
Cache User Guide
for Use with JBoss Enterprise Application Platform 5
Edition 5.2.0
Abstract
JBoss Cache is deprecated and will be removed in a future major release of JBoss Enterprise Application Platform. Customers are advised to migrate away from this feature in existing implementations, and not use it in new implementations.
Part I. Introduction to JBoss Cache
Chapter 1. Overview
1.1. What is JBoss Cache?
1.1.1. And what is POJO Cache?
- maintaining object references even after replication or persistence
- fine grained replication, where only modified object fields are replicated
- "API-less" clustering model where POJOs are simply annotated as being clustered
1.2. Summary of Features
1.2.1. Caching objects
- cached in-memory for efficient, thread-safe retrieval
- replicated to some or all cache instances in a cluster
- persisted to disk and/or a remote, in-memory cache cluster ("far-cache")
- garbage collected from memory when memory runs low, and passivated to disk so state is not lost
- being able to participate in JTA transactions (works with most Java EE compliant transaction managers);
- attach to JMX consoles and provide runtime statistics on the state of the cache;
- allow client code to attach listeners and receive notifications on cache events;
- allow grouping of cache operations into batches, for efficient replication.
1.2.2. Local and clustered modes
java.io.Serializable.
1.2.3. Clustered caches and transactions
1.2.4. Thread safety
1.3. Requirements
1.4. License
Chapter 2. User API
2.1. API Classes
Cache interface is the primary mechanism for interacting with JBoss Cache. It is constructed and optionally started using the CacheFactory. The CacheFactory allows you to create a Cache either from a Configuration object or an XML file. The cache organizes data into a tree structure, made up of nodes. Once you have a reference to a Cache, you can use it to look up Node objects in the tree structure, and store data in the tree.

2.2. Instantiating and Starting the Cache
Cache interface can only be created via a CacheFactory. This is unlike JBoss Cache 1.x, where an instance of the old TreeCache class could be directly instantiated.
CacheFactory provides a number of overloaded methods for creating a Cache, but they all fundamentally do the same thing:
- Gain access to a
Configuration, either by having one passed in as a method parameter or by parsing XML content and constructing one. The XML content can come from a provided input stream, from a classpath or file system location. See the Chapter 3, Configuration for more on obtaining aConfiguration. - Instantiate the
Cacheand provide it with a reference to theConfiguration. - Optionally invoke the cache's
create()andstart()methods.
CacheFactory factory = new DefaultCacheFactory(); Cache cache = factory.createCache();
CacheFactory to find and parse a configuration file on the classpath:
CacheFactory factory = new DefaultCacheFactory();
Cache cache = factory.createCache("cache-configuration.xml");
CacheFactory factory = new DefaultCacheFactory();
Cache cache = factory.createCache("/opt/configurations/cache-configuration.xml", false);
Configuration config = cache.getConfiguration();
config.setClusterName(this.getClusterName());
// Have to create and start cache before using it
cache.create();
cache.start();
2.3. Caching and Retrieving Data
Cache API to access a Node in the cache and then do some simple reads and writes to that node.
// Let us get a hold of the root node.
Node rootNode = cache.getRoot();
// Remember, JBoss Cache stores data in a tree structure.
// All nodes in the tree structure are identified by Fqn objects.
Fqn peterGriffinFqn = Fqn.fromString("/griffin/peter");
// Create a new Node
Node peterGriffin = rootNode.addChild(peterGriffinFqn);
// let us store some data in the node
peterGriffin.put("isCartoonCharacter", Boolean.TRUE);
peterGriffin.put("favoriteDrink", new Beer());
// some tests (just assume this code is in a JUnit test case)
assertTrue(peterGriffin.get("isCartoonCharacter"));
assertEquals(peterGriffinFqn, peterGriffin.getFqn());
assertTrue(rootNode.hasChild(peterGriffinFqn));
Set keys = new HashSet();
keys.add("isCartoonCharacter");
keys.add("favoriteDrink");
assertEquals(keys, peterGriffin.getKeys());
// let us remove some data from the node
peterGriffin.remove("favoriteDrink");
assertNull(peterGriffin.get("favoriteDrink");
// let us remove the node altogether
rootNode.removeChild(peterGriffinFqn);
assertFalse(rootNode.hasChild(peterGriffinFqn));
Cache interface also exposes put/get/remove operations that take an Section 2.4, “ The Fqn Class ” as an argument, for convenience:
Fqn peterGriffinFqn = Fqn.fromString("/griffin/peter");
cache.put(peterGriffinFqn, "isCartoonCharacter", Boolean.TRUE);
cache.put(peterGriffinFqn, "favoriteDrink", new Beer());
assertTrue(peterGriffin.get(peterGriffinFqn, "isCartoonCharacter"));
assertTrue(cache.getRootNode().hasChild(peterGriffinFqn));
cache.remove(peterGriffinFqn, "favoriteDrink");
assertNull(cache.get(peterGriffinFqn, "favoriteDrink");
cache.removeNode(peterGriffinFqn);
assertFalse(cache.getRootNode().hasChild(peterGriffinFqn));
2.3.1. Organizing Your Data and Using the Node Structure
2.4. The Fqn Class
Fqn class in its examples; now let us learn a bit more about that class.
Strings but can be any Object or a mix of different types.
Fqn will tell you whether the API expects a relative or absolute Fqn.
Fqn class provides are variety of factory methods; see the Javadoc for all the possibilities. The following illustrates the most commonly used approaches to creating an Fqn:
// Create an Fqn pointing to node 'Joe' under parent node 'Smith'
// under the 'people' section of the tree
// Parse it from a String
Fqn abc = Fqn.fromString("/people/Smith/Joe/");
// Here we want to use types other than String
Fqn acctFqn = Fqn.fromElements("accounts", "NY", new Integer(12345));
Fqn f = Fqn.fromElements("a", "b", "c");Fqn f = Fqn.fromString("/a/b/c");2.5. Stopping and Destroying the Cache
cache.stop(); cache.destroy();
stop() invoked on it can be started again with a new call to start() . Similarly, a cache that has had destroy() invoked on it can be created again with a new call to create() (and then started again with a start() call).
2.6. Cache Modes
put or remove operation, so we will briefly mention the various modes here.
org.jboss.cache.config.Configuration.CacheMode enumeration. They consist of:
- LOCAL - local, non-clustered cache. Local caches do not join a cluster and do not communicate with other caches in a cluster.
- REPL_SYNC - synchronous replication. Replicated caches replicate all changes to the other caches in the cluster. Synchronous replication means that changes are replicated and the caller blocks until replication acknowledgements are received.
- REPL_ASYNC - asynchronous replication. Similar to REPL_SYNC above, replicated caches replicate all changes to the other caches in the cluster. Being asynchronous, the caller does not block until replication acknowledgements are received.
- INVALIDATION_SYNC - if a cache is configured for invalidation rather than replication, every time data is changed in a cache other caches in the cluster receive a message informing them that their data is now stale and should be evicted from memory. This reduces replication overhead while still being able to invalidate stale data on remote caches.
- INVALIDATION_ASYNC - as above, except this invalidation mode causes invalidation messages to be broadcast asynchronously.
2.7. Adding a Cache Listener - registering for cache events
Object myListener = new MyCacheListener(); cache.addCacheListener(myListener);
Cache interface for more details.
@CacheListener annotation. In addition, the class needs to have one or more methods annotated with one of the method-level annotations (in the org.jboss.cache.notifications.annotation package). Methods annotated as such need to be public, have a void return type, and accept a single parameter of type org.jboss.cache.notifications.event.Event or one of its subtypes.
@CacheStarted- methods annotated such receive a notification when the cache is started. Methods need to accept a parameter type which is assignable fromCacheStartedEvent.@CacheStopped- methods annotated such receive a notification when the cache is stopped. Methods need to accept a parameter type which is assignable fromCacheStoppedEvent.@NodeCreated- methods annotated such receive a notification when a node is created. Methods need to accept a parameter type which is assignable fromNodeCreatedEvent.@NodeRemoved- methods annotated such receive a notification when a node is removed. Methods need to accept a parameter type which is assignable fromNodeRemovedEvent.@NodeModified- methods annotated such receive a notification when a node is modified. Methods need to accept a parameter type which is assignable fromNodeModifiedEvent.@NodeMoved- methods annotated such receive a notification when a node is moved. Methods need to accept a parameter type which is assignable fromNodeMovedEvent.@NodeVisited- methods annotated such receive a notification when a node is started. Methods need to accept a parameter type which is assignable fromNodeVisitedEvent.@NodeLoaded- methods annotated such receive a notification when a node is loaded from aCacheLoader. Methods need to accept a parameter type which is assignable fromNodeLoadedEvent.@NodeEvicted- methods annotated such receive a notification when a node is evicted from memory. Methods need to accept a parameter type which is assignable fromNodeEvictedEvent.@NodeInvalidated- methods annotated such receive a notification when a node is evicted from memory due to a remote invalidation event. Methods need to accept a parameter type which is assignable fromNodeInvalidatedEvent.@NodeActivated- methods annotated such receive a notification when a node is activated. Methods need to accept a parameter type which is assignable fromNodeActivatedEvent.@NodePassivated- methods annotated such receive a notification when a node is passivated. Methods need to accept a parameter type which is assignable fromNodePassivatedEvent.@TransactionRegistered- methods annotated such receive a notification when the cache registers ajavax.transaction.Synchronizationwith a registered transaction manager. Methods need to accept a parameter type which is assignable fromTransactionRegisteredEvent.@TransactionCompleted- methods annotated such receive a notification when the cache receives a commit or rollback call from a registered transaction manager. Methods need to accept a parameter type which is assignable fromTransactionCompletedEvent.@ViewChanged- methods annotated such receive a notification when the group structure of the cluster changes. Methods need to accept a parameter type which is assignable fromViewChangedEvent.@CacheBlocked- methods annotated such receive a notification when the cluster requests that cache operations are blocked for a state transfer event. Methods need to accept a parameter type which is assignable fromCacheBlockedEvent.@CacheUnblocked- methods annotated such receive a notification when the cluster requests that cache operations are unblocked after a state transfer event. Methods need to accept a parameter type which is assignable fromCacheUnblockedEvent.@BuddyGroupChanged- methods annotated such receive a notification when a node changes its buddy group, perhaps due to a buddy falling out of the cluster or a newer, closer buddy joining. Methods need to accept a parameter type which is assignable fromBuddyGroupChangedEvent.
Event subtypes for details of what is passed in to your method, and when.
@CacheListener
public class MyListener
{
@CacheStarted
@CacheStopped
public void cacheStartStopEvent(Event e)
{
switch (e.getType())
{
case CACHE_STARTED:
System.out.println("Cache has started");
break;
case CACHE_STOPPED:
System.out.println("Cache has stopped");
break;
}
}
@NodeCreated
@NodeRemoved
@NodeVisited
@NodeModified
@NodeMoved
public void logNodeEvent(NodeEvent ne)
{
log("An event on node " + ne.getFqn() + " has occured");
}
}
2.7.1. Synchronous and Asynchronous Notifications
CacheListener.sync attribute to false, in which case you will not be notified in the caller's thread. See the Table 12.13, “The <listeners /> Element” on tuning this thread pool and size of blocking queue.
2.8. Using Cache Loaders
org.jboss.cache.loader.FileCacheLoader- a basic, file system based cache loader that persists data to disk. Non-transactional and not very performant, but a very simple solution. Used mainly for testing and not recommended for production use.org.jboss.cache.loader.JDBCCacheLoader- uses a JDBC connection to store data. Connections could be created and maintained in an internal pool (uses the c3p0 pooling library) or from a configured DataSource. The database this CacheLoader connects to could be local or remotely located.org.jboss.cache.loader.BdbjeCacheLoader- uses Oracle's BerkeleyDB file-based transactional database to persist data. Transactional and very performant, but potentially restrictive license.org.jboss.cache.loader.JdbmCacheLoader- an open source alternative to the BerkeleyDB.org.jboss.cache.loader.tcp.TcpCacheLoader- uses a TCP socket to "persist" data to a remote cluster, using a "far cache" pattern.org.jboss.cache.loader.ClusteredCacheLoader- used as a "read-only" cache loader, where other nodes in the cluster are queried for state. Useful when full state transfer is too expensive and it is preferred that state is lazily loaded.
2.9. Using Eviction Policies
org.jboss.cache.eviction.LRUPolicy- an eviction policy that evicts the least recently used nodes when thresholds are hit.org.jboss.cache.eviction.LFUPolicy- an eviction policy that evicts the least frequently used nodes when thresholds are hit.org.jboss.cache.eviction.MRUPolicy- an eviction policy that evicts the most recently used nodes when thresholds are hit.org.jboss.cache.eviction.FIFOPolicy- an eviction policy that creates a first-in-first-out queue and evicts the oldest nodes when thresholds are hit.org.jboss.cache.eviction.ExpirationPolicy- an eviction policy that selects nodes for eviction based on an expiry time each node is configured with.org.jboss.cache.eviction.ElementSizePolicy- an eviction policy that selects nodes for eviction based on the number of key/value pairs held in the node.
Chapter 3. Configuration
3.1. Configuration Overview
org.jboss.cache.config.Configuration class (along with its Section 3.3, “Composition of a Configuration Object ”) is a Java Bean that encapsulates the configuration of the Cache and all of its architectural elements (cache loaders, evictions policies, etc.)
Configuration exposes numerous properties which are summarized in the Section 12.2, “Configuration File Quick Reference” section of this book and many of which are discussed in later chapters. Any time you see a configuration option discussed in this book, you can assume that the Configuration class or one of its component parts exposes a simple property setter/getter for that configuration option.
3.2. Creating a Configuration
Cache can be created, the CacheFactory must be provided with a Configuration object or with a file name or input stream to use to parse a Configuration from XML. The following sections describe how to accomplish this.
3.2.1. Parsing an XML-based Configuration File
<?xml version="1.0" encoding="UTF-8"?>
<jbosscache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:jboss:jbosscache-core:config:3.2">
</jbosscache>
3.2.2. Validating Configuration Files
-Djbosscache.config.validate=false JVM parameter. Alternately, you could specify your own schema to validate against, using the -Djbosscache.config.schemaLocation=url parameter.
jbosscache-core.jar. Most XML editing tools can be used with this schema to ensure the configuration file you create is correct and valid.
3.2.3. Programmatic Configuration
Configuration can be built up programmatically, using the simple property mutators exposed by Configuration and its components. When constructed, the Configuration object is preset with JBoss Cache defaults and can even be used as-is for a quick start.
Configuration config = new Configuration(); config.setTransactionManagerLookupClass( GenericTransactionManagerLookup.class.getName() ); config.setIsolationLevel(IsolationLevel.READ_COMMITTED); config.setCacheMode(CacheMode.LOCAL); config.setLockAcquisitionTimeout(15000); CacheFactory factory = new DefaultCacheFactory(); Cache cache = factory.createCache(config);
Configuration object to programmatically change a few items from the defaults, add an eviction region, etc.
