
开发 Hibernate 应用程序
面向希望开发和部署 Jakarta Persistence API(JPA)或 Hibernate 应用程序以用于红帽 JBoss 企业应用平台的开发人员和管理员的说明和信息。
摘要
第 1 章 简介
1.1. 关于 Hibernate 内核
Hibernate Core 是 Java 语言的对象关系映射框架。它提供了一个将面向对象的域模型映射到关系数据库的框架,允许应用避免直接与数据库交互。Hibernate 通过用高级别对象处理功能替代直接持久数据库访问,解决对象关系不匹配问题。
1.2. Hibernate EntityManager
Hibernate 实体管理器实施由 Jakarta Persistence 2.2 规范定义的编程接口和生命周期规则。此打包程序与 Hibernate 批注一起,在成熟的 Hibernate 核心基础上实施独立的 Jakarta Persistence 解决方案。您可以组合使用所有三个组件、不带 Jakarta Persistence 编程接口和生命周期的注释,甚至还可以根据项目的业务和技术需求使用纯原生 Hibernate 内核。您随时可以回退到 Hibernate 原生 API,或者在需要时甚至退回到原生 JDBC 和 SQL。它为 JBoss EAP 提供了完整的 Jakarta Persistence 解决方案。
JBoss EAP 的 7.3 发行版本符合 Jakarta Persistence 2.2 规范,其符合 Jakarta EE 8 中定义的规范。
Hibernate 还提供规范的其他功能。若要开始使用 Jakarta Persistence 和 JBoss EAP,请参阅 JBoss EAP 附带的 bean-validation、gleter 和 Kitchen sink 快速入门。
Jakarta Persistence 在容器中(如 Jakarta Enterprise Beans 3 或更现代化的 Jakarta Contexts 和 Dependency Injection)以及独立 Java SE 应用在特定容器外执行。两种环境中都提供以下编程接口和构件:
如果您计划将安全管理器与 Hibernate 一起使用,请注意,Hibernate 仅在 JBoss EAP 服务器引导 实体管理器Factory 时支持它。当应用程序引导 EntityManagerFactory 或 SessionFactory 时不支持它。
- EntityManagerFactory
- 实体管理器工厂提供实体管理器实例,所有实例都配置为连接到同一数据库,使用由特定实施定义的相同默认设置等。您可以准备多个实体管理器工厂来访问多个数据存储。此界面与原生 Hibernate 中的 SessionFactory 类似。
- EntityManager
- 实体管理器 API 用于访问特定工作单元中的数据库。它用于创建和删除持久实体实例,按主要密钥身份查找实体,以及对所有实体进行查询。此界面与 Hibernate 中的 Session 类似。
- 持久性上下文
- 持久上下文是一组实体实例,其中任何持久实体身份都有唯一的实体实例。在持久上下文中,实体实例及其生命周期由特定实体管理器管理。此上下文的范围可以是事务,也可以是扩展工作单元。
- persistence 单元
- 可由给定实体管理器管理的实体类型集合由持久性单元定义。持久性单元定义应用相关或分组的所有类的集合,它们在映射到单个数据存储时必须共存。
- 容器管理的实体管理器
- 生命周期由容器管理的实体管理器。
- 应用程序管理的实体管理器
- 生命周期由应用程序管理的实体管理器。
- Jakarta Transactions 实体经理
- 参与雅加达交易的实体经理.
- 资源本地实体管理器
- 使用资源交易(而不是 Jakarta 交易)的实体管理器。
第 2 章 Hibernate 配置
2.1. Hibernate 配置
应用服务器内和独立应用中实体管理器的配置都位于持久存档中。持久存档是一种 JAR 文件,必须定义驻留在 META-INF/ 文件夹中的 persistence.xml 文件。
您可以使用 persistence.xml 文件连接数据库。有两种方法可以做到这一点:
指定 JBoss EAP 的
datasources子系统中配置的数据源。jta-data-source指向此持久性单元映射到的数据源的 Java 命名和目录接口名称。java:jboss/datasources/ExampleDS此处指向 JBoss EAP 中嵌入的H2 DB。persistence.xml文件中的object-relational-mapping示例<persistence> <persistence-unit name="myapp"> <provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source> <properties> ... ... </properties> </persistence-unit> </persistence>通过指定连接属性,显式配置
persistence.xml文件。在
persistence.xml文件中指定连接属性示例<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver"/> <property name="javax.persistence.jdbc.user" value="sa"/> <property name="javax.persistence.jdbc.password" value=""/> <property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:."/>
有关连接属性的完整列表,请参阅
persistence.xml文件中可配置的连接属性。
有许多属性控制 Hibernate 在运行时的行为。所有都是可选的,且具有合理的默认值。这些 Hibernate 属性均在 persistence.xml 文件中使用。有关所有可配置 Hibernate 属性的完整列表,请参阅 Hibernate Properties。
2.2. 第二级缓存
2.2.1. 关于第二级缓存
第二级缓存是在应用会话外保留信息的本地数据存储。缓存由持久性提供商管理,通过将数据与应用分开来改进运行时。
JBoss EAP 支持用于以下目的的缓存:
- Web Session Clustering
- 有状态的 Session Bean Clustering
- SSO 集群
- Hibernate 第二级缓存
- Jakarta Persistence second-level Cache
每个缓存容器定义一个 repl 和一个 dist 缓存。用户应用不应直接使用这些缓存。
2.2.2. 为 Hibernate 配置二级缓存
可以通过两种方式进行 Infinispan 配置为 Hibernate 的二级缓存:
-
建议您使用
persistence.xml文件通过 Jakarta Persistence 应用 配置第二级缓存,如 JBoss EAP 开发指南中所述。 -
或者,您可以使用
hibernate.cfg.xml文件通过 Hibernate 原生应用程序配置二级缓存,如下所述。
使用 Hibernate 原生应用程序配置 Hibernate 的第二级缓存
-
在部署的类路径中创建
hibernate.cfg.xml文件。 将以下 XML 添加到
hibernate.cfg.xml文件中:XML 需要位于<session-factory>标签中:<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property> <property name="hibernate.cache.region.factory_class">org.jboss.as.jpa.hibernate5.infinispan.InfinispanRegionFactory</property>
要在应用程序中使用 Hibernate 原生 API,您必须在
MANIFEST.MF文件中添加以下依赖项:Dependencies: org.infinispan,org.hibernate
第 3 章 Hibernate 标注
3.1. Hibernate 标注
org.hibernate.annotations 软件包包含在标准 Jakarta Persistence 注释之上,由 Hibernate 提供的一些注释。
表 3.1. 常规注解
| 注解 | 描述 |
|---|---|
|
| 可以在类、属性或集合级别上定义的任意 SQL 检查限制。 |
|
| 将实体或集合标记为不可变。无注释表示该元素是可变的。 不可变实体可能不会由应用更新。不可变实体的更新将被忽略,但不会抛出异常。
集合上放置 |
表 3.2. 缓存实体
| 注解 | 描述 |
|---|---|
|
| 向 root 实体或集合添加缓存策略。 |
表 3.3. 集合相关注解
| 注解 | 描述 |
|---|---|
|
| 定义永久映射的密钥类型。 |
|
|
定义指向不同实体类型的 |
|
| 使用 SQL 排序(而非 HQL 排序)订购集合。 |
|
|
用于集合、数组和接合子类的策略。目前不支持次要表的 |
|
| 指定自定义持久化器。 |
|
| 集合排序(Java 级别排序)。 |
|
| 其中,要添加到集合的元素实体或目标实体的子句。子句使用 SQL 编写。 |
|
| 其中,要添加到集合连接表的子句。子句使用 SQL 编写。 |
表 3.4. CRUD Operations 的自定义 SQL
| 注解 | 描述 |
|---|---|
|
|
覆盖 Hibernate 默认 |
|
|
覆盖 Hibernate 默认 |
|
|
覆盖 Hibernate 默认 |
|
|
覆盖 Hibernate 默认 |
|
|
覆盖 Hibernate 默认 |
|
| 将不可变和只读实体映射到给定 SQL 子选择表达式。 |
|
|
确保自动清空正确,并且对派生实体的查询不会返回过时的数据。主要用于 |
表 3.5. 实体
| 注解 | 描述 |
|---|---|
|
| 对关联应用级联战略。 |
|
|
添加可能需要超过标准
|
|
| 用于定义多形 Hibernate 的类型适用于实体层次结构。 |
|
| 特定类的 lazy 和代理配置。 |
|
| 表的补充信息,可以是主要或次要信息。 |
|
| 表的复数注释. |
|
| 定义明确的目标,避免误会和通用解决方案。 |
|
| 为实体或组件定义导体。 |
|
| 为实体或组件定义一组教学程序。 |
表 3.6. 获取
| 注解 | 描述 |
|---|---|
|
| 用于 SQL 加载的批处理大小. |
|
| 定义获取策略配置文件。 |
|
|
|
|
|
指定应当获取实体属性以及属于同一组的所有其他属性。为了加载实体属性 lazily,需要进行字节代码增强。默认情况下,所有非收集属性都会加载到一个名为 |
表 3.7. 过滤器
| 注解 | 描述 |
|---|---|
|
| 向集合的实体或目标实体添加过滤器。 |
|
| 过滤定义. |
|
| 过滤器定义数组。 |
|
| 为连接表集合添加过滤器。 |
|
|
将多个 |
|
|
添加多个 |
|
| 参数定义。 |
表 3.8. 主密钥
| 注解 | 描述 |
|---|---|
|
| 此注释的属性由数据库生成。 |
|
| 以取消输入的方式描述任何类型的 Hibernate 生成器的生成器注释。 |
|
| 通用生成器定义的数组。 |
|
| 指定属性是实体的自然 ID 的一部分。 |
|
| 键/值模式. |
|
|
支持 Hibernate 的 |
表 3.9. 继承
| 注解 | 描述 |
|---|---|
|
| 将要放置在根实体上的磁盘公式。 |
|
| 用于表达 Hibernate 特定磁盘属性的可选注释。 |
|
| 将给定的分级值映射到对应的实体类型。 |
表 3.10. 映射 JP-QL/HQL Queries
| 注解 | 描述 |
|---|---|
|
|
扩展 |
|
|
使用 Hibernate 功能扩展 |
|
|
扩展 |
|
|
使用 Hibernate 功能扩展 |
表 3.11. 映射简单属性
| 注解 | 描述 |
|---|---|
|
| 属性访问类型. |
|
| 支持一组列.对于组件用户类型映射很有用。 |
|
| 用于从 中读取值并将值写入列的自定义 SQL 表达式。使用 直接加载/保存对象以及查询。写入表达式必须只包含一个值的 '?' 占位符。 |
|
|
|
表 3.12. 属性
| 注解 | 描述 |
|---|---|
|
|
在大多数地方用作 |
|
| 定义数据库索引。 |
|
|
可用于替换大多数位置的 |
|
| 将属性作为指针引用给所有者(通常是自有实体)。 |
|
| Hibernate 类型. |
|
| Hibernate 类型定义. |
|
| Hibernate 类型定义数组. |
表 3.13. 单个关联备注
| 注解 | 描述 |
|---|---|
|
| 定义指向多个实体类型的 ToOne 关联。与按实体类型匹配是通过元数据磁盘列实现的。此类映射应该只有很少的映射。 |
|
|
定义 |
|
|
定义 |
|
| 定义用于给定关联的 fetching 策略。 |
|
| 定义集合的延迟状态。 |
|
|
定义 ToOne 关联(即 |
|
| 关联上找不到某一元素时要执行的操作. |
表 3.14. 静止的锁定
| 注解 | 描述 |
|---|---|
|
| 注释的属性更改将触发实体版本递增。如果没有该注释,该属性将涉及开放式锁定策略(默认)。 |
|
| 用于定义应用于实体的开放式锁定方式。在层次结构中,仅在 root 实体上有效。 |
|
| 可选注解与 Version 和时间戳版本属性组合。注解值决定时间戳的生成位置。 |
第 4 章 Hibernate 查询语言
4.1. 关于 Hibernate 查询语言
Java Persistence 查询语言简介
Java Persistence 查询语言是一种独立于平台的对象导向查询语言,定义为 Java Persistence API 规范的一部分。Jakarta 等效于 Java Persistence 查询语言是 Jakarta Persistence 查询语言,它被定义为 Jakarta Persistence 规范的一部分。
Java Persistence 查询语言用于对存储在关系数据库中的实体进行查询。它受到 SQL 的极大启发,其查询语法类似于 SQL 查询,但针对 Java Persistence API 实体对象运行,而不是直接使用数据库表。
HQL 简介
Hibernate 查询语言(HQL)是一个功能强大的查询语言,类似于 SQL。但是,与 SQL 相比,HQL 完全面向对象,并且理解继承、多形性和关联等概念。
HQL 是 Java Persistence 查询语言的超集。HQL 查询并不总是是一个有效的 Java Persistence 查询语言查询,但 Java Persistence 查询语言查询始终是有效的 HQL 查询。
HQL 和 Java Persistence 查询语言都不是执行查询操作的非类型安全方法。标准查询提供了用于查询的类型安全方法。
4.2. 关于 HQL 语句
HQL 和 Java Persistence 查询语言都允许 SELECT、UPDATE 和 DELETE 语句。HQL 还允许 INSERT 语句,其格式类似于 SQL INSERT-SELECT。
下表显示了各种 HQL 语句的 Backus-Naur Form(BNF)表示法中的语法。
表 4.1. HQL 语句
| 声明 | 描述 |
|---|---|
|
|
HQL 中用于 select_statement :: =
[select_clause]
from_clause
[where_clause]
[groupby_clause]
[having_clause]
[orderby_clause]
|
|
|
HQL update_statement ::= update_clause [where_clause]
update_clause ::= UPDATE entity_name [[AS] identification_variable]
SET update_item {, update_item}*
update_item ::= [identification_variable.]{state_field | single_valued_object_field}
= new_value
new_value ::= scalar_expression |
simple_entity_expression |
NULL
|
|
|
HQL 中的 delete_statement ::= delete_clause [where_clause] delete_clause ::= DELETE FROM entity_name [[AS] identification_variable] |
|
|
HQL 中的 insert_statement ::= insert_clause select_statement insert_clause ::= INSERT INTO entity_name (attribute_list) attribute_list ::= state_field[, state_field ]* 没有与它对应的 Java Persistence 查询语言。 |
Hibernate 允许使用数据操作语言(DML)直接通过 Hibernate 查询语言(HQL)批量插入、更新和删除数据。
使用 DML 可能会违反对象/关系映射,并可能会影响对象状态。对象状态保留在内存中,使用 DML 时,内存中对象的状态不受影响,具体取决于对底层数据库执行的操作。如果使用 DML,则必须小心使用内存中数据。
关于 UPDATE 和 DELETE 语句
UPDATE 和 DELETE 语句的伪syntax 是:
(更新 | 从中删除 )EntityName(WHERE where_conditions)?。
FROM 关键字和 WHERE 术语是可选的。FROM 子句负责定义可供查询的其余部分使用的对象模型类型的范围。它还负责定义其余查询可用的所有标识变量。WHERE 子句允许您优化返回的实例列表。
执行 UPDATE 或 DELETE 语句的结果是实际受影响的行数(更新或删除)。
示例:批量更新语句
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlUpdate = "update Company set name = :newName where name = :oldName";
int updatedEntities = s.createQuery( hqlUpdate )
.setString( "newName", newName )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
示例:批量删除语句
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlDelete = "delete Company where name = :oldName";
int deletedEntities = s.createQuery( hqlDelete )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
Query.executeUpdate() 方法返回的 int 值指示受操作影响的数据库内实体数量。
在内部,数据库可能会使用多个 SQL 语句来执行响应 DML 更新 或删除 请求 的操作。这可能是因为表和需要更新或删除的连接表之间存在关系。
例如,如上例所示,发出删除声明可能实际上不仅对使用 oldName 命名的 公司的 Company 表执行删除,而且会对合并表执行删除。因此 , 由于 成功执行了上例,与 Employee 表的双向多对多关系也会从相应的加入表中丢弃行。
已删除的Entries 值包含操作影响的所有行的计数,包括 join 表中的行。
执行批量更新或删除操作时应小心,因为它们可能会导致数据库和活动持久化上下文中的实体不一致。通常,批量更新和删除操作应只在新持久性上下文中的事务内执行,或者在获取或访问状态可能受到此类操作影响的实体之前执行。
关于 INSERT 语句
HQL 添加了定义 INSERT 语句的功能。没有与它对应的 Java Persistence 查询语言。HQL INSERT 语句的 Backus-Naur Form(BNF)是:
insert_statement ::= insert_clause select_statement insert_clause ::= INSERT INTO entity_name (attribute_list) attribute_list ::= state_field[, state_field ]*
attribute_list 与 SQL INSERT 语句中的列规格类似。对于涉及映射继承的实体,在 properties _list 中只能使用直接在指定实体上定义的属性。不允许超级类属性,子类属性并不合理。换句话说,INSERT 语句本质上是非私有的。
select_statement 可以是任何有效的 HQL 选择查询,注意返回类型必须与插入预期的类型匹配。目前,这会在查询编译过程中检查,而不是让检查与数据库相连接。这可能会导致 Hibernate 类型与相等的问题 。例如,这可能会导致映射为 org.hibernate.type.DateType 的属性和定义为 org.hibernate.type.TimestampType 的属性之间不匹配问题,即使数据库可能无法区分或处理转换。
对于 id 属性,插入语句为您提供两个选项:您可以在 attribute_list 中明确指定 id 属性,在这种情况下,从对应的 select 表达式获取它的值,或者从 attribute_list 中省略它,在这种情况下使用生成的值。只有使用"在数据库中操作"的 id 生成器时才可使用后一种选项;尝试将此选项用于任何"内存中"类型生成器将导致解析过程中出现异常情况。
对于不确定的锁定属性,插入语句再次为您提供两个选项:您可以在 attribute_list 中指定 属性,在这种情况下,它的值取自对应的选择表达式,或者从 attribute_list 中省略它,在这种情况下,使用了对应的 org.hibernate.type.VersionType 定义的 seed 值。
示例:INSERT 查询语句
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ..."; int createdEntities = s.createQuery(hqlInsert).executeUpdate();
示例: Bulkert Statement
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlInsert = "insert into Account (id, name) select c.id, c.name from Customer c where ...";
int createdEntities = s.createQuery( hqlInsert )
.executeUpdate();
tx.commit();
session.close();
如果不使用 SELECT 语句提供 id 属性的值,则会为您生成标识符,只要底层数据库支持自动生成的密钥。此批量插入操作的返回值是数据库中实际创建的条目数。
4.3. 关于 HQL 排序
查询的结果也可以排序。ORDER BY 子句用于指定用于排序结果的选定值。作为按顺序子句的一部分,表达式的类型被视为有效,包括:
- 状态字段
- 组件/嵌入式属性
- 星形表达式,如算术运算、函数等。
- 在 select 子句中为任一表达式类型声明的标识变量
HQL 不强制在 select 子句中命名排序句中引用的所有值,但它需要 Java Persistence 查询语言。代表数据库可移植性的应用程序应该意识到,并非所有数据库都支持在 select 子句中引用未引用的顺序子句中的值。
排序中的各个表达式可以通过 ASC (发送)或 DESC (降序)来指示所需的排序方向。
示例:订单人
// legal because p.name is implicitly part of p
select p
from Person p
order by p.name
select c.id, sum( o.total ) as t
from Order o
inner join o.customer c
group by c.id
order by t
4.4. 关于集合成员参考
引用集合值的关联实际上指的是该集合的值。
示例:集合参考
select c
from Customer c
join c.orders o
join o.lineItems l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
// alternate syntax
select c
from Customer c,
in(c.orders) o,
in(o.lineItems) l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
在这个示例中,标识变量 o 实际指的是对象模型类型顺序,这是客户#顺序关联元素的类型。
示例还显示了使用 IN 语法指定集合关联接合的替代语法。两种形式都是等同的。哪种应用程序选择使用就只是一个体验问题。
4.5. 关于限定路径表达式
之前已指出收集值的关联实际指的是该集合的值。根据集合的类型,也提供一组明确的资格表达式。
表 4.2. 路径表达式
| expression | 描述 |
|---|---|
|
| 指的是集合值。与未指定限定符相同。用于明确显示意图.对任何类型的 collection-valued 引用有效。 |
|
|
根据 HQL 规则,这对于指定 javax.persistence.OrderColumn 注解的 Map 和 Lists 都有效,以引用 Map 键或 List 位置(回答 OrderColumn 值)。但是,Java Persistence 查询语言保留在 List 案例中使用,并为 MAP 案例添加 |
|
| 仅对映射有效。指地图的密钥。如果密钥本身是一个实体,可以进一步导航。 |
|
|
仅对映射有效。引用 Map 的逻辑 java.util.Map.Entry tuple(其键和值的组合)。 |
示例:限定集合参考
// Product.images is a Map<String,String> : key = a name, value = file path
// select all the image file paths (the map value) for Product#123
select i
from Product p
join p.images i
where p.id = 123
// same as above
select value(i)
from Product p
join p.images i
where p.id = 123
// select all the image names (the map key) for Product#123
select key(i)
from Product p
join p.images i
where p.id = 123
// select all the image names and file paths (the 'Map.Entry') for Product#123
select entry(i)
from Product p
join p.images i
where p.id = 123
// total the value of the initial line items for all orders for a customer
select sum( li.amount )
from Customer c
join c.orders o
join o.lineItems li
where c.id = 123
and index(li) = 1
4.6. 关于 HQL 功能
HQL 定义一些可用的标准功能,无论使用的底层数据库是什么。HQL 也可以了解方形图和应用程序中定义的其他功能。
4.6.1. 关于 HQL 标准化功能
无论使用的底层数据库是什么,HQL 中都提供以下功能:
表 4.3. HQL 标准化功能
| 功能 | 描述 |
|---|---|
|
| 返回二进制数据的长度。 |
|
| 执行 SQL 广播.cast 目标应命名为要使用的 Hibernate 映射类型。 |
|
| 根据日期时间值执行 SQL 提取.提取将返回日期/时间值的一部分,如当年。请参见以下简写表格。 |
|
| 用于提取第二个的缩写提取表单。 |
|
| 用于提取分钟的缩写提取表单。 |
|
| 用于提取小时的缩写提取表单。 |
|
| 用于提取日期的缩写提取表单. |
|
| 用于提取月份的简短提取表单。 |
|
| 用于提取年度的简短提取表单. |
|
| 转换值作为字符数据的简写形式。 |
4.6.2. 关于 HQL 非标准化功能
Hibernate 拨号可以注册已知可用于该特定数据库产品的其他功能。它们只有在使用该数据库或拨号时才可用。以数据库可移植性为目标的应用应避免在此类别中使用函数。
应用程序开发人员还可以提供自己的一组功能。这通常代表自定义 SQL 函数或 SQL 片段的别名。此类功能声明通过使用 org.hibernate.cfg.Configuration 的 addSqlFunction 方法进行。
4.6.3. 关于连接操作
HQL 除了支持串联(CONCAT)功能外,还定义了串联运算符。这不是由 Java Persistence 查询语言定义的,因此便携式应用应避免使用它。连接运算符取自 SQL 串联运算符(||)。
示例:连接操作示例
select 'Mr. ' || c.name.first || ' ' || c.name.last from Customer c where c.gender = Gender.MALE
4.7. 关于动态注入
特定的表达式类型仅在 select 子句中有效。Hibernate 将此"动态实例化"称为"动态实例化"。Java Persistence 查询语言支持部分功能,并将其称为"结构表达式"。
示例:动态注入示例 - 结构
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offspr
因此,我们不在这里处理 Object[],而是将值嵌套在 type-safe java 对象中,该对象将作为查询的结果返回。类引用必须完全限定,并且必须具有匹配的构造器。
此处的类不需要映射。如果确实代表某一实体,则生成的实例将返回为 NEW 状态(非 managed!)。
这也是 Java Persistence 查询语言支持的部分。HQL 支持其他"动态实例化"功能。首先,查询可以指定返回列表,而不是用于 scalar 结果的 Object[]:
示例:动态注入示例 - 列表
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
这个查询的结果将是 List<List>,而不是 List<Object[]>。
HQL 还支持将井号结果换算成一个映射。
示例:动态注入示例 - 映射
select new map( mother as mother, offspr as offspr, mate as mate )
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
select new map( max(c.bodyWeight) as max, min(c.bodyWeight) as min, count(*) as n )
from Cat cxt
这个查询的结果将是 List<Map<String,Object>>,而不是 List<Object[]>。映射的键由提供给所选表达式的别名定义。
4.8. 关于 HQL predicates
predicates 形成 where 子句、包含 子句 和 搜索案例表达式的基础。它们是可解析为真实值的表达式,通常是 TRUE 或 FALSE,尽管涉及 NULL 值的布尔值比较通常解析为 UNKNOWN。
HQL 谓词
null Predicate
检查 null 值。可以应用到基本属性引用、实体引用和参数。HQL 还允许将它应用到组件/嵌入式类型。
示例:NULL Check
// select everyone with an associated address select p from Person p where p.address is not null // select everyone without an associated address select p from Person p where p.address is null
像 Predicate
执行类似于字符串值的比较。语法为:
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]语义遵循 SQL 等表达式的语义。
pattern_value是在 string_expression 中尝试匹配的模式。正如 SQL 一样,mod_value可以使用_(下划线)和%(百分比)作为通配符。含义相同。_匹配任何单个字符。%匹配任意数量的字符。可选的s
cap_character用于指定用于转义pattern_value中_和%的特殊含义的转义字符。这在需要搜索模式(包括_ 或%)时非常有用。示例:LIKE Predicate
select p from Person p where p.name like '%Schmidt' select p from Person p where p.name not like 'Jingleheimmer%' // find any with name starting with "sp_" select sp from StoredProcedureMetadata sp where sp.name like 'sp|_%' escape '|'
Predicate 间
类似于 SQL
BETWEEN表达式。执行评估,说明值在 2 个其他值范围内。所有操作对象都应具有可比较类型。示例:BETWEEN Predicate
select p from Customer c join c.paymentHistory p where c.id = 123 and index(p) between 0 and 9 select c from Customer c where c.president.dateOfBirth between {d '1945-01-01'} and {d '1965-01-01'} select o from Order o where o.total between 500 and 5000 select p from Person p where p.name between 'A' and 'E'IN Predicate
INpredicate 执行检查特定值是否在值列表中。它的语法是:in_expression ::= single_valued_expression [NOT] IN single_valued_list single_valued_list ::= constructor_expression | (subquery) | collection_valued_input_parameter constructor_expression ::= (expression[, expression]*)single_valued_expression 的类型和 single_valued_list 中的单个值必须一致。Java Persistence 查询语言将此处的有效类型限制为字符串、数字、日期、时间、时间戳和枚举类型。在 Java Persistence 查询语言 中,single_valued_expression 只能指:- "状态字段",这是简单属性的术语。特别是,这不包括关联和组件/嵌入式属性。
实体类型表达式.
