
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
存储管理指南
在 RHEL 7 中部署和配置单节点存储
摘要
第 1 章 概述
1.1. Red Hat Enterprise Linux 7 中的新功能和增强功能
不包括 eCryptfs
系统存储管理器
XFS 是默认文件系统
文件系统重组
/bin、/sbin、/lib 和 /lib64 现在嵌套在 /usr 下。
snapper
Btrfs(技术预览)
NFSv2 没有支持长
部分 I. 文件系统
第 2 章 文件系统结构和维护
- 可共享和不可取的文件
- 可以在本地和远程主机访问 可共享 文件。Unsharable 文件仅在本地可用。
- 变量和静态文件
- 变量文件 (如文档)可以随时更改。静态文件 (如二进制文件)不会在没有系统管理员的操作的情况下改变。
2.1. 文件系统层次结构标准(FHS)概述.
- 与其他符合 FHS 的系统兼容
- 能够以只读形式挂载
/usr/分区。这很重要,因为/usr/包含常见的可执行文件,用户不应更改。此外,由于/usr/以只读形式挂载,它应该可以从 CD-ROM 驱动器或通过只读 NFS 挂载从另一台机器挂载。
2.1.1. FHS 组织
2.1.1.1. 收集文件系统信息
df 命令
例 2.1. df 命令输出
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shm
例 2.2. df -h 命令输出
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm
/dev/shm 代表系统的虚拟内存文件系统。
DU 命令
GNOME 系统监控器
图 2.1. GNOME 系统监控器中的文件系统选项卡

[D]
2.1.1.2. /boot/ 目录
/boot/ 目录包含引导系统所需的静态文件,例如 Linux 内核。这些文件对于系统正常启动至关重要。
/boot/ 目录。这样做会使系统无法启动。
2.1.1.3. /dev/ 目录
/dev/ 目录包含代表以下设备类型的设备节点:
- 连接到系统的设备;
- 内核提供的虚拟设备.
/dev/ 中创建和删除设备节点。
/dev/ 目录和子目录中的设备定义为 字符 (仅提供输入和输出的串行流,如鼠标或键盘)或 块 (随机访问,如硬盘驱动器或软盘驱动器)。如果安装了 GNOME 或 KDE,则连接(如使用 USB)或插入(如 CD 或者 DVD 驱动器)时会自动检测一些存储设备,并显示其内容的弹出窗口。
表 2.1. /dev 目录中通用文件的示例
| File | 描述 |
|---|---|
/dev/hda | 主 IDE 通道上的主设备。 |
/dev/hdb | 主 IDE 通道上的从设备. |
/dev/tty0 | 第一个虚拟控制台. |
/dev/tty1 | 第二个虚拟控制台. |
/dev/sda | 主 SCSI 或 SATA 通道中的第一个设备。 |
/dev/lp0 | 第一个并行端口。 |
- 映射设备
- 卷组中的逻辑卷,例如
/dev/mapper/VolGroup00-LogVol02。 - 静态设备
- 传统存储卷,例如 /dev/sdbX,其中 sdb 是存储设备名称,X 是分区号。
/dev/sdbX也可以是/dev/disk/by-id/WWID,或/dev/disk/by-uuid/UUID。如需更多信息,请参阅 第 25.8 节 “持久性命名”。
2.1.1.4. /etc/ 目录
/etc/ 目录保留机器本地的配置文件。它不应包含任何二进制文件;如果存在二进制文件,请将其移到 /usr/bin/ 或 /usr/sbin/。
/etc/skel/ 目录存储"框架"用户文件,这些文件用于在首次创建用户时填充主目录。应用也将其配置文件存储在此目录中,并且在执行时可能会引用这些文件。/etc/exports 文件控制哪些文件系统导出到远程主机。
2.1.1.5. /mnt/ 目录
/mnt/ 目录,如 NFS 文件系统挂载。对于所有可移动存储介质,请使用 /media/ 目录。自动检测到的可移动介质挂载在 /media 目录中。
/mnt 目录。
2.1.1.6. /opt/ 目录
/opt/ 目录通常为不属于默认安装的软件和附加软件包保留。安装到 /opt/ 的软件包会创建一个目录,例如,/opt/packagename/。在大多数情况下,此类软件包遵循可预测的子目录结构;大多数软件包将其二进制文件存储在 /opt/packagename/bin/ 中,其 man page 存储在 /opt/packagename/man/ 中。
2.1.1.7. /proc/ 目录
2.1.1.8. /srv/ 目录
/srv/ 目录包含 Red Hat Enterprise Linux 系统提供的特定于站点的数据。此目录为用户提供特定服务(如 FTP、WWW 或 CVS)的数据文件的位置。仅与特定用户相关的数据应位于 /home/ 目录中。
2.1.1.9. /sys/ 目录
/sys/ 目录利用特定于内核的新 sysfs 虚拟文件系统。随着对内核中热插硬件设备的支持,/sys/ 目录包含与 /proc/ 持有的信息相似,但显示特定于热插拔设备的设备信息的层次结构视图。
2.1.1.10. /usr/ 目录
/usr/ 目录用于可在多台机器之间共享的文件。/usr/ 目录通常位于其自己的分区上,并以只读形式挂载。至少,/usr/ 应该包含以下子目录:
/usr/bin- 此目录用于二进制文件。
/usr/etc- 此目录用于系统范围的配置文件。
/usr/games- 此目录存储游戏。
/usr/include- 此目录用于 C 头文件。
/usr/kerberos- 此目录用于与 Kerberos 相关的二进制文件和文件。
/usr/lib- 此目录用于设计不是由 shell 脚本或用户直接使用的对象文件和库。从 Red Hat Enterprise Linux 7.0 开始,
/lib/目录已与/usr/lib合并。现在,它还包含在/usr/bin/和 /usr/sbin/ 中执行二进制文件所需的库。这些共享库镜像用于引导系统或执行根文件系统中的命令。 /usr/libexec- 此目录包含其他程序调用的小型帮助程序。
/usr/sbin- 从 Red Hat Enterprise Linux 7.0 开始,
/sbin已移到/usr/sbin中。这意味着它包含所有系统管理二进制文件,包括启动、恢复、恢复或修复系统所必需的。/usr/sbin/中的二进制文件需要 root 特权才能使用。 /usr/share- 此目录存储不特定于架构的文件。
/usr/src- 此目录存储源代码。
/usr/tmp链接到/var/tmp- 此目录存储临时文件。
/usr/ 目录还应包含 /local/ 子目录。根据 FHS,系统管理员在本地安装软件时会使用这个子目录,在系统更新时应该不会被覆盖。/usr/local 目录的结构与 /usr/ 类似,包含以下子目录:
/usr/local/bin/usr/local/etc/usr/local/games/usr/local/include/usr/local/lib/usr/local/libexec/usr/local/sbin/usr/local/share/usr/local/src
/usr/local/ 的使用与 FHS 稍有不同。FHS 指出 /usr/local/ 应该用于存储系统软件升级安全的软件。由于 RPM Package Manager 可以安全地执行软件升级,因此不需要通过将文件存储在 /usr/local/ 中来保护文件。
/usr/local/ 用于机器本地的软件。例如,如果 /usr/ 目录作为只读 NFS 共享从远程主机挂载,那么仍然可以将软件包或程序安装到 /usr/local/ 目录下。
2.1.1.11. /var/ 目录
/usr/ 挂载为只读,因此任何写入日志文件或需要 spool/ 或 lock/ 目录的程序都应将它们写入 /var/ 目录。FHS 指出 /var/ 用于变量数据,其中包括 spool 目录和文件、日志记录数据、临时和临时文件。
/var/ 目录中找到的一些目录:
/var/account//var/arpwatch//var/cache//var/crash//var/db//var/empty//var/ftp//var/gdm//var/kerberos//var/lib//var/local//var/lock//var/log/- 链接到
/var/spool/mail/的/var/mail /var/mailman//var/named//var/nis//var/opt//var/preserve//var/run//var/spool//var/tmp//var/tux//var/www//var/yp/
/var/run/media/user 目录包含用作可移动介质挂载点的子目录,如 USB 存储介质、DVD、CD-ROM 和 Zip 磁盘。请注意,/media/ 目录用于此目的。
messages 和 lastlog )位于 /var/log/ 目录中。/var/lib/rpm/ 目录包含 RPM 系统数据库。锁定文件位于 /var/lock/ 目录中,通常位于使用该文件的程序的目录中。/var/spool/ 目录有存储某些程序数据文件的子目录。这些子目录包括:
/var/spool/at//var/spool/clientmqueue//var/spool/cron//var/spool/cups//var/spool/exim//var/spool/lpd//var/spool/mail//var/spool/mailman//var/spool/mqueue//var/spool/news//var/spool/postfix//var/spool/repackage//var/spool/rwho//var/spool/samba//var/spool/squid//var/spool/squirrelmail//var/spool/up2date//var/spool/uucp//var/spool/uucppublic//var/spool/vbox/
2.2. 特殊 Red Hat Enterprise Linux 文件位置
/var/lib/rpm/ 目录中。有关 RPM 的更多信息,请参阅 man rpm。
/var/cache/yum/ 目录包含 Package Updater 使用的文件,包括系统的 RPM 标头信息。此位置还可用于在更新系统时临时存储下载的 RPM。有关红帽网络的详情请参考 https://rhn.redhat.com/。
/etc/sysconfig/ 目录。该目录存储各种配置信息。许多在启动时运行的脚本都使用此目录中的文件。
2.3. /proc 虚拟文件系统
/proc 既不包含文本文件,也不包含二进制文件。由于它托管了 虚拟文件,/proc 被称为虚拟文件系统。这些虚拟文件的大小通常为零字节,即使它们包含大量信息。
/proc 文件系统不用于存储。它的主要用途是为硬件、内存、运行进程和其他系统组件提供基于文件的接口。可以通过查看相应的 /proc 文件,在多个系统组件上检索实时信息。还可以操作 /proc 中的某些文件(用户和应用程序)来配置内核。
/proc 文件与管理和监控系统存储相关:
- /proc/devices
- 显示当前配置的各种字符和块设备。
- /proc/filesystems
- 列出内核当前支持的所有文件系统类型。
- /proc/mdstat
- 包含系统上多个磁盘或 RAID 配置(如果存在)的当前信息。
- /proc/mounts
- 列出系统当前使用的所有挂载。
- /proc/partitions
- 包含分区块分配信息.
/proc 文件系统的更多信息,请参阅 Red Hat Enterprise Linux 7 部署指南。
2.4. 丢弃未使用的块
- 批量丢弃操作 由用户使用 fstrim 命令显式运行。此命令丢弃文件系统中符合用户条件的所有未使用的块。
- 在线丢弃操作 在挂载时指定,可以使用
-o discard选项作为 mount 命令的一部分,也可以使用/etc/fstab文件中的discard选项。它们在没有用户干预的情况下实时运行。在线丢弃操作只丢弃从已使用转变为空闲的块。
/sys/block/设备/queue/discard_max_bytes 文件中存储的值不为零,则支持物理丢弃操作。
- 不支持丢弃操作的设备,或者
- 一个由多个设备组成的逻辑设备(LVM 或者 MD),其中任何一个设备都不支持丢弃操作
fstrim -v /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supported
第 3 章 XFS 文件系统
- XFS 的主要功能
- XFS 支持 元数据日志 ,这有助于更快地恢复崩溃。
- XFS 文件系统可以在挂载和激活时进行碎片整理和放大。
- 另外,Red Hat Enterprise Linux 7 支持特定于 XFS 的备份和恢复工具。
- 分配功能
- XFS 具有以下分配方案:
- 基于数据块的分配
- 条带化分配策略
- 延迟分配
- 空间预分配
延迟分配和其他性能优化对 XFS 的影响与对 ext4 的影响一样。即,程序对 XFS 文件系统的写操作无法保证为磁盘上,除非程序随后发出 fsync () 调用。有关延迟分配对文件系统(ext4 和 XFS)的影响的更多信息,请参阅 分配功能 中的 第 5 章 ext4 文件系统。注意创建或扩展文件偶尔会失败,并显示意外的 ENOSPC 写入失败,即使磁盘空间似乎足够了。这是因为 XFS 的性能导向型设计。实际上,它不会成为问题,因为它只有在剩余空间只是几个块时才会发生。 - 其他 XFS 功能
- XFS 文件系统还支持以下内容:
- 扩展的属性 (
xattr) - 这允许系统能够按文件关联多个额外的名称/值对。它会被默认启用。
- 配额日志
- 这可避免在崩溃后需要进行冗长的配额一致性检查。
- 项目/目录配额
- 这允许对目录树的配额限制。
- 小于秒的时间戳
- 这允许时间戳进入亚秒。
- 扩展的属性 (
- 默认 atime 行为是 relatime
- 对于 XFS,relatime 默认为 on。与 noatime 相比,它几乎没有开销,同时仍维护 sane atime 值。
3.1. 创建 XFS 文件系统
- 要创建 XFS 文件系统,请使用以下命令:
#mkfs.xfs block_device- 使用到块设备的路径替换 block_device。例如:
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a, 或/dev/my-volgroup/my-lv。 - 一般情况下,默认选项是常见用途的最佳选择。
- 在包含现有文件系统的块设备上使用 mkfs.xfs 时,添加
-f选项来覆盖该文件系统。
例 3.1. mkfs.xfs 命令输出
meta-data=/dev/device isize=256 agcount=4, agsize=3277258 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=13109032, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=6400, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
条带块设备
mkfs 工具(用于 ext3、ext4 和 xfs)将自动使用此 geometry。如果 mkfs 工具没有检测到条带几何结构,即使存储确实有条带几何结构,则可以在使用以下选项创建文件系统时手动指定它:
- su=value
- 指定条带单位或 RAID 块大小。该值必须 以字节为单位,使用可选的
k、m或g后缀。 - sw=value
- 指定 RAID 设备中数据磁盘的数量,或者条带中条带单位的数量。
# mkfs.xfs -d su=64k,sw=4 /dev/block_device其它资源
3.2. 挂载 XFS 文件系统
# mount /dev/device /mount/pointmke2fs 不同,mkfs.xfs 不使用配置文件;它们都是在命令行中指定的。
写屏障
# mount -o nobarrier /dev/device /mount/point直接访问技术预览
直接访问 (DAX)。应用是一种将持久内存直接映射到其地址空间的方法。要使用 DAX,系统必须有某种可用的持久性内存,通常使用一个或多个非易失性双内存模块(NVDIMM),必须在 NVDIMM 上创建支持 DAX 的文件系统。另外,该文件系统必须使用 dax 挂载选项挂载。然后,在 dax 挂载的文件系统中的一个文件 mmap 会导致存储直接映射到应用程序的地址空间中。
3.3. XFS 配额管理
- uquota/uqnoenforce: 用户配额
- gquota/gqnoenforce: 组配额
- pquota/pqnoenforce: 项目配额
- quota username/userID
- 显示给定 username 或数字 userID的使用情况和限制
- df
- 显示块和 inode 的空闲和已使用数。
# xfs_quota -x- report /path
- 报告特定文件系统的配额信息。
- limit
- 修改配额限制。
例 3.2. 显示示例配额报告
/home 的配额报告示例(在 /dev/blockdevice上),请使用命令 xfs_quota -x -c 'report -h' /home。此时会显示类似如下的输出:
User quota on /home (/dev/blockdevice) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 0 0 0 00 [------] testuser 103.4G 0 0 00 [------] ...
john 设置软和硬内节点计数限制为 500 和 700,其主目录为 /home/john,请使用以下命令:
# xfs_quota -x -c 'limit isoft=500 ihard=700 john' /home/例 3.3. 设置 Soft 和 Hard Block Limit
/target/path 文件系统上的 accounting 进行分组,请使用以下命令:
# xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/path设置项目限制
- 将项目控制的目录添加到
/etc/projects。例如,以下命令将唯一 ID 为 11 的/var/log路径添加到/etc/projects。您的项目 ID 可以是任何映射到项目的数字值。#echo 11:/var/log >> /etc/projects - 将项目名称添加到
/etc/projid,将项目 ID 映射到项目名称。例如,以下命令将名为 logfiles 的项目与上一步中定义的项目 ID 11 关联:#echo logfiles:11 >> /etc/projid - 初始化项目目录。例如,以下命令初始化项目目录
/var:#xfs_quota -x -c 'project -s logfiles' /var - 为使用初始化目录的项目配置配额:
#xfs_quota -x -c 'limit -p bhard=lg logfiles' /var
3.4. 增加 XFS 文件系统的大小
# xfs_growfs /mount/point -D size3.5. 修复 XFS 文件系统
# xfs_repair /dev/device3.6. 暂停 XFS 文件系统
# xfs_freeze mount-pointxfsprogs 软件包提供,该软件包仅适用于 x86_64。
# xfs_freeze -f /mount/point
# xfs_freeze -u /mount/point3.7. 备份和恢复 XFS 文件系统
- 用于创建备份的 xfsdump
- xfsrestore 用于从备份中恢复
3.7.1. XFS 备份和恢复的功能
Backup
xfsdump 工具来:
- 对常规文件镜像执行备份。只能将一个备份写入常规文件。
- 在磁带驱动器中执行备份。
xfsdump工具还允许您将多个备份写入同一磁带。备份可跨越多个标题。要将多个文件系统备份到单个磁带设备,只需将备份写入已包含 XFS 备份的磁带。这会将新备份附加到上一个备份。默认情况下,xfsdump不会覆盖现有的备份。 - 创建增量备份。
xfsdump工具使用 转储级别 来决定其他备份相对的基本备份。从0到9的数字指的是增加的转储级别。增量备份只备份自上一次较低级别转储以来发生变化的文件:- 要执行全备份,请在 文件系统中执行 0 级 转储。
- 1 级转储是全备份后的第一个增量备份。下一个增量备份为 2 级,它仅备份自上 1 级转储后更改的文件,以此类推,最多为 9 级。
- 使用大小、子树或 inode 标志从备份中排除文件,以过滤它们。
恢复
xfsrestore 交互模式。交互模式提供了一组命令来操作备份文件。
3.7.2. 备份 XFS 文件系统
过程 3.1. 备份 XFS 文件系统
- 使用以下命令备份 XFS 文件系统:
#xfsdump -l level [-L label] -f backup-destination path-to-xfs-filesystem- 使用备份的转储级别替换 level。使用
0执行完整备份,或1到9执行后续增量备份。 - 使用您要存储备份的路径替换 backup-destination。目的地可以是常规文件、磁带驱动器或远程磁带设备。例如:用于文件的
/backup-files/Data.xfsdump,对于磁带驱动器,/dev/st0。 - 使用您要备份的 XFS 文件系统的挂载点替换 path-to-xfs-filesystem。例如:
/mnt/data/。文件系统必须挂载。 - 当备份多个文件系统并将其保存到单个磁带设备中时,使用
-L label选项为每个备份添加一个会话标签,以便在恢复时更容易识别它们。使用备份的任何名称替换 label :例如backup_data。
例 3.4. 备份多个 XFS 文件系统
- 要备份挂载在
/boot/和/data/目录中的 XFS 文件系统的内容,并将其保存为/backup-files/目录中的文件:#xfsdump -l 0 -f /backup-files/boot.xfsdump /boot#xfsdump -l 0 -f /backup-files/data.xfsdump /data - 要备份单个磁带设备中的多个文件系统,请使用
-L label选项为每个备份添加一个会话标签:#xfsdump -l 0 -L "backup_boot" -f /dev/st0 /boot#xfsdump -l 0 -L "backup_data" -f /dev/st0 /data
其它资源
- 有关备份 XFS 文件系统的详情请参考 xfsdump(8) man page。
3.7.3. 从备份中恢复 XFS 文件系统
先决条件
- 您需要 XFS 文件系统的文件或者磁带备份,如 第 3.7.2 节 “备份 XFS 文件系统” 所述。
过程 3.2. 从备份中恢复 XFS 文件系统
- 恢复备份的命令因您是从全备份或增量备份中恢复,还是从单个磁带设备恢复多个备份而有所不同:
#xfsrestore [-r] [-S session-id] [-L session-label] [-i]-f backup-locationrestoration-path- 使用备份位置替换 backup-location。这可以是常规文件、磁带驱动器或远程磁带设备。例如:用于文件的
/backup-files/Data.xfsdump,对于磁带驱动器,/dev/st0。 - 使用您要 恢复文件系统的目录的路径替换 restore- path。例如:
/mnt/data/。 - 要从增量(1 级到 9 级)备份恢复文件系统,请添加
-r选项。 - 要从包含多个备份的磁带设备恢复备份,请使用
-S或-L选项指定备份。-S允许您通过其会话 ID 选择备份,而-L则允许您按会话标签选择。要获取会话 ID 和会话标签,请使用 xfsrestore -I 命令。使用备份的会话 ID 替换 session-id。例如,b74a3586-e52e-4a4a-8775-c3334fa8ea2c。使用备份的会话标签替换 session-label。例如,my_backup_session_label。 - 要以交互方式使用
xfsrestore,请使用-i选项。xfsrestore完成读取指定设备后,交互式对话框开始。交互式xfsrestoreshell 中的可用命令包括 cd,ls,add,delete, 和 extract; 如需命令的完整列表,请使用 help 命令。
例 3.5. 恢复多个 XFS 文件系统
/mnt/ 下的目录中:
#xfsrestore -f /backup-files/boot.xfsdump /mnt/boot/#xfsrestore -f /backup-files/data.xfsdump /mnt/data/
#xfsrestore -f /dev/st0 -L "backup_boot" /mnt/boot/#xfsrestore -f /dev/st0 -S "45e9af35-efd2-4244-87bc-4762e476cbab" /mnt/data/
从 Tape 恢复备份时的信息性消息
xfsrestore 工具可能会发出信息。当 xfsrestore 按顺序检查磁带上的每个备份时,信息会告知您是否找到了与请求的备份相匹配。例如:
xfsrestore: preparing drive xfsrestore: examining media file 0 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) xfsrestore: examining media file 1 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) [...]
其它资源
- 有关恢复 XFS 文件系统的详情请参考 xfsrestore(8) man page。
3.8. 配置错误行为
- 继续重试,直到出现以下任一操作:
- I/O 操作成功,或者
- 超过 I/O 操作重试计数或时间限制。
- 考虑永久错误并停止系统。
EIO: 在尝试写入设备时出现错误ENOSPC: 该设备中没有剩余空间ENODEV: Device cannot found
3.8.1. 特定和未定义的条件的配置文件
/sys/fs/xfs/device/error/ 目录中。
/sys/fs/xfs/设备/error/metadata/ 目录包含每个特定错误条件的子目录:
- 用于
EIO 错误条件的 /sys/fs/xfs/device/error/metadata/EIO/ /sys/fs/xfs/device/error/metadata/ENODEV/用于ENODEV错误条件/sys/fs/xfs/device/error/metadata/ENOSPC/用于ENOSPC错误条件
/sys/fs/xfs/device/error/metadata/condition/max_retries: 控制 XFS 重新尝试操作的最大次数。/sys/fs/xfs/device/error/metadata/condition/retry_timeout_seconds: XFS 将停止重试操作的时间限制(以秒为单位)
/sys/fs/xfs/device/error/metadata/default/max_retries: 控制重试的最大次数/sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds: 控制重试的时间限制
3.8.2. 为特定和未定义条件设置文件系统行为
max_retries 文件。
- 对于特定条件:
#echo value > /sys/fs/xfs/device/error/metadata/condition/max_retries - 对于未定义的条件:
#echo value > /sys/fs/xfs/device/error/metadata/default/max_retries
-1 和最大可能值为 int 的值(C 签名的整数类型)之间的数字。64 位 Linux 中是 2147483647。
retry_timeout_seconds 文件。
- 对于特定条件:
#echo value > /sys/fs/xfs/device/error/metadata/condition/retry_timeout_seconds - 对于未定义的条件:
#echo value > /sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds
-1 和 86400 之间的数字,这是一天的秒数。
max_retries 和 retry_timeout_seconds 选项中,-1 表示重试 forever 和 0 以立即停止。
/dev/ 目录中找到,例如: sda。
ENODEV )被视为致命且不可恢复的,无论重试计数如何,其默认值为 0。
3.8.3. 设置卸载行为
fail_at_unmount 选项,文件系统会在卸载过程中覆盖所有其他错误配置,并在不重试 I/O 操作的情况下立即修改文件系统。这允许卸载操作在出现持久错误时也可以成功。
# echo value > /sys/fs/xfs/device/error/fail_at_unmount1 或 0 :
1表示如果找到错误,则立即取消重试。0表示遵守max_retries和retry_timeout_seconds选项。
/dev/ 目录中找到,例如: sda。
fail_at_unmount 选项。启动卸载操作后,配置文件和目录可能无法使用。
3.9. 其他 XFS 文件系统工具
- xfs_fsr
- 用于对已挂载的 XFS 文件系统进行碎片整理。当不使用任何参数调用时,xfs_fsr 会对所有挂载的 XFS 文件系统中的所有常规文件进行碎片整理。此工具还允许用户在指定的时间暂停碎片整理,并在以后从其停止的地方恢复。另外,xfs_fsr 还允许只对一个文件进行碎片整理,如 xfs_fsr /path/to/file中所述。红帽建议不要定期取消整个文件系统碎片,因为 XFS 默认避免碎片。系统范围的碎片整理可能会导致空闲空间出现碎片的影响。
- xfs_bmap
- 打印 XFS 文件系统中文件所使用的磁盘块图。此图列出了指定文件所使用的每一个块,以及文件中没有相应块(即漏洞)的区域。
- xfs_info
- 打印 XFS 文件系统信息.
- xfs_admin
- 更改 XFS 文件系统的参数.xfs_admin 工具只能修改卸载的设备或文件系统的参数。
- xfs_copy
- 将整个 XFS 文件系统的内容并行复制到一个或多个目的地。
- xfs_metadump
- 将 XFS 文件系统元数据复制到文件中。红帽只支持使用 xfs_metadump 工具复制卸载的文件系统或只读挂载的文件系统;否则,生成的转储可能会损坏或不一致。
- xfs_mdrestore
- 将 XFS metadump 镜像(使用 xfs_metadump生成)恢复到文件系统镜像。
- xfs_db
- 调试 XFS 文件系统。
3.10. 从 ext4 迁移到 XFS
3.10.1. Ext3/4 和 XFS 之间的区别
- 文件系统修复
- Ext3/4 在引导时在用户空间中运行 e2fsck,以便根据需要恢复日志。相比之下,XFS 在挂载时在内核空间中执行日志恢复。提供了
fsck.xfsshell 脚本,但不执行任何有用的操作,因为它只能满足 initscript 要求。当请求 XFS 文件系统修复或检查时,请使用 xfs_repair 命令。使用 -n 选项进行只读检查。xfs_repair 命令不会在带有脏日志的文件系统上运行。要修复此类文件系统 挂载和卸载 ,必须首先执行重新执行来回放日志。如果日志损坏且无法重新执行,可以在日志中使用 -L 选项为零。有关 XFS 文件系统修复文件系统的更多信息,请参阅 第 12.2.2 节 “XFS” - 元数据错误行为
- 当遇到元数据错误时,ext3/4 文件系统具有可配置的行为,其默认设置只是继续。当 XFS 遇到不可恢复的元数据错误时,它将关闭文件系统并返回
EFSCORRUPTED错误。系统日志将包含遇到的错误的详情,并在需要时推荐运行 xfs_repair。 - 配额
- XFS 配额不是一个可重新挂载的选项。必须在初始挂载上指定 -o quota 选项,才能使配额生效。虽然 quota 软件包中的标准工具可以执行基本的配额管理任务(如 setquota 和 repquota), xfs_quota 工具可用于特定于 XFS 的功能,如项目配额管理。quotacheck 命令对 XFS 文件系统没有影响。第一次在 XFS 上打开配额核算时,会在内部执行自动 quotacheck。由于 XFS 配额元数据是第一类,因此日志的元数据对象将始终一致,直到手动关闭配额为止。
- 文件系统重新定义大小
- XFS 文件系统没有工具来缩小文件系统。XFS 文件系统可以通过 xfs_growfs 命令在线增长。
- 内节点(inode)号
- 对于大于 1 TB 且具有 256 字节索引节点的文件系统,或者大于 2 TB,XFS 索引节点编号可能超过 2^32。这种大型索引节点编号会导致 32 位 stat 调用失败,并显示 EOVERFLOW 返回值。使用默认的 Red Hat Enterprise Linux 7 配置时,上面描述的问题可能会发生:使用四个分配组非条带化。自定义配置(如文件系统扩展或更改 XFS 文件系统参数)可能会导致不同的行为。应用程序通常正确处理此类更大的索引节点编号。如果需要,使用 -o inode32 参数挂载 XFS 文件系统,以强制低于 2^32 的 inode 号。请注意,使用
inode32不会影响已分配了 64 位数的 inode。重要除非特定环境需要,否则不要使用inode32选项。inode32选项可改变分配行为。因此,如果没有可用空间在较低磁盘块中分配 inode,则可能会出现 ENOSPC 错误。 - 定性预分配
- XFS 使用 规范预分配 来分配块过去 EOF,因为文件被写入。这可避免因为 NFS 服务器上的并发流写工作负载造成文件碎片。默认情况下,此预分配会增加文件大小,并将在"du"输出中明显显示。如果没有在五分钟内没有指定指定预分配的文件,则会丢弃预分配。如果内节点在这个时间前从缓存中循环,则当内节点被回收时,将丢弃预分配。如果因为定性预分配而看到了预规划 ENOSPC 问题,可以使用 -o allocsize=amount 挂载选项指定固定的预分配量。
- 与碎片相关的工具
- 由于 Heuristics 和行为(如延迟分配和规范预分配)导致 XFS 文件系统来说,碎片很少发生。但是,存在用于衡量文件系统碎片的工具,以及对文件系统进行碎片整理。不鼓励使用它们。xfs_db frag 命令尝试将所有文件系统分配成单个碎片编号,以百分比表示。命令的输出需要大量的专业知识才能理解其含义。例如,一个碎片因数为 75% 意味着每个文件平均有 4 个扩展。因此,xfs_db 的 frag 的输出不被视为有用,并建议更小心地分析任何碎片问题。警告xfs_fsr 命令可用于对单个文件或文件系统上的所有文件进行碎片整理。强烈建议不要这样做,因为它可能会破坏文件的本地性,并可能出现碎片释放的空间。
使用 ext3 和 ext4 的命令与 XFS 的比较
表 3.1. ext3 和 ext4 的通用命令与 XFS 的比较
| 任务 | ext3/4 | XFS |
|---|---|---|
| 创建文件系统 | mkfs.ext4 or mkfs.ext3 | mkfs.xfs |
| 文件系统检查 | e2fsck | xfs_repair |
| 重新定义文件系统大小 | resize2fs | xfs_growfs |
| 保存文件系统的镜像 | e2image | xfs_metadump 和 xfs_mdrestore |
| 标签或者调整文件系统 | tune2fs | xfs_admin |
| 备份文件系统 | dump 和 restore | xfsdump 和 xfsrestore |
表 3.2. ext4 和 XFS 的通用工具
| 任务 | ext4 | XFS |
|---|---|---|
| Quota | quota | xfs_quota |
| 文件映射 | filefrag | xfs_bmap |
第 4 章 ext3 文件系统
- 可用性
- 在意外的电源故障或系统崩溃(也称为 未清理的系统关闭)后,机器上每个挂载的 ext2 文件系统都必须通过 e2fsck 程序检查一致性。这是一个耗时的过程,可能会显著延迟系统引导时间,特别是对于包含大量文件的大量卷而言。在这段时间中,卷上的任何数据都不可访问。可以在实时文件系统上运行 fsck -n。但是,如果遇到写入了部分元数据,它不会进行任何更改,并且可能会产生误导。如果在堆栈中使用 LVM,另一个选项是生成文件系统的 LVM 快照,并在其上运行 fsck。最后,您可以选择以只读形式重新挂载文件系统。然后,在重新挂载前,所有待处理的元数据更新(及写入)都会强制到磁盘中。这样可确保文件系统处于一致状态,前提是之前没有损坏。现在,可以运行 fsck -n。ext3 文件系统提供的日志意味着,在未清理的系统关闭后,不再需要此类文件系统检查。使用 ext3 进行一致性检查的唯一时间是在某些罕见的硬件故障情形中,如硬盘驱动器故障。在未清理的系统关闭后恢复 ext3 文件系统的时间不取决于文件系统的大小或文件的数量,而是取决于用于保持一致性的 日志 的大小。默认日志大小大约需要一秒钟就能恢复,具体取决于硬件的速度。注意红帽支持的 ext3 中的唯一日志模式是 data=ordered (默认)。
- 数据完整性
- ext3 文件系统防止发生未清理系统关闭时数据完整性的丢失。ext3 文件系统允许您选择数据接受的保护类型和级别。对于文件系统的状态,ext3 卷配置为默认保持高级别的数据一致性。
- 速度
- 尽管多次写入一些数据,但大多数情况下, ext3 的吞吐量高于 ext2,因为 ext3 的日志优化了硬盘驱动器磁头的移动。您可以从三种日志记录模式中进行选择来优化速度,但这样做意味着在系统出现故障时要权衡数据的完整性。注意红帽支持的 ext3 中的唯一日志模式是 data=ordered (默认)。
- 轻松迁移
- 可轻松从 ext2 迁移到 ext3,并获得强大的日志记录文件系统的优势,而无需重新格式化。有关执行此任务的详情,请参考 第 4.2 节 “转换为 ext3 文件系统”。
ext4.ko。这意味着,无论使用的 ext 文件系统是什么,内核信息总是指 ext4。
4.1. 创建 ext3 文件系统
- 使用
mkfs.ext3工具使用 ext3 文件系统格式化分区或 LVM 卷:#mkfs.ext3 block_device- 使用到块设备的路径替换 block_device。例如:
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a, 或/dev/my-volgroup/my-lv。
- 使用
e2label工具标记文件系统:#e2label block_device volume_label
配置 UUID
-U 选项:
# mkfs.ext3 -U UUID device- 使用您要设置的 UUID 替换 UUID:例如
7cd65de3-e0be-41d9-b66d-96d749c02da7。 - 使用 ext3 文件系统的路径替换 device,以将 UUID 添加到其中:例如
/dev/sda8。
其它资源
- mkfs.ext3(8) man page
- e2label(8) man page
4.2. 转换为 ext3 文件系统
ext2 文件系统转换为 ext3。
ext2 文件系统转换为 ext3,以 root 身份登录并在终端中输入以下命令:
# tune2fs -j block_device4.3. 恢复回 Ext2 文件系统
/dev/mapper/VolGroup00-LogVol02
过程 4.1. 从 ext3 恢复回 ext2
- 以 root 身份登录,并输入以下内容来卸载分区:
# umount /dev/mapper/VolGroup00-LogVol02 - 输入以下命令将文件系统类型改为 ext2:
# tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02 - 输入以下命令检查分区是否有错误:
# e2fsck -y /dev/mapper/VolGroup00-LogVol02 - 然后,通过输入以下内容将该分区再次挂载为 ext2 文件系统:
# mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point使用分区的挂载点替换 /mount/point。注意如果分区的根级别存在.journal文件,请将其删除。
/etc/fstab 文件,否则它将在引导后恢复回来。
第 5 章 ext4 文件系统
- 主要功能
- ext4 文件系统使用扩展(与 ext2 和 ext3 使用的传统块映射方案相反),这提高了使用大型文件时的性能,并减少大型文件的元数据开销。此外,ext4 还相应地标记未分配的块组和 inode 表部分,这允许在文件系统检查期间跳过它们。这样可加快文件系统检查的速度,随着文件系统大小的增加,这将变得更加有益。
- 分配功能
- ext4 文件系统具有以下分配方案:
- 持久性预分配
- 延迟分配
- 多块分配
- 条带感知分配
由于延迟分配和其他性能优化,ext4 向磁盘写文件的行为与 ext3 不同。在 ext4 中,当程序写入文件系统时,无法保证为磁盘上,除非程序随后发出 fsync () 调用。默认情况下,ext3 会自动立即将新创建的文件强制到磁盘,即使没有 fsync ()。此行为隐藏了程序中的错误,这些程序不使用 fsync () 来确保写入的数据在磁盘上。另一方面,ext4 文件系统通常会等待几秒钟才能将更改写入磁盘,从而允许它合并并重新排序写操作,以获得比 ext3 更好的磁盘性能。警告与 ext3 不同,ext4 文件系统不会在事务提交时强制数据写到磁盘。因此,将缓冲的写入刷新到磁盘需要更长的时间。与任何文件系统一样,请使用 fsync () 等数据完整性调用来确保数据被写入持久性存储。 - 其他 ext4 功能
- ext4 文件系统还支持以下内容:
- 扩展属性 (
xattr) - 这允许系统为每个文件关联几个额外的名称和值对。 - 配额日志 - 这避免了崩溃后需要冗长的配额一致性检查。注意ext4 中唯一支持的日志模式是 data=ordered (默认)。
- 亚秒时间戳 - 这向亚秒提供时间戳。
5.1. 创建 ext4 文件系统
- 要创建 ext4 文件系统,请使用以下命令:
#mkfs.ext4 block_device- 使用到块设备的路径替换 block_device。例如:
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-5945339ceb2a, 或/dev/my-volgroup/my-lv。 - 一般说来,默认选项适用于大多数使用场景。
例 5.1. mkfs.ext4 命令输出
~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
245280 inodes, 979456 blocks
48972 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1006632960
30 block groups
32768 blocks per group, 32768 fragments per group
8176 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
条带块设备
- stride=value
- 指定 RAID 块大小。
- stripe-width=value
- 指定 RAID 设备中数据磁盘的数量,或者条带中条带单位的数量。
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/block_device配置 UUID
-U 选项:
# mkfs.ext4 -U UUID device- 使用您要设置的 UUID 替换 UUID:例如
7cd65de3-e0be-41d9-b66d-96d749c02da7。 - 使用 ext4 文件系统的路径替换 device,以将 UUID 添加到其中:例如
/dev/sda8。
其它资源
- mkfs.ext4(8) man page
5.2. 挂载 ext4 文件系统
# mount /dev/device /mount/point
# mount -o acl,user_xattr /dev/device /mount/point
# mount -o data_err=abort /dev/device /mount/point写屏障
# mount -o nobarrier /dev/device /mount/point直接访问技术预览
Direct Access (DAX)提供,作为 ext4 和 XFS 文件系统上的一个技术预览,一个应用程序可以将持久内存直接映射到其地址空间中。要使用 DAX,系统必须有某种可用的持久内存,通常使用一个或多个非线内存模块(NVDIMM),且必须在 NVDIMM 上创建支持 DAX 的文件系统。另外,该文件系统必须使用 dax 挂载选项挂载。然后,在 dax 挂载的文件系统中的一个文件 mmap 会导致存储直接映射到应用程序的地址空间中。
5.3. 重新定义 ext4 文件系统大小
# resize2fs /mount/device size
# resize2fs /dev/device size- s - 512 字节扇区
- K — kilobytes
- M - MB
- G — gigabytes
5.4. 备份 ext2、ext3 或 ext4 文件系统
先决条件
- 如果系统运行了很长时间,请在备份前在分区上运行
e2fsck工具:#e2fsck /dev/device
过程 5.1. 备份 ext2、ext3 或 ext4 文件系统
- 备份配置信息,包括
/etc/fstab文件的内容和 fdisk -l 命令的输出。这对恢复分区非常有用。要捕获这些信息,请运行sosreport或sysreport工具。有关sosreport的更多信息,请参阅 sosreport 是什么以及如何在 Red Hat Enterprise Linux 4.6 及之后的版本中创建?Kdowledgebase 文章。 - 根据分区的角色:
- 如果您要备份的分区是一个操作系统分区,请将您的系统引导至救援模式。请参阅 系统管理员 指南中的引导到救援模式 部分。
- 备份常规的数据分区时,将其卸载。虽然可以在挂载数据时备份数据分区,但备份挂载数据分区的结果可能会无法预测。如果您需要使用
dump实用程序备份挂载的文件系统,当文件系统没有负载过重时,这样做。备份时,文件系统上会出现更多的活动,备份损坏的风险越高。
- 使用
dump程序备份分区的内容:#dump -0uf backup-file /dev/device使用您要存储备份的文件的路径替换 backup-file。使用您要备份的 ext4 分区的名称替换 device。确保您将备份保存到挂载在与您要备份分区不同的分区的目录中。例 5.2. 备份多个 ext4 分区
要将 /dev/sda1、和/dev/sda2/dev/sda3分区的内容备份到存储在/backup-files/目录中的备份文件,请使用以下命令:#dump -0uf /backup-files/sda1.dump /dev/sda1#dump -0uf /backup-files/sda2.dump /dev/sda2#dump -0uf /backup-files/sda3.dump /dev/sda3要执行远程备份,请使用ssh实用程序或配置免密码ssh登录。有关ssh和无密码登录的更多信息,请参阅 系统管理员指南中的使用 ssh 实用程序 和使用基于密钥的身份验证部分。https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html-single/system_administrators_guide/index#s2-ssh-configuration-keypairs例如,在使用ssh时:例 5.3. 使用
ssh执行远程备份#dump -0u -f - /dev/device | ssh root@remoteserver.example.com dd of=backup-file请注意,如果使用标准重定向,则必须单独传递-f选项。
其它资源
- 如需更多信息,请参阅 dump(8) man page。
5.5. 恢复 ext2、ext3 或 ext4 文件系统
先决条件
- 您需要备份分区及其元数据,如 第 5.4 节 “备份 ext2、ext3 或 ext4 文件系统” 所述。
过程 5.2. 恢复 ext2、ext3 或 ext4 文件系统
- 如果您要恢复操作系统分区,请将您的系统引导至救援模式。请参阅 系统管理员 指南中的引导到救援模式 部分。普通数据分区不需要这一步。
- 使用
fdisk或partedutilites 重建您要恢复的分区。如果分区不再存在,重新创建它们。新分区必须足够大以包含恢复的数据。正确获取开始和结束号非常重要;它们是在备份时从fdisk实用程序获取的分区的开始和结束扇区号。有关修改分区的详情,请参考 第 13 章 分区 - 使用
mkfs工具格式化目标分区:#mkfs.ext4 /dev/device重要不要 格式化存储您的备份文件的分区。 - 如果您创建了新分区,请重新标记所有分区,以便它们与
/etc/fstab文件中的条目匹配:#e2label /dev/device label - 创建临时挂载点并在其上挂载分区:
#mkdir /mnt/device#mount -t ext4 /dev/device /mnt/device - 从挂载的分区上的备份中恢复数据:
#cd /mnt/device#restore -rf device-backup-file请注意,您需要为以下命令配置免密码登录。有关设置免密码ssh登录的更多信息,请参阅 系统管理员 指南中的使用基于密钥的身份验证部分。- 从存储在同一台机器上的备份文件恢复远程机器上的分区:
#ssh remote-address "cd /mnt/device && cat backup-file | /usr/sbin/restore -r -f -" - 从存储在不同远程机器上的备份文件恢复远程机器上的分区:
#ssh remote-machine-1 "cd /mnt/device && RSH=/usr/bin/ssh /usr/sbin/restore -rf remote-machine-2:backup-file"
- reboot:
#systemctl reboot
例 5.4. 恢复多个 ext4 分区
- 使用 fdisk 命令重建您要恢复的分区。
- 格式化目标分区:
#mkfs.ext4 /dev/sda1#mkfs.ext4 /dev/sda2#mkfs.ext4 /dev/sda3 - 重新标记所有分区,以便它们与
/etc/fstab文件匹配:#e2label /dev/sda1 Boot1#e2label /dev/sda2 Root#e2label /dev/sda3 Data - 准备工作目录。挂载新分区:
#mkdir /mnt/sda1#mount -t ext4 /dev/sda1 /mnt/sda1#mkdir /mnt/sda2#mount -t ext4 /dev/sda2 /mnt/sda2#mkdir /mnt/sda3#mount -t ext4 /dev/sda3 /mnt/sda3挂载包含备份文件的分区:#mkdir /backup-files#mount -t ext4 /dev/sda6 /backup-files - 将数据从备份恢复到挂载的分区:
#cd /mnt/sda1#restore -rf /backup-files/sda1.dump#cd /mnt/sda2#restore -rf /backup-files/sda2.dump#cd /mnt/sda3#restore -rf /backup-files/sda3.dump - reboot:
#systemctl reboot
其它资源
- 如需更多信息,请参阅 restore(8) man page。
5.6. 其他 ext4 文件系统实用程序
- e2fsck
- 用于修复 ext4 文件系统.由于 ext4 磁盘结构的更新,此工具对 ext4 文件系统的检查和修复比对 ext3 更高效。
- e2label
- 更改 ext4 文件系统上的标签。此工具也适用于 ext2 和 ext3 文件系统。
- quota
- fsfreeze
- 要暂停对文件系统的访问,请使用命令 # fsfreeze -f mount-point 来冻结它,而 # fsfreeze -u mount-point to unfreeze it。这会停止对文件系统的访问,并在磁盘上创建稳定的镜像。注意对于设备映射器驱动器,不需要使用 fsfreeze。如需更多信息,请参阅 fsfreeze (8) 手册页。
- debugfs
- 调试 ext2、ext3 或 ext4 文件系统。
- e2image
- 将重要的 ext2、ext3 或 ext4 文件系统元数据保存到文件中。
第 6 章 Btrfs(技术预览)
6.1. 创建 btrfs 文件系统
# mkfs.btrfs /dev/device6.2. 挂载 btrfs 文件系统
# mount /dev/device /mount-point
- device=/dev/name
- 在 mount 命令中附加这个选项会告知 btrfs 扫描指定设备的 btrfs 卷。这用于确保挂载成功,因为尝试挂载不是 btrfs 的设备将导致挂载失败。注意这并不意味着所有设备都会添加到文件系统中,它只扫描它们。
- max_inline=number
- 使用此选项设置可用于元数据 B-tree leaf 中的内联数据的最大空间量(以字节为单位)。默认值为 8192 字节。对于 4k 页,它会被限制为 3900 字节,因为额外的标头需要容纳到 leaf。
- alloc_start=number
- 使用这个选项设置磁盘分配开始的位置。
- thread_pool=number
- 使用这个选项分配分配的 worker 线程数量。
- discard
- 使用这个选项在空闲块中启用 discard/TRIM。
- noacl
- 使用这个选项禁用 ACL 的使用。
- space_cache
- 使用这个选项将可用空间数据存储在磁盘上,以便更快地缓存块组。这是一个持久的更改,可以安全地引导到旧内核。
- nospace_cache
- 使用这个选项禁用上述 space_cache。
- clear_cache
- 使用这个选项清除挂载期间的所有可用空间缓存。这是一个安全的选项,但将触发要重新构建的空间缓存。因此,让文件系统保持挂载,以便重建过程完成。这个挂载选项旨在被使用一次,且仅在问题出现可用空间后才被使用。
- enospc_debug
- 这个选项用于调试"无空格"的问题。
- recovery
- 使用这个选项在挂载时启用自动恢复。
6.3. 调整 btrfs 文件系统的大小
放大 btrfs 文件系统
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize +200M /btrfssingle Resize '/btrfssingle' of '+200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 后,使用以下命令:
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:+200M /btrfstest Resize '/btrfstest/' of '2:+200M'
缩小 btrfs 文件系统
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize -200M /btrfssingle Resize '/btrfssingle' of '-200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 后,使用以下命令:
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:-200M /btrfstest Resize '/btrfstest' of '2:-200M'
设置文件系统大小
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize 700M /btrfssingle Resize '/btrfssingle' of '700M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 724.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 后,使用以下命令:
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:300M /btrfstest Resize '/btrfstest' of '2:300M'
6.4. 多个设备的集成卷管理
6.4.1. 创建使用多个设备的文件系统
- raid0
- raid1
- raid10
- dup
- 单个
例 6.1. 创建 RAID 10 btrfs 文件系统
# mkfs.btrfs /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m raid0 /dev/device1 /dev/device2
# mkfs.btrfs -m raid10 -d raid10 /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m single /dev/device
# mkfs.btrfs -d single /dev/device1 /dev/device2 /dev/device3
# btrfs device add /dev/device1 /mount-point
6.4.2. 扫描 btrfs 设备
/dev 下的所有块设备,并探测 btrfs 卷。如果在文件系统中有多个设备运行时,则必须在载入 btrfs 模块后执行此操作。
# btrfs device scan
# btrfs device scan /dev/device
6.4.3. 在 btrfs 文件系统中添加新设备
例 6.2. 在 btrfs 文件系统中添加新设备
# mkfs.btrfs /dev/device1 # mount /dev/device1
# btrfs device add /dev/device2 /mount-point
/dev/device1 中。现在,它必须平衡才能分散到所有设备上。
# btrfs filesystem balance /mount-point
6.4.4. 转换 btrfs 文件系统
例 6.3. 转换 btrfs 文件系统
/dev/sdb 1)转换为两个设备,raid1 系统以便防止单个磁盘失败,请使用以下命令:
# mount /dev/sdb1 /mnt # btrfs device add /dev/sdc1 /mnt # btrfs balance start -dconvert=raid1 -mconvert=raid1 /mnt
6.4.5. 删除 btrfs 设备
例 6.4. 删除 btrfs 文件系统上的设备
# mkfs.btrfs /dev/sdb /dev/sdc /dev/sdd /dev/sde # mount /dev/sdb /mnt
# btrfs device delete /dev/sdc /mnt
6.4.6. 在 btrfs 文件系统中替换失败的设备
# mkfs.btrfs -m raid1 /dev/sdb /dev/sdc /dev/sdd /dev/sde ssd is destroyed or removed, use -o degraded to force the mount to ignore missing devices # mount -o degraded /dev/sdb /mnt 'missing' is a special device name # btrfs device delete missing /mnt
- 以 degraded 模式挂载,
- 添加新设备,
- 和 删除缺少的设备。
6.4.7. 在 /etc/fstab中注册 btrfs 文件系统
