
配置数据网格缓存
Red Hat Data Grid
数据网格是高性能分布式内存数据存储。
- Schemaless 数据结构
- 灵活性以将不同对象存储为键值对。
- 基于网格的数据存储
- 旨在在集群中分发和复制数据。
- 弹性扩展
- 动态调整节点数量,以在不中断服务的情况下满足需求。
- 数据互操作性
- 从不同端点在网格中存储、检索和查询数据。
Data Grid 文档
红帽客户门户网站中提供了数据网格的文档。
Data Grid 下载
访问红帽客户门户网站中的 Data Grid 软件下载。
您必须有一个红帽帐户才能访问和下载 Data Grid 软件。
使开源包含更多
红帽致力于替换我们的代码、文档和 Web 属性中存在问题的语言。我们从这四个术语开始:master、slave、黑名单和白名单。由于此项工作十分艰巨,这些更改将在即将推出的几个发行版本中逐步实施。详情请查看 CTO Chris Wright 的信息。
第 1 章 Data Grid 缓存
数据网格缓存提供灵活、内存数据存储,您可以配置它们以适合以下用例:
- 使用高速本地缓存提高应用程序性能。
- 通过减少写入操作的卷来优化数据库。
- 为跨集群的一致性数据提供弹性和持久性。
1.1. 缓存 API
cache<K,V > 是数据网格的中心界面,并扩展了 java.util.concurrent.ConcurrentMap。
缓存条目是高并发数据结构,采用 key:value 格式,支持广泛的、可配置的各种数据类型,从简单字符串到更复杂的对象。
1.2. 缓存管理器
CacheManager API 是与 Data Grid 缓存交互的起点。缓存管理器控制缓存生命周期,创建、修改和删除缓存实例。
Data Grid 提供了两个 CacheManager 实现:
EmbeddedCacheManager- 在与客户端应用程序相同的 Java 虚拟机(JVM)中运行 Data Grid 时缓存的入口点。
RemoteCacheManager-
在其自己的 JVM 中运行 Data Grid Server 时缓存的入口点。当您实例化
RemoteCacheManager时,它通过 Hot Rod 端点建立与 Data Grid Server 的持久 TCP 连接。
嵌入和远程 缓存管理器 实施共享一些方法和属性。但是,EmbeddedCacheManager 和 RemoteCacheManager 之间存在语义差别。
1.3. 缓存模式
数据网格缓存管理器可以创建和控制使用多个使用不同模式的缓存。例如,您可以使用相同的缓存管理器进行本地缓存、分布式缓存以及带有 invalidation 模式的缓存。
- Local
- 数据网格作为单一节点运行,永远不会在缓存条目上复制读取或写入操作。
- 复制
- 数据网格在集群中的所有节点上复制所有缓存条目,仅执行本地读取操作。
- 分布式
-
数据网格在集群中的节点子集上复制缓存条目,并为固定的所有者节点分配条目。
数据网格请求从所有者节点读取操作以确保其返回正确的值。 - 失效
- 每当操作修改缓存中的条目时,Data Grid 会从所有节点驱除过时的数据。数据网格仅执行本地读取操作。
- 分散
-
数据网格在节点子集中存储缓存条目。
默认情况下,数据网格为分散缓存中的每个缓存条目分配一个主要所有者和备份所有者。
数据网格通过与分布式缓存相同的方法分配主要所有者,而备份所有者始终为启动写入操作的节点。
数据网格请求至少从一个所有者节点读取操作,以确保返回正确的值。
1.3.1. 缓存模式的比较
您选择的缓存模式取决于数据的质量和保证。
下表总结了缓存模式之间的主要区别:
| 缓存模式 | 集群? | 读取性能 | 写入性能 | 容量 | 可用性 | 功能 |
|---|---|---|---|---|---|---|
| Local | 否 | 高 (本地) | 高 (本地) | 单一节点 | 单一节点 | complete |
| Simple(简单) | 否 | 最高 (本地) | 最高 (本地) | 单一节点 | 单一节点 | 部分: 无事务、持久性或索引。 |
| 失效 | 是 | 高 (本地) | 低 (所有节点,无数据) | 单一节点 | 单一节点 | partial: 不索引。 |
| 复制 | 是 | 高 (本地) | 最低 (所有节点) | 最小的节点 | 所有节点 | complete |
| 分布式 | 是 | 中 (所有者) | 中 (所有者节点) | 所有节点容量的总和除以所有者数。 | 所有者节点 | complete |
| 分散 | 是 | 中 (主要) | 更高的 (单一 RPC) | 所有节点容量的总和除以 2 分。 | 所有者节点 | 部分: 无事务. |
1.4. 本地缓存
数据网格提供了一个本地缓存模式,它类似于 ConcurrentHashMap。
缓存提供比简单映射更多的功能,包括直写和直写到持久性存储,以及驱除和过期等管理功能。
Data Grid Cache API 在 Java 中扩展了 ConcurrentMap API,因此可以轻松地从映射迁移到数据网格缓存。
本地缓存配置
XML
<local-cache name="mycache"
statistics="true">
<encoding media-type="application/x-protostream"/>
</local-cache>
JSON
{
"local-cache": {
"name": "mycache",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
}
}
}
YAML
localCache:
name: "mycache"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
1.4.1. 简单缓存
简单的缓存是本地缓存类型,它禁用对以下功能的支持:
- 事务和调用批处理
- 持久性存储
- 自定义拦截器
- 索引
- transcoding
但是,您可以将其他数据网格功能用于简单缓存,如 expiration、驱除、统计和安全功能。如果您配置了一个与简单缓存不兼容的功能,Data Grid 会抛出异常。
简单缓存配置
XML
<local-cache simple-cache="true" />
JSON
{
"local-cache" : {
"simple-cache" : "true"
}
}
YAML
localCache: simpleCache: "true"
第 2 章 集群缓存
您可以在 Data Grid 集群上创建嵌入和远程缓存,以便在节点间复制数据。
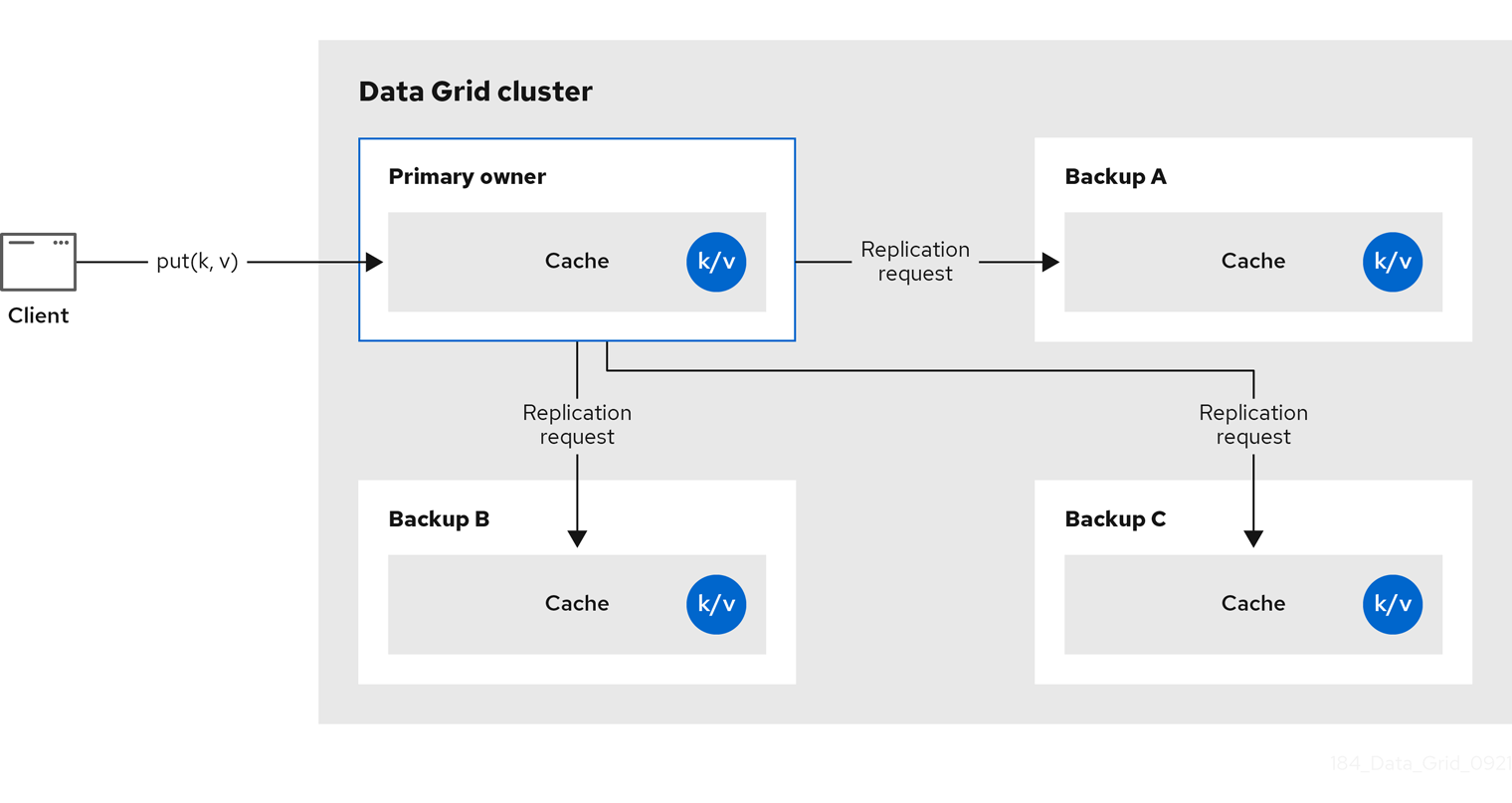
2.1. 复制缓存
Data Grid 将缓存中的所有条目复制到集群中的所有节点。每个节点可以在本地执行读取操作。
复制的缓存提供了在集群间共享状态的简单方法,但适合小于 10 个节点的集群。由于复制请求数量与集群中的节点数量线性扩展,所以在大型集群中使用复制缓存会降低性能。但是,您可以使用 UDP 多播来复制请求来提高性能。
每个密钥都有一个主要所有者,用于对数据容器更新进行序列化以提供一致性。
图 2.1. 复制缓存
同步或异步复制
-
同步复制会拦截 caller (例如,在
cache.put (key, value)上),直到修改成功复制到集群中的所有节点。 - 异步复制在后台执行复制,并立即返回写入操作。不建议使用异步复制,因为通信错误或远程节点上出现的错误不会报告给调用者。
Transactions
如果启用了事务,则不通过主所有者复制写操作。
由于具有保守的锁定,每个写入都会触发锁定信息,该消息被广播到所有节点。在事务提交过程中,originator 广播一个单阶段准备消息和解锁信息(可选)。单阶段准备或解锁信息为 fire-and-forget。
通过光驱锁定,原始器将广播准备消息、提交消息和解锁信息(可选)。同样,一次性准备或解锁信息是 fire-and-forget。
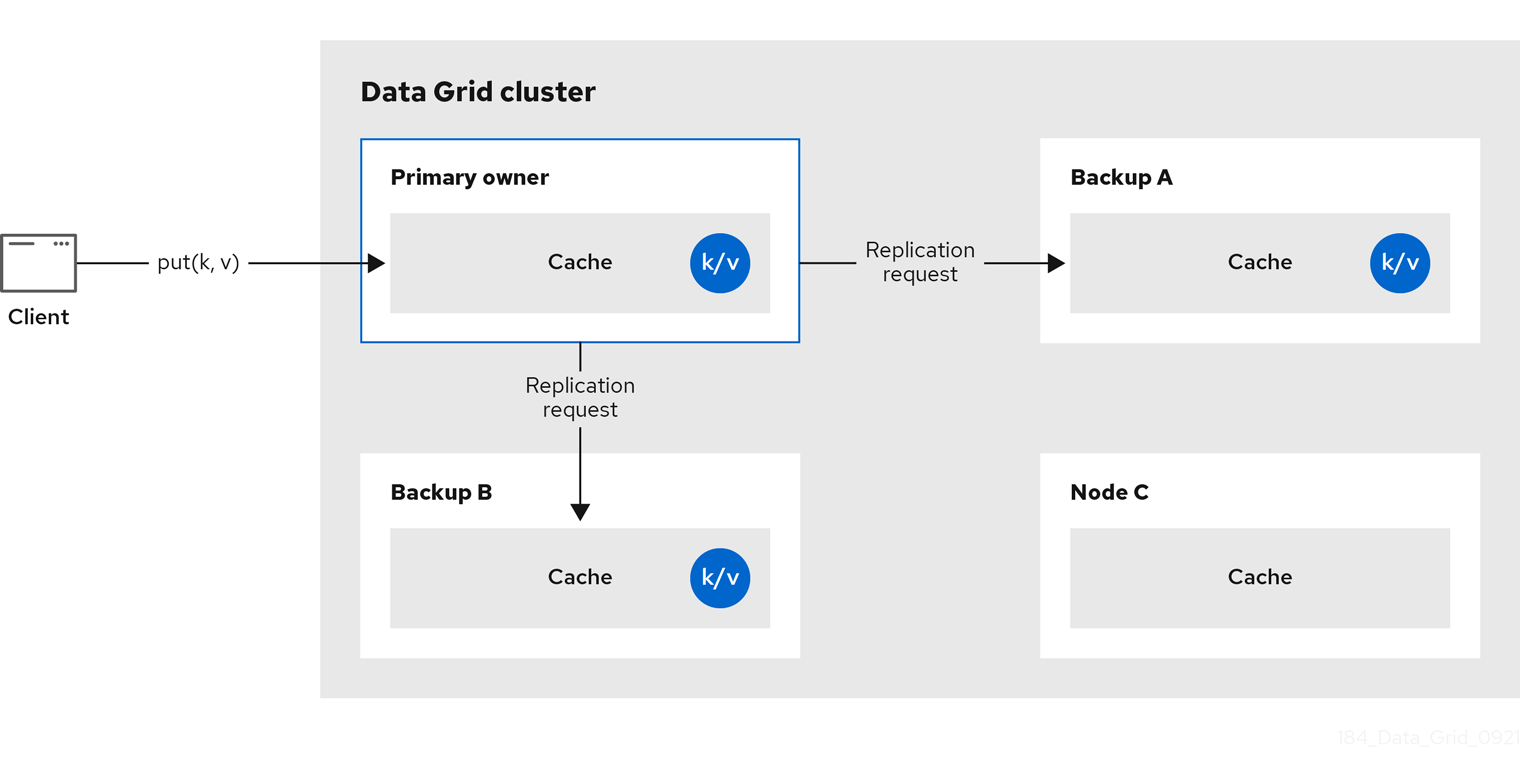
2.2. 分布式缓存
数据网格会尝试将缓存中任何条目的固定副本数配置为 numOwners。这允许分布式缓存线性扩展,在节点添加到集群中时存储更多数据。
当节点加入并离开集群时,当键超过 numOwners 的副本时,会出现一些时间。特别是,如果 numOwners 节点保留了快速成功,则一些条目将会丢失,因此,分布式缓存容许 numOwners - 1 个节点失败。
复制次数代表性能和数据持久性之间的利弊。您维护的副本数越多,较低性能也会降低因为服务器或网络故障而丢失数据的风险。
数据网格将密钥的所有者拆分为一个 主要所有者,后者协调对密钥的写入,以及零个或多个 备份所有者。
下图显示了客户端发送到备份所有者的写入操作。在这种情况下,备份节点会将写操作转发到主所有者,然后将写入复制到备份。
图 2.2. 集群复制
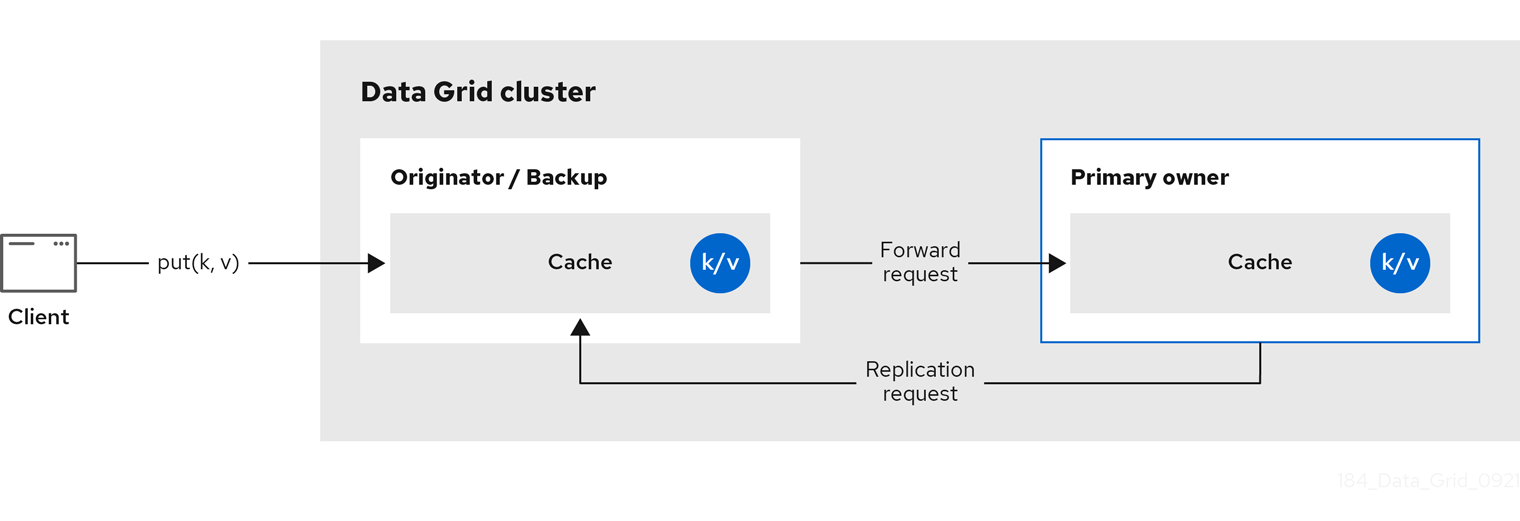
图 2.3. 分布式缓存
读取操作
读取操作从主所有者请求值。如果主所有者在合理的时间内没有响应,Data Grid 也从备份所有者请求值。
如果本地缓存中存在密钥,读取操作可能需要 0 信息,如果所有所有者都很慢,则读取操作可能需要最多 2 * numOwners 信息。
写操作
写入操作最多为 2 * numOwners 信息。从原始机构到主所有者和 numOwners - 1 信息(从主到备份节点)的消息以及相应的确认信息。
缓存拓扑更改可能会导致重试和写入操作的额外信息。
同步或异步复制
不建议使用异步复制,因为它可能会丢失更新。除了丢失更新外,异步分布式缓存还会在线程写入密钥时看到过时的值,然后立即读取相同的密钥。
Transactions
事务性分布式缓存仅将锁定/准备/过量消息发送到受影响的节点,这意味着所有拥有对事务影响的键的节点。作为优化,如果事务写入一个密钥,并且原始器是密钥的主所有者,则不会复制锁定消息。
2.2.1. 读取一致性
即使使用同步复制,分布式缓存也不是线性化的。对于事务缓存,不支持序列化/快照隔离。
例如,线程会执行一个请求:
cache.get(k) -> v1 cache.put(k, v2) cache.get(k) -> v2
但是,另一个线程可能会以不同的顺序看到值:
cache.get(k) -> v2 cache.get(k) -> v1
其原因在于,读取可以从任何所有者返回值,具体根据主所有者回复速度。写入不是在所有所有者中原子的。实际上,仅在从备份收到确认后更新的主要提交。在 primary 正在等待备份的确认消息时,从备份中读取时将看到新值,但从主中读取内容将看到旧信息。
2.2.2. 密钥所有权
分布式缓存将条目分成固定数量的片段,并将每个网段分配给所有者节点列表。复制缓存执行相同的操作,但每个节点都是一个所有者。
所有者列表中的第一个节点是主所有者。列表中的其他节点是 备份所有者。当缓存拓扑更改时,因为节点加入或离开集群,片段所有权表会广播到每个节点。这样,节点可以在不为每个密钥发出多播请求或维护元数据的情况下定位密钥。
numSegments 属性配置可用的片段数量。但是,除非集群重启,否则片段的数量无法更改。
与键对映射相同,也无法更改。无论集群拓扑的变化如何,键必须始终映射到同一片段。重要的一点是,在尽量减少集群拓扑更改时,键与分段映射平均分配分配给每个节点的片段数量非常重要。
| 一致的哈希值工厂实现 | 描述 |
|---|---|
|
| 根据 一致的散列 使用算法。当服务器提示被禁用时,默认选择。 只要集群是对称,这个实现始终都会将密钥分配给每个缓存中的同一节点。换句话说,所有缓存在所有节点上都运行。这个实现的负点会有一些负点,负载分布略微不均匀。它还可使片段比加入或保留的严格必要条件移动。 |
|
|
相当于 |
|
|
实现比 |
|
|
相当于 |
|
| 内部用于实施复制缓存。您不能在分布式缓存中显式选择这个算法。 |
散列配置
您可以配置 ConsistentHashFactory 实现,包括只带有内嵌缓存的自定义设置。
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />
ConfigurationBuilder
Configuration c = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.hash()
.numOwners(2)
.numSegments(100)
.capacityFactor(2)
.build();
其他资源
2.2.3. 容量因素
容量因素根据集群中每个节点的可用资源分配片段数量。
节点的容量因素适用于该节点主要所有者和备份所有者的片段。换句话说,capacity factor 指定的容量是节点与集群中的其他节点相比的总容量。
默认值为 1,表示集群中的所有节点都有相等的容量和数据网格,为集群中的所有节点分配相同的片段数量。
但是,如果节点有不同数量的可用内存,您可以配置容量因素,以便 Data Grid 哈希算法为每个节点分配容量加权的片段。
容量工厂配置的值必须是正数,可以是 1.5 分的一部分。您还可以配置容量因 0, 但建议只针对临时加入集群的节点,而应使用零容量配置。
2.2.3.1. 零容量节点
您可以为每个缓存、用户定义的缓存和内部缓存配置容量因素为 0 的节点。在定义零容量节点时,节点不会保存任何数据。
零容量节点配置
XML
<infinispan> <cache-container zero-capacity-node="true" /> </infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"zero-capacity-node" : "true"
}
}
}
YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"
ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);
2.2.4. 级别一(L1)缓存
当数据节点从集群中的另一节点检索条目时,Data Grid 节点会创建本地副本。L1 缓存避免重复在主所有者节点上查找条目并添加性能。
下图演示了 L1 缓存如何工作:
图 2.4. L1 缓存
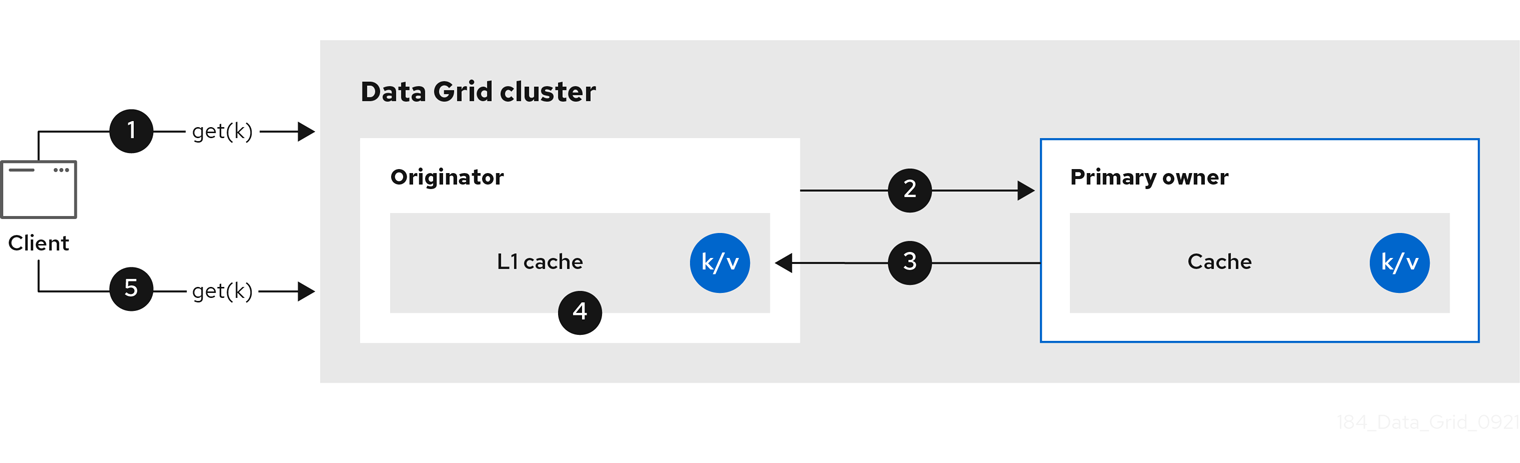
在 "L1 缓存" 图表中:
-
客户端调用
cache.get ()来读取集群中另一节点是主所有者的条目。 - originator 节点将读取操作转发到主所有者。
- 主所有者返回 key/value 条目。
- 原始器节点创建本地副本。
-
后续的
cache.get ()调用会返回本地条目,而不转发到主所有者。
L1 缓存性能
启用 L1 提高了读取操作的性能,但需要主所有者节点在修改条目时广播无效的消息。这样可确保数据网格在集群中删除任何日期副本。然而,这也降低了写操作的性能并增加内存用量,从而减少缓存的整体容量。
与任何其他缓存条目一样,数据网格驱除并过期本地副本或 L1 条目。
L1 缓存配置
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>
JSON
{
"distributed-cache": {
"l1-lifespan": "5000",
"l1-cleanup-interval": "60000"
}
}
YAML
distributedCache: l1Lifespan: "5000" l1-cleanup-interval: "60000"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);
2.2.5. 服务器提示
服务器提示通过尽可能在多个服务器、机架和数据中心中复制条目来增加分布式缓存中的数据可用性。
服务器提示仅适用于分布式缓存。
当数据网格发布数据的副本时,它会按照优先级顺序排列:站点、机架、机器和节点。所有配置属性都是可选的。例如,当您只指定机架 ID 时,Data Grid 会将副本分布到不同的机架和节点上。
如果缓存的片段数量太低,则服务器提示可能会影响集群重新平衡操作。
多个数据中心中的集群的替代选择是跨站点复制。
服务器提示配置
XML
<cache-container>
<transport cluster="MyCluster"
machine="LinuxServer01"
rack="Rack01"
site="US-WestCoast"/>
</cache-container>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"cluster" : "MyCluster",
"machine" : "LinuxServer01",
"rack" : "Rack01",
"site" : "US-WestCoast"
}
}
}
}
YAML
cacheContainer:
transport:
cluster: "MyCluster"
machine: "LinuxServer01"
rack: "Rack01"
site: "US-WestCoast"
GlobalConfigurationBuilder
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.clusterName("MyCluster")
.machineId("LinuxServer01")
.rackId("Rack01")
.siteId("US-WestCoast");
2.2.6. 关键关联性服务
在分布式缓存中,密钥被分配到一个带有不透明算法的节点列表。无法轻松撤销计算并生成映射到特定节点的键。但是,数据网格可生成一系列(伪)随机键,查看其主所有者是哪一个,并在需要密钥映射到特定节点时将其转移到应用程序。
以下代码片段描述了如何获取和使用该服务。
// 1. Obtain a reference to a cache
Cache cache = ...
