
分布式计算节点和存储部署
部署 Red Hat OpenStack Platform 分布式计算节点技术
摘要
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 信息 . :leveloffset: +0
对红帽文档提供反馈
我们感谢您对文档提供反馈信息。与我们分享您的成功秘诀。
使用直接文档反馈(DDF)功能
使用 添加反馈 DDF 功能,用于特定句子、段落或代码块上的直接注释。
- 以 Multi-page HTML 格式查看文档。
- 请确定您看到文档右上角的 反馈 按钮。
- 用鼠标指针高亮显示您想评论的文本部分。
- 点 添加反馈。
- 在添加反馈项中输入您的意见。
- 可选:添加您的电子邮件地址,以便文档团队可以联系您以讨论您的问题。
- 点 Submit。
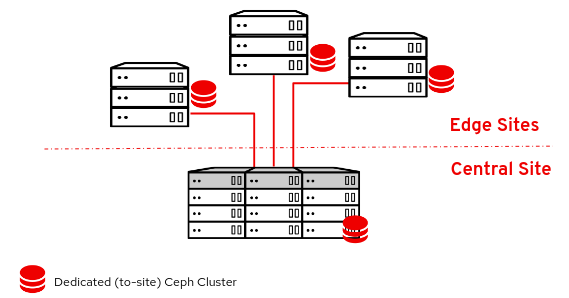
第 1 章 了解 DCN
分布式计算节点(DCN)架构适用于边缘用例,允许在共享常见的中央化 control plane 时远程部署远程计算节点。DCN 架构允许您定位更接近操作需求的工作负载,以提高性能。
中央位置可由任何角色组成,但至少需要三个控制器。Compute 节点可以存在于边缘,也可存在于中央位置。
DCN 架构是一个 hub 和 spoke 路由网络部署。DCN 与使用 Red Hat OpenStack Platform director 路由置备和 control plane 网络相关的 spine 和 leaf 部署类似。
- hub 是包含核心路由器和数据中心网关(DC-GW)的中央网站。
- spoke 是远程边缘或页(leaf)。
边缘位置没有控制器,使其架构与 Red Hat OpenStack Platform 的传统部署不同:
- control plane 服务在中央位置远程运行。
- 没有安装 Pacemaker。
- 块存储服务(cinder)以主动/主动模式运行。
- etcd 部署为分布式锁定管理器(DLM)。
1.1. 分布式计算节点架构所需的软件
下表显示了在分布式计算节点(DCN)架构中部署 Red Hat OpenStack Platform 所需的软件和最小版本:
| 平台 | 版本 | 选填 |
|---|---|---|
| Red Hat Enterprise Linux | 8 | 否 |
| Red Hat OpenStack Platform | 16.1 | 否 |
| Red Hat Ceph Storage | 4 | 是 |
1.2. 多堆栈设计
当您使用 DCN 设计部署 Red Hat OpenStack Platform (RHOSP)时,您可以使用 Red Hat director 的功能进行多个堆栈部署和管理,将每个站点部署为不同的堆栈。
不支持将 DCN 架构作为单一堆栈进行管理,除非部署是从 Red Hat OpenStack Platform 13 的升级。不支持分割现有堆栈的方法,但您可以将堆栈添加到预先存在的部署中。更多信息请参阅 第 A.3 节 “迁移到多堆栈部署”。
中央位置是 RHOSP 的传统堆栈部署,但您不需要使用中央堆栈部署 Compute 节点或 Red Hat Ceph 存储。
使用 DCN 时,您可以将每个位置部署为不同的可用区(AZ)。
1.3. DCN 存储
您可以在超融合节点上部署每个边缘站点,可以是没有存储,也可以使用 Ceph 部署。您部署的存储专用于您部署到的站点。
DCN 架构使用 Glance 多存储。对于在没有存储的情况下部署的边缘站点,提供了额外的工具,以便您可以在计算服务(nova)缓存中缓存和存储镜像。nova 中的缓存 glance 镜像通过避免在 WAN 链接中下载镜像的过程,为实例提供更快的引导时间。更多信息请参阅 第 9 章 将 glance 镜像预缓存到 nova。
1.4. DCN edge
使用分布式 Compute 节点架构时,中央位置使用管理边缘位置的控制节点进行部署。当您部署边缘位置时,您将仅部署计算节点,使边缘站点架构与 Red Hat OpenStack Platform 的传统部署不同。在边缘位置:
- control plane 服务在中央位置远程运行。
- Pacemaker 不在 DCN 站点中运行。
- 块存储服务(cinder)以主动/主动模式运行。
- etcd 部署为分布式锁定管理器(DLM)。
第 2 章 规划分布式 Compute 节点(DCN)部署
在规划 DCN 架构时,请检查您需要的技术是否可用并支持。
2.1. DCN 架构存储注意事项
DCN 架构目前不支持以下功能:
- 从 Red Hat OpenStack Platform 13 都 16,在分布式计算节点架构中快进更新 (FFU)。
- 边缘站点非超融合存储节点。
- 在边缘站点间复制卷快照。您可以通过从卷创建镜像并使用 glance 复制镜像来解决这个问题。复制镜像后,您可以从其中创建卷。
- 在站点之间迁移或重新处理卷。
- 边缘的 Ceph Rados 网关(RGW)
- CephFS 位于边缘。
- 边缘站点上的实例高可用性(HA)。
- 站点之间的 RBD 镜像。
-
实例迁移、实时或冷站点,也可从中央位置到边缘站点。您仍然可以在站点边界内迁移实例。要在站点之间移动镜像,您必须对镜像进行快照,并使用
glance image-import。如需更多信息,请参阅 确认可以在站点之间创建和复制镜像快照。
另外,您必须考虑以下几点:
- 您必须将镜像上传到中央位置,然后才能将镜像复制到边缘站点;每个镜像的副本必须存在于中央位置的镜像服务(glance)中。
- 在边缘站点创建实例前,您必须在该边缘站点具有镜像的本地副本。
- 您必须将 RBD 存储驱动程序用于 Image、Compute 和 Block Storage 服务。
- 对于每个站点,分配一个唯一可用区,并将相同的值用于 NovaComputeAvailabilityZone 和 CinderStorageAvailabilityZone 参数。
2.2. DCN 架构上的网络注意事项
DCN 架构目前不支持以下功能:
- Octavia
- DPDK 节点上的 DHCP
- conntrack 用于 TC Flower Hardware Offload
ML2/OVN 机制驱动程序作为技术预览在 DCN 上提供,因此红帽不完全支持使用这些解决方案。此功能应该只用于 DCN 进行测试,不应在生产环境中部署。如需有关技术预览功能的更多信息,请参阅覆盖范围详情。
在 DCN 环境之外完全支持 ML2/OVN 机制驱动程序。
ML2/OVS 支持以下网络技术:
- DPDK 节点上没有 DHCP 的 DPDK
- SR-IOV
- TC Flower 硬件卸载,没有 conntrack
- 边缘使用网络器节点的 Neutron 可用区(AZ),每个站点的 AZ
- 路由供应商网络
另外,您必须考虑以下几点:
- 网络延迟:根据往返时间(RTT)来测量延迟,以及预期的并发 API 操作数来保持可接受的性能。最大 TCP/IP 吞吐量与 RTT 相反。您可以通过调整内核 TCP 参数来降低带有高带宽的高延迟连接的一些问题。如果跨站点通信超过 100 ms,则红帽支持红帽支持。
- Network drop outs:如果边缘站点暂时丢失与中央站点的连接,则在停机期间无法在受影响的边缘站点内执行 OpenStack control plane API 或 CLI 操作。例如,边缘站点上的 Compute 节点无法创建实例的快照、发布身份验证令牌或删除镜像。常规 OpenStack control plane API 和 CLI 操作在此中断过程中仍然可以正常工作,并可继续为具有工作连接的任何其他边缘站点提供服务。镜像类型:在使用 Ceph 存储部署 DCN 架构时,您必须使用 raw 镜像。
镜像大小:
- Overcloud 节点镜像 - 从中央 undercloud 节点下载 overcloud 节点镜像。这些镜像可能是大型文件,在调配期间,所有必要网络将从中央站点传输到边缘站点。
实例镜像:如果没有边缘的块存储,则镜像服务镜像会在第一次使用过程中遍历 WAN。镜像会在本地复制到目标边缘节点,以便随后使用。glance 镜像没有大小限制。传输时间因可用带宽和网络延迟而异。
如果边缘存在块存储,则镜像将通过 WAN 异步复制,以便更快地在边缘引导时复制。
- 提供商网络:这是 DCN 部署的建议网络方法。如果您在远程站点中使用提供商网络,那么您必须考虑网络服务(neutron)不会放置任何限制或检查您可以附加可用网络的位置。例如,如果您只在边缘站点 A 中使用提供商网络,您必须确保不要尝试附加到边缘站点 B 中的提供商网络。这是因为,将其绑定到 Compute 节点时,供应商网络中没有验证检查。
- 特定于站点的网络:如果您使用特定于特定站点的网络,则 DCN 网络中会出现一个限制:当您使用 Compute 节点部署集中式 neutron 控制器时,neutron 中没有触发器将特定的 Compute 节点识别为远程节点。因此,计算节点接收其他 Compute 节点列表,并在彼此之间自动形成隧道;隧道从边缘到边缘,通过中央站点从边缘到边缘。如果您使用 VXLAN 或 Geneve,每个站点中的每个 Compute 节点都会与所有其他 Compute 节点和 Controller 节点组成一个隧道,无论它们是本地还是远程节点。如果您在任何位置使用相同的 neutron 网络,则这不是问题。使用 VLAN 时,neutron 期望所有 Compute 节点具有相同的网桥映射,并且所有 VLAN 都位于每个站点。
- 其他站点:如果您需要从中央站点扩展到额外的远程站点,您可以使用 Red Hat OpenStack Platform director 上的 openstack CLI 来添加新的网络段和子网。
- 如果边缘服务器没有被预置备,您必须配置 DHCP 转发,以便在路由片段上内省和置备。
- 路由必须在云或将每个边缘站点连接到 hub 的网络基础架构中配置。您应该实施网络设计,为每个 Red Hat OpenStack Platform 集群网络(外部、内部 API 等)分配 L3 子网,每个站点都是唯一的。
2.3. 边缘的存储拓扑和角色
当您使用分布式计算节点架构部署 Red Hat OpenStack 平台时,您必须决定是否需要边缘存储。根据存储和性能需求,您可以使用三种配置之一部署每个站点。并非所有边缘站点都必须具有相同的配置。
如果没有在边缘部署块存储,您必须遵循文档 第 6.1 节 “在没有存储的情况下部署边缘节点” 部分。如果边缘站点没有块存储:
- Swift 用作 Glance 后端
- 边缘上的计算节点可能仅缓存镜像。
- 边缘站点没有 Cinder 等卷服务。
如果您计划在任何位置在边缘部署存储,还必须在中央位置部署块存储。按照文档 第 5.2 节 “使用存储部署中央站点” 部分操作。如果边缘站点中存在块存储:
- Ceph RBD 用作 Glance 后端
- 镜像可以存储在边缘站点
- Cinder 卷服务可通过 Ceph RBD 驱动程序获得。
部署所需的角色会根据您在边缘部署块存储的不同而有所不同:
边缘不需要块存储 :
- Compute
-
当您在没有块存储的情况下部署边缘位置时,请使用传统的
compute角色。
边缘需要块存储 :
- DistributedComputeHCI
此角色包括以下内容:
- 默认计算服务
- Block Storage (cinder)卷服务
- Ceph Mon
- Ceph Mgr
- Ceph OSD
- GlanceApiEdge
Etcd
此角色在边缘启用超融合部署。使用
DistributedComputeHCI角色时,您必须使用三个节点。
- DistributedComputeHCIScaleOut
-
此角色包含
Ceph OSD服务,允许在添加更多节点到边缘时通过计算资源扩展存储容量。此角色还包括HAproxyEdge服务,用于将镜像下载请求重定向到边缘站点的GlanceAPIEdge节点。 - DistributedComputeScaleOut
-
如果要在没有存储的情况下在边缘扩展计算资源,您可以使用
DistributedComputeScaleOut角色。
第 3 章 在 undercloud 中配置路由 spine-leaf
本节论述了如何配置 undercloud 以容纳与可组合网络相关的路由热插拔的用例。
3.1. 配置 spine leaf provisioning 网络
要为 spine leaf 基础架构配置 provisioning 网络,请编辑 undercloud.conf 文件并设置以下流程中包含的相关参数。
流程
-
以
stack用户的身份登录 undercloud。 如果您还没有
undercloud.conf文件,请复制示例模板文件:[stack@director ~]$ cp /usr/share/python-tripleoclient/undercloud.conf.sample ~/undercloud.conf
-
编辑
undercloud.conf文件。 在
[DEFAULT]部分中设置以下值:将
local_ip设置为leaf0上的 undercloud IP:local_ip = 192.168.10.1/24
将
undercloud_public_host设置为 undercloud 的面向外部的 IP 地址:undercloud_public_host = 10.1.1.1
将
undercloud_admin_host设置为 undercloud 的管理 IP 地址。这个 IP 地址通常位于 leaf0 上:undercloud_admin_host = 192.168.10.2
将
local_interface设置为本地网络的桥接接口:local_interface = eth1
将
enable_routed_networks设置为true:enable_routed_networks = true
使用
subnets参数定义子网列表。在路由 spine 和 leaf 中为每个 L2 片段定义一个子网:subnets = leaf0,leaf1,leaf2
使用
local_subnet参数指定与 undercloud 本地的物理 L2 段关联的子网:local_subnet = leaf0
设置
undercloud_nameservers的值。undercloud_nameservers = 10.11.5.19,10.11.5.20
提示您可以通过查看 /etc/resolv.conf 来查找用于 undercloud 名称服务器的 DNS 服务器的当前 IP 地址。
为您在
subnets参数中定义的每个子网创建一个新部分:[leaf0] cidr = 192.168.10.0/24 dhcp_start = 192.168.10.10 dhcp_end = 192.168.10.90 inspection_iprange = 192.168.10.100,192.168.10.190 gateway = 192.168.10.1 masquerade = False [leaf1] cidr = 192.168.11.0/24 dhcp_start = 192.168.11.10 dhcp_end = 192.168.11.90 inspection_iprange = 192.168.11.100,192.168.11.190 gateway = 192.168.11.1 masquerade = False [leaf2] cidr = 192.168.12.0/24 dhcp_start = 192.168.12.10 dhcp_end = 192.168.12.90 inspection_iprange = 192.168.12.100,192.168.12.190 gateway = 192.168.12.1 masquerade = False
