Cluster Administration
Configuring and Managing the High Availability Add-On
Abstract
Introduction
- Red Hat Enterprise Linux Installation Guide — Provides information regarding installation of Red Hat Enterprise Linux 6.
- Red Hat Enterprise Linux Deployment Guide — Provides information regarding the deployment, configuration and administration of Red Hat Enterprise Linux 6.
- High Availability Add-On Overview — Provides a high-level overview of the Red Hat High Availability Add-On.
- Logical Volume Manager Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Global File System 2: Configuration and Administration — Provides information about installing, configuring, and maintaining Red Hat GFS2 (Red Hat Global File System 2), which is included in the Resilient Storage Add-On.
- DM Multipath — Provides information about using the Device-Mapper Multipath feature of Red Hat Enterprise Linux 6.
- Load Balancer Administration — Provides information on configuring high-performance systems and services with the Load Balancer Add-On, a set of integrated software components that provide Linux Virtual Servers (LVS) for balancing IP load across a set of real servers.
- Release Notes — Provides information about the current release of Red Hat products.
1. Feedback
Cluster_Administration(EN)-6 (2017-3-07T16:26)
Chapter 1. Red Hat High Availability Add-On Configuration and Management Overview
Note
1.1. New and Changed Features
1.1.1. New and Changed Features for Red Hat Enterprise Linux 6.1
- As of the Red Hat Enterprise Linux 6.1 release and later, the Red Hat High Availability Add-On provides support for SNMP traps. For information on configuring SNMP traps with the Red Hat High Availability Add-On, see Chapter 11, SNMP Configuration with the Red Hat High Availability Add-On.
- As of the Red Hat Enterprise Linux 6.1 release and later, the Red Hat High Availability Add-On provides support for the
ccscluster configuration command. For information on theccscommand, see Chapter 6, Configuring Red Hat High Availability Add-On With the ccs Command and Chapter 7, Managing Red Hat High Availability Add-On With ccs. - The documentation for configuring and managing Red Hat High Availability Add-On software using Conga has been updated to reflect updated Conga screens and feature support.
- For the Red Hat Enterprise Linux 6.1 release and later, using
riccirequires a password the first time you propagate updated cluster configuration from any particular node. For information onriccisee Section 3.13, “Considerations forricci”. - You can now specify a Restart-Disable failure policy for a service, indicating that the system should attempt to restart the service in place if it fails, but if restarting the service fails the service will be disabled instead of being moved to another host in the cluster. This feature is documented in Section 4.10, “Adding a Cluster Service to the Cluster” and Appendix B, HA Resource Parameters.
- You can now configure an independent subtree as non-critical, indicating that if the resource fails then only that resource is disabled. For information on this feature see Section 4.10, “Adding a Cluster Service to the Cluster” and Section C.4, “Failure Recovery and Independent Subtrees”.
- This document now includes the new chapter Chapter 10, Diagnosing and Correcting Problems in a Cluster.
1.1.2. New and Changed Features for Red Hat Enterprise Linux 6.2
- Red Hat Enterprise Linux now provides support for running Clustered Samba in an active/active configuration. For information on clustered Samba configuration, see Chapter 12, Clustered Samba Configuration.
- Any user able to authenticate on the system that is hosting luci can log in to luci. As of Red Hat Enterprise Linux 6.2, only the root user on the system that is running luci can access any of the luci components until an administrator (the root user or a user with administrator permission) sets permissions for that user. For information on setting luci permissions for users, see Section 4.3, “Controlling Access to luci”.
- The nodes in a cluster can communicate with each other using the UDP unicast transport mechanism. For information on configuring UDP unicast, see Section 3.12, “UDP Unicast Traffic”.
- You can now configure some aspects of luci's behavior by means of the
/etc/sysconfig/lucifile. For example, you can specifically configure the only IP address luci is being served at. For information on configuring the only IP address luci is being served at, see Table 3.2, “Enabled IP Port on a Computer That Runs luci”. For information on the/etc/sysconfig/lucifile in general, see Section 3.4, “Configuring luci with/etc/sysconfig/luci”. - The
ccscommand now includes the--lsfenceoptsoption, which prints a list of available fence devices, and the--lsfenceoptsfence_type option, which prints each available fence type. For information on these options, see Section 6.6, “Listing Fence Devices and Fence Device Options”. - The
ccscommand now includes the--lsserviceoptsoption, which prints a list of cluster services currently available for your cluster, and the--lsserviceoptsservice_type option, which prints a list of the options you can specify for a particular service type. For information on these options, see Section 6.11, “Listing Available Cluster Services and Resources”. - The Red Hat Enterprise Linux 6.2 release provides support for the VMware (SOAP Interface) fence agent. For information on fence device parameters, see Appendix A, Fence Device Parameters.
- The Red Hat Enterprise Linux 6.2 release provides support for the RHEV-M REST API fence agent, against RHEV 3.0 and later. For information on fence device parameters, see Appendix A, Fence Device Parameters.
- As of the Red Hat Enterprise Linux 6.2 release, when you configure a virtual machine in a cluster with the
ccscommand you can use the--addvmoption (rather than theaddserviceoption). This ensures that thevmresource is defined directly under thermconfiguration node in the cluster configuration file. For information on configuring virtual machine resources with theccscommand, see Section 6.12, “Virtual Machine Resources”. - This document includes a new appendix, Appendix D, Modifying and Enforcing Cluster Service Resource Actions. This appendix describes how
rgmanagermonitors the status of cluster resources, and how to modify the status check interval. The appendix also describes the__enforce_timeoutsservice parameter, which indicates that a timeout for an operation should cause a service to fail. - This document includes a new section, Section 3.3.3, “Configuring the iptables Firewall to Allow Cluster Components”. This section shows the filtering you can use to allow multicast traffic through the
iptablesfirewall for the various cluster components.
1.1.3. New and Changed Features for Red Hat Enterprise Linux 6.3
- The Red Hat Enterprise Linux 6.3 release provides support for the
condorresource agent. For information on HA resource parameters, see Appendix B, HA Resource Parameters. - This document includes a new appendix, Appendix F, High Availability LVM (HA-LVM).
- Information throughout this document clarifies which configuration changes require a cluster restart. For a summary of these changes, see Section 10.1, “Configuration Changes Do Not Take Effect”.
- The documentation now notes that there is an idle timeout for luci that logs you out after 15 minutes of inactivity. For information on starting luci, see Section 4.2, “Starting luci”.
- The
fence_ipmilanfence device supports a privilege level parameter. For information on fence device parameters, see Appendix A, Fence Device Parameters. - This document includes a new section, Section 3.14, “Configuring Virtual Machines in a Clustered Environment”.
- This document includes a new section, Section 5.6, “Backing Up and Restoring the luci Configuration”.
- This document includes a new section, Section 10.4, “Cluster Daemon crashes”.
- This document provides information on setting debug options in Section 6.14.4, “Logging”, Section 8.7, “Configuring Debug Options”, and Section 10.13, “Debug Logging for Distributed Lock Manager (DLM) Needs to be Enabled”.
- As of Red Hat Enterprise Linux 6.3, the root user or a user who has been granted luci administrator permissions can also use the luci interface to add users to the system, as described in Section 4.3, “Controlling Access to luci”.
- As of the Red Hat Enterprise Linux 6.3 release, the
ccscommand validates the configuration according to the cluster schema at/usr/share/cluster/cluster.rngon the node that you specify with the-hoption. Previously theccscommand always used the cluster schema that was packaged with theccscommand itself,/usr/share/ccs/cluster.rngon the local system. For information on configuration validation, see Section 6.1.6, “Configuration Validation”. - The tables describing the fence device parameters in Appendix A, Fence Device Parameters and the tables describing the HA resource parameters in Appendix B, HA Resource Parameters now include the names of those parameters as they appear in the
cluster.conffile.
1.1.4. New and Changed Features for Red Hat Enterprise Linux 6.4
- The Red Hat Enterprise Linux 6.4 release provides support for the Eaton Network Power Controller (SNMP Interface) fence agent, the HP BladeSystem fence agent, and the IBM iPDU fence agent. For information on fence device parameters, see Appendix A, Fence Device Parameters.
- Appendix B, HA Resource Parameters now provides a description of the NFS Server resource agent.
- As of Red Hat Enterprise Linux 6.4, the root user or a user who has been granted luci administrator permissions can also use the luci interface to delete users from the system. This is documented in Section 4.3, “Controlling Access to luci”.
- Appendix B, HA Resource Parameters provides a description of the new
nfsrestartparameter for the Filesystem and GFS2 HA resources. - This document includes a new section, Section 6.1.5, “Commands that Overwrite Previous Settings”.
- Section 3.3, “Enabling IP Ports” now includes information on filtering the
iptablesfirewall forigmp. - The IPMI LAN fence agent now supports a parameter to configure the privilege level on the IPMI device, as documented in Appendix A, Fence Device Parameters.
- In addition to Ethernet bonding mode 1, bonding modes 0 and 2 are now supported for inter-node communication in a cluster. Troubleshooting advice in this document that suggests you ensure that you are using only supported bonding modes now notes this.
- VLAN-tagged network devices are now supported for cluster heartbeat communication. Troubleshooting advice indicating that this is not supported has been removed from this document.
- The Red Hat High Availability Add-On now supports the configuration of redundant ring protocol. For general information on using this feature and configuring the
cluster.confconfiguration file, see Section 8.6, “Configuring Redundant Ring Protocol”. For information on configuring redundant ring protocol with luci, see Section 4.5.4, “Configuring Redundant Ring Protocol”. For information on configuring redundant ring protocol with theccscommand, see Section 6.14.5, “Configuring Redundant Ring Protocol”.
1.1.5. New and Changed Features for Red Hat Enterprise Linux 6.5
- This document includes a new section, Section 8.8, “Configuring nfsexport and nfsserver Resources”.
- The tables of fence device parameters in Appendix A, Fence Device Parameters have been updated to reflect small updates to the luci interface.
1.1.6. New and Changed Features for Red Hat Enterprise Linux 6.6
- The tables of fence device parameters in Appendix A, Fence Device Parameters have been updated to reflect small updates to the luci interface.
- The tables of resource agent parameters in Appendix B, HA Resource Parameters have been updated to reflect small updates to the luci interface.
- Table B.3, “Bind Mount (
bind-mountResource) (Red Hat Enterprise Linux 6.6 and later)” documents the parameters for the Bind Mount resource agent. - As of Red Hat Enterprise Linux 6.6 release, you can use the
--noenableoption of theccs --startallcommand to prevent cluster services from being enabled, as documented in Section 7.2, “Starting and Stopping a Cluster” - Table A.26, “Fence kdump” documents the parameters for the kdump fence agent.
- As of the Red Hat Enterprise Linux 6.6 release, you can sort the columns in a resource list on the luci display by clicking on the header for the sort category, as described in Section 4.9, “Configuring Global Cluster Resources”.
1.1.7. New and Changed Features for Red Hat Enterprise Linux 6.7
- This document now includes a new chapter, Chapter 2, Getting Started: Overview, which provides a summary procedure for setting up a basic Red Hat High Availability cluster.
- Appendix A, Fence Device Parameters now includes a table listing the parameters for the Emerson Network Power Switch (SNMP interface).
- Appendix A, Fence Device Parameters now includes a table listing the parameters for the
fence_xvmfence agent, titled as "Fence virt (Multicast Mode"). The table listing the parameters for thefence_virtfence agent is now titled "Fence virt ((Serial/VMChannel Mode)". Both tables have been updated to reflect the luci display. - Appendix A, Fence Device Parameters now includes a table listing the parameters for the
fence_xvmfence agent, titled as "Fence virt (Multicast Mode"). The table listing the parameters for thefence_virtfence agent is now titled "Fence virt ((Serial/VMChannel Mode)". Both tables have been updated to reflect the luci display. - The troubleshooting procedure described in Section 10.10, “Quorum Disk Does Not Appear as Cluster Member” has been updated.
1.1.8. New and Changed Features for Red Hat Enterprise Linux 6.8
- Appendix A, Fence Device Parameters now includes a table listing the parameters for the
fence_mpathfence agent, titled as "Multipath Persistent Reservation Fencing". The table listing the parameters for thefence_ipmilan,fence_idrac,fence_imm,fence_ilo3, andfence_ilo4fence agents has been updated to reflect the luci display. - Section F.3, “Creating New Logical Volumes for an Existing Cluster” now provides a procedure for creating new logical volumes in an existing cluster when using HA-LVM.
1.1.9. New and Changed Features for Red Hat Enterprise Linux 6.9
- As of Red Hat Enterprise Linux 6.9, after you have entered a node name on the luci dialog box or the screen, the fingerprint of the certificate of the ricci host is displayed for confirmation, as described in Section 4.4, “Creating a Cluster” and Section 5.1, “Adding an Existing Cluster to the luci Interface”.Similarly, the fingerprint of the certificate of the ricci host is displayed for confirmation when you add a new node to a running cluster, as described in Section 5.3.3, “Adding a Member to a Running Cluster”.
- The luci display for a selected service group now includes a table showing the actions that have been configured for each resource in that service group. For information on resource actions, see Appendix D, Modifying and Enforcing Cluster Service Resource Actions.
1.2. Configuration Basics
- Setting up hardware. Refer to Section 1.3, “Setting Up Hardware”.
- Installing Red Hat High Availability Add-On software. Refer to Section 1.4, “Installing Red Hat High Availability Add-On software”.
- Configuring Red Hat High Availability Add-On Software. Refer to Section 1.5, “Configuring Red Hat High Availability Add-On Software”.
1.3. Setting Up Hardware
- Cluster nodes — Computers that are capable of running Red Hat Enterprise Linux 6 software, with at least 1GB of RAM.
- Network switches for public network — This is required for client access to the cluster.
- Network switches for private network — This is required for communication among the cluster nodes and other cluster hardware such as network power switches and Fibre Channel switches.
- Fencing device — A fencing device is required. A network power switch is recommended to perform fencing in an enterprise-level cluster. For information about supported fencing devices, see Appendix A, Fence Device Parameters.
- Storage — Some type of storage is required for a cluster. Figure 1.1, “Red Hat High Availability Add-On Hardware Overview” shows shared storage, but shared storage may not be required for your specific use.
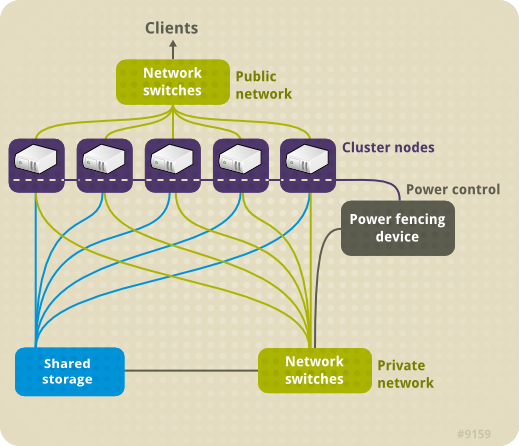
Figure 1.1. Red Hat High Availability Add-On Hardware Overview
1.4. Installing Red Hat High Availability Add-On software
yum install command to install the Red Hat High Availability Add-On software packages:
# yum install rgmanager lvm2-cluster gfs2-utilsrgmanager will pull in all necessary dependencies to create an HA cluster from the HighAvailability channel. The lvm2-cluster and gfs2-utils packages are part of ResilientStorage channel and may not be needed by your site.
Warning
Upgrading Red Hat High Availability Add-On Software
- Shut down all cluster services on a single cluster node. For instructions on stopping cluster software on a node, see Section 9.1.2, “Stopping Cluster Software”. It may be desirable to manually relocate cluster-managed services and virtual machines off of the host prior to stopping
rgmanager. - Execute the
yum updatecommand to update installed packages. - Reboot the cluster node or restart the cluster services manually. For instructions on starting cluster software on a node, see Section 9.1.1, “Starting Cluster Software”.
1.5. Configuring Red Hat High Availability Add-On Software
- Conga — This is a comprehensive user interface for installing, configuring, and managing Red Hat High Availability Add-On. Refer to Chapter 4, Configuring Red Hat High Availability Add-On With Conga and Chapter 5, Managing Red Hat High Availability Add-On With Conga for information about configuring and managing High Availability Add-On with Conga.
- The
ccscommand — This command configures and manages Red Hat High Availability Add-On. Refer to Chapter 6, Configuring Red Hat High Availability Add-On With the ccs Command and Chapter 7, Managing Red Hat High Availability Add-On With ccs for information about configuring and managing High Availability Add-On with theccscommand. - Command-line tools — This is a set of command-line tools for configuring and managing Red Hat High Availability Add-On. Refer to Chapter 8, Configuring Red Hat High Availability Manually and Chapter 9, Managing Red Hat High Availability Add-On With Command Line Tools for information about configuring and managing a cluster with command-line tools. Refer to Appendix E, Command Line Tools Summary for a summary of preferred command-line tools.
Note
system-config-cluster is not available in Red Hat Enterprise Linux 6.
Chapter 2. Getting Started: Overview
2.1. Installation and System Setup
- Ensure that your Red Hat account includes the following support entitlements:
- RHEL: Server
- Red Hat Applications: High availability
- Red Hat Applications: Resilient Storage, if using the Clustered Logical Volume Manager (CLVM) and GFS2 file systems.
- Register the cluster systems for software updates, using either Red Hat Subscriptions Manager (RHSM) or RHN Classic.
- On each node in the cluster, configure the iptables firewall. The iptables firewall can be disabled, or it can be configured to allow cluster traffic to pass through.To disable the iptables system firewall, execute the following commands.
#
service iptables stop#chkconfig iptables offFor information on configuring the iptables firewall to allow cluster traffic to pass through, see Section 3.3, “Enabling IP Ports”. - On each node in the cluster, configure SELinux. SELinux is supported on Red Hat Enterprise Linux 6 cluster nodes in Enforcing or Permissive mode with a targeted policy, or it can be disabled. To check the current SELinux state, run the
getenforce:#
getenforcePermissiveFor information on enabling and disabling SELinux, see the Security-Enhanced Linux user guide. - Install the cluster packages and package groups.
- On each node in the cluster, install the
High AvailabilityandResiliant Storagepackage groups.#
yum groupinstall 'High Availability' 'Resilient Storage' - On the node that will be hosting the web management interface, install the luci package.
#
yum install luci
2.2. Starting Cluster Services
- On both nodes in the cluster, start the
ricciservice and set a password for userricci.#
service ricci startStarting ricci: [ OK ] #passwd ricciNew password: Retype new password: - On the node that will be hosting the web management interface, start the luci service. This will provide the link from which to access luci on this node.
#
service luci startStarting luci: generating https SSL certificates... done [ OK ] Please, point your web browser to https://example-01:8084 to access luci
2.3. Creating the Cluster
- To access the High Availability management web interface, point your browser to the link provided by the luci service and log in using the root account on the node hosting luci. Logging in to luci displays the luci page.
- To create a cluster, click on from the menu on the left navigation pane of the page. This displays the page.
- From the page, click the button. This displays the screen.
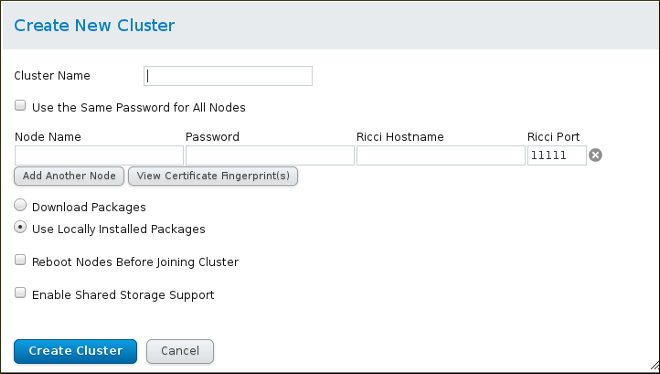
Figure 2.1. Clusters menu
- On the screen, enter the parameters for the cluster you are creating. The field will be the
riccipassword you defined for the indicated node. For more detailed information about the parameters on this screen and information about verifying the certificate fingerprint of thericciserver, see Section 4.4, “Creating a Cluster”.
Figure 2.2. Create New Cluster screen
- After you have completed entering the parameters for the cluster, click the button. A progress bar is displayed with the cluster is formed. Once cluster creation has completed, luci displays the cluster general properties.
- Verify the cluster status by running the
clustatcommand on either node of the cluster.#
clustatCluster Status for exampleHA @ Thu Sep 29 12:17:39 2011 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node1.example.com 1 Online, Local node2.example.com 2 OnlineIf you cannot create the cluster, double check the firewall settings, as described in Section 3.3.3, “Configuring the iptables Firewall to Allow Cluster Components”.If you can create the cluster (there is an/etc/cluster/cluster.confon each node) but the cluster will not form, you may have multicast issues. To test this, change the transport mode from UDP multicast to UDP unicast, as described in Section 3.12, “UDP Unicast Traffic”. Note, however, that in unicast mode there is a traffic increase compared to multicast mode, which adds to the processing load of the node.
2.4. Configuring Fencing
2.5. Configuring a High Availability Application
- Configure shared storage and file systems required by your application. For information on high availability logical volumes, see Appendix F, High Availability LVM (HA-LVM). For information on the GFS2 clustered file system, see the Global File System 2 manual.
- Optionally, you can customize your cluster's behavior by configuring a failover domain. A failover domain determines which cluster nodes an application will run on in what circumstances, determined by a set of failover domain configuration options. For information on failover domain options and how they determine a cluster's behavior, see the High Availability Add-On Overview. For information on configuring failover domains, see Section 4.8, “Configuring a Failover Domain”.
- Configure cluster resources for your system. Cluster resources are the individual components of the applications running on a cluster node. For information on configuring cluster resources, see Section 4.9, “Configuring Global Cluster Resources”.
- Configure the cluster services for your cluster. A cluster service is the collection of cluster resources required by an application running on a cluster node that can fail over to another node in a high availability cluster. You can configure the startup and recovery policies for a cluster service, and you can configure resource trees for the resources that constitute the service, which determine startup and shutdown order for the resources as well as the relationships between the resources. For information on service policies, resource trees, service operations, and resource actions, see the High Availability Add-On Overview. For information on configuring cluster services, see Section 4.10, “Adding a Cluster Service to the Cluster”.
2.6. Testing the Configuration
- Verify that the service you created is running with the
clustatcommand, which you can run on either cluster node. In this example, the serviceexample_apacheis running onnode1.example.com.#
clustatCluster Status for exampleHA @ Thu Sep 29 12:17:39 2011 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node1.example.com 1 Online, Local node2.example.com 2 Online Service Name Owner (Last) State ------ ---- ----- ------ ----- service:example_apache node-01.example.com started - Check whether the service is operational. How you do this depends on the application. For example, if you are running an Apache web server, point a browser to the URL you defined for the server to see if the display is correct.
- Shut down the cluster software on the node on which the service is running, which you can determine from the
clustatdisplay.- Click on the cluster name beneath from the menu on the left side of the luci page. This displays the nodes that constitute the cluster.
- Select the node you want to leave the cluster by clicking the check box for that node.
- Select the function from the menu at the top of the page. This causes a message to appear at the top of the page indicating that the node is being stopped.
- Refresh the page to see the updated status of the node.
- Run the
clustatcommand again to see if the service is now running on the other cluster node. If it is, check again to see if the service is still operational. For example, if you are running an apache web server, check whether you can still display the website. - Make sure you have the node you disabled rejoin the cluster by returning to the cluster node display, selecting the node, and selecting .
Chapter 3. Before Configuring the Red Hat High Availability Add-On
Important
3.1. General Configuration Considerations
- Number of cluster nodes supported
- The maximum number of cluster nodes supported by the High Availability Add-On is 16.
- Single site clusters
- Only single site clusters are fully supported at this time. Clusters spread across multiple physical locations are not formally supported. For more details and to discuss multi-site clusters, speak to your Red Hat sales or support representative.
- GFS2
- Although a GFS2 file system can be implemented in a standalone system or as part of a cluster configuration, Red Hat does not support the use of GFS2 as a single-node file system. Red Hat does support a number of high-performance single-node file systems that are optimized for single node, which have generally lower overhead than a cluster file system. Red Hat recommends using those file systems in preference to GFS2 in cases where only a single node needs to mount the file system. Red Hat will continue to support single-node GFS2 file systems for existing customers.When you configure a GFS2 file system as a cluster file system, you must ensure that all nodes in the cluster have access to the shared file system. Asymmetric cluster configurations in which some nodes have access to the file system and others do not are not supported.This does not require that all nodes actually mount the GFS2 file system itself.
- No-single-point-of-failure hardware configuration
- Clusters can include a dual-controller RAID array, multiple bonded network channels, multiple paths between cluster members and storage, and redundant un-interruptible power supply (UPS) systems to ensure that no single failure results in application down time or loss of data.Alternatively, a low-cost cluster can be set up to provide less availability than a no-single-point-of-failure cluster. For example, you can set up a cluster with a single-controller RAID array and only a single Ethernet channel.Certain low-cost alternatives, such as host RAID controllers, software RAID without cluster support, and multi-initiator parallel SCSI configurations are not compatible or appropriate for use as shared cluster storage.
- Data integrity assurance
- To ensure data integrity, only one node can run a cluster service and access cluster-service data at a time. The use of power switches in the cluster hardware configuration enables a node to power-cycle another node before restarting that node's HA services during a failover process. This prevents two nodes from simultaneously accessing the same data and corrupting it. Fence devices (hardware or software solutions that remotely power, shutdown, and reboot cluster nodes) are used to guarantee data integrity under all failure conditions.
- Ethernet channel bonding
- Cluster quorum and node health is determined by communication of messages among cluster nodes by means of Ethernet. In addition, cluster nodes use Ethernet for a variety of other critical cluster functions (for example, fencing). With Ethernet channel bonding, multiple Ethernet interfaces are configured to behave as one, reducing the risk of a single-point-of-failure in the typical switched Ethernet connection among cluster nodes and other cluster hardware.As of Red Hat Enterprise Linux 6.4, bonding modes 0, 1, and 2 are supported.
- IPv4 and IPv6
- The High Availability Add-On supports both IPv4 and IPv6 Internet Protocols. Support of IPv6 in the High Availability Add-On is new for Red Hat Enterprise Linux 6.
3.2. Compatible Hardware
3.3. Enabling IP Ports
iptables rules for enabling IP ports needed by the Red Hat High Availability Add-On:
3.3.1. Enabling IP Ports on Cluster Nodes
system-config-firewall to enable the IP ports.
| IP Port Number | Protocol | Component |
|---|---|---|
| 5404, 5405 | UDP | corosync/cman (Cluster Manager) |
| 11111 | TCP | ricci (propagates updated cluster information) |
| 21064 | TCP | dlm (Distributed Lock Manager) |
| 16851 | TCP | modclusterd |
3.3.2. Enabling the IP Port for luci
Note
| IP Port Number | Protocol | Component |
|---|---|---|
| 8084 | TCP | luci (Conga user interface server) |
/etc/sysconfig/luci file, you can specifically configure the only IP address luci is being served at. You can use this capability if your server infrastructure incorporates more than one network and you want to access luci from the internal network only. To do this, uncomment and edit the line in the file that specifies host. For example, to change the host setting in the file to 10.10.10.10, edit the host line as follows:
host = 10.10.10.10
/etc/sysconfig/luci file, see Section 3.4, “Configuring luci with /etc/sysconfig/luci”.
3.3.3. Configuring the iptables Firewall to Allow Cluster Components
cman (Cluster Manager), use the following filtering.
$iptables -I INPUT -m state --state NEW -m multiport -p udp -s 192.168.1.0/24 -d 192.168.1.0/24 --dports 5404,5405 -j ACCEPT$iptables -I INPUT -m addrtype --dst-type MULTICAST -m state --state NEW -m multiport -p udp -s 192.168.1.0/24 --dports 5404,5405 -j ACCEPT
dlm (Distributed Lock Manager):
$ iptables -I INPUT -m state --state NEW -p tcp -s 192.168.1.0/24 -d 192.168.1.0/24 --dport 21064 -j ACCEPT ricci (part of Conga remote agent):
$ iptables -I INPUT -m state --state NEW -p tcp -s 192.168.1.0/24 -d 192.168.1.0/24 --dport 11111 -j ACCEPTmodclusterd (part of Conga remote agent):
$ iptables -I INPUT -m state --state NEW -p tcp -s 192.168.1.0/24 -d 192.168.1.0/24 --dport 16851 -j ACCEPTluci (Conga User Interface server):
$ iptables -I INPUT -m state --state NEW -p tcp -s 192.168.1.0/24 -d 192.168.1.0/24 --dport 8084 -j ACCEPTigmp (Internet Group Management Protocol):
$ iptables -I INPUT -p igmp -j ACCEPT$ service iptables save ; service iptables restart3.4. Configuring luci with /etc/sysconfig/luci
/etc/sysconfig/luci file. The parameters you can change with this file include auxiliary settings of the running environment used by the init script as well as server configuration. In addition, you can edit this file to modify some application configuration parameters. There are instructions within the file itself describing which configuration parameters you can change by editing this file.
/etc/sysconfig/luci file when you edit the file. Additionally, you should take care to follow the required syntax for this file, particularly for the INITSCRIPT section which does not allow for white spaces around the equal sign and requires that you use quotation marks to enclose strings containing white spaces.
/etc/sysconfig/luci file.
- Uncomment the following line in the
/etc/sysconfig/lucifile:#port = 4443
- Replace 4443 with the desired port number, which must be higher than or equal to 1024 (not a privileged port). For example, you can edit that line of the file as follows to set the port at which luci is being served to 8084 (commenting the line out again would have the same affect, as this is the default value).
port = 8084
- Restart the luci service for the changes to take effect.
ssl_cipher_list configuration parameter in /etc/sysconfig/luci. This parameter can be used to impose restrictions as expressed with OpenSSL cipher notation.
Important
/etc/sysconfig/luci file to redefine a default value, you should take care to use the new value in place of the documented default value. For example, when you modify the port at which luci is being served, make sure that you specify the modified value when you enable an IP port for luci, as described in Section 3.3.2, “Enabling the IP Port for luci”.
/etc/sysconfig/luci file, refer to the documentation within the file itself.
3.5. Configuring ACPI For Use with Integrated Fence Devices
shutdown -h now). Otherwise, if ACPI Soft-Off is enabled, an integrated fence device can take four or more seconds to turn off a node (refer to note that follows). In addition, if ACPI Soft-Off is enabled and a node panics or freezes during shutdown, an integrated fence device may not be able to turn off the node. Under those circumstances, fencing is delayed or unsuccessful. Consequently, when a node is fenced with an integrated fence device and ACPI Soft-Off is enabled, a cluster recovers slowly or requires administrative intervention to recover.
Note
- Use
chkconfigmanagement and verify that the node turns off immediately when fenced, as described in Section 3.5.2, “Disabling ACPI Soft-Off withchkconfigManagement”. This is the first alternate method. - Appending
acpi=offto the kernel boot command line of the/boot/grub/grub.conffile, as described in Section 3.5.3, “Disabling ACPI Completely in thegrub.confFile”. This is the second alternate method.Important
This method completely disables ACPI; some computers do not boot correctly if ACPI is completely disabled. Use this method only if the other methods are not effective for your cluster.
3.5.1. Disabling ACPI Soft-Off with the BIOS
Note
- Reboot the node and start the
BIOS CMOS Setup Utilityprogram. - Navigate to the menu (or equivalent power management menu).
- At the menu, set the function (or equivalent) to (or the equivalent setting that turns off the node by means of the power button without delay). Example 3.1, “
BIOS CMOS Setup Utility: set to ” shows a menu with set to and set to .Note
The equivalents to , , and may vary among computers. However, the objective of this procedure is to configure the BIOS so that the computer is turned off by means of the power button without delay. - Exit the
BIOS CMOS Setup Utilityprogram, saving the BIOS configuration. - When the cluster is configured and running, verify that the node turns off immediately when fenced.
Note
You can fence the node with thefence_nodecommand or Conga.
Example 3.1. BIOS CMOS Setup Utility: set to
+---------------------------------------------|-------------------+ | ACPI Function [Enabled] | Item Help | | ACPI Suspend Type [S1(POS)] |-------------------| | x Run VGABIOS if S3 Resume Auto | Menu Level * | | Suspend Mode [Disabled] | | | HDD Power Down [Disabled] | | | Soft-Off by PWR-BTTN [Instant-Off | | | CPU THRM-Throttling [50.0%] | | | Wake-Up by PCI card [Enabled] | | | Power On by Ring [Enabled] | | | Wake Up On LAN [Enabled] | | | x USB KB Wake-Up From S3 Disabled | | | Resume by Alarm [Disabled] | | | x Date(of Month) Alarm 0 | | | x Time(hh:mm:ss) Alarm 0 : 0 : | | | POWER ON Function [BUTTON ONLY | | | x KB Power ON Password Enter | | | x Hot Key Power ON Ctrl-F1 | | | | | | | | +---------------------------------------------|-------------------+
3.5.2. Disabling ACPI Soft-Off with chkconfig Management
chkconfig management to disable ACPI Soft-Off either by removing the ACPI daemon (acpid) from chkconfig management or by turning off acpid.
Note
chkconfig management at each cluster node as follows:
- Run either of the following commands:
chkconfig --del acpid— This command removesacpidfromchkconfigmanagement.— OR —chkconfig --level 345 acpid off— This command turns offacpid.
- Reboot the node.
- When the cluster is configured and running, verify that the node turns off immediately when fenced.
Note
You can fence the node with thefence_nodecommand or Conga.
3.5.3. Disabling ACPI Completely in the grub.conf File
chkconfig management (Section 3.5.2, “Disabling ACPI Soft-Off with chkconfig Management”). If the preferred method is not effective for your cluster, you can disable ACPI Soft-Off with the BIOS power management (Section 3.5.1, “Disabling ACPI Soft-Off with the BIOS”). If neither of those methods is effective for your cluster, you can disable ACPI completely by appending acpi=off to the kernel boot command line in the grub.conf file.
