
Developer Guide
For use with Red Hat JBoss Data Grid 6.3.2
Abstract
Part I. Programmable APIs
- Cache
- Batching
- Grouping
- Persistence (formerly CacheStore)
- ConfigurationBuilder
- Externalizable
- Notification (also known as the Listener API because it deals with Notifications and Listeners)
Chapter 1. The Cache API
ConcurrentMap interface. How entries are stored depends on the cache mode in use. For example, an entry may be replicated to a remote node or an entry may be looked up in a cache store.
Note
1.1. Using the ConfigurationBuilder API to Configure the Cache API
ConfigurationBuilder helper object.
Example 1.1. Programmatic Cache Configuration
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC).build();
String newCacheName = "repl";
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);
An explanation of each line of the provided configuration is as follows:
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC).build();
In the first line of the configuration, a new cache configuration object (namedc) is created using theConfigurationBuilder. Configurationcis assigned the default values for all cache configuration options except the cache mode, which is overridden and set to synchronous replication (REPL_SYNC).String newCacheName = "repl";
In the second line of the configuration, a new variable (of typeString) is created and assigned the valuerepl.manager.defineConfiguration(newCacheName, c);
In the third line of the configuration, the cache manager is used to define a named cache configuration for itself. This named cache configuration is calledrepland its configuration is based on the configuration provided for cache configurationcin the first line.Cache<String, String> cache = manager.getCache(newCacheName);
In the fourth line of the configuration, the cache manager is used to obtain a reference to the unique instance of thereplthat is held by the cache manager. This cache instance is now ready to be used to perform operations to store and retrieve data.
Note
org.infinispan.jmx.JmxDomainConflictException: Domain already registered org.infinispan.
GlobalConfiguration glob = new GlobalConfigurationBuilder()
.clusteredDefault()
.globalJmxStatistics()
.allowDuplicateDomains(true)
.enable()
.build();
1.2. Per-Invocation Flags
1.2.1. Per-Invocation Flag Functions
putForExternalRead() method in Red Hat JBoss Data Grid's Cache API uses flags internally. This method can load a JBoss Data Grid cache with data loaded from an external resource. To improve the efficiency of this call, JBoss Data Grid calls a normal put operation passing the following flags:
- The
ZERO_LOCK_ACQUISITION_TIMEOUTflag: JBoss Data Grid uses an almost zero lock acquisition time when loading data from an external source into a cache. - The
FAIL_SILENTLYflag: If the locks cannot be acquired, JBoss Data Grid fails silently without throwing any lock acquisition exceptions. - The
FORCE_ASYNCHRONOUSflag: If clustered, the cache replicates asynchronously, irrespective of the cache mode set. As a result, a response from other nodes is not required.
putForExternalRead calls of this type are used because the client can retrieve the required data from a persistent store if the data cannot be found in memory. If the client encounters a cache miss, it retries the operation.
1.2.2. Configure Per-Invocation Flags
withFlags() method call.
Example 1.2. Configuring Per-Invocation Flags
Cache cache = ...
cache.getAdvancedCache()
.withFlags(Flag.SKIP_CACHE_STORE, Flag.CACHE_MODE_LOCAL)
.put("local", "only");Note
withFlags() method for each invocation. If the cache operation must be replicated onto another node, the flags are also carried over to the remote nodes.
1.2.3. Per-Invocation Flags Example
put(), must not return the previous value, the IGNORE_RETURN_VALUES flag is used. This flag prevents a remote lookup (to get the previous value) in a distributed environment, which in turn prevents the retrieval of the undesired, potential, previous value. Additionally, if the cache is configured with a cache loader, this flag prevents the previous value from being loaded from its cache store.
Example 1.3. Using the IGNORE_RETURN_VALUES Flag
Cache cache = ...
cache.getAdvancedCache()
.withFlags(Flag.IGNORE_RETURN_VALUES)
.put("local", "only")1.3. The AdvancedCache Interface
AdvancedCache interface, geared towards extending JBoss Data Grid, in addition to its simple Cache Interface. The AdvancedCache Interface can:
- Inject custom interceptors
- Access certain internal components
- Apply flags to alter the behavior of certain cache methods
AdvancedCache:
AdvancedCache advancedCache = cache.getAdvancedCache();
1.3.1. Flag Usage with the AdvancedCache Interface
AdvancedCache.withFlags() to apply any number of flags to a cache invocation.
Example 1.4. Applying Flags to a Cache Invocation
advancedCache.withFlags(Flag.CACHE_MODE_LOCAL, Flag.SKIP_LOCKING)
.withFlags(Flag.FORCE_SYNCHRONOUS)
.put("hello", "world");1.3.2. Custom Interceptors and the AdvancedCache Interface
AdvancedCache Interface provides a mechanism that allows advanced developers to attach custom interceptors. Custom interceptors can alter the behavior of the Cache API methods and the AdvacedCache Interface can be used to attach such interceptors programmatically at run time.
1.3.3. Custom Interceptors
1.3.3.1. Custom Interceptor Design
- A custom interceptor must extend the
CommandInterceptor. - A custom interceptor must declare a public, empty constructor to allow for instantiation.
- A custom interceptor must have JavaBean style setters defined for any property that is defined through the
propertyelement.
1.3.3.2. Adding Custom Interceptors Declaratively
Procedure 1.1. Adding Custom Interceptors
Define Custom Interceptors
All custom interceptors must extend org.jboss.cache.interceptors.base.CommandInterceptor. Use the customInterceptors method to add custom interceptors to the cache:<namedCache name="cacheWithCustomInterceptors"> <customInterceptors>
Define the Position of the New Custom Interceptor
Interceptors must have a defined position. Valid options are:FIRST- Specifies that the new interceptor is placed first in the chain.LAST- Specifies that the new interceptor is placed last in the chain.OTHER_THAN_FIRST_OR_LAST- Specifies that the new interceptor can be placed anywhere except first or last in the chain.
<namedCache name="cacheWithCustomInterceptors"> <customInterceptors> <interceptor position="FIRST" class="com.mycompany.CustomInterceptor1">Define Interceptor Properties
Define specific interceptor properties.<namedCache name="cacheWithCustomInterceptors"> <customInterceptors> <interceptor position="FIRST" class="com.mycompany.CustomInterceptor1"> <properties> <property name="attributeOne" value="value1" /> <property name="attributeTwo" value="value2" /> </properties> </interceptor>
Apply Other Custom Interceptors
In this example, the next custom interceptor is called CustomInterceptor2.<namedCache name="cacheWithCustomInterceptors"> <customInterceptors> <interceptor position="FIRST" class="com.mycompany.CustomInterceptor1"> <properties> <property name="attributeOne" value="value1" /> <property name="attributeTwo" value="value2" /> </properties> </interceptor> <interceptor position="LAST" class="com.mycompany.CustomInterceptor2"/>Define the
index,before, andafterAttributes.- The
indexidentifies the position of this interceptor in the chain, with 0 being the first position. This attribute is mutually exclusive withposition,before, andafter. - The
aftermethod places the new interceptor directly after the instance of the named interceptor specified via its fully qualified class name. This attribute is mutually exclusive withposition,before, andindex. - The
beforemethod places the new interceptor directly before the instance of the named interceptor specified via its fully qualified class name. This attribute is mutually exclusive withposition,after, andindex.
<namedCache name="cacheWithCustomInterceptors"> <customInterceptors> <interceptor position="FIRST" class="com.mycompany.CustomInterceptor1"> <properties> <property name="attributeOne" value="value1" /> <property name="attributeTwo" value="value2" /> </properties> </interceptor> <interceptor position="LAST" class="com.mycompany.CustomInterceptor2"/> <interceptor index="3" class="com.mycompany.CustomInterceptor1"/> <interceptor before="org.infinispan.interceptors.CallInterceptor" class="com.mycompany.CustomInterceptor2"/> <interceptor after="org.infinispan.interceptors.CallInterceptor" class="com.mycompany.CustomInterceptor1"/> </customInterceptors> </namedCache>
Note
1.3.3.3. Adding Custom Interceptors Programmatically
AdvancedCache.
Example 1.5. Obtain a Reference to the AdvancedCache
CacheManager cm = getCacheManager();
Cache aCache = cm.getCache("aName");
AdvancedCache advCache = aCache.getAdvancedCache();addInterceptor() method to add the interceptor.
Example 1.6. Add the Interceptor
advCache.addInterceptor(new MyInterceptor(), 0);
1.3.4. Other Management Tools and Operations
1.3.4.1. Accessing Data via URLs
put() and post() methods place data in the cache, and the URL used determines the cache name and key(s) used. The data is the value placed into the cache, and is placed in the body of the request.
GET and HEAD methods are used for data retrieval while other headers control cache settings and behavior.
Note
1.3.4.2. Limitations of Map Methods
size(), values(), keySet() and entrySet(), can be used with certain limitations with Red Hat JBoss Data Grid as they are unreliable. These methods do not acquire locks (global or local) and concurrent modification, additions and removals are excluded from consideration in these calls. Furthermore, the listed methods are only operational on the local cache and do not provide a global view of state.
From Red Hat JBoss Data Grid 6.3 onwards, the map methods size(), values(), keySet(), and entrySet() include entries in the cache loader by default whereas previously these methods only included the local data container. The underlying cache loader directly affects the performance of these commands. As an example, when using a database, these methods run a complete scan of the table where data is stored which can result in slower processing. Use Cache.getAdvancedCache().withFlags(Flag.SKIP_CACHE_LOAD).values() to maintain the old behavior and not loading from the cache loader which would avoid the slower performance.
Chapter 2. The Batching API
Note
2.1. About Java Transaction API
- First, it retrieves the transactions currently associated with the thread.
- If not already done, it registers an
XAResourcewith the transaction manager to receive notifications when a transaction is committed or rolled back.
2.2. Batching and the Java Transaction API (JTA)
- Locks acquired during an invocation are retained until the transaction commits or rolls back.
- All changes are replicated in a batch on all nodes in the cluster as part of the transaction commit process. Ensuring that multiple changes occur within the single transaction, the replication traffic remains lower and improves performance.
- When using synchronous replication or invalidation, a replication or invalidation failure causes the transaction to roll back.
- When a cache is transactional and a cache loader is present, the cache loader is not enlisted in the cache's transaction. This results in potential inconsistencies at the cache loader level when the transaction applies the in-memory state but (partially) fails to apply the changes to the store.
- All configurations related to a transaction apply for batching as well.
Example 2.1. Configuring a Transaction that Applies for Batching
<transaction syncRollbackPhase="false" syncCommitPhase="false" useEagerLocking="true" eagerLockSingleNode="true" />
Note
2.3. Using the Batching API
2.3.1. Enable the Batching API
Example 2.2. Enable Invocation Batching
<distributed-cache name="default" batching="true" statistics="true"> ... </distributed-cache>
2.3.2. Configure the Batching API
To configure the Batching API in the XML file:
<invocationBatching enabled="true" />
To configure the Batching API programmatically use:
Configuration c = new ConfigurationBuilder().invocationBatching().enable().build();
Note
2.3.3. Use the Batching API
startBatch() and endBatch() on the cache as follows to use batching:
Cache cache = cacheManager.getCache();
Example 2.3. Without Using Batch
cache.put("key", "value"); cache.put(key, value); line executes, the values are replaced immediately.
Example 2.4. Using Batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(true);
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(false); cache.endBatch(true); executes, all modifications made since the batch started are replicated.
cache.endBatch(false); executes, changes made in the batch are discarded.
2.3.4. Batching API Usage Example
Example 2.5. Batching API Usage Example
Chapter 3. The Grouping API
3.1. Grouping API Operations
- Every node can determine which node owns a particular key without expensive metadata updates across nodes.
- Redundancy is improved because ownership information does not need to be replicated if a node fails.
- Intrinsic to the entry, which means it was generated by the key class.
- Extrinsic to the entry, which means it was generated by an external function.
3.2. Grouping API Use Case
Example 3.1. Grouping API Example
DistributedExecutor only checks node AB and quickly and easily retrieves the required employee records.
3.3. Configure the Grouping API
- Enable groups using either the declarative or programmatic method.
- Specify either an intrinsic or extrinsic group. For more information about these group types, see Section 3.1, “Grouping API Operations”
- Register all specified groupers.
3.3.1. Enable Groups
Example 3.2. Declaratively Enable Groups
<clustering>
<hash>
<groups enabled="true" />
</hash>
</clustering>Example 3.3. Programmatically Enable Groups
Configuration c = new ConfigurationBuilder().clustering().hash().groups().enabled().build();
3.3.2. Specify an Intrinsic Group
- the key class definition can be altered, that is if it is not part of an unmodifiable library.
- if the key class is not concerned with the determination of a key/value pair group.
@Group annotation in the relevant method to specify an intrinsic group. The group must always be a String, as illustrated in the example:
Example 3.4. Specifying an Intrinsic Group Example
class User {
...
String office;
...
public int hashCode()) {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group, all keys in the same
// group end up with the same owner
@Group
String getOffice() {
return office;
}
}3.3.3. Specify an Extrinsic Group
- the key class definition cannot be altered, that is if it is part of an unmodifiable library.
- if the key class is concerned with the determination of a key/value pair group.
Grouper interface. This interface uses the computeGroup method to return the group.
Grouper interface acts as an interceptor by passing the computed value to computeGroup. If the @Group annotation is used, the group using it is passed to the first Grouper. As a result, using an intrinsic group provides even greater control.
Example 3.5. Specifying an Extrinsic Group Example
Grouper that uses the key class to extract the group from a key using a pattern. Any group information specified on the key class is ignored in such a situation.
public class KXGrouper implements Grouper<String> {
// A pattern that can extract from a "kX" (e.g. k1, k2) style key
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "1" or group "2".
private static Pattern kPattern = Pattern.compile("(^k)(\\d)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else
return null;
}
public Class<String> getKeyType() {
return String.class;
}
}3.3.4. Register Groupers
Example 3.6. Declaratively Register a Grouper
<clustering>
<hash>
<groups enabled="true">
<grouper class="com.acme.KXGrouper" />
</groups>
</hash>
</clustering>Example 3.7. Programmatically Register a Grouper
Configuration c = new ConfigurationBuilder().clustering().hash().groups().addGrouper(new KXGrouper()).enabled().build();
Chapter 4. The Persistence SPI
- Memory is volatile and a cache store can increase the life span of the information in the cache, which results in improved durability.
- Using persistent external stores as a caching layer between an application and a custom storage engine provides improved Write-Through functionality.
- Using a combination of eviction and passivation, only the frequently required information is stored in-memory and other data is stored in the external storage.
4.1. Persistence SPI Benefits
- Alignment with JSR-107 (http://jcp.org/en/jsr/detail?id=107). JBoss Data Grid's
CacheWriterandCacheLoaderinterfaces are similar to the JSR-107 writer and reader. As a result, alignment with JSR-107 provides improved portability for stores across JCache-compliant vendors. - Simplified transaction integration. JBoss Data Grid handles locking automatically and so implementations do not have to coordinate concurrent access to the store. Depending on the locking mode, concurrent writes on the same key may not occur. However, implementors expect operations on the store to originate from multiple threads and add the implementation code accordingly.
- Reduced serialization, resulting in reduced CPU usage. The new SPI exposes stored entries in a serialized format. If an entry is fetched from persistent storage to be sent remotely, it does not need to be serialized (when reading from the store) and then serialized again (when writing to the wire). Instead, the entry is written to the wire in the serialized format as fetched from the storage.
4.2. Programmatically Configure the Persistence SPI
Example 4.1. Configure the Single File Store via the Persistence SPI
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.passivation(false)
.addSingleFileStore()
.preload(true)
.shared(false)
.fetchPersistentState(true)
.ignoreModifications(false)
.purgeOnStartup(false)
.location(System.getProperty("java.io.tmpdir"))
.async()
.enabled(true)
.threadPoolSize(5)
.singleton()
.enabled(true)
.pushStateWhenCoordinator(true)
.pushStateTimeout(20000);Note
Chapter 5. The ConfigurationBuilder API
- Chain coding of configuration options in order to make the coding process more efficient
- Improve the readability of the configuration
5.1. Using the ConfigurationBuilder API
5.1.1. Programmatically Create a CacheManager and Replicated Cache
Example 5.1. Configure the CacheManager Programmatically
EmbeddedCacheManager manager = new DefaultCacheManager("my-config-file.xml");
Cache defaultCache = manager.getCache();
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC)
.build();
String newCacheName = "repl";
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);Procedure 5.1. Steps for Programmatic Configuration in JBoss Data Grid
- Create a CacheManager as a starting point in an XML file. If required, this CacheManager can be programmed in runtime to the specification that meets the requirements of the use case. The following is an example of how to create a CacheManager:
EmbeddedCacheManager manager = new DefaultCacheManager("my-config-file.xml"); Cache defaultCache = manager.getCache(); - Create a new synchronously replicated cache programmatically.
- Create a new configuration object instance using the ConfigurationBuilder helper object:
Configuration c = new ConfigurationBuilder().clustering().cacheMode(CacheMode.REPL_SYNC) .build();
In the first line of the configuration, a new cache configuration object (namedc) is created using theConfigurationBuilder. Configurationcis assigned the default values for all cache configuration options except the cache mode, which is overridden and set to synchronous replication (REPL_SYNC). - Set the cache mode to synchronous replication:
String newCacheName = "repl";
In the second line of the configuration, a new variable (of typeString) is created and assigned the valuerepl. - Define or register the configuration with a manager:
manager.defineConfiguration(newCacheName, c);
In the third line of the configuration, the cache manager is used to define a named cache configuration for itself. This named cache configuration is calledrepland its configuration is based on the configuration provided for cache configurationcin the first line. Cache<String, String> cache = manager.getCache(newCacheName);
In the fourth line of the configuration, the cache manager is used to obtain a reference to the unique instance of thereplthat is held by the cache manager. This cache instance is now ready to be used to perform operations to store and retrieve data.
Note
5.1.2. Create a Customized Cache Using the Default Named Cache
infinispan-config-file.xml specifies the configuration for a replicated cache as a default and a distributed cache with a customized lifespan value is required. The required distributed cache must retain all aspects of the default cache specified in the infinispan-config-file.xml file except the mentioned aspects.
