配置数据网格缓存
Red Hat Data Grid
Data Grid 是一个高性能分布式内存数据存储。
- 无架构数据结构
- 将不同对象存储为键值对的灵活性。
- 基于网格的数据存储
- 旨在在集群中分发和复制数据。
- 弹性扩展
- 动态调整节点数量,以便在不中断服务的情况下满足需求。
- 数据互操作性
- 从不同端点在网格中存储、检索和查询数据。
Data Grid 文档
红帽客户门户网站中提供了 Data Grid 的文档。
Data Grid 下载
访问红帽客户门户上的 Data Grid 软件下载。
您必须有一个红帽帐户才能访问和下载数据中心软件。
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
第 1 章 Data Grid 缓存
Data Grid 缓存提供灵活的内存中数据存储,您可以配置它们以适应用例,例如:
- 使用高速本地缓存提高应用程序性能.
- 通过减少写入操作的卷来优化数据库。
- 为跨集群的一致性数据提供弹性和持久性。
1.1. Cache API
cache<K,V > 是 Data Grid 的核心接口,扩展 java.util.concurrent.ConcurrentMap。
缓存条目是 key:value 格式的高度并发数据结构,它支持广泛的、可配置的数据类型,从简单字符串到更复杂的对象。
1.2. 缓存管理器
CacheManager API 是与 Data Grid 交互的入口点。缓存管理器控制缓存生命周期;创建、修改和删除缓存实例。缓存管理器还提供集群管理和监控,以及跨节点执行代码的功能。
Data Grid 提供两个 CacheManager 实现:
EmbeddedCacheManager- 在与客户端应用程序相同的 Java 虚拟机(JVM)中运行 Data Grid 时,缓存的入口点。
RemoteCacheManager-
在其自己的 JVM 中运行 Data Grid 服务器时的缓存入口点。当您实例化
RemoteCacheManager时,它会通过 Hot Rod 端点建立与 Data Grid 服务器的持久 TCP 连接。
嵌入式和远程缓存 管理器 实施共享一些方法和属性。但是,嵌入式CacheManager 和 之间存在语义差异。
RemoteCacheManager
1.3. 缓存模式
Data Grid 缓存管理器可以创建和管理使用不同模式的多个缓存。例如,您可以使用与 invalidation 模式进行本地缓存、分布式缓存和缓存相同的缓存管理器。
- Local
- Data Grid 作为单一节点运行,永远不会在缓存条目上复制读取或写入操作。
- 复制
- 网格复制集群中所有节点上的所有缓存条目,并且仅执行本地读取操作。
- 分布式
-
网格在集群的一个节点中复制缓存条目,并将条目分配给固定所有者节点。
Data Grid 从所有者节点请求读取操作,以确保它返回正确的值。 - invalidation
- 当操作修改缓存中的条目时,Data Grid 会从所有节点中驱除过时的数据。Data Grid 仅执行本地读取操作。
1.3.1. 缓存模式比较
您应选择的缓存模式取决于您的数据所需的质量和保证。
下表总结了缓存模式的主要区别:
| 缓存模式 | clustered? | 读取性能 | 写性能 | 容量 | 可用性 | 功能 |
|---|---|---|---|---|---|---|
| Local | 否 | 高 (本地) | 高 (本地) | 单一节点 | 单一节点 | complete |
| Simple(简单) | 否 | 最高 (本地) | 最高 (本地) | 单一节点 | 单一节点 | 部分: 无事务、持久性或索引。 |
| invalidation | 是 | 高 (本地) | 低 (所有节点,无数据) | 单一节点 | 单一节点 | 部分: 无索引。 |
| 复制 | 是 | 高 (本地) | 最低 (所有节点) | 最小节点 | 所有节点 | complete |
| 分布式 | 是 | 中 (所有者) | 中 (所有者节点) | 所有节点容量总和除以所有者数。 | 所有者节点 | complete |
| scattered | 是 | 中 (主) | 更高 (单个 RPC) | 所有节点容量总和除以 2 个。 | 所有者节点 | 部分: 无事务。 |
1.4. 本地缓存
Data Grid 提供与 ConcurrentHashMap 类似的本地缓存模式。
缓存提供比简单映射更多的功能,包括直写和写入持久性存储,以及驱除和过期等管理功能。
Data Grid Cache API 扩展 Java 中的 ConcurrentMap API,使其可以轻松地从映射迁移到 Data Grid 缓存。
本地缓存配置
XML
<local-cache name="mycache"
statistics="true">
<encoding media-type="application/x-protostream"/>
</local-cache>
JSON
{
"local-cache": {
"name": "mycache",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
}
}
}
YAML
localCache:
name: "mycache"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
1.4.1. 简单缓存
简单的缓存是禁用对以下功能的支持的本地缓存类型:
- 事务和调用批处理
- 持久性存储
- 自定义拦截器
- 索引
- transcoding
但是,您可以将其他 Data Grid 功能与简单缓存一起使用,如过期、驱除、统计信息和安全功能。如果您配置了一个与简单缓存不兼容的功能,Data Grid 会抛出异常。
简单缓存配置
XML
<local-cache simple-cache="true" />
JSON
{
"local-cache" : {
"simple-cache" : "true"
}
}
YAML
localCache: simpleCache: "true"
第 2 章 集群缓存
您可以在 Data Grid 集群中创建在跨节点间复制数据的嵌入式和远程缓存。
2.1. 复制的缓存
Data Grid 将缓存中的所有条目复制到集群中的所有节点。每个节点都可以在本地执行读取操作。
复制缓存提供了一种快速轻松地在集群中共享状态的方法,但适用于小于 10 个节点的集群。由于复制请求数量与集群中的节点数量线性扩展,所以使用带有更大集群的复制缓存会降低性能。但是,您可以将 UDP 多播用于复制请求来提高性能。
每个密钥都有一个主所有者,用于序列化数据容器更新,以提供一致性。
图 2.1. 复制缓存

同步或异步复制
-
同步复制会阻止调用者(例如,在
cache.put (key, value)上),直到修改成功复制到集群中的所有节点。 - 异步复制在后台执行复制,写入操作会立即返回。不建议异步复制,因为远程节点上发生的通信错误或错误不会向调用者报告。
Transactions
如果启用了事务,则不会通过主所有者复制写入操作。
使用 pesimistic locking 时,每个写入都会触发锁定消息,该消息会广播到所有节点。在事务提交过程中,originator 广播一阶段准备消息和解锁消息(可选)。one-phase 准备或解锁信息都是 fire-and-forget。
使用最佳锁定时,源器广播准备消息、提交消息和解锁消息(可选)。同样,1phase 准备或解锁信息都是 fire-and-forget。
2.2. 分布式缓存
Data Grid 会尝试在缓存中保留任何条目的固定数量(配置为 numOwners )。这允许分布式缓存线性扩展,在向集群添加节点时存储更多数据。
当节点加入并离开集群时,当键有超过个或小于 numOwners 副本时,会出现一些时间。特别是,如果 numOwners 节点存在快速连续,某些条目将会丢失,因此我们表示分布式缓存容许 numOwners - 1 节点失败。
副本数代表在性能和数据的持久性之间权衡。您维护的更多副本,性能越低,但会降低由于服务器或网络故障而丢失数据的风险。
Data Grid 将密钥的所有者分成一个 主要所有者,它将协调对密钥的写入,以及零个或多个 备份所有者。
下图显示了客户端发送到备份所有者的写入操作。在这种情况下,备份节点将写入转发到主所有者,然后将写入复制到备份。
图 2.2. 集群复制
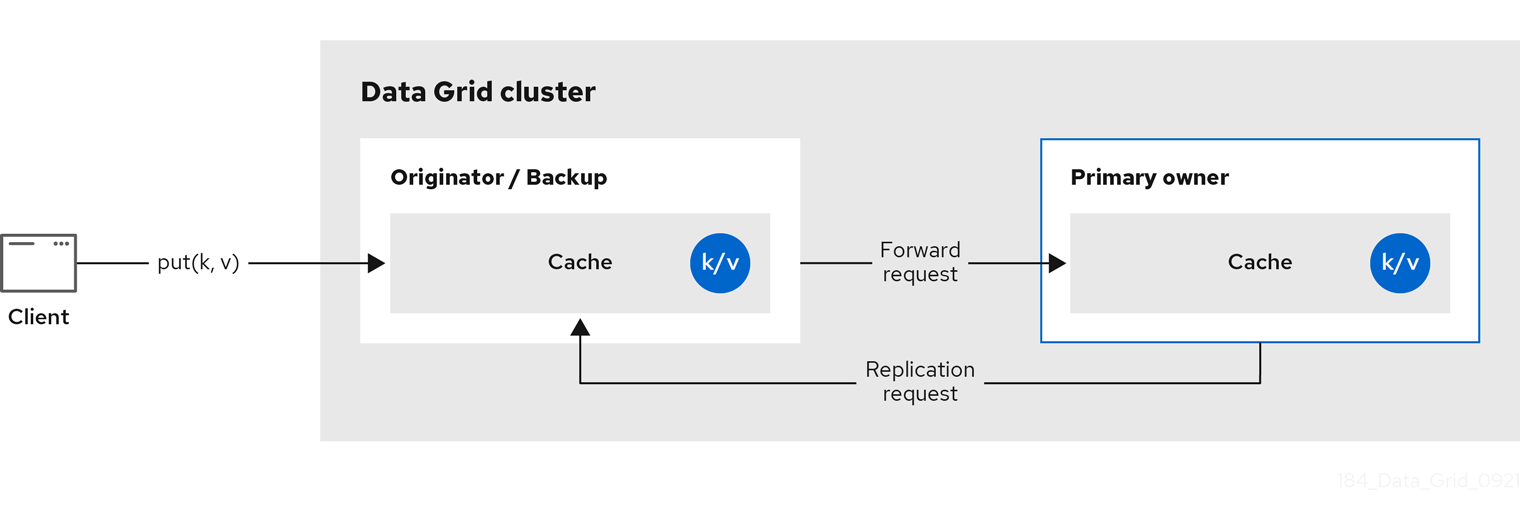
图 2.3. 分布式缓存

读取操作
读取操作从主所有者请求值。如果主所有者没有以合理的时间响应,Data Grid 也从备份所有者请求值。
如果本地缓存中存在密钥,或者所有所有者都较慢,则读取操作可能需要 0 个信息,或者最多 2 个 * numOwners 信息。
写操作
写入操作最多会导致 2 个 * numOwners 信息。来自 originator 到主所有者和 numOwners - 1 消息从主到备份节点的消息以及相应的确认消息。
缓存拓扑更改可能会导致读取和写入操作重试和额外信息。
同步或异步复制
不建议异步复制,因为它可能会丢失更新。除了丢失更新外,当线程写入到键时,异步分布式缓存也可以看到 stale 值,然后立即读取同一密钥。
Transactions
事务分布式缓存将 lock/prepare/commit/unlock 消息发送到受影响的节点,这意味着至少有一个密钥受事务影响。作为优化,如果事务写入单个密钥,并且 originator 是密钥的主所有者,则不会复制锁定信息。
2.2.1. 读取一致性
即使是同步复制,分布式缓存也不可线性。对于事务缓存,它们不支持序列化/快照隔离。
例如,线程正在执行单个放置请求:
cache.get(k) -> v1 cache.put(k, v2) cache.get(k) -> v2
但是另一个线程可能会以不同顺序看到值:
cache.get(k) -> v2 cache.get(k) -> v1
该原因是从任何所有者返回值,具体取决于主所有者回复的速度。写入不是所有所有者的原子性。实际上,只有在从备份收到确认后,才会提交更新。在主等待备份的确认消息时,从备份中读取会显示新值,但从主读取将看到旧值。
2.2.2. 密钥所有权
分布式缓存将条目分成固定数量的片段,并将每个片段分配给所有者节点列表。复制缓存执行相同的操作,但每个节点都是一个所有者。
owners 列表中的第一个节点 是主所有者。列表中的其他节点是 备份所有者。当缓存拓扑更改时,因为节点加入或离开集群时,片段所有权表会广播到每个节点。这允许节点定位密钥,而无需为每个密钥发出多播请求或维护元数据。
numSegments 属性配置可用的片段数量。但是,除非集群重启,片段数量不会改变。
同样,键到网段映射无法更改。无论集群拓扑更改是什么,键必须始终映射到同一片段。务必要确保 key-to-segment 映射平均分配分配给每个节点的片段数量,同时尽量减少集群拓扑更改时必须移动的片段数量。
| 一致的哈希工厂实现 | 描述 |
|---|---|
|
| 使用基于 一致哈希的算法。当禁用服务器提示时,默认选择。 这种实现始终将密钥分配给每个缓存中的同一节点,只要集群是对称的。换句话说,所有缓存在所有节点上运行。这种实施确实有一些负点,负载分布稍微不均匀。它还比加入或离开更严格要求更多片段。 |
|
|
等同于 |
|
|
实现比 |
|
|
等同于 |
|
| 用于内部实施复制缓存。您不应该在分布式缓存中显式选择此算法。 |
哈希配置
您可以配置 ConsistentHashFactory 实现,包括自定义的带有嵌入式缓存。
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />
ConfigurationBuilder
Configuration c = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.hash()
.numOwners(2)
.numSegments(100)
.capacityFactor(2)
.build();
其他资源
2.2.3. 容量因素
容量因素根据集群中每个节点的可用资源分配片段数量。
节点的容量因素适用于该节点是主所有者和备份所有者的片段。换句话说,容量因素指定节点与集群中的其他节点相比的总容量。
默认值为 1,这意味着集群中的所有节点都有相等的容量,Data Grid 为集群中的所有节点分配相同的片段数量。
但是,如果节点有不同数量的可用内存,您可以配置容量因素,以便 Data Grid 哈希算法为每个节点分配大量按其容量权重的片段。
容量因素配置的值必须是正数,可以是 1.5 所示的比例。您还可以配置容量因数 0, 但建议临时加入集群的节点,应该改为使用零容量配置。
2.2.3.1. 零容量节点
您可以为每个缓存、用户定义的缓存和内部缓存配置容量因子为 0 的节点。在定义零容量节点时,该节点不会保存任何数据。
零容量节点配置
XML
<infinispan> <cache-container zero-capacity-node="true" /> </infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"zero-capacity-node" : "true"
}
}
}
YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"
ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);
2.2.4. 一级(L1)缓存
Data Grid 节点会在从集群中的另一节点检索条目时创建本地副本。L1 缓存避免在主所有者节点上重复查找条目并提高性能。
下图演示了 L1 缓存的工作方式:
图 2.4. L1 缓存

在 "L1 缓存"图中:
-
客户端调用
cache.get ()来读取集群中另一个节点是主所有者的条目。 - 原始器节点将读取操作转发到主所有者。
- 主所有者返回键/值条目。
- 原始器节点会创建一个本地副本。
-
后续的
cache.get ()调用会返回本地条目,而不是转发到主所有者。
L1 缓存性能
启用 L1 提高了读取操作的性能,但需要主所有者节点在修改条目时广播失效消息。这样可确保 Data Grid 在集群中删除任何过时的副本。但是,这也降低了写操作的性能并增加内存用量,从而减少缓存的整体容量。
与任何其他缓存条目一样,Data Grid 驱除和过期本地副本或 L1 条目。
L1 缓存配置
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>
JSON
{
"distributed-cache": {
"l1-lifespan": "5000",
"l1-cleanup-interval": "60000"
}
}
YAML
distributedCache: l1Lifespan: "5000" l1-cleanup-interval: "60000"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);
2.2.5. 服务器提示
服务器提示通过尽可能在多个服务器、机架和数据中心中复制条目来提高分布式缓存中数据的可用性。
服务器提示仅适用于分布式缓存。
当 Data Grid 分发您的数据的副本时,它遵循优先级顺序:site、rack、machine 和 node。所有配置属性都是可选的。例如,当您只指定机架 ID 时,Data Grid 会将副本分布到不同的机架和节点上。
如果缓存的片段数量过低,服务器提示可能会影响集群重新平衡操作。
多个数据中心中的集群的替代方法是跨站点复制。
服务器提示配置
XML
<cache-container>
<transport cluster="MyCluster"
machine="LinuxServer01"
rack="Rack01"
site="US-WestCoast"/>
</cache-container>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"cluster" : "MyCluster",
"machine" : "LinuxServer01",
"rack" : "Rack01",
"site" : "US-WestCoast"
}
}
}
}
YAML
cacheContainer:
transport:
cluster: "MyCluster"
machine: "LinuxServer01"
rack: "Rack01"
site: "US-WestCoast"
GlobalConfigurationBuilder
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.clusterName("MyCluster")
.machineId("LinuxServer01")
.rackId("Rack01")
.siteId("US-WestCoast");
2.2.6. 关键关联性服务
在分布式缓存中,使用不透明算法将密钥分配给节点列表。无法反转计算并生成映射到特定节点的密钥。但是,Data Grid 可以生成一系列(pseudo-) random 键,查看其主所有者,并在需要关键映射到特定节点时将其移入应用程序。
以下代码片段演示了如何获取和使用对此服务的引用。
// 1. Obtain a reference to a cache
Cache cache = ...
Address address = cache.getCacheManager().getAddress();
// 2. Create the affinity service
KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
// 3. Obtain a key for which the local node is the primary owner
Object localKey = keyAffinityService.getKeyForAddress(address);
// 4. Insert the key in the cache
cache.put(localKey, "yourValue");服务在第 2 步启动:此时,它使用提供的 Executor 生成和队列密钥。在第 3 步,我们从服务获得密钥,在第 4 步中使用该密钥。
生命周期
KeyAffinityService 扩展 生命周期,它允许停止和(重新)启动它:
public interface Lifecycle {
void start();
void stop();
}
服务通过 KeyAffinityServiceFactory 实例化。所有工厂方法都有一个 Executor 参数,用于异步密钥生成(因此它不会在调用者的线程中发生)。用户负责处理此可执行文件的关闭 。
启动后,KeyAffinityService 需要被显式停止。这会停止后台密钥生成,并释放其他保存的资源。
在 KeyAffinityService 停止它的唯一情况下,当它被注册的缓存管理器被关闭时。
拓扑更改
当缓存拓扑更改时,KeyAffinityService 生成的密钥的所有权可能会改变。key affinity 服务跟踪这些拓扑更改,且不会返回当前映射到不同节点的键,但它不会对之前生成的密钥进行任何操作。
因此,应用程序应该只将 KeyAffinityService 视为优化,它们不应该依赖生成的密钥的位置来获得正确的。
特别是,应用程序不应依赖 KeyAffinityService 生成的密钥,以便始终位于同一地址。密钥共存仅由 Grouping API 提供。
2.2.7. Grouping API
与 Key affinity 服务补充,分组 API 允许您在同一节点上并置一组条目,但不能选择实际节点。
默认情况下,使用密钥的 hashCode () 计算密钥的片段。如果您使用 Grouping API,Data Grid 将计算组的网段,并将其用作密钥的网段。
使用 Grouping API 时,务必要确保每个节点仍然可以计算每个密钥的所有者,而无需联系其他节点。因此,无法手动指定组。组可以刻录到条目(由密钥类生成)或 extrinsic (由外部函数生成)。
要使用 Grouping API,您必须启用组。
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled() .build();
<distributed-cache> <groups enabled="true"/> </distributed-cache>
如果您有关键类的控制(您可以更改类定义,它不是一个不可修改的库的一部分),我们建议使用一个内部组。内部组通过向方法添加 @Group 注释来指定,例如:
class User {
...
String office;
...
public int hashCode() {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group
// All keys in the same group end up with the same owners
@Group
public String getOffice() {
return office;
}
}
}
group 方法必须返回 String
如果您没有对密钥类的控制权,或者组的确定是关键类的正面问题,我们建议使用 extrinsic 组。通过实施 Grouper 接口来指定 extrinsic 组。
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
如果为同一密钥类型配置了多个 Grouper 类,则会调用它们的所有类,接收上一个密钥计算的值。如果密钥类也具有 @Group 注释,则第一个 组 将接收由注释方法计算的组。这允许您在使用 内部组时对组进行更大的控制。
Grouper 实现示例
public class KXGrouper implements Grouper<String> {
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "0" or group "1".
private static Pattern kPattern = Pattern.compile("(^k)(<a>\\d</a>)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else {
return null;
}
}
public Class<String> getKeyType() {
return String.class;
}
}
组群 实现必须在缓存配置中显式注册。如果您要以编程方式配置 Data Grid:
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled().addGrouper(new KXGrouper()) .build();
或者,如果您使用 XML:
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>高级 API
AdvancedCache 有两个特定于组的方法:
-
getGroup (groupName)检索属于组的所有密钥。 -
removeGroup (groupName)会删除属于组的所有密钥。
两种方法会迭代整个数据容器和存储(如果存在),因此当缓存包含大量小组时,它们可能会较慢。
2.3. 无效的缓存
Data Grid 中的无效缓存模式旨在优化对共享持久数据存储执行大量读取操作的系统。您可以使用 invalidation 模式来减少在状态发生变化时数据库写入的数量。
对于 Data Grid 远程部署,无效缓存模式已弃用。使用带有存储在共享缓存存储中的嵌入式缓存模式的 invalidation 缓存模式。
只有在您具有持久性数据存储(如数据库)且仅在 read-heavy 系统中使用 Data Grid 优化时,无效缓存模式才会生效。
当为无效配置缓存时,缓存中的每个数据更改都会触发对集群中其他缓存的消息,通知它们的数据现在已过时,应该从内存中删除。validation 消息从其他节点的内存中删除过时的值。与复制整个值相比,消息非常小,并且集群中的其他缓存会以 lazy 方法查找修改的数据,仅在需要时才会查找修改的数据。对共享存储的更新通常由用户应用程序代码或 Hibernate 处理。
图 2.5. 无效的缓存

有时,应用会从外部存储中读取值,并希望将其写入本地缓存,而无需将其从其他节点中删除。要做到这一点,它必须调用 Cache.putForExternalRead (key, value) 而不是 Cache.put (key, value)。
invalidation 模式仅适用于所有节点可以访问同一数据的共享存储。在没有持久性存储的情况下使用 invalidation 模式是不切实际的,因为更新的值需要从共享存储中读取,以实现跨节点的一致性。
切勿将无效模式与本地非共享缓存存储一起使用。invalidation 消息不会删除本地存储中的条目,一些节点会保持过时的值。
无效的缓存也可以使用特殊的缓存加载程序 ClusterLoader 进行配置。启用 ClusterLoader 时,在本地节点上找不到密钥的读取操作将首先从所有其他节点请求,并将其保存在本地内存中。这可能会导致存储过时的值,因此只有在您对过时的值具有高容错时才使用它。
同步或异步复制
当同步时,写入操作块直到集群中的所有节点都被驱除了 stale 值。当异步时,原始器会广播失效消息,但不会等待响应。这意味着,其他节点仍然会在原始器的写入完成后看到一个过时的值。
Transactions
事务可用于批处理失效消息。事务在主所有者上获取密钥锁定。
使用 pesimistic locking 时,每个写入都会触发锁定消息,该消息会广播到所有节点。在事务提交过程中,原始器广播一个单阶段准备消息(可选)准备消息(可选)使所有受影响的密钥和释放锁无效。
使用最佳锁定时,源器广播准备消息、提交消息和解锁消息(可选)。第一阶段准备或解锁消息为 fire-and-forget,最后一条消息始终释放锁。
2.4. 异步复制
所有集群缓存模式都可以配置为在 < replicated-cache/>、< 使用与 distributed-cache> 或 < invalidation-cache/& gt; 元素中mode="ASYNC" 属性的异步通信。
通过异步通信,原始器节点不会收到来自其他节点有关操作状态的任何确认,因此无法检查它是否在其他节点上成功。
我们不推荐一般推荐异步通信,因为它们可能会导致数据中的不一致,并且结果很难考虑。然而,有时速度比一致性更重要,而选项则适用于这些情况。
Asynchronous API
Asynchronous API 允许您使用同步通信,但不阻止用户线程。
存在一个注意事项:异步操作不会保留程序顺序。如果线程调用 cache.putAsync (k, v1); cache.putAsync (k, v2),则 k 的最终值可以是 v1 或 v2。与使用异步通信相比,最终的值不能在一个节点上是 v1,而 v2 则位于另一个节点上。
2.4.1. 使用异步复制返回值
由于 缓存 接口扩展了 java.util.Map,因此默认情况下写入方法(如 put (key, value) 和 remove (key) 会返回之前的值。
在某些情况下,返回的值可能不正确:
-
将
AdvancedCache.withFlags ()与Flag.IGNORE_RETURN_VALUE,Flag.SKIP_REMOTE_LOOKUP, 或Flag.SKIP_CACHE_LOAD. -
当使用
不可靠的-return-values="true" 配置缓存时。 - 使用异步通信时。
- 当同一键有多个并发写入时,缓存拓扑会改变。拓扑更改将使 Data Grid 重试写操作,而重试操作的返回值并不可靠。
事务缓存在 3 和 4 情况下返回正确的值。但是,事务性缓存在分布式模式下也有一个 gotcha:,read-committed 的隔离级别被实施为可重复读取。这意味着,"double-checked locking"示例无法正常工作:
Cache cache = ...