Address address = cache.getCacheManager().getAddress();
// 2. Create the affinity service
KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
// 3. Obtain a key for which the local node is the primary owner
Object localKey = keyAffinityService.getKeyForAddress(address);
// 4. Insert the key in the cache
cache.put(localKey, "yourValue");服务从第 2 步启动:此时使用提供的 Executor 生成和队列键。在第 3 步中,我们从服务中获取密钥,并在第 4 步中使用它。
生命周期
KeyAffinityService 扩展 生命周期,允许停止和(重新)启动它:
public interface Lifecycle {
void start();
void stop();
}
该服务通过 KeyAffinityServiceFactory 进行实例化。所有工厂方法都有 Executor 参数,该参数用于异步密钥生成(因此它不会在调用者的线程中发生)。用户负责处理此可执行文件的关闭 。
启动后,需要显式停止 KeyAffinityService。这会停止后台密钥生成并释放其他保存的资源。
唯一停止的 KeyAffinityService 才会在关闭了它注册的缓存管理器时。
拓扑更改
当缓存拓扑更改时,KeyAffinityService 生成的密钥所有权可能会改变。关键关联性服务会跟踪这些拓扑的更改,且不会返回当前映射到不同节点的键,但它不会执行之前生成的密钥。
因此,应用程序应该完全将 KeyAffinityService 视为优化,它们不应依赖于生成的密钥的位置来获得正确性。
特别是,应用程序不应该依赖 KeyAffinityService 生成的密钥来始终放在一起。密钥的并置仅由组 API 提供。
2.2.7. 分组 API
除了键关联服务之外,Grouping API 允许您在同一节点上并置一组条目,但无法选择实际节点。
默认情况下,使用密钥的 hashCode () 计算密钥片段。如果使用 Grouping API,Data Grid 将计算该组的片段,并使用该片段作为密钥的片段。
使用 Grouping API 时,务必要确保每个节点仍然可以计算每个密钥的所有者,而无需联系其他节点。因此,无法手动指定组。组可以不属于条目(由密钥类生成的)或 extrinsic (由外部功能生成)。
要使用 Grouping API,您必须启用组。
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled() .build();
<distributed-cache> <groups enabled="true"/> </distributed-cache>
如果您已控制密钥类(您可以更改类定义,而不是不可修改库的一部分),那么我们建议使用一个内部组。内部组通过向方法添加 @Group 注释来指定,例如:
class User {
...
String office;
...
public int hashCode() {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group
// All keys in the same group end up with the same owners
@Group
public String getOffice() {
return office;
}
}
}
组方法必须返回 String
如果您没有对密钥类控制,或者组的确定性是与密钥类相关的一个或临时性问题,我们推荐使用 extrinsic 组。通过实施组 器接口来指定 extrinsic 组。
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
如果为同一密钥类型配置了多个 组 类,则所有这些类都会被调用,接收上一个密钥计算的值。如果键类也具有 @Group 注释,则第一个 Grouper 将接收由注释方法计算的组。这样,在使用内部组时,您可以更好地控制组。
Grouper 实施示例
public class KXGrouper implements Grouper<String> {
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "0" or group "1".
private static Pattern kPattern = Pattern.compile("(^k)(<a>\\d</a>)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else {
return null;
}
}
public Class<String> getKeyType() {
return String.class;
}
}
组器 实施必须在缓存配置中明确注册。如果您要以编程方式配置数据网格:
Configuration c = new ConfigurationBuilder() .clustering().hash().groups().enabled().addGrouper(new KXGrouper()) .build();
或者,如果您使用 XML:
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>高级 API
AdvancedCache 有两个特定于组的方法:
-
getGroup (groupName)检索到组的缓存中的所有密钥。 -
removeGroup (groupName)删除属于组的缓存中的所有密钥。
这两种方法都迭代整个数据容器和存储(如果存在),因此当缓存包含大量小组时,它们可能会很慢。
2.3. 失效缓存
您可以在validation 模式中使用数据网格来优化执行读操作卷的系统。一个好的示例是使用 invalidation 以防止在状态更改时进行大量数据库写入。
只有当您拥有另一个数据库等数据永久存储时,这种缓存模式才有意义,并且仅在读写系统中使用数据网格作为优化,以防止每个读取的数据库出现。如果为无效配置缓存,则每个数据在缓存中都会有变化,集群中的其他缓存都会收到一条信息,告知它们的数据已经过期,并应该从内存中删除,并应该从任何本地存储中删除。
图 2.5. 失效缓存
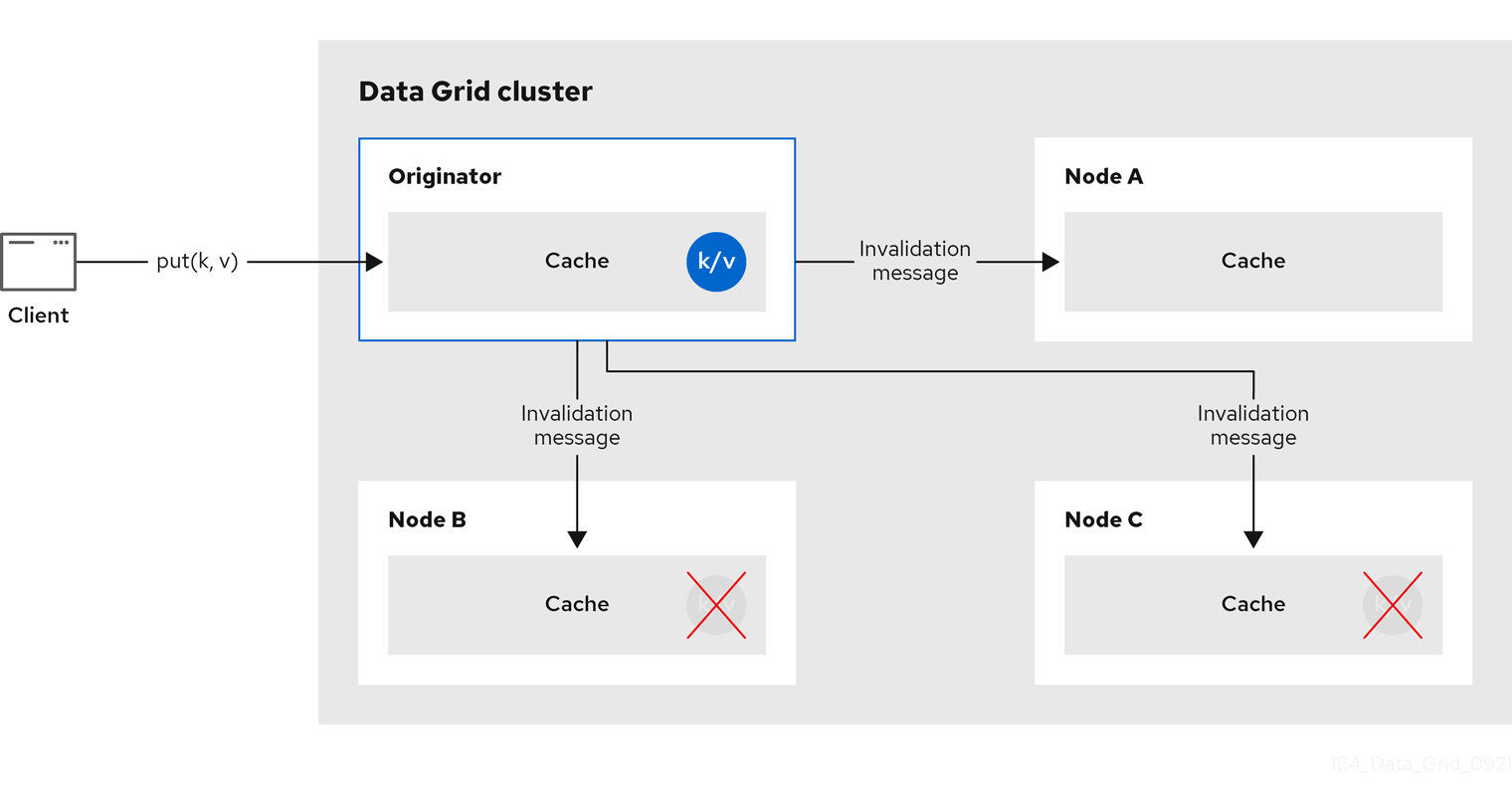
有时,应用程序会从外部存储中读取值并希望将其写入本地缓存中,而不将其从其他节点中删除。要做到这一点,它必须调用 Cache.putForExternalRead (key, value) 而不是 Cache.put (key, value)。
Invalidation 模式可以与共享缓存存储一起使用。写入操作都会更新共享存储,它将从其他节点的内存中删除过时的值。这样做的好处是两倍:网络流量尽可能减少,与复制整个值相比,网络流量尽可能小,而且集群中的其他缓存会以极快的方式查找修改的数据,这仅在需要时才会显示修改的数据。
不会在本地、非共享、缓存存储中使用无效模式。invalidation 消息不会删除本地存储中的条目,有些节点会看到过时的值。
也可以使用特殊的缓存加载程序( ClusterLoader )配置失效的缓存。启用 ClusterLoader 时,读取找不到本地节点上的密钥的操作将首先从所有其他节点请求,并在本地将其保存在内存中。在某些情况下,它将存储陈旧的值,因此只有在对过时值有较高的容错能力时才使用它。
同步或异步复制
同步时,写入块直到集群中的所有节点都被驱除掉过时的值。异步时,原始器会广播无效的消息,但不会等待响应。这意味着,当在原始器上写入完成后,其他节点仍然可以看到过时的值。
Transactions
事务可用于批量无效消息。事务获取主所有者上的密钥锁定。
由于具有保守的锁定,每个写入都会触发锁定信息,该消息被广播到所有节点。在事务提交过程中,originator 广播一个单阶段准备消息(可选 fire-and-forget),它会导致所有受影响的键并释放锁。
通过光驱锁定,原始器将广播准备消息、提交消息和解锁信息(可选)。单阶段准备或解锁信息为 fire-and-forget,最后一条消息会释放锁定。
2.4. 分散缓存
分散缓存与分布式缓存非常相似,因为它们允许线性扩展集群。分散缓存通过维护数据的两个副本(numOwners=2),允许单个节点故障。与分布式缓存不同,数据的位置不会被修复;而我们使用相同的 Consistent Hash 算法来查找主所有者,备份副本会存储在最后一次写入数据的节点中。当写入源自主所有者时,备份副本存储在任何其他节点上(此副本的确切位置不重要)。
这就具有单一远程过程调用(RPC)的优势,用于任何写入(分布式缓存需要一或两个 RPC),但读取必须始终以主所有者为目标。这样可加快写入速度,但可能速度较慢,因此这个模式更适合写密集型应用程序。
存储多个备份副本也会带来稍高的内存消耗。要删除过时的备份副本,无效的消息会在集群中广播,这会产生一些开销。这可降低具有大量节点的集群中分散缓存的性能。
当节点崩溃时,主副本可能会丢失。因此,集群必须协调备份并找出最后一次写入的备份副本。这个过程会在状态传输过程中产生更多的网络流量。
因为数据的写入程序也是备份,即使集群在传输级别上指定 machine/rack/site ID 无法在同一台机器/rack/site 上处理多个故障。
您不能将分散的缓存用于事务或异步复制。
缓存的方式与其他缓存模式类似,以下是声明性配置的示例:
<scattered-cache name="scatteredCache" />
Configuration c = new ConfigurationBuilder() .clustering().cacheMode(CacheMode.SCATTERED_SYNC) .build();
分散模式不会在服务器配置中公开,因为服务器通常通过 Hot Rod 协议进行访问。该协议自动为写入选择主所有者,因此写入(具有两个所有者的分布式模式)也要求集群中的单个 RPC。因此,分散缓存不会带来性能优势。
2.5. 异步复制
所有集群的缓存模式都可配置为使用与 <replicated-cache /> 中的 < replicated-cache/> 的异步通信,或 & lt; invalidation-cache/> 元素。
使用异步通信时,原始器节点不会接收来自操作状态的其他节点,因此无法检查它是否在其他节点上成功。
我们一般不推荐使用异步通信,因为它们可能会导致数据不一致,因此原因就困难。然而,有时速度比一致性更为重要,因此对于这些情况,可以选择。
异步 API
一个异步 API 允许您使用同步通信,但不阻止用户线程。
有一个注意事项:异步操作不会保留程序顺序。如果线程调用 cache.putAsync (k, v1); cache.putAsync (k, v2),则 k 的最终值可以是 v1 或 v2。与使用异步通信相比,其优势在于最终的值不能在一个节点和 v2 上处于 v1 上。
2.5.1. 使用异步复制返回值
由于 Cache 接口扩展了 java.util.Map,因此默认情况下,put (key, value) 和 remove (key) 等写入方法返回上一个值。
在某些情况下,返回值可能不正确:
-
将
AdvancedCache.withFlags ()与Flag.IGNORE_RETURN_VALUE,Flag.SKIP_REMOTE_LOOKUP或Flag.SKIP_CACHE_LOAD. -
当缓存配置了 Not
return-values="true"时。 - 使用异步通信时。
- 当对同一密钥进行多个并发写入时,缓存拓扑会改变。拓扑更改将使 Data Grid 重试写入操作,并且重试操作的返回值并不可靠。
事务缓存在 3 和 4 中返回正确的之前值。但是,事务缓存也具有 getcha:在分布式模式下,读写的隔离级别被实施为可重复读取。这意味着"ouble-checked locking"示例无法正常工作:
Cache cache = ...
