
在 OpenShift 中使用 AMQ Streams
用于 OpenShift Container Platform 上的 AMQ Streams 1.6
摘要
第 1 章 AMQ 流概述
AMQ Streams 简化了在 OpenShift 集群中运行 Apache Kafka 的过程。
本指南提供有关配置 Kafka 组件和使用 AMQ Streams Operator 的说明。步骤与您可能想要修改部署的方式相关,并引进其他功能,如 Cruise Control 或分布式追踪。
您可以使用 AMQ Streams 自定义资源 配置部署。自定义资源 API 引用 描述了您可以在配置中使用的属性。
您是否想要开始使用 AMQ Streams?有关逐步部署说明,请参阅 OpenShift 中的部署和升级 AMQ Streams 指南 。
1.1. Kafka 功能
Kafka 的底层数据流处理功能和组件架构可以提供:
- 微服务和其他应用以极高的吞吐量和低延迟共享数据
- 消息排序保证
- 从数据存储中重获/重播消息以重建应用程序状态
- 使用键值日志时删除旧记录的消息紧凑
- 集群配置中的水平可扩展性
- 数据复制来控制容错
- 保留大量数据以便立即访问
1.2. Kafka 用例
Kafka 的功能使其适合:
- 事件驱动的架构
- 事件源,以捕获对应用状态的更改作为事件日志
- 消息代理
- 网站活动跟踪
- 通过指标进行操作监控
- 日志收集和聚合
- 为分布式系统提交日志
- 流处理,以便应用程序能够实时响应数据
1.3. AMQ 流如何支持 Kafka
AMQ Streams 提供容器镜像和 Operator,以便在 OpenShift 上运行 Kafka。AMQ Streams Operator 是运行 AMQ Streams 的基础。AMQ Streams 提供的 Operator 是专门构建的,具有可有效管理 Kafka 的专业操作知识。
Operator 简化了以下流程:
- 部署和运行 Kafka 集群
- 部署和运行 Kafka 组件
- 配置对 Kafka 的访问
- 保护对 Kafka 的访问
- 升级 Kafka
- 管理代理
- 创建和管理主题
- 创建和管理用户
1.4. AMQ Streams Operator
AMQ Streams 支持使用 Operator 的 Kafka 来部署和管理 Kafka 到 OpenShift 的组件和依赖项。
Operator 是一种打包、部署和管理 OpenShift 应用的方法。AMQ Streams Operator 扩展 OpenShift 功能,自动执行与 Kafka 部署相关的常见复杂任务。通过在代码中了解 Kafka 操作,Kafka 管理任务可以简化,无需人工干预。