@Dynamic . Dynamic properties are also marked as such in the Section 12.2, “Configuration File Quick Reference” table. Attempting to change a non-dynamic property will result in a ConfigurationException .
3.2.4. Using an IOC Framework
Configuration class and its Section 3.3, “Composition of a Configuration Object ” are all Java Beans that expose all configuration elements via simple setters and getters. Therefore, any good IOC framework such as JBoss Microcontainer should be able to build up a Configuration from an XML file in the framework's own format. See the Section 5.2, “Via JBoss Microcontainer (EAP 5.x)” section for an example of this.
3.3. Composition of a Configuration Object
Configuration is composed of a number of subobjects:

Configuration . See the Javadoc and the linked chapters in this book for a more complete explanation of the configurations associated with each component.
Configuration: top level object in the hierarchy; exposes the configuration properties listed in the Section 12.2, “Configuration File Quick Reference” section of this book.BuddyReplicationConfig: only relevant if Section 8.1.2.2, “Buddy Replication” is used. General buddy replication configuration options. Must include a:BuddyLocatorConfig: implementation-specific configuration object for theBuddyLocatorimplementation being used. What configuration elements are exposed depends on the needs of theBuddyLocatorimplementation.EvictionConfig: only relevant if Chapter 10, Eviction is used. General eviction configuration options. Must include at least one:EvictionRegionConfig: one for each eviction region; names the region, etc. Must include a:EvictionAlgorithmConfig: implementation-specific configuration object for theEvictionAlgorithmimplementation being used. What configuration elements are exposed depends on the needs of theEvictionAlgorithmimplementation.CacheLoaderConfig: only relevant if a Chapter 9, Cache Loaders is used. General cache loader configuration options. Must include at least one:IndividualCacheLoaderConfig: implementation-specific configuration object for theCacheLoaderimplementation being used. What configuration elements are exposed depends on the needs of theCacheLoaderimplementation.RuntimeConfig: exposes to cache clients certain information about the cache's runtime environment (e.g. membership in buddy replication groups if Section 8.1.2.2, “Buddy Replication” is used.) Also allows direct injection into the cache of needed external services like a JTATransactionManageror a JGroupsChannelFactory.
3.4. Dynamic Reconfiguration
Configuration object from the running cache and changing values. E.g.,
Configuration liveConfig = cache.getConfiguration(); liveConfig.setLockAcquisitionTimeout(2000);
org.jboss.cache.config.ConfigurationException will be thrown if you attempt to change a setting that is not dynamic.
3.4.1. Overriding the Configuration via the Option API
org.jboss.cache.config.Option , setting the options you wish to override on the Option object and passing it in the InvocationContext before invoking your method on the cache.
// first start a transaction
cache.getInvocationContext().getOptionOverrides().setForceWriteLock(true);
Node n = cache.getNode(Fqn.fromString("/a/b/c"));
// make changes to the node
// commit transaction
Node node = cache.getChild(Fqn.fromString("/a/b/c"));
cache.getInvocationContext().getOptionOverrides().setLocalOnly(true);
node.put("localCounter", new Integer(2));
Option class for details on the options available.
Chapter 4. Batching API
4.1. Introduction
4.2. Configuring batching
Configuration object:
Configuration.setInvocationBatchingEnabled(true);
<invocationBatching enabled="true"/>
4.3. Batching API
startBatch() and endBatch() on Cache. E.g.,
Cache cache = getCache();
// not using a batch
cache.put("/a", "key", "value"); // will replicate immediately
// using a batch
cache.startBatch();
cache.put("/a", "key", "value");
cache.put("/b", "key", "value");
cache.put("/c", "key", "value");
cache.endBatch(true); // This will now replicate the modifications since the batch was started.
cache.startBatch();
cache.put("/a", "key", "value");
cache.put("/b", "key", "value");
cache.put("/c", "key", "value");
cache.endBatch(false); // This will "discard" changes made in the batch
Chapter 5. Deploying JBoss Cache
5.1. Standalone Use/Programatic Deployment
CacheFactory and a Configuration instance or an XML file, as discussed in the Section 2.2, “Instantiating and Starting the Cache” and Section 3.2, “Creating a Configuration ” chapters.
javax.servlet.ServletContextListener.
5.2. Via JBoss Microcontainer (EAP 5.x)
-jboss-beans.xml. A POJO service is one whose implementation is via a "Plain Old Java Object", meaning a simple java bean that is not required to implement any special interfaces or extend any particular superclass. A Cache is a POJO service, and all the components in a Configuration are also POJOs, so deploying a cache in this way is a natural step.
-jboss-beans.xml file is basically a descriptor that tells the IOC framework how to assemble the various beans that make up a POJO service.
Configuration components, a getter/setter must be defined in the configuration class. This is required so that JBoss Microcontainer can, in typical IOC way, call these methods when the corresponding properties have been configured.
jbosscache-core.jar and jgroups.jar libraries are in your server's lib directory. This is usually the case when you use EAP in its all configuration. Note that you will have to bring in any optional jars you require, such as jdbm.jar based on your cache configuration.
-beans.xml file. If you look in the server/all/deploy directory of a EAP 5 installation, you can find several more examples.
<?xml version="1.0" encoding="UTF-8"?>
<deployment xmlns="urn:jboss:bean-deployer:2.0">
<!-- First we create a Configuration object for the cache -->
<bean name="ExampleCacheConfig"
class="org.jboss.cache.config.Configuration">
<!-- Externally injected services -->
<property name="runtimeConfig">
<bean class="org.jboss.cache.config.RuntimeConfig">
<property name="transactionManager">
<inject bean="jboss:service=TransactionManager"
property="TransactionManager"/>
</property>
<property name="muxChannelFactory"><inject bean="JChannelFactory"/></property>
</bean>
</property>
<property name="multiplexerStack">udp</property>
<property name="clusterName">Example-EntityCache</property>
<property name="isolationLevel">REPEATABLE_READ</property>
<property name="cacheMode">REPL_SYNC</property>
<property name="stateRetrievalTimeout">15000</property>
<property name="syncReplTimeout">20000</property>
<property name="lockAcquisitionTimeout">15000</property>
<property name="exposeManagementStatistics">true</property>
</bean>
<!-- Factory to build the Cache. -->
<bean name="DefaultCacheFactory" class="org.jboss.cache.DefaultCacheFactory">
<constructor factoryClass="org.jboss.cache.DefaultCacheFactory"
factoryMethod="getInstance" />
</bean>
<!-- The cache itself -->
<bean name="ExampleCache" class="org.jboss.cache.Cache">
<constructor factoryMethod="createCache">
<factory bean="DefaultCacheFactory"/>
<parameter class="org.jboss.cache.config.Configuration"><inject bean="ExampleCacheConfig"/></parameter>
<parameter class="boolean">false</parameter>
</constructor>
</bean>
</deployment>
bean element represents an object and is used to create a Configuration and its Section 3.3, “Composition of a Configuration Object ” The DefaultCacheFactory bean constructs the cache, conceptually doing the same thing as is shown in the Section 2.2, “Instantiating and Starting the Cache” chapter.
RuntimeConfig object. External resources like a TransactionManager and a JGroups ChannelFactory that are visible to the microcontainer are dependency injected into the RuntimeConfig. The assumption here is that in some other deployment descriptor in the AS, the referenced beans have already been described.
5.3. Automatic binding to JNDI in EAP
5.4. Runtime Management Information
5.4.1. JBoss Cache MBeans
org.jboss.cache.jmx.CacheJmxWrapper. It is a StandardMBean, so its MBean interface is org.jboss.cache.jmx.CacheJmxWrapperMBean. This MBean can be used to:
- Get a reference to the underlying
Cache. - Invoke create/start/stop/destroy lifecycle operations on the underlying
Cache. - Inspect various details about the cache's current state (number of nodes, lock information, etc.)
- See numerous details about the cache's configuration, and change those configuration items that can be changed when the cache has already been started.
CacheJmxWrapperMBean Javadoc for more details.
CacheJmxWrapper is registered, JBoss Cache also provides MBeans for several other internal components and subsystems. These MBeans are used to capture and expose statistics related to the subsystems they represent. They are hierarchically associated with the CacheJmxWrapper MBean and have service names that reflect this relationship. For example, a replication interceptor MBean for the jboss.cache:service=TomcatClusteringCache instance will be accessible through the service named jboss.cache:service=TomcatClusteringCache,cache-interceptor=ReplicationInterceptor.
5.4.2. Registering the CacheJmxWrapper with the MBeanServer
CacheJmxWrapper is registered in JMX depends on how you are deploying your cache.
5.4.2.1. Programatic Registration with a Cache instance
Cache and pass it to the JmxRegistrationManager constructor.
CacheFactory factory = new DefaultCacheFactory();
// Build but do not start the cache
// (although it would work OK if we started it)
Cache cache = factory.createCache("cache-configuration.xml");
MBeanServer server = getMBeanServer(); // however you do it
ObjectName on = new ObjectName("jboss.cache:service=Cache");
JmxRegistrationManager jmxManager = new JmxRegistrationManager(server, cache, on);
jmxManager.registerAllMBeans();
... use the cache
... on application shutdown
jmxManager.unregisterAllMBeans();
cache.stop();
5.4.2.2. Programatic Registration with a Configuration instance
Configuration object and pass it to the CacheJmxWrapper. The wrapper will construct the Cache on your behalf.
Configuration config = buildConfiguration(); // whatever it does
CacheJmxWrapperMBean wrapper = new CacheJmxWrapper(config);
MBeanServer server = getMBeanServer(); // however you do it
ObjectName on = new ObjectName("jboss.cache:service=TreeCache");
server.registerMBean(wrapper, on);
// Call to wrapper.create() will build the Cache if one wasn't injected
wrapper.create();
wrapper.start();
// Now that it's built, created and started, get the cache from the wrapper
Cache cache = wrapper.getCache();
... use the cache
... on application shutdown
wrapper.stop();
wrapper.destroy();
5.4.2.3. JMX-Based Deployment in EAP (EAP 5.x)
CacheJmxWrapper is a POJO, so the microcontainer has no problem creating one. The trick is getting it to register your bean in JMX. This can be done by specifying the org.jboss.aop.microcontainer.aspects.jmx.JMX annotation on the CacheJmxWrapper bean:
<?xml version="1.0" encoding="UTF-8"?>
<deployment xmlns="urn:jboss:bean-deployer:2.0">
<!-- First we create a Configuration object for the cache -->
<bean name="ExampleCacheConfig"
class="org.jboss.cache.config.Configuration">
... build up the Configuration
</bean>
<!-- Factory to build the Cache. -->
<bean name="DefaultCacheFactory" class="org.jboss.cache.DefaultCacheFactory">
<constructor factoryClass="org.jboss.cache.DefaultCacheFactory"
factoryMethod="getInstance" />
</bean>
<!-- The cache itself -->
<bean name="ExampleCache" class="org.jboss.cache.CacheImpl">
<constructor factoryMethod="createnewInstance">
<factory bean="DefaultCacheFactory"/>
<parameter><inject bean="ExampleCacheConfig"/></parameter>
<parameter>false</parameter>
</constructor>
</bean>
<!-- JMX Management -->
<bean name="ExampleCacheJmxWrapper" class="org.jboss.cache.jmx.CacheJmxWrapper">
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX(name="jboss.cache:service=ExampleTreeCache",
exposedInterface=org.jboss.cache.jmx.CacheJmxWrapperMBean.class,
registerDirectly=true)</annotation>
<constructor>
<parameter><inject bean="ExampleCache"/></parameter>
</constructor>
</bean>
</deployment>
CacheJmxWrapper can do the work of building, creating and starting the Cache if it is provided with a Configuration. With the microcontainer, this is the preferred approach, as it saves the boilerplate XML needed to create the CacheFactory.
<?xml version="1.0" encoding="UTF-8"?>
<deployment xmlns="urn:jboss:bean-deployer:2.0">
<!-- First we create a Configuration object for the cache -->
<bean name="ExampleCacheConfig"
class="org.jboss.cache.config.Configuration">
... build up the Configuration
</bean>
<bean name="ExampleCache" class="org.jboss.cache.jmx.CacheJmxWrapper">
<annotation>@org.jboss.aop.microcontainer.aspects.jmx.JMX
(name="jboss.cache:service=ExampleTreeCache",
exposedInterface=org.jboss.cache.jmx.CacheJmxWrapperMBean.class,
registerDirectly=true)</annotation>
<constructor>
<parameter><inject bean="ExampleCacheConfig"/></parameter>
</constructor>
</bean>
</deployment>
5.4.3. JBoss Cache Statistics
Configuration.setExposeManagementStatistics() setter. Note that the majority of the statistics are provided by the CacheMgmtInterceptor, so this MBean is the most significant in this regard. If you want to disable all statistics for performance reasons, you set Configuration.setExposeManagementStatistics(false) and this will prevent the CacheMgmtInterceptor from being included in the cache's interceptor stack when the cache is started.
CacheJmxWrapper is registered with JMX, the wrapper also ensures that an MBean is registered in JMX for each interceptor and component that exposes statistics.
Note
CacheJmxWrapper is not registered in JMX, the interceptor MBeans will not be registered either. The JBoss Cache 1.4 releases included code that would try to "discover" an MBeanServer and automatically register the interceptor MBeans with it. For JBoss Cache 2.x we decided that this sort of "discovery" of the JMX environment was beyond the proper scope of a caching library, so we removed this functionality.
5.4.4. Receiving JMX Notifications
NotificationListener for the CacheJmxWrapper.
CacheJmxWrapper.
MyListener listener = new MyListener();
NotificationFilterSupport filter = null;
// get reference to MBean server
Context ic = new InitialContext();
MBeanServerConnection server = (MBeanServerConnection)ic.lookup("jmx/invoker/RMIAdaptor");
// get reference to CacheMgmtInterceptor MBean
String cache_service = "jboss.cache:service=TomcatClusteringCache";
ObjectName mgmt_name = new ObjectName(cache_service);
// configure a filter to only receive node created and removed events
filter = new NotificationFilterSupport();
filter.disableAllTypes();
filter.enableType(CacheNotificationBroadcaster.NOTIF_NODE_CREATED);
filter.enableType(CacheNotificationBroadcaster.NOTIF_NODE_REMOVED);
// register the listener with a filter
// leave the filter null to receive all cache events
server.addNotificationListener(mgmt_name, listener, filter, null);
// ...
// on completion of processing, unregister the listener
server.removeNotificationListener(mgmt_name, listener, filter, null);
private class MyListener implements NotificationListener, Serializable
{
public void handleNotification(Notification notification, Object handback)
{
String message = notification.getMessage();
String type = notification.getType();
Object userData = notification.getUserData();
System.out.println(type + ": " + message);
if (userData == null)
{
System.out.println("notification data is null");
}
else if (userData instanceof String)
{
System.out.println("notification data: " + (String) userData);
}
else if (userData instanceof Object[])
{
Object[] ud = (Object[]) userData;
for (Object data : ud)
{
System.out.println("notification data: " + data.toString());
}
}
else
{
System.out.println("notification data class: " + userData.getClass().getName());
}
}
}
5.4.5. Accessing Cache MBeans in a Standalone Environment using the jconsole Utility
jconsole tool. When running a standalone cache outside of an application server, you can access the cache's MBeans as follows.