TransactionManager tm = ...
tm.begin();
try {
Integer v1 = cache.get(k);
// Increment the value
Integer v2 = cache.put(k, v1 + 1);
if (Objects.equals(v1, v2) {
// success
} else {
// retry
}
} finally {
tm.commit();
}
实现这一点的正确方法是使用 cache.getAdvancedCache ().withFlags (Flag.FORCE_WRITE_LOCK).get (k)。
在使用 optimistic 锁定缓存中,写入也可能会返回过时的值。写入 skew 检查可以避免过时的值。
2.6. 配置初始集群大小
数据网格可动态处理集群拓扑更改。这意味着,在 Data Grid 初始化缓存前,节点不需要等待其他节点加入集群。
如果应用程序在缓存启动前需要集群中特定数量的节点,您可以将初始集群大小配置为传输的一部分。
流程
- 打开 Data Grid 配置进行编辑。
-
在缓存以
initial-cluster-size属性或initialClusterSize ()方法启动时设置所需的最少节点数量。 -
在缓存管理器不以
initial-cluster-timeout属性或initialClusterTimeout ()方法启动时设置超时(毫秒)。 - 保存并关闭您的数据网格配置。
初始集群大小配置
XML
<infinispan>
<cache-container>
<transport initial-cluster-size="4"
initial-cluster-timeout="30000" />
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"initial-cluster-size" : "4",
"initial-cluster-timeout" : "30000"
}
}
}
}
YAML
infinispan:
cacheContainer:
transport:
initialClusterSize: "4"
initialClusterTimeout: "30000"
ConfigurationBuilder
GlobalConfiguration global = GlobalConfigurationBuilder.defaultClusteredBuilder() .transport() .initialClusterSize(4) .initialClusterTimeout(30000, TimeUnit.MILLISECONDS);
第 3 章 数据网格缓存配置
缓存配置控制数据网格如何存储数据。
作为缓存配置的一部分,您要声明要使用的缓存模式。例如,您可以配置 Data Grid 集群以使用复制缓存或分布式缓存。
您的配置还定义了缓存的特性,并支持要在处理数据时使用的数据网格功能。例如,您可以配置缓存中的 Data Grid 对条目的编码方式,无论是在节点间同步或异步复制请求,则条目为 mortal 或 immortal 等等。
3.1. 声明性缓存配置
您可以根据 Data Grid 模式,以 XML 或 JSON 格式以声明性配置缓存。
与编程配置相比,声明缓存配置有以下优点:
- 可移植性
-
在独立文件中定义每个配置,可用于创建嵌入和远程缓存。
您也可以使用声明性配置来为 OpenShift 上运行的集群创建 Data Grid Operator 缓存。 - 简洁
-
使语言保持独立于编程语言。
例如,创建远程缓存通常最好不要直接将复杂的 XML 添加到 Java 代码。
数据网格服务器配置扩展了 infinispan.xml,使其包含集群传输机制、安全域和端点配置。如果您将缓存声明为 Data Grid Server 配置的一部分,您应该使用管理工具(如 Ansible 或 Chef)使其在集群中保持同步。
要在 Data Grid 集群间动态同步远程缓存,在运行时创建它们。
3.1.1. 缓存配置
您可以使用 XML、JSON 和 YAML 格式创建声明缓存配置。
所有声明缓存都必须符合 Data Grid 模式。JSON 格式的配置必须遵循 XML 配置的结构,元素对应于对象和属性与字段对应。
数据网格将字符限制为最多 255 个用于缓存名称或缓存模板名称。如果您超过这个字符限制,数据网格服务器可能会在不发出异常信息的情况下停止。编写 succinct 缓存名称和缓存模板名称。
文件系统可能会对文件名的长度设定限制,因此请确保缓存的名称没有超过这个限制。如果缓存名称超过文件系统的命名限制,则导致该缓存的常规操作或初始操作可能会失败。编写 succinct 缓存名称和缓存模板名称。
分布式缓存
XML
<distributed-cache owners="2"
segments="256"
capacity-factor="1.0"
l1-lifespan="5000"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<locking isolation="REPEATABLE_READ"/>
<transaction mode="FULL_XA"
locking="OPTIMISTIC"/>
<expiration lifespan="5000"
max-idle="1000" />
<memory max-count="1000000"
when-full="REMOVE"/>
<indexing enabled="true"
storage="local-heap">
<index-reader refresh-interval="1000"/>
</indexing>
<partition-handling when-split="ALLOW_READ_WRITES"
merge-policy="PREFERRED_NON_NULL"/>
<persistence passivation="false">
<!-- Persistent storage configuration. -->
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"mode": "SYNC",
"owners": "2",
"segments": "256",
"capacity-factor": "1.0",
"l1-lifespan": "5000",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"locking": {
"isolation": "REPEATABLE_READ"
},
"transaction": {
"mode": "FULL_XA",
"locking": "OPTIMISTIC"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
},
"indexing" : {
"enabled" : true,
"storage" : "local-heap",
"index-reader" : {
"refresh-interval" : "1000"
}
},
"partition-handling" : {
"when-split" : "ALLOW_READ_WRITES",
"merge-policy" : "PREFERRED_NON_NULL"
},
"persistence" : {
"passivation" : false
}
}
}
YAML
distributedCache:
mode: "SYNC"
owners: "2"
segments: "256"
capacityFactor: "1.0"
l1Lifespan: "5000"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
locking:
isolation: "REPEATABLE_READ"
transaction:
mode: "FULL_XA"
locking: "OPTIMISTIC"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
indexing:
enabled: "true"
storage: "local-heap"
indexReader:
refreshInterval: "1000"
partitionHandling:
whenSplit: "ALLOW_READ_WRITES"
mergePolicy: "PREFERRED_NON_NULL"
persistence:
passivation: "false"
# Persistent storage configuration.
复制缓存
XML
<replicated-cache segments="256"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<locking isolation="REPEATABLE_READ"/>
<transaction mode="FULL_XA"
locking="OPTIMISTIC"/>
<expiration lifespan="5000"
max-idle="1000" />
<memory max-count="1000000"
when-full="REMOVE"/>
<indexing enabled="true"
storage="local-heap">
<index-reader refresh-interval="1000"/>
</indexing>
<partition-handling when-split="ALLOW_READ_WRITES"
merge-policy="PREFERRED_NON_NULL"/>
<persistence passivation="false">
<!-- Persistent storage configuration. -->
</persistence>
</replicated-cache>
JSON
{
"replicated-cache": {
"mode": "SYNC",
"segments": "256",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"locking": {
"isolation": "REPEATABLE_READ"
},
"transaction": {
"mode": "FULL_XA",
"locking": "OPTIMISTIC"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
},
"indexing" : {
"enabled" : true,
"storage" : "local-heap",
"index-reader" : {
"refresh-interval" : "1000"
}
},
"partition-handling" : {
"when-split" : "ALLOW_READ_WRITES",
"merge-policy" : "PREFERRED_NON_NULL"
},
"persistence" : {
"passivation" : false
}
}
}
YAML
replicatedCache:
mode: "SYNC"
segments: "256"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
locking:
isolation: "REPEATABLE_READ"
transaction:
mode: "FULL_XA"
locking: "OPTIMISTIC"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
indexing:
enabled: "true"
storage: "local-heap"
indexReader:
refreshInterval: "1000"
partitionHandling:
whenSplit: "ALLOW_READ_WRITES"
mergePolicy: "PREFERRED_NON_NULL"
persistence:
passivation: "false"
# Persistent storage configuration.
多个缓存
XML
<infinispan
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:13.0 https://infinispan.org/schemas/infinispan-config-13.0.xsd
urn:infinispan:server:13.0 https://infinispan.org/schemas/infinispan-server-13.0.xsd"
xmlns="urn:infinispan:config:13.0"
xmlns:server="urn:infinispan:server:13.0">
<cache-container name="default"
statistics="true">
<distributed-cache name="mycacheone"
mode="ASYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="300000"/>
<memory max-size="400MB"
when-full="REMOVE"/>
</distributed-cache>
<distributed-cache name="mycachetwo"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="300000"/>
<memory max-size="400MB"
when-full="REMOVE"/>
</distributed-cache>
</cache-container>
</infinispan>
YAML
infinispan:
cacheContainer:
name: "default"
statistics: "true"
caches:
mycacheone:
distributedCache:
mode: "ASYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "300000"
memory:
maxSize: "400MB"
whenFull: "REMOVE"
mycachetwo:
distributedCache:
mode: "SYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "300000"
memory:
maxSize: "400MB"
whenFull: "REMOVE"
JSON
{
"infinispan" : {
"cache-container" : {
"name" : "default",
"statistics" : "true",
"caches" : {
"mycacheone" : {
"distributed-cache" : {
"mode": "ASYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "300000"
},
"memory": {
"max-size": "400MB",
"when-full": "REMOVE"
}
}
},
"mycachetwo" : {
"distributed-cache" : {
"mode": "SYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "300000"
},
"memory": {
"max-size": "400MB",
"when-full": "REMOVE"
}
}
}
}
}
}
}
3.2. 添加缓存模板
Data Grid 模式包括可用于创建模板的 *-cache-configuration 元素。然后,您可以多次使用相同的配置创建缓存。
流程
- 打开 Data Grid 配置进行编辑。
-
使用适当的
*-cache-configuration元素或对象添加缓存配置到缓存管理器。 - 保存并关闭您的数据网格配置。
缓存模板示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="my-dist-template"
mode="SYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
<memory max-count="1000000"
when-full="REMOVE"/>
<expiration lifespan="5000"
max-idle="1000"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"distributed-cache-configuration" : {
"name" : "my-dist-template",
"mode": "SYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
},
"memory": {
"max-count": "1000000",
"when-full": "REMOVE"
}
}
}
}
}
YAML
infinispan:
cacheContainer:
distributedCacheConfiguration:
name: "my-dist-template"
mode: "SYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "5000"
maxIdle: "1000"
memory:
maxCount: "1000000"
whenFull: "REMOVE"
3.2.1. 从模板创建缓存
从配置模板创建缓存。
Data Grid Console 中的 Cache 模板 菜单提供了远程缓存的模板。
先决条件
- 在缓存管理器中至少添加一个缓存模板。
流程
- 打开 Data Grid 配置进行编辑。
-
指定缓存使用
configuration属性或字段继承的模板。 - 保存并关闭您的数据网格配置。
从模板继承的缓存配置
XML
<distributed-cache configuration="my-dist-template" />
JSON
{
"distributed-cache": {
"configuration": "my-dist-template"
}
}
YAML
distributedCache: configuration: "my-dist-template"
3.2.2. 缓存模板继承
缓存配置模板可以从其他模板继承以扩展和覆盖设置。
缓存模板继承为分级。要使子配置模板从父模板继承,您必须在父模板后面包含它。
另外,对于具有多个值的元素,模板继承是可添加的。从另一个模板继承的缓存会合并来自该模板的值,这些缓存可覆盖属性。
模板继承示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="base-template">
<expiration lifespan="5000"/>
</distributed-cache-configuration>
<distributed-cache-configuration name="extended-template"
configuration="base-template">
<encoding media-type="application/x-protostream"/>
<expiration lifespan="10000"
max-idle="1000"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"caches" : {
"base-template" : {
"distributed-cache-configuration" : {
"expiration" : {
"lifespan" : "5000"
}
}
},
"extended-template" : {
"distributed-cache-configuration" : {
"configuration" : "base-template",
"encoding": {
"media-type": "application/x-protostream"
},
"expiration" : {
"lifespan" : "10000",
"max-idle" : "1000"
}
}
}
}
}
}
}
YAML
infinispan:
cacheContainer:
caches:
base-template:
distributedCacheConfiguration:
expiration:
lifespan: "5000"
extended-template:
distributedCacheConfiguration:
configuration: "base-template"
encoding:
mediaType: "application/x-protostream"
expiration:
lifespan: "10000"
maxIdle: "1000"
3.2.3. 缓存模板通配符
您可以添加通配符来缓存配置模板名称。如果您创建名称与通配符匹配的缓存,Data Grid 会应用配置模板。
如果缓存名称匹配多个通配符,则数据网格会抛出异常。
模板通配符示例
XML
<infinispan>
<cache-container>
<distributed-cache-configuration name="async-dist-cache-*"
mode="ASYNC"
statistics="true">
<encoding media-type="application/x-protostream"/>
</distributed-cache-configuration>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"distributed-cache-configuration" : {
"name" : "async-dist-cache-*",
"mode": "ASYNC",
"statistics": "true",
"encoding": {
"media-type": "application/x-protostream"
}
}
}
}
}
YAML
infinispan:
cacheContainer:
distributedCacheConfiguration:
name: "async-dist-cache-*"
mode: "ASYNC"
statistics: "true"
encoding:
mediaType: "application/x-protostream"
使用上述示例,如果您创建一个名为 "async-dist-cache-prod" 的缓存,则 Data Grid 会使用 async-dist-cache-* 模板的配置。
3.2.4. 从多个 XML 文件缓存模板
将缓存配置模板分成多个 XML 文件,使其具有粒度灵活性并通过 XML 包含(排除)进行引用。
数据网格为 XInclude 规格提供最少支持。这意味着您无法使用 xpointer 属性、xi:fallback 元素、文本处理或内容协商。
您还必须将 xmlns:xi="http://www.w3.org/2001/XInclude" 命名空间添加到 infinispan.xml 中,以使用 XInclude。
Xinclude 缓存模板
<infinispan xmlns:xi="http://www.w3.org/2001/XInclude">
<cache-container default-cache="cache-1">
<!-- References files that contain cache configuration templates. -->
<xi:include href="distributed-cache-template.xml" />
<xi:include href="replicated-cache-template.xml" />
</cache-container>
</infinispan>
数据网格还提供 infinispan-config-fragment-13.0.xsd 模式,您可将其用于配置片段。
配置片段模式
<local-cache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:infinispan:config:13.0 https://infinispan.org/schemas/infinispan-config-fragment-13.0.xsd"
xmlns="urn:infinispan:config:13.0"
name="mycache"/>
其他资源
3.3. 创建远程缓存
当您在运行时创建远程缓存时,Data Grid 服务器会在集群间同步您的配置,以便所有节点都具有副本。因此,您应该总是使用以下机制动态创建远程缓存:
- Data Grid Console
- Data Grid 命令行界面(CLI)
- 热环或 HTTP 客户端
3.3.1. 默认缓存管理器
Data Grid Server 提供了一个默认缓存管理器,用于控制远程缓存的生命周期。启动 Data Grid Server 会自动实例化 Cache Manager,以便您可以创建和删除远程缓存和其他资源,如 Protobuf 模式。
启动 Data Grid Server 并添加用户凭证后,您可以查看 Cache Manager 的详情,并从 Data Grid Console 获取集群信息。
-
在任意浏览器中打开
127.0.0.1:11222。
您还可以通过命令行界面(CLI)或 REST API 获取有关缓存管理器的信息:
- CLI
在默认容器中运行
describe命令。[//containers/default]> describe
- REST
-
在任意浏览器中打开
127.0.0.1:11222/rest/v2/cache-managers/default/。
默认缓存管理器配置
XML
<infinispan>
<!-- Creates a Cache Manager named "default" and enables metrics. -->
<cache-container name="default"
statistics="true">
<!-- Adds cluster transport that uses the default JGroups TCP stack. -->
<transport cluster="${infinispan.cluster.name:cluster}"
stack="${infinispan.cluster.stack:tcp}"
node-name="${infinispan.node.name:}"/>
<!-- Requires user permission to access caches and perform operations. -->
<security>
<authorization/>
</security>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"jgroups" : {
"transport" : "org.infinispan.remoting.transport.jgroups.JGroupsTransport"
},
"cache-container" : {
"name" : "default",
"statistics" : "true",
"transport" : {
"cluster" : "cluster",
"node-name" : "",
"stack" : "tcp"
},
"security" : {
"authorization" : {}
}
}
}
}
YAML
infinispan:
jgroups:
transport: "org.infinispan.remoting.transport.jgroups.JGroupsTransport"
cacheContainer:
name: "default"
statistics: "true"
transport:
cluster: "cluster"
nodeName: ""
stack: "tcp"
security:
authorization: ~
3.3.2. 使用 Data Grid 控制台创建缓存
使用数据网格控制台在任何 Web 浏览器的直观直观界面中创建远程缓存。
先决条件
-
创建具有管理权限的 Data Grid
用户。 - 至少启动一个数据网格服务器实例。
- 具有数据网格缓存配置。
流程
-
在任意浏览器中打开
127.0.0.1:11222/console/。 - 选择 Create Cache 并按照 Data Grid Console 指南的步骤进行操作。
3.3.3. 使用 Data Grid CLI 创建远程缓存
使用 Data Grid 命令行界面(CLI)在 Data Grid Server 中添加远程缓存。
先决条件
-
创建具有管理权限的 Data Grid
用户。 - 至少启动一个数据网格服务器实例。
- 具有数据网格缓存配置。
流程
启动 CLI 并在系统提示时输入您的凭证。
bin/cli.sh
使用
create cache命令创建远程缓存。例如,从名为
mycache.xml的文件创建一个名为 "mycache" 的缓存,如下所示:create cache --file=mycache.xml mycache
验证
使用
ls命令列出所有远程缓存。ls caches mycache
使用
describe命令查看缓存配置。describe caches/mycache
3.3.4. 从 Hot Rod 客户端创建远程缓存
使用 Data Grid Hot Rod API 从 Java、C++、.NET/C#、JS 客户端等在 Data Grid Server 上创建远程缓存。
此流程演示了如何使用 Hot Rod Java 客户端在第一次引导时创建远程缓存。您可以在 Data Grid Tutorials 中找到其他 Hot Rod 客户端的代码示例。
先决条件
-
创建具有管理权限的 Data Grid
用户。 - 至少启动一个数据网格服务器实例。
- 具有数据网格缓存配置。
流程
-
调用
remoteCache ()方法,作为ConfigurationBuilder的一部分。 -
在类路径上的
hotrod-client.properties文件中设置configuration或configuration_uri属性。
ConfigurationBuilder
File file = new File("path/to/infinispan.xml")
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.remoteCache("another-cache")
.configuration("<distributed-cache name=\"another-cache\"/>");
builder.remoteCache("my.other.cache")
.configurationURI(file.toURI());
hotrod-client.properties
infinispan.client.hotrod.cache.another-cache.configuration=<distributed-cache name=\"another-cache\"/> infinispan.client.hotrod.cache.[my.other.cache].configuration_uri=file:///path/to/infinispan.xml
如果远程缓存的名称包含 . 字符,在使用 hotrod-client.properties 文件时,必须将其括在方括号中。
3.3.5. 使用 REST API 创建远程缓存
使用 Data Grid REST API 在 Data Grid Server 上创建来自任何合适的 HTTP 客户端的远程缓存。
先决条件
-
创建具有管理权限的 Data Grid
用户。 - 至少启动一个数据网格服务器实例。
- 具有数据网格缓存配置。
流程
-
使用有效负载中的缓存配置调用
POST请求到/rest/v2/caches/<cache_name>。
其他资源
3.4. 创建嵌入缓存
数据网格提供了一个 EmbeddedCacheManager API,可让您以编程方式控制缓存管理器和嵌入式缓存生命周期。
3.4.1. 在您的项目中添加 Data Grid
将 Data Grid 添加到项目,以便在应用程序中创建嵌入式缓存。
先决条件
- 配置项目以从 Maven 存储库获取 Data Grid 工件。
流程
-
将
infinispan-core工件作为依赖项添加到pom.xml中,如下所示:
<dependencies>
<dependency>
<groupId>org.infinispan</groupId>
<artifactId>infinispan-core</artifactId>
</dependency>
</dependencies>3.4.2. 配置嵌入缓存
Data Grid 提供了一个 GlobalConfigurationBuilder API,用于控制缓存管理器和配置内嵌缓存的 ConfigurationBuilder API。
先决条件
-
添加
infinispan-core工件作为pom.xml中的依赖项。
流程
- 初始化默认缓存管理器,以便您可以添加内嵌缓存。
-
使用
ConfigurationBuilderAPI 添加至少一个嵌入式缓存。 -
调用
getOrCreateCache ()方法,该方法可在集群中的所有节点上创建嵌入式缓存,或者返回已存在的缓存。
// Set up a clustered cache manager.
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder();
// Initialize the default cache manager.
DefaultCacheManager cacheManager = new DefaultCacheManager(global.build());
// Create a distributed cache with synchronous replication.
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC);
// Obtain a volatile cache.
Cache<String, String> cache = cacheManager.administration().withFlags(CacheContainerAdmin.AdminFlag.VOLATILE).getOrCreateCache("myCache", builder.build());第 4 章 启用和配置数据网格统计信息和 JMX 监控
数据网格可以提供缓存管理器和缓存统计信息,以及导出 JMX MBean。
4.1. 配置 Data Grid 指标
数据网格会生成兼容 MicroProfile 指标 API 的指标。
- 量表提供值,如用于写操作或 JVM 运行时间的平均纳秒数。
- histograms 提供有关读取、写入和删除时间等操作执行时间的详细信息。
默认情况下,Data Grid 在启用统计数据时会生成量表,但您也可以将其配置为生成直方图。
流程
- 打开 Data Grid 配置进行编辑。
-
将
metrics元素或对象添加到缓存容器。 -
通过量表属性或字段启用或禁用量表。
-
使用直
方属性或字段启用或禁用直方图。 - 保存并关闭您的客户端配置。
指标配置
XML
<infinispan>
<cache-container statistics="true">
<metrics gauges="true"
histograms="true" />
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"metrics" : {
"gauges" : "true",
"histograms" : "true"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
metrics:
gauges: "true"
histograms: "true"
4.2. 注册 JMX MBeans
数据网格可以注册 JMX MBeans,用于收集统计信息和执行管理操作。您还必须为 JMX MBeans 中的所有统计属性提供 0 值。
流程
- 打开 Data Grid 配置进行编辑。
-
将
jmx元素或对象添加到缓存容器,并将true指定为enabled属性或字段的值。 -
添加
domain属性或字段,并根据需要指定公开 JMX MBeans 的域。 - 保存并关闭您的客户端配置。
JMX 配置
XML
<infinispan>
<cache-container statistics="true">
<jmx enabled="true"
domain="example.com"/>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"jmx" : {
"enabled" : "true",
"domain" : "example.com"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
jmx:
enabled: "true"
domain: "example.com"
4.2.1. 启用 JMX 远程端口
提供唯一的远程 JMX 端口,以通过 JMXServiceURL 格式的连接公开数据网格 MBeans。
您可以使用以下方法之一启用远程 JMX 端口:
- 启用需要身份验证到其中一个数据网格服务器安全域的远程 JMX 端口。
- 使用标准的 Java 管理配置选项手动启用远程 JMX 端口。
先决条件
-
对于具有身份验证的远程 JMX,请使用默认安全域定义用户角色。用户必须具有读写访问权限的
controlRole或具有只读访问权限的monitorRole才能访问任何 JMX 资源。
流程
使用以下方法之一启动启用了远程 JMX 端口的 Data Grid 服务器:
通过端口
9999启用远程 JMX。bin/server.sh --jmx 9999
警告禁用了 SSL 的远程 JMX 不用于生产环境。
在启动时将以下系统属性传递给 Data Grid 服务器:
bin/server.sh -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
警告在无需身份验证或 SSL 的情况下启用远程 JMX 并不安全,不建议在任何环境中使用。禁用身份验证和 SSL 可让未授权用户连接到您的服务器并访问其中托管的数据。
其他资源
4.2.2. Data Grid MBeans
数据网格公开了代表可管理资源的 JMX MBeans。
org.infinispan:type=Cache- 用于缓存实例的属性和操作。
org.infinispan:type=CacheManager- 用于缓存管理器的属性和操作,包括数据网格缓存和集群健康统计。
有关可用 JMX MBeans 以及描述以及可用操作和属性的完整列表,请参阅 数据网格 JMX 组件 文档。
其他资源
4.2.3. 在自定义 MBean 服务器中注册 MBeans
数据网格包含一个 MBeanServerLookup 接口,可用于在自定义 MBeanServer 实例中注册 MBeans。
先决条件
-
创建
MBeanServerLookup的实施,使getMBeanServer ()方法返回自定义 MBeanServer 实例。 - 配置数据网格以注册 JMX MBeans.