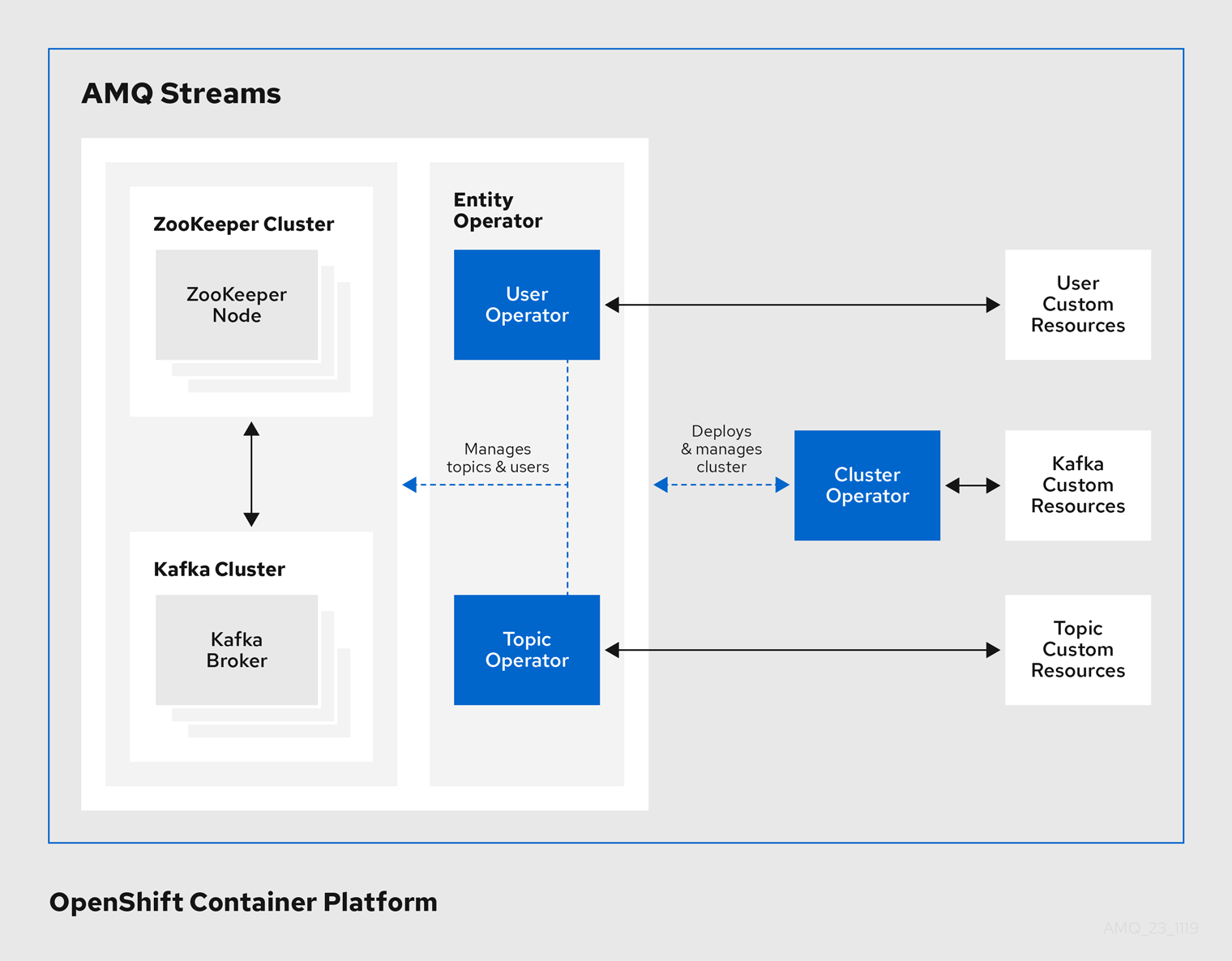
Operator
AMQ Streams 提供 Operator 来管理在 OpenShift 集群中运行的 Kafka 集群。
- Cluster Operator
- 部署和管理 Apache Kafka 集群、Kafka Connect、Kafka MirrorMaker、Kafka Bridge、Kafka Exporter 和 Entity Operator
- 实体 Operator
- 由主题 Operator 和 User Operator 组成
- 主题 Operator
- 管理 Kafka 主题
- User Operator
- 管理 Kafka 用户
Cluster Operator 可以与 Kafka 集群同时部署 Topic Operator 和 User Operator 作为 Entity Operator 配置的一部分。
AMQ Streams 架构中的 Operator
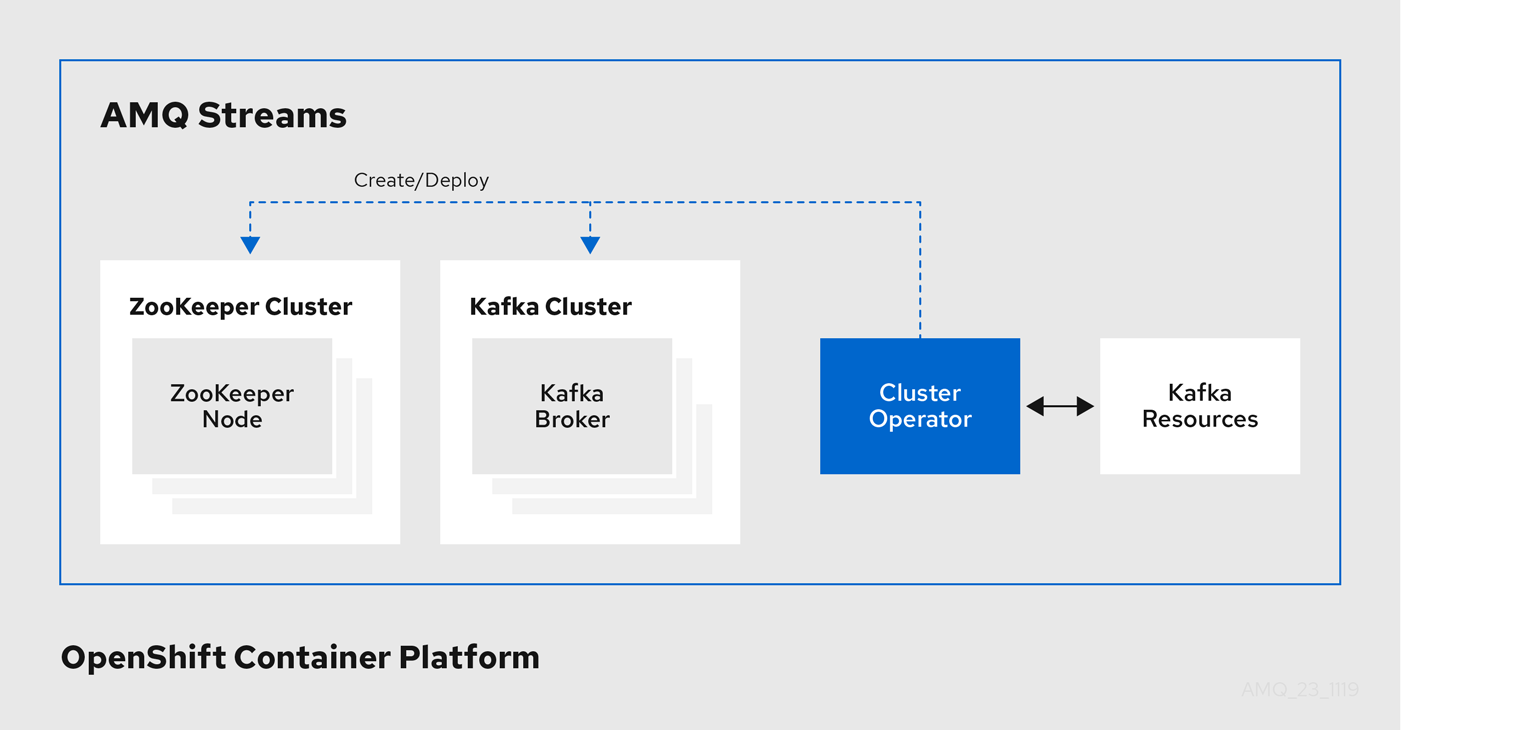
1.4.1. Cluster Operator
AMQ Streams 使用 Cluster Operator 来部署和管理集群:
- Kafka(包括 ZooKeeper、实体 Operator、Kafka Exporter 和 Cruise Control)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
自定义资源用于部署集群。
例如,部署 Kafka 集群:
-
在
OpenShift 集群中创建了带有集群配置的 Kafka资源。 -
Cluster Operator 根据 Kafka 资源中声明的内容部署对应的
Kafka集群。
Cluster Operator 也可以部署(通过配置 Kafka 资源):
-
通过
KafkaTopic自定义资源提供 operator 风格主题管理的主题 Operator -
一个 User Operator,通过
KafkaUser自定义资源提供 operator 风格的用户管理
部署的 Entity Operator 中的 Topic Operator 和 User Operator 功能。
Cluster Operator 的架构示例
1.4.2. 主题 Operator
Topic Operator 提供了通过 OpenShift 资源管理 Kafka 集群中主题的方法。
Topic Operator 的架构示例
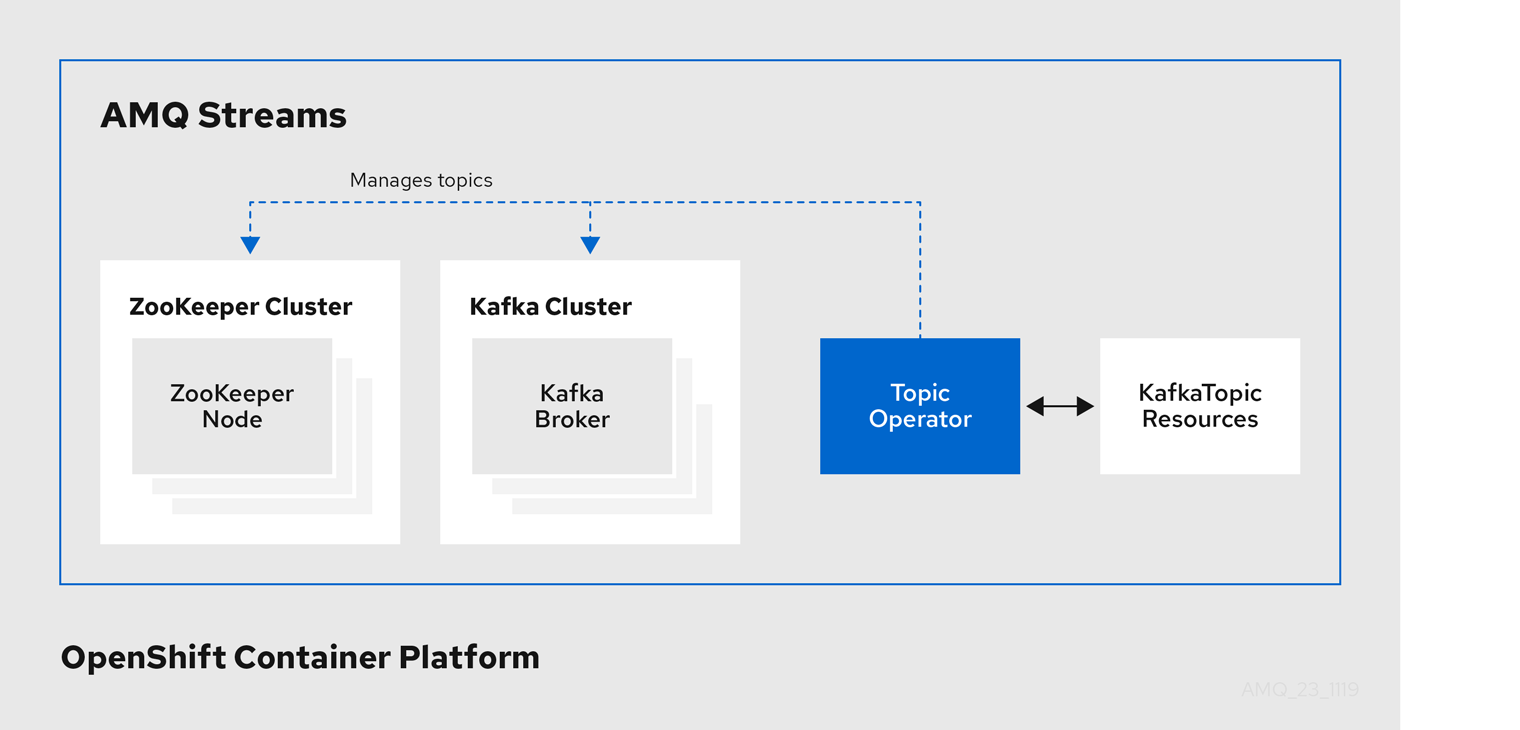