在 HQL 中,
single_valued_expression 可以指一组更广泛的表达式类型。允许单值关联。同样是组件/嵌入式属性,尽管该功能取决于底层数据库中对元或"行值构造器语法"的支持级别。此外,HQL 不会以任何方式限制值类型,但应用开发人员应该意识到,不同的类型可能会基于底层数据库供应商获得有限的支持。这主要是 Java Persistence 查询语言限制的原因。值列表可能来自多个不同来源。在
constructor_expression和collection_valued_input_parameter中,值列表不能为空;它必须至少包含一个值。示例:IN Predicate
select p from Payment p where type(p) in (CreditCardPayment, WireTransferPayment) select c from Customer c where c.hqAddress.state in ('TX', 'OK', 'LA', 'NM') select c from Customer c where c.hqAddress.state in ? select c from Customer c where c.hqAddress.state in ( select dm.state from DeliveryMetadata dm where dm.salesTax is not null ) // Not Java Persistence query language compliant! select c from Customer c where c.name in ( ('John','Doe'), ('Jane','Doe') ) // Not Java Persistence query language compliant! select c from Customer c where c.chiefExecutive in ( select p from Person p where ... )
4.9. 关于关系比较
比较涉及比较运算符之一 - =, >, >=, <, ›, <>。HQL 还定义了 != 作为与 <> 的比较运算符。操作对象应该是相同的类型。
示例:关系比较示例
// numeric comparison
select c
from Customer c
where c.chiefExecutive.age < 30
// string comparison
select c
from Customer c
where c.name = 'Acme'
// datetime comparison
select c
from Customer c
where c.inceptionDate < {d '2000-01-01'}
// enum comparison
select c
from Customer c
where c.chiefExecutive.gender = com.acme.Gender.MALE
// boolean comparison
select c
from Customer c
where c.sendEmail = true
// entity type comparison
select p
from Payment p
where type(p) = WireTransferPayment
// entity value comparison
select c
from Customer c
where c.chiefExecutive = c.chiefTechnologist
比较还可能涉及子队列限定符 - ALL、ANY、SOM E。SOME 和 ANY 是同义词。
如果对子队列结果中的所有值进行比较都为 true,则 ALL 限定符会解析为 true。如果子队列结果为空,它将解析为 false。
示例:所有 Subquery Comparison Qualifier 示例
// select all players that scored at least 3 points // in every game. select p from Player p where 3 > all ( select spg.points from StatsPerGame spg where spg.player = p )
如果对子 队列结果中至少一个值进行比较为 true,ANY /SOME 限定符会解析为 true。如果子队列结果为空,它将解析为 false。
4.10. 字节码增强
4.10.1. lazy Attribute Loading
lazy 属性加载是一种字节码增强,它允许您告知 Hibernate,从数据库获取时仅应加载实体的特定部分,以及应在何时加载其他剩余部分。这与基于代理加载的理念不同,后者是实体中心,即在需要时一次性加载实体的状态。通过字节码增强,根据需要加载各个属性或属性组。
可以将 lazy 属性指定为一起加载,这称为 lazy 组。默认情况下,所有单数属性都是单个组的一部分。访问一个 lazy singular 属性时,会加载所有 lazy 单数属性。与单片组不同,lazy 复数属性是各个离散的 lazy 组。此行为可通过 @org.hibernate.annotations.LazyGroup 注释显式控制。
@Entity
public class Customer {
@Id
private Integer id;
private String name;
@Basic( fetch = FetchType.LAZY )
private UUID accountsPayableXrefId;
@Lob
@Basic( fetch = FetchType.LAZY )
@LazyGroup( "lobs" )
private Blob image;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public UUID getAccountsPayableXrefId() {
return accountsPayableXrefId;
}
public void setAccountsPayableXrefId(UUID accountsPayableXrefId) {
this.accountsPayableXrefId = accountsPayableXrefId;
}
public Blob getImage() {
return image;
}
public void setImage(Blob image) {
this.image = image;
}
}
在上例中,有两个 lazy 属性:accounts PayableXrefId 和 image。这些属性各自属于不同的获取组。accountsPayableXrefId 属性是默认 fetch 组的一部分,这意味着访问 accountsPayableXrefId 不会强制加载 映像 属性,反之亦然。
第 5 章 Hibernate 服务
5.1. 关于 Hibernate 服务
服务是向 Hibernate 提供各种功能的可插拔实现的类。具体来说,它们是某些服务合同接口的实施。接口称为服务角色;实施类称为服务实施。般而言,用户可以插入所有标准服务角色(覆盖)的替代实施;他们还可以定义服务角色基础组之外的其他服务(扩展)。
5.2. 关于服务合同
服务的基本要求是实施标记接口 org.hibernate.service.Service。Hibernate 在内部将此用于某些基本类型安全。
服务也可以实施 org.hibernate.service.spi.Startable 和 org.hibernate.service.spi.Stoppable 接口来接收启动和停止的通知。另一个可选服务合同是 org.hibernate.service.spi.Manageable,在 Jakarta 管理中将服务标记为可管理,但 Jakarta 管理集成已启用。
5.3. 服务依赖项类型
允许服务使用以下方法之一声明对其他服务的依赖:
- @org.hibernate.service.spi.InjectService
服务实施类上接受单个参数并标有
@InjectService的任何方法都被视为请求注入其他服务。默认情况下,方法参数的类型应当是要注入的服务角色。如果参数类型与 service 角色不同,则应当使用
InjectService 的serviceRole属性来显式命名该角色。默认情况下,注入的服务被视为必需,如果缺少指定的依赖服务,则启动该服务将失败。如果要注入的服务是可选的,
InjectService 的required 属性应声明为false。默认值为true。- org.hibernate.service.spi.ServiceRegistryAwareService
第二种方法是拉取方法,其中服务实施可选的服务接口
org.hibernate.service.spi.ServiceRegistryAwareService,它声明了单一注入服务方法。在启动过程中,Hibernate 会将
org.hibernate.service.ServiceRegistry自身注入到实施此接口的服务中。然后,服务可以使用ServiceRegistry引用来查找所需的任何其他服务。
5.3.1. Service Registry
5.3.1.1. 关于 ServiceRegistry
除服务本身外,中央服务 API 是 org.hibernate.service.ServiceRegistry 接口。服务注册表的主要用途是保存、管理和提供对服务的访问。
服务注册表采用层次结构。个注册表中的服务可以依赖于并使用同一注册表中的服务以及任何父注册表。
使用 org.hibernate.service.ServiceRegistryBuilder 构建 org.hibernate.service.ServiceRegistry 实例。
使用 ServiceRegistryBuilder 创建 ServiceRegistry 的示例
ServiceRegistryBuilder registryBuilder =
new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
5.3.2. 自定义服务
5.3.2.1. 关于自定义服务
旦创建了 org.hibernate.service.ServiceRegistry,则该服务本身可能会接受重新配置,但此处的不可变性意味着添加或替换服务。因此 org.hibernate.service.ServiceRegistryBuilder 提供的另一个角色是允许对从中生成的 org.hibernate.service.ServiceRegistry 中包含的服务进行调整。
有两种方法可以告知 org.hibernate.service.ServiceRegistryBuilder 相关信息。
-
实施
org.hibernate.service.spi.BasicServiceInitiator类,以控制服务类按需构建,并使用其addInitiator方法将它添加到org.hibernate.service.ServiceRegistryBuilder中。 -
只需实例化服务类,并使用其
addService 方法将它添加到中。org.hibernate.service.ServiceRegistryBuilder
这两种方法都可用于扩展注册表,例如添加新的服务角色和覆盖服务,如替换服务实施。
示例:使用 ServiceRegistryBuilder 将现有服务替换为自定义服务
ServiceRegistryBuilder registryBuilder =
new ServiceRegistryBuilder(bootstrapServiceRegistry);
registryBuilder.addService(JdbcServices.class, new MyCustomJdbcService());
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
public class MyCustomJdbcService implements JdbcServices{
@Override
public ConnectionProvider getConnectionProvider() {
return null;
}
@Override
public Dialect getDialect() {
return null;
}
@Override
public SqlStatementLogger getSqlStatementLogger() {
return null;
}
@Override
public SqlExceptionHelper getSqlExceptionHelper() {
return null;
}
@Override
public ExtractedDatabaseMetaData getExtractedMetaDataSupport() {
return null;
}
@Override
public LobCreator getLobCreator(LobCreationContext lobCreationContext) {
return null;
}
@Override
public ResultSetWrapper getResultSetWrapper() {
return null;
}
}
5.3.3. Boot-Strap Registry
5.3.3.1. 关于 Boot-strap Registry
boot-strap 注册表存放绝对必须可用的服务,大多数操作都必须可用。这里的主要服务是 ClassLoaderService,这是一个完美的例子。即使解析配置文件也需要访问类加载服务,如资源查找。这是通常使用的根注册表,而不是父注册表。
boot-strap 注册表的实例使用 org.hibernate.service.BootstrapServiceRegistryBuilder 类构建。
Using BootstrapServiceRegistryBuilder
示例:使用 BootstrapServiceRegistryBuilder
BootstrapServiceRegistry bootstrapServiceRegistry =
new BootstrapServiceRegistryBuilder()
// pass in org.hibernate.integrator.spi.Integrator instances which are not
// auto-discovered (for whatever reason) but which should be included
.with(anExplicitIntegrator)
// pass in a class loader that Hibernate should use to load application classes
.with(anExplicitClassLoaderForApplicationClasses)
// pass in a class loader that Hibernate should use to load resources
.with(anExplicitClassLoaderForResources)
// see BootstrapServiceRegistryBuilder for rest of available methods
...
// finally, build the bootstrap registry with all the above options
.build();
5.3.3.2. BootstrapRegistry 服务
org.hibernate.service.classloading.spi.ClassLoaderServiceHibernate 需要与类加载器交互。但是,Hibernate 或任何库与类加载器交互的方式因托管应用的运行时环境而异。应用程序服务器、OSGi 容器和其他模块化类加载系统带来了非常具体的类加载要求。此服务从这种环境复杂性中提供 Hibernate 抽象。更重要的是,它以单一兼容的方式做到这一点。
在与类加载器交互方面,Hibernate 需要以下功能:
- 定位应用程序类的功能
- 定位集成类的功能
- 查找资源(如属性文件和 XML 文件)的功能
加载
java.util.ServiceLoader 的功能注意目前,加载应用类的功能和加载集成类的功能组合到服务的单个负载类功能中。这可能在以后的版本中有所改变。
org.hibernate.integrator.spi.IntegratorService应用程序、附加组件和其他模块需要与 Hibernate 集成。以上方法需要一个组件(通常是应用)来协调各个模块的注册。此注册代表每个模块的集成商进行。
此服务侧重于发现方面。它利用
org.hibernate功能来发现.service.classloading.spi.ClassLoaderService 提供的标准 Java java.util.ServiceLoaderorg.hibernate.integrator.spi.Integrator合同的实施。集成器只需定义一个名为
/META-INF/services/org.hibernate.integrator.spi.Integrator的文件,并使其在类路径中可用。此文件由
java.util.ServiceLoader机制使用。它将列出实施org.hibernate.integrator.spi.Integrator接口的完全限定类名称,每行一个。
5.3.4. SessionFactory Registry
虽然最佳做法是将所有 registry 类型的实例视为针对给定 机构。SessionFactory,但该组中的服务实例明确属于单个 org.hibernate.SessionFactory。
差别在于需要发起它们的时间问题。通常他们需要访问 org.hibernate.SessionFactory 才能启动。这个特殊 registry 是 org.hibernate.service.spi.SessionFactoryServiceRegistry。
5.3.4.1. SessionFactory 服务
org.hibernate.event.service.spi.EventListenerRegistry
- 描述
- 用于管理事件侦听器的服务。
- initiator
-
org.hibernate.event.service.internal.EventListenerServiceInitiator - 实施
-
org.hibernate.event.service.internal.EventListenerRegistryImpl
5.3.5. 集成器
org.hibernate.integrator.spi.Integrator 旨在提供一种简单的途径,让开发人员能够将信息集中到构建可正常工作的 SessionFactory 的过程中。org.hibernate.integrator.spi.Integrator 接口定义了两种感兴趣的方法:
-
集成使我们能够在构建过程中 hook -
解除集成使我们可以固定在SessionFactory关机中。
org.hibernate.integrator.spi.Integrator 中定义了第三个方法,它是一个超载的集成形式,接受 org.hibernate.metamodel.source.MetadataImplementor 而不是 org.hibernate.cfg.Configuration。
除了 IntegratorService 提供的发现方法外,应用在构建 时可以手动注册 Integrator 实施。
BootstrapService Registry
5.3.5.1. 集成器用例
org.hibernate.integrator.spi.Integrator 注册事件监听程序和提供服务,请参阅 org.hibernate.integrator.spi.ServiceContributingIntegrator。
示例:注册事件列表
public class MyIntegrator implements org.hibernate.integrator.spi.Integrator {
public void integrate(
Configuration configuration,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// As you might expect, an EventListenerRegistry is the thing with which event listeners are registered It is a
// service so we look it up using the service registry
final EventListenerRegistry eventListenerRegistry = serviceRegistry.getService(EventListenerRegistry.class);
// If you wish to have custom determination and handling of "duplicate" listeners, you would have to add an
// implementation of the org.hibernate.event.service.spi.DuplicationStrategy contract like this
eventListenerRegistry.addDuplicationStrategy(myDuplicationStrategy);
// EventListenerRegistry defines 3 ways to register listeners:
// 1) This form overrides any existing registrations with
eventListenerRegistry.setListeners(EventType.AUTO_FLUSH, myCompleteSetOfListeners);
// 2) This form adds the specified listener(s) to the beginning of the listener chain
eventListenerRegistry.prependListeners(EventType.AUTO_FLUSH, myListenersToBeCalledFirst);
// 3) This form adds the specified listener(s) to the end of the listener chain
eventListenerRegistry.appendListeners(EventType.AUTO_FLUSH, myListenersToBeCalledLast);
}
}
第 6 章 Hibernate Envers
6.1. 关于 Hibernate Envers
Hibernate Envers 是一种审计和版本化系统,为 JBoss EAP 提供了一种途径来跟踪永久类的历史变化。为标有 @Audited 的实体创建审计表,该实体存储对实体所做的更改历史记录。然后可以检索和查询数据。
Envers 允许开发人员:
- 审计根据 Jakarta Persistence 规范定义的所有映射
- 审核扩展 Jakarta Persistence 规范的所有 hibernate 映射
- 由或使用原生 Hibernate API 映射的审计实体
- 使用修订实体记录每个修订版本的数据
- 查询历史数据
6.2. 关于审计持久性类
持久类审计通过 Hibernate Envers 和 @Audited 注释在 JBoss EAP 中完成。当注解应用到类时,将创建一个表,用于存储实体的修订历史记录。
每次对类进行更改时,都会向 audit 表中添加一个条目。该条目包含对类的更改,并获得修订号。这意味着可以回滚更改,也可以查看以前的修订版本。
6.3. 审计策略
6.3.1. 关于审计策略
审计策略定义了审计信息的持久性、查询和存储方式。Hibernate Envers 目前有两种审计策略:
- 默认审计策略
- 此策略将审计数据与开始修订一起保留。对于在审计表中插入、更新或删除的每一行,在审计表中插入一行或多行,以及其有效期的开始修订。
- 插入后不会更新审计表中的行。对审计信息查询使用子查询来选择审计表中适用的行,这些行速度慢且难以索引。
- 有效期审计策略
- 此策略存储启动修订以及审计信息的结束修订。对于在审计表中插入、更新或删除的每一行,在审计表中插入一行或多行,以及其有效期的开始修订。
- 同时,上一审计行(如果可用)的结束修订字段被设置为这个修订版本。然后,对审计信息的查询可以在开始和结束修订版本之间使用,而不是子查询。这意味着保留审计信息的速度稍慢,因为增加了更新,但检索审计信息的速度要快得多。
- 这也可以通过添加额外的索引来改进。
如需有关审计的更多信息,请参阅关于审计持久类。要为应用设置审计策略,请参阅 设置审计策略。
6.3.2. 设置审计策略
JBoss EAP 支持两种审计策略:
- 默认审计策略
- 有效期审计策略
定义审计策略
在应用的 persistence 属性。如果在 .xml 文件中配置 org.hibernate.envers. audit_strategypersistence.xml 文件中未设置 属性,则使用默认的审计策略。
设置默认审计策略
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>
设置Validity Audit 策略
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>
6.3.3. 将审计支持添加到 Jakarta Persistence Entity
流程
JBoss EAP 通过 Hibernate Envers 使用实体审核来跟踪永久类的历史更改。本节介绍添加对 Jakarta Persistence 实体的审计支持。
将审计支持添加到 Jakarta Persistence Entity
- 配置可用的审计参数以适合部署。详情请参阅 配置 Envers 参数。
- 打开 Jakarta Persistence 实体进行审计。
-
导入
org.hibernate.envers.Audited接口。 将
@Audited注释应用到要审核的每个字段或属性,或将它应用到整个类。示例:审计两个字段
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity public class Person { @Id @GeneratedValue private int id; @Audited private String name; private String surname; @ManyToOne @Audited private Address address; // add getters, setters, constructors, equals and hashCode here }示例:审计最终类
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity @Audited public class Person { @Id @GeneratedValue private int id; private String name; private String surname; @ManyToOne private Address address; // add getters, setters, constructors, equals and hashCode here }
为审核配置了 Jakarta Persistence 实体时,将创建一个名为 _AUD 的表来存储历史更改。
6.4. Configuration
6.4.1. 配置端点参数
JBoss EAP 通过 Hibernate Envers 使用实体审计来跟踪永久类的历史更改。
配置可用的端点参数
-
打开
应用的 persistent.xml文件。 根据需要添加、删除或配置 Envers 属性。有关可用属性列表,请参阅 Envers Configuration Properties。
示例:结束参数
<persistence-unit name="mypc"> <description>Persistence Unit.</description> <jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source> <shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode> <properties> <property name="hibernate.hbm2ddl.auto" value="create-drop" /> <property name="hibernate.show_sql" value="true" /> <property name="hibernate.cache.use_second_level_cache" value="true" /> <property name="hibernate.cache.use_query_cache" value="true" /> <property name="hibernate.generate_statistics" value="true" /> <property name="org.hibernate.envers.versionsTableSuffix" value="_V" /> <property name="org.hibernate.envers.revisionFieldName" value="ver_rev" /> </properties> </persistence-unit>
6.4.2. 在运行时启用或禁用审计
在运行时启用或禁用实体版本审核
-
子类
AuditEventListener类。 覆盖在 Hibernate 事件中调用的以下方法:
-
onPostInsert -
onPostUpdate -
onPostDelete -
onPreUpdateCollection -
onPreRemoveCollection -
onPostRecreateCollection
-
- 将子类指定为事件的监听程序。
- 确定是否应审计更改。
- 如果更改应该被审计,则将调用传递到超级类。
6.4.3. 配置条件审计
Hibernate Envers 使用一系列事件监听器以对各种 Hibernate 事件的响应保留审计数据。如果 Envers JAR 在类路径中,则这些监听程序会自动注册。
实施条件审计
-
在
persistenceHibernate 属性设置为 false。.xml 文件中将 hibernate.listeners.envers.autoRegister - 子类要覆盖的每个事件监听程序。将条件审计逻辑放在子类中,并在应当执行审计时调用超级方法。
-
创建
org.hibernate.integrator.spi.Integrator的自定义实施,类似于org.hibernate.envers.event.EnversIntegrator。使用在第 2 步中创建的事件监听器子类,而不是默认的类。 -
将
META-INF/services/org.hibernate.integrator.spi.Integrator文件添加到 JAR。此文件应当包含实施接口的类的完全限定名称。
6.4.4. Envers 配置属性
表 6.1. 实体数据版本配置参数
| 属性名称 | 默认值 | 描述 |
|---|---|---|
|
| 在被审计实体名称前加上字符串,以创建保存审计信息的实体的名称。 | |
|
| _AUD |
附加到已审计实体名称的字符串,以创建保存审计信息的实体的名称。例如,如果对表名称为 |
|
| REV | 包含修订号的审计实体中的字段名称。 |
|
| REVTYPE |
存放修订类型的审计实体中的字段名称。当前可能的修订类型有: |
|
| true |
此属性决定是否应生成修订项,如果关系字段未拥有的更改。这可以是一对多关系中的集合,也可以是使用一对一关系中的 mapping |
|
| true |
为 true 时,用于开放式锁定的属性(使用 |
|
| false | 此属性定义在删除实体时是否应将实体数据存储在修订中,所有其他属性均标记为 null(而非 ID)。这通常不需要,因为数据存在于最后一处的修订版本中。但有时候,在最后一个修订版本中访问它更为简单和高效。但是,这意味着在删除前包含的数据被存储两次。 |
|
| Null(与普通表相同) |
用于审计表的默认架构名称。可以使用 |
|
| Null(与普通表相同) |
应用于审计表的默认目录名称。可以使用 |
|
|
|
此属性定义在持久保留审计数据时应使用的审计策略。默认情况下,仅存储了实体修改的修订版本。另外, |
|
| REVEND | 在审计实体中保存最终修订版本的列名称。只有使用了有效期审计策略时,此属性才有效。 |
|
| false |
此属性定义除结束修订本身外,是否应将最终修订的时间戳(数据在最后有效的位置)存储下来。这对于使用表分区从关系数据库中清除旧的审计记录非常有用。分区需要表中存在的列。只有在使用了Validity |
|
| REVEND_TSTMP |
结束修订版本时间戳的列名称,即数据仍有效。只有在使用了Validity |
6.5. 查询审计信息
6.5.1. 通过队列检索审计信息
Hibernate Envers 提供通过查询检索审计信息的功能。
许多情况下,对审计数据的查询比 实时数据 的相应查询要慢得多,因为它们涉及关联的子选择。
通过给定修订版本查询类实体
此查询的入口点为:
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
然后,可以使用 AuditEntity 工厂类别指定限制。以下查询仅选择 name 属性等于 John 的实体:
query.add(AuditEntity.property("name").eq("John"));以下查询只选择与给定实体相关的实体:
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));然后可以订购、限制结果,并且设置聚合和预测(分组除外)。以下示例是一个完整的查询。
