
部署红帽超融合基础架构
有关部署红帽超融合基础架构的说明
摘要
第 1 章 已知问题
本节记录了会对红帽超融合基础架构 (RHHI) 造成影响的已知问题。
- BZ#1395087 - 虚拟机在网络不可用时会无限期暂停。
- 当 Gluster 和迁移流量所用的网络不可用时,您将无法访问执行 I/O 操作的虚拟机,且无法完成至其他节点的迁移,直至系统管理程序重新启动。这是使用现有隔离和迁移方法时会出现的正常现象。对于这一问题,目前没有相应的解决方法。
- BZ#1401969 - 仲裁块变为修复源
- 如果仲裁卷中的数据块在离线后又逐一恢复了在线状态,那么在修复其他数据块时此类仲裁块会被错误地识别为正确数据的来源。这会导致虚拟机暂停,因为仲裁数据块只能包含元数据。对于这一问题,目前没有相应的解决方法。
- BZ#1412930 - 在 TLS/SSL 已启用的情况下,存储空间不可用会导致产生大量日志记录
- 如果已在 Red Hat Gluster Storage 卷上启用传输层安全 (TLS/SSL),那么当某个 Red Hat Gluster Storage 服务器变得不可用时,大量连接错误消息会被记录,直至该 Red Hat Gluster Storage 服务器再次变为可用状态。出现这种情况是因为:在尝试重新连接后,所记录的消息没有更改为更低级别的日志消息。对于这一问题,目前没有相应的解决方法。
- BZ#1413845 - 当管理网络不可用时,承载引擎不会迁移
- 如果管理网络在迁移期间变得不可用,承载引擎虚拟机会重新启动,但承载引擎本身不会重新启动。要解决这一问题,请手动重新启动 ovirt-engine 服务。
- BZ#1425767 - 健全性检查脚本不会失败
-
即使磁盘不存在或不为空,健全性检查脚本有时仍会返回零(成功)。由于健全性检查显示为成功,因此 gdeploy 会尝试创建物理卷并以失败告终。要解决这一问题,请确保 gdeploy 配置文件中的
disk值正确无误,并且磁盘上没有任何分区或标签,然后重新尝试进行部署。
- BZ#1432326 - 将网络与主机关联会导致网络无法同步
- 当 Gluster 网络与某个 Red Hat Gluster Storage 节点的网络接口关联时,Gluster 网络会进入无法同步的状态。要解决这一问题,请单击与该节点对应的管理选项卡,然后单击刷新功能。
- BZ#1434105 - 实时存储迁移失败
- 如果在从基于 Gluster 的存储域进行实时迁移时 I/O 操作仍在执行中,则迁移会失败。对于这一问题,目前没有相应的解决方法。
- BZ#1437799 - 无法使用 SSH 将 ISO 上传至 Gluster 存储域
在使用 SSH 将 ISO 上传至基于 Gluster 的存储域时,
ovirt-iso-uploader工具会使用错误的路径并失败,最终显示以下错误。OSError: [Errno 2] No such file or directory: '/ISO_Volume' ERROR: Unable to copy RHGSS-3.1.3-RHEL-7-20160616.2-RHGSS-x86_64-dvd1.iso to ISO storage domain on ISODomain1. ERROR: Error message is "unable to test the available space on /ISO_Volume
要解决这一问题,请启用 Gluster 卷上的 NFS 访问权限,然后使用 NFS(而非 SSH)来上传。
- BZ#1439069 - 重新安装节点会导致 /etc/ovirt-hosted-engine/hosted-engine.conf 被覆盖
如果在替换主 Red Hat Gluster Storage 服务器后重新安装了某个节点,那么
/etc/ovirt-hosted-engine/hosted-engine.conf文件中的内容会被旧主要主机的相关详细信息覆盖。这会导致集群处于非运行状态。要解决这一问题,请将重新安装的节点置于维护模式,并更新