Topic Operator 的角色是保留一组 KafkaTopic OpenShift 资源,描述与对应的 Kafka 主题同步中的 Kafka 主题。
特别是,如果 KafkaTopic 是:
- 创建,主题 Operator 会创建该主题
- 删除的,主题 Operator 会删除该主题
- 更改,主题 Operator 更新该主题
在另一个方向上工作,如果一个主题是:
-
在 Kafka 集群中创建,Operator 会创建一个
KafkaTopic -
从 Kafka 集群中删除,Operator 会删除
KafkaTopic -
在 Kafka 集群中更改,Operator 会更新
KafkaTopic
这可让您声明 KafkaTopic 作为应用程序部署的一部分,Topic Operator 将为您创建该主题。您的应用程序只需要处理从所需主题中产生或使用的内容。
如果该主题被重新配置或重新分配给不同的 Kafka 节点,KafkaTopic 将始终保持最新状态。
1.4.3. User Operator
User Operator 通过监视 Kafka 用户描述 Kafka 用户并确保在 Kafka 集群中正确配置了这些用户来管理 Kafka 集群的 Kafka 用户。
例如,如果 KafkaUser 是:
- 创建,User Operator 创建它描述的用户
- 删除时,User Operator 会删除它所描述的用户
- 更改后,User Operator 会更新它所描述的用户
与主题 Operator 不同,User Operator 不会将 Kafka 集群的任何更改与 OpenShift 资源同步。Kafka 主题可以直接由 Kafka 中的应用程序创建,但用户不必与 User Operator 并行直接在 Kafka 集群中管理。
User Operator 允许您将 KafkaUser 资源声明为应用程序部署的一部分。您可以为用户指定身份验证和授权机制。您还可以配置 用户配额 来控制对 Kafka 资源的使用,例如,确保用户不会专利对代理的访问。
创建用户时,会在 Secret 中创建用户凭据。您的应用需要使用用户 及其凭据进行身份验证,并生成或使用消息。
除了管理用于身份验证的凭证外,User Operator 还通过在 KafkaUser 声明中包含用户访问权限描述来管理授权规则。
1.5. AMQ Streams 自定义资源
使用 AMQ Streams 将 Kafka 组件部署到 OpenShift 集群可通过应用自定义资源进行高度配置。自定义资源作为自定义资源定义(CRD)添加的 API 实例创建,以扩展 OpenShift 资源。
CRD 用作描述 OpenShift 集群中自定义资源的配置说明,并为部署中使用的每个 Kafka 组件以及用户和主题提供 AMQ Streams。CRD 和自定义资源定义为 YAML 文件。AMQ Streams 发行版提供了示例 YAML 文件。
