
Red Hat Training
A Red Hat training course is available for RHEL 8
4.5. 测试 I/O 请求大小对 VDO 性能的影响
使用这些测试,您可以识别 VDO 在最佳 I/O 深度时获得最佳性能的块大小。
测试在固定 I/O 深度下执行四个测试,块大小为 8 KiB 到 1 MiB。
先决条件
您已经确定了最佳 I/O 深度值。详情请查看 第 4.4 节 “测试 I/O 深度对 VDO 性能的影响”。
在以下测试中,使用最佳 I/O 深度值替换 best-depth。
4.5.1. 测试 I/O 请求大小对 VDO 中连续写入操作的影响
此测试决定了在不同 I/O 请求大小的 VDO 卷上如何执行后续写入操作。
流程
创建一个新的 VDO 卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过对测试卷执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1为后续写入测试记录报告的吞吐量和延迟:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.5.2. 测试 I/O 请求大小在 VDO 中随机写入时的影响
此测试决定了在不同 I/O 请求大小的 VDO 卷中随机写入操作如何执行。
您必须在每个 I/O 请求大小测试运行之间重新创建 VDO 卷。
流程
针对大小为 4k、8k、16k、32k、64k、128k 、256k、512k 和 1024k 的 I/O 请求大小分别执行以下系列步骤:
创建一个新的 VDO 卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过对测试卷执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1记录随机写入测试所报告吞吐量和延迟时间:
# fio --rw=randwrite \ --bs=request-size \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.5.3. 测试 I/O 请求大小对 VDO 中顺序读取的影响
此测试决定了在不同 I/O 请求大小的 VDO 卷上如何执行后续读操作。
流程
创建一个新的 VDO 卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过对测试卷执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1为后续读测试记录报告的吞吐量和延迟:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=read \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.5.4. 测试 VDO 中 I/O 请求大小对随机读取的影响
此测试决定了在不同 I/O 请求大小的 VDO 卷中随机读操作如何执行。
流程
创建一个新的 VDO 卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过对测试卷执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1记录随机读取测试所报告吞吐量和延迟时间:
# for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=read \ --bs=${iosize}k \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=optimal-depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.5.5. 分析不同 I/O 请求大小中的 VDO 性能
以下示例分析了对不同的 I/O 请求大小记录的 VDO 吞吐量和延迟。
例 4.2. I/O 请求大小分析
图 4.3. 请求大小与吞吐量分析,以及关键拐点
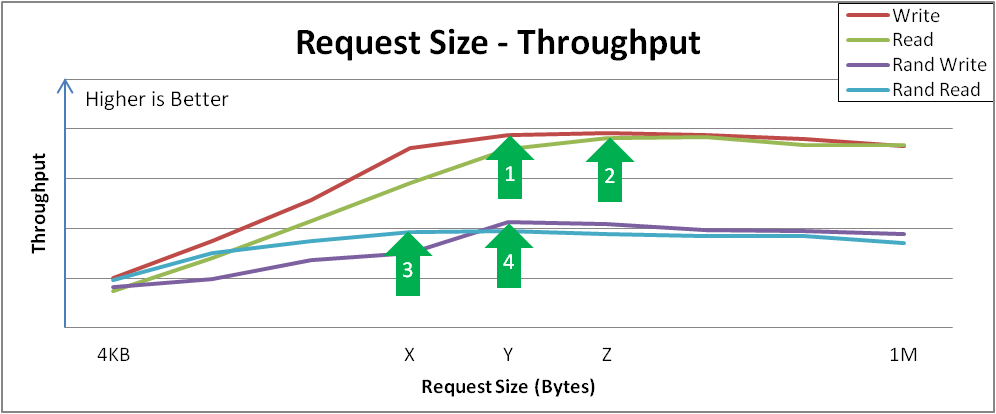
分析示例结果:
顺序写在请求大小 Y 处达到峰时吞吐量。
此曲线演示了可配置或由特定请求大小自然主导的应用程序如何感知性能。较大的请求大小通常会提供更大的吞吐量,因为 4 KiB I/O 操作可能会从合并中受益。
序列读取在 Z 点达到类似的峰值吞吐量。
在达到这些峰值时,I/O 操作完成前的总体延迟会增加,且无额外的吞吐量。您应该调整该设备,使其不接受大于这个大小的 I/O 操作。
随机读取在 X 点达到峰时吞吐量。
当出现大的随机访问请求时,某些设备可能达到近似连续的吞吐率,但其他系统可能会在顺序访问时受到更多的损失。
随机写入在 Y 点达到峰值吞吐量。
随机写入主要涉及和 deduplication 设备的交互,VDO 会获得高性能,特别是请求的大小或者 I/O 深度较大时。