후 변경 사항을 참조하십시오. -
이전 버전에서 OpenShift Container Storage 4.6으로 업그레이드하는 경우 업그레이드 후 프로시저를 따라
LocalVolumeSet오브젝트를 생성해야 합니다. 자세한 내용은 업데이트 후 변경 사항을 참조하십시오."
절차
- 클러스터 또는 영구 스토리지 대시 보드에서
클러스터 또는 영구 스토리지 대시보드를 엽니다.
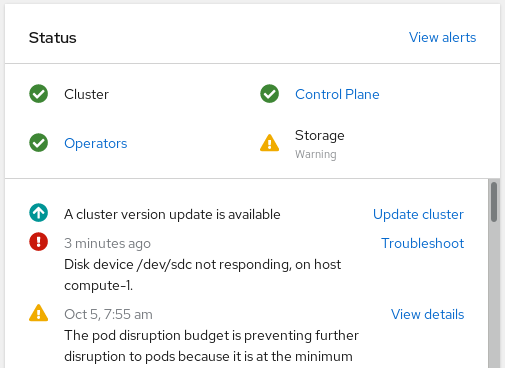
OpenShift 웹 콘솔의 왼쪽 탐색 모음에서 홈 → 개요 → 클러스터를 클릭합니다.
그림 4.1. 경고가 있는 클러스터 대시보드
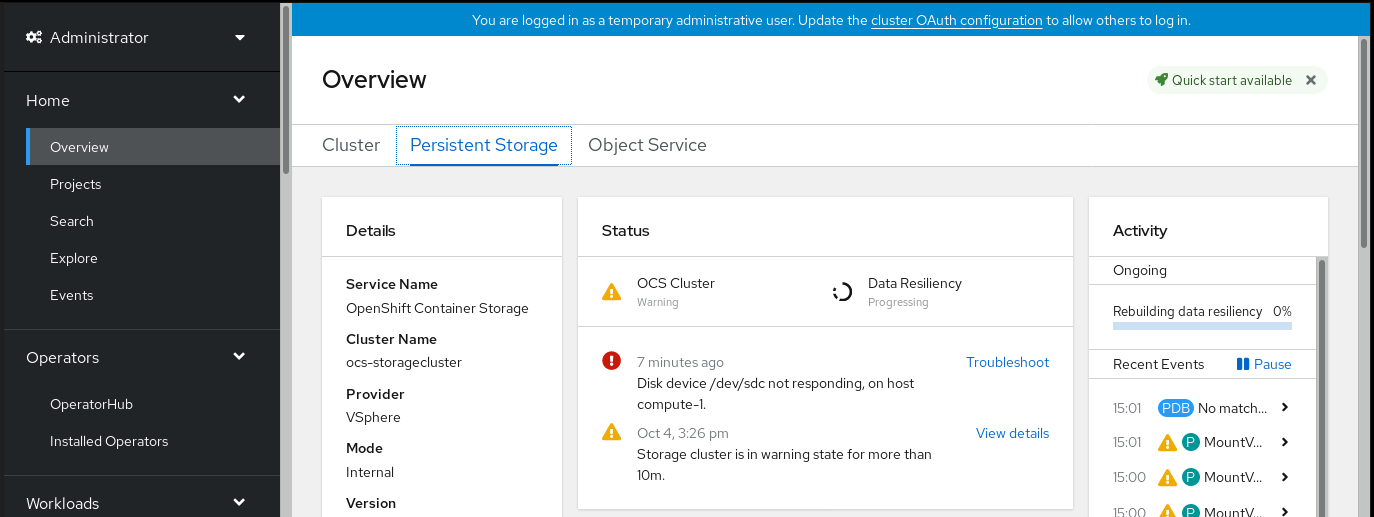
OpenShift 웹 콘솔의 왼쪽 탐색 모음에서 홈 → 개요 → 영구 스토리지를 클릭합니다.
그림 4.2. 경고가 포함된 영구 스토리지 대시보드
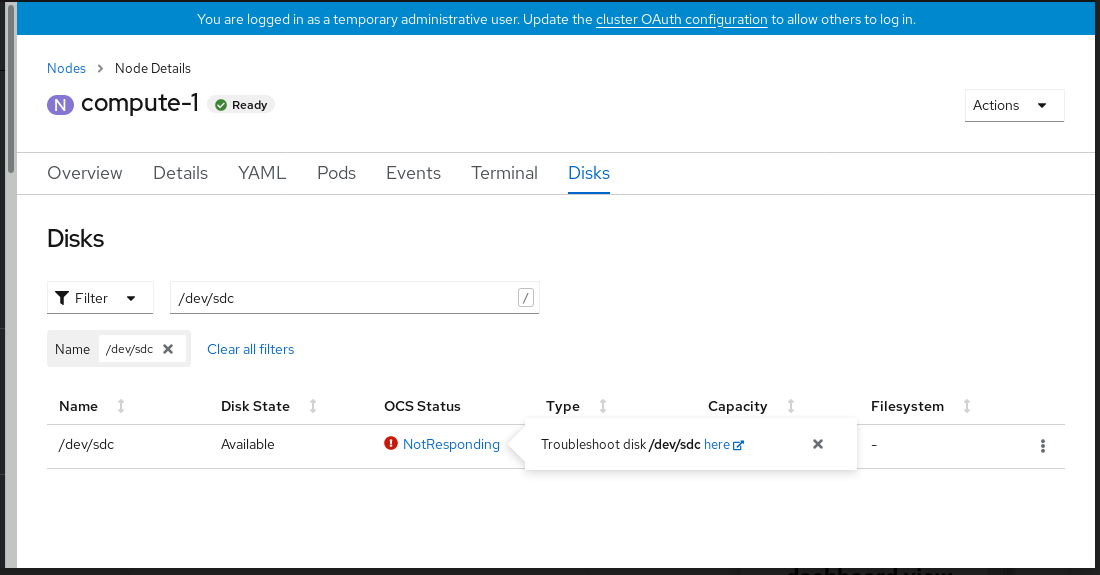
디스크 & lt; disk1 >에서 응답하지 않거나디스크 < disk1 >에 액세스할 수 없는경고를 클릭합니다.참고디스크 오류가 디스크를 제거한 경우 링크를 클릭하면 실패한 디스크가 표시되지 않을 수 있습니다. 이러한 시나리오에서는 로컬 스토리지 장치 섹션에서 지원하는 클러스터에 운영 또는 실패한 스토리지 장치 교체에 설명된 대로 명령줄 단계를 수행해야 합니다.