CRD 还允许 AMQ Streams 资源受益于原生 OpenShift 功能,如 CLI 访问和配置验证。
1.5.1. AMQ Streams 自定义资源示例
CRD 需要在集群中进行一次性安装,以定义用于实例化和管理 AMQ Streams 特定资源的 schema。
通过安装 CRD 在集群中添加新的自定义资源类型后,您可以根据具体规格创建资源实例。
根据集群设置,安装通常需要集群管理员特权。
管理自定义资源的访问权限仅限于 AMQ Streams 管理员。如需更多信息,请参阅 OpenShift 上部署和升级 AMQ 流指南中的指定 AMQ 流 管理员。
CRD 在 OpenShift 集群中定义 一种 新型资源,如 kind:Kafka。
Kubernetes API 服务器允许基于 kind 创建自定义资源,并且从 CRD 中了解如何在添加到 OpenShift 集群时验证和存储自定义资源。
当 CRD 被删除时,该类型的自定义资源也会被删除。另外,自定义资源创建的资源也会被删除,如 pod 和 statefulsets。
每个 AMQ Streams 特定自定义资源都符合 CRD 为资源类型定义的 schema 。AMQ Streams 组件的自定义资源具有常见的配置属性,这些属性在 spec 下定义。
要了解 CRD 和自定义资源之间的关系,让我们看一下 Kafka 主题的 CRD 示例。
Kafka 主题 CRD
apiVersion: kafka.strimzi.io/v1beta1 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta1 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- 主题 CRD 的元数据、名称和标识 CRD 的标签。
- 2
- 此 CRD 的规格,包括组(域)名称、复数名称和支持的 schema 版本,用于 URL 以访问该主题的 API。其他名称用于标识 CLI 中的实例资源。例如,oc
get kafkatopic my-topic或oc get kafkatopics。 - 3
- 可以在 CLI 命令中使用短名称。例如,
oc get kt可用作缩写而不是oc get kafkatopic。 - 4
- 在自定义资源上使用
get命令时显示的信息。 - 5
- CRD 的当前状态,如资源的 schema 引用 中所述。
- 6
- OpenAPIV3Schema 验证提供了用于创建主题自定义资源的验证。例如,一个主题至少需要一个分区和一个副本。
