スケーラビリティーおよびパフォーマンス
実稼働環境における OpenShift Container Platform クラスターのスケーリングおよびパフォーマンスチューニング
概要
第1章 ホストについての推奨されるプラクティス
このトピックでは、OpenShift Container Platform のホストについての推奨プラクティスについて説明します。
これらのガイドラインは、Open Virtual Network (OVN) ではなく、ソフトウェア定義ネットワーク (SDN) を使用する OpenShift Container Platform に該当します。
1.1. ノードホストについての推奨プラクティス
OpenShift Container Platform ノードの設定ファイルには、重要なオプションが含まれています。たとえば、podsPerCore および maxPods の 2 つのパラメーターはノードにスケジュールできる Pod の最大数を制御します。
両方のオプションが使用されている場合、2 つの値の低い方の値により、ノード上の Pod 数が制限されます。これらの値を超えると、以下の状態が生じる可能性があります。
- CPU 使用率の増大。
- Pod のスケジューリングの速度が遅くなる。
- (ノードのメモリー量によって) メモリー不足のシナリオが生じる可能性。
- IP アドレスのプールを消費する。
- リソースのオーバーコミット、およびこれによるアプリケーションのパフォーマンスの低下。
Kubernetes では、単一コンテナーを保持する Pod は実際には 2 つのコンテナーを使用します。2 つ目のコンテナーは実際のコンテナーの起動前にネットワークを設定するために使用されます。そのため、10 の Pod を使用するシステムでは、実際には 20 のコンテナーが実行されていることになります。
クラウドプロバイダーからのディスク IOPS スロットリングは CRI-O および kubelet に影響を与える可能性があります。ノード上に多数の I/O 集約型 Pod が実行されている場合、それらはオーバーロードする可能性があります。ノード上のディスク I/O を監視し、ワークロード用に十分なスループットを持つボリュームを使用することが推奨されます。
podsPerCore は、ノードのプロセッサーコア数に基づいてノードが実行できる Pod 数を設定します。たとえば、4 プロセッサーコアを搭載したノードで podsPerCore が 10 に設定される場合、このノードで許可される Pod の最大数は 40 になります。
kubeletConfig: podsPerCore: 10
podsPerCore を 0 に設定すると、この制限が無効になります。デフォルトは 0 です。podsPerCore は maxPods を超えることができません。
maxPods は、ノードのプロパティーにかかわらず、ノードが実行できる Pod 数を固定値に設定します。
kubeletConfig:
maxPods: 2501.2. kubelet パラメーターを編集するための KubeletConfig CRD の作成
kubelet 設定は、現時点で Ignition 設定としてシリアル化されているため、直接編集することができます。ただし、新規の kubelet-config-controller も Machine Config Controller (MCC) に追加されます。これにより、KubeletConfig カスタムリソース (CR) を使用して kubelet パラメーターを編集できます。
kubeletConfig オブジェクトのフィールドはアップストリーム Kubernetes から kubelet に直接渡されるため、kubelet はそれらの値を直接検証します。kubeletConfig オブジェクトに無効な値により、クラスターノードが利用できなくなります。有効な値は、Kubernetes ドキュメント を参照してください。
以下のガイダンスを参照してください。
-
マシン設定プールごとに、そのプールに加える設定変更をすべて含めて、
KubeletConfigCR を 1 つ作成します。同じコンテンツをすべてのプールに適用している場合には、すべてのプールにKubeletConfigCR を 1 つだけ設定する必要があります。 -
既存の
KubeletConfigCR を編集して既存の設定を編集するか、変更ごとに新規 CR を作成する代わりに新規の設定を追加する必要があります。CR を作成するのは、別のマシン設定プールを変更する場合、または一時的な変更を目的とした変更の場合のみにして、変更を元に戻すことができるようにすることをお勧めします。 -
必要に応じて、クラスターごとに 10 を制限し、複数の
KubeletConfigCR を作成します。最初のKubeletConfigCR について、Machine Config Operator (MCO) はkubeletで追加されたマシン設定を作成します。それぞれの後続の CR で、コントローラーは数字の接尾辞が付いた別のkubeletマシン設定を作成します。たとえば、kubeletマシン設定があり、その接尾辞が-2の場合に、次のkubeletマシン設定には-3が付けられます。
マシン設定を削除する場合は、制限を超えないようにそれらを逆の順序で削除する必要があります。たとえば、kubelet-3 マシン設定を、kubelet-2 マシン設定を削除する前に削除する必要があります。
接尾辞が kubelet-9 のマシン設定があり、別の KubeletConfig CR を作成する場合には、kubelet マシン設定が 10 未満の場合でも新規マシン設定は作成されません。
KubeletConfig CR の例
$ oc get kubeletconfig
NAME AGE set-max-pods 15m
KubeletConfig マシン設定を示す例
$ oc get mc | grep kubelet
... 99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m ...
以下の手順は、ワーカーノードでノードあたりの Pod の最大数を設定する方法を示しています。
前提条件
設定するノードタイプの静的な
MachineConfigPoolCR に関連付けられたラベルを取得します。以下のいずれかの手順を実行します。マシン設定プールを表示します。
$ oc describe machineconfigpool <name>
以下に例を示します。
$ oc describe machineconfigpool worker
出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods 1- 1
- ラベルが追加されると、
labelsの下に表示されます。
ラベルが存在しない場合は、キー/値のペアを追加します。
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
手順
これは、選択可能なマシン設定オブジェクトを表示します。
$ oc get machineconfig
デフォルトで、2 つの kubelet 関連の設定である
01-master-kubeletおよび01-worker-kubeletを選択できます。ノードあたりの最大 Pod の現在の値を確認します。
$ oc describe node <node_name>
以下に例を示します。
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94
Allocatableスタンザでvalue: pods: <value>を検索します。出力例
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250
ワーカーノードでノードあたりの最大の Pod を設定するには、kubelet 設定を含むカスタムリソースファイルを作成します。
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods 1 kubeletConfig: maxPods: 500 2注記kubelet が API サーバーと通信する速度は、1 秒あたりのクエリー (QPS) およびバースト値により異なります。デフォルト値の
50(kubeAPIQPSの場合) および100(kubeAPIBurstの場合) は、各ノードで制限された Pod が実行されている場合には十分な値です。ノード上に CPU およびメモリーリソースが十分にある場合には、kubelet QPS およびバーストレートを更新することが推奨されます。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>ラベルを使用してワーカーのマシン設定プールを更新します。
$ oc label machineconfigpool worker custom-kubelet=large-pods
KubeletConfigオブジェクトを作成します。$ oc create -f change-maxPods-cr.yaml
KubeletConfigオブジェクトが作成されていることを確認します。$ oc get kubeletconfig
出力例
NAME AGE set-max-pods 15m
クラスター内のワーカーノードの数によっては、ワーカーノードが 1 つずつ再起動されるのを待機します。3 つのワーカーノードを持つクラスターの場合は、10 分 から 15 分程度かかる可能性があります。
変更がノードに適用されていることを確認します。
maxPods値が変更されたワーカーノードで確認します。$ oc describe node <node_name>
Allocatableスタンザを見つけます。... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 500 1 ...- 1
- この例では、
podsパラメーターはKubeletConfigオブジェクトに設定した値を報告するはずです。
KubeletConfigオブジェクトの変更を確認します。$ oc get kubeletconfigs set-max-pods -o yaml
これは、以下の例のように
Trueおよびtype:Successのステータスを表示します。spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
1.4. コントロールプレーンノードのサイジング
コントロールプレーンノードリソースの要件は、クラスター内のノード数によって異なります。コントロールプレーンノードのサイズについての以下の推奨内容は、テストに重点を置いた場合のコントロールプレーンの密度の結果に基づいています。コントロールプレーンのテストでは、ノード数に応じて各 namespace でクラスター全体に展開される以下のオブジェクトを作成します。
- 12 イメージストリーム
- 3 ビルド設定
- 6 ビルド
- それぞれに 2 つのシークレットをマウントする 2 Pod レプリカのある 1 デプロイメント
- 2 つのシークレットをマウントする 1 Pod レプリカのある 2 デプロイメント
- 先のデプロイメントを参照する 3 つのサービス
- 先のデプロイメントを参照する 3 つのルート
- 10 のシークレット (それらの内の 2 つは先ののデプロイメントでマウントされる)
- 10 の設定マップ (それらの内の 2 つは先のデプロイメントでマウントされる)
| ワーカーノードの数 | クラスターの負荷 (namespace) | CPU コア数 | メモリー (GB) |
|---|---|---|---|
| 25 | 500 | 4 | 16 |
| 100 | 1000 | 8 | 32 |
| 250 | 4000 | 16 | 96 |
3 つのコントロールプレーンノード (またはマスターノード) がある大規模で高密度のクラスターでは、いずれかのノードが停止、起動、または障害が発生すると、CPU とメモリーの使用量が急上昇します。障害は、コストを節約するためにシャットダウンした後にクラスターが再起動する意図的なケースに加えて、電源、ネットワーク、または基礎となるインフラストラクチャーの予期しない問題が発生することが原因である可能性があります。残りの 2 つのコントロールプレーンノードは、高可用性を維持するために負荷を処理する必要があります。これにより、リソースの使用量が増えます。これは、マスターが遮断 (cordon)、ドレイン (解放) され、オペレーティングシステムおよびコントロールプレーン Operator の更新を適用するために順次再起動されるため、アップグレード時に想定される動作になります。障害が繰り返し発生しないようにするには、コントロールプレーンノードでの全体的な CPU およびメモリーリソース使用状況を、利用可能な容量の最大 60% に維持し、使用量の急増に対応できるようにします。リソース不足による潜在的なダウンタイムを回避するために、コントロールプレーンノードの CPU およびメモリーを適宜増やします。
ノードのサイジングは、クラスター内のノードおよびオブジェクトの数によって異なります。また、オブジェクトがそのクラスター上でアクティブに作成されるかどうかによっても異なります。オブジェクトの作成時に、コントロールプレーンは、オブジェクトが running フェーズにある場合と比較し、リソースの使用状況においてよりアクティブな状態になります。
Operator Lifecycle Manager (OLM) はコントロールプレーンノードで実行され、OLM のメモリーフットプリントは OLM がクラスター上で管理する必要のある namespace およびユーザーによってインストールされる Operator の数によって異なります。OOM による強制終了を防ぐには、コントロールプレーンノードのサイズを適切に設定する必要があります。以下のデータポイントは、クラスター最大のテストの結果に基づいています。
| namespace 数 | アイドル状態の OLM メモリー (GB) | ユーザー Operator が 5 つインストールされている OLM メモリー (GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
以下の設定でのみ、実行中の OpenShift Container Platform 4.9 クラスターでコントロールプレーンのノードサイズを変更できます。
- ユーザーがプロビジョニングしたインストール方法でインストールされたクラスター。
- インストーラーによってプロビジョニングされたインフラストラクチャーインストール方法でインストールされた AWS クラスター。
他のすべての設定では、合計ノード数を見積もり、インストール時に推奨されるコントロールプレーンノードサイズを使用する必要があります。
この推奨事項は、ネットワークプラグインとして OpenShift SDN を使用して OpenShift Container Platform クラスターでキャプチャーされたデータポイントに基づいています。
OpenShift Container Platform 4.9 では、デフォルトで CPU コア (500 ミリコア) の半分がシステムによって予約されます (OpenShift Container Platform 3.11 以前のバージョンと比較)。サイズはこれを考慮に入れて決定されます。
1.4.1. コントロールプレーンマシン用により大きな Amazon Web Services インスタンスタイプを選択する
Amazon Web Services (AWS) クラスター内のコントロールプレーンマシンがより多くのリソースを必要とする場合は、コントロールプレーンマシンが使用するより大きな AWS インスタンスタイプを選択できます。
1.4.1.1. AWS コンソールを使用して Amazon Web Services インスタンスタイプを変更する
AWS コンソールでインスタンスタイプを更新することにより、コントロールプレーンマシンが使用するアマゾンウェブサービス (AWS) インスタンスタイプを変更できます。
前提条件
- クラスターの EC2 インスタンスを変更するために必要なアクセス許可を持つ AWS コンソールにアクセスできます。
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにアクセスできます。
手順
- AWS コンソールを開き、コントロールプレーンマシンのインスタンスを取得します。
コントロールプレーンマシンインスタンスを 1 つ選択します。
- 選択したコントロールプレーンマシンについて、etcd スナップショットを作成して etcd データをバックアップします。詳細については、etcd のバックアップを参照してください。
- AWS コンソールで、コントロールプレーンマシンインスタンスを停止します。
- 停止したインスタンスを選択し、Actions → Instance Settings → Change instance type をクリックします。
-
インスタンスをより大きなタイプに変更し、タイプが前の選択と同じベースであることを確認して、変更を適用します。たとえば、
m6i.xlargeをm6i.2xlargeまたはm6i.4xlargeに変更できます。 - インスタンスを起動します。
-
OpenShift Container Platform クラスターにインスタンスに対応する
Machineオブジェクトがある場合、AWS コンソールで設定されたインスタンスタイプと一致するようにオブジェクトのインスタンスタイプを更新します。
- コントロールプレーンマシンごとにこのプロセスを繰り返します。
関連情報
1.5. etcd についての推奨されるプラクティス
etcd はデータをディスクに書き込み、プロポーザルをディスクに保持するため、そのパフォーマンスはディスクのパフォーマンスに依存します。etcd は特に I/O を集中的に使用するわけではありませんが、最適なパフォーマンスと安定性を得るには、低レイテンシーのブロックデバイスが必要です。etcd のコンセンサスプロトコルは、メタデータをログ (WAL) に永続的に保存することに依存しているため、etcd はディスク書き込みの遅延に敏感です。遅いディスクと他のプロセスからのディスクアクティビティーは、長い fsync 待ち時間を引き起こす可能性があります。
これらの待ち時間により、etcd はハートビートを見逃し、新しいプロポーザルを時間どおりにディスクにコミットせず、最終的にリクエストのタイムアウトと一時的なリーダーの喪失を経験する可能性があります。書き込みレイテンシーが高いと、OpenShift API の速度も低下し、クラスターのパフォーマンスに影響します。これらの理由により、コントロールプレーンノードに他のワークロードを併置することは避けてください。
レイテンシーに関しては、8000 バイト長の 50 IOPS 以上を連続して書き込むことができるブロックデバイス上で etcd を実行します。つまり、レイテンシーが 20 ミリ秒の場合、fdatasync を使用して WAL の各書き込みを同期することに注意してください。負荷の高いクラスターの場合、8000 バイト (2 ミリ秒) の連続 500 IOPS が推奨されます。これらの数値を測定するには、fio などのベンチマークツールを使用できます。
このようなパフォーマンスを実現するには、低レイテンシーで高スループットの SSD または NVMe ディスクに支えられたマシンで etcd を実行します。シングルレベルセル (SLC) ソリッドステートドライブ (SSD) を検討してください。これは、メモリーセルごとに 1 ビットを提供し、耐久性と信頼性が高く、書き込みの多いワークロードに最適です。
次のハードディスク機能は、最適な etcd パフォーマンスを提供します。
- 高速読み取り操作をサポートするための低レイテンシー。
- 圧縮と最適化を高速化するための高帯域幅書き込み。
- 障害からの回復を高速化するための高帯域幅読み取り。
- 最低限の選択肢としてソリッドステートドライブがありますが、NVMe ドライブが推奨されます。
- 信頼性を高めるためのさまざまなメーカーのサーバーグレードのハードウェア。
- パフォーマンス向上のための RAID0 テクノロジー。
- 専用の etcd ドライブ。etcd ドライブにログファイルやその他の重いワークロードを配置しないでください。
NAS または SAN のセットアップ、および回転するドライブは避けてください。fio などのユーティリティーを使用して、常にベンチマークを行ってください。クラスターのパフォーマンスが向上するにつれて、そのパフォーマンスを継続的に監視します。
ネットワークファイルシステム (NFS) プロトコルまたはその他のネットワークベースのファイルシステムの使用は避けてください。
デプロイされた OpenShift Container Platform クラスターでモニターする主要なメトリクスの一部は、etcd ディスクの write ahead log 期間の p99 と etcd リーダーの変更数です。Prometheus を使用してこれらのメトリクスを追跡します。
OpenShift Container Platform クラスターの作成前または作成後に etcd のハードウェアを検証するには、fio を使用できます。
前提条件
- Podman や Docker などのコンテナーランタイムは、テストしているマシンにインストールされます。
-
データは
/var/lib/etcdパスに書き込まれます。
手順
fio を実行し、結果を分析します。
Podman を使用する場合は、次のコマンドを実行します。
$ sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
Docker を使用する場合は、次のコマンドを実行します。
$ sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
この出力では、実行からキャプチャーされた fsync メトリクスの 99 パーセンタイルの比較でディスクが 20 ms 未満かどうかを確認して、ディスクの速度が etcd をホストするのに十分であるかどうかを報告します。I/O パフォーマンスの影響を受ける可能性のある最も重要な etcd メトリックのいくつかを以下に示します。
-
etcd_disk_wal_fsync_duration_seconds_bucketメトリックは、etcd の WAL fsync 期間を報告します。 -
etcd_disk_backend_commit_duration_seconds_bucketメトリクスは、etcd バックエンドコミットの待機時間を報告します。 -
etcd_server_leader_changes_seen_totalメトリックは、リーダーの変更を報告します。
etcd はすべてのメンバー間で要求を複製するため、そのパフォーマンスはネットワーク入出力 (I/O) のレイテンシーによって大きく変わります。ネットワークのレイテンシーが高くなると、etcd のハートビートの時間は選択のタイムアウトよりも長くなり、その結果、クラスターに中断をもたらすリーダーの選択が発生します。デプロイされた OpenShift Container Platform クラスターでのモニターの主要なメトリクスは、各 etcd クラスターメンバーの etcd ネットワークピアレイテンシーの 99 番目のパーセンタイルになります。Prometheus を使用してメトリクスを追跡します。
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m])) メトリックは、etcd がメンバー間でクライアントリクエストの複製を完了するまでのラウンドトリップ時間をレポートします。50 ミリ秒未満であることを確認してください。
1.6. etcd を別のディスクに移動する
etcd を共有ディスクから別のディスクに移動して、パフォーマンスの問題を防止または解決できます。
前提条件
-
MachineConfigPoolはmetadata.labelsmachineconfiguration.openshift.io/roleと一致する必要があります。これは、コントローラー、ワーカー、またはカスタムプールに適用されます。 -
/dev/sdbなどのノードの補助記憶装置は、sdb と一致する必要があります。ファイル内のすべての場所でこの参照を変更します。
この手順では、/var/ などのルートファイルシステムの一部を、インストール済みノードの別のディスクまたはパーティションに移動しません。
Machine Config Operator (MCO) は、OpenShift Container Platform 4.13 コンテナーストレージのセカンダリーディスクのマウントを担当します。
次の手順を使用して、etcd を別のデバイスに移動します。
手順
etcd-mc.ymlという名前のmachineconfigYAML ファイルを作成して、次の情報を追加します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 98-var-lib-etcd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=Make File System on /dev/sdb DefaultDependencies=no BindsTo=dev-sdb.device After=dev-sdb.device var.mount Before=systemd-fsck@dev-sdb.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/lib/systemd/systemd-makefs xfs /dev/sdb TimeoutSec=0 [Install] WantedBy=var-lib-containers.mount enabled: true name: systemd-mkfs@dev-sdb.service - contents: | [Unit] Description=Mount /dev/sdb to /var/lib/etcd Before=local-fs.target Requires=systemd-mkfs@dev-sdb.service After=systemd-mkfs@dev-sdb.service var.mount [Mount] What=/dev/sdb Where=/var/lib/etcd Type=xfs Options=defaults,prjquota [Install] WantedBy=local-fs.target enabled: true name: var-lib-etcd.mount - contents: | [Unit] Description=Sync etcd data if new mount is empty DefaultDependencies=no After=var-lib-etcd.mount var.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecCondition=/usr/bin/test ! -d /var/lib/etcd/member ExecStart=/usr/sbin/setenforce 0 ExecStart=/bin/rsync -ar /sysroot/ostree/deploy/rhcos/var/lib/etcd/ /var/lib/etcd/ ExecStart=/usr/sbin/setenforce 1 TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target enabled: true name: sync-var-lib-etcd-to-etcd.service - contents: | [Unit] Description=Restore recursive SELinux security contexts DefaultDependencies=no After=var-lib-etcd.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/sbin/restorecon -R /var/lib/etcd/ TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target enabled: true name: restorecon-var-lib-etcd.service次のコマンドを入力して、マシン設定を作成します。
$ oc login -u ${ADMIN} -p ${ADMINPASSWORD} ${API} ... output omitted ...$ oc create -f etcd-mc.yml machineconfig.machineconfiguration.openshift.io/98-var-lib-etcd created
$ oc login -u ${ADMIN} -p ${ADMINPASSWORD} ${API} [... output omitted ...]$ oc create -f etcd-mc.yml machineconfig.machineconfiguration.openshift.io/98-var-lib-etcd created
ノードが更新され、再起動されます。再起動が完了すると、次のイベントが発生します。
- 指定したディスクに XFS ファイルシステムが作成されます。
-
ディスクは
/var/lib/etcにマウントされます。 -
/sysroot/ostree/deploy/rhcos/var/lib/etcdのコンテンツは/var/lib/etcdに同期されます。 -
/var/lib/etcdのSELinuxラベルの復元が強制されます。 - 古いコンテンツは削除されません。
ノードが別のディスクに配置されたら、マシン設定ファイル
etcd-mc.ymlを次の情報で更新します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 98-var-lib-etcd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=Mount /dev/sdb to /var/lib/etcd Before=local-fs.target Requires=systemd-mkfs@dev-sdb.service After=systemd-mkfs@dev-sdb.service var.mount [Mount] What=/dev/sdb Where=/var/lib/etcd Type=xfs Options=defaults,prjquota [Install] WantedBy=local-fs.target enabled: true name: var-lib-etcd.mount次のコマンドを入力して、デバイスを作成および同期するためのロジックを削除する変更されたバージョンを適用します。
$ oc replace -f etcd-mc.yml
前の手順により、ノードが再起動されなくなります。
1.7. etcd データのデフラグ
大規模で密度の高いクラスターの場合に、キースペースが過剰に拡大し、スペースのクォータを超過すると、etcd は低下するパフォーマンスの影響を受ける可能性があります。etcd を定期的に維持および最適化して、データストアのスペースを解放します。Prometheus で etcd メトリックをモニターし、必要に応じてデフラグします。そうしないと、etcd はクラスター全体のアラームを発生させ、クラスターをメンテナンスモードにして、キーの読み取りと削除のみを受け入れる可能性があります。
これらの主要な指標をモニターします。
-
etcd_server_quota_backend_bytes、これは現在のクォータ制限です -
etcd_mvcc_db_total_size_in_use_in_bytes、これはヒストリーコンパクション後の実際のデータベース使用状況を示します。 -
etcd_mvcc_db_total_size_in_bytesはデフラグ待ちの空き領域を含むデータベースサイズを表します。
etcd データをデフラグし、etcd 履歴の圧縮などのディスクの断片化を引き起こすイベント後にディスク領域を回収します。
履歴の圧縮は 5 分ごとに自動的に行われ、これによりバックエンドデータベースにギャップが生じます。この断片化された領域は etcd が使用できますが、ホストファイルシステムでは利用できません。ホストファイルシステムでこの領域を使用できるようにするには、etcd をデフラグする必要があります。
デフラグは自動的に行われますが、手動でトリガーすることもできます。
etcd Operator はクラスター情報を使用してユーザーの最も効率的な操作を決定するため、ほとんどの場合、自動デフラグが適しています。
1.7.1. 自動デフラグ
etcd Operator はディスクを自動的にデフラグします。手動による介入は必要ありません。
以下のログのいずれかを表示して、デフラグプロセスが成功したことを確認します。
- etcd ログ
- cluster-etcd-operator Pod
- Operator ステータスのエラーログ
自動デフラグにより、Kubernetes コントローラーマネージャーなどのさまざまな OpenShift コアコンポーネントでリーダー選出の失敗が発生し、失敗したコンポーネントの再起動がトリガーされる可能性があります。再起動は無害であり、次に実行中のインスタンスへのフェイルオーバーをトリガーするか、再起動後にコンポーネントが再び作業を再開します。
ログ出力の例
I0907 08:43:12.171919 1 defragcontroller.go:198] etcd member "ip- 10-0-191-150.example.redhat.com" backend store fragmented: 39.33 %, dbSize: 349138944
1.7.2. 手動デフラグ
etcd_db_total_size_in_bytes メトリクスをモニターして、手動でのデフラグが必要であるかどうかを判別することができます。
また、PromQL 式を使用した最適化によって解放される etcd データベースのサイズ (MB 単位) を確認することで、最適化が必要かどうかを判断することもできます ((etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes)/1024/1024)。
etcd のデフラグはプロセスを阻止するアクションです。etcd メンバーはデフラグが完了するまで応答しません。このため、各 Pod のデフラグアクションごとに少なくとも 1 分間待機し、クラスターが回復できるようにします。
以下の手順に従って、各 etcd メンバーで etcd データをデフラグします。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
リーダーを最後にデフラグする必要があるため、どの etcd メンバーがリーダーであるかを判別します。
etcd Pod の一覧を取得します。
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
出力例
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
Pod を選択し、以下のコマンドを実行して、どの etcd メンバーがリーダーであるかを判別します。
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
出力例
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
この出力の
IS LEADER列に基づいて、https://10.0.199.170:2379エンドポイントがリーダーになります。このエンドポイントを直前の手順の出力に一致させると、リーダーの Pod 名はetcd-ip-10-0-199-170.example.redhat.comになります。
etcd メンバーのデフラグ。
実行中の etcd コンテナーに接続し、リーダーでは ない Pod の名前を渡します。
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
ETCDCTL_ENDPOINTS環境変数の設定を解除します。sh-4.4# unset ETCDCTL_ENDPOINTS
etcd メンバーのデフラグを実行します。
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
出力例
Finished defragmenting etcd member[https://localhost:2379]
タイムアウトエラーが発生した場合は、コマンドが正常に実行されるまで
--command-timeoutの値を増やします。データベースサイズが縮小されていることを確認します。
sh-4.4# etcdctl endpoint status -w table --cluster
出力例
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 41 MB | false | false | 7 | 91624 | 91624 | | 1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+この例では、この etcd メンバーのデータベースサイズは、開始時のサイズの 104 MB ではなく 41 MB です。
これらの手順を繰り返して他の etcd メンバーのそれぞれに接続し、デフラグします。常に最後にリーダーをデフラグします。
etcd Pod が回復するように、デフラグアクションごとに 1 分以上待機します。etcd Pod が回復するまで、etcd メンバーは応答しません。
領域のクォータの超過により
NOSPACEアラームがトリガーされる場合、それらをクリアします。NOSPACEアラームがあるかどうかを確認します。sh-4.4# etcdctl alarm list
出力例
memberID:12345678912345678912 alarm:NOSPACE
アラームをクリアします。
sh-4.4# etcdctl alarm disarm
1.8. OpenShift Container Platform インフラストラクチャーコンポーネント
以下のインフラストラクチャーワークロードでは、OpenShift Container Platform ワーカーのサブスクリプションは不要です。
- マスターで実行される Kubernetes および OpenShift Container Platform コントロールプレーンサービス
- デフォルトルーター
- 統合コンテナーイメージレジストリー
- HAProxy ベースの Ingress Controller
- ユーザー定義プロジェクトのモニタリング用のコンポーネントを含む、クラスターメトリクスの収集またはモニタリングサービス
- クラスター集計ロギング
- サービスブローカー
- Red Hat Quay
- Red Hat OpenShift Container Storage
- Red Hat Advanced Cluster Manager
- Kubernetes 用 Red Hat Advanced Cluster Security
- Red Hat OpenShift GitOps
- Red Hat OpenShift Pipelines
他のコンテナー、Pod またはコンポーネントを実行するノードは、サブスクリプションが適用される必要のあるワーカーノードです。
インフラストラクチャーノードおよびインフラストラクチャーノードで実行できるコンポーネントの詳細は、OpenShift sizing and subscription guide for enterprise Kubernetes の"Red Hat OpenShift control plane and infrastructure nodes"セクションを参照してください。
1.9. モニタリングソリューションの移動
監視スタックには、Prometheus、Grafana、Alertmanager などの複数のコンポーネントが含まれています。Cluster Monitoring Operator は、このスタックを管理します。モニタリングスタックをインフラストラクチャーノードに再デプロイするために、カスタム config map を作成して適用できます。
手順
cluster-monitoring-config設定マップを編集し、nodeSelectorを変更してinfraラベルを使用します。$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute grafana: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecuteモニタリング Pod が新規マシンに移行することを確認します。
$ watch 'oc get pod -n openshift-monitoring -o wide'
コンポーネントが
infraノードに移動していない場合は、このコンポーネントを持つ Pod を削除します。$ oc delete pod -n openshift-monitoring <pod>
削除された Pod からのコンポーネントが
infraノードに再作成されます。
1.10. デフォルトレジストリーの移行
レジストリー Operator を、その Pod を複数の異なるノードにデプロイするように設定します。
前提条件
- 追加のマシンセットを OpenShift Container Platform クラスターに設定します。
手順
config/instanceオブジェクトを表示します。$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml
出力例
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instanceオブジェクトを編集します。$ oc edit configs.imageregistry.operator.openshift.io/cluster
spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
レジストリー Pod がインフラストラクチャーノードに移動していることを確認します。
以下のコマンドを実行して、レジストリー Pod が置かれているノードを特定します。
$ oc get pods -o wide -n openshift-image-registry
ノードに指定したラベルがあることを確認します。
$ oc describe node <node_name>
コマンド出力を確認し、
node-role.kubernetes.io/infraがLABELS一覧にあることを確認します。
1.11. ルーターの移動
ルーター Pod を異なるマシンセットにデプロイできます。デフォルトで、この Pod はワーカーノードにデプロイされます。
前提条件
- 追加のマシンセットを OpenShift Container Platform クラスターに設定します。
手順
ルーター Operator の
IngressControllerカスタムリソースを表示します。$ oc get ingresscontroller default -n openshift-ingress-operator -o yaml
コマンド出力は以下のテキストのようになります。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontrollerリソースを編集し、nodeSelectorをinfraラベルを使用するように変更します。$ oc edit ingresscontroller default -n openshift-ingress-operator
spec: nodePlacement: nodeSelector: 1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
ルーター Pod が
infraノードで実行されていることを確認します。ルーター Pod の一覧を表示し、実行中の Pod のノード名をメモします。
$ oc get pod -n openshift-ingress -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>
この例では、実行中の Pod は
ip-10-0-217-226.ec2.internalノードにあります。実行中の Pod のノードのステータスを表示します。
$ oc get node <node_name> 1- 1
- Pod の一覧より取得した
<node_name>を指定します。
出力例
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.22.1
ロールの一覧に
infraが含まれているため、Pod は正しいノードで実行されます。
1.12. インフラストラクチャーノードのサイジング
インフラストラクチャーノード は、OpenShift Container Platform 環境の各部分を実行するようにラベル付けされたノードです。これらの要素により、Prometheus のメトリクスまたは時系列の数が増加する可能性があり、インフラストラクチャーノードのリソース要件はクラスターのクラスターの使用年数、ノード、およびオブジェクトによって異なります。以下のインフラストラクチャーノードのサイズの推奨内容は、クラスターの最大値およびコントロールプレーンの密度に重点を置いたテストの結果に基づいています。
| ワーカーノードの数 | CPU コア数 | メモリー (GB) |
|---|---|---|
| 25 | 4 | 16 |
| 100 | 8 | 32 |
| 250 | 16 | 128 |
| 500 | 32 | 128 |
通常、3 つのインフラストラクチャーノードはクラスターごとに推奨されます。
これらのサイジングの推奨内容は、クラスター全体に多数のオブジェクトを作成するスケーリングのテストに基づいています。これらのテストでは、一部のクラスターの最大値に達しいます。OpenShift Container Platform 4.9 クラスターでノード数が 250 および 500 の場合、これらの最大値は、10000 の namespace に 61000 の Pod、10000 のデプロイメント、181000 のシークレット、400 の設定マップなどになります。Prometheus はメモリー集約型のアプリケーションであり、リソースの使用率はノード数、オブジェクト数、Prometheus メトリクスの収集間隔、メトリクスまたは時系列、クラスターの使用年数などのさまざまな要素によって異なります。ディスクサイズは保持期間によっても変わります。これらの要素を考慮し、これらに応じてサイズを設定する必要があります。
これらのサイジングの推奨内容は、クラスターのインストール時にインストールされるインフラストラクチャーコンポーネント (Prometheus、ルーターおよびレジストリー) についてのみ適用されます。ロギングは Day 2 の操作で、これらの推奨事項には含まれていません。
OpenShift Container Platform 4.9 では、デフォルトで CPU コア (500 ミリコア) の半分がシステムによって予約されます (OpenShift Container Platform 3.11 以前のバージョンと比較)。これは、上記のサイジングの推奨内容に影響します。
1.13. 関連情報
第2章 IBM Z および LinuxONE 環境に推奨されるホストプラクティス
このトピックでは、IBM Z および LinuxONE での OpenShift Container Platform のホストについての推奨プラクティスについて説明します。
s390x アーキテクチャーは、多くの側面に固有のものです。したがって、ここで説明する推奨事項によっては、他のプラットフォームには適用されない可能性があります。
特に指定がない限り、これらのプラクティスは IBM Z および LinuxONE での z/VM および Red Hat Enterprise Linux (RHEL) KVM インストールの両方に適用されます。
2.1. CPU のオーバーコミットの管理
高度に仮想化された IBM Z 環境では、インフラストラクチャーのセットアップとサイズ設定を慎重に計画する必要があります。仮想化の最も重要な機能の 1 つは、リソースのオーバーコミットを実行する機能であり、ハイパーバイザーレベルで実際に利用可能なリソースよりも多くのリソースを仮想マシンに割り当てます。これはワークロードに大きく依存し、すべてのセットアップに適用できる黄金律はありません。
設定によっては、CPU のオーバーコミットに関する以下のベストプラクティスを考慮してください。
- LPAR レベル (PR/SM ハイパーバイザー) で、利用可能な物理コア (IFL) を各 LPAR に割り当てないようにします。たとえば、4 つの物理 IFL が利用可能な場合は、それぞれ 4 つの論理 IFL を持つ 3 つの LPAR を定義しないでください。
- LPAR 共有および重みを確認します。
- 仮想 CPU の数が多すぎると、パフォーマンスに悪影響を与える可能性があります。論理プロセッサーが LPAR に定義されているよりも多くの仮想プロセッサーをゲストに定義しないでください。
- ピーク時の負荷に対して、ゲストごとの仮想プロセッサー数を設定し、それ以上は設定しません。
- 小規模から始めて、ワークロードを監視します。必要に応じて、vCPU の数値を段階的に増やします。
- すべてのワークロードが、高いオーバーコミットメント率に適しているわけではありません。ワークロードが CPU 集約型である場合、パフォーマンスの問題なしに高い比率を実現できない可能性が高くなります。より多くの I/O 集約値であるワークロードは、オーバーコミットの使用率が高い場合でも、パフォーマンスの一貫性を保つことができます。
2.2. Transparent Huge Pages (THP) の無効
Transparent Huge Page (THP) は、Huge Page を作成し、管理し、使用するためのほとんどの要素を自動化しようとします。THP は Huge Page を自動的に管理するため、すべてのタイプのワークロードに対して常に最適に処理される訳ではありません。THP は、多くのアプリケーションが独自の Huge Page を処理するため、パフォーマンス低下につながる可能性があります。したがって、THP を無効にすることを検討してください。
2.3. Receive Flow Steering を使用したネットワークパフォーマンスの強化
Receive Flow Steering (RFS) は、ネットワークレイテンシーをさらに短縮して Receive Packet Steering (RPS) を拡張します。RFS は技術的には RPS をベースとしており、CPU キャッシュのヒットレートを増やして、パケット処理の効率を向上させます。RFS はこれを実現すると共に、計算に最も便利な CPU を決定することによってキューの長さを考慮し、キャッシュヒットが CPU 内で発生する可能性が高くなります。そのため、CPU キャッシュは無効化され、キャッシュを再構築するサイクルが少なくて済みます。これにより、パケット処理の実行時間を減らすのに役立ちます。
2.3.1. Machine Config Operator (MCO) を使用した RFS のアクティブ化
手順
以下の MCO サンプルプロファイルを YAML ファイルにコピーします。たとえば、
enable-rfs.yamlのようになります。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 50-enable-rfs spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:text/plain;charset=US-ASCII,%23%20turn%20on%20Receive%20Flow%20Steering%20%28RFS%29%20for%20all%20network%20interfaces%0ASUBSYSTEM%3D%3D%22net%22%2C%20ACTION%3D%3D%22add%22%2C%20RUN%7Bprogram%7D%2B%3D%22/bin/bash%20-c%20%27for%20x%20in%20/sys/%24DEVPATH/queues/rx-%2A%3B%20do%20echo%208192%20%3E%20%24x/rps_flow_cnt%3B%20%20done%27%22%0A filesystem: root mode: 0644 path: /etc/udev/rules.d/70-persistent-net.rules - contents: source: data:text/plain;charset=US-ASCII,%23%20define%20sock%20flow%20enbtried%20for%20%20Receive%20Flow%20Steering%20%28RFS%29%0Anet.core.rps_sock_flow_entries%3D8192%0A filesystem: root mode: 0644 path: /etc/sysctl.d/95-enable-rps.confMCO プロファイルを作成します。
$ oc create -f enable-rfs.yaml
50-enable-rfsという名前のエントリーが表示されていることを確認します。$ oc get mc
非アクティブにするには、次のコマンドを実行します。
$ oc delete mc 50-enable-rfs
2.4. ネットワーク設定の選択
ネットワークスタックは、OpenShift Container Platform などの Kubernetes ベースの製品の最も重要なコンポーネントの 1 つです。IBM Z 設定では、ネットワーク設定は選択したハイパーバイザーによって異なります。ワークロードとアプリケーションに応じて、最適なものは通常、ユースケースとトラフィックパターンによって異なります。
設定によっては、以下のベストプラクティスを考慮してください。
- トラフィックパターンを最適化するためにネットワークデバイスに関するすべてのオプションを検討してください。OSA-Express、RoCE Express、HiperSockets、z/VM VSwitch、Linux Bridge (KVM) の利点を調べて、セットアップに最大のメリットをもたらすオプションを決定します。
- 常に利用可能な最新の NIC バージョンを使用してください。たとえば、OSA Express 7S 10 GbE は、OSA Express 6S 10 GbE とトランザクションワークロードタイプと比べ、10 GbE アダプターよりも優れた改善を示しています。
- 各仮想スイッチは、追加のレイテンシーのレイヤーを追加します。
- ロードバランサーは、クラスター外のネットワーク通信に重要なロールを果たします。お使いのアプリケーションに重要な場合は、実稼働環境グレードのハードウェアロードバランサーの使用を検討してください。
- OpenShift Container Platform SDN では、ネットワークパフォーマンスに影響を与えるフローおよびルールが導入されました。コミュニケーションが重要なサービスの局所性から利益を得るには、Pod の親和性と配置を必ず検討してください。
- パフォーマンスと機能間のトレードオフのバランスを取ります。
2.5. z/VM の HyperPAV でディスクのパフォーマンスが高いことを確認します。
DASD デバイスおよび ECKD デバイスは、IBM Z 環境で一般的に使用されているディスクタイプです。z/VM 環境で通常の OpenShift Container Platform 設定では、DASD ディスクがノードのローカルストレージをサポートするのに一般的に使用されます。HyperPAV エイリアスデバイスを設定して、z/VM ゲストをサポートする DASD ディスクに対してスループットおよび全体的な I/O パフォーマンスを向上できます。
ローカルストレージデバイスに HyperPAV を使用すると、パフォーマンスが大幅に向上します。ただし、スループットと CPU コストのトレードオフがあることに注意してください。
2.5.1. z/VM フルパックミニディスクを使用してノードで HyperPAV エイリアスをアクティブにするために Machine Config Operator (MCO) を使用します。
フルパックミニディスクを使用する z/VM ベースの OpenShift Container Platform セットアップの場合、すべてのノードで HyperPAV エイリアスをアクティベートして MCO プロファイルを利用できます。コントロールプレーンノードおよびコンピュートノードの YAML 設定を追加する必要があります。
手順
以下の MCO サンプルプロファイルをコントロールプレーンノードの YAML ファイルにコピーします。たとえば、
05-master-kernelarg-hpav.yamlです。$ cat 05-master-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 05-master-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805以下の MCO サンプルプロファイルをコンピュートノードの YAML ファイルにコピーします。たとえば、
05-worker-kernelarg-hpav.yamlです。$ cat 05-worker-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805注記デバイス ID に合わせて
rd.dasd引数を変更する必要があります。MCO プロファイルを作成します。
$ oc create -f 05-master-kernelarg-hpav.yaml
$ oc create -f 05-worker-kernelarg-hpav.yaml
非アクティブにするには、次のコマンドを実行します。
$ oc delete -f 05-master-kernelarg-hpav.yaml
$ oc delete -f 05-worker-kernelarg-hpav.yaml
2.6. IBM Z ホストの RHEL KVM の推奨事項
KVM 仮想サーバーの環境を最適化すると、仮想サーバーと利用可能なリソースの可用性が大きく変わります。ある環境のパフォーマンスを向上させる同じアクションは、別の環境で悪影響を与える可能性があります。特定の設定に最適なバランスを見つけることは困難な場合があり、多くの場合は実験が必要です。
以下のセクションでは、IBM Z および LinuxONE 環境で RHEL KVM とともに OpenShift Container Platform を使用する場合のベストプラクティスについて説明します。
2.6.1. VirtIO ネットワークインターフェイスに複数のキューを使用
複数の仮想 CPU を使用すると、受信パケットおよび送信パケットに複数のキューを指定すると、パッケージを並行して転送できます。driver 要素の queues 属性を使用して複数のキューを設定します。仮想サーバーの仮想 CPU の数を超えない 2 以上の整数を指定します。
以下の仕様の例では、ネットワークインターフェイスの入出力キューを 2 つ設定します。
<interface type="direct">
<source network="net01"/>
<model type="virtio"/>
<driver ... queues="2"/>
</interface>複数のキューは、ネットワークインターフェイス用に強化されたパフォーマンスを提供するように設計されていますが、メモリーおよび CPU リソースも使用します。ビジーなインターフェイス用の 2 つのキューの定義を開始します。次に、トラフィックが少ないインターフェイスの場合は 2 つのキューを、ビジーなインターフェイスの場合は 3 つ以上のキューを試してください。
2.6.2. 仮想ブロックデバイスの I/O スレッドの使用
I/O スレッドを使用するように仮想ブロックデバイスを設定するには、仮想サーバー用に 1 つ以上の I/O スレッドを設定し、各仮想ブロックデバイスがこれらの I/O スレッドの 1 つを使用するように設定する必要があります。
以下の例は、<iothreads>3</iothreads> を指定し、3 つの I/O スレッドを連続して 1、2、および 3 に設定します。iothread="2" パラメーターは、ID 2 で I/O スレッドを使用するディスクデバイスのドライバー要素を指定します。
I/O スレッド仕様のサンプル
... <domain> <iothreads>3</iothreads>1 ... <devices> ... <disk type="block" device="disk">2 <driver ... iothread="2"/> </disk> ... </devices> ... </domain>
スレッドは、ディスクデバイスの I/O 操作のパフォーマンスを向上させることができますが、メモリーおよび CPU リソースも使用します。同じスレッドを使用するように複数のデバイスを設定できます。スレッドからデバイスへの最適なマッピングは、利用可能なリソースとワークロードによって異なります。
少数の I/O スレッドから始めます。多くの場合は、すべてのディスクデバイスの単一の I/O スレッドで十分です。仮想 CPU の数を超えてスレッドを設定しないでください。アイドル状態のスレッドを設定しません。
virsh iothreadadd コマンドを使用して、特定のスレッド ID の I/O スレッドを稼働中の仮想サーバーに追加できます。
2.6.3. 仮想 SCSI デバイスの回避
SCSI 固有のインターフェイスを介してデバイスに対応する必要がある場合にのみ、仮想 SCSI デバイスを設定します。ホスト上でバッキングされるかどうかにかかわらず、仮想 SCSI デバイスではなく、ディスク領域を仮想ブロックデバイスとして設定します。
ただし、以下には、SCSI 固有のインターフェイスが必要になる場合があります。
- ホスト上で SCSI 接続のテープドライブ用の LUN。
- 仮想 DVD ドライブにマウントされるホストファイルシステムの DVD ISO ファイル。
2.6.4. ディスクについてのゲストキャッシュの設定
ホストではなく、ゲストでキャッシュするようにディスクデバイスを設定します。
ディスクデバイスのドライバー要素に cache="none" パラメーターおよび io="native" パラメーターが含まれていることを確認します。
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>2.6.5. メモリーバルーンデバイスを除外します。
動的メモリーサイズが必要ない場合は、メモリーバルーンデバイスを定義せず、libvirt が管理者用に作成しないようにする必要があります。memballoon パラメーターを、ドメイン設定 XML ファイルの devices 要素の子として含めます。
アクティブなプロファイルの一覧を確認します。
<memballoon model="none"/>
2.6.6. ホストスケジューラーの CPU 移行アルゴリズムの調整
影響を把握する専門家がない限り、スケジューラーの設定は変更しないでください。テストせずに実稼働システムに変更を適用せず、目的の効果を確認しないでください。
kernel.sched_migration_cost_ns パラメーターは、ナノ秒の間隔を指定します。タスクの最後の実行後、CPU キャッシュは、この間隔が期限切れになるまで有用なコンテンツを持つと見なされます。この間隔を大きくすると、タスクの移行が少なくなります。デフォルト値は 500000 ns です。
実行可能なプロセスがあるときに CPU アイドル時間が予想よりも長い場合は、この間隔を短くしてみてください。タスクが CPU またはノード間で頻繁にバウンスする場合は、それを増やしてみてください。
間隔を 60000 ns に動的に設定するには、以下のコマンドを入力します。
# sysctl kernel.sched_migration_cost_ns=60000
値を 60000 ns に永続的に変更するには、次のエントリーを /etc/sysctl.conf に追加します。
kernel.sched_migration_cost_ns=60000
2.6.7. cpuset cgroup コントローラーの無効化
この設定は、cgroups バージョン 1 の KVM ホストにのみ適用されます。ホストで CPU ホットプラグを有効にするには、cgroup コントローラーを無効にします。
手順
-
任意のエディターで
/etc/libvirt/qemu.confを開きます。 -
cgroup_controllers行に移動します。 - 行全体を複製し、コピーから先頭の番号記号 (#) を削除します。
cpusetエントリーを以下のように削除します。cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]
新しい設定を有効にするには、libvirtd デーモンを再起動する必要があります。
- すべての仮想マシンを停止します。
以下のコマンドを実行します。
# systemctl restart libvirtd
- 仮想マシンを再起動します。
この設定は、ホストの再起動後も維持されます。
