
director 的安装和使用
使用 Red Hat Enterprise Linux OpenStack Platform director 创建 OpenStack 云环境
摘要
第 1 章 简介
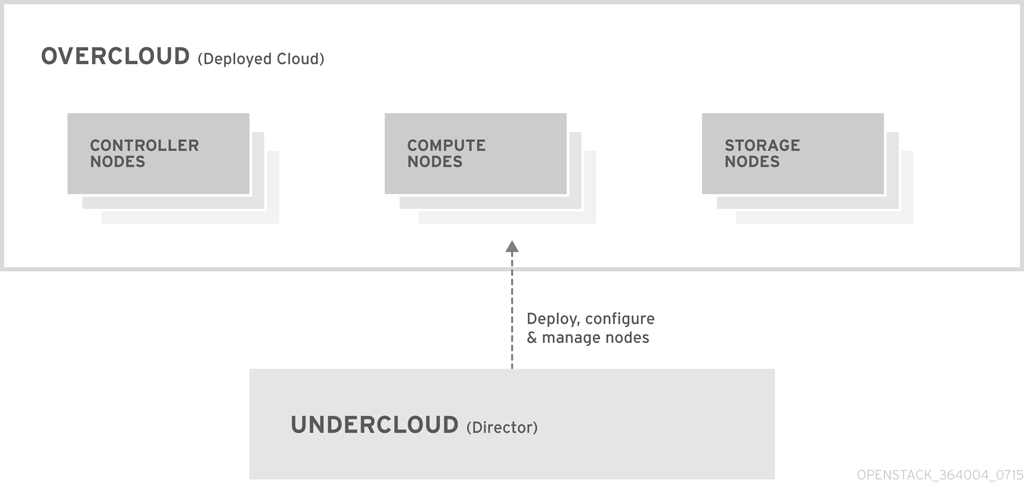
图 1.1. Undercloud 和 Overcloud 的基本结构
1.1. Undercloud
- 环境规划 - Undercloud 提供了为用户分配 Red Hat Enterprise Linux OpenStack Platform 角色(Compute、Controller 和不同的存储节点)的功能。
- 逻辑系统控制 - Undercloud 使用每个节点的智能平台管理界面(Platform Management Interface,简称 IPMI)来进行电源管理控制,并使用一个基于 PXE 的服务来发现硬件的属性来在每个节点上安装 OpenStack。通过这个功能,可以把裸机系统部署为 OpenStack 节点。
- 编配(Orchestration) - Undercloud 提供了一组 YAML 模板来创建一个 OpenStack 环境。
- OpenStack Dashboard(Horizon) - director 的基于 web 的控制台。
- OpenStack Bare Metal(Ironic)和 OpenStack Compute(Nova) - 管理裸机节点。
- OpenStack Networking(Neutron)和 Open vSwitch - 控制裸机节点的网络。
- OpenStack Image Server(Glance) - 存储写到裸机上的镜像。
- OpenStack Orchestation(Heat)和 Puppet - 提供对节点的编配功能,并在 director 把 Overcloud 镜像写入到磁盘后配置节点。
- OpenStack Telemetry(Ceilometer) - 监控并采集数据。
- OpenStack Identity(Keystone) - director 组件的验证。
- MariaDB - director 的数据库。
- RabbitMQ - director 组件的消息队列。
1.2. Overcloud
- Controller(控制器) - 为 OpenStack 环境提供管理、网络和高可用性服务的节点。在一个理想的 OpenStack 环境中,推荐在一个高可用性集群中使用 3 个这类节点。一个默认 Controller 节点包括以下组件:Horizon、Keystone、Nova API、Neutron Server、Open vSwitch、Glance、Cinder Volume、Cinder API、Swift Storage、Swift Proxy、Heat Engine、Heat API、Ceilometer、MariaDB 和 RabbitMQ。Controller 还会使用 Pacemaker 和 Galera 来实现高可用性功能。
- Compute(计算) - 为 OpenStack 环境提供计算资源的节点。随着时间的推移,可以通过添加更多节点来扩展您的环境。一个默认的 Compute 节点包括以下组件:Nova Compute、Nova KVM、Ceilometer Agent 和 Open vSwitch
- Storage(存储) - 为 OpenStack 环境提供存储的节点。它可以包括以下节点:
- Ceph Storage 节点 - 用来组成存储集群,每个节点包括一个 Ceph Object Storage Daemon(OSD)。另外,director 会在实施 Ceph Storage 节点的 Controller 节点上安装 Ceph Monitor。
- Block storage(Cinder)- 作为 HA Controller 节点的外部块存储。这类节点包括以下组件:Cinder Volume、Ceilometer Agent 和 Open vSwitch。
- Object storage(Swift) - 作为 HA Controller 节点的外部对象存储。这类节点包括以下组件:Cinder Storage、Ceilometer Agent 和 Open vSwitch。
1.3. 高可用性
- Pacemaker - Pacemaker 是集群资源的管理者,它会管理并监控一个集群中的所有 OpenStack 组件的可用性。
- HA Proxy(HA 代理) - 为集群提供负载均衡和代理服务。
- Galera - 提供在集群中复制 OpenStack Platform 数据库的服务。
- Memcached - 提供数据库缓存服务。
注意
1.4. Ceph 存储
第 2 章 要求
2.1. 环境配置要求
最小的配置要求
- 一个作为 Red Hat Enterprise Linux OpenStack Platform director 的主机
- 一个作为 Red Hat Enterprise Linux OpenStack Platform Compute 节点的主机
- 一个作为 Red Hat Enterprise Linux OpenStack Platform Controller 节点的主机
推荐的配置要求
- 一个作为 Red Hat Enterprise Linux OpenStack Platform director 的主机
- 3 个作为 Red Hat Enterprise Linux OpenStack Platform Compute 节点的主机
- 3 个作为一个集群中的 Red Hat Enterprise Linux OpenStack Platform Controller 节点的主机
- 3 个作为一个集群中的 Red Hat Ceph Storage 节点的主机
- 推荐所有主机都使用裸机系统。最起码,Compute 节点需要使用裸机系统。
- 因为 director 需要控制电源管理,所以全部 Overcloud 裸机系统都需要一个智能平台管理界面(IPMI)。
2.2. Undercloud 的配置要求
- 支持 Intel 64 或 AMD64 CPU 扩展的 64 位 x86 处理器。
- 最少 6GB 内存。
- 最少具有 40GB 可用磁盘空间。
- 最少两个 1 Gbps 网卡。但是,推荐使用 10 Gbps 网卡来作为 Provisioning 网络的接口,特别是您的 Overcloud 环境中有大量的节点。
- 安装 Red Hat Enterprise Linux 7.1 作为主机操作系统。
2.3. 网络要求
- Provisioning 网络 - director 用来部署和管理 Overcloud 节点的私人网络。Provisioning 网络提供了 DHCP 和 PXE 引导功能来帮助发现在 Overcloud 中使用的主机。这个网络最好使用一个主干(trunk)接口中的原生 VLAN,这样 director 服务器就可以处理 PXE 引导和 DHCP 请求。另外,这个网络还被用来通过 IPMI 对所有 Overcloud 节点进行电源管理。
- External 网络 - 用来远程连接到所有节点的一个独立网络。连接到这个网络的接口需要一个可路由的 IP 地址(静态定义或通过一个外部 DHCP 服务动态分配)。
- 所有机器都最少需要两个 NIC。其中的一个 NIC 通过一个原生的 VLAN 作为 Provisioning 网络;另外一个 NIC 被用来作为 tagged VLAN 来使不同的 Overcloud 网络类型使用不同的子网。
- 这个网络环境需要一个支持 802.1Q 标准的交换机来提供 tagged VLAN。
- 所有 Overcloud 裸机系统都需要一个 IPMI 连接到 Provisioning 网络。director 需要使用它来控制每个节点的电源管理。
- 在 Overcloud 创建节点时,我们在所有 Overcloud 机器间使用一个名称指代 NIC。理想情况下,您应该在每个系统上对每个相关的网络都使用相同的 NIC 来避免混淆。例如,Provisioning 网络使用主(primary)NIC, OpenStack 服务使用从(secondary) NIC。
- 额外的 NIC 可以被用来创建网络绑定,或处理 tagged VLAN 的网络流量。
- 确保 Provisioning 网络的 NIC 和在 director 机器上用来进行远程连接的 NIC 不同。director 会使用 Provisioning NIC 创建一个网桥,它会忽略所有远程连接。在 director 系统上需要使用 External NIC 进行远程连接。
- 把所有 Overcloud 系统设置为使用 Provisioning NIC 进行 PXE 引导,并在 External NIC 以及系统的所有其它 NIC 上禁用 PXE 引导。另外,还需要确保 Provisioning NIC 的 PXE 引导位于引导顺序的最上面(在硬盘和 CD/DVD 驱动之前引导)。
- 请记录下每个 Overcloud 系统的以下信息:Provisioning NIC 的 MAC 地址、IPMI NIC 的 IP 地址、IPMI 用户名和 IPMI 密码。在设置 Overcloud 节点时需要使用这些信息。
2.4. Overcloud 的配置要求
2.4.1. Compute 节点的配置要求
- 处理器
- 支持带有 Intel 64 或 AMD64 CPU 扩展并启用了 Intel VT 硬件虚拟扩展的 64 位 x86 处理器。我们推荐所使用的处理器最少有 4 个内核。
- 内存
- 最少 6GB 内存。另外,还需要加上提供给虚拟机实例使用的内存。
- 磁盘空间
- 最少具有 40GB 可用磁盘空间。
- 网据接口卡
- 最少两个 1 Gbps 网络接口卡。额外的网卡可以组成绑定接口,或处理标记的 VLAN 网络(tagged VLAN)流量。
- 智能平台管理界面(Intelligent Platform Management Interface,简称 IPMI)
- 每个 Compute 节点需要服务器主板具有 IPMI 功能。
2.4.2. Controller 节点的要求
- 处理器
- 支持 Intel 64 或 AMD64 CPU 扩展的 64 位 x86 处理器。
- 内存
- 最少 6GB 内存。
- 磁盘空间
- 最少具有 40GB 可用磁盘空间。
- 网据接口卡
- 最少两个 1 Gbps 网络接口卡。额外的网卡可以组成绑定接口,或处理标记的 VLAN 网络(tagged VLAN)流量。
- 智能平台管理界面(Intelligent Platform Management Interface,简称 IPMI)
- 每个 Controller 节点需要服务器主板具有 IPMI 功能。
2.4.3. Ceph 存储节点的要求
- 处理器
- 支持 Intel 64 或 AMD64 CPU 扩展的 64 位 x86 处理器。
- 内存
- 所需的内存数量取决于存储空间的数量。理想情况下,每 1TB 硬盘空间需要最少 1GB 内存。
- 磁盘空间
- 所需的存储数量取决于内存空间的数量。理想情况下,每 1TB 硬盘空间需要最少 1GB 内存。
- 磁盘布局
- 每个 Ceph 存储节点需要和以下类似的磁盘布局:
/dev/sda- root 磁盘。director 把主 Overcloud 镜像复制到这个磁盘。/dev/sdb- journal 磁盘。这个磁盘被分为不同的分区来保存 Ceph OSD 的日志信息。例如,/dev/sdb1、/dev/sdb2、/dev/sdb3等。/dev/sdc和后续 - OSD 磁盘。可以根据您的存储需要使用多个磁盘。
本文档包括了把您的 Ceph 存储磁盘映射到 director 的方法。 - 网络接口卡
- 最少两个 1 Gbps 网络接口卡。额外的网卡可以组成绑定接口,或处理标记的 VLAN 网络(tagged VLAN)流量。推荐为存储节点使用10 Gbps 接口,特别是所创建的 OpenStack Platform 环境需要处理大量网络数据时。
- 智能平台管理界面(Intelligent Platform Management Interface,简称 IPMI)
- 每个 Ceph 节点需要服务器主板具有 IPMI 功能。
第 3 章 安装 Undercloud
3.1. 创建一个 director 安装用户
stack 的用户并设置密码:
[root@director ~]# useradd stack [root@director ~]# passwd stack # specify a password
sudo 时不需要密码:
[root@director ~]# echo "stack ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/stack [root@director ~]# chmod 0440 /etc/sudoers.d/stack
stack 用户:
[root@director ~]# su - stack [stack@director ~]$
stack 用户继续安装的过程。
3.2. 为模板和镜像创建目录
$ mkdir ~/images $ mkdir ~/templates
3.3. 在 director 主机上启用 IP 转发(IP Forwarding)
/etc/sysctl.conf 文件:
net.ipv4.ip_forward = 1
$ sudo sysctl -p /etc/sysctl.conf
3.4. 为系统设置主机名(Hostname)
$ hostname # Checks the base hostname $ hostname -f # Checks the long hostname (FQDN)
hostnamectl 设置主机名:
$ sudo hostnamectl set-hostname manager.example.com $ sudo hostnamectl set-hostname --transient manager.example.com $ sudo export HOSTNAME=manager.example.com
/etc/hosts 文件中包括一个带有系统主机名和基本名的项。例如,您系统的名称是 manager.example.com,/etc/hosts 则需要包括一个和以下类似的项:
127.0.0.1 manager.example.com manager
3.5. 注册您的系统
过程 3.1. 使用 Subscription Manager 订阅所需的频道
- 在 Content Delivery Network 中注册您的系统,在提示时输入您的客户门户网站(Customer Portal)的用户名和密码:
$ sudo subscription-manager register
- 找到 Red Hat Enterprise Linux OpenStack Platform director 所在的权利池。
$ sudo subscription-manager list --available --all
- 使用上个命令中获得的池 ID 添加 Red Hat Enterprise Linux OpenStack Platform 7 权利:
$ sudo subscription-manager attach --pool=pool_id
- 启用 Red Hat Enterprise Linux 仓库:
$ sudo subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-optional-rpms --enable=rhel-7-server-extras-rpms --enable=rhel-7-server-openstack-7.0-rpms --enable=rhel-7-server-openstack-7.0-director-rpms这些仓库包括了安装 director 所需的软件包。 - 对您系统上的软件进行一个更新来确保使用了最新的基本系统软件包:
$ sudo yum update -y
3.6. 安装 director 软件包
[stack@director ~]$ sudo yum install -y python-rdomanager-oscplugin
3.7. 配置 director
stack 用户的家目录中的一个模板中(undercloud.conf)
stack 用户的家目录中:
$ cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.conf
- image_path
- 指定到用于实施角色的镜像的路径。它的值被设为
stack用户的images:/home/stack/images - local_ip
- director 的 Provisioning NIC 的 IP 地址。它同时还是 director 用来作为它的 DHCP 和 PXE 引导服务的 IP 地址。除非您需要为 Provisioning 网络使用不同的子网(比如,因为默认值和存在的 IP 地址或环境中的其它子网冲突),请保留使用默认值
192.0.2.1/24。 - undercloud_public_vip
- director 的 Public API 的 IP 地址。使用 Provisioning 网络中的一个与其它任何 IP 地址或地址范围都不冲突的 IP 地址。
- undercloud_admin_vip
- director 的 Admin API 的 IP 地址。使用 Provisioning 网络中的一个与其它任何 IP 地址或地址范围都不冲突的 IP 地址。
- undercloud_service_certificate
- 用于 OpenStack SSL 通讯的证书的位置和文件名。最理想的情况是从一个信任的证书颁发机构获得这个证书。您也可以使用以下命令生成一个自签发的证书:
$ openssl genrsa -out privkey.pem 2048 $ openssl req -new -x509 -key privkey.pem -out cacert.pem -days 365 $ cat cacert.pem privkey.pem > undercloud.pem