您可以识别 AMQ Streams 安装文件提供的 CRD YAML 文件,因为文件名包含索引号后跟 'Crd'。
以下是 KafkaTopic 自定义资源的对应示例。
Kafka 主题自定义资源
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
自定义资源可以通过平台 CLI 应用到集群。创建自定义资源时,它将使用与 Kubernetes API 内置资源相同的验证。
创建 KafkaTopic 自定义资源后,Tpic Operator 将获得通知,并在 AMQ Streams 中创建对应的 Kafka 主题。
1.6. 监听程序配置
侦听器用于连接到 Kafka 代理。
AMQ Streams 提供了一个 generic GenericKafkaListener 模式,其中包含用于通过 Kafka 资源配置监听器的属性。
The GenericKafkaListener 提供了用于监听器配置的灵活方法。
您可以指定属性来配置 内部 侦听器,以便在 OpenShift 集群内连接,或者指定 外部 侦听器以连接 OpenShift 集群外部。
通用监听程序配置
每个监听程序都 定义为 Kafka 资源中的一个数组。
有关监听器配置的更多信息,请参阅 GenericKafkaListener 模式参考。
通用监听程序配置使用 KafkaListeners 模式参考替换了之前的监听程序配置方法,该参考 已被弃用。但是,您可以使用向后兼容将 旧格式转换为新格式。
KafkaListeners 模式将子属性用于 纯文本、tls 和外部 监听程序,以及每个节点的固定端口。由于架构架构固有的限制,只能配置三个监听器,配置选项仅限于监听器类型。
使用 GenericKafkaListener 模式时,您可以根据需要配置多个监听器,只要它们的名称和端口是唯一的。
您可能希望配置多个外部监听器,例如,以处理来自需要不同身份验证机制的网络的访问。或者,您可能需要将 OpenShift 网络加入外部网络。在这种情况下,您可以配置内部侦听器( 使用ServiceDnsDomain 属性),以便不使用 OpenShift 服务 DNS 域(通常为 .cluster.local)。
配置监听程序来保护对 Kafka 代理的访问
您可以使用身份验证为安全连接配置监听程序。有关保护对 Kafka 代理的访问的更多信息,请参阅管理对 Kafka 的访问。
为 OpenShift 外部的客户端访问配置外部侦听器
您可以使用指定的连接机制(如 loadbalancer),为 OpenShift 环境外的客户端访问配置外部侦听器。有关连接外部客户端的配置选项的更多信息,请参阅配置外部监听程序。
监听程序证书
