5.6. pyramid Erasure Code
pyramid 纠删代码基本上是一种基于原始纠删代码算法的改进算法,可改善数据的访问和恢复。对于任何给定(n、k)的给定(n, k),其中 k 是原始数据区块数,n , n 是编码过程后的数据区块总数,它是 Reed-Solomon 之类的任何现有 MDS(主解析)代码。由于 Pyramid 代码基于标准 MDS 代码,因此具有相同的编码/编码方法。pyramid 编码的数据池具有相同的写入开销和类似普通纠删代码池等任意故障的恢复能力。pyramid 代码的唯一优势在于,与普通纠删代码相比,它可显著降低读取开销。
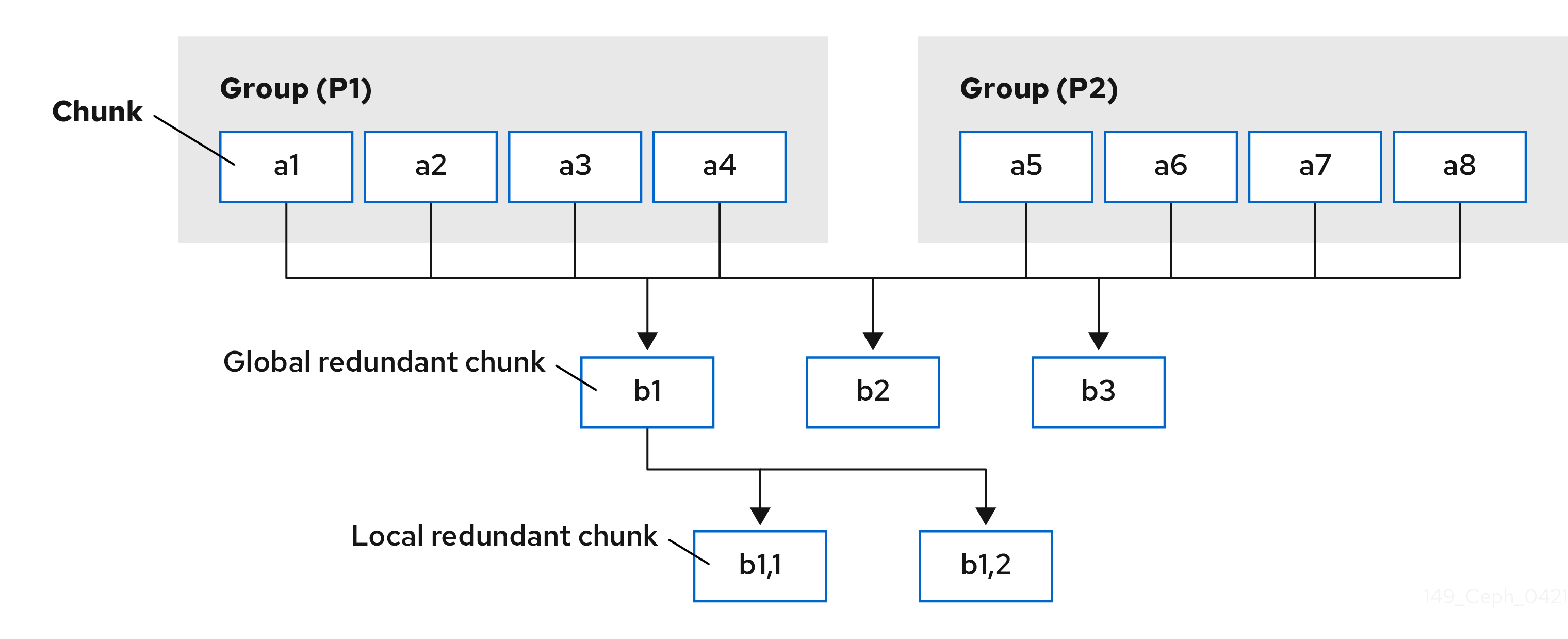
我们来举一个(11, 8)纠删代码池的示例,并在其中应用 pyramid 代码方法。我们将(11, 8)纠删代码池转换为(12、8) Pyramid 代码池。纠删代码池有 8 个 数据区块,11 - 8 = 3 个 冗余块。Pyramid Code 将 8 个数据区块划分为两个相等的大小组,如 P1 = {a1、a2、a3、a4} 和 P2 = {a5、a6、a7、a8}。它使其中两个冗余区块保持不变(say b2 和 b3)。这两个块现在被称为全局冗余区块,因为它们覆盖了所有 8 个数据区块。接下来,为组 P1 计算一个新的冗余块,它表示为组(或本地)冗余块 b1,1。计算方式与原始纠删代码中的计算 b1 相同,但将 P2 中的所有数据区块设置为 0 除外。类似地,为 P2 计算组冗余块 b1,2。组冗余区块仅受到相应组中的数据区块的影响,而不会受到其他组的影响。组冗余区块可以解释为纠删代码中原始冗余区块的投射到每个组,如 b1,1 + b1,2 = b1。因此,在这种情况下,当一个数据区块出现故障时,对于普通纠删代码池,可以使用 4 的读取开销而不是 8 来恢复它。例如,如果 P1 中的 a3 失败,并且 a1 是负责清理的 Primary OSD,它可以使用 a1、a2、a4 和 b1,1 来恢复 a3,而不是从 P2 读取。仅当同一组中缺少多个块时,才需要读取所有块。
此 Pyramid 代码的写入开销与原始纠删代码相同。每当更新数据区块时,Pyramid 代码需要更新 3 个冗余区块(b2、b3 加上 b1、b1 或 b1,2),而纠删代码也需要更新 3 个冗余区块(b1、b2 和 b3)。此外,它可以恢复 3 个与普通纠删代码相同的任意纠删代码。如前文所述,唯一好处是阅读开销更少,其代价是使用一个额外的冗余区块。因此,Pyramid 代码交易存储空间以提高访问效率。
下图显示了构建的 pyramid 代码: