ファイルシステムの管理
Red Hat Enterprise Linux 8 でのファイルシステムの作成、変更、管理
概要
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
第1章 利用可能なファイルシステムの概要
利用可能な選択肢と、関連するトレードオフが多数あるため、アプリケーションに適したファイルシステムを選択することが重要になります。
次のセクションでは、Red Hat Enterprise Linux 8 にデフォルトで含まれるファイルシステムと、アプリケーションに最適なファイルシステムに関する推奨事項について説明します。
1.1. ファイルシステムの種類
Red Hat Enterprise Linux 8 は、さまざまなファイルシステム (FS) に対応します。さまざまな種類のファイルシステムがさまざまな問題を解決し、その使用はアプリケーションによって異なります。最も一般的なレベルでは、利用可能なファイルシステムを以下の主要なタイプにまとめることができます。
| タイプ | ファイルシステム | 属性とユースケース |
|---|---|---|
| ディスクまたはローカルのファイルシステム | XFS | XFS は、RHEL におけるデフォルトファイルシステムです。Red Hat は、互換性や、パフォーマンスおいて稀に発生する難しい問題などの特別な理由がない限り、XFS をローカルファイルシステムとしてデプロイすることを推奨します。 |
| ext4 | 従来の ext2 および ext3 ファイルシステムから進化した ext4 には、Linux で馴染みやすいという利点があります。多くの場合、パフォーマンスでは XFS に匹敵します。ext4 ファイルシステムとファイルサイズのサポート制限は、XFS よりも小さくなっています。 | |
| ネットワーク、またはクライアント/サーバーのファイルシステム | NFS | NFS は、同じネットワークにある複数のシステムでのファイル共有に使用します。 |
| SMB | SMB は、Microsoft Windows システムとのファイル共有に使用します。 | |
| 共有ストレージまたは共有ディスクのファイルシステム | GFS2 | GFS2 は、コンピュートクラスターのメンバーに共有書き込みアクセスを提供します。可能な限り、ローカルファイルシステムの機能的経験を備えた安定性と信頼性に重点が置かれています。SAS Grid、Tibco MQ、IBM Websphere MQ、および Red Hat Active MQ は、GFS2 に問題なくデプロイされています。 |
| ボリューム管理ファイルシステム | Stratis (テクノロジープレビュー) | Stratis は、XFS と LVM を組み合わせて構築されたボリュームマネージャーです。Stratis の目的は、Btrfs や ZFS などのボリューム管理ファイルシステムにより提供される機能をエミュレートすることです。このスタックを手動で構築することは可能ですが、Stratis は設定の複雑さを軽減し、ベストプラクティスを実装し、エラー情報を統合します。 |
1.2. ローカルファイルシステム
ローカルファイルシステムは、1 台のローカルサーバーで実行し、ストレージに直接接続されているファイルシステムです。
たとえば、ローカルファイルシステムは、内部 SATA ディスクまたは SAS ディスクにおける唯一の選択肢であり、ローカルドライブを備えた内蔵ハードウェア RAID コントローラーがサーバーにある場合に使用されます。ローカルファイルシステムは、SAN にエクスポートされたデバイスが共有されていない場合に、SAN が接続したストレージに最もよく使用されているファイルシステムです。
ローカルファイルシステムはすべて POSIX に準拠しており、サポートされているすべての Red Hat Enterprise Linux リリースと完全に互換性があります。POSIX 準拠のファイルシステムは、read()、write()、seek() など、明確に定義されたシステムコールのセットに対応します。
ファイルシステムの選択肢を検討するときは、必要なファイルシステムのサイズ、必要な固有の機能、実際の作業負荷下でのパフォーマンスに基づいてファイルシステムを選択してください。
- 利用可能なローカルファイルシステム
- XFS
- ext4
1.3. XFS ファイルシステム
XFS は、拡張性が高く、高性能で堅牢な、成熟した 64 ビットのジャーナリングファイルシステムで、1 台のホストで非常に大きなファイルおよびファイルシステムに対応します。Red Hat Enterprise Linux 8 ではデフォルトのファイルシステムになります。XFS は、元々 1990 年代の前半に SGI により開発され、極めて大規模なサーバーおよびストレージアレイで実行されてきた長い歴史があります。
XFS の機能は次のとおりです。
- 信頼性
- メタデータジャーナリング - システムの再起動時、およびファイルシステムの再マウント時に再生できるファイルシステム操作の記録を保持することで、システムクラッシュ後のファイルシステムの整合性を確保します。
- 広範囲に及ぶランタイムメタデータの整合性チェック
- 拡張性が高く、高速な修復ユーティリティー
- クォータジャーナリングクラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- スケーラビリティーおよびパフォーマンス
- 対応するファイルシステムのサイズが最大 1024 TiB
- 多数の同時操作に対応する機能
- 空き領域管理のスケーラビリティーに関する B-Tree インデックス
- 高度なメタデータ先読みアルゴリズム
- ストリーミングビデオのワークロードの最適化
- 割り当てスキーム
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
- 動的に割り当てられる inode
- その他の機能
- Reflink ベースのファイルのコピー
- 密接に統合されたバックアップおよび復元のユーティリティー
- オンラインのデフラグ
- オンラインのファイルシステム拡張
- 包括的な診断機能
-
拡張属性 (
xattr)。これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 - プロジェクトまたはディレクトリーのクォータ。ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
パフォーマンスの特徴
XFS は、エンタープライズレベルのワークロードがある大規模なシステムで優れたパフォーマンスを発揮します。大規模なシステムとは、相対的に CPU 数が多く、さらには複数の HBA、および外部ディスクアレイへの接続を備えたシステムです。XFS は、マルチスレッドの並列 I/O ワークロードを備えた小規模のシステムでも適切に実行します。
XFS は、シングルスレッドで、メタデータ集約型のワークロードのパフォーマンスが比較的低くなります。たとえば、シングルスレッドで小さなファイルを多数作成し、削除するワークロードがこれに当てはまります。
1.4. ext4 ファイルシステム
ext4 ファイルシステムは、ext ファイルシステムファミリーの第 4 世代です。これは、Red Hat Enterprise Linux 6 でデフォルトのファイルシステムです。
ext4 ドライバーは、ext2 および ext3 のファイルシステムの読み取りと書き込みが可能ですが、ext4 ファイルシステムのフォーマットは、ext2 ドライバーおよび ext3 ドライバーと互換性がありません。
ext4 には、以下のような新機能、および改善された機能が追加されました。
- 対応するファイルシステムのサイズが最大 50 TiB
- エクステントベースのメタデータ
- 遅延割り当て
- ジャーナルのチェックサム
- 大規模なストレージサポート
エクステントベースのメタデータと遅延割り当て機能は、ファイルシステムで使用されている領域を追跡する、よりコンパクトで効率的な方法を提供します。このような機能により、ファイルシステムのパフォーマンスが向上し、メタデータが使用する領域が低減します。遅延割り当てにより、ファイルシステムは、データがディスクにフラッシュされるまで、新しく書き込まれたユーザーデータの永続的な場所の選択を保留できます。これにより、より大きく、より連続した割り当てが可能になり、より優れた情報に基づいてファイルシステムが決定を下すことができるため、パフォーマンスが向上します。
ext4 で fsck ユーティリティーを使用するファイルシステムの修復時間は、ext2 と ext3 よりも高速です。一部のファイルシステムの修復では、最大 6 倍のパフォーマンスの向上が実証されています。
1.5. XFS と ext4 の比較
XFS は、RHEL におけるデフォルトファイルシステムです。このセクションでは、XFS および ext4 の使用方法と機能を比較します。
- メタデータエラーの動作
-
ext4 では、ファイルシステムがメタデータのエラーに遭遇した場合の動作を設定できます。デフォルトの動作では、操作を継続します。XFS が復旧できないメタデータエラーに遭遇すると、ファイルシステムをシャットダウンし、
EFSCORRUPTEDエラーを返します。 - クォータ
ext4 では、既存のファイルシステムにファイルシステムを作成する場合にクォータを有効にできます。次に、マウントオプションを使用してクォータの適用を設定できます。
XFS クォータは再マウントできるオプションではありません。初期マウントでクォータをアクティブにする必要があります。
XFS ファイルシステムで
quotacheckコマンドを実行すると影響しません。クォータアカウンティングを初めてオンにすると、XFS はクォータを自動的にチェックします。- ファイルシステムのサイズ変更
- XFS には、ファイルシステムのサイズを縮小するユーティリティーがありません。XFS ファイルシステムのサイズのみを増やすことができます。ext4 は、ファイルシステムの拡張と縮小の両方をサポートします。
- Inode 番号
ext4 ファイルシステムは、232 個を超える inode をサポートしません。
XFS は動的な inode 割り当てをサポートしています。XFS ファイルシステム上で inode が消費できる領域の量は、ファイルシステムの合計領域のパーセンテージとして計算されます。管理者は、システムの inode が不足するのを防ぐために、ファイルシステムの作成後にこのパーセンテージを調整できます (ファイルシステムに空き領域が残っている場合)。
特定のアプリケーションは、XFS ファイルシステムで 232 個を超える inode を適切に処理できません。このようなアプリケーションでは、戻り値
EOVERFLOWで 32 ビットの統計呼び出しに失敗する可能性があります。Inode 番号は、以下の条件下で 232 個を超えます。- ファイルシステムが 256 バイトの inode を持つ 1 TiB を超える。
- ファイルシステムが 512 バイトの inode を持つ 2 TiB を超える。
inode 番号が大きくてアプリケーションが失敗した場合は、
-o inode32オプションを使用して XFS ファイルシステムをマウントし、232 未満の inode 番号を実施します。inode32を使用しても、すでに 64 ビットの数値が割り当てられている inode には影響しません。重要特定の環境に必要な場合を除き、
inode32オプションは 使用しない でください。inode32オプションは割り当ての動作を変更します。これにより、下層のディスクブロックに inode を割り当てるための領域がない場合に、ENOSPCエラーが発生する可能性があります。
1.6. ローカルファイルシステムの選択
アプリケーション要件を満たすファイルシステムを選択するには、ファイルシステムをデプロイするターゲットシステムを理解する必要があります。一般的には、ext4 を特定の用途で使用する場合を除き、XFS を使用してください。
- XFS
- 大規模なデプロイメントの場合、特に大きなファイル (数百メガバイト) や大量の I/O 並行処理を扱う場合は、XFS を使用します。XFS は、高帯域幅 (200 MB/秒以上) および 1000 IOPS を超える環境で最適に動作します。ただし、ext4 と比較してメタデータ操作に多くの CPU リソースを消費します。また、ファイルシステムの縮小をサポートしていません。
- ext4
- 小規模なシステムや I/O 帯域幅が制限されている環境では、ext4 のほうが適している可能性があります。シングルスレッド、少量の I/O ワークロード、およびスループット要件が低い環境の場合は、パフォーマンスが向上します。また、ext4 はオフラインの縮小をサポートしています。これはファイルシステムのサイズ変更が必要な場合に役立ちます。
ターゲットサーバーとストレージシステムでアプリケーションのパフォーマンスをベンチマークし、選択したファイルシステムがパフォーマンスとスケーラビリティーの要件を満たしていることを確認してください。
| シナリオ | 推奨されるファイルシステム |
|---|---|
| 特別なユースケースなし | XFS |
| 大規模サーバー | XFS |
| 大規模なストレージデバイス | XFS |
| 大規模なファイル | XFS |
| マルチスレッド I/O | XFS |
| シングルスレッド I/O | ext4 |
| 制限された I/O 機能 (1000 IOPS 未満) | ext4 |
| 制限された帯域幅 (200MB/s 未満) | ext4 |
| CPU にバインドされているワークロード | ext4 |
| オフラインの縮小への対応 | ext4 |
1.7. ネットワークファイルシステム
クライアント/サーバーファイルシステムとも呼ばれるネットワークファイルシステムにより、クライアントシステムは、共有サーバーに保存されているファイルにアクセスできます。これにより、複数のシステムの、複数のユーザーが、ファイルやストレージリソースを共有できます。
このようなファイルシステムは、ファイルシステムのセットを 1 つ以上のクライアントにエクスポートする、1 つ以上のサーバーから構築されます。クライアントノードは、基盤となるブロックストレージにアクセスできませんが、より良いアクセス制御を可能にするプロトコルを使用してストレージと対話します。
- 利用可能なネットワークファイルシステム
- RHEL で最も一般的なクライアント/サーバーファイルシステムは、NFS ファイルシステムです。RHEL は、ネットワーク経由でローカルファイルシステムをエクスポートする NFS サーバーコンポーネントと、このようなファイルシステムをインポートする NFS クライアントの両方を提供します。
- RHEL には、Windows の相互運用性で一般的に使用されている Microsoft SMB ファイルサーバーに対応する CIFS クライアントも含まれています。ユーザー空間 Samba サーバーは、RHEL サーバーから Microsoft SMB サービスを使用する Windows クライアントを提供します。
1.10. ボリューム管理ファイルシステム
ボリューム管理ファイルシステムは、簡素化とスタック内の最適化の目的で、ストレージスタック全体を統合します。
- 利用可能なボリューム管理ファイルシステム
- Red Hat Enterprise Linux 8 は、Stratis ボリュームマネージャーがテクノロジープレビューとして提供します。Stratis は、ファイルシステム層に XFS を使用し、LVM、Device Mapper、およびその他のコンポーネントと統合します。
Stratis は、Red Hat Enterprise Linux 8.0 で初めてリリースされました。Red Hat が Btrfs を非推奨にした時に生じたギップを埋めると考えられています。Stratis 1.0 は、ユーザーによる複雑さを隠しつつ、重要なストレージ管理操作を実行できる直感的なコマンドラインベースのボリュームマネージャーです。
- ボリュームの管理
- プールの作成
- シンストレージプール
- スナップショット
- 自動化読み取りキャッシュ
Stratis は強力な機能を提供しますが、現時点では Btrfs や ZFS といったその他の製品と比較される可能性がある機能をいつくか欠いています。たとえば、セルフ修復を含む CRC には対応していません。
第2章 RHEL システムロールを使用したローカルストレージの管理
Ansible を使用して LVM とローカルファイルシステム (FS) を管理するには、RHEL 8 で使用可能な RHEL システムロールの 1 つである storage ロールを使用できます。
storage ロールを使用すると、ディスク上のファイルシステム、複数のマシンにある論理ボリューム、および RHEL 7.7 以降の全バージョンでのファイルシステムの管理を自動化できます。
RHEL システムロールと、その適用方法の詳細は、RHEL システムロールの概要 を参照してください。
2.1. storage RHEL システムロールを使用してブロックデバイスに XFS ファイルシステムを作成する
Ansible Playbook の例では、storage ロールを適用して、デフォルトのパラメーターを使用してブロックデバイス上に XFS ファイルシステムを作成します。
storage ロールは、パーティションが分割されていないディスク全体または論理ボリューム (LV) でのみファイルシステムを作成できます。パーティションにファイルシステムを作成することはできません。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs-
現在、ボリューム名 (この例では
barefs) は任意です。storageロールは、disks:属性にリスト表示されているディスクデバイスでボリュームを特定します。 -
XFS は RHEL 8 のデフォルトファイルシステムであるため、
fs_type: xfs行を省略することができます。 論理ボリュームにファイルシステムを作成するには、エンクロージングボリュームグループを含む
disks:属性の下に LVM 設定を指定します。詳細は、storage RHEL システムロールを使用して論理ボリュームを作成またはサイズ変更する を参照してください。LV デバイスへのパスを指定しないでください。
-
現在、ボリューム名 (この例では
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.2. storage RHEL システムロールを使用してファイルシステムを永続的にマウントする
Ansible の例では、storage ロールを適用して、XFS ファイルシステムを即時かつ永続的にマウントします。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_user: somebody mount_group: somegroup mount_mode: 0755-
この Playbook は、ファイルシステムを
/etc/fstabファイルに追加し、ファイルシステムを即座にマウントします。 -
/dev/sdbデバイス上のファイルシステム、またはマウントポイントのディレクトリーが存在しない場合は、Playbook により作成されます。
-
この Playbook は、ファイルシステムを
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.3. storage RHEL システムロールを使用して論理ボリュームを作成またはサイズ変更する
storage ロールを使用して、次のタスクを実行します。
- 多数のディスクで構成されるボリュームグループに LVM 論理ボリュームを作成する
- LVM 上の既存のファイルシステムのサイズを変更する
- LVM ボリュームのサイズをプールの合計サイズのパーセンテージで表す
ボリュームグループが存在しない場合、このロールによって作成されます。ボリュームグループ内に論理ボリュームが存在する場合に、そのサイズが Playbook で指定されたサイズと一致しないと、サイズが変更されます。
論理ボリュームを縮小する場合、データの損失を防ぐために、その論理ボリューム上のファイルシステムによって、縮小する論理ボリューム内の領域が使用されていないことを確認する必要があります。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create logical volume ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_pools: - name: myvg disks: - sda - sdb - sdc volumes: - name: mylv size: 2G fs_type: ext4 mount_point: /mnt/dataサンプル Playbook で指定されている設定は次のとおりです。
size: <size>- 単位 (GiB など) またはパーセンテージ (60% など) を使用してサイズを指定する必要があります。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
指定したボリュームが作成されたこと、または要求したサイズに変更されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs myvg'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.4. storage RHEL システムロールを使用してオンラインブロック破棄を有効にする
オンラインブロック破棄オプションを使用すると、XFS ファイルシステムをマウントし、未使用のブロックを自動的に破棄できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Enable online block discard ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_options: discardPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
オンラインブロック破棄オプションが有効になっていることを確認します。
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.5. storage RHEL システムロールを使用して Ext4 ファイルシステムを作成およびマウントする
Ansible Playbook の例では、storage ロールを適用して、Ext4 ファイルシステムを作成してマウントします。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: ext4 fs_label: label-name mount_point: /mnt/data-
この Playbook は、
/dev/sdbディスクにファイルシステムを作成します。 -
この Playbook は、ファイルシステムを
/mnt/dataディレクトリーに永続的にマウントします。 -
ファイルシステムのラベルは
label-nameです。
-
この Playbook は、
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.6. storage RHEL システムロールを使用して Ext3 ファイルシステムを作成およびマウントする
Ansible Playbook の例では、storage ロールを適用して Ext3 ファイルシステムを作成してマウントします。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - hosts: all roles: - rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: ext3 fs_label: label-name mount_point: /mnt/data mount_user: somebody mount_group: somegroup mount_mode: 0755-
この Playbook は、
/dev/sdbディスクにファイルシステムを作成します。 -
この Playbook は、ファイルシステムを
/mnt/dataディレクトリーに永続的にマウントします。 -
ファイルシステムのラベルは
label-nameです。
-
この Playbook は、
Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.7. storage RHEL システムロールを使用してスワップボリュームを作成する
このセクションでは、Ansible Playbook の例を示します。この Playbook は、storage ロールを適用し、デフォルトのパラメーターを使用して、ブロックデバイスにスワップボリュームが存在しない場合は作成し、スワップボリュームがすでに存在する場合はそれを変更します。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Create a disk device with swap hosts: managed-node-01.example.com roles: - rhel-system-roles.storage vars: storage_volumes: - name: swap_fs type: disk disks: - /dev/sdb size: 15 GiB fs_type: swap現在、ボリューム名 (この例では
swap_fs) は任意です。storageロールは、disks:属性にリスト表示されているディスクデバイスでボリュームを特定します。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.8. storage RHEL システムロールを使用した RAID ボリュームの設定
storage システムロールを使用すると、Red Hat Ansible Automation Platform と Ansible-Core を使用して RHEL に RAID ボリュームを設定できます。要件に合わせて RAID ボリュームを設定するためのパラメーターを使用して、Ansible Playbook を作成します。
特定の状況でデバイス名が変更する場合があります。たとえば、新しいディスクをシステムに追加するときなどです。したがって、データの損失を防ぐために、Playbook では永続的な命名属性を使用してください。永続的な命名属性の詳細は、永続的な命名属性の概要を 参照してください。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create a RAID on sdd, sde, sdf, and sdg ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
アレイが正しく作成されたことを確認します。
# ansible managed-node-01.example.com -m command -a 'mdadm --detail /dev/md/data'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー - RAID の管理
2.9. storage RHEL システムロールを使用して RAID を備えた LVM プールを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RAID を備えた LVM プールを RHEL に設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure LVM pool with RAID ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
プールが RAID 上にあることを確認します。
# ansible managed-node-01.example.com -m command -a 'lsblk'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー - RAID の管理
2.10. storage RHEL システムロールを使用して RAID LVM ボリュームのストライプサイズを設定する
storage システムロールを使用すると、Red Hat Ansible Automation Platform を使用して、RHEL の RAID LVM ボリュームのストライプサイズを設定できます。利用可能なパラメーターを使用して Ansible Playbook を設定し、RAID を備えた LVM プールを設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Configure stripe size for RAID LVM volumes ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] volumes: - name: my_volume size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs raid_level: raid0 raid_stripe_size: "256 KiB" state: presentPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
ストライプサイズが必要なサイズに設定されていることを確認します。
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー - RAID の管理
2.11. storage RHEL システムロールを使用して LVM-VDO ボリュームを設定する
storage RHEL システムロールを使用して、圧縮と重複排除を有効にした LVM 上の VDO ボリューム (LVM-VDO) を作成できます。
storage システムロールが LVM VDO を使用するため、プールごとに作成できるボリュームは 1 つだけです。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Create LVM-VDO volume under volume group 'myvg' ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_pools: - name: myvg disks: - /dev/sdb volumes: - name: mylv1 compression: true deduplication: true vdo_pool_size: 10 GiB size: 30 GiB mount_point: /mnt/app/sharedサンプル Playbook で指定されている設定は次のとおりです。
vdo_pool_size: <size>- デバイス上でボリュームが占める実際のサイズ。サイズは、10 GiB など、人間が判読できる形式で指定できます。単位を指定しない場合、デフォルトでバイト単位に設定されます。
size: <size>- VDO ボリュームの仮想サイズ。
Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
圧縮と重複排除の現在のステータスを表示します。
$ ansible managed-node-01.example.com -m command -a 'lvs -o+vdo_compression,vdo_compression_state,vdo_deduplication,vdo_index_state' LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState VDODeduplication VDOIndexState mylv1 myvg vwi-a-v--- 3.00t vpool0 enabled online enabled online
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
2.12. storage RHEL システムロールを使用して LUKS2 暗号化ボリュームを作成する
storage ロールを使用し、Ansible Playbook を実行して、LUKS で暗号化されたボリュームを作成および設定できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
機密性の高い変数を暗号化されたファイルに保存します。
vault を作成します。
$ ansible-vault create vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>
ansible-vault createコマンドでエディターが開いたら、機密データを<key>: <value>形式で入力します。luks_password: <password>- 変更を保存して、エディターを閉じます。Ansible は vault 内のデータを暗号化します。
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com vars_files: - vault.yml tasks: - name: Create and configure a volume encrypted with LUKS ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: <label> mount_point: /mnt/data encryption: true encryption_password: "{{ luks_password }}"Playbook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook --ask-vault-pass ~/playbook.yml
検証
LUKS 暗号化ボリュームの
luksUUID値を見つけます。# ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5cボリュームの暗号化ステータスを表示します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup status luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c' /dev/mapper/luks-4e4e7970-1822-470e-b55a-e91efe5d0f5c is active and is in use. type: LUKS2 cipher: aes-xts-plain64 keysize: 512 bits key location: keyring device: /dev/sdb ...作成された LUKS 暗号化ボリュームを確認します。
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksDump /dev/sdb' LUKS header information Version: 2 Epoch: 3 Metadata area: 16384 [bytes] Keyslots area: 16744448 [bytes] UUID: 4e4e7970-1822-470e-b55a-e91efe5d0f5c Label: (no label) Subsystem: (no subsystem) Flags: (no flags) Data segments: 0: crypt offset: 16777216 [bytes] length: (whole device) cipher: aes-xts-plain64 sector: 512 [bytes] ...