流程
- 打开 Data Grid 配置进行编辑。
-
将
mbean-server-lookup属性或字段添加到缓存管理器的 JMX 配置中。 -
指定
MBeanServerLookup实施的完全限定域名(FQN)。 - 保存并关闭您的客户端配置。
JMX MBean 服务器查找配置
XML
<infinispan>
<cache-container statistics="true">
<jmx enabled="true"
domain="example.com"
mbean-server-lookup="com.example.MyMBeanServerLookup"/>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"statistics" : "true",
"jmx" : {
"enabled" : "true",
"domain" : "example.com",
"mbean-server-lookup" : "com.example.MyMBeanServerLookup"
}
}
}
}
YAML
infinispan:
cacheContainer:
statistics: "true"
jmx:
enabled: "true"
domain: "example.com"
mbeanServerLookup: "com.example.MyMBeanServerLookup"
第 5 章 配置 JVM 内存用量
通过以下方法控制数据网格如何在 JVM 内存中存储数据:
- 使用驱除管理 JVM 内存用量,从缓存自动删除数据。
- 添加 lifespan 和最大空闲时间以过期条目并防止过时的数据。
- 配置数据网格以在非堆、原生内存中存储数据.
5.1. 默认内存配置
默认情况下,数据网格将缓存条目存储为 JVM 堆中的对象。随着应用程序添加条目,缓存的大小可能会超过 JVM 可用的内存量。同样,如果数据网格不是主数据存储,则条目过时,这意味着您的缓存包含陈旧数据。
XML
<distributed-cache> <memory storage="HEAP"/> </distributed-cache>
JSON
{
"distributed-cache": {
"memory" : {
"storage": "HEAP"
}
}
}
YAML
distributedCache:
memory:
storage: "HEAP"
5.2. 驱除和过期
驱除和过期时间是两个策略,可通过删除旧的未使用条目来清理数据容器。虽然驱除和过期时间类似,但它们有一些重要的区别。
- 采用 ✓ 驱除功能,在容器变得大于配置的阈值时,可以通过删除条目来控制数据容器的大小。
-
✓ 过期限制可以存在的时间条目量。数据网格使用调度程序来定期删除过期的条目。已过期但还没有删除的条目会在访问时立即删除。在这种情况下,过期的条目的
get ()调用会返回 "null" 值。 - ✓ eviction 是 Data Grid 节点的本地分配。
- 在 Data Grid 集群中进行 ✓ 过期。
- ✓ 您可以组合使用驱除和过期时间,也可以相互独立使用。
-
✓ 您可以在
infinispan.xml中配置驱除和过期声明,以对条目应用缓存范围默认值。 - ✓ 您可以明确为特定条目定义过期设置,但您无法根据每个条目定义驱除。
- ✓ 您可以手动驱除条目并手动触发过期。
5.3. 使用 Data Grid 缓存驱除
驱除可让您以以下两种方式之一从内存中删除条目来控制数据容器的大小:
-
条目总数(
max-count)。 -
最大内存量(
最大大小)。
驱除会一次性丢弃来自数据容器的一个条目,并且是本地的到它发生的节点。
从内存中移除条目,但不会从持久缓存存储中删除条目。要确保在 Data Grid 驱除后条目仍然可用,并防止与数据不一致,您应该配置持久性存储。
当您配置内存时,Data Grid approximates data 容器的当前内存用量。添加或修改条目时,Data Grid 会将数据容器的当前内存用量与最大大小进行比较。如果大小超过最大,Data Grid 将执行驱除。
驱除在线程中立即发生,它会添加一个超过最大大小的条目。
5.3.1. 驱除策略
当您配置 Data Grid 驱除时,可以指定:
- 数据容器的最大大小。
- 缓存达到阈值时删除条目的策略。
您可以手动执行驱除或配置 Data Grid 以执行以下操作之一:
- 删除旧条目,为新条目腾出空间。
引发
ContainerFullException并防止创建新条目。例外驱除策略只适用于使用 2 阶段提交的事务缓存,而不适用于 1 阶段提交或同步优化。
有关驱除策略的详情,请参阅架构参考。
数据网格包括 Caffeine 缓存库,它实现了 Least Frently Used (LFU)缓存替换算法(称为 TinyLFU)的变体。对于 off-heap 存储,Data Grid 使用 Least Recently Used (LRU)算法的自定义实现。
其他资源
5.3.2. 配置最大计数驱除
将 Data Grid 缓存的大小限制为条目总数。
流程
- 打开 Data Grid 配置进行编辑。
-
使用
max-count属性或maxCount ()方法指定缓存在 Data Grid 执行驱除前可以包含的条目总数。 将以下内容设置为驱除策略来控制数据网格如何使用
when-full属性或whenFull ()方法删除条目。-
REMOVE数据网格执行驱除。这是默认的策略。 -
MANUAL您为嵌入式缓存手动执行驱除。 -
EXCEPTION数据网格丢弃异常,而不是驱除条目。
-
- 保存并关闭您的数据网格配置。
最大计数驱除
在以下示例中,Data Grid 会在缓存包含总计 500 个条目并且创建一个新条目时删除条目:
XML
<distributed-cache> <memory max-count="500" when-full="REMOVE"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"memory" : {
"max-count" : "500",
"when-full" : "REMOVE"
}
}
}
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "REMOVE"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(500).whenFull(EvictionStrategy.REMOVE);
5.3.3. 配置最大大小驱除
将数据网格缓存的大小限制为最大内存量。
流程
- 打开 Data Grid 配置进行编辑。
指定
application/x-protostream作为缓存编码的介质类型。您必须指定一个二进制介质类型才能使用最大大小驱除。
-
使用
max-size属性或maxSize ()方法配置在 Data Grid 执行驱除前可以使用的最大内存量(以字节为单位)。 (可选)指定字节测量单位。
默认值为 B (字节)。请参考支持的单元的配置模式。
将以下内容设置为驱除策略来控制数据网格如何使用
when-full属性或whenFull ()方法删除条目。-
REMOVE数据网格执行驱除。这是默认的策略。 -
MANUAL您为嵌入式缓存手动执行驱除。 -
EXCEPTION数据网格丢弃异常,而不是驱除条目。
-
- 保存并关闭您的数据网格配置。
最大大小驱除
在以下示例中,Data Grid 会在缓存大小达到 1.5 GB (千兆字节)并且创建新条目时删除条目:
XML
<distributed-cache> <encoding media-type="application/x-protostream"/> <memory max-size="1.5GB" when-full="REMOVE"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"encoding" : {
"media-type" : "application/x-protostream"
},
"memory" : {
"max-size" : "1.5GB",
"when-full" : "REMOVE"
}
}
}
YAML
distributedCache:
encoding:
mediaType: "application/x-protostream"
memory:
maxSize: "1.5GB"
whenFull: "REMOVE"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
5.3.4. 手动驱除
如果您选择手动驱除策略,Data Grid 不会执行驱除。您必须使用 evict () 方法手动完成此操作。
您应该只在嵌入缓存中使用手动驱除。对于远程缓存,您应该始终使用 REMOVE 或 EXCEPTION 驱除策略配置数据网格。
当您启用 passivation 时,这个配置可防止警告消息,但不会配置驱除。
XML
<distributed-cache> <memory max-count="500" when-full="MANUAL"/> </distributed-cache>
JSON
{
"distributed-cache" : {
"memory" : {
"max-count" : "500",
"when-full" : "MANUAL"
}
}
}
YAML
distributedCache:
memory:
maxCount: "500"
whenFull: "MANUAL"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.encoding().mediaType("application/x-protostream")
.memory()
.maxSize("1.5GB")
.whenFull(EvictionStrategy.REMOVE);
5.3.5. 通过驱除传递
在 Data Grid 驱除条目时,传递会持久保留数据到缓存存储。如果您启用通过,您应该总是启用驱除,如下例所示:
XML
<distributed-cache>
<persistence passivation="true">
<!-- Persistent storage configuration. -->
</persistence>
<memory max-count="100"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"memory" : {
"max-count" : "100"
},
"persistence" : {
"passivation" : true
}
}
}
YAML
distributedCache:
memory:
maxCount: "100"
persistence:
passivation: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().maxCount(100); builder.persistence().passivation(true); //Persistent storage configuration
5.4. 带有 lifespan 和最大闲置的过期
expiration 配置 Data Grid,以在访问以下时间限制之一时从缓存中删除条目:
- lifespan
- 设置条目可以存在的最长时间。
- 最大闲置
- 指定条目可以保持闲置的时长。如果条目没有发生操作,它们就会变为空闲状态。
目前,最大闲置有效期不支持使用持久性存储的缓存。
如果您使用 EXCEPTION 驱除策略的过期和驱除,则过期但尚未从缓存中移除的条目,则计入数据容器的大小。
5.4.1. 过期如何工作
当您配置过期时,数据网格使用元数据存储密钥,以确定条目何时过期。
-
lifespan 使用
创建时间戳,以及 lifespan配置属性的值。 -
最大空闲时间
使用最后使用的时间戳和max-idle配置属性的值。
数据网格检查是否设置了 lifespan 或最大闲置元数据,然后将值与当前时间进行比较。
如果 (creation + lifespan < currentTime) 或 (lastUsed + maxIdle < currentTime),Data Grid 检测到条目已过期。
每当访问或者由过期程序访问或找到条目时,就会发生过期时间。
例如,k1 达到最大空闲时间,客户端发出 Cache.get (k1) 请求。在本例中,Data Grid 检测到条目已过期并将其从数据容器中删除。Cache.get (k1) 请求返回 null。
数据网格还从缓存存储过期条目,但仅过期时间。最大空闲的过期时间无法使用缓存存储。在缓存加载程序的情况下,Data Grid 无法过期条目,因为加载程序只能从外部存储中读取。
数据网格为缓存条目的 原语 数据类型添加过期元数据。这可以将密钥大小增加到 32 字节。
5.4.2. 过期获取器
数据网格使用定期运行的已消耗程序线程来检测和删除过期的条目。过期删除程序确保删除不再访问的过期条目。
Data Grid ExpirationManager 接口处理过期程序,并公开 processExpiration () 方法。
在某些情况下,您可以通过调用 processExpiration ()来禁用过期条目,并通过调用 processExpiration () 手动过期条目;如果您使用的是本地缓存模式,该模式会定期运行维护线程。
如果使用集群缓存模式,您绝不应该禁用过期程序。
在使用缓存存储时,数据网格总是使用过期。在这种情况下,您无法禁用它。
5.4.3. 最大闲置和集群缓存
因为最大空闲的过期时间依赖于缓存条目的最后访问时间,所以集群缓存模式有一些限制。
随着 lifespan 过期,缓存条目的创建时间提供了在集群缓存之间一致的值。例如,所有节点上的 k1 的创建时间始终都相同。
对于使用集群缓存的最大空闲过期时间,所有节点上的条目的最后访问时间并不总是相同。要确保在集群间有相同的相对访问时间,Data Grid 会在访问密钥时将 touch 命令发送到所有所有者。
数据网格发送的 touch 命令有以下考虑:
-
cache.get ()请求不会返回,直到所有 touch 命令都完成。这个同步行为会增加客户端请求的延迟。 - touch 命令还会更新 "recently accessed" 元数据,用于所有所有者上的缓存条目,以供数据网格用于驱除。
- 通过使用分散的缓存模式,数据网格将命令发送到所有节点,而不仅仅是主和备份所有者。
附加信息
- 最大空闲的过期时间无法用于无效的模式。
- 在集群缓存中迭代可能会返回超过最大空闲时间限制的过期条目。这个行为可确保性能,因为在迭代过程中不会执行任何远程调用。另请注意,迭代不会刷新任何过期的条目。
5.4.4. 为缓存配置 lifespan 和最大闲置时间
为缓存中的所有条目设置 lifespan 和最大闲置时间。
流程
- 打开 Data Grid 配置进行编辑。
-
使用
lifespan属性或lifespan ()方法指定条目可在缓存中的时间量(以毫秒为单位)。 -
使用
max-idle属性或maxIdle ()方法,以毫秒为单位指定条目在最后一次访问后可以保持闲置的时间量。 - 保存并关闭您的数据网格配置。
数据网格缓存过期
在以下示例中,Data Grid 会在上次访问时间后 5 秒或 1 秒后过期所有缓存条目,以防出现以下情况:
XML
<replicated-cache> <expiration lifespan="5000" max-idle="1000" /> </replicated-cache>
JSON
{
"replicated-cache" : {
"expiration" : {
"lifespan" : "5000",
"max-idle" : "1000"
}
}
}
YAML
replicatedCache:
expiration:
lifespan: "5000"
maxIdle: "1000"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.expiration().lifespan(5000, TimeUnit.MILLISECONDS)
.maxIdle(1000, TimeUnit.MILLISECONDS);
5.4.5. 配置 lifespan 以及每个条目的最大闲置时间
指定单个条目的 lifespan 和最大闲置时间。当您向条目添加 lifespan 和最大闲置时间时,这些值优先于缓存的过期配置。
当您明确为缓存条目定义 lifespan 和最大闲置时间值时,Data Grid 会将这些值与缓存条目一起复制。同样,Data Grid 也会将过期值与条目一起写入持久性存储。
流程
对于远程缓存,您可以使用 Data Grid 控制台以交互方式将 lifespan 和最大闲置时间添加到条目。
通过 Data Grid 命令行界面(CLI),在
put命令中使用--max-idle=和--ttl=参数。对于远程和嵌入缓存,您可以使用
cache.put ()调用添加 lifespan 和最大闲置时间。//Lifespan of 5 seconds. //Maximum idle time of 1 second. cache.put("hello", "world", 5, TimeUnit.SECONDS, 1, TimeUnit.SECONDS); //Lifespan is disabled with a value of -1. //Maximum idle time of 1 second. cache.put("hello", "world", -1, TimeUnit.SECONDS, 1, TimeUnit.SECONDS);
5.5. JVM 堆和非堆内存
默认情况下,Data Grid 将缓存条目存储在 JVM 堆内存中。您可以将 Data Grid 配置为使用非堆存储,这意味着您的数据在受管 JVM 内存空间之外发生原生内存。
下图显示了数据网格运行的 JVM 进程的内存空间简图:
图 5.1. JVM 内存空间

JVM 堆内存
堆分成了年轻且旧的代,可帮助保持引用的 Java 对象和其他应用程序数据在内存中。GC 进程从无法访问的对象回收空间,在ng generation 内存池中运行更频繁。
当 Data Grid 将缓存条目存储在 JVM 堆内存中时,GC 运行会在开始将数据添加到缓存时完成。因为 GC 是一个密集型过程,所以较长且更频繁的运行可能会降低应用程序的性能。
off-heap 内存
off-heap 内存是 JVM 内存管理之外的本地可用内存。JVM 内存空间 图显示包含类元数据的 元空间 内存池,以及从原生内存分配。该图还表示包含 Data Grid 缓存条目的原生内存的一部分。
非堆内存:
- 每个条目使用较少的内存。
- 通过避免 Garbage Collector (GC)运行来提高整个 JVM 性能。
然而,一个缺点是 JVM 堆转储不会显示存储在非堆内存中的条目。
5.5.1. 非堆数据存储
当您向非堆缓存添加条目时,Data Grid 会动态地分配原生内存到数据。
数据网格将每个密钥的序列化 byte[] 分为与标准 Java HashMap 类似的存储桶中。bucket 包括数据网格用来查找您存储在非堆内存中的条目的地址指针。
尽管数据网格将缓存条目存储在原生内存中,但运行时操作需要这些对象的 JVM 堆表示。例如,cache.get () 操作将对象读取到堆内存,然后再返回。同样,状态传输操作将对象的子集存放在堆内存中。
对象相等
数据网格使用每个对象的序列化字节[] 而非对象实例确定低堆存储中的 Java 对象的相等性。
数据一致性
数据网格使用一组锁定来保护非堆地址空间。锁定数量是两倍的内核数,然后舍入到两个最接近的幂数。这样可确保即使是 ReadWriteLock 实例分布,以防止写操作阻止读操作。
5.5.2. 配置非堆内存
配置 Data Grid,将缓存条目存储在 JVM 堆空间之外的原生内存中。
流程
- 打开 Data Grid 配置进行编辑。
-
将
OFF_HEAP设置为storage属性或storage ()方法的值。 - 通过配置驱除,为缓存的大小设置一个边界。
- 保存并关闭您的数据网格配置。
off-heap 存储
数据网格以字节为单位存储缓存条目。当数据容器有 100 个条目且数据网格获得创建新条目的请求时,会发生驱除:
XML
<replicated-cache> <memory storage="OFF_HEAP" max-count="500"/> </replicated-cache>
JSON
{
"replicated-cache" : {
"memory" : {
"storage" : "OBJECT",
"max-count" : "500"
}
}
}
YAML
replicatedCache:
memory:
storage: "OFF_HEAP"
maxCount: "500"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.memory().storage(StorageType.OFF_HEAP).maxCount(500);
第 6 章 配置持久性存储
数据网格使用缓存存储和加载程序与持久性存储交互。
- durability
- 通过添加缓存存储,您可以将数据持久保留到非易失性存储中,因此可以在重启后保留。
- 直写缓存
- 在持久性存储前将 Data Grid 配置为缓存层简化了应用程序的数据访问,因为数据网格处理与外部存储之间的所有交互。
- 数据溢出
- 使用驱除和传递技巧可确保数据网格只保留频繁使用的数据,并将旧的条目写入持久性存储。
6.1. 激ivation
传递将数据网格配置为在从内存中驱除这些条目时将条目写入缓存存储。通过这种方式,传递可确保仅维护某一条目的单一副本、内存中或缓存存储中的单个副本,这样可以防止不必要的且可能代价被写入持久性存储。
当试图访问 passivated 条目时,激活是指从缓存存储中恢复条目的过程。因此,当您启用通过时,您必须配置实施 CacheWriter 和 CacheLoader 接口的缓存存储,以便它们可以从持久性存储中写入和加载条目。
当数据网格从缓存中驱除条目时,它会通知缓存监听程序,该条目通过传递,然后将该条目存储在缓存存储中。当 Data Grid 获取被驱除条目的访问请求时,它会延迟将条目从缓存存储加载到内存中,然后通知条目被激活的缓存监听程序。
- 传递使用 Data Grid 配置中的第一个缓存加载程序并忽略所有其他缓存程序。
不支持使用以下方法:
- 事务型存储。传递写入并从实际数据网格提交边界范围之外的存储中删除条目。
- 共享存储.共享缓存存储需要始终存在于其他所有者的存储中。因此,不支持 passivation,因为无法删除条目。
如果您启用了通过事务存储或共享存储的传递,Data Grid 会抛出异常。
6.1.1. 激ivation 如何工作
禁用传递
写入内存中的数据会导致写入持久性存储。
如果 Data Grid 从内存驱除数据,则持久性存储中的数据包括从内存中驱除的条目。这样,持久性存储是内存缓存的超集。
如果您没有配置驱除,则持久存储中的数据提供了内存中的数据副本。
启用传递
只有当数据从内存中驱除数据时,Data Grid 才会将数据添加到持久性存储中。
当 Data Grid 激活条目时,它会在内存中恢复数据并从持久性存储中删除数据。这样,持久存储形式的内存和数据都是整个数据集的单独子集,在两者之间没有交集。
在使用共享缓存存储时,持久性存储中的条目可能会过时。这是因为,Data Grid 在激活时不会从共享缓存存储中删除 passivated 条目。
值会更新在内存中,但之前传递的条目会停留在带有过期值的持久性存储中。
下表显示了一系列操作后内存和持久性存储中的数据:
| 操作 | 禁用传递 | 启用传递 | 使用共享缓存存储来传递启用 |
|---|---|---|---|
| 插入 k1。 |
memory: k1 |
memory: k1 |
memory: k1 |
| 插入 k2。 |
memory: k1, k2 |
memory: k1, k2 |
memory: k1, k2 |
| 驱除线程运行并驱除 k1。 |
memory: k2 |
memory: k2 |
memory: k2 |
| 阅读 k1。 |
memory: k1, k2 |
memory: k1, k2 |
memory: k1, k2 |
| 驱除线程运行并驱除 k2。 |
memory: k1 |
memory: k1 |
memory: k1 |
| 删除 k2。 |