Example 5.2. Configuring Customized Default Cache
EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml");
Configuration dcc = cacheManager.getDefaultCacheConfiguration();
Configuration c = new ConfigurationBuilder().read(dcc).clustering()
.cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable()
.build();
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);Procedure 5.2. Customize the Default Cache
- Read an instance of a default Configuration object to get the default configuration:
EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml"); Configuration dcc = cacheManager.getDefaultCacheConfiguration(); - Use the ConfigurationBuilder to construct and modify the cache mode and L1 cache lifespan on a new configuration object:
Configuration c = new ConfigurationBuilder().read(dcc).clustering() .cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable() .build();
- Register/define your cache configuration with a cache manager, where cacheName is name of cache specified in
infinispan-config-file.xml:manager.defineConfiguration(newCacheName, c);
- Get default cache with custom configuration changes:
Cache<String, String> cache = manager.getCache(newCacheName);
5.1.3. Create a Customized Cache Using a Non-Default Named Cache
replicatedCache as the base instead of the default cache.
Example 5.3. Creating a Customized Cache Using a Non-Default Named Cache
EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml");
Configuration rc = cacheManager.getCacheConfiguration("replicatedCache");
Configuration c = new ConfigurationBuilder().read(rc).clustering()
.cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable()
.build();
manager.defineConfiguration(newCacheName, c);
Cache<String, String> cache = manager.getCache(newCacheName);Procedure 5.3. Create a Customized Cache Using a Non-Default Named Cache
- Read the
replicatedCacheto get the default configuration:EmbeddedCacheManager manager = new DefaultCacheManager("infinispan-config-file.xml"); Configuration rc = cacheManager.getCacheConfiguration("replicatedCache"); - Use the ConfigurationBuilder to construct and modify the desired configuration on a new configuration object:
Configuration c = new ConfigurationBuilder().read(rc).clustering() .cacheMode(CacheMode.DIST_SYNC).l1().lifespan(60000L).enable() .build();
- Register/define your cache configuration with a cache manager where newCacheName is the name of cache specified in
infinispan-config-file.xmlmanager.defineConfiguration(newCacheName, c);
- Get a default cache with custom configuration changes:
Cache<String, String> cache = manager.getCache(newCacheName);
5.1.4. Using the Configuration Builder to Create Caches Programmatically
5.1.5. Global Configuration Examples
5.1.5.1. Globally Configure the Transport Layer
Example 5.4. Configuring the Transport Layer
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder() .globalJmxStatistics().enable() .build();
5.1.5.2. Globally Configure the Cache Manager Name
Example 5.5. Configuring the Cache Manager Name
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.globalJmxStatistics()
.cacheManagerName("SalesCacheManager")
.mBeanServerLookup(new JBossMBeanServerLookup())
.enable()
.build();5.1.5.3. Globally Customize Thread Pool Executors
Example 5.6. Customize Thread Pool Executors
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.replicationQueueScheduledExecutor()
.factory(new DefaultScheduledExecutorFactory())
.addProperty("threadNamePrefix", "RQThread")
.build();5.1.6. Cache Level Configuration Examples
5.1.6.1. Cache Level Configuration for the Cluster Mode
Example 5.7. Configure Cluster Mode at Cache Level
Configuration config = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.sync()
.l1().lifespan(25000L).enable()
.hash().numOwners(3)
.build();5.1.6.2. Cache Level Eviction and Expiration Configuration
Example 5.8. Configuring Expiration and Eviction at the Cache Level
Configuration config = new ConfigurationBuilder()
.eviction()
.maxEntries(20000).strategy(EvictionStrategy.LIRS).expiration()
.wakeUpInterval(5000L)
.maxIdle(120000L)
.build();5.1.6.3. Cache Level Configuration for JTA Transactions
Example 5.9. Configuring JTA Transactions at Cache Level
Configuration config = new ConfigurationBuilder()
.locking()
.concurrencyLevel(10000).isolationLevel(IsolationLevel.REPEATABLE_READ)
.lockAcquisitionTimeout(12000L).useLockStriping(false).writeSkewCheck(true)
.transaction()
.transactionManagerLookup(new GenericTransactionManagerLookup())
.recovery().enable()
.jmxStatistics().enable()
.build();5.1.6.4. Cache Level Configuration Using Chained Persistent Stores
Example 5.10. Configuring Chained Persistent Stores at Cache Level
Configuration config = new ConfigurationBuilder()
.persistence()
.passivation(false)
.addSingleFileStore().shared(false).preload(false).location("/tmp").async().enable().threadPoolSize(20).build();5.1.6.5. Cache Level Configuration for Advanced Externalizers
Example 5.11. Configuring Advanced Externalizers at Cache Level
GlobalConfiguration globalConfig = new GlobalConfigurationBuilder()
.serialization()
.addAdvancedExternalizer(new PersonExternalizer())
.addAdvancedExternalizer(999, new AddressExternalizer())
.build();Chapter 6. The Externalizable API
Externalizer is a class that can:
- Marshall a given object type to a byte array.
- Unmarshall the contents of a byte array into an instance of the object type.
6.1. Customize Externalizers
- Use an Externalizable Interface. For details, see the Red Hat JBoss Data Grid Developer Guide's The Externalizable API chapter.
- Use an advanced externalizer.
6.2. Annotating Objects for Marshalling Using @SerializeWith
@SerializeWith indicating the Externalizer class to use.
Example 6.1. Using the @SerializeWith Annotation
import org.infinispan.commons.marshall.Externalizer;
import org.infinispan.commons.marshall.SerializeWith;
@SerializeWith(Person.PersonExternalizer.class)
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public static class PersonExternalizer implements Externalizer<Person> {
@Override
public void writeObject(ObjectOutput output, Person person)
throws IOException {
output.writeObject(person.name);
output.writeInt(person.age);
}
@Override
public Person readObject(ObjectInput input)
throws IOException, ClassNotFoundException {
return new Person((String) input.readObject(), input.readInt());
}
}
}@SerializeWith annotation. JBoss Marshalling will therefore marshall the object using the Externalizer class passed.
- The payload sizes generated using this method are not the most efficient. This is due to some constraints in the model, such as support for different versions of the same class, or the need to marshall the Externalizer class.
- This model requires the marshalled class to be annotated with
@SerializeWith, however an Externalizer may need to be provided for a class for which source code is not available, or for any other constraints, it cannot be modified. - Annotations used in this model may be limiting for framework developers or service providers that attempt to abstract lower level details, such as the marshalling layer, away from the user.
Note
6.3. Using an Advanced Externalizer
- Define and implement the
readObject()andwriteObject()methods. - Link externalizers with marshaller classes.
- Register the advanced externalizer.
6.3.1. Implement the Methods
readObject() and writeObject() methods. The following is a sample definition:
Example 6.2. Define and Implement the Methods
import org.infinispan.commons.marshall.AdvancedExternalizer;
public class Person {
final String name;
final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public static class PersonExternalizer implements AdvancedExternalizer<Person> {
@Override
public void writeObject(ObjectOutput output, Person person)
throws IOException {
output.writeObject(person.name);
output.writeInt(person.age);
}
@Override
public Person readObject(ObjectInput input)
throws IOException, ClassNotFoundException {
return new Person((String) input.readObject(), input.readInt());
}
@Override
public Set<Class<? extends Person>> getTypeClasses() {
return Util.<Class<? extends Person>>asSet(Person.class);
}
@Override
public Integer getId() {
return 2345;
}
}
}Note
6.3.2. Link Externalizers with Marshaller Classes
getTypeClasses() to discover the classes that this externalizer can marshall and to link the readObject() and writeObject() classes.
import org.infinispan.util.Util;
...
@Override
public Set<Class<? extends ReplicableCommand>> getTypeClasses() {
return Util.asSet(LockControlCommand.class, GetKeyValueCommand.class,
ClusteredGetCommand.class, MultipleRpcCommand.class,
SingleRpcCommand.class, CommitCommand.class,
PrepareCommand.class, RollbackCommand.class,
ClearCommand.class, EvictCommand.class,
InvalidateCommand.class, InvalidateL1Command.class,
PutKeyValueCommand.class, PutMapCommand.class,
RemoveCommand.class, ReplaceCommand.class);
}ReplicableCommandExternalizer indicates that it can externalize several command types. This sample marshalls all commands that extend the ReplicableCommand interface but the framework only supports class equality comparison so it is not possible to indicate that the classes marshalled are all children of a particular class or interface.
@Override
public Set<Class<? extends List>> getTypeClasses() {
return Util.<Class<? extends List>>asSet(
Util.<List>loadClass("java.util.Collections$SingletonList", null));
}6.3.3. Register the Advanced Externalizer (Declaratively)
Procedure 6.1. Register the Advanced Externalizer
- Add the
globalelement to theinfinispanelement:<infinispan> <global /> </infinispan>
- Add the
serializationelement to theglobalelement as follows:<infinispan> <global> <serialization /> </global> </infinispan> - Add the
advancedExternalizerselement to add information about the new advanced externalizer as follows:<infinispan> <global> <serialization> <advancedExternalizers /> </serialization> </global> </infinispan> - Define the externalizer class using the
externalizerClassattribute as follows:<infinispan> <global> <serialization> <advancedExternalizers> <advancedExternalizer externalizerClass="org.infinispan.marshall.AdvancedExternalizerTest$IdViaAnnotationObj$Externalizer"/> </advancedExternalizers> </serialization> </global> </infinispan>Replace the $IdViaAnnotationObj and $AdvancedExternalizer values as required.
6.3.4. Register the Advanced Externalizer (Programmatically)
Example 6.3. Registering the Advanced Externalizer Programmatically
GlobalConfigurationBuilder builder = ... builder.serialization() .addAdvancedExternalizer(new Person.PersonExternalizer());
6.3.5. Register Multiple Externalizers
GlobalConfiguration.addExternalizer() accepts varargs. Before registering the new externalizers, ensure that their IDs are already defined using the @Marshalls annotation.
Example 6.4. Registering Multiple Externalizers
builder.serialization()
.addAdvancedExternalizer(new Person.PersonExternalizer(),
new Address.AddressExternalizer());6.4. Custom Externalizer ID Values
Table 6.1. Reserved Externalizer ID Ranges
| ID Range | Reserved For |
|---|---|
| 1000-1099 | The Infinispan Tree Module |
| 1100-1199 | Red Hat JBoss Data Grid Server modules |
| 1200-1299 | Hibernate Infinispan Second Level Cache |
| 1300-1399 | JBoss Data Grid Lucene Directory |
| 1400-1499 | Hibernate OGM |
| 1500-1599 | Hibernate Search |
| 1600-1699 | Infinispan Query Module |
| 1700-1799 | Infinispan Remote Query Module |
6.4.1. Customize the Externalizer ID (Declaratively)
Procedure 6.2. Customizing the Externalizer ID (Declaratively)
- Add the
globalelement to theinfinispanelement:<infinispan> <global /> </infinispan>
- Add the
serializationelement to theglobalelement as follows:<infinispan> <global> <serialization /> </global> </infinispan> - Add the
advancedExternalizerelement to add information about the new advanced externalizer as follows:<infinispan> <global> <serialization> <advancedExternalizer /> </serialization> </global> </infinispan> - Define the externalizer ID using the
idattribute as follows:<infinispan> <global> <serialization> <advancedExternalizers> <advancedExternalizer id="$ID" /> </advancedExternalizers> </serialization> </global> </infinispan>Ensure that the selected ID is not from the range of IDs reserved for other modules. - Define the externalizer class using the
externalizerClassattribute as follows:<infinispan> <global> <serialization> <advancedExternalizers> <advancedExternalizer id="$ID" externalizerClass="org.infinispan.marshall.AdvancedExternalizerTest$IdViaConfigObj$Externalizer"/> </advancedExternalizers> </serialization> </global> </infinispan>Replace the $IdViaAnnotationObj and $AdvancedExternalizer values as required.
6.4.2. Customize the Externalizer ID (Programmatically)
Example 6.5. Assign an ID to the Externalizer
GlobalConfiguration globalConfiguration = new GlobalConfigurationBuilder()
.serialization()
.addAdvancedExternalizer($ID, new Person.PersonExternalizer())
.build();Chapter 7. The Notification/Listener API
7.1. Listener Example
Example 7.1. Configuring a Listener
@Listener
public class PrintWhenAdded {
@CacheEntryCreated
public void print(CacheEntryCreatedEvent event) {
System.out.println("New entry " + event.getKey() + " created in the cache");
}
}7.2. Cache Entry Modified Listener Configuration
getValue() method's behavior is specific to whether the callback is triggered before or after the actual operation has been performed. For example, if event.isPre() is true, then event.getValue() would return the old value, prior to modification. If event.isPre() is false, then event.getValue() would return new value. If the event is creating and inserting a new entry, the old value would be null. For more information about isPre(), see the Red Hat JBoss Data Grid API Documentation's listing for the org.infinispan.notifications.cachelistener.event package.
7.3. Listener Notifications
@Listener. A Listenable is an interface that denotes that the implementation can have listeners attached to it. Each listener is registered using methods defined in the Listenable.
7.3.1. About Cache-level Notifications
7.3.2. Cache Manager-level Notifications
- Nodes joining or leaving a cluster;
- The starting and stopping of caches
7.3.3. About Synchronous and Asynchronous Notifications
@Listener (sync = false)
public class MyAsyncListener { .... }<asyncListenerExecutor/> element in the configuration file to tune the thread pool that is used to dispatch asynchronous notifications.
7.4. NotifyingFutures
Futures, but a sub-interface known as a NotifyingFuture. Unlike a JDK Future, a listener can be attached to a NotifyingFuture to notify the user about a completed future.
Note
NotifyingFutures are only available in JBoss Data Grid Library mode.
7.4.1. NotifyingFutures Example
NotifyingFutures in Red Hat JBoss Data Grid:
Example 7.2. Configuring NotifyingFutures
FutureListener futureListener = new FutureListener() {
public void futureDone(Future future) {
try {
future.get();
} catch (Exception e) {
// Future did not complete successfully
System.out.println("Help!");
}
}
};
cache.putAsync("key", "value").attachListener(futureListener);Part II. Securing Data in Red Hat JBoss Data Grid
JBoss Data Grid features role-based access control for operations on designated secured caches. Roles can be assigned to users who access your application, with roles mapped to permissions for cache and cache-manager operations. Only authenticated users are able to perform the operations that are authorized for their role.
Node-level security requires new nodes or merging partitions to authenticate before joining a cluster. Only authenticated nodes that are authorized to join the cluster are permitted to do so. This provides data protection by preventing authorized servers from storing your data.
JBoss Data Grid increases data security by supporting encrypted communications between the nodes in a cluster by using a user-specified cryptography algorithm, as supported by Java Cryptography Architecture (JCA).
Chapter 8. Red Hat JBoss Data Grid Security: Authorization and Authentication
8.1. Red Hat JBoss Data Grid Security: Authorization and Authentication
SecureCache. SecureCache is a simple wrapper around a cache, which checks whether the "current user" has the permissions required to perform an operation. The "current user" is a Subject associated with the AccessControlContext.
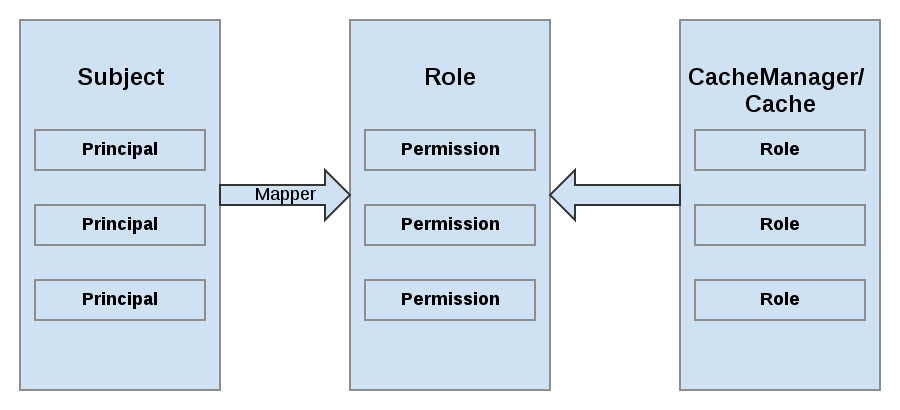
Figure 8.1. Roles and Permissions Mapping
8.2. Permissions
Table 8.1. CacheManager Permissions
| Permission | Function | Description |
|---|---|---|
| CONFIGURATION | defineConfiguration | Whether a new cache configuration can be defined. |
| LISTEN | addListener | Whether listeners can be registered against a cache manager. |
| LIFECYCLE | stop, start | Whether the cache manager can be stopped or started respectively. |
| ALL | A convenience permission which includes all of the above. |
Table 8.2. Cache Permissions
| Permission | Function | Description |
|---|---|---|
| READ | get, contains | Whether entries can be retrieved from the cache. |
| WRITE | put, putIfAbsent, replace, remove, evict | Whether data can be written/replaced/removed/evicted from the cache. |
| EXEC | distexec, mapreduce | Whether code execution can be run against the cache. |
| LISTEN | addListener | Whether listeners can be registered against a cache. |
| BULK_READ | keySet, values, entrySet,query | Whether bulk retrieve operations can be executed. |
| BULK_WRITE | clear, putAll | Whether bulk write operations can be executed. |
| LIFECYCLE | start, stop | Whether a cache can be started / stopped. |
| ADMIN | getVersion, addInterceptor*, removeInterceptor, getInterceptorChain, getEvictionManager, getComponentRegistry, getDistributionManager, getAuthorizationManager, evict, getRpcManager, getCacheConfiguration, getCacheManager, getInvocationContextContainer, setAvailability, getDataContainer, getStats, getXAResource | Whether access to the underlying components/internal structures is allowed. |
| ALL | A convenience permission which includes all of the above. | |
| ALL_READ | Combines READ and BULK_READ. | |
| ALL_WRITE | Combines WRITE and BULK_WRITE. |
Note
8.3. Role Mapping
PrincipalRoleMapper must be specified in the global configuration. Red Hat JBoss Data Grid ships with three mappers, and also allows you to provide a custom mapper.