这会创建一个undercloud.pem文件来和undercloud_service_certificate选项一起使用。另外,这个文件还需要一个特殊的 SELinux context,从而使 HAProxy 工具可以读取它。请参照以下示例:$ sudo mkdir /etc/pki/instack-certs $ sudo cp ~/undercloud.pem /etc/pki/instack-certs/. $ sudo semanage fcontext haproxy_t /etc/pki/instack-certs/* $ sudo restorecon -R /etc/pki/instack-certs
- local_interface
- 指定 director 的 Provisioning NIC 的接口。它同时还是 director 用来作为它的 DHCP 和 PXE 引导服务的设备。把这个项的值改为您需要使用的值。使用
ip addr命令可以查看连接了哪些设备。以下是一个ip addr命令的结果输出示例:2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:75:24:09 brd ff:ff:ff:ff:ff:ff inet 192.168.122.178/24 brd 192.168.122.255 scope global dynamic eth0 valid_lft 3462sec preferred_lft 3462sec inet6 fe80::5054:ff:fe75:2409/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noop state DOWN link/ether 42:0b:c2:a5:c1:26 brd ff:ff:ff:ff:ff:ff在这个例子中,External NIC 使用eth0,Provisioning NIC 使用eth1(当前没有被配置)。在这种情况下,把local_interface设置为eth1。配置脚本会把这个接口附加到一个自定义的网桥(由discovery_interface参数定义)上。 - masquerade_network
- 定义用于外部访问的网络伪装。这为 Provisioning 网络提供了一定程度的网络地址转换(network address translation,简称 NAT)功能,从而可以通过 director 实现外部访问。除非 Provisioning 网络使用了不同的子网,请保留使用默认的值(
192.0.2.0/24)。 - dhcp_start, dhcp_end
- Overcloud 节点的 DHCP 分配范围的开始值和终止值。请确保这个范围可以为您的节点提供足够的 IP 地址。
- network_cidr
- director 用来管理 Overcloud 实例的网络,它是 Provisioning 网络。除非您的 Provisioning 网络使用了不同的子网,保留使用默认值(
192.0.2.0/24)。 - network_gateway
- Overcloud 实例的网关。它是发现主机(discovery host),会把网络流量转发到 External 网络。除非您的 director 使用不同的 IP 地址,或直接使用一个外部网关,请保留使用默认的值(
192.0.2.1)。 - discovery_interface
- director 用来进行节点发现的网桥。这是 director 配置创建的一个自定义网桥。
LOCAL_INTERFACE会附加到这个网桥。请保留使用默认的值(br-ctlplane)。 - discovery_iprange
- 在 PXE 引导和部署过程中,director 发现服务使用的 IP 地址范围。使用逗号分隔范围的起始值和终止值。例如,
192.0.2.100,192.0.2.120。请确保这个范围有足够的 IP 地址,并和dhcp_start与dhcp_end指定的范围不冲突。 - discovery_runbench
- 在节点发现过程中运行一组基准数据。把它设为
1来启用这个功能。如果您需要在检查注册节点的硬件时执行基准数据分析操作,可以使用这个选项。详情请参阅 第 6.3.3 节 “使用自动健康检查(Automated Health Check,简称 AHC)工具自动为节点加标签”。 - undercloud_debug
- 把 Undercloud 服务的日志级别设置为
DEBUG。把它设为true来启用它。 - undercloud_db_password, undercloud_admin_token, undercloud_admin_password, undercloud_glance_password, 等等
- 剩下的参数用来定义 director 服务的访问信息。我们推荐您把这些参数的值保留为空,director 的配置脚本会自动产生这些值。在配置脚本完成后,您可以获得这些值。
$ openstack undercloud install
undercloud.conf 中的设置相符合的情况。这个脚本会需要一些时间来完成。
undercloud-passwords.conf- director 服务的所有密码列表。stackrc- 用来访问 director 命令行工具的一组初始变量。
stack 用户来使用命令行工具:
$ source ~/stackrc
3.8. 为 Overcloud 节点获得镜像
- 一个发现内核和 ramdisk - 用来在 PXE 引导时发现裸机系统。
- 一个实施内核和 ramdisk - 用于系统部署和实施。
- 一个 Overcloud 内核、ramdisk 和完整镜像 - 写到节点硬盘中的一个基本的 Overcloud 系统。
stack 用户的家目录的 images 目录中(/home/stack/images/)。运行以下命令把这些镜像导入到 director:
$ openstack overcloud image upload
bm-deploy-kernel、bm-deploy-ramdisk、overcloud-full、overcloud-full-initrd 和 overcloud-full-vmlinuz 镜像上传到 director。这些是实施和 Overcloud 所需的镜像。这个脚本也会在 director 的 PXE 服务器上安装发现镜像。
$ openstack image list +--------------------------------------+------------------------+ | ID | Name | +--------------------------------------+------------------------+ | 765a46af-4417-4592-91e5-a300ead3faf6 | bm-deploy-ramdisk | | 09b40e3d-0382-4925-a356-3a4b4f36b514 | bm-deploy-kernel | | ef793cd0-e65c-456a-a675-63cd57610bd5 | overcloud-full | | 9a51a6cb-4670-40de-b64b-b70f4dd44152 | overcloud-full-initrd | | 4f7e33f4-d617-47c1-b36f-cbe90f132e5d | overcloud-full-vmlinuz | +--------------------------------------+------------------------+
discovery-ramdisk.*)。director 会把这些文件复制到 /httpboot。
[stack@host1 ~]$ ls /httpboot -l total 151636 -rw-r--r--. 1 ironic ironic 269 Sep 19 02:43 boot.ipxe -rw-r--r--. 1 root root 252 Sep 10 15:35 discoverd.ipxe -rwxr-xr-x. 1 root root 5027584 Sep 10 16:32 discovery.kernel -rw-r--r--. 1 root root 150230861 Sep 10 16:32 discovery.ramdisk drwxr-xr-x. 2 ironic ironic 4096 Sep 19 02:45 pxelinux.cfg
3.9. 为 Overcloud 设置一个名称解析服务器(Nameserver)
neutron 子网中定义。使用以下命令设置名称解析服务器:
$ neutron subnet-list $ neutron subnet-update [subnet-uuid] --dns-nameserver [nameserver-ip]
$ neutron subnet-show [subnet-uuid] +-------------------+-----------------------------------------------+ | Field | Value | +-------------------+-----------------------------------------------+ | ... | | | dns_nameservers | 8.8.8.8 | | ... | | +-------------------+-----------------------------------------------+
3.10. 完成 Undercloud 的配置
第 4 章 规划您的 Overcloud
4.1. 规划节点的实施角色
- Controller
- 为控制您的环境提供关键服务。它包括 dashboard 服务(Horizon)、用户验证服务(Keystone)、镜像存储服务(Glance)、网络服务(Neutron)和编配服务(Heat),以及在使用多个 Controller 节点时的高可用性服务。一个基本的 Red Hat Enterprise Linux OpenStack Platform 环境中需要最少一个 Controller 节点。
- Compute
- 一个作为虚拟机监控程序(hypervisor)的主机,它为环境中运行的虚拟机提供处理能力。一个基本的 Red Hat Enterprise Linux OpenStack Platform 环境中需要最少一个 Compute 节点。
- Ceph-Storage
- 提供 Red Hat Ceph Storage 的一个主机。额外的 Ceph Storage 主机可以在一个集群中扩展。这个实施角色是可选的。
- Cinder-Storage
- 为 OpenStack 的 Cinder 服务提供外部块存储的主机。这个实施角色是可选的。
- Swift-Storage
- 为 OpenStack 的 Swift 服务提供外部对象存储的主机。这个实施角色是可选的。
表 4.1. 使用情景的节点部署角色
| |
Controller
|
Compute
|
Ceph-Storage
|
Swift-Storage
|
Cinder-Storage
|
总计
|
|---|---|---|---|---|---|---|
|
测试环境
|
1
|
1
|
-
|
-
|
-
|
2
|
|
基本环境
|
1
|
1
|
-
|
-
|
-
|
2
|
|
带有 Ceph Storage 的高级环境
|
3
|
3
|
3
|
-
|
-
|
9
|
4.2. 规划网络
表 4.2. 网络类型分配
|
网络类型
|
描述
|
用于
|
|---|---|---|
|
IPMI
|
节点电源管理的网络。这个网络在安装 Undercloud 前被预先定义。
|
所有节点
|
|
Provisioning
|
director 使用这个网络类型来通过 PXE 引导实施新的节点,并调配在 Overcloud 裸机服务器上进行的 OpenStack 安装。这个网络在安装 Undercloud 前被预先定义。
|
所有节点
|
|
Internal API
|
Internal API 网络被用来处理经过 API 、RPC 消息和数据库进行的 OpenStack 服务间的通讯。
|
Controller、Compute、Cinder Storage、Swift Storage
|
|
Tenant
|
Neutron 为每个租户提供自己的网络。这可以通过使用 VLAN 隔离(VLAN segregation,每个租户网络都是一个网络 VLAN)实现,也可以使用 VXLAN 或 GRE 通道(tunneling)实现。每个租户网络的网络数据会被相互隔离,并都有一个相关联的 IP 子网。多个租户子网可以使用相同的地址。
|
Controller、Compute
|
|
Storage
|
块存储、NFS、iSCSI 和其它存储。在理想情况下,因为性能的原因,这个网络应该位于一个完全独立的网络交换环境中。
|
所有节点
|
|
Storage Management
|
OpenStack Object Storage(swift)使用这个网络来在相关的副本节点中同步数据项。代理服务(proxy service)在用户请求和底层的存储层间起到一个主机接口的作用。这个代理会接收用户的请求,并找到所需的副本来获得所需的数据。使用 Ceph 作为后端的服务会通过 Storage Management 网络进行连接,因为它们不会和 Ceph 直接进行交流,而是使用前端的服务。请注意,RBD 驱动是个例外,它会直接连接到 Ceph。
|
Controller、Ceph Storage、Cinder Storage、Swift Storage
|
|
External
|
允许入站的网络流量到达相关实例,它使用 1 对 1 的 IP 地址映射把浮动 IP 地址和在租户网络中实际分配给实例的 IP 地址相关联。另外,还支持 OpenStack Dashboard(horizon)进行图形化的系统管理、OpenStack 服务的公共 API 以及对入站网络流量进行 SNAT 处理来把它们导向正确的目标。如果 external 网络使用私有 IP 地址(RFC-1918),还需要对来自于互联网的流量进行额外的 NAT 处理。
|
Controller
|
- Internal API
- Storage
- Storage Management
- Tenant
- External
nic2 和 nic3)的绑定来通过相关的 VLAN 提供网络功能。同时,所有 Overcloud 节点都使用 nic1 通过原生的 VLAN 来通过 Provisioning 网络和 Undercloud 进行通讯。
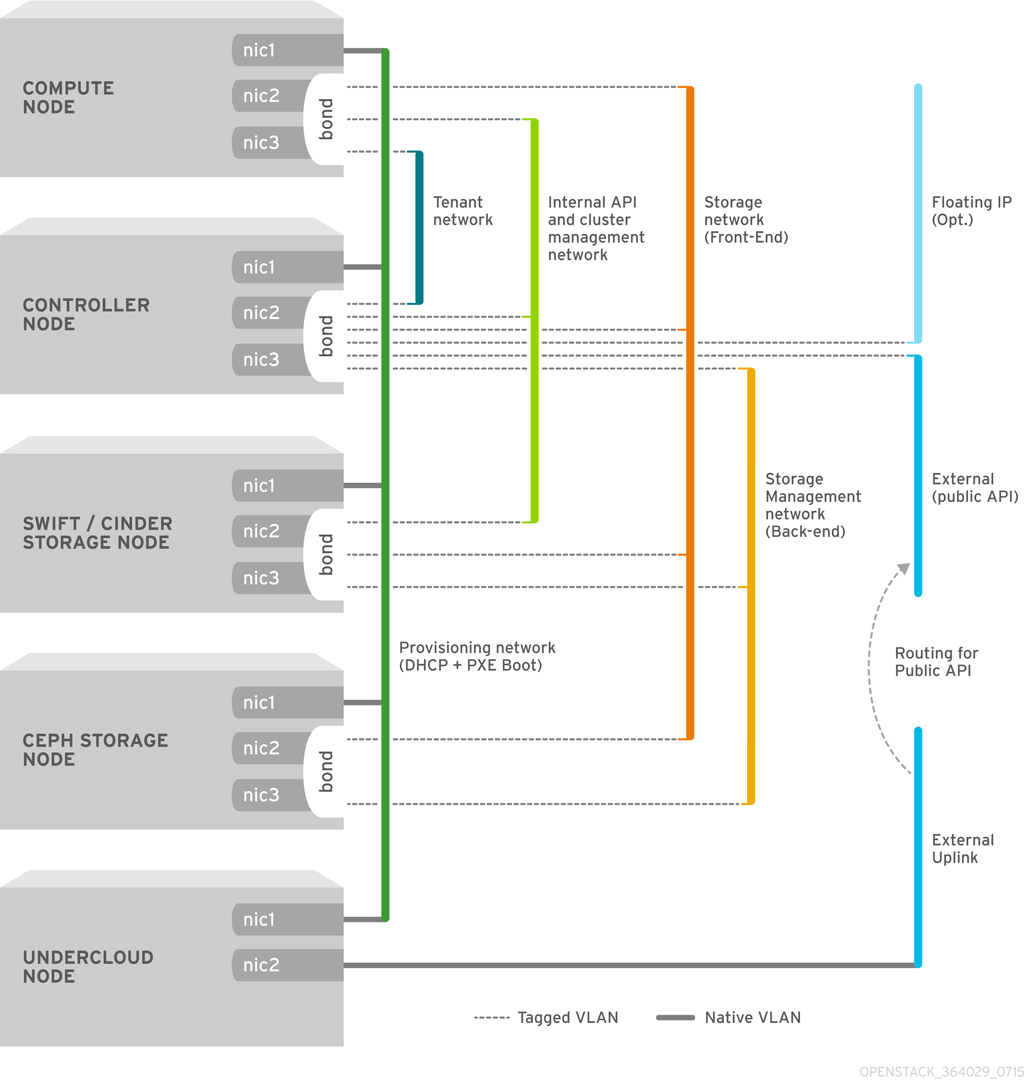
图 4.1. 使用绑定接口的 VLAN 拓扑结构示例
表 4.3. 网络映射
| |
映射
|
接口总数
|
VLAN 总数
|
|---|---|---|---|
|
测试环境
|
网络 1 - Provisioning、Internal API、Storage、Storage Management、Tenant Networks、 External
|
1
|
1
|
|
基本环境
|
网络 1 - Provisioning、Internal API、Storage、Storage Management、Tenant Networks
网络 2 - External
|
2
|
2
|
|
带有 Ceph Storage 的高级环境
|
网络 1 - Provisioning
网络 2 - Internal API
网络 3 - Tenant Networks
网络 4 - Storage
网络 5 - Storage Management
网络 6 - External
|
3(包括 2 个绑定接口)
|
6
|
4.3. 规划存储
- Ceph Storage 节点
- director 使用 Red Hat Ceph Storage 创建一组可扩展的存储节点。Overcloud 使用这些节点用于:
- 镜像 - OpenStack Glance 管理虚拟机的镜像。镜像是不可变的,OpenStack 把镜像看做为二进制数据块,并根据它们的实际情况进行下载。您可以使用 OpenStack Glance 在一个 Ceph 块设备中存储镜像。
- 卷 - OpenStack Cinder 卷是块设备。OpenStack 使用卷来引导虚拟机,或把卷附加到运行的虚拟机上。OpenStack 使用 Cinder 服务管理卷,您可以使用 Cinder,通过一个镜像的写时复制(copy-on-write,简称 COW) 克隆引导虚拟机。
- 客户端磁盘 - 客户端磁盘就是客户端(虚拟机)操作系统磁盘。在默认情况下,当使用 Nova 引导虚拟机时,它的磁盘会以一个文件的形式出现在虚拟机监控程序(hypervisor)上,通常位于
/var/lib/nova/instances/<uuid>/。现在,可以直接在 Ceph 中直接引导每个虚拟机,这可以使您在实时迁移时更容易地执行维护操作。例如,如果您的 hypervisor 出现问题,它还可以方便地触发nova evacuate,从而使在其它地方运行虚拟机的过程几乎可以“无缝”地实现。
重要
Ceph 不支持提供 QCOW2 虚拟机磁盘。如果您需要在 Ceph 中引导虚拟机(临时后端或从卷引导),Glance 镜像的格式必须是RAW。如需了解更多信息,请参阅 Red Hat Ceph Storage Architecture Guide。 - Cinder 存储节点
- director 会创建一个外部的块存储节点。当您需要扩展或替换 Overcloud 环境中的 controller 节点,同时需要在一个高可用性集群外保留块存储时,这将非常有用。
- Swift 存储节点
- director 会创建一个外部的对象存储节点。当您需要扩展或替换 Overcloud 环境中的 controller 节点,同时需要在一个高可用性集群外保留块存储时,这将非常有用。
第 5 章 了解 Heat 模板
5.1. Heat 模板
- 参数 - 一组传递给 Heat 的参数,可以被用来自定义一个堆栈,并设置在没有传递值时相关参数所使用的默认值。这些参数在模板的
parameters项中定义。 - 资源 - 一组作为堆栈的一部分需要创建和配置的对象。OpenStack 包括一组分布在所有组件中的资源,它们在模板的
resources项中定义。 - 输出 - 一组在堆栈创建后传递给 Heat 的值。您可以通过 Heat API 或客户端工具程序来访问这些值。它们在模板的
output项中定义。
heat_template_version: 2013-05-23
description: > A very basic Heat template.