您可以为启用了 TLS 加密的 TLS 监听程序或者外部监听程序提供自己的服务器证书,称为 Kafka 侦听程序证书。如需更多信息,请参阅 Kafka 侦听程序证书。
1.7. 文档约定
Replaceables
在本文档中,可替换的文本采用 单空间 格式,使用斜体、大写和连字符。
例如,在以下代码中,您要将 MY-NAMESPACE 替换为命名空间的名称:
sed -i 's/namespace: .*/namespace: MY-NAMESPACE/' install/cluster-operator/*RoleBinding*.yaml第 2 章 部署配置
本章论述了如何为支持的部署配置不同方面:
- Kafka 集群
- Kafka Connect 集群
- 支持 Source2Image 的 Kafka Connect 集群
- Kafka Mirror Maker
- Kafka Bridge
- 基于令牌的 OAuth 2.0 身份验证
- 基于令牌的 OAuth 2.0 授权
2.1. Kafka 集群配置
Kafka 资源的完整 schema 信息包括在 第 B.2 节 “Kafka 模式参考” 中。应用到所需 Kafka 资源的所有标签也将应用到组成 Kafka 集群的 OpenShift 资源。这提供了一种便捷的机制,可使资源根据需要进行标记。
2.1.1. Kafka YAML 配置示例
有关了解 Kafka 部署可用的配置选项的帮助,请参考此处提供的示例 YAML 文件。
示例只显示一些可能的选项,但尤为重要的配置选项包括:
- 资源请求(CPU / Memory)
- 用于最大和最小内存分配的 JVM 选项
- 侦听器(及身份验证)
- 认证
- 存储
- 机架感知
- 指标
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 3 1
version: 1.6 2
resources: 3
requests:
memory: 64Gi
cpu: "8"
limits: 4
memory: 64Gi
cpu: "12"
jvmOptions: 5
-Xms: 8192m
-Xmx: 8192m
listeners: 6
- name: plain 7
port: 9092 8
type: internal 9
tls: false 10
configuration:
useServiceDnsDomain: true 11
- name: tls
port: 9093
type: internal
tls: true
authentication: 12
type: tls
- name: external 13
port: 9094
type: route
tls: true
configuration:
brokerCertChainAndKey: 14
secretName: my-secret
certificate: my-certificate.crt
key: my-key.key
authorization: 15
type: simple
config: 16
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 17
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
storage: 18
type: persistent-claim 19
size: 10000Gi 20
rack: 21
topologyKey: topology.kubernetes.io/zone
metrics: 22
lowercaseOutputName: true
rules: 23
# Special cases and very specific rules
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
# ...
zookeeper: 24
replicas: 3
resources:
requests:
memory: 8Gi
cpu: "2"
limits:
memory: 8Gi
cpu: "2"
jvmOptions:
-Xms: 4096m
-Xmx: 4096m
storage:
type: persistent-claim
size: 1000Gi
metrics:
# ...
entityOperator: 25
topicOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
userOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
kafkaExporter: 26
# ...
cruiseControl: 27
# ...- 1
- replicas 指定代理节点的数量。
- 2
- Kafka 版本,可按照 升级过程 更改。
- 3
- 资源请求 指定要为给定容器保留的资源。
- 4
- 资源限值指定容器可以消耗的最大资源。
- 5
- JVM 选项可以为 JVM 指定最小(
-Xms)和最大内存分配(-Xmx)。 - 6
- 侦听器配置客户端如何通过 bootstrap 地址连接到 Kafka 集群。侦听器 配置为内部或外部 侦听器,用于 OpenShift 集群 内部和外部 的连接。
- 7
- 用于标识侦听器的名称。在 Kafka 集群中必须是唯一的。
- 8
- Kafka 内侦听器使用的端口号。在给定 Kafka 集群中,端口号必须是唯一的。允许的端口号是 9092 及以上,但端口 9404 和 9999 除外,它们已用于 Prometheus 和 JMX。根据监听程序类型,端口号可能与连接 Kafka 客户端的端口号不同。
- 9
- 侦听器类型指定为
内部,或用于外部监听器,作为路由、负载均衡器、节点端口或入口。 - 10
- 为每个侦听器启用 TLS 加密。默认为
false。路由监听程序不需要 TLS 加密。 - 11
- 定义是否分配了包括集群服务后缀(通常.
cluster.local)在内的完全限定 DNS 名称。 - 12
- 13
- 14
- 由外部 证书颁发机构管理的 Kafka 侦听器 证书的可选配置。
brokerCertChainAndKey属性指定包含服务器证书和私钥的Secret。也可以为 TLS 侦听程序配置 Kafka 侦听程序证书。 - 15
- 授权在 Kafka 代理上启用简单、OAUTH 2.0 或 OPA 授权。简单授权使用
AclAuthorizerKafka 插件。 - 16
- config 指定代理配置。标准 Apache Kafka 配置可能会提供,仅限于不是由 AMQ Streams 直接管理的属性。
- 17
- 18
- 19
- 20
- 21
- 将机架感知配置为在 不同机架之间分布副本。
拓扑键必须与集群节点标签匹配。 - 22
- 23
- 通过 JMX Exporter 将指标导出到 Grafana 仪表板的 Kafka 规则。可在您的 Kafka 资源配置中复制由 AMQ Streams 提供的一组规则。
- 24
- zookeeper 特定的配置,其中包含与 Kafka 配置类似的属性。
- 25
- 实体 Operator 配置,用于指定 Topic Operator 和 User Operator 的配置。
- 26
- Kafka Exporter 配置,用于将数据公开为 Prometheus 指标数据。
- 27
- 精简控制配置 ,用于重新平衡 Kafka 集群。
2.1.2. 数据存储注意事项
高效的数据存储基础架构对于 AMQ 流的最佳性能至关重要。
块存储是必需的。文件存储(如 NFS)无法使用 Kafka。
对于块存储,您可以选择:
- 基于云的块存储解决方案,如 Amazon Elastic Block Store(EBS)
- 本地持久性卷
- 通过 光纤通道 或 iSCSI等协议访问的存储区域网络(SAN)卷
AMQ Streams 不需要 OpenShift 原始块卷。