List personsAtAddress = getAuditReader().createQuery()
.forEntitiesAtRevision(Person.class, 12)
.addOrder(AuditEntity.property("surname").desc())
.add(AuditEntity.relatedId("address").eq(addressId))
.setFirstResult(4)
.setMaxResults(2)
.getResultList();查询修订,其中给定类的实体更改
此查询的入口点为:
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);限制可以添加到此查询中,方式与上例相同。这个查询还有其它可能:
AuditEntity.revisionNumber()- 指定修改审计实体的修订版本号的限制、预测和顺序。
AuditEntity.revisionProperty(propertyName)- 指定修订实体属性的限制、预测和订单,对应于修改审计实体的修订版本。
AuditEntity.revisionType()- 提供对修订版本类型的访问(ADD、MOD、DEL)。
然后可以根据需要调整查询结果。以下查询选择 MyEntity 类的实体的最小修订号,其中的 entity Id ID 在修订号 42 后更改:
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.id().eq(entityId))
.add(AuditEntity.revisionNumber().gt(42))
.getSingleResult();
对修订的查询也可以最小化/最大化属性。以下查询选择给定实体的 actualDate 值大于给定值的修订版本,但尽量小:
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
// We are only interested in the first revision
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.property("actualDate").minimize()
.add(AuditEntity.property("actualDate").ge(givenDate))
.add(AuditEntity.id().eq(givenEntityId)))
.getSingleResult();
mini ()和 属性的实体必须满足此条件。
max()方法 返回一个条件,可以向其中添加约束,但具有最大/最小
创建查询时传递两个布尔值参数:
selectEntitiesOnly-
这个参数只有在未设置显式投射时才有效。
如果为true,则查询的结果将是满足指定限制修订版本时更改的实体列表。
若为 false,则结果将是三个元素数组的列表。第一个元素是更改后的实体实例。第二个是包含修订数据的实体。如果不使用自定义实体,这将是DefaultRevisionEntity实例。第三个元素数组将是修订的类型(ADD、MOD、DEL)。 selectDeletedEntities-
此参数指定是否必须将删除实体的修订包含在结果中。如果为 true,实体将具有修订类型
DEL,除 id 外的所有字段都将值为null。
查询修改后属性的实体的修订
以下查询将返回 MyEntity 及给定 ID 的所有修订,其中的 actualDate 属性已更改。
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
hasChanged 条件可以和附加标准组合。以下查询将在生成 revisionNumber 时为 MyEntity 返回一个横向片段。它仅限于修改 prop1 但不修改 prop 2 的修订版本。
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
结果集还包含数字低于 revisionNumber 的修订版本。这意味着,这个查询无法读取为"通过 prop1 修改和 prop 2 不更改的 revisionNumber 中所有 MyEntities 更改"。
以下查询显示如何使用 forEntitiesModifiedAtRevision 查询返回这个结果:
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());在给定修订版本中修改查询实体
以下示例显示了给定修订中修改的实体的基本查询。它允许检索指定修订中更改的实体名称和对应 Java 类:
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);还可以从 org.hibernate.envers.CrossTypeRevisionChangesReader 访问许多其他查询:
list<Object> findEntities(Number)-
返回给定修订中更改(添加、更新和删除)的所有审计实体的快照。执行
n+1SQL 查询,其中n是指定修订版本中修改的多个不同实体类。 List<Object> findEntities(Number, RevisionType)-
返回给定修订版本中更改(添加、更新或删除)的所有审计实体的快照,并按照修改类型过滤。执行
n+1SQL 查询,其中n是指定修订版本中修改的多个不同实体类。Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)-
返回包含由修改操作分组的实体快照列表的映射,如添加、更新或删除。执行
3n+1SQL 查询,其中n是指定修订版本中修改的多个不同实体类。
6.5.2. 使用参考实体属性的遍历实体协会
您可以使用引用实体的属性来遍历查询中的实体。这可让您查询一对一和多对一关联。
以下示例演示了您可以在查询中遍历实体的一些方式。
在修订号 1 中,查找所有者年龄为 20 岁或住在地址号 30 的车子,然后按照汽车制作排列结果。
List<Car> resultList = auditReader.createQuery() .forEntitiesAtRevision( Car.class, 1 ) .traverseRelation( "owner", JoinType.INNER, "p" ) .traverseRelation( "address", JoinType.INNER, "a" ) .up().up().add( AuditEntity.disjunction().add(AuditEntity.property( "p", "age" ) .eq( 20 ) ).add( AuditEntity.property( "a", "number" ).eq( 30 ) ) ) .addOrder( AuditEntity.property( "make" ).asc() ).getResultList();在修订号 1 中,查找所有者期限等于所有者地址号的车辆。
Car result = (Car) auditReader.createQuery() .forEntitiesAtRevision( Car.class, 1 ) .traverseRelation( "owner", JoinType.INNER, "p" ) .traverseRelation( "address", JoinType.INNER, "a" ) .up().up().add(AuditEntity.property( "p", "age" ) .eqProperty( "a", "number" ) ).getSingleResult();在修订号 1 中,查找所有者为 20 岁或没有所有者的所有车辆。
List<Car> resultList = auditReader.createQuery() .forEntitiesAtRevision( Car.class, 1 ) .traverseRelation( "owner", JoinType.LEFT, "p" ) .up().add( AuditEntity.or( AuditEntity.property( "p", "age").eq( 20 ), AuditEntity.relatedId( "owner" ).eq( null ) ) ) .addOrder( AuditEntity.property( "make" ).asc() ).getResultList();在修订号 1 中,找到 make 等于"car3"且所有者年龄为 30 或没有所有者的所有车辆。
List<Car> resultList = auditReader.createQuery() .forEntitiesAtRevision( Car.class, 1 ) .traverseRelation( "owner", JoinType.LEFT, "p" ) .up().add( AuditEntity.and( AuditEntity.property( "make" ).eq( "car3" ), AuditEntity.property( "p", "age" ).eq( 30 ) ) ) .getResultList();在修订号 1 中,查找 make 等于"car3"或所有者为 10 或没有所有者的所有车。
List<Car> resultList = auditReader.createQuery() .forEntitiesAtRevision( Car.class, 1 ) .traverseRelation( "owner", JoinType.LEFT, "p" ) .up().add( AuditEntity.or( AuditEntity.property( "make" ).eq( "car3" ), AuditEntity.property( "p", "age" ).eq( 10 ) ) ) .getResultList();
6.6. 性能调优
6.6.1. 备用批处理算法
Hibernate 允许您使用以下四种获取策略之一为关联加载数据: join、Select、subselect 和 batch。在这四种策略中,批处理加载允许最大的性能提升,因为它是选择获取的优化策略。在此策略中,Hibernate 通过指定主或外键列表,在单个 SELECT 语句中检索一组实体实例或集合。批处理获取是对 lazy 选择获取策略的优化。
有两种方法可以配置批处理获取:每个类级别或每收集级别。
按类级别
当 Hibernate 在每个类级别上加载数据时,它需要批量大小的关联,以便在查询时预加载。例如,请考虑在运行时您有 30 个加载到会话中的
car对象实例。每个car对象属于一个所有者对象。如果您要迭代所有汽车对象并请求其所有者,通过加载lazy,Hibernate 将发出 30 个选择声明 - 每个所有者一个。这是性能瓶颈。您可以在通过查询请求之前,告诉 Hibernate 预加载下一批所有者的数据。查询了
所有者对象后,Hibernate 将在同一个 SELECT 语句中查询更多这些对象。提前要查询
的所有者对象数量取决于配置时指定的batch-size参数:<class name="owner" batch-size="10"></class>
这会让 Hibernate 查询至少 10 个
所有者对象,预计在不久的将来会需要它们。当用户查询A 车的所有者时,汽车 B的所有者可能已经作为批处理加载的一部分加载。当用户实际需要car B的所有者,而不是前往数据库(并发出 SELECT 语句)时,可以从当前会话检索该值。除了
batch-size参数外,Hibernate 4.2.0 还引进了新的配置项,以提高批处理加载性能。配置项称为Batch Fetch Style配置,由hibernate.batch_fetch_style参数指定。支持三种不同的批处理获取方式:inrigacY、PADDED 和 DYNAMIC。要指定要使用的样式,请使用
org.hibernate.cfg.AvailableSettings#BATCH_FETCH_STYLE。强制要求:在旧式加载中,使用一组基于
ArrayHelper.getBatchSizes(int)预先构建的批处理大小。使用现有可批处理标识符数的下一个小型预构建批处理大小来加载批处理。继续前面的示例,
批处理大小设置为 30,预先构建的批处理大小为 [30、15、10、9、8、7、. 1]。尝试批量加载 29 个标识符将导致批处理 15、10 和 4。将会有 3 个对应的 SQL 查询,每个查询都从数据库中加载 15、10 和 4 所有者。PADDED - 添加类似于udACY 批处理加载样式。它仍然使用预先构建的批处理大小,但使用下一个bigger 批处理大小,并固定额外的标识符占位符。
与上例所示,如果初始化 30 个所有者对象,则仅对数据库执行一项查询。
但是,如果要初始化 29 个所有者对象,Hibernate 仍将仅执行一个批处理大小为 30 的 SQL 选择声明,使用带有重复标识符添加的额外空间 padded。
动态 - 虽然符合批处理大小限制,但这种批处理加载的方式使用要加载的实际对象数量动态构建其 SQL SELECT 语句。
例如,对于 30 所有者对象,最大批处理大小为 30,检索 30 所有者对象的调用将产生一个 SQL SELECT 语句。调用来检索 35 将产生两个分别批处理大小为 30 和 5 的 SQL 语句。Hibernate 将动态更改第二个 SQL 语句,使其保持为 5(所需数量),同时仍保持为批处理大小限制为 30。这与 PADDED 版本不同,因为第二个 SQL 不会获得 PADDED,与 criACY 样式不同,第二个 SQL 语句没有固定大小 - 第二个 SQL 是动态创建的。
对于少于 30 个标识符的查询,这种样式只会动态加载请求的标识符数。
按收集级别
Hibernate 还可以按照上述每个类部分中列出的批处理获取大小和样式进行批处理加载集合。
要反转上一节中使用的示例,请考虑您需要加载每个
所有者对象拥有的所有车对象。如果在当前会话迭代过程中加载 10 个所有者对象,则迭代所有所有者将生成 10 个 SELECT 语句,每个调用getCars()方法一个。如果在 Owner 映射中为行车集合启用批量获取,Hibernate 可以预先获取这些集合,如下所示:<class name="Owner"><set name="cars" batch-size="5"></set></class>
因此,由于批量大小为 5 个,并且使用传统的批处理样式来加载 10 个集合,Hibernate 将执行两个 SELECT 语句,各自检索五个集合。
6.6.2. 不可更改数据的第二级对象缓存
Hibernate 自动在内存中缓存数据以提高性能。这通过内存中缓存实现,该缓存可减少数据库查找的次数,特别是很少更改的数据。
Hibernate 维护两种类型的缓存:主缓存(也称为一级缓存)是必需的。此缓存与当前会话关联,并且所有请求都必须通过它。辅助缓存也称为第二级缓存,是可选的,仅在查询了主缓存后才会使用。
通过先将数据存储到一个状态数组中,数据存储在二级缓存中。这个数组会被深度复制,并将深度副本放入缓存中。相反,可以从缓存读取。这非常适合改变(可传递数据)的数据,但对不可变数据效率较低。
从内存使用情况和处理速度来看,深度复制数据是一项代价昂贵的操作。对于大型数据集,内存和处理速度成为了性能限制因素。Hibernate 允许您指定引用而非复制的不可变数据。Hibernate 现在可以将对数据的引用存储在缓存中,而不是复制整个数据集。
这可以通过将配置设置 hibernate.cache.use_reference_entries 的值更改为 true 来完成。默认情况下,hibernate.cache.use_reference_entries 设置为 false。
当 hibernate.cache.use_reference_entries 设置为 true 时,没有任何关联的不可变数据对象不会复制到二级缓存中,并且仅存储对其的引用。
当 hibernate.cache.use_reference_entries 设为 true 时,具有关联的不可变数据对象仍会深入复制到二级缓存中。
第 7 章 Hibernate Search
7.1. Hibernate Search 入门
7.1.1. 关于 Hibernate Search
Hibernate 搜索为 Hibernate 应用程序提供全文本搜索功能。尤其适合搜索基于 SQL 的解决方案不适合的应用程序,包括全文本、模糊搜索和地理位置搜索。Hibernate Search 使用 Apache Lucene 作为其全文本搜索引擎,但旨在最大限度地降低维护开销。配置后,索引、群集和数据同步将保持透明,让您专注于满足您的业务需求。
之前的 JBoss EAP 版本包括 Hibernate 4.2 和 Hibernate Search 4.6。JBoss EAP 7 包括 Hibernate 5 和 Hibernate Search 5.5。
Hibernate Search 5.5 与 Java 7 协同工作,现在基于 Lucene 5.3.x 构建。如果您使用任何原生 Lucene API,请确保与这个版本一致。
7.1.2. Hibernate 搜索概述
Hibernate 搜索由索引组件和索引搜索组件组成,它们都由 Apache Lucene 支持。每次从数据库插入、更新或删除实体时,Hibernate Search 都会通过 Hibernate 事件系统跟踪此事件并计划索引更新。所有这些更新都会被处理,而无需直接与 Apache Lucene API 交互。相反,与底层 Lucene 索引的交互是通过索引 管理器 来处理的。默认情况下,IndexManager 和 Lucene 索引之间有一个一对一的关系。IndexManager 会提取特定的索引配置,包括所选后端、readread 策略和 DirectoryProvider。
索引创建后,您可以搜索实体并返回受管实体列表,而不是处理底层 Lucene 基础架构。Hibernate 和 Hibernate 搜索之间共享相同的持久性上下文。FullTextSession 类构建在 Hibernate 会话 类之上,以便应用程序代码可以使用统一 org.hibernate.Query 或 javax.persistence.Query API,其方式与 HQL、Java Persistence 查询语言(JPQL)或原生查询相同。
建议在所有操作中使用事务性批处理模式,无论它们是基于 Java 命名和目录接口。
建议针对您的数据库和 Hibernate 搜索在事务中执行您的操作,无论是 Java 命名和目录界面还是 Jakarta Transactions。
Hibernate 搜索在 Hibernate 或实体管理器长对话模式中运行完美,称为原子对话。
7.1.3. 关于目录提供程序
Apache Lucene 是 Hibernate Search 基础架构的一部分,拥有用于存储索引的目录的概念。Hibernate Search 通过目录提供程序处理 Lucene Directory 实例的初始化和配置。
directory_provider 属性指定用于存储索引的目录提供程序。默认文件系统目录提供商是 filesystem,它使用本地文件系统来存储索引。
7.1.4. 关于工作程序
Lucene 索引的更新由 Hibernate Search Worker 处理,它接收所有实体更改,按照上下文对其进行队列,并在上下文结束时应用它们。最常见的上下文是事务,但可能取决于实体更改的数量或其他一些应用事件。
为提高效率,交互分批,一般在上下文结束时应用。在事务之外,索引更新操作会在实际数据库操作后执行。如果是持续事务,则为事务提交阶段调度索引更新操作,并在交易回滚时丢弃。工作程序可以配置特定的批处理大小限制,之后无论上下文如何进行索引。
这种处理索引更新的方法有两大好处:
- 性能:Lucene 索引在批量执行时效果更好。
- acidity:执行的工作范围与数据库事务所执行的范围相同,并且仅在提交事务时执行。这在严格意义上不是 ACID,但 ACID 行为对于完整文本搜索索引很少有用,因为它们可以随时从源重建。
两种批处理模式(无范围与事务)等同于 autocommit 与事务性行为。从性能角度看,建议使用事务模式。范围选择是透明的。Hibernate Search 可检测是否存在交易并调整范围范围。
7.1.5. 后端设置和操作
7.1.5.1. 后端
Hibernate Search 使用各种后端来处理批量工作。后端不限于配置选项 default.worker.backend。此属性指定 BackendQueueProcessor 接口的实施,该接口是后端配置的一部分。设置后端需要额外的设置,如 Jakarta Messaging 后端。
7.1.5.2. lucene
在 Lucene 模式中,节点的所有索引更新都由同一节点使用目录提供程序对 Lucene 目录执行。在非集群环境中或带有共享目录存储的集群环境中使用此模式。
图 7.1. Lucene 后端配置
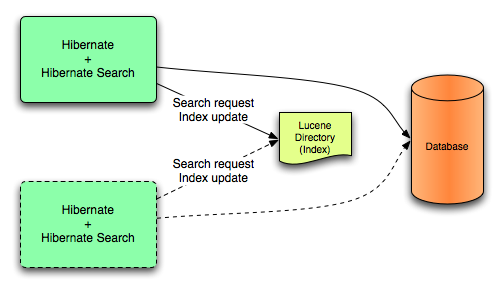
Lucene 模式针对目录管理锁定策略的非集群或集群应用程序。Lucene 模式的主要优点是简单性和 Lucene 查询中更改的即时可见性。Near Real Time(NRT)后端是非集群和非共享索引配置的替代后端。
7.1.5.3. Jakarta Messaging
节点的索引更新发送到 Jakarta 消息传递队列。唯一的读取器处理队列并更新主索引。随后,主索引定期复制到从副本,从而建立主和从模式。主控机负责 Lucene 索引更新。slave 接受读写操作,但处理本地索引副本中的读取操作。主设备全权负责更新 Lucene 索引。仅 master 应用更新操作中的本地更改。
图 7.2. Jakarta 消息传递服务后端配置
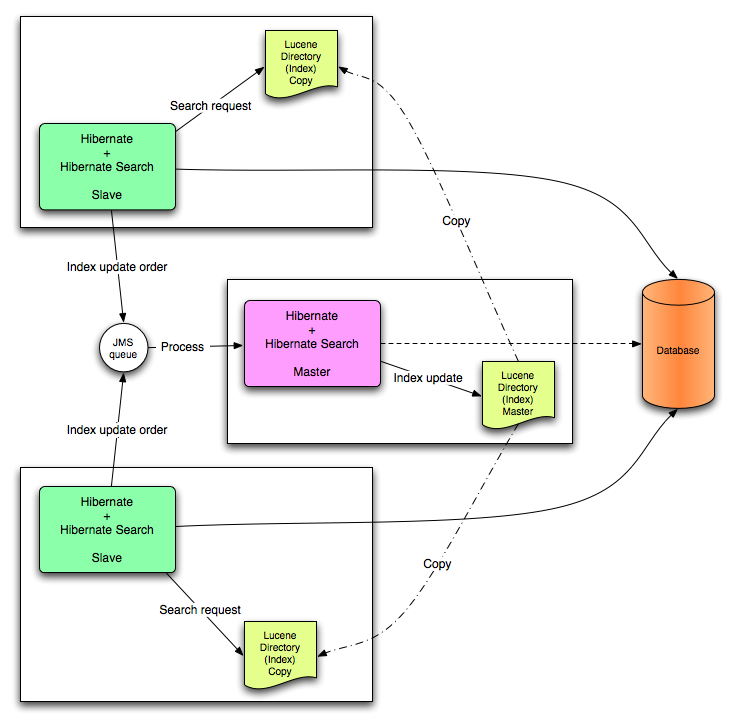
此模式面向集群环境,其中吞吐量至关重要,并且可以节省索引更新延迟。Jakarta 消息传递供应商确保可靠性,并使用从设备更改本地索引副本。
7.1.6. 读取器策略
在执行查询时,Hibernate Search 使用 reader 策略与 Apache Lucene 索引交互。根据应用的配置集选择一个 reader 策略,如频繁更新、阅读主要异步索引更新。
7.1.6.3. 自定义 Reader 策略
您可以使用 org.hibernate.search.reader.ReaderProvider 编写自定义 reader 策略。实施必须安全进行。
7.2. Configuration
7.2.1. 最低配置
Hibernate Search 旨在为其配置和操作提供灵活性,并且仔细选择默认值以适合大多数用例。至少必须配置目录提供程序及其属性。默认目录提供程序是 filesystem,它使用本地文件系统进行索引存储。有关可用目录提供程序及其配置的详细信息,请参阅 DirectoryProvider 配置。
如果您直接使用 Hibernate,必须在配置文件中设置 DirectoryProvider 等设置,可以是 hibernate.properties 或 hibernate.cfg.xml。如果您通过 Jakarta Persistence 使用 Hibernate,则配置文件为 persistence.xml。
其它资源
- 有关可用目录提供程序及其配置的详细信息,请参阅 DirectoryProvider 配置。
7.2.2. 配置 IndexManager
Hibernate Search 为这个接口提供几个实现:
-
基于目录:默认实施,它使用 LuceneDirectory抽象来管理索引文件。 -
近实时:避免在每次提交时清空到磁盘的写入。此索引管理器也基于目录,但使用 Lucene 的近乎实时 NRT 功能。
要指定默认以外的 IndexManager,请指定以下属性:
hibernate.search.[default|<indexname>].indexmanager = near-real-time
7.2.2.1. 基于目录
基于目录 的实施是默认的 IndexManager 实施。它高度可配置,允许为 reader 策略、后端和目录提供程序进行单独的配置。
7.2.2.2. 接近实时
NRTIndexManager 是默认 索引管理器 的扩展,它利用 Lucene NRT、Near Real Time(低延迟索引写入)功能。但是,它会忽略 lucene 以外的备用后端的配置设置,并在 目录 上获取专用写入锁定。
IndexWriter 不会刷新磁盘的每个更改来提供低延迟。查询可以从未清空的索引写入缓冲区读取更新的状态。但是,这意味着如果 IndexWriter 被终止或应用程序崩溃,可能会丢失更新,因此必须重建索引。
由于上述缺点,建议对数据有限的非集群网站采用 Near Real Time 配置,因为可以单独配置主节点以提高性能。
7.2.2.3. Custom
为自定义实现指定完全限定类名称,以设置自定义 IndexManager。为实施设置 no-gument 构造器,如下所示:
[default|<indexname>].indexmanager = my.corp.myapp.CustomIndexManager
自定义索引管理器实现不需要与默认实施相同的组件。例如,委派到不公开 目录 接口的远程索引服务。
7.2.3. DirectoryProvider 配置
DirectoryProvider 是围绕 Lucene Directory 的 Hibernate 搜索抽象,处理底层 Lucene 资源的配置和初始化。目录提供程序及其属性显示了 Hibernate Search 中提供的目录提供程序的列表,以及对应的选项。
每个索引化实体都与 Lucene 索引关联(多个实体共享同一索引的情况除外)。索引的名称由 @Indexed 注释的 index 属性提供。如果未指定 索引 属性,则索引的类的完全限定名称将用作名称(推荐)。
DirectoryProvider 及任何其他选项都可使用前缀 hibernate.search.<indexname> 进行配置。名称 default (hibernate.search.default)保留,可用于定义适用于所有索引的属性。配置目录提供程序 显示如何使用 hibernate.search.default.directory_provider 将默认目录提供程序设置为文件系统。Hibernate.search.default.indexBase 设置索引的默认基础目录。因此,在 /usr/lucene/indexes/org.hibernate.example.Status 中创建实体 状态 索引。
但是,规则 实体的索引正在使用内存中目录,因为此实体的默认目录提供商将被属性 hibernate.search.Rules.directory_provider 覆盖。
最后,Action 实体使用由 hibernate.search.Actions.directory_provider 指定的自定义目录供应商 CustomDirectoryProvider。
指定索引名称
package org.hibernate.example;
@Indexed
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }
@Indexed(index="Actions")
public class Action { ... }
配置目录提供程序
hibernate.search.default.directory_provider = filesystem hibernate.search.default.indexBase=/usr/lucene/indexes hibernate.search.Rules.directory_provider = ram hibernate.search.Actions.directory_provider = com.acme.hibernate.CustomDirectoryProvider
使用上述配置方案,您可以轻松定义常见的规则,如目录提供程序和基础目录,并在以后按索引覆盖这些默认值。
目录提供程序及其属性
- ram
- 无
- Filesystem
基于文件系统的目录.使用的目录为 <indexBase>/< indexName >
- indexBase : base directory
- indexName :覆盖 @Indexed.index(对于分片索引非常有用)
- locking_strategy : 可选,请参阅 LockFactory 配置
-
filesystem_access_type :允许 确定此
DirectoryProvider使用的FSDirectory实施的确切类型。允许的值为auto(默认值,在非 Windows系统上选择 NIOFSDirectory,Windows 上的SimpleFSDirectory)、SimpleFSDirectory、nio(NIOFSDirectory)、mmap(MMapDirectory)。更改此设置之前,请参阅这些目录实施的 Java 文档。尽管NIOFSDirectory或MMapDirectory能够带来显著的性能提升,他们也有自己的问题。
filesystem-master基于文件系统的目录.比如
文件系统.它还定期将索引复制到源目录(aka copy 目录)。刷新周期的建议值是(至少) 50%,复制信息的时间要高于 3600 秒 - 60 分钟。
请注意,副本基于增量复制机制,减少了平均复制时间。
DirectoryProvider 通常用于 Jakarta Messaging 后端集群中的主节点。
buffer_size_on_copyBest 取决于您的操作系统和可用的 RAM;大多数用户使用 16 到 64MB 之间的值报告良好的结果。- indexBase: base directory
- indexName :覆盖 @Indexed.index(对于分片索引非常有用)
- sourceBase :源(复制)基础目录。
-
source :源目录后缀(默认为
@Indexed.index)。实际的源目录名称为<sourceBase>/<source> - 刷新 :刷新周期(每次刷新秒将发生一次复制 )。如果在以下刷新期满时副本仍在进行中,则将跳过第二个复制操作。
- buffer_size_on_copy :在单个低级复制指令中移动的 MegaBytes 数量;默认为 16MB。
- locking_strategy : 可选,请参阅 LockFactory 配置
-
filesystem_access_type :允许 确定此
DirectoryProvider使用的FSDirectory实施的确切类型。允许的值为auto(默认值,在非 Windows系统上选择 NIOFSDirectory,Windows 上的SimpleFSDirectory)、SimpleFSDirectory、nio(NIOFSDirectory)、mmap(MMapDirectory)。更改此设置之前,请参阅这些目录实施的 Java 文档。尽管NIOFSDirectory或MMapDirectory可以大幅提升性能,但您也需要意识到这些问题。
filesystem-slave基于文件系统的目录.与
文件系统类似,但会定期检索主版本(来源)。为避免锁定和不一致的搜索结果,保留 2 个本地副本。刷新周期的建议值是(至少) 50%,复制信息的时间要高于 3600 秒 - 60 分钟。
请注意,副本基于增量复制机制,减少了平均复制时间。如果刷新周期为限时副本仍在进行中,则将跳过第二个复制操作。
DirectoryProvider 通常用于使用 Jakarta 消息传递后端的从节点。
buffer_size_on_copyBest 取决于您的操作系统和可用的 RAM;大多数用户使用 16 到 64MB 之间的值报告良好的结果。- indexBase: Base directory
- indexName :覆盖 @Indexed.index(对于分片索引非常有用)
- SourceBase:源代码 (复制)基础目录。
-
Source: 源代码 目录后缀(默认为
@Indexed.index)。实际的源目录名称为<sourceBase>/<source> - refresh :刷新周期(复制将每刷新秒发生一次)。
- buffer_size_on_copy :在单个低级复制指令中移动的 MegaBytes 数量;默认为 16MB。
- locking_strategy : 可选,请参阅 LockFactory 配置
- retry_marker_lookup :可选,默认为 0。定义在失败前 Hibernate Search 检查源目录中标记文件的次数。在每次尝试之间等待 5 秒。
-
retry_initialize_period : 可选,以秒为单位设置整数值以启用重试初始化功能:如果从系统找不到主索引,它将再次尝试直到在后台找到它,而不阻止应用启动:在索引初始化前执行的完整Text 查询不会被阻断,而是返回空结果。如果不启用 选项或将其明确设置为零,它将失败,但有一个例外,而不是调度重试计时器。要防止应用程序在没有无效索引的情况下启动,但仍控制初始化超时,请参阅
retry_marker_lookup。 -
filesystem_access_type :允许 确定此
DirectoryProvider使用的FSDirectory实施的确切类型。允许的值为 auto(默认值,在非 Windows系统上选择 NIOFSDirectory,Windows 上的SimpleFSDirectory)、SimpleFSDirectory、nio(NIOFSDirectory)、mmap(MMapDirectory)。更改此设置之前,请参阅这些目录实施的 Java 文档。尽管NIOFSDirectory或MMapDirectory可以大幅提升性能,您也需要意识到这些问题。
如果内置目录提供商不适合您的需要,您可以通过实施 org.hibernate.store.DirectoryProvider 接口来编写自己的目录提供商。在这种情况下,将您的提供程序的完全限定类名称传递到 directory_provider 属性。您可以使用前缀 hibernate.search.<indexname> 传递任何其他属性。
7.2.4. Worker 配置
Hibernate Search 可通过 worker 配置与 Lucene 进行交互。有几个架构组件和可能的扩展点。让我们来详细了解一下.