/etc/ovirt-hosted-engine/hosted-engine.conf的内容以指向替换后的主服务器。然后,重新启动并重新激活这个重新安装的节点,以使其处于在线状态并挂载所有卷。- BZ#1443169 - 在桥接配置期间,承载引擎的部署会失败
-
在采用桥接网络配置的系统上设置自承载引擎时,设置会在 firewalld 服务重新启动后失败。要解决这一问题,请先从
/etc/sysconfig/network-scripts/目录中删除所有*.bak文件,然后再部署自承载引擎。
部分 I. 计划
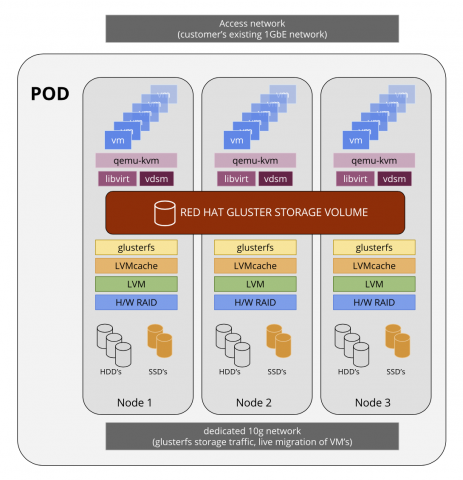
第 2 章 架构
红帽超融合基础架构 (RHHI) 将计算、存储、网络和管理功能结合在一个部署中。
RHHI 会使用 Red Hat Gluster Storage 3.2 和 Red Hat Virtualization 4.1 在 3 台物理机间进行部署,以创建离散集群或 pod。
此类部署主要用于远程和分支机构 (ROBO) 环境。通过这个环境,远程机构可以定期将数据同步到中央数据中心,而且可以在不连接到中央数据中心的情况下正常工作。
下图展示了单个集群的基本架构。
第 3 章 支持要求
请查阅本节内容,以确保您所规划的部署满足红帽的支持要求。
3.1. 操作系统
只有位于 Red Hat Virtualization Host 4.1 上的红帽超融合基础架构才能获得支持。请使用 Red Hat Virtualization Host 4.1 作为所有其他配置的基础。
请查看 Red Hat Virtualization 的《安装指南》,以详细了解 Red Hat Virtualization 的相关要求:https://access.redhat.com/documentation/zh-cn/red_hat_virtualization/4.1/html/installation_guide/chap-system_requirements
3.2. 物理机
红帽超融合基础架构 (RHHI) 需要至少 3 台物理机。也支持扩展到 6 台物理机或 9 台物理机。
每一台物理机都必须满足以下要求:
- 每台物理机至少有 2 个 NIC,分别用于数据和管理流量(请查看第 3.4 节 “网络”,以了解详细信息)
对于小规模部署:
- 至少 12 个内核
- 至少 64GB RAM
- 最多 48TB 的存储空间
对于中等规模部署:
- 至少 12 个内核
- 至少 128GB RAM
- 最多 64TB 的存储空间
对于大规模部署:
- 至少 16 个内核
- 至少 256GB RAM
- 最多 80TB 的存储空间
3.3. 虚拟机
每台虚拟机最多可以配备 4 个虚拟 CPU 和 2TB 虚拟磁盘空间。
受支持的虚拟机数量取决于其大小和资源使用情况。
3.4. 网络
需要两个独立的网络,以便将集群中的客户端流量和管理流量分开。
- 前端网络
用作网桥以开展 ovirt 管理。
- 分配给前端网络的 IP 地址应该来自同一子网,并且应该来自不同于后端 IP 地址的子网。
- 后端网络
用来传输对等存储节点间的存储和迁移流量。
- 红帽建议使用 10Gbps 网络作为后端网络。
- Red Hat Gluster Storage 要求对等节点间最多只能出现 5 毫秒的延迟。
- 分配给后端网络的 IP 地址应该来自同一子网,并且应该来自不同于前端 IP 地址的子网。
DNS 应该能对所有主机的 FQDN 以及承载引擎虚拟机的 FQDN 进行正向和反向解析。
在为承载引擎虚拟机选择 DHCP 网络配置时,需要使用 DHCP 服务器。
3.5. 存储
3.5.1. 架构
一个 Red Hat Gluster Storage 集群可以有 3 到 4 个卷。
- 1 个用于承载引擎的 engine 卷
- 1 个用于虚拟机引导磁盘镜像的 vmstore 卷
- 1 个用于其他虚拟机磁盘镜像的可选 data 卷
