
Fault Tolerant Messaging
Hardening your Red Hat JBoss A-MQ environment against downtime
Copyright © 2011-2014 Red Hat, Inc. and/or its affiliates.
Abstract
Chapter 1. Introduction
Abstract
Overview
- deploying multiple brokers into a topology that allows one broker to pick up the duties of a failed broker
- configuring clients to fail over to a new broker in the event that its current broker fails
Client fail over
- the failover protocol—allows you to provide a list of brokers that a client can use
- the discovery protocol—allows clients to automatically discover the brokers available for fail over
Master/Slave topologies
Chapter 2. Client Failover
Abstract
2.1. Failover Protocol
Abstract
2.1.1. Static Failover
Overview
Failover URI
failover:uri1,...,uriN
failover:(uri1,...,uriN)?TransportOptions
uri1,...,uriN) is a comma-separated list containing the list of broker endpoint URIs to which the client can connect. The transport options(?TransportOptions) specified in the form of a query list, allow you to configure some of the failoiver behaviors.
Transport options
Table 2.1. Failover Transport Options
| Option | Default | Description |
|---|---|---|
initialReconnectDelay | 10 | Specifies the number of milliseconds to wait before the first reconnect attempt. |
maxReconnectDelay | 30000 | Specifies the maximum amount of time, in milliseconds, to wait between reconnect attempts. |
useExponentialBackOff | true | Specifies whether to use an exponential back-off between reconnect attempts. |
backOffMultiplier | 2 | Specifies the exponent used in the exponential back-off algorithm. |
maxReconnectAttempts | -1 | Specifies the maximum number of reconnect attempts before an error is returned to the client. -1 specifies unlimited attempts. 0 specifies that an initial connection attempt is made at start-up, but no attempts to fail over to a secondary broker will be made. |
startupMaxReconnectAttempts | -1 | Specifies the maximum number of reconnect attempts before an error is returned to the client on the first attempt by the client to start a connection. -1 specifies unlimited attempts and 0 specifies no retry attempts. |
randomize | true | Specifies if a URI is chosen at random from the list. Otherwise, the list is traversed from left to right. |
backup | false | Specifies if the protocol initializes and holds a second transport connection to enable fast failover. |
timeout | -1 | Specifies the amount of time, in milliseconds, to wait before sending an error if a new connection is not established. -1 specifies an infinite timeout value. |
trackMessages | false | Specifies if the protocol keeps a cache of in-flight messages that are flushed to a broker on reconnect. |
maxCacheSize | 131072 | Specifies the size, in bytes, used for the cache used to track messages. |
updateURIsSupported | true | Specifies whether the client accepts updates to its list of known URIs from the connected broker. Setting this to false inhibits the client's ability to use dynamic failover. See Section 2.1.2, “Dynamic Failover”. |
updateURIsURL | Specifies a URL locating a text file that contains a comma-separated list of URIs to use for reconnect in the case of failure. See Section 2.1.2, “Dynamic Failover”. |
Example
Example 2.1. Simple Failover URI
failover:(tcp://localhost:61616,tcp://remotehost:61616)?initialReconnectDelay=100
2.1.2. Dynamic Failover
Abstract
Overview
Set-up
- The client's must be configured to use the failover protocol when connecting with its broker.
- The client must be configured to accept URI lists from a broker.
- The brokers must be configured to form a network of brokers.
- The broker's transport connector must set the failover properties needed to update its consumers.
Client-side configuration
- The failover URI can consist of a single broker URI.
- The
updateURIsSupportedoption must be set totrue. - The
updateURIsURLoption should be set so that the transport can failover to a new broker when none of the broker's in the dynamically supplied list are available.
Broker-side configuration
- The broker must be configured to participate in a network of brokers that can be available for failovers.See "Using Networks of Brokers" for information about setting up a network of brokers.
- The broker's transport connector must set the failover properties needed to update its consumers.
transportConnector element.