그림 4.3. 실패한 디스크를 교체하기 위한 디스크 페이지
디스크 페이지에서 다음 중 하나를 수행할 수 있습니다.
- 문제 해결 팝업 대화 상자에서 이 링크를 클릭하고 Troubleshooting OpenShift Container Storage 가이드의 단계에 따라 디스크가 실제로 실패했는지 확인합니다.
- 실패한 디스크의 Action (hiera) 메뉴에서 디스크 교체 시작을 클릭합니다.
-
디스크의 OpenShift Container Storage 상태필드가PreparingToReplace로 변경됩니다.OpenShift Container Storage Status필드가ReplacementReady으로 변경될 때까지 기다립니다. - 알림 벨을 클릭하여 디스크 경고가 더 이상 나타나지 않는지 확인합니다.
- 디스크를 교체하고 인벤토리 목록에 나타날 때까지 기다립니다.
교체된 디스크에 대한 ocs-osd-removal 작업을 삭제합니다.
- OpenShift 웹 콘솔에서 Workloads( 워크로드)Jobs (작업) 로 이동합니다.
- 이름별 검색 필터를 사용하여 ocs-osd-removal 을 찾습니다. 선택한 프로젝트가 openshift-storage 인지 확인합니다.
- 나열된 작업의 경우 Action(작업)(작업 ) 메뉴를 클릭하고 Delete Job ( 작업 삭제)를 선택합니다.
- 작업이 삭제되었는지 확인합니다.
교체된 디스크와 연결된 PersistentVolume 리소스를 삭제합니다.
- OpenShift 웹 콘솔에서 스토리지 → PersistentVolumes 로 이동합니다.
- Name 필터로 검색을 사용하여 Released 상태에서 PersistentVolume을 찾습니다.
-
LocalVolumeSet 생성의 일부로 생성된 스토리지 클래스에서 나열된 PersistentVolume에 대해 (예:
localblock) 메뉴를 클릭하고 PersistentVolume 삭제를 선택합니다.
-
새로 추가된 디스크에 대해
OpenShift Container Storage Status가Online으로 표시되는지 확인합니다.
- 인벤토리 목록에서
OpenShift 웹 콘솔에서 컴퓨팅 → 노드 를 클릭합니다.
그림 4.4. 노드 페이지의 디스크 인벤토리 목록
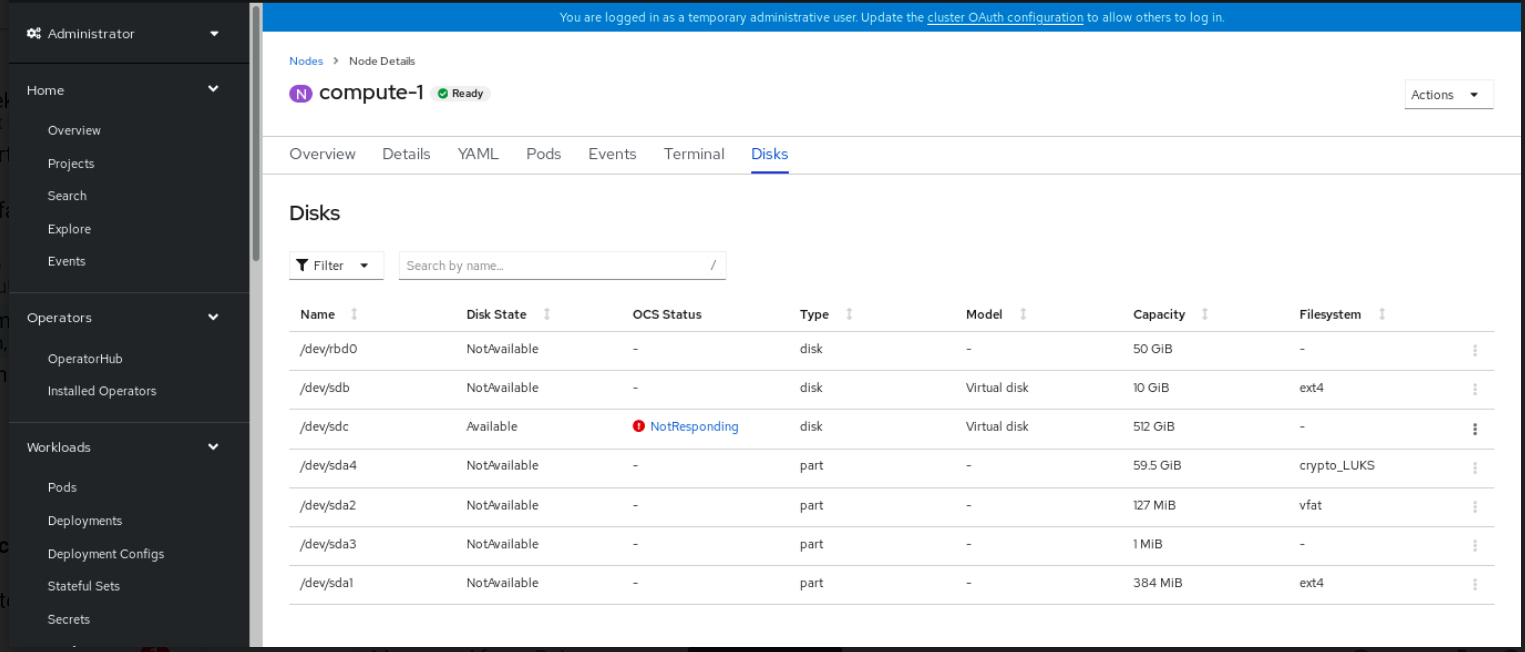
- 디스크 탭을 클릭합니다. 실패한 디스크의 작업 (:) 메뉴에서 디스크 교체 시작을 클릭합니다.
-
디스크의 OpenShift Container Storage 상태필드가PreparingToReplace로 변경됩니다.OpenShift Container Storage Status필드가ReplacementReady으로 변경될 때까지 기다립니다. - 알림 벨을 클릭하여 디스크 경고가 더 이상 나타나지 않는지 확인합니다.
- 디스크를 교체하고 인벤토리 목록에 나타날 때까지 기다립니다.