使用 worker 配置优化 Infinispan Query 与 Lucene 交互的方式。此配置中有多种架构组件和可能的扩展点。
首先有一名 工作者。Worker 界面的实施负责接收所有实体更改,按照上下文排队,并在上下文结束时应用它们。最为直观的上下文(特别是在与 ORM 的连接时)就是事务。因此,Hibernate Search 默认使用 TransactionalWorker 来限制每次事务的所有更改。但是,可以想象一下上下文取决于实体数量或其它应用程序生命周期事件的情况。
表 7.1. 范围配置
| 属性 | 描述 |
|---|---|
|
|
要使用的 |
|
|
前缀为 |
|
|
定义每个上下文所批处理索引操作的最大数量。旦达到限制,即使上下文尚未结束,也会触发索引。只有 |
上下文结束后,应准备和应用索引更改。这可以在新线程内同步或异步完成。同步更新具有索引始终与数据库同步的优势。另一方面,异步更新可以帮助最小化用户响应时间。缺点是数据库和索引状态之间可能存在差异。
以下选项在每个索引上可能会有所不同;实际上,它们需要 indexName 前缀或使用 default 来为所有索引设置默认值。
表 7.2. 执行配置
| 属性 | 描述 |
|---|---|
|
|
|
|
| 后端可以使用线程池并行应用来自同一事务上下文(或批处理)的更新。默认值为 1。如果您每次事务都有多个操作,则可以使用更大的值进行试验。 |
|
| 定义线程池不足时的最大工作队列数。仅适用于异步执行.默认为无限.如果达到限制,则工作由主线程完成。 |
目前,所有工作都在同一个虚拟机(VM)中完成,无论哪种执行模式。单个虚拟机的工作总量还没有改变。幸运的是,有一个更好的方法,即委派。通过配置 hibernate.search.default.worker.backend,可以将索引工作发送到其他服务器。同样,这个选项可以针对每个索引配置不同。
表 7.3. 后端配置
| 属性 | 描述 |
|---|---|
|
|
您还可以指定实施 |
- Java 消息传递服务后端配置
| 属性 | 描述 |
|
| 定义 Java 命名和目录接口属性,以启动 InitialContext(如有必要)。Java 命名和目录接口仅供 Java 消息传递服务后端使用。 |
|
|
Java 消息传递服务后端必填.定义 Java 命名和目录接口名称,从中查找 Java 消息传递服务连接工厂(红帽 JBoss 企业应用平台中默认为 |
|
| Java 消息传递服务后端必填.定义 Java 命名和目录接口名称,从中查找 Java 消息传递服务队列。该队列将用于发布工作消息。 |
正如您可能注意到的,一些显示的属性是相关联的,这意味着并非所有属性值组合都有意义。实际上,您可以生成非功能配置。这在您自己提供部分显示接口的实现的情况下尤为正确。在编写自己的工作 程序或 后端队列程序实施 前,请务必研究现有的代码。
7.2.4.1. Jakarta Messaging Master/Slave Backd
这部分论述了如何配置主/从 Hibernate Search 架构。
图 7.3. Jakarta 消息传递后端配置
7.2.4.2. 从属节点
每个索引更新操作都会发送到 Jakarta 消息传递队列。索引查询操作在本地索引副本中执行。
Jakarta Messaging Slave 配置
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-slave ## Back-end configuration hibernate.search.default.worker.backend = jms hibernate.search.default.worker.jms.connection_factory = /ConnectionFactory hibernate.search.default.worker.jms.queue = queue/hibernatesearch #optional jndi configuration (check your Jakarta Messaging provider for more information) ## Optional asynchronous execution strategy # hibernate.search.default.worker.execution = async # hibernate.search.default.worker.thread_pool.size = 2 # hibernate.search.default.worker.buffer_queue.max = 50
建议使用文件系统本地副本来加快搜索结果。
7.2.4.3. Master 节点
每个索引更新操作都从 Jakarta 消息传递队列执行并执行。主索引定期复制。
执行 Jakarta Messaging 队列中的索引更新操作,并定期复制主索引。
Jakarta 消息传递服务主配置
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-master ## Back-end configuration #Back-end is the default for Lucene
除了 Hibernate Search 框架配置外,还必须编写和设置消息驱动型 Bean,以便通过 Jakarta Messaging 处理索引工作队列。
消息驱动的 Bean 处理索引队列
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType",
propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination",
propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController
implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}
本例继承了 Hibernate Search 源代码中提供的抽象 Jakarta 消息传递控制器类,并实施 Jakarta EE MDB。此实施以示例形式提供,并可通过利用非 Jakarta EE 消息驱动型 Bean 而进行调整。
7.2.5. 调优 Lucene 索引
7.2.5.1. 调优 Lucene 索引性能
Hibernate Search 用于通过指定传递给底层 Lucene IndexWriter (如 mergeFactor、 maxMergeDocs 和 的一组参数来调整 Lucene 索引性能。指定这些参数作为为所有索引应用、基于索引甚至每个分片的默认值。
maxBufferedDocs )
有几个低级别 IndexWriter 设置可以针对不同的用例进行调整。这些参数按照 indexwriter 关键字分组:
hibernate.search.[default|<indexname>].indexwriter.<parameter_name>
如果没有在特定分片配置中为 索引写入器值 设置值,Hibernate Search 会检查 index 部分,然后在 default 部分。
下表中的配置将导致这些设置应用于 Animal 索引的第二个分片 :
-
max_merge_docs= 10 -
merge_factor= 20 -
ram_buffer_size= 64MB -
term_index_interval= Lucene default
所有其他值将使用 Lucene 中定义的默认值。
所有值的默认值都是保留为 Lucene 自己的默认值。索引性能和行为属性中列出的值取决于您使用的 Lucene 版本。显示的值相对于版本 2.4。
以前版本的 Hibernate Search 具有 批处理 和 事务 属性的概念。情况已不再如此,因为后端始终使用相同的设置执行工作。
表 7.4. 索引性能和行为属性
| 属性 | 描述 | 默认值 |
|---|---|---|
|
|
当其他进程不需要写入同一索引时,设置为 |
|
|
|
每个索引都有一个单独的"pipeline",其中包含要应用到索引的更新。当此队列满时,向队列添加更多操作将变为阻止操作。除非 |
|
|
| 确定应用和清空缓冲区内删除术语前所需的最小删除术语数量。如果当时内存中有被缓冲的文档,则它们会被合并并创建新的网段。 | 禁用(按 RAM 使用情况清空) |
|
| 控制索引期间内存中缓冲的文档数量。消耗的 RAM 量越大。 | 禁用(按 RAM 使用情况清空) |
|
| 定义片段中允许的最大文件数。较小的值在经常更改索引时表现更好,如果索引不经常改变,更大的值可以提供更好的搜索性能。 | 无限(Integer.MAX_VALUE) |
|
| 控制片段合并频率和大小。 确定插入时段索引的合并频率。使用较小的值时,索引和搜索未优化索引时会使用较少的 RAM,但索引速度较慢。当值较大时,索引期间会使用更多的 RAM,而搜索未优化索引时速度较慢,索引速度也更快。因此,较大的值(> 10)最适合创建批处理索引,更适合以互动方式维护的索引的更小的值(< 10)。该值不能低于 2。 | 10 |
|
|
控制片段合并频率和大小。在下一个片段合并操作中始终考虑小于这个大小的片段(以 MB 为单位)。设置这个太大可能会导致合并操作昂贵,即使它们的频率较低。See also | 0 MB(实际为 ~1K) |
|
| 控制片段合并频率和大小。 大于这个大小的片段(以 MB 为单位)永远不会合并到更大的网段。 这有助于降低内存要求并避免以最佳搜索速度为代价进行一些合并操作。在优化索引时,这个值将被忽略。
See also | 无限 |
|
| 控制片段合并频率和大小。
即使优化索引,大于这个大小的片段(以 MB 为单位)也不会合并(请参阅
Applied to | 无限 |
|
| 控制片段合并频率和大小。
设置为
应用到 |
|
|
| 控制专用于文档缓冲区的 RAM 量(以 MB 为单位)。在一起使用 max_buffered_docs 时,会首先进行刷新(以此类事件为准)。 通常,为了提高索引性能,最好使用 RAM 刷新,而不是按文档计数进行清除,并使用尽可能大的 RAM 缓冲区。 | 16 MB |
|
| 设置索引术语之间的间隔。 较大的值会导致 IndexReader 使用的内存减少,但随机访问速度较慢。Small 值会导致 IndexReader 使用更多内存,并加快对术语的随机访问。详情请查看 Lucene 文档。 | 128 |
|
|
使用复合文件格式的优点是使用较少的文件描述符。缺点是索引需要更长的时间和临时磁盘空间。您可以在改进索引时间时将此参数设置为
布尔值参数,使用 | true |
|
| 并非所有实体更改都需要 Lucene 索引更新。如果没有索引所有更新的实体属性(脏属性),Hibernate Search 将跳过重新索引的过程。
如果您使用需要在每次更新事件中调用的自定义
此优化不应用于使用
布尔值参数,使用 | true |
黑色后端 不应在生产环境中使用,而是仅作为识别索引瓶颈的工具。
7.2.5.2. Lucene IndexWriter
有几个低级别 IndexWriter 设置可以针对不同的用例进行调整。这些参数按照 indexwriter 关键字分组:
default.<indexname>.indexwriter.<parameter_name>
如果没有在分片配置中为 indexwriter 设置值,Hibernate Search 会查看 index 部分,然后查看 default 部分。
7.2.5.3. 性能选项配置
以下配置将导致这些设置应用到 Animal 索引的第二个分片中 :
性能选项配置示例
default.Animals.2.indexwriter.max_merge_docs = 10 default.Animals.2.indexwriter.merge_factor = 20 default.Animals.2.indexwriter.term_index_interval = default default.indexwriter.max_merge_docs = 100 default.indexwriter.ram_buffer_size = 64
-
max_merge_docs= 10 -
merge_factor= 20 -
ram_buffer_size= 64MB -
term_index_interval= Lucene default
所有其他值将使用 Lucene 中定义的默认值。
Lucene 默认值是 Hibernate Search 的默认设置。因此,下表中列出的值取决于所使用的 Lucene 版本。显示的值相对于版本 2.4。有关 Lucene 索引性能的更多信息,请参阅 Lucene 文档。
后端始终使用相同的设置执行工作。
表 7.5. 索引性能和行为属性
| 属性 | 描述 | 默认值 |
|---|---|---|
|
|
当其他进程不需要写入同一索引时,设置为 |
|
|
|
每个索引都有一个单独的"pipeline",其中包含要应用到索引的更新。当此队列满时,向队列添加更多操作将变为阻止操作。除非 |
|
|
| 确定应用和清空缓冲区内删除术语前所需的最小删除术语数量。如果当时内存中有被缓冲的文档,则它们会被合并并创建新的网段。 | 禁用(按 RAM 使用情况清空) |
|
| 控制索引期间内存中缓冲的文档数量。消耗的 RAM 量越大。 | 禁用(按 RAM 使用情况清空) |
|
| 定义片段中允许的最大文件数。较小的值在经常更改索引时表现更好,如果索引不经常改变,更大的值可以提供更好的搜索性能。 | 无限(Integer.MAX_VALUE) |
|
| 控制片段合并频率和大小。 确定插入时段索引的合并频率。使用较小的值时,索引和搜索未优化索引时会使用较少的 RAM,但索引速度较慢。当值较大时,索引期间会使用更多的 RAM,而搜索未优化索引时速度较慢,索引速度也更快。因此,较大的值(> 10)最适合创建批处理索引,更适合以互动方式维护的索引的更小的值(< 10)。该值不能低于 2。 | 10 |
|
| 控制片段合并频率和大小。 在下一个片段合并操作中始终考虑小于这个大小的片段(以 MB 为单位)。 设置这个太大可能会导致合并操作昂贵,即使它们的频率较低。
See also | 0 MB(实际为 ~1K) |
|
| 控制片段合并频率和大小。 大于这个大小的片段(以 MB 为单位)永远不会合并到更大的网段。 这有助于降低内存要求并避免以最佳搜索速度为代价进行一些合并操作。在优化索引时,这个值将被忽略。
See also | 无限 |
|
| 控制片段合并频率和大小。
即使优化索引,大于这个大小的片段(以 MB 为单位)也不会合并(请参阅
Applied to | 无限 |
|
| 控制片段合并频率和大小。
设置为
应用到 |
|
|
| 控制专用于文档缓冲区的 RAM 量(以 MB 为单位)。在一起使用 max_buffered_docs 时,会首先进行刷新(以此类事件为准)。 通常,为了提高索引性能,最好使用 RAM 刷新,而不是按文档计数进行清除,并使用尽可能大的 RAM 缓冲区。 | 16 MB |
|
| 设置索引术语之间的间隔。 较大的值会导致 IndexReader 使用的内存减少,但术语随机访问速度较慢。小的值可让 IndexReader 使用更多内存,并加快术语随机访问的速度。详情请查看 Lucene 文档。 | 128 |
|
|
使用复合文件格式的优点是使用较少的文件描述符。缺点是索引需要更长的时间和临时磁盘空间。您可以在改进索引时间时将此参数设置为
布尔值参数,使用 | true |
|
| 并非所有实体更改都需要 Lucene 索引更新。如果没有索引所有更新的实体属性(脏属性),Hibernate Search 将跳过重新索引的过程。
如果您使用需要在每次更新事件中调用的自定义
此优化不应用于使用
布尔值参数,使用 | true |
7.2.5.4. 调整索引速度
架构允许时,保留 default.exclusive_index_use=true,以提高索引写入效率。
在调优索引速度时,推荐的方法首先侧重于优化对象加载,然后使用您实现的计时来调整索引过程。将 黑色设置为 worker 后端,并启动索引例程。此后端不禁用 Hibernate 搜索。它将生成必要的更改集到索引,但丢弃它们而不是将它们清空到索引。与将 hibernate.search.indexing_strategy 设置为 manual 不同,使用 黑色可能会从数据库中加载更多数据,因为相关实体也会 重新索引。
hibernate.search.[default|<indexname>].worker.backend blackhole
黑色后端 不会在生产环境中使用,而是作为识别索引瓶颈的诊断工具。
7.2.5.5. 控制分段大小
以下选项配置所创建的片段的最大大小:
-
merge_max_size -
merge_max_optimize_size -
merge_calibrate_by_deletes
控制分段大小
//to be fairly confident no files grow above 15MB, use: hibernate.search.default.indexwriter.ram_buffer_size = 10 hibernate.search.default.indexwriter.merge_max_optimize_size = 7 hibernate.search.default.indexwriter.merge_max_size = 7
将合并操作的 max_size 设置为硬限制段大小小于一半,因为合并片段将两个片段合并为一个更大的片段。
新网段最初可能比预期大小更大,但创建网段永远不会显著大于 ram_buffer_size。将此阈值检查为估计值。
7.2.6. LockFactory 配置
Lucene Directory 可通过 LockingFactory(通过 Hibernate Search 管理的每个索引的 LockingFactory )进行配置。
有些锁定策略需要文件系统级别锁定,并可用于基于 RAM 的索引。在使用此策略时,必须指定 IndexBase 配置选项以指向存储锁定标记文件的文件系统位置。
要选择一个锁定工厂,将 hibernate.search.<index>.locking_strategy 选项设置为以下选项:
- simple
- native
- 单
- none
表 7.6. 可用 LockFactory 实施列表
| 名称 | class | 描述 |
|---|---|---|
|
LockFactory 配置 | org.apache.lucene.store.SimpleFSLockFactory | 基于 Java 文件 API 的安全实施,它通过创建标志文件来标记索引的使用。 如果出于某种原因您必须终止应用程序,则需要先删除此文件,然后才能将其重新启动。 |
|
| org.apache.lucene.store.NativeFSLockFactory |
就像 这种实施在 NFS 上存在已知问题,避免在网络共享中产生问题。
|
|
| org.apache.lucene.store.SingleInstanceLockFactory | 此 LockFactory 不使用文件标记,而是内存中保留的 Java 对象锁定;因此,只有在您确定索引不会由任何其他进程共享时,才可以使用它。
这是 |
|
| org.apache.lucene.store.NoLockFactory | 对此索引的更改不会通过锁定协调。 |
以下是锁定策略配置示例:
hibernate.search.default.locking_strategy = simple hibernate.search.Animals.locking_strategy = native hibernate.search.Books.locking_strategy = org.custom.components.MyLockingFactory
7.2.7. 索引格式兼容性
Hibernate Search 目前不提供向后兼容 API 或工具来协助将应用程序移植到较新版本。API 使用 Apache Lucene 编写和搜索索引。有时可能需要更新索引格式。在这种情况下,如果 Lucene 无法读取旧格式,则可能需要重新索引数据。
在尝试更新索引格式前备份索引。
Hibernate Search 公开 hibernate.search.lucene_version 配置属性。此属性指示 Analyzers 和其他 Lucene 类遵守旧版 Lucene 中定义的行为。另请参见 lu 。如果未指定 选项,Hibernate Search 会指示 Lucene 使用版本默认值。建议在配置中明确定义使用的版本,以防止在升级发生时自动更改。升级后,可以根据需要明确更新配置值。
cene-core.jar 中包含的 org.apache.lucene.util. Version
强制 Analyzers 与创建 Lucene 3.0 创建的索引兼容
hibernate.search.lucene_version = LUCENE_30
配置的 SearchFactory 是全局的,会影响包含相关参数的所有 Lucene API。如果使用 Lucene 并且 Hibernate Search 被绕过,请对其应用相同的值,以获得一致的结果。
7.3. 应用程序的 Hibernate 搜索
7.3.1. Hibernate Search 的第一步
要开始使用应用程序的 Hibernate 搜索,请按照以下主题操作:
7.3.2. 使用 Maven 启用 Hibernate Search
在 Maven 项目中使用以下配置添加 hibernate-search-orm 依赖项:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-orm</artifactId>
<version>5.5.1.Final-redhat-1</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-orm</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>7.3.3. 添加注解
对于本节,请考虑您拥有包含图书详细信息的数据库的示例。您的应用包含 Hibernate 管理的类 example.Book 和 example.Author,您想要为您的应用添加免费文本搜索功能以启用搜索图书。
示例:在添加 Hibernate 搜索特定注释前实体书和授权
package example;
...
@Entity
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
private String subtitle;
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
private Date publicationDate;
public Book() {}
// standard getters/setters follow here
...
}
package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
public Author() {}
// standard getters/setters follow here
...
}
要达到此目的,您必须向 Book 和 Author 类添加一些注释。第一个注释 @Indexed 将 Book 标记为可索引。按照设计,Hibernate Search 在索引中存储一个未描述的 ID,以确保给定实体的索引不可变。@DocumentId 标记用于此目的的属性,并且在大多数情况下与数据库主密钥相同。如果存在 @Id 注释,则 注释是可选的。
@Document Id
接下来,您要使可搜索的字段必须标记为。在本例中,以标题 和副 标题 开头,并以@Field 标注。参数 index=Index.YES 将确保对文本进行索引,而 analyze=Analyze.YES 则确保将使用默认的 Lucene 分析器分析文本。通常,分析意味着将句子划分为单个单词,并可能排除诸如 "a"或. “”我们稍后将深入探讨分析器。我们在 @Field (storage=Store.NO )中指定的第三个参数确保实际数据不会存储在索引中。此数据存储在索引中是否与搜索它的能力无关。从 Lucene 的角度来看,在索引创建后不需要保留数据。存储它的好处是能够通过预测来检索。
如果不进行预测,Hibernate Search 默认为执行 Lucene 查询,以查找符合查询条件的实体的数据库标识符,并使用这些标识符从数据库中检索受管对象。对预测或预测的决定必须逐例做出。建议使用默认行为,因为它返回受管对象,而 仅返回对象数组。请注意,index=Index.YES,analyze=Analyze.YES 和 store=Store.NO 是这些参数的默认值,可以省略。
尚未讨论的另一个注释是 @DateBridge。此注释是 Hibernate Search 中的内置字段桥之一。Lucene 索引纯粹基于字符串。因此,Hibernate Search 必须将索引字段的数据类型转换为字符串,反之亦然。提供了一系列预定义的网桥,包括 DateBridge,它使用指定的解析将 java.util.Date 转换为字符串。如需了解更多详细信息,请参阅网桥。
这将为我们保留 @IndexedEmbedded。此注释用于为所属实体(@ManyToMany、@*ToOne、@Embedded 和 @ElementCollection)索引关联实体。这是必要的,因为 Lucene 索引文档是一个扁平数据结构,它不知道对象关系。为确保作者姓名可以搜索,您必须确保将姓名作为本书本身的一部分进行索引。在 @IndexedEmbedded 的顶部,您还必须标记您希望在 @Indexed 索引中包含的关联实体的所有字段。如需了解更多详细信息,请参阅嵌入式对象和关联对象。
这些设置现在应该已足够。有关实体映射的详情,请参阅映射实体。
示例:添加 Hibernate 搜索注解后的实体
package example;
...
@Entity
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
private String subtitle;
@Field(index = Index.YES, analyze=Analyze.NO, store = Store.YES)
@DateBridge(resolution = Resolution.DAY)
private Date publicationDate;
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
public Book() {
}
// standard getters/setters follow here
...
}
package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
public Author() {
}
// standard getters/setters follow here
...
}7.3.4. 索引
Hibernate Search 将通过 Hibernate 核心以透明的方式索引每个实体保留、更新或删除。但是,您必须为数据库中已存在的数据创建初始 Lucene 索引。添加上述属性和注释后,应当触发工作簿中的初始批处理索引。您可以使用以下代码片段之一来实现此目的(请参阅 ):
示例:使用 Hibernate 会话索引数据
FullTextSession fullTextSession = org.hibernate.search.Search.getFullTextSession(session); fullTextSession.createIndexer().startAndWait();
示例:使用 Jakarta Persistence 来索引数据
EntityManager em = entityManagerFactory.createEntityManager(); FullTextEntityManager fullTextEntityManager = org.hibernate.search.jpa.Search.getFullTextEntityManager(em); fullTextEntityManager.createIndexer().startAndWait();
执行上述代码后,您应能够在 /var/lucene/indexes/example.Book 下看到 Lucene 索引。使用 Luke 检查此索引以帮助您了解 Hibernate 搜索的工作原理。
7.3.5. 搜索
要执行搜索,请使用 Lucene API 或 Hibernate Search query DSL 创建 Lucene 查询查询。将查询嵌套在 org.hibernate.Query 中,以从 Hibernate API 获取所需的功能。以下代码根据索引字段准备查询。执行代码将返回 Books 列表。
示例:使用 Hibernate 搜索会话创建和执行搜索
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
// create native Lucene query using the query DSL
// alternatively you can write the Lucene query using the Lucene query parser
// or the Lucene programmatic API. The Hibernate Search DSL is recommended though
QueryBuilder qb = fullTextSession.getSearchFactory()
.buildQueryBuilder().forEntity( Book.class ).get();
org.apache.lucene.search.Query query = qb
.keyword()
.onFields("title", "subtitle", "authors.name", "publicationDate")
.matching("Java rocks!")
.createQuery();
// wrap Lucene query in a org.hibernate.Query
org.hibernate.Query hibQuery =
fullTextSession.createFullTextQuery(query, Book.class);
// execute search
List result = hibQuery.list();
tx.commit();
session.close();
示例:使用 Jakarta Persistence 创建和执行搜索
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
em.getTransaction().begin();
// create native Lucene query using the query DSL
// alternatively you can write the Lucene query using the Lucene query parser
// or the Lucene programmatic API. The Hibernate Search DSL is recommended though
QueryBuilder qb = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Book.class ).get();
org.apache.lucene.search.Query query = qb
.keyword()
.onFields("title", "subtitle", "authors.name", "publicationDate")
.matching("Java rocks!")
.createQuery();
// wrap Lucene query in a javax.persistence.Query
javax.persistence.Query persistenceQuery =
fullTextEntityManager.createFullTextQuery(query, Book.class);
// execute search
List result = persistenceQuery.getResultList();
em.getTransaction().commit();
em.close();
7.3.6. Analyzer
假设索引图书实体的标题 重构:改进现有代码的设计,并且 以下查询需要点击: 重构、重 构、 重构 和 重构。在 Lucene 中选择一个分析器类,该类在索引和搜索时应用单词强制。Hibernate Search 提供多种配置分析器的方法(请参阅默认分析器和按类分析器 ),了解更多信息:
-
在配置文件中设置
analyzer属性。指定类成为默认分析器。 -
在实体级别上设置
@Analyzer注释。 -
在字段级别上设置
@Analyzer注释。
指定要使用的完全限定类名称或分析器,或者查看由 @AnalyzerDef 注释定义的分析器,以及 @Analyzer 注释。使用 Solr 分析器框架及其工厂选择后一个选项。有关工厂类的更多信息,请参阅 Solr JavaDoc 或阅读 Solr Wiki 的对应章节。
在示例中,两个过滤器工厂使用 StandardTokenizerFactory:LowerCaseFilterFactory 和 SnowballPorterFilterFactory。令牌者在标点字符和连字符分割单词,但保持电子邮件地址和互联网主机名不变。标准令牌程序是这一操作和其他常规操作的理想选择。小写过滤器将令牌中的所有字母转换为小写,snowball 过滤器则应用特定于语言的逻辑。
如果使用 Solr 框架,请使用带任意数量的过滤器的令牌程序。
示例:使用 @AnalyzerDef 和 Solr Framework 来定义和使用分析器
@Indexed
@AnalyzerDef(
name = "customanalyzer",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = SnowballPorterFilterFactory.class,
params = { @Parameter(name = "language", value = "English") })
})
public class Book implements Serializable {
@Field
@Analyzer(definition = "customanalyzer")
private String title;
@Field
@Analyzer(definition = "customanalyzer")
private String subtitle;
@IndexedEmbedded
private Set authors = new HashSet();
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.YES)
@DateBridge(resolution = Resolution.DAY)
private Date publicationDate;
public Book() {
}
// standard getters/setters follow here
...
}
使用 @AnalyzerDef 定义分析器,然后使用 @Analyzer 将它应用到实体和属性。在该示例中,定义了 customanalyzer,但不应用于实体。分析器仅适用于 标题 属性。分析器定义是全局的。为实体定义分析器,并根据需要为实体重新利用定义。
和副标题
7.4. 将实体映射到索引结构
7.4.1. 映射实体
索引实体所需的所有元数据信息都通过注释进行描述,因此无需 XML 映射文件。您仍然可以将 Hibernate 映射文件用于基本 Hibernate 配置,但是必须通过注释来表示 Hibernate Search 特定配置。
7.4.1.1. 基本映射
让我们从最常用于映射实体的注释开始。
基于 Lucene 的查询 API 使用以下常见注解来映射实体:
- @Indexed
- @Field
- @NumericField
- @Id
7.4.1.2. @Indexed
最重要的是,我们必须将持久类声明为可索引。这可以通过使用 @Indexed 为类添加注解(索引流程将忽略未注释 @Indexed 的 所有实体):
@Entity
@Indexed
public class Essay {
...