Table 2.2. Broker-side Failover Properties
Example
Example 2.2. Broker for Dynamic Failover
<beans ... >
<broker>
...
<networkConnectors>
1 <networkConnector uri="multicast://default" />
</networkConnectors>
...
<transportConnectors>
<transportConnector name="openwire"
uri="tcp://0.0.0.0:61616"
2 discoveryUri="multicast://default"
3 updateClusterClients="true"
4 updateClusterFilter="A.*,B.*" />
</transportConnectors>
...
</broker>
</beans>- 1
- Creates a network connector that connects to any discoverable broker that uses the multicast transport.
- 2
- Makes the broker discoverable by other brokers over the multicast protocol.
- 3
- Makes the broker update the list of available brokers for clients that connect using the failover protocol.NoteClients will only be updated when new brokers join the cluster, not when a broker leaves the cluster.
- 4
- Creates a filter so that only those brokers whose names start with the letter
Aor the letterBare considered to belong to the failover cluster.
Example 2.3. Failover URI for Connecting to a Failover Cluster
failover:(tcp://0.0.0.0:61616)?initialReconnectDelay=100
2.2. Discovery Protocol
Abstract
- discovery URI—looks up all of the discoverable brokers and presents them as a list of actual URIs for use by the client or network connector
- discovery agents—components that advertise the list of available brokers
2.2.1. Discovery URI
Abstract
Overview
URI syntax
Example 2.4. Discovery URI
discovery:(DiscoveryAgentUri)?Options
?Options, are specified in the form of a query list. The discovery options are described in Table 2.3, “Dynamic Discovery Protocol Options”. You can also inject transport options as described in the section called “Setting options on the discovered transports”.
Transport options
Table 2.3. Dynamic Discovery Protocol Options
Sample URI
Example 2.5. Discovery Protocol URI
discovery:(multicast://default)?initialReconnectDelay=100
Setting options on the discovered transports
connectionTimeout option to 10 seconds.
Example 2.6. Injecting Transport Options into a Discovered Transport
discovery:(multicast://default)?connectionTimeout=10000
2.2.2. Discovery Agents
Abstract
transportConnector element as shown in Example 2.7, “Enabling a Discovery Agent on a Broker”.
Example 2.7. Enabling a Discovery Agent on a Broker
<transportConnectors>
<transportConnector name="openwire"
uri="tcp://localhost:61716"
discoveryUri="multicast://default" />
</transportConnectors>discoveryUri attribute on the transportConnector element is initialized to multicast://default.
2.2.2.1. Fuse Fabric Discovery Agent
Abstract
Overview
URI
Example 2.8. Fuse Fabric Discovery Agent URI Format
fabric://GID
Configuring a broker
Configuring a client
Example 2.9. Client Connection URL using Fuse Fabric Discovery
discovery:(fabric://nwBrokers)
nwBrokers broker group and generate a list of brokers to which it can connect.
2.2.2.2. Static Discovery Agent
Abstract
Overview
Using the agent
Example 2.10. Static Discovery Agent URI Format
static://(URI1,URI2,URI3,...)
Example
Example 2.11. Discovery URI using the Static Discovery Agent
discovery:(static://(tcp://localhost:61716,tcp://localhost:61816))
2.2.2.3. Multicast Discovery Agent
Abstract
Overview
URI
Example 2.12. Multicast Discovery Agent URI Format
multicast://GroupID
Configuring a broker
transportConnector element's discoveryUri attribute to a mulitcast discovery agent URI as shown in Example 2.13, “Enabling a Multicast Discovery Agent on a Broker”.
Example 2.13. Enabling a Multicast Discovery Agent on a Broker
<transportConnectors>
<transportConnector name="openwire"
uri="tcp://localhost:61716"
discoveryUri="multicast://default" />
</transportConnectors>default.
Configuring a client
Example 2.14. Client Connection URL using Multicast Discovery
discovery:(multicast://default)
default multicast group and generate a list of brokers to which it can connect.