TransactionManager tm = ...
tm.begin();
try {
Integer v1 = cache.get(k);
// Increment the value
Integer v2 = cache.put(k, v1 + 1);
if (Objects.equals(v1, v2) {
// success
} else {
// retry
}
} finally {
tm.commit();
}
实现这一点的正确方法是使用 cache.getAdvancedCache ().withFlags (Flag.FORCE_WRITE_LOCK).get (k)。
在具有最佳锁定的缓存中,写入也可以返回过时的之前值。编写偏移检查可以避免过时的之前值。
2.5. 配置初始集群大小
Data Grid 动态处理集群拓扑更改。这意味着,在 Data Grid 初始化缓存前,节点不需要等待其他节点加入集群。
如果应用程序在缓存启动前需要集群中的特定数量的节点,您可以将初始集群大小配置为传输的一部分。
流程
- 打开 Data Grid 配置以进行编辑。
-
在缓存以
initial-cluster-size属性或initialClusterSize ()方法开头前,设置所需的最少节点数。 -
设置 timeout,以毫秒为单位,之后缓存管理器不会以
initial-cluster-timeout属性或initialClusterTimeout ()方法开头。 - 保存并关闭您的 Data Grid 配置。
初始集群大小配置
XML
<infinispan>
<cache-container>
<transport initial-cluster-size="4"
initial-cluster-timeout="30000" />
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"initial-cluster-size" : "4",
"initial-cluster-timeout" : "30000"
}
}
}
}
YAML
infinispan:
cacheContainer:
transport:
initialClusterSize: "4"
initialClusterTimeout: "30000"
ConfigurationBuilder
GlobalConfiguration global = GlobalConfigurationBuilder.defaultClusteredBuilder() .transport() .initialClusterSize(4) .initialClusterTimeout(30000, TimeUnit.MILLISECONDS);
第 3 章 Data Grid 缓存配置
缓存配置控制 Data Grid 如何存储您的数据。
作为缓存配置的一部分,您可以声明您要使用的缓存模式。例如,您可以将 Data Grid 集群配置为使用复制缓存或分布式缓存。
您的配置还定义了缓存的特性并启用您要在处理数据时使用的 Data Grid 功能。例如,您可以配置 Data Grid 对缓存中的条目进行编码的方式,无论是同步还是在节点间异步发生复制请求,如果条目是 mortal 或 immortal,等等。
3.1. 声明性缓存配置
您可以根据 Data Grid 模式,以 XML、JSON 和 YAML 格式配置缓存。
与编程配置相比,声明性缓存配置有以下优点:
- 可移植性
-
在独立文件中定义每个配置,可用于创建嵌入和远程缓存。
您还可以使用声明配置,通过 Data Grid Operator 为 OpenShift 上运行的集群创建缓存。 - 简单性
-
保留独立于编程语言的标记语言。
例如,创建远程缓存通常最好不要直接向 Java 代码添加复杂的 XML。
Data Grid 服务器配置扩展了 infinispan.xml,使其包含集群传输机制、安全域和端点配置。如果您将缓存声明为 Data Grid Server 配置的一部分,您应该使用管理工具,如 Ansible 或 Chef,使其在集群中同步。
要在 Data Grid 集群中动态同步远程缓存,请在运行时创建它们。
3.1.1. 缓存配置
您可以使用 XML、JSON 和 YAML 格式创建声明性缓存配置。
所有声明缓存都必须符合 Data Grid 模式。JSON 格式的配置必须遵循 XML 配置的结构,元素对应于字段和属性。
Data Grid 将字符限制为最多 255 个缓存名称或缓存模板名称。如果您超过这个字符限制,Data Grid 会抛出异常。编写 succinct 缓存名称和缓存模板名称。
文件系统可能会为文件名长度设置限制,因此请确保缓存的名称不超过这个限制。如果缓存名称超过文件系统的命名限制,则对该缓存的一般操作或初始操作可能会失败。写入 succinct 文件名。
分布式缓存
XML
<distributed-cache owners="2"
segments="256"
capacity-factor="1.0"
l1-lifespan="5000"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<locking isolation="REPEATABLE_READ"/>
<transaction mode="FULL_XA"
locking="OPTIMISTIC"/>
<expiration lifespan="5000"
max-idle="1000" />
<memory max-count="1000000"
when-full="REMOVE"/>
<indexing enabled="true"
storage="local-heap">
<index-reader refresh-interval="1000"/>
<indexed-entities>
<indexed-entity>org.infinispan.Person</indexed-entity>
</indexed-entities>
</indexing>
<partition-handling when-split="ALLOW_READ_WRITES"
merge-policy="PREFERRED_NON_NULL"/>
<persistence passivation="false">
<!-- Persistent storage configuration. -->
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"mode": "SYNC",
"owners": "2",
"segments": "256",
"capacity-factor": "1.0",
"l1-lifespan": "5000",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"locking": {
"isolation": "REPEATABLE_READ"
},
"transaction": {
"mode": "FULL_XA",
"locking": "OPTIMISTIC"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
},
"indexing" : {
"enabled" : true,
"storage" : "local-heap",
"index-reader" : {
"refresh-interval" : "1000"
},
"indexed-entities": [
"org.infinispan.Person"
]
},
"partition-handling" : {
"when-split" : "ALLOW_READ_WRITES",
"merge-policy" : "PREFERRED_NON_NULL"
},
"persistence" : {
"passivation" : false
}
}
}
YAML
distributedCache:
mode: "SYNC"
owners: "2"
segments: "256"
capacityFactor: "1.0"
l1Lifespan: "5000"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
locking:
isolation: "REPEATABLE_READ"
transaction:
mode: "FULL_XA"
locking: "OPTIMISTIC"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
indexing:
enabled: "true"
storage: "local-heap"
indexReader:
refreshInterval: "1000"
indexedEntities:
- "org.infinispan.Person"
partitionHandling:
whenSplit: "ALLOW_READ_WRITES"
mergePolicy: "PREFERRED_NON_NULL"
persistence:
passivation: "false"
# Persistent storage configuration.
复制的缓存
XML
<replicated-cache segments="256"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<locking isolation="REPEATABLE_READ"/>
<transaction mode="FULL_XA"
locking="OPTIMISTIC"/>
<expiration lifespan="5000"
max-idle="1000" />
<memory max-count="1000000"
when-full="REMOVE"/>
<indexing enabled="true"
storage="local-heap">
<index-reader refresh-interval="1000"/>
<indexed-entities>
<indexed-entity>org.infinispan.Person</indexed-entity>
</indexed-entities>
</indexing>
<partition-handling when-split="ALLOW_READ_WRITES"
merge-policy="PREFERRED_NON_NULL"/>
<persistence passivation="false">
<!-- Persistent storage configuration. -->
</persistence>
</replicated-cache>
JSON
{
"replicated-cache": {
"mode": "SYNC",
"segments": "256",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"locking": {
"isolation": "REPEATABLE_READ"
},
"transaction": {
"mode": "FULL_XA",
"locking": "OPTIMISTIC"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
},
"indexing" : {
"enabled" : true,
"storage" : "local-heap",
"index-reader" : {
"refresh-interval" : "1000"
},
"indexed-entities": [
"org.infinispan.Person"
]
},
"partition-handling" : {
"when-split" : "ALLOW_READ_WRITES",
"merge-policy" : "PREFERRED_NON_NULL"
},
"persistence" : {
"passivation" : false
}
}
}
YAML
replicatedCache:
mode: "SYNC"
segments: "256"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
locking:
isolation: "REPEATABLE_READ"
transaction:
mode: "FULL_XA"
locking: "OPTIMISTIC"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
indexing:
enabled: "true"
storage: "local-heap"
indexReader:
refreshInterval: "1000"
indexedEntities:
- "org.infinispan.Person"
partitionHandling:
whenSplit: "ALLOW_READ_WRITES"
mergePolicy: "PREFERRED_NON_NULL"
persistence:
passivation: "false"
# Persistent storage configuration.
多个缓存
XML
<infinispan
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:15.0 https://infinispan.org/schemas/infinispan-config-15.0.xsd
urn:infinispan:server:15.0 https://infinispan.org/schemas/infinispan-server-15.0.xsd"
xmlns="urn:infinispan:config:15.0"
xmlns:server="urn:infinispan:server:15.0">
<cache-container name="default"
statistics="true">
<distributed-cache name="mycacheone"
mode="ASYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="300000"/>
<memory max-size="400MB"
when-full="REMOVE"/>
</distributed-cache>
<distributed-cache name="mycachetwo"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="300000"/>
<memory max-size="400MB"
when-full="REMOVE"/>
</distributed-cache>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"name" : "default",
"statistics" : "true",
"caches" : {
"mycacheone" : {
"distributed-cache" : {
"mode": "ASYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "300000"
},
"memory": {
"max-size": "400MB",
"when-full": "REMOVE"
}
}
},
"mycachetwo" : {
"distributed-cache" : {
"mode": "SYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "300000"
},
"memory": {
"max-size": "400MB",
"when-full": "REMOVE"
}
}
}
}
}
}
}
YAML
infinispan:
cacheContainer:
name: "default"
statistics: "true"
caches:
mycacheone:
distributedCache:
mode: "ASYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "300000"
memory:
maxSize: "400MB"
whenFull: "REMOVE"
mycachetwo:
distributedCache:
mode: "SYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "300000"
memory:
maxSize: "400MB"
whenFull: "REMOVE"
3.2. 添加缓存模板
Data Grid 模式包括可用于创建模板的 *-cache-configuration 元素。然后,您可以根据需要创建缓存,多次使用相同的配置。
流程
- 打开 Data Grid 配置以进行编辑。
-
使用适当的
*-cache-configuration元素或对象将缓存配置添加到 Cache Manager。 - 保存并关闭您的 Data Grid 配置。
缓存模板示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="my-dist-template"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<memory max-count="1000000"
when-full="REMOVE"/>
<expiration lifespan="5000"
max-idle="1000"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"distributed-cache-configuration" : {
"name" : "my-dist-template",
"mode": "SYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
}
}
}
}
}
YAML
infinispan:
cacheContainer:
distributedCacheConfiguration:
name: "my-dist-template"
mode: "SYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
3.2.1. 从模板创建缓存
从配置模板创建缓存。
远程缓存的模板可从 Data Grid 控制台中的 Cache templates 菜单获得。
先决条件
- 将至少一个缓存模板添加到缓存管理器。
流程
- 打开 Data Grid 配置以进行编辑。
-
指定缓存使用
配置属性或字段继承的模板。 - 保存并关闭您的 Data Grid 配置。
从模板继承的缓存配置
XML
<distributed-cache configuration="my-dist-template" />
JSON
{
"distributed-cache": {
"configuration": "my-dist-template"
}
}
YAML
distributedCache: configuration: "my-dist-template"
3.2.2. 缓存模板继承
缓存配置模板可以从其他模板继承,以扩展和覆盖设置。
缓存模板继承是分层的。要使子配置模板从父项继承,您必须在父模板后面包含它。
另外,对于具有多个值的元素,模板继承性是添加的。从另一个模板继承的缓存会合并该模板中的值,这可能会覆盖属性。
模板继承示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="base-template">
<expiration lifespan="5000"/>
</distributed-cache-configuration>
<distributed-cache-configuration name="extended-template"
configuration="base-template">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="10000"
max-idle="1000"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"caches" : {
"base-template" : {
"distributed-cache-configuration" : {
"expiration" : {
"lifespan" : "5000"
}
}
},
"extended-template" : {
"distributed-cache-configuration" : {
"configuration" : "base-template",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "10000",
"max-idle" : "1000"
}
}
}
}
}
}
}
YAML
infinispan:
cacheContainer:
caches:
base-template:
distributedCacheConfiguration:
expiration:
lifespan: "5000"
extended-template:
distributedCacheConfiguration:
configuration: "base-template"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "10000"
maxIdle: "1000"
3.2.3. 缓存模板通配符
您可以将通配符添加到缓存模板名称。如果您创建名称与通配符匹配的缓存,Data Grid 应用配置模板。
如果缓存名称与多个通配符匹配,则数据网格会抛出异常。
模板通配符示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="async-dist-cache-*"
mode="ASYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"distributed-cache-configuration" : {
"name" : "async-dist-cache-*",
"mode": "ASYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
}
}
}
}
}
YAML
infinispan:
cacheContainer:
distributedCacheConfiguration:
name: "async-dist-cache-*"
mode: "ASYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
使用前面的示例,如果您创建一个名为 "async-dist-cache-prod" 的缓存,则 Data Grid 会使用 async-dist-cache reasonable 模板的配置。
3.2.4. 从多个 XML 文件缓存模板
将缓存配置模板分成多个 XML 文件,以获得细致的灵活性,并通过 XML 包括(XInclude)引用它们。
Data Grid 为 XInclude 规格提供最少的支持。这意味着您无法使用 xpointer 属性、xi:fallback 元素、文本处理或内容协商。
您还必须将 xmlns:xi="http://www.w3.org/2001/XInclude" 命名空间添加到 infinispan.xml 才能使用 XInclude。
Xinclude 缓存模板
<infinispan xmlns:xi="http://www.w3.org/2001/XInclude">
<cache-container default-cache="cache-1">
<!-- References files that contain cache configuration templates. -->
<xi:include href="distributed-cache-template.xml" />
<xi:include href="replicated-cache-template.xml" />
</cache-container>
</infinispan>
Data Grid 还提供了一个 infinispan-config-fragment-15.0.xsd 模式,供您用于配置片段。
配置片段模式
<local-cache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:15.0 https://infinispan.org/schemas/infinispan-config-fragment-15.0.xsd"
xmlns="urn:infinispan:config:15.0"
name="mycache"/>
其他资源
3.3. 缓存别名
为缓存添加别名以使用不同名称访问它们。
缓存配置的 alias 属性在运行时是 updatable。将别名重新分配给不同的缓存,以快速切换缓存内容。
XML
<distributed-cache name="acache" aliases="0 anothername"/>
JSON
{
"distributed-cache": {
"aliases": ["0", "anothername"]
}
}
YAML
distributedCache:
aliases:
- "0"
- "anothername"
3.4. 创建远程缓存
当您在运行时创建远程缓存时,Data Grid 服务器会在集群中同步您的配置,以便所有节点都有副本。因此,您应该始终使用以下机制动态创建远程缓存:
- Data Grid 控制台
- Data Grid 命令行界面(CLI)
- 热 Rod 或 HTTP 客户端
3.4.1. 默认缓存管理器
Data Grid Server 提供了一个默认的缓存管理器,用于控制远程缓存的生命周期。启动 Data Grid 服务器会自动实例化缓存管理器,以便您可以创建和删除远程缓存和其他资源,如 Protobuf 模式。
启动 Data Grid 服务器并添加用户凭证后,您可以查看缓存管理器的详情,并从 Data Grid 控制台获取集群信息。
-
在任何浏览器中打开
127.0.0.1:11222。
您还可以通过命令行界面(CLI)或 REST API 获取有关缓存管理器的信息:
- CLI
在 default 容器中运行
describe命令。[//containers/default]> describe
- REST
-
在任何浏览器中打开
127.0.0.1:11222/rest/v2/container/。
默认缓存管理器配置
XML
<infinispan>
<!-- Creates a Cache Manager named "default" and enables metrics. -->
<cache-container name="default"
statistics="true">
<!-- Adds cluster transport that uses the default JGroups TCP stack. -->
<transport cluster="${infinispan.cluster.name:cluster}"
stack="${infinispan.cluster.stack:tcp}"
node-name="${infinispan.node.name:}"/>
<!-- Requires user permission to access caches and perform operations. -->
<security>
<authorization/>
</security>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"jgroups" : {
"transport" : "org.infinispan.remoting.transport.jgroups.JGroupsTransport"
},
"cache-container" : {
"name" : "default",
"statistics" : "true",
"transport" : {
"cluster" : "cluster",
"node-name" : "",
"stack" : "tcp"
},
"security" : {
"authorization" : {}
}
}
}
}
YAML
infinispan:
jgroups:
transport: "org.infinispan.remoting.transport.jgroups.JGroupsTransport"
cacheContainer:
name: "default"
statistics: "true"
transport:
cluster: "cluster"
nodeName: ""
stack: "tcp"
security:
authorization: ~
3.4.2. 使用 Data Grid 控制台创建缓存
使用 Data Grid 控制台从任何 Web 浏览器使用直观的可视化界面创建远程缓存。
先决条件
-
创建具有
admin权限的 Data Grid 用户。 - 至少启动一个 Data Grid 服务器实例。
- 具有 Data Grid 缓存配置。
流程
-
在任意浏览器中打开
127.0.0.1:11222/console/。 - 选择 Create Cache 并按照步骤操作,作为 Data Grid Console 指南。
3.4.3. 使用 Data Grid CLI 创建远程缓存
使用 Data Grid 命令行界面(CLI)在 Data Grid Server 中添加远程缓存。
先决条件
-
创建具有
admin权限的 Data Grid 用户。 - 至少启动一个 Data Grid 服务器实例。
- 具有 Data Grid 缓存配置。
流程
启动 CLI。
bin/cli.sh
-
运行
connect命令,并在提示时输入您的用户名和密码。 使用
create cache命令创建远程缓存。例如,从名为
mycache.xml的文件创建一个名为 "mycache" 的缓存,如下所示:create cache --file=mycache.xml mycache
验证
使用
ls命令列出所有远程缓存。ls caches mycache
使用
describe命令查看缓存配置。describe caches/mycache
3.4.4. 从 Hot Rod 客户端创建远程缓存
使用 Data Grid Hot Rod API 从 Java、C++、.NET/C#、JS 客户端等在 Data Grid Server 上创建远程缓存。
此流程演示了如何使用 Hot Rod Java 客户端在首次访问时创建远程缓存。您可以在 Data Grid Tutorials 中找到其他 Hot Rod 客户端的代码示例。
先决条件
-
创建具有
admin权限的 Data Grid 用户。 - 至少启动一个 Data Grid 服务器实例。
- 具有 Data Grid 缓存配置。
流程
-
调用
remoteCache ()方法,作为ConfigurationBuilder的一部分。 -
在 classpath 上的
hotrod-client.properties文件中设置configuration或configuration_uri属性。
ConfigurationBuilder
File file = new File("path/to/infinispan.xml")
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.remoteCache("another-cache")
.configuration("<distributed-cache name=\"another-cache\"/>");
builder.remoteCache("my.other.cache")
.configurationURI(file.toURI());
hotrod-client.properties
infinispan.client.hotrod.cache.another-cache.configuration=<distributed-cache name=\"another-cache\"/> infinispan.client.hotrod.cache.[my.other.cache].configuration_uri=file:///path/to/infinispan.xml
如果远程缓存的名称包含 . 字符,则必须在使用 hotrod-client.properties 文件时将其放在方括号中。
3.4.5. 使用 REST API 创建远程缓存
使用 Data Grid REST API 从任何合适的 HTTP 客户端在 Data Grid Server 上创建远程缓存。
先决条件
-
创建具有
admin权限的 Data Grid 用户。 - 至少启动一个 Data Grid 服务器实例。
- 具有 Data Grid 缓存配置。
流程
-
使用有效负载中的缓存配置调用
POST请求到/rest/v2/caches/<cache_name>。
其他资源
3.5. 创建嵌入式缓存
Data Grid 提供了一个 EmbeddedCacheManager API,可让您以编程方式控制缓存管理器和嵌入式缓存生命周期。
3.5.1. 在项目中添加 Data Grid
将 Data Grid 添加到项目,以便在您的应用程序中创建嵌入的缓存。
先决条件
- 配置项目以从 Maven 存储库获取数据网格工件。
流程
-
将
infinispan-core工件作为依赖项添加到pom.xml中,如下所示:
<dependencies>
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-core</artifactId>
</dependency>
</dependencies>3.5.2. 创建和使用嵌入式缓存
Data Grid 提供了一个 GlobalConfigurationBuilder API,用于控制 Cache Manager 和用于配置缓存的 ConfigurationBuilder API。
先决条件
-
将
infinispan-core工件添加为pom.xml中的依赖项。
流程
初始化
CacheManager。注意在创建缓存前,您必须始终调用
cacheManager.start ()方法来初始化CacheManager。默认构造器为您完成此操作,但构建器的超载版本不会为您这样做。缓存管理器也是重量的对象,Data Grid 建议实例化每个 JVM 只有一个实例。
-
使用
ConfigurationBuilderAPI 定义缓存配置。 使用
getCache ()、createCache ()或getOrCreateCache ()方法获取缓存。Data Grid 建议使用
getOrCreateCache ()方法,因为它在所有节点上创建一个缓存或返回现有的缓存。-
如有必要,对缓存使用
PERMANENT标志,以在重启后保留。 -
通过调用
cacheManager.stop ()方法以释放 JVM 资源并正常关闭任何缓存,以停止CacheManager。
// Set up a clustered Cache Manager.
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder();
// Initialize the default Cache Manager.
DefaultCacheManager cacheManager = new DefaultCacheManager(global.build());
// Create a distributed cache with synchronous replication.
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC);
// Obtain a volatile cache.
Cache<String, String> cache = cacheManager.administration().withFlags(CacheContainerAdmin.AdminFlag.VOLATILE).getOrCreateCache("myCache", builder.build());
// Stop the Cache Manager.
cacheManager.stop();getCache () 方法
调用 getCache (String) 方法以获取缓存,如下所示:
Cache<String, String> myCache = manager.getCache("myCache");
前面的操作会创建一个名为 myCache 的缓存(如果尚未存在),并返回它。
使用 getCache () 方法仅在您调用方法的节点上创建缓存。换句话说,它会执行一个本地操作,它必须在集群中的每个节点上调用。通常,在多个节点间部署的应用程序会在初始化过程中获取缓存,以确保缓存都是 对称的,并在每个节点上存在。
createCache () 方法
调用 createCache () 方法,以在整个集群中动态创建缓存。
Cache<String, String> myCache = manager.administration().createCache("myCache", "myTemplate");前面的操作还会在随后加入集群的任何节点上自动创建缓存。
默认情况下,您使用 createCache () 方法创建的缓存是临时的。如果整个集群关闭,则缓存重启后不会自动创建。
PERMANENT 标志
使用 PERMANENT 标志来确保缓存可以在重启后保留。
Cache<String, String> myCache = manager.administration().withFlags(AdminFlag.PERMANENT).createCache("myCache", "myTemplate");要使 PERMANENT 标志生效,您必须启用全局状态并设置配置存储提供程序。
有关配置存储供应商的更多信息,请参阅 GlobalStateConfigurationBuilder#configurationStorage ()。
3.5.3. Cache API
Data Grid 提供了一个 Cache 接口,它公开简单的方法来添加、检索和删除条目,包括 JDK 的 ConcurrentMap 接口公开的原子机制。根据所使用的缓存模式,调用这些方法会触发多个事情,甚至可能包括将条目复制到远程节点或从远程节点查找条目,或可能缓存存储。
对于简单使用,使用 Cache API 不应与使用 JDK Map API 不同,因此从基于映射到 Data Grid 的缓存的简单内存缓存迁移应该很简单。
Certain Map 方法的性能一致性
与 Data Grid 一起使用时,在 Map 中公开的某些方法具有一定的性能后果,如 size ()、value ()、keySet () 和 entrySet ()。有关 keySet、value 和 entrySet 的具体方法,请参阅其 Javadoc 了解更多详情。
试图全局执行这些操作会对性能有很大的影响,并成为可扩展性瓶颈。因此,这些方法应该仅用于信息或调试目的。
应注意,在 withFlags () 方法中使用某些标记可以缓解其中的一些问题,请检查每个方法的文档以了解更多详情。
Mortal 和 Immortal Data
除了仅存储条目外,Data Grid 的缓存 API 允许您向数据附加 mortality 信息。例如,只是使用 put (键,值) 会创建一个 immortal 条目,例如,一个存在于缓存中的条目(永久存在),直到它被删除(或逐出内存以防止耗尽内存)。但是,如果您使用 put (key, value, lifespan, timeunit) 将数据放入缓存中,这会创建一个 mortal 条目,即具有固定生命周期的条目,并在该生命周期后过期。
除了 Lifespan 外,Data Grid 还支持 maxIdle 作为额外的指标,以决定到期。可以使用任何 lifespans 或 maxIdles 的组合。
putForExternalRead 操作
Data Grid 的 Cache 类包含不同的"put"操作,称为 putForExternalRead。当 Data Grid 用作在其他位置保留数据的临时缓存时,此操作特别有用。在大量读取场景中,缓存中的竞争不应延迟实时事务,因为缓存应该只是优化,而不是以某种方式获得。
要达到此目的,putForExternalRead () 充当 put 调用,只有在缓存中不存在密钥时才运行,并在另一个线程尝试同时存储同一密钥时失败。在这个特殊情况下,缓存数据是优化系统的方法,而不需要缓存失败会影响到持续的事务,因此为什么以不同的方式处理失败。putForExternalRead () 被视为快速操作,因为无论它是否成功,它都不会等待任何锁定,因此会立即返回到调用者。
要了解如何使用此操作,让我们来看基本的示例。试想一下,个人实例的缓存,每个由 PersonId 的密钥,其数据源自于单独的数据存储中。以下代码显示了在此示例上下文中使用 putForExternalRead 的最常见模式:
// Id of the person to look up, provided by the application
PersonId id = ...;
// Get a reference to the cache where person instances will be stored
Cache<PersonId, Person> cache = ...;
// First, check whether the cache contains the person instance
// associated with with the given id
Person cachedPerson = cache.get(id);
if (cachedPerson == null) {
// The person is not cached yet, so query the data store with the id
Person person = dataStore.lookup(id);
// Cache the person along with the id so that future requests can
// retrieve it from memory rather than going to the data store
cache.putForExternalRead(id, person);
} else {
// The person was found in the cache, so return it to the application
return cachedPerson;
}请注意,putForExternalRead 不应用作使用源自应用程序执行的新 Person 实例更新缓存的机制(例如,来自修改人员地址的事务)。更新缓存的值时,请使用标准 放置 操作,否则可能会出现缓存损坏数据的可能性。
3.5.3.1. AdvancedCache API
除了简单缓存接口外,Data Grid 还提供 AdvancedCache 接口,并提供给扩展作者。AdvancedCache 提供了访问某些内部组件,并应用标志来改变某些缓存方法的默认行为。以下代码片段描述了如何获取 AdvancedCache:
AdvancedCache advancedCache = cache.getAdvancedCache();
3.5.3.1.1. 标记
标志应用到常规缓存方法,以更改某些方法的行为。有关所有可用标志及其效果的列表,请查看 标记 枚举。使用 AdvancedCache.withFlags () 应用标志。此 builder 方法可用于将任意数量的标记应用到缓存调用,例如:
advancedCache.withFlags(Flag.CACHE_MODE_LOCAL, Flag.SKIP_LOCKING)
.withFlags(Flag.FORCE_SYNCHRONOUS)
.put("hello", "world");3.5.3.2. Asynchronous API
除了同步的 API 方法(如 Cache.put ()、Cache.remove () 等)之外,数据网格也有一个异步的非阻塞 API,您可以在其中实现相同的结果。
这些方法的命名方式与阻塞计数器类似,并附加"Async"。 例如,Cache.putAsync ()、Cache.removeAsync () 等。 这些异步对应部分返回一个包含操作实际结果的 CompletableFuture。
例如,在 cache 参数中,在 Cache<String, String>, Cache.put (String key, String value) 返回 String while Cache.putAsync (String key) returns Complet ableFuture<String>。
3.5.3.2.1. 为什么使用这种 API?
非阻塞 API 非常强大,它们提供了所有同步通信保证 - 能够处理通信故障和例外 - 在调用完成后不需要阻止。 这可让您更好地利用系统中的并行性。 例如:
Set<CompletableFuture<?>> futures = new HashSet<>(); futures.add(cache.putAsync(key1, value1)); // does not block futures.add(cache.putAsync(key2, value2)); // does not block futures.add(cache.putAsync(key3, value3)); // does not block // the remote calls for the 3 puts will effectively be executed // in parallel, particularly useful if running in distributed mode // and the 3 keys would typically be pushed to 3 different nodes // in the cluster // check that the puts completed successfully for (CompletableFuture<?> f: futures) f.get();
3.5.3.2.2. 哪些进程实际发生在异步中?
