
Red Hat Training
A Red Hat training course is available for JBoss Enterprise SOA Platform
JBPM リファレンスガイド
JBoss 開発者向け
5.3.1 エディッション
概要
第1章 はじめに
1.1. 概要
図1.1 jPDL コンポーネントの概要
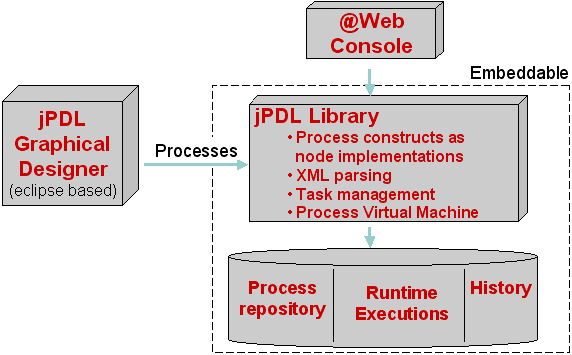
1.2. jPDL スイート
- config
- database
- deploy
- designer
- examples
- lib
- src
- jBPM Web コンソール
- これは Web アーカイブとしてパッケージ化されています。プロセス参加者 と jBPM 管理者の両方がこのコンソールを使用できます。
- jBPM テーブル
- これらは、デフォルトの Hypersonic データベースに含まれています。(このデータベースには、すでにプロセスが含まれています。)
- サンプルプロセス
- 1 つのサンプルプロセスが、すでに jBPM データベースにデプロイされています。
- アイデンティティーコンポーネント
- アイデンティティーコンポーネントライブラリーは、コンソール Web アプリケーション の一部です。データベース内にある
JBPM_ID_接頭辞を持つテーブルを所有しています。
1.3. jPDL グラフィカルプロセスデザイナー
1.4. jBPM コンソール Web アプリケーション
1.5. jBPM コアライブラリー
Enterprise Java Bean、Web サービスなど、あらゆる Java 環境で使用できます。
Enterprise Java Bean としてパッケージ化して公開することもできます。クラスターデプロイメントを作成する必要がある場合、または非常に高いスループットを実現するためにスケーラビリティーを提供する必要がある場合は、これを行ってください。(ステートレスセッション Enterprise Java Bean は J2EE 1.3 仕様に準拠しているため、任意のアプリケーションサーバーにデプロイできます。)
jbpm-jpdl.jar ファイルの一部は、Hibernate や Dom4J などのサードパーティーライブラリーに依存していることに注意してください。
1.6. アイデンティティーコンポーネント
1.7. jBPM ジョブエグゼキューター
TimerService をこの目的に使用する場合があります。ジョブエグゼキューターは "標準" の環境で使用するのが最適です。)
jbpm-jpdl ライブラリーにパッケージ化されています。次の 2 つのシナリオのいずれかでのみデプロイできます。
JbpmThreadsServletがジョブエグゼキューターを起動するように設定されている場合。- 別個の Java 仮想マシンを起動し、その中からジョブエグゼキュータースレッドを実行できるようにした場合。
1.8. まとめ
第2章 チュートリアル
src/java.examples サブディレクトリーにある JBPM ダウンロードパッケージにあります。
2.1. "Hello World" の例
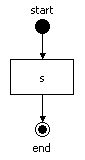
Hello World プロセス定義には、以下のノードが 3 つあります。(デザイナーツールl を使用せずにこの単純なプロセスを調べて、その仕組みを学習することをお勧めします。) 次の図は、Hello World プロセスをグラフィカルに表現したものです。
図2.1 Hello World プロセスの図
public void testHelloWorldProcess() {
// This method shows a process definition and one execution
// of the process definition. The process definition has
// 3 nodes: an unnamed start-state, a state 's' and an
// end-state named 'end'.
// The next line parses a piece of xml text into a
// ProcessDefinition. A ProcessDefinition is the formal
// description of a process represented as a java object.
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString(
"<process-definition>" +
" <start-state>" +
" <transition to='s' />" +
" </start-state>" +
" <state name='s'>" +
" <transition to='end' />" +
" </state>" +
" <end-state name='end' />" +
"</process-definition>"
);
// The next line creates one execution of the process definition.
// After construction, the process execution has one main path
// of execution (=the root token) that is positioned in the
// start-state.
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
// After construction, the process execution has one main path
// of execution (=the root token).
Token token = processInstance.getRootToken();
// Also after construction, the main path of execution is positioned
// in the start-state of the process definition.
assertSame(processDefinition.getStartState(), token.getNode());
// Let's start the process execution, leaving the start-state
// over its default transition.
token.signal();
// The signal method will block until the process execution
// enters a wait state.
// The process execution will have entered the first wait state
// in state 's'. So the main path of execution is now
// positioned in state 's'
assertSame(processDefinition.getNode("s"), token.getNode());
// Let's send another signal. This will resume execution by
// leaving the state 's' over its default transition.
token.signal();
// Now the signal method returned because the process instance
// has arrived in the end-state.
assertSame(processDefinition.getNode("end"), token.getNode());
}2.2. データベースの例
待機状態 の間、データベースプロセスの実行を永続化する機能があります。次の例は、この機能を示しており、jBPM データベースにプロセスインスタンスを保存しています。
メソッド を作成することによって機能します。たとえば、Web アプリケーション内のユーザーコードの一部がプロセスを起動し、データベース内で実行を "永続化" します。その後、メッセージ駆動型 Bean がそのプロセスインスタンスをロードし、その実行を再開します。
メソッド が作成されます。たとえば、Web アプリケーションのコードがプロセスを起動し、データベース内で実行を "永続化" します。その後、メッセージ駆動型 Bean プロセスインスタンスをロードし、その実行を再開します。
public class HelloWorldDbTest extends TestCase {
static JbpmConfiguration jbpmConfiguration = null;
static {
// An example configuration file such as this can be found in
// 'src/config.files'. Typically the configuration information
// is in the resource file 'jbpm.cfg.xml', but here we pass in
// the configuration information as an XML string.
// First we create a JbpmConfiguration statically. One
// JbpmConfiguration can be used for all threads in the system,
// that is why we can safely make it static.
jbpmConfiguration = JbpmConfiguration.parseXmlString(
"<jbpm-configuration>" +
// A jbpm-context mechanism separates the jbpm core
// engine from the services that jbpm uses from
// the environment.
"<jbpm-context>"+
"<service name='persistence' "+
" factory='org.jbpm.persistence.db.DbPersistenceServiceFactory' />" +
"</jbpm-context>"+
// Also all the resource files that are used by jbpm are
// referenced from the jbpm.cfg.xml
"<string name='resource.hibernate.cfg.xml' " +
" value='hibernate.cfg.xml' />" +
"<string name='resource.business.calendar' " +
" value='org/jbpm/calendar/jbpm.business.calendar.properties' />" +
"<string name='resource.default.modules' " +
" value='org/jbpm/graph/def/jbpm.default.modules.properties' />" +
"<string name='resource.converter' " +
" value='org/jbpm/db/hibernate/jbpm.converter.properties' />" +
"<string name='resource.action.types' " +
" value='org/jbpm/graph/action/action.types.xml' />" +
"<string name='resource.node.types' " +
" value='org/jbpm/graph/node/node.types.xml' />" +
"<string name='resource.varmapping' " +
" value='org/jbpm/context/exe/jbpm.varmapping.xml' />" +
"</jbpm-configuration>"
);
}
public void setUp() {
jbpmConfiguration.createSchema();
}
public void tearDown() {
jbpmConfiguration.dropSchema();
}
public void testSimplePersistence() {
// Between the 3 method calls below, all data is passed via the
// database. Here, in this unit test, these 3 methods are executed
// right after each other because we want to test a complete process
// scenario. But in reality, these methods represent different
// requests to a server.
// Since we start with a clean, empty in-memory database, we have to
// deploy the process first. In reality, this is done once by the
// process developer.
deployProcessDefinition();
// Suppose we want to start a process instance (=process execution)
// when a user submits a form in a web application...
processInstanceIsCreatedWhenUserSubmitsWebappForm();
// Then, later, upon the arrival of an asynchronous message the
// execution must continue.
theProcessInstanceContinuesWhenAnAsyncMessageIsReceived();
}
public void deployProcessDefinition() {
// This test shows a process definition and one execution
// of the process definition. The process definition has
// 3 nodes: an unnamed start-state, a state 's' and an
// end-state named 'end'.
ProcessDefinition processDefinition =
ProcessDefinition.parseXmlString(
"<process-definition name='hello world'>" +
" <start-state name='start'>" +
" <transition to='s' />" +
" </start-state>" +
" <state name='s'>" +
" <transition to='end' />" +
" </state>" +
" <end-state name='end' />" +
"</process-definition>"
);
//Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
// Deploy the process definition in the database
jbpmContext.deployProcessDefinition(processDefinition);
} finally {
// Tear down the pojo persistence context.
// This includes flush the SQL for inserting the process definition
// to the database.
jbpmContext.close();
}
}
public void processInstanceIsCreatedWhenUserSubmitsWebappForm() {
// The code in this method could be inside a struts-action
// or a JSF managed bean.
//Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
GraphSession graphSession = jbpmContext.getGraphSession();
ProcessDefinition processDefinition =
graphSession.findLatestProcessDefinition("hello world");
//With the processDefinition that we retrieved from the database, we
//can create an execution of the process definition just like in the
//hello world example (which was without persistence).
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
Token token = processInstance.getRootToken();
assertEquals("start", token.getNode().getName());
// Let's start the process execution
token.signal();
// Now the process is in the state 's'.
assertEquals("s", token.getNode().getName());
// Now the processInstance is saved in the database. So the
// current state of the execution of the process is stored in the
// database.
jbpmContext.save(processInstance);
// The method below will get the process instance back out
// of the database and resume execution by providing another
// external signal.
} finally {
// Tear down the pojo persistence context.
jbpmContext.close();
}
}
public void theProcessInstanceContinuesWhenAnAsyncMessageIsReceived() {
//The code in this method could be the content of a message driven bean.
// Lookup the pojo persistence context-builder that is configured above
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
GraphSession graphSession = jbpmContext.getGraphSession();
// First, we need to get the process instance back out of the
// database. There are several options to know what process
// instance we are dealing with here. The easiest in this simple
// test case is just to look for the full list of process instances.
// That should give us only one result. So let's look up the
// process definition.
ProcessDefinition processDefinition =
graphSession.findLatestProcessDefinition("hello world");
//Now search for all process instances of this process definition.
List processInstances =
graphSession.findProcessInstances(processDefinition.getId());
// Because we know that in the context of this unit test, there is
// only one execution. In real life, the processInstanceId can be
// extracted from the content of the message that arrived or from
// the user making a choice.
ProcessInstance processInstance =
(ProcessInstance) processInstances.get(0);
// Now we can continue the execution. Note that the processInstance
// delegates signals to the main path of execution (=the root token).
processInstance.signal();
// After this signal, we know the process execution should have
// arrived in the end-state.
assertTrue(processInstance.hasEnded());
// Now we can update the state of the execution in the database
jbpmContext.save(processInstance);
} finally {
// Tear down the pojo persistence context.
jbpmContext.close();
}
}
}2.3. コンテキストの例: プロセス変数
java.util.Map クラスに似ており、後者は Java オブジェクトに相当します。(プロセス変数は、プロセスインスタンスの一部として "永続化" されます。)
// This example also starts from the hello world process.
// This time even without modification.
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString(
"<process-definition>" +
" <start-state>" +
" <transition to='s' />" +
" </start-state>" +
" <state name='s'>" +
" <transition to='end' />" +
" </state>" +
" <end-state name='end' />" +
"</process-definition>"
);
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
// Fetch the context instance from the process instance
// for working with the process variables.
ContextInstance contextInstance =
processInstance.getContextInstance();
// Before the process has left the start-state,
// we are going to set some process variables in the
// context of the process instance.
contextInstance.setVariable("amount", new Integer(500));
contextInstance.setVariable("reason", "i met my deadline");
// From now on, these variables are associated with the
// process instance. The process variables are now accessible
// by user code via the API shown here, but also in the actions
// and node implementations. The process variables are also
// stored into the database as a part of the process instance.
processInstance.signal();
// The variables are accessible via the contextInstance.
assertEquals(new Integer(500),
contextInstance.getVariable("amount"));
assertEquals("i met my deadline",
contextInstance.getVariable("reason"));2.4. タスク割り当ての例
AssignmentHandler の実装を指定し、それを使用してタスクのアクターの計算を含めます。
public void testTaskAssignment() {
// The process shown below is based on the hello world process.
// The state node is replaced by a task-node. The task-node
// is a node in JPDL that represents a wait state and generates
// task(s) to be completed before the process can continue to
// execute.
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString(
"<process-definition name='the baby process'>" +
" <start-state>" +
" <transition name='baby cries' to='t' />" +
" </start-state>" +
" <task-node name='t'>" +
" <task name='change nappy'>" +
" <assignment" +
" class='org.jbpm.tutorial.taskmgmt.NappyAssignmentHandler' />" +
" </task>" +
" <transition to='end' />" +
" </task-node>" +
" <end-state name='end' />" +
"</process-definition>"
);
// Create an execution of the process definition.
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
Token token = processInstance.getRootToken();
// Let's start the process execution, leaving the start-state
// over its default transition.
token.signal();
// The signal method will block until the process execution
// enters a wait state. In this case, that is the task-node.
assertSame(processDefinition.getNode("t"), token.getNode());
// When execution arrived in the task-node, a task 'change nappy'
// was created and the NappyAssignmentHandler was called to determine
// to whom the task should be assigned. The NappyAssignmentHandler
// returned 'papa'.
// In a real environment, the tasks would be fetched from the
// database with the methods in the org.jbpm.db.TaskMgmtSession.
// Since we don't want to include the persistence complexity in
// this example, we just take the first task-instance of this
// process instance (we know there is only one in this test
// scenario).
TaskInstance taskInstance = (TaskInstance)
processInstance
.getTaskMgmtInstance()
.getTaskInstances()
.iterator().next();
// Now, we check if the taskInstance was actually assigned to 'papa'.
assertEquals("papa", taskInstance.getActorId() );
// Now we suppose that 'papa' has done his duties and mark the task
// as done.
taskInstance.end();
// Since this was the last (only) task to do, the completion of this
// task triggered the continuation of the process instance execution.
assertSame(processDefinition.getNode("end"), token.getNode());
}2.5. カスタムアクションの例
MyActionHandler の実装をご覧ください。それ自体は特に驚くようなものではありません。ブール型変数 isExecuted を true に設定しているだけです。この変数は静的であるため、アクションハンドラー内から (およびアクション自体から) アクセスして、その値を確認することができます。
// MyActionHandler represents a class that could execute
// some user code during the execution of a jBPM process.
public class MyActionHandler implements ActionHandler {
// Before each test (in the setUp), the isExecuted member
// will be set to false.
public static boolean isExecuted = false;
// The action will set the isExecuted to true so the
// unit test will be able to show when the action
// is being executed.
public void execute(ExecutionContext executionContext) {
isExecuted = true;
}
}MyActionHandler.isExecuted をfalse に設定してください。
// Each test will start with setting the static isExecuted
// member of MyActionHandler to false.
public void setUp() {
MyActionHandler.isExecuted = false;
}public void testTransitionAction() {
// The next process is a variant of the hello world process.
// We have added an action on the transition from state 's'
// to the end-state. The purpose of this test is to show
// how easy it is to integrate Java code in a jBPM process.
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString(
"<process-definition>" +
" <start-state>" +
" <transition to='s' />" +
" </start-state>" +
" <state name='s'>" +
" <transition to='end'>" +
" <action class='org.jbpm.tutorial.action.MyActionHandler' />" +
" </transition>" +
" </state>" +
" <end-state name='end' />" +
"</process-definition>"
);
// Let's start a new execution for the process definition.
ProcessInstance processInstance =
new ProcessInstance(processDefinition);
// The next signal will cause the execution to leave the start
// state and enter the state 's'
processInstance.signal();
// Here we show that MyActionHandler was not yet executed.
assertFalse(MyActionHandler.isExecuted);
// ... and that the main path of execution is positioned in
// the state 's'
assertSame(processDefinition.getNode("s"),
processInstance.getRootToken().getNode());
// The next signal will trigger the execution of the root
// token. The token will take the transition with the
// action and the action will be executed during the
// call to the signal method.
processInstance.signal();
// Here we can see that MyActionHandler was executed during
// the call to the signal method.
assertTrue(MyActionHandler.isExecuted);
}enter-node イベントと leave-node イベントの両方に同じアクションが配置されていることを示しています。ノードには複数のイベントタイプがあることに注意してください。これは、イベントが 1 つしかない 遷移 とは対照的です。したがって、ノードにアクションを配置するときは、常にイベント要素に配置してください。
ProcessDefinition processDefinition = ProcessDefinition.parseXmlString( "<process-definition>" + " <start-state>" + " <transition to='s' />" + " </start-state>" + " <state name='s'>" + " <event type='node-enter'>" + " <action class='org.jbpm.tutorial.action.MyActionHandler' />" + " </event>" + " <event type='node-leave'>" + " <action class='org.jbpm.tutorial.action.MyActionHandler' />" + " </event>" + " <transition to='end'/>" + " </state>" + " <end-state name='end' />" + "</process-definition>" ); ProcessInstance processInstance = new ProcessInstance(processDefinition); assertFalse(MyActionHandler.isExecuted); // The next signal will cause the execution to leave the start // state and enter the state 's'. So the state 's' is entered // and hence the action is executed. processInstance.signal(); assertTrue(MyActionHandler.isExecuted); // Let's reset the MyActionHandler.isExecuted MyActionHandler.isExecuted = false; // The next signal will trigger execution to leave the // state 's'. So the action will be executed again. processInstance.signal(); // Voila. assertTrue(MyActionHandler.isExecuted);
第3章 設定
jbpm.cfg.xml 設定ファイルをクラスパスのルートに配置することです。ファイルをリソースとして使用できない場合は、代わりにデフォルトの最小設定が使用されます。この最小設定は jBPM ライブラリー (org/jbpm/default.jbpm.cfg.xml) に含まれています。 jBPM 設定ファイルが提供されている場合、そこに含まれる値がデフォルト値として使用されます。したがって、デフォルトの設定ファイルの値とは異なる値を指定するだけで済みます。
org.jbpm.JbpmConfiguration と呼ばれる Java クラスによって表されます。これは、シングルトン インスタンスメソッド (JbpmConfiguration.getInstance()) を使用して取得します。
JbpmConfiguration.parseXxxx メソッドを使用します。
static JbpmConfinguration jbpmConfiguration = JbpmConfinguration.parseResource("my.jbpm.cfg.xml");
JbpmConfiguration は "スレッドセーフ" であるため、静的メンバー に保持できます。
JbpmContext オブジェクトの ファクトリー として JbpmConfiguration を使用できます。JbpmContext は通常、1 つのトランザクションを表します。これらは、次のような コンテキストブロック 内でサービスを利用できるようにします。
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
// This is what we call a context block.
