
将应用程序与 Fuse Online 集成
前言
Red Hat Fuse 是一个分布式、云原生的集成解决方案,可为架构、部署和工具提供选择。Fuse Online 是红帽基于 Web 的 Fuse 发行版。Syndesis 是 Fuse Online 的开源项目。Fuse Online 在 OpenShift Online、OpenShift Dedicated 和 OpenShift Container Platform 上运行。
本指南提供有关使用 Fuse 在线 Web 界面集成应用程序的信息和说明。内容被组织如下:
要了解如何通过创建示例集成来使用 Fuse Online,请参阅 示例集成教程。
要获得支持,请在 Fuse Online 的左侧导航面板中,点 Support,或者在右上角点
 ,然后选择 Support。
,然后选择 Support。
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看我们的 CTO Chris Wright 信息。
第 1 章 Fuse Online 的高级别概述
使用 Fuse Online,您可以从应用程序或服务获取数据,如果需要,请在该数据上运行,然后将数据发送到完全不同的应用程序或服务。不需要编码来完成这个目标。
以下主题提供了 Fuse 在线的高级概述:
1.1. Fuse Online 的工作原理
Fuse Online 提供了一个 Web 浏览器界面,可让您集成两个或更多不同的应用程序或服务,而无需编写代码。它还提供可让您在复杂用例中引入代码的功能。
Fuse Online 可让您在不同应用程序间实现数据传输。例如,业务分析员可以使用 Fuse Online 来捕获提及客户,然后利用 Twitter 获取的数据来更新 Salesforce 帐户。另一个例子是提供库存交易建议的服务。您可以使用 Fuse Online 捕获购买或销售兴趣库存的建议,并将这些建议转发给自动化库存传输的服务。
要创建并运行简单集成,主要步骤如下:
- 创建与您要集成的每个应用程序的连接。
选择启动连接。此连接是包含您要与另一个应用程序共享的数据的应用程序。
或者,您可以启动与接受 HTTP 请求的计时器或 webhook 的集成。
- 选择 finish 连接。此连接指向从启动连接接收数据并完成集成的应用程序。
- 在完成连接中,将开始连接中的数据字段映射到数据字段。
- 为集成指定一个名称,以及可选的描述、标签和自定义环境变量。
- 单击 Publish 以开始运行集成。
另一种集成是 API 供应商集成。API 提供程序集成允许 REST API 客户端调用触发执行集成的命令。要创建并运行 API 供应商集成,您可以将 OpenAPI 3(或 2)文档上传到 Fuse Online。本文档指定了客户端可以调用的操作。对于每个操作,您可以指定并配置执行该操作的连接和步骤,如数据映射或过滤步骤。简单集成有一个主要流,而 API 供应商集成具有每个操作的主流。
借助 Fuse 在线仪表板,您可以监控和管理集成。您可以查看哪些集成正在运行,您可以启动、停止和编辑集成。
1.2. Fuse Online 适合谁
Fuse Online 适用于业务专家,例如:财务、人力资源或营销,他们不希望编写代码,以便在两个不同的应用程序间共享数据。他们使用多种软件即服务(SaaS)应用程序可以了解业务需求、工作流和相关数据。
作为商业用户,您可以使用 Fuse Online 进行:
- 捕获涉及您的公司、过滤和在 Salesforce 环境中创建新的联系人(当二十个未知源时)。
- 确定 Salesforce 领导更新,然后执行 SQL 存储的步骤来保持相关的数据库最新。
- 订阅 AMQ 代理接收的订购,然后针对那些带有自定义 API 的订购操作。
- 从 Amazon S3 存储桶获取数据,并将其添加到 Dropbox 文件夹中。
这些只是一些业务用户在没有编写代码的情况下可以执行的操作。
1.3. 使用 Fuse Online 的好处
Fuse Online 具有诸多优点:
- 在不编写代码的情况下集成来自不同应用程序或服务的数据。
- 在公共云或 OpenShift Container Platform 上运行 OpenShift Online 的集成。
- 使用可视数据映射器将一个应用程序中的数据字段映射到另一应用程序中的数据字段。
- 利用开源软件的所有优势。您可以扩展功能并自定义接口。如果 Fuse Online 没有为您要集成的应用程序或服务提供连接器,则开发人员可以创建所需的连接器。
1.4. Fuse Online 结构的描述
要使用 Fuse Online,您可以通过操作连接器、连接、操作、步骤和流来创建集成。对这些结构有基本的了解是很有帮助的。
Fuse Online 的每个安装都被称为 Fuse 在线环境。当红帽安装并管理您的 Fuse Online 环境时,它会在 OpenShift Online 或 OpenShift Dedicated 上运行。当您安装和管理 Fuse Online 环境时,通常在 OpenShift Container Platform 上运行,但它可以在 OpenShift Dedicated 上运行。
集成
在 Fuse Online 中,没有简单的集成和 API 供应商集成。
简单的集成是 Fuse Online 执行的一组排序步骤。此设置包括:
- 连接到应用程序以启动集成的一个步骤。这个连接提供集成运行的初始数据。后续连接可以提供额外的数据。
- 连接到应用程序以完成集成的步骤。此连接接收前面步骤中输出的任何数据并完成集成。
在启动和完成连接间连接至应用程序的可选附加步骤。根据集成步骤序列中的附加连接位置,额外连接可以进行任何或全部执行:
- 为集成提供额外数据以便其操作
- 处理集成数据
- 将结果输出到集成
- 在连接到应用程序间的数据操作可选步骤。通常,有一个步骤可将前面连接中的数据字段映射到下一个连接使用的数据字段。
API 供应商集成发布了一个 REST API 服务,用于提供 OpenAPI 模式。来自 REST API 客户端的调用会触发 API 供应商集成的执行。这个调用可以调用 REST API 实施的任何操作。尽管简单的集成具有执行的一个主要流程,但 API 供应商集成具有每个操作的主要流。每个操作流程都连接到应用程序,并根据您在创建集成时添加到该操作流的步骤处理数据。每个操作流程都会返回您指定的响应,客户端调用触发了集成的执行。
连接器
Fuse Online 提供一组连接器。连接器代表您要从或发送数据到的特定应用程序。每个连接器都是创建与该特定应用程序的连接的模板。例如,您可以使用 Salesforce 连接器创建与 Salesforce 的连接。
要连接到的应用程序可能会使用 OAuth 协议来验证用户。在这种情况下,您可以将 Fuse 在线环境注册为可访问该应用程序的客户端。注册与那个应用程序的连接器关联。您只需要为每个使用 OAuth 的应用程序注册特定的 Fuse Online 环境。注册会扩展到您从该连接器中创建的每个连接。
如果 Fuse Online 不提供您需要的连接器,开发人员可以创建所需的连接器。
连接
在创建集成前,必须先创建与您要从数据获取数据的每个应用程序或服务的连接。要创建连接,您可以选择连接器并添加配置信息。例如,要连接到集成中的 AMQ 代理,您可以选择 AMQ 连接器来创建连接,然后按照提示识别要连接的代理以及用于连接的帐户。
连接是其从其创建的连接器的一个特定实例。您可以从一个连接器创建任意数量的连接。例如,您可以使用 AMQ 连接器创建三个 AMQ 连接,每个连接访问不同的代理。
要创建简单集成,您可以选择启动集成的连接、结束集成的连接,以及访问附加应用程序的一个或多个连接。要创建 API 供应商集成,您可以添加一个或多个到每个操作流的连接。任意数量的集成和操作流程都可以使用相同的连接。特定集成或流程可以多次使用相同的连接。
详情请参阅 关于到您要集成的应用程序的连接。
Actions
在集成中,每个连接都会执行一个操作。当您创建集成时,您可以选择要添加到流的连接,然后选择连接执行的操作。例如,当您将 Salesforce 连接添加到流时,您可以从包含的一组操作中选择,但不仅限于创建 Salesforce 帐户、更新 Salesforce 帐户和搜索 Salesforce。
有些操作需要额外的配置,Fuse Online 会提示您输入此信息。
步骤
简单的集成是一组排序的步骤。在 API 供应商集成中,每个操作流都是一组排序的步骤。
每个步骤都在数据上运行。有些步骤在连接到 Fuse Online 之外的应用程序或服务时对数据进行操作。这些步骤是连接。在连接之间,还有其它在 Fuse Online 中数据的操作步骤。通常,步骤( steps)包括了一个步骤,它可映射之前连接到流程中下一连接中使用的数据字段的数据字段。除了简单集成中的启动连接外,每个步骤都运行它从前面的步骤接收的数据。
要在连接间操作数据,Fuse Online 提供如下步骤:
- 将一个应用程序中的数据字段映射到另一应用程序中的数据字段。
- 过滤数据,仅当您定义的数据处理时,才会继续执行集成。
- 将一组记录放置在单独的记录中,以便 Fuse Online 能够迭代执行后续步骤,每个记录一次。
- 将各个记录聚合到一个集合中,以便 Fuse Online 在集合时执行后续步骤。
- 通过将数据插入到自由标记器、Mustache 或 Velocity 模板来生成相同的一致的输出。
- 除了 Fuse Online 自动提供的默认日志记录外,还要记录信息。
要在没有内置 Fuse Online 中的连接间操作数据,您可以上传一个提供自定义步骤的扩展。请参阅 开发 Fuse Online 扩展。
流
流是集成执行的一组排序步骤。
简单集成有一个主要流程。API 提供程序集成具有 REST API 定义的每个操作的主流。每个操作的主要流程都是处理调用该操作的调用的步骤集合。
主要流程可以具有条件流。集成会评估您指定的条件,以确定是否执行其关联的流。
在流中,每个步骤都可以对上一步中输出的数据进行操作。要确定一个流中需要的步骤,请参阅 规划集成 的注意事项。
第 2 章 如何准备好创建集成
有些计划和了解创建集成的工作流可以帮助您创建满足您需求的集成。以下主题提供准备创建集成的信息。
2.1. 规划您的集成注意事项
在创建集成前请考虑以下问题。
如何触发集成执行?
- 是否要设置定时器,按您指定的间隔触发执行?
- 是否要发送 HTTP 请求?
是否要连接到应用程序以获取数据?
- 在该应用程序中,什么会触发获取数据的操作?例如,一个首先从 Twitter 获取数据来实现的集成可能会提到witter。
- 感兴趣的数据字段是什么?
- Fuse Online 使用什么凭据来访问此应用?
您是否要发布 REST API 服务,以便客户端能够调用 REST API 调用来触发操作流的执行?
- 该服务的 OpenAPI 模式是否已经定义?
- 如果没有,服务将定义什么操作?
完成简单集成:
- 是否有应用程序接收数据,或者您希望将信息发送到集成日志?
- 如果您要将数据发送到某个应用程序,那么集成将执行什么操作?
- 感兴趣的数据字段是什么?
- Fuse Online 使用什么凭据来访问此应用?
在流的步骤集中:
您需要访问任何其他应用程序吗?对于需要访问的任何其他应用程序:
- 流需要连接到哪个应用程序?
- 连接应该执行什么操作?
- 感兴趣的数据字段是什么?
- 连接应当使用哪个凭据来连接此应用?
流是否需要在连接间操作数据?例如:
- 流是否过滤运行的数据?
- 在源和目标应用程序之间是否字段名称不同?如果这样做,则需要数据映射。
- 流是否对集合运行?如果报错,流可以使用数据映射程序来处理集合,或者流程是否需要将集合划分为单独的记录?流是否需要将记录聚合到一个集合中?
- 模板是否对以一致格式的数据进行输出很有用?
- 是否要将有关正在处理的消息的信息发送给集成日志吗?
- 流是否需要以某种自定义方式对数据进行操作?
- 您需要根据集成数据的内容的不同执行流?也就是说,是否需要条件流?
2.2. 创建简单集成的一般工作流
登录 Fuse Online 控制台后,您可以开始创建与您要集成的应用程序的连接。对于您要集成和使用 OAuth 协议的应用程序,将 Fuse Online 注册为应用程序的客户端。您必须注册的应用程序包括:
- dropbox
- Google 应用程序(Gmail、Calendar、Sheets)
- Salesforce
- SAP Concur
- wwitter
通过对这些应用程序的注册,创建简单集成的工作流如下所示:

其他资源
2.3. 创建 Salesforce 到数据库的简单集成的工作流示例
了解使用 Fuse Online 创建简单集成的工作流的最佳方式是根据示例集成 教程中的说明创建示例集成。
下图显示了为数据库集成创建示例 Salesforce 的工作流。
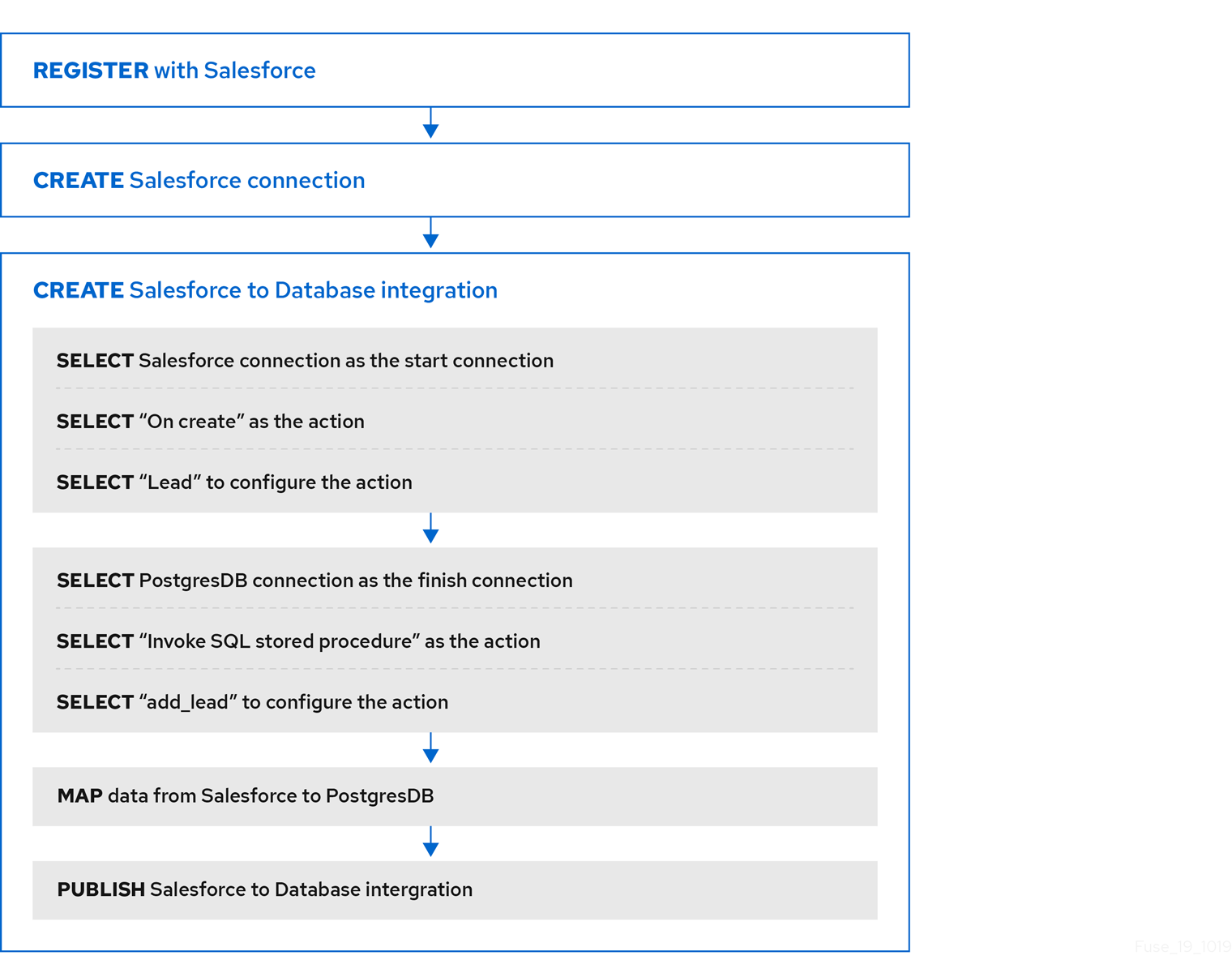
在发布集成后,Fuse Online 仪表板会在集成就绪执行时,会在集成名称旁边显示 Running。
第 3 章 关于您要集成的应用程序的连接
要连接到您要集成的应用程序,主要步骤包括:
- 创建与您要集成的每个应用程序或服务的连接。
- 创建与您要集成的每个应用程序连接的集成。
创建连接的过程因每个应用程序或服务而异。创建每种连接并为特定集成配置的详情,请访问将 Fuse Online 连接到应用程序和服务。
以下主题提供有关连接的一般信息:
3.1. 关于从 Fuse Online 创建到应用程序的连接
要创建连接,您可以选择要连接到的应用程序的连接器,然后在输入字段中输入值来配置应用程序的连接。您需要为每个应用程序提供不同的配置详情。配置连接后,您可以为其提供名称,可帮助您将其与任何其他应用程序的连接区分开来。另外,您还可以指定连接的描述。
您可以使用同一连接器来创建与该应用程序的任何数目连接。例如,您可以使用 AMQ 连接器来创建三个不同的连接。每个 AMQ 连接都可以指定不同的代理。
例如,请参阅:
3.2. 获取授权的一般步骤
在集成中,您可能想要连接到使用 OAuth 协议验证访问请求的应用程序。为此,您必须注册 Fuse Online 的安装才能访问该应用程序。注册会将您的 Fuse 在线安装中的所有连接授权至给定的应用程序。例如,如果您用 Salesforce 注册了 Fuse Online 安装,则所有来自 Fuse Online 安装的连接都使用相同的 Salesforce 客户端 ID 和注册提供的同一 Salesforce 客户端 secret。
在每个 Fuse 在线环境中,对于使用 OAuth 的每个应用程序,都需要一个 Fuse Online 注册。此注册可让您创建多个连接,每个连接都可以使用不同的用户凭证。
虽然具体步骤因您要连接的每个 OAuth 应用程序的不同而有所不同,但注册始终为 Fuse 在线环境提供客户端 ID 和客户端 secret。有些应用对客户端 ID 和客户端 secret 使用其他标签。例如,Salesforce 会生成消费者密钥和消费者 secret。
对于某些 OAuth 应用程序,Fuse Online 在 Settings 页面中提供了一个条目,用于添加注册提供的客户端 ID 和客户端 secret。要查看其应用到的应用,请在 Fuse Online 左侧面板中点 Settings。
先决条件
- 在 Fuse Online Settings 页面中,有一个条目供应用使用 OAuth 协议来授权访问。
流程概述
- 在 Fuse Online OAuth Application Management 页面中,展开您要注册 Fuse Online 的应用的条目。这将显示客户端 ID 和客户端 secret 字段。
-
在 OAuth Application Management 页面顶部,
在注册过程中看到,输入此回调 URL:,将该 URL 复制到剪贴板。 - 在另一个浏览器标签页中,进入您要注册的应用程序的网站,并执行获得客户端 ID 和 secret 所需的步骤。这些步骤之一就是输入 Fuse 在线环境的回调 URL。在第二个步骤中粘贴您复制到剪贴板的 URL。
- 在 Settings 页面中,粘贴客户端 ID 和客户端 secret,再保存设置。
其他资源
在 Settings 页面中注册应用程序的示例:
- 使用 Fuse Online Settings 页面中没有条目的应用程序 注册示例: 将 Fuse Online 作为 Dropbox 客户端注册
- 有关使用自定义连接器的信息,您可以访问使用 OAuth 协议的应用程序: 关于从自定义连接器创建连接。
3.3. 关于连接验证
在获得 Fuse Online 的授权后,您可以访问使用 OAuth 的应用,您可以创建该应用程序的一个或多个连接。当您创建与 OAuth 应用程序的连接时,Fuse Online 对其进行验证以确认授权是否就位。在任何时候,您可以再次验证连接,以确保授权仍处于位。
有些 OAuth 应用授予具有过期日期的访问令牌。如果访问令牌过期,您可以重新连接到应用程序以获取新的访问令牌。
验证使用 OAuth 或获取 OAuth 应用程序的新访问令牌的连接:
- 在左侧面板中,点 Connections。
- 点您要验证或获取新访问令牌的连接。
- 在连接详情页面中,单击 Validate 或点 Reconnect。
如果验证或重新连接失败,则使用 application/service provider 检查,以确定应用程序的 OAuth 密钥、ID、令牌或 secret 是否仍然有效。项目可能已过期或被撤销。
如果您发现 OAuth 项无效、已过期或已撤销,请获取新的值并将其粘贴到应用的 Fuse Online 设置中。请参阅将 Fuse Online 连接到 Applications and Services 中的说明,以注册连接无法验证的应用程序。更新的设置后,请按照上面的说明尝试验证更新的连接。如果验证成功,并且有一个正在运行的集成正在使用这个连接,请重启集成。要重启集成,请停止它并启动它。
如果验证失败,但重新连接失败但所有在服务提供商中都有效,请尝试重新使用应用程序重新注册您的 Fuse 在线环境,然后重新创建连接。Fuse Online 在重新创建时验证连接。如果重新创建连接,且有一个使用连接的集成,您必须编辑集成以删除旧连接并添加新连接。如果集成正在运行,则必须停止它并重启它。
3.4. 关于向集成添加连接
当您将连接添加到简单集成或操作流中时,Fuse Online 会显示连接在连接到应用程序时可以执行的操作的列表。您必须只选择一个操作。在正在运行的集成中,每个连接仅执行您选择的操作。例如,当您将 Twitter 连接添加为集成的启动连接时,您可能会选择 Mention 操作,该操作会监控 Twitter 来处理的调整。
选择一些操作会提示您指定一个或多个配置操作的参数。例如,如果您在集成中添加 Salesforce 连接并选择 On create 操作,则必须指明您需要创建的对象类型,如领导或联系人。
3.5. 如何查看和编辑连接信息
创建连接后,Fuse Online 为连接分配内部标识符。这个标识符不会改变。您可以更改连接的名称、描述或配置值,Fuse Online 可以识别与连接相同的连接。
可以通过两种方式查看并编辑连接信息:
- 在左侧面板中,点 Connections,然后点任意连接来查看其详情。
在左侧面板中,点 Integrations,然后查看任何集成以查看其摘要页面。在集成的流程图中:
- 对于简单集成,请点击连接图标来查看该连接的详细信息。
-
对于 API 供应商集成,点 view
 以显示集成的操作列表。点流包含您要查看详情的连接的操作。
以显示集成的操作列表。点流包含您要查看详情的连接的操作。
在 Connection Details 页面中,对于您要编辑的连接,点字段旁的
 来编辑该字段。或者,对于某些连接,在配置字段的下面点击 Edit 以更改配置值。如果更改任何值,请确定点击 Save。
来编辑该字段。或者,对于某些连接,在配置字段的下面点击 Edit 以更改配置值。如果更改任何值,请确定点击 Save。
如果您更新在运行的集成中使用的连接,您必须重新发布集成。
对于使用 OAuth 协议授权访问的应用程序的连接,您无法更改连接使用的登录凭证。要连接到应用程序并使用不同的登录凭证,您必须创建一个新连接。
3.6. 关于从自定义连接器创建连接
上传定义了自定义连接器的扩展后,可以使用自定义连接器。您可以使用自定义连接器以同样的方式创建连接,方法是使用 Fuse Online-provided 连接器来创建连接。
自定义连接器可能是用于使用 OAuth 协议的应用程序。在从这种类型的连接器创建连接前,您必须注册 Fuse 在线环境,以便访问连接器所用于的应用程序。您可以在连接器所用于的应用程序的界面中完成此操作。如何注册 Fuse 在线环境的详细信息因每个应用程序而异。
例如,假设自定义连接器用于创建到 Yammer 的连接。您需要在 Yammer 中创建一个新应用程序来注册 Fuse Online 环境。注册为 Fuse Online 提供 Yammer 客户端 ID,为 Fuse Online 提供 Yammer 客户端 secret 值。从 Fuse 在线环境到 Yammer 的连接必须提供这两个值。
请注意,应用程序可能会将不同的名称用于这些值,如消费者 ID 或消费者机密。
注册 Fuse Online 环境后,您可以创建与应用程序的连接。配置连接时,应该有用于输入客户端 ID 和客户端 secret 的参数。如果这些参数不可用,您需要与扩展名开发人员对话,并询问更新的扩展程序可让您指定客户端 ID 和客户端 secret。
第 4 章 创建集成
在进行一些规划和准备后,您就可以创建集成。在 Fuse Online Web 界面中,点 Create Integration, Fuse Online 指导您创建集成的步骤。
先决条件
- 规划您的集成注意事项
根据您要创建的集成类型:
以下主题提供了创建集成的信息和说明:
4.1. 准备创建集成
准备创建集成时,首先使用 规划集成注意事项 中列出的问题的答案。在进行集成的计划后,您需要执行以下操作,然后才能创建集成:
确定您要连接的应用程序是否使用 OAuth 协议。对于使用 OAuth 的每个应用,将 Fuse 在线注册为有权访问该应用的客户端。使用 OAuth 协议的应用程序包括:
- dropbox
- Google 应用程序(Gmail、Calendar、Sheets)
- Salesforce
- SAP Concur
- wwitter
- 确定您要连接的应用程序是否使用 HTTP 基本身份验证。对于每个应用程序,标识用于访问该应用的用户名和密码。您需要在创建连接时提供此信息。
- 对于您要集成的每个应用程序,创建一个连接。
4.2. 触发集成执行的替代方法
当您创建集成时,集成中的第一个步骤决定了如何触发集成执行。集成的第一个步骤可以是以下之一:
连接到应用程序或服务。您可以为特定应用程序或服务配置连接。示例:
- 到 Twitter 的连接可监控调整器并在包含您指定的文本时触发对简单集成的执行。
- 当任何人都创建新领导时,到 Salesforce 的连接可触发简单的集成执行。
- 与 AWS S3 的连接可以定期轮询特定的存储桶,并在存储桶包含文件时触发简单集成的执行。
-
计时器.Fuse Online 触发器按您指定的间隔执行简单集成。这可以是简单的计时器或
cron作业。 -
Webhook.客户端可以将 HTTP
GET或POST请求发送到 Fuse Online 公开的 HTTP 端点。请求触发了简单集成的执行。 - API 提供程序.API 提供程序集成从 REST API 服务开始。此 REST API 服务由您在创建 API 供应商集成时提供的 OpenAPI 3(或 2)文档定义。发布 API 提供程序集成后,Fuse Online 将 REST API 服务部署到 OpenShift。任何有权访问集成端点的客户端都可以触发对集成的执行。
4.3. 创建简单集成的一般步骤
Fuse Online 为您提供创建简单集成的过程。它提示您选择启动连接、完成连接、可选中间连接和其他步骤。当集成完成后,您可以发布它以便其正在运行,也可以在以后保存以进行发布。
要了解创建 API 供应商集成的步骤,请参阅 第 5.3 节 “创建 API 供应商集成”。
先决条件
- 您制定了集成步骤的计划。
- 您创建了连接到此集成的每个应用程序或服务的连接。
流程
- 在 Fuse Online 的左侧面板中,单击 Integrations。
- 点 Create Integration。
选择并配置启动连接:
- 在 Choose a connection 页面中,点击您要用来开始集成的连接。当此集成运行时,Fuse Online 将连接至此应用程序,并获取您希望集成操作的数据。
- 在 Choose a action 页面中,选择您希望此连接执行的操作。可用的操作因各个连接而异。
- 在用于配置操作的页面上,在字段中输入值。
- 另外,如果连接需要数据类型规格,Fuse Online 会提示您点击 Next 来指定操作的输入和/或输出类型。
- 点 Next 添加启动连接。
作为连接到应用程序的替代选择,启动连接可以是计时器,以您指定的间隔触发集成执行,也可以是一个接受 HTTP 请求的 Webhook。
+ 选择并配置启动连接后,Fuse Online 提示您选择完成连接。
选择并配置完成连接:
- 在 Choose a connection 页面中,点击您要用来完成集成的连接。当此集成运行时,Fuse Online 将使用此应用程序连接到此应用程序。
- 在 Choose a action 页面中,选择您希望此连接执行的操作。可用的操作因各个连接而异。
- 在用于配置操作的页面上,在字段中输入值。
- 另外,如果连接需要数据类型规格,Fuse Online 会提示您点击 Next 来指定操作的输入和/或输出类型。
- 点 Next 添加完成连接。
作为连接到应用程序的替代选择,完成连接可以将信息发送到集成处理的消息中。为此,可选择 Log when Fuse Online 提示来选择完成的连接。
- (可选)在启动连接和完成连接之间添加一个或多个连接。对于每个连接,选择其操作并输入任何所需的配置详情。
- (可选)添加一个或多个在连接间操作集成数据的步骤。请参阅关于在连接 之间添加步骤。
-
在集成视觉化中,查找任何
 图标。这些警告表示在此连接前需要数据映射程序步骤。添加所需的数据映射程序步骤。
图标。这些警告表示在此连接前需要数据映射程序步骤。添加所需的数据映射程序步骤。
添加所需的数据映射程序步骤后,
图标仍可以被显示(可能会因为以下原因在编辑过程中显示任何时间)。
- 其中一个源步骤已更改了其输出
- 目标步骤的输入与映射程序的输出不兼容
- 缺少源步骤
目标步骤缺失
在这种情况下,这个警告表示必须编辑在第 7 步中添加的数据映射程序步骤。
- 当集成包含所有必需的步骤时,根据您是否要开始运行集成,单击 Save 或 Publish。
- 在 Name 字段中输入可将此集成与任何其他集成相区分的名称。
- (可选)在 Description 字段中输入描述信息,例如,您可以指定此集成的作用。
- 另外,在 Labels 字段中,为集成添加一个或多个标签。标签(label)是一个键值对标签,您可以应用到集成(或其他 OpenShift 资源)以便稍后过滤并在 OpenShift 中选择。例如,OpenShift admin 用户可以按照标签过滤正在运行的 Pod 或部署的列表。
-
另外,还可为集成添加一个或多个自定义环境变量。您可以使用这些环境变量来设置 Spring Boot 配置选项,如
SERVER_MAX_HTTP_HEADER_SIZE。请注意,当您保存集成时,在 Fuse Online 中设置这些环境变量不会影响手动设置的其他环境设置,例如通过 OpenShift Web 控制台界面。 另外,从您导入的库扩展列表中,您可以选择一个或多个与集成关联的库扩展。请注意,如果希望它出现在此列表中,您必须已导入一个库
.jar文件作为 Fuse Online 扩展,以便可以选择它。有关库扩展的更多信息,请参阅如何开发库扩展。
如果您已准备好开始运行集成,请单击 Save 并发布。
Fuse Online 显示集成摘要。您可以看到 Fuse Online 处于发布过程中。可能需要稍等片刻,集成的状态才会变为 Running。
如果您不想发布集成,请单击 Save。Fuse Online 保存集成并显示其流程视觉化。您可以继续编辑它。或者,在页面顶部的面包面包中,单击 Integrations 以显示集成列表。如果您保存但未发布集成,则集成条目上会出现 停止。
4.4. 添加计时器连接来触发集成执行
要根据您指定的计划触发集成的执行,请将计时器连接添加为简单的集成启动连接。计时器连接不能处于流中,或者在流结束时。
流程
- 在 Fuse Online 中,单击左侧的 Integrations。
- 点 Create Integration。
在 Choose a connection 页面上,单击 Timer。
Fuse Online 提供 定时器 连接,您不需要创建计时器连接。