Data Grid 中有 4 个事情,它们被视为典型写入操作的关键路径。这些是成本顺序:
- 网络调用
- Marshalling
- 写入缓存存储(可选)
- 锁定
使用 async 方法将取网络调用和划分出关键路径。 然而,出于各种技术原因,写入缓存存储和获取锁定,但仍然出现在调用者的线程中。
第 4 章 启用并配置 Data Grid 统计和 JMX 监控
网格可以提供缓存管理器和缓存统计信息,以及导出 JMX MBeans。
4.1. 配置 Data Grid 指标
Data Grid 生成与任何监控系统兼容的指标。
- 量表提供值,如写操作或 JVM 正常运行时间的平均纳秒数。
- histograms 提供有关操作执行时间的详细信息,如读取、写入和删除时间。
默认情况下,当启用统计数据时,Data Grid 会生成量表,但您也可以将其配置为生成直方图。
Data Grid 指标在 供应商 范围内提供。与 JVM 相关的指标 在基本 范围内提供。
流程
- 打开 Data Grid 配置以进行编辑。
-
将
metrics元素或对象添加到缓存容器。 -
使用量表属性或字段启用或禁用
量表。 -
使用
histograms属性或字段启用或禁用直方图。 - 保存并关闭您的客户端配置。
指标配置
XML
<infinispan>
<cache-container statistics="true">
<metrics gauges="true"
histograms="true" />
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"metrics" : {
"gauges" : "true",
"histograms" : "true"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
metrics:
gauges: "true"
histograms: "true"
4.2. 注册 JMX MBeans
Data Grid 可以注册可以用来收集统计信息并执行管理操作的 JMX MBeans。您还必须启用统计信息,否则 Data Grid 为 JMX MBeans 中的所有统计属性提供 0 值。
只有在 Data Grid 嵌入于应用程序中而不是远程 Data Grid 服务器时,使用 JMX Mbeans 来收集统计信息。
当您使用 JMX Mbeans 从远程 Data Grid 服务器收集统计信息时,从 JMX Mbeans 接收的数据可能与 REST 等其他 API 接收的数据不同。在这种情况下,从其他 API 接收的数据更为准确。
流程
- 打开 Data Grid 配置以进行编辑。
-
将
jmx元素或对象添加到缓存容器,并将true指定为enabled属性或字段的值。 -
添加
domain属性或字段,并指定公开 JMX MBeans 的域(如果需要)。 - 保存并关闭您的客户端配置。
JMX 配置
XML
<infinispan>
<cache-container statistics="true">
<jmx enabled="true"
domain="example.com"/>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"jmx" : {
"enabled" : "true",
"domain" : "example.com"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
jmx:
enabled: "true"
domain: "example.com"
4.2.1. 启用 JMX 远程端口
提供唯一的远程 JMX 端口,以通过 JMXServiceURL 格式的连接公开数据网格 MBean。
您可以使用以下方法之一启用远程 JMX 端口:
- 启用需要向其中一个 Data Grid 服务器安全域进行身份验证的远程 JMX 端口。
- 使用标准 Java 管理配置选项手动启用远程 JMX 端口。
先决条件
-
对于带有身份验证的远程 JMX,请使用默认安全域定义 JMX 特定的用户角色。用户必须具有具有读/写访问权限的
controlRole,或者具有只读访问权限的monitorRole才能访问任何 JMX 资源。Data Grid 会自动将全局ADMIN和MONITOR权限映射到 JMXcontrolRole和monitorRole角色。
流程
使用以下方法之一启动启用了远程 JMX 端口的 Data Grid 服务器:
通过端口
9999启用远程 JMX。bin/server.sh --jmx 9999
警告在生产环境中不适用于禁用 SSL 的远程 JMX。
在启动时将以下系统属性传递给 Data Grid 服务器。
bin/server.sh -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
警告启用没有身份验证或 SSL 的远程 JMX 不安全,在任何环境中都不推荐使用。禁用身份验证和 SSL 允许未授权用户连接到服务器并访问托管的数据。
其他资源
4.2.2. Data Grid MBeans
Data Grid 公开了代表可管理资源的 JMX MBeans。
org.infinispan:type=Cache- 可用于缓存实例的属性和操作。
org.infinispan:type=CacheManager- 可用于缓存管理器的属性和操作,包括数据网格缓存和集群健康统计信息。
有关可用 JMX MBeans 的完整列表以及描述和可用的操作和属性,请参阅 Data Grid JMX 组件 文档。
其他资源
4.2.3. 在自定义 MBean 服务器中注册 MBeans
Data Grid 包含一个 MBeanServerLookup 接口,可用于在自定义 MBeanServer 实例中注册 MBeans。
先决条件
-
创建
MBeanServerLookup的实现,以便getMBeanServer ()方法返回自定义 MBeanServer 实例。 - 配置数据网格以注册 JMX MBeans。
流程
- 打开 Data Grid 配置以进行编辑。
-
将
mbean-server-lookup属性或字段添加到 Cache Manager 的 JMX 配置。 -
指定
MBeanServerLookup实施的完全限定名称(FQN)。 - 保存并关闭您的客户端配置。
JMX MBean 服务器查找配置
XML
<infinispan>
<cache-container statistics="true">
<jmx enabled="true"
domain="example.com"
mbean-server-lookup="com.example.MyMBeanServerLookup"/>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"jmx" : {
"enabled" : "true",
"domain" : "example.com",
"mbean-server-lookup" : "com.example.MyMBeanServerLookup"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
jmx:
enabled: "true"
domain: "example.com"
mbeanServerLookup: "com.example.MyMBeanServerLookup"
4.3. 在状态传输操作过程中导出指标
您可以为跨节点分布集群缓存导出时间指标。
当集群缓存拓扑更改时,状态传输操作发生,如加入或离开集群的节点。在状态传输操作期间,Data Grid 会导出每个缓存中的指标,以便您可以确定缓存的状态。状态传输将属性作为属性公开,以便 Data Grid 可以从每个缓存中导出指标。
您不能在无效模式下执行状态传输操作。
Data Grid 生成与 REST API 和 JMX API 兼容的时间指标。
先决条件
- 配置数据网格指标。
- 为您的缓存类型启用指标,如嵌入式缓存或远程缓存。
- 通过更改集群缓存拓扑来启动状态传输操作。
流程
选择以下任一方法:
- 配置 Data Grid 以使用 REST API 来收集指标。
- 配置 Data Grid 以使用 JMX API 来收集指标。
4.4. 监控跨站点复制的状态
监控备份位置的站点状态,以检测站点之间的通信中断。当远程站点状态变为 离线时,Data Grid 会停止将数据复制到备份位置。您的数据不同步,您必须在使集群重新上线前修复不一致的问题。
对于早期问题检测,需要监控跨站点事件。使用以下监控策略之一:
使用 REST API 监控跨站点复制
使用 REST 端点监控所有缓存的跨站点复制状态。您可以实施自定义脚本来轮询 REST 端点,或者使用以下示例。
先决条件
- 启用跨站点复制。
流程
实施脚本以轮询 REST 端点。
以下示例演示了如何使用 Python 脚本每 5 秒轮询站点状态。
#!/usr/bin/python3
import time
import requests
from requests.auth import HTTPDigestAuth
class InfinispanConnection:
def __init__(self, server: str = 'http://localhost:11222', cache_manager: str = 'default',
auth: tuple = ('admin', 'change_me')) -> None:
super().__init__()
self.__url = f'{server}/rest/v2/container/x-site/backups/'
self.__auth = auth
self.__headers = {
'accept': 'application/json'
}
def get_sites_status(self):
try:
rsp = requests.get(self.__url, headers=self.__headers, auth=HTTPDigestAuth(self.__auth[0], self.__auth[1]))
if rsp.status_code != 200:
return None
return rsp.json()
except:
return None
# Specify credentials for Data Grid user with permission to access the REST endpoint
USERNAME = 'admin'
PASSWORD = 'change_me'
# Set an interval between cross-site status checks
POLL_INTERVAL_SEC = 5
# Provide a list of servers
SERVERS = [
InfinispanConnection('http://127.0.0.1:11222', auth=(USERNAME, PASSWORD)),
InfinispanConnection('http://127.0.0.1:12222', auth=(USERNAME, PASSWORD))
]
#Specify the names of remote sites
REMOTE_SITES = [
'nyc'
]
#Provide a list of caches to monitor
CACHES = [
'work',
'sessions'
]
def on_event(site: str, cache: str, old_status: str, new_status: str):
# TODO implement your handling code here
print(f'site={site} cache={cache} Status changed {old_status} -> {new_status}')
def __handle_mixed_state(state: dict, site: str, site_status: dict):
if site not in state:
state[site] = {c: 'online' if c in site_status['online'] else 'offline' for c in CACHES}
return
for cache in CACHES:
__update_cache_state(state, site, cache, 'online' if cache in site_status['online'] else 'offline')
def __handle_online_or_offline_state(state: dict, site: str, new_status: str):
if site not in state:
state[site] = {c: new_status for c in CACHES}
return
for cache in CACHES:
__update_cache_state(state, site, cache, new_status)
def __update_cache_state(state: dict, site: str, cache: str, new_status: str):
old_status = state[site].get(cache)
if old_status != new_status:
on_event(site, cache, old_status, new_status)
state[site][cache] = new_status
def update_state(state: dict):
rsp = None
for conn in SERVERS:
rsp = conn.get_sites_status()
if rsp:
break
if rsp is None:
print('Unable to fetch site status from any server')
return
for site in REMOTE_SITES:
site_status = rsp.get(site, {})
new_status = site_status.get('status')
if new_status == 'mixed':
__handle_mixed_state(state, site, site_status)
else:
__handle_online_or_offline_state(state, site, new_status)
if __name__ == '__main__':
_state = {}
while True:
update_state(_state)
time.sleep(POLL_INTERVAL_SEC)
当站点状态从 Online 变为 offline 或 vice-versa 时,调用 on_event 的功能。
如果要使用这个脚本,您必须指定以下变量:
-
USERNAME和PASSWORD:Data Grid 用户的用户名和密码,有权访问 REST 端点。 -
POLL_INTERVAL_SEC:轮询之间的秒数。 -
SERVERS:此站点的数据网格服务器列表。该脚本只需要一个有效的响应,但提供了列表以允许故障切换。 -
REMOTE_SITES: 要监控这些服务器上的远程站点列表。 -
CACHES:要监控的缓存名称列表。
其他资源
使用 Prometheus 指标监控跨站点复制
Prometheus 和其他监控系统可让您配置警报来检测站点状态何时更改为 离线。
监控跨站点延迟指标可帮助您发现潜在的问题。
先决条件
- 启用跨站点复制。
流程
- 配置数据网格指标。
使用 Prometheus 指标格式配置警报规则。
-
对于站点状态,
在线使用1,0代表离线。 对于
exprfiled,请使用以下格式:vendor_cache_manager_default_cache_<cache name>_x_site_admin_<site name>_status。在以下示例中,当 NYC 站点为名为
work或 session 的缓存离线时,Prometheus会发出警告。groups: - name: Cross Site Rules rules: - alert: Cache Work and Site NYC expr: vendor_cache_manager_default_cache_work_x_site_admin_nyc_status == 0 - alert: Cache Sessions and Site NYC expr: vendor_cache_manager_default_cache_sessions_x_site_admin_nyc_status == 0下图显示了 NYC 站点
离线进行缓存工作的警报。图 4.1. Prometheus Alert

-
对于站点状态,
第 5 章 配置 JVM 内存用量
控制 Data Grid 如何通过以下方式将数据存储在 JVM 内存中:
- 使用驱除来管理 JVM 内存用量,以自动从缓存中删除数据。
- 将 lifespan 和最大空闲时间添加到过期条目,并防止过时的数据。
- 配置 Data Grid 以将数据保存在非堆原生内存中.
5.1. 默认内存配置
默认情况下,Data Grid 将缓存条目作为对象存储在 JVM 堆中。随着应用添加条目的时间,缓存的大小可能会超过 JVM 可用的内存量。同样,如果 Data Grid 不是主要数据存储,则条目已过时,这意味着您的缓存包含过时的数据。
XML
<distributed-cache> <memory storage="HEAP"/> </distributed-cache>
JSON
{
"distributed-cache": {
"memory" : {
"storage": "HEAP"
}
}
}
YAML
distributedCache:
memory:
storage: "HEAP"
5.2. 驱除和过期
驱除和过期是通过删除旧未使用的条目来清理数据容器的两个策略。虽然驱除和过期时间类似,但它们有一些重要的区别。
- 当容器变得大于配置的阈值时,Data Grid 驱除可让 Data Grid 控制数据容器的大小。
-
rhacm 到期时间限制可以存在的时间条目量。Data Grid 使用调度程序来定期删除过期的条目。过期的但尚未删除的条目会在访问时立即删除;在本例中,已过期条目的
get ()调用返回 "null" 值。 - HEKETI 驱除是 Data Grid 节点的本地。
- 在 Data Grid 集群中进行 5-6 过期。
- swig 您可以将驱除和过期一起使用,也可以相互独立使用。
-
您可以在
infinispan.xml中以声明性方式配置驱除和过期,以便为条目应用缓存范围内的默认值。 - swig 您可以为特定条目显式定义过期设置,但无法基于每个条目定义驱除。
- xmlrpc,您可以手动驱除条目并手动触发过期。
5.3. 使用 Data Grid 缓存驱除
驱除可让您以两种方式之一从内存中删除条目来控制数据容器的大小:
-
条目总数(
max-count)。 -
最大内存量(
max-size)。
驱除一次从数据容器丢弃一个条目,并且对发生的节点而言是本地的。
驱除从内存中删除条目,但不会从持久缓存存储中删除条目。要确保条目在 Data Grid 驱除它们后仍然可用,并防止数据不一致,您应该配置持久性存储。
当您配置 内存 时,Data Grid 大致大致是数据容器的当前内存用量。添加或修改条目时,Data Grid 将数据容器的当前内存用量与最大大小进行比较。如果大小超过最大值,Data Grid 会执行驱除。
驱除会在线程中立即发生,添加超过最大大小的条目。
5.3.1. 驱除策略
当您配置 Data Grid 驱除时,您可以指定:
- 数据容器的最大大小。
- 在缓存达到阈值时删除条目的策略。
您可以手动执行驱除,或者将 Data Grid 配置为执行以下操作之一:
- 删除旧条目以为新条目腾出空间。
抛出
ContainerFullException,并阻止创建新条目。例外驱除策略只适用于使用 2 阶段提交的事务缓存,而不适用于 1 阶段提交或同步优化。
有关驱除策略的详情,请参阅架构引用。
Data Grid 包括 Caffeine 缓存库,它实现了 Least Frequently Used (LFU)缓存替换算法,称为 TinyLFU。对于非堆存储,Data Grid 使用 Least Recently Used (LRU)算法的自定义实现。
其他资源
5.3.2. 配置最大计数驱除
将 Data Grid 缓存的大小限制为条目总数。
流程
- 打开 Data Grid 配置以进行编辑。
-
指定缓存在 Data Grid 执行驱除前可以包含的条目总数,使用
max-count属性或maxCount ()方法。 将以下之一设置为驱除策略,以控制 Data Grid 如何使用
when-full属性或Full ()方法删除条目。-
REMOVEData Grid 执行驱除。这是默认策略。 -
MANUAL为嵌入式缓存手动执行驱除。 -
EXCEPTIONData Grid 会抛出异常而不是驱除条目。
-
- 保存并关闭您的 Data Grid 配置。
最大计数驱除
在以下示例中,当缓存包含总计 500 个条目和新条目时,Data Grid 会删除条目:
XML
<distributed-cache> <memory max-count="500" when-full="REMOVE"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"memory" : {
"max-count" : "500",
"when-full" : "REMOVE"
}
}
}
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "REMOVE"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(500).whenFull(EvictionStrategy.REMOVE);
5.3.3. 配置最大大小驱除
将 Data Grid 缓存的大小限制为最大内存量。
流程
- 打开 Data Grid 配置以进行编辑。
指定
application/x-protostream作为缓存编码的介质类型。您必须指定二进制介质类型才能使用最大大小驱除。
-
配置最大内存量(以字节为单位),缓存可在 Data Grid 使用
max-size属性或maxSize ()方法执行驱除前使用。 (可选)指定测量单位。
默认值为 B (字节)。请参阅 支持的单元的配置模式。
将以下之一设置为驱除策略,以控制 Data Grid 如何使用
when-full属性或whenFull ()方法删除条目。-
REMOVEData Grid 执行驱除。这是默认策略。 -
MANUAL为嵌入式缓存手动执行驱除。 -
EXCEPTIONData Grid 会抛出异常而不是驱除条目。
-
- 保存并关闭您的 Data Grid 配置。
最大大小驱除
在以下示例中,当缓存的大小达到 1.5 GB (千兆字节)和新条目时,Data Grid 会删除条目:
XML
<distributed-cache> <encoding media-type="application/x-protostream"/> <memory max-size="1.5GB" when-full="REMOVE"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"encoding" : {
"media-type" : "application/x-protostream"
},
"memory" : {
"max-size" : "1.5GB",
"when-full" : "REMOVE"
}
}
}
YAML
distributedCache:
encoding:
mediaType: "application/x-protostream"
memory:
maxSize: "1.5GB"
whenFull: "REMOVE"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
5.3.4. 手动驱除
如果您选择手动驱除策略,Data Grid 不会执行驱除。您必须使用 evict () 方法手动完成此操作。
您应该只在嵌入式缓存中使用手动驱除。对于远程缓存,您应该始终使用 REMOVE 或 EXCEPTION 驱除策略配置 Data Grid。
此配置可防止当您启用 passivation 时警告信息,但没有配置驱除。
XML
<distributed-cache> <memory max-count="500" when-full="MANUAL"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"memory" : {
"max-count" : "500",
"when-full" : "MANUAL"
}
}
}
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "MANUAL"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
5.3.5. 使用驱除进行传递
当 Data Grid 驱除条目时,传递会保留数据到缓存存储。如果启用 passivation,则应始终启用驱除,如下例所示:
XML
<distributed-cache>
<persistence passivation="true">
<!-- Persistent storage configuration. -->
</persistence>
<memory max-count="100"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"memory" : {
"max-count" : "100"
},
"persistence" : {
"passivation" : true
}
}
}
YAML
distributedCache:
memory:
maxCount: "100"
persistence:
passivation: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(100); builder.persistence().passivation(true); //Persistent storage configuration
5.4. 带有生命周期和最大闲置的过期时间
expiration 配置 Data Grid,以便在达到以下时间限制时从缓存中删除条目:
- Lifespan
- 设置条目可以存在的最长时间。
- 最大闲置
- 指定条目可以保持闲置的时长。如果没有对条目发生操作,则它们就会被闲置。
最大闲置过期目前不支持使用持久性存储的缓存。
如果您将过期和驱除用于 EXCEPTION 驱除策略、已过期但尚未从缓存中删除的条目,则计数为数据容器的大小。
5.4.1. 过期如何工作
当您配置过期时,Data Grid 会使用决定何时过期的元数据存储密钥。
-
lifespan 使用
创建时间戳和 lifespan配置属性的值。 -
最大闲置使用
最后一个使用的时间戳,以及max-idle配置属性的值。
Data Grid 检查是否设置了 lifespan 或最大空闲元数据,然后将值与当前时间进行比较。
如果 (creation + lifespan < currentTime) 或 (lastUsed + maxIdle < currentTime),Data Grid 检测到该条目已过期。
每当访问条目或由过期后找到条目时,就会过期。
例如,k1 达到最大空闲时间,客户端发出 Cache.get (k1) 请求。在这种情况下,Data Grid 检测到条目已过期,并将其从数据容器中删除。Cache.get (k1) 请求返回 null。
网格也会从缓存存储中过期条目,但只适用于生命周期到期。最大闲置过期不适用于缓存存储。对于缓存加载程序,Data Grid 无法使条目过期,因为加载程序只能从外部存储读取。
Data Grid 将 长 原语数据类型添加到缓存条目的过期元数据。这可增加密钥的大小,其大小为 32 字节。
5.4.2. 过期原因
Data Grid 使用一个定期运行的收款线程来检测和删除过期的条目。过期后期将确保不再访问的过期条目已被删除。
Data Grid ExpirationManager 接口处理 expiration reaper,并公开 processExpiration () 方法。
在某些情况下,您可以禁用过期时间恢复程序并通过调用 processExpiration () 来手动过期条目;例如,如果您使用本地缓存模式并定期运行维护线程的自定义应用程序。
如果使用集群缓存模式,则永远不会禁用过期过程。
在使用缓存存储时,网格始终使用过期程序。在这种情况下,您无法禁用它。
5.4.3. 最大闲置和集群缓存
因为最大闲置过期取决于缓存条目的最后访问时间,所以它有一些集群缓存模式的限制。
通过生命周期期限,缓存条目的创建时间提供跨集群缓存的一致性值。例如,所有节点上的 k1 创建时间都相同。
对于使用集群缓存的最大闲置过期,条目的最后访问时间并不始终在所有节点上相同。为确保在集群间都有相同的相对访问时间,当访问密钥时,Data Grid 会将 touch 命令发送到所有所有者。
Data Grid 发送的 touch 命令具有以下注意事项:
-
cache.get ()请求不会返回,直到所有 touch 命令都完成。此同步行为会增加客户端请求的延迟。 - touch 命令还会更新所有所有者上的缓存条目的"重新访问"元数据,Data Grid 用于驱除。
附加信息
- 最大闲置过期不适用于 invalidation 模式。
- 集群缓存中的迭代可以返回超过最大空闲时间限制的过期条目。此行为可确保性能,因为在迭代过程中不会执行远程调用。另请注意,迭代不会刷新任何过期的条目。
5.4.4. 为缓存配置 lifespan 和最大闲置时间
为缓存中的所有条目设置 lifespan 和最大闲置时间。
流程
- 打开 Data Grid 配置以进行编辑。
-
指定条目可以使用
lifespan属性或lifespan ()方法保留在缓存中的时间(以毫秒为单位)。 -
使用
max-idle属性或maxIdle ()方法,指定条目在最后一次访问后可以保持闲置的时间(以毫秒为单位)。 - 保存并关闭您的 Data Grid 配置。
Data Grid 缓存过期
在以下示例中,Data Grid 会在最后一次访问时间后 5 秒或 1 秒后过期所有缓存条目,以先发生:
XML
<replicated-cache> <expiration lifespan="5000" max-idle="1000" /> </replicated-cache>
JSON
{
"replicated-cache" : {
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
}
}
}
YAML
replicatedCache:
expiration:
lifespan: "5000"
maxIdle: "1000"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.expiration().lifespan(5000, TimeUnit.MILLISECONDS)
.maxIdle(1000, TimeUnit.MILLISECONDS);
5.4.5. 配置每个条目的 lifespan 和最大闲置时间
为单个条目指定 lifespan 和最大闲置时间。当您向条目添加 lifespan 和最大闲置时间时,这些值优先于缓存过期配置。
当您为缓存条目明确定义 lifespan 和最大空闲时间值时,Data Grid 会在集群中复制这些值,以及缓存条目。同样,Data Grid 也会将过期值和条目写入持久性存储。
流程
对于远程缓存,您可以将 lifespan 和最大闲置时间添加到通过 Data Grid 控制台交互的条目。
使用 Data Grid 命令行界面(CLI),通过
put命令使用--max-idle参数。=和--ttl=对于远程和嵌入式缓存,您可以使用
cache.put ()调用添加 lifespan 和 maximum idle times。//Lifespan of 5 seconds. //Maximum idle time of 1 second. cache.put("hello", "world", 5, TimeUnit.SECONDS, 1, TimeUnit.SECONDS); //Lifespan is disabled with a value of -1. //Maximum idle time of 1 second. cache.put("hello", "world", -1, TimeUnit.SECONDS, 1, TimeUnit.SECONDS);
5.5. JVM heap 和 off-heap 内存