Important
grub.conf file of each cluster node as follows:
- Open
/boot/grub/grub.confwith a text editor. - Append
acpi=offto the kernel boot command line in/boot/grub/grub.conf(see Example 3.2, “Kernel Boot Command Line withacpi=offAppended to It”). - Reboot the node.
- When the cluster is configured and running, verify that the node turns off immediately when fenced.
Note
You can fence the node with thefence_nodecommand or Conga.
Example 3.2. Kernel Boot Command Line with acpi=off Appended to It
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You have a /boot partition. This means that
# all kernel and initrd paths are relative to /boot/, eg.
# root (hd0,0)
# kernel /vmlinuz-version ro root=/dev/mapper/vg_doc01-lv_root
# initrd /initrd-[generic-]version.img
#boot=/dev/hda
default=0
timeout=5
serial --unit=0 --speed=115200
terminal --timeout=5 serial console
title Red Hat Enterprise Linux Server (2.6.32-193.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-193.el6.x86_64 ro root=/dev/mapper/vg_doc01-lv_root console=ttyS0,115200n8 acpi=off
initrd /initramfs-2.6.32-131.0.15.el6.x86_64.img
acpi=off has been appended to the kernel boot command line — the line starting with "kernel /vmlinuz-2.6.32-193.el6.x86_64.img".
3.6. Considerations for Configuring HA Services
rgmanager, implements cold failover for off-the-shelf applications. In the Red Hat High Availability Add-On, an application is configured with other cluster resources to form an HA service that can fail over from one cluster node to another with no apparent interruption to cluster clients. HA-service failover can occur if a cluster node fails or if a cluster system administrator moves the service from one cluster node to another (for example, for a planned outage of a cluster node).
- IP address resource — IP address 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS2 named "gfs2-content-webserver".
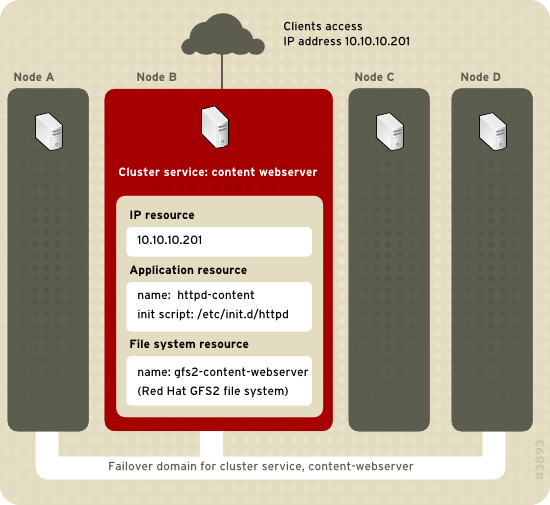
Figure 3.1. Web Server Cluster Service Example
Note
/etc/cluster/cluster.conf (in each cluster node). In the cluster configuration file, each resource tree is an XML representation that specifies each resource, its attributes, and its relationship among other resources in the resource tree (parent, child, and sibling relationships).
Note
- The types of resources needed to create a service
- Parent, child, and sibling relationships among resources
3.7. Configuration Validation
/usr/share/cluster/cluster.rng during startup time and when a configuration is reloaded. Also, you can validate a cluster configuration any time by using the ccs_config_validate command. For information on configuration validation when using the ccs command, see Section 6.1.6, “Configuration Validation”.
/usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
- XML validity — Checks that the configuration file is a valid XML file.
- Configuration options — Checks to make sure that options (XML elements and attributes) are valid.
- Option values — Checks that the options contain valid data (limited).
- Valid configuration — Example 3.3, “
cluster.confSample Configuration: Valid File” - Invalid option — Example 3.5, “
cluster.confSample Configuration: Invalid Option” - Invalid option value — Example 3.6, “
cluster.confSample Configuration: Invalid Option Value”
Example 3.3. cluster.conf Sample Configuration: Valid File
<cluster name="mycluster" config_version="1">
<logging debug="off"/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
</cluster>
Example 3.4. cluster.conf Sample Configuration: Invalid XML
<cluster name="mycluster" config_version="1">
<logging debug="off"/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
<cluster> <----------------INVALID
<cluster> instead of </cluster>.
Example 3.5. cluster.conf Sample Configuration: Invalid Option
<cluster name="mycluster" config_version="1">
<loging debug="off"/> <----------------INVALID
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
<cluster>
loging instead of logging.
Example 3.6. cluster.conf Sample Configuration: Invalid Option Value
<cluster name="mycluster" config_version="1">
<loging debug="off"/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="-1"> <--------INVALID
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
<cluster>
nodeid in the clusternode line for node-01.example.com. The value is a negative value ("-1") instead of a positive value ("1"). For the nodeid attribute, the value must be a positive value.
3.8. Considerations for NetworkManager
Note
cman service will not start if NetworkManager is either running or has been configured to run with the chkconfig command.
3.9. Considerations for Using Quorum Disk
qdiskd, that provides supplemental heuristics to determine node fitness. With heuristics you can determine factors that are important to the operation of the node in the event of a network partition. For example, in a four-node cluster with a 3:1 split, ordinarily, the three nodes automatically "win" because of the three-to-one majority. Under those circumstances, the one node is fenced. With qdiskd however, you can set up heuristics that allow the one node to win based on access to a critical resource (for example, a critical network path). If your cluster requires additional methods of determining node health, then you should configure qdiskd to meet those needs.
Note
qdiskd is not required unless you have special requirements for node health. An example of a special requirement is an "all-but-one" configuration. In an all-but-one configuration, qdiskd is configured to provide enough quorum votes to maintain quorum even though only one node is working.
Important
qdiskd parameters for your deployment depend on the site environment and special requirements needed. To understand the use of heuristics and other qdiskd parameters, see the qdisk(5) man page. If you require assistance understanding and using qdiskd for your site, contact an authorized Red Hat support representative.
qdiskd, you should take into account the following considerations:
- Cluster node votes
- When using Quorum Disk, each cluster node must have one vote.
- CMAN membership timeout value
- The
qdiskdmembership timeout value is automatically configured based on the CMAN membership timeout value (the time a node needs to be unresponsive before CMAN considers that node to be dead, and not a member).qdiskdalso performs extra sanity checks to guarantee that it can operate within the CMAN timeout. If you find that you need to reset this value, you must take the following into account:The CMAN membership timeout value should be at least two times that of theqdiskdmembership timeout value. The reason is because the quorum daemon must detect failed nodes on its own, and can take much longer to do so than CMAN. Other site-specific conditions may affect the relationship between the membership timeout values of CMAN andqdiskd. For assistance with adjusting the CMAN membership timeout value, contact an authorized Red Hat support representative. - Fencing
- To ensure reliable fencing when using
qdiskd, use power fencing. While other types of fencing can be reliable for clusters not configured withqdiskd, they are not reliable for a cluster configured withqdiskd. - Maximum nodes
- A cluster configured with
qdiskdsupports a maximum of 16 nodes. The reason for the limit is because of scalability; increasing the node count increases the amount of synchronous I/O contention on the shared quorum disk device. - Quorum disk device
- A quorum disk device should be a shared block device with concurrent read/write access by all nodes in a cluster. The minimum size of the block device is 10 Megabytes. Examples of shared block devices that can be used by
qdiskdare a multi-port SCSI RAID array, a Fibre Channel RAID SAN, or a RAID-configured iSCSI target. You can create a quorum disk device withmkqdisk, the Cluster Quorum Disk Utility. For information about using the utility see the mkqdisk(8) man page.Note
Using JBOD as a quorum disk is not recommended. A JBOD cannot provide dependable performance and therefore may not allow a node to write to it quickly enough. If a node is unable to write to a quorum disk device quickly enough, the node is falsely evicted from a cluster.
3.10. Red Hat High Availability Add-On and SELinux
enforcing state with the SELinux policy type set to targeted.
Note
fenced_can_network_connect is persistently set to on. This allows the fence_xvm fencing agent to work properly, enabling the system to fence virtual machines.
3.11. Multicast Addresses
Note
3.12. UDP Unicast Traffic
cman transport="udpu" parameter in the cluster.conf configuration file. You can also specify Unicast from the page of the Conga user interface, as described in Section 4.5.3, “Network Configuration”.
3.13. Considerations for ricci
ricci replaces ccsd. Therefore, it is necessary that ricci is running in each cluster node to be able to propagate updated cluster configuration whether it is by means of the cman_tool version -r command, the ccs command, or the luci user interface server. You can start ricci by using service ricci start or by enabling it to start at boot time by means of chkconfig. For information on enabling IP ports for ricci, see Section 3.3.1, “Enabling IP Ports on Cluster Nodes”.
ricci requires a password the first time you propagate updated cluster configuration from any particular node. You set the ricci password as root after you install ricci on your system. To set this password, execute the passwd ricci command, for user ricci.
3.14. Configuring Virtual Machines in a Clustered Environment
rgmanager tools to start and stop the virtual machines. Using virsh to start the machine can result in the virtual machine running in more than one place, which can cause data corruption in the virtual machine.
virsh, as the configuration file will be unknown out of the box to virsh.
path attribute of a virtual machine resource. Note that the path attribute is a directory or set of directories separated by the colon ':' character, not a path to a specific file.
Warning
libvirt-guests service should be disabled on all the nodes that are running rgmanager. If a virtual machine autostarts or resumes, this can result in the virtual machine running in more than one place, which can cause data corruption in the virtual machine.
vm Resource)”.
Chapter 4. Configuring Red Hat High Availability Add-On With Conga
Note
4.1. Configuration Tasks
- Configuring and running the Conga configuration user interface — the luci server. Refer to Section 4.2, “Starting luci”.
- Creating a cluster. Refer to Section 4.4, “Creating a Cluster”.
- Configuring global cluster properties. Refer to Section 4.5, “Global Cluster Properties”.
- Configuring fence devices. Refer to Section 4.6, “Configuring Fence Devices”.
- Configuring fencing for cluster members. Refer to Section 4.7, “Configuring Fencing for Cluster Members”.
- Creating failover domains. Refer to Section 4.8, “Configuring a Failover Domain”.
- Creating resources. Refer to Section 4.9, “Configuring Global Cluster Resources”.
- Creating cluster services. Refer to Section 4.10, “Adding a Cluster Service to the Cluster”.
4.2. Starting luci
Note
luci to configure a cluster requires that ricci be installed and running on the cluster nodes, as described in Section 3.13, “Considerations for ricci”. As noted in that section, using ricci requires a password which luci requires you to enter for each cluster node when you create a cluster, as described in Section 4.4, “Creating a Cluster”.
- Select a computer to host luci and install the luci software on that computer. For example:
#
yum install luciNote
Typically, a computer in a server cage or a data center hosts luci; however, a cluster computer can host luci. - Start luci using
service luci start. For example:#
service luci startStarting luci: generating https SSL certificates... done [ OK ] Please, point your web browser to https://nano-01:8084 to access luciNote
As of Red Hat Enterprise Linux release 6.1, you can configure some aspects of luci's behavior by means of the/etc/sysconfig/lucifile, including the port and host parameters, as described in Section 3.4, “Configuring luci with/etc/sysconfig/luci”. Modified port and host parameters will automatically be reflected in the URL displayed when the luci service starts. - At a Web browser, place the URL of the luci server into the URL address box and click
Go(or the equivalent). The URL syntax for the luci server ishttps://luci_server_hostname:luci_server_port. The default value of luci_server_port is8084.The first time you access luci, a web browser specific prompt regarding the self-signed SSL certificate (of the luci server) is displayed. Upon acknowledging the dialog box or boxes, your Web browser displays the luci login page. - Any user able to authenticate on the system that is hosting luci can log in to luci. As of Red Hat Enterprise Linux 6.2 only the root user on the system that is running luci can access any of the luci components until an administrator (the root user or a user with administrator permission) sets permissions for that user. For information on setting luci permissions for users, see Section 4.3, “Controlling Access to luci”.
Figure 4.1. luci Homebase page
Note
4.3. Controlling Access to luci
- As of Red Hat Enterprise Linux 6.2, the root user or a user who has been granted luci administrator permissions on a system running luci can control access to the various luci components by setting permissions for the individual users on a system.
- As of Red Hat Enterprise Linux 6.3, the root user or a user who has been granted luci administrator permissions can add users to the luci interface and then set the user permissions for that user. You will still need to add that user to the system and set up a password for that user, but this feature allows you to configure permissions for the user before the user has logged in to luci for the first time.
- As of Red Hat Enterprise Linux 6.4, the root user or a user who has been granted luci administrator permissions can also use the luci interface to delete users from the luci interface, which resets any permissions you have configured for that user.
Note
/etc/pam.d/luci file on the system. For information on using Linux-PAM, see the pam(8) man page.
root or as a user who has previously been granted administrator permissions and click the selection in the upper right corner of the luci screen. This brings up the page, which displays the existing users.
- Grants the user the same permissions as the root user, with full permissions on all clusters and the ability to set or remove permissions on all other users except root, whose permissions cannot be restricted.
- Allows the user to create new clusters, as described in Section 4.4, “Creating a Cluster”.
- Allows the user to add an existing cluster to the luci interface, as described in Section 5.1, “Adding an Existing Cluster to the luci Interface”.
- Allows the user to view the specified cluster.
- Allows the user to modify the configuration for the specified cluster, with the exception of adding and removing cluster nodes.
- Allows the user to manage high-availability services, as described in Section 5.5, “Managing High-Availability Services”.
- Allows the user to manage the individual nodes of a cluster, as described in Section 5.3, “Managing Cluster Nodes”.
- Allows the user to add and delete nodes from a cluster, as described in Section 4.4, “Creating a Cluster”.
- Allows the user to remove a cluster from the luci interface, as described in Section 5.4, “Starting, Stopping, Restarting, and Deleting Clusters”.
4.4. Creating a Cluster
- Click from the menu on the left side of the luci page. The screen appears, as shown in Figure 4.2, “luci cluster management page”.
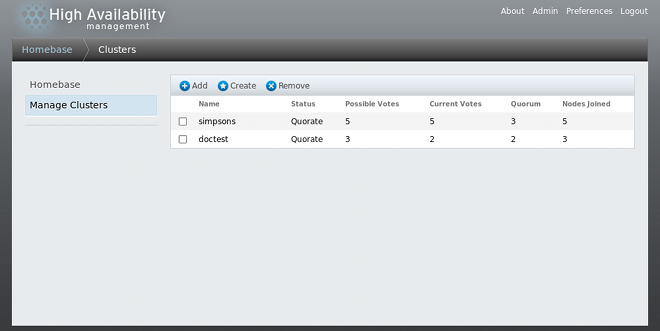
Figure 4.2. luci cluster management page
- Click . The dialog box appears, as shown in Figure 4.3, “luci cluster creation dialog box”.
Figure 4.3. luci cluster creation dialog box
- Enter the following parameters on the dialog box, as necessary:
- At the text box, enter a cluster name. The cluster name cannot exceed 15 characters.
- If each node in the cluster has the same ricci password, you can check to autofill the field as you add nodes.
- Enter the node name for a node in the cluster in the column. A node name can be up to 255 bytes in length.
- After you have entered the node name, the node name is reused as the ricci host name. If your system is configured with a dedicated private network that is used only for cluster traffic, you may want to configure luci to communicate with ricci on an address that is different from the address to which the cluster node name resolves. You can do this by entering that address as the .
- As of Red Hat Enterprise Linux 6.9, after you have entered the node name and, if necessary, adjusted the ricci host name, the fingerprint of the certificate of the ricci host is displayed for confirmation. You can verify whether this matches the expected fingerprint. If it is legitimate, enter the ricci password and add the next node. You can remove the fingerprint display by clicking on the display window, and you can restore this display (or enforce it at any time) by clicking the button.
Important
It is strongly advised that you verify the certificate fingerprint of the ricci server you are going to authenticate against. Providing an unverified entity on the network with the ricci password may constitute a confidentiality breach, and communication with an unverified entity may cause an integrity breach. - If you are using a different port for the ricci agent than the default of 11111, you can change that parameter.
- Click and enter the node name and ricci password for each additional node in the cluster.Figure 4.4, “luci cluster creation with certificate fingerprint display”. shows the dialog box after two nodes have been entered, showing the certificate fingerprints of the ricci hosts (Red Hat Enterprise Linux 6.9 and later).
Figure 4.4. luci cluster creation with certificate fingerprint display
- If you do not want to upgrade the cluster software packages that are already installed on the nodes when you create the cluster, leave the option selected. If you want to upgrade all cluster software packages, select the option.
Note
Whether you select the or the option, if any of the base cluster components are missing (cman,rgmanager,modclusterand all their dependencies), they will be installed. If they cannot be installed, the node creation will fail. - Check if desired.
- Select if clustered storage is required; this downloads the packages that support clustered storage and enables clustered LVM. You should select this only when you have access to the Resilient Storage Add-On or the Scalable File System Add-On.
- Click . Clicking causes the following actions:
- If you have selected , the cluster software packages are downloaded onto the nodes.
- Cluster software is installed onto the nodes (or it is verified that the appropriate software packages are installed).
- The cluster configuration file is updated and propagated to each node in the cluster.
- The added nodes join the cluster.
A message is displayed indicating that the cluster is being created. When the cluster is ready, the display shows the status of the newly created cluster, as shown in Figure 4.5, “Cluster node display”. Note that if ricci is not running on any of the nodes, the cluster creation will fail.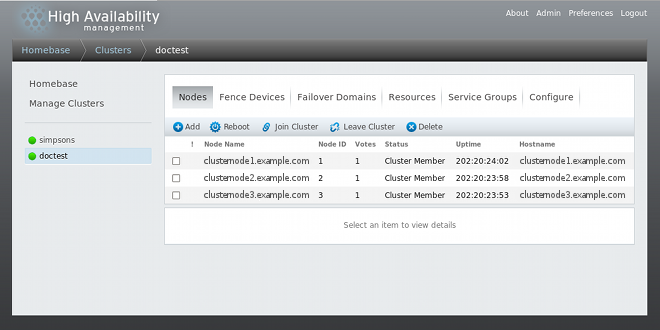
Figure 4.5. Cluster node display
- After clicking , you can add or delete nodes from the cluster by clicking the or function from the menu at the top of the cluster node display page. Unless you are deleting an entire cluster, nodes must be stopped before being deleted. For information on deleting a node from an existing cluster that is currently in operation, see Section 5.3.4, “Deleting a Member from a Cluster”.
Warning
Removing a cluster node from the cluster is a destructive operation that cannot be undone.
4.5. Global Cluster Properties
4.5.1. Configuring General Properties
- The text box displays the cluster name; it does not accept a cluster name change. The only way to change the name of a cluster is to create a new cluster configuration with the new name.
- The value is set to
1at the time of cluster creation and is automatically incremented each time you modify your cluster configuration. However, if you need to set it to another value, you can specify it at the text box.
4.5.2. Configuring Fence Daemon Properties
- The parameter is the number of seconds the fence daemon (
fenced) waits before fencing a node (a member of the fence domain) after the node has failed. The default value is0. Its value may be varied to suit cluster and network performance. - The parameter is the number of seconds the fence daemon (
fenced) waits before fencing a node after the node joins the fence domain. luci sets the value to6. A typical setting for is between 20 and 30 seconds, but can vary according to cluster and network performance.
Note
4.5.3. Network Configuration
- This is the default setting. With this option selected, the Red Hat High Availability Add-On software creates a multicast address based on the cluster ID. It generates the lower 16 bits of the address and appends them to the upper portion of the address according to whether the IP protocol is IPv4 or IPv6:
- For IPv4 — The address formed is 239.192. plus the lower 16 bits generated by Red Hat High Availability Add-On software.
- For IPv6 — The address formed is FF15:: plus the lower 16 bits generated by Red Hat High Availability Add-On software.
Note
The cluster ID is a unique identifier thatcmangenerates for each cluster. To view the cluster ID, run thecman_tool statuscommand on a cluster node. - If you need to use a specific multicast address, select this option enter a multicast address into the text box.If you do specify a multicast address, you should use the 239.192.x.x series (or FF15:: for IPv6) that
cmanuses. Otherwise, using a multicast address outside that range may cause unpredictable results. For example, using 224.0.0.x (which is "All hosts on the network") may not be routed correctly, or even routed at all by some hardware.If you specify or modify a multicast address, you must restart the cluster for this to take effect. For information on starting and stopping a cluster with Conga, see Section 5.4, “Starting, Stopping, Restarting, and Deleting Clusters”.Note
If you specify a multicast address, make sure that you check the configuration of routers that cluster packets pass through. Some routers may take a long time to learn addresses, seriously impacting cluster performance. - As of the Red Hat Enterprise Linux 6.2 release, the nodes in a cluster can communicate with each other using the UDP Unicast transport mechanism. It is recommended, however, that you use IP multicasting for the cluster network. UDP Unicast is an alternative that can be used when IP multicasting is not available. For GFS2 deployments using UDP Unicast is not recommended.
4.5.4. Configuring Redundant Ring Protocol
4.5.5. Quorum Disk Configuration
Note
| Parameter | Description | ||||
|---|---|---|---|---|---|
Specifies the quorum disk label created by the mkqdisk utility. If this field is used, the quorum daemon reads the /proc/partitions file and checks for qdisk signatures on every block device found, comparing the label against the specified label. This is useful in configurations where the quorum device name differs among nodes. | |||||
| |||||
The minimum score for a node to be considered "alive". If omitted or set to 0, the default function, floor((n+1)/2), is used, where n is the sum of the heuristics scores. The value must never exceed the sum of the heuristic scores; otherwise, the quorum disk cannot be available. |
Note
/etc/cluster/cluster.conf) in each cluster node. However, for the quorum disk to operate or for any modifications you have made to the quorum disk parameters to take effect, you must restart the cluster (see Section 5.4, “Starting, Stopping, Restarting, and Deleting Clusters”), ensuring that you have restarted the qdiskd daemon on each node.
4.5.6. Logging Configuration
- Checking enables debugging messages in the log file.
- Checking enables messages to
syslog. You can select the and the . The setting indicates that messages at the selected level and higher are sent tosyslog. - Checking enables messages to the log file. You can specify the name. The setting indicates that messages at the selected level and higher are written to the log file.
syslog and log file settings for that daemon.
4.6. Configuring Fence Devices
Note
- Creating fence devices — Refer to Section 4.6.1, “Creating a Fence Device”. Once you have created and named a fence device, you can configure the fence devices for each node in the cluster, as described in Section 4.7, “Configuring Fencing for Cluster Members”.
- Updating fence devices — Refer to Section 4.6.2, “Modifying a Fence Device”.
- Deleting fence devices — Refer to Section 4.6.3, “Deleting a Fence Device”.
Note
Figure 4.6. luci fence devices configuration page
4.6.1. Creating a Fence Device
- From the configuration page, click . Clicking displays the Add Fence Device (Instance) dialog box. From this dialog box, select the type of fence device to configure.
- Specify the information in the Add Fence Device (Instance) dialog box according to the type of fence device. Refer to Appendix A, Fence Device Parameters for more information about fence device parameters. In some cases you will need to specify additional node-specific parameters for the fence device when you configure fencing for the individual nodes, as described in Section 4.7, “Configuring Fencing for Cluster Members”.
- Click .
4.6.2. Modifying a Fence Device
- From the configuration page, click on the name of the fence device to modify. This displays the dialog box for that fence device, with the values that have been configured for the device.
- To modify the fence device, enter changes to the parameters displayed. Refer to Appendix A, Fence Device Parameters for more information.
- Click and wait for the configuration to be updated.
4.6.3. Deleting a Fence Device
Note
- From the configuration page, check the box to the left of the fence device or devices to select the devices to delete.
- Click and wait for the configuration to be updated. A message appears indicating which devices are being deleted.
4.7. Configuring Fencing for Cluster Members
4.7.1. Configuring a Single Fence Device for a Node
- From the cluster-specific page, you can configure fencing for the nodes in the cluster by clicking on along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
- Click on a node name. Clicking a link for a node causes a page to be displayed for that link showing how that node is configured.The node-specific page displays any services that are currently running on the node, as well as any failover domains of which this node is a member. You can modify an existing failover domain by clicking on its name. For information on configuring failover domains, see Section 4.8, “Configuring a Failover Domain”.
- On the node-specific page, under , click . This displays the dialog box.
- Enter a for the fencing method that you are configuring for this node. This is an arbitrary name that will be used by Red Hat High Availability Add-On; it is not the same as the DNS name for the device.
- Click . This displays the node-specific screen that now displays the method you have just added under .
- Configure a fence instance for this method by clicking the button that appears beneath the fence method. This displays the drop-down menu from which you can select a fence device you have previously configured, as described in Section 4.6.1, “Creating a Fence Device”.
- Select a fence device for this method. If this fence device requires that you configure node-specific parameters, the display shows the parameters to configure. For information on fencing parameters, see Appendix A, Fence Device Parameters.
Note
For non-power fence methods (that is, SAN/storage fencing), is selected by default on the node-specific parameters display. This ensures that a fenced node's access to storage is not re-enabled until the node has been rebooted. When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For information on unfencing a node, see thefence_node(8) man page. - Click . This returns you to the node-specific screen with the fence method and fence instance displayed.
4.7.2. Configuring a Backup Fence Device
- Use the procedure provided in Section 4.7.1, “Configuring a Single Fence Device for a Node” to configure the primary fencing method for a node.
- Beneath the display of the primary method you defined, click .
- Enter a name for the backup fencing method that you are configuring for this node and click . This displays the node-specific screen that now displays the method you have just added, below the primary fence method.
- Configure a fence instance for this method by clicking . This displays a drop-down menu from which you can select a fence device you have previously configured, as described in Section 4.6.1, “Creating a Fence Device”.
- Select a fence device for this method. If this fence device requires that you configure node-specific parameters, the display shows the parameters to configure. For information on fencing parameters, see Appendix A, Fence Device Parameters.
- Click . This returns you to the node-specific screen with the fence method and fence instance displayed.
4.7.3. Configuring a Node with Redundant Power
- Before you can configure fencing for a node with redundant power, you must configure each of the power switches as a fence device for the cluster. For information on configuring fence devices, see Section 4.6, “Configuring Fence Devices”.
- From the cluster-specific page, click on along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
- Click on a node name. Clicking a link for a node causes a page to be displayed for that link showing how that node is configured.
- On the node-specific page, click .
- Enter a name for the fencing method that you are configuring for this node.
- Click . This displays the node-specific screen that now displays the method you have just added under .
- Configure the first power supply as a fence instance for this method by clicking . This displays a drop-down menu from which you can select one of the power fencing devices you have previously configured, as described in Section 4.6.1, “Creating a Fence Device”.
- Select one of the power fence devices for this method and enter the appropriate parameters for this device.
- Click . This returns you to the node-specific screen with the fence method and fence instance displayed.
- Under the same fence method for which you have configured the first power fencing device, click . This displays a drop-down menu from which you can select the second power fencing devices you have previously configured, as described in Section 4.6.1, “Creating a Fence Device”.
- Select the second of the power fence devices for this method and enter the appropriate parameters for this device.
- Click . This returns you to the node-specific screen with the fence methods and fence instances displayed, showing that each device will power the system off in sequence and power the system on in sequence. This is shown in Figure 4.7, “Dual-Power Fencing Configuration”.
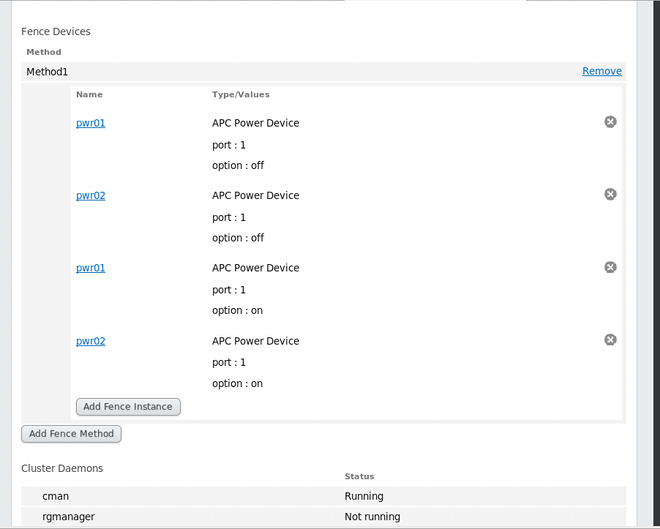
Figure 4.7. Dual-Power Fencing Configuration
4.7.4. Testing the Fence Configuration
fence_check utility.
[root@host-098 ~]# fence_check
fence_check run at Wed Jul 23 09:13:57 CDT 2014 pid: 4769
Testing host-098 method 1: success
Testing host-099 method 1: success
Testing host-100 method 1: success
fence_check(8) man page.
4.8. Configuring a Failover Domain
- Unrestricted — Allows you to specify that a subset of members are preferred, but that a cluster service assigned to this domain can run on any available member.
- Restricted — Allows you to restrict the members that can run a particular cluster service. If none of the members in a restricted failover domain are available, the cluster service cannot be started (either manually or by the cluster software).
- Unordered — When a cluster service is assigned to an unordered failover domain, the member on which the cluster service runs is chosen from the available failover domain members with no priority ordering.
- Ordered — Allows you to specify a preference order among the members of a failover domain. The member at the top of the list is the most preferred, followed by the second member in the list, and so on.
- Failback — Allows you to specify whether a service in the failover domain should fail back to the node that it was originally running on before that node failed. Configuring this characteristic is useful in circumstances where a node repeatedly fails and is part of an ordered failover domain. In that circumstance, if a node is the preferred node in a failover domain, it is possible for a service to fail over and fail back repeatedly between the preferred node and another node, causing severe impact on performance.
Note
The failback characteristic is applicable only if ordered failover is configured.
Note
Note
httpd), which requires you to set up the configuration identically on all members that run the cluster service. Instead of setting up the entire cluster to run the cluster service, you can set up only the members in the restricted failover domain that you associate with the cluster service.
Note
4.8.1. Adding a Failover Domain
- From the cluster-specific page, you can configure failover domains for that cluster by clicking on along the top of the cluster display. This displays the failover domains that have been configured for this cluster.
- Click . Clicking causes the display of the Add Failover Domain to Cluster dialog box, as shown in Figure 4.8, “luci failover domain configuration dialog box”.

Figure 4.8. luci failover domain configuration dialog box
- In the Add Failover Domain to Cluster dialog box, specify a failover domain name at the text box.
Note
The name should be descriptive enough to distinguish its purpose relative to other names used in your cluster. - To enable setting failover priority of the members in the failover domain, click the check box. With checked, you can set the priority value, , for each node selected as members of the failover domain.
Note
The priority value is applicable only if ordered failover is configured. - To restrict failover to members in this failover domain, click the check box. With checked, services assigned to this failover domain fail over only to nodes in this failover domain.
- To specify that a node does not fail back in this failover domain, click the check box. With checked, if a service fails over from a preferred node, the service does not fail back to the original node once it has recovered.
- Configure members for this failover domain. Click the check box for each node that is to be a member of the failover domain. If is checked, set the priority in the text box for each member of the failover domain.
- Click . This displays the Failover Domains page with the newly-created failover domain displayed. A message indicates that the new domain is being created. Refresh the page for an updated status.
4.8.2. Modifying a Failover Domain
- From the cluster-specific page, you can configure Failover Domains for that cluster by clicking on along the top of the cluster display. This displays the failover domains that have been configured for this cluster.
- Click on the name of a failover domain. This displays the configuration page for that failover domain.
- To modify the , , or properties for the failover domain, click or unclick the check box next to the property and click .
- To modify the failover domain membership, click or unclick the check box next to the cluster member. If the failover domain is prioritized, you can also modify the priority setting for the cluster member. Click .
4.8.3. Deleting a Failover Domain
- From the cluster-specific page, you can configure Failover Domains for that cluster by clicking on along the top of the cluster display. This displays the failover domains that have been configured for this cluster.
- Select the check box for the failover domain to delete.
- Click .
4.9. Configuring Global Cluster Resources
- From the cluster-specific page, you can add resources to that cluster by clicking on along the top of the cluster display. This displays the resources that have been configured for that cluster.
- Click . This displays the drop-down menu.
- Click the drop-down box under and select the type of resource to configure.
- Enter the resource parameters for the resource you are adding. Appendix B, HA Resource Parameters describes resource parameters.
- Click . Clicking returns to the resources page that displays the display of Resources, which displays the added resource (and other resources).
- From the luci page, click on the name of the resource to modify. This displays the parameters for that resource.
- Edit the resource parameters.
- Click .
- From the luci page, click the check box for any resources to delete.
- Click .
- Clicking on the header once sorts the resources alphabetically, according to resource name. Clicking on the header a second time sourts the resources in reverse alphabetic order, according to resource name.
- Clicking on the header once sorts the resources alphabetically, according to resource type. Clicking on the header a second time sourts the resources in reverse alphabetic order, according to resource type.
- Clicking on the header once sorts the resources so that they are grouped according to whether they are in use or not.
4.10. Adding a Cluster Service to the Cluster
- From the cluster-specific page, you can add services to that cluster by clicking on along the top of the cluster display. This displays the services that have been configured for that cluster. (From the page, you can also start, restart, and disable a service, as described in Section 5.5, “Managing High-Availability Services”.)
- Click . This displays the dialog box.
- On the Add Service Group to Cluster dialog box, at the text box, type the name of the service.
Note
Use a descriptive name that clearly distinguishes the service from other services in the cluster. - Check the check box if you want the service to start automatically when a cluster is started and running. If the check box is not checked, the service must be started manually any time the cluster comes up from the stopped state.
- Check the check box to set a policy wherein the service only runs on nodes that have no other services running on them.
- If you have configured failover domains for the cluster, you can use the drop-down menu of the parameter to select a failover domain for this service. For information on configuring failover domains, see Section 4.8, “Configuring a Failover Domain”.