- Set the system property
-Dcom.sun.management.jmxremotewhen starting the JVM where the cache will run. - Once the JVM is running, start the
jconsoleutility, located in your JDK's/bindirectory. - When the utility loads, you will be able to select your running JVM and connect to it. The JBoss Cache MBeans will be available on the MBeans panel.
jconsole utility will automatically register as a listener for cache notifications when connected to a JVM running JBoss Cache instances.
Chapter 6. Version Compatibility and Interoperability
6.1. API compatibility
6.2. Wire-level interoperability
Configuration.setReplicationVersion(), is available and is used to control the wire format of inter-cache communications. They can be wound back from more efficient and newer protocols to "compatible" versions when talking to older releases. This mechanism allows us to improve JBoss Cache by using more efficient wire formats while still providing a means to preserve interoperability.
6.3. Compatibility Matrix
Part II. JBoss Cache Architecture
Chapter 7. Architecture
7.1. Data Structures Within The Cache
Cache consists of a collection of Node instances, organized in a tree structure. Each Node contains a Map which holds the data objects to be cached. It is important to note that the structure is a mathematical tree, and not a graph; each Node has one and only one parent, and the root node is denoted by the constant fully qualified name, Fqn.ROOT.
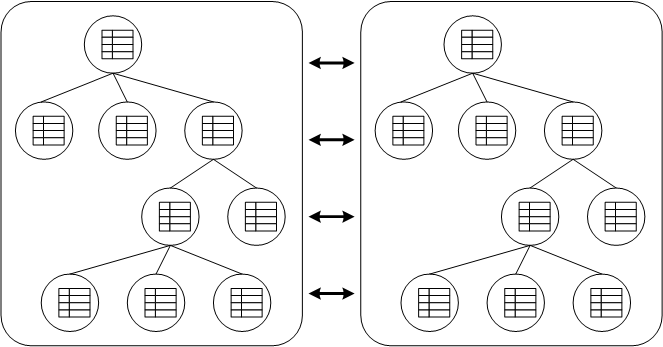
Figure 7.1. Data structured as a tree
7.2. SPI Interfaces
Cache and Node interfaces, JBoss Cache exposes more powerful CacheSPI and NodeSPI interfaces, which offer more control over the internals of JBoss Cache. These interfaces are not intended for general use, but are designed for people who wish to extend and enhance JBoss Cache, or write custom Interceptor or CacheLoader instances.

Figure 7.2. SPI Interfaces
CacheSPI interface cannot be created, but is injected into Interceptor and CacheLoader implementations by the setCache(CacheSPI cache) methods on these interfaces. CacheSPI extends Cache so all the functionality of the basic API is also available.
NodeSPI interface cannot be created. Instead, one is obtained by performing operations on CacheSPI, obtained as above. For example, Cache.getRoot() : Node is overridden as CacheSPI.getRoot() : NodeSPI.
Cache or Node to its SPI counterpart is not recommended and is bad practice, since the inheritance of interfaces it is not a contract that is guaranteed to be upheld moving forward. The exposed public APIs, on the other hand, is guaranteed to be upheld.
7.3. Method Invocations On Nodes
NodeSPI offers some methods (such as the xxxDirect() method family) that operate on a node directly without passing through the interceptor stack. Plug-in authors should note that using such methods will affect the aspects of the cache that may need to be applied, such as locking, replication, etc. To put it simply, do not use such methods unless you really know what you are doing!
7.3.1. Interceptors
DataContainer - and aspects and features are implemented using interceptors in front of this data structure. A CommandInterceptor is an abstract class, interceptor implementations extend this.
CommandInterceptor implements the Visitor interface so it is able to alter commands in a strongly typed manner as the command makes its way to the data structure. More on visitors and commands in the next section.
InterceptorChain class, which dispatches a command across the chain of interceptors. A special interceptor, the CallInterceptor, always sits at the end of this chain to invoke the command being passed up the chain by calling the command's process() method.
TxInterceptor- looks for ongoing transactions and registers with transaction managers to participate in synchronization eventsReplicationInterceptor- replicates state across a cluster using the RpcManager classCacheLoaderInterceptor- loads data from a persistent store if the data requested is not available in memory
CacheSPI.getInterceptorChain(), which returns an ordered List of interceptors in the order in which they would be encountered by a command.
7.3.1.1. Writing Custom Interceptors
CommandInterceptor and overriding the relevant visitXXX() methods based on the commands you are interested in intercepting. There are other abstract interceptors you could extend instead, such as the PrePostProcessingCommandInterceptor and the SkipCheckChainedInterceptor. Please see their respective javadocs for details on the extra features provided.
Cache.addInterceptor() methods. See the javadocs on these methods for details.
7.3.2. Commands and Visitors
CacheInvocationDelegate, which implements the Cache interface, creates an instance of VisitableCommand and dispatches this command up a chain of interceptors. Interceptors, which implement the Visitor interface, are able to handle VisitableCommands they are interested in, and add behavior to the command.
process() method. For example, the RemoveNodeCommand is created and passed up the interceptor chain when Cache.removeNode() is called, and RemoveNodeCommand.process() has the necessary knowledge of how to remove a node from the data structure.
7.3.3. InvocationContexts
InvocationContext holds intermediate state for the duration of a single invocation, and is set up and destroyed by the InvocationContextInterceptor which sits at the start of the interceptor chain.
InvocationContext, as its name implies, holds contextual information associated with a single cache method invocation. Contextual information includes associated javax.transaction.Transaction or org.jboss.cache.transaction.GlobalTransaction, method invocation origin ( InvocationContext.isOriginLocal() ) as well as Section 3.4.1, “Overriding the Configuration via the Option API”, and information around which nodes have been locked, etc.
InvocationContext can be obtained by calling Cache.getInvocationContext().
7.4. Managers For Subsystems
CacheSPI interface.
7.4.1. RpcManager
7.4.2. BuddyManager
7.4.3. CacheLoaderManager
CacheLoader instances in delegating classes, such as SingletonStoreCacheLoader or AsyncCacheLoader, or may add the CacheLoader to a chain using the ChainingCacheLoader.
7.5. Marshaling And Wire Formats
ObjectOutputStream during replication. Over various releases in the JBoss Cache 1.x.x series this approach was gradually deprecated in favor of a more mature marshaling framework. In the JBoss Cache 2.x.x series, this is the only officially supported and recommended mechanism for writing objects to datastreams.

Figure 7.3. The Marshaler interface
7.5.1. The Marshaler Interface
Marshaler interface extends RpcDispatcher.Marshaler from JGroups. This interface has two main implementations - a delegating VersionAwareMarshaller and a concrete CacheMarshaller300 .
CacheSPI.getMarshaller(), and defaults to the VersionAwareMarshaller. Users may also write their own marshalers by implementing the Marshaler interface or extending the AbstractMarshaller class, and adding it to their configuration by using the Configuration.setMarshallerClass() setter.
7.5.2. VersionAwareMarshaller
short to the start of any stream when writing, enabling similar VersionAwareMarshaller instances to read the version short and know which specific Marshaler implementation to delegate the call to. For example, CacheMarshaller200 is the Marshaler for JBoss Cache 2.0.x. JBoss Cache 3.0.x ships with CacheMarshaller300 with an improved wire protocol. Using a VersionAwareMarshaller helps achieve wire protocol compatibility between minor releases but still affords us the flexibility to tweak and improve the wire protocol between minor or micro releases.
7.6. Class Loading and Regions
HttpSession object) which would require replication. It is common for application servers to assign separate ClassLoader instances to each application deployed, but have JBoss Cache libraries referenced by the application server's ClassLoader.
Cache.getRegion(Fqn fqn, boolean createIfNotExists) method, and returns an implementation of the Region interface. Once a region is obtained, a class loader for the region can be set or unset, and the region can be activated/deactivated. By default, regions are active unless the InactiveOnStartup configuration attribute is set to true.
Chapter 8. Cache Modes and Clustering
8.1. Cache Replication Modes
8.1.1. Local Mode
8.1.2. Replicated Caches
put() ) until the modifications have been replicated successfully to all nodes in a cluster. Asynchronous replication performs replication in the background (the put() returns immediately). JBoss Cache also offers a replication queue, where modifications are replicated periodically (i.e. interval-based), or when the queue size exceeds a number of elements, or a combination thereof. A replication queue can therefore offer much higher performance as the actual replication is performed by a background thread.
8.1.2.1. Replicated Caches and Transactions
8.1.2.1.1. One Phase Commits
8.1.2.1.2. Two Phase Commits
SyncCommitPhase and SyncRollbackPhase configuration attributes.
8.1.2.2. Buddy Replication
8.1.2.2.1. Selecting Buddies
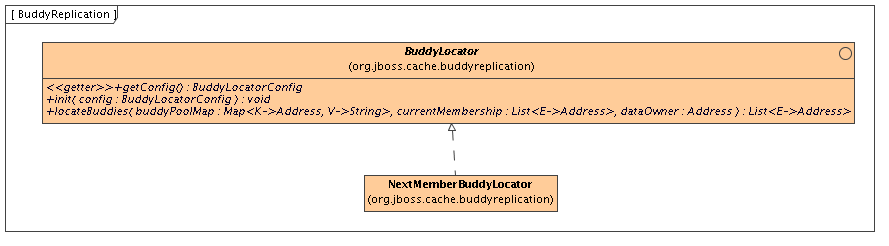
Figure 8.1. BuddyLocator
BuddyLocator which contains the logic used to select buddies in a network. JBoss Cache currently ships with a single implementation, NextMemberBuddyLocator, which is used as a default if no implementation is provided. The NextMemberBuddyLocator selects the next member in the cluster, as the name suggests, and guarantees an even spread of buddies for each instance.
NextMemberBuddyLocator takes in 2 parameters, both optional.
numBuddies- specifies how many buddies each instance should pick to back its data onto. This defaults to 1.ignoreColocatedBuddies- means that each instance will try to select a buddy on a different physical host. If not able to do so though, it will fall back to co-located instances. This defaults totrue.
8.1.2.2.2. BuddyPools
BuddyLocator s that support buddy pools would try and select buddies sharing the same buddy pool name. This allows system administrators a degree of flexibility and control over how buddies are selected. For example, a sysadmin may put two instances on two separate physical servers that may be on two separate physical racks in the same buddy pool. So rather than picking an instance on a different host on the same rack, BuddyLocator s would rather pick the instance in the same buddy pool, on a separate rack which may add a degree of redundancy.
8.1.2.2.3. Failover
dataGravitationRemoveOnFind- forces all remote caches that own the data or hold backups for the data to remove that data, thereby making the requesting cache the new data owner. This removal, of course, only happens after the new owner finishes replicating data to its buddy. If set tofalsean evict is broadcast instead of a remove, so any state persisted in cache loaders will remain. This is useful if you have a shared cache loader configured. Defaults totrue.dataGravitationSearchBackupTrees- Asks remote instances to search through their backups as well as main data trees. Defaults totrue. The resulting effect is that if this istruethen backup nodes can respond to data gravitation requests in addition to data owners.autoDataGravitation- Whether data gravitation occurs for every cache miss. By default this is set tofalseto prevent unnecessary network calls. Most use cases will know when it may need to gravitate data and will pass in anOptionto enable data gravitation on a per-invocation basis. IfautoDataGravitationistruethisOptionis unnecessary.
8.1.2.2.4. Configuration
8.2. Invalidation
8.3. State Transfer
8.3.1. State Transfer Types
8.3.2. Byte array and streaming based state transfer
8.3.3. Full and partial state transfer
- Initial state transfer. This occurs when the cache is first started (as part of the processing of the
start()method). This is a full state transfer. The state is retrieved from the cache instance that has been operational the longest. [1] If there is any problem receiving or integrating the state, the cache will not start.Initial state transfer will occur unless:- The cache's
InactiveOnStartupproperty istrue. This property is used in conjunction with region-based marshaling. - Buddy replication is used. See below for more on state transfer with buddy replication.
- Partial state transfer following region activation. When region-based marshaling is used, the application needs to register a specific class loader with the cache. This class loader is used to unmarshal the state for a specific region (subtree) of the cache.After registration, the application calls
cache.getRegion(fqn, true).activate(), which initiates a partial state transfer of the relevant subtree's state. The request is first made to the oldest cache instance in the cluster. However, if that instance responds with no state, it is then requested from each instance in turn until one either provides state or all instances have been queried.Typically when region-based marshaling is used, the cache'sInactiveOnStartupproperty is set totrue. This suppresses initial state transfer, which would fail due to the inability to deserialize the transferred state. - Buddy replication. When buddy replication is used, initial state transfer is disabled. Instead, when a cache instance joins the cluster, it becomes the buddy of one or more other instances, and one or more other instances become its buddy. Each time an instance determines it has a new buddy providing backup for it, it pushes its current state to the new buddy. This "pushing" of state to the new buddy is slightly different from other forms of state transfer, which are based on a "pull" approach (i.e. recipient asks for and receives state). However, the process of preparing and integrating the state is the same.This "push" of state upon buddy group formation only occurs if the
InactiveOnStartupproperty is set tofalse. If it istrue, state transfer amongst the buddies only occurs when the application activates the region on the various members of the group.Partial state transfer following a region activation call is slightly different in the buddy replication case as well. Instead of requesting the partial state from one cache instance, and trying all instances until one responds, with buddy replication the instance that is activating a region will request partial state from each instance for which it is serving as a backup.
8.3.4. Transient ("in-memory") and persistent state transfer
- "Transient" or "in-memory" state. This consists of the actual in-memory state of another cache instance - the contents of the various in-memory nodes in the cache that is providing state are serialized and transferred; the recipient deserializes the data, creates corresponding nodes in its own in-memory tree, and populates them with the transferred data."In-memory" state transfer is enabled by setting the cache's
FetchInMemoryStateconfiguration attribute totrue. - "Persistent" state. Only applicable if a non-shared cache loader is used. The state stored in the state-provider cache's persistent store is deserialized and transferred; the recipient passes the data to its own cache loader, which persists it to the recipient's persistent store."Persistent" state transfer is enabled by setting a cache loader's
fetchPersistentStateattribute totrue. If multiple cache loaders are configured in a chain, only one can have this property set to true; otherwise you will get an exception at start up.Persistent state transfer with a shared cache loader does not make sense, as the same persistent store that provides the data will just end up receiving it. Therefore, if a shared cache loader is used, the cache will not allow a persistent state transfer even if a cache loader hasfetchPersistentStateset totrue.
- If a write-through cache loader is used, the current cache state is fully represented by the persistent state. Data may have been evicted from the in-memory state, but it will still be in the persistent store. In this case, if the cache loader is not shared, persistent state transfer is used to ensure the new cache has the correct state. In-memory state can be transferred as well if the desire is to have a "hot" cache -- one that has all relevant data in memory when the cache begins providing service. (Note that the
<preload>element in the<loaders>configuration element can be used as well to provide a "warm" or "hot" cache without requiring an in-memory state transfer. This approach somewhat reduces the burden on the cache instance providing state, but increases the load on the persistent store on the recipient side.) - If a cache loader is used with passivation, the full representation of the state can only be obtained by combining the in-memory (i.e. non-passivated) and persistent (i.e. passivated) states. Therefore an in-memory state transfer is necessary. A persistent state transfer is necessary if the cache loader is not shared.
