
管理并分配存储资源
有关如何将存储分配到核心服务和托管应用程序的说明,包括快照和克隆。
摘要
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
对红帽文档提供反馈
我们感谢您对文档提供反馈信息。请告诉我们如何让它更好。提供反馈:
关于特定内容的简单评论:
- 请确定您使用 Multi-page HTML 格式查看文档。另外,确定 Feedback 按钮出现在文档页的右上方。
- 用鼠标指针高亮显示您想评论的文本部分。
- 点在高亮文本上弹出的 Add Feedback。
- 按照显示的步骤操作。
要提交更复杂的反馈,请创建一个 Bugzilla ticket:
- 进入 Bugzilla 网站。
- 在 Component 部分中,选择 文档。
- 在 Description 中输入您要提供的信息。包括文档相关部分的链接。
- 点 Submit Bug。
第 1 章 概述
阅读本文档,了解如何在 Red Hat OpenShift Data Foundation 中创建、配置和分配存储到核心服务或托管应用程序。
- 第 2 章 存储类 显示如何创建自定义存储类。
- 第 3 章 块池 为您提供有关如何创建、更新和删除块池的信息。
- 第 4 章 为 OpenShift Container Platform 服务配置存储 演示了如何将 OpenShift Data Foundation 用于 OpenShift Container Platform 核心服务。
- 第 5 章 使用 OpenShift Data Foundation 支持 OpenShift Container Platform 应用程序 提供有关如何配置 OpenShift 容器平台应用以使用 OpenShift Data Foundation 的信息。
- 将文件和对象存储添加到现有外部 OpenShift Data Foundation 集群
- 第 7 章 如何在 Red Hat OpenShift Data Foundation 中使用专用 worker 节点 提供有关如何为 Red Hat OpenShift Data Foundation 使用专用工作程序节点的信息。
- 第 8 章 管理持久性卷声明 提供有关管理持久卷声明请求和自动完成这些请求的信息。
- 第 9 章 卷快照 向您演示如何创建、恢复和删除卷快照。
- 第 10 章 卷克隆 显示如何创建卷克隆。
- 第 11 章 管理容器存储接口(CSI)组件放置 提供有关设置容忍度以在节点上调出容器存储接口组件的信息。
第 2 章 存储类
OpenShift Data Foundation Operator 根据使用的平台安装默认存储类。这个默认存储类由 Operator 所有和控制,且无法删除或修改。但是,您可以创建客户存储类来使用其他存储资源或为应用提供不同的行为。
外部模式 OpenShift Data Foundation 集群不支持自定义存储类。
2.1. 创建存储类和池
您可以使用现有池创建存储类,也可以在创建存储类时为存储类创建新池。
先决条件
-
确保您已登录到 OpenShift Container Platform Web 控制台,并且 OpenShift Data Foundation 集群处于
Ready状态。
流程
- 点 Storage → StorageClasses。
- 点 Create Storage Class。
- 输入存储类 Name 和 Description。
Reclaim Policy 设置为
Delete作为默认选项。使用这个设置。如果您在存储类中将重新声明策略改为
Retain,则持久性卷(PV)会处于Released状态,即使在删除持久性卷声明(PVC)后也是如此。卷绑定模式设置为
WaitForConsumer作为默认选项。如果您选择了
Immediate选项,则在创建 PVC 时也会同时创建 PV。- 选择 RBD Provisioner,这是用于置备持久性卷的插件。
从列表中选择现有存储池,或创建新池。
- 创建新池
- 单击 Create New Pool。
- 输入 池名称。
- 选择 2-way-Replication 或 3-way-Replication作为数据保护策略。
如果需要压缩数据,选择启用压缩。
启用压缩可能会影响应用程序的性能,在已压缩或加密的数据时可能会证明无效。在启用压缩之前写入的数据不会压缩。
- 单击 Create 以创建新存储池。
- 创建池后,单击 Finish。
- 可选:选择启用加密复选框。
- 点 Create 创建存储类。
2.2. 为持久性卷加密创建存储类
持久性卷(PV)加密可确保租户(应用程序)之间的隔离和保密性。在使用 PV 加密前,您必须为 PV 加密创建一个存储类。
OpenShift Data Foundation 支持在 HashiCorp Vault 中存储加密密码短语。使用以下步骤创建加密的存储类,使用外部密钥管理系统(KMS)进行持久性卷加密。持久卷加密仅可用于 RBD PV。您可以通过两种不同的方式配置对 KMS 的访问:
-
使用
vaulttoken允许用户使用令牌进行身份验证 -
使用
vaulttenantsa(技术预览):允许用户使用 serviceaccounts 通过 Vault 进行身份验证
使用 vaulttenantsa 访问 KMS 是一项技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需更多信息,请参阅技术预览功能支持范围。
在按照创建存储类的步骤之前,请参阅您的用例的相关先决条件部分:
2.2.1. 使用 vaulttoken 的先决条件
-
OpenShift 数据基础集群处于
Ready状态。 在外部密钥管理系统 (KMS) 上,
- 确保存在具有令牌的策略,并且启用了 Vault 中的键值后端路径。如需更多信息,请参阅在 Vault 中启用键值和策略。
- 确保您在 Vault 服务器上使用签名的证书。
在租户命名空间中创建一个 secret,如下所示:
- 在 OpenShift Container Platform web 控制台中进入 Workloads → Secrets。
- 点 Create → Key/value secret。
-
输入 Secret Name 作为
ceph-csi-kms-token。 -
输入 Key 作为
token。 - 输入 Value。它是来自 Vault 的令牌。您可以单击 Browse 来选择并上传含有令牌的文件,或者直接在文本框中输入令牌。
- 点击 Create。
只有在所有使用 ceph-csi-kms-token 的加密 PVC 已被删除后,才能删除令牌。
接下来,按照 第 2.2.3 节 “为 PV 加密创建存储类的步骤” 中的步骤操作。
2.2.2. 使用 vaulttenantsa的先决条件
-
OpenShift 数据基础集群处于
Ready状态。 在外部密钥管理系统 (KMS) 上,
- 确保策略存在,并且已启用 Vault 中的键值后端路径。如需更多信息,请参阅在 Vault 中启用键值和策略。
- 确保您在 Vault 服务器上使用签名的证书。
在租户命名空间中创建以下 serviceaccount,如下所示:
$ cat <<EOF | oc create -f - apiVersion: v1 kind: ServiceAccount metadata: name: ceph-csi-vault-sa EOF必须配置 Kubernetes 身份验证方法,然后才能使用 OpenShift 数据基础进行身份验证并开始使用 Vault。以下说明创建并配置所需的
serviceAccount、ClusterRole和ClusterRoleBinding,以允许 OpenShift Data Foundation 使用 Vault 进行身份验证。将以下 YAML 应用到您的 Openshift 集群:
apiVersion: v1 kind: ServiceAccount metadata: name: rbd-csi-vault-token-review --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-csi-vault-token-review rules: - apiGroups: ["authentication.k8s.io"] resources: ["tokenreviews"] verbs: ["create", "get", "list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-csi-vault-token-review subjects: - kind: ServiceAccount name: rbd-csi-vault-token-review namespace: openshift-storage roleRef: kind: ClusterRole name: rbd-csi-vault-token-review apiGroup: rbac.authorization.k8s.io识别与上述创建的 serviceaccount(SA)关联的 secret 名称:
$ oc -n openshift-storage get sa rbd-csi-vault-token-review -o jsonpath="{.secrets[*]['name']}"从 secret 获取令牌和 CA 证书:
$ oc get secret <secret associated with SA> -o jsonpath="{.data['token']}" | base64 --decode; echo $ oc get secret <secret associated with SA> -o jsonpath="{.data['ca\.crt']}" | base64 --decode; echo检索 OCP 集群端点:
$ oc config view --minify --flatten -o jsonpath="{.clusters[0].cluster.server}"使用上面步骤中收集的信息在 Vault 中设置 kubernetes 验证方法,如下所示:
$ vault auth enable kubernetes $ vault write auth/kubernetes/config token_reviewer_jwt=<SA token> kubernetes_host=<OCP cluster endpoint> kubernetes_ca_cert=<SA CA certificate>
在 Vault 中为租户命名空间创建一个角色:
$ vault write "auth/kubernetes/role/csi-kubernetes" bound_service_account_names="ceph-csi-vault-sa" bound_service_account_namespaces=<tenant_namespace> policies=<policy_name_in_vault>