2.2.2.4. Zeroconf Discovery Agent
Abstract
Overview
URI
Example 2.15. Zeroconf Discovery Agent URI Format
zeroconf://GroupID
Configuring a broker
transportConnector element's discoveryUri attribute to a mulitcast discovery agent URI as shown in Example 2.16, “Enabling a Multicast Discovery Agent on a Broker”.
Example 2.16. Enabling a Multicast Discovery Agent on a Broker
<transportConnectors>
<transportConnector name="openwire"
uri="tcp://localhost:61716"
discoveryUri="multicast://NEGroup" />
</transportConnectors>NEGroup.
Configuring a client
Example 2.17. Client Connection URL using Zeroconf Discovery
discovery:(zeroconf://NEGroup)
NEGroup multicast group and generate a list of brokers to which it can connect.
Chapter 3. Master/Slave
Abstract
- Shared file system—the master and the slaves use a common persistence store that is located on a shared file system
- Shared JDBC database—the masters and the slaves use a common JDBC persistence store
3.1. Shared File System Master/Slave
Overview
Supported network file systems
- NFSv4
- GFS2
File locking requirements
persistenceAdaptor element in the broker configuration. For example, like this: <kahaDB directory="/sharedFileSystem/sharedBrokerData" lockKeepAlivePeriod="5000" />
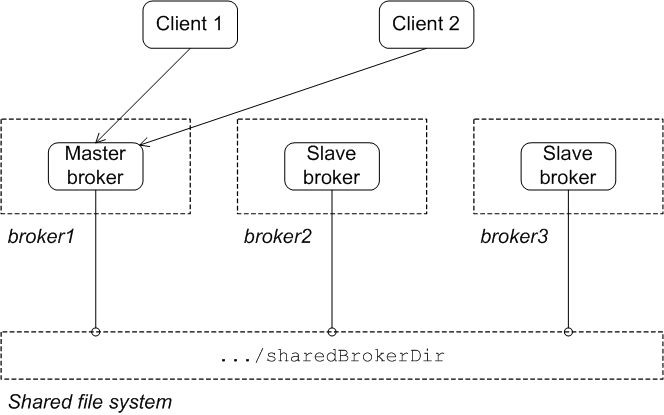
Initial state
Figure 3.1. Shared File System Initial State
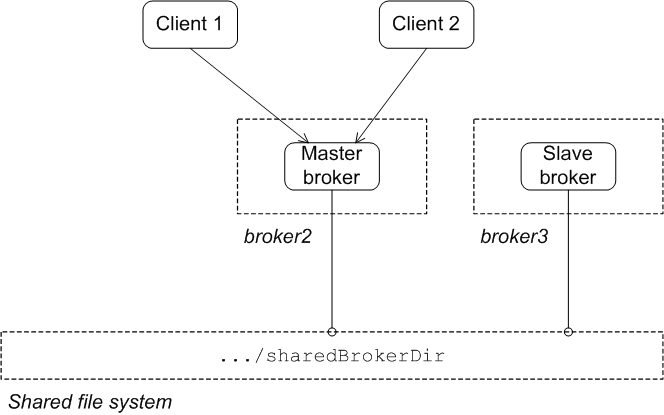
State after failure of the master
Figure 3.2. Shared File System after Master Failure
Configuring the brokers
/sharedFileSystem/sharedBrokerData and uses the KahaDB persistence store.
persistenceAdapter element.
Configuring the clients
broker1, broker2, and broker3.