// Here you can perform workflow operations
} finally {
jbpmContext.close();
}JbpmContext は、一連のサービスと構成設定の両方を Business Process Manager で使用できるようにします。サービスは、jbpm.cfg.xml ファイルの値によって設定されます。これらは、環境内で利用可能なあらゆるサービスを使用して、jBPM を任意の Java 環境で実行できるようにします。
JbpmContext のデフォルトの構成設定は次のとおりです。
<jbpm-configuration>
<jbpm-context>
<service name='persistence'
factory='org.jbpm.persistence.db.DbPersistenceServiceFactory' />
<service name='message'
factory='org.jbpm.msg.db.DbMessageServiceFactory' />
<service name='scheduler'
factory='org.jbpm.scheduler.db.DbSchedulerServiceFactory' />
<service name='logging'
factory='org.jbpm.logging.db.DbLoggingServiceFactory' />
<service name='authentication'
factory=
'org.jbpm.security.authentication.DefaultAuthenticationServiceFactory' />
</jbpm-context>
<!-- configuration resource files pointing to default
configuration files in jbpm-{version}.jar -->
<string name='resource.hibernate.cfg.xml' value='hibernate.cfg.xml' />
<!-- <string name='resource.hibernate.properties'
value='hibernate.properties' /> -->
<string name='resource.business.calendar'
value='org/jbpm/calendar/jbpm.business.calendar.properties' />
<string name='resource.default.modules'
value='org/jbpm/graph/def/jbpm.default.modules.properties' />
<string name='resource.converter'
value='org/jbpm/db/hibernate/jbpm.converter.properties' />
<string name='resource.action.types'
value='org/jbpm/graph/action/action.types.xml' />
<string name='resource.node.types'
value='org/jbpm/graph/node/node.types.xml' />
<string name='resource.parsers'
value='org/jbpm/jpdl/par/jbpm.parsers.xml' />
<string name='resource.varmapping'
value='org/jbpm/context/exe/jbpm.varmapping.xml' />
<string name='resource.mail.templates'
value='jbpm.mail.templates.xml' />
<int name='jbpm.byte.block.size' value="1024" singleton="true" />
<bean name='jbpm.task.instance.factory'
class='org.jbpm.taskmgmt.impl.DefaultTaskInstanceFactoryImpl'
singleton='true' />
<bean name='jbpm.variable.resolver'
class='org.jbpm.jpdl.el.impl.JbpmVariableResolver'
singleton='true' />
<string name='jbpm.mail.smtp.host' value='localhost' />
<bean name='jbpm.mail.address.resolver'
class='org.jbpm.identity.mail.IdentityAddressResolver'
singleton='true' />
<string name='jbpm.mail.from.address' value='jbpm@noreply' />
<bean name='jbpm.job.executor'
class='org.jbpm.job.executor.JobExecutor'>
<field name='jbpmConfiguration'><ref bean='jbpmConfiguration' />
</field>
<field name='name'><string value='JbpmJobExecutor' /></field>
<field name='nbrOfThreads'><int value='1' /></field>
<field name='idleInterval'><int value='60000' /></field>
<field name='retryInterval'><int value='4000' /></field>
<!-- 1 hour -->
<field name='maxIdleInterval'><int value='3600000' /></field>
<field name='historyMaxSize'><int value='20' /></field>
<!-- 10 minutes -->
<field name='maxLockTime'><int value='600000' /></field>
<!-- 1 minute -->
<field name='lockMonitorInterval'><int value='60000' /></field>
<!-- 5 seconds -->
<field name='lockBufferTime'><int value='5000' /></field>
</bean>
</jbpm-configuration>
JbpmContextを設定する一連の サービス実装。(可能な設定オプションは、特定のサービスの実装に関する章で詳しく説明されています。)- 設定リソースへの参照をリンクするすべてのマッピング。設定ファイルの 1 つをカスタマイズする場合は、これらのマッピングを更新します。これを行うには、必ず最初にデフォルトの設定ファイル (
jbpm-3.x.jar) をクラスパス上の別の場所にバックアップしてください。その後、jBPM が使用するカスタマイズされたバージョンを指すように、このファイルの参照を更新してください。 - jBPM で使用するためのさまざまな設定。(これらは、該当する特定のトピックに関する章で説明されています。)
JbpmContext には、ほとんどの一般的なプロセス操作のための 便利なメソッド が含まれています。これらを次のコードサンプルに示します。
public void deployProcessDefinition(ProcessDefinition processDefinition) public List getTaskList() public List getTaskList(String actorId) public List getGroupTaskList(List actorIds) public TaskInstance loadTaskInstance(long taskInstanceId) public TaskInstance loadTaskInstanceForUpdate(long taskInstanceId) public Token loadToken(long tokenId) public Token loadTokenForUpdate(long tokenId) public ProcessInstance loadProcessInstance(long processInstanceId) public ProcessInstance loadProcessInstanceForUpdate(long processInstanceId) public ProcessInstance newProcessInstance(String processDefinitionName) public void save(ProcessInstance processInstance) public void save(Token token) public void save(TaskInstance taskInstance) public void setRollbackOnly()
XxxForUpdate メソッドは、ロードされたオブジェクトを "自動保存" に登録するように設計されているためです。
jbpm-context を指定することができます。これを行うには、それぞれに一意の name 属性を指定する必要があります。(JbpmConfiguration.createContext(String name); を使用して、名前付きコンテキストを取得します。)
JbpmContext.getServices().getService(String name) によって作成を要求された場合にのみ作成されます。
ファクトリー は、属性ではなく 要素 として指定することもできます。これは、一部の設定情報をファクトリーオブジェクトに挿入するときに必要です。
オブジェクトファクトリー と呼ばれることに注意してください。
3.1. ファクトリーのカスタマイズ
StateObjectStateException 例外をログに記録し、スタックトレース を生成します。後者を削除するには、org.hibernate.event.def.AbstractFlushingEventListener を FATAL に設定します。(log4j を使用している場合、削除するには設定に log4j.logger.org.hibernate.event.def.AbstractFlushingEventListener=FATAL 行を設定します。
<service name='persistence'
factory='org.jbpm.persistence.db.DbPersistenceServiceFactory' />
<service name="persistence">
<factory>
<bean class="org.jbpm.persistence.db.DbPersistenceServiceFactory">
<field name="dataSourceJndiName">
<string value="java:/myDataSource"/>
</field>
<field name="isCurrentSessionEnabled"><true /></field>
<field name="isTransactionEnabled"><false /></field>
</bean>
</factory>
</service>3.2. 設定プロパティー
- jbpm.byte.block.size
- 添付ファイルとバイナリー変数は、固定サイズのバイナリーオブジェクトリストの形式でデータベースに格納されます。(これの目的は、異なるデータベース間の移植性を向上させることです。これにより、jBPM をより簡単に埋め込むこともできます。) このパラメーターは、これらの固定長チャンクのサイズを制御します。
- jbpm.task.instance.factory
- タスクインスタンスの作成方法をカスタマイズするには、このプロパティーに対して完全修飾クラス名を指定します。(これは、
TaskInstanceBean をカスタマイズして新しいプロパティーを追加する場合に必要になることがよくあります。) 指定されたクラス名がorg.jbpm.taskmgmt.TaskInstanceFactoryインターフェイスを実装していることを確認してください。(詳細は、「 タスクインスタンスのカスタマイズ 」 を参照してください。) - jbpm.variable.resolver
- これを使用して、"JSF" ライクな式に含まれる最初の用語を jBPM が検索する方法をカスタマイズします。
- jbpm.class.loader
- このプロパティーを使用して jBPM クラスをロードします。
- jbpm.sub.process.async
- このプロパティーを使用して、サブプロセスの非同期シグナリングを許可します。
- jbpm.job.retries
- この設定は、失敗したジョブを破棄するタイミングを決定します。設定ファイルを確認すれば、そのようなジョブを破棄する前に指定した回数だけ処理を試行するようにエントリーを設定できます。
- jbpm.mail.from.address
- このプロパティーは、ジョブがどこから来たかを表示します。デフォルトは jbpm@noreply です。
3.3. その他の設定ファイル
hibernate.cfg.xml- これには、Hibernate マッピングリソースファイルへの参照と設定の詳細が含まれます。jBPM が使用する
hibernate.cfg.xmlファイルを変更するには、jbpm.cfg.xmlファイルで次のプロパティーを設定します。<string name="resource.hibernate.cfg.xml" value="new.hibernate.cfg.xml"/>jbpm.cfg.xml ファイルは、${soa.home}/jboss-as/server/${server.config}/jbpm.esb にあります。 org/jbpm/db/hibernate.queries.hbm.xml- このファイルには、jBPM セッション (
org.jbpm.db.*Session) で使用される Hibernate クエリーが含まれています。 org/jbpm/graph/node/node.types.xml- このファイルは、XML ノード要素を
Node実装クラスにマップするために使用されます。 org/jbpm/graph/action/action.types.xml- このファイルは、XML アクション要素を
Action実装クラスにマップするために使用されます。 org/jbpm/calendar/jbpm.business.calendar.properties- これには、"業務時間" と "自由時間" の定義が含まれています。
org/jbpm/context/exe/jbpm.varmapping.xml- これは、プロセス変数の値 (Java オブジェクト) を変数インスタンスに変換して jBPM データベースに保存する方法を指定します。
org/jbpm/db/hibernate/jbpm.converter.properties- これは、
id-to-classnameマッピングを指定します。id はデータベースに格納されます。org.jbpm.db.hibernate.ConverterEnumTypeクラスは、識別子をシングルトンオブジェクトにマップするために使用されます。 org/jbpm/graph/def/jbpm.default.modules.properties- これは、新しい
ProcessDefinitionにデフォルトで追加するモジュールを指定します。 org/jbpm/jpdl/par/jbpm.parsers.xml- これは、プロセスアーカイブ解析 のフェーズを指定します。
3.4. 楽観的な並行処理の例外のロギング
org.hibernate.StateObjectStateException 例外が発生することがあります。これが発生した場合、Hibernate は単純なメッセージで例外をログに記録します。
optimistic locking
failed
.
StateObjectStateException をログに記録することもできます。これらのスタックトレースを削除するには、org.hibernate.event.def.AbstractFlushingEventListener クラスを FATAL に設定します。次の設定を使用して、log4j でこれを行います。
log4j.logger.org.hibernate.event.def.AbstractFlushingEventListener=FATAL
3.5. オブジェクトファクトリー
<beans>
<bean name="task" class="org.jbpm.taskmgmt.exe.TaskInstance"/>
<string name="greeting">hello world</string>
<int name="answer">42</int>
<boolean name="javaisold">true</boolean>
<float name="percentage">10.2</float>
<double name="salary">100000000.32</double>
<char name="java">j</char>
<null name="dusttodust" />
</beans>ObjectFactory of = ObjectFactory.parseXmlFromAbove();
assertEquals(TaskInstance.class, of.getNewObject("task").getClass());
assertEquals("hello world", of.getNewObject("greeting"));
assertEquals(new Integer(42), of.getNewObject("answer"));
assertEquals(Boolean.TRUE, of.getNewObject("javaisold"));
assertEquals(new Float(10.2), of.getNewObject("percentage"));
assertEquals(new Double(100000000.32), of.getNewObject("salary"));
assertEquals(new Character('j'), of.getNewObject("java"));
assertNull(of.getNewObject("dusttodust"));]]><beans>
<list name="numbers">
<string>one</string>
<string>two</string>
<string>three</string>
</list>
</beans><beans>
<map name="numbers">
<entry>
<key><int>1</int></key>
<value><string>one</string></value>
</entry>
<entry>
<key><int>2</int></key>
<value><string>two</string></value>
</entry>
<entry>
<key><int>3</int></key>
<value><string>three</string></value>
</entry>
</map>
</beans>setter メソッドを使用して、Bean を設定します。
<beans>
<bean name="task" class="org.jbpm.taskmgmt.exe.TaskInstance" >
<field name="name"><string>do dishes</string></field>
<property name="actorId"><string>theotherguy</string></property>
</bean>
</beans><beans>
<bean name="a" class="org.jbpm.A" />
<ref name="b" bean="a" />
</beans><beans>
<bean name="task" class="org.jbpm.taskmgmt.exe.TaskInstance" >
<constructor>
<parameter class="java.lang.String">
<string>do dishes</string>
</parameter>
<parameter class="java.lang.String">
<string>theotherguy</string>
</parameter>
</constructor>
</bean>
</beans>factory メソッドを使用して構築できます。
<beans>
<bean name="taskFactory"
class="org.jbpm.UnexistingTaskInstanceFactory"
singleton="true"/>
<bean name="task" class="org.jbpm.taskmgmt.exe.TaskInstance" >
<constructor factory="taskFactory" method="createTask" >
<parameter class="java.lang.String">
<string>do dishes</string>
</parameter>
<parameter class="java.lang.String">
<string>theotherguy</string>
</parameter>
</constructor>
</bean>
</beans>static factory メソッドを使用して構築できます。
<beans>
<bean name="task" class="org.jbpm.taskmgmt.exe.TaskInstance" >
<constructor
factory-class="org.jbpm.UnexistingTaskInstanceFactory"
method="createTask" >
<parameter class="java.lang.String">
<string>do dishes</string>
</parameter>
<parameter class="java.lang.String">
<string>theotherguy</string>
</parameter>
</constructor>
</bean>
</beans>singleton="true" を使用して、名前付きの各オブジェクトを シングルトン としてマークします。そうすることで、特定の オブジェクトファクトリー が各リクエストに対して常に同じオブジェクトを返すようになります。
シングルトン は、異なるオブジェクトファクトリー間で共有できません。
シングルトン 機能は、getObject と getNewObject というメソッドの区別を生み出します。通常は、getNewObject を使用する必要があります。これを使用すると、新しいオブジェクトグラフを構築する前に、オブジェクトファクトリー の オブジェクトキャッシュ がクリアされるためです。
オブジェクトファクトリー のキャッシュに格納されます。これにより、1 つのオブジェクトへの参照を共有できます。シングルトンオブジェクトキャッシュ は プレーンオブジェクトキャッシュ とは異なることに注意してください。シングルトン キャッシュは決してクリアされませんが、プレーンキャッシュは getNewObject メソッドが開始されるたびにクリアされます。
第4章 永続性
図4.1 変換とさまざまな形式
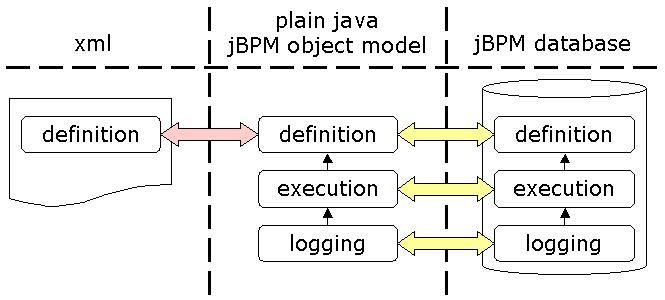
4.1. 永続性アプリケーションプログラミングインターフェイス
4.1.1. 設定フレームワークとの関係
JbpmContext の convenience persistence メソッドの一部を公開し、jBPM の コンテキストブロック が永続性 API 操作を呼び出せるようにすることで実現されています。
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
// Invoke persistence operations here
} finally {
jbpmContext.close();
}4.1.2. JbpmContext の便利なメソッド
- プロセスデプロイメント
- 新しいプロセスの実行開始
- プロセスの実行継続
deployprocess ant タスクから直接実行されます。ただし、Java から直接実行するには、次のコードを使用します。
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
ProcessDefinition processDefinition = ...;
jbpmContext.deployProcessDefinition(processDefinition);
} finally {
jbpmContext.close();
}JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
String processName = ...;
ProcessInstance processInstance =
jbpmContext.newProcessInstance(processName);
} finally {
jbpmContext.close();
}taskInstance を取得し、POJO (Plain Old Java Object) jBPM オブジェクトでいくつかのメソッドを呼び出します。さrない、processInstance に加えられた更新をデータベースに保存します。
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
long processInstanceId = ...;
ProcessInstance processInstance =
jbpmContext.loadProcessInstance(processInstanceId);
processInstance.signal();
jbpmContext.save(processInstance);
} finally {
jbpmContext.close();
}ForUpdate メソッドを JbpmContext クラスで使用する場合、jbpmContext.save メソッドを明示的に呼び出す必要はないことに注意してください。これは、jbpmContext クラスが閉じられると、保存プロセスが自動的に実行されるためです。たとえば、taskInstance が完了したことを jBPM に通知したい場合があります。これにより実行の継続が引き起こされることがあるため、taskInstance に関連する processInstance を保存する必要があります。これを行う最も便利な方法は、loadTaskInstanceForUpdate メソッドを使用することです。
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
long taskInstanceId = ...;
TaskInstance taskInstance =
jbpmContext.loadTaskInstanceForUpdate(taskInstanceId);
taskInstance.end();
}
finally {
jbpmContext.close();
}JbpmConfiguration は、一連の ServiceFactories を維持します。これらは jbpm.cfg.xml ファイルを介して設定され、必要に応じてインスタンス化されます。
DbPersistenceServiceFactory は、最初に必要になったときにのみインスタンス化されます。その後、ServiceFactory は JbpmConfiguration で維持されます。
DbPersistenceServiceFactory は Hibernate ServiceFactory を管理しますが、これは最初に要求されたときにのみインスタンス化されます。
isTransactionEnabledsessionFactoryJndiNamedataSourceJndiNameisCurrentSessionEnabled
図4.2 永続性関連のクラス
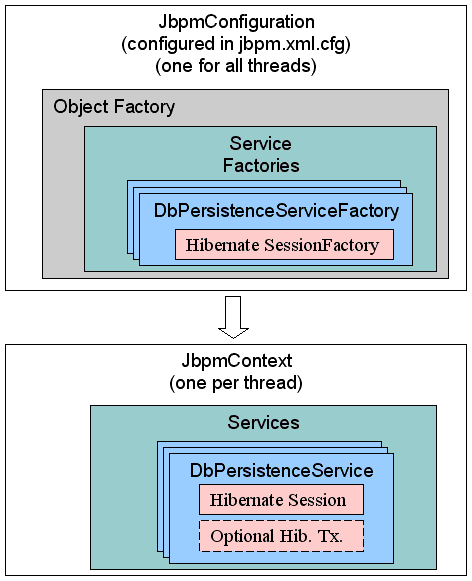
jbpmConfiguration.createJbpmContext () クラスが呼び出されると、JbpmContext のみが作成されます。この時点では、それ以上の永続性関連の初期化は行われません。JbpmContext は、DbPersistenceService クラスを管理します。このクラスは、最初に要求されたときにインスタンス化されます。DbPersistenceService クラスは、Hibernate セッションを管理します。これも、最初に必要になったときにのみインスタンス化されます。(つまり、Hibernate セッションは、永続性を必要とする最初の操作が呼び出されたときにのみ開かれます。)
4.2. 永続性サービスの設定
4.2.1. DbPersistenceServiceFactory
DbPersistenceServiceFactory クラスには、さらに isTransactionEnabled、sessionFactoryJndiName、および dataSourceJndiName という 3 つの設定プロパティーがあります。jbpm.cfg.xml ファイルでこれらのプロパティーを指定するには、factory 要素内で Bean として Service Factory を指定します。このサンプルコードは、その方法を示しています。
<jbpm-context>
<service name="persistence">
<factory>
<bean class="org.jbpm.persistence.db.DbPersistenceServiceFactory">
<field name="isTransactionEnabled"><false /></field>
<field name="sessionFactoryJndiName">
<string value="java:/myHibSessFactJndiName" />
</field>
<field name="dataSourceJndiName">
<string value="java:/myDataSourceJndiName" />
</field>
</bean>
</factory>
</service>
...