-
保存
undercloud.conf文件。 运行 undercloud 安装命令:
[stack@director ~]$ openstack undercloud install
此配置在 provisioning 网络或 control plane 上创建三个子网。overcloud 使用每个网络来置备每个对应叶中的系统。
为确保正确将 DHCP 请求转发到 undercloud,您可能需要配置 DHCP 转发。
3.2. 配置 DHCP 转发
您可以在连接到要转发请求的远程网络段的交换机、路由器或服务器上运行 DHCP 转发服务。
不要在 undercloud 上运行 DHCP 转发服务。
undercloud 在 provisioning 网络中使用两个 DHCP 服务器:
- 内省 DHCP 服务器。
- 置备 DHCP 服务器。
您必须将 DHCP 转发配置为将 DHCP 请求转发到 undercloud 上的两个 DHCP 服务器。
您可以将 UDP 广播与支持它的设备一起使用,将 DHCP 请求转发到 undercloud 置备网络的 L2 网络段。或者,您可以使用 UDP 单播,将 DHCP 请求转发到特定的 IP 地址。
在特定设备类型中配置 DHCP 转发超出了本文档的范围。作为参考,本文档提供了使用 ISC DHCP 软件中的实现的 DHCP 转发配置示例。如需更多信息,请参阅手册页 dhcrelay (8)。
某些中继需要 DHCP 选项 79,特别是提供 DHCPv6 地址的转发,以及不通过原始 MAC 地址的中继。如需更多信息,请参阅 RFC6939。
广播 DHCP 转发
此方法使用 UDP 广播流量将 DHCP 请求转发到 DHCP 服务器或服务器所在的 L2 网络段。网络段上的所有设备都会接收广播流量。使用 UDP 广播时,undercloud 上的两个 DHCP 服务器都会接收中继的 DHCP 请求。根据实现,您可以通过指定接口或 IP 网络地址来配置它:
- Interface
- 指定连接到 DHCP 请求中继的 L2 网络段的接口。
- IP 网络地址
- 指定 DHCP 请求转发的 IP 网络的网络地址。
单播 DHCP 转发
此方法使用 UDP 单播流量将 DHCP 请求转发到特定的 DHCP 服务器。当使用 UDP 单播时,您需要配置一个设备,这个设备为转发 DHCP 请求进行转发到在 undercloud 中进行内省的接口所分配的 IP地址,以及 OpenStack Networking (neutron) 服务创建用于为 ctlplane 网络托管 DHCP 服务的网络命名空间的 IP 地址。
用于内省的接口是在 undercloud.conf 文件中定义为 inspection_interface 的接口。如果没有设置此参数,undercloud 的默认接口为 br-ctlplane。
使用 br-ctlplane 接口进行内省很常见。您在 undercloud.conf 文件中定义为 local_ip 的 IP 地址位于 br-ctlplane 接口上。
分配给 Neutron DHCP 命名空间的 IP 地址是您为 undercloud.conf 文件中的 local_subnet 配置的 IP 范围中的第一个地址。IP 范围中的第一个地址是您在配置中定义为 dhcp_start 的地址。例如,如果您使用以下配置,则 192.168.10.10 是 IP 地址:
[DEFAULT] local_subnet = leaf0 subnets = leaf0,leaf1,leaf2 [leaf0] cidr = 192.168.10.0/24 dhcp_start = 192.168.10.10 dhcp_end = 192.168.10.90 inspection_iprange = 192.168.10.100,192.168.10.190 gateway = 192.168.10.1 masquerade = False
DHCP 命名空间的 IP 地址会被自动分配。在大多数情况下,这个地址是 IP 范围中的第一个地址。要验证是否是这种情况,请在 undercloud 上运行以下命令:
$ openstack port list --device-owner network:dhcp -c "Fixed IP Addresses" +----------------------------------------------------------------------------+ | Fixed IP Addresses | +----------------------------------------------------------------------------+ | ip_address='192.168.10.10', subnet_id='7526fbe3-f52a-4b39-a828-ec59f4ed12b2' | +----------------------------------------------------------------------------+ $ openstack subnet show 7526fbe3-f52a-4b39-a828-ec59f4ed12b2 -c name +-------+--------+ | Field | Value | +-------+--------+ | name | leaf0 | +-------+--------+
dhcrelay 配置示例
在以下示例中,dhcp 软件包中的 dhcrelay 命令使用以下配置:
-
转发传入的 DHCP 请求的接口:
eth1、eth2和eth3。 -
网络接口网络段上的 undercloud DHCP 服务器连接到
eth0。 -
用于内省的 DHCP 服务器正在侦听 IP 地址
:192.168.1680.1。 -
用于置备的 DHCP 服务器侦听 IP 地址
192.168.10.10。
这会生成以下 dhcrelay 命令:
dhcrelay版本 4.2.x:$ sudo dhcrelay -d --no-pid 192.168.10.10 192.168.10.1 \ -i eth0 -i eth1 -i eth2 -i eth3
dhcrelay版本 4.3.x 及更新的版本:$ sudo dhcrelay -d --no-pid 192.168.10.10 192.168.10.1 \ -iu eth0 -id eth1 -id eth2 -id eth3
Cisco IOS 路由交换机配置示例
这个示例使用以下 Cisco IOS 配置来执行以下任务:
- 配置 VLAN 以用于 provisioning 网络。
- 添加叶的 IP 地址。
-
将 UDP 和 BOOTP 请求转发到侦听 IP 地址的内省 DHCP 服务器:
192.168.10.1。 -
将 UDP 和 BOOTP 请求转发到侦听 IP 地址
192.168.10.10的调配 DHCP 服务器。
interface vlan 2 ip address 192.168.24.254 255.255.255.0 ip helper-address 192.168.10.1 ip helper-address 192.168.10.10 !
现在,您已配置了 provisioning 网络,您可以配置剩余的 overcloud leaf 网络。
3.3. 为叶网络创建类别和标记节点
每个叶网络中的每个角色都需要一个类别和角色分配,以便您可以将节点标记为对应的叶。完成以下步骤以创建各个类别并将其分配到角色。
流程
Source
stackrc文件:[stack@director ~]$ source ~/stackrc
为每个自定义角色创建类别:
$ ROLES="control compute_leaf0 compute_leaf1 compute_leaf2 ceph-storage_leaf0 ceph-storage_leaf1 ceph-storage_leaf2" $ for ROLE in $ROLES; do openstack flavor create --id auto --ram <ram_size_mb> --disk <disk_size_gb> --vcpus <no_vcpus> $ROLE ; done $ for ROLE in $ROLES; do openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property resources:DISK_GB='0' --property resources:MEMORY_MB='0' --property resources:VCPU='0' $ROLE ; done
-
将
<ram_size_mb>替换为裸机节点的 RAM,以 MB 为单位。 -
将
<disk_size_gb>替换为裸机节点中的磁盘大小(以 GB 为单位)。 -
将
<no_vcpus>替换为裸机节点中的 CPU 数量。
-
将
检索节点列表来识别它们的 UUID:
(undercloud)$ openstack baremetal node list
使用自定义资源类将每个裸机节点标记为其叶网络和角色:
(undercloud)$ openstack baremetal node set \ --resource-class baremetal.LEAF-ROLE <node>
将
<node>替换为裸机节点的 ID。例如,输入以下命令将带有 UUID
58c3d07e-24f2-48a7-bbb6-6843f0e8ee13的节点标记为 Leaf2 上的 Compute 角色:(undercloud)$ openstack baremetal node set \ --resource-class baremetal.COMPUTE-LEAF2 58c3d07e-24f2-48a7-bbb6-6843f0e8ee13
将每个叶网络角色类别与自定义资源类关联:
(undercloud)$ openstack flavor set \ --property resources:CUSTOM_BAREMETAL_LEAF_ROLE=1 \ <custom_role>
要确定与裸机置备服务节点的资源类对应的自定义资源类的名称,请将资源类转换为大写,请将每个 punctuation 标记替换为下划线,并将前缀替换为
CUSTOM_。注意类别只能请求一个裸机资源类实例。
在
node-info.yaml文件中,指定要用于每个自定义叶角色的类别,以及为每个自定义叶角色分配的节点数量。例如,以下配置指定要使用的类别,以及为compute_leaf0,compute_leaf1,compute_leaf2,ceph-storage_leaf0,ceph-storage_leaf1, 和ceph-storage_leaf2自定义叶角色分配的节点数量:parameter_defaults: OvercloudControllerFlavor: control OvercloudComputeLeaf0Flavor: compute_leaf0 OvercloudComputeLeaf1Flavor: compute_leaf1 OvercloudComputeLeaf2Flavor: compute_leaf2 OvercloudCephStorageLeaf0Flavor: ceph-storage_leaf0 OvercloudCephStorageLeaf1Flavor: ceph-storage_leaf1 OvercloudCephStorageLeaf2Flavor: ceph-storage_leaf2 ControllerLeaf0Count: 3 ComputeLeaf0Count: 3 ComputeLeaf1Count: 3 ComputeLeaf2Count: 3 CephStorageLeaf0Count: 3 CephStorageLeaf1Count: 3 CephStorageLeaf2Count: 3
3.4. 将裸机节点端口映射到 control plane 网络片段
要在 L3 路由网络中启用部署,您必须在裸机端口上配置 physical_network 字段。每个裸机端口都与 OpenStack Bare Metal (ironic)服务中的裸机节点关联。物理网络名称是您在 undercloud 配置中的 subnets 选项中包含的名称。
在 undercloud.conf 文件中指定为 local_subnet 子网的物理网络名称始终被命名为 ctlplane。
流程
Source
stackrc文件:$ source ~/stackrc
检查裸机节点:
$ openstack baremetal node list
确保裸机节点处于 Register 或
manageablephysical_network属性的命令会失败。要将所有节点设置为manageable状态,请运行以下命令:$ for node in $(openstack baremetal node list -f value -c Name); do openstack baremetal node manage $node --wait; done
检查哪个 baremetal 端口与哪个 baremetal 节点关联:
$ openstack baremetal port list --node <node-uuid>
为端口设置
physical-network参数。在以下示例中,在配置中定义三个子网:leaf0,leaf1, 和leaf2。local_subnet 是leaf0。由于local_subnet的物理网络始终为ctlplane,因此连接到leaf0的 baremetal 端口使用 ctlplane。剩余的端口使用其他 leaf 名称:$ openstack baremetal port set --physical-network ctlplane <port-uuid> $ openstack baremetal port set --physical-network leaf1 <port-uuid> $ openstack baremetal port set --physical-network leaf2 <port-uuid>
在部署 overcloud 前内省节点。包含
--all-manageable和--provide选项来设置可用于部署的节点:$ openstack overcloud node introspect --all-manageable --provide
3.5. 将一个新的叶添加到 spine-leaf provisioning 网络