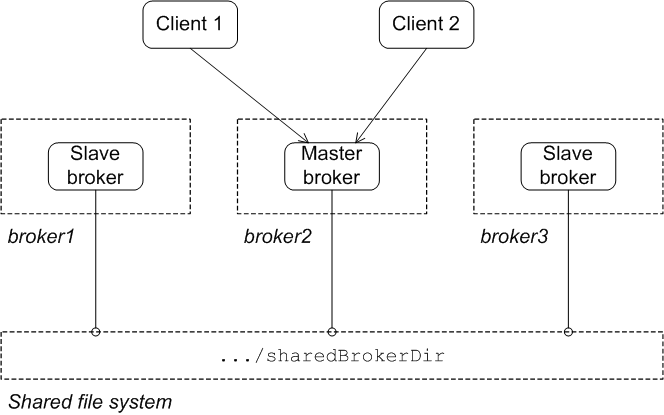
Reintroducing a failed node
Figure 3.3. Shared File System after Master Restart
3.2. Shared JDBC Master/Slave
Overview
- The shared database is a single point of failure. This disadvantage can be mitigated by using a database with built in high availability(HA) functionality. The database will handle replication and fail over of the data store.
- You cannot enable high speed journaling. This has a significant impact on performance.
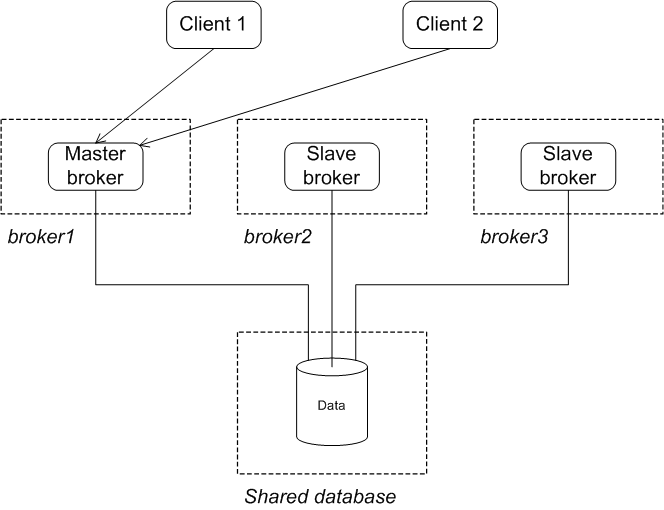
Initial state
Figure 3.4. JDBC Master/Slave Initial State
After failure of the master
Figure 3.5. JDBC Master/Slave after Master Failure
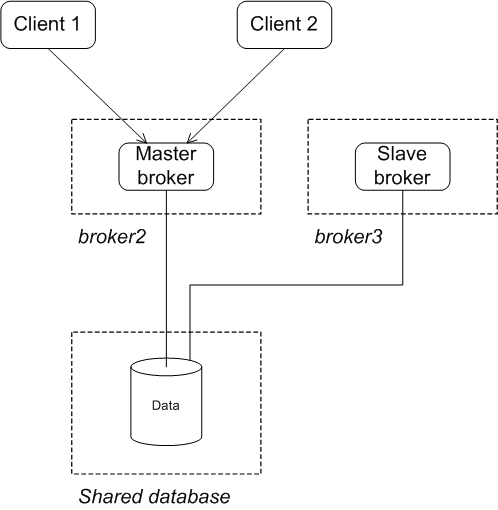
Configuring the brokers
Example 3.3. JDBC Master/Slave Broker Configuration
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:amq="http://activemq.apache.org/schema/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://activemq.apache.org/schema/core
http://activemq.apache.org/schema/core/activemq-core.xsd">
<broker xmlns="http://activemq.apache.org/schema/core"
brokerName="brokerA">
...
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#oracle-ds"/>
</persistenceAdapter>
...
</broker>
<bean id="oracle-ds"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@localhost:1521:AMQDB"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>Configuring the clients
broker1, broker2, and broker3.
