
Red Hat Training
A Red Hat training course is available for RHEL 8
4.4. 测试 I/O 深度对 VDO 性能的影响
这些测试为 VDO 配置决定了产生最佳吞吐量和最低延迟的 I/O 深度。I/O 深度代表 fio 工具一次提交的 I/O 请求数。
由于 VDO 使用 4 KiB 扇区大小,因此测试在 4 KiB I/O 操作以及 1、8、16、32、64、128、256、512 和 1024 的 I/O 深度时执行四角测试。
4.4.1. 测试 I/O 深度对 VDO 中顺序 100% 读的影响
此测试决定了在不同 I/O 深度值的 VDO 卷中顺序 100% 读操作如何执行。
流程
创建一个新的 VDO 卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过对测试卷执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1为顺序 100% 读记录报告的吞吐量和延迟:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=read \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.4.2. 测试 I/O 深度对 VDO 中顺序 100% 写的影响
此测试决定了在不同 I/O 深度值的 VDO 卷中顺序 100% 写操作如何执行。
流程
创建一个新的 VDO 测试卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1为顺序 100% 写记录报告的吞吐量和延迟:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.4.3. 测试 I/O 深度对 VDO 中随机 100% 读取的影响
此测试决定了在不同 I/O 深度值的 VDO 卷中随机 100% 读取操作如何执行。
流程
创建一个新的 VDO 测试卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1记录随机 100% 报告的吞吐量和延迟时间:
# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=randread \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=$depth \ --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.4.4. 在 VDO 中测试 I/O 深度对随机 100% 写入的影响
此测试决定了在不同 I/O 深度值的 VDO 卷中随机 100% 写入操作如何执行。
您必须在每个 I/O 深度测试运行之间重新创建 VDO 卷。
流程
根据 1、2、4、8、16、32、64、128、256、512、1024 和 2048 的 I/O 深度值单独执行以下步骤:
创建一个新的 VDO 测试卷。
详情请查看 第 4.2 节 “创建用于性能测试的 VDO 卷”。
通过执行写
fio作业来预先填充测试可能会访问的区域:# fio --rw=write \ --bs=8M \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --thread \ --direct=1 \ --scramble_buffers=1记录随机 100% 写的吞吐量和延迟时间:
# fio --rw=randwrite \ --bs=4096 \ --name=vdo \ --filename=/dev/mapper/vdo-test \ --ioengine=libaio \ --numjobs=1 \ --thread \ --norandommap \ --runtime=300 \ --direct=1 \ --iodepth=depth-value --scramble_buffers=1 \ --offset=0 \ --size=100g done删除 VDO 测试卷。
详情请查看 第 4.3 节 “清理 VDO 性能测试卷”。
4.4.5. 在不同 I/O 深度下分析 VDO 性能
以下示例采用以不同 I/O 深度值记录的 VDO 吞吐量和延迟。
观察整个范围内的行为和拐点,其中增加的 I/O 深度会降低吞吐量收益。顺序访问和随机访问的峰值可能不同,但对于所有类型的存储配置,峰值可能都有所不同。
例 4.1. I/O 深度分析
图 4.1. VDO 吞吐量分析

注意每个性能曲线中的"knee":
- 标记 1 标识 X 点的峰值顺序吞吐量。此特定配置不从大于 X 的顺序 4 KiB I/O 深度中受益。
- 标识 2 识别在 Z 点处的峰值随机 4 KiB 吞吐量。此特定配置不从大于 Z 的随机 4 KiB I/O 深度中受益。
除了点 X 和 Z 处的 I/O 深度外,带宽收益在逐渐减少,每增加一个 I/O 请求,平均请求延迟就会增加 1:1。
下图显示了上图中在曲线的 "knee" 之后随机写入延迟的示例。您应该在这些点上测试导致最小响应时间损失的最大吞吐量。
图 4.2. VDO 延迟分析
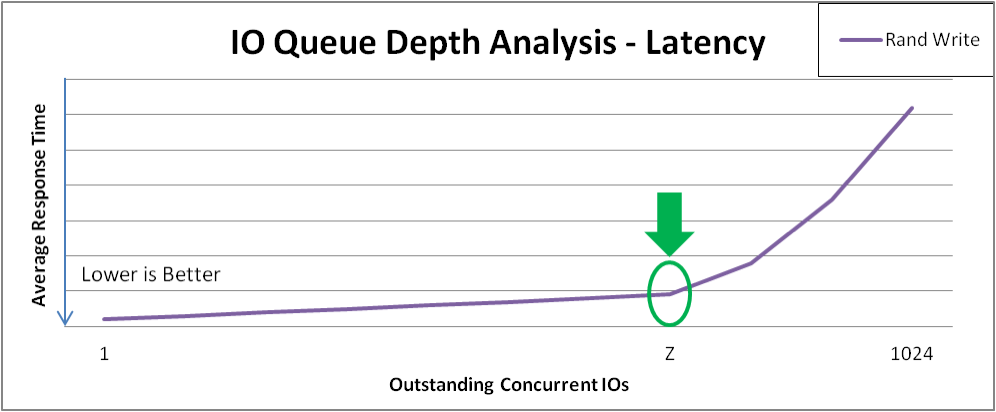
最佳 I/O 深度
点 Z 标记最佳 I/O 深度。测试计划收集 I/O 深度等于 Z 的额外数据。