在 Choose a action 页面中,选择 Cron 或 Simple。
-
cron计时器需要一个cron表达式,用于指定触发集成执行调度的调度。 -
一个简单的计时器提示您指定一个周期及其时间单位,例如
5 秒,1 小时。可用单位为毫秒、秒、分钟、小时、天。
-
-
根据您要添加的计时器类型,输入
cron表达式或带有所选时间单元的周期。 - 点 Next 添加 Timer 连接,作为集成的启动连接。
4.5. 数据位于集合中的集成行为
有时,连接会返回一个集合,其中包含了相同类型的多个值。当连接返回集合时,流可以通过多种方式在集合上操作,包括:
- 为集合执行一次每个步骤。
- 为集合中的每个元素执行一次每个步骤。
- 为集合执行一次这些步骤,并为集合中的每个元素执行一次其他步骤。
要决定如何对流中的集合进行操作,您需要了解流连接到哪些应用程序,以及是否可以处理集合,以及您希望流程完成的内容。然后,您可以使用以下主题中的信息向处理集合的流中添加步骤:
4.5.1. 关于数据类型和集合
data mapper 显示源字段和目标字段,您可以定义您需要的字段到字段映射。
在 data mapper 中,字段可以是:
-
存储单个值的原语类型。原语类型示例包括
布尔值、char、字节、短、int、长、浮点数和双倍。原语类型不可扩展,因为它是一个字段。 - 复杂的 类型,由多个不同类型组成的字段组成。您可以在设计时定义复杂类型的子字段。在数据映射器中,一种复杂的类型可以扩展,以便您可以查看其子字段。
每种字段类型(专用和复杂)也可以是一个集合。集合是一个可以有多个值的单个字段。集合中的项目数量在运行时决定。在设计时,在数据映射程序中,集合由
![]() 表示。数据映射程序界面中是否可扩展集合是否由其类型决定。当集合是原语类型时,它不可扩展。当集合是复杂的类型时,数据映射程序可以被扩展来显示集合的子字段。您可以从/映射到每个字段。
表示。数据映射程序界面中是否可扩展集合是否由其类型决定。当集合是原语类型时,它不可扩展。当集合是复杂的类型时,数据映射程序可以被扩展来显示集合的子字段。您可以从/映射到每个字段。
以下是一些示例:
-
ID是原语类型字段(int)。在运行时,员工只能有一个ID。例如:ID=823。因此,ID是非集合的原语类型。在数据映射器中,ID不可扩展。 -
email是原语类型字段(字符串)。在运行时,员工可以具有多个电子邮件值。例如:email<0>=aslan@home.com和email<1>=aslan@business.com。因此,电子邮件是一个原语类型,也是集合。数据映射程序使用 表示
表示 电子邮件字段是一个集合,但电子邮件无法扩展,因为它是一个原语类型(没有子字段)。 -
staff是复杂的对象字段,具有多个子字段,包括ID和电子邮件。在运行时,员工也是一个集合,因为公司有许多员工。
在设计时,数据映射程序使用
来表示 员工是一个集合。employees字段可扩展,因为它是包含子字段的复杂类型。
4.5.2. 关于处理集合
流处理集合的最简单方法是使用 data mapper 将源集合中的字段映射到目标集合中字段。对于很多流,这是需要的。例如,流可能会从数据库中获取一系列员工记录,然后将这些记录插入到电子表格中。在数据库连接和 Google Sheets 连接之间,数据映射程序步骤将数据库字段映射到 Google Sheets 字段。由于源和目标都是集合,因此当 Fuse Online 执行流时,它会同时调用 Google Sheets 连接。在该调用中,Fuse Online 会迭代记录并正确地填充电子表格。
在一些流程中,您可能需要将集合分成单独的对象。例如,有一个流,它连接到数据库,并获得了在一定日期之前丢失分配时间的员工集合。然后,流程需要向每个员工发送电子邮件通知。在这个流程中,您可以在数据库连接后添加 split 步骤。然后,您将添加一个数据映射程序步骤,将员工记录的源字段映射到发送邮件的 Gmail 连接中的 target 字段。当 Fuse Online 执行流时,它会对每个员工执行 data mapper 步骤和 Gmail 连接。
有时,在流中分离集合后,在流中对集合执行一些步骤后,每个元素都会再次在集合上操作。考虑上一段落中的示例。假设在 Gmail 连接后向每个员工发送一条信息,您希望添加一个向电子表格通知的员工列表。在这种情况下,在 Gmail 连接后,添加一个聚合步骤来创建员工名称的集合。然后添加一个数据映射程序,将源集合中的字段映射到目标 Google Sheets 连接中的字段。当 Fuse Online 执行流时,会为集合执行新的 data mapper 步骤和 Google Sheets 连接。
这些是在流中处理集合的最常见场景。然而,更复杂的处理也成为可能。例如,当集合中的元素本身是集合时,您可以在其他分离和聚合步骤中嵌套分割和聚合步骤。
4.5.3. 使用 data mapper 处理集合
在流中,当步骤输出集合以及流中的后续连接时,需要一个集合作为输入,您可以使用 datamapper 指定如何处理集合的方式。
当步骤输出集合时,流视觉化会在步骤的详细信息中显示 Collection。例如:
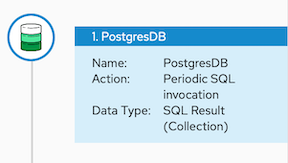
在提供集合并在需要映射的步骤之前,添加数据映射步骤。在此数据映射程序步骤中的流程需要完全取决于流程中的其它步骤。下图显示了从源集合字段到目标集合字段的映射:
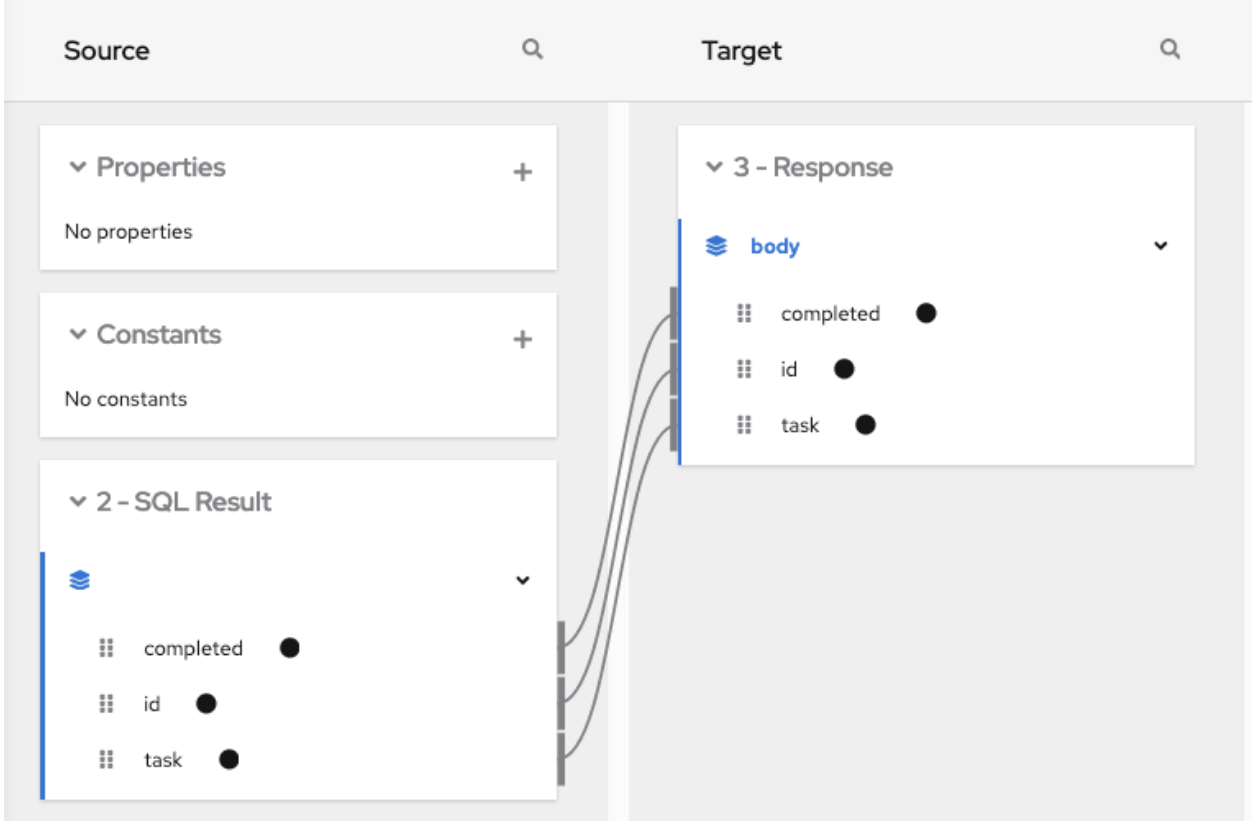
在源和目标面板中,数据映射器会显示
![]() 来表示集合。
来表示集合。
当集合是复杂的类型时,数据映射程序会显示集合的子字段。您可以从/映射到每个字段。
当源字段嵌套到多个集合中时,您可以将其映射到满足这些状况的目标字段:
target 字段嵌套在与 source 字段相同的集合数量中。例如,允许这些映射:
- /A<>/B<>/C → /D<>/E<>/F
- /A<>/B<>/C → /G<>/H/I<>/J
target 字段只嵌套在一个集合中。例如,允许这个映射:
/A<>/B<>/C → /K<>/L
在这种情况下,数据映射程序使用深度第一算法来迭代源中的所有值。因此,数据映射程序会将源值放在单个目标集合中。
不允许使用以下映射:
/A<>/B<>/C cannot-map-to /M<>/N/O<>/P<>/Q
当 Fuse Online 执行流时,它会迭代源集合元素来填充目标集合元素。如果您将一个或多个源集合字段映射到目标集合或目标集合字段,则目标集合元素仅包含映射字段的值。
如果您将源集合中的源集合或字段映射到不在集合中的目标字段,那么当 Fuse Online 执行流时,它将仅从源集合中的最后一个元素分配值。集合中的所有其他元素在此映射步骤中会被忽略。但是,任何后续映射步骤都可以访问源集合中的所有元素。
当连接返回 JSON 或 Java 文档中定义的集合时,数据映射程序通常可以将源文档作为集合处理。
4.5.4. 添加分割步骤
在执行流期间,当连接返回一组对象时,Fuse Online 对集合执行一次后续步骤。如果要为集合中的每个对象执行一次后续步骤,请添加 split 步骤。例如,Google Sheets 连接会返回一行对象的集合。要对每个行执行一次后续步骤,请在 Google Sheets 连接后添加一个拆分步骤。
确定到 split 步骤的输入始终是一个集合。如果分割步骤获取一个不是集合类型的源文档,步骤会在每个空间上分离输入。例如,Fuse Online 将"Hello world!"输入分成两个元素:"Hello"和"world!",并将这些两个元素传递到网络流中的下一步。特别是,XML 数据不是集合类型。
先决条件
- 正在创建或编辑一个流。
- 流已具有所需的所有连接。
- 在流视觉化中,获取源数据的连接表示数据是一个 (Collection)。
流程
-
在流视觉化中,点您要添加分割步骤的位置
 。
。
- 点 Split。此步骤不需要任何配置。
- 点击 Next。
附加信息
通常,要在添加数据映射程序步骤前添加任何分割步骤和聚合步骤。这是因为数据是集合还是单个对象是否影响映射。如果您添加一个数据映射程序,然后添加分割步骤,您通常需要重做映射。同样,如果您删除了分割或聚合步骤,则需要恢复任何映射。
4.5.5. 添加聚合步骤
在流中,添加一个聚合步骤,您要使用 Fuse Online 从单个对象创建集合。在执行聚合步骤后,Fuse Online 对每个对象执行一次后续步骤,而对集合执行一次后续步骤。
在决定是否将聚合步骤添加到流时,请考虑流中的连接。对于每个后续连接,Fuse Online 会为每个流程数据中的每个元素连接一次应用程序。对于某些连接,最好一次连接一次,而不是多次连接。
先决条件
- 正在创建或编辑一个流。
- 流已具有所需的所有连接。
- 上一步将集合分成单个对象。
流程
-
在流视觉化中,您要在流中添加聚合步骤,点
。
- 点 Aggregate。此步骤不需要任何配置。
- 点击 Next。
附加信息
通常,要在添加数据映射程序步骤前添加任何分割和聚合步骤。这是因为数据是集合还是单个对象是否影响映射。如果您添加一个数据映射程序,然后添加一个聚合步骤,通常需要重做映射。同样,如果您删除了聚合步骤,则需要恢复任何映射。
4.5.6. 在流中处理集合示例
此简单集成从随 Fuse Online 提供的样本数据库中获取一组任务。流将集合分成单个任务对象,然后过滤这些对象来查找已完成的任务。然后,流会在集合中聚合完成的任务,将该集合中的字段映射到电子表格中的字段,并通过向电子表格添加完成的任务列表来完成。
以下流程提供了创建此简单集成的说明。
先决条件
- 您创建了 Google Sheets 连接。
- 在 Google Sheets 连接访问的帐户中,有一个用于接收数据库记录的电子表格。
流程
- 点 Create Integration。
添加启动连接:
- 在 Choose a connection 页面上,单击 PostgresDB。
- 在 Choose a action 页面上,选择 Periodic SQL Invocation。
-
在 SQL 语句 字段中,输入
选择 * from todo,然后单击 Next。
此连接返回一组任务对象。
添加完成连接:
- 在 Choose a connection 页面中,点 Google Sheets 连接。
- 在 Choose a action 页面中,选择 Append values to asheet。
- 在 SpreadsheetId 字段中输入电子表格的 ID,将任务列表添加到其中。
-
在 Range 字段中,输入
A:B作为您要附加值的目标列。第一列 A 用于任务 ID。第二列 B 用于任务名称。 - 接受 Major Dimension 和 Value Input Option 的默认值,然后单击 Next。
Google Sheets 连接通过将集合中的每个元素添加到电子表格,从而完成网络流。
在流中添加分割步骤:
- 在流视觉化中,点加号。
- 点 Split。
在流程执行分割步骤后,结果是一组单独的任务对象。Fuse Online 为每个任务对象执行一次流程中的后续步骤。
在流中添加过滤器步骤:
- 在流视觉化中,在分割步骤后点加号。
点 Basic Filter 并配置过滤器:
-
单击第一个字段中的,然后选择包含您要评估数据的字段名称。
- 在第二个字段中,选择 等于 completed 字段值必须满足的条件。
-
在第三个字段中,将
1指定为必须在 completed 字段中的值。1表示任务已完成。
-
单击第一个字段中的,然后选择包含您要评估数据的字段名称。
- 点击 Next。
在执行过程中,流程为每个任务对象执行过滤器步骤一次。其结果是一组单独的完成的任务对象。
在流中添加聚合步骤:
- 在流视觉化中,在过滤器步骤后点加号。
- 点 Aggregate。
现在,结果集包含一个集合,其中包含每个完成的任务的一个元素。
在流中添加数据映射步骤:
- 在流视觉化中,在聚合步骤后点加号。
点 Data Mapper,将 SQL 结果源集中的以下字段映射到 Google Sheets 目标集合:
- ID 到 A
- 任务 到 B
- 点 Done。
- 单击 Publish。
结果
当集成运行时,它会每分钟从示例数据库获取任务,然后将完成的任务添加到电子表格中的第一个表中。该集成将任务 ID 映射到第一列 A,它会将任务名称映射到第二列 B。
4.6. 关于在连接间添加步骤
虽然这不是强制要求,但建议是将所有需要的连接添加到主流中,然后根据您希望流程执行的处理添加附加步骤。在流程中,每个步骤都在从之前连接中获取的数据和之前的步骤中运行。在流程中,生成的数据可供下一步使用。
通常,您必须将从连接接收的数据字段映射到流中下一连接可以操作的 data 字段。将所有连接添加到流后,检查流视觉化。对于需要数据映射的每个连接,然后再对输入数据进行操作,Fuse Online 会显示
 。点击这个图标查看 Data Type Mismatch: Add a data mapper 步骤,再这个连接来解决不同的区别。
。点击这个图标查看 Data Type Mismatch: Add a data mapper 步骤,再这个连接来解决不同的区别。
您可以点击消息中的链接来显示添加和指定数据映射程序步骤的 Configure Mapper 页面。但是,建议您添加其它所需步骤,然后最后添加数据映射步骤。
4.7. 评估集成数据以确定执行流
在流中,Condition al Flows 步骤会根据您指定的条件评估集成数据。对于每个指定的条件,您可以在与该条件关联的流中添加连接和其他步骤。在执行期间,Condition al Flows 步骤会评估传入的数据,以确定要执行的流。
以下主题提供详情:
4.7.1. 条件流 的行为
在集成开发过程中,您可以在流中添加条件流步骤并定义一个或多个条件。对于每个条件,您可以在仅与该条件关联的条件流中添加步骤。在集成执行过程中,对于前面的集成步骤传递给 Conditional Flows 步骤的每个消息,Conditional Flows 步骤会根据您在 Fuse Online 页面中定义条件的顺序评估消息内容,以指定条件。
在 条件流 步骤中,其行为是以下之一:
- 对于评估为 true 的第一个条件,该集成将执行与该条件关联的条件流。
- 如果没有条件评估为 true,且没有默认的条件流,则集成将执行该流。
- 如果没有条件评估为 true,且没有默认的条件流,则集成不会执行条件流。
在执行条件流后,或没有条件评估为 true 且没有默认条件流后,该集成会在主流中执行下一步。
4.7.2. Conditional Flows 步骤示例
假设集成连接到 SQL 数据库以获取有关每个员工拥有的付费时间(PTO)的信息。返回的数据表示:
- 如果某些员工没有在特定日期使用,则可能会丢失 PTO。
- 其他员工已经使用 PTO 比获得更多。
- 其余的员工拥有 PTO,无需时间限制即可使用。
在 Conditional Flows 步骤中,本示例集成可以定义两个条件,每个条件的执行流以及默认执行流:
- 当 PTO 大于某个数字时,这表示某些 PTO 可能会在特定日期未使用时丢失。当此条件评估为 true 时,集成将执行向受影响的员工发送电子邮件的流。该电子邮件包含必须使用的 PTO 量以及必须使用的日期。
- 当 PTO 为负数时,这表示一些 PTO 已被使用,但不获得。当此条件评估为 true 时,集成将执行向受影响的员工发送电子邮件的流。该电子邮件包含员工已过撤回的 PTO 量,并指定员工再次进入加速 PTO 的日期。
- 当两个条件都没有评估为 true 时,该集成将执行默认流。这个示例集成为 PTO 不是一个负数字,或超过某些指定数字的红帽员工执行默认条件流。default 流向那些员工发送一封电子邮件,其声明是员工拥有的 PTO 量。
4.7.3. 配置 条件流 步骤的一般步骤
在向流中添加了 Conditional Flows 步骤后,配置步骤的工作流如下:
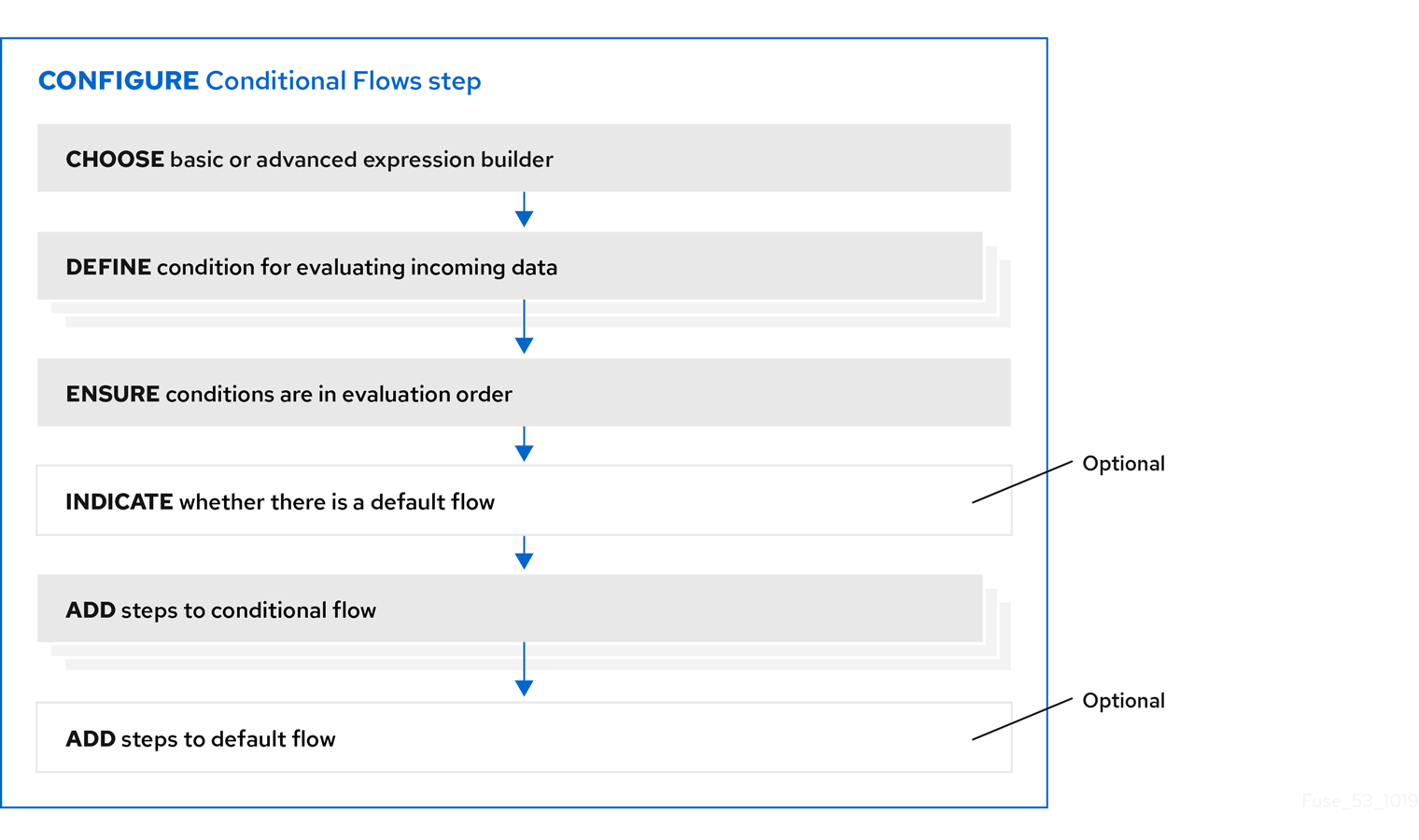
有关工作流的更多信息
- 基本表达式构建器提示您包含您要评估的内容以及要测试的条件和值的属性。基本表达式构建器适用于大多数 条件流 步骤。
- 高级表达式构建器允许您在 Camel Simple 语言中指定条件表达式。
- 所有条件都必须使用相同的表达式构建器。换句话说,若要配置 条件流 步骤,您必须使用基本表达式构建器或高级表达式构建器。您不能使用两者。
- 在条件流中,您无法添加条件 流 步骤。
4.7.4. 使用基本表达式构建器指定条件
在流程中,当您要评估进入的数据以确定集成的执行路径时,添加一个条件 流 步骤。此处描述的步骤演示了如何使用基本表达式构建器指定条件。
先决条件
- 正在创建或编辑主流。如果这是简单的集成,则添加了开始和完成连接。
- 对 条件流 步骤的输入必须是单个消息。在集成视觉化中,如果上一步的 Data Type 显示 (Collection),请在上一步后添加 Split 步骤,并在此条件 流步骤前添加 Split 步骤。
- 您熟悉了集成传递给您要添加的 Conditional Flows 步骤的消息中。
流程
-
在集成视觉化中,您要添加 条件流 步骤,点
。
- 点 Conditional Flows。
- 在 Basic 表达式构建器 条目中,单击 Select。
在 Configure Conditional Flows 页面中,定义一个或多个条件:
- 在初始 when 字段中 点。
- 在属性列表中,点击包含您希望 Conditional Flows 步骤评估的内容的属性。
- 在下一个字段中,接受 包含 步骤评估数据或选择另一个条件的条件。您在此字段中选择的条件必须评估要在下一个字段中输入的值。
- 在第三个字段中,指定条件测试的值。
- 可选。点 Add another condition 指定另一个条件。
- 对您要定义的每个额外条件重复这组步骤。
- 可选。点条件右侧的上箭头更改集成评估定义条件的顺序。
可选。如果要有一个默认条件流,请单击 Execute default flow。
如果您选择 Execute default flow,在执行过程中,如果没有指定的评估为 true 的条件,则集成将执行默认条件流。如果您没有选择 Execute default 流,在执行过程中没有您指定的评估为 true 的条件,集成将继续执行遵循此条件 流 步骤的步骤。
- 点击 Next。
- 可选。如果 Fuse Online 提示提供它,请指定输出数据类型。作为此条件流步骤 一部分的所有条件流 均必须具有相同的输出类型。
点击 Next。
Fuse Online 显示流程视觉化。在添加的条件流步骤下,您指定的每个条件都有一个条目,如果您表示 Conditional Flows 步骤 有 默认流,则为其它范围默认流的条目。
后续步骤
对于每个条件,为它关联的流添加步骤。如果有默认流,在默认流中添加步骤。
其他资源
- 有关您可以在每个条件的中间字段中选择的条件的详细信息,请参阅 Camel Simple Language 运算符。请注意,匹配条件 对应于 Simple Language regex 运算符。
- 如果无法使用基本表达式构建器定义您需要的条件,请参阅使用高级表达式构建器指定条件。
4.7.5. 使用高级表达式构建器指定条件
在流程中,当您要评估进入的数据以确定集成的执行路径时,添加一个条件 流 步骤。此处描述的步骤演示了如何使用高级表达式构建器在 Camel Simple 语言中指定条件表达式。
先决条件
- 正在创建或编辑主流。如果这是简单的集成,则添加了开始和完成连接。
- 对 条件流 步骤的输入必须是单个消息。在集成视觉化中,如果上一步的 Data Type 显示 (Collection),请添加 Split 步骤。
- 您熟悉了集成传递给您要添加的 Conditional Flows 步骤的消息中。
- 您熟悉 Camel Simple Expression 语言,或者您有需要评估的条件的表达式。
流程
-
在集成视觉化中,您要添加 条件流 步骤,点
。
- 点 Conditional Flows。
- 在 Advanced 表达式构建器条目中点 Select。
在 Configure Conditional Flows 页面中,定义一个或多个条件:
在初始 when 字段中,输入 Camel Simple Language 条件表达式。表达式的左侧必须是以 ${…} 括起的变量表达式。
以下是有效表达式的示例:
${header.type} == 'note'${body.title} contains 'Important'以下是无效表达式的示例:
'note' == ${header.type}下面是一个示例,它演示了如何编写在消息正文包含大于
160的pto字段时评估为 true 的表达式:${body.pto} > 160当此表达式评估为 true 时,该集成将执行您创建的条件流并与该条件关联。
注意在表达式中,当 Conditional Flows 步骤位于以下一种流中时,需要一个额外的属性规格:
- API 供应商集成操作流
- 以 Webhook 连接开头的简单集成
- 以自定义 REST API 连接开始的简单集成
在这些流程中,Fuse Online 会将实际消息内容嵌套在
正文属性中。这意味着,Conditional Flows 步骤的输入包含一个正文属性,其中包含另一个包含实际消息内容的正文属性。因此,在处于这些流之一的条件 流 步骤中的表达式中,您必须指定两个正文实例。例如,假设您要评估输入消息pto字段中的内容。指定类似如下的表达式:${body.body.pto} > 160- 可选。单击 Add another 条件,再重复前面的步骤。对于您要定义的每个额外条件,请执行此操作。
- 可选。点击 condition 字段右侧的向上或下箭头,更改 Conditional Flows 步骤评估定义的条件的顺序。
可选。如果要有一个默认条件流,请单击 Execute default flow。
如果您选择 Execute default flow,在执行过程中,如果没有指定的评估为 true 的条件,则集成将执行默认条件流。如果您没有选择 Execute default 流,在执行过程中没有您指定的评估为 true 的条件,集成将继续执行遵循此条件 流 步骤的步骤。
- 点击 Next。
- 可选。如果 Fuse Online 提示提供它,请指定输出数据类型。作为此条件流步骤 一部分的所有条件流 均必须具有相同的输出类型。
点击 Next。
Fuse Online 显示流程视觉化。在添加的条件流步骤下,您指定的每个条件都有一个条目,如果您表示 Conditional Flows 步骤 有 默认流,则为其它范围默认流的条目。
后续步骤
对于每个条件,为它关联的流添加步骤。如果有默认流,在默认流中添加步骤。
其他资源
4.7.6. 为条件流添加步骤
在 Conditional Flows 步骤中,在为每个条件定义条件后,为与该条件关联的流添加步骤。在执行期间,当 Conditional Flows 步骤评估为 true 时,它会执行与该条件关联的流。
先决条件
- 您定义了此条件 流步骤 的条件。
- 您熟悉了集成传递给此条件 流 步骤的消息中的字段。
- 您创建了您要添加到条件流的每个连接。
流程
在集成视觉化中,对于您要添加到的条件,点 Open Flow。
Fuse Online 显示页面顶部附近的状况。条件流程视觉化显示所有条件 流拥有的 流开始 和流结束 步骤。
-
在流视觉化中,点击您要在这个条件流中添加步骤的
。
点击您要添加的步骤。您可以添加任何可添加到主流的连接或步骤。
Flow Start 步骤的输出始终与在此条件流步骤前的主流步骤的输出相同。例如,如果您将过滤器步骤或数据映射程序添加到此条件流中,可用字段是主流程中可用的字段。
- 根据需要配置步骤。
- 对您要添加到此条件流的每个步骤重复前面的三个指令。
- 在页面的顶部,在 Flow 字段中,单击 down carat 并单击 Back to primary flow,它会保存此条件流并显示主要流。
- 对于您要添加到的每个条件流,请重复此步骤。
结果
主流程都有一个条件流,用于您在 Conditional Flows 步骤中定义的每个条件。如果选择了 Execute default flow 选项,则主流也有默认的条件流。
在执行期间,Conditional Flows 步骤执行与评估为 true 的第一个条件关联的条件流。然后集成将执行遵循 条件流步骤的步骤。
如果没有条件评估为 true,则条件 流 步骤执行默认条件流。然后集成将执行遵循 条件流步骤的步骤。
如果两者都正确:
- 无条件评估为 true。
- 没有默认条件流。
然后,该集成执行遵循 条件流 步骤的步骤。
4.8. 添加数据映射程序步骤
几乎所有集成都需要数据映射。数据映射步骤步骤将来自之前连接的数据字段以及其它步骤映射到流程中下一个连接可以操作的 data 字段。例如,假设集成数据包含 Name 字段,且流中的下一个连接具有 customer Name 字段。您需要将 source Name 字段映射到目标 customer Name 字段。
data mapper 显示可以通过之前集成步骤提供的最大源字段集。但是,不是所有连接都提供每个显示的源字段中的数据。例如,对第三方应用程序的更改可能会停止在特定字段中提供数据。在创建集成时,如果您发现数据映射没有被象预期的一样,请确保要映射的源字段包含您所期望的数据。
前提条件
正在创建或编辑一个流。
流程
-
在您要添加数据映射程序步骤的流视觉化中,点
。
- 点 Data Mapper 显示 datamapper Canvas 中的源字段和目标字段。
后续步骤
4.9. 添加基本过滤器步骤
您可以添加一个步骤到流,以过滤流操作的数据。在过滤器步骤中,Fuse Online 检查数据,只有在内容满足您定义的条件时才继续。例如,在来自witter 获取数据的流中,您可以指定只有包含 "Red Hat" 的TWeets才可以继续执行。
先决条件
- 流包含需要的所有连接。
- 正在创建或编辑一个流。
流程
-
在您要添加过滤器步骤的流视觉化中,点
。
- 单击 Basic Filter。
在 Configure Basic Filter Step 页面中,只有在传入的数据 match 字段中才会继续 中:
- 接受必须满足所有定义的规则的默认值。
- 或者,选择 以下内容的 ANY 以指示必须只需要一个规则。
定义过滤器规则:
在 Property Name 字段中,输入或选择包含要评估过滤器的内容的字段名称。例如,假设进入步骤的数据由涉及您的Twitter 句柄的调整人员组成。只有在调整包含某些内容时才需要继续执行。TWeet 在名为
text的字段中,因此您可以输入或选择text作为属性名称字段中的值。您可以使用以下方法定义属性名称:
- 开始键入:该字段具有一个 typeahead 功能,可在弹出框中为您提供可能的完成列表。从列表中选择正确的选项。
- 在字段中点击。此时会出现一个下拉菜单,其中包含可用属性列表。从列表中选择所需属性。
- 在 Operator 字段中,从下拉菜单中选择一个 operator。此设置默认为 Contains。要继续执行,您在此字段中选择的条件必须评估您在 Keywords 字段中输入的值为 true。
- 在 Keywords 字段中,输入要过滤的值。例如,假设您接受默认的 Contains 操作器,并且您希望仅在传入文本提及特定产品时继续进行集成。在这里输入产品名称。
(可选)单击 + Add another rule 并定义其他规则。
您可以点击规则条目右上角的 trash can 图标来删除规则。
- 过滤器步骤完成后,点 Done 将其添加到流程中。
其他资源
- 如需有关操作员和指定评估文本的示例,请参阅 Camel Simple Language operator。请注意,基本过滤器步骤 匹配 运算符对应于 Simple Language regex 运算符。
- 如果无法在基本过滤器步骤中定义您需要的过滤器,请参阅添加 高级过滤器步骤。
4.10. 添加高级过滤器步骤
在过滤器步骤中,Fuse Online 检查数据,只有在内容满足您定义的条件时才继续执行流。如果基本过滤器步骤没有让您定义所需的确切过滤器,则添加一个高级过滤器步骤。
先决条件
- 流包含需要的所有连接。
- 正在创建或编辑一个流。
- 您熟悉 Camel Simple Language,或者您已提供过滤器表达式。
流程
-
在流视觉化中,您要在流中添加高级过滤器步骤,点
。
- 点 Advanced Filter。
在编辑框中,使用 Camel Simple Language 指定过滤器表达式。例如,当消息标题的
type字段设置为widget时,以下表达式将评估为 true:${in.header.type} == 'widget'在以下示例中,当邮件正文包含
标题字段时,表达式将评估为 true:${in.body.title}- 点 Next 将 advanced filter 步骤添加到流程中。
某些流程中的附加属性规格
在表达式中,当高级过滤器步骤位于以下一种流程中时,需要一个额外的属性规格:
- API 供应商集成操作流