在增加可添加新的物理站点的网络容量时,您可能需要向 Red Hat OpenStack Platform spine-leaf provisioning 网络添加新的叶和对应的子网。在 overcloud 上置备叶时,会使用对应的 undercloud leaf。
先决条件
- 您的 RHOSP 部署使用 spine-leaf 网络拓扑。
流程
- 以 stack 用户身份登录 undercloud 主机。
查找 undercloud 凭证文件:
$ source ~/stackrc
在
/home/stack/undercloud.conf文件中执行以下操作:找到
subnets参数,并为要添加的叶添加新子网。子网代表路由的 spine 和 leaf 中的 L2 片段:
示例
在本例中,为新叶(
leaf3)添加新子网(leaf3):subnets = leaf0,leaf1,leaf2,leaf3
为您添加的子网创建一个部分。
示例
在本例中,为新子网添加了
[leaf3]部分(leaf3):[leaf0] cidr = 192.168.10.0/24 dhcp_start = 192.168.10.10 dhcp_end = 192.168.10.90 inspection_iprange = 192.168.10.100,192.168.10.190 gateway = 192.168.10.1 masquerade = False [leaf1] cidr = 192.168.11.0/24 dhcp_start = 192.168.11.10 dhcp_end = 192.168.11.90 inspection_iprange = 192.168.11.100,192.168.11.190 gateway = 192.168.11.1 masquerade = False [leaf2] cidr = 192.168.12.0/24 dhcp_start = 192.168.12.10 dhcp_end = 192.168.12.90 inspection_iprange = 192.168.12.100,192.168.12.190 gateway = 192.168.12.1 masquerade = False [leaf3] cidr = 192.168.13.0/24 dhcp_start = 192.168.13.10 dhcp_end = 192.168.13.90 inspection_iprange = 192.168.13.100,192.168.13.190 gateway = 192.168.13.1 masquerade = False
-
保存
undercloud.conf文件。 重新安装 undercloud:
$ openstack undercloud install
其他资源
第 4 章 为 DCN 部署准备 overcloud 模板
4.1. 使用独立 heat 堆栈的先决条件
在使用单独的 heat 堆栈创建部署前,您的环境必须满足以下先决条件:
- 正常工作的 Red Hat OpenStack Platform 16 undercloud。
- 对于 Ceph Storage 用户:访问 Red Hat Ceph Storage 4。
- 对于中央位置:三个能够充当中央 Controller 节点的节点。所有这三个 Controller 节点都必须位于同一 heat 堆栈中。您不能将 Controller 节点或任何 control plane 服务分割到单独的 heat 堆栈。
- 如果您计划在边缘部署 Ceph 存储,Ceph 存储是中央位置的要求。
- 对于每个额外的 DCN 网站:三个 HCI 计算节点。
- 所有节点都必须预先置备,或者从中央部署网络进行 PXE 引导。您可以使用 DHCP 转发来为 DCN 启用这个连接。
- 所有节点都由 ironic 内省。
-
红帽建议将 <role>HostnameFormat 参数保留为默认值: %stackname%-<role>-%index%。如果没有包含 %stackname% 前缀,则您的 overcloud 在不同的堆栈中为分布式计算节点使用相同的主机名。确保分布式计算节点使用 %stackname% 前缀来区分节点与不同边缘站点的节点。例如,如果您部署两个名为
dcn0和dcn1的边缘站点,则堆栈名称前缀可帮助您在 undercloud 上运行openstack server list命令时区分 dcn0-distributedcompute-0 和 dcn1-distributedcompute-0。 -
提供
centralrc身份验证文件,以在边缘站点和中央位置调度工作负载。您不需要为边缘站点自动生成身份验证文件。
4.2. 独立 heat 堆栈部署示例的限制
本文档提供了在 Red Hat OpenStack Platform 上使用单独的 heat 堆栈的示例部署。这个示例环境有以下限制:
- spine/Leaf 网络 - 本指南中的示例不演示路由要求,这是分布式计算节点(DCN)部署中所需的路由要求。
- Ironic DHCP Relay - 本指南不包括如何使用 DHCP 转发配置 Ironic。
4.3. 设计单独的 heat 堆栈部署
要在单独的 heat 堆栈内分段部署,您必须首先使用 control plane 部署单个 overcloud。然后,您可以为分布式计算节点(DCN)站点创建单独的堆栈。以下示例显示了不同节点类型的独立堆栈:
-
Controller 节点:名为
central的独立 heat 堆栈,例如部署控制器。为 DCN 站点创建新的 heat 堆栈时,您必须使用中央堆栈中的数据创建它们。Controller 节点必须可用于任何实例管理任务。 -
DCN 站点:您可以有单独的、唯一命名的 heat 堆栈,如
dcn0、dcn1等等。使用 DHCP 转发将 provisioning 网络扩展到远程站点。
您必须为每个堆栈创建单独的可用区(AZ)。
如果使用 spine/leaf 网络,则必须使用特定格式来定义 Storage 和 StorageMgmt 网络,以便 ceph-ansible 正确配置 Ceph 以使用这些网络。将 Storage 和 StorageMgmt 网络定义为覆盖值,并使用单引号括起值。在以下示例中,存储网络(称为 public_network)跨越两个子网,用逗号分开,并使用单引号括起来:
CephAnsibleExtraConfig: public_network: '172.23.1.0/24,172.23.2.0/24'
4.4. 在多个堆栈中重复使用网络资源
您可以将多个堆栈配置为使用相同的网络资源,如 VIP 和子网。您可以使用 ManageNetworks 设置或 external_resource the 字段在堆栈之间重复网络资源。
如果您使用 external_resource 114 字段,请不要使用 ManageNetworks 设置。
如果您没有在堆栈间重复使用网络,在 network_data.yaml 中定义的每个网络都必须在所有部署的堆栈中具有唯一的名称。例如,除非打算在堆栈之间共享网络,否则网络名称 internal_api 无法重复使用。为网络指定不同的 name 和 name_lower 属性,如 InternalApiCompute0 和 internal_api_compute_0。
4.5. 使用 ManageNetworks 来重复利用网络资源
使用 ManageNetworks 设置时,多个堆栈可以使用相同的 network_data.yaml 文件,并且该设置全局应用于所有网络资源。network_data.yaml 文件定义堆栈使用的网络资源:
- name: StorageBackup
vip: true
name_lower: storage_backup
ip_subnet: '172.21.1.0/24'
allocation_pools: [{'start': '171.21.1.4', 'end': '172.21.1.250'}]
gateway_ip: '172.21.1.1'
将 ManageNetworks 设置为 false 时,节点将使用已在 中央 堆栈中创建的现有网络。
使用以下序列,以便新堆栈不管理现有的网络资源。
流程
-
使用
ManageNetworks: true部署中央堆栈,或保留为未设置。 -
使用
ManageNetworks: false部署额外的堆栈。
当您添加新网络资源时,例如,当您在 spine/leaf 部署中添加新保留时,您必须使用新的 network_data.yaml 更新中央堆栈。这是因为中央堆栈仍然拥有和管理网络资源。在中央堆栈中可用网络资源后,您可以部署额外的堆栈以使用它们。
4.6. 使用 UUID 来重复利用网络资源
如果需要更多控制堆栈间重复使用哪些网络,您可以在 network_data.yaml 文件中将 external_resource bang 字段用于 network_data.yaml 文件中的资源,包括网络、子网、网段或 VIP。这些资源标记为外部管理,heat 不会对其执行任何创建、更新或删除操作。
在 network_data.yaml 文件中为每个所需的网络定义添加一个条目。然后,该资源可用于在单独的堆栈上部署:
external_resource_network_id: Existing Network UUID external_resource_subnet_id: Existing Subnet UUID external_resource_segment_id: Existing Segment UUID external_resource_vip_id: Existing VIP UUID
本例重复使用单独的堆栈中的 control plane 堆栈的 internal_api 网络。
流程
识别相关网络资源的 UUID:
$ openstack network show internal_api -c id -f value $ openstack subnet show internal_api_subnet -c id -f value $ openstack port show internal_api_virtual_ip -c id -f value
保存以上命令的输出中显示的值,并将它们添加到单独堆栈的
network_data.yaml文件中的internal_api网络的网络定义中:- name: InternalApi external_resource_network_id: 93861871-7814-4dbc-9e6c-7f51496b43af external_resource_subnet_id: c85c8670-51c1-4b17-a580-1cfb4344de27 external_resource_vip_id: 8bb9d96f-72bf-4964-a05c-5d3fed203eb7 name_lower: internal_api vip: true ip_subnet: '172.16.2.0/24' allocation_pools: [{'start': '172.16.2.4', 'end': '172.16.2.250'}] ipv6_subnet: 'fd00:fd00:fd00:2000::/64' ipv6_allocation_pools: [{'start': 'fd00:fd00:fd00:2000::10', 'end': 'fd00:fd00:fd00:2000:ffff:ffff:ffff:fffe'}] mtu: 1400
4.7. 管理独立的 heat 堆栈
本指南中的步骤演示了如何为三个 heat 堆栈组织环境文件: central、dcn0 和 dcn1。红帽建议将每个 heat 堆栈的模板存储在一个单独的目录中,以保持与每个部署相关的信息。
流程
定义
中央heat 堆栈:$ mkdir central $ touch central/overrides.yaml
将
中央heat 堆栈中的数据提取到所有 DCN 站点的通用目录中:$ mkdir dcn-common $ touch dcn-common/overrides.yaml $ touch dcn-common/central-export.yaml
central-export.yaml文件由openstack overcloud export命令创建。它位于dcn-common目录中,因为本指南中的所有 DCN 部署都必须使用此文件。定义
dcn0站点。$ mkdir dcn0 $ touch dcn0/overrides.yaml
要部署更多 DCN 站点,请按数字创建额外的 dcn 目录。
该触点用于提供文件组织示例。每个文件必须包含成功部署的适当内容。
4.8. 检索容器镜像
使用以下步骤及其示例文件内容来检索使用单独的 heat 堆栈部署所需的容器镜像。您必须通过运行带有边缘站点的环境文件的 openstack container image prepare 命令来确保包含可选或特定于边缘服务的容器镜像。
如需更多信息,请参阅 准备容器镜像。
流程
将 Registry 服务帐户凭证添加到
containers.yaml。parameter_defaults: ContainerImagePrepare: - push_destination: true set: ceph_namespace: registry.redhat.io/rhceph ceph_image: rhceph-4-rhel8 ceph_tag: latest name_prefix: openstack- namespace: registry.redhat.io/rhosp16-rhel8 tag: latest ContainerImageRegistryCredentials: # https://access.redhat.com/RegistryAuthentication registry.redhat.io: registry-service-account-username: registry-service-account-password将环境文件生成为
images-env.yaml:sudo openstack tripleo container image prepare \ -e containers.yaml \ --output-env-file images-env.yaml
生成的
images-env.yaml文件作为生成它的堆栈的 overcloud 部署流程的一部分。
4.9. 为边缘创建快速数据路径角色
要在边缘上使用快速数据路径服务,您必须创建一个自定义角色来定义快速数据路径和边缘服务。为部署创建角色文件时,您可以包括新创建的角色来定义分布式计算节点架构和快速数据路径服务(如 DPDK 或 SR-IOV)所需的服务。
例如,使用 DPDK 为 distributedCompute 创建自定义角色:
先决条件
成功安装 undercloud。如需更多信息 ,请参阅安装 undercloud。
流程
-
以
stack用户身份登录 undercloud 主机。 复制
默认角色目录:cp -r /usr/share/openstack-tripleo-heat-templates/roles ~/.