Example 3.4. Client URL for a Shared JDBC Master/Slave Group
failover:(tcp://broker1:61616,tcp://broker2:61616,tcp://broker3:61616)
Reintroducing a failed node
Figure 3.6. JDBC Master/Slave after Master Restart
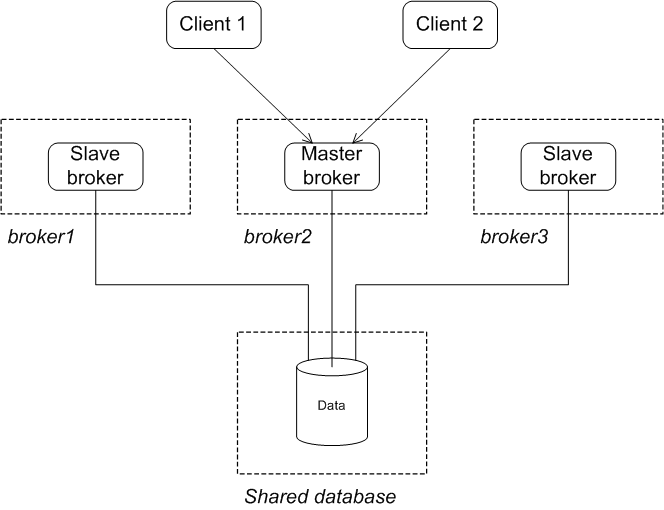
Chapter 4. Master/Slave and Broker Networks
Abstract
Overview
- Network connectors to a master/slave group use a special protocol.
- A broker cannot open a network connection to another member of its master/slave group.
Configuring the connection to a master/slave group
- Open a connection to the master broker without connecting to the slave brokers.
- Connect to the new master in the case of a failure.
Example 4.1. Network Connector to a Master/Slave Group
<networkConnectors>
<networkConnector name="linkToCluster"
uri="masterslave:(tcp://masterHost:61002,tcp://slaveHost:61002)"
... />
</networkConnectors>Host pair with master/slave groups
Figure 4.1. Master/Slave Groups on Two Host Machines
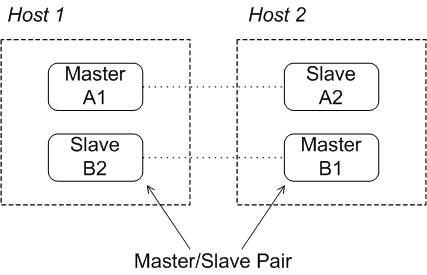
brokerB1 should be configured to connect to at most brokerA1 and brokerA2.
Network of multiple host pairs
Figure 4.2. Broker Network Consisting of Host Pairs
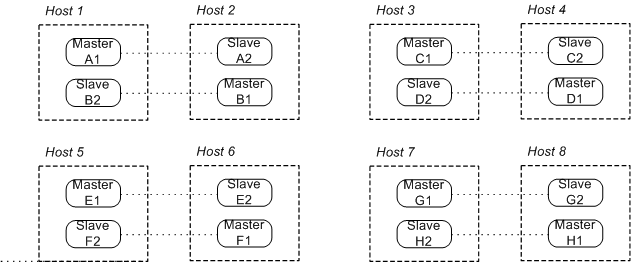
brokerA1 can connect to at most the following brokers: brokerB*, brokerC*, brokerD*, brokerE*, brokerF*, brokerG*, and brokerH*.