}
您可以选择指定 @Indexed 注释的 index 属性,以更改索引的默认名称。
7.4.1.3. @Field
对于实体的每个属性(或属性),您可以描述如何对其进行索引。默认(不存在)表示索引过程中会忽略该属性。
在 Hibernate Search 5 之前,只有通过 @NumericField 明确请求时,才会选择数字字段编码。从 Hibernate Search 5 开始,系统将自动为数字类型选择此编码。为避免数字编码,您可以通过 @Field.bridge 或 明确指定非数字字段网桥。软件包 @Field Bridgeorg.hibernate.search.bridge.builtin 包含一组网桥,这些网桥编号编码为字符串,如 org.hibernate.search.bridge.builtin.IntegerBridge。
@field 确实将属性声明 为索引,并允许通过设置以下一个或多个属性来配置索引过程的多个方面:
-
Name :describe 在哪个名称下,该属性应存储在 Lucene 文档中。默认值为属性名称(遵循 JavaBeans 约定) -
存储:描述属性是否存储在 Lucene 索引中。您可以存储值Store.YES(在索引中消耗更多空间,但允许 投射,以压缩方式存储 Store.COMPRESS(这确实消耗更多 CPU),或者避免任何存储Store.NO(这是默认值)。存储属性时,您可以从 Lucene 文档检索其原始值。这与元素是否索引无关。 index:描述属性是否索引。不同的值是 index.NO,这表示它不会被索引,不能被查询和Index.YES找到,即元素会被索引并可以搜索。默认值为Index.YES。index. no在不需要可搜索属性但应该可用于投射的情形中,将非常有用。注意index.NO与 Analyze.YES或Norms.YES结合使用,因为分析和强制要求对该属性进行索引。分析:确定属性是否被分析(Analyze.YES)还是不分析(Analyze.NO)。默认值为 Analyze.YES。注意是否要分析属性取决于您是否希望按原样搜索元素,或按其包含的词语搜索。分析文本字段会有意义,但可能不是日期字段。
注意不得分析用于排序的字段。
-
强制:描述索引时间提升信息应存储(Norms.YES)还是不存储(Norms.NO)。不存储存储会节省大量内存,但没有任何索引时间提高可用信息。默认值为Norms.YES。 termVector:描述术语频率对的集合。这个属性允许在索引过程中将术语向量存储在文档中。默认值为TermVector.NO。此属性的不同值有:
值 定义 TermVector.YES
存储每个文档的术语向量。这会生成两个同步的数组,一个包含文档术语,另一个包含术语的频率。
TermVector.NO
不要存储术语向量。
TermVector.WITH_OFFSETS
存储术语向量和令牌偏移信息。这与 TermVector.YES 加上它包含术语的起始和结束偏移位置信息相同。
TermVector.WITH_POSITIONS
存储术语向量和令牌位置信息。这与 TermVector.YES 相同,还包含每一次在文档中出现某个术语的规范。
TermVector.WITH_POSITION_OFFSETS
存储术语向量、令牌位置和偏移信息。这是 YES、WITH_OFFSETS 和 WITH_POSITIONS 的组合。
indexNullAs: Per default null 值将被忽略且未索引。不过,您可以使用indexNullAs指定一个字符串,该字符串将被插入为null值的令牌。默认情况下,此值设置为Field。DO_NOT_INDEX_NULL表示不应索引null值。您可以将这个值设置为Field.DEFAULT_NULL_TOKEN,以指示应使用默认的空令牌。可以使用hibernate.search.default_null_token在配置中指定此默认空令牌。如果未设置此属性,并且指定了Field.DEFAULT_NULL_TOKEN,则字符串 "null" 将用作默认值。注意使用
indexNullAs参数时,务必要在搜索查询中使用相同的令牌来搜索null值。此外,建议仅在未分析的字段(分析.NO)中使用此功能。警告在实施自定义 FieldBridge 或 TwoWayFieldBridge 时,开发人员可以处理 null 值的索引(请参阅 JavaDocs LuceneOptions.indexNullAs())。
7.4.1.4. @NumericField
@Field 有一个相应的注释,名为 @NumericField,其范围与 @Field 或 @DocumentId 相同。它可用于 Integer、Long、Float 和 Double 属性。在索引时,将使用 Trie 结构对该值进行索引。当属性索引为数字字段时,它实现了有效的范围查询和排序,与对标准 @Field 属性执行相同的查询相比,它实现了高效的范围查询和排序。@NumericField 注释接受以下参数:
| 值 | 定义 |
|---|---|
| forField | (可选)指定将索引为数字的相关 @Field 的名称。只有 属性包含超过 @Field 声明时,才强制使用它 |
| precisionStep | (可选)更改 Trie 结构存储在索引中的方式。较小的精度Steps会导致更多磁盘空间使用量、更快的范围和排序查询。较大的值会导致使用空间减少,范围查询性能更接近普通 @Fields 中的范围查询。默认值为 4。 |
@NumericField 仅支持 Double、Long、Integer 和 Float。其他数字类型无法利用 Lucene 中的类似功能,因此其余类型应使用默认或自定义 TwoWayFieldBridge 进行字符串编码。
假设您可以在类型转换过程中处理近似值,可以使用自定义 NumericFieldBridge:
示例:定义自定义数字FieldBridge
public class BigDecimalNumericFieldBridge extends NumericFieldBridge {
private static final BigDecimal storeFactor = BigDecimal.valueOf(100);
@Override
public void set(String name, Object value, Document document, LuceneOptions luceneOptions) {
if ( value != null ) {
BigDecimal decimalValue = (BigDecimal) value;
Long indexedValue = Long.valueOf( decimalValue.multiply( storeFactor ).longValue() );
luceneOptions.addNumericFieldToDocument( name, indexedValue, document );
}
}
@Override
public Object get(String name, Document document) {
String fromLucene = document.get( name );
BigDecimal storedBigDecimal = new BigDecimal( fromLucene );
return storedBigDecimal.divide( storeFactor );
}
}
7.4.1.5. @Id
最后,实体的 id (识别符)属性是 Hibernate Search 使用的特殊属性,用于确保给定实体的索引唯一性。按照设计,必须存储 id,且不能进行令牌化。要将属性标记为索引标识符,可使用 @DocumentId 注释。如果您使用的是 Jakarta Persistence 并且指定了 @Id,您可以省略 @DocumentId。选定的实体标识符也可用作文档标识符。
Infinispan Query 使用实体的 id 属性来确保索引唯一标识。按照设计,ID 会存储,且不得转换为令牌。要将属性标记为索引 ID,可使用 @DocumentId 注释。
示例:指定索引的属性
@Entity
@Indexed
public class Essay {
...
@Id
@DocumentId
public Long getId() { return id; }
@Field(name="Abstract", store=Store.YES)
public String getSummary() { return summary; }
@Lob
@Field
public String getText() { return text; }
@Field @NumericField( precisionStep = 6)
public float getGrade() { return grade; }
}
上例定义了四个字段的索引: id、Abs tract、文本 和 评级。请注意,默认情况下字段名称没有大写,符合 JavaBean 规范。grade 字段标为数字,其精确步骤略大于默认值。
7.4.1.6. 映射属性多次
有时,您需要为每个索引多次映射一个属性,索引策略略有不同。例如,根据字段排序查询需要取消分析字段。要按此属性上的词语搜索,仍需要对它进行索引 - 旦分析过,一旦未分析一次。@Fields 允许您实现此目标。
示例:使用 @Fields 映射多个属性时间
@Entity
@Indexed(index = "Book" )
public class Book {
@Fields( {
@Field,
@Field(name = "summary_forSort", analyze = Analyze.NO, store = Store.YES)
} )
public String getSummary() {
return summary;
}
...
}
在本例中,字段 概述 被索引两次,一次以令牌化的方式作为 概述,一次是以未令牌的方式作为 summary_forSort 索引。
7.4.1.7. 嵌入式和关联对象
可以将关联的对象和嵌入式对象作为根实体索引的一部分进行索引。如果您希望根据相关对象的属性搜索给定实体,这很有用。目标是返回相关城市为 Atlanta 的位置(在 Lucene 查询解析器语言中,语言将转换为 address.city:Atlanta)。位置字段将在位置索引中 索引。Place 索引文档还将包含您可以 查询的 address.id、address . 字段。
street 和 address.city
示例:索引关联
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field
private String street;
@Field
private String city;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}
由于在使用 @IndexedEmbedded 技术时,Lucene 索引中数据已被非常规化,因此 Hibernate Search 必须了解 Place 对象中的任何变化,以及 Address 对象中的任何更改,以便索引保持最新。为确保在地址发生更改时 Lucene 文档得到更新,请使用 @ContainedIn 标记双向关系的另一侧。
@ContainedIn 对于指向实体的关联和嵌入式(收集)对象的关联都很有用。
若要对此展开,以下示例演示了嵌套 @IndexedEmbedded :
示例:@IndexedEmbedded 和 @ContainedIn 的嵌套使用
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field
private String street;
@Field
private String city;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_")
private Owner ownedBy;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}
@Embeddable
public class Owner {
@Field
private String name;
...
}
任何 @*ToMany、@*ToOne 和 @Embedded 属性都可以标上 @IndexedEmbedded。然后,关联的类的属性将添加到主实体索引中。索引将包含以下字段:
- id
- name
- address.street
- address.city
- address.ownedBy_name
默认前缀是 propertyName.,遵循传统的对象导航约定。您可以使用 prefix 属性覆盖它,如 ownedBy 属性中所示。
前缀不能设置为空字符串。
当对象图包含类(而非实例)的循环依赖项时,需要 深度 属性。例如,如果所有者指向位置:Hibernate 搜索将在到达预期深度(或到达对象图形边界)后停止包含索引的嵌入式属性。具有自引用的类是 cyclic 依赖项示例。在我们的示例中,由于 深度 设置为 1,Owner 中的任何 @IndexedEmbedded 属性都将被忽略。
使用 @IndexedEmbedded 作为对象关联可让您表达查询(使用 Lucene 的查询语法),例如:
返回名称包含 JBoss 以及地址城市为 Atlanta 的位置。在 Lucene 查询中,这是:
+name:jboss +address.city:atlanta
返回名称包含 JBoss 的位置,以及所有者名称包含 Joe 的位置。在 Lucene 查询中,该选项为
+name:jboss +address.ownedBy_name:joe
此行为以更有效的方式(降低数据重复的成本)模仿关系连接操作。请记住,开箱即用时 Lucene 索引没有任何关联概念,连接操作也不存在。这有助于保持关系模式规范化,同时从完整的文本索引速度和特性丰富的中受益。
关联的对象本身(但不必)为 @Indexed
当 @IndexedEmbedded 指向某一实体时,其关联必须是方向的,并且必须给另一方添加注释 @ContainedIn (如上例中所示)。如果没有,Hibernate Search 将无法在相关实体更新时更新根索引(在本示例中,相关地址实例更新时必须更新 Place 索引文档)。
有时,由 @IndexedEmbedded 标注的对象类型并非 Hibernate 和 Hibernate Search 所针对的对象类型。当接口用于代替其实施时,尤其会出现这种情况。因此,您可以使用 targetElement 参数覆盖 Hibernate Search 所针对的对象类型。
示例:使用 @IndexedEmbedded targetElement 属性
@Entity
@Indexed
public class Address {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String street;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_", )
@Target(Owner.class)
private Person ownedBy;
...
}
@Embeddable
public class Owner implements Person { ... }
7.4.1.8. 将对象嵌入式限制为特定路径
@IndexedEmbedded 注释也提供 includePaths 属性,可用于作为深度的替代方案或与其组合。
仅使用深度时,会在同一深度以递归方式添加嵌入式类型的所有索引字段。这样更加难以仅选择特定路径而不添加所有其他字段,而可能不需要这些字段。
为避免不必要的加载和索引实体,您可以精确指定所需的路径。典型的应用程序可能需要不同路径的不同深度,或者换句话说可能需要明确指定路径,如下例所示:
示例:使用 @IndexedEmbedded 的 includePaths 属性
@Entity
@Indexed
public class Person {
@Id
public int getId() {
return id;
}
@Field
public String getName() {
return name;
}
@Field
public String getSurname() {
return surname;
}
@OneToMany
@IndexedEmbedded(includePaths = { "name" })
public Set<Person> getParents() {
return parents;
}
@ContainedIn
@ManyToOne
public Human getChild() {
return child;
}
...//other fields omitted
使用上例中所示的映射,您可以按 名称和 /或 姓氏 搜索 Person,以及/或父 名称。它不会索引父名称 的姓氏,因此无法对父名进行搜索,但会加快索引、节省空间并提高整体性能。
@IndexedEmbeddedincludePaths 除常规地为深度指定有限值的索引外,还包括指定的路径。使用 includePaths 并保留深度未定义时,行为等同于设置 depth=0:只有包含的路径才会被索引。
示例:使用 @IndexedEmbedded 的 includePaths 属性
@Entity
@Indexed
public class Human {
@Id
public int getId() {
return id;
}
@Field
public String getName() {
return name;
}
@Field
public String getSurname() {
return surname;
}
@OneToMany
@IndexedEmbedded(depth = 2, includePaths = { "parents.parents.name" })
public Set<Human> getParents() {
return parents;
}
@ContainedIn
@ManyToOne
public Human getChild() {
return child;
}
...//other fields omitted
在上面的示例中,每个人都将拥有其名称和姓氏属性索引。父项的名称和姓氏也将进行索引,其中最多可递归为第二行,因为存在depth 属性。可以按姓名或姓氏直接搜索该人员、其父项或父项。除第二个级别外,我们还会再为一个级别编制索引,而仅索引名称,而非姓氏。
这会在索引中生成以下字段:
-
ID:作为主密钥 -
_hibernate_class:存储实体类型 -
名称:作为直接字段 -
Surname:作为直接字段 -
parent.name:作为嵌入式字段(深度 1) -
parent.surname:作为嵌入式字段,在深度 1 中 -
parent.parents.name:作为嵌入式字段,位于深度 2 -
parent.parents.surname:作为嵌入式字段,显示深度 2 -
parent.parents.parents.name:作为 includePaths 指定的额外路径。第一个父级.从字段名称中推断,剩余的路径是 includePaths 的属性。
如果您要首先定义所需的查询(如此时您准确知道需要哪些字段)以及不需要哪些其他字段来实施您的用例,那么明确控制索引路径可能会更加简单。
7.4.2. boosting
Lucene 具有增强概念,使您可以提供某些文档或字段的重要性比其他文档或字段多或更低。Lucene 区分索引和搜索时间提升。以下小节介绍了如何使用 Hibernate Search 实现索引时间提升。
7.4.2.1. 静态索引时间嵌套
若要为索引化的类或属性定义静态提升值,您可以使用 @Boost 注释。您可以在 @Field 内使用此注释,或者直接在方法或类级别上指定。
示例:使用 @Boost 的不同方式
@Entity
@Indexed
public class Essay {
...
@Id
@DocumentId
public Long getId() { return id; }
@Field(name="Abstract", store=Store.YES, boost=@Boost(2f))
@Boost(1.5f)
public String getSummary() { return summary; }
@Lob
@Field(boost=@Boost(1.2f))
public String getText() { return text; }
@Field
public String getISBN() { return isbn; }
}
在上面的示例中,Essay 达到搜索列表顶部的可能性将乘以 1.7。summary 字段将为 3.0(2 * 1.5),因为属性上的 @Field.boost 和 @Boost 是累加的,比 isbn 字段更重要。文本字段将比 isbn 字段更重要 1.2 倍。请注意,该解释最严格无误,但对于所有实际用途而言,它非常简单,非常接近现实。
7.4.2.2. 动态索引时间嵌套
Static Index Time Boosting 中使用的 @Boost 注释定义一个静态提升因子,它独立于运行时索引的实体的状态。然而,在有些用例中,增速因素可能取决于实体的实际状态。在这种情况下,您可以使用 @DynamicBoost 注释和附带的自定义 BoostStrategy。
示例:Dynamic Boost
public enum PersonType {
NORMAL,
VIP
}
@Entity
@Indexed
@DynamicBoost(impl = VIPBoostStrategy.class)
public class Person {
private PersonType type;
// ....
}
public class VIPBoostStrategy implements BoostStrategy {
public float defineBoost(Object value) {
Person person = ( Person ) value;
if ( person.getType().equals( PersonType.VIP ) ) {
return 2.0f;
}
else {
return 1.0f;
}
}
}
在上例中,在将 VIPBoostStrategy 指定为要在索引时使用的 BoostStrategy 接口的实现的类级别上定义动态提升。您可以将 @DynamicBoost 放置在类或字段级别上。根据注释的放置,整个实体都传递到 defineBoost 方法,或者仅传递注解的字段/质量值。您要将传递的对象投给正确的类型。在示例中,VIP 人员的所有索引值都将与普通人的值加倍。
指定的 BoostStrategy 实现必须定义一个公共的 no-arg 构造器。
当然,您可以在实体中混合和匹配 @Boost 和 @DynamicBoost 注释。所有定义的增压因素都是累计的。
7.4.3. 分析
分析 是将文本转换为单个术语(词)的过程,可以视为全文本搜索引擎的主要功能之一。Lucene 利用分析器的概念来控制此过程。在下一节中,我们将介绍 Hibernate 搜索提供的多种方式来配置分析器。
7.4.3.1. 类的默认 Analyzer 和 Analyzer
用于索引令牌字段的默认分析器类可通过 hibernate.search.analyzer 属性进行配置。此属性的默认值为 org.apache.lucene.analysis.standard.StandardAnalyzer。
您还可以为每个实体定义分析器类、属性甚至每个 @Field(在一个属性中索引多个字段时很有用)。
示例:使用 @Analyzer 的不同方式
@Entity
@Indexed
@Analyzer(impl = EntityAnalyzer.class)
public class MyEntity {
@Id
@GeneratedValue
@DocumentId
private Integer id;
@Field
private String name;
@Field
@Analyzer(impl = PropertyAnalyzer.class)
private String summary;
@Field(analyzer = @Analyzer(impl = FieldAnalyzer.class)
private String body;
...
}
在本例中,EnityAnalyzer 用于索引令牌化属性(名称),但 摘要 和 正文 除外,它们分别使用 propertiesAnalyzer 和 FieldAnalyzer 索引。
在同一个实体中混合不同的分析器大部分时候是不良做法。它使查询构建更复杂,结果更难以预测(对于 novice),尤其是如果您使用 QueryParser(对整个查询使用同一个分析器)。作为经验法,对于任何给定字段,应将同一分析器用于索引和查询。
7.4.3.2. 命名分析器
分析器可能会变得非常复杂。因此,增加了 Hibernate 搜索分析器定义的概念。分析器定义可以被许多 @Analyzer 声明重复使用,其包含:
- name:用于引用定义的唯一字符串
- char 过滤器列表:每个 char 过滤器负责在令牌化之前预先处理输入字符。Char 过滤器可以添加、更改或删除字符;一个常用的用法是字符规范化
- 令牌器:负责将输入流令牌到单个单词
- 过滤器列表:每个过滤器负责删除、修改或有时在 tokenizer 提供的流中添加词语
这种任务分离(一个 char 过滤器列表和一个跟一个过滤器列表)可轻松重复利用各个组件,并让您以非常灵活的方式(如 Lego)构建自定义分析器。通常而言,Car 过滤器在字符输入中执行一些预处理,然后令牌程序通过将字符输入转换为令牌来启动令牌化过程,然后由 TokenFilters 进一步处理。Hibernate Search 利用 Solr 分析器框架来支持此基础架构。
让我们回顾一下下面描述的一个具体示例。首先,一个 char 过滤器由工厂定义。在我们的示例中,使用了映射 char 过滤器,并将根据映射文件中指定的规则替换输入中的字符。接下来定义了令牌程序。这个示例使用标准令牌程序。最后但并非最不重要的是,一个过滤器列表由其工厂定义。在我们的示例中,StopFilter 过滤器构建为读取专用的词语属性文件。过滤器还应忽略大小写。
示例:@AnalyzerDef 和 Solr Framework
@AnalyzerDef(name="customanalyzer",
charFilters = {
@CharFilterDef(factory = MappingCharFilterFactory.class, params = {
@Parameter(name = "mapping",
value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties")
})
},
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words",
value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ),
@Parameter(name="ignoreCase", value="true")
})
})
public class Team {
...
}
过滤器和 char 过滤器按照 @AnalyzerDef 注释中定义的顺序应用。订单很重要!
某些令牌程序、令牌过滤器或 char 过滤器会加载资源,如配置或元数据文件。stop 过滤器和同义词过滤器就是这种情况。如果资源 charset 没有使用虚拟机默认值,您可以通过添加 resource_charset 参数来显式指定它。
示例:使用特定 Charset 加载属性文件
@AnalyzerDef(name="customanalyzer",
charFilters = {
@CharFilterDef(factory = MappingCharFilterFactory.class, params = {
@Parameter(name = "mapping",
value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties")
})
},
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words",
value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ),
@Parameter(name="resource_charset", value = "UTF-16BE"),
@Parameter(name="ignoreCase", value="true")
})
})
public class Team {
...
}
定义之后,分析器定义就可通过 @Analyzer 声明重复利用,如下例中所示:
示例:按名称引用分析器
@Entity
@Indexed
@AnalyzerDef(name="customanalyzer", ... )
public class Team {
@Id
@DocumentId
@GeneratedValue
private Integer id;
@Field
private String name;
@Field
private String location;
@Field
@Analyzer(definition = "customanalyzer")
private String description;
}
@AnalyzerDef 声明的 AnalyzerDef 实例通过其名称在 SearchFactory 中也可用,该名称在构建查询时非常有用。
Analyzer analyzer = fullTextSession.getSearchFactory().getAnalyzer("customanalyzer");查询中的字段必须使用用于索引字段的同一分析器进行分析,以便它们使用共同"语言":在查询和索引过程之间重复利用相同的令牌。该规则有一些例外情况,但大部分时候确实如此。尊重它,除非您知道自己正在做什么。
7.4.3.3. 可用分析器
SOLR 和 Lucene 附带许多有用的默认 char 过滤器、令牌程序和过滤器。您可以在 http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters 找到 char 过滤器工厂、令牌方工厂和过滤工厂的完整列表。我们来看一下其中几个。
表 7.7. 可用的 Char Filters
| 工厂 | 描述 | 参数 |
|---|---|---|
| MappingCharFilterFactory | 根据资源文件中指定的映射,将一个或多个字符替换为一个或多个字符 |
|
| HTMLStripCharFilterFactory | 删除 HTML 标准标签,保留文本 | none |
表 7.8. 可用令牌程序
| 工厂 | 描述 | 参数 |
|---|---|---|
| StandardTokenizerFactory | 使用 Lucene StandardTokenizer | none |
| HTMLStripCharFilterFactory | 删除 HTML 标签,保留文本并将其传递到标准Tokenizer。 | none |
| PatternTokenizerFactory | 将文本拆分到指定的正则表达式模式. | pattern :用于令牌化的正则表达式 Group :表示要提取到令牌中的哪个模式组 |
表 7.9. 可用的过滤器
| 工厂 | 描述 | 参数 |
|---|---|---|
| StandardFilterFactory | 从单词中删除缩写和 的点数 | none |
| LowerCaseFilterFactory | 小写所有单词 | none |
| StopFilterFactory | 删除与 stop 词语列表匹配的词语(令牌) | word: 指向包含 stop 词语的资源文件 ignoreCase: true,如果比较 stop 字时应忽略大小写,否则为 false |
| SnowballPorterFilterFactory | 以给定语言将单词减到其 root。(例如:保护、保护、保护共享同一根)。使用这样的过滤器可以搜索匹配相关的词语。 |
|
我们建议检查 IDE 中 org.apache.lucene.analysis.TokenizerFactory 和 org.apache.lucene.analysis.TokenFilterFactory 中的所有实施,以查看可用的实施。
7.4.3.4. 动态分析器选择
目前,所有介绍的指定分析器的方法都是静态的。然而,在某些用例中,根据要索引的实体的当前状态(例如在多语言应用程序中)来选择分析器很有用。例如,对于 BlogEntry 类,分析器可能依赖于条目的语言属性。根据此属性,应当选择正确的语言特定语言来索引实际文本。
要启用此动态分析器选择 Hibernate Search,请引入 AnalyzerDiscriminator 注释。以下示例演示了此注解的用法。
示例:@AnalyzerDiscriminator 的使用
@Entity
@Indexed
@AnalyzerDefs({
@AnalyzerDef(name = "en",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = EnglishPorterFilterFactory.class
)
}),
@AnalyzerDef(name = "de",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = GermanStemFilterFactory.class)
})
})
public class BlogEntry {
@Id
@GeneratedValue
@DocumentId
private Integer id;
@Field
@AnalyzerDiscriminator(impl = LanguageDiscriminator.class)
private String language;
@Field
private String text;
private Set<BlogEntry> references;
// standard getter/setter
...
}
public class LanguageDiscriminator implements Discriminator {
public String getAnalyzerDefinitionName(Object value, Object entity, String field) {
if ( value == null || !( entity instanceof BlogEntry ) ) {
return null;
}
return (String) value;
}
}
使用 @AnalyzerDiscriminator 的先决条件是,将要动态使用的所有分析器都通过 @AnalyzerDef 定义预定义。如果出现这种情况,可以将 @AnalyzerDiscriminator 注释放在该类或动态选择分析器的实体的特定属性上。通过 AnalyzerDiscriminator 的 impl 参数,您可以指定特定的 Discriminator 接口实施。您要为此接口提供一个实施。您唯一需要实施的方法是 getAnalyzerDefinitionName(),它为添加到 Lucene 文档中的每个字段调用。索引化的实体也传递到 interface 方法。只有在将 AnalyzerDiscriminator 放置到属性级别而不是类级别时,才会设置 value 参数。在本例中,值表示此属性的当前值。
如果不应覆盖默认分析器,则 Discriminator 接口的实施必须返回现有分析器定义的名称或 null。上面的示例假定语言参数为 'de' 或 'en',它与 @AnalyzerDefs 中的 指定名称匹配。
7.4.3.5. 检索分析器
当在域模型中使用了多个分析器时,可以检索分析器,以便从医疗或手机近似中受益。在这种情况下,使用相同的分析器来构建查询。或者,使用 Hibernate Search 查询 DSL,它会自动选择正确的分析器。请查看
无论您是使用 Lucene 编程 API,还是 Lucene 查询解析器,您都可以检索给定实体的范围分析器。有作用域分析器是一个分析器,它根据字段索引来应用正确的分析器。请记住,可以在给定实体上定义多个分析器,每个实体都在单个字段上工作。一个作用域分析器可将所有这些分析器统一到上下文感知分析器中。尽管该理论似乎比较复杂,但在查询中使用正确的分析器非常简单。
当您对子实体使用编程映射时,只能查看子实体定义的字段。从父实体继承的字段或方法(使用 @MappedSuperclass 标注)不可配置。要配置从父实体继承的属性,可覆盖子实体中的 属性,或者为父实体创建编程映射。这模拟了注解的使用,除非子实体中重新定义了父实体的字段或方法。
示例:构建全文本查询时使用 Scoped Analyzer
org.apache.lucene.queryParser.QueryParser parser = new QueryParser(
"title",
fullTextSession.getSearchFactory().getAnalyzer( Song.class )
);
org.apache.lucene.search.Query luceneQuery =
parser.parse( "title:sky Or title_stemmed:diamond" );
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Song.class );
List result = fullTextQuery.list(); //return a list of managed objects
在上例中,歌曲标题按照两个字段索引:标准分析器在字段 标题中 使用,greject _stemmed 字段中则使用一个适当的 分析器。通过使用搜索工厂提供的分析器,查询会根据目标字段使用适当的分析器。
您还可以使用 searchFactory.getAnalyzer(String)根据定义名称检索 @Analyzer Def 定义的分析器。
7.4.4. 网桥
在讨论实体的基本映射时,到目前为止一个重要的事实被忽略。在 Lucene 中,所有索引字段都必须以字符串表示。标有 @Field 的所有实体 属性都必须转换为要索引的字符串。我们目前尚未提到过的原因是,对于您的大多数属性,Hibernate Search 为您承担了转换任务,得益于一组内置桥。然而,在某些情况下,您需要更精细地控制转换过程。
7.4.4.1. 内置网桥
Hibernate Search 附带一组 Java 属性类型和完整文本表示法之间的内置桥接。
- null
-
每个默认
null元素都没有索引。Lucene 不支持 null 元素。但在某些情况下,插入代表空值的自定义令牌会很有用。如需更多信息,请参阅。 - java.lang.String
- 字符串的索引方式是短、短、整数、Integer、长、Long、float、Float、双.
