
存储策略指南
为 Red Hat Ceph Storage 集群创建存储策略
摘要
第 1 章 概述
从 Ceph 客户端的视角,与 Ceph 存储集群交互非常简单:
- 连接到集群
- 创建池 I/O 上下文
这种显著简单的界面是 Ceph 客户端如何选择您定义的某一个存储策略。存储策略对 Ceph 客户端在存储容量和性能并不可见。
下图显示了从客户端开始到 Red Hat Ceph Storage 集群的逻辑数据流。
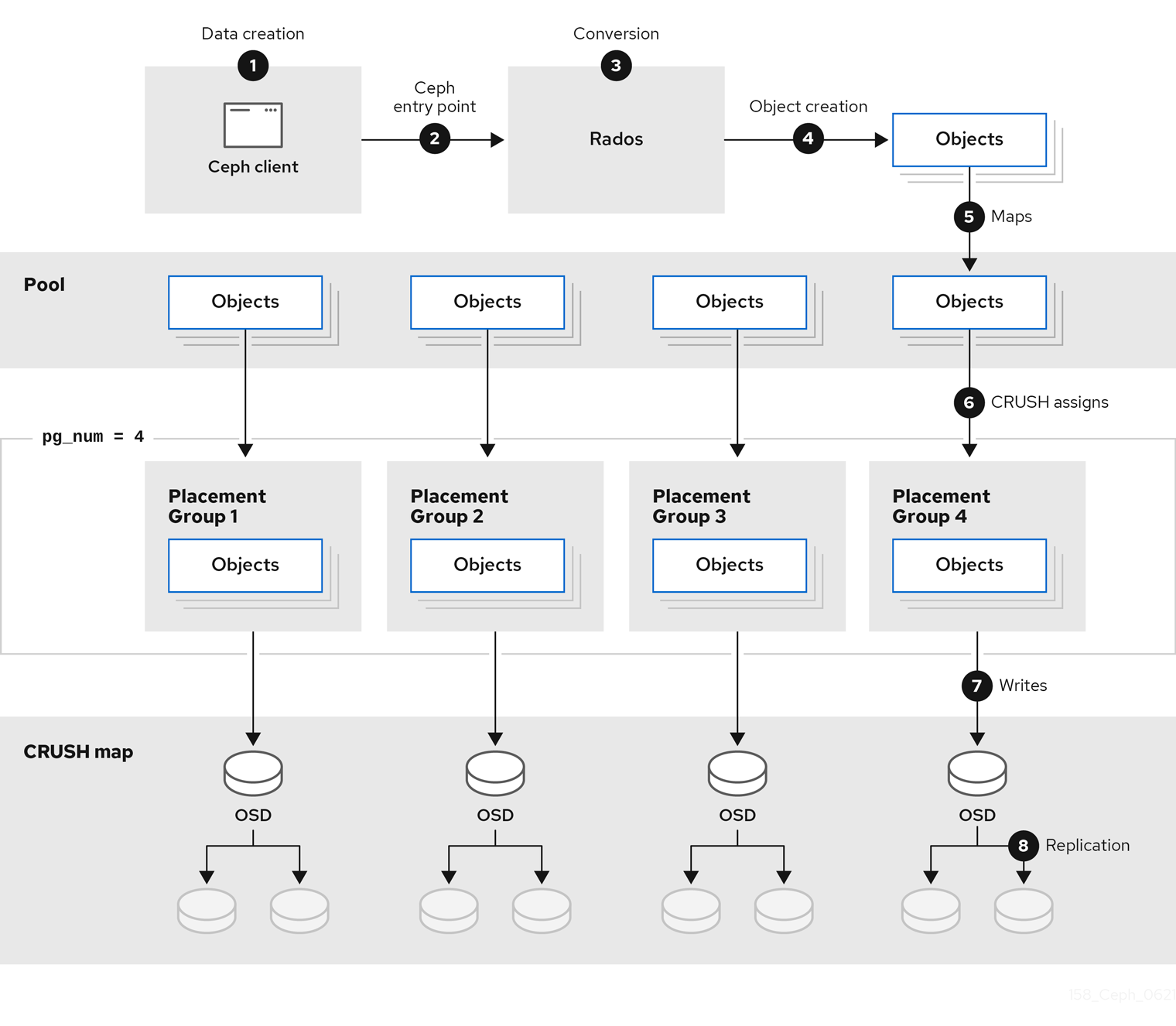
1.1. 什么是存储策略?
存储策略是一种存储服务特定用例的数据的方法。例如,如果您需要为 OpenStack 等云平台存储卷和镜像,您可以选择以合理方式存储数据并使用基于 SSD 的日志的 SAS 驱动器。相反,如果您需要为与 S3 或 Swift 兼容的网关存储对象数据,您可以选择使用更经济的设备,例如 SATA 驱动器等。Ceph 可以在同一 Ceph 集群中同时容纳这两个场景,但您需要为云平台(如 OpenStack 中的 Glance 和 Cinder)提供 SAS/SSD 存储策略,以及为您的对象存储提供 SATA 存储的方法。
存储策略包括存储介质(硬驱动器、SSD 和 rest), CRUSH 映射为存储介质设置性能和故障域、放置组数量和池接口。Ceph 支持多种存储策略。用例、成本/受益性和数据持久性是驱动存储策略的主要考虑因素。
- 使用案例: Ceph 提供巨大的存储容量,它支持多种用例。例如,Ceph 块设备客户端是云平台(如 OpenStack)提供无限存储的领先存储后端,它提供了一个高性能功能的高性能功能(如 copy-on-write 克隆)。同样,Ceph 可以为 OpenShift 环境提供基于容器的存储。相比之下,Ceph 对象网关客户端是适用于云平台的领先存储后端,为音频、位图、视频和其他数据等对象提供 RESTful S3 兼容对象存储和 Swift 兼容对象存储。
- 成本/性能优势: 更高的性能更好。越大越好。越耐用越好。但是,每种出色的质量、相应的成本与收益权衡都有价格。从性能角度考虑以下用例:SSD 可以为相对较小的数据和日志量提供非常快速的存储。存储数据库或对象索引可能会从非常快速的 SSD 池中受益,但对其他数据来说过于昂贵。带有 SSD 日志的 SAS 驱动器以经济的价格为卷和图像提供快速性能。没有 SSD 日志地 SATA 驱动器可提供低成本存储,同时整体性能也较低。在创建 OSD 的 CRUSH 层次结构时,您需要考虑用例和可接受的成本/性能权衡。
-
持久性:在大规模集群中,硬件故障是期望的,而不是例外。但是,数据丢失和服务中断仍然不可接受。因此,数据的持久性非常重要。Ceph 通过对象的多个深度副本解决数据持久性问题,或使用纠删代码和多个编码区块来解决数据持久性。多个副本或多个编码区块会带来额外的成本与好处权衡:存储更少的副本或编码区块会更便宜,但可能会导致在降级状态中为写入请求提供服务。通常,带有两个额外副本(即
size = 3)或两个编码块的对象允许集群在集群恢复时以降级状态进行写入。CRUSH 算法通过确保 Ceph 在集群中的不同位置存储额外副本或编码区块来协助此过程。这样可确保,在单个存储设备或节点出现故障时,不会丢失为了防止数据丢失所需的所有副本或编码区块。
您可以规划一个存储策略来实现用例、性能成本/收益的平衡,以及数据的持久性,然后将它作为存储池呈现给 Ceph 客户端。
Ceph 的对象副本或编码区块使 RAID 过时。不要使用 RAID,因为 Ceph 已经处理数据持久性,降级的 RAID 对性能有负面影响,并且使用 RAID 恢复数据比使用深度副本或纠删代码区块要慢得多。
1.2. 配置存储策略
配置存储策略代表将 Ceph OSD 分配给 CRUSH 层次结构,定义池的放置组数量,以及创建池。一般步骤是:
- 定义存储策略: 存储策略需要您分析您的用例、性能的成本/收益以及数据持久性。然后,您要创建适合该用例的 OSD。例如,您可以为高性能池创建由 SSD 支持的 OSD;使用 SAS 驱动器/SSD 日志支持的 OSD 用于高性能块设备卷和镜像;或者使用由 SATA 支持的 OSD 用于低成本存储。理想情况下,用例的每个 OSD 应该具有相同的硬件配置,以便您具有一致的性能配置集。
-
定义 CRUSH 层次结构: Ceph 规则在 CRUSH 层次结构中选择节点,通常是
root,并标识用于存储放置组及其包含的对象的适当 OSD。您必须为存储策略创建 CRUSH 层次结构和 CRUSH 规则。CRUSH 层次结构通过 CRUSH 规则集直接分配给池。 - 计算放置组: Ceph 将池分片为放置组。您不必为池手动设置放置组数量。PG 自动缩放器为您的池设置适当的放置组数量,当将多个池分配给同一 CRUSH 规则时,该池处于健康的最大放置组数量中。
-
创建池: 最后,您需要创建一个池,并确定它是否使用复制或擦除存储。您必须为池设置放置组数量、池的规则和持久性的规则,如 size 或
K+M编码区块。
请记住,池是 Ceph 客户端与存储集群的接口,但存储策略对 Ceph 客户端完全透明,但容量和性能除外。
第 2 章 CRUSH 管理
可扩展哈希下的受控复制(Controled Replication Under Scalable Hashing)算法决定如何通过计算数据存储位置存储和检索数据。
任何足够高级的技术都与魔法几乎没有区别。 | ||
| -- Arthur C. Clarke | ||
2.1. CRUSH 简介
存储集群的 CRUSH 映射描述了 CRUSH 层次结构中的设备位置,以及确定 Ceph 如何存储数据的层次结构的规则。
CRUSH 映射至少包含一个节点层次结构,并保留。Ceph 中名为"buckets"的节点是其类型定义的任何存储位置聚合。例如,行、机架、机箱、主机和设备。层次结构的每个叶位置基本上由存储设备列表中的其中一个存储设备组成。leaf 始终包含在一个节点或 "bucket"。 CRUSH map 也有规则列表,用于决定 CRUSH 存储和检索数据的方式。
在向集群添加 OSD 时,存储设备会添加到 CRUSH map 中。
CRUSH 算法根据每个设备的权重值将数据对象分布到存储设备中,从而达到统一性分布。CRUSH 根据层次结构 cluster map 定义,分发对象及其副本或编码区块。CRUSH 映射代表可用的存储设备以及包含该规则的逻辑存储桶,并扩展使用该规则的每个池。
要将放置组映射到 OSD 跨故障域或性能域,CRUSH 映射定义了 bucket 类型的层次结构列表;即,在生成的 CRUSH 映射中的 类型 下。创建存储桶层次结构的目的是,通过其故障域或性能域来隔离叶节点。故障域包括主机、机箱、机架、电源分配单元、pod、行、房间和数据中心。安全域包括特定配置的故障域和 OSD。例如: SSD、SAS 驱动器以及 SSD 日志、SATA 驱动器等。设备具有 类 的概念,如 hdd、ssd 和 nvme,以便更快速地构建具有类设备的 CRUSH 层次结构。
除了代表 OSD 的叶节点外,层次结构的其余部分是任意的,如果默认类型不适合您的要求,您可以根据您自己的需求进行定义。我们推荐将您的 CRUSH 映射 bucket 类型调整为组织的硬件命名约定,并使用反映物理硬件名称的实例名称。通过良好的命名规则,您可以更轻松地管理集群,并在 OSD 或其他硬件故障时方便排除问题,并方便管理员远程或物理访问主机或其他硬件。
在以下示例中,bucket 层次结构有四个页存储桶(osd 1-4)、两个节点存储桶(主机 1-2)和一个机架节点(rack 1)。
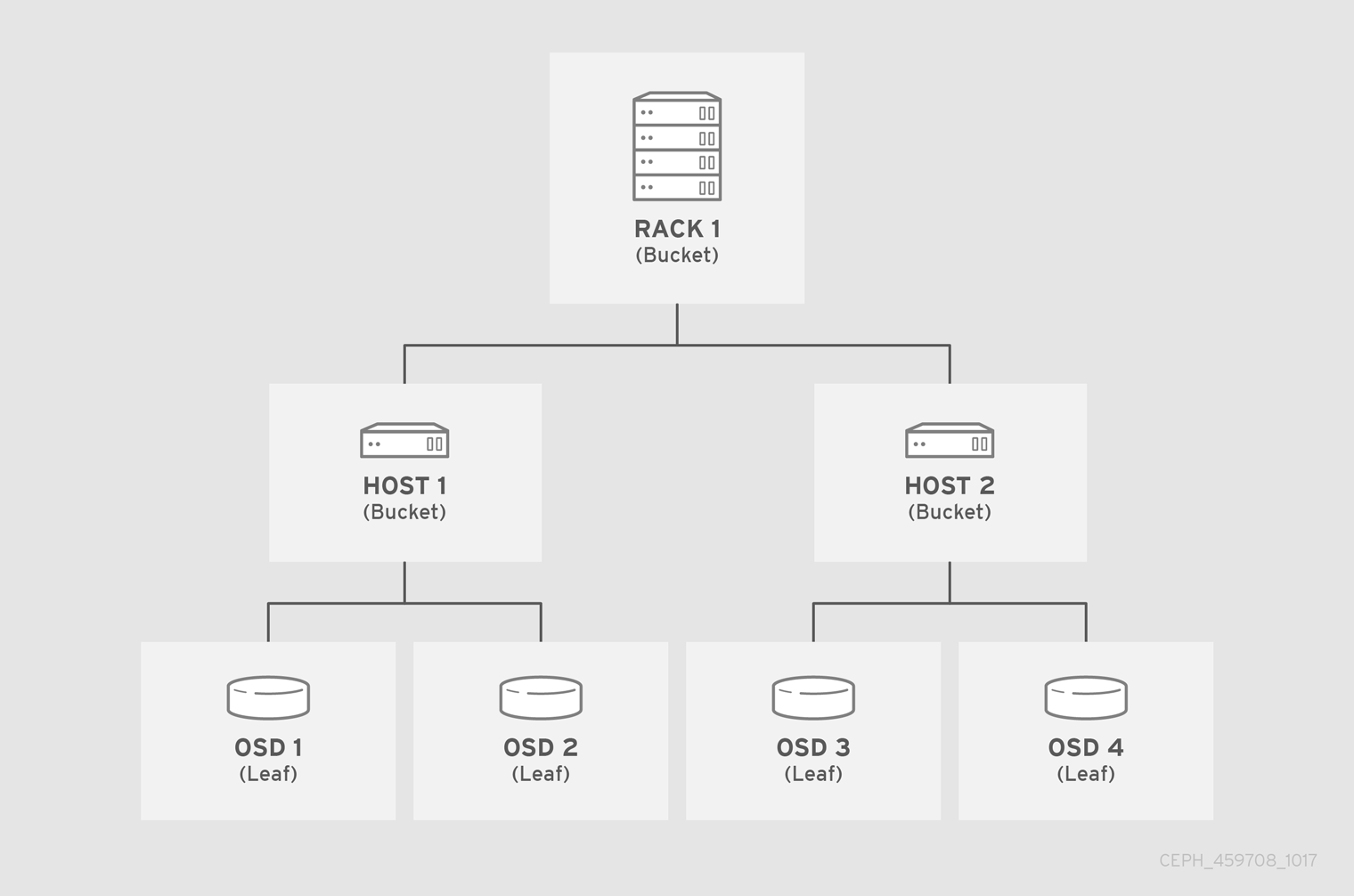
由于 leaf 节点反映在 CRUSH map 开头的设备列表下声明的 存储设备,因此无需将它们声明为 bucket 实例。层次结构中第二个最低存储桶类型通常会聚合设备;即,通常是包含存储介质的计算机,并使用管理员喜欢描述它的任何术语,如 "node"、"computer"、"host"、"host"、"machine"等。在高密度环境中,每个卡和每个机箱有多个主机/节点比较常见。确保考虑卡和机箱失败的情况,例如,如果在一个节点失败时需要拔出相关的卡或机箱时,可能会导致大量主机/节点及其 OSD 无法使用。
在声明存储桶实例时,指定其类型作为字符串的唯一名称,请为它分配一个可选的唯一 ID,以负整数表示,指定相对于其项目的总容量或能力的权重,指定存储桶算法,如 straw2,以及哈希算法,它通常为 0,代表 rjenkins1 哈希算法。bucket 可以具有一个或多个项目。这些项目可由节点 bucket 或 leave 组成。项目可以有一个权重,来反映项目的相对权重。
2.1.1. 以动态方式放置数据
Ceph 客户端和 Ceph OSD 都使用 CRUSH map 和 CRUSH 算法。
- Ceph 客户端: 通过将 CRUSH map 分发到 Ceph 客户端,OSD 可让 Ceph 客户端直接与 OSD 通信。这意味着 Ceph 客户端避免了中央对象查找表,它们可以充当单一故障点、性能瓶颈、集中查找服务器的连接限制以及存储集群可扩展性的物理限制。
- Ceph OSD: 通过分发 CRUSH map 到 Ceph OSD,Ceph 支持 OSD 处理复制、回填和恢复。这意味着 Ceph OSD 代表 Ceph 客户端处理对象副本(或编码区块)的存储。它还意味着 Ceph OSD 知道集群足以重新平衡集群(重新填充),并从失败动态恢复。
2.1.2. 建立故障域
具有多个对象副本或 M 擦除编码块有助于防止数据丢失,但它不足以解决高可用性问题。通过反映 Ceph Storage 集群的底层物理组织,libvirt 可以建模,从而解决了关联设备故障的地址潜在的资源。通过将集群的拓扑编码到集群映射中,CRUSH 放置策略可在不同的故障域间分离对象副本或纠删代码区块,同时仍维护所需的伪随机分布。例如,为解决并发故障的可能性,可能最好确保数据副本或纠删代码区块在不同的 shelves、机架、电源、控制器或物理位置上的设备上。这有助于防止数据丢失并允许集群以降级状态运行。
2.1.3. 建立基域
Ceph 可以支持多个层次结构,将一种类型的硬件性能配置集与其他类型的硬件性能配置集分开。例如,虽然 CRUSH 可以为硬盘创建一个层次结构,为 SSD 创建另一个层次结构。使用性能域 (考虑到底层硬件的性能特性的分级结构)变得非常流行 ,因此通常会需要满足不同的性能要求。在操作上,它们只是具有多个 根 类型 bucket 的 CRUSH map。用例示例包括:
- 对象存储: 用作 S3 和 Swift 接口的对象存储后端的 Ceph 主机可能会使用廉价的存储介质,如 SATA 驱动器,它们可能不适用于虚拟机,但对于对象存储可以降低增加额外 GB 存储空间的成本。这样,可以将廉价的存储主机与需要高性能的系统(例如用于在云平台中存储卷和镜像的系统)分离。HTTP 往往是对象存储系统中的瓶颈。
- 冷存储 :为冷存储而设计的系统 - 绝对访问的数据或具有宽松性能要求的数据检索 - 优点是利用成本较低的存储介质和擦除编码。但是,擦除编码可能需要一些额外的 RAM 和 CPU,因此与用于对象存储或虚拟机的主机的 RAM 和 CPU 要求有所不同。
-
SSD 支持的池: SSD 昂贵,但与硬盘相比,它们有显著优势。SSD 没有查找时间,它们提供高吞吐量。除了将 SSD 用于日志外,集群还可以支持 SSD 支持的池。常见用例包括高性能 SSD 池。例如,可以将 Ceph 对象网关的
.rgw.buckets.index池映射到 SSD,而非 SATA 驱动器。
CRUSH 映射支持 设备类别 的概念。Ceph 可以发现存储设备的各个方面,并且自动分配类,如 hdd、ssd 或 nvme。但是,虽然 CRUSH 不仅限于这些默认值。例如,可以使用 CRUSH 层次结构来分隔不同类型的工作负载。例如,SSD 可以用于日志或直写日志,bucket 索引或原始对象存储。CRUSH 可支持不同的设备类别,如 sd -bucket-index 或 ssd-object-storage,因此 Ceph 无法将相同的存储介质用于不同的工作负载,因此性能更加可预测且一致。
在 scenes 后面,Ceph 为每个设备类生成一个 crush root。这些根应仅通过在 OSD 中设置或更改设备类来修改。您可以使用以下命令查看生成的 roots:
示例
[ceph: root@host01 /]# ceph osd crush tree --show-shadow ID CLASS WEIGHT TYPE NAME -24 ssd 4.54849 root default~ssd -19 ssd 0.90970 host ceph01~ssd 8 ssd 0.90970 osd.8 -20 ssd 0.90970 host ceph02~ssd 7 ssd 0.90970 osd.7 -21 ssd 0.90970 host ceph03~ssd 3 ssd 0.90970 osd.3 -22 ssd 0.90970 host ceph04~ssd 5 ssd 0.90970 osd.5 -23 ssd 0.90970 host ceph05~ssd 6 ssd 0.90970 osd.6 -2 hdd 50.94173 root default~hdd -4 hdd 7.27739 host ceph01~hdd 10 hdd 7.27739 osd.10 -12 hdd 14.55478 host ceph02~hdd 0 hdd 7.27739 osd.0 12 hdd 7.27739 osd.12 -6 hdd 14.55478 host ceph03~hdd 4 hdd 7.27739 osd.4 11 hdd 7.27739 osd.11 -10 hdd 7.27739 host ceph04~hdd 1 hdd 7.27739 osd.1 -8 hdd 7.27739 host ceph05~hdd 2 hdd 7.27739 osd.2 -1 55.49022 root default -3 8.18709 host ceph01 10 hdd 7.27739 osd.10 8 ssd 0.90970 osd.8 -11 15.46448 host ceph02 0 hdd 7.27739 osd.0 12 hdd 7.27739 osd.12 7 ssd 0.90970 osd.7 -5 15.46448 host ceph03 4 hdd 7.27739 osd.4 11 hdd 7.27739 osd.11 3 ssd 0.90970 osd.3 -9 8.18709 host ceph04 1 hdd 7.27739 osd.1 5 ssd 0.90970 osd.5 -7 8.18709 host ceph05 2 hdd 7.27739 osd.2 6 ssd 0.90970 osd.6
2.1.4. 使用不同的设备类型
要创建性能域,请使用设备类和单一 CRUSH 层次结构。在此特定操作中不需要手动编辑 CRUSH map。只需将 OSD 添加到 CRUSH 层次结构中,然后执行以下操作:
为每个设备添加一个类:
语法
ceph osd crush set-device-class CLASS OSD_ID [OSD_ID]
示例
[ceph root@host01 /]# ceph osd crush set-device-class hdd osd.0 osd.1 osd.4 osd.5 [ceph root@host01 /]# ceph osd crush set-device-class ssd osd.2 osd.3 osd.6 osd.7
创建规则以使用设备:
语法
ceph osd crush rule create-replicated RULE_NAME ROOT FAILURE_DOMAIN_TYPE CLASS
示例
[ceph root@host01 /]# ceph osd crush rule create-replicated cold default host hdd [ceph root@host01 /]# ceph osd crush rule create-replicated hot default host ssd
将池设置为使用规则:
语法
ceph osd pool set POOL_NAME crush_rule RULE_NAME
示例
[ceph root@host01 /]# ceph osd pool set cold_tier crush_rule cold [ceph root@host01 /]# ceph osd pool set hot_tier crush_rule hot
2.2. CRUSH 层次结构