默认情况下,Data Grid 将缓存条目存储在 JVM 堆内存中。您可以将 Data Grid 配置为使用非堆存储,这意味着您的数据会占用受管 JVM 内存空间之外的原生内存。
下图显示了运行 Data Grid 的 JVM 进程的内存空间:
图 5.1. JVM 内存空间

JVM 堆内存
堆分为年轻而旧代,可帮助在内存中保持引用的 Java 对象和其他应用数据。GC 进程从无法访问的对象回收空间,在生成内存池中更频繁地运行。
当 Data Grid 将缓存条目存储在 JVM 堆内存中时,GC 运行可能需要更长的时间才能开始向缓存中添加数据。因为 GC 是一个密集型过程,所以更频繁地运行可能会降低应用程序性能。
off-heap 内存
off-heap 内存是 JVM 内存管理之外的原生可用内存。JVM 内存空间 图显示包含类元数据且从原生内存分配的 Metaspace 内存池。该图还代表了包含 Data Grid 缓存条目的原生内存部分。
off-heap 内存:
- 每个条目使用较少的内存。
- 通过避免 Garbage Collector (GC)运行来提高整体 JVM 性能。
但是,一个缺点是 JVM 堆转储不显示存储在 off-heap 内存中的条目。
5.5.1. 非堆数据存储
当您向现成缓存中添加条目时,Data Grid 会动态地为您的数据分配原生内存。
Data Grid 将每个 键的序列化字节[] 哈希到与标准 Java HashMap 类似的存储桶中。bucket 包括 Data Grid 用来查找存储在 off-heap 内存中的条目的地址指针。
虽然 Data Grid 将缓存条目存储在原生内存中,但运行时操作需要这些对象的 JVM 堆表示。例如,cache.get () 操作会在返回前将对象读取到堆内存中。同样,状态传输操作在堆内存中保存对象子集。
对象相等
Data Grid 使用每个对象的序列化字节[]表示,而不是对象实例,以非堆存储的形式确定 Java 对象的相等性。
数据一致性
Data Grid 使用数组锁定来保护非堆地址空间。锁定的数量是内核数的两倍,然后舍入到最接近的 2 的指数。这样可确保存在 ReadWriteLock 实例甚至分配,以防止写入操作阻止读操作。
5.5.2. 配置离线内存
配置 Data Grid,以将缓存条目存储在 JVM 堆空间之外的原生内存中。
流程
- 打开 Data Grid 配置以进行编辑。
-
将
OFF_HEAP设置为storage属性或storage ()方法的值。 - 通过配置驱除来为缓存大小设置边界。
- 保存并关闭您的 Data Grid 配置。
off-heap 存储
网格将缓存条目存储为原生内存中的字节。当数据容器中有 100 个条目,并且 Data Grid 获取创建新条目的请求时发生驱除:
XML
<replicated-cache> <memory storage="OFF_HEAP" max-count="500"/> </replicated-cache>
JSON
{
"replicated-cache" : {
"memory" : {
"storage" : "OFF_HEAP",
"max-count" : "500"
}
}
}
YAML
replicatedCache:
memory:
storage: "OFF_HEAP"
maxCount: "500"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().storage(StorageType.OFF_HEAP).maxCount(500);
第 6 章 配置持久性存储
网格使用缓存存储和加载程序与持久性存储交互。
- 持久性
- 通过添加缓存存储,您可以将数据持久化到非易失性存储中,以便在重启后保留。
- 直写缓存
- 将 Data Grid 配置为持久性存储前面的缓存层简化了应用程序的数据访问,因为 Data Grid 处理与外部存储的所有交互。
- 数据溢出
- 使用驱除和传递技术可确保 Data Grid 只保留频繁使用的数据在内存中,并将旧的条目写入持久性存储。
6.1. passivation
传递配置 Data Grid,以便在从内存中驱除这些条目时将条目写入缓存存储。这样,传递可以防止不必要的,可能昂贵的写入持久性存储。
当尝试访问传递的条目时,激活是从缓存存储恢复到内存的过程。因此,当启用传递时,您必须配置实现 CacheWriter 和 CacheLoader 接口的缓存存储,以便它们可以从持久性存储写入和加载条目。
当 Data Grid 从缓存中驱除条目时,它会通知缓存监听程序,该条目被传递,然后将条目存储在缓存存储中。当 Data Grid 获得对被驱除条目的访问请求时,它会很快地将缓存存储中的条目加载到内存中,然后通知缓存监听程序,使条目在存储中保持仍然在存储中。
- passivation 使用 Data Grid 配置中的第一个缓存加载程序,并忽略所有其他缓存。
不支持 passivation:
- 事务性存储.传递写入并从实际 Data Grid 提交边界范围以外的存储中删除条目。
- 共享存储。共享缓存存储需要条目始终存在于其他所有者的存储中。因此,不支持 passivation,因为无法删除条目。
如果您启用对事务存储或共享存储的 passivation,Data Grid 会抛出异常。
6.1.1. 传递是如何工作的
禁用传递
写入内存中的数据会导致写入持久性存储。
如果 Data Grid 从内存中驱除数据,则持久性存储中的数据包括从内存中驱除的条目。这样,持久性存储是内存缓存的超集。当您需要最高一致性时,建议您这样做,因为存储可以在崩溃后再次读取。
如果没有配置驱除,则持久性存储中的数据会在内存中提供数据副本。
启用 passivation
网格仅在从内存驱除数据时将数据添加到持久性存储中,条目会被删除或关闭该节点。
当 Data Grid 激活条目时,它会在内存中恢复数据,但仍然保留存储中的数据。这样,写入可以在没有存储的情况下尽快进行,并且仍然保持一致性。当只创建或更新一个条目时,将更新内存中的,因此存储将已过时。
当存储也配置为共享时,不支持 passivation。这是因为当写入被驱除与读相比,条目可能会在节点间不同步。
为了提高数据一致性,任何不是共享的存储都应启用 purgeOnStartup。对于启用或禁用 passivation,因此这是正确的,因为存储可能会保存一个过时的条目,同时停止它,并在以后被忽略。
下表显示了在一系列操作后内存和持久性存储中的数据:
| 操作 | 禁用传递 | 启用 passivation |
|---|---|---|
| 插入 k1。 |
memory: k1 |
内存: k1 |
| 插入 k2. |
memory: k1, k2 |
memory: k1, k2 |
| 驱除线程运行和驱除 k1。 |
memory: k2 |
memory: k2 |
| 读取 k1。 |
memory: k1, k2 |
memory: k1, k2 |
| 驱除线程运行和驱除 k2。 |
memory: k1 |
memory: k1 |
| 删除 k2。 |
memory: k1 |
memory: k1 |
6.2. 直写缓存存储
直写模式是一种缓存写入模式,对缓存存储进行写入和写入是同步的。当客户端应用程序通过调用 Cache.put () 更新缓存条目时,在大多数情形中,Data Grid 不会返回调用,直到更新缓存存储为止。这个缓存写入模式会导致客户端线程边界内对缓存存储进行更新。
write-through 模式的主要优点是,缓存和缓存存储会同时更新,这样可确保缓存存储始终与缓存一致。
但是,直写模式可能会降低性能,因为访问和更新缓存存储直接为缓存操作添加延迟。
直写配置
网格使用直写模式,除非您在缓存中明确添加 write-behind 配置。配置直写模式没有单独的元素或方法。
例如,以下配置在隐式使用 write-through 模式的缓存中添加了一个基于文件的存储:
<distributed-cache>
<persistence passivation="false">
<file-store>
<index path="path/to/index" />
<data path="path/to/data" />
</file-store>
</persistence>
</distributed-cache>6.3. write-behind 缓存存储
write-behind 是一个缓存写入模式,对内存的写入是同步的,对缓存存储的写入是异步的。
当客户端发送写入请求时,Data Grid 会将这些操作添加到修改队列中。Data Grid 在它们加入队列时处理操作,因此调用线程不会被阻止,操作会立即完成。
如果修改队列中的写入操作数量超过队列的大小,Data Grid 会将这些额外的操作添加到队列中。但是,在 Data Grid 进程已在队列中已有的操作之前,这些操作才会完成。
例如,调用 Cache.putAsync 可立即返回,如果修改队列未满,Stage 也会立即完成。如果修改队列已满,或者 Data Grid 当前正在处理一系列写入操作,则 Cache.putAsync 立即返回,Stage 则完成。
write-behind 模式比直写模式提供了性能优势,因为缓存操作不需要等待对底层缓存存储的更新完成。但是,缓存存储中的数据会与缓存中的数据不一致,直到处理修改队列为止。因此,write-behind 模式适用于具有低延迟的缓存存储,如未共享和基于文件的缓存存储,其中写入缓存的时间和对缓存存储的写入是尽可能小的。
write-behind 配置
XML
<distributed-cache>
<persistence>
<table-jdbc-store xmlns="urn:infinispan:config:store:sql:15.0"
dialect="H2"
shared="true"
table-name="books">
<connection-pool connection-url="jdbc:h2:mem:infinispan"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
<write-behind modification-queue-size="2048"
fail-silently="true"/>
</table-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"table-jdbc-store": {
"dialect": "H2",
"shared": "true",
"table-name": "books",
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
},
"write-behind" : {
"modification-queue-size" : "2048",
"fail-silently" : true
}
}
}
}
}
YAML
distributedCache:
persistence:
tableJdbcStore:
dialect: "H2"
shared: "true"
tableName: "books"
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan"
driver: "org.h2.Driver"
username: "sa"
password: "changeme"
writeBehind:
modificationQueueSize: "2048"
failSilently: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.async()
.modificationQueueSize(2048)
.failSilently(true);
静默失败
write-behind 配置包含一个 fail-silently 参数,用于控制缓存存储不可用或者修改队列已满时发生的情况。
-
如果
fail-silently="true",Data Grid 会记录 WARN 消息并拒绝写操作。 如果
fail-silently="false",如果 Data Grid 在写操作过程中检测到缓存存储不可用,则 Data Grid 会抛出异常。同样,如果修改队列已满,Data Grid 会抛出异常。在某些情况下,如果修改队列中存在 Data Grid 重启和写操作,则可能会出现数据丢失。例如,缓存存储离线,但在检测缓存存储不可用时,写入操作会添加到修改队列中,因为它没有满。如果在缓存存储恢复前 Data Grid 重启或其他不可用,则修改队列中的写入操作将会丢失,因为它们不会被保留。
6.4. 分段缓存存储
缓存存储可以将数据组织到哪些键映射的散列空间片段中。
片段存储提高了批量操作的读取性能;例如,通过数据流(Cache.size、Cache.entrySet.stream)、预加载缓存以及执行状态传输操作。
但是,片段存储也可以导致写操作的性能丢失。此性能丢失特别适用于批量写入操作,它们可能会发生事务或写入性存储。因此,您应该在启用网段存储前评估写操作的开销。如果写入操作有显著的性能损失,则批量读取操作的性能可能无法接受。
为缓存存储配置的片段数量必须与您在 Data Grid 配置中定义的片段数与 cluster. hash.numSegments 参数匹配。
如果在添加分段缓存存储后更改了配置中的 numSegments 参数,Data Grid 无法从该缓存存储中读取数据。
6.6. 带有持久缓存存储的事务
Data Grid 仅支持使用基于 JDBC 的缓存存储的事务操作。要将缓存配置为事务,请设置 transactional=true,使持久性存储中的数据与内存中的数据同步。
对于所有其他缓存存储,Data Grid 在事务操作中不会包括缓存加载程序。如果事务成功在内存中修改数据,这可能会导致数据不一致,但不会完全应用缓存存储中数据的更改。在这些情况下,无法使用缓存存储进行手动恢复。
6.7. 全局持久性位置
Data Grid 保留全局状态,以便它在重启后可以恢复集群拓扑和缓存的数据。
Data Grid 使用文件锁定来防止并发访问全局持久位置。锁定在启动时获取,并在节点关闭时释放。存在悬停的锁定文件表示节点没有完全关闭,无论是因为崩溃或外部终止而被完全关闭。在默认配置中,Data Grid 将拒绝启动以避免出现以下消息的数据损坏:
ISPN000693: Dangling lock file '%s' in persistent global state, probably left behind by an unclean shutdown
通过将全局状态 unclean-shutdown-action 设置配置为以下之一来更改行为:
-
FAIL: 如果 dangling 锁定文件处于持久的全局状态,则缓存管理器的启动。这是默认的行为。 -
PURGE:清除持久的全局状态,如果 dangling 锁定文件处于持久全局状态。 -
IGNORE:忽略持久性全局状态下形锁定文件。
远程缓存
Data Grid 服务器将集群状态保存到 $RHDG_HOME/server/data 目录中。
您不应该删除或修改 server/data 目录或其内容。在重启服务器实例时,Data Grid 从此目录恢复集群状态。
更改默认配置或直接修改 server/data 目录可能会导致意外行为,并导致数据丢失。
嵌入式缓存
Data Grid 默认为 user.dir 系统属性作为全局持久位置。在大多数情况下,这是应用程序启动的目录。
对于复制或分布式集群嵌入式缓存,您应该始终启用并配置全局持久位置来恢复集群拓扑。
您永远不会为基于文件的缓存存储配置绝对路径,该存储位于全局持久位置之外。如果您这样做,Data Grid 会将以下例外写入日志:
ISPN000558: "The store location 'foo' is not a child of the global persistent location 'bar'"
6.7.1. 配置全局持久位置
启用并配置 Data Grid 存储集群嵌入式缓存的全局状态的位置。
Data Grid 服务器实现全局持久性并配置默认位置。您不应该禁用全局持久性或更改远程缓存的默认配置。
先决条件
- 将 Data Grid 添加到您的项目。
流程
使用以下方法之一启用全局状态:
-
将
global-state元素添加到您的 Data Grid 配置中。 -
在
GlobalConfigurationBuilderAPI 中调用globalState ().enable ()方法。
-
将
定义全局持久位置是否对每个节点是唯一的,还是在集群间共享。
位置类型 配置 每个节点的唯一
persistent-location元素或persistentLocation ()方法在集群中共享
shared-persistent-location元素或sharedPersistentLocation (String)方法设置 Data Grid 存储集群状态的路径。
例如,基于文件的缓存存储了路径是主机文件系统上的目录。
值可以是:
- 绝对并包含完整位置,包括 root 用户。
- 相对于根位置。
如果为路径指定相对值,还必须指定一个解析为根位置的系统属性。
例如,在 Linux 主机系统中,您将
global/state设置为路径。您还可以设置解析到/opt/data根位置的my.data属性。在这种情况下,Data Grid 使用/opt/data/global/state作为全局持久位置。
全局持久性位置配置
XML
<infinispan>
<cache-container>
<global-state>
<persistent-location path="global/state" relative-to="my.data"/>
</global-state>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"global-state": {
"persistent-location" : {
"path" : "global/state",
"relative-to" : "my.data"
}
}
}
}
}
YAML
cacheContainer:
globalState:
persistentLocation:
path: "global/state"
relativeTo : "my.data"
GlobalConfigurationBuilder
new GlobalConfigurationBuilder().globalState()
.enable()
.persistentLocation("global/state", "my.data");
6.8. 基于文件的缓存存储
基于文件的缓存存储可在运行 Data Grid 的本地主机文件系统上提供持久存储。对于集群缓存,基于文件的缓存存储对于每个 Data Grid 节点都是唯一的。
切勿将基于文件系统的缓存存储在共享文件系统上,如 NFS 或 Samba 共享,因为它们不提供文件锁定功能和数据损坏。
另外,如果您试图将事务缓存与共享文件系统搭配使用,在提交阶段写入文件时可能会出现不可恢复的故障。
soft-Index File Stores
SoftIndexFileStore 是基于文件的缓存存储的默认实现,并将数据存储在一组仅附加文件中。
当只附加文件时:
- 达到其最大大小时,Data Grid 会创建一个新文件并开始写入该文件。
- 达到低于 50% 的压缩阈值,Data Grid 将条目覆盖新文件,然后删除旧文件。
在集群缓存中使用 SoftIndexFileStore 应该在启动时启用清除,以确保不会重新恢复过时的条目。
b+ 树
为提高性能,SoftIndexFileStore 中仅附加文件使用可保存在磁盘和内存中的 B+ Tree 进行索引。内存中索引使用 Java 软引用来确保如果由 Garbage Collection (GC)删除,则可以重新构建它,然后再次请求。
由于 SoftIndexFileStore 使用 Java 软引用来在内存中保留索引,因此这有助于防止内存不足异常。GC 在消耗太多内存前删除索引,同时仍然回退到磁盘。
SoftIndexFileStore 为每个配置的缓存段创建一个 B+ 树。这提供了一个额外的 "index",因为它只有多个元素,并为索引更新提供额外的并行性。目前,我们允许一个基于缓存片段数量的 6 个并行数量。
B+ 树中的每个条目都是节点。默认情况下,每个节点的大小限制为 4096 字节。如果密钥在序列化发生后较长,SoftIndexFileStore 会抛出异常。
文件限制
SoftIndexFileStore 将使用两个以及给定时间配置的 openFilesLimit 数量。为新更新的数据保留两个额外的文件指针,为日志附加器保留另一个用于压缩条目到新文件中。
为索引分配的打开的文件量是配置的 openFilesLimit 的总数之一。这个数字至少为 1 或缓存片段数。为打开数据文件本身分配从配置的限制中重新处理的任何数字。
分段
软索引文件存储始终是网段的。附加日志不是直接分段的,分段直接由索引处理。
过期
SoftIndexFileStore 对过期条目及其要求有全面支持。
单个文件缓存存储
单个文件缓存存储现已弃用,并计划删除。
单个文件缓存存储,SingleFileStore,将数据保留到文件。Data Grid 还维护一个键的内存中索引,而键和值则存储在文件中。
由于 SingleFileStore 保留一个键的内存索引和值位置,因此需要额外的内存,具体取决于密钥大小和键数量。因此,对于密钥较大或者数量较大,我们不推荐使用 SingleFileStore。
在某些情况下,SingleFileStore 也可以变得碎片。如果值大小持续增加,则不会使用单个文件中的可用空间,但该条目会附加到文件末尾。只有在条目可以适合时,才会使用文件中的可用空间。同样,如果您从内存中删除所有条目,则单个文件存储不会减小或进行碎片整理。
分段
默认情况下,单个文件缓存存储被分段为为每个片段有一个单独的实例,这会导致多个目录。每个目录都是代表数据映射段的数字。
6.8.1. 配置基于文件的缓存存储
将基于文件的缓存存储到 Data Grid,以在主机文件系统中保留数据。
先决条件
- 如果您要配置嵌入式缓存,请启用全局状态并配置全局持久位置。
流程
-
在您的缓存配置中添加
persistence元素。 -
(可选)指定
true作为passivation属性的值,以便仅在数据从内存中驱除时写入基于文件的缓存存储。 -
包含
file-store元素,并根据情况配置属性。 指定
false作为shared属性的值。基于文件的缓存存储对于每个 Data Grid 实例应始终是唯一的。如果要在集群中使用相同的持久性,请配置基于 JDBC 字符串的缓存存储等共享存储。
-
配置
索引和数据元素,以指定 Data Grid 创建索引并存储数据的位置。 -
如果要使用
write-behind模式配置缓存存储,请包含 write-behind 元素。
基于文件的缓存存储配置
XML
<distributed-cache>
<persistence passivation="true">
<file-store shared="false">
<data path="data"/>
<index path="index"/>
<write-behind modification-queue-size="2048" />
</file-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"passivation": true,
"file-store" : {
"shared": false,
"data": {
"path": "data"
},
"index": {
"path": "index"
},
"write-behind": {
"modification-queue-size": "2048"
}
}
}
}
}
YAML
distributedCache:
persistence:
passivation: "true"
fileStore:
shared: "false"
data:
path: "data"
index:
path: "index"
writeBehind:
modificationQueueSize: "2048"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().passivation(true)
.addSoftIndexFileStore()
.shared(false)
.dataLocation("data")
.indexLocation("index")
.modificationQueueSize(2048);
6.8.2. 配置单个文件缓存存储
如果需要,您可以将 Data Grid 配置为创建单个文件存储。
单个文件存储已弃用。与单个文件存储相比,您应该使用 soft-index 文件存储来提高性能和数据一致性。
先决条件
- 如果您要配置嵌入式缓存,请启用全局状态并配置全局持久位置。
流程
-
在您的缓存配置中添加
persistence元素。 -
(可选)指定
true作为passivation属性的值,以便仅在数据从内存中驱除时写入基于文件的缓存存储。 -
包含
single-file-store元素。 -
指定
false作为shared属性的值。 - 根据需要配置任何其他属性。
-
包含
write-behind元素,将缓存存储配置为后面的写入,而不是作为写入。
单个文件缓存存储配置
XML
<distributed-cache>
<persistence passivation="true">
<single-file-store shared="false"
preload="true"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"passivation" : true,
"single-file-store" : {
"shared" : false,
"preload" : true
}
}
}
}
YAML
distributedCache:
persistence:
passivation: "true"
singleFileStore:
shared: "false"
preload: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().passivation(true)
.addStore(SingleFileStoreConfigurationBuilder.class)
.shared(false)
.preload(true);
6.9. JDBC 连接工厂
Data Grid 提供不同的 ConnectionFactory 实施,供您连接到数据库。您可以将 JDBC 连接与 SQL 缓存存储搭配使用,以及基于 JDBC 字符串的缓存存储。
连接池
连接池适合独立 Data Grid 部署,且基于 Agroal。
XML
<distributed-cache>
<persistence>
<connection-pool connection-url="jdbc:h2:mem:infinispan;DB_CLOSE_DELAY=-1"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan_string_based",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
YAML
distributedCache:
persistence:
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan_string_based;DB_CLOSE_DELAY=-1"
driver: org.h2.Driver
username: sa
password: changeme
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan_string_based;DB_CLOSE_DELAY=-1")
.username("sa")
.driverClass("org.h2.Driver");
受管数据源
数据源连接适合托管环境,如应用服务器。
XML
<distributed-cache>
<persistence>
<data-source jndi-url="java:/StringStoreWithManagedConnectionTest/DS" />
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"data-source": {
"jndi-url": "java:/StringStoreWithManagedConnectionTest/DS"
}
}
}
}
YAML
distributedCache:
persistence:
dataSource:
jndiUrl: "java:/StringStoreWithManagedConnectionTest/DS"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.dataSource()
.jndiUrl("java:/StringStoreWithManagedConnectionTest/DS");
简单连接
简单的连接工厂在每个调用基础上创建数据库连接,仅用于测试或开发环境。
XML
<distributed-cache>
<persistence>
<simple-connection connection-url="jdbc:h2://localhost"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"simple-connection": {
"connection-url": "jdbc:h2://localhost",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
YAML
distributedCache:
persistence:
simpleConnection:
connectionUrl: "jdbc:h2://localhost"
driver: org.h2.Driver
username: sa
password: changeme
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.simpleConnection()
.connectionUrl("jdbc:h2://localhost")
.driverClass("org.h2.Driver")
.username("admin")
.password("changeme");
其他资源
6.9.1. 配置受管数据源
作为 Data Grid 服务器配置的一部分创建受管数据源,以优化 JDBC 数据库连接的连接池和性能。然后,您可以在缓存中指定受管数据源的 JDNI 名称,它将为您的部署集中 JDBC 连接配置。
先决条件
将数据库驱动程序复制到 Data Grid Server 安装中的
server/lib目录中。提示使用带有 Data Grid 命令行界面(CLI)的
install命令,将所需的驱动程序下载到server/lib目录中,例如:install org.postgresql:postgresql:42.4.3
流程
- 打开 Data Grid Server 配置以进行编辑。
-
在
data-sources部分添加新的数据源 -
使用
name属性或字段唯一标识数据源。 使用
jndi-name属性或字段为数据源指定 JNDI 名称。提示您可以使用 JNDI 名称在 JDBC 缓存存储配置中指定数据源。
-
将
true设置为statistics属性或字段的值,以通过/metrics端点启用数据源的统计信息。 提供 JDBC 驱动程序详细信息,用于定义如何在
connection-factory部分中连接到数据源。-
使用
driver属性或字段指定数据库驱动程序的名称。 -
使用 url 属性或字段指定 JDBC 连接
url。 -
使用
用户名和密码属性或字段指定 - 根据需要提供任何其他配置。
-
使用
-
定义 Data Grid Server 节点如何池,并在
connection-pool部分中定义连接池调优属性的连接。 - 保存对配置的更改。
验证
使用 Data Grid 命令行界面(CLI)测试数据源连接,如下所示:
启动 CLI 会话。
bin/cli.sh
列出所有数据源,并确认您创建的数据源可用。
server datasource ls
测试数据源连接。
server datasource test my-datasource
受管数据源配置
XML
<server xmlns="urn:infinispan:server:15.0">
<data-sources>
<!-- Defines a unique name for the datasource and JNDI name that you
reference in JDBC cache store configuration.