从
DistributedCompute.yaml文件中创建一个名为DistributedComputeDpdk.yaml的新文件:cp roles/DistributedCompute.yaml roles/DistributedComputeDpdk.yaml
将 DPDK 服务添加到新的
DistributedComputeDpdk.yaml文件中。您可以通过在ComputeOvsDpdk.yaml文件中识别没有存在于DistributedComputeDpdk.yaml文件中的的参数来识别需要添加的参数。diff -u roles/DistributedComputeDpdk.yaml roles/ComputeOvsDpdk.yaml
在输出中,ComputeOvsDpdk.yaml 文件前面带有
+的参数存在于 DistributedComputeDpdk.yaml 文件中。将这些参数包含在新的DistributedComputeDpdk.yaml文件中。使用
DistributedComputeDpdk.yaml创建DistributedComputeDpdk角色文件:openstack overcloud roles generate --roles-path ~/roles/ -o ~/roles/roles-custom.yaml DistributedComputeDpdk
您可以使用同样的方法为 SR-IOV 创建快速数据路径角色,或 SR-IOV 和 DPDK 的组合来满足您的要求。
如果您计划在没有块存储的情况下部署边缘站点,请参阅以下内容:
如果您计划使用 Ceph 存储部署边缘站点,请参阅以下内容:
第 5 章 安装中央位置
当您为分布式计算节点(DCN)架构部署中央位置时,您可以部署集群:
- 使用或不使用 Compute 节点
- 使用或不使用 Red Hat Ceph Storage
如果您在中央位置没有 Red Hat Ceph Storage 部署 Red Hat OpenStack Platform,则无法使用 Red Hat Ceph Storage 部署任何边缘站点。此外,您无法选择通过重新部署将 Red Hat Ceph Storage 添加到中央位置。
5.1. 在没有边缘存储的情况下部署中央控制器
如果您使用 Object Storage 服务(swift)作为中央位置镜像服务(glance)的后端,您可以在边缘站点部署没有块存储的分布式计算节点集群。因为每个架构的不同角色和网络配置集,以后无法更新没有块存储的站点,使其具有块存储。
重要:以下步骤使用 lvm 作为 Cinder 的后端,在生产环境中不支持。您必须将经认证的块存储解决方案部署为 Cinder 的后端。
以类似于典型的 overcloud 部署的方式部署中央控制器集群。此集群不需要任何 Compute 节点,因此您可以将 Compute 数量设置为 0 来覆盖默认值 1。Central 控制器具有特定存储和 Oslo 配置要求。使用以下步骤满足这些要求。
流程
以下流程概述了中央位置初始部署的步骤。
以下步骤详细介绍了与 DCN 部署关联的部署命令和环境文件,而无需 glance 多存储。这些步骤不包括不相关的、但在网络等配置的各个方面。
在主目录中,为您计划部署的每个堆栈创建目录。
mkdir /home/stack/central mkdir /home/stack/dcn0 mkdir /home/stack/dcn1
使用类似如下的设置,创建一个名为
central/overrides.yaml的文件:parameter_defaults: NtpServer: - 0.pool.ntp.org - 1.pool.ntp.org ControllerCount: 3 ComputeCount: 0 OvercloudControllerFlavor: baremetal OvercloudComputeFlavor: baremetal ControllerSchedulerHints: 'capabilities:node': '0-controller-%index%' GlanceBackend: swift-
ControllerCount:3指定将部署三个节点。这些会将 swift 用于 glance,lvm 用于 cinder,并为边缘计算节点托管 control-plane 服务。 -
ComputeCount: 0是一个可选参数,可防止使用中央 Controller 节点部署 Compute 节点。 GlanceBackend: swift使用 Object Storage (swift)作为镜像服务(glance)后端。生成的配置通过以下方式与分布式计算节点(DCN)交互:
DCN 上的镜像服务创建从中央对象存储后端接收的镜像的缓存副本。镜像服务使用 HTTP 将镜像从对象存储复制到本地磁盘缓存中。
注意中央 Controller 节点必须能够连接到分布式计算节点(DCN)站点。中央 Controller 节点可以使用路由层 3 连接。
-
使用适合您的环境的角色为中央位置生成角色:
openstack overcloud roles generate Controller \ -o ~/central/control_plane_roles.yaml
生成环境文件
~/central/central-images-env.yaml:sudo openstack tripleo container image prepare \ -e containers.yaml \ --output-env-file ~/central/central-images-env.yaml
在
site-name.yaml环境文件中为站点配置命名约定。Nova 可用区 Cinder 存储可用区必须匹配:cat > /home/stack/central/site-name.yaml << EOF parameter_defaults: NovaComputeAvailabilityZone: central ControllerExtraConfig: nova::availability_zone::default_schedule_zone: central NovaCrossAZAttach: false CinderStorageAvailabilityZone: central EOF部署中央 Controller 节点。例如,您可以使用包含以下内容的
deploy.sh文件:#!/bin/bash source ~/stackrc time openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/containers-env-file.yaml \ -e ~/central/overrides.yaml \ -e ~/central/site-name.yaml
您必须在 openstack overcloud deploy 命令中包含用于配置网络配置的 heat 模板。为边缘架构设计需要 spine 和 leaf 网络。如需了解更多详细信息,请参阅 Spine Leaf Networking。
5.2. 使用存储部署中央站点
要使用多个存储部署镜像服务,并将 Ceph Storage 用作后端,请完成以下步骤:
前提条件
- hub 和每个可用区的 Ceph 集群的硬件,或者在需要存储服务的每个地理位置。
- 您必须在超融合架构中部署边缘站点。
- hub 和每个可用区的三个镜像服务服务器的硬件,或者在需要存储服务的每个地理位置。
以下是部署两个或多个堆栈的示例:
-
一个堆栈位于中央位置,称为
central -
一个堆栈位于名为
dcn0的边缘站点。 -
部署的其他堆栈与
dcn0类似,如dcn1、dcn2等。
流程
以下流程概述了中央位置初始部署的步骤。
以下步骤详细介绍了与使用多个存储的镜像服务的 DCN 部署关联的部署命令和环境文件。这些步骤不包括不相关的、但在网络等配置的各个方面。
在主目录中,为您计划部署的每个堆栈创建目录。
mkdir /home/stack/central mkdir /home/stack/dcn0 mkdir /home/stack/dcn1
设置 Ceph 集群的名称,以及相对于可用硬件的配置参数。如需更多信息,请参阅使用自定义配置设置配置 Ceph :
cat > /home/stack/central/ceph.yaml << EOF parameter_defaults: CephClusterName: central CephAnsibleDisksConfig: osd_scenario: lvm osd_objectstore: bluestore devices: - /dev/sda - /dev/sdb CephPoolDefaultSize: 3 CephPoolDefaultPgNum: 128 EOF使用适合您的环境的角色为中央位置生成角色:
openstack overcloud roles generate Compute Controller CephStorage \ -o ~/central/central_roles.yaml cat > /home/stack/central/role-counts.yaml << EOF parameter_defaults: ControllerCount: 3 ComputeCount: 2 CephStorage: 3 EOF
生成环境文件
~/central/central-images-env.yamlsudo openstack tripleo container image prepare \ -e containers.yaml \ --output-env-file ~/central/central-images-env.yaml
在
site-name.yaml环境文件中为站点配置命名约定。Nova 可用区和 Cinder 存储可用区必须匹配:cat > /home/stack/central/site-name.yaml << EOF parameter_defaults: NovaComputeAvailabilityZone: central ControllerExtraConfig: nova::availability_zone::default_schedule_zone: central NovaCrossAZAttach: false CinderStorageAvailabilityZone: central GlanceBackendID: central EOF使用类似如下的内容配置
glance.yaml模板:parameter_defaults: GlanceEnabledImportMethods: web-download,copy-image GlanceBackend: rbd GlanceStoreDescription: 'central rbd glance store' GlanceBackendID: central CephClusterName: central准备所有其他模板后,部署
中央堆栈:openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/central/central_roles.yaml \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/central-images-env.yaml \ -e ~/central/role-counts.yaml \ -e ~/central/site-name.yaml \ -e ~/central/ceph.yaml \ -e ~/central/glance.yaml
您必须在 openstack overcloud deploy 命令中包含用于配置网络配置的 heat 模板。为边缘架构设计需要 spine 和 leaf 网络。如需了解更多详细信息,请参阅 Spine Leaf Networking。
ceph-ansible.yaml 文件配置有以下参数:
- NovaEnableRbdBackend: true
- GlanceBackend: rbd
当您将这些设置一起使用时,glance.conf 参数 image_import_plugins 由 heat 配置成具有值 image_conversion,使用 glance image-create-via-import --disk-format qcow2 等命令自动化 QCOW2 镜像转换。
这是 Ceph RBD 的最佳选择。如果要禁用镜像转换,请使用 GlanceImageImportPlugin 参数:
parameter_defaults:
GlanceImageImportPlugin: []5.3. 集成外部 Ceph
您可以部署分布式计算节点(DCN)架构的中心位置,并集成预部署的 Red Hat Ceph Storage 解决方案。
先决条件
- 位于中央位置和每个可用区的 Ceph 集群的硬件,或者在需要存储服务的每个地理位置。
- 您必须在超融合架构中部署边缘站点。
- 位于中央位置和每个可用区的三个镜像服务服务器的硬件,或者在需要存储服务的每个地理位置。
以下是部署两个或多个堆栈的示例:
-
一个堆栈位于中央位置,称为
central -
一个堆栈位于名为
dcn0的边缘站点。 -
部署的其他堆栈与
dcn0类似,如dcn1、dcn2等。

您可以按照将 Overcloud 与现有 Red Hat Ceph Cluster 集成的步骤,安装中央位置,使其与预先存在的 Red Hat Ceph Storage 解决方案集成。将 Red Hat Ceph Storage 与 DCN 部署的中央站点集成没有特殊要求,但在部署 overcloud 前,您仍需要完成 DCN 具体步骤:
在主目录中,为您计划部署的每个堆栈创建目录。使用它来分隔针对其相应站点设计的模板。
mkdir /home/stack/central mkdir /home/stack/dcn0 mkdir /home/stack/dcn1
使用 Red Hat OpenStack Platform director 管理的角色为中央位置生成角色。在与外部 Ceph 集成时,请不要使用 Ceph 角色:
cat > /home/stack/central/role-counts.yaml << EOF parameter_defaults: ControllerCount: 3 ComputeCount: 2 EOF
生成环境文件 ~/central/central-images-env.yaml
sudo openstack tripleo container image prepare \ -e containers.yaml \ --output-env-file ~/central/central-images-env.yaml
在 site-name.yaml 环境文件中为站点配置命名约定。Nova 可用区和 Cinder 存储可用区必须匹配:
cat > /home/stack/central/site-name.yaml << EOF parameter_defaults: NovaComputeAvailabilityZone: central ControllerExtraConfig: nova::availability_zone::default_schedule_zone: central NovaCrossAZAttach: false CinderStorageAvailabilityZone: central GlanceBackendID: central EOF使用类似如下的内容配置 glance.yaml 模板:
parameter_defaults: GlanceEnabledImportMethods: web-download,copy-image GlanceBackend: rbd GlanceStoreDescription: 'central rbd glance store' GlanceBackendID: central CephClusterName: central当在没有 Red Hat OpenStack Platform director 的情况下部署 Ceph 时,请不要使用
ceph-ansible.yaml环境文件。改为使用ceph-ansible-external.yaml环境文件。openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/central/central_roles.yaml \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible-external.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/central-images-env.yaml \ -e ~/central/role-counts.yaml \ -e ~/central/site-name.yaml \ -e ~/central/ceph.yaml \ -e ~/central/glance.yaml
第 6 章 在没有存储的情况下部署边缘
如果您使用 Object Storage 服务(swift)作为中央位置镜像服务(glance)的后端,您可以在边缘站点部署没有块存储的分布式计算节点集群。因为每个架构的不同角色和网络配置集,以后无法更新没有块存储的站点,使其具有块存储。
以下流程使用 lvm 作为块存储服务(cinder)的后端,在生产环境中不支持。您必须将经认证的块存储解决方案部署为块存储服务的后端。
6.1. 在没有存储的情况下部署边缘节点
您可以部署使用中央位置作为 control plane 的边缘计算节点。此流程演示了如何向部署添加新的 DCN 堆栈,并重复使用现有 heat 堆栈的配置来创建新环境文件。第一个 heat 堆栈在中央数据中心中部署 overcloud。创建额外的 heat 堆栈,将计算节点部署到远程位置。
6.1.1. 配置分布式计算节点环境文件
此流程创建一个新的 central-export.yaml 环境文件,并使用 overcloud 的 plan-environment.yaml 文件中的密码。central-export.yaml 文件包含敏感的安全数据。要提高安全性,您可以在不再需要该文件时删除该文件。
当您为 --config-download-dir 选项指定目录时,请使用 director 部署期间在 /var/lib/mistral 中创建的中央 hub Ansible 配置。不要使用您在 openstack overcloud config download 命令中使用手动生成的 Ansible 配置。手动生成的配置缺少了仅在部署操作期间创建的某些文件。
您必须将镜像上传到中央位置,然后才能将镜像复制到边缘站点;每个镜像的副本必须存在于中央位置的镜像服务(glance)中。
您必须将 RBD 存储驱动程序用于镜像、计算和块存储服务。
流程
生成 DCN 站点所需的配置文件:
openstack overcloud export \ --config-download-dir /var/lib/mistral/central \ --stack central --output-file ~/dcn-common/central-export.yaml
使用适合您的环境的角色为边缘位置生成角色:
openstack overcloud roles generate Compute -o ~/dcn0/dcn0_roles.yaml
如果将 ML2/OVS 用于网络覆盖,您必须编辑您创建的角色文件,使其包含 NeutronDhcpAgent 和 NeutronMetadataAgent 角色:
...