- Use the drop-down box to select a recovery policy for the service. The options are to , , , or the service.Selecting the option indicates that the system should attempt to restart the failed service before relocating the service. Selecting the option indicates that the system should try to restart the service in a different node. Selecting the option indicates that the system should disable the resource group if any component fails. Selecting the option indicates that the system should attempt to restart the service in place if it fails, but if restarting the service fails the service will be disabled instead of being moved to another host in the cluster.If you select or as the recovery policy for the service, you can specify the maximum number of restart failures before relocating or disabling the service, and you can specify the length of time in seconds after which to forget a restart.
- To add a resource to the service, click . Clicking causes the display of the drop-down box that allows you to add an existing global resource or to add a new resource that is available only to this service.
Note
When configuring a cluster service that includes a floating IP address resource, you must configure the IP resource as the first entry.- To add an existing global resource, click on the name of the existing resource from the drop-down box. This displays the resource and its parameters on the page for the service you are configuring. For information on adding or modifying global resources, see Section 4.9, “Configuring Global Cluster Resources”).
- To add a new resource that is available only to this service, select the type of resource to configure from the drop-down box and enter the resource parameters for the resource you are adding. Appendix B, HA Resource Parameters describes resource parameters.
- When adding a resource to a service, whether it is an existing global resource or a resource available only to this service, you can specify whether the resource is an or a .If you specify that a resource is an independent subtree, then if that resource fails only that resource is restarted (rather than the entire service) before the system attempting normal recovery. You can specify the maximum number of restarts to attempt for that resource on a node before implementing the recovery policy for the service. You can also specify the length of time in seconds after which the system will implement the recovery policy for the service.If you specify that the resource is a non-critical resource, then if that resource fails only that resource is restarted, and if the resource continues to fail then only that resource is disabled, rather than the entire service. You can specify the maximum number of restarts to attempt for that resource on a node before disabling that resource. You can also specify the length of time in seconds after which the system will disable that resource.
- If you want to add child resources to the resource you are defining, click . Clicking causes the display of the drop-down box, from which you can add an existing global resource or add a new resource that is available only to this service. You can continue adding children resources to the resource to suit your requirements.
Note
If you are adding a Samba-service resource, add it directly to the service, not as a child of another resource.Note
When configuring a dependency tree for a cluster service that includes a floating IP address resource, you must configure the IP resource as the first entry and not as the child of another resource. - When you have completed adding resources to the service, and have completed adding children resources to resources, click . Clicking returns to the page displaying the added service (and other services).
Note
Note
/sbin/ip addr show command on a cluster node (rather than the obsoleted ifconfig command). The following output shows the /sbin/ip addr show command executed on a node running a cluster service:
1: lo: <LOOPBACK,UP> mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP> mtu 1356 qdisc pfifo_fast qlen 1000
link/ether 00:05:5d:9a:d8:91 brd ff:ff:ff:ff:ff:ff
inet 10.11.4.31/22 brd 10.11.7.255 scope global eth0
inet6 fe80::205:5dff:fe9a:d891/64 scope link
inet 10.11.4.240/22 scope global secondary eth0
valid_lft forever preferred_lft forever
- From the dialog box, click on the name of the service to modify. This displays the parameters and resources that have been configured for that service.
- Edit the service parameters.
- Click .
- From the luci page, click the check box for any services to delete.
- Click .
- As of Red Hat Enterprise Linux 6.3, before luci deletes any services a message appears asking you to confirm that you intend to delete the service groups or groups, which stops the resources that comprise it. Click to close the dialog box without deleting any services, or click to remove the selected service or services.
Chapter 5. Managing Red Hat High Availability Add-On With Conga
5.1. Adding an Existing Cluster to the luci Interface
- Click from the menu on the left side of the luci page. The screen appears.
- Click . The screen appears.
- Enter the node host name for any of the nodes in the existing cluster. After you have entered the node name, the node name is reused as the ricci host name; you can override this if you are communicating with ricci on an address that is different from the address to which the cluster node name resolves.As of Red Hat Enterprise Linux 6.9, after you have entered the node name and ricci host name, the fingerprint of the certificate of the ricci host is displayed for confirmation. If it is legitimate, enter the ricci password
Important
It is strongly advised that you verify the certificate fingerprint of the ricci server you are going to authenticate against. Providing an unverified entity on the network with the ricci password may constitute a confidentiality breach, and communication with an unverified entity may cause an integrity breach.Since each node in the cluster contains all of the configuration information for the cluster, this should provide enough information to add the cluster to the luci interface. - Click . The screen then displays the cluster name and the remaining nodes in the cluster.
- Enter the individual ricci passwords for each node in the cluster, or enter one password and select .
- Click . The previously-configured cluster now displays on the screen.
5.2. Removing a Cluster from the luci Interface
- Click from the menu on the left side of the luci page. The screen appears.
- Select the cluster or clusters you wish to remove.
- Click . The system will ask you to confirm whether to remove the cluster from the luci management GUI.
5.3. Managing Cluster Nodes
5.3.1. Rebooting a Cluster Node
- From the cluster-specific page, click on along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
- Select the node to reboot by clicking the check box for that node.
- Select the function from the menu at the top of the page. This causes the selected node to reboot and a message appears at the top of the page indicating that the node is being rebooted.
- Refresh the page to see the updated status of the node.
5.3.2. Causing a Node to Leave or Join a Cluster
Not a cluster member. For information on deleting the node entirely from the cluster configuration, see Section 5.3.4, “Deleting a Member from a Cluster”.
- From the cluster-specific page, click on along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
- Select the node you want to leave the cluster by clicking the check box for that node.
- Select the function from the menu at the top of the page. This causes a message to appear at the top of the page indicating that the node is being stopped.
- Refresh the page to see the updated status of the node.
5.3.3. Adding a Member to a Running Cluster
- From the cluster-specific page, click along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
- Click . Clicking causes the display of the Add Nodes To Cluster dialog box.
- Enter the node name in the text box. After you have entered the node name, the node name is reused as the ricci host name; you can override this if you are communicating with ricci on an address that is different from the address to which the cluster node name resolves.
- As of Red Hat Enterprise Linux 6.9, after you have entered the node name and, if necessary, adjusted the ricci host name, the fingerprint of the certificate of the ricci host is displayed for confirmation. You can verify whether this matches the expected fingerprint. If it is legitimate, enter the ricci password.
Important
It is strongly advised that you verify the certificate fingerprint of the ricci server you are going to authenticate against. Providing an unverified entity on the network with the ricci password may constitute a confidentiality breach, and communication with an unverified entity may cause an integrity breach. - If you are using a different port for the ricci agent than the default of 11111, change this parameter to the port you are using.
- Check the check box if clustered storage is required to download the packages that support clustered storage and enable clustered LVM; you should select this only when you have access to the Resilient Storage Add-On or the Scalable File System Add-On.
- If you want to add more nodes, click and enter the node name and password for the each additional node.
- Click . Clicking causes the following actions:
- If you have selected , the cluster software packages are downloaded onto the nodes.
- Cluster software is installed onto the nodes (or it is verified that the appropriate software packages are installed).
- The cluster configuration file is updated and propagated to each node in the cluster — including the added node.
- The added node joins the cluster.
The page appears with a message indicating that the node is being added to the cluster. Refresh the page to update the status. - When the process of adding a node is complete, click on the node name for the newly-added node to configure fencing for this node, as described in Section 4.6, “Configuring Fence Devices”.
Note
5.3.4. Deleting a Member from a Cluster
- From the cluster-specific page, click along the top of the cluster display. This displays the nodes that constitute the cluster. This is also the default page that appears when you click on the cluster name beneath from the menu on the left side of the luci page.
Note
To allow services running on a node to fail over when the node is deleted, skip the next step. - Disable or relocate each service that is running on the node to be deleted. For information on disabling and relocating services, see Section 5.5, “Managing High-Availability Services”.
- Select the node or nodes to delete.
- Click . The Nodes page indicates that the node is being removed. Refresh the page to see the current status.
Important
5.4. Starting, Stopping, Restarting, and Deleting Clusters
Not a cluster member.
- Select all of the nodes in the cluster by clicking on the check box next to each node.
- Select the function from the menu at the top of the page. This causes a message to appear at the top of the page indicating that each node is being stopped.
- Refresh the page to see the updated status of the nodes.
- Select all of the nodes in the cluster by clicking on the check box next to each node.
- Select the function from the menu at the top of the page.
- Refresh the page to see the updated status of the nodes.
Important
- Select all of the nodes in the cluster by clicking on the check box next to each node.
- Select the function from the menu at the top of the page.
5.5. Managing High-Availability Services
- Start a service
- Restart a service
- Disable a service
- Delete a service
- Relocate a service
- — To start any services that are not currently running, select any services you want to start by clicking the check box for that service and clicking .
- — To restart any services that are currently running, select any services you want to restart by clicking the check box for that service and clicking .
- — To disable any service that is currently running, select any services you want to disable by clicking the check box for that service and clicking .
- — To delete any services that are not currently running, select any services you want to disable by clicking the check box for that service and clicking .
- — To relocate a running service, click on the name of the service in the services display. This causes the services configuration page for the service to be displayed, with a display indicating on which node the service is currently running.From the Start on node... drop-down box, select the node on which you want to relocate the service, and click on the icon. A message appears at the top of the screen indicating that the service is being started. You may need to refresh the screen to see the new display indicating that the service is running on the node you have selected.
Note
If the running service you have selected is avmservice, the drop-down box will show amigrateoption instead of arelocateoption.
Note
5.6. Backing Up and Restoring the luci Configuration
/var/lib/luci/data/luci.db file. This is not the cluster configuration itself, which is stored in the cluster.conf file. Instead, it contains the list of users and clusters and related properties that luci maintains. By default, the backup this procedure creates will be written to the same directory as the luci.db file.
- Execute
service luci stop. - Execute
service luci backup-db.Optionally, you can specify a file name as a parameter for thebackup-dbcommand, which will write the luci database to that file. For example, to write the luci database to the file/root/luci.db.backup, you can execute the commandservice luci backup-db /root/luci.db.backup. Note, however, that backup files that are written to places other than/var/lib/luci/data/(for backups whose filenames you specify when usingservice luci backup-db) will not show up in the output of thelist-backupscommand. - Execute
service luci start.
- Execute
service luci stop. - Execute
service luci list-backupsand note the file name to restore. - Execute
service luci restore-db /var/lib/luci/data/lucibackupfilewhere lucibackupfile is the backup file to restore.For example, the following command restores the luci configuration information that was stored in the backup fileluci-backup20110923062526.db:service luci restore-db /var/lib/luci/data/luci-backup20110923062526.db
- Execute
service luci start.
host.pem file from the machine on which you created the backup because of a complete reinstallation, for example, you will need to add your clusters back to luci manually in order to re-authenticate the cluster nodes.
luci1 and the backup is restored on the machine luci2.
- Execute the following sequence of commands to create a luci backup on
luci1and copy both the SSL certificate file and the luci backup ontoluci2.[root@luci1 ~]#
service luci stop[root@luci1 ~]#service luci backup-db[root@luci1 ~]#service luci list-backups/var/lib/luci/data/luci-backup20120504134051.db [root@luci1 ~]#scp /var/lib/luci/certs/host.pem /var/lib/luci/data/luci-backup20120504134051.db root@luci2: - On the
luci2machine, ensure that luci has been installed and is not running. Install the package, if is not already installed. - Execute the following sequence of commands to ensure that the authentications are in place and to restore the luci database from
luci1ontoluci2.[root@luci2 ~]#
cp host.pem /var/lib/luci/certs/[root@luci2 ~]#chown luci: /var/lib/luci/certs/host.pem[root@luci2 ~]#/etc/init.d/luci restore-db ~/luci-backup20120504134051.db[root@luci2 ~]#shred -u ~/host.pem ~/luci-backup20120504134051.db[root@luci2 ~]#service luci start
Chapter 6. Configuring Red Hat High Availability Add-On With the ccs Command
ccs cluster configuration command. The ccs command allows an administrator to create, modify and view the cluster.conf cluster configuration file. You can use the ccs command to configure a cluster configuration file on a local file system or on a remote node. Using the ccs command, an administrator can also start and stop the cluster services on one or all of the nodes in a configured cluster.
ccs command. For information on using the ccs command to manage a running cluster, see Chapter 7, Managing Red Hat High Availability Add-On With ccs.
Note
Note
cluster.conf elements and attributes. For a comprehensive list and description of cluster.conf elements and attributes, see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
6.1. Operational Overview
ccs command to configure a cluster:
6.1.1. Creating the Cluster Configuration File on a Local System
ccs command, you can create a cluster configuration file on a cluster node, or you can create a cluster configuration file on a local file system and then send that file to a host in a cluster. This allows you to work on a file from a local machine, where you can maintain it under version control or otherwise tag the file according to your needs. Using the ccs command does not require root privilege.
ccs command, you use the -h option to specify the name of the host. This creates and edits the /etc/cluster/cluster.conf file on the host:
ccs -h host [options]
-f option of the ccs command to specify the name of the configuration file when you perform a cluster operation. You can name this file anything you want.
ccs -f file [options]
-h or the -f parameter of the ccs command, the ccs will attempt to connect to the localhost. This is the equivalent of specifying -h localhost.
--setconf option of the ccs command. On a host machine in a cluster, the file you send will be named cluster.conf and it will be placed in the /etc/cluster directory.
ccs -h host -f file --setconf
--setconf option of the ccs command, see Section 6.15, “Propagating the Configuration File to the Cluster Nodes”.
6.1.2. Viewing the Current Cluster Configuration
ccs -h host --getconf
-f option instead of the -h option, as described in Section 6.1.1, “Creating the Cluster Configuration File on a Local System”.
6.1.3. Specifying ricci Passwords with the ccs Command
ccs commands that distribute copies of the cluster.conf file to the nodes of a cluster requires that ricci be installed and running on the cluster nodes, as described in Section 3.13, “Considerations for ricci”. Using ricci requires a password the first time you interact with ricci from any specific machine.
ccs command requires it. Alternately, you can use the -p option to specify a ricci password on the command line.
ccs -h host -p password --sync --activate
cluster.conf file to all of the nodes in the cluster with the --sync option of the ccs command and you specify a ricci password for the command, the ccs command will use that password for each node in the cluster. If you need to set different passwords for ricci on individual nodes, you can use the --setconf option with the -p option to distribute the configuration file to one node at a time.
6.1.4. Modifying Cluster Configuration Components
ccs command to configure cluster components and their attributes in the cluster configuration file. After you have added a cluster component to the file, in order to modify the attributes of that component you must remove the component you have defined and add the component again, with the modified attributes. Information on how to do this with each component is provided in the individual sections of this chapter.
cman cluster component provide an exception to this procedure for modifying cluster components. To modify these attributes, you execute the --setcman option of the ccs command, specifying the new attributes. Note that specifying this option resets all values that you do not explicitly specify to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
6.1.5. Commands that Overwrite Previous Settings
ccs command that implement overwriting semantics when setting properties. This means that you can issue the ccs command with one of these options without specifying any settings, and it will reset all settings to their default values. These options are as follows:
--settotem--setdlm--setrm--setcman--setmulticast--setaltmulticast--setfencedaemon--setlogging--setquorumd
# ccs -h hostname --setfencedaemonpost_fail_delay property to 5:
# ccs -h hostname --setfencedaemon post_fail_delay=5post_join_delay property to 10, the post_fail_delay property will be restored to its default value:
# ccs -h hostname --setfencedaemon post_join_delay=10post_fail_delay and the post_join_delay properties, you indicate them both on the same command, as in the following example:
# ccs -h hostname --setfencedaemon post_fail_delay=5 post_join_delay=106.1.6. Configuration Validation
ccs command to create and edit the cluster configuration file, the configuration is automatically validated according to the cluster schema. As of the Red Hat Enterprise Linux 6.3 release, the ccs command validates the configuration according to the cluster schema at /usr/share/cluster/cluster.rng on the node that you specify with the -h option. Previously the ccs command always used the cluster schema that was packaged with the ccs command itself, /usr/share/ccs/cluster.rng on the local system. When you use the -f option to specify the local system, the ccs command still uses the cluster schema /usr/share/ccs/cluster.rng that was packaged with the ccs command itself on that system.
6.2. Configuration Tasks
ccs consists of the following steps:
- Ensuring that ricci is running on all nodes in the cluster. Refer to Section 6.3, “Starting ricci”.
- Creating a cluster. Refer to Section 6.4, “Creating and Modifying a Cluster”.
- Configuring fence devices. Refer to Section 6.5, “Configuring Fence Devices”.
- Configuring fencing for cluster members. Refer to Section 6.7, “Configuring Fencing for Cluster Members”.
- Creating failover domains. Refer to Section 6.8, “Configuring a Failover Domain”.
- Creating resources. Refer to Section 6.9, “Configuring Global Cluster Resources”.
- Creating cluster services. Refer to Section 6.10, “Adding a Cluster Service to the Cluster”.
- Configuring a quorum disk, if necessary. Refer to Section 6.13, “Configuring a Quorum Disk”.
- Configuring global cluster properties. Refer to Section 6.14, “Miscellaneous Cluster Configuration”.
- Propagating the cluster configuration file to all of the cluster nodes. Refer to Section 6.15, “Propagating the Configuration File to the Cluster Nodes”.
6.3. Starting ricci
- The IP ports on your cluster nodes should be enabled for ricci. For information on enabling IP ports on cluster nodes, see Section 3.3.1, “Enabling IP Ports on Cluster Nodes”.
- The ricci service is installed on all nodes in the cluster and assigned a ricci password, as described in Section 3.13, “Considerations for
ricci”.
# service ricci start
Starting ricci: [ OK ]
6.4. Creating and Modifying a Cluster
ccs command without fencing, failover domains, and HA services. Subsequent sections describe how to configure those parts of the configuration.
- Create a cluster configuration file on one of the nodes in the cluster by executing the
ccscommand using the-hparameter to specify the node on which to create the file and thecreateclusteroption to specify a name for the cluster:ccs -h host --createcluster clustername
For example, the following command creates a configuration file onnode-01.example.comnamedmycluster:ccs -h node-01.example.com --createcluster mycluster
The cluster name cannot exceed 15 characters.If acluster.conffile already exists on the host that you specify, use the-ioption when executing this command to replace that existing file.If you want to create a cluster configuration file on your local system you can specify the-foption instead of the-hoption. For information on creating the file locally, see Section 6.1.1, “Creating the Cluster Configuration File on a Local System”. - To configure the nodes that the cluster contains, execute the following command for each node in the cluster. A node name can be up to 255 bytes in length.
ccs -h host --addnode node
For example, the following three commands add the nodesnode-01.example.com,node-02.example.com, andnode-03.example.comto the configuration file onnode-01.example.com:ccs -h node-01.example.com --addnode node-01.example.com ccs -h node-01.example.com --addnode node-02.example.com ccs -h node-01.example.com --addnode node-03.example.com
To view a list of the nodes that have been configured for a cluster, execute the following command:ccs -h host --lsnodes
Example 6.1, “cluster.confFile After Adding Three Nodes” shows acluster.confconfiguration file after you have created the clustermyclusterthat contains the nodesnode-01.example.com,node-02.example.com, andnode-03.example.com.Example 6.1.
cluster.confFile After Adding Three Nodes<cluster name="mycluster" config_version="2"> <clusternodes> <clusternode name="node-01.example.com" nodeid="1"> <fence> </fence> </clusternode> <clusternode name="node-02.example.com" nodeid="2"> <fence> </fence> </clusternode> <clusternode name="node-03.example.com" nodeid="3"> <fence> </fence> </clusternode> </clusternodes> <fencedevices> </fencedevices> <rm> </rm> </cluster>Note
When you add a node to a cluster that uses UDPU transport, you must restart all nodes in the cluster for the change to take effect.When you add a node to the cluster, you can specify the number of votes the node contributes to determine whether there is a quorum. To set the number of votes for a cluster node, use the following command:ccs -h host --addnode host --votes votes
When you add a node, theccsassigns the node a unique integer that is used as the node identifier. If you want to specify the node identifier manually when creating a node, use the following command:ccs -h host --addnode host --nodeid nodeid
To remove a node from a cluster, execute the following command:ccs -h host --rmnode node
6.5. Configuring Fence Devices
- The
post_fail_delayattribute is the number of seconds the fence daemon (fenced) waits before fencing a node (a member of the fence domain) after the node has failed. Thepost_fail_delaydefault value is0. Its value may be varied to suit cluster and network performance. - The
post-join_delayattribute is the number of seconds the fence daemon (fenced) waits before fencing a node after the node joins the fence domain. Thepost_join_delaydefault value is6. A typical setting forpost_join_delayis between 20 and 30 seconds, but can vary according to cluster and network performance.
post_fail_delay and post_join_delay attributes with the --setfencedaemon option of the ccs command. Note, however, that executing the ccs --setfencedaemon command overwrites all existing fence daemon properties that have been explicitly set and restores them to their default values.
post_fail_delay attribute, execute the following command. This command will overwrite the values of all other existing fence daemon properties that you have set with this command and restore them to their default values.
ccs -h host --setfencedaemon post_fail_delay=value
post_join_delay attribute, execute the following command. This command will overwrite the values of all other existing fence daemon properties that you have set with this command and restore them to their default values.
ccs -h host --setfencedaemon post_join_delay=value
post_join_delay attribute and the post_fail_delay attribute, execute the following command:
ccs -h host --setfencedaemon post_fail_delay=value post_join_delay=value
Note
post_join_delay and post_fail_delay attributes as well as the additional fence daemon properties you can modify, see the fenced(8) man page and see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html.
ccs -h host --addfencedev devicename [fencedeviceoptions]
node1 named my_apc with an IP address of apc_ip_example, a login of login_example, and a password of password_example, execute the following command:
ccs -h node1 --addfencedev myfence agent=fence_apc ipaddr=apc_ip_example login=login_example passwd=password_example
fencedevices section of the cluster.conf configuration file after you have added this APC fence device:
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="my_apc" passwd="password_example"/>
</fencedevices>
ccs command to print a list of available fence devices and options or to print a list of fence devices currently configured for your cluster, see Section 6.6, “Listing Fence Devices and Fence Device Options”.
ccs -h host --rmfencedev fence_device_name
myfence from the cluster configuration file on cluster node node1, execute the following command:
ccs -h node1 --rmfencedev myfence
6.6. Listing Fence Devices and Fence Device Options
ccs command to print a list of available fence devices and to print a list of options for each available fence type. You can also use the ccs command to print a list of fence devices currently configured for your cluster.
ccs -h host --lsfenceopts
node1, showing sample output.
[root@ask-03 ~]# ccs -h node1 --lsfenceopts
fence_rps10 - RPS10 Serial Switch
fence_vixel - No description available
fence_egenera - No description available
fence_xcat - No description available
fence_na - Node Assassin
fence_apc - Fence agent for APC over telnet/ssh
fence_apc_snmp - Fence agent for APC over SNMP
fence_bladecenter - Fence agent for IBM BladeCenter
fence_bladecenter_snmp - Fence agent for IBM BladeCenter over SNMP
fence_cisco_mds - Fence agent for Cisco MDS
fence_cisco_ucs - Fence agent for Cisco UCS
fence_drac5 - Fence agent for Dell DRAC CMC/5
fence_eps - Fence agent for ePowerSwitch
fence_ibmblade - Fence agent for IBM BladeCenter over SNMP
fence_ifmib - Fence agent for IF MIB
fence_ilo - Fence agent for HP iLO
fence_ilo_mp - Fence agent for HP iLO MP
fence_intelmodular - Fence agent for Intel Modular
fence_ipmilan - Fence agent for IPMI over LAN
fence_kdump - Fence agent for use with kdump
fence_rhevm - Fence agent for RHEV-M REST API
fence_rsa - Fence agent for IBM RSA
fence_sanbox2 - Fence agent for QLogic SANBox2 FC switches
fence_scsi - fence agent for SCSI-3 persistent reservations
fence_virsh - Fence agent for virsh
fence_virt - Fence agent for virtual machines
fence_vmware - Fence agent for VMware
fence_vmware_soap - Fence agent for VMware over SOAP API
fence_wti - Fence agent for WTI
fence_xvm - Fence agent for virtual machines
ccs -h host --lsfenceopts fence_type
fence_wti fence agent.
[root@ask-03 ~]# ccs -h node1 --lsfenceopts fence_wti
fence_wti - Fence agent for WTI
Required Options:
Optional Options:
option: No description available
action: Fencing Action
ipaddr: IP Address or Hostname
login: Login Name
passwd: Login password or passphrase
passwd_script: Script to retrieve password
cmd_prompt: Force command prompt
secure: SSH connection
identity_file: Identity file for ssh
port: Physical plug number or name of virtual machine
inet4_only: Forces agent to use IPv4 addresses only
inet6_only: Forces agent to use IPv6 addresses only
ipport: TCP port to use for connection with device
verbose: Verbose mode
debug: Write debug information to given file
version: Display version information and exit
help: Display help and exit
separator: Separator for CSV created by operation list
power_timeout: Test X seconds for status change after ON/OFF
shell_timeout: Wait X seconds for cmd prompt after issuing command
login_timeout: Wait X seconds for cmd prompt after login
power_wait: Wait X seconds after issuing ON/OFF
delay: Wait X seconds before fencing is started
retry_on: Count of attempts to retry power on
ccs -h host --lsfencedev
6.7. Configuring Fencing for Cluster Members
Note
6.7.1. Configuring a Single Power-Based Fence Device for a Node
my_apc, which uses the fence_apc fencing agent. In this example, the device named my_apc was previously configured with the --addfencedev option, as described in Section 6.5, “Configuring Fence Devices”.
- Add a fence method for the node, providing a name for the fence method.
ccs -h host --addmethod method node
For example, to configure a fence method namedAPCfor the nodenode-01.example.comin the configuration file on the cluster nodenode-01.example.com, execute the following command:ccs -h node01.example.com --addmethod APC node01.example.com
- Add a fence instance for the method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node:
ccs -h host --addfenceinst fencedevicename node method [options]
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses power port 1 on the APC switch for the fence device namedmy_apcto fence cluster nodenode-01.example.comusing the method namedAPC, execute the following command:ccs -h node01.example.com --addfenceinst my_apc node01.example.com APC port=1
APC. The device for the fence method specifies my_apc as the device name, which is a device previously configured with the --addfencedev option, as described in Section 6.5, “Configuring Fence Devices”. Each node is configured with a unique APC switch power port number: The port number for node-01.example.com is 1, the port number for node-02.example.com is 2, and the port number for node-03.example.com is 3.
ccs -h node01.example.com --addmethod APC node01.example.com ccs -h node01.example.com --addmethod APC node02.example.com ccs -h node01.example.com --addmethod APC node03.example.com ccs -h node01.example.com --addfenceinst my_apc node01.example.com APC port=1 ccs -h node01.example.com --addfenceinst my_apc node02.example.com APC port=2 ccs -h node01.example.com --addfenceinst my_apc node03.example.com APC port=3
cluster.conf After Adding Power-Based Fence Methods ” shows a cluster.conf configuration file after you have added these fencing methods and instances to each node in the cluster.
Example 6.2. cluster.conf After Adding Power-Based Fence Methods
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="my_apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="my_apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="my_apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="my_apc" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
6.7.2. Configuring a Single Storage-Based Fence Device for a Node
on or enable.
fence_node(8) man page.
sanswitch1, which uses the fence_sanbox2 fencing agent.
- Add a fence method for the node, providing a name for the fence method.
ccs -h host --addmethod method node
For example, to configure a fence method namedSANfor the nodenode-01.example.comin the configuration file on the cluster nodenode-01.example.com, execute the following command:ccs -h node01.example.com --addmethod SAN node01.example.com
- Add a fence instance for the method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node:
ccs -h host --addfenceinst fencedevicename node method [options]
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the SAN switch power port 11 on the fence device namedsanswitch1to fence cluster nodenode-01.example.comusing the method namedSAN, execute the following command:ccs -h node01.example.com --addfenceinst sanswitch1 node01.example.com SAN port=11
- To configure unfencing for the storage-based fence device on this node, execute the following command:
ccs -h host --addunfence fencedevicename node action=on|off
SAN. The device for the fence method specifies sanswitch as the device name, which is a device previously configured with the --addfencedev option, as described in Section 6.5, “Configuring Fence Devices”. Each node is configured with a unique SAN physical port number: The port number for node-01.example.com is 11, the port number for node-02.example.com is 12, and the port number for node-03.example.com is 13.
ccs -h node01.example.com --addmethod SAN node01.example.com ccs -h node01.example.com --addmethod SAN node02.example.com ccs -h node01.example.com --addmethod SAN node03.example.com ccs -h node01.example.com --addfenceinst sanswitch1 node01.example.com SAN port=11 ccs -h node01.example.com --addfenceinst sanswitch1 node02.example.com SAN port=12 ccs -h node01.example.com --addfenceinst sanswitch1 node03.example.com SAN port=13 ccs -h node01.example.com --addunfence sanswitch1 node01.example.com port=11 action=on ccs -h node01.example.com --addunfence sanswitch1 node02.example.com port=12 action=on ccs -h node01.example.com --addunfence sanswitch1 node03.example.com port=13 action=on
cluster.conf After Adding Storage-Based Fence Methods ” shows a cluster.conf configuration file after you have added fencing methods, fencing instances, and unfencing to each node in the cluster.
Example 6.3. cluster.conf After Adding Storage-Based Fence Methods
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="SAN">
<device name="sanswitch1" port="11"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="11" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="SAN">
<device name="sanswitch1" port="12"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="12" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="SAN">
<device name="sanswitch1" port="13"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="13" action="on"/>
</unfence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_sanbox2" ipaddr="san_ip_example"
login="login_example" name="sanswitch1" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
6.7.3. Configuring a Backup Fence Device
Note
ccs command is the primary fencing method, and the second method you configure is the backup fencing method. To change the order, you can remove the primary fencing method from the configuration file, then add that method back.
ccs -h host --lsfenceinst [node]
my_apc, which uses the fence_apc fencing agent, and a backup fencing device that uses a fence device named sanswitch1, which uses the fence_sanbox2 fencing agent. Since the sanswitch1 device is a storage-based fencing agent, you will need to configure unfencing for that device as well.
- Add a primary fence method for the node, providing a name for the fence method.
ccs -h host --addmethod method node
For example, to configure a fence method namedAPCas the primary method for the nodenode-01.example.comin the configuration file on the cluster nodenode-01.example.com, execute the following command:ccs -h node01.example.com --addmethod APC node01.example.com
- Add a fence instance for the primary method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node:
ccs -h host --addfenceinst fencedevicename node method [options]
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the APC switch power port 1 on the fence device namedmy_apcto fence cluster nodenode-01.example.comusing the method namedAPC, execute the following command:ccs -h node01.example.com --addfenceinst my_apc node01.example.com APC port=1
- Add a backup fence method for the node, providing a name for the fence method.
ccs -h host --addmethod method node
For example, to configure a backup fence method namedSANfor the nodenode-01.example.comin the configuration file on the cluster nodenode-01.example.com, execute the following command:ccs -h node01.example.com --addmethod SAN node01.example.com
- Add a fence instance for the backup method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node:
ccs -h host --addfenceinst fencedevicename node method [options]
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the SAN switch power port 11 on the fence device namedsanswitch1to fence cluster nodenode-01.example.comusing the method namedSAN, execute the following command:ccs -h node01.example.com --addfenceinst sanswitch1 node01.example.com SAN port=11
- Since the
sanswitch1device is a storage-based device, you must configure unfencing for this device.ccs -h node01.example.com --addunfence sanswitch1 node01.example.com port=11 action=on
cluster.conf After Adding Backup Fence Methods ” shows a cluster.conf configuration file after you have added a power-based primary fencing method and a storage-based backup fencing method to each node in the cluster.
Example 6.4. cluster.conf After Adding Backup Fence Methods
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="my_apc" port="1"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="11"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="11" action="on"/>
</unfence
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="my_apc" port="2"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="12"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="12" action="on"/>
</unfence
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="my_apc" port="3"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="13"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="13" action="on"/>
</unfence
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="my_apc" passwd="password_example"/>
<fencedevice agent="fence_sanbox2" ipaddr="san_ip_example" login="login_example" name="sanswitch1" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
Note
6.7.4. Configuring a Node with Redundant Power
action attribute of off before configuring each of the devices with an action attribute of on.
- Before you can configure fencing for a node with redundant power, you must configure each of the power switches as a fence device for the cluster. For information on configuring fence devices, see Section 6.5, “Configuring Fence Devices”.To print a list of fence devices currently configured for your cluster, execute the following command:
ccs -h host --lsfencedev
- Add a fence method for the node, providing a name for the fence method.
ccs -h host --addmethod method node
For example, to configure a fence method namedAPC-dualfor the nodenode-01.example.comin the configuration file on the cluster nodenode-01.example.com, execute the following command:ccs -h node01.example.com --addmethod APC-dual node01.example.com
- Add a fence instance for the first power supply to the fence method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node. At this point you configure the
actionattribute asoff.ccs -h host --addfenceinst fencedevicename node method [options] action=off
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the APC switch power port 1 on the fence device namedapc1to fence cluster nodenode-01.example.comusing the method namedAPC-dual, and setting theactionattribute tooff, execute the following command:ccs -h node01.example.com --addfenceinst apc1 node01.example.com APC-dual port=1 action=off
- Add a fence instance for the second power supply to the fence method. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node. At this point you configure the
actionattribute asofffor this instance as well:ccs -h host --addfenceinst fencedevicename node method [options] action=off
For example, to configure a second fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the APC switch power port 1 on the fence device namedapc2to fence cluster nodenode-01.example.comusing the same method as you specified for the first instance namedAPC-dual, and setting theactionattribute tooff, execute the following command:ccs -h node01.example.com --addfenceinst apc2 node01.example.com APC-dual port=1 action=off
- At this point, add another fence instance for the first power supply to the fence method, configuring the
actionattribute ason. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node, and specifying theactionattribute ason:ccs -h host --addfenceinst fencedevicename node method [options] action=on
For example, to configure a fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the APC switch power port 1 on the fence device namedapc1to fence cluster nodenode-01.example.comusing the method namedAPC-dual, and setting theactionattribute toon, execute the following command:ccs -h node01.example.com --addfenceinst apc1 node01.example.com APC-dual port=1 action=on
- Add another fence instance for second power supply to the fence method, specifying the
actionattribute asonfor this instance. You must specify the fence device to use for the node, the node this instance applies to, the name of the method, and any options for this method that are specific to this node as well as theactionattribute ofon.ccs -h host --addfenceinst fencedevicename node method [options] action=on
For example, to configure a second fence instance in the configuration file on the cluster nodenode-01.example.comthat uses the APC switch power port 1 on the fence device namedapc2to fence cluster nodenode-01.example.comusing the same method as you specified for the first instance namedAPC-dualand setting theactionattribute toon, execute the following command:ccs -h node01.example.com --addfenceinst apc2 node01.example.com APC-dual port=1 action=on
cluster.conf After Adding Dual-Power Fencing ” shows a cluster.conf configuration file after you have added fencing for two power supplies for each node in a cluster.
