
Administration and Configuration Guide
A guide for configuring and administrating Red Hat JBoss Data Grid 6.
Edition 1
Abstract
Preface
Chapter 1. JBoss Data Grid
1.1. About JBoss Data Grid
- Schemaless key-value store – Red Hat JBoss Data Grid is a NoSQL database that provides the flexibility to store different objects without a fixed data model.
- Grid-based data storage – Red Hat JBoss Data Grid is designed to easily replicate data across multiple nodes.
- Elastic scaling – Adding and removing nodes is achieved simply and is non-disruptive.
- Multiple access protocols – It is easy to access to the data grid using REST, Memcached, Hot Rod, or simple map-like API.
1.2. JBoss Data Grid Usage Modes
- Remote Client-Server mode
- Remote Client-Server mode provides a managed, distributed and clusterable data grid server. Applications can remotely access the data grid server using Hot Rod, Memcached or REST client APIs.
- Library mode
- Library mode provides all the binaries required to build and deploy a custom runtime environment. The library usage mode allows local access to a single node in a distributed cluster. This usage mode gives the application access to data grid functionality within a virtual machine in the container being used. Supported containers include Tomcat 7 and JBoss Enterprise Application Platform 6.
1.3. JBoss Data Grid Benefits
Benefits of JBoss Data Grid
- Massive Heap and High Availability
- In JBoss Data Grid, applications no longer need to delegate the majority of their data lookup processes to a large single server database for performance benefits. JBoss Data Grid completely removes the bottleneck that exists in the vast majority of current enterprise applications.
Example 1.1. Massive Heap and High Availability Example
In a sample grid with one hundred blade servers, each node has 2 GB storage space dedicated for a replicated cache. In this case, all the data in the grid is copies of the 2 GB data. In contrast, using a distributed grid (assuming the requirement of one copy per data item) the resulting memory backed virtual heap contains 100 GB data. This data can now be effectively accessed from anywhere in the grid. In case of a server failure, the grid promptly creates new copies of the lost data and places them on operational servers in the grid. - Scalability
- Due to the even distribution of data in JBoss Data Grid, the only upper limit for the size of the grid is the group communication on the network. The network's group communication is minimal and restricted only to the discovery of new nodes. Nodes are permitted by all data access patterns to communicate directly via peer-to-peer connections, facilitating further improved scalability. JBoss Data Grid clusters can be scaled up or down in real time without requiring an infrastructure restart. The result of the real time application of changes in scaling policies results in an exceptionally flexible environment.
- Data Distribution
- JBoss Data Grid uses consistent hash algorithms to determine the locations for keys in clusters. Benefits associated with consistent hashing include:Data distribution ensures that sufficient copies exist within the cluster to provide durability and fault tolerance, while not an abundance of copies, which would reduce the environment's scalability.
- cost effectiveness.
- speed.
- deterministic location of keys with no requirements for further metadata or network traffic.
- Persistence
- JBoss Data Grid exposes a
CacheStoreinterface and several high-performance implementations, including the JDBC Cache stores and file system based cache stores. Cache stores can be used to seed the cache and to ensure that the relevant data remains safe from corruption. The cache store also overflows data to the disk when required if a process runs out of memory. - Language bindings
- JBoss Data Grid supports both the popular Memcached protocol, with existing clients for a large number of popular programming languages, as well as an optimized JBoss Data Grid specific protocol called Hot Rod. As a result, instead of being restricted to Java, JBoss Data Grid can be used for any major website or application.
- Management
- In a grid environment of several hundred or more servers, management is an important feature. JBoss Operations Network, the enterprise network management software, is the best tool to manage multiple JBoss Data Grid instances. JBoss Operations Network's features allow easy and effective monitoring of the Cache Manager and cache instances.
1.4. JBoss Data Grid Prerequisites
1.5. JBoss Data Grid Version Information
1.6. JBoss Data Grid Cache Architecture
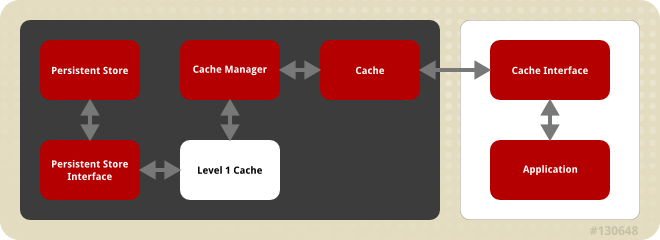
Figure 1.1. JBoss Data Grid Cache Architecture
- Elements that a user cannot directly interact with (depicted within a dark box), which includes the Cache, Cache Manager, Level 1 Cache, Persistent Store Interfaces and the Persistent Store.
- Elements that a user can interact directly with (depicted within a white box), which includes Cache Interfaces and the Application.
JBoss Data Grid's cache architecture includes the following elements:
- The Persistent Store permanently houses cache instances and entries.
- JBoss Data Grid offers two Persistent Store Interfaces to access the persistent store. Persistent store interfaces can be either:
- A cache loader is a read only interface that provides a connection to a persistent data store. A cache loader can locate and retrieve data from cache instances and from the persistent store. For details, see Section 10.8, “Cache Loaders”.
- A cache store extends the cache loader functionality to include write capabilities by exposing methods that allow the cache loader to load and store states. For details, see Chapter 10, Cache Stores and Cache Loaders.
- The Level 1 Cache (or L1 Cache) stores remote cache entries after they are initially accessed, preventing unnecessary remote fetch operations for each subsequent use of the same entries. For details, see Chapter 14, The L1 Cache.
- The Cache Manager is the primary mechanism used to retrieve a Cache instance in JBoss Data Grid, and can be used as a starting point for using the Cache. For details, see Chapter 11, Cache Managers.
- The Cache houses cache instances retrieved by a Cache Manager.
- Cache Interfaces use protocols such as Memcached and Hot Rod, or REST to interface with the cache. For details about the remote interfaces, refer to the Developer Guide.
- Memcached is an in-memory caching system used to improve response and operation times for database-driver websites. The Memcached caching system defines a text based, client-server caching protocol called the Memcached protocol.
- Hot Rod is a binary TCP client-server protocol used in JBoss Data Grid. It was created to overcome deficiencies in other client/server protocols, such as Memcached. Hot Rod enables clients to do smart routing of requests in partitioned or distributed JBoss Data Grid server clusters.
- The REST protocol eliminates the need for tightly coupled client libraries and bindings. The REST API introduces an overhead, and requires a REST client or custom code to understand and create REST calls.
- An application allows the user to interact with the cache via a cache interface. Browsers are a common example of such end-user applications.
1.7. JBoss Data Grid APIs
1.7.1. JBoss Data Grid APIs
- Cache
- Batching
- Grouping
- CacheStore
- Externalizable
- The Asynchronous API (can only be used in conjunction with the Hot Rod Client in Remote Client-Server Mode)
- The REST Interface
- The Memcached Interface
- The Hot Rod Interface
- The RemoteCache API
1.7.2. About the Asynchronous API
Async appended to each method name. Asynchronous methods return a Future that contains the result of the operation.
Cache(String, String), Cache.put(String key, String value) returns a String, while Cache.putAsync(String key, String value) returns a Future(String).
1.7.3. About the Batching API
Note
1.7.4. About the Cache API
ConcurrentMap interface. How entries are stored depends on the cache mode in use. For example, an entry may be replicated to a remote node or an entry may be looked up in a cache store.
Note
1.7.5. About the RemoteCache Interface
1.8. Tools and Operations
1.8.1. About Management Tools
1.8.2. Accessing Data via URLs
put() and post() methods place data in the cache, and the URL used determines the cache name and key(s) used. The data is the value placed into the cache, and is placed in the body of the request.
GET and HEAD methods are used for data retrieval while other headers control cache settings and behavior.
Note
1.8.3. Limitations of Map Methods
Map methods, such as size(), values(), keySet() and entrySet(), can be used with certain limitations with JBoss Data Grid as they are unreliable. These methods do not acquire locks (global or local) and concurrent modification, additions and removals are excluded from consideration in these calls. Furthermore, the listed methods are only operational on the local data container and do not provide a global view of state.
Chapter 2. Logging in JBoss Data Grid
2.1. An Overview of Logging in JBoss Data Grid
2.2. Supported Application Logging Frameworks
2.2.1. Supported Application Logging Frameworks
- JBoss Logging, which is included with JBoss Data Grid 6.
2.2.2. About JBoss Logging
2.2.3. JBoss Logging Features
- Provides an innovative, easy to use typed logger.
- Full support for internationalization and localization. Translators work with message bundles in properties files while developers can work with interfaces and annotations.
- Build-time tooling to generate typed loggers for production, and runtime generation of typed loggers for development.
2.3. Configure Logging
2.3.1. About Boot Logging
2.3.2. Configure Boot Logging
logging.properties file to configure the boot log. This file is a standard Java properties file and can be edited in a text editor. Each line in the file has the format of property=value.
logging.properties file is available in the $JDG_HOME/standalone/configuration folder.
2.3.3. Default Log File Locations
Table 2.1. Default Log File Locations
| Log File | Location | Description |
|---|---|---|
boot.log | $JDG_HOME/standalone/log/ | The Server Boot Log. Contains log messages related to the start up of the server. |
server.log | $JDG_HOME/standalone/log/ | The Server Log. Contains all log messages once the server has launched. |
2.4. Logging Attributes
2.4.1. About Log Levels
TRACEDEBUGINFOWARNERRORFATAL
WARN will only record messages of the levels WARN, ERROR and FATAL.
2.4.2. Supported Log Levels
Table 2.2. Supported Log Levels
| Log Level | Value | Description |
|---|---|---|
| FINEST | 300 | - |
| FINER | 400 | - |
| TRACE | 400 | Used for messages that provide detailed information about the running state of an application. TRACE level log messages are captured when the server runs with the TRACE level enabled. |
| DEBUG | 500 | Used for messages that indicate the progress of individual requests or activities of an application. DEBUG level log messages are captured when the server runs with the DEBUG level enabled. |
| FINE | 500 | - |
| CONFIG | 700 | - |
| INFO | 800 | Used for messages that indicate the overall progress of the application. Used for application start up, shut down and other major lifecycle events. |
| WARN | 900 | Used to indicate a situation that is not in error but is not considered ideal. Indicates circumstances that can lead to errors in the future. |
| WARNING | 900 | - |
| ERROR | 1000 | Used to indicate an error that has occurred that could prevent the current activity or request from completing but will not prevent the application from running. |
| FATAL | 1100 | Used to indicate events that could cause critical service failure and application shutdown and possibly cause JBoss Data Grid 6 to shut down. |
2.4.3. About Log Categories
DEBUG log level results in log values of 300, 400 and 500 are captured.
2.4.4. About the Root Logger
server.log. This file is sometimes referred to as the server log.
2.4.5. About Log Handlers
ConsoleFilePeriodicSizeAsyncCustom
2.4.6. Log Handler Types
Table 2.3. Log Handler Types
| Log Handler Type | Description |
|---|---|
| Console | Console log handlers write log messages to either the host operating system’s standard out (stdout) or standard error (stderr) stream. These messages are displayed when JBoss Data Grid 6 is run from a command line prompt. The messages from a Console log handler are not saved unless the operating system is configured to capture the standard out or standard error stream. |
| File | File log handlers are the simplest log handlers. Their primary use is to write log messages to a specified file. |
| Periodic | Periodic file handlers write log messages to a named file until a specified period of time has elapsed. Once the time period has elapsed, the specified time stamp is appended to the file name. The handler then continues to write into the newly created log file with the original name. |
| Size | Size log handlers write log messages to a named file until the file reaches a specified size. When the file reaches a specified size, it is renamed with a numeric prefix and the handler continues to write into a newly created log file with the original name. Each size log handler must specify the maximum number of files to be kept in this fashion. |
| Async | Async log handlers are wrapper log handlers that provide asynchronous behavior for one or more other log handlers. These are useful for log handlers that have high latency or other performance problems such as writing a log file to a network file system. |
| Custom | Custom log handlers enable to you to configure new types of log handlers that have been implemented. A custom handler must be implemented as a Java class that extends java.util.logging.Handler and be contained in a module. |
2.4.7. About Log Formatters
java.util.Formatter class.