memory: k1 |
memory: k1 |
memory: k1 |
6.2. 直写缓存存储
直写(write-through)是一种缓存写入模式,可同步写入缓存存储并写入缓存存储。当客户端应用程序更新缓存条目时,在大多数情况下,通过调用 Cache.put (),Data Grid 不会返回调用,直到更新缓存存储为止。此缓存写入模式会导致缓存存储在客户端线程的界限中产生更新。
write-through 模式的主要优点是同时更新缓存和缓存存储,这样可确保缓存存储始终与缓存一致。
但是,直写模式可能会降低性能,因为需要直接访问和更新缓存存储,这会为缓存操作添加延迟。
直写配置
数据网格使用直写模式,除非您明确向缓存添加直写配置。没有单独的元素或方法来配置直写模式。
例如,以下配置将基于文件的存储添加到隐式使用直写模式的缓存中:
<distributed-cache>
<persistence passivation="false">
<file-store fetch-state="true">
<index path="path/to/index" />
<data path="path/to/data" />
</file-store>
</persistence>
</distributed-cache>6.3. write-behind 缓存存储
write-behind 是一个缓存写模式,对内存的写入是同步的,对缓存存储的写入操作是异步的。
当客户端发送写入请求时,Data Grid 将这些操作添加到修改队列。数据网格处理操作,因为它们加入队列,使调用线程不会被阻止,操作会立即完成。
如果修改队列中的写入操作数量超过队列的大小,Data Grid 会将这些附加操作添加到队列中。但是,这些操作在队列中的 Data Grid 进程操作之前不会完成。
例如,调用 Cache.putAsync 会立即返回,如果修改队列未满,Stage 也会立即完成。如果修改队列已满,或者数据网格当前正在处理一系列写操作,那么 Cache.putAsync 会立即返回,Stage 会在以后完成。
与直写模式相比,write-behind 模式提供了性能优势,因为缓存操作不需要等待对底层缓存存储进行更新。但是,缓存存储中的数据与缓存中的数据不一致,直到处理修改队列为止。因此,write-behind 模式适合具有低延迟的缓存存储,如未共享和基于文件的缓存存储,写入缓存的时间就尽可能小。
write-behind 配置
XML
<distributed-cache>
<persistence>
<table-jdbc-store xmlns="urn:infinispan:config:store:sql:13.0"
dialect="H2"
shared="true"
table-name="books">
<connection-pool connection-url="jdbc:h2:mem:infinispan"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
<write-behind modification-queue-size="2048"
fail-silently="true"/>
</table-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"table-jdbc-store": {
"dialect": "H2",
"shared": "true",
"table-name": "books",
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
},
"write-behind" : {
"modification-queue-size" : "2048",
"fail-silently" : true
}
}
}
}
}
YAML
distributedCache:
persistence:
tableJdbcStore:
dialect: "H2"
shared: "true"
tableName: "books"
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan"
driver: "org.h2.Driver"
username: "sa"
password: "changeme"
writeBehind:
modificationQueueSize: "2048"
failSilently: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.async()
.modificationQueueSize(2048)
.failSilently(true);
静默失败
write-behind 配置包含一个故障切换参数,用于控制缓存存储不可用或修改队列已满时所发生的情况。
-
如果
fail-silently="true",Data Grid logs WARN 消息和拒绝写入操作。 如果
fail-silently="false",当数据网格检测到缓存存储在写入操作期间不可用时,数据网格会抛出异常。同样,如果修改队列已满,Data Grid 会抛出异常。在某些情况下,如果数据网格重启并在修改队列中存在写入操作,则可能发生数据丢失。例如,缓存存储离线,但在检测到缓存存储不可用时,写入操作会添加到修改队列中,因为它没有满。如果 Data Grid 在缓存存储恢复在线前重启或者不可用,修改队列中的写入操作将会丢失,因为它们不会被保留。
6.4. 分段缓存存储
缓存存储可将数据整理到哪些键映射中。
片段存储提高了批量操作的读取性能;例如,流处理数据(Cache.size、Cache.entrySet.stream)、预加载缓存以及执行状态传输操作。
但是,分段存储也可以导致写入操作的性能丢失。这个性能损失特别适用于通过交易或手写存储进行批量写入操作。因此,您应该在启用片段存储前评估写操作的开销。如果写操作有显著的性能损失,则对批量读取操作的性能提升可能无法接受。
为缓存存储配置的片段数量必须与您在Data Grid 配置中定义的片段数量与 cluster. hash.numSegments 参数匹配。
如果您在添加分段缓存存储后更改配置中的 numSegments 参数,Data Grid 无法从该缓存存储中读取数据。
6.6. 使用持久缓存存储的事务
数据网格仅支持使用基于 JDBC 的缓存存储进行事务操作。要将缓存配置为事务性,您需要设置 transactional=true,以在与内存中同步数据的持久性存储中保持数据。
对于所有其他缓存存储,Data Grid 不会在事务操作中 enlist 缓存加载程序。如果修改内存中的数据成功,但不会完全应用缓存存储中的数据更改,则可能会导致数据不一致。在这种情况下,无法进行缓存存储进行手动恢复。
6.7. 全球持久性位置
数据网格保留全局状态,以便它可以在重启后恢复集群拓扑和缓存的数据。
远程缓存
Data Grid Server 将集群状态保存到 $RHDG_HOME/server/data 目录。
您不应该删除或修改 server/data 目录或其内容。在重启服务器实例时,Data Grid 将从这个目录中恢复集群状态。
更改默认配置或直接修改 server/data 目录可能会导致意外行为,并导致数据丢失。
嵌入缓存
Data Grid 默认为 user.dir 系统属性,作为全局持久位置。在大多数情况下,这是应用程序启动的目录。
对于集群的内嵌缓存,如复制或分布式,您应该始终启用并配置全局持久位置,以恢复集群拓扑。
您不能为位于全局持久位置以外的基于文件的缓存存储配置绝对路径。如果这样做,Data Grid 将以下例外写入日志:
ISPN000558: "The store location 'foo' is not a child of the global persistent location 'bar'"
6.7.1. 配置全局持久位置
启用并配置数据网格为集群嵌入式缓存存储全局状态的位置。
数据网格服务器支持全局持久性并配置默认位置。您不应该禁用全局持久性,或更改远程缓存的默认配置。
先决条件
- 将 Data Grid 添加到您的项目。
流程
使用以下方法之一启用全局状态:
-
将
global-state元素添加到您的 Data Grid 配置中。 -
在
GlobalConfigurationBuilderAPI 中调用globalState ().enable ()方法。
-
将
定义全局持久位置是否与每个节点唯一或在集群间共享。
位置类型 Configuration 每个节点唯一
persistent-location元素或persistentLocation ()方法在集群间共享
shared-persistent-location元素或sharedPersistentLocation (String)方法设置数据网格存储集群状态的路径。
例如,基于文件的缓存存储路径是主机文件系统中的一个目录。
值可以是:
- 绝对位置,并包含根用户。
- 相对于根位置.
如果为路径指定相对值,还必须指定一个解析为根位置的系统属性。
例如,在 Linux 主机系统上,您要将
global/state设置为路径。您还设置解析到/opt/data根位置的my.data属性。在这种情况下,Data Grid 使用/opt/data/global/state作为全局持久位置。
全局持久位置配置
XML
<infinispan>
<cache-container>
<global-state>
<persistent-location path="global/state" relative-to="my.data"/>
</global-state>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"global-state": {
"persistent-location" : {
"path" : "global/state",
"relative-to" : "my.data"
}
}
}
}
}
YAML
cacheContainer:
globalState:
persistentLocation:
path: "global/state"
relativeTo : "my.data"
GlobalConfigurationBuilder
new GlobalConfigurationBuilder().globalState()
.enable()
.persistentLocation("global/state", "my.data");
6.8. 基于文件的缓存存储
基于文件的缓存存储在运行 Data Grid 的本地主机文件系统中提供持久性存储。对于群集缓存,基于文件的缓存存储对于每个 Data Grid 节点来说是唯一的。
切勿使用共享文件系统上的基于文件系统的缓存存储,如 NFS 或 Samba 共享,因为它们不提供文件锁定功能和数据崩溃。
另外,如果您试图将事务缓存与共享文件系统搭配使用,在提交阶段写入文件时无法恢复的故障时可能会出现。
soft-Index File Stores
SoftIndexFileStore 是基于文件的缓存存储的默认实现,并将其数据存储在仅附加文件中。
当只附加文件时:
- 达到其最大大小,Data Grid 将创建一个新文件并开始写入该文件。
- 达到 50% 用量小于 50% 的压缩阈值,Data Grid 会将条目覆盖到新文件,然后删除旧文件。
b+ 树
为提高性能,可使用 B+ 树 在磁盘和内存中存储 SoftIndexFileStore 中仅附加文件进行索引。内存索引使用 Java 软引用来确保在 Garbage Collection (GC)中删除后重新进行重建。
由于 SoftIndexFileStore 使用 Java 软引用来保留索引内存,所以它有助于防止内存不足的情况。GC 在消耗太多内存前删除索引,同时仍然回退到磁盘。
您可以使用索引元素中的 片段 属性,或使用 方法来配置任意数量的 B+ 树。默认情况下,数据网格创建最多 16 个 B+ 树,这意味着最多可以有 16 个索引。有多个索引可防止对索引进行并发写入操作,并减少数据网格需要在内存中保留的条目数量。由于迭代了 soft-index 文件存储,Data Grid 会同时读取索引中的所有条目。
index Segments ()
B+ 树中的每个条目都是节点。默认情况下,每个节点的大小限制为 4096 字节。如果键在序列化后较长,SoftIndexFileStore 会抛出异常。
分段
soft-index 文件存储始终被分段。
AdvancedStore.purgeExpired () 方法在 SoftIndexFileStore 中未实现。
单个文件缓存存储
单个文件缓存存储现已弃用,计划删除。
单个文件缓存存储、单一文件存储、将数据存储在文件中。数据网格还维护一个内存密钥索引,而键和值则存储在 文件中。
由于 SingleFileStore 会保留内存密钥索引和值位置,它需要额外内存,具体取决于密钥大小和键的数量。因此,不建议使用 SingleFileStore,其中键较大或者有多个密钥。
在某些情况下,single FileStore 也可能会变得碎片。如果值大小持续增加,则不会使用单一文件中的可用空间,但该条目附加到文件的末尾。只有在条目可以容纳时,才会使用该文件中的可用空间。同样,如果您从内存中删除所有条目,则单个文件存储的大小不会降低或进行碎片整理。
分段
默认情况下,单个文件缓存被分段,每个片段使用单独的实例,这样会导致多个目录。每个目录都是代表数据映射的片段的数字。
6.8.1. 配置基于文件的缓存存储
将基于文件的缓存存储添加到 Data Grid,以在主机文件系统中持久保留数据。
先决条件
- 如果您配置嵌入缓存,请启用全局持久位置。
流程
-
将
persistence元素添加到缓存配置中。 -
(可选)指定
true作为 passivation 属性的值,仅在数据从内存驱除时写入基于文件的缓存存储。 -
包含
file-store元素,并根据情况配置属性。 指定
false作为shared属性的值。基于文件的缓存存储应该始终特定于每个数据网格实例。如果要在集群中使用相同的持久性,请配置共享存储,如 JDBC 字符串的缓存存储。
-
配置
索引和数据元素,以指定数据网格创建索引和存储数据的位置。 -
如果要使用
write-behind模式配置缓存存储,请包含 write-behind 元素。
基于文件的缓存存储配置
XML
<distributed-cache>
<persistence passivation="true">
<file-store shared="false">
<data path="data"/>
<index path="index"/>
<write-behind modification-queue-size="2048" />
</file-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"passivation": true,
"file-store" : {
"shared": false,
"data": {
"path": "data"
},
"index": {
"path": "index"
},
"write-behind": {
"modification-queue-size": "2048"
}
}
}
}
}
YAML
distributedCache:
persistence:
passivation: "true"
fileStore:
shared: "false"
data:
path: "data"
index:
path: "index"
writeBehind:
modificationQueueSize: "2048"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().passivation(true)
.addSoftIndexFileStore()
.shared(false)
.dataLocation("data")
.indexLocation("index")
.modificationQueueSize(2048);
6.8.2. 配置单个文件缓存存储
如果需要,您可以配置 Data Grid 来创建单一文件存储。
单个文件存储已弃用。与单一文件存储相比,您应该使用 soft-index 文件存储提高了性能和数据一致性。
先决条件
- 如果您配置嵌入缓存,请启用全局持久位置。
流程
-
将
persistence元素添加到缓存配置中。 -
(可选)指定
true作为 passivation 属性的值,仅在数据从内存驱除时写入基于文件的缓存存储。 -
包含
single-file-store元素。 -
指定
false作为shared属性的值。 - 根据需要配置任何其他属性。
-
包含
write-behind元素,以将缓存存储配置为后面的写入操作,而不是作为写入操作。
单个文件缓存存储配置
XML
<distributed-cache>
<persistence passivation="true">
<single-file-store shared="false"
preload="true"
fetch-state="true"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"passivation" : true,
"single-file-store" : {
"shared" : false,
"preload" : true,
"fetch-state" : true
}
}
}
}
YAML
distributedCache:
persistence:
passivation: "true"
singleFileStore:
shared: "false"
preload: "true"
fetchState: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().passivation(true)
.addStore(SingleFileStoreConfigurationBuilder.class)
.shared(false)
.preload(true)
.fetchPersistentState(true);
6.9. JDBC 连接工厂
数据网格提供了不同的 ConnectionFactory 实施,可让您连接到数据库。您可以使用带有 SQL 缓存存储和 JDBC 字符串的缓存存储的 JDBC 连接。
连接池
连接池适合独立数据网格部署,基于 Agroal。
XML
<distributed-cache>
<persistence>
<connection-pool connection-url="jdbc:h2:mem:infinispan;DB_CLOSE_DELAY=-1"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan_string_based",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
YAML
distributedCache:
persistence:
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan_string_based;DB_CLOSE_DELAY=-1"
driver: org.h2.Driver
username: sa
password: changeme
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan_string_based;DB_CLOSE_DELAY=-1")
.username("sa")
.driverClass("org.h2.Driver");
managed datasources
数据源连接适用于应用服务器等受管环境。
XML
<distributed-cache>
<persistence>
<data-source jndi-url="java:/StringStoreWithManagedConnectionTest/DS" />
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"data-source": {
"jndi-url": "java:/StringStoreWithManagedConnectionTest/DS"
}
}
}
}
YAML
distributedCache:
persistence:
dataSource:
jndiUrl: "java:/StringStoreWithManagedConnectionTest/DS"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.dataSource()
.jndiUrl("java:/StringStoreWithManagedConnectionTest/DS");
简单连接
简单连接工厂为每个调用创建数据库连接,仅用于用于测试或开发环境。
XML
<distributed-cache>
<persistence>
<simple-connection connection-url="jdbc:h2://localhost"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"simple-connection": {
"connection-url": "jdbc:h2://localhost",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
YAML
distributedCache:
persistence:
simpleConnection:
connectionUrl: "jdbc:h2://localhost"
driver: org.h2.Driver
username: sa
password: changeme
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence()
.simpleConnection()
.connectionUrl("jdbc:h2://localhost")
.driverClass("org.h2.Driver")
.username("admin")
.password("changeme");
其他资源
6.9.1. 配置受管数据源
作为 Data Grid 服务器配置的一部分创建受管 datasources,以优化 JDBC 数据库连接的连接池和性能。然后,您可以在缓存中指定受管数据源的 JDNI 名称,这会集中部署的 JDBC 连接配置。
先决条件
-
将数据库驱动程序复制到 Data Grid Server 安装中的
server/lib目录中。
流程
- 打开 Data Grid Server 配置进行编辑。
-
将新的
数据源添加到部分。data-sources -
通过
name属性或字段唯一标识数据源。 使用
jndi-name属性或字段为数据源指定 JNDI 名称。提示您可以使用 JNDI 名称在 JDBC 缓存存储配置中指定数据源。
-
将
true设置为statistics属性或字段的值,以通过/metrics端点为数据源启用统计。 提供 JDBC 驱动程序详细信息,以定义如何在
connection-factory部分中定义数据源连接。-
使用
driver属性或字段指定数据库驱动程序的名称。 -
使用 url 属性或字段指定 JDBC 连接
url。 -
使用
用户名和密码 - 根据需要提供任何其他配置。
-
使用
-
在
connection-pool部分中,定义 Data Grid Server 节点池并重复使用与连接池调整属性的连接。 - 保存对您的配置的更改。
验证
使用 Data Grid 命令行界面(CLI)测试数据源连接,如下所示:
启动 CLI 会话。
bin/cli.sh
列出所有数据源,并确认您创建的数据源可用。
server datasource ls
测试数据源连接。
server datasource test my-datasource
管理的数据源配置
XML
<server xmlns="urn:infinispan:server:13.0">
<data-sources>
<!-- Defines a unique name for the datasource and JNDI name that you
reference in JDBC cache store configuration.