CRUSH 映射是一种指示图,因此它可以容纳多个层次结构,例如性能域。创建和修改 CRUSH 层次结构的最简单方式是使用 Ceph CLI,但您也可以编译 CRUSH map、对其进行编辑、重新编译并激活它。
在使用 Ceph CLI 声明存储桶实例时,您必须指定其类型并将其指定为唯一字符串名称。Ceph 自动分配一个存储桶 ID,将算法设置为 straw2,将哈希值设置为 0, 反映 rjenkins1 并设置一个权重。当修改 decompiled CRUSH map 时,将 bucket 分配为负整数的唯一 ID(可选),指定相对于其项目的总容量/大写性的权重,请指定存储桶算法(通常是 straw2),以及 hash(通常为 0,代表哈希算法 rjenkins1)。
bucket 可以具有一个或多个项目。这些项目可由节点存储桶(如 racks、rows、hosts)或 leaves(如 OSD 磁盘)组成。项目可以有一个权重,来反映项目的相对权重。
在修改 decompiled CRUSH map 时,您可以使用以下语法声明节点存储桶:
[bucket-type] [bucket-name] {
id [a unique negative numeric ID]
weight [the relative capacity/capability of the item(s)]
alg [the bucket type: uniform | list | tree | straw2 ]
hash [the hash type: 0 by default]
item [item-name] weight [weight]
}例如,使用上图中,我们将定义两个主机存储桶和一个机架 bucket。OSD 声明为主机 bucket 中的项目:
host node1 {
id -1
alg straw2
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
}
host node2 {
id -2
alg straw2
hash 0
item osd.2 weight 1.00
item osd.3 weight 1.00
}
rack rack1 {
id -3
alg straw2
hash 0
item node1 weight 2.00
item node2 weight 2.00
}例如,注意 rack bucket 不包含任何 OSD。它包含较低级别的主机存储桶,并在项目条目中包含其权重的总和。
2.2.1. CRUSH 位置
CRUSH 位置是 OSD 在 CRUSH map 的层次结构中的位置。在命令行界面中表达 CRUSH 位置时,即 CRUSH 位置指定符采用描述 OSD 位置的 name/value 对列表。例如,如果 OSD 位于特定行、机架、机箱和主机中,并且是默认 CRUSH 树的一部分,则其 crush 位置可以描述如下:
root=default row=a rack=a2 chassis=a2a host=a2a1
备注:
- 密钥的顺序无关紧要。
-
密钥名称(
=左侧)必须是有效的 CRUSH类型。默认情况下,包括root,datacenter,room,row,pod,pdu,rack,chassis和host.您可以编辑 CRUSH 映射,以更改类型以满足您的需求。 -
您不需要指定所有 bucket/keys。例如,默认情况下,Ceph 自动将
ceph-osd守护进程的位置设置为root=default host={HOSTNAME}(基于hostname -s的输出)。
2.2.2. 添加 Bucket
要将存储桶实例添加到 CRUSH 层次结构中,请指定存储桶名称及其类型。bucket 名称在 CRUSH map 中必须是唯一的。
ceph osd crush add-bucket {name} {type}不支持在存储桶名称中使用冒号(:)。
添加层次结构所需的每个 bucket 类型的实例。以下示例演示了为一行添加含有对象存储的 SSD 主机和一架主机:
ceph osd crush add-bucket ssd-row1 row ceph osd crush add-bucket ssd-row1-rack1 rack ceph osd crush add-bucket ssd-row1-rack1-host1 host ceph osd crush add-bucket ssd-row1-rack1-host2 host ceph osd crush add-bucket hdd-row1 row ceph osd crush add-bucket hdd-row1-rack2 rack ceph osd crush add-bucket hdd-row1-rack1-host1 host ceph osd crush add-bucket hdd-row1-rack1-host2 host ceph osd crush add-bucket hdd-row1-rack1-host3 host ceph osd crush add-bucket hdd-row1-rack1-host4 host
完成这些步骤后,查看您的树。
ceph osd tree
请注意,层次结构保持扁平。在将存储桶添加到 CRUSH map 后,您必须将存储桶移到层次结构中。
2.2.3. 移动 Bucket
在创建初始集群时,Ceph 具有默认的 CRUSH map,其根存储桶为 default,您的初始 OSD 主机会显示在 默认 存储桶下。将存储桶实例添加到 CRUSH map 时,它将显示在 CRUSH 层次结构中,但它不一定出现在特定的 bucket 中。
要将存储桶实例移到 CRUSH 层次结构中的特定位置,请指定存储桶名称及其类型。例如:
ceph osd crush move ssd-row1 root=ssd-root ceph osd crush move ssd-row1-rack1 row=ssd-row1 ceph osd crush move ssd-row1-rack1-host1 rack=ssd-row1-rack1 ceph osd crush move ssd-row1-rack1-host2 rack=ssd-row1-rack1
完成这些步骤后,您可以查看您的树。
ceph osd tree
您还可以使用 ceph osd crush create-or-move 在移动 OSD 时创建一个位置。
2.2.4. 删除 Bucket
要从 CRUSH 层次结构中移除存储桶实例,请指定存储桶名称。例如:
ceph osd crush remove {bucket-name}或者:
ceph osd crush rm {bucket-name}bucket 必须为空,才能移除它。
如果您要删除更高级别的存储桶(例如,一个 root 用户(如 default)),请检查池是否使用了选择该 bucket 的 CRUSH 规则。如果是这样,您需要修改 CRUSH 规则,否则对等规则会失败。
2.2.5. bucket Algorithms
使用 Ceph CLI 创建存储桶时,Ceph 默认将算法设置为 straw2。Ceph 支持四个存储桶算法,各自代表性能和重组织效率之间的利弊。如果您不确定要使用的存储桶类型,我们建议使用 straw2 存储桶。bucket 算法有:
-
统一: 统一存储桶聚合设备 , 具有相同的权重。例如,当公司委托或停用硬件时,通常会在许多具有相同物理配置(如批量购买)的机器上进行。当存储设备完全相同的权重时,您可以使用
统一存储桶类型,这样 CRUSH 可将副本映射到统一存储桶,以恒定的时间将副本映射到统一存储桶。使用非统一权重时,您应该使用另一个存储桶算法。 - 列表 :将存储桶作为链接列表来聚合。基于 RUSH (Replication Under Scalable Hashing) P 算法,对于一个扩展集群,列表是一种自然而直观的选择:一个对象会被重新定位到具有一些适当的概率的新设备上,或者仍保留在旧的设备上。当项目添加到存储桶时,结果是最佳的数据迁移。但是,从列表的中间或尾部删除项目可能导致大量不必要的移动,因此列表存储桶最适用于永不或很少被缩小的情况。
- Tree :树形 bucket 使用二进制搜索树。当存储桶包含大量项目时,它们比列表存储桶更高效。基于 RUSH (Replication Under Scalable Hashing) R 算法,树形存储桶可将放置时间缩短为零(log n),使它们适合管理大型设备或嵌套的存储桶。
-
Straw2(默认):类别和树存储桶以某种方式划分和排序策略,例如,在列表开始时提供某些项目优先级;例如,列表开头或组合需要考虑整个项目的整个子树。这提高了副本放置过程的性能,但也可以因为项目的添加、删除或重新加权更改存储桶内容时引入不够优化的重新组织行为。
straw2bucket 类型允许所有项目相互公平"竞争",以便通过类似于 straws 的流程来放置副本。
2.3. CRUSH 中的 Ceph OSD
具有 OSD 的 CRUSH 层次结构后,请将 OSD 添加到 CRUSH 层次结构中。您也可以从现有层次结构移动或移除 OSD。Ceph CLI 使用有以下值:
- id
- 描述
- OSD 的数字 ID。
- 类型
- 整数
- 必需
- 是
- 示例
-
0
- name
- 描述
- OSD 的全名。
- 类型
- 字符串
- 必填
- 是
- 示例
-
osd.0
- weight
- 描述
- OSD 的 CRUSH 权重。
- 类型
- 双
- 必填
- 是
- 示例
-
2.0
- root
- 描述
- OSD 所在的层次结构或树的根 bucket 的名称。
- 类型
- 键-值对。
- 必填
- 是
- 示例
-
root=default、root=replicated_rule等等
- bucket-type
- 描述
- 一个或多个 name-value 对,其中 name 是存储桶类型,值是存储桶的名称。您可以在 CRUSH 层次结构中指定 OSD 的 CRUSH 位置。
- 类型
- 健值对。
- 必填
- 否
- 示例
-
datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
2.3.1. 在 CRUSH 中查看 OSD
ceph osd crush tree 命令在树视图中打印 CRUSH bucket 和项目。使用此命令来确定特定 bucket 中的 OSD 列表。它将打印与 ceph osd tree 类似的输出。
要返回附加详情,请执行以下操作:
# ceph osd crush tree -f json-pretty
该命令会返回类似如下的输出:
[
{
"id": -2,
"name": "ssd",
"type": "root",
"type_id": 10,
"items": [
{
"id": -6,
"name": "dell-per630-11-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 6,
"name": "osd.6",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
},
{
"id": -7,
"name": "dell-per630-12-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 7,
"name": "osd.7",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
},
{
"id": -8,
"name": "dell-per630-13-ssd",
"type": "host",
"type_id": 1,
"items": [
{
"id": 8,
"name": "osd.8",
"type": "osd",
"type_id": 0,
"crush_weight": 0.099991,
"depth": 2
}
]
}
]
},
{
"id": -1,
"name": "default",
"type": "root",
"type_id": 10,
"items": [
{
"id": -3,
"name": "dell-per630-11",
"type": "host",
"type_id": 1,
"items": [
{
"id": 0,
"name": "osd.0",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 3,
"name": "osd.3",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
},
{
"id": -4,
"name": "dell-per630-12",
"type": "host",
"type_id": 1,
"items": [
{
"id": 1,
"name": "osd.1",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 4,
"name": "osd.4",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
},
{
"id": -5,
"name": "dell-per630-13",
"type": "host",
"type_id": 1,
"items": [
{
"id": 2,
"name": "osd.2",
"type": "osd",
"type_id": 0,
"crush_weight": 0.449997,
"depth": 2
},
{
"id": 5,
"name": "osd.5",
"type": "osd",
"type_id": 0,
"crush_weight": 0.289993,
"depth": 2
}
]
}
]
}
]2.3.2. 将 OSD 添加到 CRUSH
在可以启动一个 OSD(为 up 和 in)且 Ceph 为 OSD 分配放置组前,将一个 Ceph OSD 添加到 CRUSH 层次结构中是最终的步骤。
Red Hat Ceph Storage 5 及更新的版本使用 Ceph 编排器在 CRUSH 层次结构中部署 OSD。有关更多信息,请参阅在所有可用设备上部署 Ceph OSD。
若要手动添加 OSD,您必须先准备 Ceph OSD,然后才能将其添加到 CRUSH 层次结构中。例如,在单一节点上创建 Ceph OSD:
ceph orch daemon add osd {host}:{device},[{device}]
CRUSH 层次结构不重要,因此 ceph osd crush add 命令允许您根据需要将 OSD 添加到 CRUSH 层次结构中。您指定的位置应反映其实际位置。如果您至少指定了一个存储桶,命令会将 OSD 放入您指定的最具体的存储桶中,并 将它移到您指定的任何其他 bucket 下。
将 OSD 添加到 CRUSH 层次结构中:
ceph osd crush add {id-or-name} {weight} [{bucket-type}={bucket-name} ...]如果您仅指定根存储桶,该命令会直接将 OSD 附加到 root。但是,虽然 CRUSH 规则应该位于主机或机箱内,host 或 chassis 则 应当位于 反映您的集群拓扑的其他 bucket 中。
以下示例将 osd.0 添加到层次结构中:
ceph osd crush add osd.0 1.0 root=default datacenter=dc1 room=room1 row=foo rack=bar host=foo-bar-1
您还可以使用 ceph osd crush set 或 ceph osd crush create-or-move 将 OSD 添加到 CRUSH 层次结构中。
2.3.3. 在 CRUSH 层次结构内移动 OSD
对于 Red Hat Ceph Storage 5 及更新的版本,您可以使用 Ceph 编排器为主机设置初始 CRUSH 位置。如需更多信息,请参阅设置主机的初始 CRUSH 位置。
要替换 OSD,请参阅使用 Ceph 编排器替换 OSD
如果存储集群拓扑更改,您可以手动移动 CRUSH 层次结构中的 OSD,以反映其实际位置。
在 CRUSH 层次结构中移动 OSD 意味着 Ceph 会重新计算将哪些放置组分配到 OSD,这可能会导致大量重新分发数据。
要在 CRUSH 层次结构中移动 OSD:
ceph osd crush set {id-or-name} {weight} root={pool-name} [{bucket-type}={bucket-name} ...]