Example 6.5. cluster.conf After Adding Dual-Power Fencing
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC-dual">
<device name="apc1" port="1"action="off"/>
<device name="apc2" port="1"action="off"/>
<device name="apc1" port="1"action="on"/>
<device name="apc2" port="1"action="on"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC-dual">
<device name="apc1" port="2"action="off"/>
<device name="apc2" port="2"action="off"/>
<device name="apc1" port="2"action="on"/>
<device name="apc2" port="2"action="on"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC-dual">
<device name="apc1" port="3"action="off"/>
<device name="apc2" port="3"action="off"/>
<device name="apc1" port="3"action="on"/>
<device name="apc2" port="3"action="on"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc1" passwd="password_example"/>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc2" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
6.7.5. Testing the Fence Configuration
fence_check utility.
[root@host-098 ~]# fence_check
fence_check run at Wed Jul 23 09:13:57 CDT 2014 pid: 4769
Testing host-098 method 1: success
Testing host-099 method 1: success
Testing host-100 method 1: success
fence_check(8) man page.
6.7.6. Removing Fence Methods and Fence Instances
ccs -h host --rmmethod method node
APC that you have configured for node01.example.com from the cluster configuration file on cluster node node01.example.com, execute the following command:
ccs -h node01.example.com --rmmethod APC node01.example.com
ccs -h host --rmfenceinst fencedevicename node method
apc1 from the method named APC-dual configured for node01.example.com from the cluster configuration file on cluster node node01.example.com, execute the following command:
ccs -h node01.example.com --rmfenceinst apc1 node01.example.com APC-dual
6.8. Configuring a Failover Domain
- Unrestricted — Allows you to specify that a subset of members are preferred, but that a cluster service assigned to this domain can run on any available member.
- Restricted — Allows you to restrict the members that can run a particular cluster service. If none of the members in a restricted failover domain are available, the cluster service cannot be started (either manually or by the cluster software).
- Unordered — When a cluster service is assigned to an unordered failover domain, the member on which the cluster service runs is chosen from the available failover domain members with no priority ordering.
- Ordered — Allows you to specify a preference order among the members of a failover domain. The member at the top of the list is the most preferred, followed by the second member in the list, and so on.
- Failback — Allows you to specify whether a service in the failover domain should fail back to the node that it was originally running on before that node failed. Configuring this characteristic is useful in circumstances where a node repeatedly fails and is part of an ordered failover domain. In that circumstance, if a node is the preferred node in a failover domain, it is possible for a service to fail over and fail back repeatedly between the preferred node and another node, causing severe impact on performance.
Note
The failback characteristic is applicable only if ordered failover is configured.
Note
Note
httpd) which requires you to set up the configuration identically on all members that run the cluster service. Instead of setting up the entire cluster to run the cluster service, you can set up only the members in the restricted failover domain that you associate with the cluster service.
Note
- To add a failover domain, execute the following command:
ccs -h host --addfailoverdomain name [restricted] [ordered] [nofailback]
Note
The name should be descriptive enough to distinguish its purpose relative to other names used in your cluster.For example, the following command configures a failover domain namedexample_prionnode-01.example.comthat is unrestricted, ordered, and allows failback:ccs -h node-01.example.com --addfailoverdomain example_pri ordered
- To add a node to a failover domain, execute the following command:
ccs -h host --addfailoverdomainnode failoverdomain node priority
For example, to configure the failover domainexample_priin the configuration file onnode-01.example.comso that it containsnode-01.example.comwith a priority of 1,node-02.example.comwith a priority of 2, andnode-03.example.comwith a priority of 3, execute the following commands:ccs -h node-01.example.com --addfailoverdomainnode example_pri node-01.example.com 1 ccs -h node-01.example.com --addfailoverdomainnode example_pri node-02.example.com 2 ccs -h node-01.example.com --addfailoverdomainnode example_pri node-03.example.com 3
Note
The priority value is applicable only if ordered failover is configured.
ccs -h host --lsfailoverdomain
ccs -h host --rmfailoverdomain name
ccs -h host --rmfailoverdomainnode failoverdomain node
6.9. Configuring Global Cluster Resources
- Global — Resources that are available to any service in the cluster.
- Service-specific — Resources that are available to only one service.
ccs -h host --lsservices
ccs -h host --addresource resourcetype [resource options]
node01.example.com. The name of the resource is web_fs, the file system device is /dev/sdd2, the file system mountpoint is /var/www, and the file system type is ext3.
ccs -h node01.example.com --addresource fs name=web_fs device=/dev/sdd2 mountpoint=/var/www fstype=ext3
ccs -h host --rmresource resourcetype [resource options]
6.10. Adding a Cluster Service to the Cluster
- Add a service to the cluster with the following command:
ccs -h host --addservice servicename [service options]
Note
Use a descriptive name that clearly distinguishes the service from other services in the cluster.When you add a service to the cluster configuration, you configure the following attributes:autostart— Specifies whether to autostart the service when the cluster starts. Use "1" to enable and "0" to disable; the default is enabled.domain— Specifies a failover domain (if required).exclusive— Specifies a policy wherein the service only runs on nodes that have no other services running on them.recovery— Specifies a recovery policy for the service. The options are to relocate, restart, disable, or restart-disable the service. The restart recovery policy indicates that the system should attempt to restart the failed service before trying to relocate the service to another node. The relocate policy indicates that the system should try to restart the service in a different node. The disable policy indicates that the system should disable the resource group if any component fails. The restart-disable policy indicates that the system should attempt to restart the service in place if it fails, but if restarting the service fails the service will be disabled instead of being moved to another host in the cluster.If you select or as the recovery policy for the service, you can specify the maximum number of restart failures before relocating or disabling the service, and you can specify the length of time in seconds after which to forget a restart.
For example, to add a service to the configuration file on the cluster nodenode-01.example.comnamedexample_apachethat uses the failover domainexample_pri, and that has recovery policy ofrelocate, execute the following command:ccs -h node-01.example.com --addservice example_apache domain=example_pri recovery=relocate
When configuring services for a cluster, you may find it useful to see a listing of available services for your cluster and the options available for each service. For information on using theccscommand to print a list of available services and their options, see Section 6.11, “Listing Available Cluster Services and Resources”. - Add resources to the service with the following command:
ccs -h host --addsubservice servicename subservice [service options]
Depending on the type of resources you want to use, populate the service with global or service-specific resources. To add a global resource, use the--addsubserviceoption of theccsto add a resource. For example, to add the global file system resource namedweb_fsto the service namedexample_apacheon the cluster configuration file onnode-01.example.com, execute the following command:ccs -h node01.example.com --addsubservice example_apache fs ref=web_fs
To add a service-specific resource to the service, you need to specify all of the service options. For example, if you had not previously definedweb_fsas a global service, you could add it as a service-specific resource with the following command:ccs -h node01.example.com --addsubservice example_apache fs name=web_fs device=/dev/sdd2 mountpoint=/var/www fstype=ext3
- To add a child service to the service, you also use the
--addsubserviceoption of theccscommand, specifying the service options.If you need to add services within a tree structure of dependencies, use a colon (":") to separate elements and brackets to identify subservices of the same type. The following example adds a thirdnfsclientservice as a subservice of annfsclientservice which is in itself a subservice of annfsclientservice which is a subservice of a service namedservice_a:ccs -h node01.example.com --addsubservice service_a nfsclient[1]:nfsclient[2]:nfsclient
Note
If you are adding a Samba-service resource, add it directly to the service, not as a child of another resource.Note
When configuring a dependency tree for a cluster service that includes a floating IP address resource, you must configure the IP resource as the first entry.
Note
/sbin/ip addr show command on a cluster node (rather than the obsoleted ifconfig command). The following output shows the /sbin/ip addr show command executed on a node running a cluster service:
1: lo: <LOOPBACK,UP> mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP> mtu 1356 qdisc pfifo_fast qlen 1000
link/ether 00:05:5d:9a:d8:91 brd ff:ff:ff:ff:ff:ff
inet 10.11.4.31/22 brd 10.11.7.255 scope global eth0
inet6 fe80::205:5dff:fe9a:d891/64 scope link
inet 10.11.4.240/22 scope global secondary eth0
valid_lft forever preferred_lft forever
ccs -h host --rmservice servicename
ccs -h host --rmsubservice servicename subservice [service options]
6.11. Listing Available Cluster Services and Resources
ccs command to print a list of resources and services that are available for a cluster. You can also use the ccs command to print a list of the options you can specify for a particular service or resource type.
--lsresourceopts is an alias to --lsserviceopts):
ccs -h host --lsserviceopts ccs -h host --lsresourceopts
node1, showing sample output.
[root@ask-03 ~]# ccs -h node1 --lsserviceopts
service - Defines a service (resource group).
ASEHAagent - Sybase ASE Failover Instance
SAPDatabase - SAP database resource agent
SAPInstance - SAP instance resource agent
apache - Defines an Apache web server
clusterfs - Defines a cluster file system mount.
fs - Defines a file system mount.
ip - This is an IP address.
lvm - LVM Failover script
mysql - Defines a MySQL database server
named - Defines an instance of named server
netfs - Defines an NFS/CIFS file system mount.
nfsclient - Defines an NFS client.
nfsexport - This defines an NFS export.
nfsserver - This defines an NFS server resource.
openldap - Defines an Open LDAP server
oracledb - Oracle 10g Failover Instance
orainstance - Oracle 10g Failover Instance
oralistener - Oracle 10g Listener Instance
postgres-8 - Defines a PostgreSQL server
samba - Dynamic smbd/nmbd resource agent
script - LSB-compliant init script as a clustered resource.
tomcat-6 - Defines a Tomcat server
vm - Defines a Virtual Machine
action - Overrides resource action timings for a resource instance.
ccs -h host --lsserviceopts service_type
vm service.
[root@ask-03 ~]# ccs -f node1 --lsserviceopts vm
vm - Defines a Virtual Machine
Required Options:
name: Name
Optional Options:
domain: Cluster failover Domain
autostart: Automatic start after quorum formation
exclusive: Exclusive resource group
recovery: Failure recovery policy
migration_mapping: memberhost:targethost,memberhost:targethost ..
use_virsh: If set to 1, vm.sh will use the virsh command to manage virtual machines instead of xm. This is required when using non-Xen virtual machines (e.g. qemu / KVM).
xmlfile: Full path to libvirt XML file describing the domain.
migrate: Migration type (live or pause, default = live).
path: Path to virtual machine configuration files.
snapshot: Path to the snapshot directory where the virtual machine image will be stored.
depend: Top-level service this depends on, in service:name format.
depend_mode: Service dependency mode (soft or hard).
max_restarts: Maximum restarts for this service.
restart_expire_time: Restart expiration time; amount of time before a restart is forgotten.
status_program: Additional status check program
hypervisor: Hypervisor
hypervisor_uri: Hypervisor URI (normally automatic).
migration_uri: Migration URI (normally automatic).
__independent_subtree: Treat this and all children as an independent subtree.
__enforce_timeouts: Consider a timeout for operations as fatal.
__max_failures: Maximum number of failures before returning a failure to a status check.
__failure_expire_time: Amount of time before a failure is forgotten.
__max_restarts: Maximum number restarts for an independent subtree before giving up.
__restart_expire_time: Amount of time before a failure is forgotten for an independent subtree.
6.12. Virtual Machine Resources
ccs command you can use the --addvm (rather than the addservice option). This ensures that the vm resource is defined directly under the rm configuration node in the cluster configuration file.
name and a path attribute. The name attribute should match the name of the libvirt domain and the path attribute should specify the directory where the shared virtual machine definitions are stored.
Note
path attribute in the cluster configuration file is a path specification or a directory name, not a path to an individual file.
/mnt/vm_defs, the following command will define a virtual machine named guest1:
# ccs -h node1.example.com --addvm guest1 path=/mnt/vm_defsrm configuration node in the cluster.conf file:
<vm name="guest1" path="/mnt/vm_defs"/>
6.13. Configuring a Quorum Disk
Note
ccs -h host --setquorumd [quorumd options]
--setquorumd option to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
/usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html.
| Parameter | Description |
|---|---|
| The frequency of read/write cycles, in seconds. | |
The number of votes the quorum daemon advertises to cman when it has a high enough score. | |
| The number of cycles a node must miss to be declared dead. | |
The minimum score for a node to be considered "alive". If omitted or set to 0, the default function, floor((n+1)/2), is used, where n is the sum of the heuristics scores. The value must never exceed the sum of the heuristic scores; otherwise, the quorum disk cannot be available. | |
| The storage device the quorum daemon uses. The device must be the same on all nodes. | |
Specifies the quorum disk label created by the mkqdisk utility. If this field contains an entry, the label overrides the field. If this field is used, the quorum daemon reads /proc/partitions and checks for qdisk signatures on every block device found, comparing the label against the specified label. This is useful in configurations where the quorum device name differs among nodes. |
ccs -h host --addheuristic [heuristic options]
| Parameter | Description |
|---|---|
The path to the program used to determine if this heuristic is available. This can be anything that can be executed by /bin/sh -c. A return value of 0 indicates success; anything else indicates failure. This parameter is required to use a quorum disk. | |
| The frequency (in seconds) at which the heuristic is polled. The default interval for every heuristic is 2 seconds. | |
| The weight of this heuristic. Be careful when determining scores for heuristics. The default score for each heuristic is 1. | |
| The number of consecutive failures required before this heuristic is declared unavailable. |
ccs -h host --lsquorum
ccs -h host rmheuristic [heuristic options]
Note
qdiskd daemon on each node.
6.14. Miscellaneous Cluster Configuration
ccs command to configure the following:
ccs command to set advanced cluster configuration parameters, including totem options, dlm options, rm options and cman options. For information on setting these parameters see the ccs(8) man page and the annotated cluster configuration file schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html.
ccs -h host --lsmisc
6.14.1. Cluster Configuration Version
1 by default when you create a cluster configuration file and it is automatically incremented each time you modify your cluster configuration. However, if you need to set it to another value, you can specify it with the following command:
ccs -h host --setversion n
ccs -h host --getversion
ccs -h host --incversion
6.14.2. Multicast Configuration
- For IPv4 — The address formed is 239.192. plus the lower 16 bits generated by Red Hat High Availability Add-On software.
- For IPv6 — The address formed is FF15:: plus the lower 16 bits generated by Red Hat High Availability Add-On software.
Note
cman generates for each cluster. To view the cluster ID, run the cman_tool status command on a cluster node.
ccs -h host --setmulticast multicastaddress
--setmulticast option to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
cman uses. Otherwise, using a multicast address outside that range may cause unpredictable results. For example, using 224.0.0.x (which is "All hosts on the network") may not be routed correctly, or even routed at all by some hardware.
ccs command, see Section 7.2, “Starting and Stopping a Cluster”.
Note
--setmulticast option of the ccs but do not specify a multicast address:
ccs -h host --setmulticast
6.14.3. Configuring a Two-Node Cluster
ccs -h host --setcman two_node=1 expected_votes=1
--setcman option to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
ccs --setcman command to add, remove, or modify the two_node option, you must restart the cluster for this change to take effect. For information on starting and stopping a cluster with the ccs command, see Section 7.2, “Starting and Stopping a Cluster”.
6.14.4. Logging
/var/log/cluster/daemon.log file.
ccs -h host --setlogging [logging options]
# ccs -h node1.example.com --setlogging debug=on--setlogging option to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
ccs -h host --addlogging [logging daemon options]
corosync and fenced daemons.
#ccs -h node1.example.com --addlogging name=corosync debug=on#ccs -h node1.example.com --addlogging name=fenced debug=on
ccs -h host --rmlogging name=clusterprocess
fenced daemon
ccs -h host --rmlogging name=fenced
cluster.conf(5) man page.
6.14.5. Configuring Redundant Ring Protocol
--addalt option of the ccs command:
ccs -h host --addalt node_name alt_name
clusternet-node1-eth2 for the cluster node clusternet-node1-eth1:
# ccs -h clusternet-node1-eth1 --addalt clusternet-node1-eth1 clusternet-node1-eth2--setaltmulticast option of the ccs command:
ccs -h host --setaltmulticast [alt_multicast_address] [alt_multicast_options].
cluster.conf file on node clusternet-node1-eth1:
ccs -h clusternet-node1-eth1 --setaltmulticast 239.192.99.88 port=888 ttl=3
--setaltmulticast option of the ccs command but do not specify a multicast address. Note that executing this command resets all other properties that you can set with the --setaltmulticast option to their default values, as described in Section 6.1.5, “Commands that Overwrite Previous Settings”.
6.15. Propagating the Configuration File to the Cluster Nodes
--activate option, you must also specify the --sync option for the activation to take affect.
ccs -h host --sync --activate
ccs -h host --checkconf
ccs -f file -h host --setconf
ccs -f file --checkconf
Chapter 7. Managing Red Hat High Availability Add-On With ccs
ccs command, which is supported as of the Red Hat Enterprise Linux 6.1 release and later. This chapter consists of the following sections:
7.1. Managing Cluster Nodes
ccs command:
7.1.1. Causing a Node to Leave or Join a Cluster
ccs command to cause a node to leave a cluster by stopping cluster services on that node. Causing a node to leave a cluster does not remove the cluster configuration information from that node. Making a node leave a cluster prevents the node from automatically joining the cluster when it is rebooted.
-h option:
ccs -h host --stop
--rmnode option of the ccs command, as described in Section 6.4, “Creating and Modifying a Cluster”.
-h option:
ccs -h host --start
7.1.2. Adding a Member to a Running Cluster
Note
7.2. Starting and Stopping a Cluster
ccs command to stop a cluster by using the following command to stop cluster services on all nodes in the cluster:
ccs -h host --stopall
ccs command to start a cluster that is not running by using the following command to start cluster services on all nodes in the cluster:
ccs -h host --startall
--startall option of the ccs command to start a cluster, the command automatically enables the cluster resources. For some configurations, such as when services have been intentionally disabled on one node to disable fence loops, you may not want to enable the services on that node. As of Red Hat Enterprise Linux 6.6 release, you can use the --noenable option of the ccs --startall command to prevent the services from being enabled:
ccs -h host --startall --noenable
7.3. Diagnosing and Correcting Problems in a Cluster
ccs command, however.
ccs -h host --checkconf
ccs -f file --checkconf
Chapter 8. Configuring Red Hat High Availability Manually
/etc/cluster/cluster.conf) and using command-line tools. The chapter provides procedures about building a configuration file one section at a time, starting with a sample file provided in the chapter. As an alternative to starting with a sample file provided here, you could copy a skeleton configuration file from the cluster.conf man page. However, doing so would not necessarily align with information provided in subsequent procedures in this chapter. There are other ways to create and configure a cluster configuration file; this chapter provides procedures about building a configuration file one section at a time. Also, keep in mind that this is just a starting point for developing a configuration file to suit your clustering needs.
Important
Important
cluster.conf elements and attributes. For a comprehensive list and description of cluster.conf elements and attributes, see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
Important
cman_tool version -r command to propagate a cluster configuration throughout a cluster. Using that command requires that ricci is running. Using ricci requires a password the first time you interact with ricci from any specific machine. For information on the ricci service, refer to Section 3.13, “Considerations for ricci”.
Note
8.1. Configuration Tasks
- Creating a cluster. Refer to Section 8.2, “Creating a Basic Cluster Configuration File”.
- Configuring fencing. Refer to Section 8.3, “Configuring Fencing”.
- Configuring failover domains. Refer to Section 8.4, “Configuring Failover Domains”.
- Configuring HA services. Refer to Section 8.5, “Configuring HA Services”.
- Verifying a configuration. Refer to Section 8.9, “Verifying a Configuration”.
8.2. Creating a Basic Cluster Configuration File
/etc/cluster/cluster.conf) and start running the High Availability Add-On. As a starting point only, this section describes how to create a skeleton cluster configuration file without fencing, failover domains, and HA services. Subsequent sections describe how to configure those parts of the configuration file.
Important
- At any node in the cluster, create
/etc/cluster/cluster.conf, using the template of the example in Example 8.1, “cluster.confSample: Basic Configuration”. - (Optional) If you are configuring a two-node cluster, you can add the following line to the configuration file to allow a single node to maintain quorum (for example, if one node fails):
<cman two_node="1" expected_votes="1"/>When you add or remove thetwo_nodeoption from thecluster.conffile, you must restart the cluster for this change to take effect when you update the configuration. For information on updating a cluster configuration, see Section 9.4, “Updating a Configuration”. For an example of specifying thetwo_nodeoption, see Example 8.2, “cluster.confSample: Basic Two-Node Configuration”. - Specify the cluster name and the configuration version number using the
clusterattributes:nameandconfig_version(see Example 8.1, “cluster.confSample: Basic Configuration” or Example 8.2, “cluster.confSample: Basic Two-Node Configuration”). - In the
clusternodessection, specify the node name and the node ID of each node using theclusternodeattributes:nameandnodeid. The node name can be up to 255 bytes in length. - Save
/etc/cluster/cluster.conf. - Validate the file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Propagate the configuration file to
/etc/cluster/in each cluster node. For example, you could propagate the file to other cluster nodes using thescpcommand.Note
Propagating the cluster configuration file this way is necessary the first time a cluster is created. Once a cluster is installed and running, the cluster configuration file can be propagated using thecman_tool version -rcommand. It is possible to use thescpcommand to propagate an updated configuration file; however, the cluster software must be stopped on all nodes while using thescpcommand. In addition, you should runccs_config_validateif you propagate an updated configuration file by means of thescpcommand.Note
While there are other elements and attributes present in the sample configuration file (for example,fenceandfencedevices), there is no need to populate them now. Subsequent procedures in this chapter provide information about specifying other elements and attributes. - Start the cluster. At each cluster node enter the following command:
service cman startFor example:[root@example-01 ~]#
service cman startStarting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] - At any cluster node, run
cman_tool nodesto verify that the nodes are functioning as members in the cluster (signified as "M" in the status column, "Sts"). For example:[root@example-01 ~]#
cman_tool nodesNode Sts Inc Joined Name 1 M 548 2010-09-28 10:52:21 node-01.example.com 2 M 548 2010-09-28 10:52:21 node-02.example.com 3 M 544 2010-09-28 10:52:21 node-03.example.com - If the cluster is running, proceed to Section 8.3, “Configuring Fencing”.
Basic Configuration Examples
cluster.conf Sample: Basic Configuration” and Example 8.2, “cluster.conf Sample: Basic Two-Node Configuration” (for a two-node cluster) each provide a very basic sample cluster configuration file as a starting point. Subsequent procedures in this chapter provide information about configuring fencing and HA services.
Example 8.1. cluster.conf Sample: Basic Configuration
<cluster name="mycluster" config_version="2">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
</cluster>
Example 8.2. cluster.conf Sample: Basic Two-Node Configuration
<cluster name="mycluster" config_version="2">
<cman two_node="1" expected_votes="1"/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
</rm>
</cluster>
The consensus Value for totem in a Two-Node Cluster
consensus value in the totem tag in the cluster.conf file so that the consensus value is calculated automatically. When the consensus value is calculated automatically, the following rules are used:
- If there are two nodes or fewer, the
consensusvalue will be (token * 0.2), with a ceiling of 2000 msec and a floor of 200 msec. - If there are three or more nodes, the
consensusvalue will be (token + 2000 msec)
cman utility configure your consensus timeout in this fashion, then moving at a later time from two to three (or more) nodes will require a cluster restart, since the consensus timeout will need to change to the larger value based on the token timeout.
cluster.conf as follows:
<totem token="X" consensus="X + 2000" />
cman, the number of physical nodes is what matters and not the presence of the two_node=1 directive in the cluster.conf file.
8.3. Configuring Fencing
Note
cluster.conf as follows:
- In the
fencedevicessection, specify each fence device, using afencedeviceelement and fence-device dependent attributes. Example 8.3, “APC Fence Device Added tocluster.conf” shows an example of a configuration file with an APC fence device added to it. - At the
clusternodessection, within thefenceelement of eachclusternodesection, specify each fence method of the node. Specify the fence method name, using themethodattribute,name. Specify the fence device for each fence method, using thedeviceelement and its attributes,nameand fence-device-specific parameters. Example 8.4, “Fence Methods Added tocluster.conf” shows an example of a fence method with one fence device for each node in the cluster. - For non-power fence methods (that is, SAN/storage fencing), at the
clusternodessection, add anunfencesection. This ensures that a fenced node is not re-enabled until the node has been rebooted. When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For more information about unfencing a node, see thefence_node(8) man page.Theunfencesection does not containmethodsections like thefencesection does. It containsdevicereferences directly, which mirror the corresponding device sections forfence, with the notable addition of the explicit action (action) of "on" or "enable". The samefencedeviceis referenced by bothfenceandunfencedevicelines, and the same per-node arguments should be repeated.Specifying theactionattribute as "on" or "enable" enables the node when rebooted. Example 8.4, “Fence Methods Added tocluster.conf” and Example 8.5, “cluster.conf: Multiple Fence Methods per Node” include examples of theunfenceelements and attributed.For more information aboutunfencesee thefence_nodeman page. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the updated file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. This will also run additional validation. It is necessary thatriccibe running in each cluster node to be able to propagate updated cluster configuration information. - Verify that the updated configuration file has been propagated.
- Proceed to Section 8.4, “Configuring Failover Domains”.
fenced, the fence daemon, tries the next method, and continues to cycle through methods until one succeeds.
fenced runs the fence agent once for each fence-device line; all must succeed for fencing to be considered successful.
fence_apc). In addition, you can get more information about fencing parameters from Appendix A, Fence Device Parameters, the fence agents in /usr/sbin/, the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example, /usr/share/doc/cman-3.0.12/cluster_conf.html).
Note
fence_check utility. For information on this utility, see the fence_check(8) man page.
Fencing Configuration Examples
Note
Example 8.3. APC Fence Device Added to cluster.conf
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
fencedevice) has been added to the fencedevices element, specifying the fence agent (agent) as fence_apc, the IP address (ipaddr) as apc_ip_example, the login (login) as login_example, the name of the fence device (name) as apc, and the password (passwd) as password_example.
Example 8.4. Fence Methods Added to cluster.conf
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
method) has been added to each node. The name of the fence method (name) for each node is APC. The device (device) for the fence method in each node specifies the name (name) as apc and a unique APC switch power port number (port) for each node. For example, the port number for node-01.example.com is 1 (port="1"). The device name for each node (device name="apc") points to the fence device by the name (name) of apc in this line of the fencedevices element: fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example".
Example 8.5. cluster.conf: Multiple Fence Methods per Node
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="11"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="11" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="12"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="12" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
<method name="SAN">
<device name="sanswitch1" port="13"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="13" action="on"/>
</unfence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
<fencedevice agent="fence_sanbox2" ipaddr="san_ip_example"
login="login_example" name="sanswitch1" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
Example 8.6. cluster.conf: Fencing, Multipath Multiple Ports
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="SAN-multi">
<device name="sanswitch1" port="11"/>
<device name="sanswitch2" port="11"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="11" action="on"/>
<device name="sanswitch2" port="11" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="SAN-multi">
<device name="sanswitch1" port="12"/>
<device name="sanswitch2" port="12"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="12" action="on"/>
<device name="sanswitch2" port="12" action="on"/>
</unfence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="SAN-multi">
<device name="sanswitch1" port="13"/>
<device name="sanswitch2" port="13"/>
</method>
</fence>
<unfence>
<device name="sanswitch1" port="13" action="on"/>
<device name="sanswitch2" port="13" action="on"/>
</unfence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_sanbox2" ipaddr="san_ip_example"
login="login_example" name="sanswitch1" passwd="password_example"/>
<fencedevice agent="fence_sanbox2" ipaddr="san_ip_example"
login="login_example" name="sanswitch2" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
Example 8.7. cluster.conf: Fencing Nodes with Dual Power Supplies
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC-dual">
<device name="apc1" port="1"action="off"/>
<device name="apc2" port="1"action="off"/>
<device name="apc1" port="1"action="on"/>
<device name="apc2" port="1"action="on"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC-dual">
<device name="apc1" port="2"action="off"/>
<device name="apc2" port="2"action="off"/>
<device name="apc1" port="2"action="on"/>
<device name="apc2" port="2"action="on"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC-dual">
<device name="apc1" port="3"action="off"/>
<device name="apc2" port="3"action="off"/>
<device name="apc1" port="3"action="on"/>
<device name="apc2" port="3"action="on"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc1" passwd="password_example"/>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc2" passwd="password_example"/>
</fencedevices>
<rm>
</rm>
</cluster>
8.4. Configuring Failover Domains
- Unrestricted — Allows you to specify that a subset of members are preferred, but that a cluster service assigned to this domain can run on any available member.
- Restricted — Allows you to restrict the members that can run a particular cluster service. If none of the members in a restricted failover domain are available, the cluster service cannot be started (either manually or by the cluster software).
- Unordered — When a cluster service is assigned to an unordered failover domain, the member on which the cluster service runs is chosen from the available failover domain members with no priority ordering.
- Ordered — Allows you to specify a preference order among the members of a failover domain. Ordered failover domains select the node with the lowest priority number first. That is, the node in a failover domain with a priority number of "1" specifies the highest priority, and therefore is the most preferred node in a failover domain. After that node, the next preferred node would be the node with the next highest priority number, and so on.
- Failback — Allows you to specify whether a service in the failover domain should fail back to the node that it was originally running on before that node failed. Configuring this characteristic is useful in circumstances where a node repeatedly fails and is part of an ordered failover domain. In that circumstance, if a node is the preferred node in a failover domain, it is possible for a service to fail over and fail back repeatedly between the preferred node and another node, causing severe impact on performance.
Note
The failback characteristic is applicable only if ordered failover is configured.
Note
Note
httpd), which requires you to set up the configuration identically on all members that run the cluster service. Instead of setting up the entire cluster to run the cluster service, you can set up only the members in the restricted failover domain that you associate with the cluster service.
Note
- Open
/etc/cluster/cluster.confat any node in the cluster. - Add the following skeleton section within the
rmelement for each failover domain to be used:<failoverdomains> <failoverdomain name="" nofailback="" ordered="" restricted=""> <failoverdomainnode name="" priority=""/> <failoverdomainnode name="" priority=""/> <failoverdomainnode name="" priority=""/> </failoverdomain> </failoverdomains>Note
The number offailoverdomainnodeattributes depends on the number of nodes in the failover domain. The skeletonfailoverdomainsection in preceding text shows threefailoverdomainnodeelements (with no node names specified), signifying that there are three nodes in the failover domain. - In the
failoverdomainsection, provide the values for the elements and attributes. For descriptions of the elements and attributes, see the failoverdomain section of the annotated cluster schema. The annotated cluster schema is available at/usr/share/doc/cman-X.Y.ZZ/cluster_conf.html(for example/usr/share/doc/cman-3.0.12/cluster_conf.html) in any of the cluster nodes. For an example of afailoverdomainssection, see Example 8.8, “A Failover Domain Added tocluster.conf”. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. - Proceed to Section 8.5, “Configuring HA Services”.
cluster.conf ” shows an example of a configuration with an ordered, unrestricted failover domain.
Example 8.8. A Failover Domain Added to cluster.conf
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="example_pri" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="node-01.example.com" priority="1"/>
<failoverdomainnode name="node-02.example.com" priority="2"/>
<failoverdomainnode name="node-03.example.com" priority="3"/>
</failoverdomain>
</failoverdomains>
</rm>
</cluster>
failoverdomains section contains a failoverdomain section for each failover domain in the cluster. This example has one failover domain. In the failoverdomain line, the name (name) is specified as example_pri. In addition, it specifies that resources using this domain should fail-back to lower-priority-score nodes when possible (nofailback="0"), that failover is ordered (ordered="1"), and that the failover domain is unrestricted (restricted="0").
priority value is applicable only if ordered failover is configured.
8.5. Configuring HA Services
/etc/cluster/cluster.conf to add resources and services.
Important
8.5.1. Adding Cluster Resources
- Global — Resources that are available to any service in the cluster. These are configured in the
resourcessection of the configuration file (within thermelement). - Service-specific — Resources that are available to only one service. These are configured in each
servicesection of the configuration file (within thermelement).
- Open
/etc/cluster/cluster.confat any node in the cluster. - Add a
resourcessection within thermelement. For example:<rm> <resources> </resources> </rm> - Populate it with resources according to the services you want to create. For example, here are resources that are to be used in an Apache service. They consist of a file system (
fs) resource, an IP (ip) resource, and an Apache (apache) resource.<rm> <resources> <fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3"/> <ip address="127.143.131.100" monitor_link="yes" sleeptime="10"/> <apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/> </resources> </rm>Example 8.9, “cluster.confFile with Resources Added ” shows an example of acluster.conffile with theresourcessection added. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3"). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. - Verify that the updated configuration file has been propagated.