More information
Index
B
- broker networks
- master/slave, Configuring the connection to a master/slave group
- broker properties
- rebalanceClusterClients, Broker-side configuration
- updateClusterClients, Broker-side configuration
- updateClusterClientsOnRemove, Broker-side configuration
- updateClusterFilter, Broker-side configuration
D
- discovery agent
- Fuse Fabric, Fuse Fabric Discovery Agent
- multicast, Multicast Discovery Agent
- static, Static Discovery Agent
- zeroconf, Zeroconf Discovery Agent
- discovery protocol
- backOffMultiplier, Transport options
- initialReconnectDelay, Transport options
- maxReconnectAttempts, Transport options
- maxReconnectDelay, Transport options
- URI, URI syntax
- useExponentialBackOff, Transport options
- discovery URI, URI syntax
- discovery:, URI syntax
- discoveryUri, Configuring a broker, Configuring a broker
- dynamic failover, Dynamic Failover
- broker configuration, Broker-side configuration
- client configuration, Client-side configuration
F
- fabric://, URI
- failover, Failover Protocol
- backOffMultiplier, Transport options
- backup, Transport options
- broker properties, Broker-side configuration
- dynamic, Dynamic Failover
- initialReconnectDelay, Transport options
- maxCacheSize, Transport options
- maxReconnectAttempts, Transport options
- maxReconnectDelay, Transport options
- randomize, Transport options
- startupMaxReconnectAttempts, Transport options
- static, Static Failover
- timeout, Transport options
- trackMessages, Transport options
- updateURIsSupported, Transport options
- updateURIsURL, Transport options
- useExponentialBackOff, Transport options
- failover URI, Failover URI
- transport options, Transport options
- failover://, Failover URI
- Fuse Fabric discovery agent
- URI, URI
J
- jdbcPersistenceAdapter, Configuring the brokers
M
- master broker
- reintroduction
- shared file system, Reintroducing a failed node
- shared JDBC, Reintroducing a failed node
- master/slave
- broker networks, Configuring the connection to a master/slave group
- network of brokers, Configuring the connection to a master/slave group
- masterslave, Configuring the connection to a master/slave group
- multicast discovery agent
- broker configuration, Configuring a broker
- URI, URI
- multicast://, URI
N
- network of brokers
- master/slave, Configuring the connection to a master/slave group
- NFSv3, File locking requirements
- NFSv4, File locking requirements
O
- OCFS2, File locking requirements
P
- persistenceAdapter, Configuring the brokers, Configuring the brokers
S
- shared file system master/slave
- advantages, Overview
- broker configuration, Configuring the brokers, Configuring the brokers
- client configuration, Configuring the clients
- disadvantages, Overview
- incompatible SANs, File locking requirements
- initial state, Initial state
- master failure, State after failure of the master
- NFSv3, File locking requirements
- NFSv4, File locking requirements
- OCFS2, File locking requirements
- recovery strategies, State after failure of the master
- reintroducing a node, Reintroducing a failed node
- shared JDBC master/slave
- advantages, Overview
- client configuration, Configuring the clients
- disadvantages, Overview
- initial state, Initial state
- master failure, After failure of the master
- recovery strategies, After failure of the master
- reintroducing a node, Reintroducing a failed node
- static discovery agent
- URI, Using the agent
- static failover, Static Failover
- static://, Using the agent
T
- transportConnector
- discoveryUri, Configuring a broker, Configuring a broker
Z
- zeroconf discovery agent
- broker configuration, Configuring a broker
- URI, URI
- zeroconf://, URI
Legal Notice
Trademark Disclaimer
Legal Notice
Third Party Acknowledgements
- JLine (http://jline.sourceforge.net) jline:jline:jar:1.0License: BSD (LICENSE.txt) - Copyright (c) 2002-2006, Marc Prud'hommeaux
mwp1@cornell.eduAll rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of JLine nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - Stax2 API (http://woodstox.codehaus.org/StAX2) org.codehaus.woodstox:stax2-api:jar:3.1.1License: The BSD License (http://www.opensource.org/licenses/bsd-license.php)Copyright (c) <YEAR>, <OWNER> All rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - jibx-run - JiBX runtime (http://www.jibx.org/main-reactor/jibx-run) org.jibx:jibx-run:bundle:1.2.3License: BSD (http://jibx.sourceforge.net/jibx-license.html) Copyright (c) 2003-2010, Dennis M. Sosnoski.All rights reserved.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of JiBX nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - JavaAssist (http://www.jboss.org/javassist) org.jboss.javassist:com.springsource.javassist:jar:3.9.0.GA:compileLicense: MPL (http://www.mozilla.org/MPL/MPL-1.1.html)
- HAPI-OSGI-Base Module (http://hl7api.sourceforge.net/hapi-osgi-base/) ca.uhn.hapi:hapi-osgi-base:bundle:1.2License: Mozilla Public License 1.1 (http://www.mozilla.org/MPL/MPL-1.1.txt)