Table 8.3. Mappers
| Mapper Name | Java | XML | Description |
|---|---|---|---|
| IdentityRoleMapper | org.infinispan.security.impl.IdentityRoleMapper | <identity-role-mapper /> | Uses the Principal name as the role name. |
| CommonNameRoleMapper | org.infinispan.security.impl.CommonRoleMapper | <common-name-role-mapper /> | If the Principal name is a Distinguished Name (DN), this mapper extracts the Common Name (CN) and uses it as a role name. For example the DN cn=managers,ou=people,dc=example,dc=com will be mapped to the role managers. |
| ClusterRoleMapper | org.infinispan.security.impl.ClusterRoleMapper | <cluster-role-mapper /> | Uses the ClusterRegistry to store principal to role mappings. This allows the use of the CLI’s GRANT and DENY commands to add/remove roles to a Principal. |
| Custom Role Mapper | <custom-role-mapper class="a.b.c" /> | Supply the fully-qualified class name of an implementation of org.infinispan.security.impl.PrincipalRoleMapper |
8.4. Configuring Authentication and Role Mapping using JBoss EAP Login Modules
IdentityRoleMapper:
Example 8.1. Mapping a Principal from JBoss EAP's Login Module
public class SimplePrincipalGroupRoleMapper implements PrincipalRoleMapper {
@Override
public Set<String> principalToRoles(Principal principal) {
if (principal instanceof SimpleGroup) {
Enumeration<Principal> members = ((SimpleGroup) principal).members();
if (members.hasMoreElements()) {
Set<String> roles = new HashSet<String>();
while (members.hasMoreElements()) {
Principal innerPrincipal = members.nextElement();
if (innerPrincipal instanceof SimplePrincipal) {
SimplePrincipal sp = (SimplePrincipal) innerPrincipal;
roles.add(sp.getName());
}
}
return roles;
}
}
return null;
}
}Example 8.2. Example of JBoss EAP LDAP login module configuration
<security-domain name="ispn-secure" cache-type="default">
<authentication>
<login-module code="org.jboss.security.auth.spi.LdapLoginModule" flag="required">
<module-option name="java.naming.factory.initial" value="com.sun.jndi.ldap.LdapCtxFactory"/>
<module-option name="java.naming.provider.url" value="ldap://localhost:389"/>
<module-option name="java.naming.security.authentication" value="simple"/>
<module-option name="principalDNPrefix" value="uid="/>
<module-option name="principalDNSuffix" value=",ou=People,dc=infinispan,dc=org"/>
<module-option name="rolesCtxDN" value="ou=Roles,dc=infinispan,dc=org"/>
<module-option name="uidAttributeID" value="member"/>
<module-option name="matchOnUserDN" value="true"/>
<module-option name="roleAttributeID" value="cn"/>
<module-option name="roleAttributeIsDN" value="false"/>
<module-option name="searchScope" value="ONELEVEL_SCOPE"/>
</login-module>
</authentication>
</security-domain>Example 8.3. Example of JBoss EAP Login Module Configuration
<security-domain name="krb-admin" cache-type="default">
<authentication>
<login-module code="Kerberos" flag="required">
<module-option name="useKeyTab" value="true"/>
<module-option name="principal" value="admin@INFINISPAN.ORG"/>
<module-option name="keyTab" value="${basedir}/keytab/admin.keytab"/>
</login-module>
</authentication>
</security-domain>Important
8.5. Configuring Red Hat JBoss Data Grid for Authorization
The following is an example configuration for authorization at the CacheManager level:
Example 8.4. CacheManager Authorization (Declarative Configuration)
<cache-container name="local" default-cache="default">
<security>
<authorization>
<identity-role-mapper />
<role name="admin" permissions="ALL"/>
<role name="reader" permissions="READ"/>
<role name="writer" permissions="WRITE"/>
<role name="supervisor" permissions="ALL_READ ALL_WRITE"/>
</authorization>
</security>
</cache-container>- whether to use authorization.
- a class which will map principals to a set of roles.
- a set of named roles and the permissions they represent.
Roles for each cache can be defined as follows:
Example 8.5. Defining Roles
<local-cache name="secured">
<security>
<authorization roles="admin reader writer supervisor"/>
</security>
</local-cache>The following example shows how to set up the same authorization parameters for Library mode using programmatic configuration:
Example 8.6. CacheManager Authorization Programmatic Configuration
GlobalConfigurationBuilder global = new GlobalConfigurationBuilder();
global
.security()
.authorization()
.principalRoleMapper(new IdentityRoleMapper())
.role("admin")
.permission(CachePermission.ALL)
.role("supervisor")
.permission(CachePermission.EXEC)
.permission(CachePermission.READ)
.permission(CachePermission.WRITE)
.role("reader")
.permission(CachePermission.READ);
ConfigurationBuilder config = new ConfigurationBuilder();
config
.security()
.enable()
.authorization()
.role("admin")
.role("supervisor")
.role("reader");8.6. Data Security for Library Mode
8.6.1. Subject and Principal Classes
Subject class is the central class in JAAS. A Subject represents information for a single entity, such as a person or service. It encompasses the entity's principals, public credentials, and private credentials. The JAAS APIs use the existing Java 2 java.security.Principal interface to represent a principal, which is a typed name.
public Set getPrincipals() {...}
public Set getPrincipals(Class c) {...}
getPrincipals() returns all principals contained in the subject. getPrincipals(Class c) returns only those principals that are instances of class c or one of its subclasses. An empty set is returned if the subject has no matching principals.
Note
java.security.acl.Group interface is a sub-interface of java.security.Principal, so an instance in the principals set may represent a logical grouping of other principals or groups of principals.
8.6.2. Obtaining a Subject
javax.security.auth.Subject. The Subject represents information for a single cache entity, such as a person or a service.
Subject subject = SecurityContextAssociation.getSubject();
- Servlets:
ServletRequest.getUserPrincipal() - EJBs:
EJBContext.getCallerPrincipal() - MessageDrivenBeans:
MessageDrivenContext.getCallerPrincipal()
mapper is then used to identify the principals associated with the Subject and convert them into roles that correspond to those you have defined at the container level.
java.security.AccessControlContext. Either the container sets the Subject on the AccessControlContext, or the user must map the Principal to an appropriate Subject before wrapping the call to the JBoss Data Grid API using a Security.doAs() method.
Example 8.7. Obtaining a Subject
import org.infinispan.security.Security;
Security.doAs(subject, new PrivilegedExceptionAction<Void>() {
public Void run() throws Exception {
cache.put("key", "value");
}
});Security.doAs() method is in place of the typical Subject.doAs() method. Unless the AccessControlContext must be modified for reasons specific to your application's security model, using Security.doAs() provides a performance advantage.
Security.getSubject();, which will retrieve the Subject from either the JBoss Data Grid context, or from the AccessControlContext.
8.6.3. Subject Authentication
- An application instantiates a
LoginContextand passes in the name of the login configuration and aCallbackHandlerto populate theCallbackobjects, as required by the configurationLoginModules. - The
LoginContextconsults aConfigurationto load all theLoginModulesincluded in the named login configuration. If no such named configuration exists theotherconfiguration is used as a default. - The application invokes the
LoginContext.loginmethod. - The login method invokes all the loaded
LoginModules. As eachLoginModuleattempts to authenticate the subject, it invokes the handle method on the associatedCallbackHandlerto obtain the information required for the authentication process. The required information is passed to the handle method in the form of an array ofCallbackobjects. Upon success, theLoginModules associate relevant principals and credentials with the subject. - The
LoginContextreturns the authentication status to the application. Success is represented by a return from the login method. Failure is represented through a LoginException being thrown by the login method. - If authentication succeeds, the application retrieves the authenticated subject using the
LoginContext.getSubjectmethod. - After the scope of the subject authentication is complete, all principals and related information associated with the subject by the
loginmethod can be removed by invoking theLoginContext.logoutmethod.
LoginContext class provides the basic methods for authenticating subjects and offers a way to develop an application that is independent of the underlying authentication technology. The LoginContext consults a Configuration to determine the authentication services configured for a particular application. LoginModule classes represent the authentication services. Therefore, you can plug different login modules into an application without changing the application itself. The following code shows the steps required by an application to authenticate a subject.
CallbackHandler handler = new MyHandler();
LoginContext lc = new LoginContext("some-config", handler);
try {
lc.login();
Subject subject = lc.getSubject();
} catch(LoginException e) {
System.out.println("authentication failed");
e.printStackTrace();
}
// Perform work as authenticated Subject
// ...
// Scope of work complete, logout to remove authentication info
try {
lc.logout();
} catch(LoginException e) {
System.out.println("logout failed");
e.printStackTrace();
}
// A sample MyHandler class
class MyHandler
implements CallbackHandler
{
public void handle(Callback[] callbacks) throws
IOException, UnsupportedCallbackException
{
for (int i = 0; i < callbacks.length; i++) {
if (callbacks[i] instanceof NameCallback) {
NameCallback nc = (NameCallback)callbacks[i];
nc.setName(username);
} else if (callbacks[i] instanceof PasswordCallback) {
PasswordCallback pc = (PasswordCallback)callbacks[i];
pc.setPassword(password);
} else {
throw new UnsupportedCallbackException(callbacks[i],
"Unrecognized Callback");
}
}
}
}
LoginModule interface. This allows an administrator to plug different authentication technologies into an application. You can chain together multiple LoginModules to allow for more than one authentication technology to participate in the authentication process. For example, one LoginModule may perform user name/password-based authentication, while another may interface to hardware devices such as smart card readers or biometric authenticators.
LoginModule is driven by the LoginContext object against which the client creates and issues the login method. The process consists of two phases. The steps of the process are as follows:
- The
LoginContextcreates each configuredLoginModuleusing its public no-arg constructor. - Each
LoginModuleis initialized with a call to its initialize method. TheSubjectargument is guaranteed to be non-null. The signature of the initialize method is:public void initialize(Subject subject, CallbackHandler callbackHandler, Map sharedState, Map options) - The
loginmethod is called to start the authentication process. For example, a method implementation might prompt the user for a user name and password and then verify the information against data stored in a naming service such as NIS or LDAP. Alternative implementations might interface to smart cards and biometric devices, or simply extract user information from the underlying operating system. The validation of user identity by eachLoginModuleis considered phase 1 of JAAS authentication. The signature of theloginmethod isboolean login() throws LoginException. ALoginExceptionindicates failure. A return value of true indicates that the method succeeded, whereas a return value of false indicates that the login module should be ignored. - If the
LoginContext's overall authentication succeeds,commitis invoked on eachLoginModule. If phase 1 succeeds for aLoginModule, then the commit method continues with phase 2 and associates the relevant principals, public credentials, and/or private credentials with the subject. If phase 1 fails for aLoginModule, thencommitremoves any previously stored authentication state, such as user names or passwords. The signature of thecommitmethod is:boolean commit() throws LoginException. Failure to complete the commit phase is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored. - If the
LoginContext's overall authentication fails, then theabortmethod is invoked on eachLoginModule. Theabortmethod removes or destroys any authentication state created by the login or initialize methods. The signature of theabortmethod isboolean abort() throws LoginException. Failure to complete theabortphase is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored. - To remove the authentication state after a successful login, the application invokes
logouton theLoginContext. This in turn results in alogoutmethod invocation on eachLoginModule. Thelogoutmethod removes the principals and credentials originally associated with the subject during thecommitoperation. Credentials should be destroyed upon removal. The signature of thelogoutmethod is:boolean logout() throws LoginException. Failure to complete the logout process is indicated by throwing aLoginException. A return of true indicates that the method succeeded, whereas a return of false indicates that the login module should be ignored.
LoginModule must communicate with the user to obtain authentication information, it uses a CallbackHandler object. Applications implement the CallbackHandler interface and pass it to the LoginContext, which send the authentication information directly to the underlying login modules.
CallbackHandler both to gather input from users, such as a password or smart card PIN, and to supply information to users, such as status information. By allowing the application to specify the CallbackHandler, underlying LoginModules remain independent from the different ways applications interact with users. For example, a CallbackHandler's implementation for a GUI application might display a window to solicit user input. On the other hand, a CallbackHandler implementation for a non-GUI environment, such as an application server, might simply obtain credential information by using an application server API. The CallbackHandler interface has one method to implement:
void handle(Callback[] callbacks)
throws java.io.IOException,
UnsupportedCallbackException;
Callback interface is the last authentication class we will look at. This is a tagging interface for which several default implementations are provided, including the NameCallback and PasswordCallback used in an earlier example. A LoginModule uses a Callback to request information required by the authentication mechanism. LoginModules pass an array of Callbacks directly to the CallbackHandler.handle method during the authentication's login phase. If a callbackhandler does not understand how to use a Callback object passed into the handle method, it throws an UnsupportedCallbackException to abort the login call.
8.6.4. Authorization Using a SecurityManager
java -Djava.security.manager ...
System.setSecurityManager(new SecurityManager());
8.6.5. Security Manager in Java
8.6.5.1. About the Java Security Manager
The Java Security Manager is a class that manages the external boundary of the Java Virtual Machine (JVM) sandbox, controlling how code executing within the JVM can interact with resources outside the JVM. When the Java Security Manager is activated, the Java API checks with the security manager for approval before executing a wide range of potentially unsafe operations.
8.6.5.2. About Java Security Manager Policies
A set of defined permissions for different classes of code. The Java Security Manager compares actions requested by applications against the security policy. If an action is allowed by the policy, the Security Manager will permit that action to take place. If the action is not allowed by the policy, the Security Manager will deny that action. The security policy can define permissions based on the location of code, on the code's signature, or based on the subject's principals.
java.security.manager and java.security.policy.
A security policy's entry consists of the following configuration elements, which are connected to the policytool:
- CodeBase
- The URL location (excluding the host and domain information) where the code originates from. This parameter is optional.
- SignedBy
- The alias used in the keystore to reference the signer whose private key was used to sign the code. This can be a single value or a comma-separated list of values. This parameter is optional. If omitted, presence or lack of a signature has no impact on the Java Security Manager.
- Principals
- A list of
principal_type/principal_namepairs, which must be present within the executing thread's principal set. The Principals entry is optional. If it is omitted, it signifies that the principals of the executing thread will have no impact on the Java Security Manager. - Permissions
- A permission is the access which is granted to the code. Many permissions are provided as part of the Java Enterprise Edition 6 (Java EE 6) specification. This document only covers additional permissions which are provided by JBoss EAP 6.
Important
8.6.5.3. Write a Java Security Manager Policy
An application called policytool is included with most JDK and JRE distributions, for the purpose of creating and editing Java Security Manager security policies. Detailed information about policytool is linked from http://docs.oracle.com/javase/6/docs/technotes/tools/.
Procedure 8.1. Setup a new Java Security Manager Policy
Start
policytool.Start thepolicytooltool in one of the following ways.Red Hat Enterprise Linux
From your GUI or a command prompt, run/usr/bin/policytool.Microsoft Windows Server
Runpolicytool.exefrom your Start menu or from thebin\of your Java installation. The location can vary.
Create a policy.
To create a policy, select . Add the parameters you need, then click .Edit an existing policy
Select the policy from the list of existing policies, and select the button. Edit the parameters as needed.Delete an existing policy.
Select the policy from the list of existing policies, and select the button.
8.6.5.4. Run Red Hat JBoss Data Grid Server Within the Java Security Manager
domain.sh or standalone.sh scripts. The following procedure guides you through the steps of configuring your instance to run within a Java Security Manager policy.
Prerequisites
- Before you following this procedure, you need to write a security policy, using the
policytoolcommand which is included with your Java Development Kit (JDK). This procedure assumes that your policy is located atJDG_HOME/bin/server.policy. As an alternative, write the security policy using any text editor and manually save it asJDG_HOME/bin/server.policy - The domain or standalone server must be completely stopped before you edit any configuration files.
Procedure 8.2. Configure the Security Manager for JBoss Data Grid Server
Open the configuration file.
Open the configuration file for editing. This file is located in one of two places, depending on whether you use a managed domain or standalone server. This is not the executable file used to start the server or domain.Managed Domain
- For Linux:
JDG_HOME/bin/domain.conf - For Windows:
JDG_HOME\bin\domain.conf.bat
Standalone Server
- For Linux:
JDG_HOME/bin/standalone.conf - For Windows:
JDG_HOME\bin\standalone.conf.bat
Add the Java options to the file.
To ensure the Java options are used, add them to the code block that begins with:if [ "x$JAVA_OPTS" = "x" ]; then
You can modify the-Djava.security.policyvalue to specify the exact location of your security policy. It should go onto one line only, with no line break. Using==when setting the-Djava.security.policyproperty specifies that the security manager will use only the specified policy file. Using=specifies that the security manager will use the specified policy combined with the policy set in thepolicy.urlsection ofJAVA_HOME/lib/security/java.security.Important
JBoss Enterprise Application Platform releases from 6.2.2 onwards require that the system propertyjboss.modules.policy-permissionsis set to true.Example 8.8. domain.conf
JAVA_OPTS="$JAVA_OPTS -Djava.security.manager -Djava.security.policy==$PWD/server.policy -Djboss.home.dir=/path/to/JDG_HOME -Djboss.modules.policy-permissions=true"
Example 8.9. domain.conf.bat
set "JAVA_OPTS=%JAVA_OPTS% -Djava.security.manager -Djava.security.policy==\path\to\server.policy -Djboss.home.dir=\path\to\JDG_HOME -Djboss.modules.policy-permissions=true"
Example 8.10. standalone.conf
JAVA_OPTS="$JAVA_OPTS -Djava.security.manager -Djava.security.policy==$PWD/server.policy -Djboss.home.dir=$JBOSS_HOME -Djboss.modules.policy-permissions=true"
Example 8.11. standalone.conf.bat
set "JAVA_OPTS=%JAVA_OPTS% -Djava.security.manager -Djava.security.policy==\path\to\server.policy -Djboss.home.dir=%JBOSS_HOME% -Djboss.modules.policy-permissions=true"
Start the domain or server.
Start the domain or server as normal.
8.7. Data Security for Remote Client Server Mode
8.7.1. About Security Realms
ManagementRealmstores authentication information for the Management API, which provides the functionality for the Management CLI and web-based Management Console. It provides an authentication system for managing JBoss Data Grid Server itself. You could also use theManagementRealmif your application needed to authenticate with the same business rules you use for the Management API.ApplicationRealmstores user, password, and role information for Web Applications and EJBs.