- If no cache loader is used and the cache is solely a write-aside cache (i.e. one that is used to cache data that can also be found in a persistent store, e.g. a database), whether or not in-memory state should be transferred depends on whether or not a "hot" cache is desired.
8.3.5. Configuring State Transfer
Chapter 9. Cache Loaders
CacheLoader to back up the in-memory cache to a back end datastore. If JBoss Cache is configured with a cache loader, then the following features are provided:
- Whenever a cache element is accessed, and that element is not in the cache (e.g. due to eviction or due to server restart), then the cache loader transparently loads the element into the cache if found in the back end store.
- Whenever an element is modified, added or removed, then that modification is persisted in the back end store via the cache loader. If transactions are used, all modifications created within a transaction are persisted. To this end, the
CacheLoadertakes part in the two phase commit protocol run by the transaction manager, although it does not do so explicitly.
9.1. The CacheLoader Interface and Lifecycle

Figure 9.1. The CacheLoader interface
CacheLoader implementation is as follows. When CacheLoaderConfiguration (see below) is non-null, an instance of each configured CacheLoader is created when the cache is created, and started when the cache is started.
CacheLoader.create() and CacheLoader.start() are called when the cache is started. Correspondingly, stop() and destroy() are called when the cache is stopped.
setConfig() and setCache() are called. The latter can be used to store a reference to the cache, the former is used to configure this instance of the CacheLoader . For example, here a database cache loader could establish a connection to the database.
CacheLoader interface has a set of methods that are called when no transactions are used: get() , put() , remove() and removeData() : they get/set/remove the value immediately. These methods are described as javadoc comments in the interface.
prepare() , commit() and rollback() . The prepare() method is called when a transaction is to be committed. It has a transaction object and a list of modifications as argument. The transaction object can be used as a key into a hashmap of transactions, where the values are the lists of modifications. Each modification list has a number of Modification elements, which represent the changes made to a cache for a given transaction. When prepare() returns successfully, then the cache loader must be able to commit (or rollback) the transaction successfully.
commit() method tells the cache loader to commit the transaction, and the rollback() method tells the cache loader to discard the changes associated with that transaction.
9.2. Configuration
ignoreModifications element has been set to true for a specific cache loader. See the configuration section below for details.
...
<!-- Cache loader config block -->
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loaders passivation="false" shared="false">
<preload>
<!-- Fqns to preload -->
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.driver=com.mysql.jdbc.Driver
cache.jdbc.url=jdbc:mysql://localhost:3306/jbossdb
cache.jdbc.user=root
cache.jdbc.password=
</properties>
</loader>
</loaders>
class element defines the class of the cache loader implementation. (Note that, because of a bug in the properties editor in EAP, backslashes in variables for Windows file names might not get expanded correctly, so replace="false" may be necessary). Note that an implementation of cache loader has to have an empty constructor.
properties element defines a configuration specific to the given implementation. The file system-based implementation for example defines the root directory to be used, whereas a database implementation might define the database URL, name and password to establish a database connection. This configuration is passed to the cache loader implementation via CacheLoader.setConfig(Properties). Note that backspaces may have to be escaped.
preload allows us to define a list of nodes, or even entire subtrees, that are visited by the cache on start up, in order to preload the data associated with those nodes. The default ("/") loads the entire data available in the back end store into the cache, which is probably not a good idea given that the data in the back end store might be large. As an example, /a, /product/catalogue loads the subtrees /a and /product/catalogue into the cache, but nothing else. Anything else is loaded lazily when accessed. Preloading makes sense when one anticipates using elements under a given subtree frequently. .
fetchPersistentState determines whether or not to fetch the persistent state of a cache when joining a cluster. Only one configured cache loader may set this property to true; if more than one cache loader does so, a configuration exception will be thrown when starting your cache service.
async determines whether writes to the cache loader block until completed, or are run on a separate thread so writes return immediately. If this is set to true, an instance of org.jboss.cache.loader.AsyncCacheLoader is constructed with an instance of the actual cache loader to be used. The AsyncCacheLoader then delegates all requests to the underlying cache loader, using a separate thread if necessary. See the Javadocs on AsyncCacheLoader for more details. If unspecified, the async element defaults to false.
Note
async element to true.
ignoreModifications determines whether write methods are pushed down to the specific cache loader. Situations may arise where transient application data should only reside in a file based cache loader on the same server as the in-memory cache, for example, with a further shared JDBCCacheLoader used by all servers in the network. This feature allows you to write to the 'local' file cache loader but not the shared JDBCCacheLoader. This property defaults to false, so writes are propagated to all cache loaders configured.
purgeOnStatup empties the specified cache loader (if ignoreModifications is false) when the cache loader starts up.
shared indicates that the cache loader is shared among different cache instances, for example where all instances in a cluster use the same JDBC settings t talk to the same remote, shared database. Setting this to true prevents repeated and unnecessary writes of the same data to the cache loader by different cache instances. Default value is false .
9.2.1. Singleton Store Configuration
<loaders passivation="false" shared="true">
<preload>
<node fqn="/a/b/c"/>
<node fqn="/f/r/s"/>
</preload>
<!-- we can now have multiple cache loaders, which get chained -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="false"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.datasource=java:/DefaultDS
</properties>
<singletonStore enabled="true" class="org.jboss.cache.loader.SingletonStoreCacheLoader">
<properties>
pushStateWhenCoordinator=true
pushStateWhenCoordinatorTimeout=20000
</properties>
</singletonStore>
</loader>
</loaders>
singletonStore element enables modifications to be stored by only one node in the cluster, the coordinator. Essentially, whenever any data comes in to some node it is always replicated so as to keep the caches' in-memory states in sync; the coordinator, though, has the sole responsibility of pushing that state to disk. This functionality can be activated setting the enabled subelement to true in all nodes, but again only the coordinator of the cluster will store the modifications in the underlying cache loader as defined in loader element. You cannot define a cache loader as shared and with singletonStore enabled at the same time. Default value for enabled is false.
singletonStore element, you can define a class element that specifies the implementation class that provides the singleton store functionality. This class must extend org.jboss.cache.loader.AbstractDelegatingCacheLoader, and if absent, it defaults to org.jboss.cache.loader.SingletonStoreCacheLoader.
properties subelement defines properties that allow changing the behavior of the class providing the singleton store functionality. By default, pushStateWhenCoordinator and pushStateWhenCoordinatorTimeout properties have been defined, but more could be added as required by the user-defined class providing singleton store functionality.
pushStateWhenCoordinator allows the in-memory state to be pushed to the cache store when a node becomes the coordinator, as a result of the new election of coordinator due to a cluster topology change. This can be very useful in situations where the coordinator crashes and there's a gap in time until the new coordinator is elected. During this time, if this property was set to false and the cache was updated, these changes would never be persisted. Setting this property to true would ensure that any changes during this process also get stored in the cache loader. You would also want to set this property to true if each node's cache loader is configured with a different location. Default value is true.
pushStateWhenCoordinatorTimeout is only relevant if pushStateWhenCoordinator is true in which case, sets the maximum number of milliseconds that the process of pushing the in-memory state to the underlying cache loader should take, reporting a PushStateException if exceeded. Default value is 20000.
Note
9.3. Shipped Implementations
9.3.1. File system based cache loaders
<loader><properties> configuration element contains a location property, which maps to a directory to be used as a persistent store (e.g., location=/tmp/myDataStore ). Used mainly for testing and not recommended for production use.
FileCacheLoader, which is a simple file system-based implementation. By default, this cache loader checks for any potential character portability issues in the location or tree node names, for example invalid characters, producing warning messages. These checks can be disabled addingcheck.character.portabilityproperty to the<properties>element and setting it tofalse(e.g.,check.character.portability=false).The FileCacheLoader has some severe limitations which restrict its use in a production environment, or if used in such an environment, it should be used with due care and sufficient understanding of these limitations.- Due to the way the FileCacheLoader represents a tree structure on disk (directories and files) traversal is inefficient for deep trees.
- Usage on shared file systems like NFS, Windows shares, etc. should be avoided as these do not implement proper file locking and can cause data corruption.
- Usage with an isolation level of NONE can cause corrupt writes as multiple threads attempt to write to the same file.
- File systems are inherently not transactional, so when attempting to use your cache in a transactional context, failures when writing to the file (which happens during the commit phase) cannot be recovered.
As a rule of thumb, it is recommended that the FileCacheLoader not be used in a highly concurrent, transactional or stressful environment, and its use is restricted to testing.BdbjeCacheLoader, which is a cache loader implementation based on the Oracle/Sleepycat's BerkeleyDB Java Edition.JdbmCacheLoader, which is a cache loader implementation based on the JDBM engine, a fast and free alternative to BerkeleyDB.
9.3.2. Cache loaders that delegate to other caches
LocalDelegatingCacheLoader, which enables loading from and storing to another local (same JVM) cache.ClusteredCacheLoader, which allows querying of other caches in the same cluster for in-memory data via the same clustering protocols used to replicate data. Writes are not 'stored' though, as replication would take care of any updates needed. You need to specify a property calledtimeout, a long value telling the cache loader how many milliseconds to wait for responses from the cluster before assuming a null value. For example,timeout = 3000would use a timeout value of 3 seconds.
9.3.3. JDBCCacheLoader
org.jboss.cache.loader.JDBCCacheLoader.
- column for
Fqn(which is also a primary key column) - column for node contents (attribute/value pairs)
- column for parent
Fqn
Fqns are stored as strings. Node content is stored as a BLOB.
Warning
Fqn but this implementation of cache loader requires Fqn to contain only objects of type java.lang.String. Another limitation for Fqn is its length. Since Fqn is a primary key, its default column type is VARCHAR which can store text values up to some maximum length determined by the database in use.
9.3.3.1. JDBCCacheLoader configuration
9.3.3.1.1. Table configuration
- cache.jdbc.table.name - the name of the table. Can be prepended with schema name for the given table:
{schema_name}.{table_name}. The default value is 'jbosscache'. - cache.jdbc.table.primarykey - the name of the primary key for the table. The default value is 'jbosscache_pk'.
- cache.jdbc.table.create - can be true or false. Indicates whether to create the table during start up. If true, the table is created if it does not already exist. The default value is true.
- cache.jdbc.table.drop - can be true or false. Indicates whether to drop the table during shutdown. The default value is true.
- cache.jdbc.fqn.column - FQN column name. The default value is 'fqn'.
- cache.jdbc.fqn.type - FQN column type. The default value is 'varchar(255)'.
- cache.jdbc.node.column - node contents column name. The default value is 'node'.
- cache.jdbc.node.type - node contents column type. The default value is 'blob'. This type must specify a valid binary data type for the database being used.
9.3.3.1.2. DataSource
- cache.jdbc.datasource - JNDI name of the DataSource. The default value is
java:/DefaultDS.
9.3.3.1.3. JDBC driver
- cache.jdbc.driver - fully qualified JDBC driver name.
- cache.jdbc.url - URL to connect to the database.
- cache.jdbc.user - user name to connect to the database.
- cache.jdbc.password - password to connect to the database.
9.3.3.1.4. c3p0 connection pooling
- cache.jdbc.connection.factory - Connection factory class name. If not set, it defaults to standard non-pooled implementation. To enable c3p0 pooling, just set the connection factory class for c3p0. See example below.
-Dc3p0.maxPoolSize=20 . If a c3p0 property is not defined in either the configuration file or as a System property, default value, as indicated in the c3p0 documentation, will apply.
9.3.3.1.5. Configuration example
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.table.primarykey=jbosscache_pk
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=VARCHAR(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=BLOB
cache.jdbc.parent.column=parent
cache.jdbc.driver=oracle.jdbc.OracleDriver
cache.jdbc.url=jdbc:oracle:thin:@localhost:1521:JBOSSDB
cache.jdbc.user=SCOTT
cache.jdbc.password=TIGER
</properties>
</loader>
</loaders>
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.datasource=java:/DefaultDS
</properties>
</loader>
</loaders>
<loaders passivation="false" shared="false">
<preload>
<node fqn="/some/stuff"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="false" fetchPersistentState="true"
ignoreModifications="false" purgeOnStartup="false">
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
cache.jdbc.table.primarykey=jbosscache_pk
cache.jdbc.fqn.column=fqn
cache.jdbc.fqn.type=VARCHAR(255)
cache.jdbc.node.column=node
cache.jdbc.node.type=BLOB
cache.jdbc.parent.column=parent
cache.jdbc.driver=oracle.jdbc.OracleDriver
cache.jdbc.url=jdbc:oracle:thin:@localhost:1521:JBOSSDB
cache.jdbc.user=SCOTT
cache.jdbc.password=TIGER
cache.jdbc.connection.factory=org.jboss.cache.loader.C3p0ConnectionFactory
c3p0.maxPoolSize=20
c3p0.checkoutTimeout=5000
</properties>
</loader>
</loaders>
9.3.4. S3CacheLoader
S3CacheLoader uses the Amazon S3 (Simple Storage Solution) for storing cache data. Since Amazon S3 is remote network storage and has fairly high latency, it is really best for caches that store large pieces of data, such as media or files. But consider this cache loader over the JDBC or file system based cache loaders if you want remotely managed, highly reliable storage. Or, use it for applications running on Amazon's EC2 (Elastic Compute Cloud).
CacheSPI.getMarshaller() instance. Read the javadoc on how data is structured and stored. Data is stored using Java serialization. Be aware this means data is not readily accessible over HTTP to non-JBoss Cache clients. Your feedback and help would be appreciated to extend this cache loader for that purpose.
Node.remove(Object) and Node.put(Object, Object) are the slowest as data is stored in a single Map instance. Use bulk operations such as Node.replaceAll(Map) and Node.clearData() for more efficiency. Try the cache.s3.optimize option as well.
9.3.4.1. Amazon S3 Library
<repository>
<id>e-xml.sourceforge.net</id>
<url>http://e-xml.sourceforge.net/maven2/repository</url>
</repository>
...