Enables statistics for the datasource, if required. -->
<data-source name="ds"
jndi-name="jdbc/postgres"
statistics="true">
<!-- Specifies the JDBC driver that creates connections. -->
<connection-factory driver="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/postgres"
username="postgres"
password="changeme">
<!-- Sets optional JDBC driver-specific connection properties. -->
<connection-property name="name">value</connection-property>
</connection-factory>
<!-- Defines connection pool tuning properties. -->
<connection-pool initial-size="1"
max-size="10"
min-size="3"
background-validation="1000"
idle-removal="1"
blocking-timeout="1000"
leak-detection="10000"/>
</data-source>
</data-sources>
</server>
JSON
{
"server": {
"data-sources": [{
"name": "ds",
"jndi-name": "jdbc/postgres",
"statistics": true,
"connection-factory": {
"driver": "org.postgresql.Driver",
"url": "jdbc:postgresql://localhost:5432/postgres",
"username": "postgres",
"password": "changeme",
"connection-properties": {
"name": "value"
}
},
"connection-pool": {
"initial-size": 1,
"max-size": 10,
"min-size": 3,
"background-validation": 1000,
"idle-removal": 1,
"blocking-timeout": 1000,
"leak-detection": 10000
}
}]
}
}
YAML
server:
dataSources:
- name: ds
jndiName: 'jdbc/postgres'
statistics: true
connectionFactory:
driver: "org.postgresql.Driver"
url: "jdbc:postgresql://localhost:5432/postgres"
username: "postgres"
password: "changeme"
connectionProperties:
name: value
connectionPool:
initialSize: 1
maxSize: 10
minSize: 3
backgroundValidation: 1000
idleRemoval: 1
blockingTimeout: 1000
leakDetection: 10000
6.9.1.1. 使用 JNDI 名称配置缓存
将受管数据源添加到 Data Grid 服务器时,您可以将 JNDI 名称添加到基于 JDBC 的缓存存储配置中。
先决条件
- 使用受管理数据源配置 Data Grid 服务器。
流程
- 打开缓存配置进行编辑。
-
将
data-source元素或字段添加到基于 JDBC 的缓存存储配置中。 -
将受管数据源的 JNDI 名称指定为
jndi-url属性的值。 - 根据情况配置基于 JDBC 的缓存存储。
- 保存对您的配置的更改。
缓存配置中的 JNDI 名称
XML
<distributed-cache>
<persistence>
<jdbc:string-keyed-jdbc-store>
<!-- Specifies the JNDI name of a managed datasource on Data Grid Server. -->
<jdbc:data-source jndi-url="jdbc/postgres"/>
<jdbc:string-keyed-table drop-on-exit="true" create-on-start="true" prefix="TBL">
<jdbc:id-column name="ID" type="VARCHAR(255)"/>
<jdbc:data-column name="DATA" type="BYTEA"/>
<jdbc:timestamp-column name="TS" type="BIGINT"/>
<jdbc:segment-column name="S" type="INT"/>
</jdbc:string-keyed-table>
</jdbc:string-keyed-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"string-keyed-jdbc-store": {
"data-source": {
"jndi-url": "jdbc/postgres"
},
"string-keyed-table": {
"prefix": "TBL",
"drop-on-exit": true,
"create-on-start": true,
"id-column": {
"name": "ID",
"type": "VARCHAR(255)"
},
"data-column": {
"name": "DATA",
"type": "BYTEA"
},
"timestamp-column": {
"name": "TS",
"type": "BIGINT"
},
"segment-column": {
"name": "S",
"type": "INT"
}
}
}
}
}
}
YAML
distributedCache:
persistence:
stringKeyedJdbcStore:
dataSource:
jndi-url: "jdbc/postgres"
stringKeyedTable:
prefix: "TBL"
dropOnExit: true
createOnStart: true
idColumn:
name: "ID"
type: "VARCHAR(255)"
dataColumn:
name: "DATA"
type: "BYTEA"
timestampColumn:
name: "TS"
type: "BIGINT"
segmentColumn:
name: "S"
type: "INT"
6.9.1.2. 连接池调整属性
您可以在 Data Grid Server 配置中为 managed datasources 调优 JDBC 连接池。
| 属性 | 描述 |
|---|---|
|
| 池应有的初始连接数。 |
|
| 池中的最大连接数。 |
|
| 池应拥有的最低连接数。 |
|
|
在引发异常前,在等待连接时以毫秒为单位进行阻止的最大时间(毫秒)。如果创建新连接需要较长的时间内,这不会抛出异常。默认值为 |
|
|
后台验证运行间隔的时间(毫秒)。 |
|
|
在获取前,连接闲置时间超过这个值(以毫秒为单位指定)在被验证前进行验证。 |
|
| 在删除连接前,连接必须闲置时间(以分钟为单位)。 |
|
| 在泄漏警告前,连接必须保留以毫秒为单位。 |
6.9.2. 使用 Agroal 属性配置 JDBC 连接池
您可以使用属性文件为 JDBC 字符串的缓存存储配置池连接工厂。
流程
使用
org.infinispan.agroal.*属性指定 JDBC 连接池配置,如下例所示:org.infinispan.agroal.metricsEnabled=false org.infinispan.agroal.minSize=10 org.infinispan.agroal.maxSize=100 org.infinispan.agroal.initialSize=20 org.infinispan.agroal.acquisitionTimeout_s=1 org.infinispan.agroal.validationTimeout_m=1 org.infinispan.agroal.leakTimeout_s=10 org.infinispan.agroal.reapTimeout_m=10 org.infinispan.agroal.metricsEnabled=false org.infinispan.agroal.autoCommit=true org.infinispan.agroal.jdbcTransactionIsolation=READ_COMMITTED org.infinispan.agroal.jdbcUrl=jdbc:h2:mem:PooledConnectionFactoryTest;DB_CLOSE_DELAY=-1 org.infinispan.agroal.driverClassName=org.h2.Driver.class org.infinispan.agroal.principal=sa org.infinispan.agroal.credential=sa
配置 Data Grid,以使用
properties-file属性或PooledConnectionFactoryConfiguration.propertyFile ()方法。XML
<connection-pool properties-file="path/to/agroal.properties"/>
JSON
"persistence": { "connection-pool": { "properties-file": "path/to/agroal.properties" } }YAML
persistence: connectionPool: propertiesFile: path/to/agroal.propertiesConfigurationBuilder
.connectionPool().propertyFile("path/to/agroal.properties")
其他资源
6.10. SQL 缓存存储
SQL 缓存存储可让您从现有数据库表中加载数据网格缓存。数据网格提供两种类型的 SQL 缓存存储:
- 表
- 数据网格从单个数据库表中加载条目。
- 查询
- 数据网格使用 SQL 查询从单一或多个数据库表加载条目,包括来自这些表格中的子列,并执行插入、更新和删除操作。
访问代码教程,以尝试在操作中尝试 SQL 缓存存储。请参阅 远程缓存的 Persistence 代码指南。
SQL 表和查询存储:
- 允许对持久性存储进行读写操作。
- 可以是只读并充当缓存加载程序。
支持与单个数据库列或多个数据库列的复合对应的键和值。
对于复合键和值,您必须为数据网格提供描述键和值的 Protobuf 模式(
.proto文件)。通过使用 Data Grid Server,您可以使用 Data Grid Console 或命令行界面(CLI)添加模式。
SQL 缓存存储不支持过期或分段。
6.10.1. 密钥和值的数据类型
数据网格通过 SQL 缓存存储从数据库表中的列加载键和值,并使用适当的数据类型自动加载。以下 CREATE 语句添加名为"books"的表,它含有两个列,即 isbn 和 title :
带有两个列的数据库表
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120)
PRIMARY KEY(isbn)
);
当您将这个表与 SQL 缓存存储搭配使用时,Data Grid 会将一个条目使用 isbn 列作为键,标题 列作为值。
其他资源
6.10.1.1. 复合键和值
您可以将 SQL 存储与包含复合主键或复合值的数据库表搭配使用。
要使用复合键或值,您必须为 Data Grid 提供描述数据类型的 Protobuf 模式。您还必须在 SQL 存储中添加 架构 配置,并指定键和值的消息名称。
数据网格建议使用 Protobuf 处理器生成 Protobuf 模式。然后,您可以通过 Data Grid Console、CLI 或 REST API 上传远程缓存的 Protobuf 模式。
复合值
下表包含 标题和 作者 列的复合值:
CREATE TABLE books (
isbn NUMBER(13),
title varchar(120),
author varchar(80)
PRIMARY KEY(isbn)
);
Data Grid 使用 isbn 列作为密钥在缓存中添加条目。对于值,Data Grid 需要 Protobuf 模式来映射 title 列和 作者 列:
package library;
message books_value {
optional string title = 1;
optional string author = 2;
}复合键和值
下表包含复合主键和复合值,每个列有两个列:
CREATE TABLE books (
isbn NUMBER(13),
reprint INT,
title varchar(120),
author varchar(80)
PRIMARY KEY(isbn, reprint)
);对于键和值,Data Grid 需要一个 Protobuf 模式,用于将列映射到键和值:
package library;
message books_key {
required string isbn = 1;
required int32 reprint = 2;
}
message books_value {
optional string title = 1;
optional string author = 2;
}6.10.1.2. 嵌入式密钥
protobuf 模式可在值中包含键,如下例所示:
带有嵌入式键的 protobuf 模式
package library;
message books_key {
required string isbn = 1;
required int32 reprint = 2;
}
message books_value {
required string isbn = 1;
required string reprint = 2;
optional string title = 3;
optional string author = 4;
}
要使用嵌入的密钥,您必须在 SQL 存储配置中包含 embedded-key="true" 属性或 embeddedKey (true) 方法。
6.10.1.3. SQL 类型到 Protobuf 类型
下表包含 SQL 数据类型到 Protobuf 数据类型的默认映射:
| SQL 类型 | protobuf type |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其他资源
6.10.2. 从数据库表载入 Data Grid 缓存
如果您希望数据网格从数据库表中加载数据,请在配置中添加 SQL 表缓存存储。当它连接到数据库时,Data Grid 使用表中的元数据来检测列名称和数据类型。数据网格还自动决定数据库中哪些列是主密钥的一部分。
先决条件
-
具有 JDBC 连接详情。
您可以将 JDBC 连接工厂直接添加到您的缓存配置中。
对于生产环境中的远程缓存,您应该将受管数据源添加到 Data Grid Server 配置中,并在缓存配置中指定 JNDI 名称。 为任何复合密钥或复合值生成 Protobuf 模式,并使用 Data Grid 注册您的模式。
提示数据网格建议使用 Protobuf 处理器生成 Protobuf 模式。对于远程缓存,您可以通过数据网格控制台、CLI 或 REST API 来添加模式来注册模式。
流程
在 Data Grid 部署中添加数据库驱动程序。
-
远程缓存:将数据库驱动程序复制到 Data Grid 服务器安装的
server/lib目录中。 嵌入式缓存:在您的
pom文件中添加infinispan-cachestore-sql依赖项。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
-
远程缓存:将数据库驱动程序复制到 Data Grid 服务器安装的
- 打开 Data Grid 配置进行编辑。
添加 SQL 表缓存存储。
声明性
table-jdbc-store xmlns="urn:infinispan:config:store:sql:13.0"
programmatic
persistence().addStore(TableJdbcStoreConfigurationBuilder.class)
-
使用
dialect=""或dialect ()指定数据库死信,如dialect="H2"或dialect="postgres"。 使用您需要的属性配置 SQL 缓存存储,例如:
-
要在集群中使用相同的缓存存储,请设置
shared="true"或shared (true)。 -
要创建只读缓存存储,请设置
read-only="true"或.ignoreModifications (true)。
-
要在集群中使用相同的缓存存储,请设置
-
使用 table
-name="<database_table_name>" 或 table.name("<database_table_name>")来加载缓存的数据库表。 添加
schema元素或.schemaJdbcConfigurationBuilder ()方法,并为复合键或值添加 Protobuf 模式配置。-
使用 package 属性或
package() -
使用
message-name属性或messageName ()方法指定复合值。 -
使用
key-message-name属性或keyMessageName ()方法指定复合键。 -
如果您的 schema 包含值 in values 中的键,则为
嵌入式-key属性或嵌入式Key ()true。
-
使用 package 属性或
- 保存对您的配置的更改。
SQL 表存储配置
以下示例使用 Protobuf 模式中定义的复合值从名为"books"的数据库表中加载分布式缓存:
XML
<distributed-cache>
<persistence>
<table-jdbc-store xmlns="urn:infinispan:config:store:sql:13.0"
dialect="H2"
shared="true"
table-name="books">
<schema message-name="books_value"
package="library"/>
</table-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"table-jdbc-store": {
"dialect": "H2",
"shared": "true",
"table-name": "books",
"schema": {
"message-name": "books_value",
"package": "library"
}
}
}
}
}
YAML
distributedCache:
persistence:
tableJdbcStore:
dialect: "H2"
shared: "true"
tableName: "books"
schema:
messageName: "books_value"
package: "library"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(TableJdbcStoreConfigurationBuilder.class)
.dialect(DatabaseType.H2)
.shared("true")
.tableName("books")
.schemaJdbcConfigurationBuilder()
.messageName("books_value")
.packageName("library");
6.10.3. 使用 SQL 查询来加载数据并执行操作
SQL 查询缓存存储使您可以从多个数据库表加载缓存,包括数据库表中的子列,并执行插入、更新和删除操作。
先决条件
-
具有 JDBC 连接详情。
您可以将 JDBC 连接工厂直接添加到您的缓存配置中。
对于生产环境中的远程缓存,您应该将受管数据源添加到 Data Grid Server 配置中,并在缓存配置中指定 JNDI 名称。 为任何复合密钥或复合值生成 Protobuf 模式,并使用 Data Grid 注册您的模式。
提示数据网格建议使用 Protobuf 处理器生成 Protobuf 模式。对于远程缓存,您可以通过数据网格控制台、CLI 或 REST API 来添加模式来注册模式。
流程
在 Data Grid 部署中添加数据库驱动程序。
-
远程缓存:将数据库驱动程序复制到 Data Grid 服务器安装的
server/lib目录中。 嵌入式缓存:将
infinispan-cachestore-sql依赖关系添加到您的pom文件,并确保数据库驱动程序在您的应用程序类路径上。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-sql</artifactId> </dependency>
-
远程缓存:将数据库驱动程序复制到 Data Grid 服务器安装的
- 打开 Data Grid 配置进行编辑。
添加 SQL 查询缓存存储。
声明性
query-jdbc-store xmlns="urn:infinispan:config:store:jdbc:13.0"
programmatic
persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)
-
使用
dialect=""或dialect ()指定数据库死信,如dialect="H2"或dialect="postgres"。 使用您需要的属性配置 SQL 缓存存储,例如:
-
要在集群中使用相同的缓存存储,请设置
shared="true"或shared (true)。 -
要创建只读缓存存储,请设置
read-only="true"或.ignoreModifications (true)。
-
要在集群中使用相同的缓存存储,请设置
定义 SQL 查询语句,该语句使用
查询元素或queries ()方法来加载数据并修改数据库表。query 语句 描述 选择将单个条目加载到缓存中。您可以使用通配符,但必须为键指定参数。您可以使用标记的表达式。
选择所有将多个条目加载到缓存中。如果返回的列数与 key 和 value 列匹配,您可以使用
*通配符。您可以使用标记的表达式。SIZE计算缓存中条目的数量。
DELETE从缓存中删除单个条目。
全部删除从缓存中删除所有条目。
UPSERT修改缓存中的条目。
注意DELETE、DELEALL和UPSERT语句不适用于只读缓存存储,但如果缓存存储允许修改,则需要使用。DELETE语句中的参数必须与SELECT语句中的参数完全匹配。UPSERT语句中的变量必须具有与SELECT和SELECT ALL语句返回相同的唯一命名变量数。例如,如果SELECT返回foo和barthis 语句必须仅采用:foo和:bar作为变量。但是,您可以在声明中多次应用同一命名变量。SQL 查询可以包含
JOIN、ON以及数据库支持的任何其他子句。添加
schema元素或.schemaJdbcConfigurationBuilder ()方法,并为复合键或值添加 Protobuf 模式配置。-
使用 package 属性或
package() -
使用
message-name属性或messageName ()方法指定复合值。 -
使用
key-message-name属性或keyMessageName ()方法指定复合键。 -
如果您的 schema 包含值 in values 中的键,则为
嵌入式-key属性或嵌入式Key ()true。
-
使用 package 属性或
- 保存对您的配置的更改。
其他资源
6.10.3.1. SQL 查询存储配置
本节提供了 SQL 查询缓存存储示例配置,它使用两个数据库表中的数据来加载分布式缓存:"person"和"address"。
SQL 语句
用于"个人"和"地址"表的 SQL 数据定义语言(DDL)语句如下:
"人"表的 SQL 语句
CREATE TABLE Person ( name VARCHAR(255) NOT NULL, picture VARBINARY(255), sex VARCHAR(255), birthdate TIMESTAMP, accepted_tos BOOLEAN, notused VARCHAR(255), PRIMARY KEY (name) );
"address"表的 SQL 语句
CREATE TABLE Address ( name VARCHAR(255) NOT NULL, street VARCHAR(255), city VARCHAR(255), zip INT, PRIMARY KEY (name) );
protobuf schema
protobuf 用于 "person" 和 "address" 表的 schema,如下所示:
protobuf schema for the "person" 表
package com.example
enum Sex {
FEMALE = 1;
MALE = 2;
}
message Person {
optional string name = 1;
optional Address address = 2;
optional bytes picture = 3;
optional Sex sex = 4;
optional fixed64 birthDate = 5 [default = 0];
optional bool accepted_tos = 6 [default = false];
}
protobuf schema for the "address" 表
package com.example
message Address {
optional string street = 1;
optional string city = 2 [default = "San Jose"];
optional int32 zip = 3 [default = 0];
}
缓存配置
以下示例使用包含 JOIN 子句的 SQL 查询从"person"和"地址"表中加载分布式缓存:
XML
<distributed-cache>
<persistence>
<query-jdbc-store xmlns="urn:infinispan:config:store:jdbc:13.0"
dialect="POSTGRES"
shared="true">
<queries key-columns="name">
<select-single>SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name WHERE t1.name = :name</select-single>
<select-all>SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name</select-all>
<delete-single>DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name</delete-single>
<delete-all>DELETE FROM Person; DELETE FROM Address</delete-all>
<upsert>INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)</upsert>
<size>SELECT COUNT(*) FROM Person</size>
</queries>
<schema message-name="Person"
package="com.example"
embedded-key="true"/>
</query-jdbc-store>
</persistence>
<distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"query-jdbc-store": {
"dialect": "POSTGRES",
"shared": "true",
"key-columns": "name",
"queries": {
"select-single": "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name WHERE t1.name = :name",
"select-all": "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name",
"delete-single": "DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name",
"delete-all": "DELETE FROM Person; DELETE FROM Address",
"upsert": "INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)",
"size": "SELECT COUNT(*) FROM Person"
},
"schema": {
"message-name": "Person",
"package": "com.example",
"embedded-key": "true"
}
}
}
}
}
YAML
distributedCache:
persistence:
queryJdbcStore:
dialect: "POSTGRES"
shared: "true"
keyColumns: "name"
queries:
selectSingle: "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name WHERE t1.name = :name"
selectAll: "SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name"
deleteSingle: "DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name"
deleteAll: "DELETE FROM Person; DELETE FROM Address"
upsert: "INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)"
size: "SELECT COUNT(*) FROM Person"
schema:
messageName: "Person"
package: "com.example"
embeddedKey: "true"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(QueriesJdbcStoreConfigurationBuilder.class)
.dialect(DatabaseType.POSTGRES)
.shared("true")
.keyColumns("name")
.queriesJdbcConfigurationBuilder()
.select("SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name WHERE t1.name = :name")
.selectAll("SELECT t1.name, t1.picture, t1.sex, t1.birthdate, t1.accepted_tos, t2.street, t2.city, t2.zip FROM Person t1 JOIN Address t2 ON t1.name = t2.name")
.delete("DELETE FROM Person t1 WHERE t1.name = :name; DELETE FROM Address t2 where t2.name = :name")
.deleteAll("DELETE FROM Person; DELETE FROM Address")
.upsert("INSERT INTO Person (name, picture, sex, birthdate, accepted_tos) VALUES (:name, :picture, :sex, :birthdate, :accepted_tos); INSERT INTO Address(name, street, city, zip) VALUES (:name, :street, :city, :zip)")
.size("SELECT COUNT(*) FROM Person")
.schemaJdbcConfigurationBuilder()
.messageName("Person")
.packageName("com.example")
.embeddedKey(true);
其他资源
6.10.4. SQL 缓存存储故障排除
查找有关 SQL 缓存存储的常见问题和错误以及如何对其进行故障排除。
ISPN008064: No primary keys found for table <table_name>, check case sensitivity
数据网格在以下情况下记录这个信息:
- 数据库表不存在。
- 数据库表名称区分大小写,需要所有小写或所有大写,具体取决于数据库提供程序。
- 数据库表没有定义任何主密钥。
要解决这个问题,应该:
- 检查您的 SQL 缓存存储配置,并确保指定现有表的名称。
- 确保数据库表名称符合问题单敏感度要求。
- 确保您的数据库表有唯一标识相应行的主键。
6.11. JDBC 字符串的缓存存储
JDBC String 型缓存存储 JdbcStringBasedStore,使用 JDBC 驱动程序在底层数据库中加载和存储值。
JDBC String-Based 缓存存储:
- 将每个条目存储在表中,以提高并发负载吞吐量。
-
使用一个简单的一对一映射,使用键到
字符串接口将每个键映射到String对象。
数据网格提供了一个处理原语类型的默认实施DefaultTwoWayKey2StringMapper。
除了用于存储缓存条目的数据表外,存储还会创建一个 _META 表来存储元数据。此表用于确保任何现有数据库内容与当前数据网格版本和配置兼容。
默认情况下,Data Grid 共享不存储,这意味着集群中的所有节点都写入每个更新上的底层存储。如果只想操作对底层数据库进行写入,则必须将 JDBC 存储配置为共享。
分段
JdbcStringBasedStore 默认使用分段,它需要一个数据库表中的列来代表条目属于的片段。
6.11.1. 配置基于字符串的 JDBC 缓存存储
使用 JDBC 字符串的缓存配置可连接到数据库的数据网格缓存。
先决条件
-
远程缓存:将数据库驱动程序复制到 Data Grid 服务器安装的
server/lib目录中。 嵌入式缓存:将
infinispan-cachestore-jdbc依赖项添加到您的pom文件。<dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-cachestore-jdbc</artifactId> </dependency>
流程
使用以下方法之一创建基于 JDBC 字符串的缓存存储配置:
声明性,添加
持久性元素或字段,然后添加带有以下架构命名空间的string-keyed-jdbc-store:xmlns="urn:infinispan:config:store:jdbc:13.0"
以编程方式,将以下方法添加到
ConfigurationBuilder中:persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
-
使用
dialect属性或dialect ()方法指定数据库的 dialect。 根据情况配置 JDBC 字符串的缓存存储的任何属性。
例如,指定缓存存储是否与带有 shared 属性或
shared()- 添加 JDBC 连接工厂,使数据网格能够连接到数据库。
- 添加存储缓存条目的数据库表。
JDBC 字符串的缓存存储配置
XML
<distributed-cache>
<persistence>
<string-keyed-jdbc-store xmlns="urn:infinispan:config:store:jdbc:13.0"
dialect="H2">
<connection-pool connection-url="jdbc:h2:mem:infinispan"
username="sa"
password="changeme"
driver="org.h2.Driver"/>
<string-keyed-table create-on-start="true"
prefix="ISPN_STRING_TABLE">
<id-column name="ID_COLUMN"
type="VARCHAR(255)" />
<data-column name="DATA_COLUMN"
type="BINARY" />
<timestamp-column name="TIMESTAMP_COLUMN"
type="BIGINT" />
<segment-column name="SEGMENT_COLUMN"
type="INT"/>
</string-keyed-table>
</string-keyed-jdbc-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence": {
"string-keyed-jdbc-store": {
"dialect": "H2",
"string-keyed-table": {
"prefix": "ISPN_STRING_TABLE",
"create-on-start": true,
"id-column": {
"name": "ID_COLUMN",
"type": "VARCHAR(255)"
},
"data-column": {
"name": "DATA_COLUMN",
"type": "BINARY"
},
"timestamp-column": {
"name": "TIMESTAMP_COLUMN",
"type": "BIGINT"
},
"segment-column": {
"name": "SEGMENT_COLUMN",
"type": "INT"
}
},
"connection-pool": {
"connection-url": "jdbc:h2:mem:infinispan",
"driver": "org.h2.Driver",
"username": "sa",
"password": "changeme"
}
}
}
}
}
YAML
distributedCache:
persistence:
stringKeyedJdbcStore:
dialect: "H2"
stringKeyedTable:
prefix: "ISPN_STRING_TABLE"
createOnStart: true
idColumn:
name: "ID_COLUMN"
type: "VARCHAR(255)"
dataColumn:
name: "DATA_COLUMN"
type: "BINARY"
timestampColumn:
name: "TIMESTAMP_COLUMN"
type: "BIGINT"
segmentColumn:
name: "SEGMENT_COLUMN"
type: "INT"
connectionPool:
connectionUrl: "jdbc:h2:mem:infinispan"
driver: "org.h2.Driver"
username: "sa"
password: "changeme"
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
.dialect(DatabaseType.H2)
.table()
.dropOnExit(true)
.createOnStart(true)
.tableNamePrefix("ISPN_STRING_TABLE")
.idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)")
.dataColumnName("DATA_COLUMN").dataColumnType("BINARY")
.timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")
.segmentColumnName("SEGMENT_COLUMN").segmentColumnType("INT")
.connectionPool()
.connectionUrl("jdbc:h2:mem:infinispan")
.username("sa")
.password("changeme")
.driverClass("org.h2.Driver");
其他资源
6.12. rocksdb 缓存存储
rocksdb 提供基于密钥值的文件系统存储,具有高度并发环境的高性能和可靠性。
rocksdb 缓存存储 RocksDBStore 使用两个数据库。一个数据库为内存中的数据提供主缓存存储 ; 其他数据库包含 Data Grid 从内存过期的条目。
表 6.1. 配置参数
| 参数 | 描述 |
|---|---|
|
| 指定提供主缓存存储的 RocksDB 数据库的路径。如果您没有设置位置,则会自动创建。请注意,该路径必须相对于全局持久位置。 |
|
| 指定 RocksDB 数据库的路径,该数据库为过期数据提供缓存存储。如果您没有设置位置,则会自动创建。请注意,该路径必须相对于全局持久位置。 |
|
| 为过期条目设置内存队列的大小。当队列达到大小时,Data Grid 清空到 RocksDB 缓存存储中的过期。 |
|
| 在删除并重新初始化(重新初始化)之前设置 RocksDB 数据库的最大条目数。对于较小的大小缓存存储,迭代所有条目并单独删除每个条目可以提供一种更快的方法。 |
调优参数
您还可以指定以下 RocksDB 调优参数:
-
compressionType -
blockSize -
cacheSize
配置属性
另外,还可在配置中设置属性,如下所示:
-
为数据库添加前缀属性来调整和调优 RocksDB 数据库。
-
前缀属性
及数据,以配置 RocksDB 存储您的数据的列系列。
<property name="database.max_background_compactions">2</property> <property name="data.write_buffer_size">64MB</property> <property name="data.compression_per_level">kNoCompression:kNoCompression:kNoCompression:kSnappyCompression:kZSTD:kZSTD</property>
分段
RocksDBStore 支持分段,并为每个网段创建一个单独的列系列。分段的 RocksDB 缓存存储提高了查找性能和迭代,但对写操作的性能稍降低。
您不应该配置几百个片段。rocksdb 不设计为具有无限数量的列系列。太多片段也会显著增加缓存存储启动时间。
rocksdb 缓存存储配置
XML
<local-cache>
<persistence>
<rocksdb-store xmlns="urn:infinispan:config:store:rocksdb:13.0"
path="rocksdb/data">
<expiration path="rocksdb/expired"/>
</rocksdb-store>
</persistence>
</local-cache>
JSON
{
"local-cache": {
"persistence": {
"rocksdb-store": {
"path": "rocksdb/data",
"expiration": {
"path": "rocksdb/expired"
}
}
}
}
}
YAML
localCache:
persistence:
rocksdbStore:
path: "rocksdb/data"
expiration:
path: "rocksdb/expired"
ConfigurationBuilder
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(RocksDBStoreConfigurationBuilder.class)
.build();
EmbeddedCacheManager cacheManager = new DefaultCacheManager(cacheConfig);
Cache<String, User> usersCache = cacheManager.getCache("usersCache");
usersCache.put("raytsang", new User(...));
带有属性的 ConfigurationBuilder
Properties props = new Properties();
props.put("database.max_background_compactions", "2");
props.put("data.write_buffer_size", "512MB");
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(RocksDBStoreConfigurationBuilder.class)
.location("rocksdb/data")
.expiredLocation("rocksdb/expired")
.properties(props)
.build();
6.13. 远程缓存存储
远程缓存存储 RemoteStore,使用 Hot Rod 协议在 Data Grid 集群上存储数据。
如果将远程缓存存储配置为共享,则无法预加载数据。换句话说,如果在配置中 shared="true",那么您必须设置 preload="false "。
分段
RemoteStore 支持分段,并可按网段发布密钥和条目,从而提高了批量操作的效率。但是,分段仅通过 Data Grid Hot Rod 协议版本 2.3 或更高版本提供。
当您为 RemoteStore 启用分段时,它使用您在 Data Grid 服务器配置中定义的片段数量。
如果源缓存被分段并使用与 RemoteStore 不同的片段,则会为批量操作返回不正确的值。在这种情况下,您应该禁用 RemoteStore 的分段。
远程缓存存储配置
XML
<distributed-cache>
<persistence>
<remote-store xmlns="urn:infinispan:config:store:remote:13.0"
cache="mycache"
raw-values="true">
<remote-server host="one"
port="12111" />
<remote-server host="two" />
<connection-pool max-active="10"
exhausted-action="CREATE_NEW" />
</remote-store>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"remote-store": {
"cache": "mycache",
"raw-values": "true",
"remote-server": [
{
"host": "one",
"port": "12111"
},
{
"host": "two"
}
],
"connection-pool": {
"max-active": "10",
"exhausted-action": "CREATE_NEW"
}
}
}
}
YAML
distributedCache:
remoteStore:
cache: "mycache"
rawValues: "true"
remoteServer:
- host: "one"
port: "12111"
- host: "two"
connectionPool:
maxActive: "10"
exhaustedAction: "CREATE_NEW"
ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence().addStore(RemoteStoreConfigurationBuilder.class)
.fetchPersistentState(false)
.ignoreModifications(false)
.purgeOnStartup(false)
.remoteCacheName("mycache")
.rawValues(true)
.addServer()
.host("one").port(12111)
.addServer()
.host("two")
.connectionPool()
.maxActive(10)
.exhaustedAction(ExhaustedAction.CREATE_NEW)
.async().enable();
6.14. JPA 缓存存储
JPA (Java Persistence API)缓存存储,JpaStore,使用正式模式来持久保留数据。
然后,其他应用程序可以从持久性存储读取,以从 Data Grid 加载数据。但是,其他应用程序不应该与 Data Grid 同时使用持久性存储。
使用 JPA 缓存存储时,您应该考虑以下问题:
- 密钥应为实体的 ID。值应该是实体对象。
-
只允许一个
@Id或@EmbeddedId注释。 -
不支持使用
@GeneratedValue注释自动生成的 ID。 - 所有条目都存储为 immortal。
- JPA 缓存存储不支持分段。
您应该只使用带嵌入式数据网格缓存的 JPA 缓存存储。
JPA 缓存存储配置
XML
<local-cache name="vehicleCache">
<persistence passivation="false">
<jpa-store xmlns="urn:infinispan:config:store:jpa:13.0"
persistence-unit="org.infinispan.persistence.jpa.configurationTest"
entity-class="org.infinispan.persistence.jpa.entity.Vehicle">
/>
</persistence>
</local-cache>
ConfigurationBuilder
Configuration cacheConfig = new ConfigurationBuilder().persistence()
.addStore(JpaStoreConfigurationBuilder.class)
.persistenceUnitName("org.infinispan.loaders.jpa.configurationTest")
.entityClass(User.class)
.build();
配置参数
| 声明性 | programmatic | 描述 |
|---|---|---|
|
|
|
指定 JPA 配置文件 |
|
|
| 指定期望在此缓存中存储的完全限定域名。只允许一个类。 |
6.14.1. JPA 缓存存储示例
这部分提供了使用 JPA 缓存存储的示例。
先决条件
- 配置数据网格以汇总您的 JPA 实体。
流程
在
persistence.xml中定义持久性单元 "myPersistenceUnit"。<persistence-unit name="myPersistenceUnit"> <!-- Persistence configuration goes here. --> </persistence-unit>
创建用户实体类。
@Entity public class User implements Serializable { @Id private String username; private String firstName; private String lastName; ... }使用 JPA 缓存存储配置名为"usersCache"的缓存。
然后,您可以将缓存"usersCache"配置为使用 JPA Cache Store,以便在将数据放置到缓存中时,数据将基于 JPA 配置持久到数据库中。
EmbeddedCacheManager cacheManager = ...; Configuration cacheConfig = new ConfigurationBuilder().persistence() .addStore(JpaStoreConfigurationBuilder.class) .persistenceUnitName("org.infinispan.loaders.jpa.configurationTest") .entityClass(User.class) .build(); cacheManager.defineCache("usersCache", cacheConfig); Cache<String, User> usersCache = cacheManager.getCache("usersCache"); usersCache.put("raytsang", new User(...));使用 JPA 缓存存储的缓存只能存储一种数据类型,如下例所示:
Cache<String, User> usersCache = cacheManager.getCache("myJPACache"); // Cache is configured for the User entity class usersCache.put("username", new User()); // Cannot configure caches to use another entity class with JPA cache stores Cache<Integer, Teacher> teachersCache = cacheManager.getCache("myJPACache"); teachersCache.put(1, new Teacher()); // The put request does not work for the Teacher entity class@EmbeddedId注释允许您使用复合键,如下例所示:@Entity public class Vehicle implements Serializable { @EmbeddedId private VehicleId id; private String color; ... } @Embeddable public class VehicleId implements Serializable { private String state; private String licensePlate; ... }
其他资源
6.15. 集群缓存加载程序
ClusterCacheLoader 从其他 Data Grid 群集成员检索数据,但不保留数据。换句话说,ClusterCacheLoader 不是缓存存储。
Cluster loader 已弃用,并计划在以后的发行版本中删除。
ClusterCacheLoader 提供一个非阻塞替代状态传输。如果这些密钥在本地节点上不可用,ClusterCacheLoader 会根据需要从其他节点获取密钥,这与 lazily 加载缓存内容类似。
以下点也适用于 ClusterCacheLoader :
-
预加载不会生效(
preload=true)。 -
不支持获取持久状态(
fetch-state=true)。 - 不支持分段。
集群缓存加载程序配置
XML
<distributed-cache>
<persistence>
<cluster-loader preload="true" remote-timeout="500"/>
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"cluster-loader" : {
"preload" : true,
"remote-timeout" : "500"
}
}
}
}
YAML
distributedCache:
persistence:
clusterLoader:
preload: "true"
remoteTimeout: "500"
ConfigurationBuilder
ConfigurationBuilder b = new ConfigurationBuilder();
b.persistence()
.addClusterLoader()
.remoteCallTimeout(500);
6.16. 创建自定义缓存存储实现
您可以通过 Data Grid persistent SPI 创建自定义缓存存储。
6.16.1. 数据网格持久性 SPI
Data Grid Service Provider Interface (SPI)通过 NonBlockingStore 接口为外部存储启用读写操作,并具有以下功能:
- JCache 兼容供应商的可移植性
-
数据网格使用处理块代码的适配器,在
NonBlockingStore和JSR-107JCache 规范之间保持兼容性。 - 简化的事务集成
- 数据网格会自动处理锁定,因此您的实施不需要协调对持久性存储的并发访问。根据您使用的锁定模式,通常不会发生对同一密钥的并发写入。但是,您应该期望对持久存储上的操作源自多个线程,并创建实施来容许此行为。
- 并行迭代
- 数据网格允许您迭代带有多个线程的持久存储条目。
- 减少序列化,从而减少 CPU 用量
- 数据网格以序列化格式公开存储的条目,可远程传输。因此,Data Grid 不需要对从持久性存储检索的条目进行反序列化,然后在写入线时再次序列化。
6.16.2. 创建缓存存储
使用 NonBlockingStore API 的实现创建自定义缓存存储。
流程
- 实施适当的数据网格持久的 SPI。
-
如果含有自定义配置,则使用
@ConfiguredBy注释给存储类标注。 如果需要,创建自定义缓存存储配置和构建器。
-
扩展
AbstractStoreConfiguration和AbstractStoreConfigurationBuilder。 (可选)将以下注解添加到存储配置类中,以确保您的自定义配置构建器从 XML 解析您的缓存存储配置:
-
@ConfigurationFor @BuiltBy如果没有添加这些注解,则
CustomStoreConfigurationBuilder会解析AbstractStoreConfiguration中定义的常见存储属性,并且任何额外元素都会被忽略。注意如果配置没有声明
@ConfigurationFor注释,当 Data Grid 初始化缓存时,会记录警告消息。
-
-
扩展
6.16.3. 自定义缓存存储配置示例
以下示例演示了如何使用自定义缓存存储实现配置 Data Grid:
XML
<distributed-cache>
<persistence>
<store class="org.infinispan.persistence.example.MyInMemoryStore" />
</persistence>
</distributed-cache>
JSON
{
"distributed-cache": {
"persistence" : {
"store" : {
"class" : "org.infinispan.persistence.example.MyInMemoryStore"
}
}
}
}
YAML
distributedCache:
persistence:
store:
class: "org.infinispan.persistence.example.MyInMemoryStore"
ConfigurationBuilder
Configuration config = new ConfigurationBuilder()
.persistence()
.addStore(CustomStoreConfigurationBuilder.class)
.build();
6.16.4. 部署自定义缓存存储
要将缓存存储实施用于 Data Grid Server,您必须为其提供 JAR 文件。
先决条件
如果数据网格服务器正在运行,停止该服务器。
数据网格仅在启动时加载 JAR 文件。
流程
- 在 JAR 文件中打包您的自定义缓存存储实施。
-
将您的 JAR 文件添加到 Data Grid Server 安装的
server/lib目录中。
6.17. 在缓存存储间迁移数据
数据网格提供了一个将数据从一个缓存存储迁移到另一个缓存存储的工具。
6.17.1. 缓存存储器
Data Grid 提供 StoreMigrator.java 实用程序,用于为最新数据网格缓存存储实施重新创建数据。
StoreMigrator 将之前版本的 Data Grid 的缓存存储用作源,并使用缓存存储实施作为目标。
运行 StoreMigrator 时,它会使用您使用 EmbeddedCacheManager 接口定义的缓存类型创建目标缓存。然后,StoreMigrator 将条目从源代码存储加载到内存中,然后将它们放入目标缓存中。
StoreMigrator 还允许您将数据从一种缓存存储迁移到另一种。例如,您可以将基于 JDBC 字符串的缓存存储迁移到 RocksDB 缓存存储。
StoreMigrator 无法将数据从分段的缓存存储迁移到:
- 非分段缓存存储。
- 有不同数量的片段的分段缓存存储。
6.17.2. 获取缓存存储器
StoreMigrator 作为 Data Grid 工具库的一部分提供,infinispan-tools 包含在 Maven 存储库中。
流程
为
StoreMigrator配置pom.xml,如下所示:<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.infinispan.example</groupId> <artifactId>jdbc-migrator-example</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.infinispan</groupId> <artifactId>infinispan-tools</artifactId> </dependency> <!-- Additional dependencies --> </dependencies> <build> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>java</goal> </goals> </execution> </executions> <configuration> <mainClass>org.infinispan.tools.store.migrator.StoreMigrator</mainClass> <arguments> <argument>path/to/migrator.properties</argument> </arguments> </configuration> </plugin> </plugins> </build> </project>
6.17.3. 配置缓存存储器
在 migrator.properties 文件中设置源和目标缓存存储的属性。
流程
-
创建
migrator.properties文件。 在
migrator.properties中配置源缓存存储。使用
源添加所有配置属性。如下例所示:source.type=SOFT_INDEX_FILE_STORE source.cache_name=myCache source.location=/path/to/source/sifs source.version=<version>
在
migrator.properties中配置目标缓存存储。使用
目标添加所有配置属性。如下例所示:target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/target/sfs.dat
6.17.3.1. 缓存存储器的配置属性
配置源和目标缓存存储在 StoreMigrator 属性中。
表 6.2. 缓存存储类型 Property
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 指定源或目标的缓存存储类型。
| 必需 |
表 6.3. 常见属性
| 属性 | 描述 | 值示例 | 必填/选填 |
|---|---|---|---|
|
| 将存储后端的缓存进行命名。 |
| 必需 |
|
| 指定可以使用分段的目标缓存存储位置的片段数量。
片段的数量必须与 Data Grid 配置中的 换句话说,缓存存储的片段数量必须与对应缓存的片段数量匹配。如果片段的数量不同,Data Grid 无法从缓存存储中读取数据。 |
| 选填 |
表 6.4. JDBC 属性
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 指定底层数据库的数量。 | 必需 |
|
|
指定源缓存存储位置的 marshaller 版本。
*
*
*
*
*
* | 仅限源代码存储需要。 |
|
| 指定自定义 marshaller 类。 | 如果使用自定义 marshallers,则需要此项。 |
|
|
指定以这个格式加载的自定义 | 选填 |
|
| 指定 JDBC 连接 URL。 | 必需 |
|
| 指定 JDBC 驱动程序的类。 | 必需 |
|
| 指定数据库用户名。 | 必需 |
|
| 指定数据库用户名的密码。 | 必需 |
|
| 设置数据库主版本。 | 选填 |
|
| 设置数据库次要版本。 | 选填 |
|
| 禁用数据库。 | 选填 |
|
| 指定是否创建了表索引。 | 选填 |
|
| 指定表名称的额外前缀。 | 选填 |
|
| 指定列名称。 | 必需 |
|
| 指定列类型。 | 必需 |
|
|
指定 | 选填 |
要从旧的 Data Grid 版本中的 Binary 缓存存储,将 table.string.* 改为 table.binary.\*,在以下属性中:
-
source.table.binary.table_name_prefix -
source.table.binary.<id\|data\|timestamp>.name -
source.table.binary.<id\|data\|timestamp>.type