- 1 个用于异地复制元数据的 shared_storage 卷
一个 Red Hat Gluster Storage 集群最多可以包含 1 个异地复制卷。
此外,红帽还建议为每个服务器至少提供一个本地热备份驱动器。
3.5.2. RAID
RAID 配置限制取决于所用的技术。
- RAID6 支持 SAS/SATA 7k 磁盘(最多 10+2 个)
以下技术支持 SAS 10k 和 15k 磁盘:
- RAID10
- RAID5(最多 7+1 个)
- RAID6(最多 10+2 个)
RAID 卡的写缓存必须使用 flash 实现。
3.5.3. JBOD
使用 JBOD 配置时需要进行架构审查。请联系您的红帽代表,以了解详细信息。
3.5.4. 卷类型
红帽超融合基础架构 (RHHI) 只支持复制或仲裁复制卷类型。
仲裁复制卷类型还存在以下额外限制:
- 仲裁复制卷只在前 3 个节点上被支持。
-
仲裁复制卷必须使用
replica 3 arbiter 1配置。 仲裁数据块不会存储文件数据;它们只会存储文件名、结构和元数据。
这意味着,要实现同等水平的一致性,三向仲裁复制卷所需的存储空间为三向复制卷所需存储空间的 75%。
但是,由于仲裁数据块只会存储元数据,因此三向仲裁复制卷只具备与双向复制卷相当的可用性。
有关更多详细信息,请查看 Red Hat Gluster Storage 3.2 的《管理指南》:https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.2/html-single/administration_guide/#Creating_Arbitrated_Replicated_Volumes
3.6. 支持限制
- 一个仲裁复制卷会作为红帽超融合基础架构 (RHHI) 初始部署的一部分来获得支持。不支持扩展这个仲裁复制卷,也不支持额外添加仲裁复制卷。
-
目前只有采用
replica 3 arbiter 1配置的仲裁复制卷能够获得相应支持。
有关这些卷类型的更多详细信息,请查看 Red Hat Gluster Storage 的《管理指南》:
3.7. 灾难恢复
红帽强烈建议配置灾难恢复解决方案。有关将异地复制配置为灾难恢复解决方案的详细信息,请查看《维护红帽超融合基础架构》:https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.2/html/maintaining_red_hats_hyperconverged_infrastructure/disaster_recovery。
在配置异地复制时,请注意以下支持限制:
- 红帽超融合基础架构 (RHHI) 只能支持一个异地复制卷。因此,红帽建议备份那些用来存储您的虚拟机数据的卷。
- 异地复制的源和目标卷必须由不同的 Red Hat Virtualization Manager 实例来加以管理。
部分 II. 部署
第 4 章 部署工作流程
红帽超融合基础架构 (RHHI) 的部署工作流程如下所示:
- 验证您规划的部署是否满足第 3 章 支持要求。
- 安装作为虚拟主机的物理机(第 5 章 安装物理主机以作为)。
- 配置身份验证以实现主机的自动配置(第 6 章 配置基于公钥的 SSH 身份验证)。
- 在主机上使用 Cockpit UI 进行存储配置(第 7 章 使用 Cockpit UI 为承载引擎配置 Red Hat Gluster Storage)。
- 使用 Cockpit UI 部署承载引擎(第 8 章 使用 Cockpit UI 部署承载引擎)。
- 从 Red Hat Gluster Storage 节点使用 Red Hat Virtualization 管理 UI 配置存储域(第 9 章 将 Red Hat Gluster Storage 配置为 Red Hat Virtualization 存储域)。
第 5 章 安装物理主机