2.6.8. アイドル状態の仮想 CPU のポーリング期間の調整
仮想 CPU がアイドル状態になると、KVM は仮想 CPU のウェイクアップ条件をポーリングしてからホストリソースを割り当てます。ポーリングが sysfs の /sys/module/kvm/parameters/halt_poll_ns に配置される時間間隔を指定できます。指定された時間中、ポーリングにより、リソースの使用量を犠牲にして、仮想 CPU のウェイクアップレイテンシーが短縮されます。ワークロードに応じて、ポーリングの時間を長くしたり短くしたりすることが有益な場合があります。間隔はナノ秒で指定します。デフォルトは 50000 ns です。
CPU の使用率が低い場合を最適化するには、小さい値または書き込み 0 を入力してポーリングを無効にします。
# echo 0 > /sys/module/kvm/parameters/halt_poll_ns
トランザクションワークロードなどの低レイテンシーを最適化するには、大きな値を入力します。
# echo 80000 > /sys/module/kvm/parameters/halt_poll_ns
第3章 クラスタースケーリングに関する推奨プラクティス
本セクションのガイダンスは、クラウドプロバイダーの統合によるインストールにのみ関連します。
これらのガイドラインは、Open Virtual Network (OVN) ではなく、ソフトウェア定義ネットワーク (SDN) を使用する OpenShift Container Platform に該当します。
以下のベストプラクティスを適用して、OpenShift Container Platform クラスター内のワーカーマシンの数をスケーリングします。ワーカーのマシンセットで定義されるレプリカ数を増やしたり、減らしたりしてワーカーマシンをスケーリングします。
3.1. クラスターのスケーリングに関する推奨プラクティス
クラスターをノード数のより高い値にスケールアップする場合:
- 高可用性を確保するために、ノードを利用可能なすべてのゾーンに分散します。
- 1 度に 25 未満のマシンごとに 50 マシンまでスケールアップします。
- 定期的なプロバイダーの容量関連の制約を軽減するために、同様のサイズの別のインスタンスタイプを使用して、利用可能なゾーンごとに新規のマシンセットを作成することを検討してください。たとえば、AWS で、m5.large および m5d.large を使用します。
クラウドプロバイダーは API サービスのクォータを実装する可能性があります。そのため、クラスターは段階的にスケーリングします。
マシンセットのレプリカが 1 度に高い値に設定される場合に、コントローラーはマシンを作成できなくなる可能性があります。OpenShift Container Platform が上部にデプロイされているクラウドプラットフォームが処理できる要求の数はプロセスに影響を与えます。コントローラーは、該当するステータスのマシンの作成、確認、および更新を試行する間に、追加のクエリーを開始します。OpenShift Container Platform がデプロイされるクラウドプラットフォームには API 要求の制限があり、過剰なクエリーが生じると、クラウドプラットフォームの制限によりマシンの作成が失敗する場合があります。
大規模なノード数にスケーリングする際にマシンヘルスチェックを有効にします。障害が発生する場合、ヘルスチェックは状態を監視し、正常でないマシンを自動的に修復します。
大規模で高密度のクラスターをノード数を減らしてスケールダウンする場合には、長い時間がかかる可能性があります。このプロセスで、終了するノードで実行されているオブジェクトのドレイン (解放) またはエビクトが並行して実行されるためです。また、エビクトするオブジェクトが多過ぎる場合に、クライアントはリクエストのスロットリングを開始する可能性があります。デフォルトのクライアント QPS およびバーストレートは、現時点で 5 と 10 にそれぞれ設定されています。これらは OpenShift Container Platform で変更することはできません。
3.2. マシンセットの変更
マシンセットを変更するには、MachineSet YAML を編集します。次に、各マシンを削除するか、またはマシンセットを 0 レプリカにスケールダウンしてマシンセットに関連付けられたすべてのマシンを削除します。レプリカは必要な数にスケーリングします。マシンセットへの変更は既存のマシンに影響を与えません。
他の変更を加えずに、マシンセットをスケーリングする必要がある場合、マシンを削除する必要はありません。
デフォルトで、OpenShift Container Platform ルーター Pod はワーカーにデプロイされます。ルーターは Web コンソールなどの一部のクラスターリソースにアクセスすることが必要であるため、 ルーター Pod をまず再配置しない限り、ワーカーのマシンセットを 0 にスケーリングできません。
前提条件
-
OpenShift Container Platform クラスターおよび
ocコマンドラインをインストールすること。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
マシンセットを編集します。
$ oc edit machineset <machineset> -n openshift-machine-api
マシンセットを
0にスケールダウンします。$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
または、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-api
ヒントまたは、以下の YAML を適用してマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0
マシンが削除されるまで待機します。
マシンセットを随時スケールアップします。
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
または、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-api
ヒントまたは、以下の YAML を適用してマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2
マシンが起動するまで待ちます。新規マシンにはマシンセットに加えられた変更が含まれます。
3.3. マシンのヘルスチェック
マシンのヘルスチェックは特定のマシンプールの正常ではないマシンを自動的に修復します。
マシンの正常性を監視するには、リソースを作成し、コントローラーの設定を定義します。5 分間 NotReady ステータスにすることや、 node-problem-detector に永続的な条件を表示すること、および監視する一連のマシンのラベルなど、チェックする条件を設定します。
マスターロールのあるマシンにマシンヘルスチェックを適用することはできません。
MachineHealthCheck リソースを監視するコントローラーは定義済みのステータスをチェックします。マシンがヘルスチェックに失敗した場合、このマシンは自動的に検出され、その代わりとなるマシンが作成されます。マシンが削除されると、machine deleted イベントが表示されます。
マシンの削除による破壊的な影響を制限するために、コントローラーは 1 度に 1 つのノードのみをドレイン (解放) し、これを削除します。マシンのターゲットプールで許可される maxUnhealthy しきい値を上回る数の正常でないマシンがある場合、修復が停止するため、手動による介入が可能になります。
タイムアウトについて注意深い検討が必要であり、ワークロードと要件を考慮してください。
- タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
-
タイムアウトが短すぎると、修復ループが生じる可能性があります。たとえば、
NotReadyステータスを確認するためのタイムアウトについては、マシンが起動プロセスを完了できるように十分な時間を設定する必要があります。
チェックを停止するには、リソースを削除します。
3.3.1. マシンヘルスチェックのデプロイ時の制限
マシンヘルスチェックをデプロイする前に考慮すべき制限事項があります。
- マシンセットが所有するマシンのみがマシンヘルスチェックによって修復されます。
- コントロールプレーンマシンは現在サポートされておらず、それらが正常でない場合にも修正されません。
- マシンのノードがクラスターから削除される場合、マシンヘルスチェックはマシンが正常ではないとみなし、すぐにこれを修復します。
-
nodeStartupTimeoutの後にマシンの対応するノードがクラスターに加わらない場合、マシンは修復されます。 -
MachineリソースフェーズがFailedの場合、マシンはすぐに修復されます。
3.4. サンプル MachineHealthCheck リソース
ベアメタルを除くすべてのクラウドベースのインストールタイプの MachineHealthCheck リソースは、以下の YAML ファイルのようになります。
apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example 1 namespace: openshift-machine-api spec: selector: matchLabels: machine.openshift.io/cluster-api-machine-role: <role> 2 machine.openshift.io/cluster-api-machine-type: <role> 3 machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone> 4 unhealthyConditions: - type: "Ready" timeout: "300s" 5 status: "False" - type: "Ready" timeout: "300s" 6 status: "Unknown" maxUnhealthy: "40%" 7 nodeStartupTimeout: "10m" 8
- 1
- デプロイするマシンヘルスチェックの名前を指定します。
- 2 3
- チェックする必要のあるマシンプールのラベルを指定します。
- 4
- 追跡するマシンセットを
<cluster_name>-<label>-<zone>形式で指定します。たとえば、prod-node-us-east-1aとします。 - 5 6
- ノードの状態のタイムアウト期間を指定します。タイムアウト期間の条件が満たされると、マシンは修正されます。タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
- 7
- ターゲットプールで同時に修復できるマシンの数を指定します。これはパーセンテージまたは整数として設定できます。正常でないマシンの数が
maxUnhealthyで設定された制限を超える場合、修復は実行されません。 - 8
- マシンが正常でないと判別される前に、ノードがクラスターに参加するまでマシンヘルスチェックが待機する必要のあるタイムアウト期間を指定します。
matchLabels はあくまでもサンプルであるため、特定のニーズに応じてマシングループをマッピングする必要があります。
3.4.1. マシンヘルスチェックによる修復の一時停止 (short-circuiting)
一時停止 (short-circuiting) が実行されることにより、マシンのヘルスチェックはクラスターが正常な場合にのみマシンを修復するようになります。一時停止 (short-circuiting) は、MachineHealthCheck リソースの maxUnhealthy フィールドで設定されます。
ユーザーがマシンの修復前に maxUnhealthy フィールドの値を定義する場合、MachineHealthCheck は maxUnhealthy の値を、正常でないと判別するターゲットプール内のマシン数と比較します。正常でないマシンの数が maxUnhealthy の制限を超える場合、修復は実行されません。
maxUnhealthy が設定されていない場合、値は 100% にデフォルト設定され、マシンはクラスターの状態に関係なく修復されます。
適切な maxUnhealthy 値は、デプロイするクラスターの規模や、MachineHealthCheck が対応するマシンの数によって異なります。たとえば、maxUnhealthy 値を使用して複数のアベイラビリティーゾーン間で複数のマシンセットに対応でき、ゾーン全体が失われると、maxUnhealthy の設定によりクラスター内で追加の修復を防ぐことができます。
maxUnhealthy フィールドは整数またはパーセンテージのいずれかに設定できます。maxUnhealthy の値によって、修復の実装が異なります。
3.4.1.1. 絶対値を使用した maxUnhealthy の設定
maxUnhealthy が 2 に設定される場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
これらの値は、マシンヘルスチェックによってチェックされるマシン数と別個の値です。
3.4.1.2. パーセンテージを使用した maxUnhealthy の設定
maxUnhealthy が 40% に設定され、25 のマシンがチェックされる場合:
- 10 以下のノードが正常でない場合に、修復が実行されます。
- 11 以上のノードが正常でない場合は、修復は実行されません。
maxUnhealthy が 40% に設定され、6 マシンがチェックされる場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
チェックされる maxUnhealthy マシンの割合が整数ではない場合、マシンの許可される数は切り捨てられます。
3.5. MachineHealthCheck リソースの作成
クラスターに、すべての MachineSets の MachineHealthCheck リソースを作成できます。コントロールプレーンマシンをターゲットとする MachineHealthCheck リソースを作成することはできません。
前提条件
-
ocコマンドラインインターフェイスをインストールします。
手順
-
マシンヘルスチェックの定義を含む
healthcheck.ymlファイルを作成します。 healthcheck.ymlファイルをクラスターに適用します。$ oc apply -f healthcheck.yml
第4章 Node Tuning Operator の使用
Node Tuning Operator について説明し、この Operator を使用し、Tuned デーモンのオーケストレーションを実行してノードレベルのチューニングを管理する方法について説明します。
4.1. Node Tuning Operator について
Node Tuning Operator は、TuneD デーモンのオーケストレーションによるノードレベルのチューニングの管理に役立ちます。ほとんどの高パフォーマンスアプリケーションでは、一定レベルのカーネルのチューニングが必要です。Node Tuning Operator は、ノードレベルの sysctl の統一された管理インターフェイスをユーザーに提供し、ユーザーが指定するカスタムチューニングを追加できるよう柔軟性を提供します。
Operator は、コンテナー化された OpenShift Container Platform の TuneD デーモンを Kubernetes デーモンセットとして管理します。これにより、カスタムチューニング仕様が、デーモンが認識する形式でクラスターで実行されるすべてのコンテナー化された TuneD デーモンに渡されます。デーモンは、ノードごとに 1 つずつ、クラスターのすべてのノードで実行されます。
コンテナー化された TuneD デーモンによって適用されるノードレベルの設定は、プロファイルの変更をトリガーするイベントで、または終了シグナルの受信および処理によってコンテナー化された TuneD デーモンが正常に終了する際にロールバックされます。
Node Tuning Operator は、バージョン 4.1 以降における標準的な OpenShift Container Platform インストールの一部となっています。
4.2. Node Tuning Operator 仕様サンプルへのアクセス
このプロセスを使用して Node Tuning Operator 仕様サンプルにアクセスします。
手順
以下を実行します。
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
デフォルトの CR は、OpenShift Container Platform プラットフォームの標準的なノードレベルのチューニングを提供することを目的としており、Operator 管理の状態を設定するためにのみ変更できます。デフォルト CR へのその他のカスタム変更は、Operator によって上書きされます。カスタムチューニングの場合は、独自のチューニングされた CR を作成します。新規に作成された CR は、ノード/Pod ラベルおよびプロファイルの優先順位に基づいて OpenShift Container Platform ノードに適用されるデフォルトの CR およびカスタムチューニングと組み合わされます。
特定の状況で Pod ラベルのサポートは必要なチューニングを自動的に配信する便利な方法ですが、この方法は推奨されず、とくに大規模なクラスターにおいて注意が必要です。デフォルトの調整された CR は Pod ラベル一致のない状態で提供されます。カスタムプロファイルが Pod ラベル一致のある状態で作成される場合、この機能はその時点で有効になります。Pod ラベル機能は、Node Tuning Operator の今後のバージョンで非推奨になる場合があります。
4.3. クラスターに設定されるデフォルトのプロファイル
以下は、クラスターに設定されるデフォルトのプロファイルです。
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
recommend:
- profile: "openshift-control-plane"
priority: 30
match:
- label: "node-role.kubernetes.io/master"
- label: "node-role.kubernetes.io/infra"
- profile: "openshift-node"
priority: 40
OpenShift Container Platform 4.9 以降では、すべての OpenShift TuneD プロファイルが TuneD パッケージに含まれています。oc exec コマンドを使用して、これらのプロファイルの内容を表示できます。
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;4.4. TuneD プロファイルが適用されていることの確認
クラスターノードに適用されている Tune D プロファイルを確認します。
$ oc get profile -n openshift-cluster-node-tuning-operator
出力例
NAME TUNED APPLIED DEGRADED AGE master-0 openshift-control-plane True False 6h33m master-1 openshift-control-plane True False 6h33m master-2 openshift-control-plane True False 6h33m worker-a openshift-node True False 6h28m worker-b openshift-node True False 6h28m
-
NAME: Profile オブジェクトの名前。ノードごとに Profile オブジェクトが 1 つあり、それぞれの名前が一致します。 -
TUNED: 適用する任意の TuneD プロファイルの名前。 -
APPLIED: TuneD デーモンが任意のプロファイルを適用する場合はTrue。(true/False/Unknown)。 -
DEGRADED: TuneD プロファイルのアプリケーション中にエラーが報告される場合はTrue(True/False/Unknown) -
AGE: Profile オブジェクトの作成からの経過時間。
4.5. カスタムチューニング仕様
Operator のカスタムリソース (CR) には 2 つの重要なセクションがあります。1 つ目のセクションの profile: は TuneD プロファイルおよびそれらの名前の一覧です。2 つ目の recommend: は、プロファイル選択ロジックを定義します。
複数のカスタムチューニング仕様は、Operator の namespace に複数の CR として共存できます。新規 CR の存在または古い CR の削除は Operator によって検出されます。既存のカスタムチューニング仕様はすべてマージされ、コンテナー化された TuneD デーモンの適切なオブジェクトは更新されます。
管理状態
Operator 管理の状態は、デフォルトの Tuned CR を調整して設定されます。デフォルトで、Operator は Managed 状態であり、spec.managementState フィールドはデフォルトの Tuned CR に表示されません。Operator Management 状態の有効な値は以下のとおりです。
- Managed: Operator は設定リソースが更新されるとそのオペランドを更新します。
- Unmanaged: Operator は設定リソースへの変更を無視します。
- Removed: Operator は Operator がプロビジョニングしたオペランドおよびリソースを削除します。
プロファイルデータ
profile: セクションは、TuneD プロファイルおよびそれらの名前を一覧表示します。
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings推奨プロファイル
profile: 選択ロジックは、CR の recommend: セクションによって定義されます。recommend: セクションは、選択基準に基づくプロファイルの推奨項目の一覧です。
recommend: <recommend-item-1> # ... <recommend-item-n>
一覧の個別項目:
- machineConfigLabels: 1 <mcLabels> 2 match: 3 <match> 4 priority: <priority> 5 profile: <tuned_profile_name> 6 operand: 7 debug: <bool> 8
- 1
- オプション:
- 2
- キー/値の
MachineConfigラベルのディクショナリー。キーは一意である必要があります。 - 3
- 省略する場合は、優先度の高いプロファイルが最初に一致するか、または
machineConfigLabelsが設定されていない限り、プロファイルの一致が想定されます。 - 4
- オプションの一覧。
- 5
- プロファイルの順序付けの優先度。数値が小さいほど優先度が高くなります (
0が最も高い優先度になります)。 - 6
- 一致に適用する TuneD プロファイル。例:
tuned_profile_1 - 7
- オプションのオペランド設定。
- 8
- TuneD デーモンのデバッグオンまたはオフを有効にします。オプションは、オンの場合は
true、オフの場合はfalseです。デフォルトはfalseです。
<match> は、以下のように再帰的に定義されるオプションの一覧です。
- label: <label_name> 1 value: <label_value> 2 type: <label_type> 3 <match> 4
<match> が省略されない場合、ネストされたすべての <match> セクションが true に評価される必要もあります。そうでない場合には false が想定され、それぞれの <match> セクションのあるプロファイルは適用されず、推奨されません。そのため、ネスト化 (子の <match> セクション) は論理 AND 演算子として機能します。これとは逆に、<match> 一覧のいずれかの項目が一致する場合、<match> の一覧全体が true に評価されます。そのため、一覧は論理 OR 演算子として機能します。
machineConfigLabels が定義されている場合、マシン設定プールベースのマッチングが指定の recommend: 一覧の項目に対してオンになります。<mcLabels> はマシン設定のラベルを指定します。マシン設定は、プロファイル <tuned_profile_name> についてカーネル起動パラメーターなどのホスト設定を適用するために自動的に作成されます。この場合、マシン設定セレクターが <mcLabels> に一致するすべてのマシン設定プールを検索し、プロファイル <tuned_profile_name> を確認されるマシン設定プールが割り当てられるすべてのノードに設定する必要があります。マスターロールとワーカーのロールの両方を持つノードをターゲットにするには、マスターロールを使用する必要があります。
一覧項目の match および machineConfigLabels は論理 OR 演算子によって接続されます。match 項目は、最初にショートサーキット方式で評価されます。そのため、true と評価される場合、machineConfigLabels 項目は考慮されません。
マシン設定プールベースのマッチングを使用する場合、同じハードウェア設定を持つノードを同じマシン設定プールにグループ化することが推奨されます。この方法に従わない場合は、TuneD オペランドが同じマシン設定プールを共有する 2 つ以上のノードの競合するカーネルパラメーターを計算する可能性があります。
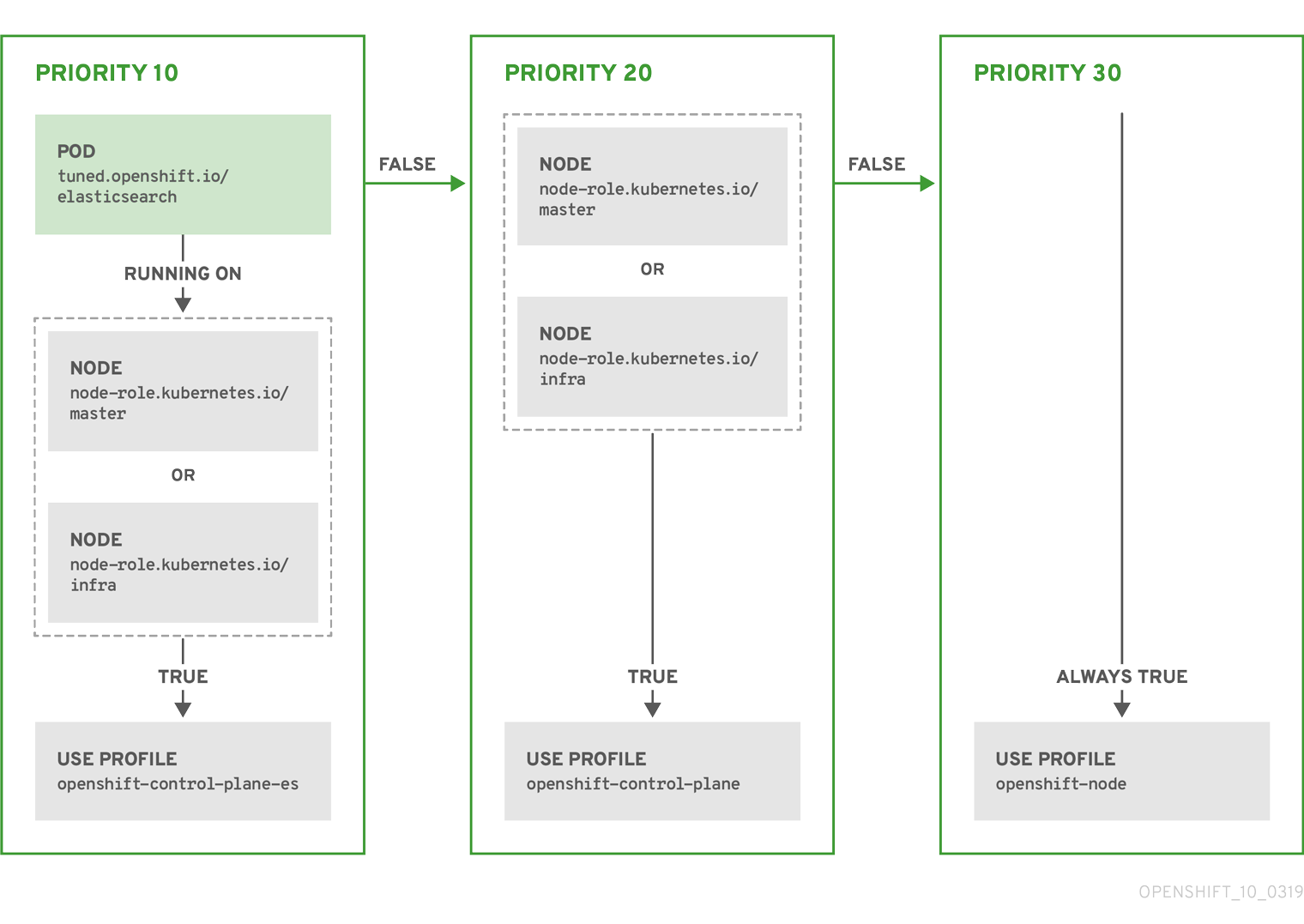
例: ノード/Pod ラベルベースのマッチング
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
上記のコンテナー化された TuneD デーモンの CR は、プロファイルの優先順位に基づいてその recommend.conf ファイルに変換されます。最も高い優先順位 (10) を持つプロファイルは openshift-control-plane-es であるため、これが最初に考慮されます。指定されたノードで実行されるコンテナー化された TuneD デーモンは、同じノードに tuned.openshift.io/elasticsearch ラベルが設定された Pod が実行されているかどうかを確認します。これがない場合、 <match> セクション全体が false として評価されます。このラベルを持つこのような Pod がある場合、 <match> セクションが true に評価されるようにするには、ノードラベルは node-role.kubernetes.io/master または node-role.kubernetes.io/infra である必要もあります。
優先順位が 10 のプロファイルのラベルが一致した場合、openshift-control-plane-es プロファイルが適用され、その他のプロファイルは考慮されません。ノード/Pod ラベルの組み合わせが一致しない場合、2 番目に高い優先順位プロファイル (openshift-control-plane) が考慮されます。このプロファイルは、コンテナー化された TuneD Pod が node-role.kubernetes.io/master または node-role.kubernetes.io/infra ラベルを持つノードで実行される場合に適用されます。
最後に、プロファイル openshift-node には最低の優先順位である 30 が設定されます。これには <match> セクションがないため、常に一致します。これは、より高い優先順位の他のプロファイルが指定されたノードで一致しない場合に openshift-node プロファイルを設定するために、最低の優先順位のノードが適用される汎用的な (catch-all) プロファイルとして機能します。
例: マシン設定プールベースのマッチング
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom
ノードの再起動を最小限にするには、ターゲットノードにマシン設定プールのノードセレクターが一致するラベルを使用してラベルを付け、上記の Tuned CR を作成してから、最後にカスタムのマシン設定プール自体を作成します。
4.6. カスタムチューニングの例
デフォルト CR からの TuneD プロファイルの使用
以下の CR は、ラベル tuned.openshift.io/ingress-node-label を任意の値に設定した状態で OpenShift Container Platform ノードのカスタムノードレベルのチューニングを適用します。
例: openshift-control-plane TuneD プロファイルを使用したカスタムチューニング
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
カスタムプロファイル作成者は、デフォルトの TuneD CR に含まれるデフォルトの調整されたデーモンプロファイルを組み込むことが強く推奨されます。上記の例では、デフォルトの openshift-control-plane プロファイルを使用してこれを実行します。
ビルトイン TuneD プロファイルの使用
NTO が管理するデーモンセットのロールアウトに成功すると、TuneD オペランドはすべて同じバージョンの TuneD デーモンを管理します。デーモンがサポートするビルトイン TuneD プロファイルを一覧表示するには、以下の方法で TuneD Pod をクエリーします。
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
このコマンドで取得したプロファイル名をカスタムのチューニング仕様で使用できます。
例: built-in hpc-compute TuneD プロファイルの使用
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-hpc-compute
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile for HPC compute workloads
include=openshift-node,hpc-compute
name: openshift-node-hpc-compute
recommend:
- match:
- label: tuned.openshift.io/openshift-node-hpc-compute
priority: 20
profile: openshift-node-hpc-compute
ビルトインの hpc-compute プロファイルに加えて、上記の例には、デフォルトの Tuned CR に同梱される openshift-node TuneD デーモンプロファイルが含まれており、コンピュートノードに OpenShift 固有のチューニングを使用します。
4.7. サポートされている TuneD デーモンプラグイン
[main] セクションを除き、以下の TuneD プラグインは、Tuned CR の profile: セクションで定義されたカスタムプロファイルを使用する場合にサポートされます。
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
これらのプラグインの一部によって提供される動的チューニング機能の中に、サポートされていない機能があります。以下の TuneD プラグインは現時点でサポートされていません。
- bootloader
- script
- systemd
詳細は、利用可能な TuneD プラグイン および TuneD の使用 を参照してください。
第5章 クラスターローダーの使用
クラスターローダーとは、クラスターに対してさまざまなオブジェクトを多数デプロイするツールであり、ユーザー定義のクラスターオブジェクトを作成します。クラスターローダーをビルド、設定、実行して、さまざまなクラスターの状態にある OpenShift Container Platform デプロイメントのパフォーマンスメトリクスを測定します。
クラスターローダーが非推奨になり、今後のリリースで削除されます。
5.1. クラスターローダーのインストール
手順
コンテナーイメージをプルするには、以下を実行します。
$ podman pull quay.io/openshift/origin-tests:4.9
5.2. クラスターローダーの実行
前提条件
- リポジトリーは認証を要求するプロンプトを出します。レジストリーの認証情報を使用すると、一般的に利用できないイメージにアクセスできます。インストールからの既存の認証情報を使用します。
手順
組み込まれているテスト設定を使用してクラスターローダーを実行し、5 つのテンプレートビルドをデプロイして、デプロイメントが完了するまで待ちます。
$ podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z -i \ quay.io/openshift/origin-tests:4.9 /bin/bash -c 'export KUBECONFIG=/root/.kube/config && \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'または、
VIPERCONFIGの環境変数を設定して、ユーザー定義の設定でクラスターローダーを実行します。$ podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z \ -v ${LOCAL_CONFIG_FILE_PATH}:/root/configs/:z \ -i quay.io/openshift/origin-tests:4.9 \ /bin/bash -c 'KUBECONFIG=/root/.kube/config VIPERCONFIG=/root/configs/test.yaml \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'この例では、
${LOCAL_KUBECONFIG}はローカルファイルシステムのkubeconfigのパスを参照します。さらに、${LOCAL_CONFIG_FILE_PATH}というディレクトリーがあり、これはtest.yamlという設定ファイルが含まれるコンテナーにマウントされます。また、test.yamlが外部テンプレートファイルや podspec ファイルを参照する場合、これらもコンテナーにマウントされる必要があります。
5.3. クラスターローダーの設定
このツールは、複数のテンプレートや Pod を含む namespace (プロジェクト) を複数作成します。
5.3.1. クラスターローダー設定ファイルの例
クラスターローダーの設定ファイルは基本的な YAML ファイルです。
provider: local 1 ClusterLoader: cleanup: true projects: - num: 1 basename: clusterloader-cakephp-mysql tuning: default ifexists: reuse templates: - num: 1 file: cakephp-mysql.json - num: 1 basename: clusterloader-dancer-mysql tuning: default ifexists: reuse templates: - num: 1 file: dancer-mysql.json - num: 1 basename: clusterloader-django-postgresql tuning: default ifexists: reuse templates: - num: 1 file: django-postgresql.json - num: 1 basename: clusterloader-nodejs-mongodb tuning: default ifexists: reuse templates: - num: 1 file: quickstarts/nodejs-mongodb.json - num: 1 basename: clusterloader-rails-postgresql tuning: default templates: - num: 1 file: rails-postgresql.json tuningsets: 2 - name: default pods: stepping: 3 stepsize: 5 pause: 0 s rate_limit: 4 delay: 0 ms
この例では、外部テンプレートファイルや Pod 仕様ファイルへの参照もコンテナーにマウントされていることを前提とします。
Microsoft Azure でクラスターローダーを実行している場合、AZURE_AUTH_LOCATION 変数を、インストーラーディレクトリーにある terraform.azure.auto.tfvars.json の出力が含まれるファイルに設定する必要があります。
5.3.2. 設定フィールド
| フィールド | 説明 |
|---|---|
|
|
|
|
|
1 つまたは多数の定義が指定されたサブオブジェクト。 |
|
|
設定ごとに 1 つの定義が指定されたサブオブジェクト。 |
|
| 設定ごとに 1 つの定義が指定されたオプションのサブオブジェクト。オブジェクト作成時に同期できるかどうかについて追加します。 |
| フィールド | 説明 |
|---|---|
|
| 整数。作成するプロジェクト数の 1 つの定義。 |
|
|
文字列。プロジェクトのベース名の定義。競合が発生しないように、同一の namespace の数が |
|
| 文字列。オブジェクトに適用するチューニングセットの 1 つの定義。 これは対象の namespace にデプロイします。 |
|
|
|
|
| キーと値のペア一覧。キーは設定マップの名前で、値はこの設定マップの作成元のファイルへのパスです。 |
|
| キーと値のペア一覧。キーはシークレットの名前で、値はこのシークレットの作成元のファイルへのパスです。 |
|
| デプロイする Pod の 1 つまたは多数の定義を持つサブオブジェクト |
|
| デプロイするテンプレートの 1 つまたは多数の定義を持つサブオブジェクト |
| フィールド | 説明 |
|---|---|
|
| 整数。デプロイする Pod またはテンプレート数。 |
|
| 文字列。プルが可能なリポジトリーに対する Docker イメージの URL |
|
| 文字列。作成するテンプレート (または Pod) のベース名の 1 つの定義。 |
|
| 文字列。ローカルファイルへのパス。 作成する Pod 仕様またはテンプレートのいずれかです。 |
|
|
キーと値のペア。 |
| フィールド | 説明 |
|---|---|
|
| 文字列。チューニングセットの名前。 プロジェクトのチューニングを定義する時に指定した名前と一致します。 |
|
|
Pod に適用される |
|
|
テンプレートに適用される |
| フィールド | 説明 |
|---|---|
|
| サブオブジェクト。ステップ作成パターンでオブジェクトを作成する場合に使用するステップ設定。 |
|
| サブオブジェクト。オブジェクト作成速度を制限するための速度制限チューニングセットの設定。 |
| フィールド | 説明 |
|---|---|
|
| 整数。オブジェクト作成を一時停止するまでに作成するオブジェクト数。 |
|
|
整数。 |
|
| 整数。オブジェクト作成に成功しなかった場合に失敗するまで待機する秒数。 |
|
| 整数。次の作成要求まで待機する時間 (ミリ秒)。 |
| フィールド | 説明 |
|---|---|
|
|
|
|
|
ブール値。 |
|
|
ブール値。 |
|
|
|
|
|
文字列。 |
5.4. 既知の問題
- クラスターローダーは設定なしで呼び出される場合に失敗します。(BZ#1761925)
IDENTIFIERパラメーターがユーザーテンプレートで定義されていない場合には、テンプレートの作成はerror: unknown parameter name "IDENTIFIER"エラーを出して失敗します。テンプレートをデプロイする場合は、このエラーが発生しないように、以下のパラメーターをテンプレートに追加してください。{ "name": "IDENTIFIER", "description": "Number to append to the name of resources", "value": "1" }Pod をデプロイする場合は、このパラメーターを追加する必要はありません。
第6章 CPU マネージャーおよび Topology Manager の使用
CPU マネージャーは、CPU グループを管理して、ワークロードを特定の CPU に制限します。
CPU マネージャーは、以下のような属性が含まれるワークロードに有用です。
- できるだけ長い CPU 時間が必要な場合
- プロセッサーのキャッシュミスの影響を受ける場合
- レイテンシーが低いネットワークアプリケーションの場合
- 他のプロセスと連携し、単一のプロセッサーキャッシュを共有することに利点がある場合
Topology Manager は、CPU マネージャー、デバイスマネージャー、およびその他の Hint Provider からヒントを収集し、同じ Non-Uniform Memory Access (NUMA) ノード上のすべての QoS (Quality of Service) クラスについて CPU、SR-IOV VF、その他デバイスリソースなどの Pod リソースを調整します。
Topology Manager は、収集したヒントのトポロジー情報を使用し、設定される Topology Manager ポリシーおよび要求される Pod リソースに基づいて、pod がノードから許可されるか、または拒否されるかどうかを判別します。
Topology Manager は、ハードウェアアクセラレーターを使用して低遅延 (latency-critical) の実行と高スループットの並列計算をサポートするワークロードの場合に役立ちます。
Topology Manager を使用するには、static ポリシーで CPU マネージャーを設定する必要があります。
6.1. CPU マネージャーの設定
手順
オプション: ノードにラベルを指定します。
# oc label node perf-node.example.com cpumanager=true
CPU マネージャーを有効にする必要のあるノードの
MachineConfigPoolを編集します。この例では、すべてのワーカーで CPU マネージャーが有効にされています。# oc edit machineconfigpool worker
ラベルをワーカーのマシン設定プールに追加します。
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig、cpumanager-kubeletconfig.yaml、カスタムリソース (CR) を作成します。直前の手順で作成したラベルを参照し、適切なノードを新規の kubelet 設定で更新します。machineConfigPoolSelectorセクションを参照してください。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2動的な kubelet 設定を作成します。
# oc create -f cpumanager-kubeletconfig.yaml
これにより、CPU マネージャー機能が kubelet 設定に追加され、必要な場合には Machine Config Operator (MCO) がノードを再起動します。CPU マネージャーを有効にするために再起動する必要はありません。
マージされた kubelet 設定を確認します。
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
出力例
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]ワーカーで更新された
kubelet.confを確認します。# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager
出力例
cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2
コア 1 つまたは複数を要求する Pod を作成します。制限および要求の CPU の値は整数にする必要があります。これは、対象の Pod 専用のコア数です。
# cat cpumanager-pod.yaml
出力例
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Pod を作成します。
# oc create -f cpumanager-pod.yaml
Pod がラベル指定されたノードにスケジュールされていることを確認します。
# oc describe pod cpumanager
出力例
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=truecgroupsが正しく設定されていることを確認します。pauseプロセスのプロセス ID (PID) を取得します。# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause
QoS (quality of service) 層
Guaranteedの Pod は、kubepods.sliceに配置されます。他の QoS 層の Pod は、kubepodsの子であるcgroupsに配置されます。# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done
出力例
cpuset.cpus 1 tasks 32706
対象のタスクで許可される CPU 一覧を確認します。
# grep ^Cpus_allowed_list /proc/32706/status
出力例
Cpus_allowed_list: 1
システム上の別の Pod (この場合は
burstableQoS 層にある Pod) が、GuaranteedPod に割り当てられたコアで実行できないことを確認します。# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.com
出力例
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)
この仮想マシンには、2 つの CPU コアがあります。
system-reserved設定は 500 ミリコアを予約し、Node Allocatableの量になるようにノードの全容量からコアの半分を引きます。ここでAllocatable CPUは 1500 ミリコアであることを確認できます。これは、それぞれがコアを 1 つ受け入れるので、CPU マネージャー Pod の 1 つを実行できることを意味します。1 つのコア全体は 1000 ミリコアに相当します。2 つ目の Pod をスケジュールしようとする場合、システムは Pod を受け入れますが、これがスケジュールされることはありません。NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
6.2. Topology Manager ポリシー
Topology Manager は、CPU マネージャーやデバイスマネージャーなどの Hint Provider からトポロジーのヒントを収集し、収集したヒントを使用して Pod リソースを調整することで、すべての QoS (Quality of Service) クラスの Pod リソースを調整します。
Topology Manager は、cpumanager-enabled カスタムリソース (CR) で割り当てる 4 つの割り当てポリシーをサポートします。
noneポリシー- これはデフォルトのポリシーで、トポロジーの配置は実行しません。
best-effortポリシー-
best-effortトポロジー管理ポリシーを持つ Pod のそれぞれのコンテナーの場合、kubelet は 各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は、そのコンテナーの推奨される NUMA ノードのアフィニティーを保存します。アフィニティーが優先されない場合、Topology Manager はこれを保管し、ノードに対して Pod を許可します。 restrictedポリシー-
restrictedトポロジー管理ポリシーを持つ Pod のそれぞれのコンテナーの場合、kubelet は 各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は、そのコンテナーの推奨される NUMA ノードのアフィニティーを保存します。アフィニティーが優先されない場合、Topology Manager はこの Pod をノードから拒否します。これにより、Pod が Pod の受付の失敗によりTerminated状態になります。 single-numa-nodeポリシー-
single-numa-nodeトポロジー管理ポリシーがある Pod のそれぞれのコンテナーの場合、kubelet は各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は単一の NUMA ノードのアフィニティーが可能かどうかを判別します。可能である場合、Pod はノードに許可されます。単一の NUMA ノードアフィニティーが使用できない場合には、Topology Manager は Pod をノードから拒否します。これにより、Pod は Pod の受付失敗と共に Terminated (終了) 状態になります。
6.3. Topology Manager のセットアップ
Topology Manager を使用するには、 cpumanager-enabled カスタムリソース (CR) で割り当てポリシーを設定する必要があります。CPU マネージャーをセットアップしている場合は、このファイルが存在している可能性があります。ファイルが存在しない場合は、作成できます。
前提条件
-
CPU マネージャーのポリシーを
staticに設定します。
手順
Topololgy Manager をアクティブにするには、以下を実行します。
cpumanager-enabledカスタムリソース (CR) で Topology Manager 割り当てポリシーを設定します。$ oc edit KubeletConfig cpumanager-enabled
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node 2
6.4. Pod の Topology Manager ポリシーとの対話
以下のサンプル Pod 仕様は、Pod の Topology Manger との対話について説明しています。
以下の Pod は、リソース要求や制限が指定されていないために BestEffort QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
以下の Pod は、要求が制限よりも小さいために Burstable QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
選択したポリシーが none 以外の場合は、Topology Manager はこれらの Pod 仕様のいずれかも考慮しません。
以下の最後のサンプル Pod は、要求が制限と等しいために Guaranteed QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"Topology Manager はこの Pod を考慮します。Topology Manager はヒントプロバイダー (CPU マネージャーおよびデバイスマネージャー) を参照して、Pod のトポロジーヒントを取得します。
Topology Manager はこの情報を使用して、このコンテナーに最適なトポロジーを保管します。この Pod の場合、CPU マネージャーおよびデバイスマネージャーは、リソース割り当ての段階でこの保存された情報を使用します。
第7章 Cluster Monitoring Operator のスケーリング
OpenShift Container Platform は、Cluster Monitoring Operator が収集し、Prometheus ベースのモニターリングスタックに保存するメトリクスを公開します。管理者は、システムリソース、コンテナー、およびコンポーネントのメトリックを 1 つのダッシュボードインターフェイスである Grafana で表示できます。
7.1. Prometheus データベースのストレージ要件
Red Hat では、異なるスケールサイズに応じて各種のテストが実行されました。
以下の Prometheus ストレージ要件は規定されていません。ワークロードのアクティビティーおよびリソースの使用に応じて、クラスターで観察されるリソースの消費量が大きくなる可能性があります。
| ノード数 | Pod 数 | 1 日あたりの Prometheus ストレージの増加量 | 15 日ごとの Prometheus ストレージの増加量 | RAM 領域 (スケールサイズに基づく) | ネットワーク (tsdb チャンクに基づく) |
|---|---|---|---|---|---|
| 50 | 1800 | 6.3 GB | 94 GB | 6 GB | 16 MB |
| 100 | 3600 | 13 GB | 195 GB | 10 GB | 26 MB |
| 150 | 5400 | 19 GB | 283 GB | 12 GB | 36 MB |
| 200 | 7200 | 25 GB | 375 GB | 14 GB | 46 MB |
ストレージ要件が計算値を超過しないようにするために、オーバーヘッドとして予期されたサイズのおよそ 20% が追加されています。
上記の計算は、デフォルトの OpenShift Container Platform Cluster Monitoring Operator についての計算です。
CPU の使用率による影響は大きくありません。比率については、およそ 50 ノードおよび 1800 Pod ごとに 1 コア (/40) になります。
OpenShift Container Platform についての推奨事項
- 3 つ以上のインフラストラクチャー (infra) ノードを使用します。
- NVMe (non-volatile memory express) ドライブを搭載した 3 つ以上の openshift-container-storage ノードを使用します。
7.2. クラスターモニターリングの設定
クラスターモニターリングスタック内の Prometheus コンポーネントのストレージ容量を増やすことができます。
手順
Prometheus のストレージ容量を拡張するには、以下を実行します。
YAML 設定ファイル
cluster-monitoring-config.ymlを作成します。以下に例を示します。apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}} 1 nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}} 3 alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 4 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}} 5 metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- 標準の値は
PROMETHEUS_RETENTION_PERIOD=15dになります。時間は、接尾辞 s、m、h、d のいずれかを使用する単位で測定されます。 - 2 4
- クラスターのストレージクラス。
- 3
- 標準の値は
PROMETHEUS_STORAGE_SIZE=2000Giです。ストレージの値には、接尾辞 E、P、T、G、M、K のいずれかを使用した単純な整数または固定小数点整数を使用できます。 また、2 のべき乗の値 (Ei、Pi、Ti、Gi、Mi、Ki) を使用することもできます。 - 5
- 標準の値は
ALERTMANAGER_STORAGE_SIZE=20Giです。ストレージの値には、接尾辞 E、P、T、G、M、K のいずれかを使用した単純な整数または固定小数点整数を使用できます。 また、2 のべき乗の値 (Ei、Pi、Ti、Gi、Mi、Ki) を使用することもできます。
- 保存期間、ストレージクラス、およびストレージサイズの値を追加します。
- ファイルを保存します。
以下を実行して変更を適用します。
$ oc create -f cluster-monitoring-config.yaml
第8章 オブジェクトの最大値に合わせた環境計画
OpenShift Container Platform クラスターの計画時に以下のテスト済みのオブジェクトの最大値を考慮します。
これらのガイドラインは、最大規模のクラスターに基づいています。小規模なクラスターの場合、最大値はこれより低くなります。指定のしきい値に影響を与える要因には、etcd バージョンやストレージデータ形式などの多数の要因があります。
これらのガイドラインは、Open Virtual Network (OVN) ではなく、ソフトウェア定義ネットワーク (SDN) を使用する OpenShift Container Platform に該当します。
ほとんど場合、これらの制限値を超えると、パフォーマンスが全体的に低下します。ただし、これによって必ずしもクラスターに障害が発生する訳ではありません。
Pod の起動および停止が多数あるクラスターなど、急速な変更が生じるクラスターは、実質的な最大サイズが記録よりも小さくなることがあります。
8.1. メジャーリリースについての OpenShift Container Platform のテスト済みクラスターの最大値
OpenShift Container Platform 3.x のテスト済みクラウドプラットフォーム: Red Hat OpenStack (RHOSP)、Amazon Web Services および Microsoft AzureOpenShift Container Platform 4.x のテスト済み Cloud Platform : Amazon Web Services、Microsoft Azure および Google Cloud Platform
| 最大値のタイプ | 3.x テスト済みの最大値 | 4.x テスト済みの最大値 |
|---|---|---|
| ノード数 | 2,000 | 2,000 [1] |
| Pod の数[2] | 150,000 | 150,000 |
| ノードあたりの Pod 数 | 250 | 500 [3] |
| コアあたりの Pod 数 | デフォルト値はありません。 | デフォルト値はありません。 |
| namespace の数[4] | 10,000 | 10,000 |
| ビルド数 | 10,000(デフォルト Pod RAM 512 Mi)- Pipeline ストラテジー | 10,000(デフォルト Pod RAM 512 Mi)- Source-to-Image (S2I) ビルドストラテジー |
| namespace ごとの Pod の数[5] | 25,000 | 25,000 |
| Ingress Controller ごとのルートとバックエンドの数 | ルーターあたり 2,000 | ルーターあたり 2,000 |
| シークレットの数 | 80,000 | 80,000 |
| config map の数 | 90,000 | 90,000 |
| サービスの数[6] | 10,000 | 10,000 |
| namespace ごとのサービス数 | 5,000 | 5,000 |
| サービスごとのバックエンド数 | 5,000 | 5,000 |
| namespace ごとのデプロイメントの数[5] | 2,000 | 2,000 |
| ビルド設定の数 | 12,000 | 12,000 |
| カスタムリソース定義 (CRD) の数 | デフォルト値はありません。 | 512 [7] |
- 一時停止 Pod は、2000 ノードスケールで OpenShift Container Platform のコントロールプレーンコンポーネントにストレスをかけるためにデプロイされました。
- ここで表示される Pod 数はテスト用の Pod 数です。実際の Pod 数は、アプリケーションのメモリー、CPU、ストレージ要件により異なります。
-
これは、ワーカーノードごとに 500 の Pod を持つ 100 ワーカーノードを含むクラスターでテストされています。デフォルトの
maxPodsは 250 です。500maxPodsに到達するには、クラスターはカスタム kubelet 設定を使用し、maxPodsが500に設定された状態で作成される必要があります。500 ユーザー Pod が必要な場合は、ノード上に 10-15 のシステム Pod がすでに実行されているため、hostPrefixが22である必要があります。永続ボリューム要求 (PVC) が割り当てられている Pod の最大数は、PVC の割り当て元のストレージバックエンドによって異なります。このテストでは、OpenShift Container Storage v4 (OCS v4) のみが本書で説明されているノードごとの Pod 数に対応することができました。 - 有効なプロジェクトが多数ある場合、キースペースが過剰に拡大し、スペースのクォータを超過すると、etcd はパフォーマンスの低下による影響を受ける可能性があります。etcd ストレージを解放するために、デフラグを含む etcd の定期的なメンテナンスを行うことを強くお勧めします。
- システムには、状態の変更に対する対応として特定の namespace にある全オブジェクトに対して反復する多数のコントロールループがあります。単一の namespace に特定タイプのオブジェクトの数が多くなると、ループのコストが上昇し、特定の状態変更を処理する速度が低下します。この制限については、アプリケーションの各種要件を満たすのに十分な CPU、メモリー、およびディスクがシステムにあることが前提となっています。
- 各サービスポートと各サービスのバックエンドには、iptables の対応するエントリーがあります。特定のサービスのバックエンド数は、エンドポイントのオブジェクトサイズに影響があり、その結果、システム全体に送信されるデータサイズにも影響を与えます。
-
OpenShift Container Platform には、OpenShift Container Platform によってインストールされたもの、OpenShift Container Platform と統合された製品、およびユーザー作成の CRD を含め、合計 512 のカスタムリソース定義 (CRD) の制限があります。512 を超える CRD が作成されている場合は、
ocコマンドリクエストのスロットリングが適用される可能性があります。
Red Hat は、OpenShift Container Platform クラスターのサイズ設定に関する直接的なガイダンスを提供していません。これは、クラスターが OpenShift Container Platform のサポート範囲内にあるかどうかを判断するには、クラスターのスケールを制限するすべての多次元な要因を慎重に検討する必要があるためです。
8.2. クラスターの最大値がテスト済みの OpenShift Container Platform 環境および設定
AWS クラウドプラットフォーム:
| ノード | フレーバー | vCPU | RAM(GiB) | ディスクタイプ | ディスクサイズ (GiB)/IOS | カウント | リージョン |
|---|---|---|---|---|---|---|---|
| マスター/etcd [1] | r5.4xlarge | 16 | 128 | gp3 | 220 | 3 | us-west-2 |
| インフラ [2] | m5.12xlarge | 48 | 192 | gp3 | 100 | 3 | us-west-2 |
| ワークロード [3] | m5.4xlarge | 16 | 64 | gp3 | 500 [4] | 1 | us-west-2 |
| ワーカー | m5.2xlarge | 8 | 32 | gp3 | 100 | 3/25/250/500 [5] | us-west-2 |
- etcd は遅延の影響を受けやすいため、ベースラインパフォーマンスが 3000 IOPS で毎秒 125 MiB の gp3 ディスクがコントロールプレーン/etcd ノードに使用されます。gp3 ボリュームはバーストパフォーマンスを使用しません。
- インフラストラクチャーノードは、モニターリング、Ingress およびレジストリーコンポーネントをホストするために使用され、これにより、それらが大規模に実行する場合に必要とするリソースを十分に確保することができます。