2.5. Logging Configuration Properties
2.5.1. Root Logger Properties
Table 2.4. Root Logger Properties
| Property | Datatype | Description |
|---|---|---|
| level | string |
The maximum level of log message that the root logger records.
|
| handlers | list of strings |
A list of log handlers that are used by the root logger.
|
2.5.2. Log Category Properties
Table 2.5. Log Category Properties
| Property | Datatype | Description |
|---|---|---|
| level | string |
The maximum level of log message that the log category records.
|
| handlers | list of strings |
A list of log handlers that are used by the root logger.
|
| use-parent-handlers | boolean |
If set to true, this category will use the log handlers of the root logger in addition to any other assigned handlers.
|
| category | string |
The log category from which log messages will be captured.
|
2.5.3. Console Log Handler Properties
Table 2.6. Console Log Handler Properties
| Property | Datatype | Description |
|---|---|---|
| level | string |
The maximum level of log message the log handler records.
|
| encoding | string |
The character encoding scheme to be used for the output.
|
| formatter | string |
The log formatter used by this log handler.
|
| target | string |
The system output stream where the output of the log handler goes. This can be System.err or System.out for the system error stream or standard out stream respectively.
|
| autoflush | boolean |
If set to true the log messages will be sent to the handlers target immediately upon receipt.
|
| name | string |
The unique identifier for this log handler.
|
2.5.4. File Log Handler Properties
Table 2.7. File Log Handler Properties
| Property | Datatype | Description |
|---|---|---|
| level | string |
The maximum level of log message the log handler records.
|
| encoding | string |
The character encoding scheme to be used for the output.
|
| formatter | string |
The log formatter used by this log handler.
|
| append | boolean |
If set to true then all messages written by this handler will be appended to the file if it already exists. If set to false a new file will be created each time the application server launches. Changes to
append require a server reboot to take effect.
|
| autoflush | boolean |
If set to true the log messages will be sent to the handlers assigned file immediately upon receipt. Changes to
autoflush require a server reboot to take effect.
|
| name | string |
The unique identifier for this log handler.
|
| file | object |
The object that represents the file where the output of this log handler is written to. It has two configuration properties,
relative-to and path.
|
| relative-to | string |
This is a property of the file object and is the directory where the log file is written to. JBoss Enterprise Application Platform 6 file path variables can be specified here. The
jboss.server.log.dir variable points to the log/ directory of the server.
|
| path | string |
This is a property of the file object and is the name of the file where the log messages will be written. It is a relative path name that is appended to the value of the
relative-to property to determine the complete path.
|
2.5.5. Periodic Log Handler Properties
Table 2.8. Periodic Log Handler Properties
| Property | Datatype | Description |
|---|---|---|
| append | boolean |
If set to true then all messages written by this handler will be appended to the file if it already exists. If set to false a new file will be created each time the application server launches. Changes to append require a server reboot to take effect.
|
| autoflush | boolean |
If set to true the log messages will be sent to the handlers assigned file immediately upon receipt. Changes to autoflush require a server reboot to take effect.
|
| encoding | string |
The character encoding scheme to be used for the output.
|
| formatter | string |
The log formatter used by this log handler.
|
| level | string |
The maximum level of log message the log handler records.
|
| name | string |
The unique identifier for this log handler.
|
| file | object |
Object that represents the file where the output of this log handler is written to. It has two configuration properties,
relative-to and path.
|
| relative-to | string |
This is a property of the file object and is the directory where the log file is written to. File path variables can be specified here. The
jboss.server.log.dir variable points to the log/> directory of the server.
|
| path | string |
This is a property of the file object and is the name of the file where the log messages will be written. It is a relative path name that is appended to the value of the
relative-to property to determine the complete path.
|
| suffix | string |
This is a string with is both appended to filename of the rotated logs and is used to determine the frequency of rotation. The format of the suffix is a dot (.) followed by a date string which is parsable by the
java.text.SimpleDateFormat class. The log is rotated on the basis of the smallest time unit defined by the suffix. For example the suffix .yyyy-MM-dd will result in daily log rotation.
|
2.5.6. Size Log Handler Properties
Table 2.9. Size Log Handler Properties
| Property | Datatype | Description |
|---|---|---|
| append | boolean |
If set to true then all messages written by this handler will be appended to the file if it already exists. If set to false a new file will be created each time the application server launches. Changes to append require a server reboot to take effect.
|
| autoflush | boolean |
If set to true the log messages will be sent to the handlers assigned file immediately upon receipt. Changes to autoflush require a server reboot to take effect.
|
| encoding | string |
The character encoding scheme to be used for the output.
|
| formatter | string |
The log formatter used by this log handler.
|
| level | string |
The maximum level of log message the log handler records.
|
| name | string |
The unique identifier for this log handler.
|
| file | object |
Object that represents the file where the output of this log handler is written to. It has two configuration properties,
relative-to and path.
|
| relative-to | string |
This is a property of the file object and is the directory where the log file is written to. File path variables can be specified here. The
jboss.server.log.dir variable points to the log/ directory of the server.
|
| path | string |
This is a property of the file object and is the name of the file where the log messages will be written. It is a relative path name that is appended to the value of the
relative-to property to determine the complete path.
|
| rotate-size | integer |
The maximum size that the log file can reach before it is rotated. A single character appended to the number indicates the size units:
b for bytes, k for kilobytes, m for megabytes, g for gigabytes. Eg. 50m for 50 megabytes.
|
| max-backup-index | integer |
The maximum number of rotated logs that are kept. When this number is reached, the oldest log is reused.
|
2.5.7. Async Log Handler Properties
Table 2.10. Async Log Handler Properties
| Property | Datatype | Description |
|---|---|---|
| level | string |
The maximum level of log message the log handler records.
|
| name | string |
The unique identifier for this log handler.
|
| Queue-length | integer |
Maximum number of log messages that will be held by this handler while waiting for sub-handlers to respond.
|
| overflow-action | string |
How this handler responds when its queue length is exceeded. This can be set to
BLOCK or DISCARD. BLOCK makes the logging application wait until there is available space in the queue. This is the same behavior as an non-async log handler. DISCARD allows the logging application to continue but the log message is deleted.
|
| subhandlers | list of strings |
This is the list of log handlers to which this async handler passes its log messages.
|
2.6. Logging Sample Configurations
2.6.1. Sample XML Configuration for the Root Logger
<subsystem xmlns="urn:jboss:domain:logging:1.1">
<root-logger>
<level name="INFO"/>
<handlers>
<handler name="CONSOLE"/>
<handler name="FILE"/>
</handlers>
</root-logger>
</subsystem>
2.6.2. Sample XML Configuration for a Log Category
<subsystem xmlns="urn:jboss:domain:logging:1.1">
<logger category="com.company.accounts.rec">
<handlers>
<handler name="accounts-rec"/>
</handlers>
</logger>
</subsystem>
2.6.3. Sample XML Configuration for a Console Log Handler
<subsystem xmlns="urn:jboss:domain:logging:1.1">
<console-handler name="CONSOLE">
<level name="INFO"/>
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
</console-handler>
</subsystem>
2.6.4. Sample XML Configuration for a File Log Handler
<file-handler name="accounts-rec-trail" autoflush="true">
<level name="INFO"/>
<file relative-to="jboss.server.log.dir" path="accounts-rec-trail.log"/>
<append value="true"/>
</file-handler>
2.6.5. Sample XML Configuration for a Periodic Log Handler
<periodic-rotating-file-handler name="FILE">
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
<file relative-to="jboss.server.log.dir" path="server.log"/>
<suffix value=".yyyy-MM-dd"/>
<append value="true"/>
</periodic-rotating-file-handler>
2.6.6. Sample XML Configuration for a Size Log Handler
<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/> <max-backup-index value="5"/> <append value="true"/> </size-rotating-file-handler>
2.6.7. Sample XML Configuration for a Async Log Handler
<async-handler name="Async_NFS_handlers">
<level name="INFO"/>
<queue-length value="512"/>
<overflow-action value="block"/>
<subhandlers>
<handler name="FILE"/>
<handler name="accounts-record"/>
</subhandlers>
</async-handler>
Chapter 3. High Availability Using Server Hinting
3.1. About Server Hinting
3.2. Establishing Server Hinting with JGroups
3.3. Configure Server Hinting in Remote Client-Server Mode
<subsystem xmlns="urn:jboss:domain:jgroups:1.1"
default-stack="${jboss.default.jgroups.stack:udp}" >
<stack name="udp">
<transport type="UDP"
socket-binding="jgroups-udp"
site="${jboss.jgroups.transport.site:s1}"
rack="${jboss.jgroups.transport.rack:r1}"
machine="${jboss.jgroups.transport.machine:m1}">
...
</transport>
</stack>
</subsystem>
3.4. Configure Server Hinting in Library Mode
<transport clusterName = "MyCluster"
machineId = "LinuxServer01"
rackId = "Rack01"
siteId = "US-WestCoast" />
- The
clusterNameattribute specifies the name assigned to the cluster. - The
machineIdattribute specifies the JVM instance that houses the original data. This is particularly useful for nodes with multiple JVMs and physical hosts with multiple virtual hosts. - The
rackIdparameter specifies the rack that contains the original data, so that other racks are used for backups. - The
siteIdparameter differentiates between nodes in different data centers replicating to each other.
Chapter 4. Cache Modes
4.1. About Cache Modes
- Local (Standalone) mode.
- Clustered mode.
4.2. Local Mode
4.2.1. About Local Mode
4.2.2. Local Mode Operations
- Write-through and write-behind caching to persist data.
- Entry eviction to prevent the Java Virtual Machine (JVM) running out of memory.
- Support for entries that expire after a defined period.
ConcurrentMap, resulting in a simple migration process from a map to JBoss Data Grid.
4.2.3. Configure Local Mode
<cache-container name="local" default-cache="default" listener-executor="infinispan-listener"> <local-cache name="default" start="EAGER"> <locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" /> <transaction mode="NONE" /> </local-cache> </cache-container>
DefaultCacheManager with the "no-argument" constructor. Both of these methods create a local default cache.
<transport/> it can only contain local caches. The container used in the example can only contain local caches as it does not have a <transport/>.
ConcurrentMap and is compatible with multiple cache systems.
4.3. Clustered Modes
4.3.1. About Clustered Modes
4.3.2. Clustered Mode Operations
- Replication Mode replicates any entry that is added across all cache instances in the cluster.
- Invalidation Mode does not share any data, but but signals remote caches to initiate the removal of invalid entries.
- Distribution Mode stores each entry on a subset of nodes instead of on all nodes in the cluster.
4.3.3. Asynchronous and Synchronous Operations
4.3.4. Cache Mode Troubleshooting
4.3.4.1. Invalid Data in ReadExternal
readExternal, it can be because when using Cache.putAsync(), starting serialization can cause your object to be modified, causing the datastream passed to readExternal to be corrupted. This can be resolved if access to the object is synchronized.
4.3.4.2. About Asynchronous Communications
local-cache, distributed-cache and replicated-cache elements respectively. Each of these elements contains a mode property, the value of which can be set to SYNC for synchronous or ASYNC for asynchronous communications.
<replicated-cache name="default"
start="EAGER"
mode="SYNC"
batching="false" >
...
</replicated-cache>
Note
4.3.4.3. Cluster Physical Address Retrieval
The physical address can be retrieved using an instance method call. For example: AdvancedCache.getRpcManager().getTransport().getPhysicalAddresses().
Chapter 5. Distribution Mode
5.1. About Distribution Mode
5.2. Distribution Mode's Consistent Hash Algorithm
5.3. Locating Entries in Distribution Mode
PUT operation can result in as many remote calls as specified by the num_copies parameter, while a GET operation executed on any node in the cluster results in a single remote call. In the background, the GET operation results in the same number of remote calls as a PUT operation (specifically the value of the num_copies parameter), but these occur in parallel and the returned entry is passed to the caller as soon as one returns.
5.4. Return Values in Distribution Mode
5.5. Configure Distribution Mode
<cache-container name="local" default-cache="default" listener-executor="infinispan-listener"> <distributed-cache name="default" start="EAGER"> <locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" /> <transaction mode="NONE" /> </distributed-cache> </cache-container>
Important
5.6. Synchronous and Asynchronous Distribution
5.6.1. About Synchronous and Asynchronous Distribution
Example 5.1. Communication Mode example
A, B and C, and a key K that maps cache A to B. Perform an operation on cluster C that requires a return value, for example Cache.remove(K). To execute successfully, the operation must first synchronously forward the call to both cache A and B, and then wait for a result returned from either cache A or B. If asynchronous communication was used, the usefulness of the returned values cannot be guaranteed, despite the operation behaving as expected.
5.7. GET and PUT Usage in Distribution Mode
5.7.1. About GET and PUT Operations in Distribution Mode
GET command before a write command. This occurs because certain methods (for example, Cache.put()) return the previous value associated with the specified key according to the java.util.Map contract. When this is performed on an instance that does not own the key and the entry is not found in the L1 cache, the only reliable way to elicit this return value is to perform a remote GET before the PUT.
GET operation that occurs before the PUT operation is always synchronous, whether the cache is synchronous or asynchronous, because JBoss Data Grid must wait for the return value.
5.7.2. Distributed GET and PUT Operation Resource Usage
GET operation before executing the desired PUT operation.
GET operation does not wait for all responses, which would result in wasted resources. The GET process accepts the first valid response received, which allows its performance to be unrelated to cluster size.
Flag.SKIP_REMOTE_LOOKUP flag for a per-invocation setting if return values are not required for your implementation.
java.util.Map interface contract. The contract breaks because unreliable and inaccurate return values are provided to certain methods. As a result, ensure that these return values are not used for any important purpose on your configuration.