您还可以使用 ceph osd crush create-or-move 将 OSD 移到 CRUSH 层次结构中。
2.3.4. 从 CRUSH 层次结构移除 OSD
从 CRUSH 层次结构中移除 OSD 是您要从集群中移除 OSD 的第一步。从 CRUSH map 移除 OSD 时,OSD 会重新计算哪些 OSD 相应获取放置组和数据重新平衡。如需了解更多详细信息,请参阅添加/删除 OSD。
对于 Red Hat Ceph Storage 5 及更新的版本,您可以使用 Ceph 编排器从存储集群中移除 OSD。有关更多信息,请参阅使用 Ceph 编排器删除 OSD 守护进程。
要从正在运行的集群的 CRUSH map 中手动删除 OSD,请执行以下操作:
ceph osd crush remove {name}2.4. 设备类
Ceph 的 CRUSH map 在控制数据放置方面提供了非常规灵活性。这是 Ceph 的最大优势之一。早期 Ceph 部署使用硬盘几乎完全使用。现在,Ceph 集群经常会使用多种类型的存储设备构建: HDD、SSD、NVMe 甚至各种更旧的类型。例如,在 Ceph 对象网关部署中通常会有存储策略,以供客户端在较慢的 HDD 中保存数据和其他存储策略,用于将数据存储到快 SSD 上。Ceph 对象网关部署可能甚至可能有一个由 fast SSD 支持的池用于存储桶索引。此外,OSD 节点也经常使用 SSD 用于日志或直写日志,它们没有出现在 CRUSH 映射中。这些复杂的硬件场景过去需要手动编辑 CRUSH map,这可能非常耗时。对于不同的存储设备类别,并不需要不同的 CRUSH 层次结构。
CRUSH 规则在 CRUSH 层次结构中工作。但是,如果不同的存储设备类别驻留在相同的主机上,该过程会变得更加复杂 - 需要用户为每个设备类创建多个 CRUSH 层次结构,然后禁用 osd crush update on start 选项,以自动执行许多 CRUSH 层次结构管理。设备类别通过告知 CRUSH 规则应使用的设备类别,从而大大简化了 CRUSH 管理任务,从而消除了此繁琐的问题。
ceph osd tree 命令有一个列,它反映了一个设备类。
以下小节详细介绍了设备类使用。如需了解更多示例,请参阅 Using Different Device Classes 和 CRUSH Storage Strategy Examples。
2.4.1. 设置设备类
要为 OSD 设置设备类,请执行以下操作:
# ceph osd crush set-device-class <class> <osdId> [<osdId>...]
例如:
# ceph osd crush set-device-class hdd osd.0 osd.1 # ceph osd crush set-device-class ssd osd.2 osd.3 # ceph osd crush set-device-class bucket-index osd.4
Ceph 可能会自动为设备分配类。但是,类名称只是任意字符串。不需要遵循 hdd、ssd 或 nvme。在忘记示例中,名为 bucket-index 的设备类可能会指出 Ceph 对象网关池使用唯一的 bucket 索引工作负载的 SSD 设备。要更改已设置的设备类,首先使用 ceph osd crush rm-device-class。
2.4.2. 删除设备类
要为 OSD 删除设备类,请执行以下操作:
# ceph osd crush rm-device-class <class> <osdId> [<osdId>...]
例如:
# ceph osd crush rm-device-class hdd osd.0 osd.1 # ceph osd crush rm-device-class ssd osd.2 osd.3 # ceph osd crush rm-device-class bucket-index osd.4
2.4.3. 重命名设备类
要为使用该类的所有 OSD 重命名设备类,请执行以下操作:
# ceph osd crush class rename <oldName> <newName>
例如:
# ceph osd crush class rename hdd sas15k
2.4.4. 列出设备类
要列出 CRUSH 映射中的设备类,请执行以下操作:
# ceph osd crush class ls
输出将类似如下:
[
"hdd",
"ssd",
"bucket-index"
]2.4.5. 列出设备类的 OSD
要列出属于特定类的所有 OSD,请执行以下操作:
# ceph osd crush class ls-osd <class>
例如:
# ceph osd crush class ls-osd hdd
输出是一个 OSD 号列表。例如:
0 1 2 3 4 5 6
2.4.6. 按类列出 CRUSH 规则
要列出引用同一类的所有 crush 规则,请执行以下操作:
# ceph osd crush rule ls-by-class <class>
例如:
# ceph osd crush rule ls-by-class hdd
2.5. CRUSH Weights
CRUSH 算法为每个 OSD 设备分配一个权重值(按约定),目的是将新数据对象分配给 OSD 的写入请求来应用统一探测分布。因此,作为最佳实践,我们建议使用相同类型和大小的设备创建 CRUSH 层次结构,并分配相同的权重。我们还建议使用具有相同 I/O 和吞吐量的设备,这样您也会在 CRUSH 层次结构中具有统一的性能特征,即使性能特性不会影响数据分发。
由于使用统一的硬件并不总是实际,您可能会合并不同大小的 OSD 设备,并使用相对权重,以便 Ceph 将更多的数据分发到较大的设备,并将较少的数据分发到较小的设备。
2.5.1. 在 Terabytes 中设置 OSD 的 Weight
要在 CRUSH 映射中的 Terabytes 中设置 OSD CRUSH 权重,请执行以下命令
ceph osd crush reweight {name} {weight}其中:
- name
- 描述
- OSD 的全名。
- 类型
- 字符串
- 必填
- 是
- 示例
-
osd.0
- weight
- 描述
-
OSD 的 CRUSH 权重。这应该是以 Terabytes 为单位的 OSD 大小,其中
1.0为 1 Terabyte。 - 类型
- 双
- 必填
- 是
- 示例
-
2.0
在创建 OSD 时使用此设置,或者在添加 OSD 后立即调整 CRUSH 权重。它通常不会更改 OSD 生命周期。
2.5.2. 设置 Bucket 的 OSD Weights
使用 ceph osd crush reweight 可能非常耗时。您可以通过执行以下内容来设置(或重置)存储桶下的所有 Ceph OSD 权重(row、rack 和 node 等):
osd crush reweight-subtree <name>
其中,
name 是 CRUSH bucket 的名称。
2.5.3. 设置 OSD 的 in 权重
对于 ceph osd in 和 ceph osd out,一个 OSD 为 in 集群,或 out 集群。这是 monitor 如何记录 OSD 的状态。但是,尽管一个 OSD 为 in 集群,它可能遇到了一个故障情况,在出现这种情况下,您不应该完全依赖它,直到相关的问题被解决(例如,替换存储驱动器、更改控制器等)。
您可以通过执行以下操作为为一个特定的 OSD 增加或减少 in 权重(无需改变它在 Terabytes 中的权重):
ceph osd reweight {id} {weight}其中:
-
id是 OSD 号。 -
weight是 0.0-1.0 的一个范围,其中0代表不是in集群(也就是说,没有分配给它的 PG),1.0 代表为in集群(即OSD 接收与其他 OSD 相同的 PG 数量)。
2.5.4. 通过 Utilization 设置 OSD 的 Weight
CRUSH 旨在为写入请求分配新数据对象 PG 和 PG 到 OSD 的写入请求提供统一的概率分布。但是,集群可能会变得没有平衡。这可能会因多种原因而发生。例如:
- 多个池: 您可以将多个池分配给 CRUSH 层次结构,但池可能具有不同的放置组数量、大小(用于存储的副本数)和对象大小特征。
-
自定义客户端: Ceph 客户端(如块设备、对象网关和文件系统)从其客户端共享数据,并将数据作为统一较小的 RADOS 对象来将数据作为统一化的 RADOS 对象。因此,除了忘记的场景外,libvirtd 通常实现了其目标。但是,在另一个情况下,集群可能会变为 imbalanced:也就是说,使用
librados存储数据而不对对象大小进行规范化。此方案可能会导致群集失控(例如,存储 100 1 MB 对象和 10 4 MB 对象将使一些 OSD 含有比其他 OSD 更多的数据)。 - Probability: 统一分布将导致一些 OSD 带有更多 PG,一些 OSD 有更少的 PG。对于有很多 OSD 的集群,统计处理者将进一步耗尽。
您可以通过执行以下命令来重新加权 OSD:
ceph osd reweight-by-utilization [threshold] [weight_change_amount] [number_of_OSDs] [--no-increasing]
例如:
ceph osd test-reweight-by-utilization 110 .5 4 --no-increasing
其中:
-
阈值是利用率百分比,使得 OSD 面临更高数据存储负载将收到较低的权重,从而减少了分配给它们的 PG。默认值为120,它反映了 120%。100+中的任何值都是有效的阈值。可选。 -
weight_change_amount是更改权重的数量。有效值大于0.0 - 1.0。默认值为0.05。可选。 -
number_of_OSD是重新加权的最大 OSD 数。对于大型集群,限制 OSD 数量以重新加权防止大量重新平衡。可选。 -
no-increasing默认为 off。在使用reweight-by-utilization或test-reweight-utilization命令时允许增加 osd 权重。如果此选项与这些命令搭配使用,它会防止 OSD 权重增加,即使 OSD 未被充分利用。可选。
建议为大型集群执行 重新加权 使用。利用率可能会随时间变化,随着集群大小或硬件的变化,可能需要更新权重来反映更改的利用率。如果您选择通过使用率重新加权,则可能需要在利用率、硬件或集群大小发生变化时重新运行该命令。
执行这个命令或其他权重命令会覆盖由这个命令分配的权重(例如,osd reweight-by-utilization, osd crush weight, osd weight, in 或 out)。
2.5.5. 设置 PG Distribution 的 OSD 的 Weight
在 CRUSH 层次结构的 OSD 中,一些 OSD 有可能获得比其他 OSD 更多的 PG,从而导致负载更高。您可以通过执行以下操作来重新由 PG 分发来重新加权 OSD 以解决这种情况:
osd reweight-by-pg <poolname>
其中:
-
poolname是池的名称。Ceph 将检查池如何为 OSD 分配 PG 以及根据这个池的 PG 分发来重新加权 OSD。请注意,可以将多个池分配到同一个 CRUSH 层次结构。根据一个池的分发,重新加权 OSD 可能会对分配给同一 CRUSH 层次结构的其他池具有意外的影响(如果它们没有相同的大小(副本数)和 PG。
2.5.6. 重新计算 CRUSH Tree 的 Weights
CRUSH 树 bucket 应该是其leaf weight 的总和。如果手动编辑 CRUSH map 权重,您应该执行以下内容,以确保 CRUSH bucket 树准确反映 bucket 下的叶 OSD 的总和。
osd crush reweight-all
2.6. 主关联性
当 Ceph 客户端读取或写入数据时,它始终联系活动集合中的 Primary OSD。对于设置 [2, 3, 4],osd.2 是主。有时,OSD 并不适合于作为与其他 OSD 之间的主要操作(例如,它具有慢的磁盘或较慢的控制器)。为了防止性能瓶颈(特别是对于读取操作)同时最大限度地提高硬件利用率,您可以设置 Ceph OSD 的 primary affinity,以便 CRUSH 不太可能将 OSD 用作行为集的主要性。
ceph osd primary-affinity <osd-id> <weight>
主关联默认为 1(这代表,一个 OSD 可以作为一个 primary)。您可以在 0-1 之间设置 OSD 主要范围,其中 0 表示 OSD 可能没有用作主,1 则表示 OSD 可能被用作主。当 weight 是 & lt; 1 时,虽然 CRUSH 将选择要充当主服务器的 Ceph OSD 守护进程,这不太容易。
2.7. CRUSH 规则
CRUSH 规则定义 Ceph 客户端如何选择 bucket 以及其中的 Primary OSD 来存储对象,以及主要 OSD 选择存储桶和次要 OSD 以存储副本或编码区块的方式。例如,您可以创建一个规则,为两个对象副本选择由 SSD 支持的一对目标 OSD,以及另一规则为三个副本选择由 SAS 驱动器支持的三个目标 OSD。
规则采用以下格式:
rule <rulename> {
id <unique number>
type [replicated | erasure]
min_size <min-size>
max_size <max-size>
step take <bucket-type> [class <class-name>]
step [choose|chooseleaf] [firstn|indep] <N> <bucket-type>
step emit
}- id
- 描述
- 用于标识规则的唯一整数。
- 用途
- 规则掩码的组件。
- 类型
- 整数
- 必需
- 是
- 默认
-
0
- type
- 描述
- 描述存储驱动器复制或退出代码的规则。
- 用途
- 规则掩码的组件。
- 类型
- 字符串
- 必需
- 是
- 默认
-
复制 - 有效值
-
目前仅能为
replicated
- min_size
- 描述
- 如果池形成的副本数少于这个数目,则 CRUSH 不会选择这一规则。
- 类型
- 整数
- 用途
- 规则掩码的组件。
- 必填
- 是
- 默认
-
1
- max_size
- 描述
- 如果池形成的副本数超过这个数目,则 CRUSH 不会选择这一规则。
- 类型
- 整数
- 用途
- 规则掩码的组件。
- 必填
- 是
- 默认
-
10
- 步骤使用 <bucket-name> [class <class-name>]
- 描述
- 取 bucket 名称,然后开始迭代树。
- 用途
- 规则的一个组件。
- 必填
- 是
- 示例
-
step take datastep take data class ssd
- 步骤选 firstn <num> type <bucket-type>
- 描述
选择给定类型的 bucket 数量。数字通常是池中副本数量(即池大小)。
-
如果
<num> == 0,选择pool-num-replicasbucket(所有可用的)。 -
如果 &
lt;num> > 0 && < pool-num-replicas,请选择这个数量的存储桶。 -
如果
<num>< 0,则表示pool-num-replicas - {num}。
-
如果
- 用途
- 规则的一个组件。
- 前提条件
-
按照步骤
执行或步骤选。 - 示例
-
步骤选 firstn 1 类型行
- 步骤选择leaf firstn <num> type <bucket-type>
- 描述
选择一组
{bucket-type}的存储桶,然后从 bucket 集合中的每个 bucket 的子树中选择树叶节点。集合中的 bucket 数量通常是池中副本数量(即池大小)。-
如果
<num> == 0,选择pool-num-replicasbucket(所有可用的)。 -
如果 &
lt;num> > 0 && < pool-num-replicas,请选择这个数量的存储桶。 -
如果
<num> < 0,则表示pool-num-replicas - <num>。
-
如果
- 用途
- 规则的一个组件。使用方法不再需要选择使用两个步骤的设备。
- 前提条件
-
接下来
步骤取或步骤,选择。 - 示例
-
步骤选择leaf firstn 0 type row
- step emit
- 描述
- 输出当前值并模拟堆栈。通常在规则末尾使用,但也可能用于从同一规则中的不同树提取。
- 用途
- 规则的一个组件。
- 前提条件
-
跟随
step choose。 - 示例
-
step emit
- firstn 与 indep
- 描述
-
控制 OSD 在 CRUSH map 中被标记为 down 时使用 replacement 策略。如果此规则将与复制池一起使用,则它应当是
firstn,并且它用于区块编码的池,则应该位于dep。 - 示例
-
您有 PG 存储在 OSD 1、2、3、4、5 上,其中 3 个出现故障。在第一种场景中,使用
firstn模式,CRUSH 会将其计算调整为选择 1 和 2,然后选择 3,但发现它已关闭,因此它重试并选择 4 和 5,然后进入 以选择新的 OSD 6。最后的 CRUSH 映射更改为从 1, 2, 3, 4, 5 到 1, 2, 4, 5, 6。在第二个情景中,在一个纠删代码池中使用indep模式,CRUSH 会尝试选择失败的 OSD 3,再次尝试并选择 6 用于从 1, 2, 3, 4, 5 到 1, 2, 6, 4, 5 的最终转换。
可以将给定的 CRUSH 规则分配给多个池,但单个池无法具有多个 CRUSH 规则。
2.7.1. 列出规则
要从命令行列出 CRUSH 规则,请执行以下操作:
ceph osd crush rule list ceph osd crush rule ls
2.7.2. 转储规则
要转储特定 CRUSH 规则的内容,请执行以下操作:
ceph osd crush rule dump {name}2.7.3. 添加简单规则
要添加 CRUSH 规则,您必须指定规则名称、要使用的层次结构的根节点、您要复制到的存储桶类型(例如:"rack'、'row' 等等),以及选择存储桶的模式。
ceph osd crush rule create-simple {rulename} {root} {bucket-type} {firstn|indep}
Ceph 将创建具有您指定的 类型选择leaf 和 1 存储桶的规则。
例如:
ceph osd crush rule create-simple deleteme default host firstn
创建以下规则:
{ "id": 1,
"rule_name": "deleteme",
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{ "op": "take",
"item": -1,
"item_name": "default"},
{ "op": "chooseleaf_firstn",
"num": 0,
"type": "host"},
{ "op": "emit"}]}2.7.4. 添加复制规则
要为复制池创建 CRUSH 规则,请执行以下操作:
# ceph osd crush rule create-replicated <name> <root> <failure-domain> <class>
其中:
-
<name> :规则的名称。 -
<root> : CRUSH 层次结构的根部。 -
<failure-domain>: 故障域。例如:host或rack。 -
<class> : 存储设备类。例如:hdd或ssd。
例如:
# ceph osd crush rule create-replicated fast default host ssd
2.7.5. 添加 Erasure Code 规则
要添加与纠删代码池一起使用的 CRUSH 规则,您可以指定规则名称和纠删代码 profile。