REALM-users.propertiesstores usernames and hashed passwords.REALM-roles.propertiesstores user-to-role mappings.mgmt-groups.propertiesstores user-to-role mapping file forManagementRealm.
domain/configuration/ and standalone/configuration/ directories. The files are written simultaneously by the add-user.sh or add-user.bat command. When you run the command, the first decision you make is which realm to add your new user to.
8.7.2. Add a New Security Realm
Run the Management CLI.
Start thecli.shorcli.batcommand and connect to the server.Create the new security realm itself.
Run the following command to create a new security realm namedMyDomainRealmon a domain controller or a standalone server./host=master/core-service=management/security-realm=MyDomainRealm:add()
Create the references to the properties file which will store information about the new role.
Run the following command to create a pointer a file namedmyfile.properties, which will contain the properties pertaining to the new role.Note
The newly-created properties file is not managed by the includedadd-user.shandadd-user.batscripts. It must be managed externally./host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
Your new security realm is created. When you add users and roles to this new realm, the information will be stored in a separate file from the default security realms. You can manage this new file using your own applications or procedures.
8.7.3. Add a User to a Security Realm
Run the
add-user.shoradd-user.batcommand.Open a terminal and change directories to theJDG_HOME/bin/directory. If you run Red Hat Enterprise Linux or another UNIX-like operating system, runadd-user.sh. If you run Microsoft Windows Server, runadd-user.bat.Choose whether to add a Management User or Application User.
For this procedure, typebto add an Application User.Choose the realm the user will be added to.
By default, the only available realm isApplicationRealm. If you have added a custom realm, you can type its name instead.Type the username, password, and roles, when prompted.
Type the desired username, password, and optional roles when prompted. Verify your choice by typingyes, or typenoto cancel the changes. The changes are written to each of the properties files for the security realm.
8.7.4. Configuring Security Realms Declaratively
Example 8.12. Configuring Security Realms Declaratively
<security-realms>
<security-realm name="ManagementRealm">
<authentication>
<local default-user="$local" skip-group-loading="true"/>
<properties path="mgmt-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization map-groups-to-roles="false">
<properties path="mgmt-groups.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
<security-realm name="ApplicationRealm">
<authentication>
<local default-user="$local" allowed-users="*" skip-group-loading="true"/>
<properties path="application-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="application-roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
</security-realms>8.7.5. Loading Roles from LDAP for Authorization (Remote Client-Server Mode)
memberOf attributes; a group entity may map which users belong to it through uniqueMember attributes; or both mappings may be maintained by the LDAP server.
force attribute is set to "false". When force is true, the search is performed again during authorization (while loading groups). This is typically done when different servers perform authentication and authorization.
<authorization>
<ldap connection="...">
<!-- OPTIONAL -->
<username-to-dn force="true">
<!-- Only one of the following. -->
<username-is-dn />
<username-filter base-dn="..." recursive="..." user-dn-attribute="..." attribute="..." />
<advanced-filter base-dn="..." recursive="..." user-dn-attribute="..." filter="..." />
</username-to-dn>
<group-search group-name="..." iterative="..." group-dn-attribute="..." group-name-attribute="..." >
<!-- One of the following -->
<group-to-principal base-dn="..." recursive="..." search-by="...">
<membership-filter principal-attribute="..." />
</group-to-principal>
<principal-to-group group-attribute="..." />
</group-search>
</ldap>
</authorization>Important
force attribute. It is required, even when set to the default value of false.
username-to-dn
username-to-dn element specifies how to map the user name to the distinguished name of their entry in the LDAP directory. This element is only required when both of the following are true:
- The authentication and authorization steps are against different LDAP servers.
- The group search uses the distinguished name.
- 1:1 username-to-dn
- This specifies that the user name entered by the remote user is the user's distinguished name.
<username-to-dn force="false"> <username-is-dn /> </username-to-dn>
This defines a 1:1 mapping and there is no additional configuration. - username-filter
- The next option is very similar to the simple option described above for the authentication step. A specified attribute is searched for a match against the supplied user name.
<username-to-dn force="true"> <username-filter base-dn="dc=people,dc=harold,dc=example,dc=com" recursive="false" attribute="sn" user-dn-attribute="dn" /> </username-to-dn>The attributes that can be set here are:base-dn: The distinguished name of the context to begin the search.recursive: Whether the search will extend to sub contexts. Defaults tofalse.attribute: The attribute of the users entry to try and match against the supplied user name. Defaults touid.user-dn-attribute: The attribute to read to obtain the users distinguished name. Defaults todn.
- advanced-filter
- The final option is to specify an advanced filter, as in the authentication section this is an opportunity to use a custom filter to locate the users distinguished name.
<username-to-dn force="true"> <advanced-filter base-dn="dc=people,dc=harold,dc=example,dc=com" recursive="false" filter="sAMAccountName={0}" user-dn-attribute="dn" /> </username-to-dn>For the attributes that match those in the username-filter example, the meaning and default values are the same. There is one new attribute:filter: Custom filter used to search for a user's entry where the user name will be substituted in the{0}place holder.
Important
The XML must remain valid after the filter is defined so if any special characters are used such as&ensure the proper form is used. For example&for the&character.
The Group Search
Example 8.13. Principal to Group - LDIF example.
TestUserOne who is a member of GroupOne, GroupOne is in turn a member of GroupFive. The group membership is shown by the use of a memberOf attribute which is set to the distinguished name of the group of which the user (or group) is a member.
memberOf attributes set, one for each group of which the user is directly a member.
dn: uid=TestUserOne,ou=users,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: inetOrgPerson objectClass: uidObject objectClass: person objectClass: organizationalPerson cn: Test User One sn: Test User One uid: TestUserOne distinguishedName: uid=TestUserOne,ou=users,dc=principal-to-group,dc=example,dc=org memberOf: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org memberOf: uid=Slashy/Group,ou=groups,dc=principal-to-group,dc=example,dc=org userPassword:: e1NTSEF9WFpURzhLVjc4WVZBQUJNbEI3Ym96UVAva0RTNlFNWUpLOTdTMUE9PQ== dn: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: group objectClass: uidObject uid: GroupOne distinguishedName: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org memberOf: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org dn: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: group objectClass: uidObject uid: GroupFive distinguishedName: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org
Example 8.14. Group to Principal - LDIF Example
TestUserOne who is a member of GroupOne which is in turn a member of GroupFive - however in this case it is an attribute uniqueMember from the group to the user being used for the cross reference.
dn: uid=TestUserOne,ou=users,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: inetOrgPerson objectClass: uidObject objectClass: person objectClass: organizationalPerson cn: Test User One sn: Test User One uid: TestUserOne userPassword:: e1NTSEF9SjR0OTRDR1ltaHc1VVZQOEJvbXhUYjl1dkFVd1lQTmRLSEdzaWc9PQ== dn: uid=GroupOne,ou=groups,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: groupOfUniqueNames objectClass: uidObject cn: Group One uid: GroupOne uniqueMember: uid=TestUserOne,ou=users,dc=group-to-principal,dc=example,dc=org dn: uid=GroupFive,ou=subgroups,ou=groups,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: groupOfUniqueNames objectClass: uidObject cn: Group Five uid: GroupFive uniqueMember: uid=TestUserFive,ou=users,dc=group-to-principal,dc=example,dc=org uniqueMember: uid=GroupOne,ou=groups,dc=group-to-principal,dc=example,dc=org
General Group Searching
<group-search group-name="..." iterative="..." group-dn-attribute="..." group-name-attribute="..." >
...
</group-search>group-name: This attribute is used to specify the form that should be used for the group name returned as the list of groups of which the user is a member. This can either be the simple form of the group name or the group's distinguished name. If the distinguished name is required this attribute can be set toDISTINGUISHED_NAME. Defaults toSIMPLE.iterative: This attribute is used to indicate if, after identifying the groups a user is a member of, we should also iteratively search based on the groups to identify which groups the groups are a member of. If iterative searching is enabled we keep going until either we reach a group that is not a member if any other groups or a cycle is detected. Defaults tofalse.
Important
group-dn-attribute: On an entry for a group which attribute is its distinguished name. Defaults todn.group-name-attribute: On an entry for a group which attribute is its simple name. Defaults touid.
Example 8.15. Principal to Group Example Configuration
memberOf attribute on the user.
<authorization>
<ldap connection="LocalLdap">
<username-to-dn>
<username-filter base-dn="ou=users,dc=principal-to-group,dc=example,dc=org" recursive="false" attribute="uid" user-dn-attribute="dn" />
</username-to-dn>
<group-search group-name="SIMPLE" iterative="true" group-dn-attribute="dn" group-name-attribute="uid">
<principal-to-group group-attribute="memberOf" />
</group-search>
</ldap>
</authorization>principal-to-group element has been added with a single attribute.
group-attribute: The name of the attribute on the user entry that matches the distinguished name of the group the user is a member of. Defaults tomemberOf.
Example 8.16. Group to Principal Example Configuration
<authorization>
<ldap connection="LocalLdap">
<username-to-dn>
<username-filter base-dn="ou=users,dc=group-to-principal,dc=example,dc=org" recursive="false" attribute="uid" user-dn-attribute="dn" />
</username-to-dn>
<group-search group-name="SIMPLE" iterative="true" group-dn-attribute="dn" group-name-attribute="uid">
<group-to-principal base-dn="ou=groups,dc=group-to-principal,dc=example,dc=org" recursive="true" search-by="DISTINGUISHED_NAME">
<membership-filter principal-attribute="uniqueMember" />
</group-to-principal>
</group-search>
</ldap>
</authorization>group-to-principal is added. This element is used to define how searches for groups that reference the user entry will be performed. The following attributes are set:
base-dn: The distinguished name of the context to use to begin the search.recursive: Whether sub-contexts also be searched. Defaults tofalse.search-by: The form of the role name used in searches. Valid values areSIMPLEandDISTINGUISHED_NAME. Defaults toDISTINGUISHED_NAME.
principal-attribute: The name of the attribute on the group entry that references the user entry. Defaults tomember.
8.7.6. Hot Rod Interface Security
8.7.6.1. Publish Hot Rod Endpoints as a Public Interface
interface parameter in the socket-binding element from management to public as follows:
<socket-binding name="hotrod" interface="public" port="11222" />
8.7.6.2. Encryption of communication between Hot Rod Server and Hot Rod client
Procedure 8.3. Secure Hot Rod Using SSL/TLS
Generate a Keystore
Create a Java Keystore using the keytool application distributed with the JDK and add your certificate to it. The certificate can be either self signed, or obtained from a trusted CA depending on your security policy.Place the Keystore in the Configuration Directory
Put the keystore in the~/JDG_HOME/standalone/configurationdirectory with thestandalone-hotrod-ssl.xmlfile from the~/JDG_HOME/docs/examples/configsdirectory.Declare an SSL Server Identity
Declare an SSL server identity within a security realm in the management section of the configuration file. The SSL server identity must specify the path to a keystore and its secret key.<server-identities> <ssl protocol="..."> <keystore path="..." relative-to="..." keystore-password="${VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::ENCRYPTED_VALUE}" /> </ssl> <secret value="..." /> </server-identities>See Section 8.7.7.4, “Configure Hot Rod Authentication (X.509)” for details about these parameters.Add the Security Element
Add the security element to the Hot Rod connector as follows:<hotrod-connector socket-binding="hotrod" cache-container="local"> <encryption ssl="true" security-realm="ApplicationRealm" require-ssl-client-auth="false" /> </hotrod-connector>Server Authentication of Certificate
If you require the server to perform authentication of the client certificate, create a truststore that contains the valid client certificates and set therequire-ssl-client-authattribute totrue.
Start the Server
Start the server using the following:bin/standalone.sh -c standalone-hotrod-ssl.xml
This will start a server with a Hot Rod endpoint on port 11222. This endpoint will only accept SSL connections.
Example 8.17. Secure Hot Rod Using SSL/TLS
package org.infinispan.client.hotrod.configuration;
import java.util.Arrays;
import javax.net.ssl.KeyManager;
import javax.net.ssl.SSLContext;
import javax.net.ssl.TrustManager;
public class SslConfiguration {
private final boolean enabled;
private final String keyStoreFileName;
private final char[] VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::keyStorePassword;
private final SSLContext sslContext;
private final String trustStoreFileName;
private final char[] VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::trustStorePassword;
SslConfiguration(boolean enabled, String keyStoreFileName, char[] keyStorePassword, SSLContext sslContext, String trustStoreFileName, char[] trustStorePassword) {
this.enabled = enabled;
this.keyStoreFileName = keyStoreFileName;
this.keyStorePassword = VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::keyStorePassword;
this.sslContext = sslContext;
this.trustStoreFileName = trustStoreFileName;
this.trustStorePassword = VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::trustStorePassword;
}
public boolean enabled() {
return enabled;
}
public String keyStoreFileName() {
return keyStoreFileName;
}
public char[] keyStorePassword() {
return keyStorePassword;
}
public SSLContext sslContext() {
return sslContext;
}
public String trustStoreFileName() {
return trustStoreFileName;
}
public char[] trustStorePassword() {
return trustStorePassword;
}
@Override
public String toString() {
return "SslConfiguration [enabled=" + enabled + ", keyStoreFileName="
+ keyStoreFileName + ", sslContext=" + sslContext + ", trustStoreFileName=" + trustStoreFileName + "]";
}
}
Important
8.7.7. User Authentication over Hot Rod Using SASL
PLAINis the least secure mechanism because credentials are transported in plain text format. However, it is also the simplest mechanism to implement. This mechanism can be used in conjunction with encryption (SSL) for additional security.DIGEST-MD5is a mechanism than hashes the credentials before transporting them. As a result, it is more secure than thePLAINmechanism.GSSAPIis a mechanism that uses Kerberos tickets. As a result, it requires a correctly configured Kerberos Domain Controller (for example, Microsoft Active Directory).EXTERNALis a mechanism that obtains the required credentials from the underlying transport (for example, from aX.509client certificate) and therefore requires client certificate encryption to work correctly.
8.7.7.1. Configure Hot Rod Authentication (GSSAPI/Kerberos)
Procedure 8.4. Configure SASL GSSAPI/Kerberos Authentication
Server-side Configuration
The following steps must be configured on the server-side:- Define a Kerberos security login module using the security domain subsystem:
<system-properties> <property name="java.security.krb5.conf" value="/tmp/infinispan/krb5.conf"/> <property name="java.security.krb5.debug" value="true"/> <property name="jboss.security.disable.secdomain.option" value="true"/> </system-properties> <security-domain name="infinispan-server" cache-type="default"> <authentication> <login-module code="Kerberos" flag="required"> <module-option name="debug" value="true"/> <module-option name="storeKey" value="true"/> <module-option name="refreshKrb5Config" value="true"/> <module-option name="useKeyTab" value="true"/> <module-option name="doNotPrompt" value="true"/> <module-option name="keyTab" value="/tmp/infinispan/infinispan.keytab"/> <module-option name="principal" value="HOTROD/localhost@INFINISPAN.ORG"/> </login-module> </authentication> </security-domain> - Configure a Hot Rod connector as follows:
<hotrod-connector socket-binding="hotrod" cache-container="default"> <authentication security-realm="ApplicationRealm"> <sasl server-name="node0" mechanisms="{mechanism_name}" qop="{qop_name}" strength="{value}"> <policy> <no-anonymous value="true" /> </policy> <property name="com.sun.security.sasl.digest.utf8">true</property> </sasl> </authentication> </hotrod-connector>- The
server-nameattribute specifies the name that the server declares to incoming clients. The client configuration must also contain the same server name value. - The
server-context-nameattribute specifies the name of the login context used to retrieve a server subject for certain SASL mechanisms (for example, GSSAPI). - The
mechanismsattribute specifies the authentication mechanism in use. See Section 8.7.7, “User Authentication over Hot Rod Using SASL” for a list of supported mechanisms. - The
qopattribute specifies the SASL quality of protection value for the configuration. Supported values for this attribute areauth(authentication),auth-int(authentication and integrity, meaning that messages are verified against checksums to detect tampering), andauth-conf(authentication, integrity, and confidentiality, meaning that messages are also encrypted). Multiple values can be specified, for example,auth-int auth-conf. The ordering implies preference, so the first value which matches both the client and server's preference is chosen. - The
strengthattribute specifies the SASL cipher strength. Valid values arelow,medium, andhigh. - The
no-anonymouselement within thepolicyelement specifies whether mechanisms that accept anonymous login are permitted. Set this value tofalseto permit andtrueto deny.
Client-side Configuration
The following steps must be configured on the client-side:- Define a login module in a login configuration file (
gss.conf) on the client side:GssExample { com.sun.security.auth.module.Krb5LoginModule required client=TRUE; }; - Set up the following system properties:
java.security.auth.login.config=gss.conf java.security.krb5.conf=/etc/krb5.conf
Note
Thekrb5.conffile is dependent on the environment and must point to the Kerberos Key Distribution Center. - Configure the Hot Rod Client:
public class MyCallbackHandler implements CallbackHandler { final private String username; final private char[] password; final private String realm; public MyCallbackHandler() { } public MyCallbackHandler (String username, String realm, char[] password) { this.username = username; this.password = password; this.realm = realm; } @Override public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException { for (Callback callback : callbacks) { if (callback instanceof NameCallback) { NameCallback nameCallback = (NameCallback) callback; nameCallback.setName(username); } else if (callback instanceof PasswordCallback) { PasswordCallback passwordCallback = (PasswordCallback) callback; passwordCallback.setPassword(password); } else if (callback instanceof AuthorizeCallback) { AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback; authorizeCallback.setAuthorized(authorizeCallback.getAuthenticationID().equals( authorizeCallback.getAuthorizationID())); } else if (callback instanceof RealmCallback) { RealmCallback realmCallback = (RealmCallback) callback; realmCallback.setText(realm); } else { throw new UnsupportedCallbackException(callback); } } }} LoginContext lc = new LoginContext("GssExample", new MyCallbackHandler("krb_user", "krb_password".toCharArray()));lc.login();Subject clientSubject = lc.getSubject(); ConfigurationBuilder clientBuilder = new ConfigurationBuilder();clientBuilder .addServer() .host("127.0.0.1") .port(11222) .socketTimeout(1200000) .security() .authentication() .enable() .serverName("infinispan-server") .saslMechanism("GSSAPI") .clientSubject(clientSubject) .callbackHandler(new MyCallbackHandler());remoteCacheManager = new RemoteCacheManager(clientBuilder.build());RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
8.7.7.2. Configure Hot Rod Authentication (MD5)
Procedure 8.5. Configure Hot Rod Authentication (MD5)
- Set up the Hot Rod Connector configuration by adding the
saslelement to theauthenticationelement (for details on theauthenticationelement, see Section 8.7.4, “Configuring Security Realms Declaratively”) as follows:<hotrod-connector socket-binding="hotrod" cache-container="default"> <authentication security-realm="ApplicationRealm"> <sasl server-name="myhotrodserver" mechanisms="DIGEST-MD5" qop="auth" /> </authentication> </hotrod-connector>- The
server-nameattribute specifies the name that the server declares to incoming clients. The client configuration must also contain the same server name value. - The
mechanismsattribute specifies the authentication mechanism in use. See Section 8.7.7, “User Authentication over Hot Rod Using SASL” for a list of supported mechanisms. - The
qopattribute specifies the SASL quality of production value for the configuration. Supported values for this attribute areauth,auth-int, andauth-conf.