csi-kubernetes是 OpenShift Data Foundation 在 Vault 中寻找的默认角色名称。Openshift Data Foundation 集群中租户命名空间中的默认服务帐户名称为ceph-csi-vault-sa。这些默认值可以通过在租户命名空间中创建 ConfigMap 来覆盖。有关覆盖默认名称的更多信息,请参阅使用租户 ConfigMap 覆盖 Vault 连接详情。
要创建一个使用
vaulttenantsa方法进行 PV 保护的存储类,您必须编辑现有的 ConfigMap 或创建名为csi-kms-connection-details的配置映射,它将保存建立与 Vault 连接所需的所有信息。以下提供的 yaml 示例可用于更新或创建
csi-kms-connection-detailConfigMap:apiVersion: v1 data: vault-tenant-sa: |- { "encryptionKMSType": "vaulttenantsa", "vaultAddress": "<https://hostname_or_ip_of_vault_server:port>", "vaultTLSServerName": "<vault TLS server name>", "vaultAuthPath": "/v1/auth/kubernetes/login", "vaultAuthNamespace": "<vault auth namespace name>" "vaultNamespace": "<vault namespace name>", "vaultBackendPath": "<vault backend path name>", "vaultCAFromSecret": "<secret containing CA cert>", "vaultClientCertFromSecret": "<secret containing client cert>", "vaultClientCertKeyFromSecret": "<secret containing client private key>", "tenantSAName": "<service account name in the tenant namespace>" } metadata: name: csi-kms-connection-details-
encryptionKMSType:应设置为vaulttenantsa,以使用服务帐户通过 vault 进行身份验证。 -
vaultAddress: 使用端口号的 vault 服务器的主机名或 IP 地址。 -
vaultTLSServerName:(可选) vault TLS 服务器名称 -
vaultAuthPath:(可选)在 Vault 中启用 kubernetes auth 方法的路径。默认路径为kubernetes。如果在kubernetes之外的其他路径中启用了 auth 方法,则需要将此变量设置为"/v1/auth/<path>/login"。 -
vaultAuthNamespace:(可选)启用了 kubernetes auth 方法的 Vault 命名空间。 -
vaultNamespace:(可选)用于存储密钥的后端路径的 Vault 命名空间 -
vaultBackendPath:存储加密密钥的 Vault 中的后端路径 -
vaultCAFromSecret: 包含来自 Vault 的 CA 证书的 OpenShift Data Foundation 集群中的 secret -
vaultClientCertFromSecret: OpenShift Data Foundation 集群中的 secret,其中包含来自 Vault 的客户端证书 -
vaultClientCertKeyFromSecret: OpenShift Data Foundation 集群中的 secret,其中包含来自 Vault 的客户端私钥 -
tenantSAName:(可选)租户命名空间中的服务帐户名称。默认值为ceph-csi-vault-sa。如果要使用其他名称,则必须相应地设置此变量。
-
接下来,按照 第 2.2.3 节 “为 PV 加密创建存储类的步骤” 中的步骤操作。
2.2.3. 为 PV 加密创建存储类的步骤
在为 vaulttoken 或 vaulttenantsa 执行必要的先决条件后,请执行以下步骤来创建启用了加密的存储类。
- 进入 Storage → StorageClasses。
- 点 Create Storage Class。
- 输入存储类 Name 和 Description。
- 为 Reclaim Policy 选择 Delete 或 Retain。默认情况下,选择 Delete。
- 选择 Immediate 或 WaitForFirstConsumer 作为卷绑定模式。WaitForConsumer 设置为默认选项。
-
选择 RBD Provisioner
openshift-storage.rbd.csi.ceph.com,这是用于调配持久卷的插件。 - 选择 存储池,其中卷数据将存储到列表中或创建新池。
选中 Enable encryption 复选框。有两个选项可用来设置 KMS 连接详情:
-
选择现有的 KMS 连接 :从下拉列表中选择现有的 KMS 连接。该列表填充自
csi-kms-connection-detailsConfigMap 中的连接详情。 创建新的 KMS 连接 :这仅适用于
vaulttoken。- 默认情况下,Key Management Service Provider 设置为 Vault。
-
输入唯一的 Vault Service Name、Vault 服务器的主机地址 (
https://<hostname 或 ip>)和端口号 。 展开 Advanced Settings ,以根据您的 Vault 配置输入其他设置和证书详情。
- 在 后端路径中输入为 OpenShift Data Foundation 专用且唯一的 Key Value secret 路径。
- 可选 :输入 TLS Server Name 和 Vault Enterprise Namespace。
- 通过上传相应的 PEM 编码证书文件提供 CA 证书、客户端证书和客户端私钥。
- 单击 Save。
- 点击 Save。
-
选择现有的 KMS 连接 :从下拉列表中选择现有的 KMS 连接。该列表填充自
- 点击 Create。
如果 HashiCorp Vault 设置不允许自动检测后端路径使用的 Key/Value(KV)secret 引擎 API 版本,请编辑 ConfigMap 以添加
VAULT_BACKEND或vaultBackend参数。注意VAULT_BACKEND或vaultBackend是已添加到 configmap 中的可选参数,以指定与后端路径关联的 KV secret 引擎 API 的版本。确保值与为后端路径设置的 KV secret 引擎 API 版本匹配,否则可能会导致持久性卷声明(PVC)创建过程中失败。识别新创建的存储类使用的 encryptionKMSID。
- 在 OpenShift Web 控制台中,导航到 Storage → Storage Classes。
- 点 Storage class name → YAML 标签页。
捕获存储类使用的 encryptionKMSID。
例如:
encryptionKMSID: 1-vault
- 在 OpenShift Web 控制台中,导航到 Workloads → ConfigMaps。
- 要查看 KMS 连接详情,请单击点击 csi-kms-connection-details。
编辑 ConfigMap。
- 点击 Action 菜单 (⋮) → Edit ConfigMap。
根据为之前标识的 encryptionKMSID 配置的后端,添加
VAULT_BACKEND或vaultBackend参数。您可以为 KV secret engine API、版本 1 和
kv-v2分配 kv 用于 KV secret engine API(版本 2)。例如:
kind: ConfigMap apiVersion: v1 metadata: name: csi-kms-connection-details [...] data: 1-vault: |- { "KMS_PROVIDER": "vaulttokens", "KMS_SERVICE_NAME": "1-vault", [...] "VAULT_BACKEND": "kv-v2" } 2-vault: |- { "encryptionKMSType": "vaulttenantsa", [...] "vaultBackend": "kv-v2" }- 点 Save
后续步骤
2.2.3.1. 使用租户 ConfigMap 覆盖 Vault 连接详情
可以通过在 Openshift 命名空间中创建 ConfigMap 来为每个租户重新配置 Vault 连接详情,其配置选项与 openshift-storage 命名空间中的 csi-kms-connection-details ConfigMap 中设置的值不同。ConfigMap 需要位于租户命名空间中。租户命名空间中的 ConfigMap 中的值将覆盖在该命名空间中创建的加密持久性卷的 csi-kms-connection-details ConfigMap 中设置的值。
流程
- 确保您位于租户命名空间中。
- 点 Workloads → ConfigMaps。
- 点 Create ConfigMap。
以下是 yaml 示例。给定租户命名空间要覆盖的值可以在
data部分下指定,如下所示:--- apiVersion: v1 kind: ConfigMap metadata: name: ceph-csi-kms-config data: vaultAddress: "<vault_address:port>" vaultBackendPath: "<backend_path>" vaultTLSServerName: "<vault_tls_server_name>" vaultNamespace: "<vault_namespace>"
- 编辑完 yaml 后,点 Create。
第 3 章 块池
OpenShift Data Foundation Operator 根据使用的平台会安装一组默认存储类。这些默认存储池由操作器拥有和控制,且无法删除或修改。在 OpenShift Container Platform 中,您可以创建多个自定义存储池,它们映射到提供以下功能的存储类:
- 使具有自身高可用性的应用能够使用具有两个副本的持久卷,从而可能提高应用性能。
- 使用启用了压缩的存储类为持久性卷声明节省空间。
外部模式 OpenShift Data Foundation 集群不支持多个块池。
3.1. 创建一个块池
先决条件
- 您需要以集群管理员身份登录 OpenShift Container Platform Web 控制台。
流程
- 点 Storage → OpenShift Data Foundation。