- 以 Webhook 连接开头的简单集成
- 以自定义 REST API 连接开始的简单集成
在这些流程中,Fuse Online 会将实际消息内容嵌套在 正文 属性中。这意味着高级过滤器的输入包含 正文 属性,其中包含另一个包含实际消息内容 的正文 属性。因此,在其中一种流程中的高级过滤器表达式中,您必须指定两条 正文 实例。例如,假设您要评估输入消息的 completed 字段中的内容。指定类似如下的表达式:
${body.body.completed} = 14.11. 添加模板步骤
在流中,模板步骤从来源获取数据,并将其插入到您在上传到 Fuse Online 的模板中定义的格式。模板步骤的好处是,它以您指定的一致格式提供数据输出。
在模板中,您可以定义占位符并指定静态文本。在创建流时,您将添加模板步骤,将源字段映射到模板占位符,然后将模板内容映射到流程中的下一步。当 Fuse Online 执行流时,它会将位于映射源字段中的值插入到模板的实例中,并将结果提供给流程中的下一步。
如果流程包含模板步骤,那么该流程中很可能是唯一模板步骤。但是,一个流中允许多个模板步骤。
Fuse Online 支持以下类型的模板: 自由标记、Mustache、Velocity。
先决条件
- 您必须创建或编辑一个流。
- 如果您要创建简单集成,则必须已开始和完成连接。
流程
-
在流视觉化中,点您要添加模板步骤的
。
- 点 Template。此时会打开 Upload Template 页面。
- 指定模板类型,即 Freemarker、Mustache 或 Velocity。
要定义模板,请执行以下操作之一:
- 将模板文件或包含您要修改的文本的文件拖放到模板编辑器中。
- 单击 浏览以上传,导航至文件并上传该文件。
- 在模板编辑器中,开始键入 以定义模板。
-
在模板编辑器中,确保模板有效以用于 Fuse Online。有效的模板示例在此流程之后。Fuse Online 在一行的左侧显示
 ,其中包含语法错误。将鼠标悬停在语法错误指示器上显示了如何解决错误的提示。
,其中包含语法错误。将鼠标悬停在语法错误指示器上显示了如何解决错误的提示。
点 Done 将模板步骤添加到流程中。
如果没有启用 Done 按钮,则必须至少有一个语法错误。
模板步骤的输入必须采用 JSON 对象的形式。因此,您必须在模板步骤前添加数据映射步骤。
在模板步骤前添加数据映射步骤:
-
在流视觉化中,点您刚刚添加的模板步骤前的
。
- 点 Data Mapper。
在 data mapper 中,将源字段映射到每个模板占位符字段。
例如,使用此流程之后的示例模板,将 source 字段映射到每个模板字段:
-
time -
name -
text
-
- 在右上角,点 Done 将 data mapper 步骤添加到网络流中。
模板步骤的输出始终是一个 JSON 对象。因此,您必须在模板步骤后添加数据映射程序步骤。
-
在流视觉化中,点您刚刚添加的模板步骤前的
在模板步骤后添加数据映射程序步骤:
-
在流视觉化中,点您刚刚添加的模板步骤后立即使用
。
- 点 Data Mapper。
- 在 datamapper 中,将模板的 message 字段映射,该字段始终包含将源字段插入到模板的结果,再映射到目标字段。例如,假设 Gmail 连接在流中下一位,您希望发送模板步骤的结果,作为 Gmail 消息的内容。为此,您可以将 message source 字段映射到 文本 目标字段。
- 在右上角,单击 Done。
-
在流视觉化中,点您刚刚添加的模板步骤后立即使用
模板示例
Mustache 模板示例:
At {{time}}, {{name}} tweeted:
{{text}}Freemarker 和 Velocity 支持这个示例模板:
At ${time}, ${name} tweeted:
${text}velocity 也支持没有大括号的语法,如本例中所示:
At $time, $name tweeted: $text
占位符不能包含一个 . (句点)。
其他资源
有关映射字段的详情,请参阅为下一个连接 映射集成数据到字段。
4.12. 添加自定义步骤
如果 Fuse Online 没有提供流程中您需要的步骤,开发人员可以在扩展中定义一个或多个自定义步骤。自定义步骤可用于流中连接间的数据。
以您添加内置步骤的方式向流添加自定义步骤。对于简单集成,请选择开始和完成连接,根据需要添加其他连接,然后添加额外的步骤。对于 API 供应商集成,选择流执行自定义步骤的操作,根据需要添加连接,然后添加其他步骤。添加步骤后,Fuse Online 在流程中从上一步中接收的数据上运行。
先决条件
- 将自定义步骤扩展上传到 Fuse Online。请参阅 使自定义功能可用。
- 正在创建或编辑一个流。
- 流已具有所需的所有连接。
流程
-
在您要添加自定义步骤的流视觉化中,点
。
点您要添加的自定义步骤。
可用步骤包括在您的 Fuse 在线环境中定义的任何自定义步骤。
- 响应,以提示输入执行步骤所需的任何信息。此信息因各个自定义步骤而异。
第 5 章 创建由 REST API 调用触发的集成
要按需触发集成的执行,请开始与您提供的 REST API 描述文档集成。以这种方式实现的集成称为 API 提供程序集成。API 提供程序集成允许 REST API 客户端调用触发执行集成的命令。
当 Fuse Online 发布 API 供应商集成时,任何对集成端点的客户端都可以触发集成的执行。
如果您在 OpenShift Container Platform 上使用 Fuse Online,管理员可以配置 Fuse Online 服务器,以便红帽 3scale 发现 API 供应商集成 API。默认情况下,Fuse Online 对 API 供应商的集成 API 服务定义进行了注解,用于 3scale,但不公开这些 API 以供自动 3scale 发现。如果没有 3scale 发现功能,就无法有访问控制。通过 3scale 发现功能,您可以设置访问策略,集中控制并为 API 供应商集成 API 提供高可用性。如需更多信息,请参阅 Red Hat 3scale 文档页面中的 API 网关文档。
以下主题提供了创建 API 供应商集成的信息和说明:
有关如何创建、发布和测试 API 供应商集成的视频,请参阅 https://youtu.be/sox8SSqJ0zQ。
5.1. 创建 API 供应商集成的好处、概述和工作流
API 提供程序集成从 REST API 服务开始。此 REST API 服务由您在创建 API 供应商集成时提供的 OpenAPI 3(或 2)文档定义。发布 API 提供程序集成后,Fuse Online 将 REST API 服务部署到 OpenShift。API 供应商集成的好处是 REST API 客户端能够调用触发集成的执行调用。
多个执行流程
API 供应商集成有多个执行路径,称为流。OpenAPI 文档定义的每个操作都有自己的流。在 Fuse Online 中,对于 OpenAPI 文档定义的每个操作,您可以在该操作的执行流中添加连接和其他步骤。这些步骤将按照特定操作需要处理数据。
执行流程示例
例如,考虑调用 Fuse Online 提供的 REST API 服务的人工资源应用。假设调用操作,该操作会添加新员工。处理此调用的操作流程可能会:
- 连接到为新员工设备产生费用报告的应用程序。
- 连接到 SQL 数据库以添加设置新设备的内部票据。
- 连接到 Google 邮件,以向新员工发送邮件,并提供情况提示信息。
触发执行的方法
调用 REST API 的方法有很多来触发集成执行,包括:
- 一个 Web 浏览器页面,用于获取数据输入并生成调用。
-
明确调用 REST API(如
curl实用程序)的应用。 - 调用 REST API 的其他 API,如 webhook。
编辑流程的方法
对于每个操作,您可以编辑其流:
- 添加与需要处理数据的应用程序的连接。
- 在连接间添加步骤,包括分割、聚合和数据映射步骤。
- 映射连接错误消息,以在完成流的 HTTP 响应中返回代码。其响应指向调用触发了集成的执行调用的应用程序。
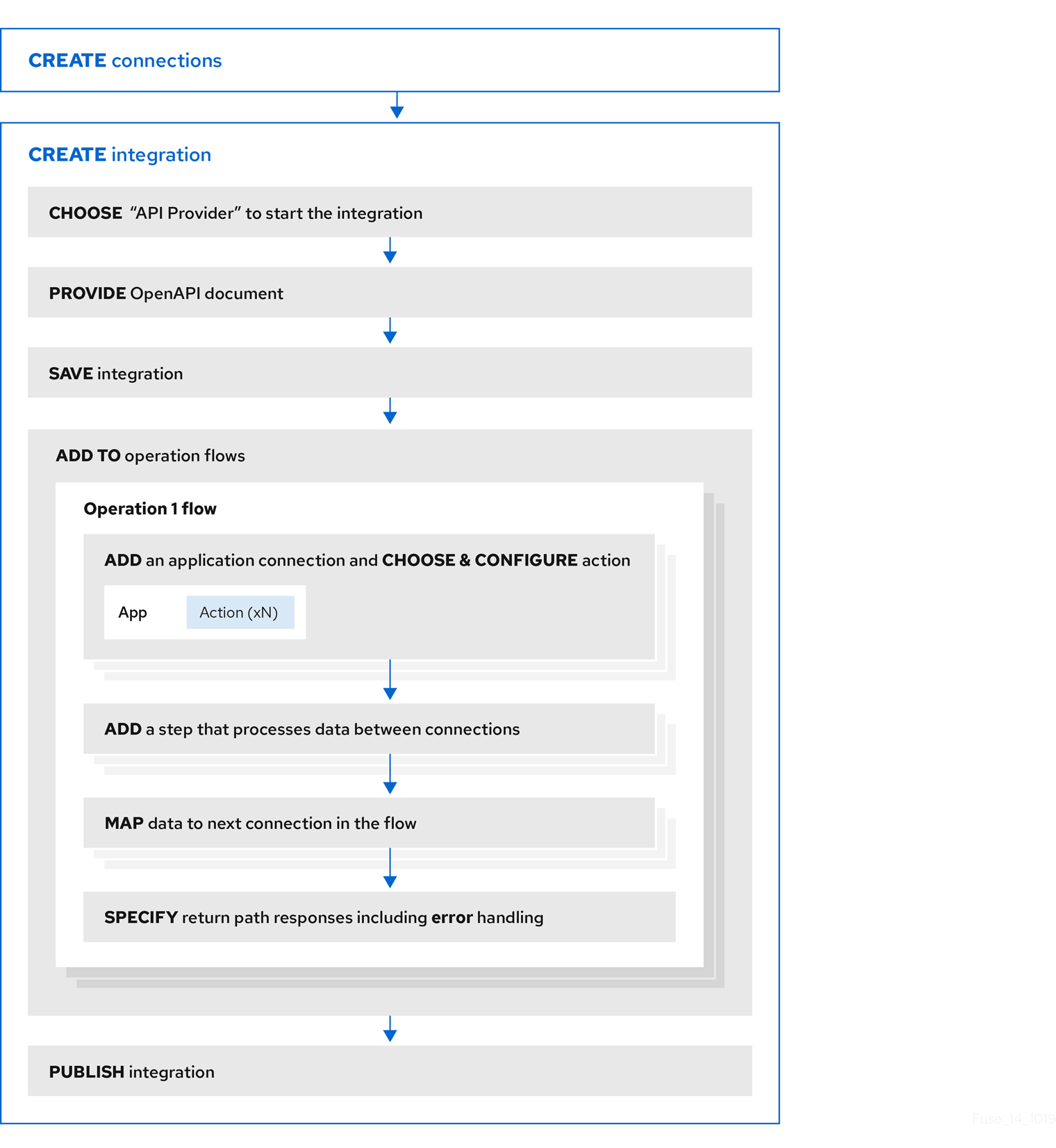
创建 API 供应商集成的工作流
以下示意图中显示了用于创建 API 供应商集成的 一般 工作流:
发布 API 供应商集成
发布 API 供应商集成后,在集成摘要页面中,Fuse Online 会显示 REST API 服务的外部 URL。此外部 URL 是客户端用来调用 REST API 服务的基本 URL。
对于 OCP 上的 Fuse Online 环境,可能会启用红帽 3scale API 供应商集成的发现。在这种情况下,3scale 会发布调用服务的 URL。
测试 API 供应商集成
要测试 API 供应商集成的流,您可以使用 curl 实用程序。例如,以下 curl 命令会触发 REST API 服务 URL 的 Get Task(按 ID 操作)的执行流: https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/。
HTTP GET 命令是默认请求,因此无需指定 GET。URL 的最后一部分指定要获取的任务 ID:
curl -k https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/todo/1
5.2. OpenAPI 操作与 API 供应商集成流程相关
API 供应商集成的 OpenAPI 文档定义了 REST API 客户端可以调用的操作。每个 OpenAPI 操作都有自己的 API 供应商集成流。因此,每个操作也可以有自己的 REST API 服务 URL。每个 URL 由 API 服务的基本 URL 以及子路径(可选)定义。REST API 调用指定一个操作的 URL,用于触发对该操作的流执行。
您的 OpenAPI 文档决定了哪些 HTTP 动词(如 GET、POST、POST 和DELETE 等)可以在 REST API 服务 URL 中指定。对 API 供应商 URL 的调用示例位于 尝试 API 供应商快速启动示例 的说明。
您的 OpenAPI 文档还决定了操作可以返回的可能 HTTP 状态代码。操作的返回路径只能处理 OpenAPI 文档定义的响应。例如,基于其 ID 删除对象的操作可能会定义这些可能的响应:
"responses": {
"204": {
"description": "Task deleted"
},
"404": {
"description": "No Record found with this ID"
},
"500": {
"description": "Server Error"
}
}API 供应商集成示例
下图显示了处理相关人员数据的 API 供应商集成。外部 REST API 客户端调用由 API 供应商集成部署的 REST API URL。调用 URL 会触发对一个 REST 操作的流执行。此 API 供应商集成有 3 个流程。每个流程都可以使用 Fuse Online 中的任何连接或步骤。REST API 及其流程是一台 Fuse 在线 API 供应商集成,部署在一个 OpenShift Pod 中。

在创建 API 供应商集成时编辑 OpenAPI 文档
在为 API 供应商集成指定 OpenAPI 文档后,您可以根据需要更新文档,同时为 API 操作定义执行流。为此,请点击您要编辑 API 供应商集成的页面右上角的 View/Edit API Definition。这会在 API Designer 编辑器中显示您的 OpenAPI 文档。编辑 并保存文档,以更改已反映在 Fuse Online 中。
编辑 OpenAPI 文档时的注意事项:
用于同步的
operationId属性API Designer 编辑器和 Fuse Online 集成编辑器中的 OpenAPI 文档之间的同步依赖于分配给文档中各个操作的唯一
operationId属性。您可以为每个操作分配特定的operationId属性值,或使用 Fuse Online 生成的值。请求和响应定义
在每个操作的定义中,您可以提供一个 JSON 模式来定义操作的请求和响应。Fuse Online 使用 JSON 模式:
- 作为操作输入和输出数据创建的基础
- 要显示 data mapper 中的操作字段
没有 cyclic 模式引用
API 供应商集成操作的 JSON 模式不能有cyclic 模式引用。例如,指定请求或响应正文的 JSON 模式无法整体引用,也无法通过中间 JSON 模式引用其中的任何部分。
5.3. 创建 API 供应商集成
要创建 API 供应商集成,提供一个 OpenAPI 文档(.json、.yaml 或 .yml 文件),以定义集成可以执行的操作。Fuse Online 为每个操作创建一个执行流。编辑每个操作的网络流,以添加根据该操作要求处理集成数据的连接和步骤。
先决条件
您可以为您要集成的 REST API 操作提供或定义 OpenAPI 文档。
要试验,请下载
task-api.json文件 的原始版本,它是 API 供应商快速入门的 OpenAPI 文档。当 Fuse Online 提示您输入 OpenAPI 文档时,您可以上传此文件。另外,您可以为 rawtask-api.json文件指定 URL,即 https://raw.githubusercontent.com/syndesisio/syndesis-quickstarts/1.14/api-provider/task-api.json。- 每个 OpenAPI 操作都有一个流的计划。
- 您为添加到操作流的每个应用程序或服务创建了一个连接。
流程
- 在 Fuse Online 中,在左侧导航面板中,单击 Integrations。
- 点 Create Integration。
- 在 Choose a connection 页面上,单击 API Provider。
在 Start 与 API 调用页面集成 :
- 如果您有定义 REST API 操作的 OpenAPI 文档,请上传 OpenAPI 文档。
- 如果您需要定义 OpenAPI 文档,请选择 Create a new OpenAPI 3.x 文档,或者创建一个新的 OpenAPI 2.x 文档。
点击 Next。
如果您上传了文档,请查看或编辑它:
- 点 Review/Edit 打开 API Designer 编辑器。
根据需要检查并编辑。
另外,如果您的文档使用 OpenAPI 2 规格,如果希望 API Designer 转换您的文档以符合 OpenAPI 3 规格,可以点 Convert to OpenAPI 3。
- 在右上角,单击 Save 或 Cancel 以关闭编辑器。
- 点击 Next。
如果您要创建文档,请在 Fuse Online 中打开的 API Designer 编辑器:
- 按照设计所述定义 OpenAPI 文档 ,并使用 API Designer 开发 API 定义。
- 在右上角,单击 Save,它将关闭编辑器。
- 点击 Next。
结果
Fuse Online 显示 OpenAPI 文档定义的操作列表。
后续步骤
对于每个操作,定义一个执行该操作的流。
5.4. 为 API 供应商集成定义操作流
定义 REST API 服务的 OpenAPI 文档定义了服务可以执行的操作。创建 API 供应商集成后,您可以编辑每个操作的网络流。
每个操作都只有一个流。在操作流程中,您可以添加连接到其他应用程序和服务,以及对连接间的数据执行操作的步骤。
当您添加到操作流中时,您可能会发现您需要更新 API 供应商集成的 OpenAPI 文档。为此,请在编辑 API 供应商集成的页面右上角点击 View/Edit API Definition。这会在 API Designer 编辑器中显示您的文档。在 OpenAPI 定义中,只要每个操作都有唯一的 operationId 属性,您可以在 API Designer 中保存您的更新,Fuse Online 可以同步 API 供应商集成的流程定义,使其具有您的更新。
先决条件
- 您创建了 API 供应商集成,为它指定一个名称并保存它。
- 您创建了与您希望操作流连接的每个应用程序或服务的连接。详情请查看 创建连接 的信息。
- Fuse Online 显示 API 定义的操作列表。
流程
- 在 Operations 列表页面中,针对您要定义的流的操作,单击 Create flow。
对于您要添加到此流的每个连接:
- 在流视觉化中,点加号在那个位置添加连接。
- 点您要添加的连接。
- 选择您希望此连接执行的操作。
- 通过在带标签的字段中输入数据来配置操作。
- 点击 Next。
在继续操作前,将所有必需的连接添加到流。
在这个操作流程中,要处理连接间的数据:
- 在流视觉化中,点您要添加步骤的加号。
- 点击您要添加的步骤。
- 通过在带标签的字段中输入数据来配置步骤。
点击 Next。
如需帮助,请参阅 连接间的添加步骤。
如果您要添加在连接间处理数据的另一个步骤,请重复这一指令子集。
将数据映射到下一个连接中的字段:
-
在流视觉化中,检查数据类型不匹配
图标,这表示连接无法处理传入的数据。您需要在此处添加数据映射程序步骤。
对于流视觉化中的每个数据不匹配图标:
- 点击刚才在这一步前的加号。
- 点 Data Mapper。
- 定义所需的映射。如需更多信息,请参阅 在下一个连接 中将集成数据映射到字段。
- 点击 完成 将 data mapper 步骤添加到流程中。
-
在流视觉化中,检查数据类型不匹配
在流视觉化中,在 Provided API return Path 步骤中,点 Configure。
每个 API 供应商集成都通过向负责执行操作流的 REST API 调用者发送响应来完成每个操作流的流。响应包含用于完成操作流的 Provided API return Path 步骤配置的返回代码之一。配置返回路径步骤,如下所示:
- 在 Default Response 下,在 return Code 字段中接受 Fuse Online 显示的默认响应,或者点击 care caret 并滚动来选择您想要的默认响应。在执行操作流时,流程不会返回任何配置的错误响应。通常,默认响应返回代码表示成功操作。
在 Error Handling 下,指明是否要在返回邮件正文中包含错误消息。
在开发过程中,您通常要返回错误消息。但是,在生产环境中,如果包含敏感或专有信息,您可能希望隐藏错误消息。错误消息是一个 JSON 格式的字符串,其中包含
响应代码、类别、消息和错误元素,例如:{ responseCode: 404, category: "ENTITY_NOT_FOUND_ERROR", message: "SQL SELECT did not SELECT any records" error: SYNDESIS_CONNECTION_ERROR }请注意,在开发过程中,知道发生错误的最可靠方法是检查对调用者的响应中的
HTTP_RESPONSE STATUS标头。您还可以检查集成 Pod 的日志INFO消息。该集成的活动日志显示成功交换,且错误始终不会在 Activity 日志中显示。在 Error Response Code 下,Fuse Online 显示为流中连接可能会返回的每个错误的条目。对于每个错误,接受 200 All is good default 返回代码,或者点击 以选择另一个 HTTP 状态返回代码。
您可以从中选择的返回代码是 OpenAPI 文档为这个流程执行的操作定义的返回代码。如果 Fuse Online 没有显示您需要的返回代码,您可以编辑 OpenAPI 文档来添加它。
为此,请单击右上角的 View/Edit API Definition。根据需要编辑 OpenAPI 文档。完成后,保存 OpenAPI 文档。Fuse Online 返回编辑 Provided API return Path 并反映了您保存的任何更改。
- 点击 Next 以完成返回路径的配置。
如果这个流程都有所有必需的连接和步骤,且不存在数据不匹配图标,或者如果不再需要编辑流,请执行以下操作之一:
- 发布 时间为:在右上角开始运行集成,单击 Publish。这会构建集成,将 REST API 服务部署到 OpenShift,并使集成能够执行。每次您完成操作流的创建时,或每次编辑操作流时,您可以发布集成。
- 保存 InventoryService-latexTo 显示操作列表(在右上角),单击 Save。
重复此步骤以编辑另一个操作的流程。
测试 API 供应商集成
测试 API 供应商集成在其中一个平台中运行:
- OpenShift Online
- OpenShift Dedicated
- 当 API 发现被禁用时,OpenShift Container Platform
您可以使用
curl实用程序确认该集成正常工作。在curl命令中,指定 Fuse Online 在发布 API 供应商集成后显示的外部 URL。有关这样做的示例,请参阅 测试 API 供应商 Quickstart 集成。启用 API 发现时,在 OpenShift Container Platform 上运行的测试 API供应商集成
Red Hat 3scale 发布您的 API 供应商集成。要测试集成,请打开 3scale 控制面板以获取集成的 URL。
如果 API 供应商集成禁用发现,例如,如果您不希望红帽 3scale 来控制对集成的 API 的访问,或者您希望在 Fuse Online 中测试 API 供应商集成。如果您禁用了发现功能,Fuse Online 会重新发布集成并提供用于调用和测试集成执行的外部 URL。为此,可在 Fuse Online 中进入集成的摘要页面。在这个页面上,单击 Disable discovery。Fuse Online 重新发布集成并提供集成的 URL。有关如何测试集成的示例,请参阅 测试 API 供应商 Quickstart 集成。测试后,您可以重新启用 API 供应商集成的发现,以便 3scale 发布它。
您可以为每个 API 供应商集成启用或禁用发现。
5.5. 导入并发布示例 API 供应商快速入门集成
Fuse Online 提供了一个 API 供应商快速入门集成,您可以导入到 Fuse 在线环境中。此快速入门包括用于任务管理 API 的 OpenAPI 文档。导入 Quickstart 集成后,您可以检查流,然后发布集成。完成下面描述的步骤后,TaskAPI 集成将运行并准备执行。
API 供应商快速入门可帮助您快速了解如何配置、发布和测试 API 供应商集成。但它不是一个实际示例,说明 API 供应商集成是怎样的。在现实示例中,假设您已使用 Fuse Online 发布多个简单集成。您可以定义一个 OpenAPI 文档来触发这些集成的执行。要做到这一点,您可以编辑每个 OpenAPI 操作的流,使其与已发布的简单集成几乎相同。
先决条件
- Fuse Online 在浏览器中被打开。
-
Fuse Online 环境必须包含
Todo示例应用程序和示例 PostgreSQL 数据库,如将 示例数据添加到 OCP 上运行的 Fuse Online 环境 中所述。
流程
导入 TaskAPI Quickstart 集成:
-
进入 https://github.com/syndesisio/syndesis-quickstarts/api-provider 并下载
TaskAPI-export.zip。 - 在 Fuse Online 中,在左侧导航面板中,单击 Integrations。
- 在右上角,单击 Import。
-
将您下载的
TaskAPI-export.zip文件拖到 Import 页面中。Fuse Online 表示它已成功导入该文件。 - 在左侧导航面板中,点 Integrations 查看您刚刚导入的 TaskAPI 集成的条目。虽然该条目表示需要配置,但此集成已准备好发布。
-
进入 https://github.com/syndesisio/syndesis-quickstarts/api-provider 并下载
-
在 TaskAPI 条目中,点
 ,然后点 Edit 显示此 API 提供的操作列表。
,然后点 Edit 显示此 API 提供的操作列表。
检查每个操作的流:
点它的 Edit flow 按钮显示该流的视觉化。
每个流都已经具有数据库连接、一个或多个数据映射程序步骤,以及可完成 流的 Provided API return Path 步骤。
- 对于 Invoke SQL 步骤,请点击 Configure 以查看连接执行的 SQL 语句。然后点击 Cancel 以返回到该操作的视觉化流。
- 对于数据映射步骤,请点击 Configure 以查看映射。然后点击 Cancel 以返回到视觉化呈现。
- 对于 Provided API return Path 步骤,它是每个操作流中的最后一步,点 Configure 来查看操作可能会发送到调用者的 HTTP 返回代码。点 Cancel 返回视觉化。
- 检查一个操作流后,点 Integrations> TaskAPI> Operation 下拉菜单,然后选择另一个操作。
- 重复这一步骤子集以检查每个流。
检查流后,点 Publish,编辑集成名称(如果您想要),然后单击 Save 并发布。
Fuse Online 显示此集成的摘要页面,并在其汇编、构建、部署并开始集成时显示发布进度。
当 TaskAPI 集成摘要页面显示为 Running 时,Fuse Online 显示 Task API 服务的外部 URL。它如下所示:
https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api/在这里,Fuse Online 使 Task API 服务可用。REST API 调用指定以此基本 URL 开头的 URL。
如果您在 OpenShift Container Platform 上使用 Fuse Online,如果外部 URL 不在集成摘要页面中,则管理员启用了 Red Hat 3scale 发现。这意味着,Red Hat 3scale 控制对集成的 API 的访问,并发布您的 API 供应商集成。要测试集成,请打开 3scale 控制面板以获取集成的 URL。
如果您不希望红帽 3scale 控制对集成的 API 的访问,可以禁用发现。您可以通过查看集成摘要页面在 Fuse Online 中执行此操作。在这个页面上,单击 Disable discovery。Fuse Online 重新发布集成并提供外部 URL,以调用集成执行。
您可以为每个 API 供应商集成启用或禁用发现。
5.6. 测试 API 供应商快速入门集成示例
当 Fuse Online TaskAPI Quickstart 集成运行时,您可以调用将 HTTP 请求发送到任务 API 服务的 curl 实用程序命令。如何指定 HTTP 请求决定了调用触发器的流。
先决条件
- Fuse Online 表示 TaskAPI 集成正在运行 。
- 如果您的 Fuse Online 环境在 OCP 上运行,则 Fuse Online 不会配置为公开 API 到 3scale,或者您为 TaskAPI 集成禁用发现。
流程
- 在 Fuse Online 中,在左侧导航面板中,单击 Integrations。
- 在 TaskAPI 集成条目中,点 View 以显示集成概述。
- 复制集成的外部 URL。
在终端中,调用诸如以下内容的命令,以将集成的外部 URL 分配给
externalURL环境变量。务必将此示例命令中的 URL 替换为您复制的 URL。export externalURL="https://i-task-api-proj319352.6a63.fuse-ignite.openshiftapps.com/api"
调用
curl命令,触发 Create new task 操作的流执行:curl -k --header "Content-Type: application/json" --request POST --data '{ "task":"my new task!"}' $externalURL/todo-
-k允许curl在其他被视为不安全服务器连接时继续运行,即使服务器连接也被视为不安全。 -
--header表示命令正在发送 JSON 格式数据。 -
--request指定 HTTPPOST命令,用于存储数据。 -
--data指定要存储的 JSON 格式内容。在本例中,内容为{ "task":"my new task!"}。 $externalURL/todo是要调用的 URL。此命令向 Task API 服务发送 HTTP
POST请求,该服务会触发 Create new task 操作流的执行。流执行向示例数据库添加新任务并返回类似以下内容的消息,以指示它的作用:
{"completed":false,"id":1,"task":"my new task!"}-
调用
curl命令,按 ID 操作触发 Fetch 任务 流的执行:curl -k $externalURL/todo/1
要获取任务,