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー - LUKS を使用したブロックデバイスの暗号化
- Ansible vault
第3章 Web コンソールでパーティションの管理
Web コンソールを使用して、RHEL 8 でファイルシステムを管理する方法を説明します。
3.1. ファイルシステムでフォーマットされたパーティションを Web コンソールに表示
Web コンソールの ストレージ セクションには、ファイルシステム テーブルで使用可能なファイルシステムがすべて表示されます。
ファイルシステムでフォーマットされたパーティションのリストに加えて、新しいストレージを作成するためのページも使用できます。
前提条件
-
cockpit-storagedパッケージがシステムにインストールされている。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
Storage タブをクリックします。
ストレージ テーブルでは、ファイルシステムでフォーマットされたすべての使用可能なパーティション、それらの ID、タイプ、場所、サイズ、および各パーティションで使用可能な容量を確認できます。
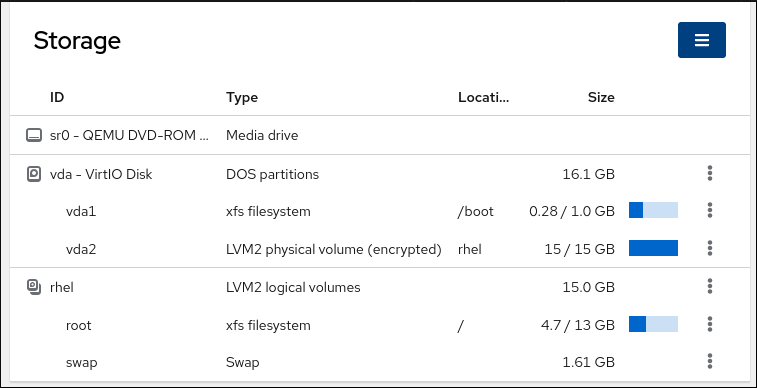
右上隅のドロップダウンメニューを使用して、新しいローカルストレージまたはネットワークストレージを作成することもできます。
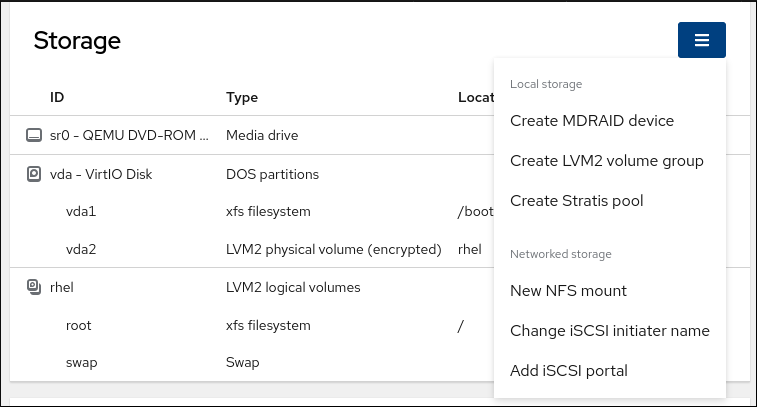
3.2. Web コンソールでパーティションの作成
新しいパーティションを作成するには、以下を行います。
- 既存のパーティションテーブルを使用する
- パーティションを作成する
前提条件
-
cockpit-storagedパッケージがシステムにインストールされている。 - Web コンソールがインストールされており、アクセス可能である。詳細は、Web コンソールのインストール を参照してください。
- システムに接続されたフォーマットされていないボリュームは、Storage タブの Storage テーブルに表示されます。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage タブをクリックします。
- Storage テーブルで、パーティションを分割するデバイスをクリックして、そのデバイスのページとオプションを開きます。
- デバイスページで、メニューボタン をクリックし、Create partition table を選択します。
Initialize disk ダイアログボックスで、以下を選択します。
パーティション設定:
- すべてのシステムおよびデバイスと互換性あり (MBR)
- 最新のシステムおよび 2TB (GPT) 以上のハードディスクと互換性あり
- パーティションなし
オーバーライト:
RHEL Web コンソールでディスク全体をゼロで書き換える場合は、Overwrite existing data with zeros チェックボックスをオンにします。このプログラムはディスク全体を調べるため、このオプションを使用すると遅くなりますが、安全性は高まります。ディスクにデータが含まれていて、上書きする必要がある場合は、このオプションを使用します。
Overwrite existing data with zeros チェックボックスを選択しない場合、RHEL Web コンソールはディスクヘッダーのみを書き換えます。これにより、フォーマットの速度が向上します。
- をクリックします。
- 作成したパーティションテーブルの横にあるメニューボタン をクリックします。デフォルトでは Free space という名前が付けられます。
- をクリックします。
- Create partition ダイアログボックスで、ファイルシステムの Name を入力します。
- Mount point を追加します。
Type ドロップダウンメニューで、ファイルシステムを選択します。
- XFS ファイルシステムは大規模な論理ボリュームをサポートし、オンラインの物理ドライブを停止せずに、既存のファイルシステムの拡大および縮小を行うことができます。別のストレージの使用を希望しない場合は、このファイルシステムを選択したままにしてください。
ext4 ファイルシステムは以下に対応します。
- 論理ボリューム
- オンラインの物理ドライブを停止せずに切り替え
- ファイルシステムの拡張
- ファイルシステムの縮小
追加オプションは、LUKS (Linux Unified Key Setup) によって行われるパーティションの暗号化を有効にすることです。これにより、パスフレーズでボリュームを暗号化できます。
- 作成するボリュームの Size を入力します。
RHEL Web コンソールでディスク全体をゼロで書き換える場合は、Overwrite existing data with zeros チェックボックスをオンにします。このプログラムはディスク全体を調べるため、このオプションを使用すると遅くなりますが、安全性は高まります。ディスクにデータが含まれていて、上書きする必要がある場合は、このオプションを使用します。
Overwrite existing data with zeros チェックボックスを選択しない場合、RHEL Web コンソールはディスクヘッダーのみを書き換えます。これにより、フォーマットの速度が向上します。
ボリュームを暗号化する場合は、Encryption ドロップダウンメニューで暗号化の種類を選択します。
ボリュームを暗号化しない場合は、No encryption を選択します。
- At boot ドロップダウンメニューで、ボリュームをマウントするタイミングを選択します。
Mount options セクションで:
- ボリュームを読み取り専用論理ボリュームとしてマウントする場合は、Mount read only チェックボックスをオンにします。
- デフォルトのマウントオプションを変更する場合は、Custom mount options チェックボックスをオンにしてマウントオプションを追加します。
パーティションを作成します。
- パーティションを作成してマウントする場合は、 ボタンをクリックします。
パーティションのみを作成する場合は、 ボタンをクリックします。
ボリュームのサイズや、選択するオプションによって、フォーマットに数分かかることがあります。
検証
- パーティションが正常に追加されたことを確認するには、Storage タブに切り替えて Storage テーブルを確認し、新しいパーティションがリストされているかどうかを確認します。
3.3. Web コンソールでパーティションの削除
Web コンソールインターフェイスでパーティションを削除できます。
前提条件
-
cockpit-storagedパッケージがシステムにインストールされている。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage タブをクリックします。
- パーティションを削除するデバイスをクリックします。
- デバイスページの GPT partitions セクションで、削除するパーティションの横にあるメニューボタン をクリックします。
ドロップダウンメニューから を選択します。
RHEL Web コンソールは、パーティションを削除する前に、現在パーティションを使用しているすべてのプロセスを終了し、パーティションをアンマウントします。
検証
- パーティションが正常に削除されたことを確認するには、ストレージ タブに切り替えて、コンテンツ テーブルを確認します。
第4章 NFS 共有のマウント
システム管理者は、システムにリモート NFS 共有をマウントすると、共有データにアクセスできます。
4.6. Web コンソールで NFS マウントの接続
NFS を使用して、リモートディレクトリーをファイルシステムに接続します。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
cockpit-storagedパッケージがシステムにインストールされている。 - NFS サーバー名または IP アドレス。
- リモートサーバーのディレクトリーのパス
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage をクリックします。
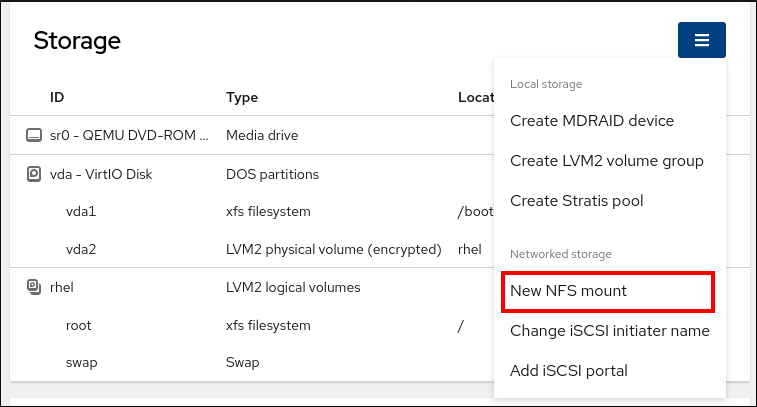
- Storage テーブルで、メニューボタンをクリックします。
ドロップダウンメニューから、New NFS mount を選択します。
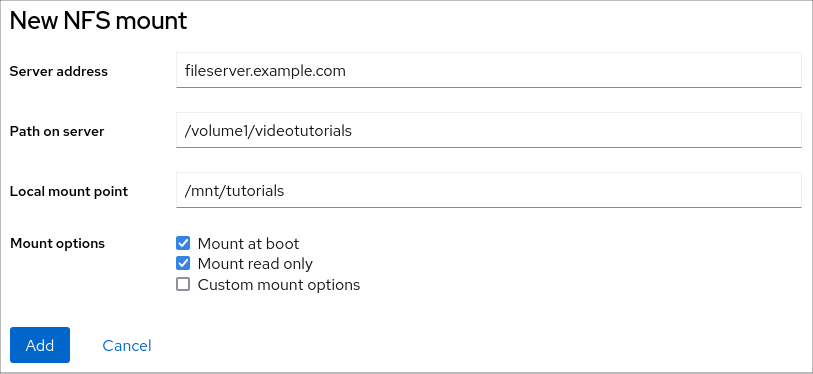
- NFS の新規マウント ダイアログボックスに、リモートサーバーのサーバー名または IP アドレスを入力します。
- サーバーのパス フィールドに、マウントするディレクトリーのパスを入力します。
- Local Mount Point フィールドに、NFS をマウントするローカルシステム上のディレクトリーへのパスを入力します。
Mount options チェックボックスリストで、NFS をマウントする方法を選択します。要件に応じて複数のオプションを選択できます。
- ローカルシステムを再起動した後でもディレクトリーにアクセスできるようにするには、Mount at boot をオンにします。
- NFS の内容を変更したくない場合は、Mount read only ボックスをオンにします。
デフォルトのマウントオプションを変更する場合は、Custom mount options ボックスをオンにしてマウントオプションを追加します。
- をクリックします。
検証
- マウントしたディレクトリーを開き、コンテンツがアクセスできることを確認します。
4.11. NFS コンテンツのクライアント側キャッシュの有効化
FS-Cache は、クライアント上の永続的なローカルキャッシュです。ファイルシステムがネットワーク経由で取得したデータを取得してローカルディスクにキャッシュするために使用できます。これにより、ネットワークトラフィックを最小限に抑えることができます。
4.11.1. NFS キャッシュの仕組み
以下の図は、FS-Cache の仕組みの概要を示しています。
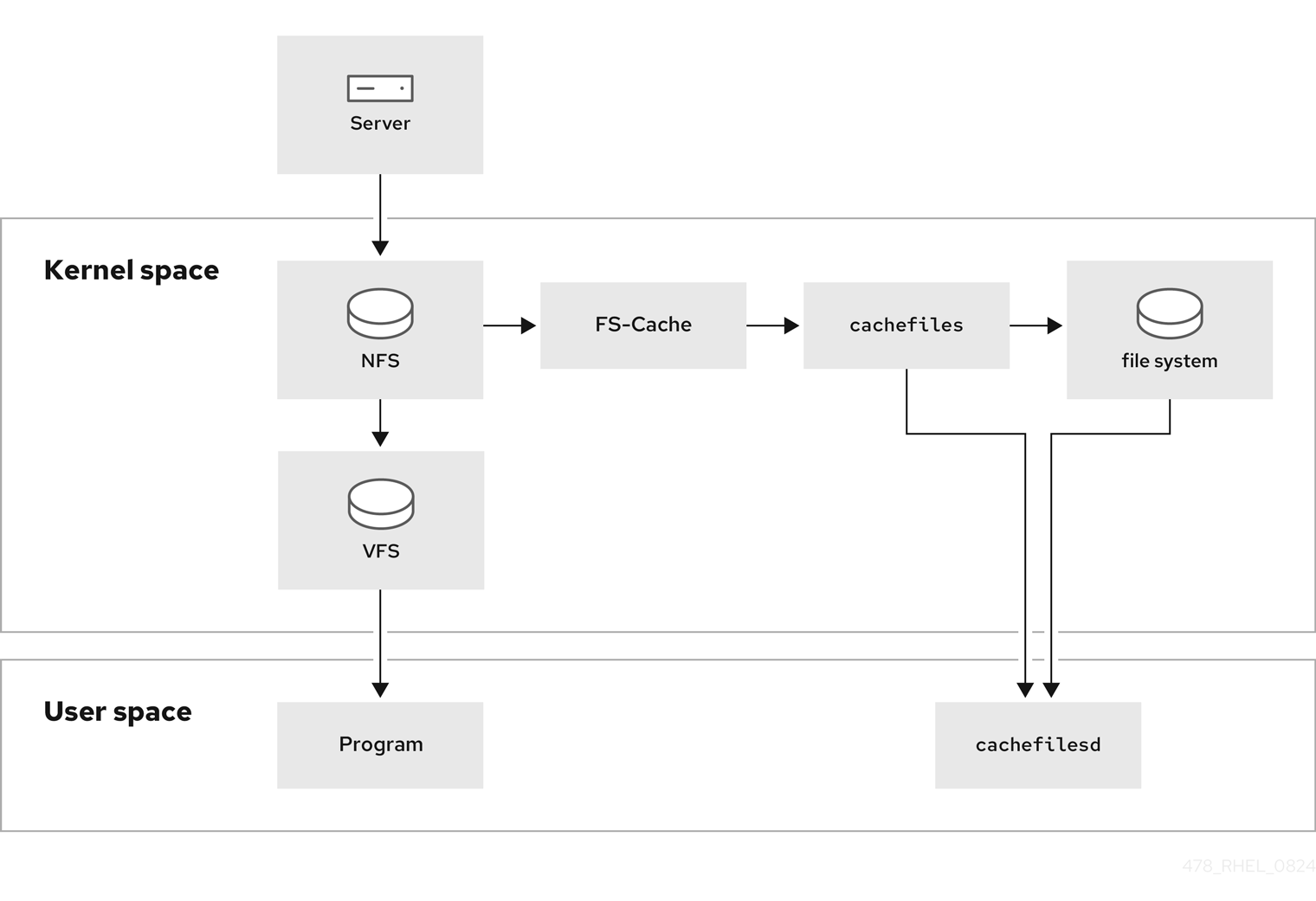
FS-Cache は、システムのユーザーおよび管理者が可能な限り透過的になるように設計されています。FS-Cache を使用すると、オーバーマウントされたファイルシステムを作成することなく、サーバー上のファイルシステムがクライアントのローカルキャッシュと直接対話できるようになります。NFS では、マウントオプションにより、FS-cache が有効になっている NFS 共有をマウントするようにクライアントに指示します。マウントポイントにより、fscache と cachefiles の 2 つのカーネルモジュールの自動アップロードが実行します。cachefilesd デーモンは、カーネルモジュールと通信してキャッシュを実装します。
FS-Cache は、ネットワーク上で動作するファイルシステムの基本操作を変更しません。単に、そのファイルシステムに、データをキャッシュできる永続的な場所を提供するだけです。たとえば、クライアントは FS-Cache が有効になっているかどうかに関わらず、NFS 共有をマウントできます。さらに、キャッシュされた NFS は、ファイルが部分的にキャッシュされ、事前完全に読み込む必要がないため、ファイル (個別または一括) に収まらないファイルを処理できます。また、FS-Cache は、クライアントファイルシステムドライバーからキャッシュで発生するすべての I/O エラーも非表示にします。
キャッシュサービスを提供するには、FS-Cache にキャッシュバックエンド、つまり cachefiles サービスが必要です。FS-Cache には、ブロックマッピング (bmap) と拡張属性をキャッシュバックエンドとしてサポートするマウントされたブロックベースのファイルシステムが必要です。
- XFS
- ext3
- ext4
FS-Cache は、ネットワークを介するかどうかに関係なく、あらゆるファイルシステムを任意にキャッシュすることはできません。FS-Cache の操作、データの保存または取得、およびメタデータの設定と検証を実行できるよう、共有ファイルシステムのドライバーが変更されている必要があります。FS-Cache では、永続性に対応するためにキャッシュされたファイルシステムの インデックスキー と 一貫性データ が必要になります。インデックスキーはファイルシステムオブジェクトをキャッシュオブジェクトに一致させ、一貫性データを使用してキャッシュオブジェクトが有効のままかどうかを判断します。
FS-Cache を使用する際には、さまざまな要素の妥協点を探すことになります。FS-Cache を使用して NFS トラフィックをキャッシュすると、クライアントの速度が低下する可能性があります。一方で、ネットワーク帯域幅を消費せずに読み取り要求をローカルで満たせるため、ネットワークとサーバーの負荷を大幅に軽減できます。
4.11.2. cachefilesd サービスのインストールと設定
Red Hat Enterprise Linux は、cachefiles キャッシュバックエンドのみを提供します。cachefilesd サービスは、cachefiles を起動および管理します。/etc/cachefilesd.conf ファイルは、cachefiles によるキャッシュサービスの提供方法を制御します。
前提条件
-
/var/cache/fscache/ディレクトリーの下にマウントされるファイルシステムは、ext3、ext4、またはxfsです。 -
/var/cache/fscache/の下にマウントされたファイルシステムは、拡張属性を使用します。これは、RHEL 8 以降でファイルシステムを作成した場合のデフォルトです。
手順
cachefilesdパッケージをインストールします。# dnf install cachefilesdcachefilesdサービスを有効にして起動します。# systemctl enable --now cachefilesd
検証
fscオプションを使用して NFS 共有をマウントし、キャッシュを使用します。共有を一時的にマウントするには、次のように入力します。
# mount -o fsc server.example.com:/nfs/projects/ /mnt/共有を永続的にマウントするには、
/etc/fstabファイルのエントリーにfscオプションを追加します。<nfs_server_ip_or_hostname>:/<exported_share> <mount point> nfs fsc 0 0
FS キャッシュの統計情報を表示します。
# cat /proc/fs/fscache/stats
関連情報
-
/usr/share/doc/cachefilesd/READMEファイル -
kernel-docパッケージにより提供されている/usr/share/doc/kernel-doc-<kernel_version>/Documentation/filesystems/caching/fscache.rst
4.11.3. NFS キャッシュの共有
キャッシュは永続的であるため、キャッシュ内のデータブロックは 4 つのキーのシーケンスでインデックス化されます。
- レベル 1: サーバーの詳細
- レベル 2: 一部のマウントオプション、セキュリティータイプ、FSID、識別子文字列
- レベル 3: ファイルハンドル
- レベル 4: ファイル内のページ番号
スーパーブロック間の整合性の管理に関する問題を回避するには、データのキャッシュを必要とする NFS のすべてのスーパーブロックに、固有のレベル 2 キーを設定します。通常、同じソースボリュームとオプションを持つ 2 つの NFS マウントは、スーパーブロックを共有しているため、そのボリューム内に異なるディレクトリーをマウントする場合でもキャッシュを共有することになります。
例4.1 NFS キャッシュ共有:
次の 2 つのマウントは、同じマウントオプションを持つため (特に NFS サーバー上の同じパーティションからのものであるため)、スーパーブロックを共有している可能性があります。
# mount -o fsc home0:/nfs/projects /projects # mount -o fsc home0:/nfs/home /home/
マウントオプションが異なる場合、スーパーブロックは共有されません。
# mount -o fsc,rsize=8192 home0:/nfs/projects /projects # mount -o fsc,rsize=65536 home0:/nfs/home /home/
ユーザーは、異なる通信またはプロトコルパラメーターを持つスーパーブロック間でキャッシュを共有することはできません。たとえば、NFSv4.0 と NFSv3 の間、NFSv4.1 と NFSv4.2 の間でキャッシュを共有することはできません。これは、強制されるスーパーブロックが異なるためです。また、読み取りサイズ (rsize) などのパラメーターを設定した場合も、別のスーパーブロックが強制されるため、キャッシュの共有ができなくなります。
4.11.4. NFS キャッシュの制限
NFS にはキャッシュの制限がいくつかあります。
- ダイレクト I/O で共有ファイルシステムからファイルを開くと、自動的にキャッシュが回避されます。これは、この種のアクセスがサーバーに直接行なわれる必要があるためです。
- ダイレクト I/O または書き込みのいずれかで共有ファイルシステムからファイルを開くと、キャッシュされたファイルのコピーがフラッシュされます。ダイレクト I/O や書き込みのためにファイルが開かれなくなるまで、FS-Cache はファイルを再キャッシュしません。
- さらに、FS-Cache の今回のリリースでは、通常の NFS ファイルのみをキャッシュします。FS-Cache は、ディレクトリー、シンボリックリンク、デバイスファイル、FIFO、ソケットをキャッシュしません。
4.11.5. キャッシュカリングの仕組み
cachefilesd サービスは、共有ファイルシステムからのリモートデータをキャッシュして、ローカルディスクの領域を解放することで機能します。これにより、使用可能な空き領域がすべて消費される可能性があり、ディスクにルートパーティションも含まれている場合は問題が発生する可能性があります。これを制御するために、cachefilesd は、最近のアクセスが少ないオブジェクトなどの古いオブジェクトをキャッシュから破棄して、一定量の空き領域を維持しようとします。この動作はキャッシュカリングと呼ばれます。
キャッシュカリングは、基盤となるファイルシステムで使用可能なブロックのパーセンテージとファイルのパーセンテージに基づいて行われます。/etc/cachefilesd.conf には、6 つの制限を制御する設定が存在します。
- brun N% (ブロックのパーセンテージ)、frun N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限を上回ると、カリングはオフになります。
- bcull N% (ブロックのパーセンテージ)、fcull N% (ファイルのパーセンテージ)
- キャッシュの空き領域と利用可能なファイルの数がこれらの制限のいずれかを下回ると、カリング動作が開始します。
- bstop N% (ブロックのパーセンテージ)、fstop N% (ファイルのパーセンテージ)
- キャッシュ内の使用可能な領域または使用可能なファイルの数がこの制限のいずれかを下回ると、カリングによってこれらの制限を超える状態になるまで、ディスク領域またはファイルのそれ以上の割り当ては許可されません。
各設定の N のデフォルト値は以下の通りです。
-
brun/frun: 10% -
bcull/fcull: 7% -
bstop/fstop: 3%
この設定を行う場合は、以下の条件を満たす必要があります。
-
0 ≤
bstop<bcull<brun< 100 -
0 ≤
fstop<fcull<frun< 100
これは、空き領域と利用可能なファイルの割合であり、100 から、df プログラムで表示される割合を引いたものではありません。
カリングは、bxxx と fxxx のペアを同時に依存します。ユーザーが個別に処理することはできません。
第6章 永続的な命名属性の概要
システム管理者は、永続的な命名属性を使用してストレージボリュームを参照し、再起動を何度も行っても信頼できるストレージ設定を構築する必要があります。
6.1. 非永続的な命名属性のデメリット
Red Hat Enterprise Linux では、ストレージデバイスを識別する方法が複数あります。特にドライブへのインストール時やドライブの再フォーマット時に誤ったデバイスにアクセスしないようにするため、適切なオプションを使用して各デバイスを識別することが重要になります。
従来、/dev/sd(メジャー番号)(マイナー番号) の形式の非永続的な名前は、ストレージデバイスを参照するために Linux 上で使用されます。メジャー番号とマイナー番号の範囲、および関連する sd 名は、検出されると各デバイスに割り当てられます。つまり、デバイスの検出順序が変わると、メジャー番号とマイナー番号の範囲、および関連する sd 名の関連付けが変わる可能性があります。
このような順序の変更は、以下の状況で発生する可能性があります。
- システム起動プロセスの並列化により、システム起動ごとに異なる順序でストレージデバイスが検出された場合。
-
ディスクが起動しなかったり、SCSI コントローラーに応答しなかった場合。この場合は、通常のデバイスプローブにより検出されません。ディスクはシステムにアクセスできなくなり、後続のデバイスは関連する次の
sd名が含まれる、メジャー番号およびマイナー番号の範囲があります。たとえば、通常sdbと呼ばれるディスクが検出されないと、sdcと呼ばれるディスクがsdbとして代わりに表示されます。 -
SCSI コントローラー (ホストバスアダプターまたは HBA) が初期化に失敗し、その HBA に接続されているすべてのディスクが検出されなかった場合。後続のプローブされた HBA に接続しているディスクは、別のメジャー番号およびマイナー番号の範囲、および関連する別の
sd名が割り当てられます。 - システムに異なるタイプの HBA が存在する場合は、ドライバー初期化の順序が変更する可能性があります。これにより、HBA に接続されているディスクが異なる順序で検出される可能性があります。また、HBA がシステムの他の PCI スロットに移動した場合でも発生する可能性があります。
-
ストレージアレイや干渉するスイッチの電源が切れた場合など、ストレージデバイスがプローブされたときに、ファイバーチャネル、iSCSI、または FCoE アダプターを持つシステムに接続されたディスクがアクセスできなくなる可能性があります。システムが起動するまでの時間よりもストレージアレイがオンラインになるまでの時間の方が長い場合に、電源の障害後にシステムが再起動すると、この問題が発生する可能性があります。一部のファイバーチャネルドライバーは WWPN マッピングへの永続 SCSI ターゲット ID を指定するメカニズムをサポートしますが、メジャー番号およびマイナー番号の範囲や関連する
sd名は予約されず、一貫性のある SCSI ターゲット ID 番号のみが提供されます。
そのため、/etc/fstab ファイルなどにあるデバイスを参照するときにメジャー番号およびマイナー番号の範囲や関連する sd 名を使用することは望ましくありません。誤ったデバイスがマウントされ、データが破損する可能性があります。
しかし、場合によっては他のメカニズムが使用される場合でも sd 名の参照が必要になる場合もあります (デバイスによりエラーが報告される場合など)。これは、Linux カーネルはデバイスに関するカーネルメッセージで sd 名 (および SCSI ホスト、チャネル、ターゲット、LUN タプル) を使用するためです。
6.2. ファイルシステムおよびデバイスの識別子
ファイルシステムの識別子は、ファイルシステム自体に関連付けられます。一方、デバイスの識別子は、物理ブロックデバイスに紐付けられます。適切なストレージ管理を行うには、その違いを理解することが重要です。
ファイルシステムの識別子
ファイルシステムの識別子は、ブロックデバイス上に作成された特定のファイルシステムに関連付けられます。識別子はファイルシステムの一部としても格納されます。ファイルシステムを別のデバイスにコピーしても、ファイルシステム識別子は同じです。ただし、mkfs ユーティリティーでフォーマットするなどしてデバイスを書き換えると、デバイスはその属性を失います。
ファイルシステムの識別子に含まれるものは、次のとおりです。
- 一意の ID (UUID)
- ラベル
デバイスの識別子
デバイス識別子は、ブロックデバイス (ディスクやパーティションなど) に関連付けられます。mkfs ユーティリティーでフォーマットするなどしてデバイスを書き換えた場合、デバイスはファイルシステムに格納されていないため、属性を保持します。
デバイスの識別子に含まれるものは、次のとおりです。
- World Wide Identifier (WWID)
- パーティション UUID
- シリアル番号
推奨事項
- 論理ボリュームなどの一部のファイルシステムは、複数のデバイスにまたがっています。Red Hat は、デバイスの識別子ではなくファイルシステムの識別子を使用してこのファイルシステムにアクセスすることを推奨します。
6.3. /dev/disk/ にある udev メカニズムにより管理されるデバイス名
udev メカニズムは、Linux のすべてのタイプのデバイスに使用され、ストレージデバイスだけに限定されません。/dev/disk/ ディレクトリーにさまざまな種類の永続的な命名属性を提供します。ストレージデバイスの場合、Red Hat Enterprise Linux には /dev/disk/ ディレクトリーにシンボリックリンクを作成する udev ルールが含まれています。これにより、次の方法でストレージデバイスを参照できます。
- ストレージデバイスのコンテンツ
- 一意の ID
- シリアル番号
udev の命名属性は永続的なものですが、システムを再起動しても自動的には変更されないため、設定可能なものもあります。
6.3.1. ファイルシステムの識別子
/dev/disk/by-uuid/ の UUID 属性
このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内の 一意の ID (UUID) によりストレージデバイスを参照するシンボリック名を提供します。以下に例を示します。
/dev/disk/by-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
次の構文を使用することで、UUID を使用して /etc/fstab ファイルのデバイスを参照できます。
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6ファイルシステムを作成する際に UUID 属性を設定できます。後で変更することもできます。
/dev/disk/by-label/ のラベル属性
このディレクトリーのエントリーは、デバイスに格納されているコンテンツ (つまりデータ) 内の ラベル により、ストレージデバイスを参照するシンボリック名を提供します。
以下に例を示します。
/dev/disk/by-label/Boot
次の構文を使用することで、ラベルを使用して /etc/fstab ファイルのデバイスを参照できます。
LABEL=Bootファイルシステムを作成するときにラベル属性を設定できます。また、後で変更することもできます。
6.3.2. デバイスの識別子
/dev/disk/by-id/ の WWID 属性
World Wide Identifier (WWID) は永続的で、SCSI 規格によりすべての SCSI デバイスが必要とする システムに依存しない識別子 です。各ストレージデバイスの WWID 識別子は一意となることが保証され、デバイスのアクセスに使用されるパスに依存しません。この識別子はデバイスのプロパティーですが、デバイスのコンテンツ (つまりデータ) には格納されません。
この識別子は、SCSI Inquiry を発行して Device Identification Vital Product Data (0x83 ページ) または Unit Serial Number (0x80 ページ) を取得することにより獲得できます。
Red Hat Enterprise Linux では、WWID ベースのデバイス名から、そのシステムの現在の /dev/sd 名への正しいマッピングを自動的に維持します。デバイスへのパスが変更したり、別のシステムからそのデバイスへのアクセスがあった場合にも、アプリケーションはディスク上のデータ参照に /dev/disk/by-id/ を使用できます。
例6.1 WWID マッピング
| WWID シンボリックリンク | 非永続的なデバイス | 備考 |
|---|---|---|
|
|
|
ページ |
|
|
|
ページ |
|