- OS::TripleO::Services::MySQLClient
- OS::TripleO::Services::NeutronBgpVpnBagpipe
+ - OS::TripleO::Services::NeutronDhcpAgent
+ - OS::TripleO::Services::NeutronMetadataAgent
- OS::TripleO::Services::NeutronLinuxbridgeAgent
- OS::TripleO::Services::NeutronVppAgent
- OS::TripleO::Services::NovaAZConfig
- OS::TripleO::Services::NovaCompute
...如需更多信息,请参阅准备路由的供应商网络。
6.1.2. 将 Compute 节点部署到 DCN 站点
此流程使用 Compute 角色将 Compute 节点部署到名为 dcn0 的可用区(AZ)中。在分布式计算节点(DC)上下文中,此角色用于没有存储的站点。
流程
查看 dcn0/overrides.yaml 中分布式计算(DCN)站点的覆盖
parameter_defaults: ComputeCount: 3 ComputeFlavor: baremetal ComputeSchedulerHints: 'capabilities:node': '0-compute-%index%' NovaAZAttach: false在
~/dcn0目录中创建一个名为site-name.yaml的新文件,其内容如下:resource_registry: OS::TripleO::Services::NovaAZConfig: /usr/share/openstack-tripleo-heat-templates/deployment/nova/nova-az-config.yaml parameter_defaults: NovaComputeAvailabilityZone: dcn0 RootStackName: dcn0
检索 DCN 站点的容器镜像:
sudo openstack tripleo container image prepare \ --environment-directory dcn0 \ -r ~/dcn0/roles_data.yaml \ -e ~/dcn-common/central-export.yaml \ -e ~/containers-prepare-parameter.yaml \ --output-env-file ~/dcn0/dcn0-images-env.yaml
为 dcn0 运行 deploy.sh 部署脚本:
#!/bin/bash STACK=dcn0 source ~/stackrc time openstack overcloud deploy \ --stack $STACK \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/dcn-common/central-export.yaml \ -e ~/dcn0/dcn0-images-env.yaml \ -e ~/dcn0/site-name.yaml \ -e ~/dcn0/overrides.yaml如果部署需要编辑
network_data.yaml文件的额外边缘站点,您必须在中央位置执行堆栈更新。
您必须在 openstack overcloud deploy 命令中包含用于配置网络配置的 heat 模板。为边缘架构设计需要 spine 和 leaf 网络。如需了解更多详细信息,请参阅 Spine Leaf Networking。
第 7 章 在边缘部署存储
您可以使用 Red Hat OpenStack Platform director 扩展分布式计算节点部署,以使用 Red Hat OpenStack Platform 和 Ceph Storage 的优点在边缘包含分布式镜像和持久性存储。

7.1. 使用存储部署边缘站点
部署中心站点后,构建边缘站点并确保每个边缘位置主要连接到自己的存储后端,以及中央位置的存储后端。
spine 和 leaf network configuration 应当包含在这一配置中,以及 ceph 需要的 storage 和 storage_mgmt 网络。如需更多信息,请参阅 Spine leaf 网络。
您必须在中央位置和存储网络之间具有连接,以便您可以在站点之间移动 glance 镜像。
确保中央位置可以在每个边缘站点与 mons 和 osds 通信。但是,您应该以站点位置边界终止存储管理网络,因为存储管理网络用于 OSD 重新平衡。
流程
从中央堆栈导出堆栈信息。在运行此命令前,您必须部署中央堆栈:openstack overcloud export \ --config-download-dir /var/lib/mistral/central/ \ --stack central \ --output-file ~/dcn-common/central-export.yaml注意config-download-dir值默认为/var/lib/mistral/<stack>/。创建
central_ceph_external.yaml文件。此环境文件将 DCN 站点连接到中央 hub Ceph 集群,因此信息特定于前面步骤中部署的 Ceph 集群。sudo -E openstack overcloud export ceph \ --stack central \ --config-download-dir /var/lib/mistral \ --output-file ~/dcn-common/central_ceph_external.yaml
当在没有 Red Hat OpenStack Platform director 的情况下部署 Ceph 时,无法运行
openstack overcloud export ceph命令。手动创建central_ceph_external.yaml文件:parameter_defaults: CephExternalMultiConfig: - cluster: "central" fsid: "3161a3b4-e5ff-42a0-9f53-860403b29a33" external_cluster_mon_ips: "172.16.11.84, 172.16.11.87, 172.16.11.92" keys: - name: "client.openstack" caps: mgr: "allow *" mon: "profile rbd" osd: "profile rbd pool=vms, profile rbd pool=volumes, profile rbd pool=images" key: "AQD29WteAAAAABAAphgOjFD7nyjdYe8Lz0mQ5Q==" mode: "0600" dashboard_enabled: false ceph_conf_overrides: client: keyring: /etc/ceph/central.client.openstack.keyringfsid参数是 Ceph Storage 集群的文件系统 ID:这个值在[global]部分的集群配置文件中指定:[global] fsid = 4b5c8c0a-ff60-454b-a1b4-9747aa737d19 ...
key参数是 openstack 帐户的 ceph 客户端密钥:[root@ceph ~]# ceph auth list ... [client.openstack] key = AQC+vYNXgDAgAhAAc8UoYt+OTz5uhV7ItLdwUw== caps mgr = "allow *" caps mon = "profile rbd" caps osd = "profile rbd pool=volumes, profile rbd pool=vms, profile rbd pool=images, profile rbd pool=backups, profile rbd pool=metrics" ...有关示例
central_ceph_external.yaml文件中显示的参数的更多信息,请参阅 创建自定义环境文件。
为镜像服务配置覆盖创建
~/dcn0/glance.yaml文件:parameter_defaults: GlanceEnabledImportMethods: web-download,copy-image GlanceBackend: rbd GlanceStoreDescription: 'dcn0 rbd glance store' GlanceBackendID: dcn0 GlanceMultistoreConfig: central: GlanceBackend: rbd GlanceStoreDescription: 'central rbd glance store' CephClientUserName: 'openstack' CephClusterName: central使用与可用硬件相关的配置参数配置
ceph.yaml文件。cat > /home/stack/dcn0/ceph.yaml << EOF parameter_defaults: CephClusterName: dcn0 CephAnsibleDisksConfig: osd_scenario: lvm osd_objectstore: bluestore devices: - /dev/sda - /dev/sdb CephPoolDefaultSize: 3 CephPoolDefaultPgNum: 128 EOF有关更多信息,请参阅 映射 Ceph Storage 节点磁盘布局。
使用包含根据您的环境要求调整的以下参数的文件实现系统性能优化:
cat > /home/stack/dcn0/tuning.yaml << EOF parameter_defaults: CephAnsibleExtraConfig: is_hci: true CephConfigOverrides: osd_recovery_op_priority: 3 osd_recovery_max_active: 3 osd_max_backfills: 1 ## Set relative to your hardware: # DistributedComputeHCIParameters: # NovaReservedHostMemory: 181000 # DistributedComputeHCIExtraConfig: # nova::cpu_allocation_ratio: 8.2 EOF-
有关为
CephAnsibleExtraConfig设置值的更多信息,请参阅设置 ceph-ansible 组变量。 -
有关为
CephConfigOverrides设置值的更多信息,请参阅自定义 Ceph Storage 集群。
-
有关为
在
site-name.yaml环境文件中为站点配置命名约定。Nova 可用区和 Cinder 存储可用区必须匹配。部署带有存储的边缘站点时,包括CinderVolumeCluster参数。当 cinder-volume 部署为 active/active (在边缘站点需要)时,使用此参数。作为最佳实践,将 Cinder 集群名称设置为与可用区匹配:cat > /home/stack/central/site-name.yaml << EOF parameter_defaults: ... NovaComputeAvailabilityZone: dcn0 NovaCrossAZAttach: false CinderStorageAvailabilityZone: dcn0 CinderVolumeCluster: dcn0生成用于 dcn0 部署的
roles.yaml文件,例如:openstack overcloud roles generate DistributedComputeHCI DistributedComputeHCIScaleOut -o ~/dcn0/roles_data.yaml
通过为每个角色创建
~/dcn0/roles-counts.yaml文件来设置每个角色中的数量系统。在使用超融合基础架构(HCI)时,您必须将三个节点分配给 DistributedComputeHCICount 角色,以满足 Ceph Mon 和
GlanceApiEdge服务的要求。parameter_defaults: ControllerCount: 0 ComputeCount: 0 DistributedComputeHCICount: 3 DistributedComputeHCIScaleOutCount: 1 # Optional DistributedComputeScaleOutCount: 1 # Optional
检索边缘站点的容器镜像:
sudo openstack tripleo container image prepare \ --environment-directory dcn0 \ -r ~/dcn0/roles_data.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ ... -e /home/stack/dcn-common/central-export.yaml \ -e /home/stack/containers-prepare-parameter.yaml \ --output-env-file ~/dcn0/dcn0-images-env.yaml
注意您必须在
openstack tripleo container image prepare命令中包含用于部署的所有环境文件。部署边缘站点:
openstack overcloud deploy \ --stack dcn0 \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/dcn0/roles_data.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/dcn-hci.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/dnc0/dcn0-images-env.yaml \ .... -e ~/dcn-common/central-export.yaml \ -e ~/dcn-common/central_ceph_external.yaml \ -e ~/dcn0/dcn_ceph_keys.yaml \ -e ~/dcn0/role-counts.yaml \ -e ~/dcn0/ceph.yaml \ -e ~/dcn0/site-name.yaml \ -e ~/dcn0/tuning.yaml \ -e ~/dcn0/glance.yaml注意您必须在
openstack overcloud deploy命令中包含用于配置网络配置的 heat 模板。为边缘架构设计需要 spine 和 leaf 网络。如需了解更多详细信息,请参阅 Spine Leaf Networking。
7.2. 创建额外的分布式计算节点站点
新的分布式计算节点(DCN)站点在 undercloud 上具有自己的 YAML 文件的目录。更多信息请参阅 第 4.7 节 “管理独立的 heat 堆栈”。这个过程包含示例命令。
流程
在 undercloud 上以 stack 用户身份,为
dcn9创建一个新目录:$ cd ~ $ mkdir dcn9
将现有的
dcn0模板复制到新目录中,并将dcn0字符串替换为dcn9:$ cp dcn0/ceph.yaml dcn9/ceph.yaml $ sed s/dcn0/dcn9/g -i dcn9/ceph.yaml $ cp dcn0/overrides.yaml dcn9/overrides.yaml $ sed s/dcn0/dcn9/g -i dcn9/overrides.yaml $ sed s/"0-ceph-%index%"/"9-ceph-%index%"/g -i dcn9/overrides.yaml $ cp dcn0/deploy.sh dcn9/deploy.sh $ sed s/dcn0/dcn9/g -i dcn9/deploy.sh
-
检查
dcn9目录中的文件,以确认您的要求。 编辑 undercloud.conf 以添加新的叶。在以下示例中,leaf9 添加到 undercloud.conf 中:
[leaf0] cidr = 192.168.10.0/24 dhcp_start = 192.168.10.10 dhcp_end = 192.168.10.90 inspection_iprange = 192.168.10.100,192.168.10.190 gateway = 192.168.10.1 masquerade = False … [leaf9] cidr = 192.168.19.0/24 dhcp_start = 192.168.19.10 dhcp_end = 192.168.19.90 inspection_iprange = 192.168.19.100,192.168.19.190 gateway = 192.168.10.1 masquerade = False