curl命令只需要指定 URL。HTTPGET命令是默认请求。URL 的最后一部分指定要获取的任务 ID。调用
curl命令,触发对 Delete 任务执行 ID 操作:curl -k -X DELETE $externalURL/todo/1
此命令调用 HTTP
DELETE命令,其 URL 与通过 ID 获取任务的命令相同。
第 6 章 创建由 HTTP 请求(Webhook)触发的集成
您可以通过向 Fuse Online 公开的 HTTP GET 或 POST 请求发送 HTTP GET 或 POST 请求来触发简单集成执行。以下主题提供详情:
6.1. 使用 Fuse Online Webhook 的一般步骤
要触发与 HTTP GET 或 POST 请求集成的执行,您必须执行以下操作:
-
决定是否要将
GET请求发送到FuseOnline。 - 规划您的集成以处理此请求。
创建完成集成的连接。
Fuse Online 提供了一个 Webhook 连接,供您用作启动连接。
- 创建您要添加到集成中的任何其他连接。
创建集成:
- 添加 Webhook 连接作为启动连接。
添加完成连接,然后添加集成所需的任何其他连接。完成连接和任何中间连接处理触发集成的执行 HTTP 请求。您需要选择并指定最合适的 HTTP 请求来实现您的目标。请记住以下几点:
- 向应用程序添加包含您要获取的数据或包含您要更新数据的应用程序的连接。
-
GET请求仅限于指定 key/value 参数。 -
POST请求可以提供任意正文,如 XML 或 JSON 实例。 -
Fuse Online 只返回 HTTP 状态标头,且不会返回任何数据。因此,您可以定义一个由
GET请求触发的集成,以及更新数据而不是获取数据。同样,您可以定义由POST请求触发的集成,以及获取数据而不是更新数据。
在 Webhook 连接后添加数据映射程序步骤。
对于
GET请求,将 HTTP 请求中的参数字段映射到下一个连接中的数据字段。对于
POST请求,您可能已通过传递 JSON 实例、JSON 模式、XML 实例、XML 模式或 CSV 实例来指定在请求中形成的输出数据。如果没有,在添加 Webhook 连接作为集成的开始连接时,Fuse Online 会提示您指定输出数据类型。如果没有,则默认的 Webhook 连接输出数据类型为 JSON 格式。- 添加集成需要的任何其他步骤。
- 发布集成并等待它正在运行 。
- 前往集成摘要页面,再复制 Fuse Online 提供的外部 URL。
-
修改此外部 URL 以构建您的
GET或POST请求。 -
实施向 Fuse Online 发送 HTTP
GET或POST请求的应用程序。
6.2. 创建 HTTP 请求可以触发的集成
要触发与 HTTP GET 或 POST 请求集成的集成的执行,请添加 Webhook 连接,作为集成的启动连接。
流程
- 在左侧的 Fuse Online 面板中,单击 Integrations。
- 点 Create Integration。
- 在 Choose a connection 页面中,点 Webhook 连接。
在 Choose an action 页面上,选择 Incoming Webhook 操作。
在 Webhook Configuration 页面中,Fuse Online 显示 Fuse Online 为此集成生成的 Webhook 令牌。
构建 HTTP 请求时,此令牌是 URL 的最后一个部分。在发布此集成并运行后,Fuse Online 会显示 Fuse Online external URL,该 URL 在结束时使用这个令牌。
Webhook 配置页面 还包括" 默认响应 "和" 错误处理 "部分。Webhook 步骤将响应发送到调用它的 HTTP 客户端。响应包含一个返回代码,默认情况下,返回消息正文中的错误消息。
- 在 Default Response 下,在 return Code 字段中接受 Fuse Online 显示的默认响应,或使用下拉列表选择您想要的默认响应。在执行操作流时,流程不会返回任何配置的错误响应。通常,默认响应返回代码表示成功操作。
在 Error Handling 下,指明是否要在返回邮件正文中包含错误消息。
在开发过程中,您通常要返回错误消息。但是,在生产环境中,如果包含敏感或专有信息,您可能希望隐藏错误消息。错误消息是一个 JSON 格式的字符串,其中包含
响应代码、类别、消息和错误元素,例如:{ responseCode: 404, category: "ENTITY_NOT_FOUND_ERROR", message: "SQL SELECT did not SELECT any records" error: SYNDESIS_CONNECTION_ERROR }请注意,在开发过程中,知道发生错误的最可靠方法是检查对调用者的响应中的
HTTP_RESPONSE STATUS标头。您还可以检查集成 Pod 的日志INFO消息。该集成的活动日志显示成功交换,且错误始终不会在 Activity 日志中显示。- 对于 webhook 步骤可能返回的每个错误,接受默认返回代码,或使用下拉列表选择另一个 HTTP 状态返回代码。
- 点击 Next。
在 Specify Output Data Type 页面中:
- 在 Select Type 字段中,选择 JSON schema。
- 在 Definition 字段中,粘贴在 HTTP 请求中定义参数的数据类型的 JSON 模式。有关 指定请求参数,请参阅关于 JSON 模式。
- 在 Data Type Name 字段中,指定此数据类型的名称。虽然这是可选的,如果您指定了名称,但它会出现在 data mapper Sources 列表中,这可让您更轻松地映射字段。
- (可选)在 Data Type Description 字段中提供一些可帮助您区分此数据类型的信息。
- 点击 Next。
- 添加完成与集成的连接。
- 添加任何其他所需连接。
- 添加任何其他所需步骤。
- 在启动连接后,添加数据映射步骤。
- 单击 Publish,为集成指定一个名称,以及描述、自定义环境变量和一个或多个标签。
- 单击 Save 并发布。
6.3. Fuse Online 如何处理 HTTP 请求
您可以指定 HTTP GET 或 POST 请求来触发简单集成的执行。虽然 GET 请求通常会获取数据,而 POST 请求通常会更新数据,但您可以使用任一请求触发任一操作的集成。请求中的任何参数都可用于映射到集成中的下一个连接中的数据字段。详情请参阅 关于 JSON 模式 以指定请求参数。
Webhook 连接仅会将接收的数据传递给集成中的下一个连接。当 Fuse Online 收到 HTTP 请求时,它会:
-
将 HTTP 状态标头返回给请求者。当请求成功触发了集成的执行时,Fuse Online 返回代码为
201。当请求无法触发集成执行时,Fuse Online 返回代码为5xx。 - 不将任何其他数据返回给请求者。换句话说,响应的 HTTP 正文中不包含包含状态标头的数据。
- 将请求中的数据传递给集成中的下一个连接。
这意味着您可以定义一个由 GET 请求触发的简单集成,以及更新数据,而不是获取数据。同样,您可以定义一个由 POST 请求触发的简单集成,以及获取数据而不是更新数据。
在集成的 活动 选项卡中,每次都 成功 Webhook 步骤的状态。此 成功 状态表示 Fuse Online} Webhook 和调用它的 HTTP 客户端之间的通信状态。这个 成功 状态并不表示成功传递且任何步骤都没有错误。HTTP 请求生成的错误不会在集成的 Activity 日志中显示。
当您配置 Webhook 时,默认 检查返回正文选项中的 Include 错误消息。选中此选项时,要验证 webhook 请求生成的错误是否包含在 Webhook 响应中,发送一个将生成错误的测试请求,然后检查响应标头。您还可以检查集成 Pod 的日志 INFO 消息。使用以下命令查看集成的 pod 日志,其中 example-integration-pod 是 pod 的名称。
oc logs -f pod/example-integration-pod
6.4. 调用 Fuse Online Webhook 的 HTTP 客户端指南
当您实施将 HTTP 请求发送到 Fuse Online 的客户端时,您的实施应该:
-
将 添加到 Fuse Online-provided 的外部 URL,以构造发出
GET或POST请求的 URL。 -
在 URL 请求中,指定 HTTP 标头和查询参数值,其数据类型遵循
io:syndesis:webhookJSON 模式。有关 指定请求参数,请参阅关于 JSON 模式。当标头和查询参数遵循此数据类型规格时,您可以将参数字段映射到集成中下一连接可以处理的字段。 -
如果请求成功,可处理返回成功代码
201。 -
如果请求失败,处理 HTTP
5xx错误代码。 - 不会影响 Fuse Online 的任何其他响应。换句话说,发送请求不会直接向返回代码以外的请求客户端返回数据。
6.5. 关于指定请求参数的 JSON 模式
在集成中,您通常会将 HTTP 请求中的标头和查询参数映射到集成中下一个连接的数据字段。要实现这一点,在将 Webhook 连接添加到集成时,在具有以下结构的 JSON 模式中指定输出数据类型:
{
"$schema": "http://json-schema.org/schema#",
"id": "io:syndesis:webhook",
"type": "object",
"properties": {
"parameters": {
"type": "object",
"properties": { 1
}
},
"body": {
"type": "object",
"properties": { 2
}
}
}
}要为 HTTP 请求添加您需要的数据结构,在 JSON 实例中:
虽然 HTTP 客户端发送的所有数据都可用于集成,当 Webhook 连接的数据形成符合此 JSON 模式时,则查询参数和正文内容可用于映射。
例如,请参阅 如何指定 HTTP 请求。
6.6. 如何指定 HTTP 请求
以下示例演示了如何为 Fuse Online Webhook 指定 HTTP 请求。
只使用 HTTP 正文的 POST 请求的 Webhook 示例
考虑以 Webhook 连接开头的集成,然后在 Fuse Online-provided 数据库的 Todo 表中创建一个行:

在创建这种集成时,当您添加 Webhook 启动连接时,您可以使用具有此内容的 JSON 实例指定其输出数据类型: {"todo":"text"} :

当您将 PostgresDB 连接添加为完成连接时,您可以选择 Invoke SQL 操作并指定此 SQL 语句:
插入 TODO(任务)值(:#TASK)
添加数据库连接后,您添加一个映射步骤:
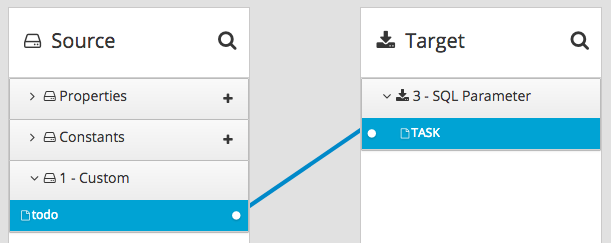
您保存并发布集成。当它运行时,您可以复制 Fuse Online 提供的外部 URL:
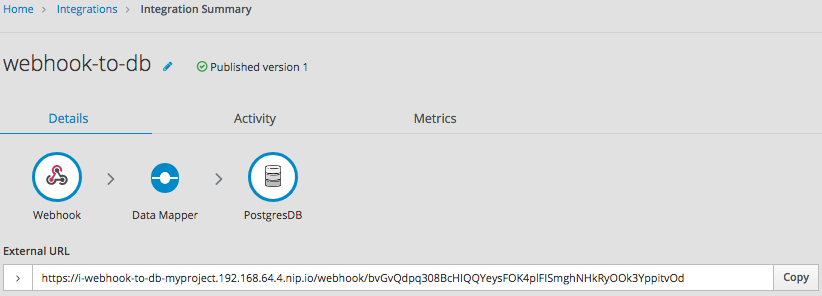
要了解外部 URL 的部分,请考虑这个示例 URL:
https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
| 值 | 描述 |
|---|---|
|
| Fuse Online 始终在 URL 的开头插入这个值。 |
|
| 集成的名称。 |
|
| 包含运行集成的 pod 的 OpenShift 命名空间。 |
|
| 为 OpenShift 配置的 DNS 域。这表示提供 webhook 的 Fuse Online 环境。 |
|
| 出现在每个 Webhook 连接 URL 中。 |
|
| 在将 Webhook 连接添加到集成时,Fuse Online 提供的 Webhook 连接令牌。令牌是一个随机字符串,在 中提供安全性的随机字符串使 URL 难以识别,这可以防止其他人发送请求。 在请求中,您可以指定 Fuse Online 提供的令牌,也可以自行定义。如果您自行定义,请确保很难猜测。 |
正如您在外部 URL 中看到的那样,Fuse Online 从集成名称、OpenShift 命名空间名称和 OpenShift DNS 域中构造主机名。Fuse Online 删除 illegal 字符,并将空格转换为连字符。在外部 URL 示例中,这是主机名:
https://i-webhook-to-db-myproject.192.168.64.4.nip.io
要使用 curl 调用 Webhook,您需要指定该命令,如下所示:
curl -H 'Content-Type: application/json' -d '{"todo":"from webhook"}' https://i-webhook-to-db-myproject.192.168.64.4.nip.io/webhook/bvGvQdpq308BcHIQQYeysFOK4plFISmghNHkRyOOk3YppitvOd
-
-H选项指定 HTTPContent-Type标头。 -
d选项默认将 HTTP 方法设置为POST。
这个命令的执行会触发集成。数据库完成连接将新任务插入到 tasks 表中。要查看这一点,请显示 Todo app,例如 https://todo-myproject.192.168.64.4.nip.io,点 Update,您应该在新任务中看到 Webhook。
带有查询参数的 POST 请求的 Webhook 示例
在本例中,请考虑与上例中的相同的集成:
但在本示例中,您可以通过使用此内容指定 JSON 模式来定义 Webhook 连接输出数据类型:
{
"type": "object",
"definitions": {},
"$schema": "http://json-schema.org/draft-07/schema#",
"id": "io:syndesis:webhook",
"properties": {
"parameters": {
"type": "object",
"properties": {
"source": {
"type": "string"
},
"status": {
"type": "string"
}
}
},
"body": {
"type": "object",
"properties": {
"company": {
"type": "string"
},
"email": {
"type": "string"
},
"phone": {
"type": "string"
}
}
}
}
}在这个 JSON 模式中:
-
id必须设置为io.syndesis.webhook。 -
parameters部分必须指定 HTTP 查询参数。 -
body部分必须指定正文内容,如果需要,它可能很复杂。例如,它可以定义嵌套属性和数组。
这提供了 Webhook 连接器需要为集成中下一步准备内容的信息。
要使用 curl 发送 HTTP 请求,请调用类似如下的命令:
curl -H 'Content-Type: application/json' -d '{"company":"Gadgets","email":"sales@gadgets.com","phone":"+1-202-555-0152"}'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=new
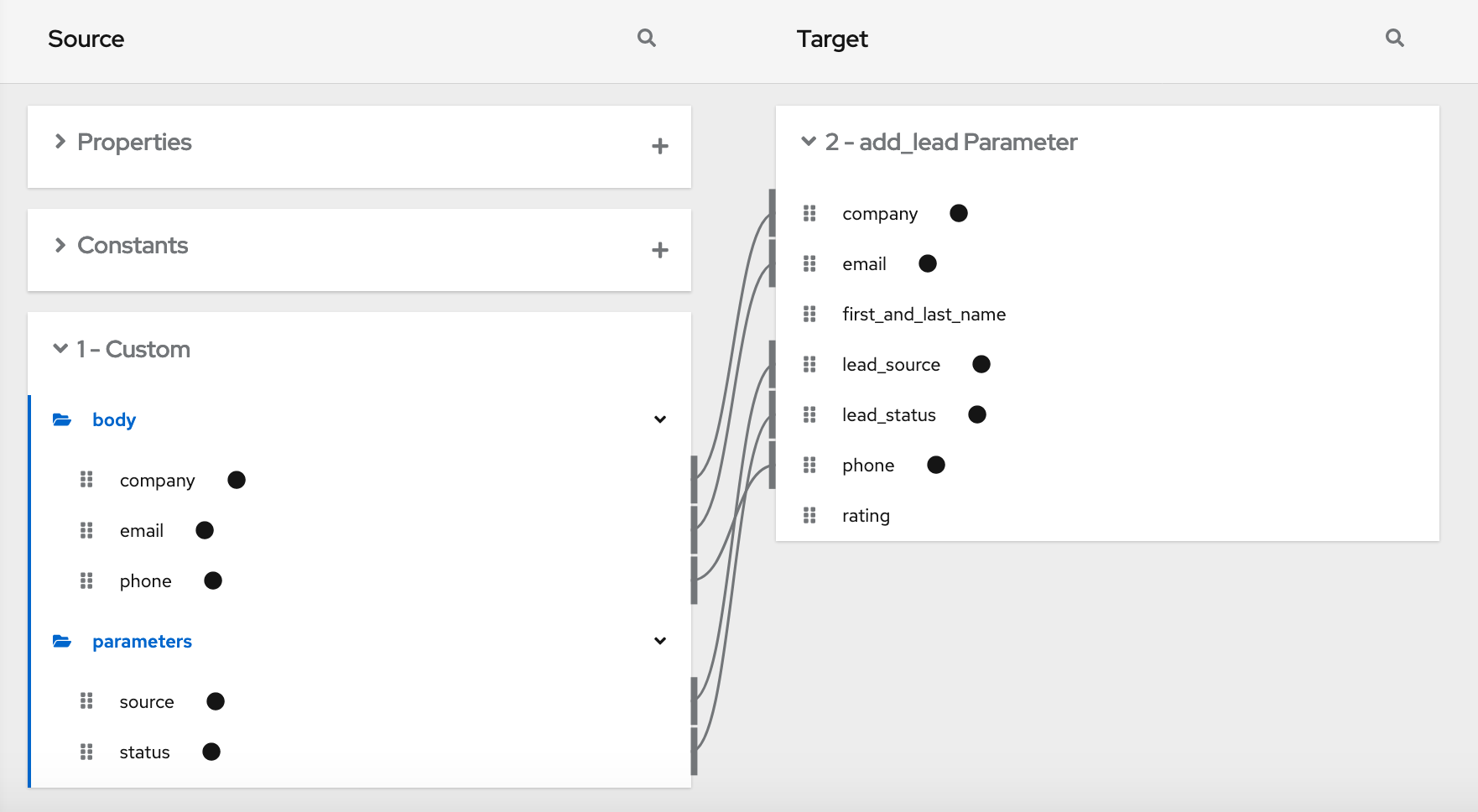
当 Webhook 连接收到这个请求时,它会创建一个类似如下的 JSON 实例:
{
"parameters": {
"source": "web",
"status": "new"
},
"body": {
"company": "Gadgets",
"email": "sales@gadgets.com",
"phone": "+1-202-555-0152"
}
}这是启用以下映射的内部 JSON 实例:
带有 GET 的 Webhook 示例
要触发与不提供输入数据的 GET 请求的集成,请将 Webhook 连接输出数据形式指定为带有定义 '{}' 的 JSON 实例。然后您可以调用以下 curl 命令,该命令没有指定查询参数:
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg'
您可以更改前面的 POST 示例,以使用查询参数但没有正文来发送 GET 请求。您可以将 Webhook 连接输出数据形式指定为 JSON 模式,其定义如下。
{
"type": "object",
"definitions": {},
"$schema": "http://json-schema.org/draft-07/schema#",
"id": "io:syndesis:webhook",
"properties": {
"parameters": {
"type": "object",
"properties": {
"source": {
"type": "string"
},
"status": {
"type": "string"
}
}
}
}
}
以下是发送 GET 请求的 curl 命令:
curl 'https://i-webhook-params-to-db-myproject.192.168.42.235.nip.io/webhook/ZYWrhaW7dVk097vNsLX3YJ1GyxUFMFRteLpw0z4O69MW7d2Kjg?source=web&status=new'`
第 7 章 将集成数据映射到下一个连接的字段
在大多数流程中,您需要将已获取或处理的数据字段映射到流中下一个连接可以处理的数据字段。Fuse Online 提供了一个数据映射程序,帮助您实现这一目标。在流中,在您需要映射数据字段的每个情况下,添加一个数据映射步骤。
当您添加数据映射程序步骤时,Syndesis 会显示 data mapper canvas with: * Source data fields by previous connections * Target data fields by the后续连接所需的数据字段
data mapper 显示可以通过之前集成步骤提供的最大源字段集。但是,不是所有连接都提供每个显示的源字段中的数据。例如,对第三方应用程序的更改可能会停止在特定字段中提供数据。在创建集成时,如果您发现数据映射没有被象预期的一样,请确保要映射的源字段包含您所期望的数据。
映射数据字段的详情在以下主题中:
- 第 7.1 节 “查看步骤中的映射”
- 第 7.2 节 “确定需要数据映射的位置”
- 第 7.3 节 “查找您要映射的 data 字段”
- 第 7.4 节 “关于数据类型和集合”
- 第 7.5 节 “关于映射类型”
- 第 7.6 节 “将一个源字段映射到一个目标字段”
- 第 7.7 节 “提供缺少的源或目标值”
- 第 7.8 节 “在合并或分离字段时缺少或不需要的数据示例”
- 第 7.9 节 “将多个源字段合并到一个目标字段”
- 第 7.10 节 “将一个源字段分成多个目标字段”
- 第 7.11 节 “使用 data mapper 处理集合”
- 第 7.12 节 “关于集合和非集合之间的映射”
- 第 7.13 节 “转换源或目标数据”
- 第 7.15 节 “数据映射故障排除”
7.1. 查看步骤中的映射
在添加或编辑数据映射程序步骤时,您可以查看已在此步骤中定义的映射。这个选项可让您检查正确的映射是否就位。
先决条件
- 正在创建或编辑集成。
- 您要添加数据映射程序步骤。也就是说,数据映射程序是可见的。
流程
-
要查看映射的表视图,请点
 。
。
-
要忽略映射的表视图,并重新显示源和目标字段,请点
 。
。
7.2. 确定需要数据映射的位置
Fuse Online 显示警告图标,以指明流需要数据映射的位置。
先决条件
- 正在创建或编辑一个流。
- 流包含它需要的所有连接。
流程
-
在流视觉化中,查找任何
图标。
- 点击图标查看 Data Type Mismatch 通知。
- 在消息中,单击 Add a data mapping step,它将显示 data mapper。
添加所需的数据映射程序步骤后,
图标仍可以被显示(可能会因为以下原因在编辑过程中显示任何时间)。
- 其中一个源步骤已更改了其输出
- 目标步骤的输入与映射程序的输出不兼容
- 缺少源步骤
目标步骤缺失
在这种情况下,这个警告表示必须编辑上面添加的数据映射程序步骤。
7.3. 查找您要映射的 data 字段
在相对较少的步骤中,映射数据字段简单直观。在处理大量数据字段的更复杂的流程或流程中,当您使用数据映射程序时,可以更轻松地从源映射到目标。
data mapper 显示数据字段的两列:
- Source 是一个在流中获取或处理的所有步骤的数据字段列表。
- 目标是 流中下一个连接预期并可以处理的数据字段的列表。
要快速查找要映射的 data 字段,您可以执行以下任一操作:
搜索它。
Sources 面板和 Target 面板各自具有搜索字段。如果搜索字段不可见,请点击 Sources 或 Target 面板右上角的
 。
。
键入您要映射的字段的名称。在 Sources 搜索字段中,键入 source 字段的名称。在 Target 搜索字段中,键入您要映射到的字段的名称。
-
使用
 和
和
 选项过滤可见的字段。
选项过滤可见的字段。
展开和折叠文件夹,以限制可见字段。
要查看特定步骤中可用的数据字段,请展开该步骤的文件夹。
当您向流中添加步骤时,Fuse 在线数字并重新编号以指明 Fuse 在线处理步骤的顺序。当您添加数据映射程序步骤时,在 Sources 面板和 Target 面板中的 folder 标签中会显示步骤号。
-
如果要查看每个字段的数据类型,点
 显示(或隐藏)每个字段标签中的数据类型。文件夹标签还显示该步骤输出的数据类型的名称。文件夹标签还显示该步骤输出的数据类型的名称。连接到应用程序(如 Twitter、Salesforceforce 和 SQL)会定义自己的数据类型。对于连接到 Amazon S3、AMQ、AMQ、AMQ、Dropbox 和 FTP/SFTP 等应用程序,您可以在将连接添加到流时定义连接的输入和/或输出类型,然后选择连接执行的操作。当您指定数据类型时,您也为类型指定一个名称。您指定的类型名称显示为 data mapper 中的文件夹名称。如果在声明数据类型时指定描述,则类型描述将出现在映射程序中的 step 文件夹上时。
显示(或隐藏)每个字段标签中的数据类型。文件夹标签还显示该步骤输出的数据类型的名称。文件夹标签还显示该步骤输出的数据类型的名称。连接到应用程序(如 Twitter、Salesforceforce 和 SQL)会定义自己的数据类型。对于连接到 Amazon S3、AMQ、AMQ、AMQ、Dropbox 和 FTP/SFTP 等应用程序,您可以在将连接添加到流时定义连接的输入和/或输出类型,然后选择连接执行的操作。当您指定数据类型时,您也为类型指定一个名称。您指定的类型名称显示为 data mapper 中的文件夹名称。如果在声明数据类型时指定描述,则类型描述将出现在映射程序中的 step 文件夹上时。
7.4. 关于数据类型和集合
data mapper 显示源字段和目标字段,您可以定义您需要的字段到字段映射。
在 data mapper 中,字段可以是:
-
存储单个值的原语类型。原语类型示例包括
布尔值、char、字节、短、int、长、浮点数和双倍。原语类型不可扩展,因为它是一个字段。 - 复杂的 类型,由多个不同类型组成的字段组成。您可以在设计时定义复杂类型的子字段。在数据映射器中,一种复杂的类型可以扩展,以便您可以查看其子字段。
每种字段类型(专用和复杂)也可以是一个集合。集合是一个可以有多个值的单个字段。集合中的项目数量在运行时决定。在设计时,在数据映射程序中,集合由
![]() 表示。数据映射程序界面中是否可扩展集合是否由其类型决定。当集合是原语类型时,它不可扩展。当集合是复杂的类型时,数据映射程序可以被扩展来显示集合的子字段。您可以从/映射到每个字段。
表示。数据映射程序界面中是否可扩展集合是否由其类型决定。当集合是原语类型时,它不可扩展。当集合是复杂的类型时,数据映射程序可以被扩展来显示集合的子字段。您可以从/映射到每个字段。
以下是一些示例:
-
ID是原语类型字段(int)。在运行时,员工只能有一个ID。例如:ID=823。因此,ID是非集合的原语类型。在数据映射器中,ID不可扩展。 -
email是原语类型字段(字符串)。在运行时,员工可以具有多个电子邮件值。例如:email<0>=aslan@home.com和email<1>=aslan@business.com。因此,电子邮件是一个原语类型,也是集合。数据映射程序使用
表示 电子邮件字段是一个集合,但电子邮件无法扩展,因为它是一个原语类型(没有子字段)。 -
staff是复杂的对象字段,具有多个子字段,包括ID和电子邮件。在运行时,员工也是一个集合,因为公司有许多员工。
在设计时,数据映射程序使用
来表示 员工是一个集合。employees字段可扩展,因为它是包含子字段的复杂类型。
7.5. 关于映射类型
数据映射程序支持以下通用映射类型:
- one 到 one - 将一个源字段映射到一个目标字段。
- 很多 - 将多个源字段映射到一个目标字段。您可以指定数据映射器在映射源字段之间的 target 字段中插入的分隔符字符。默认分隔符是空格。
- one 到多个 - 将一个源字段映射到多个目标字段。您可以指定位于 source 字段中的分隔符字符。AtlasMap 将每个分隔的值映射到您选择的目标字段。
- 对于每个 - 将一个源集合字段映射到一个目标集合字段。
7.6. 将一个源字段映射到一个目标字段
默认映射行为将一个源字段映射到一个目标字段。例如,将 Name 字段映射到 CustomerName 字段。
流程
在 Sources 面板中:
如有必要,展开一个步骤以查看它所提供的数据字段。
当有很多源字段时,您可以通过点
并在搜索字段中输入 data 字段来搜索感兴趣的字段。
-
点击您要从中映射的数据字段,然后点
 。此时会打开 Mapping Details 面板。
。此时会打开 Mapping Details 面板。
在 Target 面板中,找到您要映射到的数据字段,然后点
 。
。
data mapper 显示一行,连接您刚刚选择的两个字段。
(可选)预览数据映射结果。当您将转换添加到映射或映射需要类型转换时,这个选项非常有用。
-
在数据映射程序的右上角,点
 在 source 字段中显示文本输入字段,在 target 字段中显示只读结果字段。
在 source 字段中显示文本输入字段,在 target 字段中显示只读结果字段。
- 在 source 字段的数据输入字段中,键入示例输入值。映射结果会出现在 target 字段中的只读字段中。
- 另外,要查看转换的结果,请在 Mapping Details 面板中添加转换。
-
要隐藏预览字段,请再次点
。
-
在数据映射程序的右上角,点
另外,要确认定义了映射,请点击
以显示定义的映射。
在此视图中,您还可以预览数据映射结果。如果预览字段不可见,点
。按照上一步中描述输入数据。
+ 在定义的映射表中,仅显示所选映射的 preview 字段。
- 要查看其他映射的预览字段,请选择它。
-
再次点击
以显示数据字段面板。
- 在右上角,点 Done 将 data mapper 步骤添加到集成中。
故障排除提示
data mapper 显示可以通过之前集成步骤提供的最大源字段集。但是,不是所有连接都提供每个显示的源字段中的数据。例如,对第三方应用程序的更改可能会停止在特定字段中提供数据。在创建集成时,如果您发现数据映射没有被象预期的一样,请确保要映射的源字段包含您所期望的数据。
7.7. 提供缺少的源或目标值
当您映射字段时,您可能会发现源数据形成的不提供目标数据形成需要的值,反之亦然。您可以选择通过定义属性或常量来提供缺失的值。
例如,假设目标数据形成了一个 Layout 字段,其值必须是 HORIZONTAL 或 VERTICAL。源数据形成不会提供此字段。您可以创建一个恒定的,然后将其映射到 Layout target 字段。
前提条件
- 在 data mapper 中,打开 Mapping Details 面板。
流程
定义一个常量:
在 Source 或 Target 面板的顶部,单击 Constants 右侧的 Add (+)。
此时会打开 Create Constant 对话框。
- 键入恒定值。
- 选择数据类型。
- 单击 Save 以创建新字段。
定义属性:
在 Source 或 Target 面板的右侧,单击 Add (+)。
此时会打开 Create Property 对话框。
- 键入属性名称。
- 选择数据类型。
在 Scope 下拉菜单中选择其中一个选项来定义属性的范围:
- 当前消息标题 - 传递给上一步的 Data Mapper 步骤的消息标头。
- Camel Exchange Property - 针对 Camel 特定属性.