- 在 Storage Systems 选项卡中,选择 storage 系统,然后单击 BlockPools 选项卡。
- 点 Create Block Pool。
- 输入 池名称。
-
为数据保护策略选择
双向复制或三向复制。 - 选择卷类型。
可选:如果您需要压缩数据,请选择 启用压缩 复选框。
启用压缩可能会影响应用程序的性能,在已压缩或加密的数据时可能会证明无效。在启用压缩之前写入的数据不会压缩。
- 点击 Create。
3.2. 更新现有池
先决条件
- 您需要以集群管理员身份登录 OpenShift Container Platform Web 控制台。
流程
- 点 Storage → OpenShift Data Foundation。
- 在 Storage Systems 选项卡中,选择 storage 系统,然后单击 BlockPools。
- 点击您要更新的池末尾的 Action Menu(⋮)。
- 单击 Edit Block Pool。
修改表单详情,如下所示:
- 将数据保护策略更改为双向复制或三向复制。
启用或禁用压缩选项。
启用压缩可能会影响应用程序的性能,在已压缩或加密的数据时可能会证明无效。在启用压缩之前写入的数据不会压缩。
- 点击 Save。
3.3. 删除池
使用此流程删除 OpenShift Data Foundation 中的池。
先决条件
- 您需要以集群管理员身份登录 OpenShift Container Platform Web 控制台。
流程
- .点 Storage → OpenShift Data Foundation。
- 在 Storage Systems 选项卡中,选择 storage 系统,然后单击 BlockPools 选项卡。
- 点击您要删除的池末尾的 Action Menu(⋮)。
- 单击 Delete Block Pool。
- 单击 Delete 确认删除池。
当池绑定到 PVC 时,无法删除它。您必须分离所有资源,然后才能执行此活动。
第 4 章 为 OpenShift Container Platform 服务配置存储
您可以使用 OpenShift Data Foundation 为 OpenShift Container Platform 服务(如镜像 registry、监控和日志记录)提供存储。
为这些服务配置存储的过程取决于 OpenShift Data Foundation 部署中使用的基础架构。
始终确保您具有适用于这些服务的大量存储容量。如果这些关键服务的存储空间不足,集群就会变得不可用,且很难恢复。
红帽建议为这些服务配置较短的策展和保留间隔。详情请参阅 OpenShift Container Platform 文档中的为 Prometheus 指标数据配置 Curator 调度和修改保留时间。
如果您确实耗尽这些服务的存储空间,请联系红帽客户支持。
4.1. 将镜像 registry 配置为使用 OpenShift Data Foundation
OpenShift Container Platform 提供了一个内建的容器镜像 Registry,它作为一个标准的工作负载在集群中运行。registry 通常用作集群中构建的镜像的发布目标,以及在集群中运行的工作负载的镜像源。
按照本节中的说明,将 OpenShift Data Foundation 配置为 Container Image Registry 的存储。在 AWS 中,不需要更改 registry 的存储。但是,建议将存储更改为 vSphere 和裸机平台的 OpenShift Data Foundation 持久卷。
此过程不会将数据从现有镜像 registry 迁移到新镜像 registry。如果您在现有 registry 中已有容器镜像,请在完成此过程前备份 registry,并在这个过程完成后重新注册您的镜像。
先决条件
- 具有 OpenShift Web 控制台的管理访问权限。
-
OpenShift Data Foundation Operator 在
openshift-storage命名空间上安装并运行。在 OpenShift Web 控制台中,点 Operators → Installed Operators 查看已安装的 Operator。 -
Image Registry Operator 在
openshift-image-registry命名空间中安装并运行。在 OpenShift Web 控制台中,点 Administration → Cluster Settings → Cluster Operators 查看集群操作器。 -
带有 provisioner
openshift-storage.cephfs.csi.ceph.com的存储类可用。在 OpenShift Web 控制台中,点 Storage → StorageClasses 查看可用的存储类。
流程
为镜像 Registry 创建一个持久性卷声明。
- 在 OpenShift Web 控制台中,点击 Storage → Persistent Volume Claims。
-
将 Project 设置为
openshift-image-registry。 单击 Create Persistent Volume Claim。
-
在上方检索的可用存储类列表中,使用置备程序
openshift-storage.cephfs.csi.ceph.com指定存储类。 -
指定持久性卷声明 名称,如
ocs4registry。 -
指定
Shared Access (RWX)访问模式。 - 将 Size 指定为最少 100 GB。
点击 Create。
等待新持久卷声明的状态变为
Bound。
-
在上方检索的可用存储类列表中,使用置备程序
将集群的 Image Registry 配置为使用新的持久卷声明。
- 点 Administration → Custom Resource Definitions。
-
点与
imageregistry.operator.openshift.io组关联的Config自定义资源定义。 - 点 实例 选项卡。
- 在集群实例外,点 Action Menu(⋮) → Edit Config。
添加新的持久性卷声明作为镜像 Registry 的持久性存储。
在
spec:下添加以下内容,并替换现有的storage:部分(如有必要)。storage: pvc: claim: <new-pvc-name>例如:
storage: pvc: claim: ocs4registry- 点击 Save。
验证新配置是否正在使用。
- 点击 Workloads → Pods。
-
将 Project 设置为
openshift-image-registry。 -
验证新的
image-registry-*pod 的状态是否为Running,并且以前的image-registry-*pod 已终止。 -
点击新
image-registry-*Pod 查看 pod 详情。 -
向下滚动到 Volumes,再验证
registry-storage卷是否具有与您的新持久性卷声明匹配的 Type,如ocs4registry。
4.2. 配置监控以使用 OpenShift 数据基础
OpenShift 数据基础提供由 Prometheus 和 Alert Manager 组成的监控堆栈。
按照本节中的说明,将 OpenShift 数据基础配置为监控堆栈的存储。
如果存储空间不足,则监控将无法正常工作。始终确保您拥有大量用于监控的存储容量。
红帽建议为此服务配置简短的保留间隔。详情请参阅 OpenShift Container Platform 文档中的 Prometheus 指标指南的修改保留时间。
先决条件
- 具有 OpenShift Web 控制台的管理访问权限。
-
OpenShift Data Foundation Operator 在
openshift-storage命名空间上安装并运行。在 OpenShift Web 控制台中,点 Operators → Installed Operators 查看已安装的 Operator。 -
监控 Operator 在
openshift-monitoring命名空间内安装并运行。在 OpenShift Web 控制台中,点 Administration → Cluster Settings → Cluster Operators 查看集群操作器。 -
带有 provisioner
openshift-storage.rbd.csi.ceph.com的存储类可用。在 OpenShift Web 控制台中,点 Storage → StorageClasses 查看可用的存储类。
流程
- 在 OpenShift Web 控制台中,前往 Workloads → Config Maps。
-
将 Project 下拉菜单设置为
openshift-monitoring。 - 单击 Create Config Map。
使用以下命令定义一个新的
cluster-monitoring-configConfig Map:将尖括号 (
<,>) 中的内容替换为您自己的值,如retention: 24h或storage: 40Gi。将 storageClassName 替换为使用 provisioner
openshift-storage.rbd.csi.ceph.com的storageclass。在下例中,storageclass 的名称为ocs-storagecluster-ceph-rbd。cluster-monitoring-configConfig Map 示例apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time to retain monitoring files, e.g. 24h> volumeClaimTemplate: metadata: name: ocs-prometheus-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi> alertmanagerMain: volumeClaimTemplate: metadata: name: ocs-alertmanager-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi>- 单击 Create 以保存并创建 Config Map。
验证步骤
验证持久卷声明是否已绑定到 pod。
- 进入 Storage → Persistent Volume Claims。
-
将 Project 下拉菜单设置为
openshift-monitoring。 验证 5 持久性卷声明是否可见,状态为
Bound,附加到三个alertmanager-main-*pod,以及两个prometheus-k8s-*pod。图 4.1. 监控创建和绑定的存储

验证新
alertmanager-main-*pod 的状态是否显示为Running。- 进入 Workloads → Pods。
-
点击新
alertmanager-main-*pod 查看 pod 详情。 向下滚动到 Volumes,再验证卷是否具有 Type (