Example 8.9. cluster.conf File with Resources Added
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="example_pri" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="node-01.example.com" priority="1"/>
<failoverdomainnode name="node-02.example.com" priority="2"/>
<failoverdomainnode name="node-03.example.com" priority="3"/>
</failoverdomain>
</failoverdomains>
<resources>
<fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3"/>
<ip address="127.143.131.100" monitor_link="yes" sleeptime="10"/>
<apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/>
</resources>
</rm>
</cluster>
8.5.2. Adding a Cluster Service to the Cluster
Note
- Open
/etc/cluster/cluster.confat any node in the cluster. - Add a
servicesection within thermelement for each service. For example:<rm> <service autostart="1" domain="" exclusive="0" name="" recovery="restart"> </service> </rm> - Configure the following parameters (attributes) in the
serviceelement:autostart— Specifies whether to autostart the service when the cluster starts. Use '1' to enable and '0' to disable; the default is enabled.domain— Specifies a failover domain (if required).exclusive— Specifies a policy wherein the service only runs on nodes that have no other services running on them.recovery— Specifies a recovery policy for the service. The options are to relocate, restart, disable, or restart-disable the service.
- Depending on the type of resources you want to use, populate the service with global or service-specific resourcesFor example, here is an Apache service that uses global resources:
<rm> <resources> <fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3"/> <ip address="127.143.131.100" monitor_link="yes" sleeptime="10"/> <apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/> </resources> <service autostart="1" domain="example_pri" exclusive="0" name="example_apache" recovery="relocate"> <fs ref="web_fs"/> <ip ref="127.143.131.100"/> <apache ref="example_server"/> </service> </rm>For example, here is an Apache service that uses service-specific resources:<rm> <service autostart="0" domain="example_pri" exclusive="0" name="example_apache2" recovery="relocate"> <fs name="web_fs2" device="/dev/sdd3" mountpoint="/var/www2" fstype="ext3"/> <ip address="127.143.131.101" monitor_link="yes" sleeptime="10"/> <apache config_file="conf/httpd.conf" name="example_server2" server_root="/etc/httpd" shutdown_wait="0"/> </service> </rm>Example 8.10, “cluster.confwith Services Added: One Using Global Resources and One Using Service-Specific Resources ” shows an example of acluster.conffile with two services:example_apache— This service uses global resourcesweb_fs,127.143.131.100, andexample_server.example_apache2— This service uses service-specific resourcesweb_fs2,127.143.131.101, andexample_server2.
- Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the updated file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. - Verify that the updated configuration file has been propagated.
- Proceed to Section 8.9, “Verifying a Configuration”.
Example 8.10. cluster.conf with Services Added: One Using Global Resources and One Using Service-Specific Resources
<cluster name="mycluster" config_version="3">
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="example_pri" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="node-01.example.com" priority="1"/>
<failoverdomainnode name="node-02.example.com" priority="2"/>
<failoverdomainnode name="node-03.example.com" priority="3"/>
</failoverdomain>
</failoverdomains>
<resources>
<fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3"/>
<ip address="127.143.131.100" monitor_link="yes" sleeptime="10"/>
<apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/>
</resources>
<service autostart="1" domain="example_pri" exclusive="0" name="example_apache" recovery="relocate">
<fs ref="web_fs"/>
<ip ref="127.143.131.100"/>
<apache ref="example_server"/>
</service>
<service autostart="0" domain="example_pri" exclusive="0" name="example_apache2" recovery="relocate">
<fs name="web_fs2" device="/dev/sdd3" mountpoint="/var/www2" fstype="ext3"/>
<ip address="127.143.131.101" monitor_link="yes" sleeptime="10"/>
<apache config_file="conf/httpd.conf" name="example_server2" server_root="/etc/httpd" shutdown_wait="0"/>
</service>
</rm>
</cluster>
8.6. Configuring Redundant Ring Protocol
- Do not specify more than two rings.
- Each ring must use the same protocol; do not mix IPv4 and IPv6.
- If necessary, you can manually specify a multicast address for the second ring. If you specify a multicast address for the second ring, either the alternate multicast address or the alternate port must be different from the multicast address for the first ring. If you do not specify an alternate multicast address, the system will automatically use a different multicast address for the second ring.If you specify an alternate port, the port numbers of the first ring and the second ring must differ by at least two, since the system itself uses port and port-1 to perform operations.
- Do not use two different interfaces on the same subnet.
- In general, it is a good practice to configure redundant ring protocol on two different NICs and two different switches, in case one NIC or one switch fails.
- Do not use the
ifdowncommand or theservice network stopcommand to simulate network failure. This destroys the whole cluster and requires that you restart all of the nodes in the cluster to recover. - Do not use
NetworkManager, since it will execute theifdowncommand if the cable is unplugged. - When one node of a NIC fails, the entire ring is marked as failed.
- No manual intervention is required to recover a failed ring. To recover, you only need to fix the original reason for the failure, such as a failed NIC or switch.
altname component to the clusternode section of the cluster.conf configuration file. When specifying altname, you must specify a name attribute to indicate a second host name or IP address for the node.
clusternet-node1-eth2 as the alternate name for cluster node clusternet-node1-eth1.
<cluster name="mycluster" config_version="3" >
<logging debug="on"/>
<clusternodes>
<clusternode name="clusternet-node1-eth1" votes="1" nodeid="1">
<fence>
<method name="single">
<device name="xvm" domain="clusternet-node1"/>
</method>
</fence>
<altname name="clusternet-node1-eth2"/>
</clusternode>
altname section within the clusternode block is not position dependent. It can come before or after the fence section. Do not specify more than one altname component for a cluster node or the system will fail to start.
altmulticast component in the cman section of the cluster.conf configuration file. The altmulticast component accepts an addr, a port, and a ttl parameter.
cman section of a cluster configuration file that sets a multicast address, port, and TTL for the second ring.
<cman> <multicast addr="239.192.99.73" port="666" ttl="2"/> <altmulticast addr="239.192.99.88" port="888" ttl="3"/> </cman>
8.7. Configuring Debug Options
/etc/cluster/cluster.conf. By default, logging is directed to the /var/log/cluster/daemon.log file.
<cluster config_version="7" name="rh6cluster"> <logging debug="on"/> ... </cluster>
/etc/cluster/cluster.conf file. Per-daemon logging configuration overrides the global settings.
<cluster config_version="7" name="rh6cluster">
...
<logging>
<!-- turning on per-subsystem debug logging -->
<logging_daemon name="corosync" debug="on" />
<logging_daemon name="fenced" debug="on" />
<logging_daemon name="qdiskd" debug="on" />
<logging_daemon name="rgmanager" debug="on" />
<logging_daemon name="dlm_controld" debug="on" />
<logging_daemon name="gfs_controld" debug="on" />
</logging>
...
</cluster>
cluster.conf(5) man page.
8.8. Configuring nfsexport and nfsserver Resources
nfsexport or an nfsserver resource.
nfsexport resource agent works with NFSv2 and NFSv3 clients. When using nfsexport, you must do the following:
- Ensure that
nfsandnfslockare enabled at boot. - Add
RPCNFSDARGS="-N 4"to the/etc/sysconfig/nfsfile on all cluster nodes. The"-N 4"option prevents NFSv4 clients from being able to connect to the server. - Add
STATDARG="-H /usr/sbin/clunfslock"to the/etc/sysconfig/nfsfile on all cluster nodes. - Add
nfslock="1"to theservicecomponent in thecluster.conffile. - Structure your service as follows:
<service nfslock="1" ... > <fs name="myfs" ... > <nfsexport name="exports"> <nfsclient ref="client1" /> <nfsclient ref="client2" /> ... </nfsexport> </fs> <ip address="10.1.1.2" /> ... </service>
nfsserver resource agent works with NFSv3 and NFSv4 clients. When using nfsserver, you must do the following:
- Ensure that
nfsandnfslockare disabled at boot - Ensure that
nfslock="1"is not set for the service. - Structure your service as follows:
<service ... > <fs name="myfs" ... > <nfsserver name="server"> <nfsclient ref="client1" /> <nfsclient ref="client2" /> <ip address="10.1.1.2" /> ... </nfsserver> </fs> ... </service>
nfsserver resource agent for use with NFSv3 and NFSv4, you must account for the following limitations:
- Configure only one
nfsserverresource per cluster. If you require more, you must use restricted failover domains to ensure that the two services in question can never start on the same host. - Do not reference a globally-configured
nfsserverresource in more than one service. - Do not mix old-style NFS services with the new
nfsserverin the same cluster. Older NFS services required the NFS daemons to be running;nfsserverrequires the daemons to be stopped when the service is started. - When using multiple file systems, you will be unable to use inheritance for the exports; thus reuse of
nfsclientresources in services with multiple file systems is limited. You may, however, explicitly define target and path attributes for as manynfsclientsas you like.
8.9. Verifying a Configuration
- At each node, restart the cluster software. That action ensures that any configuration additions that are checked only at startup time are included in the running configuration. You can restart the cluster software by running
service cman restart. For example:[root@example-01 ~]#
service cman restartStopping cluster: Leaving fence domain... [ OK ] Stopping gfs_controld... [ OK ] Stopping dlm_controld... [ OK ] Stopping fenced... [ OK ] Stopping cman... [ OK ] Waiting for corosync to shutdown: [ OK ] Unloading kernel modules... [ OK ] Unmounting configfs... [ OK ] Starting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] - Run
service clvmd start, if CLVM is being used to create clustered volumes. For example:[root@example-01 ~]#
service clvmd startActivating VGs: [ OK ] - Run
service gfs2 start, if you are using Red Hat GFS2. For example:[root@example-01 ~]#
service gfs2 startMounting GFS2 filesystem (/mnt/gfsA): [ OK ] Mounting GFS2 filesystem (/mnt/gfsB): [ OK ] - Run
service rgmanager start, if you using high-availability (HA) services. For example:[root@example-01 ~]#
service rgmanager startStarting Cluster Service Manager: [ OK ] - At any cluster node, run
cman_tool nodesto verify that the nodes are functioning as members in the cluster (signified as "M" in the status column, "Sts"). For example:[root@example-01 ~]#
cman_tool nodesNode Sts Inc Joined Name 1 M 548 2010-09-28 10:52:21 node-01.example.com 2 M 548 2010-09-28 10:52:21 node-02.example.com 3 M 544 2010-09-28 10:52:21 node-03.example.com - At any node, using the
clustatutility, verify that the HA services are running as expected. In addition,clustatdisplays status of the cluster nodes. For example:[root@example-01 ~]#
clustatCluster Status for mycluster @ Wed Nov 17 05:40:00 2010 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node-03.example.com 3 Online, rgmanager node-02.example.com 2 Online, rgmanager node-01.example.com 1 Online, Local, rgmanager Service Name Owner (Last) State ------- ---- ----- ------ ----- service:example_apache node-01.example.com started service:example_apache2 (none) disabled - If the cluster is running as expected, you are done with creating a configuration file. You can manage the cluster with command-line tools described in Chapter 9, Managing Red Hat High Availability Add-On With Command Line Tools.
Chapter 9. Managing Red Hat High Availability Add-On With Command Line Tools
Important
Important
cluster.conf elements and attributes. For a comprehensive list and description of cluster.conf elements and attributes, see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
Important
cman_tool version -r command to propagate a cluster configuration throughout a cluster. Using that command requires that ricci is running.
Note
9.1. Starting and Stopping the Cluster Software
9.1.1. Starting Cluster Software
service cman startservice clvmd start, if CLVM has been used to create clustered volumesservice gfs2 start, if you are using Red Hat GFS2service rgmanager start, if you using high-availability (HA) services (rgmanager).
[root@example-01 ~]#service cman startStarting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] [root@example-01 ~]#service clvmd startStarting clvmd: [ OK ] Activating VG(s): 2 logical volume(s) in volume group "vg_example" now active [ OK ] [root@example-01 ~]#service gfs2 startMounting GFS2 filesystem (/mnt/gfsA): [ OK ] Mounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service rgmanager startStarting Cluster Service Manager: [ OK ] [root@example-01 ~]#
9.1.2. Stopping Cluster Software
service rgmanager stop, if you using high-availability (HA) services (rgmanager).service gfs2 stop, if you are using Red Hat GFS2umount -at gfs2, if you are using Red Hat GFS2 in conjunction withrgmanager, to ensure that any GFS2 files mounted duringrgmanagerstartup (but not unmounted during shutdown) were also unmounted.service clvmd stop, if CLVM has been used to create clustered volumesservice cman stop
[root@example-01 ~]#service rgmanager stopStopping Cluster Service Manager: [ OK ] [root@example-01 ~]#service gfs2 stopUnmounting GFS2 filesystem (/mnt/gfsA): [ OK ] Unmounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#umount -at gfs2[root@example-01 ~]#service clvmd stopSignaling clvmd to exit [ OK ] clvmd terminated [ OK ] [root@example-01 ~]#service cman stopStopping cluster: Leaving fence domain... [ OK ] Stopping gfs_controld... [ OK ] Stopping dlm_controld... [ OK ] Stopping fenced... [ OK ] Stopping cman... [ OK ] Waiting for corosync to shutdown: [ OK ] Unloading kernel modules... [ OK ] Unmounting configfs... [ OK ] [root@example-01 ~]#
Note
9.2. Deleting or Adding a Node
9.2.1. Deleting a Node from a Cluster
Important
- At any node, use the
clusvcadmutility to relocate, migrate, or stop each HA service running on the node that is being deleted from the cluster. For information about usingclusvcadm, see Section 9.3, “Managing High-Availability Services”. - At the node to be deleted from the cluster, stop the cluster software according to Section 9.1.2, “Stopping Cluster Software”. For example:
[root@example-01 ~]#
service rgmanager stopStopping Cluster Service Manager: [ OK ] [root@example-01 ~]#service gfs2 stopUnmounting GFS2 filesystem (/mnt/gfsA): [ OK ] Unmounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service clvmd stopSignaling clvmd to exit [ OK ] clvmd terminated [ OK ] [root@example-01 ~]#service cman stopStopping cluster: Leaving fence domain... [ OK ] Stopping gfs_controld... [ OK ] Stopping dlm_controld... [ OK ] Stopping fenced... [ OK ] Stopping cman... [ OK ] Waiting for corosync to shutdown: [ OK ] Unloading kernel modules... [ OK ] Unmounting configfs... [ OK ] [root@example-01 ~]# - At any node in the cluster, edit the
/etc/cluster/cluster.confto remove theclusternodesection of the node that is to be deleted. For example, in Example 9.1, “Three-node Cluster Configuration”, if node-03.example.com is supposed to be removed, then delete theclusternodesection for that node. If removing a node (or nodes) causes the cluster to be a two-node cluster, you can add the following line to the configuration file to allow a single node to maintain quorum (for example, if one node fails):<cman two_node="1" expected_votes="1"/>Refer to Section 9.2.3, “Examples of Three-Node and Two-Node Configurations” for comparison between a three-node and a two-node configuration. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the updated file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. - Verify that the updated configuration file has been propagated.
- If the node count of the cluster has transitioned from greater than two nodes to two nodes, you must restart the cluster software as follows:
- At each node, stop the cluster software according to Section 9.1.2, “Stopping Cluster Software”. For example:
[root@example-01 ~]#
service rgmanager stopStopping Cluster Service Manager: [ OK ] [root@example-01 ~]#service gfs2 stopUnmounting GFS2 filesystem (/mnt/gfsA): [ OK ] Unmounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service clvmd stopSignaling clvmd to exit [ OK ] clvmd terminated [ OK ] [root@example-01 ~]#service cman stopStopping cluster: Leaving fence domain... [ OK ] Stopping gfs_controld... [ OK ] Stopping dlm_controld... [ OK ] Stopping fenced... [ OK ] Stopping cman... [ OK ] Waiting for corosync to shutdown: [ OK ] Unloading kernel modules... [ OK ] Unmounting configfs... [ OK ] [root@example-01 ~]# - At each node, start the cluster software according to Section 9.1.1, “Starting Cluster Software”. For example:
[root@example-01 ~]#
service cman startStarting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] [root@example-01 ~]#service clvmd startStarting clvmd: [ OK ] Activating VG(s): 2 logical volume(s) in volume group "vg_example" now active [ OK ] [root@example-01 ~]#service gfs2 startMounting GFS2 filesystem (/mnt/gfsA): [ OK ] Mounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service rgmanager startStarting Cluster Service Manager: [ OK ] [root@example-01 ~]# - At any cluster node, run
cman_tool nodesto verify that the nodes are functioning as members in the cluster (signified as "M" in the status column, "Sts"). For example:[root@example-01 ~]#
cman_tool nodesNode Sts Inc Joined Name 1 M 548 2010-09-28 10:52:21 node-01.example.com 2 M 548 2010-09-28 10:52:21 node-02.example.com - At any node, using the
clustatutility, verify that the HA services are running as expected. In addition,clustatdisplays status of the cluster nodes. For example:[root@example-01 ~]#
clustatCluster Status for mycluster @ Wed Nov 17 05:40:00 2010 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node-02.example.com 2 Online, rgmanager node-01.example.com 1 Online, Local, rgmanager Service Name Owner (Last) State ------- ---- ----- ------ ----- service:example_apache node-01.example.com started service:example_apache2 (none) disabled
9.2.2. Adding a Node to a Cluster
- At any node in the cluster, edit the
/etc/cluster/cluster.confto add aclusternodesection for the node that is to be added. For example, in Example 9.2, “Two-node Cluster Configuration”, if node-03.example.com is supposed to be added, then add aclusternodesection for that node. If adding a node (or nodes) causes the cluster to transition from a two-node cluster to a cluster with three or more nodes, remove the followingcmanattributes from/etc/cluster/cluster.conf:cman two_node="1"expected_votes="1"
Refer to Section 9.2.3, “Examples of Three-Node and Two-Node Configurations” for comparison between a three-node and a two-node configuration. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - (Optional) Validate the updated file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. - Verify that the updated configuration file has been propagated.
- Propagate the updated configuration file to
/etc/cluster/in each node to be added to the cluster. For example, use thescpcommand to send the updated configuration file to each node to be added to the cluster. - If the node count of the cluster has transitioned from two nodes to greater than two nodes, you must restart the cluster software in the existing cluster nodes as follows:
- At each node, stop the cluster software according to Section 9.1.2, “Stopping Cluster Software”. For example:
[root@example-01 ~]#
service rgmanager stopStopping Cluster Service Manager: [ OK ] [root@example-01 ~]#service gfs2 stopUnmounting GFS2 filesystem (/mnt/gfsA): [ OK ] Unmounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service clvmd stopSignaling clvmd to exit [ OK ] clvmd terminated [ OK ] [root@example-01 ~]#service cman stopStopping cluster: Leaving fence domain... [ OK ] Stopping gfs_controld... [ OK ] Stopping dlm_controld... [ OK ] Stopping fenced... [ OK ] Stopping cman... [ OK ] Waiting for corosync to shutdown: [ OK ] Unloading kernel modules... [ OK ] Unmounting configfs... [ OK ] [root@example-01 ~]# - At each node, start the cluster software according to Section 9.1.1, “Starting Cluster Software”. For example:
[root@example-01 ~]#
service cman startStarting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] [root@example-01 ~]#service clvmd startStarting clvmd: [ OK ] Activating VG(s): 2 logical volume(s) in volume group "vg_example" now active [ OK ] [root@example-01 ~]#service gfs2 startMounting GFS2 filesystem (/mnt/gfsA): [ OK ] Mounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service rgmanager startStarting Cluster Service Manager: [ OK ] [root@example-01 ~]#
- At each node to be added to the cluster, start the cluster software according to Section 9.1.1, “Starting Cluster Software”. For example:
[root@example-01 ~]#
service cman startStarting cluster: Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ] [root@example-01 ~]#service clvmd startStarting clvmd: [ OK ] Activating VG(s): 2 logical volume(s) in volume group "vg_example" now active [ OK ] [root@example-01 ~]#service gfs2 startMounting GFS2 filesystem (/mnt/gfsA): [ OK ] Mounting GFS2 filesystem (/mnt/gfsB): [ OK ] [root@example-01 ~]#service rgmanager startStarting Cluster Service Manager: [ OK ] [root@example-01 ~]# - At any node, using the
clustatutility, verify that each added node is running and part of the cluster. For example:[root@example-01 ~]#
clustatCluster Status for mycluster @ Wed Nov 17 05:40:00 2010 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node-03.example.com 3 Online, rgmanager node-02.example.com 2 Online, rgmanager node-01.example.com 1 Online, Local, rgmanager Service Name Owner (Last) State ------- ---- ----- ------ ----- service:example_apache node-01.example.com started service:example_apache2 (none) disabledFor information about usingclustat, see Section 9.3, “Managing High-Availability Services”.In addition, you can usecman_tool statusto verify node votes, node count, and quorum count. For example:[root@example-01 ~]#
cman_tool statusVersion: 6.2.0 Config Version: 19 Cluster Name: mycluster Cluster Id: 3794 Cluster Member: Yes Cluster Generation: 548 Membership state: Cluster-Member Nodes: 3 Expected votes: 3 Total votes: 3 Node votes: 1 Quorum: 2 Active subsystems: 9 Flags: Ports Bound: 0 11 177 Node name: node-01.example.com Node ID: 3 Multicast addresses: 239.192.14.224 Node addresses: 10.15.90.58 - At any node, you can use the
clusvcadmutility to migrate or relocate a running service to the newly joined node. Also, you can enable any disabled services. For information about usingclusvcadm, see Section 9.3, “Managing High-Availability Services”
Note
9.2.3. Examples of Three-Node and Two-Node Configurations
Example 9.1. Three-node Cluster Configuration
<cluster name="mycluster" config_version="3">
<cman/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternode>
<clusternode name="node-03.example.com" nodeid="3">
<fence>
<method name="APC">
<device name="apc" port="3"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="example_pri" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="node-01.example.com" priority="1"/>
<failoverdomainnode name="node-02.example.com" priority="2"/>
<failoverdomainnode name="node-03.example.com" priority="3"/>
</failoverdomain>
</failoverdomains>
<resources>
<ip address="127.143.131.100" monitor_link="yes" sleeptime="10">
<fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3">
<apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/>
</fs>
</ip>
</resources>
<service autostart="0" domain="example_pri" exclusive="0" name="example_apache" recovery="relocate">
<fs ref="web_fs"/>
<ip ref="127.143.131.100"/>
<apache ref="example_server"/>
</service>
<service autostart="0" domain="example_pri" exclusive="0" name="example_apache2" recovery="relocate">
<fs name="web_fs2" device="/dev/sdd3" mountpoint="/var/www" fstype="ext3"/>
<ip address="127.143.131.101" monitor_link="yes" sleeptime="10"/>
<apache config_file="conf/httpd.conf" name="example_server2" server_root="/etc/httpd" shutdown_wait="0"/>
</service>
</rm>
</cluster>
Example 9.2. Two-node Cluster Configuration
<cluster name="mycluster" config_version="3">
<cman two_node="1" expected_votes="1"/>
<clusternodes>
<clusternode name="node-01.example.com" nodeid="1">
<fence>
<method name="APC">
<device name="apc" port="1"/>
</method>
</fence>
</clusternode>
<clusternode name="node-02.example.com" nodeid="2">
<fence>
<method name="APC">
<device name="apc" port="2"/>
</method>
</fence>
</clusternodes>
<fencedevices>
<fencedevice agent="fence_apc" ipaddr="apc_ip_example" login="login_example" name="apc" passwd="password_example"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="example_pri" nofailback="0" ordered="1" restricted="0">
<failoverdomainnode name="node-01.example.com" priority="1"/>
<failoverdomainnode name="node-02.example.com" priority="2"/>
</failoverdomain>
</failoverdomains>
<resources>
<ip address="127.143.131.100" monitor_link="yes" sleeptime="10">
<fs name="web_fs" device="/dev/sdd2" mountpoint="/var/www" fstype="ext3">
<apache config_file="conf/httpd.conf" name="example_server" server_root="/etc/httpd" shutdown_wait="0"/>
</fs>
</ip>
</resources>
<service autostart="0" domain="example_pri" exclusive="0" name="example_apache" recovery="relocate">
<fs ref="web_fs"/>
<ip ref="127.143.131.100"/>
<apache ref="example_server"/>
</service>
<service autostart="0" domain="example_pri" exclusive="0" name="example_apache2" recovery="relocate">
<fs name="web_fs2" device="/dev/sdd3" mountpoint="/var/www" fstype="ext3"/>
<ip address="127.143.131.101" monitor_link="yes" sleeptime="10"/>
<apache config_file="conf/httpd.conf" name="example_server2" server_root="/etc/httpd" shutdown_wait="0"/>
</service>
</rm>
</cluster>
9.3. Managing High-Availability Services
clustat, and the Cluster User Service Administration Utility, clusvcadm. clustat displays the status of a cluster and clusvcadm provides the means to manage high-availability services.
clustat and clusvcadm commands. It consists of the following subsections:
9.3.1. Displaying HA Service Status with clustat
clustat displays cluster-wide status. It shows membership information, quorum view, the state of all high-availability services, and indicates which node the clustat command is being run at (Local). Table 9.1, “Services Status” describes the states that services can be in and are displayed when running clustat. Example 9.3, “clustat Display” shows an example of a clustat display. For more detailed information about running the clustat command see the clustat man page.
| Services Status | Description |
|---|---|
| The service resources are configured and available on the cluster system that owns the service. | |
| The service is pending start on another node. | |
| The service has been disabled, and does not have an assigned owner. A disabled service is never restarted automatically by the cluster. | |
| In the stopped state, the service will be evaluated for starting after the next service or node transition. This is a temporary state. You may disable or enable the service from this state. | |
The service is presumed dead. A service is placed into this state whenever a resource's stop operation fails. After a service is placed into this state, you must verify that there are no resources allocated (mounted file systems, for example) prior to issuing a disable request. The only operation that can take place when a service has entered this state is disable. | |
This state can appear in certain cases during startup and running clustat -f. |
Example 9.3. clustat Display
[root@example-01 ~]#clustat
Cluster Status for mycluster @ Wed Nov 17 05:40:15 2010
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node-03.example.com 3 Online, rgmanager
node-02.example.com 2 Online, rgmanager
node-01.example.com 1 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:example_apache node-01.example.com started
service:example_apache2 (none) disabled
9.3.2. Managing HA Services with clusvcadm
clusvcadm command. With it you can perform the following operations:
- Enable and start a service.
- Disable a service.
- Stop a service.
- Freeze a service
- Unfreeze a service
- Migrate a service (for virtual machine services only)
- Relocate a service.
- Restart a service.
- Restart failed non-critical resources in a resource group
clusvcadm utility man page.
| Service Operation | Description | Command Syntax |
|---|---|---|
Start the service, optionally on a preferred target and optionally according to failover domain rules. In the absence of either a preferred target or failover domain rules, the local host where clusvcadm is run will start the service. If the original start fails, the service behaves as though a relocate operation was requested (see in this table). If the operation succeeds, the service is placed in the started state. | clusvcadm -e <service_name> or clusvcadm -e <service_name> -m <member> (Using the -m option specifies the preferred target member on which to start the service.) | |
| Stop the service and place into the disabled state. This is the only permissible operation when a service is in the failed state. | clusvcadm -d <service_name> | |
Move the service to another node. Optionally, you may specify a preferred node to receive the service, but the inability of the service to run on that host (for example, if the service fails to start or the host is offline) does not prevent relocation, and another node is chosen. rgmanager attempts to start the service on every permissible node in the cluster. If no permissible target node in the cluster successfully starts the service, the relocation fails and the service is attempted to be restarted on the original owner. If the original owner cannot restart the service, the service is placed in the stopped state. | clusvcadm -r <service_name> or clusvcadm -r <service_name> -m <member> (Using the -m option specifies the preferred target member on which to start the service.) | |
| Stop the service and place into the stopped state. | clusvcadm -s <service_name> | |
| Freeze a service on the node where it is currently running. This prevents status checks of the service as well as failover in the event the node fails or rgmanager is stopped. This can be used to suspend a service to allow maintenance of underlying resources. Refer to the section called “Considerations for Using the Freeze and Unfreeze Operations” for important information about using the freeze and unfreeze operations. | clusvcadm -Z <service_name> | |
| Unfreeze takes a service out of the freeze state. This re-enables status checks. Refer to the section called “Considerations for Using the Freeze and Unfreeze Operations” for important information about using the freeze and unfreeze operations. | clusvcadm -U <service_name> | |
| Migrate a virtual machine to another node. You must specify a target node. Depending on the failure, a failure to migrate may result with the virtual machine in the failed state or in the started state on the original owner. | clusvcadm -M <service_name> -m <member> Important
For the migrate operation, you must specify a target node using the -m <member> option.
| |
| Restart a service on the node where it is currently running. | clusvcadm -R <service_name> | |
Convalesce (repair, fix) a resource group. Whenever a non-critical subtree's maximum restart threshold is exceeded, the subtree is stopped, and the service gains a P flag (partial), which is displayed in the output of the clustat command next to one of the cluster resource groups. The convalesce operation attempts to start failed, non-critical resources in a service group and clears the P flag if the failed, non-critical resources successfully start. | clusvcadm -c <service_name> |
Considerations for Using the Freeze and Unfreeze Operations
rgmanager services. For example, if you have a database and a web server in one rgmanager service, you may freeze the rgmanager service, stop the database, perform maintenance, restart the database, and unfreeze the service.
- Status checks are disabled.
- Start operations are disabled.
- Stop operations are disabled.
- Failover will not occur (even if you power off the service owner).
Important
- You must not stop all instances of rgmanager when a service is frozen unless you plan to reboot the hosts prior to restarting rgmanager.
- You must not unfreeze a service until the reported owner of the service rejoins the cluster and restarts rgmanager.
9.4. Updating a Configuration
/etc/cluster/cluster.conf) and propagating it to each node in the cluster. You can update the configuration using either of the following procedures:
9.4.1. Updating a Configuration Using cman_tool version -r
cman_tool version -r command, perform the following steps:
- At any node in the cluster, edit the
/etc/cluster/cluster.conffile. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3"). - Save
/etc/cluster/cluster.conf. - Run the
cman_tool version -rcommand to propagate the configuration to the rest of the cluster nodes. It is necessary thatriccibe running in each cluster node to be able to propagate updated cluster configuration information. - Verify that the updated
cluster.confconfiguration file has been propagated. If not, use thescpcommand to propagate it to/etc/cluster/in each cluster node. - You may skip this step (restarting cluster software) if you have made only the following configuration changes:
- Deleting a node from the cluster configuration—except where the node count changes from greater than two nodes to two nodes. For information about deleting a node from a cluster and transitioning from greater than two nodes to two nodes, see Section 9.2, “Deleting or Adding a Node”.
- Adding a node to the cluster configuration—except where the node count changes from two nodes to greater than two nodes. For information about adding a node to a cluster and transitioning from two nodes to greater than two nodes, see Section 9.2.2, “Adding a Node to a Cluster”.
- Changes to how daemons log information.
- HA service/VM maintenance (adding, editing, or deleting).
- Resource maintenance (adding, editing, or deleting).
- Failover domain maintenance (adding, editing, or deleting).
Otherwise, you must restart the cluster software as follows:- At each node, stop the cluster software according to Section 9.1.2, “Stopping Cluster Software”.
- At each node, start the cluster software according to Section 9.1.1, “Starting Cluster Software”.
Stopping and starting the cluster software ensures that any configuration changes that are checked only at startup time are included in the running configuration. - At any cluster node, run
cman_tool nodesto verify that the nodes are functioning as members in the cluster (signified as "M" in the status column, "Sts"). For example:[root@example-01 ~]#
cman_tool nodesNode Sts Inc Joined Name 1 M 548 2010-09-28 10:52:21 node-01.example.com 2 M 548 2010-09-28 10:52:21 node-02.example.com 3 M 544 2010-09-28 10:52:21 node-03.example.com - At any node, using the
clustatutility, verify that the HA services are running as expected. In addition,clustatdisplays status of the cluster nodes. For example:[root@example-01 ~]#
clustatCluster Status for mycluster @ Wed Nov 17 05:40:00 2010 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node-03.example.com 3 Online, rgmanager node-02.example.com 2 Online, rgmanager node-01.example.com 1 Online, Local, rgmanager Service Name Owner (Last) State ------- ---- ----- ------ ----- service:example_apache node-01.example.com started service:example_apache2 (none) disabled - If the cluster is running as expected, you are done updating the configuration.
9.4.2. Updating a Configuration Using scp
scp command, perform the following steps:
- At any node in the cluster, edit the
/etc/cluster/cluster.conffile. - Update the
config_versionattribute by incrementing its value (for example, changing fromconfig_version="2"toconfig_version="3">). - Save
/etc/cluster/cluster.conf. - Validate the updated file against the cluster schema (
cluster.rng) by running theccs_config_validatecommand. For example:[root@example-01 ~]#
ccs_config_validateConfiguration validates - If the updated file is valid, use the
scpcommand to propagate it to/etc/cluster/in each cluster node. - Verify that the updated configuration file has been propagated.
- To reload the new configuration, execute the following command on one of the cluster nodes:
cman_tool version -r -S
- You may skip this step (restarting cluster software) if you have made only the following configuration changes:
- Deleting a node from the cluster configuration—except where the node count changes from greater than two nodes to two nodes. For information about deleting a node from a cluster and transitioning from greater than two nodes to two nodes, see Section 9.2, “Deleting or Adding a Node”.
- Adding a node to the cluster configuration—except where the node count changes from two nodes to greater than two nodes. For information about adding a node to a cluster and transitioning from two nodes to greater than two nodes, see Section 9.2.2, “Adding a Node to a Cluster”.
- Changes to how daemons log information.
- HA service/VM maintenance (adding, editing, or deleting).
- Resource maintenance (adding, editing, or deleting).
- Failover domain maintenance (adding, editing, or deleting).
Otherwise, you must restart the cluster software as follows:- At each node, stop the cluster software according to Section 9.1.2, “Stopping Cluster Software”.