在 3 台物理机上安装 Red Hat Virtualization Host 4.1。有关安装虚拟化主机的详细信息,请查看以下部分:https://access.redhat.com/documentation/en/red-hat-virtualization/4.1/paged/installation-guide/chapter-6-red-hat-virtualization-hosts。
第 6 章 配置基于公钥的 SSH 身份验证
通过第一台虚拟化主机,将适用于 root 用户的基于公钥身份验证的 SSH 配置到所有 3 台虚拟化主机上。
确保您使用的是与后端管理网络关联的主机名或 IP 地址。
有关更多详细信息,请查看 Red Hat Enterprise Linux 7 的《安装指南》:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/s1-ssh-configuration.html#s2-ssh-configuration-keypairs。
第 7 章 使用 Cockpit UI 为承载引擎配置 Red Hat Gluster Storage
请确保已被指定为本部署流程一部分的磁盘上没有任何分区或标签。
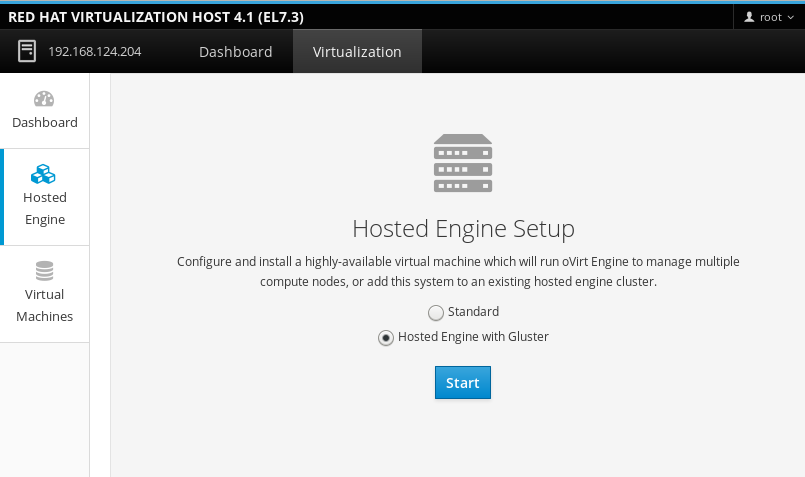
登录 Cockpit UI
浏览至第一台虚拟化主机的 Cockpit 管理界面(例如,https://node1.example.com:9090/),然后使用您在“A. 安装物理机”中创建的凭证登录。
启动部署向导
单击“虚拟化”>“承载引擎”,选择“使用 Gluster 的承载引擎”,然后单击“启动”。部署向导会随即出现。
部署向导:指定存储主机
指定三台虚拟化主机的后端 gluster 网络地址(不是管理网络地址)。可以使用密钥对进行 SSH 的虚拟化主机应该列在最上面,因为它将会是运行 gdeploy 和承载引擎的主机。
注意如果您计划创建仲裁复制卷,请确保在此把将包含仲裁数据块的主机指定为 Host3。
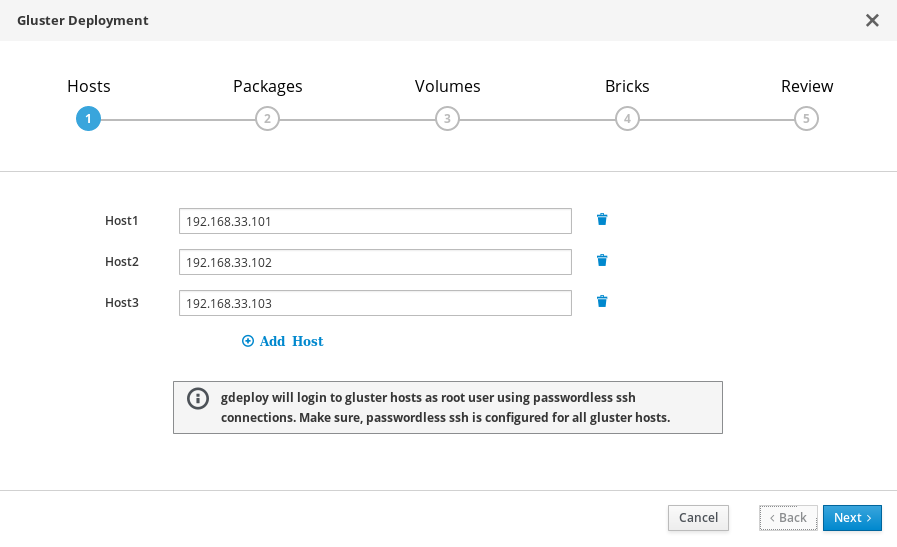
单击“下一步”。
部署向导:指定软件包
无需安装任何软件包。请删除这些字段中的所有值,并取消对选择框的选择。
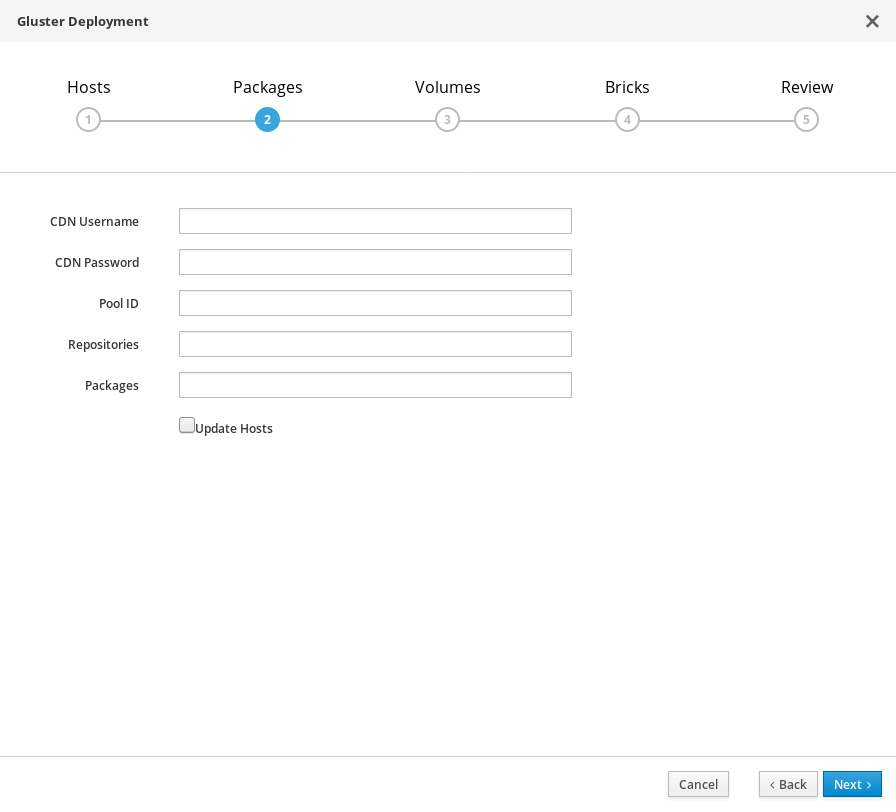
单击“下一步”。
部署向导:指定卷
指定要创建的卷。
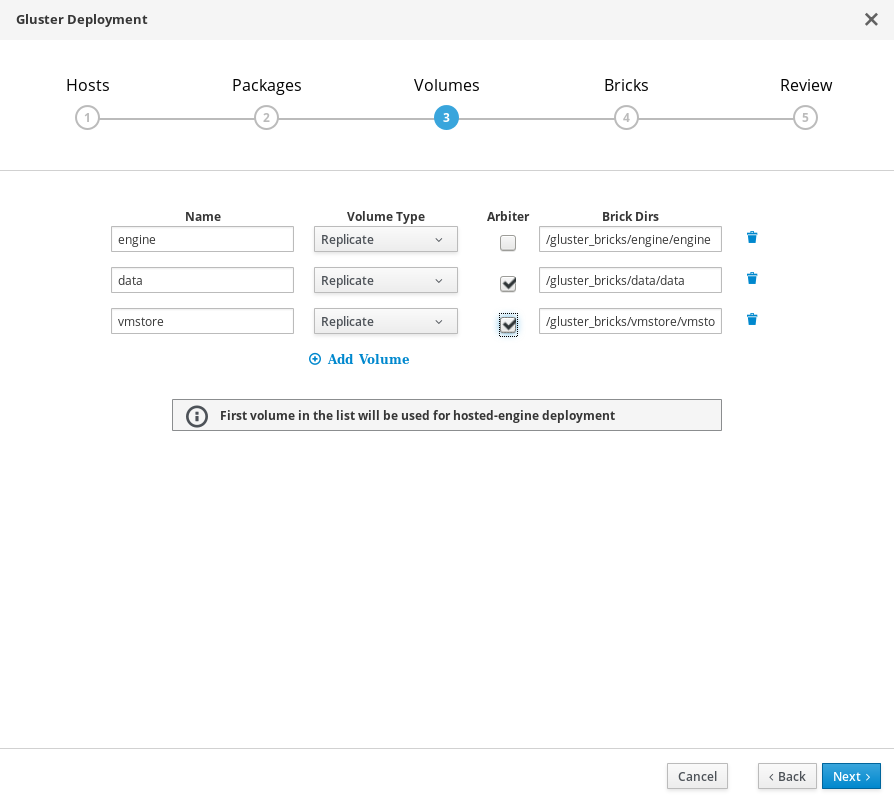
- 名称
- 指定要创建的卷的名称。
- 卷类型
- 指定一个 Replicate 卷类型。此版本只支持复制卷。
- 仲裁
- 指定是否要创建包含仲裁数据块的卷。如果选中此框,则第三个磁盘只会存储元数据。
- 数据块目录
- 包含该卷数据块的目录。
默认值适用于大多数安装。
部署向导:指定数据块
指定要创建的数据块。
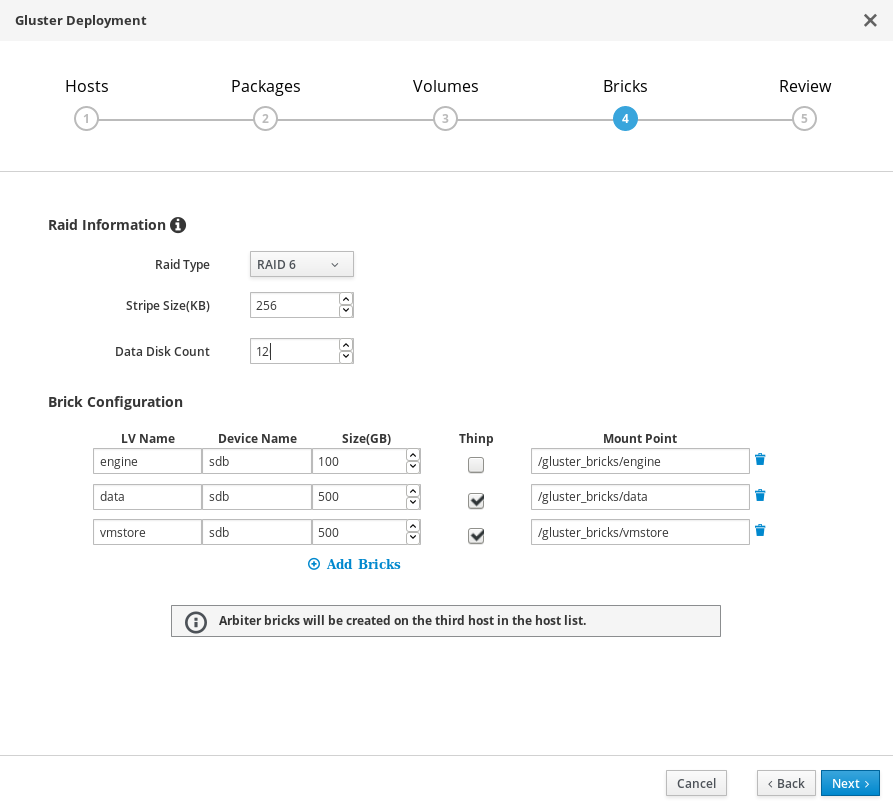
- LV 名称
- 指定要创建的逻辑卷的名称。
- 设备
- 指定您想要使用的原始设备。红帽建议使用未分区的设备。
- 大小
- 指定要创建的逻辑卷的大小(以 GB 为单位)。不要输入单位,请只输入数字。
- 挂载点
- 为逻辑卷指定挂载点。这应该与您在本向导的上一页面中指定的数据块目录匹配。
- Thinp
- 指定是否要对卷进行精简置备。请注意,我们建议对 engine 卷进行厚置备。
- RAID
- 指定要使用的 RAID 配置。这应该与您主机的 RAID 配置匹配。受支持的值为:raid5、raid6、raid10 和 jbod。
- 条带大小
- 指定 RAID 条带的大小(以 KB 为单位)。不要输入单位,请只输入数字。对于 JBOD 配置,可以忽略这一设置。
- 磁盘计数
- 指定 RAID 卷所含的数据磁盘数量。对于 JBOD 配置,可以忽略这一设置。
部署向导:检查并编辑配置
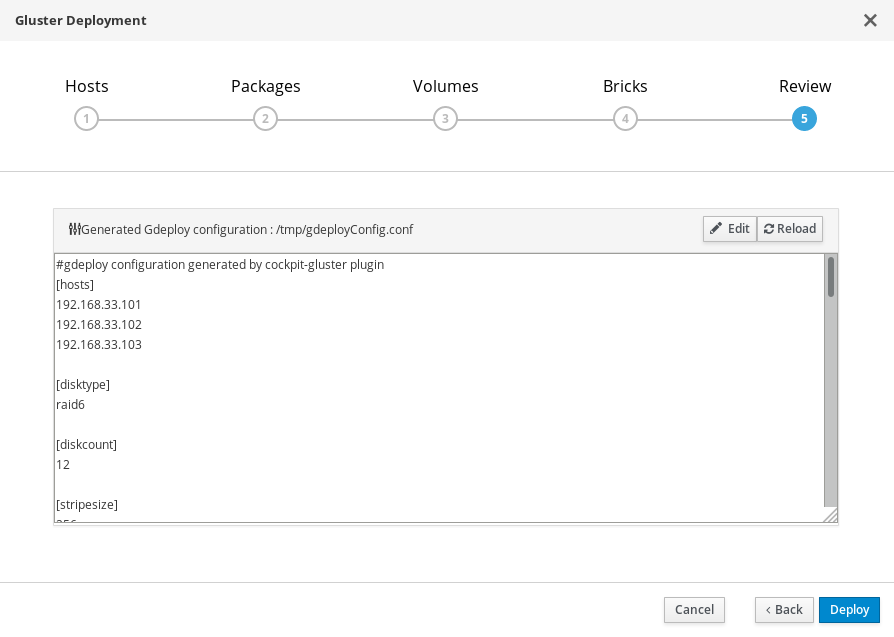
- 单击编辑以开始编辑所生成的 gdeployConfig.conf 文件。