Chapter 6. Replication Mode
6.1. About Replication Mode
6.2. Optimized Replication Mode Usage
6.3. Return Values in Replication Mode
6.4. Configure Replication Mode
<cache-container name="local" default-cache="default" listener-executor="infinispan-listener"> <replicated-cache name="default" start="EAGER"> <locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" /> <transaction mode="NONE" /> </replicated-cache> </cache-container>
Important
6.5. Synchronous and Asynchronous Replication
6.5.1. Synchronous and Asynchronous Replication
- Synchronous replication blocks a thread or caller (for example on a
put()operation) until the modifications are replicated across all nodes in the cluster.By waiting for acknowledgments, synchronous replication ensures that all replications are successfully applied before the operation is concluded. - Asynchronous replication operates significantly faster than synchronous replication because it does not need to wait for responses from nodes.Asynchronous replication performs the replication in the background and the call returns immediately. Errors that occur during asynchronous replication are written to a log. As a result, a transaction can be successfully completed despite the fact that replication of the transaction may not have succeeded on all the cache instances in the cluster.
6.5.2. Troubleshooting Asynchronous Replication Behavior
- Disable state transfer and use a
ClusteredCacheLoaderto lazily look up remote state as and when needed. - Enable state transfer and
REPL_SYNC. Use the Asynchronous API (for example, thecache.putAsync(k, v)) to activate 'fire-and-forget' capabilities. - Enable state transfer and
REPL_ASYNC. All RPCs end up becoming synchronous, but client threads will not be held up if you enable a replication queue (which is recommended for asynchronous mode).
6.6. The Replication Queue
6.6.1. Replication Queue
- Previously set intervals.
- The queue size exceeding the number of elements.
- A combination of previously set intervals and the queue size exceeding the number of elements.
6.6.2. Replication Queue Operations
6.6.3. Replication Queue Usage
- Disable asynchronous marshalling; or
- Set the
max-threadscount value to1for thetransport executor. Thetransport executoris defined instandalone.xmlas follows:<transport executor="infinispan-transport"/>
queue-flush-interval, value is in milliseconds) and queue size (queue-size) as follows:
<replicated-cache name="asyncCache"
start="EAGER"
mode="ASYNC"
batching="false"
indexing="NONE"
queue-size="1000"
queue-flush-interval="500">
...
</replicated-cache>
6.7. Frequently Asked Questions
6.7.1. About Replication Guarantees
6.7.2. Replication Traffic on Internal Networks
IP addresses than for traffic over public IP addresses, or do not charge at all for internal network traffic (for example, GoGrid ). To take advantage of lower rates, you can configure JBoss Data Grid to transfer replication traffic using the internal network. With such a configuration, it is difficult to know the internal IP address you are assigned. JBoss Data Grid uses JGroups interfaces to solve this problem.
Chapter 7. Invalidation Mode
7.1. About Invalidation Mode
7.2. Using Invalidation Mode
7.3. Configure Invalidation Mode
<cache-container name="local" default-cache="default" listener-executor="infinispan-listener"> <invalidated-cache name="default" start="EAGER"> <locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false" /> <transaction mode="NONE" /> </invalidated-cache> </cache-container>
Important
7.4. Synchronous/Asynchronous Invalidation
- Synchronous invalidation blocks the thread until all caches in the cluster have received invalidation messages and evicted the obsolete data.
- Asynchronous invalidation operates in a fire-and-forget mode that allows invalidation messages to be broadcast without blocking a thread to wait for responses.
7.5. The L1 Cache Invalidation
7.5.1. The L1 Cache and Invalidation
Chapter 8. Cache Writing Modes
8.1. Write-Through and Write-Behind Caching
- Write-Through (Synchronous)
- Write-Behind (Asynchronous)
8.2. Write-Through Caching
8.2.1. About Write-Through Caching
Cache.put() invocation), the call does not return until JBoss Data Grid has located and updated the underlying cache store. This feature allows updates to the cache store to be concluded within the client thread boundaries.
8.2.2. Write-Through Caching Benefits
8.2.3. Write-Through Caching Configuration (Library Mode)
<infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:infinispan:config:5.0">
<global />
<default />
<namedCache name="persistentCache">
<loaders shared="false">
<loader class="org.infinispan.loaders.file.FileCacheStore"
fetchPersistentState="true" ignoreModifications="false"
purgeOnStartup="false">
<properties>
<property name="location"
value="${java.io.tmpdir}" />
</properties>
</loader>
</loaders>
</namedCache>
</infinispan>
8.3. Write-Behind Caching
8.3.1. About Write-Behind Caching
8.3.2. Write-Behind Caching Configuration
write-behind element to a cache store. The following example illustrates adding the write-behind element to a remote cache store configuration specifically, but can be used with any cache store type in the same manner:
<remote-store cache="default"
socket-timeout="60000"
tcp-no-delay="true"
fetch-state="false"
passivation="true"
preload="true"
purge="false">
<remote-server outbound-socket-binding="remote-store-hotrod-server" />
<write-behind flush-lock-timeout="1"
modification-queue-size="1024"
shutdown-timeout="25000"
thread-pool-size="1" />
</remote-store>
Note
8.3.3. About Unscheduled Write-Behind Strategy
8.3.4. Unscheduled Write-Behind Strategy Library Configuration
<infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:infinispan:config:5.0">
<global />
<default />
<namedCache name="persistentCache">
<loaders shared="false">
<loader class="org.infinispan.loaders.file.FileCacheStore"
fetchPersistentState="true"
ignoreModifications="false"
purgeOnStartup="false">
<properties>
<property name="location"
value="${java.io.tmpdir}" />
</properties>
<async enabled="true" threadPoolSize="10" />
</loader>
</loaders>
</namedCache>
</infinispan>
<async enabled="true" threadPoolSize="10" />
8.3.5. Unscheduled Write-Behind Strategy Remote Configuration
write-behind element within the file-store element allows configuration for Unscheduled Write-Behind strategy for all cache stores.
<file-store passivation="true" relative-to="temp" path="nc" purge="true" shared="false"> <write-behind flush-lock-timeout="1" modification-queue-size="1024" shutdown-timeout="25000" thread-pool-size="1"/> </file-store>
Chapter 9. Locking
9.1. About Optimistic Locking
writeSkewCheck enabled, transactions in optimistic locking mode roll back if one or more conflicting modifications are made to the data before the transaction completes.
9.2. About Pessimistic Locking
9.3. Pessimistic Locking Types
- Explicit Pessimistic Locking, which uses the JBoss Data Grid Lock API to allow cache users to explicitly lock cache keys for the duration of a transaction. The Lock call attempts to obtain locks on specified cache keys across all nodes in a cluster. This attempt either fails or succeeds for all specified cache keys. All locks are released during the commit or rollback phase.
- Implicit Pessimistic Locking ensures that cache keys are locked in the background as they are accessed for modification operations. Using Implicit Pessimistic Locking causes JBoss Data Grid to check and ensure that cache keys are locked locally for each modification operation. Discovering unlocked cache keys causes JBoss Data Grid to request a cluster-wide lock to acquire a lock on the unlocked cache key.
9.4. Explicit Pessimistic Locking Example
tx.begin() cache.lock(K) cache.put(K,V5) tx.commit()
cache.lock(K) executes, a cluster-wide lock is acquired on K.
cache.put(K,V5) executes, it guarantees success.
tx.commit() executes, the locks held for this process are released.
9.5. Implicit Pessimistic Locking Example
tx.begin() cache.put(K,V) cache.put(K2,V2) cache.put(K,V5) tx.commit()
- When the line
cache.put(K,V)executes, a cluster-wide lock is acquired onK. - When the line
cache.put(K2,V2)executes, a cluster-wide lock is acquired onK2. - When the line
cache.put(K,V5)executes, the lock acquisition is non operational because a cluster-wide lock forKhas been previously acquired. Theputoperation will still occur. - When the line
tx.commit()executes, all locks held for this transaction are released.
9.6. Configure Optimistic and Pessimistic Locking
locking parameter within the transaction element.
Configure optimistic locking as follows:
<transaction locking="OPTIMISTIC" />
Configure pessimistic locking as follows:
<transaction locking="PESSIMISTIC" />
9.7. Locking Operations
9.7.1. About the LockManager
LockManager component is responsible for locking an entry before a write process initiates. The LockManager uses a LockContainer to locate, hold and create locks. The two types of LockContainers generally used in such implementations are available. The first type offers support for lock striping while the second type supports one lock per entry.
See Also:
9.7.2. About Lock Acquisition
9.7.3. About Concurrency Levels
ConcurrentHashMap based collections, such as those internal to DataContainers.
9.8. Lock Striping
9.8.1. About Lock Striping
9.8.2. Configure Lock Striping
striping element to true.
<locking isolation="REPEATABLE_READ" acquire-timeout="20000" concurrency-level="500" striping="true" />
9.8.3. Alternatives to Lock Striping
9.9. Isolation Levels
9.9.1. About Isolation Levels
READ_COMMITTED and REPEATABLE_READ are the two isolation modes offered in JBoss Data Grid.
READ_COMMITTED. This is the default isolation level because it is applicable to a wide variety of requirements.REPEATABLE_READ. This can be configured using thelockingconfiguration element.
9.9.2. About READ_COMMITTED
READ_COMMITTED is one of two isolation modes available in JBoss Data Grid.
READ_COMMITTED mode, write operations are made to copies of data rather than the data itself. A write operation blocks other data from being written, however writes do not block read operations. As a result, both READ_COMMITTED and REPEATABLE_READ modes permit read operations at any time, regardless of when write operations occur.
READ_COMMITTED mode multiple reads of the same key within a transaction can return different results due to write operations modifying data between reads. This phenomenon is known as non-repeatable reads and is avoided in REPEATABLE_READ mode.
9.9.3. About REPEATABLE_READ
REPEATABLE_READ is one of two isolation modes available in JBoss Data Grid.
REPEATABLE_READ does not allow write operations while read operations are in progress, nor does it allow read operations when write operations occur. This prevents the "non-repeatable read" phenomenon, which occurs when a single transaction has two read operations on the same row but the retrieved values differ (possibly due to a write operating modifying the value between the two read operations).
REPEATABLE_READ isolation mode preserves the value of a row before a modification occurs. As a result, the "non-repeatable read" phenomenon is avoided because a second read operation on the same row retrieves the preserved value rather than the new modified value. As a result, the two values retrieved by the two read operations will always match, even if a write operation occurs between the two reads.
Chapter 10. Cache Stores and Cache Loaders
10.1. About Cache Stores
- fetch data from the data store when a copy is not in the cache.
- push modifications made to the data in cache back to the data store.
10.2. About File System Based Cache Stores
FileCacheStore.
FileCacheStore is a simple, file system based implementation.
FileCacheStore can be used in a limited capacity in production environments. It should not be used on shared file system (such as NFS and Windows shares) due to a lack of proper file locking, resulting in data corruption. Furthermore, file systems are not inherently transactional, resulting in file writing failures during the commit phase if the cache is used in a transactional context.
FileCacheStore is ideal for testing usage and is not suited to use in highly concurrent, transactional or stress-based environments.
10.3. File Cache Store Configuration
<local-cache name="default">
<file-store />
</local-cache>
- The
nameparameter of thelocal-cacheattribute is used to specify a name for the cache. - The
file-storeelement specifies configuration information for the file cache store. Attributes for this element include therelative-toparameter used to define a named path, and thepathparameter used to specify a directory withinrelative-to.
10.4. Remote Cache Stores
10.4.1. About Remote Cache Stores
RemoteCacheStore is an implementation of the cache loader that stores data in a remote JBoss Data Grid cluster. The RemoteCacheStore uses the Hot Rod client-server architecture to communicate with the remote cluster.
RemoteCacheStore and the cluster.
10.4.2. Remote Cache Store Configuration (Remote Client-Server Mode)
<remote-store cache="default"
socket-timeout="60000"
tcp-no-delay="true"
fetch-state="false"
passivation="true"
preload="true"
purge="false">
<remote-server outbound-socket-binding="remote-store-hotrod-server" />
</remote-store>
10.4.3. Remote Cache Store Configuration (Library Mode)
Create and include a file named hotrod.properties in the relevant classpath.
The following is a sample remote cache store configuration for JBoss Data Grid's Library mode.
<loaders shared="true" preload="true" purge="false"> <loader class="org.infinispan.loaders.remote.RemoteCacheStore"> <properties> <property name="remoteCacheName" value="default"/> <property name="hotRodClientPropertiesFile" value="hotrod.properties" /> </properties> </loader> </loaders>
Important
hotRodClientPropertiesFile refers to the hotrod.properties file. This file must be defined for the Remote Cache Store to operate correctly.
10.4.4. Remote Cache Store Configuration Attributes
The remote-store element specifies the configuration information for a remote cache store accessed using Hot Rod. Properties defined within the remote-store element are treated as Hot Rod client properties.
- The
cacheparameter specifies the name of the cache in use. - The
socket-timeoutparameter specifies the socket timeout time for the remote cache. - The
tcp-no-delayparameter specifies whether TCP packets will be delayed and sent out in batches. Valid values for this parameter aretrueandfalse. - The
fetch-stateparameter determines whether the persistent state is fetched when joining a cluster. Valid values for this parameter aretrueandfalse. - The
passivationparameter determines whether entries in the cache are passivated (true) or if the cache store retains a copy of the contents in memory (false). - The
preloadparameter specifies whether to load entries into the cache during start up. Valid values for this parameter aretrueandfalse. - The
purgeparameter specifies whether or not the cache store is purged when it is started. Valid values for this parameter aretrueandfalse.