# Example configuration for migrating to a JDBC String-Based cache store target.type=STRING target.cache_name=myCache target.dialect=POSTGRES target.marshaller.class=org.example.CustomMarshaller target.marshaller.externalizers=25:Externalizer1,org.example.Externalizer2 target.connection_pool.connection_url=jdbc:postgresql:postgres target.connection_pool.driver_class=org.postrgesql.Driver target.connection_pool.username=postgres target.connection_pool.password=redhat target.db.major_version=9 target.db.minor_version=5 target.db.disable_upsert=false target.db.disable_indexing=false target.table.string.table_name_prefix=tablePrefix target.table.string.id.name=id_column target.table.string.data.name=datum_column target.table.string.timestamp.name=timestamp_column target.table.string.id.type=VARCHAR target.table.string.data.type=bytea target.table.string.timestamp.type=BIGINT target.key_to_string_mapper=org.infinispan.persistence.keymappers. DefaultTwoWayKey2StringMapper
表 6.5. rocksdb 属性
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
| 设置数据库目录。 | 必需 |
|
| 指定要使用的压缩类型。 | 选填 |
# Example configuration for migrating from a RocksDB cache store. source.type=ROCKSDB source.cache_name=myCache source.location=/path/to/rocksdb/database source.compression=SNAPPY
表 6.6. SingleFileStore Properties
| 属性 | 描述 | 必填/选填 |
|---|---|---|
|
|
设置包含缓存存储 | 必需 |
# Example configuration for migrating to a Single File cache store. target.type=SINGLE_FILE_STORE target.cache_name=myCache target.location=/path/to/sfs.dat
表 6.7. SoftIndexFileStore Properties
| 属性 | 描述 | 值 |
|---|---|---|
| 必填/选填 |
| 设置数据库目录。 |
| 必需 |
| 设置数据库索引目录。 |
# Example configuration for migrating to a Soft-Index File cache store. target.type=SOFT_INDEX_FILE_STORE target.cache_name=myCache target.location=path/to/sifs/database target.location=path/to/sifs/index
6.17.4. 迁移 Data Grid 缓存存储
运行 StoreMigrator 将数据从一个缓存存储迁移到另一个缓存。
先决条件
-
get
infinispan-tools.jar. -
创建一个
migrator.properties文件来配置源和目标缓存存储。
流程
如果从源构建
infinispan-tools.jar,请执行以下操作:-
将源和目标数据库(如 JDBC 驱动程序)的
infinispan-tools.jar和依赖项添加到您的类路径。 -
指定
migrator.properties文件,作为StoreMigrator的参数。
-
将源和目标数据库(如 JDBC 驱动程序)的
如果从 Maven 存储库拉取
infinispan-tools.jar,请运行以下命令:mvn exec:java
第 7 章 配置 Data Grid 以处理网络分区
数据网格集群可以分成网络分区,其中节点子集相互隔离。此条件会导致集群缓存的可用性或一致性丢失。数据网格自动检测崩溃节点,并解决将缓存合并在一起的冲突。
7.1. 分离集群和网络分区
网络分区是运行环境中错误条件的结果,比如当网络路由器崩溃时。当集群分割成分区时,节点会创建一个 JGroups 集群视图,该视图仅包含该分区中的节点。此条件意味着一个分区中的节点可以独立于其他分区的节点运行。
检测分割
要自动检测网络分区,Data Grid 使用默认 JGroups 堆栈中的 FD_ALL 协议来确定节点何时离开集群。
Data Grid 无法检测导致节点停滞的问题。这不仅在出现网络故障时发生,而且出于其他原因,比如当 Garbage Collection (GC)暂停 JVM 时。
Data Grid 怀疑节点在单位为毫秒后崩溃:
FD_ALL.timeout + FD_ALL.interval + VERIFY_SUSPECT.timeout + GMS.view_ack_collection_timeout
当检测到集群被分成网络分区时,Data Grid 会使用一个策略来处理缓存操作。根据您的应用程序要求 Data Grid,可以:
- 允许读和/或写入操作以实现高可用性
- 拒绝读取和写入操作的一致性
将分区合并在一起
要修复分割集群,Data Grid 会将分区合并在一起。在合并过程中,Data Grid 使用 .equals () 方法来确定是否存在任何冲突。要解决在分区上发现的副本之间的任何冲突,Data Grid 会使用一个可以配置的合并策略。
7.1.1. 分割集群中的数据一致性
导致数据网格集群分割为分区的网络中断或错误可能导致数据丢失或一致性问题,而不管处理策略或合并策略是什么。
分割和检测间的
如果在发生分割时,在一个次要分区的节点上发生写入操作,而在 Data Grid 检测到分割后,该值会在合并期间将状态传输到该次要分区时丢失。
如果所有分区都处于 DEGRADED 模式,则该值不会丢失,因为没有状态转移,但该条目可能具有不一致的值。对于事务缓存写操作,当分割发生在某些节点上时正在进行的操作,并在其他节点上回滚,这会产生不一致的值。
在分割和 Data Grid 检测到它的过程中,可能会从未输入 DEGRADED 模式的次要分区中的缓存退出。
在合并过程中
当数据网格开始删除分区节点时,使用一系列合并事件重新连接到集群。在进行这个合并过程完成前,可以在某些节点上成功对事务缓存进行写入操作,而在更新条目前可能会导致过时的读取。
7.2. 缓存可用性和降级模式
为保持数据一致性,数据网格可将缓存置于 DEGRADED 模式(如果使用 DENY_READ_WRITES 或 ALLOW_READS 分区处理策略)。
当以下条件满足以下条件时,Data Grid 会将缓存置于 DEGRADED 模式中:
-
至少一个片段丢失了所有所有者。
当多个节点等于或大于分布式缓存的所有者数量时,会出现这种情况。 -
分区中没有大多数节点。
大多数节点都是集群中最新稳定拓扑中节点总数的一半以上,这是集群重新平衡操作成功完成的时间。
当缓存处于 DEGRADED 模式时,Data Grid:
- 只有在条目的所有副本都驻留在同一分区中时,才允许读写操作。
如果分区不包含条目的所有副本,则拒绝读取和写入操作并引发
AvailabilityException。注意借助
ALLOW_READS策略,Data Grid 在DEGRADED模式中的缓存允许读取操作。
DEGRADED 模式通过确保在不同分区中不会为同一密钥执行写入操作来确保一致性。另外,DEGRADED 模式还可防止在一个分区中更新密钥而出现过时的读取操作,但要在另一个分区中读取。
如果所有分区都处于 DEGRADED 模式,则只有在集群包含最新 stable 拓扑中的大多数节点并且每个条目至少有一个副本时,缓存才会再次可用。当集群至少有一个条目的副本时,没有丢失密钥,Data Grid 可以根据集群重新平衡期间的所有者数量创建新副本。
在某些情况下,一个分区中的缓存可在在另一个分区中输入 DEGRADED 模式时仍然可用。当可用分区发生时,通常会仍然缓存操作,而数据网格会尝试在这些节点上重新平衡数据。要将缓存合并到 Data Grid 时,始终从可用分区转移到 DEGRADED 模式中的分区。
7.2.1. 降级缓存恢复示例
本主题演示了数据网格如何使用 DENY_READ_WRITES 分区处理策略缓存从分割集群中恢复。
例如,Data Grid 集群有 4 个节点,包括每个条目有两个副本的分布式缓存(owners=2)。缓存、k1、 和 k2、k 3k4 中有四个条目。
使用 DENY_READ_WRITES 策略时,如果集群分割为分区,则数据网格只有在所有条目的副本都位于同一分区时才允许缓存操作。
在下图中,缓存被分成分区,而数据网格允许在分区 1 和 k4 上对 k1 进行读写操作。因为 1 分区 1 或分区 2 中只有一个 k2 和 k3 的副本,所以数据网格会拒绝对这些条目的读写操作。
当网络条件允许节点重新加入同一集群视图时,Data Grid 会在没有状态传输的情况下合并分区,并恢复正常的缓存操作。
7.2.2. 在网络分区中验证缓存可用性
确定数据网格集群上的缓存是否在网络分区期间处于 AVAILABLE 模式或 DEGRADED 模式。
当 Data Grid 集群分割为分区时,这些分区中的节点可以进入 DEGRADED 模式来保证数据一致性。在 DEGRADED 模式中,集群不允许缓存操作,从而导致可用性丢失。
流程
通过以下方法之一验证网络分区中的集群缓存的可用性:
-
检查 Data Grid 日志的
ISPN100011消息,该消息指示集群是否可用,或者至少一个缓存处于DEGRADED模式。 通过 Data Grid Console 或 REST API 获取远程缓存的可用性。
- 在任意浏览器中打开 Data Grid Console,选择 Data Container 选项卡,然后在 Health 列中找到可用性状态。
从 REST API 检索缓存健康状况。
GET /rest/v2/cache-managers/<cacheManagerName>/health
-
以编程方式使用 advanced
CacheAPI 中的getAvailability ()方法检索嵌入式缓存的可用性。
7.2.3. 使缓存可用
通过强制使用 DEGRADED 模式,使缓存可用于读取和写入操作。
只有在部署可以容忍数据丢失和不一致时,您应该强制使用 DEGRADED 模式的集群。
流程
使用以下方法之一提供缓存:
使用 REST API 更改远程缓存的可用性。
POST /v2/caches/<cacheName>?action=set-availability&availability=AVAILABLE
以编程方式使用
AdvancedCacheAPI 更改嵌入式缓存的可用性。AdvancedCache ac = cache.getAdvancedCache(); // Retrieve cache availability boolean available = ac.getAvailability() == AvailabilityMode.AVAILABLE; // Make the cache available if (!available) { ac.setAvailability(AvailabilityMode.AVAILABLE); }
7.3. 配置分区处理
配置 Data Grid 以使用分区处理策略和合并策略,以便在出现网络问题时解决分割集群。默认情况下,数据网格使用一种可降低数据一致性保障的策略。当因为网络分区客户端造成集群分离时,您可以继续在缓存上执行读写操作。
如果可用性需要一致性,您可以配置 Data Grid,以拒绝将集群分成分区的读写操作。另外,您可以允许读取操作并拒绝写操作。您还可以指定配置 Data Grid 的自定义合并策略实现,使用根据您的要求定制的逻辑进行拆分。
先决条件
具有数据网格集群,您可以创建复制或分布式缓存。
注意分区处理配置仅适用于复制和分布式缓存。
流程
- 打开 Data Grid 配置进行编辑。
-
使用分区操作元素或分区
Handling ()方法向缓存添加分区处理配置。 指定在集群通过
when-split属性或whenSplit ()方法分割为分区时使用的 Data Grid 策略。默认分区处理策略是
ALLOW_READ_WRITES,因此缓存仍保持vailabile。如果您的用例需要缓存可用性的数据一致性,请指定DENY_READ_WRITES策略。指定在使用
merge-policy属性或mergePolicy ()方法合并分区时,Data Grid 用来解析冲突条目的策略。默认情况下,数据网格无法解决合并上的冲突。
- 保存对 Data Grid 配置的更改。
分区处理配置
XML
<distributed-cache>
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_ALWAYS"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "PREFERRED_ALWAYS"
}
}
}
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: PREFERRED_ALWAYS
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(MergePolicy.PREFERRED_NON_NULL);
7.4. 分区处理策略
分区处理策略控制数据网格是否允许在集群分割时进行读写操作。您配置的策略决定了缓存可用性或数据一致性。
表 7.1. 分区处理策略
| 策略 | 描述 | 可用性或一致性 |
|---|---|---|
|
| 数据网格允许在群集分割为网络分区时对缓存进行读写操作。每个分区中的节点可以独立使用且可以正常工作。这是默认的分区处理策略。 | 可用性 |
|
| 只有当一个条目的所有副本都在分区中时,Data Grid 才允许读取和写入操作。如果分区不包含条目的所有副本,Data Grid 会阻止缓存该条目的操作。 | 一致性 |
|
| 数据网格允许读取条目操作并防止写操作,除非分区包含所有条目的副本。 | 一致性与读取可用性 |
7.5. 合并策略
合并策略控制数据网格如何在将集群分区组合在一起时解决副本之间的冲突。您可以使用 Data Grid 提供的合并策略之一,也可以创建 EntryMergePolicy API 的自定义实现。
表 7.2. 数据网格合并策略
| 合并策略 | 描述 | 注意事项 |
|---|---|---|
|
| 数据网格在合并分割集群时不会解决冲突。这是默认的合并策略。 | 节点会丢弃不是主所有者的片段,这可能会导致数据丢失。 |
|
| Data Grid 找到集群中大多数节点上存在的值,并使用它来解决冲突。 | Data Grid 可以使用过时的值来解决冲突。即使条目有大多数节点,但最后的更新可能会在次要分区中发生。 |
|
| Data Grid 使用集群中找到的第一个非null 值来解决冲突。 | 数据网格可以恢复删除的条目。 |
|
| 数据网格从缓存中删除任何冲突的条目。 | 在合并分割集群时,会导致任何具有不同值的条目丢失。 |
7.6. 配置自定义合并策略
配置 Data Grid,以便在处理网络分区时使用 EntryMergePolicy API 的自定义实现。
先决条件
实施
EntryMergePolicyAPI。public class CustomMergePolicy implements EntryMergePolicy<String, String> { @Override public CacheEntry<String, String> merge(CacheEntry<String, String> preferredEntry, List<CacheEntry<String, String>> otherEntries) { // Decide which entry resolves the conflict return the_solved_CacheEntry; }
流程
如果使用远程缓存,请将您的合并策略实施部署到 Data Grid Server。
将您的类打包为 JAR 文件,该文件中包含
META-INF/services/org.infinispan.conflict.EntryMergePolicy文件,该文件包含合并策略的完全限定域名。# List implementations of EntryMergePolicy with the full qualified class name org.example.CustomMergePolicy
-
将 JAR 文件添加到
server/lib目录。
- 打开 Data Grid 配置进行编辑。
根据具体情况,使用编码元素或
encoding()对于远程缓存,如果您只使用对象元数据在合并条目时进行比较,您可以使用
application/x-protostream作为介质类型。在这种情况下,Data Grid 会将条目返回到EntryMergePolicy,存为byte[]。如果您在合并冲突时要求对象本身,则您应该使用
application/x-java-object介质类型配置缓存。在这种情况下,您必须将相关的 ProtoStream marshallers 部署到 Data Grid 服务器,以便在客户端使用 Protobuf 编码时,它就可以对对象执行字节[]。-
使用
merge-policy属性或mergePolicy ()方法指定您的自定义合并策略,作为分区处理配置的一部分。 - 保存您的更改。
自定义合并策略配置
XML
<distributed-cache name="mycache">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="org.example.CustomMergePolicy"/>
</distributed-cache>
JSON
{
"distributed-cache": {
"partition-handling" : {
"when-split": "DENY_READ_WRITES",
"merge-policy": "org.example.CustomMergePolicy"
}
}
}
YAML
distributedCache:
partitionHandling:
whenSplit: DENY_READ_WRITES
mergePolicy: org.example.CustomMergePolicy
ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.partitionHandling()
.whenSplit(PartitionHandling.DENY_READ_WRITES)
.mergePolicy(new CustomMergePolicy());
7.7. 在嵌入式缓存中手动合并分区
检测并解决冲突的条目,以便在发生网络分区后手动合并嵌入缓存。
流程
从
EmbeddedCacheManager检索ConflictManager,以检测和解决缓存中冲突的条目,如下例所示:EmbeddedCacheManager manager = new DefaultCacheManager("example-config.xml"); Cache<Integer, String> cache = manager.getCache("testCache"); ConflictManager<Integer, String> crm = ConflictManagerFactory.get(cache.getAdvancedCache()); // Get all versions of a key Map<Address, InternalCacheValue<String>> versions = crm.getAllVersions(1); // Process conflicts stream and perform some operation on the cache Stream<Map<Address, CacheEntry<Integer, String>>> conflicts = crm.getConflicts(); conflicts.forEach(map -> { CacheEntry<Integer, String> entry = map.values().iterator().next(); Object conflictKey = entry.getKey(); cache.remove(conflictKey); }); // Detect and then resolve conflicts using the configured EntryMergePolicy crm.resolveConflicts(); // Detect and then resolve conflicts using the passed EntryMergePolicy instance crm.resolveConflicts((preferredEntry, otherEntries) -> preferredEntry);
虽然 ConflictManager::getConflicts 流由每个条目处理,但底层的拆分器对每个网段上的缓存条目进行延迟。
第 8 章 配置用户角色和权限
授权是一项安全功能,要求用户具有某些权限,然后才能访问缓存或与 Data Grid 资源交互。您可以为提供不同权限级别的用户分配角色,从只读访问权限授予完整、超级用户权限。
8.1. 安全授权
数据网格授权通过限制用户访问保护您的部署。
用户应用程序或客户端必须属于分配了足够权限的角色,然后才能对缓存管理器或缓存执行操作。
例如,您可以在特定缓存实例上配置授权,以便调用 Cache.get () 的身份需要在 Cache.put ()处分配角色,而 Cache.put () 需要具有写入权限的角色。
在这种情况下,如果具有 io 角色的用户应用程序或客户端试图编写条目,Data Grid 会拒绝请求并抛出一个安全例外。如果具有 writer 角色的用户应用程序或客户端发送了写入请求,Data Grid 会验证授权并发出令牌以供后续操作。
身份
身份身份是 java.security.Principal 的安全主体。使用 javax.security.auth.Subject 类实施的主题代表一组安全主体。换句话说,使用者代表一个用户及其所属的所有组。
角色身份
Data Grid 使用角色映射程序,以便安全主体对应于您分配一个或多个权限的角色。
下图说明了安全主体与角色的对应方式:
8.1.1. 用户角色和权限
Data Grid 包含一组默认的角色,可授予用户访问数据并与 Data Grid 资源交互。
ClusterRoleMapper 是 Data Grid 用来将安全主体与授权角色关联的默认机制。
ClusterRoleMapper 与角色名称匹配的主体名称。名为 admin 的用户会自动获得 admin 权限,名为 deployer 的用户会获取 deployer 权限,以此类推。
| 角色 | 权限 | 描述 |
|---|---|---|
|
| ALL | 具有所有权限的超级用户,包括缓存管理器生命周期的控制。 |
|
| ALL_READ, ALL_WRITE, LISTEN, EXEC, MONITOR, CREATE |
除了 |
|
| ALL_READ, ALL_WRITE, LISTEN, EXEC, MONITOR |
除 |
|
| ALL_READ, MONITOR |
除了监控权限外,还具有对数据网格 |
|
| MONITOR |
可以通过 JMX 和 |
8.1.2. 权限
授权角色具有不同的权限,并有不同的访问级别到 Data Grid。权限可让您限制用户对缓存管理器和缓存的访问。
8.1.2.1. 缓存管理器权限
| 权限 | 功能 | 描述 |
|---|---|---|
| 配置 |
| 定义新的缓存配置。 |
| LISTEN |
| 针对缓存管理器注册监听程序。 |
| 生命周期 |
| 停止缓存管理器。 |
| 创建 |
| 创建和删除容器资源,如缓存、计数器、架构和脚本。 |
| MONITOR |
|
允许访问 JMX 统计数据和 |
| ALL | - | 包括所有缓存管理器权限。 |
8.1.2.2. 缓存权限
| 权限 | 功能 | 描述 |
|---|---|---|
| READ |
| 从缓存检索条目。 |
| 写 |
| 在缓存中写入、替换、删除、驱除数据。 |
| EXEC |
| 允许对缓存执行代码。 |
| LISTEN |
| 根据缓存注册监听程序。 |
| BULK_READ |
| 执行批量检索操作。 |
| BULK_WRITE |
| 执行批量写入操作。 |
| 生命周期 |
| 启动和停止缓存。 |
| ADMIN |
| 允许访问底层组件和内部结构。 |
| MONITOR |
|
允许访问 JMX 统计数据和 |
| ALL | - | 包括所有缓存权限。 |
| ALL_READ | - | 组合 READ 和 BULK_READ 权限。 |
| ALL_WRITE | - | 组合 WRITE 和 BULK_WRITE 权限。 |
8.1.3. 角色映射器
Data Grid 包括一个 PrincipalRoleMapper API,它将对象中的安全主体映射到您可以分配给用户的授权角色。
8.1.3.1. 集群角色映射器
ClusterRoleMapper 使用持久复制缓存来动态存储默认角色和权限的 principal-to-role 映射。
默认情况下,使用 Principal 名称作为角色名称,并实施 org.infinispan.security.MutableRoleMapper,它会公开方法在运行时更改角色映射。
-
Java 类:
org.infinispan.security.mappers.ClusterRoleMapper -
声明性配置:&
lt;cluster-role-mapper />
8.1.3.2. 身份角色映射器
IdentityRoleMapper 使用主体名称作为角色名称。
-
Java 类:
org.infinispan.security.mappers.IdentityRoleMapper -
声明配置:&
lt;identity-role-mapper />
8.1.3.3. CommonName 角色映射器
如果主体名称是 Distinguished Name (DN),则 CommonNameRoleMapper 使用 Common Name (CN)作为角色名称。
例如,cn=managers,ou= person,dc=example,dc=com 映射到 managers 角色。
-
Java 类:
org.infinispan.security.mappers.CommonRoleMapper -
声明配置:&
lt;common-name-role-mapper />
8.1.3.4. 自定义角色映射器
自定义角色映射程序是 org.infinispan.security.PrincipalRoleMapper 实施。
-
声明配置:&
lt;custom-role-mapper class="my.custom.RoleMapper" />
8.2. 访问控制列表(ACL)缓存
数据网格缓存您在内部授予用户以获得最佳性能的角色。每当向用户授予或拒绝角色时,Data Grid 会清除 ACL 缓存以确保正确应用用户权限。
如果需要,您可以禁用 ACL 缓存,或使用 cache-size 和 cache-timeout 属性进行配置。
XML
<infinispan>
<cache-container name="acl-cache-configuration">
<security cache-size="1000"
cache-timeout="300000">
<authorization/>
</security>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"name" : "acl-cache-configuration",
"security" : {
"cache-size" : "1000",
"cache-timeout" : "300000",
"authorization" : {}
}
}
}
}
YAML
infinispan:
cacheContainer:
name: "acl-cache-configuration"
security:
cache-size: "1000"
cache-timeout: "300000"
authorization: ~
其他资源
8.3. 自定义角色和权限
您可以在 Data Grid 配置中自定义授权设置,以使用带有不同角色和权限组合的角色映射程序。
流程
- 在 Cache Manager 配置中声明一个角色映射程序以及一组自定义角色和权限。
- 配置缓存的授权,以限制基于用户角色的访问。
自定义角色和权限配置
XML
<infinispan>
<cache-container name="custom-authorization">
<security>
<authorization>
<!-- Declare a role mapper that associates a security principal
to each role. -->
<identity-role-mapper />
<!-- Specify user roles and corresponding permissions. -->
<role name="admin" permissions="ALL" />
<role name="reader" permissions="READ" />
<role name="writer" permissions="WRITE" />
<role name="supervisor" permissions="READ WRITE EXEC"/>
</authorization>
</security>
</cache-container>
</infinispan>
JSON
{
"infinispan" : {
"cache-container" : {
"name" : "custom-authorization",
"security" : {
"authorization" : {
"identity-role-mapper" : null,
"roles" : {
"reader" : {
"role" : {
"permissions" : "READ"
}
},
"admin" : {
"role" : {
"permissions" : "ALL"
}
},
"writer" : {
"role" : {
"permissions" : "WRITE"
}
},
"supervisor" : {
"role" : {
"permissions" : "READ WRITE EXEC"
}
}
}
}
}
}
}
}
YAML
infinispan:
cacheContainer:
name: "custom-authorization"
security:
authorization:
identityRoleMapper: "null"
roles:
reader:
role:
permissions:
- "READ"
admin:
role:
permissions:
- "ALL"
writer:
role:
permissions:
- "WRITE"
supervisor:
role:
permissions:
- "READ"
- "WRITE"
- "EXEC"
8.4. 使用安全授权配置缓存
在缓存配置中使用授权来限制用户访问。在他们可以读取或写缓存条目或删除缓存之前,用户必须具有足够级别的权限。
先决条件
确保
authorization元素包含在cache-container配置的security部分中。Data Grid 默认在 Cache Manager 中启用安全授权,并为缓存提供一组全局角色和权限。
- 如有必要,在 Cache Manager 配置中声明自定义角色和权限。
流程
- 打开缓存配置进行编辑。
-
添加
authorization元素以缓存,以根据用户的角色和权限限制用户访问权限。 - 保存对您的配置的更改。
授权配置
以下配置演示了如何将隐式授权配置与默认角色和权限一起使用:
XML
<distributed-cache>
<security>
<!-- Inherit authorization settings from the cache-container. --> <authorization/>
</security>
</distributed-cache>
JSON
{
"distributed-cache": {
"security": {
"authorization": {
"enabled": true
}
}
}
}
YAML
distributedCache:
security:
authorization:
enabled: true
自定义角色和权限
XML
<distributed-cache>
<security>
<authorization roles="admin supervisor"/>
</security>
</distributed-cache>
JSON
{
"distributed-cache": {
"security": {
"authorization": {
"enabled": true,
"roles": ["admin","supervisor"]
}
}
}
}
YAML
distributedCache:
security:
authorization:
enabled: true
roles: ["admin","supervisor"]
8.5. 禁用安全授权
在本地开发环境中,您可以禁用授权,以便用户不需要角色和权限。禁用安全授权意味着任何用户都可以访问数据并与数据网格资源交互。
流程
- 打开 Data Grid 配置进行编辑。
-
从 Cache Manager
的安全配置中删除任何授权元素。 -
从缓存中删除任何
授权配置。 - 保存对您的配置的更改。