</jbpm-context>isTransactionEnabled- デフォルトでは、jBPM はセッションが初めて取得されたときに Hibernate トランザクションを開始します。
jbpmContextが閉じられると、Hibernate トランザクションは終了します。その後、jbpmContext.setRollbackOnlyが呼び出されたかどうかに応じて、トランザクションはコミットまたはロールバックされます。(isRollbackOnly プロパティーはTxServiceで維持されます。) トランザクションを無効にし、jBPM が Hibernate でそれらを管理するのを禁止するには、isTransactionEnabled プロパティー値をfalseに設定します。(このプロパティーはjbpmContextの動作のみを制御します。DbPersistenceService.beginTransaction()は、isTransactionEnabled 設定を無視するアプリケーションプログラミングインターフェイスを使用して直接呼び出すことができます。) トランザクションの詳細は、「 Hibernate トランザクション 」 を参照してください。 sessionFactoryJndiName- デフォルトでは、これは
nullです。これは、セッションファクトリーが JNDI から取得されないことを意味します。このプロパティーが設定されていて、Hibernate セッションを作成するためにセッションファクトリーが必要な場合は、JNDI から取得されます。 dataSourceJndiName- デフォルトでは、これは
nullです。その結果、JDBC 接続が作成され、Hibernate に委譲されます。データソースを指定すると、Business Process Manager は新しいセッションを開くとともに、データソースから JDBC 接続を取得し、それを Hibernate に提供します。
4.2.1.1. Hibernate セッションファクトリー
DbPersistenceServiceFactory はクラスパスのルートにある hibernate.cfg.xml ファイルを使用して、Hibernate セッションファクトリーを作成します。Hibernate 設定ファイルのリソースが jbpm.hibernate.cfg.xml にマップされていることに注意してください。これは、jbpm.cfg.xml を再設定してカスタマイズします。
<jbpm-configuration>
<!-- configuration resource files pointing to default
configuration files in jbpm-{version}.jar -->
<string name='resource.hibernate.cfg.xml'
value='hibernate.cfg.xml' />
<!-- <string name='resource.hibernate.properties'
value='hibernate.properties' /> -->
</jbpm-configuration>hibernate.cfg.xml のすべてのプロパティーを上書きします。データベースを参照するように hibernate.cfg.xml を更新するのではなく、hibernate.properties を使用して jBPM のアップグレードを処理してください。そうすることで、変更を再適用することなく hibernate.cfg.xml ファイルをコピーできます。
4.2.1.2. C3PO 接続プールの設定
4.2.1.3. ehCache プロバイダーの設定
hibernate.cfg.xml ファイルには、次の行が含まれています。
<property name="hibernate.cache.provider_class">
org.hibernate.cache.HashtableCacheProvider
</property>HashtableCacheProvider を実稼働環境で使用しないでください。
HashtableCacheProvider の代わりに ehcache を使用するには、関連する行をクラスパスから削除し、代わりに ehcache.jar を使用します。お使いの環境と互換性のある正しい ehcache ライブラリーバージョンの検索が必要になる場合があることに注意してください。
4.2.2. Hibernate トランザクション
jbpmContext で永続的な操作が呼び出されたときに初めてセッションが開かれると、jBPM は Hibernate トランザクションを開始します。トランザクションは、Hibernate セッションが閉じられる直前にコミットされます。これは jbpmContext.close() 内で実行されます。
jbpmContext.setRollbackOnly() を使用して、ロールバック対象のトランザクションをマークします。そうすることで、セッションが jbpmContext.close() メソッド内で閉じられる直前にトランザクションがロールバックされます。
false に設定します。これについては、「DbPersistenceServiceFactory」 で詳しく説明しています。
4.2.3. JTA トランザクション
<jbpm-context>
<service name="persistence">
<factory>
<bean class="org.jbpm.persistence.db.DbPersistenceServiceFactory">
<field name="isTransactionEnabled"><false /></field>
<field name="isCurrentSessionEnabled"><true /></field>
<field name="sessionFactoryJndiName">
<string value="java:/myHibSessFactJndiName" />
</field>
</bean>
</factory>
</service>
</jbpm-context>XA datasource にバインドします。
<hibernate-configuration>
<session-factory>
<!-- hibernate dialect -->
<property name="hibernate.dialect">
org.hibernate.dialect.HSQLDialect
</property>
<!-- DataSource properties (begin) -->
<property name="hibernate.connection.datasource">
java:/JbpmDS
</property>
<!-- JTA transaction properties (begin) -->
<property name="hibernate.transaction.factory_class">
org.hibernate.transaction.JTATransactionFactory
</property>
<property name="hibernate.transaction.manager_lookup_class">
org.hibernate.transaction.JBossTransactionManagerLookup
</property>
<property name="jta.UserTransaction">
java:comp/UserTransaction
</property>
</session-factory>
</hibernate-configuration>XA datasource を使用するように Hibernate を設定します。
4.2.4. クエリーのカスタマイズ
hibernate.cfg.xml 設定ファイルで参照されます。
<hibernate-configuration>
<!-- hql queries and type defs -->
<mapping resource="org/jbpm/db/hibernate.queries.hbm.xml" />
</hibernate-configuration>hibernate.cfg.xml の org/jbpm/db/hibernate.queries.hbm.xml への参照を更新します。
4.2.5. データベースの互換性
4.2.5.1. JDBC 接続の分離レベル
READ_COMMITTED に設定します。
READ_UNCOMMITTED (分離レベルゼロ、Hypersonic でサポートされる唯一の分離レベル) に設定されている場合、ジョブエグゼキューター で競合状態が発生する可能性があります。これは、複数のトークンの同期が行われているときにも発生する可能性があります。
4.2.5.2. データベースの変更
- JDBC ドライバーライブラリーアーカイブをクラスパスに配置します。
- jBPM が使用する Hibernate 設定を更新します。
- 新しいデータベースにスキーマを作成します。
4.2.5.3. データベーススキーマ
jbpm.db サブプロジェクトには、ユーザーが選択したデータベースの使用を開始するのに役立つドライバー、手順、およびスクリプトが含まれています。詳細は、jbpm.db プロジェクトのルートにある readme.html を参照してください。
create-drop に設定すると、データベースがアプリケーションで初めて使用されるときに、スキーマが自動的に作成されます。アプリケーションが終了すると、スキーマは削除されます。
4.2.5.3.1. プログラムによるデータベーススキーマ操作
org.jbpm.JbpmConfiguration のメソッド createSchema および dropSchema を介して、データベーススキーマを作成および削除するための API を提供します。これらのメソッドの呼び出しには、設定されたデータベースユーザーの権限以外に制約がないことに注意してください。
org.jbpm.db.JbpmSchema によって提供される、より広範な機能へのファサードを構成します。
4.2.5.4. Hibernate クラスの組み合わせ
hibernate.cfg.xml ファイルを 1 つ作成します。デフォルトの jBPM hibernate.cfg.xml を出発点として使用し、独自の Hibernate マッピングファイルへの参照を追加してカスタマイズするのが最も簡単です。
4.2.5.5. jBPM Hibernate マッピングファイルのカスタマイズ
- ソース (
src/jbpm-jpdl-sources.jar) から jBPM Hibernate マッピングファイルをコピーします。 - コピーをクラスパスの任意の場所に配置します (以前と同じ場所でないことを確認します)。
hibernate.cfg.xml内のカスタマイズしたマッピングファイルへの参照を更新します。
4.2.5.6. 2 次キャッシュ
<cache usage="nonstrict-read-write"/>
nonstrict-read-write に設定されています。ランタイム実行時に、プロセス定義が静的なままとなるため、最大限のキャッシュを実現できます。理論的には、read-only キャッシュストラテジーのほうがランタイム実行にはさらに適していますが、その設定では新しいプロセス定義のデプロイメントが許可されません。
第5章 Java EE アプリケーションサーバーの機能
5.1. エンタープライズ Bean
CommandServiceBean は ステートレスセッション Bean であり、別の jBPM コンテキスト内の execute メソッドを呼び出すことにより、Business Process Manager コマンドを実行します。使用可能な環境エントリーとカスタマイズ可能なリソースを次の表にまとめます。
表5.1 コマンドサービス Bean 環境
| 名前 | タイプ | 説明 |
|---|---|---|
JbpmCfgResource | 環境エントリー | これは、jBPM 設定の読み取り元となるクラスパスリソースです。オプションであり、デフォルトは jbpm.cfg.xml です。 |
ejb/TimerEntityBean | EJB 参照 | これは、スケジューラーサービスを実装するローカルエンティティー Bean へのリンクです。タイマーを含むプロセスに必要です。 |
jdbc/JbpmDataSource | リソースマネージャー参照 | これは、jBPM 永続性サービスへの JDBC 接続を提供するデータソースの論理名です。Hibernate 設定ファイルの hibernate.connection.datasource プロパティーと一致する必要があります。 |
jms/JbpmConnectionFactory | リソースマネージャー参照 | これは、JMS 接続を jBPM メッセージサービスに提供するファクトリーの論理名です。非同期継続を含むプロセスに必要です。 |
jms/JobQueue | メッセージ宛先参照 | jBPM メッセージサービスは、ジョブメッセージをこのキューに送信します。ジョブリスナー Bean のメッセージ受信元のキューとこのキューが必ず同じになるように、message-destination-link は共通の論理宛先である JobQueue を参照します。 |
jms/CommandQueue | メッセージ宛先参照 | コマンドリスナー Bean は、このキューからメッセージを受信します。コマンドメッセージ送信先のキューとこのキューが必ず同じになるように、message-destination-link 要素は共通の論理宛先である CommandQueue を参照します。 |
CommandListenerBean は、コマンドメッセージの CommandQueue をリッスンするメッセージ駆動型 Bean です。この Bean は、コマンドの実行を CommandServiceBean に委譲します。
org.jbpm.Command インターフェイスを実装できる Java オブジェクトでなければなりません。(メッセージプロパティーがある場合は無視されます。) メッセージが想定される形式でない場合、メッセージは DeadLetterQueue に転送され、それ以上処理されません。宛先参照が存在しない場合も、メッセージは拒否されます。
replyTo が指定されている場合、コマンド実行結果が オブジェクトメッセージ にラップされて送信されます。
コマンド接続ファクトリー環境参照 は、Java Message Service 接続を提供するために使用されるリソースマネージャーを参照します。
JobListenerBean は、非同期継続 をサポートするために、ジョブメッセージの JbpmJobQueue をリッスンするメッセージ駆動型 Bean です。
long 型の jobId というプロパティーが必要であることに注意してください。このプロパティには、データベース内にある保留中の Job への参照が含まれている必要があります。メッセージ本文が存在する場合、それは無視されます。
CommandListenerBean を拡張します。後者の環境エントリーとカスタマイズ可能なそのリソース参照を継承します。
表5.2 コマンド/ジョブリスナー Bean 環境
| 名前 | タイプ | 説明 |
|---|---|---|
ejb/LocalCommandServiceBean | EJB 参照 | これは、別の jBPM コンテキストでコマンドを実行するローカルセッション Bean へのリンクです。 |
jms/JbpmConnectionFactory | リソースマネージャー参照 | これは、結果メッセージを生成するための Java Message Service 接続を提供するファクトリーの論理名です。返信先を示すコマンドメッセージに必要です。 |
jms/DeadLetterQueue | メッセージ宛先参照 | コマンドを含まないメッセージは、ここで参照されているキューに送信されます。これはオプションです。これがない場合、そのようなメッセージは拒否され、コンテナーが再配信されることがあります。 |
| - | ||
| メッセージ宛先参照 | コマンドを含まないメッセージは、ここで参照されているキューに送信されます。これがない場合、そのようなメッセージは拒否され、コンテナーが再配信されることがあります。 |
TimerEntityBean は、Enterprise Java Bean タイマーサービス でスケジューリングに使用されます。Bean の有効期限が切れると、タイマーの実行が command service Bean に委譲されます。
TimerEntityBean は、Business Process Manager のデータソースへのアクセスを必要とします。Enterprise Java Bean デプロイメント記述子は、エンティティー Bean をデータベースにマップする方法を定義しません。(これはコンテナー提供者に任されています。) JBoss Application Server では、jbosscmp-jdbc.xml 記述子が、データソースの JNDI 名とリレーショナルマッピングデータ (テーブル名や列名など) を定義します。
java:comp/env/jdbc/JbpmDataSource) とは異なり、グローバル JNDI 名 (java:JbpmDS) を使用します。
TimerServiceBean というステートレスセッション Bean を使用して、Enterprise Java Bean タイマーサービスと対話していました。セッション方式は、cancelation メソッドのボトルネックが避けられなかったため、断念せざるを得ませんでした。セッション Bean には ID がないため、タイマーサービスは すべて のタイマーをイテレートして、キャンセルする必要のあるタイマーを見つける必要がありました。
TimerEntityBean と同じ環境で動作するため、移行が容易です。
表5.3 タイマーエンティティー/サービス Bean 環境
| 名前 | タイプ | 説明 |
|---|---|---|
ejb/LocalCommandServiceBean | EJB 参照 | これは、別の jBPM コンテキストでタイマーを実行するローカルセッション Bean へのリンクです。 |
5.2. jBPM エンタープライズ設定
jbpm.cfg.xml に含まれています。
<jbpm-context>
<service name="persistence"
factory="org.jbpm.persistence.jta.JtaDbPersistenceServiceFactory" />
<service name="message"
factory="org.jbpm.msg.jms.JmsMessageServiceFactory" />
<service name="scheduler"
factory="org.jbpm.scheduler.ejbtimer.EntitySchedulerServiceFactory" />
</jbpm-context>JtaDbPersistenceServiceFactory により、Business Process Manager は JTA トランザクションに参加できます。既存のトランザクションが進行中の場合、JTA 永続性サービスはそれを "保持" します。そうでない場合は、新しいトランザクションを開始します。Business Process Manager のエンタープライズ Bean は、トランザクション管理をコンテナーに委譲するように設定されています。ただし、トランザクションがアクティブでない環境 (Web アプリケーションなど) で JbpmContext を作成すると、新しいトランザクションが自動的に開始されます。 JTA 永続性サービスファクトリー には、以下で説明する設定可能なフィールドが含まれています。
- isCurrentSessionEnabled
- これを
trueに設定すると、Business Process Manager は、進行中の JTA トランザクションに関連付けられた "現在" の Hibernate セッションを使用します。これはデフォルト設定です。詳細は、http://www.hibernate.org/hib_docs/v3/reference/en/html/architecture.html#architecture-current-session を参照してください。コンテキストセッションメカニズムを利用して、アプリケーションの他の部分で jBPM と同じセッションを使用します。これは、SessionFactory.getCurrentSession()の呼び出しを通じて行われます。または、isCurrentSessionEnabled をfalseに設定し、JbpmContext.setSession(session)メソッドを介してセッションを注入することで、jBPM に Hibernate セッションを提供します。これにより、jBPM がアプリケーションの他の部分と同じ Hibernate セッションを使用することも保証されます。注記Hibernate セッションは (永続性コンテキストなどを介して) ステートレスセッション Bean に注入できます。 - isTransactionEnabled
trueに設定すると、jBPM は Hibernate のtransaction APIを介してトランザクションを開始し、JbpmConfiguration.createJbpmContext()メソッドを使用してトランザクションをコミットします。(JbpmContext.close()が呼び出されると、Hibernate セッションは閉じられます。)警告これは、Business Process Manager が EAR としてデプロイされている場合に望ましい動作ではないため、isTransactionEnabled はデフォルトではfalseに設定されています。(詳細は、http://www.hibernate.org/hib_docs/v3/reference/en/html/transactions.html#transactions-demarcation を参照してください。)
JmsMessageServiceFactory は、 Java Message Service インターフェイスを通じて公開される信頼性の高い通信インフラストラクチャーを利用して、非同期継続メッセージ を JobListenerBean に配信します。JmsMessageServiceFactory は、次の設定可能なフィールドを公開します。
- connectionFactoryJndiName
- これは、JNDI 初期コンテキストでの JMS 接続ファクトリーの名前です。デフォルトは
java:comp/env/jms/JbpmConnectionFactoryです。 - destinationJndiName
- これは、ジョブメッセージ送信先の JMS 宛先の名前です。これは、
JobListenerBeanがメッセージを受信する宛先と一致する必要があります。デフォルトはjava:comp/env/jms/JobQueueです。 - isCommitEnabled
- これは、Business Process Manager が
JbpmContext.close()で Java Message Service セッションをコミットする必要があるかどうかを指定します。JMS メッセージサービスによって生成されたメッセージは、現在のトランザクションがコミットされる前に受信されることを意図したものではありません。そのため、このサービスによって作成されたセッションは、常にトランザクション処理されます。デフォルト値はfalseです。これは、使用中の接続ファクトリーが XA 対応である場合に適しています。Java Message Service セッションによって生成されるメッセージは、JTA トランザクション全体によって制御されるためです。JMS 接続ファクトリーが XA 対応でない場合は、Business Process Manager が JMS セッションのローカルトランザクションを明示的にコミットするように、このフィールドをtrueに設定する必要があります。
EntitySchedulerServiceFactory は、ビジネスプロセスタイマーをスケジュールするために使用されます。これは、Enterprise Java Bean コンテナーによって提供される時間指定イベントのトランザクション通知サービスに基づいて構築することによって行われます。EJB スケジューラーサービスファクトリー には、以下で説明する設定可能なフィールドがあります。
- timerEntityHomeJndiName
- これは、JNDI 初期コンテキストでの
TimerEntityBeanのローカルホームインターフェイスの名前です。デフォルト値はjava:comp/env/ejb/TimerEntityBeanです。
5.3. Hibernate エンタープライズ設定
hibernate.cfg.xml ファイルには、次の設定項目が含まれています。他のデータベースまたはアプリケーションサーバーをサポートするには、これらを変更します。
<!-- sql dialect -->
<property name="hibernate.dialect">
org.hibernate.dialect.HSQLDialect
</property>
<property name="hibernate.cache.provider_class">
org.hibernate.cache.HashtableCacheProvider
</property>
<!-- DataSource properties (begin) -->
<property name="hibernate.connection.datasource">
java:comp/env/jdbc/JbpmDataSource
</property>
<!-- DataSource properties (end) -->
<!-- JTA transaction properties (begin) -->
<property name="hibernate.transaction.factory_class">
org.hibernate.transaction.JTATransactionFactory
</property>
<property name="hibernate.transaction.manager_lookup_class">
org.hibernate.transaction.JBossTransactionManagerLookup
</property>
<!-- JTA transaction properties (end) -->
<!-- CMT transaction properties (begin) ===
<property name="hibernate.transaction.factory_class">
org.hibernate.transaction.CMTTransactionFactory
</property>
<property name="hibernate.transaction.manager_lookup_class">
org.hibernate.transaction.JBossTransactionManagerLookup
</property>
==== CMT transaction properties (end) -->hibernate.dialect 設定は、お使いのデータベース管理システムに適した設定に置き換えます。(詳細は、http://www.hibernate.org/hib_docs/v3/reference/en/html/session-configuration.html#configuration-optional-dialects を参照してください。)
HashtableCacheProvider は、サポートされている他のキャッシュプロバイダーに置き換えることができます。(詳細は、http://www.hibernate.org/hib_docs/v3/reference/en/html/performance.html#performance-cache を参照してください。)
JTATransactionFactory を使用するように設定されています。既存のトランザクションが進行中の場合、JTA トランザクションファクトリーはそれを使用します。それ以外の場合は、新しいトランザクションが作成されます。jBPM のエンタープライズ Bean は、トランザクション管理をコンテナーに委譲するように設定されています。ただし、アクティブなトランザクションがないコンテキスト (Web アプリケーションなど) で jBPM API が使用されている場合、トランザクションが自動的に開始されます。
CMTTransactionFactory に切り替えます。この設定により、Hibernate が常に既存のトランザクションを探し、見つからない場合は問題を報告するようになります。
5.4. クライアントコンポーネント
<session>
<ejb-name>MyClientBean</ejb-name>
<home>org.example.RemoteClientHome</home>
<remote>org.example.RemoteClient</remote>
<local-home>org.example.LocalClientHome</local-home>
<local>org.example.LocalClient</local>
<ejb-class>org.example.ClientBean</ejb-class>
<session-type>Stateless</session-type>
<transaction-type>Container</transaction-type>
<ejb-local-ref>
<ejb-ref-name>ejb/TimerEntityBean</ejb-ref-name>
<ejb-ref-type>Entity</ejb-ref-type>
<local-home>org.jbpm.ejb.LocalTimerEntityHome</local-home>
<local>org.jbpm.ejb.LocalTimerEntity</local>
</ejb-local-ref>
<resource-ref>
<res-ref-name>jdbc/JbpmDataSource</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
<resource-ref>
<res-ref-name>jms/JbpmConnectionFactory</res-ref-name>
<res-type>javax.jms.ConnnectionFactory</res-type>
<res-auth>Container</res-auth>
</resource-ref>
<message-destination-ref>
<message-destination-ref-name>
jms/JobQueue
</message-destination-ref-name>
<message-destination-type>javax.jms.Queue</message-destination-type>
<message-destination-usage>Produces</message-destination-usage>
</message-destination-ref>
</session><session>
<ejb-name>MyClientBean</ejb-name>
<jndi-name>ejb/MyClientBean</jndi-name>
<local-jndi-name>java:ejb/MyClientBean</local-jndi-name>
<ejb-local-ref>
<ejb-ref-name>ejb/TimerEntityBean</ejb-ref-name>
<local-jndi-name>java:ejb/TimerEntityBean</local-jndi-name>
</ejb-local-ref>
<resource-ref>
<res-ref-name>jdbc/JbpmDataSource</res-ref-name>
<jndi-name>java:JbpmDS</jndi-name>
</resource-ref>
<resource-ref>
<res-ref-name>jms/JbpmConnectionFactory</res-ref-name>
<jndi-name>java:JmsXA</jndi-name>
</resource-ref>
<message-destination-ref>
<message-destination-ref-name>
jms/JobQueue
</message-destination-ref-name>
<jndi-name>queue/JbpmJobQueue</jndi-name>
</message-destination-ref>
</session><web-app>
<servlet>
<servlet-name>MyClientServlet</servlet-name>
<servlet-class>org.example.ClientServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>MyClientServlet</servlet-name>
<url-pattern>/client/servlet</url-pattern>
</servlet-mapping>
<ejb-local-ref>
<ejb-ref-name>ejb/TimerEntityBean</ejb-ref-name>
<ejb-ref-type>Entity</ejb-ref-type>
<local-home>org.jbpm.ejb.LocalTimerEntityHome</local-home>