교체된 디스크에 대한 ocs-osd-removal 작업을 삭제합니다.
- OpenShift 웹 콘솔에서 Workloads( 워크로드)Jobs (작업) 로 이동합니다.
- 이름별 검색 필터를 사용하여 ocs-osd-removal 을 찾습니다. 선택한 프로젝트가 openshift-storage 인지 확인합니다.
- 나열된 작업의 경우 Action(작업)(작업 ) 메뉴를 클릭하고 Delete Job ( 작업 삭제)를 선택합니다.
- 작업이 삭제되었는지 확인합니다.
교체된 디스크와 연결된 PersistentVolume 리소스를 삭제합니다.
- OpenShift 웹 콘솔에서 스토리지 → PersistentVolumes 로 이동합니다.
- Name 필터로 검색을 사용하여 Released 상태에서 PersistentVolume을 찾습니다.
-
LocalVolumeSet 생성의 일부로 생성된 스토리지 클래스에서 나열된 PersistentVolume에 대해 (예:
localblock) 메뉴를 클릭하고 PersistentVolume 삭제를 선택합니다.
-
새로 추가된 디스크에 대해
OpenShift Container Storage Status가Online으로 표시되는지 확인합니다.
- 알림에서
- 홈 → 개요 → 영구저장장치 또는 클러스터 대시보드를 클릭하거나 컴퓨팅 → 노드 → 디스크 탭을 클릭합니다.
클러스터 또는 영구 스토리지 대시보드 또는 노드 페이지에서 다음 경고 중 하나를 찾습니다.
-
CephOSDDiskUnavailable -
CephOSDDiskNotResponding
-
경고 알림에서 문제 해결을 클릭합니다.
참고디스크 오류가 디스크를 제거한 경우 링크를 클릭하면 실패한 디스크가 표시되지 않을 수 있습니다. 이러한 시나리오에서는 로컬 스토리지 장치 섹션에서 지원하는 클러스터에 운영 또는 실패한 스토리지 장치 교체에 설명된 대로 명령줄 단계를 수행해야 합니다.
그림 4.5. 디스크 오류 알림
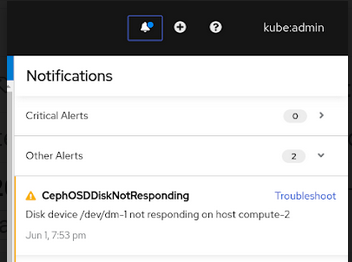
디스크 페이지에서 다음 중 하나를 수행할 수 있습니다.
- 문제 해결 팝업 대화 상자에서 이 링크를 클릭하고 Troubleshooting OpenShift Container Storage 가이드의 단계에 따라 디스크가 실제로 실패했는지 확인합니다.
- 실패한 디스크의 Action (hiera) 메뉴에서 디스크 교체 시작을 클릭합니다.
-
디스크의 OpenShift Container Storage 상태가PreparingToReplace로 변경되고 교체 준비가 되면 상태가ReplacementReady로 변경됩니다. - 알림 벨을 클릭하여 디스크 경고가 더 이상 나타나지 않는지 확인합니다.
- 디스크를 교체하고 인벤토리 목록에 나타날 때까지 기다립니다.
교체된 디스크에 대한 ocs-osd-removal 작업을 삭제합니다.