- 重新运行 openstack undercloud install 命令以更新环境配置。
在 overcloud 模板中,将
NetworkDeploymentActions参数的值从["CREATE"]的值更新为["CREATE", "UPDATE"]。如果模板中目前没有包括此参数,请将其添加到其中一个环境文件中,或创建新环境文件。cat > /home/stack/central/network-environment.yaml << EOF parameter_defaults: NetworkDeploymentActions: ["CREATE", "UPDATE"] EOF
为中央位置运行部署脚本。包括您首次部署中央位置时使用的所有模板,以及新创建的 network-environment.yaml 文件:
openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/central/roles_data.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/dcn-hci.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/dcn9-images-env.yaml \ .... -e ~/dcn-common/central-export.yaml \ -e ~/dcn-common/central_ceph_external.yaml \ -e ~/central/dcn_ceph_keys.yaml \ -e ~/central/role-counts.yaml \ -e ~/central/ceph.yaml \ -e ~/central/site-name.yaml \ -e ~/central/tuning.yaml \ -e ~/central/glance.yaml验证您的节点是否可用,且处于
Provisioning 状态:$ openstack baremetal node list
当节点可用时,使用所有适当的模板部署新的边缘站点:
openstack overcloud deploy \ --stack dcn9 \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/dcn9/roles_data.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/dcn-hci.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/dnc9/dcn9-images-env.yaml \ .... -e ~/dcn-common/central-export.yaml \ -e ~/dcn-common/central_ceph_external.yaml \ -e ~/dcn9/dcn_ceph_keys.yaml \ -e ~/dcn9/role-counts.yaml \ -e ~/dcn9/ceph.yaml \ -e ~/dcn9/site-name.yaml \ -e ~/dcn9/tuning.yaml \ -e ~/dcn9/glance.yaml- 如果您使用直接边缘到边缘通信部署位置,您必须重新部署每个边缘站点以更新路由并与新位置建立通信。
7.3. 更新中央位置
使用示例过程配置和部署所有边缘站点后,更新中央位置的配置,以便中央镜像服务可将镜像推送到边缘站点。
此流程重启镜像服务(glance),并中断任何长时间运行的镜像服务进程。例如,如果镜像从中央镜像服务服务器复制到 DCN 镜像服务服务器,该镜像副本将中断,您必须重启该镜像。如需更多信息,请参阅 在 镜像服务进程中断后清除遗留的数据。
流程
创建一个类似如下的
~/central/glance_update.yaml文件:这个示例包括两个边缘站点 dcn0 和 dcn1 的配置:parameter_defaults: GlanceEnabledImportMethods: web-download,copy-image GlanceBackend: rbd GlanceStoreDescription: 'central rbd glance store' CephClusterName: central GlanceBackendID: central GlanceMultistoreConfig: dcn0: GlanceBackend: rbd GlanceStoreDescription: 'dcn0 rbd glance store' CephClientUserName: 'openstack' CephClusterName: dcn0 GlanceBackendID: dcn0 dcn1: GlanceBackend: rbd GlanceStoreDescription: 'dcn1 rbd glance store' CephClientUserName: 'openstack' CephClusterName: dcn1 GlanceBackendID: dcn1创建
dcn_ceph.yaml文件。在以下示例中,此文件将中央站点上的 glance 服务配置为边缘站点dcn0和dcn1的 Ceph 集群的客户端。sudo -E openstack overcloud export ceph \ --stack dcn0,dcn1 \ --config-download-dir /var/lib/mistral \ --output-file ~/central/dcn_ceph.yaml
使用原始模板重新部署中央站点,并包含新创建的
dcn_ceph.yaml和glance_update.yaml文件。openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/central/central_roles.yaml \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/central-images-env.yaml \ -e ~/central/role-counts.yaml \ -e ~/central/site-name.yaml -e ~/central/ceph.yaml \ -e ~/central/ceph_keys.yaml \ -e ~/central/glance.yaml \ -e ~/central/dcn_ceph_external.yaml在中央位置的控制器上,重新启动
cinder-volume服务。如果您使用cinder-backup服务部署中央位置,则重启cinder-backup服务:ssh heat-admin@controller-0 sudo pcs resource restart openstack-cinder-volume ssh heat-admin@controller-0 sudo pcs resource restart openstack-cinder-backup
7.3.1. 在镜像服务进程中断后清除数据
当您重启中央位置时,任何长时间运行的镜像服务(glance)进程都会中断。在重启这些进程前,您必须首先清理您重启的 Controller 节点上的数据,并在 Ceph 和镜像服务数据库中。
流程
检查并清除重启的 Controller 节点中的遗留数据。将暂存存储的
glance-api.conf文件中的文件与镜像服务数据库中的对应镜像进行比较,如 <image_ID>.raw。- 如果这些对应的镜像显示导入状态,您必须重新创建镜像。
- 如果镜像显示 active 状态,您必须从暂存中删除数据并重启副本导入。
-
检查和清除 Ceph 存储中的遗留数据。从暂存区域清理的镜像必须具有包含镜像的 Ceph 存储的
stores属性中的匹配记录。Ceph 中的镜像名称是镜像服务数据库中的镜像 ID。 清除镜像服务数据库。清除从导入作业导入状态的任何镜像都会中断:
$ glance image-delete <image_id>
7.4. 在 DCN 上部署 Red Hat Ceph Storage Dashboard
流程
要将 Red Hat Ceph Storage 仪表板部署到中央位置,请参阅将 Red Hat Ceph Storage 仪表板添加到 overcloud 部署中。这些步骤应该在部署中央位置前完成。
要将 Red Hat Ceph Storage Dashboard 部署到边缘位置,请完成您为中央相同的步骤,但您必须完成以下操作:
在模板中,为部署边缘站点,确保
ManageNetworks参数的值为false。将ManageNetworks设置为false时,Edge 站点将使用已在中央堆栈中创建的现有网络:parameter_defaults: ManageNetworks: false
- 您必须部署自己的解决方案才能进行负载平衡,才能创建高可用性虚拟 IP。边缘站点不部署 haproxy,也不部署 pacemaker。当您将 Red Hat Ceph Storage Dashboard 部署到边缘位置时,部署会在存储网络上公开。控制面板安装在三个具有不同 IP 地址的 DistributedComputeHCI 节点上,而无需负载均衡解决方案。
7.4.1. 为虚拟 IP 创建可组合网络
您可以创建额外网络来托管可以公开 Ceph 控制面板的虚拟 IP。您不能为多个堆栈重复使用网络资源。有关重复使用网络资源的更多信息,请参阅在多个堆栈中重复使用网络资源。
要创建此额外网络资源,请使用提供的 network_data_dashboard.yaml heat 模板。创建的网络的名称是 StorageDashboard。
流程
-
以
堆栈身份登录到 Red Hat OpenStack Platform Director。 生成
DistributedComputeHCIDashboard角色以及适用于您的环境的任何其他角色:openstack overcloud roles generate DistributedComputeHCIDashboard -o ~/dnc0/roles.yaml
在 overcloud deploy 命令中包含
roles.yaml和network_data_dashboard.yaml:$ openstack overcloud deploy --templates \ -r ~/<dcn>/<dcn_site_roles>.yaml \ -n /usr/share/openstack-tripleo-heat-templates/network_data_dashboard.yaml \ -e <overcloud_environment_files> \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-dashboard.yaml
部署提供了在存储网络上启用仪表板的三个 ip 地址。
验证
若要确认控制面板在中央位置运行,并且它从 Ceph 集群显示的数据正确,请参阅 访问 Ceph 仪表板。
您可以通过类似的步骤确认控制面板正在边缘位置运行,但存在例外情况,因为边缘位置没有负载均衡器。
-
从
/var/lib/mistral/<stackname>/ceph-ansible/group_vars/all.yml检索特定于所选堆栈的仪表板 admin 登录凭证 在特定于所选堆栈的清单中,
/var/lib/mistral/<stackname>/ceph-ansible/inventory.yml,找到 DistributedComputeHCI 角色主机列表并保存所有三个storage_ip值。在以下示例中,前两个仪表板 IP 是 172.16.11.84 和 172.16.11.87 :DistributedComputeHCI: hosts: dcn1-distributed-compute-hci-0: ansible_host: 192.168.24.16 ... storage_hostname: dcn1-distributed-compute-hci-0.storage.localdomain storage_ip: 172.16.11.84 ... dcn1-distributed-compute-hci-1: ansible_host: 192.168.24.22 ... storage_hostname: dcn1-distributed-compute-hci-1.storage.localdomain storage_ip: 172.16.11.87- 如果 Ceph 控制面板可以访问这些 IP 地址之一,您可以检查 Ceph 控制面板是否活跃。这些 IP 地址位于存储网络中,且不会被路由。如果这些 IP 地址不可用,您必须为从清单中获取的三个 IP 地址配置负载均衡器,以获取虚拟 IP 地址进行验证。
第 8 章 使用密钥管理器进行部署
如果您在 Red Hat OpenStack Platform 16.1.2 发布前部署了边缘站点,则需要重新生成 roles.yaml 才能实现此功能:要实现这个功能:要实现该功能,请重新生成用于 DCN 站点部署的 roles.yaml 文件。
$ openstack overcloud roles generate DistributedComputeHCI DistributedComputeHCIScaleOut -o ~/dcn0/roles_data.yaml
8.1. 使用密钥管理器部署边缘站点
如果要在边缘站点包含对密钥管理器(barbican)服务的访问权限,您必须在中央位置配置 barbican。有关安装和配置 barbican 的详情,请参考 部署 Barbican。
您可以通过包括
/usr/share/openstack-tripleo-heat-templates/environments/services/barbican-edge.yaml来配置从 DCN 站点对 barbican 的访问。openstack overcloud deploy \ --stack dcn0 \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/dcn0/roles_data.yaml \ .... -e /usr/share/openstack-tripleo-heat-templates/environments/services/barbican-edge.yaml
第 9 章 将 glance 镜像预缓存到 nova
当您将 OpenStack Compute 配置为使用本地临时存储时,glance 镜像会被缓存来加快实例部署。如果实例所需的镜像尚未缓存,则在创建实例时将其下载到 Compute 节点的本地磁盘。
下载 glance 镜像的过程需要变量的时间,具体取决于镜像大小和网络特征,如带宽和延迟。
如果您尝试启动实例,且镜像在本地的 Ceph 集群上不可用,则启动实例会失败并显示以下信息:
Build of instance 3c04e982-c1d1-4364-b6bd-f876e399325b aborted: Image 20c5ff9d-5f54-4b74-830f-88e78b9999ed is unacceptable: No image locations are accessible
您可以在 Compute 服务日志中看到以下内容:
'Image %s is not on my ceph and [workarounds]/ never_download_image_if_on_rbd=True; refusing to fetch and upload.',
由于 nova.conf 配置文件中的一个参数(名为 never_download_image_if_on_rbd)对于 DCN 部署被默认设为 true,则实例会启动失败。您可以使用 heat 参数 NovaDisableImageDownloadToRbd 控制这个值,您可以在 dcn-hci.yaml 文件中找到。
如果在部署 overcloud 前将 NovaDisableImageDownloadToRbd 的值设置为 false,则会出现以下情况:
-
如果镜像在本地不可用,计算服务(nova)将自动流传输在
中央位置可用的镜像。 - 您无法使用 glance 镜像中的 COW 副本。
- 计算(nova)存储可能会包含同一镜像的多个副本,具体取决于使用它的实例数量。
-
您可以饱和 WAN 链接到
中央位置和 nova 存储池。
红帽建议将此值设置为 true,并确保在启动实例前在本地提供所需的镜像。有关使镜像提供给边缘的更多信息,请参阅 第 A.1.3 节 “将镜像复制到新站点”。
对于本地的镜像,您可以使用 tripleo_nova_image_cache.yml ansible playbook 来预缓存常用的镜像或镜像,从而加快虚拟机创建速度。
9.1. 运行 tripleo_nova_image_cache.yml ansible playbook
先决条件
- 在 shell 环境中对正确的 API 进行身份验证凭据。