<local>org.jbpm.ejb.LocalTimerEntity</local>
<ejb-link>TimerEntityBean</ejb-link>
</ejb-local-ref>
<resource-ref>
<res-ref-name>jdbc/JbpmDataSource</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
<resource-ref>
<res-ref-name>jms/JbpmConnectionFactory</res-ref-name>
<res-type>javax.jms.ConnectionFactory</res-type>
<res-auth>Container</res-auth>
</resource-ref>
<message-destination-ref>
<message-destination-ref-name>
jms/JobQueue
</message-destination-ref-name>
<message-destination-type>javax.jms.Queue</message-destination-type>
<message-destination-usage>Produces</message-destination-usage>
<message-destination-link>JobQueue</message-destination-link>
</message-destination-ref>
</web-app><jboss-web>
<ejb-local-ref>
<ejb-ref-name>ejb/TimerEntityBean</ejb-ref-name>
<local-jndi-name>java:ejb/TimerEntityBean</local-jndi-name>
</ejb-local-ref>
<resource-ref>
<res-ref-name>jdbc/JbpmDataSource</res-ref-name>
<jndi-name>java:JbpmDS</jndi-name>
</resource-ref>
<resource-ref>
<res-ref-name>jms/JbpmConnectionFactory</res-ref-name>
<jndi-name>java:JmsXA</jndi-name>
</resource-ref>
<message-destination-ref>
<message-destination-ref-name>
jms/JobQueue
</message-destination-ref-name>
<jndi-name>queue/JbpmJobQueue</jndi-name>
</message-destination-ref>
</jboss-web>5.5. まとめ
第6章 プロセスモデリング
6.1. 役に立つ定義
ノード進入、ノード退出、遷移取得 です。
6.2. プロセスグラフ
processdefinition.xml というファイルにあります。各ノードには タイプ が必要です (状態、決定、フォーク、および ジョイン など)。 各ノードには、一連の 退出遷移 があります。ノードから退出する遷移には、それらを区別するために名前を付けることができます。たとえば、次の図は、オークションプロセスのプロセスグラフを示しています。
図6.1 オークションプロセスのグラフ
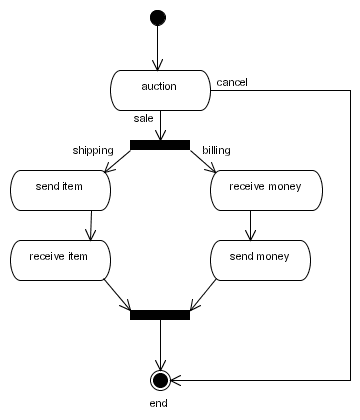
<process-definition>
<start-state>
<transition to="auction" />
</start-state>
<state name="auction">
<transition name="auction ends" to="salefork" />
<transition name="cancel" to="end" />
</state>
<fork name="salefork">
<transition name="shipping" to="send item" />
<transition name="billing" to="receive money" />
</fork>
<state name="send item">
<transition to="receive item" />
</state>
<state name="receive item">
<transition to="salejoin" />
</state>
<state name="receive money">
<transition to="send money" />
</state>
<state name="send money">
<transition to="salejoin" />
</state>
<join name="salejoin">
<transition to="end" />
</join>
<end-state name="end" />
</process-definition>6.3. ノード
6.3.1. ノードの役割
- 実行を伝播できない。(ノードは
待機状態として動作します。) - ノードの
退出遷移の 1 つを介して実行を伝播できる。(これは、最初にノードに到達したトークンが、API 呼び出しexecutionContext.leaveNode(String)により退出遷移の 1 つを介して渡されることを意味します。) ノードは、いくつかのカスタムプログラミングロジックを実行し、待機せずにプロセスの実行を自動的に続行するという意味で、自動的に動作します。 - 新しいトークンの作成を "決定" できる。新しい各トークンは、新しい実行パスを表します。これらの新しいトークンはそれぞれ、ノードの
退出遷移を介して起動できます。この種の動作の良い例はフォークノードです。 - 実行パスを終了できる。これは、トークンが終了したことを意味します。
- プロセスインスタンスの ランタイム構造 全体を変更できる。ランタイム構造は、トークンのツリーを含むプロセスインスタンスであり、それぞれが実行パスを表します。ノードは、トークンを作成および終了し、各トークンをグラフのノードに配置し、遷移を介してトークンを起動できます。
6.3.2. ノードタイプ: タスクノード
待機状態 に入ります。ユーザーがタスクを完了すると、実行がトリガーされて再開されます。
6.3.3. ノードタイプ: 状態
待機状態 です。これは、どのタスクリストに対してもタスクインスタンスが作成されないという点で、タスクノードとは異なります。これは、プロセスが外部システムを待機している場合に役立ちます。その後、プロセスは待機状態になります。外部システムが応答メッセージを送信すると、通常 token.signal() が呼び出され、プロセス実行の再開をトリガーします。
6.3.4. ノードタイプ: 決定
- プロセスによって決定を行う。そのため、決定をプロセス定義で指定する。
- 外部エンティティーによって決定を行う。
決定ノード を使用します。2 つの方法のいずれかで決定基準を指定します。最も簡単な方法は、条件要素を遷移に追加することです。(条件は、ブール値を返す EL 式または Beanshell スクリプトです。)
退出遷移 をループします。決定ノードは、XML で指定された順序でこれらの遷移を最初に評価します。条件が true に解決される最初の遷移が取得されます。すべての遷移の条件が false に解決された場合、デフォルトの遷移 (XML の最初の遷移) が代わりに取得されます。デフォルトの遷移が見つからない場合、JbpmException が出力されます。
退出遷移 に解決する必要があります。
DecisionHandler インターフェイスを実装できます。このシナリオでは、決定は Java クラスによって計算され、選択された 退出遷移 が DecisionHandler 実装に属する decide メソッドによって返されます。
状態 または 待機状態 ノードから退出する複数の遷移を常に使用してください。待機状態 が完了した後に実行を再開する外部トリガーで退出遷移を指定できます (Token.signal(String transitionName) や TaskInstance.end(String transitionName) など)。
6.3.5. ノードタイプ: フォーク
6.3.6. ノードタイプ: ジョイン
退出遷移 に渡されます。アクティブな兄弟トークンがまだある場合、ジョインは 待機状態 として動作します。
6.3.7. ノードタイプ: ノード
actionhandler に記述されたカスタムコードは、任意の処理を実行できますが、実行を渡す役割もあることに注意してください。詳細は、「 ノードの役割 」 を参照してください。
6.4. 遷移
Map getLeavingTransitionsMap() メソッドは、List getLeavingTransitions() よりも少ない要素を返します。)
6.5. アクション
図6.2 データベース更新アクション
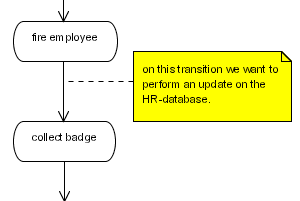
public class RemoveEmployeeUpdate implements ActionHandler {
public void execute(ExecutionContext ctx) throws Exception {
// get the fired employee from the process variables.
String firedEmployee =
(String) ctx.getContextInstance().getVariable("fired employee");
// by taking the same database connection as used for the jbpm
// updates, we reuse the jbpm transaction for our database update.
Connection connection =
ctx.getProcessInstance().getJbpmSession().getSession().getConnection();
Statement statement = connection.createStatement();
statement.execute("DELETE FROM EMPLOYEE WHERE ...");
statement.execute();
statement.close();
}
}<process-definition name="yearly evaluation">
<state name="fire employee">
<transition to="collect badge">
<action class="com.nomercy.hr.RemoveEmployeeUpdate" />
</transition>
</state>
<state name="collect badge">
</process-definition>6.5.1. アクションリファレンス
6.5.2. イベント
node-enter イベントと node-leave イベントの両方を発生させることができます。(イベントはアクションの "フック" です。各イベントにはアクションのリストがあります。jBPM エンジンがイベントを発生させると、アクションのリストが実行されます。)
6.5.3. イベントの受け渡し
6.5.4. スクリプト
- executionContext
- トークン (token)
- node
- task
- taskInstance
<process-definition>
<event type="node-enter">
<script>
System.out.println("this script is entering node "+node);
</script>
</event>
...
</process-definition><process-definition>
<event type="process-end">
<script>
<expression>
a = b + c;
</expression>
<variable name='XXX' access='write' mapped-name='a' />
<variable name='YYY' access='read' mapped-name='b' />
<variable name='ZZZ' access='read' mapped-name='c' />
</script>
</event>
...
</process-definition>YYY および ZZZ が、それぞれスクリプト変数 b および c としてスクリプトで使用できるようになります。スクリプトが完了すると、スクリプト変数 a の値が、プロセス変数 XXX に格納されます。
read が含まれている場合、プロセス変数は、スクリプトが評価される前にスクリプト変数としてロードされます。access 属性に write が含まれている場合、スクリプト変数は評価後にプロセス変数として保存されます。mapped-name 属性を使用すると、スクリプト内でプロセス変数を別の名前で使用できます。これは、プロセス変数名にスペースやその他の無効な文字が含まれている場合に使用します。
6.5.5. カスタムイベント
GraphElement.fireEvent(String eventType, ExecutionContext executionContext); メソッドを呼び出すことで、プロセスの実行中に自由にカスタムイベントを実行できます。イベントタイプの名前は自由に選択してください。
6.6. スーパーステート
6.6.1. スーパーステート遷移
6.6.2. スーパーステートイベント
superstate-enter および superstate-leave という固有のイベントが 2 つあります。これらのイベントは、ノードがどの遷移に進入したか、またはどの遷移から退出したかに関係なく、発生します。スーパーステート内でトークンが遷移を取得する限り、これらのイベントは発生しません。
6.6.3. 階層名
/) 区切りの相対名で指定します。ノード名はスラッシュで区切られます。.. を使用して、上位レベルを参照します。次の例は、スーパーステートのノードを参照する方法を示しています。
<process-definition>
<state name="preparation">
<transition to="phase one/invite murphy"/>
</state>
<super-state name="phase one">
<state name="invite murphy"/>
</super-state>
</process-definition><process-definition>
<super-state name="phase one">
<state name="preparation">
<transition to="../phase two/invite murphy"/>
</state>
</super-state>
<super-state name="phase two">
<state name="invite murphy"/>
</super-state>
</process-definition>6.7. 例外処理
exception-handler のリストは、process-definition、node、transition で指定できます。これらの各例外ハンドラーには、アクションのリストがあります。委譲クラスで例外が発生すると、プロセス要素の親階層で適切な exception-handler が検索され、そのアクションが実行されます。
token.signal() メソッドを呼び出したクライアントに出力されます。キャッチされた例外がある場合は、何も発生しなかったかのようにグラフ実行が続行されます。
アクション のグラフ内にある任意のノードにトークンを配置するには、Token.setNode(Node node) を使用します。
6.8. プロセス構成
process-state によって プロセス構成 をサポートしています。この状態は、別のプロセス定義に関連付けられている状態です。グラフ実行が process-state に到達すると、サブプロセスの新しいインスタンスが作成されます。このサブプロセスは、プロセス状態に到達した実行パスに関連付けられます。スーパープロセスの実行パスは、サブプロセスが終了するまで待機し、その後プロセス状態から退出し、スーパープロセスでグラフ実行を継続します。
<process-definition name="hire">
<start-state>
<transition to="initial interview" />
</start-state>
<process-state name="initial interview">
<sub-process name="interview" />
<variable name="a" access="read,write" mapped-name="aa" />
<variable name="b" access="read" mapped-name="bb" />
<transition to="..." />
</process-state>
...
</process-definition>
hire プロセスには、interview プロセスを生成する process-state が含まれています。first interview に実行が到達すると、interview プロセスの新しい実行 (つまり、プロセスインスタンス) が作成されます。バージョンが明示的に指定されていない場合、サブプロセスの最新バージョンが使用されます。Business Process Manager で特定のバージョンをインスタンス化するには、オプションの version 属性を指定します。サブプロセスが実際に作成されるまで、指定したバージョンまたは最新バージョンのバインドを延期するには、オプションの binding 属性を late に設定します。
hire プロセス変数 a を interview プロセス変数 aa にコピーします。同様に、hire 変数 b を インタビュー変数 bb にコピーします。面接プロセスが完了すると、変数 aa のみが a 変数に再びコピーされます。
6.9. カスタムノードの動作
ActionHandler の特別な実装を使用して、カスタムノードを作成します。以下の例では、ERP システムから値を読み取り、(プロセス変数から) 金額を追加し、結果を ERP システムに保存します。金額の大きさに基づいて、 small amounts 遷移または large amounts 遷移を使用して終了します。
図6.3 ERP 更新用のプロセススニペットの例
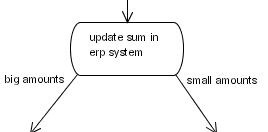
public class AmountUpdate implements ActionHandler {
public void execute(ExecutionContext ctx) throws Exception {
// business logic
Float erpAmount = ...get amount from erp-system...;
Float processAmount = (Float) ctx.getContextInstance().getVariable("amount");
float result = erpAmount.floatValue() + processAmount.floatValue();
...update erp-system with the result...;
// graph execution propagation
if (result > 5000) {
ctx.leaveNode(ctx, "big amounts");
} else {
ctx.leaveNode(ctx, "small amounts");
}
}
}6.10. グラフ実行
待機状態 のように動作します。
待機状態 に進入するまで続行されます。
待機状態 の間、データベースで永続化することができます。
図6.4 グラフ実行関連のメソッド
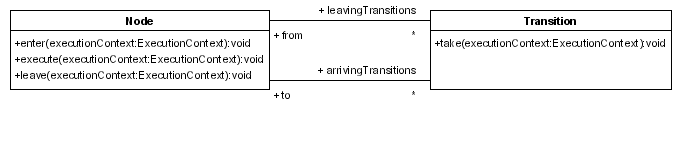
退出遷移 を指定する必要があります。最初の遷移がデフォルトです。トークンにシグナルが送信されると、遷移はトークンの現在のノードを取得し、Node.leave(ExecutionContext,Transition) メソッドを呼び出します。(ExecutionContext は、その中の主要なオブジェクトがトークンであるため、トークンと考えるのが最適です。) Node.leave(ExecutionContext,Transition) メソッドは node-leave イベントを発生させ、Transition.take(ExecutionContext) を呼び出します。このメソッドは遷移イベントを実行し、遷移の宛先ノードで Node.enter(ExecutionContext) を呼び出します。さらに、このメソッドが node-enter イベントを発生させ、Node.execute(ExecutionContext) を呼び出します。
execute メソッドを介して実装されます。各ノードには、Node.leave(ExecutionContext,Transition) を再度呼び出して、グラフ実行を受け渡す役割があります。つまり、以下のようになります。
Token.signal(Transition)Node.leave(ExecutionContext,Transition)Transition.take(ExecutionContext)Node.enter(ExecutionContext)Node.execute(ExecutionContext)
6.11. トランザクションの境界
待機状態 に進入したときにのみ、token.signal() または taskInstance.end() が返されることを意味します。
async="true" 属性をサポートします。非同期ノードは、クライアントのスレッドでは実行されません。代わりに、非同期メッセージングシステムを介してメッセージが送信され、スレッドがクライアントに返されます (つまり、token.signal() または taskInstance.end() が返されます。)
org.jbpm.command.ExecuteNodeCommand メッセージが非同期メッセージングシステムから jBPM Command Executor に送信されます。これにより、キューからコマンドが読み取られ、実行されます。org.jbpm.command.ExecuteNodeCommand の場合、ノード実行時に処理が継続されます。(各コマンドは別々のトランザクションで実行されます。)
jBPM Command Executor が実行されていることを確認してください。これを行うには、Web アプリケーションの CommandExecutionServlet を設定します。
待機状態 に進入するまで計算全体を実行します。(async="true" を使用して、プロセス内のトランザクションを区別します。)
<start-state> <transition to="one" /> </start-state> <node async="true" name="one"> <action class="com...MyAutomaticAction" /> <transition to="two" /> </node> <node async="true" name="two"> <action class="com...MyAutomaticAction" /> <transition to="three" /> </node> <node async="true" name="three"> <action class="com...MyAutomaticAction" /> <transition to="end" /> </node> <end-state name="end" /> ...
//start a transaction
JbpmContext jbpmContext = jbpmConfiguration.createContext();
try {
ProcessInstance processInstance =
jbpmContext.newProcessInstance("my async process");
processInstance.signal();
jbpmContext.save(processInstance);
} finally {
jbpmContext.close();
}root token が node one を参照し、ExecuteNodeCommand メッセージがコマンドエグゼキューターに送信されます。
node one を実行します。アクションは、実行を渡すか、待機状態 に進入するかを決定できます。実行を渡すことを選択した場合、実行が node two に到達したときにトランザクションは終了します。
第7章 コンテキスト
7.1. プロセス変数へのアクセス
org.jbpm.context.exe.ContextInstance は、プロセス変数の中心的なインターフェイスとして機能します。次の方法で、プロセスインスタンスから ContextInstance を取得します。
ProcessInstance processInstance = ...; ContextInstance contextInstance = (ContextInstance) processInstance.getInstance(ContextInstance.class);
void ContextInstance.setVariable(String variableName, Object value); void ContextInstance.setVariable( String variableName, Object value, Token token); Object ContextInstance.getVariable(String variableName); Object ContextInstance.getVariable(String variableName, Token token);
java.lang.String です。デフォルトでは、Business Process Manager は次の値の型をサポートしています。(Hibernate で永続化できる他の型もサポートしています。)
java.lang.String | java.lang.Boolean |
java.lang.Character | java.lang.Float |
java.lang.Double | java.lang.Long |
java.lang.Byte | java.lang.Integer |
java.util.Date | byte[] |
java.io.Serializable |
7.2. 変数の寿命
java.util.Map と同じ方法で作成されます。また、変数は削除することもできます。
ContextInstance.deleteVariable(String variableName); ContextInstance.deleteVariable(String variableName, Token token);
7.3. 可変永続性
7.4. 可変スコープ
ルートトークン がデフォルトで使用されます。
ルートトークン に作成されます。(そのため、各変数にはデフォルトでプロセススコープがあります。) 変数トークンを "ローカル" にするには、次の例に従って明示的に作成します。
ContextInstance.createVariable(String name, Object value, Token token);
7.4.1. 変数のオーバーロード
7.4.2. 変数のオーバーライド
contact という名前の変数を、ネストされた実行パス shipping および billing 内のこの変数でオーバーライドできます。
7.4.3. タスクインスタンス変数のスコープ
7.5. 一時変数
ProcessInstance Java オブジェクトの寿命と同じです。
processdefinition.xml ファイルで宣言する必要はありません。
Object ContextInstance.getTransientVariable(String name); void ContextInstance.setTransientVariable(String name, Object value);
第8章 タスク管理
8.1. タスク
task-node および process-definition で定義します。最も一般的な方法は、task-node で 1 つ以上の タスク を定義することです。その場合、task-node はユーザーが引き受けるタスクを表します。プロセスの実行は、アクターがタスクを完了するまで待機する必要があります。アクターがタスクを完了すると、プロセスの実行が続行されます。task-node に追加のタスクが指定されている場合、デフォルトの動作では、すべてのタスクが終了するまで待機します。
process-definition で指定することもできます。この方法で指定したタスクは、名前を検索して見つけることができます。task-node 内からそれらを参照したり、アクション内から使用したりすることもできます。実際、名前が付けられたすべてのタスク (または task-node) は、process-definition で見つけることができます。
優先度 を設定します。これは、このタスク用に作成された各タスクインスタンスの初期優先度として使用されます。(この初期優先度は、後でタスクインスタンスによって変更できます。)
8.2. タスクインスタンス
actorId (java.lang.String) に割り当てることができます。すべてのタスクインスタンスは 1 つのテーブル (JBPM_TASKINSTANCE) に格納されます。 特定のユーザーのタスクリストを取得するには、このテーブルを照会し、特定の actorId のすべてのタスクインスタンスを取得します。
8.2.1. タスクインスタンスのライフサイクル
- タスクインスタンスは通常、プロセスの実行が
task-nodeに進入したときに (TaskMgmtInstance.createTaskInstance(...)メソッドを介して) 作成されます。 - ユーザーインターフェイスコンポーネントが、データベースにタスクリストを照会します。これは、
TaskMgmtSession.findTaskInstancesByActorId(...)メソッドを使用して行われます。 - ユーザーからの入力を収集した後、UI コンポーネントが
TaskInstance.assign(String)、TaskInstance.start()、またはTaskInstance.end(...)を呼び出します。
createstartend
TaskInstance にあるそれぞれの "ゲッター" を介してこれらのプロパティーにアクセスします。
JBPM_TASKINSTANCE テーブルに残ります。
8.2.2. タスクインスタンスとグラフ実行
task-node から退出することを禁止するタスクインスタンスです。デフォルトでは、タスクインスタンスはシグナリングおよび非ブロッキングになるように設定されています。
task-node に関連付けられている場合、プロセス開発者は、タスクインスタンスの完了がプロセスの継続に影響を与える方法を指定できます。以下の値のいずれかを task-node の signal-property に与えます。
- last
- これはデフォルトです。最後のタスクインスタンスが完了すると、実行が続行されます。このノードへの進入時にタスクが作成されていない場合、実行が続行されます。
- last-wait
- 最後のタスクインスタンスが完了すると、実行が続行されます。このノードへの進入時にタスクが作成されていない場合、タスクが作成されるまで、タスクノードで実行が待機されます。
- first
- 最初のタスクインスタンスが完了すると、実行が続行されます。このノードへの進入時にタスクが作成されていない場合、実行が続行されます。
- first-wait
- 最初のタスクインスタンスが完了すると、実行が続行されます。このノードへの進入時にタスクが作成されていない場合、タスクが作成されるまで、タスクノードで実行が待機されます。
- unsynchronized
- この場合、タスクが作成されているか未完了であるかに関係なく、実行は常に続行されます。
- never
- この場合、タスクが作成されているか未完了であるかに関係なく、実行は続行されません。
ActionHandler を task-node の node-enter イベントに追加し、create-tasks="false" を設定します。以下に例を示します。
public class CreateTasks implements ActionHandler {
public void execute(ExecutionContext executionContext) throws Exception {
Token token = executionContext.getToken();
TaskMgmtInstance tmi = executionContext.getTaskMgmtInstance();
TaskNode taskNode = (TaskNode) executionContext.getNode();
Task changeNappy = taskNode.getTask("change nappy");
// now, 2 task instances are created for the same task.