ocs-alertmanager-claim),它与您的新持久性卷声明匹配,如ocs-alertmanager-claim-alertmanager-main-0。图 4.2. 附加到
alertmanager-main-*pod 的持久性卷声明
验证新的
prometheus-k8s-*pod 的状态是否为Running。-
点新的
prometheus-k8s-*Pod 查看 pod 详情。 向下滚动到 Volumes,再验证卷是否具有 Type (
ocs-prometheus-claim),它与您的新持久性卷声明匹配,如ocs-prometheus-claim-prometheus-k8s-0。图 4.3. 附加到
prometheus-k8s-*pod 的持久性卷声明
-
点新的
4.3. Overprovision level 策略控制[技术预览]
Overprovision control 是一个机制,它允许您根据特定应用程序命名空间定义从存储集群消耗的持久性卷声明(PVC)量的配额。
当您启用 overprovision 控制机制时,它会阻止置备存储集群消耗的 PVC。OpenShift 提供了定义约束的灵活性,使用 OpenShift 的 ClusterResourceQuota 有助于限制集群范围内聚合的资源消耗。
通过超额置备控制,会启动 ClusteResourceQuota,您可以为每个存储类设置存储容量限制。当消耗了 80% 的容量限制时,警报将触发。
Overprovision 级别策略控制是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。如需更多信息,请参阅技术预览功能支持范围。
如需有关部署的更多信息,请参阅产品文档,并根据平台选择部署过程。
配置配额限制以接收过度置备控制警报
先决条件
- 确保创建了 OpenShift Data Foundation 集群。
流程
编辑
storagecluster,以在存储类上设置配额限制。记住在退出编辑器之前进行保存。执行以下命令来编辑
storagecluster:$ oc edit storagecluster -n openshift-storage <ocs_storagecluster_name><ocs_storagecluster_name>- 指定存储集群的名称。
添加以下行来为存储类设置所需的配额限制:
apiVersion: ocs.openshift.io/v1 kind: StorageCluster spec: [...] overprovisionControl: - capacity: <desired_quota_limit> storageClassName: <storage_class_name> quotaName: <desired_quota_name> selector: labels: matchLabels: storagequota: <desired_label>
<desired_quota_limit>-
为存储类指定所需的配额限制,例如
27Ti。 <storage_class_name>-
指定要设置配额限制的存储类的名称,如
ocs-storagecluster-ceph-rbd。 <desired_quota_name>-
为存储配额指定一个名称,如
quota1。 <desired_label>-
为存储配额指定一个标签,如
storagequota1。
标记应用程序命名空间。
apiVersion: v1 kind: Namespace metadata: name: <desired_name> labels: storagequota: <desired_label>
<desired_name>-
为 application 命名空间指定一个名称,如
quota-rbd。 <desired_label>-
为存储配额指定一个标签,如
storagequota1。
确保定义了
clusterresourcequota。注意预期
clusterresourcequota使用您定义的quotaName,如quota1。$ oc get clusterresourcequota -A
$ oc describe clusterresourcequota -A
4.4. OpenShift 数据基础的集群日志记录
您可以部署集群日志记录来聚合一系列 OpenShift Container Platform 服务的日志。有关如何部署集群日志记录的详情,请参考部署集群日志记录。
在初始 OpenShift Container Platform 部署时,默认情况下不配置 OpenShift Data Foundation,OpenShift Container Platform 集群将依赖于节点提供的默认存储。您可以编辑 OpenShift 日志记录(ElasticSearch)的默认配置,使其由 OpenShift Data Foundation 支持,使 OpenShift Data Foundation 支持日志(Elasticsearch)。
始终确保您具有适用于这些服务的大量存储容量。如果您对这些关键服务的存储空间不足,日志记录应用将变得不可用,很难恢复。
红帽建议为这些服务配置较短的策展和保留间隔。详情请参阅 OpenShift Container Platform 文档中的 集群日志记录 Curator。
如果您缺少这些服务的存储空间,请联系红帽客户支持。
4.4.1. 配置持久性存储
您可以使用存储类名称和大小参数为 Elasticsearch 集群配置持久性存储类和大小。Cluster Logging Operator 根据这些参数为 Elasticsearch 集群中的每个数据节点创建一个持久性卷声明。例如:
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage:
storageClassName: "ocs-storagecluster-ceph-rbd”
size: "200G"
本例指定,集群中的每个数据节点将绑定到请求 200GiB 的 ocs-storagecluster-ceph-rbd 存储的持久性卷声明。每个主分片将由单个副本支持。分片的副本会在所有节点之间复制,并且始终可用;如果因为单一冗余策略至少存在两个节点,则可以恢复副本。有关 Elasticsearch 复制策略的详情,请参考关于部署和配置集群日志记录中的 Elasticsearch 复制策略。
缺少存储块将导致默认存储支持部署。例如:
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage: {}如需更多信息,请参阅配置集群日志记录。
4.4.2. 配置集群日志记录以使用 OpenShift Data Foundation
按照本节中的说明,将 OpenShift Data Foundation 配置为 OpenShift 集群日志记录的存储。
当您首次在 OpenShift 数据基础中配置日志记录时,您可以获取所有日志。但是,在卸载和重新安装日志记录后,会删除旧日志并只处理新日志。
先决条件
- 具有 OpenShift Web 控制台的管理访问权限。
-
OpenShift Data Foundation Operator 在
openshift-storage命名空间上安装并运行。 -
Cluster logging Operator 已安装并在
openshift-logging命名空间中运行。
流程
- 从 OpenShift Web 控制台左侧窗格中,点击 Administration → Custom Resource Definitions。
- 在 Custom Resource Definitions 页面中点 ClusterLogging。
- 在 Custom Resource Definition Overview 页面上,从 Actions 菜单中选择 View Instances,或者点击 Instances 选项卡。
在 Cluster Logging 页面上,点击 Create Cluster Logging。
您可能需要刷新页面来加载数据。
在 YAML 中,将 storageClassName 替换为使用 provisioner
openshift-storage.rbd.csi.ceph.com的storageclass。在下例中,storageclass 的名称为ocs-storagecluster-ceph-rbd:apiVersion: "logging.openshift.io/v1" kind: "ClusterLogging" metadata: name: "instance" namespace: "openshift-logging" spec: managementState: "Managed" logStore: type: "elasticsearch" elasticsearch: nodeCount: 3 storage: storageClassName: ocs-storagecluster-ceph-rbd size: 200G # Change as per your requirement redundancyPolicy: "SingleRedundancy" visualization: type: "kibana" kibana: replicas: 1 curation: type: "curator" curator: schedule: "30 3 * * *" collection: logs: type: "fluentd" fluentd: {}如果 OpenShift Data Foundation 节点带有污点,您必须添加容限,以启用为日志调度 daemonset pod。
spec: [...] collection: logs: fluentd: tolerations: - effect: NoSchedule key: node.ocs.openshift.io/storage value: 'true' type: fluentd- 点击 Save。
验证步骤
验证持久卷声明是否已绑定到
elasticsearchPod。- 进入 Storage → Persistent Volume Claims。
-
将 Project 下拉菜单设置为
openshift-logging。 验证持久卷声明是否可见,状态为
Bound,附加到elasticsearch-* pod。图 4.4. 创建并绑定集群日志记录

验证是否在使用新集群日志记录。
- 点 Workload → Pods。
-
将项目设置为
openshift-logging。 -
验证新的
elasticsearch-* Pod 的状态是否为Running。 -
点新的
elasticsearch-* Pod 查看 pod 详情。 -
向下滚动到 Volumes,再验证 elasticsearch 卷是否具有与新持久性卷声明匹配的 Type,如