- Double, BigInteger, BigDecimal
数字转换为字符串表示法。请注意,数字不能由 Lucene(即在范围查询中使用)从开箱即用:它们必须被 padded。
注意使用 Range 查询存在缺点,另一种方法是使用 Filter 查询,它将结果查询过滤到适当的范围。Hibernate Search 还支持使用自定义 StringBridge,如自定义网桥中所述。
- java.util.Date
日期存储为 yyyMMddHHmmsSSS,时间为 yyyMMddHHmmsSSS,时间为 2006 年 11 月 7 日 4:03PM 和 12ms EST。您不应该真正对内部格式造成干扰。重要的是,在使用 TermRangeQuery 时,您应该知道日期必须以 GMT 时间表示。
通常,不需要存储毫秒的最新数据。
@DateBridge定义您希望在索引中存储的适当解析(@DateBridge(resolution=Resolution.DAY)。然后,将相应地截断日期模式。
@Entity
@Indexed
public class Meeting {
@Field(analyze=Analyze.NO)
private Date date;
...
解析低于 MILLISECOND 的日期不能是 @DocumentId。
默认日期网桥使用 Lucene 的 DateTools 从和转换为 String。这意味着所有日期都以 GMT 时间表示。如果您的要求要在固定的时区中存储日期,您必须实施自定义日期桥接。确保您了解应用程序与日期索引和搜索相关的要求。
- java.net.URI, java.net.URL
- URI 和 URL 将转换为其字符串表示法。
- java.lang.Class
- class 将转换为其完全限定类名称。重新验证类时,使用线程上下文类加载程序。
7.4.4.2. 自定义网桥
有时,Hibernate Search 的内置网桥不涵盖某些属性类型,或者网桥使用的字符串表示不满足您的要求。以下段落描述了此问题的几种解决方案。
7.4.4.2.1. StringBridge
最简单的自定义解决方案是让 Hibernate 搜索您的预期对象实施到 String 网桥。为此,您需要实施 org.hibernate.search.bridge.StringBridge 接口。所有实施都必须是并发使用线程安全。
示例:自定义字符串实现
/**
* Padding Integer bridge.
* All numbers will be padded with 0 to match 5 digits
*
* @author Emmanuel Bernard
*/
public class PaddedIntegerBridge implements StringBridge {
private int PADDING = 5;
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > PADDING)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < PADDING ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
}
根据上例中定义的字符串网桥,任何属性或字段都可通过 @FieldBridge 注释来使用此网桥:
@FieldBridge(impl = PaddedIntegerBridge.class) private Integer length;
7.4.4.2.2. 参数网桥
参数也可以传递到网桥实施,使其更灵活。下例实施参数化Bridge 接口和参数通过 @FieldBridge 注释传递:
示例:将参数传递给网桥实施
public class PaddedIntegerBridge implements StringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map<String,String> parameters) {
String padding = parameters.get( PADDING_PROPERTY );
if (padding != null) this.padding = Integer.parseInt( padding );
}
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
}
//property
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name="padding", value="10")
)
private Integer length;
ParameterizedBridge 接口可通过TwoWayString 实施来实现。
Bridge 和 BridgeFieldBridge 实现 String
所有实施都必须是线程安全,但参数在初始化过程中设置,此阶段不需要特别注意。
7.4.4.2.3. 类型 Aware Bridge
有时对于获得应用桥接的类型很有用:
- 字段/工具级网桥的属性的返回类型。
- 类级网桥的类类型。
例如,一个网桥,它以自定义的方式处理枚举,但需要访问实际的枚举类型。实现 AppliedOnTypeAwareBridge 的任何网桥都会获得注入时应用桥接的类型。与参数一样,注入的类型无需特别注意线程安全。
7.4.4.2.4. 双Way Bridge
如果您希望在 id 属性(即带有 @DocumentId 注释)上使用网桥实施,您需要使用名为 TwoWayString Bridge 的 String Bridge 版本。Hibernate Search 需要读取标识符的字符串表示,并从中生成对象。使用 @FieldBridge 注释的方式没有区别。
示例:实施双WayStringBridge Usable for id Properties
public class PaddedIntegerBridge implements TwoWayStringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map parameters) {
Object padding = parameters.get( PADDING_PROPERTY );
if (padding != null) this.padding = (Integer) padding;
}
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
public Object stringToObject(String stringValue) {
return new Integer(stringValue);
}
}
//id property
@DocumentId
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name="padding", value="10")
private Integer id;
双向过程务必要具有幂等性(即,object = stringToObject(objectToString(对象))。
7.4.4.2.5. FieldBridge
当将属性映射到 Lucene 索引时,有些用例需要不仅仅是简单的对象来字符串转换。为为您提供最大灵活性,您还可以将桥实施为 FieldBridge。此界面为您提供一个属性值,并允许您在 Lucene Document 中按照您想要的方式对其进行映射。例如,您可以在两个不同的文档字段中存储属性。接口的概念与 Hibernate 用户类型非常相似。
示例:实施 FieldBridge Interface
/**
* Store the date in 3 different fields - year, month, day - to ease Range Query per
* year, month or day (eg get all the elements of December for the last 5 years).
* @author Emmanuel Bernard
*/
public class DateSplitBridge implements FieldBridge {
private final static TimeZone GMT = TimeZone.getTimeZone("GMT");
public void set(String name, Object value, Document document, LuceneOptions luceneOptions) {
Date date = (Date) value;
Calendar cal = GregorianCalendar.getInstance(GMT);
cal.setTime(date);
int year = cal.get(Calendar.YEAR);
int month = cal.get(Calendar.MONTH) + 1;
int day = cal.get(Calendar.DAY_OF_MONTH);
// set year
luceneOptions.addFieldToDocument(
name + ".year",
String.valueOf( year ),
document );
// set month and pad it if needed
luceneOptions.addFieldToDocument(
name + ".month",
month < 10 ? "0" : "" + String.valueOf( month ),
document );
// set day and pad it if needed
luceneOptions.addFieldToDocument(
name + ".day",
day < 10 ? "0" : "" + String.valueOf( day ),
document );
}
}
//property
@FieldBridge(impl = DateSplitBridge.class)
private Date date;
在上面的示例中,这些字段不会直接添加到 Document 中。相反,添加被委派给 LuceneOptions 帮助程序;此帮助程序将应用您在 @Field( 如 Store 或 TermVector )上选择的选项,或应用所选的 @Boost 值。封装 COMPRESS 实施的复杂性特别有用。尽管建议将任何字段委派给 LuceneOptions 以向文档添加字段,但不会阻止您直接编辑文档,并在您需要时忽略 LuceneOptions。
创建类似 LuceneOptions 的类,以方便您的应用程序免受 Lucene API 的变化,并简化您的代码。如果您愿意,请使用它们,但如果您需要更大的灵活性,则不需要.
7.4.4.2.6. ClassBridge
有时,组合给定实体的多个属性并以特定的方式将此组合索引到 Lucene 索引中很有用。@ClassBridge 和 @ClassBridges 注释可以在类级别上定义,而非属性级别。在本例中,自定义字段网桥实施接收实体实例作为 value 参数,而不是特定属性。虽然如下例中未显示,但 @ClassBridge 支持 Basic Mapping 部分中讨论的 termVector 属性。
示例:实施类桥接
@Entity
@Indexed
(name="branchnetwork",
store=Store.YES,
impl = CatFieldsClassBridge.class,
params = @Parameter( name="sepChar", value=" " ) )
public class Department {
private int id;
private String network;
private String branchHead;
private String branch;
private Integer maxEmployees
...
}
public class CatFieldsClassBridge implements FieldBridge, ParameterizedBridge {
private String sepChar;
public void setParameterValues(Map parameters) {
this.sepChar = (String) parameters.get( "sepChar" );
}
public void set( String name, Object value, Document document, LuceneOptions luceneOptions) {
// In this particular class the name of the new field was passed
// from the name field of the ClassBridge Annotation. This is not
// a requirement. It just works that way in this instance. The
// actual name could be supplied by hard coding it below.
Department dep = (Department) value;
String fieldValue1 = dep.getBranch();
if ( fieldValue1 == null ) {
fieldValue1 = "";
}
String fieldValue2 = dep.getNetwork();
if ( fieldValue2 == null ) {
fieldValue2 = "";
}
String fieldValue = fieldValue1 + sepChar + fieldValue2;
Field field = new Field( name, fieldValue, luceneOptions.getStore(),
luceneOptions.getIndex(), luceneOptions.getTermVector() );
field.setBoost( luceneOptions.getBoost() );
document.add( field );
}
}
在本例中,特定的 CatFieldsClassBridge 应用到 部门 实例,字段桥接随后串联分支和网络,并索引串联。
7.5. 使用 Hibernate Search 执行 Lucene 查询
流程
Hibernate Search 可以执行 Lucene 查询并检索由 InfinispanHibernate 会话管理的域对象。搜索提供了 Lucene 的强大功能,无需离开 Hibernate 范式,为 Hibernate 典型搜索机制(HQL、标准查询、本地 SQL 查询)提供了另一个维度。
准备并执行查询由以下四个步骤组成:
- 创建 FullTextSession
- 使用 Hibernate QueryHibernate Search 查询 DSL(推荐)或使用 Lucene 查询 API 创建 Lucene 查询 API
- 使用 org.hibernate.Query 包装 Lucene 查询
- 通过调用 example list()或 scroll()执行搜索.
若要访问查询功能,请使用 FullTextSession。此搜索特定会话打包了一个常规 org.hibernate.Session,以提供查询和索引功能。
示例:创建 FullTextSession
Session session = sessionFactory.openSession(); ... FullTextSession fullTextSession = Search.getFullTextSession(session);
使用 FullTextSession 使用 Hibernate Search 查询 DSL 或原生 Lucene 查询构建全文本查询。
在使用 Hibernate Search 查询 DSL 时,请使用以下代码:
final QueryBuilder b = fullTextSession.getSearchFactory().buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
List result = fullTextQuery.list(); //return a list of managed objects另外,也可使用 Lucene 查询解析器或 Lucene 编程 API 编写 Lucene 查询。
示例:使用 QueryParser 创建 Lucene Query
SearchFactory searchFactory = fullTextSession.getSearchFactory();
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", searchFactory.getAnalyzer(Myth.class) );
try {
org.apache.lucene.search.Query luceneQuery = parser.parse( "history:storm^3" );
}
catch (ParseException e) {
//handle parsing failure
}
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery(luceneQuery);
List result = fullTextQuery.list(); //return a list of managed objects
基于 Lucene 查询构建的 Hibernate 查询是 org.hibernate.Query。此查询保留与其他 Hibernate 查询工具相同,如 HQL(Hibernate 查询语言)、Native 和 Criteria。使用 list()、uniqueResult()、heerate()和 scroll()等方法以及查询。
Hibernate Jakarta Persistence 也提供相同的扩展:
示例:使用 Jakarta Persistence 创建搜索查询
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
...
final QueryBuilder b = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
javax.persistence.Query fullTextQuery = fullTextEntityManager.createFullTextQuery( luceneQuery );
List result = fullTextQuery.getResultList(); //return a list of managed objects
这些示例中使用了 Hibernate API。通过调整 FullTextQuery 的检索方式,也可使用 Jakarta Persistence 编写相同的示例。
7.5.1. 构建队列
Hibernate 搜索查询基于 Lucene 查询构建,允许用户使用任何 Lucene 查询类型。构建查询时,Hibernate Search 使用 org.hibernate.Query 作为查询操作 API,以进行进一步查询处理。
7.5.1.1. 使用 Lucene API 构建 Lucene 查询
使用 Lucene API 时,可以使用查询解析器(简单查询)或 Lucene 编程 API(复杂查询)。构建 Lucene 查询超出了 Hibernate 搜索文档的范围。详情请查看在线 Lucene 文档或 Lucene in Action 或 Hibernate Search in Action 的副本。
7.5.1.2. 构建 Lucene Query
Lucene 编程 API 启用全文本查询。但是,在使用 Lucene 编程 API 时,参数必须转换为字符串等效,并且还必须将正确的分析器应用到正确的字段。例如,ngram 分析器使用多个 ngrams 作为给定词的令牌,应进行此类搜索。建议将 QueryBuilder 用于此任务。
Hibernate Search 查询 API 流畅,具有以下关键特征:
- 方法名称为英文。因此,API 操作可以被阅读和理解为一系列英语短语和指令。
- 它使用 IDE 自动完成功能,可帮助当前输入前缀的补全并允许用户选择正确的选项。
- 它通常使用连锁方法模式。
- 易于使用和阅读 API 操作。
要使用 API,首先创建一个附加到给定 索引类型的 查询构建器。此 QueryBuilder 知道要使用的分析器以及要应用的字段桥接。可以创建几个 QueryBuilders(涉及查询根目录的每个实体类型一个)。QueryBuilder 派生自 SearchFactory。
QueryBuilder mythQB = searchFactory.buildQueryBuilder().forEntity( Myth.class ).get();
用于给定字段或字段的分析器也可以被覆盖。
QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();查询构建器现在用于构建 Lucene 查询。使用 Lucene 的查询解析器或 Query 对象通过 Lucene 编程 API 生成自定义查询与 Hibernate Search DSL 一起使用。
7.5.1.3. 关键字查询
以下示例演示了如何搜索特定词语:
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();表 7.10. 关键字查询参数
| 参数 | 描述 |
|---|---|
| keyword() | 使用此参数查找特定词语。 |
| onField() | 使用此参数指定要在哪个 lucene 字段中搜索单词。 |
| matching() | 使用此参数指定搜索字符串的匹配项 |
| createQuery() | 创建 Lucene 查询对象。 |
-
值"storm"通过
historyFieldBridge 传递。这在涉及数字或日期时很有用。 -
然后,字段桥接值传递到用于索引字段
历史记录的分析器。这样可确保查询使用与索引相同的术语转换(小写、ngram、调整等)。如果分析过程为给定词生成了多个术语,则布尔值查询与SHOULD逻辑(大约是一个OR逻辑)一起使用。
要搜索不是字符串类型的属性:
@Indexed
public class Myth {
@Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
public Date getCreationDate() { return creationDate; }
public Date setCreationDate(Date creationDate) { this.creationDate = creationDate; }
private Date creationDate;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("creationDate").matching(birthdate).createQuery();在普通 Lucene 中,Lucene 必须转换为其字符串表示法,本例中为一年。
这种转换适用于任何对象,只要 FieldBridge 具有 objectToString 方法(以及所有内置的 FieldBridge 实施)。
下一个示例搜索使用 ngram 分析器的字段。ngram分析器单词 ngrams 的索引顺序,这有助于避免用户拼写错误。例如,hibernate 的 3 小时是 hib, ibe, ber, ern, rna, nat, ate, ate。
@AnalyzerDef(name = "ngram",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class ),
filters = {
@TokenFilterDef(factory = StandardFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class),
@TokenFilterDef(factory = NGramFilterFactory.class,
params = {
@Parameter(name = "minGramSize", value = "3"),
@Parameter(name = "maxGramSize", value = "3") } )
}
)
public class Myth {
@Field(analyzer=@Analyzer(definition="ngram")
public String getName() { return name; }
public String setName(String name) { this.name = name; }
private String name;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("name").matching("Sisiphus")
.createQuery();
匹配单词"Sisiphus"将小写,然后分为 3 型图:sis、iso、sip、iph、phu、hus。这些 ngram 各自将成为查询的一部分。然后,用户可以找到 Sysiphus 神话(使用 y)。所有操作都为用户透明地完成。
如果用户不希望特定字段使用字段网桥或分析器,则可以调用 ignoreAnalyzer()或 ignoreFieldBridge()函数。
要在同一个字段中搜索多个可能的词语,请在匹配的 子句中添加它们。
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();要在多个字段中搜索相同的词语,请使用 onFields 方法。
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();有时,即使搜索同一术语,也要与另一个字段不同对待一个字段,为此使用 和Field()方法。
Query luceneQuery = mythQB.keyword()
.onField("history")
.andField("name")
.boostedTo(5)
.andField("description")
.matching("storm")
.createQuery();在上例中,只有字段名称增加到 5。
7.5.1.4. Fuzzy Queries
要执行 fuzzy 查询(基于 Levenshtein 距离算法),以 关键字 查询开头并添加 fuzzy 标志。
Query luceneQuery = mythQB
.keyword()
.fuzzy()
.withThreshold( .8f )
.withPrefixLength( 1 )
.onField("history")
.matching("starm")
.createQuery();
阈值 是两个术语正在考虑匹配的限制。它是 0 到 1 之间的小数,默认值为 0.5。prefixLength 是"fuzzyness"忽略的前缀长度。虽然默认值为 0,但建议对包含大量不同术语的索引使用非零值。
7.5.1.5. 通配符查询
通配符查询在只知道部分词语的情况下很有用。? 表示单个字符,* 代表多个字符。请注意,出于性能考虑,建议查询不以?或 * 开头。
Query luceneQuery = mythQB
.keyword()
.wildcard()
.onField("history")
.matching("sto*")
.createQuery();
通配符查询不会对匹配的术语应用分析器。* 或 ? 被盗的风险太大。
7.5.1.6. 密码队列
到目前为止,我们一直在寻找词语或词组,用户还可以搜索准确或大概的句子。使用 phrase()执行此操作。
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();可以通过添加滑动因子来搜索大致句子。滑动因子表示句子中允许的换句话数:这类似于操作符内或附近的运算符。
Query luceneQuery = mythQB
.phrase()
.withSlop(3)
.onField("history")
.sentence("Thou kill")
.createQuery();7.5.1.7. 范围查询
范围查询搜索给定边界(包含与否)或给定边界以下或以上值之间的值。
//look for 0 <= starred < 3
Query luceneQuery = mythQB
.range()
.onField("starred")
.from(0).to(3).excludeLimit()
.createQuery();
//look for myths strictly BC
Date beforeChrist = ...;
Query luceneQuery = mythQB
.range()
.onField("creationDate")
.below(beforeChrist).excludeLimit()
.createQuery();7.5.1.8. 组合查询
可以组合查询来创建更复杂的查询。可用的聚合操作器如下:
-
SHOULD:查询应包含该子队列的匹配元素。 -
MUST:查询必须包含子队列的匹配元素。 -
MUST:查询不得包含子队列的匹配元素。
子查询可以是任何 Lucene 查询,包括布尔值查询本身。
示例:SHOULD 查询
//look for popular myths that are preferably urban
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();
示例:MUST 查询
//look for popular urban myths
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();
示例: MUST not Query
//look for popular modern myths that are not urban
Date twentiethCentury = ...;
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.not()
.must( mythQB.range().onField("starred").above(4).createQuery() )
.must( mythQB
.range()
.onField("creationDate")
.above(twentiethCentury)
.createQuery() )
.createQuery();
7.5.1.9. 查询选项
Hibernate Search 查询 DSL 是一种易于使用的查询 API。在接受和生成 Lucene 查询时,您可以纳入 DSL 不支持的查询类型。
以下是查询类型和字段的查询选项概述:
- boostedTo (在查询类型和字段上)可将整个查询或特定字段扩展至给定因素。
- withConstantScore (在查询时)返回与查询匹配的所有结果,其恒定分数等于增长值。
- 使用 Filter 实例过滤edBy(Filter )(查询时)过滤查询结果。
- 处理此字段时,ignoreAnalyzer (字段)会忽略分析器。
- 处理此字段时,忽略FieldBridge (on 字段)忽略字段桥接。
示例:Query 选项的组合
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.should( mythQB
.keyword()
.onField("name")
.boostedTo(3)
.ignoreAnalyzer()
.matching("urban").createQuery() )
.must( mythQB
.range()
.boostedTo(5).withConstantScore()
.onField("starred").above(4).createQuery() )
.createQuery();
7.5.1.10. 构建 Hibernate Search Query
7.5.1.10.1. 常规性
构建 Lucene 查询后,将其包装到 Hibernate 查询中。查询会搜索所有索引化实体并返回所有索引化类类型,除非明确配置为不这样做。
示例:在 Hibernate 查询中抓取 Lucene 查询
FullTextSession fullTextSession = Search.getFullTextSession( session ); org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
要提高性能,请限制返回的类型,如下所示:
示例:按实体类型过滤搜索结果
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Customer.class );
// or
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Item.class, Actor.class );
第二个示例中的第一部分仅返回匹配的客户。同一示例的第二部分返回匹配的操作程序和项目。类型限制是多态限制。因此,如果基本类 Person 返回的两个子类 Salesman 和客户,请指定 Person.class 以根据结果类型进行过滤。
7.5.1.10.2. 分页
为避免性能下降,建议限制每个查询返回的对象数量。用户从一个页面导航至另一页面是一个非常常见的用例。定义分页的方式类似于在普通 HQL 或标准查询中定义分页。
示例:定义搜索查询的粘贴
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Customer.class );
fullTextQuery.setFirstResult(15); //start from the 15th element
fullTextQuery.setMaxResults(10); //return 10 elements
无论通过 fulltextQuery.getResultSize()分页,仍然可以获得匹配元素的总数。
7.5.1.10.3. 排序
Apache Lucene 包含灵活而强大的结果排序机制。默认是相关的排序,适用于各种用例。排序机制可以更改为由其他属性排序,使用 Lucene sortrt 对象应用 Lucene 排序策略。
示例:指定Lucene排序
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( query, Book.class );
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
List results = query.list();
用于排序的字段不能被令牌化。有关令牌大小的更多信息,请参阅 @Field。
7.5.1.10.4. 获取策略
Hibernate 搜索是否将返回类型限制为一个类,使用单个查询来加载对象。Hibernate Search 受到域模型中定义的静态获取策略的限制。可根据特定用例优化获取策略,如下所示:
示例:在查询中指定 FetchMode
Criteria criteria =
s.createCriteria( Book.class ).setFetchMode( "authors", FetchMode.JOIN );
s.createFullTextQuery( luceneQuery ).setCriteriaQuery( criteria );
在本例中,查询将返回与 LuceneQuery 匹配的所有 Book。使用 SQL 外部连接从同一查询加载作者集合。
在标准查询定义中,会根据提供的标准查询来猜测类型。因此,不需要限制返回实体类型。
fetch 模式是唯一可调整的属性。不要在标准查询上使用限制(一个位置的 子句),因为 getResultSize()如果与有限制的标准结合使用,则抛出 SearchException。
如果预期有多个实体,请不要使用 setCriteriaQuery。
7.5.1.10.5. 投射
在某些情况下,只需要一小部分属性。使用 Hibernate Search 返回属性子集,如下所示:
Hibernate Search 从 Lucene 索引中提取属性,并将它们转换为其对象表示法并返回对象[] 列表。预测可防止数据库往返用时。但是,它们有以下限制:
-
生成的属性必须存储在索引(@
Field(store=Store.YES))中,这会增加索引大小。 生成的属性必须使用 field
Bridge实施 org.hibernate.search.bridge.TwoWayFieldBridge 或org.hibernate.search.bridge.TwoWayStringBridge,后者是简单的版本。注意所有 Hibernate 搜索内置类型都是双向的。
- 只有索引实体或其嵌入式关联的简单属性才能被投射。因此无法预测整个嵌入式实体。
- 投射不适用于通过 @IndexedEmbedded 索引的集合或映射。
Lucene 提供有关查询结果的元数据信息。使用投射常量来检索元数据。
示例:使用 Projection Retrieve Metadata
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.;
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
float score = firstResult[0];
Book book = firstResult[1];
String authorName = firstResult[2];
字段可以与以下投射常量混合:
- FullTextQuery.THIS:返回初始化的和管理实体 (作为非投射查询完成)。
- FullTextQuery.DOCUMENT:返回与投射对象相关的 Lucene Document。
- FullTextQuery.OBJECT_CLASS:返回索引实体的类。
- FullTextQuery.SCORE:返回查询中的文档分数。分数可以轻松地将一个结果与给定查询的另一个结果进行比较,但在比较不同查询的结果时却毫无用处。
- FullTextQuery.ID:投射对象的 ID 属性值。
- FullTextQuery.DOCUMENT_ID:Lucene 文档 ID。谨慎使用这个值作为 Lucene 文档 ID 可能会在两个不同的 IndexReader 打开之间随时间变化。
- FullTextQuery.EXPLANATION:返回给定查询中匹配对象 /文档的 Lucene Explanation 对象。这不适用于检索大量数据。运行解释通常与每个匹配元素运行整个 Lucene 查询的成本相同。因此,建议预测。
7.5.1.10.6. 自定义对象初始化策略
默认情况下,Hibernate Search 使用最合适的策略来初始化与完整文本查询匹配的实体。它将执行一个或多个查询,以检索所需的实体。这种方法可最大程度减少数据库行程,其中仅有些检索到的实体存在于持久性上下文(会话)或第二级缓存中。
如果第二级缓存中存在实体,请强制 Hibernate Search 在检索数据库对象之前查看缓存。
示例:使用查询检查第二个缓存前的
FullTextQuery query = session.createFullTextQuery(luceneQuery, User.class);
query.initializeObjectWith(
ObjectLookupMethod.SECOND_LEVEL_CACHE,
DatabaseRetrievalMethod.QUERY
);
ObjectLookupMethod 定义用于检查对象是否可轻松访问的策略(不从数据库获取)。其他选项有:
-
ObjectLookupMethod.PERSISTENCE_CONTEXT如果很多匹配实体已加载到持久上下文(加载在 Session 或 EntityManager 中),则会使用。 -
ObjectLookupMethod.SECOND_LEVEL_CACHE检查持久上下文,然后检查第二级缓存。
将以下内容设置为在二级缓存中搜索:
- 正确配置和激活第二级缓存。
- 为相关实体启用第二级缓存。这通过 @Cacheable 等注释来完成。
-
为 Session、实体管理器或查询启用二级缓存读取访问权限。在 Hibernate 原生 API 或 Jakarta Persistence 中的
CacheRetrieveMode.USE 中使用 CacheMode.NORMAL。
除非第二级缓存实施为 Infinispan,否则不使用 ObjectLookupMethod.SECOND_LEVEL_CACHE。其他第二级缓存提供商无法有效地实施此操作。
使用 DatabaseRetrievalMethod 自定义从数据库加载对象的方式,如下所示:
- QUERY (默认)使用一组查询来加载每个批处理中的多个对象。建议采用这种方法。
-
FIND_BY_ID 使用
Session.get或EntityManager.find语义一次加载一个对象。如果为实体设置了批处理大小,则建议这样做,这将允许 Hibernate Core 批量加载实体。
7.5.1.10.7. 限制查询的时间
按照如下所述,限制 Hibernate 指南中查询花费的时间:
- 在达到极限时引发异常。
- 限制为在引发时间限制时检索的结果数。
7.5.1.10.8. 引发时间限制例外
如果查询使用的时间超过定义的时间,则会引发 QueryTimeoutException(org.hibernate.QueryTimeoutException 或 javax.persistence.QueryTimeoutException,具体取决于编程 API)。
要使用原生 Hibernate API 时定义限制,请使用以下方法之一:
示例:在查询执行中定义超时
Query luceneQuery = ...;
FullTextQuery query = fullTextSession.createFullTextQuery(luceneQuery, User.class);
//define the timeout in seconds
query.setTimeout(5);