tmi.createTaskInstance(changeNappy, token);
tmi.createTaskInstance(changeNappy, token);
}
}task-node で指定します。また、process-definition で指定して、TaskMgmtDefinition から取得することもできます。(TaskMgmtDefinition は、タスク管理情報を追加してプロセス定義を拡張します。)
TaskInstance.end() メソッドは、タスクインスタンスを完了としてマークするために使用します。必要に応じて、end メソッドで遷移を指定できます。このタスクインスタンスの完了によって実行の継続がトリガーされた場合、指定された遷移を介して task-node から退出します。
8.3. 割り当て
task-node には、0 個以上のタスクが含まれます。タスクは、プロセス定義の一部を静的に記述したものです。ランタイム時にタスクを実行すると、タスクインスタンスが作成されます。タスクインスタンスは、個人のタスクリストの 1 つのエントリーに対応します。
8.3.1. 割り当てのインターフェイス
AssignmentHandler インターフェイスを介してタスクインスタンスを割り当てます。
public interface AssignmentHandler extends Serializable {
void assign( Assignable assignable, ExecutionContext executionContext );
}AssignmentHandler の実装は、割り当て可能なメソッド (setActorId または setPooledActors) を呼び出し、タスクを割り当てます。割り当て可能な項目は、TaskInstance または SwimlaneInstance (プロセスロール) です。
public interface Assignable {
public void setActorId(String actorId);
public void setPooledActors(String[] pooledActors);
}TaskInstance と SwimlaneInstance の両方を、特定のユーザーまたはアクターのプールに割り当てることができます。TaskInstance をユーザーに割り当てるには、Assignable.setActorId(String actorId) を呼び出します。TaskInstance を候補アクターのプールに割り当てるには、Assignable.setPooledActors(String[] actorIds) を呼び出します。
AssignmentHandler を作成するには、processdefinition.xml ファイルを使用してそれぞれを設定します。(割り当てハンドラーに設定を追加する方法の詳細は、「委譲」 を参照してください。)
8.3.2. 割り当てのデータモデル
TaskInstance には、actorId とプールされたアクターのセットがあります。
図8.1 割り当てモデルのクラス図
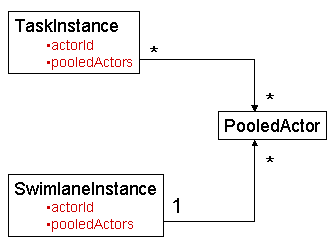
actorId はタスクの責任者です。プールされたアクターのセットは、候補者のコレクションを表します。候補者はタスクを引き受けると、責任者になります。actorId と pooledActors はどちらもオプションであり、組み合わせることもできます。
8.3.3. 個人タスクリスト
TaskInstance の actorId プロパティーの存在によって示されます。次のいずれかの方法で、TaskInstance を個人のタスクリストに追加します。
- タスク要素の
actor-id属性に式を指定する - コード内の任意の場所から
TaskInstance.setActorId(String)メソッドを使用する AssignmentHandlerでassignable.setActorId(String)を使用する
TaskMgmtSession.findTaskInstances(String actorId) を使用します。
8.3.4. グループタスクリスト
taskInstance をユーザーのグループタスクリストに入れるには、ユーザーの actorId またはユーザーの groupId の 1 つを pooledActorIds に追加します。プールされたアクターを指定するには、次のいずれかの方法を使用します。
- プロセス内のタスク要素の属性
pooled-actor-idsに式を指定する - コード内のいずれかの場所で
TaskInstance.setPooledActorIds(String[])を使用する - AssignmentHandler で
assignable.setPooledActorIds(String[])を使用する
TaskMgmtSession.findPooledTaskInstances(String actorId) または TaskMgmtSession.findPooledTaskInstances(List actorIds) を使用して、個人タスクリストになく (actorId==null)、プールされた actorId に一致するタスクインスタンスを検索します。
pooledActorId のリストを持つ taskInstance は、アクターの個人タスクリストにのみ表示されます。タスクインスタンスをグループに戻すには、taskInstance の actorId プロパティを null に設定して、pooledActorId を保持します。
8.4. タスクインスタンス変数
8.5. タスクコントローラー
- タスクインスタンス変数のコピーを作成して、プロセスが完了するまでタスクインスタンス変数への中間更新がプロセス変数に影響を与えないようにします。この時点で、コピーがプロセス変数に送信されます。
- タスクインスタンス変数は、プロセス変数と 1 対 1 の関係を持ちません。たとえば、プロセスに
sales in January、sales in January sales、およびsales in Marchという名前の変数がある場合、タスクインスタンスのフォームで、それらの 3 か月の平均売上を表示しなければならないこともあります。
図8.2 タスクコントローラー
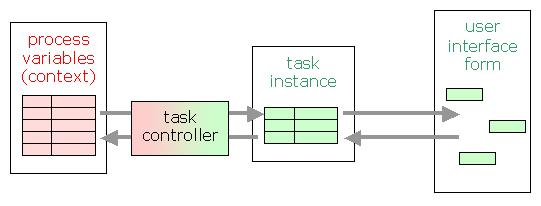
variable 要素のリストを取得します。
<task name="clean ceiling">
<controller>
<variable name="a" access="read" mapped-name="x" />
<variable name="b" access="read,write,required" mapped-name="y" />
<variable name="c" access="read,write" />
</controller>
</task>
read,write です。
task-node は多くのタスクを持つことができますが、start-state は 1 つのタスクしか持ちません。
TaskControllerHandler 実装を作成します。そのためのインターフェイスを以下に示します。
public interface TaskControllerHandler extends Serializable {
void initializeTaskVariables(TaskInstance taskInstance, ContextInstance contextInstance, Token token);
void submitTaskVariables(TaskInstance taskInstance, ContextInstance contextInstance, Token token);
}<task name="clean ceiling">
<controller class="com.yourcom.CleanCeilingTaskControllerHandler">
-- here goes your task controller handler configuration --
</controller>
</task>
8.6. スイムレーン
割り当て があります。総裁は、「 割り当て 」 を参照してください。
AssignmentHandler が呼び出されます。AssignmentHandler に渡される Assignable (割り当て可能な) 項目は、SwimlaneInstance です。特定のスイムレーンのタスクインスタンスで引き受けられた割り当ては、すべてスイムレーンインスタンスに伝播されます。タスクを引き受けるユーザーはその特定のプロセスに関する知識を持っているため、これがデフォルトの動作となっています。したがって、そのスイムレーンの後続のタスクインスタンスは、自動的にそのユーザーに割り当てられます。
8.7. 開始タスクのスイムレーン
Authentication.getAuthenticatedActorId() メソッドによりキャプチャーされます。アクターは開始タスクのスイムレーンに格納されます。
<process-definition>
<swimlane name='initiator' />
<start-state>
<task swimlane='initiator' />
<transition to='...' />
</start-state>
...
</process-definition>8.8. タスクイベント
task-create: タスクインスタンスが作成されたときに発生します。task-assign: タスクインスタンスが割り当てられるときに発生します。このイベントで実行されるアクションでは、executionContext.getTaskInstance().getPreviousActorId();メソッドを使用して前のアクターにアクセスできます。task-start:TaskInstance.start()メソッドが呼び出されたときに発生します。このオプション機能は、ユーザーが実際にタスクインスタンスの作業を開始していることを示すために使用します。task-end:TaskInstance.end(...)が呼び出されたときに発生します。これは、タスクの完了を示します。タスクがプロセスの実行に関連している場合、この呼び出しによってプロセスの実行が再開されることがあります。
8.9. タスクタイマー
8.10. タスクインスタンスのカスタマイズ
TaskInstanceのサブクラスを作成します。org.jbpm.taskmgmt.TaskInstanceFactory実装を作成します。- jbpm.task.instance.factory 設定プロパティーを
jbpm.cfg.xmlファイルの完全修飾クラス名に設定し、実装を設定します。 TaskInstanceのサブクラスを使用する場合は、サブクラスの Hibernate マッピングファイルを作成します (extends="org.jbpm.taskmgmt.exe.TaskInstance"を使用)。- そのマッピングファイルを
hibernate.cfg.xmlのリストに追加します。
8.11. アイデンティティーコンポーネント
java.lang.String として表されます。そのため、組織モデルとそのデータの構造に関する情報は、jBPM のコアエンジンの範囲外です。
8.11.1. アイデンティティーモデル
図8.3 アイデンティティーモデルのクラス図
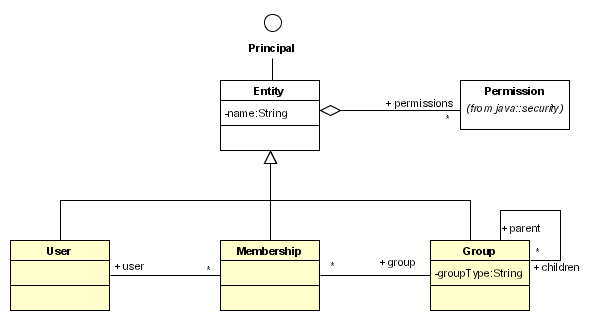
User は、ユーザーまたはサービスを表します。Group は、あらゆる種類のユーザーグループです。グループをネストすることで、チーム、ビジネスユニット、および会社全体の間の関係をモデル化できます。グループには、階層グループと髪の色グループなどを区別するためのタイプがあります。Membership は、ユーザーとグループ間の多対多の関係を表します。メンバーシップは、会社内の役職を表すために使用できます。メンバーシップの名前は、ユーザーがグループ内で果たす役割を示すために使用できます。
8.11.2. 割り当て式
<process-definition>
<task-node name='a'>
<task name='laundry'>
<assignment expression='previous --> group(hierarchy) --> member(boss)' />
</task>
<transition to='b' />
</task-node>
<para>Syntax of the assignment expression is like this:</para>
first-term --> next-term --> next-term --> ... --> next-term
where
first-term ::= previous |
swimlane(swimlane-name) |
variable(variable-name) |
user(user-name) |
group(group-name)
and
next-term ::= group(group-type) |
member(role-name)
</programlisting>8.11.2.1. 最初の項
User または Group を指定します。後続の項は、中間のユーザーまたはグループからの次の項を計算します。
previous は、タスクが現在の認証済みアクターに割り当てられていることを意味します。これは、プロセスの前のステップを実行したアクターを意味します。
swimlane(swimlane-name) は、指定されたスイムレーンインスタンスからユーザーまたはグループを取得することを意味します。
variable(variable-name) は、指定された変数インスタンスからユーザーまたはグループを取得することを意味します。変数インスタンスには java.lang.String を含めることができます。その場合、そのユーザーまたはグループは、アイデンティティーコンポーネントから取得されます。または、変数インスタンスに User または Group オブジェクトが含まれています。
user(user-name) は、アイデンティティーコンポーネントから特定のユーザーを取得することを意味します。
group(group-name) は、アイデンティティーコンポーネントから特定のグループを取得することを意味します。
8.11.2.2. 次の項
group(group-type) は、ユーザーのグループを取得します。これは、前の項の結果が User である必要があることを意味します。この項は、ユーザーのすべてのメンバーシップで、指定された group-type のグループを検索します。
member(role-name) は、グループの特定のロールを実行するユーザーを取得します。前の項の結果が Group である必要があります。この項は、メンバーシップの名前が特定の role-name と一致するグループのメンバーシップを持つユーザーを検索します。
8.11.3. アイデンティティーコンポーネントの削除
hibernate.cfg.xml から次の行を削除することです。
<mapping resource="org/jbpm/identity/User.hbm.xml"/> <mapping resource="org/jbpm/identity/Group.hbm.xml"/> <mapping resource="org/jbpm/identity/Membership.hbm.xml"/>
ExpressionAssignmentHandler は、アイデンティティーコンポーネントに依存しているため、そのまま使用することはできません。ExpressionAssignmentHandler を再利用してユーザーデータストアにバインドする場合は、ExpressionAssignmentHandler から拡張し、getExpressionSession メソッドをオーバーライドできます。
protected ExpressionSession getExpressionSession(AssignmentContext assignmentContext);
第9章 スケジューラー
9.1. タイマー
<state name='catch crooks'>
<timer name='reminder'
duedate='3 business hours'
repeat='10 business minutes'
transition='time-out-transition' >
<action class='the-remainder-action-class-name' />
</timer>
<transition name='time-out-transition' to='...' />
</state>- タイプが
timerのイベントが発生します。 - アクションが指定されている場合、それが実行されます。
- シグナルにより、指定された遷移で実行が再開されます。
timer 要素に名前が指定されていない場合、デフォルトでノードの名前が使用されます。
action や script など) をサポートするには、タイマーアクションを使用します。
action-element は、create-timer と cancel-timer です。実際には、上記の timer 要素は、node-enter での create-timer アクションと node-leave での cancel-timer アクションの簡略表記です。
9.2. スケジューラーのデプロイメント
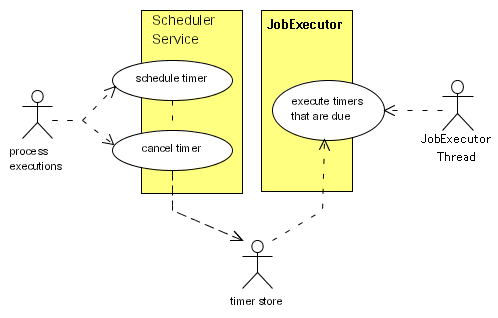
タイマーランナー がこのストアを確認し、各タイマーを適切なタイミングで実行します。
図9.1 スケジューラーコンポーネントの概要
第10章 非同期継続
10.1. 概念
async="true" 属性で指定できます。async="true" は、イベントでトリガーされた場合にのみサポートされますが、すべてのノードタイプとすべてのアクションタイプで指定できます。
10.2. 例
図10.1 例 1: 非同期継続のないプロセス

GraphSession.saveProcessInstance の結果として、Hibernate によって生成されます。次に、自動化されたアクションが何らかのトランザクションリソースにアクセスして更新する場合、そのような更新は結合するか、同じトランザクションの一部にする必要があります。
async="true" 属性を設定することによって非同期としてマークされます。
async="true" をノード 'b' に追加すると、プロセスの実行が 2 つの部分に分割されます。1 つ目の部分は、ノード 'b' が実行されるポイントまでプロセスを実行します。2 つ目の部分は、ノード 'b' を実行します。 その実行は待機状態 'c' で停止します。
Token.signal メソッドの呼び出し) が必要ですが、2 つ目のトランザクションは jBPM が自動的にトリガーして実行します。
図10.2 非同期継続を伴うプロセス

async="true" 属性でマークされたアクションは、プロセスを実行するスレッドの外部で実行されます。永続性が設定されている場合 (デフォルトの設定)、アクションは別のトランザクションで実行されます。
10.3. ジョブエグゼキューター
ExecuteNodeJob と ExecuteActionJob です。
Job (Plain Old Java Object) が MessageService に送信されます。メッセージサービスは、JbpmContext に関連付けられており、送信する必要があるすべてのメッセージを収集します。
JbpmContext.close() の一部として送信されます。このメソッドは、close() の呼び出しを、関連するすべてのサービスに対してカスケードします。実際のサービスは jbpm.cfg.xml で設定できます。サービスの 1 つである JmsMessageService は、デフォルトで設定されており、新しいジョブメッセージが利用可能であることをジョブエグゼキューターに通知します。
MessageServiceFactory および MessageService を使用してメッセージを送信します。これは、非同期メッセージングサービスを設定可能にするためです (これも jbpm.cfg.xml にあります)。Java EE 環境では、DbMessageService を JmsMessageService に置き換えて、アプリケーションサーバーの機能を活用できます。
- ディスパッチャースレッドはジョブを取得する必要があります。
- エグゼキュータースレッドはジョブを実行する必要があります。
REPEATABLE_READ に設定する必要があります。REPEATABLE_READ に設定すると、競合するトランザクションのうちの 1 つに含まれる 1 つの行だけが、このクエリーによって確実に更新されます。
update JBPM_JOB job
set job.version = 2
job.lockOwner = '192.168.1.3:2'
where
job.version = 1READ_COMMITTED では、繰り返し不可能な読み取りが発生する可能性があるため、十分ではありません。そのため、複数のジョブ実行スレッドを設定する場合は、REPEATABLE_READ が必要です。
- jbpmConfiguration
- 設定の取得元の Bean。
- name
- このエグゼキューターの名前。重要1 台のマシンで複数の jBPM インスタンスが起動している場合、この名前はノードごとに一意である必要があります。
- nbrOfThreads
- 起動しているエグゼキュータースレッドの数。
- idleInterval
- 保留中のジョブがない場合に、ジョブキューを確認するまでにディスパッチャースレッドが待機する間隔。注記ジョブがキューに追加されると、ディスパッチャースレッドに自動的に通知されます。
- retryInterval
- 実行中にジョブが失敗した場合に、ジョブが次の再試行まで待機する間隔。このデフォルト値は 3 回です。注記再試行の最大回数は、jbpm.job.retries で設定されます。
- maxIdleInterval
- idleInterval の最長期間。
- historyMaxSize
- このプロパティーは非推奨であり、効果はありません。
- maxLockTime
- ロックモニタースレッドがロックを解除する前にジョブをロックできる最大時間。
- lockMonitorInterval
- ロックされたジョブの確認の間にロックモニタースレッドがスリープする期間。
- lockBufferTime
- このプロパティーは非推奨であり、効果はありません。
10.4. jBPM のビルトインの非同期メッセージング
JBPM_JOB テーブルに格納されます。
org.jbpm.msg.command.CommandExecutor) は、データベーステーブルからメッセージを読み取り、実行します。POJO コマンドエグゼキューターの典型的なトランザクションは次のようになります。
- 次のコマンドメッセージの読み取り
- コマンドメッセージの実行
- コマンドメッセージの削除
図10.3 POJO コマンドエグゼキューターのトランザクション
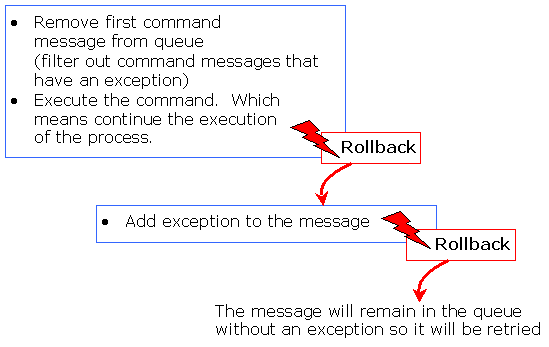
第11章 ビジネスカレンダー
11.1. 期日
duedate ::= [<basedate> +/-] <duration>
11.1.1. 期間
duration ::= <quantity> [business] <unit>
<quantity> は、Double.parseDouble (quantity) で解析可能なテキストである必要があります。<unit> は、秒、分、時、日、週、月、年のいずれかになります。オプションの business フラグを追加すると、当該の期間で営業時間のみが考慮されます。(これがない場合、期間は絶対時間として解釈されます。)
11.1.2. 基準日
basedate ::= <EL>
<EL> は、Java Date または Calendar オブジェクトに解決される任意の Java Expression Language 式にすることができます。
JbpmException エラーが発生します。
11.1.3. 期日の例
<timer name="daysBeforeHoliday" duedate="5 business days">...</timer>
<timer name="pensionDate" duedate="#{dateOfBirth} + 65 years" >...</timer>
<timer name="pensionReminder" duedate="#{dateOfPension} - 1 year" >...</timer>
<timer name="fireWorks" duedate="#{chineseNewYear} repeat="1 year" >...</timer>
<reminder name="hitBoss" duedate="#{payRaiseDay} + 3 days" repeat="1 week" />
11.2. カレンダーの設定
org/jbpm/calendar/jbpm.business.calendar.properties ファイルで営業時間を定義します。(この設定ファイルをカスタマイズするには、変更したコピーをクラスパスのルートに配置します。)
jbpm.business.calendar.properties にあるデフォルトの営業時間の仕様です。
hour.format=HH:mm #weekday ::= [<daypart> [& <daypart>]*] #daypart ::= <start-hour>-<to-hour> #start-hour and to-hour must be in the hour.format #dayparts have to be ordered weekday.monday= 9:00-12:00 & 12:30-17:00 weekday.tuesday= 9:00-12:00 & 12:30-17:00 weekday.wednesday= 9:00-12:00 & 12:30-17:00 weekday.thursday= 9:00-12:00 & 12:30-17:00 weekday.friday= 9:00-12:00 & 12:30-17:00 weekday.saturday= weekday.sunday= day.format=dd/MM/yyyy # holiday syntax: <holiday> # holiday period syntax: <start-day>-<end-day> # below are the belgian official holidays holiday.1= 01/01/2005 # nieuwjaar holiday.2= 27/3/2005 # pasen holiday.3= 28/3/2005 # paasmaandag holiday.4= 1/5/2005 # feest van de arbeid holiday.5= 5/5/2005 # hemelvaart holiday.6= 15/5/2005 # pinksteren holiday.7= 16/5/2005 # pinkstermaandag holiday.8= 21/7/2005 # my birthday holiday.9= 15/8/2005 # moederkesdag holiday.10= 1/11/2005 # allerheiligen holiday.11= 11/11/2005 # wapenstilstand holiday.12= 25/12/2005 # kerstmis business.day.expressed.in.hours= 8 business.week.expressed.in.hours= 40 business.month.expressed.in.business.days= 21 business.year.expressed.in.business.days= 220