parameters:
key_name:
type: string
default: lars
description: Name of an existing key pair to use for the instance
flavor:
type: string
description: Instance type for the instance to be created
default: m1.small
image:
type: string
default: cirros
description: ID or name of the image to use for the instance
resources:
my_instance:
type: OS::Nova::Server
properties:
name: My Cirros Instance
image: { get_param: image }
flavor: { get_param: flavor }
key_name: { get_param: key_name }
output:
instance_name:
description: Get the instance's name
value: { get_attr: [ my_instance, name ] }
type: OS::Nova::Server 创建一个名为 my_instance 的实例,它具有特定的 flavor、镜像和关键字。这个堆栈会返回 instance_name 的值(My Cirros Instance)。
5.2. 环境文件
- 参数 - 应用到一个模板参数的常规设置。它们在环境文件的
parameters项中设置。 - 参数默认值 - 这些参数被用来修改模板中的参数的默认值。它们在环境文件的
parameter_defaults项中设置。 - 资源注册表 - 它设置了自定义资源名,并连接到其它 Heat 模板。这提供了一个创建没有存在于核心资源集合中的自定义资源的方法。它在环境文件的
resource_registry项中设置。
resource_registry: OS::Nova::Server::MyServer: myserver.yaml parameter_defaults: NetworkName: my_network parameters: MyIP: 192.168.0.1
OS::Nova::Server::MyServer 的资源类型。myserver.yaml 是一个 Heat 模板文件,它被用来创建这个资源类型来覆盖内建的资源类型。
5.3. 默认的 director 计划
$ openstack management plan list
overcloud,它是 Overcloud 的配置。使用以下命令可以显示 Overcloud 计划的详细信息:
$ openstack management plan show [UUID]
stack 用户的 templates 目录下的一个目录中。
$ mkdir ~/templates/overcloud-plan $ openstack management plan download [UUID] -O ~/templates/overcloud-plan/
plan.yaml)和一个环境文件(environment.yaml)。这个模板集合还包括了不同的目录和模板文件,作为资源在环境文件中注册。
5.4. 默认 director 模板
/usr/share/openstack-tripleo-heat-templates 中。
overcloud-without-mergepy.yaml- 这是创建 Overcloud 环境所使用的主要模板。overcloud-resource-registry-puppet.yaml- 这是创建 Overcloud 环境所使用的主要环境文件。它为 Puppet 模块提供了一组存储在 Overcloud 镜像中的配置。当 director 为每个节点写入 Overcloud 镜像后,Heat 将使用在环境文件中注册的资源来为每个节点进行配置。overcloud-resource-registry.yaml- 这是创建 Overcloud 环境的一个标准环境文件,overcloud-resource-registry-puppet.yaml会基于这个文件。它被用来对环境进行自定义配置。
overcloud-without-mergepy.yaml 模板和 overcloud-resource-registry-puppet.yaml 环境文件为每个节点配置 Overcloud 镜像。我们还会创建一个环境文件来在高级使用情景中配置网络隔离。
第 6 章 安装 Overcloud
表 6.1. 使用情景概述
|
使用情景
|
级别
|
主题
|
|---|---|---|
|
测试 Overcloud
|
低
|
Web UI 的使用、节点注册、手工标记节点、基于计划创建 Overcloud
|
|
基本 Overcloud
|
中级
|
CLI 工具程序的使用、节点注册、手工标记节点、基本的网络分离和基于计划创建 Overcloud
|
|
高级 Overcloud
|
高级
|
CLI 工具程序的使用、节点注册、基于硬件的自动节点标记、Ceph Storage 设置、高级的网络分离、Overcloud 的创建、高可用性隔离配置
|
6.1. 使用情景 1:使用 Web UI 创建一个用于测试的 Overcloud
libvirt/virsh 进行虚拟化。这个使用情景主要使用 director 的 web UI 来控制对测试 Overcloud 的创建过程。通过这个用户情景,可以向用户展示使用 director 创建一个用于“概念验证(proof-of-concept)” 的基本 Red Hat Enterprise Linux OpenStack Platform 环境。
重要
流程
- 在 director 的 web UI 中注册空节点。
- 检查所有节点的硬件。
- 为节点创建默认的 flavor。
- 为实施角色分配 flavor 和镜像。
- 使用 director 的默认计划创建 Overcloud 环境。
配置要求
- 第 3.1 节 “创建一个 director 安装用户” 中创建的 director 节点
- 一个安装了
libvirt虚拟化工具的 Red Hat Enterprise Linux 7.1 裸机,这个系统作为包括 Overcloud 的虚拟节点的主机。如需了解设置libvirt虚拟化的信息,请参阅 Virtualization Getting Started Guide(Red Hat Enterprise Linux 7)。 - director 主机和 Overcloud 主机间的网络连接。这个网络作为 provisioning 网络。在这个示例中,使用 192.0.2.0/24 作为 provisioning 网络,director 使用 192.0.2.1 作为它的 IP 地址,Overcloud 主机使用 192.0.2.2 作为它的 IP 地址。
6.1.1. 配置 Overcloud 主机
过程 6.1. 在 Overcloud 主机上创建虚拟机
- 从 Overcloud 主机上访问 Virtual Machine Manager。
- 使用以下配置创建两个虚拟机:
- 1 个 vCPU
- 6144 MB 内存
- 网络引导(PXE)
- 40 GiB 存储
- 网络选择:主机设备 eth0:macvtap,源模式:Bridge
选择 macvtap 会把虚拟机设置为共享主机的以太网接口,这样,director 就可以直接访问这些节点。 - 关闭所有虚拟机。
- 记录下每个虚拟机的 MAC 地址。在这个示例中,使用以下 MAC 地址:
aa:aa:aa:aa:aa:aa和bb:bb:bb:bb:bb:bb
virsh 来控制虚拟机的电源状态。接下来会为 director 创建用来和 Overcloud 主机进行连接所需要的 SSH 密钥对。
过程 6.2. 创建一个 SSH 密钥对
- 以
stack用户登录到 director,创建一个新的 SSH 密钥:[stack@director ~]$ ssh-keygen -t rsa -b 2048 -C "dmacpher@redhat.com" -f ./virtkey
这个命令会要求输入一个密码。在这里请不要输入密码。这个命令会创建两个文件:私人密钥文件(virtkey)和公共密钥文件(virtkey.pub)。 - 把公共密钥中的内容复制到 Overcloud 主机的
root用户的/root/.ssh/authorized_keys文件中:[stack@director ~]$ ssh-copy-id -i virtkey root@192.0.2.2
- 安全地保存私人密钥(
virtkey)以供使用。
6.1.2. 访问 director
http://192.0.2.1。一个 director 的登录界面会显示。
图 6.1. OpenStack Platform director 登录界面
stack 用户运行以下命令来获得您的环境的管理密码:
[stack@director ~]$ sudo hiera admin_password 3f2f4295a5eb6ad967b832d35e048852
admin 用户身份登录到 director 的 UI。
6.1.3. 注册节点
过程 6.3. 注册节点
- 以
admin用户身份登录到 director。 - 进入主菜单中的 Nodes。
- 点 + 按钮。节点注册界面会出现。
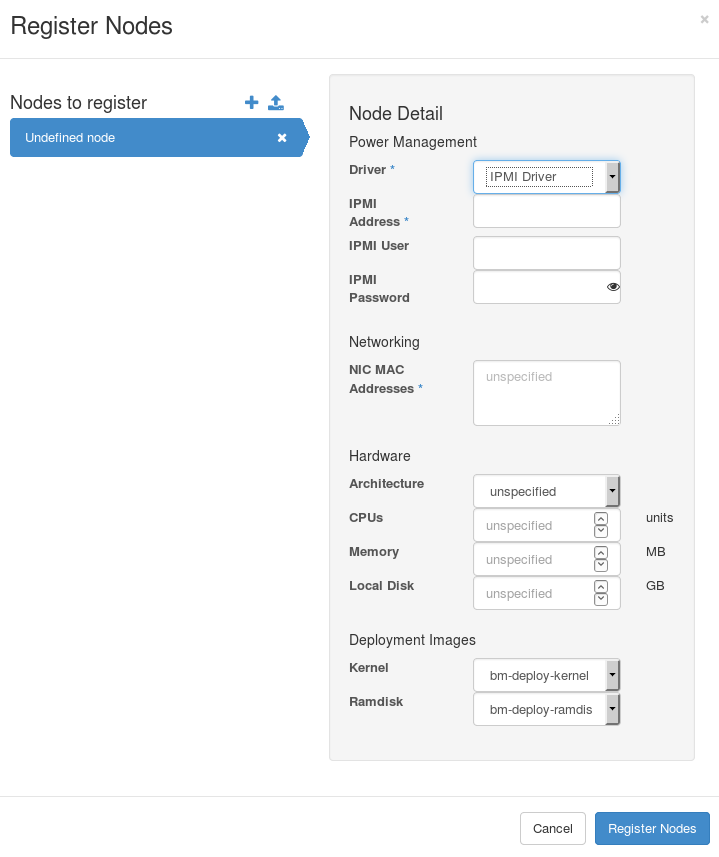
图 6.2. 节点注册界面
- 为两个节点输入以下信息:
- 节点 1:
- Driver: PXE + SSH
- SSH Address: Overcloud 主机
- SSH User: root
- SSH Key Contents: 粘贴
virtkey中的内容 - NIC MAC Addresses: aa:aa:aa:aa:aa:aa
- Architecture: x86_64
- CPUs: 1
- Memory: 6144 MB
- Local Disk: 40 GB
- Kernel: bm-deploy-kernel
- Ramdisk: bm-deploy-ramdisk
- 节点 2:
- Driver: PXE + SSH
- SSH Address: Overcloud 主机
- SSH User: root
- SSH Key Contents: 粘贴
virtkey中的内容 - NIC MAC Addresses: bb:bb:bb:bb:bb:bb
- Architecture: x86_64
- CPUs: 1
- Memory: 6144 MB
- Local Disk: 40 GB
- Kernel: bm-deploy-kernel
- Ramdisk: bm-deploy-ramdisk
- 点 Register Nodes。
$ openstack baremetal introspection bulk start
6.1.4. 产生硬件档案
baremetal flavor。使用 UI 产生一个名为 baremetal 的 flavor:
过程 6.4. 产生硬件档案
- 进入主菜单中的 Flavors。
- 点 + 按钮。创建 flavor 节点界面会出现。
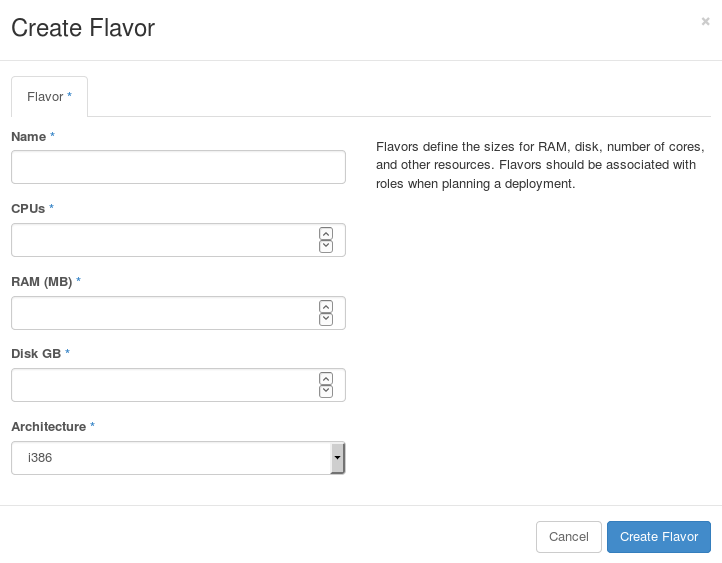
图 6.3. 创建 flavor 界面
- 为两个节点输入以下信息:
- Name:
baremetal - CPUs: 1
- RAM (MB): 6144
- Disk GB: 40 GB
- Architecture: x86_64
- 点 Create Flavor。
- 在终端中运行下列命令来为 flavor 设置以下能力:
$ openstack flavor set --property "capabilities:boot_option"="local" baremetal
6.1.5. 为实施的角色分配镜像
baremetal flavor,但实施角色仍然需要需要分配一个镜像。
过程 6.5. 为实施的角色分配镜像
- 进入主菜单中的 Deployment Roles。
- 为 Compute 实施角色点 Edit 按钮。编辑实施角色的界面会显示。
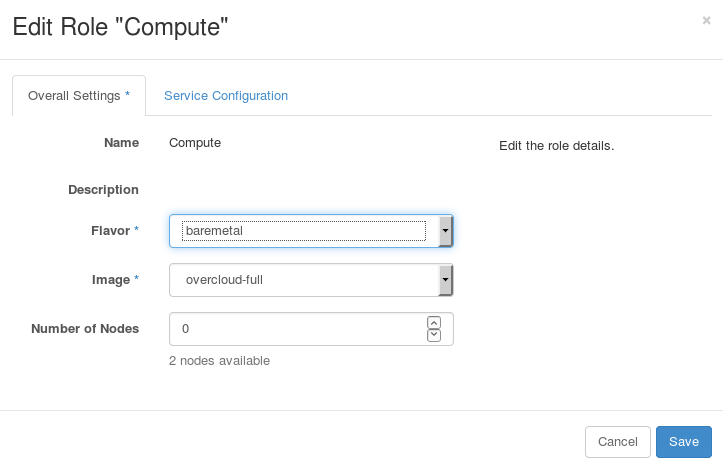
图 6.4. 编辑实施角色
- 确认 Flavor 被设置为
baremetal,Image 被设置为overcloud-full。点 Save。 - 为其它实施角色重复这个操作。
6.1.6. 创建测试 Overcloud
过程 6.6. 创建 Overcloud
- 进入主菜单中的 Overview。
- 在左面检查实施计划中的节点数量。默认的计划会从
baremetalflavor 中分配一个 Controller 节点和一个 Compute 节点。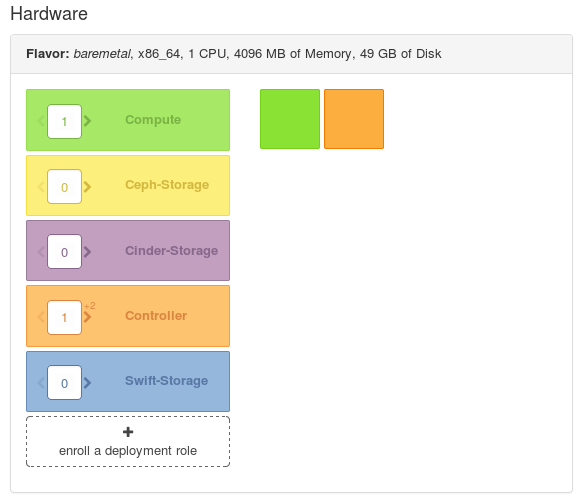
图 6.5. Overcloud 计划
- 在准备好开始创建过程时,点 Verify and Deploy 按钮。

图 6.6. 验证和实施
6.1.7. 访问测试 Overcloud
6.1.8. 完成对测试 Overcloud 环境的创建和配置
6.2. 使用情景 2:使用 CLI 创建一个基本的 Overcloud
流程
- 在 director 中创建一个节点定义模板并注册空白节点。
- 检查所有节点的硬件。
- 手工为节点添加标签(tag)来标记为角色。
- 创建 flavor 并通过添加标签把它们标记为角色。
- 创建 Heat 模板来分离 External 网络。
- 使用 director 的默认计划和额外的网络分离模板创建 Overcloud 环境。
配置要求
- 第 3 章 安装 Undercloud 中创建的 director 节点
- 两个裸机。这些系统需要满足 Controller 节点和 Compute 节点对配置的要求。请参阅以下内容:因为 director 会把 Red Hat Enterprise Linux 7 镜像复制到每个节点,因此这些节点当前不需要操作系统。
- Provisioning 网络的一个网络连接(被配置为一个原生 VLAM)。所有节点必须都连接到这个网络,并需要满足 第 2.3 节 “网络要求” 中的要求。在这个示例中,我们使用 192.0.2.0/24 作为 Provisioning 子网,分配的 IP 地址信息如下:
表 6.2. Provisioning 网络 IP 分配信息
节点名IP 地址MAC 地址IPMI IP 地址director192.0.2.1aa:aa:aa:aa:aa:aaControllerDHCPbb:bb:bb:bb:bb:bb192.0.2.205ComputeDHCPcc:cc:cc:cc:cc:cc192.0.2.206 - 用来进行 External 网络连接的一个网络。所有节点必须连接到这个网络。在这个示例中,我们使用 10.1.1.0/24 作为 External 网络。
- 所有其它网络类型使用 Provisioning 网络作为 OpenStack 服务
6.2.1. 为基本 Overcloud 注册节点
instackenv.json)是一个 JSON 格式的文件,它包括了环境中的两个节点的硬件信息和电源管理信息。例如:
{
"nodes":[
{
"mac":[
"bb:bb:bb:bb:bb:bb"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.205"
},
{
"mac":[
"cc:cc:cc:cc:cc:cc"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.206"
}
]
}
- mac
- 节点上的网络接口的 MAC 地址列表。只为每个系统的 Provisioning NIC 使用 MAC 地址。
- cpu
- 节点上的 CPU 数量。
- memory
- 内存大小(以 MB 为单位)。
- disk
- 硬盘的大小(以 GB 为单位)。
- arch
- 系统架构。
- pm_type
- 使用的电源管理驱动。在这个示例中使用 IPMI 驱动(
pxe_ipmitool)。 - pm_user, pm_password
- IPMI 的用户名和密码。
- pm_addr
- IPMI 设备的 IP 地址。
注意
stack 用户的家目录(/home/stack/instackenv.json),然后把它导入到 director。使用以下命令:
$ openstack baremetal import --json ~/instackenv.json
$ openstack baremetal configure boot
$ openstack baremetal list
6.2.2. 检查节点硬件
$ openstack baremetal introspection bulk start
重要
6.2.3. 手工为节点添加标签
profile 选项添加到每个节点的 properties/capabilities 参数中。例如,把环境中的两个节点分别标记为使用 controller 档案和 compute 档案,使用以下命令:
$ ironic node-update 58c3d07e-24f2-48a7-bbb6-6843f0e8ee13 add properties/capabilities='profile:compute,boot_option:local' $ ironic node-update 1a4e30da-b6dc-499d-ba87-0bd8a3819bc0 add properties/capabilities='profile:control,boot_option:local'
profile:compute 和 profile:control 选项会把节点标记为相关的档案。
boot_option:local 参数,它定义了每个节点的引导模式。
6.2.4. 为基本使用情景创建 flavor
$ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 control $ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute
control 和 compute。我们还为每个 flavor 设置了额外的属性。
$ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="compute" compute $ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="control" control
capabilities:boot_option 为 flavor 设置了引导模式,capabilities:profile 定义了要使用的档案。这会和在 第 6.2.3 节 “手工为节点添加标签” 中被添加了相同标签的相关节点进行连接。
6.2.5. 分离 External 网络
- 网络 1 - Provisioning 网络。Internal API、Storage、Storage Management 和 Tenant 网络也使用这个网络。
- 网络 2 - External 网络。这个网络使用一个专用的接口来连接 Overcloud 以外的环境。
6.2.5.1. 创建自定义接口模板
/usr/share/openstack-tripleo-heat-templates/network/config/single-nic-vlans- 这个目录中包括了基于角色的、带有 VLAN 配置的单独 NIC 的模板。/usr/share/openstack-tripleo-heat-templates/network/config/bond-with-vlans- 这个目录中包括了基于角色的、绑定 NIC 配置的模板。
stack 用户的家目录,命名为 nic-configs。
$ cp -r /usr/share/openstack-tripleo-heat-templates/network/config/single-nic-vlans ~/templates/nic-configs
parameters、resources 和 output 项。这里,我们只编辑 resources 项,每个 resources 以以下内容开始:
resources:
OsNetConfigImpl:
type: OS::Heat::StructuredConfig
properties:
group: os-apply-config
config:
os_net_config:
network_config:
os-apply-config 命令和 os-net-config 子命令的请求来为一个节点配置网络属性。network_config 项中包括了自定义的接口配置,这些配置以类型的形式进行组织,它们包括:
- interface
- 定义一个单独网络接口。这个配置指定了每个接口需要使用实际的接口名("eth0"、"eth1"、"enp0s25")还是使用接口编号("nic1"、"nic2"、"nic3")。
- type: interface name: nic2 - vlan
- 定义一个 VLAN。使用从
parameters项中传递来的 VLAN ID 和子网。- type: vlan vlan_id: {get_param: ExternalNetworkVlanID} addresses: - ip_netmask: {get_param: ExternalIpSubnet} - ovs_bond
- 定义 Open vSwitch 中的绑定。一个绑定会把两个
interfaces组合在一起来起到冗余和增加带宽的目的。- type: ovs_bond name: bond1 members: - type: interface name: nic2 - type: interface name: nic3 - ovs_bridge
- 在 Open vSwitch 中定义网桥。网桥把多个