elasticsearch-elasticsearch-cdm-9r624biv-3。 - 点 Persistent Volume Claim 名称,然后在 PersistentVolumeClaim Overview 页面中验证存储类名称。
确保使用较短的 Curator 时间,以避免在附加到 Elasticsearch Pod 的 PV 上 PV 完整场景。
您可以配置 Curator,以根据保留设置删除 Elasticsearch 数据。建议您将以下默认索引数据保留 5 天设为默认值。
config.yaml: |
openshift-storage:
delete:
days: 5如需了解更多详细信息,请参阅 Elasticsearch 数据。
要卸载由持久性卷声明支持的集群日志记录,请使用相应部署指南的卸载章节中从 OpenShift Data Foundation 中删除集群日志记录 Operator 的步骤。
第 5 章 使用 OpenShift Data Foundation 支持 OpenShift Container Platform 应用程序
您无法在 OpenShift Container Platform 安装过程中直接安装 OpenShift Data Foundation。但是,您可以使用 Operator Hub 在现有 OpenShift Container Platform 上安装 OpenShift Data Foundation,然后将 OpenShift Container Platform 应用程序配置为由 OpenShift Data Foundation 支持。
先决条件
- 已安装 OpenShift Container Platform,您还可管理 OpenShift Web 控制台。
-
OpenShift Data Foundation 在
openshift-storage命名空间上安装并运行。
流程
在 OpenShift Web 控制台中执行以下任一操作:
点 Workloads → Deployments。
在 Deployments 页面中,您可以执行以下操作之一:
- 从 Action 菜单中选择任何现有部署并点击 Add Storage 选项。
创建新部署,然后添加存储。
- 单击 Create Deployment 以创建新部署。
-
根据您的要求编辑
YAML以创建部署。 - 点击 Create。
- 从页面右上角的 Actions 下拉菜单中选择 Add Storage。
点 Workloads → Deployment Configs。
在 Deployment Configs 页面中,您可以执行以下操作之一:
- 从 Action 菜单中选择任何现有部署并点击 Add Storage 选项。
创建新部署,然后添加存储。
- 单击 Create Deployment Config 以创建新部署。
-
根据您的要求编辑
YAML以创建部署。 - 点击 Create。
- 从页面右上角的 Actions 下拉菜单中选择 Add Storage。
在 Add Storage 页面中,您可以选择以下选项之一:
- 点击 Use existing claim 选项,然后从下拉菜单中选择适合的 PVC。
单击 Create new claim 选项。
-
从 Storage Class 下拉列表中,选择适当的
CephFS或RBD存储类。 - 为持久性卷声明提供名称。
选择 ReadWriteOnce (RWO) 或 ReadWriteMany (RWX) 访问模式。
注意ReadOnlyMany (ROX) 已被取消激活,因为它不受支持。
选择所需存储容量的大小。
注意您可以扩展块 PV,但无法在创建持久性卷声明后减少存储容量。
-
从 Storage Class 下拉列表中,选择适当的
- 指定容器内挂载路径卷的挂载路径和子路径(如果需要)。
- 点击 Save。
验证步骤
根据您的配置,执行以下任一操作:
- 点 Workloads → Deployments。
- 点 Workloads → Deployment Configs。
- 根据需要设置项目。
- 单击您添加存储的部署,以显示部署详情。
- 向下滚动到 Volumes,再验证您的部署带有一个与您分配的持久性卷声明相匹配的类型。
- 点 Persistent Volume Claim 名称,然后在 Persistent Volume Claim Overview 页面中验证存储类名称。
第 6 章 将文件和对象存储添加到现有外部 OpenShift Data Foundation 集群
当 OpenShift Data Foundation 配置为外部模式时,可以通过多种方式为持久性卷声明和对象存储桶声明提供存储。
- 块存储的持久卷声明直接从外部 Red Hat Ceph Storage 集群提供。
- 文件存储的持久卷声明可以通过向外部 Red Hat Ceph Storage 添加元数据服务器(MDS)提供。
- 对象存储的对象 bucket 声明可以通过使用 Multicloud 对象网关或将 Ceph 对象网关添加到外部 Red Hat Ceph Storage 集群来提供。
使用以下流程,将文件存储(使用元数据服务器)或对象存储(使用 Ceph 对象网关)添加到最初部署为仅提供块存储的外部 OpenShift Data Foundation 集群。
先决条件
-
您已在 OpenShift Container Platform 版本 4.9 或更高版本上安装了 OpenShift Data Foundation 4.9。另外,外部模式的 OpenShift Data Foundation 集群处于
Ready状态。 您的外部 Red Hat Ceph Storage 集群被配置为以下一个或多个集群:
- 一个 Ceph 对象网关(RGW)端点,可由 OpenShift Container Platform 集群访问以用于对象存储
- 用于文件存储的元数据服务器(MDS)池
-
确保您知道在外部 OpenShift Data Foundation 集群部署期间用于
ceph-external-cluster-details-exporter.py脚本的参数。
流程
使用以下命令下载 OpenShift Data Foundation 的
ceph-external-cluster-details-exporter.pypython 脚本:oc get csv $(oc get csv -n openshift-storage | grep ocs-operator | awk '{print $1}') -n openshift-storage -o jsonpath='{.metadata.annotations.external\.features\.ocs\.openshift\.io/export-script}' | base64 --decode > ceph-external-cluster-details-exporter.py通过在外部 Red Hat Ceph Storage 集群中的任何客户端节点上运行
ceph-external-cluster-details-exporter.py,更新外部 Red Hat Ceph Storage 存储集群的权限上限。您可能需要要求您的 Red Hat Ceph Storage 管理员来执行此操作。# python3 ceph-external-cluster-details-exporter.py --upgrade \ --run-as-user=ocs-client-name \ --rgw-pool-prefix rgw-pool-prefix
--run-as-user-
在 OpenShift Data Foundation 集群部署期间使用的客户端名称。如果未设置其他客户端名称,请使用默认的客户端名称
client.healthchecker。 --rgw-pool-prefix- 用于 Ceph 对象网关池的前缀。如果使用默认前缀,可以省略它。
从外部 Red Hat Ceph Storage 生成并保存配置详情。
通过在外部 Red Hat Ceph Storage 集群中的任何客户端节点上运行
ceph-external-cluster-details-exporter.py生成配置详情。# python3 ceph-external-cluster-details-exporter.py --rbd-data-pool-name rbd-block-pool-name --monitoring-endpoint ceph-mgr-prometheus-exporter-endpoint --monitoring-endpoint-port ceph-mgr-prometheus-exporter-port --run-as-user ocs-client-name --rgw-endpoint rgw-endpoint --rgw-pool-prefix rgw-pool-prefix
--monitoring-endpoint- 是可选的。它接受可从 OpenShift Container Platform 集群访问的活跃和待机 mgrs 的以逗号分隔的 IP 地址列表。如果没有提供,则会自动填充该值。
--monitoring-endpoint-port-
是可选的。它是与
--monitoring-endpoint指定的 ceph-mgr Prometheus exporter 关联的端口。如果没有提供,则会自动填充该值。 --run-as-user- 在 OpenShift Data Foundation 集群部署期间使用的客户端名称。如果未设置其他客户端名称,请使用默认的客户端名称 client.healthchecker。
--rgw-endpoint- 提供此参数,以通过 Ceph 对象网关为 OpenShift Data Foundation 置备对象存储(可选参数)。
--rgw-pool-prefix- 用于 Ceph 对象网关池的前缀。如果使用默认前缀,可以省略它。
用户权限已更新,如下所示:
caps: [mgr] allow command config caps: [mon] allow r, allow command quorum_status, allow command version caps: [osd] allow rwx pool=default.rgw.meta, allow r pool=.rgw.root, allow rw pool=default.rgw.control, allow rx pool=default.rgw.log, allow x pool=default.rgw.buckets.index
注意确保除 Ceph 对象网关详细信息(如果提供)之外的所有参数(包括可选参数)与在外部模式中部署 OpenShift Data Foundation 期间所用的相同。
将脚本的输出保存到
external-cluster-config.json文件中。以下示例输出以粗体文本显示生成的配置更改。