The remote-server element provides information about the remote server used by the remote cache store.
- The
outbound-socket-bindingparameter specifies the outbound socket for the remote cache store.
Important
standalone.xml file as well to use the remote cache store.
10.4.5. The hotrod.properties File
infinispan.client.hotrod.server_list=remote-server:11222
infinispan.client.hotrod.request_balancing_strategy- For replicated (vs distributed) Hot Rod server clusters, the client balances requests to the servers according to this strategy.The default value for this property is
org.infinispan.client.hotrod.impl.transport.tcp.RoundRobinBalancingStrategy. infinispan.client.hotrod.server_list- This is the initial list of Hot Rod servers to connect to, specified in the following format: host1:port1;host2:port2... At least one host:port must be specified.The default value for this property is
127.0.0.1:11222. infinispan.client.hotrod.force_return_values- Whether or not to implicitly Flag.FORCE_RETURN_VALUE for all calls.The default value for this property is
false. infinispan.client.hotrod.tcp_no_delay- Affects TCP NODELAY on the TCP stack.The default value for this property is
true. infinispan.client.hotrod.ping_on_startup- If true, a ping request is sent to a back end server in order to fetch cluster's topology.The default value for this property is
true. infinispan.client.hotrod.transport_factory- Controls which transport will be used. Currently only the TcpTransport is supported.The default value for this property is
org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory. infinispan.client.hotrod.marshaller- Allows you to specify a custom Marshaller implementation to serialize and deserialize user objects.The default value for this property is
org.infinispan.marshall.jboss.GenericJBossMarshaller. infinispan.client.hotrod.async_executor_factory- Allows you to specify a custom asynchronous executor for async calls.The default value for this property is
org.infinispan.client.hotrod.impl.async.DefaultAsyncExecutorFactory. infinispan.client.hotrod.default_executor_factory.pool_size- If the default executor is used, this configures the number of threads to initialize the executor with.The default value for this property is
10. infinispan.client.hotrod.default_executor_factory.queue_size- If the default executor is used, this configures the queue size to initialize the executor with.The default value for this property is
100000. infinispan.client.hotrod.hash_function_impl.1- This specifies the version of the hash function and consistent hash algorithm in use, and is closely tied with the Hot Rod server version used.The default value for this property is the
Hash function specified by the server in the responses as indicated in ConsistentHashFactory. infinispan.client.hotrod.key_size_estimate- This hint allows sizing of byte buffers when serializing and deserializing keys, to minimize array resizing.The default value for this property is
64. infinispan.client.hotrod.value_size_estimate- This hint allows sizing of byte buffers when serializing and deserializing values, to minimize array resizing.The default value for this property is
512. infinispan.client.hotrod.socket_timeout- This property defines the maximum socket read timeout before giving up waiting for bytes from the server.The default value for this property is
60000 (equals 60 seconds). infinispan.client.hotrod.protocol_version- This property defines the protocol version that this client should use. Other valid values include 1.0.The default value for this property is
1.1. infinispan.client.hotrod.connect_timeout- This property defines the maximum socket connect timeout before giving up connecting to the server.The default value for this property is
60000 (equals 60 seconds).
10.4.6. Define the Outbound Socket for the Remote Cache Store
outbound-socket-binding element in a standalone.xml file.
standalone.xml file is as follows:
<outbound-socket-binding name="remote-store-hotrod-server"> <remote-destination host="127.0.0.1" port="11322"/> </outbound-socket-binding>
10.5. JDBC Based Cache Stores
10.5.1. About JDBC Based Cache Stores
JdbcBinaryCacheStore.JdbcStringBasedCacheStore.JdbcMixedCacheStore.
10.5.2. JDBC Cache Selection
JdbcStringBasedCacheStore is ideal for when you control the key types because it offers better throughput when under stress.
JdbcStringBasedCacheStore can only be used when you can write a Key2StringMapper to map keys to string objects. If the JdbcStringBasedCacheStore cannot be used, JdbcBinaryCacheStore or JdbcMixedCacheStore can be used instead. The JdbcMixedCacheStore is more appropriate when JdbcStringBasedCacheStore is handling the majority of the keys, but some keys cannot be converted using Key2StringMapper.
10.5.3. JdbcBinaryCacheStores
10.5.3.1. About JdbcBinaryCacheStore
JdbcBinaryCacheStore supports all key types. It stores all keys with the same hash value (hashCode method on the key) in the same table row/blob. The hash value common to the included keys is set as the primary key for the table row/blob. As a result of this hash value, JdbcBinaryCacheStore offers excellent flexibility but at the cost of concurrency and throughput.
k1, k2 and k3) have the same hash code, they are stored in the same table row. If three different threads attempt to concurrently update k1, k2 and k3, they must do it sequentially because all three keys share the same row and therefore cannot be simultaneously updated.
10.5.3.2. JdbcBinaryCacheStore Remote Configuration with Passivation Enabled
JdbcBinaryCacheStore using JBoss Data Grid's Remote Client-Server mode with Passivation enabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="default"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="default"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<eviction strategy="LRU"
max-entries="2" />
<binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="true"
preload="false"
purge="false">
<property name="databaseType">${database.type}</property>
<binary-keyed-table prefix="JDG">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</binary-keyed-table>
</binary-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.3.3. JdbcBinaryCacheStore Remote Configuration with Passivation Disabled
JdbcBinaryCacheStore using JBoss Data Grid's Remote Client-Server mode with Passivation disabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="default"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="default"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="false"
preload="true"
purge="false">
<property name="databaseType">${database.type}</property>
<binary-keyed-table prefix="JDG">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</binary-keyed-table>
</binary-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.3.4. JdbcBinaryCacheStore Remote Configuration Attributes
JdbcBinaryCacheStore in JBoss Data Grid's Remote Client-Server mode.
The cache-container element specifies information about the cache container using the following parameters:
- The
nameparameter defines the name of the cache container. - The
default-cacheparameter defines the name of the default cache used with the cache container. - The
listener-executordefines the executor used for asynchronous cache listener notifications. - The
startparameter indicates where the cache container starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY.
The local-cache element specifies information about the local cache used with the cache container using the following parameters:
- The
nameparameter specifies the name of the local cache to use. - The
startparameter indicates where the cache starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY. - The
batchingparameter specifies whether batching is enabled for the local cache. - The
indexingparameter specifies the type of indexing used for the local cache. Valid values for this parameter areNONE,LOCALandALL.
The locking element details the locking configuration for the local cache.
- The
isolationparameter defines the isolation level used for the local cache. Valid values for this parameter areREPEATABLE_READandREAD_COMMITTED. - The
acquire-timeoutparameter specifies the number of milliseconds after which an acquire operation will time out. - The
concurrency-levelparameter defines the number of lock stripes used by the LockManager. - The
stripingparameter specifies whether lock striping will be used for the local cache.
The transaction element specifies transaction related settings for the local cache.
- The
modeparameter specifies the transaction mode used for the local cache. Valid values for this parameter areNONE,NON_XA(does not use XAResource),NON_DURABLE_XA(uses XAResource without recovery) andFULL_XA(used XAResource with recovery).
The eviction element specifies eviction configuration information for the local cache.
- The
strategyparameter specifies the eviction strategy or algorithm used. Valid values for this parameter includeNONE,FIFO,LRU,UNORDEREDandLIRS. - The
max-entriesparameter specifies the maximum number of entries in a cache instance.
The binary-keyed-jdbc-store element specifies the configuration for a binary keyed cache JDBC store.
- The
datasourceparameter defines the name of a JNDI for the datasource. - The
passivationparameter determines whether entries in the cache are passivated (true) or if the cache store retains a copy of the contents in memory (false). - The
preloadparameter specifies whether to load entries into the cache during start up. Valid values for this parameter aretrueandfalse. - The
purgeparameter specifies whether or not the cache store is purged when it is started. Valid values for this parameter aretrueandfalse.
The property element contains information about properties related to the cache store.
- The
nameparameter specifies the name of the cache store. - The value ${database.type} must be replaced by a valid database type value, such as
DB2_390,SQL_SERVER,MYSQL,ORACLE,POSTGRESorSYBASE.
The binary-keyed-table element specifies information about the database table used to store binary cache entries.
- The
prefixparameter specifies a prefix string for the database table name.
The id-column element specifies information about a database column that holds cache entry IDs.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The data-column element contains information about a database column that holds cache entry data.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The timestamp-column element specifies information about the database column that holds cache entry timestamps.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
10.5.3.5. JdbcBinaryCacheStore Library Mode Configuration
JdbcBinaryCacheStore:
<loaders>
<loader class="org.infinispan.loaders.jdbc.binary.JdbcBinaryCacheStore" fetchPersistentState="false"ignoreModifications="false"
purgeOnStartup="false">
<properties>
<property name="bucketTableNamePrefix" value="ISPN_BUCKET_TABLE"/>
<property name="idColumnName" value="ID_COLUMN"/>
<property name="dataColumnName" value="DATA_COLUMN"/>
<property name="timestampColumnName" value="TIMESTAMP_COLUMN"/>
<property name="timestampColumnType" value="BIGINT"/>
<property name="connectionFactoryClass" value="org.infinispan.loaders.jdbc.connectionfactory.PooledConnectionFactory"/>
<property name="connectionUrl" value="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1"/>
<property name="userName" value="sa"/>
<property name="driverClass" value="org.h2.Driver"/>
<property name="idColumnType" value="VARCHAR(255)"/>
<property name="dataColumnType" value="BINARY"/>
<property name="dropTableOnExit" value="true"/>
<property name="createTableOnStart" value="true"/>
</properties>
</loader>
</loaders>
10.5.4. JdbcStringBasedCacheStores
10.5.4.1. About JdbcStringBasedCacheStore
JdbcStringBasedCacheStore stores each entry its own row in the table, instead of grouping multiple entries into each row, resulting in increased throughput under a concurrent load. It also uses a (pluggable) bijection that maps each key to a String object. The Key2StringMapper interface defines the bijection.
DefaultTwoWayKey2StringMapper that handles primitive types.
10.5.4.2. JdbcStringBasedCacheStore Remote Configuration for Multiple Nodes
JdbcStringBasedCacheStore in JBoss Data Grid's Remote Client-Server mode. This configuration is used when multiple nodes must be used.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="memcachedCache"
listener-executor="infinispan-listener"
start="EAGER">
<transport stack="${stack}"
executor="infinispan-transport"
lock-timeout="240000"/>
<replicated-cache name="memcachedCache"
start="EAGER"
mode="SYNC"
batching="false"
indexing="NONE"
remote-timeout="60000">
<locking isolation="REPEATABLE_READ"
acquire-timeout="30000"
concurrency-level="1000"
striping="false" />
<transaction mode="NONE" />
<state-transfer enabled="true"
timeout="60000" />
<string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
fetch-state="true"
passivation="false"
preload="false"
purge="false"
shared="false"
singleton="true">
<property name="databaseType">${database.type}</property>
<string-keyed-table prefix="JDG">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</replicated-cache>
</cache-container>
</subsystem>
10.5.4.3. JdbcStringBasedCacheStore Remote Configuration with Passivation Enabled
JdbcStringBasedCacheStore for JBoss Data Grid's Remote Client-Server mode with Passivation enabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="memcachedCache"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="memcachedCache"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<eviction strategy="LRU"
max-entries="2" />
<string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="true"
preload="false"
purge="false">
<property name="databaseType">${database.type}</property>
<string-keyed-table prefix="JDG">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.4.4. JdbcStringBasedCacheStore Remote Configuration with Passivation Disabled
JdbcStringBasedCacheStore in JBoss Data Grid's Remote Client-Server mode with Passivation disabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="memcachedCache"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="memcachedCache"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="false"
preload="true"
purge="false">
<property name="databaseType">${database.type}</property>
<string-keyed-table prefix="JDG">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.4.5. JdbcStringBasedCacheStore Remote Configuration Attributes
JdbcStringBasedCacheStore in JBoss Data Grid's Remote Client-Server mode.
The cache-container element specifies information about the cache container.
- The
nameparameter defines the name of the cache container. - The
default-cacheparameter defines the name of the default cache used with the cache container. - The
listener-executordefines the executor used for asynchronous cache listener notifications. - The
startparameter indicates where the cache container starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY.
The local-cache element specifies information about the local cache used with the cache container.
- The
nameparameter specifies the name of the local cache to use. - The
startparameter indicates where the cache starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY. - The
batchingparameter specifies whether batching is enabled for the local cache. - The
indexingparameter specifies the type of indexing used for the local cache. Valid values for this parameter areNONE,LOCALandALL.
The transport element contains a description of the transport used by the cache container.
- The
stackparameter specified the JGroups stack used for the transport. - The
executorparameter specifies the executor used for the transport. - The
lock-timeoutparameter specifies the timeout value for locks for the transport.
The replicated-cache element specifies information about the replicated cache in use.