|
| ディスクパーティション |
システムにより提供される永続的な名前のほかに、udev ルールを使用して独自の永続的な名前を実装し、ストレージの WWID にマップすることもできます。
/dev/disk/by-partuuid のパーティション UUID 属性
パーティション UUID (PARTUUID) 属性は、GPT パーティションテーブルにより定義されているパーティションを識別します。
例6.2 パーティション UUID のマッピング
| PARTUUID シンボリックリンク | 非永続的なデバイス |
|---|---|
|
|
|
|
|
|
|
|
|
/dev/disk/by-path/ のパス属性
この属性は、デバイスへのアクセスに使用される ハードウェアパス がストレージデバイスを参照するシンボル名を提供します。
ハードウェアパス (PCI ID、ターゲットポート、LUN 番号など) の一部が変更されると、パス属性に失敗します。このため、パス属性は信頼性に欠けます。ただし、パス属性は以下のいずれかのシナリオで役に立ちます。
- 後で置き換える予定のディスクを特定する必要があります。
- 特定の場所にあるディスクにストレージサービスをインストールする予定です。
6.4. DM Multipath を使用した World Wide Identifier
Device Mapper (DM) Multipath を設定して、World Wide Identifier (WWID) と非永続的なデバイス名をマッピングできます。
システムからデバイスへのパスが複数ある場合、DM Multipath はこれを検出するために WWID を使用します。その後、DM Multipath は /dev/mapper/wwid ディレクトリー (例: /dev/mapper/3600508b400105df70000e00000ac0000) に単一の "疑似デバイス" を表示します。
コマンド multipath -l は、非永続的な識別子へのマッピングを示します。
-
Host:Channel:Target:LUN -
/dev/sd名 -
major:minor数値
例6.3 マルチパス設定での WWID マッピング
multipath -l コマンドの出力例:
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
DM Multipath は、各 WWID ベースのデバイス名から、システムで対応する /dev/sd 名への適切なマッピングを自動的に維持します。これらの名前は、パスが変更しても持続し、他のシステムからデバイスにアクセスする際に一貫性を保持します。
DM Multipath の user_friendly_names 機能を使用すると、WWID は /dev/mapper/mpathN 形式の名前にマップされます。デフォルトでは、このマッピングは /etc/multipath/bindings ファイルに保持されています。これらの mpathN 名は、そのファイルが維持されている限り永続的です。
user_friendly_names を使用する場合は、クラスター内で一貫した名前を取得するために追加の手順が必要です。
6.5. udev デバイス命名規則の制約
udev 命名規則の制約の一部は次のとおりです。
-
udevイベントに対してudevルールが処理されるときに、udevメカニズムはストレージデバイスをクエリーする機能に依存する可能性があるため、クエリーの実行時にデバイスにアクセスできない可能性があります。これは、ファイバーチャネル、iSCSI、または FCoE ストレージデバイスといった、デバイスがサーバーシャーシにない場合に発生する可能性が高くなります。 -
カーネルは
udevイベントをいつでも送信する可能性があるため、デバイスにアクセスできない場合に/dev/disk/by-*/リンクが削除される可能性があります。 -
udevイベントが生成されそのイベントが処理されるまでに遅延が生じる場合があります (大量のデバイスが検出され、ユーザー空間のudevサービスによる各デバイスのルールを処理するのにある程度の時間がかかる場合など)。これにより、カーネルがデバイスを検出してから、/dev/disk/by-*/の名前が利用できるようになるまでに遅延が生じる可能性があります。 -
ルールに呼び出される
blkidなどの外部プログラムによってデバイスが短期間開き、他の目的でデバイスにアクセスできなくなる可能性があります。 -
/dev/disk/ の
udevメカニズムで管理されるデバイス名は、メジャーリリース間で変更される可能性があるため、リンクの更新が必要になる場合があります。
6.6. 永続的な命名属性のリスト表示
非永続ストレージデバイスの永続的な命名属性を確認できます。
手順
UUID 属性とラベル属性をリスト表示するには、
lsblkユーティリティーを使用します。$ lsblk --fs storage-device以下に例を示します。
例6.4 ファイルシステムの UUID とラベルの表示
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /boot
PARTUUID 属性をリスト表示するには、
--output +PARTUUIDオプションを指定してlsblkユーティリティーを使用します。$ lsblk --output +PARTUUID以下に例を示します。
例6.5 パーティションの PARTUUID 属性の表示
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01
WWID 属性をリスト表示するには、
/dev/disk/by-id/ディレクトリーのシンボリックリンクのターゲットを調べます。以下に例を示します。例6.6 システムにある全ストレージデバイスの WWID の表示
$ file /dev/disk/by-id/* /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001 symbolic link to ../../sda /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part1 symbolic link to ../../sda1 /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part2 symbolic link to ../../sda2 /dev/disk/by-id/dm-name-rhel_rhel8-root symbolic link to ../../dm-0 /dev/disk/by-id/dm-name-rhel_rhel8-swap symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhP0RMFsNyySVihqEl2cWWbR7MjXJolD6g symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhXqH2M45hD2H9nAf2qfWSrlRLhzfMyOKd symbolic link to ../../dm-0 /dev/disk/by-id/lvm-pv-uuid-atlr2Y-vuMo-ueoH-CpMG-4JuH-AhEF-wu4QQm symbolic link to ../../sda2
6.7. 永続的な命名属性の変更
ファイルシステムの UUID またはラベルの永続的な命名属性を変更できます。
udev 属性の変更はバックグラウンドで行われ、時間がかかる場合があります。udevadm settle コマンドは、変更が完全に登録されるまで待機します。そのため、その後のコマンドで確実に新しい属性を正しく使用できます。
以下のコマンドでは、次を行います。
-
new-uuid を、設定する UUID (例:
1cdfbc07-1c90-4984-b5ec-f61943f5ea50) に置き換えます。uuidgenコマンドを使用して UUID を生成できます。 -
new-label を、ラベル (例:
backup_data) に置き換えます。
前提条件
- XFS ファイルシステムをアンマウントしている (XFS ファイルシステムの属性を変更する場合)。
手順
XFS ファイルシステムの UUID またはラベル属性を変更するには、
xfs_adminユーティリティーを使用します。# xfs_admin -U new-uuid -L new-label storage-device # udevadm settle
ext4 ファイルシステム、ext3 ファイルシステム、ext2 ファイルシステムの UUID またはラベル属性を変更するには、
tune2fsユーティリティーを使用します。# tune2fs -U new-uuid -L new-label storage-device # udevadm settle
スワップボリュームの UUID またはラベル属性を変更するには、
swaplabelユーティリティーを使用します。# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settle
第7章 parted でのパーティション操作
parted は、ディスクパーティションを操作するプログラムです。MS-DOS や GPT など、複数のパーティションテーブル形式をサポートしています。これは、新しいオペレーティングシステム用のスペースの作成、ディスクの使用方法の再編成、および新しいハードディスクへのデータのコピーに役立ちます。
7.1. parted でパーティションテーブルの表示
ブロックデバイスのパーティションテーブルを表示して、パーティションレイアウトと個々のパーティションの詳細を確認します。parted ユーティリティーを使用して、ブロックデバイスのパーティションテーブルを表示できます。
手順
partedユーティリティーを起動します。たとえば、次の出力は、デバイス/dev/sdaをリストします。# parted /dev/sdaパーティションテーブルを表示します。
(parted) print Model: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logicalオプション: 次に調べるデバイスに切り替えます。
(parted) select block-device
print コマンドの出力の詳細は、以下を参照してください。
Model: ATA SAMSUNG MZNLN256 (scsi)- ディスクタイプ、製造元、モデル番号、およびインターフェイス。
Disk /dev/sda: 256GB- ブロックデバイスへのファイルパスとストレージ容量。
Partition Table: msdos- ディスクラベルの種類。
Number-
パーティション番号。たとえば、マイナー番号 1 のパーティションは、
/dev/sda1に対応します。 StartおよびEnd- デバイスにおけるパーティションの開始場所と終了場所。
Type- 有効なタイプは、メタデータ、フリー、プライマリー、拡張、または論理です。
File system-
ファイルシステムの種類。ファイルシステムの種類が不明な場合は、デバイスの
File systemフィールドに値が表示されません。partedユーティリティーは、暗号化されたデバイスのファイルシステムを認識できません。 Flags-
パーティションのフラグ設定リスト。利用可能なフラグは、
boot、root、swap、hidden、raid、lvm、またはlbaです。
関連情報
-
システム上の
parted(8)man ページ
7.2. parted でディスクにパーティションテーブルを作成
parted ユーティリティーを使用して、より簡単にパーティションテーブルでブロックデバイスをフォーマットできます。
パーティションテーブルを使用してブロックデバイスをフォーマットすると、そのデバイスに保存されているすべてのデータが削除されます。
手順
インタラクティブな
partedシェルを起動します。# parted block-deviceデバイスにパーティションテーブルがあるかどうかを確認します。
(parted) printデバイスにパーティションが含まれている場合は、次の手順でパーティションを削除します。
新しいパーティションテーブルを作成します。
(parted) mklabel table-typetable-type を、使用するパーティションテーブルのタイプに置き換えます。
-
msdos(MBR の場合) -
gpt(GPT の場合)
-
例7.1 GUID パーティションテーブル (GPT) テーブルの作成
ディスクに GPT テーブルを作成するには、次のコマンドを使用します。
(parted) mklabel gptこのコマンドを入力すると、変更の適用が開始されます。
パーティションテーブルを表示して、作成されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quit
関連情報
-
システム上の
parted(8)man ページ
7.3. parted を使用したパーティションの作成
システム管理者は、parted ユーティリティーを使用してディスクに新しいパーティションを作成できます。
必要なパーティションは、swap、/boot/、および /(root) です。
前提条件
- ディスクのパーティションテーブル。
- 2TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしておく。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示し、十分な空き領域があるかどうかを確認します。
(parted) print- 十分な空き容量がない場合は、パーティションのサイズを変更してください。
パーティションテーブルから、以下を確認します。
- 新しいパーティションの開始点と終了点
- MBR で、どのパーティションタイプにすべきか
新しいパーティションを作成します。
(parted) mkpart part-type name fs-type start end-
part-type を
primary、logical、またはextendedに置き換えます。これは MBR パーティションテーブルにのみ適用されます。 - name を任意のパーティション名に置き換えます。これは GPT パーティションテーブルに必要です。
-
fs-type を、
xfs、ext2、ext3、ext4、fat16、fat32、hfs、hfs+、linux-swap、ntfs、またはreiserfsに置き換えます。fs-type パラメーターは任意です。partedユーティリティーは、パーティションにファイルシステムを作成しないことに注意してください。 -
start と end を、パーティションの開始点と終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。
例7.2 小さなプライマリーパーティションの作成
MBR テーブルに 1024MiB から 2048MiB までのプライマリーパーティションを作成するには、次のコマンドを使用します。
(parted) mkpart primary 1024MiB 2048MiBコマンドを入力すると、変更の適用が開始されます。
-
part-type を
パーティションテーブルを表示して、作成されたパーティションのパーティションタイプ、ファイルシステムタイプ、サイズが、パーティションテーブルに正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quit新規デバイスノードを登録します。
# udevadm settleカーネルが新しいパーティションを認識していることを確認します。
# cat /proc/partitions
関連情報
-
システム上の
parted(8)man ページ - parted でディスクにパーティションテーブルを作成
- parted でパーティションのサイズ変更
7.4. parted でパーティションの削除
parted ユーティリティーを使用すると、ディスクパーティションを削除して、ディスク領域を解放できます。
パーティションを削除すると、そのパーティションに保存されているすべてのデータが削除されます。
手順
インタラクティブな
partedシェルを起動します。# parted block-device-
block-device を、パーティションを削除するデバイスへのパス (例:
/dev/sda) に置き換えます。
-
block-device を、パーティションを削除するデバイスへのパス (例:
現在のパーティションテーブルを表示して、削除するパーティションのマイナー番号を確認します。
(parted) printパーティションを削除します。
(parted) rm minor-number- minor-number を、削除するパーティションのマイナー番号に置き換えます。
このコマンドを実行すると、すぐに変更の適用が開始されます。
パーティションテーブルからパーティションが削除されたことを確認します。
(parted) printpartedシェルを終了します。(parted) quitパーティションが削除されたことをカーネルが登録していることを確認します。
# cat /proc/partitions-
パーティションが存在する場合は、
/etc/fstabファイルからパーティションを削除します。削除したパーティションを宣言している行を見つけ、ファイルから削除します。 システムが新しい
/etc/fstab設定を登録するように、マウントユニットを再生成します。# systemctl daemon-reloadスワップパーティション、または LVM の一部を削除した場合は、カーネルコマンドラインからパーティションへの参照をすべて削除します。
アクティブなカーネルオプションを一覧表示し、削除されたパーティションを参照するオプションがないか確認します。
# grubby --info=ALL削除されたパーティションを参照するカーネルオプションを削除します。
# grubby --update-kernel=ALL --remove-args="option"
アーリーブートシステムに変更を登録するには、
initramfsファイルシステムを再構築します。# dracut --force --verbose
関連情報
-
システム上の
parted(8)man ページ
7.5. parted でパーティションのサイズ変更
parted ユーティリティーを使用して、パーティションを拡張して未使用のディスク領域を利用したり、パーティションを縮小してその容量をさまざまな目的に使用したりできます。
前提条件
- パーティションを縮小する前にデータをバックアップする。
- 2TiB を超えるパーティションを作成する場合は、GUID Partition Table (GPT) でディスクをフォーマットしておく。
- パーティションを縮小する場合は、サイズを変更したパーティションより大きくならないように、最初にファイルシステムを縮小しておく。
XFS は縮小に対応していません。
手順
partedユーティリティーを起動します。# parted block-device現在のパーティションテーブルを表示します。
(parted) printパーティションテーブルから、以下を確認します。
- パーティションのマイナー番号。
- 既存のパーティションの位置とサイズ変更後の新しい終了点。
パーティションのサイズを変更します。
(parted) resizepart 1 2GiB- 1 を、サイズを変更するパーティションのマイナー番号に置き換えます。
-
2 を、サイズを変更するパーティションの新しい終了点を決定するサイズに置き換えます (ディスクの開始からカウントします)。
512MiB、20GiB、1.5TiBなどのサイズ接尾辞を使用できます。デフォルトサイズの単位はメガバイトです。
パーティションテーブルを表示して、サイズ変更したパーティションのサイズが、パーティションテーブルで正しく表示されていることを確認します。
(parted) printpartedシェルを終了します。(parted) quitカーネルが新しいパーティションを登録していることを確認します。
# cat /proc/partitions- オプション: パーティションを拡張した場合は、そこにあるファイルシステムも拡張します。
関連情報
-
システム上の
parted(8)man ページ
第8章 ディスクを再設定するストラテジー
ディスクのパーティションを再設定する方法は複数あります。これには以下が含まれます。
- パーティションが分割されていない空き領域が利用できる。
- 未使用のパーティションが利用可能である。
- アクティブに使用されているパーティションの空き領域が利用可能である。
以下の例は、わかりやすくするために単純化されており、実際に Red Hat Enterprise Linux をインストールするときの正確なパーティションレイアウトは反映していません。
8.1. パーティションが分割されていない空き領域の使用
すでに定義されているパーティションはハードディスク全体にまたがらないため、定義されたパーティションには含まれない未割り当ての領域が残されます。次の図は、これがどのようになるかを示しています。
図8.1 パーティションが分割されていない空き領域があるディスク

最初の図は、1 つのプライマリーパーティションと未割り当て領域のある未定義のパーティションを持つディスクを表しています。2 番目の図は、スペースが割り当てられた 2 つの定義済みパーティションを持つディスクを表しています。
未使用のハードディスクもこのカテゴリーに分類されます。唯一の違いは、すべて の領域が定義されたパーティションの一部ではないことです。
新しいディスクでは、未使用の領域から必要なパーティションを作成できます。ほとんどのオペレーティングシステムは、ディスクドライブ上の利用可能な領域をすべて取得するように設定されています。
8.2. 未使用パーティションの領域の使用
次の例の最初の図は、未使用のパーティションを持つディスクを表しています。2 番目の図は、Linux の未使用パーティションの再割り当てを表しています。
図8.2 未使用のパーティションがあるディスク

未使用のパーティションに割り当てられた領域を使用するには、パーティションを削除してから、代わりに適切な Linux パーティションを作成します。または、インストールプロセス時に未使用のパーティションを削除し、新しいパーティションを手動で作成します。
8.3. アクティブなパーティションの空き領域の使用
すでに使用されているアクティブなパーティションには、必要な空き領域が含まれているため、このプロセスの管理は困難な場合があります。ほとんどの場合、ソフトウェアが事前にインストールされているコンピューターのハードディスクには、オペレーティングシステムとデータを保持する大きなパーティションが 1 つ含まれます。
アクティブなパーティションでオペレーティングシステム (OS) を使用する場合は、OS を再インストールする必要があります。ソフトウェアが事前にインストールされている一部のコンピューターには、元の OS を再インストールするためのインストールメディアが含まれていないことに注意してください。元のパーティションと OS インストールを破棄する前に、これが OS に当てはまるか確認してください。
使用可能な空き領域の使用を最適化するには、破壊的または非破壊的なパーティション再設定の方法を使用できます。
8.3.1. 破壊的な再設定
破壊的なパーティション再設定は、ハードドライブのパーティションを破棄し、代わりにいくつかの小さなパーティションを作成します。この方法は完全にコンテンツを削除するため、元のパーティションから必要なデータをバックアップします。
既存のオペレーティングシステム用に小規模なパーティションを作成すると、以下が可能になります。
- ソフトウェアをの再インストール。
- データの復元。
- Red Hat Enterprise Linux インストールの開始。
以下の図は、破壊的なパーティション再設定の方法を使用を簡潔に示しています。
図8.3 ディスク上での破壊的な再パーティション処理

このメソッドは、元のパーティションに保存されたデータをすべて削除します。
8.3.2. 非破壊的な再パーティション
非破壊的なパーティション再設定では、データの損失なしにパーティションのサイズを変更します。この方法は信頼性できますが、大きなドライブでは処理に時間がかかります。
以下は、破壊的なパーティション再設定の開始に役立つメソッドのリストです。
- 既存データの圧縮
一部のデータの保存場所は変更できません。これにより、必要なサイズへのパーティションのサイズ変更が妨げられ、最終的に破壊的なパーティション再設定プロセスが必要になる可能性があります。既存のパーティションでデータを圧縮すると、必要に応じてパーティションのサイズを変更できます。また、使用可能な空き容量を最大化することもできます。
以下の図は、このプロセスを簡略化したものです。
図8.4 ディスク上でのデータ圧縮
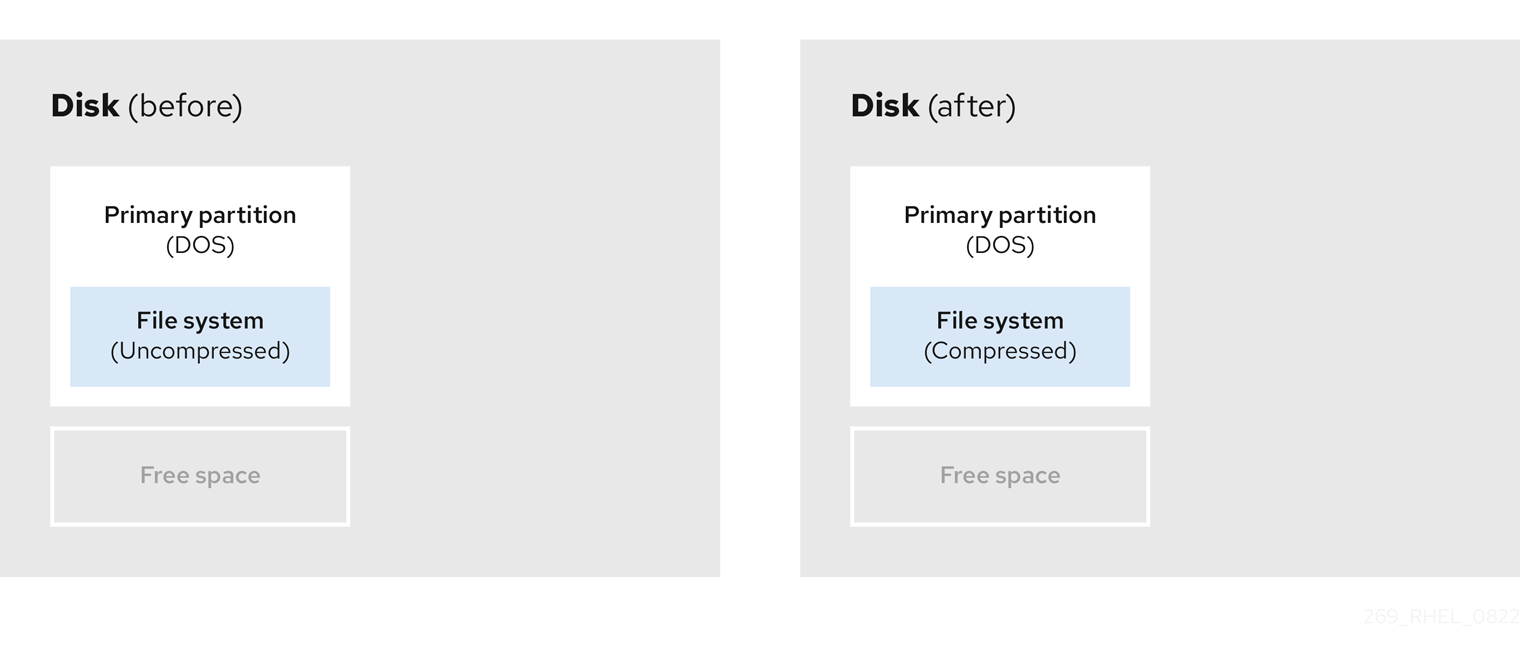
データ損失の可能性を回避するには、圧縮プロセスを続行する前にバックアップを作成します。
- 既存パーティションのサイズ変更
既存のパーティションのサイズを変更すると、より多くの領域を解放できます。結果は、サイズ変更ソフトウェアにより異なります。多くの場合、元のパーティションと同じタイプのフォーマットされていない新しいパーティションを作成できます。
サイズ変更後の手順は、使用するソフトウェアにより異なります。以下の例では、新しい DOS (Disk Operating System) パーティションを削除し、代わりに Linux パーティションを作成することを推奨します。サイズ変更プロセスを開始する前に、何がディスクに最適か確認してください。
図8.5 ディスク上でのパーティションのサイズ変更

- オプション: 新規パーティションの作成
一部のサイズ変更ソフトウェアは、Linux ベースのシステムをサポートしています。この場合、サイズ変更後に新たに作成されたパーティションを削除する必要はありません。新しいパーティションの作成方法は、使用するソフトウェアによって異なります。
以下の図は、新しいパーティションを作成する前後のディスクの状態を示しています。
図8.6 最終パーティション設定のディスク

第9章 XFS の使用
これは、XFS ファイルシステムを作成および維持する方法の概要です。
9.1. XFS ファイルシステム
XFS は、拡張性が高く、高性能で堅牢な、成熟した 64 ビットのジャーナリングファイルシステムで、1 台のホストで非常に大きなファイルおよびファイルシステムに対応します。Red Hat Enterprise Linux 8 ではデフォルトのファイルシステムになります。XFS は、元々 1990 年代の前半に SGI により開発され、極めて大規模なサーバーおよびストレージアレイで実行されてきた長い歴史があります。
XFS の機能は次のとおりです。
- 信頼性
- メタデータジャーナリング - システムの再起動時、およびファイルシステムの再マウント時に再生できるファイルシステム操作の記録を保持することで、システムクラッシュ後のファイルシステムの整合性を確保します。
- 広範囲に及ぶランタイムメタデータの整合性チェック
- 拡張性が高く、高速な修復ユーティリティー
- クォータジャーナリングクラッシュ後に行なわれる、時間がかかるクォータの整合性チェックが不要になります。
- スケーラビリティーおよびパフォーマンス
- 対応するファイルシステムのサイズが最大 1024 TiB
- 多数の同時操作に対応する機能
- 空き領域管理のスケーラビリティーに関する B-Tree インデックス
- 高度なメタデータ先読みアルゴリズム
- ストリーミングビデオのワークロードの最適化
- 割り当てスキーム
- エクステント (領域) ベースの割り当て
- ストライプを認識できる割り当てポリシー
- 遅延割り当て
- 領域の事前割り当て
- 動的に割り当てられる inode
- その他の機能
- Reflink ベースのファイルのコピー
- 密接に統合されたバックアップおよび復元のユーティリティー
- オンラインのデフラグ
- オンラインのファイルシステム拡張
- 包括的な診断機能
-
拡張属性 (
xattr)。これにより、システムが、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 - プロジェクトまたはディレクトリーのクォータ。ディレクトリーツリー全体にクォータ制限を適用できます。
- サブセカンド (一秒未満) のタイムスタンプ
パフォーマンスの特徴
XFS は、エンタープライズレベルのワークロードがある大規模なシステムで優れたパフォーマンスを発揮します。大規模なシステムとは、相対的に CPU 数が多く、さらには複数の HBA、および外部ディスクアレイへの接続を備えたシステムです。XFS は、マルチスレッドの並列 I/O ワークロードを備えた小規模のシステムでも適切に実行します。
XFS は、シングルスレッドで、メタデータ集約型のワークロードのパフォーマンスが比較的低くなります。たとえば、シングルスレッドで小さなファイルを多数作成し、削除するワークロードがこれに当てはまります。