ceph osd crush rule create-erasure {rulename} {profilename}2.7.6. 删除规则
要删除规则,请执行以下内容并指定 CRUSH 规则名称:
ceph osd crush rule rm {name}2.8. CRUSH 可调项
Ceph 项目随着许多变化和新功能呈指数级增长。从 Ceph 的第一个商业支持主要版本 v0.48(Argonaut)开始,Ceph 提供了调整 CRUSH 算法的某些参数,即设置不在源代码中。
需要考虑以下几个重要点:
- 调整 CRUSH 值可能会导致在存储节点间切换一些 PG。如果 Ceph 集群已经存储了大量大量数据,准备进行一些要移动的数据。
-
ceph-osd和ceph-mon守护进程将在收到更新映射时立即要求新连接的功能位。但是,已连接过的客户端实际上已得到提高,如果它们不支持新功能,则会错误地发现。当您升级 Ceph Storage Cluster 守护进程时,请确定您更新 Ceph 客户端。 -
如果将 CRUSH 可调项设置为非传统值,之后再更改回旧值,则不需要
ceph-osd守护进程来支持该功能。但是,OSD 对等过程需要检查和理解旧 map。因此,如果集群之前已使用了非传统 CRUSH 值,则不应运行ceph-osd守护进程的旧版本,即使映射的最新版本已切换回使用传统默认值。
2.8.1. 调整 CRUSH
在调优 CRUSH 之前,您应该确保所有 Ceph 客户端和所有 Ceph 守护进程都使用相同的版本。如果您最近已升级,请确保您已重启守护进程并重新连接客户端。
调整 CRUSH 可调项的最简单方法是通过更改到已知配置文件。这些是:
-
legacy:v0.47(pre-Argonaut)和更早版本中的传统行为。 -
argonaut: v0.48(Argonaut)发行版本支持的旧值。 -
bobtail:v0.56(Bobtail)发行版本支持的值。 -
firefly:v0.80(Firefly)发行版本支持的值。 -
hammer:v0.94(Hammer)发行版本支持的值。 -
Jewel:v10.0.2(Jewel)发行版本支持的值。 -
最佳:当前最佳值。 -
default:新集群的当前默认值。
您可以使用以下命令在正在运行的集群中选择配置集:
# ceph osd crush tunables <profile>
这可能导致一些数据移动。
通常,您应该在升级后设置 CRUSH 可调项,或者收到警告。从 v0.74 开始,如果 CRUSH 可调项没有设置为其最佳值,Ceph 将发出一个健康警告,其最佳值为 v0.73。要进行这个警告,有两个选项:
在现有集群上调整可调项。请注意,这将导致一些数据移动(可能有 10%)。这是首选的路由,但应该小心谨慎,数据移动可能会影响性能。您可以使用以下方法启用最佳可调项:
# ceph osd crush tunables optimal
如果事情发生不佳(例如,负载过大),或者存在客户端兼容性问题(旧的内核 cephfs 或 rbd 客户端,或者预先购买 librados 客户端),您可以切回到更早的配置集:
# ceph osd crush tunables <profile>
例如,要恢复 pre-v0.48(Argonaut)值,请执行:
# ceph osd crush tunables legacy
您可以通过在
ceph.conf文件的[mon]部分添加以下选项,在不对 CRUSH 进行任何更改的情况下进行警告:mon warn on legacy crush tunables = false
要使更改生效,请重启 monitor,或者应用选项来运行 monitor:
# ceph tell mon.\* injectargs --no-mon-warn-on-legacy-crush-tunables
2.8.2. 调优 CRUSH,硬盘方式
如果确保所有客户端都在运行最新的代码,可以通过提取 CRUSH 映射、修改值并将其注入集群中来调整可调项。
提取最新的 CRUSH map:
ceph osd getcrushmap -o /tmp/crush
调整可调项。这些值显示为为我们测试的大型集群和小集群提供最佳行为。此外,您需要额外指定
--enable-unsafe-tunables参数到crushtool才能正常工作。请谨慎使用这个选项:crushtool -i /tmp/crush --set-choose-local-tries 0 --set-choose-local-fallback-tries 0 --set-choose-total-tries 50 -o /tmp/crush.new
重新注入修改后的映射:
ceph osd setcrushmap -i /tmp/crush.new
2.8.3. 旧值
为了方便参考,可以使用以下内容设置 CRUSH 可调项的旧值:
crushtool -i /tmp/crush --set-choose-local-tries 2 --set-choose-local-fallback-tries 5 --set-choose-total-tries 19 --set-chooseleaf-descend-once 0 --set-chooseleaf-vary-r 0 -o /tmp/crush.legacy
同样,需要特殊的 --enable-unsafe-tunables 选项。如上所述,请在恢复到旧值后小心运行 ceph-osd 守护进程的旧版本,因为功能位不完全强制实施。
2.9. 编辑 CRUSH map
通常,使用 Ceph CLI 修改 CRUSH map 比手动编辑 CRUSH map 更方便。但是,在有些情况下,您可能需要选择编辑它,如更改默认的存储桶类型,或者使用 straw2 以外的存储桶算法。
编辑现有的 CRUSH map:
- 获取 CRUSH 映射。
- 解译 CRUSH map。
- 至少编辑其中一个设备,以及 Buckets 和 规则。
- 重新编译 CRUSH map。
- 设置 CRUSH map。
要为特定池激活 CRUSH map 规则,请识别常见的规则编号,并在创建池时指定池的规则编号。
2.9.1. 获取 CRUSH map
要获取集群的 CRUSH 映射,请执行以下操作:
ceph osd getcrushmap -o {compiled-crushmap-filename}Ceph 将输出(-o)编译的 CRUSH map 到您指定的文件名。由于 CRUSH 映射采用编译的形式,因此您必须先将其解译,然后才能编辑它。
2.9.2. 解译 CRUSH map
要解译 CRUSH 映射,请执行以下操作:
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}Ceph 会将已编译的 CRUSH map 和输出(-o)替换为您指定的文件名。
2.9.3. 编译 CRUSH map
要编译 CRUSH 映射,请执行以下操作:
crushtool -c {decompiled-crush-map-filename} -o {compiled-crush-map-filename}Ceph 将已编译的 CRUSH map 存储到您指定的文件名。
2.9.4. 设置 CRUSH map
要为集群设置 CRUSH 映射,请执行以下操作:
ceph osd setcrushmap -i {compiled-crushmap-filename}Ceph 将输入您指定为群集 CRUSH map 的文件名的已编译 CRUSH map。
2.10. CRUSH 存储策略示例
如果您希望大多数池都默认为大型硬盘支持的 OSD,但有一些池 map 到由快速固态驱动器(SSD)支持的 OSD。CRUSH 可轻松处理这些场景。
使用设备类别。这个过程很简单,可向每个设备添加一个类。例如:
# ceph osd crush set-device-class <class> <osdId> [<osdId>] # ceph osd crush set-device-class hdd osd.0 osd.1 osd.4 osd.5 # ceph osd crush set-device-class ssd osd.2 osd.3 osd.6 osd.7
然后,创建规则以使用该设备。
# ceph osd crush rule create-replicated <rule-name> <root> <failure-domain-type> <device-class>: # ceph osd crush rule create-replicated cold default host hdd # ceph osd crush rule create-replicated hot default host ssd
最后,将池设置为使用规则。
ceph osd pool set <poolname> crush_rule <rule-name> ceph osd pool set cold crush_rule hdd ceph osd pool set hot crush_rule ssd
不需要手动编辑 CRUSH map,因为一个层次结构可以提供多个设备类别。
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class ssd
device 3 osd.3 class ssd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class ssd
device 7 osd.7 class ssd
host ceph-osd-server-1 {
id -1
alg straw2
hash 0
item osd.0 weight 1.00
item osd.1 weight 1.00
item osd.2 weight 1.00
item osd.3 weight 1.00
}
host ceph-osd-server-2 {
id -2
alg straw2
hash 0
item osd.4 weight 1.00
item osd.5 weight 1.00
item osd.6 weight 1.00
item osd.7 weight 1.00
}
root default {
id -3
alg straw2
hash 0
item ceph-osd-server-1 weight 4.00
item ceph-osd-server-2 weight 4.00
}
rule cold {
ruleset 0
type replicated
min_size 2
max_size 11
step take default class hdd
step chooseleaf firstn 0 type host
step emit
}
rule hot {
ruleset 1
type replicated
min_size 2
max_size 11
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}第 3 章 放置组 (PG)
放置组(PG)不适用于 Ceph 客户端,但它们在 Ceph Storage 集群中发挥重要角色。
Ceph Storage 集群可能需要数以千计的 OSD 才能达到 PB 级的存储容量。Ceph 客户端将对象存储在池中,这是整个集群的逻辑子集。存储在池中的对象数量可能容易在数百万和以后运行。具有数以百万计的对象或更无法现实地跟踪每个对象上的放置的系统,仍然表现良好。Ceph 将对象分配到放置组,并将放置组分配给 OSD,以便重新平衡动态和高效。
计算机科学中的所有问题均可由另一级间接处理,除非有太多间接的问题除外。 | ||
| -- David Wheeler | ||
3.1. 关于放置组
在池内每个对象上跟踪对象放置的计算代价比较高。为便于大规模提高性能,Ceph 将池划分到放置组中,将每个对象分配到放置组,并将放置组分配到 Primary OSD。如果 OSD 失败或集群重新平衡,Ceph 可以移动或复制整个放置组,即,PG 中的所有对象都不需要单独解析各个对象。这样,Ceph 集群就可以有效地重新平衡或恢复。
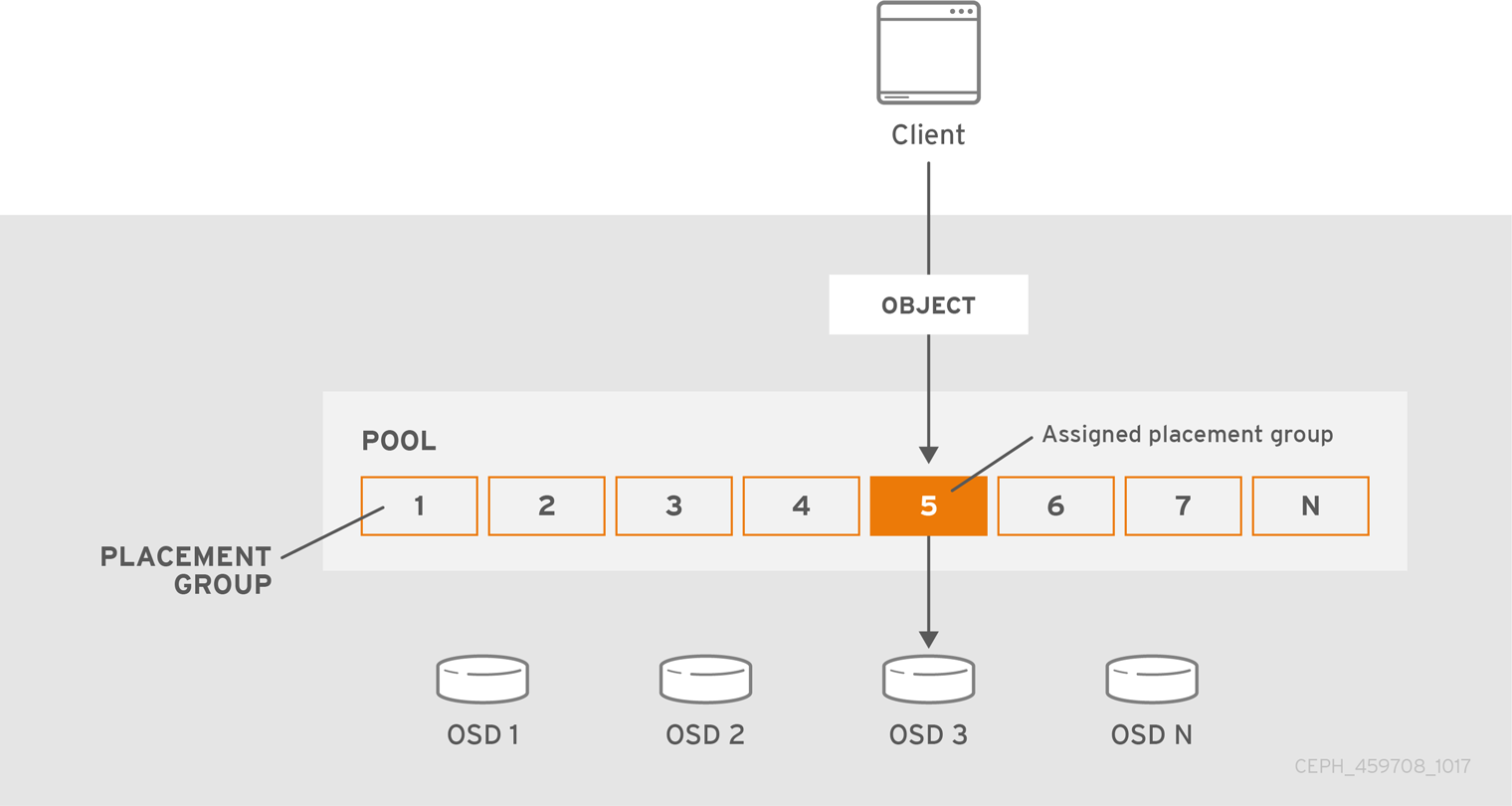
当 CRUSH 分配放置组到 OSD 时,它会计算一系列 OSD- 是主组。osd_pool_default_size 设置减 1 用于复制池,而用于纠删代码池的编码区块 M 数量决定了存储放置组的 OSD 的数量,而不会永久丢失数据。主 OSD 使用 CRUSH 确定次要 OSD,并将 PG 的内容复制到次要 OSD。例如,如果 CRUSH 将对象分配给放置组,并且放置组分配到 OSD 5 作为 Primary OSD,如果 CRUSH 计算 OSD 1 和 OSD 8 是放置组的次要 OSD,则主要 OSD 5 会将数据复制到 OSD 1 和 8。通过代表客户端复制数据,Ceph 简化了客户端接口并减少客户端工作负载。相同的进程允许 Ceph 集群动态恢复和重新平衡。
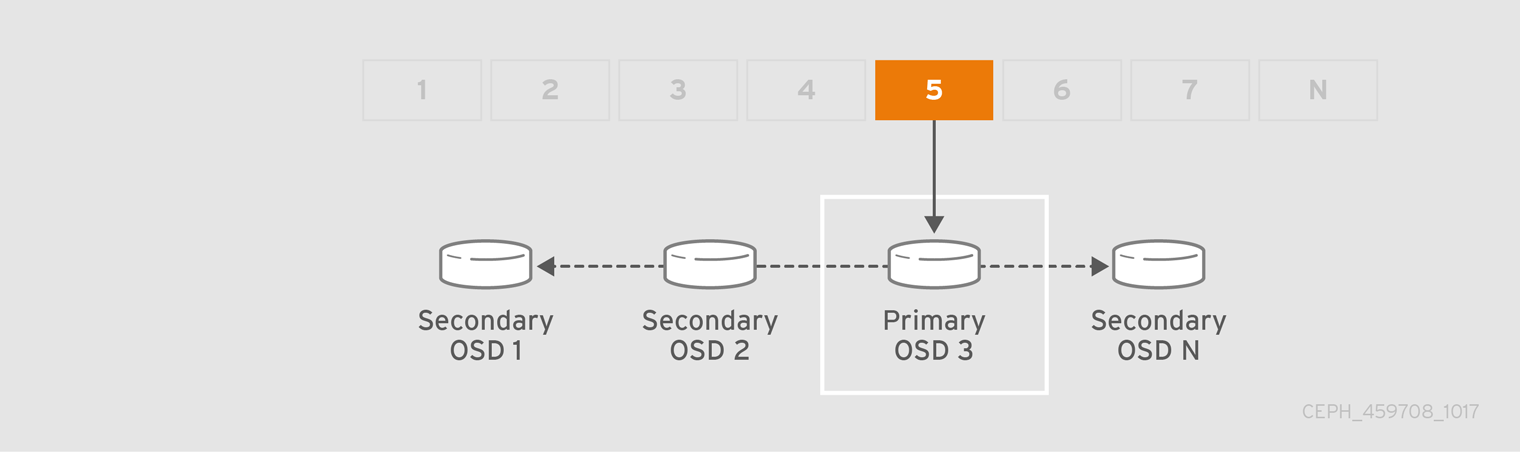
当 Primary OSD 出现故障并标记为群集时,libvirt 会将放置组分配到另一个 OSD,后者接收 PG 中的对象副本。Up Set 中的另一个 OSD 将假定主 OSD 的角色。
增加对象副本或编码区块数量时,OSD 将根据需要为每个放置组分配到额外的 OSD。
PG 不拥有 OSD。CRUSH 为每个 OSD 分配多个放置组,以随机方式分配到群集上均匀分布数据。
3.2. 放置组状态
当您使用 ceph -s 或 ceph -w 命令检查存储集群的状态时,Ceph 将报告放置组(PG)的状态。PG 具有一个或多个状态。PG map 中的 PG 的最佳状态是 active + clean 状态。
- 激活
- PG 已对等,但还没有激活。
- active
- Ceph 处理对 PG 的请求。
- backfill_toofull
- 回填操作正在等待,因为目标 OSD 处于回填 full 比率。
- backfill_unfound
- 回填会因为没有找到对象而停止。
- backfill_wait
- PG 正在以行形式启动回填。
- 回填
- Ceph 正在扫描并同步 PG 的整个内容,而不是推断内容需要从最近的操作日志同步。回填是恢复的特殊情况。
- 清理
- Ceph 会准确复制 PG 中的所有对象。
- 创建
- Ceph 仍然在创建 PG。
- deep
- Ceph 会根据存储的校验和检查 PG 数据。
- degraded
- Ceph 尚未准确复制 PG 中的一些对象。
- down
-
具有必要数据的副本停机,因此 PG 为离线。小于
min_size副本的 PG 被标记为 down。使用ceph 健康详情了解后备 OSD 状态。 - forced_backfill
- 该 PG 的高回填优先级由用户强制实施。
- forced_recovery
- 该 PG 的高恢复优先级由用户强制实施。
- incomplete
-
Ceph 检测到 PG 缺少关于可能发生写入的信息,或者没有任何健康副本。如果您看到此状态,请尝试启动可能包含所需信息的任何失败 OSD。如果是纠删代码池,暂时减少
min_size可能允许恢复。 - 不一致
- Ceph 在 PG 中检测一个或多个对象副本的不一致,如对象是错误的大小,在恢复完成后从一个副本中缺少对象。
- peering
- PG 正在进入 peering 过程。对等进程应该清除没有延迟,但如果它保留,且处于 peering 状态的 PG 数量不会减少数字,对等进程可能会卡住。
- peered
-
PG 已对等,但无法服务客户端 IO,因为没有足够的副本来访问池的配置的
min_size参数。恢复可能发生在此状态下,因此 PG 可能会修复到min_size最终。 - recovering
- Ceph 正在迁移或同步对象及其副本。
- recovery_toofull
- 恢复操作正在等待,因为目标 OSD 超过了其全满比率。
- recovery_unfound
- 恢复会因为没有找到对象而停止。
- recovery_wait
- PG 正在以 行形式开始恢复。
- remapped
- PG 临时映射到 CRUSH 指定的不同组 OSD。
- repair
- Ceph 正在检查 PG 并修复它发现的所有不一致(如有可能)。
- replay
- 在 OSD 崩溃后,PG 正在等待客户端重放操作。
- snaptrim
- 修剪快照。
- snaptrim_error
- 错误停止修剪快照。
- snaptrim_wait
- 排队以修建快照。
- 清理
- Ceph 正在检查 PG 元数据是否存在不一致。
- splitting
- Ceph 将 PG 拆分为多个 PG。
- stale
- PG 处于未知状态; monitor 没有收到更新,因为 PG 映射已更改。
- undersized
- PG 的副本数少于配置的池复制级别。
- unknown
-
自 Ceph Manager 启动时,
ceph-mgr尚未收到 PG 状态的任何信息。
其他资源
- 如需更多信息 ,请参阅 Ceph 集群中可能使用的放置组状态。
3.3. 放置组 tradeoffs
所有 OSD 中的数据持久性和数据分布调用更多的放置组,但为了节省 CPU 和内存资源,其数量应减小到满足要求的最小值。
3.3.1. 数据持续时间
Ceph 可以通过防止永久丢失数据获得好处。但是,在 OSD 失败后,永久数据丢失的风险会增加,直到其数据被完全恢复为止。仍然有可能造成持久性数据丢失。以下场景描述了如何在带有三个数据副本的单个放置组中永久丢失数据:
- OSD 失败,并且它所包含的对象的所有副本都会丢失。对于 OSD 上存储的所有对象,副本的数量会突然从三个下降到两个。
- Ceph 通过选择新 OSD 为故障 OSD 重新创建所有对象的第三个副本,从而开始恢复故障 OSD。
- 在新 OSD 完全填充了第三个副本之前,第二个包含相同放置组副本的 OSD 会失败。然后,一些对象仅有一个 Surviving 副本。
- Ceph 选择了另一个 OSD,并保留复制对象以恢复所需的副本数。
- 在恢复完成前,包含相同放置组副本的第三个 OSD 会失败。如果此 OSD 包含对象的唯一剩余副本,则对象将永久丢失。
硬件故障不是例外,而是预计中的情况。要防止持续的场景,理想的恢复过程应该尽可能快。集群的大小、您的硬件配置和放置组的数量在总恢复时扮演重要角色。
小型集群无法快速恢复。
在三个副本池中包含有 512 个放置组的 10 个 OSD 的集群中,OSD 将为每个放置组提供三个 OSD。每个 OSD 都将结束主机 (512 * 3)/ 10 = ~150 放置组。当第一个 OSD 出现故障时,集群将同时对所有 150 个放置组启动恢复。
Ceph 可能会在 9 个剩余的 OSD 间随机存储剩余的 150 个放置组。因此,每个剩余的 OSD 可能会向所有其他 OSD 发送副本,并接收一些新的对象,因为剩余的 OSD 现在已负责分配给它们的一些 150 个放置组。
总恢复时间取决于支持池的硬件。例如,在一个 10 个 OSD 集群中,如果一个主机包含一个带有 1 TB SSD 的 OSD,且 10 GB/s 交换机连接每个 10 个主机,则恢复时间将花费 M 分钟。相反,如果主机包含两个 SATA OSD,1 GB/s 交换机连接五个主机,恢复将大大延长。值得注意的是,在这种大小的集群中,放置组的数量对数据持久性几乎没有影响。放置组计数可以是 128 或 8192,恢复不能慢或更快。
但是,相同的 Ceph 集群增加到 20 个 OSD,而不是 10 个 OSD 才可以加快恢复速度,因而能显著提高数据持久性。这是因为什么?每个 OSD 现在只参与 75 个放置组,而不是 150 个。20 个 OSD 集群仍然需要所有剩余的 19 个 OSD 执行相同副本操作,以便恢复。在 10 个 OSD 集群中,每个 OSD 必须复制大约 100 GB。在 20 个 OSD 集群中,每个 OSD 必须分别复制 50 GB。如果网络瓶颈是瓶颈,恢复将尽快发生两次。换句话说,随着 OSD 数量增加,恢复时间会减少。
在大型集群中,PG 数量很重要!