- The
nameparameter specifies the name of the replicated cache. - The
startparameter specifies whether the cache starts up on demand or immediately. Valid values for this parameter areEAGERandLAZY. - The
modeparameter specifies the cache mode for the replicated cache. Valid values for this parameter areSYNCandASYNC. - The
batchingparameter specifies whether batching can be used with the replicated cache. - The
indexingparameter specifies whether entries added to the cache are indexed. If enabled, indexes update as entries change or are removed from the replicated cache. - The
remote-timeoutparameter specifies the time period a remote call waits for acknowledgment. After the specified interval, the remote call aborts and an exception is thrown. This parameter is used in conjunction with theASYNCmode parameter.
The locking element details the locking configuration for the local cache.
- The
isolationparameter defines the isolation level used for the local cache. Valid values for this parameter areREPEATABLE_READandREAD_COMMITTED. - The
acquire-timeoutparameter specifies the number of milliseconds after which an acquire operation will time out. - The
concurrency-levelparameter defines the number of lock stripes used by the LockManager. - The
stripingparameter specifies whether lock striping will be used for the local cache.
The transaction element specifies transaction related settings for the local cache.
- The
modeparameter specifies the transaction mode used for the local cache. Valid values for this parameter areNONE,NON_XA(does not use XAResource),NON_DURABLE_XA(uses XAResource without recovery) andFULL_XA(used XAResource with recovery).
The eviction element specifies eviction configuration information for the local cache.
- The
strategyparameter specifies the eviction strategy or algorithm used. Valid values for this parameter includeNONE,FIFO,LRU,UNORDEREDandLIRS. - The
max-entriesparameter specifies the maximum number of entries in a cache instance.
The string-keyed-jdbc-store element specifies the configuration for a string based keyed cache JDBC store.
- The
datasourceparameter defines the name of a JNDI for the datasource. - The
passivationparameter determines whether entries in the cache are passivated (true) or if the cache store retains a copy of the contents in memory (false). - The
preloadparameter specifies whether to load entries into the cache during start up. Valid values for this parameter aretrueandfalse. - The
purgeparameter specifies whether or not the cache store is purged when it is started. Valid values for this parameter aretrueandfalse. - The
sharedparameter is used when multiple cache instances share a cache store. This parameter can be set to prevent multiple cache instances writing the same modification multiple times. Valid values for this parameter areENABLEDandDISABLED. - The
singletonparameter enables a singleton store that is used if a cluster interacts with the underlying store.
The property element contains information about properties related to the cache store.
- The
nameparameter specifies the name of the cache store. - The value ${database.type} must be replaced by a valid database type value, such as
DB2_390,SQL_SERVER,MYSQL,ORACLE,POSTGRESorSYBASE.
The string-keyed-table element specifies information about the database table used to store string based cache entries.
- The
prefixparameter specifies a prefix string for the database table name.
The id-column element specifies information about a database column that holds cache entry IDs.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The data-column element contains information about a database column that holds cache entry data.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The timestamp-column element specifies information about the database column that holds cache entry timestamps.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
10.5.4.6. JdbcStringBasedCacheStore Library Mode Configuration
JdbcStringBasedCacheStore:
<loaders>
<loader class="org.infinispan.loaders.jdbc.stringbased.JdbcStringBasedCacheStore" fetchPersistentState="false" ignoreModifications="false"
purgeOnStartup="false">
<properties>
<property name="stringsTableNamePrefix" value="ISPN_STRING_TABLE"/>
<property name="idColumnName" value="ID_COLUMN"/>
<property name="dataColumnName" value="DATA_COLUMN"/>
<property name="timestampColumnName" value="TIMESTAMP_COLUMN"/>
<property name="timestampColumnType" value="BIGINT"/>
<property name="connectionFactoryClass" value="org.infinispan.loaders.jdbc.connectionfactory.PooledConnectionFactory"/>
<property name="connectionUrl" value="jdbc:h2:mem:string_based_db;DB_CLOSE_DELAY=-1"/>
<property name="userName" value="sa"/>
<property name="driverClass" value="org.h2.Driver"/>
<property name="idColumnType" value="VARCHAR(255)"/>
<property name="dataColumnType" value="BINARY"/>
<property name="dropTableOnExit" value="true"/>
<property name="createTableOnStart" value="true"/>
</properties>
</loader>
</loaders>
10.5.5. JdbcMixedCacheStore
10.5.5.1. About JdbcMixedCacheStore
JdbcMixedCacheStore is a hybrid implementation that delegates keys based on their type to either the JdbcBinaryCacheStore or JdbcStringBasedCacheStore.
10.5.5.2. JdbcMixedCacheStore Remote Configuration with Passivation Enabled
JdbcMixedCacheStore for JBoss Data Grid's Remote Client-Server mode with Passivation enabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="memcachedCache"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="memcachedCache"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<eviction strategy="LRU"
max-entries="2" />
<mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="true"
preload="false"
purge="false">
<property name="databaseType">${database.type}</property>
<binary-keyed-table prefix="MIX_BKT2">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</binary-keyed-table>
<string-keyed-table prefix="MIX_STR2">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</string-keyed-table>
</mixed-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.5.3. JdbcMixedCacheStore Remote Configuration with Passivation Disabled
JdbcMixedCacheStore using JBoss Data Grid's Remote Client-Server mode with Passivation disabled.
<subsystem xmlns="urn:jboss:domain:infinispan:1.2" default-cache-container="default">
<cache-container name="default"
default-cache="memcachedCache"
listener-executor="infinispan-listener"
start="EAGER">
<local-cache name="memcachedCache"
start="EAGER"
batching="false"
indexing="NONE">
<locking isolation="REPEATABLE_READ"
acquire-timeout="20000"
concurrency-level="500"
striping="false" />
<transaction mode="NONE" />
<mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS"
passivation="false"
preload="true"
purge="false">
<property name="databaseType">${database.type}</property>
<binary-keyed-table prefix="MIX_BKT">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</binary-keyed-table>
<string-keyed-table prefix="MIX_STR">
<id-column name="id"
type="${id.column.type}"/>
<data-column name="datum"
type="${data.column.type}"/>
<timestamp-column name="version"
type="${timestamp.column.type}"/>
</string-keyed-table>
</mixed-keyed-jdbc-store>
</local-cache>
</cache-container>
</subsystem>
10.5.5.4. JdbcMixedCacheStore Remote Configuration Attributes
JdbcMixedCacheStore in JBoss Data Grid's Remote Client-Server mode.
The cache-container element specifies information about the cache container using the following parameters:
- The
nameparameter defines the name of the cache container. - The
default-cacheparameter defines the name of the default cache used with the cache container. - The
listener-executordefines the executor used for asynchronous cache listener notifications. - The
startparameter indicates where the cache container starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY.
The local-cache element specifies information about the local cache used with the cache container using the following parameters:
- The
nameparameter specifies the name of the local cache to use. - The
startparameter indicates where the cache starts, i.e. whether it will start lazily when requested or when the server starts up. Valid values for this parameter areEAGERandLAZY. - The
batchingparameter specifies whether batching is enabled for the local cache. - The
indexingparameter specifies the type of indexing used for the local cache. Valid values for this parameter areNONE,LOCALandALL.
The locking element details the locking configuration for the local cache.
- The
isolationparameter defines the isolation level used for the local cache. Valid values for this parameter areREPEATABLE_READandREAD_COMMITTED. - The
acquire-timeoutparameter specifies the number of milliseconds after which an acquire operation will time out. - The
concurrency-levelparameter defines the number of lock stripes used by the LockManager. - The
stripingparameter specifies whether lock striping will be used for the local cache.
The transaction element specifies transaction related settings for the local cache.
- The
modeparameter specifies the transaction mode used for the local cache. Valid values for this parameter areNONE,NON_XA(does not use XAResource),NON_DURABLE_XA(uses XAResource without recovery) andFULL_XA(used XAResource with recovery).
The eviction element specifies eviction configuration information for the local cache.
- The
strategyparameter specifies the eviction strategy or algorithm used. Valid values for this parameter includeNONE,FIFO,LRU,UNORDEREDandLIRS. - The
max-entriesparameter specifies the maximum number of entries in a cache instance.
The mixed-keyed-jdbc-store element specifies the configuration for a mixed keyed cache JDBC store.
- The
datasourceparameter defines the name of a JNDI for the datasource. - The
passivationparameter determines whether entries in the cache are passivated (true) or if the cache store retains a copy of the contents in memory (false). - The
preloadparameter specifies whether to load entries into the cache during start up. Valid values for this parameter aretrueandfalse. - The
purgeparameter specifies whether or not the cache store is purged when it is started. Valid values for this parameter aretrueandfalse.
The property element contains information about properties related to the cache store.
- The
nameparameter specifies the name of the cache store. - The value ${database.type} must be replaced by a valid database type value, such as
DB2_390,SQL_SERVER,MYSQL,ORACLE,POSTGRESorSYBASE.
The mixed-keyed-table element specifies information about the database table used to store mixed cache entries.
- The
prefixparameter specifies a prefix string for the database table name.
The string-keyed-table element specifies information about the database table used to store string based cache entries.
- The
prefixparameter specifies a prefix string for the database table name.
The id-column element specifies information about a database column that holds cache entry IDs.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The data-column element contains information about a database column that holds cache entry data.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
The timestamp-column element specifies information about the database column that holds cache entry timestamps.
- The
nameparameter specifies the name of the database column. - The
typeparameter specifies the type of the database column.
10.5.5.5. JdbcMixedCacheStore Library Mode Configuration
JdbcMixedCacheStore:
<loaders>
<loader class="org.infinispan.loaders.jdbc.mixed.JdbcMixedCacheStore"
fetchPersistentState="false"
ignoreModifications="false"
purgeOnStartup="false">
<properties>
<property name="tableNamePrefixForStrings" value="ISPN_MIXED_STR_TABLE"/>
<property name="tableNamePrefixForBinary" value="ISPN_MIXED_BINARY_TABLE"/>
<property name="idColumnNameForStrings" value="ID_COLUMN"/>
<property name="idColumnNameForBinary" value="ID_COLUMN"/>
<property name="dataColumnNameForStrings" value="DATA_COLUMN"/>
<property name="dataColumnNameForBinary" value="DATA_COLUMN"/>
<property name="timestampColumnNameForStrings" value="TIMESTAMP_COLUMN"/>
<property name="timestampColumnNameForBinary" value="TIMESTAMP_COLUMN"/>
<property name="timestampColumnTypeForStrings" value="BIGINT"/>
<property name="timestampColumnTypeForBinary" value="BIGINT"/>
<property name="connectionFactoryClass" value="org.infinispan.loaders.jdbc.connectionfactory.PooledConnectionFactory"/>
<property name="connectionUrl" value="jdbc:h2:mem:infinispan_mixed_cs;DB_CLOSE_DELAY=-1"/>
<property name="userName" value="sa"/>
<property name="driverClass" value="org.h2.Driver"/>
<property name="idColumnTypeForStrings" value="VARCHAR(255)"/>
<property name="idColumnTypeForBinary" value="VARCHAR(255)"/>
<property name="dataColumnTypeForStrings" value="BINARY"/>
<property name="dataColumnTypeForBinary" value="BINARY"/>
<property name="dropTableOnExitForStrings" value="false"/>
<property name="dropTableOnExitForBinary" value="false"/>
<property name="createTableOnStartForStrings" value="true"/>
<property name="createTableOnStartForBinary" value="true"/>
<property name="createTableOnStartForStrings" value="true"/>
<property name="createTableOnStartForBinary" value="true"/>
</properties>
</loader>
</loaders>
10.5.6. Custom Cache Stores
10.5.6.1. About Custom Cache Stores
10.5.6.2. Custom Cache Store Configuration (Remote Mode)
<local-cache name="default">
<store class="my.package.CustomCacheStore">
<properties>
<property name="customStoreProperty" value="10" />
</properties>
</store>
</local-cache>
Important
org.jboss.as.clustering.infinispan module dependencies.
10.5.6.3. Custom Cache Store Configuration (Library Mode)
<loaders shared="true" preload="true" purge="false"> <loader class="org.infinispan..custom.CustomCacheStore"> <properties> <property name="CustomCacheName" value="default"/> </properties> </loader> </loaders>
10.6. Frequently Asked Questions
10.6.1. About Asynchronous Cache Store Modifications
10.7. Cache Store Troubleshooting
10.7.1. IOExceptions with JdbcStringBasedCacheStore
JdbcStringBasedCacheStore indicates that your data column type is set to VARCHAR, CLOB or something similar instead of the correct type, BLOB or VARBINARY. Despite its name, JdbcStringBasedCacheStore only requires that the keys are strings while the values can be any data type, so that they can be stored in a binary column.
10.8. Cache Loaders
10.8.1. About Cache Loaders
10.8.2. Cache Loaders and Cache Stores
CacheLoader interface and a number of implementations. JBoss Data Grid has divided these into two distinct interfaces, a CacheLoader and a CacheStore. The CacheLoader loads a previously existing state from another location, while the CacheStore (which extends CacheLoader) exposes methods to store states as well as loading them. This division allows easier definition of read-only sources.