9.2. ext4 および XFS で使用されるツールの比較
このセクションでは、ext4 ファイルシステムおよび XFS ファイルシステムで一般的なタスクを行うのに使用するツールを比較します。
| タスク | ext4 | XFS |
|---|---|---|
| ファイルシステムを作成する |
|
|
| ファイルシステム検査 |
|
|
| ファイルシステムのサイズを変更する |
|
|
| ファイルシステムのイメージを保存する |
|
|
| ファイルシステムのラベル付けまたはチューニングを行う |
|
|
| ファイルシステムのバックアップを作成する |
|
|
| クォータ管理 |
|
|
| ファイルマッピング |
|
|
第10章 XFS ファイルシステムの作成
システム管理者は、ブロックデバイスに XFS ファイルシステムを作成して、ファイルやディレクトリーを格納できます。
10.1. mkfs.xfs で XFS ファイルシステムの作成
この手順では、ブロックデバイスに XFS ファイルシステムを作成する方法を説明します。
手順
ファイルシステムを作成する場合は、以下の手順を実行します。
デバイスが通常のパーティション、LVM ボリューム、MD ボリューム、ディスク、または類似デバイスである場合は、次のコマンドを使用します。
# mkfs.xfs block-device-
block-device を、ブロックデバイスへのパスに置き換えます。たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。 - 通常、デフォルトのオプションは、一般的な使用に最適なものです。
-
既存のファイルシステムを含むブロックデバイスで
mkfs.xfsを使用する場合は、そのファイルシステムを上書きする-fオプションを追加してください。
-
block-device を、ブロックデバイスへのパスに置き換えます。たとえば、
ハードウェア RAID デバイスにファイルシステムを作成する場合は、システムがデバイスのストライプジオメトリーを正しく検出しているかどうかを確認します。
ストライプジオメトリー情報が正しい場合は、追加のオプションが必要ありません。ファイルシステムを作成します。
# mkfs.xfs block-device情報が正しくない場合は、
-dオプションのsuパラメーターおよびswパラメーターを使用して、ストライプジオメトリーを手動で指定します。suパラメーターは RAID チャンクサイズを指定し、swパラメーターは RAID デバイス内のデータディスクの数を指定します。以下に例を示します。
# mkfs.xfs -d su=64k,sw=4 /dev/sda3
次のコマンドを使用して、システムが新しいデバイスノードを登録するまで待機します。
# udevadm settle
関連情報
-
システム上の
mkfs.xfs(8)man ページ
第11章 XFS ファイルシステムのバックアップ
システム管理者は、xfsdump を使用して XFS ファイルシステムをファイルまたはテープにバックアップできます。これは、簡単なバックアップメカニズムを提供します。
11.1. XFS バックアップの機能
このセクションでは、xfsdump ユーティリティーを使用して XFS ファイルシステムをバックアップする場合の主な概念と機能を説明します。
xfsdump ユーティリティーを使用すると次のことができます。
通常のファイルイメージへのバックアップ
通常のファイルに書き込むことができるバックアップは 1 つだけです。
テープドライブへのバックアップ
xfsdumpユーティリティーを使用すると、同じテープに複数のバックアップを書き込むこともできます。バックアップは、複数のテープを分割して書き込むことができます。複数のファイルシステムのバックアップを 1 つのテープデバイスに作成するには、XFS バックアップがすでに含まれているテープにバックアップを書き込みます。これにより、古いバックアップに、新しいバックアップが追加されます。
xfsdumpは、デフォルトでは既存のバックアップを上書しません。増分バックアップの作成
xfsdumpユーティリティーはダンプレベルを使用して、その他のバックアップの相対的なベースバックアップを決定します。0 から 9 までの数字は、ダンプレベルの増加を表します。増分バックアップは、下位レベルの最後のダンプ以降に変更したファイルのみが対象となります。- フルバックアップを実行する場合は、ファイルシステムでレベル 0 のダンプを実行します。
- レベル 1 のダンプは、フルバックアップ後の最初の増分バックアップです。次の増分バックアップはレベル 2 になります。これは、前回のレベル 1 のダンプ以降に変更したファイルのみが対象となります。レベル 9 まで同様です。
- ファイルを絞り込むサイズ、サブツリー、または inode のフラグを使用して、バックアップからファイルを除外
関連情報
-
システム上の
xfsdump(8)man ページ
11.2. xfsdump で XFS ファイルシステムのバックアップ
この手順では、XFS ファイルシステムのコンテンツのバックアップを、ファイルまたはテープに作成する方法を説明します。
前提条件
- バックアップが可能な XFS ファイルシステム
- バックアップを保存できる別のファイルシステムまたはテープドライブ
手順
次のコマンドを使用して、XFS ファイルシステムのバックアップを作成します。
# xfsdump -l level [-L label] \ -f backup-destination path-to-xfs-filesystem-
level を、バックアップのダンプレベルに置き換えます。フルバックアップを実行する場合は
0を使用し、それに続く増分バックアップを実行する場合は1から9を使用します。 -
backup-destination を、バックアップを保存する場所のパスに置き換えます。保存場所は、通常のファイル、テープドライブ、またはリモートテープデバイスです。たとえば、ファイルの場合は
/backup-files/Data.xfsdump、テープドライブの場合は/dev/st0に置き換えます。 -
path-to-xfs-filesystem を、バックアップを作成する XFS ファイルシステムのマウントポイントに置き換えます。たとえば、
/mnt/data/に置き換えます。ファイルシステムをマウントする必要があります。 -
複数のファイルシステムのバックアップを作成して 1 つのテープデバイスに保存する場合は、復元時にそれらを簡単に識別できるように
-L labelオプションを使用して、各バックアップにセッションラベルを追加します。label を、バックアップの名前 (例:backup_data) に置き換えます。
-
level を、バックアップのダンプレベルに置き換えます。フルバックアップを実行する場合は
例11.1 複数の XFS ファイルシステムのバックアップ
/boot/ディレクトリーおよび/data/ディレクトリーにマウントされている XFS ファイルシステムのコンテンツのバックアップを作成し、作成したバックアップ内容をファイルとして/backup-files/ディレクトリーに保存するには、次のコマンドを実行します。# xfsdump -l 0 -f /backup-files/boot.xfsdump /boot # xfsdump -l 0 -f /backup-files/data.xfsdump /data
1 つのテープデバイスにある複数のファイルシステムのバックアップを作成する場合は、
-L labelオプションを使用して、各バックアップにセッションラベルを追加します。# xfsdump -l 0 -L "backup_boot" -f /dev/st0 /boot # xfsdump -l 0 -L "backup_data" -f /dev/st0 /data
関連情報
-
システム上の
xfsdump(8)man ページ
第12章 バックアップからの XFS ファイルシステムの復元
システム管理者は、xfsrestore ユーティリティーを使用して、xfsdump ユーティリティーで作成され、ファイルまたはテープに保存されている XFS バックアップを復元できます。
12.1. バックアップから XFS を復元する機能
xfsrestore ユーティリティーは、xfsdump により作成されたバックアップからファイルシステムを復元します。xfsrestore ユーティリティーには 2 つのモードがあります。
- simple モードでは、ユーザーはレベル 0 のダンプからファイルシステム全体を復元できます。これがデフォルトのモードです。
- cumulative モードでは、増分バックアップ (つまりレベル 1 からレベル 9) からファイルシステムを復元できます。
各バックアップは、session ID または session label で一意に識別されます。複数のバックアップを含むテープからバックアップを復元するには、対応するセッション ID またはラベルが必要です。
バックアップから特定のファイルを抽出、追加、または削除するには、xfsrestore インタラクティブモードを起動します。インタラクティブモードでは、バックアップファイルを操作する一連のコマンドが提供されます。
関連情報
-
システム上の
xfsrestore(8)man ページ
12.2. xfsrestore を使用してバックアップから XFS ファイルシステムを復元
この手順では、XFS ファイルシステムの内容を、ファイルまたはテープのバックアップから復元する方法を説明します。
前提条件
- XFS ファイルシステムのバックアップの作成 の説明に従って、XFS ファイルシステムのファイルまたはテープのバックアップ
- バックアップを復元できるストレージデバイス。
手順
バックアップを復元するコマンドは、フルバックアップから復元するか、増分バックアップから復元するか、1 つのテープデバイスから複数のバックアップを復元するかによって異なります。
# xfsrestore [-r] [-S session-id] [-L session-label] [-i] -f backup-location restoration-path-
backup-location を、バックアップの場所に置き換えます。これは、通常のファイル、テープドライブ、またはリモートテープデバイスになります。たとえば、ファイルの場合は
/backup-files/Data.xfsdump、テープドライブの場合は/dev/st0に置き換えます。 -
restoration-path を、ファイルシステムを復元するディレクトリーへのパスに置き換えます。たとえば、
/mnt/data/に置き換えます。 -
ファイルシステムを増分 (レベル 1 からレベル 9) バックアップから復元するには、
-rオプションを追加します。 複数のバックアップを含むテープデバイスからバックアップを復元するには、
-Sオプションまたは-Lオプションを使用してバックアップを指定します。-Sオプションではセッション ID でバックアップを選択でき、-Lオプションではセッションラベルで選択できます。セッション ID とセッションラベルを取得するには、xfsrestore -Iコマンドを使用します。session-id を、バックアップのセッション ID に置き換えます。たとえば、
b74a3586-e52e-4a4a-8775-c3334fa8ea2cに置き換えます。session-label を、バックアップのセッションラベルに置き換えます。たとえば、my_backup_session_labelに置き換えます。xfsrestoreをインタラクティブに使用するには、-iオプションを使用します。インタラクティブダイアログは、指定されたデバイスの、
xfsrestoreによる読み取りが終了してから始まります。インタラクティブなxfsrestoreシェルの使用可能なコマンドには、cd、ls、add、delete、extractがあります。コマンドの全リストを見るには、helpコマンドを使用します。
-
backup-location を、バックアップの場所に置き換えます。これは、通常のファイル、テープドライブ、またはリモートテープデバイスになります。たとえば、ファイルの場合は
例12.1 複数の XFS ファイルシステムの復元
XFS バックアップファイルを復元し、その内容を
/mnt/配下のディレクトリーに保存するには、次のコマンドを実行します。# xfsrestore -f /backup-files/boot.xfsdump /mnt/boot/ # xfsrestore -f /backup-files/data.xfsdump /mnt/data/
複数のバックアップを含むテープデバイスから復元するには、各バックアップをセッションラベルまたはセッション ID で指定します。
# xfsrestore -L "backup_boot" -f /dev/st0 /mnt/boot/ # xfsrestore -S "45e9af35-efd2-4244-87bc-4762e476cbab" \ -f /dev/st0 /mnt/data/
関連情報
-
システム上の
xfsrestore(8)man ページ
12.3. テープから XFS バックアップを復元するときの情報メッセージ
複数のファイルシステムのバックアップを使用してテープからバックアップを復元するとき、xfsrestore ユーティリティーがメッセージを出力することがあります。メッセージは、xfsrestore がテープ上の各バックアップを順番に調べたときに、要求されたバックアップと一致するものが見つかったかどうかを通知します。以下に例を示します。
xfsrestore: preparing drive xfsrestore: examining media file 0 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) xfsrestore: examining media file 1 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) [...]
情報メッセージは、一致するバックアップが見つかるまで継続して表示されます。
第13章 XFS ファイルシステムのサイズの拡大
システム管理者は、XFS ファイルシステムのサイズを増やして、より大きなストレージ容量を最大限に活用できます。
現在、XFS ファイルシステムのサイズを縮小することはできません。
13.1. xfs_growfs で XFS ファイルシステムのサイズの拡大
この手順では、xfs_growfs ユーティリティーを使用して XFS ファイルシステムを拡張する方法を説明します。
前提条件
- 基礎となるブロックデバイスのサイズが、後でファイルシステムのサイズを変更するのに十分な大きさである。該当するブロックデバイスのサイズを変更する場合は、ブロックデバイスに適した方法を選択してください。
- XFS ファイルシステムをマウントしている。
手順
XFS ファイルシステムのマウント時に、
xfs_growfsユーティリティーを使用してサイズを大きくします。# xfs_growfs file-system -D new-size- file-system を、XFS ファイルシステムのマウントポイントに置き換えます。
-Dオプションを指定して、new-size を、ファイルシステムブロックの数で指定されているファイルシステムの新しいサイズに置き換えます。特定の XFS ファイルシステムのブロックサイズ (KB 単位) を調べるには、
xfs_infoユーティリティーを使用します。# xfs_info block-device ... data = bsize=4096 ...-
xfs_growfsは、-Dオプションを指定しないと、基となるデバイスがサポートする最大サイズまでファイルシステムを拡張します。
関連情報
-
システム上の
xfs_growfs(8)man ページ
第14章 XFS エラー動作の設定
異なる I/O エラーが発生すると、XFS ファイルシステムの動作を設定できます。
14.1. XFS で設定可能なエラー処理
XFS ファイルシステムは、I/O 操作中にエラーが発生すると、以下のいずれかの方法で応答します。
XFS は、操作が成功するまで、または XFS が設定制限に到達するまで I/O 操作を繰り返し再試行します。
この制限は、再試行の最大数または再試行の最大時間を基にしています。
- XFS は、エラーを永続的に考慮し、ファイルシステムで操作を停止します。
XFS が以下のエラー条件に反応する方法を設定できます。
EIO- 読み取りまたは書き込み時のエラー
ENOSPC- デバイスに空き容量がない
ENODEV- デバイスが見つからない
最大再試行回数と、XFS がエラーを永続的と見なすまでの最大時間を秒単位で設定できます。XFS は、いずれかの制限に達すると操作の再試行を停止します。
また、ファイルシステムのマウントを解除するときに、他の設定に関係なく XFS が再試行を即座にキャンセルするように XFS を設定することもできます。この設定により、永続的なエラーを出しても、マウント解除操作は成功します。
デフォルトの動作
各 XFS エラー条件のデフォルトの動作は、エラーコンテキストによって異なります。ENODEV などの XFS エラーは、リトライ回数に関係なく致命的で回復不能とみなされます。デフォルトの再試行制限は 0 です。
14.2. 特定の、未定義の XFS エラー条件の設定ファイル
以下のディレクトリーは、さまざまなエラー状態に対して XFS エラー動作を制御する設定ファイルを保存します。
/sys/fs/xfs/device/error/metadata/EIO/-
EIOエラー条件の場合 /sys/fs/xfs/device/error/metadata/ENODEV/-
ENODEVエラー条件の場合 /sys/fs/xfs/device/error/metadata/ENOSPC/-
ENOSPCエラー条件の場合 /sys/fs/xfs/device/error/default/- その他のすべての未定義エラー条件の共通設定
各ディレクトリーには、再試行制限を設定するために以下の設定ファイルが含まれています。
max_retries- XFS が操作を再試行する最大回数を制御します。
retry_timeout_seconds- XFS が操作の再試行を停止するまでの時間制限を秒単位で指定します。
14.3. 特定の条件に対する XFS 動作の設定
この手順では、XFS が特定のエラー条件にどのように反応するかを設定します。
手順
再試行の最大数、再試行時間制限、またはその両方を設定します。
再試行の最大数を設定するには、必要な数を
max_retriesファイルに書き込みます。# echo value > /sys/fs/xfs/device/error/metadata/condition/max_retries時間制限を設定するには、希望する秒数を
retry_timeout_secondsファイルに書き込みます。# echo value > /sys/fs/xfs/device/error/metadata/condition/retry_timeout_second
value は、-1 から C 符号付き整数型の可能な最大値です。これは、64 ビットの Linux では 2147483647 です。
いずれの制限も、
-1の値は継続的な再試行に使用され、0は即座に停止するために使用されます。device は、
/dev/ディレクトリーにあるデバイス名です。たとえば、sdaです。
14.4. 未定義の条件に対する XFS 動作の設定
この手順では、XFS が、共通の設定を共有するすべての未定義のエラー条件に反応する方法を設定します。
手順
再試行の最大数、再試行時間制限、またはその両方を設定します。
再試行の最大数を設定するには、必要な数を
max_retriesファイルに書き込みます。# echo value > /sys/fs/xfs/device/error/metadata/default/max_retries時間制限を設定するには、希望する秒数を
retry_timeout_secondsファイルに書き込みます。# echo value > /sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds
value は、-1 から C 符号付き整数型の可能な最大値です。これは、64 ビットの Linux では 2147483647 です。
いずれの制限も、
-1の値は継続的な再試行に使用され、0は即座に停止するために使用されます。device は、
/dev/ディレクトリーにあるデバイス名です。たとえば、sdaです。
14.5. XFS アンマウント動作の設定
この手順では、ファイルシステムのアンマウント時に XFS がエラー状態に対応するように設定します。
ファイルシステムに fail_at_unmount オプションを設定すると、マウント解除時にその他すべてのエラー設定が上書きされ、I/O 操作を再試行せずにすぐにファイルシステムをマウント解除します。これにより、永続的なエラーが発生した場合でも、マウント解除操作を成功できます。
マウント解除プロセスの開始後に fail_at_unmount の値を変更することはできません。アンマウントプロセスにより、設定ファイルが各ファイルシステムの sysfs インターフェイスから削除されます。ファイルシステムのマウント解除を開始する前に、マウント解除動作を設定する必要があります。
手順
fail_at_unmountオプションを有効または無効にします。ファイルシステムのマウント解除時にすべての操作を再試行する場合は、オプションを有効にします。
# echo 1 > /sys/fs/xfs/device/error/fail_at_unmountファイルシステムのマウント解除時に、再試行制限の
max_retriesおよびretry_timeout_secondsを回避するには、オプションを無効にします。# echo 0 > /sys/fs/xfs/device/error/fail_at_unmount
device は、
/dev/ディレクトリーにあるデバイス名です。たとえば、sdaです。
第15章 ファイルシステムの検査と修復
RHEL は、ファイルシステムの検査および修復が可能なファイルシステム管理ユーティリティーを提供します。このツールは、通常 fsck ツールと呼ばれることが多く、fsck は、file system check を短くした名前になります。ほとんどの場合、このようなユーティリティーは、必要に応じてシステムの起動時に自動的に実行しますが、必要な場合は手動で呼び出すこともできます。
ファイルシステムチェッカーは、ファイルシステム全体のメタデータの整合性のみを保証します。チェッカーは、ファイルシステムに含まれる実際のデータを認識しないため、データのリカバリーツールではありません。
15.1. ファイルシステムの検査が必要なシナリオ
以下のいずれかが発生した場合は、関連する fsck ツールを使用してシステムを検査できます。
- システムが起動しない
- 特定ディスクのファイルが破損する
- 不整合によりファイルシステムがシャットダウンするか、読み取り専用に変更する
- ファイルシステムのファイルにアクセスできない
ファイルシステムの不整合は、ハードウェアエラー、ストレージ管理エラー、ソフトウェアバグなどのさまざまな理由で発生する可能性があります。
ファイルシステムの検査ツールは、ハードウェアの問題を修復できません。修復を正常に動作させるには、ファイルシステムが完全に読み取り可能かつ書き込み可能である必要があります。ハードウェアエラーが原因でファイルシステムが破損した場合は、まず dd(8) ユーティリティーなどを使用して、ファイルシステムを適切なディスクに移動する必要があります。
ジャーナリングファイルシステムの場合、システムの起動時に通常必要なのは、必要に応じてジャーナルを再生することだけで、これは通常非常に短い操作になります。
ただし、ジャーナリングファイルシステムであっても、ファイルシステムの不整合や破損が発生した場合は、ファイルシステムチェッカーを使用してファイルシステムを修復する必要があります。
/etc/fstab の 6 番目のフィールドを 0 に設定すると、システムの起動時にファイルシステムの検査を無効にできます。ただし、Red Hat は、システムの起動時に fsck に問題がある場合 (非常に大きなファイルシステムやリモートファイルシステムなど) を除いて、無効にすることを推奨しません。
関連情報
-
システム上の
fstab(5)、fsck(8)、およびdd(8)man ページ
15.2. fsck の実行による潜在的な悪影響
通常、ファイルシステムの検査および修復のツールを実行すると、検出された不整合の少なくとも一部が自動的に修復されることが期待できます。場合によっては、以下の問題が発生する場合があります。
- inode やディレクトリーが大幅に損傷し、修復できない場合は、破棄される場合があります。
- ファイルシステムが大きく変更する場合があります。
予期しない変更や、望ましくない変更が永続的に行われないようにするには、この手順にまとめられている予防手順を行ってください。
15.3. XFS のエラー処理メカニズム
このセクションでは、XFS がファイルシステム内のさまざまな種類のエラーを処理する方法を説明します。
不完全なアンマウント
ジャーナリングは、ファイルシステムで発生したメタデータの変更のトランザクション記録を保持します。
システムクラッシュ、電源障害、またはその他の不完全なアンマウントが発生した場合、XFS はジャーナル (ログとも呼ばれる) を使用してファイルシステムを復旧します。カーネルは XFS ファイルシステムをマウントするときにジャーナルの復旧を実行します。
破損
この文脈での 破損 は、次のような原因によるファイルシステムのエラーを意味します。
- ハードウェア障害
- ストレージファームウェア、デバイスドライバー、ソフトウェアスタック、またはファイルシステム自体のバグ
- ファイルシステムの一部が、ファイルシステム外の何かにより上書きされる問題
XFS は、ファイルシステムまたはファイルシステムメタデータの破損を検出すると、ファイルシステムをシャットダウンして、システムログにインシデントを報告することがあります。/var ディレクトリーが置かれているファイルシステムで破損が発生すると、このログは再起動後に利用できなくなります。
例15.1 XFS の破損を報告するシステムログエントリー
# dmesg --notime | tail -15
XFS (loop0): Mounting V5 Filesystem
XFS (loop0): Metadata CRC error detected at xfs_agi_read_verify+0xcb/0xf0 [xfs], xfs_agi block 0x2
XFS (loop0): Unmount and run xfs_repair
XFS (loop0): First 128 bytes of corrupted metadata buffer:
00000000027b3b56: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000005f9abc7a: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000005b0aef35: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000000da9d2ded: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000001e265b07: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000006a40df69: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
000000000b272907: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000000e484aac5: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
XFS (loop0): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x2 len 1 error 74
XFS (loop0): xfs_imap_lookup: xfs_ialloc_read_agi() returned error -117, agno 0
XFS (loop0): Failed to read root inode 0x80, error 11ユーザー空間ユーティリティーは通常、破損した XFS ファイルシステムにアクセスしようとすると Input/output error メッセージを報告します。破損したログを使用して XFS ファイルシステムをマウントすると、マウントに失敗し、次のエラーメッセージが表示されます。
mount: /mount-point: mount(2) system call failed: Structure needs cleaning.