- OpenShift 웹 콘솔에서 Workloads( 워크로드)Jobs (작업) 로 이동합니다.
- 이름별 검색 필터를 사용하여 ocs-osd-removal 을 찾습니다. 선택한 프로젝트가 openshift-storage 인지 확인합니다.
- 나열된 작업의 경우 Action(작업)(작업 ) 메뉴를 클릭하고 Delete Job ( 작업 삭제)를 선택합니다.
- 작업이 삭제되었는지 확인합니다.
교체된 디스크와 연결된 PersistentVolume 리소스를 삭제합니다.
- OpenShift 웹 콘솔에서 스토리지 → PersistentVolumes 로 이동합니다.
- Name 필터로 검색을 사용하여 Released 상태에서 PersistentVolume을 찾습니다.
-
LocalVolumeSet 생성의 일부로 생성된 스토리지 클래스에서 나열된 PersistentVolume에 대해 (예:
localblock) 메뉴를 클릭하고 PersistentVolume 삭제를 선택합니다.
-
새로 추가된 디스크에 대해
OpenShift Container Storage Status가Online으로 표시되는지 확인합니다.
4.3. 로컬 스토리지 장치에서 지원하는 클러스터에서 운영 또는 실패한 스토리지 장치 교체
베어 메탈 및 VMware 인프라의 로컬 스토리지 장치를 사용하여 배포된 OpenShift Container Storage의 OSD(오브젝트 스토리지 장치)를 교체할 수 있습니다. 하나 이상의 기본 스토리지 장치를 교체해야 하는 경우 이 절차를 사용하십시오.
사전 요구 사항
- 교체 중인 노드에 유사한 인프라 및 리소스로 대체 노드를 구성하는 것이 좋습니다.
-
이전 버전에서 OpenShift Container Storage 4.6으로 업그레이드하는 경우 업그레이드 후 프로시저를 따라
LocalVolumeDiscovery오브젝트를 생성해야 합니다. 자세한 내용은 업데이트 후 변경 사항을 참조하십시오. -
이전 버전에서 OpenShift Container Storage 4.6으로 업그레이드하는 경우 업그레이드 후 프로시저를 따라
LocalVolumeSet오브젝트를 생성해야 합니다. 자세한 내용은 업데이트 후 변경 사항을 참조하십시오.
절차
교체해야 하는 OSD와 OSD가 예약된 OpenShift Container Platform 노드를 식별합니다.
$ oc get -n openshift-storage pods -l app=rook-ceph-osd -o wide
출력 예:
rook-ceph-osd-0-6d77d6c7c6-m8xj6 0/1 CrashLoopBackOff 0 24h 10.129.0.16 compute-2 <none> <none> rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 24h 10.128.2.24 compute-0 <none> <none> rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 24h 10.130.0.18 compute-1 <none> <none>
이 예에서는
rook-ceph-osd-0-6d77d6c7c6-m8xj6을 교체해야 하며,compute-2는 OSD가 예약된 OpenShift Container Platform 노드입니다.참고교체할 OSD가 정상이면 Pod 상태가
Running이 됩니다.OSD를 교체할 OSD 배포를 축소합니다.
$ osd_id_to_remove=0 $ oc scale -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove} --replicas=0여기서
osd_id_to_remove는rook-ceph-osd접두사 바로 직후 pod 이름의 정수입니다. 이 예에서 배포 이름은rook-ceph-osd-0입니다.출력 예:
deployment.extensions/rook-ceph-osd-0 scaled
rook-ceph-osd포드가 종료되었는지 확인합니다.$ oc get -n openshift-storage pods -l ceph-osd-id=${osd_id_to_remove}출력 예:
No resources found in openshift-storage namespace.
참고rook-ceph-osdPod가 몇 분 이상종료상태인 경우force옵션을 사용하여 Pod를 삭제합니다.$ oc delete -n openshift-storage pod rook-ceph-osd-0-6d77d6c7c6-m8xj6 --grace-period=0 --force
출력 예:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "rook-ceph-osd-0-6d77d6c7c6-m8xj6" force deleted
새 OSD를 추가할 수 있도록 클러스터에서 이전 OSD를 제거합니다.
이전
ocs-osd-removal작업을 삭제합니다.$ oc delete -n openshift-storage job ocs-osd-removal-${osd_id_to_remove}출력 예:
job.batch "ocs-osd-removal-0" deleted
openshift-storage프로젝트로 변경합니다.$ oc project openshift-storage
클러스터에서 이전 OSD를 제거합니다.
$ oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_IDS=${osd_id_to_remove} |oc create -n openshift-storage -f -주의이 단계에서는 OSD가 클러스터에서 완전히 제거됩니다.
osd_id_to_remove의 올바른 값이 제공되는지 확인합니다.
ocs-osd-removalPod의 상태를 확인하여 OSD가 성공적으로 제거되었는지 확인합니다.완료된상태로 OSD 제거 작업이 성공했는지 확인합니다.$ oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage참고ocs-osd-removal이 실패하고 Pod가 예상Completed상태가 아닌 경우 Pod 로그에서 추가 디버깅을 확인합니다. 예:$ oc logs -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage --tail=-1설치 시 암호화가 활성화된 경우 해당 OpenShift Container Storage 노드에서 제거된 OSD 장치에서
dm매핑을 제거합니다.-crypt관리 장치-mapperocs-osd-removal-jobPod 로그에서 교체된 OSD의 PVC 이름을 가져옵니다.$ oc logs -l job-name=ocs-osd-removal-job -n openshift-storage --tail=-1 |egrep -i ‘pvc|deviceset’
예:
2021-05-12 14:31:34.666000 I | cephosd: removing the OSD PVC "ocs-deviceset-xxxx-xxx-xxx-xxx"
단계 #1에서 식별된 각 노드에 대해 다음을 수행합니다.