(可选)配置传输层安全 (TLS/SSL)
这一设置可在部署期间或在部署完成后进行配置。如果您想在部署过程中配置 TLS/SSL 加密功能,请查看以下任一部分:
检查配置文件
如果您满意各项配置详细信息,请单击“保存”,然后再单击“部署”。
等待部署完成
在使用生成的配置文件运行 gdeploy 进程的过程中,您可以通过文本字段观察部署流程。
如果部署失败
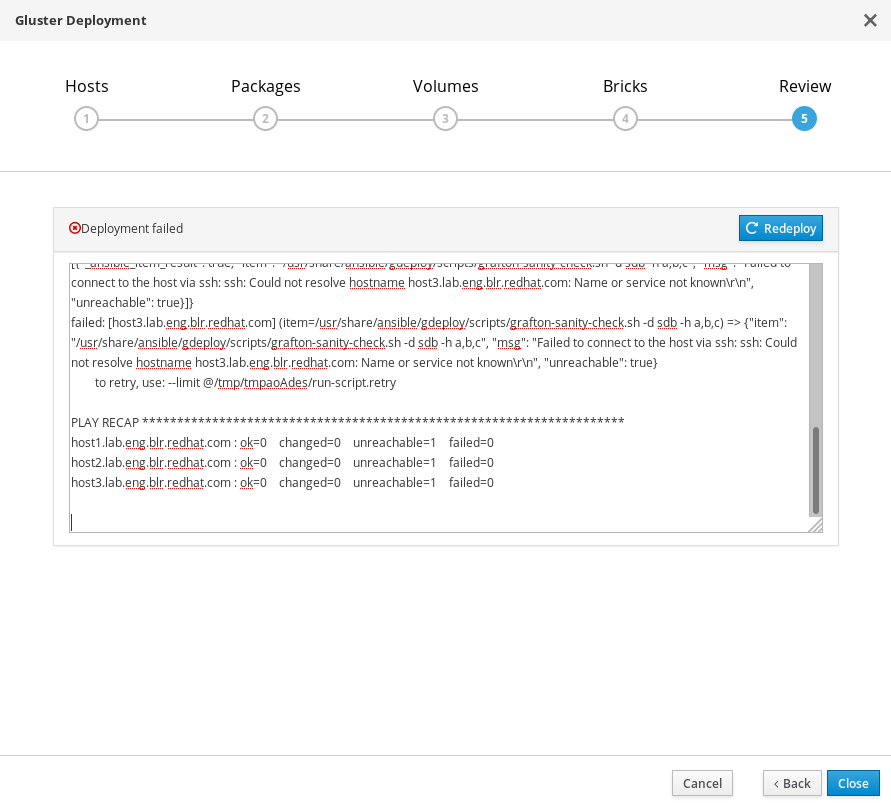
如果部署失败,请单击重新部署按钮。这样即可回到检查并编辑配置选项卡,以便让您在重新尝试部署之前先纠正所生成配置文件中的所有问题。
在重试之前,您可能需要先清理以前的部署尝试。请按照第 11 章 清除自动 Red Hat Gluster Storage 部署错误中的步骤,清理以前的尝试。
部署脚本完成并显示已成功部署 gluster。
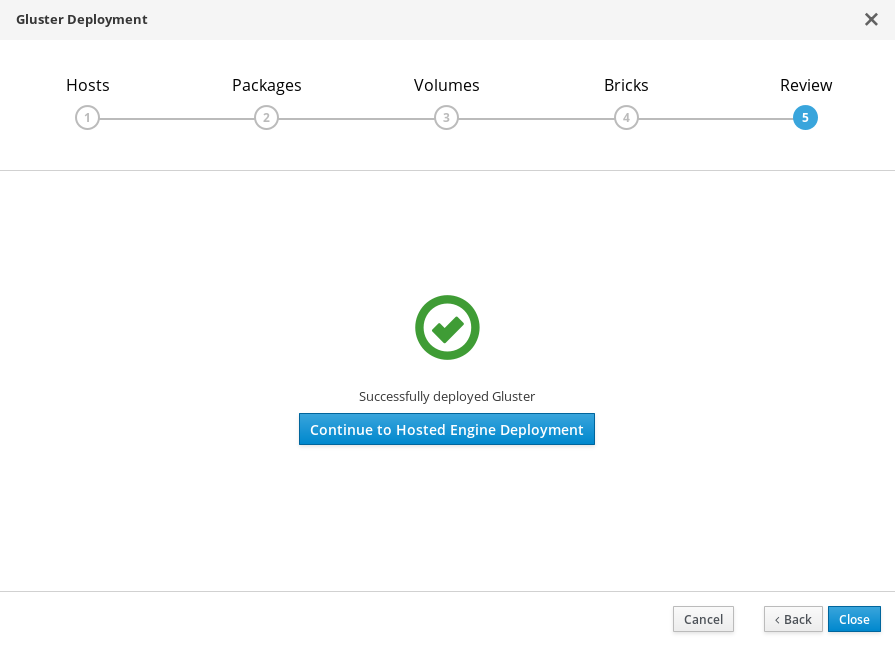
第 8 章 使用 Cockpit UI 部署承载引擎
本节将说明如何使用 Cockpit UI 部署承载引擎。只要按照本流程操作,即可让 Red Hat Virtualization Manager 作为您部署中的第一台物理机上的虚拟机来运行。本流程还会配置一个由三台物理机组成的默认集群,并为该集群中的每一台机器启用 Red Hat Gluster Storage 功能和 virtual-host tuned 性能配置文件。
导航至承载引擎部署向导
在完成第 7 章 使用 Cockpit UI 为承载引擎配置 Red Hat Gluster Storage之后,请单击继续进行承载引擎部署以转至这一向导。
同意安装
Continuing will configure this host for serving as hypervisor and create a VM where you have to install the engine afterwards. Are you sure you want to continue?
输入 Yes。单击下一步,然后等待环境完成设置。
在出现提示时回答相应的部署问题
回答承载引擎部署向导显示的各项提示,以安装并配置承载引擎。您可以随时按下 Ctrl+D,以停止该流程。
表 8.1. 承载引擎部署向导提示
提示文本 操作 Do you wish to install ovirt-engine-appliance rpm?
输入 Yes。
Do you want to configure this host and its cluster for gluster?
输入 Yes。
iptables was detected on your computer, do you wish setup to configure it?
输入 No。
Please indicate a pingable gateway IP address
输入前端网关服务器的 IP 地址。
Please indicate a nic to set ovirtmgmt bridge on
输入前端管理网络的地址。
The following appliance have been found on your system: [1] The RHV-M Appliance image (OVA) - 4.1.20170328.1.el7ev [2] Directly select an OVA file. Please select an appliance
输入承载引擎设备数量(通常为 1)。
Would you like to use cloud-init to customize the appliance on first boot
输入 Yes。
Would you like to generate on-fly a cloud-init ISO image (of no-cloud type) or do you have an existing one?