- ワークロードノードは、パフォーマンスとスケーラビリティーのワークロードジェネレーターを実行するための専用ノードです。
- パフォーマンスおよびスケーラビリティーのテストの実行中に収集される大容量のデータを保存するのに十分な領域を確保できるように、大きなディスクサイズが使用されます。
- クラスターは反復的にスケーリングされ、パフォーマンスおよびスケーラビリティーテストは指定されたノード数で実行されます。
IBM Power プラットフォーム:
| ノード | vCPU | RAM(GiB) | ディスクタイプ | ディスクサイズ (GiB)/IOS | カウント |
|---|---|---|---|---|---|
| マスター/etcd [1] | 16 | 32 | io1 | GiB あたり 120/10 IOPS | 3 |
| インフラ [2] | 16 | 64 | gp2 | 120 | 2 |
| ワークロード [3] | 16 | 256 | gp2 | 120 [4] | 1 |
| ワーカー | 16 | 64 | gp2 | 120 | 3/25/250/500 [5] |
- GB あたり 120 / 3 IOPS を持つ io1 ディスクは、etcd が I/O 集約型であり、かつレイテンシーの影響を受けやすいため、マスター/etcd ノードに使用されます。
- インフラストラクチャーノードは、モニターリング、Ingress およびレジストリーコンポーネントをホストするために使用され、これにより、それらが大規模に実行する場合に必要とするリソースを十分に確保することができます。
- ワークロードノードは、パフォーマンスとスケーラビリティーのワークロードジェネレーターを実行するための専用ノードです。
- パフォーマンスおよびスケーラビリティーのテストの実行中に収集される大容量のデータを保存するのに十分な領域を確保できるように、大きなディスクサイズが使用されます。
- クラスターは反復的にスケーリングされ、パフォーマンスおよびスケーラビリティーテストは指定されたノード数で実行されます。
8.2.1. IBM Z プラットフォーム
| ノード | vCPU [4] | RAM(GiB)[5] | ディスクタイプ | ディスクサイズ (GiB)/IOS | カウント |
|---|---|---|---|---|---|
| コントロールプレーン/etcd [1,2] | 8 | 32 | ds8k | 300 / LCU 1 | 3 |
| コンピュート [1,3] | 8 | 32 | ds8k | 150 / LCU 2 | 4 ノード (ノードあたり 100/250/500 Pod にスケーリング) |
- ノードは 2 つの論理制御ユニット (LCU) 間で分散され、コントロールプレーン/etcd ノードのディスク I/O 負荷を最適化します。etcd の I/O 需要が他のワークロードに干渉してはなりません。
- 100/250/500 Pod で同時に複数の反復を実行するテストには、4 つの計算ノードが使用されます。まず、Pod をインスタンス化できるかどうかを評価するために、アイドリング Pod が使用されました。次に、ネットワークと CPU を必要とするクライアント/サーバーのワークロードを使用して、ストレス下でのシステムの安定性を評価しました。クライアント Pod とサーバー Pod はペアで展開され、各ペアは 2 つのコンピューティングノードに分散されました。
- 個別のワークロードノードは使用されませんでした。ワークロードは、2 つの計算ノード間のマイクロサービスワークロードをシミュレートします。
- 使用されるプロセッサーの物理的な数は、6 つの Integrated Facilities for Linux (IFL) です。
- 使用される物理メモリーの合計は 512 GiB です。
8.3. テスト済みのクラスターの最大値に基づく環境計画
ノード上で物理リソースを過剰にサブスクライブすると、Kubernetes スケジューラーが Pod の配置時に行うリソースの保証に影響が及びます。メモリースワップを防ぐために実行できる処置について確認してください。
一部のテスト済みの最大値については、単一の namespace/ユーザーが作成するオブジェクトでのみ変更されます。これらの制限はクラスター上で数多くのオブジェクトが実行されている場合には異なります。
本書に記載されている数は、Red Hat のテスト方法、セットアップ、設定、およびチューニングに基づいています。これらの数は、独自のセットアップおよび環境に応じて異なります。
環境の計画時に、ノードに配置できる Pod 数を判別します。
required pods per cluster / pods per node = total number of nodes needed
ノードあたりの現在の Pod の最大数は 250 です。ただし、ノードに適合する Pod 数はアプリケーション自体によって異なります。アプリケーション要件に合わせて環境計画を立てる方法で説明されているように、アプリケーションのメモリー、CPU およびストレージの要件を検討してください。
シナリオ例
クラスターごとに 2200 の Pod のあるクラスターのスコープを設定する場合、ノードごとに最大 500 の Pod があることを前提として、最低でも 5 つのノードが必要になります。
2200 / 500 = 4.4
ノード数を 20 に増やす場合は、Pod 配分がノードごとに 110 の Pod に変わります。
2200 / 20 = 110
ここで、
required pods per cluster / total number of nodes = expected pods per node
8.4. アプリケーション要件に合わせて環境計画を立てる方法
アプリケーション環境の例を考えてみましょう。
| Pod タイプ | Pod 数 | 最大メモリー | CPU コア数 | 永続ストレージ |
|---|---|---|---|---|
| apache | 100 | 500 MB | 0.5 | 1 GB |
| node.js | 200 | 1 GB | 1 | 1 GB |
| postgresql | 100 | 1 GB | 2 | 10 GB |
| JBoss EAP | 100 | 1 GB | 1 | 1 GB |
推定要件: CPU コア 550 個、メモリー 450GB およびストレージ 1.4TB
ノードのインスタンスサイズは、希望に応じて増減を調整できます。ノードのリソースはオーバーコミットされることが多く、デプロイメントシナリオでは、小さいノードで数を増やしたり、大きいノードで数を減らしたりして、同じリソース量を提供することもできます。このデプロイメントシナリオでは、小さいノードで数を増やしたり、大きいノードで数を減らしたりして、同じリソース量を提供することもできます。運用上の敏捷性やインスタンスあたりのコストなどの要因を考慮する必要があります。
| ノードのタイプ | 数量 | CPU | RAM (GB) |
|---|---|---|---|
| ノード (オプション 1) | 100 | 4 | 16 |
| ノード (オプション 2) | 50 | 8 | 32 |
| ノード (オプション 3) | 25 | 16 | 64 |
アプリケーションによってはオーバーコミットの環境に適しているものもあれば、そうでないものもあります。たとえば、Java アプリケーションや Huge Page を使用するアプリケーションの多くは、オーバーコミットに対応できません。対象のメモリーは、他のアプリケーションに使用できません。上記の例では、環境は一般的な比率として約 30 % オーバーコミットされています。
アプリケーション Pod は環境変数または DNS のいずれかを使用してサービスにアクセスできます。環境変数を使用する場合、それぞれのアクティブなサービスについて、変数が Pod がノードで実行される際に kubelet によって挿入されます。クラスター対応の DNS サーバーは、Kubernetes API で新規サービスの有無を監視し、それぞれに DNS レコードのセットを作成します。DNS がクラスター全体で有効にされている場合、すべての Pod は DNS 名でサービスを自動的に解決できるはずです。DNS を使用したサービス検出は、5000 サービスを超える使用できる場合があります。サービス検出に環境変数を使用する場合、引数の一覧は namespace で 5000 サービスを超える場合の許可される長さを超えると、Pod およびデプロイメントは失敗します。デプロイメントのサービス仕様ファイルのサービスリンクを無効にして、以下を解消します。
---
apiVersion: template.openshift.io/v1
kind: Template
metadata:
name: deployment-config-template
creationTimestamp:
annotations:
description: This template will create a deploymentConfig with 1 replica, 4 env vars and a service.
tags: ''
objects:
- apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: deploymentconfig${IDENTIFIER}
spec:
template:
metadata:
labels:
name: replicationcontroller${IDENTIFIER}
spec:
enableServiceLinks: false
containers:
- name: pause${IDENTIFIER}
image: "${IMAGE}"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: ENVVAR1_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR2_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR3_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR4_${IDENTIFIER}
value: "${ENV_VALUE}"
resources: {}
imagePullPolicy: IfNotPresent
capabilities: {}
securityContext:
capabilities: {}
privileged: false
restartPolicy: Always
serviceAccount: ''
replicas: 1
selector:
name: replicationcontroller${IDENTIFIER}
triggers:
- type: ConfigChange
strategy:
type: Rolling
- apiVersion: v1
kind: Service
metadata:
name: service${IDENTIFIER}
spec:
selector:
name: replicationcontroller${IDENTIFIER}
ports:
- name: serviceport${IDENTIFIER}
protocol: TCP
port: 80
targetPort: 8080
clusterIP: ''
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}
parameters:
- name: IDENTIFIER
description: Number to append to the name of resources
value: '1'
required: true
- name: IMAGE
description: Image to use for deploymentConfig
value: gcr.io/google-containers/pause-amd64:3.0
required: false
- name: ENV_VALUE
description: Value to use for environment variables
generate: expression
from: "[A-Za-z0-9]{255}"
required: false
labels:
template: deployment-config-template
namespace で実行できるアプリケーション Pod の数は、環境変数がサービス検出に使用される場合にサービスの数およびサービス名の長さによって異なります。システムの ARG_MAX は、新規プロセスの引数の最大の長さを定義し、デフォルトで 2097152 KiB に設定されます。Kubelet は、以下を含む namespace で実行するようにスケジュールされる各 Pod に環境変数を挿入します。
-
<SERVICE_NAME>_SERVICE_HOST=<IP> -
<SERVICE_NAME>_SERVICE_PORT=<PORT> -
<SERVICE_NAME>_PORT=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_PROTO=tcp -
<SERVICE_NAME>_PORT_<PORT>_TCP_PORT=<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_ADDR=<ADDR>
引数の長さが許可される値を超え、サービス名の文字数がこれに影響する場合、namespace の Pod は起動に失敗し始めます。たとえば、5000 サービスを含む namespace では、サービス名の制限は 33 文字であり、これにより namespace で 5000 Pod を実行できます。
第9章 ストレージの最適化
ストレージを最適化すると、すべてのリソースでストレージの使用を最小限に抑えることができます。管理者は、ストレージを最適化することで、既存のストレージリソースが効率的に機能できるようにすることができます。
9.1. 利用可能な永続ストレージオプション
永続ストレージオプションについて理解し、OpenShift Container Platform 環境を最適化できるようにします。
| ストレージタイプ | 説明 | 例 |
|---|---|---|
| ブロック |
| AWS EBS および VMware vSphere は、OpenShift Container Platform で永続ボリューム (PV) の動的なプロビジョニングをサポートします。 |
| ファイル |
| RHEL NFS、NetApp NFS [1]、および Vendor NFS |
| オブジェクト |
| AWS S3 |
- NetApp NFS は Trident を使用する場合に動的 PV のプロビジョニングをサポートします。
現時点で、CNS は OpenShift Container Platform 4.9 ではサポートされていません。
9.2. 設定可能な推奨のストレージ技術
以下の表では、特定の OpenShift Container Platform クラスターアプリケーション向けに設定可能な推奨のストレージ技術についてまとめています。
| ストレージタイプ | ROX1 | RWX2 | レジストリー | スケーリングされたレジストリー | メトリクス3 | ロギング | アプリ |
|---|---|---|---|---|---|---|---|
|
1
2 3 Prometheus はメトリクスに使用される基礎となるテクノロジーです。 4 これは、物理ディスク、VM 物理ディスク、VMDK、NFS 経由のループバック、AWS EBS、および Azure Disk には該当しません。
5 メトリクスの場合、 6 ロギングの場合、共有ストレージを使用することはアンチパターンとなります。elasticsearch ごとに 1 つのボリュームが必要です。 7 オブジェクトストレージは、OpenShift Container Platform の PV/PVC で消費されません。アプリは、オブジェクトストレージの REST API と統合する必要があります。 | |||||||
| ブロック | はい4 | いいえ | 設定可能 | 設定不可 | 推奨 | 推奨 | 推奨 |
| ファイル | はい4 | ○ | 設定可能 | 設定可能 | 設定可能5 | 設定可能6 | 推奨 |
| オブジェクト | ○ | ○ | 推奨 | 推奨 | 設定不可 | 設定不可 | 設定不可7 |
スケーリングされたレジストリーとは、2 つ以上の Pod レプリカが稼働する OpenShift Container Platform レジストリーのことです。
9.2.1. 特定アプリケーションのストレージの推奨事項
テストにより、NFS サーバーを Red Hat Enterprise Linux (RHEL) でコアサービスのストレージバックエンドとして使用することに関する問題が検出されています。これには、OpenShift Container レジストリーおよび Quay、メトリクスストレージの Prometheus、およびロギングストレージの Elasticsearch が含まれます。そのため、コアサービスで使用される PV をサポートするために RHEL NFS を使用することは推奨されていません。
他の NFS の実装ではこれらの問題が検出されない可能性があります。OpenShift Container Platform コアコンポーネントに対して実施された可能性のあるテストに関する詳細情報は、個別の NFS 実装ベンダーにお問い合わせください。
9.2.1.1. レジストリー
スケーリングなし/高可用性 (HA) ではない OpenShift Container Platform レジストリークラスターのデプロイメント:
- ストレージ技術は、RWX アクセスモードをサポートする必要はありません。
- ストレージ技術は、リードアフターライト (Read-After-Write) の一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージであり、次はブロックストレージです。
- ファイルストレージは、実稼働環境のワークロードを処理する OpenShift Container Platform レジストリークラスターのデプロイメントには推奨されません。
9.2.1.2. スケーリングされたレジストリー
スケーリングされた/高可用性 (HA) の OpenShift Container Platform レジストリーのクラスターデプロイメント:
- ストレージ技術は、RWX アクセスモードをサポートする必要があります。
- ストレージ技術は、リードアフターライト (Read-After-Write) の一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージです。
- Red Hat OpenShift Data Foundation (ODF)、Amazon Simple Storage Service (Amazon S3)、Google Cloud Storage (GCS)、Microsoft Azure Blob Storage、および OpenStack Swift がサポートされています。
- オブジェクトストレージは S3 または Swift に準拠する必要があります。
- vSphere やベアメタルインストールなどのクラウド以外のプラットフォームの場合、設定可能な技術はファイルストレージのみです。
- ブロックストレージは設定できません。
9.2.1.3. メトリクス
OpenShift Container Platform がホストするメトリクスのクラスターデプロイメント:
- 推奨されるストレージ技術はブロックストレージです。
- オブジェクトストレージは設定できません。
実稼働ワークロードがあるホスト型のメトリクスクラスターデプロイメントにファイルストレージを使用することは推奨されません。
9.2.1.4. ロギング
OpenShift Container Platform がホストするロギングのクラスターデプロイメント:
- 推奨されるストレージ技術はブロックストレージです。
- オブジェクトストレージは設定できません。
9.2.1.5. アプリケーション
以下の例で説明されているように、アプリケーションのユースケースはアプリケーションごとに異なります。
- 動的な PV プロビジョニングをサポートするストレージ技術は、マウント時のレイテンシーが低く、ノードに関連付けられておらず、正常なクラスターをサポートします。
- アプリケーション開発者はアプリケーションのストレージ要件や、それがどのように提供されているストレージと共に機能するかを理解し、アプリケーションのスケーリング時やストレージレイヤーと対話する際に問題が発生しないようにしておく必要があります。
9.2.2. 特定のアプリケーションおよびストレージの他の推奨事項
etcd などの Write 集中型ワークロードで RAID 設定を使用することはお勧めしません。RAID 設定で etcd を実行している場合、ワークロードでパフォーマンスの問題が発生するリスクがある可能性があります。
- Red Hat OpenStack Platform (RHOSP) Cinder: RHOSP Cinder は ROX アクセスモードのユースケースで適切に機能する傾向があります。
- データベース: データベース (RDBMS、NoSQL DB など) は、専用のブロックストレージで最適に機能することが予想されます。
- etcd データベースには、大規模なクラスターを有効にするのに十分なストレージと十分なパフォーマンス容量が必要です。十分なストレージと高性能環境を確立するための監視およびベンチマークツールに関する情報は、推奨される etcd プラクティス に記載されています。
9.3. データストレージ管理
以下の表は、OpenShift Container Platform コンポーネントがデータを書き込むメインディレクトリーの概要を示しています。
| ディレクトリー | 注記 | サイジング | 予想される拡張 |
|---|---|---|---|
| /var/log | すべてのコンポーネントのログファイルです。 | 10 から 30 GB。 | ログファイルはすぐに拡張する可能性があります。サイズは拡張するディスク別に管理するか、ログローテーションを使用して管理できます。 |
| /var/lib/etcd | データベースを保存する際に etcd ストレージに使用されます。 | 20 GB 未満。 データベースは、最大 8 GB まで拡張できます。 | 環境と共に徐々に拡張します。メタデータのみを格納します。 メモリーに 8 GB が追加されるたびに 20-25 GB を追加します。 |
| /var/lib/containers | これは CRI-O ランタイムのマウントポイントです。アクティブなコンテナーランタイム (Pod を含む) およびローカルイメージのストレージに使用されるストレージです。レジストリーストレージには使用されません。 | 16 GB メモリーの場合、1 ノードにつき 50 GB。このサイジングは、クラスターの最小要件の決定には使用しないでください。 メモリーに 8 GB が追加されるたびに 20-25 GB を追加します。 | 拡張は実行中のコンテナーの容量によって制限されます。 |
| /var/lib/kubelet | Pod の一時ボリュームストレージです。これには、ランタイムにコンテナーにマウントされる外部のすべての内容が含まれます。環境変数、kube シークレット、および永続ボリュームでサポートされていないデータボリュームが含まれます。 | 変動あり。 | ストレージを必要とする Pod が永続ボリュームを使用している場合は最小になります。一時ストレージを使用する場合はすぐに拡張する可能性があります。 |
第10章 ルーティングの最適化
OpenShift Container Platform HAProxy ルーターは、パフォーマンスを最適化するためにスケーリングまたは設定できます。
10.1. ベースライン Ingress コントローラー (ルーター) のパフォーマンス
OpenShift Container Platform Ingress コントローラー (ルーター) は、ルートとイングレスを使用して設定されたアプリケーションとサービスのイングレストラフィックのイングレスポイントです。
1 秒に処理される HTTP 要求について、単一の HAProxy ルーターを評価する場合に、パフォーマンスは多くの要因により左右されます。特に以下が含まれます。
- HTTP keep-alive/close モード
- ルートタイプ
- TLS セッション再開のクライアントサポート
- ターゲットルートごとの同時接続数
- ターゲットルート数
- バックエンドサーバーのページサイズ
- 基礎となるインフラストラクチャー (ネットワーク/SDN ソリューション、CPU など)
特定の環境でのパフォーマンスは異なりますが、Red Hat ラボはサイズが 4 vCPU/16GB RAM のパブリッククラウドインスタンスでテストしています。1kB 静的ページを提供するバックエンドで終端する 100 ルートを処理する単一の HAProxy ルーターは、1 秒あたりに以下の数のトランザクションを処理できます。
HTTP keep-alive モードのシナリオの場合:
| 暗号化 | LoadBalancerService | HostNetwork |
|---|---|---|
| なし | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
HTTP close (keep-alive なし) のシナリオの場合:
| 暗号化 | LoadBalancerService | HostNetwork |
|---|---|---|
| なし | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
デフォルトの Ingress Controller 設定は、spec.tuningOptions.threadCount フィールドを 4 に設定して、使用されました。Load Balancer Service と Host Network という 2 つの異なるエンドポイント公開戦略がテストされました。TLS セッション再開は暗号化ルートについて使用されています。HTTP keep-alive では、1 台の HAProxy ルーターで、8kB という小さなページサイズで 1Gbit の NIC を飽和させることができます。
最新のプロセッサーが搭載されたベアメタルで実行する場合は、上記のパブリッククラウドインスタンスのパフォーマンスの約 2 倍のパフォーマンスになることを予想できます。このオーバーヘッドは、パブリッククラウドにある仮想化レイヤーにより発生し、プライベートクラウドベースの仮想化にも多くの場合、該当します。以下の表は、ルーターの背後で使用するアプリケーション数についてのガイドです。
| アプリケーション数 | アプリケーションタイプ |
|---|---|
| 5-10 | 静的なファイル/Web サーバーまたはキャッシュプロキシー |
| 100-1000 | 動的なコンテンツを生成するアプリケーション |
通常、HAProxy は、使用しているテクノロジーに応じて、最大 1000 個のアプリケーションのルートをサポートできます。Ingress コントローラーのパフォーマンスは、言語や静的コンテンツと動的コンテンツの違いを含め、その背後にあるアプリケーションの機能およびパフォーマンスによって制限される可能性があります。
Ingress またはルーターのシャード化は、アプリケーションに対してより多くのルートを提供するために使用され、ルーティング層の水平スケーリングに役立ちます。
Ingress のシャード化についての詳細は、Configuring Ingress Controller sharding by using route labels および Configuring Ingress Controller sharding by using namespace labels を参照してください。
スレッドの Ingress Controller スレッド数の設定、タイムアウトの Ingress Controller 設定パラメーター、および Ingress Controller 仕様のその他のチューニング設定で提供されている情報を使用して、Ingress Controller デプロイメントを変更できます。
第11章 ネットワークの最適化
OpenShift SDN は OpenvSwitch、VXLAN (Virtual extensible LAN) トンネル、OpenFlow ルール、iptables を使用します。このネットワークは、ジャンボフレーム、ネットワークインターフェイスコントローラー (NIC) オフロード、マルチキュー、および ethtool 設定を使用して調整できます。
OVN-Kubernetes は、トンネルプロトコルとして VXLAN ではなく Geneve (Generic Network Virtualization Encapsulation) を使用します。
VXLAN は、4096 から 1600 万以上にネットワーク数が増え、物理ネットワーク全体で階層 2 の接続が追加されるなど、VLAN での利点が提供されます。これにより、異なるシステム上で実行されている場合でも、サービスの背後にある Pod すべてが相互に通信できるようになります。
VXLAN は、User Datagram Protocol (UDP) パケットにトンネル化されたトラフィックをすべてカプセル化しますが、CPU 使用率が上昇してしまいます。これらの外部および内部パケットは、移動中にデータが破損しないようにするために通常のチェックサムルールの対象になります。これらの外部および内部パケットはどちらも、移動中にデータが破損しないように通常のチェックサムルールの対象になります。CPU のパフォーマンスによっては、この追加の処理オーバーヘッドによってスループットが減り、従来の非オーバーレイネットワークと比較してレイテンシーが高くなります。
クラウド、仮想マシン、ベアメタルの CPU パフォーマンスでは、1 Gbps をはるかに超えるネットワークスループットを処理できます。10 または 40 Gbps などの高い帯域幅のリンクを使用する場合には、パフォーマンスが低減する場合があります。これは、VXLAN ベースの環境では既知の問題で、コンテナーや OpenShift Container Platform 固有の問題ではありません。VXLAN トンネルに依存するネットワークも、VXLAN 実装により同様のパフォーマンスになります。
1 Gbps 以上にするには、以下を実行してください。
- Border Gateway Protocol (BGP) など、異なるルーティング技術を実装するネットワークプラグインを評価する。
- VXLAN オフロード対応のネットワークアダプターを使用します。VXLAN オフロードは、システムの CPU から、パケットのチェックサム計算と関連の CPU オーバーヘッドを、ネットワークアダプター上の専用のハードウェアに移動します。これにより、CPU サイクルを Pod やアプリケーションで使用できるように開放し、ネットワークインフラストラクチャーの帯域幅すべてをユーザーは活用できるようになります。
VXLAN オフロードはレイテンシーを短縮しません。ただし、CPU の使用率はレイテンシーテストでも削減されます。
11.1. ネットワークでの MTU の最適化
重要な Maximum Transmission Unit (MTU) が 2 つあります。1 つはネットワークインターフェイスコントローラー (NIC) MTU で、もう 1 つはクラスターネットワーク MTU です。
NIC MTU は OpenShift Container Platform のインストール時にのみ設定されます。MTU は、お使いのネットワークの NIC でサポートされる最大の値以下でなければなりません。スループットを最適化する場合は、可能な限り大きい値を選択します。レイテンシーを最低限に抑えるために最適化するには、より小さい値を選択します。
SDN オーバーレイの MTU は、最低でも NIC MTU より 50 バイト少なくなければなりません。これは、SDN オーバーレイのヘッダーに相当します。そのため、通常のイーサネットネットワークでは、この値を 1450 に設定します。ジャンボフレームのイーサネットネットワークの場合は、これを 8950 に設定します。
OVN および Geneve については、MTU は最低でも NIC MTU より 100 バイト少なくなければなりません。
50 バイトのオーバーレイヘッダーは OpenShift SDN に関連します。他の SDN ソリューションの場合はこの値を若干変動させる必要があります。
11.2. 大規模なクラスターのインストールに推奨されるプラクティス
大規模なクラスターをインストールする場合や、クラスターを大規模なノード数に拡張する場合、クラスターをインストールする前に、install-config.yaml ファイルに適宜クラスターネットワーク cidr を設定します。
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
クラスターのサイズが 500 を超える場合、デフォルトのクラスターネットワーク cidr 10.128.0.0/14 を使用することはできません。500 ノードを超えるノード数にするには、10.128.0.0/12 または 10.128.0.0/10 に設定する必要があります。
11.3. IPsec の影響
ノードホストの暗号化、復号化に CPU 機能が使用されるので、使用する IP セキュリティーシステムにかかわらず、ノードのスループットおよび CPU 使用率の両方でのパフォーマンスに影響があります。
IPSec は、NIC に到達する前に IP ペイロードレベルでトラフィックを暗号化して、NIC オフロードに使用されてしまう可能性のあるフィールドを保護します。つまり、IPSec が有効な場合には、NIC アクセラレーション機能を使用できない場合があり、スループットの減少、CPU 使用率の上昇につながります。
第12章 ベアメタルホストの管理
OpenShift Container Platform をベアメタルクラスターにインストールする場合、クラスターに存在するベアメタルホストの machine および machineset カスタムリソース (CR) を使用して、ベアメタルノードをプロビジョニングし、管理できます。
12.1. ベアメタルホストおよびノードについて
Red Hat Enterprise Linux CoreOS (RHCOS) ベアメタルホストをクラスター内のノードとしてプロビジョニングするには、まずベアメタルホストハードウェアに対応する MachineSet カスタムリソース (CR) オブジェクトを作成します。ベアメタルホストマシンセットは、お使いの設定に固有のインフラストラクチャーコンポーネントを記述します。特定の Kubernetes ラベルをこれらのマシンセットに適用してから、インフラストラクチャーコンポーネントを更新して、それらのマシンでのみ実行されるようにします。
Machine CR は、metal3.io/autoscale-to-hosts アノテーションを含む関連する MachineSet をスケールアップする際に自動的に作成されます。OpenShift Container Platform は Machine CR を使用して、MachineSet CR で指定されるホストに対応するベアメタルノードをプロビジョニングします。
12.2. ベアメタルホストのメンテナンス
OpenShift Container Platform Web コンソールからクラスター内のベアメタルホストの詳細を維持することができます。Compute → Bare Metal Hosts に移動し、Actions ドロップダウンメニューからタスクを選択します。ここでは、BMC の詳細、ホストの起動 MAC アドレス、電源管理の有効化などの項目を管理できます。また、ホストのネットワークインターフェイスおよびドライブの詳細を確認することもできます。
ベアメタルホストをメンテナンスモードに移行できます。ホストをメンテナンスモードに移行すると、スケジューラーはすべての管理ワークロードを対応するベアメタルノードから移動します。新しいワークロードは、メンテナンスモードの間はスケジュールされません。
Web コンソールでベアメタルホストのプロビジョニングを解除することができます。ホストのプロビジョニング解除により以下のアクションが実行されます。
-
ベアメタルホスト CR に
cluster.k8s.io/delete-machine: trueのアノテーションを付けます。 - 関連するマシンセットをスケールダウンします。
デーモンセットおよび管理対象外の静的 Pod を別のノードに最初に移動することなく、ホストの電源をオフにすると、サービスの中断やデータの損失が生じる場合があります。
関連情報
12.2.1. Web コンソールを使用したベアメタルホストのクラスターへの追加
Web コンソールのクラスターにベアメタルホストを追加できます。
前提条件
- RHCOS クラスターのベアメタルへのインストール
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- Web コンソールで、Compute → Bare Metal Hosts に移動します。
- Add Host → New with Dialog を選択します。
- 新規ベアメタルホストの一意の名前を指定します。
- Boot MAC address を設定します。
- Baseboard Management Console (BMC) Address を設定します。
- ホストのベースボード管理コントローラー (BMC) のユーザー認証情報を入力します。
- 作成後にホストの電源をオンにすることを選択し、Create を選択します。
- 利用可能なベアメタルホストの数に一致するようにレプリカ数をスケールアップします。Compute → MachineSets に移動し、Actions ドロップダウンメニューから Edit Machine count を選択してクラスター内のマシンレプリカ数を増やします。
oc scale コマンドおよび適切なベアメタルマシンセットを使用して、ベアメタルノードの数を管理することもできます。
12.2.2. Web コンソールの YAML を使用したベアメタルホストのクラスターへの追加
ベアメタルホストを記述する YAML ファイルを使用して、Web コンソールのクラスターにベアメタルホストを追加できます。
前提条件
- クラスターで使用するために RHCOS コンピュートマシンをベアメタルインフラストラクチャーにインストールします。
-
cluster-admin権限を持つユーザーとしてログインしている。 -
ベアメタルホストの
SecretCR を作成します。
手順
- Web コンソールで、Compute → Bare Metal Hosts に移動します。
- Add Host → New from YAML を選択します。
以下の YAML をコピーして貼り付け、ホストの詳細で関連フィールドを変更します。
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bare_metal_host_name> spec: online: true bmc: address: <bmc_address> credentialsName: <secret_credentials_name> 1 disableCertificateVerification: True 2 bootMACAddress: <host_boot_mac_address>- 1
credentialsNameは有効なSecretCR を参照する必要があります。baremetal-operatorは、credentialsNameで参照される有効なSecretなしに、ベアメタルホストを管理できません。シークレットの詳細および作成方法については、 シークレットについて を参照してください。- 2
disableCertificateVerificationをtrueに設定すると、クラスターとベースボード管理コントローラー (BMC) の間の TLS ホスト検証が無効になります。
- Create を選択して YAML を保存し、新規ベアメタルホストを作成します。
利用可能なベアメタルホストの数に一致するようにレプリカ数をスケールアップします。Compute → MachineSets に移動し、Actions ドロップダウンメニューから Edit Machine count を選択してクラスター内のマシン数を増やします。
注記oc scaleコマンドおよび適切なベアメタルマシンセットを使用して、ベアメタルノードの数を管理することもできます。
12.2.3. 利用可能なベアメタルホストの数へのマシンの自動スケーリング
利用可能な BareMetalHost オブジェクトの数に一致する Machine オブジェクトの数を自動的に作成するには、metal3.io/autoscale-to-hosts アノテーションを MachineSet オブジェクトに追加します。
前提条件
-
クラスターで使用する RHCOS ベアメタルコンピュートマシンをインストールし、対応する
BareMetalHostオブジェクトを作成します。 -
OpenShift Container Platform CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
metal3.io/autoscale-to-hostsアノテーションを追加して、自動スケーリング用に設定するマシンセットにアノテーションを付けます。<machineset>を、マシンセット名に置き換えます。$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'
新しいスケーリングされたマシンが起動するまで待ちます。
BareMetalHost オブジェクトを使用してクラスター内にマシンを作成し、その後ラベルまたはセレクターが BareMetalHost で変更される場合、BareMetalHost オブジェクトは Machine オブジェクトが作成された MachineSet に対して引き続きカウントされます。
12.2.4. プロビジョナーノードからのベアメタルホストの削除
特定の状況では、プロビジョナーノードからベアメタルホストを一時的に削除する場合があります。たとえば、OpenShift Container Platform 管理コンソールを使用して、または Machine Config Pool の更新の結果として、ベアメタルホストの再起動がトリガーされたプロビジョニング中に、OpenShift Container Platform は統合された Dell Remote Access Controller (iDrac) にログインし、ジョブキューの削除を発行します。
利用可能な BareMetalHost オブジェクトの数と一致する数の Machine オブジェクトを管理しないようにするには、baremetalhost.metal3.io/detached アノテーションを MachineSet オブジェクトに追加します。
このアノテーションは、Provisioned、ExternallyProvisioned、または Ready/Available 状態の BareMetalHost オブジェクトに対してのみ効果があります。
前提条件
-
クラスターで使用する RHCOS ベアメタルコンピュートマシンをインストールし、対応する
BareMetalHostオブジェクトを作成します。 -
OpenShift Container Platform CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
プロビジョナーノードから削除するコンピューティングマシンセットに、
baremetalhost.metal3.io/detachedアノテーションを追加してアノテーションを付けます。$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'
新しいマシンが起動するまで待ちます。
注記BareMetalHostオブジェクトを使用してクラスター内にマシンを作成し、その後ラベルまたはセレクターがBareMetalHostで変更される場合、BareMetalHostオブジェクトはMachineオブジェクトが作成されたMachineSetに対して引き続きカウントされます。プロビジョニングのユースケースでは、次のコマンドを使用して、再起動が完了した後にアノテーションを削除します。
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
第13章 Huge Page の機能およびそれらがアプリケーションによって消費される仕組み
13.1. Huge Page の機能
メモリーは Page と呼ばれるブロックで管理されます。多くのシステムでは、1 ページは 4Ki です。メモリー 1Mi は 256 ページに、メモリー 1Gi は 256,000 ページに相当します。CPU には、内蔵のメモリー管理ユニットがあり、ハードウェアでこのようなページリストを管理します。トランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffer) は、仮想から物理へのページマッピングの小規模なハードウェアキャッシュのことです。ハードウェアの指示で渡された仮想アドレスが TLB にあれば、マッピングをすばやく決定できます。そうでない場合には、TLB ミスが発生し、システムは速度が遅く、ソフトウェアベースのアドレス変換にフォールバックされ、パフォーマンスの問題が発生します。TLB のサイズは固定されているので、TLB ミスの発生率を減らすには Page サイズを大きくする必要があります。
Huge Page とは、4Ki より大きいメモリーページのことです。x86_64 アーキテクチャーでは、2Mi と 1Gi の 2 つが一般的な Huge Page サイズです。別のアーキテクチャーではサイズは異なります。Huge Page を使用するには、アプリケーションが認識できるようにコードを書き込む必要があります。Transparent Huge Pages (THP) は、アプリケーションによる認識なしに、Huge Page の管理を自動化しようとしますが、制約があります。特に、ページサイズは 2Mi に制限されます。THP では、THP のデフラグが原因で、メモリー使用率が高くなり、断片化が起こり、パフォーマンスの低下につながり、メモリーページがロックされてしまう可能性があります。このような理由から、アプリケーションは THP ではなく、事前割り当て済みの Huge Page を使用するように設計 (また推奨) される場合があります。
OpenShift Container Platform では、Pod のアプリケーションが事前に割り当てられた Huge Page を割り当て、消費することができます。
13.2. Huge Page がアプリケーションによって消費される仕組み
ノードは、Huge Page の容量をレポートできるように Huge Page を事前に割り当てる必要があります。ノードは、単一サイズの Huge Page のみを事前に割り当てることができます。
Huge Page は、リソース名の hugepages-<size> を使用してコンテナーレベルのリソース要件で消費可能です。この場合、サイズは特定のノードでサポートされる整数値を使用した最もコンパクトなバイナリー表記です。たとえば、ノードが 2048KiB ページサイズをサポートする場合、これはスケジュール可能なリソース hugepages-2Mi を公開します。CPU やメモリーとは異なり、Huge Page はオーバーコミットをサポートしません。
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepagesのメモリー量は、実際に割り当てる量に指定します。この値は、ページサイズで乗算したhugepagesのメモリー量に指定しないでください。たとえば、Huge Page サイズが 2MB と仮定し、アプリケーションに Huge Page でバックアップする RAM 100 MB を使用する場合には、Huge Page は 50 に指定します。OpenShift Container Platform により、計算処理が実行されます。上記の例にあるように、100MBを直接指定できます。
指定されたサイズの Huge Page の割り当て
プラットフォームによっては、複数の Huge Page サイズをサポートするものもあります。特定のサイズの Huge Page を割り当てるには、Huge Page の起動コマンドパラメーターの前に、Huge Page サイズの選択パラメーター hugepagesz=<size> を指定してください。<size> の値は、バイトで指定する必要があります。その際、オプションでスケール接尾辞 [kKmMgG] を指定できます。デフォルトの Huge Page サイズは、default_hugepagesz=<size> の起動パラメーターで定義できます。
Huge page の要件
- Huge Page 要求は制限と同じでなければなりません。制限が指定されているにもかかわらず、要求が指定されていない場合には、これがデフォルトになります。
- Huge Page は、Pod のスコープで分割されます。コンテナーの分割は、今後のバージョンで予定されています。
-
Huge Page がサポートする
EmptyDirボリュームは、Pod 要求よりも多くの Huge Page メモリーを消費することはできません。 -
shmget()でSHM_HUGETLBを使用して Huge Page を消費するアプリケーションは、proc/sys/vm/hugetlb_shm_group に一致する補助グループで実行する必要があります。
13.3. Downward API を使用した Huge Page リソースの使用
Downward API を使用して、コンテナーで使用する Huge Page リソースに関する情報を挿入できます。
リソースの割り当ては、環境変数、ボリュームプラグイン、またはその両方として挿入できます。コンテナーで開発および実行するアプリケーションは、指定されたボリューム内の環境変数またはファイルを読み取ることで、利用可能なリソースを判別できます。
手順
以下の例のような
hugepages-volume-pod.yamlファイルを作成します。apiVersion: v1 kind: Pod metadata: generateName: hugepages-volume- labels: app: hugepages-example spec: containers: - securityContext: capabilities: add: [ "IPC_LOCK" ] image: rhel7:latest command: - sleep - inf name: example volumeMounts: - mountPath: /dev/hugepages name: hugepage - mountPath: /etc/podinfo name: podinfo resources: limits: hugepages-1Gi: 2Gi memory: "1Gi" cpu: "1" requests: hugepages-1Gi: 2Gi env: - name: REQUESTS_HUGEPAGES_1GI <.> valueFrom: resourceFieldRef: containerName: example resource: requests.hugepages-1Gi volumes: - name: hugepage emptyDir: medium: HugePages - name: podinfo downwardAPI: items: - path: "hugepages_1G_request" <.> resourceFieldRef: containerName: example resource: requests.hugepages-1Gi divisor: 1Gi<.> では、
requests.hugepages-1Giからリソースの使用を読み取り、REQUESTS_HUGEPAGES_1GI環境変数としてその値を公開するように指定し、2 つ目の <.> は、requests.hugepages-1Giからのリソースの使用を読み取り、/etc/podinfo/hugepages_1G_requestファイルとして値を公開するように指定します。hugepages-volume-pod.yamlファイルから Pod を作成します。$ oc create -f hugepages-volume-pod.yaml
検証
REQUESTS_HUGEPAGES_1GI 環境変数の値を確認します。$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GI出力例
REQUESTS_HUGEPAGES_1GI=2147483648
/etc/podinfo/hugepages_1G_requestファイルの値を確認します。$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_request出力例
2
13.4. Huge Page の設定
ノードは、OpenShift Container Platform クラスターで使用される Huge Page を事前に割り当てる必要があります。Huge Page を予約する方法は、ブート時とランタイム時に実行する 2 つの方法があります。ブート時の予約は、メモリーが大幅に断片化されていないために成功する可能性が高くなります。Node Tuning Operator は、現時点で特定のノードでの Huge Page のブート時の割り当てをサポートします。
13.4.1. ブート時
手順
ノードの再起動を最小限にするには、以下の手順の順序に従う必要があります。
ラベルを使用して同じ Huge Page 設定を必要とするすべてのノードにラベルを付けます。
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
以下の内容でファイルを作成し、これに
hugepages-tuned-boottime.yamlという名前を付けます。apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages 1 namespace: openshift-cluster-node-tuning-operator spec: profile: 2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 3 name: openshift-node-hugepages recommend: - machineConfigLabels: 4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages
チューニングされた
hugepagesオブジェクトの作成$ oc create -f hugepages-tuned-boottime.yaml
以下の内容でファイルを作成し、これに
hugepages-mcp.yamlという名前を付けます。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""マシン設定プールを作成します。
$ oc create -f hugepages-mcp.yaml
断片化されていないメモリーが十分にある場合、worker-hp マシン設定プールのすべてのノードには 50 2Mi の Huge Page が割り当てられているはずです。
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100Mi
この機能は、現在 Red Hat Enterprise Linux CoreOS (RHCOS) 8.x ワーカーノードでのみサポートされています。Red Hat Enterprise Linux (RHEL) 7.x ワーカーノードでは、TuneD [bootloader] プラグインは現時点でサポートされていません。
13.5. Transparent Huge Pages (THP) の無効化
Transparent Huge Page (THP) は、Huge Page を作成し、管理し、使用するためのほとんどの要素を自動化しようとします。THP は Huge Page を自動的に管理するため、すべてのタイプのワークロードに対して常に最適に処理される訳ではありません。THP は、多くのアプリケーションが独自の Huge Page を処理するため、パフォーマンス低下につながる可能性があります。したがって、THP を無効にすることを検討してください。以下の手順では、Node Tuning Operator (NTO) を使用して THP を無効にする方法を説明します。
手順
以下の内容でファイルを作成し、
thp-disable-tuned.yamlという名前を付けます。apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: thp-workers-profile namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom tuned profile for OpenShift to turn off THP on worker nodes include=openshift-node [vm] transparent_hugepages=never name: openshift-thp-never-worker recommend: - match: - label: node-role.kubernetes.io/worker priority: 25 profile: openshift-thp-never-workerTuned オブジェクトを作成します。
$ oc create -f thp-disable-tuned.yaml
アクティブなプロファイルの一覧を確認します。
$ oc get profile -n openshift-cluster-node-tuning-operator
検証
ノードのいずれかにログインし、通常の THP チェックを実行して、ノードがプロファイルを正常に適用したかどうかを確認します。
$ cat /sys/kernel/mm/transparent_hugepage/enabled
出力例
always madvise [never]
第14章 低レイテンシーのノード向けの Performance Addon Operator
14.1. 低レイテンシー
Telco / 5G の領域でのエッジコンピューティングの台頭は、レイテンシーと輻輳を軽減し、アプリケーションのパフォーマンスを向上させる上で重要なロールを果たします。
簡単に言うと、レイテンシーは、データ (パケット) が送信側から受信側に移動し、受信側の処理後に送信側に戻るスピードを決定します。レイテンシーによる遅延を最小限に抑えた状態でネットワークアーキテクチャーを維持することが 5 G のネットワークパフォーマンス要件を満たすのに鍵となります。4G テクノロジーと比較し、平均レイテンシーが 50ms の 5G では、レイテンシーの数値を 1ms 以下にするようにターゲットが設定されます。このレイテンシーの減少により、ワイヤレスのスループットが 10 倍向上します。
Telco 領域にデプロイされるアプリケーションの多くは、ゼロパケットロスに耐えられる低レイテンシーを必要とします。パケットロスをゼロに調整すると、ネットワークのパフォーマンス低下させる固有の問題を軽減することができます。詳細は、Tuning for Zero Packet Loss in Red Hat OpenStack Platform (RHOSP) を参照してください。
エッジコンピューティングの取り組みは、レイテンシーの削減にも役立ちます。コンピュート能力が文字通りクラウドのエッジ上にあり、ユーザーの近く置かれること考えてください。これにより、ユーザーと離れた場所にあるデータセンター間の距離が大幅に削減されるため、アプリケーションの応答時間とパフォーマンスのレイテンシーが短縮されます。
管理者は、すべてのデプロイメントを可能な限り低い管理コストで実行できるように、多数のエッジサイトおよびローカルサービスを一元管理できるようにする必要があります。また、リアルタイムの低レイテンシーおよび高パフォーマンスを実現するために、クラスターの特定のノードをデプロイし、設定するための簡単な方法も必要になります。低レイテンシーノードは、Cloud-native Network Functions (CNF) や Data Plane Development Kit (DPDK) などのアプリケーションに役立ちます。
現時点で、OpenShift Container Platform はリアルタイムの実行および低レイテンシーを実現するために OpenShift Container Platform クラスターでソフトウェアを調整するメカニズムを提供します (約 20 マイクロ秒未満の応答時間)。これには、カーネルおよび OpenShift Container Platform の設定値のチューニング、カーネルのインストール、およびマシンの再設定が含まれます。ただし、この方法では 4 つの異なる Operator を設定し、手動で実行する場合に複雑であり、間違いが生じる可能性がある多くの設定を行う必要があります。
OpenShift Container Platform は、OpenShift アプリケーションの低レイテンシーパフォーマンスを実現するために自動チューニングを実装する Performance Addon Operator を提供します。クラスター管理者は、このパフォーマンスプロファイル設定を使用することにより、より信頼性の高い方法でこれらの変更をより容易に実行することができます。管理者は、カーネルを kernel-rt に更新するかどうかを指定し、Pod の infra コンテナーなどのクラスターおよびオペレーティングシステムのハウスキーピング向けに CPU を予約して、アプリケーションコンテナーがワークロードを実行するように CPU を分離することができます。
14.1.1. 低レイテンシーおよびリアルタイムのアプリケーションのハイパースレッディングについて
ハイパースレッディングは、物理 CPU プロセッサーコアが 2 つの論理コアとして機能することを可能にする Intel プロセッサーテクノロジーで、2 つの独立したスレッドを同時に実行します。ハイパースレッディングにより、並列処理が効果的な特定のワークロードタイプのシステムスループットを向上できます。デフォルトの OpenShift Container Platform 設定では、ハイパースレッディングがデフォルトで有効にされることが予想されます。
通信アプリケーションの場合、可能な限りレイテンシーを最小限に抑えられるようにアプリケーションインフラストラクチャーを設計することが重要です。ハイパースレッディングは、パフォーマンスを低下させる可能性があり、低レイテンシーを必要とするコンピュート集約型のワークロードのスループットにマイナスの影響を及ぼす可能性があります。ハイパースレッディングを無効にすると、予測可能なパフォーマンスが確保され、これらのワークロードの処理時間が短縮されます。
ハイパースレッディングの実装および設定は、OpenShift Container Platform を実行しているハードウェアによって異なります。ハードウェアに固有のハイパースレッディング実装についての詳細は、関連するホストハードウェアのチューニング情報を参照してください。ハイパースレッディングを無効にすると、クラスターのコアごとにコストが増大する可能性があります。
関連情報
14.2. Performance Addon Operator のインストール
Performance Addon Operator は、一連のノードで高度なノードのパフォーマンスチューニングを有効にする機能を提供します。クラスター管理者は、OpenShift Container Platform CLI または Web コンソールを使用して Performance Addon Operator をインストールできます。
14.2.1. CLI を使用した Operator のインストール
クラスター管理者は、CLI を使用して Operator をインストールできます。
前提条件
- ベアメタルハードウェアにインストールされたクラスター。
-
OpenShift CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下のアクションを実行して、Performance Addon Operator の namespace を作成します。
openshift-performance-addon-operatornamespace を定義する以下の Namespace カスタムリソース (CR) を作成し、YAML をpao-namespace.yamlファイルに保存します。apiVersion: v1 kind: Namespace metadata: name: openshift-performance-addon-operator annotations: workload.openshift.io/allowed: management以下のコマンドを実行して namespace を作成します。
$ oc create -f pao-namespace.yaml