<dependency>
<groupId>net.noderunner</groupId>
<artifactId>amazon-s3</artifactId>
<version>1.0.0.0</version>
<scope>runtime</scope>
</dependency>
9.3.4.2. Configuration
cache.s3.accessKeyId- Amazon S3 Access Key, available from your account profile.cache.s3.secretAccessKey- Amazon S3 Secret Access Key, available from your account profile. As this is a password, be careful not to distribute it or include this secret key in built software.cache.s3.secure- The default isfalse: Traffic is sent unencrypted over the public Internet. Set totrueto use HTTPS. Note that unencrypted uploads and downloads use less CPU.cache.s3.bucket- Name of the bucket to store data. For different caches using the same access key, use a different bucket name. Read the S3 documentation on the definition of a bucket. The default value isjboss-cache.cache.s3.callingFormat- One ofPATH,SUBDOMAIN, orVANITY. Read the S3 documentation on the use of calling domains. The default value isSUBDOMAIN.cache.s3.optimize- The default isfalse. If true,put(Map)operations replace the data stored at an Fqn rather than attempt to fetch and merge. (This option is fairly experimental at the moment.)cache.s3.parentCache- The default istrue. Set this value tofalseif you are using multiple caches sharing the same S3 bucket, that remove parent nodes of nodes being created in other caches. (This is not a common use case.)JBoss Cache stores nodes in a tree format and automatically creates intermediate parent nodes as necessary. The S3 cache loader must also create these parent nodes as well to allow for operations such asgetChildrenNamesto work properly. Checking if all parent nodes exists for everyputoperation is fairly expensive, so by default the cache loader caches the existence of these parent nodes.cache.s3.location- This denotes a primary storage location for your data to reduce loading and retrieval latency. Set toEUto store data in Europe. The default isnull, to store data in the United States.
9.3.5. TcpDelegatingCacheLoader
org.jboss.cache.loader.tcp.TcpCacheServer , which can be a standalone process started on the command line, or embedded as an MBean inside EAP. The TcpCacheServer has a reference to another JBoss Cache instance, which it can create itself, or which is given to it (e.g. by JBoss, using dependency injection).
TcpDelegatingCacheLoader transparently handles reconnects if the connection to the TcpCacheServer is lost.
timeout property (defaults to 5000) specifies the length of time the cache loader must continue retrying to connect to the TcpCacheServer before giving up and throwing an exception. The reconnectWaitTime (defaults to 500) is how long the cache loader should wait before attempting a reconnect if it detects a communication failure. The last two parameters can be used to add a level of fault tolerance to the cache loader, do deal with TcpCacheServer restarts.
<loaders passivation="false" shared="false">
<preload>
<node fqn="/"/>
</preload>
<!-- if passivation is true, only the first cache loader is used; the rest are ignored -->
<loader class="org.jboss.cache.loader.TcpDelegatingCacheLoader">
<properties>
host=myRemoteServer
port=7500
timeout=10000
reconnectWaitTime=250
</properties>
</loader>
</loaders>
myRemoteServer:7500 .
9.3.6. Transforming Cache Loaders
FileCacheLoader and JDBCCacheLoader based cache stores has changed in JBoss Cache 2.0 in such way that these cache loaders now write and read data using the same marshaling framework used to replicate data across the network. Such change is trivial for replication purposes as it just requires the rest of the nodes to understand this format. However, changing the format of the data in cache stores brings up a new problem: how do users, which have their data stored in JBoss Cache 1.x.x format, migrate their stores to JBoss Cache 2.0 format?
org.jboss.cache.loader.TransformingFileCacheLoader and org.jboss.cache.loader.TransformingJDBCCacheLoader located within the optional jbosscache-cacheloader-migration.jar file. These are one-off cache loaders that read data from the cache store in JBoss Cache 1.x.x format and write data to cache stores in JBoss Cache 2.0 format.
examples/cacheloader-migration directory within the JBoss Cache distribution. This example, called examples.TransformStore , is independent of the actual data stored in the cache as it writes back whatever it was read recursively. It is highly recommended that anyone interested in porting their data run this example first, which contains a readme.txt file with detailed information about the example itself, and also use it as base for their own application.
9.4. Cache Passivation
passivation to true. The default is false . When passivation is used, only the first cache loader configured is used and all others are ignored.
9.4.1. Cache Loader Behavior with Passivation Disabled vs. Enabled
- Insert /A
- Insert /B
- Eviction thread runs, evicts /A
- Read /A
- Eviction thread runs, evicts /B
- Remove /B
1) Memory: /A Disk: /A
2) Memory: /A, /B Disk: /A, /B
3) Memory: /B Disk: /A, /B
4) Memory: /A, /B Disk: /A, /B
5) Memory: /A Disk: /A, /B
6) Memory: /A Disk: /A
1) Memory: /A Disk:
2) Memory: /A, /B Disk:
3) Memory: /B Disk: /A
4) Memory: /A, /B Disk:
5) Memory: /A Disk: /B
6) Memory: /A Disk:
9.5. Strategies
9.5.1. Local Cache With Store
LOCAL , therefore no replication is going on. The cache loader simply loads non-existing elements from the store and stores modifications back to the store. When the cache is started, depending on the preload element, certain data can be preloaded, so that the cache is partly warmed up.
9.5.2. Replicated Caches With All Caches Sharing The Same Store
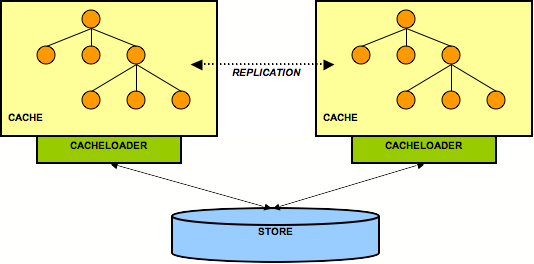
Figure 9.2. 2 nodes sharing a back end store
Note
FetchInMemoryState attribute could be set to false, resulting in a 'cold' cache, that gradually warms up as elements are accessed and loaded for the first time. This would mean that individual caches in a cluster might have different in-memory state at any given time (largely depending on their preloading and eviction strategies).
9.5.3. Replicated Caches With Only One Cache Having A Store
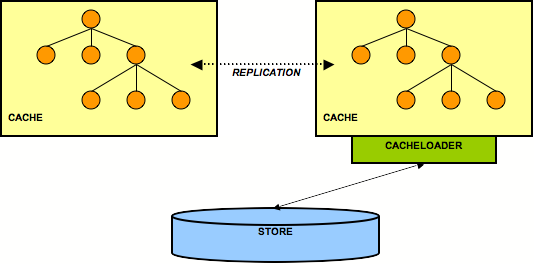
Figure 9.3. 2 nodes but only one accesses the back end store
singletonStore configuration to true. With this kind of setup, one but only one node will always be writing to a persistent store. However, this complicates the restart problem, as before restarting you need to determine which cache was writing before the shutdown/failure and then start that cache first.
9.5.4. Replicated Caches With Each Cache Having Its Own Store
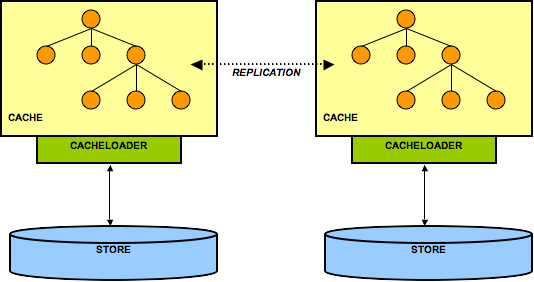
Figure 9.4. 2 nodes each having its own back end store
- Tell the coordinator (oldest node in a cluster) to send it the state. This is always a full state transfer, overwriting any state that may already be present.
- The coordinator then needs to wait until all in-flight transactions have completed. During this time, it will not allow for new transactions to be started.
- Then the coordinator asks its cache loader for the entire state using
loadEntireState(). It then sends back that state to the new node. - The new node then tells its cache loader to store that state in its store, overwriting the old state. This is the
CacheLoader.storeEntireState()method - As an option, the transient (in-memory) state can be transferred as well during the state transfer.
- The new node now has the same state in its back end store as everyone else in the cluster, and modifications received from other nodes will now be persisted using the local cache loader.
9.5.5. Hierarchical Caches
LocalDelegatingCacheLoader . This type of hierarchy can currently only be set up programmatically.
TcpDelegatingCacheLoader .
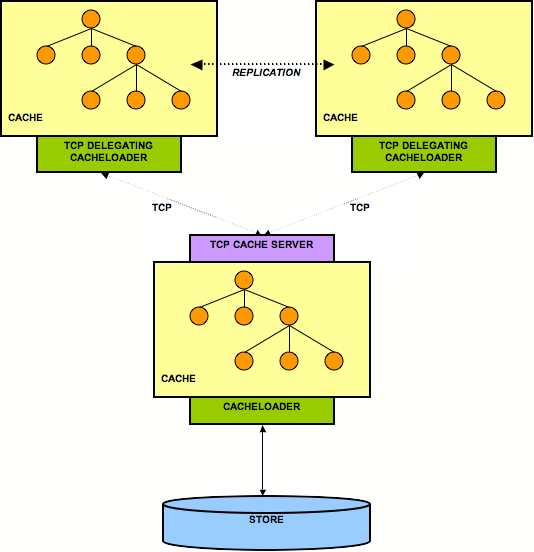
Figure 9.5. TCP delegating cache loader
9.5.6. Multiple Cache Loaders
ChainingCacheLoader is used, with references to each cache loader you have configured. Use cases vary depending on the type of cache loaders used in the chain. One example is using a file system based cache loader, co-located on the same host as the JVM, used as an overflow for memory. This ensures data is available relatively easily and with low cost. An additional remote cache loader, such as a TcpDelegatingCacheLoader provides resilience between server restarts.

Figure 9.6. Multiple cache loaders in a chain
Chapter 10. Eviction
10.1. Design
- 1. Collecting statistics
- 2. Determining which nodes to evict
- 3. How nodes are evicted
- 4. Eviction threads.
10.1.1. Collecting Statistics
EvictionInterceptor is added to the interceptor chain and events are recorded in an event queue. Events are denoted by the EvictionEvent class. Event queues are held on specific Regions so each region has its own event queue.
EvictionInterceptor is either added to the interceptor chain or not, depending on whether eviction is enabled.
10.1.2. Determining Which Nodes to Evict
EvictionAlgorithm implementation processes the eviction queue to decide which nodes to evict. JBoss Cache ships with a number of implementations, including FIFOAlgorithm, LRUAlgorithm, LFUAlgorithm, etc. Each implementation has a corresponding EvictionAlgorithmConfig implementation with configuration details for the algorithm.
EvictionAlgorithm implementations can be provided by implementing the interface or extending one of the provided implementations.
process() method and passing in the event queue to process. This is typically done by calling Region.processEvictionQueues(), which will locate the Algorithm assigned to the region.
10.1.3. How Nodes are Evicted
EvictionAlgorithm decides which nodes to evict, it uses an implementation of EvictionActionPolicy to determine how to evict nodes. This is configurable on a per-region basis, and defaults to DefaultEvictionActionPolicy, which invokes Cache.evict() for each node that needs to be evicted.
RemoveOnEvictActionPolicy, which calls Cache.removeNode() for each node that needs to be evicted, instead of Cache.evict().
EvictionActionPolicy implementations can be used as well.
10.1.4. Eviction threads
Region.processEvictionQueues() on each region. The frequency with which this thread runs can be configured using the wakeUpInterval attribute in the eviction configuration element, and defaults to 5000 milliseconds if not specified.
wakeUpInterval to 0. This can be useful if you have your own periodic maintenance thread running and would like to iterate through regions and call Region.processEvictionQueues() yourself.
10.2. Eviction Regions
Region class were Section 7.6, “Class Loading and Regions” when talking about marshaling. Regions are also used to define the eviction behavior for nodes within that region. In addition to using a region-specific configuration, you can also configure default, cache-wide eviction behavior for nodes that do not fall into predefined regions or if you do not wish to define specific regions. It is important to note that when defining regions using the configuration XML file, all elements of the Fqn that defines the region are String objects.
/a/b/c, and another defined for /a/b/c/d (which is just the d subtree of the /a/b/c sub-tree). The algorithm, in order to handle scenarios like this consistently, will always choose the first region it encounters. In this way, if the algorithm needed to decide how to handle node /a/b/c/d/e, it would start from there and work its way up the tree until it hits the first defined region - in this case /a/b/c/d.
10.2.1. Resident Nodes
Node.setResident() API) will be ignored by the eviction policies both when checking whether to trigger the eviction and when proceeding with the actual eviction of nodes. E.g. if a region is configured to have a maximum of 10 nodes, resident nodes will not be counted when deciding whether to evict nodes in that region. In addition, resident nodes will not be considered for eviction when the region's eviction threshold is reached.
Node.setResident() API should be used. By default, the newly created nodes are not resident. The resident attribute of a node is neither replicated, persisted nor transaction-aware.
...
Map lotsOfData = generateData();
cache.put("/a/b/c", lotsOfData);
cache.getRoot().getChild("/a").setResident(true);
cache.getRoot().getChild("/a/b").setResident(true);
...
/a and /a/b are paths which exist solely to support the existence of node /a/b/c and do not hold any data themselves. As such, they are good candidates for being marked as resident. This would lead to better memory management as no eviction events would be generated when accessing /a and/a/b.
Note
cache.put("/a", "k", "v") in the above example, it would make sense to mark the nodes as non-resident again and let them be considered for eviction.
10.3. Configuring Eviction
10.3.1. Basic Configuration
...
<eviction wakeUpInterval="500" eventQueueSize="100000">
<default algorithmClass="org.jboss.cache.eviction.LRUAlgorithm">
<property name="maxNodes" value="5000" />
<property name="timeToLive" value="1000" />
</default>
</eviction>
...
wakeUpInterval- this required parameter defines how often the eviction thread runs, in milliseconds.eventQueueSize- this optional parameter defines the size of the bounded queue which holds eviction events. If your eviction thread does not run often enough, you may find that the event queue fills up. It may then be necessary to get your eviction thread to run more frequently, or increase the size of your event queue. This configuration is just the default event queue size, and can be overridden in specific eviction regions. If not specified, this defaults to200000.algorithmClass- this is required, unless you set individualalgorithmClassattributes on each and every region. This defines the default eviction algorithm to use if one is not defined for a region.- Algorithm configuration attributes - these are specific to the algorithm specified in
algorithmClass. See the section specific to the algorithm you are interested in for details.
10.3.2. Programmatic Configuration
Configuration object entails the use of the org.jboss.cache.config.EvictionConfig bean, which is passed into Configuration.setEvictionConfig(). See the Chapter 3, Configuration for more on building a Configuration programmatically.
LRUAlgorithm but a different number of maxNodes:
Fqn fqn = Fqn.fromString("/org/jboss/fifo");
// Create a configuration for an LRUPolicy
LRUAlgorithmConfig lruc = new LRUAlgorithmConfig();
lruc.setMaxNodes(10000);
// Create an eviction region config
EvictionRegionConfig erc = new EvictionRegionConfig(fqn, lruc);
// Create the region and set the config
Region region = cache.getRegion(fqn, true);
region.setEvictionRegionConfig(erc);
10.4. Shipped Eviction Policies
10.4.1. LRUAlgorithm - Least Recently Used
org.jboss.cache.eviction.LRUAlgorithm controls both the node lifetime and age. This policy guarantees a constant order ( O (1) ) for adds, removals and lookups (visits). It has the following configuration parameters:
maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.timeToLive- The amount of time a node is not written to or read (in milliseconds) before the node is swept away. 0 denotes immediate expiry, -1 denotes no limit.maxAge- Lifespan of a node (in milliseconds) regardless of idle time before the node is swept away. 0 denotes immediate expiry, -1 denotes no limit.minTimeToLive- the minimum amount of time a node must be allowed to live after being accessed before it is allowed to be considered for eviction. 0 denotes that this feature is disabled, which is the default value.