- At each node, start the cluster software according to Section 9.1.1, “Starting Cluster Software”.
Stopping and starting the cluster software ensures that any configuration changes that are checked only at startup time are included in the running configuration. - Verify that that the nodes are functioning as members in the cluster and that the HA services are running as expected.
- At any cluster node, run
cman_tool nodesto verify that the nodes are functioning as members in the cluster (signified as "M" in the status column, "Sts"). For example:[root@example-01 ~]#
cman_tool nodesNode Sts Inc Joined Name 1 M 548 2010-09-28 10:52:21 node-01.example.com 2 M 548 2010-09-28 10:52:21 node-02.example.com 3 M 544 2010-09-28 10:52:21 node-03.example.com - At any node, using the
clustatutility, verify that the HA services are running as expected. In addition,clustatdisplays status of the cluster nodes. For example:[root@example-01 ~]#
clustatCluster Status for mycluster @ Wed Nov 17 05:40:00 2010 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ node-03.example.com 3 Online, rgmanager node-02.example.com 2 Online, rgmanager node-01.example.com 1 Online, Local, rgmanager Service Name Owner (Last) State ------- ---- ----- ------ ----- service:example_apache node-01.example.com started service:example_apache2 (none) disabled
If the cluster is running as expected, you are done updating the configuration.
Chapter 10. Diagnosing and Correcting Problems in a Cluster
10.1. Configuration Changes Do Not Take Effect
- When you configure a cluster using Conga, Conga propagates the changes automatically when you apply the changes.
- For information on propagating changes to cluster configuration with the
ccscommand, see Section 6.15, “Propagating the Configuration File to the Cluster Nodes”. - For information on propagating changes to cluster configuration with command line tools, see Section 9.4, “Updating a Configuration”.
- Deleting a node from the cluster configuration—except where the node count changes from greater than two nodes to two nodes.
- Adding a node to the cluster configuration—except where the node count changes from two nodes to greater than two nodes.
- Changing the logging settings.
- Adding, editing, or deleting HA services or VM components.
- Adding, editing, or deleting cluster resources.
- Adding, editing, or deleting failover domains.
- Changing any
corosyncoropenaistimers.
- Adding or removing the
two_nodeoption from the cluster configuration file. - Renaming the cluster.
- Adding, changing, or deleting heuristics for quorum disk, changing any quorum disk timers, or changing the quorum disk device. For these changes to take effect, a global restart of the
qdiskddaemon is required. - Changing the
central_processingmode forrgmanager. For this change to take effect, a global restart ofrgmanageris required. - Changing the multicast address.
- Switching the transport mode from UDP multicast to UDP unicast, or switching from UDP unicast to UDP multicast.
ccs command, or command line tools,
- For information on restarting a cluster with Conga, see Section 5.4, “Starting, Stopping, Restarting, and Deleting Clusters”.
- For information on restarting a cluster with the
ccscommand, see Section 7.2, “Starting and Stopping a Cluster”. - For information on restarting a cluster with command line tools, see Section 9.1, “Starting and Stopping the Cluster Software”.
10.2. Cluster Does Not Form
- Make sure you have name resolution set up correctly. The cluster node name in the
cluster.conffile should correspond to the name used to resolve that cluster's address over the network that cluster will be using to communicate. For example, if your cluster's node names arenodeaandnodebmake sure both nodes have entries in the/etc/cluster/cluster.conffile and/etc/hostsfile that match those names. - If the cluster uses multicast for communication between nodes, make sure that multicast traffic is not being blocked, delayed, or otherwise interfered with on the network that the cluster is using to communicate. Note that some Cisco switches have features that may cause delays in multicast traffic.
- Use
telnetorSSHto verify whether you can reach remote nodes. - Execute the
ethtool eth1 | grep linkcommand to check whether the ethernet link is up. - Use the
tcpdumpcommand at each node to check the network traffic. - Ensure that you do not have firewall rules blocking communication between your nodes.
- Ensure that the interfaces the cluster uses for inter-node communication are not using any bonding mode other than 0, 1, or 2. (Bonding modes 0 and 2 are supported as of Red Hat Enterprise Linux 6.4.)
10.3. Nodes Unable to Rejoin Cluster after Fence or Reboot
- Clusters that are passing their traffic through a Cisco Catalyst switch may experience this problem.
- Ensure that all cluster nodes have the same version of the
cluster.conffile. If thecluster.conffile is different on any of the nodes, then nodes may be unable to join the cluster post fence.As of Red Hat Enterprise Linux 6.1, you can use the following command to verify that all of the nodes specified in the host's cluster configuration file have the identical cluster configuration file:ccs -h host --checkconf
For information on theccscommand, see Chapter 6, Configuring Red Hat High Availability Add-On With the ccs Command and Chapter 7, Managing Red Hat High Availability Add-On With ccs. - Make sure that you have configured
chkconfig onfor cluster services in the node that is attempting to join the cluster. - Ensure that no firewall rules are blocking the node from communicating with other nodes in the cluster.
10.4. Cluster Daemon crashes
rgmanager process fails unexpectedly. This causes the cluster node to get fenced and rgmanager to recover the service on another host. When the watchdog daemon detects that the main rgmanager process has crashed then it will reboot the cluster node, and the active cluster nodes will detect that the cluster node has left and evict it from the cluster.
gcore can aid in troubleshooting a crashed daemon.
rgmanager and rgmanager-debuginfo are the same version or the captured application core might be unusable.
$ yum -y --enablerepo=rhel-debuginfo install gdb rgmanager-debuginfo
10.4.1. Capturing the rgmanager Core at Runtime
rgmanager processes that are running as it is started. You must capture the core for the rgmanager process with the higher PID.
ps command showing two processes for rgmanager.
$ ps aux | grep rgmanager | grep -v grep root 22482 0.0 0.5 23544 5136 ? S<Ls Dec01 0:00 rgmanager root 22483 0.0 0.2 78372 2060 ? S<l Dec01 0:47 rgmanager
pidof program is used to automatically determine the higher-numbered pid, which is the appropriate pid to create the core. The full command captures the application core for the process 22483 which has the higher pid number.
$ gcore -o /tmp/rgmanager-$(date '+%F_%s').core $(pidof -s rgmanager)
10.4.2. Capturing the Core When the Daemon Crashes
/etc/init.d/functions script blocks core files from daemons called by /etc/init.d/rgmanager. For the daemon to create application cores, you must enable that option. This procedure must be done on all cluster nodes that need an application core caught.
/etc/sysconfig/cluster file. The DAEMONCOREFILELIMIT parameter allows the daemon to create core files if the process crashes. There is a -w option that prevents the watchdog process from running. The watchdog daemon is responsible for rebooting the cluster node if rgmanager crashes and, in some cases, if the watchdog daemon is running then the core file will not be generated, so it must be disabled to capture core files.
DAEMONCOREFILELIMIT="unlimited" RGMGR_OPTS="-w"
service rgmanager restart
Note
rgmanager process.
ls /core*
/core.11926
rgmanager to capture the application core. The cluster node that experienced the rgmanager crash should be rebooted or fenced after the core is captured to ensure that the watchdog process was not running.
10.4.3. Recording a gdb Backtrace Session
gdb, the GNU Debugger. To record a script session of gdb on the core file from the affected system, run the following:
$ script /tmp/gdb-rgmanager.txt $ gdb /usr/sbin/rgmanager /tmp/rgmanager-.core.
gdb session, while script records it to the appropriate text file. While in gdb, run the following commands:
(gdb) thread apply all bt full (gdb) quit
ctrl-D to stop the script session and save it to the text file.
10.5. Cluster Services Hang
- The cluster may have attempted to fence a node and the fence operation may have failed.
- Look through the
/var/log/messagesfile on all nodes and see if there are any failed fence messages. If so, then reboot the nodes in the cluster and configure fencing correctly. - Verify that a network partition did not occur, as described in Section 10.8, “Each Node in a Two-Node Cluster Reports Second Node Down”. and verify that communication between nodes is still possible and that the network is up.
- If nodes leave the cluster the remaining nodes may be inquorate. The cluster needs to be quorate to operate. If nodes are removed such that the cluster is no longer quorate then services and storage will hang. Either adjust the expected votes or return the required amount of nodes to the cluster.
Note
fence_node command or with Conga. For information, see the fence_node man page and Section 5.3.2, “Causing a Node to Leave or Join a Cluster”.
10.6. Cluster Service Will Not Start
- There may be a syntax error in the service configuration in the
cluster.conffile. You can use therg_testcommand to validate the syntax in your configuration. If there are any configuration or syntax faults, therg_testwill inform you what the problem is.$
rg_test test /etc/cluster/cluster.conf start service servicenameFor more information on therg_testcommand, see Section C.5, “Debugging and Testing Services and Resource Ordering”.If the configuration is valid, then increase the resource group manager's logging and then read the messages logs to determine what is causing the service start to fail. You can increase the log level by adding theloglevel="7"parameter to thermtag in thecluster.conffile. You will then get increased verbosity in your messages logs with regards to starting, stopping, and migrating clustered services.
10.7. Cluster-Controlled Services Fails to Migrate
- Ensure that the resources required to run a given service are present on all nodes in the cluster that may be required to run that service. For example, if your clustered service assumes a script file in a specific location or a file system mounted at a specific mount point then you must ensure that those resources are available in the expected places on all nodes in the cluster.
- Ensure that failover domains, service dependency, and service exclusivity are not configured in such a way that you are unable to migrate services to nodes as you would expect.
- If the service in question is a virtual machine resource, check the documentation to ensure that all of the correct configuration work has been completed.
- Increase the resource group manager's logging, as described in Section 10.6, “Cluster Service Will Not Start”, and then read the messages logs to determine what is causing the service start to fail to migrate.
10.8. Each Node in a Two-Node Cluster Reports Second Node Down
10.9. Nodes are Fenced on LUN Path Failure
10.10. Quorum Disk Does Not Appear as Cluster Member
- Review the
/var/log/cluster/qdiskd.logfile. - Run
ps -ef | grep qdiskto determine if the process is running. - Ensure that
<quorumd...>is configured correctly in the/etc/cluster/cluster.conffile. - Enable debugging output for the
qdiskddaemon.- For information on enabling debugging in the
/etc/cluster/cluster.conffile, see Section 8.7, “Configuring Debug Options”. - For information on enabling debugging using
luci, see Section 4.5.6, “Logging Configuration”. - For information on enabling debugging with the
ccscommand, see Section 6.14.4, “Logging”.
- Note that it may take multiple minutes for the quorum disk to register with the cluster. This is normal and expected behavior.
10.11. Unusual Failover Behavior
10.12. Fencing Occurs at Random
- The root cause of fences is always a node losing token, meaning that it lost communication with the rest of the cluster and stopped returning heartbeat.
- Any situation that results in a system not returning heartbeat within the specified token interval could lead to a fence. By default the token interval is 10 seconds. It can be specified by adding the desired value (in milliseconds) to the token parameter of the totem tag in the
cluster.conffile (for example, settingtotem token="30000"for 30 seconds). - Ensure that the network is sound and working as expected.
- Ensure that the interfaces the cluster uses for inter-node communication are not using any bonding mode other than 0, 1, or 2. (Bonding modes 0 and 2 are supported as of Red Hat Enterprise Linux 6.4.)
- Take measures to determine if the system is "freezing" or kernel panicking. Set up the
kdumputility and see if you get a core during one of these fences. - Make sure some situation is not arising that you are wrongly attributing to a fence, for example the quorum disk ejecting a node due to a storage failure or a third party product like Oracle RAC rebooting a node due to some outside condition. The messages logs are often very helpful in determining such problems. Whenever fences or node reboots occur it should be standard practice to inspect the messages logs of all nodes in the cluster from the time the reboot/fence occurred.
- Thoroughly inspect the system for hardware faults that may lead to the system not responding to heartbeat when expected.
10.13. Debug Logging for Distributed Lock Manager (DLM) Needs to be Enabled
/etc/cluster/cluster.conf file to add configuration options to the dlm tag. The log_debug option enables DLM kernel debugging messages, and the plock_debug option enables POSIX lock debugging messages.
/etc/cluster/cluster.conf file shows the dlm tag that enables both DLM debug options:
<cluster config_version="42" name="cluster1"> ... <dlm log_debug="1" plock_debug="1"/> ... </cluster>
/etc/cluster/cluster.conf file, run the cman_tool version -r command to propagate the configuration to the rest of the cluster nodes.
Chapter 11. SNMP Configuration with the Red Hat High Availability Add-On
11.1. SNMP and the Red Hat High Availability Add-On
foghorn, which emits the SNMP traps. The foghorn subagent talks to the snmpd daemon by means of the AgentX Protocol. The foghorn subagent only creates SNMP traps; it does not support other SNMP operations such as get or set.
config options for the foghorn subagent. It cannot be configured to use a specific socket; only the default AgentX socket is currently supported.
11.2. Configuring SNMP with the Red Hat High Availability Add-On
- To use SNMP traps with the Red Hat High Availability Add-On, the
snmpdservice is required and acts as the master agent. Since thefoghornservice is the subagent and uses the AgentX protocol, you must add the following line to the/etc/snmp/snmpd.conffile to enable AgentX support:master agentx
- To specify the host where the SNMP trap notifications should be sent, add the following line to the to the
/etc/snmp/snmpd.conffile:trap2sink host
For more information on notification handling, see thesnmpd.confman page. - Make sure that the
snmpddaemon is enabled and running by executing the following commands:#
chkconfig snmpd on#service snmpd start - If the
messagebusdaemon is not already enabled and running, execute the following commands:#
chkconfig messagebus on#service messagebus start - Make sure that the
foghorndaemon is enabled and running by executing the following commands:#
chkconfig foghorn on#service foghorn start - Execute the following command to configure your system so that the
COROSYNC-MIBgenerates SNMP traps and to ensure that thecorosync-notifyddaemon is enabled and running:#
echo "OPTIONS=\"-d\" " > /etc/sysconfig/corosync-notifyd#chkconfig corosync-notifyd on#service corosync-notifyd start
foghorn service and translated into SNMPv2 traps. These traps are then passed to the host that you defined with the trapsink entry to receive SNMPv2 traps.
11.3. Forwarding SNMP traps
snmptrapd daemon on the external machine and customize how to respond to the notifications.
- For each node in the cluster, follow the procedure described in Section 11.2, “Configuring SNMP with the Red Hat High Availability Add-On”, setting the
trap2sink hostentry in the/etc/snmp/snmpd.conffile to specify the external host that will be running thesnmptrapddaemon. - On the external host that will receive the traps, edit the
/etc/snmp/snmptrapd.confconfiguration file to specify your community strings. For example, you can use the following entry to allow thesnmptrapddaemon to process notifications using thepubliccommunity string.authCommunity log,execute,net public
- On the external host that will receive the traps, make sure that the
snmptrapddaemon is enabled and running by executing the following commands:#
chkconfig snmptrapd on#service snmptrapd start
snmptrapd.conf man page.
11.4. SNMP Traps Produced by Red Hat High Availability Add-On
foghorn daemon generates the following traps:
fenceNotifyFenceNodeThis trap occurs whenever a fenced node attempts to fence another node. Note that this trap is only generated on one node - the node that attempted to perform the fence operation. The notification includes the following fields:fenceNodeName- name of the fenced nodefenceNodeID- node id of the fenced nodefenceResult- the result of the fence operation (0 for success, -1 for something went wrong, -2 for no fencing methods defined)
rgmanagerServiceStateChangeThis trap occurs when the state of a cluster service changes. The notification includes the following fields:rgmanagerServiceName- the name of the service, which includes the service type (for example,service:fooorvm:foo).rgmanagerServiceState- the state of the service. This excludes transitional states such asstartingandstoppingto reduce clutter in the traps.rgmanagerServiceFlags- the service flags. There are currently two supported flags:frozen, indicating a service which has been frozen usingclusvcadm -Z, andpartial, indicating a service in which a failed resource has been flagged asnon-criticalso that the resource may fail and its components manually restarted without the entire service being affected.rgmanagerServiceCurrentOwner- the service owner. If the service is not running, this will be(none).rgmanagerServicePreviousOwner- the last service owner, if known. If the last owner is not known, this may indicate(none).
corosync-nodifyd daemon generates the following traps:
corosyncNoticesNodeStatusThis trap occurs when a node joins or leaves the cluster. The notification includes the following fields:corosyncObjectsNodeName- node namecorosyncObjectsNodeID- node idcorosyncObjectsNodeAddress- node IP addresscorosyncObjectsNodeStatus- node status (joinedorleft)
corosyncNoticesQuorumStatusThis trap occurs when the quorum state changes. The notification includes the following fields:corosyncObjectsNodeName- node namecorosyncObjectsNodeID- node idcorosyncObjectsQuorumStatus- new state of the quorum (quorateorNOT quorate)
corosyncNoticesAppStatusThis trap occurs when a client application connects or disconnects from Corosync.corosyncObjectsNodeName- node namecorosyncObjectsNodeID- node idcorosyncObjectsAppName- application namecorosyncObjectsAppStatus- new state of the application (connectedordisconnected)
Chapter 12. Clustered Samba Configuration
Note
Note
12.1. CTDB Overview
12.2. Required Packages
ctdbsambasamba-commonsamba-winbind-clients
12.3. GFS2 Configuration
/dev/csmb_vg/csmb_lv, which will hold the user data that will be exported by means of a Samba share and should be sized accordingly. This example creates a logical volume that is 100GB in size./dev/csmb_vg/ctdb_lv, which will store the shared CTDB state information and needs to be 1GB in size.
mkfs.gfs2 command. You run this command on one cluster node only.
/dev/csmb_vg/csmb_lv, execute the following command:
[root@clusmb-01 ~]# mkfs.gfs2 -j3 -p lock_dlm -t csmb:gfs2 /dev/csmb_vg/csmb_lv-j- Specifies the number of journals to create in the filesystem. This example uses a cluster with three nodes, so we create one journal per node.
-p- Specifies the locking protocol.
lock_dlmis the locking protocol GFS2 uses for inter-node communication. -t- Specifies the lock table name and is of the format cluster_name:fs_name. In this example, the cluster name as specified in the
cluster.conffile iscsmb, and we usegfs2as the name for the file system.
This will destroy any data on /dev/csmb_vg/csmb_lv.
It appears to contain a gfs2 filesystem.
Are you sure you want to proceed? [y/n] y
Device:
/dev/csmb_vg/csmb_lv
Blocksize: 4096
Device Size 100.00 GB (26214400 blocks)
Filesystem Size: 100.00 GB (26214398 blocks)
Journals: 3
Resource Groups: 400
Locking Protocol: "lock_dlm"
Lock Table: "csmb:gfs2"
UUID:
94297529-ABG3-7285-4B19-182F4F2DF2D7
/dev/csmb_vg/csmb_lv file system will be mounted at /mnt/gfs2 on all nodes. This mount point must match the value that you specify as the location of the share directory with the path = option in the /etc/samba/smb.conf file, as described in Section 12.5, “Samba Configuration”.
/dev/csmb_vg/ctdb_lv, execute the following command:
[root@clusmb-01 ~]# mkfs.gfs2 -j3 -p lock_dlm -t csmb:ctdb_state /dev/csmb_vg/ctdb_lv/dev/csmb_vg/csmb_lv. This distinguishes the lock table names for the different devices used for the file systems.
mkfs.gfs2 appears as follows:
This will destroy any data on /dev/csmb_vg/ctdb_lv.
It appears to contain a gfs2 filesystem.
Are you sure you want to proceed? [y/n] y
Device:
/dev/csmb_vg/ctdb_lv
Blocksize: 4096
Device Size 1.00 GB (262144 blocks)
Filesystem Size: 1.00 GB (262142 blocks)
Journals: 3
Resource Groups: 4
Locking Protocol: "lock_dlm"
Lock Table: "csmb:ctdb_state"
UUID:
BCDA8025-CAF3-85BB-B062-CC0AB8849A03
/dev/csmb_vg/ctdb_lv file system will be mounted at /mnt/ctdb on all nodes. This mount point must match the value that you specify as the location of the .ctdb.lock file with the CTDB_RECOVERY_LOCK option in the /etc/sysconfig/ctdb file, as described in Section 12.4, “CTDB Configuration”.
12.4. CTDB Configuration
/etc/sysconfig/ctdb. The mandatory fields that must be configured for CTDB operation are as follows:
CTDB_NODESCTDB_PUBLIC_ADDRESSESCTDB_RECOVERY_LOCKCTDB_MANAGES_SAMBA(must be enabled)CTDB_MANAGES_WINBIND(must be enabled if running on a member server)
CTDB_NODES=/etc/ctdb/nodes CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses CTDB_RECOVERY_LOCK="/mnt/ctdb/.ctdb.lock" CTDB_MANAGES_SAMBA=yes CTDB_MANAGES_WINBIND=yes
CTDB_NODES- Specifies the location of the file which contains the cluster node list.The
/etc/ctdb/nodesfile thatCTDB_NODESreferences simply lists the IP addresses of the cluster nodes, as in the following example:192.168.1.151 192.168.1.152 192.168.1.153
In this example, there is only one interface/IP on each node that is used for both cluster/CTDB communication and serving clients. However, it is highly recommended that each cluster node have two network interfaces so that one set of interfaces can be dedicated to cluster/CTDB communication and another set of interfaces can be dedicated to public client access. Use the appropriate IP addresses of the cluster network here and make sure the hostnames/IP addresses used in thecluster.conffile are the same. Similarly, use the appropriate interfaces of the public network for client access in thepublic_addressesfile.It is critical that the/etc/ctdb/nodesfile is identical on all nodes because the ordering is important and CTDB will fail if it finds different information on different nodes. CTDB_PUBLIC_ADDRESSES- Specifies the location of the file that lists the IP addresses that can be used to access the Samba shares exported by this cluster. These are the IP addresses that you should configure in DNS for the name of the clustered Samba server and are the addresses that CIFS clients will connect to. Configure the name of the clustered Samba server as one DNS type A record with multiple IP addresses and let round-robin DNS distribute the clients across the nodes of the cluster.For this example, we have configured a round-robin DNS entry
csmb-serverwith all the addresses listed in the/etc/ctdb/public_addressesfile. DNS will distribute the clients that use this entry across the cluster in a round-robin fashion.The contents of the/etc/ctdb/public_addressesfile on each node are as follows:192.168.1.201/0 eth0 192.168.1.202/0 eth0 192.168.1.203/0 eth0
This example uses three addresses that are currently unused on the network. In your own configuration, choose addresses that can be accessed by the intended clients.Alternately, this example shows the contents of the/etc/ctdb/public_addressesfiles in a cluster in which there are three nodes but a total of four public addresses. In this example, IP address 198.162.2.1 can be hosted by either node 0 or node 1 and will be available to clients as long as at least one of these nodes is available. Only if both nodes 0 and 1 fail does this public address become unavailable to clients. All other public addresses can only be served by one single node respectively and will therefore only be available if the respective node is also available.The/etc/ctdb/public_addressesfile on node 0 includes the following contents:198.162.1.1/24 eth0 198.162.2.1/24 eth1
The/etc/ctdb/public_addressesfile on node 1 includes the following contents:198.162.2.1/24 eth1 198.162.3.1/24 eth2
The/etc/ctdb/public_addressesfile on node 2 includes the following contents:198.162.3.2/24 eth2
CTDB_RECOVERY_LOCK- Specifies a lock file that CTDB uses internally for recovery. This file must reside on shared storage such that all the cluster nodes have access to it. The example in this section uses the GFS2 file system that will be mounted at
/mnt/ctdbon all nodes. This is different from the GFS2 file system that will host the Samba share that will be exported. This recovery lock file is used to prevent split-brain scenarios. With newer versions of CTDB (1.0.112 and later), specifying this file is optional as long as it is substituted with another split-brain prevention mechanism. CTDB_MANAGES_SAMBA- When enabling by setting it to
yes, specifies that CTDB is allowed to start and stop the Samba service as it deems necessary to provide service migration/failover.WhenCTDB_MANAGES_SAMBAis enabled, you should disable automaticinitstartup of thesmbandnmbdaemons by executing the following commands:[root@clusmb-01 ~]#
chkconfig snb off[root@clusmb-01 ~]#chkconfig nmb off CTDB_MANAGES_WINBIND- When enabling by setting it to
yes, specifies that CTDB is allowed to start and stop thewinbinddaemon as required. This should be enabled when you are using CTDB in a Windows domain or in active directory security mode.WhenCTDB_MANAGES_WINBINDis enabled, you should disable automaticinitstartup of thewinbinddaemon by executing the following command:[root@clusmb-01 ~]#
chkconfig windinbd off
12.5. Samba Configuration
smb.conf is located at /etc/samba/smb.conf in this example. It contains the following parameters:
[global] guest ok = yes clustering = yes netbios name = csmb-server [csmb] comment = Clustered Samba public = yes path = /mnt/gfs2/share writeable = yes ea support = yes
csmb located at /mnt/gfs2/share. This is different from the GFS2 shared filesystem at /mnt/ctdb/.ctdb.lock that we specified as the CTDB_RECOVERY_LOCK parameter in the CTDB configuration file at /etc/sysconfig/ctdb.
share directory in /mnt/gfs2 when we mount it for the first time. The clustering = yes entry instructs Samba to use CTDB. The netbios name = csmb-server entry explicitly sets all the nodes to have a common NetBIOS name. The ea support parameter is required if you plan to use extended attributes.
smb.conf configuration file must be identical on all of the cluster nodes.
net conf command to automatically keep configuration in sync between cluster members without having to manually copy configuration files among the cluster nodes. For information on the net conf command, see the net(8) man page.
12.6. Starting CTDB and Samba Services
share directory and user accounts on the cluster nodes should be set up for client access.
ctdbd daemon. Since this example configured CTDB with CTDB_MANAGES_SAMBA=yes, CTDB will also start up the Samba service on all nodes and export all configured Samba shares.
[root@clusmb-01 ~]# service ctdb startctdb status shows the status of CTDB, as in the following example:
[root@clusmb-01 ~]# ctdb status
Number of nodes:3
pnn:0 192.168.1.151 OK (THIS NODE)
pnn:1 192.168.1.152 OK
pnn:2 192.168.1.153 OK
Generation:1410259202
Size:3
hash:0 lmaster:0
hash:1 lmaster:1
hash:2 lmaster:2
Recovery mode:NORMAL (0)
Recovery master:0
12.7. Using the Clustered Samba Server
/etc/ctdb/public_addresses file, or using the csmb-server DNS entry we configured earlier, as shown below:
[root@clusmb-01 ~]# mount -t cifs //csmb-server/csmb /mnt/sambashare -o user=testmonkey[user@clusmb-01 ~]$ smbclient //csmb-server/csmbAppendix A. Fence Device Parameters
ccs command, or by editing the etc/cluster/cluster.conf file. For a comprehensive list and description of the fence device parameters for each fence agent, see the man page for that agent.
Note
Note
/etc/cluster/cluster.conf).
fence_apc, the fence agent for APC over telnet/SSH.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the APC device connected to the cluster into which the fence daemon logs by means of telnet/ssh. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP Port (optional) | ipport | The TCP port to use to connect to the device. The default port is 23, or 22 if Use SSH is selected. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port | port | The port. |
| Switch (optional) | switch | The switch number for the APC switch that connects to the node when you have multiple daisy-chained switches. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Use SSH | secure | Indicates that system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
fence_apc_snmp, the fence agent for APC that logs into the SNP device by means of the SNMP protocol.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the APC device connected to the cluster into which the fence daemon logs by means of the SNMP protocol. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP port | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string; the default value is private. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | The port. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_brocade, the fence agent for Brocade FC switches.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Brocade device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address assigned to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Force IP Family | inet4_only, inet6_only | Force the agent to use IPv4 or IPv6 addresses only |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’\$’. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port | port | The switch outlet number. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
| Unfencing | unfence section of the cluster configuration file | When enabled, this ensures that a fenced node is not re-enabled until the node has been rebooted. This is necessary for non-power fence methods (that is, SAN/storage fencing). When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For more information about unfencing a node, see the fence_node(8) man page. For information about configuring unfencing in the cluster configuration file, see Section 8.3, “Configuring Fencing”. For information about configuring unfencing with the ccs command, see Section 6.7.2, “Configuring a Single Storage-Based Fence Device for a Node”. |
fence_cisco_mds, the fence agent for Cisco MDS.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Cisco MDS 9000 series device with SNMP enabled. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP port (optional) | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3). |
| SNMP Community | community | The SNMP community string. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | The port. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_cisco_ucs, the fence agent for Cisco UCS.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Cisco UCS device. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP port (optional) | ipport | The TCP port to use to connect to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSL | ssl | Use SSL connections to communicate with the device. |
| Sub-Organization | suborg | Additional path needed to access suborganization. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_drac5, the fence agent for Dell DRAC 5.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | The name assigned to the DRAC. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the DRAC. |
| IP Port (optional) | ipport | The TCP port to use to connect to the device. |
| Login | login | The login name used to access the DRAC. |
| Password | passwd | The password used to authenticate the connection to the DRAC. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
| Module Name | module_name | (optional) The module name for the DRAC when you have multiple DRAC modules. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’\$’. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_eaton_snmp, the fence agent for the Eaton over SNMP network power switch.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Eaton network power switch connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port (optional) | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string; the default value is private. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. This parameter is always required. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_egenera, the fence agent for the Egenera BladeFrame.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Egenera BladeFrame device connected to the cluster. |
| CServer | cserver | The host name (and optionally the user name in the form of username@hostname) assigned to the device. Refer to the fence_egenera(8) man page for more information. |
| ESH Path (optional) | esh | The path to the esh command on the cserver (default is /opt/panmgr/bin/esh) |
| Username | user | The login name. The default value is root. |
| lpan | lpan | The logical process area network (LPAN) of the device. |
| pserver | pserver | The processing blade (pserver) name of the device. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Unfencing | unfence section of the cluster configuration file | When enabled, this ensures that a fenced node is not re-enabled until the node has been rebooted. This is necessary for non-power fence methods (that is, SAN/storage fencing). When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For more information about unfencing a node, see the fence_node(8) man page. For information about configuring unfencing in the cluster configuration file, see Section 8.3, “Configuring Fencing”. For information about configuring unfencing with the ccs command, see Section 6.7.2, “Configuring a Single Storage-Based Fence Device for a Node”. |
fence_emerson, the fence agent for Emerson over SNMP.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Emerson Network Power Switch device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port (optional) | udpport | UDP/TCP port to use for connections with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP privacy protocol password | snmp_priv_passwd | The SNMP Privacy Protocol Password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_eps, the fence agent for ePowerSwitch.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the ePowerSwitch device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Name of Hidden Page | hidden_page | The name of the hidden page for the device. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_virt, the fence agent for virtual machines using VM channel or serial mode .