initrd 或它没有执行 btrfs 设备扫描,则可以通过将文件系统中所有设备明确传递给 mount 命令来挂载多卷 btrfs 文件系统。
例 6.5. /etc/fstab 条目示例
/etc/fstab 条目示例为:
/dev/sdb /mnt btrfs device=/dev/sdb,device=/dev/sdc,device=/dev/sdd,device=/dev/sde 0
6.5. SSD 优化
mkfs.btrfs,在单个设备上为 /sys/block/设备/queue/rotational 关闭元数据重复。这等同于在命令行中指定 -m single。它可以通过提供 -m dup 选项来覆盖和重复元数据。由于 SSD 固件可能会丢失两个副本,因此不需要重复。这种浪费空间是性能成本。
- 它允许更大的元数据集群分配。
- 它尽可能顺序分配数据。
- 它禁用 btree leaf rewting 来匹配密钥和块顺序。
- 它在不批量多个进程的情况下提交日志片段。
6.6. Btrfs 参考
- 用于管理快照的所有子卷命令。
- 用于管理
设备的设备命令。 - 清理、平衡、平衡 和 碎片整理 命令。
第 7 章 全局文件系统 2
gfs2.ko 内核模块实现 GFS2 文件系统,并加载在 GFS2 集群节点上。
第 8 章 网络文件系统 (NFS)
8.1. NFS 简介
- NFS 版本 3 (NFSv3)支持安全异步写入,并在处理错误时比之前的 NFSv2 更强大。它还支持 64 位文件大小和偏移量,允许客户端访问超过 2 GB 的文件数据。
- NFS 版本 4 (NFSv4)通过防火墙,并在 Internet 上工作,不再需要 rpcbind 服务,支持 ACL,并且使用有状态操作。
- 稀疏文件 :它验证文件的空间效率,并允许占位符提高存储效率。它是具有一个或多个漏洞的文件;漏洞是未分配的或未初始化的数据块,仅包含零。
lseek()NFSv4.2 中的操作支持seek_hole()和seek_data(),它允许应用程序在稀疏文件中映射漏洞的位置。 - 空间保留:它允许存储服务器保留空闲空间,从而禁止服务器耗尽空间。NFSv4.2 支持
allocate()操作来保留空间、deallocate()操作,以及fallocate()操作来预分配或取消分配文件中的空间。 - 标记的 NFS:它会强制实施数据访问权限,并为 NFS 文件系统上的单个文件在客户端和服务器之间启用 SELinux 标签。
- 布局增强:NFSv4.2 提供新的操作
layoutstats(),客户端可以使用它来通知元数据服务器有关其与布局的通信。
- 提高了网络的性能和安全性,还包括对并行 NFS (pNFS)的客户端支持。
- 对于回调不再需要单独的 TCP 连接,这允许 NFS 服务器授予委托,即使它无法联系客户端。例如,当 NAT 或防火墙干扰时。
- 它只提供一次语义(除重启操作外),防止之前的问题,当回复丢失并且操作被发送两次时,某些操作可能会返回不准确的结果。
/etc/exports 配置文件,以确定是否允许客户端访问任何导出的文件系统。一旦被验证,所有文件和目录操作都对用户有效。
8.1.1. 所需的服务
- nfs
- systemctl start nfs 启动 NFS 服务器,以及为共享 NFS 文件系统请求提供服务的适当 RPC 进程。
- nfslock
- systemctl start nfs-lock 激活一个强制服务,该服务启动适当的 RPC 进程,允许 NFS 客户端锁定服务器上的文件。
- rpcbind
- rpcbind 接受本地 RPC 服务的端口保留。这些端口随后可用(或发布),以便相应的远程 RPC 服务可以访问它们。rpcbind 响应对 RPC 服务的请求,并设置到请求的 RPC 服务的连接。这不能与 NFSv4 一起使用。
- rpc.mountd
- NFS 服务器使用这个进程来处理来自 NFSv3 客户端的 MOUNT 请求。它检查所请求的 NFS 共享是否目前由 NFS 服务器导出,并且允许客户端访问它。如果允许挂载请求,rpc.mountd 服务器会以
Success状态回复,并将这个 NFS 共享的文件处理返回给 NFS 客户端。 - rpc.nfsd
- rpc.nfsd 允许定义服务器公告的显式 NFS 版本和协议。它与 Linux 内核配合使用,以满足 NFS 客户端的动态需求,例如在每次 NFS 客户端连接时提供服务器线程。这个进程对应于 nfs 服务。
- lockd
- lockd 是一个在客户端和服务器上运行的内核线程。它实现了 网络锁定管理器 (NLM)协议,它允许 NFSv3 客户端锁定服务器上的文件。每当运行 NFS 服务器以及挂载 NFS 文件系统时,它会自动启动。
- rpc.statd
- 这个进程实现 网络状态监控器 (NSM)RPC 协议,该协议在 NFS 服务器没有正常关闭而重新启动时,通知 NFS 客户端。RPC.statd 由 nfslock 服务自动启动,不需要用户配置。这不能与 NFSv4 一起使用。
- rpc.rquotad
- 这个过程为远程用户提供用户配额信息。RPC.rquotad 由 nfs 服务自动启动,不需要用户配置。
- rpc.idmapd
- rpc.idmapd 提供 NFSv4 客户端和服务器上调用,这些调用在线 NFSv4 名称(以
user@domain形式的字符串)和本地 UID 和 GID 之间进行映射。要使 idmapd 与 NFSv4 正常工作,必须配置/etc/idmapd.conf文件。至少应指定"Domain"参数,该参数定义 NFSv4 映射域。如果 NFSv4 映射域与 DNS 域名相同,可以跳过这个参数。客户端和服务器必须同意 NFSv4 映射域才能使 ID 映射正常工作。注意在 Red Hat Enterprise Linux 7 中,只有 NFSv4 服务器使用 rpc.idmapd。NFSv4 客户端使用基于密钥环的 idmapper nfsidmap。nfsidmap 是一个独立程序,由内核按需调用来执行 ID 映射;它不是一个守护进程。如果 nfsidmap 出现问题,客户端会回退到使用 rpc.idmapd。有关 nfsidmap 的更多信息,请参阅 nfsidmap 手册页。
8.2. 配置 NFS 客户端
# mount -t nfs -o options server:/remote/export /local/directory- options
- 以逗号分隔的挂载选项列表 ; 有关有效 NFS 挂载选项的详情,请参考 第 8.4 节 “常用 NFS 挂载选项”。
- server
- 导出您要挂载的文件系统的服务器的主机名、IP 地址或完全限定域名
- /remote/export
- 从 server 导出的文件系统或目录,即您要挂载的目录
- /local/directory
- 挂载 /remote/export 的客户端位置
/etc/fstab 文件和 autofs 服务。如需更多信息,请参阅 第 8.2.1 节 “使用 /etc/fstab挂载 NFS 文件系统” 和 第 8.3 节 “autofs”。
8.2.1. 使用 /etc/fstab挂载 NFS 文件系统
/etc/fstab 文件中添加一行。行必须指定 NFS 服务器的主机名、要导出的服务器上的目录,以及 NFS 共享要挂载在本地计算机上的目录。您必须是 root 用户才能修改 /etc/fstab 文件。
例 8.1. 语法示例
/etc/fstab 中行的一般语法如下:
server:/usr/local/pub /pub nfs defaults 0 0
/pub。将这一行添加到客户端系统上的 /etc/fstab 后,使用命令 mount /pub,挂载点 /pub 是从服务器挂载的。
/etc/fstab 条目应包含以下信息:
server:/remote/export /local/directory nfs options 0 0
/etc/fstab 之前,客户端上必须存在挂载点 /local/directory。否则,挂载会失败。
/etc/fstab 后,重新生成挂载单元,以便您的系统注册新配置:
# systemctl daemon-reload其它资源
- 有关
/etc/fstab的详情,请参考 man fstab。
8.3. autofs
/etc/fstab 的一个缺点是,无论用户如何经常访问 NFS 挂载的文件系统,系统都必须指定资源来保持挂载的文件系统。对于一个或两个挂载没有问题,但当系统一次维护多个系统的挂载时,整体的系统性能可能会受到影响。/etc/fstab 的替代方法是使用基于内核的 automount 工具。自动挂载程序由两个组件组成:
- 实现文件系统的内核模块,以及
- 执行所有其他功能的用户空间守护进程。
/etc/auto.master (主映射)作为其默认主配置文件。可以使用 autofs 配置(在 /etc/sysconfig/autofs中)与名称服务交换机(NSS)机制结合使用其他支持的网络源和名称。为主映射中配置的每个挂载点运行一个 autofs 版本 4 守护进程的实例,因此可以在命令行中针对任何给定挂载点手动运行。autofs 版本 5 无法实现,因为它使用单个守护进程来管理所有配置的挂载点;因此,必须在主映射中配置所有自动挂载。这符合其他行业标准自动挂载程序的常规要求。挂载点、主机名、导出的目录和选项都可以在一组文件(或其他支持的网络源)中指定,而不必为每个主机手动配置它们。
8.3.1. 相对于版本 4 , autofs 版本 5 的改进
- 直接映射支持
- autofs 中的直接映射提供了一种在文件系统层次结构中的任意点自动挂载文件系统的机制。直接映射由主映射中的挂载点
/-表示。直接映射中的条目包含一个作为键的绝对路径名称(而不是间接映射中使用的相对路径名称)。 - Lazy 挂载和卸载支持
- 多挂载映射条目描述了单个键下的挂载点层次结构。一个很好的例子是
-hosts映射,通常用于将主机/net/主机中的所有导出自动挂载为多挂载映射条目。使用-hosts映射时,/net/主机的 ls 将为每个来自 主机 的导出挂载 autofs 触发器挂载。然后,它们将在被访问时进行挂载并使其过期。这可大幅减少访问具有大量导出的服务器时所需的活动挂载数量。 - 增强的 LDAP 支持
- autofs 配置文件(
/etc/sysconfig/autofs)提供了一种机制来指定站点实施的 autofs 模式,从而防止在应用程序本身中通过试用和错误来确定这一点。此外,现在支持对 LDAP 服务器进行身份验证的绑定,使用常见 LDAP 服务器实现支持的大多数机制。为此支持添加了一个新的配置文件:/etc/autofs_ldap_auth.conf。默认的配置文件是自文档文件,使用 XML 格式。 - 正确使用名称服务切换(nsswitch)配置。
- 名称服务切换配置文件的存在是为了提供一种方法来确定特定的配置数据来自哪里。这种配置的原因是让管理员可以灵活地使用选择的后端数据库,同时维护统一的软件接口来访问数据。尽管在处理 NSS 配置时,版本 4 自动挂载程序变得越来越好,但它仍然不完整。另一方面,autofs 版本 5 是一个完整的实现。有关此文件支持的语法的更多信息,请参阅 man nsswitch.conf。并非所有 NSS 数据库都是有效的映射源,解析器将拒绝无效的映射源。有效的源是 file, yp,nis,nisplus,ldap, 和 hesiod。
- 每个 autofs 挂载点都有多个主映射条目
- 经常使用但还没有提及的一件事是处理直接挂载点
/-的多个主映射条目。每个条目的映射键被合并,并表现为一个映射的形式。例 8.2. 每个 autofs 挂载点都有多个主映射条目
以下是直接挂载的 connectathon 测试映射中的示例:/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
8.3.2. 配置 autofs
/etc/auto.master,也称为主映射,如 第 8.3.1 节 “相对于版本 4 , autofs 版本 5 的改进” 所述。主映射列出了系统上 autofs- 控制的挂载点,以及它们相应的配置文件或网络来源,称为自动挂载映射。master 映射的格式如下:
mount-point map-name options
- mount-point
- 例如,autofs 挂载点
/home。 - map-name
- 包含挂载点列表的映射源的名称,以及挂载这些挂载点的文件系统的位置。
- options
- 如果提供,它们适用于给定映射中的所有条目,只要它们本身没有指定选项。这个行为与 autofs 版本 4 不同,其中选项是累积的。这已被修改来实现混合环境兼容性。
例 8.3. /etc/auto.master 文件
/etc/auto.master 文件的示例行(使用 cat /etc/auto.master显示):
/home /etc/auto.misc
mount-point [options] location
- mount-point
- 这指的是 autofs 挂载点。这可以是间接挂载的单个目录名称,也可以是直接挂载的挂载点的完整路径。每个直接和间接映射条目键(挂载点)后面可以跟一个以空格分隔的偏移目录列表(每个以
/开头的子目录名称)使其称为多挂载条目。 - options
- 每当提供时,这些都是未指定其自身选项的映射条目的挂载选项。
- 位置
- 这指的是文件系统位置,如本地文件系统路径(对于以
/开头的映射名称,前面带有 Sun 映射格式转义字符":")、NFS 文件系统或其他有效的文件系统位置。
/etc/auto.misc)中的内容示例:
payroll -fstype=nfs personnel:/dev/hda3 sales -fstype=ext3 :/dev/hda4
sales 和 payroll )。第二列显示 autofs 挂载的选项,第三列则指示挂载的来源。在给定配置后,autofs 挂载点将是 /home/payroll 和 /home/sales。通常省略 -fstype= 选项,通常不需要正确的操作。
# systemctl start autofs# systemctl restart autofs/home/payroll/2006/July.sxc,则自动挂载守护进程会自动挂载该目录。如果指定了超时,则如果在超时时间内没有访问该目录,则目录会被自动卸载。
# systemctl status autofs8.3.3. 覆盖或增加站点配置文件
- 自动挂载程序映射存储在 NIS 中,
/etc/nsswitch.conf文件具有以下指令:automount: files nis
auto.master文件包含:+auto.master
- NIS
auto.master映射文件包含:/home auto.home
- NIS
auto.home映射包含:beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
- 文件映射
/etc/auto.home不存在。
auto.home 并从其他服务器挂载主目录。在这种情况下,客户端需要使用以下 /etc/auto.master 映射:
/home /etc/auto.home +auto.master
/etc/auto.home 映射包含条目:
* labserver.example.com:/export/home/&
/home 包含 /etc/auto.home 的内容,而不是 NIS auto.home 映射。
auto.home 映射,请创建一个 /etc/auto.home 文件映射,并在其中放置新条目。在结尾处,包含 NIS auto.home 映射。然后 /etc/auto.home 文件映射类似:
mydir someserver:/export/mydir +auto.home
auto.home 映射条件时,ls /home 命令输出:
beth joe mydir
8.3.4. 使用 LDAP 来存储自动挂载程序映射
openldap 软件包应作为 自动挂载程序 的依赖项自动安装。要配置 LDAP 访问,请修改 /etc/openldap/ldap.conf。确保为您的站点正确设置了 BASE、URI 和 模式。
rfc2307bis 描述了在 LDAP 中存储自动挂载映射的最新建立的模式。要使用此模式,必须通过从架构定义中删除注释字符,在 autofs 配置(/etc/sysconfig/autofs)中设置它。例如:
例 8.4. 设置 autofs 配置
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
rfc2307bis 模式中的 cn 属性。以下是 LDAP 数据交换格式(LDIF)配置示例:
例 8.5. LDF 配置
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
8.4. 常用 NFS 挂载选项
/etc/fstab 设置和 autofs。
- lookupcache=mode
- 指定内核应该如何管理给定挂载点的目录条目缓存。模式 的有效参数为
all、none或pos/positive。 - nfsvers=version
- 指定要使用的 NFS 协议版本,其中 version 为 3 或 4。这对于运行多个 NFS 服务器的主机很有用。如果没有指定版本,NFS 将使用内核和 mount 命令支持的最高版本。选项 vers 等同于 nfsvers ,出于兼容性的原因包含在此发行版本中。
- noacl
- 关闭所有 ACL 处理。当与旧版本的 Red Hat Enterprise Linux、Red Hat Linux 或 Solaris 交互时,可能会需要此功能,因为最新的 ACL 技术与较旧的系统不兼容。
- nolock
- 禁用文件锁定。当连接到非常旧的 NFS 服务器时,有时需要这个设置。
- noexec
- 防止在挂载的文件系统中执行二进制文件。这在系统挂载不兼容二进制文件的非 Linux 文件系统时有用。
- nosuid
- 禁用
set-user-identifier或set-group-identifier位。这可防止远程用户通过运行 setuid 程序获得更高的特权。 - port=num
- 指定 NFS 服务器端口的数字值。如果 num 是 0 ( 默认值),则 mount 会查询远程主机的 rpcbind 服务,以获取要使用的端口号。如果远程主机的 NFS 守护进程没有注册到其 rpcbind 服务,则会使用标准 NFS 端口号 TCP 2049。
- rsize=num 和 wsize=num
- 这些选项设定在单个 NFS 读取或写入操作中传输的最大字节数。
rsize和wsize没有固定的默认值。默认情况下,NFS 使用服务器和客户端都支持的最大的可能值。在 Red Hat Enterprise Linux 7 中,客户端和服务器的最大值为 1,048,576 字节。详情请查看 rsize 和 wsize 的默认和最大值是什么?Kbase 文章。 - sec=flavors
- 用于访问挂载导出上文件的安全类别。flavors 值是以冒号分隔的一个或多个安全类型列表。默认情况下,客户端会尝试查找客户端和服务器都支持的安全类别。如果服务器不支持任何选定的类别,挂载操作将失败。
sec=sys使用本地 UNIX UID 和 GID。它们使用AUTH_SYS验证 NFS 操作。sec=krb5使用 Kerberos V5 ,而不是本地 UNIX UID 和 GID 来验证用户。sec=krb5i使用 Kerberos V5 进行用户身份验证,并使用安全校验和执行 NFS 操作的完整性检查,以防止数据被篡改。sec=krb5p使用 Kerberos V5 进行用户身份验证、完整性检查,并加密 NFS 流量以防止流量嗅探。这是最安全的设置,但它也会涉及最大的性能开销。 - tcp
- 指示 NFS 挂载使用 TCP 协议。
- udp
- 指示 NFS 挂载使用 UDP 协议。
8.5. 启动和停止 NFS 服务器
先决条件
$systemctl status rpcbind要配置只使用 NFSv4 的服务器,它不需要rpcbind,请参阅 第 8.6.7 节 “配置只使用 NFSv4 的服务器”。- 在 Red Hat Enterprise Linux 7.0 中,如果您的 NFS 服务器导出 NFSv3 并在引导时启用,则需要手动启动并启用
nfs-lock服务:#systemctl start nfs-lock#systemctl enable nfs-lock在 Red Hat Enterprise Linux 7.1 及更高版本中,如果需要,nfs-lock会自动启动,并尝试手动启用它。
流程
- 要启动 NFS 服务器,请使用以下命令:
# systemctl start nfs - 要使 NFS 在引导时启动,请使用以下命令:
# systemctl enable nfs - 要停止服务器,请使用:
# systemctl stop nfs restart选项是停止然后启动 NFS 的简写方式。这是编辑 NFS 配置文件后使配置更改生效的最有效方式。要重启服务器的类型:# systemctl restart nfs- 编辑
/etc/sysconfig/nfs文件后,运行以下命令来重启 nfs-config 服务,使新值生效:# systemctl restart nfs-config try-restart命令仅在当前正在运行时启动 nfs。此命令等同于 Red Hat init 脚本中的 condrestart (有条件重启)非常有用,因为它不会在 NFS 未运行时启动守护进程。要有条件地重启服务器,请输入:# systemctl try-restart nfs- 要在不重启服务类型的情况下重新载入 NFS 服务器配置文件:
# systemctl reload nfs
8.6. 配置 NFS 服务器
- 手动编辑 NFS 配置文件,即
/etc/exports,以及 - 通过命令行,即使用 exportfs命令
8.6.1. /etc/exports 配置文件
/etc/exports 文件控制哪些文件系统被导出到远程主机,并指定选项。它遵循以下语法规则:
- 空白行将被忽略。
- 要添加注释,以井号(#)开始一行。
- 您可以使用反斜杠(\)换行长行。
- 每个导出的文件系统都应该独立。
- 所有在导出的文件系统后放置的授权主机列表都必须用空格分开。
- 每个主机的选项必须在主机标识符后直接放在括号中,没有空格分离主机和第一个括号。
export host(options)
- export
- 导出的目录
- host
- 导出要共享的主机或网络
- options
- 用于 host 的选项
export host1(options1) host2(options2) host3(options3)
/etc/exports 文件只指定导出的目录和允许访问它的主机,如下例所示:
例 8.6. /etc/exports 文件
/exported/directory bob.example.com
bob.example.com 可以从 NFS 服务器挂载 /exported/directory/。因为在这个示例中没有指定选项,所以 NFS 将 使用默认设置。
- ro
- 导出的文件系统是只读的。远程主机无法更改文件系统中共享的数据。要允许主机更改文件系统(即读写),请指定
rw选项。 - 同步
- 在将之前的请求所做的更改写入磁盘前,NFS 服务器不会回复请求。要启用异步写入,请指定
async选项。 - wdelay
- 如果 NFS 服务器预期另外一个写入请求即将发生,则 NFS 服务器会延迟写入磁盘。这可以提高性能,因为它可减少不同的写命令访问磁盘的次数,从而减少写开销。要禁用此功能,请指定
no_wdelay。只有指定了默认的sync选项时,no_wdelay才可用。 - root_squash
- 这可防止远程连接的 root 用户(而不是本地)具有 root 权限;相反,NFS 服务器会为他们分配用户 ID
nfsnobody。这可以有效地将远程 root 用户的权限"挤压"成最低的本地用户,从而防止在远程服务器上可能的未经授权的写操作。要禁用 root 压缩,请指定no_root_squash。
all_squash :要指定 NFS 服务器应该分配给来自特定主机的远程用户的用户 ID 和组 ID,请分别使用 anonuid 和 anongid 选项,如下所示:
export host(anonuid=uid,anongid=gid)
anonuid 和 anongid 选项允许您创建特殊的用户和组帐户,为远程 NFS 用户共享。
rw 选项,则导出的文件系统将以只读形式共享。以下是 /etc/exports 中的示例行,其覆盖两个默认选项:
/another/exported/directory/ 读写,对磁盘的所有写入都是异步的。有关导出选项的更多信息,请参阅 man exportfs。
/etc/exports 文件的格式要求非常精确,特别是在空格字符的使用方面。需要将导出的文件系统与主机、不同主机间使用空格分隔。但是,除了注释行外,文件中不应该包括其他空格。
/home bob.example.com(rw) /home bob.example.com (rw)
bob.example.com 中的用户对 /home 目录进行读写访问。第二行允许来自 bob.example.com 的用户以只读方式挂载目录(默认),而其他用户可以将其挂载为读/写。
8.6.2. exportfs 命令
/etc/exports 文件中。当 nfs 服务启动时,/usr/sbin/exportfs 命令启动并读取此文件,将控制传递给实际挂载进程的 rpc.mountd (如果 NFSv3),然后传给 rpc.nfsd,然后供远程用户使用。
/var/lib/nfs/xtab。由于 rpc.mountd 在决定对文件系统的访问权限时引用 xtab 文件,因此对导出的文件系统列表的更改会立即生效。
- -r
- 通过在
/var/lib/nfs/etab中构建新的导出列表,将/etc/exports中列出的所有目录导出。如果对/etc/exports做了任何更改,这个选项可以有效地刷新导出列表。 - -a
- 根据将哪些其他选项传给 /usr/sbin/exportfs,导致所有目录被导出或取消导出。如果没有指定其他选项,/usr/sbin/exportfs 会导出
/etc/exports中指定的所有文件系统。 - -o file-systems
- 指定没有在
/etc/exports中列出的要导出的目录。将 file-systems 替换为要导出的其它文件系统。这些文件系统的格式化方式必须与/etc/exports中指定的方式相同。此选项通常用于在将导出的文件系统永久添加到导出的文件系统列表之前,对其进行测试。有关/etc/exports语法的详情,请参考 第 8.6.1 节 “/etc/exports配置文件”。 - -i
- 忽略
/etc/exports;只有命令行上指定的选项才会用于定义导出的文件系统。 - -u
- 不导出所有共享目录。命令 /usr/sbin/exportfs -ua 可暂停 NFS 文件共享,同时保持所有 NFS 守护进程正常运行。要重新启用 NFS 共享,请使用 exportfs -r。
- -v
- 详细操作,当执行 exportfs 命令时,更详细地显示正在导出的或取消导出的文件系统。
8.6.2.1. 使用带有 NFSv4 的 exportfs
/etc/sysconfig/nfs 中设置 RPCNFSDARGS= -N 4 来将其关闭。
8.6.3. 在防火墙后面运行 NFS
/etc/sysconfig/nfs 文件来设置 RPC 服务运行的端口。要允许客户端通过防火墙访问 RPC 配额,请参阅 第 8.6.4 节 “通过防火墙访问 RPC 配额”。
/etc/sysconfig/nfs 文件在所有系统中都不存在。如果 /etc/sysconfig/nfs 不存在,请创建并指定以下内容:
- RPCMOUNTDOPTS="-p port"
- 这会将"-p port"添加到 rpc.mount 命令行: rpc.mount -p port。
nlockmgr 服务使用的端口,请在 /etc/modprobe.d/lockd.conf 文件中设置 nlm_tcpport 和 nlm_udpport 选项的端口号。
/var/log/messages。通常,如果指定了已在使用的端口号,NFS 将无法启动。编辑 /etc/sysconfig/nfs 后,您需要重启 nfs-config 服务,以便新值在 Red Hat Enterprise Linux 7.2 中生效,然后再运行以下命令:
# systemctl restart nfs-config
然后,重启 NFS 服务器:
# systemctl restart nfs-server
运行 rpcinfo -p 以确认更改生效。
/proc/sys/fs/nfs/nfs_callback_tcpport,并允许服务器连接到客户端上的该端口。
mountd、statd 和 lockd 的其他端口。
8.6.3.1. 发现 NFS 导出
- 在支持 NFSv3 的任何服务器上,使用 showmount 命令:
$showmount -e myserver Export list for mysever /exports/foo /exports/bar - 在支持 NFSv4 的任何服务器上,挂载 根目录并查找。
#mount myserver:/ /mnt/#cd /mnt/ exports#ls exports foo bar
8.6.4. 通过防火墙访问 RPC 配额
过程 8.1. 使 RPC 配额访问防火墙不可行
- 要启用
rpc-rquotad服务,请使用以下命令:#systemctl enable rpc-rquotad - 要启动
rpc-rquotad服务,请使用以下命令:
请注意,如果启用#systemctl start rpc-rquotadrpc-rquotad,则自动启动nfs-server服务。 - 要使配额 RPC 服务在防火墙后面访问,需要打开 UDP 或 TCP 端口
875。默认端口号定义在/etc/services文件中。您可以通过将-p port-number附加到/etc/sysconfig/rpc-rquotad文件中的RPCRQUOTADOPTS变量来覆盖默认端口号。 - 重启
rpc-rquotad以使/etc/sysconfig/rpc-rquotad文件中的更改生效:#systemctl restart rpc-rquotad
从远程主机设置配额
-S 选项附加到 /etc/sysconfig/rpc-rquotad 文件中的 RPCRQUOTADOPTS 变量中。
rpc-rquotad 以使 /etc/sysconfig/rpc-rquotad 文件中的更改生效:
# systemctl restart rpc-rquotad
8.6.5. 主机名格式
- 单台机器
- 完全限定域名(可由服务器解析)、主机名(可由服务器解析)或 IP 地址。
- 使用通配符指定的一系列机器
- 使用
*或?字符指定字符串匹配项。通配符不能用于 IP 地址;但是,如果反向 DNS 查找失败,则可能会意外起作用。当在完全限定域名中指定通配符时,点(.)不会包含在通配符中。例如:*.example.com包含one.example.com,但不包括include one.two.example.com。 - IP 网络
- 使用 a.b.c.d/z,其中 a.b.c.d 是网络,z 是子网掩码的位数(如 192.168.0.0/24)。另一种可接受的格式是 a.b.c.d/netmask,其中 a.b.c.d 是网络,netmask 是子网掩码(例如 192.168.100.8/255.255.255.0)。
- Netgroups
- 使用格式 @group-name ,其中 group-name 是 NIS netgroup 名称。
8.6.6. 启用通过 RDMA(NFSoRDMA) 的 NFS
- 安装 rdma 和 rdma-core 软件包。
/etc/rdma/rdma.conf文件包含默认设置XPRTRDMA_LOAD=yes的行,它请求rdma服务加载 NFSoRDMA 客户端 模块。 - 要启用自动载入 NFSoRDMA 服务器模块,请在
/etc/rdma/rdma.conf中的新行中添加SVCRDMA_LOAD=yes。RPCNFSDARGS="--rdma=20049"在/etc/sysconfig/nfs文件中指定 NFSoRDMA 服务侦听客户端的端口号。RFC 5667 指定服务器在通过 RDMA 提供 NFSv4 服务时必须侦听端口20049。 - 编辑
/etc/rdma/rdma.conf文件后重启nfs服务:#systemctl restart nfs请注意,在较早的内核版本中,编辑/etc/rdma/rdma.conf后需要重启系统才能使更改生效。
8.6.7. 配置只使用 NFSv4 的服务器
rpcbind 服务来侦听网络。
Requested NFS version or transport protocol is not supported.
过程 8.2. 配置只使用 NFSv4 的服务器
- 通过在
/etc/sysconfig/nfs配置文件中添加以下行来禁用 NFSv2、NFSv3 和 UDP:RPCNFSDARGS="-N 2 -N 3 -U"
- (可选)禁用对
RPCBIND、MOUNT和NSM协议调用的监听,这在仅使用 NFSv4 的情况下不需要。禁用这些选项的影响有:- 尝试使用 NFSv2 或 NFSv3 从服务器挂载共享的客户端变得无响应。
- NFS 服务器本身无法挂载 NFSv2 和 NFSv3 文件系统。
禁用这些选项:- 在
/etc/sysconfig/nfs文件中添加以下内容:RPCMOUNTDOPTS="-N 2 -N 3"
- 禁用相关服务:
#systemctl mask --now rpc-statd.service rpcbind.service rpcbind.socket
- 重启 NFS 服务器:
#systemctl restart nfs一旦启动或重启 NFS 服务器,这些改变就会生效。
验证仅 NFSv4 配置
netstat 实用程序验证您的 NFS 服务器是否在 NFSv4 模式中配置。
- 以下是仅使用 NFSv4 服务器上的
netstat输出示例;也禁用了对RPCBIND、MOUNT和NSM的监听。在这里,nfs是唯一侦听 NFS 服务:#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* - 相比之下,在配置只使用 NFSv4 的服务器前
netstat输出会包括sunrpc和mountd服务:#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:36069 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:52364 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:mountd 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:34941 [::]:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:mountd [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:56881 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:37190 0.0.0.0:* udp 0 0 0.0.0.0:876 0.0.0.0:* udp 0 0 localhost:877 0.0.0.0:* udp 0 0 0.0.0.0:mountd 0.0.0.0:* udp 0 0 0.0.0.0:38588 0.0.0.0:* udp 0 0 0.0.0.0:nfs 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp 0 0 0.0.0.0:sunrpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* udp6 0 0 [::]:57683 [::]:* udp6 0 0 [::]:876 [::]:* udp6 0 0 [::]:mountd [::]:* udp6 0 0 [::]:40874 [::]:* udp6 0 0 [::]:nfs [::]:* udp6 0 0 [::]:sunrpc [::]:*
8.7. 保护 NFS
8.7.1. 具有 AUTH_SYS 和导出控制的 NFS 安全性
AUTH_SYS (也称为 AUTH_UNIX)执行此操作,它依赖于客户端来声明用户的 UID 和 GID。请注意,这意味着恶意或配置错误的客户端可能会很容易地出现这个错误,并允许用户访问他不应该访问的文件。
8.7.2. 带有 AUTH_GSS的 NFS 安全性
配置 Kerberos
过程 8.3. 为 IdM 配置 NFS 服务器和客户端以使用 RPCSEC_GSS
- 在 NFS 服务器端创建
nfs/hostname.domain@REALM主体。 - 在服务器和客户端端创建
host/hostname.domain@REALM主体。注意主机名 必须与 NFS 服务器主机名相同。 - 将对应的密钥添加到客户端和服务器的 keytab 中。
具体步骤请查看 Red Hat Enterprise Linux 7 Linux Domain Identity, Authentication, and Policy Guide 中的 Adding and Editing Service Entries and Keytabs and setting an Kerberos-aware NFS Server 部分。- 在服务器端,使用
sec=选项启用所需的安全类型。启用所有安全类型和非加密挂载:/export *(sec=sys:krb5:krb5i:krb5p)
与sec=选项一起使用的有效安全类型为:sys: 没有加密保护,默认krb5: authentication onlykrb5i: 完整性保护krb5p: 隐私保护
- 在客户端,将
sec=krb5(或sec=krb5i, 或sec=krb5p,具体取决于设置)添加到挂载选项:# mount -o sec=krb5 server:/export /mnt
有关如何配置 NFS 客户端的详情,请参考 Red Hat Enterprise Linux 7 Linux 域身份、身份验证和策略指南中的 设置 Kerberos 感知 NFS 客户端 部分。
其它资源
- 虽然红帽建议使用 IdM,但也支持 Active Directory (AD) Kerberos 服务器。详情请查看以下红帽知识库文章: 如何使用 SSSD 和 Active Directory 在 RHEL 7 中使用 Kerberos 身份验证设置 NFS。
- 如果您需要以 root 用户身份在 Kerberos 保护的 NFS 共享中写入文件,并对这些文件保留 root 所有权,请参阅 https://access.redhat.com/articles/4040141。请注意,我们不推荐进行此配置。
8.7.2.1. 使用 NFSv4 的 NFS 安全性
MOUNT 协议来挂载文件系统。MOUNT 协议存在安全风险,因为协议处理文件句柄的方式。
8.7.3. 文件权限
nobody。root squashing 由默认选项 root_squash 控制 ; 有关这个选项的详情请参考 第 8.6.1 节 “/etc/exports 配置文件”。如果可能的话,切勿禁用 root 压缩。
all_squash 选项。这个选项使访问导出的文件系统的每个用户都使用 nfsnobody 用户的用户 ID。
8.8. NFS 和 rpcbind
rpcbind 服务以便向后兼容的 NFSv3 实现。
rpcbind )的详情,请参考 第 8.6.7 节 “配置只使用 NFSv4 的服务器”。
8.8.1. NFS 和 rpcbind故障排除
# rpcinfo -p例 8.7. rpcinfo -p 命令输出
program vers proto port service
100021 1 udp 32774 nlockmgr
100021 3 udp 32774 nlockmgr
100021 4 udp 32774 nlockmgr
100021 1 tcp 34437 nlockmgr
100021 3 tcp 34437 nlockmgr
100021 4 tcp 34437 nlockmgr
100011 1 udp 819 rquotad
100011 2 udp 819 rquotad
100011 1 tcp 822 rquotad
100011 2 tcp 822 rquotad
100003 2 udp 2049 nfs
100003 3 udp 2049 nfs
100003 2 tcp 2049 nfs
100003 3 tcp 2049 nfs
100005 1 udp 836 mountd
100005 1 tcp 839 mountd
100005 2 udp 836 mountd
100005 2 tcp 839 mountd
100005 3 udp 836 mountd
100005 3 tcp 839 mountd8.9. pNFS
pNFS Flex 文件
挂载 pNFS 共享
- 要启用 pNFS 功能,使用 NFS 版本 4.1 或更高版本从启用了 pNFS 的服务器挂载共享:
#mount -t nfs -o v4.1 server:/remote-export /local-directory服务器启用 pNFS 后,在第一次挂载时会自动载入nfs_layout_nfsv41_files内核。输出中的挂载条目应包含minorversion=1。使用以下命令验证模块是否已加载:$ lsmod | grep nfs_layout_nfsv41_files - 要从支持 Flex Files 的服务器中挂载带有 Flex Files 功能的 NFS 共享,请使用 NFS 版本 4.2 或更高版本:
#mount -t nfs -o v4.2 server:/remote-export /local-directory验证nfs_layout_flexfiles模块是否已加载:$lsmod | grep nfs_layout_flexfiles
其它资源
8.10. 在 NFS 中启用 pNFS SCSI 布局
先决条件
- 客户端和服务器必须能够向同一个块设备发送 SCSI 命令。就是说块设备必须位于共享的 SCSI 总线中。
- 块设备必须包含 XFS 文件系统。
- SCSI 设备必须支持 SCSI Persistent Reservations,如 SCSI-3 Ppriary Commands 规格中所述。
8.10.1. pNFS SCSI 布局
客户端和服务器之间的操作
LAYOUTGET 操作。服务器会使用文件在 SCSI 设备中的位置进行响应。客户端可能需要执行 GETDEVICEINFO 的额外操作,以确定要使用哪个 SCSI 设备。如果这些操作正常工作,客户端可以直接向 SCSI 设备发出 I/O 请求,而不是向服务器发送 READ 和 WRITE 操作。
READ 和 WRITE 操作,而不是直接向 SCSI 设备发送 I/O 请求。
设备保留
8.10.2. 检查与 pNFS 兼容的 SCSI 设备
先决条件
- 安装 sg3_utils 软件包:
# yum install sg3_utils
过程 8.4. 检查与 pNFS 兼容的 SCSI 设备
- 在服务器和客户端中检查正确的 SCSI 设备支持:
# sg_persist --in --report-capabilities --verbose path-to-scsi-device
确保设置了 Persist Through Power Los Active (PTPL_A)位。例 8.8. 支持 pNFS SCSI 的 SCSI 设备
以下是支持 pNFS SCSI 的 SCSI 设备的sg_persist输出示例。PTPL_A位报告1。inquiry cdb: 12 00 00 00 24 00 Persistent Reservation In cmd: 5e 02 00 00 00 00 00 20 00 00 LIO-ORG block11 4.0 Peripheral device type: disk Report capabilities response: Compatible Reservation Handling(CRH): 1 Specify Initiator Ports Capable(SIP_C): 1 All Target Ports Capable(ATP_C): 1 Persist Through Power Loss Capable(PTPL_C): 1 Type Mask Valid(TMV): 1 Allow Commands: 1 Persist Through Power Loss Active(PTPL_A): 1 Support indicated in Type mask: Write Exclusive, all registrants: 1 Exclusive Access, registrants only: 1 Write Exclusive, registrants only: 1 Exclusive Access: 1 Write Exclusive: 1 Exclusive Access, all registrants: 1
其它资源
- sg_persist(8) man page
8.10.3. 在服务器中设置 pNFS SCSI
过程 8.5. 在服务器中设置 pNFS SCSI
- 在服务器中挂载在 SCSI 设备中创建的 XFS 文件系统。
- 将 NFS 服务器配置为导出 NFS 版本 4.1 或更高版本。在
/etc/nfs.conf文件的[nfsd]部分中设置以下选项:[nfsd] vers4.1=y
- 将 NFS 服务器配置为通过 NFS 导出 XFS 文件系统,使用
pnfs选项:例 8.9. /etc/exports 中的条目导出 pNFS SCSI
/etc/exports配置文件中的以下条目将挂载到/exported/directory/的文件系统导出到allowed.example.com客户端,来作为 pNFS SCSI 布局:/exported/directory allowed.example.com(pnfs)
其它资源
- 有关配置 NFS 服务器的详情请参考 第 8.6 节 “配置 NFS 服务器”。
8.10.4. 在客户端中设置 pNFS SCSI
先决条件
- NFS 服务器被配置为通过 pNFS SCSI 导出 XFS 文件系统。请参阅 第 8.10.3 节 “在服务器中设置 pNFS SCSI”。
过程 8.6. 在客户端中设置 pNFS SCSI
- 在客户端中使用 NFS 版本 4.1 或更高版本挂载导出的 XFS 文件系统:
# mount -t nfs -o nfsvers=4.1 host:/remote/export /local/directory
不要在没有 NFS 的情况下直接挂载 XFS 文件系统。
其它资源
- 有关挂载 NFS 共享的详情请参考 第 8.2 节 “配置 NFS 客户端”。
8.10.5. 在服务器中释放 pNFS SCSI 保留
先决条件
- 安装 sg3_utils 软件包:
# yum install sg3_utils
过程 8.7. 在服务器中释放 pNFS SCSI 保留
- 在服务器上查询现有保留:
# sg_persist --read-reservation path-to-scsi-device
例 8.10. 在 /dev/sda 上查询保留
# sg_persist --read-reservation /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk PR generation=0x8, Reservation follows: Key=0x100000000000000 scope: LU_SCOPE, type: Exclusive Access, registrants only - 删除服务器上的现有注册:
# sg_persist --out \ --release \ --param-rk=reservation-key \ --prout-type=6 \ path-to-scsi-device例 8.11. 删除 /dev/sda 上的保留
# sg_persist --out \ --release \ --param-rk=0x100000000000000 \ --prout-type=6 \ /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk
其它资源
- sg_persist(8) man page
8.10.6. 监控 pNFS SCSI 布局功能
先决条件
- 配置了 pNFS SCSI 客户端和服务器。
8.10.6.1. 从使用 nfsstat 的服务器检查 pNFS SCSI 操作
nfsstat 工具来监控服务器的 pNFS SCSI 操作。
过程 8.8. 从使用 nfsstat 的服务器检查 pNFS SCSI 操作
- 监控服务器中服务的操作:
# watch --differences \ "nfsstat --server | egrep --after-context=1 read\|write\|layout" Every 2.0s: nfsstat --server | egrep --after-context=1 read\|write\|layout putrootfh read readdir readlink remove rename 2 0% 0 0% 1 0% 0 0% 0 0% 0 0% -- setcltidconf verify write rellockowner bc_ctl bind_conn 0 0% 0 0% 0 0% 0 0% 0 0% 0 0% -- getdevlist layoutcommit layoutget layoutreturn secinfononam sequence 0 0% 29 1% 49 1% 5 0% 0 0% 2435 86% - 客户端和服务器在以下情况下使用 pNFS SCSI 操作:
layoutget、layoutreturn和layoutcommit计数器递增。这意味着服务器提供布局。- 服务器
读写
8.10.6.2. 使用 mountstats 从客户端检查 pNFS SCSI 操作
/proc/self/mountstats 文件来监控客户端的 pNFS SCSI 操作。
过程 8.9. 使用 mountstats 从客户端检查 pNFS SCSI 操作
- 列出每个挂载的操作计数器:
# cat /proc/self/mountstats \ | awk /scsi_lun_0/,/^$/ \ | egrep device\|READ\|WRITE\|LAYOUT device 192.168.122.73:/exports/scsi_lun_0 mounted on /mnt/rhel7/scsi_lun_0 with fstype nfs4 statvers=1.1 nfsv4: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x803,acl=0x3,sessions,pnfs=LAYOUT_SCSI READ: 0 0 0 0 0 0 0 0 WRITE: 0 0 0 0 0 0 0 0 READLINK: 0 0 0 0 0 0 0 0 READDIR: 0 0 0 0 0 0 0 0 LAYOUTGET: 49 49 0 11172 9604 2 19448 19454 LAYOUTCOMMIT: 28 28 0 7776 4808 0 24719 24722 LAYOUTRETURN: 0 0 0 0 0 0 0 0 LAYOUTSTATS: 0 0 0 0 0 0 0 0 - 在结果中:
LAYOUT统计指示客户端和服务器使用 pNFS SCSI 操作的请求。READ和WRITE统计指示客户端和服务器回退到 NFS 操作的请求。
8.11. NFS 参考
安装的文档
- man mount - 包含了全面查看 NFS 服务器和客户端配置的挂载选项。
- man fstab - 提供在启动时挂载文件系统的
/etc/fstab文件格式的详细信息。 - man nfs - 提供特定于 NFS 文件系统导出和挂载选项的详情。
- man exports - 显示导出 NFS 文件系统时
/etc/exports文件中使用的常见选项。
有用的网站
- http://linux-nfs.org - 开发人员查看项目状态更新的的当前站点。
- http://nfs.sourceforge.net/ - 开发人员的老家,里面仍然包含了很多有用的信息。
- http://www.citi.umich.edu/projects/nfsv4/linux/ - Linux 2.6 内核资源的 NFSv4。
- http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.4086 - 关于 NFS 版本 4 协议的功能和加强的完美白皮书。
第 9 章 服务器消息块(SMB)
cifs-utils 工具从远程服务器挂载 SMB 共享。
cifs。
第 10 章 FS-Cache
图 10.1. FS-Cache 概述
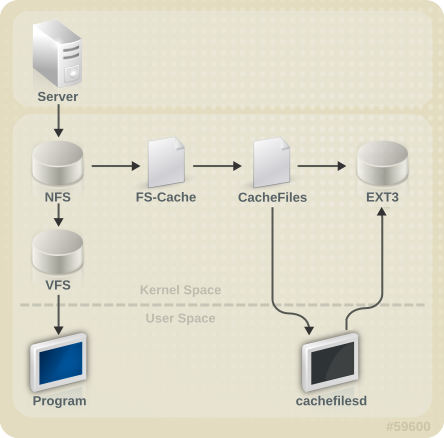
[D]
10.1. 性能保证
10.2. 设置缓存
/etc/cachefilesd.conf 文件控制 cachefile 如何提供缓存服务。
$ dir /path/to/cache/etc/cachefilesd.conf 中被设置为 /var/cache/fscache,如下所示:
$ dir /var/cache/fscache
/var/cache/fscache 相同:
#semanage fcontext -a -e /var/cache/fscache /path/to/cache#restorecon -Rv /path/to/cache
#semanage permissive -a cachefilesd_t#semanage permissive -a cachefiles_kernel_t
/)作为主机文件系统,但对于桌面计算机而言,更谨慎地挂载专门用于缓存的磁盘分区。
- ext3(启用了扩展属性)
- ext4
- Btrfs
- XFS
# tune2fs -o user_xattr /dev/device
# mount /dev/device /path/to/cache -o user_xattrcachefilesd 服务:
# systemctl start cachefilesd
# systemctl enable cachefilesd10.3. 在 NFS 中使用缓存
# mount nfs-share:/ /mount/point -o fsc10.3.1. 缓存共享
- 第 1 级:服务器详情
- 第 2 级:一些挂载选项;安全类型;FSID;uniquifier
- 第 3 级:文件处理
- 第 4 级:文件中的页号
例 10.1. 缓存共享
/home/fred 和 /home/jim 可能会共享超级块,因为它们具有相同的选项,特别是当它们来自 NFS 服务器(home0)上的相同卷/分区时。现在,考虑接下来的两个挂载命令:
/home/fred 和 /home/jim 不会共享超级块,因为它们具有不同的网络访问参数,这些参数是第 2 级密钥的一部分。以下的挂载序列也是如此:
/home/fred1 和 /home/fred2)将缓存 两次。
home0:/disk0/fred 和 home0:/disk0/jim 的第 2 级密钥。要解决这个问题,请在至少一个挂载上添加一个 唯一标识符,即 fsc=unique-identifier。例如:
/home/jim 缓存中使用的第 2 级键中。
10.3.2. 使用 NFS 的缓存限制
- 为直接 I/O 打开共享文件系统的文件将自动绕过缓存。这是因为这种访问类型必须与服务器直接进行。
- 打开共享文件系统的文件进行写入不适用于 NFS 版本 2 和 3。这些版本的协议无法为客户端提供足够的一致性管理信息,来检测另一客户端对同一文件的并发写入。
- 从共享文件系统打开一个文件直接 I/O 或写入清除文件缓存的副本。FS-Cache 不会再次缓存文件,直到它不再为直接 I/O 或写操作而打开。
- 另外,FS-Cache 的这个发行版本只缓存常规 NFS 文件。FS-Cache 不会 缓存目录、符号链接、设备文件、FIFO 和套接字。
10.4. 设置缓存剔除限制
/etc/cachefilesd.conf 中的设置控制六个限制:
N 的默认值如下:
- brun/frun - 10%
- bcull/fcull - 7%
- bstop/fstop - 3%
- 0 PROFILE bstop < bcull < brun < 100
- 0 PROFILE fstop < fcull < frun < 100
10.5. 统计信息
# cat /proc/fs/fscache/stats/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
10.6. FS-Cache 参考
/usr/share/doc/cachefilesd-version-number/README/usr/share/man/man5/cachefilesd.conf.5.gz/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
部分 II. 存储管理
第 11 章 安装过程中的存储注意事项
11.1. 特殊注意事项
/home、/opt、/usr/local 的单独分区
/home、/opt 和 /usr/local 放在单独的设备中。这可让您重新格式化包含操作系统的设备或文件系统,同时保留您的用户和应用程序数据。
IBM System Z 上的 DASD 和 zFCP 设备
DASD= 参数。
FCP_x= 行允许您为安装程序指定此信息。
使用 LUKS 加密块设备
过时的 BIOS RAID 元数据
# dmraid -r -E /device/iSCSI 检测和配置
FCoE 检测和配置
DASD
启用了 DIF/DIX 的块设备
第 12 章 文件系统检查
/etc/fstab 中列出的每个文件系统上运行文件系统检查。对于日志记录文件系统,这通常是一个非常短的操作,因为即使崩溃,文件系统的元数据日志也会确保一致性。
/etc/fstab 中的第六个字段设置为 0,可以在引导时禁用文件系统检查。12.1. fsck 的最佳实践
- 空运行
- 大多数文件系统检查程序都有一个操作模式,用于检查但不修复文件系统。在这个模式中,检查程序会输出它发现的任何错误以及它所执行的操作,而无需实际修改文件系统。注意稍后一致性检查阶段可能会打印额外的错误,因为在修复模式下运行时,它会发现可能在早期阶段已经修复了的不一致问题。
- 首先对文件系统镜像进行操作
- 大多数文件系统都支持创建 元数据镜像,这是仅包含元数据的文件系统的稀疏副本。由于文件系统检查程序仅在元数据上运行,因此此类镜像可用于对实际文件系统修复执行空运行,以评估实际要进行的更改。如果更改可以接受,则可以对文件系统本身进行修复。注意严重损坏的文件系统可能会导致元数据镜像创建出现问题。
- 保存文件系统镜像以进行支持调查
- 如果因为软件错误导致损坏,则预修复文件系统元数据镜像通常有助于支持调查。修复前镜像中存在的损坏模式可能有助于根本原因的分析。
- 仅在卸载的文件系统上运行
- 文件系统修复必须只在卸载的文件系统上运行。该工具必须具有对文件系统的唯一访问权限,或者可能导致进一步的损坏。大多数文件系统工具在修复模式下强制实施这个要求,虽然有些文件系统只支持在挂载的文件系统中只检查模式。如果在挂载的文件系统上运行只检查模式,则可能发现在卸载的文件系统上运行时未找到的错误。
- 磁盘错误
- 文件系统检查工具不能修复硬件问题。如果修复操作成功,文件系统必须是完全可读写的。如果文件系统因为硬件错误而损坏,则必须首先将文件系统移至良好磁盘,例如使用 dd (8) 工具。
12.2. fsck 的文件系统特定信息
12.2.1. ext2、ext3 和 ext4
e2fsck 二进制文件来执行文件系统检查和修复。文件名 fsck.ext2、 fsck.ext3 和 fsck.ext4 是同一二进制文件的硬链接。这些二进制文件在引导时自动运行,其行为因正在检查的文件系统和文件系统的状态而异。
- -n
- 无修改模式.仅检查操作.