10.4.2. FIFOAlgorithm - First In, First Out
org.jboss.cache.eviction.FIFOAlgorithm controls the eviction in a proper first in first out order. This policy guarantees a constant order ( O (1) ) for adds, removals and lookups (visits). It has the following configuration parameters:
maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.minTimeToLive- the minimum amount of time a node must be allowed to live after being accessed before it is allowed to be considered for eviction. 0 denotes that this feature is disabled, which is the default value.
10.4.3. MRUAlgorithm - Most Recently Used
org.jboss.cache.eviction.MRUAlgorithm controls the eviction in based on most recently used algorithm. The most recently used nodes will be the first to evict with this policy. This policy guarantees a constant order ( O (1) ) for adds, removals and lookups (visits). It has the following configuration parameters:
maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.minTimeToLive- the minimum amount of time a node must be allowed to live after being accessed before it is allowed to be considered for eviction. 0 denotes that this feature is disabled, which is the default value.
10.4.4. LFUAlgorithm - Least Frequently Used
org.jboss.cache.eviction.LFUAlgorithm controls the eviction in based on least frequently used algorithm. The least frequently used nodes will be the first to evict with this policy. Node usage starts at 1 when a node is first added. Each time it is visited, the node usage counter increments by 1. This number is used to determine which nodes are least frequently used. LFU is also a sorted eviction algorithm. The underlying EvictionQueue implementation and algorithm is sorted in ascending order of the node visits counter. This class guarantees a constant order ( O (1) ) for adds, removal and searches. However, when any number of nodes are added/visited to the queue for a given processing pass, a single quasilinear ( O (n * log n) ) operation is used to resort the queue in proper LFU order. Similarly if any nodes are removed or evicted, a single linear ( O (n) ) pruning operation is necessary to clean up the EvictionQueue. LFU has the following configuration parameters:
maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.minNodes- This is the minimum number of nodes allowed in this region. This value determines what the eviction queue should prune down to per pass. e.g. If minNodes is 10 and the cache grows to 100 nodes, the cache is pruned down to the 10 most frequently used nodes when the eviction timer makes a pass through the eviction algorithm.minTimeToLive- the minimum amount of time a node must be allowed to live after being accessed before it is allowed to be considered for eviction. 0 denotes that this feature is disabled, which is the default value.
10.4.5. ExpirationAlgorithm
org.jboss.cache.eviction.ExpirationAlgorithm is a policy that evicts nodes based on an absolute expiration time. The expiration time is indicated using the org.jboss.cache.Node.put() method, using a String key expiration and the absolute time as a java.lang.Long object, with a value indicated as milliseconds past midnight January 1st, 1970 UTC (the same relative time as provided by java.lang.System.currentTimeMillis() ).
O (1) ) for adds and removals. Internally, a sorted set (TreeSet) containing the expiration time and Fqn of the nodes is stored, which essentially functions as a heap.
expirationKeyName- This is the Node key name used in the eviction algorithm. The configuration default isexpiration.maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.
Cache cache = DefaultCacheFactory.createCache();
Fqn fqn1 = Fqn.fromString("/node/1");
Long future = new Long(System.currentTimeMillis() + 2000);
// sets the expiry time for a node
cache.getRoot().addChild(fqn1).put(ExpirationConfiguration.EXPIRATION_KEY, future);
assertTrue(cache.getRoot().hasChild(fqn1));
Thread.sleep(5000);
// after 5 seconds, expiration completes
assertFalse(cache.getRoot().hasChild(fqn1));
wakeUpIntervalSeconds , so eviction may happen a few seconds later than indicated.
10.4.6. ElementSizeAlgorithm - Eviction based on number of key/value pairs in a node
org.jboss.cache.eviction.ElementSizeAlgorithm controls the eviction based on the number of key/value pairs in the node. The most recently used nodes will be the first to evict with this policy. It has the following configuration parameters:
maxNodes- This is the maximum number of nodes allowed in this region. 0 denotes immediate expiry, -1 denotes no limit.maxElementsPerNode- This is the trigger number of attributes per node for the node to be selected for eviction. 0 denotes immediate expiry, -1 denotes no limit.minTimeToLive- the minimum amount of time a node must be allowed to live after being accessed before it is allowed to be considered for eviction. 0 denotes that this feature is disabled, which is the default value.
Chapter 11. Transactions and Concurrency
11.1. Concurrent Access
11.1.1. Multi-Version Concurrency Control (MVCC)
11.1.1.1. MVCC Concepts
- Readers that do not block writers
- Writers that fail fast
11.1.1.2. MVCC Implementation
- Readers do not acquire any locks
- Only one additional version is maintained for shared state, for a single writer
- All writes happen sequentially, to provide fail-fast semantics
MVCCLockingInterceptor wraps state in a lightweight container object, which is placed in the thread's InvocationContext (or TransactionContext if running in a transaction). All subsequent operations on the state happens via the container object. This use of Java references allows for repeatable read semantics even if the actual state changes simultaneously.
concurrencyLevel attribute of the locking element. See the Chapter 12, Configuration References for details. After acquiring an exclusive lock on an Fqn, the writer thread then wraps the state to be modified in a container as well, just like with reader threads, and then copies this state for writing. When copying, a reference to the original version is still maintained in the container (for rollbacks). Changes are then made to the copy and the copy is finally written to the data structure when the write completes.
TimeoutException is thrown. This lock acquisition timeout defaults to 10000 milliseconds and can be configured using the lockAcquisitionTimeout attribute of the locking element. See the Chapter 12, Configuration References for details.
11.1.1.2.1. Isolation Levels
11.1.1.2.2. Concurrent Writers and Write-Skews
DataVersioningException, when it is detected when copying state for writing. However, in most applications, a write skew may not be an issue (for example, if the state written has no relationship to the state originally read) and should be allowed. If your application does not care about write skews, you can allow them to happen by setting the writeSkewCheck configuration attribute to false. See the Chapter 12, Configuration References for details.
11.1.1.3. Configuring Locking
<locking /> configuration tag, as follows:
<locking
isolationLevel="REPEATABLE_READ"
lockAcquisitionTimeout="10234"
nodeLockingScheme="mvcc"
writeSkewCheck="false"
concurrencyLevel="1000" />
nodeLockingScheme- the node locking scheme used. Defaults to MVCC if not provided, deprecated schemes such aspessimisticoroptimisticmay be used but is not encouraged.isolationLevel- transaction isolation level. Defaults to REPEATABLE_READ if not provided.writeSkewCheck- defaults totrueif not provided.concurrencyLevel- defaults to 500 if not provided.lockAcquisitionTimeout- only applies to writers when using MVCC. Defaults to 10000 if not provided.
11.1.2. Pessimistic and Optimistic Locking Schemes
11.2. JTA Support
- Retrieve the current
javax.transaction.Transactionassociated with the thread - If not already done, register a
javax.transaction.Synchronizationwith the transaction manager to be notified when a transaction commits or is rolled back.
javax.transaction.TransactionManager. This is usually done by configuring the cache with the class name of an implementation of the TransactionManagerLookup interface. When the cache starts, it will create an instance of this class and invoke its getTransactionManager() method, which returns a reference to the TransactionManager.
JBossTransactionManagerLookup and GenericTransactionManagerLookup. The JBossTransactionManagerLookup is able to bind to a running EAP instance and retrieve a TransactionManager while the GenericTransactionManagerLookup is able to bind to most popular Java EE application servers and provide the same functionality. A dummy implementation - DummyTransactionManagerLookup - is also provided for unit tests. Being a dummy, this is not recommended for production use a it has some severe limitations to do with concurrent transactions and recovery.
TransactionManagerLookup is to programmatically inject a reference to the TransactionManager into the Configuration object's RuntimeConfig element:
TransactionManager tm = getTransactionManager(); // magic method cache.getConfiguration().getRuntimeConfig().setTransactionManager(tm);
TransactionManager is the recommended approach when the Configuration is built by some sort of IOC container that already has a reference to the TransactionManager.
Part III. JBoss Cache Configuration References
Chapter 12. Configuration References
12.1. Sample XML Configuration File
<?xml version="1.0" encoding="UTF-8"?>
<jbosscache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:jboss:jbosscache-core:config:3.1">
<!--
isolation levels supported: READ_COMMITTED and REPEATABLE_READ
nodeLockingSchemes: mvcc, pessimistic (deprecated), optimistic (deprecated)
-->
<locking
isolationLevel="REPEATABLE_READ"
lockParentForChildInsertRemove="false"
lockAcquisitionTimeout="20000"
nodeLockingScheme="mvcc"
writeSkewCheck="false"
useLockStriping="true"
concurrencyLevel="500"/>
<!--
Used to register a transaction manager and participate in ongoing transactions.
-->
<transaction
transactionManagerLookupClass="org.jboss.cache.transaction.GenericTransactionManagerLookup"
syncRollbackPhase="false"
syncCommitPhase="false"/>
<!--
Used to register JMX statistics in any available MBean server
-->
<jmxStatistics
enabled="false"/>
<!--
If region based marshalling is used, defines whether new regions are inactive on startup.
-->
<startup
regionsInactiveOnStartup="true"/>
<!--
Used to register JVM shutdown hooks.
hookBehavior: DEFAULT, REGISTER, DONT_REGISTER
-->
<shutdown
hookBehavior="DEFAULT"/>
<!--
Used to define async listener notification thread pool size
-->
<listeners
asyncPoolSize="1"
asyncQueueSize="100000"/>
<!--
Used to enable invocation batching and allow the use of Cache.startBatch()/endBatch() methods.
-->
<invocationBatching
enabled="false"/>
<!--
serialization related configuration, used for replication and cache loading
-->
<serialization
objectInputStreamPoolSize="12"
objectOutputStreamPoolSize="14"
version="3.0.0"
marshallerClass="org.jboss.cache.marshall.VersionAwareMarshaller"
useLazyDeserialization="false"
useRegionBasedMarshalling="false"/>
<!--
This element specifies that the cache is clustered.
modes supported: replication (r) or invalidation (i).
-->
<clustering mode="replication" clusterName="JBossCache-cluster">
<!--
Defines whether to retrieve state on startup
-->
<stateRetrieval timeout="20000" fetchInMemoryState="false"/>
<!--
Network calls are synchronous.
-->
<sync replTimeout="20000"/>
<!--
Uncomment this for async replication.
-->
<!--<async useReplQueue="true" replQueueInterval="10000" replQueueMaxElements="500" serializationExecutorPoolSize="20" serializationExecutorQueueSize="5000000"/>-->
<!-- Uncomment to use Buddy Replication -->
<!--
<buddy enabled="true" poolName="myBuddyPoolReplicationGroup" communicationTimeout="2000">
<dataGravitation auto="true" removeOnFind="true" searchBackupTrees="true"/>
<locator class="org.jboss.cache.buddyreplication.NextMemberBuddyLocator">
<properties>
numBuddies = 1
ignoreColocatedBuddies = true
</properties>
</locator>
</buddy>
-->
<!--
Configures the JGroups channel. Looks up a JGroups config file on the classpath or filesystem. udp.xml
ships with jgroups.jar and will be picked up by the class loader.
-->
<jgroupsConfig configFile="udp.xml">
<!-- uncomment to define a JGroups stack here
<PING timeout="2000" num_initial_members="3"/>
<MERGE2 max_interval="30000" min_interval="10000"/>
<FD_SOCK/>
<FD timeout="10000" max_tries="5" shun="true"/>
<VERIFY_SUSPECT timeout="1500"/>
<pbcast.NAKACK use_mcast_xmit="false" gc_lag="0"
retransmit_timeout="300,600,1200,2400,4800"
discard_delivered_msgs="true"/>
<UNICAST timeout="300,600,1200,2400,3600"/>
<pbcast.STABLE stability_delay="1000" desired_avg_gossip="50000"
max_bytes="400000"/>
<pbcast.GMS print_local_addr="true" join_timeout="5000" shun="false"
view_bundling="true" view_ack_collection_timeout="5000"/>
<FRAG2 frag_size="60000"/>
<pbcast.STREAMING_STATE_TRANSFER use_reading_thread="true"/>
<pbcast.FLUSH timeout="0"/>
-->
</jgroupsConfig>
</clustering>
<!--
Eviction configuration. WakeupInterval defines how often the eviction thread runs, in milliseconds. 0 means
the eviction thread will never run.
-->
<eviction wakeUpInterval="500">
<default algorithmClass="org.jboss.cache.eviction.LRUAlgorithm" eventQueueSize="200000">
<property name="maxNodes" value="5000" />
<property name="timeToLive" value="1000" />
</default>
<region name="/org/jboss/data1">
<property name="timeToLive" value="2000" />
</region>
<region name="/org/jboss/data2" algorithmClass="org.jboss.cache.eviction.FIFOAlgorithm" eventQueueSize="100000">
<property name="maxNodes" value="3000" />
<property name="minTimeToLive" value="4000" />
</region>
</eviction>
<!--
Cache loaders.
If passivation is enabled, state is offloaded to the cache loaders ONLY when evicted. Similarly, when the state
is accessed again, it is removed from the cache loader and loaded into memory.
Otherwise, state is always maintained in the cache loader as well as in memory.
Set 'shared' to true if all instances in the cluster use the same cache loader instance, e.g., are talking to the
same database.
-->
<loaders passivation="false" shared="false">
<preload>
<node fqn="/org/jboss"/>
<node fqn="/org/tempdata"/>
</preload>
<!--
we can have multiple cache loaders, which get chained
-->
<loader class="org.jboss.cache.loader.JDBCCacheLoader" async="true" fetchPersistentState="true"
ignoreModifications="true" purgeOnStartup="true">
<properties>
cache.jdbc.table.name=jbosscache
cache.jdbc.table.create=true
cache.jdbc.table.drop=true
</properties>
<singletonStore enabled="true" class="org.jboss.cache.loader.SingletonStoreCacheLoader">
<properties>
pushStateWhenCoordinator=true
pushStateWhenCoordinatorTimeout=20000
</properties>
</singletonStore>
</loader>
</loaders>
<!--
Define custom interceptors. All custom interceptors need to extend org.jboss.cache.interceptors.base.CommandInterceptor
-->
<!--
<customInterceptors>
<interceptor position="first"
class="org.jboss.cache.config.parsing.custominterceptors.AaaCustomInterceptor">
<property name="attrOne" value="value1" />
<property name="attrTwo" value="value2" />
</interceptor>
<interceptor position="last"
class="org.jboss.cache.config.parsing.custominterceptors.BbbCustomInterceptor"/>
<interceptor index="3"
class="org.jboss.cache.config.parsing.custominterceptors.AaaCustomInterceptor"/>
<interceptor before="org.jboss.cache.interceptors.CallInterceptor"
class="org.jboss.cache.config.parsing.custominterceptors.BbbCustomInterceptor"/>
<interceptor after="org.jboss.cache.interceptors.CallInterceptor"
class="org.jboss.cache.config.parsing.custominterceptors.AaaCustomInterceptor"/>
</customInterceptors>
-->
</jbosscache>
12.1.1. XML validation
jbosscache-core.jar and is also available online: http://www.jboss.org/jbosscache/jbosscache-config-3.0.xsd. Most IDEs and XML authoring tools will be able to use this schema to validate your configuration file as you write it.