[{"name": "rook-ceph-mon-endpoints", "kind": "ConfigMap", "data": {"data": "xxx.xxx.xxx.xxx:xxxx", "maxMonId": "0", "mapping": "{}"}}, {"name": "rook-ceph-mon", "kind": "Secret", "data": {"admin-secret": "admin-secret", "fsid": "<fs-id>", "mon-secret": "mon-secret"}}, {"name": "rook-ceph-operator-creds", "kind": "Secret", "data": {"userID": "<user-id>", "userKey": "<user-key>"}}, {"name": "rook-csi-rbd-node", "kind": "Secret", "data": {"userID": "csi-rbd-node", "userKey": "<user-key>"}}, {"name": "ceph-rbd", "kind": "StorageClass", "data": {"pool": "<pool>"}}, {"name": "monitoring-endpoint", "kind": "CephCluster", "data": {"MonitoringEndpoint": "xxx.xxx.xxx.xxx", "MonitoringPort": "xxxx"}}, {"name": "rook-ceph-dashboard-link", "kind": "Secret", "data": {"userID": "ceph-dashboard-link", "userKey": "<user-key>"}}, {"name": "rook-csi-rbd-provisioner", "kind": "Secret", "data": {"userID": "csi-rbd-provisioner", "userKey": "<user-key>"}}, {"name": "rook-csi-cephfs-provisioner", "kind": "Secret", "data": {"adminID": "csi-cephfs-provisioner", "adminKey": "<admin-key>"}}, {"name": "rook-csi-cephfs-node", "kind": "Secret", "data": {"adminID": "csi-cephfs-node", "adminKey": "<admin-key>"}}, {"name": "cephfs", "kind": "StorageClass", "data": {"fsName": "cephfs", "pool": "cephfs_data"}}, {"name": "ceph-rgw", "kind": "StorageClass", "data": {"endpoint": "xxx.xxx.xxx.xxx:xxxx", "poolPrefix": "default"}}, {"name": "rgw-admin-ops-user", "kind": "Secret", "data": {"accessKey": "<access-key>", "secretKey": "<secret-key>"}}]
上传生成的 JSON 文件。
- 登录 OpenShift Web 控制台。
- 点 Workloads → Secrets。
-
将 project 设置为
openshift-storage。 - 点 rook-ceph-external-cluster-details。
- 点 Actions (⋮) → Edit Secret
-
点 Browse 并上传
external-cluster-config.json文件。 - 点击 Save。
验证步骤
要验证 OpenShift Data Foundation 集群是否健康且数据具有弹性,请导航到 Storage → OpenShift Data foundation → Storage Systems 选项卡,然后点击存储系统名称。
- 在 Overview → Block and File 选项卡中,检查 Status 卡以确认存储集群有一个绿色勾号表示其健康。
如果您为文件存储添加了元数据服务器:
-
点 Workloads → Pods,验证
csi-cephfsplugin-*pod 是否已创建新并处于 Running 状态。 -
点 Storage → Storage Classes 并验证是否已创建
ocs-external-storagecluster-cephfs存储类。
-
点 Workloads → Pods,验证
如果您为对象存储添加了 Ceph 对象网关:
-
点 Storage → Storage Classes 并验证是否已创建
ocs-external-storagecluster-ceph-rgw存储类。 - 要验证 OpenShift Data Foundation 集群是否健康且数据具有弹性,请导航到 Storage → OpenShift Data foundation → Storage Systems 选项卡,然后点击存储系统名称。
- 单击 Object 选项卡,并确认 Object Service 和数据弹性具有绿色勾号,指示其运行正常。
-
点 Storage → Storage Classes 并验证是否已创建
第 7 章 如何在 Red Hat OpenShift Data Foundation 中使用专用 worker 节点
任何 Red Hat OpenShift Container Platform 订阅都需要一个 OpenShift Data Foundation 订阅。但是,如果您使用基础架构节点调度 OpenShift 数据基础资源,您可以在 OpenShift Container Platform 订阅上保存。
务必要在不同环境中维持 Machine API 支持的一致性。因此,强烈建议在所有情形中都有特殊类别的节点标记为 worker 或 infra,或者同时具有这两个角色。如需更多信息,请参阅 第 7.3 节 “手动创建基础架构节点” 部分。
7.1. 基础架构节点分析
用于 OpenShift Data Foundation 的基础架构节点有几个属性:需要 infra node-role 标签,以确保节点不使用 RHOCP 权利。infra node-role 标签负责确保运行 OpenShift Data Foundation 的节点仅需要 OpenShift Data Foundation 权利。
-
标记了
node-role.kubernetes.io/infra
还需要添加具有 NoSchedule effect 的 OpenShift Data Foundation 污点,以便 infra 节点只调度 OpenShift Data Foundation 资源。
-
使用
node.ocs.openshift.io/storage="true"污点
该标签将 RHOCP 节点识别为 infra 节点,以便不应用 RHOCP 订阅成本。该污点可防止将非 OpenShift Data Foundation 资源调度到污点节点上。
在节点上添加存储污点可能需要对其他 daemonset pod(如 openshift-dns daemonset )进行容限处理。有关如何管理容限的详情,请参考知识库文章 https://access.redhat.com/solutions/6592171。
用于运行 OpenShift Data Foundation 服务的基础架构节点上的污点和标签示例:
spec:
taints:
- effect: NoSchedule
key: node.ocs.openshift.io/storage
value: "true"
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/worker: ""
node-role.kubernetes.io/infra: ""
cluster.ocs.openshift.io/openshift-storage: ""7.2. 用于创建基础架构节点的机器集
如果环境中支持 Machine API,则应将标签添加到要调配基础架构节点的 Machine Sets 的模板中。避免将标签手动添加到机器 API 创建的节点的反模式。这样做类似于向部署创建的 pod 添加标签。在这两种情况下,pod/节点失败时,替代的 pod/节点都将没有适当的标签。
在 EC2 环境中,您将需要三个计算机集,各自配置为在不同的可用区(如 us-east-2a、us-east-2b、us-east-2b、us-east-2c)中调配基础架构节点。目前,OpenShift Data Foundation 不支持在超过三个可用区部署。
以下 Machine Set 模板示例创建具有基础架构节点所需的适当污点和标签的节点。这将用于运行 OpenShift Data Foundation 服务。
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: kb-s25vf
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
machine.openshift.io/cluster-api-machineset: kb-s25vf-infra-us-west-2a
spec:
taints:
- effect: NoSchedule
key: node.ocs.openshift.io/storage
value: "true"
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
cluster.ocs.openshift.io/openshift-storage: ""如果向基础架构节点添加污点,您还需要为其他工作负载的污点添加容限,如 fluentd pod。如需更多信息,请参阅 OpenShift 4 中的红帽知识库解决方案 基础架构节点。
7.3. 手动创建基础架构节点
只有环境中不支持 Machine API 时,标签才应直接应用到节点。手动创建要求至少可使用 3 个 RHOCP worker 节点来调度 OpenShift Data Foundation 服务,并且这些节点有足够的 CPU 和内存资源。要避免 RHOCP 订阅成本,需要以下内容:
oc label node <node> node-role.kubernetes.io/infra="" oc label node <node> cluster.ocs.openshift.io/openshift-storage=""
还需要添加一个 NoSchedule OpenShift Data Foundation 污点,以便 infra 节点只调度 OpenShift Data Foundation 资源并代表任何其他非 OpenShift Data Foundation 工作负载。
oc adm taint node <node> node.ocs.openshift.io/storage="true":NoSchedule