- -b superblock
- 如果主块被损坏,请指定备用的 suprerblock 的块数。
- -f
- 如果超级块没有记录的错误,也强制进行全面检查。
- -j journal-dev
- 指定外部日志设备(若有的话)。
- -p
- 自动修复或"复制"文件系统,无需用户输入。
- -y
- 假设所有问题的答案都为"是"。
- Inode、块和大小检查.
- 目录结构检查。
- 目录连接性检查。
- 参考计数检查。
- 组摘要信息检查。
12.2.2. XFS
fsck.xfs 二进制文件,但这仅用于满足在启动时查找 fsck 的 initscripts。文件系统 二进制文件。fsck.xfs 立即退出,退出代码为 0。
- -n
- 无修改模式。仅检查操作.
- -L
- 将元数据日志归零。仅当无法通过 mount 重新执行日志时才使用。
- -m maxmem
- 将运行期间使用的内存限制为 maxmem MB。可以指定 0 来粗略估算所需的最小内存。
- -l logdev
- 如果存在,指定外部日志设备。
- inode 和 inode 块映射(寻址)检查.
- inode 分配映射检查。
- inode 大小检查。
- 目录检查。
- 路径名称检查。
- 链接数检查。
- 空闲映射检查。
- 超级块检查。
12.2.3. Btrfs
- 扩展检查。
- 文件系统 root 检查。
- 根参考计数检查。
第 13 章 分区
- 查看现有的分区表。
- 更改现有分区的大小。
- 从可用空间或其他硬盘添加分区。
# parted /dev/sda使用中的设备处理分区
修改分区表
# partx --update --nr partition-number disk
- 如果磁盘中的分区无法卸载,则以救援模式引导系统,例如在系统磁盘的情况下。
- 当提示挂载文件系统时,请选择 。
表 13.1. parted 命令
| 命令 | 描述 |
|---|---|
| 帮助 | 显示可用命令列表 |
| mklabel label | 为分区表创建磁盘标签 |
| mkpart part-type [fs-type] start-mb end-mb | 在不创建新文件系统的情况下创建分区 |
| name minor-num name | 只为 Mac 和 PC98 磁盘标签命名分区 |
| 显示分区表 | |
| quit | 退出 parted |
| rescue start-mb end-mb | 抢救丢失的分区(从 Start-mb 到 end-mb) |
| rm minor-num | 删除分区 |
| 选择设备 | 选择要配置的其他设备 |
| set minor-num flag state | 在分区中设置标志 ; state 为 on 或 off |
| toggle [NUMBER [FLAG] | 切换分区 NUMBER上的 FLAG 状态 |
| unit UNIT | 将默认单位设置为 UNIT |
13.1. 查看分区表
- 启动 parted。
- 使用以下命令查看分区表:
(parted)print
例 13.1. 分区表
Model: ATA ST3160812AS (scsi) Disk /dev/sda: 160GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 107MB 107MB primary ext3 boot 2 107MB 105GB 105GB primary ext3 3 105GB 107GB 2147MB primary linux-swap 4 107GB 160GB 52.9GB extended root 5 107GB 133GB 26.2GB logical ext3 6 133GB 133GB 107MB logical ext3 7 133GB 160GB 26.6GB logical lvm
- 模型:ATA ST3160812AS (scsi) :解释磁盘类型、制造商、型号号和接口。
- 磁盘 /dev/sda: 160GB :显示块设备和存储容量的文件路径。
- partition Table: msdos: 显示磁盘标签类型。
- 在分区表中,
Number是分区号。例如,次号 1 的分区对应于/dev/sda1。Start和End值以 MB 为单位。有效的Types是 metadata, free, primary, extended, or logical。File system是文件系统类型。Flags 列中列出了为分区设置的标志。可用的标志有 boot、root、swap、hidden、raid、lvm 或 lba。
File system 可以是以下任意一种:
- ext2
- ext3
- fat16
- fat32
- hfs
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
File system 没有显示值,这意味着其文件系统类型未知。
13.2. 创建分区
过程 13.1. 创建分区
- 在创建分区前,引导进入救援模式,或者卸载该设备中的任何分区,并关闭该设备上的任何交换空间。
- 启动 parted :
# parted /dev/sda使用您要在其上创建分区的设备名称替换 /dev/sda。 - 查看当前的分区表来确定是否有足够空闲空间:
(parted)print如果没有足够的可用空间,您可以调整现有分区的大小。如需更多信息,请参阅 第 13.5 节 “使用 fdisk 重新定义分区大小”。 - 创建分区:
(parted)mkpart part-type name fs-type start end根据您的要求,将 part-type 替换为 primary、logical 或 extended。使用分区名称替换 name ;GPT 分区表需要 name。使用 btrfs、ext2、ext3、ext4、fat16、fat32、hfs、hfs+、linux-swap、ntfs、reiserfs 或 xfs; fs-type 之一替换 fs-type。根据您的要求,将 start 以 MB 为单位表示。例如,要在硬盘上创建从 1024MB 到 2048 MB 的 ext3 文件系统的主分区,请输入以下命令:(parted)mkpart primary 1024 2048注意如果您使用 mkpartfs 命令,文件系统会在分区创建后创建。但是 parted 不支持创建 ext3 文件系统。因此,如果要创建 ext3 文件系统,请使用 mkpart 并使用 mkfs 命令创建文件系统,如稍后所述。按 Enter 键后,这些更改就会生效,因此请在执行前检查命令。 - 使用以下命令,查看分区表以确认创建的分区位于分区表中,并具有正确的分区类型、文件系统类型和大小:
(parted)print还请记住新分区的次要号,以便您可以在其上面标记任何文件系统。 - 退出 parted shell:
(parted)quit - 在 parted 关闭后使用以下命令,以确保内核识别新分区:
#cat /proc/partitions
13.2.1. 格式化和标记分区
过程 13.2. 格式化和标记分区
- 分区没有文件系统。要创建
ext4文件系统,请使用:#mkfs.ext4 /dev/sda6警告格式化分区会永久销毁分区上当前存在的任何数据。 - 标记分区中的文件系统。例如:如果新分区中的文件系统是
/dev/sda6,而您想要将其标记为Work,请使用:#e2label /dev/sda6 "Work"默认情况下,安装程序使用分区挂载点作为标签,以确保标签是唯一的。您可以使用您想要的任何标签。 - 以 root 身份创建挂载点(如
/work)。
13.2.2. 将分区添加到 /etc/fstab
- 以 root 用户身份,编辑
/etc/fstab文件,以使用分区的 UUID 包含新分区。使用命令 blkid -o list 获取分区 UUID 的完整列表,或使用 blkid 设备 获取单个设备详情。在/etc/fstab中:- 第一列应当包含
UUID=,后跟文件系统的 UUID。 - 第二列应包含新分区的挂载点。
- 第三列应为文件系统类型:例如
ext4或swap。 - 第四列列出了文件系统的挂载选项。此处的单词
defaults表示分区在引导时使用默认选项挂载。 - 第五个字段和第六个字段指定 backup 和 check 选项。非 root 分区的值示例为
0 2。
- 重新生成挂载单元以便您的系统注册新配置:
#systemctl daemon-reload - 尝试挂载文件系统来验证配置是否正常工作:
# mount /work
其它信息
- 如果您需要有关
/etc/fstab格式的更多信息,请参阅 fstab(5) man page。
13.3. 删除分区
过程 13.3. 删除分区
- 在删除分区前,请执行以下操作之一:
- 引导至救援模式,或者
- 卸载该设备中的任何分区,并关闭该设备上的任何交换空间。
- 启动
parted工具:# parted device使用删除分区的设备替换 device :例如/dev/sda。 - 查看当前的分区表以确定要删除的分区的次号:
(parted) print - 使用命令 rm 删除分区。例如:要删除次要号为 3 的分区:
(parted) rm 3按 Enter 键后,这些更改就会生效,因此请在提交前检查命令。 - 删除分区后,使用 print 命令确认它已从分区表中删除:
(parted) print - 从
partedshell 退出:(parted) quit - 检查
/proc/partitions文件的内容,以确保内核知道分区已被删除:# cat /proc/partitions - 从
/etc/fstab文件中删除分区。找到声明删除的分区的行,并将其从文件中删除。 - 重新生成挂载单元,以便您的系统注册新的
/etc/fstab配置:#systemctl daemon-reload
13.4. 设置分区类型
systemd-gpt-auto-generator,它使用分区类型来自动识别和挂载设备。
fdisk 工具,并使用 t 命令设置分区类型。以下示例演示了如何将第一个分区的分区类型改为 0x83,在 Linux 中默认:
#fdisk /dev/sdc Command (m for help): t Selected partition1Partition type (type L to list all types):83Changed type of partition 'Linux LVM' to 'Linux'.
parted 工具尝试将分区类型映射到"flags" (对最终用户来说并不方便)来提供一些分区类型控制。parted 工具只能处理某些分区类型,如 LVM 或 RAID。例如,要使用 parted 从第一个分区中删除 lvm 标志,请使用:
# parted /dev/sdc 'set 1 lvm off'
13.5. 使用 fdisk 重新定义分区大小
fdisk 实用程序允许您创建和操作 GPT、R MBR、SGI 和 BSD 分区表。建议在带有 GUID 分区表(GPT)的磁盘上,建议使用 parted 工具,因为 fdisk GPT 支持处于实验性阶段。
fdisk 更改分区大小的唯一方法是通过删除和重新创建分区。
过程 13.4. 调整分区大小
fdisk 调整分区大小:
- 卸载该设备:
#umount /dev/vda - 运行 fdisk disk_name。例如:
#fdisk /dev/vda Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): - 使用
p选项确定要删除的分区的行号。Command (m for help): p Disk /dev/vda: 16.1 GB, 16106127360 bytes, 31457280 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0006d09a Device Boot Start End Blocks Id System /dev/vda1 * 2048 1026047 512000 83 Linux /dev/vda2 1026048 31457279 15215616 8e Linux LVM
- 使用 d 选项删除分区。如果有多个分区可用,fdisk 会提示您提供要删除的多个分区:
Command (m for help): d Partition number (1,2, default 2): 2 Partition 2 is deleted
- 使用
n选项创建分区并按照提示进行操作。允许足够空间以供将来重新定义大小。fdisk 默认行为(按Enter)是使用设备上的所有空间。您可以根据扇区指定分区的结束,或使用 + <size> <suffix> 指定人类可读的大小,如 +500M 或 +10G。如果您不想使用所有可用空间,红帽建议使用人类可读的大小规格,因为 fdisk 将分区的末尾与物理扇区一致。如果您通过提供准确数字(扇区)来指定大小,fdisk 不会对齐分区的末尾。Command (m for help): n Partition type: p primary (1 primary, 0 extended, 3 free) e extended Select (default p): *Enter* Using default response p Partition number (2-4, default 2): *Enter* First sector (1026048-31457279, default 1026048): *Enter* Using default value 1026048 Last sector, +sectors or +size{K,M,G} (1026048-31457279, default 31457279): +500M Partition 2 of type Linux and of size 500 MiB is set - 将分区类型设置为 LVM:
Command (m for help): t Partition number (1,2, default 2): *Enter* Hex code (type L to list all codes): 8e Changed type of partition 'Linux' to 'Linux LVM'
- 当您确定更改正确时,使用 w 选项写入更改,因为错误可能会导致所选分区不稳定。
- 在设备上运行 e2fsck 来检查一致性:
#e2fsck /dev/vda e2fsck 1.41.12 (17-May-2010) Pass 1:Checking inodes, blocks, and sizes Pass 2:Checking directory structure Pass 3:Checking directory connectivity Pass 4:Checking reference counts Pass 5:Checking group summary information ext4-1:11/131072 files (0.0% non-contiguous),27050/524128 blocks - 挂载该设备:
#mount /dev/vda
第 14 章 使用 Snapper 创建和维护快照
14.1. 创建 Initial Snapper 配置
过程 14.1. 创建 Snapper 配置文件
- 创建或选择:
- 一个精简配置的逻辑卷,它有一个红帽支持的文件系统,或者
- Btrfs 子卷。
- 挂载文件系统。
- 创建定义此卷的配置文件。对于 LVM2:
#snapper -c config_name create-config -f "lvm(fs_type)" /mount-point例如,要使用 ext4 文件系统(挂载于 /lvm_mount)在 LVM2 子卷上创建一个名为 lvm_config 的配置文件,请使用:#snapper -c lvm_config create-config -f "lvm(ext4)" /lvm_mount对于 Btrfs:#snapper -c config_name create-config -f btrfs /mount-point- -c config_name 选项指定配置文件的名称。
- create-config 告知 snapper 创建配置文件。
- f file_system 告知 snapper 要使用的文件系统;如果忽略了 snapper,则尝试检测文件系统。
- /mount-point 是挂载子卷或精简配置的 LVM2 文件系统的位置。
或者,要在挂载到/btrfs_mount的 Btrfs 子卷上创建一个名为btrfs_config的配置文件,请使用:#snapper -c btrfs_config create-config -f btrfs /btrfs_mount
/etc/snapper/configs/ 目录中。
14.2. 创建 Snapper 快照
- pre Snapshot
- pre 快照充当后快照的原始卷。这两个操作都紧密关联,旨在跟踪两个点之间的文件系统修改。必须在创建快照前创建预快照。
- 后快照
- post 快照充当预快照的端点。组合 pre 和 post 快照定义了要比较的范围。默认情况下,每个新 snapper 卷都配置为在成功创建相关后创建快照后创建后台比较。
- 单个快照
- 单个快照是在特定时间创建的独立快照。它们可用于跟踪修改时间表,并具有以后返回的一般点。
14.2.1. 创建 Pre 和 Post Snapshot Pair
14.2.1.1. 使用 Snapper 创建 Pre Snapshot
# snapper -c config_name create -t prepre、post 或 single。
lvm_config 配置文件创建预快照,如 第 14.1 节 “创建 Initial Snapper 配置” 中创建,请使用:
# snapper -c SnapperExample create -t pre -p
1
-p 选项打印创建快照的数量,并是可选的。
14.2.1.2. 使用 Snapper 创建 Post Snapshot
过程 14.2. 创建后快照
- 确定预快照的数量:
#snapper -c config_name list例如,要显示使用配置文件lvm_config创建的快照列表,请使用:#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | |此输出显示预快照为数字 1。 - 创建链接到之前创建的预快照的后快照:
#snapper -c config_file create -t post --pre-num pre_snapshot_number- t post 选项指定创建快照类型的创建。
- --pre-num 选项指定对应的 pre snapshot。
例如,要使用lvm_config配置文件创建后快照并链接到预快照号 1,请使用:#snapper -c lvm_config create -t post --pre-num 1 -p 2-p选项打印创建快照的数量,并是可选的。 - 现在创建并配对了 pre 和 post 快照 1 和 2。使用 list 命令验证:
#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | | post | 2 | 1 | Mon 06<...> | root | | |
14.2.1.3. 在 Pre 和 Post Snapshots 中嵌套命令
- 运行 snapper create pre snapshot 命令。
- 运行命令或命令列表,以对文件系统内容有可能的影响。
- 运行 snapper create post snapshot 命令。
过程 14.3. 在 Pre 和 Post Snapshots 中嵌套命令
- 在预快照和后快照中嵌套命令:
#snapper -c lvm_config create --command "command_to_be_tracked"例如,要跟踪/lvm_mount/hello_file文件的创建:#snapper -c lvm_config create --command "echo Hello > /lvm_mount/hello_file" - 要验证这一点,请使用 status 命令:
#snapper -c config_file status first_snapshot_number..second_snapshot_number例如,要跟踪第一步中所做的更改:#snapper -c lvm_config status 3..4 +..... /lvm_mount/hello_file如果需要,使用 list 命令验证快照的数量。有关 status 命令的详情请参考 第 14.3 节 “跟踪 Snapper Snapshots 间的更改”。
14.2.2. 创建单个 Snapper 快照
-t 选项指定单个。单个快照用于随着时间的推移创建单个快照,而不与任何其他快照相关。但是,如果您想创建 LVM2 精简卷的快照,而无需自动生成比较或列出附加信息,红帽建议为此使用 System Storage Manager 而不是 Snapper,如 第 16.2.6 节 “Snapshot” 所述。
# snapper -c config_name create -t singlelvm_config 配置文件创建单个快照。
# snapper -c lvm_config create -t single14.2.3. 配置 Snapper 以获取自动化快照
- 10 每小时快照,最终每小时快照保存为"每天"快照。
- 10 个每日快照,一个月的最终每日快照会保存为"月"快照。
- 10 个月快照,最终每月快照保存为"每年"快照。
- 10 年快照。
/etc/snapper/config-templates/default 文件中指定。当您使用 snapper create-config 命令创建配置时,会根据默认配置设置任何未指定的值。您可以编辑 /etc/snapper/configs/config_name 文件中任何定义的卷的配置。
14.3. 跟踪 Snapper Snapshots 间的更改
- status
- status 命令显示在两个快照之间创建、修改或删除的文件和目录列表,这是两个快照之间更改的完整列表。您可以使用此命令获得更改的概述,而无需过量详情。如需更多信息,请参阅 第 14.3.1 节 “将更改与 status 命令进行比较”。
- diff
- 如果至少检测到一次修改,则 diff 命令显示从 status 命令接收的两个快照之间的修改文件和目录差异。如需更多信息,请参阅 第 14.3.2 节 “将更改与 diff 命令进行比较”。
- xadiff
- xadiff 命令比较两个快照之间文件或目录的扩展属性变化。如需更多信息,请参阅 第 14.3.3 节 “将更改与 xadiff 命令进行比较”。
14.3.1. 将更改与 status 命令进行比较
# snapper -c config_file status first_snapshot_number..second_snapshot_numberlvm_config 显示快照 1 和 2 之间所做的更改。
#snapper -c lvm_config status 1..2
tp.... /lvm_mount/dir1
-..... /lvm_mount/dir1/file_a
c.ug.. /lvm_mount/file2
+..... /lvm_mount/file3
....x. /lvm_mount/file4
cp..xa /lvm_mount/file5
+..... /lvm_mount/file3 |||||| 123456
| 输出 | 含义 |
|---|---|
| . | 没有改变。 |
| + | 文件已创建。 |
| - | 删除文件。 |
| c | 内容更改。 |
| t | 目录条目的类型已更改。例如,前一个符号链接已更改为具有相同文件名的常规文件。 |
| 输出 | 含义 |
|---|---|
| . | 没有更改权限。 |
| p | 更改了权限。 |
| 输出 | 含义 |
|---|---|
| . | 没有更改用户所有权。 |
| u | 用户所有权已更改。 |
| 输出 | 含义 |
|---|---|
| . | 没有更改组所有权。 |
| g | 组所有权已更改。 |
| 输出 | 含义 |
|---|---|
| . | 没有更改扩展属性。 |
| x | 扩展属性已更改。 |
| 输出 | 含义 |
|---|---|
| . | 没有更改 ACL。 |
| a | 修改 ACL。 |
14.3.2. 将更改与 diff 命令进行比较
# snapper -c config_name diff first_snapshot_number..second_snapshot_numberlvm_config 配置文件在快照 1 和快照 2 之间所做的更改,请使用:
# snapper -c lvm_config diff 1..2
--- /lvm_mount/.snapshots/13/snapshot/file4 19<...>
+++ /lvm_mount/.snapshots/14/snapshot/file4 20<...>
@@ -0,0 +1 @@
+words
file4 已被修改,以将"词语"添加到文件中。
14.3.3. 将更改与 xadiff 命令进行比较
# snapper -c config_name xadiff first_snapshot_number..second_snapshot_numberlvm_config 配置文件执行的快照号 1 和快照号 2 之间的 xadiff 输出,请使用:
# snapper -c lvm_config xadiff 1..214.4. 在快照之间撤销更改
1 是第一个快照,2 是第二个快照:
snapper -c config_name undochange 1..2
图 14.1. snapper Status over Time
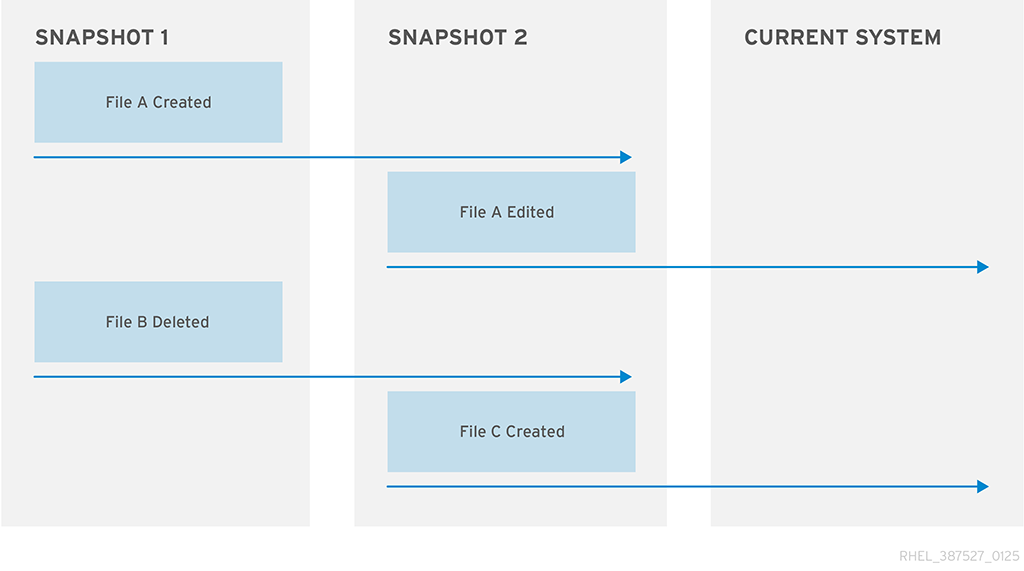
[D]
snapshot_1 的时间点,创建 file_a,然后删除 file_b。然后,会创建 Snapshot_2,之后编辑 file_a 并创建了 file_c。现在,这是系统的当前状态。当前系统具有 file_a 的编辑版本,无 file_b 以及新创建的 file_c。
file_a 已创建;删除了 file_b ),并将其应用到当前的系统。因此:
- 当前系统没有
file_a,因为它必须在snapshot_1创建时创建。 file_b将存在,从snapshot_1复制到当前系统。file_c将存在,因为它的创建是在指定时间之外。
file_b 和 file_c 冲突,系统可能会损坏。
file_a 版本替换为从 snapshot_1 复制的版本,这会撤销在创建 snapshot_2 后对该文件的编辑。
使用 mount 和 unmount 命令反向更改
/etc/snapper/configs/config_name 文件包含 ALLOW_USERS= 和 ALLOW_GROUPS= 变量,您可以在其中添加用户和组。然后,snapper d 允许您为添加的用户和组执行挂载操作。
14.5. 删除 Snapper 快照
# snapper -c config_name delete snapshot_number第 15 章 swap 空间
表 15.1. 推荐的系统交换空间
| 系统中的 RAM 量 | 推荐的 swap 空间 | 如果允许休眠则推荐使用 swap 空间 |
|---|---|---|
| ⩽ 2 GB | RAM 量的 2 倍 | RAM 量的 3 倍 |
| > 2 GB – 8 GB | 与 RAM 量相等 | RAM 量的 2 倍 |
| > 8 GB – 64 GB | 至少 4 GB | RAM 量的 1.5 倍 |
| > 64 GB | 至少 4 GB | 不推荐休眠 |
救援模式 引导时,您应该修改交换空间,请参阅 Red Hat Enterprise Linux 7 安装指南 中的 在 Rescue Mode 中引导您的计算机。当提示挂载文件系统时,请选择 。
15.1. 添加交换空间
15.1.1. 在 LVM2 逻辑卷上扩展交换空间
/dev/VolGroup00/LogVol01 是您要扩展为 2 GB 的卷):
过程 15.1. 在 LVM2 逻辑卷上扩展交换空间
- 为关联的逻辑卷禁用交换:
# swapoff -v /dev/VolGroup00/LogVol01 - 将 LVM2 逻辑卷大小调整 2 GB:
# lvresize /dev/VolGroup00/LogVol01 -L +2G - 格式化新 swap 空间:
# mkswap /dev/VolGroup00/LogVol01 - 启用扩展的逻辑卷:
# swapon -v /dev/VolGroup00/LogVol01 - 要测试是否成功扩展并激活 swap 逻辑卷,请检查活跃 swap 空间:
$ cat /proc/swaps $ free -h
15.1.2. 为交换空间创建 LVM2 逻辑卷
/dev/VolGroup00/LogVol02 是您要添加的交换卷:
- 创建大小为 2 GB 的 LVM2 逻辑卷:
# lvcreate VolGroup00 -n LogVol02 -L 2G - 格式化新 swap 空间:
# mkswap /dev/VolGroup00/LogVol02 - 在
/etc/fstab文件中添加以下条目:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
- 重新生成挂载单元以便您的系统注册新配置:
#systemctl daemon-reload - 在逻辑卷中激活 swap:
# swapon -v /dev/VolGroup00/LogVol02 - 要测试是否成功创建并激活 swap 逻辑卷,请检查活跃 swap 空间:
$ cat /proc/swaps $ free -h
15.1.3. 创建一个交换文件
过程 15.2. 添加交换文件
- 以 MB 为单位确定新交换文件的大小,再乘以 1024 来确定块的数量。例如: 64MB swap 文件的块大小为 65536。
- 创建一个空文件:
# dd if=/dev/zero of=/swapfile bs=1024 count=65536使用与所需块大小相等的值替换 count。 - 使用以下命令设定 swap 文件:
# mkswap /swapfile - 更改交换文件的安全性,使其不可读。
# chmod 0600 /swapfile - 要在引导时启用 swap 文件,以 root 用户身份编辑
/etc/fstab,使其包含以下条目:/swapfile swap swap defaults 0 0
下次系统引导时,它会激活新的 swap 文件。 - 重新生成挂载单元,以便您的系统注册新的
/etc/fstab配置:#systemctl daemon-reload - 立即激活 swap 文件:
# swapon /swapfile - 要测试新 swap 文件是否已成功创建并激活,请检查活跃 swap 空间:
$ cat /proc/swaps $ free -h
15.2. 删除交换空间
15.2.1. 减少 LVM2 逻辑卷上的交换空间
/dev/VolGroup00/LogVol01 是您要减少的卷):
过程 15.3. 减少 LVM2 交换空间
- 为关联的逻辑卷禁用交换:
# swapoff -v /dev/VolGroup00/LogVol01 - 将 LVM2 逻辑卷减少 512 MB:
# lvreduce /dev/VolGroup00/LogVol01 -L -512M - 格式化新 swap 空间:
# mkswap /dev/VolGroup00/LogVol01 - 在逻辑卷中激活 swap:
# swapon -v /dev/VolGroup00/LogVol01 - 要测试是否成功缩小 swap 逻辑卷,请检查活跃 swap 空间:
$ cat /proc/swaps $ free -h
15.2.2. 为交换空间删除一个 LVM2 逻辑卷
/dev/VolGroup00/LogVol02 是您要删除的交换卷):
过程 15.4. 删除一个交换空间卷组
- 为关联的逻辑卷禁用交换:
#swapoff -v /dev/VolGroup00/LogVol02 - 删除 LVM2 逻辑卷:
#lvremove /dev/VolGroup00/LogVol02 - 从
/etc/fstab文件中删除以下关联的条目:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
- 重新生成挂载单元以便您的系统注册新配置:
#systemctl daemon-reload - 从
/etc/default/grub文件中删除对已删除 swap 存储的所有引用:#vi /etc/default/grub - 重建 grub 配置:
- 在基于 BIOS 的机器上运行:
#grub2-mkconfig -o /boot/grub2/grub.cfg - 在基于 UEFI 的机器上,运行:
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 要测试是否成功删除了逻辑卷,请检查活跃 swap 空间:
$ cat /proc/swaps $ free -h
15.2.3. 删除一个交换文件
过程 15.5. 删除一个交换文件
- 在 shell 提示符下,执行以下命令禁用交换文件(其中
/swapfile是交换文件):# swapoff -v /swapfile - 从
/etc/fstab文件中删除其条目。 - 重新生成挂载单元以便您的系统注册新配置:
#systemctl daemon-reload - 删除实际的文件:
# rm /swapfile
15.3. 移动交换空间
- 删除 swap 空间 第 15.2 节 “删除交换空间”。
- 添加 swap 空间 第 15.1 节 “添加交换空间”。
第 16 章 系统存储管理器(SSM)
16.1. SSM 后端
ssmlib/main.py 中的核心抽象层,它符合设备、池和卷抽象,忽略底层技术的细节。后端可以在 ssmlib/main.py 中注册,以处理特定的存储技术方法,如创建、快照 或移除 卷和池。
16.1.1. Btrfs 后端
16.1.1.1. Btrfs Pool
btrfs_pool。
btrfs_device_base_name。
16.1.1.2. Btrfs 卷
/dev/lvm_pool/lvol001。此路径中的每个对象都必须存在,才能创建卷。也可通过其挂载点引用卷。
16.1.1.3. Btrfs Snapshot
16.1.1.4. Btrfs 设备
16.1.2. LVM 后端
16.1.2.1. LVM 池
lvm_pool。
16.1.2.2. LVM 卷
16.1.2.3. LVM 快照
快照卷,然后可以像任何其他 LVM 卷一样处理。与 Btrfs 不同,LVM 能够从常规卷区分快照,因此不需要快照名称来匹配特定的模式。
16.1.2.4. LVM 设备
16.1.3. crypt 后端
16.1.3.1. 加密卷
16.1.3.2. crypt Snapshot
16.1.4. 多个设备(MD)后端
16.2. 常见 SSM 任务
16.2.1. 安装 SSM
# yum install system-storage-manager
- LVM 后端需要
lvm2软件包。 - Btrfs 后端需要
btrfs-progs软件包。 - Crypt 后端需要
device-mapper和cryptsetup软件包。
16.2.2. 显示有关所有删除的设备的信息
# ssm list
----------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------
/dev/sda 2.00 GB PARTITIONED
/dev/sda1 47.83 MB /test
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
----------------------------------------------------------
------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------
---------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
---------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/sda1 47.83 MB xfs 44.50 MB 44.41 MB part /test
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
---------------------------------------------------------------------------------
- 运行 devices 或 dev 参数会省略一些设备。例如,CDROMS 和 DM/MD 设备被有意隐藏,因为它们被列为卷。
- 有些后端不支持快照,且无法区分快照和常规卷。在其中一个后端上运行 snapshot 参数会导致 SSM 尝试识别卷名称来识别快照。如果 SSM 正则表达式与快照模式不匹配,则不能识别快照。
- 除了主 Btrfs 卷(文件系统本身)外,任何卸载的 Btrfs 卷都不会显示。
16.2.3. 创建新池、逻辑卷和文件系统
/dev/vdb 和 /dev/vdc、1G 的逻辑卷和 XFS 文件系统。
- --fs 选项指定所需的文件系统类型。当前支持的文件系统类型有:
- ext3
- ext4
- xfs
- btrfs
- -s 指定逻辑卷的大小。支持以下后缀来定义单元:
k或k表示 KBM或m用于 MBG或G表示千兆字节T或tfor TBP或pfor PBse或e用于 exabytes
- Additionaly 使用 -s 选项,新大小可指定为百分比。查看示例:
- 总池大小达到
10% - 空闲池空间的
10%FREE 10%USED是已用池空间的 10%
/dev/vdb 和 /dev/vdc 是您要创建的两个设备。
# ssm create --fs xfs -s 1G /dev/vdb /dev/vdc
Physical volume "/dev/vdb" successfully created
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully created
Logical volume "lvol001" created
lvm_pool。但是,要使用特定名称来适应任何现有命名约定,应使用 -p 选项。
# ssm create --fs xfs -p new_pool -n XFS_Volume /dev/vdd
Volume group "new_pool" successfully created
Logical volume "XFS_Volume" created
16.2.4. 检查文件系统的一致性
lvol001 中的所有设备,请运行命令 ssm check /dev/lvm_pool/lvol001。
# ssm check /dev/lvm_pool/lvol001
Checking xfs file system on '/dev/mapper/lvm_pool-lvol001'.
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
16.2.5. 增加卷的大小
/dev/vdb 上有一个逻辑卷,名为 lvol001。
# ssm list
-----------------------------------------------------------------
Device Free Used Total Pool Mount point
-----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 120.00 MB 900.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
-----------------------------------------------------------------
---------------------------------------------------------
Pool Type Devices Free Used Total
---------------------------------------------------------
lvm_pool lvm 1 120.00 MB 900.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
---------------------------------------------------------
--------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
--------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
--------------------------------------------------------------------------------------------
~]# ssm resize -s +500M /dev/lvm_pool/lvol001 /dev/vdc
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully extended
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
Extending logical volume lvol001 to 1.37 GiB
Logical volume lvol001 successfully resized
meta-data=/dev/mapper/lvm_pool-lvol001 isize=256 agcount=4, agsize=57600 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=230400, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal bsize=4096 blocks=853, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 230400 to 358400
# ssm list
------------------------------------------------------------------
Device Free Used Total Pool Mount point
------------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 640.00 MB 380.00 MB 1.00 GB lvm_pool
------------------------------------------------------------------
------------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------------
lvm_pool lvm 2 640.00 MB 1.37 GB 1.99 GB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 1.37 GB xfs 1.36 GB 1.36 GB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
# ssm resize -s-50M /dev/lvm_pool/lvol002
Rounding size to boundary between physical extents: 972.00 MiB
WARNING: Reducing active logical volume to 972.00 MiB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce lvol002? [y/n]: y
Reducing logical volume lvol002 to 972.00 MiB
Logical volume lvol002 successfully resized
16.2.6. Snapshot
lvol001 创建快照,请使用以下命令:
# ssm snapshot /dev/lvm_pool/lvol001
Logical volume "snap20150519T130900" created
# ssm list
----------------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
----------------------------------------------------------------
--------------------------------------------------------
Pool Type Devices Free Used Total
--------------------------------------------------------
lvm_pool lvm 1 0.00 KB 1020.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
--------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------
Snapshot Origin Pool Volume size Size Type
----------------------------------------------------------------------------------
/dev/lvm_pool/snap20150519T130900 lvol001 lvm_pool 120.00 MB 0.00 KB linear
----------------------------------------------------------------------------------
16.2.7. 删除项
# ssm remove lvm_pool
Do you really want to remove volume group "lvm_pool" containing 2 logical volumes? [y/n]: y
Do you really want to remove active logical volume snap20150519T130900? [y/n]: y
Logical volume "snap20150519T130900" successfully removed
Do you really want to remove active logical volume lvol001? [y/n]: y
Logical volume "lvol001" successfully removed
Volume group "lvm_pool" successfully removed
16.3. SSM 资源
- man ssm 页面提供了很好的描述和示例,以及有关所有命令和选项的详细信息,具体要记录在此处。
- SSM 的本地文档存储在
doc/目录中。 - SSM wiki 可从 访问 http://storagemanager.sourceforge.net/index.html。
- 邮件列表可从 中订阅,并从 https://lists.sourceforge.net/lists/listinfo/storagemanager-devel 中邮件列表存档 http://sourceforge.net/mailarchive/forum.php?forum_name=storagemanager-devel。邮件列表是开发人员通信的位置。当前没有用户邮件列表,因此也可以自由地发布问题。
第 17 章 磁盘配额
17.1. 配置磁盘配额
- 通过修改
/etc/fstab文件,为每个文件系统启用配额。 - 重新挂载文件系统。
- 创建配额数据库文件,并生成磁盘使用情况表。
- 分配配额策略。
17.1.1. 启用配额
过程 17.1. 启用配额
- 以 root 身份登录。
- 编辑
/etc/fstab文件。 - 将 usrquota 或 grpquota 或两个选项添加到需要配额的文件系统中。
例 17.1. 编辑 /etc/fstab
vim,请键入以下内容:
# vim /etc/fstab例 17.2. 添加配额
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 /dev/VolGroup00/LogVol02 /home ext3 defaults,usrquota,grpquota 1 2 /dev/VolGroup00/LogVol01 swap swap defaults 0 0 . . .