-Djbosscache.config.validate=false to your JVM when you start up. Alternatively, you can point the validator to a different schema by passing in -Djbosscache.config.schemaLocation=url.
12.2. Configuration File Quick Reference
Table 12.1. The <jbosscache /> Element
The <jbosscache /> Element | |
|---|---|
|
Description
|
This is the root element for the JBoss Cache configuration file. This is the only mandatory element in a valid JBoss Cache configuration file.
|
|
Parent
|
none (is root element)
|
|
Children
|
Table 12.40, “The
<clustering /> Element”, Table 12.37, “The <customInterceptors /> Element”, Table 12.19, “The <eviction /> Element”, Table 12.15, “The <invocationBatching /> Element”, Table 12.7, “The <jmxStatistics /> Element”, Table 12.13, “The <listeners /> Element”, Table 12.27, “The <loaders /> Element”, Table 12.3, “The <locking /> Element”, Table 12.17, “The <serialization /> Element”, Table 12.11, “The <shutdown /> Element”, Table 12.9, “The <startup /> Element”, Table 12.5, “The <transaction /> Element”
|
|
Bean Equivalent
| Configuration
|
Table 12.2. <jbosscache /> Attributes
<jbosscache /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| xmlns | - | urn:jboss:jbosscache-core:config:3.1 | urn:jboss:jbosscache-core:config:3.1 | Defines the XML namespace for all configuration entries. |
| xmlns:xsi | - | http://www.w3.org/2001/XMLSchema-instance | http://www.w3.org/2001/XMLSchema-instance | Defines the XML schema instance for the configuration. |
Table 12.3. The <locking /> Element
The <locking /> Element | |
|---|---|
|
Description
|
This element specifies locking behavior on the cache.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.4. <locking /> Attributes
<locking /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| isolationLevel | isolationLevel | READ_COMMITTED, REPEATABLE_READ | REPEATABLE_READ | The isolation level used for transactions. |
| lockParentForChildInsertRemove | lockParentForChildInsertRemove | true, false | false | Specifies whether parent nodes are locked when inserting or removing children. This can also be configured on a per-node basis (see Node.setLockForChildInsertRemove() |
| lockAcquisitionTimeout | lockAcquisitionTimeout (dynamic) | Any positive long value | 10000 | Length of time, in milliseconds, that a thread will try and acquire a lock. A TimeoutException is usually thrown if a lock cannot be acquired in this given timeframe. Can be overridden on a per-invocation basis using Option.setLockAcquisitionTimeout() |
| nodeLockingScheme (deprecated) | nodeLockingScheme | mvcc, pessimistic, optimistic | mvcc | Specifies the node locking scheme to be used. |
| writeSkewCheck | writeSkewCheck | true, false | false | Specifies whether to check for write skews. Only used if nodeLockingScheme is mvcc and isolationLevel is REPEATABLE_READ. See the Section 11.1.1.2.2, “Concurrent Writers and Write-Skews” for a more detailed discussion. |
| useLockStriping | useLockStriping | true, false | true | Specifies whether lock striping is used. Only used if nodeLockingScheme is mvcc. Lock striping usually offers greater performance and better memory usage, although in certain cases deadlocks may occur where several Fqns map to the same shared lock. This can be mitigated by increasing your concurrency level, though the only concrete solution is to disable lock striping altogether. |
| concurrencyLevel | concurrencyLevel | Any positive integer; 0 not allowed. | 500 | Specifies the number of shared locks to use for write locks acquired. Only used if nodeLockingScheme is mvcc. See the Section 11.1.1.2, “MVCC Implementation” for a more detailed discussion. |
Table 12.5. The <transaction /> Element
The <transaction /> Element | |
|---|---|
|
Description
|
This element specifies transactional behavior on the cache.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.6. <transaction /> Attributes
<transaction /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| transactionManagerLookupClass | transactionManagerLookupClass | A valid class that is available on the classpath | none | Specifies the TransactionManagerLookupClass implementation to use to obtain a transaction manager. If not specified (and a TransactionManager is not injected using RuntimeConfig.setTransactionManager()), the cache will not be able to participate in any transactions. |
| syncCommitPhase | syncCommitPhase (dynamic) | true, false | false | If enabled, commit messages that are broadcast around a cluster are done so synchronously. This is usually of little value since detecting a failure in broadcasting a commit means little else can be done except log a message, since some nodes in a cluster may have already committed and cannot rollback. |
| syncRollbackPhase | syncRollbackPhase (dynamic) | true, false | false | If enabled, rollback messages that are broadcast around a cluster are done so synchronously. This is usually of little value since detecting a failure in broadcasting a rollback means little else can be done except log a message, since some nodes in a cluster may have already committed and cannot rollback. |
Table 12.7. The <jmxStatistics /> Element
The <jmxStatistics /> Element | |
|---|---|
|
Description
|
This element specifies whether cache statistics are gathered and reported via JMX.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.8. <jmxStatistics /> Attributes
<jmxStatistics /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| enabled | exposeManagementStatistics | true, false | true | Controls whether cache statistics are gathered and exposed via JMX. |
Table 12.9. The <startup /> Element
The <startup /> Element | |
|---|---|
|
Description
|
This element specifies behavior when the cache starts up.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.10. <startup /> Attributes
<startup /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| regionsInactiveOnStartup | inactiveOnStartup | true, false | false | If Section 7.6, “Class Loading and Regions” is enabled, this attribute controls whether new regions created are inactive on start up. |
Table 12.11. The <shutdown /> Element
The <shutdown /> Element | |
|---|---|
|
Description
|
This element specifies behavior when the cache shuts down.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.12. <shutdown /> Attributes
<shutdown /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| hookBehavior | shutdownHookBehavior | DEFAULT, DONT_REGISTER, REGISTER | DEFAULT | This attribute determines whether the cache registers a JVM shutdown hook so that it can clean up resources if the JVM is receives a shutdown signal. By default a shutdown hook is registered if no MBean server (apart from the JDK default) is detected. REGISTER forces the cache to register a shutdown hook even if an MBean server is detected, and DONT_REGISTER forces the cache NOT to register a shutdown hook, even if no MBean server is detected. |
Table 12.13. The <listeners /> Element
The <listeners /> Element | |
|---|---|
|
Description
|
This element specifies behavior of registered cache listeners.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.14. <listeners /> Attributes
<listeners /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| asyncPoolSize | listenerAsyncPoolSize | integer | 1 | The size of the thread pool used to dispatch events to cache listeners that have registered as asynchronous listeners. If this number is less than 1, all asynchronous listeners will be treated as synchronous listeners and notified synchronously. |
| asyncQueueSize | listenerAsyncQueueSize | positive integer | 50000 | The size of the bounded queue used by the async listener thread pool. Only considered if asyncPoolSize is greater than 0. Increase this if you see a lot of threads blocking trying to add events to this queue. |
Table 12.15. The <invocationBatching /> Element
The <invocationBatching /> Element | |
|---|---|
|
Description
|
This element specifies behavior of invocation batching.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.16. <invocationBatching /> Attributes
<invocationBatching /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| enabled | invocationBatchingEnabled | true, false | false | Whether invocation batching is enabled or not. See the chapter on Chapter 4, Batching API for details. |
Table 12.17. The <serialization /> Element
The <serialization /> Element | |
|---|---|
|
Description
|
This element specifies behavior of object serialization in JBoss Cache.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| Configuration
|
Table 12.18. <serialization /> Attributes
<serialization /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| marshallerClass | marshallerClass | A valid class that is available on the classpath | VersionAwareMarshaller | Specifies the marshaler to use when serializing and deserializing objects, either for replication or persistence. |
| useLazyDeserialization | useLazyDeserialization | true, false | false | A mechanism by which serialization and deserialization of objects is deferred till the point in time in which they are used and needed. This typically means that any deserialization happens using the thread context class loader of the invocation that requires deserialization, and is an effective mechanism to provide classloader isolation. |
| useRegionBasedMarshalling (deprecated) | useRegionBasedMarshalling | true, false | false | An older mechanism by which classloader isolation was achieved, by registering classloaders on specific regions. |
| version | replicationVersion | Valid JBoss Cache version string | Current version | Used by the VersionAwareMarshaller in determining which version stream parser to use by default when initiating communications in a cluster. Useful when you need to run a newer version of JBoss Cache in a cluster containing older versions, and can be used to perform rolling upgrades. |
| objectInputStreamPoolSize | objectInputStreamPoolSize | Positive integer | 50 | Not used at the moment. |
| objectOutputStreamPoolSize | objectOutputStreamPoolSize | Positive integer | 50 | Not used at the moment. |
Table 12.19. The <eviction /> Element
The <eviction /> Element | |
|---|---|
|
Description
|
This element controls how eviction works in the cache.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| EvictionConfig
|
Table 12.20. <eviction /> Attributes
<eviction /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| wakeUpInterval | wakeupInterval | integer | 5000 | The frequency with which the eviction thread runs, in milliseconds. If set to less than 1, the eviction thread never runs and is effectively disabled. |
Table 12.21. The <default /> Element
The <default /> Element | |
|---|---|
|
Description
|
This element defines the default eviction region.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| EvictionRegionConfig
|
Table 12.22. <default /> Attributes
<default /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| algorithmClass | evictionAlgorithmConfig | A valid class that is available on the classpath | none | This attribute needs to be specified if this tag is being used. Note that if being configured programmatically, the eviction algorithm's corresponding EvictionAlgorithmConfig file should be used instead. E.g., where you would use LRUAlgorithm in XML, you would use an instance of LRUAlgorithmConfig programmatically. |
| actionPolicyClass | evictionActionPolicyClassName | A valid class that is available on the classpath | DefaultEvictionActionPolicy | The eviction action policy class, defining what happens when a node needs to be evicted. |
| eventQueueSize | eventQueueSize (dynamic | integer | 200000 | The size of the bounded eviction event queue. |
Table 12.23. The <region /> Element
The <region /> Element | |
|---|---|
|
Description
|
This element defines an eviction region. Multiple instances of this tag can exist provided they have unique
name attributes.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
| EvictionRegionConfig
|
Table 12.24. <region /> Attributes
<region /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| name | regionFqn | A String that could be parsed using Fqn.fromString() | none | This should be a unique name that defines this region. See the Section 10.2, “Eviction Regions” for details of eviction regions. |
| algorithmClass | evictionAlgorithmConfig | A valid class that is available on the classpath | none | This attribute needs to be specified if this tag is being used. Note that if being configured programmatically, the eviction algorithm's corresponding EvictionAlgorithmConfig file should be used instead. E.g., where you would use LRUAlgorithm in XML, you would use an instance of LRUAlgorithmConfig programmatically. |
| actionPolicyClass | evictionActionPolicyClassName | A valid class that is available on the classpath | DefaultEvictionActionPolicy | The eviction action policy class, defining what happens when a node needs to be evicted. |
| eventQueueSize | eventQueueSize (dynamic | integer | 200000 | The size of the bounded eviction event queue. |
Table 12.25. The <property /> Element
The <property /> Element | |
|---|---|
|
Description
|
A mechanism of passing in name-value properties to the enclosing configuration element.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
Either direct setters or
setProperties() enclosing bean
|
Table 12.26. <property /> Attributes
<property /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| name | Either direct setters or setProperties() enclosing bean | String | none | Property name |
| value | Either direct setters or setProperties() enclosing bean | String | none | Property value |
Table 12.27. The <loaders /> Element
The <loaders /> Element | |
|---|---|
|
Description
|
Defines any cache loaders.
|
|
Parent
| |
|
Children
| Table 12.29, “The <preload /> Element”, Table 12.32, “The <loader /> Element” |
|
Bean equivalent
|
CacheLoaderConfig
|
Table 12.28. <loaders /> Attributes
<loaders /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| passivation | passivation | true, false | false | If true, cache loaders are used in passivation mode. See the Chapter 9, Cache Loaders for a detailed discussion on this. |
| shared | shared | true, false | false | If true, cache loaders are used in shared mode. See the Chapter 9, Cache Loaders for a detailed discussion on this. |
Table 12.29. The <preload /> Element
The <preload /> Element | |
|---|---|
|
Description
|
Defines preloading of Fqn subtrees when a cache starts up. This element has no attributes.
|
|
Parent
| |
|
Children
| Table 12.30, “The <node /> Element” |
|
Bean equivalent
|
CacheLoaderConfig
|
Table 12.30. The <node /> Element
The <node /> Element | |
|---|---|
|
Description
|
This element defines a subtree under which all content will be preloaded from the cache loaders when the cache starts. Multiple subtrees can be preloaded, although it only makes sense to define more than one subtree if they do not overlap.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
CacheLoaderConfig
|
Table 12.31. <node /> Attributes
<node /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| fqn | preload | String | none | An Fqn to preload. This should be a String that can be parsed with Fqn.fromString(). When doing this programmatically, you should create a single String containing all of the Fqns you wish to preload, separated by spaces, and pass that into CacheLoaderConfig.setPreload(). |
Table 12.32. The <loader /> Element
The <loader /> Element | |
|---|---|
|
Description
|
This element defines a cache loader. Multiple elements may be used to create cache loader chains.
|
|
Parent
| |
|
Children
| Table 12.34, “The <properties /> Element”, Table 12.35, “The <singletonStore /> Element” |
|
Bean equivalent
|
IndividualCacheLoaderConfig
|
Table 12.33. <loader /> Attributes
<loader /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| class | className | A valid class that is available on the classpath | none | A cache loader implementation to use. |
| async | async | true, false | false | All modifications to this cache loader happen asynchronously, on a separate thread. |
| fetchPersistentState | fetchPersistentState | true, false | false | When a cache starts up, retrieve persistent state from the cache loaders in other caches in the cluster. Only one loader element may set this to true. Also, only makes sense if the Table 12.40, “The <clustering /> Element” tag is present. |
| purgeOnStartup | purgeOnStartup | true, false | false | Purges this cache loader when it starts up. |
Table 12.34. The <properties /> Element
The <properties /> Element | |
|---|---|
|
Description
|
This element contains a set of properties that can be read by a
java.util.Properties instance. This tag has no attributes, and the contents of this tag will be parsed by Properties.load().