输入 Generate。
Please provide the FQDN you would like to use for the engine appliance. Note: This will be the FQDN of the engine VM you are now going to launch, it should not point to the base host or to any other existing machine. Engine VM FQDN:
输入您想要用于承载引擎的完全限定域名。
Please provide the domain name you would like to use for the engine appliance. Engine VM domain:
验证所检测到的域名是否正确。
Automatically execute engine-setup on the engine appliance on first boot
输入 Yes。
Enter root password that will be used for the engine appliance
输入在远程登录承载引擎时要使用的密码。
Confirm appliance root password
再次输入在远程登录承载引擎时要使用的密码。
Enter ssh public key for the root user that will be used for the engine appliance
让该字段留空。
Do you want to enable ssh access for the root user
输入 Yes。
Please specify the memory size of the VM in MB
使用默认值。
The following CPU types are supported by this host:
Please specify the CPU type to be used by the VM
使用默认值
Please specify the number of virtual CPUs for the VM
使用默认值。
You may specify a unicast MAC address for the VM or accept a randomly generated default
输入 MAC 地址,这个地址可以解析为承载引擎指定的完全限定域名。
How should the engine VM network be configured
输入 DHCP。
Add lines for the appliance itself and for this host to /etc/hosts on the engine VM? (Note: ensuring that this host could resolve the engine VM hostname is still up to you)
输入 No。
Enter engine admin password (for the RHV UI)
输入 Red Hat Virtualization Manager 管理员将要使用的密码。
Confirm engine admin password
再次输入 Red Hat Virtualization Manager 管理员将要使用的密码。
Please provide the name of the SMTP server through which we will send notifications
使用默认值。
Please provide the TCP port number of the SMTP server
使用默认值。
Please provide the email address from which notifications will be sent
使用默认值。
Please provide a comma-separated list of email addresses which will get notifications
输入您希望能从承载引擎收到通知的任何电子邮件地址。使用默认值 (root@localhost) 即可。
确认安装设置
Please confirm installation settings
查看配置值,并验证它们是否正确。如果对这些值感到满意,请在所提供的字段中输入 Yes,然后单击下一步。
注意目前,您无法在该流程的这一环节中编辑配置;如果配置的详细信息有误,那么您需要重新启动该流程以更正相关信息,您也可以继续执行该流程并在部署期间进行更正。
等待部署完成
这需要一些时间才能完成(大约 30 分钟)。
部署完成后,将显示以下消息:
Hosted Engine Setup successfully completed!
现在,您可登录 Red Hat Virtualization Manager 以完成配置。
如果部署没有完成,请查看第 10 章 处理承载引擎部署错误。
第 9 章 将 Red Hat Gluster Storage 配置为 Red Hat Virtualization 存储域
9.1. 创建用于传输 gluster 流量的逻辑网络
登录引擎
浏览至引擎,并使用您在第 8 章 使用 Cockpit UI 部署承载引擎中配置的管理凭证登录。
创建用于传输 gluster 流量的逻辑网络
- 单击网络选项卡,然后单击新建。新建逻辑网络向导会随即显示。
- 在该向导的常规选项卡上,为新逻辑网络提供一个名称,并取消选中虚拟机网路复选框。
- 在该向导的集群选项卡上,取消选中需要复选框。
- 单击确定以创建新的逻辑网络。
为 gluster 启用新的逻辑网络
- 单击网络选项卡,然后选中新的逻辑网络。
- 单击集群子选项卡,然后单击管理网络。管理网络对话框会随即显示。
- 在管理网络对话框中,选中迁移网络和 Gluster 网络复选框。
- 单击确定进行保存。
为主机连接 gluster 网络
- 单击主机选项卡,并选中主机。
- 单击网络接口子选项卡,然后单击设置主机网络。
- 将新创建的网络拖放到正确的接口。
- 确保验证连接性复选框已选中。
- 确保保存网络配置复选框已选中。
- 单击确定进行保存。
验证网络的运行状况
单击主机选项卡,并选中主机。单击网络子选项卡,并查看主机网络的状态。
如果网络接口进入“无法同步”状态或没有 IPv4 地址,请单击主机对应的管理选项卡,再单击刷新功能。
9.2. 创建主存储域
- 单击存储选项卡,然后单击新建域。
- 选择 GlusterFS 作为存储类型,并为域提供一个名称。
单击使用受管 gluster 卷选项。
集群的可用卷列表会随即显示。
选择 vmstore 卷,并将以下内容添加到挂载选项中:
backup-volfile-servers=server2:server3
- 单击确定进行保存。
承载引擎存储域会在主存储域创建后自动导入。
请耐心等待,直至承载引擎虚拟机及其存储域变为可用状态,然后再继续执行其他任务;这样可确保“承载引擎”选项卡可供使用。
9.3. 将其余的虚拟化主机添加至承载引擎
在 Red Hat Virtualization Manager 中逐一针对其他主机执行以下步骤。
- 单击主机选项卡,然后单击新建以打开新建主机对话框。
- 为新主机提供名称、地址和密码。
- 取消选中自动配置主机防火墙复选框,因为防火墙规则已由 gdeploy 进行配置。
- 在新建主机对话框的承载引擎选项卡中,将选择承载引擎部署操作的值设置为部署。
- 单击部署。
为主机连接 gluster 网络
- 单击主机选项卡,并选中主机。
- 单击网络接口子选项卡,然后单击设置主机网络。
- 将新创建的网络拖放到正确的接口。
- 确保验证连接性复选框已选中。
- 确保保存网络配置复选框已选中。
- 单击确定进行保存。
验证网络的运行状况
单击主机选项卡,并选中主机。单击网络子选项卡,并查看主机网络的状态。
如果网络接口进入“无法同步”状态或没有 IPv4 地址,请单击主机对应的管理选项卡,再单击刷新功能。
有关更多详细信息,请查看 Red Hat Virtualization 4.1 的《自承载引擎指南》:https://access.redhat.com/documentation/en/red-hat-virtualization/4.1/paged/self-hosted-engine-guide/chapter-7-installing-additional-hosts-to-a-self-hosted-environment
部分 III. 故障排除
第 10 章 处理承载引擎部署错误
如果在承载引擎部署期间出现错误,部署会暂停,并显示以下消息:
Please check Engine VM configuration Make a selection from the options below: (1) Continue setup - Engine VM configuration has been fixed (2) Abort setup
随后,错误的相关详细信息会以红色文本列出。您可以登录承载引擎并尝试纠正错误,以便继续进行设置。请注意,您需要停止并再次启动 ovirt-engine 服务以应用更正后的内容,然后再选择继续设置。
第 11 章 清除自动 Red Hat Gluster Storage 部署错误