interface、bond和vlan对象连接在一起。- type: ovs_bridge name: {get_input: bridge_name} members: - type: ovs_bond name: bond1 members: - type: interface name: nic2 primary: true - type: interface name: nic3 - type: vlan device: bond1 vlan_id: {get_param: ExternalNetworkVlanID} addresses: - ip_netmask: {get_param: ExternalIpSubnet}
nic2。这可以保证在每个节点上使用第二个网络接口作为 External 网络。例如,在 templates/nic-configs/controller.yaml 模板中:
network_config:
- type: ovs_bridge
name: {get_input: bridge_name}
use_dhcp: true
members:
- type: interface
name: nic1
# force the MAC address of the bridge to this interface
primary: true
- type: vlan
vlan_id: {get_param: InternalApiNetworkVlanID}
addresses:
- ip_netmask: {get_param: InternalApiIpSubnet}
- type: vlan
vlan_id: {get_param: StorageNetworkVlanID}
addresses:
- ip_netmask: {get_param: StorageIpSubnet}
- type: vlan
vlan_id: {get_param: StorageMgmtNetworkVlanID}
addresses:
- ip_netmask: {get_param: StorageMgmtIpSubnet}
- type: vlan
vlan_id: {get_param: TenantNetworkVlanID}
addresses:
- ip_netmask: {get_param: TenantIpSubnet}
- type: interface
name: nic2
addresses:
- ip_netmask: {get_param: ExternalIpSubnet}
routes:
- ip_netmask: 0.0.0.0/0
next_hop: {get_param: ExternalInterfaceDefaultRoute}
nic2),重新分配 External 网络地址,并路由到新的接口。
get_param 功能。我们在一个针对于我们的网络所创建的一个环境文件中定义它们。
重要
- type: interface name: nic1 use_dhcp: true
6.2.5.2. 创建一个基本 Overcloud 网络环境模板
/home/stack/templates/network-environment.yaml):
resource_registry:
OS::TripleO::BlockStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/cinder-storage.yaml
OS::TripleO::Compute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute.yaml
OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller.yaml
OS::TripleO::ObjectStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/swift-storage.yaml
OS::TripleO::CephStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/ceph-storage.yaml
parameters:
# Set to "br-ex" if using floating IPs on native VLAN on bridge br-ex
Controller-1::NeutronExternalNetworkBridge: "''"
parameter_defaults:
ExternalNetCidr: 10.1.1.0/24
ExternalAllocationPools: [{'start': '10.1.1.2', 'end': '10.1.1.50'}]
ExternalNetworkVlanID: 100
ExternalInterfaceDefaultRoute: 10.1.1.1
resource_registry 项包括了到每个节点角色的网络接口模板的连接。请注意,ExternalAllocationPools 参数只定义了一个小的 IP 地址范围。因此,我们可以在以后定义一个独立的浮动 IP 地址范围。
parameters 项为浮动 IP 地址定义了使用的网桥。如果浮动 IP 地址使用标记的 VLAN(tagged VLAN),把这个值设为一对单引号(这会使用默认值 br-int)。在其它情况下,把它设置为默认的外部网桥值(通常是 br-ex)。
重要
NeutronExternalNetworkBridge 参数需要 Controller-1:: 前缀,并在创建一个基于计划的 Overcloud 时是 parameters 项的一般分。这是因为计划处理参数的方式。如果需要创建一个自定义的、基于 Heat 模板的 Overcloud(如高级 Overcloud 使用情景中提到的系统),这个参数只是 NeutronExternalNetworkBridge,并被放置在 parameter_defaults 项中。如需了解这两者间的不同,请参阅 第 6.3.7.2 节 “创建一个高级的 Overcloud 网络环境模板”。
parameter_defaults 项包括了一组参数,它们被用来定义每个网络类型的网络选项。如需获得这些参数的详细信息,请参阅 附录 F, 网络环境选项。
重要
6.2.6. 创建基本的 Overcloud
过程 6.7. 创建 Overcloud
- 运行以下命令来查看 Overcloud 计划:
$ openstack management plan list
这会显示计划以及它的 UUID。记录下 UUID 以供下一步使用。 - 运行以下命令开始基本 Overcloud 的创建。使用前一步获得的实际 UUID 值替换 [UUID]:
$ openstack overcloud deploy --plan "[UUID]" -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /home/stack/network-environment.yaml --control-flavor control --compute-flavor compute
这个命令包括以下的额外选项:--plan- 指定创建 Overcloud 使用的计划。它的值是 Overcloud 计划的 UUID。-e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml--e选项为 Overcloud 计划添加了一个额外的环境文件。在这里,它是一个初始化网络分离配置的环境文件。-e /home/stack/templates/network-environment.yaml--e选项为 Overcloud 计划添加了一个环境文件。在这里,它是在 第 6.2.5.2 节 “创建一个基本 Overcloud 网络环境模板” 中创建的网络环境文件。--control-flavor control- 为 Controller 节点使用一个特定的 flavor。--compute-flavor compute- 为 Compute 节点使用一个特定的 flavor。
注意
stack 用户身份运行:
$ source ~/stackrc # Initializes the stack user to use the CLI commands $ heat stack-list --show-nested
heat stack-list --show-nested 命令会显示创建 Overcloud 的当前状态。
重要
-e 选项为 Overcloud 添加了环境文件。director 需要为 第 7 章 创建 Overcloud 后执行的任务 中的特定功能使用这些环境文件。
6.2.7. 访问基本的 Overcloud
stack 用户家目录的 overcloudrc 文件。运行以下命令来使用这个文件:
$ source ~/overcloudrc
$ source ~/stackrc
6.2.8. 完成基本的 Overcloud 创建
6.3. 使用情景 3:使用 CLI 创建一个带有 Ceph 节点的高级 Overcloud
- 3 个带有高可用性的 Controller 节点
- 3 个 Compute 节点
- 带有 3 个 Red Hat Ceph Storage 节点的集群
流程
- 在 director 中创建一个节点定义模板并注册空白节点。
- 检查所有节点的硬件并创建基准数据。
- 使用自动健康检查(Automated Health Check,简称 AHC)工具定义策略来自动使用标签把节点标记为不同的角色。
- 创建 flavor 并通过添加标签把它们标记为角色。
- 创建 director 的默认 Heat 模板的一个副本。
- 创建 Heat 模板来分离所有网络。
- 使用默认的 Heat 模板和额外的网络分离模板创建 Overcloud 环境。
- 为高可用性集群中的每个 Controller 节点添加隔离(fencing)信息。
配置要求
- 第 3 章 安装 Undercloud 中创建的 director 节点
- 9 个裸机。这些系统需要满足 Controller 节点、Compute 节点和 Ceph Storage 节点对配置的要求。请参阅以下内容:因为 director 会把 Red Hat Enterprise Linux 7 镜像复制到每个节点,因此这些节点当前不需要操作系统。
- Provisioning 网络的一个网络连接(被配置为一个原生 VLAM)。所有节点必须都连接到这个网络,并需要满足 第 2.3 节 “网络要求” 中的要求。在这个示例中,我们使用 192.0.2.0/24 作为 Provisioning 子网,分配的 IP 地址信息如下:
表 6.3. Provisioning 网络 IP 分配信息
节点名IP 地址MAC 地址IPMI IP 地址director192.0.2.1aa:aa:aa:aa:aa:aaController 1DHCPb1:b1:b1:b1:b1:b1192.0.2.205Controller 2DHCPb2:b2:b2:b2:b2:b2192.0.2.206Controller 3DHCPb3:b3:b3:b3:b3:b3192.0.2.207Compute 1DHCPc1:c1:c1:c1:c1:c1192.0.2.208Compute 2DHCPc2:c2:c2:c2:c2:c2192.0.2.209Compute 3DHCPc3:c3:c3:c3:c3:c3192.0.2.210Ceph 1DHCPd1:d1:d1:d1:d1:d1192.0.2.211Ceph 2DHCPd2:d2:d2:d2:d2:d2192.0.2.212Ceph 3DHCPd3:d3:d3:d3:d3:d3192.0.2.213 - 每个 Overcloud 节点使用剩下的两个网络接口组成网络绑定来处理标记 VLAN(tagged VLAN)中的网络。这个绑定使用以下网络设置:
表 6.4. 网络子网和 VLAN 分配
网络类型子网VLANInternal API172.16.0.0/24201Tenant172.17.0.0/24202Storage172.18.0.0/24203Storage Management172.19.0.0/24204External / Floating IP10.1.1.0/24100
6.3.1. 为高级 Overcloud 注册节点
instackenv.json)是一个 JSON 格式的文件,它包括了环境中的 9 个节点的硬件信息和电源管理信息。例如:
{
"nodes":[
{
"mac":[
"b1:b1:b1:b1:b1:b1"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.205"
},
{
"mac":[
"b2:b2:b2:b2:b2:b2"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.206"
},
{
"mac":[
"b3:b3:b3:b3:b3:b3"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.207"
},
{
"mac":[
"c1:c1:c1:c1:c1:c1"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.208"
},
{
"mac":[
"c2:c2:c2:c2:c2:c2"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.209"
},
{
"mac":[
"c3:c3:c3:c3:c3:c3"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.210"
},
{
"mac":[
"d1:d1:d1:d1:d1:d1"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.211"
},
{
"mac":[
"d2:d2:d2:d2:d2:d2"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.212"
},
{
"mac":[
"d3:d3:d3:d3:d3:d3"
],
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.0.2.213"
}
]
}
- mac
- 节点上的网络接口的 MAC 地址列表。只为每个系统的 Provisioning NIC 使用 MAC 地址。
- cpu
- 节点上的 CPU 数量。
- memory
- 内存大小(以 MB 为单位)。
- disk
- 硬盘的大小(以 GB 为单位)。
- arch
- 系统架构。
- pm_type
- 使用的电源管理驱动。在这个示例中使用 IPMI 驱动(
pxe_ipmitool)。 - pm_user, pm_password
- IPMI 的用户名和密码。
- pm_addr
- IPMI 设备的 IP 地址。
注意
stack 用户的家目录(/home/stack/instackenv.json),然后把它导入到 director。使用以下命令:
$ openstack baremetal import --json ~/instackenv.json
$ openstack baremetal configure boot
$ openstack baremetal list
6.3.2. 检查节点硬件
重要
discovery_runbench 选项设置为“true"(请参阅 第 3.7 节 “配置 director”)。
/httpboot/discoverd.ipxe,把 RUNBENCH 内核参数设置为 1。
$ openstack baremetal introspection bulk start
重要
6.3.3. 使用自动健康检查(Automated Health Check,简称 AHC)工具自动为节点加标签
$ sudo yum install -y ahc-tools
ahc-report:提供基准数据测试的报告。ahc-match:根据策略,通过为节点加标签来为节点指定角色。
重要
/etc/ahc-tools/ahc-tools.conf 文件中设置的 Ironic 和 Swift 的凭证信息。它们同 /etc/ironic-discoverd/discoverd.conf 中的凭证信息相同。使用以下命令为 /etc/ahc-tools/ahc-tools.conf 添加相关信息:
$ sudo -i # sed 's/\[discoverd/\[ironic/' /etc/ironic-discoverd/discoverd.conf > /etc/ahc-tools/ahc-tools.conf # chmod 0600 /etc/ahc-tools/ahc-tools.conf # exit
6.3.3.1. ahc-report
ahc-report 脚本会产生多个与您的节点相关的报告。要查看报告的全部,使用 --full 选项。
$ ahc-report --full
ahc-report 还可以被用来专注于一个报告的特定部分。例如,使用 --categories 可以根据节点的硬件(处理器、网卡、固件、内存和其它硬件控制器)进行分类。这还会把具有相似硬件档案的节点进行分组。例如,在示例中的两个节点的 Processors 项会和以下类似:
###################### ##### Processors ##### 2 identical systems : [u'7F8831F1-0D81-464E-A767-7577DF49AAA5', u'7884BC95-6EF8-4447-BDE5-D19561718B29'] [(u'cpu', u'logical', u'number', u'4'), (u'cpu', u'physical', u'number', u'4'), (u'cpu', u'physical_0', u'flags', u'fpu fpu_exception wp de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pse36 clflush mmx fxsr sse sse2 syscall nx x86-64 rep_good nopl pni cx16 hypervisor lahf_lm'), (u'cpu', u'physical_0', u'frequency', u'2000000000'), (u'cpu', u'physical_0', u'physid', u'0'), (u'cpu', u'physical_0', u'product', u'Intel(R) Xeon(TM) CPU E3-1271v3 @ 3.6GHz'), (u'cpu', u'physical_0', u'vendor', u'GenuineIntel'), (u'cpu', u'physical_1', u'flags', u'fpu fpu_exception wp de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pse36 clflush mmx fxsr sse sse2 syscall nx x86-64 rep_good nopl pni cx16 hypervisor lahf_lm'), (u'cpu', u'physical_0', u'frequency', u'2000000000'), (u'cpu', u'physical_0', u'physid', u'0'), (u'cpu', u'physical_0', u'product', u'Intel(R) Xeon(TM) CPU E3-1271v3 @ 3.6GHz'), (u'cpu', u'physical_0', u'vendor', u'GenuineIntel') ... ]
ahc-report 工具还可以识别在您的节点数据中的“局外者(outliers)”。使用 --outliers 选项来启用这个功能:
$ ahc-report --outliers Group 0 : Checking logical disks perf standalone_randread_4k_KBps : INFO : sda : Group performance : min=45296.00, mean=53604.67, max=67923.00, stddev=12453.21 standalone_randread_4k_KBps : ERROR : sda : Group's variance is too important : 23.23% of 53604.67 whereas limit is set to 15.00% standalone_randread_4k_KBps : ERROR : sda : Group performance : UNSTABLE standalone_read_1M_IOps : INFO : sda : Group performance : min= 1199.00, mean= 1259.00, max= 1357.00, stddev= 85.58 standalone_read_1M_IOps : INFO : sda : Group performance = 1259.00 : CONSISTENT standalone_randread_4k_IOps : INFO : sda : Group performance : min=11320.00, mean=13397.33, max=16977.00, stddev= 3113.39 standalone_randread_4k_IOps : ERROR : sda : Group's variance is too important : 23.24% of 13397.33 whereas limit is set to 15.00% standalone_randread_4k_IOps : ERROR : sda : Group performance : UNSTABLE standalone_read_1M_KBps : INFO : sda : Group performance : min=1231155.00, mean=1292799.67, max=1393152.00, stddev=87661.11 standalone_read_1M_KBps : INFO : sda : Group performance = 1292799.67 : CONSISTENT ...