스토리지 노드의 호스트에
디버그Pod 및chroot를 생성합니다.$ oc debug node/<node name> $ chroot /host
이전 단계에서 확인한 PVC 이름을 기반으로 관련 장치 이름을 찾습니다.
sh-4.4# dmsetup ls| grep <pvc name> ocs-deviceset-xxx-xxx-xxx-xxx-block-dmcrypt (253:0)
매핑된 장치를 제거합니다.
$ cryptsetup luksClose --debug --verbose ocs-deviceset-xxx-xxx-xxx-xxx-block-dmcrypt
참고충분하지 않은 권한으로 인해 위 명령이 중단되는 경우 다음 명령을 실행합니다.
-
CTRL+Z를 눌러 위의 명령을 종료합니다. 정지된 프로세스의 PID를 찾습니다.
$ ps -ef | grep crypt
kill명령을 사용하여 프로세스를 종료합니다.$ kill -9 <PID>
장치 이름이 제거되었는지 확인합니다.
$ dmsetup ls
-
명령으로 삭제해야 하는 PV(영구 볼륨)를 찾습니다.
$ oc get pv -L kubernetes.io/hostname | grep localblock | grep Released local-pv-d6bf175b 1490Gi RWO Delete Released openshift-storage/ocs-deviceset-0-data-0-6c5pw localblock 2d22h compute-1
영구 볼륨을 삭제합니다.
$ oc delete pv local-pv-d6bf175b
물리적으로 노드에 새 장치를 추가합니다.
이전 장치(선택 사항)를 제거할 수도 있습니다.
다음 명령을 사용하여
deviceInclusionSpec과 일치하는 장치에 대한 영구 볼륨의 프로비저닝을 추적합니다. 영구 볼륨을 프로비저닝하는 데 몇 분이 걸릴 수 있습니다.$ oc -n openshift-local-storage describe localvolumeset localblock
출력 예:
[...] Status: Conditions: Last Transition Time: 2020-11-17T05:03:32Z Message: DiskMaker: Available, LocalProvisioner: Available Status: True Type: DaemonSetsAvailable Last Transition Time: 2020-11-17T05:03:34Z Message: Operator reconciled successfully. Status: True Type: Available Observed Generation: 1 Total Provisioned Device Count: 4 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Discovered 2m30s (x4 localvolumeset- node.example.com - NewDevice over 2m30s) symlink-controller found possible matching disk, waiting 1m to claim Normal FoundMatch 89s (x4 localvolumeset- node.example.com - ingDisk over 89s) symlink-controller symlinking matching disk영구 볼륨이 프로비저닝되면 프로비저닝된 볼륨에 대해 새 OSD 포드가 자동으로 생성됩니다.
ocs-osd-removal작업을 삭제합니다.$ oc delete -n openshift-storage job ocs-osd-removal-${osd_id_to_remove}
검증 단계
새 OSD가 실행되고 있는지 확인합니다.
$ oc get -n openshift-storage pods -l app=rook-ceph-osd
출력 예:
rook-ceph-osd-0-5f7f4747d4-snshw 1/1 Running 0 4m47s rook-ceph-osd-1-85d99fb95f-2svc7 1/1 Running 0 1d20h rook-ceph-osd-2-6c66cdb977-jp542 1/1 Running 0 1d20h
참고새 OSD가 몇 분 후에
Running으로 표시되지 않으면rook-ceph-operator포드를 다시 시작하여 조정을 강제 적용합니다.$ oc delete pod -n openshift-storage -l app=rook-ceph-operator
출력 예:
pod "rook-ceph-operator-6f74fb5bff-2d982" deleted
새 PVC가 생성되었는지 확인합니다.
# oc get -n openshift-storage pvc | grep localblock
출력 예:
ocs-deviceset-0-0-c2mqb Bound local-pv-b481410 1490Gi RWO localblock 5m ocs-deviceset-1-0-959rp Bound local-pv-414755e0 1490Gi RWO localblock 1d20h ocs-deviceset-2-0-79j94 Bound local-pv-3e8964d3 1490Gi RWO localblock 1d20h
(선택 사항) 클러스터에서 데이터 암호화가 활성화된 경우 새 OSD 장치가 암호화되었는지 확인합니다.
새 OSD 포드가 실행 중인 노드를 식별합니다.
$ oc get -o=custom-columns=NODE:.spec.nodeName pod/<OSD pod name>
예:
oc get -o=custom-columns=NODE:.spec.nodeName pod/rook-ceph-osd-0-544db49d7f-qrgqm
이전 단계에서 확인한 각 노드에서 다음을 수행합니다.
디버그 Pod를 생성하고 선택한 호스트에 대한 chroot 환경을 엽니다.
$ oc debug node/<node name> $ chroot /host
"lsblk"를 실행하고
ocs-deviceset이름 옆에 "crypt" 키워드를 확인합니다.$ lsblk
OpenShift 웹 콘솔에 로그인하고 스토리지 대시보드에서 OSD 상태를 확인합니다.