//alternatively, define the timeout in any given time unit
query.setTimeout(450, TimeUnit.MILLISECONDS);
try {
query.list();
}
catch (org.hibernate.QueryTimeoutException e) {
//do something, too slow
}
getResultSize()、heerate()和 scroll()遵循超时,直到方法调用的末尾。因此,Sterable 或 ScrollableResults 会忽略超时。另外,explain()也不满足这个超时期限。此方法用于调试,并检查查询性能较慢的原因。
以下是使用 Jakarta Persistence 限制执行时间的标准方法:
示例:在查询执行中定义超时
Query luceneQuery = ...;
FullTextQuery query = fullTextEM.createFullTextQuery(luceneQuery, User.class);
//define the timeout in milliseconds
query.setHint( "javax.persistence.query.timeout", 450 );
try {
query.getResultList();
}
catch (javax.persistence.QueryTimeoutException e) {
//do something, too slow
}
示例代码不能保证查询以指定的结果数量停止。
7.5.2. 检索结果
构建 Hibernate 查询后,它将像 HQL 或标准查询一样执行。同样的范式和对象语义适用于 Lucene Query 查询,以及 list()、unique Result()、iterate () 和 scroll () 等常见操作。
7.5.2.1. 性能注意事项
如果您期望合理数量的结果(例如使用分页)并且希望对所有结果进行处理,则建议使用 )。如果实体 list() 或唯一Result(批处理大小设置正确,则 效果最佳。请注意,在使用 list( )list()、 在分 唯一结果()和iterate()时,Hibernate Search 必须 处理所有 Lucene Hits 元素(页中 )。
如果要最大程度减少 Lucene 文档加载,滚动() 更为合适。完成后,不要忘记关闭 ScrollableResults 对象,因为它会保留 Lucene 资源。如果您计划使用滚动,但希望批量加载对象,您可以使用 query。setFetchSize( )。当对象被访问后,如果还没有加载,Hibernate Search 将通过一次加载下一个 fetchSize 对象。
分页优先于滚动。
7.5.2.2. 结果大小
有时,了解匹配文档总数很有用:
- 提供由 Google 搜索提供的总搜索结果功能。例如,"在大约 888,000,000 结果中,1-10"
- 实施快速分页导航
- 实施多步骤搜索引擎,以便在受限查询返回零或没有足够的结果时添加约法
当然,检索所有匹配文件的成本过高。Hibernate Search 允许您检索匹配文档的总数,而不考虑分页参数。更有趣的是,您可以检索匹配元素的数量,而无需触发单个对象负载。
示例:确定查询的结果大小
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
//return the number of matching books without loading a single one
assert 3245 == ;
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setMaxResult(10);
List results = query.list();
//return the total number of matching books regardless of pagination
assert 3245 == ;
与 Google 一样,如果索引未完全与数据库保持最新(例如,异步集群),则结果数量是近似的。
7.5.2.3. ResultTransformer
投射结果返回为对象数组。如果对象使用的数据结构与应用的要求不匹配,请应用 ResultTransformer。ResultTransformer 在执行查询后构建必要的数据结构。
示例:在 Projections 中使用 ResultTransformer
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "title", "mainAuthor.name" );
query.setResultTransformer( new StaticAliasToBeanResultTransformer( BookView.class, "title", "author" ) );
List<BookView> results = (List<BookView>) query.list();
for(BookView view : results) {
log.info( "Book: " + view.getTitle() + ", " + view.getAuthor() );
}
ResultTransformer 实施示例可在 Hibernate 核心代码库中找到。
7.5.2.4. 了解结果
如果查询的结果不是您预期的,luke 工具 对了解结果很有用。但是,Hibernate Search 还允许您访问给定结果(给定查询中)的 Lucene Explanation 对象。此类对于 Lucene 用户而言比较先进,但可以很好地理解对象的评分。您可以通过两种方式访问给定结果的说明对象:
-
使用
fullTextQuery.explain(int)方法 - 使用投射
第一种方法将文档 ID 用作参数并返回说明对象。文档 ID 可使用投影和 FullTextQuery.DOCUMENT_ID 常量来检索。
文档 ID 与实体 ID 无关。注意不要混淆这些概念。
在第二种方法中,您使用 FullTextQuery.EXPLANATION 常数来预测说明对象。
示例:使用 Projection 检索 Lucene 解释对象
FullTextQuery ftQuery = s.createFullTextQuery( luceneQuery, Dvd.class )
.setProjection(
FullTextQuery.DOCUMENT_ID,
,
FullTextQuery.THIS );
@SuppressWarnings("unchecked") List<Object[]> results = ftQuery.list();
for (Object[] result : results) {
Explanation e = (Explanation) result[1];
display( e.toString() );
}
只有在需要时才使用说明对象,因为它与再次运行 Lucene 查询的成本大致相同。
7.5.2.5. 过滤器
Apache Lucene 具有强大的功能,允许您根据自定义过滤流程过滤查询结果。这是应用其他数据限制的一种非常强大的方式,特别是可以缓存和重复利用过滤器。使用案例包括:
- security
- 时序数据(例如,仅查看上个月的数据)
- 填充过滤器(例如,搜索仅限于给定类别)
Hibernate 搜索通过引入透明缓存的可参数名称过滤器的概念来进一步推动概念。对于熟悉 Hibernate 内核过滤器概念的用户,API 非常相似:
示例:为查询启用 Fulltext Filters
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("bestDriver");
fullTextQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
fullTextQuery.list(); //returns only best drivers where andre has credentials
在本例中,我们在查询之上启用了两个过滤器:您可以根据需要启用或禁用任意数量的过滤器。
声明过滤器是通过 @FullTextFilterDef 注释来完成的。此注释可以位于任何 @Indexed 实体上,无论过滤器稍后要应用到哪一个查询。这意味着过滤定义是全局的,并且它们的名称必须唯一。如果定义了两个名称相同的注释,则会抛出 SearchException,以防有两个不同的 @FullTextFilterDef 注释。每个命名过滤器都必须指定其实际的过滤器实施。
示例:定义和实施过滤器
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }
public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet( reader.maxDoc() );
TermDocs termDocs = reader.termDocs( new Term( "score", "5" ) );
while ( termDocs.next() ) {
bitSet.set( termDocs.doc() );
}
return bitSet;
}
}
BestDriversFilter 是一个简单的 Lucene 过滤器的例子,它可将结果集减少到分数为 5 的驱动程序。在本例中,指定的过滤器直接实施 org.apache.lucene.search.Filter,并且包含 no-arg 构造器。
如果您的 Filter 创建需要额外的步骤,或者您想要使用的过滤器没有 no-arg 构造器,您可以使用工厂模式:
示例:使用 Factory Pattern 创建过滤器
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}
Hibernate Search 将查找带注释的 @Factory 方法,并使用它来构建过滤器实例。工厂必须具有 no-arg 构造器。
Infinispan Query 使用 @Factory 注释的方法来构建过滤器实例。该工厂必须具有无参数构造器。
使用命名过滤器时,参数必须传递到过滤器。例如,安全过滤器可能想要了解您要应用哪个安全级别:
示例:将参数传递给定义的过滤器
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("security").setParameter( "level", 5 );
每一参数名称应对过滤器或过滤目标命名过滤器定义的工厂关联集合器。
示例:在实际过滤器实施中使用参数
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter( level );
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery( new Term("level", level.toString() ) );
return new CachingWrapperFilter( new QueryWrapperFilter(query) );
}
}
注意注释为 @Key 的方法返回 FilterKey 对象。返回的对象具有特殊合同:密钥对象必须实现等效的()/ hashCode(),这样,只有在给定 Filter 类型相同并且参数集相同时,两个键才相等。换句话说,两个过滤器键是相等的,只有在可以交换从中生成键的过滤器时才适用。密钥对象用作缓存机制中的密钥。
只有在以下情况下才需要 @key 方法:
- 过滤器缓存系统被启用(默认启用)
- 过滤器有参数
在大多数情况下,使用 StandardFilterKey 实现会足够好。它将等号()/ hashCode()实现委派到每个参数等于和 hashcode 方法。
如前文所述,定义的过滤器按默认设置进行缓存,缓存使用硬链接和软引用组合来允许在需要时处理内存。硬引用缓存跟踪最近使用的过滤器,并在需要时转换最不用于 SoftReferences 的过滤器。达到硬引用缓存的限制后,其他过滤器将缓存为 SoftReferences。要调整硬引用缓存的大小,请使用 hibernate.search.filter.cache_strategy.size (默认为 128)。如需高级使用过滤器缓存,请实现您自己的 FilterCachingStrategy。classname 由 hibernate.search.filter.cache_strategy 定义。
此过滤器缓存机制不应与缓存实际过滤器结果混淆。在 Lucene 中,通常的做法是使用 IndexReader 围绕 CachingWrapperFilter 包装过滤器。打包程序将缓存 getDocIdSet(IndexReader reader) 方法返回的 DocIdSet,以避免昂贵的重新输入。务必要提及,计算的 DocIdSet 仅适用于同一 IndexReader 实例,因为读取器在打开时有效地代表索引的状态。打开的 IndexReader 中无法更改文档列表。但是,不同的/新的 IndexReader 实例可能会在另一组文档中正常工作(可以是来自不同的索引,还是仅仅因为索引已更改),因此必须重新计算缓存的 DocIdSet。
Hibernate 搜索也有助于实现缓存的这一方面。默认情况下,@FullTextFilterDef 的 缓存 标志被设置为 FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS,它将自动缓存过滤器实例,并将指定的过滤器围绕 CachingWrapperFilter 的 Hibernate 实施包装。与此类 SoftReferences 的 Lucene 版本和硬参考计数一起使用(请参阅关于过滤缓存)。可以使用 hibernate.search.filter.cache_docidresults.size (默认为 5)来调整硬引用计数。可以使用 @FullTextFilterDef.cache 参数控制嵌套行为。这个参数有三个不同的值:
| 值 | 定义 |
|---|---|
| FilterCacheModeType.NONE | 没有过滤实例,Hibernate Search 也不会缓存任何结果。对于每个过滤器调用,都会创建一个新的过滤器实例。此设置对于快速更改数据集或大量内存受限环境可能有用。 |
| FilterCacheModeType.INSTANCE_ONLY | 过滤器实例在并发 Filter.getDocIdSet()调用之间缓存和重复利用。DocIdSet 结果不会被缓存。当过滤器使用自己的特定缓存机制或过滤器结果因为应用程序特定的事件在这两种情况下都不需要造成 DocIdSet 缓存而动态更改时,此设置很有用。 |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | 过滤器实例和 DocIdSet 结果都会被缓存。这是默认值。 |
在以下情况下,应缓存过滤器:
- 系统不会经常更新目标实体索引(换句话说,IndexReader 被大量重用)
- Filter 的 DocIdSet 计算成本高昂(与执行查询的时间相对相对)
7.5.2.6. 在共享环境中使用过滤器
在分片环境中,可以对可用分片的子集执行查询。这可以通过两个步骤完成:
查询索引共享的子集
- 创建一个分片策略,它将根据过滤器配置选择 IndexManagers 的子集。
- 在查询时激活过滤器。
示例:查询索引共享的子集
在本例中,如果激活了 客户 过滤器,查询会针对特定的客户分片运行。
public class CustomerShardingStrategy implements IndexShardingStrategy {
// stored IndexManagers in an array indexed by customerID
private IndexManager[] indexManagers;
public void initialize(Properties properties, IndexManager[] indexManagers) {
this.indexManagers = indexManagers;
}
public IndexManager[] getIndexManagersForAllShards() {
return indexManagers;
}
public IndexManager getIndexManagerForAddition(
Class<?> entity, Serializable id, String idInString, Document document) {
Integer customerID = Integer.parseInt(document.getFieldable("customerID").stringValue());
return indexManagers[customerID];
}
public IndexManager[] getIndexManagersForDeletion(
Class<?> entity, Serializable id, String idInString) {
return getIndexManagersForAllShards();
}
/**
* Optimization; don't search ALL shards and union the results; in this case, we
* can be certain that all the data for a particular customer Filter is in a single
* shard; simply return that shard by customerID.
*/
public IndexManager[] getIndexManagersForQuery(
FullTextFilterImplementor[] filters) {
FullTextFilter filter = getCustomerFilter(filters, "customer");
if (filter == null) {
return getIndexManagersForAllShards();
}
else {
return new IndexManager[] { indexManagers[Integer.parseInt(
filter.getParameter("customerID").toString())] };
}
}
private FullTextFilter getCustomerFilter(FullTextFilterImplementor[] filters, String name) {
for (FullTextFilterImplementor filter: filters) {
if (filter.getName().equals(name)) return filter;
}
return null;
}
}
在本例中,如果存在名为 customer 的过滤器,则只会查询专用于此客户的分片,否则将返回所有分片。给定分片策略可以响应一个或多个过滤器,并依赖于其参数。
第二步是在查询时激活过滤器。尽管过滤器可以是常规过滤器(如 中定义的),它也在查询后过滤 Lucene 结果,但您可以使用仅传递给分片策略(否则将被忽略)的特殊过滤器。
要使用此功能,请在声明过滤器时指定 ShardSensitiveOnlyFilter 类。
@Indexed
@FullTextFilterDef(name="customer", impl=ShardSensitiveOnlyFilter.class)
public class Customer {
...
}
FullTextQuery query = ftEm.createFullTextQuery(luceneQuery, Customer.class);
query.enableFulltextFilter("customer").setParameter("CustomerID", 5);
@SuppressWarnings("unchecked")
List<Customer> results = query.getResultList();请注意,通过使用 ShardSensitiveOnlyFilter,您不必实施任何 Lucene 过滤器。建议使用过滤器和分片策略来加快分片环境中的查询。
7.5.3. Faceting
分面搜索是一种将查询结果划分为多个类别的技术。这种分类包括每个类别的点击数计算,以及根据这些方面进一步限制搜索结果的能力(说明)。以下示例显示了一个现实示例。搜索结果以 15 次命中显示在页面主部分中。但是,左侧的导航栏显示了计算机和互联网类别及其子类别 编程、计算机科学、数据库、软件、Web 开发、 网络和家庭 计算。对于每个子类别,显示图书数量与主要搜索标准相符,并属于相应的子类别。这种"计算机和互联网"类别划分是一个具体的搜索面。另一个是平均客户评论。
分面搜索将查询的结果划分为不同的类别。分类包括每个类别的点击数计算,并根据这些方面(类别)进一步限制搜索结果。以下示例在主页面中以 15 个命中显示单面搜索结果。
左侧导航栏显示类别和子类别。对于每个子类别,图书的数量都与主要搜索标准匹配,并属于相应的子类别。这种"计算机和互联网"类别划分是一个具体的搜索面。另一个例子是平均客户评论。
示例:在 Amazon 上搜索 Hibernate Search
在 Hibernate Search 中,类 QueryBuilder 和 FullTextQuery 是面临 API 的入口点。前者会创建各种请求,后者将访问 FacetManager。FacetManager 对查询应用各种请求,并选择添加到现有查询中的侧面,以优化搜索结果。示例使用实体 Cd,如下例所示:
示例:实体 Cd
@Indexed
public class Cd {
private int id;
@Fields( {
@Field,
@Field(name = "name_un_analyzed", analyze = Analyze.NO)
})
private String name;
@Field(analyze = Analyze.NO)
@NumericField
private int price;
Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date releaseYear;
@Field(analyze = Analyze.NO)
private String label;
// setter/getter
...
在 Hibernate Search 5.2 之前,无需显式使用 @Facet 注释。在 Hibernate Search 5.2 中,为了使用 Lucene 的原生面 API,有必要使用 Lucene。
7.5.3.1. 创建 Faceting 请求
进行分面搜索的第一步是创建 FacetingRequest。目前支持两种类型的相互竞争请求。第一种类型称为离散面,第二个类型 范围则面临请求。如果是离散的面貌请求,您可以指定您要在哪个索引字段上查看(分类)以及要应用哪些选项。以下示例中显示了离散侧面请求的示例:
示例:创建离散 Faceting 请求
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest labelFacetingRequest = builder.facet()
.name( "labelFaceting" )
.onField( "label")
.discrete()
.orderedBy( FacetSortOrder.COUNT_DESC )
.includeZeroCounts( false )
.maxFacetCount( 1 )
.createFacetingRequest();
在执行此竞争请求时,将为索引化字段 标签 的每个离散值创建 Facet 实例。Facet 实例将记录实际字段值,包括此特定字段值在原始查询结果中发生的频率。orderBy、includeZeroCounts 和 maxFacetCount 是可选参数,可在任何面临请求时应用。OrderBy 允许指定返回所创建面的顺序。默认值为 FacetSortOrder.COUNT_DESC,但您也可以根据字段值或指定范围的顺序排序。includeZeroCount 决定结果中是否包括数为 0 的面数(默认为 ),而 maxFacetCount 允许限制返回的最大面数。
目前,索引化字段必须满足几个前提条件才能对其应用。索引化属性必须是 String、Date 或 Number 和 null 值的子类型。此外,该属性必须使用 Analyze .NO 进行索引,如果是数值属性 @NumericField,则需要指定。
范围侧面请求的创建非常相似,除非我们必须为所面对的字段值指定范围。下面列出了指定了三个不同价格范围的范围。以下 及以上 只能指定一次,但您可以根据需要 从 - 指定为 范围。对于每个范围边界,您还可以通过 excludeLimit 来指定它是否包含在范围中。
示例:创建一个范围 Faceting 请求
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest priceFacetingRequest = builder.facet()
.name( "priceFaceting" )
.onField( "price" )
.range()
.below( 1000 )
.from( 1001 ).to( 1500 )
.above( 1500 ).excludeLimit()
.createFacetingRequest();
7.5.3.2. 应用查找请求
侧面请求通过 FacetManager 类应用到查询,该类可通过 FullTextQuery 类检索。
您可以像您一样启用任意数量的请求,并在随后通过 getFacets()指定对象请求名称来检索它们。还有一个 disableFaceting()方法,允许您通过指定它的名称来禁用遇到请求。
可以利用 FacetManager 对查询应用竞争请求,该请求可通过 FullTextQuery 检索。
示例:应用查找请求
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Cd.class ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cds List<Cd> cds = fullTextQuery.list(); ... // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); ...
可以使用 getFacets() 并指定 faceting 请求名称来检索多个侧面请求。
disableFaceting() 方法通过指定名称来禁用争用请求。
7.5.3.3. 限制查询结果
最后,您可以将任何返回的 Facets 应用为原始查询的额外标准,以实现"中断"功能。为此,可使用 FacetSelection。FacetSelections 可以通过 FacetManager 使用,并允许您将一个面t选为查询标准(selectFacets)、删除面限制(deselectFacets)、移除所有面限制(clearSelectedFacets),并检索所有当前选定的侧面(getSelectedFacets)。以下代码片段演示了一个示例:
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, clazz ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cd List<Cd> cds = fullTextQuery.list(); assertTrue(cds.size() == 10); // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); assertTrue(facets.get(0).getCount() == 2) // apply first facet as additional search criteria facetManager.getFacetGroup( "priceFaceting" ).selectFacets( facets.get( 0 ) ); // re-execute the query cds = fullTextQuery.list(); assertTrue(cds.size() == 2);
7.5.4. 优化查询过程
查询性能取决于几个条件:
- Lucene 查询。
- 加载的对象数量:使用分页(始终)或索引投射(如果需要)。
- Hibernate 搜索与 Lucene 读取器交互的方式:定义相应的读取器策略。
- 从索引中缓存经常提取的值。如需更多信息,请参阅 缓存索引值:fieldCache。
7.5.4.1. 缓存索引值:fieldCache
Lucene 索引的主要功能是识别与您查询的匹配项。在执行查询后,必须分析结果,以提取有用的信息。Hibernate 搜索通常需要提取类类型和主密钥。
从索引中提取所需的值具有性能成本,在某些情况下这可能非常低且不容易,但在某些情况下,这可能是缓存的良好候选者。
要求取决于使用的 Projections 的类型,因为在某些情况下不需要类类型,因为它可以从查询上下文或其他方法推断出来。
使用 @CacheFromIndex 注释,您可以试验 Hibernate Search 所需的各种主元数据字段:
import static org.hibernate.search.annotations.FieldCacheType.CLASS;
import static org.hibernate.search.annotations.FieldCacheType.ID;
@Indexed
@CacheFromIndex( { CLASS, ID } )
public class Essay {
...可以使用此注解缓存类类型和 ID:
CLASS:Hibernate Search 将使用 Lucene FieldCache 来提高从索引中提取类类型的性能。此值默认为启用,如果您不指定 @CacheFromIndex 注释,则应用 Hibernate Search。
-
ID:提取主标识符将使用缓存。这有可能提供最佳性能查询,但会消耗更多的内存,进而可能会降低性能。
测量静止后性能和内存消耗的影响(执行某些查询)。通过启用字段缓存可以提高性能,但情况并非始终如此。
使用 FieldCache 有两个缺点需要考虑:
- 内存使用情况:这些缓存可能会相当耗尽内存。通常 CLASS 缓存的要求低于 ID 缓存。
- 索引温:使用字段缓存时,新索引或分段上的第一个查询将比未启用缓存时慢。
对于某些查询,根本不需要类类型,在这种情况下,即使您启用了 CLASS 字段缓存,也可能不会使用它;例如,如果您的目标为一个类,很明显,所有返回的值都将是该类型(每次查询执行中都会评估)。
若要使用 ID FieldCache,目标实体的 ID 必须使用 TwoWayFieldBridge(作为所有构建的网桥),并且特定查询中加载的所有类型都必须将 fieldname 用于 id,并且具有相同类型的 ID(每次执行查询时都会进行评估)。
7.6. 手动索引更改
当 Hibernate Core 对数据库应用更改时,Hibernate Search 会检测到这些更改并自动更新索引(除非禁用了 EventListeners)。有时会在不使用 Hibernate 的情况下对数据库进行更改,因为备份恢复或者您的数据会受到影响。在这些情况下,Hibernate Search 会公开 Manual Index API 来显式更新或删除索引中的单个实体,重建整个数据库的索引,或删除对特定类型的所有引用。
所有这些方法仅影响 Lucene index,不会对数据库应用任何更改。
7.6.1. 将实例添加到索引
使用 FullTextSession.index(T 实体),您可以直接添加或更新特定对象实例到索引。如果此实体已经索引,则会更新索引。对索引的更改仅在事务提交时应用。
使用 FullTextSession.index(T 实体) 直接将对象或实例添加到索引中。索引会在实体索引时更新。Infinispan Query 在事务提交过程中对索引应用更改。
示例:使用 FullTextSession.index(T 实体)来索引实体.
FullTextSession fullTextSession = Search.getFullTextSession(session); Transaction tx = fullTextSession.beginTransaction(); Object customer = fullTextSession.load( Customer.class, 8 ); fullTextSession.index(customer); tx.commit(); //index only updated at commit time
如果您想要为类型或者所有索引类型添加所有实例,推荐的方法是使用 MassIndexer:请参阅 以了解更多详细信息。
使用 MassIndexer 添加类型(或所有索引类型)的所有实例。如需更多信息,请参阅使用 MassIndexer。
7.6.2. 从索引中删除实例
可以从 Lucene 索引中删除给定类型的实体或所有实体,而无需将它们从数据库中物理删除。此操作名为清除,也通过 FullTextSession 进行。
清除操作允许从 Lucene 索引中删除单个实体或指定类型的所有实体,而无需将它们从数据库中物理删除。此操作使用 FullTextSession 来执行。
示例:从索引中清除实体的特定实例
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
for (Customer customer : customers) {
fullTextSession.purgeAll( Customer.class );
//optionally optimize the index
//fullTextSession.getSearchFactory().optimize( Customer.class );
tx.commit(); //index is updated at commit time
建议在此类操作后优化索引。
FullTextEntityManager 上也提供方法索引、清除和清除All。
所有手动索引方法(index、purge 和 purgeAll)都只会影响索引,而不是数据库,但是在事务成功提交或您使用 flushToIndexes 之前不会应用它们。
7.6.3. 重新构建索引
如果您更改了实体映射到索引,则有可能需要更新整个索引;例如,如果您决定使用其他分析器索引现有字段,您需要重新构建受影响类型的索引。另外,如果数据库被替换(例如从备份中恢复,从传统系统导入),您将希望能够从现有数据重建索引。Hibernate Search 提供两种主要策略:
在索引器中更改实体映射可能需要更新整个索引。例如,如果要使用其他分析器索引现有字段,则需要为受影响的类型重新构建索引。
此外,如果数据库被从备份中恢复或从传统系统导入,则需要从现有数据重新构建索引。Infinispan Query 提供两个主要策略:
-
定期使用
FullTextSession.flushToIndexes(),同时在所有实体上使用 FullTextSession.index()。 -
使用
MassIndexer。
7.6.3.1. 使用 flushToIndexes()
此策略包括删除现有索引,然后使用 FullTextSession.purgeAll()和 FullTextSession.index() 将所有实体重新添加到索引中,但有一些内存和效率限制。为最大程度提高效率 Hibernate 搜索批处理索引操作,并在提交时执行它们。如果您希望为大量数据编制索引,您需要小心谨慎,因为所有文档都会保留在队列中,直到事务提交为止。如果您不定期清空队列,则可能会出现 OutOfMemoryException; 要使用 fullTextSession.flushToIndexes( )。每次 调用 fullTextSession.flushToIndexes( )(或者提交事务时),都会处理批处理队列,并应用所有索引更改。请注意,一旦刷新,更改就无法回滚。
示例:使用 index()和 flushToIndexes()索引重建
fullTextSession.setFlushMode(FlushMode.MANUAL);
fullTextSession.setCacheMode(CacheMode.IGNORE);
transaction = fullTextSession.beginTransaction();
//Scrollable results will avoid loading too many objects in memory
ScrollableResults results = fullTextSession.createCriteria( Email.class )
.setFetchSize(BATCH_SIZE)
.scroll( ScrollMode.FORWARD_ONLY );
int index = 0;
while( results.next() ) {
index++;
fullTextSession.index( results.get(0) ); //index each element
if (index % BATCH_SIZE == 0) {
fullTextSession.flushToIndexes(); //apply changes to indexes
fullTextSession.clear(); //free memory since the queue is processed
}
}
transaction.commit();
Hibernate.search.default.worker.batch_size 已被弃用,现在它提供了更好的控制
尝试使用批处理大小来确保您的应用不会超出内存:随着批处理大小的对象更快从数据库获取,但需要更多内存。
7.6.3.2. 使用 MassIndexer
Hibernate Search 的 MassIndexer 使用多个并行线程重建索引。您可以选择选择需要重新加载哪些实体或重新索引所有实体。这种方法针对最佳性能进行了优化,但需要将应用程序设置为维护模式。当 MassIndexer 忙碌时,不建议查询索引。
示例:使用 MassIndexer 重新构建索引
fullTextSession.createIndexer().startAndWait();
这将重建索引,将其删除,然后从数据库重新加载所有实体。虽然使用起来简单,但建议进行一些调整以加快流程。
在 MassIndexer 过程中,索引的内容没有定义。如果在 MassIndexer 工作时执行查询,则很可能缺少某些结果。
示例:使用 Tuned MassIndexer
fullTextSession .createIndexer( User.class ) .batchSizeToLoadObjects( 25 ) .cacheMode( CacheMode.NORMAL ) .threadsToLoadObjects( 12 ) .idFetchSize( 150 ) .progressMonitor( monitor ) //a MassIndexerProgressMonitor implementation .startAndWait();
这将重新构建所有用户实例的索引(及子类型),并将创建 12 个并行线程,以在每个查询使用 25 个对象的批处理来加载用户实例。这些相同的 12 个线程还需要处理索引化的嵌入式关系和自定义 FieldBridges 或 ClassBridges,以输出 Lucene 文档。在转换过程中,线程会触发额外属性加载。因此,需要大量并行工作线程。用于实际索引写入的线程数量由每个索引的后端配置定义。
建议将 cacheMode 保留至 CacheMode.IGNORE (默认值),因为在大多数重新索引的情况下,缓存会成为无用的额外开销。根据您的数据启用一些其他缓存模型 可能会很有用,因为如果主实体与索引中包含的类似数字数据相关,可能会提高性能。
实现最佳性能的线程数量理想取决于您的整体架构、数据库设计和数据值。所有内部线程组都有有意义的名称,因此能够使用大多数诊断工具(包括线程转储)轻松识别它们。
MassIndexer 不知道事务,因此无需再开始一项交易或提交。由于它不是事务性的,因此不建议允许用户在处理过程中使用系统,因为它不太可能找到结果,系统负载也可能太高。
其他影响索引时间和内存消耗的参数有:
-
hibernate.search.[default|<indexname>].exclusive_index_use -
hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs -
hibernate.search.[default|<indexname>].indexwriter.max_merge_docs -
hibernate.search.[default|<indexname>].indexwriter.merge_factor -
hibernate.search.[default|<indexname>].indexwriter.merge_min_size -
hibernate.search.[default|<indexname>].indexwriter.merge_max_size -
hibernate.search.[default|<indexname>].indexwriter.merge_max_optimize_size -
hibernate.search.[default|<indexname>].indexwriter.merge_calibrate_by_deletes -
hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size -
hibernate.search.[default|<indexname>].indexwriter.term_index_interval
之前的版本也具有 max_field_length,但这已从 Lucene 中删除。通过使用 LimitTokenCountAnalyzer 可以获得类似的效果。
all .indexwriter 参数是特定于 Lucene 的,Hibernate 搜索通过这些参数.