10.8.4. Connection Factories
10.8.4.1. About Connection Factories
ConnectionFactory implementation to obtain a database connection. This process is also known as connection management or pooling.
ConnectionFactoryClass configuration attribute. JBoss Data Grid includes the following ConnectionFactory implementations:
- ManagedConnectionFactory
- SimpleConnectionFactory.
10.8.4.2. About ManagedConnectionFactory
ManagedConnectionFactory is a connection factory that is ideal for use within managed environments such as application servers. This connection factory can explore a configured location in the JNDI tree and delegate connection management to the DataSource. ManagedConnectionFactory is used within a managed environment that contains a DataSource. This Datasource is delegated the connection pooling.
10.8.4.3. About SimpleConnectionFactory
SimpleConnectionFactory is a connection factory that creates database connections on a per invocation basis. This connection factory is not designed for use in a production environment.
Chapter 11. Cache Managers
11.1. About Cache Managers
11.2. Multiple Cache Managers
11.2.1. Create Multiple Caches with a Single Cache Manager
11.2.2. Using Multiple Cache Managers
Chapter 12. Eviction
12.1. About Eviction
12.2. Eviction Operations
12.3. Eviction Usage
12.4. Eviction Strategies
12.4.1. About Eviction Strategies
EvictionStrategy.NONE: No eviction strategy set.EvictionStrategy.FIFO: First In, First Out eviction strategy.EvictionStrategy.LRU: Least Recently Used eviction strategy. This is the default eviction algorithm due to its compatibility with requirements for a wide variety of deployments.EvictionStrategy.UNORDERED: Unordered eviction strategy.EvictionStrategy.LIRS: Low Inter-reference Recency Set eviction strategy.
12.4.2. LRU Eviction Algorithm Limitations
- Single use access entries are not replaced in time.
- Entries that are accessed first are unnecessarily replaced.
12.5. Using Eviction
12.5.1. Initialize Eviction
max-entries attributes value to a number greater than zero. Adjust the value set for max-entries to discover the optimal value for your configuration. It is important to remember that if too large a value is set for max-entries, JBoss Data Grid runs out of memory.
12.5.2. Default Eviction Configuration
eviction element is used to enable eviction, the following default values are used:
- Strategy: If no eviction strategy is specified,
EvictionStrategy.NONEis assumed as a default. - max-entries: If no value is specified, the
max-entriesvalue is set to-1, which allows unlimited entries.- Set the
max-entriesvalue to0to disallow any entries. As a result, the eviction thread strives to keep the cache empty.
12.5.3. Eviction Configuration Example
An example of a valid eviction XML configuration for JBoss Data Grid's Library Mode is:
<eviction strategy="LRU" maxEntries="2000"/>
Eviction configuration can be defined programmatically in JBoss Data Grid's Library Mode using:
Configuration c = new ConfigurationBuilder().eviction().strategy(EvictionStrategy.LRU)
.maxEntries(2000)
.build();
An example of eviction configuration using XML in JBoss Data Grid's Remote Client-Server Mode is:
<eviction strategy="FIFO" max-entries="20"/>
Note
maxEntries parameter while Remote Client-Server mode uses the max-entries parameter to configure eviction.
12.5.4. Eviction Configuration Troubleshooting
max-entries parameter of the configuration element. This is because although the max-entries value can be configured to a value that is not a power of two, the underlying algorithm will alter the value to V, where V is the closest power of two value that is larger than the max-entries value. Eviction algorithms are in place to ensure that the size of the cache container will never exceed the value V.
12.6. Eviction and Passivation
12.6.1. About Eviction and Passivation
See Also:
Chapter 13. Expiration
13.1. About Expiration
- A lifespan value.
- A maximum idle time value.
-1 when created.
13.2. Expiration Operations
lifespan) or maximum idle time (maxIdle in Library Mode and max-idle in Remote Client-Server Mode) defined for an individual key/value pair overrides the cache-wide default for the entry in question.
13.3. Eviction and Expiration Comparison
lifespan) and idle time (maxIdle in Library Mode and max-idle in Remote Client-Server Mode) values are replicated alongside each cache entry.
13.4. Cache Entry Expiration Notifications
- A user thread requests an entry and discovers that the entry has expired.
- An entry is passivated/overflowed to disk and is discovered to have expired.
- The eviction maintenance thread discovers that an entry it has found is expired.
13.5. Expiration Configuration
The following sample configuration depicts how to configure expiration in JBoss Data Grid's Library Mode:
<expiration lifespan="2000" maxIdle="1000" />
The following sample configuration depicts how to configure expiration in JBoss Data Grids' Remote Client-Server Mode:
<expiration lifespan="2000" max-idle="1000" />
13.6. Mortal and Immortal Data
13.6.1. About Data Mortality
put(key, value) creates an entry that will never expire, called an immortal entry. Alternatively, an entry created using put(key, value, lifespan, timeunit) is a mortal entry that has a specified fixed life span, after which it expires.
lifespan parameter, JBoss Data Grid also provides a maxIdle parameter used to determine expiration. The maxIdle and lifespan parameters can be used in various combinations to set the life span of an entry.
13.6.2. Default Data Mortality
13.6.3. Configure Data Mortality
13.7. Troubleshooting
13.7.1. Expiration Troubleshooting
put() are passed a life span value as a parameter. This value defines the interval after which the entry must expire. In cases where eviction is not configured and the life span interval expires, it can appear as if JBoss Data Grid has not removed the entry. For example, when viewing JMX statistics, such as the number of entries, you may see an out of date count, or the persistent store associated with JBoss Data Grid may still contain this entry. Behind the scenes, JBoss Data Grid has marked it as an expired entry, but has not removed it. Removal of such entries happens in one of two ways:
- Any attempt to use
get()orcontainsKey()for the expired entry, causes JBoss Data Grid to detect the entry as an expired one and remove it. - Enabling the eviction feature causes the eviction thread to periodically detect and purge expired entries.
Chapter 14. The L1 Cache
14.1. About the L1 Cache
disabled by default.
14.2. L1 Cache Entries
14.2.1. L1 Cache Entries
14.2.2. L1 Cache Entry Life Spans
600,000 milliseconds (10 minutes). The life span value can be altered to meet user requirements.
14.3. L1 Cache Operations
14.3.1. The L1 Cache and Invalidation
14.3.2. Using the L1 Cache with GET Operations
GET operations performed on the same key generate repeated remote calls. To reduce the number of unnecessary GET operations on the same key, enable L1 caching.
Chapter 15. Listeners and Notifications
15.1. About the Listener API
15.2. Listener Example
@Listener
public class PrintWhenAdded {
@CacheEntryCreated
public void print(CacheEntryCreatedEvent event) {
System.out.println("New entry " + event.getKey() + " created in the cache");
}
}
15.3. Cache Entry Modified Listener Configuration
Cache.get() when isPre equals false
CacheEntryModifiedEvent.getValue() to retrieve the new value of the modified entry.
15.4. Notifications
15.4.1. About Listener Notifications
@Listener. A Listenable is an interface that denotes that the implementation can have listeners attached to it. Each listener is registered using methods defined in the Listenable.
15.4.2. About Cache-level Notifications
15.4.3. Cache Manager-level Notifications
- Nodes joining or leaving a cluster;
- The starting and stopping of caches
15.4.4. About Synchronous and Asynchronous Notifications
@Listener (sync = false)public class MyAsyncListener { .... }
<asyncListenerExecutor/> element in the configuration file to tune the thread pool that is used to dispatch asynchronous notifications.
15.5. Notifying Futures
15.5.1. About NotifyingFutures
Futures, but a sub-interface known as a NotifyingFuture. Unlike a JDK Future, a listener can be attached to a NotifyingFuture to notify the user about a completed future.
Note
NotifyingFutures are only available in Library mode.
15.5.2. NotifyingFutures Example
NotifyingFutures in JBoss Data Grid:
FutureListener futureListener = new FutureListener() {
public void futureDone(Future future) {
try {
future.get();
} catch (Exception e) {
// Future did not complete successfully
System.out.println("Help!");
}
}
};
cache.putAsync("key", "value").attachListener(futureListener);
Chapter 16. Activation and Passivation Modes
16.1. About Activation Mode
16.2. About Passivation Mode
16.3. Passivation Mode Benefits
16.4. About the Passivation Flag
16.5. Eviction and Passivation
16.5.1. About Eviction and Passivation
16.5.2. Eviction and Passivation Usage
- A notification regarding the passivated entry is emitted to the cache listeners.
- The evicted entry is stored.
16.5.3. Eviction Example when Passivation is Disabled
Table 16.1. Eviction when Passivation is Disabled
| Step | Key in Memory | Key on Disk |
|---|---|---|
Insert keyOne | Memory: keyOne | Disk: keyOne |
Insert keyTwo | Memory: keyOne, keyTwo | Disk: keyOne, keyTwo |
Eviction thread runs, evicts keyOne | Memory: keyTwo | Disk: keyOne, keyTwo |
Read keyOne | Memory: keyOne, keyTwo | Disk: keyOne, keyTwo |
Eviction thread runs, evicts keyTwo | Memory: keyOne | Disk: keyOne, keyTwo |
Remove keyTwo | Memory: keyOne | Disk: keyOne |
16.5.4. Eviction Example when Passivation is Enabled
Table 16.2. Eviction when Passivation is Enabled
| Step | Key in Memory | Key on Disk |
|---|---|---|
Insert keyOne | Memory: keyOne | Disk: |
Insert keyTwo | Memory: keyOne, keyTwo | Disk: |
Eviction thread runs, evicts keyOne | Memory: keyTwo | Disk: keyOne |
Read keyOne | Memory: keyOne, keyTwo | Disk: |
Eviction thread runs, evicts keyTwo | Memory: keyOne | Disk: keyTwo |
Remove keyTwo | Memory: keyOne | Disk: |
Chapter 17. Custom Interceptors
17.1. About Custom Interceptors
17.2. Custom Interceptor Design
- A custom interceptor must extend the
CommandInterceptor. - A custom interceptor must declare a public, empty constructor to allow for instantiation.
- A custom interceptor must have JavaBean style setters defined for any property that is defined through the
propertyelement.
17.3. Adding Custom Interceptors
17.3.1. Adding Custom Interceptors Declaratively
<namedCache name="cacheWithCustomInterceptors">
<!--
Define custom interceptors. All custom interceptors need to extend org.jboss.cache.interceptors.base.CommandInterceptor
-->
<customInterceptors>
<interceptor position="FIRST" class="com.mycompany.CustomInterceptor1">
<properties>
<property name="attributeOne" value="value1" />
<property name="attributeTwo" value="value2" />
</properties>
</interceptor>
<interceptor position="LAST" class="com.mycompany.CustomInterceptor2"/>
<interceptor index="3" class="com.mycompany.CustomInterceptor1"/>
<interceptor before="org.infinispanpan.interceptors.CallInterceptor" class="com.mycompany.CustomInterceptor2"/>
<interceptor after="org.infinispanpan.interceptors.CallInterceptor" class="com.mycompany.CustomInterceptor1"/>
</customInterceptors>
</namedCache>
Note
17.3.2. Adding Custom Interceptors Programmatically
AdvancedCache.
CacheManager cm = getCacheManager();
Cache aCache = cm.getCache("aName");
AdvancedCache advCache = aCache.getAdvancedCache();
addInterceptor() method to add the interceptor.
advCache.addInterceptor(new MyInterceptor(), 0);
Chapter 18. Transactions
18.1. About Java Transaction API Transactions
- First, it retrieves the transactions currently associated with the thread.
- If not already done, it registers
XAResourcewith the transaction manager to receive notifications when a transaction is committed or rolled back.
Important
ExceptionTimeout where JBoss Data Grid is Unable to acquire lock after {time} on key {key} for requester {thread}, enable transactions. This occurs because non-transactional caches acquire locks on each node they write on. Using transactions prevents deadlocks because caches acquire locks on a single node.
18.2. Transactions Spanning Multiple Cache Instances
18.3. Transaction/Batching and Invalidation Messages
18.4. The Transaction Manager
18.4.1. About JTA Transaction Manager Lookup Classes
TransactionManagerLookup interface. When initialized, the cache creates an instance of the specified class and invokes its getTransactionManager() method to locate and return a reference to the Transaction Manager.
- The
DummyTransactionManagerLookupprovides a transaction manager for testing purposes. This testing transaction manager is not for use in a production environment and is severely limited in terms of functionality, specifically for concurrent transactions and recovery. - The
JBossStandaloneJTAManagerLookupis the default transaction manager when JBoss Data Grid runs in a standalone environment. It is a fully functional JBoss Transactions based transaction manager that overcomes the functionality limits of theDummyTransactionManagerLookup. - The
GenericTransactionManagaerLookupis a lookup class used to locate transaction managers in most Java EE application servers. If no transaction manager is located, it defaults toDummyTransactionManagerLookup. - The
JBossTransactionManagerLookupis a lookup class that locates a transaction manager within a JBoss Application Server instance.