그림 4.6. 장치 교체 후 OpenShift Container Platform 스토리지 대시보드의 OSD 상태
복구되는 데이터 볼륨에 따라 전체 데이터 복구가 더 오래 걸릴 수 있습니다.
4.4. IBM Power Systems에서 운영 또는 실패한 스토리지 장치 교체
IBM Power Systems의 로컬 스토리지 장치를 사용하여 배포된 OpenShift Container Storage의 OSD(오브젝트 스토리지 장치)를 교체할 수 있습니다. 기본 스토리지 장치를 교체해야 하는 경우 이 절차를 사용하십시오.
절차
교체해야 하는 OSD와 OSD가 예약된 OpenShift Container Platform 노드를 식별합니다.
# oc get -n openshift-storage pods -l app=rook-ceph-osd -o wide
출력 예:
rook-ceph-osd-0-86bf8cdc8-4nb5t 0/1 crashLoopBackOff 0 24h 10.129.2.26 worker-0 <none> <none> rook-ceph-osd-1-7c99657cfb-jdzvz 1/1 Running 0 24h 10.128.2.46 worker-1 <none> <none> rook-ceph-osd-2-5f9f6dfb5b-2mnw9 1/1 Running 0 24h 10.131.0.33 worker-2 <none> <none>
이 예에서
rook-ceph-osd-0-86bf8cdc8-4nb5t를 교체해야 하며worker-0은 OSD가 예약된 RuntimeClass 노드입니다.참고교체할 OSD가 정상이면 Pod 상태가
Running이 됩니다.OSD를 교체할 OSD 배포를 축소합니다.
# osd_id_to_remove=0 # oc scale -n openshift-storage deployment rook-ceph-osd-${osd_id_to_remove} --replicas=0여기서
osd_id_to_remove는rook-ceph-osd접두사 바로 직후 pod 이름의 정수입니다. 이 예에서 배포 이름은rook-ceph-osd-0입니다.출력 예:
deployment.apps/rook-ceph-osd-0 scaled
rook-ceph-osd포드가 종료되었는지 확인합니다.# oc get -n openshift-storage pods -l ceph-osd-id=${osd_id_to_remove}출력 예:
No resources found in openshift-storage namespace.
참고rook-ceph-osdPod가종료상태인 경우force옵션을 사용하여 Pod를 삭제합니다.# oc delete pod rook-ceph-osd-0-86bf8cdc8-4nb5t --grace-period=0 --force
출력 예:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "rook-ceph-osd-0-86bf8cdc8-4nb5t" force deleted
새 OSD를 추가할 수 있도록 클러스터에서 이전 OSD를 제거합니다.
교체할 OSD
와 연결된 장치세트를 식별합니다.# oc get -n openshift-storage -o yaml deployment rook-ceph-osd-${osd_id_to_remove} | grep ceph.rook.io/pvc출력 예:
ceph.rook.io/pvc: ocs-deviceset-localblock-0-data-0-64xjl ceph.rook.io/pvc: ocs-deviceset-localblock-0-data-0-64xjl이 예에서 PVC 이름은
ocs-deviceset-localblock-0-data-0-64xjl입니다.클러스터에서 이전 OSD 제거
# oc process -n openshift-storage ocs-osd-removal -p FAILED_OSD_IDS=${osd_id_to_remove} | oc -n openshift-storage create -f -출력 예:
job.batch/ocs-osd-removal-0 created
주의이 단계에서는 OSD가 클러스터에서 완전히 제거됩니다.
osd_id_to_remove의 올바른 값이 제공되는지 확인합니다.
ocs-osd-removalPod의 상태를 확인하여 OSD가 성공적으로 제거되었는지 확인합니다.완료된상태로 OSD 제거 작업이 성공적으로 완료되었는지 확인합니다.# oc get pod -l job-name=ocs-osd-removal-${osd_id_to_remove} -n openshift-storage참고ocs-osd-removal이 실패하고 Pod가 예상Completed상태가 아닌 경우 Pod 로그에서 추가 디버깅을 확인합니다. 예:# oc logs ${osd_id_to_remove} -n openshift-storage --tail=-1교체할 OSD와 연결된 PVC(영구 볼륨 클레임) 리소스를 삭제합니다.
PVC와 연결된 PV를 확인합니다.
# oc get -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>
여기서,
X,y,pvc-suffix는 단계 4(a)에서 식별된DeviceSet의 값입니다.출력 예:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ocs-deviceset-localblock-0-data-0-64xjl Bound local-pv-8137c873 256Gi RWO localblock 24h
이 예에서 연결된 PV는
local-pv-8137c873입니다.교체할 장치의 이름을 확인합니다.