/home 文件系统同时启用了用户和组配额。
/etc/fstab 文件中的配额策略。
17.1.2. 重新挂载文件系统
fstab 条目的每个文件系统。如果文件系统没有被任何进程使用,请使用以下方法之一:
- 运行 umount 命令,后跟 mount 命令以重新挂载文件系统。有关挂载和卸载各种文件系统类型的具体语法,请参阅 umount 和 mount man page。
- 运行 mount -o remount file-system 命令(其中 file-system 是文件系统的名称)以重新挂载文件系统。例如,要重新挂载
/home文件系统,请运行 mount -o remount /home 命令。
17.1.3. 创建配额数据库文件
过程 17.2. 创建配额数据库文件
- 使用以下命令在文件系统中创建配额文件:
#quotacheck -cug /file system - 使用以下命令为每个文件系统生成当前磁盘用量表:
#quotacheck -avug
- c
- 指定应为每个启用配额的文件系统创建配额文件。
- u
- 检查用户配额。
- g
- 检查组配额。如果只指定
-g,则仅创建组配额文件。
-u 或 -g 选项,则仅创建用户配额文件。
- a
- 检查所有启用了配额的、本地挂载的文件系统
- v
- 在配额检查进行时显示详细的状态信息
- u
- 检查用户磁盘配额信息
- g
- 检查组磁盘配额信息
/home )的数据。
17.1.4. 为每个用户分配配额
- 用户必须在设置用户配额前存在。
过程 17.3. 为每个用户分配配额
- 要为用户分配配额,请使用以下命令:
#edquota username使用您要为其分配配额的用户替换 username。 - 要验证是否为该用户设定了配额,使用以下命令:
#quota username
例 17.3. 为用户分配配额
/etc/fstab 中为 /home 分区(以下示例中的/dev/VolGroup00/LogVol02 )启用了配额,并且执行了命令 edquota testuser,则会在配置为系统默认设置的编辑器中显示以下内容:
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
EDITOR 环境变量定义的文本编辑器。要更改编辑器,将 ~/.bash_profile 文件中的 EDITOR 环境变量设置为您选择的编辑器的完整路径。
inodes 列显示用户当前使用的 inode 数。最后两列是为该用户在文件系统中设定软和硬的内节点限制。
例 17.4. 更改限制
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
# quota testuser
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 0
17.1.5. 为每个组分配配额
- 组群在设定组群配额前必须已经存在。
过程 17.4. 为每个组分配配额
- 要设置组配额,请使用以下命令:
#edquota -g groupname - 要验证是否设定了组群配额,请使用以下命令:
#quota -g groupname
例 17.5. 为组分配配额
devel 组设置组配额,请使用以下命令:
# edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
# quota -g devel17.1.6. 为软限制设置宽限期
# edquota -t17.2. 管理磁盘配额
17.2.1. 启用和禁用
# quotaoff -vaug-u 或 -g 选项,则仅禁用用户配额。如果只指定 -g,则只禁用组配额。-v 开关会在命令执行时显示详细状态信息。
# quotaon# quotaon -vaug-u 或 -g 选项,则只启用用户配额。如果只指定 -g,则只启用组配额。
/home )启用配额,请使用以下命令:
# quotaon -vug /home17.2.2. 报告磁盘配额
例 17.6. repquota 命令的输出
*** Report for user quotas on device /dev/mapper/VolGroup00-LogVol02 Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
-a),请使用命令:
# repquota -a-- 是确定是否超过块或内节点限制的快速方法。如果超过了任何一个软限制,则 + 会出现在对应的 - 的位置,第一个 - 代表块限制,第二个代表内节点限制。
grace 列通常为空。如果超过了软限制,则该列包含的时间规格等同于宽限期中剩余的时间量。如果宽限期已过期,none 会出现在其位置上。
17.2.3. 使配额保持准确
# quotacheck- 确保 quotacheck 在下次重启时运行
- 大多数系统的最佳方法这个方法最适合定期重启的多用户系统。使用以下命令将 shell 脚本保存到
/etc/cron.daily/或/etc/cron.weekly/目录中,或者使用以下命令调度一个:#crontab -ecrontab -e 命令包含 touch /forcequotacheck 命令。这会在根目录中创建一个空的forcequotacheck文件,系统初始化脚本会在引导时查找该文件。如果找到了,初始化脚本将运行 quotacheck。之后,初始化脚本会删除/forcequotacheck文件;因此,使用cron定期创建此文件,确保在下次重启时运行 quotacheck。有关 cron 的更多信息,请参阅 man cron。 - 在单用户模式下运行 quotacheck
- 安全运行 quotacheck 的替代方法是将系统引导至单用户模式,以防止配额文件中出现数据崩溃并运行以下命令:
#quotaoff -vug /file_system#quotacheck -vug /file_system#quotaon -vug /file_system - 在运行的系统上运行 quotacheck
- 如有必要,可以在没有用户登录的情况下在机器上运行 quotacheck,因此没有正在检查的文件系统上的打开文件。运行 quotacheck -vug file_system 命令;如果 quotacheck 无法以只读形式重新挂载给定的 file_system,此命令将失败。请注意,在检查后,文件系统将以读写形式重新挂载。警告不建议在以读写形式挂载的实时文件系统上运行 quotacheck,因为可能会损坏配额文件。
17.3. 磁盘配额参考
- quotacheck
- edquota
- repquota
- quota
- quotaon
- quotaoff
第 18 章 独立磁盘冗余阵列(RAID)
- 加强速度
- 使用单一虚拟磁盘增加存储容量
- 尽可能减少磁盘失败的数据丢失
18.1. RAID 类型
固件 RAID
硬件 RAID
软件 RAID
- 多线程设计
- 在不同的 Linux 机器间移动磁盘阵列不需要重新构建数据
- 使用空闲系统资源进行后台阵列重构
- 热插拔驱动器的支持
- 自动 CPU 检测,以利用某些 CPU 功能,如流 SIMD 支持
- 自动更正阵列磁盘上坏扇区
- 定期检查 RAID 数据,以确保阵列健康
- 主动监控阵列,在发生重要事件时将电子邮件报警发送到指定的电子邮件地址
- 写意图位图通过允许内核准确了解磁盘的哪些部分需要重新同步,而不必重新同步整个阵列,从而大大提高了重新同步事件的速度
- 重新同步检查点,以便如果您在重新同步期间重新启动计算机,则在启动时重新同步会从其停止的地方开始,而不是从头开始
- 安装后更改阵列参数的能力。例如:当有新磁盘需要添加时,您可以将 4 磁盘 RAID5 阵列增加成 5 磁盘 RAID5 阵列。这种增加操作是实时的,不需要您在新阵列上重新安装。
18.2. RAID 级和线性支持
- 0 级
- RAID 0,通常称为"条带化",是一种面向性能的条带数据映射技术。这意味着写入阵列的数据被分成条,写入到阵列的成员磁盘上,从而以较低的成本提供较高的 I/O 性能,但不提供冗余。许多 RAID 0 实现只会在成员设备上条带化数据,最大条带为阵列中最小设备的大小。这意味着,如果您有多个设备,它们的大小稍有不同,则每个设备都会被视为与最小驱动器的大小相同。因此,级别 0 阵列的一般存储容量等于,硬件 RAID 中容量最小的成员磁盘的容量,或软件 RAID 中的最小成员分区的容量,在乘以阵列中的磁盘或分区的数量。
- 1 级
- RAID 1 或 "镜像" 比任何其它形式的 RAID 使用的时间都长。1 级通过将相同的数据写入阵列的每个成员磁盘来提供冗余,在每个磁盘上都保留一个"镜像"副本。因为其简单且数据高度可用,RAID 1 仍然被广泛使用。级别 1 需要两个或者多个磁盘,它提供了很好的数据可靠性,提高了需要读取的应用程序的性能,但是成本相对高。[3]级别 1 阵列的存储容量等于硬件 RAID 中最小镜像硬盘或者软件 RAID 中最小镜像分区的容量相同。级别 1 所提供的冗余性是所有 RAID 级别中最高的,因为阵列只需要在有一个成员可以正常工作的情况下就可以提供数据。
- 4 级
- 4 级使用奇偶校验 [4] 集中在单个磁盘驱动器上来保护数据.因为 RAID 4 使用一个专门的偶校验磁盘,因此这个磁盘就会成为对 RAID 阵列的写入操作的一个固有的瓶颈。所以, RAID 4 较少被使用。因此,Anaconda 中并没有提供 RAID 4 这个选项。但是,如果真正需要,用户可以手动创建它。硬件 RAID 4 的存储容量等于分区数量减一乘以最小成员分区的容量。RAID 4 阵列的性能总是非对称的,即读比写的性能要好。这是因为,写会在生成奇偶校验时消耗额外的 CPU 和主内存带宽,然后在将实际数据写入磁盘时也会消耗额外的总线带宽,因为您不仅写数据,而且还写奇偶校验。读取只需要读取数据而不是奇偶校验,除非该阵列处于降级状态。因此,在正常操作条件下,对于相同数量的数据传输,读会对驱动器和计算机总线产生较少的流量。
- 5 级
- 这是最常见的 RAID 类型。通过将奇偶校验分布在阵列的所有成员磁盘驱动器上,RAID 5 消除了 4 级中固有的写瓶颈。唯一性能瓶颈是奇偶校验计算过程本身。在使用现代 CPU 和软件 RAID 时,这通常不会成为瓶颈,因为现代 CPU 可能会非常快速地生成奇偶校验。然而,如果您的软件 RAID5 阵列中有大量成员设备,且在所有设备间有大量的数据进行传输时,就可能出现瓶颈。与 4 级一样,5 级具有非对称性能,其读性能大大优于写性能。RAID 5 的存储容量的计算方法与级别 4 的计算方法是一样的。
- 级别 6
- 如果数据的冗余性和保护性比性能更重要,且无法接受 RAID 1 的空间利用率低的问题,则通常会选择使用级别 6。级别 6 使用一个复杂的奇偶校验方式,可以在阵列中出现任意两个磁盘失败的情况下进行恢复。因为使用的奇偶校验方式比较复杂,软件 RAID 设备会对 CPU 造成较大负担,同时对写操作造成更大的负担。因此,与级别 4 和 5 相比,级别 6 的性能不对称性更严重。RAID 6 阵列的总容量与 RAID 5 和 4 类似,但您必须从额外奇偶校验存储空间的设备数中减去 2 个设备(而不是 1 个)。
- 级别 10
- 这个 RAID 级别将级别 0 的性能优势与级别 1 的冗余合并。它还有助于减少在有多于 2 个设备时,级别 1 阵列中的利用率低的问题。对于 10 级,可以创建一个 3 个驱动器阵列,来仅存储每块数据的 2 个副本,然后允许整个阵列的大小为最小设备的 1.5 倍,而不是只等于最小设备(这与 3 设备1 级阵列类似)。创建 10 级阵列时可用的选项数量,以及为特定用例选择正确的选项的复杂性,使在安装过程中创建它们不切实际。可以使用命令行 mdadm 工具手动创建一个。有关选项及其各自性能权衡的更多信息,请参阅 man md。
- 线性 RAID
- 线性 RAID 是创建更大的虚拟驱动器的一组驱动器。在线性 RAID 中,块会被从一个成员驱动器中按顺序分配,只有在第一个完全填充时才会进入下一个驱动器。这个分组方法不会提供性能优势,因为 I/O 操作不太可能在不同成员间同时进行。线性 RAID 也不提供冗余性并降低可靠性 ; 如果任何一个成员驱动器失败,则整个阵列无法使用。该容量是所有成员磁盘的总量。
18.3. Linux RAID 子系统
Linux 硬件 RAID 控制器驱动程序
mdraid
dmraid
18.4. Anaconda 安装程序中的 RAID 支持
18.5. 安装后将根磁盘转换为 RAID1
- 将 PowerPC Reference Platform (PReP) 引导分区从
/dev/sda1复制到/dev/sdb1:#dd if=/dev/sda1 of=/dev/sdb1 - 在两个磁盘的第一个分区中更新 Prep 和 boot 标志:
$parted /dev/sda set 1 prep on$parted /dev/sda set 1 boot on$parted /dev/sdb set 1 prep on$parted /dev/sdb set 1 boot on
18.6. 配置 RAID 集
mdadm
dmraid
18.7. 创建高级 RAID 设备
/boot 或 root 文件系统阵列;在这种情况下,您可能需要使用 Anaconda 不支持的数组选项。要临时解决这个问题,请执行以下步骤:
过程 18.1. 创建高级 RAID 设备
- 插入安装磁盘。
- 在初始引导过程中,选择 而不是 或 。当系统完全引导到 Rescue mode 时,用户会看到一个命令行终端。
- 在这个终端中,使用 parted 在目标硬盘上创建 RAID 分区。然后,使用 mdadm 使用任何以及所有可用的设置和选项从这些分区手动创建 raid 阵列。有关如何进行此操作的更多信息,请参阅 第 13 章 分区、man parted 和 man mdadm。
- 创建阵列后,您可以选择在阵列上创建文件系统。
- 重启计算机,此时选择 或 以正常安装。当 Anaconda 搜索系统中的磁盘时,它将找到预先存在的 RAID 设备。
- 当被问到如何使用系统中的磁盘时,请选择 并单击 。在设备列表中,会列出预先存在的 MD RAID 设备。
- 选择 RAID 设备,点 并配置其挂载点,并(可选)应使用的文件系统类型(如果您之前没有创建),然后点 。Anaconda 将对此预先存在的 RAID 设备执行安装,在 Rescue Mode 中创建时保留您选择的自定义选项。
第 19 章 使用 mount 命令
19.1. 列出当前挂载的文件系统
$ mountdevice on directory type type (options)
$ findmnt19.1.1. 指定文件系统类型
sysfs 和 tmpfs。要只显示具有特定文件系统类型的设备,请提供 -t 选项:
$ mount -t type$ findmnt -t typeext4 文件系统”。
例 19.1. 列出当前挂载的 ext4 文件系统
/ 和 /boot 分区都被格式化为使用 ext4。要只显示使用此文件系统的挂载点,请使用以下命令:
$ mount -t ext4
/dev/sda2 on / type ext4 (rw)
/dev/sda1 on /boot type ext4 (rw)
$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered
/boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered
19.2. 挂载文件系统
$ mount [option…] device directory- 块设备 的完整路径:例如
/dev/sda3 - 通用唯一标识符 (UUID):例如
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cb - 卷标签 :例如
LABEL=home
findmnt directory; echo $?1。
/etc/fstab 文件的内容,以检查是否列出了给定的文件系统。/etc/fstab 文件包含设备名称列表、所选文件系统要挂载的目录,以及文件系统类型和挂载选项。因此,当挂载在 /etc/fstab 中指定的文件系统时,您可以选择以下选项之一:
mount [option…] directory mount [option…] device
root 用户身份运行命令,否则挂载文件系统需要权限(请参阅 第 19.2.2 节 “指定挂载选项”)。
blkid device/dev/sda3 的信息:
# blkid /dev/sda3
/dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"
19.2.1. 指定文件系统类型
NFS (网络文件系统)或 CIFS (通用互联网文件系统),它们不能被识别,需要手动指定。要指定文件系统类型,请使用以下格式的 mount 命令:
$ mount -t type device directory表 19.1. 通用文件系统类型
| Type | 描述 |
|---|---|
ext2 | ext2 文件系统。 |
ext3 | ext3 文件系统。 |
ext4 | ext4 文件系统。 |
btrfs | btrfs 文件系统。 |
xfs | xfs 文件系统。 |
iso9660 | ISO 9660 文件系统。它通常由光学介质(通常为 CD)使用。 |
nfs | NFS 文件系统。它通常用于通过网络访问文件。 |
nfs4 | NFSv4 文件系统。它通常用于通过网络访问文件。 |
udf | UDF 文件系统。它通常由光学介质(通常为 DVD)使用。 |
vfat | FAT 文件系统。它通常用于运行 Windows 操作系统的机器,以及某些数字媒体,如 USB 闪存驱动器或软盘。 |
例 19.2. 挂载 USB 闪存驱动器
/dev/sdc1 设备,并且 /media/flashdisk/ 目录存在,请以 root 用户身份在 shell 提示符后输入以下内容来将其挂载到此目录:
~]# mount -t vfat /dev/sdc1 /media/flashdisk19.2.2. 指定挂载选项
mount -o options device directory表 19.2. 常用挂载选项
| 选项 | 描述 |
|---|---|
async | 允许文件系统上的异步输入/输出操作。 |
auto | 允许使用 mount -a 命令自动挂载文件系统。 |
默认值 | 为 async,auto,dev,exec,nouser,rw,suid 提供别名。 |
exec | 允许在特定文件系统中执行二进制文件。 |
loop | 将镜像挂载为 loop 设备。 |
noauto | 默认行为不允许使用 mount -a 命令自动挂载文件系统。 |
noexec | 不允许在特定文件系统中执行二进制文件。 |
nouser | 不允许普通用户(即 root以外的用户)挂载和卸载文件系统。 |
remount | 如果已经挂载文件系统,则会重新挂载文件系统。 |
ro | 仅挂载文件系统以读取。 |
rw | 挂载文件系统以进行读和写操作。 |
user | 允许普通用户(即 root以外的用户)挂载和卸载文件系统。 |
例 19.3. 挂载 ISO 镜像
/media/cdrom/ 目录存在,请运行以下命令将镜像挂载到这个目录中:
# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom19.2.3. 共享挂载
--bind 选项,它提供复制某些挂载的方法。其用法如下:
$ mount --bind old_directory new_directory$ mount --rbind old_directory new_directory- 共享挂载
- 共享挂载允许创建给定挂载点的精确副本。当挂载点标记为共享挂载时,原始挂载点中的任何挂载都会反映在其中,反之亦然。要将挂载点类型改为共享挂载,请在 shell 提示符下输入以下内容:
$mount --make-shared mount_point或者,要更改所选挂载点的挂载类型,以及其下的所有挂载点:$mount --make-rshared mount_point有关示例用法,请查看 例 19.4 “创建共享挂载点”。 - 从属挂载
- 从属挂载允许创建给定挂载点的有限副本。当挂载点标记为从属挂载时,原始挂载点中的任何挂载都会反映在其中,但从属挂载中的挂载不会反映在其原始挂载点中。要将挂载点类型改为从属挂载,在 shell 提示符下输入以下内容:
mount
--make-slavemount_point或者,要更改所选挂载点的挂载类型,以及其下的所有挂载点,请输入:mount
--make-rslavemount_point有关示例用法,请查看 例 19.5 “创建从属挂载点”。例 19.5. 创建从属挂载点
本例演示了如何使/media/目录的内容也出现在/mnt/中,但/mnt/目录中的任何挂载都不会反映在/media/目录中。以root用户身份,首先将/media/目录标记为共享:~]# mount --bind /media /media ~]# mount --make-shared /media
然后,在/mnt/中创建副本,但将其标记为"slave":~]# mount --bind /media /mnt ~]# mount --make-slave /mnt
现在,验证/media/中的挂载是否也出现在/mnt/中。例如,如果 CD-ROM 驱动器包含非空介质,并且/media/cdrom/目录存在,请运行以下命令:~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom EFI GPL isolinux LiveOS
同时还要验证/mnt/目录中挂载的文件系统没有反映在/media/中。例如,如果插入了使用/dev/sdc1设备的非空 USB 闪存驱动器,并且存在/mnt/flashdisk/目录,请输入:~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- 私有挂载
- 私有挂载是默认挂载类型,与共享或从属挂载不同,它不接收或转发任何传播事件。要将挂载点显式标记为私有挂载,在 shell 提示符下输入以下内容:
mount
--make-privatemount_point另外,也可以更改所选挂载点的挂载类型,以及其下的所有挂载点:mount
--make-rprivatemount_point有关示例用法,请查看 例 19.6 “创建私有挂载点”。例 19.6. 创建私有挂载点
考虑 例 19.4 “创建共享挂载点” 中的场景,假设之前已以root用户身份使用以下命令创建了共享挂载点:~]# mount --bind /media /media ~]# mount --make-shared /media ~]# mount --bind /media /mnt
要将/mnt/目录标记为私有,请输入:~]# mount --make-private /mnt现在,可以验证/media/中的挂载没有出现在/mnt/中。例如,如果 CD-ROM 驱动器包含非空介质,并且/media/cdrom/目录存在,请运行以下命令:~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom ~]#
也可以验证/mnt/目录中挂载的文件系统没有反映在/media/中。例如,如果插入了使用/dev/sdc1设备的非空 USB 闪存驱动器,并且存在/mnt/flashdisk/目录,请输入:~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- 不可绑定挂载
- 为了防止指定挂载点重复,需要使用不可绑定挂载。要将挂载点类型更改为不可绑定挂载,在 shell 提示符下输入以下内容:
mount
--make-unbindablemount_point另外,也可以更改所选挂载点的挂载类型,以及其下的所有挂载点:mount
--make-runbindablemount_point有关示例用法,请查看 例 19.7 “创建不可绑定挂载点”。例 19.7. 创建不可绑定挂载点
要防止/media/目录被共享,以root用户身份:#mount --bind /media /media#mount --make-unbindable /media这样,任何后续尝试重复此挂载都会失败,并显示错误:#mount --bind /media /mnt mount: wrong fs type, bad option, bad superblock on /media, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
19.2.4. 移动挂载点
# mount --move old_directory new_directory例 19.8. 移动现有的 NFS 挂载点
/mnt/userdirs/ 中。以 root 用户身份,使用以下命令将此挂载点移到 /home :
# mount --move /mnt/userdirs /home#ls /mnt/userdirs#ls /home jill joe
19.2.5. 为 root设置只读权限
19.2.5.1. 将 root 配置为在引导时使用只读权限挂载
- 在
/etc/sysconfig/readonly-root文件中,将READONLY更改为yes:# Set to 'yes' to mount the file systems as read-only. READONLY=yes [output truncated] - 在
/etc/fstab文件中的 root 条目(/)中将默认更改为ro:/dev/mapper/luks-c376919e... / ext4 ro,x-systemd.device-timeout=0 1 1 - 将
ro添加到/etc/default/grub文件中的GRUB_CMDLINE_LINUX指令中,并确保它不包含rw:GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ro" - 重新创建 GRUB2 配置文件:
#grub2-mkconfig -o /boot/grub2/grub.cfg - 如果您需要在
tmpfs文件系统中添加需要挂载具有写权限的文件和目录,请在/etc/rwtab.d/目录中创建一个文本文件,并将配置放在其中。例如,要挂载具有写入权限的/etc/example/file,请将此行添加到/etc/rwtab.d/示例文件中:files /etc/example/file
重要对tmpfs中的文件和目录所做的更改不会在启动后保留。有关此步骤的详情,请查看 第 19.2.5.3 节 “保留写权限的文件和目录”。 - 重启系统。
19.2.5.2. 重新挂载 root Instantly
/)在系统引导时以只读权限挂载,您可以使用写入权限重新挂载它:
# mount -o remount,rw // 错误地挂载了只读权限时,这特别有用。
/,请运行:
# mount -o remount,ro /19.2.5.3. 保留写权限的文件和目录
tmpfs 临时文件系统的 RAM 中。这些文件和目录的默认集合是从 /etc/rwtab 文件中读取的,该文件包含:
dirs /var/cache/man dirs /var/gdm [output truncated] empty /tmp empty /var/cache/foomatic [output truncated] files /etc/adjtime files /etc/ntp.conf [output truncated]
/etc/rwtab 文件中的条目遵循以下格式:
how the file or directory is copied to tmpfs path to the file or directory
tmpfs :
空 路径:空路径复制到tmpfs。示例:空 /tmp目录路径:目录树被复制到tmpfs,空。示例:dirs /var/run文件路径:将文件或目录树复制到tmpfs。示例:文件 /etc/resolv.conf
/etc/rwtab.d/ 添加自定义路径时,也适用相同的格式。
19.3. 卸载文件系统
$umount directory$umount device
root 身份登录时执行此操作,否则必须有正确的权限才能卸载文件系统。如需更多信息,请参阅 第 19.2.2 节 “指定挂载选项”。有关示例用法,请查看 例 19.9 “卸载 CD”。
$fuser-mdirectory
/media/cdrom/ 目录的文件系统的进程:
$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672c
例 19.9. 卸载 CD
/media/cdrom/ 目录的 CD,请使用以下命令:
$ umount /media/cdrom19.4. mount 命令参考
手册页文档
- man 8 mount : mount 命令的手册页,提供了有关其使用的完整文档。
- man 8 umount: umount 命令的手册页,提供了有关其使用的完整文档。
- man 8 findmnt : findmnt 命令的手册页,提供了有关其使用的完整文档。
- man 5 fstab :手册页提供了
/etc/fstab文件格式的详细描述。
有用的网站
- 共享子树 - 涵盖了共享子树概念的 LWN 文章。
第 20 章 volume_key Function
20.1. volume_key 命令
volume_key [OPTION]... OPERAND- --save
- 此命令需要操作对象 volume [packet]。如果提供了 数据包,则 volume_key 将从中提取密钥和密码短语。如果没有提供 数据包,则 volume _key 将从卷中提取密钥和密码短语,并在需要时提示用户输入。然后这些密钥和密码短语将存储在一个或多个输出数据包中。
- --restore
- 此命令需要操作对象 volume packet。然后,它打开 volume ,并使用 packet 中的密钥和密码短语使 volume 可再次访问,并在需要时提示用户,例如允许用户输入新的密语。
- --setup-volume
- 此命令需要操作对象 volume packet name。然后,它打开 volume ,并使用 packet 中的密钥和密码短语来设置 volume,以便将解密的数据用作 name。Name 是 dm-crypt 卷的名称。此操作使解密的卷作为
/dev/mapper/名称提供。例如,此操作不会通过添加新密码短语来永久更改 volume。用户可以访问和修改解密的卷,从而可以在过程中修改 volume。 - --reencrypt、--secrets 和 --dump
- 这三个命令使用不同的输出方法执行类似的功能。它们每个都需要操作对象 packet,并且每个都打开 packet,根据需要对其进行解密。然后 --reencrypt 将信息存储在一个或多个新输出数据包中。--secrets 输出包含在 数据包 中的密钥和密码短语。--dump 输出数据包的内容,但默认情况下不会输出密钥和密码短语。这可以通过在命令中附加 --with-secrets 来更改。也可以使用 --unencrypted 命令仅转储数据包的未加密部分(若有)。这不需要任何密语或私钥访问。
- -o,--output packet
- 此命令将默认密钥或密语写入 packet。默认密钥或密语取决于卷格式。确保它不太可能过期,并且允许 --restore 恢复对卷的访问。
- --output-format format
- 此命令对所有输出数据包使用指定的 format。目前,format 可以是以下之一:
- 非对称 :使用 CMS 来加密整个数据包,并且需要证书
- asymmetric_wrap_secret_only: 仅打包 secret 或密钥和密码短语,并且需要证书
- 密码短语 :使用 GPG 来加密整个数据包,并且需要密码短语
- --create-random-passphrase packet
- 此命令生成随机的字母数字密码短语,将它添加到 volume 中(而不影响其他密语),然后将此随机密语存储到 packet 中。
20.2. 将 volume_key 用作单个用户
/path/to/volume 是 LUKS 设备,而不是包含在其中的明文设备。blkid -s type /path/to/volume 应该报告 type="crypto_LUKS"。
过程 20.1. 使用 volume_key Stand-alone
- 运行:
volume_key --save然后,系统将出现提示,要求使用托管包密语来保护密钥。/path/to/volume-o escrow-packet - 保存生成的
escrow-packet文件,确保不会忘记密码短语。
过程 20.2. 使用 Escrow Packet 将数据访问恢复到数据
- 在可以运行 volume_key 且托管数据包可用的环境中引导系统(例如,救援模式)。
- 运行:
volume_key --restore将显示一个提示,提示创建托管数据包时使用的托管数据包密码短语,以及卷的新密语。/path/to/volumeescrow-packet - 使用所选的密码短语挂载卷。
20.3. 在大型机构中使用 volume_key
20.3.1. 准备保存加密密钥
过程 20.3. 准备
- 创建 X509 证书/专用对。
- 指定信任的用户,这些用户可信,不会泄露私钥。这些用户将能够解密托管数据包。
- 选择将使用哪些系统解密托管数据包。在这些系统上,建立包含私钥的 NSS 数据库。如果没有在 NSS 数据库中创建私钥,请按照以下步骤操作:
- 将证书和私钥存储在
PKCScriu 文件中。 - 运行:
certutil -d/the/nss/directory-N此时,可以选择 NSS 数据库密码。每个 NSS 数据库都有不同的密码,因此如果每个用户使用单独的 NSS 数据库,则指定的用户无需共享单个密码。 - 运行:
pk12util -d/the/nss/directory-ithe-pkcs12-file
- 将证书分发给安装系统或将密钥保存在现有系统上的任何人。
- 对于保存的私钥,准备允许按机器和卷查找它们的存储。例如,这可以是一个简单的目录,每台机器有一个子目录,或者用于其他系统管理任务的数据库。
20.3.2. 保存加密密钥
/path/to/volume 是 LUKS 设备,而不是包含的明文设备; blkid -s 类型 /path/to/volume 应报告 type="crypto_LUKS"。
过程 20.4. 保存加密密钥
- 运行:
volume_key --save/path/to/volume-c/path/to/certescrow-packet - 将生成的
escrow-packet文件保存到准备好的存储中,将其与系统和卷相关联。
20.3.3. 恢复对卷的访问
过程 20.5. 恢复对卷的访问
- 从数据包存储中获取卷的托管数据包,并将其发送到指定用户之一进行解密。
- 指定的用户运行:
volume_key --reencrypt -d/the/nss/directoryescrow-packet-in -o escrow-packet-out提供 NSS 数据库密码后,指定的用户选择加密 escrow-packet-out 的密码短语。此密语每次都可能会有所不同,且只在加密密钥从指定用户移至目标系统时保护加密密钥。 - 从指定的用户获取
escrow-packet-out文件和密码短语。 - 在可以运行 volume_key 且可以使用
escrow-packet-out文件的环境中引导目标系统,比如在救援模式下。 - 运行:
volume_key --restore/path/to/volumeescrow-packet-out将出现一个提示,提示指定用户所选择的数据包密码,以及卷的新密码。 - 使用所选的卷密语挂载卷。
20.3.4. 设置紧急密码
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packetpassphrase-packet 中。也可以组合 --create-random-passphrase 和 -o 选项,以同时生成这两个数据包。
volume_key --secrets -d /your/nss/directory passphrase-packet20.4. volume_key 参考
- 在位于
/usr/share/doc/volume_keyMAP/README的 readme 文件中 - 在使用 man volume_key 的 volume_key 手册页上
第 21 章 固态磁盘部署指南
- 可用空间仍可在文件系统中可用。
- 底层存储设备上的大多数逻辑块已被写入。
/sys/block/sda/queue/discard_granularity,这是设备的内部分配单元的大小。
部署注意事项
- 非确定的 TRIM
- 确定性 TRIM (DRAT)
- TRIM (RZAT)后确定性读零
# hdparm -I /dev/sda | grep TRIM
Data Set Management TRIM supported (limit 8 block)
Deterministic read data after TRIM
丢弃,则使用 RAID 5 与 SSD 的性能会较低。您可以在 raid456.conf 文件中设置 discard,或者在 GRUB2 配置中设置 discard。具体步骤请查看以下步骤。
过程 21.1. 在 raid456.conf 中设置 discard
devices_handle_discard_safely 模块参数在 raid456 模块中设置。在 raid456.conf 文件中启用丢弃:
- 验证您的硬件支持丢弃:
#cat /sys/block/disk-name/queue/discard_zeroes_data如果返回的值是1,则支持丢弃。如果命令返回0,RAID 代码必须归零磁盘,这需要更长的时间。 - 创建
/etc/modprobe.d/raid456.conf文件,并包含以下行:options raid456 devices_handle_discard_safely=Y
- 使用 dracut -f 命令重建初始 ramdisk (
initrd)。 - 重启系统以使更改生效。
过程 21.2. 在 GRUB2 配置中设置 discard
devices_handle_discard_safely 模块参数在 raid456 模块中设置。在 GRUB2 配置中启用丢弃:
- 验证您的硬件支持丢弃:
#cat /sys/block/disk-name/queue/discard_zeroes_data如果返回的值是1,则支持丢弃。如果命令返回0,RAID 代码必须归零磁盘,这需要更长的时间。 - 在
/etc/default/grub文件中添加以下行:raid456.devices_handle_discard_safely=Y
- 在使用 BIOS 固件以及带有 UEFI 的系统中,GRUB2 配置文件的位置有所不同。使用以下命令之一重新创建 GRUB2 配置文件。
- 在带有 BIOS 固件的系统中,使用:
#grub2-mkconfig -o /boot/grub2/grub.cfg - 在具有 UEFI 固件的系统中,使用:
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 重启系统以使更改生效。
/dev/sda2 挂载到启用了 discard 的 /mnt 中,请使用:
# mount -t ext4 -o discard /dev/sda2 /mnt性能调优注意事项
第 22 章 写屏障
22.1. 写屏障的重要性
- 文件系统将事务正文发送到存储设备。
- 文件系统发送提交块。
- 如果事务及其相应的提交块写入了磁盘,则文件系统假定事务将在任何电源失败后都能生存。
写障碍是如何工作的
- 磁盘包含所有数据。
- 未发生重新排序。
22.2. 启用和禁用写障碍
/var/log/messages。如需更多信息,请参阅 表 22.1 “每个文件系统的写障碍错误消息”。
表 22.1. 每个文件系统的写障碍错误消息
| 文件系统 | 错误消息 |
|---|---|
| ext3/ext4 | JBD: barrier-based sync failed on device - disabling barriers |
| XFS | Filesystem device - Disabling barriers, trial barrier write failed |
| btrfs | btrfs: disabling barriers on dev device |
22.3. 写障碍注意事项
禁用写缓存
# hdparm -W0 /device/电池支持的写缓存
# MegaCli64 -LDGetProp -DskCache -LAll -aALL# MegaCli64 -LDSetProp -DisDskCache -Lall -aALL高端阵列
NFS
第 23 章 存储 I/O 校准和大小
23.1. 存储访问参数
- physical_block_size
- 设备可操作的最小内部单位
- logical_block_size
- 用于外部定位设备上的位置
- alignment_offset
- Linux 块设备开始的字节数(分区/MD/LVM 设备)是底层物理校准的偏移量
- minimum_io_size
- 设备用于随机 I/O 的首选最小单位
- optimal_io_size
- 设备用于流 I/O 的首选单位
23.2. 用户空间访问
libblkid-devel 软件包提供。
sysfs 接口
- /sys/block/
disk/alignment_offset或者/sys/block/disk/partition/alignment_offset注意文件位置取决于磁盘是物理磁盘(即本地磁盘、本地 RAID 或者多路径 LUN)还是虚拟磁盘。第一个文件位置适用于物理磁盘,第二个文件位置适用于虚拟磁盘。其原因是 virtio-blk 始终会报告分区的对齐值。物理磁盘可能也可能不会报告对齐值。 - /sys/block/
disk/queue/physical_block_size - /sys/block/
disk/queue/logical_block_size - /sys/block/
disk/queue/minimum_io_size - /sys/block/
disk/queue/optimal_io_size
例 23.1. sysfs 接口
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
块设备 ioctls
- BLKALIGNOFF:
alignment_offset - BLKPBSZGET:
physical_block_size - BLKSSZGET:
logical_block_size - BLKIOMIN:
minimum_io_size - BLKIOOPT :
optimal_io_size
23.3. I/O 标准
ATA
SCSI
BLOCK LIMITS VPD 页面)和 READ CAPACITY (16) 命令。
LOGICAL BLOCK LENGTH IN BYTES用于派生/sys/block/磁盘/queue/physical_block_sizeLOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENT用于派生/sys/block/磁盘/queue/logical_block_sizeLOWEST ALIGNED LOGICAL BLOCK ADDRESS用于派生:/sys/block/disk/alignment_offset/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD 页面(0xb0)提供 I/O 提示。它还使用 OPTIMAL TRANSFER LENGTH GRANULARITY 和 OPTIMAL TRANSFER LENGTH 派生:
/sys/block/disk/queue/minimum_io_size/sys/block/disk/queue/optimal_io_size
sg3_utils 软件包提供 sg_inq 工具,可用于访问 BLOCK LIMITS VPD 页面。为此,请运行:
# sg_inq -p 0xb0 disk23.4. 堆栈 I/O 参数
- 对于非零 alignment_offset,仅应调整 I/O 堆栈中的一个层;当层相应地调整后,它将导出具有 alignment_offset 为 0 的设备。
- 使用 LVM 创建的条状设备映射器(DM)设备必须导出相对于条带数(磁盘数)和用户提供的块大小的 minimum_io_size 和 optimal_io_size。
23.5. 逻辑卷管理器
/etc/lvm/lvm.conf 中将 data_alignment_offset_detection 设置为 0 来禁用此行为。不建议禁用此功能。
/etc/lvm/lvm.conf 中将 data_alignment_detection 设置为 0 来禁用此行为。不建议禁用此功能。
23.6. 分区和文件系统工具
util-linux-ng 的 libblkid 和 fdisk
util-linux-ng 软件包提供的 libblkid 库包括用于访问设备的 I/O 参数的编程 API。libblkid 允许应用程序(特别是那些使用直接 I/O 的应用程序)正确调整其 I/O 请求的大小。util-linux-ng 的 fdisk 工具使用 libblkid 来确定设备的 I/O 参数,以优化所有分区的位置。fdisk 实用程序将在 1MB 边界上校准所有分区。
parted 和 libparted
libparted 库也使用 libblkid 的 I/O 参数 API。Red Hat Enterprise Linux 7 安装程序 Anaconda 使用 libparted,这意味着由安装程序或 parted 创建的所有分区都会被正确对齐。对于在似乎不提供 I/O 参数的设备上创建的所有分区,默认校准为 1MB。
- 始终使用报告的 alignment_offset 作为第一个主分区开头的偏移量。
- 如果定义了 optimal_io_size (即不是 0),在 optimal_io_size 边界上校准所有分区。
- 如果 optimal_io_size 未定义(即 0 ),则 alignment_offset 为 0,而 minimum_io_size 是 2 的指数,使用 1MB 默认对齐。这是对“遗留”设备的总称,这些设备似乎不提供 I/O 提示。因此,默认情况下,所有分区将在 1MB 边界上校准。注意Red Hat Enterprise Linux 7 无法区分不提供 I/O 提示的设备和使用 alignment_offset=0 和 optimal_io_size=0 的设备。此类设备可能是单个 SAS 4K 设备;因此,最坏情况下,磁盘开始时会丢失 1MB 空间。
文件系统工具
第 24 章 设置远程无盘系统
tftp-serverxinetddhcpsyslinuxdracut-network注意安装dracut-network软件包后,请在/etc/dracut.conf中添加以下行:add_dracutmodules+="nfs"
tftp-server提供)和 DHCP 服务(由 dhcp提供)。tftp 服务用于通过 PXE 加载程序通过网络检索内核镜像和 initrd。
/etc/sysconfig/nfs 中明确启用 NFS:
/var/lib/tftpboot/pxelinux.cfg/default 中,将 root=nfs:server-ip:/exported/root/directory 改为 root=nfs:server-ip:/exported/root/directory,vers=4.2。
24.1. 为无盘客户端配置 tftp 服务
先决条件
- 安装所需软件包。请查看 第 24 章 设置远程无盘系统
流程
过程 24.1. 配置 tftp
- 通过网络启用 PXE 引导:
#systemctl enable --now tftp - tftp 根目录(chroot)位于
/var/lib/tftpboot中。将/usr/share/syslinux/pxelinux.0复制到/var/lib/tftpboot/:#cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/ - 在 tftp 根目录中创建
pxelinux.cfg目录:#mkdir -p /var/lib/tftpboot/pxelinux.cfg/ - 配置防火墙规则以允许 tftp 流量。因为 tftp 支持 TCP 包装器,您可以在
/etc/hosts.allow配置文件中配置主机对 tftp 的访问。有关配置 TCP 包装器和/etc/hosts.allow配置文件的更多信息,请参阅 Red Hat Enterprise Linux 7 安全指南。hosts_access(5) 也提供有关/etc/hosts.allow的信息。
后续步骤
24.2. 为无盘客户端配置 DHCP
先决条件
- 安装所需软件包。请查看 第 24 章 设置远程无盘系统
- 配置
tftp服务。请参阅 第 24.1 节 “为无盘客户端配置 tftp 服务”。
流程
- 配置 tftp 服务器后,您需要在同一主机上设置 DHCP 服务。有关设置 DHCP 服务器的步骤,请参阅 配置 DHCP 服务器。
- 通过在
/etc/dhcp/dhcpd.conf中添加以下配置,在 DHCP 服务器上启用 PXE 引导:allow booting; allow bootp; class "pxeclients" { match if substring(option vendor-class-identifier, 0, 9) = "PXEClient"; next-server server-ip; filename "pxelinux.0"; }- 使用 tftp 和 DHCP 服务所在的主机的 IP 地址替换
server-ip。
注意当 libvirt 虚拟机用作无盘客户端时,libvirt 提供 DHCP 服务,并且不使用独立 DHCP 服务器。在这种情况下,必须使用 libvirt 网络配置中的 bootp file='filename' 选项启用网络引导,virsh net-edit。
后续步骤
24.3. 为无盘客户端配置导出的文件系统
先决条件
- 安装所需软件包。请查看 第 24 章 设置远程无盘系统
- 配置
tftp服务。请参阅 第 24.1 节 “为无盘客户端配置 tftp 服务”。 - 配置 DHCP。请参阅 第 24.2 节 “为无盘客户端配置 DHCP”。
流程
- 导出的文件系统的根目录(由网络中的无盘客户端使用)通过 NFS 共享。通过将根目录添加到
/etc/exports,将 NFS 服务配置为导出根目录。有关如何操作的步骤,请查看 第 8.6.1 节 “/etc/exports配置文件”。 - 要完全使用无盘客户机,根目录应该包含完整的 Red Hat Enterprise Linux。您可以克隆现有安装或安装新的基本系统:
- 要与正在运行的系统同步,请使用
rsync工具:#rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' \ hostname.com:/exported-root-directory- 使用要通过
rsync进行同步的正在运行的系统的主机名替换 hostname.com。 - 使用导出的文件系统的路径替换 exported-root-directory。
- 要将 Red Hat Enterprise Linux 安装到导出的位置,请使用带有
--installroot选项的yum工具:#yum install @Base kernel dracut-network nfs-utils \ --installroot=exported-root-directory --releasever=/
过程 24.2. 配置文件系统
- 选择无盘客户端应使用的内核(
vmlinuz-kernel-version)并将其复制到 tftp 引导目录中:#cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/ - 使用 NFS 支持创建
initrd(即initramfs-kernel-version.img):#dracut --add nfs initramfs-kernel-version.img kernel-version - 使用以下命令将 initrd 的文件权限改为 644:
#chmod 644 initramfs-kernel-version.img警告如果没有更改 initrd 的文件权限,pxelinux.0 引导装载程序将失败,并显示 "file not found" 错误。 - 同时,将生成的
initramfs-kernel-version.img复制到 tftp 引导目录中。 - 编辑默认启动配置,以使用
/var/lib/tftpboot/目录中的initrd和内核。此配置应指示无盘客户端的 root 用户以读写形式挂载导出的文件系统(/exported/root/directory)。在/var/lib/tftpboot/pxelinux.cfg/default文件中添加以下配置:default rhel7 label rhel7 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rw
使用 tftp 和 DHCP 服务所在的主机的 IP 地址替换server-ip。
第 25 章 在线存储管理
/usr/share/doc/kernel-doc-版本/Documentation/sysfs-rules.txt。
25.1. 目标设置
#systemctl start target#systemctl enable target
25.1.1. 安装并运行 targetcli
# yum install targetcli目标 服务:
# systemctl start target将目标 配置为在引导时启动:
# systemctl enable target3260,并重新载入防火墙配置:
#firewall-cmd --permanent --add-port=3260/tcp Success#firewall-cmd --reload Success
# targetcli
:
/> ls
o- /........................................[...]
o- backstores.............................[...]