ahc-report 把 standalone_randread_4k_KBps 和 standalone_randread_4k_IOps 磁盘数据标记为“unstable(不稳定)”。当有两个节点的磁盘数据传输率显著不同时,就会出现这个情况。
ahc-match 命令把节点设为特定的角色。
6.3.3.2. ahc-match
ahc-match 命令会对 Overcloud 计划应用一组策略来帮助把节点设置为特定角色。在使用这个命令前,创建一组匹配节点和角色的策略。
ahc-tools 软件包会安装 /etc/ahc-tools/edeploy 下的一组策略文件。包括:
state- 声明文件,它声明了每个角色的节点数量。compute.specs、controller.specs- 匹配 Compute 节点和 Controller 节点的策略文件。
声明文件
state 文件包括了每个角色所具有的节点数量信息。默认的配置文件会显示:
[('control', '1'), ('compute', '*')]
ahc-match 分配一个 Contorller 节点和任意数量的 Compute 节点。在本使用情景中,编辑这个文件:
[('control', '3'), ('ceph-storage', '3'), ('compute', '*')]
策略文件
compute.specs 和 controller.specs 文件分别列出了相关角色的分配规则。这个文件的内容以数组形式出现,例如:
[
('cpu', 'logical', 'number', 'ge(2)'),
('disk', '$disk', 'size', 'gt(4)'),
('network', '$eth', 'ipv4', 'network(192.0.2.0/24)'),
('memory', 'total', 'size', 'ge(4294967296)'),
]
network()- 指定网络中的网络接口。gt()、ge()- 大于(或等于)。lt()、le()- 低于(或等于)。in()- 匹配的项包括在特定集合中。regexp()- 使用正则表达式进行匹配。or()、and()、not()- 布尔函数。or()和and()使用两个参数,not()带有一个参数。
standalone_randread_4k_KBps 和 standalone_randread_4k_IOps 的值来把 Controller 角色的分配限制为磁盘访问速率高于平均值的节点。规则如下:
[
('disk', '$disk', 'standalone_randread_4k_KBps', 'gt(53604)'),
('disk', '$disk', 'standalone_randread_4k_IOps', 'gt(13397)')
]
ceph-storage.spec 档案。确保这些新文件(不带扩展)包括在 state 文件中。
运行匹配工具
ahc-match 工具来分配您的节点。
$ sudo ahc-match
/etc/ahc-tools/edeploy/state 中定义的角色。当一个节点匹配一个角色时,ahc-match 在 Ironic 中把角色添加到节点作为一个能力(capability)。
$ ironic node-show b73fb5fa-1a2c-49c6-b38e-8de41e3c0532 | grep properties -A2
| properties | {u'memory_mb': u'6144', u'cpu_arch': u'x86_64', u'local_gb': u'40', |
| | u'cpus': u'4', u'capabilities': u'profile:control,boot_option:local'} |
| instance_uuid | None |
profile 标签来匹配具有相同标签的角色和 flavor。
6.3.4. 创建硬件档案
$ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 control $ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute $ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 ceph-storage
$ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="compute" compute $ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="control" control $ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="ceph-storage" ceph-storage
capabilities:boot_option 为 flavor 设置了引导模式,capabilities:profile 定义了使用的档案。
6.3.5. 使用默认的 Overcloud Heat 模板
/usr/share/openstack-tripleo-heat-templates。对于这个使用情景,我们把这些模板复制到 stack 用户的家目录中:
$ cp -r /usr/share/openstack-tripleo-heat-templates ~/templates/my-overcloud
openstack overcloud deploy 时,我们使用了 --templates 选项来指定本地的模板目录。
注意
--templates 选项设置值,director 会使用默认的模板目录(/usr/share/openstack-tripleo-heat-templates)。
6.3.6. 创建 Ceph Storage
puppet/ceph-storage-puppet.yaml- 用来编配 Ceph Storage 节点、Ceph Storage 节点与 Overcloud 的集成以及它们的 Puppet 配置的 Heat 模板。puppet/manifest/overcloud_cephstorage.pp- 用来为 Ceph Storage 节点配置基本环境,并在 Overcloud 镜像中应用 Ceph Puppet 模块的 Puppet manifest。puppet/hieradata/ceph.yaml- 传递给 Ceph Storage 节点上的 Puppet 配置的 Puppet hiera 数据。puppet/ceph-storage-post-puppet.yaml- 用来编配 Ceph Storage 节点后配置操作的 Heat 模板。puppet/ceph-cluster-config.yaml- 用来在 Controller 节点上编配 Ceph Monitor 的 Heat 模板。
puppet/hieradata/ceph.yaml,使用 ceph::profile::params::osds 参数把相关的 journal 分区和磁盘进行映射。例如,一个带有 4 个磁盘的 Ceph 节点可以有以下结构:
/dev/sda- 包括 Overcloud 镜像的 root 磁盘/dev/sdb- 包括 journal 分区的磁盘/dev/sdc和/dev/sdd- OSD 磁盘
puppet/hieradata/ceph.yaml 可能包括以下内容:
ceph::profile::params::osds:
'/dev/sdc':
journal: '/dev/sdb1'
'/dev/sdd':
journal: '/dev/sdb2'
puppet/hieradata/ceph.yaml 中的相关参数。
puppet/hieradata/ceph.yaml 文件。当实施 Overcloud 时,Ceph Storage 节点将会使用相关的磁盘映射和自定义设置。
6.3.7. 把所有网络分离到 VLAN
- 网络 1 - Provisioning
- 网络 2 - Internal API
- 网络 3 - Tenant Networks
- 网络 4 - Storage
- 网络 5 - Storage Management
- 网络 6 - External
6.3.7.1. 创建自定义接口模板
/usr/share/openstack-tripleo-heat-templates/network/config/single-nic-vlans- 这个目录中包括了基于角色的、带有 VLAN 配置的单独 NIC 的模板。/usr/share/openstack-tripleo-heat-templates/network/config/bond-with-vlans- 这个目录中包括了基于角色的、绑定 NIC 配置的模板。
stack 用户的家目录,并命名为 nic-configs。
$ cp -r /usr/share/openstack-tripleo-heat-templates/network/config/bond-with-vlans ~/templates/nic-configs
parameters、resources 和 output 项。这里,我们只编辑 resources 项,每个 resources 以以下内容开始:
resources:
OsNetConfigImpl:
type: OS::Heat::StructuredConfig
properties:
group: os-apply-config
config:
os_net_config:
network_config:
os-apply-config 命令和 os-net-config 子命令的请求来为一个节点配置网络属性。network_config 项中包括了自定义的接口配置,这些配置以类型的形式进行组织,它们包括:
- interface
- 定义一个单独网络接口。这个配置指定了每个接口需要使用实际的接口名("eth0"、"eth1"、"enp0s25")还是使用接口编号("nic1"、"nic2"、"nic3")。
- type: interface name: nic2 - vlan
- 定义一个 VLAN。使用从
parameters项中传递来的 VLAN ID 和子网。- type: vlan vlan_id: {get_param: ExternalNetworkVlanID} addresses: - ip_netmask: {get_param: ExternalIpSubnet} - ovs_bond
- 定义 Open vSwitch 中的绑定。一个绑定会把两个
interfaces组合在一起来起到冗余和增加带宽的目的。- type: ovs_bond name: bond1 members: - type: interface name: nic2 - type: interface name: nic3 - ovs_bridge
- 在 Open vSwitch 中定义网桥。网桥把多个
interface、bond和vlan对象连接在一起。- type: ovs_bridge name: {get_input: bridge_name} members: - type: ovs_bond name: bond1 members: - type: interface name: nic2 primary: true - type: interface name: nic3 - type: vlan device: bond1 vlan_id: {get_param: ExternalNetworkVlanID} addresses: - ip_netmask: {get_param: ExternalIpSubnet}
templates/nic-configs/controller.yaml 模板使用以下 network_config 设置:
network_config:
- type: ovs_bridge
name: {get_input: bridge_name}
members:
- type: ovs_bond
name: bond1
ovs_options: {get_param: BondInterfaceOvsOptions}
members:
- type: interface
name: nic2
primary: true
- type: interface
name: nic3
- type: vlan
device: bond1
vlan_id: {get_param: ExternalNetworkVlanID}
addresses:
- ip_netmask: {get_param: ExternalIpSubnet}
routes:
- ip_netmask: 0.0.0.0/0
next_hop: {get_param: ExternalInterfaceDefaultRoute}
- type: vlan
device: bond1
vlan_id: {get_param: InternalApiNetworkVlanID}
addresses:
- ip_netmask: {get_param: InternalApiIpSubnet}
- type: vlan
device: bond1
vlan_id: {get_param: StorageNetworkVlanID}
addresses:
- ip_netmask: {get_param: StorageIpSubnet}
- type: vlan
device: bond1
vlan_id: {get_param: StorageMgmtNetworkVlanID}
addresses:
- ip_netmask: {get_param: StorageMgmtIpSubnet}
- type: vlan
device: bond1
vlan_id: {get_param: TenantNetworkVlanID}
addresses:
- ip_netmask: {get_param: TenantIpSubnet}
br-ex 的外部网桥),并创建了一个由两个编号的接口(nic2 和 nic3)组成的一个名为 bond1 的绑定接口。这个网络还包括了一组加标签的 VLAN(tagged VLAN)设备,并使用 bond1 作为父设备。
get_param 功能。我们在一个针对于我们的网络所创建的一个环境文件中定义它们。
重要
- type: interface name: nic1 use_dhcp: true
ovs_bridge 设备上删除了这些接口。
6.3.7.2. 创建一个高级的 Overcloud 网络环境模板
/home/stack/templates/network-environment.yaml):
resource_registry:
OS::TripleO::BlockStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/cinder-storage.yaml
OS::TripleO::Compute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute.yaml
OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller.yaml
OS::TripleO::ObjectStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/swift-storage.yaml
OS::TripleO::CephStorage::Net::SoftwareConfig: /home/stack/templates/nic-configs/ceph-storage.yaml
parameter_defaults:
InternalApiNetCidr: 172.16.0.0/24
TenantNetCidr: 172.17.0.0/24
StorageNetCidr: 172.18.0.0/24
StorageMgmtNetCidr: 172.19.0.0/24
ExternalNetCidr: 10.1.1.0/24
InternalApiAllocationPools: [{'start': '172.16.0.10', 'end': '172.16.0.200'}]
TenantAllocationPools: [{'start': '172.17.0.10', 'end': '172.17.0.200'}]
StorageAllocationPools: [{'start': '172.18.0.10', 'end': '172.18.0.200'}]
StorageMgmtAllocationPools: [{'start': '172.19.0.10', 'end': '172.19.0.200'}]
# Leave room for floating IPs in the External allocation pool
ExternalAllocationPools: [{'start': '10.1.1.10', 'end': '10.1.1.50'}]
InternalApiNetworkVlanID: 201
StorageNetworkVlanID: 202
StorageMgmtNetworkVlanID: 203
TenantNetworkVlanID: 204
ExternalNetworkVlanID: 100
# Set to the router gateway on the external network
ExternalInterfaceDefaultRoute: 10.1.1.1
# Set to "br-ex" if using floating IPs on native VLAN on bridge br-ex
NeutronExternalNetworkBridge: default: "''"
# Customize bonding options if required
BondInterfaceOvsOptions:
"bond_mode=balance-tcp lacp=active other-config:lacp-fallback-ab=true"
resource_registry 项包括了到每个节点角色的网络接口模板的连接。
parameter_defaults 项包括了一组参数,它们被用来定义每个网络类型的网络选项。如需获得这些参数的详细信息,请参阅 附录 F, 网络环境选项。
重要
NeutronExternalNetworkBridge 参数在创建一个基于计划的 Overcloud 时需要是 parameter_defaults 项的一般分。这是因为计划处理参数的方式。如果创建一个基于计划的 Overcloud(如在基本 Overcloud 使用情景中的 Overcloud),这个参数需要是 Controller-1::NeutronExternalNetworkBridge,并被放置在 parameters 项中。请参阅 第 6.2.5.2 节 “创建一个基本 Overcloud 网络环境模板” 来了解它们的不同。
重要
6.3.7.3. 把 OpenStack 服务分配到分离的网络
/home/stack/templates/network-environment.yaml)中定义一个新的网络映射来把 OpenStack 服务重新分配给不同的网络类型。ServiceNetMap 参数决定了每个服务所使用的网络类型。
...