以下のオブジェクトを作成して、直前の手順で作成した namespace に Performance Addon Operator をインストールします。
以下の
OperatorGroupCR を作成し、YAML をpao-operatorgroup.yamlファイルに保存します。apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-performance-addon-operator namespace: openshift-performance-addon-operator
以下のコマンドを実行して
OperatorGroupCR を作成します。$ oc create -f pao-operatorgroup.yaml
以下のコマンドを実行して、次の手順に必要な
channelの値を取得します。$ oc get packagemanifest performance-addon-operator -n openshift-marketplace -o jsonpath='{.status.defaultChannel}'出力例
4.9
以下の Subscription CR を作成し、YAML を
pao-sub.yamlファイルに保存します。Subscription の例
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-performance-addon-operator-subscription namespace: openshift-performance-addon-operator spec: channel: "<channel>" 1 name: performance-addon-operator source: redhat-operators 2 sourceNamespace: openshift-marketplace
以下のコマンドを実行して Subscription オブジェクトを作成します。
$ oc create -f pao-sub.yaml
openshift-performance-addon-operatorプロジェクトに切り替えます。$ oc project openshift-performance-addon-operator
14.2.2. Web コンソールを使用した Performance Addon Operator のインストール
クラスター管理者は、Web コンソールを使用して Performance Addon Operator をインストールできます。
先のセクションで説明されているように Namespace CR および OperatorGroup CR を作成する必要があります。
手順
OpenShift Container Platform Web コンソールを使用して Performance Addon Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 利用可能な Operator の一覧から Performance Addon Operator を選択してから Install をクリックします。
- Install Operator ページで、All namespaces on the cluster を選択します。次に、Install をクリックします。
オプション: performance-addon-operator が正常にインストールされていることを確認します。
- Operators → Installed Operators ページに切り替えます。
Performance Addon Operator が openshift-operators プロジェクトに Succeeded の Status でリストされていることを確認します。
注記インストール時に、 Operator は Failed ステータスを表示する可能性があります。インストールが成功し、Succeeded メッセージが表示された場合は、Failed メッセージを無視できます。
Operator がインストール済みとして表示されない場合は、さらにトラブルシューティングを行うことができます。
- Operators → Installed Operators ページに移動し、Operator Subscriptions および Install Plans タブで Status にエラーがあるかどうかを検査します。
-
Workloads → Pods ページに移動し、
openshift-operatorsプロジェクトで Pod のログを確認します。
14.3. Performance Addon Operator のアップグレード
次のマイナーバージョンの Performance Addon Operator に手動でアップグレードし、Web コンソールを使用して更新のステータスをモニターできます。
14.3.1. Performance Addon Operator のアップグレードについて
- OpenShift Container Platform Web コンソールを使用して Operator サブスクリプションのチャネルを変更することで、Performance Addon Operator の次のマイナーバージョンにアップグレードできます。
- Performance Addon Operator のインストール時に z-stream の自動更新を有効にできます。
- 更新は、OpenShift Container Platform のインストール時にデプロイされる Marketplace Operator 経由で提供されます。Marketplace Operator は外部 Operator をクラスターで利用可能にします。
- 更新の完了までにかかる時間は、ネットワーク接続によって異なります。ほとんどの自動更新は 15 分以内に完了します。
14.3.1.1. Performance Addon Operator のクラスターへの影響
- 低レイテンシーのチューニング Huge Page は影響を受けません。
- Operator を更新しても、予期しない再起動は発生しません。
14.3.1.2. Performance Addon Operator の次のマイナーバージョンへのアップグレード
OpenShift Container Platform Web コンソールを使用して Operator サブスクリプションのチャネルを変更することで、Performance Addon Operator を次のマイナーバージョンに手動でアップグレードできます。
前提条件
- cluster-admin ロールを持つユーザーとしてのクラスターへのアクセスがあること。
手順
- Web コンソールにアクセスし、Operators → Installed Operators に移動します。
- Performance Addon Operator をクリックし、Operator details ページを開きます。
- Subscription タブをクリックし、Subscription details ページを開きます。
- Update channel ペインで、バージョン番号の右側にある鉛筆アイコンをクリックし、Change Subscription update channel ウィンドウを開きます。
- 次のマイナーバージョンを選択します。たとえば、Performance Addon Operator 4.9 にアップグレードする場合は、4.9 を選択します。
- Save をクリックします。
Operators → Installed Operators に移動してアップグレードのステータスを確認します。以下の
ocコマンドを実行してステータスを確認することもできます。$ oc get csv -n openshift-performance-addon-operator
14.3.1.3. 以前に特定の namespace にインストールされている場合の Performance Addon Operator のアップグレード
Performance Addon Operator をクラスターの特定の namespace(例: openshift-performance-addon-operator) にインストールしている場合、OperatorGroup オブジェクトを変更して、アップグレード前に targetNamespaces エントリーを削除します。
前提条件
- OpenShift Container Platform CLI (oc) をインストールします。
- cluster-admin 権限を持つユーザーとして OpenShift クラスターにログインします。
手順
Performance Addon Operator
OperatorGroupCR を編集し、以下のコマンドを実行してtargetNamespacesエントリーが含まれるspec要素を削除します。$ oc patch operatorgroup -n openshift-performance-addon-operator openshift-performance-addon-operator --type json -p '[{ "op": "remove", "path": "/spec" }]'- Operator Lifecycle Manager (OLM) が変更を処理するまで待機します。
OperatorGroup CR の変更が正常に適用されていることを確認します。
OperatorGroupCR のspec要素が削除されていることを確認します。$ oc describe -n openshift-performance-addon-operator og openshift-performance-addon-operator
- Performance Addon Operator のアップグレードに進みます。
14.3.2. アップグレードステータスの監視
Performance Addon Operator アップグレードステータスをモニターする最適な方法として、ClusterServiceVersion (CSV) PHASE を監視できます。Web コンソールを使用するか、または oc get csv コマンドを実行して CSV の状態をモニターすることもできます。
PHASE および状態の値は利用可能な情報に基づく近似値になります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) をインストールしている。
手順
以下のコマンドを実行します。
$ oc get csv
出力を確認し、
PHASEフィールドをチェックします。以下に例を示します。VERSION REPLACES PHASE 4.9.0 performance-addon-operator.v4.9.0 Installing 4.8.0 Replacing
get csvを再度実行して出力を確認します。# oc get csv
出力例
NAME DISPLAY VERSION REPLACES PHASE performance-addon-operator.v4.9.0 Performance Addon Operator 4.9.0 performance-addon-operator.v4.8.0 Succeeded
14.4. リアルタイムおよび低レイテンシーワークロードのプロビジョニング
多くの企業や組織は、非常に高性能なコンピューティングを必要としており、とくに金融業界や通信業界では、低い、予測可能なレイテンシーが必要になる場合があります。このような固有の要件を持つ業界では、OpenShift Container Platform は Performance Addon Operator を提供して、OpenShift Container Platform アプリケーションの低レイテンシーのパフォーマンスと一貫性のある応答時間を実現するための自動チューニングを実装します。
クラスター管理者は、このパフォーマンスプロファイル設定を使用することにより、より信頼性の高い方法でこれらの変更を加えることができます。管理者は、カーネルを kernel-rt (リアルタイム) に更新するかどうかを指定し、Pod の infra コンテナーなどのクラスターおよびオペレーティングシステムのハウスキーピング向けに CPU を予約して、アプリケーションコンテナーがワークロードを実行するように CPU を分離することができます。
保証された CPU を必要とするアプリケーションと組み合わせて実行プローブを使用すると、レイテンシースパイクが発生する可能性があります。代わりに、適切に設定されたネットワークプローブのセットなど、他のプローブを使用することをお勧めします。
14.4.1. リアルタイムの既知の制限
ほとんどのデプロイメントで、3 つのコントロールプレーンノードと 3 つのワーカーノードを持つ標準クラスターを使用する場合、kernel-rt はワーカーノードでのみサポートされます。OpenShift Container Platform デプロイメントのコンパクトノードと単一ノードには例外があります。単一ノードへのインストールの場合、kernel-rt は単一のコントロールプレーンノードでサポートされます。
リアルタイムモードを完全に使用するには、コンテナーを昇格した権限で実行する必要があります。権限の付与についての情報は、Set capabilities for a Container を参照してください。
OpenShift Container Platform は許可される機能を制限するため、SecurityContext を作成する必要がある場合もあります。
この手順は、Red Hat Enterprise Linux CoreOS (RHCOS) システムを使用したベアメタルのインストールで完全にサポートされます。
パフォーマンスの期待値を設定する必要があるということは、リアルタイムカーネルがあらゆる問題の解決策ではないということを意味します。リアルタイムカーネルは、一貫性のある、低レイテンシーの、決定論に基づく予測可能な応答時間を提供します。リアルタイムカーネルに関連して、追加のカーネルオーバーヘッドがあります。これは、主に個別にスケジュールされたスレッドでハードウェア割り込みを処理することによって生じます。一部のワークロードのオーバーヘッドが増加すると、スループット全体が低下します。ワークロードによって異なりますが、パフォーマンスの低下の程度は 0% から 30% の範囲になります。ただし、このコストは決定論をベースとしています。
14.4.2. リアルタイム機能のあるワーカーのプロビジョニング
- Performance Addon Operator をクラスターにインストールします。
- オプション: ノードを OpenShift Container Platform クラスターに追加します。BIOS パラメーターの設定 について参照してください。
-
ocコマンドを使用して、リアルタイム機能を必要とするワーカーノードにラベルworker-rtを追加します。 リアルタイムノード用の新しいマシン設定プールを作成します。
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-rt labels: machineconfiguration.openshift.io/role: worker-rt spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker, worker-rt], } paused: false nodeSelector: matchLabels: node-role.kubernetes.io/worker-rt: ""マシン設定プール worker-rt は、
worker-rtというラベルを持つノードのグループに対して作成されることに注意してください。ノードロールラベルを使用して、ノードを適切なマシン設定プールに追加します。
注記リアルタイムワークロードで設定するノードを決定する必要があります。クラスター内のすべてのノード、またはノードのサブセットを設定できます。Performance Addon Operator は、すべてのノードが専用のマシン設定プールの一部であることを想定します。すべてのノードを使用する場合は、Performance Addon Operator がワーカーノードのロールラベルを指すようにする必要があります。サブセットを使用する場合、ノードを新規のマシン設定プールにグループ化する必要があります。
-
ハウスキーピングコアの適切なセットと
realTimeKernel: enabled: trueを設定してPerformanceProfileを作成します。 PerformanceProfileでmachineConfigPoolSelectorを設定する必要があります:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: ... realTimeKernel: enabled: true nodeSelector: node-role.kubernetes.io/worker-rt: "" machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-rt一致するマシン設定プールがラベルを持つことを確認します。
$ oc describe mcp/worker-rt
出力例
Name: worker-rt Namespace: Labels: machineconfiguration.openshift.io/role=worker-rt
- OpenShift Container Platform はノードの設定を開始しますが、これにより複数の再起動が伴う可能性があります。ノードが起動し、安定するのを待機します。特定のハードウェアの場合に、これには長い時間がかかる可能性がありますが、ノードごとに 20 分の時間がかかることが予想されます。
- すべてが予想通りに機能していることを確認します。
14.4.3. リアルタイムカーネルのインストールの確認
以下のコマンドを使用して、リアルタイムカーネルがインストールされていることを確認します。
$ oc get node -o wide
文字列 4.18.0-211.rt5.23.el8.x86_64 が含まれる、ロール worker-rt を持つワーカーに留意してください。
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME rt-worker-0.example.com Ready worker,worker-rt 5d17h v1.22.1 128.66.135.107 <none> Red Hat Enterprise Linux CoreOS 46.82.202008252340-0 (Ootpa) 4.18.0-211.rt5.23.el8.x86_64 cri-o://1.22.1-90.rhaos4.9.git4a0ac05.el8-rc.1 [...]
14.4.4. リアルタイムで機能するワークロードの作成
リアルタイム機能を使用するワークロードを準備するには、以下の手順を使用します。
手順
-
QoS クラスの
Guaranteedを指定して Pod を作成します。 - オプション: DPDK の CPU 負荷分散を無効にします。
- 適切なノードセレクターを割り当てます。
アプリケーションを作成する場合には、アプリケーションのチューニングとデプロイメント に記載されている一般的な推奨事項に従ってください。
14.4.5. QoS クラスの Guaranteed を指定した Pod の作成
QoS クラスの Guaranteed が指定されている Pod を作成する際には、以下を考慮してください。
- Pod のすべてのコンテナーにはメモリー制限およびメモリー要求があり、それらは同じである必要があります。
- Pod のすべてのコンテナーには CPU の制限と CPU 要求が必要であり、それらは同じである必要があります。
以下の例は、1 つのコンテナーを持つ Pod の設定ファイルを示しています。コンテナーにはメモリー制限とメモリー要求があり、どちらも 200 MiB に相当します。コンテナーには CPU 制限と CPU 要求があり、どちらも 1 CPU に相当します。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: <image-pull-spec>
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "200Mi"
cpu: "1"Pod を作成します。
$ oc apply -f qos-pod.yaml --namespace=qos-example
Pod についての詳細情報を表示します。
$ oc get pod qos-demo --namespace=qos-example --output=yaml
出力例
spec: containers: ... status: qosClass: Guaranteed注記コンテナーが独自のメモリー制限を指定するものの、メモリー要求を指定しない場合、OpenShift Container Platform は制限に一致するメモリー要求を自動的に割り当てます。同様に、コンテナーが独自の CPU 制限を指定するものの、CPU 要求を指定しない場合、OpenShift Container Platform は制限に一致する CPU 要求を自動的に割り当てます。
14.4.6. オプション: DPDK 用の CPU 負荷分散の無効化
CPU 負荷分散を無効または有効にする機能は CRI-O レベルで実装されます。CRI-O のコードは、以下の要件を満たす場合にのみ CPU の負荷分散を無効または有効にします。
Pod は
performance-<profile-name>ランタイムクラスを使用する必要があります。以下に示すように、パフォーマンスプロファイルのステータスを確認して、適切な名前を取得できます。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile ... status: ... runtimeClass: performance-manual
-
Pod には
cpu-load-balancing.crio.io: trueアノテーションが必要です。
Performance Addon Operator は、該当するノードで高パフォーマンスのランタイムハンドラー設定スニペットの作成や、クラスターで高パフォーマンスのランタイムクラスの作成を行います。これには、 CPU 負荷分散の設定機能を有効にすることを除くと、デフォルトのランタイムハンドラーと同じ内容が含まれます。
Pod の CPU 負荷分散を無効にするには、 Pod 仕様に以下のフィールドが含まれる必要があります。
apiVersion: v1
kind: Pod
metadata:
...
annotations:
...
cpu-load-balancing.crio.io: "disable"
...
...
spec:
...
runtimeClassName: performance-<profile_name>
...CPU マネージャーの静的ポリシーが有効にされている場合に、CPU 全体を使用する Guaranteed QoS を持つ Pod について CPU 負荷分散を無効にします。これ以外の場合に CPU 負荷分散を無効にすると、クラスター内の他のコンテナーのパフォーマンスに影響する可能性があります。
14.4.7. 適切なノードセレクターの割り当て
Pod をノードに割り当てる方法として、以下に示すようにパフォーマンスプロファイルが使用するものと同じノードセレクターを使用することが推奨されます。
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
# ...
nodeSelector:
node-role.kubernetes.io/worker-rt: ""ノードセレクターの詳細は、Placing pods on specific nodes using node selectors を参照してください。
14.4.8. リアルタイム機能を備えたワーカーへのワークロードのスケジューリング
Performance Addon Operator によって低レイテンシーを確保するために設定されたマシン設定プールに割り当てられるノードに一致するラベルセレクターを使用します。詳細は、Assigning pods to nodes を参照してください。
14.4.9. Guaranteed Pod の分離された CPU のデバイス割り込み処理の管理
Performance Addon Operator は、Pod Infra コンテナーなど、予約された CPU をクラスターおよびオペレーティングシステムのハウスキーピングタスクに、分離された CPU をワークロード実行用のアプリケーションコンテナーに分割して、ホストの CPU を管理できます。これにより、低レイテンシーのワークロード用の CPU を isolated (分離された CPU) として設定できます。
デバイスの割り込みについては、Guaranteed Pod が実行されている CPU を除き、CPU のオーバーロードを防ぐためにすべての分離された CPU および予約された CPU 間で負荷が分散されます。Guaranteed Pod の CPU は、関連するアノテーションが Pod に設定されている場合にデバイス割り込みを処理できなくなります。
パフォーマンスプロファイルで、 globallyDisableIrqLoadBalancing は、デバイス割り込みが処理されるかどうかを管理するために使用されます。特定のワークロードでは、予約された CPU は、デバイスの割り込みを処理するのに常に十分な訳ではないため、デバイスの割り込みは分離された CPU でグローバルに無効にされません。デフォルトで、Performance Addon Operator は分離された CPU でデバイス割り込みを無効にしません。
ワークロードの低レイテンシーを確保するには、一部の (すべてではない) Pod で、それらが実行されている CPU がデバイス割り込みを処理しないようにする必要があります。Pod アノテーション irq-load-balancing.crio.io は、デバイス割り込みが処理されるかどうかを定義するために使用されます。CRI-O は (設定されている場合)、Pod が実行されている場合にのみデバイス割り込みを無効にします。
14.4.9.1. CPU CFS クォータの無効化
保証された個々の Pod の CPU スロットル調整を減らすには、アノテーション cpu-quota.crio.io: "disable" を付けて、Pod 仕様を作成します。このアノテーションは、Pod の実行時に CPU Completely Fair Scheduler (CFS) のクォータを無効にします。次の Pod 仕様には、このアノテーションが含まれています。
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...CPU マネージャーの静的ポリシーが有効になっている場合、および CPU 全体を使用する Guaranteed QoS を持つ Pod の場合にのみ、CPU CFS クォータを無効にします。これ以外の場合に CPU CFS クォータを無効にすると、クラスター内の他のコンテナーのパフォーマンスに影響を与える可能性があります。
14.4.9.2. Performance Addon Operator でのグローバルデバイス割り込み処理の無効化
Performance Addon Operator を分離された CPU セットのグローバルデバイス割り込みを無効にするように設定するには、パフォーマンスプロファイルの globallyDisableIrqLoadBalancing フィールドを true に設定します。true の場合、競合する Pod アノテーションは無視されます。false の場合、すべての CPU 間で IRQ 負荷が分散されます。
パフォーマンスプロファイルのスニペットは、この設定を示しています。
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: globallyDisableIrqLoadBalancing: true ...
14.4.9.3. 個別の Pod の割り込み処理の無効化
個別の Pod の割り込み処理を無効にするには、パフォーマンスプロファイルで globalDisableIrqLoadBalancing が false に設定されていることを確認します。次に、Pod 仕様で、irq-load-balancing.crio.io Pod アノテーションを disable に設定します。次の Pod 仕様には、このアノテーションが含まれています。
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
irq-load-balancing.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...14.4.10. デバイス割り込み処理を使用するためのパフォーマンスプロファイルのアップグレード
Performance Addon Operator パフォーマンスプロファイルのカスタムリソース定義 (CRD) を v1 または v1alpha1 から v2 にアップグレードする場合、globallyDisableIrqLoadBalancing は true に設定されます。
globallyDisableIrqLoadBalancing は、IRQ ロードバランシングを分離 CPU セットに対して無効にするかどうかを切り替えます。このオプションを true に設定すると、分離 CPU セットの IRQ ロードバランシングが無効になります。オプションを false に設定すると、IRQ をすべての CPU 間でバランスさせることができます。
14.4.10.1. サポート対象の API バージョン
Performance Addon Operator は、パフォーマンスプロファイル apiVersion フィールドの v2、v1、および v1alpha1 をサポートします。v1 および v1alpha1 API は同一です。v2 API には、デフォルト値の false が設定されたオプションのブール値フィールド globallyDisableIrqLoadBalancing が含まれます。
14.4.10.1.1. Performance Addon Operator の v1alpha1 から v1 へのアップグレード
Performance Addon Operator API バージョンを v1alpha1 から v1 にアップグレードする場合、v1alpha1 パフォーマンスプロファイルは None 変換ストラテジーを使用して即時にオンザフライで変換され、API バージョン v1 の Performance Addon Operator に送信されます。
14.4.10.1.2. Performance Addon Operator API の v1alpha1 または v1 から v2 へのアップグレード
古い Performance Addon Operator API バージョンからアップグレードする場合、既存の v1 および v1alpha1 パフォーマンスプロファイルは、globallyDisableIrqLoadBalancing フィールドに true の値を挿入する変換 Webhook を使用して変換されます。
14.4.11. IRQ 動的負荷分散用ノードの設定
IRQ 動的負荷分散を処理するクラスターノードを設定するには、以下を実行します。
- cluster-admin 権限を持つユーザーとして OpenShift Container Platform クラスターにログインします。
-
パフォーマンスプロファイルの
apiVersionをperformance.openshift.io/v2を使用するように設定します。 -
globallyDisableIrqLoadBalancingフィールドを削除するか、またはこれをfalseに設定します。 適切な分離された CPU と予約された CPU を設定します。以下のスニペットは、2 つの CPU を確保するプロファイルを示しています。IRQ 負荷分散は、
isolatedCPU セットで実行されている Pod について有効にされます。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: dynamic-irq-profile spec: cpu: isolated: 2-5 reserved: 0-1 ...注記予約および分離された CPU を設定する場合に、Pod 内の infra コンテナーは予約された CPU を使用し、アプリケーションコンテナーは分離された CPU を使用します。
排他的な CPU を使用する Pod を作成し、
irq-load-balancing.crio.ioおよびcpu-quota.crio.ioアノテーションをdisableに設定します。以下に例を示します。apiVersion: v1 kind: Pod metadata: name: dynamic-irq-pod annotations: irq-load-balancing.crio.io: "disable" cpu-quota.crio.io: "disable" spec: containers: - name: dynamic-irq-pod image: "quay.io/openshift-kni/cnf-tests:4.9" command: ["sleep", "10h"] resources: requests: cpu: 2 memory: "200M" limits: cpu: 2 memory: "200M" nodeSelector: node-role.kubernetes.io/worker-cnf: "" runtimeClassName: performance-dynamic-irq-profile ...-
performance-<profile_name> の形式で Pod
runtimeClassNameを入力します。ここで、<profile_name> はPerformanceProfileYAML のnameです (例:performance-dynamic-irq-profile)。 - ノードセレクターを cnf-worker をターゲットに設定するように設定します。
Pod が正常に実行されていることを確認します。ステータスが
runningであり、正しい cnf-worker ノードが設定されている必要があります。$ oc get pod -o wide
予想される出力
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES dynamic-irq-pod 1/1 Running 0 5h33m <ip-address> <node-name> <none> <none>
IRQ の動的負荷分散向けに設定された Pod が実行される CPU を取得します。
$ oc exec -it dynamic-irq-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"予想される出力
Cpus_allowed_list: 2-3
ノードの設定が正しく適用されていることを確認します。そのノードに対して SSH を実行し、設定を確認します。
$ oc debug node/<node-name>
予想される出力
Starting pod/<node-name>-debug ... To use host binaries, run `chroot /host` Pod IP: <ip-address> If you don't see a command prompt, try pressing enter. sh-4.4#
ノードのファイルシステムを使用できることを確認します。
sh-4.4# chroot /host
予想される出力
sh-4.4#
デフォルトのシステム CPU アフィニティーマスクに
dynamic-irq-podCPU(例: CPU 2 および 3) が含まれないようにします。$ cat /proc/irq/default_smp_affinity
出力例
33
システム IRQ が
dynamic-irq-podCPU で実行されるように設定されていないことを確認します。find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;出力例
/proc/irq/0/smp_affinity_list: 0-5 /proc/irq/1/smp_affinity_list: 5 /proc/irq/2/smp_affinity_list: 0-5 /proc/irq/3/smp_affinity_list: 0-5 /proc/irq/4/smp_affinity_list: 0 /proc/irq/5/smp_affinity_list: 0-5 /proc/irq/6/smp_affinity_list: 0-5 /proc/irq/7/smp_affinity_list: 0-5 /proc/irq/8/smp_affinity_list: 4 /proc/irq/9/smp_affinity_list: 4 /proc/irq/10/smp_affinity_list: 0-5 /proc/irq/11/smp_affinity_list: 0 /proc/irq/12/smp_affinity_list: 1 /proc/irq/13/smp_affinity_list: 0-5 /proc/irq/14/smp_affinity_list: 1 /proc/irq/15/smp_affinity_list: 0 /proc/irq/24/smp_affinity_list: 1 /proc/irq/25/smp_affinity_list: 1 /proc/irq/26/smp_affinity_list: 1 /proc/irq/27/smp_affinity_list: 5 /proc/irq/28/smp_affinity_list: 1 /proc/irq/29/smp_affinity_list: 0 /proc/irq/30/smp_affinity_list: 0-5
一部の IRQ コントローラーは IRQ リバランスをサポートせず、常にすべてのオンライン CPU を IRQ マスクとして公開します。これらの IRQ コントローラーは CPU 0 で正常に実行されます。ホスト設定についての詳細は、ホストに対して SSH を実行し、<irq-num> をクエリーする CPU 番号に置き換えて以下を実行して参照してください。
$ cat /proc/irq/<irq-num>/effective_affinity
14.4.12. クラスターのハイパースレッディングの設定
OpenShift Container Platform クラスターのハイパースレッディングを設定するには、パフォーマンスプロファイルの CPU スレッドを、予約または分離された CPU プールに設定された同じコアに設定します。
パフォーマンスプロファイルを設定してから、ホストのハイパースレッディング設定を変更する場合は、新規の設定に一致するように PerformanceProfile YAML の CPU の isolated および reserved フィールドを更新するようにしてください。
以前に有効にされたホストのハイパースレッディング設定を無効にすると、PerformanceProfile YAML に一覧表示されている CPU コア ID が正しくなくなる可能性があります。この設定が間違っていると、一覧表示される CPU が見つからなくなるため、ノードが利用できなくなる可能性があります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - OpenShift CLI (oc) のインストール。
手順
設定する必要のあるホストのどの CPU でどのスレッドが実行されているかを確認します。
クラスターにログインして以下のコマンドを実行し、ホスト CPU で実行されているスレッドを表示できます。
$ lscpu --all --extended
出力例
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4800.0000 400.0000 1 0 0 1 1:1:1:0 yes 4800.0000 400.0000 2 0 0 2 2:2:2:0 yes 4800.0000 400.0000 3 0 0 3 3:3:3:0 yes 4800.0000 400.0000 4 0 0 0 0:0:0:0 yes 4800.0000 400.0000 5 0 0 1 1:1:1:0 yes 4800.0000 400.0000 6 0 0 2 2:2:2:0 yes 4800.0000 400.0000 7 0 0 3 3:3:3:0 yes 4800.0000 400.0000
この例では、4 つの物理 CPU コアで 8 つの論理 CPU コアが実行されています。CPU0 および CPU4 は物理コアの Core0 で実行されており、CPU1 および CPU5 は物理コア 1 で実行されています。
または、特定の物理 CPU コア (以下の例では
cpu0) に設定されているスレッドを表示するには、コマンドプロンプトを開いて以下のコマンドを実行します。$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
出力例
0-4
PerformanceProfileYAML で分離された CPU および予約された CPU を適用します。たとえば、論理コア CPU0 と CPU4 をisolatedとして設定し、論理コア CPU1 から CPU3 および CPU5 から CPU7 をreservedとして設定できます。予約および分離された CPU を設定する場合に、Pod 内の infra コンテナーは予約された CPU を使用し、アプリケーションコンテナーは分離された CPU を使用します。... cpu: isolated: 0,4 reserved: 1-3,5-7 ...注記予約済みの CPU プールと分離された CPU プールは重複してはならず、これらは共に、ワーカーノードの利用可能なすべてのコアに広がる必要があります。
ハイパースレッディングは、ほとんどの Intel プロセッサーでデフォルトで有効にされます。ハイパースレッディングを有効にする場合、特定のコアによって処理されるスレッドはすべて、同じコアで分離されるか、処理される必要があります。
14.4.12.1. 低レイテンシーアプリケーションのハイパースレッディングの無効化
低レイテンシー処理用にクラスターを設定する場合、クラスターをデプロイする前にハイパースレッディングを無効にするかどうかを考慮してください。ハイパースレッディングを無効にするには、以下を実行します。
- ハードウェアとトポロジーに適したパフォーマンスプロファイルを作成します。
nosmtを追加のカーネル引数として設定します。以下のパフォーマンスプロファイルの例は、この設定について示しています。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - nosmt cpu: isolated: 2-3 reserved: 0-1 hugepages: defaultHugepagesSize: 1G pages: - count: 2 node: 0 size: 1G nodeSelector: node-role.kubernetes.io/performance: '' realTimeKernel: enabled: true注記予約および分離された CPU を設定する場合に、Pod 内の infra コンテナーは予約された CPU を使用し、アプリケーションコンテナーは分離された CPU を使用します。
14.5. パフォーマンスプロファイルによる低レイテンシーを実現するためのノードのチューニング
パフォーマンスプロファイルを使用すると、特定のマシン設定プールに属するノードのレイテンシーの調整を制御できます。設定を指定すると、PerformanceProfile オブジェクトは実際のノードレベルのチューニングを実行する複数のオブジェクトにコンパイルされます。
-
ノードを操作する
MachineConfigファイル。 -
Topology Manager、CPU マネージャー、および OpenShift Container Platform ノードを設定する
KubeletConfigファイル。 - Node Tuning Operator を設定する Tuned プロファイル。
パフォーマンスプロファイルを使用して、カーネルを kernel-rt に更新して Huge Page を割り当て、ハウスキーピングデータの実行やワークロードの実行用に CPU をパーティションに分割するかどうかを指定できます。
PerformanceProfile オブジェクトを手動で作成するか、Performance Profile Creator (PPC) を使用してパフォーマンスプロファイルを生成することができます。PPC の詳細については、以下の関連情報を参照してください。
パフォーマンスプロファイルの例
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: "5-15" 1 reserved: "0-4" 2 hugepages: defaultHugepagesSize: "1G" pages: - size: "1G" count: 16 node: 0 realTimeKernel: enabled: true 3 numa: 4 topologyPolicy: "best-effort" nodeSelector: node-role.kubernetes.io/worker-cnf: "" 5
- 1
- このフィールドでは、特定の CPU を分離し、ワークロード用に、アプリケーションコンテナーで使用します。
- 2
- このフィールドでは、特定の CPU を予約し、ハウスキーピング用に infra コンテナーで使用します。
- 3
- このフィールドでは、ノード上にリアルタイムカーネルをインストールします。有効な値は
trueまたはfalseです。true値を設定すると、ノード上にリアルタイムカーネルがインストールされます。 - 4
- Topology Manager ポリシーを設定するには、このフィールドを使用します。有効な値は
none(デフォルト)、best-effort、restricted、およびsingle-numa-nodeです。詳細は、Topology Manager Policies を参照してください。 - 5
- このフィールドを使用してノードセレクターを指定し、パフォーマンスプロファイルを特定のノードに適用します。
関連情報
- Performance Profile Creator (PPC) を使用してパフォーマンスプロファイルを生成する方法の詳細は、Creating a performance profile を参照してください。
14.5.1. Huge Page の設定
ノードは、OpenShift Container Platform クラスターで使用される Huge Page を事前に割り当てる必要があります。Performance Addon Operator を使用し、特定のノードで Huge Page を割り当てます。
OpenShift Container Platform は、Huge Page を作成し、割り当てる方法を提供します。Performance Addon Operator は、パーマンスプロファイルを使用してこれを実行するための簡単な方法を提供します。
たとえば、パフォーマンスプロファイルの hugepages pages セクションで、size、count、およびオプションで node の複数のブロックを指定できます。
hugepages:
defaultHugepagesSize: "1G"
pages:
- size: "1G"
count: 4
node: 0 1- 1
nodeは、Huge Page が割り当てられる NUMA ノードです。nodeを省略すると、ページはすべての NUMA ノード間で均等に分散されます。
更新が完了したことを示す関連するマシン設定プールのステータスを待機します。
これらは、Huge Page を割り当てるのに必要な唯一の設定手順です。
検証
設定を確認するには、ノード上の
/proc/meminfoファイルを参照します。$ oc debug node/ip-10-0-141-105.ec2.internal
# grep -i huge /proc/meminfo
出力例
AnonHugePages: ###### ## ShmemHugePages: 0 kB HugePages_Total: 2 HugePages_Free: 2 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: #### ## Hugetlb: #### ##
新規サイズを報告するには、
oc describeを使用します。$ oc describe node worker-0.ocp4poc.example.com | grep -i huge
出力例
hugepages-1g=true hugepages-###: ### hugepages-###: ###
14.5.2. 複数の Huge Page サイズの割り当て
同じコンテナーで異なるサイズの Huge Page を要求できます。これにより、Huge Page サイズのニーズの異なる複数のコンテナーで設定されるより複雑な Pod を定義できます。
たとえば、サイズ 1G と 2M を定義でき、Performance Addon Operator は以下に示すようにノード上に両方のサイズを設定できます。
spec:
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 1024
node: 0
size: 2M
- count: 4
node: 1
size: 1G14.5.3. infra およびアプリケーションコンテナーの CPU の制限
一般的なハウスキーピングおよびワークロードタスクは、レイテンシーの影響を受けやすいプロセスに影響を与える可能性のある方法で CPU を使用します。デフォルトでは、コンテナーランタイムはすべてのオンライン CPU を使用して、すべてのコンテナーを一緒に実行します。これが原因で、コンテキストスイッチおよびレイテンシーが急増する可能性があります。CPU をパーティション化することで、ノイズの多いプロセスとレイテンシーの影響を受けやすいプロセスを分離し、干渉を防ぐことができます。以下の表は、Performance Add-On Operator を使用してノードを調整した後、CPU でプロセスがどのように実行されるかを示しています。
| プロセスタイプ | Details |
|---|---|
|
| 低レイテンシーのワークロードが実行されている場合を除き、任意の CPU で実行されます。 |
| インフラストラクチャー Pod | 低レイテンシーのワークロードが実行されている場合を除き、任意の CPU で実行されます。 |
| 割り込み | 予約済み CPU にリダイレクトします (OpenShift Container Platform 4.7 以降ではオプション) |
| カーネルプロセス | 予約済み CPU へのピン |
| レイテンシーの影響を受けやすいワークロード Pod | 分離されたプールからの排他的 CPU の特定のセットへのピン |
| OS プロセス/systemd サービス | 予約済み CPU へのピン |
すべての QoS プロセスタイプ (Burstable、BestEffort、または Guaranteed) の Pod に割り当て可能なノード上のコアの容量は、分離されたプールの容量と同じです。予約済みプールの容量は、クラスターおよびオペレーティングシステムのハウスキーピング業務で使用するためにノードの合計コア容量から削除されます。
例 1
ノードは 100 コアの容量を備えています。クラスター管理者は、パフォーマンスプロファイルを使用して、50 コアを分離プールに割り当て、50 コアを予約プールに割り当てます。クラスター管理者は、25 コアを QoS Guaranteed Pod に割り当て、25 コアを BestEffort または Burstable Pod に割り当てます。これは、分離されたプールの容量と一致します。
例 2
ノードは 100 コアの容量を備えています。クラスター管理者は、パフォーマンスプロファイルを使用して、50 コアを分離プールに割り当て、50 コアを予約プールに割り当てます。クラスター管理者は、50 個のコアを QoS Guaranteed Pod に割り当て、1 個のコアを BestEffort または Burstable Pod に割り当てます。これは、分離されたプールの容量を 1 コア超えています。CPU 容量が不十分なため、Pod のスケジューリングが失敗します。
使用する正確なパーティショニングパターンは、ハードウェア、ワークロードの特性、予想されるシステム負荷などの多くの要因によって異なります。いくつかのサンプルユースケースは次のとおりです。
- レイテンシーの影響を受けやすいワークロードがネットワークインターフェイスコントローラー (NIC) などの特定のハードウェアを使用する場合は、分離されたプール内の CPU が、このハードウェアにできるだけ近いことを確認してください。少なくとも、ワークロードを同じ Non-Uniform Memory Access (NUMA) ノードに配置する必要があります。
- 予約済みプールは、すべての割り込みを処理するために使用されます。システムネットワークに依存する場合は、すべての着信パケット割り込みを処理するために、十分なサイズの予約プールを割り当てます。4.9 以降のバージョンでは、ワークロードはオプションで機密としてラベル付けできます。
予約済みパーティションと分離パーティションにどの特定の CPU を使用するかを決定するには、詳細な分析と測定が必要です。デバイスやメモリーの NUMA アフィニティーなどの要因が作用しています。選択は、ワークロードアーキテクチャーと特定のユースケースにも依存します。
予約済みの CPU プールと分離された CPU プールは重複してはならず、これらは共に、ワーカーノードの利用可能なすべてのコアに広がる必要があります。
ハウスキーピングタスクとワークロードが相互に干渉しないようにするには、パフォーマンスプロファイルの spec セクションで CPU の 2 つのグループを指定します。
-
isolated- アプリケーションコンテナーワークロードの CPU を指定します。これらの CPU のレイテンシーが一番低くなります。このグループのプロセスには割り込みがないため、DPDK ゼロパケットロスの帯域幅がより高くなります。 -
reserved- クラスターおよびオペレーティングシステムのハウスキーピング業務用の CPU を指定します。reservedグループのスレッドは、ビジーであることが多いです。reservedグループでレイテンシーの影響を受けやすいアプリケーションを実行しないでください。レイテンシーの影響を受けやすいアプリケーションは、isolatedグループで実行されます。
手順
- 環境のハードウェアとトポロジーに適したパフォーマンスプロファイルを作成します。
infra およびアプリケーションコンテナー用に予約して分離する CPU で、
reservedおよびisolatedパラメーターを追加します。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: infra-cpus spec: cpu: reserved: "0-4,9" 1 isolated: "5-8" 2 nodeSelector: 3 node-role.kubernetes.io/worker: ""
14.6. Performance Addon Operator を使用した NIC キューの削減
Performance Addon Operator を使用すると、パフォーマンスプロファイルを設定して、各ネットワークデバイスの Network Interface Card (NIC) キュー数を調整できます。デバイスネットワークキューを使用すると、パケットを複数の異なる物理キューに分散でき、各キューはパケット処理用に個別のスレッドを取得します。
リアルタイムまたは低レイテンシーシステムでは、分離 CPU にピニングされる不要な割り込み要求の行 (IRQ) をすべて予約またはハウスキーピング CPU に移動する必要があります。
OpenShift Container Platform ネットワークなど、システムが必要なアプリケーションのデプロイメントにおいて、または Data Plane Development Kit (DPDK) ワークロードを使用する混在型のデプロイメントにおいて、適切なスループットを実現するには複数のキューが必要であり、NIC キュー数は調整するか、変更しないようにする必要があります。たとえば、レイテンシーを低くするには、DPDK ベースのワークロードの NIC キューの数を、予約またはハウスキーピング CPU の数だけに減らす必要があります。
デフォルトでは CPU ごとに過剰なキューが作成されるので、チューニングしてレイテンシーを低くすると CPU のハウスキーピング向けの中断テーブルに収まりません。キューの数を減らすことで、適切なチューニングが可能になります。キューの数が少ないと、IRQ テーブルに適合する割り込みの数が少なくなります。
14.6.1. パフォーマンスプロファイルによる NIC キューの調整
パフォーマンスプロファイルを使用すると、各ネットワークデバイスのキュー数を調整できます。
サポート対象のネットワークデバイスは以下のとおりです。
- 非仮想ネットワークデバイス
- 複数のキュー (チャネル) をサポートするネットワークデバイス
サポート対象外のネットワークデバイスは以下の通りです。
- Pure Software ネットワークインターフェイス
- ブロックデバイス
- Intel DPDK Virtual Function
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) をインストールしている。
手順
-
cluster-admin権限を持つユーザーとして、Performance Addon Operator を実行する OpenShift Container Platform クラスターにログインします。 - お使いのハードウェアとトポロジーに適したパフォーマンスプロファイルを作成して適用します。プロファイルの作成に関するガイダンスは、パフォーマンスプロファイルの作成のセクションを参照してください。
この作成したパフォーマンスプロファイルを編集します。
$ oc edit -f <your_profile_name>.yaml
specフィールドにnetオブジェクトを設定します。オブジェクトリストには、以下の 2 つのフィールドを含めることができます。-
userLevelNetworkingは、ブール値フラグとして指定される必須フィールドです。userLevelNetworkingがtrueの場合、サポートされているすべてのデバイスのキュー数は、予約された CPU 数に設定されます。デフォルトはfalseです。 devicesは、キューを予約 CPU 数に設定するデバイスの一覧を指定する任意のフィールドです。デバイス一覧に何も指定しないと、設定がすべてのネットワークデバイスに適用されます。設定は以下のとおりです。InterfaceName: このフィールドはインターフェイス名を指定し、正または負のシェルスタイルのワイルドカードをサポートします。-
ワイルドカード構文の例:
<string> .* -
負のルールには、感嘆符のプリフィックスが付きます。除外リスト以外のすべてのデバイスにネットキューの変更を適用するには、
!<device>を使用します (例:!eno1)。
-
ワイルドカード構文の例:
-
vendorID: 16 ビット (16 進数) として表されるネットワークデバイスベンダー ID。接頭辞は0xです。 9
deviceID: 16 ビット (16 進数) として表されるネットワークデバイス ID (モデル)。接頭辞は0xです。注記deviceIDが指定されている場合は、vendorIDも定義する必要があります。デバイスエントリーinterfaceName、vendorID、またはvendorIDとdeviceIDのペアで指定されているすべてのデバイス識別子に一致するデバイスは、ネットワークデバイスとしての資格があります。その後、このネットワークデバイスは net キュー数が予約 CPU 数に設定されます。2 つ以上のデバイスを指定すると、net キュー数は、それらのいずれかに一致する net デバイスに設定されます。
-
このパフォーマンスプロファイルの例を使用して、キュー数をすべてのデバイスの予約 CPU 数に設定します。
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-cnf: ""このパフォーマンスプロファイルの例を使用して、定義されたデバイス識別子に一致するすべてのデバイスの予約 CPU 数にキュー数を設定します。
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - interfaceName: “eth1” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""このパフォーマンスプロファイルの例を使用して、インターフェイス名
ethで始まるすべてのデバイスの予約 CPU 数にキュー数を設定します。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth*” nodeSelector: node-role.kubernetes.io/worker-cnf: ""このパフォーマンスプロファイルの例を使用して、
eno1以外の名前のインターフェイスを持つすべてのデバイスの予約 CPU 数にキュー数を設定します。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “!eno1” nodeSelector: node-role.kubernetes.io/worker-cnf: ""このパフォーマンスプロファイルの例を使用して、インターフェイス名
eth0、0x1af4のvendorID、および0x1000のdeviceIDを持つすべてのデバイスの予約 CPU 数にキュー数を設定します。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""更新されたパフォーマンスプロファイルを適用します。
$ oc apply -f <your_profile_name>.yaml
関連情報
14.6.2. キューステータスの確認
このセクションでは、さまざまなパフォーマンスプロファイルについて、変更の適用を検証する方法を複数例示しています。
例 1
この例では、サポートされている すべて のデバイスの net キュー数は、予約された CPU 数 (2) に設定されます。
パフォーマンスプロファイルの関連セクションは次のとおりです。
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
# ...以下のコマンドを使用して、デバイスに関連付けられたキューのステータスを表示します。
注記パフォーマンスプロファイルが適用されたノードで、以下のコマンドを実行します。
$ ethtool -l <device>
プロファイルの適用前にキューのステータスを確認します。
$ ethtool -l ens4
出力例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4
プロファイルの適用後にキューのステータスを確認します。
$ ethtool -l ens4
出力例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
- チャネルを組み合わせると、すべての サポート対象のデバイスの予約 CPU の合計数は 2 になります。これは、パフォーマンスプロファイルでの設定内容と一致します。
例 2
この例では、サポートされている すべて のネットワークデバイスの net キュー数は、予約された CPU 数 (2) に特定の vendorID を指定して、設定されます。
パフォーマンスプロファイルの関連セクションは次のとおりです。
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
devices:
- vendorID = 0x1af4
# ...以下のコマンドを使用して、デバイスに関連付けられたキューのステータスを表示します。
注記パフォーマンスプロファイルが適用されたノードで、以下のコマンドを実行します。
$ ethtool -l <device>
プロファイルの適用後にキューのステータスを確認します。
$ ethtool -l ens4
出力例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
vendorID=0x1af4であるサポート対象の全デバイスの合計予約 CPU 数は 2 となります。たとえば、vendorID=0x1af4のネットワークデバイスens2が別に存在する場合に、このデバイスも合計で 2 つの net キューを持ちます。これは、パフォーマンスプロファイルでの設定内容と一致します。
例 3
この例では、サポートされている すべて のネットワークデバイスが定義したデバイス ID のいずれかに一致する場合に、そのネットワークデバイスの net キュー数は、予約された CPU 数 (2) に設定されます。