MassIndexer 使用正向结果仅滚动到要加载的主键,但 MySQL 的 JDBC 驱动程序会加载内存中的所有值。为了避免这个"优化"将 idFetchSize 设置为 Integer.MIN_VALUE。
7.7. 索引优化
Lucene 索引需要不时地进行优化。进程本质上是碎片整理。在触发优化前,Lucene 仅标记已删除的文档,不会应用物理文件。在优化过程中,将应用删除,这也会影响 Lucene 目录中的文件数量。
优化 Lucene 索引可以加快搜索速度,但不影响索引(更新)性能。在优化期间,可以执行搜索,但很有可能会减慢速度。所有索引更新都将停止。建议您调度优化:
优化 Lucene 索引可以加快搜索速度,但不影响索引更新性能。可以在优化过程中执行搜索,但它们比预期要慢。所有索引更新在优化过程中都会被保留。因此,建议调度优化:
- 在空闲的系统上或搜索频率最低时。
- 应用大量索引修改后。
MassIndexer 在处理开始和结束时默认优化索引。使用 MassIndexer.optimizeAfterPurge 和 MassIndexer.optimizeOnFinish 更改此默认行为。如需更多信息,请参阅使用 MassIndexer。
7.7.1. 自动优化
Hibernate 搜索可以在以下任一后自动优化索引:
Infinispan Query 在以下自动优化索引:
- 特定的操作(插入或删除)。
- 特定的交易量。
自动索引优化配置可以全局定义,也可以为每个索引定义:
示例:定义自动优化参数
hibernate.search.default.optimizer.operation_limit.max = 1000 hibernate.search.default.optimizer.transaction_limit.max = 100 hibernate.search.Animal.optimizer.transaction_limit.max = 50
优化过程会立即触发 Animal 索引:
-
添加和删除的数量达到
1000。 -
事务数量达到
50(hibernate.search.Animal.optimizer.transaction_limit.max)具有高于hibernate.search.default.optimizer.transaction_limit.max的优先级。
如果没有定义任何这些参数,则不会自动处理优化。
OptimizerStrategy 的默认实现可以被实现 org.hibernate.search.store.optimization.OptimizerStrategy 覆盖,并将 optimizer. implementation 属性 设置为实施的完全限定名称。此实施必须实施 接口(为公共类),并且具有不带任何参数的公共构造器。
示例:载入自定义 OptimizerStrategy
hibernate.search.default.optimizer.implementation = com.acme.worlddomination.SmartOptimizer hibernate.search.default.optimizer.SomeOption = CustomConfigurationValue hibernate.search.humans.optimizer.implementation = default
关键字 default 可用于选择 Hibernate Search 默认实施;启动时,.optimizer 键分隔符之后的所有属性都将传递给实施的初始方法。
7.7.2. 手动优化
您可以通过 SearchFactory 以编程方式从 Hibernate Search 优化(碎片)Lucene 索引:
示例:编程索引优化
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory(); searchFactory.optimize(Order.class); // or searchFactory.optimize();
第一个示例优化了保存顺序的 Lucene 索引,第二个示例优化了所有索引。
searchFactory.optimize() 对 Jakarta 消息传递后端没有影响。您必须在 Master 节点上应用优化操作。
searchFactory.optimize() 应用到 master 节点,因为它不会影响 Jakarta Messaging 后端。
7.7.3. 调整优化
Apache Lucene 有几个参数可影响执行优化的方式。Hibernate Search 可公开这些参数。
进一步索引优化参数包括:
-
hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs -
hibernate.search.[default|<indexname>].indexwriter.max_merge_docs -
hibernate.search.[default|<indexname>].indexwriter.merge_factor -
hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size -
hibernate.search.[default|<indexname>].indexwriter.term_index_interval
7.8. 高级功能
7.8.1. 访问 SearchFactory
SearchFactory 对象跟踪 Hibernate Search 的底层 Lucene 资源。它是原生访问 Lucene 的便捷方式。SearchFactory 可以从 FullTextSession 访问:
示例:访问 SearchFactory
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory();
7.8.2. 使用 IndexReader
Lucene 中的查询在 IndexReader 上执行。Hibernate 搜索可能会缓存索引读取器以最大化性能,或者提供其他有效策略来检索更新的 indexReader 最小化 I/O 操作。您的代码可以访问这些缓存的资源,但有几个要求。
示例:访问 IndexReader
IndexReader reader = searchFactory.getIndexReaderAccessor().open(Order.class);
try {
//perform read-only operations on the reader
}
finally {
searchFactory.getIndexReaderAccessor().close(reader);
}
在本例中,SearchFactory 确定查询此实体需要哪些索引(包含分片策略)。使用每个索引上配置的 ReaderProvider,它会在所有涉及的索引之上返回复合 IndexReader。因为这个 IndexReader 在多个客户端间共享,所以您必须遵循以下规则:
- 从不调用 indexReader.close(),而是在需要时使用 readerProvider.closeReader(reader),最好是在最后的块中。
- 不要使用此 IndexReader 进行修改操作(它是只读 indexReader,任何这种尝试都将导致异常)。
除了这些规则外,您还可以自由使用 IndexReader,特别是执行原生 Lucene 查询。使用共享 IndexReaders 时,与从文件系统直接打开一个查询相比,将提高大多数查询的效率。
作为方法 open(Class… type)的替代方案,您可以使用 open(String… indexNames),允许您传递一个或多个索引名称。如果使用分片,您还可以使用此策略为任何索引类型选择索引子集。
示例:按索引名称访问 IndexReader
IndexReader reader = searchFactory.getIndexReaderAccessor().open("Products.1", "Products.3");
7.8.3. 访问 Lucene 目录
目录是 Lucene 用来表示索引存储的最常见抽象;Hibernate Search 不会直接与 Lucene Directory 交互,而是通过索引管理器提取这些交互:索引不一定需要由目录实施。
如果您知道您的索引是表示为目录且需要访问它,您可以通过 IndexManager 获得对目录的引用。将 IndexManager 转换为 DirectoryBasedIndexManager,然后使用 getDirectoryProvider().getDirectory() 来获取对底层目录的引用。不建议您这样做,我们鼓励改为使用 IndexReader。
7.8.4. sharding Indexes
在某些情况下,将给定实体的索引化数据分到几个 Lucene 索引中非常有用。
只有在优点大于缺点时才应实施分片。搜索分片索引通常较慢,因为所有分片都必须打开一次搜索。
分片的可能用例是:
- 单个索引非常大,因此索引更新时间正在减慢应用程序的速度。
- 典型的搜索只会达到索引的一个子集,例如数据自然被客户、区域或应用细分。
默认情况下不启用分片,除非配置了分片数量。要做到这一点,请使用 hibernate.search.<indexName>.sharding_strategy.nbr_of_shards 属性。
示例:启用索引划分
在本例中,启用五个分片。
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards = 5
负责将数据拆分为 sub-indexes 是 indexShardingStrategy。默认分片策略会根据 ID 字符串表示法的散列值(由 FieldBridge 生成)来分割数据。这可确保比较平衡的分片。您可以通过实施自定义 IndexShardingStrategy 来替换默认策略。要使用自定义策略,您必须设置 hibernate.search.<indexName>.sharding_strategy 属性。
示例:指定自定义划分策略
hibernate.search.<indexName>.sharding_strategy = my.shardingstrategy.Implementation
IndexShardingStrategy 属性还允许通过选择针对哪个分片运行查询来优化搜索。通过激活过滤器,分片策略可以选择用于应答查询的分片的子集(IndexShardingStrategy.getIndexManagersForQuery),从而加快查询执行。
每个分片都有独立的 IndexManager,因此可以配置为使用不同的目录供应商和后端配置。以下示例中 Animal 实体的 IndexManager 索引名称是 Animal.0 到 Animal.4。换句话说,每个分片都有其自己的索引的名称,后跟 . (dot)及其索引号。
示例:对实体 Animal 进行划分配置
hibernate.search.default.indexBase = /usr/lucene/indexes hibernate.search.Animal.sharding_strategy.nbr_of_shards = 5 hibernate.search.Animal.directory_provider = filesystem hibernate.search.Animal.0.indexName = Animal00 hibernate.search.Animal.3.indexBase = /usr/lucene/sharded hibernate.search.Animal.3.indexName = Animal03
在上例中,配置使用默认的 id 字符串散列策略,并将 Animal 索引分片为 5 子索引。所有子索引都是文件系统实例,以及存储每个子索引的目录如下:
-
对于 sub-index 0:
/usr/lucene/indexes/Animal00(共享 indexBase,但覆盖 indexName) -
对于子索引 1:
/usr/lucene/indexes/Animal.1(共享索引Base,默认 indexName) -
对于子索引 2:
/usr/lucene/indexes/Animal.2(共享 indexBase,默认 indexName) -
对于 sub-index 3:
/usr/lucene/shared/Animal03(覆盖索引Base,覆盖 indexName) -
对于子索引 4:
/usr/lucene/indexes/Animal.4(共享 indexBase,默认 indexName)
在实施 IndexShardingStrategy 时,可使用任何字段来确定分片选择。考虑为了处理删除、清除 和清除All 操作,实施可能需要返回一个或多个索引,而无需读取所有字段值或主标识符。在这种情况下,信息不足以选择一个索引,应该返回所有索引,以便将删除操作传播到所有可能包含要删除的文档的索引。
7.8.5. 自定义 Lucene 的 Scoring Formula
Lucene 允许用户通过扩展 org.apache.lucene.search.Similarity 来自定义其评分公式。此类中定义的抽象方法与计算文档 d 查询 q 分数的以下公式因素相符:
扩展 org.apache.lucene.search.Similarity,以自定义 Lucene 的评分公式。抽象方法与 用于计算 文档 d 查询分数的公式匹配,如下所示:
*score(q,d) = coord(q,d) · queryNorm(q) · ∑ ~t in q~ ( tf(t in d) · idf(t) ^2^ · t.getBoost() · norm(t,d) )*
| factor | 描述 |
|---|---|
| tf(t ind) | 文档(d)中术语(t)的术语频率因素。 |
| idf(t) | 术语的反向文档频率。 |
| coord(q,d) | 根据在指定文档中找到多少查询术语的分数因素。 |
| queryNorm(q) | 用于在查询之间对分数进行可比较的规范化因素。 |
| t.getBoost() | 字段推动. |
| norm(t,d) | 封装几个(索引时间)增高和长度因素。 |
本手册无法更加详细地解释此公式。如需更多信息,请参阅 Similarity 的 Java 文档。
Hibernate Search 提供三种方法来修改 Lucene 的相似性计算:
首先,您可以使用属性 hibernate.search.similarity 指定一个完全指定的类名称来设置默认的相似性。默认值为 org.apache.lucene.search.DefaultSimilarity。
您还可以通过设置相似性属性来覆盖用于特定索引 的相似性
hibernate.search.default.similarity = my.custom.Similarity
最后,您可以使用 @Similarity 注释覆盖类级别上的默认相似性。
@Entity
@Indexed
@Similarity(impl = DummySimilarity.class)
public class Book {
...
}例如,让我们假设术语在文档中出现的频率并不重要。出现过多个术语的文档的评分应与多次出现的文档相同。在这种情况下,您的自定义方法 tf(float freq)应该返回 1.0。
当两个实体共享相同的索引时,它们必须声明相同的相似实施。同一类层次结构中的类始终共享索引,因此不允许覆盖子类型中的相似性实施。
同样,通过索引设置和类级设置定义相似性(因为它们会发生冲突)也不有意义。此类配置将被拒绝。
7.8.6. 异常处理配置
Hibernate Search 允许您配置在索引过程中如何处理异常。如果没有提供配置,则默认将异常记录到日志输出。可以显式声明异常日志记录机制,如下所示:
hibernate.search.error_handler = log
默认异常处理适用于同步和异步索引。Hibernate Search 提供了一种简单的机制,可以覆盖默认的错误处理实施。
为了提供自己的实施,您必须实施 ErrorHandler 接口,它提供 handle(ErrorContext context) 方法。ErrorContext 提供了对主 LuceneWork 实例的引用、底层异常以及因为主要例外而无法处理的随后 LuceneWork 实例。
public interface ErrorContext {
List<LuceneWork> getFailingOperations();
LuceneWork getOperationAtFault();
Throwable getThrowable();
boolean hasErrors();
}要使用 Hibernate Search 注册此错误处理程序,您必须在配置属性中声明 ErrorHandler 实现的完全限定类名称:
hibernate.search.error_handler = CustomerErrorHandler
7.8.7. 禁用 Hibernate Search
可以根据需要部分或完全禁用 Hibernate 搜索.可以禁用 Hibernate Search 的索引,例如,如果索引是只读的,或者您更喜欢手动执行索引,而不是自动执行。也可以完全禁用 Hibernate 搜索,防止索引和搜索。
- 禁用索引
要禁用 Hibernate Search 索引,请将 indexing
_strategy配置选项更改为manual,然后重新启动 JBoss EAP。hibernate.search.indexing_strategy = manual
- 完全禁用 Hibernate 搜索
要完全禁用 Hibernate 搜索,请通过将
autoregister_listeners配置选项更改为false来禁用所有侦听器,然后重新启动 JBoss EAP。hibernate.search.autoregister_listeners = false
7.9. 监控
Hibernate Search 通过 SearchFactory.getStatistics() 提供对 statistics 对象 的访问。例如,它允许您确定索引哪些类以及索引中有多少个实体。此信息始终可用。但是,通过在配置中指定 hibernate.search.generate_statistics 属性,您还可以收集总和平均 Lucene 查询和对象加载时间。
通过 Jakarta 管理访问统计信息
要通过 Jakarta Management 启用对统计信息的访问,请将 hibernate.search.jmx_enabled 属性设置为 true。这将自动注册 StatisticsInfoMBean bean,提供对 statistics 对象 的访问。根据您的配置,IndexingProgressMonitorMBean bean 也可以注册。
监控索引
如果使用量索引器 API,您可以使用 IndexingProgressMonitorMBean bean 监控索引进度。Bean 仅在索引进行时绑定到雅加达管理。
通过将系统属性 com.sun.management.jmxremote 设置为 true,可以使用 JConsole 远程访问 Jakarta 管理 Bean。
附录 A. 参考资料
A.1. Hibernate 属性
表 A.1. 在 persistence.xml 文件中配置的连接属性
| 属性名称 | 值 | 描述 |
|---|---|---|
|
|
| 要使用的 JDBC 驱动程序的类名称。 |
|
| SA | 用户名。 |
|
| 密码. | |
|
|
| JDBC 连接 URL. |
表 A.2. Hibernate 配置属性
| 属性名称 | 描述 |
|---|---|
| hibernate.dialect |
Hibernate
在大多数情况下,Hibernate 将能够根据 JDBC 驱动程序返回的 JDBC 元数据,选择正确的 |
| hibernate.show_sql |
布尔值.将所有 SQL 语句写入控制台。这是将日志类别 |
| hibernate.format_sql | 布尔值.在日志和控制台中仔细打印 SQL。 |
| hibernate.default_schema | 使用生成的 SQL 中给定的 schema/tablespace 限定非限定表名称。 |
| hibernate.default_catalog | 使用生成的 SQL 中的给定目录限定非限定表名称。 |
| hibernate.session_factory_name |
org.hibernate.SessionFactory 将在创建后在 Java Naming 和 Directory 界面中自动绑定到此名称。例如: |
| hibernate.max_fetch_depth |
为单点关联(一对一,多对一)设置外部连接获取树的最大深度。 |
| hibernate.default_batch_fetch_size |
设置用于 Hibernate 批处理获取关联的默认大小。建议的值为 |
| hibernate.default_entity_mode |
为从此 |
| hibernate.order_updates | 布尔值.强制 Hibernate 按照正在更新的项目的主键值对 SQL 更新进行排序。这将导致高度并发系统中的事务死锁减少。 |
| hibernate.generate_statistics | 布尔值.如果启用,Hibernate 将收集对性能调优有用的统计信息。 |
| hibernate.use_identifier_rollback | 布尔值.如果启用,则在删除对象时,生成的标识符属性将重置为默认值。 |
| hibernate.use_sql_comments |
布尔值.如果启用,Hibernate 将在 SQL 中生成注释,以便于调试。默认值为 |
| hibernate.id.new_generator_mappings |
布尔值.此属性在使用 @GeneratedValue 时相关。它指示新的 IdentifierGenerator 实施是否用于 javax.persistence.GenerationType.AUTO、javax.persistence.GenerationType.TABLE 和 javax.persistence.GenerationType.SEQUENCE.默认值为 |
| hibernate.ejb.naming_strategy |
使用 Hibernate EntityManager 时,选择 org.hibernate.cfg.NamingStrategy 实施。 如果应用程序不使用 EntityManager,请按照这里的说明配置 NamingStrategy: Hibernate Reference 文档 - Naming Strategies。
有关使用 MetadataBuilder 原生 bootstrapping 并应用隐式命名策略的示例,请参阅 Hibernate 5.0 文档中的 http://docs.jboss.org/hibernate/orm/5.0/userguide/html_single/Hibernate_User_Guide.html#bootstrap-native-metadata。物理命名策略可使用 |
| hibernate.implicit_naming_strategy |
指定要使用的
默认设置由 |
| hibernate.physical_naming_strategy |
可插拔策略合同,用于为数据库对象名称应用物理命名规则。指定要使用的 PhysicalNamingStrategy 类。 |
对于 hibernate.id.new_generator_mappings,新应用程序应保留默认值 true。使用 Hibernate 3.3.x 的现有应用可能需要将其更改为 false,以继续使用基于序列对象或表的生成器,并且保持向后兼容性。
表 A.3. Hibernate JDBC 和连接属性
| 属性名称 | 描述 |
|---|---|
| hibernate.jdbc.fetch_size |
决定 JDBC 获取大小的非零值(calls |
| hibernate.jdbc.batch_size |
非零值可启用 Hibernate 使用 JDBC2 批处理更新。建议的值介于 |
| hibernate.jdbc.batch_versioned_data |
布尔值.如果 JDBC 驱动程序返回来自 |
| hibernate.jdbc.factory_class | 选择自定义 org.hibernate.jdbc.Batcher。大多数应用都不需要此配置属性。 |
| hibernate.jdbc.use_scrollable_resultset | 布尔值.启用通过 Hibernate 使用 JDBC2 可滚动结果集。只有使用用户提供的 JDBC 连接时才需要此属性。Hibernate 使用连接元数据,否则,Hibernate 将使用连接元数据。 |
| hibernate.jdbc.use_streams_for_binary |
布尔值.这是一个系统级属性。在将 |
| hibernate.jdbc.use_get_generated_keys |
布尔值.启用 JDBC3 Prepared |
| hibernate.connection.provider_class | 自定义 org.hibernate.connection.ConnectionProvider 的类名称,它为 Hibernate 提供 JDBC 连接。 |
| hibernate.connection.isolation |
设置 JDBC 事务隔离级别。检查 java.sql.Connection 以获得有意义的值,但请注意,大多数数据库不支持所有隔离级别,另一些则定义了额外的非标准隔离。标准值为 |
| hibernate.connection.autocommit | 布尔值.不建议使用此属性。为 JDBC 池连接启用自动提交。 |
| hibernate.connection.release_mode |
指定 Hibernate 应何时释放 JDBC 连接。默认情况下,保留 JDBC 连接,直到会话被显式关闭或断开连接。默认值为
可用值为 auto (默认)、on_close、fin
此设置仅影响 |
| hibernate.connection.<propertyName> |
将 JDBC 属性 <propertyName> 传递给 |
| hibernate.jndi.<propertyName> |
将属性 <propertyName> 传递给 Java 命名和目录接口 |
表 A.4. Hibernate 缓存属性
| 属性名称 | 描述 |
|---|---|
|
|
自定义 |
|
| 布尔值.优化企业级缓存操作,以最小化写入,代价是更频繁的读取。此设置对群集缓存最有用,在 Hibernate3 中,群集缓存实施默认启用此设置。 |
|
| 布尔值.启用查询缓存。单个查询仍然需要设置可缓存。 |
|
|
布尔值.用于完全禁用第二级缓存,默认为指定 |
|
|
自定义 |
|
| 用于第二级缓存区域名称的前缀。 |
|
| 布尔值.强制 Hibernate 以更易人性的格式将数据存储在第二级缓存中。 |
|
|
使用 @Cacheable 或 @Cache 时用于指定默认 org.hibernate.annotations.CacheConcurrencyStrategy 的名称的设置。 |
表 A.5. Hibernate 事务属性
| 属性名称 | 描述 |
|---|---|
|
|
与 Hibernate |
|
|
|
|
|
|
|
| 布尔值.如果启用,会话将在交易完成前自动清空。内置和自动会话上下文管理是首选的。 |
|
| 布尔值.如果启用,会话将在交易完成后自动关闭。内置和自动会话上下文管理是首选的。 |
表 A.6. 其他 Hibernate 属性
| 属性名称 | 描述 |
|---|---|
|
|
为"当前" |
|
|
选择 HQL 解析器实施: |
|
|
用于从 Hibernate 查询中的令牌映射到 SQL 令牌(令牌可以是功能或字面名称)。例如, |
|
|
指明 Java 常量是否遵循 Java 命名约定。默认为
将此设置为
当此属性设为 |
|
|
创建 |
|
|
可选文件的逗号分隔名称,其中包含在 SessionFactory 创建期间执行的 SQL DML 语句。这对于测试或演示非常有用。例如,通过添加 INSERT 语句,可以在部署时使用一组最小的数据进行填充。示例值为
文件顺序很重要,因为执行给定文件的语句后再执行下列文件的声明:这些语句仅在创建架构时才执行,例如将 |
|
| 自定义 ImportSqlCommandExtractor 的类名称。默认为内置 SingleLineSqlCommandExtractor。这可用于实施一个从每个导入文件提取单个 SQL 语句的专用解析器。Hibernate 还提供 MultipleLinesSqlCommandExtractor,它支持拆分于多行(每个语句末尾的强制分号)的指令/注释和带引号的字符串。 |
|
|
布尔值.这是一个系统级属性,无法在 |
|
|
javasist 或 cglib 都可以用作字节操作引擎。默认值为 |
表 A.7. Hibernate SQL Dialects(hibernate.dialect)
| RDBMS | dialect |
|---|---|
| DB2 |
|
| DB2 AS/400 |
|
| DB2 OS390 |
|
| Firebird |
|
| FrontBase |
|
| H2 数据库 |
|
| HypersonicSQL |
|
| Informix |
|
| Ingres |
|
| InterBase |
|
| MariaDB 10 |
|
| MariaDB Galera Cluster 10 |
|
| Mckoi SQL |
|
| Microsoft SQL Server 2000 |
|
| Microsoft SQL Server 2005 |
|
| Microsoft SQL Server 2008 |
|
| Microsoft SQL Server 2012 |
|
| Microsoft SQL Server 2014 |
|
| Microsoft SQL Server 2016 |
|
| MySQL5 |
|
| MySQL5.5 |
|
| MySQL5.7 |
|
| Oracle(任何版本) |
|
| Oracle 9i |
|
| Oracle 10g |
|
| Oracle 11g |
|
| Oracle 12c |
|
| Pointbase |
|
| PostgreSQL |
|
| PostgreSQL 9.2 |
|
| PostgreSQL 9.3 |
|
| PostgreSQL 9.4 |
|
| Postgres Plus Advanced Server |
|
| progress |
|
| SAP DB |
|
| Sybase |
|
| Sybase 15.7 |
|
| Sybase 16 |
|
| Sybase 任意位置 |
|
hibernate.dialect 属性应设置为应用数据库的正确 org.hibernate.dialect.Dialect.Dialect 子类。如果指定了点数,Hibernate 将会对某些其他属性使用明智的默认值。这意味着不需要手动指定它们。
修订了 2022 年 2 月 18:22:39 +1000