11.3. 例
<timer name="daysBeforeHoliday" duedate="5 business days">...</timer>
<timer name="pensionDate" duedate="#{dateOfBirth} + 65 years" >...</timer>
<timer name="pensionReminder" duedate="#{dateOfPension} - 1 year" >...</timer>
<timer name="fireWorks" duedate="#{chineseNewYear} repeat="1 year" >...</timer>
<reminder name="hitBoss" duedate="#{payRaiseDay} + 3 days" repeat="1 week" />
hour.format=HH:mm #weekday ::= [<daypart> [& <daypart>]*] #daypart ::= <start-hour>-<to-hour> #start-hour and to-hour must be in the hour.format #dayparts have to be ordered weekday.monday= 9:00-12:00 & 12:30-17:00 weekday.tuesday= 9:00-12:00 & 12:30-17:00 weekday.wednesday= 9:00-12:00 & 12:30-17:00 weekday.thursday= 9:00-12:00 & 12:30-17:00 weekday.friday= 9:00-12:00 & 12:30-17:00 weekday.saturday= weekday.sunday= day.format=dd/MM/yyyy # holiday syntax: <holiday> # holiday period syntax: <start-day>-<end-day> # below are the belgian official holidays holiday.1= 01/01/2005 # nieuwjaar holiday.2= 27/3/2005 # pasen holiday.3= 28/3/2005 # paasmaandag holiday.4= 1/5/2005 # feest van de arbeid holiday.5= 5/5/2005 # hemelvaart holiday.6= 15/5/2005 # pinksteren holiday.7= 16/5/2005 # pinkstermaandag holiday.8= 21/7/2005 # my birthday holiday.9= 15/8/2005 # moederkesdag holiday.10= 1/11/2005 # allerheiligen holiday.11= 11/11/2005 # wapenstilstand holiday.12= 25/12/2005 # kerstmis business.day.expressed.in.hours= 8 business.week.expressed.in.hours= 40 business.month.expressed.in.business.days= 21 business.year.expressed.in.business.days= 220
第12章 メールサポート
12.1. JPDL におけるメール
12.1.1. メールアクション
<mail actors="#{president}" subject="readmylips" text="nomoretaxes" />
<mail actors="#{president}" >
<subject>readmylips</subject>
<text>nomoretaxes</text>
</mail><mail
to='#{initiator}'
subject='websale'
text='your websale of #{quantity} #{item} was approved' /><mail
to='admin@mycompany.com'
subject='urgent'
text='the mailserver is down :-)' /><mail template='sillystatement' actors="#{president}" />12.1.2. メールノード
メールアクション とまったく同じ属性と要素をサポートします。(詳細は、「 メールアクション 」 を参照してください。)
<mail-node name="send email"
to="#{president}"
subject="readmylips"
text="nomoretaxes">
<transition to="the next node" />
</mail-node>12.1.3. "タスク割り当て" メール
notify="yes" 属性を追加します。
<task-node name='a'>
<task name='laundry' swimlane="grandma" notify='yes' />
<transition to='b' />
</task-node>yes、true、または on に設定すると、Business Process Manager は、タスクに割り当てられているアクターにメールを送信します。(このメールはテンプレートに基づいており、Web アプリケーションのタスクページへのリンクが含まれています。)
12.1.4. "タスクリマインダー" メール
<task-node name='a'>
<task name='laundry' swimlane="grandma" notify='yes'>
<reminder duedate="2 business days" repeat="2 business hours"/>
</task>
<transition to='b' />
</task-node>12.2. メールにおける式
jbpm.cfg.xml ファイルで設定します。
president という名前の swimlane が存在することを前提としています。
<mail actors="#{president}"
subject="readmylips"
text="nomoretaxes" />president として振る舞うユーザーにメールを送信します。
12.3. メールの受信者の指定
12.3.1. 複数の受信者
12.3.2. BCC アドレスへのメールの送信
<mail to='#{initiator}'
bcc='bcc@mycompany.com'
subject='websale'
text='your websale of #{quantity} #{item} was approved' />jbpm.cfg.xml で一元的に設定されている場所に BCC メッセージを常に送信する方法があります。次の例は、その方法を示しています。
<jbpm-configuration>
...
<string name="jbpm.mail.bcc.address" value="bcc@mycompany.com" />
</jbpm-configuration>12.3.3. アドレス解決
actorIds によって参照されます。これは、プロセスの参加者を識別するための文字列です。アドレスリゾルバー は、actorIds をメールアドレスに変換します。
public interface AddressResolver extends Serializable {
Object resolveAddress(String actorId);
}actorId のメールアドレスを表すものである必要があります。)
jbpm.mail.address.resolver という名前の jbpm.cfg.xml ファイルで設定する必要があります。
<jbpm-configuration>
<bean name='jbpm.mail.address.resolver'
class='org.jbpm.identity.mail.IdentityAddressResolver'
singleton='true' />
</jbpm-configuration>アイデンティティー コンポーネントには、アドレスリゾルバーが含まれています。このアドレスリゾルバーは、特定の actorId のユーザーを探します。ユーザーが存在する場合、そのメールアドレスが返されます。そうでない場合は、null が返されます。
12.4. メールテンプレート
processdefinition.xml ファイルを使用してメールを指定する代わりに、テンプレートを使用できます。この場合も、各フィールドを processdefinition.xml で上書きできます。次のようにテンプレートを指定します。
<mail-templates>
<variable name="BaseTaskListURL"
value="http://localhost:8080/jbpm/task?id=" />
<mail-template name='task-assign'>
<actors>#{taskInstance.actorId}</actors>
<subject>Task '#{taskInstance.name}'</subject>
<text><![CDATA[Hi,
Task '#{taskInstance.name}' has been assigned to you.
Go for it: #{BaseTaskListURL}#{taskInstance.id}
Thanks.
---powered by JBoss jBPM---]]></text>
</mail-template>
<mail-template name='task-reminder'>
<actors>#{taskInstance.actorId}</actors>
<subject>Task '#{taskInstance.name}' !</subject>
<text><![CDATA[Hey,
Don't forget about #{BaseTaskListURL}#{taskInstance.id}
Get going !
---powered by JBoss jBPM---]]></text>
</mail-template>
</mail-templates>jbpm.cfg.xml でテンプレートを含むリソースを設定します。
<jbpm-configuration> <string name="resource.mail.templates" value="jbpm.mail.templates.xml" /> </jbpm-configuration>
12.5. メールサーバーの設定
jbpm.cfg.xml ファイルの jbpm.mail.smtp.host プロパティーを設定して、メールサーバーを設定します。
<jbpm-configuration>
<string name="jbpm.mail.smtp.host" value="localhost" />
</jbpm-configuration><jbpm-configuration> <string name='resource.mail.properties' value='jbpm.mail.properties' /> </jbpm-configuration>
12.6. メール認証
12.6.1. メール認証の設定
表12.1 jBPM のメール認証プロパティー
| プロパティー | タイプ | 説明 |
|---|---|---|
| jbpm.mail.user |
string
|
ユーザーのメールアドレス
|
| jbpm.mail.password |
string
|
そのメールアドレスのパスワード
|
| jbpm.mail.smtp.starttls |
boolean
|
SMTP サーバーで STARTTLS プロトコルを使用するかどうか
|
| jbpm.mail.smtp.auth |
boolean
|
SMTP 認証プロトコルを使用するかどうか
|
| jbpm.mail.debug |
boolean
|
javax.mail.Session インスタンスをデバッグモードに設定するかどうか
|
12.6.2. メール認証のロジック
- mail.smtp.submitter プロパティーが jbpm.mail.user プロパティーの値で設定されます。
- jbpm エンジンが、メールの送信時に smtp サーバーへのログインを試みます。
- この場合にも、少なくとも jbpm.mail.user を設定した場合の処理が行われます。
- jbpm.mail.smtp.auth プロパティーの値に関係なく、mail.smtp.auth プロパティーは true に設定されます。
12.7. "From" アドレスの設定
From アドレスフィールドのデフォルト値は、jbpm@noreply です。次のように、キー jbpm.mail.from.address を使用して jbpm.xfg.xml ファイルで設定します。
<jbpm-configuration>
<string name='jbpm.mail.from.address' value='jbpm@yourcompany.com' />
</jbpm-configuration>12.8. メールサポートのカスタマイズ
org.jbpm.mail.Mail に一元化されています。このクラスは ActionHandler の実装です。process XML でメールが指定されるたびに、mail クラスへの委譲が行われます。特定のニーズに合わせて、mail クラスから継承し、特定の動作をカスタマイズすることができます。メール委譲に使用するクラスを設定するには、次のように jbpm.cfg.xml で jbpm.mail.class.name 設定文字列を指定します。
<jbpm-configuration> <string name='jbpm.mail.class.name' value='com.your.specific.CustomMail' /> </jbpm-configuration>
第13章 ロギング
13.1. ログの作成
org.jbpm.logging.log.ProcessLog から継承する Java オブジェクトです。) プロセスログのエントリーは、ProcessInstance のオプションの拡張である LoggingInstance に追加されます。
org.jbpm.logging.log.ProcessLog から始めることをお勧めします。これを使用して、継承ツリー の下層に移動することができるためです。
LoggingInstance は、すべてのログエントリーを収集します。ProcessInstance が保存されると、ログエントリーはここからデータベースにフラッシュされます。(ProcessInstance の logs フィールドは Hibernate にマッピングされていません。これは、各トランザクションでデータベースから取得されるこれらのログを回避するためです。)
ProcessInstance は実行パスのコンテキストで作成されるため、ProcessLog はそのトークンを参照します。トークンは、インデックスシーケンスジェネレーター としても機能します。(これにより後続のトランザクションで生成されるログに連続したシーケンス番号が付けられるため、これはログの取得にとって重要です。)
public class LoggingInstance extends ModuleInstance {
...
public void addLog(ProcessLog processLog) {...}
...
}図13.1 jBPM のログ情報のクラス図
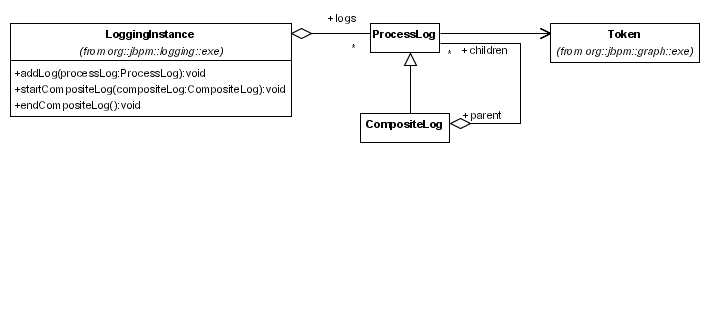
public class LoggingInstance extends ModuleInstance {
...
public void startCompositeLog(CompositeLog compositeLog) {...}
public void endCompositeLog() {...}
...
}CompositeLog は常に try-finally-block で呼び出す必要があります。以下はその例です。
startCompositeLog(new MyCompositeLog());
try {
...
} finally {
endCompositeLog();
}13.2. ログ設定
jbpm.cfg.xml 設定ファイルのセクション jbpm-context からロギングの行を削除します。
<service name='logging'
factory='org.jbpm.logging.db.DbLoggingServiceFactory' />LoggingService のカスタム実装を記述します (これは DbLoggingService のサブクラスです)。その後、ロギング用のカスタム ServiceFactory を作成し、それを factory 属性で指定します。
13.3. ログの取得
LoggingSession を介してこれを実現するには、2 つの方法があります。
ProcessLog のリストをプロセスインスタンス内のすべてのトークンに関連付けます。リストには、作成された順序と同じ順序で ProcessLogs が含まれます。
public class LoggingSession {
...
public Map findLogsByProcessInstance(long processInstanceId) {...}
...
}ProcessLogs が含まれます。
public class LoggingSession {
public List findLogsByToken(long tokenId) {...}
...
}第14章 jBPM プロセス定義言語
14.1. プロセスアーカイブ
processdefinition.xml と呼ばれます。このファイルは、ビジネスプロセスを jPDL 表記で定義し、自動化されたアクションとヒューマンタスクに関する情報を提供します。プロセスアーカイブには、アクションハンドラークラスやユーザーインターフェイスタスクフォームなど、プロセスに関連する他のファイルも含まれます。
14.1.1. プロセスアーカイブのデプロイ
プロセスアーカイブ は、次のいずれかの方法でデプロイできます。
- Process Designer Tool
- ant タスク
- プログラム
GPD Deployer Servlet と呼ばれる、プロセスアーカイブをアップロードするためのサーブレットを備えています。このサーブレットは、プロセスアーカイブを受信し、設定されたデータベースにデプロイできます。
<target name="deploy-process">
<taskdef name="deployproc" classname="org.jbpm.ant.DeployProcessTask">
<classpath location="jbpm-jpdl.jar" />
</taskdef>
<deployproc process="build/myprocess.par" />
</target>DeployProcessTask の属性は次のとおりです。
表14.1 DeployProcessTask の属性
| 属性 | 説明 | 必須かどうか |
|---|---|---|
| process |
プロセスアーカイブへのパス。
|
はい。ネストされたリソースコレクション要素が使用されている場合を除きます。
|
| jbpmcfg |
デプロイメント時にロードする jBPM 設定リソース。
|
いいえ。デフォルトは
jbpm.cfg.xml です。
|
| failonerror |
false の場合、プロセス定義がデプロイに失敗したときに、警告メッセージをログに記録しますが、ビルドは停止しません。
| いいえ。デフォルトは true です。 |
org.jbpm.graph.def.ProcessDefinition クラスのいずれかの parseXXX メソッドを使用します。
14.1.2. プロセスのバージョン管理
- jBPM クラスローダーがこれらのクラスを認識できるようにするそのためには、委譲クラスを
jbpm-jpdl.jarの "隣" の.jarファイルに入れて、すべてのプロセス定義がそのクラスファイルを参照できるようにします。Java クラスもプロセスアーカイブに含めることができます。委譲クラスをプロセスアーカイブに含めた場合 (そしてそれらが jbpm クラスローダーによって認識されない場合)、jBPM はこれらのクラスをプロセス定義内でバージョン管理します。注記プロセスクラスローディングの詳細は、「委譲」 を参照してください。
-1 という形でバージョン付けされます。)
14.1.3. デプロイされたプロセス定義の変更
org.jbpm.db.GraphSessionのメソッドloadProcessDefinition、findProcessDefinitionを介してロードされたプロセス定義、またはアソシエーショントラバーサルを介して到達されたプロセス定義の更新に制限はありません。ただし、setStartState(null)などのいくつかの呼び出しにより、プロセスが台無しになることが 非常によくある ため、注意してください。- プロセス定義は変更されることが想定されていないため、出荷時の Hibernate 設定では、定義クラスとコレクションの
nonstrict-read-writeキャッシュストラテジーが指定されています。このストラテジーにより、コミットされていない更新を他のトランザクションから認識できるようになります。
14.1.4. プロセスインスタンスの移行
ChangeProcessInstanceVersionCommand を実行します。
new ChangeProcessInstanceVersionCommand()
.processName("commute")
.nodeNameMappingAdd("drive to destination", "ride bike to destination")
.execute(jbpmContext);
14.2. 委譲
14.2.1. jBPM クラスローダー
jbpm-jpdl.jar と同じ場所に配置します。Web アプリケーションの場合、カスタム JAR ファイルを jbpm-jpdl.jar と一緒に WEB-INF/lib に配置します。
14.2.2. プロセスクラスローダー
classes ディレクトリーに配置します。これは、プロセス定義に追加されたクラスをバージョン管理する場合にのみ役立つことに注意してください。バージョン管理が不要な場合は、代わりにクラスを jBPM クラスローダーで使用できるようにします。
classes ディレクトリーからも読み込まれます。このディレクトリーの外にあるリソースをロードするには、パスの先頭に二重スラッシュ (//) を付けます。たとえば、プロセスアーカイブのルートにある data.xml をロードするには、class.getResource("//data.xml") を呼び出します。
14.2.3. 委譲の設定
ActionHandler インターフェイスの実装を呼び出すことができます。委譲は、processdefinition.xml ファイルで指定します。委譲を指定するときに、次の 3 つのデータを指定できます。
- クラス名 (必須): これは委譲クラスの完全修飾名です。
- 設定タイプ (オプション): これは、委譲オブジェクトをインスタンス化して設定する方法を指定します。デフォルトでは、コンストラクターが使用され、設定情報は無視されます。
- 設定 (オプション): これは委譲オブジェクトの設定であり、設定タイプに必要な形式である必要があります。
14.2.3.1. config-type フィールド
- 文字列はトリミングされますが、変換されません。
- int、long、float、double などのプリミティブ型。
- プリミティブ型の基本的なラッパークラス。
- リスト、セット、およびコレクション。このような場合、xml-content の各要素はコレクションの要素と見なされ、変換を適用して再帰的に解析されます。要素の型が
java.lang.Stringと異なる場合は、完全修飾型名で type 属性を指定することにより、その型を指定します。たとえば、このコードは文字列のArrayListを numbers フィールドに挿入します。<numbers> <element>one</element> <element>two</element> <element>three</element> </numbers>
要素内のテキストは、文字列コンストラクターを持つ任意のオブジェクトに変換できます。文字列以外の型を使用するには、フィールド (この場合は numbers) で element-type を指定します。マップの別の例を次に示します。<numbers> <entry><key>one</key><value>1</value></entry> <entry><key>two</key><value>2</value></entry> <entry><key>three</key><value>3</value></entry> </numbers>
- この場合、フィールド要素のそれぞれに、1 つの key と 1 つの value サブ要素がある必要があります。変換規則を再帰的に使用して、これらの両方を解析します。コレクションと同様に、type 属性を指定しなかった場合は、
java.lang.Stringへの変換が意図されていると見なされます。 org.dom4j.Element- その他の型の場合は、文字列コンストラクターが使用されます。
public class MyAction implements ActionHandler {
// access specifiers can be private, default, protected or public
private String city;
Integer rounds;
...
}... <action class="org.test.MyAction"> <city>Atlanta</city> <rounds>5</rounds> </action> ...