udevadm info コマンドで、デバイスの詳細なレポートを確認できます。以下の例では、デバイスは以下のようになります。
# udevadm info -p /sys/class/net/ens4 ... E: ID_MODEL_ID=0x1000 E: ID_VENDOR_ID=0x1af4 E: INTERFACE=ens4 ...
# udevadm info -p /sys/class/net/eth0 ... E: ID_MODEL_ID=0x1002 E: ID_VENDOR_ID=0x1001 E: INTERFACE=eth0 ...
interfaceNameがeth0のデバイスの場合に net キューを 2 に、vendorID=0x1af4を持つデバイスには、以下のパフォーマンスプロファイルを設定します。apiVersion: performance.openshift.io/v2 metadata: name: performance spec: kind: PerformanceProfile spec: cpu: reserved: 0-1 #total = 2 isolated: 2-8 net: userLevelNetworking: true devices: - interfaceName = eth0 - vendorID = 0x1af4 ...プロファイルの適用後にキューのステータスを確認します。
$ ethtool -l ens4
出力例
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1- 1
vendorID=0x1af4であるサポート対象の全デバイスの合計予約 CPU 数は 2 に設定されます。たとえば、vendorID=0x1af4のネットワークデバイスens2が別に存在する場合に、このデバイスも合計で 2 つの net キューを持ちます。同様に、interfaceNameがeth0のデバイスには、合計 net キューが 2 に設定されます。
14.6.3. NIC キューの調整に関するロギング
割り当てられたデバイスの詳細を示すログメッセージは、それぞれの Tuned デーモンログに記録されます。以下のメッセージは、/var/log/tuned/tuned.log ファイルに記録される場合があります。
正常に割り当てられたデバイスの詳細を示す
INFOメッセージが記録されます。INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3
割り当てることのできるデバイスがない場合は、
WARNINGメッセージが記録されます。WARNING tuned.plugins.base: instance net_test: no matching devices available
14.7. 低レイテンシー CNF チューニングステータスのデバッグ
PerformanceProfile カスタムリソース (CR) には、チューニングのステータスを報告し、レイテンシーのパフォーマンスの低下の問題をデバッグするためのステータスフィールドが含まれます。これらのフィールドは、Operator の調整機能の状態を記述する状態について報告します。
パフォーマンスプロファイルに割り当てられるマシン設定プールのステータスが degraded 状態になると典型的な問題が発生する可能性があり、これにより PerformanceProfile のステータスが低下します。この場合、マシン設定プールは失敗メッセージを発行します。
Performance Addon Operator には performanceProfile.spec.status.Conditions ステータスフィールドが含まれます。
Status:
Conditions:
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Available
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Upgradeable
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Progressing
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Degraded
Status フィールドには、 パフォーマンスプロファイルのステータスを示す Type 値を指定する Conditions が含まれます。
Available- すべてのマシン設定および Tuned プロファイルが正常に作成され、クラスターコンポーネントで利用可能になり、それら (NTO、MCO、Kubelet) を処理します。
Upgradeable- Operator によって維持されるリソースは、アップグレードを実行する際に安全な状態にあるかどうかを示します。
Progressing- パフォーマンスプロファイルからのデプロイメントプロセスが開始されたことを示します。
Degraded以下の場合にエラーを示します。
- パーマンスプロファイルの検証に失敗しました。
- すべての関連するコンポーネントの作成が完了しませんでした。
これらのタイプには、それぞれ以下のフィールドが含まれます。
Status-
特定のタイプの状態 (
trueまたはfalse)。 Timestamp- トランザクションのタイムスタンプ。
Reason string- マシンの読み取り可能な理由。
Message string- 状態とエラーの詳細を説明する人が判読できる理由 (ある場合)。
14.7.1. マシン設定プール
パフォーマンスプロファイルとその作成される製品は、関連付けられたマシン設定プール (MCP) に従ってノードに適用されます。MCP は、カーネル引数、kube 設定、Huge Page の割り当て、および rt-kernel のデプロイメントを含むパフォーマンスアドオンが作成するマシン設定の適用についての進捗に関する貴重な情報を保持します。パフォーマンスアドオンコントローラーは MCP の変更を監視し、それに応じてパフォーマンスプロファイルのステータスを更新します。
MCP がパフォーマンスプロファイルのステータスに返す状態は、MCP が Degraded の場合のみとなり、この場合、performaceProfile.status.condition.Degraded = true になります。
例
以下の例は、これに作成された関連付けられたマシン設定プール (worker-cnf) を持つパフォーマンスプロファイルのサンプルです。
関連付けられたマシン設定プールの状態は degraded (低下) になります。
# oc get mcp
出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20h
MCP の
describeセクションには理由が示されます。# oc describe mcp worker-cnf
出力例
Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncdegraded (低下) の状態は、
degraded = trueとマークされたパフォーマンスプロファイルのstatusフィールドにも表示されるはずです。# oc describe performanceprofiles performance
出力例
Message: Machine config pool worker-cnf Degraded Reason: 1 nodes are reporting degraded status on sync. Machine config pool worker-cnf Degraded Message: Node yquinn-q8s5v-w-b-z5lqn.c.openshift-gce-devel.internal is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found". Reason: MCPDegraded Status: True Type: Degraded
14.8. Red Hat サポート向けの低レイテンシーのチューニングデバッグデータの収集
サポートケースを作成する際、ご使用のクラスターについてのデバッグ情報を Red Hat サポートに提供していただくと Red Hat のサポートに役立ちます。
must-gather ツールを使用すると、ノードのチューニング、NUMA トポロジー、および低レイテンシーの設定に関する問題のデバッグに必要な OpenShift Container Platform クラスターについての診断情報を収集できます。
迅速なサポートを得るには、OpenShift Container Platform と低レイテンシーチューニングの両方の診断情報を提供してください。
14.8.1. must-gather ツールについて
oc adm must-gather CLI コマンドは、以下のような問題のデバッグに必要となる可能性のあるクラスターからの情報を収集します。
- リソース定義
- 監査ログ
- サービスログ
--image 引数を指定してコマンドを実行する際にイメージを指定できます。イメージを指定する際、ツールはその機能または製品に関連するデータを収集します。oc adm must-gather を実行すると、新しい Pod がクラスターに作成されます。データは Pod で収集され、must-gather.local で始まる新規ディレクトリーに保存されます。このディレクトリーは、現行の作業ディレクトリーに作成されます。
14.8.2. 低レイテンシーチューニングデータの収集について
oc adm must-gather CLI コマンドを使用してクラスターについての情報を収集できます。これには、以下を始めとする低レイテンシーチューニングに関連する機能およびオブジェクトが含まれます。
- Performance Addon Operator namespace および子オブジェクト
-
MachineConfigPoolおよび関連付けられたMachineConfigオブジェクト - Node Tuning Operator および関連付けられた Tuned オブジェクト
- Linux カーネルコマンドラインオプション
- CPU および NUMA トポロジー
- 基本的な PCI デバイス情報と NUMA 局所性
must-gatherを使用して Performance Addon Operator のデバッグ情報を収集するには、Performance Addon Operator のmust-gatherイメージを指定する必要があります。
--image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.9.
14.8.3. 特定の機能に関するデータ収集
oc adm must-gather CLI コマンドを --image または --image-stream 引数と共に使用して、特定に機能についてのデバッグ情報を収集できます。must-gather ツールは複数のイメージをサポートするため、単一のコマンドを実行して複数の機能についてのデータを収集できます。
特定の機能データに加えてデフォルトの must-gather データを収集するには、--image-stream=openshift/must-gather 引数を追加します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - OpenShift Container Platform CLI (oc) がインストールされている。
手順
-
must-gatherデータを保存するディレクトリーに移動します。 oc adm must-gatherコマンドを 1 つまたは複数の--imageまたは--image-stream引数と共に実行します。たとえば、以下のコマンドは、デフォルトのクラスターデータと Performance Addon Operator に固有の情報の両方を収集します。$ oc adm must-gather \ --image-stream=openshift/must-gather \ 1 --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.9 2
作業ディレクトリーに作成された
must-gatherディレクトリーから圧縮ファイルを作成します。たとえば、Linux オペレーティングシステムを使用するコンピューターで以下のコマンドを実行します。$ tar cvaf must-gather.tar.gz must-gather.local.5421342344627712289/ 1- 1
must-gather-local.5421342344627712289/を実際のディレクトリー名に置き換えます。
- 圧縮ファイルを Red Hat カスタマーポータル で作成したサポートケースに添付します。
関連情報
- MachineConfig および KubeletConfig についての詳細は、ノードの管理 を参照してください。
- Node Tuning Operator についての詳細は、Node Tuning Operator の使用 を参照してください。
- PerformanceProfile についての詳細は、Huge Page の設定 を参照してください。
- コンテナーからの Huge Page の消費に関する詳細は、Huge Page がアプリケーションによって消費される仕組み を参照してください。
第15章 プラットフォーム検証のためのレイテンシーテストの実行
Cloud-native Network Functions (CNF) テストイメージを使用して、CNF ワークロードの実行に必要なすべてのコンポーネントがインストールされている CNF 対応の OpenShift Container Platform クラスターでレイテンシーテストを実行できます。レイテンシーテストを実行して、ワークロードのノードチューニングを検証します。
cnf-tests コンテナーイメージは、registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 で入手できます。
cnf-tests イメージには、現時点で Red Hat がサポートしていないいくつかのテストも含まれています。Red Hat がサポートしているのはレイテンシーテストのみです。
15.1. レイテンシーテストを実行するための前提条件
レイテンシーテストを実行するには、クラスターが次の要件を満たしている必要があります。
- Performance Addon Operator を使用してパフォーマンスプロファイルを設定しました。
- 必要なすべての CNF 設定をクラスターに適用しました。
-
クラスターに既存の
MachineConfigPoolCR が適用されている。デフォルトのワーカープールはworker-cnfです。
関連情報
- クラスターパフォーマンスプロファイルの作成の詳細は、リアルタイムおよび低待機時間のワークロードのプロビジョニング を参照してください。
15.2. レイテンシーテストの検出モードについて
検出モードでは、設定を変更せずにクラスターの機能を検証できます。既存の環境設定はテストに使用されます。テストは、必要な設定アイテムを見つけ、それらのアイテムを使用してテストを実行できます。特定のテストの実行に必要なリソースが見つからない場合、テストは省略され、ユーザーに適切なメッセージが表示されます。テストが完了すると、事前に設定された設定項目のクリーンアップは行われず、テスト環境は別のテストの実行にすぐに使用できます。
レイテンシーテストを実行するときは、必ず -e DISCOVERY_MODE=true および -ginkgo.focus を適切なレイテンシーテストに設定してテストを実行してください。遅延テストを検出モードで実行しない場合、既存のライブクラスターパフォーマンスプロファイル設定は、テストの実行によって変更されます。
テスト中に使用されるノードの制限
-e NODES_SELECTOR=node-role.kubernetes.io/worker-cnf などの NODES_SELECTOR 環境変数を指定することで、テストが実行されるノードを制限できます。テストによって作成されるリソースは、ラベルが一致するノードに限定されます。
デフォルトのワーカープールをオーバーライドする場合は、適切なラベルを指定するコマンドに -e ROLE_WORKER_CNF=<custom_worker_pool> 変数を渡します。
15.3. レイテンシーの測定
cnf-tests イメージは、3 つのツールを使用してシステムのレイテンシーを測定します。
-
hwlatdetect -
cyclictest -
oslat
各ツールには特定の用途があります。信頼できるテスト結果を得るために、ツールを順番に使用します。
- hwlatdetect
-
ベアメタルハードウェアが達成できるベースラインを測定します。次のレイテンシーテストに進む前に、
hwlatdetectによって報告されるレイテンシーが必要なしきい値を満たしていることを確認してください。これは、オペレーティングシステムのチューニングによってハードウェアレイテンシーのスパイクを修正することはできないためです。 - cyclictest
-
hwlatdetectが検証に合格した後、リアルタイムのカーネルスケジューラーのレイテンシーを検証します。cyclictestツールは繰り返しタイマーをスケジュールし、希望のトリガー時間と実際のトリガーの時間の違いを測定します。この違いは、割り込みまたはプロセスの優先度によって生じるチューニングで、基本的な問題を発見できます。ツールはリアルタイムカーネルで実行する必要があります。 - oslat
- CPU 集約型 DPDK アプリケーションと同様に動作し、CPU の高いデータ処理をシミュレーションするビジーループにすべての中断と中断を測定します。
テストでは、次の環境変数が導入されます。
| 環境変数 | 説明 |
|---|---|
|
| テストの実行を開始するまでの時間を秒単位で指定します。この変数を使用すると、CPU マネージャーの調整ループでデフォルトの CPU プールを更新できるようになります。デフォルト値は 0 です。 |
|
| レイテンシーテストを実行する Pod が使用する CPU の数を指定します。変数を設定しない場合、デフォルト設定にはすべての分離された CPU が含まれます。 |
|
| レイテンシーテストを実行する必要がある時間を秒単位で指定します。デフォルト値は 300 秒です。 |
|
|
ワークロードとオペレーティングシステムの最大許容ハードウェアレイテンシーをマイクロ秒単位で指定します。 |
|
|
|
|
|
|
|
| 最大許容レイテンシーをマイクロ秒単位で指定する統合変数。利用可能なすべてのレイテンシーツールに適用できます。 |
|
|
テストを実行するかどうかを示すブールパラメーター。 |
レイテンシーツールに固有の変数は、統合された変数よりも優先されます。たとえば、OSLAT_MAXIMUM_LATENCY が 30 マイクロ秒に設定され、MAXIMUM_LATENCY が 10 マイクロ秒に設定されている場合、oslat テストは 30 マイクロ秒の最大許容遅延で実行されます。
15.4. レイテンシーテストの実行
クラスターレイテンシーテストを実行して、クラウドネイティブネットワーク機能 (CNF) ワークロードのノードチューニングを検証します。
遅延テストは 常に DISCOVERY_MODE=true を設定して実行してください。そうしないと、テストスイートは実行中のクラスター設定に変更を加えます。
非 root または非特権ユーザーとして podman コマンドを実行すると、パスのマウントが permission denied エラーで失敗する場合があります。podman コマンドを機能させるには、作成したボリュームに :Z を追加します。たとえば、-v $(pwd)/:/kubeconfig:Z です。これにより、podman は適切な SELinux の再ラベル付けを行うことができます。
手順
kubeconfigファイルを含むディレクトリーでシェルプロンプトを開きます。現在のディレクトリーにある
kubeconfigファイルとそれに関連する$KUBECONFIG環境変数を含むテストイメージを提供し、ボリュームを介してマウントします。これにより、実行中のコンテナーがコンテナー内からkubeconfigファイルを使用できるようになります。次のコマンドを入力して、レイテンシーテストを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
-
オプション:
-ginkgo.dryRunを追加して、ドライランモードでレイテンシーテストを実行します。これは、テストの実行内容を確認するのに役立ちます。 -
オプション:
-ginkgo.vを追加して、詳細度を上げてテストを実行します。 オプション: 特定のパフォーマンスプロファイルに対してレイテンシーテストを実行するには、次のコマンドを実行し、適切な値を置き換えます。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ -e PERF_TEST_PROFILE=<performance_profile> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.focus="[performance]\ Latency\ Test"
ここでは、以下のようになります。
- <performance_profile>
- レイテンシーテストを実行するパフォーマンスプロファイルの名前です。
重要有効なレイテンシーテストの結果を得るには、テストを少なくとも 12 時間実行します。
15.4.1. hwlatdetect の実行
hwlatdetect ツールは、Red Hat Enterprise Linux (RHEL) 8.x の通常のサブスクリプションを含む rt-kernel パッケージで利用できます。
遅延テストは 常に DISCOVERY_MODE=true を設定して実行してください。そうしないと、テストスイートは実行中のクラスター設定に変更を加えます。
非 root または非特権ユーザーとして podman コマンドを実行すると、パスのマウントが permission denied エラーで失敗する場合があります。podman コマンドを機能させるには、作成したボリュームに :Z を追加します。たとえば、-v $(pwd)/:/kubeconfig:Z です。これにより、podman は適切な SELinux の再ラベル付けを行うことができます。
前提条件
- クラスターにリアルタイムカーネルをインストールしました。
-
カスタマーポータルの認証情報を使用して、
registry.redhat.ioにログインしました。
手順
hwlatdetectテストを実行するには、変数値を適切に置き換えて、次のコマンドを実行します。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="hwlatdetect"
hwlatdetectテストは 10 分間 (600 秒) 実行されます。観測された最大レイテンシーがMAXIMUM_LATENCY(20 μs) よりも低い場合、テストは正常に実行されます。結果がレイテンシーのしきい値を超えると、テストは失敗します。
重要有効な結果を得るには、テストを少なくとも 12 時間実行する必要があります。
障害出力の例
running /usr/bin/validationsuite -ginkgo.v -ginkgo.focus=hwlatdetect I0210 17:08:38.607699 7 request.go:668] Waited for 1.047200253s due to client-side throttling, not priority and fairness, request: GET:https://api.ocp.demo.lab:6443/apis/apps.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e validation ========================================== Random Seed: 1644512917 Will run 0 of 48 specs SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS Ran 0 of 48 Specs in 0.001 seconds SUCCESS! -- 0 Passed | 0 Failed | 0 Pending | 48 Skipped PASS Discovery mode enabled, skipping setup running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=hwlatdetect I0210 17:08:41.179269 40 request.go:668] Waited for 1.046001096s due to client-side throttling, not priority and fairness, request: GET:https://api.ocp.demo.lab:6443/apis/storage.k8s.io/v1beta1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1644512920 Will run 1 of 151 specs SSSSSSS ------------------------------ [performance] Latency Test with the hwlatdetect image should succeed /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:221 STEP: Waiting two minutes to download the latencyTest image STEP: Waiting another two minutes to give enough time for the cluster to move the pod to Succeeded phase Feb 10 17:10:56.045: [INFO]: found mcd machine-config-daemon-dzpw7 for node ocp-worker-0.demo.lab Feb 10 17:10:56.259: [INFO]: found mcd machine-config-daemon-dzpw7 for node ocp-worker-0.demo.lab Feb 10 17:11:56.825: [ERROR]: timed out waiting for the condition • Failure [193.903 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:60 with the hwlatdetect image /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:213 should succeed [It] /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:221 Log file created at: 2022/02/10 17:08:45 Running on machine: hwlatdetect-cd8b6 Binary: Built with gc go1.16.6 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0210 17:08:45.716288 1 node.go:37] Environment information: /proc/cmdline: BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-56fabc639a679b757ebae30e5f01b2ebd38e9fde9ecae91c41be41d3e89b37f8/vmlinuz-4.18.0-305.34.2.rt7.107.el8_4.x86_64 random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ignition.platform.id=qemu ostree=/ostree/boot.0/rhcos/56fabc639a679b757ebae30e5f01b2ebd38e9fde9ecae91c41be41d3e89b37f8/0 root=UUID=56731f4f-f558-46a3-85d3-d1b579683385 rw rootflags=prjquota skew_tick=1 nohz=on rcu_nocbs=3-5 tuned.non_isolcpus=ffffffc7 intel_pstate=disable nosoftlockup tsc=nowatchdog intel_iommu=on iommu=pt isolcpus=managed_irq,3-5 systemd.cpu_affinity=0,1,2,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31 + + I0210 17:08:45.716782 1 node.go:44] Environment information: kernel version 4.18.0-305.34.2.rt7.107.el8_4.x86_64 I0210 17:08:45.716861 1 main.go:50] running the hwlatdetect command with arguments [/usr/bin/hwlatdetect --threshold 1 --hardlimit 1 --duration 10 --window 10000000us --width 950000us] F0210 17:08:56.815204 1 main.go:53] failed to run hwlatdetect command; out: hwlatdetect: test duration 10 seconds detector: tracer parameters: Latency threshold: 1us 1 Sample window: 10000000us Sample width: 950000us Non-sampling period: 9050000us Output File: None Starting test test finished Max Latency: 24us 2 Samples recorded: 1 Samples exceeding threshold: 1 ts: 1644512927.163556381, inner:20, outer:24 ; err: exit status 1 goroutine 1 [running]: k8s.io/klog.stacks(0xc000010001, 0xc00012e000, 0x25b, 0x2710) /remote-source/app/vendor/k8s.io/klog/klog.go:875 +0xb9 k8s.io/klog.(*loggingT).output(0x5bed00, 0xc000000003, 0xc0000121c0, 0x53ea81, 0x7, 0x35, 0x0) /remote-source/app/vendor/k8s.io/klog/klog.go:829 +0x1b0 k8s.io/klog.(*loggingT).printf(0x5bed00, 0x3, 0x5082da, 0x33, 0xc000113f58, 0x2, 0x2) /remote-source/app/vendor/k8s.io/klog/klog.go:707 +0x153 k8s.io/klog.Fatalf(...) /remote-source/app/vendor/k8s.io/klog/klog.go:1276 main.main() /remote-source/app/cnf-tests/pod-utils/hwlatdetect-runner/main.go:53 +0x897 goroutine 6 [chan receive]: k8s.io/klog.(*loggingT).flushDaemon(0x5bed00) /remote-source/app/vendor/k8s.io/klog/klog.go:1010 +0x8b created by k8s.io/klog.init.0 /remote-source/app/vendor/k8s.io/klog/klog.go:411 +0xd8 goroutine 7 [chan receive]: k8s.io/klog/v2.(*loggingT).flushDaemon(0x5bede0) /remote-source/app/vendor/k8s.io/klog/v2/klog.go:1169 +0x8b created by k8s.io/klog/v2.init.0 /remote-source/app/vendor/k8s.io/klog/v2/klog.go:420 +0xdf Unexpected error: <*errors.errorString | 0xc000418ed0>: { s: "timed out waiting for the condition", } timed out waiting for the condition occurred /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:433 ------------------------------ SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS JUnit report was created: /junit.xml/cnftests-junit.xml Summarizing 1 Failure: [Fail] [performance] Latency Test with the hwlatdetect image [It] should succeed /remote-source/app/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:433 Ran 1 of 151 Specs in 222.254 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 150 Skipped --- FAIL: TestTest (222.45s) FAIL
hwlatdetect テスト結果の例
以下のタイプの結果をキャプチャーできます。
- テスト中に行われた変更への影響の履歴を作成するために、各実行後に収集される大まかな結果
- 最良の結果と設定設定を備えたラフテストの組み合わせセット
良い結果の例
hwlatdetect: test duration 3600 seconds detector: tracer parameters: Latency threshold: 10us Sample window: 1000000us Sample width: 950000us Non-sampling period: 50000us Output File: None Starting test test finished Max Latency: Below threshold Samples recorded: 0
hwlatdetect ツールは、サンプルが指定されたしきい値を超えた場合にのみ出力を提供します。
悪い結果の例
hwlatdetect: test duration 3600 seconds detector: tracer parameters:Latency threshold: 10usSample window: 1000000us Sample width: 950000usNon-sampling period: 50000usOutput File: None Starting tests:1610542421.275784439, inner:78, outer:81 ts: 1610542444.330561619, inner:27, outer:28 ts: 1610542445.332549975, inner:39, outer:38 ts: 1610542541.568546097, inner:47, outer:32 ts: 1610542590.681548531, inner:13, outer:17 ts: 1610543033.818801482, inner:29, outer:30 ts: 1610543080.938801990, inner:90, outer:76 ts: 1610543129.065549639, inner:28, outer:39 ts: 1610543474.859552115, inner:28, outer:35 ts: 1610543523.973856571, inner:52, outer:49 ts: 1610543572.089799738, inner:27, outer:30 ts: 1610543573.091550771, inner:34, outer:28 ts: 1610543574.093555202, inner:116, outer:63
hwlatdetect の出力は、複数のサンプルがしきい値を超えていることを示しています。ただし、同じ出力は、次の要因に基づいて異なる結果を示す可能性があります。
- テストの期間
- CPU コアの数
- ホストファームウェアの設定
次のレイテンシーテストに進む前に、hwlatdetect によって報告されたレイテンシーが必要なしきい値を満たしていることを確認してください。ハードウェアによって生じるレイテンシーを修正するには、システムベンダーのサポートに連絡しないといけない場合があります。
すべての遅延スパイクがハードウェアに関連しているわけではありません。ワークロードの要件を満たすようにホストファームウェアを調整してください。詳細は、システムチューニング用のファームウェアパラメーターの設定 を参照してください。
15.4.2. cyclictest の実行
cyclictest ツールは、指定された CPU でのリアルタイムカーネルスケジューラーのレイテンシーを測定します。
遅延テストは 常に DISCOVERY_MODE=true を設定して実行してください。そうしないと、テストスイートは実行中のクラスター設定に変更を加えます。
非 root または非特権ユーザーとして podman コマンドを実行すると、パスのマウントが permission denied エラーで失敗する場合があります。podman コマンドを機能させるには、作成したボリュームに :Z を追加します。たとえば、-v $(pwd)/:/kubeconfig:Z です。これにより、podman は適切な SELinux の再ラベル付けを行うことができます。
前提条件
-
カスタマーポータルの認証情報を使用して、
registry.redhat.ioにログインしました。 - クラスターにリアルタイムカーネルをインストールしました。
- Performance アドオンオペレーターを使用して、クラスターパフォーマンスプロファイルを適用しました。
手順
cyclictestを実行するには、次のコマンドを実行し、必要に応じて変数の値を置き換えます。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="cyclictest"
このコマンドは、
cyclictestツールを 10 分 (600 秒) 実行します。観測された最大レイテンシーがMAXIMUM_LATENCY(この例では 20 μs) よりも低い場合、テストは正常に実行されます。20 マイクロ秒以上の遅延スパイクは、一般に、通信事業者の RAN ワークロードでは受け入れられません。結果がレイテンシーのしきい値を超えると、テストは失敗します。
重要有効な結果を得るには、テストを少なくとも 12 時間実行する必要があります。
障害出力の例
Discovery mode enabled, skipping setup running /usr/bin//cnftests -ginkgo.v -ginkgo.focus=cyclictest I0811 15:02:36.350033 20 request.go:668] Waited for 1.049965918s due to client-side throttling, not priority and fairness, request: GET:https://api.cnfdc8.t5g.lab.eng.bos.redhat.com:6443/apis/machineconfiguration.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1628694153 Will run 1 of 138 specs SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS ------------------------------ [performance] Latency Test with the cyclictest image should succeed /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:200 STEP: Waiting two minutes to download the latencyTest image STEP: Waiting another two minutes to give enough time for the cluster to move the pod to Succeeded phase Aug 11 15:03:06.826: [INFO]: found mcd machine-config-daemon-wf4w8 for node cnfdc8.clus2.t5g.lab.eng.bos.redhat.com • Failure [22.527 seconds] [performance] Latency Test /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:84 with the cyclictest image /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:188 should succeed [It] /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:200 The current latency 27 is bigger than the expected one 20 Expected <bool>: false to be true /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:219 Log file created at: 2021/08/11 15:02:51 Running on machine: cyclictest-knk7d Binary: Built with gc go1.16.6 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0811 15:02:51.092254 1 node.go:37] Environment information: /proc/cmdline: BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/vmlinuz-4.18.0-305.10.2.rt7.83.el8_4.x86_64 ip=dhcp random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ostree=/ostree/boot.1/rhcos/612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/0 ignition.platform.id=openstack root=UUID=5a4ddf16-9372-44d9-ac4e-3ee329e16ab3 rw rootflags=prjquota skew_tick=1 nohz=on rcu_nocbs=1-3 tuned.non_isolcpus=000000ff,ffffffff,ffffffff,fffffff1 intel_pstate=disable nosoftlockup tsc=nowatchdog intel_iommu=on iommu=pt isolcpus=managed_irq,1-3 systemd.cpu_affinity=0,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103 default_hugepagesz=1G hugepagesz=2M hugepages=128 nmi_watchdog=0 audit=0 mce=off processor.max_cstate=1 idle=poll intel_idle.max_cstate=0 I0811 15:02:51.092427 1 node.go:44] Environment information: kernel version 4.18.0-305.10.2.rt7.83.el8_4.x86_64 I0811 15:02:51.092450 1 main.go:48] running the cyclictest command with arguments \ [-D 600 -95 1 -t 10 -a 2,4,6,8,10,54,56,58,60,62 -h 30 -i 1000 --quiet] I0811 15:03:06.147253 1 main.go:54] succeeded to run the cyclictest command: # /dev/cpu_dma_latency set to 0us # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 005561 027778 037704 011987 000000 120755 238981 081847 300186 000002 587440 581106 564207 554323 577416 590635 474442 357940 513895 296033 000003 011751 011441 006449 006761 008409 007904 002893 002066 003349 003089 000004 000527 001079 000914 000712 001451 001120 000779 000283 000350 000251 More histogram entries ... # Min Latencies: 00002 00001 00001 00001 00001 00002 00001 00001 00001 00001 # Avg Latencies: 00002 00002 00002 00001 00002 00002 00001 00001 00001 00001 # Max Latencies: 00018 00465 00361 00395 00208 00301 02052 00289 00327 00114 # Histogram Overflows: 00000 00220 00159 00128 00202 00017 00069 00059 00045 00120 # Histogram Overflow at cycle number: # Thread 0: # Thread 1: 01142 01439 05305 … # 00190 others # Thread 2: 20895 21351 30624 … # 00129 others # Thread 3: 01143 17921 18334 … # 00098 others # Thread 4: 30499 30622 31566 ... # 00172 others # Thread 5: 145221 170910 171888 ... # Thread 6: 01684 26291 30623 ...# 00039 others # Thread 7: 28983 92112 167011 … 00029 others # Thread 8: 45766 56169 56171 ...# 00015 others # Thread 9: 02974 08094 13214 ... # 00090 others
サイクルテスト結果の例
同じ出力は、ワークロードごとに異なる結果を示す可能性があります。たとえば、18μs までのスパイクは 4G DU ワークロードでは許容されますが、5G DU ワークロードでは許容されません。
良い結果の例
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 579506 535967 418614 573648 532870 529897 489306 558076 582350 585188 583793 223781 532480 569130 472250 576043 More histogram entries ... # Total: 000600000 000600000 000600000 000599999 000599999 000599999 000599998 000599998 000599998 000599997 000599997 000599996 000599996 000599995 000599995 000599995 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00005 00005 00004 00005 00004 00004 00005 00005 00006 00005 00004 00005 00004 00004 00005 00004 # Histogram Overflows: 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 # Histogram Overflow at cycle number: # Thread 0: # Thread 1: # Thread 2: # Thread 3: # Thread 4: # Thread 5: # Thread 6: # Thread 7: # Thread 8: # Thread 9: # Thread 10: # Thread 11: # Thread 12: # Thread 13: # Thread 14: # Thread 15:
悪い結果の例
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 564632 579686 354911 563036 492543 521983 515884 378266 592621 463547 482764 591976 590409 588145 589556 353518 More histogram entries ... # Total: 000599999 000599999 000599999 000599997 000599997 000599998 000599998 000599997 000599997 000599996 000599995 000599996 000599995 000599995 000599995 000599993 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00493 00387 00271 00619 00541 00513 00009 00389 00252 00215 00539 00498 00363 00204 00068 00520 # Histogram Overflows: 00001 00001 00001 00002 00002 00001 00000 00001 00001 00001 00002 00001 00001 00001 00001 00002 # Histogram Overflow at cycle number: # Thread 0: 155922 # Thread 1: 110064 # Thread 2: 110064 # Thread 3: 110063 155921 # Thread 4: 110063 155921 # Thread 5: 155920 # Thread 6: # Thread 7: 110062 # Thread 8: 110062 # Thread 9: 155919 # Thread 10: 110061 155919 # Thread 11: 155918 # Thread 12: 155918 # Thread 13: 110060 # Thread 14: 110060 # Thread 15: 110059 155917
15.4.3. oslat の実行
oslat テストは、CPU を集中的に使用する DPDK アプリケーションをシミュレートし、すべての中断と中断を測定して、クラスターが CPU の負荷の高いデータ処理をどのように処理するかをテストします。
遅延テストは 常に DISCOVERY_MODE=true を設定して実行してください。そうしないと、テストスイートは実行中のクラスター設定に変更を加えます。
非 root または非特権ユーザーとして podman コマンドを実行すると、パスのマウントが permission denied エラーで失敗する場合があります。podman コマンドを機能させるには、作成したボリュームに :Z を追加します。たとえば、-v $(pwd)/:/kubeconfig:Z です。これにより、podman は適切な SELinux の再ラベル付けを行うことができます。
前提条件
-
カスタマーポータルの認証情報を使用して、
registry.redhat.ioにログインしました。 - Performance アドオンオペレーターを使用して、クラスターパフォーマンスプロファイルを適用しました。
手順
oslatテストを実行するには、変数値を適切に置き換えて、次のコマンドを実行します。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_CPUS=7 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="oslat"
LATENCY_TEST_CPUSは、oslatコマンドでテストする CPU のリストを指定します。このコマンドは、
oslatツールを 10 分 (600 秒) 実行します。観測された最大レイテンシーがMAXIMUM_LATENCY(20 μs) よりも低い場合、テストは正常に実行されます。結果がレイテンシーのしきい値を超えると、テストは失敗します。
重要有効な結果を得るには、テストを少なくとも 12 時間実行する必要があります。
障害出力の例
running /usr/bin//validationsuite -ginkgo.v -ginkgo.focus=oslat I0829 12:36:55.386776 8 request.go:668] Waited for 1.000303471s due to client-side throttling, not priority and fairness, request: GET:https://api.cnfdc8.t5g.lab.eng.bos.redhat.com:6443/apis/authentication.k8s.io/v1?timeout=32s Running Suite: CNF Features e2e validation ========================================== Discovery mode enabled, skipping setup running /usr/bin//cnftests -ginkgo.v -ginkgo.focus=oslat I0829 12:37:01.219077 20 request.go:668] Waited for 1.050010755s due to client-side throttling, not priority and fairness, request: GET:https://api.cnfdc8.t5g.lab.eng.bos.redhat.com:6443/apis/snapshot.storage.k8s.io/v1beta1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1630240617 Will run 1 of 142 specs SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS ------------------------------ [performance] Latency Test with the oslat image should succeed /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:134 STEP: Waiting two minutes to download the latencyTest image STEP: Waiting another two minutes to give enough time for the cluster to move the pod to Succeeded phase Aug 29 12:37:59.324: [INFO]: found mcd machine-config-daemon-wf4w8 for node cnfdc8.clus2.t5g.lab.eng.bos.redhat.com • Failure [49.246 seconds] [performance] Latency Test /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:59 with the oslat image /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:112 should succeed [It] /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:134 The current latency 27 is bigger than the expected one 20 1 Expected <bool>: false to be true /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:168 Log file created at: 2021/08/29 13:25:21 Running on machine: oslat-57c2g Binary: Built with gc go1.16.6 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0829 13:25:21.569182 1 node.go:37] Environment information: /proc/cmdline: BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/vmlinuz-4.18.0-305.10.2.rt7.83.el8_4.x86_64 ip=dhcp random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ostree=/ostree/boot.0/rhcos/612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/0 ignition.platform.id=openstack root=UUID=5a4ddf16-9372-44d9-ac4e-3ee329e16ab3 rw rootflags=prjquota skew_tick=1 nohz=on rcu_nocbs=1-3 tuned.non_isolcpus=000000ff,ffffffff,ffffffff,fffffff1 intel_pstate=disable nosoftlockup tsc=nowatchdog intel_iommu=on iommu=pt isolcpus=managed_irq,1-3 systemd.cpu_affinity=0,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103 default_hugepagesz=1G hugepagesz=2M hugepages=128 nmi_watchdog=0 audit=0 mce=off processor.max_cstate=1 idle=poll intel_idle.max_cstate=0 I0829 13:25:21.569345 1 node.go:44] Environment information: kernel version 4.18.0-305.10.2.rt7.83.el8_4.x86_64 I0829 13:25:21.569367 1 main.go:53] Running the oslat command with arguments \ [--duration 600 --rtprio 1 --cpu-list 4,6,52,54,56,58 --cpu-main-thread 2] I0829 13:35:22.632263 1 main.go:59] Succeeded to run the oslat command: oslat V 2.00 Total runtime: 600 seconds Thread priority: SCHED_FIFO:1 CPU list: 4,6,52,54,56,58 CPU for main thread: 2 Workload: no Workload mem: 0 (KiB) Preheat cores: 6 Pre-heat for 1 seconds... Test starts... Test completed. Core: 4 6 52 54 56 58 CPU Freq: 2096 2096 2096 2096 2096 2096 (Mhz) 001 (us): 19390720316 19141129810 20265099129 20280959461 19391991159 19119877333 002 (us): 5304 5249 5777 5947 6829 4971 003 (us): 28 14 434 47 208 21 004 (us): 1388 853 123568 152817 5576 0 005 (us): 207850 223544 103827 91812 227236 231563 006 (us): 60770 122038 277581 323120 122633 122357 007 (us): 280023 223992 63016 25896 214194 218395 008 (us): 40604 25152 24368 4264 24440 25115 009 (us): 6858 3065 5815 810 3286 2116 010 (us): 1947 936 1452 151 474 361 ... Minimum: 1 1 1 1 1 1 (us) Average: 1.000 1.000 1.000 1.000 1.000 1.000 (us) Maximum: 37 38 49 28 28 19 (us) Max-Min: 36 37 48 27 27 18 (us) Duration: 599.667 599.667 599.667 599.667 599.667 599.667 (sec)- 1
- この例では、測定されたレイテンシーが最大許容値を超えています。
15.5. レイテンシーテストの失敗レポートの生成
次の手順を使用して、JUnit レイテンシーテストの出力とテストの失敗レポートを生成します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
レポートがダンプされる場所へのパスを
--reportパラメーターを渡すことで、クラスターの状態とトラブルシューティング用のリソースに関する情報を含むテスト失敗レポートを作成します。$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh --report <report_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
ここでは、以下のようになります。
- <report_folder_path>
- レポートが生成されるフォルダーへのパスです。
15.6. JUnit レイテンシーテストレポートの生成
次の手順を使用して、JUnit レイテンシーテストの出力とテストの失敗レポートを生成します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
レポートがダンプされる場所へのパスとともに
--junitパラメーターを渡すことにより、JUnit 準拠の XML レポートを作成します。$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junitdest:<junit_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh --junit <junit_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
ここでは、以下のようになります。
- <junit_folder_path>
- junit レポートが生成されるフォルダーへのパスです。
15.7. 単一ノードの OpenShift クラスターでレイテンシーテストを実行する
単一ノードの OpenShift クラスターでレイテンシーテストを実行できます。
遅延テストは 常に DISCOVERY_MODE=true を設定して実行してください。そうしないと、テストスイートは実行中のクラスター設定に変更を加えます。
非 root または非特権ユーザーとして podman コマンドを実行すると、パスのマウントが permission denied エラーで失敗する場合があります。podman コマンドを機能させるには、作成したボリュームに :Z を追加します。たとえば、-v $(pwd)/:/kubeconfig:Z です。これにより、podman は適切な SELinux の再ラベル付けを行うことができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
単一ノードの OpenShift クラスターでレイテンシーテストを実行するには、次のコマンドを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e ROLE_WORKER_CNF=master \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
注記ROLE_WORKER_CNF=masterは、ノードが所属する唯一のマシンプールであるため必須です。レイテンシーテストに必要なMachineConfigPoolの設定は、レイテンシーテストを実行するための前提条件を参照してください。テストスイートの実行後に、未解決のリソースすべてがクリーンアップされます。
15.8. 切断されたクラスターでのレイテンシーテストの実行
CNF テストイメージは、外部レジストリーに到達できない切断されたクラスターでテストを実行できます。これには、次の 2 つの手順が必要です。
-
cnf-testsイメージをカスタム切断レジストリーにミラーリングします。 - カスタムの切断されたレジストリーからイメージを使用するようにテストに指示します。
クラスターからアクセスできるカスタムレジストリーへのイメージのミラーリング
mirror 実行ファイルがイメージに同梱されており、テストイメージをローカルレジストリーにミラーリングするために oc が必要とする入力を提供します。
クラスターおよび registry.redhat.io にアクセスできる中間マシンから次のコマンドを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -
ここでは、以下のようになります。
- <disconnected_registry>
-
my.local.registry:5000/など、設定した切断されたミラーレジストリーです。
cnf-testsイメージを切断されたレジストリーにミラーリングした場合は、テストの実行時にイメージの取得に使用された元のレジストリーをオーバーライドする必要があります。次に例を示します。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.9" \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
カスタムレジストリーからのイメージを使用するためのテストの設定
CNF_TESTS_IMAGE 変数と IMAGE_REGISTRY 変数を使用して、カスタムテストイメージとイメージレジストリーを使用してレイテンシーテストを実行できます。
カスタムテストイメージとイメージレジストリーを使用するようにレイテンシーテストを設定するには、次のコマンドを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 /usr/bin/test-run.sh
ここでは、以下のようになります。
- <custom_image_registry>
-
custom.registry:5000/などのカスタムイメージレジストリーです。 - <custom_cnf-tests_image>
-
custom-cnf-tests-image:latestなどのカスタム cnf-tests イメージです。
クラスター内部レジストリーへのイメージのミラーリング
OpenShift Container Platform は、クラスター上の標準ワークロードとして実行される組み込まれたコンテナーイメージレジストリーを提供します。
手順
レジストリーをルートを使用して公開し、レジストリーへの外部アクセスを取得します。
$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge次のコマンドを実行して、レジストリーエンドポイントを取得します。
$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')イメージを公開する namespace を作成します。
$ oc create ns cnftests
イメージストリームを、テストに使用されるすべての namespace で利用可能にします。これは、テスト namespace が