Enables statistics for the datasource, if required. -->
<data-source name="ds"
jndi-name="jdbc/postgres"
statistics="true">
<!-- Specifies the JDBC driver that creates connections. -->
<connection-factory driver="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/postgres"
username="postgres"
password="changeme">
<!-- Sets optional JDBC driver-specific connection properties. -->
<connection-property name="name">value</connection-property>
</connection-factory>
<!-- Defines connection pool tuning properties. -->
<connection-pool initial-size="1"
max-size="10"
min-size="3"
background-validation="1000"
idle-removal="1"
blocking-timeout="1000"
leak-detection="10000"/>
</data-source>
</data-sources>
</server>
JSON
{
"server": {
"data-sources": [{
"name": "ds",
"jndi-name": "jdbc/postgres",
"statistics": true,
"connection-factory": {
"driver": "org.postgresql.Driver",
"url": "jdbc:postgresql://localhost:5432/postgres",
"username": "postgres",
"password": "changeme",
"connection-properties": {
"name": "value"
}
},
"connection-pool": {
"initial-size": 1,
"max-size": 10,
"min-size": 3,
"background-validation": 1000,
"idle-removal": 1,
"blocking-timeout": 1000,
"leak-detection": 10000
}
}]
}
}
YAML
server:
dataSources:
- name: ds
jndiName: 'jdbc/postgres'
statistics: true
connectionFactory:
driver: "org.postgresql.Driver"
url: "jdbc:postgresql://localhost:5432/postgres"
username: "postgres"
password: "changeme"
connectionProperties:
name: value
connectionPool:
initialSize: 1
maxSize: 10
minSize: 3
backgroundValidation: 1000
idleRemoval: 1
blockingTimeout: 1000
leakDetection: 10000
6.9.1.1. 使用 JNDI 名称配置缓存
将受管数据源添加到 Data Grid 服务器时,您可以将 JNDI 名称添加到基于 JDBC 的缓存存储配置中。
先决条件
- 使用托管数据源配置 Data Grid 服务器。
流程
- 打开缓存配置进行编辑。
-
将
data-source元素或字段添加到基于 JDBC 的缓存存储配置中。 -
将受管数据源的 JNDI 名称指定为
jndi-url属性的值。 - 根据情况配置基于 JDBC 的缓存存储。
- 保存对配置的更改。
缓存配置中的 JNDI 名称
XML
<distributed-cache>
<persistence>
<jdbc:string-keyed-jdbc-store>
<!-- Specifies the JNDI name of a managed datasource on Data Grid Server. -->
<jdbc:data-source jndi-url="jdbc/postgres"/>
<jdbc:string-keyed-table drop-on-exit="true" create-on-start="true" prefix="TBL">
<jdbc:id-column name="ID" type="VARCHAR(255)"/>
<jdbc:data-column name="DATA" type="BYTEA"/>
<jdbc:timestamp-column name="TS" type="BIGINT"/>
<jdbc:segment-column name="S" type="INT"/>
</jdbc:string-keyed-table>
</jdbc:string-keyed-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"string-keyed-jdbc-store": {
"data-source": {
"jndi-url": "jdbc/postgres"
},
"string-keyed-table": {
"prefix": "TBL",
"drop-on-exit": true,
"create-on-start": true,
"id-column": {
"name": "ID",
"type": "VARCHAR(255)"
},
"data-column": {
"name": "DATA",
"type": "BYTEA"
},
"timestamp-column": {
"name": "TS",
"type": "BIGINT"
},
"segment-column": {
"name": "S",
"type": "INT"
}
}
}
}
}
}
YAML
distributedCache:
persistence:
stringKeyedJdbcStore:
dataSource:
jndi-url: "jdbc/postgres"
stringKeyedTable:
prefix: "TBL"
dropOnExit: true
createOnStart: true
idColumn:
name: "ID"
type: "VARCHAR(255)"
dataColumn:
name: "DATA"
type: "BYTEA"
timestampColumn:
name: "TS"
type: "BIGINT"
segmentColumn:
name: "S"
type: "INT"
6.9.1.2. 连接池调优属性
您可以在 Data Grid Server 配置中针对受管数据源调整 JDBC 连接池。
| 属性 | 描述 |
|---|---|
|
| 池应保留的初始连接数。 |
|
| 池中的最大连接数。 |
|
| 池应保留的最小连接数。 |
|
|
在抛出异常前等待连接时的最大时间(毫秒)。如果创建新连接需要很长时间,则这永远不会抛出异常。默认值为 |
|
|
后台验证运行之间的时间(毫秒)。持续时间为 |
|
|
闲置的时间比这个时间更长的时间(以毫秒为单位指定)会在获取前验证(foreground 验证)。持续时间为 |
|
| 在几分钟内,连接必须处于闲置状态才能被删除。 |
|
| 在泄漏警告前,必须保留连接的时间(毫秒)。 |
6.9.2. 使用 Agroal 属性配置 JDBC 连接池
您可以使用属性文件为基于 JDBC 字符串的缓存存储配置池连接工厂。
流程
使用
org.infinispan.agroalllowedRegistries 属性指定JDBC 连接池配置,如下例所示:org.infinispan.agroal.metricsEnabled=false org.infinispan.agroal.minSize=10 org.infinispan.agroal.maxSize=100 org.infinispan.agroal.initialSize=20 org.infinispan.agroal.acquisitionTimeout_s=1 org.infinispan.agroal.validationTimeout_m=1 org.infinispan.agroal.leakTimeout_s=10 org.infinispan.agroal.reapTimeout_m=10 org.infinispan.agroal.metricsEnabled=false org.infinispan.agroal.autoCommit=true org.infinispan.agroal.jdbcTransactionIsolation=READ_COMMITTED org.infinispan.agroal.jdbcUrl=jdbc:h2:mem:PooledConnectionFactoryTest;DB_CLOSE_DELAY=-1 org.infinispan.agroal.driverClassName=org.h2.Driver.class org.infinispan.agroal.principal=sa org.infinispan.agroal.credential=sa
将 Data Grid 配置为使用带有
properties-file属性或PooledConnectionFactoryConfiguration.propertyFile ()方法的属性文件。XML
<connection-pool properties-file="path/to/agroal.properties"/>
JSON
"persistence": { "connection-pool": { "properties-file": "path/to/agroal.properties" } }YAML
persistence: connectionPool: propertiesFile: path/to/agroal.propertiesConfigurationBuilder
.connectionPool().propertyFile("path/to/agroal.properties")
其他资源
6.10. SQL 缓存存储
SQL 缓存存储可让您从现有数据库表加载 Data Grid 缓存。Data Grid 提供两种类型的 SQL 缓存存储:
- 表
- Data Grid 从单个数据库表中加载条目。
- 查询
- Data Grid 使用 SQL 查询来加载来自单个或多个数据库表的条目,包括这些表中的子列,以及执行插入、更新和删除操作。
访问代码教程,以尝试操作中的 SQL 缓存存储。请参阅适用于 远程缓存的 Persistence 代码教程。
SQL 表和查询存储:
- 允许对持久性存储的读取和写入操作。
- 可以是只读的,作为缓存加载程序。
支持与单个数据库列或多个数据库列复合对应的键和值。
对于复合键和值,您必须为 Data Grid 提供用于描述键和值的 Protobuf 模式(
.proto文件)。借助 Data Grid 服务器,您可以使用 schema 命令通过 Data Grid Console 或命令行界面(CLI)添加模式。
SQL 缓存存储用于现有数据库表。因此,它不会存储任何元数据,包括过期、片段和版本元数据。由于没有版本存储,SQL 存储不支持最佳事务缓存和异步跨站点复制。这个限制还扩展至 Hot Rod 版本的操作。
当 SQL 缓存存储配置为只读时,它与 SQL 缓存存储一起使用过期。expiration 从内存中删除过时的值,从而导致缓存再次从数据库中获取值并将其缓存。
6.10.1. 键和值的数据类型
Data Grid 通过 SQL 缓存存储从数据库表中的列加载键和值,自动使用适当的数据类型。以下 CREATE 语句添加名为"books"的表,它有两个列,即 isbn 和 title :
带有两列的数据库表
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120)
PRIMARY KEY(isbn)
);
当您将此表与 SQL 缓存存储搭配使用时,Data Grid 会使用 isbn 列作为键,将 title 列作为值添加到缓存中。
其他资源
6.10.1.1. 复合键和值
您可以将 SQL 存储与包含复合主键或复合值的数据库表一起使用。
要使用复合键或值,您必须为 Data Grid 提供用于描述数据类型的 Protobuf 模式。您还必须在 SQL 存储中添加 schema 配置,并为键和值指定消息名称。
Data Grid 建议使用 ProtoStream 处理器生成 Protobuf 模式。然后,您可以通过 Data Grid Console、CLI 或 REST API 上传远程缓存的 Protobuf 模式。
复合值
以下数据库表包含 title 和 author 列的复合值:
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120),
author varchar(80)
PRIMARY KEY(isbn)
);
Data Grid 使用 isbn 列作为密钥在缓存中添加一个条目。对于该值,Data Grid 需要 Protobuf 模式来映射 title 列和 作者 列:
package library;
message books_value {
optional string title = 1;
optional string author = 2;
}复合键和值
以下数据库表包含一个复合主键和一个组合值,各自有两个列:
CREATE TABLE books (
isbn NUMBER(13),
reprint INT,
title varchar(120),
author varchar(80)
PRIMARY KEY(isbn, reprint)
);对于 key 和 value,Data Grid 需要 Protobuf 模式,它将列映射到键和值:
package library;
message books_key {
required string isbn = 1;
required int32 reprint = 2;
}
message books_value {
optional string title = 1;
optional string author = 2;
}6.10.1.2. 嵌入式密钥
protobuf 模式可在值中包含键,如下例所示:
带有嵌入式密钥的 protobuf 模式
package library;
message books_key {
required string isbn = 1;
required int32 reprint = 2;
}
message books_value {
required string isbn = 1;
required string reprint = 2;
optional string title = 3;
optional string author = 4;
}
要使用嵌入的密钥,您必须在 SQL 存储配置中包含 embedded-key="true" 属性或 embeddedKey (true) 方法。
6.10.1.3. SQL 类型到 Protobuf 类型
下表包含 SQL 数据类型的默认映射到 Protobuf 数据类型:
| SQL 类型 | protobuf 类型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其他资源
6.10.2. 从数据库表加载 Data Grid 缓存
如果您希望 Data Grid 从数据库表载入数据,请将 SQL 表缓存存储到配置中。当它连接到数据库时,Data Grid 使用表中的元数据来检测列名称和数据类型。Data Grid 还自动决定数据库中哪些列是主密钥的一部分。
先决条件
-
具有 JDBC 连接详细信息。
您可以在缓存配置中直接添加 JDBC 连接工厂。
对于生产环境中的远程缓存,您应该将受管数据源添加到 Data Grid Server 配置中,并在缓存配置中指定 JNDI 名称。 为任何复合键或复合值生成 Protobuf 模式,并将您的架构注册到 Data Grid。
提示Data Grid 建议使用 ProtoStream 处理器生成 Protobuf 模式。对于远程缓存,您可以通过 Data Grid Console、CLI 或 REST API 添加架构来注册您的模式。
流程
在您的 Data Grid 部署中添加数据库驱动程序。
远程缓存:将数据库驱动程序复制到 Data Grid Server 安装中的
server/lib目录。提示使用带有 Data Grid 命令行界面(CLI)的
install命令,将所需的驱动程序下载到server/lib目录中,例如:install org.postgresql:postgresql:42.4.3
嵌入式缓存:将
infinispan-cachestore-sql依赖项添加到pom文件中。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
- 打开 Data Grid 配置以进行编辑。
添加 SQL 表缓存存储。
声明
table-jdbc-store xmlns="urn:infinispan:config:store:sql:15.0"
programmatic
persistence().addStore(TableJdbcStoreConfigurationBuilder.class)
-
使用
dialect=""或 dialect ()指定数据库dialect (),如dialect="H2"或dialect="postgres"。 使用您需要的属性配置 SQL 缓存存储,例如:
-
要在集群中使用相同的缓存存储,请设置
shared="true"或shared (true)。 -
要创建只读缓存存储,请设置
read-only="true"或.ignoreModifications (true)。
-
要在集群中使用相同的缓存存储,请设置
-
使用 table
-name="<database_table_name>" 或 table加载缓存的数据库表。.name ("<database_table_name>") 添加
schema元素或.schemaJdbcConfigurationBuilder ()方法,并为复合键或值添加 Protobuf 模式配置。-
使用 package 属性或
package() -
使用
message-name属性或messageName ()方法指定复合值。 -
使用
key-message-name属性或keyMessageName ()方法指定复合键。 -
如果您的 schema 在值中包含键,请为
embedded-key属性或embeddedKey ()方法设置true值。
-
使用 package 属性或
- 保存对配置的更改。
SQL 表存储配置
以下示例使用 Protobuf 模式中定义的复合值从名为"books"的数据库表加载分布式缓存:
XML
<distributed-cache>
<persistence>
<table-jdbc-store xmlns="urn:infinispan:config:store:sql:15.0"
dialect="H2"
shared="true"
table-name="books">
<schema message-name="books_value"
package="library"/>
</table-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"table-jdbc-store": {
"dialect": "H2",
"shared": "true",
"table-name": "books",
"schema": {
"message-name": "books_value",
"package": "library"
}
}
}
}
}
YAML
distributedCache:
persistence:
tableJdbcStore:
dialect: "H2"
shared: "true"
tableName: "books"
schema:
messageName: "books_value"
package: "library"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(TableJdbcStoreConfigurationBuilder.class)
.dialect(DatabaseType.H2)
.shared("true")
.tableName("books")
.schemaJdbcConfigurationBuilder()
.messageName("books_value")
.packageName("library");
6.10.3. 使用 SQL 查询来加载数据并执行操作
SQL 查询缓存存储可让您从多个数据库表加载缓存,包括从数据库表中的子列加载缓存,以及执行插入、更新和删除操作。
先决条件
-
具有 JDBC 连接详细信息。
您可以在缓存配置中直接添加 JDBC 连接工厂。
对于生产环境中的远程缓存,您应该将受管数据源添加到 Data Grid Server 配置中,并在缓存配置中指定 JNDI 名称。 为任何复合键或复合值生成 Protobuf 模式,并将您的架构注册到 Data Grid。
提示Data Grid 建议使用 ProtoStream 处理器生成 Protobuf 模式。对于远程缓存,您可以通过 Data Grid Console、CLI 或 REST API 添加架构来注册您的模式。
流程
在您的 Data Grid 部署中添加数据库驱动程序。
远程缓存:将数据库驱动程序复制到 Data Grid Server 安装中的
server/lib目录。提示使用带有 Data Grid 命令行界面(CLI)的
install命令,将所需的驱动程序下载到server/lib目录中,例如:install org.postgresql:postgresql:42.4.3
嵌入式缓存:将
infinispan-cachestore-sql依赖项添加到pom文件中,并确保数据库驱动程序位于应用程序 classpath 中。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
- 打开 Data Grid 配置以进行编辑。
添加 SQL 查询缓存存储。
声明
query-jdbc-store xmlns="urn:infinispan:config:store:sql:15.0"
programmatic
persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)
-
使用
dialect=""或 dialect ()指定数据库dialect (),如dialect="H2"或dialect="postgres"。 使用您需要的属性配置 SQL 缓存存储,例如:
-
要在集群中使用相同的缓存存储,请设置
shared="true"或shared (true)。 -
要创建只读缓存存储,请设置
read-only="true"或.ignoreModifications (true)。
-
要在集群中使用相同的缓存存储,请设置
定义 SQL 查询语句,以使用
queries元素或queries ()方法加载缓存并修改数据库表。query 语句 描述 选择将单个条目加载到缓存中。您可以使用通配符,但必须为密钥指定参数。您可以使用标记的表达式。
选择所有将多个条目加载到缓存中。如果返回的列数与 key 和 value 列匹配,您可以使用
*通配符。您可以使用标记的表达式。SIZE计算缓存中的条目数。
DELETE从缓存中删除单个条目。
全部删除从缓存中删除所有条目。
UPSERT修改缓存中的条目。
注意DELETE、DELETE ALL和UPSERT语句不适用于只读缓存存储,但当缓存存储允许修改时是必需的。DELETE语句中的参数必须完全匹配SELECT语句中的参数。UPSERT语句中的变量必须具有与SELECT和SELECT ALL语句返回相同的唯一命名变量。例如,如果SELECT返回foo,barthis 语句必须只使用:foo和:bar作为变量。但是,您可以在 语句中应用相同的命名变量。SQL 查询可以包含
JOIN、ON以及数据库支持的任何其他子句。添加
schema元素或.schemaJdbcConfigurationBuilder ()方法,并为复合键或值添加 Protobuf 模式配置。-
使用 package 属性或
package() -
使用
message-name属性或messageName ()方法指定复合值。 -
使用
key-message-name属性或keyMessageName ()方法指定复合键。 -
如果您的 schema 在值中包含键,请为
embedded-key属性或embeddedKey ()方法设置true值。
-
使用 package 属性或
- 保存对配置的更改。
其他资源
6.10.3.1. SQL 查询存储配置
本节为 SQL 查询缓存存储提供了一个示例配置,它加载带有两个数据库表的数据的分布式缓存:"person" 和 "address"。
SQL 语句
以下示例演示了"person"和"address"表的 SQL 数据定义语言(DDL)语句。示例中描述的数据类型仅适用于 PostgreSQL 数据库。
"person" 表的 SQL 语句
CREATE TABLE Person ( name VARCHAR(255) NOT NULL, picture BYTEA, sex VARCHAR(255), birthdate TIMESTAMP, accepted_tos BOOLEAN, notused VARCHAR(255), PRIMARY KEY (name) );
"address" 表的 SQL 语句
CREATE TABLE Address ( name VARCHAR(255) NOT NULL, street VARCHAR(255), city VARCHAR(255), zip INT, PRIMARY KEY (name) );
protobuf 模式
"person"和"address"表的 protobuf 模式如下:
"address" 表的 protobuf 模式
package com.example;
message Address {
optional string street = 1;
optional string city = 2 [default = "San Jose"];
optional int32 zip = 3 [default = 0];
}
"person" 表的 protobuf 模式
package com.example;
import "/path/to/address.proto";
enum Sex {
FEMALE = 1;
MALE = 2;
}
message Person {
optional string name = 1;
optional Address address = 2;
optional bytes picture = 3;
optional Sex sex = 4;
optional fixed64 birthDate = 5 [default = 0];
optional bool accepted_tos = 6 [default = false];
}
缓存配置
以下示例使用包含 JOIN 子句的 SQL 查询从"person"和"地址"表中加载分布式缓存:
XML
<distributed-cache>
<persistence>
<query-jdbc-store xmlns="urn:infinispan:config:store:sql:15.0"
dialect="POSTGRES"
shared="true" key-columns="name">
<connection-pool driver="org.postgresql.Driver"
connection-url="jdbc:postgresql://localhost:5432/postgres"
username="postgres"
password="changeme"/>
<queries select-single="SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = :name AND t2.name = :name"
select-all="SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name"
delete-single="DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name"
delete-all="DELETE FROM Person; DELETE FROM Address"
upsert="INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)"
size="SELECT COUNT(*) FROM Person"
/>
<schema message-name="Person"
package="com.example"
embedded-key="true"/>
</query-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"query-jdbc-store": {
"dialect": "POSTGRES",
"shared": "true",
"key-columns": "name",
"connection-pool": {
"username": "postgres",
"password": "changeme",
"driver": "org.postgresql.Driver",
"connection-url": "jdbc:postgresql://localhost:5432/postgres"
},
"queries": {
"select-single": "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = :name AND t2.name = :name",
"select-all": "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name",
"delete-single": "DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name",
"delete-all": "DELETE FROM Person; DELETE FROM Address",
"upsert": "INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)",
"size": "SELECT COUNT(*) FROM Person"
},
"schema": {
"message-name": "Person",
"package": "com.example",
"embedded-key": "true"
}
}
}
}
}
YAML
distributedCache:
persistence:
queryJdbcStore:
dialect: "POSTGRES"
shared: "true"
keyColumns: "name"
connectionPool:
username: "postgres"
password: "changeme"
driver: "org.postgresql.Driver"
connectionUrl: "jdbc:postgresql://localhost:5432/postgres"
queries:
selectSingle: "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = :name AND t2.name = :name"
selectAll: "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name"
deleteSingle: "DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name"
deleteAll: "DELETE FROM Person; DELETE FROM Address"
upsert: "INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)"
size: "SELECT COUNT(*) FROM Person"
schema:
messageName: "Person"
package: "com.example"
embeddedKey: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)
.dialect(DatabaseType.POSTGRES)
.shared("true")
.keyColumns("name")
.queriesJdbcConfigurationBuilder()
.select("SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = :name AND t2.name = :name")
.selectAll("SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name")
.delete("DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name")
.deleteAll("DELETE FROM Person; DELETE FROM Address")
.upsert("INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)")
.size("SELECT COUNT(*) FROM Person")
.schemaJdbcConfigurationBuilder()
.messageName("Person")
.packageName("com.example")
.embeddedKey(true);
其他资源
6.10.4. SQL 缓存存储故障排除
查找有关 SQL 缓存存储的常见问题和错误以及如何对它们进行故障排除。
ISPN008064: No primary keys found for table <table_name>, check case sensitivity
在以下情况下,Data Grid 会记录此消息:
- 数据库表不存在。
- 数据库表名称区分大小写,需要都是小写或所有大写,具体取决于数据库提供程序。
- 数据库表没有定义任何主键。
要解决这个问题,您应该:
- 检查 SQL 缓存存储配置,并确保指定了现有表的名称。
- 确保数据库表名称符合问题单敏感度要求。
- 确保您的数据库表具有唯一标识适当行的主要键。
6.11. 基于 JDBC 字符串的缓存存储
基于 JDBC 字符串的缓存存储 JdbcStringBasedStore,使用 JDBC 驱动程序在底层数据库中加载和存储值。
基于 JDBC 字符串的缓存存储:
- 在表格中,将每个条目存储在其自己的行中,以增加并发负载的吞吐量。
-
使用简单的单对一映射,利用
key-to-string-mapper接口将每个键映射到String对象。
Data Grid 提供处理原语类型的默认实施DefaultTwoWayKey2StringMapper。
除了用于存储缓存条目的 data 表外,存储还会创建一个用于存储元数据的 _META 表。此表用于确保任何现有数据库内容与当前的 Data Grid 版本和配置兼容。
默认情况下,Data Grid 共享不存储,这意味着集群中的每个节点上的所有节点都写入底层存储。如果您希望操作只写入底层数据库一次,您必须将 JDBC 存储配置为共享。
分段
JdbcStringBasedStore 默认使用分段,并要求数据库表中的列表示条目所属的片段。
6.11.1. 配置基于 JDBC 字符串的缓存存储
使用可以连接到数据库的基于 JDBC 字符串的缓存存储配置 Data Grid 缓存。
先决条件
-
远程缓存:将数据库驱动程序复制到 Data Grid Server 安装中的
server/lib目录。 嵌入式缓存:将
infinispan-cachestore-jdbc依赖项添加到pom文件中。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-jdbc</artifactId> </dependency>
流程
使用以下方法之一创建基于 JDBC 字符串的缓存存储配置:
声明性地添加
persistence元素或字段,然后使用以下 schema 命名空间添加string-keyed-jdbc-store:xmlns="urn:infinispan:config:store:jdbc:15.0"
以编程方式,将以下方法添加到
ConfigurationBuilder中:persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
-
使用 dialect 属性或
dialect() 根据情况,配置基于 JDBC 字符串的缓存存储的任何属性。
例如,指定缓存存储是否使用
shared属性或shared ()方法与多个缓存实例共享。- 添加 JDBC 连接工厂,以便 Data Grid 可以连接到数据库。
- 添加存储缓存条目的数据库表。
使用不当的数据类型配置 string-keyed-jdbc-store 可能会导致加载或存储缓存条目时出现异常。如需更多信息,以及作为 Data Grid 版本一部分测试的数据类型列表,请参阅为 Data Grid string-keyed-jdbc-store persistence (Login required)测试的数据库设置。
基于 JDBC 字符串的缓存存储配置
XML