- 基于附录 B, gdeploy 的清理配置文件示例中的 volume_cleanup.conf 文件创建一个 volume_cleanup.conf 文件。
使用该 volume_cleanup.conf 文件运行 gdeploy。
# gdeploy -c volume_cleanup.conf
- 基于附录 B, gdeploy 的清理配置文件示例中的 lv_cleanup.conf 文件创建一个 lv_cleanup.conf 文件。
使用该 lv_cleanup.conf 文件运行 gdeploy。
# gdeploy -c lv_cleanup.conf
检查所有主机上的挂载配置
检查所有主机上的 /etc/fstab 文件,并删除与自动创建的数据块的 XFS 挂载对应的所有行。
部分 IV. 验证
第 12 章 验证部署
部署完成后,请使用 Red Hat Virtualization Manager 检查部署状态。
创建一个虚拟机,以验证部署能否正常运行。有关详细信息,请查看 Red Hat Virtualization 的《虚拟机管理指南》:https://access.redhat.com/documentation/zh-cn/red_hat_virtualization/4.1/html/virtual_machine_management_guide/。
部分 V. 参考资料
附录 A. 在部署期间配置加密功能
A.1. 在部署期间使用证书颁发机构签署的证书来配置 TLS/SSL
A.1.1. 开始之前
请先确保您已拥有证书颁发机构签署的适当证书,然后再继续操作。证书的获取不在本文的阐述范围内。
A.1.2. 使用证书颁发机构签署的证书配置 TLS/SSL 加密功能
确保所有节点都存在以下文件。
- /etc/ssl/glusterfs.key
- 节点的私钥。
- /etc/ssl/glusterfs.pem
- 证书颁发机构签署的证书,它会成为相应节点的证书。
- /etc/ssl/glusterfs.ca
- 证书颁发机构的证书。对于自签名配置,该文件则包含所有节点的串联证书。
启用管理加密功能。
在各个节点创建 /var/lib/glusterd/secure-access 文件。
# touch /var/lib/glusterd/secure-access
配置加密功能。
将以下各行添加到在第 7 章 使用 Cockpit UI 为承载引擎配置 Red Hat Gluster Storage的过程中生成的配置文件所列出的各个卷中。这样即可在部署过程中,使用证书颁发机构签署的证书在各个 gluster 卷之间创建并配置基于 TLS/SSL 的加密功能。
key=client.ssl,server.ssl,auth.ssl-allow value=on,on,"host1;host2;host3"
请先确保您已保存所生成的文件,然后再进行编辑。
A.2. 在部署期间使用自签名证书配置 TLS/SSL 加密功能
将以下各行添加到在第 7 章 使用 Cockpit UI 为承载引擎配置 Red Hat Gluster Storage 时所生成的配置文件中,以在部署过程中使用自签名证书在各个 gluster 卷之间创建并配置基于 TLS/SSL 的加密功能。gdeploy 所生成证书的有效期为一年。
在配置第一个卷时,请为 enable_ssl 和 ssl_clients 参数及其值添加相应的行:
[volume1] enable_ssl=yes ssl_clients=<Gluster_Network_IP1>,<Gluster_Network_IP2>,<Gluster_Network_IP3>
在配置后续卷时,请添加以下各行以定义 client.ssl、server.ssl 和 auth.ssl-allow 参数的值:
[volumeX] key=client.ssl,server.ssl,auth.ssl-allow value=on,on,"<Gluster_Network_IP1>;<Gluster_Network_IP2>;<Gluster_Network_IP3>"
附录 B. gdeploy 的清理配置文件示例
如果部署失败,则需要先清理以前的部署尝试,然后再重新尝试部署。在重新尝试部署前,您可以通过 gdeploy 运行以下两个示例文件以清理以前的失败部署尝试。
volume_cleanup.conf
[hosts] <Gluster_Network_NodeA> <Gluster_Network_NodeB> <Gluster_Network_NodeC> [volume1] action=delete volname=engine [volume2] action=delete volname=vmstore [volume3] action=delete volname=data [peer] action=detach
lv_cleanup.conf
[hosts] <Gluster_Network_NodeA> <Gluster_Network_NodeB> <Gluster_Network_NodeC> [backend-reset] pvs=sdb,sdc unmount=yes
附录 C. 了解所生成的 gdeploy 配置文件
Gdeploy 会基于配置文件自动使用 Red Hat Gluster Storage 置备一台或多台机器。
Cockpit UI 提供了一个向导,可帮助用户生成适合用来实施红帽超融合基础架构基础级别部署的 gdeploy 配置文件。
本节介绍了当已在 Cockpit UI 中指定以下配置详细信息时将会生成的 gdeploy 配置文件:
- 3 个主机,其 IP 地址分别为 192.168.0.101、192.168.0.102 和 192.168.0.103
- 没有其他软件包或库。
- 适用于所有卷的仲裁配置。
- 12 个使用 RAID 6 进行配置的数据块,条带大小为 256 KB。
这会使得 gdeploy 配置文件包含以下各个部分。
有关此处定义的所有部分的更多详细信息,请查看 Red Hat Gluster Storage 的《管理指南》:https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3.2/html/administration_guide/chap-red_hat_storage_volumes#chap-Red_Hat_Storage_Volumes-gdeploy_configfile。
[hosts] 部分
[hosts] 192.168.0.101 192.168.0.102 192.168.0.103
[hosts] 部分定义了要根据该配置文件配置的三台物理机的 IP 地址。
[script1] 部分
[script1] action=execute ignore_script_errors=no file=/usr/share/ansible/gdeploy/scripts/grafton-sanity-check.sh -d sdb -h 192.168.0.101,192.168.0.102,192.168.0.103
[script1] 部分指定了要运行的脚本,该脚本会验证所有主机是否都已经正确配置,以使 gdeploy 能在不出现任何错误的情况下运行。
底层存储配置
[disktype] raid6 [diskcount] 12 [stripesize] 256
[disktype] 部分指定了适用于所有主机的底层存储硬件配置。
[diskcount] 部分指定了 RAID 存储空间中的磁盘数量。对于 JBOD 配置,您可以忽略这一设置。
[stripesize] 部分指定了 RAID 存储空间的条带大小(以千字节为单位)。对于 JBOD 配置,您可以忽略这一设置。
启用并重新启动 NTPD
[service1] action=enable service=ntpd [service2] action=restart service=ntpd
这两个 service 部分会在所有主机上启用并重新启动网络时间协议守护进程,即 NTPD。
在所有主机上创建物理卷
[pv1] action=create devices=sdb ignore_pv_errors=no
[pv1] 部分会在所有主机的 sdb 设备上创建一个物理卷。
在所有主机上创建卷组
[vg1] action=create vgname=gluster_vg_sdb pvname=sdb ignore_vg_errors=no
[vg1] 部分会在所有主机以前创建的物理卷中创建一个卷组。
创建逻辑卷精简池
[lv1:{192.168.0.101,192.168.0.102}]
action=create
poolname=gluster_thinpool_sdb
ignore_lv_errors=no
vgname=gluster_vg_sdb
lvtype=thinpool
poolmetadatasize=16GB
size=1000GB
[lv2:192.168.0.103]
action=create
poolname=gluster_thinpool_sdb
ignore_lv_errors=no
vgname=gluster_vg_sdb
lvtype=thinpool
poolmetadatasize=16GB
size=20GB
[lv1:*] 部分会在前两个主机上创建一个大小为 1000 GB 的精简池,其元数据池的大小则为 16 GB。