# oc get pv local-pv-<pv-suffix> -o yaml | grep path
여기서
pv-suffix는 이전 단계에서 확인한 PV 이름의 값입니다.출력 예:
path: /mnt/local-storage/localblock/vdc
이 예에서 장치 이름은tekton
입니다.교체할 OSD와 연결된
prepare-pod를 확인합니다.# oc describe -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix> | grep Mounted
여기서
,X ,y및pvc-suffix는 이전 단계에서 식별된DeviceSet의 값입니다.출력 예:
Mounted By: rook-ceph-osd-prepare-ocs-deviceset-localblock-0-data-0-64knzkc
이 예에서
prepare-pod이름은rook-ceph-osd-prepare-ocs-deviceset-localblock-0-data-0-64knzkc입니다.연결된 PVC를 제거하기 전에
osd-preparePod를 삭제합니다.# oc delete -n openshift-storage pod rook-ceph-osd-prepare-ocs-deviceset-<x>-<y>-<pvc-suffix>-<pod-suffix>
여기서,
x,y, y,pvc-suffix,pod-suffix는 이전 단계에서 확인된osd-preparepod 이름의 값입니다.출력 예:
pod "rook-ceph-osd-prepare-ocs-deviceset-localblock-0-data-0-64knzkc" deleted
교체할 OSD와 연결된 PVC를 삭제합니다.
# oc delete -n openshift-storage pvc ocs-deviceset-<x>-<y>-<pvc-suffix>
여기서
,X ,y및pvc-suffix는 이전 단계에서 식별된DeviceSet의 값입니다.출력 예:
persistentvolumeclaim "ocs-deviceset-localblock-0-data-0-64xjl" deleted
이전 장치를 교체하고 새 장치를 사용하여 새 OpenShift Container Platform PV를 생성합니다.
교체할 장치로 OpenShift Container Platform 노드에 로그인합니다. 이 예에서 OpenShift Container Platform 노드는
worker-0입니다.# oc debug node/worker-0
출력 예:
Starting pod/worker-0-debug ... To use host binaries, run `chroot /host` Pod IP: 192.168.88.21 If you don't see a command prompt, try pressing enter. # chroot /host
/dev/disk를 장치 이름, ProfileBundle (이전에 식별)을 사용하여 교체하도록 기록합니다.# ls -alh /mnt/local-storage/localblock
출력 예:
total 0 drwxr-xr-x. 2 root root 17 Nov 18 15:23 . drwxr-xr-x. 3 root root 24 Nov 18 15:23 .. lrwxrwxrwx. 1 root root 8 Nov 18 15:23 vdc -> /dev/vdc
LocalVolumeSetCR의 이름을 찾아 교체할 장치/dev/disk를 제거하거나 주석 처리합니다.# oc get -n openshift-local-storage localvolumeset NAME AGE localblock 25h
교체할 장치로 OpenShift Container Platform 노드에 로그인하고 이전
심볼릭링크를 제거합니다.# oc debug node/worker-0
출력 예:
Starting pod/worker-0-debug ... To use host binaries, run `chroot /host` Pod IP: 192.168.88.21 If you don't see a command prompt, try pressing enter. # chroot /host
교체할 장치 이름에 대한 이전
심볼릭 링크를확인합니다. 이 예에서 장치 이름은tekton입니다.# ls -alh /mnt/local-storage/localblock
출력 예:
total 0 drwxr-xr-x. 2 root root 17 Nov 18 15:23 . drwxr-xr-x. 3 root root 24 Nov 18 15:23 .. lrwxrwxrwx. 1 root root 8 Nov 18 15:23 vdc -> /dev/vdc
심볼릭링크를 제거합니다.# rm /mnt/local-storage/localblock/vdc
심볼릭링크가 제거되었는지 확인합니다.# ls -alh /mnt/local-storage/localblock
출력 예:
total 0 drwxr-xr-x. 2 root root 6 Nov 18 17:11 . drwxr-xr-x. 3 root root 24 Nov 18 15:23 ..
중요OpenShift Container Storage 4.5 이상 버전의 새 배포의 경우 LVM을 사용하지 않으며
ceph-volumeraw 모드가 대신 사용됩니다. 따라서 추가 검증이 필요하지 않으며 다음 단계로 진행할 수 있습니다.
교체할 장치와 연결된 PV를 삭제합니다. 이 PV는 이전 단계에서 확인되었습니다. 이 예에서 PV 이름은
local-pv-8137c873입니다.# oc delete pv local-pv-8137c873
출력 예:
persistentvolume "local-pv-8137c873" deleted
- 장치를 새 장치로 바꿉니다.
올바른 OpenShift Cotainer Platform 노드에 다시 로그인하고 새 드라이브의 장치 이름을 확인합니다. 동일한 장치를 다시 정렬하지 않는 한 장치 이름을 변경해야 합니다.
# lsblk
출력 예:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 40G 0 disk |-vda1 252:1 0 4M 0 part |-vda2 252:2 0 384M 0 part /boot `-vda4 252:4 0 39.6G 0 part `-coreos-luks-root-nocrypt 253:0 0 39.6G 0 dm /sysroot vdb 252:16 0 512B 1 disk vdd 252:32 0 256G 0 disk
이 예에서 새 장치 이름은
vdd입니다.-
새
/dev/disk를 사용할 수 있게 되면 localvolumeset에 의해 자동으로 감지됩니다. 사용가능한 새 PV와 올바른 크기의 새 PV가 있는지 확인합니다.# oc get pv | grep 256Gi
출력 예:
local-pv-1e31f771 256Gi RWO Delete Bound openshift-storage/ocs-deviceset-localblock-2-data-0-6xhkf localblock 24h local-pv-ec7f2b80 256Gi RWO Delete Bound openshift-storage/ocs-deviceset-localblock-1-data-0-hr2fx localblock 24h local-pv-8137c873 256Gi RWO Delete Available localblock 32m
새 장치를 위한 새 OSD를 만듭니다.