<distributed-cache>
<persistence>
<string-keyed-jdbc-store xmlns="urn:infinispan:config:store:jdbc:15.0"
dialect="H2">
<connection-pool connection-url="jdbc:h2:mem:infinispan"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
<string-keyed-table create-on-start="true"
prefix="ISPN_STRING_TABLE">
<id-column name="ID_COLUMN"
type="VARCHAR(255)" />
<data-column name="DATA_COLUMN"
type="BINARY" />
<timestamp-column name="TIMESTAMP_COLUMN"
type="BIGINT" />
<segment-column name="SEGMENT_COLUMN"
type="INT"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"string-keyed-jdbc-store": {
"dialect": "H2",
"string-keyed-table": {
"prefix": "ISPN_STRING_TABLE",
"create-on-start": true,
"id-column": {
"name": "ID_COLUMN",
"type": "VARCHAR(255)"
},
"data-column": {
"name": "DATA_COLUMN",
"type": "BINARY"
},
"timestamp-column": {
"name": "TIMESTAMP_COLUMN",
"type": "BIGINT"
},
"segment-column": {
"name": "SEGMENT_COLUMN",
"type": "INT"
}
},
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
}
YAML
distributedCache:
persistence:
stringKeyedJdbcStore:
dialect: "H2"
stringKeyedTable:
prefix: "ISPN_STRING_TABLE"
createOnStart: true
idColumn:
name: "ID_COLUMN"
type: "VARCHAR(255)"
dataColumn:
name: "DATA_COLUMN"
type: "BINARY"
timestampColumn:
name: "TIMESTAMP_COLUMN"
type: "BIGINT"
segmentColumn:
name: "SEGMENT_COLUMN"
type: "INT"
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan"
driver: "org.h2.Driver"
username: "sa"
password: "changeme"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
.dialect(DatabaseType.H2)
.table()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_STRING_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.segmentColumnName("SEGMENT_COLUMN").segmentColumnType("INT")
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan")
.username("sa")
.password("changeme")
.driverClass("org.h2.Driver");
其他资源
6.12. RocksDB 缓存存储
RocksDB 为高度并发环境提供基于键值文件系统的存储,具有高性能和可靠性。
RocksDB 缓存存储 RocksDBStore 使用两个数据库。一个数据库为内存中数据提供主缓存存储;其他数据库包含 Data Grid 从内存中过期的条目。
| 参数 | 描述 |
|---|---|
|
| 指定提供主缓存存储的 RocksDB 数据库的路径。如果您没有设置位置,则会自动创建。请注意,路径必须相对于全局持久位置。 |
|
| 指定为过期的数据提供缓存存储的 RocksDB 数据库的路径。如果您没有设置位置,则会自动创建。请注意,路径必须相对于全局持久位置。 |
|
| 为过期条目设置内存队列的大小。当队列达到大小时,Data Grid 会将已过期刷新到 RocksDB 缓存存储中。 |
|
| 在删除和重新初始化(re-init) RocksDB 数据库前设置条目的最大数量。对于较小的大小缓存存储,它会对所有条目进行迭代,并单独删除每个条目可以提供一个更快的方法。 |
调整参数
您还可以指定以下 RocksDB 调优参数:
-
compressionType -
blockSize -
cacheSize
配置属性
(可选)在配置中设置属性,如下所示:
-
使用
数据库的前缀属性来调整和调优 RocksDB 数据库。 -
使用
数据添加前缀属性,以配置 RocksDB 存储您的数据的列系列。
<property name="database.max_background_compactions">2</property> <property name="data.write_buffer_size">64MB</property> <property name="data.compression_per_level">kNoCompression:kNoCompression:kNoCompression:kSnappyCompression:kZSTD:kZSTD</property>
分段
RocksDBStore 支持分段,并创建每个网段的独立列系列。片段的 RocksDB 缓存存储提高了查找性能和迭代,但写入操作的性能稍微降低。
您不应该配置超过几百个片段。RocksDB 不设计为拥有无限数量的列系列。太多片段也会显著增加缓存存储启动时间。
RocksDB 缓存存储配置
XML
<local-cache>
<persistence>
<rocksdb-store xmlns="urn:infinispan:config:store:rocksdb:15.0"
path="rocksdb/data">
<expiration path="rocksdb/expired"/>
</rocksdb-store>
</persistence>
</local-cache>
JSON
{
"local-cache": {
"persistence": {
"rocksdb-store": {
"path": "rocksdb/data",
"expiration": {
"path": "rocksdb/expired"
}
}
}
}
}
YAML
localCache:
persistence:
rocksdbStore:
path: "rocksdb/data"
expiration:
path: "rocksdb/expired"
ConfigurationBuilder
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(RocksDBStoreConfigurationBuilder.class)
.build();
EmbeddedCacheManager cacheManager = new DefaultCacheManager(cacheConfig);
Cache<String, User> usersCache = cacheManager.getCache("usersCache");
usersCache.put("raytsang", new User(...));
带有属性的 ConfigurationBuilder
Properties props = new Properties();
props.put("database.max_background_compactions", "2");
props.put("data.write_buffer_size", "512MB");
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(RocksDBStoreConfigurationBuilder.class)
.location("rocksdb/data")
.expiredLocation("rocksdb/expired")
.properties(props)
.build();
6.13. 远程缓存存储
远程缓存存储 RemoteStore 使用 Hot Rod 协议在 Data Grid 集群上存储数据。
如果您将远程缓存存储配置为共享,则无法预加载数据。在您的配置中为 shared="true" 换句话说,您必须设置 preload="false"。
共享远程缓存容器
每个远程缓存存储都会创建一个专用的远程缓存管理器。如果有多个远程存储连接到同一服务器,则这会浪费资源。使用 remote-cache-containers 配置创建共享远程缓存管理器,并使用 remote-store 定义中的名称来引用它们。
如果只有一个 remote-cache-container,则默认在所有远程缓存存储中使用它,但不明确指定一个。
分段
RemoteStore 支持分段,并可按网段发布密钥和证书,从而使批量操作更高效。但是,分段仅适用于 Data Grid Hot Rod 协议版本 2.3 或更高版本。
当您为 RemoteStore 启用分段时,会使用您在 Data Grid 服务器配置中定义的片段数量。
如果源缓存被分段并使用与 RemoteStore 不同的片段数,则为批量操作返回不正确的值。在这种情况下,您应该禁用 RemoteStore 的分段。
使用共享远程容器的远程缓存存储配置
XML
<infinispan>
<remote-cache-containers>
<remote-cache-container uri="hotrod://one,two:12111?max-active=10&exhausted-action=CREATE_NEW"/>
</remote-cache-containers>
<cache-container>
<distributed-cache>
<persistence>
<remote-store xmlns="urn:infinispan:config:store:remote:15.0"
cache="mycache"
raw-values="true"
/>
</persistence>
</distributed-cache>
</cache-container>
</infinispan>
JSON
{
"infinispan": {
"remote-cache-containers": [
{
"uri": "hotrod://one,two:12111?max-active=10&exhausted-action=CREATE_NEW"
}
],
"cache-container": {
"caches": {
"mycache": {
"distributed-cache": {
"remote-store": {
"cache": "mycache",
"raw-values": "true"
}
}
}
}
}
}
}
YAML
infinispan:
remoteCacheContainers:
- uri: "hotrod://one,two:12111?max-active=10&exhausted-action=CREATE_NEW"
cacheContainer:
caches:
mycache:
distributedCache:
remoteStore:
cache: "mycache"
rawValues: "true"
remoteServer:
- host: "one"
port: "12111"
- host: "two"
connectionPool:
maxActive: "10"
exhaustedAction: "CREATE_NEW"
ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence().addStore(RemoteStoreConfigurationBuilder.class)
.ignoreModifications(false)
.purgeOnStartup(false)
.remoteCacheName("mycache")
.rawValues(true)
.addServer()
.host("one").port(12111)
.addServer()
.host("two")
.connectionPool()
.maxActive(10)
.exhaustedAction(ExhaustedAction.CREATE_NEW)
.async().enable();
使用私有远程容器的远程缓存存储配置
XML
<distributed-cache>
<persistence>
<remote-store xmlns="urn:infinispan:config:store:remote:15.0"
cache="mycache"
raw-values="true">
<remote-server host="one"
port="12111" />
<remote-server host="two" />
<connection-pool max-active="10"
exhausted-action="CREATE_NEW" />
</remote-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"remote-store": {
"cache": "mycache",
"raw-values": "true",
"remote-server": [
{
"host": "one",
"port": "12111"
},
{
"host": "two"
}
],
"connection-pool": {
"max-active": "10",
"exhausted-action": "CREATE_NEW"
}
}
}
}
YAML
distributedCache:
remoteStore:
cache: "mycache"
rawValues: "true"
remoteServer:
- host: "one"
port: "12111"
- host: "two"
connectionPool:
maxActive: "10"
exhaustedAction: "CREATE_NEW"
ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence().addStore(RemoteStoreConfigurationBuilder.class)
.ignoreModifications(false)
.purgeOnStartup(false)
.remoteCacheName("mycache")
.rawValues(true)
.addServer()
.host("one").port(12111)
.addServer()
.host("two")
.connectionPool()
.maxActive(10)
.exhaustedAction(ExhaustedAction.CREATE_NEW)
.async().enable();
6.14. 集群缓存加载程序
ClusterCacheLoader 从其他 Data Grid 集群成员检索数据,但不会持久数据。换句话说,ClusterCacheLoader 不是缓存存储。
Cluster loader 已被弃用,计划在以后的版本中删除。
ClusterCacheLoader 为状态传输提供了非阻塞的替代方案。如果本地节点上没有这些密钥,ClusterCacheLoader 会按需从其他节点获取密钥,这和 lazily 加载缓存内容类似。
以下点也适用于 ClusterCacheLoader :
-
preloading 不生效(
preload=true)。 - 不支持分段。
集群缓存加载程序配置
XML
<distributed-cache>
<persistence>
<cluster-loader preload="true" remote-timeout="500"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"cluster-loader" : {
"preload" : true,
"remote-timeout" : "500"
}
}
}
}
YAML
distributedCache:
persistence:
clusterLoader:
preload: "true"
remoteTimeout: "500"
ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence()
.addClusterLoader()
.remoteCallTimeout(500);
6.15. 创建自定义缓存存储实现
您可以通过 Data Grid 持久 SPI 创建自定义缓存存储。
6.15.1. Data Grid Persistence SPI
Data Grid Service Provider Interface (SPI)通过 NonBlockingStore 接口启用对外部存储的读写操作,具有以下特性:
- 简化事务集成
- Data Grid 会自动处理锁定,因此您的实施不需要协调对持久性存储的并发访问。根据您使用的锁定模式,通常不会发生对同一键的并发写入。但是,您应该预期持久存储的操作来自多个线程,并创建实现来容许此行为。
- 并行迭代
- 网格可让您并行迭代带有多个线程的持久性存储中的条目。
- 减少序列化结果,从而减少 CPU 用量
- 网格以序列化格式公开存储的条目,这些条目可以远程传输。因此,Data Grid 不需要反序列化条目,它从持久性存储检索,然后在写入线时再次序列化。
6.15.2. 创建缓存存储
使用 NonBlockingStore API 的实现创建自定义缓存存储。
流程
- 实施适当的 Data Grid 持久 SPI。
-
如果有自定义配置,使用
@ConfiguredBy注释给您的存储类添加注解。 如果需要,创建自定义缓存存储配置和构建器。
-
扩展
AbstractStoreConfiguration和AbstractStoreConfigurationBuilder。 (可选)在存储配置类中添加以下注解,以确保自定义配置构建器从 XML 解析您的缓存存储配置:
-
@ConfigurationFor @BuiltBy如果没有添加这些注解,则
CustomStoreConfigurationBuilder会解析AbstractStoreConfiguration中定义的通用存储属性,并且任何额外的元素都会被忽略。注意如果配置没有声明
@ConfigurationFor注释,当 Data Grid 初始化缓存时,会记录警告消息。
-
-
扩展
6.15.3. 自定义缓存存储配置示例
以下示例演示了如何使用自定义缓存存储实现配置 Data Grid:
XML
<distributed-cache>
<persistence>
<store class="org.infinispan.persistence.example.MyInMemoryStore" />
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"store" : {
"class" : "org.infinispan.persistence.example.MyInMemoryStore"
}
}
}
}
YAML
distributedCache:
persistence:
store:
class: "org.infinispan.persistence.example.MyInMemoryStore"
ConfigurationBuilder
Configuration config = new ConfigurationBuilder()
.persistence()
.addStore(CustomStoreConfigurationBuilder.class)
.build();
6.15.4. 部署自定义缓存存储
要将缓存存储实现与 Data Grid Server 搭配使用,您必须为其提供 JAR 文件。
先决条件
如果 Data Grid Server 正在运行,则停止它。
Data Grid 仅在启动时加载 JAR 文件。
流程
- 将自定义缓存存储实施打包到 JAR 文件中。
-
将您的 JAR 文件添加到 Data Grid Server 安装的
server/lib目录中。
6.16. 在缓存存储之间迁移数据
Data Grid 提供了一个将数据从一个缓存存储迁移到另一个缓存的工具。
6.16.1. 缓存存储 migrator
Data Grid 提供 CLI migrate store 命令,用于为最新的数据网格缓存存储实施重新创建数据。
存储 migrator 从以前的 Data Grid 版本获取缓存存储作为源,并使用缓存存储实现作为目标。
当您运行存储 migrator 时,它会使用您使用 EmbeddedCacheManager 接口定义的缓存存储类型创建目标缓存。存储 migrator 然后将源存储中的条目加载到内存中,然后将其放入目标缓存中。
存储 migrator 还允许您将数据从一种类型的缓存存储迁移到另一种缓存存储。例如,您可以从基于 JDBC 字符串的缓存存储迁移到 SIFS 缓存存储。
存储 migrator 无法将数据从分段缓存存储迁移到:
- 非分段缓存存储。
- 分段缓存存储,它们具有不同的片段数。
6.16.2. 配置缓存存储 migrator
使用 migrator.properties 文件配置源和目标缓存存储的属性。
流程
-
创建
migrator.properties文件。 使用
migrator.properties文件配置源和目标缓存存储的属性。将
source.前缀添加到源缓存存储的所有配置属性中。源缓存存储示例
source.type=SOFT_INDEX_FILE_STORE source.cache_name=myCache source.location=/path/to/source/sifs source.version=<version>
重要要从分段缓存存储迁移数据,还必须使用
source.segment_count属性配置片段数量。片段的数量必须与 Data Grid 配置中的cluster.hash.numSegments匹配。如果缓存存储的片段数量与对应缓存的片段数量不匹配,则数据网格无法从缓存存储读取数据。将
target.前缀添加到目标缓存存储的所有配置属性中。目标缓存存储示例
target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/target/sfs.dat
6.16.2.1. 缓存存储 migrator 的配置属性
在 StoreMigrator 属性中配置源和目标缓存存储。
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 指定源或目标缓存存储的缓存存储类型。
| 必填 |
| 属性 | 描述 | 值示例 | 必填/选填 |
|---|---|---|---|
|
| 要备份的缓存的名称。 |
| 必填 |
|
| 可以使用分段的目标缓存存储的片段数量。
片段数量必须与 Data Grid 配置中的 |
| 选填 |
|
| 指定自定义 marshaller 类。 | 使用自定义 marshallers 时需要此项。 |
|
| 指定允许反序列化的完全限定类名称列表。 | 选填 |
| 指定以逗号分隔的正则表达式列表,用于决定允许哪些类反序列化。 |
| 选填 |
|
指定以逗号分隔的自定义 | 选填 |
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 指定底层数据库的 dialect。 | 必填 |
|
|
指定源缓存存储的 marshaller 版本。
*
*
*
*
*
* | 仅用于源存储。 |
|
| 指定 JDBC 连接 URL。 | 必填 |
|
| 指定 JDBC 驱动程序的类。 | 必填 |
|
| 指定数据库用户名。 | 必填 |
|
| 指定数据库用户名的密码。 | 必填 |
|
| 禁用数据库 upsert。 | 选填 |
|
| 指定是否创建表索引。 | 选填 |
|
| 指定表名称的额外前缀。 | 选填 |
|
| 指定列名称。 | 必填 |
|
| 指定列类型。 | 必填 |
|
|
指定 | 选填 |
要从旧的 Data Grid 版本中迁移 Binary 缓存存储,请在以下属性中将 table.string view 改为 table.binary.\* :
-
source.table.binary.table_name_prefix -
source.table.binary.<id\|data\|timestamp>.name -
source.table.binary.<id\|data\|timestamp>.type
# Example configuration for migrating to a JDBC String-Based cache store target.type=STRING target.cache_name=myCache target.dialect=POSTGRES target.marshaller.class=org.infinispan.commons.marshall.JavaSerializationMarshaller target.marshaller.allow-list.classes=org.example.Person,org.example.Animal target.marshaller.allow-list.regexps="org.another.example.*" target.marshaller.externalizers=25:Externalizer1,org.example.Externalizer2 target.connection_pool.connection_url=jdbc:postgresql:postgres target.connection_pool.driver_class=org.postrgesql.Driver target.connection_pool.username=postgres target.connection_pool.password=redhat target.db.disable_upsert=false target.db.disable_indexing=false target.table.string.table_name_prefix=tablePrefix target.table.string.id.name=id_column target.table.string.data.name=datum_column target.table.string.timestamp.name=timestamp_column target.table.string.id.type=VARCHAR target.table.string.data.type=bytea target.table.string.timestamp.type=BIGINT target.key_to_string_mapper=org.infinispan.persistence.keymappers. DefaultTwoWayKey2StringMapper
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 设置数据库目录。 | 必填 |
|
| 指定要使用的压缩类型。 | 选填 |
# Example configuration for migrating from a RocksDB cache store. source.type=ROCKSDB source.cache_name=myCache source.location=/path/to/rocksdb/database source.compression=SNAPPY
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
|
设置包含缓存存储 | 必填 |
# Example configuration for migrating to a Single File cache store. target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/sfs.dat
| 属性 | 描述 | value |
|---|---|---|
| 必填/选填 |
| 设置数据库目录。 |
| 必填 |
| 设置数据库索引目录。 |
# Example configuration for migrating to a Soft-Index File cache store. target.type=SOFT_INDEX_FILE_STORE target.cache_name=myCache target.location=path/to/sifs/database target.location=path/to/sifs/index
6.16.3. 迁移 Data Grid 缓存存储
运行存储 migrator 将数据从一个缓存存储迁移到另一个缓存存储。
先决条件
- 获取 Data Grid CLI。
-
创建
migrator.properties文件,以配置源和目标缓存存储。
流程
-
运行
migrate store -p /path/to/migrator.propertiesCLI 命令
第 7 章 配置 Data Grid 以处理网络分区
Data Grid 集群可以分成网络分区,其中节点子集相互隔离。这种情况会导致集群缓存的可用性或一致性丢失。Data Grid 会自动检测崩溃的节点,并解决冲突,以将缓存合并回一起。
7.1. 分割集群和网络分区
网络分区是运行环境中错误条件的结果,比如当网络路由器崩溃时。当集群划分为分区时,节点会创建一个 JGroups 集群视图,该视图仅包含该分区中的节点。这意味着一个分区中的节点可以独立于其他分区中的节点运行。
检测分割
为了自动检测网络分区,Data Grid 使用默认 JGroups 堆栈中的 FD_ALL 协议来确定节点是否立即离开集群。
Data Grid 无法检测导致节点立即离开的原因。这不仅当有网络故障,也可能会发生,例如当 Garbage Collection (GC)暂停 JVM 时。
Data Grid 怀疑节点在以下毫秒数后崩溃:
FD_ALL[2|3].timeout + FD_ALL[2|3].interval + VERIFY_SUSPECT[2].timeout + GMS.view_ack_collection_timeout
当它检测到集群被分成网络分区时,Data Grid 使用一个策略来处理缓存操作。根据您的应用程序要求,Data Grid 可以:
- 允许读和/或写操作以实现可用性
- 拒绝为一致性的读写操作
将分区合并在一起
要修复分割集群,Data Grid 会将分区合并回一起。在合并过程中,Data Grid 将 .equals () 方法用于缓存条目的值,以确定是否存在任何冲突。要解决它在分区上发现的副本之间的任何冲突,Data Grid 使用您可以配置的合并策略。
7.1.1. 分割集群中的数据一致性
无论任何处理策略或合并策略是什么,导致 Data Grid 集群被分成分区的网络中断或错误都可能会导致数据丢失或一致性问题。
在分割和检测之间
如果写入操作发生在分割时位于次要分区的节点上,且在 Data Grid 检测到分割前,当 Data Grid 在合并过程中向这个次要分区传输状态时,该值将会丢失。
如果所有分区都处于 DEGRADED 模式,该值不会丢失,因为没有发生状态传输,但条目可能具有不一致的值。对于在分割发生时正在进行的事务缓存写操作,可以在某些节点上提交并回滚其他节点上,这也会导致值不一致。
在分割和 Data Grid 检测到它的时间里,可以在尚未进入 DEGRADED 模式的次要分区中获取过时的缓存读取。
在合并过程中
当 Data Grid 开始删除分区节点,通过一系列合并事件重新连接到集群。在此合并过程完成前,有可能在某些节点上成功对事务缓存写操作,但不能在更新条目前生成过时的读取。
7.2. 缓存可用性和降级模式
为了保持数据一致性,如果将缓存配置为使用 DENY_READ_WRITES 或 ALLOW_READS 分区处理策略,则 Data Grid 可以将缓存置于 DEGRADED 模式。
当以下条件满足时,Data Grid 会将缓存置于 DEGRADED 模式:
-
至少一个片段丢失了所有所有者。
当多个节点等于或大于分布式缓存的所有者数量时,会出现这种情况。 -
分区中没有大多数节点。
大多数节点都比集群中节点从最新的稳定拓扑中的一半大于一半,这是集群重新平衡操作成功完成的时间。
当缓存处于 DEGRADED 模式时,Data Grid:
- 只有在条目的所有副本都位于同一分区中时,才允许读取和写入操作。
拒绝读取和写入操作,并在分区不包含条目的所有副本时抛出
AvailabilityException。注意使用
ALLOW_READS策略时,Data Grid 允许以DEGRADED模式对缓存进行读操作。
DEGRADED 模式通过确保在不同的分区中不会对同一密钥进行写入操作保证一致性。另外,DEGRADED 模式可防止在一个分区中更新密钥但在另一个分区中读取时发生的过时的读操作。
如果所有分区都处于 DEGRADED 模式,则缓存仅在集群包含最新稳定拓扑中的大多数节点时再次可用,且每个条目至少有一个副本。当集群至少有一个副本的每个条目时,不会丢失密钥,Data Grid 可以在集群重新平衡过程中根据所有者数量创建新副本。
在某些情况下,在另一个分区中输入 DEGRADED 模式时,一个分区中的缓存可以保持可用。当发生这种情况时,可用分区会正常继续缓存操作,Data Grid 会尝试跨这些节点重新平衡数据。要将缓存合并为 Data Grid,始终将可用分区中的状态转移到 DEGRADED 模式中的分区。
7.2.1. 降级缓存恢复示例
本节介绍 Data Grid 从使用 DENY_READ_WRITES 分区处理策略的缓存从分割集群中恢复。
例如,一个 Data Grid 集群有四个节点,并包括一个分布式缓存,其中包含每个条目的两个副本(owners=2)。缓存( k1 )、k2、k2、k3 和 k4 中有四个条目。
使用 DENY_READ_WRITES 策略时,如果集群分割为分区,则当条目的所有副本都位于同一分区中时,Data Grid 才允许缓存操作。
在以下示意图中,当缓存分割为分区时,Data Grid 在分区 1 和分区 2 上允许 的读写操作。由于分区 1 或分区 2 上只有一个 k 1k2 和 k3 副本,因此 Data Grid 拒绝这些条目的读写操作。
当网络条件允许节点重新加入相同的集群视图时,Data Grid 合并了没有状态传输的分区,并恢复普通的缓存操作。
7.2.2. 在网络分区过程中验证缓存可用性
确定在网络分区过程中 Data Grid 集群上的缓存是否处于 AVAILABLE 模式或 DEGRADED 模式。
当 Data Grid 集群划分为分区时,这些分区中的节点可以进入 DEGRADED 模式以确保数据一致性。在 DEGRADED 模式中,不允许缓存操作导致可用性丢失。
流程
使用以下方法之一验证在网络分区中集群缓存的可用性:
-
检查 Data Grid 日志中的
ISPN100011消息,该消息表示集群是否可用,或者至少有一个缓存是否处于DEGRADED模式。 通过 Data Grid Console 或 REST API 获取远程缓存的可用性。
- 在任何浏览器中打开 Data Grid Console,选择 Data Container 选项卡,然后在 Health 列中找到可用状态。
从 REST API 检索缓存健康状况。
GET /rest/v2/container/health
-
使用
AdvancedCacheAPI 中的getAvailability ()方法,以编程方式检索嵌入式缓存的可用性。
7.2.3. 使缓存可用
通过强制缓存使用 DEGRADED 模式,使缓存可用于读写操作。
只有在部署可以容忍数据丢失和不一致时,才应强制集群处于 DEGRADED 模式。
流程
通过以下方法之一提供缓存:
- 打开 Data Grid Console 并选择 Make available 选项。
使用 REST API 更改远程缓存的可用性。
POST /rest/v2/caches/<cacheName>?action=set-availability&availability=AVAILABLE
使用
AdvancedCacheAPI 以编程方式更改嵌入式缓存的可用性。AdvancedCache ac = cache.getAdvancedCache(); // Retrieve cache availability boolean available = ac.getAvailability() == AvailabilityMode.AVAILABLE; // Make the cache available if (!available) { ac.setAvailability(AvailabilityMode.AVAILABLE); }
7.3. 配置分区处理
将 Data Grid 配置为使用分区处理策略和合并策略,以便在发生网络问题时解析分割集群。默认情况下,Data Grid 使用一种策略,以降低数据一致性保证成本来提供可用性。当因为网络分区客户端造成集群分割时,客户端可以继续对缓存执行读写操作。
如果您需要在可用性上一致性,您可以将 Data Grid 配置为在集群分割为分区时拒绝读写操作。或者,您可以允许读操作和拒绝写操作。您还可以指定配置 Data Grid 的自定义合并策略实现,以使用根据您的要求定制的自定义逻辑来解析分割。
先决条件