Note
18.4.2. Use the Transaction Manager
18.4.2.1. Obtain the Transaction Manager From the Cache
Procedure 18.1. Obtain the Transaction Manager from the Cache
- Define a
transactionManagerLookupClassby adding the following property to yourBasicCacheContainer's configuration location properties:Configuration config = new ConfigurationBuilder() ... .transaction().transactionManagerLookup(new GenericTransactionManagerLookup())
- Call
TransactionManagerLookup.getTransactionManageras follows:TransactionManager tm = cache.getAdvancedCache().getTransactionManager();
18.4.2.2. Transaction Configuration
<cache>
..
<transaction mode="NONE"
stop-timeout="30000"
locking="OPTIMISTIC" />
...
</cache>
- The
modeattribute sets the cache transaction mode. Valid values for this attribute areNONE(default),NON_XA,NON_DURABLE_XA,FULL_XA. - The
stop-timeoutattribute indicates the number of milliseconds JBoss Data Grid waits for ongoing remote and local transactions to conclude when the cache is stopped. - The
lockingattribute specifies the locking mode used for the cache. Valid values for this attribute areOPTIMISTIC(default) andPESSIMISTIC.
18.4.2.3. Transaction Manager and XAResources
XAResource implementation to run XAResource.recover on it.
18.4.2.4. Obtain a XAResource Reference
XAResource, use the following API:
XAResource xar = cache.getAdvancedCache().getXAResource();
18.4.2.5. Default Distributed Transaction Behavior
XAResource. In situations where JBoss Data Grid does not need to be a participant in a transaction, it can be notified about the lifecycle status (for example, prepare, complete, etc.) of the transaction via a synchronization.
18.5. Transaction Synchronization
18.5.1. About Transaction (JTA) Synchronizations
XAResource. As a result, the Transaction Manager optimizes transaction operations so that they require the one phase commit (1PC) algorithm instead of the two phase commit (2PC) algorithm.
18.5.2. Enable Synchronization
NONE(synchronous), or;NO_XA(synchronous).
Note
18.6. State Reconciliation
18.6.1. About State Reconciliation
18.6.2. About Transaction Recovery
18.6.3. Enable Transaction Recovery
Enable transaction recovery using XML configuration as follows:
<transaction useEagerLocking="true" eagerLockSingleNode="true">
<recovery enabled="true" recoveryInfoCacheName="noRecovery"/>
</transaction>
recoveryInfoCacheName attribute is optional.
Alternatively, enable transaction recovery through the fluent configuration API as follows:
Procedure 18.2. Configure Transaction Recovery Programmatically
- To enable JBoss Data Grid's Transaction Recovery, call
.recovery:configuration.fluent().transaction().recovery();
- To check Transactions Recovery's status, use the following programmatic configuration:
boolean isRecoveryEnabled = configuration.isTransactionRecoveryEnabled();
- To disable JBoss Data Grid's Transaction recovery, use the following programmatic configuration:
configuration.fluent().transaction().recovery().disable();
18.6.4. Transaction Recovery Process
Procedure 18.3. The Transaction Recovery Process
- The Transaction Manager creates a list of transactions that require intervention.
- The system administrator, connected to JBoss Data Grid using JMX, is presented with the list of transactions (including transaction IDs) using email or logs. The status of each transaction is either
COMMITTEDorPREPARED. If some transactions are in bothCOMMITTEDandPREPAREDstates, it indicates that the transaction was committed on some nodes while in the preparation state on others. - The System Administrator visually maps the XID received from the Transaction Manager to a JBoss Data Grid internal ID. This step is necessary because the XID (a byte array) cannot be conveniently passed to the JMX tool and then reassembled by JBoss Data Grid without this mapping.
- The system administrator forces the commit or rollback process for a transaction based on the mapped internal ID.
18.6.5. Transaction Recovery Example
Example 18.1. Money Transfer from an Account Stored in a Database to an Account in JBoss Data Grid
- The
TransactionManager.commit()method is invoked to to run the two phase commit protocol between the source (the database) and the destination (JBoss Data Grid) resources. - The
TransactionManagertells the database and JBoss Data Grid to initiate the prepare phase (the first phase of a Two Phase Commit).
18.6.6. Transaction Memory and JMX Support
18.6.7. Forced Commit and Rollback Operations
18.6.8. Transactions and Exceptions
CacheException (or a subclass of the CacheException) within the scope of a JTA transaction, the transaction is automatically marked to be rolled back.
18.7. Deadlock Detection
18.7.1. About Deadlock Detection
disabled by default.
18.7.2. Enable Deadlock Detection
disabled by default but can be enabled and configured for each cache using the namedCache configuration element by adding the following:
<deadlockDetection enabled="true" spinDuration="1000"/>
Note
Chapter 19. Marshalling
19.1. About Marshalling
19.2. Marshalling Benefits
- To transform data for relay to other JBoss Data Grid nodes within the cluster.
- To transform data to be stored in underlying cache stores.
19.3. About Marshalling Framework
java.io.ObjectOutput and java.io.ObjectInput implementations compared to the standard java.io.ObjectOutputStream and java.io.ObjectInputStream.
19.4. Support for Non-Serializable Objects
Serializable or Externalizable support into your classes, you could (as an example) use XStream to convert the non-serializable objects into a String that can be stored in JBoss Data Grid.
Note
19.5. Troubleshooting
19.5.1. Marshalling Troubleshooting
java.io.NotSerializableException: java.lang.Object at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:857) at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407) at org.infinispan.marshall.exts.ReplicableCommandExternalizer.writeObject(ReplicableCommandExternalizer.java:54) at org.infinispan.marshall.jboss.ConstantObjectTable$ExternalizerAdapter.writeObject(ConstantObjectTable.java:267) at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:143) at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407) at org.infinispan.marshall.jboss.JBossMarshaller.objectToObjectStream(JBossMarshaller.java:167) at org.infinispan.marshall.VersionAwareMarshaller.objectToBuffer(VersionAwareMarshaller.java:92) at org.infinispan.marshall.VersionAwareMarshaller.objectToByteBuffer(VersionAwareMarshaller.java:170) at org.infinispan.marshall.VersionAwareMarshallerTest.testNestedNonSerializable(VersionAwareMarshallerTest.java:415) Caused by: an exception which occurred: in object java.lang.Object@b40ec4 in object org.infinispan.commands.write.PutKeyValueCommand@df661da7 ... Removed 22 stack frames
java.lang.Object instance within an org.infinispan.commands.write.PutKeyValueCommand instance cannot be serialized because java.lang.Object@b40ec4 is not serializable.
DEBUG or TRACE logging levels are enabled, marshalling exceptions will contain toString() representations of objects in the stack trace. The following is an example that depicts such a scenario:
java.io.NotSerializableException: java.lang.Object
...
Caused by: an exception which occurred:
in object java.lang.Object@b40ec4
-> toString = java.lang.Object@b40ec4
in object org.infinispan.commands.write.PutKeyValueCommand@df661da7
-> toString = PutKeyValueCommand{key=k, value=java.lang.Object@b40ec4, putIfAbsent=false, lifespanMillis=0, maxIdleTimeMillis=0}
java.io.IOException: Injected failue! at org.infinispan.marshall.VersionAwareMarshallerTest$1.readExternal(VersionAwareMarshallerTest.java:426) at org.jboss.marshalling.river.RiverUnmarshaller.doReadNewObject(RiverUnmarshaller.java:1172) at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:273) at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:210) at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85) at org.infinispan.marshall.jboss.JBossMarshaller.objectFromObjectStream(JBossMarshaller.java:210) at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:104) at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:177) at org.infinispan.marshall.VersionAwareMarshallerTest.testErrorUnmarshalling(VersionAwareMarshallerTest.java:431) Caused by: an exception which occurred: in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1
IOException was thrown when an instance of the inner class org.infinispan.marshall.VersionAwareMarshallerTest$1 is unmarshalled.
DEBUG or TRACE logging levels are enabled, the class type's classloader information is provided. An example of this classloader information is as follows:
java.io.IOException: Injected failue! ... Caused by: an exception which occurred: in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1 -> classloader hierarchy: -> type classloader = sun.misc.Launcher$AppClassLoader@198dfaf ->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/eclipse-testng.jar ->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/lib/testng-jdk15.jar ->...file:/home/galder/jboss/infinispan/code/trunk/core/target/test-classes/ ->...file:/home/galder/jboss/infinispan/code/trunk/core/target/classes/ ->...file:/home/galder/.m2/repository/org/testng/testng/5.9/testng-5.9-jdk15.jar ->...file:/home/galder/.m2/repository/net/jcip/jcip-annotations/1.0/jcip-annotations-1.0.jar ->...file:/home/galder/.m2/repository/org/easymock/easymockclassextension/2.4/easymockclassextension-2.4.jar ->...file:/home/galder/.m2/repository/org/easymock/easymock/2.4/easymock-2.4.jar ->...file:/home/galder/.m2/repository/cglib/cglib-nodep/2.1_3/cglib-nodep-2.1_3.jar ->...file:/home/galder/.m2/repository/javax/xml/bind/jaxb-api/2.1/jaxb-api-2.1.jar ->...file:/home/galder/.m2/repository/javax/xml/stream/stax-api/1.0-2/stax-api-1.0-2.jar ->...file:/home/galder/.m2/repository/javax/activation/activation/1.1/activation-1.1.jar ->...file:/home/galder/.m2/repository/jgroups/jgroups/2.8.0.CR1/jgroups-2.8.0.CR1.jar ->...file:/home/galder/.m2/repository/org/jboss/javaee/jboss-transaction-api/1.0.1.GA/jboss-transaction-api-1.0.1.GA.jar ->...file:/home/galder/.m2/repository/org/jboss/marshalling/river/1.2.0.CR4-SNAPSHOT/river-1.2.0.CR4-SNAPSHOT.jar ->...file:/home/galder/.m2/repository/org/jboss/marshalling/marshalling-api/1.2.0.CR4-SNAPSHOT/marshalling-api-1.2.0.CR4-SNAPSHOT.jar ->...file:/home/galder/.m2/repository/org/jboss/jboss-common-core/2.2.14.GA/jboss-common-core-2.2.14.GA.jar ->...file:/home/galder/.m2/repository/org/jboss/logging/jboss-logging-spi/2.0.5.GA/jboss-logging-spi-2.0.5.GA.jar ->...file:/home/galder/.m2/repository/log4j/log4j/1.2.14/log4j-1.2.14.jar ->...file:/home/galder/.m2/repository/com/thoughtworks/xstream/xstream/1.2/xstream-1.2.jar ->...file:/home/galder/.m2/repository/xpp3/xpp3_min/1.1.3.4.O/xpp3_min-1.1.3.4.O.jar ->...file:/home/galder/.m2/repository/com/sun/xml/bind/jaxb-impl/2.1.3/jaxb-impl-2.1.3.jar -> parent classloader = sun.misc.Launcher$ExtClassLoader@1858610 ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/localedata.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunpkcs11.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunjce_provider.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/dnsns.jar ... Removed 22 stack frames
19.5.2. State Receiver EOFExceptions
2010-12-09 10:26:21,533 20267 ERROR [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (STREAMING_STATE_TRANSFER-sender-1,Infinispan-Cluster,NodeJ-2368:) Caught while responding to state transfer request
org.infinispan.statetransfer.StateTransferException: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:175)
at org.infinispan.remoting.InboundInvocationHandlerImpl.generateState(InboundInvocationHandlerImpl.java:119)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.getState(JGroupsTransport.java:586)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.handleUpEvent(MessageDispatcher.java:691)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.up(MessageDispatcher.java:772)
at org.jgroups.JChannel.up(JChannel.java:1465)
at org.jgroups.stack.ProtocolStack.up(ProtocolStack.java:954)
at org.jgroups.protocols.pbcast.FLUSH.up(FLUSH.java:478)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderHandler.process(STREAMING_STATE_TRANSFER.java:653)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderThreadSpawner$1.run(STREAMING_STATE_TRANSFER.java:582)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:680)
Caused by: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.remoting.transport.jgroups.JGroupsDistSync.acquireProcessingLock(JGroupsDistSync.java:71)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateTransactionLog(StateTransferManagerImpl.java:202)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:165)
... 12 more
EOFException, displayed as follows, when failing to read the transaction log that was not written by the sender:
2010-12-09 10:26:21,535 20269 TRACE [org.infinispan.marshall.VersionAwareMarshaller] (Incoming-2,Infinispan-Cluster,NodeI-38030:) Log exception reported
java.io.EOFException: Read past end of file
at org.jboss.marshalling.AbstractUnmarshaller.eofOnRead(AbstractUnmarshaller.java:184)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByteDirect(AbstractUnmarshaller.java:319)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByte(AbstractUnmarshaller.java:280)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:207)
at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85)
at org.infinispan.marshall.jboss.GenericJBossMarshaller.objectFromObjectStream(GenericJBossMarshaller.java:175)
at org.infinispan.marshall.VersionAwareMarshaller.objectFromObjectStream(VersionAwareMarshaller.java:184)
at org.infinispan.statetransfer.StateTransferManagerImpl.processCommitLog(StateTransferManagerImpl.java:228)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyTransactionLog(StateTransferManagerImpl.java:250)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyState(StateTransferManagerImpl.java:320)
at org.infinispan.remoting.InboundInvocationHandlerImpl.applyState(InboundInvocationHandlerImpl.java:102)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.setState(JGroupsTransport.java:603)
...