结果 - 来自之前步骤的消息标头。
重要Scope 选项只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些功能提供早期访问将来的产品功能,使客户能够在开发过程中测试功能并提供反馈信息。如需了解红帽 技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
- 单击 Save 以创建新字段。
7.8. 在合并或分离字段时缺少或不需要的数据示例
在数据映射中,当 source 或 target 字段包含复合数据时,您可能需要识别丢失或不需要的数据。例如,考虑一个具有以下格式的 long_address 字段:
编号外围城市州 zip zip+4 国家
假设您想将 long_address 字段分隔为 数字、street、城市、 州和 zip 的离散字段。要做到这一点,您可以选择 long_address 作为 source 字段,然后选择 target 字段。然后,您可以在不需要的源字段的部分位置添加 padding 字段。在这个示例中,不需要的部分不同是、zip+4 和 国家。
要识别不需要的部分,您需要了解各部分的顺序。顺序表示 compound 字段中内容的每一个部分的索引。例如,long_address 字段有 8 个排序的部分。从 1 开始,每个部分的索引为:
| 1 | number |
| 2 | Street |
| 3 | 公有 |
| 4 | City |
| 5 | state |
| 6 | zip |
| 7 | zip+4 |
| 8 | 国家/地区 |
在数据映射器中,要识别缺失的、zip+4 和 国家/地区,您可以在索引 3、7 和 8 中添加 padding 字段。请参阅将多个源字段组合到一个目标字段中。
现在假设您想将 数字 street、城市、state 和 zip 的源字段组合成一个 long_address 目标字段。再进一步假设没有源字段来为外围、zip+4 和 国家/地区提供 内容。在数据映射器中,您需要识别这些字段,如缺失。同样,您可以在索引 3、7 和 8 中添加 padding 字段。请参阅 9 月一个源字段到多个目标字段。
7.9. 将多个源字段合并到一个目标字段
在数据映射器步骤中,您可以将多个源字段合并到一个复合目标字段中。例如,您可以将 FirstName 和 LastName 字段映射到 customer Name 字段。
前提条件
对于 target 字段,您必须知道此复合字段的每一个部分、内容的次序和索引,以及部分之间的分隔符,如空格或逗号。请参阅 缺少或不需要的数据的示例。
流程
-
在 Target 面板中,点您要将多个源字段映射到的字段,然后点
。此时会打开 Mapping Details 面板。
在 Mapping Details 面板中,从 Source 下拉列表中选择您要映射的一个或多个数据字段。
完成后,您应该会看到从每个源字段到 target 字段的行。
在 Mapping Details 面板中,在 Source 上,数据映射程序会显示默认的多层次转换,即。 这表示,执行映射会将 Concatenate 转换为所选源字段中的值,并将串联的值映射到所选目标字段。
在 Mapping Details 面板中,按如下所示配置映射:
- 在 Sources 下,在 Delimiter 字段中,接受或选择 data mapper 在不同源字段之间的 target 字段中插入的字符。默认为空格。
-
另外,在每个 source 字段条目中,您可以在映射到 target 字段前点
 将转换应用到 source 字段值。
将转换应用到 source 字段值。
在 Sources 下,检查您选择的源字段的条目顺序。条目必须与复合目标字段中对应的内容的顺序相同。
如果条目不正确顺序,请更改字段条目的索引号,使其达到同样顺序。
如果您将源字段映射到复合目标字段的每个部分,请跳过下一步。
对于每个源字段条目,与 target 字段中对应的数据没有相同的索引,将索引编辑为相同。每个 source 字段条目都必须与 target 字段中对应的数据相同的索引。数据映射程序根据需要自动添加 padding 字段来指示缺少数据。
如果您意外创建太多 padding 字段,请为每个额外的 padding 字段点
 来删除它。
来删除它。
-
(可选)在 Targets 下,点
将内容映射到目标字段,然后应用转换,如 转换源或目标数据 中所述。
(可选)预览数据映射结果:
-
点
在当前所选映射的每个源字段中显示一个文本输入字段,在当前所选映射的目标字段中显示一个只读结果字段。
在源数据输入字段中,键入示例值。
如果您对源字段重新排序或向映射添加转换,则 target 字段中的 result 字段会显示这个值。如果数据映射器检测到错误,它会在 Mapping Details 面板的顶部显示信息。
再次单击
来隐藏预览字段。
如果您重新显示 preview 字段,您在其中输入的任何数据仍会存在,并在您退出 data mapper 前保留。
-
点
要确认正确定义了映射,点
显示(表格式)在此步骤中定义的映射。将多个 source 字段的值合并到一个 target 字段中的映射如下所示:
 。
。
您也可以在此视图中显示预览映射结果。点
,然后输入文本,如上一步中所述。仅显示所选映射的 Preview 字段。点表中的另一个映射查看预览字段。
其他资源
添加 padding 字段示例: 9 月一个源字段到多个目标字段。
虽然该示例可用于一对多映射,但原则是相同的。
7.10. 将一个源字段分成多个目标字段
在数据映射器步骤中,您可以将复合源字段划分为多个目标字段。例如,将 Name 字段映射到 FirstName 和 LastName 字段。
前提条件
对于 source 字段,您必须知道此复合字段的每一个部分、内容的次序和索引,以及部分之间的分隔符,如空格或逗号。请参阅 缺少或不需要的数据的示例。
流程
-
在 Sources 面板中,点您要独立内容的字段,然后点
。
在 Mapping Details 面板中,从 Target 下拉列表中选择您要映射到的数据字段。
当完成选择目标字段后,您应该会看到 source 字段中的行到您选择的每个目标字段。
在 Mapping Details 面板的顶部,data mapper 会显示 Split,表示对源字段值进行映射分割并将其映射到多个目标字段。
在 Targets 下,您选择的每个目标字段都有一个条目。
在 Mapping Details 面板中,按如下所示配置映射:
- 在 Sources 下,在 Delimiter 字段中接受或选择 source 字段中的字符,用于指示源字段值的所在位置。默认为空格。
-
(可选)点
将转换应用到 source 字段值,然后再映射到 target 字段。
在 Targets 下,检查您选择的目标字段的条目顺序。条目必须与复合源字段中对应的内容的顺序相同。在 source 字段中,您是否为一个或多个内容部分指定 target 字段。
如果条目不正确顺序,请更改字段条目的索引号,使其达到同样顺序。
如果您将复合源字段的每个部分映射到目标字段,则跳至下一步。
如果 source 字段包含您不需要的数据,在 Mapping Details 面板中,编辑还没有与源字段中对应的数据的索引。每个目标字段条目必须具有与在 source 字段中对应的数据相同的索引。数据映射程序根据需要自动添加 padding 字段来指示不需要的数据。
请查看此流程末尾的示例。
-
(可选)点
将内容映射到目标字段,然后应用转换,如 转换源或目标数据 中所述。
(可选)预览数据映射结果:
-
点击
在源字段中显示一个文本输入字段,在每个 target 字段中显示只读结果字段。
在 source 字段的数据输入字段中,键入示例值。请务必在字段的部分部分之间输入分隔符。映射结果会出现在目标字段的只读字段中。
如果您对目标字段重新排序或向目标字段添加转换,则目标字段上的结果字段会反映此值。如果数据映射器检测到错误,它会在 Mapping Details 面板的顶部显示信息。
再次单击
来隐藏预览字段。
如果您重新显示 preview 字段,您在其中输入的任何数据仍会存在,并在您退出 data mapper 前保留。
-
点击
要确认正确定义了映射,点
显示此步骤中定义的映射。将 source 字段的值分隔到多个目标字段的映射如下所示:
 。
。
您也可以在此视图中显示预览映射结果。点
,然后键入文本,如上一步中所述。仅显示所选映射的 Preview 字段。点表中的另一个映射查看预览字段。
将一个字段分成多个字段的示例
假设源数据包含一个地址字段,并使用逗号分隔内容部分,例如:
77 Hill Street, Brooklyn, New York, United States, 12345, 6789
在 address 字段中,内容的部分有这些索引:
| 内容 | 索引 |
|---|---|
| number 和 street | 1 |
| City | 2 |
| 状态 | 3 |
| 国家/地区 | 4 |
| zip 代码 | 5 |
| Zip+4 | 6 |
现在假设目标数据有两个字段用于地址:
number-and-street city state zip
要定义映射,请执行以下操作:
-
选择 source 字段,然后点
。
- 在 Mapping Details 面板中,选择 Sources 部分中的分隔符,本例中为逗号。
- 选择四个目标字段。
完成此操作后,在 Targets 下的 Mapping Details 面板中,您选择的每个目标字段都有一个条目,例如:
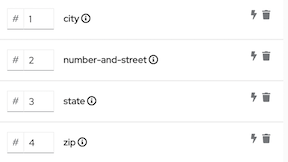 .
.
data mapper 以它们在 data mapper 中出现的顺序显示目标条目,按字母顺序排列。您需要更改这个顺序,以便它镜像 source 字段中的顺序。在这个示例中,source 字段包含 城市 内容前的 number-and-street 内容。要更正目标条目的顺序,请编辑 城市 索引字段为 2。结果如下:
 .
.
在 target 字段条目中,索引编号表示 source 字段的内容将映射到这个目标字段。其中一个索引值需要更改才能实现正确的 target 字段值。考虑每个目标字段:
-
number-and-street- 在 source 字段中,数字和 street 内容的索引为 1。将索引 1 源映射到number-and-street目标字段是正确的。这个目标条目不需要更改。 -
City- 在源字段中,城市内容包含 2 的索引。这个目标条目也正确。 -
State- 在 source 字段中,状态内容包含 3 的索引。这个目标条目也正确。 -
zip- 在 source 字段中,zip 代码内容的索引为 5。target 字段条目的索引为 4。如果您没有在执行期间更改它,则 source 字段的 country 部分会映射到ziptarget 字段。您需要将索引更改为 5。这会指示 datamapper 将索引 5 源内容映射到ziptarget 字段。更改索引后,数据映射程序会添加一个带有索引 4 的 padding 字段。结果如下:
 .
.
这个映射现已完成。虽然 source 字段在 index 6(zip+4)处有附加内容,但目标不需要数据,而不需要任何操作。
7.11. 使用 data mapper 处理集合
在流中,当步骤输出集合以及流中的后续连接时,需要一个集合作为输入,您可以使用 datamapper 指定如何处理集合的方式。
当步骤输出集合时,流视觉化会在步骤的详细信息中显示 Collection。例如:
在提供集合并在需要映射的步骤之前,添加数据映射步骤。在此数据映射程序步骤中的流程需要完全取决于流程中的其它步骤。下图显示了从源集合字段到目标集合字段的映射:
在源和目标面板中,数据映射器会显示
![]() 来表示集合。
来表示集合。
当集合是复杂的类型时,数据映射程序会显示集合的子字段。您可以从/映射到每个字段。
当源字段嵌套到多个集合中时,您可以将其映射到满足这些状况的目标字段:
target 字段嵌套在与 source 字段相同的集合数量中。例如,允许这些映射:
- /A<>/B<>/C → /D<>/E<>/F
- /A<>/B<>/C → /G<>/H/I<>/J
target 字段只嵌套在一个集合中。例如,允许这个映射:
/A<>/B<>/C → /K<>/L
在这种情况下,数据映射程序使用深度第一算法来迭代源中的所有值。因此,数据映射程序会将源值放在单个目标集合中。
不允许使用以下映射:
/A<>/B<>/C cannot-map-to /M<>/N/O<>/P<>/Q
当 Fuse Online 执行流时,它会迭代源集合元素来填充目标集合元素。如果您将一个或多个源集合字段映射到目标集合或目标集合字段,则目标集合元素仅包含映射字段的值。
如果您将源集合中的源集合或字段映射到不在集合中的目标字段,那么当 Fuse Online 执行流时,它将仅从源集合中的最后一个元素分配值。集合中的所有其他元素在此映射步骤中会被忽略。但是,任何后续映射步骤都可以访问源集合中的所有元素。
当连接返回 JSON 或 Java 文档中定义的集合时,数据映射程序通常可以将源文档作为集合处理。
7.12. 关于集合和非集合之间的映射
在 data mapper Source 和 Target 面板中:
-
表示集合。如果集合包含一个原语类型,您可以直接从或映射到该集合。如果集合包含两个或多个不同的类型,则 data mapper 会显示集合的子字段,您可以映射到或与集合字段映射。
-
 表示是一个复杂类型的可扩展容器。复杂的类型包含多个不同类型的字段。复杂类型中的字段可以是一个集合(如数组)的类型。您不能映射复杂的类型容器本身。您只能映射复杂类型中的字段。
表示是一个复杂类型的可扩展容器。复杂的类型包含多个不同类型的字段。复杂类型中的字段可以是一个集合(如数组)的类型。您不能映射复杂的类型容器本身。您只能映射复杂类型中的字段。
要切换数据类型的显示,如 (COMPLEX), STRING, INTEGER,点
![]() 。
。
集合到非集合(多到一)映射
当您从集合字段映射到非集合字段时,数据映射程序会识别多个到一的映射。默认行为是,数据映射器会将 Concatenate 转换为源收集或源收集字段。默认分隔符是空格。例如,考虑这个源集合:
- 在第一个元素中,城市 字段的值是 波士顿。
- 在第二个元素中,city 字段的值是 Paris。
- 在第三个元素中,city 字段的值为 东京。
在执行过程中,data mapper 会用填充 target 字段
波兰部
您可以通过应用不同的转换来更改此默认行为。例如,要只映射到您选择的元素,可将 Item At 转换为源并指定索引。要映射源集合中第一个元素中的值,请为索引指定 0。
如果源集合包含您没有映射的字段,则这些字段仍可用于流程中的后续步骤。
非集合集合(一对多)映射
当您从非集合源字段映射到目标集合或位于集合元素中的 target 字段时,Data mapper 会识别一对多映射。默认行为是数据映射器使用空格作为分隔符,并将源值拆分为多个值,以此应用 Split 转换。在执行过程中,数据映射器会将每个拆分值插入到目标集合中自己的元素中。例如,如果 source 字段被分成 4 值,则 target 集合有 4 个元素。
例如,考虑一个非集合、cities 源字段,其中包含:
波兰部
您可以将这个源字段映射到目标集合,或映射到集合中的目标字段。在执行过程中,数据映射器会将 城市 字段的值分成空格分隔符。其结果是包含三个元素的集合。在第一个元素中,城市 字段的值是 波士顿。在第二个元素中,city 字段的值是 Paris。在第三个元素中,city 字段的值为 东京。
7.13. 转换源或目标数据
在数据映射程序中,定义映射后,您可以在映射中转换任何字段。转换数据字段定义如何存储数据。例如,您可以指定 Capitalize 转换,以确保数据值的第一个字母是大写的。
您可以在同一映射中对不同字段应用不同的转换。在一对一的映射中,将一个源字段映射到一个目标字段,无论是否将转换应用到源字段还是 target 字段。
在一对多次映射或多到一的映射中,请考虑 target 字段值在指定转换时所需要的内容。例如,考虑将数字、street、city 和 state 的源字段合并成一个目标地址字段的多到一的映射。如果您希望目标地址字段中的字符串都为大写,请选择目标地址字段并应用大写的转换。如果只需要大写状态,请选择源状态字段,再应用大写的转换。
您可以将源字段转换为执行预处理,而 target 字段转换则执行后处理。
注: 如果要将条件添加到映射,则需要将任何转换放置在条件表达式中,如应用 条件到映射 所述。
流程
- 映射字段。这可以是一对一的映射、组合映射或分离映射。
-
在 Mapping Details 面板中,在 Sources 或 Targets 下,在您要转换的字段的框中,点
。这个选项显示可用转换的下拉列表。
- 选择您要数据映射程序执行的转换。
- 如果转换需要任何输入参数,请在相应的输入字段中指定它们。
-
要添加另一个转换,请再次点
。
其他资源
7.13.1. 关于在映射到一个目标字段前在多个源值转换
有些转换可以应用到多个源字段,或应用于包含多个值(如集合)的 source 字段中的值。data 映射器将转换的结果插入到 target 字段中。下表描述了这些多厂商转换。
| 多层次转换 | 描述 |
|---|---|
| 添加 | 添加数字源值,并将 sum 插入到 target 字段中。所选源字段或选定集合中的值必须是数字。 |
| average | 计算数字源值的平均值,并将结果插入到 target 字段中。所选源字段或选定集合中的值必须是数字。 |
| 串联 | 加入源值,并将结果插入到 target 字段中。您可以接受空格作为分隔符或指定其他字符。数据映射程序在源值之间的 target 字段中插入这个字符。这个转换的常见用法是组合多个源字段值,如 FirstName、SinedName 和 LastName,在一个目标字段中,如 customer Name。 |
| contains | 评估源值,以确定任何值是否包含您指定的参数值。如果有任何源值包含指定参数值,则 data mapper 会将 true 插入到 target 字段中。如果没有 source 值,则 data mapper 会将 false 插入到 target 字段中。 例如,假设您要跟踪与特定客户相关的活动。您可以选择一个源集合字段,每个集合成员都包含客户信息。对于 Value 参数,您可以指定一个特定的电子邮件地址。当数据映射器在集合中找到指定的电子邮件地址时,它会在 target 字段中插入 true。 |
| 数量 | 在 target 字段中插入源值的数量。当源字段是集合时,这很有用。data 映射器在 target 字段中插入集合的大小。 例如,假设您选择一个 Order source 字段,它是项对象的集合。应用 Count 转换会将顺序中的项目数插入到 target 字段中。 另外,如果您选择 4 个单独的源字段,则 data mapper 会在 target 字段中插入 4。 |
| 划分 |
将第一个源值除以第二个源值,并在 target 字段中插入结果。如果有两个源值,则执行将继续将结果除以下一个数字。例如,考虑一个包含 |
| 格式 | 用您选择的源字段的值替换您在模板中的占位符。data mapper 在 target 字段中插入生成的字符串。例如,假设您选择了三个源字段:
时间 您可选择 Format 转换并在 Template 参数中指定:
在 target 字段中,结果类似如下: 早上 8 月 AM,阿特约:ROAR! 这和 Java 和 C 等编程语言可用的机制类似。 |
| 项目亚 | 对于您选择的 source 字段,data mapper 会在您在 target 字段中指定的索引中找到值,并在 target 字段中插入该值。source 字段必须是包含带有分隔符的多个值的集合或字段。 例如,假设所选的源字段是客户电子邮件地址的集合。选择 Item At transformation 后,在 Index parameter 字段中指定 0。data mapper 在 target 字段中插入第一个电子邮件地址(位于索引 0)。 |
| 最大值 | 评估源值并在 target 字段中插入最高值。源值必须是数字。 |
| 最小值 | 评估源值并在 target 字段中插入最低值。源值必须是数字。 |
| 多ply |
将第一个源值乘以第二个源值,并在 target 字段中插入结果。如果有两个源值,则执行将继续按下一个数字来指定结果。例如,考虑一个包含 |
| 减法 |
从第一个源值中减去第二个源值,并在 target 字段中插入结果。如果有两个源值,则执行将继续从前面的结果中减去下一个数字。例如,考虑一个包含 |
7.13.2. 可用转换的描述
下表描述了可用的转换。日期和时间类型通常是指这些概念的任何形式。即数字,例如: 整数,长,长,双。日期包括,例如 日期、Time、ZonedDateTime。
| 转型 | 输入类型 | 输出类型 | 参数(* = 必需) | 描述 |
|---|---|---|---|---|
|
| number | number | 无 | 返回数字的绝对值。 |
|
| date | date |
| 向日期添加天数。默认值为 0 天。 |
|
| date | date |
| 将秒数添加到日期。默认值为 0 秒。 |
|
| 字符串 | 字符串 | 字符串 | 在字符串的末尾附加字符串。默认值为不附加。 |
|
| 字符串 | 字符串 | 无 | 通过删除空格将短语转换为 camelized 字符串,使第一个单词小写,并大写每个后续单词的第一个字母。 |
|
| 字符串 | 字符串 | 无 | 大写字符串中的第一个字符。 |
|
| number | number | 无 | 返回数字的整数。 |
|
| any | 布尔值 |
| 如果字段包含指定的值,则返回为 true。 |
|
| 任何简单类型 | 阵列中的任何简单类型 | index* |
对于集合,将字符串字段的值复制到目标集合的指定字段中,而不进行拆分。index 参数定义目标集合中字段的索引。默认值为 |
|
| number | number |
|
将代表区域的数字转换为另一个单元。对于 |
|
| number | number |
|
转换代表到另一个单元的距离的数字。对于 |
|
| number | number |
|
转换代表到另一个单元的数字。对于 |
|
| number | number |
|
将代表卷的数字转换为另一个单元。对于 |
|
| date | number | 无 | 返回与日期对应的一周(1 到 7)的当天。 |
|
| date | number | 无 | 返回与日期对应的年日(1 到 366)。 |
|
| 字符串 | 布尔值 |
|
如果字符串以指定字符串结尾且在两个 |
|
| any | 布尔值 |
|
如果输入字段等于 |
|
| 字符串 | 字符串 | 无 | 从代表文件名的字符串中返回不带点的文件扩展。 |
|
| number | number | 无 | 返回数字的整数。 |
|
| any | 字符串 |
|
|
|
|
string | number |
|
返回输入字符串中字符的索引,即参数字符串的第一个字符。如果找不到参数字符串,则返回 |
|
| any | 布尔值 | 无 | 如果字段是 null,则返回 true。 |
|
|
string | number |
|
返回输入字符串中字符的索引,即参数字符串的最后一个字符。如果找不到参数字符串,则返回 |
|
| any | number | 无 |
返回字段的长度,如果字段是 null,则返回 |
|
| 字符串 | 字符串 | 无 | 将字符串转换为小写。 |
|
| 字符串 | 字符串 | 无 | 使用单个空格替换连续的空格,并修剪字符串中的空格和结尾空格。 |
|
| 字符串 | 字符串 |
|
在字符串的开头插入 |
|
| 字符串 | 字符串 |
|
在字符串的末尾插入 |
|
| 字符串 | 字符串 |
|
|
|
| 字符串 | 字符串 |
|
在字符串中,将提供的匹配字符串的所有位置替换为提供的新 |
|
| 字符串 | 字符串 |
|
在字符串中,将指定 |
|
| 任何简单类型 | 阵列中的任何简单类型 |
| 将简单类型映射到阵列类型时,请用从简单类型获取的值填充多个数组元素。 |
|
| number | number | 无 | 返回数字的整数。 |
|
| 字符串 | 字符串 | 无 | 将每个出现的空格、冒号(:)、下划线(_)、加号(+)和等于(=)替换为连字符(-)。 |
|
| 字符串 | 字符串 | 无 | 将每个出现的空格、冒号(:)、连字符(-)和(+)和等于(=)替换为下划线(_)。 |
|
| 复合类型 | any | 无 | 根据源复合字段中的分隔符,将复合字段划分为多个目标字段。默认分隔符是空格。 |
|
| 字符串 | 布尔值 |
| 如果字符串以指定字符串(包括大小写)开头,则返回为 true。 |
|
| 字符串 | 字符串 |
|
从指定的 inclusive |
|
| 字符串 | 字符串 |
|
从指定的 inclusiveIndex 到指定的专用 |
|
| 字符串 | 字符串 |
|
从提供的 startIndex 提供的 |
|
| 字符串 | 字符串 | 无 | 从字符串中修剪前导和尾随空格。 |
|
| 字符串 | 字符串 | 无 | 从字符串中修剪前导空格。 |
|
| 字符串 | 字符串 | 无 | 从字符串中修剪空格。 |
|
| 字符串 | 字符串 | 无 | 将字符串转换为大写。 |
7.14. 应用条件到映射
在某些集成中,向映射添加条件处理会很有帮助。例如,假设您将 source zip code 字段映射到目标 zip code 字段。如果 source zip code 字段为空,您可能想要使用 99999 填写 target 字段。为此,您可以指定一个测试 zip 代码源字段的表达式,以确定是否为空,如果为空,将 99999 插入到 zip 代码目标字段中。
应用条件到映射只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。有关红帽技术预览功能支持范围的详情,请参考 https://access.redhat.com/support/offerings/techpreview/。
data mapper 支持表达式类似于 Microsoft Excel 表达式,但不支持所有 Microsoft Excel 表达式语法。条件表达式可以引用单个字段或位于集合中的字段。
您可以为每个映射定义零个或一个条件。
以下流程开始使用应用条件到映射。
注: 在将条件添加到映射后,源和目标转换选项被禁用。您必须将任何转换放在条件表达式中。
先决条件
- 您是在 Data Mapper 步骤中映射字段。
- 您熟悉 Microsoft Excel 表达式或者您有要应用到映射的条件表达式。
流程
如果数据类型还没有可见,点
来显示它们。
虽然这不是指定条件的要求,但查看数据类型会很有帮助。
创建您要应用条件到的映射,或者确保当前选择的映射是您要将条件应用到的映射。例如,考虑这个映射:
在左上角,点
 以显示条件表达式输入字段。
以显示条件表达式输入字段。
在表达式字段中,Data mapper 会自动在当前映射中显示源字段的名称。例如:

在表达式输入字段中,源字段的顺序是您在创建映射时选择它们的顺序。这很重要,因为默认映射行为是 data mapper 会按此顺序串联字段值,以便在 target 字段中插入结果。在这个示例中,要创建此映射,首先选择了
lastName,然后选择firstName。编辑表达式输入字段,以指定您希望 data mapper 应用到映射的条件表达式。有关支持条件表达式的详情,请按照以下步骤操作。
如果要在条件映射中包含转换,您必须将转换添加到条件表达式中。
在指定表达式时,您可以键入
@和 start 来键入字段的名称。data mapper 显示与您输入的内容匹配的字段列表。选择您要在表达式中指定的字段。当您向表达式中添加字段名称时,data mapper 会将该字段添加到映射中。例如,考虑此条件表达式:
在执行过程中,如果 data mapper 确定
lastName字段是否为空,它只会将firstName字段映射到目标customerName字段。如果lastName字段包含的值,即不是空的,数据映射程序会串联源orderId和phone字段中的值,并在customerName字段中插入结果。(本例中显示了逻辑的工作方式,但可能不是有用的示例,因为lastName字段中的值是值,您很可能希望 data mapper 仅执行映射,且不会将某些其他值映射到目标。)在本例中,输入表达式后,数据映射为:
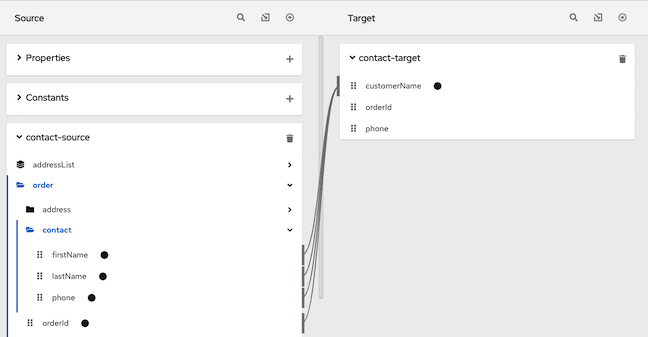
在条件表达式中,如果您删除在表达式应用到的映射中的字段名称,则 data mapper 将从映射中删除该字段。换句话说,映射中的每个字段名称都必须位于条件表达式中。
-
如果映射预览字段尚未可见,点
来显示它们。
- 在源预览输入字段中键入示例数据,以确保 target 字段或目标字段得到正确的值。
(可选)点击您要应用转换的每个字段旁的
来把一个或多个源或目标字段应用到所选映射中的一个或多个源或目标字段,然后从下拉菜单中选择所需的转换。
例如,在此流程中介绍的同一映射中,在 Mapping Details 面板中,您可以将
Uppercase转换应用到firstName字段。您可以通过在firstName字段的 preview 输入字段中输入数据来测试这一点。- 根据需要编辑条件表达式以获取所需结果。
条件表达式中支持的功能
SELECT(FILTER(source-collection-name, source-field-name1 != 'v1' ), source-field-name2)对于具有多个字段的集合,数据映射程序会根据不同源字段的值(在同一集合中)过滤一个 source 字段中的值。例如,如果集合(用户)包含多个字段,包括
namegender,您可以使用以下条件表达式根据gender字段的值过滤名称,以便只有 male 名称映射到 target 字段:SELECT(FILTER(person, gender = 'male' ), name)`ISEMPTY(source-field-name1 [+ source-field-name2])ISEMPTY()函数的结果是一个布尔值。至少指定一个参数,这是您要将条件应用到的映射中的 source 字段的名称。当指定的 source 字段为空时,ISEMPTY()函数会返回 true。另外,还可使用附加字段添加 +(concatenation)operator,例如:
ISEMPTY(lastName + firstName)如果源字段
lastName和firstName都为空,则此表达式将评估为 true。通常,
ISEMPTY()函数是IF()函数中的第一个参数。IF(boolean-expression,,,)当
boolean-expression评估为 true 时,数据映射程序会返回。当boolean-expression评估为 false 时,数据映射程序会返回其他。需要所有三个参数。最后一个参数可以是 null,这意味着当boolean-expression评估为 false 时,不会映射任何内容。例如,考虑目标
customerName字段中的lastName和firstName源字段的映射。您可以指定此条件表达式:IF(ISEMPTY(lastName), firstName, lastName + ',' + firstName)在执行过程中,数据映射程序会评估
lastName字段。-
如果
lastName字段为空,即ISEMPTY(lastName)返回 true,则 data mapper 只会将firstName值插入到目标customerName字段中。 如果
lastName字段包含值,即ISEMPTY(lastName)返回 false,则 data mapper 会映射lastName值,后面有一个逗号,后接在目标customerName字段中的firstName值。现在,如果此表达式中的第三个参数是 null,请考虑其行为:
IF(ISEMPTY(lastName)、firstName、null)在执行过程中,数据映射程序会评估
lastName字段。-
如上例所示,如果
lastName字段为空,即ISEMPTY(lastName)返回 true,则 datamapper 只会将firstName值插入到目标customerName字段中。 -
但是,当第三个参数为 null 时,如果
lastName字段包含值,即ISEMPTY(lastName)返回 false,则 data mapper 不会将任何内容映射到目标customerName字段。
-
如果
LT(x,y)或 <(x,y)数据映射程序评估
x和y,并返回较低值。x和y都必须是数字。TOLOWER(字符串)数据映射程序将指定字符串转换为小写并返回它。
表 7.1. 条件表达式中支持的 operator
| Operator | 描述 |
|
| 添加数值或串联字符串值。 |
|
| 从另一个数字值中减去数字值。 |
|
| 数值乘以数值。 |
|
| 划分数值。 |
|
| 如果左和右运算对象为 true,则返回 true。每个操作对象都必须返回布尔值。 |
|
| 如果左侧运算对象为 true,或者右侧运算对象为 true,则返回 true,或者两个操作对象都为 true。每个操作对象都必须返回布尔值。 |
|
| Not |
|
| 如果左侧数字运算对象大于右侧数字运算对象,则返回为 true。 |
|
< | 如果左侧数字运算对象小于右侧数字运算对象,则返回为 true。 |
|
| 如果左侧运算对象和右侧运算对象相同,则返回为 true。 |
7.15. 数据映射故障排除
data mapper 显示可以通过之前集成步骤提供的最大源字段集。但是,不是所有连接都提供每个显示的源字段中的数据。例如,对第三方应用程序的更改可能会停止在特定字段中提供数据。在创建集成时,如果您发现数据映射没有被象预期的一样,请确保要映射的源字段包含您所期望的数据。
数据形成变化,影响已映射的字段可能会阻止 datamapper 加载文档。在这种情况下,当您尝试编辑映射受影响字段的数据映射器步骤时,数据映射程序将无法显示源和目标面板。相反,它会显示一个错误,表示它无法加载或无法找到文档。错误消息类似于以下信息之一:
-
Data Mapper UI imultaneous Error: Could not load document '-La_rwMD_ggphAW6nE9o': undefined undefined -
无法在 URI atlas:json:-LaX4LMC1CfVJYp3JXM6 的 mapped 字段 'last_name' 找到文档
您必须删除这个 data mapper 步骤,并将其替换为映射更新字段的新 datamapper 步骤。
虽然形成数据形成的更改始终需要您恢复映射,但您不需要删除 data mapper 步骤。例如,如果 XML 实例指定了输入数据形成的,并且您更改元素的名称,则数据映射程序会从旧字段名称中删除映射到/的映射。您只需使用更新的名称从字段映射到/。
可以通过以下方法为映射字段更改形成数据:
在 API 供应商集成中,在编辑流时,您可以编辑定义操作的 OpenAPI 文档。
更改操作响应的格式始终可防止数据映射程序加载文档。
在流中,您可以为这类连接之一编辑输入数据类型和/或输出数据类型:
- Amazon S3
- AMQ
- AMQP
- dropbox
- FTP/SFTP
- HTTP/HTTPS
- Kafka
- IRC
- MQTT
第 8 章 管理集成
常见的设置是拥有 Fuse 在线开发环境、Fuse 在线测试环境和 Fuse 在线部署环境。为方便这一点,Fuse Online 提供了从一个 Fuse 在线环境导出集成的能力,然后将该集成导入到另一个 Fuse 在线环境中。除非特别说明,在各种 Fuse 在线环境中管理集成的信息和流程是相同的。
以下主题提供可帮助您管理集成的信息:
8.1. 关于集成生命周期处理
创建并发布集成后,您可能需要更新集成的作用。您可以编辑已发布集成的草稿,然后将运行的版本替换为更新版本。为促进这一需求,对于每个集成,Fuse Online 维护多个版本以及每个版本的状态。了解集成版本和状态有助于管理集成。
集成版本的描述
在每个 Fuse 在线环境中,每个集成都可以有多个版本。支持多个集成版本有以下优点:
- 如果您发布无法正常工作的版本,则可以返回运行正确版本的集成。要做到这一点,您要停止不正确的版本,并启动一个运行它的方式的版本。
- 随着要求或工具的变化,您可以逐步更新集成。您不需要创建新集成。
Fuse Online 每次开始运行新版本的集成时都会分配一个新的版本号。例如,假设您将 Twitter 发布到 Salesforce 示例集成。运行之后,您将更新集成以使用其他帐户连接到 Twitter。然后发布更新的集成。Fuse Online 会停止运行的集成的运行版本,并使用递增版本号发布集成的更新版本。
运行的初始集成是版本 1。现在运行的已更新的集成是版本 2。如果您编辑版本 2,例如使用其他帐户连接到 Salesforce,然后发布该版本,则会成为集成版本 3。