破損を修復するには、手動で xfs_repair ユーティリティーを使用する必要があります。
関連情報
-
システム上の
xfs_repair(8)man ページ
15.4. xfs_repair による XFS ファイルシステムの検査
xfs_repair ユーティリティーを使用して、XFS ファイルシステムの読み取り専用チェックを実行します。xfs_repair は、その他のファイルシステム修復ユーティリティーとは異なり、XFS ファイルシステムが正しくアンマウントされていなくても起動時には動作しません。正しくアンマウントされていない場合も、XFS はマウント時にログを再生するだけで、一貫したファイルシステムを確保します。xfs_repair は、ダーティーログがある XFS ファイルシステムを修復する場合、先にファイルシステムを再マウントする必要があります。
xfsprogs パッケージには fsck.xfs バイナリーがありますが、これは、システムの起動時に fsck.file システムバイナリーを検索する initscripts を満たすためにのみ存在します。fsck.xfs は、すぐに終了コード 0 で終了します。
手順
ファイルシステムをマウントおよびアンマウントしてログを再生します。
# mount file-system # umount file-system
注記マウントが structure needs cleaning (構造のクリーニングが必要) エラーで失敗した場合は、ログが破損しているため再生できません。ドライランは、結果として、より多くのディスク上の破損を検出して報告する必要があります。
xfs_repairユーティリティーを使用してドライランを実行し、ファイルシステムを検査します。エラーが表示され、ファイルシステムを変更せずに実行できるアクションが示されます。# xfs_repair -n block-deviceファイルシステムをマウントします。
# mount file-system
関連情報
-
システム上の
xfs_repair(8)およびxfs_metadump(8)man ページ
15.5. xfs_repair で XFS ファイルシステムの修復
この手順では、xfs_repair ユーティリティーを使用して破損した XFS ファイルシステムを修復します。
手順
xfs_metadumpユーティリティーを使用して、診断またはテストの目的で、修復する前にメタデータイメージを作成します。修復前のファイルシステムメタデータイメージは、破損がソフトウェアのバグによるものであるかどうかのサポート調査に役立ちます。修復前のイメージに含まれる破損のパターンは、根本的な分析に役に立つ場合があります。xfs_metadumpデバッグツールを使用して、XFS ファイルシステムからファイルにメタデータをコピーします。サポートに大きなメタダンプファイルを送信する必要がある場合は、標準の圧縮ユーティリティーを使用して生成されたメタダンプファイルを圧縮してファイルサイズを縮小できます。# xfs_metadump block-device metadump-file
ファイルシステムを再マウントしてログを再生します。
# mount file-system # umount file-system
アンマウントしたファイルシステムを修復するには、
xfs_repairユーティリティーを使用します。マウントが成功した場合、追加のオプションは必要ありません。
# xfs_repair block-deviceマウントが Structure needs cleaning エラーで失敗した場合は、ログが破損しているため再生できません。ログを消去するには、
-Lオプション (force log zeroing) を使用します。警告このコマンドを実行すると、クラッシュ時に進行中だったすべてのメタデータの更新が失われます。これにより、ファイルシステムに重大な損傷やデータ損失が生じる可能性があります。これは、ログを再生できない場合に最後の手段としてのみ使用してください。
# xfs_repair -L block-device
ファイルシステムをマウントします。
# mount file-system
関連情報
-
システム上の
xfs_repair(8)man ページ
15.6. ext2、ext3、および ext4 でエラー処理メカニズム
ext2、ext3、および ext4 のファイルシステムは、e2fsck ユーティリティーを使用して、ファイルシステムの検査と修復を実行します。ファイル名の fsck.ext2、fsck.ext3、および fsck.ext4 は、e2fsck ユーティリティーへのハードリンクです。これらのバイナリーは、システムの起動時に自動的に実行し、その動作は確認されるファイルシステムと、そのファイルシステムの状態によって異なります。
完全なファイルシステムの検査および修復は、メタデータジャーナリングファイルシステムではない ext2 や、ジャーナルのない ext4 ファイルシステムに対して呼び出されます。
メタデータジャーナリング機能のある ext3 ファイルシステムおよび ext4 ファイルシステムの場合、ジャーナルはユーザー空間で再生され、ユーティリティーは終了します。これは、ジャーナルの再生によりクラッシュ後のファイルシステムの整合性が確保されるためのデフォルト動作になります。
このファイルシステムで、マウント中にメタデータの不整合が生じると、その事実がファイルシステムのスーパーブロックに記録されます。e2fsck が、このようなエラーでファイルシステムがマークされていることを検出すると、e2fsck はジャーナル (がある場合) の再生後にフルチェックを実行します。
関連情報
-
システム上の
fsck(8)およびe2fsck(8)man ページ
15.7. e2fsck で ext2、ext3、または ext4 ファイルシステムの検査
この手順では、e2fsck ユーティリティーを使用して、ext2 ファイルシステム、ext3 ファイルシステム、または ext4 ファイルシステムを検査します。
手順
ファイルシステムを再マウントしてログを再生します。
# mount file-system # umount file-system
ドライランを実行して、ファイルシステムを検査します。
# e2fsck -n block-device注記エラーが表示され、ファイルシステムを変更せずに実行できるアクションが示されます。整合性チェック後のフェーズでは、修復モードで実行していた場合に前のフェーズで修正されていた不整合が検出される可能性があるため、追加のエラーが出力される場合があります。
関連情報
-
システム上の
e2image(8)およびe2fsck(8)man ページ
15.8. e2fsck で ext2、ext3、または ext4 ファイルシステムの修復
この手順では、e2fsck ユーティリティーを使用して、破損した ext2、ext3、または ext 4 のファイルシステムを修復します。
手順
サポート調査のためにファイルシステムイメージを保存します。修復前のファイルシステムメタデータイメージは、破損がソフトウェアのバグによるものであるかどうかのサポート調査に役立ちます。修復前のイメージに含まれる破損のパターンは、根本的な分析に役に立つ場合があります。
注記ファイルシステムが大幅に損傷している場合は、メタデータイメージの作成に関連して問題が発生する可能性があります。
テスト目的でイメージを作成する場合は、
-rオプションを指定して、ファイルシステム自体と同じサイズのスパースファイルを作成します。その後、e2fsckは作成されたファイルで直接操作できます。# e2image -r block-device image-file診断用にアーカイブまたは提供するイメージを作成する場合は、
-Qオプションを使用して、転送に適したよりコンパクトなファイル形式を作成します。# e2image -Q block-device image-file
ファイルシステムを再マウントしてログを再生します。
# mount file-system # umount file-system
ファイルシステムを自動的に修復します。ユーザーの介入が必要な場合は、
e2fsckが出力の未修正の問題を示し、このステータスを終了コードに反映させます。# e2fsck -p block-device関連情報
-
システム上の
e2image(8)man ページ -
システム上の
e2fsck(8)man ページ
-
システム上の
第16章 ファイルシステムのマウント
システム管理者は、システムにファイルシステムをマウントすると、ファイルシステムのデータにアクセスできます。
16.1. Linux のマウントメカニズム
以下は、Linux でのファイルシステムのマウントに関する基本的な概念です。
Linux、UNIX、および類似のオペレーティングシステムでは、さまざまなパーティションおよびリムーバブルデバイス (CD、DVD、USB フラッシュドライブなど) にあるファイルシステムをディレクトリーツリーの特定のポイント (マウントポイント) に接続して、再度切り離すことができます。ファイルシステムがディレクトリーにマウントされている間は、そのディレクトリーの元の内容にアクセスすることはできません。
Linux では、ファイルシステムがすでに接続されているディレクトリーにファイルシステムをマウントできます。
マウント時には、次の方法でデバイスを識別できます。
-
UUID (universally unique identifier):
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cbなど -
ボリュームラベル -
LABEL=homeなど -
非永続的なブロックデバイスへのフルパス -
/dev/sda3など
デバイス名、目的のディレクトリー、ファイルシステムタイプなど、必要な情報をすべて指定せずに mount コマンドを使用してファイルシステムをマウントすると、mount ユーティリティーは /etc/fstab ファイルの内容を読み取り、指定のファイルシステムが記載されているかどうかを確認します。/etc/fstab ファイルには、選択したファイルシステムがマウントされるデバイス名およびディレクトリーのリスト、ファイルシステムタイプ、およびマウントオプションが含まれます。そのため、/etc/fstab で指定されたファイルシステムをマウントする場合は、以下のコマンド構文で十分です。
マウントポイントによるマウント:
# mount directoryブロックデバイスによるマウント:
# mount device
関連情報
-
システム上の
mount(8)man ページ - UUID などの永続的な命名属性のリストを表示する方法。
16.2. 現在マウントされているファイルシステムのリスト表示
findmnt ユーティリティーを使用して、現在マウントされているすべてのファイルシステムを、コマンドラインでリスト表示します。
手順
マウントされているファイルシステムのリストを表示するには、
findmntユーティリティーを使用します。$ findmntリスト表示されているファイルシステムを、特定のファイルシステムタイプに制限するには、
--typesオプションを追加します。$ findmnt --types fs-type以下に例を示します。
例16.1 XFS ファイルシステムのみを表示
$ findmnt --types xfs TARGET SOURCE FSTYPE OPTIONS / /dev/mapper/luks-5564ed00-6aac-4406-bfb4-c59bf5de48b5 xfs rw,relatime ├─/boot /dev/sda1 xfs rw,relatime └─/home /dev/mapper/luks-9d185660-7537-414d-b727-d92ea036051e xfs rw,relatime
関連情報
-
システム上の
findmnt(8)man ページ
16.3. mount でファイルシステムのマウント
mount ユーティリティーを使用してファイルシステムをマウントします。
前提条件
選択したマウントポイントにファイルシステムがまだマウントされていないことを確認する。
$ findmnt mount-point
手順
特定のファイルシステムを添付する場合は、
mountユーティリティーを使用します。# mount device mount-point例16.2 XFS ファイルシステムのマウント
たとえば、UUID により識別されるローカル XFS ファイルシステムをマウントするには、次のコマンドを実行します。
# mount UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /mnt/datamountがファイルシステムタイプを自動的に認識できない場合は、--typesオプションで指定します。# mount --types type device mount-point例16.3 NFS ファイルシステムのマウント
たとえば、リモートの NFS ファイルシステムをマウントするには、次のコマンドを実行します。
# mount --types nfs4 host:/remote-export /mnt/nfs
関連情報
-
システム上の
mount(8)man ページ
16.4. マウントポイントの移動
mount ユーティリティーを使用して、マウントされたファイルシステムのマウントポイントを別のディレクトリーに変更します。
手順
ファイルシステムがマウントされているディレクトリーを変更するには、以下のコマンドを実行します。
# mount --move old-directory new-directory例16.4 ホームファイルシステムの移動
たとえば、
/mnt/userdirs/ディレクトリーにマウントされたファイルシステムを/home/マウントポイントに移動するには、以下のコマンドを実行します。# mount --move /mnt/userdirs /homeファイルシステムが想定どおりに移動したことを確認します。
$ findmnt $ ls old-directory $ ls new-directory
関連情報
-
システム上の
mount(8)man ページ
16.5. umount でファイルシステムのアンマウント
umount ユーティリティーを使用してファイルシステムをアンマウントします。
手順
次のいずれかのコマンドを使用してファイルシステムをアンマウントします。
マウントポイントで行う場合は、以下のコマンドを実行します。
# umount mount-pointデバイスで行う場合は、以下のコマンドを実行します。
# umount device
コマンドが次のようなエラーで失敗した場合は、プロセスがリソースを使用しているため、ファイルシステムが使用中であることを意味します。
umount: /run/media/user/FlashDrive: target is busy.ファイルシステムが使用中の場合は、
fuserユーティリティーを使用して、ファイルシステムにアクセスしているプロセスを特定します。以下に例を示します。$ fuser --mount /run/media/user/FlashDrive /run/media/user/FlashDrive: 18351その後、ファイルシステムを使用しているプロセスを停止し、再度アンマウントを試みます。
16.6. Web コンソールでのファイルシステムのマウントとマウント解除
RHEL システムでパーティションを使用できるようにするには、パーティションにファイルシステムをデバイスとしてマウントする必要があります。
ファイルシステムのマウントを解除することもできます。アンマウントすると RHEL システムはその使用を停止します。ファイルシステムのマウントを解除すると、デバイスを削除 (delete または remove) または再読み込みできるようになります。
前提条件
-
cockpit-storagedパッケージがシステムにインストールされている。
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
- ファイルシステムのマウントを解除する場合は、システムがパーティションに保存されているファイル、サービス、またはアプリケーションを使用しないようにする。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- Storage タブをクリックします。
- Storage テーブルで、パーティションを削除するボリュームを選択します。
- GPT partitions セクションで、ファイルシステムをマウントまたはマウント解除するパーティションの横にあるメニューボタン をクリックします。
- または をクリックします。
16.7. 一般的なマウントオプション
次の表に、mount ユーティリティーの最も一般的なオプションを示します。次の構文を使用して、これらのマウントオプションを適用できます。
# mount --options option1,option2,option3 device mount-point| オプション | 説明 |
|---|---|
|
| ファイルシステムで非同期の入出力を可能にします。 |
|
|
|
|
|
オプション |
|
| 特定のファイルシステムでのバイナリーファイルの実行を許可します。 |
|
| イメージをループデバイスとしてマウントします。 |
|
|
デフォルトでは、 |
|
| 特定のファイルシステムでのバイナリーファイルの実行は許可しません。 |
|
| 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントは許可しません。 |
|
| ファイルシステムがすでにマウントされている場合は再度マウントを行います。 |
|
| 読み取り専用でファイルシステムをマウントします。 |
|
| ファイルシステムを読み取りと書き込み両方でマウントします。 |
|
| 普通のユーザー (つまり root 以外のユーザー) によるファイルシステムのマウントおよびアンマウントを許可します。 |
第17章 複数のマウントポイントでのマウント共有
システム管理者は、マウントポイントを複製して、複数のディレクトリーからファイルシステムにアクセスするようにできます。
17.2. プライベートマウントポイントの複製の作成
マウントポイントをプライベートマウントとして複製します。複製後に、複製または元のマウントポイントにマウントするファイルシステムは、他方のマウントポイントには反映されません。
手順
元のマウントポイントから仮想ファイルシステム (VFS) ノードを作成します。
# mount --bind original-dir original-dir元のマウントポイントをプライベートとしてマークします。
# mount --make-private original-dirあるいは、選択したマウントポイントと、その下のすべてのマウントポイントのマウントタイプを変更するには、
--make-privateではなく、--make-rprivateオプションを使用します。複製を作成します。
# mount --bind original-dir duplicate-dir
例17.1 プライベートマウントポイントとして /mnt に /media を複製
/mediaディレクトリーから VFS ノードを作成します。# mount --bind /media /media/mediaディレクトリーをプライベートとしてマークします。# mount --make-private /mediaそのコピーを
/mntに作成します。# mount --bind /media /mntこれで、
/mediaと/mntはコンテンツを共有してますが、/media内のマウントはいずれも/mntに現れていないことが確認できます。たとえば、CD-ROM ドライブに空でないメディアがあり、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom #
また、
/mntディレクトリーにマウントされているファイルシステムが/mediaに反映されていないことを確認することもできます。たとえば、/dev/sdc1デバイスを使用する、空でない USB フラッシュドライブをプラグインしており、/mnt/flashdisk/ディレクトリーが存在する場合は、次のコマンドを実行します。# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
関連情報
-
システム上の
mount(8)man ページ
17.4. スレーブマウントポイントの複製の作成
マウントポイントを slave マウントタイプとして複製します。複製後に、元のマウントポイントにマウントしたファイルシステムは複製に反映されますが、その逆は反映されません。
手順
元のマウントポイントから仮想ファイルシステム (VFS) ノードを作成します。
# mount --bind original-dir original-dir元のマウントポイントを共有としてマークします。
# mount --make-shared original-dirあるいは、選択したマウントポイントとその下のすべてのマウントポイントのマウントタイプを変更する場合は、
--make-sharedではなく、--make-rsharedオプションを使用します。複製を作成し、これを
slaveタイプとしてマークします。# mount --bind original-dir duplicate-dir # mount --make-slave duplicate-dir
例17.3 スレーブマウントポイントとして /mnt に /media を複製
この例は、/media ディレクトリーのコンテンツが /mnt にも表示され、/mnt ディレクトリーのマウントが /media に反映されないようにする方法を示しています。
/mediaディレクトリーから VFS ノードを作成します。# mount --bind /media /media/mediaディレクトリーを共有としてマークします。# mount --make-shared /mediaその複製を
/mntに作成し、slaveとしてマークします。# mount --bind /media /mnt # mount --make-slave /mnt
/media内のマウントが/mntにも表示されていることを確認します。たとえば、CD-ROM ドライブに空でないメディアがあり、/media/cdrom/ディレクトリーが存在する場合は、以下のコマンドを実行します。# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom EFI GPL isolinux LiveOS
また、
/mntディレクトリー内にマウントされているファイルシステムが/mediaに反映されていないことを確認します。たとえば、/dev/sdc1デバイスを使用する、空でない USB フラッシュドライブをプラグインしており、/mnt/flashdisk/ディレクトリーが存在する場合は、次のコマンドを実行します。# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfg
関連情報
-
システム上の
mount(8)man ページ
17.5. マウントポイントが複製されないようにする
マウントポイントをバインド不可としてマークし、別のマウントポイントに複製できないようにします。
手順
マウントポイントのタイプをバインド不可なマウントに変更するには、以下のコマンドを使用します。
# mount --bind mount-point mount-point # mount --make-unbindable mount-point
あるいは、選択したマウントポイントとその下のすべてのマウントポイントのマウントタイプを変更する場合は、
--make-unbindableの代わりに、--make-runbindableオプションを使用します。これ以降、このマウントの複製を作成しようとすると、以下のエラーが出て失敗します。
# mount --bind mount-point duplicate-dir mount: wrong fs type, bad option, bad superblock on mount-point, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
例17.4 /media が複製されないようにする
/mediaディレクトリーが共有されないようにするには、以下のコマンドを実行します。# mount --bind /media /media # mount --make-unbindable /media
関連情報
-
システム上の
mount(8)man ページ
第18章 ファイルシステムの永続的なマウント
システム管理者は、ファイルシステムを永続的にマウントして、非リムーバブルストレージを設定できます。
18.1. /etc/fstab ファイル
/etc/fstab 設定ファイルを使用して、ファイルシステムの永続的なマウントポイントを制御します。/etc/fstab ファイルの各行は、ファイルシステムのマウントポイントを定義します。
空白で区切られた 6 つのフィールドが含まれています。
-
/devディレクトリーの永続的な属性またはパスで識別されるブロックデバイス。 - デバイスがマウントされるディレクトリー。
- デバイス上のファイルシステム。
-
ファイルシステムのマウントオプション。これには、ブート時にデフォルトオプションでパーティションをマウントする
defaultsオプションが含まれます。マウントオプションフィールドは、x-systemd.option形式のsystemdマウントユニットオプションも認識します。 -
dumpユーティリティーのオプションのバックアップを作成します。 -
fsckユーティリティーの順序を確認します。
systemd-fstab-generator は、エントリーを /etc/fstab ファイルから systemd-mount ユニットに動的に変換します。systemd-mount ユニットがマスクされていない限り、systemd は手動アクティベーション中に /etc/fstab から LVM ボリュームを自動マウントします。
例18.1 /etc/fstab の /boot ファイルシステム
| ブロックデバイス | マウントポイント | ファイルシステム | オプション | バックアップ | チェック |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
systemd サービスは、/etc/fstab のエントリーからマウントユニットを自動的に生成します。
関連情報
-
システム上の
fstab(5)およびsystemd.mount(5)man ページ
18.2. /etc/fstab へのファイルシステムの追加
/etc/fstab 設定ファイルでファイルシステムの永続的なマウントポイントを設定します。
手順
ファイルシステムの UUID 属性を調べます。
$ lsblk --fs storage-device以下に例を示します。
例18.2 パーティションの UUID の表示
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot
このマウントポイントのディレクトリーがない場合は、作成します。
# mkdir --parents mount-pointroot で
/etc/fstabファイルを編集し、ファイルシステムに行を追加します (UUID で識別されます)。以下に例を示します。
例18.3 /etc/fstab の /boot マウントポイント
UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot xfs defaults 0 0
システムが新しい設定を登録するように、マウントユニットを再生成します。
# systemctl daemon-reloadファイルシステムをマウントして、設定が機能することを確認します。
# mount mount-point
関連情報
第19章 オンデマンドでのファイルシステムのマウント
システム管理者は、NFS などのファイルシステムをオンデマンドで自動的にマウントするように設定できます。
19.1. autofs サービス
autofs サービスは、ファイルシステムの自動マウントおよび自動アンマウントが可能なため (オンデマンド)、システムのリソースを節約できます。このサービスは、NFS、AFS、SMBFS、CIFS、およびローカルなどのファイルシステムをマウントする場合にも使用できます。
/etc/fstab 設定を使用した永続的なマウントの欠点の 1 つは、マウントされたファイルシステムにユーザーがアクセスする頻度に関わらず、マウントされたファイルシステムを所定の場所で維持するために、システムがリソースを割り当てる必要があることです。これは、システムが一度に多数のシステムへの NFS マウントを維持している場合などに、システムのパフォーマンスに影響を与える可能性があります。
/etc/fstab に代わるのは、カーネルベースの autofs サービスの使用です。これは次のコンポーネントで構成されています。
- ファイルシステムを実装するカーネルモジュール
- 他のすべての機能を実行するユーザー空間サービス
関連情報
-
システム上の
autofs(8)man ページ
19.2. autofs 設定ファイル
このセクションでは、autofs サービスで使用される設定ファイルの使用方法と構文を説明します。
マスターマップファイル
autofs サービスは、デフォルトの主要設定ファイルとして、/etc/auto.master (マスターマップ) を使用します。これは、/etc/autofs.conf 設定ファイルの autofs 設定を Name Service Switch (NSS) メカニズムとともに使用することで、対応している別のネットワークソースと名前を使用するように変更できます。
すべてのオンデマンドマウントポイントはマスターマップで設定する必要があります。マウントポイント、ホスト名、エクスポートされたディレクトリー、オプションはすべて、ホストごとに手動で設定するのではなく、一連のファイル (またはサポートされているその他のネットワークソース) で指定できます。
マスターマップファイルには、autofs により制御されるマウントポイントと、それに対応する設定ファイルまたは自動マウントマップと呼ばれるネットワークソースがリスト表示されます。マスターマップの形式は次のとおりです。
mount-point map-name options
この形式で使用されている変数を以下に示します。
- mount-point
-
autofsマウントポイント (例:/mnt/data/) です。 - map-file
- マウントポイントのリストと、マウントポイントがマウントされるファイルシステムの場所が記載されているマップソースファイルです。
- options
- 指定した場合に、エントリーにオプションが指定されていなければ、指定されたマップ内のすべてのエントリーに適用されます。
例19.1 /etc/auto.master ファイル
以下は /etc/auto.master ファイルのサンプル行です。
/mnt/data /etc/auto.data
マップファイル
マップファイルは、個々のオンデマンドマウントポイントのプロパティーを設定します。
ディレクトリーが存在しない場合、自動マウント機能はディレクトリーを作成します。ディレクトリーが存在している状況で自動マウント機能が起動した場合は、自動マウント機能の終了時にディレクトリーが削除されることはありません。タイムアウトを指定した場合は、タイムアウト期間中ディレクトリーにアクセスしないと、ディレクトリーが自動的にアンマウントされます。
マップの一般的な形式は、マスターマップに似ています。ただし、マスターマップでは、オプションフィールドはエントリーの末尾ではなく、マウントポイントと場所の間に表示されます。
mount-point options location
この形式で使用されている変数を以下に示します。
- mount-point
-
これは、
autofsのマウントポイントを参照しています。これは 1 つのインダイレクトマウント用の 1 つのディレクトリー名にすることも、複数のダイレクトマウント用のマウントポイントの完全パスにすることもできます。ダイレクトマップとインダイレクトマップの各エントリーキー (mount-point) の後に空白で区切られたオフセットディレクトリー (/で始まるサブディレクトリー名) が記載されます。これがマルチマウントエントリーと呼ばれるものです。 - options
-
このオプションを指定すると、マスターマップエントリーのオプション (存在する場合) に追加されます。設定エントリーの
append_optionsがnoに設定されている場合は、マスターマップのオプションの代わりにこのオプションが使用されます。 - location
-
ローカルファイルシステムのパス (Sun マップ形式のエスケープ文字
:が先頭に付き、マップ名が/で始まります)、NFS ファイルシステム、他の有効なファイルシステムの場所などのファイルシステムの場所を参照します。
例19.2 マップファイル
以下は、マップファイルのサンプルです (例: /etc/auto.misc)。
payroll -fstype=nfs4 personnel:/exports/payroll sales -fstype=xfs :/dev/hda4
マップファイルの最初の列は、autofs マウントポイント (personnel サーバーからの sales と payroll) を示しています。2 列目は、autofs マウントのオプションを示しています。3 列目はマウントのソースを示しています。
任意の設定に基づき、autofs マウントポイントは、/home/payroll と /home/sales になります。-fstype= オプションは多くの場合省略されており、ファイルシステムが NFS の場合は必要ありません。これには、システムのデフォルトが NFS マウント用の NFSv4 である場合の NFSv4 のマウントも含まれます。
与えられた設定を使用して、プロセスが /home/payroll/2006/July.sxc などのアンマウントされたディレクトリー autofs へのアクセスを要求すると、autofs サービスは自動的にディレクトリーをマウントします。
amd マップ形式
autofs サービスは、amd 形式のマップ設定も認識します。これは Red Hat Enterprise Linux から削除された、am-utils サービス用に書き込まれた既存の自動マウント機能の設定を再利用する場合に便利です。
ただし、Red Hat は、前述のセクションで説明した簡単な autofs 形式の使用を推奨しています。
関連情報
-
システム上の
autofs(5)、autofs.conf(5)、およびauto.master(5)man ページ -
/usr/share/doc/autofs/README.amd-mapsファイル
19.3. autofs マウントポイントの設定
autofs サービスを使用してオンデマンドマウントポイントを設定します。
前提条件
autofsパッケージをインストールしている。# yum install autofsautofsサービスを起動して有効にしている。# systemctl enable --now autofs
手順
-
/etc/auto.identifierにあるオンデマンドマウントポイント用のマップファイルを作成します。identifier を、マウントポイントを識別する名前に置き換えます。 - マップファイルで、autofs 設定ファイル セクションの説明に従って、マウントポイント、オプション、および場所の各フィールドを入力します。
- autofs 設定ファイル セクションの説明に従って、マップファイルをマスターマップファイルに登録します。
設定の再読み込みを許可し、新しく設定した
autofsマウントを管理できるようにします。# systemctl reload autofs.serviceオンデマンドディレクトリーのコンテンツへのアクセスを試みます。
# ls automounted-directory
19.4. autofs サービスを使用した NFS サーバーユーザーのホームディレクトリーの自動マウント
ユーザーのホームディレクトリーを自動的にマウントするように autofs サービスを設定します。
前提条件
- autofs パッケージがインストールされている。
- autofs サービスが有効で、実行している。