14.2.3.2. config-type Bean
14.2.3.3. config-type コンストラクター
14.2.3.4. config-type configuration-property
void configure(String); メソッドに渡します。
14.3. 式
expression="#{myVar.handler[assignments].assign}" のような式を記述できます。
#{...} 表記を採用し、メソッドバインディングのサポートを備えています。
- taskInstance (
org.jbpm.taskmgmt.exe.TaskInstance) - processInstance (
org.jbpm.graph.exe.ProcessInstance) - processDefinition (
org.jbpm.graph.def.ProcessDefinition) - token (
org.jbpm.graph.exe.Token) - taskMgmtInstance (
org.jbpm.taskmgmt.exe.TaskMgmtInstance) - contextInstance (
org.jbpm.context.exe.ContextInstance)
14.4. jPDL XML スキーマ
processdefinition.xml ファイルで使用されるスキーマです。
14.4.1. 検証
- スキーマは XML ドキュメントで参照されます。
<process-definition xmlns="urn:jbpm.org:jpdl-3.2"> ... </process-definition>
- Xerces パーサーはクラスパスにあります。
${jbpm.home}/src/java.jbpm/org/jbpm/jpdl/xml/jpdl-3.2.xsd または http://jbpm.org/jpdl-3.2.xsd で確認してください。
14.4.2. process-definition
表14.2 プロセス定義スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | これはプロセスの名前です。 |
| swimlane | 要素 | [0..*] | これはプロセスで使用される swim-lane です。swim-lane はプロセスの役割を表し、タスクの割り当てに使用されます。 |
| start-state | 要素 | [0..1] | これはプロセスの開始状態です。start-state のないプロセスは有効ですが、実行できないことに注意してください。 |
| {end-state|state|node|task-node|process-state|super-state|fork|join|decision} | 要素 | [0..*] | これらはプロセス定義のノードです。ノードのないプロセスは有効ですが、実行できないことに注意してください。 |
| event | 要素 | [0..*] | これはアクションのコンテナーとして機能します。 |
| {action|script|create-timer|cancel-timer} | 要素 | [0..*] | これらは、イベントおよび遷移から参照できるグローバルに定義されたアクションです。これらのアクションを参照するには、名前を指定する必要があることに注意してください。 |
| task | 要素 | [0..*] | これは、アクションなどで使用できるグローバルに定義されたタスクです。 |
| exception-handler | 要素 | [0..*] | これは、このプロセス定義の委譲クラスによって出力されたすべてのエラーに適用される例外ハンドラーのリストです。 |
14.4.3. node
表14.3 ノードスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| {action|script|create-timer|cancel-timer} | 要素 | 1 | これは、このノードの動作を表すカスタムアクションです。 |
| 共通のノード要素 | 「共通のノード要素」 |
14.4.4. 共通のノード要素
表14.4 共通のノードスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | required | これはノードの名前です。 |
| async | 属性 | { true | false }、デフォルトは false | true に設定すると、このノードは非同期で実行されます。10章 非同期継続 も併せて参照してください。 |
| transition | 要素 | [0..*] | これは退出遷移です。ノードから退出する各遷移には、個別の名前が *必要* です。名前を持たない遷移は、最大 1 つまで許可されます。指定された最初の遷移は、デフォルト遷移と呼ばれます。遷移を指定せずにノードから退出すると、デフォルトの遷移が取得されます。 |
| event | 要素 | [0..*] | サポートされているイベントタイプは、{node-enter|node-leave} の 2 つです。 |
| exception-handler | 要素 | [0..*] | これは、このプロセスノード内から委譲クラスによって出力されたすべてのバグに適用される例外ハンドラーのリストです。 |
| timer | 要素 | [0..*] | これは、このノードでの実行時間をモニタリングするタイマーを指定します。 |
14.4.5. start-state
表14.5 開始状態スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | これはノードの名前です。 |
| task | 要素 | [0..1] | これは、このプロセスの新しいインスタンスを開始するため、またはプロセスのイニシエーターをキャプチャーするために使用されるタスクです。「 開始タスクのスイムレーン 」 を参照 |
| event | 要素 | [0..*] | サポートされているイベントタイプは {node-leave} です。 |
| transition | 要素 | [0..*] | これは退出遷移です。ノードから退出する各遷移には、個別の名前が必要です。 |
| exception-handler | 要素 | [0..*] | これは、このプロセスノード内から委譲クラスによって出力されたすべてのバグに適用される例外ハンドラーのリストです。 |
14.4.6. end-state
表14.6 終了状態スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | required | これは end-state の名前です。 |
| end-complete-process | 属性 | 任意 | end-complete-process が false に設定されている場合、この end-state を完了するトークンのみが完了します。このトークンが最後に終了した子だった場合、親トークンが再帰的に終了します。プロセスインスタンス全体を確実に終了するには、このプロパティーを true に設定します。 |
| event | 要素 | [0..*] | サポートされているイベントタイプは {node-enter} です。 |
| exception-handler | 要素 | [0..*] | これは、このプロセスノード内から委譲クラスによって出力されたすべてのバグに適用される例外ハンドラーのリストです。 |
14.4.7. state
表14.7 状態スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.8. task-node
表14.8 タスクノードスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| signal | 属性 | 任意 | これは {unsynchronized|never|first|first-wait|last|last-wait} で、デフォルトは last です。タスクの完了が プロセスの実行継続 に影響を与える方法を指定します。 |
| create-tasks | 属性 | 任意 | これは {yes|no|true|false} で、デフォルトは true です。ランタイム時の計算で、どのタスクを作成する必要があるかを決定する必要がある場合は、false に設定します。その場合、node-enter にアクションを追加し、そのアクションにタスクを作成して create-tasks を false に設定します。 |
| end-tasks | 属性 | 任意 | これは {yes|no|true|false} で、デフォルトは false です。node-leave で remove-tasks が true に設定されている場合、開いているすべてのタスクが終了します。 |
| task | 要素 | [0..*] | これは、実行がこのタスクノードに到達したときに作成されるタスクです。 |
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.9. process-state
表14.9 プロセス状態スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| sub-process | 要素 | 1 | これは、このノードに関連付けられているサブプロセスです。 |
| variable | 要素 | [0..*] | これは、開始時にスーパープロセスからサブプロセスにデータをコピーする方法と、サブプロセスの完了時にサブプロセスからスーパープロセスにデータをコピーする方法を指定します。 |
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.10. super-state
表14.10 スーパーステートスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| {end-state|state|node|task-node|process-state|super-state|fork|join|decision} | 要素 | [0..*] | これらはスーパーステートのノードです。スーパーステートはネストできます。 |
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.11. fork
表14.11 フォークスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.12. join
表14.12 結合スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.13. decision
表14.13 決定スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| handler | 要素 | 'handler' 要素または遷移の条件のいずれかを指定する必要があります。 | org.jbpm.jpdl.Def.DecisionHandler 実装の名前 |
| transition conditions | 決定から退出する遷移の属性または要素のテキスト |
すべての遷移には保護条件が含まれる場合があります。決定ノードは、条件を持つ退出遷移を調べ、条件が真である最初の遷移を選択します。
条件が満たされない場合は、デフォルト の遷移が取得されます。デフォルト遷移は、存在する場合は最初の無条件遷移であり、存在しない場合は最初の条件付き遷移です。遷移はドキュメント順に考慮されます。
条件付き ("保護された") 遷移のみが使用可能で、遷移の条件がいずれも true と評価されない場合、例外が出力されます。
| |
| 共通のノード要素 | 「共通のノード要素」 を参照 |
14.4.14. event
表14.14 イベントスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| type | 属性 | required | これは、イベントが配置される要素に対して相対的に表現されるイベントタイプです。 |
| {action|script|create-timer|cancel-timer} | 要素 | [0..*] | これは、このイベントで実行する必要があるアクションのリストです。 |
14.4.15. transition
表14.15 遷移スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | これは遷移の名前です。ノードから退出する各遷移には、個別の名前が *必要* であることに注意してください。 |
| to | 属性 | required | これは宛先ノードの階層名です。階層名の詳細は、「 階層名 」 を参照してください。 |
| condition | 属性または要素のテキスト | 任意 | これは 保護条件 式です。この条件属性 (または子要素) を決定ノードで使用するか、ランタイム時にトークンで使用可能な遷移を計算します。条件は、決定ノードから退出する遷移でのみ許可されます。 |
| {action|script|create-timer|cancel-timer} | 要素 | [0..*] | これらは、この遷移が発生したときに実行されるアクションです。遷移のアクションはイベントに入れる必要がないことに注意してください (イベントは 1 つしかないため)。 |
| exception-handler | 要素 | [0..*] | これは、このプロセスノード内から委譲クラスによって出力されたすべてのバグに適用される例外ハンドラーのリストです。 |
14.4.16. action
表14.16 アクションスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | これはアクションの名前です。アクションに名前を付けると、プロセス定義から検索できます。これは、ランタイムアクションやアクションの宣言を 1 回だけ行う場合に役立ちます。 |
| class | 属性 | ref-name または expression のいずれか | これは、org.jbpm.graph.def.ActionHandler インターフェイスを実装するクラスの完全修飾クラス名です。 |
| ref-name | 属性 | ref-name または class のいずれか | これは参照されるアクションの名前です。参照されるアクションが指定されている場合、このアクションの内容はそれ以上処理されません。 |
| expression | 属性 | expression、class 、または ref-name のいずれか | これは、メソッドに解決される jPDL 式です。「 式 」 も併せて参照してください。 |
| accept-propagated-events | 属性 | 任意 | オプションは {yes|no|true|false} です。デフォルトは yes|true です。false に設定した場合、アクションは、このアクションの要素で発生したイベントでのみ実行されます。詳細は、「 イベントの受け渡し 」 を参照してください。 |
| config-type | 属性 | 任意 | オプションは {field|bean|constructor|configuration-property} です。これは、action-object を構築する方法と、この要素の内容をその action-object の設定情報として使用する方法を指定します。 |
| async | 属性 | {true|false} | 'async="true" は、イベントでトリガーされた場合にのみ、アクション でサポートされます。デフォルト値は false です。これは、アクション が実行のスレッドで実行されることを意味します。true に設定した場合、メッセージがコマンドエグゼキューターに送信され、そのコンポーネントがアクションを別のトランザクションで非同期に実行します。 |
| {content} | 任意 | アクションの内容は、カスタムアクション実装の設定情報として使用できます。これにより、再利用可能な委譲クラスを作成できます。 |
14.4.17. script
表14.17 スクリプトスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | これはスクリプトアクションの名前です。アクションに名前を付けると、プロセス定義から検索できます。これは、ランタイムアクションやアクションの宣言を 1 回だけ行う場合に役立ちます。 |
| accept-propagated-events | 属性 | 任意 [0..*] | {yes|no|true|false}。デフォルトは yes|true です。false に設定すると、アクションは、このアクションの要素で発生したイベントでのみ実行されます。詳細は、「 イベントの受け渡し 」 を参照してください。 |
| expression | 要素 | [0..1] | Beanshell スクリプト。variable 要素を指定しない場合は、式を script 要素の内容として記述できます (expression 要素タグは省略します)。 |
| variable | 要素 | [0..*] | スクリプトの in 変数。in 変数が指定されていない場合、現在のトークンのすべての変数がスクリプト評価にロードされます。スクリプト評価にロードする変数の数を制限する場合は、in 変数を使用します。 |
14.4.18. expression
表14.18 式スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| {content} | Bean シェルスクリプト。 |
14.4.19. variable
表14.19 変数スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | required | プロセスの変数名 |
| access | 属性 | 任意 | デフォルトは read,write です。これは、アクセス指定子のコンマ区切りリストです。これまでに使用したアクセス指定子は、read、write、および required のみです。"required" は、タスク変数をプロセス変数に送信する場合にのみ関係します。 |
| mapped-name | 属性 | 任意 | デフォルト設定は変数名です。これは変数名がマップされる名前を指定します。mapped-name の意味は、この要素が使用されるコンテキストに依存します。スクリプトの場合、これは script-variable-name になります。タスクコントローラーの場合、これはタスクフォームパラメーターのラベルになります。プロセス状態の場合、これはサブプロセスで使用される変数名になります。 |
14.4.20. handler
表14.20 ハンドラースキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| expression | 属性 | expression または class のいずれか | jPDL 式。返された結果は toString () メソッドで文字列に変換されます。結果の文字列が退出遷移の 1 つと一致する必要があります。「 式 」も併せて参照してください。 |
| class | 属性 | class または ref-name のいずれか | org.jbpm.graph.node.DecisionHandler インターフェイスを実装するクラスの完全修飾クラス名。 |
| config-type | 属性 | 任意 | {field|bean|constructor|configuration-property}。action-object を構築する方法と、この要素の内容をその action-object の設定情報として使用する方法を指定します。 |
| {content} | 任意 | ハンドラーの内容は、カスタムハンドラー実装の設定情報として使用できます。これにより、再利用可能な委譲クラスを作成できます。 |
14.4.21. timer
表14.21 タイマースキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | タイマーの名前。名前が指定されていない場合は、包含するノードの名前が使用されます。すべてのタイマーには一意の名前が必要であることに注意してください。 |
| duedate | 属性 | required | タイマーの作成からタイマーの実行までの期間を指定する時間幅 (必要に応じて営業時間で表します)。この構文については、「 期間 」 を参照してください。 |
| repeat | 属性 | 任意 | {duration | 'yes' | 'true'}。duedate にタイマーを実行した後、'repeat' により、必要に応じてノードから退出するまでタイマー実行を繰り返す期間を指定します。yes または true を指定した場合、duedate と同じ期間が繰り返されます。この構文については、「 期間 」 を参照してください。 |
| transition | 属性 | 任意 | タイマーイベントが発生し、アクション (存在する場合) が実行された後、タイマーが実行されるときに取得される遷移の名前。 |
| cancel-event | 属性 | 任意 | この属性は、タスクのタイマーでのみ使用されます。タイマーをキャンセルするイベントを指定します。デフォルトでは、これは task-end イベントですが、たとえば task-assign や task-start にも設定できます。属性のコンマ区切りリストで指定することで、cancel-event タイプを組み合わせることができます。 |
| {action|script|create-timer|cancel-timer} | 要素 | [0..1] | このタイマーが起動したときに実行する必要があるアクション。 |
14.4.22. create-timer
表14.22 タイマー作成スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | タイマーの名前。この名前は、cancel-timer アクションでタイマーをキャンセルするために使用できます。 |
| duedate | 属性 | required | タイマーの作成からタイマーの実行までの期間を指定する時間幅 (必要に応じて営業時間で表します)。この構文については、「 期間 」 を参照してください。 |
| repeat | 属性 | 任意 | {duration | 'yes' | 'true'}。duedate にタイマーを実行した後、'repeat' により、必要に応じてノードから退出するまでタイマー実行を繰り返す期間を指定します。yes または true を指定した場合、duedate と同じ期間が繰り返されます。この構文については、「 期間 」 を参照してください。 |
| transition | 属性 | 任意 | タイマーイベントが発生し、アクション (存在する場合) が実行された後、タイマーが実行されるときに取得される遷移の名前。 |
14.4.23. cancel-timer
表14.23 キャンセルタイマースキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | キャンセルするタイマーの名前。 |
14.4.24. task
表14.24 タスクスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | 任意 | タスクの名前。名前付きのタスクは、TaskMgmtDefinition を介して参照および検索できます。 |
| blocking | 属性 | 任意 | {yes|no|true|false}。デフォルトは false です。blocking を true に設定した場合、タスクが完了していないときにノードから退出することはできません。false (デフォルト) に設定すると、トークンのシグナルは実行を継続してノードから退出することができます。blocking は通常、ユーザーインターフェイスによって強制されるため、デフォルトは false に設定されています。 |
| signalling | 属性 | 任意 | {yes|no|true|false}。デフォルトは true です。signalling を false に設定した場合、このタスクがトークンの継続をトリガーする機能を持つことはありません。 |
| duedate | 属性 | 任意 | 11章 ビジネスカレンダー で説明されているように、絶対時間または営業時間で表される期間です。 |
| swimlane | 属性 | 任意 | スイムレーンへの参照。タスクにスイムレーンが指定されている場合、割り当ては無視されます。 |
| priority | 属性 | 任意 | {highest, high, normal, low, lowest} のいずれか。または、優先順位として任意の整数を指定できます。参考: (最高 = 1、最低 = 5) |
| assignment | 要素 | 任意 | タスクの作成時にアクターにタスクを割り当てる委譲を記述します。 |
| event | 要素 | [0..*] | サポートされているイベントタイプは、{task-create|task-start|task-assign|task-end} です。task-assign については、TaskInstance に非永続プロパティー previousActorId が追加されています。 |
| exception-handler | 要素 | [0..*] | このプロセスノードでスローされる委譲クラスによってスローされるすべての例外に適用される例外ハンドラーのリスト。 |
| timer | 要素 | [0..*] | このタスクの実行時間をモニタリングするタイマーを指定します。タスクタイマーに特化した cancel-event を指定できます。デフォルトでは cancel-event は task-end ですが、task-assign や task-start などにカスタマイズできます。 |
| controller | 要素 | [0..1] | プロセス変数をタスクフォームパラメーターに変換する方法を指定します。タスクフォームパラメーターは、タスクフォームをユーザーに表示するためにユーザーインターフェイスによって使用されます。 |
14.4.25. スイムレーン
表14.25 スイムレーンスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | required | スイムレーンの名前。スイムレーンは、TaskMgmtDefinition を介して参照および検索できます。 |
| assignment | 要素 | [1..1] | このスイムレーンの割り当てを指定します。割り当ては、このスイムレーンで最初のタスクインスタンスが作成されたときに実行されます。 |
14.4.26. 割り当て
表14.26 割り当てスキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| expression | 属性 | 任意 | 歴史的な理由から、この属性式は、jPDL 式を 参照するものではなく、jBPM アイデンティティーコンポーネントの割り当て式です。jBPM アイデンティティーコンポーネント式の記述方法の詳細は、「割り当て式」 を参照してください。この実装は、jbpm アイデンティティーコンポーネントに依存していることに注意してください。 |
| actor-id | 属性 | 任意 | actorId。pooled-actors と組み合わせて使用できます。actor-id は式として解決されます。したがって、actor-id="bobthebuilder" のように、固定の actorId を参照できます。または、actor-id="myVar.actorId" のように、文字列を返すプロパティーまたはメソッドを参照できます。これは、タスクインスタンス変数 "myVar" で getActorId メソッドを呼び出します。 |
| pooled-actors | 属性 | 任意 | actorId のコンマ区切りリスト。actor-id と組み合わせて使用できます。プールされたアクターの固定セットは、pooled-actors="chicagobulls, pointersisters" のように指定できます。pooled-actors は式として解決されます。そのため、返すべきプロパティーまたはメソッド、String[]、コレクション、またはプールされたアクターのコンマ区切りリストを参照することもできます。 |
| class | 属性 | 任意 | org.jbpm.taskmgmt.def.AssignmentHandler の実装の完全修飾クラス名。 |
| config-type | 属性 | 任意 | {field|bean|constructor|configuration-property}。assignment-handler-object を構築する方法と、この要素の内容をその assignment-handler-object の設定情報として使用する方法を指定します。 |
| {content} | 任意 | assignment-element の内容は、AssignmentHandler 実装の設定情報として使用できます。これにより、再利用可能な委譲クラスを作成できます。 |
14.4.27. Controller
表14.27 コントローラースキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| class | 属性 | 任意 | org.jbpm.taskmgmt.def.TaskControllerHandler の実装の完全修飾クラス名。 |
| config-type | 属性 | 任意 | {field|bean|constructor|configuration-property}。これは、assignment-handler-object を構築する方法と、この要素の内容をその assignment-handler-object の設定情報として使用する方法を指定します。 |
| {content} | これは、コントローラーの内容か、指定されたタスクコントローラーハンドラーの設定です (class 属性が指定されている場合。タスクコントローラーハンドラーが指定されていない場合、内容は variable 要素のリストである必要があります)。 | ||
| variable | 要素 | [0..*] | class 属性でタスクコントローラーハンドラーが指定されていない場合、controller 要素の内容は変数のリストである必要があります。 |
14.4.28. sub-process
表14.28 サブプロセススキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| name | 属性 | required | 呼び出すサブプロセスの名前。String として評価される必要がある EL 式を指定できます。 |
| version | 属性 | 任意 | 呼び出すサブプロセスのバージョン。version が指定されていない場合、process-state は特定のプロセスの最新バージョン使用します。 |
| binding | 属性 | 任意 | サブプロセスが解決される瞬間を定義します。オプションは {early|late} です。デフォルトでは early、つまりデプロイメント時に解決されます。binding が late として定義されている場合、process-state は、実行ごとに特定のプロセスの最新バージョンを解決します。late binding は、固定バージョンと組み合わせると意味がありません。したがって、version 属性は binding="late" の場合、無視されます。 |
14.4.29. condition
表14.29 条件スキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
オプションは {content} です。後方互換性のために、expression 属性で条件を入力することもできますが、この属性はバージョン 3.2 以降非推奨となりました。 | required | condition 要素の内容は、ブール値として評価される必要がある jPDL 式です。決定は、(processdefinition.xml ファイルの順序に従って) 式が true に解決される最初の遷移を取得します。どの条件も true に解決されない場合、デフォルトの退出遷移 (最初の遷移) が使用されます。条件は、決定ノードから退出する遷移でのみ許可されます。 |
14.4.30. exception-handler
表14.30 例外ハンドラースキーマ
| 名前 | タイプ | 多重度 | 説明 |
|---|---|---|---|
| exception-class | 属性 | 任意 | これは、この例外ハンドラーと一致する Java の "スロー可能" なクラスの完全修飾名を指定します。この属性が指定されていない場合、すべての例外に一致します (java.lang.Throwable)。 |
| action | 要素 | [1..*] | これは、この例外ハンドラーによってエラーが処理されているときに実行されるアクションのリストです。 |
第15章 ワークフローのテスト駆動開発
15.1. ワークフローのテスト駆動開発の概要
図15.1 オークションのテストプロセス
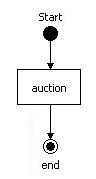
public class AuctionTest extends TestCase {
// parse the process definition
static ProcessDefinition auctionProcess =
ProcessDefinition.parseParResource("org/jbpm/tdd/auction.par");
// get the nodes for easy asserting
static StartState start = auctionProcess.getStartState();
static State auction = (State) auctionProcess.getNode("auction");
static EndState end = (EndState) auctionProcess.getNode("end");
// the process instance
ProcessInstance processInstance;
// the main path of execution
Token token;
public void setUp() {
// create a new process instance for the given process definition
processInstance = new ProcessInstance(auctionProcess);
// the main path of execution is the root token
token = processInstance.getRootToken();
}
public void testMainScenario() {
// after process instance creation, the main path of
// execution is positioned in the start state.