| o- block.................[Storage Objects: 0]
| o- fileio................[Storage Objects: 0]
| o- pscsi.................[Storage Objects: 0]
| o- ramdisk...............[Storage Ojbects: 0]
o- iscsi...........................[Targets: 0]
o- loopback........................[Targets: 0]
25.1.2. 创建后端存储
- FILEIO (Linux 文件支持的存储)
- FILEIO 存储对象可以支持 write_back 或 write_thru 操作。write_back 启用本地文件系统缓存。这提高了性能,但会增加数据丢失的风险。建议您使用 write_back=false 禁用 write_back,而是使用 write_thru。要创建 fileio 存储对象,请运行命令 /backstores/fileio create file_name file_location file_size write_back=false。例如:
/> /backstores/fileio create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
- BLOCK (Linux BLOCK 设备)
- 块驱动程序允许使用
/sys/block中出现的任何块设备与 LIO 一起使用。这包括物理设备(如 HDD、SSD、CD、DVD)和逻辑设备(如软件或硬件 RAID 卷或 LVM 卷)。注意BLOCK backstores 通常提供最佳性能。要使用任何块设备创建 BLOCK 后端存储,请使用以下命令:#fdisk/dev/vdbWelcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x39dc48fb. Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): *Enter* Using default response p Partition number (1-4, default 1): *Enter* First sector (2048-2097151, default 2048): *Enter* Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +250M Partition 1 of type Linux and of size 250 MiB is set Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks./> /backstores/block create name=block_backend dev=/dev/vdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
注意您还可以在逻辑卷中创建 BLOCK 后端存储。 - PSCSI (Linux 直通 SCSI 设备)
- 任何支持直接传递 SCSI 命令且无 SCSI 模拟的存储对象,并且使用
/proc/scsi/scsi(如 SAS 硬盘驱动器)中显示的底层 SCSI 设备可以配置为后备存储。这个子系统支持 SCSI-3 及更高系统。警告PSCSI 应该只供高级用户使用。高级 SCSI 命令(如 Aysmmetric Logical Unit Assignment (ALUAs)或 Persistent Reservations (ALUAs))或 Persistent Reservations (如 VMware ESX 和 vSphere 使用)通常不会在设备固件中实施,并可能导致故障或崩溃。如果有疑问,请对生产环境设置使用 BLOCK。要为物理 SCSI 设备创建 PSCSI 后端存储,本例中使用/dev/sr0的 TYPE_ROM 设备,请使用:/> backstores/pscsi/ create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0
- 内存复制 RAM 磁盘(Linux RAMDISK_MCP)
- Memory Copy RAM 磁盘(ramdisk)为 RAM 磁盘提供完整的 SCSI 模拟,并使用启动器的内存副本来分隔内存映射。这为多会话提供了功能,对于生产环境的快速易失性存储特别有用。要创建 1GB RAM 磁盘后备存储,请使用以下命令:
/> backstores/ramdisk/ create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
25.1.3. 创建 iSCSI 目标
过程 25.1. 创建 iSCSI 目标
- 运行 targetcli。
- 移动到 iSCSI 配置路径:
/> iscsi/
注意cd 命令还可接受更改目录,并只是列出要移动到的路径。 - 使用默认目标名称创建 iSCSI 目标。
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
或者使用指定名称创建 iSCSI 目标。/iscsi > create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1
- 使用 ls 列出目标时,验证新创建的目标是否可见。
/iscsi > ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
25.1.4. 配置 iSCSI 门户
过程 25.2. 创建 iSCSI 门户
- 移至 TPG。
/iscsi> iqn.2006-04.example:444/tpg1/
- 创建门户的方法有两种:创建一个默认门户,或者创建一个门户,指定要侦听的 IP 地址。创建默认门户使用默认 iSCSI 端口 3260,并允许目标侦听该端口上的所有 IP 地址。
/iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
要创建门户,请指定要侦听的 IP 地址,请使用以下命令:/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
- 使用 ls 命令,验证新创建的门户是否可见。
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
25.1.5. 配置 LUN
过程 25.3. 配置 LUN
- 创建已创建的存储对象的 LUN。
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
- 显示更改。
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
注意请注意,默认的 LUN 名称从 0 开始,而不是在 Red Hat Enterprise Linux 6 中使用 tgtd 时为 1。 - 配置 ACL。如需更多信息,请参阅 第 25.1.6 节 “配置 ACL”。
过程 25.4. 创建一个只读 LUN
- 要创建具有只读权限的 LUN,首先使用以下命令:
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
这样可防止 LUN 自动映射到现有 ACL,从而允许手动映射 LUN。 - 接下来,使用命令 iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/ create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1 来手动创建 LUN。
/> iscsi/iqn.2015-06.com.redhat:target/tpg1/acls/iqn.2015-06.com.redhat:initiator/ create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1. /> ls o- / ...................................................... [...] o- backstores ........................................... [...] <snip> o- iscsi ......................................... [Targets: 1] | o- iqn.2015-06.com.redhat:target .................. [TPGs: 1] | o- tpg1 ............................ [no-gen-acls, no-auth] | o- acls ....................................... [ACLs: 2] | | o- iqn.2015-06.com.redhat:initiator .. [Mapped LUNs: 2] | | | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | | | o- mapped_lun1 .............. [lun1 block/disk2 (ro)] | o- luns ....................................... [LUNs: 2] | | o- lun0 ...................... [block/disk1 (/dev/vdb)] | | o- lun1 ...................... [block/disk2 (/dev/vdc)] <snip>
mapping_lun1 行现在在结尾有(ro) (不像 mapping_lun0's (rw)),表示它是只读的。 - 配置 ACL。如需更多信息,请参阅 第 25.1.6 节 “配置 ACL”。
25.1.6. 配置 ACL
/etc/iscsi/initiatorname.iscsi 中找到。
过程 25.5. 配置 ACL
- 移动到 acls 目录。
/iscsi/iqn.20...mple:444/tpg1> acls/
- 创建 ACL。使用启动器上
/etc/iscsi/initiatorname.iscsi中找到的启动器名称,或者使用更易于记住的名称,请参阅 第 25.2 节 “创建 iSCSI 启动器” 来确保 ACL 与启动器匹配。例如:/iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
注意给定示例的行为取决于所使用的设置。在这种情况下,使用全局设置 auto_add_mapped_luns。这会自动将 LUN 映射到任何创建的 ACL。您可以在目标服务器上的 TPG 节点中设置用户创建的 ACL:/iscsi/iqn.20...scsi:444/tpg1>set attribute generate_node_acls=1 - 显示更改。
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
25.1.7. 通过以太网配置光纤通道(FCoE)目标
过程 25.6. 配置 FCoE 目标
- 在 FCoE 接口上创建 FCoE 目标实例。
/> tcm_fc/ create 00:11:22:33:44:55:66:77如果系统上存在 FCoE 接口,则创建后相应的选项卡将列出可用的接口。如果没有,请确保fcoeadm -i显示活动的接口。 - 将后端存储映射到目标实例。
例 25.1. 将后端存储映射到目标实例的示例
/> tcm_fc/00:11:22:33:44:55:66:77/> luns/ create /backstores/fileio/example2 - 允许从 FCoE 启动器访问 LUN。
/> acls/ create 00:99:88:77:66:55:44:33现在,LUN 应该可以被该启动器访问。 - 要使更改在重启后保留,请使用 saveconfig 命令,并在提示时输入 yes。如果没有这样做,则配置将在重新引导后丢失。
- 通过键入 exit 或输入 ctrl+D 退出 targetcli。
25.1.8. 使用 targetcli删除对象
/> /backstores/backstore-type/backstore-name
/> /iscsi/iqn-name/tpg/acls/ delete iqn-name
/> /iscsi delete iqn-name
25.1.9. targetcli 参考
- man targetcli
- targetcli 手册页。它包括示例步骤。
- Linux SCSI Target Wiki
- Andy Grover 的录屏
- 注意这于 2012 年 2 月 28 日上传。因此,服务名称已从 targetcli 改为 target。
25.2. 创建 iSCSI 启动器
过程 25.7. 创建 iSCSI 启动器
- 安装 iscsi-initiator-utils:
#yum install iscsi-initiator-utils -y - 如果 ACL 在 第 25.1.6 节 “配置 ACL” 中被授予自定义名称,请相应地修改
/etc/iscsi/initiatorname.iscsi文件。例如:#cat /etc/iscsi/initiatorname.iscsi InitiatorName=iqn.2006-04.com.example.node1#vi /etc/iscsi/initiatorname.iscsi - 发现目标:
#iscsiadm -m discovery -t st -p target-ip-address 10.64.24.179:3260,1 iqn.2006-04.com.example:3260 - 使用在第 3 步中发现的目标 IQN 登录到目标:
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -l Logging in to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] successful.对于连接到同一 LUN 的任意数量的 initator,只要将其特定启动器名称添加到 ACL 中,就可以遵循这个过程,如 第 25.1.6 节 “配置 ACL” 所述。 - 找到 iSCSI 磁盘名称并在这个 iSCSI 磁盘中创建文件系统:
#grep "Attached SCSI" /var/log/messages#mkfs.ext4/dev/disk_name使用/var/log/messages中显示的 iSCSI 磁盘名称替换 disk_name。 - 挂载文件系统:
#mkdir /mount/point#mount/dev/disk_name/mount/point使用分区的挂载点替换 /mount/point。 - 编辑
/etc/fstab以在系统引导时自动挂载文件系统:#vim /etc/fstab/dev/disk_name/mount/point ext4 _netdev 0 0使用 iSCSI 磁盘名称替换 disk_name。 - 从目标登出:
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -u
25.3. 设置 Challenge-Handshake 身份验证协议
过程 25.8. 为目标设置 CHAP
- 设置属性身份验证:
/iscsi/iqn.20...mple:444/tpg1>set attribute authentication=1 Parameter authentication is now '1'. - 设置 userid 和密码:
/iscsi/iqn.20...mple:444/tpg1>set auth userid=redhat Parameter userid is now 'redhat'./iscsi/iqn.20...mple:444/tpg1>set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
过程 25.9. 为发起方设置 CHAP
- 编辑
iscsid.conf文件:- 在
iscsid.conf文件中启用 CHAP 身份验证:#vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP默认情况下,node.session.auth.authmethod 选项被设置为 None。 - 在
iscsid.conf文件中添加目标用户名和密码:node.session.auth.username = redhat node.session.auth.password = redhat_passwd
- 重启 iscsid 服务:
#systemctl restart iscsid.service
25.4. Fibre Channel
25.4.1. 光纤通道 API
/sys/class/ 目录的列表,其中包含用于提供用户空间 API 的文件。在每个项目中,主机号由 H 指定,总线号为 B,目标为 T,逻辑单元号(LUN)为 L,远程端口号为 R。
- Transport:
/sys/class/fc_transport/targetH:B:T/ port_id- 24 位端口 ID/地址node_name- 64 位节点名称port_name- 64 位端口名称
- Remote Port:
/sys/class/fc_remote_ports/rport-H:B-R/ port_idnode_nameport_namedev_loss_tmo:控制 scsi 设备从系统中删除的时间。在dev_loss_tmo触发后,scsi 设备被删除。在multipath.conf中,您可以将dev_loss_tmo设置为infinity,它将它的值设为 2,147,483,647 秒, 或 68 年,它是dev_loss_tmo的最大值。在 Red Hat Enterprise Linux 7 中,如果您没有设置fast_io_fail_tmo选项,dev_loss_tmo的上限为 600 秒。默认情况下,如果multipathd服务正在运行,fast_io_fail_tmo会在 Red Hat Enterprise Linux 7 中被设置为 5 秒;否则,它被设置为off。fast_io_fail_tmo: 指定在将链接标记为"bad"前要等待的秒数。链接被标记为坏的后,现有正在运行的 I/O 或相应路径上的任何新 I/O 都将失败。如果 I/O 处于阻塞队列中,则在dev_loss_tmo到期前和队列未阻塞前,它不会失败。如果fast_io_fail_tmo设置为除off以外的任何值,则会取消dev_loss_tmo。如果fast_io_fail_tmo设为off,则在从系统中删除该设备前不会出现 I/O 失败。如果fast_io_fail_tmo设置为一个数字,则在达到fast_io_fail_tmo设置的超时会立即触发 I/O 失败。
- Host:
/sys/class/fc_host/hostH/ port_idissue_lip:指示驱动程序重新发现远程端口。
25.4.2. 原生光纤通道驱动程序和能力
lpfcqla2xxxzfcpbfa
qlini_mode 模块参数启用光纤通道目标模式。
/usr/lib/modprobe.d/qla2xxx.conf qla2xxx 模块配置文件中添加以下参数:
options qla2xxx qlini_mode=disabled
initrd),并重启系统以使更改生效。
25.5. 通过以太网接口配置光纤通道
fcoe-utilslldpad
过程 25.10. 将以太网接口配置为使用 FCoE
- 要配置新的 VLAN,请制作现有网络脚本的副本,如
/etc/fcoe/cfg-eth0,并将名称改为支持 FCoE 的以太网设备。这为您提供了一个要配置的默认文件。假设 FCoE 设备是 ethX,请运行:# cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-ethX
根据需要修改cfg-ethX的内容。值得注意的是,对于实现硬件数据中心桥接交换(DCBX)协议客户端的网络接口,将DCB_REQUIRED设置为no。 - 如果您希望设备在引导时自动载入,请在相应的
/etc/sysconfig/network-scripts/ifcfg-ethX文件中设置ONBOOT=yes。例如,如果 FCoE 设备是 eth2,请相应地编辑/etc/sysconfig/network-scripts/ifcfg-eth2。 - 运行以下命令启动数据中心桥接守护进程(dcbd):
# systemctl start lldpad
- 对于实现硬件 DCBX 客户端的网络接口,请跳过这一步。对于需要软件 DCBX 客户端的接口,请运行以下命令在以太网接口上启用数据中心桥接:
# dcbtool sc ethX dcb on
然后,运行以下命令在以太网接口上启用 FCoE:# dcbtool sc ethX app:fcoe e:1
请注意,只有在以太网接口的 dcbd 设置没有改变时,这些命令才起作用。 - 现在使用以下方法载入 FCoE 设备:
# ip link set dev ethX up
- 使用以下方法启动 FCoE:
# systemctl start fcoe
如果光纤上的所有其他设置都正确,则 FCoE 设备很快出现。要查看配置的 FCoE 设备,请运行:# fcoeadm -i
lldpad 服务设置为在启动时运行。要做到这一点,请使用 systemctl 工具:
# systemctl enable lldpad
# systemctl enable fcoe25.6. 将 FCoE 接口配置为在引导时自动挂载
/usr/share/doc/fcoe-utils-版本/README 中。有关小版本的任何可能的更改,请参阅该文档。
/lib/systemd/system/fcoe.service。
例 25.2. FCoE 挂载代码
/etc/fstab 中通配符指定的挂载文件系统的 FCoE 挂载代码示例:
mount_fcoe_disks_from_fstab()
{
local timeout=20
local done=1
local fcoe_disks=($(egrep 'by-path\/fc-.*_netdev' /etc/fstab | cut -d ' ' -f1))
test -z $fcoe_disks && return 0
echo -n "Waiting for fcoe disks . "
while [ $timeout -gt 0 ]; do
for disk in ${fcoe_disks[*]}; do
if ! test -b $disk; then
done=0
break
fi
done
test $done -eq 1 && break;
sleep 1
echo -n ". "
done=1
let timeout--
done
if test $timeout -eq 0; then
echo "timeout!"
else
echo "done!"
fi
# mount any newly discovered disk
mount -a 2>/dev/null
}/etc/fstab 中的以下路径指定的 FCoE 磁盘:
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
fc- 和 _netdev 子字符串的条目启用 mount_fcoe_disks_from_fstab 功能来识别 FCoE 磁盘挂载条目。有关 /etc/fstab 条目的更多信息,请参阅 man 5 fstab。
25.7. iSCSI
iscsi-initiator-utils 软件包来安装 iscsi-initiator-utils 软件包。
node.startup = automatic 的节点,则 iSCSI 服务将不会启动,直到运行 iscsiadm 命令需要 iscsid 或 iscsi 内核模块启动。例如,运行发现命令 iscsiadm -m discovery -t st -p ip:port 将导致 iscsiadm 启动 iSCSI 服务。
25.7.1. iSCSI API
# iscsiadm -m session -P 3
# iscsiadm -m session -P 0
# iscsiadm -m session
driver [sid] target_ip:port,target_portal_group_tag proper_target_name
例 25.3. iscsisadm -m session 命令的输出
# iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
/usr/share/doc/iscsi-initiator-utils-版本/README。
25.8. 持久性命名
25.8.1. 存储设备的主和次号
sd 驱动程序管理的存储设备由一组主要设备号及其关联的副号码来标识。用于此目的的主要设备号不在连续范围内。每个存储设备都由一个主号和一系列次要号表示,用于标识整个设备或设备中的分区。以 sd <letter (s)> 号的形式分配给设备和[号码在主号和次号之间进行直接关联]。每当 sd 驱动程序检测到新设备时,都会分配一个可用的主号码和次号范围。每当从操作系统中删除设备时,主号码和次号范围都会被释放,以便稍后重复使用。
sd 名称。这意味着,如果设备检测顺序发生了变化,主号和次号范围之间的关联以及相关的 sd 名称可能会发生变化。虽然这对于一些硬件配置(例如,内部 SCSI 控制器和磁盘将其 SCSI 目标 ID 被它们在机箱中的物理位置分配的 SCSI 目标 ID)不同,但它永远不会发生。可能发生这种情况的情况示例如下:
- 磁盘可能无法启动或响应 SCSI 控制器。这会导致正常设备探测不会检测到它。这个磁盘无法被系统访问,后续的设备将具有其主号和次号范围,包括相关的
sd名称下移。例如,如果没有检测到通常称为sdb的磁盘,则通常称为sdc的磁盘将显示为sdb。 - SCSI 控制器(主机总线适配器或 HBA)可能无法初始化,从而导致无法检测到连接到那个 HBA 的所有磁盘。任何连接到随后探测到的 HBA 的磁盘都会被分配不同的主号和次号范围,以及不同的相关
sd名称。 - 如果系统中存在不同类型的 HBA,则驱动程序初始化顺序可能会改变。这会导致以不同顺序检测到连接到这些 HBA 的磁盘。如果 HBA 移到系统的不同 PCI 插槽中,也会发生这种情况。
- 连接到带有光纤通道、iSCSI 或 FCoE 适配器的系统的磁盘可能在检测存储设备时无法访问,例如,由于存储阵列或中间交换机断电。如果存储阵列需要比系统启动的时间更长,则系统在电源失败后重启时会出现这种情况。虽然某些光纤通道驱动程序支持一种机制来向 WWPN 映射指定持久的 SCSI 目标 ID,但这不会导致主号和次号范围,以及相关的
sd名称被保留,它只提供一致的 SCSI 目标 ID 号。
/etc/fstab文件中的)时不希望使用主号和次号范围或相关的 sd 名称。可能挂载错误的设备,并可能导致数据崩溃。
sd 名称,即使使用了其他机制(比如当设备报告错误时)。这是因为 Linux 内核在有关设备的内核消息中使用 sd 名称(以及 SCSI 主机/通道/目标/LUN 元组)。
25.8.2. 全球标识符(WWID)
0x 83 页)或 单元序列号 (第 0x80页)来获取此标识符。在 /dev/disk/by-id/ 目录中维护的符号链接中,可以看到从这些 WWID 到当前 /dev/sd 名称的映射。
例 25.4. WWID
0x83 标识符的设备应该有:
scsi-3600508b400105e210000900000490000 -> ../../sda
0x80 标识符的设备应该有:
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
/dev/sd 名称的正确映射。应用程序可以使用 /dev/disk/by-id/ 名称来引用磁盘上的数据,即使设备的路径有变化,即使从不同的系统访问该设备也一样。
/dev/mapper/wwid 目录中显示一个"pseudo-device",如 /dev/mapper/3600508b400105df70000e00000ac0000。
Host:Channel:Target:LUN, /dev/sd name, 和 major:minor 号。
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
/dev/sd 名称的正确映射。这些名称可在路径更改之间保留,在从不同系统访问该设备时会保持一致。
user_friendly_names 功能( DM 多路径)时,WWID 会映射到 /dev/mapper/mpathn 格式的名称。默认情况下,此映射在 /etc/multipath/bindings 文件中维护。只要该文件被维护,这些 mpathn 名称就会持久存在。
udev 规则来实现映射到存储的 WWID 的持久名称。
25.8.3. 由 /dev/disk/byjpeg 中的 udev 机制管理的设备名称
udev 机制管理的设备名称udev 机制由三个主要组件组成:
- 内核
- 生成在设备添加、删除或更改时发送到用户空间的事件。
udevd服务- 接收事件。
udev规则- 指定
udev服务接收内核事件时要执行的操作。
udev 规则,该规则在 /dev/disk/ 目录中创建符号链接,允许存储设备被其内容引用、唯一标识符、序列号或用于访问该设备的硬件路径。
/dev/disk/by-label/- 此目录中的条目提供一个符号链接名称,它通过存储在设备上的内容(即数据)中的标签引用存储设备。blkid 实用程序用于从设备读取数据,并确定该设备的名称(即标签)。例如:
/dev/disk/by-label/Boot
注意该信息从设备上的内容(即数据)获取,以便在内容复制到另一个设备时,标签将保持不变。该标签也可用于使用以下语法指向/etc/fstab中的设备:LABEL=Boot
/dev/disk/by-uuid/- 此目录中的条目提供一个符号链接名称,它通过存储在设备上的内容(即数据)中的唯一标识符来引用存储设备。blkid 实用程序用于从设备读取数据,并获取该设备的唯一标识符(即 UUID)。例如:
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6
/dev/disk/by-id/- 这个目录中的条目提供了一个符号链接名称,它通过唯一标识符(与所有其他存储设备不同)指向存储设备。标识符是设备的属性,但不存储在设备上的内容(即数据)中。例如:
/dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05
id 从设备的全球 ID 或设备序列号获得。/dev/disk/by-id/条目也可以包含分区号。例如:/dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-path/- 这个目录中的条目提供了一个符号链接名称,它通过用于访问该设备的硬件路径引用,从 PCI 层次结构中的存储控制器的引用,包括 SCSI 主机、频道、目标和 LUN 号,以及可选的分区号。虽然这些名称最好使用主号和次号或
sd名称,但必须小心谨慎,以确保目标号在光纤通道 SAN 环境中不会改变(例如,通过使用持久绑定),如果主机适配器移至不同的 PCI 插槽,则更新名称。另外,如果 HBA 无法探测、如果以不同顺序载入驱动程序,或者系统上安装了新的 HBA,则 SCSI 主机号可能会改变。by-path 列表的示例如下:/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0
/dev/disk/by-path/条目可能还包括分区号,例如:/dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0-part1
25.8.3.1. udev 设备命名约定的限制
udev 命名规则的一些限制。
- 执行查询时可能无法访问该设备,因为
udev机制可能依赖于为 udev 事件处理udev规则时查询存储设备的能力。当设备不在服务器机箱中时,这更可能会在光纤频道、iSCSI 或者 FCoE 存储设备中发生。 - 内核也可以随时发送
udev事件,从而导致规则被处理,并可能导致/dev/disk/by KafkaUser/链接在设备无法访问时被删除。 - 当
udev事件生成和处理时(如检测到大量设备且用户空间udevd服务需要一定时间来处理每个事件)之间可能会有延迟。这可能会导致内核检测到该设备和/dev/disk/byjpeg/名称可用之间延迟。 - 规则调用的 blkid 等外部程序可以在短时间内打开该设备,使设备无法被其他用途访问。
25.8.3.2. 修改持久性命名属性
udev 命名属性是持久的,但它们在系统重启后不会自行更改,但有一部分也是可以配置的。您可以为以下持久性命名属性设置自定义值:
UUID:文件系统 UUIDLABEL: 文件系统标签
UUID 和 LABEL 属性与文件系统相关,因此您需要使用的工具取决于该分区上的文件系统。
- 要更改 XFS 文件系统的
UUID或LABEL属性,请卸载文件系统,然后使用 xfs_admin 工具更改属性:#umount /dev/device#xfs_admin [-U new_uuid] [-L new_label] /dev/device#udevadm settle - 要更改 ext4、ext3 或 ext2 文件系统的
UUID或LABEL属性,请使用 tune2fs 工具:#tune2fs [-U new_uuid] [-L new_label] /dev/device#udevadm settle
1cdfbc07-1c90-4984-b5ec-f61943f5ea50。使用标签替换 new_label,例如 backup_data。
udev 属性在后台进行,可能需要很长时间。udevadm settle 命令一直等待直到更改完全注册,这样可确保您的下一个命令能够正确使用新属性。
PARTUUID 或 PARTLABEL 属性的分区后,或者在创建新文件系统后使用。
25.9. 删除存储设备
- 可用内存小于每 100 超过 10 个样本的 5%( 可用 命令也可用于显示总内存)。
- 交换处于活跃状态( vmstat 输出中的非零
si和so列)。
过程 25.11. 确保彻底的设备删除
- 根据需要,关闭设备的所有用户,并备份设备数据。
- 使用 umount 卸载挂载该设备的任何文件系统。
- 使用它的任何 md 和 LVM 卷中删除该设备。如果设备是 LVM 卷组的成员,那么可能需要使用 pvmove 命令将数据移出设备,然后使用 vgreduce 命令删除物理卷,以及(可选) pvremove 从磁盘中删除 LVM 元数据。
- 运行 multipath -l 命令来查找配置为多路径设备 的设备列表。如果该设备被配置为多路径设备,请运行 multipath -f device 命令来清除任何未完成的 I/O 并删除多路径设备。
- 将未完成的 I/O 刷新到已用路径。这对 raw 设备非常重要,其中没有 umount 或 vgreduce 操作来导致 I/O 刷新。只有在出现以下情况时,才需要执行此步骤:
- 该设备没有配置为多路径设备,或者
- 该设备被配置为多路径设备,I/O 是在过去某个点直接发布到其独立路径。
使用以下命令刷新任何未完成的 I/O:#blockdev --flushbufs device - 删除对设备的基于路径名称的任何引用,如
/dev/sd、/dev/disk/by-path或系统上的 major:minor 号、应用程序、脚本或工具。这对于确保以后添加的不同设备不会被误认为是当前设备非常重要。 - 最后,从 SCSI 子系统中删除该设备的每个路径。为此,请使用命令 echo 1 > /sys/block/device-name/device/delete,例如,其中 device-name 可以是
sde。此操作的另一个变化是 echo 1 > /sys/class/scsi_device/h:c:t:l/device/delete,其中 h 是 HBA 号,c 是 HBA 上的频道,t 是 SCSI 目标 ID,l 是 LUN。注意这些命令的旧形式 echo "scsi remove-single-device 0 0 0 0" > /proc/scsi/scsi 已被弃用。
25.10. 删除存储设备的路径
过程 25.12. 删除存储设备的路径
- 删除对设备的基于路径名称的任何引用,如
/dev/sd或/dev/disk/by-path或系统上的 major:minor 号、应用程序、脚本或工具。这对于确保以后添加的不同设备不会被误认为是当前设备非常重要。 - 使用 echo offline > /sys/block/sda/device/state 使路径离线。这将导致发送至该路径上设备的任何后续 I/O 立即失败。device-mapper-multipath 将继续使用设备的剩余路径。
- 从 SCSI 子系统中删除路径。为此,请使用命令 echo 1 > /sys/block/device-name/device/delete,其中 device-name 可以是
sde(如 过程 25.11, “确保彻底的设备删除”所述)。
25.11. 添加存储设备或路径
/dev/disk/by-path 名称)。因此,请确保已删除所有对基于路径的设备名称的旧引用。否则,新设备可能会被误认为是旧设备。
过程 25.13. 添加存储设备或路径
- 添加存储设备或路径的第一步是物理启用对新存储设备的访问,或对现有设备的新路径的访问。这是通过对光纤通道或 iSCSI 存储服务器使用特定于供应商的命令来完成的。执行此操作时,请注意将呈现给您的主机的新存储的 LUN 值。如果存储服务器是光纤通道,可记下存储服务器的 全球节点名称 (WWNN),并确定存储服务器上的所有端口是否有单个 WWNN。否则,请注意将用于访问新 LUN 的每个端口的 全球端口名称 (WWPN)。
- 接下来,使操作系统知道新的存储设备,或现有设备的路径。建议使用的命令有:
$ echo "c t l" > /sys/class/scsi_host/hosth/scan
在上一命令中,h 是 HBA 号,c 是 HBA 上的频道,t 是 SCSI 目标 ID,l 是 LUN。注意此命令的旧形式 echo "scsi add-single-device 0 0 0 0" > /proc/scsi/scsi 已被弃用。- 在某些光纤通道硬件中,RAID 阵列上新创建的 LUN 可能在执行 循环初始化协议(LIP)操作之前无法被操作系统看到。有关如何操作的说明,请参阅 第 25.12 节 “扫描存储互连”。重要如果需要 LIP,则需要在执行此操作时需要停止 I/O。
- 如果在 RAID 阵列中添加了新的 LUN,但仍然没有被操作系统配置,请使用 sg_luns 命令(这是 sg3_utils 软件包的一部分)确认阵列导出的 LUN 列表。这会将 SCSI REPORT LUNS 命令发布到 RAID 阵列,并返回存在的 LUN 列表。
对于为所有端口实现单个 WWNN 的光纤通道存储服务器,您可以通过搜索 sysfs 中的 WWNN 来确定正确的 h、c 和 t 值(如 HBA 号、HBA 通道和 SCSI 目标 ID)。例 25.5. 确定正确的 h、c 和 t 值
例如,如果存储服务器的 WWNN 是0x5006016090203181,请使用:$ grep 5006016090203181 /sys/class/fc_transport/*/node_name
这应该显示类似于如下的输出:/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
这表示有四个光纤通道路由到这个目标(两个单通道 HBA,各自指向两个存储端口)。假设 LUN 值为56,以下命令将配置第一个路径:$ echo "0 2 56" > /sys/class/scsi_host/host5/scan
必须为新设备的每个路径完成此操作。对于不为所有端口实现单个 WWN 的光纤通道存储服务器,您可以通过在 sysfs 中搜索每个 WWPN 来确定正确的 HBA 号、HBA 通道和 SCSI 目标 ID。确定 HBA 号、HBA 通道和 SCSI 目标 ID 的另一种方法是参考已在与新设备相同的路径上配置的另一个设备。这可以通过各种命令完成,如 lsscsi、scsi_id、multipath -l 和 ls -l /dev/disk/byrew。此信息以及新设备的 LUN 号,可以探测并配置新设备的路径,如上所示。 - 向设备添加所有 SCSI 路径后,执行 multipath 命令,并检查该设备是否已正确配置。此时,可以将设备添加到 md、LVM、mkfs 或 mount 中。
25.12. 扫描存储互连
- 在执行此流程前,必须暂停并刷新受影响的互连上的所有 I/O,并在 I/O 恢复前检查扫描的结果。
- 与删除设备一样,当系统面临内存压力时,不建议进行互连扫描。要确定内存压力的级别,请运行 vmstat 1 100 命令。如果每 100 个样本中超过 10 个样本的空闲内存小于总内存的 5%,则不建议进行互连扫描。另外,如果交换处于活跃状态( vmstat 输出中的非零
si和so列),则不建议进行互连扫描。free 命令还可以显示总内存。
- echo "1" > /sys/class/fc_host/hostN/issue_lip
- (用主机号替换 N。)此操作执行 循环初始化协议 (LIP),扫描互连,并导致更新 SCSI 层以反映总线上当前的设备。基本上,LIP 是总线重置,导致设备添加和删除。为了在光纤通道互连上配置新的 SCSI 目标,这个流程是必需的。请注意,issue_lip 是异步操作。该命令可以在整个扫描完成之前完成。您必须监控
/var/log/messages,以确定 issue_lip 何时完成。lpfc、qla2xxx和bnx2fc驱动程序支持 issue_lip。有关 Red Hat Enterprise Linux 中每个驱动程序支持的 API 功能的更多信息,请参阅 表 25.1 “Fibre Channel API 功能”。 /usr/bin/rescan-scsi-bus.sh- Red Hat Enterprise Linux 5.4 中引入了
/usr/bin/rescan-scsi-bus.sh脚本。默认情况下,此脚本会扫描系统上的所有 SCSI 总线,并更新 SCSI 层以反映总线上的新设备。脚本提供了允许移除设备和发布 LIP 的附加选项。有关此脚本的详情,包括已知问题,请参阅 第 25.18 节 “通过 rescan-scsi-bus.sh 添加/删除逻辑单元”。 - echo "- - -" > /sys/class/scsi_host/hosth/scan
- 这与 第 25.11 节 “添加存储设备或路径” 中所述的添加存储设备或路径的命令相同。然而,在这种情况下,通道号、SCSI 目标 ID 和 LUN 值会被通配符替代。允许标识符和通配符的任意组合,以便您可以根据需要将命令设置为特定的或广泛的。这个流程添加了 LUN,但不会删除它们。
- modprobe --remove driver-name, modprobe driver-name
- 运行 modprobe --remove driver-name 命令,后跟 modprobe driver-name 命令完全重新初始化由驱动程序控制的所有互连的状态。尽管非常极端,但在某些情况下,使用上述命令可能是合适的。例如,命令可用于使用不同的模块参数值重新启动驱动程序。
25.13. iSCSI 发现配置
/etc/iscsi/iscsid.conf。此文件包含 iscsid 和 iscsiadm 使用的 iSCSI 设置。
/etc/iscsi/iscsid.conf 中的设置来创建两种类型的记录:
/var/lib/iscsi/nodes中的节点记录- 登录到目标时,iscsiadm 会使用此文件中的设置。
/var/lib/iscsi/discovery_type中的发现记录- 向同一目标执行发现时,iscsiadm 会使用此文件中的设置。
/var/lib/iscsi/discovery_type)。要做到这一点,请使用以下命令:[5]
# iscsiadm -m discovery -t discovery_type -p target_IP:port -o deletesendtargets、isns 或 fw。
- 在执行发现前,直接编辑
/etc/iscsi/iscsid.conf文件。发现设置使用前缀发现; 查看它们,请运行:#iscsiadm -m discovery -t discovery_type -p target_IP:port - 或者,iscsiadm 也可用于直接更改发现记录设置,如下所示:
#iscsiadm -m discovery -t discovery_type -p target_IP:port -o update -n setting -v %value有关可用 设置选项 和有效值选项的详情,请参考 iscsiadm(8) man page。
/etc/iscsi/iscsid.conf 文件还包含正确的配置语法示例。
25.14. 配置 iSCSI 卸载和接口绑定
$ ping -I ethX target_IP
25.14.1. 查看可用的 iface 配置
- 软件 iSCSI
- 此堆栈为每个会话分配一个 iSCSI 主机实例(即 scsi_host),每个会话都有一个连接。因此,
/sys/class_scsi_host和/proc/scsi将为您登录的每个连接/会话报告一个 scsi_host。 - 卸载 iSCSI
- 此堆栈为每个 PCI 设备分配一个 scsi_host。因此,主机总线适配器中的每个端口都显示为不同的 PCI 设备,每个 HBA 端口都有不同的 scsi_host。
/var/lib/iscsi/ifaces 中输入 iface 配置。
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name
表 25.2. iface 设置
| 设置 | 描述 |
|---|---|
| iface_name | iface 配置名称。 |
| transport_name | 驱动程序的名称 |
| hardware_address | MAC 地址 |
| ip_address | 此端口使用的 IP 地址 |
| net_iface_name | 用于软件 iSCSI 会话的 vlan 或别名绑定的名称。对于 iSCSI 卸载,net_iface_name 将是 <empty>,因为这个值在重启后不会保留。 |
| initiator_name | 此设置用于覆盖启动器的默认名称,该名称在 /etc/iscsi/initiatorname.iscsi中定义 |
例 25.6. iscsiadm -m iface 命令的输出示例
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
例 25.7. 带有 Chelsio 网卡的 iscsiadm -m iface 输出
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
iface.setting = value
例 25.8. 使用带有 Chelsio 融合网络适配器的 iface 设置
# BEGIN RECORD 2.0-871 iface.iscsi_ifacename = cxgb3i.00:07:43:05:97:07 iface.net_ifacename = <empty> iface.ipaddress = <empty> iface.hwaddress = 00:07:43:05:97:07 iface.transport_name = cxgb3i iface.initiatorname = <empty> # END RECORD
25.14.2. 为软件 iSCSI 配置 iface
# iscsiadm -m iface -I iface_name --op=new
# iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
例 25.9. 设置 MAC 地址 iface0
iface0 的 MAC 地址(hardware_address)设置为 00:0F:1F:92:6B:BF,请运行:
# iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
default 或 iser 作为 iface 名称。这两个字符串都是 iscsiadm 使用的特殊值,用于向后兼容。任何手动创建的名为 default 或 iser 的 iface 配置都会禁用向后兼容。
25.14.3. 为 iSCSI 卸载配置 iface
iscsiadm 为每个端口创建一个 iface 配置。要查看可用的 iface 配置,请使用软件 iSCSI 中的相同命令: iscsiadm -m iface。
iface.ipaddress 值设置为接口应使用的启动器 IP 地址:
- 对于使用
be2iscsi驱动程序的设备,IP 地址在 BIOS 设置屏幕中配置。 - 对于所有其他设备,若要配置
iface的 IP 地址,请使用:# iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v initiator_ip_address
例 25.10. 设置 Chelsio 卡的 iface IP 地址
iface 名称 cxgb3i.00:07:43:05:97:07 时,要将 iface IP 地址设置为 20.15.0.66,请使用:
# iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
25.14.4. 绑定/解绑到端口的 iface
/var/lib/iscsi/ifaces 中每个 iface 配置的 iface.transport 设置。然后,iscsiadm 工具将发现的端口绑定到其 iface.transport 为 tcp 的任何 iface。
# iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1 [5]
tcp。因此,iface 配置需要手动绑定到发现的门户。
default 作为 iface_name,如下所示:
# iscsiadm -m discovery -t st -p IP:port -I default -P 1
# iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[6]
# iscsiadm -m node -I iface_name --op=delete
# iscsiadm -m node -p IP:port -I iface_name --op=delete
/var/lib/iscsi/ iface 中定义的 iface 配置,并且没有使用 -I 选项,iscsiadm 将允许网络子系统决定特定门户应使用哪个设备。
25.15. 扫描 iSCSI Interconnects
# iscsiadm -m discovery -t sendtargets -p target_IP:port [5]
target_IP:port,target_portal_group_tag proper_target_name
例 25.11. 使用 iscsiadm 发出 sendtargets 命令
iqn.1992-08.com.netapp:sn.33615311 且 target_IP:port 为 10.15.85.19:3260 的目标中,输出可能显示为:
10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
10.15.84.19:3260 和 10.15.85.19:3260。
Target: proper_target_name
Portal: target_IP:port,target_portal_group_tag
Iface Name: iface_name例 25.12. 查看 iface 配置
Target: iqn.1992-08.com.netapp:sn.33615311
Portal: 10.15.84.19:3260,2
Iface Name: iface2
Portal: 10.15.85.19:3260,3
Iface Name: iface2
iqn.1992-08.com.netapp:sn.33615311 将使用 iface2 作为其 iface 配置。
# iscsiadm -m session --rescan
# iscsiadm -m session -r SID --rescan[7]
/var/lib/iscsi/nodes 数据库的内容。然后,将使用 /etc/iscsi/iscsid.conf 中的设置重新填充此数据库。但是,如果会话当前已登录并在使用,则不会发生这种情况。
/var/lib/iscsi/nodes 的情况下添加新目标/端口,请使用以下命令:
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes 条目,请使用:
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
ip:port,target_portal_group_tag proper_target_name
例 25.13. sendtargets 命令的输出
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
# iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [8]
例 25.14. 完整的 iscsiadm 命令
# iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[8]
25.16. 登录到 iSCSI 目标
# systemctl start iscsi初始化脚本 将自动登录到目标,其中 node.startup 设置被配置为 automatic。这是所有目标 node.startup 的默认值。
node.startup 设置为 manual。要做到这一点,请运行以下命令:
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o update -n node.startup -v manual
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o delete
/etc/fstab 中为挂载添加一个分区条目。例如:要在启动时自动将 iSCSI 设备 sdb 挂载到 /mount/iscsi,请在 /etc/fstab 中添加以下行:
/dev/sdb /mnt/iscsi ext3 _netdev 0 0
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -l
25.17. 重新调整在线逻辑单元的大小
25.17.1. 重新调整光纤通道逻辑单元的大小
$ echo 1 > /sys/block/sdX/device/rescan
25.17.2. 重新调整 iSCSI 逻辑单元的大小
# iscsiadm -m node --targetname target_name -R [5]
# iscsiadm -m node -R -I interface
- 它使用与命令 echo "- - -" > /sys/class/scsi_host/host/scan 相同的方式扫描新设备(请参阅 第 25.15 节 “扫描 iSCSI Interconnects”)。
- 它使用与命令 echo 1 > /sys/block/sdX/device/rescan 相同的方式重新扫描新的/ 修改逻辑单元。请注意,这个命令与重新扫描光纤通道逻辑单元的命令相同。
25.17.3. 更新多路径设备的大小
# multipathd -k"resize map multipath_device"
/dev/mapper 中设备的对应多路径条目。根据多路径在您的系统上是如何设置的,multipath_device 可以是两种格式之一:
- mpathX,其中 X 是设备的对应条目(例如 mpath0)
- WWID;例如 3600508b400105e210000900000490000
/etc/multipath.conf中)设置为 "queue" 时,不要使用此命令,且设备没有主动路径。
25.17.4. 更改在线逻辑单元的读/写状态
# blockdev --getro /dev/sdXYZ
# cat /sys/block/sdXYZ/ro 1 = read-only 0 = read-write36001438005deb4710000500000640000 dm-8 GZ,GZ500 [size=20G][features=0][hwhandler=0][ro] \_ round-robin 0 [prio=200][active] \_ 6:0:4:1 sdax 67:16 [active][ready] \_ 6:0:5:1 sday 67:32 [active][ready] \_ round-robin 0 [prio=40][enabled] \_ 6:0:6:1 sdaz 67:48 [active][ready] \_ 6:0:7:1 sdba 67:64 [active][ready]
过程 25.14. 更改 R/W 状态
- 要将设备从 RO 移到 R/W,请参阅第 2 步。要将设备从 R/W 移到 RO,请确保不再发出写操作。通过停止应用程序,或使用合适的、特定于应用的操作来完成此操作。使用以下命令确保所有未完成的写 I/O 都完成了:
# blockdev --flushbufs /dev/device使用所需的设计器替换 device ;对于设备映射器多路径,这是dev/mapper中您设备的条目。例如:/dev/mapper/mpath3。 - 使用存储设备的管理界面,将逻辑单元的状态从 R/W 改为 RO,或者从 RO 改为 R/W。其流程因每个阵列而异。如需更多信息,请参阅适用的存储阵列供应商文档。
- 执行设备的重新扫描,以更新操作系统的设备 R/W 状态视图。如果使用设备映射器多路径,请对设备的每个路径执行此重新扫描,然后再发出命令告诉多路径重新加载其设备映射。这一过程在 第 25.17.4.1 节 “重新扫描逻辑单元” 中进行了更详细的说明。
25.17.4.1. 重新扫描逻辑单元
# echo 1 > /sys/block/sdX/device/rescan例 25.15. 使用 multipath -11 命令
# echo 1 > /sys/block/sdax/device/rescan # echo 1 > /sys/block/sday/device/rescan # echo 1 > /sys/block/sdaz/device/rescan # echo 1 > /sys/block/sdba/device/rescan
25.17.4.2. 更新多路径设备的 R/W 状态
# multipath -r25.17.4.3. Documentation
25.18. 通过 rescan-scsi-bus.sh 添加/删除逻辑单元
sg3_utils 软件包提供 rescan-scsi-bus.sh 脚本,该脚本可以根据需要自动更新主机的逻辑单元配置(在设备添加到系统后)。rescan-scsi-bus.sh 脚本还可以对支持的设备执行 issue_lip。有关如何使用此脚本的更多信息,请参阅 rescan-scsi-bus.sh --help。
sg3_utils 软件包,请运行 yum install sg3_utils。
rescan-scsi-bus.sh 的已知问题
rescan-scsi-bus.sh 脚本时,请注意以下已知问题:
- 要使
rescan-scsi-bus.sh正常工作,LUN0 必须是第一个映射的逻辑单元。rescan-scsi-bus.sh只能检测第一个映射的逻辑单元(如果它是 LUN0 )。rescan-scsi-bus.sh将无法扫描任何其他逻辑单元,除非它检测到第一个映射的逻辑单元,即使您使用了 --nooptscan 选项。 - 如果第一次映射逻辑单元,则竞争条件要求运行
rescan-scsi-bus.sh两次。在第一次扫描过程中,rescan-scsi-bus.sh仅添加 LUN0 ;在第二次扫描中添加所有其他逻辑单元。 - 当使用 --remove 选项时,
rescan-scsi-bus.sh脚本中的一个错误会错误地执行识别逻辑单元大小变化的功能。 rescan-scsi-bus.sh脚本无法识别 ISCSI 逻辑单元删除。
25.19. 修改链接丢失行为
25.19.1. Fibre Channel
dev_loss_tmo 回调,当检测到传输问题时,通过链接访问设备的尝试将被阻止。要验证设备是否被阻止,请运行以下命令:
$ cat /sys/block/device/device/state
blocked。如果设备正常运行,这个命令会返回 running。
过程 25.15. 确定远程端口的状态
- 要确定远程端口的状态,请运行以下命令:
$ cat /sys/class/fc_remote_port/rport-H:B:R/port_state
- 当远程端口(以及通过它访问的设备)被阻止时,这个命令将返回
Blocked。如果远程端口正常运行,命令将返回Online。 - 如果没有在
dev_loss_tmo秒内解决问题,则 rport 和设备将被取消阻塞,且在该设备上运行的所有 I/O (以及发送到该设备的任何新的 I/O)都将失败。
过程 25.16. 更改 dev_loss_tmo
- 要更改
dev_loss_tmo值,请将所需值 echo 到该文件。例如,要将dev_loss_tmo设置为 30 秒,请运行:$ echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
dev_loss_tmo 的更多信息,请参阅 第 25.4.1 节 “光纤通道 API”。
dev_loss_tmo 时,会删除 scsi_device 和 sdN 设备。通常,光纤通道类会将设备保留原样;例如 /dev/sdx 将保持 /dev/sdx。这是因为,目标绑定由 Fibre Channel 驱动程序保存,因此当目标端口返回时,SCSI 地址会被重新创建。但是,无法保证这一点;只有在未进行 LUN 的存储框中配置时,才会恢复 sdx。
25.19.2. 使用 dm-multipath的 iSCSI 设置
/etc/multipath.conf 中的 device { 下嵌套以下行:
features "1 queue_if_no_path"
25.19.2.1. NOP-Out Interval/Timeout
5 秒。要调整此功能,请打开 /etc/iscsi/iscsid.conf 并编辑以下行:
node.conn[0].timeo.noop_out_interval = [interval value]
node.conn[0].timeo.noop_out_timeout = [timeout value]
SCSI 错误处理程序
# iscsiadm -m session -P 3
25.19.2.2. replacement_timeout
/etc/iscsi/iscsid.conf 并编辑以下行:
node.session.timeo.replacement_timeout = [replacement_timeout]
/etc/multipath.conf 中的 1 queue_if_no_path 选项设置 iSCSI 计时器,以立即将命令延迟到多路径层(请参考 第 25.19.2 节 “使用 dm-multipath的 iSCSI 设置”)。此设置可防止 I/O 错误传播到应用程序;因此,您可以将 replacement_timeout 设置为 15-20 秒。
/etc/multipath.conf 中的设置而不是 /etc/iscsi/iscsid.conf 中的设置在内部排队 I/O。
iSCSI 和 DM 多路径覆盖
restore_tmo sysfs 选项控制一个特定 iSCSI 设备的超时时间。以下选项会在全局范围内覆盖 recovery_tmo 值:
replacement_timeout配置选项会全局覆盖所有 iSCSI 设备的recovery_tmo值。- 对于由 DM 多路径管理的所有 iSCSI 设备,DM 多路径中的
fast_io_fail_tmo选项会全局覆盖recovery_tmo值。DM 多路径中的fast_io_fail_tmo选项会覆盖光纤通道设备的fast_io_fail_tmo选项。DM 多路径fast_io_fail_tmo选项优先于replacement_timeout。红帽不推荐使用replacement_timeout覆盖由 DM 多路径管理的设备中的recovery_tmo,因为在multipathd服务重新载入时 DM 多路径总是重置recovery_tmo。
25.19.3. iSCSI 根
/etc/iscsi/iscsid.conf 并编辑如下:
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
/etc/iscsi/iscsid.conf 并编辑以下行:
node.session.timeo.replacement_timeout = replacement_timeout
/etc/iscsi/iscsid.conf 后,您必须对受影响的存储执行重新发现。这将允许系统加载和使用 /etc/iscsi/iscsid.conf 中的任何新值。有关如何发现 iSCSI 设备的详情,请参考 第 25.15 节 “扫描 iSCSI Interconnects”。
为特定会话配置超时
/etc/iscsi/iscsid.conf)。为此,请运行以下命令(相应地替换变量):
# iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
25.20. 控制 SCSI 命令计时器和设备状态
- 中止命令。
- 重置设备。
- 重置总线。
- 重置主机。
设备状态
$ cat /sys/block/device-name/device/state
# echo running > /sys/block/device-name/device/state
命令计时器
/sys/block/device-name/device/timeout 文件:
# echo value > /sys/block/device-name/device/timeout
25.21. 在线存储配置故障排除
- 逻辑单元删除状态不会在主机上反映。
- 在配置的文件上删除逻辑单元时,该更改不会在主机上反映。在这种情况下,当使用 dm-multipath 时 lvm 命令会无限期挂起,因为逻辑单元现已过时。要临时解决这个问题,请执行以下步骤:
过程 25.17. 围绕过时的逻辑单元进行工作
- 确定
/etc/lvm/cache/.cache中的哪些 mpath 链接条目特定于过时的逻辑单元。要做到这一点,请运行以下命令:$ ls -l /dev/mpath | grep stale-logical-unit
例 25.16. 确定特定 mpath 链接条目
例如,如果 stale-logical-unit 是 3600d0230003414f30000203a7bc41a00,则可能会出现以下结果:lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
这意味着 3600d0230003414f30000203a7bc41a00 被映射到两个 mpath 链接: dm-4 和 dm-5。 - 接下来,打开
/etc/lvm/cache/.cache。删除包含 stale-logical-unit 和 stale-logical-unit 映射到的 mpath 链接的所有行。例 25.17. 删除相关行
使用上一步中的同一示例,您需要删除的行是:/dev/dm-4 /dev/dm-5 /dev/mapper/3600d0230003414f30000203a7bc41a00 /dev/mapper/3600d0230003414f30000203a7bc41a00p1 /dev/mpath/3600d0230003414f30000203a7bc41a00 /dev/mpath/3600d0230003414f30000203a7bc41a00p1
25.22. 使用 eh_deadline 为错误恢复配置最大时间
eh_deadline 参数。在某些特定情况下,使用 eh_deadline 参数很有用,例如,如果在光纤通道交换机和目标端口之间发生链接丢失,主机总线适配器(HBA)不会接收 Registered State Change Notifications (RSCN)。在这种情况下,I/O 请求和错误恢复命令会超时,而不是遇到错误。在这个环境中的 eh_deadline 设置会为恢复时间设置上限,它允许在多路径的另一个可用路径中重试失败的 I/O。
eh_deadline 功能不会提供额外的好处,因为 I/O 和错误恢复命令会立即失败,这允许多路径重试。
eh_deadline 参数允许您配置 SCSI 错误处理机制在停止和重置整个 HBA 前尝试执行错误恢复的最长时间。
eh_deadline 的值以秒为单位指定。默认设置为 off,它会禁用时间限制并允许进行所有错误恢复。除了使用 sysfs 外,还可使用 scsi_mod.eh_deadline 内核参数为所有 SCSI HBA 设置默认值。
eh_deadline 过期时,HBA 被重置,这会影响那个 HBA 中的所有目标路径,而不仅仅是失败的路径。因此,如果某些冗余路径因其他原因不可用,则可能会出现 I/O 错误。仅在所有目标中有完全冗余的多路径配置时才启用 eh_deadline。
第 26 章 虚拟机的设备映射器多路径(DM 多路径)和存储
26.1. 虚拟机存储
- Fibre Channel
- iSCSI
- NFS
- GFS2
- 本地存储池
- 本地存储包括直接附加到主机、本地目录、直接附加的磁盘和 LVM 卷组的存储设备、文件或目录。
- 联网的(共享)存储池
- 网络存储涵盖使用标准协议通过网络共享的存储设备。它包括使用光纤通道、iSCSI、NFS、GFS2 和 SCSI RDMA 协议的共享存储设备,是在主机之间迁移虚拟客户机的要求。
26.2. DM Multipath
- 冗余
- DM 多路径可在主动/被动(active/passive)配置中提供故障切换。在主动/被动配置中,对于 I/O,任何时候都只会使用一半的路径。如果 I/O 路径的任何元素失败,DM 多路径会切换到备用路径。
- 改进的性能
- 可将 DM 多路径配置为主动/主动模式,其中 I/O 以轮循方式分布到路径中。在某些配置中,DM-Multipath 可以检测 I/O 路径上的加载,并动态重新平衡负载。
第 27 章 外部阵列管理(libStorageMgmt)
libStorageMgmt。
27.1. libStorageMgmt 简介
libStorageMgmt 库是一个独立于应用程序编程接口(API)的存储阵列。作为开发者,您可以使用此 API 管理不同的存储阵列,并利用硬件加速功能。
libStorageMgmt 库,您可以执行以下操作:
- 列出存储池、卷、访问组或文件系统。
- 创建和删除卷、访问组、文件系统或 NFS 导出。
- 授予和移除对卷、访问组或启动器的访问权限。
- 使用快照、克隆和副本复制卷。
- 创建和删除访问组,并编辑组成员。
- 用于客户端应用程序和插件开发人员的稳定 C 和 Python API。
- 使用库的命令行界面(
lsmcli)。 - 执行插件(
lsmd)的守护进程。 - 允许测试客户端应用程序(
sim)的模拟插件。 - 用于与数组交互的插件架构。
libStorageMgmt 库添加了默认的 udev 规则,以处理 REPORTED LUNS DATA HAS CHANGED 单元注意。
sysfs 自动扫描。
/lib/udev/rules.d/90-scsi-ua.rules 包含示例规则,用于枚举内核可生成的其他事件。
27.2. libStorageMgmt Terminology
- 存储阵列
- 任何通过网络连接存储(NAS)提供块访问(FC、FCoE、iSCSI)或文件访问的存储系统。
- 卷
- 存储区域网络(SAN)存储阵列可以通过不同的传输(如 FC、iSCSI 或 FCoE)向主机总线适配器(HBA)公开卷。主机操作系统将其视为块设备。如果启用了
多路径[2],一个卷可以公开给多个磁盘。这也被称为逻辑单元号(LUN),带有 SNIA 术语的 StorageVolume 或虚拟磁盘。 - pool
- 一组存储空间。可以从池中创建文件系统或卷。池可以从磁盘、卷和其他池创建。池也可以保存 RAID 设置或精简配置设置。这也称为带有 SNIA 术语的 StoragePool。
- Snapshot
- 时间点,即只读、空间高效数据副本。这也称为只读快照。
- 克隆
- 时间点、可读取、空间高效数据副本。这也被称为可读写快照。
- Copy
- 数据的全位副本。它占据了完整的空间。
- mirror
- 持续更新的副本(同步和异步)。
- 访问组
- 被授予对一个或多个存储卷访问权限的 iSCSI、FC 和 FCoE 启动器的集合。这样可确保只有存储卷可以被指定的启动器访问。这也被称为 initiator 组。
- access Grant
- 将卷公开给指定的访问组或启动器.