有一个 Data Grid 集群,您可以在其中创建复制或分布式缓存。
注意分区处理配置仅适用于复制和分布式缓存。
流程
- 打开 Data Grid 配置以进行编辑。
-
使用
partition-handling元素或partitionHandling ()方法向缓存添加分区处理配置。 指定当集群通过
when-split属性或whenSplit ()方法分割为使用 Data Grid 的策略。默认分区处理策略是
ALLOW_READ_WRITES,因此缓存仍可使用。如果您的用例需要缓存可用性的数据一致性,请指定DENY_READ_WRITES策略。指定在将分区与
merge-policy属性或mergePolicy ()方法合并时用于解析冲突条目的策略。默认情况下,Data Grid 不会在合并时解决冲突。
- 保存对 Data Grid 配置的更改。
分区处理配置
XML
<distributed-cache>
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "PREFERRED_ALWAYS"
}
}
}
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: PREFERRED_ALWAYS
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(MergePolicy.PREFERRED_NON_NULL);
7.4. 分区处理策略
分区处理策略控制,如果 Data Grid 在分割集群时允许读写操作。您配置的策略决定了是否获得缓存可用性或数据一致性。
| 策略 | 描述 | 可用性或一致性 |
|---|---|---|
|
| 网格允许在集群分割为网络分区时对缓存进行读写操作。每个分区中的节点保持可用且可相互独立运行。这是默认的分区处理策略。 | 可用性 |
|
| 只有在条目的所有副本都位于分区中时,Data Grid 才允许读取和写入操作。如果分区不包含条目的所有副本,Data Grid 会阻止该条目的缓存操作。 | 一致性 |
|
| 网格允许对条目进行读取操作,并防止写操作,除非分区包含条目的所有副本。 | 与读取可用性保持一致 |
7.5. 合并策略
合并策略控制 Data Grid 在将集群分区合并时如何在副本间解决冲突。您可以使用 Data Grid 提供的合并策略之一,也可以创建 EntryMergePolicy API 的自定义实现。
| 合并策略 | 描述 | 注意事项 |
|---|---|---|
|
| 在合并分割集群时,Data Grid 无法解决冲突。这是默认的合并策略。 | 节点丢弃它们不是主所有者的片段,这可能会导致数据丢失。 |
|
| Data Grid 找到集群中大多数节点上存在的值,并使用它来解决冲突。 | Data Grid 可以使用过时的值来解决冲突。即使条目可用大多数节点,最后一个更新也会在次要分区中发生。 |
|
| Data Grid 使用它在群集上找到的第一个非null 值来解决冲突。 | Data Grid 可以恢复已删除的条目。 |
|
| Data Grid 从缓存中删除任何冲突条目。 | 这会导致在合并分割集群时丢失具有不同值的条目。 |
7.6. 配置自定义合并策略
在处理网络分区时,将 Data Grid 配置为使用 EntryMergePolicy API 的自定义实现。
先决条件
实现
EntryMergePolicyAPI。public class CustomMergePolicy implements EntryMergePolicy<String, String> { @Override public CacheEntry<String, String> merge(CacheEntry<String, String> preferredEntry, List<CacheEntry<String, String>> otherEntries) { // Decide which entry resolves the conflict return the_solved_CacheEntry; }
流程
如果使用远程缓存,请将合并策略实施部署到 Data Grid 服务器。
将您的类打包为 JAR 文件,其中包含
META-INF/services/org.infinispan.conflict.EntryMergePolicy文件,其中包含合并策略的完全限定域名。# List implementations of EntryMergePolicy with the full qualified class name org.example.CustomMergePolicy
将 JAR 文件添加到
server/lib目录。提示使用带有 Data Grid 命令行界面(CLI)的
install命令,将 JAR 下载到server/lib目录。
- 打开 Data Grid 配置以进行编辑。
根据情况,使用
encoding元素或encoding ()方法配置缓存编码。对于远程缓存,如果您只使用对象元数据在合并条目时进行比较,您可以使用
application/x-protostream作为介质类型。在这种情况下,Data Grid 将条目返回到EntryMergePolicy作为byte[]。如果您需要合并冲突时对象本身,您应该使用
application/x-java-object介质类型配置缓存。在这种情况下,您必须将相关的 ProtoStream marshallers 部署到 Data Grid Server,以便在客户端使用 Protobuf 编码时执行byte[]到对象转换。-
使用
merge-policy属性或mergePolicy ()方法指定自定义合并策略,作为分区处理配置的一部分。 - 保存您的更改。
自定义合并策略配置
XML
<distributed-cache name="mycache">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="org.example.CustomMergePolicy"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "org.example.CustomMergePolicy"
}
}
}
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: org.example.CustomMergePolicy
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());
7.7. 在嵌入式缓存中手动合并分区
检测并解决冲突条目,以在网络分区发生后手动合并嵌入式缓存。
流程
从
EmbeddedCacheManager检索ConflictManager,以检测并解决缓存中冲突的条目,如下例所示:EmbeddedCacheManager manager = new DefaultCacheManager("example-config.xml"); Cache<Integer, String> cache = manager.getCache("testCache"); ConflictManager<Integer, String> crm = ConflictManagerFactory.get(cache.getAdvancedCache()); // Get all versions of a key Map<Address, InternalCacheValue<String>> versions = crm.getAllVersions(1); // Process conflicts stream and perform some operation on the cache Stream<Map<Address, CacheEntry<Integer, String>>> conflicts = crm.getConflicts(); conflicts.forEach(map -> { CacheEntry<Integer, String> entry = map.values().iterator().next(); Object conflictKey = entry.getKey(); cache.remove(conflictKey); }); // Detect and then resolve conflicts using the configured EntryMergePolicy crm.resolveConflicts(); // Detect and then resolve conflicts using the passed EntryMergePolicy instance crm.resolveConflicts((preferredEntry, otherEntries) -> preferredEntry);
虽然每个条目都处理 ConflictManager::getConflicts 流,但底层分割器各自为每个片段加载缓存条目。
第 8 章 使用基于角色的访问控制进行安全授权
基于角色的访问控制(RBAC)功能使用不同的权限级别来限制用户与网格交互。
有关创建用户并配置特定于远程或嵌入式缓存的授权的详情,请参考:
8.1. Data Grid 用户角色和权限
Data Grid 包括多个角色,为用户提供访问缓存和数据网格资源的权限。
| 角色 | 权限 | 描述 |
|---|---|---|
|
| ALL | 具有所有权限的超级用户,包括控制缓存管理器生命周期。 |
|
| ALL_READ、ALL_WRITE、LISTEN、EXEC、MONITOR、CREATE |
除了 |
|
| ALL_READ, ALL_WRITE, LISTEN, EXEC, MONITOR |
除 |
|
| ALL_READ, MONITOR |
除了监控权限外,还具有对 Data Grid |
|
| MONITOR |
可以通过 JMX 和 |
8.1.1. 权限
用户角色是具有不同访问级别的权限集。
| 权限 | 功能 | 描述 |
| 配置 |
| 定义新的缓存配置。 |
| LISTEN |
| 针对缓存管理器注册监听程序。 |
| 生命周期 |
| 停止缓存管理器。 |
| CREATE |
| 创建和删除容器资源,如缓存、计数器、模式和脚本。 |
| MONITOR |
|
允许访问 JMX 统计信息和 |
| ALL | - | 包括所有缓存管理器权限。 |
| 权限 | 功能 | 描述 |
| READ |
| 从缓存检索条目。 |
| 写 |
放置 , | 写入、替换、删除、驱除缓存中的数据。 |
| EXEC |
| 允许针对缓存执行代码。 |
| LISTEN |
| 针对缓存注册监听程序。 |
| BULK_READ |
| 执行批量检索操作。 |
| BULK_WRITE |
| 执行批量写入操作。 |
| 生命周期 |
| 启动和停止缓存。 |
| ADMIN |
| 允许访问底层组件和内部结构。 |
| MONITOR |
|
允许访问 JMX 统计信息和 |
| ALL | - | 包括所有缓存权限。 |
| ALL_READ | - | 组合了 READ 和 BULK_READ 权限。 |
| ALL_WRITE | - | 组合 WRITE 和 BULK_WRITE 权限。 |
8.1.2. 角色和权限映射器
Data Grid 将用户实施为主体的集合。主体代表单独的用户身份,如用户名或用户所属的组。在内部,它们使用 javax.security.auth.Subject 类实现。
要启用授权,主体必须映射到角色名称,然后扩展到一组权限。
Data Grid 包括 PrincipalRoleMapper API,用于将安全主体与角色关联,以及用于将角色与特定权限关联的 RolePermissionMapper API。
Data Grid 提供以下角色和权限映射程序实现:
- 集群角色映射器
- 在集群 registry 中存储角色映射的主体。
- 集群权限映射器
- 在集群 registry 中存储权限映射的角色。允许您动态修改用户角色和权限。
- 身份角色映射器
- 使用主体名称作为角色名称。主体名称的类型或格式取决于源。例如,在 LDAP 目录中,主体名称可以是可辨识名称(DN)。
- 通用名称角色映射器
-
使用 Common Name (CN)作为角色名称。您可以将此角色映射程序与 LDAP 目录或包含可辨识名称(DN)的客户端证书一起使用;例如
cn=managers,ou=people,dc=example,dc=com映射到managers角色。
默认情况下,principal-to-role 映射仅应用于代表组的主体。通过将 authorization.group-only-mapping 配置属性设置为 false,可以将 Data Grid 配置为也为用户主体执行映射。
8.1.2.1. 在 Data Grid 中将用户映射到角色和权限
考虑从 LDAP 服务器检索的以下用户,作为 DN 的集合:
CN=myapplication,OU=applications,DC=mycompany CN=dataprocessors,OU=groups,DC=mycompany CN=finance,OU=groups,DC=mycompany
使用 通用名称角色映射器 时,用户将映射到以下角色:
dataprocessors finance
Data Grid 具有以下角色定义:
dataprocessors: ALL_WRITE ALL_READ finance: LISTEN
用户应具有以下权限:
ALL_WRITE ALL_READ LISTEN
8.1.3. 配置角色映射器
默认情况下,Data Grid 启用集群角色映射程序和集群权限映射程序。要将不同的实现用于角色映射,您必须配置角色映射程序。
流程
- 打开 Data Grid 配置以进行编辑。
- 在 Cache Manager 配置中,将角色映射器声明为安全授权的一部分。
- 保存对配置的更改。
角色映射器配置
XML
<cache-container>
<security>
<authorization>
<common-name-role-mapper />
</authorization>
</security>
</cache-container>
JSON
{
"infinispan" : {
"cache-container" : {
"security" : {
"authorization" : {
"common-name-role-mapper": {}
}
}
}
}
}
YAML
infinispan:
cacheContainer:
security:
authorization:
commonNameRoleMapper: ~
其他资源
8.1.4. 配置集群角色和权限映射程序
集群角色映射程序在主体和角色之间维护动态映射。集群权限映射程序维护一组动态的角色定义。在这两种情况下,映射都存储在集群注册表中,可以使用 CLI 或 REST API 在运行时操作。
先决条件
-
具有 Data Grid 的
ADMIN权限。 - 启动 Data Grid CLI。
- 连接到正在运行的 Data Grid 集群。
8.1.4.1. 创建新角色
创建新角色并设置权限。
流程
使用用户角色
create 命令创建角色,例如:user roles create --permissions=ALL_READ,ALL_WRITE simple
验证
使用用户角色 ls 命令,列出您向用户授予的角色。
user roles ls ["observer","application","admin","monitor","simple","deployer"]
描述 使用用户角色的角色 describe 命令。
user roles describe simple
{
"name" : "simple",
"permissions" : [ "ALL_READ","ALL_WRITE" ]
}8.1.4.2. 授予用户角色
为用户分配角色,并授予他们执行缓存操作并与 Data Grid 资源交互的权限。
如果要为多个用户分配同一角色并集中维护其权限,请将角色授予组而不是用户。
先决条件
-
具有 Data Grid 的
ADMIN权限。 - 创建 Data Grid 用户。
流程
- 创建与 Data Grid 的 CLI 连接。
使用
用户角色 grant 命令为用户分配角色,例如:user roles grant --roles=deployer katie
验证
使用用户角色 ls 命令,列出您向用户授予的角色。
user roles ls katie ["deployer"]
8.1.4.3. 集群角色映射程序名称重写器
默认情况下,映射是使用主体名称和角色之间的严格字符串等效性来执行。在执行查找前,可以将集群角色映射器配置为应用到主体名称的转换。
流程
- 打开 Data Grid 配置以进行编辑。
- 为集群角色映射器指定一个名称 rewriter,作为 Cache Manager 配置中的安全授权的一部分。
- 保存对配置的更改。
主体名称可能具有不同的表单,具体取决于安全域类型:
- 属性和令牌域可能会返回简单字符串
- 信任和 LDAP 域可能会返回 X.500 风格的可分辨名称
-
Kerberos 域可以返回
user@domain风格名称
使用以下转换器之一,名称可以规范化为通用形式:
8.1.4.3.1. case Principal Transformer
XML
<cache-container>
<security>
<authorization>
<cluster-role-mapper>
<name-rewriter>
<case-principal-transformer uppercase="false"/>
</name-rewriter>
</cluster-role-mapper>
</authorization>
</security>
</cache-container>
JSON
{
"cache-container": {
"security": {
"authorization": {
"cluster-role-mapper": {
"name-rewriter": {
"case-principal-transformer": {}
}
}
}
}
}
}
YAML
cacheContainer:
security:
authorization:
clusterRoleMapper:
nameRewriter:
casePrincipalTransformer:
uppercase: false
8.1.4.3.2. regex Principal Transformer
XML
<cache-container>
<security>
<authorization>
<cluster-role-mapper>
<name-rewriter>
<regex-principal-transformer pattern="cn=([^,]+),.*" replacement="$1"/>
</name-rewriter>
</cluster-role-mapper>
</authorization>
</security>
</cache-container>
JSON
{
"cache-container": {
"security": {
"authorization": {
"cluster-role-mapper": {
"name-rewriter": {
"regex-principal-transformer": {
"pattern": "cn=([^,]+),.*",
"replacement": "$1"
}
}
}
}
}
}
}
YAML
cacheContainer:
security:
authorization:
clusterRoleMapper:
nameRewriter:
regexPrincipalTransformer:
pattern: "cn=([^,]+),.*"
replacement: "$1"
其他资源
8.2. 使用安全授权配置缓存
为缓存添加安全授权来强制实施基于角色的访问控制(RBAC)。这要求 Data Grid 用户拥有足够级别权限来执行缓存操作的角色。
先决条件
- 创建 Data Grid 用户,并使用角色授予他们,或者将它们分配到组。
流程
- 打开 Data Grid 配置以进行编辑。
-
在配置中添加
security部分。 指定用户必须使用
authorization元素执行缓存操作的角色。您可以隐式添加缓存管理器中定义的所有角色,或者明确定义角色的子集。
- 保存对配置的更改。
隐式角色配置
以下配置会隐式添加缓存管理器中定义的每个角色:
XML
<distributed-cache>
<security>
<authorization/>
</security>
</distributed-cache>
JSON
{
"distributed-cache": {
"security": {
"authorization": {
"enabled": true
}
}
}
}
YAML
distributedCache:
security:
authorization:
enabled: true
显式角色配置
以下配置明确添加缓存管理器中定义的角色子集。在这种情况下,Data Grid 拒绝任何没有配置角色的用户的缓存操作。
XML
<distributed-cache>
<security>
<authorization roles="admin supervisor"/>
</security>
</distributed-cache>
JSON
{
"distributed-cache": {
"security": {
"authorization": {
"enabled": true,
"roles": ["admin","supervisor"]
}
}
}
}
YAML
distributedCache:
security:
authorization:
enabled: true
roles: ["admin","supervisor"]
第 9 章 配置事务
驻留在分布式系统上的数据容易受到临时网络中断、系统故障或只是简单人为错误造成的错误。这些外部因素不可控制,但可能会给数据质量造成严重后果。数据损坏的影响范围从降低客户的满意度到导致服务不可用的昂贵系统协调。
Data Grid 可以执行 ACID (原子性、一致性、隔离、持久性)事务,以确保缓存状态一致。
9.1. Transactions
Data Grid 可以配置为使用和参与 JTA 兼容事务。
或者,如果禁用了事务支持,它等同于在 JDBC 调用中使用 autocommit,其中修改可能会在每次更改后复制(如果启用了复制)。
在每个缓存操作 Data Grid 中执行以下操作:
- 检索与线程关联的当前 事务
- 如果尚未完成,请将 XAResource 与事务管理器注册,以便在事务提交或回滚时获得通知。
要执行此操作,必须将缓存提供给对环境的 TransactionManager 的引用。这通常是通过使用类名称配置 TransactionManagerLookup 接口的实施来实现的。当缓存启动时,它将创建此类的实例并调用其 getTransactionManager () 方法,它将返回对 TransactionManager 的引用。
Data Grid 附带几个事务管理器查找类:
事务管理器查找实现
- EmbeddedTransactionManagerLookup :这提供了一个基本的事务管理器,该管理器应在没有其他实施可用时用于嵌入式模式。这个实现对并发事务和恢复有一些严重的限制。
-
JBossStandaloneJTAManagerLookup :如果您在独立环境中运行 Data Grid,或者在 JBoss AS 7 及更早版本中运行,且 WildFly 8 9 和 10,则这应该是您的事务管理器的默认选择。它是基于 JBoss 交易的全面交易经理,它克服了
嵌入式TransactionManager的所有责任。 - WildflyTransactionManagerLookup :如果您在 WildFly 11 或更高版本中运行 Data Grid,则应该是您事务管理器的默认选择。
-
GenericTransactionManagerLookup :这是在最流行的 Java EE 应用服务器中查找事务管理器的查找类。如果没有找到事务管理器,则默认为
EmbeddedTransactionManager。
初始化后,TransactionManager 也可以从 缓存 本身获取:
//the cache must have a transactionManagerLookupClass defined Cache cache = cacheManager.getCache(); //equivalent with calling TransactionManagerLookup.getTransactionManager(); TransactionManager tm = cache.getAdvancedCache().getTransactionManager();
9.1.1. 配置事务
事务在缓存级别上配置。以下是影响每个配置属性的事务和少量描述的配置。
<locking isolation="READ_COMMITTED"/> <transaction locking="OPTIMISTIC" auto-commit="true" complete-timeout="60000" mode="NONE" notifications="true" reaper-interval="30000" recovery-cache="__recoveryInfoCacheName__" stop-timeout="30000" transaction-manager-lookup="org.infinispan.transaction.lookup.GenericTransactionManagerLookup"/>
或以编程方式:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.locking()
.isolationLevel(IsolationLevel.READ_COMMITTED);
builder.transaction()
.lockingMode(LockingMode.OPTIMISTIC)
.autoCommit(true)
.completedTxTimeout(60000)
.transactionMode(TransactionMode.NON_TRANSACTIONAL)
.useSynchronization(false)
.notifications(true)
.reaperWakeUpInterval(30000)
.cacheStopTimeout(30000)
.transactionManagerLookup(new GenericTransactionManagerLookup())
.recovery()
.enabled(false)
.recoveryInfoCacheName("__recoveryInfoCacheName__");-
isolation- 配置隔离级别。如需更多详细信息,请参阅 隔离级别。默认为REPEATABLE_READ。 -
locking- 配置缓存是否使用 optimistic 或 pessimistic locking。检查部分 事务锁定 以了解更多详细信息。默认为OPTIMISTIC。 -
auto-commit- if enable,用户不需要为单个操作手动启动事务。事务会自动启动并运行。默认为true。 -
complete-timeout- 持续时间(以毫秒为单位),以保持有关已完成的事务的信息。默认值为60000。 mode- 配置缓存是事务性。默认为NONE。可用的选项有:-
NONE非事务缓存 -
FULL_XA- XA 事务缓存,并启用了恢复。有关恢复的详情,请查看 Transaction recovery 部分。 -
NON_DURABLE_XA- XA 事务缓存,并禁用了恢复。 -
NON_XA- 通过 同步 而不是 XA 集成事务缓存。检查部分 Enlisting Synchronizations 以了解详细信息。 -
BATCH- 事务缓存,使用批处理对操作进行分组。检查部分批处理 以了解详细信息。
-
-
notifications- 启用/禁用在缓存监听程序中触发事务事件。默认为true。 -
Reaper-interval- 以 millisecond 为单位的时间间隔,其中线程会清除事务完成信息。默认值为30000。 -
recovery-cache- 配置缓存名称来存储恢复信息。有关恢复的详情,请查看 Transaction recovery 部分。默认为recoveryInfoCacheName。 -
stop-timeout- 缓存停止时 millisecond 等待的时间,以等待持续事务。默认值为30000。 -
transaction-manager-lookup- 配置类的完全限定域名,该类查找对jakarta.transaction.TransactionManager的引用。默认为org.infinispan.transaction.lookup.GenericTransactionManagerLookup。
有关如何在 Data Grid 中实施 Two-Phase-Commit (2PC)的更多详细信息,以及如何获取锁定,请参见以下部分。有关配置设置的更多详细信息,请参阅配置 参考。
9.1.2. 隔离级别
Data Grid 提供两种隔离级别 - READ_COMMITTED 和 REPEATABLE_READ。
这些隔离级别决定读者何时看到并发写入,并使用 MVCCEntry 的不同子类在内部实施,它们在不同状态如何提交回数据容器。
下面是一个更详细的示例,它可以帮助了解 Data Grid 上下文 READ_COMMITTED 和 REPEATABLE_READ 之间的差别。使用 READ_COMMITTED 时,如果同一键上的两个连续读取调用之间,密钥已被另一个事务更新,第二个读取可能会返回新的更新值:
Thread1: tx1.begin() Thread1: cache.get(k) // returns v Thread2: tx2.begin() Thread2: cache.get(k) // returns v Thread2: cache.put(k, v2) Thread2: tx2.commit() Thread1: cache.get(k) // returns v2! Thread1: tx1.commit()
使用 REPEATABLE_READ,最终 get 仍会返回 v。因此,如果您要在事务中多次检索同一密钥,您应该使用 REPEATABLE_READ。
但是,因为 read-locks 甚至没有为 REPEATABLE_READ 获取,因此这种现象可能会发生:
cache.get("A") // returns 1
cache.get("B") // returns 1
Thread1: tx1.begin()
Thread1: cache.put("A", 2)
Thread1: cache.put("B", 2)
Thread2: tx2.begin()
Thread2: cache.get("A") // returns 1
Thread1: tx1.commit()
Thread2: cache.get("B") // returns 2
Thread2: tx2.commit()9.1.3. 事务锁定
9.1.3.1. Pessimistic 事务缓存
从锁定的角度来看,模糊的事务会在写入密钥时获得密钥锁定。
- 锁定请求发送到主所有者(可以是显式锁定请求或操作)
主所有者尝试获取锁定:
- 如果成功,它会发送回正回复;
- 否则,会发送负回复,事务会被回滚。
例如:
transactionManager.begin(); cache.put(k1,v1); //k1 is locked. cache.remove(k2); //k2 is locked when this returns transactionManager.commit();
当 cache.put (k1,v1) 返回时,k1 被锁定,并且集群中任何其它事务都可以写入它。仍可读取 k1。当事务完成时(提交或回滚)时,k1 上的锁定会被释放。
对于条件操作,验证在原始卷中执行。
9.1.3.2. 最佳事务缓存
使用最佳事务锁定会在交易准备时获取,且仅保留事务提交(或回滚)的点。这与 5.0 默认锁定模型不同,其中本地锁定在进行写入时获得,在准备过程中会获取集群锁定。
- 准备将发送到所有所有者。
主要所有者尝试获取所需的锁定:
- 如果锁定成功,它将执行写入偏移检查。
- 如果写入偏移检查成功(或被禁用),请发送正回复。
- 否则,发送负回复并回滚事务。
例如:
transactionManager.begin(); cache.put(k1,v1); cache.remove(k2); transactionManager.commit(); //at prepare time, K1 and K2 is locked until committed/rolled back.
对于条件命令,验证仍然在原始卷中发生。
9.1.3.3. 我需要什么 - 保守或最佳事务?
从用例的角度来看,当同时运行多个事务之间没有许多竞争时,应使用最佳事务。这是因为,如果在读取数据和提交时间(启用了写偏移检查)之间更改了数据,则最佳事务回滚。
另一方面,当密钥和事务回滚中发生大量竞争时,模糊的事务可能会更加适合。Pessimistic 事务的性质更加昂贵:每个写入操作都可能涉及对锁定的 RPC。
9.1.4. 写 Skews
当两个事务独立,同时读取和写入同一密钥时,写入 skews。写入偏移的结果是,两个事务都成功将更新提交到同一密钥,但具有不同值。
Data Grid 会自动执行写入偏移检查,以确保在最佳事务中 REPEATABLE_READ 隔离级别的数据一致性。这使得 Data Grid 能够检测并回滚其中一个交易。
在 LOCAL 模式中运行时,写 skew 检查依赖于 Java 对象引用来比较区别,它为写 skews 提供可靠的技术。
9.1.4.1. 在 pessimitic 事务中强制写入锁定
为了避免写入带有 pessimistic 事务的 skews,使用 Flag.FORCE_WRITE_LOCK 在读取时锁定密钥。
-
在非事务缓存中,
Flag.FORCE_WRITE_LOCK无法正常工作。get ()调用读取键值,但不会远程获取锁定。 -
您应该使用
Flag.FORCE_WRITE_LOCK,并在稍后在同一事务中更新实体的事务。
将以下代码片段与 Flag.FORCE_WRITE_LOCK 示例进行比较:
// begin the transaction
if (!cache.getAdvancedCache().lock(key)) {
// abort the transaction because the key was not locked
} else {
cache.get(key);
cache.put(key, value);
// commit the transaction
}// begin the transaction
try {
// throws an exception if the key is not locked.
cache.getAdvancedCache().withFlags(Flag.FORCE_WRITE_LOCK).get(key);
cache.put(key, value);
} catch (CacheException e) {
// mark the transaction rollback-only
}
// commit or rollback the transaction9.1.5. 处理异常
如果 CacheException (或其子类)被 JTA 事务范围内的缓存方法抛出,则事务会自动标记为回滚。
9.1.6. Enlisting Synchronizations
默认情况下,通过 XAResource,将自身注册为分布式交易的第一类参与者。在某些情况下,Data Grid 不需要成为交易中的参与者,但只有其生命周期(准备、完成):例如,Data Grid 在 Hibernate 中用作第二级缓存。
网格允许通过同步进行事务 列表。若要启用它,只需使用 NON_XA 事务模式。
同步具有优势,它们允许 TransactionManager 使用 1PC 优化 2PC,其中只有其他资源被该事务列出(最后一个资源提交优化)。例如Hibernate 第二级缓存:如果 Data Grid 将自身注册到 TransactionManager 作为 XAResource 而非提交时,TransactionManager 会看到两个 XAResource (缓存和数据库),且不会进行此优化。在需要在两个资源间协调协调,才能将 tx 日志写入磁盘。另一方面,将 Data Grid 注册为 同步 会导致 TransactionManager 跳过将日志写入磁盘(性能改进)。
9.1.7. 批处理
批处理允许事务的原子性和某些特征,但不能完全混合 JTA 或 XA 功能。批量的交易通常比全体的交易要低得多。
通常而言,每当交易中唯一参与者是一个 Data Grid 集群时,应使用批处理 API。另一方面,每当事务涉及多个系统时,应使用 JTA 事务(涉及 TransactionManager)。例如,考虑交易的"Hello world!"的交易:将资金从一个银行帐户转移到另一个交易。如果这两个帐户都存储在 Data Grid 中,则可使用批处理。如果一个帐户位于数据库中,而另一个帐户是 Data Grid,则需要分布式事务。
您不必 定义事务管理器来使用批处理。
9.1.7.1. API
将缓存配置为使用批处理后,您可以通过在 Cache 上调用 startBatch () 和 endBatch () 来使用它。例如,
Cache cache = cacheManager.getCache();
// not using a batch
cache.put("key", "value"); // will replicate immediately
// using a batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k2", "value");
cache.endBatch(true); // This will now replicate the modifications since the batch was started.