assertSame(start, token.getNode());
token.signal();
// after the signal, the main path of execution has
// moved to the auction state
assertSame(auction, token.getNode());
token.signal();
// after the signal, the main path of execution has
// moved to the end state and the process has ended
assertSame(end, token.getNode());
assertTrue(processInstance.hasEnded());
}
}15.2. XML ソース
ProcessDefinition を構成する必要があります。ProcessDefinition オブジェクトを取得する最も簡単な方法は、XML を解析することです。コード補完をオンにして、ProcessDefinition.parse を入力します。さまざまな解析方法が表示されます。ProcessDefinition オブジェクトに解析できる XML を記述するには、次の 3 つの方法があります。
15.2.1. プロセスアーカイブの解析
processdefinition.xml を含む ZIP ファイルです。jBPM Process Designer プラグインは、プロセスアーカイブの読み取りと書き込みを行います。
static ProcessDefinition auctionProcess =
ProcessDefinition.parseParResource("org/jbpm/tdd/auction.par");15.2.2. XML ファイルの解析
processdefinition.xml ファイルを手動で記述するには、JpdlXmlReader を使用します。ant スクリプトを使用して、結果の ZIP ファイルをパッケージ化します。
static ProcessDefinition auctionProcess =
ProcessDefinition.parseXmlResource("org/jbpm/tdd/auction.xml");15.2.3. XML 文字列の解析
static ProcessDefinition auctionProcess =
ProcessDefinition.parseXmlString(
"<process-definition>" +
" <start-state name='start'>" +
" <transition to='auction'/>" +
" </start-state>" +
" <state name='auction'>" +
" <transition to='end'/>" +
" </state>" +
" <end-state name='end'/>" +
"</process-definition>");
付録A GNU Lesser General Public License 2.1
GNU LESSER GENERAL PUBLIC LICENSE
Version 2.1, February 1999
Copyright (C) 1991, 1999 Free Software Foundation, Inc.
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
[This is the first released version of the Lesser GPL. It also counts
as the successor of the GNU Library Public License, version 2, hence
the version number 2.1.]
Preamble
The licenses for most software are designed to take away your
freedom to share and change it. By contrast, the GNU General Public
Licenses are intended to guarantee your freedom to share and change
free software--to make sure the software is free for all its users.
This license, the Lesser General Public License, applies to some
specially designated software packages--typically libraries--of the
Free Software Foundation and other authors who decide to use it. You
can use it too, but we suggest you first think carefully about whether
this license or the ordinary General Public License is the better
strategy to use in any particular case, based on the explanations below.
When we speak of free software, we are referring to freedom of use,
not price. Our General Public Licenses are designed to make sure that
you have the freedom to distribute copies of free software (and charge
for this service if you wish); that you receive source code or can get
it if you want it; that you can change the software and use pieces of
it in new free programs; and that you are informed that you can do
these things.
To protect your rights, we need to make restrictions that forbid
distributors to deny you these rights or to ask you to surrender these
rights. These restrictions translate to certain responsibilities for
you if you distribute copies of the library or if you modify it.
For example, if you distribute copies of the library, whether gratis
or for a fee, you must give the recipients all the rights that we gave
you. You must make sure that they, too, receive or can get the source
code. If you link other code with the library, you must provide
complete object files to the recipients, so that they can relink them
with the library after making changes to the library and recompiling
it. And you must show them these terms so they know their rights.
We protect your rights with a two-step method: (1) we copyright the
library, and (2) we offer you this license, which gives you legal
permission to copy, distribute and/or modify the library.
To protect each distributor, we want to make it very clear that
there is no warranty for the free library. Also, if the library is
modified by someone else and passed on, the recipients should know
that what they have is not the original version, so that the original
author's reputation will not be affected by problems that might be
introduced by others.
Finally, software patents pose a constant threat to the existence of
any free program. We wish to make sure that a company cannot
effectively restrict the users of a free program by obtaining a
restrictive license from a patent holder. Therefore, we insist that
any patent license obtained for a version of the library must be
consistent with the full freedom of use specified in this license.
Most GNU software, including some libraries, is covered by the
ordinary GNU General Public License. This license, the GNU Lesser
General Public License, applies to certain designated libraries, and
is quite different from the ordinary General Public License. We use
this license for certain libraries in order to permit linking those
libraries into non-free programs.
When a program is linked with a library, whether statically or using
a shared library, the combination of the two is legally speaking a
combined work, a derivative of the original library. The ordinary
General Public License therefore permits such linking only if the
entire combination fits its criteria of freedom. The Lesser General
Public License permits more lax criteria for linking other code with
the library.
We call this license the "Lesser" General Public License because it
does Less to protect the user's freedom than the ordinary General
Public License. It also provides other free software developers Less
of an advantage over competing non-free programs. These disadvantages
are the reason we use the ordinary General Public License for many
libraries. However, the Lesser license provides advantages in certain
special circumstances.
For example, on rare occasions, there may be a special need to
encourage the widest possible use of a certain library, so that it becomes
a de-facto standard. To achieve this, non-free programs must be
allowed to use the library. A more frequent case is that a free
library does the same job as widely used non-free libraries. In this
case, there is little to gain by limiting the free library to free
software only, so we use the Lesser General Public License.
In other cases, permission to use a particular library in non-free
programs enables a greater number of people to use a large body of
free software. For example, permission to use the GNU C Library in
non-free programs enables many more people to use the whole GNU
operating system, as well as its variant, the GNU/Linux operating
system.
Although the Lesser General Public License is Less protective of the
users' freedom, it does ensure that the user of a program that is
linked with the Library has the freedom and the wherewithal to run
that program using a modified version of the Library.
The precise terms and conditions for copying, distribution and
modification follow. Pay close attention to the difference between a
"work based on the library" and a "work that uses the library". The
former contains code derived from the library, whereas the latter must
be combined with the library in order to run.
GNU LESSER GENERAL PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. This License Agreement applies to any software library or other
program which contains a notice placed by the copyright holder or
other authorized party saying it may be distributed under the terms of
this Lesser General Public License (also called "this License").
Each licensee is addressed as "you".
A "library" means a collection of software functions and/or data
prepared so as to be conveniently linked with application programs
(which use some of those functions and data) to form executables.
The "Library", below, refers to any such software library or work
which has been distributed under these terms. A "work based on the
Library" means either the Library or any derivative work under
copyright law: that is to say, a work containing the Library or a
portion of it, either verbatim or with modifications and/or translated
straightforwardly into another language. (Hereinafter, translation is
included without limitation in the term "modification".)
"Source code" for a work means the preferred form of the work for
making modifications to it. For a library, complete source code means
all the source code for all modules it contains, plus any associated
interface definition files, plus the scripts used to control compilation
and installation of the library.
Activities other than copying, distribution and modification are not
covered by this License; they are outside its scope. The act of
running a program using the Library is not restricted, and output from
such a program is covered only if its contents constitute a work based
on the Library (independent of the use of the Library in a tool for
writing it). Whether that is true depends on what the Library does
and what the program that uses the Library does.
1. You may copy and distribute verbatim copies of the Library's
complete source code as you receive it, in any medium, provided that
you conspicuously and appropriately publish on each copy an
appropriate copyright notice and disclaimer of warranty; keep intact
all the notices that refer to this License and to the absence of any
warranty; and distribute a copy of this License along with the
Library.
You may charge a fee for the physical act of transferring a copy,
and you may at your option offer warranty protection in exchange for a
fee.
2. You may modify your copy or copies of the Library or any portion
of it, thus forming a work based on the Library, and copy and
distribute such modifications or work under the terms of Section 1
above, provided that you also meet all of these conditions:
a) The modified work must itself be a software library.
b) You must cause the files modified to carry prominent notices
stating that you changed the files and the date of any change.
c) You must cause the whole of the work to be licensed at no
charge to all third parties under the terms of this License.
d) If a facility in the modified Library refers to a function or a
table of data to be supplied by an application program that uses
the facility, other than as an argument passed when the facility
is invoked, then you must make a good faith effort to ensure that,
in the event an application does not supply such function or
table, the facility still operates, and performs whatever part of
its purpose remains meaningful.
(For example, a function in a library to compute square roots has
a purpose that is entirely well-defined independent of the
application. Therefore, Subsection 2d requires that any
application-supplied function or table used by this function must
be optional: if the application does not supply it, the square
root function must still compute square roots.)
These requirements apply to the modified work as a whole. If
identifiable sections of that work are not derived from the Library,
and can be reasonably considered independent and separate works in
themselves, then this License, and its terms, do not apply to those
sections when you distribute them as separate works. But when you
distribute the same sections as part of a whole which is a work based
on the Library, the distribution of the whole must be on the terms of
this License, whose permissions for other licensees extend to the
entire whole, and thus to each and every part regardless of who wrote
it.
Thus, it is not the intent of this section to claim rights or contest
your rights to work written entirely by you; rather, the intent is to
exercise the right to control the distribution of derivative or
collective works based on the Library.
In addition, mere aggregation of another work not based on the Library
with the Library (or with a work based on the Library) on a volume of
a storage or distribution medium does not bring the other work under
the scope of this License.
3. You may opt to apply the terms of the ordinary GNU General Public
License instead of this License to a given copy of the Library. To do
this, you must alter all the notices that refer to this License, so
that they refer to the ordinary GNU General Public License, version 2,
instead of to this License. (If a newer version than version 2 of the
ordinary GNU General Public License has appeared, then you can specify
that version instead if you wish.) Do not make any other change in
these notices.
Once this change is made in a given copy, it is irreversible for
that copy, so the ordinary GNU General Public License applies to all
subsequent copies and derivative works made from that copy.
This option is useful when you wish to copy part of the code of
the Library into a program that is not a library.
4. You may copy and distribute the Library (or a portion or
derivative of it, under Section 2) in object code or executable form
under the terms of Sections 1 and 2 above provided that you accompany
it with the complete corresponding machine-readable source code, which
must be distributed under the terms of Sections 1 and 2 above on a
medium customarily used for software interchange.
If distribution of object code is made by offering access to copy
from a designated place, then offering equivalent access to copy the
source code from the same place satisfies the requirement to
distribute the source code, even though third parties are not
compelled to copy the source along with the object code.
5. A program that contains no derivative of any portion of the
Library, but is designed to work with the Library by being compiled or
linked with it, is called a "work that uses the Library". Such a
work, in isolation, is not a derivative work of the Library, and
therefore falls outside the scope of this License.
However, linking a "work that uses the Library" with the Library
creates an executable that is a derivative of the Library (because it
contains portions of the Library), rather than a "work that uses the
library". The executable is therefore covered by this License.
Section 6 states terms for distribution of such executables.
When a "work that uses the Library" uses material from a header file
that is part of the Library, the object code for the work may be a
derivative work of the Library even though the source code is not.
Whether this is true is especially significant if the work can be
linked without the Library, or if the work is itself a library. The
threshold for this to be true is not precisely defined by law.
If such an object file uses only numerical parameters, data
structure layouts and accessors, and small macros and small inline
functions (ten lines or less in length), then the use of the object
file is unrestricted, regardless of whether it is legally a derivative
work. (Executables containing this object code plus portions of the
Library will still fall under Section 6.)
Otherwise, if the work is a derivative of the Library, you may
distribute the object code for the work under the terms of Section 6.
Any executables containing that work also fall under Section 6,
whether or not they are linked directly with the Library itself.
6. As an exception to the Sections above, you may also combine or
link a "work that uses the Library" with the Library to produce a
work containing portions of the Library, and distribute that work
under terms of your choice, provided that the terms permit
modification of the work for the customer's own use and reverse
engineering for debugging such modifications.
You must give prominent notice with each copy of the work that the
Library is used in it and that the Library and its use are covered by
this License. You must supply a copy of this License. If the work
during execution displays copyright notices, you must include the
copyright notice for the Library among them, as well as a reference
directing the user to the copy of this License. Also, you must do one
of these things:
a) Accompany the work with the complete corresponding
machine-readable source code for the Library including whatever
changes were used in the work (which must be distributed under
Sections 1 and 2 above); and, if the work is an executable linked
with the Library, with the complete machine-readable "work that
uses the Library", as object code and/or source code, so that the
user can modify the Library and then relink to produce a modified
executable containing the modified Library. (It is understood
that the user who changes the contents of definitions files in the
Library will not necessarily be able to recompile the application
to use the modified definitions.)
b) Use a suitable shared library mechanism for linking with the
Library. A suitable mechanism is one that (1) uses at run time a
copy of the library already present on the user's computer system,
rather than copying library functions into the executable, and (2)
will operate properly with a modified version of the library, if
the user installs one, as long as the modified version is
interface-compatible with the version that the work was made with.
c) Accompany the work with a written offer, valid for at
least three years, to give the same user the materials
specified in Subsection 6a, above, for a charge no more
than the cost of performing this distribution.
d) If distribution of the work is made by offering access to copy
from a designated place, offer equivalent access to copy the above
specified materials from the same place.
e) Verify that the user has already received a copy of these
materials or that you have already sent this user a copy.
For an executable, the required form of the "work that uses the
Library" must include any data and utility programs needed for
reproducing the executable from it. However, as a special exception,
the materials to be distributed need not include anything that is
normally distributed (in either source or binary form) with the major
components (compiler, kernel, and so on) of the operating system on
which the executable runs, unless that component itself accompanies
the executable.
It may happen that this requirement contradicts the license
restrictions of other proprietary libraries that do not normally
accompany the operating system. Such a contradiction means you cannot
use both them and the Library together in an executable that you
distribute.
7. You may place library facilities that are a work based on the
Library side-by-side in a single library together with other library
facilities not covered by this License, and distribute such a combined
library, provided that the separate distribution of the work based on
the Library and of the other library facilities is otherwise
permitted, and provided that you do these two things:
a) Accompany the combined library with a copy of the same work
based on the Library, uncombined with any other library
facilities. This must be distributed under the terms of the
Sections above.
b) Give prominent notice with the combined library of the fact
that part of it is a work based on the Library, and explaining
where to find the accompanying uncombined form of the same work.
8. You may not copy, modify, sublicense, link with, or distribute
the Library except as expressly provided under this License. Any
attempt otherwise to copy, modify, sublicense, link with, or
distribute the Library is void, and will automatically terminate your
rights under this License. However, parties who have received copies,
or rights, from you under this License will not have their licenses
terminated so long as such parties remain in full compliance.
9. You are not required to accept this License, since you have not
signed it. However, nothing else grants you permission to modify or
distribute the Library or its derivative works. These actions are
prohibited by law if you do not accept this License. Therefore, by
modifying or distributing the Library (or any work based on the
Library), you indicate your acceptance of this License to do so, and
all its terms and conditions for copying, distributing or modifying
the Library or works based on it.
10. Each time you redistribute the Library (or any work based on the
Library), the recipient automatically receives a license from the
original licensor to copy, distribute, link with or modify the Library
subject to these terms and conditions. You may not impose any further
restrictions on the recipients' exercise of the rights granted herein.
You are not responsible for enforcing compliance by third parties with
this License.
11. If, as a consequence of a court judgment or allegation of patent
infringement or for any other reason (not limited to patent issues),
conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot
distribute so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you
may not distribute the Library at all. For example, if a patent
license would not permit royalty-free redistribution of the Library by
all those who receive copies directly or indirectly through you, then
the only way you could satisfy both it and this License would be to
refrain entirely from distribution of the Library.
If any portion of this section is held invalid or unenforceable under any
particular circumstance, the balance of the section is intended to apply,
and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any
patents or other property right claims or to contest validity of any
such claims; this section has the sole purpose of protecting the
integrity of the free software distribution system which is
implemented by public license practices. Many people have made
generous contributions to the wide range of software distributed
through that system in reliance on consistent application of that
system; it is up to the author/donor to decide if he or she is willing
to distribute software through any other system and a licensee cannot
impose that choice.
This section is intended to make thoroughly clear what is believed to
be a consequence of the rest of this License.
12. If the distribution and/or use of the Library is restricted in
certain countries either by patents or by copyrighted interfaces, the
original copyright holder who places the Library under this License may add
an explicit geographical distribution limitation excluding those countries,
so that distribution is permitted only in or among countries not thus
excluded. In such case, this License incorporates the limitation as if
written in the body of this License.
13. The Free Software Foundation may publish revised and/or new
versions of the Lesser General Public License from time to time.
Such new versions will be similar in spirit to the present version,
but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Library
specifies a version number of this License which applies to it and
"any later version", you have the option of following the terms and
conditions either of that version or of any later version published by
the Free Software Foundation. If the Library does not specify a
license version number, you may choose any version ever published by
the Free Software Foundation.
14. If you wish to incorporate parts of the Library into other free
programs whose distribution conditions are incompatible with these,
write to the author to ask for permission. For software which is
copyrighted by the Free Software Foundation, write to the Free
Software Foundation; we sometimes make exceptions for this. Our
decision will be guided by the two goals of preserving the free status
of all derivatives of our free software and of promoting the sharing
and reuse of software generally.
NO WARRANTY
15. BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO
WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW.
EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR
OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY
KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE
LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME
THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN
WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY
AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU
FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR
CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE
LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING
RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A
FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF
SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH
DAMAGES.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Libraries
If you develop a new library, and you want it to be of the greatest
possible use to the public, we recommend making it free software that
everyone can redistribute and change. You can do so by permitting
redistribution under these terms (or, alternatively, under the terms of the
ordinary General Public License).
To apply these terms, attach the following notices to the library. It is
safest to attach them to the start of each source file to most effectively
convey the exclusion of warranty; and each file should have at least the
"copyright" line and a pointer to where the full notice is found.
<one line to give the library's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with this library; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Also add information on how to contact you by electronic and paper mail.
You should also get your employer (if you work as a programmer) or your
school, if any, to sign a "copyright disclaimer" for the library, if
necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the
library `Frob' (a library for tweaking knobs) written by James Random Hacker.
<signature of Ty Coon>, 1 April 1990
Ty Coon, President of Vice
That's all there is to it!
付録B 更新履歴
| 改訂履歴 | |||
|---|---|---|---|
| 改訂 5.3.1-0.402 | Fri Oct 25 2013 | ||
| |||
| 改訂 5.3.1-0 | Thu Jan 10 2013 | ||
| |||
| 改訂 5.3.0-0 | Thu Mar 29 2012 | ||
| |||
| 改訂 5.2.0-0 | Wed Jun 29 2011 | ||
| |||
| 改訂 5.1.0-0 | Fri Feb 18 2011 | ||
| |||
| 改訂 5.0.2-0 | Wed May 26 2010 | ||
| |||
| 改訂 5.0.1-0 | Tue Apr 20 2010 | ||
| |||
| 改訂 5.0.0-0 | Sat Jan 30 2010 | ||
| |||