- Connect the client to the configured Hot Rod connector as follows:
public class MyCallbackHandler implements CallbackHandler { final private String username; final private char[] password; final private String realm; public MyCallbackHandler (String username, String realm, char[] password) { this.username = username; this.password = password; this.realm = realm; } @Override public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException { for (Callback callback : callbacks) { if (callback instanceof NameCallback) { NameCallback nameCallback = (NameCallback) callback; nameCallback.setName(username); } else if (callback instanceof PasswordCallback) { PasswordCallback passwordCallback = (PasswordCallback) callback; passwordCallback.setPassword(password); } else if (callback instanceof AuthorizeCallback) { AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback; authorizeCallback.setAuthorized(authorizeCallback.getAuthenticationID().equals( authorizeCallback.getAuthorizationID())); } else if (callback instanceof RealmCallback) { RealmCallback realmCallback = (RealmCallback) callback; realmCallback.setText(realm); } else { throw new UnsupportedCallbackException(callback); } } }} ConfigurationBuilder clientBuilder = new ConfigurationBuilder();clientBuilder .addServer() .host("127.0.0.1") .port(11222) .socketTimeout(1200000) .security() .authentication() .enable() .serverName("myhotrodserver") .saslMechanism("DIGEST-MD5") .callbackHandler(new MyCallbackHandler("myuser", "ApplicationRealm", "qwer1234!".toCharArray()));remoteCacheManager = new RemoteCacheManager(clientBuilder.build());RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
8.7.7.3. Configure Hot Rod Using LDAP/Active Directory
<security-realms> <security-realm name="ApplicationRealm"> <authentication> <ldap connection="ldap_connection" recursive="true" base-dn="cn=users,dc=infinispan,dc=org"> <username-filter attribute="cn" /> </ldap> </authentication> </security-realm> </security-realms> <outbound-connections> <ldap name="ldap_connection" url="ldap://my_ldap_server" search-dn="CN=test,CN=Users,DC=infinispan,DC=org" search-credential="Test_password"/> </outbound-connections>
- The
security-realmelement'snameparameter specifies the security realm to reference to use when establishing the connection. - The
authenticationelement contains the authentication details. - The
ldapelement specifies how LDAP searches are used to authenticate a user. First, a connection to LDAP is established and a search is conducted using the supplied user name to identify the distinguished name of the user. A subsequent connection to the server is established using the password supplied by the user. If the second connection succeeds, the authentication is a success.- The
connectionparameter specifies the name of the connection to use to connect to LDAP. - The (optional)
recursiveparameter specifies whether the filter is executed recursively. The default value for this parameter isfalse. - The
base-dnparameter specifies the distinguished name of the context to use to begin the search from. - The (optional)
user-dnparameter specifies which attribute to read for the user's distinguished name after the user is located. The default value for this parameter isdn.
- The
outbound-connectionselement specifies the name of the connection used to connect to the LDAP. directory. - The
ldapelement specifies the properties of the outgoing LDAP connection.- The
nameparameter specifies the unique name used to reference this connection. - The
urlparameter specifies the URL used to establish the LDAP connection. - The
search-dnparameter specifies the distinguished name of the user to authenticate and to perform the searches. - The
search-credentialparameter specifies the password required to connect to LDAP as thesearch-dn. - The (optional)
initial-context-factoryparameter allows the overriding of the initial context factory. the default value of this parameter iscom.sun.jndi.ldap.LdapCtxFactory.
8.7.7.4. Configure Hot Rod Authentication (X.509)
X.509 certificate can be installed at the node, and be made available to other nodes for authentication purposes for inbound and outbound SSL connections. This is enabled using the <server-identities/> element of a security realm definition, which defines how a server appears to external applications. This element can be used to configure a password to be used when establishing a remote connection, as well as the loading of an X.509 key.
X.509 certificate on the node.
<security-realm name="ApplicationRealm">
<server-identities>
<ssl protocol="...">
<keystore path="..." relative-to="..." keystore-password="..." alias="..." key-password="..." />
</ssl>
</server-identities>
[... authentication/authorization ...]
</security-realms>Table 8.4. <server-identities/> Options
| Parameter | Mandatory/Optional | Description |
|---|---|---|
path | Mandatory | This is the path to the keystore, this can be an absolute path or relative to the next attribute. |
relative-to | Optional | The name of a service representing a path the keystore is relative to. |
keystore-password | Mandatory | The password required to open the keystore. |
alias | Optional | The alias of the entry to use from the keystore - for a keystore with multiple entries in practice the first usable entry is used but this should not be relied on and the alias should be set to guarantee which entry is used. |
key-password | Optional | The password to load the key entry, if omitted the keystore-password will be used instead. |
Note
key-password as well as an alias to ensure only one key is loaded.
UnrecoverableKeyException: Cannot recover key
8.8. Active Directory Authentication (Non-Kerberos)
8.9. Active Directory Authentication Using Kerberos (GSSAPI)
Procedure 8.6. Configure Kerberos Authentication for Active Directory (Library Mode)
- Configure JBoss EAP server to authenticate itself to Kerberos. This can be done by configuring a dedicated security domain, for example:
<security-domain name="ldap-service" cache-type="default"> <authentication> <login-module code="Kerberos" flag="required"> <module-option name="storeKey" value="true"/> <module-option name="useKeyTab" value="true"/> <module-option name="refreshKrb5Config" value="true"/> <module-option name="principal" value="ldap/localhost@INFINISPAN.ORG"/> <module-option name="keyTab" value="${basedir}/keytab/ldap.keytab"/> <module-option name="doNotPrompt" value="true"/> </login-module> </authentication> </security-domain> - The security domain for authentication must be configured correctly for JBoss EAP, an application must have a valid Kerberos ticket. To initiate the Kerberos ticket, you must reference another security domain using
<module-option name="usernamePasswordDomain" value="krb-admin"/>
. This points to the standard Kerberos login module described in Step 3.<security-domain name="ispn-admin" cache-type="default"> <authentication> <login-module code="SPNEGO" flag="requisite"> <module-option name="password-stacking" value="useFirstPass"/> <module-option name="serverSecurityDomain" value="ldap-service"/> <module-option name="usernamePasswordDomain" value="krb-admin"/> </login-module> <login-module code="AdvancedAdLdap" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> <module-option name="bindAuthentication" value="GSSAPI"/> <module-option name="jaasSecurityDomain" value="ldap-service"/> <module-option name="java.naming.provider.url" value="ldap://localhost:389"/> <module-option name="baseCtxDN" value="ou=People,dc=infinispan,dc=org"/> <module-option name="baseFilter" value="(krb5PrincipalName={0})"/> <module-option name="rolesCtxDN" value="ou=Roles,dc=infinispan,dc=org"/> <module-option name="roleFilter" value="(member={1})"/> <module-option name="roleAttributeID" value="cn"/> </login-module> </authentication> </security-domain> - The security domain authentication configuration described in the previous step points to the following standard Kerberos login module:
<security-domain name="krb-admin" cache-type="default"> <authentication> <login-module code="Kerberos" flag="required"> <module-option name="useKeyTab" value="true"/> <module-option name="principal" value="admin@INFINISPAN.ORG"/> <module-option name="keyTab" value="${basedir}/keytab/admin.keytab"/> </login-module> </authentication> </security-domain>
8.10. The Security Audit Logger
org.infinispan.security.impl.DefaultAuditLogger. This logger outputs audit logs using the available logging framework (for example, JBoss Logging) and provides results at the TRACE level and the AUDIT category.
AUDIT category to either a log file, a JMS queue, or a database, use the appropriate log appender.
8.10.1. Configure the Security Audit Logger (Library Mode)
<infinispan> ... <global-security> <authorization audit-logger = "org.infinispan.security.impl.DefaultAuditLogger"> ... </authorization> </global-security> ... </infinispan>
GlobalConfigurationBuilder global = new GlobalConfigurationBuilder();
global.security()
.authorization()
.auditLogger(new DefaultAuditLogger());8.10.2. Configure the Security Audit Logger (Remote Client-Server Mode)
<authorization> element. The <authorization> element must be within the <cache-container> element in the Infinispan subsystem (in the standalone.xml configuration file).
<cache-container name="local" default-cache="default"> <security> <authorization audit-logger="org.infinispan.security.impl.DefaultAuditLogger"> <identity-role-mapper/> <role name="admin" permissions="ALL"/> <role name="reader" permissions="READ"/> <role name="writer" permissions="WRITE"/> <role name="supervisor" permissions="ALL_READ ALL_WRITE"/> </authorization> </security> <local-cache name="default" start="EAGER"> <locking isolation="NONE" acquire-timeout="30000" concurrency-level="1000" striping="false"/> <transaction mode="NONE"/> <security> <authorization roles="admin reader writer supervisor"/> </security> </local-cache>
Note
org.jboss.as.clustering.infinispan.subsystem.ServerAuditLogger which sends the log messages to the server audit log. See the Management Interface Audit Logging chapter in the JBoss Enterprise Application Platform Administration and Configuration Guide for more information.
8.10.3. Custom Audit Loggers
org.infinispan.security.AuditLogger interface. If no custom logger is provided, the default logger (DefaultAuditLogger) is used.
Chapter 9. Security for Cluster Traffic
9.1. Node Authentication and Authorization (Remote Client-Server Mode)
DIGEST-MD5 or GSSAPI mechanisms are currently supported.
Example 9.1. Configure SASL Authentication
<management>
<security-realms>
...
<security-realm name="ClusterRealm">
<authentication>
<properties path="cluster-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="cluster-roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
</security-realms>
...
</security-realms>
</management>
<stack name="udp">
...
<sasl mech="DIGEST-MD5" security-realm="ClusterRealm" cluster-role="cluster">
<property name="client_name">node1</property>
<property name="client_password">password</property>
</sasl>
...
</stack>
DIGEST-MD5 mechanism to authenticate against the ClusterRealm. In order to join, nodes must have the cluster role.
cluster-role attribute determines the role all nodes must belong to in the security realm in order to JOIN or MERGE with the cluster. Unless it has been specified, the cluster-role attribute is the name of the clustered <cache-container> by default. Each node identifies itself using the client-name property. If none is specified, the hostname on which the server is running will be used.
jboss.node.name system property that can be overridden on the command line. For example:
$ clustered.sh -Djboss.node.name=node001
Note
9.1.1. Configure Node Authentication for Cluster Security (DIGEST-MD5)
DIGEST-MD5 with a properties-based security realm, with a dedicated realm for cluster node.
Example 9.2. Using the DIGEST-MD5 Mechanism
<management>
<security-realms>
<security-realm name="ClusterRealm">
<authentication>
<properties path="cluster-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="cluster-roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
</security-realms>
</management>
<subsystem xmlns="urn:infinispa:server:jgroups:6.1" default-stack="${jboss.default.jgroups.stack:udp}">
<stack name="udp">
<transport type="UDP" socket-binding="jgroups-udp"/>
<protocol type="PING"/>
<protocol type="MERGE2"/>
<protocol type="FD_SOCK" socket-binding="jgroups-udp-fd"/>
<protocol type="FD_ALL"/>
<protocol type="pbcast.NAKACK"/>
<protocol type="UNICAST2"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG2"/>
<protocol type="RSVP"/>
<sasl security-realm="ClusterRealm" mech="DIGEST-MD5">
<property name="client_password>...</property>
</sasl>
</stack>
</subsystem>
<subsystem xmlns="urn:infinispan:server:core:6.1" default-cache-container="clustered">
<cache-container name="clustered" default-cache="default">
<transport executor="infinispan-transport" lock-timeout="60000" stack="udp"/>
<!-- various clustered cache definitions here -->
</cache-container>
</subsystem>node001, node002, node003, the cluster-users.properties will contain:
node001=/<node001passwordhash>/node002=/<node002passwordhash>/node003=/<node003passwordhash>/
cluster-roles.properties will contain:
- node001=clustered
- node002=clustered
- node003=clustered
add-users.sh script can be used:
$ add-user.sh -up cluster-users.properties -gp cluster-roles.properties -r ClusterRealm -u node001 -g clustered -p <password>
MD5 password hash of the node must also be placed in the "client_password" property of the <sasl/> element.
<property name="client_password>...</property>
Note
JOINing and MERGEing node's credentials against the realm before letting the node become part of the cluster view.
9.1.2. Configure Node Authentication for Cluster Security (GSSAPI/Kerberos)
GSSAPI mechanism, the client_name is used as the name of a Kerberos-enabled login module defined within the security domain subsystem. For a full procedure on how to do this, see Section 8.7.7.1, “Configure Hot Rod Authentication (GSSAPI/Kerberos)”.
Example 9.3. Using the Kerberos Login Module
<security-domain name="krb-node0" cache-type="default">
<authentication>
<login-module code="Kerberos" flag="required">
<module-option name="storeKey" value="true"/>
<module-option name="useKeyTab" value="true"/>
<module-option name="refreshKrb5Config" value="true"/>
<module-option name="principal" value="jgroups/node0/clustered@INFINISPAN.ORG"/>
<module-option name="keyTab" value="${jboss.server.config.dir}/keytabs/jgroups_node0_clustered.keytab"/>
<module-option name="doNotPrompt" value="true"/>
</login-module>
</authentication>
</security-domain><sasl ...>
<property name="login_module_name">...</property>
</sasl>authentication section of the security realm is ignored, as the nodes will be validated against the Kerberos Domain Controller. The authorization configuration is still required, as the node principal must belong to the required cluster-role.
jgroups/$NODE_NAME/$CACHE_CONTAINER_NAME@REALM
9.2. Configure Node Security in Library Mode
SASL protocol to your JGroups XML configuration.
CallbackHandlers, to obtain certain information necessary for the authentication handshake. Users must supply their own CallbackHandlers on both client and server sides.
Important
JAAS API is only available when configuring user authentication and authorization, and is not available for node security.
Note
CallbackHandler classes are examples only, and not contained in the Red Hat JBoss Data Grid release. Users must provide the appropriate CallbackHandler classes for their specific LDAP implementation.
Example 9.4. Setting Up SASL Authentication in JGroups
<SASL mech="DIGEST-MD5"
client_name="node_user"
client_password="node_password"
server_callback_handler_class="org.example.infinispan.security.JGroupsSaslServerCallbackHandler"
client_callback_handler_class="org.example.infinispan.security.JGroupsSaslClientCallbackHandler"
sasl_props="com.sun.security.sasl.digest.realm=test_realm" />DIGEST-MD5 mechanism. Each node must declare the user and password it will use when joining the cluster.
Important
CallbackHandler class. In this example, login and password are checked against values provided via Java properties when JBoss Data Grid is started, and authorization is checked against role which is defined in the class ("test_user").
Example 9.5. Callback Handler Class
public class SaslPropAuthUserCallbackHandler implements CallbackHandler {
private static final String APPROVED_USER = "test_user";
private final String name;
private final char[] password;
private final String realm;
public SaslPropAuthUserCallbackHandler() {
this.name = System.getProperty("sasl.username");
this.password = System.getProperty("sasl.password").toCharArray();
this.realm = System.getProperty("sasl.realm");
}
@Override
public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException {
for (Callback callback : callbacks) {
if (callback instanceof PasswordCallback) {
((PasswordCallback) callback).setPassword(password);
} else if (callback instanceof NameCallback) {
((NameCallback) callback).setName(name);
} else if (callback instanceof AuthorizeCallback) {
AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback;
if (APPROVED_USER.equals(authorizeCallback.getAuthorizationID())) {
authorizeCallback.setAuthorized(true);
} else {
authorizeCallback.setAuthorized(false);
}
} else if (callback instanceof RealmCallback) {
RealmCallback realmCallback = (RealmCallback) callback;
realmCallback.setText(realm);
} else {
throw new UnsupportedCallbackException(callback);
}
}
}
}
javax.security.auth.callback.NameCallback and javax.security.auth.callback.PasswordCallback callbacks
javax.security.sasl.AuthorizeCallback callback.
9.2.1. Configure Node Authentication for Library Mode (DIGEST-MD5)
CallbackHandlers are required:
- The
server_callback_handler_classis used by the coordinator. - The
client_callback_handler_classis used by other nodes.
CallbackHandlers.
Example 9.6. Callback Handlers
<SASL mech="DIGEST-MD5"
client_name="node_name"
client_password="node_password"
client_callback_handler_class="${CLIENT_CALLBACK_HANDLER_IN_CLASSPATH}"
server_callback_handler_class="${SERVER_CALLBACK_HANDLER_IN_CLASSPATH}"
sasl_props="com.sun.security.sasl.digest.realm=test_realm"
/>9.2.2. Configure Node Authentication for Library Mode (GSSAPI)
login_module_name parameter must be specified instead of callback.
server_name must also be specified, as the client principal is constructed as jgroups/$server_name@REALM.