cnf-testsイメージストリームからイメージを取得できるようにするために必要です。以下のコマンドを実行します。$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests
次のコマンドを実行して、docker シークレット名と認証トークンを取得します。
$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')dockerauth.jsonファイルを作成します。次に例を示します。$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.jsonイメージミラーリングを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.9 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -
テストを実行します。
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests \ cnf-tests-local:latest /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
異なるテストイメージセットのミラーリング
オプションで、レイテンシーテスト用にミラーリングされるデフォルトのアップストリームイメージを変更できます。
手順
mirrorコマンドは、デフォルトでアップストリームイメージをミラーリングしようとします。これは、以下の形式のファイルをイメージに渡すことで上書きできます。[ { "registry": "public.registry.io:5000", "image": "imageforcnftests:4.9" } ]ファイルを
mirrorコマンドに渡します。たとえば、images.jsonとしてローカルに保存します。以下のコマンドでは、ローカルパスはコンテナー内の/kubeconfigにマウントされ、これを mirror コマンドに渡すことができます。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
15.9. cnf-tests コンテナーでのエラーのトラブルシューティング
レイテンシーテストを実行するには、cnf-tests コンテナー内からクラスターにアクセスできる必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
次のコマンドを実行して、
cnf-testsコンテナー内からクラスターにアクセスできることを確認します。$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.9 \ oc get nodes
このコマンドが機能しない場合は、DNS 間のスパン、MTU サイズ、またはファイアウォールアクセスに関連するエラーが発生している可能性があります。
第16章 パフォーマンスプロファイルの作成
Performance Profile Creator (PPC) ツールおよび、PPC を使用してパフォーマンスプロファイルを作成する方法を説明します。
16.1. Performance Profile Creator の概要
Performance Profile Creator (PPC) は、Performance Addon Operator に含まれるコマンドラインツールでパフォーマンスプロファイルの作成に使用します。このツールは、クラスターからの must-gather データと、ユーザー指定のプロファイル引数を複数使用します。PPC は、ハードウェアとトポロジーに適したパフォーマンスプロファイルを作成します。
このツールは、以下のいずれかの方法で実行します。
-
podmanの呼び出し - ラッパースクリプトの呼び出し
16.1.1. must-gather コマンドを使用したクラスターに関するデータの収集
Performance Profile Creator (PPC) ツールには must-gather データが必要です。クラスター管理者として、must-gather コマンドを実行してクラスターについての情報を取得します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - Performance Addon Operator にアクセスできる。
-
OpenShift CLI (
oc) がインストールされている。
手順
-
must-gatherデータを保存するディレクトリーに移動します。 クラスターで
must-gatherを実行します。$ oc adm must-gather --image=<PAO_image> --dest-dir=<dir>
注記must-gatherコマンドは、performance-addon-operator-must-gatherイメージで実行する必要があります。この出力はオプションで圧縮できます。Performance Profile Creator ラッパースクリプトを実行している場合は、出力を圧縮する必要があります。例
$ oc adm must-gather --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.9 --dest-dir=must-gather
must-gatherディレクトリーから圧縮ファイルを作成します。$ tar cvaf must-gather.tar.gz must-gather/
16.1.2. podman を使用した Performance Profile Creator の実行
クラスター管理者は、podman および Performance Profile Creator を実行してパフォーマンスプロファイルを作成できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - ベアメタルハードウェアにインストールされたクラスター。
-
podmanおよび OpenShift CLI (oc) がインストールされているノード。
手順
マシン設定プールを確認します。
$ oc get mcp
出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
Podman を使用して、
registry.redhat.ioへの認証を行います。$ podman login registry.redhat.io
Username: myrhusername Password: ************
必要に応じて、PPC ツールのヘルプを表示します。
$ podman run --entrypoint performance-profile-creator registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.9 -h
出力例
A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabledPerformance Profile Creator ツールを検出モードで実行します。
注記検出モードは、
must-gatherからの出力を使用してクラスターを検査します。生成された出力には、以下のような情報が含まれます。- 割り当てられた CPU ID でパーティションされた NUMA セル
- ハイパースレッディングが有効にされているかどうか
この情報を使用して、Performance Profile Creator ツールにわたす一部の引数に適切な値を設定できます。
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.9 --info log --must-gather-dir-path /must-gather
注記このコマンドは、Performance Profile Creator を、
podmanへの新規エントリーポイントとして使用します。これは、ホストのmust-gatherデータをコンテナーイメージにマッピングし、ユーザーが提示した必須のプロファイル引数を呼び出し、my-performance-profile.yamlファイルを生成します。-vオプションでは、以下のいずれかへのパスを指定できます。-
must-gather出力ディレクトリー -
must-gatherの展開済みの tarball を含む既存のディレクトリー
infoオプションでは、出力形式を指定する値が必要です。使用できる値は log と JSON です。JSON 形式はデバッグ用に確保されています。podmanを実行します。$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.9 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=false --topology-manager-policy=single-numa-node --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency > my-performance-profile.yaml
注記Performance Profile Creator の引数については Performance Profile Creator 引数の表に示しています。必要な引数は、以下の通りです。
-
reserved-cpu-count -
mcp-name -
rt-kernel
この例の
mcp-name引数は、コマンドoc get mcpの出力に基づいてworker-cnfに設定されます。シングルノード OpenShift の場合は、--mcp-name=masterを使用します。-
作成した YAML ファイルを確認します。
$ cat my-performance-profile.yaml
出力例
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - intel_idle.max_cstate=0 - idle=poll cpu: isolated: 1,3,5,7,9,11,13,15,17,19-39,41,43,45,47,49,51,53,55,57,59-79 reserved: 0,2,4,6,8,10,12,14,16,18,40,42,44,46,48,50,52,54,56,58 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: single-numa-node realTimeKernel: enabled: true生成されたプロファイルを適用します。
注記プロファイルを適用する前に、Performance Addon Operator をインストールしてください。
$ oc apply -f my-performance-profile.yaml
16.1.2.1. podman を実行してパフォーマンスプロファイルを作成する方法
以下の例では、podman を実行して、NUMA ノード間で分割される、予約済み CPU 20 個を指定してパフォーマンスプロファイルを作成する方法を説明します。
ノードのハードウェア設定:
- CPU 80 個
- ハイパースレッディングを有効にする
- NUMA ノード 2 つ
- NUMA ノード 0 に偶数個の CPU、NUMA ノード 1 に奇数個の CPU を稼働させる
podman を実行してパフォーマンスプロファイルを作成します。
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.9 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=true --must-gather-dir-path /must-gather > my-performance-profile.yaml
作成されたプロファイルは以下の YAML に記述されます。
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: performance
spec:
cpu:
isolated: 10-39,50-79
reserved: 0-9,40-49
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numa:
topologyPolicy: restricted
realTimeKernel:
enabled: trueこの場合、CPU 10 個が NUMA ノード 0 に、残りの 10 個は NUMA ノード 1 に予約されます。
16.1.3. Performance Profile Creator ラッパースクリプトの実行
パフォーマンスプロファイルラッパースクリプトをし用すると、Performance Profile Creator (PPC) ツールの実行を簡素化できます。podman の実行に関連する煩雑性がなくなり、パフォーマンスプロファイルの作成が可能になります。
前提条件
- Performance Addon Operator にアクセスできる。
-
must-gathertarball にアクセスできる。
手順
ローカルマシンにファイル (例:
run-perf-profile-creator.sh) を作成します。$ vi run-perf-profile-creator.sh
ファイルに以下のコードを貼り付けます。
#!/bin/bash readonly CONTAINER_RUNTIME=${CONTAINER_RUNTIME:-podman} readonly CURRENT_SCRIPT=$(basename "$0") readonly CMD="${CONTAINER_RUNTIME} run --entrypoint performance-profile-creator" readonly IMG_EXISTS_CMD="${CONTAINER_RUNTIME} image exists" readonly IMG_PULL_CMD="${CONTAINER_RUNTIME} image pull" readonly MUST_GATHER_VOL="/must-gather" PAO_IMG="registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.9" MG_TARBALL="" DATA_DIR="" usage() { print "Wrapper usage:" print " ${CURRENT_SCRIPT} [-h] [-p image][-t path] -- [performance-profile-creator flags]" print "" print "Options:" print " -h help for ${CURRENT_SCRIPT}" print " -p Performance Addon Operator image" print " -t path to a must-gather tarball" ${IMG_EXISTS_CMD} "${PAO_IMG}" && ${CMD} "${PAO_IMG}" -h } function cleanup { [ -d "${DATA_DIR}" ] && rm -rf "${DATA_DIR}" } trap cleanup EXIT exit_error() { print "error: $*" usage exit 1 } print() { echo "$*" >&2 } check_requirements() { ${IMG_EXISTS_CMD} "${PAO_IMG}" || ${IMG_PULL_CMD} "${PAO_IMG}" || \ exit_error "Performance Addon Operator image not found" [ -n "${MG_TARBALL}" ] || exit_error "Must-gather tarball file path is mandatory" [ -f "${MG_TARBALL}" ] || exit_error "Must-gather tarball file not found" DATA_DIR=$(mktemp -d -t "${CURRENT_SCRIPT}XXXX") || exit_error "Cannot create the data directory" tar -zxf "${MG_TARBALL}" --directory "${DATA_DIR}" || exit_error "Cannot decompress the must-gather tarball" chmod a+rx "${DATA_DIR}" return 0 } main() { while getopts ':hp:t:' OPT; do case "${OPT}" in h) usage exit 0 ;; p) PAO_IMG="${OPTARG}" ;; t) MG_TARBALL="${OPTARG}" ;; ?) exit_error "invalid argument: ${OPTARG}" ;; esac done shift $((OPTIND - 1)) check_requirements || exit 1 ${CMD} -v "${DATA_DIR}:${MUST_GATHER_VOL}:z" "${PAO_IMG}" "$@" --must-gather-dir-path "${MUST_GATHER_VOL}" echo "" 1>&2 } main "$@"このスクリプトの実行権限を全員に追加します。
$ chmod a+x run-perf-profile-creator.sh
オプション:
run-perf-profile-creator.shコマンドの使用方法を表示します。$ ./run-perf-profile-creator.sh -h
予想される出力
Wrapper usage: run-perf-profile-creator.sh [-h] [-p image][-t path] -- [performance-profile-creator flags] Options: -h help for run-perf-profile-creator.sh -p Performance Addon Operator image 1 -t path to a must-gather tarball 2 A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled
注記引数には、以下の 2 つのタイプがあります。
-
ラッパー引数名は、
-h、-p、および-tです。 - PPC 引数
-
ラッパー引数名は、
Performance Profile Creator ツールを検出モードで実行します。
注記検出モードは、
must-gatherからの出力を使用してクラスターを検査します。生成された出力には、以下のような情報が含まれます。- 割り当てられた CPU ID を使用した NUMA セルのパーティション設定
- ハイパースレッディングが有効にされているかどうか
この情報を使用して、Performance Profile Creator ツールにわたす一部の引数に適切な値を設定できます。
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --info=log
注記infoオプションでは、出力形式を指定する値が必要です。使用できる値は log と JSON です。JSON 形式はデバッグ用に確保されています。マシン設定プールを確認します。
$ oc get mcp
出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
パフォーマンスプロファイルを作成します。
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=2 --rt-kernel=true > my-performance-profile.yaml
注記Performance Profile Creator の引数については Performance Profile Creator 引数の表に示しています。必要な引数は、以下の通りです。
-
reserved-cpu-count -
mcp-name -
rt-kernel
この例の
mcp-name引数は、コマンドoc get mcpの出力に基づいてworker-cnfに設定されます。シングルノード OpenShift の場合は、--mcp-name=masterを使用します。-
作成した YAML ファイルを確認します。
$ cat my-performance-profile.yaml
出力例
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 1-39,41-79 reserved: 0,40 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: false生成されたプロファイルを適用します。
注記プロファイルを適用する前に、Performance Addon Operator をインストールしてください。
$ oc apply -f my-performance-profile.yaml
16.1.4. Performance Profile Creator の引数
| 引数 | 説明 |
|---|---|
|
| ハイパースレッディングを無効にします。
使用できる値は
デフォルト: 警告
この引数が |
|
|
この引数では、クラスター情報を取得します。使用できるのは検出モードのみです。検出モードでは、 以下の値を使用できます。
デフォルト: |
|
|
ターゲットマシンに対応する |
|
| must gather のディレクトリーパス。このパラメーターは必須です。
ラッパースクリプトでツールを実行する場合には、 |
|
| 電力消費モード。 以下の値を使用できます。
デフォルト: |
|
|
作成するパフォーマンスプロファイルの名前。デフォルト: |
|
| 予約された CPU の数。このパラメーターは必須です。 注記 これは自然数でなければなりません。0 の値は使用できません。 |
|
| リアルタイムカーネルを有効にします。このパラメーターは必須です。
使用できる値は |
|
| NUMA ノード全体で予約された CPU を分割します。
使用できる値は
デフォルト: |
|
| 作成するパフォーマンスプロファイルの kubelet Topology Manager ポリシー。 以下の値を使用できます。
デフォルト: |
|
| ユーザーレベルのネットワーク (DPDK) を有効にして実行します。
使用できる値は
デフォルト: |
16.2. 関連情報
-
must-gatherツールの詳細は、クラスターに関するデータの収集 を参照してください。
第17章 分散ユニットを単一ノードの OpenShift に手動でデプロイ
このトピックの手順では、インストール中に分散ユニット (DU) として少数の単一ノードにクラスターを手動でデプロイする方法を説明します。
この手順では、単一ノード OpenShift のインストール方法については説明していません。これは、多くのメカニズムを通じて実現できます。むしろ、インストールプロセスの一部として設定する必要のある要素をキャプチャすることを目的としています。
- インストールの完了時にシングルノード OpenShiftDU への接続を有効にするには、ネットワークが必要です。
- ワークロードのパーティション化。インストール中にのみ設定できます。
- インストール後の潜在的な再起動を最小限に抑えるのに役立つ追加の項目。
17.1. 分散ユニット (DU) の設定
このセクションでは、分散ユニット (DU) アプリケーションの実行に必要な機能およびパフォーマンスの要件を満たすための OpenShift Container Platform クラスターの一連の設定について説明します。このコンテンツの一部はインストール時に適用する必要がありますが、その他の設定はインストール後に適用できます。
単一ノード OpenShift DU をインストールした後、プラットフォームが DU ワークロードを実行できるようにするには、追加の設定が必要です。
このセクションの設定は、DU ワークロード用にクラスターを設定するために、インストール後にクラスターに適用されます。
17.1.1. ワークロードパーティション設定の有効化
シングルノード OpenShift インストールの一部として有効にする重要な機能は、ワークロードのパーティショニングです。これにより、プラットフォームサービスの実行が許可されるコアが制限され、アプリケーションペイロードの CPU コアが最大化されます。クラスターのインストール時にワークロードのパーティショニングを設定する必要があります。
ワークロードパーティショニングを有効にできるのは、クラスターのインストール時のみです。インストール後にワークロードパーティショニングを無効にすることはできません。ただし、パフォーマンスプロファイルで定義した cpu の値と、MachineConfig カスタムリソース (CR) の関連する cpuset の値を更新して、ワークロードパーティショニングを再設定できます。
手順
以下の base64 でエンコードされたコンテンツには、管理ワークロードが制限されている CPU セットが含まれています。このコンテンツは、
performanceprofileプロファイルで指定されたセットに一致するように調整する必要があり、クラスター上のコアの数に対して正確である必要があります。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 02-master-workload-partitioning spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,W2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudF0KYWN0aXZhdGlvbl9hbm5vdGF0aW9uID0gInRhcmdldC53b3JrbG9hZC5vcGVuc2hpZnQuaW8vbWFuYWdlbWVudCIKYW5ub3RhdGlvbl9wcmVmaXggPSAicmVzb3VyY2VzLndvcmtsb2FkLm9wZW5zaGlmdC5pbyIKW2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudC5yZXNvdXJjZXNdCmNwdXNoYXJlcyA9IDAKQ1BVcyA9ICIwLTEsIDUyLTUzIgo= mode: 420 overwrite: true path: /etc/crio/crio.conf.d/01-workload-partitioning user: name: root - contents: source: data:text/plain;charset=utf-8;base64,ewogICJtYW5hZ2VtZW50IjogewogICAgImNwdXNldCI6ICIwLTEsNTItNTMiCiAgfQp9Cg== mode: 420 overwrite: true path: /etc/kubernetes/openshift-workload-pinning user: name: root/etc/crio/crio.conf.d/01-workload-partitioningの内容は次のようになります。[crio.runtime.workloads.management] activation_annotation = "target.workload.openshift.io/management" annotation_prefix = "resources.workload.openshift.io" [crio.runtime.workloads.management.resources] cpushares = 0 cpuset = "0-1, 52-53" 1- 1
cpuset の値は、インストールによって異なります。
ハイパースレッディングが有効になっている場合は、各コアの両方のスレッドを指定します。
cpuset値は、パフォーマンスプロファイルのspec.cpu.reservedフィールドで定義した予約済み CPU と一致する必要があります。
ハイパースレッディングが有効になっている場合は、各コアの両方のスレッドを指定します。CPUs の値は、パフォーマンスプロファイルで指定された予約済み CPU セットと一致する必要があります。
このコンテンツは base64 でエンコードされ、上記のマニフェストの 01-workload-partitioning-content で提供される必要があります。
/etc/kubernetes/openshift-workload-pinningの内容は次のようになります。{ "management": { "cpuset": "0-1,52-53" 1 } }- 1
cpuset は、/etc/crio/crio.conf.d/01-workload-partitioningのcpuset値と一致する必要があります。
17.1.2. コンテナーマウント namespace の設定
プラットフォームの全体的な管理フットプリントを削減するために、マウントポイントを含むマシン設定が提供されます。設定を変更する必要はありません。提供されている設定を使用します。
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: container-mount-namespace-and-kubelet-conf-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
enabled: true
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service17.1.3. SCTP (Stream Control Transmission Protocol) の有効化
SCTP は、RAN アプリケーションで使用される主要なプロトコルです。この MachineConfig オブジェクトは、SCTP カーネルモジュールをノードに追加して、このプロトコルを有効にします。
手順
設定を変更する必要はありません。提供されている設定を使用します。
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: load-sctp-module spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:, verification: {} filesystem: root mode: 420 path: /etc/modprobe.d/sctp-blacklist.conf - contents: source: data:text/plain;charset=utf-8,sctp filesystem: root mode: 420 path: /etc/modules-load.d/sctp-load.conf
17.1.4. Operator の OperatorGroups の作成
この設定は、インストール後にプラットフォームを設定するのに必要な Operator を追加できるようにするために提供されています。Local Storage Operator、Logging Operator, Performance Addon Operator、Performance Addon Operator、PTP Operator、および SRIOV Network Operator の Namespace オブジェクトと OperatorGroup オブジェクトを追加します。
手順
設定を変更する必要はありません。提供されている設定を使用します。
Local Storage Operator
apiVersion: v1 kind: Namespace metadata: annotations: workload.openshift.io/allowed: management name: openshift-local-storage --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-local-storage namespace: openshift-local-storage spec: targetNamespaces: - openshift-local-storageLogging Operator
apiVersion: v1 kind: Namespace metadata: annotations: workload.openshift.io/allowed: management name: openshift-logging --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: cluster-logging namespace: openshift-logging spec: targetNamespaces: - openshift-loggingPerformance Addon Operator
apiVersion: v1 kind: Namespace metadata: annotations: workload.openshift.io/allowed: management labels: openshift.io/cluster-monitoring: "true" name: openshift-performance-addon-operator spec: {} --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: performance-addon-operator namespace: openshift-performance-addon-operatorPTP Operator
apiVersion: v1 kind: Namespace metadata: annotations: workload.openshift.io/allowed: management labels: openshift.io/cluster-monitoring: "true" name: openshift-ptp --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ptp-operators namespace: openshift-ptp spec: targetNamespaces: - openshift-ptpSRIOV Network Operator
apiVersion: v1 kind: Namespace metadata: annotations: workload.openshift.io/allowed: management name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator
17.1.5. Operator の策スクライブ
サブスクリプションは、プラットフォーム設定に必要な Operator をダウンロードする場所を提供します。
手順
次の例を使用して、サブスクリプションを設定します。
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: cluster-logging namespace: openshift-logging spec: channel: "stable" 1 name: cluster-logging source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual 2 --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: local-storage-operator namespace: openshift-local-storage spec: channel: "stable" 3 installPlanApproval: Automatic name: local-storage-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: performance-addon-operator namespace: openshift-performance-addon-operator spec: channel: "4.10" 4 name: performance-addon-operator source: performance-addon-operator sourceNamespace: openshift-marketplace installPlanApproval: Manual --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ptp-operator-subscription namespace: openshift-ptp spec: channel: "stable" 5 name: ptp-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subscription namespace: openshift-sriov-network-operator spec: channel: "stable" 6 name: sriov-network-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual
- 1
cluster-loggingOperator を取得するチャネルを指定します。- 2
ManualまたはAutomaticを指定します。Automaticモードでは、Operator は、レジストリーで利用可能になると、チャネル内の最新バージョンに自動的に更新します。Manualモードでは、新しい Operator バージョンは、明示的に承認された後にのみインストールされます。- 3
local-storage-operatorOperator を取得するチャンネルを指定します。- 4
performance-addon-operatorOperator を取得するチャネルを指定します。- 5
ptp-operatorOperator を取得するチャンネルを指定します。- 6
sriov-network-operatorOperatorOperator を取得するチャンネルを指定します。
17.1.6. ローカルでのロギングおよび転送の設定
単一ノード分散ユニット (DU) をデバッグできるようにするには、さらに分析するためにログを保存する必要があります。
手順
openshift-loggingプロジェクトでClusterLoggingカスタムリソース (CR) を編集します。apiVersion: logging.openshift.io/v1 kind: ClusterLogging 1 metadata: name: instance namespace: openshift-logging spec: collection: logs: fluentd: {} type: fluentd curation: type: "curator" curator: schedule: "30 3 * * *" managementState: Managed --- apiVersion: logging.openshift.io/v1 kind: ClusterLogForwarder 2 metadata: name: instance namespace: openshift-logging spec: inputs: - infrastructure: {} outputs: - name: kafka-open type: kafka url: tcp://10.46.55.190:9092/test 3 pipelines: - inputRefs: - audit name: audit-logs outputRefs: - kafka-open - inputRefs: - infrastructure name: infrastructure-logs outputRefs: - kafka-open
17.1.7. Performance Addon Operator の設定
これは、単一ノード分散ユニット (DU) の重要な設定です。リアルタイム機能とサービス保証の多くは、ここで設定されます。
手順
次の例を使用して、パフォーマンスアドオンを設定します。
推奨されるパフォーマンスプロファイル設定
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: openshift-node-performance-profile 1 spec: additionalKernelArgs: - "idle=poll" - "rcupdate.rcu_normal_after_boot=0" cpu: isolated: 2-51,54-103 2 reserved: 0-1,52-53 3 hugepages: defaultHugepagesSize: 1G pages: - count: 32 4 size: 1G 5 node: 0 6 machineConfigPoolSelector: pools.operator.machineconfiguration.openshift.io/master: "" net: userLevelNetworking: true 7 nodeSelector: node-role.kubernetes.io/master: '' numa: topologyPolicy: "restricted" realTimeKernel: enabled: true 8
- 1
nameの値が、TunedPerformancePatch.yamlのspec.profile.dataフィールドとvalidatorCRs/informDuValidator.yamlのstatus.configuration.source.nameフィールドで指定された値と一致することを確認します。- 2
- 分離された CPU を設定します。すべてのハイパースレッディングペアが一致していることを確認します。
- 3
- 予約済みの CPU を設定します。ワークロードの分割が有効になっている場合、システムプロセス、カーネルスレッド、およびシステムコンテナースレッドは、これらの CPU に制限されます。分離されていないすべての CPU を予約する必要があります。
- 4
- Huge Page の数を設定します。
- 5
- Huge Page のサイズを設定します。
- 6
nodeをhugepageが割り当てられている NUMA ノードに設定します。- 7
- CPU をネットワーク割り込みから分離するには、
userLevelNetworkingをtrueに設定します。 - 8
- リアルタイム Linux カーネルをインストールするには、
enabledをtrueに設定します。
17.1.8. Precision Time Protocol (PTP) の設定
遠端では、RAN は PTP を使用してシステムを同期します。
手順
次の例を使用して PTP を設定します。
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: du-ptp-slave namespace: openshift-ptp spec: profile: - interface: ens5f0 1 name: slave phc2sysOpts: -a -r -n 24 ptp4lConf: | [global] # # Default Data Set # twoStepFlag 1 slaveOnly 0 priority1 128 priority2 128 domainNumber 24 #utc_offset 37 clockClass 248 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison ieee1588 G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval 4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type OC network_transport UDPv4 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 ptp4lOpts: -2 -s --summary_interval -4 recommend: - match: - nodeLabel: node-role.kubernetes.io/master priority: 4 profile: slave
- 1
- PTP に使用されるインターフェイスを設定します。
17.1.9. ネットワークタイムプロトコル (NTP) の無効化
システムが Precision Time Protocol 用に設定されたら、システムクロックに影響を与えないように NTP を削除する必要があります。
手順
設定を変更する必要はありません。提供されている設定を使用します。
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: disable-chronyd spec: config: systemd: units: - contents: | [Unit] Description=NTP client/server Documentation=man:chronyd(8) man:chrony.conf(5) After=ntpdate.service sntp.service ntpd.service Conflicts=ntpd.service systemd-timesyncd.service ConditionCapability=CAP_SYS_TIME [Service] Type=forking PIDFile=/run/chrony/chronyd.pid EnvironmentFile=-/etc/sysconfig/chronyd ExecStart=/usr/sbin/chronyd $OPTIONS ExecStartPost=/usr/libexec/chrony-helper update-daemon PrivateTmp=yes ProtectHome=yes ProtectSystem=full [Install] WantedBy=multi-user.target enabled: false name: chronyd.service ignition: version: 2.2.0
17.1.10. Single Root I/O Virtualization (SR-IOV) の設定
SR-IOV は通常、フロントホールおよびミッドホールネットワークを有効にするのに使用されます。
手順
次の設定を使用して、単一ノード分散ユニット (DU) で SRIOV を設定します。最初のカスタムリソース (CR) が必要であることに注意してください。次の CR は例です。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: configDaemonNodeSelector: node-role.kubernetes.io/master: "" disableDrain: true enableInjector: true enableOperatorWebhook: true --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: sriov-nw-du-mh namespace: openshift-sriov-network-operator spec: networkNamespace: openshift-sriov-network-operator resourceName: du_mh vlan: 150 1 --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: sriov-nnp-du-mh namespace: openshift-sriov-network-operator spec: deviceType: vfio-pci 2 isRdma: false nicSelector: pfNames: - ens7f0 3 nodeSelector: node-role.kubernetes.io/master: "" numVfs: 8 4 priority: 10 resourceName: du_mh --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: sriov-nw-du-fh namespace: openshift-sriov-network-operator spec: networkNamespace: openshift-sriov-network-operator resourceName: du_fh vlan: 140 5 --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: sriov-nnp-du-fh namespace: openshift-sriov-network-operator spec: deviceType: netdevice 6 isRdma: true nicSelector: pfNames: - ens5f0 7 nodeSelector: node-role.kubernetes.io/master: "" numVfs: 8 8 priority: 10 resourceName: du_fh
17.1.11. コンソール Operator の無効化
console-operator は、Web コンソールをクラスターにインストールして保守します。ノードが集中管理されている場合、Operator は不要であり、アプリケーションのワークロード用のスペースを確保します。
手順
次の設定ファイルを使用して、Operator を無効にすることができます。設定を変更する必要はありません。提供されている設定を使用します。
apiVersion: operator.openshift.io/v1 kind: Console metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "false" include.release.openshift.io/self-managed-high-availability: "false" include.release.openshift.io/single-node-developer: "false" release.openshift.io/create-only: "true" name: cluster spec: logLevel: Normal managementState: Removed operatorLogLevel: Normal
17.2. 分散ユニット (DU) 設定を単一ノードの OpenShift クラスターに適用する
次のタスクを実行して、DU の単一ノードクラスターを設定します。
- インストール時に必要な追加のインストールマニフェストを適用します。
- インストール後の設定カスタムリソース (CR) を適用します。
17.2.1. 追加のインストールマニフェストの適用
分散ユニット (DU) 設定を単一ノードクラスターに適用するには、インストール中に次の追加のインストールマニフェストを含める必要があります。
- ワークロードのパーティショニングを有効にします。
-
その他の
MachineConfigオブジェクト – デフォルトで含まれているMachineConfigカスタムリソース (CR) のセットがあります。環境に固有のこれらの追加のMachineConfigCRを含めることを選択できます。インストール後の設定中に発生する可能性のある再起動の回数を最小限に抑えるために、インストール中にこれらの CR を適用することが推奨されますが、必須ではありません。
17.2.2. インストール後の設定カスタムリソース (CR) の適用
- OpenShift Container Platform がクラスターにインストールされたら、以下のコマンドを使用して、分散ユニット (DU) 用に設定した CR を適用します。
$ oc apply -f <file_name>.yaml
第18章 単一ノード OpenShift でのワークロードパーティション設定
単一ノードの OpenShift デプロイメントなどのリソースに制約のある環境では、CPU リソースのほとんどを独自のワークロード用に確保し、ホスト内の固定数の CPU で実行するように OpenShift Container Platform を設定すると有利です。これらの環境では、コントロールプレーンを含む管理ワークロードは、通常のクラスターでデフォルトよりも少ないリソースを使用するように設定する必要があります。OpenShift Container Platform サービス、クラスター管理ワークロード、およびインフラストラクチャー Pod を分離して、予約済みの CPU セットで実行できます。
ワークロードパーティショニングを使用する場合、クラスター管理のために OpenShift Container Platform によって使用される CPU リソースは、単一ノードクラスター上のパーティション化された CPU リソースのセットに分離されます。このパーティション設定により、クラスター管理機能が定義された数の CPU に分離されます。すべてのクラスター管理機能は、その cpuset 設定でのみ動作します。
単一ノードクラスターの管理パーティションに必要な予約済み CPU の最低限の数は、4 つの CPU ハイパースレッド (HT) です。ベースラインの OpenShift Container Platform インストールを設定する Pod のセットと一般的なアドオン Operator のセットには、管理ワークロードパーティションに含めるためのアノテーションが付けられています。これらの Pod は、最低限のサイズの cpuset 設定内で正常に動作します。受け入れ可能な管理 Pod のセット以外の Operator またはワークロードを含めるには、そのパーティションに CPU HT を追加する必要があります。
ワークロードパーティション設定は、Kubernetes の通常のスケジューリング機能を使用してユーザーワークロードをプラットフォームワークロードから分離し、それらのコアに配置できる Pod の数を管理し、クラスター管理ワークロードとユーザーワークロードの混在を回避します。
ワークロードパーティション設定を使用する場合は、Performance Addon Operator をインストールし、パフォーマンスプロファイルを適用する必要があります。
-
ワークロードパーティション設定は、OpenShift Container Platform インフラストラクチャー Pod を定義済みの
cpuset設定に固定します。 -
Performance Addon Operator のパフォーマンスプロファイルは、systemd サービスを定義済みの
cpuset設定に固定します。 -
この
cpuset設定は一致する必要があります。
ワークロードパーティション設定により、定義された CPU プールまたはワークロードタイプごとに <workload-type> .workload.openshift.io/cores の新しい拡張リソースが導入されます。Kubelet はこれらの新しいリソースをアドバタイズし、プールに確保された Pod による CPU 要求は、通常の cpu リソースではなく、対応するリソース内で考慮されます。ワークロードパーティション設定が有効になっている場合、<workload-type> .workload.openshift.io/cores リソースにより、デフォルトの CPU プールだけでなく、ホストの CPU 容量にアクセスできます。
18.1. ワークロードパーティション設定の有効化
シングルノード OpenShift インストールの一部として有効にする重要な機能は、ワークロードのパーティショニングです。これにより、プラットフォームサービスの実行が許可されるコアが制限され、アプリケーションペイロードの CPU コアが最大化されます。クラスターのインストール時にワークロードのパーティショニングを設定する必要があります。
ワークロードパーティショニングを有効にできるのは、クラスターのインストール時のみです。インストール後にワークロードパーティショニングを無効にすることはできません。ただし、パフォーマンスプロファイルで定義した cpu の値と、MachineConfig カスタムリソース (CR) の関連する cpuset の値を更新して、ワークロードパーティショニングを再設定できます。
手順
以下の base64 でエンコードされたコンテンツには、管理ワークロードが制限されている CPU セットが含まれています。このコンテンツは、
performanceprofileプロファイルで指定されたセットに一致するように調整する必要があり、クラスター上のコアの数に対して正確である必要があります。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 02-master-workload-partitioning spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,W2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudF0KYWN0aXZhdGlvbl9hbm5vdGF0aW9uID0gInRhcmdldC53b3JrbG9hZC5vcGVuc2hpZnQuaW8vbWFuYWdlbWVudCIKYW5ub3RhdGlvbl9wcmVmaXggPSAicmVzb3VyY2VzLndvcmtsb2FkLm9wZW5zaGlmdC5pbyIKW2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudC5yZXNvdXJjZXNdCmNwdXNoYXJlcyA9IDAKQ1BVcyA9ICIwLTEsIDUyLTUzIgo= mode: 420 overwrite: true path: /etc/crio/crio.conf.d/01-workload-partitioning user: name: root - contents: source: data:text/plain;charset=utf-8;base64,ewogICJtYW5hZ2VtZW50IjogewogICAgImNwdXNldCI6ICIwLTEsNTItNTMiCiAgfQp9Cg== mode: 420 overwrite: true path: /etc/kubernetes/openshift-workload-pinning user: name: root/etc/crio/crio.conf.d/01-workload-partitioningの内容は次のようになります。[crio.runtime.workloads.management] activation_annotation = "target.workload.openshift.io/management" annotation_prefix = "resources.workload.openshift.io" [crio.runtime.workloads.management.resources] cpushares = 0 cpuset = "0-1, 52-53" 1- 1
cpuset の値は、インストールによって異なります。
ハイパースレッディングが有効になっている場合は、各コアの両方のスレッドを指定します。
cpuset値は、パフォーマンスプロファイルのspec.cpu.reservedフィールドで定義した予約済み CPU と一致する必要があります。
ハイパースレッディングが有効になっている場合は、各コアの両方のスレッドを指定します。CPUs の値は、パフォーマンスプロファイルで指定された予約済み CPU セットと一致する必要があります。
このコンテンツは base64 でエンコードされ、上記のマニフェストの 01-workload-partitioning-content で提供される必要があります。
/etc/kubernetes/openshift-workload-pinningの内容は次のようになります。{ "management": { "cpuset": "0-1,52-53" 1 } }- 1
cpuset は、/etc/crio/crio.conf.d/01-workload-partitioningのcpuset値と一致する必要があります。
第19章 非接続環境でのスケールでの分散ユニットのデプロイ
ゼロタッチプロビジョニング (ZTP) を使用して、非接続環境で新しいエッジサイトに分散ユニットをプロビジョニングします。ワークフローは、サイトがネットワークに接続されているときに起動し、サイトノードでデプロイされた CNF ワークロードで終了します。
RAN デプロイメント用の ZTP は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
19.1. 大規模でのエッジサイトのプロビジョニング
Telco エッジコンピューティングは、数百万ものクラスターを管理する際に、数百万ものクラスターを管理する追加の課題を数百万のロケーションで表示します。これらの課題には、できるだけゼロ (0) 人の相互作用と同様に、完全に自動化された管理ソリューションが必要になります。
ゼロタッチプロビジョニング (ZTP) により、リモートサイトでのベアメタル機器の宣言的な設定で新しいエッジサイトをプロビジョニングすることができます。テンプレートまたはオーバーレイ設定は、CNF ワークロードに必要な OpenShift Container Platform 機能をインストールします。エンドツーエンドの機能テストスイートは、CNF 関連の機能を検証するために使用されます。すべての設定は本質的に宣言的です。
エッジノードに配信される ISO イメージの宣言型設定を作成して、インストールプロセスを開始することで、ワークフローを開始します。イメージは、大量のノードを効率的にプロビジョニングするために使用されます。これにより、エッジノードについてフィールドから要件を確保できます。
サービスプロバイダーは、5G 向けに定義されたモジュラー機能フレームワークにより許可される、より分散モバイルネットワークアーキテクチャーをデプロイします。これにより、サービスプロバイダーはアプライアンスベースのラジオアクセスネットワーク (RAN) から移動し、クラウド RAN アーキテクチャーを開き、エンドユーザーにサービスを配信する柔軟性と特性を得ることができます。
以下の図は、エッジサイトフレームワーク内で ZTP が機能する仕組みを示しています。
19.2. GitOps のアプローチ
ZTP は、インフラストラクチャーのデプロイメントに GitOps デプロイメントセットを使用します。GitOps は、YAML ファイルや他の定義パターンなどの Git リポジトリーに保存される宣言型仕様を使用してこれらのタスクを実行します。これは、インフラストラクチャーをデプロイするためのフレームワークを提供します。宣言型の出力は、マルチサイトデプロイメント用に Open Cluster Manager によって使用されます。
GitOps アプローチのモノミュレーターの 1 つは、スケーリング時の信頼性の要件です。これは、GitOps が解決に役立つ重要な課題です。
GitOps は、各サイトの必要な状態についてトレース性、RBAC および単一ソースを提供することにより、信頼性に対応します。スケーリングの問題は、Webhook 経由で構造、ツール、およびイベント駆動型の操作を提供する GitOps によって対処されます。
19.3. 単一ノードの ZTP および分散ユニットについて
Red Hat Advanced Cluster Management (RHACM) (ACM) を使用して、Red Hat Advanced Cluster Management (RHACM) とコア生成の技術が有効なポリシージェネレーターを使用して、単一のノードに分散ユニット (DU) をインストールできます。DU インストールは、非接続環境のゼロタッチプロビジョニング (ZTP) を使用して行われます。
ACM は、ハブクラスターが多くのスポーククラスターを管理するハブおよびスポークアーキテクチャーでクラスターを管理します。ACM は、事前定義されたカスタムリソース (CR) からラジオアクセスネットワーク (RAN) ポリシーを適用します。ACM プロビジョニングを実行するハブクラスターでは、ZTP および AI を使用してスポーククラスターをデプロイすることができます。DU インストールは、単一ノードでの OpenShift Container Platform の AI インストールに従います。
AI サービスは、ベアメタルで実行される単一ノードでの OpenShift Container Platform のプロビジョニングを処理します。ACM には、MultiClusterHub カスタムリソースがインストールされている場合に、アシスト付きインストーラーが同梱され、デプロイします。
ZTP および AI を使用すると、OpenShift Container Platform の単一ノードをプロビジョニングし、大規模な DUs を実行できます。非接続環境での分散ユニットに対する ZTP の概要を以下に示します。
- ACM を実行しているハブクラスターは、OpenShift Container Platform リリースイメージをミラーリングする非接続内部レジストリーを管理します。内部レジストリーは、スポーク単一ノードのプロビジョニングに使用されます。
- DU のベアメタルホストマシンは、フォーマットに YAML を使用するインベントリーファイルで管理します。インベントリーファイルを Git リポジトリーに保存します。
DU ベアメタルホストマシンをサイトにインストールし、ホストをプロビジョニングできるようにします。プロビジョニングの準備をするには、ベアメタルホストごとに以下が必要です。
- ネットワークの DNS など、ネットワーク接続ホストは、ハブおよびマネージドスポーククラスター経由で到達可能である必要があります。ハブクラスターをインストールするホストと、ハブとホストの間にレイヤー 3 の接続があることを確認します。
各ホストのベースボード管理コントローラー (BMC) の詳細: ZTP は BMC の詳細を使用して、BMC にアクセスするための URL および認証情報に接続します。スポーククラスター定義 CR を作成します。これらは、マネージドクラスターの関連する要素を定義します。必要な CR は以下のとおりです。
カスタムリソース 説明 Namespace
管理ノードクラスターの namespace。
BMCSecret CR
ホスト BMC の認証情報。
Image Pull Secret CR
非接続レジストリーのプルシークレット。
AgentClusterInstall
ネットワーク、supervisor (コントロールプレーン) ノードの数など、単一ノードのクラスター設定を指定します。
ClusterDeployment
クラスター名、ドメイン、およびその他の詳細情報を定義します。
KlusterletAddonConfig
ACM 向けに ManagedCluster のアドオンのインストールおよび終了を管理します。
ManagedCluster
ACM のマネージドクラスターを記述します。
InfraEnv
アシスト付きインストーラーサービスが作成する宛先ノードにマウントされるインストール ISO を記述します。これは、マニフェスト作成フェーズの最終ステップです。
BareMetalHost
BMC や認証情報の詳細など、ベアメタルホストの詳細について説明します。
- ホストインベントリーリポジトリーで変更が検出されると、ホスト管理イベントがトリガーされ、新規または更新されたホストのプロビジョニングがトリガーされます。
-
ホストがプロビジョニングされています。ホストがプロビジョニングされ、正常に再起動すると、ホストエージェントは
Readyステータスをハブクラスターに報告します。
19.4. ゼロタッチプロビジョニングのビルディングブロック
ACM は単一ノードの OpenShift をデプロイします。初期サイト計画は小さいコンポーネントに分割され、初期設定データは Git リポジトリーに保存されます。ゼロなタッチプロビジョニングは、宣言型の GitOps アプローチを使用してこれらのノードをデプロイします。ノードのデプロイメントには、以下が含まれます。
- ホストオペレーティングシステム (RHCOS) の空のサーバーへのインストール。
- 単一ノードでの OpenShift Container Platform のデプロイ
- クラスターポリシーおよびサイトサブスクリプションの作成
- 開発に GitOps デプロイメントトポロジーを活用し、任意のモデルをデプロイします。
- サーバーオペレーティングシステムに必要なネットワーク設定を行う。
- プロファイル Operator をデプロイし、パフォーマンスプロファイル、PTP、SR-IOV などの必要なソフトウェア関連の設定を実行します。
- ワークロードの実行に必要なイメージのダウンロード (CNF)
19.5. 単一ノードクラスター
ゼロタッチプロビジョニング (ZTP) を使用して、単一ノード OpenShift クラスターをデプロイし、エッジサイトのエッジサイトで小規模なハードウェアフットプリントで分散ユニット (DUs) を実行します。単一ノードクラスターは、1 つのベアメタルホスト上で OpenShift Container Platform を実行するため、単一ノードになります。エッジサーバーには、低帯域幅または切断されたエッジサイトにデプロイされる同じホストに supervisor 関数およびワーカー機能を持つ単一ノードが含まれます。
OpenShift Container Platform は、ワークロードのパーティション設定を使用するために単一ノードで設定されます。ワークロードの分割は、クラスター管理ワークロードをユーザーワークロードから分離し、予約された CPU のセットでクラスター管理ワークロードを実行できます。ワークロードの分割は、単一ノードの実稼働デプロイメントなどのリソース制約のある環境に役立ちます。この場合、ユーザーワークロード用に CPU リソースを大量に確保し、OpenShift Container Platform がホスト内で少ない CPU リソースを使用するように設定します。
ノードで DU アプリケーションをホストする単一ノードクラスターは、以下の設定カテゴリーに分類されます。
- common: 値は、ハブクラスターが管理するすべての単一ノードクラスターサイトで同じになります。
- サイトのプール: プールに共通し、プールサイズは 1 から n にできます。
- サイト固有: 他のサイトと重複のないサイトに固有の場合 (例: vlan)。
19.6. 分散ユニットデプロイメントにおけるサイトプランニングに関する考慮事項
分散ユニット (DU) デプロイメントのサイトプランニングは複雑です。以下は、DU ホストが実稼働環境でオンライン状態になる前に完了するタスクの概要です。