在每个步骤中提供的命令前,您必须确保提供正确的身份验证文件。
流程
为堆栈创建 ansible 清单文件。您可以在以逗号分隔的列表中指定多个堆栈,以在多个站点缓存镜像:
$ source stackrc $ tripleo-ansible-inventory --plan central,dcn0,dcn1 \ --static-yaml-inventory inventory.yaml
创建您要预缓存的镜像 ID 列表:
检索可用镜像的完整列表:
$ source centralrc $ openstack image list +--------------------------------------+---------+--------+ | ID | Name | Status | +--------------------------------------+---------+--------+ | 07bc2424-753b-4f65-9da5-5a99d8383fe6 | image_0 | active | | d5187afa-c821-4f22-aa4b-4e76382bef86 | image_1 | active | +--------------------------------------+---------+--------+
创建名为
nova_cache_args.yml的 ansible playbook 参数文件,并添加您要预缓存的镜像 ID:--- tripleo_nova_image_cache_images: - id: 07bc2424-753b-4f65-9da5-5a99d8383fe6 - id: d5187afa-c821-4f22-aa4b-4e76382bef86
运行
tripleo_nova_image_cache.ymlansible playbook:$ source centralrc $ ansible-playbook -i inventory.yaml \ --extra-vars "@nova_cache_args.yml" \ /usr/share/ansible/tripleo-playbooks/tripleo_nova_image_cache.yml
9.2. 性能考虑
您可以指定您要与 ansible fork 参数同时下载的镜像数量,该参数默认为 5。您可以通过增加 fork 参数的值来缩短发布此镜像的时间,但您必须以增加网络和 glance-api 负载来平衡这个值。
使用 --forks 参数来调整并发性,如下所示:
ansible-playbook -i inventory.yaml \ --forks 10 \ --extra-vars "@nova_cache_args.yml" \ /usr/share/ansible/tripleo-playbooks/tripleo_nova_image_cache.yml
9.3. 优化镜像分发到 DCN 站点
您可以使用代理进行 glance 镜像分发来减少 WAN 流量。配置代理时:
- Glance 镜像下载到充当代理的单个 Compute 节点上。
- 代理将 glance 镜像重新分发到清单中的其他 Compute 节点。
您可以将以下参数放在 nova_cache_args.yml ansible 参数文件中,以配置代理节点。
将 tripleo_nova_image_cache_use_proxy 参数设置为 true 以启用镜像缓存代理。
镜像代理使用安全复制 scp 将镜像分发到清单中的其他节点。SCP 与具有高延迟的网络(如 DCN 站点间的 WAN)相比效率较低。红帽建议您将 playbook 目标限制为单个 DCN 位置,该位置与单个堆栈相关联。
使用 tripleo_nova_image_cache_proxy_hostname 参数来选择镜像缓存代理。默认代理是 ansible 清单文件中的第一个计算节点。使用 tripleo_nova_image_cache_plan 参数将 playbook 清单限制为单个站点:
tripleo_nova_image_cache_use_proxy: true tripleo_nova_image_cache_proxy_hostname: dcn0-novacompute-1 tripleo_nova_image_cache_plan: dcn0
9.4. 配置 nova-cache 清理
当满足以下任一条件时,后台进程会定期运行来从 nova 缓存中删除镜像:
- 该镜像不供实例使用。
-
镜像的年龄大于 nova 参数
remove_unused_original_minimum_age_seconds的值。
remove_unused_original_minimum_age_seconds 参数的默认值为 86400。该值以秒为单位表示,等于 24 小时。您可以在初始部署期间使用 NovaImageCachTTL tripleo-heat-templates 参数或云堆栈更新期间控制这个值:
parameter_defaults:
NovaImageCacheTTL: 604800 # Default to 7 days for all compute roles
Compute2Parameters:
NovaImageCacheTTL: 1209600 # Override to 14 days for the Compute2 compute role
当您指示 playbook 预缓存 Compute 节点上已存在的镜像时,ansible 不会报告更改,但镜像的年龄重置为 0。运行 ansible 频率比 NovaImageCacheTTL 参数的值更频繁,以维护镜像的缓存。
第 10 章 TLS-e 用于 DCN
您可以在为分布式计算节点基础架构设计的云中启用 TLS (传输层安全)。您可以选择启用 TLS 以进行公共访问,或使用 TLS-e 在每个网络上启用 TLS,这允许在所有内部和外部数据流上加密。
您无法在边缘堆栈上启用公共访问,因为边缘站点没有公共端点。有关 TLS 进行公共访问的更多信息,请参阅在 Overcloud 公共端点上启用 SSL/TLS。
10.1. 使用 TLS-e 部署分布式计算节点架构
先决条件
当您使用 Red Hat Identity Manager (IdM)在 Red Hat OpenStack Platform (RHOSP)分布式计算节点架构中配置 TLS-e 时,根据为 Red Hat Identity Manager 部署的 Red Hat Enterprise Linux 版本执行以下操作。
- Red Hat Enterprise Linux 8.4
-
在 Red Hat Identity Management 节点上,允许信任子网在
ipa-ext.conf文件中进行 ACL:
acl "trusted_network" { localnets; localhost; 192.168.24.0/24; 192.168.25.0/24; };在
/etc/named/ipa-options-ext.conf文件中,允许递归和查询缓存:allow-recursion { trusted_network; }; allow-query-cache { trusted_network; };重启 'named-pkcs11 服务:
systemctl restart named-pkcs11
-
在 Red Hat Identity Management 节点上,允许信任子网在
- Red Hat Enterprise Linux 8.2
- 如果您在 Red Hat Enterprise Linux (RHEL) 8.2 上有 Red Hat Identity Manager (IdM) 8.2,您必须升级 Red Hat Enterprise Linux,然后按照 RHEL 8.4 的说明进行操作
- Red Hat Enterprise Linux 7.x
-
如果您在 Red Hat Enterprise Linux (RHEL) 7.x 上有 Red Hat Identity Manager (IdM),您必须手动为您的域名添加访问控制指令(ACI)。例如,如果域名是
redhat.local,请在 Red Hat Identity Manager 上运行以下命令来配置 ACI:
ADMIN_PASSWORD=redhat_01
DOMAIN_LEVEL_1=local
DOMAIN_LEVEL_2=redhat
cat << EOF | ldapmodify -x -D "cn=Directory Manager" -w ${ADMIN_PASSWORD}
dn: cn=dns,dc=${DOMAIN_LEVEL_2},dc=${DOMAIN_LEVEL_1}
changetype: modify
add: aci
aci: (targetattr = "aaaarecord || arecord || cnamerecord || idnsname || objectclass || ptrrecord")(targetfilter = "(&(objectclass=idnsrecord)(|(aaaarecord=)(arecord=)(cnamerecord=)(ptrrecord=)(idnsZoneActive=TRUE)))")(version 3.0; acl "Allow hosts to read DNS A/AAA/CNAME/PTR records"; allow (read,search,compare) userdn = "ldap:///fqdn=*,cn=computers,cn=accounts,dc=${DOMAIN_LEVEL_2},dc=${DOMAIN_LEVEL_1}";)
EOF流程
对于分布式计算节点(DCN)架构,需要使用基于 ansible 的 tripleo-ipa 方法实施 TLS-e,而不是之前的 novajoin 方法。有关使用 tripleo-ipa 部署 TLS-e 的更多信息,请参阅使用 Ansible 实施 TLS-e。
要使用 tripleo-ipa 用于 DCN 架构部署 TLS-e,您还需要完成以下步骤:
如果要在边缘部署存储,请在修改后的用于边缘堆栈的 tripleo heat 模板中包括以下参数:
TEMPLATES=/usr/share/openstack-tripleo-heat-templates resource_registry: OS::TripleO::Services::IpaClient: ${TEMPLATES}/deployment/ipa/ipaservices-baremetal-ansible.yaml parameter_defaults: EnableEtcdInternalTLS: true
由于中央位置和边缘位置之间的设计差异,请不要在边缘堆栈中包含以下文件:
- tls-everywhere-endpoints-dns.yaml
- 此文件在边缘站点中被忽略,它集的端点会被从中央堆栈导出的端点覆盖。
- haproxy-public-tls-certmonger.yaml
- 此文件会导致部署失败,因为边缘没有公共端点。
第 11 章 创建用于外部访问的 Ceph 密钥
对 Ceph 存储的外部访问可从任何非本地站点访问 Ceph。中心位置上的 Ceph 存储是边缘(DCN)站点的外部存储,就像边缘的 Ceph 存储是中央位置的外部。
当您使用 Ceph 存储部署中央或 DCN 站点时,您可以选择将默认 openstack 密钥环用于本地和远程访问。例如,您可以创建单独的密钥供非本地站点访问。
如果您决定使用额外的 Ceph 密钥来访问外部站点,每个密钥必须具有相同的名称。密钥名称在以下示例中是外部的。
如果您使用单独的密钥进行非本地站点访问,则获得额外的安全优势,以便在不中断本地访问的情况下对外部事件进行撤销并重新发布外部密钥。但是,使用单独的密钥进行外部访问将导致丢失某些功能,如跨可用区备份和离线卷迁移。您必须根据所需的功能集对安全公开的要求进行平衡。
默认情况下,中央和所有 DCN 站点的密钥都会被共享。
11.1. 创建用于外部访问的 Ceph 密钥
完成以下步骤,为非本地访问创建 外部 密钥。
Process
创建用于外部访问的 Ceph 密钥。这个密钥是敏感的。您可以使用以下方法生成密钥:
python3 -c 'import os,struct,time,base64; key = os.urandom(16) ; \ header = struct.pack("<hiih", 1, int(time.time()), 0, len(key)) ; \ print(base64.b64encode(header + key).decode())'在您要部署的堆栈的目录中,使用密钥的输出结果创建一个
ceph_keys.yaml环境文件,其内容如下:parameter_defaults: CephExtraKeys: - name: "client.external" caps: mgr: "allow *" mon: "profile rbd" osd: "profile rbd pool=vms, profile rbd pool=volumes, profile rbd pool=images" key: "AQD29WteAAAAABAAphgOjFD7nyjdYe8Lz0mQ5Q==" mode: "0600"在站点部署中包含
ceph_keys.yaml环境文件。例如,要使用ceph_keys.yaml环境文件部署中央站点,请运行以下命令:overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ …. -e ~/central/ceph_keys.yaml
11.2. 使用外部 Ceph 密钥
您只能使用已部署的密钥。有关使用 外部 密钥部署站点的详情,请参考 第 11.1 节 “创建用于外部访问的 Ceph 密钥”。这应该为中央和边缘站点完成。
当您部署使用中心提供的一个
外部密钥的边缘站点时,请完成以下操作:为边缘站点创建
dcn_ceph_external.yaml环境文件。您必须包含cephx-key-client-name选项,才能指定要包含的部署密钥。sudo -E openstack overcloud export ceph \ --stack central \ --config-download-dir /var/lib/mistral \ --cephx-key-client-name external \ --output-file ~/dcn-common/dcn_ceph_external.yaml
-
包含
dcn_ceph_external.yaml文件,以便边缘站点可以访问中央站点的 Ceph 集群。包含ceph_keys.yaml文件,以在边缘站点为 Ceph 集群部署外部密钥。
当您在部署边缘站点后更新中央位置时,请确保中央位置使用 dcn
外部密钥:确保
CephClientUserName参数与所导出的密钥匹配。如果您使用这些示例所示的名称external,请创建glance_update.yaml类似于以下内容:parameter_defaults: GlanceEnabledImportMethods: web-download,copy-image GlanceBackend: rbd GlanceStoreDescription: 'central rbd glance store' CephClusterName: central GlanceBackendID: central GlanceMultistoreConfig: dcn0: GlanceBackend: rbd GlanceStoreDescription: 'dcn0 rbd glance store' CephClientUserName: 'external' CephClusterName: dcn0 GlanceBackendID: dcn0 dcn1: GlanceBackend: rbd GlanceStoreDescription: 'dcn1 rbd glance store' CephClientUserName: 'external' CephClusterName: dcn1 GlanceBackendID: dcn1使用
openstack overcloud export ceph命令,使其包含从中央位置访问 DCN 边缘访问的外部密钥。要做到这一点,您必须为--stack参数提供一个以逗号分隔的堆栈列表,并包含cephx-key-client-name选项:sudo -E openstack overcloud export ceph \ --stack dcn0,dcn1,dcn2 \ --config-download-dir /var/lib/mistral \ --cephx-key-client-name external \ --output-file ~/central/dcn_ceph_external.yaml
使用原始模板重新部署中央站点,并包含新创建的