parameters:
ServiceNetMap:
NeutronTenantNetwork: tenant
CeilometerApiNetwork: internal_api
MongoDbNetwork: internal_api
CinderApiNetwork: internal_api
CinderIscsiNetwork: storage
GlanceApiNetwork: storage
GlanceRegistryNetwork: internal_api
KeystoneAdminApiNetwork: internal_api
KeystonePublicApiNetwork: internal_api
NeutronApiNetwork: internal_api
HeatApiNetwork: internal_api
NovaApiNetwork: internal_api
NovaMetadataNetwork: internal_api
NovaVncProxyNetwork: internal_api
SwiftMgmtNetwork: storage_mgmt
SwiftProxyNetwork: storage
HorizonNetwork: internal_api
MemcachedNetwork: internal_api
RabbitMqNetwork: internal_api
RedisNetwork: internal_api
MysqlNetwork: internal_api
CephClusterNetwork: storage_mgmt
CephPublicNetwork: storage
storage 会把这些服务放置到 Storage 网络而不是 Storage Management 网络。这意味着,您只需要为 Storage 网络定义一组 parameter_defaults,而不是 Storage Management 网络。
6.3.8. 创建高级 Overcloud
$ openstack overcloud deploy --templates ~/templates/my-overcloud -e ~/templates/my-overcloud/environments/network-isolation.yaml -e ~/templates/network-environment.yaml --control-scale 3 --compute-scale 3 --ceph-storage-scale 3 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --ntp-server pool.ntp.org --neutron-network-type vxlan --neutron-tunnel-types vxlan
--templates ~/templates/my-overcloud- 通过一组自定义的 Heat 模板,而不是 director 存储的计划来创建 Overcloud。-e ~/templates/my-overcloud/environments/network-isolation.yaml--e选项为 Overcloud 计划添加了一个额外的环境文件。在这里,它是一个初始化网络分离配置的环境文件。-e ~/templates/network-environment.yaml--e选项为 Overcloud 计划添加了一个环境文件。在这里,它是在 第 6.3.7.2 节 “创建一个高级的 Overcloud 网络环境模板” 中创建的网络环境文件。--control-scale 3- 把 Controller 节点扩展到 3 个。--compute-scale 3- 把 Compute 节点扩展到 3 个。--ceph-storage-scale 3- 把 Ceph Storage 节点扩展到 3 个。--control-flavor control- 为 Controller 节点使用一个特定的 flavor。--compute-flavor compute- 为 Compute 节点使用一个特定的 flavor。--ceph-storage-flavor ceph-storage- 为 Ceph Storage 节点使用一个特定的 flavor。--ntp-server pool.ntp.org- 使用一个 NTP 服务器进行时间同步。这可以保持 Controller 节点集群的同步。--neutron-network-type vxlan- 在 Overcloud 中使用虚拟可扩展 LAN(Virtual Extensible LAN,简称 VXLAN)作为 Neutron 网络。--neutron-network-type vxlan- 在 Overcloud 中使用虚拟可扩展 LAN(Virtual Extensible LAN,简称 VXLAN)作为 Neutron 通道(tunneling)。
注意
stack 用户身份运行:
$ source ~/stackrc # Initializes the stack user to use the CLI commands $ heat stack-list --show-nested
heat stack-list --show-nested 命令会显示创建 Overcloud 的当前状态。
重要
-e 选项为 Overcloud 添加了环境文件。director 需要为 第 7 章 创建 Overcloud 后执行的任务 中的特定功能使用这些环境文件。
6.3.9. 访问高级 Overcloud
stack 用户家目录的 overcloudrc 文件。运行以下命令来使用这个文件:
$ source ~/overcloudrc
$ source ~/stackrc
6.3.10. 隔离 Controller 节点
注意
stack 用户以 heat-admin 用户登录到每个节点。Overcloud 会自动把 stack 用户的 SSH 密钥复制到每个节点的 heat-admin。
pcs status 验证您有一个正在运行的集群:
$ sudo pcs status Cluster name: openstackHA Last updated: Wed Jun 24 12:40:27 2015 Last change: Wed Jun 24 11:36:18 2015 Stack: corosync Current DC: lb-c1a2 (2) - partition with quorum Version: 1.1.12-a14efad 3 Nodes configured 141 Resources configured
pcs property show 验证 stonith 被禁用:
$ sudo pcs property show
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: openstackHA
dc-version: 1.1.12-a14efad
have-watchdog: false
stonith-enabled: false$ sudo pcs stonith describe fence_ipmilan
stonith 设备。在集群中使用以下命令:
$ sudo pcs stonith create my-ipmilan-for-controller01 fence_ipmilan pcmk_host_list=overcloud-controller-0 ipaddr=192.0.2.205 login=admin passwd=p@55w0rd! lanplus=1 cipher=1 op monitor interval=60s $ sudo pcs constraint location my-ipmilan-for-controller01 avoids overcloud-controller-0
$ sudo pcs stonith create my-ipmilan-for-controller02 fence_ipmilan pcmk_host_list=overcloud-controller-1 ipaddr=192.0.2.206 login=admin passwd=p@55w0rd! lanplus=1 cipher=1 op monitor interval=60s $ sudo pcs constraint location my-ipmilan-for-controller02 avoids overcloud-controller-1
$ sudo pcs stonith create my-ipmilan-for-controller03 fence_ipmilan pcmk_host_list=overcloud-controller-2 ipaddr=192.0.2.206 login=admin passwd=p@55w0rd! lanplus=1 cipher=1 op monitor interval=60s $ sudo pcs constraint location my-ipmilan-for-controller03 avoids overcloud-controller-2
注意
$ sudo pcs stonith show
$ sudo pcs stonith show [stonith-name]
stonith 属性设置为 true 来启用隔离功能:
$ sudo pcs property set stonith-enabled=true
$ sudo pcs property show
6.3.11. 完成高级 Overcloud
第 7 章 创建 Overcloud 后执行的任务
7.1. 创建 Overcloud External 网络
overcloud,并在 Neutron 中创建一个外部网络:
$ source ~/overcloudrc $ neutron net-create nova --router:external --provider:network_type flat --provider:physical_network datacentre $ neutron subnet-create --name nova --enable_dhcp=False --allocation-pool=start=10.1.1.51,end=10.1.1.250 --gateway=10.1.1.1 nova 10.1.1.0/24
neutron net-list 确定创建的网络:
$ neutron net-list +-----------------------+-------------+---------------------------------------------------+ | id | name | subnets | +-----------------------+-------------+---------------------------------------------------+ | d474fe1f-222d-4e32... | ext-net | 01c5f621-1e0f-4b9d-9c30-7dc59592a52f 192.0.2.0/24 | | d4746a34-76a4-4b88... | default-net | 4c85b94d-f868-4300-bbbc-8c499cdbbe5e 10.0.0.0/24 | +-----------------------+-------------+---------------------------------------------------+
7.2. 验证 Overcloud
heat_stack_owner 角色:
$ source ~/overcloudrc $ openstack role list +----------------------------------+------------------+ | ID | Name | +----------------------------------+------------------+ | 6226a517204846d1a26d15aae1af208f | swiftoperator | | 7c7eb03955e545dd86bbfeb73692738b | heat_stack_owner | +----------------------------------+------------------+
$ keystone role-create --name heat_stack_owner
$ openstack overcloud validate --overcloud-auth-url $OS_AUTH_URL --overcloud-admin-password $OS_PASSWORD
$OS_AUTH_URL 和 $OS_PASSWORD 这两个环境变量使用 overcloudrc 中设置的值。
注意
--tempest-args smoke 选项来只运行其中一部分的测试。
$ openstack overcloud validate --overcloud-auth-url $OS_AUTH_URL --overcloud-admin-password $OS_PASSWORD --tempest-args smoke
7.3. 扩展 Overcloud
使用 Overcloud 计划进行扩展
overcloud 计划进行更新来扩展 Overcloud。首先,找到计划的 UUID:
$ openstack management plan list
$ openstack management role list
$ openstack management plan set [UUID] -S Compute-1=5
overcloud 计划中的 Compute 节点数设置为 5。在更新完计划后,重新运行 overcloud deploy 命令:
$ openstack overcloud deploy --plan "[UUID]" -e [ENVIRONMENT_FILE]
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
使用 Heat 模板进行扩展
openstack overcloud deploy(使用所需的节点数量)。例如,扩展到 5 个 Compute 节点:
$ openstack overcloud deploy --templates ~/my-overcloud --compute-scale 5 -e [ENVIRONMENT_FILE]
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
7.4. 从 Overcloud 中删除节点
重要
使用 Overcloud 计划删除节点
overcloud 计划和堆栈进行更新来删除 Overcloud 节点。首先,找到计划的 UUID:
$ openstack management plan list
$ heat stack-list
$ nova list
$ openstack overcloud node delete --stack [STACK] --plan [PLAN_UUID] -e [ENVIRONMENT_FILE] [NODE1_UUID] [NODE2_UUID] [NODE3_UUID]
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
使用 Heat 模板删除节点
overcloud 堆栈进行更新。首先,找到 Overcloud 堆栈的 UUID:
$ heat stack-list
$ nova list
$ openstack overcloud node delete --stack [STACK] --templates ~/my-overcloud -e [ENVIRONMENT_FILE] [NODE1_UUID] [NODE2_UUID] [NODE3_UUID]
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
7.5. 替换 Compute 节点
- 迁移 Compute 节点的工作负载
- 关闭当前的 Compute 节点
- 把 Compute 节点从 Overcloud 中删除
- 使用一个新的 Compute 节点来扩展 Overcloud
过程 7.1. 设置密钥
nova 用户都可以在迁移的过程中访问这些节点。使用以下步骤在每个 Compute 节点上设置一个 SSH 密钥对。
- 创建一个 SSH 密钥:
$ ssh-keygen -t rsa -f nova_id_rsa
- 把 SSH 密钥复制到每个 Compute 节点上的
nova用户的家目录中。 - 以
nova用户登录到每个 Compute 节点,运行以下命令来设置密钥:NOVA_SSH=/var/lib/nova/.ssh mkdir ${NOVA_SSH} cp nova_id_rsa ${NOVA_SSH}/id_rsa chmod 600 ${NOVA_SSH}/id_rsa cp nova_id_rsa.pub ${NOVA_SSH}/id_rsa.pub cp nova_id_rsa.pub ${NOVA_SSH}/authorized_keys chown -R nova.nova ${NOVA_SSH} # enable login for nova user on compute hosts: usermod -s /bin/bash nova # add ssh keys of overcloud nodes into known hosts: ssh-keyscan -t rsa `os-apply-config --key hosts --type raw --key-default '' | awk '{print $1}'` >>/etc/ssh/ssh_known_hosts
过程 7.2. 从 Compute 节点上迁移虚拟机
- 从 director 上 source
overcloudrc,并获得当前的 Nova 服务列表:$ source ~stack/overcloudrc $ nova service-list
- 在要迁移的节点上禁用
nova-compute服务。$ nova service-disable [service-id] nova-compute
这会防止新的虚拟机在它上面运行。 - 开始把虚拟机从节点上迁移的过程:
# nova host-servers-migrate [service-id]
- 使用以下命令可以查看迁移过程的当前状态:
# nova migration-list
- 当每个虚拟机的迁移过程完成后,它在 Nova 中的状态将变为
VERIFY_RESIZE。您将可以确认迁移已成功完成,或把它恢复到原来的状态。要确认进行迁移,使用以下命令:# nova resize-confirm [server-name]
- 最后,当所有迁移都已完成并被确认后,在 Nova 的 Compute 节点上删除(禁用)运行的服务:
# nova service-delete [service-id]
现在,您可以重启或关闭节点(使用 Ironic API);或把它从 overcloud 环境中删除。
过程 7.3. 从 Overcloud 中删除 Compute 节点
- 根据 第 7.4 节 “从 Overcloud 中删除节点” 中的介绍进行操作。
过程 7.4. 使用一个新的 Compute 节点来扩展 Overcloud
- 根据 第 7.3 节 “扩展 Overcloud” 中的介绍进行操作。
7.6. 把虚拟机导入到 Overcloud
$ nova image-create instance_name image_name $ glance image-download image_name --file exported_vm.qcow2
$ glance image-create --name imported_image --file exported_vm.qcow2 --disk-format qcow2 --container-format bare $ nova boot --poll --key-name default --flavor m1.demo --image imported_image --nic net-id=net_id imported
重要
7.7. 更新 director 软件包和镜像
yum 来确保 director 主机使用了最新的软件包:
$ sudo yum update
stack 用户的家目录的 images 目录中(/home/stack/images/)。在获得这些镜像后,安装以下步骤来替换镜像:
过程 7.5. 更新 director 镜像
- 从 director 中删除存在的镜像。
$ openstack image list $ openstack image delete [IMAGE-UUID] [IMAGE-UUID] [IMAGE-UUID] [IMAGE-UUID] [IMAGE-UUID]
- 把最新的镜像导入到 director。
$ cd ~/images $ openstack overcloud image upload $ openstack baremetal configure boot
警告
运行openstack baremetal configure boot会从每个节点的capabilities属性中删除所有的档案信息和引导选项。每个节点的这个信息都需要被替换。如需了解更多相关信息,请参阅 BZ#1241199。
7.8. 更新 Overcloud 软件包
openstack overcloud update 来在所有节点上进行更新。
-i 选项来在每个断点上进行交互式确认。
在使用计划创建的 Overcloud 上更新软件包
overcloud 计划来更新 Overcloud 节点。首先,找到计划的 UUID:
$ openstack management plan list
$ openstack overcloud update stack --plan [PLAN_UUID] -e [ENVIRONMENT_FILE] -i overcloud
overcloud 堆栈中的所有节点的软件包更新过程。它会在 overcloud 计划中设置 UpdateIdentifier 参数,然后触发堆栈更新操作。这将在每个节点上运行 yum update。
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
在使用 Heat 模板集合创建的 Overcloud 上更新软件包
$ openstack overcloud update stack --templates [TEMPLATES_DIR] -e [ENVIRONMENT_FILE] -i overcloud
overcloud 堆栈中的所有节点的软件包更新过程。它会在 Overcloud Heat 模板集合中设置 UpdateIdentifier 参数,然后触发堆栈更新操作。这将在每个节点上运行 yum update。
重要
-e 或 --environment-file 选项再次传递它们来避免对 Overcloud 的不必要的改变。
7.9. 删除 Overcloud
过程 7.6. 删除 Overcloud
- 删除一个存在的 Overcloud:
$ heat stack-delete overcloud
- 确认删除 Overcloud:
$ heat stack-list
删除操作会需要几分钟完成。
第 8 章 创建自定义配置
8.1. 首次引导时的配置
cloud-init,您可以在其中调用使用 OS::TripleO::NodeUserData 资源类型。
/home/stack/templates/nameserver.yaml),它运行一个脚本来为每个节点的 resolv.conf 添加一个特定的名称解析服务器(nameserver)。我们使用 OS::TripleO::MultipartMime 资源类型来发送配置脚本。
heat_template_version: 2014-10-16
resources:
userdata:
type: OS::Heat::MultipartMime
properties:
parts:
- config: {get_resource: nameserver_config}
nameserver_config:
type: OS::Heat::SoftwareConfig
properties:
config: |
#!/bin/bash
echo "nameserver 192.168.1.1" >> /etc/resolve.conf
outputs:
OS::stack_id:
value: {get_resource: userdata}
/home/stack/templates/firstboot.yaml),它把我们的 Heat 模板注册为 OS::TripleO::NodeUserData 资源类型。
resource_registry: OS::TripleO::NodeUserData: ~/templates/nameserver.yaml
$ openstack overcloud deploy --templates -e ~/templates/firstboot.yaml
-e 把环境文件添加到 Overcloud 堆栈。
8.2. 创建 Overcloud 后的配置
OS::TripleO::NodeExtraConfigPost 资源来应用使用标准的 OS::Heat::SoftwareConfig 类型的配置。这会在主 Overcloud 配置完成后应用额外的配置。
/home/stack/templates/nameserver.yaml),它运行一个脚本来为每个节点的 resolv.conf 添加一个不同的名称解析服务器(nameserver)。
heat_template_version: 2014-10-16
parameters:
servers:
type: json
nameserver_ip:
type: string
resources:
ExtraConfig:
type: OS::Heat::SoftwareConfig
properties:
group: script
config:
str_replace:
template: |
#!/bin/sh
echo "nameserver _NAMESERVER_IP_" >> /etc/resolve.conf
parameters:
_NAMESERVER_IP_: {get_param: nameserver_ip}
ExtraDeployments:
type: OS::Heat::SoftwareDeployments
properties:
servers: {get_param: servers}
config: {get_resource: ExtraConfig}
actions: ['CREATE','UPDATE']
重要
servers 参数是应用配置的服务器列表,它由父模板提供。这个参数在所有 OS::TripleO::NodeExtraConfigPost 模板中都是必需的。
/home/stack/templates/post_config.yaml),它把我们的 Heat 模板注册为 OS::TripleO::NodeExtraConfigPost: 资源类型。
resource_registry: OS::TripleO::NodeExtraConfigPost: nameserver.yaml parameter_defaults: nameserver_ip: 192.168.1.1
$ openstack overcloud deploy --templates -e ~/templates/post_config.yaml
8.3. 修改 Puppet 配置数据
puppet/hieradata 下的 Heat 模板集合中。这提供了一个修改传递到 Overcloud 节点的初始参数的方法。
puppet/hieradata/compute.yaml 来把 Compute 节点的预留内存增加到 1024 MB:
nova::compute::reserved_host_memory: 1024
注意
puppet/hieradata/compute.yaml 中设置的自定义 Puppet 类必须存在于 OpenStack Puppet 模块集合中。如果没有存在,可以把这个类添加到 puppet/manifests 中的相关 Puppet manifest 中,或创建一个自定义 Puppet manifest 并在配置后进行应用。
8.4. 应用自定义 Puppet 配置
motd。这会首先创建一个 Heat 模板(/home/stack/templates/custom_puppet_config.yaml)来启动 Puppet 配置。
resources:
ExtraPuppetConfig:
type: OS::Heat::SoftwareConfig
properties:
config: {get_file: motd.pp}
group: puppet
options:
enable_hiera: True
enable_facter: False
ExtraPuppetDeployments:
type: OS::Heat::SoftwareDeployments
properties:
config: {get_resource: ExtraPuppetConfig}
servers: {get_param: servers}
/home/stack/templates/motd.pp,并把它传递给节点进行配置。motd.pp 文件本身包括了我们的 Puppet 类来进行安装和配置 motd。
/home/stack/templates/puppet_post_config.yaml),它会把我们的 Heat 模板注册为 OS::TripleO::NodeExtraConfigPost: 资源类型。
resource_registry: OS::TripleO::NodeExtraConfigPost: ~/templates/custom_puppet_config.yaml
$ openstack overcloud deploy --templates -e ~/templates/custom_puppet_config.yaml
motd.pp 中的配置应用到 Overcloud 的所有节点上。
第 9 章 对 director 进行故障排除
/var/log目录包括了许多常见 OpenStack Platform 组件的日志文件,以及标准 Red Hat Enterprise Linux 应用的日志文件。journald服务为多个组件提供日志功能。Ironic 使用两个单元:openstack-ironic-api和openstack-ironic-conductor。同样的,ironic-discoverd也使用两个单元:openstack-ironic-discoverd和openstack-ironic-discoverd-dnsmasq。以下是使用这个服务的示例:$ sudo journalctl -u openstack-ironic-discoverd -u openstack-ironic-discoverd-dnsmasq
ironic-discoverd还把 ramdisk 的日志保存在/var/log/ironic-discoverd/ramdisk/中(gz 压缩的 tar 文件)。它们的文件名中包括日期、时间和节点的 IPMI 地址。使用这些日志来对相关的服务进行诊断。
9.1. 对节点注册进行故障排除
ironic 来解决相关的问题。以下是几个示例:
过程 9.1. 修正一个不正确的 MAC 地址
- 找到分配的端口 UUID:
$ ironic node-port-list [NODE UUID]
- 更新 MAC 地址:
$ ironic port-update [PORT UUID] replace address=[NEW MAC]
过程 9.2. 修正一个不正确的 IPMI 地址
- 运行以下命令:
$ ironic node-update [NODE UUID] replace driver_info/ipmi_address=[NEW IPMI ADDRESS]
9.2. 对硬件內省的故障排除
ironic-discoverd)会默认在一个小时后出现超时。在一些时候,这意味着发现 ramdisk 有问题,但通常情况下是因为不正确的环境配置,特别是 BIOS 引导设置。
开始节点內省的错误
baremetal introspection 命令,它是一个安全调用 Ironic 服务的命令。但是,如果直接使用 ironic-discoverd,它可能在发现状态是 AVAILABLE 的节点过程中出现问题。在进行发现操作前,把节点的状态改为 MANAGEABLE:
$ ironic node-set-provision-state [NODE UUID] manage
$ ironic node-set-provision-state [NODE UUID] provide
停止发现过程
ironic-discoverd 没有提供一个直接停止发现过程的方法。我们推荐的方法是等待发现过程的超时发生。如果需要,可以修改 /etc/ironic-discoverd/discoverd.conf 中的 timeout 设置来设定一个新的超时时间(以分钟为单位)。
过程 9.3. 停止发现过程
- 把每个节点的电源状态改为 off:
$ ironic node-set-power-state [NODE UUID] off
- 删除
ironic-discoverd的缓存数据并重启它:$ rm /var/lib/ironic-discoverd/discoverd.sqlite $ sudo systemctl restart openstack-ironic-discoverd
9.3. 对创建 Overcloud 进行故障排除
- 编配(Heat 和 Nova 服务)
- 裸机部署(Ironic 服务)
- 实施后的配置(Puppet)
9.3.1. 编配
$ heat stack-list +-----------------------+------------+--------------------+----------------------+ | id | stack_name | stack_status | creation_time | +-----------------------+------------+--------------------+----------------------+ | 7e88af95-535c-4a55... | overcloud | CREATE_FAILED | 2015-04-06T17:57:16Z | +-----------------------+------------+--------------------+----------------------+
openstack overcloud deploy 后的错误信息。
9.3.2. 裸机部署
ironic 查看所有注册的节点和它们当前的状态:
$ ironic node-list +----------+------+---------------+-------------+-----------------+-------------+ | UUID | Name | Instance UUID | Power State | Provision State | Maintenance | +----------+------+---------------+-------------+-----------------+-------------+ | f1e261...| None | None | power off | available | False | | f0b8c1...| None | None | power off | available | False | +----------+------+---------------+-------------+-----------------+-------------+
- 在结果列表中检查 Provision State 和 Maintenance 栏中的数据。检查以下情况:
- 表为空,或比期望的节点数要少
- Maintenance 被设置为 True
- Provision State 被设置为
manageable
这通常意味着问题是由注册或发现过程造成的。例如,如果 Maintenance 被自动设置为 True,这通常是因为节点使用了错误的电源管理凭证。 - 如果 Provision State 的值是
available,这意味着问题发生在裸机部署开始前。 - 如果 Provision State 的值是
active,Power State 的值是power on,这意味着裸机部署已成功完成,所出现的问题发生在实施后的配置阶段。 - 如果一个节点的 Provision State 值是
wait call-back,这意味着对这个节点的裸机部署还没有完成。等待这个状态改变;或连接到出现问题的节点的虚拟控制台上检查相关的输出。 - 如果 Provision State 的值是
error或deploy failed,则意味着对这个节点的裸机部署失败。检查裸机节点的详情:$ ironic node-show [NODE UUID]
查看包括错误描述信息的last_error项。如果错误信息不明确,您可以查看相应的日志:$ sudo journalctl -u openstack-ironic-conductor -u openstack-ironic-api
- 如果您看到
wait timeout error信息,节点的 Power State 值是power on,连接到出现问题的节点的虚拟控制台上检查相关的输出。
9.3.3. 实施后的配置
过程 9.4. 诊断实施后的配置问题
- 列出 Overcloud 堆栈中的所有资源来找出哪个出现了问题:
$ heat resource-list overcloud
这会显示一个包括所有资源以及它们的状态的列表。查看带有CREATE_FAILED的资源。 - 显示出问题的资源:
$ heat resource-show overcloud [FAILED RESOURCE]
查看resource_status_reason项中的内容来帮助您进行诊断。 - 使用
nova命令查看 Overcloud 节点的 IP 地址。$ nova list
以heat-admin用户身份登录到一个实施的节点上。例如,堆栈资源列表显示一个 Controller 节点出现问题,您可以登录到那个 Controller 节点。heat-admin用户有 sudo 访问权限。$ ssh heat-admin@192.0.2.14
- 检查
os-collect-config日志找出可能造成故障的原因。$ sudo journalctl -u os-collect-config
- 在某些情况下,Nova 的整个节点实施过程都失败。在这种情况下,一个 Overcloud 角色类型的
OS::Heat::ResourceGroup会出错。使用nova来查看问题。$ nova list $ nova show [SERVER ID]
多数常见错误会显示No valid host was found错误信息,请参阅 第 9.4 节 “对 "No Valid Host Found" 错误进行故障排除” 来获得更多与排除这类错误相关的信息。在其它情况下,查看以下日志文件来进行进一步的故障排除:/var/log/nova/*/var/log/heat/*/var/log/ironic/*
- 使用 SOS 工具包来收集系统硬件和配置的信息。这些信息可被用于进行故障诊断和故障排除。技术支持和开发人员也可以通过 SOS 获得有用的信息。SOS 在 Undercloud 和 Overcloud 中都有用。运行以下命令安装
sos软件包:$ sudo yum install sos
产生一个报告$ sudo sosreport --all-logs
9.4. 对 "No Valid Host Found" 错误进行故障排除
/var/log/nova/nova-conductor.log 包括了以下错误:
NoValidHost: No valid host was found. There are not enough hosts available.