Example 9.7. Specifying the login module and server on the coordinator node
<SASL mech="GSSAPI"
server_name="node0/clustered"
login_module_name="krb-node0"
server_callback_handler_class="org.infinispan.test.integration.security.utils.SaslPropCallbackHandler" />server_callback_handler_class must be specified for node authorization. This will determine if the authenticated joining node has permission to join the cluster.
Note
jgroups/server_name, therefore the server principal in Kerberos must also be jgroups/server_name. For example, if the server name in Kerberos is jgroups/node1/mycache, then the server name must be node1/mycache.
9.2.3. Node Authorization in Library Mode
SASL protocol in JGroups is concerned only with the authentication process. To implement node authorization, you can do so within the server callback handler by throwing an Exception.
Example 9.8. Implementing Node Authorization
public class AuthorizingServerCallbackHandler implements CallbackHandler {
@Override
public void handle(Callback[] callbacks) throws IOException,
UnsupportedCallbackException {
for (Callback callback : callbacks) {
...
if (callback instanceof AuthorizeCallback) {
AuthorizeCallback acb = (AuthorizeCallback) callback;
if (!"myclusterrole".equals(acb.getAuthenticationID()))) {
throw new SecurityException("Unauthorized node " +user);
}
...
}
}
}9.3. JGroups ENCRYPT
ENCRYPT protocol to provide encryption for cluster traffic.
encrypt_entire_message must be true. ENCRYPT must also be below any protocols with headers that must be encrypted.
ENCRYPT layer is used to encrypt and decrypt communication in JGroups. The JGroups ENCRYPT protocol can be used in two ways:
- Configured with a secretKey in a keystore.
- Configured with algorithms and key sizes.
9.3.1. ENCRYPT Configured with a secretKey in a Key Store
ENCRYPT class can be configured with a secretKey in a keystore so it is usable at any layer in JGroups without requiring a coordinator. This also provides protection against passive monitoring without the complexity of key exchange.
<ENCRYPT key_store_name="defaultStore.keystore" store_password="${VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::ENCRYPTED_VALUE}" alias="myKey"/>
ENCRYPT layer in this manner. The directory containing the keystore file must be on the application classpath.
Note
KeyStoreGenerator java file is included in the demo package that can be used to generate a suitable keystore.
9.3.2. ENCRYPT Using a Key Store
ENCRYPT uses store type JCEKS. To generate a keystore compatible with JCEKS, use the following command line options:
$ keytool -genseckey -alias myKey -keypass changeit -storepass changeit -keyalg Blowfish -keysize 56 -keystore defaultStore.keystore -storetype JCEKS
ENCRYPT can then be configured by adding the following information to the JGroups file used by the application.
<ENCRYPT key_store_name="defaultStore.keystore"
store_password="${VAULT::VAULT_BLOCK::ATTRIBUTE_NAME::ENCRYPTED_VALUE}"
alias="myKey"/>
-D option during start up.
infinispan-embedded.jar, alternatively, you can create your own configuration file. See the Configure JGroups (Library Mode) section in the Red Hat JBoss Data Grid Administration and Configuration Guide for instructions on how to set up JBoss Data Grid to use custom JGroups configurations in library mode.
Note
defaultStore.keystore must be found in the classpath.
9.3.3. ENCRYPT Configured with Algorithms and Key Sizes
- The secret key is generated and distributed by the controller.
- When a view change occurs, a peer requests the secret key by sending a key request with its own public key.
- The controller encrypts the secret key with the public key, and sends it back to the peer.
- The peer then decrypts and installs the key as its own secret key.
ENCRYPT layer must be placed above the GMS protocol in the configuration.
Example 9.9. ENCRYPT Layer
<config ... >
<UDP />
<PING />
<MERGE2 />
<FD />
<VERIFY_SUSPECT />
<ENCRYPT encrypt_entire_message="false"
sym_init="128" sym_algorithm="AES/ECB/PKCS5Padding"
asym_init="512" asym_algorithm="RSA"/>
<pbcast.NAKACK />
<UNICAST />
<pbcast.STABLE />
<FRAG2 />
<pbcast.GMS />
</config>NAKACK and UNICAST protocols will be encrypted.
9.3.4. ENCRYPT Configuration Parameters
ENCRYPT JGroups protocol:
Table 9.1. Configuration Parameters
| Name | Description |
|---|---|
| alias | Alias used for recovering the key. Change the default. |
| asymAlgorithm | Cipher engine transformation for asymmetric algorithm. Default is RSA. |
| asymInit | Initial public/private key length. Default is 512. |
| asymProvider | Cryptographic Service Provider. Default is Bouncy Castle Provider. |
| encrypt_entire_message | |
| id | Give the protocol a different ID if needed so we can have multiple instances of it in the same stack. |
| keyPassword | Password for recovering the key. Change the default. |
| keyStoreName | File on classpath that contains keystore repository. |
| level | Sets the logger level (see javadocs). |
| name | Give the protocol a different name if needed so we can have multiple instances of it in the same stack. |
| stats | Determines whether to collect statistics (and expose them via JMX). Default is true. |
| storePassword | Password used to check the integrity/unlock the keystore. Change the default. It is recommended that passwords are stored using Vault. |
| symAlgorithm | Cipher engine transformation for symmetric algorithm. Default is AES. |
| symInit | Initial key length for matching symmetric algorithm. Default is 128. |
Part III. Advanced Features in Red Hat JBoss Data Grid
- Transactions
- Marshalling
- Listeners and Notifications
- The Infinispan CDI Module
- MapReduce
- Distributed Execution
- Interoperability and Compatibility Mode
Chapter 10. Transactions
10.1. About Java Transaction API
- First, it retrieves the transactions currently associated with the thread.
- If not already done, it registers an
XAResourcewith the transaction manager to receive notifications when a transaction is committed or rolled back.
10.2. Transactions Spanning Multiple Cache Instances
10.3. The Transaction Manager
TransactionManager tm = cache.getAdvancedCache().getTransactionManager();
Example 10.1. Performing Operations
tm.begin();
Object value = cache.get("A");
cache.remove("A");
Object prev = cache.put("B", value);
if (prev == null)
tm.commit();
else
tm.rollback();Note
XAResource xar = cache.getAdvancedCache().getXAResource();
10.4. About JTA Transaction Manager Lookup Classes
TransactionManagerLookup interface. When initialized, the cache creates an instance of the specified class and invokes its getTransactionManager() method to locate and return a reference to the Transaction Manager.
Table 10.1. Transaction Manager Lookup Classes
| Class Name | Details |
|---|---|
| org.infinispan.transaction.lookup.DummyTransactionManagerLookup | Used primarily for testing environments. This testing transaction manager is not for use in a production environment and is severely limited in terms of functionality, specifically for concurrent transactions and recovery. |
| org.infinispan.transaction.lookup.JBossStandaloneJTAManagerLookup | It is a fully functional JBoss Transactions based transaction manager that overcomes the functionality limits of the DummyTransactionManager. |
| org.infinispan.transaction.lookup.GenericTransactionManagerLookup | GenericTransactionManagerLookup is used by default when no transaction lookup class is specified. This lookup class is recommended when using JBoss Data Grid with Java EE-compatible environment that provides a TransactionManager interface, and is capable of locating the Transaction Manager in most Java EE application servers. If no transaction manager is located, it defaults to DummyTransactionManager. |
JBossStandaloneJTAManagerLookup, which uses JBoss Transactions.
Chapter 11. Marshalling
- transform data for relay to other JBoss Data Grid nodes within the cluster.
- transform data to be stored in underlying cache stores.
11.1. About Marshalling Framework
java.io.ObjectOutput and java.io.ObjectInput implementations compared to the standard java.io.ObjectOutputStream and java.io.ObjectInputStream.
11.2. Support for Non-Serializable Objects
Serializable or Externalizable support into your classes, you could (as an example) use XStream to convert the non-serializable objects into a String that can be stored in JBoss Data Grid.
Note
11.3. Hot Rod and Marshalling
- All data stored by clients on the JBoss Data Grid server are provided either as a byte array, or in a primitive format that is marshalling compatible for JBoss Data Grid.On the server side of JBoss Data Grid, marshalling occurs where the data stored in primitive format are converted into byte array and replicated around the cluster or stored to a cache store. No marshalling configuration is required on the server side of JBoss Data Grid.
- At the client level, marshalling must have a
Marshallerconfiguration element specified in the RemoteCacheManager configuration in order to serialize and deserialize POJOs.Due to Hot Rod's binary nature, it relies on marshalling to transform POJOs, specifically keys or values, into byte array.
11.4. Configuring the Marshaller using the RemoteCacheManager
marshaller configuration element in the RemoteCacheManager, the value of which must be the name of the class implementing the Marshaller interface. The default value for this property is org.infinispan.commons.marshall.jboss.GenericJBossMarshaller.
Procedure 11.1. Define a Marshaller
Create a ConfigurationBuilder
Create a ConfigurationBuilder and configure it with the required settings.ConfigurationBuilder builder = new ConfigurationBuilder(); //... (other configuration)
Add a Marshaller Class
Add a Marshaller class specification within the Marshaller method.builder.marshaller(GenericJBossMarshaller.class);
- Alternatively, specify a custom Marshaller instance.
builder.marshaller(new GenericJBossMarshaller());
Start the RemoteCacheManager
Build the configuration containing the Marshaller, and start a new RemoteCacheManager with it.Configuration configuration = builder.build(); RemoteCacheManager manager = new RemoteCacheManager(configuration);
Note
11.5. Troubleshooting
11.5.1. Marshalling Troubleshooting
Example 11.1. Exception Stack Trace
java.io.NotSerializableException: java.lang.Object at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:857) at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407) at org.infinispan.marshall.exts.ReplicableCommandExternalizer.writeObject(ReplicableCommandExternalizer.java:54) at org.infinispan.marshall.jboss.ConstantObjectTable$ExternalizerAdapter.writeObject(ConstantObjectTable.java:267) at org.jboss.marshalling.river.RiverMarshaller.doWriteObject(RiverMarshaller.java:143) at org.jboss.marshalling.AbstractMarshaller.writeObject(AbstractMarshaller.java:407) at org.infinispan.marshall.jboss.JBossMarshaller.objectToObjectStream(JBossMarshaller.java:167) at org.infinispan.marshall.VersionAwareMarshaller.objectToBuffer(VersionAwareMarshaller.java:92) at org.infinispan.marshall.VersionAwareMarshaller.objectToByteBuffer(VersionAwareMarshaller.java:170) at org.infinispan.marshall.VersionAwareMarshallerTest.testNestedNonSerializable(VersionAwareMarshallerTest.java:415) Caused by: an exception which occurred: in object java.lang.Object@b40ec4 in object org.infinispan.commands.write.PutKeyValueCommand@df661da7 ... Removed 22 stack frames
in object and stack traces are read in the same way: the highest in object message is the innermost one and the outermost in object message is the lowest.
java.lang.Object instance within an org.infinispan.commands.write.PutKeyValueCommand instance cannot be serialized because java.lang.Object@b40ec4 is not serializable.
DEBUG or TRACE logging levels are enabled, marshalling exceptions will contain toString() representations of objects in the stack trace. The following is an example that depicts such a scenario:
Example 11.2. Exceptions with Logging Levels Enabled
java.io.NotSerializableException: java.lang.Object
...
Caused by: an exception which occurred:
in object java.lang.Object@b40ec4
-> toString = java.lang.Object@b40ec4
in object org.infinispan.commands.write.PutKeyValueCommand@df661da7
-> toString = PutKeyValueCommand{key=k, value=java.lang.Object@b40ec4, putIfAbsent=false, lifespanMillis=0, maxIdleTimeMillis=0}Example 11.3. Unmarshalling Exceptions
java.io.IOException: Injected failue! at org.infinispan.marshall.VersionAwareMarshallerTest$1.readExternal(VersionAwareMarshallerTest.java:426) at org.jboss.marshalling.river.RiverUnmarshaller.doReadNewObject(RiverUnmarshaller.java:1172) at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:273) at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:210) at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85) at org.infinispan.marshall.jboss.JBossMarshaller.objectFromObjectStream(JBossMarshaller.java:210) at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:104) at org.infinispan.marshall.VersionAwareMarshaller.objectFromByteBuffer(VersionAwareMarshaller.java:177) at org.infinispan.marshall.VersionAwareMarshallerTest.testErrorUnmarshalling(VersionAwareMarshallerTest.java:431) Caused by: an exception which occurred: in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1
IOException was thrown when an instance of the inner class org.infinispan.marshall.VersionAwareMarshallerTest$1 is unmarshalled.
DEBUG or TRACE logging levels are enabled, the class type's classloader information is provided. An example of this classloader information is as follows:
Example 11.4. Classloader Information
java.io.IOException: Injected failue! ... Caused by: an exception which occurred: in object of type org.infinispan.marshall.VersionAwareMarshallerTest$1 -> classloader hierarchy: -> type classloader = sun.misc.Launcher$AppClassLoader@198dfaf ->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/eclipse-testng.jar ->...file:/opt/eclipse/configuration/org.eclipse.osgi/bundles/285/1/.cp/lib/testng-jdk15.jar ->...file:/home/galder/jboss/infinispan/code/trunk/core/target/test-classes/ ->...file:/home/galder/jboss/infinispan/code/trunk/core/target/classes/ ->...file:/home/galder/.m2/repository/org/testng/testng/5.9/testng-5.9-jdk15.jar ->...file:/home/galder/.m2/repository/net/jcip/jcip-annotations/1.0/jcip-annotations-1.0.jar ->...file:/home/galder/.m2/repository/org/easymock/easymockclassextension/2.4/easymockclassextension-2.4.jar ->...file:/home/galder/.m2/repository/org/easymock/easymock/2.4/easymock-2.4.jar ->...file:/home/galder/.m2/repository/cglib/cglib-nodep/2.1_3/cglib-nodep-2.1_3.jar ->...file:/home/galder/.m2/repository/javax/xml/bind/jaxb-api/2.1/jaxb-api-2.1.jar ->...file:/home/galder/.m2/repository/javax/xml/stream/stax-api/1.0-2/stax-api-1.0-2.jar ->...file:/home/galder/.m2/repository/javax/activation/activation/1.1/activation-1.1.jar ->...file:/home/galder/.m2/repository/jgroups/jgroups/2.8.0.CR1/jgroups-2.8.0.CR1.jar ->...file:/home/galder/.m2/repository/org/jboss/javaee/jboss-transaction-api/1.0.1.GA/jboss-transaction-api-1.0.1.GA.jar ->...file:/home/galder/.m2/repository/org/jboss/marshalling/river/1.2.0.CR4-SNAPSHOT/river-1.2.0.CR4-SNAPSHOT.jar ->...file:/home/galder/.m2/repository/org/jboss/marshalling/marshalling-api/1.2.0.CR4-SNAPSHOT/marshalling-api-1.2.0.CR4-SNAPSHOT.jar ->...file:/home/galder/.m2/repository/org/jboss/jboss-common-core/2.2.14.GA/jboss-common-core-2.2.14.GA.jar ->...file:/home/galder/.m2/repository/org/jboss/logging/jboss-logging-spi/2.0.5.GA/jboss-logging-spi-2.0.5.GA.jar ->...file:/home/galder/.m2/repository/log4j/log4j/1.2.14/log4j-1.2.14.jar ->...file:/home/galder/.m2/repository/com/thoughtworks/xstream/xstream/1.2/xstream-1.2.jar ->...file:/home/galder/.m2/repository/xpp3/xpp3_min/1.1.3.4.O/xpp3_min-1.1.3.4.O.jar ->...file:/home/galder/.m2/repository/com/sun/xml/bind/jaxb-impl/2.1.3/jaxb-impl-2.1.3.jar -> parent classloader = sun.misc.Launcher$ExtClassLoader@1858610 ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/localedata.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunpkcs11.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/sunjce_provider.jar ->...file:/usr/java/jdk1.5.0_19/jre/lib/ext/dnsns.jar ... Removed 22 stack frames
11.5.2. Other Marshalling Related Issues
EOFException. During a state transfer, if an EOFException is logged that states that the state receiver has Read past end of file, this can be dealt with depending on whether the state provider encounters an error when generating the state. For example, if the state provider is currently providing a state to a node, when another node requests a state, the state generator log can contain:
Example 11.5. State Generator Log
2010-12-09 10:26:21,533 20267 ERROR [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (STREAMING_STATE_TRANSFER-sender-1,Infinispan-Cluster,NodeJ-2368:) Caught while responding to state transfer request
org.infinispan.statetransfer.StateTransferException: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:175)
at org.infinispan.remoting.InboundInvocationHandlerImpl.generateState(InboundInvocationHandlerImpl.java:119)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.getState(JGroupsTransport.java:586)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.handleUpEvent(MessageDispatcher.java:691)
at org.jgroups.blocks.MessageDispatcher$ProtocolAdapter.up(MessageDispatcher.java:772)
at org.jgroups.JChannel.up(JChannel.java:1465)
at org.jgroups.stack.ProtocolStack.up(ProtocolStack.java:954)
at org.jgroups.protocols.pbcast.FLUSH.up(FLUSH.java:478)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderHandler.process(STREAMING_STATE_TRANSFER.java:653)
at org.jgroups.protocols.pbcast.STREAMING_STATE_TRANSFER$StateProviderThreadSpawner$1.run(STREAMING_STATE_TRANSFER.java:582)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:680)
Caused by: java.util.concurrent.TimeoutException: Could not obtain exclusive processing lock
at org.infinispan.remoting.transport.jgroups.JGroupsDistSync.acquireProcessingLock(JGroupsDistSync.java:71)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateTransactionLog(StateTransferManagerImpl.java:202)
at org.infinispan.statetransfer.StateTransferManagerImpl.generateState(StateTransferManagerImpl.java:165)
... 12 more
EOFException, displayed as follows, when failing to read the transaction log that was not written by the sender:
Example 11.6. EOFException
2010-12-09 10:26:21,535 20269 TRACE [org.infinispan.marshall.VersionAwareMarshaller] (Incoming-2,Infinispan-Cluster,NodeI-38030:) Log exception reported
java.io.EOFException: Read past end of file
at org.jboss.marshalling.AbstractUnmarshaller.eofOnRead(AbstractUnmarshaller.java:184)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByteDirect(AbstractUnmarshaller.java:319)
at org.jboss.marshalling.AbstractUnmarshaller.readUnsignedByte(AbstractUnmarshaller.java:280)
at org.jboss.marshalling.river.RiverUnmarshaller.doReadObject(RiverUnmarshaller.java:207)
at org.jboss.marshalling.AbstractUnmarshaller.readObject(AbstractUnmarshaller.java:85)
at org.infinispan.marshall.jboss.GenericJBossMarshaller.objectFromObjectStream(GenericJBossMarshaller.java:175)
at org.infinispan.marshall.VersionAwareMarshaller.objectFromObjectStream(VersionAwareMarshaller.java:184)
at org.infinispan.statetransfer.StateTransferManagerImpl.processCommitLog(StateTransferManagerImpl.java:228)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyTransactionLog(StateTransferManagerImpl.java:250)
at org.infinispan.statetransfer.StateTransferManagerImpl.applyState(StateTransferManagerImpl.java:320)
at org.infinispan.remoting.InboundInvocationHandlerImpl.applyState(InboundInvocationHandlerImpl.java:102)
at org.infinispan.remoting.transport.jgroups.JGroupsTransport.setState(JGroupsTransport.java:603)
...