如果 exemplary 集群增加到 40 个 OSD,则每个 OSD 将仅托管 35 个放置组。如果 OSD 出现问题,恢复时间会降低,除非有其他瓶颈被降低。但是,如果此集群增大到 200 个 OSD,则每个 OSD 将仅托管大约 7 个放置组。如果 OSD 崩溃,恢复将在这些放置组中的大多数 21 (7 * 3) OSD 之间发生: 恢复的时间比存在 40 个 OSD 时要比存在 40 个 OSD 所需的时间要长,这意味着应增加放置组的数量!
无论恢复时间有多短,在恢复过程中都会存在存储放置组的另一个 OSD 出现故障的情况。
在上述 10 个 OSD 集群中,如果任何 OSD 失败,则大约有 8 个放置组(即 75 pgs / 9 osds 被恢复)将只有一个 Surviving 副本。如果其中任何 8 个剩余的 OSD 失败,则一个放置组的最后对象可能会丢失(即 8 pgs / 8 osds,只有一个剩余副本被恢复)。这是为什么首选从一些大型集群开始(例如 50 个 OSD)。
当集群的大小增加到 20 个 OSD 时,OSD 丢失的放置组数量会损坏。第二个 OSD 大约会降级 2(即 35 pgs / 19 osds 被恢复)而不是 8,而第三个 OSD 仅在含有存活副本的两个 OSD 之一时丢失数据。换句话说,如果在恢复时间范围内丢失一个 OSD 的概率为 0.0001%,它在 10 个 OSD 的集群中为 8 * 0.0001%,在 20 个 OSD 的集群中为 2 * 0.0001%。对于数据持久性,具有 512 或 4096 个放置组的集群中大致相当于有 50 个 OSD。
概括讲,更多的 OSD 意味着快速恢复速度,降低因为级联故障导致放置组和其的向永久丢失的风险。
将 OSD 添加到集群时,可能需要很长时间才能为新的 OSD 填充放置组和对象。但是,任何对象都没有降级,而添加 OSD 不会影响数据持久性。
3.3.2. 数据分发
Ceph 寻求避免热点 - 即,一些 OSD 显著提高了超过其他 OSD 的流量。理想情况下,CRUSH 将对象分配到放置组,以便在放置组被分配给 OSD(也可以随机)时,主 OSD 存储对象会均匀分布在群集和热点上,以及因为数据分发而造成的网络超额订阅问题。
由于 CRUSH 计算每个对象的放置组,但实际上不知道该放置组中各个 OSD 中存储的数据量,因此 放置组数量和 OSD 数量之间的比率可能会大大影响数据的分布。
例如,如果三个副本池中只有一个放置组具有十个 OSD,Ceph 将仅使用三个 OSD 来存储数据,因为 CRUSH 不会有其他选择。当更多放置组可用时,CRUSH 更有可能在 OSD 之间均匀分布对象。CRUSH 也均匀地分配放置组到 OSD。
只要存在一两个数量级的放置组数量超过 OSD,分布就应该是如此。例如,3 个 OSD 256 个放置组,10 个 OSD 512 或 1024 个放置组,以此类推。
OSD 和放置组之间的比率通常解决了在实施对象条带化的 Ceph 客户端的数据分发问题。例如,4TB 块设备可能会分片为 4 MB 对象。
OSD 和放置组之间的比率无法处理其他情形中的数据分布不均匀,因为 CRUSH 不会将对象大小纳入考量。使用 librados 接口存储一些相对较小的对象,有些非常大的对象可能会导致数据分布不均匀。例如,一百万 4K 对象以 4 GB 的总数均匀分布在 10 个 OSD 上的 1000 个放置组中。它们将在每个 OSD 上使用 4 GB / 10 = 400 MB。如果一个 400 MB 对象添加到池中,为放置了该对象的放置组提供支持的三个 OSD 将会填充 400 MB + 400 MB = 800 MB,而其他七个 OSD 仍然仅被占据 400 MB。
3.3.3. 资源使用情况
对于每个放置组,OSD 和 Ceph 监视器会一直需要内存、网络和 CPU,在恢复期间甚至更多。由集群放置组中的集群对象共享这个开销是放置组存在的主要原因之一。
尽量减少放置组的数量可以节省大量资源。
3.4. PG 数量
池中放置组的数量对于集群如何对等、分布数据和重平衡操作起非常重要的作业。与大型集群相比,在小集群中增加放置组的数据对性能并不会有显著提高。但是,具有许多访问相同 OSD 的池的集群可能需要仔细考虑 PG 数量,以便 Ceph OSD 使用资源。
红帽建议每个 OSD 使用 100 到 200 个 PG。
3.4.1. PG Calculator
PG 计算器计算您和地址特定用例的放置组数量。当使用 Ceph 客户端(如 Ceph 对象网关)时,PG 计算器尤其有用,其中有许多池通常使用相同的规则(CRUSH 层次结构)。您仍然可以参照 PG Count for Small Clusters 和 Calculating PG Count 来手动计算 PG。但是,PG 计算器是计算 PG 的首选方法。
有关详细信息,请参阅红帽客户门户网站 上 每个池计算器的 Ceph 放置组(PG)。
3.4.2. 配置默认 PG 计数
当您创建池时,您还要为池创建几个放置组。如果您没有指定放置组数量,Ceph 将使用默认值 8,这不可接受。您可以为池增加放置组数量,但我们建议 Ceph 配置文件中设置合理的默认值。
osd pool default pg num = 100 osd pool default pgp num = 100
您需要设置放置组数量(总计)以及用于对象的放置组数量(在 PG 分隔中使用的数量)。它们应该相等。
3.4.3. Small 集群的 PG Count
小集群不会从大量放置组中受益。随着 OSD 数量的增加,为 pg_num 和 pgp_num 选择正确的值会变得更为重要,因为在出现问题时以及数据不稳定(这是严重事件导致数据丢失的可能性)时,对集群的行为有显著影响。使用带有小集群的 PG 计算器 非常重要。
3.4.4. 计算 PG 数量
如果您有超过 50 个 OSD,建议每个 OSD 大约有 50-100 个放置组来均衡资源使用情况、数据持久性和分布。如果您有超过 50 个 OSD,在 Small 集群的 PG Count 中选择是理想的选择。对于单个对象池,您可以使用以下公式获取基准:
(OSDs * 100)
Total PGs = ------------
pool size
其中,pool size 是复制池的副本数,或用于删除代码池的 K+M 总和(ceph osd erasure-code-profile 的返回值)。
然后,您应该检查结果是否适合您设计 Ceph 集群以最大化数据持久性、数据分布和最小化资源使用量。
结果应 向上取整为两个最接近的电源。向上舍入是可选的,但建议使用 CRUSH 在放置组之间均匀地平衡对象数量。
对于 200 个 OSD 和池大小 3 个副本的集群,您可以估计 PG 数量,如下所示:
(200 * 100)
----------- = 6667. Nearest power of 2: 8192
3在 200 个 OSD 之间分布 8192 个放置组,评估每个 OSD 大约有 41 个放置组。您还需要考虑集群中可能会使用的池数量,因为每个池也会创建放置组。确保您有合理的 最大 PG 数量。
3.4.5. 最大 PG 数量
当使用多个数据池来存储对象时,您需要确保平衡每个池的放置组数量与每个 OSD 的放置组数量,以便您可以达到合理的放置组总数。目的是在不消耗系统资源或使 peering 进程太慢的情况下,为每个 OSD 达到合理的差异。
在由 10 个池组成的 exemplary Ceph Storage 集群中,每个池在 10 个 OSD 上有 512 个放置组,总计有 5120 个 PG 分布于 10 个 OSD 中,或每个 OSD 都有 512 个放置组。取决于硬件配置,可能无法使用过多的资源。相反,如果您创建 1,000 个池,每个 PG 具有 512 个 PG,OSD 将处理 ~50,000的放置组,这需要大量资源。使用每个 OSD 的放置组数量太多的操作可能会显著降低性能,特别是重新平衡或恢复期间。
Ceph Storage 集群为每个 OSD 有一个默认值 300 个放置组。您可以在 Ceph 配置文件中设置不同的最大值。
mon pg warn max per osd
Ceph 对象网关部署有 10-15 池,因此,您可以考虑每个 OSD 使用 100 个 PG 达到合理的数量。
3.5. 自动扩展放置组
池中放置组(PG)的数量对于集群如何对等、分布数据和重平衡操作起非常重要的作业。
自动扩展 PG 数量可以更轻松地管理集群。pg-autoscaling 命令提供扩展 PG 的建议,或根据集群的使用方式自动扩展 PG。
- 要了解更多有关自动扩展如何工作的信息,请参阅 第 3.5.1 节 “放置组自动扩展”。
- 要启用或禁用自动扩展,请参阅 第 3.5.3 节 “设置放置组自动扩展模式”。
- 要查看放置组扩展建议,请参阅 第 3.5.4 节 “查看放置组扩展建议”。
- 要设置放置组自动扩展,请参阅 第 3.5.5 节 “设置放置组自动扩展”。
-
要全局更新自动扩展,请查看 第 3.5.6 节 “更新
noautoscale标记” - 要设置目标池大小,请参阅 第 3.5.7 节 “指定目标池大小”。
3.5.1. 放置组自动扩展
auto-scaler 的工作原理
自动缩放器会根据每个子树分析池并调整。由于每个池都可以映射到不同的 CRUSH 规则,并且每个规则可以在不同的设备间分布数据,Ceph 都将独立使用每个子树。例如,映射到类 ssd 的 OSD 的池以及映射到类 hdd 的 OSD 的池,各自具有取决于这些对应设备类型的最优 PG 数量。
3.5.2. 放置组分割和合并
splitting
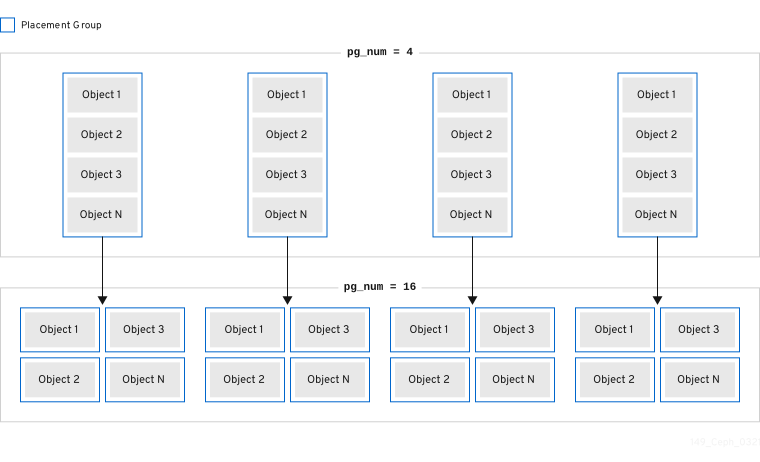
Red Hat Ceph Storage 可将现有放置组(PG)分成较小的 PG,这会增加给定池的 PG 总数。分割现有放置组(PG)使得红帽 Ceph 存储集群在存储要求增加时随时间进行扩展。PG 自动扩展功能可以增加 pg_num 值,这会导致现有 PG 分割为存储集群扩展。如果 PG 自动扩展功能被禁用,您可以手动增加 pg_num 值,这样可触发 PG 分割进程以开始。例如,将 pg_num 值从 4 增加到 16,则会分成四个部分:增加 pg_num 值也将增加 pgp_num 值,但 pgp_num 值会递增递增阶段。逐步增加是为了最大程度降低存储集群性能和客户端工作负载的影响,因为迁移对象数据给系统带来显著的负载。默认情况下,Ceph 队列,移动不超过 5% 的对象数据,这些数据处于"实际"状态。可以使用 target_max_misplaced_ratio 选项调整这个默认百分比。
合并
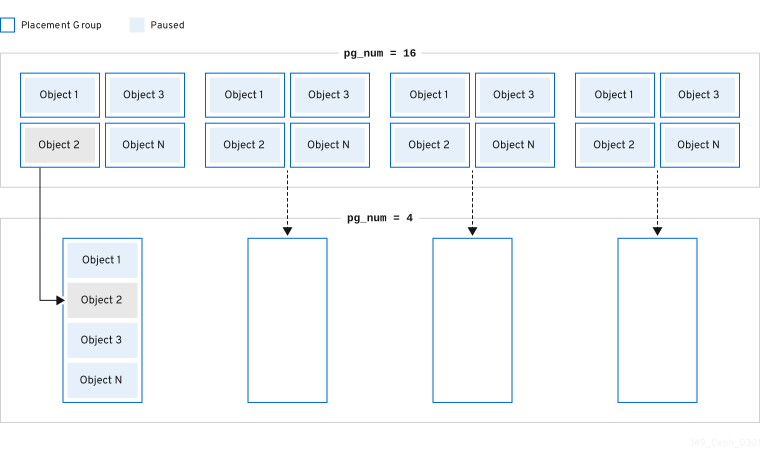
Red Hat Ceph Storage 也可以将两个现有 PG 合并到一个较大的 PG 中,这样可以减少 PG 的总数。将两个 PG 合并在一起会很有用,特别是当池中对象的相对量逐渐下降时,或者选择初始的 PG 数量太大时。合并 PG 可能很有用,但它也是一个复杂和委派的过程。在进行合并时,到 PG 的 I/O 会暂停,一次只合并一个 PG,从而最大程度降低对存储集群性能的影响。Ceph 在合并对象数据时缓慢工作,直到达到新的 pg_num 值。
3.5.3. 设置放置组自动扩展模式
Red Hat Ceph Storage 集群中的每个池都有一个 pg_autoscale_mode 属性,而 PG 的 PG 可以设置为 off、上的、或 warn。
-
off:禁用池的自动扩展。管理员最多可为每个池选择适当的 PG 数。如需更多信息,请参阅 PG 数量 部分。 -
在 上:为给定池启用自动调整 PG 数量。 -
Warn:当 PG 数量需要调整时,处理健康状态警报。
在 Red Hat Ceph Storage 5.0 及更新的版本中,pg_autoscale_mode 默认为 开启。升级的存储集群会保留现有的 pg_autoscale_mode 设置。对于新创建的池,pg_auto_scale 模式为 on。PG 数量自动调整,ceph 状态 可能会在 PG 计数调整期间显示恢复状态。
自动缩放器使用 bulk 标志来确定哪个池应当以完整补充的 PG 开头,并且仅在池之间的使用量比率不会被缩减。但是,如果池没有 bulk 标记,池以最少的 PG 开头,并且仅在池中有更多使用量时才会开始。
自动扩展程序(autoscaler)会识别任何重叠的根,并防止扩展带有重叠根的池,因为重叠的根可能会导致扩展过程出现问题。
流程
在现有池中启动自动扩展:
语法
ceph osd pool set POOL_NAME pg_autoscale_mode on示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_autoscale_mode on
在新创建的池中启用自动扩展:
语法
ceph config set global osd_pool_default_pg_autoscale_mode MODE示例
[ceph: root@host01 /]# ceph config set global osd_pool_default_pg_autoscale_mode on
使用
批量标记创建池:语法
ceph osd pool create POOL_NAME --bulk示例
[ceph: root@host01 /]# ceph osd pool create testpool --bulk
为现有池设置或取消设置
批量标记:重要该值必须写为
true、false、1或0。1等同于true,0相当于false。如果使用不同的大写或其它内容编写,则会发出错误。以下是使用错误语法编写的命令示例:
[ceph: root@host01 /]# ceph osd pool set ec_pool_overwrite bulk True Error EINVAL: expecting value 'true', 'false', '0', or '1'
语法
ceph osd pool set POOL_NAME bulk true/false/1/0
示例
[ceph: root@host01 /]# ceph osd pool set testpool bulk true
获取现有池
批量标记:语法
ceph osd pool get POOL_NAME bulk示例
[ceph: root@host01 /]# ceph osd pool get testpool bulk bulk: true
3.5.4. 查看放置组扩展建议
您可以查看池,它的相对利用率以及存储集群中 PG 数量的建议更改。
先决条件
- 正在运行的 Red Hat Ceph Storage 集群
- 所有节点的根级别访问权限。
流程
您可以使用以下命令查看每个池、其相对利用率以及对 PG 计数所做的任何更改:
[ceph: root@host01 /]# ceph osd pool autoscale-status
输出类似如下:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK device_health_metrics 0 3.0 374.9G 0.0000 1.0 1 on False cephfs.cephfs.meta 24632 3.0 374.9G 0.0000 4.0 32 on False cephfs.cephfs.data 0 3.0 374.9G 0.0000 1.0 32 on False .rgw.root 1323 3.0 374.9G 0.0000 1.0 32 on False default.rgw.log 3702 3.0 374.9G 0.0000 1.0 32 on False default.rgw.control 0 3.0 374.9G 0.0000 1.0 32 on False default.rgw.meta 382 3.0 374.9G 0.0000 4.0 8 on False
SIZE 是池中存储的数据量。
如果存在 TARGET SIZE,则管理员指定的数据量是管理员最终在此池中存储的数据量。系统在计算时会使用这两个值中的较大的值。
RATE 是决定池使用的原始存储容量的池的倍数。例如,一个 3 副本池的比率为 3.0,而 k=4,m=2 纠删代码池的比例为 1.5。
RAW CAPACITY 是 OSD 上原始存储容量的总量,它们负责存储池的数据。
RATIO 是池消耗的总容量的比例,即 ratio = 大小,即 * 速率/原始容量。
TARGET RATIO (如果存在)是管理员指定的存储比率,是与带有目标比率的其他池相对应的期望池的消耗。如果同时指定了目标大小字节和比例,则比率将具有优先权。TARGET RATIO 的默认值为 0, 除非在创建池时指定。您向池中提供的 --target_ratio 越大,您希望池具有的大量 PG。