手順
ユーザーのホームディレクトリーをマウントする必要があるサーバーの
/etc/auto.masterファイルを編集して、マップファイルのマウントポイントと場所を指定します。これを行うには、以下の行を/etc/auto.masterファイルに追加します。/home /etc/auto.home
ユーザーのホームディレクトリーをマウントする必要があるサーバー上で、
/etc/auto.homeという名前のマップファイルを作成し、以下のパラメーターでファイルを編集します。* -fstype=nfs,rw,sync host.example.com:/home/&fstypeパラメーターはデフォルトでnfsであるため、このパラメーターは飛ばして次に進むことができます。詳細は、システム上のautofs(5)man ページを参照してください。autofsサービスを再読み込みします。# systemctl reload autofs
19.5. autofs サイトの設定ファイルの上書き/拡張
クライアントシステムの特定のマウントポイントで、サイトのデフォルトを上書きすることが役に立つ場合があります。
例19.3 初期条件
たとえば、次の条件を検討します。
自動マウント機能のマップが NIS に格納され、
/etc/nsswitch.confファイルに次のようなディレクティブがある。automount: files nis
auto.masterファイルに以下を含む。+auto.master
NIS の
auto.masterマップファイルに以下を含む。/home auto.home
NIS の
auto.homeマップには以下が含まれている。beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
autofs設定オプションのBROWSE_MODEはyesに設定されています。BROWSE_MODE="yes"
-
/etc/auto.homeファイルマップが存在しない。
手順
このセクションでは、別のサーバーからホームディレクトリーをマウントし、選択したエントリーのみで auto.home を強化する例を説明します。
例19.4 別のサーバーからのホームディレクトリーのマウント
上記の条件で、クライアントシステムが NIS マップの auto.home を上書きして、別のサーバーからホームディレクトリーをマウントする必要があるとします。
この場合、クライアントは次の
/etc/auto.masterマップを使用する必要があります。/home /etc/auto.home +auto.master
/etc/auto.homeマップにエントリーが含まれています。* host.example.com:/export/home/&
自動マウント機能は最初に出現したマウントポイントのみを処理するため、/home ディレクトリーには NIS auto.home マップではなく、/etc/auto.home の内容が含まれます。
例19.5 選択されたエントリーのみを使用した auto.home の拡張
別の方法として、サイト全体の auto.home マップを少しのエントリーを使用して拡張するには、次の手順を行います。
/etc/auto.homeファイルマップを作成し、そこに新しいエントリーを追加します。最後に、NIS のauto.homeマップを含めます。これにより、/etc/auto.homeファイルマップは次のようになります。mydir someserver:/export/mydir +auto.home
この NIS の
auto.homeマップ条件で、/homeディレクトリーの出力内容をリスト表示すると次のようになります。$ ls /home beth joe mydir
autofs は、読み取り中のファイルマップと同じ名前のファイルマップの内容を組み込まないため、上記の例は期待どおりに動作します。このように、autofs は、nsswitch 設定内の次のマップソースに移動します。
19.6. LDAP で自動マウント機能マップの格納
自動マウントマップを、autofs マップファイルではなく LDAP 設定に保存するように autofs を設定します。
前提条件
-
LDAP から自動マウント機能マップを取得するように設定されているすべてのシステムに、LDAP クライアントライブラリーをインストールする必要があります。Red Hat Enterprise Linux では、
openldapパッケージは、autofsパッケージの依存関係として自動的にインストールされます。
手順
-
LDAP アクセスを設定するには、
/etc/openldap/ldap.confファイルを変更します。BASE、URI、schemaの各オプションがサイトに適切に設定されていることを確認します。 自動マウント機能マップを LDAP に格納するためにデフォルトされた最新のスキーマが、
rfc2307bisドラフトに記載されています。このスキーマを使用する場合は、スキーマの定義のコメント文字を取り除き、/etc/autofs.conf設定ファイル内に設定する必要があります。以下に例を示します。例19.6 autofs の設定
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
他のすべてのスキーマエントリーが設定内でコメントされていることを確認してください。
rfc2307bisスキーマのautomountKey属性は、rfc2307スキーマのcn属性に置き換わります。以下は、LDAP データ交換形式 (LDIF) 設定の例です。例19.7 LDIF 設定
# auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount automountKey: /home automountInformation: auto.home # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
関連情報
19.7. systemd.automount と /etc/fstab を使用してファイルシステムを必要に応じてマウントする
/etc/fstab でマウントポイントが定義されている場合、automount systemd ユニットを使用して、必要に応じてファイルシステムをマウントします。マウントごとに自動マウントユニットを追加して有効にする必要があります。
手順
ファイルシステムの永続的なマウント の説明に従って、目的の fstab エントリーを追加します。以下に例を示します。
/dev/disk/by-id/da875760-edb9-4b82-99dc-5f4b1ff2e5f4 /mount/point xfs defaults 0 0
-
前の手順で作成したエントリーの options フィールドに
x-systemd.automountを追加します。 システムが新しい設定を登録するように、新しく作成されたユニットをロードします。
# systemctl daemon-reload自動マウントユニットを起動します。
# systemctl start mount-point.automount
検証
mount-point.automountが実行されていることを確認します。# systemctl status mount-point.automount自動マウントされたディレクトリーに目的のコンテンツが含まれていることを確認します。
# ls /mount/point
関連情報
-
システム上の
systemd.automount(5)およびsystemd.mount(5)man ページ - systemd の管理
19.8. systemd.automount とマウントユニットを使用してファイルシステムを必要に応じてマウントする
マウントポイントがマウントユニットによって定義されている場合、automount systemd ユニットを使用して、ファイルシステムを必要に応じてマウントします。マウントごとに自動マウントユニットを追加して有効にする必要があります。
手順
マウントユニットを作成します。以下に例を示します。
mount-point.mount [Mount] What=/dev/disk/by-uuid/f5755511-a714-44c1-a123-cfde0e4ac688 Where=/mount/point Type=xfs
-
マウントユニットと同じ名前で、拡張子が
.automountのユニットファイルを作成します。 ファイルを開き、
[Automount]セクションを作成します。Where=オプションをマウントパスに設定します。[Automount] Where=/mount/point [Install] WantedBy=multi-user.targetシステムが新しい設定を登録するように、新しく作成されたユニットをロードします。
# systemctl daemon-reload代わりに、自動マウントユニットを有効にして起動します。
# systemctl enable --now mount-point.automount
検証
mount-point.automountが実行されていることを確認します。# systemctl status mount-point.automount自動マウントされたディレクトリーに目的のコンテンツが含まれていることを確認します。
# ls /mount/point
関連情報
-
システム上の
systemd.automount(5)およびsystemd.mount(5)man ページ - systemd の管理
第20章 IdM からの SSSD コンポーネントを使用した autofs マップのキャッシュ
システムセキュリティーサービスデーモン (System Security Services Daemon: SSSD) は、リモートサービスディレクトリーと認証メカニズムにアクセスするシステムサービスです。データキャッシュは、ネットワーク接続が遅い場合に役立ちます。SSSD サービスが autofs マップをキャッシュするように設定するには、このセクションの以下の手順に従います。
20.1. IdM サーバーを LDAP サーバーとして使用するように autofs を手動で設定する
IdM サーバーを LDAP サーバーとして使用するように autofs を設定します。
手順
/etc/autofs.confファイルを編集し、autofsが検索するスキーマ属性を指定します。# # Other common LDAP naming # map_object_class = "automountMap" entry_object_class = "automount" map_attribute = "automountMapName" entry_attribute = "automountKey" value_attribute = "automountInformation"注記ユーザーは、
/etc/autofs.confファイルに小文字と大文字の両方で属性を書き込むことができます。オプション: LDAP 設定を指定します。これには 2 通りの方法があります。最も簡単な方法は、自動マウントサービスが LDAP サーバーと場所を自分で発見するようにすることです。
ldap_uri = "ldap:///dc=example,dc=com"
このオプションでは、DNS に検出可能なサーバーの SRV レコードが含まれている必要があります。
別の方法では、使用する LDAP サーバーと LDAP 検索のベース DN を明示的に設定します。
ldap_uri = "ldap://ipa.example.com" search_base = "cn=location,cn=automount,dc=example,dc=com"autofs が IdM LDAP サーバーによるクライアント認証を許可するように
/etc/autofs_ldap_auth.confファイルを編集します。-
authrequiredを yes に変更します。 プリンシパルを IdM LDAP サーバー (host/FQDN@REALM) の Kerberos ホストプリンシパルに設定します。プリンシパル名は、GSS クライアント認証の一部として IdM ディレクトリーへの接続に使用されます。
<autofs_ldap_sasl_conf usetls="no" tlsrequired="no" authrequired="yes" authtype="GSSAPI" clientprinc="host/server.example.com@EXAMPLE.COM" />ホストプリンシパルの詳細は、IdM での正規化された DNS ホスト名の使用 を参照してください。
必要に応じて
klist -kを実行して、正確なホストプリンシパル情報を取得します。
-
20.2. autofs マップをキャッシュする SSSD の設定
SSSD サービスを使用すると、IdM サーバーに保存されている autofs マップを、IdM サーバーを使用するように autofs を設定することなくキャッシュできます。
前提条件
-
sssdパッケージがインストールされている。
手順
SSSD 設定ファイルを開きます。
# vim /etc/sssd/sssd.confSSSD が処理するサービスリストに
autofsサービスを追加します。[sssd] domains = ldap services = nss,pam,
autofs[autofs]セクションを新規作成します。autofsサービスのデフォルト設定はほとんどのインフラストラクチャーに対応するため、これを空白のままにすることができます。[nss] [pam] [sudo]
[autofs][ssh] [pac]詳細は、システム上の
sssd.confman ページを参照してください。オプション:
autofsエントリーの検索ベースを設定します。デフォルトでは、これは LDAP 検索ベースですが、ldap_autofs_search_baseパラメーターでサブツリーを指定できます。[domain/EXAMPLE] ldap_search_base = "dc=example,dc=com" ldap_autofs_search_base = "ou=automount,dc=example,dc=com"
SSSD サービスを再起動します。
# systemctl restart sssd.serviceSSSD が自動マウント設定のソースとしてリスト表示されるように、
/etc/nsswitch.confファイルを確認します。automount:
sssfilesautofsサービスを再起動します。# systemctl restart autofs.service/homeのマスターマップエントリーがあると想定し、ユーザーの/homeディレクトリーをリスト表示して設定をテストします。# ls /home/userNameリモートファイルシステムをマウントしない場合は、
/var/log/messagesファイルでエラーを確認します。必要に応じて、loggingパラメーターをdebugに設定して、/etc/sysconfig/autofsファイルのデバッグレベルを増やします。
第21章 root ファイルシステムに対する読み取り専用パーミッションの設定
場合によっては、root ファイルシステム (/) を読み取り専用パーミッションでマウントする必要があります。ユースケースの例には、システムの予期せぬ電源切断後に行うセキュリティーの向上またはデータ整合性の保持が含まれます。
21.1. 書き込みパーミッションを保持するファイルおよびディレクトリー
システムが正しく機能するためには、一部のファイルやディレクトリーで書き込みパーミッションが必要とされます。root ファイルシステムが読み取り専用モードでマウントされると、このようなファイルは、tmpfs 一時ファイルシステムを使用して RAM にマウントされます。
このようなファイルおよびディレクトリーのデフォルトセットは、/etc/rwtab ファイルから読み込まれます。このファイルをシステムに存在させるには、readonly-root パッケージが必要であることに注意してください。
dirs /var/cache/man dirs /var/gdm <content truncated> empty /tmp empty /var/cache/foomatic <content truncated> files /etc/adjtime files /etc/ntp.conf <content truncated>
/etc/rwtab ファイルのエントリーは、以下の形式に従います。
copy-method path
この構文で、以下のことを行います。
- copy-method を、ファイルまたはディレクトリーを tmpfs にコピーする方法を指定するキーワードの 1 つに置き換えます。
- path を、ファイルまたはディレクトリーへのパスに置き換えます。
/etc/rwtab ファイルは、ファイルまたはディレクトリーを tmpfs にコピーする方法として以下を認識します。
empty空のパスが
tmpfsにコピーされます。以下に例を示します。empty /tmp
dirsディレクトリーツリーが空の状態で
tmpfsにコピーされます。以下に例を示します。dirs /var/run
filesファイルやディレクトリーツリーはそのまま
tmpfsにコピーされます。以下に例を示します。files /etc/resolv.conf
カスタムパスを /etc/rwtab.d/ に追加する場合も同じ形式が適用されます。
21.2. ブート時に読み取り専用パーミッションでマウントするように root ファイルシステムの設定
この手順を行うと、今後システムが起動するたびに、root ファイルシステムが読み取り専用としてマウントされます。
手順
/etc/sysconfig/readonly-rootファイルで、READONLYオプションをyesに設定して、ファイルシステムを読み取り専用としてマウントします。READONLY=yes
/etc/fstabファイルの root エントリー (/) にroオプションを追加します。/dev/mapper/luks-c376919e... / xfs x-systemd.device-timeout=0,ro 1 1rokernel オプションを有効にします。# grubby --update-kernel=ALL --args="ro"rwカーネルオプションが無効になっていることを確認します。# grubby --update-kernel=ALL --remove-args="rw"tmpfsファイルシステムに書き込みパーミッションでマウントするファイルとディレクトリーを追加する必要がある場合は、/etc/rwtab.d/ディレクトリーにテキストファイルを作成し、そこに設定を置きます。たとえば、
/etc/example/fileファイルを書き込みパーミッションでマウントするには、この行を/etc/rwtab.d/exampleファイルに追加します。files /etc/example/file
重要tmpfsのファイルおよびディレクトリーの変更内容は、再起動後は持続しません。- システムを再起動して変更を適用します。
トラブルシューティング
誤って読み取り専用パーミッションで root ファイルシステムをマウントした場合は、次のコマンドを使用して、読み書きパーミッションで再度マウントできます。
# mount -o remount,rw /
第22章 クォータを使用した XFS でのストレージ領域の使用の制限
ディスククォータを実装して、ユーザーまたはグループに利用可能なディスク領域のサイズを制限できます。ユーザーがディスク領域を過剰に消費したり、パーティションが満杯になる前に、システム管理者に通知を出す警告レベルを定義することもできます。
XFS クォータサブシステムは、ディスク領域 (ブロック) およびファイル (inode) の使用量の制限を管理します。XFS クォータは、ユーザー、グループ、ディレクトリーレベル、またはプロジェクトレベルでこれらの項目の使用を制御または報告します。グループおよびプロジェクトのクォータは、古いデフォルト以外の XFS ディスクフォーマットでのみ相互に排他的です。
ディレクトリーまたはプロジェクトごとに管理する場合、XFS は特定のプロジェクトに関連付けられたディレクトリー階層のディスク使用量を管理します。
22.1. ディスククォータ
ほとんどのコンピューティング環境では、ディスク領域は無限ではありません。クォータサブシステムは、ディスク領域の使用量を制御するメカニズムを提供します。
ディスククォータは、ローカルファイルシステムの個々のユーザーおよびユーザーグループに設定できます。これにより、ユーザー固有のファイル (電子メールなど) に割り当てられる領域を、ユーザーが作業するプロジェクトに割り当てられた領域とは別に管理できます。クォータサブシステムは、割り当てられた制限を超えるとユーザーに警告しますが、現在の作業に追加領域を許可します (ハード制限/ソフト制限)。
クォータが実装されている場合は、クォータを超過しているかどうかを確認して、クォータが正しいことを確認する必要があります。ユーザーが繰り返しクォータを超過するか、常にソフト制限に達している場合、システム管理者は、ユーザーが使用するディスク領域を減らすか、ユーザーのディスククォータを増やす方法を決定するのを助けることができます。
クォータは、以下を制御するように設定できます。
- 消費されるディスクブロックの数。
- UNIX ファイルシステムのファイルに関する情報を含むデータ構造である inode の数。inode はファイル関連の情報を保存するため、作成可能なファイルの数を制御できます。
22.2. xfs_quota ツール
xfs_quota ツールを使用して、XFS ファイルシステム上のクォータを管理できます。さらに、有効なディスク使用量のアカウンティングシステムとして、制限の強制適用をオフにして XFS ファイルシステムを使用できます。
XFS クォータシステムは、他のファイルシステムとはさまざまな点で異なります。最も重要な点として、XFS はクォータ情報をファイルシステムのメタデータとみなし、ジャーナリングを使用して一貫性のより高いレベルの保証を提供します。
関連情報
-
システム上の
xfs_quota(8)man ページ
22.3. XFS でのファイルシステムクォータ管理
XFS クォータサブシステムは、ディスク領域 (ブロック) およびファイル (inode) の使用量の制限を管理します。XFS クォータは、ユーザー、グループ、ディレクトリーレベル、またはプロジェクトレベルでこれらの項目の使用を制御または報告します。グループおよびプロジェクトのクォータは、古いデフォルト以外の XFS ディスクフォーマットでのみ相互に排他的です。
ディレクトリーまたはプロジェクトごとに管理する場合、XFS は特定のプロジェクトに関連付けられたディレクトリー階層のディスク使用量を管理します。
22.4. XFS のディスククォータの有効化
XFS ファイルシステムのユーザー、グループ、およびプロジェクトのディスククォータを有効にします。クォータを有効にすると、xfs_quota ツールを使用して制限を設定し、ディスク使用量を報告できます。
手順
ユーザーのクォータを有効にします。
# mount -o uquota /dev/xvdb1 /xfsuquotaをuqnoenforceに置き換えて、制限を強制適用せずに使用状況の報告を可能にします。グループのクォータを有効にします。
# mount -o gquota /dev/xvdb1 /xfsgquotaをgqnoenforceに置き換えて、制限を強制適用せずに使用状況の報告を可能にします。プロジェクトのクォータを有効にします。
# mount -o pquota /dev/xvdb1 /xfspquotaをpqnoenforceに置き換え、制限を強制適用せずに使用状況の報告を可能にします。または、
/etc/fstabファイルにクォータマウントオプションを追加します。以下の例は、XFS ファイルシステムでユーザー、グループ、およびプロジェクトのクォータを有効にする/etc/fstabファイルのエントリーを示しています。以下の例では、読み取り/書き込みパーミッションでファイルシステムもマウントします。# vim /etc/fstab /dev/xvdb1 /xfs xfs rw,quota 0 0 /dev/xvdb1 /xfs xfs rw,gquota 0 0 /dev/xvdb1 /xfs xfs rw,prjquota 0 0
関連情報
-
システム上の
xfs(5)およびxfs_quota(8)man ページ
22.5. XFS 使用量の報告
xfs_quota ツールを使用して制限を設定し、ディスク使用量を報告します。xfs_quota は、デフォルトでは対話形式で基本モードで実行されます。基本モードのサブコマンドは使用量を報告するだけで、すべてのユーザーが使用できます。
前提条件
- XFS ファイルシステムに対してクォータが有効になっている。XFS のディスククォータの有効化 を参照してください。
手順
xfs_quotaシェルを起動します。# xfs_quota指定したユーザーの使用状況および制限を表示します。
xfs_quota> quota usernameブロックおよび inode の空きおよび使用済みの数を表示します。
xfs_quota> dfhelp コマンドを実行して、
xfs_quotaで利用可能な基本的なコマンドを表示します。xfs_quota> helpqを指定してxfs_quotaを終了します。xfs_quota> q
関連情報
-
システム上の
xfs_quota(8)man ページ
22.6. XFS クォータ制限の変更
-x オプションを指定して xfs_quota ツールを起動し、エキスパートモードを有効にして、クォータシステムを変更できる管理者コマンドを実行します。このモードのサブコマンドは、制限を実際に設定することができるため、昇格した特権を持つユーザーのみが利用できます。
前提条件
- XFS ファイルシステムに対してクォータが有効になっている。XFS のディスククォータの有効化 を参照してください。
手順
エキスパートモードを有効にするには、
-xオプションを指定してxfs_quotaシェルを起動します。# xfs_quota -x /path特定のファイルシステムのクォータ情報を表示します。
xfs_quota> report /pathたとえば、(
/dev/blockdeviceの)/homeのクォータレポートのサンプルを表示するには、report -h /homeコマンドを使用します。これにより、以下のような出力が表示されます。User quota on /home (/dev/blockdevice) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 0 0 0 00 [------] testuser 103.4G 0 0 00 [------]
クォータの制限を変更します。
xfs_quota> limit isoft=500m ihard=700m userたとえば、ホームディレクトリーが
/home/johnのユーザーjohnに対して、inode 数のソフト制限およびハード制限をそれぞれ 500 と 700 に設定するには、次のコマンドを使用します。# xfs_quota -x -c 'limit isoft=500 ihard=700 john' /home/この場合は、マウントされた xfs ファイルシステムである
mount_pointを渡します。xfs_quota -xで利用可能なエキスパートコマンドを表示します。xfs_quota> help
検証
クォータ制限が変更されたことを確認します。
xfs_quota> report -i -u User quota on /home (/dev/loop0) Inodes User ID Used Soft Hard Warn/ Grace ---------- -------------------------------------------------- root 3 0 0 00 [------] testuser 2 500 700 00 [------]
関連情報
-
システム上の
xfs_quota(8)man ページ
22.7. XFS のプロジェクト制限の設定
プロジェクトが制御するディレクトリーの制限を設定します。
手順
プロジェクトが制御するディレクトリーを
/etc/projectsに追加します。たとえば、以下は一意の ID が 11 の/var/logパスを/etc/projectsに追加します。プロジェクト ID には、プロジェクトにマッピングされる任意の数値を指定できます。# echo 11:/var/log >> /etc/projects/etc/projidにプロジェクト名を追加して、プロジェクト ID をプロジェクト名にマップします。たとえば、以下は、前のステップで定義されたようにlogfilesというプロジェクトをプロジェクト ID 11 に関連付けます。# echo logfiles:11 >> /etc/projidプロジェクトのディレクトリーを初期化します。たとえば、以下はプロジェクトディレクトリー
/varを初期化します。# xfs_quota -x -c 'project -s logfiles' /var初期化したディレクトリーでプロジェクトのクォータを設定します。
# xfs_quota -x -c 'limit -p bhard=1g logfiles' /var
関連情報
-
システム上の
xfs_quota(8)、projid(5)、およびprojects(5)man ページ
第23章 クォータを使用した ext4 でのストレージ領域の使用の制限
ディスククォータを割り当てる前に、システムでディスククォータを有効にする必要があります。ユーザーごと、グループごと、またはプロジェクトごとにディスククォータを割り当てることができます。ただし、ソフト制限が設定されている場合は、猶予期間として知られる設定可能な期間として、これらのクォータを超過できます。
23.1. クォータツールのインストール
ディスククォータを実装するには、RPM パッケージ quota をインストールする必要があります。
手順
quotaパッケージをインストールします。# yum install quota
23.2. ファイルシステム作成時のクォータ機能の有効化
ファイルシステムの作成時にクォータを有効にします。
手順
ファイルシステムの作成時にクォータを有効にします。
# mkfs.ext4 -O quota /dev/sda注記デフォルトでは、ユーザーとグループのクォータのみが有効になり、初期化されます。
ファイルシステムの作成時にデフォルトを変更します。
# mkfs.ext4 -O quota -E quotatype=usrquota:grpquota:prjquota /dev/sdaファイルシステムをマウントします。
# mount /dev/sda
関連情報
-
システム上の
ext4(5)man ページ
23.3. 既存のファイルシステムでのクォータ機能の有効化
tune2fs コマンドを使用して、既存のファイルシステムでクォータ機能を有効にします。
手順
ファイルシステムをアンマウントします。
# umount /dev/sda既存のファイルシステムでクォータを有効にします。
# tune2fs -O quota /dev/sda注記デフォルトでは、ユーザーとグループのクォータのみが初期化されます。
デフォルトを変更します。
# tune2fs -Q usrquota,grpquota,prjquota /dev/sdaファイルシステムをマウントします。
# mount /dev/sda
関連情報
-
システム上の
ext4(5)man ページ
23.4. クォータ強制適用の有効化
クォータアカウンティングは、追加のオプションを使用せ s ずにファイルシステムをマウントした後にデフォルトで有効になりますが、クォータの強制適用は行いません。
前提条件
- クォータ機能が有効になり、デフォルトのクォータが初期化されます。
手順
ユーザークォータに対して、
quotaonによるクォータの強制適用を有効にします。# mount /dev/sda /mnt# quotaon /mnt注記クォータの強制適用は、マウントオプション
usrquota、grpquota、またはprjquotaを使用して、マウント時に有効にできます。# mount -o usrquota,grpquota,prjquota /dev/sda /mntすべてのファイルシステムのユーザー、グループ、およびプロジェクトのクォータを有効にします。
# quotaon -vaugP-
-uオプション、-gオプション、または-Pオプションがいずれも指定されていないと、ユーザーのクォータのみが有効になります。 -
-gオプションのみを指定すると、グループのクォータのみが有効になります。 -
-Pオプションのみを指定すると、プロジェクトのクォータのみが有効になります。
-
/homeなどの特定のファイルシステムのクォータを有効にします。# quotaon -vugP /home
関連情報
-
システム上の
quotaon(8)man ページ
23.5. ユーザーごとにクォータの割り当て
ディスククォータは、edquota コマンドでユーザーに割り当てられます。
EDITOR 環境変数により定義されたテキストエディターは、edquota により使用されます。エディターを変更するには、~/.bash_profile ファイルの EDITOR 環境変数を、使用するエディターのフルパスに設定します。
前提条件
- ユーザーは、ユーザークォータを設定する前に存在する必要があります。
手順
ユーザーにクォータを割り当てます。
# edquota usernameusername を、クォータを割り当てるユーザーに置き換えます。
たとえば、
/dev/sdaパーティションのクォータを有効にし、edquota testuserコマンドを実行すると、システムに設定したデフォルトエディターに以下が表示されます。Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/sda 44043 0 0 37418 0 0
必要な制限を変更します。
いずれかの値が 0 に設定されていると、制限は設定されません。テキストエディターでこれらを変更します。
たとえば、以下は、testuser のソフトブロック制限とハードブロック制限をそれぞれ 50000 と 55000 に設定していることを示しています。
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/sda 44043 50000 55000 37418 0 0
- 最初の列は、クォータが有効になっているファイルシステムの名前です。
- 2 列目には、ユーザーが現在使用しているブロック数が示されます。
- その次の 2 列は、ファイルシステム上のユーザーのソフトブロック制限およびハードブロック制限を設定するのに使用されます。
-
inodes列には、ユーザーが現在使用している inode 数が表示されます。 最後の 2 列は、ファイルシステムのユーザーに対するソフトおよびハードの inode 制限を設定するのに使用されます。
- ハードブロック制限は、ユーザーまたはグループが使用できる最大ディスク容量 (絶対値) です。この制限に達すると、それ以上のディスク領域は使用できなくなります。
- ソフトブロック制限は、使用可能な最大ディスク容量を定義します。ただし、ハード制限とは異なり、ソフト制限は一定時間超過する可能性があります。この時間は 猶予期間 として知られています。猶予期間の単位は、秒、分、時間、日、週、または月で表されます。
検証
ユーザーのクォータが設定されていることを確認します。
# quota -v testuser Disk quotas for user testuser: Filesystem blocks quota limit grace files quota limit grace /dev/sda 1000* 1000 1000 0 0 0
23.6. グループごとにクォータの割り当て
グループごとにクォータを割り当てることができます。
前提条件
- グループは、グループクォータを設定する前に存在している必要があります。
手順
グループクォータを設定します。
# edquota -g groupnameたとえば、
develグループのグループクォータを設定するには、以下を実行します。# edquota -g develこのコマンドにより、グループの既存クォータがテキストエディターに表示されます。