集成的一个草案版本。Fuse Online 具有适用于集成草案版本的定义,但它从没有运行此版本的集成。集成的草案版本没有数字。编辑集成时,您将更新集成的草稿版本。
在 Fuse Online 中,您可以在集成摘要页面中看到集成版本列表。要查看此页面,请在左侧导航面板中点 Integrations。在您感兴趣的集成条目中,单击 View。
集成状态描述
在 Fuse Online 中,在集成版本列表中,每个条目都代表该版本的状态,其是以下之一:
| 状态 | 描述 |
| 运行中 | 正在运行的 版本正在执行;它正在服务中。只能运行一个版本的集成。也就是说,每次只能有一个版本处于 Running 状态。 |
| 已停止 | 被停止 的版本没有运行。集成的草案版本处于 Stopped 状态。每个正在一次运行的集成都一次运行,然后停止处于 Stopped 状态。 如果没有此集成的版本处于 Running 状态,您可以启动已停止的版本。 |
| 待处理 | 待处理的 版本正在迁移。Fuse Online 正在启动此版本的集成或停止此集成版本,但集成还没有运行或停止。 |
| Error |
处于 Error 状态的集成版本在启动或运行时遇到 OpenShift 错误。暂停启动或执行的错误。如果发生这种情况,请尝试启动正确运行的早期集成版本。或者,请联系技术支持寻求帮助。为此,请在右上角的任何 Fuse Online 页面中,点
|
8.2. 将集成放在服务之外
创建集成后,您可以将它保存为草案或发布,以便开始运行。当您发布集成时,Fuse Online 会汇编所需资源,构建集成运行时,部署将运行集成的 OpenShift Pod,然后开始运行集成。
您可以随时点击按钮停止运行集成。当您想再次启动集成时,Fuse Online 已拥有所需的需要,因此,启动时间比您第一次运行它的时间要短。
首次启动集成版本的过程被称为发布集成。以下主题提供详情:
8.2.1. 关于发布集成
要首次运行集成版本,您可发布它。发布集成构建并部署集成运行时。该集成开始运行。发布集成后,您可以停止它并重启它。一次只能运行一个版本的集成。
发布的替代方案
要第一次运行集成,请执行以下任一操作:
- 在您要创建或编辑集成的过程结束时,单击 Publish。
发布集成的草稿版本:
- 在左侧 Fuse Online 面板中,单击 Integrations。
-
在集成列表中,在草案条目右侧点
并选择 Publish。
关于发布进度
Fuse Online 显示发布过程的过程,它有几个阶段:
- 组合 创建构建集成所需的 pod 资源。
- 构建 可以准备好部署集成。
- 部署 会等待部署运行集成的 pod。
- 启动 会等待 pod 开始运行集成。
- deployed 表示集成正在运行。
在启动过程中,您可以点击 View Logs 来显示提供启动信息的 OpenShift 日志。
发布后集成状态
发布集成完成后,集成名称旁边会出现 Running 状态。pod 运行集成。
8.2.2. 停止集成
每个集成都可以只有一个版本正在运行。正在运行的版本处于 Running 状态。您可以随时停止运行集成。
前提条件
您要停止的集成处于 Running 状态。
流程
- 在左侧 Fuse Online 面板中,单击 Integrations。
- 在集成列表中,标识您要停止运行的集成条目。该条目显示此集成 正在运行。
-
在这个集成条目的最右侧,点
并选择 Stop。
结果
Fuse Online 停止运行集成。在集成列表中,停止和 停止 将出现在集成条目中。
8.2.3. 启动集成
您第一次启动集成时,此过程称为发布集成,因为 Fuse Online 在集成运行集成之前必须构建集成。您可以随时停止运行集成,然后再次启动它。
前提条件
您要启动的集成处于 Stopped 状态。
流程
- 在左侧导航面板中点 Integrations。
-
在集成列表中,在您要启动的集成条目右侧,点
。
- 选择 Start。
结果
Fuse Online 显示 开始 作为该集成版本的状态,然后在集成再次运行时运行。
8.2.4. 重启旧的集成版本
您可以发布一种集成,无法按照您希望的方式工作。在这种情况下,您可以停止不正确的版本,并将其替换为您之前发布的版本并运行的版本。
先决条件
- 集成的版本正在运行,但您想要停止它。
- 您还有另一个版本的集成,您想要运行该集成。
流程
- 在左侧面板中,点击 Integrations 来显示此环境中集成的列表。
- 单击您要为其发布旧版本的集成条目。Fuse Online 显示集成版本的列表。
-
在运行版本的条目中,在最右侧点
并选择 Stop。
- 点 OK 确认您要停止运行此版本。
- 等待 Stopped 出现在页面顶部附近的集成名称右侧的位置。
要按原样发布旧版本,请跳至下一步。或者,在发布旧版本前,您可以更新它:
-
在您要更新的集成版本的条目中,在右侧点
并选择 replace Draft。
- 根据需要更新集成。
- 更新完成后,在右上角单击 Publish,然后单击 Publish 进行确认。这会执行接下来的两个步骤。
-
在您要更新的集成版本的条目中,在右侧点
-
要发布旧版本,请在您要再次开始运行的集成版本的条目中,点
并选择 Start。
- 点 Start 确认您要启动此版本的集成。
结果
Fuse Online 启动集成,需要几分钟时间。当集成运行时,运行版本 n 将出现在集成名称的权利中。
8.3. 有关集成执行的日志信息
对于每个执行集成,Fuse Online 提供以下活动信息:
- 执行步骤的日期和时间
- 执行步骤所需的时间
- 执行是否成功
- 如果执行失败,则错误消息
要在 Fuse Online 中查看此信息,请显示集成的摘要,然后单击 Activity 选项卡。
要获取有关集成执行的更多详情,您可以通过向集成流添加日志步骤来记录有关集成进程的消息的信息。对于集成接收的每个消息,日志步骤可以提供一个或多个以下内容:
- 消息的上下文,提供消息的元数据,包括消息的标头。
- 邮件的正文,提供消息的内容。
- 您指定的文本可以显式或通过评估 Apache Camel Simple 语言 表达式。
以前版本中提供的 Log connection 不再添加到集成中。添加日志步骤而不是日志连接。
先决条件
- 您正在创建或编辑一个流,Fuse Online 正在提示您添加到集成中。或者,Fuse Online 提示您选择完成连接。
流程
- 在流视觉化中,点您要添加日志步骤的加号。如果 Fuse Online 提示您选择完成连接,请跳过这一步。
- 点 Log。
在 Configure Log Step 页面中,选择您要记录的内容。如果您选择 Custom 文本,然后在文本输入字段中输入以下之一:
- 要记录的文本
- Camel Simple 语言表达式
如果您输入了表达式,Fuse Online 将解析表达式并记录生成的文本。
- 日志步骤配置完成后,点击 Next 将步骤添加到流程中。
后续步骤
流完成后,发布集成以从新日志步骤中看到输出。
其他资源
执行日志步骤的流后,日志步骤的输出会出现在集成的 Activity 选项卡中。请参阅 查看集成活动信息。
8.4. 监控集成
Fuse Online 为您提供了各种方法来监控您的集成执行。请参阅:
8.4.1. 查看集成历史记录
Fuse Online 维护每个版本的集成。您始终可以查看每个集成版本的列表。
流程
- 在左侧面板中,点击 Integrations 在您的环境中显示集成列表。
- 在您要查看的版本对应的集成的条目右侧,点 View。
结果
在出现的页面中,History 部分列出了集成的版本。
 图标标识当前版本,它是最近运行的版本。对于每个版本,您还可以查看上次启动的日期。
图标标识当前版本,它是最近运行的版本。对于每个版本,您还可以查看上次启动的日期。
要编辑、启动或停止特定版本,请点击版本条目右侧的
。选择您要执行的操作。
8.4.2. 查看有关集成活动的信息
Fuse Online 为每次执行集成提供活动信息。此信息是集成日志的一部分。对于流中的每个步骤,Fuse Online 提供:
- 执行步骤的日期和时间
- 执行步骤所需的时间
- 执行是否成功
- 如果执行失败,则错误消息
您可以随时查看此信息。
先决条件
- 您想查看活动信息,或者有一个正在运行的集成。
- 此集成至少执行了一次。
流程
- 在左侧面板中,点 Integrations。
- 在您要查看活动信息的集成右侧,点 View。
- 在集成概述页面中,点 Activity 选项卡。
- (可选)输入 date 和/or 关键字过滤器来限制列出的执行。
- 点击您要查看活动信息的集成执行。
对于 API 提供程序集成或 webhook 步骤,集成的 Activity 选项卡中的信息反映了 Fuse Online 集成和调用它的客户端之间的通信。HTTP 或 REST 请求生成的错误在集成的 活动 日志中不可见。如果要查看或测试 HTTP 或 REST 请求生成的错误,请在配置 API Provider 或 Webhook 步骤时检查 返回正文选项中的 Include 错误消息 (默认检查)。然后,您可以通过检查对调用者的响应中的 HTTP 或 REST 标头来验证错误消息是否包含在响应中。您还可以检查集成 Pod 的日志文件 INFO 消息。
其他资源
- 要在两个步骤之间获取其他信息,您可以在集成中添加日志步骤。日志步骤提供有关它接收的每个消息的信息,并可提供您指定的自定义文本。如果您添加了日志步骤,则在扩展您要查看活动信息的集成执行时,它会显示为其中一个集成步骤。您可以查看 Fuse Online 信息,其方式与查看 Fuse Online 信息任何其他步骤相同。请参阅有关 集成执行 的日志记录信息。
8.4.3. 查看特定集成的指标
Fuse Online 为每个集成提供以下指标:
- Total Errors 表示过去 30 天遇到此集成的所有执行运行时错误数。
- 最后进程 显示此集成处理消息的最新日期和时间。消息可能已成功处理,或者有错误。
- 总消息 是过去 30 天内处理此集成执行的消息数量。这包括消息失败。
- uptime 指示该集成启动运行的时间以及运行的时间没有错误。
前提条件
您要查看 的指标正在运行或正在运行的集成。
流程
- 在左侧面板中,点 Integrations。
- 在您要查看指标的集成条目的右侧,点 View。
- 在集成概述页面中,点 Metrics。
8.4.4. 查看 Fuse 在线环境的指标
Fuse Online 环境的指标会出现在 Fuse Online 主页中。
流程
在左侧面板中点击 Home。
结果
Fuse Online 每 5 秒更新以下指标:
- 在此环境中定义的集成数量以及所运行的集成数量、已停止的集成数量,以及待处理的集成数量。Fuse Online 正在停止或启动待处理的集成。红色跨度表示任何正在运行但遇到暂停执行的错误的集成。
- 此环境中定义的连接数。
- 此环境中的集成在最后 30 天时间内已处理的消息总数。这包括由集成处理的消息,这些消息可能不再运行,或者可能已从此环境中删除。
- uptime 指明在运行了至少一个集成的时长。启动运行时间也出现日期和时间。
8.5. 测试集成
创建集成后,并在 Fuse 在线开发环境中正确运行,您可能希望在不同 Fuse 在线环境中运行它以进行测试。
前提条件
- 您有一个 Fuse 在线开发环境和 Fuse 在线测试环境。
- 您有一个在 Fuse 在线开发环境中正确运行的集成。
流程
- 了解 将集成复制到另一个环境的信息。
- 从开发环境导出集成。请参阅 导出集成。
- 将集成导入到测试环境。请参阅 导入集成。
8.6. 集成执行故障排除的提示
如果集成停止工作,请检查其活动和历史详情。请参阅 查看集成活动信息 和 查看集成历史记录。
集成不足
如果 Fuse Online Operator 日志显示集成的状态 尚未就绪,或者如果集成的 pod 事件报告内存不足,您可能需要编辑 集成的部署配置,如调整集成 的内存和 CPU 配置属性 所述。
连接到使用 OAuth 的应用程序
对于使用 OAuth 的应用程序的连接,您可能会看到一条错误消息,表示应用的访问令牌已过期。有时,您可能会获得一个不太明确的 403 - 访问拒绝 的消息。消息中的信息取决于集成连接的应用程序。在这种情况下,尝试重新连接应用程序,然后重新发布集成:
- 在左侧面板中,点 Integrations。
- 在集成列表中,在已停止运行的集成条目的右侧,单击 View。
在集成概述页面中,在流视觉化中点击您要重新连接的应用程序图标。
如果这是 API 供应商集成,则在集成的摘要页面中,单击其流图标以显示操作列表。然后点击其路径包含失败的连接的操作,然后在操作的路径视觉化中点击失败的连接。
- 在连接详情页面中,点 Reconnect。
对应用程序的 OAuth 工作流提示做出响应。
Fuse Online 显示一条消息,指出其对该应用的访问已被授权。对于某些应用程序,这需要几秒钟时间,但其他应用程序可能需要更长的时间。
- 重新连接到应用程序后,启动集成。
如果 reconnection 未能成功,请尝试以下操作:
- 将 Fuse Online 重新注册为应用程序的客户端。有关 获取授权 的一般步骤,请参阅。
- 创建新连接。
编辑每个使用旧连接的集成:
- 删除旧连接。
- 使用新连接替换它。
- 发布每个更新的集成。
8.7. 更新集成
创建集成后,您可能需要更新它来添加、编辑或删除步骤。
前提条件
在 Fuse Online 环境中,有一个您要更新的集成版本。
流程
- 在左侧 Fuse Online 面板中,单击 Integrations。
- 在集成列表中,点您要更新的集成的 View。
在集成概述页中,点击 Edit Integration。
如果这是简单的集成,Fuse Online 会显示集成的流程。如果这是 API 供应商集成,Fuse Online 会显示操作列表。要更新特定操作的流,请点击 该操作右侧的 Edit 流 来显示其流。
根据需要更新流:
- 要添加步骤,请在流视觉化中点击您要添加步骤的加号。然后点击代表您要添加的步骤的卡。
-
要删除步骤,在流视觉化中点您要删除的步骤
。
- 要更改步骤的配置,请在流程视觉化中点击 Configure 您要更新的步骤。在配置页面中,根据需要更新参数设置。
8.8. 为集成调整内存和 CPU 配置属性
您可以通过编辑集成的部署配置对象,为特定集成 CPU 和内存指定自定义值。您可能希望调整集成的内存和 CPU 配置属性,例如,如果集成需要的内存超过默认分配量。
前提条件
-
安装了 Red Hat OpenShift
oc客户端工具,并连接到安装了 Fuse Online 的 OCP 集群。 -
具有集群管理权限的用户为您提供了包含您要配置的集成的项目的
admin权限。
流程
使用具有带有 Fuse Online 集成的 OpenShift 项目的
admin权限的帐户登录 OpenShift。例如:oc login -u admin -p admin切换到包含 Fuse 在线集成的项目。例如:
oc project my-fuse-online-project编辑集成的部署配置对象:
输入以下命令,这通常会在编辑器中打开资源:
oc edit deploymentconfig <i-integration-name>例如,如果集成名称为
my-integration,则键入这个命令:oc edit deploymentconfig i-my-integration通过设置
spec.containers.resources来指定 CPU 和内存值来编辑配置,如下例所示:spec: containers: resources: limits: cpu: 350m requests: memory: 350Mi- 保存配置。
结果
保存更改后,集成 Pod 会重启,新 pod 使用新值运行。例如,如果您运行 oc describe <intergration-pod-name& gt; 命令(其中将 <intergration-pod-name> 替换为集成 pod 的名称,如 i-my-integration),命令会返回新值,例如:
resources:
limits:
cpu: 350m
requests:
cpu: 350m
memory: 350Mi这些值即使在发布新版集成后仍然保留。
其他资源
要为所有集成的 CPU 和内存属性设置默认值,OpenShift 集群管理员可以更新 Fuse Online 自定义资源,如在 {NameOfFuseOnlineOnOCP} 中配置 Fuse Online 的自定义资源属性描述。
8.9. 删除集成
删除集成后,Fuse Online 仍具有该集成的历史。如果您导入了已删除集成的版本,则 Fuse Online 将删除的历史记录与导入集成相关联。
流程
- 在左侧 Fuse Online 面板中,单击 Integrations。
-
在集成列表中,在您要删除的集成的条目右侧,点
并选择 Delete。
- 在弹出窗口中,单击 OK 以确认要删除该集成。
8.10. 将集成复制到另一个环境中
要在开发、登台和生产环境中运行集成,您可以导出和导入集成。环境可以全部位于单个 OpenShift 集群上,或者它们分散在多个 OpenShift 集群中。
此处描述的步骤指导您在 Fuse 在线控制台中导出和导入集成。
如果您在 OpenShift Container Platform 上运行 Fuse Online,则可能会出现持续集成/持续部署(CI/CD)管道,以导出并导入某些集成。有关这样做的详情,请参考 使用外部工具为 CI/CD 导出/导入集成。
请参见以下主题:
8.10.1. 关于复制集成
每个 Fuse 在线安装都是一个环境,您可以从其中导出集成。导出集成下载一个 zip 文件,其中包含在不同 Fuse 在线环境中重新创建集成所需的信息。
在环境中,每个集成只能有一个 Draft 版本。
导入集成的结果取决于:
- 之前是否导入了集成
- 之前是否导入了集成使用的连接
Fuse Online 为每个集成使用内部标识符,每个连接来确定将其导入的环境中是否存在。如果您更改了集成或连接的名称,Fuse Online 会将其识别和具有不同名称相同的集成或连接。
下表描述了导入集成的结果:
| 在导入环境中: | 导入操作的作用: |
|---|---|
| 之前没有导入的集成。 | 创建集成。该集成处于 Draft 状态。 |
| 之前导入了集成。 | Fuse Online 更新集成。更新的集成处于 Draft 状态。如果这个集成 有一个 Draft 版本,它将会丢失。 |
| 导入的集成使用在导入操作前环境中不存在的连接。 | Fuse Online 创建连接具有相同的设置,但 secret 除外。您必须查看每个新连接。如果没有为新环境完全配置连接,您必须添加缺少的设置。例如,您可能需要通过将这个 Fuse Online 环境注册为此连接访问的应用程序的客户端来获取 secret 设置。 |
8.10.2. 导出集成
当 Fuse Online 导出集成时,它会将 zip 文件下载到您的本地 Downloads 文件夹。此 zip 文件包含在不同 Fuse 在线环境中重新创建集成所需的信息。
导出集成也是一种备份集成的方法。但是,Fuse Online 维护集成版本,因此不需要导出集成,而不需要备份副本。
流程
- 在 Fuse Online 左侧面板中,单击 Integrations。
- 在集成列表中,标识您要导出的集成条目。
-
在条目右侧,点
并选择 Export。
后续步骤
要将集成导入另一个 Fuse 在线环境,请打开该环境并导入导出的 zip 文件。
8.10.3. 导入集成
在 Fuse 在线环境中,您可以导入从另一个 Fuse 在线环境导出的集成。导出集成会下载您上传以导入集成的 zip 文件。
先决条件
- 您有一个 zip 文件,其中包含了从另一个 Fuse Online 环境中导出的集成。
流程
- 打开您要导入集成的 Fuse 在线环境。
- 在左侧面板中,点 Integrations。
- 在右上角,单击 Import。
拖放一个或多个导出的集成 zip 文件,或导航到包含导出集成并将其选中的 zip 文件。
Fuse Online 导入文件,并在导入成功时显示消息。
- 在左侧面板中,点 Integrations。
- 在集成列表中,根据您刚才导入的集成条目,单击 View。
- 在集成摘要中,如果需要在右边需要通知配置,请单击 Edit integration。
对于每个需要配置的连接:
- 单击 Configure 按钮,以显示其详细信息。
- 根据需要输入或更改连接详情。此页面上的每一个字段都可能正确,并且只需要安全配置。
- 点击 Next。
在左侧面板中,单击 Settings。
Settings 页面显示使用 OAuth 协议的应用程序的条目。
对于每个需要配置和访问使用 OAuth 协议的应用程序的连接,请将您的 Fuse 在线环境注册到应用程序中。每个应用程序的步骤各有不同。请查看合适的主题:
- 在左侧面板中,点 Connections 并确认不再有需要配置的连接。
- 在左侧面板中,点 Integrations。在集成列表中,导入的集成在其条目的左上角有一个绿色三角形。
-
在集成列表中,在您导入的集成右侧,点
并选择 Edit。
- 在右上角,点 Save 或,如果您想要运行导入的集成,请单击 Publish。无论您是否将集成保存为草稿,还是发布集成,Fuse 在线更新集成以使用更新的连接。
第 9 章 自定义 Fuse Online
Fuse Online 提供很多连接器,可用于连接常见应用程序和服务。也有很多以常见方式处理数据的内置步骤。但是,如果 Fuse Online 没有提供您需要的功能,请与开发人员讨论您的要求。经验丰富的开发人员可以通过提供以下任一服务来帮助您自定义集成:
Fuse Online 用来为 REST API 客户端创建连接器的 OpenAPI 文档。
将这个模式上传到 Fuse Online,Fuse Online 将根据 schema 创建连接器。然后,您可以使用连接器创建可以添加到集成中的连接。例如,许多零售网站都提供了一个 REST API 客户端接口,开发人员可以在 OpenAPI 文档中捕获。
定义 REST API 服务的 OpenAPI 文档。
将此模式上传到 Fuse Online。Fuse Online 使 API 服务可用,并提供 API 调用的 URL。这可让您使用 API 调用 来触发集成执行。
- Fuse Online 可用来为 SOAP 客户端创建连接器的 WSDL 文件。
实施 Fuse Online 扩展的
JAR文件。扩展可以是以下任意一个:- 在连接间对集成数据执行一个或多个步骤
- 应用程序或服务的连接器
用于专有 SQL 数据库的 JDBC 驱动程序等库资源
您可以将这个
JAR文件上传到 Fuse Online 和 Fuse Online,从而使扩展提供了自定义功能。
详情请查看以下主题:
9.1. 开发 REST API 客户端连接器
Fuse Online 可为表述性状态传输应用程序接口(REST API)创建支持 Hypertext 传输协议(HTTP)的连接器。要做到这一点,Fuse Online 需要有效的 OpenAPI 3(或 2)文档,用于描述您要连接的 REST API。如果 API 服务供应商没有提供 OpenAPI 文档,则经验丰富的开发人员必须创建 OpenAPI 文档。
以下主题提供有关开发 REST API 连接器的信息和说明:
9.1.1. 对 REST API 客户端连接器的要求
将 OpenAPI 模式上传到 Fuse Online 后,将连接器上传到 REST API 变为可用。您可以选择连接器来创建 REST API 客户端连接。然后,您可以创建新的集成并添加 REST API 客户端连接,或者编辑现有集成以添加 REST API 客户端连接。
Fuse 在线连接器支持 OAuth 2.0、HTTP 基本授权和 API 密钥。如果访问 REST API 需要传输层安全(TLS),则 API 需要使用由可识别证书颁发机构(CA)发布的有效证书。
使用 OAuth 的 REST API 必须具有授权 URL,该 URL 使用客户端回调 URL 作为输入。在 Fuse Online 创建连接器后,在您使用连接器来创建连接前,您必须访问该 URL 将 Fuse 在线环境注册为 REST API 的客户端。这会授权您的 Fuse Online 环境访问 REST API。作为注册的一部分,您要提供 Fuse 在线回调 URL。这样做的详情请查看将 Fuse Online 连接到应用和服务,将 Fuse Online 注册为 REST API 客户端。
对于使用 OAuth 的 REST API,Fuse Online 支持授权代码授权流来获取授权。在您上传以创建连接器的 OpenAPI 文档中,在 OAuth securityDefinitions 对象中,您必须将 flow 属性设置为 accessCode,例如:
securityDefinitions:
OauthSecurity:
type: oauth2
flow: accessCode
authorizationUrl: 'https://oauth.simple.api/authorization'
tokenUrl: 'https://oauth.simple.api/token'
您不能将 流 设置为 隐式、密码 或 应用程序。
REST API 客户端连接器的 OpenAPI 模式不能有cyclic 模式引用。例如,指定请求或响应正文的 JSON 模式无法将其作为整个部分引用,也无法通过任意数量的中间模式引用自己。
Fuse Online 无法为支持 HTTP 2.0 协议的 REST API 创建连接器。
9.1.2. REST API 客户端连接器的 OpenAPI 模式指南
当 Fuse Online 创建 REST API 客户端连接器时,它会将 OpenAPI 文档中的每个资源操作映射到连接操作。action 名称和操作描述来自 OpenAPI 文档中的文档。
OpenAPI 文档提供的更多详细信息,在连接到 API 时可以提供更多支持 Fuse Online。例如,不需要 API 定义来为请求和响应声明数据类型。在没有类型声明的情况下,Fuse Online 将对应的连接操作定义为无类型。然而,在集成中,您无法在执行无类型操作的 API 连接之前或立即添加数据映射步骤。
对此的一个补救措施是在 OpenAPI 文档中添加更多的信息。识别映射到您希望 API 连接执行的操作的 OpenAPI 资源操作。在 OpenAPI 文档中,确保有一个 YAML 或 JSON 模式来指定每个操作的请求和响应类型。
上传该架构后,Fuse Online 为您提供了在 API Designer 中审核和编辑它的机会,这是一个基于 OpenAPI 文档设计 API 的可视化编辑器。您可以添加更详细的信息,保存您的更新,Fuse Online 创建了一个 API 客户端连接器,它包括了您的更新。在 Fuse Online 创建客户端连接器后,您无法编辑 OpenAPI 文档。要实现更改,您必须创建新的客户端连接器。
如果 API 的 OpenAPI 文档声明对 application/json 内容类型的支持,并且 application/xml 内容类型,则连接器使用 JSON 格式。如果 OpenAPI 文档指定 消耗 或生成 定义 application/json 和 application/xml 的参数,则连接器使用 JSON 格式。
9.1.3. 在参数中提供客户端凭证
当 Fuse Online 试图获取访问 OAuth2 应用的授权时,它使用 HTTP 基本身份验证来提供客户端凭据。如果需要,您可以更改此默认行为,以便 Fuse Online 将客户端凭证作为参数传递给供应商,而不使用 HTTP 基本身份验证。这会影响使用 tokenUrl 端点来获取 OAuth 访问令牌。
这是 技术预览功能。
要指定 Fuse Online 应将客户端凭证作为参数传递,在 OpenAPI 文档的 securityDefinitions 部分中,添加 x-authorize-using-parameters 厂商扩展,并设置 true。在以下示例中,最后一行指定 x-authorize-using-parameters :
securityDefinitions:
concur_oauth2:
type: 'oauth2'
flow: 'accessCode'
authorizationUrl: 'https://example.com/oauth/authorize'
tokenUrl: 'https://example.com/oauth/token'
scopes:
LIST: Access List API
x-authorize-using-parameters: true
x-authorize-using-parameters vendor extension 的设置是 true 或 false :
-
True表示客户端凭证位于参数中。 -
错,默认 表示 Fuse Online 使用 HTTP 基本身份验证来提供客户端凭据。
9.1.4. 自动刷新访问令牌
如果访问令牌具有过期日期,则 Fuse Online 集成使用该令牌连接到令牌过期时无法成功运行。要获取新的访问令牌,您必须重新连接到应用程序,或使用应用程序重新注册。
如果需要,您可以更改此默认行为,以便 Fuse Online 在以下情况下自动请求新的访问令牌:
- 过期日期之后。
- 当收到您指定的 HTTP 响应状态代码时。
这是 技术预览功能。
要指定 Fuse Online 应自动尝试在 OpenAPI 文档的 securityDefinitions 部分中获取新的访问令牌,请添加 x-refresh-token-retry-statuses 供应商扩展。这个扩展的设置是一个用逗号分开的列表,用于指定 HTTP 响应状态代码。当达到访问令牌的过期日期或 Fuse Online 从 OAuth2 供应商收到消息时,且消息具有这些响应状态代码之一时,Fuse Online 会自动尝试获取新的访问令牌。在以下示例中,最后一行指定了 x-refresh-token-retry-statuses :
securityDefinitions:
concur_oauth2:
type: 'oauth2'
flow: 'accessCode'
authorizationUrl: 'https://example.com/oauth/authorize'
tokenUrl: 'https://example.com/oauth/token'
scopes:
LIST: Access List API
x-refresh-token-retry-statuses: 401,402,403有时,API 操作失败,该故障的副作用是刷新访问令牌。在这种情况下,即使获取新的访问令牌也会成功,API 操作仍会失败。换句话说,Fuse Online 在收到新访问令牌后不会重试失败的 API 操作。
9.2. 添加和管理 API 客户端连接器
Fuse Online 可以创建这些 API 客户端连接器:
- 来自 OpenAPI 文档的 REST API 客户端连接器。有关 OpenAPI 文档内容的信息,请参阅 开发 REST API 客户端连接器。
- 来自 WSDL 文件的 SOAP API 客户端连接器。
以下主题提供了添加和管理 REST API 客户端连接器的信息和说明:
创建 API 客户端连接器后,以了解有关使用该连接器的详情,请参阅将 Fuse Online 连接到 Applications and Services,连接到 API 客户端。
9.2.1. 创建 REST API 客户端连接器
上传 OpenAPI 文档,以启用 Fuse Online 以创建 REST API 客户端连接器。
前提条件
您有一个 OpenAPI 文档,用于您希望 Fuse Online 创建的连接器。
流程
- 在 Fuse Online 导航面板中,点击 Customizations > API Client Connectors。下面列出了所有已可用的 API 客户端连接器。
- 点 Create API Connector。
在 Create API Connector 页面中,进行以下操作之一:
- 点击点号框并选择您要上传的 OpenAPI 文件。
- 选择 Use a URL,并在输入字段中粘贴 OpenAPI 文档的 URL。
点击 Next。如果内容无效或缺失,Fuse Online 就显示有关需要更正的内容的信息。选择不同的 OpenAPI 文件来上传或单击 Cancel,然后修改 OpenAPI 文件并上传更新的文件。
如果该模式有效,Fuse Online 会显示连接器提供的操作摘要。这可能包括与操作定义相关的错误和警告。
如果您对摘要满意,请单击 Next。
或者,若要调整 OpenAPI 文档,请点击 Review/Edit 以打开 API Designer 编辑器。根据需要更新 schema。有关使用 API 编辑器的详情,请参阅使用 API Designer 设计和开发 API 定义。完成后,保存您的更改,将更新合并到新的 API 客户端连接器中。然后点击 Next 以继续创建 API 客户端连接器。
有时,如果您为 OpenAPI 文档提供了 URL,Fuse Online 可以上传它,但不能打开它进行编辑。通常,这是由文件主机上的设置造成的。要打开编辑模式,Fuse Online 要求文件主机具有:
-
httpsURL。(httpURL 不起作用。) - 启用的 CORS。
-
指明 API 的安全要求。Fuse Online 读取 OpenAPI 定义,以确定配置连接器所需的信息以满足 API 的安全要求。Fuse Online 可显示以下任意一种:
- 没有安全性
- HTTP Basic Authorization -用于 API 服务使用 HTTP 基本授权,选择此复选框。之后,当您使用这个连接器创建连接时,Fuse Online 会提示您输入用户名和密码。
OAuth 2.0 - Fuse 在线提示您输入:
- 授权 URL 是将 Fuse Online 注册为 API 客户端的位置。注册会授权 Fuse Online 访问 API。请参阅将 Fuse Online 连接到 Applications and Services,将 Fuse Online 注册为 REST API 客户端。API 的 OpenAPI 文档或其他文档应该指定这个 URL。如果没有,您必须联系服务供应商来获取这个 URL。
- OAuth 授权需要访问令牌 URL。同样,API 的 OpenAPI 文档或其他文档应该提供这个 URL。如果没有,您必须联系服务供应商。
- API 密钥 - API 服务需要一个 API 密钥,Fuse Online 提示获取创建连接器所需的所有信息。提示基于 OpenAPI 定义。例如,您可能需要指定 API 键是否在消息标头中或查询参数中。如果 OpenAPI 定义指定了 API 密钥的安全性,以及另一个安全类型,选中该复选框以指明您要根据这个连接器在连接中使用 API 密钥安全性。之后,当您使用这个连接器来创建连接时,Fuse Online 会提示您输入 API 密钥的值。
点击 Next。Fuse Online 显示连接器的名称、描述、主机和基础 URL,如 OpenAPI 文档所示。对于您从这个连接器创建的连接,
-
Fuse Online 将主机和基础 URL 值串联起来,以定义连接的端点。例如,如果主机是
https://example.com,并且基本 URL 为/api/v1,则连接端点为https://example.com/api/v1。 - Fuse Online 将 OpenAPI 文档应用到数据映射步骤。如果 OpenAPI 文档支持多个模式,则 Fuse Online 使用 TLS(HTTPS)模式。
-
Fuse Online 将主机和基础 URL 值串联起来,以定义连接的端点。例如,如果主机是
- 查看连接器详情并选择性地上传连接器图标。如果您没有上传图标,Fuse Online 会生成一个图标。您可以稍后上传一个图标。当 Fuse Online 显示集成的流时,它会显示一个连接器的图标,以代表从该连接器创建的连接。
要覆盖从 OpenAPI 文件获取的值,请编辑您要更改的字段值。
重要在 Fuse Online 创建连接器后 ,您无法更改它。要生效,您需要上传更新的 OpenAPI 文档,以便 Fuse Online 可以创建新的连接器,或者您可以上传相同的模式,然后在 API 编辑器中编辑它。然后,继续创建新的 API 客户端连接器。
- 当您满足连接器详情时,点 Save。Fuse Online 在 API Client Connectors 列表中显示新的连接器。
后续步骤
有关使用新 API 连接器的详情,请参阅将 Fuse Online 连接到应用程序和服务,连接到 API 客户端。
9.2.2. 创建 SOAP API 客户端连接器
上传 WSDL 文件,以启用 Fuse Online 以创建 SOAP API 客户端连接器。
内联和外部(WSDL URL)支持具有唯一命名空间的多个模式。
前提条件
您有一个 WSDL 文件,用于您希望 Fuse Online 创建的 SOAP 客户端连接器。
流程
- 在 Fuse Online 导航面板中,点击 Customizations > API Client Connectors。下面列出了所有已可用的 API 客户端连接器。
- 点 Create API Connector。