EFFECTIVE RATIO 是在以两种方式调整后的目标比率:1。减少设定目标大小的池预期使用容量。2. 在带有目标比率设置的池之间规范化目标比率,以便它们一起处理剩余空间。例如,目标 ratio 1.0 的 4 池具有 0.25 的有效比例。系统使用的较大的实际比率,以及计算的有效比率。
BIAS 被视为一个倍数,根据之前有关特定池应有的 PG 量的信息,手动调整池的 PG。默认情况下,如果 1.0,否则值(除非在创建池时已指定)。您提供的池中提供的 --bias 越多,您希望池拥有的 PG 大。
PG_NUM 是池的当前 PG 数量,或者当 pg_num 更改正在进行时,池工作的 PG 数量的当前 PG 数量。NEW PG_NUM (若存在)是建议的 PG 数量(pg_num)。它始终是 2 的指数,它只有在建议的值与因当前值的不同大于 3 倍时才存在。
AUTOSCALE,是池 pg_autoscale_mode,可以为 on, off, 或 warn。
BULK 用于确定哪个池应以 PG 的完整补充开头。BULK 仅在使用量在池中的使用比率不平衡时进行缩减。如果池没有此标志,池以最少的 PG 开始,且仅在池中有更多使用量时才使用。
BULK 的值为 true, false, 1, 或 0, 其中 1 等同于 true,0 等同于 false。默认值为 false。
BULK 值可以在池创建过程中或之后设置 。
有关使用 bulk 标记的更多信息,请参阅 创建池 和设置放置组自动扩展模式。
3.5.5. 设置放置组自动扩展
允许集群根据集群使用量自动扩展 PG,是扩展 PG 的最简单方法。Red Hat Ceph Storage 使用整个系统的可用存储和 PG 的目标数量,比较每个池中存储的数据数量,并相应地应用 PG。该命令仅更改其当前 PG 数 (pg_num) 大于计算出的或建议的 PG 数的 3 倍的池。
每个 OSD 的目标 PG 数量基于 mon_target_pg_per_osd 可配置。默认值为 100。
流程
调整
mon_target_pg_per_osd:ceph config set global mon_target_pg_per_osd number例如:
$ ceph config set global mon_target_pg_per_osd 150
3.5.5.1. 为池设置最小和最大放置组数量
指定放置组(PG)的最小和最大值,以限制自动扩展范围。
如果设置了最小值,Ceph 不会自动减少或建议减少,PG 的数量为设置最小值下的值。
如果设置了最小值,Ceph 不会自动增加或推荐增加的 PG 数量,则值超过设置的最大值。
最小和最大值可以一起设置,或者单独设置。
除了此流程外,ceph osd pool create 命令还有两个命令行选项,可用于在创建池时指定最小或最大 PG 数量。
语法
ceph osd pool create --pg-num-min NUMBER ceph osd pool create --pg-num-max NUMBER
示例
ceph osd pool create --pg-num-min 50 ceph osd pool create --pg-num-max 150
先决条件
- 一个正在运行的 Red Hat Ceph Storage 集群。
- 节点的根级别访问权限。
流程
为池设置最小 PG 数量:
语法
ceph osd pool set POOL_NAME pg_num_min NUMBER
示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_num_min 50
为池设置最大 PG 数量:
语法
ceph osd pool set POOL_NAME pg_num_max NUMBER
示例
[ceph: root@host01 /]# ceph osd pool set testpool pg_num_max 150
3.5.6. 更新 noautoscale 标记
如果要同时为所有池启用或禁用自动扩展器,您可以使用 noautoscale 全局标志。当某些 OSD 被退回或集群处于维护状态时,这个全局标志很有用。您可以在任何活动前设置标志,并在活动完成后取消设置它。
默认情况下,noautoscale 标志设置为 off。当设置这个标记时,所有池 都为 off,并且所有池都禁用自动扩展器。
先决条件
- 正在运行的 Red Hat Ceph Storage 集群
- 所有节点的根级别访问权限。
流程
获取
noautoscale标志的值:示例
[ceph: root@host01 /]# ceph osd pool get noautoscale
在任何活动前设置
noautoscale标志:示例
[ceph: root@host01 /]# ceph osd pool set noautoscale
在完成活动时取消设置
noautoscale标志:示例
[ceph: root@host01 /]# ceph osd pool unset noautoscale
3.5.7. 指定目标池大小
新创建的池消耗少量集群容量,并出现在需要少量的 PG 的系统中。然而,在大多数情形中,集群管理员知道哪些池预期消耗了大多数系统容量。如果提供此信息,称为 Red Hat Ceph Storage 的目标大小,此类池可以从头开始使用更合适的 PG 数(pg_num)。此方法可防止 pg_num 中的后续更改,并在进行这些调整时与移动数据相关的开销。
您可以使用以下方法指定池 的目标大小 :
3.5.7.1. 使用池的绝对大小指定目标大小
流程
使用池的绝对
大小(以字节为单位)设置目标大小:ceph osd pool set pool-name target_size_bytes value
例如,要指示
mypool的系统预期消耗 100T 空间:$ ceph osd pool set mypool target_size_bytes 100T
您还可以通过将可选的 --target-size-bytes <bytes> 参数添加到 ceph osd pool create 命令中,来设置池创建的目标大小。
3.5.7.2. 使用集群容量总量指定目标大小
流程
使用集群容量总数来设置
目标大小:ceph osd pool set pool-name target_size_ratio ratio
例如:
$ ceph osd pool set mypool target_size_ratio 1.0
告诉系统,池
mypool期望消耗 1.0,相对于其他设置了target_size_ratio的池。如果mypool是集群中唯一的池,这意味着预期使用总容量的 100%。如果存在第二个池,其target_size_ratio为 1.0,两个池都希望使用 50% 的集群容量。
您还可以通过将可选的 --target-size-ratio <ratio> 参数添加到 ceph osd pool create 命令,在创建时设置池的目标大小。
如果您指定了无法达到的目标大小值,例如:大于总集群的容量,或者设置比例的总和大于 1.0,集群会引发 POOL_TARGET_SIZE_RATIO_OVERCOMMITTED 或 POOL_TARGET_SIZE_BYTES_OVERCOMMITTED 健康警告。
如果您同时为池指定 target_size_ratio 和 target_size_bytes,集群只会考虑比例,并引发 POOL_HAS_TARGET_BYTES_AND_RATIO 健康警告。
3.6. PG 命令行参考
您可以通过 ceph CLI 设置并获取池的放置组数量,查看 PG map 和检索 PG 统计信息。
3.6.1. 设置 PG 的数量
要在池中设置放置组数量,您必须在创建池时指定放置组数量。详情请查看创建池。为池设置放置组后,您可以增加或减少放置组数量。要更改放置组数量,请使用以下命令:
语法
ceph osd pool set POOL_NAME pg_num PG_NUMBER
示例
[ceph: root@host01 /]# ceph osd pool set pool1 pg_num 60 set pool 2 pg_num to 60
增加或减少放置组数量后,还必须在集群重新平衡前调整放置的放置组数量(pgp_num)。pgp_num 应当等于 pg_num。
语法
ceph osd pool set POOL_NAME pgp_num PGP_NUMBER
示例
[ceph: root@host01 /]# ceph osd pool set pool1 pgp_num 60 set pool 2 pgp_num to 60
3.6.2. 获取 PG 数量
获取池中的放置组数量:
语法
ceph osd pool get POOL_NAME pg_num
示例
[ceph: root@host01 /]# ceph osd pool get pool1 pg_num pg_num: 60
3.6.3. 获取 Cluster PG 统计
获取放置组的统计信息:
语法
ceph pg dump [--format FORMAT]
有效格式为 plain (默认)和 json。
3.6.4. 获取 Stuck PG 的统计
获取所有放置组的统计信息处于指定状态:
语法
ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} INTEGER
Inactive 放置组无法处理读取或写入,因为它们正在等待具有最新数据最多的 OSD 上线并在内。
Unclean 放置组包含没有复制所需时间的对象。它们应该是恢复。
过时的 放置组处于未知状态 - 托管它们尚未报告给 monitor 集群的 OSD(配置为 mon_osd_report_timeout)。
有效格式为 plain (默认)和 json。阈值定义了放置组在返回统计之前卡住的最小秒数(默认为 300 秒)。
3.6.5. 获取 PG map
获取特定放置组的放置组映射:
语法
ceph pg map PG_ID
示例
[ceph: root@host01 /]# ceph pg map 1.6c osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
Ceph 返回放置组映射、放置组和 OSD 状态。
3.6.6. 获取 PG 统计
检索特定放置组的统计信息:
语法
ceph pg PG_ID query
3.6.7. 清理放置组
清理放置组:
语法
ceph pg scrub PG_ID
Ceph 检查主节点和任何副本节点,生成放置组中所有对象的目录,并比较它们以确保没有对象丢失或不匹配,并且其内容一致。假设副本都匹配,最终语义 sweep 可确保所有与快照相关的对象元数据一致。通过日志报告错误。
3.6.8. 恢复丢失
如果集群丢失了一个或多个对象,并且您决定取消搜索丢失数据,您必须将未找到的对象标记为 lost。
如果查询了所有可能的位置,并且对象仍然丢失,您可能需要放弃丢失的对象。这有不常的故障组合,允许集群了解在进行写入本身恢复之前执行的写入操作。
Ceph 仅支持"revert"选项,该选项可回滚到对象的各种版本,或者如果它是新对象,则可以忘记它。要将 "unfound" 对象标记为 "lost",请使用以下命令:
语法
ceph pg PG_ID mark_unfound_lost revert|delete
请谨慎使用此功能,因为它可能会混淆预期对象存在的应用程序。
第 4 章 池
Ceph 客户端在池中存储数据。创建池时,您要为客户端创建一个 I/O 接口来存储数据。从 Ceph 客户端的角度来看,即块设备、网关和与 Ceph 存储集群交互非常简单:创建集群处理并连接到集群;然后,创建一个 I/O 上下文来读取和写入对象及其扩展属性。
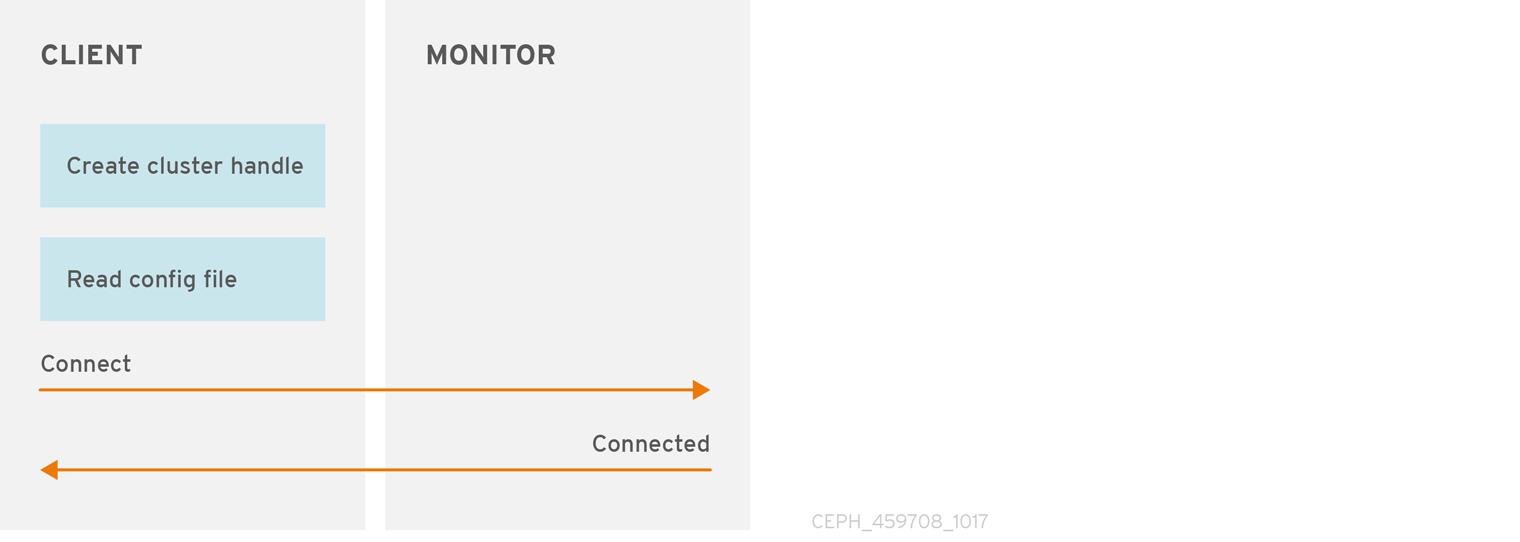
创建集群处理和连接到集群
要连接到 Ceph 存储集群,Ceph 客户端需要集群名称(默认为 ceph ),以及初始监控地址。Ceph 客户端通常使用 Ceph 配置文件的默认路径检索这些参数,然后从文件读取,但用户也可以在命令行中指定参数。Ceph 客户端还提供用户名和密钥,身份验证默认为 on。然后,客户端联系 Ceph 监控集群,并检索 cluster map 的最新副本,包括其 monitor、OSD 和池。
创建池 I/O 上下文
若要读取和写入数据,Ceph 客户端会创建一个 I/O 上下文到 Ceph 存储集群中的特定池。如果指定的用户具有池的权限,Ceph 客户端可以从中读取并写入到指定的池。

Ceph 的架构可让存储集群为 Ceph 客户端提供一个简单的接口。客户端可以通过指定池名称并创建 I/O 上下文来选择其中一个定义的复杂的存储策略。存储策略对 Ceph 客户端在所有容量和性能方面不可见。同样,Ceph 客户端的复杂性(如将对象映射到块设备表示或提供 S3 或 Swift RESTful 服务)对 Ceph 存储集群不可见。
池为您提供了:
-
弹性 :您可以设置允许多少 OSD 失败,而不丢失数据。对于复制池,它是对象所需的副本数。典型的配置存储对象和一个额外副本,
大小为 2,但您可以确定副本数或副本数。对于纠删代码池,它是 纠删代码 profile 中的m=2的编码区块数量。 - 放置组 :您可以为池设置放置组(PG)的数量。典型的配置使用每个 OSD 大约 50-100 的 PG 来提供最佳平衡,而无需使用太多计算资源。在设置多个池时,请确保为池和整个集群设置合理的 PG 数量。
- CRUSH 规则 :当您在池中存储数据时,映射到池的 CRUSH 规则可让 CRUSH 识别每个对象放置及其副本的规则,或者集群中纠删代码池的区块。您可以为池创建自定义 CRUSH 规则。
-
配额 :当您在
ceph osd pool set-quota的池上设置配额时,您可以限制在指定池中存储的最大字节数或最大字节数。
4.1. 池和存储策略
要管理池,您可以列出、创建和删除池。您还可以查看各个池的使用情况统计信息。
4.2. 列出池
要列出集群的池,请运行:
示例
[ceph: root@host01 /]# ceph osd lspools
4.3. 创建池
在创建池之前,请参见 Red Hat Ceph Storage 5 配置指南中的池、PG 和 CRUSH 配置参考一章。
在 Red Hat Ceph Storage 3 及更新的版本中,系统管理员必须明确使池从 Ceph 客户端接收 I/O 操作。详情请参阅 启用应用程序。如果不启用池,则会导致 HEALTH_WARN 状态。
最好为 Ceph 配置文件中的放置组数量调整默认值,因为默认值不必适合您的需要。
示例
# osd pool default pg num = 100 # osd pool default pgp num = 100
要创建复制池,请运行:
语法
ceph osd pool create POOL_NAME PG_NUMBER PGP_NUMBER [replicated] \ [crush-rule-name] [expected-num-objects]
要创建批量池,请运行:
语法
ceph osd pool create POOL_NAME --bulk
要创建纠删代码池,请运行:
语法
ceph osd pool create POOL_NAME PG_NUMBER PGP_NUMBER erasure \ [erasure-code-profile] [crush-rule-name] [expected-num-objects]
其中:
- POOL_NAME
- 描述
- 池的名称。它必须是唯一的。
- 类型
- 字符串
- 必需
- 是。如果未指定,它将设置为 Ceph 配置文件中列出的值,或设置为默认值。
- 默认
-
ceph
- PG_NUMBER
- 描述
-
池的放置组总数。有关计算合适的数目的详细信息,请参阅 每个池 计算器的放置组部分和 Ceph 放置组(PG)。默认值
8不适用于大多数系统。 - 类型
- 整数
- 必需
- 是
- 默认
-
8
- PGP_NUMBER
- 描述
- 用于放置使用的放置组总数。这个值必须等于放置组总数,但放置组分割场景除外。
- 类型
- 整数
- 必需
- 是。如果未指定,它被设置为 Ceph 配置文件中列出的值,或设置为默认值。
- 默认
-
8
复制或擦除- 描述
-
池类型可以是
replicated,它通过保持多个对象的副本来恢复丢失的 OSD;或erasure来实现通用的 RAID5 的功能。复制池需要更多原始存储,但实施所有 Ceph 操作。纠删代码池需要较少的原始存储,但仅实现可用操作的一个子集。 - 类型
- 字符串
- 必需
- 否
- 默认
-
复制
- crush-rule-name