Disk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/sda 440400 0 0 37418 0 0
- 制限を変更し、ファイルを保存します。
検証
グループクォータが設定されていることを確認します。
# quota -vg groupname
23.7. プロジェクトごとにクォータの割り当て
プロジェクトごとにクォータを割り当てることができます。
前提条件
- プロジェクトクォータがファイルシステムで有効になっている。
手順
プロジェクトが制御するディレクトリーを
/etc/projectsに追加します。たとえば、以下は一意の ID が 11 の/var/logパスを/etc/projectsに追加します。プロジェクト ID には、プロジェクトにマッピングされる任意の数値を指定できます。# echo 11:/var/log >> /etc/projects/etc/projidにプロジェクト名を追加して、プロジェクト ID をプロジェクト名にマップします。たとえば、以下は、前のステップで定義されたようにLogsというプロジェクトをプロジェクト ID 11 に関連付けます。# echo Logs:11 >> /etc/projid必要な制限を設定します。
# edquota -P 11注記プロジェクトは、プロジェクト ID (この場合は
11)、または名前 (この場合はLogs) で選択できます。quotaonを使用して、クォータの強制適用を有効にします。クォータ強制適用の有効化 を参照してください。
検証
プロジェクトのクォータが設定されていることを確認します。
# quota -vP 11注記プロジェクト ID またはプロジェクト名のいずれかで検証できます。
関連情報
-
システム上の
edquota(8)、projid(5)、projects(5)man ページ
23.8. ソフト制限の猶予期間の設定
特定のクォータにソフト制限がある場合、猶予期間 (ソフト制限を超過できる期間) を編集できます。ユーザー、グループ、またはプロジェクトの猶予期間を設定できます。
手順
猶予期間を編集します。
# edquota -t
他の edquota コマンドは特定のユーザー、グループ、またはプロジェクトのクォータで機能しますが、-t オプションはクォータが有効になっているすべてのファイルシステムで機能します。
関連情報
-
システム上の
edquota(8)man ページ
23.9. ファイルシステムのクォータをオフにする
quotaoff を使用して、指定されたファイルシステムでディスククォータの強制適用をオフにします。クォータアカウンティングは、このコマンド実行後も有効のままになります。
手順
すべてのユーザーとグループのクォータをオフにするには、次のコマンドを実行します。
# quotaoff -vaugP-
-uオプション、-gオプション、または-Pオプションがいずれも指定されていないと、ユーザーのクォータのみが無効になります。 -
-gオプションのみを指定すると、グループクォータのみが無効になります。 -
-Pオプションのみを指定すると、プロジェクトのクォータのみが無効になります。 -
-vスイッチにより、コマンドの実行時に詳細なステータス情報が表示されます。
-
関連情報
-
システム上の
quotaoff(8)man ページ
23.10. ディスククォータに関するレポート
repquota ユーティリティーを使用して、ディスククォータに関するレポートを作成します。
手順
repquotaコマンドを実行します。# repquotaたとえば、
repquota /dev/sdaコマンドは次のような出力を生成します。*** Report for user quotas on device /dev/sda Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
クォータが有効化された全ファイルシステムのディスク使用状況レポートを表示します。
# repquota -augP
各ユーザーに続いて表示される -- 記号で、ブロックまたは inode の制限を超えたかどうかを簡単に判断できます。ソフト制限のいずれかを超えると、対応する - 文字の代わりに + 文字が表示されます。最初の - 文字はブロック制限を表し、次の文字は inode 制限を表します。
通常、grace 列は空白です。ソフト制限が超過した場合、その列には猶予期間に残り時間量に相当する時間指定が含まれます。猶予期間の期間が過ぎると、その時間には 何も 表示されません。
関連情報
詳細は、repquota(8) man ページを参照してください。
第24章 未使用ブロックの破棄
破棄操作に対応するブロックデバイスで破棄操作を実行するか、そのスケジュールを設定できます。ブロック破棄操作では、マウントされたファイルシステムによって使用されなくなったファイルシステムブロックを、基盤となるストレージに伝達します。ブロック破棄操作により、SSD はガベージコレクションルーチンを最適化でき、シンプロビジョニングされたストレージに未使用の物理ブロックを再利用するように通知できます。
要件
ファイルシステムの基礎となるブロックデバイスは、物理的な破棄操作に対応している必要があります。
/sys/block/<device>/queue/discard_max_bytesファイルの値がゼロではない場合は、物理的な破棄操作はサポートされます。
24.1. ブロック破棄操作のタイプ
以下のような、さまざまな方法で破棄操作を実行できます。
- バッチ破棄
- これは、ユーザーによって明示的にトリガーされ、選択したファイルシステム内の未使用のブロックをすべて破棄します。
- オンライン破棄
-
これは、マウント時に指定され、ユーザーの介入なしにリアルタイムでトリガーされます。オンライン破棄操作は、
usedからfree状態に移行中のブロックのみを破棄します。 - 定期的な破棄
-
systemdサービスが定期的に実行するバッチ操作です。
すべてのタイプは、XFS ファイルシステムおよび ext4 ファイルシステムでサポートされます。
推奨事項
Red Hat は、バッチ破棄または周期破棄を使用することを推奨します。
以下の場合にのみ、オンライン破棄を使用してください。
- システムのワークロードでバッチ破棄が実行できない場合
- パフォーマンス維持にオンライン破棄操作が必要な場合
24.2. バッチブロック破棄の実行
バッチブロック破棄操作を実行して、マウントされたファイルシステムの未使用ブロックを破棄することができます。
前提条件
- ファイルシステムがマウントされている。
- ファイルシステムの基礎となるブロックデバイスが物理的な破棄操作に対応している。
手順
fstrimユーティリティーを使用します。選択したファイルシステムでのみ破棄を実行するには、次のコマンドを使用します。
# fstrim mount-pointマウントされているすべてのファイルシステムで破棄を実行するには、次のコマンドを使用します。
# fstrim --all
fstrim コマンドを以下のいずれかで実行している場合は、
- 破棄操作に対応していないデバイス
- 複数のデバイスから構成され、そのデバイスの 1 つが破棄操作に対応していない論理デバイス (LVM または MD)
次のメッセージが表示されます。
# fstrim /mnt/non_discard fstrim: /mnt/non_discard: the discard operation is not supported
関連情報
-
システム上の
fstrim(8)man ページ
24.3. オンラインブロック破棄の有効化
オンラインブロック破棄操作を実行して、サポートしているすべてのファイルシステムで未使用のブロックを自動的に破棄できます。
手順
マウント時のオンライン破棄を有効にします。
ファイルシステムを手動でマウントするには、
-o discardマウントオプションを追加します。# mount -o discard device mount-point-
ファイルシステムを永続的にマウントするには、
/etc/fstabファイルのマウントエントリーにdiscardオプションを追加します。
関連情報
-
システム上の
mount(8)およびfstab(5)man ページ
24.4. storage RHEL システムロールを使用してオンラインブロック破棄を有効にする
オンラインブロック破棄オプションを使用すると、XFS ファイルシステムをマウントし、未使用のブロックを自動的に破棄できます。
前提条件
- コントロールノードと管理対象ノードの準備が完了している。
- 管理対象ノードで Playbook を実行できるユーザーとしてコントロールノードにログインしている。
-
管理対象ノードへの接続に使用するアカウントに、そのノードに対する
sudo権限がある。
手順
次の内容を含む Playbook ファイル (例:
~/playbook.yml) を作成します。--- - name: Manage local storage hosts: managed-node-01.example.com tasks: - name: Enable online block discard ansible.builtin.include_role: name: rhel-system-roles.storage vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs mount_point: /mnt/data mount_options: discardPlaybook で使用されるすべての変数の詳細は、コントロールノードの
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイルを参照してください。Playbook の構文を検証します。
$ ansible-playbook --syntax-check ~/playbook.ymlこのコマンドは構文を検証するだけであり、有効だが不適切な設定から保護するものではないことに注意してください。
Playbook を実行します。
$ ansible-playbook ~/playbook.yml
検証
オンラインブロック破棄オプションが有効になっていることを確認します。
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
関連情報
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.mdファイル -
/usr/share/doc/rhel-system-roles/storage/ディレクトリー
24.5. 定期的なブロック破棄の有効化
systemd タイマーを有効にして、サポートしているすべてのファイルシステムで未使用ブロックを定期的に破棄できます。
手順
systemdタイマーを有効にして起動します。# systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
検証
タイマーのステータスを確認します。
# systemctl status fstrim.timer fstrim.timer - Discard unused blocks once a week Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: disabled) Active: active (waiting) since Wed 2023-05-17 13:24:41 CEST; 3min 15s ago Trigger: Mon 2023-05-22 01:20:46 CEST; 4 days left Docs: man:fstrim May 17 13:24:41 localhost.localdomain systemd[1]: Started Discard unused blocks once a week.
第25章 Stratis ファイルシステムの設定
Stratis は、物理ストレージデバイスのプールを管理するためにサービスとして実行され、複雑なストレージ設定のセットアップと管理を支援しながら、ローカルストレージ管理を使いやすく簡素化します。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
25.1. Stratis とは
Stratis は、Linux 用のローカルストレージ管理ソリューションです。これは、シンプルさと使いやすさに力を入れており、高度なストレージ機能にアクセスできます。
Stratis を使用すると、以下の活動をより簡単に行うことができます。
- ストレージの初期設定
- その後の変更
- 高度なストレージ機能の使用
Stratis は、高度なストレージ機能をサポートするローカルストレージ管理システムです。Stratis は、ストレージ プール の概念を中心としています。このプールは 1 つ以上のローカルディスクまたはパーティションから作成され、ファイルシステムはプールから作成されます。
プールにより、次のような多くの便利な機能を使用できます。
- ファイルシステムのスナップショット
- シンプロビジョニング
- 階層化
- 暗号化
関連情報
25.2. Stratis ボリュームのコンポーネント
Stratis ボリュームを構成するコンポーネントを説明します。
外部的には、Stratis はコマンドラインと API で次のボリュームコンポーネントを提供します。
blockdev- ディスクやディスクパーティションなどのブロックデバイス。
pool1 つ以上のブロックデバイスで設定されています。
プールの合計サイズは固定で、ブロックデバイスのサイズと同じです。
プールには、
dm-cacheターゲットを使用した不揮発性データキャッシュなど、ほとんどの Stratis レイヤーが含まれています。Stratis は、各プールの
/dev/stratis/my-pool/ディレクトリーを作成します。このディレクトリーには、プール内の Stratis ファイルシステムを表すデバイスへのリンクが含まれています。
filesystem各プールには、ファイルを格納する 1 つ以上のファイルシステムを含めることができます。
ファイルシステムはシンプロビジョニングされており、合計サイズは固定されていません。ファイルシステムの実際のサイズは、そこに格納されているデータとともに大きくなります。データのサイズがファイルシステムの仮想サイズに近づくと、Stratis はシンボリュームとファイルシステムを自動的に拡張します。
ファイルシステムは XFS でフォーマットされています。
重要Stratis は、Stratis を使用して作成したファイルシステムに関する情報を追跡し、XFS はそれを認識しません。また、XFS を使用して変更を行っても、自動的に Stratis に更新を作成しません。ユーザーは、Stratis が管理する XFS ファイルシステムを再フォーマットまたは再設定しないでください。
Stratis は、
/dev/stratis/my-pool/my-fsパスにファイルシステムへのリンクを作成します。
Stratis は、dmsetup リストと /proc/partitions ファイルに表示される多くの Device Mapper デバイスを使用します。同様に、lsblk コマンドの出力は、Stratis の内部の仕組みとレイヤーを反映します。
25.3. Stratis で使用可能なブロックデバイス
Stratis で使用可能なストレージデバイス。
対応デバイス
Stratis プールは、次の種類のブロックデバイスで動作するかどうかをテスト済みです。
- LUKS
- LVM 論理ボリューム
- MD RAID
- DM Multipath
- iSCSI
- HDD および SSD
- NVMe デバイス
対応していないデバイス
Stratis にはシンプロビジョニングレイヤーが含まれているため、Red Hat はすでにシンプロビジョニングされているブロックデバイスに Stratis プールを配置することを推奨しません。
25.4. Stratis のインストール
Stratis に必要なパッケージをインストールします。
手順
Stratis サービスとコマンドラインユーティリティーを提供するパッケージをインストールします。
# yum install stratisd stratis-clistratisdサービスが有効になっていることを確認します。# systemctl enable --now stratisd
25.5. 暗号化されていない Stratis プールの作成
1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis プールを作成するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールを作成する各ブロックデバイスが、1 GB 以上である。
IBM Z アーキテクチャーでは、
/dev/dasd*ブロックデバイスをパーティションに分割している。Stratis プールの作成には、パーティションデバイスを使用します。DASD デバイスのパーティション設定の詳細は、IBM Z での Linux インスタンスの設定 を参照してください。
暗号化されていない Stratis プールを暗号化することはできません。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceここで、
block-deviceは、ブロックデバイスへのパスになります (例:/dev/sdb)。選択したブロックデバイスに新しい暗号化されていない Stratis プールを作成します。
# stratis pool create my-pool block-deviceここで、
block-deviceは、空のブロックデバイスまたは消去したブロックデバイスへのパスになります。次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
25.6. Web コンソールを使用した暗号化されていない Stratis プールの作成
Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化されていない Stratis プールを作成できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールを作成するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールを作成する各ブロックデバイスが、1 GB 以上である。
暗号化されていない Stratis プールの作成後に、当該 Stratis プールを暗号化することはできません。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、メニューボタンをクリックし、Create Stratis pool を選択します。
- Name フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
- オプション: プールに作成する各ファイルシステムの最大サイズを指定する場合は、Manage filesystem sizes を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
25.7. 暗号化された Stratis プールの作成
データを保護するために、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
暗号化された Stratis プールを作成すると、カーネルキーリングはプライマリー暗号化メカニズムとして使用されます。その後のシステムを再起動すると、このカーネルキーリングは、暗号化された Stratis プールのロックを解除します。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
-
各ブロックデバイスは
cryptsetupライブラリーを使用して暗号化され、LUKS2形式を実装します。 - 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータ層に追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
- Stratis v2.1.0 以降がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis プールを作成するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールを作成するブロックデバイスが、それぞれ 1GB 以上である。
IBM Z アーキテクチャーでは、
/dev/dasd*ブロックデバイスをパーティションに分割している。Stratis プールでパーティションを使用します。DASD デバイスのパーティション設定の詳細は、IBM Z での Linux インスタンスの設定 を参照してください。
手順
Stratis プールで使用する各ブロックデバイスに存在するファイルシステム、パーティションテーブル、または RAID 署名をすべて削除します。
# wipefs --all block-deviceここで、
block-deviceは、ブロックデバイスへのパスになります (例:/dev/sdb)。キーセットをまだ作成していない場合には、以下のコマンドを実行してプロンプトに従って、暗号化に使用するキーセットを作成します。
# stratis key set --capture-key key-descriptionここでの
key-descriptionは、カーネルキーリングで作成されるキーへの参照になります。暗号化した Stratis プールを作成し、暗号化に使用する鍵の説明を指定します。
key-descriptionオプションを使用する代わりに、--keyfile-pathオプションを使用してキーのパスを指定することもできます。# stratis pool create --key-desc key-description my-pool block-deviceここでは、以下のようになります。
key-description- 直前の手順で作成したカーネルキーリングに存在するキーを参照します。
my-pool- 新しい Stratis プールの名前を指定します。
block-device空のブロックデバイスまたは消去したブロックデバイスへのパスを指定します。
次のコマンドを使用して、1 行に複数のブロックデバイスを指定することもできます。
# stratis pool create --key-desc key-description my-pool block-device-1 block-device-2
検証
新しい Stratis プールが作成されていることを確認します。
# stratis pool list
25.8. Web コンソールを使用した暗号化された Stratis プールの作成
データを保護するために、Web コンソールを使用して、1 つ以上のブロックデバイスから暗号化された Stratis プールを作成できます。
1 つ以上のブロックデバイスから暗号化された Stratis プールを作成する場合は、次の点に注意してください。
- 各ブロックデバイスは cryptsetup ライブラリーを使用して暗号化され、LUKS2 形式を実装します。
- 各 Stratis プールは、一意の鍵を持つか、他のプールと同じ鍵を共有できます。これらのキーはカーネルキーリングに保存されます。
- Stratis プールを構成するブロックデバイスは、すべて暗号化または暗号化されていないデバイスである必要があります。同じ Stratis プールに、暗号化したブロックデバイスと暗号化されていないブロックデバイスの両方を含めることはできません。
- 暗号化 Stratis プールのデータ層に追加されるブロックデバイスは、自動的に暗号化されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
- Stratis v2.1.0 以降がインストールされている。
-
stratisdサービスを実行している。 - Stratis プールを作成するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールを作成する各ブロックデバイスが、1 GB 以上である。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、メニューボタンをクリックし、Create Stratis pool を選択します。
- Name フィールドに、Stratis プールの名前を入力します。
- Stratis プールの作成元となる Block devices を選択します。
暗号化のタイプを選択します。パスフレーズ、Tang キーサーバー、またはその両方を使用できます。
パスフレーズ:
- パスフレーズを入力します。
- パスフレーズを確定します。
Tang キーサーバー:
- キーサーバーのアドレスを入力します。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
- オプション: プールに作成する各ファイルシステムの最大サイズを指定する場合は、Manage filesystem sizes を選択します。
- をクリックします。
検証
- Storage セクションに移動し、Devices テーブルに新しい Stratis プールが表示されていることを確認します。
25.9. Web コンソールを使用した Stratis プールの名前変更
Web コンソールを使用して、既存の Stratis プールの名前を変更できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされている。
Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、名前を変更する Stratis プールをクリックします。
- Stratis pool ページで、Name フィールドの横にある をクリックします。
- Rename Stratis pool ダイアログボックスで、新しい名前を入力します。
- をクリックします。
25.10. Stratis ファイルシステムでのオーバープロビジョニングモードの設定
ストレージスタックは、オーバープロビジョニングの状態になる可能性があります。ファイルシステムのサイズが、そのファイルシステムをサポートするプールよりも大きい場合には、プールがいっぱいになります。これを防ぐには、オーバープロビジョニングを無効にし、プール上の全ファイルシステムの合計サイズが、プールによって提供される使用可能な物理ストレージを超えないようにします。重要なアプリケーションやルートファイルシステムに Stratis を使用する場合、このモードにより特定の障害を防止できます。
オーバープロビジョニングを有効にすると、ストレージが完全に割り当てられたことを API シグナルに通知します。通知は、残りのプールスペースがすべていっぱいになると、Stratis に拡張するスペースが残っていないことをユーザーに通知する警告として機能します。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
手順
プールを正しく設定するには、次の 2 つの方法があります。
1 つ以上のブロックデバイスからプールを作成します。
# stratis pool create pool-name /dev/sdb既存のプールにオーバープロビジョニングモードを設定します。
# stratis pool overprovision pool-name <yes|no>- "yes" に設定すると、プールへのオーバープロビジョニングが有効になります。これは、プールによってサポートされる Stratis ファイルシステムの論理サイズの合計が、利用可能なデータ領域の量を超える可能性があることを意味します。
検証
以下のコマンドを実行し、Stratis プールの全一覧を表示します。
# stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
-
stratis pool listの出力に、プールのオーバープロビジョニングモードフラグが表示されているかどうかを確認します。" ~ " は "NOT" を表す数学記号であるため、~Opはオーバープロビジョニングなしという意味です。 オプション: 以下のコマンドを実行して、特定のプールでオーバープロビジョニングを確認します。
# stratis pool overprovision pool-name yes # stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
25.11. Stratis プールの NBDE へのバインド
暗号化された Stratis プールを Network Bound Disk Encryption (NBDE) にバインドするには、Tang サーバーが必要です。Stratis プールを含むシステムが再起動すると、Tang サーバーに接続して、カーネルキーリングの説明を指定しなくても、暗号化したプールのロックを自動的に解除します。
Stratis プールを補助 Clevis 暗号化メカニズムにバインドすると、プライマリーカーネルキーリング暗号化は削除されません。
前提条件
- Stratis v2.3.0 以降がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - 暗号化した Stratis プールを作成し、暗号化に使用されたキーの説明がある。詳細は、暗号化された Stratis プールの作成 を参照してください。
- Tang サーバーに接続できる。詳細は、SELinux を Enforcing モードで有効にした Tang サーバーのデプロイメント を参照してください。
手順
暗号化された Stratis プールを NBDE にバインドする。
# stratis pool bind nbde --trust-url my-pool tang-serverここでは、以下のようになります。
my-pool- 暗号化された Stratis プールの名前を指定します。
tang-server- Tang サーバーの IP アドレスまたは URL を指定します。
25.12. Stratis プールの TPM へのバインド
暗号化された Stratis プールを Trusted Platform Module (TPM) 2.0 にバインドすると、プールを含むシステムが再起動され、カーネルキーリングの説明を指定しなくても、プールは自動的にロック解除されます。
前提条件
- Stratis v2.3.0 以降がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - 暗号化された Stratis プールを作成している。詳細は、暗号化された Stratis プールの作成 を参照してください。
手順
暗号化された Stratis プールを TPM にバインドします。
# stratis pool bind tpm my-pool key-descriptionここでは、以下のようになります。
my-pool- 暗号化された Stratis プールの名前を指定します。
key-description- 暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。
25.13. カーネルキーリングを使用した暗号化 Stratis プールのロック解除
システムの再起動後、暗号化した Stratis プール、またはこれを構成するブロックデバイスが表示されない場合があります。プールの暗号化に使用したカーネルキーリングを使用して、プールのロックを解除できます。
前提条件
- Stratis v2.1.0 がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - 暗号化された Stratis プールを作成している。詳細は、暗号化された Stratis プールの作成 を参照してください。
手順
以前使用したものと同じキー記述を使用して、キーセットを再作成します。
# stratis key set --capture-key key-descriptionここで、key-description は、暗号化された Stratis プールの作成時に生成されたカーネルキーリングに存在するキーを参照します。
Stratis プールが表示されることを確認します。
# stratis pool list
25.14. 補助暗号化からの Stratis プールのバインド解除
暗号化した Stratis プールを、サポート対象の補助暗号化メカニズムからバインドを解除すると、プライマリーカーネルキーリングの暗号化はそのまま残ります。これは、最初から Clevis 暗号化を使用して作成されたプールには当てはまりません。
前提条件
- Stratis v2.3.0 以降がシステムにインストールされている。詳細は、Stratis のインストール を参照してください。
- 暗号化された Stratis プールを作成している。詳細は、暗号化された Stratis プールの作成 を参照してください。
- 暗号化した Stratis プールは、サポート対象の補助暗号化メカニズムにバインドされます。
手順
補助暗号化メカニズムから暗号化された Stratis プールのバインドを解除します。
# stratis pool unbind clevis my-poolここでは、以下のようになります。
my-poolは、バインドを解除する Stratis プールの名前を指定します。
25.15. Stratis プールの開始および停止
Stratis プールを開始および停止できます。この操作により、ファイルシステム、キャッシュデバイス、シンプール、暗号化されたデバイスなど、プールの構築に使用されたすべてのオブジェクトを解体または停止できます。プールがデバイスまたはファイルシステムをアクティブに使用している場合は、警告が表示され、停止できない可能性があることに注意してください。
停止状態は、プールのメタデータに記録されます。これらのプールは、プールが開始コマンドを受信するまで、次のブートでは開始されません。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - 暗号化されていない、または暗号化された Stratis プールを作成している。暗号化されていない Stratis プールの作成 または 暗号化された Stratis プールの作成 を参照してください。
手順
以下のコマンドを使用して Stratis プールを起動します。
--unlock-methodオプションは、プールが暗号化されている場合にプールのロックを解除する方法を指定します。# stratis pool start pool-uuid --unlock-method <keyring|clevis>または、以下のコマンドを使用して Stratis プールを停止します。これにより、ストレージスタックが切断されますが、メタデータはすべて保持されます。
# stratis pool stop pool-name
検証
以下のコマンドを使用して、システム上のプールを一覧表示します。
# stratis pool list以下のコマンドを使用して、以前に起動していないプールの一覧を表示します。UUID を指定すると、このコマンドは UUID に対応するプールに関する詳細情報を出力します。
# stratis pool list --stopped --uuid UUID
25.16. Stratis ファイルシステムの作成
既存の Stratis プールに Stratis ファイルシステムを作成します。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis プールを作成している。暗号化されていない Stratis プールの作成 または 暗号化された Stratis プールの作成 を参照してください。
手順
プールに Stratis ファイルシステムを作成します。
# stratis filesystem create --size number-and-unit my-pool my-fsここでは、以下のようになります。
number-and-unit- ファイルシステムのサイズを指定します。仕様形式は、入力の標準サイズ指定形式 (B、KiB、MiB、GiB、TiB、または PiB) に準拠する必要があります。
my-pool- Stratis プールの名前を指定します。
my-fsファイルシステムの任意名を指定します。
以下に例を示します。
例25.1 Stratis ファイルシステムの作成