dcn_ceph_external.yaml和glance_update.yaml文件。openstack overcloud deploy \ --stack central \ --templates /usr/share/openstack-tripleo-heat-templates/ \ -r ~/central/central_roles.yaml \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/nova-az-config.yaml \ -e ~/central/central-images-env.yaml \ -e ~/central/role-counts.yaml \ -e ~/central/site-name.yaml -e ~/central/ceph.yaml \ -e ~/central/ceph_keys.yaml \ -e ~/central/glance.yaml \ -e ~/central/dcn_ceph_external.yaml
附录 A. 部署迁移选项
本节包含与 DCN 存储相关的主题,以及迁移或更改架构。
A.1. 验证边缘存储
通过测试 glance 多存储和实例创建,确保中央和边缘站点的部署正在工作。
您可以将镜像导入到本地文件系统上可用的 glance 中,或者在 web 服务器上可用。
始终将镜像副本存储在中央站点,即使没有在中央位置使用该镜像的实例。
先决条件
使用
glance stores-info命令检查镜像服务可用的存储。在以下示例中,提供了三个存储: central、dcn1 和 dcn2。它们分别与 glance 分别存储在中央位置和边缘站点:$ glance stores-info +----------+----------------------------------------------------------------------------------+ | Property | Value | +----------+----------------------------------------------------------------------------------+ | stores | [{"default": "true", "id": "central", "description": "central rbd glance | | | store"}, {"id": "dcn0", "description": "dcn0 rbd glance store"}, | | | {"id": "dcn1", "description": "dcn1 rbd glance store"}] | +----------+----------------------------------------------------------------------------------+
A.1.1. 从本地文件导入
您必须首先将镜像上传到中央位置的存储中,然后将镜像复制到远程站点。
确保您的镜像文件采用 RAW 格式。如果镜像不采用 raw 格式,则必须在将镜像导入到镜像服务前转换镜像:
file cirros-0.5.1-x86_64-disk.img cirros-0.5.1-x86_64-disk.img: QEMU QCOW2 Image (v3), 117440512 bytes qemu-img convert -f qcow2 -O raw cirros-0.5.1-x86_64-disk.img cirros-0.5.1-x86_64-disk.raw
Import the image into the default back end at the central site:
glance image-create \ --disk-format raw --container-format bare \ --name cirros --file cirros-0.5.1-x86_64-disk.raw \ --store central
A.1.2. 从 Web 服务器导入镜像
如果镜像托管在 web 服务器上,您可以使用 GlanceImageImportPlugins 参数将镜像上传到多个存储。
此流程假设在 glance 中启用了默认镜像转换插件。此功能自动将 QCOW2 文件格式转换为 RAW 镜像,这是 Ceph RBD 的最佳选择。您可以通过运行 glance image-show ID | grep disk_format 来确认 glance 镜像采用 RAW 格式。
流程
使用
glance命令的image-create-via-import参数从 Web 服务器导入镜像。使用--stores参数。# glance image-create-via-import \ --disk-format qcow2 \ --container-format bare \ --name cirros \ --uri http://download.cirros-cloud.net/0.4.0/cirros-0.4.0-x86_64-disk.img \ --import-method web-download \ --stores central,dcn1
在本例中,qcow2 cirros 镜像从官方 Cirros 站点下载,由 glance 转换为 RAW,并导入到由
--stores参数指定的中央站点和边缘站点 1。
或者,您可以将 --stores 替换为 --all-stores True,以将镜像上传到所有存储。
A.1.3. 将镜像复制到新站点
您可以将现有镜像从中央位置复制到边缘站点,这可让您在新创建的位置访问之前创建的镜像。
将 glance 镜像的 UUID 用于复制操作:
ID=$(openstack image show cirros -c id -f value) glance image-import $ID --stores dcn0,dcn1 --import-method copy-image
注意在本例中,--
stores选项指定cirros镜像将从中央站点复制到边缘站点 dcn1 和 dcn2。或者,您可以使用--all-stores True选项,该选项将镜像上传到当前没有镜像的所有存储中。确认镜像的副本位于每个存储中。请注意,store 键(属性映射中的最后一个项)被设置为
central,dcn0,dcn1:$ openstack image show $ID | grep properties | properties | direct_url=rbd://d25504ce-459f-432d-b6fa-79854d786f2b/images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076/snap, locations=[{u'url: u'rbd://d25504ce-459f-432d-b6fa-79854d786f2b/images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076/snap', u'metadata': {u'store': u'central'}}, {u'url': u'rbd://0c10d6b5-a455-4c4d-bd53-8f2b9357c3c7/images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076/snap', u'metadata': {u'store': u'dcn0'}}, {u'url': u'rbd://8649d6c3-dcb3-4aae-8c19-8c2fe5a853ac/images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076/snap', u'metadata': {u'store': u'dcn1'}}], os_glance_failed_import=', os_glance_importing_to_stores=', os_hash_algo='sha512, os_hash_value=b795f047a1b10ba0b7c95b43b2a481a59289dc4cf2e49845e60b194a911819d3ada03767bbba4143b44c93fd7f66c96c5a621e28dff51d1196dae64974ce240e, os_hidden=False, stores=central,dcn0,dcn1 |
即使没有在该站点上使用虚拟机,也始终将镜像副本存储在中央站点。
A.1.4. 确认边缘站点中的实例可以使用基于镜像的卷引导
您可以使用边缘站点中的镜像来创建持久的根卷。
流程
识别要作为卷创建的镜像 ID,并将该 ID 传递给
openstack volume create命令:IMG_ID=$(openstack image show cirros -c id -f value) openstack volume create --size 8 --availability-zone dcn0 pet-volume-dcn0 --image $IMG_ID
识别新创建的卷的卷 ID,并将其传递给
openstack server create命令:VOL_ID=$(openstack volume show -f value -c id pet-volume-dcn0) openstack server create --flavor tiny --key-name dcn0-key --network dcn0-network --security-group basic --availability-zone dcn0 --volume $VOL_ID pet-server-dcn0
您可以通过在 dcn0 边缘站点的 ceph-mon 容器中运行 rbd 命令来验证卷是否基于镜像,以列出卷池。
$ sudo podman exec ceph-mon-$HOSTNAME rbd --cluster dcn0 -p volumes ls -l NAME SIZE PARENT FMT PROT LOCK volume-28c6fc32-047b-4306-ad2d-de2be02716b7 8 GiB images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076@snap 2 excl $
确认您可以创建实例的根卷的 cinder 快照。确保服务器停止以静止数据以创建干净的快照。使用 --force 选项,因为实例关闭时卷状态会一直
使用。openstack server stop pet-server-dcn0 openstack volume snapshot create pet-volume-dcn0-snap --volume $VOL_ID --force openstack server start pet-server-dcn0
列出 dcn0 Ceph 集群上 volumes 池的内容,以显示新创建的快照。
$ sudo podman exec ceph-mon-$HOSTNAME rbd --cluster dcn0 -p volumes ls -l NAME SIZE PARENT FMT PROT LOCK volume-28c6fc32-047b-4306-ad2d-de2be02716b7 8 GiB images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076@snap 2 excl volume-28c6fc32-047b-4306-ad2d-de2be02716b7@snapshot-a1ca8602-6819-45b4-a228-b4cd3e5adf60 8 GiB images/8083c7e7-32d8-4f7a-b1da-0ed7884f1076@snap 2 yes
A.1.5. 确认可以在站点之间创建和复制镜像快照
验证您可以在 dcn0 网站创建新镜像。确保服务器停止以静止数据来创建干净的快照:
NOVA_ID=$(openstack server show pet-server-dcn0 -f value -c id) openstack server stop $NOVA_ID openstack server image create --name cirros-snapshot $NOVA_ID openstack server start $NOVA_ID
将镜像从
dcn0边缘站点复制到 hub 位置,这是 glance 的默认后端:IMAGE_ID=$(openstack image show cirros-snapshot -f value -c id) glance image-import $IMAGE_ID --stores central --import-method copy-image
有关 glance 多存储操作的更多信息,请参阅 具有多个存储的镜像服务。
A.2. 迁移到 spine 和 leaf 部署
可将预先存在的网络配置的现有云迁移到具有 spine leaf 架构的一个。因此,需要以下条件:
-
所有裸机端口都必须将其
physical-network属性值设置为ctlplane。 -
参数
enable_routed_networks被添加,在 undercloud.conf 中设置为true,随后重新运行 undercloud 安装命令,openstack undercloud install。
重新部署 undercloud 后,overcloud 被视为一个 spine leaf0,它带有一个 leaf leaf0。您可以按照以下步骤为部署添加额外的置备。
- 将所需的子网添加到 undercloud.conf,如在 undercloud 中配置路由的 spine-leaf 所示。
-
重新运行 undercloud 安装命令
openstack undercloud install。 分别将所需的额外网络和角色添加到 overcloud 模板
network_data.yaml和roles_data.yaml中。注意如果您在网络配置文件中使用
{{network.name}}InterfaceRoutes参数,则需要确保NetworkDeploymentActions参数包含值 UPDATE。NetworkDeploymentActions: ['CREATE','UPDATE'])
- 最后,重新运行 overcloud 安装脚本,其中包含用于您的云部署的所有相关 heat 模板。
A.3. 迁移到多堆栈部署
您可以通过将现有部署视为中央站点并添加额外的边缘站点,从单一堆栈部署迁移到多堆栈部署。
从本发行版本中从单堆栈迁移到多堆栈的功能 是技术预览,因此不受红帽完全支持。它只应用于测试,不应部署在生产环境中。有关技术预览功能的更多信息,请参阅覆盖范围详细信息。
您无法分割现有的堆栈。如果需要,您可以缩减现有堆栈以移除计算节点。然后可将这些计算节点添加到边缘站点。
如果删除了所有计算节点,此操作会创建工作负载中断。
A.4. 在边缘站点间备份和恢复
您可以在边缘站点和可用区中的分布式计算节点(DCN)架构中备份和恢复块存储服务(cinder)卷。cinder-backup 服务在中央可用区(AZ)中运行,备份存储在中央 AZ 中。块存储服务不会在 DCN 站点存储备份。
先决条件
-
中央站点使用位于
/usr/share/openstack-tripleo-heat-templates/environments中的cinder-backup.yaml环境文件进行部署。如需更多信息,请参阅块存储备份服务部署。 - Block Storage 服务(cinder) CLI 可用。
-
所有站点都必须使用通用的
openstackcephx 客户端名称。有关更多信息,请参阅为外部访问创建 Ceph 密钥。
流程
在第一个 DCN 站点中创建卷备份:
$ cinder --os-volume-api-version 3.51 backup-create --name <volume_backup> --availability-zone <az_central> <edge_volume>
-
将
<volume_backup> 替换为卷备份的名称。 -
将
<az_central> 替换为托管cinder-backup服务的中央可用区的名称。 将 <
edge_volume> 替换为您要备份的卷的名称。注意如果遇到 Ceph 密钥环的问题,您可能需要重启
cinder-backup容器,以便主机中的密钥环成功复制到容器。
-
将
将备份恢复到第二个 DCN 站点中的新卷:
$ cinder --os-volume-api-version 3.51 create --availability-zone <az_2> --name <new_volume> --backup-id <volume_backup> <volume_size>
-
将 <
;az_2> 替换为您要恢复备份的可用区的名称。 -
将
<new_volume> 替换为新卷的名称。 -
将 <
;volume_backup> 替换为您在上一步中创建的卷备份的名称。 -
将 <
;volume_size> 替换为等于或大于原始卷大小的值。
-
将 <