libStorageMgmt库目前不支持 LUN 映射,能够选择特定的逻辑单元号。libStorageMgmt库允许存储阵列选择下一个可用的 LUN 进行分配。如果配置从 SAN 或屏蔽超过 256 个卷的引导,请确定读取 OS、存储阵列或 HBA 文档。访问权限授权也称为 LUN 掩码。 - System
- 代表存储阵列或直接连接的存储 RAID。
- File system
- 网络附加存储(NAS)存储阵列可使用 NFS 或 CIFS 协议通过 IP 网络公开文件系统来托管操作系统。主机操作系统将其视为挂载点或包含文件的文件夹,具体取决于客户端操作系统。
- 磁盘
- 保存数据的物理磁盘。这通常在使用 RAID 设置创建池时使用。这也称为 DiskDrive,使用 SNIA 术语。
- initiator
- 在光纤通道(FC)或以太网光纤通道(FCoE)中,发起方是全球端口名称(WWPN)或全球节点名称(WWNN)。在 iSCSI 中,启动器是 iSCSI 限定名称(IQN)。在 NFS 或 CIFS 中,启动器是主机名或主机的 IP 地址。
- 子依赖项
- 有些阵列在原始卷(父卷或文件系统)和子(如快照或克隆)之间有一个隐式关系。例如,如果父对象有一个或多个依赖的子项,则无法删除父项。API 提供了方法来确定是否存在此类关系,以及通过复制所需块来删除依赖项的方法。
27.3. Installing libStorageMgmt
libStorageMgmt 以使用命令行,所需的运行时库和 simulator 插件,请使用以下命令:
# yum install libstoragemgmt libstoragemgmt-python
# yum install libstoragemgmt-devellibStorageMgmt 用于硬件数组,请使用以下命令选择一个或多个适当的插件软件包:
# yum install libstoragemgmt-name-plugin- libstoragemgmt-smis-plugin
- 通用 SMI-S 阵列支持。
- libstoragemgmt-netapp-plugin
- 对 NetApp 文件的特定支持。
- libstoragemgmt-nstor-plugin
- 对 NexentaStor 的特定支持。
- libstoragemgmt-targetd-plugin
- 对目标的特定支持。
lsmd)的行为与系统的任何标准服务类似。
# systemctl status libstoragemgmt# systemctl stop libstoragemgmt# systemctl start libstoragemgmt27.4. 使用 libStorageMgmt
libStorageMgmt,请使用 lsmcli 工具。
- Uniform Resource Identifier (URI),用于识别插件以连接到该数组以及该阵列所需的任何可配置的选项。
- 数组的有效用户名和密码。
plugin+optional-transport://user-name@host:port/?query-string-parameters
例 27.1. 不同插件要求示例
simulator 插件需要没有用户名或密码
sim://
NetApp 插件使用用户名 root 进行 SSL
ontap+ssl://root@filer.company.com/
用于 EMC Array 的 SSL 的 SMI-S 插件
smis+ssl://admin@provider.com:5989/?namespace=root/emc
- 将 URI 作为命令的一部分传递。
$lsmcli -u sim:// - 将 URI 存储在环境变量中。
$export LSMCLI_URI=sim:// - 将 URI 放在文件
~/.lsmcli中,其中包含用 "=" 分隔的名称值对。当前唯一支持的配置是 'uri'。
-P 选项或将其放在环境变量 LSMCLI_PASSWORD 中提供密码。
例 27.2. lsmcli 示例
$ lsmcli list --type SYSTEMS
ID | Name | Status
-------+-------------------------------+--------
sim-01 | LSM simulated storage plug-in | OK
$ lsmcli list --type POOLS -H
ID | Name | Total space | Free space | System ID
-----+---------------+----------------------+----------------------+-----------
POO2 | Pool 2 | 18446744073709551616 | 18446744073709551616 | sim-01
POO3 | Pool 3 | 18446744073709551616 | 18446744073709551616 | sim-01
POO1 | Pool 1 | 18446744073709551616 | 18446744073709551616 | sim-01
POO4 | lsm_test_aggr | 18446744073709551616 | 18446744073709551616 | sim-01
$ lsmcli volume-create --name volume_name --size 20G --pool POO1 -H
ID | Name | vpd83 | bs | #blocks | status | ...
-----+-------------+----------------------------------+-----+----------+--------+----
Vol1 | volume_name | F7DDF7CA945C66238F593BC38137BD2F | 512 | 41943040 | OK | ...
$ lsmcli --create-access-group example_ag --id iqn.1994-05.com.domain:01.89bd01 --type ISCSI --system sim-01
ID | Name | Initiator ID |SystemID
---------------------------------+------------+----------------------------------+--------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 |sim-01
$ lsmcli access-group-create --name example_ag --init iqn.1994-05.com.domain:01.89bd01 --init-type ISCSI --sys sim-01
ID | Name | Initiator IDs | System ID
---------------------------------+------------+----------------------------------+-----------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 | sim-01$ lsmcli access-group-grant --ag 782d00c8ac63819d6cca7069282e03a0 --vol Vol1 --access RW-b 选项。如果退出代码为 0,则代表命令已完成。如果退出代码为 7,命令正在进行,作业标识符将写入标准输出。然后,用户或脚本可以根据需要使用 lsmcli --jobstatus JobID 来查询命令的状态。如果作业现已完成,则退出值为 0,结果将输出到标准输出。如果命令仍在进行中,返回值为 7,且完成百分比将打印到标准输出中。
例 27.3. Asynchronous 示例
-b 选项创建卷,以便命令立即返回。
$ lsmcli volume-create --name async_created --size 20G --pool POO1 -b JOB_3$ echo $?
7$ lsmcli job-status --job JOB_3
33$ echo $?
7$ lsmcli job-status --job JOB_3
ID | Name | vpd83 | Block Size | ...
-----+---------------+----------------------------------+-------------+-----
Vol2 | async_created | 855C9BA51991B0CC122A3791996F6B15 | 512 | ...
-t SeparatorCharacters 选项。这样可以更轻松地解析输出。
例 27.4. 脚本脚本示例
$ lsmcli list --type volumes -t#
Vol1#volume_name#049167B5D09EC0A173E92A63F6C3EA2A#512#41943040#21474836480#OK#sim-01#POO1
Vol2#async_created#3E771A2E807F68A32FA5E15C235B60CC#512#41943040#21474836480#OK#sim-01#POO1
$ lsmcli list --type volumes -t " | "
Vol1 | volume_name | 049167B5D09EC0A173E92A63F6C3EA2A | 512 | 41943040 | 21474836480 | OK | 21474836480 | sim-01 | POO1
Vol2 | async_created | 3E771A2E807F68A32FA5E15C235B60CC | 512 | 41943040 | 21474836480 | OK | sim-01 | POO1
$ lsmcli list --type volumes -s
---------------------------------------------
ID | Vol1
Name | volume_name
VPD83 | 049167B5D09EC0A173E92A63F6C3EA2A
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
ID | Vol2
Name | async_created
VPD83 | 3E771A2E807F68A32FA5E15C235B60CC
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
第 28 章 持久性内存:NVDIMM
pmem)也称为存储类内存,是内存和存储的组合。PMEM 将存储的持久性与低访问延迟和动态 RAM (DRAM)的高带宽相结合:
- 持久内存是字节地址的,因此可以使用 CPU 负载和存储指令访问它。除了访问传统的基于块的存储所需的
read()或write()系统调用外,pmem还支持直接加载和存储编程模型。 - 持久内存的性能特征与具有非常低访问延迟的 DRAM 类似,通常以十到百纳秒为单位。
- 关闭电源(如存储)时会保留持久内存的内容。
对于以下用例,使用持久性内存很有用:
- 快速启动:数据集已在内存中。
- 快速开始也被称为 温缓存 效果。文件服务器启动后,内存中没有文件内容。当客户端连接和读取和写入数据时,这些数据会缓存在页面缓存中。最后,缓存包括大多数热数据。重启后,系统必须再次启动该进程。如果应用设计正确,持久内存允许应用在重启后保留热缓存。在本实例中,不会涉及页面缓存:应用程序会直接在持久内存中缓存数据。
- 快速写缓存
- 在数据位于持久介质前,文件服务器通常不会确认客户端的写入请求。将持久内存用作快速写入缓存可让文件服务器快速确认写入请求,因为
pmem的低延迟。
NVDIMMs Interleaving
- 与 DRAM 一样,NVDIMM 会在配置为 interleave 集时从性能提高。
- 它可用于将多个较小的 NVDIMM 组合为一个较大的逻辑设备。
- 如果您的 NVDIMM 支持标签,则区域设备可以进一步划分为命名空间。
- 如果您的 NVDIMM 不支持标签,则区域设备只能包含一个命名空间。在这种情况下,内核会创建一个覆盖整个区域的默认命名空间。
持久性内存访问模式
扇区、fsdax、devdax (设备直接访问)或 raw 模式中的持久性内存设备:
扇区模式- 它将存储显示为一个快速块设备。使用扇区模式对于尚未修改以使用持久内存的传统应用程序或利用完整 I/O 堆栈的应用程序(包括设备映射器)非常有用。
fsdax模式- 它允许持久内存设备支持直接访问编程,如存储网络行业关联( SNIA)非易失性内存(NVM)编程模型规格 中所述。在这个模式中,I/O 会绕过内核的存储堆栈,因此无法使用很多设备映射器驱动程序。
devdax模式devdax(device DAX)模式通过使用 DAX 字符设备节点提供对持久内存的原始访问。可以使用 CPU 缓存清除和隔离指令,使devdax设备中的数据可用。某些数据库和虚拟机虚拟机监控程序可能会受益于devdax模式。无法在devdax实例上创建文件系统。原始模式- 原始模式命名空间有几个限制,不应使用。
28.1. 使用 ndctl 配置持久内存
# yum install ndctl过程 28.1. 为不支持标签的设备配置持久性内存
- 列出系统上可用的
pmem区域。在以下示例中,命令列出了不支持标签的 NVDIMM-N 设备:#ndctl list --regions [ { "dev":"region1", "size":34359738368, "available_size":0, "type":"pmem" }, { "dev":"region0", "size":34359738368, "available_size":0, "type":"pmem" } ]Red Hat Enterprise Linux 为每个区域创建一个 default 命名空间,因为这里的 NVDIMM-N 设备不支持标签。因此,可用大小为 0 字节。 - 列出系统中所有不活跃的命名空间:
#ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ] - 重新配置不活跃的命名空间,以使用此空间。例如,要将 namespace0.0 用于支持 DAX 的文件系统,请使用以下命令:
#ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem { "dev":"namespace0.0", "mode":"fsdax", "size":"32.00 GiB (34.36 GB)", "uuid":"ab91cc8f-4c3e-482e-a86f-78d177ac655d", "blockdev":"pmem0", "numa_node":0 }
过程 28.2. 为支持标签的设备配置持久性内存
- 列出系统上可用的
pmem区域。在以下示例中,命令列出了支持标签的 NVDIMM-N 设备:#ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ] - 如果 NVDIMM 设备支持标签,则不会创建默认命名空间,您可以在不使用 --force 或 --reconfigure 标志的情况下从区域分配一个或多个命名空间:
#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.0", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"9c5330b5-dc90-4f7a-bccd-5b558fa881fe", "blockdev":"pmem4", "numa_node":0 }现在,您可以从同一区域创建另一个命名空间:#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.1", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"91868e21-830c-4b8f-a472-353bf482a26d", "blockdev":"pmem4.1", "numa_node":0 }您还可以使用以下命令从同一区域创建不同类型的命名空间:#ndctl create-namespace --region=region4 --mode=devdax --align=2M --size=36G { "dev":"namespace4.2", "mode":"devdax", "size":"35.44 GiB (38.05 GB)", "uuid":"a188c847-4153-4477-81bb-7143e32ffc5c", "daxregion": { "id":4, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax4.2", "size":"35.44 GiB (38.05 GB)" }] }, "numa_node":0 }
28.2. 配置永久内存以用作块设备(Legacy 模式)
# ndctl create-namespace --force --reconfig=namespace1.0 --mode=sector
{
"dev":"namespace1.0",
"mode":"sector",
"size":17162027008,
"uuid":"029caa76-7be3-4439-8890-9c2e374bcc76",
"sector_size":4096,
"blockdev":"pmem1s"
}
namespace1.0 被重新配置为扇区模式。请注意,块设备名称从 pmem1 改为 pmem1s。这个设备可以与系统中的其它块设备相同。例如:可以对设备进行分区,您可以在设备中创建一个文件系统,可以将该设备配置为软件 RAID 集的一部分,设备可以是 dm-cache 的缓存设备。
28.3. 为文件系统直接访问配置持久内存
fsdax 模式。此模式可用于直接访问编程模型。当在 fsdax 模式中配置设备时,可以在其之上创建一个文件系统,然后使用 -o fsdax 挂载选项挂载。然后,对这个文件系统的文件执行 mmap() 操作的任何应用程序都可以直接访问其存储。请参见以下示例:
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem
{
"dev":"namespace0.0",
"mode":"fsdax",
"size":17177772032,
"uuid":"e6944638-46aa-4e06-a722-0b3f16a5acbf",
"blockdev":"pmem0"
}
namespace0.0 转换为命名空间 fsdax 模式。使用 --map=mem 参数时,ndctl 会将用于直接内存访问(DMA)的操作系统数据结构放在系统 DRAM 中。
fsdax 模式中配置命名空间后,命名空间就可以用于文件系统。从 Red Hat Enterprise Linux 7.3 开始,Ext4 和 XFS 文件系统都作为技术预览使用持久内存启用。文件系统创建不需要特殊参数。要获得 DAX 功能,请使用 dax 挂载选项挂载文件系统。例如:
#mkfs -t xfs /dev/pmem0#mount -o dax /dev/pmem0 /mnt/pmem/
/mnt/pmem/ 目录中创建文件,打开文件,并使用 mmap 操作来映射文件以进行直接访问。
pmem 设备中创建分区时,分区必须在页面边界上保持一致。在 Intel 64 和 AMD64 构架上,至少有 4KiB 校准分区的开头和结尾,但 2MiB 是首选的对齐。默认情况下,parted 工具在 1MiB 边界上对齐分区。对于第一个分区,指定 2MiB 作为分区的开头。如果分区的大小是 2MiB 的倍数,则所有其他分区也一致。
28.4. 配置持久内存以用于设备 DAX 模式
devdax)提供了应用程序直接访问存储的方法,而无需参与文件系统。设备 DAX 的好处是它提供有保证的故障粒度,可以使用 --align 选项与 ndctl 工具进行配置:
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=devdax --align=2M- 4KiB
- 2MiB
- 1GiB
/dev/daxN.M)只支持以下系统调用:
open()close()mmap()fallocate()
read() 不支持 write() 变体,因为用例与持久内存编程相关联。
28.5. NVDIMM 故障排除
28.5.1. 使用 S.M.A.R.T 监控 NVDIMM 健康状况。
先决条件
- 在有些系统中,必须载入 acpi_ipmi 驱动程序才能检索健康信息:
#modprobe acpi_ipmi
流程
- 要访问健康信息,请使用以下命令:
#ndctl list --dimms --health ... { "dev":"nmem0", "id":"802c-01-1513-b3009166", "handle":1, "phys_id":22, "health": { "health_state":"ok", "temperature_celsius":25.000000, "spares_percentage":99, "alarm_temperature":false, "alarm_spares":false, "temperature_threshold":50.000000, "spares_threshold":20, "life_used_percentage":1, "shutdown_state":"clean" } } ...
28.5.2. 检测和替换 Broken NVDIMM
- 检测哪个 NVDIMM 设备失败,
- 备份存储的数据,以及
- 物理替换该设备。
过程 28.3. 检测和替换 Broken NVDIMM
- 要检测有问题的 DIMM,请使用以下命令:
# ndctl list --dimms --regions --health --media-errors --human
badblocks字段显示哪些 NVDIMM 有问题。注意它在dev字段中的名称。在以下示例中,名为nmem0的 NVDIMM 有问题:例 28.1. NVDIMM 设备的健康状况
# ndctl list --dimms --regions --health --media-errors --human ... "regions":[ { "dev":"region0", "size":"250.00 GiB (268.44 GB)", "available_size":0, "type":"pmem", "numa_node":0, "iset_id":"0xXXXXXXXXXXXXXXXX", "mappings":[ { "dimm":"nmem1", "offset":"0x10000000", "length":"0x1f40000000", "position":1 }, { "dimm":"nmem0", "offset":"0x10000000", "length":"0x1f40000000", "position":0 } ], "badblock_count":1, "badblocks":[ { "offset":65536, "length":1, "dimms":[ "nmem0" ] } ], "persistence_domain":"memory_controller" } ] } - 使用以下命令查找有问题的 NVDIMM 的
phys_id属性:# ndctl list --dimms --human
在上例中,您知道nmem0是有问题的 NVDIMM。因此,查找nmem0的phys_id属性。在以下示例中,phys_id是0x10:例 28.2. NVDIMM 的 phys_id 属性
# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ] - 使用以下命令查找有问题的 NVDIMM 的内存插槽:
# dmidecode
在输出中,找到Handle标识符与有问题的 NVDIMM 的phys_id属性匹配的条目。Locator字段列出了有问题的 NVDIMM 使用的内存插槽。在以下示例中,nmem0设备与0x0010标识符匹配,并使用DIMM-XXX-YYYY内存插槽:例 28.3. NVDIMM 内存插槽列表
# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ... - 备份 NVDIMM 命名空间中的所有数据。如果您在替换 NVDIMM 前没有备份数据,当您从系统中删除 NVDIMM 时数据将会丢失。警告在某些情况下,比如 NVDIMM 完全无法正常工作,备份可能会失败。要防止这种情况,请使用 S.M.A.R.T 定期监控 NVDIMM 设备,如 第 28.5.1 节 “使用 S.M.A.R.T 监控 NVDIMM 健康状况。” 所述,并在它们中断前替换失败的 NVDIMM。使用以下命令列出 NVDIMM 上的命名空间:
# ndctl list --namespaces --dimm=DIMM-ID-number
在以下示例中,nmem0设备包含namespace0.0和namespace0.2命名空间,您需要备份:例 28.4. NVDIMM 命名空间列表
# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ] - 以物理方式替换失效的 NVDIMM。
第 29 章 NVMe over fabric 设备概述
NVMe :
- 使用 Remote Direct Memory Access(RDMA)的 NVMe over fabrics。有关如何配置 NVMe/RDMA 的详情,请参考 第 29.1 节 “使用 RDMA 的 NVMe over fabrics”。
- 使用光纤通道(FC)的 NVMe over fabrics。有关如何配置 FC-NVMe 的详情,请参考 第 29.2 节 “使用 FC 的光纤的 NVMe over fabrics”。
29.1. 使用 RDMA 的 NVMe over fabrics
29.1.1. 通过 RDMA 客户端配置 NVMe
nvme-cli)配置 NVMe/RDMA 客户端。
- 安装
nvme-cli软件包:#yum install nvme-cli - 如果没有加载,则加载
nvme-rdma模块:#modprobe nvme-rdma - 在 NVMe 目标中发现可用子系统:
#nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000 - 连接到发现的子系统:
#nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1#cat /sys/class/nvme/nvme0/transport rdma使用 NVMe 子系统名称替换 testnqn。将 172.31.0.202 替换为目标 IP 地址。使用端口号替换 4420。 - 列出当前连接的 NVMe 设备:
#nvme list - 可选:断开与目标的连接:
#nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s)#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
其他资源
- 如需更多信息,请参阅
nvmeman page 和 NVMe-cli Github 存储库。
29.2. 使用 FC 的光纤的 NVMe over fabrics
29.2.1. 为广播适配器配置 NVMe initiator
nvme-cli)工具为 Broadcom 适配器客户端配置 NVMe initiator。
- 安装
nvme-cli工具:#yum install nvme-cli这会在/etc/nvme/目录中创建hostnqn文件。hostn文件标识 NVMe 主机。生成一个新的hostnqn:#nvme gen-hostnqn - 使用以下内容创建
/etc/modprobe.d/lpfc.conf文件:options lpfc lpfc_enable_fc4_type=3
- 重建
initramfs镜像:# dracut --force
- 重启主机系统来重新配置
lpfc驱动程序:# systemctl reboot
- 找到本地和远程端口的 WWNN 和 WWPN,并使用输出查找子系统 NQN:
#cat /sys/class/scsi_host/host*/nvme_info NVME Initiator Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000#nvme discover --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6将 nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 替换为traddr。将 nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 替换为host_traddr。 - 使用
nvme-cli连接到 NVMe 目标:#nvme connect --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1将 nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 替换为traddr。将 nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 替换为host_traddr。将 nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 替换为subnqn。 - 验证 NVMe 设备当前是否已连接:
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
其他资源
- 如需更多信息,请参阅
nvmeman page 和 NVMe-cli Github 存储库。
29.2.2. 为 QLogic 适配器配置 NVMe initiator
(nvme-cli) 工具为 Qlogic 适配器客户端配置 NVMe initiator。
- 安装
nvme-cli工具:#yum install nvme-cli这会在/etc/nvme/目录中创建hostnqn文件。hostn文件标识 NVMe 主机。生成一个新的hostnqn:#nvme gen-hostnqn - 删除并重新载入
qla2xxx模块:#rmmod qla2xxx#modprobe qla2xxx - 查找本地和远程端口的 WWNN 和 WWPN:
#dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050d使用这个host-traddr和traddr,找到子系统 NQN:#nvme discover --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6将 nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 替换为traddr。将 nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 替换为host_traddr。 - 使用
nvme-cli工具连接到 NVMe 目标:#nvme connect --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host_traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468将 nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 替换为traddr。将 nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 替换为host_traddr。将 nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 替换为subnqn。 - 验证 NVMe 设备当前是否已连接:
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
其他资源
- 如需更多信息,请参阅
nvmeman page 和 NVMe-cli Github 存储库。
部分 III. 使用 VDO 的数据重复数据删除和压缩
第 30 章 VDO 集成
30.1. VDO 的理论概述
- 重复数据删除( Deduplication )是通过删除重复块的多个副本来减少存储资源消耗的技术。VDO 检测每个重复块,并将其记录为对原始块的引用,而不是多次写相同的数据。VDO 维护一个从逻辑块地址(由 VDO 上面的存储层使用)到物理块地址(被 VDO 下的存储层使用)的映射。去除重复数据后,多个逻辑块地址可以映射到相同的物理块地址;称为 共享块。块共享对存储用户是不可见的,用户会像 VDO 不存在一样读写块。当覆盖共享块时,会为存储新块数据分配一个新的物理块,以确保映射到共享物理块的其他逻辑块地址不会被修改。
- 压缩 是一种数据化技术,其工作方式与文件格式,不一定会表现出块级冗余,如日志文件和数据库。详情请查看 第 30.4.8 节 “使用压缩”。
kvdo- 载入 Linux 设备映射器层的内核模块,以提供重复数据删除、压缩和精简置备的块存储卷
uds- 与卷上通用的去除重复数据服务(UDS)索引通信的内核模块,并分析数据的重复内容。
- 命令行工具
- 用于配置和管理优化的存储。
30.1.1. UDS 内核模块(uds)
uds 内核模块在内核中运行。
30.1.2. VDO 内核模块(kvdo)
kvdo Linux 内核模块在 Linux 设备映射器层中提供块层 deduplication 服务。在 Linux 内核中,设备映射器充当管理块存储池的通用框架,允许在内核块接口和实际存储设备驱动程序之间插入块处理模块的存储堆栈。
kvdo 模块作为块设备公开,可直接访问块存储,或通过其中一个可用的 Linux 文件系统(如 XFS 或 ext4)提供。当 kvdo 收到从 VDO 卷读取数据的请求(逻辑)块时,它会将请求的逻辑块映射到底层物理块,然后读取并返回请求的数据。
kvdo 收到向 VDO 卷写入数据块的请求时,它会首先检查它是 DISCARD 还是 TRIM 请求,或者数据是否统一为零。如果其中任何一个条件包含,则 kvdo 会更新其块映射并确认请求。否则,将分配物理块以供请求使用。
VDO 写策略概述
kvdo 模块以同步模式运行:
- 它会在请求中临时将数据写入分配块中,然后确认请求。
- 确认完成后,会尝试通过计算块数据的 MurmurHash-3 签名来去除重复的块,该签名发送给 VDO 索引。
- 如果 VDO 索引包含具有相同签名的块的条目,
kvdo会读取指定的块,并对两个块进行字节比较,以验证它们是否相同。 - 如果它们实际上是相同的,则
kvdo会更新其块映射,以便逻辑块指向对应的物理块,并释放分配的物理块。 - 如果 VDO 索引不包含要写入的块的签名条目,或者指定的块实际上不包含相同的数据,则
kvdo会更新其块映射,使临时物理块永久。
kvdo 以异步模式运行:
- 它将立即确认请求而不是写数据。
- 然后它会尝试使用与上述步骤相同的方法来复制块。
- 如果块变为重复,则
kvdo将更新其块映射并释放分配的块。否则,它会将请求中的数据写入分配的块,并更新块映射以使物理块永久存在。
30.1.3. VDO 卷
图 30.1. VDO 磁盘机构

slabs
表 30.1. 根据物理卷大小推荐的 VDO Slab 大小
| 物理卷大小 | 推荐的 Slab 大小 |
|---|---|
| 10–99 GB | 1 GB |
| 100 GB - 1 TB | 2 GB |
| 2–256 TB | 32 GB |
--vdoSlabSize=megabytes
命令提供 vdo create 选项来控制。
物理大小和可用物理大小
- 物理大小 与底层块设备的大小相同。VDO 使用这个存储用于:
- 用户数据,这些数据可能会进行重复数据删除和压缩
- VDO 元数据,如 UDS 索引
- 可用物理大小 是 VDO 可用于用户数据的物理大小的一部分。它等同于物理大小减去元数据的大小,再减去将卷根据指定的 slab 的大小分为 slab 后剩余的值。
逻辑大小
--vdoLogicalSize 选项,则逻辑卷大小默认为可用的物理卷大小。请注意,在 图 30.1 “VDO 磁盘机构” 中,VDO 重复数据删除的存储目标完全位于块设备之上,这意味着 VDO 卷的物理大小与底层块设备的大小相同。
30.1.4. 命令行工具
30.2. 系统要求
处理器架构
RAM
- VDO 模块每 1TB 物理存储管理需要 370 MB 加额外的 268 MB。
- 通用重复数据删除服务(UDS)索引至少需要 250 MB DRAM,这也是去除重复数据使用的默认数量。有关 UDS 内存用量的详情,请参考 第 30.2.1 节 “UDS Index 内存要求”。
存储
额外的系统软件
- LVM
- Python 2.7
yum 软件包管理器将自动安装所有必要的软件依赖项。
在存储堆栈中放置 VDO
- 在 VDO 下:DM-Multipath、DM-Crypt 和软件 RAID (LVM 或
mdraid)。 - 在 VDO 之上:LVM 缓存、LVM 快照和 LVM Thin Provisioning。
- VDO 位于 VDO 卷之上:storage → VDO → LVM → VDO
- VDO 位于 LVM 快照之上
- VDO 位于 LVM Cache 之上
- VDO 位于回送设备之上
- VDO 位于 LVM Thin Provisioning 之上
- 加密的卷(位于 VDO 之上):storage → VDO → DM-Crypt
- VDO 卷中的分区:
fdisk、parted和类似的分区 - VDO 卷之上的 RAID (LVM、MD 或者任何其他类型)
sync 和 async。当 VDO 处于 同步 模式时,当底层存储永久写入数据时,会确认对 VDO 设备的写操作。当 VDO 处于 async 模式时,在写入持久性存储前会确认写入。
auto 选项,该选项会自动选择适当的策略。
30.2.1. UDS Index 内存要求
- 在内存中使用紧凑表示,每个唯一块最多包含一个条目。
- 记录在索引发生时的相关块名称的磁盘组件,按顺序记录它们。
- 对于密度索引,UDS 将每 1 GB RAM 提供 1 TB 的去除重复数据窗口。对于最多 4 TB 的存储系统,1 GB 索引通常就足够了。
- 对于稀疏索引,UDS 将每 1 GB RAM 提供 10 TB 的去除重复数据窗口。1 GB 稀疏索引一般足以满足40TB 物理存储空间。
30.2.2. VDO 存储空间要求
- VDO 将两种类型的元数据写入其底层物理存储:
- 第一个类型使用 VDO 卷的物理大小进行扩展,并为每个 4 GB 物理存储使用大约 1 MB,再加上每个 slab 的额外 1 MB。
- 第二种类型使用 VDO 卷的逻辑大小进行扩展,并为每个 1 GB 逻辑存储消耗大约 1.25 MB,舍入到最接近的 slab。
有关 slabs 的描述,请参阅 第 30.1.3 节 “VDO 卷”。 - UDS 索引存储在 VDO 卷组中,并由关联的 VDO 实例管理。所需的存储量取决于索引类型以及分配给索引的 RAM 量。对于每 1 GB RAM,密度 UDS 索引将使用 17 GB 存储,稀疏 UDS 索引将使用 170 GB 存储。
30.2.3. 按物理卷大小划分的 VDO 系统要求示例
主存储部署
表 30.2. 主存储的 VDO 存储和内存要求
| 物理卷大小 | 10 GB - 1-TB | 2-10 TB | 11-50 TB | 51–100 TB | 101–256 TB |
|---|---|---|---|---|---|
| RAM 使用量 | 250 MB |
密度:1 GB
稀疏: 250 MB
| 2 GB | 3 GB | 12 GB |
| 磁盘用量 | 2.5 GB |
密度: 10 GB
稀疏:22 GB
| 170 GB | 255 GB | 1020 GB |
| 索引类型 | 密度 | dense 或 Sparse | 稀疏 | 稀疏 | 稀疏 |
备份存储部署
表 30.3. 备份存储的 VDO 存储和内存要求
| 物理卷大小 | 10 GB - 1 TB | 2-10 TB | 11-50 TB | 51–100 TB | 101–256 TB |
|---|---|---|---|---|---|
| RAM 使用量 | 250 MB | 2 GB | 10 GB | 20 GB | 26 GB |
| 磁盘用量 | 2.5 GB | 170 GB | 850 GB | 1700 GB | 3400 GB |
| 索引类型 | 密度 | 稀疏 | 稀疏 | 稀疏 | 稀疏 |
30.3. VDO 入门
30.3.1. 简介
- 当托管活跃的虚拟机或容器时,红帽建议使用 10:1 逻辑与物理比例置备存储:也就是说,如果您使用 1TB 物理存储,您将把它显示为 10TB 逻辑存储。
- 对于对象存储,如 Ceph 提供的类型,红帽建议使用 3:1 逻辑与物理比例:1TB 的物理存储将显示为 3TB 逻辑存储。
- 虚拟化服务器的直接连接用例,比如使用 Red Hat Virtualization 构建的用户,以及
- 基于对象的分布式存储集群的云存储用例,如使用 Ceph Storage 构建的云存储用例。注意目前不支持使用 Ceph 进行 VDO 部署。
30.3.2. 安装 VDO
- vdo
- kmod-kvdo
# yum install vdo kmod-kvdo30.3.3. 创建 VDO 卷
vdo1。
- 使用 VDO Manager 创建 VDO 卷:
#vdo create \--name=vdo_name\--device=block_device\--vdoLogicalSize=logical_size \[--vdoSlabSize=slab_size]- 使用您要创建 VDO 卷的块设备的持久性名称替换 block_device。例如:
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f。重要使用持久的设备名称。如果您使用非持久性设备名称,则如果设备名称改变了,VDO 将来可能无法正常启动。有关持久性名称的更多信息,请参阅 第 25.8 节 “持久性命名”。 - 将 logical_size 替换为 VDO 卷应该存在的逻辑存储量:
- 对于活跃的虚拟机或容器存储,逻辑大小为您的块设备物理大小的 十 倍。例如,如果您的块设备大小为 1 TB,请在此处使用
10T。 - 对于对象存储,使用逻辑大小,即您的块设备物理大小的 三倍。例如,如果您的块设备大小为 1 TB,请在此处使用
3T。
- 如果块设备大于 16 TiB,请添加
--vdoSlabSize=32G,以将卷的 slab 大小增加到 32 GiB。在大于 16 TiB 的块设备上使用 2 GiB 的默认 slab 大小会导致 vdo create 命令失败,并显示以下错误:vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported
如需更多信息,请参阅 第 30.1.3 节 “VDO 卷”。
例 30.1. 为容器存储创建 VDO
例如,要为 1TB 块设备上的容器存储创建 VDO 卷,您可以使用:#vdo create \--name=vdo1\--device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f\--vdoLogicalSize=10T创建 VDO 卷时,VDO 会在/etc/vdoconf.yml配置文件中添加一个条目。然后,vdo.servicesystemd 单元使用该条目来默认启动卷。重要如果在创建 VDO 卷时发生故障,请删除要清理的卷。详情请查看 第 30.4.3.1 节 “删除 Unsuccessfully Created 卷”。 - 创建文件系统:
- 对于 XFS 文件系统:
#mkfs.xfs -K /dev/mapper/vdo_name - 对于 ext4 文件系统:
#mkfs.ext4 -E nodiscard /dev/mapper/vdo_name
- 挂载文件系统:
#mkdir -m 1777 /mnt/vdo_name#mount /dev/mapper/vdo_name /mnt/vdo_name - 要将文件系统配置为自动挂载,请使用
/etc/fstab文件或 systemd 挂载单元:- 如果您决定使用
/etc/fstab配置文件,请在文件中添加以下行:- 对于 XFS 文件系统:
/dev/mapper/vdo_name /mnt/vdo_name xfs defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- 对于 ext4 文件系统:
/dev/mapper/vdo_name /mnt/vdo_name ext4 defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- 或者,如果您决定使用 systemd 单元,请使用适当的文件名创建一个 systemd 挂载单元文件。对于 VDO 卷的挂载点,使用以下内容创建
/etc/systemd/system/mnt-vdo_name.mount文件:[Unit] Description = VDO unit file to mount file system name = vdo_name.mount Requires = vdo.service After = multi-user.target Conflicts = umount.target [Mount] What = /dev/mapper/vdo_name Where = /mnt/vdo_name Type = xfs [Install] WantedBy = multi-user.target
systemd 单元文件示例也安装在/usr/share/doc/vdo/examples/systemd/VDO.mount.example中。
- 为 VDO 设备中的文件系统启用
discard功能。批处理和在线操作都可用于 VDO。有关如何设置discard功能的详情,请参考 第 2.4 节 “丢弃未使用的块”。
30.3.4. 监控 VDO
# vdostats --human-readable
Device 1K-blocks Used Available Use% Space saving%
/dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73%
/dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo_name. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo_name is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo_name is now 96.07% full.
30.3.5. 部署示例
使用 KVM 部署 VDO
图 30.2. 使用 KVM 部署 VDO

更多部署场景
30.4. 管理 VDO
30.4.1. 启动或停止 VDO
#vdo start --name=my_vdo#vdo start --all
#vdo stop --name=my_vdo#vdo stop --all
- 卷总是为每 1GiB UDS 索引写入大约 1GiB。
- 使用稀疏 UDS 索引,卷还会写入与块映射缓存大小相等的数据量,再加上每个 slab 的 8MiB。
- 在同步模式下,在关闭前被 VDO 确认的所有写入都会被重建。
- 在异步模式中,在最后一次确认刷新请求之前确认的所有写入都会被重新构建。
30.4.2. 选择 VDO 写入模式
sync 和 auto :
- 当 VDO 处于
同步模式时,它假定写入命令将数据写入持久性存储。因此,文件系统或应用程序不需要发出 FLUSH 或 Force unit Access (FUA)请求,从而导致数据在关键点变为持久。只有当底层存储保证数据在 write 命令完成后写入持久性存储时,才必须将 VDO 设置为sync模式。也就是说,存储必须没有易变的写缓存,或者不通过缓存进行写入操作。 - 当 VDO 处于
async模式时,无法保证在确认写命令时写入持久性存储。文件系统或应用程序必须发出 FLUSH 或 FUA 请求,来确保每次事务中数据在关键点上的持久性。如果底层存储无法保证在写命令完成后写入持久性存储,则必须将 VDO 设置为async模式;也就是说,当存储具有易失性写回缓存时。有关如何查找设备是否使用易失性缓存或未易失性的详情,请参考 “检查 Volatile Cache”一节。警告当 VDO 以async模式运行时,它与 Atomicity, Consistency, Isolation, Durability (ACID)不兼容。当 VDO 卷之上假设 ACID 合规性的应用程序或文件系统时,sync mode 可能会导致意外的数据丢失。 auto模式根据每个设备的特性自动选择sync或async。这是默认选项。
--writePolicy 选项。这可以在创建 VDO 卷时指定为 第 30.3.3 节 “创建 VDO 卷”,或使用 changeWritePolicy 子命令修改现有 VDO 卷时:
# vdo changeWritePolicy --writePolicy=sync|async|auto --name=vdo_name检查 Volatile Cache
/sys/block/block_device/device/scsi_disk/标识符/cache_type sysfs 文件。例如:
- 设备
sda表示 它有一个 回写缓存:$cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back - 设备
sdb表示 它没有 回写缓存:$cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' None
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
sda设备的async模式sdb设备的同步模式
cache_type 值是 none 或通过 写入,则您应该将 VDO 配置为使用 同步 写入策略。
30.4.3. 删除 VDO 卷
# vdo remove --name=my_vdo30.4.3.1. 删除 Unsuccessfully Created 卷
vdo 工具创建 VDO 卷时失败,则该卷将处于中间状态。例如,当系统崩溃、电源失败或者管理员中断了运行的 vdo create 命令时会出现这种情况。
--force 选项删除创建失败的卷:
# vdo remove --force --name=my_vdo--force 选项,因为因为卷创建失败,管理员可能会由于更改系统配置而导致冲突。如果没有 --force 选项,vdo remove 命令会失败,并显示以下信息:
[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my_vdo: umount -f /dev/mapper/my_vdo udevadm settle dmsetup remove my_vdo vdo: ERROR - VDO volume my_vdo previous operation (create) is incomplete
30.4.4. 配置 UDS Index
--indexMem=size 选项指定索引内存的大小来确定。然后会自动决定要使用的磁盘空间量。
--sparseIndex=enabled --indexMem=0.25 选项。这个配置会导致一个 deduplication 窗口 2.5 TB(也就是说它会记住 2.5 TB 的历史记录)。在大多数用例中,2.5 TB 的去除重复数据窗口适合用于大小高达 10 TB 的去除重复数据存储池。
30.4.5. 在 Unclean Shutdown 后恢复 VDO 卷
- 如果 VDO 在同步存储上运行,并且写入策略被设置为
同步,那么写入卷的所有数据都将完全恢复。 - 如果写入策略是
async的,则在通过发送 VDO 命令或带有FLUSH标志(强制单元访问)标记的写入 I/O 时可能无法恢复一些写入。FUA这可以通过调用fsync、fdatasync、sync或umount等数据完整性操作来实现。
30.4.5.1. 在线恢复
使用中的 块和 块 free。重建完成后,这些统计数据将可用。
30.4.5.2. 强制重新构建
的操作模式 属性指示 VDO 卷是否处于只读模式。)
# vdo stop --name=my_vdo--forceRebuild 选项重启卷:
# vdo start --name=my_vdo --forceRebuild30.4.6. 在系统引导时自动启动 VDO 卷
vdo systemd 单元会自动启动所有配置为 激活 的 VDO 设备。
- 取消激活一个特定卷:
#vdo deactivate --name=my_vdo - 取消激活所有卷:
#vdo deactivate --all
- 激活一个特定卷:
#vdo activate --name=my_vdo - 激活所有卷:
#vdo activate --all
--activate=disabled 选项来创建不自动启动的 VDO 卷。
- 必须首先启动 LVM 的下层(在大多数系统中,当安装 LVM2 软件包时,会自动配置这个层)。
- 然后,必须启动
vdosystemd 单元。 - 最后,必须运行其他脚本,以便在现在运行 VDO 卷之上启动 LVM 卷或其他服务。
30.4.7. 禁用和重新启用重复数据删除
- 要在 VDO 卷上停止 deduplication,请使用以下命令:
#vdo disableDeduplication --name=my_vdo这会停止关联的 UDS 索引,并通知 VDO 卷 deduplication 不再活跃。 - 要在 VDO 卷上重启 deduplication,请使用以下命令:
#vdo enableDeduplication --name=my_vdo这会重启关联的 UDS 索引,并通知 VDO 卷再次激活 deduplication。
--deduplication=disabled 选项,在创建新 VDO 卷时禁用 deduplication。
30.4.8. 使用压缩
30.4.8.1. 简介
30.4.8.2. 启用和禁用压缩
--compression=disabled 选项来禁用压缩。
- 要停止 VDO 卷上的压缩,请使用以下命令:
#vdo disableCompression --name=my_vdo - 要再次启动它,请使用以下命令:
#vdo enableCompression --name=my_vdo
30.4.9. 管理可用空间
vdostats 工具来决定 ; 详情请查看 第 30.7.2 节 “vdostats”。此工具的默认输出列出所有运行 VDO 卷的信息,其格式与 Linux df 实用程序类似。例如:
Device 1K-blocks Used Available Use% /dev/mapper/my_vdo 211812352 105906176 105906176 50%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool my_vdo. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool my_vdo is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool my_vdo is now 96.07% full.