- ネットワークモデルを開発します。ネットワークモデルは、カバレッジの領域、ホストの数、プロジェクトのトラフィック負荷、DNS、DHCP 要件などのさまざまな要因によって異なります。
- ネットワークに十分なカバレッジおよび冗長性を提供するために必要な DU ラジオノードの数を決定します。
- DU ホストハードウェアの測定仕様および選択仕様を開発します。
- 各 DU サイトのインストールに対して構築計画を開発します。
- 実稼働環境のホスト BIOS 設定を調整し、BIOS 設定をホストにデプロイします。
- オンサイトに設置をインストールし、ホストをネットワークに接続し、電源を適用します。
- オンサイトのスイッチおよびルーターを設定します。
- ホストマシンに基本的な接続テストを実行します。
- 実稼働環境のネットワーク接続を確立し、ネットワークへのホストの接続を確認します。
- 大規模にオンサイトの DU ホストをプロビジョニングし、デプロイします。
- オンサイト操作をテストして検証し、DU ホストの負荷およびスケーリングのテストを実行してから、最後に DU インフラストラクチャーをライブ実稼働環境でオンラインにします。
19.7. 分散ユニット (DU) の低レイテンシー
低レイテンシーは、5G ネットワークの開発に不可欠です。さまざまな重要なユースケースで QoS (Quality of Service) を確実にするために、通信ネットワークでは、シグナルレイテンシーがほとんど必要ありません。
低レイテンシー処理は、機能やセキュリティーに影響するタイミング制約との通信に不可欠です。たとえば、5G Telco アプリケーションには、モノのインターネット (IoT) 要件のインターネットを満たすために 1 ミリ秒の一方向レイテンシーが必要です。低レイテンシーは、自律型車両、スマートファクトリー、オンラインゲーミングの将来的な開発にも重要です。これらの環境のネットワークには、ほぼリアルタイムのデータフローが必要です。
レイテンシーの少ないシステムは、応答時間と処理時間に関して、保証を行います。これには、通信プロトコルをスムーズに稼働させるようにし、高速な応答でエラー状態へのデバイスセキュリティーを確保することや、大量のデータを受信する際にシステムが遅れないことを確認するだけです。低レイテンシーは、無線送信を最適に同期するのに鍵です。
OpenShift Container Platform では、いくつかの技術や特殊ハードウェアデバイスを使用して、COTS ハードウェアで実行される DU の低レイテンシー処理を可能にします。
- RHCOS のリアルタイムカーネル
- ワークロードが高レベルのプロセス決定で処理されるようにします。
- CPU の分離
- CPU スケジューリングの遅延を回避し、CPU 容量が一貫して利用可能な状態にします。
- NUMA 認識
- メモリーとヒュージページを CPU および PCI デバイスに合わせて調整し、Guaranteed コンテナーのメモリーとヒュージページを NUMA ノードに固定します。これにより、レイテンシーが短縮され、ノードのパフォーマンスが向上します。
- Huge Page のメモリー管理
- Huge Page サイズを使用すると、ページテーブルへのアクセスに必要なシステムリソースの量を減らすことで、システムパフォーマンスが向上します。
- PTP を使用した精度同期
- サブマイクロ秒の正確性を持つネットワーク内のノード間の同期を可能にします。
19.8. 分散ユニットのベアメタルホスト用 BIOS の設定
分散ユニット (DU) ホストでは、ホストのプロビジョニング前に BIOS を設定する必要があります。BIOS 設定は、DU を実行する特定のハードウェアと、インストールの特定の要件によって異なります。
この開発者プレビューリリースでは、DU ベアメタルホストマシン用の BIOS の設定およびチューニングがお客様の責任です。BIOS の自動設定は、タッチのプロビジョニングワークフローでは処理されません。
手順
-
UEFI/BIOS Boot Mode を
UEFIに設定します。 - ホスト起動シーケンスの順序で、ハードドライブ を設定します。
ハードウェア用に特定の BIOS 設定を適用します。以下の表は、Intel FlexRAN 4G および 5G baseband PHY 参照設計をベースとした Intel Xeon Skylake または Intel Cascade Lake サーバーの典型的な BIOS 設定を説明しています。
重要BIOS 設定は、実際のハードウェアおよびネットワークの要件によって異なります。以下の設定例は、説明のみを目的としています。
表19.1 Intel Xeon Skylake または Cascade Lake サーバーの BIOS 設定例 BIOS 設定 設定 CPU パワーとパフォーマンスポリシー
パフォーマンス
Uncore Frequency Scaling
Disabled
パフォーマンスの制限
Disabled
Intel SpeedStep ® Tech の強化
有効
Intel Configurable TDP
有効
設定可能な TDP レベル
レベル 2
Intel® Turbo Boost Technology
有効
energy Efficient Turbo
Disabled
Hardware P-States
Disabled
Package C-State
C0/C1 の状態
C1E
Disabled
Processor C6
Disabled
ホストの BIOS でグローバル SR-IOV および VT-d 設定を有効にします。これらの設定は、ベアメタル環境に関連します。
19.9. 非接続環境の準備
スケールに分散ユニット (DU) をプロビジョニングするには、DU のプロビジョニングを処理する Red Hat Advanced Cluster Management (RHACM) をインストールする必要があります。
RHACM は、OpenShift Container Platform ハブクラスターに Operator としてデプロイされます。これは、ビルトインセキュリティーポリシーの単一コンソールからクラスターおよびアプリケーションを制御します。RHACM は DU ホストをプロビジョニングし、管理します。非接続環境で RHACM をインストールするには、必要な Operator イメージが含まれる Operator Lifecycle Manager (OLM) カタログをミラーリングするミラーレジストリーを作成します。OLM は Operator およびそれらの依存関係をクラスターで管理し、インストールし、アップグレードします。
また、非接続ミラーホストを使用して、DU ベアメタルホストのオペレーティングシステムをプロビジョニングする RHCOS ISO および RootFS ディスクイメージにも機能します。
ネットワークが制限された環境でプロビジョニングするインフラストラクチャーにクラスターをインストールする前に、必要なコンテナーイメージをその環境にミラーリングする必要があります。この手順を無制限のネットワークで使用して、クラスターが外部コンテンツにちて組織の制御の条件を満たすコンテナーイメージのみを使用するようにすることもできます。
必要なコンテナーイメージを取得するには、インターネットへのアクセスが必要です。この手順では、ご使用のネットワークとインターネットのどちらにもアクセスできるミラーホストにミラーレジストリーを配置します。ミラーホストへのアクセスがない場合は、非接続の手順に従って、イメージをネットワークの境界をまたがって移動できるデバイスにコピーします。
19.9.1. 非接続環境の前提条件
以下のレジストリーのいずれかなど、OpenShift Container Platform クラスターをホストする場所に Docker v2-2 をサポートするコンテナーイメージレジストリーが必要です。
Red Hat Quay のエンタイトルメントをお持ちの場合は、Red Hat Quay のデプロイに関するドキュメント 概念実証 (実稼働以外) 向けの Red Hat Quay のデプロイ または Quay Operator の使用による OpenShift への Red Hat Quay のデプロイ を参照してください。レジストリーの選択およびインストールがにおいてさらにサポートが必要な場合は、営業担当者または Red Hat サポートにお問い合わせください。
Red Hat は、OpenShift Container Platform を使用してサードパーティーのレジストリーをテストしません。
19.9.2. ミラーレジストリーについて
OpenShift Container Platform のインストールとその後の製品更新に必要なイメージは、Red Hat Quay、JFrog Artifactory、Sonatype Nexus Repository、Harbor などのコンテナーミラーレジストリーにミラーリングできます。大規模なコンテナーレジストリーにアクセスできない場合は、OpenShift Container Platform サブスクリプションに含まれる小規模なコンテナーレジストリーである Red Hat Openshift 導入用のミラーレジストリー を使用できます。
Red Hat Quay、Red Hat Openshift 導入用のミラーレジストリー、Artifactory、Sonatype Nexus リポジトリー、Harbor など、Dockerv2-2 をサポートする任意のコンテナーレジストリーを使用できます。選択したレジストリーに関係なく、インターネット上の Red Hat がホストするサイトから分離されたイメージレジストリーにコンテンツをミラーリングする手順は同じです。コンテンツをミラーリングした後に、各クラスターをミラーレジストリーからこのコンテンツを取得するように設定します。
OpenShift Container Platform クラスターの内部レジストリーはターゲットレジストリーとして使用できません。これは、ミラーリングプロセスで必要となるタグを使わないプッシュをサポートしないためです。
Red Hat Openshift 導入用のミラーレジストリー以外のコンテナーレジストリーを選択する場合は、プロビジョニングするクラスター内の全マシンから到達可能である必要があります。レジストリーに到達できない場合、インストール、更新、またはワークロードの再配置などの通常の操作が失敗する可能性があります。そのため、ミラーレジストリーは可用性の高い方法で実行し、ミラーレジストリーは少なくとも OpenShift Container Platform クラスターの実稼働環境の可用性の条件に一致している必要があります。
ミラーレジストリーを OpenShift Container Platform イメージで設定する場合、2 つのシナリオを実行することができます。インターネットとミラーレジストリーの両方にアクセスできるホストがあり、クラスターノードにアクセスできない場合は、そのマシンからコンテンツを直接ミラーリングできます。このプロセスは、connected mirroring (接続ミラーリング) と呼ばれます。このようなホストがない場合は、イメージをファイルシステムにミラーリングしてから、そのホストまたはリムーバブルメディアを制限された環境に配置する必要があります。このプロセスは、disconnected mirroring (非接続ミラーリング) と呼ばれます。
ミラーリングされたレジストリーの場合は、プルされたイメージのソースを表示するには、CRI-O ログで Trying to access のログエントリーを確認する必要があります。ノードで crictl images コマンドを使用するなど、イメージのプルソースを表示する他の方法では、イメージがミラーリングされた場所からプルされている場合でも、ミラーリングされていないイメージ名を表示します。
Red Hat は、OpenShift Container Platform を使用してサードパーティーのレジストリーをテストしません。
関連情報
- CRI-O ログを表示してイメージソースを表示する方法は、イメージのプルソースの表示 を参照してください。
19.9.3. ミラーホストの準備
ミラー手順を実行する前に、ホストを準備して、コンテンツを取得し、リモートの場所にプッシュできるようにする必要があります。
19.9.3.1. バイナリーのダウンロードによる OpenShift CLI のインストール
コマンドラインインターフェイスを使用して OpenShift Container Platform と対話するために CLI (oc) をインストールすることができます。oc は Linux、Windows、または macOS にインストールできます。
以前のバージョンの oc をインストールしている場合、これを使用して OpenShift Container Platform 4.9 のすべてのコマンドを実行することはできません。新規バージョンの oc をダウンロードし、インストールします。
Linux への OpenShift CLI のインストール
以下の手順を使用して、OpenShift CLI (oc) バイナリーを Linux にインストールできます。
手順
- Red Hat カスタマーポータルの OpenShift Container Platform ダウンロードページ に移動します。
- Version ドロップダウンメニューで適切なバージョンを選択します。
- OpenShift v4.9 Linux Client エントリーの横にある Download Now をクリックして、ファイルを保存します。
アーカイブを展開します。
$ tar xvf <file>
ocバイナリーを、PATHにあるディレクトリーに配置します。PATHを確認するには、以下のコマンドを実行します。$ echo $PATH
OpenShift CLI のインストール後に、oc コマンドを使用して利用できます。
$ oc <command>
Windows への OpenShift CLI のインストール
以下の手順を使用して、OpenShift CLI (oc) バイナリーを Windows にインストールできます。
手順
- Red Hat カスタマーポータルの OpenShift Container Platform ダウンロードページ に移動します。
- Version ドロップダウンメニューで適切なバージョンを選択します。
- OpenShift v4.9 Windows Client エントリーの横にある Download Now をクリックして、ファイルを保存します。
- ZIP プログラムでアーカイブを解凍します。
ocバイナリーを、PATHにあるディレクトリーに移動します。PATHを確認するには、コマンドプロンプトを開いて以下のコマンドを実行します。C:\> path
OpenShift CLI のインストール後に、oc コマンドを使用して利用できます。
C:\> oc <command>
macOC への OpenShift CLI のインストール
以下の手順を使用して、OpenShift CLI (oc) バイナリーを macOS にインストールできます。
手順
- Red Hat カスタマーポータルの OpenShift Container Platform ダウンロードページ に移動します。
- Version ドロップダウンメニューで適切なバージョンを選択します。
- OpenShift v4.9 MacOSX Client エントリーの横にある Download Now をクリックして、ファイルを保存します。
- アーカイブを展開し、解凍します。
ocバイナリーをパスにあるディレクトリーに移動します。PATHを確認するには、ターミナルを開き、以下のコマンドを実行します。$ echo $PATH
OpenShift CLI のインストール後に、oc コマンドを使用して利用できます。
$ oc <command>
19.9.3.2. イメージのミラーリングを可能にする認証情報の設定
Red Hat からミラーへのイメージのミラーリングを可能にするコンテナーイメージレジストリーの認証情報ファイルを作成します。
前提条件
- 切断された環境で使用するミラーレジストリーを設定しました。
手順
インストールホストで以下の手順を実行します。
-
registry.redhat.ioプルシークレットを Red Hat OpenShift Cluster Manager からダウンロードし、.jsonファイルに保存します。 ミラーレジストリーの base64 でエンコードされたユーザー名およびパスワードまたはトークンを生成します。
$ echo -n '<user_name>:<password>' | base64 -w0 1 BGVtbYk3ZHAtqXs=- 1
<user_name>および<password>については、レジストリーに設定したユーザー名およびパスワードを指定します。
JSON 形式でプルシークレットのコピーを作成します。
$ cat ./pull-secret.text | jq . > <path>/<pull_secret_file_in_json>1- 1
- プルシークレットを保存するフォルダーへのパスおよび作成する JSON ファイルの名前を指定します。
ファイルを
~/.docker/config.jsonまたは$XDG_RUNTIME_DIR/containers/auth.jsonとして保存します。ファイルの内容は以下の例のようになります。
{ "auths": { "cloud.openshift.com": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "quay.io": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "registry.connect.redhat.com": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" }, "registry.redhat.io": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" } } }新規ファイルを編集し、レジストリーについて記述するセクションをこれに追加します。
"auths": { "<mirror_registry>": { 1 "auth": "<credentials>", 2 "email": "you@example.com" } },ファイルは以下の例のようになります。
{ "auths": { "registry.example.com": { "auth": "BGVtbYk3ZHAtqXs=", "email": "you@example.com" }, "cloud.openshift.com": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "quay.io": { "auth": "b3BlbnNo...", "email": "you@example.com" }, "registry.connect.redhat.com": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" }, "registry.redhat.io": { "auth": "NTE3Njg5Nj...", "email": "you@example.com" } } }
19.9.3.3. OpenShift Container Platform イメージリポジトリーのミラーリング
クラスターのインストールまたはアップグレード時に使用するために、OpenShift Container Platform イメージリポジトリーをお使いのレジストリーにミラーリングします。
前提条件
- ミラーホストがインターネットにアクセスできる。
- ネットワークが制限された環境で使用するミラーレジストリーを設定し、設定した証明書および認証情報にアクセスできる。
- Red Hat OpenShift Cluster Manager からプルシークレット をダウンロードし、ミラーリポジトリーへの認証を含めるようにこれを変更している。
Subject Alternative Name が設定されていない自己署名証明書を使用する場合は、この手順の
ocコマンドの前にGODEBUG=x509ignoreCN=0を追加する必要があります。この変数を設定しない場合、ocコマンドは以下のエラーを出して失敗します。x509: certificate relies on legacy Common Name field, use SANs or temporarily enable Common Name matching with GODEBUG=x509ignoreCN=0
手順
ミラーホストで以下の手順を実行します。
- OpenShift Container Platform ダウンロード ページを確認し、インストールする必要のある OpenShift Container Platform のバージョンを判別し、Repository Tags ページで対応するタグを判別します。
必要な環境変数を設定します。
リリースバージョンをエクスポートします。
$ OCP_RELEASE=<release_version>
<release_version>について、インストールする OpenShift Container Platform のバージョンに対応するタグを指定します (例:4.5.4)。ローカルレジストリー名とホストポートをエクスポートします。
$ LOCAL_REGISTRY='<local_registry_host_name>:<local_registry_host_port>'
<local_registry_host_name>については、ミラーレジストリーのレジストリードメイン名を指定し、<local_registry_host_port>については、コンテンツの送信に使用するポートを指定します。ローカルリポジトリー名をエクスポートします。
$ LOCAL_REPOSITORY='<local_repository_name>'
<local_repository_name>については、ocp4/openshift4などのレジストリーに作成するリポジトリーの名前を指定します。ミラーリングするリポジトリーの名前をエクスポートします。
$ PRODUCT_REPO='openshift-release-dev'
実稼働環境のリリースの場合には、
openshift-release-devを指定する必要があります。パスをレジストリープルシークレットにエクスポートします。
$ LOCAL_SECRET_JSON='<path_to_pull_secret>'
<path_to_pull_secret>については、作成したミラーレジストリーのプルシークレットの絶対パスおよびファイル名を指定します。リリースミラーをエクスポートします。
$ RELEASE_NAME="ocp-release"
実稼働環境のリリースについては、
ocp-releaseを指定する必要があります。サーバーのアーキテクチャーのタイプをエクスポートします (例:
x86_64)。$ ARCHITECTURE=<server_architecture>
ミラーリングされたイメージをホストするためにディレクトリーへのパスをエクスポートします。
$ REMOVABLE_MEDIA_PATH=<path> 1- 1
- 最初のスラッシュ (/) 文字を含む完全パスを指定します。
バージョンイメージをミラーレジストリーにミラーリングします。
ミラーホストがインターネットにアクセスできない場合は、以下の操作を実行します。
- リムーバブルメディアをインターネットに接続しているシステムに接続します。
ミラーリングするイメージおよび設定マニフェストを確認します。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE} --dry-run-
直前のコマンドの出力の
imageContentSourcesセクション全体を記録します。ミラーの情報はミラーリングされたリポジトリーに一意であり、インストール時にimageContentSourcesセクションをinstall-config.yamlファイルに追加する必要があります。 イメージをリムーバブルメディア上のディレクトリーにミラーリングします。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --to-dir=${REMOVABLE_MEDIA_PATH}/mirror quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE}メディアをネットワークが制限された環境に移し、イメージをローカルコンテナーレジストリーにアップロードします。
$ oc image mirror -a ${LOCAL_SECRET_JSON} --from-dir=${REMOVABLE_MEDIA_PATH}/mirror "file://openshift/release:${OCP_RELEASE}*" ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} 1- 1
REMOVABLE_MEDIA_PATHの場合、イメージのミラーリング時に指定した同じパスを使用する必要があります。
ローカルコンテナーレジストリーがミラーホストに接続されている場合は、以下の操作を実行します。
以下のコマンドを使用して、リリースイメージをローカルレジストリーに直接プッシュします。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}このコマンドは、リリース情報をダイジェストとしてプルします。その出力には、クラスターのインストール時に必要な
imageContentSourcesデータが含まれます。直前のコマンドの出力の
imageContentSourcesセクション全体を記録します。ミラーの情報はミラーリングされたリポジトリーに一意であり、インストール時にimageContentSourcesセクションをinstall-config.yamlファイルに追加する必要があります。注記ミラーリングプロセス中にイメージ名に Quay.io のパッチが適用され、podman イメージにはブートストラップ仮想マシンのレジストリーに Quay.io が表示されます。
ミラーリングしたコンテンツをベースとしているインストールプログラムを作成するには、これを展開し、リリースに固定します。
ミラーホストがインターネットにアクセスできない場合は、以下のコマンドを実行します。
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}"ローカルコンテナーレジストリーがミラーホストに接続されている場合は、以下のコマンドを実行します。
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"重要選択した OpenShift Container Platform バージョンに適したイメージを使用するには、ミラーリングされたコンテンツからインストールプログラムを展開する必要があります。
インターネット接続のあるマシンで、このステップを実行する必要があります。
非接続環境を使用している場合には、must-gather の一部として
--imageフラグを使用し、ペイロードイメージを参照します。
インストーラーでプロビジョニングされるインフラストラクチャーを使用するクラスターの場合は、以下のコマンドを実行します。
$ openshift-install
19.9.3.4. RHCOS ISO および RootFS イメージの非接続ミラーホストへの追加
ユーザーによってプロビジョニングされるインフラストラクチャーにクラスターをインストールする前に、それが使用する Red Hat Enterprise Linux CoreOS (RHCOS) マシンを作成する必要があります。非接続ミラーを使用して、分散ユニット (DU) ベアメタルホストのプロビジョニングに必要な RHCOS イメージをホストします。
前提条件
- ネットワーク上で RHCOS イメージリソースをホストするように HTTP サーバーをデプロイして設定します。お使いのコンピューターから HTTP サーバーにアクセスでき、作成するマシンからもアクセスできる必要があります。
RHCOS イメージは OpenShift Container Platform の各リリースごとに変更されない可能性があります。インストールする OpenShift Container Platform バージョンと等しいか、それ以下のバージョンの内で最も新しいバージョンのイメージをダウンロードする必要があります。利用可能な場合は、OpenShift Container Platform バージョンに一致するイメージのバージョンを使用します。DU ホストに RHCOS をインストールするには、ISO および RootFS イメージが必要です。RHCOS qcow2 イメージは、このインストールではサポートされません。
手順
- ミラーホストにログインします。
mirror.openshift.com から RHCOS ISO イメージおよび RootFS イメージを取得します。以下は例になります。
必要なイメージ名と OpenShift Container Platform のバージョンを環境変数としてエクスポートします。
$ export ISO_IMAGE_NAME=<iso_image_name> 1$ export ROOTFS_IMAGE_NAME=<rootfs_image_name> 1$ export OCP_VERSION=<ocp_version> 1必要なイメージをダウンロードします。
$ sudo wget https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/pre-release/${OCP_VERSION}/${ISO_IMAGE_NAME} -O /var/www/html/${ISO_IMAGE_NAME}$ sudo wget https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/pre-release/${OCP_VERSION}/${ROOTFS_IMAGE_NAME} -O /var/www/html/${ROOTFS_IMAGE_NAME}
検証手順
イメージが正常にダウンロードされ、非接続ミラーホストで提供されることを確認します。以下に例を示します。
$ wget http://$(hostname)/${ISO_IMAGE_NAME}予想される出力
... Saving to: rhcos-4.9.0-fc.1-x86_64-live.x86_64.iso rhcos-4.9.0-fc.1-x86_64- 11%[====> ] 10.01M 4.71MB/s ...
19.10. 非接続環境での Red Hat Advanced Cluster Management のインストール
非接続環境のハブクラスターで Red Hat Advanced Cluster Management (RHACM) を使用して、複数のマネージドクラスターで分散ユニット (DU) プロファイルのデプロイメントを管理します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。 クラスターで使用するために非接続ミラーレジストリーを設定します。
注記Operator をスポーククラスターにデプロイする場合、それらをこのレジストリーに追加する必要もあります。詳細は、Operator カタログのミラーリング を参照してください。
手順
- 非接続環境のハブクラスターに RHACM をインストールします。非接続環境での RHACM のインストール を参照してください。
19.11. ベアメタルでの支援付きインストーラーサービスの有効化
Assisted Installer Service (AIS) は、OpenShift Container Platform クラスターをデプロイします。Red Hat Advanced Cluster Management (RHACM) は AIS に同梱されています。AIS は、RHACM ハブクラスターで MultiClusterHub Operator を有効にしたときにデプロイされます。
分散ユニット (DU) の場合、RHACM は、単一のベアメタルホストで実行される OpenShift Container Platform デプロイメントをサポートします。単一ノードクラスターはコントロールプレーンとワーカーノードの両方として機能します。
前提条件
- ハブクラスターに OpenShift Container Platform 4.9 をインストールします。
-
RHACM をインストールし、
MultiClusterHubリソースを作成します。 - データベースおよびファイルシステムストレージ用に永続ボリュームカスタムリソース (CR) を作成する。
-
OpenShift CLI (
oc) がインストールされている。
手順
HiveConfigリソースを変更し、アシストインストーラーの機能ゲートを有効にします。$ oc patch hiveconfig hive --type merge -p '{"spec":{"targetNamespace":"hive","logLevel":"debug","featureGates":{"custom":{"enabled":["AlphaAgentInstallStrategy"]},"featureSet":"Custom"}}}'Bare Metal Operator がすべての namespace を監視できるように、
Provisioningリソースを変更します。$ oc patch provisioning provisioning-configuration --type merge -p '{"spec":{"watchAllNamespaces": true }}'AgentServiceConfigCR を作成します。以下の YAML を
agent_service_config.yamlファイルに保存します。apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: databaseStorage: accessModes: - ReadWriteOnce resources: requests: storage: <db_volume_size> 1 filesystemStorage: accessModes: - ReadWriteOnce resources: requests: storage: <fs_volume_size> 2 osImages: 3 - openshiftVersion: "<ocp_version>" 4 version: "<ocp_release_version>" 5 url: "<iso_url>" 6 rootFSUrl: "<root_fs_url>" 7 cpuArchitecture: "x86_64"以下のコマンドを実行して、
AgentServiceConfigCR を作成します。$ oc create -f agent_service_config.yaml
出力例
agentserviceconfig.agent-install.openshift.io/agent created
19.12. ZTP カスタムリソース
ゼロ変更プロビジョニング (ZTP) はカスタムリソース (CR) オブジェクトを使用して Kubernetes API を拡張するか、または独自の API をプロジェクトまたはクラスターに導入します。これらの CR には、RAN アプリケーションのクラスターのインストールおよび設定に必要なサイト固有のデータが含まれます。
カスタムリソース定義 (CRD) ファイルは、独自のオブジェクトの種類を定義します。CRD をマネージドクラスターにデプロイすると、Kubernetes API サーバーはライフサイクル全体で指定された CR を提供し始めます。
マネージドクラスターの <site>.yaml ファイルの各 CR について、ZTP はデータを使用してクラスターに設定されたディレクトリーにインストール CR を作成します。
ZTP は、マネージドクラスターでの CR の定義とインストールの方法の 2 つの方法を提供します。これは、単一のクラスターをプロビジョニングする際の手動アプローチと、複数のクラスターをプロビジョニングする際の自動アプローチです。
- 単一クラスターの手動 CR の作成
- 単一クラスターの CR を作成する際に、この方法を使用します。これは、より大きなスケールにデプロイする前に CR をテストするのに適した方法です。
- 複数のマネージドクラスターの自動 CR 作成
- 複数のマネージドクラスターをインストールする場合 (たとえば、最大 100 個のクラスターでバッチ処理) する場合は、自動 SiteConfig メソッドを使用します。SiteConfig は、サイトデプロイメントの GitOps メソッドのエンジンとして ArgoCD を使用します。デプロイメントに必要なすべてのパラメーターが含まれるサイトプランの完了後に、ポリシージェネレーターはマニフェストを作成し、それらをハブクラスターに適用します。
どちらのメソッドも、以下の表に示されている CR を作成します。クラスターサイトでは、自動検出イメージ ISO ファイルは、サイト名とクラスター名のファイルを含むディレクトリーを作成します。すべてのクラスターには独自の namespace があり、すべての CR はその namespace の下にあります。namespace および CR 名はクラスター名に一致します。
| リソース | 説明 | 使用法 |
|---|---|---|
|
| ターゲットのベアメタルホストの Baseboard Management Controller (BMC) の接続情報が含まれています。 | Redfish プロトコルを使用して、ターゲットサーバーで Discovery イメージ ISO を読み込んで起動するために BMC へのアクセスを提供します。 |
|
| OpenShift Container Platform をターゲットのベアメタルホストにプルするための情報が含まれています。 | ClusterDeployment で使用され、マネージドクラスターの Discovery ISO を生成します。 |
|
|
ネットワークやスーパーバイザー (コントロールプレーン) ノードの数などのマネージドクラスターの設定を指定します。インストールの完了時に | マネージドクラスターの設定情報を指定し、クラスターのインストール時にステータスを指定します。 |
|
|
使用する |
マネージドクラスターの Discovery ISO を生成するために |
|
|
| マネージドクラスターの Kube API サーバーの静的 IP アドレスを設定します。 |
|
| ターゲットのベアメタルホストに関するハードウェア情報が含まれています。 | ターゲットマシンの Discovery イメージの ISO の起動時に、ハブ上に自動的に作成されます。 |
|
| クラスターがハブで管理されている場合は、インポートして知られている必要があります。この Kubernetes オブジェクトはそのインターフェイスを提供します。 | ハブは、このリソースを使用してマネージドクラスターのステータスを管理し、表示します。 |
|
|
|
|
|
|
ハブ上にある |
リソースを |
|
|
|
|
|
| リポジトリーおよびイメージ名などの OpenShift Container Platform イメージ情報が含まれます。 | OpenShift Container Platform イメージを提供するためにリソースに渡されます。 |
19.13. 単一のマネージドクラスターをインストールするためのカスタムリソースの作成
この手順では、単一のマネージドクラスターを手動で作成してデプロイする方法を説明します。複数のクラスター (数百など) を作成する場合は、複数のマネージドクラスターの ZTP カスタムリソースの作成で説明されている SiteConfig メソッドを使用します。
前提条件
- Assisted Installer サービスを有効にします。
ネットワーク接続を確認します。
- ハブ内のコンテナーは、ターゲットのベアメタルホストの Baseboard Management Controller (BMC) アドレスに到達できる必要があります。
マネージドクラスターは、ハブの API
hostnameおよび*.appホスト名を解決し、到達できる必要があります。ハブの API および*.appホスト名の例:console-openshift-console.apps.hub-cluster.internal.domain.com api.hub-cluster.internal.domain.com
ハブは、マネージドクラスターの API および
*.appホスト名を解決して到達できる必要があります。以下は、マネージドクラスターの API および*.appホスト名の例です。console-openshift-console.apps.sno-managed-cluster-1.internal.domain.com api.sno-managed-cluster-1.internal.domain.com
- ターゲットのベアメタルホストから IP 到達可能な DNS サーバー。
以下のハードウェアの最小要件を備えた、マネージドクラスターのターゲットベアメタルホスト:
- 4 CPU または 8 vCPU
- 32 GiB RAM
- ルートファイルシステムの 120 GiB ディスク
非接続環境で作業する場合は、リリースイメージをミラーリングする必要があります。以下のコマンドを使用して、リリースイメージをミラーリングします。
oc adm release mirror -a <pull_secret.json> --from=quay.io/openshift-release-dev/ocp-release:{{ mirror_version_spoke_release }} --to={{ provisioner_cluster_registry }}/ocp4 --to-release-image={{ provisioner_cluster_registry }}/ocp4:{{ mirror_version_spoke_release }}スポーククラスター ISO を生成するために使用される ISO および
rootfsを HTTP サーバーにミラーリングし、そこからイメージをプルできるように設定を設定している。イメージは、
ClusterImageSetのバージョンと一致する必要があります。4.9.0 バージョンをデプロイするには、rootfsおよび ISO を 4.9.0 に設定する必要があります。
手順
デプロイが必要な特定のクラスターバージョンごとに
ClusterImageSetを作成します。ClusterImageSetのフォーマットは以下のとおりです。apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: openshift-4.9.0-rc.0 1 spec: releaseImage: quay.io/openshift-release-dev/ocp-release:4.9.0-x86_64 2
マネージドクラスターの
namespace定義を作成します。apiVersion: v1 kind: Namespace metadata: name: <cluster_name> 1 labels: name: <cluster_name> 2BMC Secretカスタムリソースを作成します。apiVersion: v1 data: password: <bmc_password> 1 username: <bmc_username> 2 kind: Secret metadata: name: <cluster_name>-bmc-secret namespace: <cluster_name> type: Opaque
Image Pull Secretカスタムリソースを作成します。apiVersion: v1 data: .dockerconfigjson: <pull_secret> 1 kind: Secret metadata: name: assisted-deployment-pull-secret namespace: <cluster_name> type: kubernetes.io/dockerconfigjson- 1
- OpenShift Container Platform プルシークレット。base-64 でエンコードされている必要があります。
AgentClusterInstallカスタムリソースを作成します。apiVersion: extensions.hive.openshift.io/v1beta1 kind: AgentClusterInstall metadata: # Only include the annotation if using OVN, otherwise omit the annotation annotations: agent-install.openshift.io/install-config-overrides: '{"networking":{"networkType":"OVNKubernetes"}}' name: <cluster_name> namespace: <cluster_name> spec: clusterDeploymentRef: name: <cluster_name> imageSetRef: name: <cluster_image_set> 1 networking: clusterNetwork: - cidr: <cluster_network_cidr> 2 hostPrefix: 23 machineNetwork: - cidr: <machine_network_cidr> 3 serviceNetwork: - <service_network_cidr> 4 provisionRequirements: controlPlaneAgents: 1 workerAgents: 0 sshPublicKey: <public_key> 5- 1
- ベアメタルホストに OpenShift Container Platform をインストールするために使用される ClusterImageSet カスタムリソースの名前。
- 2
- クラスターノード間の通信に使用される CIDR 表記の IPv4 または IPv6 アドレスのブロック。
- 3
- ターゲットのベアメタルホストの外部通信に使用される CIDR 表記の IPv4 または IPv6 アドレスのブロック。DU 単一ノードクラスターをプロビジョニングするときに API および Ingress VIP アドレスを決定するためにも使用されます。
- 4
- クラスターサービスの内部通信に使用される CIDR 表記の IPv4 または IPv6 アドレスのブロック。
- 5
- プレーンテキストとして入力されました。インストールが完了したら、公開鍵を使用してノードに SSH で接続できます。
注記この時点で、マネージドクラスターの静的 IP を設定する場合は、マネージドクラスターの静的 IP アドレスを設定する方法については、本書の手順を参照してください。
ClusterDeploymentカスタムリソースを作成します。apiVersion: hive.openshift.io/v1 kind: ClusterDeployment metadata: name: <cluster_name> namespace: <cluster_name> spec: baseDomain: <base_domain> 1 clusterInstallRef: group: extensions.hive.openshift.io kind: AgentClusterInstall name: <cluster_name> version: v1beta1 clusterName: <cluster_name> platform: agentBareMetal: agentSelector: matchLabels: cluster-name: <cluster_name> pullSecretRef: name: assisted-deployment-pull-secret- 1
- マネージドクラスターのベースドメイン。
KlusterletAddonConfigカスタムリソースを作成します。apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <cluster_name> namespace: <cluster_name> spec: clusterName: <cluster_name> clusterNamespace: <cluster_name> clusterLabels: cloud: auto-detect vendor: auto-detect applicationManager: enabled: true certPolicyController: enabled: false iamPolicyController: enabled: false policyController: enabled: true searchCollector: enabled: false 1- 1
trueに設定すると KlusterletAddonConfig が有効になり、falseに設定すると KlusterletAddonConfig が無効になります。searchCollectorを無効にした状態に維持します。
ManagedClusterカスタムリソースを作成します。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: name: <cluster_name> spec: hubAcceptsClient: true
InfraEnvカスタムリソースを作成します。apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <cluster_name> namespace: <cluster_name> spec: clusterRef: name: <cluster_name> namespace: <cluster_name> sshAuthorizedKey: <public_key> 1 agentLabels: 2 location: "<label-name>" pullSecretRef: name: assisted-deployment-pull-secretBareMetalHostカスタムリソースを作成します。apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <cluster_name> namespace: <cluster_name> annotations: inspect.metal3.io: disabled labels: infraenvs.agent-install.openshift.io: "<cluster_name>" spec: bootMode: "UEFI" bmc: address: <bmc_address> 1 disableCertificateVerification: true credentialsName: <cluster_name>-bmc-secret bootMACAddress: <mac_address> 2 automatedCleaningMode: disabled online: trueオプションで、アノテーションとして
bmac.agent-install.openshift.io/hostname: <host-name>を追加して、マネージドクラスターのホスト名を設定できます。アノテーションを追加しない場合、ホスト名はデフォルトで DHCP サーバーまたはローカルホストのホスト名になります。- カスタムリソースを作成したら、生成されたカスタムリソースのディレクトリー全体を、カスタムリソースを保存するために作成した Git リポジトリーにプッシュします。
次のステップ
追加のクラスターをプロビジョニングするには、それぞれのクラスターについてこの手順を繰り返します。
19.13.1. マネージドクラスターの静的 IP アドレスの設定
オプションで、AgentClusterInstall カスタムリソースの作成後に、マネージドクラスターの静的 IP アドレスを設定できます。
ClusterDeployment カスタムリソースを作成する前に、このカスタムリソースを作成する必要があります。
前提条件
-
AgentClusterInstallカスタムリソースをデプロイして設定します。
手順
NMStateConfigカスタムリソースを作成します。apiVersion: agent-install.openshift.io/v1beta1 kind: NMStateConfig metadata: name: <cluster_name> namespace: <cluster_name> labels: sno-cluster-<cluster-name>: <cluster_name> spec: config: interfaces: - name: eth0 type: ethernet state: up ipv4: enabled: true address: - ip: <ip_address> 1 prefix-length: <public_network_prefix> 2 dhcp: false dns-resolver: config: server: - <dns_resolver> 3 routes: config: - destination: 0.0.0.0/0 next-hop-address: <gateway> 4 next-hop-interface: eth0 table-id: 254 interfaces: - name: "eth0" 5 macAddress: <mac_address> 6-
BareMetalHostカスタムリソースを作成するときは、その MAC アドレスの 1 つがNMStateConfigターゲットのベアメタルホストの MAC アドレスと一致することを確認してください。 InfraEnvカスタムリソースの作成時に、InfraEnvカスタムリソースのNMStateConfigカスタムリソースからラベル を参照します。apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <cluster_name> namespace: <cluster_name> spec: clusterRef: name: <cluster_name> namespace: <cluster_name> sshAuthorizedKey: <public_key> agentLabels: 1 location: "<label-name>" pullSecretRef: name: assisted-deployment-pull-secret nmStateConfigLabelSelector: matchLabels: sno-cluster-<cluster-name>: <cluster_name> # Match this label- 1
- 一致するラベルを設定します。ラベルは、エージェントの起動時に適用されます。
19.13.2. クラスターをプロビジョニングする自動検出イメージ ISO プロセス
カスタムリソースを作成すると、以下のアクションが自動的に行われます。
- Discovery イメージの ISO ファイルが生成され、ターゲットマシンで起動します。
- ターゲットマシンで ISO ファイルが正常に起動すると、ターゲットマシンのハードウェア情報を報告します。
- すべてのホストの検出後に、OpenShift Container Platform がインストールされます。
-
OpenShift Container Platform のインストールが完了すると、ハブは
klusterletサービスをターゲットクラスターにインストールします。 - 要求されたアドオンサービスがターゲットクラスターにインストールされている。
Discovery イメージの ISO プロセスは、マネージドクラスターのハブに Agent カスタムリソースが作成されると終了します。
19.13.3. マネージドクラスターステータスの確認
クラスターのステータスをチェックして、クラスターのプロビジョニングが正常に行われたことを確認します。
前提条件
-
すべてのカスタムリソースが設定およびプロビジョニングされ、プロビジョニングされ、マネージドクラスターのハブで
Agentカスタムリソースが作成されます。
手順
マネージドクラスターのステータスを確認します。
$ oc get managedcluster
Trueはマネージドクラスターの準備が整っていることを示します。エージェントのステータスを確認します。
$ oc get agent -n <cluster_name>
describeコマンドを使用して、エージェントの条件に関する詳細な説明を指定します。認識できるステータスには、BackendError、InputError、ValidationsFailing、InstallationFailed、およびAgentIsConnectedが含まれます。これらのステータスは、AgentおよびAgentClusterInstallカスタムリソースに関連します。$ oc describe agent -n <cluster_name>
クラスターのプロビジョニングのステータスを確認します。
$ oc get agentclusterinstall -n <cluster_name>
describeコマンドを使用して、クラスターのプロビジョニングステータスの詳細な説明を指定します。$ oc describe agentclusterinstall -n <cluster_name>
マネージドクラスターのアドオンサービスのステータスを確認します。
$ oc get managedclusteraddon -n <cluster_name>
マネージドクラスターの
kubeconfigファイルの認証情報を取得します。$ oc get secret -n <cluster_name> <cluster_name>-admin-kubeconfig -o jsonpath={.data.kubeconfig} | base64 -d > <directory>/<cluster_name>-kubeconfig
19.13.4. 非接続環境でのマネージドクラスターの設定
前述の手順を完了したら、以下の手順に従って非接続環境でマネージドクラスターを設定します。
前提条件
- Red Hat Advanced Cluster Management (RHACM) 2.3 の非接続インストール。
-
rootfsおよびisoイメージを HTTPD サーバーでホストします。
手順
ミラーレジストリー設定を含む
ConfigMapを作成します。apiVersion: v1 kind: ConfigMap metadata: name: assisted-installer-mirror-config namespace: assisted-installer labels: app: assisted-service data: ca-bundle.crt: <certificate> 1 registries.conf: | 2 unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] location = <mirror_registry_url> 3 insecure = false mirror-by-digest-only = trueこれにより、以下のように
AgentServiceConfigカスタムリソースのmirrorRegistryRefが更新されます。出力例
apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent namespace: assisted-installer spec: databaseStorage: volumeName: <db_pv_name> accessModes: - ReadWriteOnce resources: requests: storage: <db_storage_size> filesystemStorage: volumeName: <fs_pv_name> accessModes: - ReadWriteOnce resources: requests: storage: <fs_storage_size> mirrorRegistryRef: name: 'assisted-installer-mirror-config' osImages: - openshiftVersion: <ocp_version> rootfs: <rootfs_url> 1 url: <iso_url> 2非接続インストールでは、オフラインネットワーク経由で到達可能な NTP クロックをデプロイする必要があります。これは、chrony をサーバーとして機能するように設定する、
/etc/chrony.confファイルを編集し、以下の許可された IPv6 範囲を追加します。# Allow NTP client access from local network. #allow 192.168.0.0/16 local stratum 10 bindcmdaddress :: allow 2620:52:0:1310::/64
19.13.5. 非接続環境での IPv6 アドレスの設定
オプションとして、AgentClusterInstall カスタムリソースを作成する場合、マネージドクラスターの IPv6 アドレスを設定できます。
手順
AgentClusterInstallカスタムリソースで、IPv6 アドレスのclusterNetworkおよびserviceNetworkの IP アドレスを変更します。apiVersion: extensions.hive.openshift.io/v1beta1 kind: AgentClusterInstall metadata: # Only include the annotation if using OVN, otherwise omit the annotation annotations: agent-install.openshift.io/install-config-overrides: '{"networking":{"networkType":"OVNKubernetes"}}' name: <cluster_name> namespace: <cluster_name> spec: clusterDeploymentRef: name: <cluster_name> imageSetRef: name: <cluster_image_set> networking: clusterNetwork: - cidr: "fd01::/48" hostPrefix: 64 machineNetwork: - cidr: <machine_network_cidr> serviceNetwork: - "fd02::/112" provisionRequirements: controlPlaneAgents: 1 workerAgents: 0 sshPublicKey: <public_key>-
定義した IPv6 アドレスを使用して、
NMStateConfigカスタムリソースを更新します。
19.13.6. マネージドクラスターのトラブルシューティング
以下の手順を使用して、マネージドクラスターで発生する可能性のあるインストール問題を診断します。
手順
マネージドクラスターのステータスを確認します。
$ oc get managedcluster
出力例
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE SNO-cluster true True True 2d19h
AVAILABLE列のステータスがTrueの場合、マネージドクラスターはハブによって管理されます。AVAILABLE列のステータスがUnknownの場合、マネージドクラスターはハブによって管理されていません。その他の情報を取得するには、以下の手順を使用します。AgentClusterInstallインストールのステータスを確認します。$ oc get clusterdeployment -n <cluster_name>
出力例
NAME PLATFORM REGION CLUSTERTYPE INSTALLED INFRAID VERSION POWERSTATE AGE Sno0026 agent-baremetal false Initialized 2d14h
INSTALLED列のステータスがfalseの場合、インストールは失敗していました。インストールが失敗した場合は、以下のコマンドを実行して
AgentClusterInstallリソースのステータスを確認します。$ oc describe agentclusterinstall -n <cluster_name> <cluster_name>
エラーを解決し、クラスターをリセットします。
クラスターのマネージドクラスターリソースを削除します。
$ oc delete managedcluster <cluster_name>
クラスターの namespace を削除します。
$ oc delete namespace <cluster_name>
これにより、このクラスター用に作成された namespace スコープのカスタムリソースがすべて削除されます。続行する前に、
ManagedClusterCR の削除が完了するのを待つ必要があります。- マネージドクラスターのカスタムリソースを再作成します。
19.14. クラスターアクティビティーを監視するための RAN ポリシーの適用
ゼロ変更プロビジョニング (ZTP) は Red Hat Advanced Cluster Management(RHACM) を使用して、ラジオアクセスネットワーク (RAN) ポリシーを適用し、クラスターアクティビティーを自動的に監視します。
ポリシージェネレーター (PolicyGen) は、事前定義されたカスタムリソースからの ACM ポリシーの作成を容易にする Kustomize プラグインです。Policy Categorization、Source CR ポリシー、および PolicyGenTemplate の 3 つの主要な項目があります。PolicyGen は、ポリシーと配置のバインディングおよびルールを生成するものに依存します。
以下の図は、RAN ポリシージェネレーターが GitOps および ACM と対話する方法を示しています。

RAN ポリシーは主に 3 つのグループに分類されます。
- Common
-
Commonカテゴリーに存在するポリシーは、サイトプランによって表されるすべてのクラスターに適用されます。 - グループ
-
Groupsカテゴリーに存在するポリシーは、クラスターのグループに適用されます。クラスターのすべてのグループには、Groups カテゴリー下に存在する独自のポリシーを指定できます。たとえば、Groups/group1は、group1に属するクラスターに適用される独自のポリシーを持つことができます。 - サイト
-
Sitesカテゴリーに存在するポリシーが特定のクラスターに適用されます。クラスターでは、Sitesカテゴリーに存在する独自のポリシーを指定できます。たとえば、Sites/cluster1の独自のポリシーがcluster1に適用されます。
以下の図は、ポリシーの生成方法を示しています。
19.14.1. ソースカスタムリソースポリシーの適用
ソースカスタムリソースポリシーには、以下が含まれます。
- SR-IOV ポリシー
- PTP ポリシー
- Performance Add-on Operator ポリシー
- MachineConfigPool ポリシー
- SCTP ポリシー
メタデータまたは spec/data への使用可能なオーバーレイを考慮して、ACM ポリシーを生成するソースカスタムリソースを定義する必要があります。たとえば、common-namespace-policy には、全マネージドクラスターに存在する namespace 定義が含まれます。この namespace は Common category の下に配置され、すべてのクラスターではその仕様やデータは変更されません。
Namespace ポリシーの例
以下の例は、この namespace のソースカスタムリソースを示しています。
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator labels: openshift.io/run-level: "1"
出力例
この namespace を適用する生成されたポリシーには、以下の例のように変更なしに上記のように namespace が含まれます。
apiVersion: policy.open-cluster-management.io/v1
kind: Policy
metadata:
name: common-sriov-sub-ns-policy
namespace: common-sub
annotations:
policy.open-cluster-management.io/categories: CM Configuration Management
policy.open-cluster-management.io/controls: CM-2 Baseline Configuration
policy.open-cluster-management.io/standards: NIST SP 800-53
spec:
remediationAction: enforce
disabled: false
policy-templates:
- objectDefinition:
apiVersion: policy.open-cluster-management.io/v1
kind: ConfigurationPolicy
metadata:
name: common-sriov-sub-ns-policy-config
spec:
remediationAction: enforce
severity: low
namespaceselector:
exclude:
- kube-*
include:
- '*'
object-templates:
- complianceType: musthave
objectDefinition:
apiVersion: v1
kind: Namespace
metadata:
labels:
openshift.io/run-level: "1"
name: openshift-sriov-network-operatorSRIOV ポリシーの例
以下の例は、クラスターごとに異なる仕様を持つ異なるクラスターに存在する SriovNetworkNodePolicy 定義を示しています。この例では、SriovNetworkNodePolicy のソースカスタムリソースも示しています。
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: sriov-nnp
namespace: openshift-sriov-network-operator
spec:
# The $ tells the policy generator to overlay/remove the spec.item in the generated policy.
deviceType: $deviceType
isRdma: false
nicSelector:
pfNames: [$pfNames]
nodeSelector:
node-role.kubernetes.io/worker: ""
numVfs: $numVfs
priority: $priority
resourceName: $resourceName出力例
SriovNetworkNodePolicy 名と namespace はすべてのクラスターで同じであるため、どちらもソース SriovNetworkNodePolicy で定義されます。ただし、生成されたポリシーには、$deviceType、$numVfs を各クラスターのポリシーを調整するために入力パラメーターとして必要になります。以下の例のように、生成されたポリシーが表示されます。
apiVersion: policy.open-cluster-management.io/v1
kind: Policy
metadata:
name: site-du-sno-1-sriov-nnp-mh-policy
namespace: sites-sub
annotations:
policy.open-cluster-management.io/categories: CM Configuration Management
policy.open-cluster-management.io/controls: CM-2 Baseline Configuration
policy.open-cluster-management.io/standards: NIST SP 800-53
spec:
remediationAction: enforce
disabled: false
policy-templates:
- objectDefinition:
apiVersion: policy.open-cluster-management.io/v1
kind: ConfigurationPolicy
metadata:
name: site-du-sno-1-sriov-nnp-mh-policy-config
spec:
remediationAction: enforce
severity: low
namespaceselector:
exclude:
- kube-*
include:
- '*'
object-templates:
- complianceType: musthave
objectDefinition:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: sriov-nnp-du-mh
namespace: openshift-sriov-network-operator
spec:
deviceType: vfio-pci
isRdma: false
nicSelector:
pfNames:
- ens7f0
nodeSelector:
node-role.kubernetes.io/worker: ""
numVfs: 8
resourceName: du_mh
必要な入力パラメーターを $value で定義する (例: $deviceType) は必須ではありません。$ は、ポリシージェネレーターに対して、生成されたポリシーからアイテムを削除するか、または生成されたポリシーからアイテムを削除します。そうしないと、値は変更されません。
19.14.2. PolicyGenTemplate
PolicyGenTemplate.yaml ファイルはカスタムリソース定義 (CRD) で、生成されたポリシーを分類する場所と上書きする必要のある項目を指示するカスタムリソース定義 (CRD) です。
以下の例は、PolicyGenTemplate.yaml ファイルを示しています。
apiVersion: ran.openshift.io/v1
kind: PolicyGenTemplate
metadata:
name: "group-du-sno"
namespace: "group-du-sno"
spec:
bindingRules:
group-du-sno: ""
mcp: "master"
sourceFiles:
- fileName: ConsoleOperatorDisable.yaml
policyName: "console-policy"
- fileName: ClusterLogging.yaml
policyName: "cluster-log-policy"
spec:
curation:
curator:
schedule: "30 3 * * *"
collection:
logs:
type: "fluentd"
fluentd: {}
group-du-ranGen.yaml ファイルは、group-du という名前のグループ下のポリシーグループを定義します。このファイルは、sourceFiles で定義される他のポリシーのノードセレクターとして使用される MachineConfigPool worker-du を定義します。sourceFiles に存在するすべてのソースファイルに ACM ポリシーが生成されます。また、group-du ポリシーのクラスター選択ルールを有効にするために、単一の配置バインディングと配置ルールが生成されます。
ソースファイル PtpConfigSlave.yaml を例として使用し、PtpConfigSlave には PtpConfig カスタムリソース (CR) の定義があります。PtpConfigSlave サンプルの生成ポリシーは group-du-ptp-config-policy という名前です。生成された group-du-ptp-config-policy に定義される PtpConfig CR は du-ptp-slave という名前です。PtpConfigSlave.yaml で定義された spec は、du-ptp-slave の下に、ソースファイルで定義された他の spec 項目と共に配置されます。
以下の例は、group-du-ptp-config-policy を示しています。
apiVersion: policy.open-cluster-management.io/v1
kind: Policy
metadata:
name: group-du-ptp-config-policy
namespace: groups-sub
annotations:
policy.open-cluster-management.io/categories: CM Configuration Management
policy.open-cluster-management.io/controls: CM-2 Baseline Configuration
policy.open-cluster-management.io/standards: NIST SP 800-53
spec:
remediationAction: enforce
disabled: false
policy-templates:
- objectDefinition:
apiVersion: policy.open-cluster-management.io/v1
kind: ConfigurationPolicy
metadata:
name: group-du-ptp-config-policy-config
spec:
remediationAction: enforce
severity: low
namespaceselector:
exclude:
- kube-*
include:
- '*'
object-templates:
- complianceType: musthave
objectDefinition:
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: slave
namespace: openshift-ptp
spec:
recommend:
- match:
- nodeLabel: node-role.kubernetes.io/worker-du
priority: 4
profile: slave
profile:
- interface: ens5f0
name: slave
phc2sysOpts: -a -r -n 24
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
.....19.14.3. カスタムリソースポリシー作成時の考慮事項
-
ACM ポリシーの作成に使用されるカスタムリソースは、そのメタデータおよび仕様/データへの使用可能なオーバーレイに基づいて定義する必要があります。たとえば、カスタムリソース
metadata.nameがクラスター間で変更されない場合は、カスタムリソースファイルにmetadata.name値を設定する必要があります。カスタムリソースに同じクラスターに複数のインスタンスがある場合、カスタムリソースmetadata.nameはポリシーテンプレートファイルで定義する必要があります。 -
特定のマシン設定プールのノードセレクターを適用するには、ポリシージェネレーターがポリシーテンプレートで mcp の値で
$mcp値をセットアップするには、ノードセレクターの値を$mcpに設定する必要があります。 - サブスクリプションソースファイルは変更されません。
19.14.4. RAN ポリシーの生成
前提条件
- Kustomize のインストール
- Kustomize Policy Generator プラグイン をインストールします
手順
policyGenerator.yamlファイルを参照するようにkustomization.yamlファイルを設定します。以下の例は、PolicyGenerator 定義を示しています。apiVersion: policyGenerator/v1 kind: PolicyGenerator metadata: name: acm-policy namespace: acm-policy-generator # The arguments should be given and defined as below with same order --policyGenTempPath= --sourcePath= --outPath= --stdout --customResources argsOneLiner: ./ranPolicyGenTempExamples ./sourcePolicies ./out true false
ここで、
-
policyGenTempPathはpolicyGenTempファイルへのパスです。 -
sourcePath: ソースポリシーへのパスです。 -
outPath: 生成された ACM ポリシーを保存するパスです。 -
stdout:trueの場合、生成されたポリシーをコンソールに出力します。 -
CustomResources :trueの場合、ACM ポリシーなしでsourcePoliciesファイルから CR を生成します。
-
以下のコマンドを実行して PolicyGen をテストします。
$ cd cnf-features-deploy/ztp/ztp-policy-generator/
$ XDG_CONFIG_HOME=./ kustomize build --enable-alpha-plugins
以下の例のように、
outディレクトリーが想定されるポリシーで作成されます。out ├── common │ ├── common-log-sub-ns-policy.yaml │ ├── common-log-sub-oper-policy.yaml │ ├── common-log-sub-policy.yaml │ ├── common-pao-sub-catalog-policy.yaml │ ├── common-pao-sub-ns-policy.yaml │ ├── common-pao-sub-oper-policy.yaml │ ├── common-pao-sub-policy.yaml │ ├── common-policies-placementbinding.yaml │ ├── common-policies-placementrule.yaml │ ├── common-ptp-sub-ns-policy.yaml │ ├── common-ptp-sub-oper-policy.yaml │ ├── common-ptp-sub-policy.yaml │ ├── common-sriov-sub-ns-policy.yaml │ ├── common-sriov-sub-oper-policy.yaml │ └── common-sriov-sub-policy.yaml ├── groups │ ├── group-du │ │ ├── group-du-mc-chronyd-policy.yaml │ │ ├── group-du-mc-mount-ns-policy.yaml │ │ ├── group-du-mcp-du-policy.yaml │ │ ├── group-du-mc-sctp-policy.yaml │ │ ├── group-du-policies-placementbinding.yaml │ │ ├── group-du-policies-placementrule.yaml │ │ ├── group-du-ptp-config-policy.yaml │ │ └── group-du-sriov-operconfig-policy.yaml │ └── group-sno-du │ ├── group-du-sno-policies-placementbinding.yaml │ ├── group-du-sno-policies-placementrule.yaml │ ├── group-sno-du-console-policy.yaml │ ├── group-sno-du-log-forwarder-policy.yaml │ └── group-sno-du-log-policy.yaml └── sites └── site-du-sno-1 ├── site-du-sno-1-policies-placementbinding.yaml ├── site-du-sno-1-policies-placementrule.yaml ├── site-du-sno-1-sriov-nn-fh-policy.yaml ├── site-du-sno-1-sriov-nnp-mh-policy.yaml ├── site-du-sno-1-sriov-nw-fh-policy.yaml ├── site-du-sno-1-sriov-nw-mh-policy.yaml └── site-du-sno-1-.yaml一般的なポリシーは、すべてのクラスターに適用されるため、フラットです。ただし、グループとサイトには、異なるクラスターに適用されるため、グループとサイトごとにサブディレクトリーがあります。
19.15. クラスターのプロビジョニング
ゼロクリアのプロビジョニング (ZTP) は、レイヤードアプローチを使用してクラスターをプロビジョニングします。ベースコンポーネントは、Red Hat Enterprise Linux CoreOS (RHCOS)、クラスターの基本オペレーティングシステム、および OpenShift Container Platform で設定されます。これらのコンポーネントがインストールされると、ワーカーノードは既存のクラスターに参加できます。ノードが既存のクラスターに参加すると、5G RAN プロファイル Operator が適用されます。
以下の図は、このアーキテクチャーを示しています。
以下の RAN Operator はすべてのクラスターにデプロイされます。
- マシン設定
- Precision Time Protocol (PTP)
- Performance Addon Operator
- SR-IOV
- Local Storage Operator
- Logging Operator
19.15.1. Machine Config Operator
Machine Config Operator は、ワークロードのパーティション設定、NTP、SCTP などのシステム定義および低レベルのシステム設定を有効にします。この Operator は OpenShift Container Platform と共にインストールされます。
パフォーマンスプロファイルとその作成される製品は、関連付けられたマシン設定プール (MCP) に従ってノードに適用されます。MCP は、カーネル引数、kube 設定、Huge Page の割り当て、および利たるタイムカーネル (rt-kernel) のデプロイメントを含むパフォーマンスアドオンが作成するマシン設定の適用についての進捗に関する貴重な情報を保持します。パフォーマンスアドオンコントローラーは MCP の変更を監視し、それに応じてパフォーマンスプロファイルのステータスを更新します。
19.15.2. Performance Addon Operator
Performance Addon Operator は、一連のノードで高度なノードのパフォーマンスチューニングを有効にする機能を提供します。
OpenShift Container Platform は、OpenShift Container Platform アプリケーションの低レイテンシーパフォーマンスを実現するために自動チューニングを実装する Performance Addon Operator を提供します。クラスター管理者は、このパフォーマンスプロファイル設定を使用することにより、より信頼性の高い方法でこれらの変更をより容易に実行することができます。
管理者は、カーネルの更新から rt-kernel、管理ワークロード用の CPU 予約、およびワークロードを実行するための CPU の使用を指定できます。
19.15.3. SR-IOV Operator
Single Root I/O Virtualization (SR-IOV) ネットワーク Operator は、クラスターで SR-IOV ネットワークデバイスおよびネットワーク割り当てを管理します。
SR-IOV Operator は、ネットワークインターフェイスを仮想化し、クラスター内で実行されるネットワーク機能を持つデバイスレベルで共有できるようにします。
SR-IOV Network Operator は SriovOperatorConfig.sriovnetwork.openshift.io CustomResourceDefinition リソースを追加します。Operator は、openshift -sriov-network-operator namespace に default という名前の SriovOperatorConfig カスタムリソースを自動的に作成します。default カスタムリソースには、クラスターの SR-IOV ネットワーク Operator 設定が含まれます。
19.15.4. Precision Time Protocol Operator
Precision Time Protocol (PTP) Operator は、ネットワーク内でクロックを同期するために使用されるプロトコルです。ハードウェアサポートと併用する場合、PTP はマイクロ秒以下の正確性があります。PTP サポートは、カーネルとユーザースペースに分けられます。
PTP で同期するクロックは、マスター/ワーカー階層で整理されています。ワーカーはマスターと同期し、ワーカーを独自のマスターに同期できます。この階層は、best master clock (BMC) アルゴリズムで作成され、自動的に更新されます。クロックにポートが 1 つしかない場合は、マスターまたはワーカーにすることができます。このようなクロックは 通常のクロック (OC) と呼ばれます。クロックにポートが 1 つしかない場合、これはマスターにもワーカーにもなることができ、boundary クロック (BC) と呼ばれます。トップレベルのマスターは、Global Positioning System (GPS) のタイムソースを使用して同期できる グランドマスタークロック と呼ばれます。GPS ベースの時間ソースを使うことで、高度の正確性を保って異なるネットワークが同期可能になります。
19.16. 複数のマネージドクラスターの ZTP カスタムリソースの作成
複数のマネージドクラスターをインストールする場合、zero touch provisioning (ZTP) は ArgoCD と SiteConfig を使用して、GitOps アプリローチで、100 未満のバッチにおいて、カスタムリソース (CR) を作成するプロセス作成して、複数のクラスターにポリシーを適用するプロセスを管理します。
以下に示すように、クラスターのインストールとデプロイプロセスは 2 段階的プロセスで実行できます。
19.16.1. ZTP パイプラインのデプロイの前提条件
- OpenShift Container Platform クラスターバージョン 4.8 以降および Red Hat GitOps Operator がインストールされている。
- Red Hat Advanced Cluster Management (RHACM) バージョン 2.3 以降がインストールされている。
-
非接続環境では、ソースデータ Git リポジトリーおよび
ztp-site-generatorコンテナーイメージがハブクラスターからアクセスできるようにしてください。 ポリシーの追加のインストールマニフェストまたはカスタムリソース (CR) などの追加のカスタムコンテンツを
/usr/src/hook/ztp/source-crs/extra-manifest/ディレクトリーに追加します。同様に、PolicyGenTemplateから参照されている設定 CR を/usr/src/hook/ztp/source-crs/ディレクトリーに追加できます。以下のように、追加のマニフェストを Red Hat が提供するイメージに追加する
Containerfileを作成します。FROM <registry fqdn>/ztp-site-generator:latest 1 COPY myInstallManifest.yaml /usr/src/hook/ztp/source-crs/extra-manifest/ COPY mySourceCR.yaml /usr/src/hook/ztp/source-crs/- 1
- <registry fqdn> は、Red Hat が提供する
ztp-site-generatorコンテナーイメージを含むレジストリーを参照する必要があります。
これらの追加ファイルが含まれる新しいコンテナーイメージをビルドします。
$> podman build Containerfile.example
19.16.2. GitOps ZTP パイプラインのインストール
本セクションの手順では、以下のタスクを実行する方法を説明します。
- サイト設定データをホストするために必要な Git リポジトリーを準備します。
- 必要なインストールおよびポリシーカスタムリソース (CR) を生成するハブクラスターを設定します。
- ゼロタッチプロビジョニング (ZTP) を使用してマネージドクラスターをデプロイします。
19.16.2.1. ZTP Git リポジトリーの準備
サイト設定データをホストするための Git リポジトリーを作成します。ゼロタッチプロビジョニング (ZTP) パイプラインには、このリポジトリーへの読み取りアクセスが必要です。
手順
-
SiteConfigおよびPolicyGenTemplateカスタムリソース (CR) とは別のパスでディレクトリー構造を作成します。 -
resource-hook-example/<policygentemplates>/からPolicyGenTemplateCR のパスにpre-sync.yamlとpost-sync.yamlを追加します。 resource-hook-example/<siteconfig>/からSiteConfigCR のパスにpre-sync.yamlとpost-sync.yamlを追加します。注記ハブクラスターが非接続環境で動作する場合は、同期フック CR すべてとポスト同期フック CR の
imageを更新する必要があります。-
policygentemplates.ran.openshift.ioおよびsiteconfigs.ran.openshift.ioCR 定義を適用します。
19.16.2.2. ZTP 用のハブクラスターの準備
ゼロタッチプロビジョニング (ZTP) GitOps フローに基づいて、各サイトに必要なインストールおよびポリシーカスタムリソース (CR) を生成する ArgoCD アプリケーションのセットを使用して、ハブクラスターを設定できます。
手順
- ハブクラスターに Red Hat OpenShift GitOps Operator をインストールします。
ArgoCD の管理者パスワードを抽出します。
$ oc get secret openshift-gitops-cluster -n openshift-gitops -o jsonpath='{.data.admin\.password}' | base64 -dArgoCD パイプライン設定を準備します。
最新のコンテナーイメージバージョンを使用して、ZTP サイトジェネレーターコンテナーから ArgoCD デプロイメント CR を抽出します。
$ mkdir ztp $ podman run --rm -v `pwd`/ztp:/mnt/ztp:Z registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.9.0-1 /bin/bash -c "cp -ar /usr/src/hook/ztp/* /mnt/ztp/"
このセクションの残りの手順は、
ztp/gitops-subscriptions/argocd/ディレクトリーに関連しています。適切な URL、
targetRevisionブランチ、およびパス値を使用して 2 つの ArgoCD アプリケーションのソース値であるdeployment/clusters-app.yamlおよびdeployment/policies-app.yamlを変更します。パスの値は、Git リポジトリーで使用されている値と一致している必要があります。deployment/clusters-app.yamlを変更します。apiVersion: v1 kind: Namespace metadata: name: clusters-sub --- apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: clusters namespace: openshift-gitops spec: destination: server: https://kubernetes.default.svc namespace: clusters-sub project: default source: path: ztp/gitops-subscriptions/argocd/resource-hook-example/siteconfig 1 repoURL: https://github.com/openshift-kni/cnf-features-deploy 2 targetRevision: master 3 syncPolicy: automated: prune: true selfHeal: true syncOptions: - CreateNamespace=truedeployment/policies-app.yamlを変更します。apiVersion: v1 kind: Namespace metadata: name: policies-sub --- apiVersion: argoproj.io/v1alpha1 kind: Application metadata: name: policies namespace: openshift-gitops spec: destination: server: https://kubernetes.default.svc namespace: policies-sub project: default source: directory: recurse: true path: ztp/gitops-subscriptions/argocd/resource-hook-example/policygentemplates 1 repoURL: https://github.com/openshift-kni/cnf-features-deploy 2 targetRevision: master 3 syncPolicy: automated: prune: true selfHeal: true syncOptions: - CreateNamespace=true
パイプライン設定をハブクラスターに適用するには、以下のコマンドを入力します。
$ oc apply -k ./deployment
19.16.3. サイトシークレットの作成
サイトに必要なシークレットをハブクラスターに追加します。これらのリソースは、クラスター名に一致する名前を持つ namespace にある必要があります。
手順
サイトベースボード管理コントローラー (BMC) に対して認証するためのシークレットを作成します。シークレット名が
SiteConfigで使用される名前と一致することを確認します。この例では、シークレット名はtest-sno-bmh-secretです。apiVersion: v1 kind: Secret metadata: name: test-sno-bmh-secret namespace: test-sno data: password: dGVtcA== username: cm9vdA== type: Opaque
サイトのプルシークレットを作成します。プルシークレットには、OpenShift およびすべてのアドオン Operator のインストールに必要なすべての認証情報を含める必要があります。この例では、シークレット名は
assisted-deployment-pull-secretです。apiVersion: v1 kind: Secret metadata: name: assisted-deployment-pull-secret namespace: test-sno type: kubernetes.io/dockerconfigjson data: .dockerconfigjson: <Your pull secret base64 encoded>
シークレットは、名前で SiteConfig カスタムリソース (CR) から参照されます。namespace は SiteConfig namespace と一致する必要があります。
19.16.4. SiteConfig カスタムリソースの作成
ArgoCD は、サイトデプロイメントの GitOps メソッドのエンジンとして機能します。サイトのインストールに必要なカスタムリソースが含まれるサイトプランの完了後に、ポリシージェネレーターはマニフェストを作成し、それらをハブクラスターに適用します。
手順
クラスターの site-plan データが含まれる
site-config.yamlファイル (1 つ以上のSiteConfigカスタムリソース) を作成します。以下に例を示します。apiVersion: ran.openshift.io/v1 kind: SiteConfig metadata: name: "test-sno" namespace: "test-sno" spec: baseDomain: "clus2.t5g.lab.eng.bos.redhat.com" pullSecretRef: name: "assisted-deployment-pull-secret" clusterImageSetNameRef: "openshift-4.9" sshPublicKey: "ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDB3dwhI5X0ZxGBb9VK7wclcPHLc8n7WAyKjTNInFjYNP9J+Zoc/ii+l3YbGUTuqilDwZN5rVIwBux2nUyVXDfaM5kPd9kACmxWtfEWTyVRootbrNWwRfKuC2h6cOd1IlcRBM1q6IzJ4d7+JVoltAxsabqLoCbK3svxaZoKAaK7jdGG030yvJzZaNM4PiTy39VQXXkCiMDmicxEBwZx1UsA8yWQsiOQ5brod9KQRXWAAST779gbvtgXR2L+MnVNROEHf1nEjZJwjwaHxoDQYHYKERxKRHlWFtmy5dNT6BbvOpJ2e5osDFPMEd41d2mUJTfxXiC1nvyjk9Irf8YJYnqJgBIxi0IxEllUKH7mTdKykHiPrDH5D2pRlp+Donl4n+sw6qoDc/3571O93+RQ6kUSAgAsvWiXrEfB/7kGgAa/BD5FeipkFrbSEpKPVu+gue1AQeJcz9BuLqdyPUQj2VUySkSg0FuGbG7fxkKeF1h3Sga7nuDOzRxck4I/8Z7FxMF/e8DmaBpgHAUIfxXnRqAImY9TyAZUEMT5ZPSvBRZNNmLbfex1n3NLcov/GEpQOqEYcjG5y57gJ60/av4oqjcVmgtaSOOAS0kZ3y9YDhjsaOcpmRYYijJn8URAH7NrW8EZsvAoF6GUt6xHq5T258c6xSYUm5L0iKvBqrOW9EjbLw== root@cnfdc2.clus2.t5g.lab.eng.bos.redhat.com" clusters: - clusterName: "test-sno" clusterType: "sno" clusterProfile: "du" clusterLabels: group-du-sno: "" common: true sites : "test-sno" clusterNetwork: - cidr: 1001:db9::/48 hostPrefix: 64 machineNetwork: - cidr: 2620:52:0:10e7::/64 serviceNetwork: - 1001:db7::/112 additionalNTPSources: - 2620:52:0:1310::1f6 nodes: - hostName: "test-sno.clus2.t5g.lab.eng.bos.redhat.com" bmcAddress: "idrac-virtualmedia+https://[2620:52::10e7:f602:70ff:fee4:f4e2]/redfish/v1/Systems/System.Embedded.1" bmcCredentialsName: name: "test-sno-bmh-secret" bmcDisableCertificateVerification: true 1 bootMACAddress: "0C:42:A1:8A:74:EC" bootMode: "UEFI" rootDeviceHints: hctl: '0:1:0' cpuset: "0-1,52-53" nodeNetwork: interfaces: - name: eno1 macAddress: "0C:42:A1:8A:74:EC" config: interfaces: - name: eno1 type: ethernet state: up macAddress: "0C:42:A1:8A:74:EC" ipv4: enabled: false ipv6: enabled: true address: - ip: 2620:52::10e7:e42:a1ff:fe8a:900 prefix-length: 64 dns-resolver: config: search: - clus2.t5g.lab.eng.bos.redhat.com server: - 2620:52:0:1310::1f6 routes: config: - destination: ::/0 next-hop-interface: eno1 next-hop-address: 2620:52:0:10e7::fc table-id: 254- 1
UEFI SecureBootを使用している場合は、この行を追加して、無効な証明書またはローカル証明書による障害を防止します。
- ファイルを保存し、それらをハブクラスターからアクセスできるゼロな変更プロビジョニング (ZTP) Git リポジトリーにプッシュし、ArgoCD アプリケーションのソースリポジトリーとして定義します。
ArgoCD は、アプリケーションが同期していないことを検出します。同期時に、ArgoCD は PolicyGenTemplate をハブクラスターに同期し、関連付けられたリソースフックを起動します。これらのフックは、スポーククラスターに適用されるポリシーラップされた設定 CR を生成します。リソースフックはサイト定義をインストールカスタムリソースに変換し、それらをハブクラスターに適用します。
-
Namespace: サイトごとに一意 -
AgentClusterInstall -
BareMetalHost -
ClusterDeployment -
InfraEnv -
NMStateConfig -
ExtraManifestsConfigMap- Extra manifests.追加のマニフェストには、ワークロードのパーティション設定、chronyd、マウントポイントの非表示、sctp 有効化などが含まれます。 -
ManagedCluster -
KlusterletAddonConfig
Red Hat Advanced Cluster Management (RHACM) (ACM) は、ハブクラスターをデプロイします。
19.16.5. PolicyGenTemplates の作成
以下の手順を使用して PolicyGenTemplates を作成します。これは、ハブクラスターの Git リポジトリーでポリシーを生成する必要があります。
手順
-
PolicyGenTemplatesを作成し、それらをハブクラスターからアクセスできるゼロタッチプロビジョニング (ZTP) Git リポジトリーに保存し、ArgoCD アプリケーションのソースリポジトリーとして定義します。 ArgoCD は、アプリケーションが同期していないことを検出します。同期時に、ArgoCD は新規
PolicyGenTemplateをハブクラスターに適用し、関連付けられたリソースフックを起動します。これらのフックは、スポーククラスターに適用されるポリシーラップされた設定 CR を生成し、以下のアクションを実行します。- 基本的な分散ユニット (DU) プロファイルおよび必要なカスタマイズに従って、Red Hat Advanced Cluster Management (RHACM) (ACM) ポリシーを作成します。
- 生成されたポリシーをハブクラスターに適用します。
ZTP プロセスでは、ACM をダイレクトするポリシーを作成し、必要な設定をクラスターノードに適用します。
19.16.6. インストールステータスの確認
ArgoCD パイプラインは、Git リポジトリーの SiteConfig および PolicyGenTemplate カスタムリソース (CR) を検出し、それらをハブクラスターに同期します。プロセスで、インストールおよびポリシー CR を生成し、それらをハブクラスターに適用します。ArgoCD ダッシュボードでこの同期の進捗をモニターできます。
手順
以下のコマンドを使用して、クラスターのインストールの進捗を監視します。
$ export CLUSTER=<cluster_name>
$ oc get agentclusterinstall -n $CLUSTER $CLUSTER -o jsonpath='{.status.conditions[?(@.type=="Completed")]}' | jq$ curl -sk $(oc get agentclusterinstall -n $CLUSTER $CLUSTER -o jsonpath='{.status.debugInfo.eventsURL}') | jq '.[-2,-1]'- Red Hat Advanced Cluster Management (RHACM) ダッシュボードを使用して、ポリシーの調整の進捗を監視します。
19.16.7. サイトのクリーンアップ
サイトおよび関連するインストールおよびポリシーカスタムリソース (CR) を削除するには、Git リポジトリーから SiteConfig およびサイト固有の PolicyGenTemplate CR を削除します。Pipeline フックは生成された CR を削除します。
SiteConfig CR を削除する前に、ACM からクラスターをデタッチする必要があります。
19.16.7.1. ArgoCD パイプラインの削除
ArgoCD パイプラインおよび生成されたすべてのアーティファクトを削除する場合は、以下の手順を使用します。
手順
- ACM からすべてのクラスターをデタッチします。
-
Git リポジトリーからすべての
SiteConfigおよびPolicyGenTemplateカスタムリソース (CR) を削除します。 以下の namespace を削除します。
すべてのポリシー namespace:
$ oc get policy -A
-
clusters-sub -
policies-sub
Kustomize ツールを使用してディレクトリーを処理します。
$ oc delete -k cnf-features-deploy/ztp/gitops-subscriptions/argocd/deployment
19.17. GitOps ZTP のトラブルシューティング
前述のように、ArgoCD パイプラインは、Git リポジトリーからハブクラスターに SiteConfig および PolicyGenTemplate カスタムリソース (CR) を同期します。このプロセスで、同期後フックはハブクラスターにも適用されるインストールおよびポリシー CR を作成します。このプロセスで発生する可能性のある問題のトラブルシューティングを行うには、以下の手順に従います。
19.17.1. インストール CR の生成の検証
SiteConfig は、サイト名と一致する名前を持つ namespace のハブクラスターに Installation カスタムリソース (CR) を適用します。ステータスを確認するには、以下のコマンドを入力します。
$ oc get AgentClusterInstall -n <cluster_name>
オブジェクトが返されない場合は、以下の手順を使用して ArgoCD パイプラインフローを SiteConfig からインストール CR にトラブルシューティングします。
手順
以下のコマンドのいずれかを使用して、
SiteConfigからハブクラスターへの同期を確認します。$ oc get siteconfig -A
または
$ oc get siteconfig -n clusters-sub
SiteConfigがない場合、以下のいずれかの状況が発生しました。クラスター アプリケーションは、Git リポジトリーからハブへの CR の同期に失敗しました。以下のコマンドを使用してこれを確認します。
$ oc describe -n openshift-gitops application clusters
Status: SyncedおよびRevision:は、サブスクライブしたリポジトリーにプッシュしたコミットの SHA です。- 同期前のフックが失敗しました。コンテナーイメージのプルに失敗した可能性があります。ArgoCD ダッシュボードで、クラスター アプリケーションで同期前のジョブのステータスを確認します。
post フックのジョブ実行を確認します。
$ oc describe job -n clusters-sub siteconfig-post
-
成功すると、返される出力は
succeeded: 1となります。 - ジョブが失敗すると、ArgoCD はこれを再試行します。場合によっては、最初のパスが失敗し、2 番目のパスにジョブが渡されることを示すことがあります。
-
成功すると、返される出力は
post フックのジョブでエラーの有無を確認します。
$ oc get pod -n clusters-sub
siteconfig-post-xxxxxPod の名前をメモします。$ oc logs -n clusters-sub siteconfig-post-xxxxx
ログでエラーを示す場合は、条件を修正し、修正された
SiteConfigまたはPolicyGenTemplateを Git リポジトリーにプッシュします。
19.17.2. ポリシー CR の生成の検証
ArgoCD は、ポリシーカスタムリソース (CR) を作成した PolicyGenTemplate と同じ namespace に生成します。同じトラブルシューティングフローは、共通、グループ、またはサイト ベースであるかに関係なく、PolicyGenTemplate から生成されたすべてのポリシー CR に適用されます。
ポリシー CR のステータスを確認するには、以下のコマンドを入力します。
$ export NS=<namespace>
$ oc get policy -n $NS
返される出力には、ポリシーラップされた CR の予想されるセットが表示されます。オブジェクトが返されない場合は、以下の手順を使用して ArgoCD パイプラインフローを SiteConfig からポリシー CR にトラブルシューティングします。
手順
PolicyGenTemplateのハブクラスターへの同期を確認します。$ oc get policygentemplate -A
または
$ oc get policygentemplate -n $NS
PolicyGenTemplateが同期されていない場合、以下のいずれかの状況が発生しました。クラスターアプリケーションは、Git リポジトリーからハブへの CR の同期に失敗しました。以下のコマンドを使用してこれを確認します。
$ oc describe -n openshift-gitops application clusters
Status: SyncedおよびRevision:は、サブスクライブしたリポジトリーにプッシュしたコミットの SHA です。- 同期前のフックが失敗しました。コンテナーイメージのプルに失敗した可能性があります。ArgoCD ダッシュボードで、クラスター アプリケーションで同期前のジョブのステータスを確認します。
ポリシーがクラスターの namespace にコピーされていることを確認します。ACM がそのポリシーを
ManagedClusterに適用すると、ACM はポリシー CR オブジェクトをクラスターの namespace に適用します。$ oc get policy -n <cluster_name>
ACM は、該当する共通、グループ、およびサイトポリシーをすべてここにコピーします。ポリシー名は
<policyNamespace>および<policyName> です。クラスター namespace にコピーされないポリシーの配置ルールを確認します。これらのポリシーの
PlacementRuleのmatchSelectorは、ManagedClusterのラベルと一致する必要があります 。$ oc get placementrule -n $NS
見つからない common、group、または site ポリシーの
PlacementRule名をメモします。oc get placementrule -n $NS <placmentRuleName> -o yaml
-
status decisions値にはクラスター名が含まれる必要があります。 仕様の
matchSelectorのkey valueは、マネージドクラスターのラベルと一致する必要があります。ManagedClusterのラベルを確認します。oc get ManagedCluster $CLUSTER -o jsonpath='{.metadata.labels}' | jq例
apiVersion: apps.open-cluster-management.io/v1 kind: PlacementRule metadata: name: group-test1-policies-placementrules namespace: group-test1-policies spec: clusterSelector: matchExpressions: - key: group-test1 operator: In values: - "" status: decisions: - clusterName: <cluster_name> clusterNamespace: <cluster_name>
-
すべてのポリシーが準拠していることを確認します。
oc get policy -n $CLUSTER
Namespace、OperatorGroup、および Subscription ポリシーが準拠していても、Operator 設定ポリシーが準拠していない場合は、Operator がインストールされていない可能性があります。
Legal Notice
Copyright © 2024 Red Hat, Inc.
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.