Chapter 12. Listeners and Notifications
12.1. The Notification/Listener API
12.2. Listener Notifications
@Listener. A Listenable is an interface that denotes that the implementation can have listeners attached to it. Each listener is registered using methods defined in the Listenable.
12.2.1. About Cache-level Notifications
12.2.2. Cache Manager-level Notifications
- Nodes joining or leaving a cluster;
- The starting and stopping of caches
12.2.3. About Synchronous and Asynchronous Notifications
@Listener (sync = false)
public class MyAsyncListener { .... }<asyncListenerExecutor/> element in the configuration file to tune the thread pool that is used to dispatch asynchronous notifications.
12.3. Modifying Cache Entries
12.3.1. Cache Entry Modified Listener Configuration
getValue() method's behavior is specific to whether the callback is triggered before or after the actual operation has been performed. For example, if event.isPre() is true, then event.getValue() would return the old value, prior to modification. If event.isPre() is false, then event.getValue() would return new value. If the event is creating and inserting a new entry, the old value would be null. For more information about isPre(), see the Red Hat JBoss Data Grid API Documentation's listing for the org.infinispan.notifications.cachelistener.event package.
12.3.2. Listener Example
Example 12.1. Configuring a Listener
@Listener
public class PrintWhenAdded {
@CacheEntryCreated
public void print(CacheEntryCreatedEvent event) {
System.out.println("New entry " + event.getKey() + " created in the cache");
}
}12.3.3. Cache Entry Modified Listener Example
Example 12.2. Modified Listener
@Listener
public class PrintWhenModified {
@CacheEntryModified
public void print(CacheEntryModifiedEvent event) {
System.out.println("Cache entry modified. Details = " + event");
}
}12.4. NotifyingFutures
Futures, but a sub-interface known as a NotifyingFuture. Unlike a JDK Future, a listener can be attached to a NotifyingFuture to notify the user about a completed future.
Note
NotifyingFutures are only available in JBoss Data Grid Library mode.
12.4.1. NotifyingFutures Example
NotifyingFutures in Red Hat JBoss Data Grid:
Example 12.3. Configuring NotifyingFutures
FutureListener futureListener = new FutureListener() {
public void futureDone(Future future) {
try {
future.get();
} catch (Exception e) {
// Future did not complete successfully
System.out.println("Help!");
}
}
};
cache.putAsync("key", "value").attachListener(futureListener);Chapter 13. The Infinispan CDI Module
infinispan-cdi module. The infinispan-cdi module offers:
- Configuration and injection using the Cache API.
- A bridge between the cache listeners and the CDI event system.
- Partial support for the JCACHE caching annotations.
13.1. Using Infinispan CDI
13.1.1. Infinispan CDI Prerequisites
- Ensure that the most recent version of the infinispan-cdi module is used.
- Ensure that the correct dependency information is set.
13.1.2. Set the CDI Maven Dependency
pom.xml file in your maven project:
<dependencies>
...
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-cdi</artifactId>
<version>${infinispan.version}</version>
</dependency>
...
</dependencies>infinispan-cdi jar file is available at modules/infinispan-cdi in the ZIP distribution.
13.2. Using the Infinispan CDI Module
- To configure and inject Infinispan caches into CDI Beans and Java EE components.
- To configure cache managers.
- To control storage and retrieval using CDI annotations.
13.2.1. Configure and Inject Infinispan Caches
13.2.1.1. Inject an Infinispan Cache
public class MyCDIBean {
@Inject
Cache<String, String> cache;
}13.2.1.2. Inject a Remote Infinispan Cache
public class MyCDIBean {
@Inject
RemoteCache<String, String> remoteCache;
}13.2.1.3. Set the Injection's Target Cache
- Create a qualifier annotation.
- Add a producer class.
- Inject the desired class.
13.2.1.3.1. Create a Qualifier Annotation
Example 13.1. Custom Cache Qualifier
@javax.inject.Qualifier
@Target({ElementType.FIELD, ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SmallCache {}@SmallCache qualifier to specify how to create specific caches.
13.2.1.3.2. Add a Producer Class
@SmallCache qualifier (created in the previous step) specifies a way to create a cache:
Example 13.2. Using the @SmallCache Qualifier
import org.infinispan.configuration.cache.Configuration;
import org.infinispan.configuration.cache.ConfigurationBuilder;
import org.infinispan.cdi.ConfigureCache;
import javax.enterprise.inject.Proces;
public class CacheCreator {
@ConfigureCache("smallcache")
@SmallCache
@Produces
public Configuration specialCacheCfg() {
return new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(10)
.build();
}
}@ConfigureCachespecifies the name of the cache.@SmallCacheis the cache qualifier.
13.2.1.3.3. Inject the Desired Class
@SmallCache qualifier and the new producer class to inject a specific cache into the CDI bean as follows:
public class MyCDIBean {
@Inject @SmallCache
Cache<String, String> mySmallCache;
}13.2.2. Configure Cache Managers with CDI
13.2.2.1. Specify the Default Configuration
Example 13.3. Specifying the Default Configuration
public class Config {
@Produces
public Configuration defaultEmbeddedConfiguration () {
return new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(100)
.build();
}
}Note
@Default qualifier if no other qualifiers are provided.
@Produces annotation is placed in a method that returns a Configuration instance, the method is invoked when a Configuration object is required.
13.2.2.2. Override the Creation of the Embedded Cache Manager
After a producer method is annotated, this method will be called when creating an EmbeddedCacheManager, as follows:
Example 13.4. Create a Non Clustered Cache
public class Config {
@Produces
@ApplicationScoped
public EmbeddedCacheManager defaultEmbeddedCacheManager() {
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(cfg);
}
}@ApplicationScoped annotation specifies that the method is only called once.
The following configuration can be used to create an EmbeddedCacheManager that can create clustered caches.
Example 13.5. Create Clustered Caches
public class Config {
@Produces
@ApplicationScoped
public EmbeddedCacheManager defaultClusteredCacheManager() {
GlobalConfiguration g = new GlobalConfigurationBuilder()
.clusteredDefault()
.transport()
.clusterName("InfinispanCluster")
.build();
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(g, cfg);
}
}
The method annotated with @Produces in the non clustered method generates Configuration objects. The methods in the clustered cache example annonated with @Produces generate EmbeddedCacheManager objects.
EmbeddedCacheManager and injects it into the code at runtime.
Example 13.6. Generate an EmbeddedCacheManager
... @Inject EmbeddedCacheManager cacheManager; ...
13.2.2.3. Configure a Remote Cache Manager
RemoteCacheManager is configured in a manner similar to EmbeddedCacheManagers, as follows:
Example 13.7. Configuring the Remote Cache Manager
public class Config {
@Produces
@ApplicationScoped
public RemoteCacheManager defaultRemoteCacheManager() {
Configuration conf = new ConfigurationBuilder().addServer().host(ADDRESS).port(PORT).build();
return new RemoteCacheManager(conf);
}
}}13.2.2.4. Configure Multiple Cache Managers with a Single Class
Example 13.8. Configure Multiple Cache Managers
public class Config {
@Produces
@ApplicationScoped
public org.infinispan.manager.EmbeddedCacheManager
defaultEmbeddedCacheManager() {
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(cfg);
}
@Produces
@ApplicationScoped
@DefaultClustered
public org.infinispan.manager.EmbeddedCacheManager
defaultClusteredCacheManager() {
GlobalConfiguration g = new GlobalConfigurationBuilder()
.clusteredDefault()
.transport()
.clusterName("InfinispanCluster")
.build();
Configuration cfg = new ConfigurationBuilder()
.eviction()
.strategy(EvictionStrategy.LRU)
.maxEntries(150)
.build();
return new DefaultCacheManager(g, cfg);
}
@Produces
@ApplicationScoped
@DefaultRemote
public RemoteCacheManager
defaultRemoteCacheManager() {
org.infinispan.client.hotrod.configuration.Configuration conf = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder().addServer().host(ADDRESS).port(PORT).build();
return new RemoteCacheManager(conf);
}
@Produces
@ApplicationScoped
@RemoteCacheInDifferentDataCentre
public RemoteCacheManager newRemoteCacheManager() {
org.infinispan.client.hotrod.configuration.Configuration confid = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder().addServer().host(ADDRESS_FAR_AWAY).port(PORT).build();
return new RemoteCacheManager(confid);
}
}13.2.3. Storage and Retrieval Using CDI Annotations
13.2.3.1. Configure Cache Annotations
javax.cache package.
13.2.3.2. Enable Cache Annotations
beans.xml file. Adding the following code adds interceptors such as the CacheResultInterceptor, CachePutInterceptor, CacheRemoveEntryInterceptor and the CacheRemoveAllInterceptor:
Example 13.9. Adding Interceptors
<beans xmlns="http://java.sun.som/xml/ns/javaee"
xmlns:xsi="http://www/w3/org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd" >
<interceptors>
<class>
org.infinispan.cdi.interceptor.CacheResultInterceptor
</class>
<class>
org.infinispan.cdi.interceptor.CachePutInterceptor
</class>
<class>
org.infinispan.cdi.interceptor.CacheRemoveEntryInterceptor
</class>
<class>
org.infinispan.cdi.interceptor.CacheRemoveAllInterceptor
</class>
</interceptors>
</beans>Note
beans.xml file for Red Hat JBoss Data Grid to use javax.cache annotations.
13.2.3.3. Caching the Result of a Method Invocation
public String toCelsiusFormatted(float fahrenheit) {
return
NumberFormat.getInstance()
.format((fahrenheit * 5 / 9) - 32)
+ " degrees Celsius";
}toCelsiusFormatted method again and stores the result in the cache.
float f = getTemperatureInFahrenheit();
Cache<Float, String>
fahrenheitToCelsiusCache = getCache();
String celsius =
fahrenheitToCelsiusCache = get(f);
if (celsius == null) {
celsius = toCelsiusFormatted(f);
fahrenheitToCelsiusCache.put(f, celsius);
}@CacheResult annotation instead, as follows:
@javax.cache.interceptor.CacheResult
public String toCelsiusFormatted(float fahrenheit) {
return NumberFormat.getInstance()
.format((fahrenheit * 5 / 9) - 32)
+ " degrees Celsius";
}toCelsiusFormatted() method call.
Note
13.2.3.3.1. Specify the Cache Used
cacheName) to the @CacheResult annotation to specify the cache to check for results of the method call:
@CacheResult(cacheName = "mySpecialCache")
public String doSomething(String parameter) {
...
}13.2.3.3.2. Cache Keys for Cached Results
@CacheResult annotation creates a key for the results fetched from a cache. The key consists of a combination of all parameters in the relevant method.
@CacheKey annotation as follows:
Example 13.10. Create a Custom Key
@CacheResult
public String doSomething
(@CacheKey String p1,
@CacheKey String p2,
String dontCare) {
...
}p1 and p2 are used to create the cache key. The value of dontCare is not used when determining the cache key.
13.2.3.3.3. Generate a Custom Key
import javax.cache.annotation.CacheKey;
import javax.cache.annotation.CacheKeyGenerator;
import javax.cache.annotation.CacheKeyInvocationContext;
import java.lang.annotation.Annotation;
public class MyCacheKeyGenerator implements CacheKeyGenerator {
@Override
public CacheKey generateCacheKey(CacheKeyInvocationContext<? extends Annotation> ctx) {
return new MyCacheKey(
ctx.getAllParameters()[0].getValue()
);
}
}cacheKeyGenerator to the @CacheResult annotation as follows:
@CacheResult(cacheKeyGenerator = MyCacheKeyGenerator.class)
public void doSomething(String p1, String p2) {
...
}p1 contains the custom key.
13.2.4. Cache Operations
13.2.4.1. Update a Cache Entry
@CachePut annotation is invoked, a parameter (normally passed to the method annotated with @CacheValue) is stored in the cache.
Example 13.11. Sample @CachePut Annotated Method
import javax.cache.annotation.CachePut
@CachePut (cacheName = "personCache")
public void updatePerson
(@CacheKey long personId,
@CacheValue Person newPerson) {
...
}cacheName and cacheKeyGenerator in the @CachePut method. Additionally, some parameters in the invoked method may be annotated with @CacheKey to control key generation.
13.2.4.2. Remove an Entry from the Cache
@CacheRemoveEntry annotated method that is used to remove an entry from the cache:
Example 13.12. Removing an Entry from the Cache
import javax.cache.annotation.CacheRemoveEntry
@CacheRemoveEntry (cacheName = "cacheOfPeople")
public void changePersonName
(@CacheKey long personId,
string newName {
...
}cacheName and cacheKeyGenerator attributes.
13.2.4.3. Clear the Cache
@CacheRemoveAll method to clear all entries from the cache.
Example 13.13. Clear All Entries from the Cache with @CacheRemoveAll
import javax.cache.annotation.CacheResult
@CacheRemoveAll (cacheName = "statisticsCache")
public void resetStatistics() {
...
}cacheName attribute.
Chapter 14. MapReduce
- The user initiates a task on a cache instance, which runs on a cluster node (the master node).
- The master node receives the task input, divides the task, and sends tasks for map phase execution on the grid.
- Each node executes a
Mapperfunction on its input, and returns intermediate results back to the master node.- If the
useIntermediateSharedCacheparameter is set to"true", the map results are inserted in an intermediary cache, rather than being returned to the master node. - If a
Combinerhas been specified withtask.combinedWith(combiner), theCombineris called on theMapperresults and the combiner's results are returned to the master node or inserted in the intermediary cache.Note
Combiners are not required but can only be used when the function is both commutative (changing the order of the operands does not change the results) and associative (the order in which the operations are performed does not matter as long as the sequence of the operands is not changed). Combiners are advantageous to use because they can improve the speeds of MapReduceTask executions.
- The master node collects all intermediate results from the map phase and merges all intermediate values associated with the same intermediate key.
- If the
distributedReducePhaseparameter is set totrue, the merging of the intermediate values is done on each node, as theMapperorCombinerresults are inserted in the intermediary cache.The master node only receives the intermediate keys.
- The master node sends intermediate key/value pairs for reduction on the grid.
- If the
distributedReducePhaseparameter is set to"false", the reduction phase is executed only on the master node.
- The final results of the reduction phase are returned. Optionally specify the target cache for the results using the instructions in Section 14.1.2, “Specify the Target Cache”.
- If the
distributedReducePhaseparameter is set to"true", the master node running the task receives all results from the reduction phase and returns the final result to the MapReduce task initiator. - If no target cache is specified and no collator is specified (using
task.execute(Collator)), the result map is returned to the master node.
14.1. The MapReduce API
MapperReducerCollatorMapReduceTaskCombiners
Mapper class implementation is a component of MapReduceTask, which is invoked once per input cache entry key/value pair. Map is a process of applying a given function to each element of a list, returning a list of results.
Mapper on a given cache entry key/value input pair. It then transforms this cache entry key/value pair into an intermediate key/value pair, which is emitted into the provided Collector instance.
Note
Example 14.1. Executing the Mapper
public interface Mapper<KIn, VIn, KOut, VOut> extends Serializable {
/**
* Invoked once for each input cache entry KIn,VOut pair.
*/
void map(KIn key, VIn value, Collector<KOut, VOut> collector);Reducer. JBoss Data Grid's distributed execution environment creates one instance of Reducer per execution node.
Example 14.2. Reducer
public interface Reducer<KOut, VOut> extends Serializable {
/**
* Combines/reduces all intermediate values for a particular intermediate key to a single value.
* <p>
*
*/
VOut reduce(KOut reducedKey, Iterator<VOut> iter);
}Reducer interface is used for Combiners. A Combiner is similar to a Reducer, except that it must be able to work on partial results. The Combiner is executed on the results of the Mapper, on the same node, without considering the other nodes that might have generated values for the same intermediate key.
Note
Combiners only see a part of the intermediate values, they cannot be used in all scenarios, however when used they can reduce network traffic and memory consumption in the intermediate cache significantly.
Collator coordinates results from Reducers that have been executed on JBoss Data Grid, and assembles a final result that is delivered to the initiator of the MapReduceTask. The Collator is applied to the final map key/value result of MapReduceTask.
Example 14.3. Assembling the Result
public interface Collator<KOut, VOut, R> {
/**
* Collates all reduced results and returns R to invoker of distributed task.
*
* @return final result of distributed task computation
*/
R collate(Map<KOut, VOut> reducedResults);14.1.1. MapReduceTask
MapReduceTask is a distributed task, which unifies the Mapper, Combiner, Reducer, and Collator components into a cohesive computation, which can be parallelized and executed across a large-scale cluster.
Example 14.4. Specifying MapReduceTask Components
new MapReduceTask(cache)
.mappedWith(new MyMapper())
.combinedWith(new MyCombiner())
.reducedWith(new MyReducer())
.execute(new MyCollator());MapReduceTask requires a cache containing data that will be used as input for the task. The JBoss Data Grid execution environment will instantiate and migrate instances of provided Mappers and Reducers seamlessly across the nodes.
onKeys method as an input key filter.