rook-ceph-operator를 다시 시작하여 새 OSD를 배포하여 Operator 조정을 강제 적용합니다.rook-ceph-operator의 이름을 확인합니다.# oc get -n openshift-storage pod -l app=rook-ceph-operator
출력 예:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-85f6494db4-sg62v 1/1 Running 0 1d20h
rook-ceph-operator를 삭제합니다.# oc delete -n openshift-storage pod rook-ceph-operator-85f6494db4-sg62v
출력 예:
pod "rook-ceph-operator-85f6494db4-sg62v" deleted
이 예에서 rook-ceph-operator 포드 이름은
rook-ceph-operator-85f6494db4-sg62v입니다.rook-ceph-operatorPod가 다시 시작되었는지 확인합니다.# oc get -n openshift-storage pod -l app=rook-ceph-operator
출력 예:
NAME READY STATUS RESTARTS AGE rook-ceph-operator-85f6494db4-wx9xx 1/1 Running 0 50s
새 OSD를 만드는 데 Operator가 다시 시작되면 몇 분 정도 걸릴 수 있습니다.
ocs-osd-removal작업을 삭제합니다.$ oc delete -n openshift-storage job ocs-osd-removal-${osd_id_to_remove}
검증 단계
실행 중인 새 OSD와 새 PVC가 생성되었는지 확인합니다.
# oc get -n openshift-storage pods -l app=rook-ceph-osd
출력 예:
rook-ceph-osd-0-76d8fb97f9-mn8qz 1/1 Running 0 23m rook-ceph-osd-1-7c99657cfb-jdzvz 1/1 Running 1 25h rook-ceph-osd-2-5f9f6dfb5b-2mnw9 1/1 Running 0 25h
# oc get -n openshift-storage pvc | grep localblock
출력 예:
ocs-deviceset-localblock-0-data-0-q4q6b Bound local-pv-8137c873 256Gi RWO localblock 10m ocs-deviceset-localblock-1-data-0-hr2fx Bound local-pv-ec7f2b80 256Gi RWO localblock 1d20h ocs-deviceset-localblock-2-data-0-6xhkf Bound local-pv-1e31f771 256Gi RWO localblock 1d20h
OpenShift 웹 콘솔에 로그인하고 스토리지 대시보드를 확인합니다.
그림 4.7. 장치 교체 후 OpenShift Container Platform 스토리지 대시보드의 OSD 상태

4.5. IBM Z 또는 LinuxONE 인프라에서 운영 또는 실패한 스토리지 장치 교체
IBM Z 또는 LinuxONE 인프라의 운영 또는 실패한 스토리지 장치를 새 SCSI 디스크로 교체할 수 있습니다.
IBM Z 또는 LinuxONE은 외부 디스크 스토리지의 영구 스토리지 장치로 SCSI FCP 디스크 논리 장치(SCSI 디스크 장치)를 지원합니다. SCSI 디스크는 FCP 장치 번호, 글로벌 포트 이름 두 개(WkubeconfigN1 및 WWPN2) 및 논리 장치 번호(LUN)를 사용하여 식별할 수 있습니다. 자세한 내용은 https://www.ibm.com/support/knowledgecenter/SSB27U_6.4.0/com.ibm.zvm.v640.hcpa5/scsiover.html을 참조하십시오.
절차
다음 명령을 사용하여 모든 디스크를 나열합니다.
$ lszdev
출력 예:
TYPE ID zfcp-host 0.0.8204 yes yes zfcp-lun 0.0.8204:0x102107630b1b5060:0x4001402900000000 yes no sda sg0 zfcp-lun 0.0.8204:0x500407630c0b50a4:0x3002b03000000000 yes yes sdb sg1 qeth 0.0.bdd0:0.0.bdd1:0.0.bdd2 yes no encbdd0 generic-ccw 0.0.0009 yes no
SCSI 디스크는
ID섹션의 <device-id>:<wwpn>:<lun> 구조를 사용하여으로 표시됩니다. 첫 번째 디스크는 운영 체제에 사용됩니다. 스토리지 장치 하나가 실패하면 새 디스크로 교체할 수 있습니다.zfcp-lun디스크를 제거합니다.
디스크에서 다음 명령을 실행하고,
scsi-id를 교체할 디스크의 SCSI 디스크 ID로 교체합니다.$ chzdev -d scsi-id예를 들어 다음 명령은 장치 ID
0.0.8204, WkubeconfigN0x5005076a0b50a4및 다음 명령을 사용하여 LUN0x4002403000000000을 사용하여 하나의 디스크를 제거합니다.$ chzdev -d 0.0.8204:0x500407630c0b50a4:0x3002b03000000000
다음 명령을 사용하여 새 SCSI 디스크를 추가합니다.
$ chzdev -e 0.0.8204:0x500507630b1b50a4:0x4001302a00000000
참고새 디스크의 장치 ID는 교체할 디스크와 동일해야 합니다. 새 디스크는 WWPN 및 LUN ID로 식별됩니다.
모든 FCP 장치를 나열하여 새 디스크가 구성되었는지 확인합니다.
$ lszdev zfcp-lun TYPE ID ON PERS NAMES zfcp-lun 0.0.8204:0x102107630b1b5060:0x4001402900000000 yes no sda sg0 zfcp-lun 0.0.8204:0x500507630b1b50a4:0x4001302a00000000 yes yes sdb sg1