[lv2:*] 部分会在第三个主机上创建一个大小为 20 GB 的精简池,其元数据池的大小则为 16 GB。这个精简池就是用于仲裁数据块的逻辑卷。
您还可以使用 chunksize 变量,但使用时要格外小心。chunksize 定义了快照、缓存池和精简池所使用的区块大小。在默认情况下,指定该值时会以千字节为单位。对于 RAID 5 和 RAID 6 卷,gdeploy 会将条带大小乘以磁盘数,以计算出默认的区块大小。对于 RAID 10,默认的区块大小为 256 KB。
红帽建议至少使用默认区块大小。如果因区块过小而导致卷没有可用来存储元数据的空间,那么该卷将无法创建数据。红帽还建议您对逻辑卷进行监控,以确保它们能在元数据卷被占满之前得到扩展或创建更多存储空间。
创建底层引擎存储空间
[lv3:{192.168.0.101,192.168.0.102}]
action=create
lvname=gluster_lv_engine
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/engine
size=100GB
lvtype=thick
[lv4:192.168.0.103]
action=create
lvname=gluster_lv_engine
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/engine
size=10GB
lvtype=thick
[lv3:*] 部分在前两个主机上创建了一个大小为 100 GB 且名为 gluster_lv_engine 的厚置备逻辑卷。该卷被配置为挂载于 /gluster_bricks/engine。
[lv4:*] 部分在第三个主机上为引擎创建了一个大小为 10 GB 的厚置备逻辑卷。该卷被配置为挂载于 /gluster_bricks/engine。
创建底层数据和虚拟机启动磁盘存储空间
[lv5:{192.168.0.101,192.168.0.102}]
action=create
lvname=gluster_lv_data
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/data
lvtype=thinlv
poolname=gluster_thinpool_sdb
virtualsize=500GB
[lv6:192.168.0.103]
action=create
lvname=gluster_lv_data
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/data
lvtype=thinlv
poolname=gluster_thinpool_sdb
virtualsize=10GB
[lv7:{192.168.0.101,192.168.0.102}]
action=create
lvname=gluster_lv_vmstore
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/vmstore
lvtype=thinlv
poolname=gluster_thinpool_sdb
virtualsize=500GB
[lv8:192.168.0.103]
action=create
lvname=gluster_lv_vmstore
ignore_lv_errors=no
vgname=gluster_vg_sdb
mount=/gluster_bricks/vmstore
lvtype=thinlv
poolname=gluster_thinpool_sdb
virtualsize=10GB
[lv5:*] 和 [lv7:*] 部分在前两个主机上创建了一个大小为 500 GB 的逻辑卷,以用作 data 卷和 vmstore 卷的数据块。
[lv6:*] 和 [lv8:*] 部分在第三个主机上创建了一个大小为 10 GB 的逻辑卷,以用作 data 卷和 vmstore 卷的仲裁数据块。
这些数据块被配置为挂载于 /gluster_bricks/data,vmstore 数据块则被配置为挂载于 /gluster_bricks/vmstore。
配置 SELinux 文件系统标签
[selinux] yes
[selinux] 部分指定所创建的存储空间应该使用适用于 Gluster 存储空间的 SELinux 文件系统标签进行配置。
启动 glusterd
[service3] action=start service=glusterd slice_setup=yes
[service3] 部分启动了 glusterd 服务并配置了一个控制组,以确保 glusterd 不会占用所有系统资源;有关详细信息,请查看 Red Hat Enterprise Linux 的《资源管理指南》:https://access.redhat.com/documentation/zh-CN/Red_Hat_Enterprise_Linux/7/html/Resource_Management_Guide/index.html。
配置防火墙
[firewalld] action=add ports=111/tcp,2049/tcp,54321/tcp,5900/tcp,5900-6923/tcp,5666/tcp,16514/tcp services=glusterfs
[firewalld] 部分开启了进行 gluster 流量传输所需的端口。
禁用 gluster hook
[script2] action=execute file=/usr/share/ansible/gdeploy/scripts/disable-gluster-hooks.sh
[script2] 部分禁用了可能会干扰超融合基础架构的 gluster hook。
创建 gluster 卷
[volume1] action=create volname=engine transport=tcp replica=yes replica_count=3 key=group,storage.owner-uid,storage.owner-gid,network.ping-timeout,performance.strict-o-direct,network.remote-dio,cluster.granular-entry-heal value=virt,36,36,30,on,off,enable brick_dirs=192.168.0.101:/gluster_bricks/engine/engine,192.168.0.102:/gluster_bricks/engine/engine,192.168.0.103:/gluster_bricks/engine/engine ignore_volume_errors=no arbiter_count=1 [volume2] action=create volname=data transport=tcp replica=yes replica_count=3 key=group,storage.owner-uid,storage.owner-gid,network.ping-timeout,performance.strict-o-direct,network.remote-dio,cluster.granular-entry-heal value=virt,36,36,30,on,off,enable brick_dirs=192.168.0.101:/gluster_bricks/data/data,192.168.0.102:/gluster_bricks/data/data,192.168.0.103:/gluster_bricks/data/data ignore_volume_errors=no arbiter_count=1 [volume3] action=create volname=vmstore transport=tcp replica=yes replica_count=3 key=group,storage.owner-uid,storage.owner-gid,network.ping-timeout,performance.strict-o-direct,network.remote-dio,cluster.granular-entry-heal value=virt,36,36,30,on,off,enable brick_dirs=192.168.0.101:/gluster_bricks/vmstore/vmstore,192.168.0.102:/gluster_bricks/vmstore/vmstore,192.168.0.103:/gluster_bricks/vmstore/vmstore ignore_volume_errors=no arbiter_count=1
[volume*] 部分配置了三个仲裁复制 Red Hat Gluster Storage 卷:engine、data 和 vmstore。每个卷在第三个主机上都有一个相应的仲裁块。
key 和 value 参数用于设置以下选项:
-
group=virt -
storage.owner-uid=36 -
storage.owner-gid=36 -
network.ping-timeout=30 -
performance.strict-o-direct=on -
network.remote-dio=off -
cluster.granular-entry-heal=enable