- 描述
-
池的 crush 规则的名称。规则 MUST 存在。对于池,名称是
osd_pool_default_crush_rule配置设置指定的规则。对于纠删代码的池,如果您指定了默认的纠删代码 profile 或{pool-name},则名称为erasure-code。如果规则尚不存在,Ceph 将以隐式方式创建此规则。 - 类型
- 字符串
- 必需
- 否
- 默认
-
对纠删代码池使用
erasure-code。对于池,它使用 Ceph 配置中osd_pool_default_crush_rule变量的值。
- expected-num-objects
- 描述
-
池的预期对象数量。通过将此值与负
filestore_merge_threshold变量一起设置,Ceph 会在创建池时分割放置组,以避免延迟影响执行运行时目录分割。 - 类型
- 整数
- 必需
- 否
- 默认
-
0,创建池时不进行分割。
- erasure-code-profile
- 描述
-
对于纠删代码池,请使用纠删代码 profile。它必须是由 Ceph 配置文件中
osd erasure-code-profile set变量定义的现有配置集。如需更多信息,请参阅 Erasure Code Profiles 部分。 - 类型
- 字符串
- 必需
- 否
当您创建池时,将放置组数量设置为合理的值,例如 100。考虑每个 OSD 的放置组总数。放置组的计算代价比较高,因此您在带有多个放置组的多个池时(例如,50 个池,每个带有 100 个放置组),性能会降低。减弱的返回点取决于 OSD 主机的电源。
其它资源
有关计算您池的适当放置组数量的详细信息,请参阅 每个池 计算器的放置组部分和 Ceph 放置组(PG )。
4.4. 设置池配额
您可以为最大字节数和每个池的最大对象数设置池配额。
语法
ceph osd pool set-quota POOL_NAME [max_objects OBJECT_COUNT] [max_bytes BYTES]
示例
[ceph: root@host01 /]# ceph osd pool set-quota data max_objects 10000
要删除配额,请将其值设为 0。
在 Ceph 在集群中传播池使用量前,动态写入操作可能会超额运行池配额。这是正常的行为。在动态写入操作强制进行池配额可能会带来显著的性能。
4.5. 删除池
要删除池,请运行:
语法
ceph osd pool delete POOL_NAME [POOL_NAME --yes-i-really-really-mean-it]
为了保护数据,存储管理员默认无法删除池。在删除池前,设置 mon_allow_pool_delete 配置选项。
如果池具有自己的规则,请考虑在删除池后将其删除。如果池强制为用户自己使用,请考虑在删除池后删除这些用户。
4.6. 重命名池
要重命名池,请运行:
语法
ceph osd pool rename CURRENT_POOL_NAME NEW_POOL_NAME
如果您重命名了池,并且具有经过身份验证的用户的每池功能,则必须使用新的池名称更新用户的功能(大写)。
4.7. 迁移池
有时,需要将所有对象从一个池迁移到另一个池。这是在需要更改无法修改特定池中的参数的情况下完成的。例如,需要减少池的 PG 数量。
Ceph 块设备描述的迁移方法比此处记录的迁移方法更高。使用 cppool 不保留所有快照和快照相关的元数据,从而导致数据异常副本。例如,复制 RBD 池不会完全复制镜像。在这种情况下,snaps 不存在,且无法正常工作。cppool 也不会保留某些 librados 用户可能依赖的 user_version 字段。
如果迁移池是必要的,并且您的用户工作负载包含 Ceph 块设备以外的镜像,请继续按照这里介绍的步骤之一。
先决条件
如果使用
rados cppool命令:- 需要对池进行只读访问。
-
只有当您没有 RBD 镜像及其 snaps 以及 librados 消耗的
user_version时,才使用此命令。
- 如果使用本地驱动器 RADOS 命令,请验证是否有足够的集群空间可用。随着池复制因子,存在两个、三个或更多的数据副本。
流程
方法一 - 推荐的直接方法
使用 rados cppool 命令复制所有对象。
复制过程中需要对池的只读访问权限。
语法
ceph osd pool create NEW_POOL PG_NUM [ <other new pool parameters> ] rados cppool SOURCE_POOL NEW_POOL ceph osd pool rename SOURCE_POOL NEW_SOURCE_POOL_NAME ceph osd pool rename NEW_POOL SOURCE_POOL
示例
[ceph: root@host01 /]# ceph osd pool create pool1 250 [ceph: root@host01 /]# rados cppool pool2 pool1 [ceph: root@host01 /]# ceph osd pool rename pool2 pool3 [ceph: root@host01 /]# ceph osd pool rename pool1 pool2
方法 2 - 使用本地驱动器
使用
rados export和rados 导入命令和一个临时本地目录来保存所有导出的数据。语法
ceph osd pool create NEW_POOL PG_NUM [ <other new pool parameters> ] rados export --create SOURCE_POOL FILE_PATH rados import FILE_PATH NEW_POOL
示例
[ceph: root@host01 /]# ceph osd pool create pool1 250 [ceph: root@host01 /]# rados export --create pool2 <path of export file> [ceph: root@host01 /]# rados import <path of export file> pool1
- 必需。停止到源池的所有 I/O。
必需。重新同步所有修改的对象。
语法
rados export --workers 5 SOURCE_POOL FILE_PATH rados import --workers 5 FILE_PATH NEW_POOL
示例
[ceph: root@host01 /]# rados export --workers 5 pool2 <path of export file> [ceph: root@host01 /]# rados import --workers 5 <path of export file> pool1
4.8. 显示池统计
要显示池的利用率统计,请运行:
示例
[ceph: root@host01 /] rados df
4.9. 设置池值
要为池设置值,请运行以下命令:
语法
ceph osd pool set POOL_NAME KEY VALUE
Pool Values 部分列出了您可以设置的所有键值对。
4.10. 获取池值
要从池中获取值,请运行以下命令:
语法
ceph osd pool get POOL_NAME KEY
Pool Values 部分列出了您可获得的所有键值对。
4.11. 启用应用程序
Red Hat Ceph Storage 为池提供额外的保护,以防止未经授权类型的客户端将数据写入池中。这意味着系统管理员必须表达池才能从 Ceph 块设备、Ceph 对象网关、Ceph Filesystem 或自定义应用程序接收 I/O 操作。
要启用客户端应用程序对池执行 I/O 操作,请运行以下命令:
语法
ceph osd pool application enable POOL_NAME APPLICATION {--yes-i-really-mean-it}
其中 APPLICATION 是:
-
cephfs用于 Ceph 文件系统。 -
RBD,用于 Ceph 块设备。 -
rgw用于 Ceph 对象网关.
为自定义应用程序指定不同的 APPLICATION 值。
未启用的池将生成一个 HEALTH_WARN 状态。在这种情况下,ceph 健康详情 -f json-pretty 的输出将输出以下内容:
{
"checks": {
"POOL_APP_NOT_ENABLED": {
"severity": "HEALTH_WARN",
"summary": {
"message": "application not enabled on 1 pool(s)"
},
"detail": [
{
"message": "application not enabled on pool '<pool-name>'"
},
{
"message": "use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications."
}
]
}
},
"status": "HEALTH_WARN",
"overall_status": "HEALTH_WARN",
"detail": [
"'ceph health' JSON format has changed in luminous. If you see this your monitoring system is scraping the wrong fields. Disable this with 'mon health preluminous compat warning = false'"
]
}
使用 rbd pool init POOL_NAME 初始化 Ceph 块设备的池。
4.12. 禁用应用程序
要禁用客户端应用程序对池执行 I/O 操作,请运行以下命令:
语法
ceph osd pool application disable POOL_NAME APPLICATION {--yes-i-really-mean-it}
其中 APPLICATION 是:
-
cephfs用于 Ceph 文件系统。 -
RBD用于 Ceph 块设备 -
RGW用于 Ceph 对象网关
为自定义应用程序指定不同的 APPLICATION 值。
4.13. 设置应用程序元数据
提供相应的功能,用来设置描述客户端应用属性的键值对。
要在池中设置客户端应用程序元数据,请运行以下命令:
语法
ceph osd pool application set POOL_NAME APPLICATION KEY VALUE
其中 APPLICATION 是:
-
CephFS用于 Ceph 文件系统 -
RBD用于 Ceph 块设备 -
RGW用于 Ceph 对象网关
为自定义应用程序指定不同的 APPLICATION 值。
4.14. 删除应用程序元数据
要删除池中的客户端应用程序元数据,请运行以下命令:
语法
ceph osd pool application set POOL_NAME APPLICATION KEY
其中 APPLICATION 是:
-
CephFS用于 Ceph 文件系统 -
RBD用于 Ceph 块设备 -
RGW用于 Ceph 对象网关
为自定义应用程序指定不同的 APPLICATION 值。
4.15. 设置对象副本的数量
要在复制池中设置对象副本数量,请运行以下命令:
语法
ceph osd pool set POOL_NAME size NUMBER_OF_REPLICAS
您可以为每个池运行这个命令。
NUMBER_OF_REPLICAS 参数包含对象本身。如果要为对象的三个实例包含对象和对象的两个副本,请指定 3。
示例
[ceph: root@host01 /]# ceph osd pool set data size 3
对象可能会接受降级模式中的 I/O 操作,其副本数少于 pool size 设置指定的副本。要为 I/O 设置所需的副本数,请使用 min_size 设置。
示例
[ceph: root@host01 /]# ceph osd pool set data min_size 2
这可确保数据池中没有对象接收的 I/O 少于 min_size 设置指定的副本。
4.16. 获取对象副本的数量
要获取对象副本数量,请运行以下命令:
示例
[ceph: root@host01 /]# ceph osd dump | grep 'replicated size'
Ceph 将列出具有 复制大小 属性突出显示的池。默认情况下,Ceph 为一个对象创建两个副本,总共有三个副本,或大小为 3。
4.17. 池值
以下列表包含您可以设置或获取的键值对。如需更多信息,请参阅 Set Pool Values 和 Get Pool Values 部分。
- size
- 描述
- 指定池中对象的副本数量。如需了解更多详细信息,请参阅设置 Object Replicas 部分。仅适用于池。
- 类型
- 整数
- min_size
- 描述
-
指定 I/O 所需的最少副本数。如需了解更多详细信息,请参阅设置 Object Replicas 部分。对于纠删代码池,应将其设置为大于
k的值。如果在k值下允许 I/O,则在永久 OSD 出现故障时没有冗余,数据将会丢失。如需更多信息,请参阅 纠删代码池概述。 - 类型
- 整数
- crash_replay_interval
- 描述
- 指定允许客户端重播已确认但未提交的请求的秒数。
- 类型
- 整数
- pg-num
- 描述
-
池的放置组总数。有关计算合适的数量的详细信息,请参阅 Red Hat Ceph Storage 5 配置指南中的 池、放置组和 CRUSH 配置参考部分。默认值
8不适用于大多数系统。 - 类型
- 整数
- 必填
- 是。
- 默认
- 8
- pgp-num
- 描述
- 用于放置使用的放置组总数。这应当与放置组总数 相同,但放置组 分割场景除外。
- 类型
- 整数
- 必填
- 是。如果未指定,则获取默认值或 Ceph 配置值。
- 默认
- 8
- 有效范围
-
等于
pg_num变量指定的值或小于所指定的内容。
- crush_rule
- 描述
- 用于映射集群中的对象放置的规则。
- 类型
- 字符串
- hashpspool
- 描述
-
在给定的池上启用或禁用
HASHPSPOOL标志。启用此选项后,池散列和放置组映射将更改为改进池和放置组重叠的方式。 - 类型
- 整数
- 有效范围
1启用该标志,0将禁用该标志。重要不要在具有大量 OSD 和数据的集群池中启用此选项。池中的所有放置组都必须重新映射导致数据移动过多。
- fast_read
- 描述
-
在启用这个标志的池中,如果启用了这个标志,读取请求会发出后续读取操作,并等待其接收足够的分片来解码客户端。如果是
jerasure和isa erasureplug-ins,当第一个 K 回复返回后,客户端请求会立即使用来自这些回复的数据来提供。这有助于分配一些资源来提高性能。目前,这个标志只支持纠删代码池。 - 类型
- 布尔值
- 默认值
-
0
- allow_ec_overwrites
- 描述
- 写入到纠删代码池都可以更新对象的一部分,因此 Ceph Filesystem 和 Ceph Block Device 可以使用它。
- 类型
- 布尔值
- compression_algorithm
- 描述
-
设置要与 BlueStore 存储后端一起使用的内联压缩算法。此设置覆盖
bluestore_compression_algorithm配置设置。 - 类型
- 字符串
- 有效设置
-
lz4,snappy,zlib,zstd
- compression_mode
- 描述
-
为 BlueStore 存储后端设置内联压缩算法的策略。此设置会覆盖
bluestore_compression_mode配置设置。 - 类型
- 字符串
- 有效设置
-
无,passive,aggressive,force
- compression_min_blob_size
- 描述
-
BlueStore 不会压缩小于这个大小的块。此设置覆盖
bluestore_compression_min_blob_size配置设置。 - 类型
- 未签名 Integer
- compression_max_blob_size
- 描述
-
在压缩数据前,BlueStore 会将大于这个大小的块分成较小的
compression_max_blob_sizeBlob。 - 类型
- 未签名 Integer
- nodelete
- 描述
-
在给定池中设置或取消设置
NODELETE标志。 - 类型
- 整数
- 有效范围
-
1设置标记.0unsets 标记。
- nopgchange
- 描述
-
在给定池中设置或取消设置