Chapter 20. JGroups Interfaces
20.1. About JGroups Interfaces
20.2. Configure JGroups Interfaces
bind_addr property in the JGroups configuration file to a key word rather than a dotted decimal or symbolic IP address as follows:
<socket-binding name="jgroups-udp" ... interface="site-local"/>
<interfaces> <interface name="link-local"><link-local-address/></interface> <interface name="site-local"><site-local-address/></interface> <interface name="global"><any-address/></interface> <interface name="non-loopback"><not><loopback/></not></interface> </interfaces>
link-local: Uses a169.x.x.xor254.x.x.xaddress. This suits the traffic within one box.site-local: Uses a private IP address, for example192.168.x.x. This prevents extra bandwidth charged from GoGrid, and similar providers.global: Picks a public IP address. This should be avoided for replication traffic.non-loopback: Uses the first address found on an active interface that is not a127.x.x.xaddress.
20.3. About Binding Sockets
20.3.1. About Group and Individual Socket Binding
20.3.2. Binding a Single Socket Example
socket-binding element.
<socket-binding name="jgroups-udp" ... interface="site-local"/>
20.3.3. Binding a Group of Sockets Example
socket-binding-group element:
<socket-binding-group name="ha-sockets" default-interface="global"> ... </socket-binding-group>
20.4. JGroups for Clustered Modes
20.4.1. Configure JGroups for Clusterd Modes
GlobalConfiguration gc = new GlobalConfigurationBuilder()
.transport()
.defaultTransport() // <<< This call is missing...
.addProperty("configurationFile","jgroups.xml")
.build();
<infinispan>
<global>
<transport>
<properties>
<property name="configurationFile" value="jgroups.xml" />
</properties>
</transport>
</global>
...
</infinispan>
jgroups.xml in the classpath before searching for an absolute path name if it is not found in the classpath.
20.4.2. Pre-Configured JGroups Files
20.4.2.1. Using a Pre-Configured JGroups File
infinispan-core.jar, and are available on the classpath by default. In order to use one of these files, specify one of these file names instead of using jgroups.xml.
jgroups-udp.xmljgroups-tcp.xml
20.4.2.2. jgroups-udp.xml
jgroups-udp.xml is a pre-configured JGroups file in JBoss Data Grid. The jgroups-udp.xml configuration
- uses UDP as a transport and UDP multicast for discovery.
- is suitable for large clusters (over 100 nodes).
- is suitable if using Invalidation or Replication modes.
- minimizes inefficient use of sockets.
Table 20.1. jgroups-udp.xml System Properties
| System Property | Description | Default | Required? |
|---|---|---|---|
| jgroups.udp.mcast_addr | IP address to use for multicast (both for communications and discovery). Must be a valid Class D IP address, suitable for IP multicast. | 228.6.7.8 | No |
| jgroups.udp.mcast_port | Port to use for multicast socket | 46655 | No |
| jgroups.udp.ip_ttl | Specifies the time-to-live (TTL) for IP multicast packets. The value here refers to the number of network hops a packet is allowed to make before it is dropped | 2 | No |
20.4.2.3. jgroups-tcp.xml
jgroups-tcp.xml is a pre-configured JGroups file in JBoss Data Grid. The jgroups-tcp.xml configuration
- uses TCP as a transport and UDP multicast for discovery.
- is better suited to smaller clusters (under 100 nodes) only when using distribution mode. This is because TCP is more efficient as a point-to-point protocol.
Table 20.2. jgroups-udp.xml System Properties
| System Property | Description | Default | Required? |
|---|---|---|---|
| jgroups.tcp.address | IP address to use for the TCP transport. | 127.0.0.1 | No |
| jgroups.tcp.port | Port to use for TCP socket | 7800 | No |
| jgroups.udp.mcast_addr | IP address to use for multicast (for discovery). Must be a valid Class D IP address, suitable for IP multicast. | 228.6.7.8 | No |
| jgroups.udp.mcast_port | Port to use for multicast socket | 46655 | No |
| jgroups.udp.ip_ttl | Specifies the time-to-live (TTL) for IP multicast packets. The value here refers to the number of network hops a packet is allowed to make before it is dropped | 2 | No |
Chapter 21. Management Tools in JBoss Data Grid
21.1. Java Management Extensions (JMX)
21.1.1. About Java Management Extensions (JMX)
MBeans.
21.1.2. Using JMX with JBoss Data Grid
21.1.3. JMX Statistic Levels
- At the cache level, where management information is generated by individual cache instances.
- At the
CacheManagerlevel, where theCacheManageris the entity that governs all cache instances created from it. As a result, the management information is generated for all these cache instances instead of individual caches.
21.1.4. Enable JMX for Cache Instances
Add the following snippet within either the <default> element for the default cache instance, or under the target <namedCache> element for a specific named cache:
<jmxStatistics enabled="true"/>
Add the following code to programmatically enable JMX at the cache level:
Configuration configuration = ... configuration.setExposeJmxStatistics(true);
21.1.5. Enable JMX for CacheManagers
CacheManager level, JMX statistics can be enabled either declaratively or programmatically, as follows.
Add the following in the <global> element to enable JMX declaratively at the CacheManager level:
<globalJmxStatistics enabled="true"/>
Add the following code to programmatically enable JMX at the CacheManager level:
GlobalConfiguration globalConfiguration = ... globalConfiguration.setExposeGlobalJmxStatistics(true);
21.1.6. Multiple JMX Domains
CacheManager instances exist on a single virtual machine, or if the names of cache instances in different CacheManagers clash.
CacheManager in manner that allows it to be easily identified and used by monitoring tools such as JMX and JBoss Operations Network.
Add the following snippet to the relevant CacheManager configuration:
<globalJmxStatistics enabled="true" cacheManagerName="Hibernate2LC"/>
Add the following code to set the CacheManager name programmatically:
GlobalConfiguration globalConfiguration = ...
globalConfiguration.setExposeGlobalJmxStatistics(true);
globalConfiguration.setCacheManagerName("Hibernate2LC");
21.1.7. About MBeans
MBean represents a manageable resource such as a service, component, device or an application.
MBeans that monitor and manage multiple aspects. For example, MBeans that provide statistics on the transport layer are provided. If a JBoss Data Grid server is configured with JMX statistics, an MBean that provides information such as the hostname, port, bytes read, bytes written and the number of worker threads exists at the following location:
jboss.infinispan:type=Server,name=<Memcached|Hotrod>,component=Transport
21.1.8. Understanding MBeans
MBeans are available:
- If Cache Manager-level JMX statistics are enabled, an
MBeannamedjboss.infinispan:type=CacheManager,name="DefaultCacheManager"exists, with properties specified by the Cache ManagerMBean. - If the cache-level JMX statistics are enabled, multiple
MBeansdisplay depending on the configuration in use. For example, if a write behind cache store is configured, anMBeanthat exposes properties that belong to the cache store component is displayed. All cache-levelMBeansuse the same format:jboss.infinispan:type=Cache,name="<name-of-cache>(<cache-mode>)",manager="<name-of-cache-manager>",component=<component-name>
In this format:- Specify the default name for the cache using the
cache-containerelement'sdefault-cacheattribute. - The
cache-modeis replaced by the cache mode of the cache. The lower case version of the possible enumeration values represents the cache mode. - The
component-nameis replaced by one of the JMX component names from the JMX reference documentation.
MBean for a default cache configured for synchronous distribution would be named as follows:
jboss.infinispan:type=Cache,name="default(dist_sync)", manager="default",component=CacheStore
21.1.9. Registering MBeans in Non-Default MBean Servers
getMBeanServer() method returns the desired (non default) MBeanServer.
Add the following snippet:
<globalJmxStatistics enabled="true" mBeanServerLookup="com.acme.MyMBeanServerLookup"/>
Add the following code:
GlobalConfiguration globalConfiguration = ...
globalConfiguration.setExposeGlobalJmxStatistics(true);
globalConfiguration.setMBeanServerLookup("com.acme.MyMBeanServerLookup")
21.2. JBoss Operations Network (JON)
21.2.1. About JBoss Operations Network (JON)
21.2.2. JBoss Operations Network (JON) and JMX
21.2.3. Configure JBoss Operations Network (JON)
Procedure 21.1. Configure JBoss Operations Network
- Download and install a JBoss Operations Network server and initiate one or more JBoss Operations Network agents. The JBoss Operations Network agent is responsible for relaying information about the JBoss Data Grid instance to the server. The server displays the received information using the GUI. The recommended set up is to install the JBoss Operations Network agent in the machine that runs JBoss Data Grid. If multiple machines are available, an agent can exist on each machine.
- Download the most recent JBoss Data Grid version. In the
modules/rhq-plugindirectory, locate the JBoss Operations Network plug-in jar file (namedinfinispan-rhq-plugin.jar). - JBoss Operations Network can now monitor JBoss Data Grid instances.
- After each JBoss Data Grid instance is discovered, JBoss Operations Network displays a new resource in the JBoss Operations Network server's Inventory/Discovery Queue for each operational cache manager.
- Import a displayed resource. Each cache manager consequently displays as many child cache resources as caches running in the cache manager.
You can now use JBoss Operations Network to monitor JBoss Data Grid.
21.2.4. JBoss Operations Network Plug-in Quickstart
21.2.5. Remote JMX Port Values
Appendix A. References
A.1. About Apache Lucene Index
A.2. About Consistency
A.3. About Consistency Guarantee
- If Key
Kis hashed to nodes{A,B}and transactionTX1acquires a lock forKon, for example, nodeA. - If another cache access occurs on node
B, or any other node, andTX2attempts to lockK, it fails with a timeout because the transactionTX1already holds a lock onK.
K is always deterministically acquired on the same node of the cluster, irrespective of the transaction's origin.
A.4. About Java Management Extensions (JMX)
MBeans.
A.5. About JBoss Cache
A.6. About JSON
A.7. About Return Values
A.8. About Runnable Interfaces
run() method, which executes the active part of the class' code. The Runnable object can be executed in its own thread after it is passed to a thread constructor.
A.9. About Two Phase Commit (2PC)
A.10. About Key-Value Pairs
- A key is unique to a particular data entry and is composed from data attributes of the particular entry it relates to.
- A value is the data assigned to and identified by the key.
A.11. The Externalizer
A.11.1. About Externalizer
Externalizer is a class that can:
- Marshall a given object type to a byte array.
- Unmarshall the contents of a byte array into an instance of the object type.
A.11.2. Internal Externalizer Implementation Access
public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
MapExternalizer ma = new MapExternalizer();
ma.writeObject(output, object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
MapExternalizer ma = new MapExternalizer();
hi.setMap((ConcurrentHashMap<Long, Long>) ma.readObject(input));
return hi;
}
...
public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
output.writeObject(object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
hi.setMap((ConcurrentHashMap<Long, Long>) input.readObject());
return hi;
}
...
}
A.12. Hash Space Allocation
A.12.1. About Hash Space Allocation
A.12.2. Locating a Key in the Hash Space
A.12.3. Requesting a Full Byte Array
As a default, JBoss Data Grid only partially prints byte arrays to logs to avoid unnecessarily printing large byte arrays. This occurs when either:
- JBoss Data Grid caches are configured for lazy deserialization. Lazy deserialization is not available in JBoss Data Grid's Remote Client-Server mode.
- A
MemcachedorHot Rodserver is run.
-Dinfinispan.arrays.debug=true system property at start up.
Example A.1. Partial Byte Array Log
2010-04-14 15:46:09,342 TRACE [ReadCommittedEntry] (HotRodWorker-1-1) Updating entry
(key=CacheKey{data=ByteArray{size=19, hashCode=1b3278a,
array=[107, 45, 116, 101, 115, 116, 82, 101, 112, 108, ..]}}
removed=false valid=true changed=true created=true value=CacheValue{data=ByteArray{size=19,
array=[118, 45, 116, 101, 115, 116, 82, 101, 112, 108, ..]},
version=281483566645249}]
And here's a log message where the full byte array is shown:
2010-04-14 15:45:00,723 TRACE [ReadCommittedEntry] (Incoming-2,Infinispan-Cluster,eq-6834) Updating entry
(key=CacheKey{data=ByteArray{size=19, hashCode=6cc2a4,
array=[107, 45, 116, 101, 115, 116, 82, 101, 112, 108, 105, 99, 97, 116, 101, 100, 80, 117, 116]}}
removed=false valid=true changed=true created=true value=CacheValue{data=ByteArray{size=19,
array=[118, 45, 116, 101, 115, 116, 82, 101, 112, 108, 105, 99, 97, 116, 101, 100, 80, 117, 116]},
version=281483566645249}]
Appendix B. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 1.1-34 | Thu Jan 30 2014 | ||
| |||
| Revision 1.1-33.400 | 2013-10-31 | ||
| |||
| Revision 1.1-33 | Tue Aug 06 2013 | ||
| |||
| Revision 1.1-32 | Mon Jan 21 2013 | ||
| |||