不要删除 node-role node-role.kubernetes.io/worker=""
除非对 OpenShift 调度程序和 MachineConfig 资源进行了更改,否则删除 node-role.kubernetes.io/worker="" 可能会导致问题。
如果已删除,则应将其重新添加到每个 infra 节点。添加 node-role node-role.kubernetes.io/infra="" 和 OpenShift Data Foundation 污点足以满足权利的要求。
第 8 章 管理持久性卷声明
8.1. 配置应用程序 pod 以使用 OpenShift Data Foundation
按照本节中的说明,将 OpenShift Data Foundation 配置为应用 pod 的存储。
先决条件
- 具有 OpenShift Web 控制台的管理访问权限。
-
OpenShift Data Foundation Operator 在
openshift-storage命名空间上安装并运行。在 OpenShift Web 控制台中,点 Operators → Installed Operators 查看已安装的 Operator。 - OpenShift Data Foundation 提供的默认存储类可用。在 OpenShift Web 控制台中,点 Storage → Storage Classes 查看默认存储类。
流程
为要使用的应用创建持久性卷声明 (PVC)。
- 在 OpenShift Web 控制台中,点击 Storage → Persistent Volume Claims。
- 为应用程序 pod 设置 Project。
单击 Create Persistent Volume Claim。
- 指定由 OpenShift Data Foundation 提供的存储类。
-
指定 PVC Name,如
myclaim。 选择所需的 Access Mode。
注意IBM FlashSystem 不支持 Access Mode,
Shared access (RWX)。-
对于 Rados 块设备(RBD),如果 Access 模式 为 ReadWriteOnce(
RWO),请选择所需的卷模式。默认卷模式是Filesystem。 - 根据应用程序要求指定一个 大小。
-
点 Create 并等待 PVC 处于
Bound状态。
配置新的或现有应用容器集以使用新 PVC。
对于新应用程序 pod,执行以下步骤:
- 点 Workloads →Pods。
- 创建新的应用 pod。
在
spec:部分下,添加volume:部分,将新 PVC 添加为应用 Pod 的卷。volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>例如:
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
对于现有应用程序 pod,执行以下步骤:
- 点 Workloads →Deployment Configs。
- 搜索与应用程序 pod 关联的所需部署配置。
- 点击其 Action 菜单(⋮) → Edit Deployment Config。
在
spec:部分下,添加volume:部分,将新 PVC 添加为应用程序 Pod 的卷,然后点 Save。volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>例如:
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
验证新配置是否正在使用。
- 点击 Workloads → Pods。
- 为应用程序 pod 设置 Project。
-
验证应用容器集的状态是否为
Running。 - 单击应用容器集名称,以查看容器集详细信息。
-
向下滚动到 Volumes 部分,再验证卷的 Type 与您的新持久卷声明匹配,如
myclaim。
8.2. 查看持久性卷声明请求状态
使用这个流程查看 PVC 请求的状态。
先决条件
- OpenShift Data Foundation 的管理员访问权限。
流程
- 登录 OpenShift Web 控制台。
- 点 Storage → Persistent Volume Claims
- 使用 Filter 文本框搜索所需的 PVC 名称。您还可以按 Name 或 Label 过滤 PVC 列表来缩小列表范围
- 检查与所需 PVC 对应的 Status 列。
- 点所需的 Name 查看 PVC 详情。
8.3. 查看持久性卷声明请求事件
使用这个流程来查看和解决持久性卷声明 (PVC) 请求事件。
先决条件
- 管理员对 OpenShift Web 控制台的访问权限。
流程
- 在 OpenShift Web 控制台中,点击 Storage → OpenShift Data Foundation。
- 在 Storage systems 选项卡中,选择存储系统,然后点 Overview → Block and File。
- 找到 Inventory 卡,查看 PVC 数量并显示错误。
- 点 Storage → Persistent Volume Claims
- 使用 Filter 文本框搜索所需的 PVC。
- 点 PVC 名称并导航到 Events
- 根据需要或按指示处理事件。
8.4. 扩展持久性卷声明
自 OpenShift Data Foundation 4.6 开始,能够扩展持久性卷声明,在管理持久性存储资源方面提供更多灵活性。
以下持久性卷支持扩展:
-
具有 ReadWriteOnce (RWO) 和 ReadWriteMany (RWX) 访问权限的 PVC,这些访问基于 Ceph 文件系统 (CephFS),用于卷模式
Filesystem。 -
具有 ReadWriteOnce (RWO) 访问的 PVC,它基于卷模式
Filesystem的 Ceph RADOS 块设备 (RBD)。 -
具有 ReadWriteOnce (RWO) 访问的 PVC,它基于卷模式
Block的 Ceph RADOS 块设备 (RBD)。
OSD、MON 和加密 PVC 不支持 PVC 扩展。
先决条件
- 管理员对 OpenShift Web 控制台的访问权限。
流程
-
在 OpenShift Web 控制台中,导航到
Storage→Persistent Volume Claims。 - 点击您要扩展的持久性卷声明旁边的 Action Menu(⋮)。
点
Expand PVC: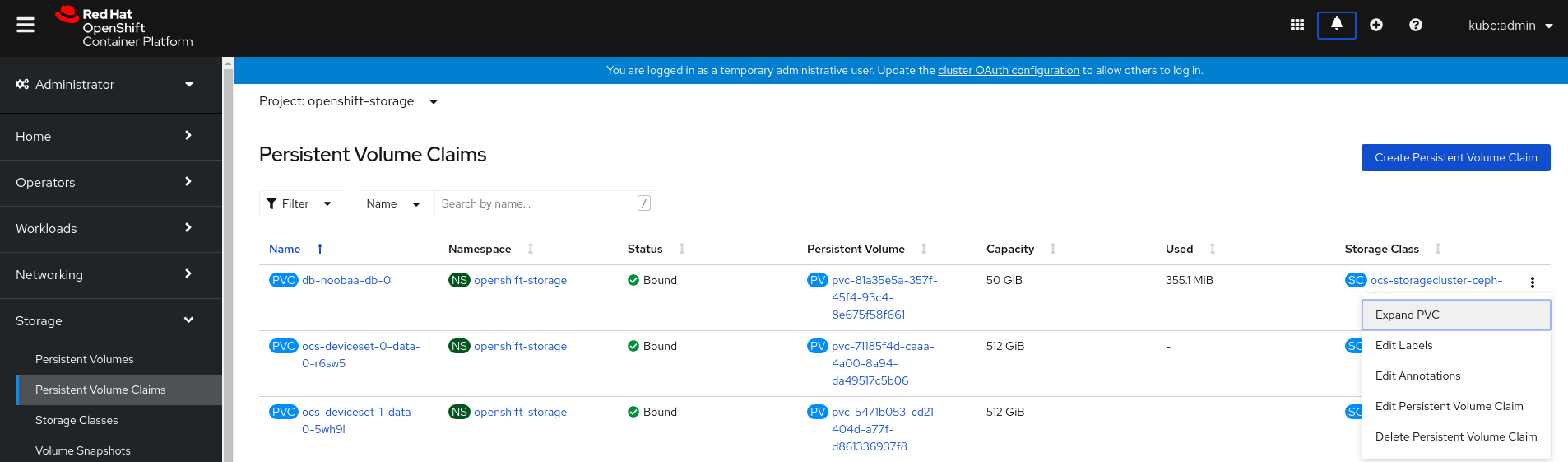
选择持久性卷声明的新大小,然后点
Expand:
要验证扩展,请导航到 PVC 的详情页面,并验证
Capacity字段是否具有请求的正确大小。注意当基于 Ceph RADOS 块设备 (RBD) 扩展 PVC 时,如果 PVC 尚未附加到 pod,
Condition type在 PVC 详情页面中为FileSystemResizePending。挂载卷后,文件系统大小调整成功,并在Capacity字段中反映新大小。
8.5. 动态置备
8.5.1. 关于动态置备
StorageClass 资源对象描述并分类了可请求的存储,并提供了根据需要为动态置备存储传递参数的方法。StorageClass 也可以作为控制不同级别的存储和访问存储的管理机制。集群管理员(cluster-admin)或者存储管理员(storage-admin)可以在无需了解底层存储卷资源的情况下,定义并创建用户可以请求的 StorageClass 对象。
OpenShift Container Platform 的持久性卷框架启用了这个功能,并允许管理员为集群提供持久性存储。该框架还可让用户在不了解底层存储架构的情况下请求这些资源。
很多存储类型都可用于 OpenShift Container Platform 中的持久性卷。虽然它们都可以由管理员静态置备,但有些类型的存储是使用内置供应商和插件 API 动态创建的。
8.5.2. OpenShift Data Foundation 中的动态置备
Red Hat OpenShift Data Foundation 是软件定义的存储,针对容器环境优化。它在 OpenShift Container Platform 上作为操作器运行,为容器提供高度集成和简化的持久性存储管理。
OpenShift Data Foundation 支持各种存储类型,包括:
- 数据库的块存储
- 共享文件存储,用于持续集成、消息传递和数据聚合
- 归档、备份和介质存储的对象存储
第 4 版使用 Red Hat Ceph Storage 来提供支持持久卷的文件、块和对象存储,以及 Rook.io 来管理和编排持久卷和声明的调配。NooBaa 提供对象存储,其多云网关允许在多个云环境中联合对象(作为技术预览使用)。
在 OpenShift Data Foundation 4 中,RADOS 块设备 (RBD) 和 Ceph 文件系统 (CephFS) 的 Red Hat Ceph Storage Container Storage Interface (CSI) 驱动程序处理动态置备请求。当 PVC 请求动态进入时,CSI 驱动程序有以下选项:
-
创建一个具有 ReadWriteOnce (RWO) 和 ReadWriteMany (RWX) 访问权限的 PVC,它基于卷模式
块的 Ceph RBD -
创建一个具有 ReadWriteOnce (RWO) 访问权限的 PVC,它基于卷模式
Filesystem的 Ceph RBD -
为卷模式
Filesystem创建基于 CephFS 的 ReadWriteOnce (RWO) 和 ReadWriteMany (RWX) 访问的 PVC
判断要使用的驱动程序(RBD 或 CephFS)取决于 storageclass.yaml 文件中的条目。
8.5.3. 可用的动态部署插件
OpenShift Container Platform 提供了以下置备程序插件,用于使用集群配置的供应商 API 创建新存储资源的动态部署:
| 存储类型 | provisioner 插件名称 | 备注 |
|---|---|---|
| OpenStack Cinder |
| |
| AWS Elastic Block Store (EBS) |
|
当在不同的区中使用多个集群进行动态置备时,使用 |
| AWS Elastic File System (EFS) | 动态置备通过 EFS provisioner pod 实现,而不是通过置备程序插件实现。 | |
| Azure Disk |
| |
| Azure File |
|
|
| GCE 持久性磁盘 (gcePD) |
| 在多区(multi-zone)配置中,建议在每个 GCE 项目中运行一个 OpenShift Container Platform 集群,以避免在当前集群没有节点的区域中创建 PV。 |
|
| ||
| Red Hat Virtualization |
|