NOPGCHANGE标志。 - 类型
- 整数
- 有效范围
-
1设置 标志。0取消设置 标志。
- nosizechange
- 描述
-
设置或取消设置给定池中的
NOSIZECHANGE标志。 - 类型
- 整数
- 有效范围
-
1设置 标志。0取消设置 标志。
- write_fadvise_dontneed
- 描述
-
在给定池中设置或取消设置
WRITE_FADVISE_DONTNEED标志。 - 类型
- 整数
- 有效范围
-
1设置 标志。0取消设置 标志。
- noscrub
- 描述
-
在给定池中设置或取消设置
NOSCRUB标志。 - 类型
- 整数
- 有效范围
-
1设置 标志。0取消设置 标志。
- nodeep-scrub
- 描述
-
在给定池中设置或取消设置
NODEEP_SCRUB标志。 - 类型
- 整数
- 有效范围
-
1设置 标志。0取消设置 标志。
- scrub_min_interval
- 描述
-
加载时池清理的最小间隔(以秒为单位)。如果是
0,Ceph 将使用osd_scrub_min_interval配置设置。 - 类型
- 双
- 默认
-
0
- scrub_max_interval
- 描述
-
池清理对集群负载的影响间隔(以秒为单位)。如果是
0,Ceph 将使用osd_scrub_max_interval配置设置。 - 类型
- 双
- 默认
-
0
- deep_scrub_interval
- 描述
-
池"deep"清理的时间间隔(以秒为单位)。如果是
0,Ceph 将使用osd_deep_scrub_interval配置设置。 - 类型
- 双
- 默认
-
0
第 5 章 后台代码池
Ceph 存储策略涉及定义数据持久性要求。数据持久性意味着,在丢失一个或多个 OSD 时可以保持数据不会丢失。
Ceph 在池中存储数据,存在两种类型的池:
- 复制
- erasure-coded
Ceph 默认使用池,即 Ceph 将每个对象从主 OSD 节点复制到一个或多个次要 OSD。
纠删代码(erasure-coded)池可以减少确保数据持久性所需的磁盘空间量,但它的计算比复制要高得多。
纠删代码是一种在 Ceph 存储群集中存储对象的方法,即:该算法将对象分割为数据区块(k)和编码区块(m),并将这些区块存储在不同的 OSD 中。
如果 OSD 出现故障,Ceph 会从其他 OSD 检索剩余的数据(k)和编码(m)区块,以及纠删代码算法从这些区块恢复对象。
红帽建议 min_size 用于纠删代码池为 K+1 或更高版本,以防止丢失写入和数据。
擦除编码使用比复制更高效的存储容量。n-replication 方法维护对象的 n 个副本(在 Ceph 中默认为 3x),而区块则仅维护 k + m 个区块。例如,3 个数据和 2 个编码区块使用 1.5x 原始对象的存储空间。
纠删代码使用比复制少的存储开销,但纠删代码池使用的内存比访问或恢复对象时使用的 CPU 数要多。当数据存储需要具有持久性和容错能力,但不需要快速读取性能(如冷存储、历史记录等)时,擦除代码具有优势。
有关纠删代码如何在 Ceph 中工作的信息,请参阅 Red Hat Ceph Storage 5 架构指南中的 Ceph Erasure Coding 部分。
Ceph 在使用 k=2 和 m=2 初始化集群时 创建默认 纠删代码 profile,这意味着 Ceph 会将对象数据分散到四个 OSD (k+m == 4)中,Ceph 可在不丢失数据的情况下丢失其中一个 OSD。要了解有关纠删代码池配置集的更多信息,请参阅 Erasure Code Profiles 部分。
仅将 .rgw.buckets 池配置为纠删代码池,并将所有其他 Ceph 对象网关池配置为复制,否则会尝试创建新存储桶失败,并带有以下错误:
set_req_state_err err_no=95 resorting to 500
这样做的原因是,纠删代码池不支持 omap 操作,某些 Ceph Object Gateway 元数据池需要 omap 支持。
5.1. 创建示例 Erasure-code 池
最简单的纠删代码池等同于 RAID5,需要至少三个主机:
$ ceph osd pool create ecpool 32 32 erasure pool 'ecpool' created $ echo ABCDEFGHI | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHI
池中的 32 代表放置组数量。
5.2. 擦除代码配置集
Ceph 定义一个带有 配置集 的纠删代码池。Ceph 在创建大写字母和关联的 CRUSH 规则时,使用 profile。
Ceph 在初始化集群时创建默认纠删代码 profile,并且提供与复制池中的两个副本相同的冗余级别。但是,它的存储容量要少 25%默认配置文件定义 k=2 和 m=2,这意味着 Ceph 会将对象数据分散到四个 OSD (k+m=4)中,Ceph 可以在不丢失数据的情况下丢失其中一个 OSD。
默认纠删代码 profile 可以保持单个 OSD 丢失。它相当于一个大小为 2 的复制池,但需要 1.5 TB 而不是 2 TB 来存储 1 TB 的数据。使用以下命令显示默认配置集:
$ ceph osd erasure-code-profile get default k=2 m=2 plugin=jerasure technique=reed_sol_van
您可以创建新配置集来提高冗余,而不增加原始存储要求。例如,一个具有 k=8 和 m=4 的配置集,可以丢失四个(m=4)OSD,这通过在 12 个 (k+m=12) OSD 中分布一个对象实现。Ceph 将对象分成 8 个块,计算 4 个编码区块以用于恢复。例如,如果对象大小为 8 MB,每个数据块都是 1 MB,每个编码区块的大小也与 1 MB 相同。即使四个 OSD 同时失败,该对象也不会丢失。
配置集最重要的参数是 k、m 和 crush-failure-domain,因为它们定义存储开销和数据持久性。
选择正确的配置集非常重要,因为您创建池后无法更改配置集。若要修改配置文件,您必须创建一个具有不同配置文件的新池,并将对象从旧池中迁移到新池中。
例如,如果所需的架构需要可以丢失两个机架,且存储开销为 40% 的开销,则可以定义以下配置集:
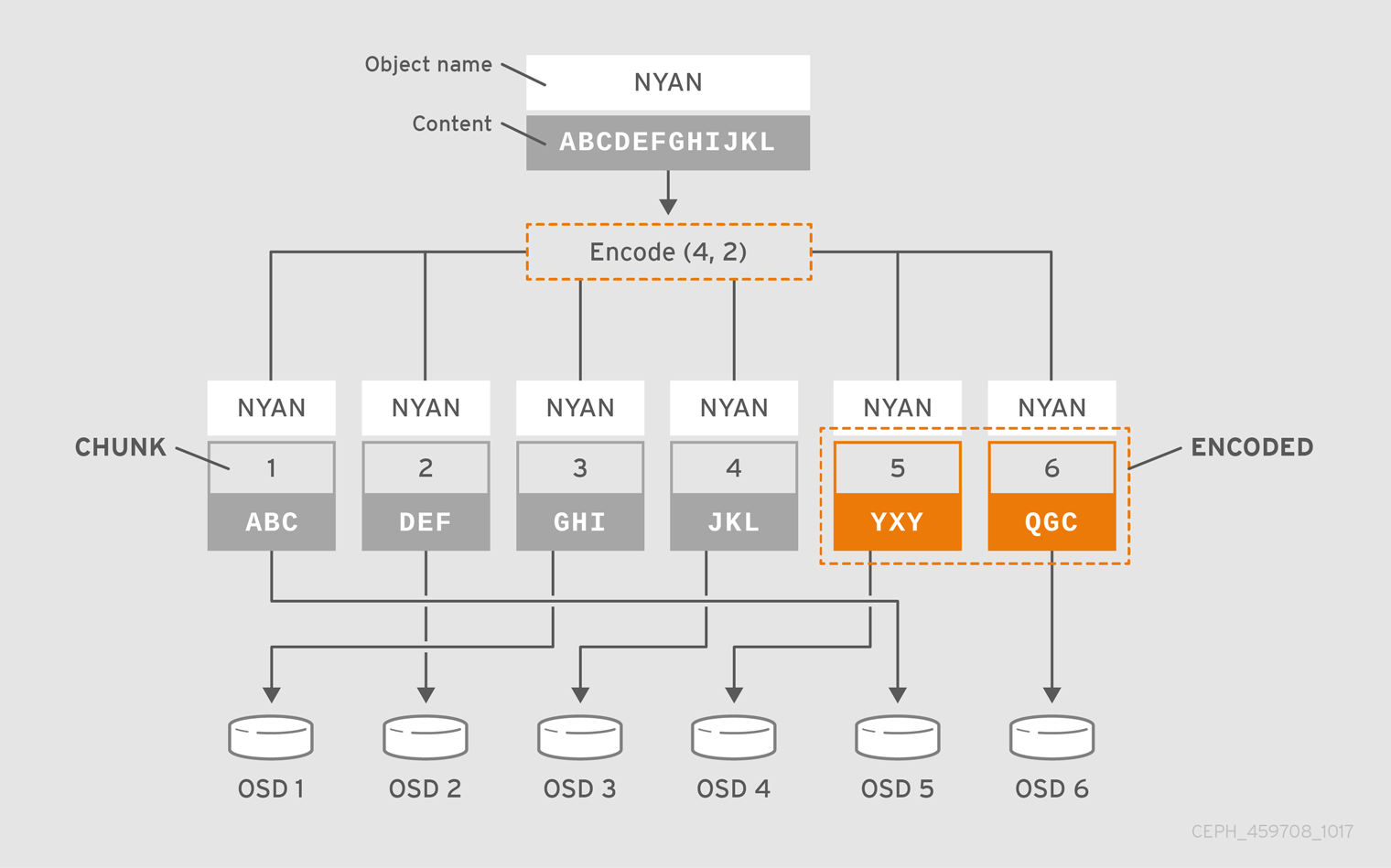
$ ceph osd erasure-code-profile set myprofile \ k=4 \ m=2 \ crush-failure-domain=rack $ ceph osd pool create ecpool 12 12 erasure *myprofile* $ echo ABCDEFGHIJKL | rados --pool ecpool put NYAN - $ rados --pool ecpool get NYAN - ABCDEFGHIJKL
主 OSD 将 NYAN 对象分成四个 (k=4) 数据块,并创建两个额外的块 (m=2)。m 的值定义可以同时丢失多少个 OSD,而不丢失任何数据。crush-failure-domain=rack 将创建一个 CRUSH 规则,确保不存储两个块。
红帽支持对 k 和 m 的以下 jerasure 编码值:
- k=8 m=3
- k=8 m=4
- k=4 m=2
如果 OSD 数量丢失等于编码区块数(m),则灾难恢复池中的某些放置组将进入不完整的状态。如果丢失的 OSD 数量小于 m,则没有放置组将进入不完整的状态。在这两种情况下,不会发生数据丢失。如果放置组处于不完整状态,请临时减少纠删代码池的 min_size,允许恢复。
5.2.1. OSD erasure-code-profile Set
要创建新的纠删代码 profile,请执行以下操作:
ceph osd erasure-code-profile set <name> \
[<directory=directory>] \
[<plugin=plugin>] \
[<stripe_unit=stripe_unit>] \
[<crush-device-class>]\
[<crush-failure-domain>]\
[<key=value> ...] \
[--force]其中:
- 目录
- 描述
- 设置载入 code 插件的目录名称。
- 类型
- 字符串
- 必填
- No.
- 默认
-
/usr/lib/ceph/erasure-code
- plugin
- 描述
- 使用纠删代码池插件计算编码区块并恢复缺少的块。详情请查看 Erasure Code 插件 部分。
- 类型
- 字符串
- 必填
- No.
- 默认
-
jerasure
- stripe_unit
- 描述
-
每个条带的数据块中的数据量。例如,带有 2 个数据块和
stripe_unit=4K的配置集会将范围 0-4K 置于块 0 中,将 4K-8K 置于块 1 中,8K-12K 再次置于块 0 中。要获得最佳性能,这应该是 4K 的倍数。创建池时,从 monitor 配置选项osd_pool_erasure_code_stripe_unit中获取了默认值。使用这个配置集的条带_width 是这个 stripe_unit 的数据区块数乘以该stripe_unit。 - 类型
- 字符串
- 必填
- No.
- 默认
-
4K
- crush-device-class
- 描述
-
设备类,如
hdd或ssd。 - 类型
- 字符串
- 必填
- 否
- 默认
-
none,这意味着 CRUSH 使用所有设备,而不需要考虑类型。
- crush-failure-domain
- 描述
-
故障域,如
host或rack。 - 类型
- 字符串
- 必填
- 否
- 默认
-
主机
- key
- 描述
- 剩余的键值对的语义由退出代码插件定义。
- 类型
- 字符串
- 必填
- No.
- --force
- 描述
- 使用相同的名称覆盖现有配置集。
- 类型
- 字符串
- 必填
- No.
5.2.2. OSD erasure-code-profile Remove
删除纠删代码 profile:
ceph osd erasure-code-profile rm <name>
如果配置集由池引用,则删除操作将失败。
5.2.3. OSD erasure-code-profile 获取
显示纠删代码池配置集:
ceph osd erasure-code-profile get <name>
5.2.4. OSD erasure-code-profile List
列出所有纠删代码 profile 的名称:
ceph osd erasure-code-profile ls
5.3. 使用 Overwrites 进行擦除
默认情况下,纠删代码池只能使用 Ceph 对象网关,该网关执行完整的对象写入和附加。从 Red Hat Ceph Storage 3.x 开始,可以基于每个池启用对纠删代码池的部分写入。
使用带有覆盖的纠删代码池可允许 Ceph 块设备和 CephFS 将其数据存储到纠删代码池中:
语法
ceph osd pool set <erasure_coded_pool_name> allow_ec_overwrites true
示例
$ ceph osd pool set ec_pool allow_ec_overwrites true
启用具有覆盖覆盖的纠删代码池只能使用 BlueStore OSD 驻留在池中。由于 BlueStore 的校验和用于在深度清理期间检测位维度或其他损坏。使用带有纠删代码池的 FileStore 不安全,与 BlueStore 相比,性能较低。
纠删代码池不支持 omap。要将纠删代码池与 Ceph 块设备和 CephFS 搭配使用,请将数据存储在纠删代码池中,并将元数据存储在复制池中。
对于 Ceph 块设备,在创建镜像期间使用 --data-pool 选项:
语法
rbd create --size <image_size>M|G|T --data-pool <erasure_coded_pool_name> <replicated_pool_name>/<image_name>
示例
$ rbd create --size 1G --data-pool ec_pool rep_pool/image01
如果将纠删代码池用于 CephFS,那么设置覆盖必须在文件布局中完成。
5.4. 擦除代码插件
Ceph 支持通过插件架构进行评分码,这意味着您可以使用不同类型的算法创建纠删代码池。Ceph 支持:- Jerasure (Default)
5.4.1. Jerasure Erasure Code 插件
jerasure 插件是最通用的灵活插件。它也是 Ceph 纠删代码池的默认值。
jerasure 插件封装 JerasureH 库。有关参数的详细信息,请参阅 jerasure 文档。
要使用 jerasure 插件创建新的纠删代码配置集,请运行以下命令:
ceph osd erasure-code-profile set <name> \
plugin=jerasure \
k=<data-chunks> \
m=<coding-chunks> \
technique=<reed_sol_van|reed_sol_r6_op|cauchy_orig|cauchy_good|liberation|blaum_roth|liber8tion> \
[crush-root=<root>] \
[crush-failure-domain=<bucket-type>] \
[directory=<directory>] \
[--force]其中:
- k
- 描述
- 每个对象分割为 data-chunks 的部分,各自存储在不同的 OSD 上。
- 类型
- 整数
- 必填
- 是。
- 示例
-
4
- m
- 描述
- 每个对象 的计算编码区块,并将它们存储在不同的 OSD 中。编码区块数也是可以停机的 OSD 的数量,而不丢失数据。
- 类型
- 整数
- 必填
- 是。
- 示例
- 2
- technique
- 描述
- 更灵活的技术是 reed_sol_van ;它足以设置 k 和 m。cauchy_good 技术更快,但您需要仔细选择 数据包大小。所有 reed_sol_r6_op,liberation,blaum_roth,liber8tion 是 RAID6 等效的,在这种意义上,它们只能被配置为 m=2。
- 类型
- 字符串
- 必填
- No.
- 有效设置
-
reed_sol_vanreed_sol_r6_opcauchy_origcauchy_goodliberationblaum_rothliber8tion - 默认
-
reed_sol_van
- packetssize
- 描述
- 该编码将一次在数据包 字节数 上进行。选择正确的数据包大小比较困难。jerasure 文档包含关于此主题的广泛信息。
- 类型
- 整数
- 必填
- No.
- 默认
-
2048
- crush-root
- 描述
- 用于规则第一步的 CRUSH bucket 的名称。例如,使用 default 步骤。
- 类型
- 字符串
- 必填
- No.
- 默认
- default
- crush-failure-domain
- 描述
- 确定在具有相同故障域的存储桶中没有两个块。例如,如果故障域是 主机 没有两个块,则将在同一主机上存储两个块。它用于创建规则步骤,如 步骤选择leaf host。
- 类型
- 字符串
- 必填
- No.
- 默认
-
主机
- 目录
- 描述
- 设置载入 code 插件的目录名称。
- 类型
- 字符串
- 必填
- No.
- 默认
-
/usr/lib/ceph/erasure-code
- --force
- 描述
- 使用相同的名称覆盖现有配置集。
- 类型
- 字符串
- 必填
- No.
5.4.2. 控制 CRUSH 放置
默认 CRUSH 规则提供位于不同主机上的 OSD。例如:
chunk nr 01234567 step 1 _cDD_cDD step 2 cDDD____ step 3 ____cDDD
需要 8 个 OSD,每个块对应一个。如果主机位于两个相邻的机架中,则前四个块可以放在第一个机架中,后 4 个放在第二个机架中。如果恢复单个 OSD 丢失,不需要在两个机架之间使用带宽。
例如:
crush-steps='[ [ "choose", "rack", 2 ], [ "chooseleaf", "host", 4 ] ]'
将创建一个规则,用于选择两个类型为 rack 的 crush bucket,并且分别选择四个 OSD,各自位于不同 bucket 中类型 的主机。
也可以手动创建该规则以进行更精细的控制。