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Fence virt fence device. |
| Serial Device | serial_device | On the host, the serial device must be mapped in each domain's configuration file. For more information, see the fence_virt man page. If this field is specified, it causes the fence_virt fencing agent to operate in serial mode. Not specifying a value causes the fence_virt fencing agent to operate in VM channel mode. |
| Serial Parameters | serial_params | The serial parameters. The default is 115200, 8N1. |
| VM Channel IP Address | channel_address | The channel IP. The default value is 10.0.2.179. |
| Timeout (optional) | timeout | Fencing timeout, in seconds. The default value is 30. |
| Domain | port (formerly domain) | Virtual machine (domain UUID or name) to fence. |
ipport | The channel port. The default value is 1229, which is the value used when configuring this fence device with luci. | |
| Delay (optional) | delay | Fencing delay, in seconds. The fence agent will wait the specified number of seconds before attempting a fencing operation. The default value is 0. |
fence_xvm, the fence agent for virtual machines using multicast.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Fence virt fence device. |
| Timeout (optional) | timeout | Fencing timeout, in seconds. The default value is 30. |
| Domain | port (formerly domain) | Virtual machine (domain UUID or name) to fence. |
| Delay (optional) | delay | Fencing delay, in seconds. The fence agent will wait the specified number of seconds before attempting a fencing operation. The default value is 0. |
fence_rsb, the fence agent for Fujitsu-Siemens RSB.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the RSB to use as a fence device. |
| IP Address or Hostname | ipaddr | The host name assigned to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| Path to SSH Identity File | identity_file | The Identity file for SSH. |
| TCP Port | ipport | The port number on which the telnet service listens. The default value is 3172. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’\$’. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_hpblade, the fence agent for HP BladeSystem.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | The name assigned to the HP Bladesystem device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the HP BladeSystem device. |
| IP Port (optional) | ipport | The TCP port to use to connect to the device. |
| Login | login | The login name used to access the HP BladeSystem device. This parameter is required. |
| Password | passwd | The password used to authenticate the connection to the fence device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’\$’. |
| Missing port returns OFF instead of failure | missing_as_off | Missing port returns OFF instead of failure. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
fence_ilo and) HP iLO2 devices (fence_ilo2) share the same implementation. Table A.16, “HP iLO and HP iLO2” lists the fence device parameters used by these agents.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the server with HP iLO support. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP Port (optional) | ipport | TCP port to use for connection with the device. The default value is 443. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_ilo_ssh), HP iLO3 devices over SSH (fence_ilo3_ssh), and HP iLO4 devices over SSH (fence_ilo4_ssh) share the same implementation. Table A.17, “HP iLO over SSH, HP iLO3 over SSH, HPiLO4 over SSH (Red Hat Enterprise Linux 6.7 and later)” lists the fence device parameters used by these agents.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the server with HP iLO support. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| Path to SSH Identity File | identity_file | The Identity file for SSH. |
| TCP Port | ipport | UDP/TCP port to use for connections with the device; the default value is 23. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’MP>’, ’hpiLO->’. |
| Method to Fence | method | The method to fence: on/off or cycle |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_ilo_mp, the fence agent for HP iLO MP devices.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the server with HP iLO support. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP Port (optional) | ipport | TCP port to use for connection with the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The Identity file for SSH. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’MP>’, ’hpiLO->’. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_ilo_moonshot, the fence agent for HP Moonshot iLO devices.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the server with HP iLO support. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSH | secure | Indicates that the system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| Path to SSH Identity File | identity_file | The Identity file for SSH. |
| TCP Port | ipport | UDP/TCP port to use for connections with the device; the default value is 22. |
| Force Command Prompt | cmd_prompt | The command prompt to use. The default value is ’MP>’, ’hpiLO->’. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Delay (seconds) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
fence_bladecenter, the fence agent for IBM BladeCenter.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the IBM BladeCenter device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP port (optional) | ipport | TCP port to use for connection with the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Use SSH | secure | Indicates that system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
fence_ibmblade, the fence agent for IBM BladeCenter over SNMP.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the IBM BladeCenter SNMP device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port (optional) | udpport | UDP/TCP port to use for connections with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP privacy protocol password | snmp_priv_passwd | The SNMP Privacy Protocol Password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_ipdu, the fence agent for iPDU over SNMP devices.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the IBM iPDU device connected to the cluster into which the fence daemon logs by means of the SNMP protocol. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string; the default value is private. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP Authentication Protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_ifmib, the fence agent for IF-MIB devices.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the IF MIB device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port (optional) | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_intelmodular, the fence agent for Intel Modular.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the Intel Modular device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| UDP/TCP Port (optional) | udpport | The UDP/TCP port to use for connection with the device; the default value is 161. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| SNMP Version | snmp_version | The SNMP version to use (1, 2c, 3); the default value is 1. |
| SNMP Community | community | The SNMP community string; the default value is private. |
| SNMP Security Level | snmp_sec_level | The SNMP security level (noAuthNoPriv, authNoPriv, authPriv). |
| SNMP Authentication Protocol | snmp_auth_prot | The SNMP authentication protocol (MD5, SHA). |
| SNMP Privacy Protocol | snmp_priv_prot | The SNMP privacy protocol (DES, AES). |
| SNMP Privacy Protocol Password | snmp_priv_passwd | The SNMP privacy protocol password. |
| SNMP Privacy Protocol Script | snmp_priv_passwd_script | The script that supplies a password for SNMP privacy protocol. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_ipmilan,) Dell iDRAC (fence_idrac), IBM Integrated Management Module (fence_imm), HP iLO3 devices (fence_ilo3), and HP iLO4 devices (fence_ilo4) share the same implementation. Table A.25, “IPMI (Intelligent Platform Management Interface) LAN, Dell iDrac, IBM Integrated Management Module, HPiLO3, HPiLO4” lists the fence device parameters used by these agents.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the fence device connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| Login | login | The login name of a user capable of issuing power on/off commands to the given port. |
| Password | passwd | The password used to authenticate the connection to the port. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Authentication Type | auth | Authentication type: none, password, or MD5. |
| Use Lanplus | lanplus | True or 1. If blank, then value is False. It is recommended that you enable Lanplus to improve the security of your connection if your hardware supports it. |
| Ciphersuite to use | cipher | The remote server authentication, integrity, and encryption algorithms to use for IPMIv2 lanplus connections. |
| Privilege level | privlvl | The privilege level on the device. |
| IPMI Operation Timeout | timeout | Timeout in seconds for IPMI operation. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. The default value is 2 seconds for fence_ipmilan, fence_idrac, fence_imm, and fence_ilo4. The default value is 4 seconds for fence_ilo3. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Method to Fence | method | The method to fence: on/off or cycle |
fence_kdump, the fence agent for kdump crash recovery service. Note that fence_kdump is not a replacement for traditional fencing methods; The fence_kdump agent can detect only that a node has entered the kdump crash recovery service. This allows the kdump crash recovery service to complete without being preempted by traditional power fencing methods.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the fence_kdump device. |
| IP Family | family | IP network family. The default value is auto. |
| IP Port (optional) | ipport | IP port number that the fence_kdump agent will use to listen for messages. The default value is 7410. |
| Operation Timeout (seconds) (optional) | timeout | Number of seconds to wait for message from failed node. |
| Node name | nodename | Name or IP address of the node to be fenced. |
fence_mpath, the fence agent for multipath persistent reservation fencing.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the fence_mpath device. |
| Devices (Comma delimited list) | devices | Comma-separated list of devices to use for the current operation. Each device must support SCSI-3 persistent reservations. |
| Use sudo when calling third-party software | sudo | Use sudo (without password) when calling 3rd party software. |
| Path to sudo binary (optional) | sudo_path | Path to sudo binary (default value is /usr/bin/sudo. |
| Path to mpathpersist binary (optional) | mpathpersist_path | Path to mpathpersist binary (default value is /sbin/mpathpersist. |
| Path to a directory where the fence agent can store information (optional) | store_path | Path to directory where fence agent can store information (default value is /var/run/cluster. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Unfencing | unfence section of the cluster configuration file | When enabled, this ensures that a fenced node is not re-enabled until the node has been rebooted. This is necessary for non-power fence methods. When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For more information about unfencing a node, see the fence_node(8) man page. For information about configuring unfencing in the cluster configuration file, see Section 8.3, “Configuring Fencing”. For information about configuring unfencing with the ccs command, see Section 6.7.2, “Configuring a Single Storage-Based Fence Device for a Node”. |
| Key for current action | key | Key to use for the current operation. This key should be unique to a node and written in /etc/multipath.conf. For the "on" action, the key specifies the key use to register the local node. For the "off" action, this key specifies the key to be removed from the device(s). This parameter is always required. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_rhevm, the fence agent for RHEV-M fencing.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Name of the RHEV-M fencing device. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP Port (optional) | ipport | The TCP port to use for connection with the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Use SSL | ssl | Use SSL connections to communicate with the device. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Port (Outlet) Number | port | Physical plug number or name of virtual machine. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_scsi, the fence agent for SCSI persistent reservations.
Note
- When using SCSI fencing, all nodes in the cluster must register with the same devices so that each node can remove another node's registration key from all the devices it is registered with.
- Devices used for the cluster volumes should be a complete LUN, not partitions. SCSI persistent reservations work on an entire LUN, meaning that access is controlled to each LUN, not individual partitions.
/dev/disk/by-id/xxx where possible. Devices specified in this format are consistent among all nodes and will point to the same disk, unlike devices specified in a format such as /dev/sda which can point to different disks from machine to machine and across reboots.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the SCSI fence device. |
| Unfencing | unfence section of the cluster configuration file | When enabled, this ensures that a fenced node is not re-enabled until the node has been rebooted. This is necessary for non-power fence methods (that is, SAN/storage fencing). When you configure a device that requires unfencing, the cluster must first be stopped and the full configuration including devices and unfencing must be added before the cluster is started. For more information about unfencing a node, see the fence_node(8) man page. For information about configuring unfencing in the cluster configuration file, see Section 8.3, “Configuring Fencing”. For information about configuring unfencing with the ccs command, see Section 6.7.2, “Configuring a Single Storage-Based Fence Device for a Node”. |
| Node name | nodename | The node name is used to generate the key value used for the current operation. |
| Key for current action | key | (overrides node name) Key to use for the current operation. This key should be unique to a node. For the "on" action, the key specifies the key use to register the local node. For the "off" action,this key specifies the key to be removed from the device(s). |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
fence_vmware_soap, the fence agent for VMware over SOAP API.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Name of the virtual machine fencing device. |
| IP Address or Hostname | ipaddr | The IP address or host name assigned to the device. |
| IP Port (optional) | ipport | The TCP port to use for connection with the device. The default port is 80, or 443 if Use SSL is selected. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| VM name | port | Name of virtual machine in inventory path format (for example, /datacenter/vm/Discovered_virtual_machine/myMachine). |
| VM UUID | uuid | The UUID of the virtual machine to fence. |
| Delay (optional) | delay | The number of seconds to wait before fencing is started. The default value is 0. |
| Use SSL | ssl | Use SSL connections to communicate with the device. |
fence_wti, the fence agent for the WTI network power switch.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | A name for the WTI power switch connected to the cluster. |
| IP Address or Hostname | ipaddr | The IP or host name address assigned to the device. |
| IP Port (optional) | ipport | The TCP port to use to connect to the device. |
| Login | login | The login name used to access the device. |
| Password | passwd | The password used to authenticate the connection to the device. |
| Password Script (optional) | passwd_script | The script that supplies a password for access to the fence device. Using this supersedes the parameter. |
| Force command prompt | cmd_prompt | The command prompt to use. The default value is [’RSM>’, ’>MPC’, ’IPS>’, ’TPS>’, ’NBB>’, ’NPS>’, ’VMR>’] |
| Power Wait (seconds) | power_wait | Number of seconds to wait after issuing a power off or power on command. |
| Power Timeout (seconds) | power_timeout | Number of seconds to continue testing for a status change after issuing a power off or power on command. The default value is 20. |
| Shell Timeout (seconds) | shell_timeout | Number of seconds to wait for a command prompt after issuing a command. The default value is 3. |
| Login Timeout (seconds) | login_timeout | Number of seconds to wait for a command prompt after login. The default value is 5. |
| Times to Retry Power On Operation | retry_on | Number of attempts to retry a power on operation. The default value is 1. |
| Use SSH | secure | Indicates that system will use SSH to access the device. When using SSH, you must specify either a password, a password script, or an identity file. |
| SSH Options | ssh_options | SSH options to use. The default value is -1 -c blowfish. |
| Path to SSH Identity File | identity_file | The identity file for SSH. |
| Port | port | Physical plug number or name of virtual machine. |
Appendix B. HA Resource Parameters
ccs command, or by editing the etc/cluster/cluster.conf file. Table B.1, “HA Resource Summary” lists the resources, their corresponding resource agents, and references to other tables containing parameter descriptions. To understand resource agents in more detail you can view them in /usr/share/cluster of any cluster node.
/usr/share/cluster directory includes a dummy OCF script for a resource group, service.sh. For more information about the parameters included in this script, see the service.sh script itself.
cluster.conf elements and attributes, see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
Note
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | The name of the Apache service. |
| Server Root | server_root | The default value is /etc/httpd. |
| Config File | config_file | Specifies the Apache configuration file. The default valuer is conf/httpd.conf. |
| httpd Options | httpd_options | Other command line options for httpd. |
| Path to httpd binary | httpd | Specifies absolute path of the httpd binary to use. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a name for the Bind Mount resource |
| Mount Point | mountpoint | Target of this bind mount |
| Source of the Bind Mount | source | Source of the bind mount |
| Force Unmount | force_unmount | If set, the cluster will kill all processes using this file system when the resource group is stopped. Otherwise, the unmount will fail, and the resource group will be restarted. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Instance Name | name | Specifies a unique name for the Condor instance. |
| Condor Subsystem Type | type | Specifies the type of Condor subsystem for this instance: schedd, job_server, or query_server. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
Specifies a name for the file system resource.
|
| Filesystem Type | fstype | If not specified, mount tries to determine the file system type. |
| Mount Point | mountpoint | Path in file system hierarchy to mount this file system. |
| Device, FS Label, or UUID | device | Specifies the device associated with the file system resource. This can be a block device, file system label, or UUID of a file system. |
| Mount Options | options | Mount options; that is, options used when the file system is mounted. These may be file-system specific. Refer to the mount(8) man page for supported mount options. |
| File System ID (optional) | fsid | Note File System ID is used only by NFS services.
When creating a new file system resource, you can leave this field blank. Leaving the field blank causes a file system ID to be assigned automatically after you commit the parameter during configuration. If you need to assign a file system ID explicitly, specify it in this field.
|
| Force Unmount | force_unmount | If enabled, forces the file system to unmount. The default setting is disabled. Force Unmount kills all processes using the mount point to free up the mount when it tries to unmount. |
| Force fsck | force_fsck | If enabled, causes fsck to be run on the file system before mounting it. The default setting is disabled. |
| Enable NFS daemon and lockd workaround (Red Hat Enterprise Linux 6.4 and later) | nfsrestart | If your file system is exported by means of NFS and occasionally fails to unmount (either during shutdown or service relocation), setting this option will drop all file system references prior to the unmount operation. Setting this option requires that you enable the option and must not be used together with the NFS Server resource. You should set this option as a last resort only, as this is a hard attempt to unmount a file system. |
| Use Quick Status Checks | quick_status | If this option is enabled it will cause the fs.sh agent to bypass the read and write tests on all status checks and simply do a mount test. |
| Reboot Host Node if Unmount Fails | self_fence | If enabled, reboots the node if unmounting this file system fails. The filesystem resource agent accepts a value of 1, yes, on, or true to enable this parameter, and a value of 0, no, off, or false to disable it. The default setting is disabled. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | The name of the file system resource. |
| Mount Point | mountpoint | The path to which the file system resource is mounted. |
| Device, FS Label, or UUID | device | The device file associated with the file system resource. |
| Filesystem Type | fstype | Set to GFS2 on luci |
| Mount Options | options | Mount options. |
| File System ID (optional) | fsid | Note File System ID is used only by NFS services.
When creating a new GFS2 resource, you can leave this field blank. Leaving the field blank causes a file system ID to be assigned automatically after you commit the parameter during configuration. If you need to assign a file system ID explicitly, specify it in this field.
|
| Force Unmount | force_unmount | If enabled, forces the file system to unmount. The default setting is disabled. Force Unmount kills all processes using the mount point to free up the mount when it tries to unmount. With GFS2 resources, the mount point is not unmounted at service tear-down unless Force Unmount is enabled. |
| Enable NFS daemon and lockd workaround (Red Hat Enterprise Linux 6.4 and later) | nfsrestart | If your file system is exported by means of NFS and occasionally fails to unmount (either during shutdown or service relocation), setting this option will drop all file system references prior to the unmount operation. Setting this option requires that you enable the option and must not be used together with the NFS Server resource. You should set this option as a last resort only, as this is a hard attempt to unmount a file system. |
| Reboot Host Node if Unmount Fails | self_fence | If enabled and unmounting the file system fails, the node will immediately reboot. Generally, this is used in conjunction with force-unmount support, but it is not required. The GFS2 resource agent accepts a value of 1, yes, on, or true to enable this parameter, and a value of 0, no, off, or false to disable it. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| IP Address, Netmask Bits | address |
The IP address (and, optionally, netmask bits) for the resource. Netmask bits, or network prefix length, may come after the address itself with a slash as a separator, complying with CIDR notation (for example, 10.1.1.1/8). This is a virtual IP address. IPv4 and IPv6 addresses are supported, as is NIC link monitoring for each IP address.
Note
A service can contain only one IP address resource.
|
| Monitor Link | monitor_link | Enabling this causes the status check to fail if the link on the NIC to which this IP address is bound is not present. |
| Disable Updates to Static Routes | disable_rdisc | Disable updating of routing using RDISC protocol. |
| Number of Seconds to Sleep After Removing an IP Address | sleeptime | Specifies the amount of time (in seconds) to sleep. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
A unique name for this LVM resource.
|
| Volume Group Name | vg_name | A descriptive name of the volume group being managed. |
| Logical Volume Name | lv_name | Name of the logical volume being managed. This parameter is optional if there is more than one logical volume in the volume group being managed. |
| Fence the Node if It is Unable to Clean UP LVM Tags | self_fence | Fence the node if it is unable to clean up LVM tags. The LVM resource agent accepts a value of 1 or yes to enable this parameter, and a value of 0 or no to disable it. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a name of the MySQL server resource. |
| Config File | config_file | Specifies the configuration file. The default value is /etc/my.cnf. |
| Listen Address | listen_address | Specifies an IP address for MySQL server. If an IP address is not provided, the first IP address from the service is taken. |
| mysqld Options | mysqld_options | Other command line options for mysqld. |
| Startup Wait (seconds) | startup_wait | Specifies the number of seconds to wait for correct end of service startup. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | The name of the named Service. |
| Full Path to Config File | config_file | The path to the named configuration file |
| Named Working Directory | named_working_Dir | The working directory for the named resource. The default value is /var/named |
| Use Simplified Database Backend | named_sdb | Reserved, currently unused |
| Other Command-Line Options | named_options | Additional command-line options of the named resource |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
Symbolic name for the NFS or CIFS mount.
Note
This resource is required when a cluster service is configured to be an NFS client.
|
| Mount Point | mountpoint | Path to which the file system resource is mounted. |
| Host | host | NFS/CIFS server IP address or host name. |
| NFS Export Directory Name or CIFS share | export | NFS Export directory name or CIFS share name. |
| Filesystem Type | fstype |
File system type:
|
| Do Not Unmount the Filesystem During a Stop of Relocation Operation. | no_unmount | If enabled, specifies that the file system should not be unmounted during a stop or relocation operation. |
| Force Unmount | force_unmount | If Force Unmount is enabled, the cluster kills all processes using this file system when the service is stopped. Killing all processes using the file system frees up the file system. Otherwise, the unmount will fail, and the service will be restarted. |
| Self-Fence If Unmount Fails | self_fence | If enabled, reboots the node if unmounting this file system fails. |
| Options | options | Mount options. Specifies a list of mount options. If none are specified, the file system is mounted -o sync. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
This is a symbolic name of a client used to reference it in the resource tree. This is not the same thing as the
Target option.
Note
An nfsclient resource must be configured as a child of a parent nfsexport resource or a parent nfsserver resource.
|
| Target Hostname, Wildcard, or Netgroup | target | This is the server from which you are mounting. It can be specified using a host name, a wildcard (IP address or host name based), or a netgroup defining a host or hosts to export to. |
| Allow Recovery of This NFS Client | allow_recover | Allow recovery. |
| Options | options | Defines a list of options for this client — for example, additional client access rights. For more information, see the exports (5) man page, General Options. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
Descriptive name of the resource. The NFS Export resource ensures that NFS daemons are running. It is fully reusable; typically, only one NFS Export resource is needed. For more information on configuring the
nfsexport resource, see Section 8.8, “Configuring nfsexport and nfsserver Resources”.
Note
Name the NFS Export resource so it is clearly distinguished from other NFS resources.
|
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name |
Descriptive name of the NFS server resource. The NFS server resource is useful for exporting NFSv4 file systems to clients. Because of the way NFSv4 works, only one NFSv4 resource may exist on a server at a time. Additionally, it is not possible to use the NFS server resource when also using local instances of NFS on each cluster node. For more information on configuring the
nfsserver resource, see Section 8.8, “Configuring nfsexport and nfsserver Resources”.
|
| NFS statd listening port (optional) | statdport | The port number used for RPC listener sockets |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a service name for logging and other purposes. |
| Config File | config_file | Specifies an absolute path to a configuration file. The default value is /etc/openldap/slapd.conf. |
| URL List | url_list | The default value is ldap:///. |
slapd Options | slapd_options | Other command line options for slapd. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Instance Name (SID) of Oracle Instance | name |
Instance name.
Note
A service can contain only one Oracle 10g/11g Failover Instance.
|
| Oracle Listener Instance Name | listener_name | Oracle listener instance name. If you have multiple instances of Oracle running, it may be necessary to have multiple listeners on the same machine with different names. |
| Oracle User Name | user | This is the user name of the Oracle user that the Oracle AS instance runs as. |
| Oracle Application Home Directory | home | This is the Oracle (application, not user) home directory. It is configured when you install Oracle. |
| Oracle Installation Type | type |
The Oracle installation type.
|
| Virtual Hostname (optional) | vhost | Virtual Hostname matching the installation host name of Oracle 10g. Note that during the start/stop of an oracledb resource, your host name is changed temporarily to this host name. Therefore, you should configure an oracledb resource as part of an exclusive service only. |
| TNS_ADMIN (optional) | tns_admin | Path to specific listener configuration file. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Instance name (SID) of Oracle instance | name | Instance name. |
| Oracle User Name | user | This is the user name of the Oracle user that the Oracle instance runs as. |
| Oracle Application Home Directory | home | This is the Oracle (application, not user) home directory. It is configured when you install Oracle. |
| List of Oracle Listeners (optional, separated by spaces) | listeners | List of Oracle listeners which will be started with the database instance. Listener names are separated by whitespace. Defaults to empty which disables listeners. |
| Path to Lock File (optional) | lockfile | Location for lockfile which will be used for checking if the Oracle should be running or not. Defaults to location under /tmp. |
| TNS_ADMIN (optional) | tns_admin | Path to specific listener configuration file. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Listener Name | name | Listener name. |
| Oracle User Name | user | This is the user name of the Oracle user that the Oracle instance runs as. |
| Oracle Application Home Directory | home | This is the Oracle (application, not user) home directory. It is configured when you install Oracle. |
| TNS_ADMIN (optional) | tns_admin | Path to specific listener configuration file. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a service name for logging and other purposes. |
| Config File | config_file | Define absolute path to configuration file. The default value is /var/lib/pgsql/data/postgresql.conf. |
| Postmaster User | postmaster_user | User who runs the database server because it cannot be run by root. The default value is postgres. |
| Postmaster Options | postmaster_options | Other command line options for postmaster. |
| Startup Wait (seconds) | startup_wait | Specifies the number of seconds to wait for correct end of service startup. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| SAP Database Name | SID | Specifies a unique SAP system identifier. For example, P01. |
| SAP Executable Directory | DIR_EXECUTABLE | Specifies the fully qualified path to sapstartsrv and sapcontrol. |
| Database Type | DBTYPE | Specifies one of the following database types: Oracle, DB6, or ADA. |
| Oracle Listener Name | NETSERVICENAME | Specifies Oracle TNS listener name. |
| ABAP Stack is Not Installed, Only Java Stack is Installed | DBJ2EE_ONLY | If you do not have an ABAP stack installed in the SAP database, enable this parameter. |
| Application Level Monitoring | STRICT_MONITORING | Activates application level monitoring. |
| Automatic Startup Recovery | AUTOMATIC_RECOVER | Enable or disable automatic startup recovery. |
| Path to Java SDK | JAVE_HOME | Path to Java SDK. |
| File Name of the JDBC Driver | DB_JARS | File name of the JDBC driver. |
| Path to a Pre-Start Script | PRE_START_USEREXIT | Path to a pre-start script. |
| Path to a Post-Start Script | POST_START_USEREXIT | Path to a post-start script. |
| Path to a Pre-Stop Script | PRE_STOP_USEREXIT | Path to a pre-stop script |
| Path to a Post-Stop Script | POST_STOP_USEREXIT | Path to a post-stop script |
| J2EE Instance Bootstrap Directory | DIR_BOOTSTRAP | The fully qualified path the J2EE instance bootstrap directory. For example, /usr/sap/P01/J00/j2ee/cluster/bootstrap. |
| J2EE Security Store Path | DIR_SECSTORE | The fully qualified path the J2EE security store directory. For example, /usr/sap/P01/SYS/global/security/lib/tools. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| SAP Instance Name | InstanceName | The fully qualified SAP instance name. For example, P01_DVEBMGS00_sapp01ci. |
| SAP Executable Directory | DIR_EXECUTABLE | The fully qualified path to sapstartsrv and sapcontrol. |
| Directory Containing the SAP START Profile | DIR_PROFILE | The fully qualified path to the SAP START profile. |
| Name of the SAP START Profile | START_PROFILE | Specifies name of the SAP START profile. |
| Number of Seconds to Wait Before Checking Startup Status | START_WAITTIME | Specifies the number of seconds to wait before checking the startup status (do not wait for J2EE-Addin). |
| Enable Automatic Startup Recovery | AUTOMATIC_RECOVER | Enable or disable automatic startup recovery. |
| Path to a Pre-Start Script | PRE_START_USEREXIT | Path to a pre-start script. |
| Path to a Post-Start Script | POST_START_USEREXIT | Path to a post-start script. |
| Path to a Pre-Stop Script | PRE_STOP_USEREXIT | Path to a pre-stop script |
| Path to a Post-Stop Script | POST_STOP_USEREXIT | Path to a post-stop script |
Note
samba Resource)”, when creating or editing a cluster service, connect a Samba-service resource directly to the service, not to a resource within a service.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies the name of the Samba server. |
| Config File | config_file | The Samba configuration file |
| Other Command-Line Options for smbd | smbd_options | Other command-line options for smbd. |
| Other Command-Line Options for nmbd | nmbd_options | Other command-line options for nmbd. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies number of seconds to wait for correct end of service shutdown. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a name for the custom user script. The script resource allows a standard LSB-compliant init script to be used to start a clustered service. |
| Full Path to Script File | file |
Enter the path where this custom script is located (for example,
/etc/init.d/userscript).
Important
Trying to manage internal cluster services (such as cman, for example) by configuring them as script resources will expose the cluster to self-inflicted failures.
|
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Instance Name | name | Specifies the instance name of the Sybase ASE resource. |
| ASE Server Name | server_name | The ASE server name that is configured for the HA service. |
| SYBASE Home directory | sybase_home | The home directory of Sybase products. |
| Login File | login_file | The full path of login file that contains the login-password pair. |
| Interfaces File | interfaces_file | The full path of the interfaces file that is used to start/access the ASE server. |
| SYBASE_ASE Directory Name | sybase_ase | The directory name under sybase_home where ASE products are installed. |
| SYBASE_OCS Directory Name | sybase_ocs | The directory name under sybase_home where OCS products are installed. For example, ASE-15_0. |
| Sybase User | sybase_user | The user who can run ASE server. |
| Start Timeout (seconds) | start_timeout | The start timeout value. |
| Shutdown Timeout (seconds) | shutdown_timeout | The shutdown timeout value. |
| Deep Probe Timeout | deep_probe_timeout | The maximum seconds to wait for the response of ASE server before determining that the server had no response while running deep probe. |
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Name | name | Specifies a service name for logging and other purposes. |
| Config File | config_file | Specifies the absolute path to the configuration file. The default value is /etc/tomcat6/tomcat6.conf. |
| Shutdown Wait (seconds) | shutdown_wait | Specifies the number of seconds to wait for correct end of service shutdown. The default value is 30. |
Important
vm Resource)”, when you configure your cluster with virtual machine resources, you should use the rgmanager tools to start and stop the virtual machines. Using virsh to start the machine can result in the virtual machine running in more than one place, which can cause data corruption in the virtual machine. For information on configuring your system to reduce the chances of administrators accidentally "double-starting" virtual machines by using both cluster and non-cluster tools, see Section 3.14, “Configuring Virtual Machines in a Clustered Environment”.
Note
Virtual Machine as the resource type and entering the virtual machine resource parameters. For information on configuring a virtual machine with the ccs, see Section 6.12, “Virtual Machine Resources”.
| luci Field | cluster.conf Attribute | Description |
|---|---|---|
| Service Name | name | Specifies the name of the virtual machine. When using the luci interface, you specify this as a service name. |
| Automatically Start This Service | autostart | If enabled, this virtual machine is started automatically after the cluster forms a quorum. If this parameter is disabled, this virtual machine is not started automatically after the cluster forms a quorum; the virtual machine is put into the disabled state. |
| Run Exclusive | exclusive | If enabled, this virtual machine can only be relocated to run on another node exclusively; that is, to run on a node that has no other virtual machines running on it. If no nodes are available for a virtual machine to run exclusively, the virtual machine is not restarted after a failure. Additionally, other virtual machines do not automatically relocate to a node running this virtual machine as Run exclusive. You can override this option by manual start or relocate operations. |
| Failover Domain | domain | Defines lists of cluster members to try in the event that a virtual machine fails. |
| Recovery Policy | recovery | Recovery policy provides the following options:
|
| Restart Options | max_restarts, restart_expire_time | With or selected as the recovery policy for a service, specifies the maximum number of restart failures before relocating or disabling the service and specifies the length of time in seconds after which to forget a restart. If you specify the max_restarts parameter, you must also specify the restart_expire_time parameter for this configuration pair to be respected. |
| Migration Type | migrate | Specifies a migration type of live or pause. The default setting is live. |
| Migration Mapping | migration_mapping |
Specifies an alternate interface for migration. You can specify this when, for example, the network address used for virtual machine migration on a node differs from the address of the node used for cluster communication.
Specifying the following indicates that when you migrate a virtual machine from
member to member2, you actually migrate to target2. Similarly, when you migrate from member2 to member, you migrate using target.
member:target,member2:target2
|
| Status Program | status_program |
Status program to run in addition to the standard check for the presence of a virtual machine. If specified, the status program is executed once per minute. This allows you to ascertain the status of critical services within a virtual machine. For example, if a virtual machine runs a web server, your status program could check to see whether a web server is up and running; if the status check fails (signified by returning a non-zero value), the virtual machine is recovered.
After a virtual machine is started, the virtual machine resource agent will periodically call the status program and wait for a successful return code (zero) prior to returning. This times out after five minutes.
|
| Path to xmlfile Used to Create the VM | xmlfile | Full path to libvirt XML file containing the libvirt domain definition. |
| VM Configuration File Path | path |
A colon-delimited path specification that the Virtual Machine Resource Agent (
vm.sh) searches for the virtual machine configuration file. For example: /mnt/guests/config:/etc/libvirt/qemu.
Important
The path should never directly point to a virtual machine configuration file.
|
| Path to the VM Snapshot Directory | snapshot | Path to the snapshot directory where the virtual machine image will be stored. |
| Hypervisor URI | hypervisor_uri | Hypervisor URI (normally automatic). |
| Migration URI | migration_uri | Migration URI (normally automatic). |
| Tunnel data over ssh during migration | tunnelled | Tunnel data over ssh during migration. |
| Do Not Force Kill VM During Stop | no_kill | Do not force kill vm during stop; instead. fail after the timeout expires. |
Appendix C. HA Resource Behavior
/etc/cluster/cluster.conf. For descriptions of HA resource parameters, see Appendix B, HA Resource Parameters. To understand resource agents in more detail you can view them in /usr/share/cluster of any cluster node.
Note
/etc/cluster/cluster.conf.
/etc/cluster/cluster.conf (in each cluster node). In the cluster configuration file, each resource tree is an XML representation that specifies each resource, its attributes, and its relationship among other resources in the resource tree (parent, child, and sibling relationships).
Note
Note
/etc/cluster/cluster.conf, for illustration purposes only.
C.1. Parent, Child, and Sibling Relationships Among Resources
rgmanager. All resources in a service run on the same node. From the perspective of rgmanager, a cluster service is one entity that can be started, stopped, or relocated. Within a cluster service, however, the hierarchy of the resources determines the order in which each resource is started and stopped.The hierarchical levels consist of parent, child, and sibling.
fs:myfs(<fs name="myfs" ...>) andip:10.1.1.2(<ip address="10.1.1.2 .../>) are siblings.fs:myfs(<fs name="myfs" ...>) is the parent ofscript:script_child(<script name="script_child"/>).script:script_child(<script name="script_child"/>) is the child offs:myfs(<fs name="myfs" ...>).
Example C.1. Resource Hierarchy of Service foo
<service name="foo" ...>
<fs name="myfs" ...>
<script name="script_child"/>
</fs>
<ip address="10.1.1.2" .../>
</service>
- Parents are started before children.
- Children must all stop cleanly before a parent may be stopped.
- For a resource to be considered in good health, all its children must be in good health.
Note
C.2. Sibling Start Ordering and Resource Child Ordering
- Designates child-type attribute (typed child resource) — If the Service resource designates a child-type attribute for a child resource, the child resource is typed. The child-type attribute explicitly determines the start and the stop order of the child resource.
- Does not designate child-type attribute (non-typed child resource) — If the Service resource does not designate a child-type attribute for a child resource, the child resource is non-typed. The Service resource does not explicitly control the starting order and stopping order of a non-typed child resource. However, a non-typed child resource is started and stopped according to its order in
/etc/cluster/cluster.conf. In addition, non-typed child resources are started after all typed child resources have started and are stopped before any typed child resources have stopped.
Note
C.2.1. Typed Child Resource Start and Stop Ordering
service.sh” shows the start and stop values as they appear in the Service resource agent, service.sh. For the Service resource, all LVM children are started first, followed by all File System children, followed by all Script children, and so forth.
| Resource | Child Type | Start-order Value | Stop-order Value |
|---|---|---|---|
| LVM | lvm | 1 | 9 |
| File System | fs | 2 | 8 |
| GFS2 File System | clusterfs | 3 | 7 |
| NFS Mount | netfs | 4 | 6 |
| NFS Export | nfsexport | 5 | 5 |
| NFS Client | nfsclient | 6 | 4 |
| IP Address | ip | 7 | 2 |
| Samba | smb | 8 | 3 |
| Script | script | 9 | 1 |
Example C.2. Resource Start and Stop Values: Excerpt from Service Resource Agent, service.sh
<special tag="rgmanager">
<attributes root="1" maxinstances="1"/>
<child type="lvm" start="1" stop="9"/>
<child type="fs" start="2" stop="8"/>
<child type="clusterfs" start="3" stop="7"/>
<child type="netfs" start="4" stop="6"/>
<child type="nfsexport" start="5" stop="5"/>
<child type="nfsclient" start="6" stop="4"/>
<child type="ip" start="7" stop="2"/>
<child type="smb" start="8" stop="3"/>
<child type="script" start="9" stop="1"/>
</special>
/etc/cluster/cluster.conf. For example, consider the starting order and stopping order of the typed child resources in Example C.3, “Ordering Within a Resource Type”.
Example C.3. Ordering Within a Resource Type
<service name="foo"> <script name="1" .../> <lvm name="1" .../> <ip address="10.1.1.1" .../> <fs name="1" .../> <lvm name="2" .../> </service>
Typed Child Resource Starting Order
lvm:1— This is an LVM resource. All LVM resources are started first.lvm:1(<lvm name="1" .../>) is the first LVM resource started among LVM resources because it is the first LVM resource listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:2— This is an LVM resource. All LVM resources are started first.lvm:2(<lvm name="2" .../>) is started afterlvm:1because it is listed afterlvm:1in the Service foo portion of/etc/cluster/cluster.conf.fs:1— This is a File System resource. If there were other File System resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.ip:10.1.1.1— This is an IP Address resource. If there were other IP Address resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.script:1— This is a Script resource. If there were other Script resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.