任何选择的置备程序插件还需要根据相关文档为相关的云、主机或者第三方供应商配置。
第 9 章 卷快照
卷快照是集群中特定时间点的存储卷的状态。这些快照有助于更有效地使用存储,不必每次都制作完整的副本,也可用作应用程序开发的构建块。
卷快照类允许管理员指定属于卷快照对象的不同属性。OpenShift Data Foundation 操作器根据使用的平台安装默认卷快照类。Operator 拥有并控制这些默认卷快照类,且无法删除或修改它们。
您可以创建同一持久性卷声明(PVC)的许多快照,但无法调度定期创建快照。
- 对于 CephFS,您可以为每个 PVC 创建最多 100 个快照。
- 对于 RADOS 块设备 (RBD),您可以为每个 PVC 创建最多 512 个快照。
持久性卷加密现在支持卷快照。
9.1. 创建卷快照
您可以从持久性卷声明 (PVC) 页面或 Volume Snapshots 页面创建卷快照。
先决条件
-
对于一致的快照,PVC 应该处于
Bound状态,且不使用。确保先停止所有 IO,然后再执行快照。
只有 pod 使用时,OpenShift Data Foundation 才会为 PVC 的卷快照提供崩溃一致性。若要确保应用一致性,请务必先停止正在运行的容器集,以确保快照的一致性,或使用应用提供的任何静默机制来确保快照的一致性。
流程
- 在持久性卷声明页中显示
- 从 OpenShift Web 控制台点 Storage → Persistent Volume Claims。
要创建卷快照,请执行以下操作之一:
- 在所需 PVC 旁边,点 Action 菜单 (⋮) → Create Snapshot。
- 点击您要创建快照的 PVC,然后点击 Actions → Create Snapshot。
- 输入卷快照的名称。
- 从下拉列表中选择 Snapshot Class。
- 点击 Create。您将被重定向到所创建的卷快照的 Details 页面。
- 从 Volume Snapshots 页面中
- 从 OpenShift Web 控制台点 Storage → Volume Snapshots。
- 在 Volume Snapshots 页面中,单击 Create Volume Snapshot。
- 从下拉列表中选择所需的 项目。
- 从下拉列表中选择持久性卷声明。
- 输入快照的名称。
- 从下拉列表中选择 Snapshot Class。
- 点击 Create。您将被重定向到所创建的卷快照的 Details 页面。
验证步骤
- 进入 PVC 的 Details 页面,然后点击 Volume Snapshots 选项卡查看卷快照列表。验证是否列出了新卷快照。
- 从 OpenShift Web 控制台点 Storage → Volume Snapshots。验证是否列出了新卷快照。
-
等待卷快照处于
Ready状态。
9.2. 恢复卷快照
恢复卷快照时,会创建一个新的持久性卷声明 (PVC)。恢复的 PVC 独立于卷快照和父 PVC。
您可以从 PVC 页面或 Volume Snapshots 页面恢复卷快照。
流程
- 在持久性卷声明页中显示
只有在存在父 PVC 时,才可以从持久性卷声明页面恢复卷快照。
- 从 OpenShift Web 控制台点 Storage → Persistent Volume Claims。
- 点击 PVC 名称及卷快照将卷快照恢复为新 PVC。
- 在 Volume Snapshots 选项卡中,点您要恢复的卷快照旁的 Action 菜单(⋮)。
- 点 Restore 作为新 PVC。
- 输入新 PVC 的名称。
选择 Storage Class 名。
注意对于 Rados 块设备(RBD),您必须选择一个与父 PVC 池相同的存储类。使用未启用加密的存储类恢复加密 PVC 的快照,反之亦然。
选择您选择的 Access Mode。
重要ReadOnlyMany(ROX)访问模式是一个开发者预览功能,它受到开发人员预览支持的限制。开发人员预览版本不应在生产环境中运行,且不受红帽客户门户网站问题单管理系统的支持。如果您需要 ReadOnlyMany 功能的帮助,请联络 ocs-devpreview@redhat.com 邮件列表和红帽开发团队成员将根据可用性和工作计划尽快为您提供协助。请参阅 使用新的只读访问模式创建克隆或恢复快照以使用 ROX 访问模式。
- 可选:对于 RBD,选择 卷模式。
- 单击 Restore。您将被重定向到新的 PVC 详情页面。
- 从 Volume Snapshots 页面中
- 从 OpenShift Web 控制台点 Storage → Volume Snapshots。
- 在 Volume Snapshots 选项卡中,点您要恢复的卷快照旁的 Action 菜单(⋮)。
- 点 Restore 作为新 PVC。
- 输入新 PVC 的名称。
选择 Storage Class 名。
注意对于 Rados 块设备(RBD),您必须选择一个与父 PVC 池相同的存储类。使用未启用加密的存储类恢复加密 PVC 的快照,反之亦然。
选择您选择的 Access Mode。
重要ReadOnlyMany(ROX)访问模式是一个开发者预览功能,它受到开发人员预览支持的限制。开发人员预览版本不应在生产环境中运行,且不受红帽客户门户网站问题单管理系统的支持。如果您需要 ReadOnlyMany 功能的帮助,请联络 ocs-devpreview@redhat.com 邮件列表和红帽开发团队成员将根据可用性和工作计划尽快为您提供协助。请参阅 使用新的只读访问模式创建克隆或恢复快照以使用 ROX 访问模式。
- 可选:对于 RBD,选择 卷模式。
- 单击 Restore。您将被重定向到新的 PVC 详情页面。
验证步骤
- 从 OpenShift Web 控制台点 Storage → Persistent Volume Claims,并确认新 PVC 在 Persistent Volume Claims 页面中列出。
-
等待新 PVC 进入
Bound状态。
9.3. 删除卷快照
先决条件
- 要删除卷快照,应存在该特定卷快照中使用的卷快照类。
流程
- 从持久性卷声明页面
- 从 OpenShift Web 控制台点 Storage → Persistent Volume Claims。
- 点击具有需要删除卷快照的 PVC 名称。
- 在 Volume Snapshots 选项卡中,点击所需卷快照旁的 Action 菜单 (⋮) → Delete Volume Snapshot。
- 从卷快照页面
- 从 OpenShift Web 控制台点 Storage → Volume Snapshots。
- 在 Volume Snapshots 页面中,点击所需卷快照菜单 (⋮) → Delete Volume Snapshot 旁。
验证步骤
- 确保 PVC 详情页面的 Volume Snapshots 选项卡中没有删除的卷快照。
- 点 Storage → Volume Snapshots 并确保不会列出删除的卷快照。
第 10 章 卷克隆
克隆是现有存储卷的副本,用作任何标准卷。您可以创建一个卷克隆,以达到数据的时间副本。持久性卷声明 (PVC) 不能使用不同的大小克隆。您可以为每个 PVC 为 CephFS 和 RADOS 块设备 (RBD) 创建最多 512 个克隆。
10.1. 创建克隆
先决条件
-
源 PVC 必须处于
Bound状态,且不得处于使用状态。
如果 Pod 正在使用 PVC,则不要创建 PVC 克隆。这样做可能会导致数据崩溃,因为 PVC 没有被静默(暂停)。
流程
- 从 OpenShift Web 控制台点 Storage → Persistent Volume Claims。
要创建克隆,请执行以下操作之一:
- 在所需的 PVC 旁边,点 Action 菜单 (⋮) → Clone PVC。
- 点击您要克隆的 PVC,然后点击 Actions → Clone PVC。
- 输入克隆的名称。
选择您选择的访问模式。
重要ReadOnlyMany(ROX)访问模式是一个开发者预览功能,它受到开发人员预览支持的限制。开发人员预览版本不应在生产环境中运行,且不受红帽客户门户网站问题单管理系统的支持。如果您需要 ReadOnlyMany 功能的帮助,请联络 ocs-devpreview@redhat.com 邮件列表和红帽开发团队成员将根据可用性和工作计划尽快为您提供协助。请参阅 使用新的只读访问模式创建克隆或恢复快照以使用 ROX 访问模式。
- 单击 Clone。您将被重定向到新的 PVC 详情页面。
等待克隆的 PVC 状态变为
Bound。克隆的 PVC 现在可以被 pod 使用。这个克隆的 PVC 独立于其 dataSource PVC。
第 11 章 管理容器存储接口(CSI)组件放置
每个集群由多个专用节点组成,如 infra 和 storage 节点。但是,具有自定义污点的 infra 节点将无法在该节点上使用 OpenShift Data Foundation 持久性卷声明(PVC)。因此,如果要使用这样的节点,可以设置容限以在节点上调出 csi-plugins。如需更多信息,请参阅 https://access.redhat.com/solutions/4827161。
流程
编辑 configmap,为自定义污点添加容限。记住在退出编辑器之前进行保存。
$ oc edit configmap rook-ceph-operator-config -n openshift-storage
显示
configmap以检查添加的容限。$ oc get configmap rook-ceph-operator-config -n openshift-storage -o yaml
为污点添加的容限的输出示例
nodetype=infra:NoSchedule:apiVersion: v1 data: [...] CSI_PLUGIN_TOLERATIONS: | - key: nodetype operator: Equal value: infra effect: NoSchedule - key: node.ocs.openshift.io/storage operator: Equal value: "true" effect: NoSchedule [...] kind: ConfigMap metadata: [...]如果
csi-cephfsplugin-* 和csi-rbdplugin-* pod 无法自行在 infra 节点上找到,则重启rook-ceph-operator。$ oc delete -n openshift-storage pod <name of the rook_ceph_operator pod>
示例:
$ oc delete -n openshift-storage pod rook-ceph-operator-5446f9b95b-jrn2j pod "rook-ceph-operator-5446f9b95b-jrn2j" deleted
验证步骤
验证 csi-cephfsplugin-* 和 csi-rbdplugin-* pod 正在 infra 节点上运行。