# stratis filesystem create --size 10GiB pool1 filesystem1
検証
プール内のファイルシステムをリスト表示して、Stratis ファイルシステムが作成されているかどうかを確認します。
# stratis fs list my-pool
25.17. Web コンソールを使用した Stratis プール上のファイルシステムの作成
Web コンソールを使用して、既存の Stratis プール上にファイルシステムを作成できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- ファイルシステムを作成する Stratis プールをクリックします。
- Stratis pool ページで、Stratis filesystems セクションまでスクロールし、 をクリックします。
- ファイルシステムの名前を入力します。
- ファイルシステムのマウントポイントを入力します。
- マウントオプションを選択します。
- At boot ドロップダウンメニューで、ファイルシステムをマウントするタイミングを選択します。
ファイルシステムを作成します。
- ファイルシステムを作成してマウントする場合は、 をクリックします。
- ファイルシステムの作成のみを行う場合は、 をクリックします。
検証
- 新しいファイルシステムは、Stratis pool ページの Stratis filesystems タブに表示されます。
25.18. Stratis ファイルシステムのマウント
既存の Stratis ファイルシステムをマウントして、コンテンツにアクセスします。
前提条件
- Stratis がインストールされている。詳細は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis ファイルシステムを作成している。詳細は、Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをマウントするには、
/dev/stratis/ディレクトリーに Stratis が維持するエントリーを使用します。# mount /dev/stratis/my-pool/my-fs mount-point
これでファイルシステムは mount-point ディレクトリーにマウントされ、使用できるようになりました。
25.19. systemd サービスを使用した /etc/fstab での非ルート Stratis ファイルシステムの設定
systemd サービスを使用して、/etc/fstab で非ルートファイルシステムの設定を管理できます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis ファイルシステムを作成している。Stratis ファイルシステムの作成 を参照してください。
手順
root として、
/etc/fstabファイルを編集し、非ルートファイルシステムを設定するための行を追加します。/dev/stratis/my-pool/my-fs mount-point xfs defaults,x-systemd.requires=stratis-fstab-setup@pool-uuid.service,x-systemd.after=stratis-fstab-setup@pool-uuid.service dump-value fsck_value
関連情報
第26章 追加のブロックデバイスでの Stratis ボリュームの拡張
Stratis ファイルシステムのストレージ容量を増やすために、追加のブロックデバイスを Stratis プールに追加できます。手動で行うことも、Web コンソールを使用して行うこともできます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
26.1. Stratis プールへのブロックデバイスの追加
Stratis プールに 1 つ以上のブロックデバイスを追加できます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis プールに追加するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールに追加するブロックデバイスは使用されておらず、それぞれ 1 GiB 以上である。
手順
1 つ以上のブロックデバイスをプールに追加するには、以下を使用します。
# stratis pool add-data my-pool device-1 device-2 device-n
関連情報
-
システム上の
stratis(8)man ページ
26.2. Web コンソールを使用した Stratis プールへのブロックデバイスの追加
Web コンソールを使用して、既存の Stratis プールにブロックデバイスを追加できます。キャッシュをブロックデバイスとして追加することもできます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - Stratis プールが作成されている。
- Stratis プールを作成するブロックデバイスは使用されておらず、マウントされていない。
- Stratis プールを作成する各ブロックデバイスが、1 GB 以上である。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、ブロックデバイスを追加する Stratis プールをクリックします。
- Stratis pool ページで、 をクリックし、ブロックデバイスをデータまたはキャッシュとして追加する Tier を選択します。
- パスフレーズで暗号化された Stratis プールにブロックデバイスを追加する場合は、パスフレーズを入力します。
- Block devices で、プールに追加するデバイスを選択します。
- をクリックします。
第27章 Stratis ファイルシステムの監視
Stratis ユーザーは、システムにある Stratis ボリュームに関する情報を表示して、その状態と空き容量を監視できます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
27.1. Stratis ボリュームの情報表示
stratis ユーティリティーを使用すると、Stratis ボリュームの合計サイズ、使用サイズ、空きサイズ、プールに属するファイルシステムとブロックデバイスなどに関する統計情報をリスト表示できます。
df などの標準 Linux ユーティリティーは、Stratis 上の XFS ファイルシステム層のサイズ (1 TiB) を報告します。Stratis の実際のストレージ使用量は、シンプロビジョニングにより少なくなっており、また XFS レイヤーが満杯に近くなると Stratis が自動的にファイルシステムを拡張するため、これは特に有用な情報ではありません。
Stratis ファイルシステムに書き込まれているデータ量を定期的に監視します。これは Total Physical Used の値として報告されます。これが Total Physical Size の値を超えていないことを確認してください。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。
手順
システムで Stratis に使用されているすべての ブロックデバイス に関する情報を表示する場合は、次のコマンドを実行します。
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Data
システムにあるすべての Stratis プール に関する情報を表示するには、次のコマンドを実行します。
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiB
システムにあるすべての Stratis ファイルシステム に関する情報を表示するには、次のコマンドを実行します。
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /dev/stratis/my-pool/my-fs
関連情報
-
システム上の
stratis(8)man ページ
27.2. Web コンソールを使用した Stratis プールの表示
Web コンソールを使用して、既存の Stratis プールとそれに含まれるファイルシステムを表示できます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
- RHEL 8 Web コンソールにログインします。
- をクリックします。
Storage テーブルで、表示する Stratis プールをクリックします。
Stratis プールページには、プールおよびプール内に作成したファイルシステムに関するすべての情報が表示されます。
第28章 Stratis ファイルシステムでのスナップショットの使用
Stratis ファイルシステムのスナップショットを使用して、ファイルシステムの状態を任意の時点でキャプチャーし、後でそれを復元できます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
28.1. Stratis スナップショットの特徴
Stratis では、スナップショットは、別の Stratis ファイルシステムのコピーとして作成した通常の Stratis ファイルシステムです。スナップショットには、元のファイルシステムと同じファイルの内容が含まれていますが、スナップショットが変更するときにファイル内容が変更する可能性があります。スナップショットにどんな変更を加えても、元のファイルシステムには反映されません。
Stratis の現在のスナップショット実装は、次のような特徴があります。
- ファイルシステムのスナップショットは別のファイルシステムです。
- スナップショットと元のファイルシステムのリンクは、有効期間中は行われません。スナップショットされたファイルシステムは、元のファイルシステムよりも長く存続します。
- スナップショットを作成するためにファイルシステムをマウントする必要はありません。
- 各スナップショットは、XFS ログに必要となる実際のバッキングストレージの約半分のギガバイトを使用します。
28.2. Stratis スナップショットの作成
既存の Stratis ファイルシステムのスナップショットとして Stratis ファイルシステムを作成できます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis ファイルシステムを作成している。Stratis ファイルシステムの作成 を参照してください。
手順
Stratis スナップショットを作成します。
# stratis fs snapshot my-pool my-fs my-fs-snapshot
関連情報
-
システム上の
stratis(8)man ページ
28.3. Stratis スナップショットのコンテンツへのアクセス
Stratis ファイルシステムのスナップショットを、読み取りおよび書き込み操作でアクセスできるようにマウントすることができます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis スナップショットを作成している。Stratis ファイルシステムの作成 を参照してください。
手順
スナップショットにアクセスするには、
/dev/stratis/my-pool/ディレクトリーから通常のファイルシステムとしてマウントします。# mount /dev/stratis/my-pool/my-fs-snapshot mount-point
関連情報
- Stratis ファイルシステムのマウント
-
システム上の
mount(8)man ページ
28.4. Stratis ファイルシステムを以前のスナップショットに戻す
Stratis ファイルシステムの内容を、Stratis スナップショットでキャプチャーされた状態に戻すことができます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis スナップショットを作成している。Stratis スナップショットの作成 を参照してください。
手順
オプション: 後でアクセスできるように、ファイルシステムの現在の状態をバックアップします。
# stratis filesystem snapshot my-pool my-fs my-fs-backup元のファイルシステムをアンマウントして削除します。
# umount /dev/stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fs
元のファイルシステムの名前でスナップショットのコピーを作成します。
# stratis filesystem snapshot my-pool my-fs-snapshot my-fs元のファイルシステムと同じ名前でアクセスできるようになったスナップショットをマウントします。
# mount /dev/stratis/my-pool/my-fs mount-point
my-fs という名前のファイルシステムの内容は、スナップショット my-fs-snapshot と同じになりました。
関連情報
-
システム上の
stratis(8)man ページ
28.5. Stratis スナップショットの削除
プールから Stratis スナップショットを削除できます。スナップショットのデータは失われます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis スナップショットを作成している。Stratis スナップショットの作成 を参照してください。
手順
スナップショットをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-snapshotスナップショットを破棄します。
# stratis filesystem destroy my-pool my-fs-snapshot
関連情報
-
システム上の
stratis(8)man ページ
第29章 Stratis ファイルシステムの削除
既存の Stratis ファイルシステムまたは Stratis プールは、そこに含まれるデータを破棄することで削除できます。
Stratis はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。Red Hat のテクノロジープレビュー機能のサポート範囲の詳細は、https://access.redhat.com/ja/support/offerings/techpreview/ を参照してください。
29.1. Stratis ファイルシステムの削除
既存の Stratis ファイルシステムを削除できます。そこに保存されているデータは失われます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - Stratis ファイルシステムを作成している。Stratis ファイルシステムの作成 を参照してください。
手順
ファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fsファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs
検証
ファイルシステムがもう存在しないことを確認します。
# stratis filesystem list my-pool
関連情報
-
システム上の
stratis(8)man ページ
29.2. Web コンソールを使用した Stratis プールからのファイルシステムの削除
Web コンソールを使用して、既存の Stratis プールからファイルシステムを削除できます。
Stratis プールのファイルシステムを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
Stratis がインストールされている。
Web コンソールがデフォルトで Stratis を検出してインストールしている。ただし、Stratis を手動でインストールする場合は、Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
- Stratis プール上にファイルシステムが作成されている。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、ファイルシステムを削除する Stratis プールをクリックします。
- Stratis pool ページで、Stratis filesystems セクションまでスクロールし、削除するファイルシステムのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Confirm deletion ダイアログボックスで、 をクリックします。
29.3. Stratis プールの削除
既存の Stratis プールを削除できます。そこに保存されているデータは失われます。
前提条件
- Stratis がインストールされている。Stratis のインストール を参照してください。
-
stratisdサービスを実行している。 Stratis プールを作成している。
- 暗号化されていないプールを作成するには、暗号化されていない Stratis プールの作成 を参照してください。
- 暗号化されたプールを作成するには、暗号化された Stratis プールの作成 を参照してください。
手順
プールにあるファイルシステムのリストを表示します。
# stratis filesystem list my-poolプール上のすべてのファイルシステムをアンマウントします。
# umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-n
ファイルシステムを破棄します。
# stratis filesystem destroy my-pool my-fs-1 my-fs-2プールを破棄します。
# stratis pool destroy my-pool
検証
プールがなくなったことを確認します。
# stratis pool list
関連情報
-
システム上の
stratis(8)man ページ
29.4. Web コンソールを使用した Stratis プールの削除
Web コンソールを使用して、既存の Stratis プールを削除できます。
Stratis プールを削除すると、そこに含まれるすべてのデータが消去されます。
前提条件
- RHEL 8 Web コンソールがインストールされている。
- cockpit サービスが有効になっている。
ユーザーアカウントが Web コンソールにログインできる。
手順は、Web コンソールのインストールおよび有効化 を参照してください。
-
stratisdサービスを実行している。 - 既存の Stratis プールがある。
手順
RHEL 8 Web コンソールにログインします。
詳細は、Web コンソールへのログイン を参照してください。
- をクリックします。
- Storage テーブルで、削除する Stratis プールのメニューボタン をクリックします。
- ドロップダウンメニューから を選択します。
- Permanently delete pool ダイアログボックスで、 をクリックします。
第30章 ext3 ファイルシステムの使用
システム管理者は、ext3 ファイルシステムの作成、マウント、サイズ変更、バックアップ、および復元が可能です。ext3 ファイルシステムは、基本的に、ext2 ファイルシステムが拡張されたバージョンです。
30.1. ext3 ファイルシステムの機能
ext3 ファイルシステムの機能は以下のとおりです。
可用性 - 予期しない電源障害やシステムクラッシュの後、ジャーナリングが提供されているため、ファイルシステムを検査する必要はありません。デフォルトのジャーナルサイズは、ハードウェアの速度に応じて、復旧するのに約 1 秒かかります
注記ext3 で対応しているジャーナリングモードは
data=ordered(デフォルト) のみです。詳細は、Red Hat ナレッジベースのソリューション Is the EXT journaling option "data=writeback" supported in RHEL? を参照してください。- データの整合性 - ext3 ファイルシステムは、予期しない電源障害やシステムクラッシュが発生したときに、データの整合性が失われないようにします。
- 速度 - 一部のデータを複数回書き込みますが、ext3 のジャーナリングにより、ハードドライブのヘッドモーションが最適化されるため、ほとんどの場合、ext3 のスループットは ext2 よりも高くなります。
- 簡単な移行 - ext2 から ext3 に簡単に移行でき、再フォーマットをせずに、堅牢なジャーナリングファイルシステムの恩恵を受けることができます。
関連情報
-
システム上の
udevman ページ
30.2. ext3 ファイルシステムの作成
システム管理者は、mkfs.ext3 コマンドを使用して、ブロックデバイスに ext3 ファイルシステムを作成できます。
前提条件
- ディスクにパーティションがある。MBR または GPT パーティションの作成は、parted を使用してディスク上にパーティションテーブルを作成する を参照してください。
.
+ もしくは、LVM ボリュームまたは MD ボリュームを使用します。
手順
ext3 ファイルシステムを作成する場合は、以下の手順を実行します。
デバイスが通常のパーティションの場合、LVM ボリューム、MD ボリューム、または類似デバイスは次のコマンドを使用します。
# mkfs.ext3 /dev/block_device/dev/block_device を、ブロックデバイスへのパスに置き換えます。
たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。一般的な用途では、デフォルトのオプションが最適です。ストライプ化されたブロックデバイス (RAID5 アレイなど) の場合は、ファイルシステムの作成時にストライプジオメトリーを指定できます。適切なストライプジオメトリーを使用することで、ext3 ファイルシステムのパフォーマンスが向上します。たとえば、4k ブロックのファイルシステムで、64k ストライド (16 x 4096) のファイルシステムを作成する場合は、次のコマンドを使用します。
# mkfs.ext3 -E stride=16,stripe-width=64 /dev/block_deviceこの例では、以下のようになります。
- stride=value - RAID チャンクサイズを指定します。
- stripe-width=value - 1 RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
注記ファイルシステムの作成時に UUID を指定する場合は、次のコマンドを実行します。
# mkfs.ext3 -U UUID /dev/block_deviceUUID を、設定する UUID (例:
7cd65de3-e0be-41d9-b66d-96d749c02da7) に置き換えます。/dev/block_device を、ext3 ファイルシステムへのパス (例:
/dev/sda8) に置き換え、UUID を追加します。ファイルシステムの作成時にラベルを指定するには、以下のコマンドを実行します。
# mkfs.ext3 -L label-name /dev/block_device
作成した ext3 ファイルシステムを表示する場合は、以下のコマンドを実行します。
# blkid
関連情報
-
システム上の
ext3およびmkfs.ext3 のman ページ
30.3. Ext3 ファイルシステムのマウント
システム管理者は、mount ユーティリティーを使用して、ext3 ファイルシステムをマウントできます。
前提条件
- ext3 ファイルシステム。ext3 ファイルシステムの作成については、ext3 ファイルシステムの作成 を参照してください。
手順
ファイルシステムをマウントするためのマウントポイントを作成するには、以下のコマンドを実行します。
# mkdir /mount/point/mount/point を、パーティションのマウントポイントを作成するディレクトリー名に置き換えます。
ext3 ファイルシステムをマウントするには、以下の手順を実行します。
ext3 ファイルシステムを追加のオプションなしでマウントするには、以下のコマンドを実行します。
# mount /dev/block_device /mount/point- ファイルシステムを永続的にマウントするには、ファイルシステムの永続的なマウント を参照してください。
マウントされたファイルシステムを表示するには、次のコマンドを実行します。
# df -h
関連情報
-
システム上の
mount、ext4、およびfstabman ページ - ファイルシステムのマウント
30.4. ext3 ファイルシステムのサイズ変更
システム管理者は、resize2fs ユーティリティーを使用して、ext3 ファイルシステムのサイズを変更できます。resize2fs ユーティリティーは、特定の単位を示す接尾辞が使用されていない限り、ファイルシステムのブロックサイズの単位でサイズを読み取ります。以下の接尾辞は、特定の単位を示しています。
-
s (セクター) -
512バイトのセクター -
K (キロバイト) -
1,024バイト -
M (メガバイト) -
1,048,576バイト -
G (ギガバイト) -
1,073,741,824バイト -
T (テラバイト) -
1,099,511,627,776バイト
前提条件
- ext3 ファイルシステム。ext3 ファイルシステムの作成については、ext3 ファイルシステムの作成 を参照してください。
- サイズ変更後にファイルシステムを保持するための、適切なサイズの基本ブロックデバイス
手順
ext3 ファイルシステムのサイズを変更する場合は、以下の手順に従ってください。
アンマウントされている ext3 ファイルシステムのサイズを縮小および拡張するには、以下のコマンドを実行します。
# umount /dev/block_device # e2fsck -f /dev/block_device # resize2fs /dev/block_device size
/dev/block_device を、ブロックデバイスへのパス (例:
/dev/sdb1) に置き換えます。size を、
s、K、M、G、およびTの接尾辞を使用して必要なサイズ変更値に置き換えます。ext3 ファイルシステムは、
resize2fsコマンドを使用して、マウントしたままの状態でサイズを大きくすることができます。# resize2fs /mount/device size注記拡張時のサイズパラメーターは任意です (多くの場合は必要ありません)。
resize2fsは、コンテナーの使用可能な領域 (通常は論理ボリュームまたはパーティション) を埋めるように、自動的に拡張します。
サイズを変更したファイルシステムを表示するには、次のコマンドを実行します。
# df -h
関連情報
-
システム上の
resize2fs、e2fsck、およびext4man ページ
第31章 ext4 ファイルシステムの使用
システム管理者は、ext4 ファイルシステムの作成、マウント、サイズ変更、バックアップ、および復元が可能です。ext4 ファイルシステムは、ext3 ファイルシステムの拡張性を高めたファイルシステムです。Red Hat Enterprise Linux 8 では、最大 16 テラバイトの個別のファイルサイズと、最大 50 テラバイトのファイルシステムに対応します。
31.1. ext4 ファイルシステムの機能
以下は、ext4 ファイルシステムの機能です。
- エクステントの使用 - ext4 ファイルシステムはエクステントを使用します。これにより、サイズが大きいファイルを使用する場合のパフォーマンスが向上し、サイズが大きいファイルのメタデータのオーバーヘッドが削減されます。
- ext4 は、未割り当てのブロックグループと、inode テーブルセクションに適宜ラベルを付けます。これにより、ファイルシステムの検査時に、ブロックグループとテーブルセクションをスキップできます。ファイルシステムの検査が簡単に行われ、ファイルシステムがサイズが大きくなるとより有益になります。
- メタデータチェックサム - この機能は、デフォルトでは Red Hat Enterprise Linux 8 で有効になっています。
以下は、ext4 ファイルシステムの割り当て機能です。
- 永続的な事前割り当て
- 遅延割り当て
- マルチブロック割り当て
- ストライプ認識割り当て
-
拡張属性 (
xattr) - これにより、システムは、ファイルごとに、名前と値の組み合わせを追加で関連付けられるようになります。 クォータジャーナリング - クラッシュ後に行なわれる時間がかかるクォータの整合性チェックが不要になります。
注記ext4 で対応しているジャーナリングモードは
data=ordered(デフォルト) のみです。詳細は、Red Hat ナレッジベースのソリューション Is the EXT journaling option "data=writeback" supported in RHEL? を参照してください。- サブセカンド (一秒未満) のタイムスタンプ - サブセカンドのタイムスタンプを指定します。
関連情報
-
システム上の
ext4man ページ
31.2. ext4 ファイルシステムの作成
システム管理者は、mkfs.ext4 コマンドを使用して、ブロックデバイスに ext4 ファイルシステムを作成できます。
前提条件
- ディスクにパーティションがある。MBR または GPT パーティションの作成は、parted を使用してディスク上にパーティションテーブルを作成する を参照してください。
- もしくは、LVM ボリュームまたは MD ボリュームを使用します。
手順
ext4 ファイルシステムを作成する場合は、以下の手順を実行します。
デバイスが通常のパーティションの場合、LVM ボリューム、MD ボリューム、または類似デバイスは次のコマンドを使用します。
# mkfs.ext4 /dev/block_device/dev/block_device を、ブロックデバイスへのパスに置き換えます。
たとえば、
/dev/sdb1、/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a、または/dev/my-volgroup/my-lvです。一般的な用途では、デフォルトのオプションが最適です。ストライプ化されたブロックデバイス (RAID5 アレイなど) の場合は、ファイルシステムの作成時にストライプジオメトリーを指定できます。適切なストライプジオメトリーを使用することで、ext4 ファイルシステムのパフォーマンスが向上します。たとえば、4k ブロックのファイルシステムで、64k ストライド (16 x 4096) のファイルシステムを作成する場合は、次のコマンドを使用します。
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/block_deviceこの例では、以下のようになります。
- stride=value - RAID チャンクサイズを指定します。
- stripe-width=value - 1 RAID デバイス内のデータディスク数、または 1 ストライプ内のストライプユニット数を指定します。
注記ファイルシステムの作成時に UUID を指定する場合は、次のコマンドを実行します。
# mkfs.ext4 -U UUID /dev/block_deviceUUID を、設定する UUID (例:
7cd65de3-e0be-41d9-b66d-96d749c02da7) に置き換えます。/dev/block_device を、ext4 ファイルシステムへのパス (例:
/dev/sda8) に置き換え、UUID を追加します。ファイルシステムの作成時にラベルを指定するには、以下のコマンドを実行します。
# mkfs.ext4 -L label-name /dev/block_device
作成した ext4 ファイルシステムを表示するには、以下のコマンドを実行します。
# blkid
関連情報
-
システム上の
ext4およびmkfs.ext4man ページ
31.3. ext4 ファイルシステムのマウント
システム管理者は、mount ユーティリティーを使用して、ext4 ファイルシステムをマウントできます。
前提条件
- ext4 ファイルシステム。ext4 ファイルシステムの作成は、ext4 ファイルシステムの作成 を参照してください。
手順
ファイルシステムをマウントするためのマウントポイントを作成するには、以下のコマンドを実行します。
# mkdir /mount/point/mount/point を、パーティションのマウントポイントを作成するディレクトリー名に置き換えます。
ext4 ファイルシステムをマウントするには、以下を行います。
ext4 ファイルシステムを追加のオプションなしでマウントするには、次のコマンドを実行します。
# mount /dev/block_device /mount/point- ファイルシステムを永続的にマウントするには、ファイルシステムの永続的なマウント を参照してください。
マウントされたファイルシステムを表示するには、次のコマンドを実行します。
# df -h
関連情報
-
システム上の
mount、ext4、およびfstabman ページ - ファイルシステムのマウント
31.4. ext4 ファイルシステムのサイズ変更
システム管理者は、resize2fs ユーティリティーを使用して、ext4 ファイルシステムのサイズを変更できます。resize2fs ユーティリティーは、特定の単位を示す接尾辞が使用されていない限り、ファイルシステムのブロックサイズの単位でサイズを読み取ります。以下の接尾辞は、特定の単位を示しています。
-
s (セクター) -
512バイトのセクター -
K (キロバイト) -
1,024バイト -
M (メガバイト) -
1,048,576バイト -
G (ギガバイト) -
1,073,741,824バイト -
T (テラバイト) -
1,099,511,627,776バイト
前提条件
- ext4 ファイルシステム。ext4 ファイルシステムの作成は、ext4 ファイルシステムの作成 を参照してください。
- サイズ変更後にファイルシステムを保持するための、適切なサイズの基本ブロックデバイス
手順
ext4 ファイルシステムのサイズを変更するには、以下の手順に従ってください。
アンマウントされている ext4 ファイルシステムのサイズを縮小および拡張するには、次のコマンドを実行します。
# umount /dev/block_device # e2fsck -f /dev/block_device # resize2fs /dev/block_device size
/dev/block_device を、ブロックデバイスへのパス (例:
/dev/sdb1) に置き換えます。size を、
s、K、M、G、およびTの接尾辞を使用して必要なサイズ変更値に置き換えます。ext4 ファイルシステムは、
resize2fsを使用して、マウントしたままの状態でサイズを大きくすることができます。# resize2fs /mount/device size注記拡張時のサイズパラメーターは任意です (多くの場合は必要ありません)。
resize2fsは、コンテナーの使用可能な領域 (通常は論理ボリュームまたはパーティション) を埋めるように、自動的に拡張します。
サイズを変更したファイルシステムを表示するには、次のコマンドを実行します。
# df -h
関連情報
-
システム上の
resize2fs、e2fsck、およびext4man ページ
31.5. ext4 および XFS で使用されるツールの比較
このセクションでは、ext4 ファイルシステムおよび XFS ファイルシステムで一般的なタスクを行うのに使用するツールを比較します。
| タスク | ext4 | XFS |
|---|---|---|
| ファイルシステムを作成する |
|
|
| ファイルシステム検査 |
|
|
| ファイルシステムのサイズを変更する |
|
|
| ファイルシステムのイメージを保存する |
|
|
| ファイルシステムのラベル付けまたはチューニングを行う |
|
|
| ファイルシステムのバックアップを作成する |
|
|
| クォータ管理 |
|
|
| ファイルマッピング |
|
|