在文件系统上重新声明空间
DISCARD、TRIM 或 UNMAP 命令告知块是空闲的,否则 VDO 无法回收空间。对于不使用 DISCARD、TRIM 或 UNMAP 的文件系统,可以通过存储由二进制零组成的文件手动回收空闲空间,然后删除该文件。
DISCARD 请求:
- 实时丢弃(也在线丢弃或内联丢弃)
- 启用实时丢弃时,当用户删除文件和释放空间时,文件系统会将
REQ_DISCARD请求发送到块层。VDO 会检索这些请求,并将空间返回到其空闲池,假设块没有共享。对于支持在线丢弃的文件系统,您可以在挂载时设置discard选项来启用它。 - 批量丢弃
- 批量丢弃是一种用户发起的操作,可导致文件系统通知块层(VDO)任何未使用的块。这可以通过向文件系统发送名为
FITRIM的ioctl请求来完成。您可以使用fstrim工具(例如从cron)将此ioctl发送到文件系统。
在没有文件系统的情况下重新声明空间
REQ_DISCARD 命令,并在适当的逻辑块地址上将请求转发到 VDO,以释放空间。如果使用其他卷管理器,它们还需要支持 REQ_DISCARD,或者等效地支持 SCSI 设备的 UNMAP 或用于 ATA 设备的 TRIM。
在光纤通道或以太网网络中回收空间
UNMAP 命令在精简配置的存储目标上释放空间,但需要配置 SCSI 目标框架来公告对这个命令的支持。这通常是通过在这些卷上启用 精简配置 来完成的。运行以下命令,可以在基于 Linux 的 SCSI 启动器上验证对 UNMAP 的支持:
# sg_vpd --page=0xb0 /dev/device30.4.10. 增加逻辑卷大小
# vdo growLogical --name=my_vdo --vdoLogicalSize=new_logical_size
30.4.11. 增加物理卷大小
- 增加底层设备的大小。确切的流程取决于设备的类型。例如:要调整 MBR 分区的大小,请使用
fdisk工具,如 第 13.5 节 “使用 fdisk 重新定义分区大小” 所述。 - 使用
growPhysical选项将新的物理存储空间添加到 VDO 卷中:#vdo growPhysical --name=my_vdo
30.4.12. 使用 Ansible 自动化 VDO
- Ansible 文档: https://docs.ansible.com/
- VDO Ansible 模块文档: https://docs.ansible.com/ansible/latest/modules/vdo_module.html
30.5. 部署场景
30.5.1. iSCSI 目标
图 30.3. 去除重复数据的块存储目标

30.5.2. 文件系统
图 30.4. Deduplicated NAS

30.5.3. LVM
LV1到 LV4)。这样,VDO 可以支持多协议统一块/文件访问底层重复数据删除的存储池。
图 30.5. 去除重复数据的统一存储
30.5.4. 加密
图 30.6. 使用带有加密的 VDO
30.6. 调整 VDO
30.6.1. VDO 调优简介
30.6.2. VDO 架构背景信息
- 逻辑区线程
- 逻辑 线程(包括字符串
kvdo:logQ)在逻辑块号(LBN)之间维护提供给 VDO 设备用户和基础存储系统中的物理块号(PBN)之间的映射。它们还实施锁定,以便尝试写入同一块的两个 I/O 操作不会被同时处理。逻辑区线程在读写操作过程中处于活动状态。LBN 划分为块( 块映射页面 包含 3 MB 以上的 LBN),这些块被分成划分在线程中 的区域。处理应该在线程中平均分配,但有些未灵活的访问模式偶尔可能集中在一个线程或其他线程中。例如,在给定块映射页面中频繁访问 LBN 将导致其中一个逻辑线程处理所有这些操作。可以使用 vdo 命令的--vdoLogicalThreads=thread count选项控制逻辑区线程数量 - 物理区线程
- 物理, 或
kvdo:physQ, threads 管理数据块分配和维护参考计数。它们在写入操作过程中处于活跃状态。与 LBNs 一样,PBNs 被分成名为 slabs 的块,这些块被进一步划分为区域,并分配给分发处理负载的 worker 线程。可以使用 vdo 命令的--vdoPhysicalThreads=thread count选项控制物理区线程数量。 - I/O 提交线程
kvdo:bioQ线程将块 I/O (bio)操作从 VDO 提交到存储系统。它们接受由其他 VDO 线程排队的 I/O 请求,并将它们传递给底层设备驱动程序。这些线程可以与设备关联的数据结构通信并更新与设备关联的数据结构,或者为设备驱动程序的内核线程设置请求进行处理。如果底层设备的请求队列已满,提交 I/O 请求可以阻止,因此此工作由专用线程完成,以避免处理延迟。如果这些线程经常由ps或top工具显示在D状态,则 VDO 通常会使存储系统忙于 I/O 请求。如果存储系统可以并行服务多个请求,或者请求处理被管道,则这通常可以正常工作。如果线程 CPU 使用率在这些期间非常低,则可能会减少 I/O 提交线程的数量。CPU 使用量和内存争用取决于 VDO 下的设备驱动程序。如果在添加更多线程时每个 I/O 请求的 CPU 使用率增加,请检查这些设备驱动程序中的 CPU、内存或锁定争用。可以使用 vdo 命令的--vdoBioThreads=thread count选项控制 I/O 提交线程数量。- CPU 处理线程
kvdo:cpuQ线程可用于执行任何 CPU 密集型工作,如计算哈希值或压缩不阻止或需要独占访问与其他线程类型关联的数据结构。可以使用 vdo 命令的--vdoCpuThreads=thread count选项控制 CPU 处理线程数量。- I/O 确认线程
kvdo:ackQ线程向位于 atop VDO 的任何位置发出回调(例如,内核页面缓存或应用程序程序线程进行直接 I/O)来报告 I/O 请求的完成。CPU 时间要求和内存争用将依赖于其他内核级别的代码。可以使用 vdo 命令的--vdoAckThreads=thread count选项控制确认线程数量。- 不可扩展的 VDO 内核线程:
- 重复数据删除线程
kvdo:dupeQ线程使用排队的 I/O 请求和联系 UDS。由于如果服务器无法快速处理请求,或者内核内存受其他系统活动限制,则套接字缓冲区可能会填满,因此如果线程应阻止,其他 VDO 处理可以继续。还有一个超时机制,用于在较长的延迟后跳过 I/O 请求(以秒为单位)。- 日志线程
kvdo:journalQ线程更新恢复日志,并调度用于写入的日志块。VDO 设备只使用一个日志,因此无法在线程间分割工作。- packer thread
- 启用压缩时,
kvdo:packerQ线程在写入路径中处于活跃状态,收集kvdo:cpuQ线程压缩的数据块,以最小化浪费的空间。每个 VDO 设备有一个 packer 数据结构,因此每个 VDO 设备有一个 packer 线程。
30.6.3. 要调整的值
30.6.3.1. CPU/内存
30.6.3.1.1. 逻辑, 物理, cpu, ack 线程数
30.6.3.1.2. CPU 关联性和 NUMA
taskset 工具在一个节点上收集 VDO 线程。如果也可以在同一节点上运行其他与 VDO 相关的工作,这可能会进一步减少竞争。在这种情况下,如果一个节点缺少 CPU 电源来满足处理需求,那么在选择线程以移动到其他节点时需要考虑内存争用。例如,如果存储设备的驱动程序具有大量用于维护的数据结构,则可能有助于将设备的中断处理和 VDO 的 I/O 提交(调用设备的驱动程序代码)移到另一节点。使 I/O 确认(线程)和更高级别的 I/O 提交线程(用户模式线程执行直接 I/O,或者内核的页面缓存 清除 线程)对也很好。
30.6.3.1.3. 频率节流
性能 写入 /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor 文件(如果它们存在)可能会生成更好的结果。如果这些 sysfs 节点不存在,Linux 或系统的 BIOS 可能会提供其他选项来配置 CPU 频率管理。
30.6.3.2. Caching
30.6.3.2.1. Block Map Cache
--blockMapCacheSize=megabytes
选项增加它。使用较大的缓存可能会给随机访问工作负载带来显著的好处。
30.6.3.2.2. 读取缓存
--readCache={enabled | disabled}
选项控制是否使用读缓存。如果启用,缓存的最小大小为 8 MB,但可使用
--readCacheSize=megabytes
选项增加。管理读取缓存会导致开销小,因此如果存储系统足够快,则它可能无法提高性能。默认情况下禁用读取缓存。
30.6.3.3. 存储系统 I/O
30.6.3.3.1. bio 线程
30.6.3.3.2. IRQ 处理
%hi 指示符)。在这种情况下,可能需要为某些内核分配 IRQ 处理,并调整 VDO 内核线程的 CPU 关联性,使其不在这些内核上运行。
30.6.3.4. 最大 Discard Sectors
/sys/kvdo/max_discard_sectors 根据系统使用情况调整 DISCARD (TRIM)操作的最大允许大小。默认值为 8 个扇区(即 4 KB 块)。可以指定较大的大小,但 VDO 仍然会在循环中处理它们,但一次一个块的一个块,确保在启动下一个块前写入一个丢弃的块的元数据更新,并刷新到磁盘。
30.6.4. 识别 Bottlenecks
top 或 ps 等实用程序中所示,线程或 CPU 使用率高于 70%,通常意味着过多的工作被集中在一个线程或一个 CPU 上。然而,在某些情况下,可能意味着 VDO 线程被调度到 CPU 上运行,但没有实际发生任何工作;这种情况可能会在硬件中断处理器处理、内核或 NUMA 节点之间内存争用,或者对 spin 锁定争用。
top 工具检查系统性能时,红帽建议运行 top -H 来分别显示所有进程线程,然后输入 1 f j 键,后跟 Enter/Return 键;然后,顶部 命令显示单个 CPU 内核的负载,并确定每个进程或线程最后一次运行的 CPU。这些信息可以提供以下 insights:
- 如果内核没有较低的
%id(空闲)和%wa(等待I/O)值,则它会一直保持在某种程度上工作。 - 如果内核的
%hi值非常低,则核心正在进行正常处理,这是由内核调度程序进行负载均衡的。向该集合添加更多内核可能会减少负载,只要它不引入 NUMA 争用。 - 如果内核的
%hi超过百分比,且只为那个内核分配一个线程,%id和%wa为零,则核心将被过度使用,且调度程序不会解决这种情况。在这种情况下,应重新分配内核线程或设备中断处理,使其保存在单独的内核中。
perf 工具可以检查许多 CPU 的性能计数器。红帽建议使用 perf top 子命令作为检查线程或处理器正在执行的工作的起点。例如,bioQ 线程会花费很多周期试图获取 spin 锁定,则 VDO 下设备驱动程序可能会太多竞争,并减少 bioQ 线程的 数量可能缓解这种情况。使用高 CPU (获取 spin 锁定或其他)也可以表示 NUMA 节点之间争用(例如,bio Q 线程和设备中断处理器在不同节点上运行。如果处理器支持它们,则诸如 stalled-cycles-backend、cache-misses 和 node-load-misses 等计数器可能值得关注。
sar 实用程序可以提供关于多个系统统计的定期报告。sar -d 1 命令报告块设备利用率级别(它们至少有一个 I/O 操作百分比)和队列长度(每秒等待的 I/O 请求数)一次。但是,并非所有块设备驱动程序都可以报告此类信息,因此 sar 有用的性可能会依赖于正在使用的设备驱动程序。
30.7. VDO 命令
30.7.1. vdo
kvdo 和 UDS 组件。
概要
vdo { activate | changeWritePolicy | create | deactivate | disableCompression | disableDeduplication | enableCompression | enableDeduplication | growLogical | growPhysical | list | modify | printConfigFile | remove | start | status | stop }
[ options... ]
sub-Commands
表 30.4. VDO Sub-Commands
| sub-Command | 描述 |
|---|---|
create
|
创建 VDO 卷及其关联的索引,并使其可用。如果指定了
osgiactivate=disabled,则创建 VDO 卷但不可用。除非给出 zFCP force,否则不会覆盖现有的文件系统或格式化的 VDO 卷。此命令必须使用 root 特权运行。适用的选项包括:
|
remove
|
删除一个或多个已停止的 VDO 卷和相关索引。此命令必须使用 root 特权运行。适用的选项包括:
|
开始
|
启动一个或多个已停止的、激活的 VDO 卷和相关服务。此命令必须使用 root 特权运行。适用的选项包括:
|
stop
|
停止一个或多个正在运行的 VDO 卷和相关服务。此命令必须使用 root 特权运行。适用的选项包括:
|
激活
|
激活一个或多个 VDO 卷。可使用
开始
|
deactivate
|
取消激活一个或多个 VDO 卷。取消激活的卷无法通过
开始
|
status
|
以 YAML 格式报告 VDO 系统和卷状态。如果没有运行,这个命令不需要 root 特权,但信息将不完整。适用的选项包括:
|
list
|
显示启动的 VDO 卷列表。
如果指定了 osgiall,它将显示启动和非启动的卷。此命令必须使用 root 特权运行。适用的选项包括:
|
修改
|
修改一个或多个 VDO 卷的配置参数。更改在下次启动 VDO 设备时生效;已在运行的设备不受影响。适用的选项包括:
|
changeWritePolicy
|
修改一个或多个正在运行的 VDO 卷的写入策略。此命令必须使用 root 特权运行。
|
enableDeduplication
|
在一个或多个 VDO 卷中启用 deduplication。此命令必须使用 root 特权运行。适用的选项包括:
|
disableDeduplication
|
在一个或多个 VDO 卷中禁用 deduplication。此命令必须使用 root 特权运行。适用的选项包括:
|
启用压缩
|
在一个或多个 VDO 卷中启用压缩。如果 VDO 卷正在运行,请立即生效。如果 VDO 卷没有运行压缩,则在下次启动 VDO 卷时将启用。此命令必须使用 root 特权运行。适用的选项包括:
|
禁用压缩
|
禁用一个或多个 VDO 卷的压缩。如果 VDO 卷正在运行,请立即生效。如果 VDO 卷没有运行压缩,则在下次启动 VDO 卷时将禁用。此命令必须使用 root 特权运行。适用的选项包括:
|
growLogical
|
在 VDO 卷中添加逻辑卷。卷必须存在,必须正在运行。此命令必须使用 root 特权运行。适用的选项包括:
|
growPhysical
|
在 VDO 卷中添加物理空间。卷必须存在,必须正在运行。此命令必须使用 root 特权运行。适用的选项包括:
|
printConfigFile
|
将配置文件输出到
stdout。此命令需要 root 特权。适用的选项包括:
|
选项
表 30.5. VDO 选项
| 选项 | 描述 |
|---|---|
--indexMem=gigabytes
| 以 GB 为单位指定 UDS 服务器内存量 ; 默认大小为 1 GB。可以使用特殊的十进制值 0.25、0.5、0.75,就像任意正整数一样。 |
--sparseIndex={enabled | disabled}
| 启用或禁用稀疏索引。默认值为 |
--all
| 表示命令应应用到所有配置的 VDO 卷。不得与 --name 一起使用。 |
--blockMapCacheSize=megabytes
| 指定为缓存块映射页面分配的内存大小;该值必须是 4096 的倍数。使用带有 B(ytes), K(ilobytes), M(egabytes), G(igabytes), T(erabytes), P(etabytes)或 E(xabytes)后缀的值是可选的。如果没有提供后缀,则该值将解释为 MB。默认值为 128M;该值必须至少为 128M,且小于 16T。请注意,内存开销为 15%。 |
--blockMapPeriod=period
| 1 到 16380 之间的值,它决定了在缓存页面刷新到磁盘前可能会累积的块映射更新数量。数值越高,在正常操作期间,崩溃会降低性能降低后的恢复时间。默认值为 16380。在调整这个参数前,请联系您的红帽代表。 |
--compression={enabled | disabled}
| 启用或禁用 VDO 设备中的压缩。默认启用默认值。如果需要,可以禁用压缩,以加快对性能的处理速度,不太可能压缩。 |
--confFile=file
| 指定备用配置文件。默认值为 /etc/vdoconf.yml。 |
--deduplication={enabled | disabled}
| 在 VDO 设备中启用或禁用 deduplication。默认是启用的。在数据没有很好的重复数据删除率但仍然需要压缩的情况下,可能会禁用 deduplication。 |
--emulate512={enabled | disabled}
| 启用 512 字节块设备模拟模式。默认值为 |
--force
| 在停止 VDO 卷前卸载挂载的文件系统。 |
--forceRebuild
| 在启动只读 VDO 卷前强制离线重建,以便它可以重新上线并可用。这个选项可能会导致数据丢失或损坏。 |
--help
| 显示 vdo 实用程序的文档。 |
--logfile=pathname
| 指定此脚本的日志消息定向到的文件。警告和错误消息也始终记录到 syslog。 |
--name=volume
| 在指定的 VDO 卷中操作。不得与 --all 一起使用。 |
--device=device
| 指定用于 VDO 存储的设备的绝对路径。 |
--activate={enabled | disabled}
| 禁用 的参数表示仅应创建 VDO 卷。卷不会被启动或启用。默认是启用的。 |
--vdoAckThreads=thread count
| 指定用于确认请求的 VDO I/O 操作的完成线程数量。默认值为 1;该值必须至少为 0,且小于或等于 100。 |
--vdoBioRotationInterval=I/O count
| 在将工作定向到下一个操作前,指定每个 bio-submission 线程要排队的 I/O 操作数量。默认值为 64;该值必须至少为 1,且小于或等于 1024。 |
--vdoBioThreads=thread count
| 指定用于向存储设备提交 I/O 操作的线程数量。最小为 1; 最大为 100。默认值为 4;该值必须至少为 1,且小于或等于 100。 |
--vdoCpuThreads=thread count
| 指定用于 CPU 密集型工作的线程数量,如哈希或压缩。默认值为 2,该值必须至少为 1,且小于或等于 100。 |
--vdoHashZoneThreads=thread count
| 根据从块数据计算的哈希值,指定 VDO 处理中分离的线程数量。默认值为 1; 该值必须至少为 0,且小于或等于 100。vdoHashZoneThreads、vdoLogicalThreads 和 vdoPhysicalThreads 都必须为零或所有非零。 |
--vdoLogicalThreads=thread count
| 根据从块数据计算的哈希值,指定 VDO 处理中分离的线程数量。该值必须至少为 0,且小于或等于 100。9 或更多个逻辑线程数还需要明确指定足够大的块映射缓存大小。vdoHashZoneThreads,vdoLogicalThreads, 和 vdoPhysicalThreads 必须是零或所有非零。默认值为 1。 |
--vdoLogLevel=level
| 指定 VDO 驱动程序日志级别: critical、error、warning、notice、info 或 debug。级别是区分大小写的;默认值为 info。 |
--vdoLogicalSize=megabytes
| 以 MB 为单位指定逻辑卷大小。使用带有 S(ectors)、B(ytes), K(ilobytes), M(egabytes), G(igabytes), T(erabytes), P(etabytes)或 E(xabytes)后缀的值是可选的。用于过度置备卷。默认为存储设备的大小。 |
--vdoPhysicalThreads=thread count
| 指定根据物理块地址在 VDO 处理中从属部分的线程数量。该值必须至少为 0,且小于或等于 16。第一个后的每个额外线程将使用额外的 10 MB RAM。vdoPhysicalThreads,vdoHashZoneThreads, 和 vdoLogicalThreads 必须是零或所有非零。默认值为 1。 |
--readCache={enabled | disabled}
| 启用或禁用 VDO 设备中的读取缓存。默认值为 |
--readCacheSize=megabytes
| 指定额外的 VDO 设备读取缓存大小(以 MB 为单位)。这个空间除一个系统定义的最小之外。使用带有 B(ytes), K(ilobytes), M(egabytes), G(igabytes), T(erabytes), P(etabytes)或 E(xabytes)后缀的值是可选的。默认值为 0M。每个 bio 线程将每 MB 读缓存使用 1.12 MB 内存。 |
--vdoSlabSize=megabytes
| 指定 VDO 增长的递增大小。使用较小的大小限制了可容纳的总物理大小。必须是 128M 到 32G 之间的 2 个电源;默认值为 2G。使用带有 S(ectors)、B(ytes), K(ilobytes), M(egabytes), G(igabytes), T(erabytes), P(etabytes)或 E(xabytes)后缀的值是可选的。如果没有使用后缀,则该值将解释为 MB。 |
--verbose
| 在执行命令前打印命令。 |
--writePolicy={ auto | sync | async }
| 指定写入策略:
|
status
子命令返回 YAML 格式的以下信息,并分为几个键,如下所示:
表 30.6. VDO 状态输出
| 键 | 描述 | |
|---|---|---|
| VDO 状态 | 此密钥中的信息涵盖正在进行状态的主机和日期和时间的名称。在此区域中报告的参数包括: | |
| 节点 | 运行 VDO 的系统的主机名。 | |
| Date | 运行 vdo status 命令的日期和时间。 | |
| 内核模块 | 这个密钥中的信息涵盖了配置的内核。 | |
| Loaded | 是否载入内核模块(True 或 False)。 | |
| 版本信息 | 已配置的 kvdo 版本的信息。 | |
| 配置 | 此密钥中的信息涵盖了 VDO 配置文件的位置和状态。 | |
| File | VDO 配置文件的位置。 | |
| 最后修改 | VDO 配置文件的最后修改日期。 | |
| VDO | 为所有 VDO 卷提供配置信息。为每个 VDO 卷报告的参数包括: | |
| 块大小 | VDO 卷的块大小,以字节为单位。 | |
| 512 字节模拟 | 指明卷是否在 512 字节模拟模式下运行。 | |
| 启用 deduplication | 是否为卷启用 deduplication。 | |
| 逻辑大小 | VDO 卷的逻辑大小。 | |
| 物理大小 | VDO 卷的基本物理存储的大小。 | |
| 写入策略 | 写入策略配置的值(sync 或 async)。 | |
| VDO 统计 | vdostats 工具的输出。 | |
30.7.2. vdostats
vdostats 工具以类似 Linux df 实用程序的格式显示每个配置(或指定)设备的统计信息。
vdostats 工具的输出可能不完整。
概要
vdostats [ --verbose | --human-readable | --si | --all ] [ --version ] [ device ...]
选项
表 30.7. vdostats 选项
| 选项 | 描述 |
|---|---|
--verbose
|
显示一个或多个 VDO 设备的利用率和块 I/O (bios)统计信息。详情请查看 表 30.9 “vdostats --verbose Output”。
|
--human-readable
| 以可读的形式显示块值(基本 2: 1 KB = 210 字节 = 1024 字节)。 |
--si
| --si 选项修改 --human-readable 选项的输出以使用 SI 单位(基本 10: 1 KB = 103 字节 = 1000 字节)。如果没有提供 --human-readable 选项,-- si 选项不会起作用。 |
--all
| 这个选项仅用于向后兼容。现在,它等同于 --verbose 选项。 |
--version
| 显示 vdostats 版本。 |
device ...
| 指定要报告的一个或多个特定卷。如果省略此参数,则 vdostats 将报告所有设备。 |
输出
Device 1K-blocks Used Available Use% Space Saving% /dev/mapper/my_vdo 1932562432 427698104 1504864328 22% 21%
表 30.8. 默认 vdostats 输出
| 项 | 描述 |
|---|---|
| 设备 | VDO 卷的路径。 |
| 1k-blocks | 为 VDO 卷分配的 1K 块总数(=物理卷大小 * 块大小 / 1024) |
| Used | VDO 卷中使用的 1K 块总数(= 物理块使用 * 块大小 / 1024) |
| 可用 | VDO 卷中可用 1K 块的总数(= 物理块 free * 块大小 / 1024) |
| use% | VDO 卷中使用的物理块的百分比(= 使用块 / 分配的块 * 100) |
| 空间节省% | VDO 卷中保存的物理块的百分比(= [逻辑块已使用 - 物理块] / logical blocks used) |
--human-readable 选项将块数转换为传统单元(1 KB = 1024 字节):
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 1.8T 407.9G 1.4T 22% 21%
--human-readable 和 --si 选项将块数转换为 SI 单位(1 KB = 1000 字节):
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 2.0T 438G 1.5T 22% 21%
--verbose (表 30.9 “vdostats --verbose Output”)选项以 YAML 格式显示一个(或全部)VDO 设备的 VDO 设备统计信息。
表 30.9. vdostats --verbose Output
| 项 | 描述 |
|---|---|
| 版本 | 这些统计数据的版本。 |
| 发行版本 | VDO 的发行版本。 |
| 已使用的数据块 | VDO 卷目前使用的物理块数量来存储数据。 |
| 使用的开销块 | VDO 卷目前使用的物理块数量来存储 VDO 元数据。 |
| 使用的逻辑块 | 当前映射的逻辑块数量。 |
| 物理块 | 为 VDO 卷分配的物理块总数。 |
| 逻辑块 | VDO 卷可以映射的最大逻辑块数。 |
| 1k-blocks | 为 VDO 卷分配的 1K 块总数(=物理卷大小 * 块大小 / 1024) |
| 1k-blocks 使用的 | VDO 卷中使用的 1K 块总数(= 物理块使用 * 块大小 / 1024) |
| 1k-blocks 可用 | VDO 卷中可用 1K 块的总数(= 物理块 free * 块大小 / 1024) |
| 已使用百分比 | VDO 卷中使用的物理块的百分比(= 使用块 / 分配的块 * 100) |
| 保存百分比 | VDO 卷中保存的物理块的百分比(= [逻辑块已使用 - 物理块] / logical blocks used) |
| 块映射缓存大小 | 块映射缓存的大小,以字节为单位。 |
| 写入策略 | 活跃的写入策略(sync 或 async)。这通过 vdo changeWritePolicy --writePolicy=auto|sync|async 配置。 |
| 块大小 | VDO 卷的块大小,以字节为单位。 |
| 完成恢复计数 | VDO 卷已从未清理关闭中恢复的次数。 |
| 只读恢复计数 | VDO 卷已从只读模式恢复的次数(通过 vdo start --forceRebuild)。 |
| 操作模式 | 指明 VDO 卷是否正常运行,处于恢复模式,或者处于只读模式。 |
| 恢复进度(%) | 指明在线恢复进度,如果卷没有处于恢复模式,则为 N/A。 |
| 编写的压缩片段 | 从 VDO 卷最后一次重启后写入的压缩片段数量。 |
| 编写的压缩块 | 从 VDO 卷最后一次重启后写入的压缩数据的物理块数量。 |
| packer 中的压缩片段 | 尚未写入的压缩片段数量。 |
| slab 数量 | slabs 的总数。 |
| slabs 已打开 | 从中分配块的 slab 总数。 |
| slabs reopened | 从 VDO 启动后,会重新打开 slabs 的次数。 |
| 日志磁盘完整计数 | 请求无法进行恢复日志条目的次数,因为恢复日志已满。 |
| 日志提交请求计数 | 恢复日志请求 slab 日志提交的次数。 |
| 日志条目批处理 | 日志条目写入的数量已开始减去写入的日志条目数。 |
| 日志条目已启动 | 内存中所做的日志条目数。 |
| 编写日志条目 | 提交中的日志条目数量减去提交到存储的日志条目数。 |
| 写入的日志条目 | 签发写入的日志条目总数。 |
| 已提交的日志条目 | 写入存储的日志条目数。 |
| 日志块批处理 | 启动的日志块写入数量减去写入的日志块的数量。 |
| 日志块已启动 | 在内存中涉及的日志块数。 |
| 日志块编写 | 编写的日志块数量(具有活动内存中的元数据主机)减去所提交的日志块数。 |
| 写入的日志条目 | 发出写入的日志块总数。 |
| 已提交的日志块 | 写入存储的日志块数量。 |
| slab 日志磁盘完整计数 | 磁盘上 slab 日志已满的次数。 |
| slab 日志清除计数 | 条目添加到通过 flush 阈值的 slab 日志中的次数。 |
| slab 日志阻止计数 | 条目添加到带有阻塞阈值的 slab 日志中的次数。 |
| 写入 slab 日志块 | 发出 slab 日志块写入的数量。 |
| slab journal tail busy count | 写入请求阻止等待 slab 日志写入的次数。 |
| 写入 slab 摘要块 | 签发的 slab 摘要块写入的数量。 |
| 编写的引用块 | 发布的引用块写入数量。 |
| 块映射脏页面 | 块映射缓存中脏页面的数量。 |
| 块映射清理页面 | 块映射缓存中清理页面的数量。 |
| 块映射空闲页面 | 块映射缓存中可用页面的数量。 |
| 块映射失败页 | 具有写入错误的块映射缓存页面数量。 |
| 块映射传入的页面 | 被读取到缓存中的块映射缓存页面数量。 |
| 块映射传出页面 | 正在写入的块映射缓存页面数量。 |
| 块映射缓存压力 | 在需要时,空闲页面不可用的次数。 |
| 块映射读取计数 | 块映射页面的总数显示为: |
| 块映射写入计数 | 块映射页面写入的总数。 |
| 块映射失败的读取 | 块映射读取错误的总数。 |
| 块映射失败的写入 | 块映射写入错误的总数。 |
| 重新声明的块映射 | 已回收的块映射页面总数。 |
| 块映射读取传出 | 要写入的页面的块映射读取总数。 |
| 缓存中找到的块映射 | 块映射缓存命中的总数。 |
| 需要块映射丢弃 | 需要丢弃页面的块映射请求总数。 |
| 块映射等待页面 | 必须等待页面的请求总数。 |
| 需要块映射获取 | 需要页面获取的请求总数。 |
| 加载的块映射页面 | 页面获取总数。 |
| 保存的块映射页面 | 保存页面的总数。 |
| 块映射冲刷计数 | 块映射发出的刷新总数。 |
| 无效的建议 PBN 数量 | 索引返回无效建议的次数 |
| 没有空格错误计数。 | 由于 VDO 卷没有空间导致的写入请求数。 |
| 只读错误计数 | 因为 VDO 卷处于只读模式而失败的写入请求数。 |
| 实例 | VDO 实例。 |
| 512 字节模拟 | 指明 512 字节模拟是否为卷打开或关闭。 |
| 正在进行中的当前 VDO IO 请求。 | VDO 当前处理的 I/O 请求数量。 |
| 正在进行中的最大 VDO IO 请求 | VDO 并发处理的最大 I/O 请求数。 |
| 当前去除重复查询 | 当前在 flight 中去除重复数据查询的数量。 |
| 最大去除重复查询 | 动态重复数据删除查询的最大数量。 |
| Dedupe 建议有效 | 数据重复数据建议的次数正确。 |
| dedupe 建议过时 | 重复数据删除建议的次数不正确。 |
| dedupe 建议超时 | 重复数据删除查询超时的次数。 |
| flush out | VDO 提交到底层存储的清空请求数。 |
| 中的 BIOS...部分的 BIOS...BIOS out...BIOS 元...BIOS 日志...BIOS 页面缓存...BIOS 已完成...bio meta completed...BIOS 日志已完成...已完成 BIOS 页面缓存...BIOS 已确认...BIOS 确认的部分...正在进行中的 BIOS... |
这些统计数据使用给定标志计算每个类别中的 bios 数量。类别是:
标记有三种类型:
|
| 读取缓存访问 | VDO 搜索读取缓存的次数。 |
| 读取缓存命中 | 读取缓存命中的数量。 |
30.8. /sys中的统计文件
/sys/kvdo/volume_name/statistics 目录中的文件读取,其中 volume_name 是 thhe VDO 卷的名称。这为 vdostats 工具生成的数据提供了一个备用接口,适合由 shell 脚本和管理软件访问。
统计 目录中还有一些文件。在以后的发行版本中无法保证支持这些额外的统计文件。
表 30.10. 统计文件
| File | 描述 |
|---|---|
dataBlocksUsed | VDO 卷目前使用的物理块数量来存储数据。 |
logicalBlocksUsed | 当前映射的逻辑块数量。 |
physicalBlocks | 为 VDO 卷分配的物理块总数。 |
logicalBlocks | VDO 卷可以映射的最大逻辑块数。 |
模式 | 指明 VDO 卷是否正常运行,处于恢复模式,或者处于只读模式。 |
第 31 章 VDO 评估
31.1. 简介
- 特定于 VDO 的可配置属性(性能调优最终用户应用程序)
- 作为原生 4 KB 块设备的影响
- 响应重复数据删除和压缩的访问模式和发布
- 高负载环境中的性能(非常重要)
- 根据应用程序分析成本与容量与性能
31.1.1. 期望和交付
- 帮助工程师识别来自测试设备的最佳响应的配置设置
- 提供对基本调优参数的信息,以帮助避免产品错误配置
- 创建一个性能结果组合,作为与"真实"应用程序结果进行比较的参考
- 识别不同的工作负载对性能和数据效率的影响
- 使用 VDO 实现加快产品面市时间
31.2. 测试环境准备
31.2.1. 系统配置
- 可用 CPU 内核数和类型。这可以通过使用
taskset实用程序来控制。 - 可用内存和总安装内存.
- 配置存储设备。
- Linux 内核版本.请注意,Red Hat Enterprise Linux 7 只提供一个 Linux 内核版本。
- 安装了软件包。
31.2.2. VDO 配置
- 分区方案
- VDO 卷中使用的文件系统
- 分配给 VDO 卷的物理存储大小
- 创建的逻辑卷的大小
- 稀疏或高密度索引
- 内存大小的 UDS Index
- VDO 的线程配置
31.2.3. 工作负载
- 生成测试数据的工具类型
- 并发客户端数
- 写入数据中重复的 4 KB 块的数量
- 读和写的特征
- 工作集大小
31.2.4. 支持的系统配置
- 灵活的 I/O Tester 版本 2.08 或更高版本;可从 fio 软件包获得
sysstat版本 8.1.2-2 或更高版本;可从 sysstat 软件包获得
31.2.5. 预测试系统准备
- 系统配置
- 确定您的 CPU 在最高级别的性能设置中运行。
- 如果使用 BIOS 配置或 Linux
cpupower工具,禁用频率扩展。 - 如果可能达到最大吞吐量,请启用 Turbo 模式。turbo 模式在测试结果中引入了一些差异,但性能将达到或超过没有 Turbo 的测试。
- Linux 配置
- 对于基于磁盘的解决方案,Linux 提供多个 I/O 调度程序算法,以在多个读写请求排队时进行处理。默认情况下,Red Hat Enterprise Linux 使用 CFQ (完全公平排队)调度程序,它以改进旋转磁盘(硬磁盘)访问的方式排列请求。我们建议将死线调度程序用于旋转磁盘,发现它在红帽实验室测试中提供更好的吞吐量和延迟。按如下方式更改设备设置:
# echo "deadline" > /sys/block/device/queue/scheduler
- 对于基于闪存的解决方案,
noop调度程序演示了红帽实验室测试中卓越的随机访问吞吐量和延迟。按如下方式更改设备设置:# echo "noop" > /sys/block/device/queue/scheduler
- 存储设备配置文件系统(ext4、XFS 等)可能会对性能有唯一影响;它们通常会降低性能,从而更难以隔离 VDO 对结果的影响。如果合理,我们建议测量原始块设备的性能。如果无法做到这一点,请使用目标实施中使用的文件系统格式化设备。
31.2.6. VDO 内部结构
31.2.7. VDO 优化
高负载
同步与.异步写策略
# vdo status --name=my_vdo
元数据缓存
VDO 多线程配置
数据内容
31.2.8. 测试读性能的特别注意事项
- 如果 从未写入 4 KB 块,VDO 不会对存储执行 I/O,并将立即使用零块响应。
- 如果 写入了 4 KB 块但包含所有零,VDO 不会对存储执行 I/O,并将立即使用零块响应。
31.2.9. cross Talk
31.3. 数据效率测试过程
测试环境
- 一个或多个 Linux 物理块设备可用。
- 目标块设备(例如
/dev/sdb)大于 512 GB。 - 已安装灵活的 I/O Tester (
fio)版本 2.1.1 或更高版本。 - 已安装 VDO。
- 使用的 Linux 构建,包括内核构建号。
- 从 rpm -qa 命令获取安装的软件包的完整列表。
- 完整的系统规格:
- CPU 类型和数量(可在
/proc/cpuinfo中提供)。 - 安装的内存以及基础操作系统运行后可用(可在
/proc/meminfo中使用)。 - 使用的驱动器控制器的类型。
- 使用的磁盘的类型和数量。
- 正在运行的进程的完整列表(从 ps aux 或类似的列表)。
- 物理卷的名称以及为 VDO 创建的卷组名称(pvs 和 vgs 列表)。
- 格式化 VDO 卷时使用的文件系统(若有)。
- 挂载的目录的权限。
/etc/vdoconf.yaml的内容。- VDO 文件的位置。
工作负载
fio 的两个实用程序,建议在测试过程中使用。
fio。了解参数对于成功评估至关重要:
表 31.1. fio 选项
| 参数 | 描述 | 值 |
|---|---|---|
--size | 数据 fio 将为每个作业发送到目标(请参阅以下 numjobs )。 | 100 GB |
--bs | fio 生成的每个读/写请求的块大小。红帽建议 4 KB 块大小来匹配 VDO 的 4 KB 默认 | 4k |
--numjobs |
fio 将为运行基准而创建的作业数量。
每个作业发送
--size 参数指定的数据量。
第一个作业将数据发送到
--offset 参数指定的偏移处的设备。除非提供了 --offset_increment 参数,否则后续作业写入磁盘的同一区域(覆盖)将使每个作业从上一个作业开始的位置偏移。要在闪存上达到峰值性能,至少有两个作业。一个作业通常足以饱和旋转型磁盘(HDD)吞吐量。
|
1 (HDD)
2 (SSD)
|
--thread | 指示 fio 作业在线程中运行,而不是被分叉,这可以通过限制上下文切换来提供更好的性能。 | <N/A> |
--ioengine |
Linux 中有几个可用的 I/O 引擎可以使用 fio 进行测试。红帽测试使用异步非缓冲引擎(
libaio)。如果您对其他引擎感兴趣,请与红帽销售工程师进行讨论。
Linux
libaio 引擎用于评估一个或多个进程同时进行随机请求的工作负载。libaio 在检索任何数据前,允许从单个线程中异步进行多个请求,这限制了在通过同步引擎提供给多个线程时所需的上下文切换数量。
| libaio |
--direct |
设置后,直接允许将请求提交到设备,绕过 Linux 内核的页面缓存。
libaio Engine:
libaio 必须与启用 direct (=1)一起使用,或者内核可能对所有 I/O 请求使用 sync API。
| 1 (libaio) |
--iodepth |
任意时间中的 I/O 缓冲区的数量。
高
iodepth 通常会提高性能,特别是用于随机读取或写入。高深度可确保控制器始终具有批处理请求。但是,设置 iodepth 太大(超过 1K,通常)可能会导致不必要的延迟。虽然红帽建议在 128 到 512 之间有一个 iodepth,但最终的值是一个利弊的,它取决于应用程序如何容忍延迟。
| 128 (最小) |
--iodepth_batch_submit | 当 iodepth 缓冲池开始为空时创建的 I/O 数量。此参数在测试过程中将任务从 I/O 限制为从 I/O 切换到缓冲区。 | 16 |
--iodepth_batch_complete | 提交批处理前要完成的 I/O 数量(iodepth_batch_complete)。此参数在测试过程中将任务从 I/O 限制为从 I/O 切换到缓冲区。 | 16 |
--gtod_reduce | 禁用日常调用来计算延迟。如果启用,此设置将降低吞吐量,因此应启用(=1),除非需要延迟测量。 | 1 |
31.3.1. 配置 VDO 测试卷
1.在 512 GB 物理卷中创建大小为 1 TB 的 VDO 卷
- 创建 VDO 卷。
- 要在同步存储之上测试 VDO
async模式,请使用--writePolicy=async选项创建一个异步卷:# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=async --verbose - 要在
同步存储之上测试 VDO 同步模式,请使用--writePolicy=sync选项创建一个同步卷:# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=sync --verbose
- 使用 XFS 或 ext4 文件系统格式化新设备。
- 对于 XFS:
# mkfs.xfs -K /dev/mapper/vdo0
- 对于 ext4:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- 挂载格式化的设备:
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
31.3.2. 测试 VDO 效率
2.测试读取和写入到 VDO 卷
- 将 32 GB 的随机数据写入 VDO 卷:
$ dd if=/dev/urandom of=/mnt/VDOVolume/testfile bs=4096 count=8388608
- 从 VDO 卷中读取数据,并将其写入 VDO 卷中的另一个位置:
$ dd if=/mnt/VDOVolume/testfile of=/home/user/testfile bs=4096
- 使用
diff比较两个文件,该文件应该报告这些文件是相同的文件:$ diff -s /mnt/VDOVolume/testfile /home/user/testfile
- 将文件复制到 VDO 卷中的第二个位置:
$ dd if=/home/user/testfile of=/mnt/VDOVolume/testfile2 bs=4096
- 将第三个文件与第二个文件进行比较。这应该报告这些文件是相同的:
$ diff -s /mnt/VDOVolume/testfile2 /home/user/testfile
3.删除 VDO 卷
- 卸载在 VDO 卷中创建的文件系统:
# umount /mnt/VDOVolume
- 运行命令从系统中删除 VDO 卷
vdo0:# vdo remove --name=vdo0
- 验证卷是否已移除。VDO 分区的 vdo 列表中 不应有列表:
# vdo list --all | grep vdo
4.测量重复数据
- 按照 第 31.3.1 节 “配置 VDO 测试卷” 创建并挂载 VDO 卷。
- 在名为
vdo1到vdo10的 VDO 卷上创建 10 个目录,以存放测试数据集的 10 个副本:$ mkdir /mnt/VDOVolume/vdo{01..10} - 根据文件系统检查所使用的磁盘空间量:
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 198M 1.4T 1% /mnt/VDOVolume
考虑在表中模拟结果:统计 裸机文件系统 seed 后 10 个副本后 文件系统使用的大小 198 MB 已使用的 VDO 数据 使用 VDO 逻辑 - 运行以下命令并记录值。"数据块使用"是 VDO 中运行的物理设备中用户数据所使用的块数。"使用的逻辑块"是优化前使用的块数。它将用作测量的起点
# vdostats --verbose | grep "blocks used" data blocks used : 1090 overhead blocks used : 538846 logical blocks used : 6059434
- 在 VDO 卷顶层创建数据源文件
$ dd if=/dev/urandom of=/mnt/VDOVolume/sourcefile bs=4096 count=1048576 4294967296 bytes (4.3 GB) copied, 540.538 s, 7.9 MB/s
- 重新检查已使用的物理磁盘空间量。这应该显示与刚才写入的文件对应的块数量的增加:
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 4.2G 1.4T 1% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050093 (increased by 4GB) overhead blocks used : 538846 (Did not change) logical blocks used : 7108036 (increased by 4GB)
- 将文件复制到 10 个子目录中的每个子目录中:
$ for i in {01..10}; do cp /mnt/VDOVolume/sourcefile /mnt/VDOVolume/vdo$i done - 再次检查已使用的物理磁盘空间量(使用的数据块)。这个数字应该与上述步骤 6 的结果类似,因为文件系统日志记录和元数据,只需要稍微增加一些:
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 45G 1.3T 4% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050836 (increased by 3M) overhead blocks used : 538846 logical blocks used : 17594127 (increased by 41G)
- 从写测试数据之前找到的值中减去文件系统所使用的空间的新值。从文件系统的角度来看,这是此测试消耗的空间量。
- 观察您记录统计中的空间节能:注意:在下表中,值已转换为 MB/GB。vdostats "blocks" 为 4,096 B。
统计 裸机文件系统 seed 后 10 个副本后 文件系统使用的大小 198 MB 4.2 GB 45 GB 已使用的 VDO 数据 4 MB 4.1 GB 4.1 GB 使用 VDO 逻辑 23.6 GB* 27.8 GB 68.7 GB * 1.6 TB 格式的驱动器的文件系统开销
5.测量压缩
- 创建一个至少 10 GB 物理和逻辑大小的 VDO 卷。添加选项来禁用 deduplication 并启用压缩:
# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=10G --verbose \ --deduplication=disabled --compression=enabled - 在传输前检查 VDO 统计;记录使用的数据块和逻辑块(两者均应为零):
# vdostats --verbose | grep "blocks used"
- 使用 XFS 或 ext4 文件系统格式化新设备。
- 对于 XFS:
# mkfs.xfs -K /dev/mapper/vdo0
- 对于 ext4:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- 挂载格式化的设备:
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
- 同步 VDO 卷以完成所有未完成压缩:
# sync && dmsetup message vdo0 0 sync-dedupe
- 再次检查 VDO 统计信息。logical blocks used - 使用的数据块数是文件系统压缩的 4 KB 块数量。VDO 优化文件系统开销以及实际的用户数据:
# vdostats --verbose | grep "blocks used"
- 将