Typed Child Resource Stopping Order
script:1— This is a Script resource. If there were other Script resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.ip:10.1.1.1— This is an IP Address resource. If there were other IP Address resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.fs:1— This is a File System resource. If there were other File System resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:2— This is an LVM resource. All LVM resources are stopped last.lvm:2(<lvm name="2" .../>) is stopped beforelvm:1; resources within a group of a resource type are stopped in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:1— This is an LVM resource. All LVM resources are stopped last.lvm:1(<lvm name="1" .../>) is stopped afterlvm:2; resources within a group of a resource type are stopped in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.
C.2.2. Non-typed Child Resource Start and Stop Ordering
/etc/cluster/cluster.conf. Additionally, non-typed child resources are started after all typed child resources and stopped before any typed child resources.
Example C.4. Non-typed and Typed Child Resource in a Service
<service name="foo"> <script name="1" .../> <nontypedresource name="foo"/> <lvm name="1" .../> <nontypedresourcetwo name="bar"/> <ip address="10.1.1.1" .../> <fs name="1" .../> <lvm name="2" .../> </service>
Non-typed Child Resource Starting Order
lvm:1— This is an LVM resource. All LVM resources are started first.lvm:1(<lvm name="1" .../>) is the first LVM resource started among LVM resources because it is the first LVM resource listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:2— This is an LVM resource. All LVM resources are started first.lvm:2(<lvm name="2" .../>) is started afterlvm:1because it is listed afterlvm:1in the Service foo portion of/etc/cluster/cluster.conf.fs:1— This is a File System resource. If there were other File System resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.ip:10.1.1.1— This is an IP Address resource. If there were other IP Address resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.script:1— This is a Script resource. If there were other Script resources in Service foo, they would start in the order listed in the Service foo portion of/etc/cluster/cluster.conf.nontypedresource:foo— This is a non-typed resource. Because it is a non-typed resource, it is started after the typed resources start. In addition, its order in the Service resource is before the other non-typed resource,nontypedresourcetwo:bar; therefore, it is started beforenontypedresourcetwo:bar. (Non-typed resources are started in the order that they appear in the Service resource.)nontypedresourcetwo:bar— This is a non-typed resource. Because it is a non-typed resource, it is started after the typed resources start. In addition, its order in the Service resource is after the other non-typed resource,nontypedresource:foo; therefore, it is started afternontypedresource:foo. (Non-typed resources are started in the order that they appear in the Service resource.)
Non-typed Child Resource Stopping Order
nontypedresourcetwo:bar— This is a non-typed resource. Because it is a non-typed resource, it is stopped before the typed resources are stopped. In addition, its order in the Service resource is after the other non-typed resource,nontypedresource:foo; therefore, it is stopped beforenontypedresource:foo. (Non-typed resources are stopped in the reverse order that they appear in the Service resource.)nontypedresource:foo— This is a non-typed resource. Because it is a non-typed resource, it is stopped before the typed resources are stopped. In addition, its order in the Service resource is before the other non-typed resource,nontypedresourcetwo:bar; therefore, it is stopped afternontypedresourcetwo:bar. (Non-typed resources are stopped in the reverse order that they appear in the Service resource.)script:1— This is a Script resource. If there were other Script resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.ip:10.1.1.1— This is an IP Address resource. If there were other IP Address resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.fs:1— This is a File System resource. If there were other File System resources in Service foo, they would stop in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:2— This is an LVM resource. All LVM resources are stopped last.lvm:2(<lvm name="2" .../>) is stopped beforelvm:1; resources within a group of a resource type are stopped in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.lvm:1— This is an LVM resource. All LVM resources are stopped last.lvm:1(<lvm name="1" .../>) is stopped afterlvm:2; resources within a group of a resource type are stopped in the reverse order listed in the Service foo portion of/etc/cluster/cluster.conf.
C.3. Inheritance, the <resources> Block, and Reusing Resources
Example C.5. NFS Service Set Up for Resource Reuse and Inheritance
<resources>
<nfsclient name="bob" target="bob.example.com" options="rw,no_root_squash"/>
<nfsclient name="jim" target="jim.example.com" options="rw,no_root_squash"/>
<nfsexport name="exports"/>
</resources>
<service name="foo">
<fs name="1" mountpoint="/mnt/foo" device="/dev/sdb1" fsid="12344">
<nfsexport ref="exports"> <!-- nfsexport's path and fsid attributes
are inherited from the mountpoint &
fsid attribute of the parent fs
resource -->
<nfsclient ref="bob"/> <!-- nfsclient's path is inherited from the
mountpoint and the fsid is added to the
options string during export -->
<nfsclient ref="jim"/>
</nfsexport>
</fs>
<fs name="2" mountpoint="/mnt/bar" device="/dev/sdb2" fsid="12345">
<nfsexport ref="exports">
<nfsclient ref="bob"/> <!-- Because all of the critical data for this
resource is either defined in the
resources block or inherited, we can
reference it again! -->
<nfsclient ref="jim"/>
</nfsexport>
</fs>
<ip address="10.2.13.20"/>
</service>
- The service would need four nfsclient resources — one per file system (a total of two for file systems), and one per target machine (a total of two for target machines).
- The service would need to specify export path and file system ID to each nfsclient, which introduces chances for errors in the configuration.
C.4. Failure Recovery and Independent Subtrees
__independent_subtree attribute. For example, in Example C.7, “Service foo Failure Recovery with __independent_subtree Attribute”, the __independent_subtree attribute is used to accomplish the following actions:
- If script:script_one fails, restart script:script_one, script:script_two, and script:script_three.
- If script:script_two fails, restart just script:script_two.
- If script:script_three fails, restart script:script_one, script:script_two, and script:script_three.
- If script:script_four fails, restart the whole service.
Example C.6. Service foo Normal Failure Recovery
<service name="foo">
<script name="script_one" ...>
<script name="script_two" .../>
</script>
<script name="script_three" .../>
</service>
Example C.7. Service foo Failure Recovery with __independent_subtree Attribute
<service name="foo">
<script name="script_one" __independent_subtree="1" ...>
<script name="script_two" __independent_subtree="1" .../>
<script name="script_three" .../>
</script>
<script name="script_four" .../>
</service>
__independent_subtree="2" attribute, which designates the independent subtree as non-critical.
Note
__max_restartsconfigures the maximum number of tolerated restarts prior to giving up.__restart_expire_timeconfigures the amount of time, in seconds, after which a restart is no longer attempted.
C.5. Debugging and Testing Services and Resource Ordering
rg_test utility. rg_test is a command-line utility provided by the rgmanager package that is run from a shell or a terminal (it is not available in Conga). Table C.2, “rg_test Utility Summary” summarizes the actions and syntax for the rg_test utility.
| Action | Syntax |
|---|---|
Display the resource rules that rg_test understands. | rg_test rules |
| Test a configuration (and /usr/share/cluster) for errors or redundant resource agents. | rg_test test /etc/cluster/cluster.conf |
| Display the start and stop ordering of a service. |
Display start order:
rg_test noop /etc/cluster/cluster.conf start service
Display stop order:
rg_test noop /etc/cluster/cluster.conf stop service
|
| Explicitly start or stop a service. | Important
Only do this on one node, and always disable the service in rgmanager first.
Start a service:
rg_test test /etc/cluster/cluster.conf start service
Stop a service:
rg_test test /etc/cluster/cluster.conf stop service
|
| Calculate and display the resource tree delta between two cluster.conf files. | rg_test delta
For example:
rg_test delta /etc/cluster/cluster.conf.bak /etc/cluster/cluster.conf
|
Appendix D. Modifying and Enforcing Cluster Service Resource Actions
meta-data action). You can override these defaults with explicit <action> specifications in the cluster.conf file:
- For the
startandstopactions, you may want to modify thetimeoutproperty. - For the
statusaction, you may want to modify thetimeout,interval, ordepthproperties. For information on thestatusaction and its properties, see Section D.1, “Modifying the Resource Status Check Interval”.
timeout property for an action is enforced only if you explicitly configure timeout enforcement, as described in Section D.2, “Enforcing Resource Timeouts”.
cluster.conf file to modify a resource action parameter, see Section D.1, “Modifying the Resource Status Check Interval”.
Note
/etc/cluster/cluster.conf. For a comprehensive list and description of cluster.conf elements and attributes, see the cluster schema at /usr/share/cluster/cluster.rng, and the annotated schema at /usr/share/doc/cman-X.Y.ZZ/cluster_conf.html (for example /usr/share/doc/cman-3.0.12/cluster_conf.html).
D.1. Modifying the Resource Status Check Interval
cluster.conf file using the special <action> tag:
<action name="status" depth="*" interval="10" />
cluster.conf file. For example, if you had a file system resource for which you wanted to override the status check interval you could specify the file system resource in the cluster.conf file as follows:
<fs name="test" device="/dev/sdb3">
<action name="status" depth="*" interval="10" />
<nfsexport...>
</nfsexport>
</fs>
depth is set to *, which indicates that these values should be used for all depths. The result is that the test file system is checked at the highest-defined depth provided by the resource-agent (in this case, 20) every 10 seconds.
D.2. Enforcing Resource Timeouts
__enforce_timeouts="1" to the reference in the cluster.conf file.
__enforce_timeouts attribute set for the netfs resource. With this attribute set, then if it takes more than 30 seconds to unmount the NFS file system during a recovery process the operation will time out, causing the service to enter the failed state.
</screen>
<rm>
<failoverdomains/>
<resources>
<netfs export="/nfstest" force_unmount="1" fstype="nfs" host="10.65.48.65"
mountpoint="/data/nfstest" name="nfstest_data" options="rw,sync,soft"/>
</resources>
<service autostart="1" exclusive="0" name="nfs_client_test" recovery="relocate">
<netfs ref="nfstest_data" __enforce_timeouts="1"/>
</service>
</rm>
Appendix E. Command Line Tools Summary
| Command Line Tool | Used With | Purpose |
|---|---|---|
ccs_config_dump — Cluster Configuration Dump Tool | Cluster Infrastructure | ccs_config_dump generates XML output of running configuration. The running configuration is, sometimes, different from the stored configuration on file because some subsystems store or set some default information into the configuration. Those values are generally not present on the on-disk version of the configuration but are required at runtime for the cluster to work properly. For more information about this tool, see the ccs_config_dump(8) man page. |
ccs_config_validate — Cluster Configuration Validation Tool | Cluster Infrastructure | ccs_config_validate validates cluster.conf against the schema, cluster.rng (located in /usr/share/cluster/cluster.rng on each node). For more information about this tool, see the ccs_config_validate(8) man page. |
clustat — Cluster Status Utility | High-availability Service Management Components | The clustat command displays the status of the cluster. It shows membership information, quorum view, and the state of all configured user services. For more information about this tool, see the clustat(8) man page. |
clusvcadm — Cluster User Service Administration Utility | High-availability Service Management Components | The clusvcadm command allows you to enable, disable, relocate, and restart high-availability services in a cluster. For more information about this tool, see the clusvcadm(8) man page. |
cman_tool — Cluster Management Tool | Cluster Infrastructure | cman_tool is a program that manages the CMAN cluster manager. It provides the capability to join a cluster, leave a cluster, kill a node, or change the expected quorum votes of a node in a cluster. For more information about this tool, see the cman_tool(8) man page. |
fence_tool — Fence Tool | Cluster Infrastructure | fence_tool is a program used to join and leave the fence domain. For more information about this tool, see the fence_tool(8) man page. |
Appendix F. High Availability LVM (HA-LVM)
- If the applications are cluster-aware and have been tuned to run simultaneously on multiple machines at a time, then CLVM should be used. Specifically, if more than one node of your cluster will require access to your storage which is then shared among the active nodes, then you must use CLVM. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured, and uses clustered locking services to manage the shared storage. For information on CLVM, and on LVM configuration in general, see Logical Volume Manager Administration.
- If the applications run optimally in active/passive (failover) configurations where only a single node that accesses the storage is active at any one time, you should use High Availability Logical Volume Management agents (HA-LVM).
- The preferred method uses CLVM, but it will only ever activate the logical volumes exclusively. This has the advantage of easier setup and better prevention of administrative mistakes (like removing a logical volume that is in use). In order to use CLVM, the High Availability Add-On and Resilient Storage Add-On software, including the
clvmddaemon, must be running.The procedure for configuring HA-LVM using this method is described in Section F.1, “Configuring HA-LVM Failover with CLVM (preferred)”. - The second method uses local machine locking and LVM "tags". This method has the advantage of not requiring any LVM cluster packages; however, there are more steps involved in setting it up and it does not prevent an administrator from mistakenly removing a logical volume from a node in the cluster where it is not active. The procedure for configuring HA-LVM using this method is described in Section F.2, “Configuring HA-LVM Failover with Tagging”.
F.1. Configuring HA-LVM Failover with CLVM (preferred)
- Ensure that your system is configured to support CLVM, which requires the following:
- The High Availability Add-On and Resilient Storage Add-On are installed, including the
cmirrorpackage if the CLVM logical volumes are to be mirrored. - The
locking_typeparameter in the global section of the/etc/lvm/lvm.conffile is set to the value '3'. - The High Availability Add-On and Resilient Storage Add-On software, including the
clvmddaemon, must be running. For CLVM mirroring, thecmirrordservice must be started as well.
- Create the logical volume and file system using standard LVM and file system commands, as in the following example.
#
pvcreate /dev/sd[cde]1#vgcreate -cy shared_vg /dev/sd[cde]1#lvcreate -L 10G -n ha_lv shared_vg#mkfs.ext4 /dev/shared_vg/ha_lv#lvchange -an shared_vg/ha_lvFor information on creating LVM logical volumes, refer to Logical Volume Manager Administration. - Edit the
/etc/cluster/cluster.conffile to include the newly created logical volume as a resource in one of your services. Alternately, you can use Conga or theccscommand to configure LVM and file system resources for the cluster. The following is a sample resource manager section from the/etc/cluster/cluster.conffile that configures a CLVM logical volume as a cluster resource:<rm> <failoverdomains> <failoverdomain name="FD" ordered="1" restricted="0"> <failoverdomainnode name="neo-01" priority="1"/> <failoverdomainnode name="neo-02" priority="2"/> </failoverdomain> </failoverdomains> <resources> <lvm name="lvm" vg_name="shared_vg" lv_name="ha-lv"/> <fs name="FS" device="/dev/shared_vg/ha-lv" force_fsck="0" force_unmount="1" fsid="64050" fstype="ext4" mountpoint="/mnt" options="" self_fence="0"/> </resources> <service autostart="1" domain="FD" name="serv" recovery="relocate"> <lvm ref="lvm"/> <fs ref="FS"/> </service> </rm>
F.2. Configuring HA-LVM Failover with Tagging
/etc/lvm/lvm.conf file, perform the following steps:
- In the global section of the
/etc/lvm/lvm.conffile, ensure that thelocking_typeparameter is set to the value '1' and theuse_lvmetadparameter is set to the value '0'.Note
As of Red Hat Enterprise Linux 6.7, you can use the--enable-halvmoption of thelvmconfto set the locking type to 1 and disablelvmetad. For information on thelvmconfcommand, see thelvmconfman page. - Create the logical volume and file system using standard LVM and file system commands, as in the following example.
#
pvcreate /dev/sd[cde]1#vgcreate shared_vg /dev/sd[cde]1#lvcreate -L 10G -n ha_lv shared_vg#mkfs.ext4 /dev/shared_vg/ha_lvFor information on creating LVM logical volumes, refer to Logical Volume Manager Administration. - Edit the
/etc/cluster/cluster.conffile to include the newly created logical volume as a resource in one of your services. Alternately, you can use Conga or theccscommand to configure LVM and file system resources for the cluster. The following is a sample resource manager section from the/etc/cluster/cluster.conffile that configures a CLVM logical volume as a cluster resource:<rm> <failoverdomains> <failoverdomain name="FD" ordered="1" restricted="0"> <failoverdomainnode name="neo-01" priority="1"/> <failoverdomainnode name="neo-02" priority="2"/> </failoverdomain> </failoverdomains> <resources> <lvm name="lvm" vg_name="shared_vg" lv_name="ha_lv"/> <fs name="FS" device="/dev/shared_vg/ha_lv" force_fsck="0" force_unmount="1" fsid="64050" fstype="ext4" mountpoint="/mnt" options="" self_fence="0"/> </resources> <service autostart="1" domain="FD" name="serv" recovery="relocate"> <lvm ref="lvm"/> <fs ref="FS"/> </service> </rm>Note
If there are multiple logical volumes in the volume group, then the logical volume name (lv_name) in thelvmresource should be left blank or unspecified. Also note that in an HA-LVM configuration, a volume group may be used by only a single service. - Edit the
volume_listfield in the/etc/lvm/lvm.conffile. Include the name of your root volume group and your host name as listed in the/etc/cluster/cluster.conffile preceded by @. The host name to include here is the machine on which you are editing thelvm.conffile, not any remote host name. Note that this string MUST match the node name given in thecluster.conffile. Below is a sample entry from the/etc/lvm/lvm.conffile:volume_list = [ "VolGroup00", "@neo-01" ]
This tag will be used to activate shared VGs or LVs. DO NOT include the names of any volume groups that are to be shared using HA-LVM. - Update the
initramfsdevice on all your cluster nodes:#
dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r) - Reboot all nodes to ensure the correct
initramfsimage is in use.
F.3. Creating New Logical Volumes for an Existing Cluster
volume_list must be temporarily bypassed or overridden to allow for creation of the volumes until they can be prepared to be configured by a cluster resource.
Note
lvm resource if lv_name is not specified. The lvm resource agent allows for only a single logical volume within a volume group if that resource is managing volumes individually, rather than at a volume group level.
- The volume group should already be tagged on the node owning that service, so simply create the volumes with a standard
lvcreatecommand on that node.Determine the current owner of the relevant service.#
clustatOn the node where the service is started, create the logical volume.#
lvcreate -l 100%FREE -n lv2 myVG - Add the volume into the service configuration in whatever way is necessary.
- Create the volume group on one node using that node's name as a tag, which should be included in the
volume_list. Specify any desired settings for this volume group as normal and specify--addtagnodename, as in the following example:#
vgcreate myNewVG /dev/mapper/mpathb --addtag node1.example.com - Create volumes within this volume group as normal, otherwise perform any necessary administration on the volume group.
- When the volume group activity is complete, deactivate the volume group and remove the tag.
#
vgchange -an myNewVg --deltag node1.example.com - Add the volume into the service configuration in whatever way is necessary.
Appendix G. Revision History
| Revision History | |||
|---|---|---|---|
| Revision 9.1-3 | Wed Oct 18 2017 | ||
| |||
| Revision 9.1-2 | Tue Mar 7 2017 | ||
| |||
| Revision 9.1-1 | Fri Dec 11 2016 | ||
| |||
| Revision 8.1-10 | Tue Apr 26 2016 | ||
| |||
| Revision 8.1-5 | Wed Mar 9 2016 | ||
| |||
| Revision 7.1-12 | Wed Jul 8 2015 | ||
| |||
| Revision 7.1-10 | Thu Apr 16 2015 | ||
| |||
| Revision 7.0-13 | Wed Oct 8 2014 | ||
| |||
| Revision 7.0-11 | Thu Aug 7 2014 | ||
| |||
| Revision 6.0-21 | Wed Nov 13 2013 | ||
| |||
| Revision 6.0-15 | Fri Sep 27 2013 | ||
| |||
| Revision 5.0-25 | Mon Feb 18 2013 | ||
| |||
| Revision 5.0-16 | Mon Nov 26 2012 | ||
| |||
| Revision 4.0-5 | Fri Jun 15 2012 | ||
| |||
| Revision 3.0-5 | Thu Dec 1 2011 | ||
| |||
| Revision 3.0-1 | Wed Sep 28 2011 | ||
| |||
| Revision 2.0-1 | Thu May 19 2011 | ||
| |||
| Revision 1.0-1 | Wed Nov 10 2010 | ||
| |||
Index
A
- ACPI
- APC power switch over SNMP fence device , Fence Device Parameters
- APC power switch over telnet/SSH fence device , Fence Device Parameters
B
- behavior, HA resources, HA Resource Behavior
- Brocade fabric switch fence device , Fence Device Parameters
C
- CISCO MDS fence device , Fence Device Parameters
- Cisco UCS fence device , Fence Device Parameters
- cluster
- administration, Before Configuring the Red Hat High Availability Add-On, Managing Red Hat High Availability Add-On With Conga, Managing Red Hat High Availability Add-On With ccs, Managing Red Hat High Availability Add-On With Command Line Tools
- diagnosing and correcting problems, Diagnosing and Correcting Problems in a Cluster, Diagnosing and Correcting Problems in a Cluster
- starting, stopping, restarting, Starting and Stopping the Cluster Software
- cluster administration, Before Configuring the Red Hat High Availability Add-On, Managing Red Hat High Availability Add-On With Conga, Managing Red Hat High Availability Add-On With ccs, Managing Red Hat High Availability Add-On With Command Line Tools
- adding cluster node, Adding a Member to a Running Cluster, Adding a Member to a Running Cluster
- compatible hardware, Compatible Hardware
- configuration validation, Configuration Validation
- configuring ACPI, Configuring ACPI For Use with Integrated Fence Devices
- configuring iptables, Enabling IP Ports
- considerations for using qdisk, Considerations for Using Quorum Disk
- considerations for using quorum disk, Considerations for Using Quorum Disk
- deleting a cluster, Starting, Stopping, Restarting, and Deleting Clusters
- deleting a node from the configuration; adding a node to the configuration , Deleting or Adding a Node
- diagnosing and correcting problems in a cluster, Diagnosing and Correcting Problems in a Cluster, Diagnosing and Correcting Problems in a Cluster
- displaying HA services with clustat, Displaying HA Service Status with clustat
- enabling IP ports, Enabling IP Ports
- general considerations, General Configuration Considerations
- joining a cluster, Causing a Node to Leave or Join a Cluster, Causing a Node to Leave or Join a Cluster
- leaving a cluster, Causing a Node to Leave or Join a Cluster, Causing a Node to Leave or Join a Cluster
- managing cluster node, Managing Cluster Nodes, Managing Cluster Nodes
- managing high-availability services, Managing High-Availability Services, Managing High-Availability Services
- managing high-availability services, freeze and unfreeze, Managing HA Services with clusvcadm, Considerations for Using the Freeze and Unfreeze Operations
- network switches and multicast addresses, Multicast Addresses
- NetworkManager, Considerations for NetworkManager
- rebooting cluster node, Rebooting a Cluster Node
- removing cluster node, Deleting a Member from a Cluster
- restarting a cluster, Starting, Stopping, Restarting, and Deleting Clusters
- ricci considerations, Considerations for ricci
- SELinux, Red Hat High Availability Add-On and SELinux
- starting a cluster, Starting, Stopping, Restarting, and Deleting Clusters, Starting and Stopping a Cluster
- starting, stopping, restarting a cluster, Starting and Stopping the Cluster Software
- stopping a cluster, Starting, Stopping, Restarting, and Deleting Clusters, Starting and Stopping a Cluster
- updating a cluster configuration using cman_tool version -r, Updating a Configuration Using cman_tool version -r
- updating a cluster configuration using scp, Updating a Configuration Using scp
- updating configuration, Updating a Configuration
- virtual machines, Configuring Virtual Machines in a Clustered Environment
- cluster configuration, Configuring Red Hat High Availability Add-On With Conga, Configuring Red Hat High Availability Add-On With the ccs Command, Configuring Red Hat High Availability Manually
- deleting or adding a node, Deleting or Adding a Node
- updating, Updating a Configuration
- cluster resource relationships, Parent, Child, and Sibling Relationships Among Resources
- cluster resource status check, Modifying and Enforcing Cluster Service Resource Actions
- cluster resource types, Considerations for Configuring HA Services
- cluster service managers
- cluster services, Adding a Cluster Service to the Cluster, Adding a Cluster Service to the Cluster, Adding a Cluster Service to the Cluster
- (see also adding to the cluster configuration)
- cluster software
- configuration
- HA service, Considerations for Configuring HA Services
- Configuring High Availability LVM, High Availability LVM (HA-LVM)
- Conga
- consensus value, The consensus Value for totem in a Two-Node Cluster
D
- Dell DRAC 5 fence device , Fence Device Parameters
- Dell iDRAC fence device , Fence Device Parameters
E
- Eaton network power switch, Fence Device Parameters
- Egenera BladeFrame fence device , Fence Device Parameters
- Emerson network power switch fence device , Fence Device Parameters
- ePowerSwitch fence device , Fence Device Parameters
F
- failover timeout, Modifying and Enforcing Cluster Service Resource Actions
- features, new and changed, New and Changed Features
- feedback, Feedback
- fence agent
- fence_apc, Fence Device Parameters
- fence_apc_snmp, Fence Device Parameters
- fence_bladecenter, Fence Device Parameters
- fence_brocade, Fence Device Parameters
- fence_cisco_mds, Fence Device Parameters
- fence_cisco_ucs, Fence Device Parameters
- fence_drac5, Fence Device Parameters
- fence_eaton_snmp, Fence Device Parameters
- fence_egenera, Fence Device Parameters
- fence_emerson, Fence Device Parameters
- fence_eps, Fence Device Parameters
- fence_hpblade, Fence Device Parameters
- fence_ibmblade, Fence Device Parameters
- fence_idrac, Fence Device Parameters
- fence_ifmib, Fence Device Parameters
- fence_ilo, Fence Device Parameters
- fence_ilo2, Fence Device Parameters
- fence_ilo3, Fence Device Parameters
- fence_ilo3_ssh, Fence Device Parameters
- fence_ilo4, Fence Device Parameters
- fence_ilo4_ssh, Fence Device Parameters
- fence_ilo_moonshot, Fence Device Parameters
- fence_ilo_mp, Fence Device Parameters
- fence_ilo_ssh, Fence Device Parameters
- fence_imm, Fence Device Parameters
- fence_intelmodular, Fence Device Parameters
- fence_ipdu, Fence Device Parameters
- fence_ipmilan, Fence Device Parameters
- fence_kdump, Fence Device Parameters
- fence_mpath, Fence Device Parameters
- fence_rhevm, Fence Device Parameters
- fence_rsb, Fence Device Parameters
- fence_scsi, Fence Device Parameters
- fence_virt, Fence Device Parameters
- fence_vmware_soap, Fence Device Parameters
- fence_wti, Fence Device Parameters
- fence_xvm, Fence Device Parameters
- fence device
- APC power switch over SNMP, Fence Device Parameters
- APC power switch over telnet/SSH, Fence Device Parameters
- Brocade fabric switch, Fence Device Parameters
- Cisco MDS, Fence Device Parameters
- Cisco UCS, Fence Device Parameters
- Dell DRAC 5, Fence Device Parameters
- Dell iDRAC, Fence Device Parameters
- Eaton network power switch, Fence Device Parameters
- Egenera BladeFrame, Fence Device Parameters
- Emerson network power switch, Fence Device Parameters
- ePowerSwitch, Fence Device Parameters
- Fence virt (fence_xvm/Multicast Mode), Fence Device Parameters
- Fence virt (Serial/VMChannel Mode), Fence Device Parameters
- Fujitsu Siemens Remoteview Service Board (RSB), Fence Device Parameters
- HP BladeSystem, Fence Device Parameters
- HP iLO, Fence Device Parameters
- HP iLO MP, Fence Device Parameters
- HP iLO over SSH, Fence Device Parameters
- HP iLO2, Fence Device Parameters
- HP iLO3, Fence Device Parameters
- HP iLO3 over SSH, Fence Device Parameters
- HP iLO4, Fence Device Parameters
- HP iLO4 over SSH, Fence Device Parameters
- HP Moonshot iLO, Fence Device Parameters
- IBM BladeCenter, Fence Device Parameters
- IBM BladeCenter SNMP, Fence Device Parameters
- IBM Integrated Management Module, Fence Device Parameters
- IBM iPDU, Fence Device Parameters
- IF MIB, Fence Device Parameters
- Intel Modular, Fence Device Parameters
- IPMI LAN, Fence Device Parameters
- multipath persistent reservation fencing, Fence Device Parameters
- RHEV-M fencing, Fence Device Parameters
- SCSI fencing, Fence Device Parameters
- VMware (SOAP Interface), Fence Device Parameters
- WTI power switch, Fence Device Parameters
- Fence virt fence device , Fence Device Parameters
- fence_apc fence agent, Fence Device Parameters
- fence_apc_snmp fence agent, Fence Device Parameters
- fence_bladecenter fence agent, Fence Device Parameters
- fence_brocade fence agent, Fence Device Parameters
- fence_cisco_mds fence agent, Fence Device Parameters
- fence_cisco_ucs fence agent, Fence Device Parameters
- fence_drac5 fence agent, Fence Device Parameters
- fence_eaton_snmp fence agent, Fence Device Parameters
- fence_egenera fence agent, Fence Device Parameters
- fence_emerson fence agent, Fence Device Parameters
- fence_eps fence agent, Fence Device Parameters
- fence_hpblade fence agent, Fence Device Parameters
- fence_ibmblade fence agent, Fence Device Parameters
- fence_idrac fence agent, Fence Device Parameters
- fence_ifmib fence agent, Fence Device Parameters
- fence_ilo fence agent, Fence Device Parameters
- fence_ilo2 fence agent, Fence Device Parameters
- fence_ilo3 fence agent, Fence Device Parameters
- fence_ilo3_ssh fence agent, Fence Device Parameters
- fence_ilo4 fence agent, Fence Device Parameters
- fence_ilo4_ssh fence agent, Fence Device Parameters
- fence_ilo_moonshot fence agent, Fence Device Parameters
- fence_ilo_mp fence agent, Fence Device Parameters
- fence_ilo_ssh fence agent, Fence Device Parameters
- fence_imm fence agent, Fence Device Parameters
- fence_intelmodular fence agent, Fence Device Parameters
- fence_ipdu fence agent, Fence Device Parameters
- fence_ipmilan fence agent, Fence Device Parameters
- fence_kdump fence agent, Fence Device Parameters
- fence_mpath fence agent, Fence Device Parameters
- fence_rhevm fence agent, Fence Device Parameters
- fence_rsb fence agent, Fence Device Parameters
- fence_scsi fence agent, Fence Device Parameters
- fence_virt fence agent, Fence Device Parameters
- fence_vmware_soap fence agent, Fence Device Parameters
- fence_wti fence agent, Fence Device Parameters
- fence_xvm fence agent, Fence Device Parameters
- Fujitsu Siemens Remoteview Service Board (RSB) fence device, Fence Device Parameters
G
- general
- considerations for cluster administration, General Configuration Considerations
H
- HA service configuration
- hardware
- compatible, Compatible Hardware
- HP Bladesystem fence device , Fence Device Parameters
- HP iLO fence device, Fence Device Parameters
- HP iLO MP fence device , Fence Device Parameters
- HP iLO over SSH fence device, Fence Device Parameters
- HP iLO2 fence device, Fence Device Parameters
- HP iLO3 fence device, Fence Device Parameters
- HP iLO3 over SSH fence device, Fence Device Parameters
- HP iLO4 fence device, Fence Device Parameters
- HP iLO4 over SSH fence device, Fence Device Parameters
- HP Moonshot iLO fence device, Fence Device Parameters
I
- IBM BladeCenter fence device , Fence Device Parameters
- IBM BladeCenter SNMP fence device , Fence Device Parameters
- IBM Integrated Management Module fence device , Fence Device Parameters
- IBM iPDU fence device , Fence Device Parameters
- IF MIB fence device , Fence Device Parameters
- integrated fence devices
- configuring ACPI, Configuring ACPI For Use with Integrated Fence Devices
- Intel Modular fence device , Fence Device Parameters
- introduction, Introduction
- other Red Hat Enterprise Linux documents, Introduction
- IP ports
- enabling, Enabling IP Ports
- IPMI LAN fence device , Fence Device Parameters
- iptables
- configuring, Enabling IP Ports
- iptables firewall, Configuring the iptables Firewall to Allow Cluster Components
L
- LVM, High Availability, High Availability LVM (HA-LVM)
M
- multicast addresses
- considerations for using with network switches and multicast addresses, Multicast Addresses
- multicast traffic, enabling, Configuring the iptables Firewall to Allow Cluster Components
- multipath persistent reservation fence device , Fence Device Parameters
N
- NetworkManager
- disable for use with cluster, Considerations for NetworkManager
- nfsexport resource, configuring, Configuring nfsexport and nfsserver Resources
- nfsserver resource, configuring, Configuring nfsexport and nfsserver Resources
O
- overview
- features, new and changed, New and Changed Features
P
- parameters, fence device, Fence Device Parameters
- parameters, HA resources, HA Resource Parameters
Q
- qdisk
- considerations for using, Considerations for Using Quorum Disk
- quorum disk
- considerations for using, Considerations for Using Quorum Disk
R
- relationships
- cluster resource, Parent, Child, and Sibling Relationships Among Resources
- RHEV-M fencing, Fence Device Parameters
- ricci
- considerations for cluster administration, Considerations for ricci
S
- SCSI fencing, Fence Device Parameters
- SELinux
- configuring, Red Hat High Availability Add-On and SELinux
- status check, cluster resource, Modifying and Enforcing Cluster Service Resource Actions
T
- tables
- fence devices, parameters, Fence Device Parameters
- HA resources, parameters, HA Resource Parameters
- timeout failover, Modifying and Enforcing Cluster Service Resource Actions
- tools, command line, Command Line Tools Summary
- totem tag
- consensus value, The consensus Value for totem in a Two-Node Cluster
- troubleshooting
- diagnosing and correcting problems in a cluster, Diagnosing and Correcting Problems in a Cluster, Diagnosing and Correcting Problems in a Cluster
- types
- cluster resource, Considerations for Configuring HA Services
V
- validation
- cluster configuration, Configuration Validation
- virtual machines, in a cluster, Configuring Virtual Machines in a Clustered Environment
- VMware (SOAP Interface) fence device , Fence Device Parameters
W
- WTI power switch fence device , Fence Device Parameters