- 确保內省可以成功完成。否则,检查每个节点都包括了需要的 Ironic 节点属性。对于每个节点:
$ ironic node-show [NODE UUID]
检查propertiesJSON 项中的cpus、cpu_arch、memory_mb和local_gb都有有效的值。 - 根据 Ironic 节点属性检查使用的 Nova flavor 没有超过特定数量:
$ nova flavor-show [FLAVOR NAME]
- 根据
ironic node-list检查有足够状态为available的节点。节点的状态为manageable通常意味着內省操作失败。 - 使用
ironic node-list检查没有处于维护模式的节点。当一个节点被自动变为维护模式时,通常意味着不正确的电源管理凭证。检查它们并删除维护模式:$ ironic node-set-maintenance [NODE UUID] off
- 如果您使用 AHC 工具程序来自动标记节点,请根据每个 flavor 和档案来检查是否有足够的相关节点。检查
ironic node-show输出中的properties项的capabilities值。例如,一个标记为 Compute 角色的节点应该包括profile:compute。 - 在进行完內省操作后,从 Ironic 为 Nova 生成节点信息可能会需要一些时间来完成。director 的工具程序通常会把这个时间考虑进去。但是,如果您手工进行了一些操作,节点可能会在一个短时间内对 Nova 无效。使用以下命令检查您的系统中的总资源:
$ nova hypervisor-stats
附录 A. 组件
共享的程序库
- diskimage-builder
diskimage-builder是一个镜像构建工具。- dib-utils
dib-utils包括了diskimage-builder使用的工具。- os-collect-config, os-refresh-config, os-apply-config, os-net-config
- 用来配置实例的一组工具。
- tripleo-image-elements
tripleo-image-elements是用来安装不同软件的diskimage-builder风格元素的存储库。
Installer
- instack
instack在当前系统上执行diskimage-builder风格元素。这可以象diskimage-builder在一个镜像构建中应用风格元素一样,在当前运行的系统上应用风格元素。- instack-undercloud
instack-undercloud是基于instack的 Undercloud 安装程序(installer)。
节点管理
- ironic
- OpenStack Ironic 项目用来部署和管理逻辑实例。
- ironic-discoverd
ironic-discoverd为新注册的节点发现硬件属性。
实施计划
- tuskar
- OpenStack Tuskar 项目被用来计划环境的实施。
实施和编配
- heat
- OpenStack Heat 项目是一个编配(orchestration)工具。它会读描述 OpenStack 环境资源的 YAML 文件,并把这些资源设置为所需的状态。
- heat-templates
openstack-heat-templates存储库包括了额外的镜像元素,可以被用来在使用 Heat 进行 Puppet 配置时产生磁盘镜像。- tripleo-heat-templates
openstack-tripleo-heat-templates仓库描述了 Heat Orchestration Template YAML 文件和 Puppet manifest 中的 OpenStack 环境。Tuskar 会处理这些模板,并使它们通过 Heat 成为一个真正的环境。- puppet-modules
- OpenStack Puppet 模板被用来通过
tripleo-heat-templates配置 OpenStack 环境。 - tripleo-puppet-elements
tripleo-puppet-elements描述了 director 用来安装 Red Hat Enterprise Linux OpenStack Platform 的磁盘镜像。
用户接口
- tuskar-ui
- 用来安装和管理 OpenStack 的图形用户接口(GUI)。它是 Horizon dashboard 的一个插件。
- tuskar-ui-extras
- 为
tuskar-uiGUI 提供了增强的功能。它是 Horizon dashboard 的一个插件。 - python-openstackclient
python-openstackclient是一个用来管理多个 OpenStack 服务和客户端的 CLI 工具。- python-rdomanager-oscplugin
python-rdomanager-oscplugin是集成在python-openstackclient中的一个 CLI 工具程序。它提供了与instack的安装和初始配置相关的功能。
附录 B. 电源管理驱动
B.1. Dell Remote Access Controller (DRAC)
- pm_type
- 把这个选项设置为
pxe_drac。 - pm_user, pm_password
- DRAC 的用户名和密码。
- pm_addr
- DRAC 主机的 IP 地址。
B.2. Integrated Lights-Out (iLO)
- pm_type
- 把这个选项设置为
pxe_ilo。 - pm_user, pm_password
- iLO 的用户名和密码。
- pm_addr
- iLO 接口的 IP 地址。
额外注记
- 编辑
/etc/ironic/ironic.conf文件,把pxe_ilo加入到enabled_drivers选项来启用这个驱动。 - director 需要为 iLo 安装一组额外的工具程序。安装
python-proliantutils软件包并重启openstack-ironic-conductor服务:$ sudo yum install python-proliantutils $ sudo systemctl restart openstack-ironic-conductor.service
- 为了成功进行內省,HP 节点必须是 2015 的固件版本。director 已经经过测试可以使用固件版本为 1.85(May 13 2015)的节点。
B.3. iBoot
- pm_type
- 把这个选项设置为
pxe_iboot。 - pm_user, pm_password
- iBoot 的用户名和密码。
- pm_addr
- iBoot 接口的 IP 地址。
- pm_relay_id(可选)
- iBoot 对于主机的中继 ID。默认值是 1。
- pm_port(可选)
- iBoot 端口。默认值是 9100。
额外注记
- 编辑
/etc/ironic/ironic.conf文件,把pxe_iboot加入到enabled_drivers选项来启用这个驱动。
B.4. SSH 和 Virsh
重要
- pm_type
- 把这个选项设置为
pxe_ssh。 - pm_user, pm_password
- SSH 的用户名和 SSH 公共密钥的内容。
- pm_addr
- virsh 主机的 IP 地址。
额外注记
- 运行 libvirt 的服务器需要一个带有在
pm_password属性中设置的公共密钥的 SSH 密钥对。 - 确保所选的
pm_user可以完全访问 libvirt 环境。
附录 C. AHC 工具程序参数
C.1. 硬盘
- 普通 SATA 控制器或 RAID 控制器上的逻辑磁盘
- 附加到 Hewlett Packard RAID 控制器的磁盘
表 C.1. 普通的 SATA 控制器参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
size
|
磁盘大小
|
('disk', 'sda', 'size', '899')
|
Medium
|
|
vendor
|
磁盘厂商
|
('disk', 'sda', 'vendor', 'HP')
|
Medium
|
|
model
|
磁盘模式
|
('disk', 'sda', 'model', 'LOGICAL VOLUME')
|
High
|
|
rev
|
磁盘的固件版本
|
('disk', 'sda', 'rev', '3.42')
|
Medium
|
|
WCE
|
启用写缓存
|
('disk', 'sda', 'WCE', '1')
|
Low
|
|
RCD
|
禁用读缓存
|
('disk', 'sda', 'RCD, '1')
|
Low
|
表 C.2. Hewlett Packard Raid 控制器参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
size
|
raw 磁盘的大小
|
('disk', '1I:1:1', 'size', '300')
|
Medium
|
|
type
|
raw 磁盘的类型
|
('disk', '1I:1:1', 'type', 'SAS')
|
Low
|
|
slot
|
raw 磁盘的 slot id
|
('disk', '1I:1:1', 'slot', '0')
|
Medium
|
C.2. 系统
表 C.3. 系统产品参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
serial
|
硬件的序列号
|
('system', 'product', 'serial', 'XXXXXX'')
|
Unique*
|
|
name
|
产品名
|
('system', 'product', 'name', 'ProLiant DL360p Gen8 (654081-B21)')
|
High
|
|
vendor
|
厂商名
|
('system', 'product', 'vendor', 'HP')
|
Medium
|
表 C.4. 系统 IPMI 参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
ipmi
|
IPMI 频道号
|
('system', 'ipmi', 'channel', 2)
|
Low
|
|
ipmi-fake
|
用于测试的假的 IPMI 接口
|
('system', 'ipmi-fake', 'channel', '0')
|
Low
|
C.3. 固件
表 C.5. 固件参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
version
|
BIOS 的版本
|
('firmware', 'bios', 'version', 'G1ET73WW (2.09 )')
|
Medium
|
|
date
|
BIOS 发行的时间
|
('firmware', 'bios', 'date', '10/19/2012')
|
Medium
|
|
vendor
|
厂商
|
('firmware', 'bios', 'vendor', 'LENOVO')
|
Low
|
C.4. 网络
表 C.6. 网络参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
serial
|
MAC 地址
|
('network', 'eth0', 'serial', 'd8:9d:67:1b:07:e4')
|
Unique
|
|
vendor
|
NIC 的厂商
|
('network', 'eth0', 'vendor', 'Broadcom Corporation')
|
Low
|
|
product
|
NIC 的描述
|
('network', 'eth0', 'product', 'NetXtreme BCM5719 Gigabit Ethernet PCIe')
|
Medium
|
|
size
|
连接的容量(bits/sec)
|
('network', 'eth0', 'size', '1000000000')
|
Low
|
|
ipv4
|
IPv4 地址
|
('network', 'eth0', 'ipv4', '10.66.6.136')
|
High
|
|
ipv4-netmask
|
IPv4 网络掩码
|
('network', 'eth0', 'ipv4-netmask', '255.255.255.0')
|
Low
|
|
ipv4-cidr
|
IPv4 cidr
|
('network', 'eth0', 'ipv4-cidr', '24')
|
Low
|
|
ipv4-network
|
IPv4 网络地址
|
('network', 'eth0', 'ipv4-network', '10.66.6.0')
|
Medium
|
|
link
|
物理连接状态
|
('network', 'eth0', 'link', 'yes')
|
Medium
|
|
driver
|
NIC 的驱动名
|
('network', 'eth0', 'driver', 'tg3')
|
Low
|
|
duplex
|
NIC 的 duplex 类型
|
('network', 'eth0', 'duplex', 'full')
|
Low
|
|
speed
|
NIC 当前的连接速度
|
('network', 'eth0', 'speed', '10Mbit/s')
|
Medium
|
|
latency
|
网络设备的 PCI 延迟
|
('network', 'eth0', 'latency', '0')
|
Low
|
|
autonegotiation
|
NIC 的 auto-negotiation
|
('network', 'eth0', 'autonegotiation', 'on')
|
Low
|
C.5. CPU
表 C.7. CPU 参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
physid
|
CPU 的物理 ID
|
('cpu', 'physical_0', 'physid', '1')
|
Low
|
|
cores
|
CPU 的内核数
|
('cpu', 'physical_0', 'cores', '2')
|
Medium
|
|
enabled_cores
|
CPU 启用的内核数
|
('cpu', 'physical_0',' enabled_cores', '2')
|
Medium
|
|
threads
|
CPU 的线程数量
|
('cpu', 'physical_0', 'threads', '4')
|
Medium
|
|
product
|
CPU 的标识字符串
|
('cpu', 'physical_0', 'product', 'Intel(R) Core(TM) i5-3320M CPU @ 2.60GHz')
|
High
|
|
vendor
|
CPU 的厂商
|
('cpu', 'physical_0', 'vendor', 'Intel Corp.')