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
IndividualCacheLoaderConfig.setProperties()
|
Table 12.35. The <singletonStore /> Element
The <singletonStore /> Element | |
|---|---|
|
Description
|
This element configures the enclosing cache loader as a Section 9.2.1, “Singleton Store Configuration”.
|
|
Parent
| |
|
Children
| Table 12.34, “The <properties /> Element” |
|
Bean equivalent
|
SingletonStoreConfig
|
Table 12.36. <singletonStore /> Attributes
<singletonStore /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| class | className | A valid class that is available on the classpath | SingletonStoreCacheLoader | A singleton store wrapper implementation to use. |
| enabled | enabled | true, false | false | If true, the singleton store cache loader is enabled. |
Table 12.37. The <customInterceptors /> Element
The <customInterceptors /> Element | |
|---|---|
|
Description
|
This element allows you to define custom interceptors for the cache. This tag has no attributes.
|
|
Parent
| |
|
Children
| Table 12.38, “The <interceptor /> Element” |
|
Bean equivalent
|
None. At runtime, instantiate your own interceptor and pass it in to the cache using
Cache.addInterceptor().
|
Table 12.38. The <interceptor /> Element
The <interceptor /> Element | |
|---|---|
|
Description
|
This element allows you configure a custom interceptor. This tag may appear multiple times.
|
|
Parent
| |
|
Children
| Table 12.25, “The <property /> Element” |
|
Bean equivalent
|
None. At runtime, instantiate your own interceptor and pass it in to the cache using
Cache.addInterceptor().
|
Table 12.39. <interceptor /> Attributes
<interceptor /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| class | - | A valid class that is available on the classpath | none | An implementation of CommandInterceptor. |
| position | - | first, last | A position at which to place this interceptor in the chain. First is the first interceptor encountered when an invocation is made on the cache, last is the last interceptor before the call is passed on to the data structure. Note that this attribute is mutually exclusive with before, after and index. | |
| before | - | Fully qualified class name of an interceptor | Will place the new interceptor directly before the instance of the named interceptor. Note that this attribute is mutually exclusive with position, after and index. | |
| after | - | Fully qualified class name of an interceptor | Will place the new interceptor directly after the instance of the named interceptor. Note that this attribute is mutually exclusive with position, before and index. | |
| index | - | Positive integers | A position at which to place this interceptor in the chain, with 0 being the first position. Note that this attribute is mutually exclusive with position, before and after. |
Table 12.40. The <clustering /> Element
The <clustering /> Element | |
|---|---|
|
Description
|
If this element is present, the cache is started in clustered mode. Attributes and child elements define clustering characteristics.
|
|
Parent
| |
|
Children
| Table 12.46, “The <stateRetrieval /> Element”, Table 12.42, “The <sync /> Element”, Table 12.44, “The <async /> Element”, Table 12.48, “The <buddy /> Element”, Table 12.54, “The <jgroupsConfig /> Element” |
|
Bean equivalent
|
Configuration
|
Table 12.41. <clustering /> Attributes
<clustering /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| mode | cacheMode | replication, invalidation, r, i | replication | See the Chapter 8, Cache Modes and Clustering for the differences between replication and invalidation. When using the bean, synchronous and asynchronous communication is combined with clustering mode to give you the enumberation Configuration.CacheMode. |
| clusterName | clusterName | String | JBossCache-cluster | A cluster name which is used to identify the cluster to join. |
Table 12.42. The <sync /> Element
The <sync /> Element | |
|---|---|
|
Description
|
If this element is present, all communications are synchronous, in that whenever a thread sends a message sent over the wire, it blocks until it receives an acknowledgement from the recipient. This element is mutually exclusive with the Table 12.44, “The
<async /> Element” element.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
Configuration.setCacheMode()
|
Table 12.43. <sync /> Attributes
<sync /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| replTimeout | syncReplTimeout (dynamic) | positive integer | 15000 | This is the timeout used to wait for an acknowledgement when making a remote call, after which an exception is thrown. |
Table 12.44. The <async /> Element
The <async /> Element | |
|---|---|
|
Description
|
If this element is present, all communications are asynchronous, in that whenever a thread sends a message sent over the wire, it does not wait for an acknowledgement before returning. This element is mutually exclusive with the Table 12.42, “The
<sync /> Element” element.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
Configuration.setCacheMode()
|
Table 12.45. <async /> Attributes
<async /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| serializationExecutorPoolSize | serializationExecutorPoolSize | positive integer | 25 | In addition to replication happening asynchronously, even serialization of contents for replication happens in a separate thread to allow the caller to return as quickly as possible. This setting controls the size of the serializer thread pool. Setting this to any value less than 1 means serialization does not happen asynchronously. |
| serializationExecutorQueueSize | serializationExecutorQueueSize | positive integer | 50000 | This is used to define the size of the bounded queue that holds tasks for the serialization executor. This is ignored if a serialization executor is not used, such as when serializationExecutorPoolSize is less than 1. |
| useReplQueue | useReplQueue | true, false | false | If true, this forces all async communications to be queued up and sent out periodically as a batch. |
| replQueueInterval | replQueueInterval | positive integer | 5000 | If useReplQueue is set to true, this attribute controls how often the asynchronous thread used to flush the replication queue runs. This should be a positive integer which represents thread wake time in milliseconds. |
| replQueueMaxElements | replQueueMaxElements | positive integer | 1000 | If useReplQueue is set to true, this attribute can be used to trigger flushing of the queue when it reaches a specific threshold. |
Table 12.46. The <stateRetrieval /> Element
The <stateRetrieval /> Element | |
|---|---|
|
Description
|
This tag controls ho state is retrieved from neighboring caches when this cache instance starts.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
Configuration
|
Table 12.47. <stateRetrieval /> Attributes
<stateRetrieval /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| fetchInMemoryState | fetchInMemoryState | true, false | true | If true, this will cause the cache to ask neighboring caches for state when it starts up, so the cache starts "warm". |
| timeout | stateRetrievalTimeout | positive integer | 10000 | This is the maximum amount of time - in milliseconds - to wait for state from neighboring caches, before throwing an exception and aborting start up. |
| nonBlocking | useNonBlockingStateTransfer | true, false | false | This configuration switch enables the Non-Blocking State Transfer mechanism, new in 3.1.0. Note that this requires MVCC as a node locking scheme, and that STREAMING_STATE_TRANSFER is present in the JGroups stack used. |
Table 12.48. The <buddy /> Element
The <buddy /> Element | |
|---|---|
|
Description
|
If this tag is present, then state is not replicated across the entire cluster. Instead, buddy replication is used to select cache instances to maintain backups on. See Section 8.1.2.2, “Buddy Replication” for details. Note that this is only used if the clustering mode is
replication, and not if it is invalidation.
|
|
Parent
| |
|
Children
| Table 12.50, “The <dataGravitation /> Element”, Table 12.52, “The <locator /> Element”, |
|
Bean equivalent
|
BuddyReplicationConfig
|
Table 12.49. <buddy /> Attributes
<buddy /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| enabled | enabled | true, false | false | If true, buddy replication is enabled. |
| communicationTimeout | buddyCommunicationTimeout | positive integer | 10000 | This is the maximum amount of time - in milliseconds - to wait for buddy group organization communications from buddy caches. |
| poolName | buddyPoolName | String | This is used as a means to identify cache instances and provide hints to the buddy selection algorithms. More information on Section 8.1.2.2, “Buddy Replication”. |
Table 12.50. The <dataGravitation /> Element
The <dataGravitation /> Element | |
|---|---|
|
Description
|
This tag configures how data gravitation is conducted. See Section 8.1.2.2, “Buddy Replication” for details.
|
|
Parent
| |
|
Children
| |
|
Bean equivalent
|
BuddyReplicationConfig
|
Table 12.51. <dataGravitation /> Attributes
<dataGravitation /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| auto | autoDataGravitation | true, false | true | If true, when a get() is performed on a cache and nothing is found, a gravitation from neighboring caches is attempted. If this is false, then gravitations can only occur if the Option.setForceDataGravitation() option is provided. |
| removeOnFind | dataGravitationRemoveOnFind | true, false | true | If true, when gravitation occurs, the instance that requests the gravitation takes ownership of the state and requests that all other instances remove the gravitated state from memory. |
| searchBackupTrees | dataGravitationSearchBackupTrees | true, false | true | If true, incoming gravitation requests will cause the cache to search not just its primary data structure but its backup structure as well. |
Table 12.52. The <locator /> Element
The <locator /> Element | |
|---|---|
|
Description
|
This tag provides a pluggable mechanism for providing buddy location algorithms.
|
|
Parent
| |
|
Children
| Table 12.34, “The <properties /> Element” |
|
Bean equivalent
|
BuddyLocatorConfig
|
Table 12.53. <locator /> Attributes
<locator /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| class | className | A valid class that is available on the classpath | NextMemberBuddyLocator | A BuddyLocator implementation to use when selecting buddies from the cluster. Please refer to BuddyLocator javadocs for details. |
Table 12.54. The <jgroupsConfig /> Element
The <jgroupsConfig /> Element | |
|---|---|
|
Description
|
This tag provides a configuration which is used with JGroups to create a network communication channel.
|
|
Parent
| |
|
Children
| A series of elements representing JGroups protocols (see JGroups documentation). Note that there are no child elements if any of the element attributes are used instead. See section on attributes. |
|
Bean equivalent
|
Configuration
|
Table 12.55. <jgroupsConfig /> Attributes
<jgroupsConfig /> Attributes | ||||
|---|---|---|---|---|
| Attribute | Bean Field | Allowed | Default | Description |
| configFile | clusterConfig | A JGroups configuration file on the classpath | udp.xml | If this attribute is used, then any JGroups elements representing protocols within this tag are ignored. Instead, JGroups settings are read from the file specified. Note that this cannot be used with the multiplexerStack attribute. |
| multiplexerStack | muxStackName | A valid multiplexer stack name that exists in the channel factory passed in to the RuntimeConfig | This can only be used with the RuntimeConfig, where you pass in a JGroups ChannelFactory instance using RuntimeConfig.setMuxChannelFactory(). If this attribute is used, then any JGroups elements representing protocols within this tag are ignored. Instead, the JGroups channel is created using the factory passed in. Note that this cannot be used with the configFile attribute. |
Chapter 13. JMX References
13.1. JBoss Cache Statistics
Table 13.1. JBoss Cache JMX MBeans
| MBean | Attribute/Operation Name | Description |
|---|---|---|
| DataContainerImpl | getNumberOfAttributes() | Returns the number of attributes in all nodes in the data container |
| getNumberOfNodes() | Returns the number of nodes in the data container | |
| printDetails() | Prints details of the data container | |
| RPCManagerImpl | localAddressString | String representation of the local address |
| membersString | String representation of the cluster view | |
| statisticsEnabled | Whether RPC statistics are being gathered | |
| replicationCount | Number of successful replications | |
| replicationFailures | Number of failed replications | |
| successRatio | RPC call success ratio | |
| RegionManagerImpl | dumpRegions() | Dumps a String representation of all registered regions, including eviction regions depicting their event queue sizes |
| numRegions | Number of registered regions | |
| BuddyManager | buddyGroup | A String representation of the cache's buddy group |
| buddyGroupsIParticipateIn | String representations of all buddy groups the cache participates in | |
| TransactionTable | numberOfRegisteredTransactions | The number of registered, ongoing transactions |
| transactionMap | A String representation of all currently registered transactions mapped to internal GlobalTransaction instances | |
| MVCCLockManager | concurrencyLevel | The configured concurrency level |
| numberOfLocksAvailable | Number of locks in the shared lock pool that are not used | |
| numberOfLocksHeld | Number of locks in the shared lock pool that are in use | |
| testHashing(String fqn) | Tests the spreading of locks across Fqns. For a given (String based) Fqn, this method returns the index in the lock array that it maps to. | |
| ActivationInterceptor | Activations | Number of passivated nodes that have been activated. |
| CacheLoaderInterceptor | CacheLoaderLoads | Number of nodes loaded through a cache loader. |
| CacheLoaderMisses | Number of unsuccessful attempts to load a node through a cache loader. | |
| CacheMgmtInterceptor | Hits | Number of successful attribute retrievals. |
| Misses | Number of unsuccessful attribute retrievals. | |
| Stores | Number of attribute store operations. | |
| Evictions | Number of node evictions. | |
| NumberOfAttributes | Number of attributes currently cached. | |
| NumberOfNodes | Number of nodes currently cached. | |
| ElapsedTime | Number of seconds that the cache has been running. | |
| TimeSinceReset | Number of seconds since the cache statistics have been reset. | |
| AverageReadTime | Average time in milliseconds to retrieve a cache attribute, including unsuccessful attribute retrievals. | |
| AverageWriteTime | Average time in milliseconds to write a cache attribute. | |
| HitMissRatio | Ratio of hits to hits and misses. A hit is a get attribute operation that results in an object being returned to the client. The retrieval may be from a cache loader if the entry is not in the local cache. | |
| ReadWriteRatio | Ratio of read operations to write operations. This is the ratio of cache hits and misses to cache stores. | |
| CacheStoreInterceptor | CacheLoaderStores | Number of nodes written to the cache loader. |
| InvalidationInterceptor | Invalidations | Number of cached nodes that have been invalidated. |
| PassivationInterceptor | Passivations | Number of cached nodes that have been passivated. |
| TxInterceptor | Prepares | Number of transaction prepare operations performed by this interceptor. |
| Commits | Number of transaction commit operations performed by this interceptor. | |
| Rollbacks | Number of transaction rollbacks operations performed by this interceptor. | |
| numberOfSyncsRegistered | Number of synchronizations registered with the transaction manager pending completion and removal. |
13.2. JMX MBean Notifications
CacheJmxWrapper MBean. Each notification represents a single event published by JBoss Cache and provides user data corresponding to the parameters of the event.
Table 13.2. JBoss Cache MBean Notifications
| Notification Type | Notification Data | CacheListener Event |
|---|---|---|
| org.jboss.cache.CacheStarted | String: cache service name | @CacheStarted |
| org.jboss.cache.CacheStopped | String: cache service name | @CacheStopped |
| org.jboss.cache.NodeCreated | String: fqn, boolean: isPre, boolean: isOriginLocal | @NodeCreated |
| org.jboss.cache.NodeEvicted | String: fqn, boolean: isPre, boolean: isOriginLocal | @NodeEvicted |
| org.jboss.cache.NodeLoaded | String: fqn, boolean: isPre | @NodeLoaded |
| org.jboss.cache.NodeModifed | String: fqn, boolean: isPre, boolean: isOriginLocal | @NodeModifed |
| org.jboss.cache.NodeRemoved | String: fqn, boolean: isPre, boolean: isOriginLocal | @NodeRemoved |
| org.jboss.cache.NodeVisited | String: fqn, boolean: isPre | @NodeVisited |
| org.jboss.cache.ViewChanged | String: view | @ViewChanged |
| org.jboss.cache.NodeActivated | String: fqn | @NodeActivated |
| org.jboss.cache.NodeMoved | String: fromFqn, String: toFqn, boolean: isPre | @NodeMoved |
| org.jboss.cache.NodePassivated | String: fqn | @NodePassivated |
Appendix A. Revision History
| Revision History | ||||
|---|---|---|---|---|
| Revision 5.2.0-100.400 | 2013-10-30 | |||
| ||||
| Revision 5.2.0-100 | Wed 23 Jan 2013 | |||
| ||||
| Revision 5.1.2-100 | Thu Dec 8 2011 | |||
| ||||
| Revision 5.1.1-100 | Mon Jul 18 2011 | |||
| ||||
| Revision 5.1.0-100 | Wed Sep 15 2010 | |||
| ||||