在 Create API Connector 页面中,进行以下操作之一:
单击带点框并选择您要上传的 WSDL(
.wsdl)文件。请注意,不支持在 WSDL 文件中引用基于磁盘的外部模式,该文件直接导入到连接器(使用 File Upload 表单)。上传的 WSDL 文件 必须使用 内联架构。
在输入字段中,选择 Use a URL 并粘贴 WSDL(
.wsdl)文件的 URL。请注意,基于 URL 的 WSDL 支持使用 WSDLs 托管的外部模式。另外,只有基于 URL 的 WSDL 支持基于 WSDL 基础路径的相对 URL 的外部模式。SOAP 连接器 必须 在运行时使用 WSDL URL 来解析和验证。因此,确保 WSDL 和模式托管于永久 URL。
- 点击 Next。
- 在 Specify service and port 页面上,验证服务和端口。
- 点击 Next。如果内容无效或缺失,Fuse Online 就显示有关需要更正的内容的信息。选择其他 WSDL 文件以上传或单击 Cancel,然后调整 WSDL 文件,然后上传更新的文件。如果 schema 有效,Fuse Online 会显示 API 定义(名称和描述)的摘要以及导入的元素列表,如操作数量。
- 点击 Next。
指明调用 WSDL 端点时要使用的安全要求。Fuse Online 读取 API 定义,以确定配置连接器所需的信息,以满足 API 的安全要求。Fuse Online 可显示以下任意一种:
- 无 (无安全性)
- HTTP Basic Authorization -用于 API 服务使用 HTTP 基本授权,选择此复选框。之后,当您使用这个连接器创建连接时,Fuse Online 会提示您输入用户名和密码。
WS-Security Username Token - Fuse Online 提示您输入以下信息:
- 时间戳 - 如果您希望 Fuse Online 为 WS-Security 标头添加时间戳,请选择这个选项。
密码类型 - 选择
Digest、文本或None。如果您选择
Text或Digest:- 指定 您的用户名和密码 。
- 如果您希望 Fuse Online 添加 Nonce 元素到 WS-Security Username Token 标头,请选择 Username Token Nonce。
- 如果您希望 Fuse Online 将"Created"时间戳元素添加到 WS-Security Username Token 标头,请选择 Username Token Created。
点击 Next。Fuse Online 显示连接器的名称、描述和 WSDL 端点地址。
(可选)上传连接器的图标。您还可以稍后上传一个图标。
注: 对于此版本,如果您没有上传图标,Fuse Online 不会 为您生成一个图标。
当 Fuse Online 显示集成的流时,它会显示一个连接器的图标,以代表从该连接器创建的连接。
- 对于" 名称 ",输入您选择的名称,可帮助您将此连接与任何其他连接区分开来。
- 另外,对于 Description,输入有助于了解这个连接的信息。
查看连接器详情并覆盖从 WSDL 文件获取的值,编辑您要更改的字段值。
重要在 Fuse Online 创建连接器后 ,您无法更改它。要生效,您需要上传更新的 OpenAPI 文档,以便 Fuse Online 可以创建新的连接器,或者您可以上传相同的模式,然后在 API 编辑器中编辑它。然后,继续创建新的 API 客户端连接器。
- 当您满足连接器详情时,点 Save。Fuse Online 在 API Client Connectors 列表中显示新的连接器。
后续步骤
有关使用新 API 连接器的详情,请参阅将 Fuse Online 连接到应用程序和服务,连接到 API 客户端。
9.2.3. 通过创建新客户端连接器来更新 API 客户端连接器
当对创建 API 客户端连接器的 OpenAPI 文档或 WSDL 文件进行更新时,并且您希望 API 客户端连接器使用这些更新,您必须创建一个新的 API 客户端连接器。您不能直接更新 API 客户端连接器。创建新的 API 客户端连接器后,您可以使用它创建新连接,然后编辑使用从过时连接器中创建的连接的每个集成。
先决条件
准备进行以下操作之一:
对于 REST API 客户端连接器:
- 上传更新的 OpenAPI 文档。
- 再次上传过时的模式,并在 API Designer 中更新它。
- 对于 SOAP API 客户端连接器,上传更新的 WSDL 文件。
流程
根据更新的 OpenAPI 文档或 WSDL 文件,创建一个新的 API 客户端连接器。为了轻松地区分旧连接器和新连接器,您可能需要在连接器名称或连接器描述中指定版本号。
请参阅 开发 REST API 客户端连接器。
- 从新的连接器创建新连接。同样,您要能够轻松地区分从旧连接器创建的连接和从新连接器创建的连接。连接名称或连接描述中的版本号会很有帮助。
- 通过删除旧连接并添加新连接,编辑使用从旧连接器中创建的连接的每个集成。
- 发布每个更新的集成。
- 建议(不要要求):删除旧的连接器和旧连接。
9.2.4. 删除 API 客户端连接器
当有从该连接器创建的连接并在集成中使用这个连接时,您无法删除连接器。删除 API 客户端连接器后,您无法使用该连接器创建的连接。
流程
- 在左侧面板中,点击 Customizations > API Client Connectors。
- 在您要删除的连接器名称右侧,点 Delete。
- 在确认弹出窗口中,如果您确定要删除连接器,点 Delete。
9.3. 开发 Fuse Online 扩展
如果 Fuse Online 不提供创建集成所需的功能,则专家开发人员可编写提供所需行为的扩展。Syndesis 扩展存储库 https://github.com/syndesisio/syndesis-extensions 包含扩展示例。
商业集成商共享对扩展代码的开发人员共享要求。开发人员提供了一个包含该扩展名的 .jar 文件。商业集成商上传 Fuse Online 中的 .jar 文件,使自定义连接器、自定义步骤或库资源可在 Fuse Online 中使用。
Red Hat Developer Studio 的 Fuse 工具插件提供了一个向导,可帮助您开发步骤扩展或连接器扩展。无论您选择是在 Developer Studio 中开发一个步骤扩展还是在一些其他 IDE 中开发一个连接器,是个人选择。有关使用 Developer Studio 插件的详情,请参考为 Fuse 在线集成开发扩展。
在本文档中,以下主题概述了流程,描述要求,并提供您在您选择的 IDE 中开发扩展的其他示例。
9.3.1. 开发扩展的一般步骤
在开始开发扩展之前,请先熟悉需要完成的任务。
集成 pod 在带有扁平类路径的 Java 进程中运行。为了避免版本冲突,请确保扩展使用的依赖项与从所有这些源导入的材料(BOM)一致:
-
org.springframework.boot:spring-boot-dependencies:$SPRING_BOOT_VERSION -
org.apache.camel:camel-spring-boot-dependencies:$CAMEL_VERSION -
io.syndesis.integration:integration-bom:$SYNDESIS_VERSION
如果其他依赖项不是导入的 BOM 的一部分,您必须:
-
将它们打包在
lib目录中的扩展 JAR 文件中。 -
从扩展名的 JSON 描述符文件的
dependencies属性中省略它们。
流程
- 了解扩展功能必须做什么。请联系您的业务同事了解功能要求。
- 确定您是否需要开发步骤扩展名、连接器扩展或库扩展。
- 设置用于开发扩展的 Maven 项目。
如果要开发一个步骤扩展:
-
决定是否将其实施为 Camel 路由或使用 Syndesis
StepAPI 实现它。Syndesis API 的信息是 http://javadoc.io/doc/io.syndesis.extension/extension-api。 -
如果您选择将扩展作为 Camel 路由实施,则决定是否实施 XML 片段、
RouteBuilder类或 bean。 -
在 Maven 项目中,指定所需的元数据,如
schemaVersion、扩展名称、extensionId等等。
-
决定是否将其实施为 Camel 路由或使用 Syndesis
- 对实施该功能的类进行编码。
-
将依赖项添加到项目的
pom.xml文件中。 对于连接器和库扩展,以及您在 XML 中实施的步骤扩展,请创建用于定义该扩展的 JSON 文件。
对于您在 Java 中实施的步骤扩展,当您在 Maven 项目中指定对应的数据结构值时,Maven 可以为您生成 JSON 扩展名文件。
- 运行 Maven 来构建扩展并创建扩展名的 JAR 文件。
- 通过将 JAR 文件上传到 Fuse 在线开发环境来测试扩展。
- 提供 JAR 文件,向您的公司同事打包扩展,并将其上传到 Fuse 在线生产环境。提供 JAR 文件时,使您的业务同事了解所有需要在 Fuse Online Web 界面中出现的信息的配置设置。
9.3.2. 扩展类型的描述
扩展定义如下之一:
- 对连接间的集成数据执行一个或多个自定义步骤。每个自定义步骤都执行一个操作。这是步骤扩展。
- 集成运行时使用的库资源。例如,库扩展可以提供 JDBC 驱动程序以连接到专有 SQL 数据库,如 Oracle。
单个自定义连接器,用于创建到您要集成的特定应用程序或服务的连接。这是一个连接器扩展。
注意Fuse Online 可以使用 OpenAPI 文档为 REST API 客户端创建连接器。请参阅 开发 REST API 客户端连接器。
商业集成商共享对扩展代码的开发人员共享要求。开发人员提供了一个包含该扩展名的 .jar 文件。商业集成商上传 Fuse Online 中的 .jar 文件,使自定义连接器、自定义步骤或库资源可在 Fuse Online 中使用。
您上传到 Fuse Online 的扩展 .jar 文件始终包含一个扩展名。
有关上传和使用一个扩展的示例,它提供在连接间的数据上运行的步骤,请参阅 AMQ 到 REST API 示例集成指南。
9.3.3. 扩展内容和结构概述
扩展是打包至 .jar 文件中的类、依赖项和资源的集合。
Fuse Online 使用 Spring Boot 来加载扩展。因此,您必须根据 Spring Boot 的可执行 JAR 格式打包扩展。例如,确保使用 ZipEntry.STORED() 方法保存嵌套的 JAR 文件。
软件包扩展的 .jar 文件的结构如下:
extension.jar | +- META-INF | | | +- syndesis | | | +- syndesis-extension-definition.json 1 | +- mycompany | | | +-project | | | +-YourClasses.class 2 | +- lib 3 | +-dependency1.jar | +-dependency2.jar
9.3.4. 扩展定义 JSON 文件中的要求
每个扩展都必须有一个 .json 文件,通过为数据结构指定值来定义扩展,如名称、描述、支持的操作和依赖项。对于每种扩展类型,下表表示 Maven 是否可以生成扩展定义 JSON 文件以及需要哪些数据结构。
| 扩展类型 | Maven Can 生成扩展定义 | 所需的数据结构 |
|---|---|---|
| Java 中的步骤扩展 | 是 |
|
| XML 中的步骤扩展 | 否 |
|
| 连接器扩展 | 否 |
|
| 库扩展 | 否 |
|
* 虽然在实践中不严格地指定依赖项,但始终存在您需要指定的依赖关系。
通常,扩展定义文件有以下布局:
{
"schemaVersion": "v1",
"name": "",
"description": "",
"version": "",
"extensionId": "",
"extensionType": "",
"properties": {
},
"actions": [
],
"dependencies": [
],
}- schemaVersion 定义 schema 的版本。在内部,Syndesis 使用 schemaVersion 来确定如何将扩展定义映射到内部模型。这允许根据旧版本的 Syndesis 进行开发,以部署在较新版本的 Syndesis 中。
- name 是扩展名。当您将扩展上传到 Fuse Online 时,会显示此名称。
- description 是您要指定的任何有用信息。Fuse Online 对这个值没有运行。
- 为方便起见,版本 会方便您区分扩展的更新。Fuse Online 对这个值没有运行。
- extensionId 为扩展定义唯一 ID。这应该最少在 Syndesis 环境间唯一。
extensionType 指示扩展提供的内容。从 Syndesis 版本 1.3 开始,支持以下扩展类型:
-
步骤 -
连接器 -
库
-
需要使用连接器扩展中顶级 的属性。它控制 Fuse Online 用户选择连接器来创建连接时显示的 Fuse Online。
此属性对象包含一组属性,用于为每个表单控制创建连接。例如:"myControlName": { "deprecated": true|false, "description": "", "displayName": "", "group": "", "kind": "", "label": "", "required": true|false, "secret": true|false, "javaType": "", "type": "", "defaultValue": "", "enum": { } }在连接器扩展中,嵌套属性对象定义 HTML 表单控制来配置连接操作。
在步骤扩展中,actions对象包含属性对象。properties对象定义一组属性,用于配置步骤的每个表单控制。另请参阅: 用户界面属性的描述。操作 定义连接器可以执行的操作,或者连接间步骤执行的操作。只有连接器和步骤扩展使用您指定的操作。操作规格的格式如下:
{ "id": "", "name": "", "description": "", "actionType": "step|connector", "descriptor": { } }- id 是操作的唯一 ID。这至少应在 Syndesis 环境中唯一。
- name 是 Fuse Online 中显示的操作名称。该集成商将此值视为连接操作的名称,或作为在连接间集成数据的一个步骤名称。
- description 是 Fuse Online 中显示的操作描述。使用此字段来帮助集成商了解该操作的作用。
- actionType 指示某个连接是否由连接间的步骤执行。
-
描述符 指定嵌套属性,如
kind、entrypoint、inputDataType、outputDatatype等等。
依赖项 定义扩展需要 Fuse Online 来提供的资源。
定义依赖项,如下所示:
{ "type": "MAVEN", "id" : "org.apache.camel:camel-telegram:jar:2.21.0" }- type 表示依赖项的类型。指定 MAVEN。(预计将来会支持其他类型。)
- id 是 Maven 依赖项的 ID,它是一个 Maven GAV。
9.3.5. 用户界面属性描述
在连接器扩展和步骤扩展中,在扩展定义 JSON 文件或 Java 类文件中指定用户界面属性。这些属性的设置定义 HTML 表单控制,Fuse Online 用户在 Fuse Online 用户创建连接时显示,配置连接操作,或者配置扩展提供的步骤。
您必须为每个要出现在 Fuse Online 控制台中的扩展用户界面中的格式控制指定属性。对于每个形式控制,以任何顺序指定部分或所有属性。
用户界面属性规格示例
在 IRC 连接器一部分的 JSON 文件中,顶级 属性 对象定义了在 Fuse Online 用户选择 IRC 连接器后出现的 HTML 表单控制来创建连接。有三种形式控制的属性定义: 主机名、密码 和端口 :
"properties": {
"hostname": {
"description": "IRC Server hostname",
"displayName": "Hostname",
"labelHint": "Hostname of the IRC server to connect to",
"order": "1",
"required": true,
"secret": false,
"type": "string"
},
"password": {
"description": "IRC Server password",
"displayName": "Password",
"labelHint": "Required if IRC server requires it to join",
"order": "3",
"required": false,
"secret": true,
"type": "string"
},
"port": {
"description": "IRC Server port",
"displayName": "Port",
"labelHint": "Port of the IRC server to connect to",
"order": "2",
"required": true,
"secret": false,
"tags": [],
"type": "int"
}
},根据这些属性规范,当 Fuse Online 用户选择 IRC 连接器时,Fuse Online 会显示以下对话框:用户在两个必填字段中输入值后,Fuse Online 创建一个 IRC 连接,该连接配置了 Fuse Online 用户输入的值。
关于扩展定义 JSON 文件中的 属性 对象
在连接器扩展中:
-
顶级
属性对象是必需的。它控制 Fuse Online 用户选择连接器来创建连接时显示的 Fuse Online。此属性对象包含一组属性,用于为每个表单控制创建连接。 -
在
actions对象中,每个操作都有一个属性对象。在每个属性对象中,每个表单控制都有一个属性来配置该操作。
在步骤扩展中,actions 对象包含 属性 对象。properties 对象定义一组属性,用于配置步骤的每个表单控制。JSON 层次结构如下:
"actions": [
{
...
"propertyDefinitionSteps": [
{
...
"properties":
{
"control-ONE": {
"type": "string",
"displayName": "Topic Name",
"order": "2",
...,
}
"control-TWO": {
"type": "boolean",
"displayName": "Urgent",
"order": "3",
...
}
"control-THREE": {
"type": "textarea",
"displayName": "Comment",
"order": "1",
...,
}
} } ]关于 Java 文件中的用户界面属性
要在 Java 文件中定义用户界面表单控制,请在每个类文件中导入 io.syndesis.extension.api.annotations.ConfigurationProperty,用于定义连接、操作或步骤的用户配置。对于您希望 Fuse Online 控制台显示的每个表单控制,请指定 @ConfigurationProperty 注释,后跟属性列表。有关您可以指定的属性的详情,请查看本节末尾的用户界面属性参考表。
以下代码显示了一种表单控制的属性定义。此代码位于示例中,使用 RouteBuilder 开发 Camel 路由:
public class LogAction extends RouteBuilder {
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")以下代码显示了两个控制的属性定义。这个代码来自使用 Syndesis Step API 的示例:
@Action(id = "split", name = "Split", description = "Split your exchange")
public class SplitAction implements Step {
@ConfigurationProperty(
name = "language",
displayName = "Language",
description = "The language used for the expression")
private String language;
@ConfigurationProperty(
name = "expression",
displayName = "Expression",
description = "The expression used to split the exchange
private String language;控制表单输入类型的描述
在各个 HTML 表单控制的属性集合中,type 属性定义 Fuse Online 显示的形式输入类型。有关 HTML 表单输入类型的详情,请参考 https://www.w3schools.com/html/html_form_input_types.asp。
下表列出了 Fuse Online 形式控制的可能输入类型。在控制的属性集合中,如果您指定了未知 类型 值,Fuse Online 会显示一个输入字段,它接受一行文本。也就是说,默认值为 "type": "text"。
type 属性的值 | HTML | Fuse Online 显示 |
|---|---|---|
|
|
| 用户可以选择或不能选择的复选框。 |
|
|
此自定义控制使 Fuse 在线用户选择时间单位:毫秒、秒、分钟、小时或天。用户还输入了一个数字,Fuse Online 返回了几毫秒。例如: | |
|
|
| 此字段没有出现在 Fuse Online 控制台中。您可以使用其他属性指定与此字段关联的数据,如某种文本数据。虽然 Fuse Online 用户无法看到或修改这些数据,但如果用户为 Fuse Online 页面选择 View Source,但隐藏字段在源显示中可见。因此,不要将隐藏字段用于安全目的。 |
|
|
| 接受数字的输入字段。 |
|
|
| Fuse Online 屏蔽用户输入字段(通常以星号)的输入字段。 |
|
|
一个 & |
具有每个标签/值对条目的下拉列表,您按照表单的 |
|
|
| 接受一行文本的输入字段。 |
|
|
| 使用 textarea 元素 |
控制表单用户界面属性的描述
在连接器或步骤扩展中,对于 Fuse Online 控制台中出现的每个 HTML 表单控制,您可以指定下表中所述的一个或多个属性。有关 HTML 表单输入类型的详情,请参考 https://www.w3schools.com/html/html_form_input_types.asp。
| 属性名称 | 类型 | 描述 |
|---|---|---|
|
| 字符串 | 控制 Fuse Online 显示的格式控制。详情请查看上表。 |
|
| number |
如果为 |
|
| 字符串 |
如果设置,则该值映射到表单控制元素的 HTML |
|
| array |
如果 |
|
|
根据 |
Fuse Online 最初以表单字段中显示这个值。 |
|
| 字符串 | 如果设置,Fuse Online 会在表单控制的下面显示这个值。通常,这是有关控制的简短、有用的消息。 |
|
| 字符串 | Fuse Online 显示这个值。 |
|
| array |
如果设置,Fuse Online 会覆盖 |
|
| 字符串 |
如果设置,则显示名称旁边会出现一个 |
|
| number |
如果为 |
|
| number |
如果为 |
|
| 布尔值 |
如果选择字段或设置了 |
|
| number |
决定 Fuse 在线控制台中的控制顺序。Fuse Online 应用一个升序,即首先显示 |
|
| 字符串 | 如果设置,Fuse Online 在输入字段中在 hazed 字体中显示这个值,以帮助用户了解预期的输入。 |
|
| 布尔值 |
控制是否对控制设置 |
|
| number |
如果 |
|
| 布尔值 |
如果指定,Fuse Online 会将 control 的 |
9.3.6. 支持扩展的 Maven 插件描述
extension-maven-plugin 支持扩展开发,方法是将扩展名打包为有效的 Spring Boot 模块。对于您在 Java 中实施的步骤扩展,此插件可生成扩展定义 JSON 文件。
在 Maven 项目的 pom.xml 文件中,添加以下插件声明:
<plugin>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-maven-plugin</artifactId>
<version>${syndesis.version}</version>
<executions>
<execution>
<goals>
<goal>generate-metadata</goal>
<goal>repackage-extension</goal>
</goals>
</execution>
</executions>
</plugin>
extension-maven-plugin 定义以下目标:
generate-metadata 生成 JSON 扩展定义文件,该文件将位于生成的 JAR 文件中,如下所示:
Maven 从
META-INF/syndesis/syndesis-extension-definition.json文件中的数据结构规格开始。如果您在 XML 中编码,则必须自己定义扩展定义 JSON 文件,且必须指定所有必需的数据结构。
如果要开发连接器或库扩展,则必须自己定义扩展定义 JSON 文件,且必须指定所有必需的数据结构。
如果您要在 Java 中开发一个步骤扩展,您可以:
- 自行创建扩展定义 JSON 文件。
- 在您的 Java 代码中,指定定义所有必要数据结构的注解。您没有创建扩展定义 JSON 文件。
- 创建扩展定义 JSON 文件,并指定 some,但不指定所有数据结构。
- 对于您在 Java 中开发的步骤扩展,Maven 从代码注解中获取缺少的规格
-
Maven 添加 dependencies 列表,它指定所提供的依赖项,范围通过
扩展正文来管理。
重新打包 -extension 软件包扩展名。
-
未通过
extension-bom管理的依赖关系和相关传输依赖关系位于生成的 JAR 的lib文件夹中。 -
对于库扩展,其范围是
系统位于生成的 JAR 的lib文件夹中。
-
未通过
例如,假设您的 Maven 项目有以下 pom.xml 文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.company</groupId>
<artifactId>my-extension</artifactId>
<version>1.0.0</version>
<name>MyExtension</name>
<description>A Sample Extension</description>
<packaging>jar</packaging>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-bom</artifactId>
<version>1.3.10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-api</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.github.lalyos</groupId>
<artifactId>jfiglet</artifactId>
<version>0.0.8</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>io.syndesis.extension</groupId>
<artifactId>extension-maven-plugin</artifactId>
<version>1.3.10</version>
<executions>
<execution>
<goals>
<goal>generate-metadata</goal>
<goal>repackage-extension</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
基于此 pom.xml 文件,生成的扩展定义 JSON 文件如下所示:
{
"name": "MyExtension",
"description": "A Sample Extension",
"extensionId": "com.company:my-extension",
"version": "1.0.0",
"dependencies": [ {
"type": "MAVEN",
"id": "io.syndesis.extension:extension-api:jar:1.3.10"
} ],
"extensionType": "Libraries",
"schemaVersion": "v1"
}生成的存档具有此结构和内容:
my-extension-1.0.0.jar
|
+- lib
| |
| + jfiglet-0.0.8.jar
|
+- META-INF
|
+- MANIFEST.MF
|
+- syndesis
|
+- syndesis-extension-definition.json9.3.7. 如何在扩展中指定形成的数据
数据形成保管数据类型元数据,供 data mapper 使用。数据映射器将此元数据转换为内部文档,用于显示数据映射器用户界面中的源和目标数据字段。在连接器或自定义步骤的扩展定义 JSON 文件中,每个操作规格定义一个输入数据图(inputDataShape)和输出数据形成(outputDataShape)。
当您开发扩展时,务必要指定数据形式的属性,允许数据映射程序正确处理和显示源和目标字段。以下数据形成属性会影响数据映射程序行为:
-
kind -
type -
规格 -
name -
description
关于 kind 属性
数据形成 属性 由 DataShapeKinds enum 代表。kind 属性的可能值有:
任何表示数据类型不是结构化的。例如,可以是字节阵列或空闲格式文本。当数据映射属性设置为任何时,数据映射会忽略形成的数据。换句话说,数据不会出现在 datamapper 中,因此您无法将任何字段映射到或从此数据映射。但是,对于自定义连接器,当其
kind属性设置为任何时,Fuse Online 会提示您在配置从自定义连接器中创建的连接时指定输入和/或输出数据类型。当您向集成添加连接时会出现这种情况。您可以指定数据形成的模式类型、您指定的模式类型的适当文档,以及数据类型的名称。-
无表示没有数据类型。对于形成的输入数据,这表明连接或步骤没有读取数据。对于形成的输出数据,这表明连接或步骤不会修改数据。例如,当输入消息正文传输到输出消息正文时,将kind属性设为none,表示数据仅通过。当kind设为none时,数据映射会忽略形成的数据。换句话说,数据不会出现在 datamapper 中,因此您无法将任何字段映射到或从此数据映射。 Java表示数据类型由 Java 类表示。按照"kind": "java"声明,为type属性指定完全限定类名称。例如:"outputDataShape": { "kind": "java", "type": "org.apache.camel.component.telegram.model.IncomingMessage" },JSON-schema表示数据类型由 JSON 架构表示。当kind设为json-schema时,请将 JSON 模式指定为数据创建规范属性的值。例如:"inputDataShape": { "description": "Person data", "kind": "json-schema", "name": "Person", "specification": "{\"$schema\":\"http://json-schema.org/draft-04/schema#\",\"title\":\"Person\",\"type\":\"object\",\"properties\":{\"firstName\":{...}}}" }SAP Concur 连接器的代码 包含由 JSON 模式 指定的数据图示例。
JSON-instance表示数据类型由 JSON 实例表示。当kind设为json-instance时,请将 JSON 实例指定为数据创建规范属性的值。例如:"inputDataShape": { "description": "Person data", "kind": "json-instance", "name": "Person", "specification": "{\"firstName\":\"John\",...}" }XML-schema表示数据类型由 XML 模式表示。当kind设为xml-schema时,请将 XML 架构指定为数据创建规范属性的值。例如:"inputDataShape": { "description": "Person data", "kind": "xml-schema", "name": "Person", "specification": "<?xml version=\"1.0\" encoding=\"UTF-8\" ?><xs:schema xmlns:xs=\"http://www.w3.org/2001/XMLSchema\">...</xs:schema>" }xml-instance表示数据类型由 XML 实例表示。当kind设为xml-instance时,请将一个 XML 实例指定为数据创建规范属性的值。例如:"inputDataShape": { "description": "Person data", "kind": "xml-instance", "name": "Person", "specification": "<?xml version=\"1.0\" encoding=\"UTF-8\" ?><Person><firstName>Jane</firstName></Person>" }csv-instance表示数据类型由 CSV 实例表示。当
kind设为csv-instance时,请将 CSV 实例指定为数据创建规范属性的值。例如:"inputDataShape": { "description": "Person data", "kind": "csv-instance", "name": "Person", "specification": "John,Doe,120 Jefferson Street,Riverside, NJ, 08075" }当
kind设为csv-instance时,您可以指定以下布尔值(true/false)参数:标签 名称 描述 允许 Duplicate Header Names
allowDuplicateHeaderNames允许 CSV 数据的标头行中重复名称。
Allow Missing Column Names
allowMissingColumnNames在解析 CSV 数据标题行时允许缺少字段名称。
注释 Marker
commentMarker指定指定 CSV 数据中注释行开头的字符。
Delimiter
delimiter指定限制 CSV 数据中的值的字符(通常为 ";", "," 或 "\t")。
Escape
escape指定 CSV 数据的转义字符。
第一个记录为标头
firstRecordAsHeader使用 CSV 数据中的第一个记录作为标题行。
忽略 Empty Lines
ignoreEmptyLines忽略 CSV 数据中的任何空行。
忽略标头问题单
ignoreHeaderCase忽略 CSV 数据标题行中的字母大小写。
忽略 Surrounding Spaces
ignoreSurroundingSpaces忽略 CSV 数据周围的所有空格字符。
null String
nullString指定在 CSV 数据中转换为和来自 null 时使用的字符串。
跳过标头记录
skipHeaderRecord跳过 CSV 数据中的标头记录。
关于 type 属性
当 kind 属性的值为 java 时,"kind": "java" 声明后跟 类型 声明,用于指定完全限定的 Java 类名称。例如:
"outputDataShape": {
"kind": "java",
"type": "org.apache.camel.component.telegram.model.IncomingMessage"
},
当 kind 属性设为 java 以外的任何其他设置时,type 属性的任何设置将被忽略。
关于 规格 属性
kind 属性的设置决定了 specification 属性的设置,如下表中所示。
kind 属性设置 | 规格 属性设置 |
|---|---|
|
| Java 检查结果.