MapReduceTask constructor parameters that determine how the intermediate values are processed:
distributedReducePhase- When set tofalse, the default setting, the reducers are only executed on the master node. If set totrue, the reducers are executed on every node in the cluster.useIntermediateSharedCache- Only important ifdistributedReducePhaseis set totrue. Iftrue, which is the default setting, this task will share intermediate value cache with other executing MapReduceTasks on the grid. If set tofalse, this task will use its own dedicated cache for intermediate values.
Note
MapReduceTask is 0 (zero). That is, the task will wait indefinitely for its completion by default.
14.1.2. Specify the Target Cache
public void execute(Cache<KOut, VOut> resultsCache) throws CacheException
public void execute(String resultsCache) throws CacheException
14.1.3. Mapper and CDI
Mapper is invoked with appropriate input key/value pairs on an executing node, however Red Hat JBoss Data Grid also provides a CDI injection for an input cache. The CDI injection can be used where additional data from the input cache is required in order to complete map transformation.
Mapper is executed on a JBoss Data Grid executing node, the JBoss Data Grid CDI module provides an appropriate cache reference, which is injected to the executing Mapper. To use the JBoss Data Grid CDI module with Mapper:
- Declare a cache field in
Mapper. - Annotate the cache field
Mapperwith@org.infinispan.cdi.Input. - Annotate with mandatory
@Inject annotation.
Example 14.5. Using a CDI Injection
public class WordCountCacheInjecterMapper implements Mapper<String, String, String, Integer> {
@Inject
@Input
private Cache<String, String> cache;
@Override
public void map(String key, String value, Collector<String, Integer> collector) {
//use injected cache if needed
StringTokenizer tokens = new StringTokenizer(value);
while (tokens.hasMoreElements()) {
for(String token : value.split("\\w")) {
collector.emit(token, 1);
}
}
}
}14.2. MapReduceTask Distributed Execution
Mapper and Reducer seamlessly across JBoss Data Grid nodes.
- Mapping phase.
- Outgoing Key and Outgoing Value Migration.
- Reduce phase.
- Map Phase
- MapReduceTask hashes task input keys and groups them by the execution node that they are hashed to. After key node mapping, MapReduceTask sends a map function and inputs keys to each node. The map function is invoked using given keys and locally loaded corresponding values.Results are collected with a Red Hat JBoss Data Grid supplied Collector, and the combine phase is initiated. A Combiner, if specified, takes KOut keys and immediately invokes the reduce phase on keys. The result of mapping phase executed on each node is KOut/VOut map. There is one resulting map per execution node per launched MapReduceTask.
Figure 14.1. Map Phase
- Intermediate KOut/VOut migration phase
- In order to proceed with reduce phase, all intermediate keys and values must be grouped by intermediate KOut keys. As map phases around the cluster can produce identical intermediate keys, all identical intermediate keys and their values must be grouped before reduce is executed on any particular intermediate key.At the end of the combine phase, each intermediate KOut key is hashed and migrated with its VOut values to the JBoss Data Grid node where keys KOut are hashed to. This is achieved using a temporary distributed cache and underlying consistent hashing mechanism.
Figure 14.2. Kout/VOut Migration
Once Map and Combine phase have finished execution, a list of KOut keys is returned to a master node and it is initiating MapReduceTask. VOut values are not returned as they are not required at the master task node. MapReduceTask is ready to start with reduce phase. - Reduce Phase
- To complete reduce phase, MapReduceTask groups KOut keys by execution node N they are hashed to. For each node and its grouped input KOut keys, MapReduceTask sends a reduce command to a node where KOut keys are hashed. Once the reduce command is executed on the target execution node, it locates the temporary cache belonging to MapReduce task. For each KOut key, the reduce command obtains a list of VOut values, wraps it with an Iterator, and invokes reduce on it.
Figure 14.3. Reduce Phase
The result of each reduce is a map where each key is KOut and value is VOut. Each JBoss Data Grid execution node returns one map with KOut/VOut result values. As all initiated reduce commands return to a calling node, MapReduceTask combines all resulting maps into a map and returns the map as a result of MapReduceTask.Distributed reduce phase is enabled by using a MapReduceTask constructor specifying the cache to use as input data for the task and boolean parameterdistributeReducePhaseset totrue. For more information, see the Map/Reduce section of the Red Hat JBoss Data Grid API Documentation.
14.3. Map Reduce Example
- Key is a String.
- Each sentence is a String.
Example 14.6. Implementing the Distributed Task
public class WordCountExample {
/**
* In this example replace c1 and c2 with
* real Cache references
*
* @param args
*/
public static void main(String[] args) {
Cache c1 = null;
Cache c2 = null;
c1.put("1", "Hello world here I am");
c2.put("2", "Infinispan rules the world");
c1.put("3", "JUDCon is in Boston");
c2.put("4", "JBoss World is in Boston as well");
c1.put("12","WildFly");
c2.put("15", "Hello world");
c1.put("14", "Infinispan community");
c2.put("15", "Hello world");
c1.put("111", "Infinispan open source");
c2.put("112", "Boston is close to Toronto");
c1.put("113", "Toronto is a capital of Ontario");
c2.put("114", "JUDCon is cool");
c1.put("211", "JBoss World is awesome");
c2.put("212", "JBoss rules");
c1.put("213", "JBoss division of RedHat ");
c2.put("214", "RedHat community");
MapReduceTask<String, String, String, Integer> t =
new MapReduceTask<String, String, String, Integer>(c1);
t.mappedWith(new WordCountMapper())
.reducedWith(new WordCountReducer());
Map<String, Integer> wordCountMap = t.execute();
}
static class WordCountMapper implements Mapper<String,String,String,Integer> {
/** The serialVersionUID */
private static final long serialVersionUID = -5943370243108735560L;
@Override
public void map(String key, String value, Collector<String, Integer> collector) {
StringTokenizer tokens = new StringTokenizer(value);
for(String token : value.split("\\w")) {
collector.emit(token, 1);
}
}
}
static class WordCountReducer implements Reducer<String, Integer> {
/** The serialVersionUID */
private static final long serialVersionUID = 1901016598354633256L;
@Override
public Integer reduce(String key, Iterator<Integer> iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
sum += i;
}
return sum;
}
}
}Collator is defined, which will transform the result of MapReduceTask Map<KOut,VOut> into a String that is returned to a task invoker. The Collator is a transformation function applied to a final result of MapReduceTask.
Example 14.7. Defining the Collator
MapReduceTask<String, String, String, Integer> t = new MapReduceTask<String, String, String, Integer>(cache);
t.mappedWith(new WordCountMapper()).reducedWith(new WordCountReducer());
String mostFrequentWord = t.execute(
new Collator<String,Integer,String>() {
@Override
public String collate(Map<String, Integer> reducedResults) {
String mostFrequent = "";
int maxCount = 0;
for (Entry<String, Integer> e : reducedResults.entrySet()) {
Integer count = e.getValue();
if(count > maxCount) {
maxCount = count;
mostFrequent = e.getKey();
}
}
return mostFrequent;
}
});
System.out.println("The most frequent word is " + mostFrequentWord);Chapter 15. Distributed Execution
ExecutorService interface. Tasks submitted for execution are executed on an entire cluster of JBoss Data Grid nodes, rather than being executed in a local JVM.
- Each
DistributedExecutorServiceis bound to a single cache. Tasks submitted have access to key/value pairs from that particular cache if the task submitted is an instance ofDistributedCallable. - Every
Callable,Runnable, and/orDistributedCallablesubmitted must be eitherSerializableorExternalizable, in order to prevent task migration to other nodes each time one of these tasks is performed. The value returned from aCallablemust also beSerializableorExternalizable.
15.1. DistributedCallable API
DistributedCallable interface is a subtype of the existing Callable from java.util.concurrent.package, and can be executed in a remote JVM and receive input from Red Hat JBoss Data Grid. The DistributedCallable interface is used to facilitate tasks that require access to JBoss Data Grid cache data.
DistributedCallable API to execute a task, the task's main algorithm remains unchanged, however the input source is changed.
Callable interface to describe task units must extend DistributedCallable and use keys from JBoss Data Grid execution environment as input for the task.
Example 15.1. Using the DistributedCallable API
public interface DistributedCallable<K, V, T> extends Callable<T> {
/**
* Invoked by execution environment after DistributedCallable
* has been migrated for execution to a specific Infinispan node.
*
* @param cache
* cache whose keys are used as input data for this
* DistributedCallable task
* @param inputKeys
* keys used as input for this DistributedCallable task
*/
public void setEnvironment(Cache<K, V> cache, Set<K> inputKeys);
}15.2. Callable and CDI
DistributedCallable cannot be implemented or is not appropriate, and a reference to input cache used in DistributedExecutorService is still required, there is an option to inject the input cache by CDI mechanism.
Callable task arrives at a Red Hat JBoss Data Grid executing node, JBoss Data Grid's CDI mechanism provides an appropriate cache reference, and injects it to the executing Callable.
Callable:
- Declare a
Cachefield inCallableand annotate it withorg.infinispan.cdi.Input - Include the mandatory
@Injectannotation.
Example 15.2. Using Callable and the CDI
public class CallableWithInjectedCache implements Callable<Integer>, Serializable {
@Inject
@Input
private Cache<String, String> cache;
@Override
public Integer call() throws Exception {
//use injected cache reference
return 1;
}
}15.3. Distributed Task Failover
- Failover due to a node failure where a task is executing.
- Failover due to a task failure; for example, if a
Callabletask throws an exception.
Runnable, Callable, and DistributedCallable tasks fail without invoking any failover mechanism.
Distributed task on another random node if one is available.
Example 15.3. Random Failover Execution Policy
DistributedExecutorService des = new DefaultExecutorService(cache); DistributedTaskBuilder<Boolean> taskBuilder = des.createDistributedTaskBuilder(new SomeCallable()); taskBuilder.failoverPolicy(DefaultExecutorService.RANDOM_NODE_FAILOVER); DistributedTask<Boolean> distributedTask = taskBuilder.build(); Future<Boolean> future = des.submit(distributedTask); Boolean r = future.get();
DistributedTaskFailoverPolicy interface can also be implemented to provide failover management.
Example 15.4. Distributed Task Failover Policy Interface
/**
* DistributedTaskFailoverPolicy allows pluggable fail over target selection for a failed remotely
* executed distributed task.
*
*/
public interface DistributedTaskFailoverPolicy {
/**
* As parts of distributively executed task can fail due to the task itself throwing an exception
* or it can be an Infinispan system caused failure (e.g node failed or left cluster during task
* execution etc).
*
* @param failoverContext
* the FailoverContext of the failed execution
* @return result the Address of the Infinispan node selected for fail over execution
*/
Address failover(FailoverContext context);
/**
* Maximum number of fail over attempts permitted by this DistributedTaskFailoverPolicy
*
* @return max number of fail over attempts
*/
int maxFailoverAttempts();
}15.4. Distributed Task Execution Policy
DistributedTaskExecutionPolicy allows tasks to specify a custom execution policy across the Red Hat JBoss Data Grid cluster, by scoping execution of tasks to a subset of nodes.
DistributedTaskExecutionPolicy can be used to manage task execution in the following cases:
- where a task is to be exclusively executed on a local network site instead of a backup remote network center.
- where only a dedicated subset of a certain JBoss Data Grid rack nodes are required for specific task execution.
Example 15.5. Using Rack Nodes to Execute a Specific Task
DistributedExecutorService des = new DefaultExecutorService(cache); DistributedTaskBuilder<Boolean> taskBuilder = des.createDistributedTaskBuilder(new SomeCallable()); taskBuilder.executionPolicy(DistributedTaskExecutionPolicy.SAME_RACK); DistributedTask<Boolean> distributedTask = taskBuilder.build(); Future<Boolean> future = des.submit(distributedTask); Boolean r = future.get();
15.5. Distributed Execution Example
- As shown below, the area of a square is:Area of a Square (S) = 4r 2
- The following is an equation for the area of a circle:Area of a Circle (C) = π x r 2
- Isolate r 2 from the first equation:r 2 = S/4
- Inject this value of r 2 into the second equation to find a value for Pi:C = Sπ/4
- Isolating π in the equation results in:C = Sπ/44C = Sπ4C/S = π

Figure 15.1. Distributed Execution Example
Example 15.6. Distributed Execution Example
public class PiAppx {
public static void main (String [] arg){
List<Cache> caches = ...;
Cache cache = ...;
int numPoints = 10000000;
int numServers = caches.size();
int numberPerWorker = numPoints / numServers;
DistributedExecutorService des = new DefaultExecutorService(cache);
long start = System.currentTimeMillis();
CircleTest ct = new CircleTest(numberPerWorker);
List<Future<Integer>> results = des.submitEverywhere(ct);
int countCircle = 0;
for (Future<Integer> f : results) {
countCircle += f.get();
}
double appxPi = 4.0 * countCircle / numPoints;
System.out.println("Distributed PI appx is " + appxPi +
" completed in " + (System.currentTimeMillis() - start) + " ms");
}
private static class CircleTest implements Callable<Integer>, Serializable {
/** The serialVersionUID */
private static final long serialVersionUID = 3496135215525904755L;
private final int loopCount;
public CircleTest(int loopCount) {
this.loopCount = loopCount;
}
@Override
public Integer call() throws Exception {
int insideCircleCount = 0;
for (int i = 0; i < loopCount; i++) {
double x = Math.random();
double y = Math.random();
if (insideCircle(x, y))
insideCircleCount++;
}
return insideCircleCount;
}
private boolean insideCircle(double x, double y) {
return (Math.pow(x - 0.5, 2) + Math.pow(y - 0.5, 2))
<= Math.pow(0.5, 2);
}
}
}Chapter 16. Data Interoperability
16.1. Interoperability Between Library and Remote Client-Server Endpoints
- store and retrieve data in a local (embedded) way
- store and retrieve data remotely using various endpoints
16.2. Using Compatibility Mode
- all endpoints configurations specify the same cache manager
- all endpoints can interact with the same target cache
16.3. Protocol Interoperability
The compatibility element's enabled parameter is set to true or false to determine whether compatibility mode is in use.
Example 16.1. Compatibility Mode Enabled
<cache-container name="local" default-cache="default" statistics="true">
<local-cache name="default" start="EAGER" statistics="true">
<compatibility enabled="true"/>
</local-cache>
</cache-container>Use a configurationBuilder with the compatibility mode enabled as follows:
ConfigurationBuilder builder = ... builder.compatibility().enable();
The compatibility element's enabled parameter is set to true or false to determine whether compatibility mode is in use.
<namedCache name="compatcache"> <compatibility enabled="true"/> </namedCache>
16.3.1. Use Cases and Requirements
Table 16.1. Compatibility Mode Use Cases
| Use Case | Client A (Reader or Writer) | Client B (Write/Read Counterpart of Client A) |
|---|---|---|
| 1 | Memcached | Hot Rod Java |
| 2 | REST | Hot Rod Java |
| 3 | Memcached | REST |
| 4 | Hot Rod Java | Hot Rod C++ |
| 5 | Embedded | Hot Rod Java |
| 6 | REST | Hot Rod C++ |
| 7 | Memcached | Hot Rod C++ |
Person instance, it would use a String as a key.
Client A Side
- A uses a third-party marshaller, such as Protobuf or Avro, to serialize the
Personvalue into a byte[]. A UTF-8 encoded string must be used as the key (according to Memcached protocol requirements). - A writes a key-value pair to the server (key as UTF-8 string, the value as byte arrays).
Client B Side
- B must read a
Personfor a specific key (String). - B serializes the same UTF-8 key into the corresponding byte[].
- B invokes
get(byte[]) - B obtains a byte[] representing the serialized object.
- B uses the same marshaller as A to unmarshall the byte[] into the corresponding
Personobject.
Note
- In Use Case 4, the Protostream Marshaller, which is included with the Hot Rod Java client, is recommended. For the Hot Rod C++ client, the Protobuf Marshaller from Google (https://developers.google.com/protocol-buffers/docs/overview) is recommended.
- In Use Case 5, the default Hot Rod marshaller can be used.
16.3.2. Protocol Interoperability Over REST
application/x-java-serialized-object, application/xml, or application/json. Any other byte arrays are treated as application/octet-stream.
Appendix A. Revision History
| Revision History | ||||||
|---|---|---|---|---|---|---|
| Revision 6.3.0-20 | Mon Jan 12 2015 | |||||
| ||||||
| Revision 6.3.0-19 | Mon Jan 05 2015 | |||||
| ||||||
| Revision 6.3.0-18 | Fri Dec 05 2014 | |||||
| ||||||
| Revision 6.3.0-17 | Wed Dec 03 2014 | |||||
| ||||||
| Revision 6.3.0-16 | Mon Nov 17 2014 | |||||
| ||||||
| Revision 6.3.0-15 | Fri Nov 07 2014 | |||||
| ||||||
| Revision 6.3.0-14 | Wed Oct 22 2014 | |||||
| ||||||
| Revision 6.3.0-13 | Wed Oct 08 2014 | |||||
| ||||||
| Revision 6.3.0-12 | Wed Sep 10 2014 | |||||
| ||||||
| Revision 6.3.0-11 | Tue Sep 02 2014 | |||||
| ||||||
| Revision 6.3.0-10 | Tue Aug 26 2014 | |||||
| ||||||
| Revision 6.3.0-9 | Mon Aug 18 2014 | |||||
| ||||||
| Revision 6.3.0-8 | Mon Aug 11 2014 | |||||
| ||||||
| Revision 6.3.0-7 | Mon Aug 04 2014 | |||||
| ||||||
| Revision 6.3.0-6 | Wed Jul 02 2014 | |||||
| ||||||
| Revision 6.3.0-5 | Thu Jun 26 2014 | |||||
| ||||||
| Revision 6.3.0-4 | Tue Jun 17 2014 | |||||
| ||||||
| Revision 6.3.0-3 | Tue May 27 2014 | |||||
| ||||||
| Revision 6.3.0-2 | Mon May 26 2014 | |||||
| ||||||
| Revision 6.3.0-1 | Thu May 22 2014 | |||||
| ||||||
| Revision 6.3.0-0 | Wed Apr 09 2014 | |||||
| ||||||