|
Low
|
|
frequency
|
CPU 的主频(Hz)
|
('cpu', 'physical_0', 'frequency', '1200000000')
|
Low
|
|
clock
|
CPU 的时钟(Hz)
|
('cpu', 'physical_0', 'clock', '100000000')
|
Low
|
表 C.8. CPU 的整合参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
number (physical)
|
物理 CPU 的总数量
|
('cpu', 'physical', 'number', 2)
|
Medium
|
|
number (logical)
|
逻辑 CPU 的总数量
|
('cpu', 'logical', 'number', '8')
|
Medium
|
C.6. 内存
表 C.9. 内存参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
total
|
主机的内存数量(以字节为单位)
|
('memory', 'total', 'size', '17179869184')
|
High
|
|
size
|
Bank 的大小(以字节为单位)
|
('memory', 'bank:0', 'size', '4294967296')
|
Medium
|
|
clock
|
内存时钟的速度(Hz)
|
('memory', 'bank:0', 'clock', '667000000')
|
Low
|
|
description
|
内存描述
|
('memory', 'bank:0', 'description', 'FB-DIMM DDR2 FB-DIMM Synchronous 667 MHz (1.5 ns)')
|
Medium
|
|
vendor
|
内存厂商
|
('memory', 'bank:0', 'vendor', 'Nanya Technology')
|
Medium
|
|
serial
|
内存序列号
|
('memory', 'bank:0', 'serial', 'C7590943')
|
Unique*
|
|
slot
|
Bank 的物理 slot
|
('memory', 'bank:0', 'slot', 'DIMM1')
|
High
|
|
banks
|
内存 bank 的数量
|
('memory', 'banks', 'count', 8)
|
Medium
|
C.7. Infiniband
表 C.10. Infiniband 卡参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
card_type
|
卡的类型
|
('infiniband', 'card0', 'card_type', 'mlx4_0')
|
Medium
|
|
device_type
|
卡的设备类型
|
('infiniband', 'card0', 'device_type', 'MT4099')
|
Medium
|
|
fw_version
|
卡的固件版本
|
('infiniband', 'card0', 'fw_version', '2.11.500')
|
High
|
|
hw_version
|
卡的硬件版本
|
('infiniband', 'card0', 'hw_version', '0')
|
Low
|
|
nb_ports
|
端口数量
|
('infiniband', 'card0', 'nb_ports', '2')
|
Low
|
|
sys_guid
|
卡的 GUID
|
('infiniband', 'card0', 'sys_guid', '0x0002c90300ea7183')
|
Unique
|
|
node_guid
|
节点的 GUID
|
('infiniband', 'card0', 'node_guid', '0x0002c90300ea7180')
|
Unique
|
表 C.11. Infiniband 端口参数
|
值
|
描述
|
配置示例
|
歧视级别
|
|---|---|---|---|
|
state
|
接口状态
|
('infiniband', 'card0_port1', 'state', 'Down')
|
High
|
|
physical_state
|
连接的物理状态
|
('infiniband', 'card0_port1', 'physical_state', 'Down')
|
High
|
|
rate
|
速度(Gbit/sec)
|
('infiniband', 'card0_port1', 'rate', '40')
|
High
|
|
base_lid
|
端口的基本本地 ID
|
('infiniband', 'card0_port1', 'base_lid', '0'
|
Low
|
|
lmc
|
本地 ID 掩码数
|
('infiniband', 'card0_port1', 'lmc', '0')
|
Low
|
|
sm_lid
|
子网管理器本地 ID
|
('infiniband', 'card0_port1', 'sm_lid', '0')
|
Low
|
|
port_guid
|
端口的 GUID
|
('infiniband', 'card0_port1', 'port_guid', '0x0002c90300ea7181')
|
Unique
|
附录 D. 网络接口参数
表 D.1. 接口选项
|
选项
|
默认值
|
描述
|
|---|---|---|
|
name
| |
接口名称
|
|
use_dhcp
|
False
|
使用 DHCP 分配 IP 地址
|
|
use_dhcpv6
|
False
|
使用 DHCP 分配 v6 IP 地址
|
|
addresses
| |
分配给接口的 IP 地址序列
|
|
routes
| |
分配给接口的路由序列
|
|
mtu
|
1500
|
连接的最大传输单元(maximum transmission unit,简称 MTU)
|
|
primary
|
False
|
作为主接口的接口
|
|
defroute
|
True
|
使用这个接口作为默认路由
|
|
nic_mapping
| |
编号的 NIC 到系统名或 MAC 地址的自定义映射
|
|
persist_mapping
|
False
|
写入设备别名设置,而不是写入系统名
|
表 D.2. VLAN 选项
|
选项
|
默认值
|
描述
|
|---|---|---|
|
vlan_id
| |
VLAN ID
|
|
device
| |
附加到 VLAN 上的 VLAN 的父设备
|
|
use_dhcp
|
False
|
使用 DHCP 分配 IP 地址
|
|
use_dhcpv6
|
False
|
使用 DHCP 分配 v6 IP 地址
|
|
addresses
| |
分配给 VLAN 的 IP 地址序列
|
|
routes
| |
分配给 VLAN 的路由序列
|
|
mtu
|
1500
|
连接的最大传输单元(maximum transmission unit,简称 MTU)
|
|
primary
|
False
|
作为主接口的 VLAN
|
|
defroute
|
True
|
使用这个接口作为默认路由
|
|
nic_mapping
| |
编号的 NIC 到系统名或 MAC 地址的自定义映射
|
|
persist_mapping
|
False
|
写入设备别名设置,而不是写入系统名
|
表 D.3. OVS 绑定选项
|
选项
|
默认值
|
描述
|
|---|---|---|
|
name
| |
绑定名
|
|
use_dhcp
|
False
|
使用 DHCP 分配 IP 地址
|
|
use_dhcpv6
|
False
|
使用 DHCP 分配 v6 IP 地址
|
|
addresses
| |
分配给绑定的 IP 地址序列
|
|
routes
| |
分配给绑定的路由序列
|
|
mtu
|
1500
|
连接的最大传输单元(maximum transmission unit,简称 MTU)
|
|
primary
|
False
|
作为主接口的接口
|
|
members
| |
在绑定中使用的接口项序列
|
|
ovs_options
| |
在创建绑定时传递给 OVS 的一组选项
|
|
ovs_extra
| |
在绑定的网络配置文件中设置为 OVS_EXTRA 参数的一组选项
|
|
defroute
|
True
|
使用这个接口作为默认路由
|
|
nic_mapping
| |
编号的 NIC 到系统名或 MAC 地址的自定义映射
|
|
persist_mapping
|
False
|
写入设备别名设置,而不是写入系统名
|
表 D.4. OVS 网桥选项
|
选项
|
默认值
|
描述
|
|---|---|---|
|
name
| |
网桥名
|
|
use_dhcp
|
False
|
使用 DHCP 分配 IP 地址
|
|
use_dhcpv6
|
False
|
使用 DHCP 分配 v6 IP 地址
|
|
addresses
| |
分配给网桥的 IP 地址序列
|
|
routes
| |
分配给网桥的路由序列
|
|
mtu
|
1500
|
连接的最大传输单元(maximum transmission unit,简称 MTU)
|
|
members
| |
在网桥中使用的一组接口、VLAN 和绑定项序列
|
|
ovs_options
| |
在创建网桥时传递给 OVS 的一组选项
|
|
ovs_extra
| |
在网桥的网络配置文件中设置为 OVS_EXTRA 参数的一组选项
|
|
defroute
|
True
|
使用这个接口作为默认路由
|
|
nic_mapping
| |
编号的 NIC 到系统名或 MAC 地址的自定义映射
|
|
persist_mapping
|
False
|
写入设备别名设置,而不是写入系统名
|
附录 E. 网络接口模板示例
E.1. 配置接口
network_config:
# Add a DHCP infrastructure network to nic2
-
type: interface
name: nic2
use_dhcp: true
-
type: ovs_bridge
name: br-bond
members:
-
type: ovs_bond
name: bond1
ovs_options: {get_param: BondInterfaceOvsOptions}
members:
# Modify bond NICs to use nic3 and nic4
-
type: interface
name: nic3
primary: true
-
type: interface
name: nic4
nic1、nic2 等)而不是使用接口名(如 eth0、eno2 等)时,在一个角色中的主机网络接口不必须是完全相同的。例如,一个主机可能有接口 em1 和 em2,而另外一个主机有接口 eno1 和 eno2,您可以使用 nic1 和 nic2 来指代这两个主机的接口。
nic1 到 nic4,并只为每个主机中的 4 个接口连接网线。
E.2. 配置路由和默认路由
defroute=no。
nic2)作为默认路由,而不是使用 Provisioning 接口,在 provisioning 接口的配置中禁用默认路由:
# No default route on the Provisioning network - type: interface name: nic1 use_dhcp: true defroute: no # Instead use this DHCP infrastructure VLAN as the default route - type: interface name: nic2 use_dhcp: true
- type: vlan
device: bond1
vlan_id: {get_param: InternalApiNetworkVlanID}
addresses:
- ip_netmask: {get_param: InternalApiIpSubnet}
routes:
- ip_netmask: 10.1.2.0/24
next_hop: 172.17.0.1
E.3. 为浮动 IP 使用原生 VLAN
br-ex 网桥上。根据是使用计划还是使用自定义的 Heat 模板集合来创建 Overcloud,参数和相关的项会有所不同。
parameters:
# Set to "br-ex" when using floating IPs on the native VLAN
Controller-1::NeutronExternalNetworkBridge: "''"
parameter_defaults:
# Set to "br-ex" when using floating IPs on the native VLAN
NeutronExternalNetworkBridge: "''"
E.4. 在一个主干接口上使用原生 VLAN
network-environment.yaml 中把 NeutronExternalNetworkBridge 参数设置为 br-ex ,而不是 ''。
network_config:
- type: ovs_bridge
name: {get_input: bridge_name}
addresses:
- ip_netmask: {get_param: ExternalIpSubnet}
routes:
- ip_netmask: 0.0.0.0/0
next_hop: {get_param: ExternalInterfaceDefaultRoute}
members:
- type: ovs_bond
name: bond1
ovs_options: {get_param: BondInterfaceOvsOptions}
members:
- type: interface
name: nic3
primary: true
- type: interface
name: nic4
注意
E.5. 配置大型帧
注意
- type: ovs_bond
name: bond1
mtu: 9000
ovs_options: {get_param: BondInterfaceOvsOptions}
members:
- type: interface
name: nic3
mtu: 9000
primary: true
- type: interface
name: nic4
mtu: 9000
# The external interface should stay at default
- type: vlan
device: bond1
vlan_id: {get_param: ExternalNetworkVlanID}
addresses:
- ip_netmask: {get_param: ExternalIpSubnet}
routes:
- ip_netmask: 0.0.0.0/0
next_hop: {get_param: ExternalInterfaceDefaultRoute}
# MTU 9000 for Internal API, Storage, and Storage Management
- type: vlan
device: bond1
mtu: 9000
vlan_id: {get_param: InternalApiNetworkVlanID}
addresses:
- ip_netmask: {get_param: InternalApiIpSubnet}
附录 F. 网络环境选项
表 F.1. 网络环境选项
|
参数
|
描述
|
示例
|
|---|---|---|
|
InternalApiNetCidr
|
Internal API 网络的网络和子网
|
172.17.0.0/24
|
|
StorageNetCidr
|
Storage 网络的网络和子网
| |
|
StorageMgmtNetCidr
|
Storage Management 网络的网络和子网
| |
|
TenantNetCidr
|
Tenant 网络的网络和子网
| |
|
ExternalNetCidr
|
External 网络的网络和子网
| |
|
InternalApiAllocationPools
|
Internal API 网络的分配池(tuple 格式)
|
[{'start': '172.17.0.10', 'end': '172.17.0.200'}]
|
|
StorageAllocationPools
|
Storage 网络的分配池(tuple 格式)
| |
|
StorageMgmtAllocationPools
|
Storage Management 网络的分配池(tuple 格式)
| |
|
TenantAllocationPools
|
Tenant 网络的分配池(tuple 格式)
| |
|
ExternalAllocationPools
|
External 网络的分配池(tuple 格式)
| |
|
InternalApiNetworkVlanID
|
Internal API 网络的 VLAN ID
|
200
|
|
StorageNetworkVlanID
|
Storage 网络的 VLAN ID
| |
|
StorageMgmtNetworkVlanID
|
Storage Management 网络的 VLAN ID
| |
|
TenantNetworkVlanID
|
Tenant 网络的 VLAN ID
| |
|
ExternalNetworkVlanID
|
External 网络的 VLAN ID
| |
|
ExternalInterfaceDefaultRoute
|
External 网络的网关 IP 地址
|
10.1.2.1
|
|
BondInterfaceOvsOptions
|
绑定接口的选项
|
bond_mode=balance-tcp lacp=active other-config:lacp-fallback-ab=true"
|
附录 G. 实施参数
openstack overcloud deploy 命令的额外参数。
表 G.1. 实施参数
|
参数
|
描述
|
示例
|
|---|---|---|
|
--plan [PLAN]
|
要实施的 Tuskar 计划的名称和 UUID
|
619ecc30-5a5d-4df4-9967-502c77ed90f6
|
|
--templates [TEMPLATES]
|
包括用来实施的 Heat 模板的目录
|
~/templates/my-overcloud
|
|
-t [TIMEOUT], --timeout [TIMEOUT]
|
实施超时时间(分钟)
|
240
|
|
--control-scale [CONTROL_SCALE]
|
扩展的 Controller 节点数量
|
3
|
|
--compute-scale [COMPUTE_SCALE]
|
扩展的 Compute 节点数量
|
3
|
|
--ceph-storage-scale [CEPH_STORAGE_SCALE]
|
扩展的 Ceph 节点数量
|
3
|
|
--block-storage-scale [BLOCK_STORAGE_SCALE]
|
扩展的 Cinder 节点数量
|
3
|
|
--swift-storage-scale [SWIFT_STORAGE_SCALE]
|
扩展的 Swift 节点数量
|
3
|
|
--control-flavor [CONTROL_FLAVOR]
|
Controller 节点使用的 flavor
|
control
|
|
--compute-flavor [COMPUTE_FLAVOR]
|
Compute 节点使用的 flavor
|
compute
|
|
--ceph-storage-flavor [CEPH_STORAGE_FLAVOR]
|
Ceph 节点使用的 flavor
|
ceph-storage
|
|
--block-storage-flavor [BLOCK_STORAGE_FLAVOR]
|
Cinder 节点使用的 flavor
|
cinder-storage
|
|
--swift-storage-flavor [SWIFT_STORAGE_FLAVOR]
|
Swift 存储节点使用的 flavor
|
swift-storage
|
|
--neutron-flat-networks [NEUTRON_FLAT_NETWORKS]
|
定义在 neutron 插件中配置的平面网络(flat nework)。默认是 "datacentre" 允许外部网络创建
|
datacentre
|
|
--neutron-physical-bridge [NEUTRON_PHYSICAL_BRIDGE]
|
在每个 hypervisor 上创建的 Open vSwitch 网桥。默认值是 "br-ex",一般情况下不需要修改它
|
br-ex
|
|
--neutron-bridge-mappings [NEUTRON_BRIDGE_MAPPINGS]
|
使用的物理网桥映射逻辑。默认情况是把主机上的外部网桥(br-ex)映射到一个物理名(datacentre)。我们使用它作为默认的浮动网络(floating network)
|
datacentre:br-ex
|
|
--neutron-public-interface [NEUTRON_PUBLIC_INTERFACE]
|
定义网络节点的 br-ex 中的网桥接口
|
nic1, eth0
|
|
--hypervisor-neutron-public-interface [HYPERVISOR_NEUTRON_PUBLIC_INTERFACE]
|
指定在每个 hypervisor 上哪个接口被添加到网桥
|
nic1, eth0
|
|
--neutron-network-type [NEUTRON_NETWORK_TYPE]
|
Neutron 的租户网络类型
|
gre 或 vxlan
|
|
--neutron-tunnel-types [NEUTRON_TUNNEL_TYPES]
|
Neutron 租户网络的通道类型。使用逗号分隔的字符串可以指定多个值
|
'vxlan' 'gre,vxlan'
|
|
--neutron-tunnel-id-ranges [NEUTRON_TUNNEL_ID_RANGES]
|
可以用来进行租户网络分配的 GRE tunnel ID 的范围
|
1:1000
|
|
--neutron-vni-ranges [NEUTRON_VNI_RANGES]
|
可以用来进行租户网络分配的 VXLAN VNI ID 范围
|
1:1000
|
|
--neutron-disable-tunneling
|
禁用 tunneling 功能来在 Neutron 中使用 VLAN 分段网络或平面网络
| |
|
--neutron-network-vlan-ranges [NEUTRON_NETWORK_VLAN_RANGES]
|
支持的 Neutron ML2 和 Open vSwitch VLAN 映射范围。默认是在 'datacentre' 物理网络中允许任何 VLAN。
|
datacentre:1:1000
|
|
--neutron-mechanism-drivers [NEUTRON_MECHANISM_DRIVERS]
|
Neutron 租户网络的驱动。默认值是 "openvswitch"。使用逗号分隔的字符串可以指定多个值
|
'openvswitch,l2_population'
|
|
--libvirt-type [LIBVIRT_TYPE]
|
hypervisor 使用的虚拟类型
|
kvm,qemu
|
|
--ntp-server [NTP_SERVER]
|
用来同步时间的 NTP 服务器
|
pool.ntp.org
|
|
--cinder-lvm
|
Cinder 存储使用的 LVM iSCSI 驱动
| |
|
--tripleo-root [TRIPLEO_ROOT]
|
director 配置文件所在的目录。使用默认的值
| |
|
--nodes-json [NODES_JSON]
|
用来进行节点注册的原始 JSON 文件。director 会在创建完 Overcloud 后对这个文件进行一些修改。默认值是 instackenv.json
| |
|
--no-proxy [NO_PROXY]
|
为环境变量 no_proxy 指定自定义值。这个环境变量被用来在代理通讯中排除特定的域扩展。
| |
|
-O [OUTPUT DIR], --output-dir [OUTPUT DIR]
|
Tuskar 模板文件写入的目录。如果它不存在,则会被创建。如果没有指定,则会使用一个临时目录
|
~/templates/plan-templates
|
|
-e [EXTRA HEAT TEMPLATE], --extra-template [EXTRA HEAT TEMPLATE]
|
传递给 Overcloud 实施的额外环境文件。可以指定多次。
|
-e ~/templates/my-config.yaml
|
|
--rhel-reg
|
把 Overcloud 节点注册到客户门户网站或 Satellite 6
| |
|
--reg-method
|
overcloud 节点使用的注册方法
|
satellite 代表 Satellite 6,portal 代表客户门户网站
|
|
--reg-org [REG_ORG]
|
注册的机构
| |
|
--reg-force
|
注册系统,即便它已经注册了
| |
|
--reg-sat-url [REG_SAT_URL]
|
注册 Overcloud 节点的 Satellite 6 服务器
| |
|
--reg-activation-key [REG_ACTIVATION_KEY]
|
用于注册的激活码
| |
附录 H. 修订历史
| 修订历史 | |||
|---|---|---|---|
| 修订 7.0-2.1 | Thu Aug 6 2015 | ||
| |||
| 修订 7.0-2 | Wed Aug 5 2015 | ||
| |||
| 修订 7.0-1 | Wed May 20 2015 | ||
| |||