对于您在 Java 中写入的每个扩展,请使用
提醒,对于以 Java 编写的步骤扩展, |
|
| 实际的 JSON 模式文档。设置不能引用文档,JSON 模式不能通过引用指向其他 JSON 架构文档。 |
|
| 包含示例数据的实际 JSON 文档。数据映射程序从示例数据中获取数据类型。此设置不能引用文档。 |
|
| 实际的 XML 模式文档。设置无法引用文档,而 XML 模式无法通过引用指向其他 XML 架构文档。 |
|
| 实际的 XML 实例文档。此设置不能引用文档。 |
|
| 实际的 CSV 实例文档。此设置不能引用文档。 |
|
|
|
|
|
|
关于 name 属性
数据形成的 name 属性指定数据类型的人类可读名称。数据映射程序在其用户界面中显示这个名称作为数据字段的标签。在以下镜像中,Person 是您在其中看到 name 属性的值的示例。
此名称也会出现在 Fuse Online 流视觉化中的数据类型指示器。
关于 description 属性
数据形成的 description 属性指定当光标悬停在数据映射用户界面中数据类型名称时作为工具提示的文本。
9.3.8. 开发步骤扩展示例
步骤扩展实施一个或多个自定义步骤。每个自定义步骤都实施一个操作,用于在连接间处理集成数据。以下示例演示了开发步骤扩展的替代方案:
Syndesis 提供自定义 Java 注解,您可以与 syndesis-extension-plugin 结合使用。当您在 Java 中实现步骤扩展或连接器扩展时,您可以指定启用 Maven 将操作定义添加到扩展定义 JSON 文件的注解。要启用注解处理,请在 Maven 项目中添加以下依赖项:
<dependency> <groupId>io.syndesis.extension</groupId> <artifactId>extension-annotation-processor</artifactId> <optional>true</optional> </dependency>
因为 Spring Boot 是集成运行时,要将 Bean 注入 Camel 上下文,请务必遵循标准的 Spring Boot 实践。例如,创建一个自动配置类,并在那里创建 Bean。但是,默认行为是扩展代码不受软件包扫描的影响。因此,您必须在步骤扩展中创建并填充 META-INF/spring.factories 文件。
9.3.8.1. 使用 XML 片段开发 Camel 路由示例
要开发自定义步骤,您可以将操作作为 XML 片段实施,该片段是一个带有 直接输入 的 Camel 路由。Syndesis 运行时会按照调用任何其他 Camel 路由的方式调用此路由。
例如,假设您要创建一个步骤来记录带有可选前缀的消息正文。以下 XML 定义了实现此目的的 Camel 路由。
<?xml version="1.0" encoding="UTF-8"?>
<routes xmlns="http://camel.apache.org/schema/spring"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://camel.apache.org/schema/spring
http://camel.apache.org/schema/spring/camel-spring.xsd">
<route id="log-body-with-prefix">
<from uri="direct:log"/>
<choice>
<when>
<simple>${header.prefix} != ''</simple>
<log message="${header.prefix} ${body}"/>
</when>
<otherwise>
<log message="Output ${body}"/>
</otherwise>
</choice>
</route>
</routes>
当您在 XML 中开发扩展时,您必须自行创建扩展定义 JSON 文件。对于这个 XML 片段,src/main/resources/META-INF/syndesis/syndesis-extension-definition.json 文件可以定义操作,如下所示:
{
"actionType": "step",
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"resource": "classpath:log-body-action.xml", 3
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 4
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string"
}
}
} ]
}
}- 1
- 操作的类型设置为
ENDPOINT。运行时调用 Camel 端点来执行此自定义步骤所提供的操作。 - 2
- 要调用的 Camel 端点是
direct:log。这是路由中的来自规格。 - 3
- 这是 XML 片段的位置。
- 4
- 这些是在自定义步骤中定义的操作的属性公开到将这一步添加到集成的集成器中。在 Fuse Online 中,集成人员在用户界面中指定的每个值都会映射到与属性同名的消息标头中。在本例中,集成商将看到一个输入字段,Log Prefix 显示名称。如需了解更多详细信息,请参阅 用户界面属性 的描述。
Syndesis 不支持完整的 Camel XML 配置。Syndesis 仅支持 <routes> 标签。
9.3.8.2. 使用 RouteBuilder开发 Camel 路由示例
您可通过将操作开发为带 RouteBuilder 类支持的 Camel 路由来实施自定义步骤。此类路由具有输入,如 direct。Syndesis 调用此路由的方式与调用任何其他 Camel 路由一样。
要实现这个示例,请创建一个使用可选前缀记录消息正文的步骤,您可以编写类似如下的内容:
import org.apache.camel.builder.RouteBuilder; import io.syndesis.extension.api.annotations.Action; import io.syndesis.extension.api.annotations.ConfigurationProperty; @Action( 1 id = "log-body-with-prefix", name = "Log body with prefix", description = "A simple body log with a prefix", entrypoint = "direct:log") public class LogAction extends RouteBuilder { @ConfigurationProperty( 2 name = "prefix", description = "The Log body prefix message", displayName = "Log Prefix", type = "string") private String prefix; @Override public void configure() throws Exception { from("direct::start") 3 .choice() .when(simple("${header.prefix} != ''")) .log("${header.prefix} ${body}") .otherwise() .log("Output ${body}") .endChoice(); } }
- 1
@Action注释表示操作定义。- 2
@ConfigurationProperty注释指示用户界面表单控制的定义。详情请查看 用户界面属性 的描述。- 3
- 这是操作实施。
此 Java 代码使用 Syndesis 注解,这意味着 extension-maven-plugin 可以自动生成操作定义。在扩展定义 JSON 文件中,操作定义如下:
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"resource": "class:io.syndesis.extension.log.LogAction", 3
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 4
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 的操作类型是
ENDPOINT。运行时调用 Camel 端点来执行此步骤实施的操作。 - 2
- 这是要调用的 Camel 端点。它是路由中的
fromspecification。 - 3
- 这是实现
RoutesBuilder的类。 - 4
- 这些是在自定义步骤中定义的操作的属性公开到将这一步添加到集成的集成器中。在 Fuse Online 中,集成人员在用户界面中指定的每个值都会映射到与属性同名的消息标头中。在本例中,集成商将看到一个输入字段,Log Prefix 显示名称。如需更多信息,请参阅 用户界面属性 的描述。
9.3.8.3. 使用 RouteBuilder 和 Spring Boot 开发 Camel 路由示例
您可以通过将操作作为 Camel 路由(支持 RouteBuilder 类以及 Spring Boot)来实施自定义步骤。在本例中,Spring Boot 是在 Camel 上下文中注册 RouteBuilder 对象的工具。Syndesis 调用此路由的方式与调用任何其他 Camel 路由一样。
要实现这个示例,请创建一个使用可选前缀记录消息正文的步骤,您可以编写类似如下的内容:
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ActionsConfiguration {
@Action( 1
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix",
entrypoint = "direct:log")
@ConfigurationProperty( 2
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
@Bean 3
public RouteBuilder logBodyWithprefix() {
return new RouteBuilder() {
@Override
public void configure() throws Exception {
from("direct::start") 4
.choice()
.when(simple("${header.prefix} != ''"))
.log("${header.prefix} ${body}")
.otherwise()
.log("Output ${body}")
.endChoice();
}
};
}
}- 1
@Action注释表示操作定义。- 2
@ConfigurationProperty注释指示用户界面表单控制的定义。详情请查看 用户界面属性 的描述。- 3
- 将
RouteBuilder对象注册为 bean。 - 4
- 这是操作实施。
此 Java 代码使用 Syndesis 注解,这意味着 extension-maven-plugin 可以自动生成操作定义。在扩展定义 JSON 文件中,操作定义如下:
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "ENDPOINT", 1
"entrypoint": "direct:log", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": { 3
"prefix": {
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 的操作类型是
ENDPOINT。运行时调用 Camel 端点来执行此步骤实施的操作。 - 2
- 这是要调用的 Camel 端点。它是路由中的
fromspecification。 - 3
- 这些是在自定义步骤中定义的操作的属性公开到将这一步添加到集成的集成器中。在 Fuse Online 中,集成人员在用户界面中指定的每个值都会映射到与属性同名的消息标头中。在本例中,集成商将看到一个输入字段,Log Prefix 显示名称。如需了解更多详细信息,请参阅 用户界面属性 的描述。
要使配置类可以被 Spring Boot 发现,您必须在名为 META-INF/spring.factories 的文件中列出它们,例如:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.company.ActionsConfiguration
在 Spring Boot 时,您最终在配置类中注册的每个 bean 都可用于 Camel 上下文。详情请参阅 Spring Boot 文档,以了解您自己的自动配置。
9.3.8.4. 使用 Camel Bean 的示例
您可以通过将操作作为 Camel Bean 处理器来实施自定义步骤。要实现这个示例,请创建一个使用可选前缀记录消息正文的步骤,您可以编写类似如下的内容:
import org.apache.camel.Body;
import org.apache.camel.Handler;
import org.apache.camel.Header;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
@Action(
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix")
public class LogAction {
private static final Logger LOGGER = LoggerFactory.getLogger(LogAction.class);
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
private String prefix;
@Handler 1
public void process(@Header("prefix") String prefix, @Body Object body) {
if (prefix == null) {
LOGGER.info("Output {}", body);
} else {
LOGGER.info("{} {}", prefix, body);
}
}
}- 1
- 这是实施该操作的功能。
此 Java 代码使用 Syndesis 注解,这意味着 extension-maven-plugin 可以自动生成操作定义。在扩展定义 JSON 文件中,操作定义如下:
{
"id": "log-body-with-prefix",
"name": "Log body with prefix",
"description": "A simple body log with a prefix",
"descriptor": {
"kind": "BEAN", 1
"entrypoint": "io.syndesis.extension.log.LogAction::process", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": {
"prefix": { 3
"componentProperty": false,
"deprecated": false,
"description": "The Log body prefix message",
"displayName": "Log Prefix",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"actionType": "step"
}- 1
- 操作的类型是
BEAN。运行时调用 Camel Bean 处理器,以便在此自定义步骤中执行操作。 - 2
- 这是要调用的 Camel Bean。
- 3
- 这些是在自定义步骤中定义的操作的属性公开到将这一步添加到集成的集成器中。在 Fuse Online 中,集成人员在用户界面中指定的每个值都会映射到与属性同名的消息标头中。在本例中,集成商将看到一个输入字段,Log Prefix 显示名称。如需了解更多详细信息,请参阅 用户界面属性 的描述。
使用 Bean 时,您可能会方便地将用户属性注入 bean,而不是从交换标头中检索它们。为此,请为您要注入的属性实施 getter 和 setter 方法。操作实施如下所示:
import org.apache.camel.Body;
import org.apache.camel.Handler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
@Action(
id = "log-body-with-prefix",
name = "Log body with prefix",
description = "A simple body log with a prefix")
public class LogAction {
private static final Logger LOGGER = LoggerFactory.getLogger(LogAction.class);
@ConfigurationProperty(
name = "prefix",
description = "The Log body prefix message",
displayName = "Log Prefix",
type = "string")
private String prefix;
public void setPrefix(String prefix) { 1
this.prefix = prefix;
}
public String getPrefix() { 2
return prefix;
}
@Handler
public void process(@Body Object body) {
if (this.prefix == null) {
LOGGER.info("Output {}", body);
} else {
LOGGER.info("{} {}", this.prefix, body);
}
}
}9.3.8.5. 使用 Syndesis 步骤 API 的示例
您可以使用 Syndesis Step API 来实施自定义步骤。这提供了一种与运行时路由创建交互的方法。您可以使用 ProcessorDefinition 类提供的任何方法,您可以创建更复杂的路由。Syndesis API 的信息是 http://javadoc.io/doc/io.syndesis.extension/extension-api。
以下是一个步骤扩展示例,它使用 Syndesis Step API 来实现拆分操作:
import java.util.Map;
import java.util.Optional;
import io.syndesis.extension.api.Step;
import io.syndesis.extension.api.annotations.Action;
import io.syndesis.extension.api.annotations.ConfigurationProperty;
import org.apache.camel.CamelContext;
import org.apache.camel.model.ProcessorDefinition;
import org.apache.camel.util.ObjectHelper;
import org.apache.camel.Expression;
import org.apache.camel.builder.Builder;
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.processor.aggregate.UseOriginalAggregationStrategy;
import org.apache.camel.spi.Language;
@Action(id = "split", name = "Split", description = "Split your exchange")
public class SplitAction implements Step {
@ConfigurationProperty(
name = "language",
displayName = "Language",
description = "The language used for the expression")
private String language;
@ConfigurationProperty(
name = "expression",
displayName = "Expression",
description = "The expression used to split the exchange")
private String expression;
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
public String getExpression() {
return expression;
}
public void setExpression(String expression) {
this.expression = expression;
}
@Override
public Optional<ProcessorDefinition> configure(
CamelContext context,
ProcessorDefinition route,
Map<String, Object> parameters) { 1
String languageName = language;
String expressionDefinition = expression;
if (ObjectHelper.isEmpty(languageName) && ObjectHelper.isEmpty(expressionDefinition)) {
route = route.split(Builder.body());
} else if (ObjectHelper.isNotEmpty(expressionDefinition)) {
if (ObjectHelper.isEmpty(languageName)) {
languageName = "simple";
}
final Language splitLanguage = context.resolveLanguage(languageName);
final Expression splitExpression = splitLanguage.createExpression(expressionDefinition);
final AggregationStrategy aggreationStrategy = new UseOriginalAggregationStrategy(null, false);
route = route.split(splitExpression).aggregationStrategy(aggreationStrategy);
}
return Optional.of(route);
}
}- 1
- 这是自定义步骤执行的操作的实施。
此 Java 代码使用 Syndesis 注解,这意味着 extension-maven-plugin 可以自动生成操作定义。在扩展定义 JSON 文件中,操作定义如下:
{
"id": "split",
"name": "Split",
"description": "Split your exchange",
"descriptor": {
"kind": "STEP", 1
"entrypoint": "io.syndesis.extension.split.SplitAction", 2
"inputDataShape": {
"kind": "none"
},
"outputDataShape": {
"kind": "none"
},
"propertyDefinitionSteps": [ {
"description": "extension-properties",
"name": "extension-properties",
"properties": {
"language": {
"componentProperty": false,
"deprecated": false,
"description": "The language used for the expression",
"displayName": "Language",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
},
"expression": {
"componentProperty": false,
"deprecated": false,
"description": "The expression used to split the exchange",
"displayName": "Expression",
"javaType": "java.lang.String",
"kind": "parameter",
"required": false,
"secret": false,
"type": "string",
"raw": false
}
}
} ]
},
"tags": [],
"actionType": "step"
}其他资源
有关用户界面属性的详情,请参阅 用户界面属性 的描述。
9.3.9. 开发连接器扩展示例
如果 Fuse Online 没有为您希望在集成中使用的应用程序或服务提供连接器,则经验丰富的开发人员可以编码一个扩展功能,为 Fuse Online 提供新的连接器。本文档介绍了开发连接器扩展名的介绍。有关开发连接器的详情,请参阅在 Syndesis 社区网站上开发 Syndesis 连接器。
对于连接器扩展,还无法从 Java 代码自动生成扩展定义 JSON 文件。
连接器本质上是 Camel 组件的代理。连接器配置底层组件,并根据在扩展定义中定义的选项以及 Fuse Online Web 界面收集的选项中创建端点。
连接器扩展定义使用下列额外数据结构扩展了步骤扩展所需的扩展定义:
componentScheme定义连接器使用的 Camel 组件。您可以为连接器或操作设置
componentScheme。如果您为连接器和动作设置了componentScheme,则操作的设置具有优先权。连接器客户指定实施 ComponentProxyCustomizer 类的类列表。每个类自定义连接器的行为。例如,在类应用到底层组件/endpoint,或者类可能会添加 pre/post 端点逻辑前,一个类可能会对属性进行操作。对于每个类,指定实施的完整类名称,如
com.mycomponent.MyCustomizer。您可以对动作和连接器设置连接器定制器。根据设置的内容,Fuse Online 首先将自定义程序应用于连接器,然后再进行操作。connectorFactory定义实现 component ProxyonnectionFactoryy 类的类,该类创建和/或配置底层组件/端点。指定实施的完整类名称。您可以为
连接器或动作设置连接器。操作具有优先权。
Customizer 示例
以下定制示例从单独的选项中设置 DataSource:
public class DataSourceCustomizer implements ComponentProxyCustomizer, CamelContextAware {
private final static Logger LOGGER = LoggerFactory.getLogger(DataSourceCustomizer.class);
private CamelContext camelContext;
@Override
public void setCamelContext(CamelContext camelContext) { 1
this.camelContext = camelContext;
}
@Override
public CamelContext getCamelContext() { 2
return this.camelContext;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
if (!options.containsKey("dataSource")) {
if (options.containsKey("user") && options.containsKey("password") && options.containsKey("url")) {
try {
BasicDataSource ds = new BasicDataSource();
consumeOption(camelContext, options, "user", String.class, ds::setUsername); 3
consumeOption(camelContext, options, "password", String.class, ds::setPassword); 4
consumeOption(camelContext, options, "url", String.class, ds::setUrl); 5
options.put("dataSource", ds);
} catch (@SuppressWarnings("PMD.AvoidCatchingGenericException") Exception e) {
throw new IllegalArgumentException(e);
}
} else {
LOGGER.debug("Not enough information provided to set-up the DataSource");
}
}
}
}注入属性示例
如果定制的 Java 约定,您也可以注入属性,如上例的这个修订版本所示:
public class DataSourceCustomizer implements ComponentProxyCustomizer, CamelContextAware {
private final static Logger LOGGER = LoggerFactory.getLogger(DataSourceCustomizer.class);
private CamelContext camelContext;
private String userName;
private String password;
private String url;
@Override
public void setCamelContext(CamelContext camelContext) { 1
this.camelContext = camelContext;
}
@Override
public CamelContext getCamelContext() { 2
return this.camelContext;
}
public void setUserName(String userName) { 3
this.userName = userName;
}
public String getUserName() { 4
return this.userName;
}
public void setPassword(String password) { 5
this.password = password;
}
public String getPassword() { 6
return this.password;
}
public void setUrl(String url) { 7
this.url = url;
}
public String getUrl() { 8
return this.url;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
if (!options.containsKey("dataSource")) {
if (userName != null && password != null && url != null) {
try {
BasicDataSource ds = new BasicDataSource();
ds.setUserName(userName);
ds.setPassword(password);
ds.setUrl(url);
options.put("dataSource", ds);
} catch (@SuppressWarnings("PMD.AvoidCatchingGenericException") Exception e) {
throw new IllegalArgumentException(e);
}
} else {
LOGGER.debug("Not enough information provided to set-up the DataSource");
}
}
}
}使用自定义器配置 before/after 逻辑
您可以使用一个自定义器配置 before/after 逻辑,如下例所示:
public class AWSS3DeleteObjectCustomizer implements ComponentProxyCustomizer {
private String filenameKey;
public void setFilenameKey(String filenameKey) {
this.filenameKey = filenameKey;
}
public String getFilenameKey() {
return this.filenameKey;
}
@Override
public void customize(ComponentProxyComponent component, Map<String, Object> options) {
component.setBeforeProducer(this::beforeProducer);
}
public void beforeProducer(final Exchange exchange) throws IOException {
exchange.getIn().setHeader(S3Constants.S3_OPERATION, S3Operations.deleteObject);
if (filenameKey != null) {
exchange.getIn().setHeader(S3Constants.KEY, filenameKey);
}
}
}自定义 component ProxyComponent的行为
component ProxyonnectionFactory y 类创建 和/或配置底层组件/端点。要自定义 ComponentProxyComponent 对象的行为,您可以覆盖 component Proxy onnectionFactoryy 创建的任何行为:
createDelegateComponent()Syndesis 在代理启动时调用这个方法,它最终使用
componentScheme选项定义的方案创建组件的专用实例。这个方法的默认行为是决定是否在组件级别应用任何连接器/操作选项。只有在端点无法应用同一选项时,方法会创建一个自定义组件实例,并根据适用的选项进行配置。
configureDelegateComponent()只有在创建了自定义组件实例来配置委派的组件实例的额外行为时,Syndesis 调用这个方法。
createDelegateEndpoint()当代理创建端点时,Syndesis 调用这个方法,默认情况下,使用 Camel 目录工具创建端点。
configureDelegateEndpoint()创建委派的端点后,Syndesis 调用此方法来配置委派的端点实例的额外行为,例如:
public class IrcComponentProxyFactory implements ComponentProxyFactory { @Override public ComponentProxyComponent newInstance(String componentId, String componentScheme) { return new ComponentProxyComponent(componentId, componentScheme) { @Override protected void configureDelegateEndpoint(ComponentDefinition definition, Endpoint endpoint, Map<String, Object> options) throws Exception { if (!(endpoint instanceof IrcEndpoint)) { throw new IllegalStateException("Endpoint should be of type IrcEndpoint"); } final IrcEndpoint ircEndpoint = (IrcEndpoint)endpoint; final String channels = (String)options.remove("channels"); if (ObjectHelper.isNotEmpty(channels)) { ircEndpoint.getConfiguration().setChannel( Arrays.asList(channels.split(",")) ); } } }; } }
9.3.10. 如何开发库扩展
库扩展提供了在运行时集成需要的资源。库扩展不会向 Fuse Online 贡献步骤或连接器。
保存集成时,您可以选择要与集成包括的一个或多个导入库扩展。
库扩展不会定义任何操作。以下是库扩展的示例定义:
{
"schemaVersion" : "v1",
"name" : "Example Library Extension",
"description" : "Syndesis Extension for adding a runtime library",
"extensionId" : "io.syndesis.extensions:syndesis-library",
"version" : "1.0.0",
"tags" : [ "my-libraries-extension" ],
"extensionType" : "Libraries"
}另请参阅示例库扩展: https://github.com/syndesisio/syndesis-extensions
除操作之外,库扩展的结构与步骤或连接器扩展的结构相同。
在用于创建库扩展的 Maven 项目中,添加来自 Maven 存储库无法的依赖项,指定 系统依赖项,例如:
<dependency>
<groupId>com.company</groupId>
<artifactId>my-library-extension</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/my-library-extension.jar</systemPath>
</dependency>9.3.11. 创建 JDBC 驱动程序库扩展
要连接到 Apache Derby、MySQL 和 PostgreSQL 以外的 SQL 数据库,您可以创建一个库扩展来打包您要连接到的数据库的 JDBC 驱动程序。将这个扩展上传到 Fuse Online 后,Fuse 在线提供的数据库连接器可以访问驱动程序以验证并创建专有数据库的连接。您不能为特定数据库创建新连接器。
Syndesis 开源社区提供了一个项目,用于创建一个可嵌套 JDBC 驱动程序的扩展。
仅打包扩展中的一个驱动程序。这样可以更轻松地管理扩展,作为管理特定数据库的一部分。但是,可以创建可包装多个驱动程序的库扩展。
先决条件
要使用 Syndesis 项目,您必须有一个 GitHub 帐户。
流程
通过执行以下操作之一,确保连接到的数据库访问 JDBC 驱动程序:
- 确认该驱动程序位于 Maven 存储库中。
- 下载驱动程序。
- 在浏览器标签页中,访问 https://github.com/syndesisio/syndesis-extensions
-
将
syndesis-extensions存储库派生到您的 GitHub 帐户。 - 从您的 fork 创建本地克隆。
在
syndesis-extensions克隆中:-
如果驱动程序不在 Maven 存储库中,请将驱动程序复制到
syndesis-library-jdbc-driver/lib文件夹中。 编辑
syndesis-library-jdbc-driver/pom.xml文件:-
将
Name元素的值更新为您为这个扩展选择的名称。 -
更新
Description元素的值,以提供有关此扩展的信息。 -
如果您已经将驱动程序复制到
syndesis-library-jdbc-driver/lib,请确保pom.xml中的systemPath指向该驱动程序文件。(可选)更改groupId、artifactId和version,以根据驱动程序反映正确的值。 -
如果驱动程序位于 Maven 存储库中,请确保对 Maven 依赖项的引用位于
pom.xml文件中。 -
检查
pom.xml文件的其余内容,并根据需要更改所有相关元数据。
-
将
-
执行
./mvnw -pl :syndesis-library-jdbc-driver clean 软件包以构建扩展。
-
如果驱动程序不在 Maven 存储库中,请将驱动程序复制到
生成的 .jar 文件位于 syndesis-library-jdbc-driver/target 文件夹中。将这个 .jar 文件导入为 Fuse Online 中的扩展。
导入库扩展后,当您在 Fuse Online 中保存集成时,您可以选择导入的库扩展并将其与集成相关联。
9.4. 添加和管理扩展
借助扩展功能,您可以将自定义添加到 Fuse Online,以便集成您需要的方式的应用程序。在开始使用在扩展中提供的自定义后,您可以识别使用这些自定义的集成。这有助于在更新或删除扩展前完成。
以下主题提供详情:
9.4.1. 使自定义功能可用
要使自定义功能可用于集成,请将扩展上传到 Fuse Online。
先决条件
-
开发人员已提供了包含 Fuse Online 扩展名的
.jar文件。
流程
- 在左侧 Fuse Online 面板中,单击 Customizations > Extensions。
- 点 Import Extension。
拖放,或选择包含您要上传的扩展名的
.jar文件。Fuse Online 立即尝试验证该文件是否包含一个扩展。如果出现问题,Fuse Online 显示有关错误的消息。您必须与扩展开发人员协调,以获取更新的
.jar文件,然后尝试上传该文件。查看扩展详情。
在 Fuse Online 验证文件后,它会提取并显示扩展的名称、ID、描述和类型。type 指明扩展是否定义了自定义连接器,或者一个或多个自定义步骤在连接间的数据上运行,还是在运行时库扩展(包括 JDBC 驱动程序)上运行。
对于连接器扩展,Fuse Online 显示可用于从此自定义连接器创建的连接可用的操作。在扩展中,开发人员可能会提供一个图标,Fuse Online 可用于代表从这个连接器创建的应用程序连接。当您从自定义连接器创建连接时,不会出现在扩展详情页面中看到这个图标。如果扩展开发人员没有提供扩展中的图标,则 Fuse Online 会生成图标。
对于步骤扩展,Fuse Online 显示扩展所定义的每个自定义步骤的名称。
对于库扩展,Fuse Online 在集成运行时类路径中包含导入的 Maven 依赖项。您必须确保导入的 Maven 依赖项不会与其他已在集成中使用的依赖关系(包括任何其他库扩展,如 JDBC 驱动程序)冲突。
- 点 Import Extension。Fuse Online 使自定义连接器或自定义步骤可用,并显示扩展的详情页面。
其他资源
9.4.2. 识别使用扩展的集成
在更新或删除扩展之前,您应该识别使用该扩展提供的自定义集成。
流程
- 在左侧 Fuse Online 面板中,单击 Customizations > Extensions。
- 在扩展列表中,找到您要更新或删除的扩展条目并点击其 Details 按钮。
结果
Fuse Online 显示有关扩展的详细信息,包括使用扩展提供的自定义集成的列表。
9.4.3. 更新扩展
当开发人员更新扩展时,您可以上传更新的 .jar 文件以在集成中实施更新。
前提条件
开发人员为您提供了一个更新的 .jar 文件,供您之前上传的一个扩展。
流程
- 在 Fuse Online 中,在左侧面板中,单击 Customizations > Extensions。
- 在您要更新的扩展条目的右侧,点 Update。
-
点击点号框可导航到并选择更新的
.jar文件,然后单击 Open。 - 确认扩展详情正确,然后点击 Import Extension。
- 在更新的扩展的详情页面中,决定哪个集成使用扩展中定义的连接器或自定义步骤。
您最好准确更新每个使用自定义连接器或更新扩展的自定义步骤的集成。至少,您必须重新发布使用更新扩展中定义的自定义每个集成。
在某些情况下,您可能需要编辑集成以更改或添加自定义配置详情。您必须与扩展开发人员通信,才能了解如何更新集成。
9.4.4. 删除扩展
您可以删除扩展,即使正在运行的集成使用了该扩展提供的步骤,或使用从该扩展提供的连接器中创建的连接。删除扩展后,您无法启动使用该扩展提供的自定义集成。
流程
- 在左侧 Fuse Online 面板中,单击 Customizations > Extensions。
- 在扩展列表中,找到您要删除的扩展条目并点击 Delete,它出现在条目的右侧。
结果
可能已停止或草案集成,它们使用您删除的扩展提供的自定义功能。要运行其中一个集成,您需要编辑集成以移除自定义。