// a new batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(false); // This will "discard" changes made in the batch9.1.7.2. 批处理和 JTA
在后台,批处理功能会启动 JTA 事务,该范围中的所有调用与其相关联。为此,它使用非常简单(如无恢复)内部 TransactionManager 实现。通过批处理,您将获得:
- 在调用期间进行锁定,直到批处理完成为止
- 在批处理中,更改都会作为批处理的一部分在批处理中复制。减少批处理中每个更新的复制 chatter。
- 如果使用同步复制或失效,则复制/验证失败将导致批处理回滚。
- 所有事务相关的配置也适用于批处理。
9.1.8. 事务恢复
恢复是 XA 事务的一个功能,它处理资源最终甚至可能出现事务管理器失败,并从此类情况中相应地恢复。
9.1.8.1. 何时使用恢复
考虑将成本从存储在外部数据库中的帐户的分布式交易转移到 Data Grid 中存储的帐户。调用 TransactionManager.commit () 时,这两个资源都成功准备(1st 阶段)。在提交(2nd)阶段,数据库在收到事务管理器的提交请求前,成功应用 whilst Data Grid 的更改会失败。此时,系统处于不一致的状态:从外部数据库中的帐户获取成本,但在 Data Grid 中还不可见(因为锁仅在双阶段提交协议的第 2 阶段发布)。恢复涉及这种情况,以确保数据库和数据网格都以一致的状态结束。
9.1.8.2. 它如何工作
恢复由事务管理器协调。事务管理器与 Data Grid 合作,以确定需要手动干预并通知系统管理员(通过电子邮件、日志警报等)的无效事务列表。这个过程是特定于事务管理器的,但通常需要事务管理器上的一些配置。
现在,系统管理员能够连接到 Data Grid 集群,并重新执行事务提交或强制回滚。Data Grid 为此提供了 JMX 工具,这在 Transaction recovery and reconciliation 部分中进行了广泛解释。
9.1.8.3. 配置恢复
Data Grid 中不默认启用恢复。如果禁用,TransactionManager 将无法与 Data Grid 合作来确定 in-doubt 事务。Transaction 配置部分 演示了如何启用它。
注意: restore-cache 属性不是强制的,它是按缓存配置的。
要恢复工作,必须将 mode 设置为 FULL_XA,因为需要全体 XA 事务。
9.1.8.3.1. 启用 JMX 支持
为了能够使用 JMX 管理恢复 JMX 支持,必须明确启用。
9.1.8.4. 恢复缓存
为了跟踪不疑的事务并能够回复它们,Data Grid 会缓存所有事务状态,以备将来使用。这个状态只适用于 in-doubt 事务,在提交/滚动阶段完成后为成功完成事务删除。
这种不疑事务数据保存在本地缓存中:这允许一块通过缓存加载程序将此信息交换到磁盘,以防其变得太大。此缓存可以通过 recovery-cache 配置属性来指定。如果没有指定 Data Grid,则会为您配置本地缓存。
可以(尽管不强制)在启用了恢复的所有 Data Grid 缓存之间共享相同的恢复缓存。如果覆盖默认恢复缓存,则指定的恢复缓存必须使用 TransactionManagerLookup,它返回不同于缓存本身使用的事务管理器。
9.1.8.5. 与事务管理器集成
虽然这是特定于事务管理器,但通常事务管理器需要引用 XAResource 实现,以便对其调用 XAResource.recover ()。要获得对 Data Grid XAResource 以下 API 的引用:
XAResource xar = cache.getAdvancedCache().getXAResource();
常见的做法是在与运行事务不同的过程中运行恢复。
9.1.8.6. 协调
事务管理器以专有方式向系统管理员告知系统管理员。在这个阶段,假定系统管理员知道事务的 XID (一个字节阵列)。
正常恢复流是:
- 第 1 步 :系统管理员通过 JMX 连接到一个 Data Grid 服务器,并列出问题中的事务。下图展示了 JConsole 连接到一个具有双疑事务的 Data Grid 节点。
图 9.1. 显示 in-doubt 事务
此时会显示每个 in-doubt 事务的状态(在本例中为 " PREPARED ")。status 字段中可能有多个元素,例如:如果事务在特定节点上提交但未在所有这些节点上提交,"REPARED"和"COMMITTED"。
- STEP 2: 系统管理员以视觉方式将从事务管理器收到的 XID 映射到 Data Grid 内部 ID,以数字表示。此步骤是必需的,因为 XID 是一个字节阵列,无法方便地传递给 JMX 工具(如 JConsole),然后在 Data Grid 的一侧重新编译。
- STEP 3 :系统管理员根据内部 ID 通过对应的 jmx 操作强制通过对应的 jmx 操作强制提交/滚动。以下镜像通过根据其内部 ID 强制提交事务来获得。
图 9.2. 强制提交
上述所有 JMX 操作都可以在任何节点上执行,无论事务源自的位置。
9.1.8.6.1. 根据 XID 强制提交/滚动
还提供了基于 XID 的 JMX 操作来强制进行交易的提交/滚动回应:这些方法接收描述 XID 的 byte[] 阵列,而不是与事务关联的数字(如第 2 步所述)。这很有用,例如,如果某人希望为某些 In-doubt 事务设置自动完成作业。这个过程被插入到事务管理器的恢复中,并可访问事务管理器的 XID 对象。
第 10 章 配置锁定和并发
Data Grid 使用多版本的并发控制(MVCC)来改进对共享数据的访问。
- 允许并发读取器和写入器
- 读取器和写入者不会阻断另一个内容
- 可以检测到并处理写 skews
- 内部锁定可以是条带的
10.1. 锁定和并发
多版本的并发控制(MVCC)是一个与关系数据库和其他数据存储流行的并发方案。MVCC 与粗粒度 Java 同步(甚至 JDK Locks)提供了许多优点,以访问共享数据。
Data Grid 的 MVCC 实现利用最小的锁和同步,更倾向于采用无锁定技术,如 比较 和交换以及无锁定数据结构,这有助于针对多 CPU 和多核环境进行优化。
特别是,Data Grid 的 MVCC 实现会对读者进行大量优化。读取器线程不会获取条目的显式锁定,而是直接读取问题中的条目。
另一方面,作者需要获取写锁。这样可确保每个条目只有一个并发写入器,从而导致并发写入器在线更改条目。
要允许并发读取,写器通过嵌套 MVCCEntry 中的条目来制作他们要修改的条目的副本。此副本隔离并发读取器来查看部分修改的状态。写入完成后,MVCCEntry.commit () 将清空对数据容器的更改,后续的读取器将看到写入的更改。
10.1.1. 集群缓存和锁定
在 Data Grid 集群中,主所有者节点负责锁定密钥。
对于非事务缓存,Data Grid 将写操作转发到密钥的主所有者,以便它能够锁定它。然后,Data Grid 将写入操作转发到其他所有者,或者在无法锁定密钥时抛出异常。
如果操作为条件并在主所有者上失败,则 Data Grid 不会将它转发到其他所有者。
对于事务缓存,主所有者可以使用最佳锁定模式锁定密钥。Data Grid 还支持不同的隔离级别,以控制事务之间的并发读取。
10.1.2. LockManager
LockManager 是一个组件,它负责锁定写条目。LockManager 使用 LockContainer 找到/hold/create 锁定。LockContainers 有两个广泛的 flavours,它支持锁定条带,并支持每个条目一个锁定。
10.1.3. 锁定条带
锁定条带要求使用固定大小、整个缓存的锁定共享集合,锁定会根据条目的哈希代码分配给条目。与 JDK 的 ConcurrentHashMap 分配锁定的方式类似,这允许在交换过程中具有高度可扩展的固定位锁定机制,以便同一锁定阻止了与相关的条目。
另一种方法是禁用锁定条带 - 这意味着 每个条目创建一个新的 锁定。这种方法 可能会 为您提供更高的并发吞吐量,但它将是额外的内存用量、垃圾收集时间等。
默认情况下禁用锁定条带,因为当不同键锁定在同一锁定条带中时可能会出现潜在的死锁。
可以使用 < locking /> 配置元素的 concurrencyLevel 属性调整锁定条带使用的共享锁定集合的大小。
配置示例:
<locking striping="false|true"/>
或者
new ConfigurationBuilder().locking().useLockStriping(false|true);
10.1.4. 并发级别
除了确定条带锁定容器的大小外,这个并发级别还用于调整任何基于 JDK ConcurrentHashMap 的集合。有关并发级别的详细讨论,请参阅 JDK ConcurrentHashMap Javadocs,因为此参数在 Data Grid 中完全相同。
配置示例:
<locking concurrency-level="32"/>
或者
new ConfigurationBuilder().locking().concurrencyLevel(32);
10.1.5. 锁定超时
锁定超时指定等待内容锁定的时间长度(以毫秒为单位)。
配置示例:
<locking acquire-timeout="10000"/>
或者
new ConfigurationBuilder().locking().lockAcquisitionTimeout(10000); //alternatively new ConfigurationBuilder().locking().lockAcquisitionTimeout(10, TimeUnit.SECONDS);
10.1.6. 一致性
单个所有者被锁定(而不是所有所有者被锁定)不会破坏以下一致性保证:如果密钥 对节点 K {A、B} 和事务 TX1 进行哈希处理时,让我们在 A 上取得一个锁定。如果另一个事务 TX2 在 B (或任何其他节点)上启动,TX2 会尝试锁定 K,然后其将失败,因为锁定已持有 TX1。这样做的原因是,无论事务源自的位置,K 的锁始终、确定地获取到集群的同一节点上。
10.1.7. 数据版本控制
Data Grid 支持两种形式的数据版本: simple 和 external。简单的版本控制用于写入偏移检查。
外部版本控制用于在 Data Grid 内封装一个外部的数据源,例如将 Data Grid 与 Hibernate 搭配使用时,后者又直接从数据库获取其数据版本信息。
在这个方案中,传递版本的机制变得有必要,而 put () 和 putForExternalRead () 的超载版本将在 AdvancedCache 中提供,采用外部数据版本。然后,这存储在 InvocationContext 中,并在提交时应用到条目。
无法编写 skew 检查,在外部数据版本控制时不会执行。
第 11 章 使用集群计数器
Data Grid 提供记录对象的计数,并在集群中的所有节点之间分布的计数器。
11.1. 集群计数器
集群计数器 是在 Data Grid 集群中所有节点分布和共享的计数器。计数器可以具有不同的一致性级别:强和弱。
虽然强/弱一致性计数器具有单独的接口,但支持更新其值,但在更新其值时返回当前值,并提供事件。在本文档中提供了详细信息,以帮助您选择最适合您的用例。
11.1.1. 安装和配置
要开始使用计数器,您需要在 Maven pom.xml 文件中添加依赖项:
pom.xml
<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-clustered-counter</artifactId> </dependency>
计数器可以通过本文档中详述的 CounterManager 接口配置 Data Grid 配置文件或按需。当 EmbeddedCacheManager 启动时,在启动时创建在 Data Grid 配置文件中配置的计数器。这些计数器可立即启动,它们在所有集群节点中可用。
configuration.xml
<infinispan>
<cache-container ...>
<!-- To persist counters, you need to configure the global state. -->
<global-state>
<!-- Global state configuration goes here. -->
</global-state>
<!-- Cache configuration goes here. -->
<counters xmlns="urn:infinispan:config:counters:15.0" num-owners="3" reliability="CONSISTENT">
<strong-counter name="c1" initial-value="1" storage="PERSISTENT"/>
<strong-counter name="c2" initial-value="2" storage="VOLATILE" lower-bound="0"/>
<strong-counter name="c3" initial-value="3" storage="PERSISTENT" upper-bound="5"/>
<strong-counter name="c4" initial-value="4" storage="VOLATILE" lower-bound="0" upper-bound="10"/>
<strong-counter name="c5" initial-value="0" upper-bound="100" lifespan="60000"/>
<weak-counter name="c6" initial-value="5" storage="PERSISTENT" concurrency-level="1"/>
</counters>
</cache-container>
</infinispan>
或以编程方式在 GlobalConfigurationBuilder 中:
GlobalConfigurationBuilder globalConfigurationBuilder = ...;
CounterManagerConfigurationBuilder builder = globalConfigurationBuilder.addModule(CounterManagerConfigurationBuilder.class);
builder.numOwner(3).reliability(Reliability.CONSISTENT);
builder.addStrongCounter().name("c1").initialValue(1).storage(Storage.PERSISTENT);
builder.addStrongCounter().name("c2").initialValue(2).lowerBound(0).storage(Storage.VOLATILE);
builder.addStrongCounter().name("c3").initialValue(3).upperBound(5).storage(Storage.PERSISTENT);
builder.addStrongCounter().name("c4").initialValue(4).lowerBound(0).upperBound(10).storage(Storage.VOLATILE);
builder.addStrongCounter().name("c5").initialValue(0).upperBound(100).lifespan(60000);
builder.addWeakCounter().name("c6").initialValue(5).concurrencyLevel(1).storage(Storage.PERSISTENT);
另一方面,可以在初始化 EmbeddedCacheManager 后随时配置计数器。
CounterManager manager = ...;
manager.defineCounter("c1", CounterConfiguration.builder(CounterType.UNBOUNDED_STRONG).initialValue(1).storage(Storage.PERSISTENT).build());
manager.defineCounter("c2", CounterConfiguration.builder(CounterType.BOUNDED_STRONG).initialValue(2).lowerBound(0).storage(Storage.VOLATILE).build());
manager.defineCounter("c3", CounterConfiguration.builder(CounterType.BOUNDED_STRONG).initialValue(3).upperBound(5).storage(Storage.PERSISTENT).build());
manager.defineCounter("c4", CounterConfiguration.builder(CounterType.BOUNDED_STRONG).initialValue(4).lowerBound(0).upperBound(10).storage(Storage.VOLATILE).build());
manager.defineCounter("c4", CounterConfiguration.builder(CounterType.BOUNDED_STRONG).initialValue(0).upperBound(100).lifespan(60000).build());
manager.defineCounter("c6", CounterConfiguration.builder(CounterType.WEAK).initialValue(5).concurrencyLevel(1).storage(Storage.PERSISTENT).build());
CounterConfiguration 是不可变的,可以被重复使用。
如果计数器配置成功或为 false,则方法 defineCounter () 将返回 true。但是,如果配置无效,则方法会抛出 CounterConfigurationException。要查找是否已定义计数器,请使用 method isDefined ()。
CounterManager manager = ...
if (!manager.isDefined("someCounter")) {
manager.define("someCounter", ...);
}其他资源
11.1.1.1. 列出计数器名称
要列出定义的所有计数器,method CounterManager.getCounterNames () 返回在集群范围创建的所有计数器名称的集合。
11.1.2. CounterManager 接口
CounterManager 接口是定义、检索和删除计数器的入口点。
嵌入式部署
CounterManager 会自动侦听 EmbeddedCacheManager 创建,然后为每个 EmbeddedCacheManager 执行实例的注册。它启动存储计数器状态所需的缓存并配置默认计数器。
检索 CounterManager 非常简单,就像调用 EmbeddedCounterManagerFactory.asCounterManager (EmbeddedCacheManager),如下例所示:
// create or obtain your EmbeddedCacheManager EmbeddedCacheManager manager = ...; // retrieve the CounterManager CounterManager counterManager = EmbeddedCounterManagerFactory.asCounterManager(manager);
服务器部署
对于 Hot Rod 客户端,CounterManager 在 RemoteCacheManager 中注册,并可以检索,如下所示:
// create or obtain your RemoteCacheManager RemoteCacheManager manager = ...; // retrieve the CounterManager CounterManager counterManager = RemoteCounterManagerFactory.asCounterManager(manager);
11.1.2.1. 通过 CounterManager 删除计数器
通过 Strong/WeakCounter 接口和 CounterManager 删除计数器之间有一个区别。CounterManager.remove (String) 从集群中删除计数器值,并删除本地计数器实例中计数器中注册的所有监听程序。另外,计数器实例不再重复使用,它可能会返回无效的结果。
在另一端,Strong/WeakCounter 删除仅移除计数器值。实例仍然可以重复使用,监听器仍然可以正常工作。
如果在移除后访问计数器,则会重新创建计数器。
11.1.3. Counter
计数器可以很强大(StrongCounter)或弱一致性(WeakCounter),它们都由一个名称来标识。它们有一个特定的接口,但它们共享一些逻辑,即它们都是异步的(每个操作返回 CompletableFuture ),提供更新事件,并可重置为其初始值。
如果您不想使用 async API,可以通过 sync () 方法返回同步计数器。API 相同,但没有 CompletableFuture 返回值。
两种方法对这两个接口是通用的:
String getName(); CompletableFuture<Long> getValue(); CompletableFuture<Void> reset(); <T extends CounterListener> Handle<T> addListener(T listener); CounterConfiguration getConfiguration(); CompletableFuture<Void> remove(); SyncStrongCounter sync(); //SyncWeakCounter for WeakCounter
-
getName ()返回计数器名称(identifier)。 -
getValue ()返回当前计数器的值。 -
reset ()允许将计数器的值重置为其初始值。 -
addListener ()注册监听程序以接收更新事件。有关它的更多详细信息,请在 Notification 和 Events 部分中。 -
getConfiguration ()返回计数器使用的配置。 -
remove ()从集群中移除计数器值。仍可使用实例,并保留监听器。 -
sync ()创建一个同步计数器。
如果在移除后访问计数器,则会重新创建计数器。
11.1.3.1. StrongCounter 接口:当一致性或绑定很重要时。
强大的计数器提供使用存储在 Data Grid 缓存中的单个密钥来提供所需的一致性。所有更新都在密钥锁定下执行,以更新其值。另一方面,读取不会获取任何锁定,并读取当前的值。此外,使用此方案时,它允许绑定计数器值并提供原子操作,如 compare-and-set/swap。
可以使用 get 方法从 StrongCounter ()CounterManager 检索 StrongCounter。例如:
CounterManager counterManager = ...
StrongCounter aCounter = counterManager.getStrongCounter("my-counter");
由于每个操作都将达到单个键,因此 StrongCounter 具有较高的竞争率。
StrongCounter 接口添加以下方法:
default CompletableFuture<Long> incrementAndGet() {
return addAndGet(1L);
}
default CompletableFuture<Long> decrementAndGet() {
return addAndGet(-1L);
}
CompletableFuture<Long> addAndGet(long delta);
CompletableFuture<Boolean> compareAndSet(long expect, long update);
CompletableFuture<Long> compareAndSwap(long expect, long update);-
incrementAndGet ()逐一递增计数器并返回新值。 -
decrementAndGet ()将计数器减少一次,并返回新值。 -
addAndGet ()将 delta 添加到计数器的值中,并返回新值。 -
compareAndSet ()和compareAndSwap ()以原子方式设置计数器的值(如果当前值是预期的)。
当完成 CompletableFuture 时,操作被视为已完成。
compare-and-set 和 compare-and-swap 之间的区别在于,如果操作成功,则前者会返回 true,稍后返回上一个值。如果返回值与预期相同,则 compare-and-swap 可以成功。
11.1.3.1.1. 已绑定的 StrongCounter
绑定后,当上述所有更新方法达到较低或上限时,所有更新方法都会抛出 CounterOutOfBoundsException。例外有以下方法检查到达哪个侧绑定:
public boolean isUpperBoundReached(); public boolean isLowerBoundReached();
11.1.3.1.2. 使用案例
在以下用例中,强计数器更适合:
- 在每次更新后需要计数器的值(例如,集群范围 ID 生成器或序列)
- 当需要有界计数器时(例如,速率限制器)
11.1.3.1.3. 使用示例
StrongCounter counter = counterManager.getStrongCounter("unbounded_counter");
// incrementing the counter
System.out.println("new value is " + counter.incrementAndGet().get());
// decrement the counter's value by 100 using the functional API
counter.addAndGet(-100).thenApply(v -> {
System.out.println("new value is " + v);
return null;
}).get();
// alternative, you can do some work while the counter is updated
CompletableFuture<Long> f = counter.addAndGet(10);
// ... do some work ...
System.out.println("new value is " + f.get());
// and then, check the current value
System.out.println("current value is " + counter.getValue().get());
// finally, reset to initial value
counter.reset().get();
System.out.println("current value is " + counter.getValue().get());
// or set to a new value if zero
System.out.println("compare and set succeeded? " + counter.compareAndSet(0, 1));以下是使用绑定计数器的另一个示例:
StrongCounter counter = counterManager.getStrongCounter("bounded_counter");
// incrementing the counter
try {
System.out.println("new value is " + counter.addAndGet(100).get());
} catch (ExecutionException e) {
Throwable cause = e.getCause();
if (cause instanceof CounterOutOfBoundsException) {
if (((CounterOutOfBoundsException) cause).isUpperBoundReached()) {
System.out.println("ops, upper bound reached.");
} else if (((CounterOutOfBoundsException) cause).isLowerBoundReached()) {
System.out.println("ops, lower bound reached.");
}
}
}
// now using the functional API
counter.addAndGet(-100).handle((v, throwable) -> {
if (throwable != null) {
Throwable cause = throwable.getCause();
if (cause instanceof CounterOutOfBoundsException) {
if (((CounterOutOfBoundsException) cause).isUpperBoundReached()) {
System.out.println("ops, upper bound reached.");
} else if (((CounterOutOfBoundsException) cause).isLowerBoundReached()) {
System.out.println("ops, lower bound reached.");
}
}
return null;
}
System.out.println("new value is " + v);
return null;
}).get();compare-and-set 与 Compare-and-swap 示例:
StrongCounter counter = counterManager.getStrongCounter("my-counter");
long oldValue, newValue;
do {
oldValue = counter.getValue().get();
newValue = someLogic(oldValue);
} while (!counter.compareAndSet(oldValue, newValue).get());
使用 compare-and-swap,它会保存一个调用计数器调用(counter.getValue ())
StrongCounter counter = counterManager.getStrongCounter("my-counter");
long oldValue = counter.getValue().get();
long currentValue, newValue;
do {
currentValue = oldValue;
newValue = someLogic(oldValue);
} while ((oldValue = counter.compareAndSwap(oldValue, newValue).get()) != currentValue);
要将强计数器用作速率限制器,请配置 上限 和 lifespan 参数,如下所示:
// 5 request per minute
CounterConfiguration configuration = CounterConfiguration.builder(CounterType.BOUNDED_STRONG)
.upperBound(5)
.lifespan(60000)
.build();
counterManager.defineCounter("rate_limiter", configuration);
StrongCounter counter = counterManager.getStrongCounter("rate_limiter");
// on each operation, invoke
try {
counter.incrementAndGet().get();
// continue with operation
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
if (e.getCause() instanceof CounterOutOfBoundsException) {
// maximum rate. discard operation
return;
} else {
// unexpected error, handling property
}
}
lifespan 参数是一个实验性功能,可能会在以后的版本中删除。
11.1.3.2. WeakCounter 接口:何时需要速度
WeakCounter 将计数器的值存储在 Data Grid 缓存中的多个键中。创建的密钥数量由 concurrency-level 属性配置。每个键存储计数器值的部分状态,并可同时更新。与 StrongCounter 相比,它的主要优点是缓存中较低争用。另一方面,其值的读取更为昂贵,不允许绑定。
reset 操作应谨慎处理。它不是 原子的,它会生成中间值。这些值可由读取操作以及注册的任何监听程序看到。
可以使用 get 方法从 WeakCounter ()CounterManager 检索 WeakCounter。例如:
CounterManager counterManager = ...
StrongCounter aCounter = counterManager.getWeakCounter("my-counter);11.1.3.2.1. 弱计数接口
WeakCounter 添加以下方法:
default CompletableFuture<Void> increment() {
return add(1L);
}
default CompletableFuture<Void> decrement() {
return add(-1L);
}
CompletableFuture<Void> add(long delta);它们与 'StrongCounter's 类似,但它们不会返回新值。
11.1.3.2.2. 使用案例
当不需要更新操作,或者不需要计数器的值时,弱计数器最适合的情况。收集统计信息是此类用例的良好示例。
11.1.3.2.3. 例子
以下是弱计数器用法的示例。
WeakCounter counter = counterManager.getWeakCounter("my_counter");
// increment the counter and check its result
counter.increment().get();
System.out.println("current value is " + counter.getValue());
CompletableFuture<Void> f = counter.add(-100);
//do some work
f.get(); //wait until finished
System.out.println("current value is " + counter.getValue().get());
//using the functional API
counter.reset().whenComplete((aVoid, throwable) -> System.out.println("Reset done " + (throwable == null ? "successfully" : "unsuccessfully"))).get();
System.out.println("current value is " + counter.getValue().get());11.1.4. 通知和事件
强和弱计数器都支持监听器接收其更新事件。侦听器必须实现 CounterListener,并可通过以下方法注册:
<T extends CounterListener> Handle<T> addListener(T listener);
CounterListener 有以下接口:
public interface CounterListener {
void onUpdate(CounterEvent entry);
}
返回的 Handle 对象具有在不再需要时删除 CounterListener 的主要目标。另外,它还允许访问它处理的 CounterListener 实例。它有以下接口:
public interface Handle<T extends CounterListener> {
T getCounterListener();
void remove();
}
最后,CounterEvent 具有之前和当前的值和状态。它有以下接口:
public interface CounterEvent {
long getOldValue();
State getOldState();
long getNewValue();
State getNewState();
}
对于未绑定的强大计数器和弱计数器,状态为 State.VALID。state.LOWER_BOUND_REACHED 和 State.UPPER_BOUND_REACHED 仅对有界强计数器有效。
弱计数器 reset () 操作将触发带有中间值的多个通知。
第 12 章 监听器和通知
与 Data Grid 一起使用监听程序,以便在缓存管理器的事件或缓存发生时获得通知。
12.1. 监听器和通知
Data Grid 提供了一个监听器 API,客户端可以在事件发生时注册并获得通知。此注解驱动的 API 适用于 2 种不同级别:缓存级别事件和缓存管理器级别事件。
事件触发分配给监听程序的通知。侦听器是使用 @Listener 注解的简单 POJO,并使用 Listenable 接口中定义的方法注册。
Cache 和 CacheManager 都实现 Listenable,这意味着您可以将监听程序附加到缓存或缓存管理器级别通知,以接收缓存级别或缓存管理器级别通知。
例如,以下类定义了一个监听程序,每次将新条目添加到缓存中时打印出一些信息:
@Listener
public class PrintWhenAdded {
Queue<CacheEntryCreatedEvent> events = new ConcurrentLinkedQueue<>();
@CacheEntryCreated
public CompletionStage<Void> print(CacheEntryCreatedEvent event) {
events.add(event);
return null;
}
}有关更全面的示例,请参阅 @Listener 的 Java 文档。
12.2. 缓存级别通知
缓存级别事件基于每个缓存发生,默认情况下仅在发生事件的节点中引发。在分布式缓存中,这些事件只会在受影响的数据所有者中产生。缓存级事件示例是正在添加、删除、修改等条目。这些事件触发通知到注册到特定缓存的监听程序。
有关所有缓存级别通知的完整列表 ,请参阅 org.infinispan.notifications.cachelistener.annotation 软件包中的 Javadocs,以及它们对应的方法级注释。
有关 Data Grid 中可用的缓存级别通知列表,请参阅 org.infinispan.notifications.cachelistener.annotation 软件包上的 Java 文档。
集群监听程序
当需要侦听单个节点上的缓存事件时,应使用集群监听程序。
为此,需要的所有情况都设置为注解您的监听程序,如集群一样。
@Listener (clustered = true)
public class MyClusterListener { .... }从非集群监听器对集群监听程序有一些限制。
-
集群侦听器只能侦听
@CacheEntryModified、@CacheEntryCreated、@CacheEntryRemoved和@CacheEntryExpired事件。请注意,这意味着对于这个监听器不会侦听任何其他类型的事件。 - 只有 post 事件发送到集群监听程序,pre 事件将被忽略。
事件过滤和转换
安装监听程序的节点上的所有适用事件都将提升到侦听器。可以使用 KeyFilter (只允许对键进行过滤)或 CacheEventFilter (用于过滤键、旧值、新元数据、新元数据、新元数据、新元数据)来动态过滤通过 KeyFilter (仅限键过滤)或 CacheEventFilter (用于过滤键)、旧值、新元数据、新元数据以及命令类型)来动态过滤哪些事件。
此处的示例显示了一个简单的 KeyFilter,它将仅在事件修改了仅 Me 键的条目时才会引发事件。
public class SpecificKeyFilter implements KeyFilter<String> {
private final String keyToAccept;
public SpecificKeyFilter(String keyToAccept) {
if (keyToAccept == null) {
throw new NullPointerException();
}
this.keyToAccept = keyToAccept;
}
public boolean accept(String key) {
return keyToAccept.equals(key);
}
}
...
cache.addListener(listener, new SpecificKeyFilter("Only Me"));
...当您要以更有效的方式限制接收的事件时,这非常有用。
另外,还提供了一个 CacheEventConverter,允许在引发事件前将值转换为另一个值。这对实现值转换的任何代码模块化可能很好。
当与 Cluster Listener 一起使用时,上述过滤器和转换器特别有用。这是因为过滤和转换是在事件源自而不是在事件侦听的节点中执行的。这可提供不需要在集群中复制事件(filter),甚至减少了有效负载(转换器)的好处。
初始状态事件
安装监听程序后,它只会在事件被完全安装后通知事件。
可能需要在第一次注册监听器时获取缓存内容的当前状态,方法是为缓存中的每个元素生成类型为 @CacheEntryCreated 的事件。在此初始阶段中生成的任何事件都会被排队,直到引发适当的事件为止。
这目前仅适用于集群监听程序。ISPN-4608 涵盖了为非集群监听程序添加此功能。
重复事件
非事务缓存中可能会接收重复的事件。当密钥的主所有者在尝试执行写入操作(如 put )时,可能会发生这种情况。
Data Grid 在内部通过将放置操作自动发送到给定密钥的新主所有者来改变放置操作,但如果写入首次复制到备份,则不能保证。因此,超过 1 个写入事件(CacheEntryCreatedEvent,CacheEntryModifiedEvent 和 CacheEntryRemovedEvent)可以在单个操作上发送。
如果生成了多个事件,则 Data Grid 会将其标记为由 retried 命令生成的事件,以帮助用户了解何时发生这个事件,而无需留意查看更改。
@Listener
public class MyRetryListener {
@CacheEntryModified
public void entryModified(CacheEntryModifiedEvent event) {
if (event.isCommandRetried()) {
// Do something
}
}
}
另外,当使用 CacheEventFilter 或 CacheEventConverter 时,EventType 包含一个方法 isRetry,以指示事件是因为重试而生成的。
12.3. 缓存管理器通知
在缓存管理器级别发生的事件是集群范围的,并涉及影响单个缓存管理器创建的所有缓存的事件。缓存管理器事件示例是加入或离开集群的节点,或缓存启动或停止。
有关所有缓存管理器 通知的完整列表,请参阅 org.infinispan.notifications.cachemanagerlistener.annotation 软件包,以及它们对应的方法级注释。
12.4. 事件同步
默认情况下,所有 async 通知都在通知线程池中分配。同步通知会延迟操作,直到监听器方法完成或完成 CompletionStage 完成后(前者会导致线程块)。或者,您可以将监听程序注解为 异步,在这种情况下,操作将立即继续,同时在通知线程池上异步完成通知。要做到这一点,只需注解您的监听器:
异步 Listener
@Listener (sync = false)
public class MyAsyncListener {
@CacheEntryCreated
void listen(CacheEntryCreatedEvent event) { }
}
阻塞 Synchronous Listener
@Listener
public class MySyncListener {
@CacheEntryCreated
void listen(CacheEntryCreatedEvent event) { }
}
非阻塞 Listener
@Listener
public class MyNonBlockingListener {
@CacheEntryCreated
CompletionStage<Void> listen(CacheEntryCreatedEvent event) { }
}
异步线程池
要调整用于分配此类异步通知的线程池,请在配置文件中使用 & lt;listener-executor /> XML 元素。