/lib的内容复制到 VDO 卷中。记录总大小:# cp -vR /lib /mnt/VDOVolume ... sent 152508960 bytes received 60448 bytes 61027763.20 bytes/sec total size is 152293104 speedup is 1.00
- 同步 Linux 缓存和 VDO 卷:
# sync && dmsetup message vdo0 0 sync-dedupe
- 再次检查 VDO 统计。观察使用的逻辑和数据块:
# vdostats --verbose | grep "blocks used"
- logical blocks used - 使用的数据块代表
/lib文件的副本所使用的空间量(以 4 KB 块为单位)。 - 总大小(来自 “4.测量重复数据”一节中的表)- (逻辑块 used-data 块使用 * 4096) = 压缩保存的字节数。
- 删除 VDO 卷:
# umount /mnt/VDOVolume && vdo remove --name=vdo0
6.测试 VDO 压缩效率
- 按照 第 31.3.1 节 “配置 VDO 测试卷” 创建并挂载 VDO 卷。
- 使用您自己的数据集进行测试。
7.了解 TRIM 和 DISCARD
TRIM 或 DISCARD 命令,以便在不再需要逻辑块时通知存储系统。这些命令可以在使用 discard 挂载选项删除块时发送,或通过运行工具(如 fstrim )以受控的方式发送这些命令,告知文件系统检测哪些逻辑块没有被使用,并以 TRIM 或 DISCARD 命令的形式向存储系统发送信息。
- 按照 第 31.3.1 节 “配置 VDO 测试卷” 创建并挂载新的 VDO 逻辑卷。
- 修剪文件系统以删除任何不需要的块(可能需要很长时间):
# fstrim /mnt/VDOVolume
- 输入以下内容记录下表中的初始状态:
$ df -m /mnt/VDOVolume
要查看文件系统中使用了多少容量,并运行 vdostats 来查看正在使用的物理和虚拟数据块的数量。 - 在 VDO 上运行的文件系统中创建一个带有非重复数据的 1 GB 文件:
$ dd if=/dev/urandom of=/mnt/VDOVolume/file bs=1M count=1K
然后收集相同的数据。该文件系统应该已经使用额外的 1 GB,使用的数据块和逻辑块的相似增加。 - 运行
fstrim /mnt/VDOVolume并确认在创建新文件后这不会影响。 - 删除 1 GB 文件:
$ rm /mnt/VDOVolume/file
检查并记录参数。文件系统知道文件已被删除,但没有更改物理或逻辑块的数量,因为文件删除尚未与底层存储通信。 - 运行
fstrim /mnt/VDOVolume并记录相同的参数。fstrim在文件系统中查找空闲块,并为未使用的地址向 VDO 卷发送 TRIM 命令,这会释放相关的逻辑块,VDO 会处理 TRIM 来释放底层物理块。步骤 已使用的文件空间(MB) 已使用的数据块 使用的逻辑块 初始空间 添加 1 GB 文件 运行 fstrim删除 1 GB 文件 运行 fstrim
fstrim 是一个命令行工具,可一次性分析多个块以提高效率。另一种方法是在挂载时使用文件系统丢弃选项。discard 选项会在每个文件系统块被删除后更新底层存储,这可能会降低吞吐量,但可为很好的利用率感知提供。另请务必了解 TRIM 或 DISCARD 未使用块对 VDO 并不独一无二;任何精简置备的存储系统都有相同的挑战
31.4. 性能测试过程
31.4.1. 阶段 1:I/O Depth 的影响,修正了 4 KB 块
- 执行 4 KB I/O 和 I/O 深度为 1, 8, 16, 32, 64, 128, 256, 512, 1024 的四级测试:
- 顺序 100% 读取,在固定 4 KB * 中
- 顺序 100% 写入,在固定 4 KB
- 随机 100% 读取,在固定 4 KB * 中
- 随机 100% 写入,在固定 4 KB **
* 通过首先执行写 fio 作业,在读取测试过程中预先填充任何可能读取的区域** 在 4 KB 随机写入 I/O 运行后重新创建 VDO 卷shell 测试输入模拟器(写入)示例:# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write --bs=4096 --name=vdo --filename=/dev/mapper/vdo0 \ --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300\ --direct=1 --iodepth=$depth --scramble_buffers=1 --offset=0 \ --size=100g done - 在各个数据点记录吞吐量和延迟,然后记录图形。
- 重复测试以完成四级测试:
--rw=randwrite、--rw=read和--rw=randread。
- 这个特定设备不会从顺序 4 KB I/O depth > X 中受益。请注意,带宽带宽收益减少,平均请求延迟将增加每个额外 I/O 请求的 1:1。
- 这个特定设备不会从随机 4 KB I/O depth > Z 中获益。请注意,带宽收益会减少,平均请求延迟会增加每个额外 I/O 请求的 1:1。
图 31.1. I/O Depth Analysis
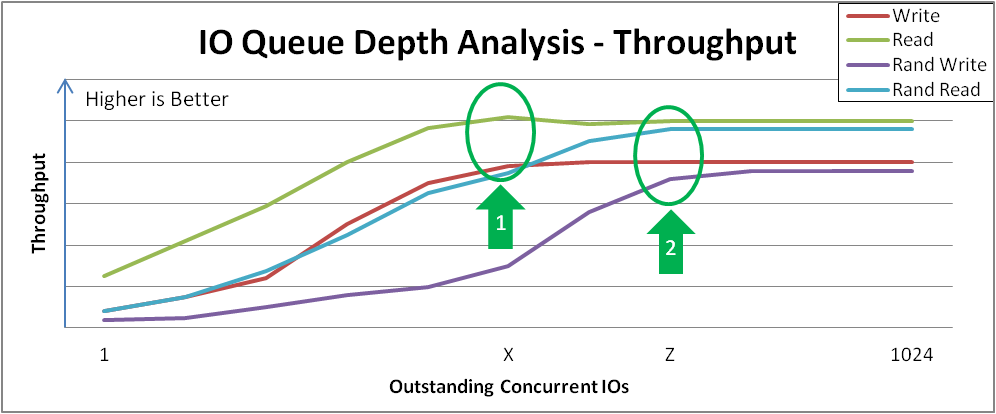
图 31.2. 为 Random Writes 增加 I/O 的延迟响应
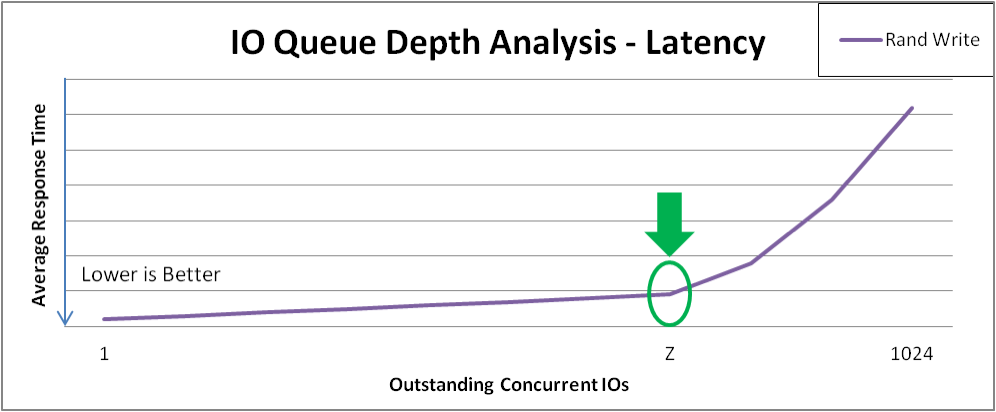
31.4.2. 阶段 2: I/O 请求大小的影响
- 在固定 I/O 深度中执行四级测试,在范围 8 KB 到 1 MB 时,块大小有不同(2 的指数为 2)。请记住,要预先填充要读取的区域,并在测试之间重新创建卷。
- 将 I/O Depth 设置为 第 31.4.1 节 “阶段 1:I/O Depth 的影响,修正了 4 KB 块” 中决定的值。测试输入模拟器(写入)示例:
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 在各个数据点记录吞吐量和延迟,然后记录图形。
- 重复测试以完成四级测试:
--rw=randwrite、--rw=read和--rw=randread。
- 顺序写入在请求大小 Y 时达到峰值吞吐量。此 curve 演示了可配置或自然地由特定请求大小划分的应用程序可能会感知性能。更大的请求大小通常会提供更多吞吐量,因为 4 KB I/O 可能会从合并中受益。
- 顺序读取在 Z 点达到类似的峰值吞吐量。请记住,在 I/O 完成后,I/O 完成后会增加一个类似的峰值吞吐量,而不会增加额外的吞吐量。将设备调优为不接受大于这个大小的 I/O 是明智的。
- 随机读取在 X 点达到峰值吞吐量。有些设备可能会在大型请求大小随机访问时达到近似的吞吐量率,而其他设备会在与纯顺序访问不同时受到更多的损失。
- 随机写入在 Y 点达到峰值吞吐量。随机写入涉及对去除重复设备的大多数交互,VDO 则实现高性能,特别是在请求大小和/或 I/O 深度较大时。
图 31.3. 请求大小与.吞吐量分析和密钥检查点
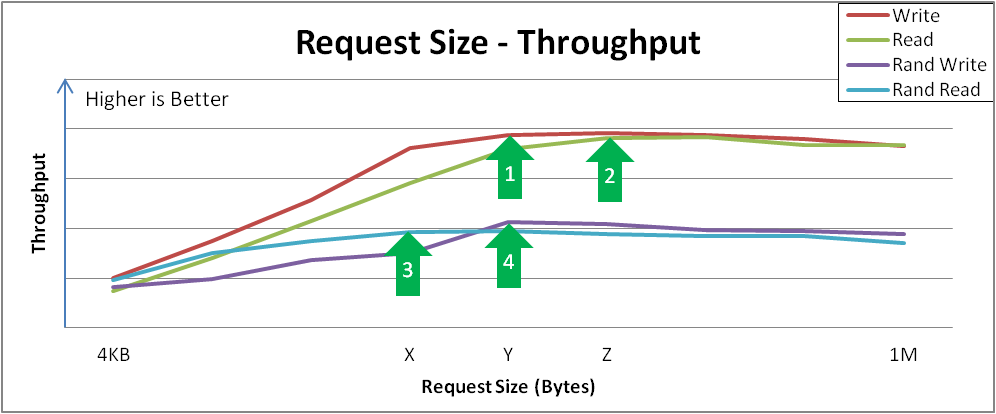
31.4.3. 阶段 3:减少密集读和写 I/O 的影响
- 在固定 I/O 深度中执行四级测试,在 8 KB 到 256 KB 的块大小(2 的指数)上进行四个测试,并以 10% 的增量设置读取百分比,从 0% 开始。请记住,要预先填充要读取的区域,并在测试之间重新创建卷。
- 将 I/O Depth 设置为 第 31.4.1 节 “阶段 1:I/O Depth 的影响,修正了 4 KB 块” 中决定的值。测试输入模拟(读/写混合)示例:
# z=[see previous step] # for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw --rwmixread=$readmix --bs=$iosize\k --name=vdo \ --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \ --norandommap --runtime=300 --direct=0 --iodepth=$z --scramble_buffers=1 \ --offset=0 --size=100g done done - 在各个数据点记录吞吐量和延迟,然后记录图形。
图 31.4. 跨 Varying Read/Write Mixes 的性能下降
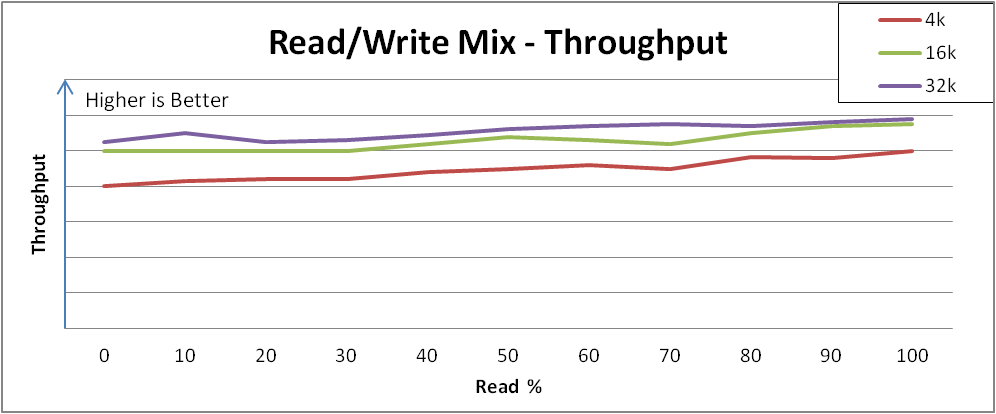
31.4.4. 阶段 4:应用程序环境
# for readmix in 20 50 80; do
for iosize in 4 8 16 32 64 128 256 512 1024; do
fio --rw=rw --rwmixread=$readmix --bsrange=4k-256k --name=vdo \
--filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \
--norandommap --runtime=300 --direct=0 --iodepth=$iosize \
--scramble_buffers=1 --offset=0 --size=100g
done
done
图 31.5. 混合环境性能
31.5. 问题报告
- 测试环境的详细描述 ; 具体信息请查看 “测试环境”一节
- VDO 配置
- 生成此问题的用例
- 在错误时执行的操作
- 控制台或终端上任何错误消息的文本
- 内核日志文件
- 内核崩溃转储(如果可用)
sosreport的结果,这将捕获描述整个 Linux 环境的数据
31.6. 总结
附录 A. 红帽客户门户网站 Labs 与存储管理相关
SCSI decoder
/log 8:0:1:: 文件或日志文件片断中的 SCSI 错误消息,因为这些错误消息可能很难了解用户。
文件系统布局计算器
root 用户身份执行它,以创建所需的文件系统。
LVM RAID Calculator
root 用户身份复制并执行生成的命令,以创建所需的 LVM。
iSCSI Helper
Samba Configuration Helper
- 点 指定基本服务器设置。
- 单击 以添加您要共享的目录
- 单击 以单独添加附加打印机。
多路径帮助器
multipath.conf 文件以进行审阅。当您达到所需的配置时,请下载安装脚本以在服务器上运行。
NFS Helper
多路径配置可视化工具
- 主机组件,包括服务器端的主机总线适配器(HBA)、本地设备和 iSCSI 设备
- 存储端的存储组件
- 服务器和存储之间的光纤或以太网组件
- 所有上述组件的路径
RHEL Backup 和 Restore Assistant
转储和恢复:用于备份 ext2、ext3 和 ext4 文件系统。tar 和 cpio:用于归档或恢复文件和文件夹,特别是在备份磁带驱动器时。rsync:执行备份操作并在位置之间同步文件和目录。dd: 通过独立于涉及的文件系统或操作系统,将文件从源复制到目标块。
- 灾难恢复
- 硬件迁移
- 分区表备份
- 重要文件夹备份
- 增量备份
- 不同的备份
附录 B. 修订历史记录
| 修订历史 | |||
|---|---|---|---|
| 修订 4-10 | Mon Aug 10 2020 | ||
| |||
| 修订 4-09 | Mon Jan 7 2019 | ||
| |||
| 修订 4-08 | Mon Oct 23 2018 | ||
| |||
| 修订 4-07 | Thu Sep 13 2018 | ||
| |||
| 修订 4-00 | Fri Apr 6 2018 | ||
| |||
| 修订 3-95 | Thu Apr 5 2018 | ||
| |||
| 修订 3-93 | Mon Mar 5 2018 | ||
| |||
| 修订 3-92 | Fri Feb 9 2018 | ||
| |||
| 修订 3-90 | Wed Dec 6 2017 | ||
| |||
| 修订 3-86 | Mon Nov 6 2017 | ||
| |||
| 修订 3-80 | Thu Jul 27 2017 | ||
| |||
| 修订 3-77 | Wed May 24 2017 | ||
| |||
| 修订 3-68 | Fri Oct 21 2016 | ||
| |||
| 修订 3-67 | Fri Jun 17 2016 | ||
| |||
| 修订 3-64 | Wed Nov 11 2015 | ||
| |||
| 修订 3-33 | Wed Feb 18 2015 | ||
| |||
| 修订 3-26 | Wed Jan 21 2015 | ||
| |||
| 修订 3-22 | Thu Dec 4 2014 | ||
| |||
| 修订 3-4 | Thu Jul 17 2014 | ||
| |||
| 修订 3-1 | Tue Jun 3 2014 | ||
| |||
索引
符号
- /boot/ directory,/boot/ 目录
- /dev/shm,df 命令
- /etc/fstab,转换为 ext3 文件系统,使用 /etc/fstab挂载 NFS 文件系统,挂载文件系统
- /etc/fstab file
- 启用磁盘配额,启用配额
- /local/directory(客户端配置、挂载)
- NFS,配置 NFS 客户端
- /proc
- /proc/devices,/proc 虚拟文件系统
- /proc/filesystems,/proc 虚拟文件系统
- /proc/mdstat,/proc 虚拟文件系统
- /proc/mounts,/proc 虚拟文件系统
- /proc/mounts/,/proc 虚拟文件系统
- /proc/partitions,/proc 虚拟文件系统
- /proc/devices
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /proc/filesystems
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /proc/mdstat
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /proc/mounts
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /proc/mounts/
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /proc/partitions
- 虚拟文件系统(/proc),/proc 虚拟文件系统
- /remote/export(客户端配置、挂载)
- NFS,配置 NFS 客户端
- 一致性数据
- FS-Cache,FS-Cache
- 不可绑定挂载,共享挂载
- 专家模式 (xfs_quota)
- XFS,XFS 配额管理
- 为存储设备添加路径,添加存储设备或路径
- 为无盘客户端配置 DHCP
- 无盘系统,为无盘客户端配置 DHCP
- 为无盘客户端配置 tftp 服务
- 无盘系统,为无盘客户端配置 tftp 服务
- 主机
- 光纤通道 API,光纤通道 API
- 主要特性
- 互连(扫描)
- iSCSI,扫描 iSCSI Interconnects
- 交互式操作(xfsrestore)
- XFS,恢复
- 交换空间,swap 空间
- 从属挂载,共享挂载
- 传输
- 光纤通道 API,光纤通道 API
- 使用 LUKS/dm-crypt 加密块设备
- 安装过程中的存储注意事项,使用 LUKS 加密块设备
- 修复带有脏日志的 XFS 文件系统
- XFS,修复 XFS 文件系统
- 修复文件系统
- XFS,修复 XFS 文件系统
- 修改链接丢失行为,修改链接丢失行为
- Fibre Channel,Fibre Channel
- 光纤通道 API,光纤通道 API
- 全局文件系统 2
- 全球识别符(WWID)
- 持久性命名,全球标识符(WWID)
- 共享子树,共享挂载
- 共享挂载,共享挂载
- 其他文件系统工具
- ext4,其他 ext4 文件系统实用程序
- 具有 NFS 的缓存限制
- FS-Cache,使用 NFS 的缓存限制
- 写屏障
- 写屏障的重要性
- 写屏障,写屏障的重要性
- 写缓存,禁用
- 写屏障,禁用写缓存
- 写障碍是如何工作的
- 写屏障,写障碍是如何工作的
- 分区
- 创建,创建分区
- 删除,删除分区
- 查看列表,查看分区表
- 格式化
- mkfs ,格式化和标记分区
- 调整大小,使用 fdisk 重新定义分区大小
- 分区表
- 查看,查看分区表
- 分配功能
- 创建
- ext4,创建 ext4 文件系统
- XFS,创建 XFS 文件系统
- 删除存储设备的路径,删除存储设备的路径
- 删除设备,删除存储设备
- 单个用户
- volume_key,将 volume_key 用作单个用户
- 单独分区(用于 /home、/opt、/usr/local)
- 安装过程中的存储注意事项,/home、/opt、/usr/local 的单独分区
- 卸载,卸载文件系统
- 卸载和接口绑定
- iSCSI,配置 iSCSI 卸载和接口绑定
- 原生光纤通道驱动程序,原生光纤通道驱动程序和能力
- 吞吐量类
- 固态磁盘,固态磁盘部署指南
- 启动器实施
- 卸载和接口绑定
- iSCSI,查看可用的 iface 配置
- 启用/禁用
- 写屏障,启用和禁用写障碍
- 启用了 DIF/DIX 的块设备
- 安装过程中的存储注意事项,启用了 DIF/DIX 的块设备
- 命令计时器(SCSI)
- Linux SCSI 层,命令计时器
- 固态磁盘
- 在线存储
- Fibre Channel,Fibre Channel
- 故障排除,在线存储配置故障排除
- 概述,在线存储管理
- sysfs,在线存储管理
- 在线逻辑单元
- 更改读/写状态,更改在线逻辑单元的读/写状态
- 块设备 ioctls(用户空间访问)
- I/O 校准和大小,块设备 ioctls
- 堆栈 I/O 参数
- I/O 校准和大小,堆栈 I/O 参数
- 增加文件系统大小
- XFS,增加 XFS 文件系统的大小
- 增强的 LDAP 支持(autofs 版本 5)
- 备份/恢复
- XFS,备份和恢复 XFS 文件系统
- 奇偶校验
- RAID,RAID 级和线性支持
- 存储互连、扫描,扫描存储互连
- 存储自动挂载程序映射,使用 LDAP 存储(autofs)
- NFS,覆盖或增加站点配置文件
- 存储设备的路径,删除,删除存储设备的路径
- 存储设备路径,添加,添加存储设备或路径
- 存储访问参数
- I/O 校准和大小,存储访问参数
- 安装存储配置
- IBM System z 上的 DASD 和 zFCP 设备,IBM System Z 上的 DASD 和 zFCP 设备
- iSCSI 检测和配置,iSCSI 检测和配置
- 使用 LUKS/dm-crypt 加密块设备,使用 LUKS 加密块设备
- 单独分区(用于 /home、/opt、/usr/local),/home、/opt、/usr/local 的单独分区
- 启用了 DIF/DIX 的块设备,启用了 DIF/DIX 的块设备
- 新功能,安装过程中的存储注意事项
- 更新,安装过程中的存储注意事项
- 过时的 BIOS RAID 元数据,过时的 BIOS RAID 元数据
- 通道命令字(CCW),IBM System Z 上的 DASD 和 zFCP 设备
- 安装程序支持
- 安装过程中的存储注意事项
- IBM System z 上的 DASD 和 zFCP 设备,IBM System Z 上的 DASD 和 zFCP 设备
- iSCSI 检测和配置,iSCSI 检测和配置
- updates,安装过程中的存储注意事项
- 使用 LUKS/dm-crypt 加密块设备,使用 LUKS 加密块设备
- 单独分区(用于 /home、/opt、/usr/local),/home、/opt、/usr/local 的单独分区
- 启用了 DIF/DIX 的块设备,启用了 DIF/DIX 的块设备
- 新功能,安装过程中的存储注意事项
- 过时的 BIOS RAID 元数据,过时的 BIOS RAID 元数据
- 通道命令字(CCW),IBM System Z 上的 DASD 和 zFCP 设备
- 导出的文件系统
- 无盘系统,为无盘客户端配置导出的文件系统
- 将以太网接口配置为使用 FCoE
- FcoE,通过以太网接口配置光纤通道
- 层次结构、文件系统,文件系统层次结构标准(FHS)概述.
- 工具(用于分区和其他文件系统功能)
- I/O 校准和大小,分区和文件系统工具
- 已知问题
- 添加/删除
- LUN(逻辑单元号),rescan-scsi-bus.sh 的已知问题
- 并行 NFS
- pNFS,pNFS
- 性能保证
- FS-Cache,性能保证
- 恢复备份
- XFS,恢复
- 所需的软件包
- FcoE,通过以太网接口配置光纤通道
- 无盘系统,设置远程无盘系统
- 添加/删除
- LUN(逻辑单元号),通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- 扫描互连
- iSCSI,扫描 iSCSI Interconnects
- 扫描存储互连,扫描存储互连
- 持久性命名,持久性命名
- 挂载,挂载文件系统
- ext4,挂载 ext4 文件系统
- XFS,挂载 XFS 文件系统
- 挂载(客户端配置)
- NFS,配置 NFS 客户端
- 控制 SCSI 命令定时器和设备状态
- Linux SCSI 层,控制 SCSI 命令计时器和设备状态
- 故障排除
- 在线存储,在线存储配置故障排除
- 文件系统,收集文件系统信息
- Btrfs,Btrfs(技术预览)
- ext2 (见 ext2)
- ext3 (见 ext3)
- FHS 标准,FHS 组织
- 层次结构,文件系统层次结构标准(FHS)概述.
- 机构,FHS 组织
- 结构,文件系统结构和维护
- 文件系统类型
- 新功能
- 安装过程中的存储注意事项,安装过程中的存储注意事项
- 无盘系统
- DHCP,配置,为无盘客户端配置 DHCP
- tftp 服务,配置,为无盘客户端配置 tftp 服务
- 导出的文件系统,为无盘客户端配置导出的文件系统
- 所需的软件包,设置远程无盘系统
- 网络引导服务,设置远程无盘系统
- 远程无盘系统,设置远程无盘系统
- 暂停
- XFS,暂停 XFS 文件系统
- 更改 dev_loss_tmo
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 更改读/写状态
- 在线逻辑单元,更改在线逻辑单元的读/写状态
- 更新
- 安装过程中的存储注意事项,安装过程中的存储注意事项
- 最大大小
- GFS2,全局文件系统 2
- 最大大小,GFS2 文件系统,全局文件系统 2
- 条带
- RAID,RAID 级和线性支持
- RAID 基础知识,独立磁盘冗余阵列(RAID)
- 条带几何结构
- ext4,创建 ext4 文件系统
- 查看可用的 iface 配置
- 卸载和接口绑定
- iSCSI,查看可用的 iface 配置
- 概述,概述
- 在线存储,在线存储管理
- 正确的 nsswitch 配置(autofs 版本 5),使用
- 步幅-宽度(指定条带几何结构)
- ext4,创建 ext4 文件系统
- 步幅(指定条带几何结构)
- ext4,创建 ext4 文件系统
- 每个 autofs 挂载点都有多个主映射条目(autofs 版本 5)
- 添加/删除
- LUN(逻辑单元号),通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- 特定于 Red Hat Enterprise Linux 的文件位置
- /etc/sysconfig/,特殊 Red Hat Enterprise Linux 文件位置
- (参见 sysconfig 目录)
- /var/cache/yum,特殊 Red Hat Enterprise Linux 文件位置
- /var/lib/rpm/,特殊 Red Hat Enterprise Linux 文件位置
- 特定会话的超时,配置
- iSCSI 配置,为特定会话配置超时
- 用户空间 API 文件
- 光纤通道 API,光纤通道 API
- 用户空间访问
- I/O 校准和大小,用户空间访问
- 电池支持的写缓存
- 写屏障,电池支持的写缓存
- 登录
- iSCSI 目标,登录到 iSCSI 目标
- 目录
- 直接映射支持(autofs 版本 5)
- 硬件 RAID (见 RAID)
- 硬件 RAID 控制器驱动程序
- 确定远程端口状态
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 磁盘存储 (见 磁盘配额)
- parted (见 parted)
- 磁盘配额,磁盘配额
- 禁用 NOP-Outs
- iSCSI 配置,iSCSI 根
- 禁用写缓存
- 写屏障,禁用写缓存
- 离线状态
- Linux SCSI 层,控制 SCSI 命令计时器和设备状态
- 私有挂载,共享挂载
- 移动挂载点,移动挂载点
- 端口状态(远程),确定
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 简介,概述
- 简单模式(xfsrestore)
- XFS,恢复
- 系统信息
- 系统存储管理器
- SSM,系统存储管理器(SSM)
- list 命令,显示有关所有删除的设备的信息
- snapshot 命令,Snapshot
- 后端,SSM 后端
- 安装,安装 SSM
- 调整命令大小,增加卷的大小
- 索引键
- FS-Cache,FS-Cache
- 累积模式(xfsrestore)
- XFS,恢复
- 级
- RAID,RAID 级和线性支持
- 线性 RAID
- RAID,RAID 级和线性支持
- 绑定/解绑到端口的 iface
- 卸载和接口绑定
- iSCSI,绑定/解绑到端口的 iface
- 统计信息(跟踪)
- FS-Cache,统计信息
- 缓存共享
- FS-Cache,缓存共享
- 缓存剔除限制
- FS-Cache,设置缓存剔除限制
- 缓存后端
- FS-Cache,FS-Cache
- 缓存设置
- FS-Cache,设置缓存
- 网络引导服务
- 无盘系统,设置远程无盘系统
- 网络文件系统 (见 NFS)
- 脏日志(修复 XFS 文件系统)
- XFS,修复 XFS 文件系统
- 虚拟文件系统(/proc)
- /proc/devices,/proc 虚拟文件系统
- /proc/filesystems,/proc 虚拟文件系统
- /proc/mdstat,/proc 虚拟文件系统
- /proc/mounts,/proc 虚拟文件系统
- /proc/mounts/,/proc 虚拟文件系统
- /proc/partitions,/proc 虚拟文件系统
- 虚拟机存储,虚拟机存储
- 被阻止的设备,验证
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 覆盖/增加站点配置文件(autofs)
- NFS,配置 autofs
- 记录类型
- discovery
- iSCSI,iSCSI 发现配置
- 设备映射器多路径,DM Multipath
- 设备状态
- Linux SCSI 层,设备状态
- 设备,删除,删除存储设备
- 设置缓存
- FS-Cache,设置缓存
- 调整大小
- ext4,重新定义 ext4 文件系统大小
- 跟踪统计信息
- FS-Cache,统计信息
- 转储级别
- XFS,Backup
- 软件 iSCSI
- iSCSI,为软件 iSCSI 配置 iface
- 卸载和接口绑定
- iSCSI,为软件 iSCSI 配置 iface
- 软件 iSCSI 的 iface
- 卸载和接口绑定
- iSCSI,为软件 iSCSI 配置 iface
- 软件 RAID (见 RAID)
- 过时的 BIOS RAID 元数据
- 安装过程中的存储注意事项,过时的 BIOS RAID 元数据
- 运行会话,检索有关的信息
- iSCSI API,iSCSI API
- 运行状态
- Linux SCSI 层,控制 SCSI 命令计时器和设备状态
- 远程无盘系统
- 无盘系统,设置远程无盘系统
- 远程端口
- 光纤通道 API,光纤通道 API
- 远程端口状态,确定
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 选项(客户端配置、挂载)
- NFS,配置 NFS 客户端
- 通过以太网光纤通道
- FcoE,通过以太网接口配置光纤通道
- 通道命令字(CCW)
- 安装过程中的存储注意事项,IBM System Z 上的 DASD 和 zFCP 设备
- 部署
- 固态磁盘,固态磁盘部署指南
- 部署指南
- 固态磁盘,固态磁盘部署指南
- 配置
- discovery
- iSCSI,iSCSI 发现配置
- 配置 RAID 集
- RAID,配置 RAID 集
- 配额管理
- XFS,XFS 配额管理
- 配额(其他 ext4 文件系统工具)
- ext4,其他 ext4 文件系统实用程序
- 重新调整 iSCSI 逻辑单元的大小,重新调整 iSCSI 逻辑单元的大小
- 重新调整调整后的逻辑单元的大小,重新调整在线逻辑单元的大小
- 重新调整逻辑单元的大小,调整大小,重新调整在线逻辑单元的大小
- 错误信息
- 写屏障,启用和禁用写障碍
- 镜像
- RAID,RAID 级和线性支持
- 项目限值(设置)
- XFS,设置项目限制
- 驱动程序(原生),光纤通道,原生光纤通道驱动程序和能力
- 验证设备是否被阻止
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- 高端阵列
- 写屏障,高端阵列
- 高级 RAID 设备创建
- RAID,创建高级 RAID 设备
A
B
- bcull(缓存剔除限制设置)
- FS-Cache,设置缓存剔除限制
- brun(缓存剔除限制设置)
- FS-Cache,设置缓存剔除限制
- bstop(缓存剔除限制设置)
- FS-Cache,设置缓存剔除限制
- Btrfs
- 文件系统,Btrfs(技术预览)
C
- cachefiles
- FS-Cache,FS-Cache
- cachefilesd
- FS-Cache,设置缓存
- CCW, 通道命令字
- 安装过程中的存储注意事项,IBM System Z 上的 DASD 和 zFCP 设备
- commands
- volume_key,volume_key 命令
D
- debugfs(其他 ext4 文件系统工具)
- ext4,其他 ext4 文件系统实用程序
- dev 目录,/dev/ 目录
- dev_loss_tmo
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- dev_loss_tmo,更改
- Fibre Channel
- 修改链接丢失行为,Fibre Channel
- df,df 命令
- DHCP,配置
- 无盘系统,为无盘客户端配置 DHCP
- discovery
- iSCSI,iSCSI 发现配置
- dm-multipath
- iSCSI 配置,使用 dm-multipath的 iSCSI 设置
- dmraid
- RAID,dmraid
- dmraid(配置 RAID 集)
- RAID,dmraid
- du,DU 命令
E
- e2fsck,恢复回 Ext2 文件系统
- e2image(其他 ext4 文件系统工具)
- ext4,其他 ext4 文件系统实用程序
- e2label
- ext4,其他 ext4 文件系统实用程序
- e2label(其他 ext4 文件系统工具)
- ext4,其他 ext4 文件系统实用程序
- etc 目录,/etc/ 目录
- ext2
- 从 ext3 恢复,恢复回 Ext2 文件系统
- ext3
- 从 ext2 转换,转换为 ext3 文件系统
- 创建,创建 ext3 文件系统
- 功能,ext3 文件系统
- ext4
- debugfs(其他 ext4 文件系统工具),其他 ext4 文件系统实用程序
- e2image(其他 ext4 文件系统工具),其他 ext4 文件系统实用程序
- e2label,其他 ext4 文件系统实用程序
- e2label(其他 ext4 文件系统工具),其他 ext4 文件系统实用程序
- fsync(),ext4 文件系统
- mkfs.ext4,创建 ext4 文件系统
- nobarrier 挂载选项,挂载 ext4 文件系统
- resize2fs(调整 ext4 大小),重新定义 ext4 文件系统大小
- tune2fs (挂载),挂载 ext4 文件系统
- 主要特性,ext4 文件系统
- 其他文件系统工具,其他 ext4 文件系统实用程序
- 写屏障,挂载 ext4 文件系统
- 分配功能,ext4 文件系统
- 创建,创建 ext4 文件系统
- 挂载,挂载 ext4 文件系统
- 文件系统类型,ext4 文件系统
- 条带几何结构,创建 ext4 文件系统
- 步幅-宽度(指定条带几何结构),创建 ext4 文件系统
- 步幅(指定条带几何结构),创建 ext4 文件系统
- 调整大小,重新定义 ext4 文件系统大小
- 配额(其他 ext4 文件系统工具),其他 ext4 文件系统实用程序
F
- FcoE
- 将以太网接口配置为使用 FCoE,通过以太网接口配置光纤通道
- 所需的软件包,通过以太网接口配置光纤通道
- 通过以太网光纤通道,通过以太网接口配置光纤通道
- FHS,文件系统层次结构标准(FHS)概述.,FHS 组织
- (参见 文件系统)
- Fibre Channel
- 在线存储,Fibre Channel
- Fibre Channel 驱动程序(原生),原生光纤通道驱动程序和能力
- findmnt (command)
- 列出挂载,列出当前挂载的文件系统
- FS-Cache
- fsync()
G
I
- I/O 参数堆栈
- I/O 校准和大小,堆栈 I/O 参数
- I/O 校准和大小,存储 I/O 校准和大小
- IBM System z 上的 DASD 和 zFCP 设备
- 安装过程中的存储注意事项,IBM System Z 上的 DASD 和 zFCP 设备
- iface 绑定/解绑
- 卸载和接口绑定
- iSCSI,绑定/解绑到端口的 iface
- iface 设置
- 卸载和接口绑定
- iSCSI,查看可用的 iface 配置
- iface 配置,查看
- 卸载和接口绑定
- iSCSI,查看可用的 iface 配置
- iface(为 iSCSI 卸载配置 )
- 卸载和接口绑定
- iSCSI,为 iSCSI 卸载配置 iface
- iSCSI
- discovery,iSCSI 发现配置
- 记录类型,iSCSI 发现配置
- 配置,iSCSI 发现配置
- targets,登录到 iSCSI 目标
- 登录,登录到 iSCSI 目标
- 卸载和接口绑定,配置 iSCSI 卸载和接口绑定
- iface 设置,查看可用的 iface 配置
- iface 配置,查看,查看可用的 iface 配置
- iface(为 iSCSI 卸载配置 ),为 iSCSI 卸载配置 iface
- 启动器实施,查看可用的 iface 配置
- 查看可用的 iface 配置,查看可用的 iface 配置
- 绑定/解绑到端口的 iface,绑定/解绑到端口的 iface
- 软件 iSCSI,为软件 iSCSI 配置 iface
- 软件 iSCSI 的 iface,为软件 iSCSI 配置 iface
- 扫描互连,扫描 iSCSI Interconnects
- 软件 iSCSI,为软件 iSCSI 配置 iface
- iSCSI API,iSCSI API
- iSCSI 根
- iSCSI 配置,iSCSI 根
- iSCSI 检测和配置
- 安装过程中的存储注意事项,iSCSI 检测和配置
- iSCSI 逻辑单元,调整大小,重新调整 iSCSI 逻辑单元的大小
L
- lazy mount/unmount 支持(autofs 版本 5)
- limit(xfs_quota 专家模式)
- XFS,XFS 配额管理
- Linux I/O 堆栈
- I/O 校准和大小,存储 I/O 校准和大小
- logical_block_size
- I/O 校准和大小,用户空间访问
- LUN(逻辑单元号)
- 添加/删除,通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- rescan-scsi-bus.sh,通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- 已知问题,rescan-scsi-bus.sh 的已知问题
- 所需的软件包,通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- LVM
- I/O 校准和大小,逻辑卷管理器
M
- mdadm(配置 RAID 集)
- RAID,mdadm
- mdraid
- RAID,mdraid
- mkfs ,格式化和标记分区
- mkfs.ext4
- ext4,创建 ext4 文件系统
- mkfs.xfs
- XFS,创建 XFS 文件系统
- mnt 目录,/mnt/ 目录
- mount (命令),使用 mount 命令
N
- NFS
- /etc/fstab ,使用 /etc/fstab挂载 NFS 文件系统
- /local/directory(客户端配置、挂载),配置 NFS 客户端
- /remote/export(客户端配置、挂载),配置 NFS 客户端
- autofs
- LDAP,使用 LDAP 来存储自动挂载程序映射
- 增加,覆盖或增加站点配置文件
- 配置,配置 autofs
- autofs 版本 5,相对于版本 4 , autofs 版本 5 的改进
- condrestart,启动和停止 NFS 服务器
- FS-Cache,在 NFS 中使用缓存
- lazy mount/unmount 支持(autofs 版本 5),相对于版本 4 , autofs 版本 5 的改进
- NFS 和 rpcbind 故障排除,NFS 和 rpcbind故障排除
- RDMA,启用通过 RDMA(NFSoRDMA) 的 NFS
- rfc2307bis (autofs),使用 LDAP 来存储自动挂载程序映射
- rpcbind ,NFS 和 rpcbind
- server(客户端配置、挂载),配置 NFS 客户端
- status,启动和停止 NFS 服务器
- TCP,NFS 简介
- UDP,NFS 简介
- 主机名格式,主机名格式
- 使用防火墙进行配置,在防火墙后面运行 NFS
- 停止,启动和停止 NFS 服务器
- 其他资源,NFS 参考
- 写屏障,NFS
- 启动,启动和停止 NFS 服务器
- 增强的 LDAP 支持(autofs 版本 5),相对于版本 4 , autofs 版本 5 的改进
- 存储自动挂载程序映射,使用 LDAP 存储(autofs),覆盖或增加站点配置文件
- 它如何工作,NFS 简介
- 安全,保护 NFS
- NFSv3 主机访问,具有 AUTH_SYS 和导出控制的 NFS 安全性
- NFSv4 主机访问,带有 AUTH_GSS的 NFS 安全性
- 文件权限,文件权限
- 客户端
- autofs ,autofs
- 挂载选项,常用 NFS 挂载选项
- 配置,配置 NFS 客户端
- 所需的服务,所需的服务
- 挂载(客户端配置),配置 NFS 客户端
- 服务器配置,配置 NFS 服务器
- /etc/exports ,/etc/exports 配置文件
- exportfs 命令,exportfs 命令
- 带有 NFSv4 的 exportfs 命令,使用带有 NFSv4 的 exportfs
- 正确的 nsswitch 配置(autofs 版本 5),使用,相对于版本 4 , autofs 版本 5 的改进
- 每个 autofs 挂载点都有多个主映射条目(autofs 版本 5),相对于版本 4 , autofs 版本 5 的改进
- 直接映射支持(autofs 版本 5),相对于版本 4 , autofs 版本 5 的改进
- 简介,网络文件系统 (NFS)
- 覆盖/增加站点配置文件(autofs),配置 autofs
- 选项(客户端配置、挂载),配置 NFS 客户端
- 重启,启动和停止 NFS 服务器
- 重新载入,启动和停止 NFS 服务器
- NFS 和 rpcbind 故障排除
- NFS(一起使用)
- FS-Cache,在 NFS 中使用缓存
- NFS(缓存限制)
- FS-Cache,使用 NFS 的缓存限制
- nobarrier 挂载选项
- ext4,挂载 ext4 文件系统
- XFS,写屏障
- NOP-Out 请求
- 修改链接丢失
- iSCSI 配置,NOP-Out Interval/Timeout
- NOP-Outs(禁用)
- iSCSI 配置,iSCSI 根
O
- opt 目录,/opt/ 目录
P
Q
- queue_if_no_path
- iSCSI 配置,使用 dm-multipath的 iSCSI 设置
- 修改链接丢失
- iSCSI 配置,replacement_timeout
- quotacheck ,创建配额数据库文件
- quotacheck 命令
- 检查配额的准确性,使配额保持准确
- quotaoff ,启用和禁用
- quotaon ,启用和禁用
R
- RAID
- 0 级,RAID 级和线性支持
- 1 级,RAID 级和线性支持
- 4 级,RAID 级和线性支持
- 5 级,RAID 级和线性支持
- Anaconda 支持,Anaconda 安装程序中的 RAID 支持
- dmraid,dmraid
- dmraid(配置 RAID 集),dmraid
- mdadm(配置 RAID 集),mdadm
- mdraid,mdraid
- RAID 子系统,Linux RAID 子系统
- 使用原因,独立磁盘冗余阵列(RAID)
- 奇偶校验,RAID 级和线性支持
- 安装程序支持,Anaconda 安装程序中的 RAID 支持
- 条带,RAID 级和线性支持
- 硬件 RAID,RAID 类型
- 硬件 RAID 控制器驱动程序,Linux 硬件 RAID 控制器驱动程序
- 级,RAID 级和线性支持
- 线性 RAID,RAID 级和线性支持
- 软件 RAID,RAID 类型
- 配置 RAID 集,配置 RAID 集
- 镜像,RAID 级和线性支持
- 高级 RAID 设备创建,创建高级 RAID 设备
- RAID 子系统
- RAID,Linux RAID 子系统
- RDMA
- READ CAPACITY(16)
- I/O 校准和大小,SCSI
- replacement_timeout
- 修改链接丢失
- iSCSI 配置,SCSI 错误处理程序,replacement_timeout
- replacement_timeoutM
- iSCSI 配置,iSCSI 根
- report (xfs_quota 专家模式)
- XFS,XFS 配额管理
- rescan-scsi-bus.sh
- 添加/删除
- LUN(逻辑单元号),通过 rescan-scsi-bus.sh 添加/删除逻辑单元
- resize2fs,恢复回 Ext2 文件系统
- resize2fs(调整 ext4 大小)
- ext4,重新定义 ext4 文件系统大小
- rfc2307bis (autofs)
- rpcbind ,NFS 和 rpcbind
- (参见 NFS)
- NFS,NFS 和 rpcbind故障排除
- rpcinfo ,NFS 和 rpcbind故障排除
- status,启动和停止 NFS 服务器
- rpcinfo ,NFS 和 rpcbind故障排除
S
- SCSI 命令计时器
- Linux SCSI 层,命令计时器
- SCSI 标准
- I/O 校准和大小,SCSI
- SCSI 错误处理程序
- 修改链接丢失
- iSCSI 配置,SCSI 错误处理程序
- server(客户端配置、挂载)
- NFS,配置 NFS 客户端
- SMB (见 SMB)
- SRV 目录,/srv/ 目录
- SSD
- 固态磁盘,固态磁盘部署指南
- SSM
- 系统存储管理器,系统存储管理器(SSM)
- list 命令,显示有关所有删除的设备的信息
- snapshot 命令,Snapshot
- 后端,SSM 后端
- 安装,安装 SSM
- 调整命令大小,增加卷的大小
- su (mkfs.xfs 子选项)
- XFS,创建 XFS 文件系统
- sw (mkfs.xfs 子选项)
- XFS,创建 XFS 文件系统
- sys 目录,/sys/ 目录
- sysconfig 目录,特殊 Red Hat Enterprise Linux 文件位置
- sysfs
- 概述
- 在线存储,在线存储管理
- sysfs 接口(用户空间访问)
- I/O 校准和大小,sysfs 接口
T
- targets
- iSCSI,登录到 iSCSI 目标
- tftp 服务,配置
- 无盘系统,为无盘客户端配置 tftp 服务
- TRIM 命令
- 固态磁盘,固态磁盘部署指南
- tune2fs
- 使用它恢复回 ext2,恢复回 Ext2 文件系统
- 使用它来转换为 ext3,转换为 ext3 文件系统
- tune2fs (挂载)
- ext4,挂载 ext4 文件系统
- tune2fs(设置缓存)
- FS-Cache,设置缓存
V
- var 目录,/var/ 目录
- var/lib/rpm/ directory,特殊 Red Hat Enterprise Linux 文件位置
- var/spool/up2date/ directory,特殊 Red Hat Enterprise Linux 文件位置
- version
- 有什么新内容
- autofs,相对于版本 4 , autofs 版本 5 的改进
- volume_key
- commands,volume_key 命令
- 单个用户,将 volume_key 用作单个用户
W
- WWID
- 持久性命名,全球标识符(WWID)
X
- XFS
- fsync(),XFS 文件系统
- gquota/gqnoenforce,XFS 配额管理
- limit(xfs_quota 专家模式),XFS 配额管理
- mkfs.xfs,创建 XFS 文件系统
- nobarrier 挂载选项,写屏障
- pquota/pqnoenforce,XFS 配额管理
- report (xfs_quota 专家模式),XFS 配额管理
- su (mkfs.xfs 子选项),创建 XFS 文件系统
- sw (mkfs.xfs 子选项),创建 XFS 文件系统
- uquota/uqnoenforce,XFS 配额管理
- xfsdump,Backup
- xfsprogs,暂停 XFS 文件系统
- xfsrestore,恢复
- xfs_admin,其他 XFS 文件系统工具
- xfs_bmap,其他 XFS 文件系统工具
- xfs_copy,其他 XFS 文件系统工具
- xfs_db,其他 XFS 文件系统工具
- xfs_freeze,暂停 XFS 文件系统
- xfs_fsr,其他 XFS 文件系统工具
- xfs_growfs,增加 XFS 文件系统的大小
- xfs_info,其他 XFS 文件系统工具
- xfs_mdrestore,其他 XFS 文件系统工具
- xfs_metadump,其他 XFS 文件系统工具
- xfs_quota,XFS 配额管理
- xfs_repair,修复 XFS 文件系统
- 专家模式 (xfs_quota),XFS 配额管理
- 主要特性,XFS 文件系统
- 交互式操作(xfsrestore),恢复
- 修复带有脏日志的 XFS 文件系统,修复 XFS 文件系统
- 修复文件系统,修复 XFS 文件系统
- 写屏障,写屏障
- 分配功能,XFS 文件系统
- 创建,创建 XFS 文件系统
- 增加文件系统大小,增加 XFS 文件系统的大小
- 备份/恢复,备份和恢复 XFS 文件系统
- 挂载,挂载 XFS 文件系统
- 文件系统类型,XFS 文件系统
- 暂停,暂停 XFS 文件系统
- 简单模式(xfsrestore),恢复
- 累积模式(xfsrestore),恢复
- 转储级别,Backup
- 配额管理,XFS 配额管理
- 项目限值(设置),设置项目限制
- xfsdump
- XFS,Backup
- xfsprogs
- XFS,暂停 XFS 文件系统
- xfsrestore
- XFS,恢复
- xfs_admin
- XFS,其他 XFS 文件系统工具
- xfs_bmap
- XFS,其他 XFS 文件系统工具
- xfs_copy
- XFS,其他 XFS 文件系统工具
- xfs_db
- XFS,其他 XFS 文件系统工具
- xfs_freeze
- XFS,暂停 XFS 文件系统
- xfs_fsr
- XFS,其他 XFS 文件系统工具
- xfs_growfs
- XFS,增加 XFS 文件系统的大小
- xfs_info
- XFS,其他 XFS 文件系统工具
- xfs_mdrestore
- XFS,其他 XFS 文件系统工具
- xfs_metadump
- XFS,其他 XFS 文件系统工具
- xfs_quota
- XFS,XFS 配额管理
- xfs_repair
- XFS,修复 XFS 文件系统