2.1.2.1. 文件系统
建议您将存储系统配置为使用 XFS 文件系统。AMQ Streams 还与 ext4 文件系统兼容,但为了获得最佳结果,可能需要额外的配置。
2.1.2.2. Apache Kafka 和 ZooKeeper 存储
Apache Kafka 和 ZooKeeper 使用单独的磁盘。
支持三种类型的数据存储:
- 临时(仅适用于开发的建议)
- persistent
- JBOD(只是一个磁盘绑定,仅适用于 Kafka)
如需更多信息,请参阅 Kafka 和 ZooKeeper 存储。
在异步发送和从多个主题接收数据的大型集群中,固态驱动器(SSD)(虽然不必要)可以提高 Kafka 的性能。SSD 在 ZooKeeper 中特别有效,它需要快速、低延迟的数据访问。
您不需要置备复制存储,因为 Kafka 和 ZooKeeper 都内置了数据复制。
2.1.3. Kafka 和 ZooKeeper 存储类型
作为有状态应用程序,Kafka 和 ZooKeeper 需要将数据存储在磁盘上。AMQ Streams 支持用于此数据的三种存储类型:
- ephemeral
- persistent
- JBOD 存储
JBOD 存储只支持 Kafka,不适用于 ZooKeeper。
在配置 Kafka 资源时,您可以指定 Kafka 代理使用的存储类型及其对应的 ZooKeeper 节点。您可以使用以下资源中的 storage 属性配置存储类型:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper
存储类型在 type 字段中配置。
部署 Kafka 集群后,无法更改存储类型。
其他资源
- 如需有关临时存储的更多信息,请参阅 临时存储模式参考。
- 有关持久性存储的更多信息,请参阅 持久性存储架构参考。
- 有关 JBOD 存储的更多信息,请参阅 JBOD 模式参考。
-
有关
Kafka模式的更多信息,请参阅Kafka模式参考。
2.1.3.1. 临时存储
临时存储使用 emptyDir 卷来存储数据。若要使用临时存储,type 字段应设置为 ephemeral。
emptyDir 卷不是持久性的,存储在其中的数据会在 Pod 重启时丢失。新 pod 启动后,它必须从集群的其他节点恢复所有数据。临时存储不适用于单一节点 ZooKeeper 集群,而对于带有复制因数 1 的 Kafka 主题,这会导致数据丢失。
临时存储示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
storage:
type: ephemeral
# ...
zookeeper:
# ...
storage:
type: ephemeral
# ...
2.1.3.1.1. 日志目录
Kafka 代理将使用临时卷作为挂载到以下路径的日志目录:
/var/lib/kafka/data/kafka-log_idx_-
其中
idx是 Kafka 代理 pod 索引。例如/var/lib/kafka/data/kafka-log0。
2.1.3.2. 持久性存储
永久存储使用持久卷声明 来调配用于存储数据的持久卷。持久卷声明可用于调配许多不同类型的卷,具体取决于要调配卷的 存储类。可以与持久卷声明一起使用的数据类型包括许多类型的 SAN 存储 和本地持久卷。
若要使用持久存储,必须将 type 设置为 persistent-claim。持久性存储支持额外的配置选项:
id(可选)-
存储标识号.对于 JBOD 存储声明中定义的存储卷,此选项是必需的。默认值为
0。 大小(必需)- 定义持久卷声明的大小,如 "1000Gi"。
class(可选)- 用于动态卷置备的 OpenShift 存储类。
selector(可选)- 允许选择要使用的特定持久性卷。它包含键:值对,代表用于选择此类卷的标签。
deleteClaim(optional)-
指定在取消部署集群时是否需要删除持久卷声明的布尔值。默认为
false。
仅支持重新定义持久性卷大小的 OpenShift 版本支持在现有 AMQ Streams 集群中增加持久性卷的大小。要调整持久性卷的大小必须使用支持卷扩展的存储类。对于不支持卷扩展的其他 OpenShift 版本和存储类,您必须在部署集群前决定必要的存储大小。无法减少现有持久性卷的大小。
使用 1000Gi 大小的持久性存储配置片段示例
# ... storage: type: persistent-claim size: 1000Gi # ...
以下示例演示了存储类的使用。
使用特定存储类的持久性存储配置片段示例
# ... storage: type: persistent-claim size: 1Gi class: my-storage-class # ...
最后,可以利用 选择器 来选择特定的标记持久卷,以提供 SSD 等必要功能。
使用选择器的持久性存储配置片段示例
# ...
storage:
type: persistent-claim
size: 1Gi
selector:
hdd-type: ssd
deleteClaim: true
# ...
2.1.3.2.1. 存储类覆盖
您可以为一个或多个 Kafka 代理或 ZooKeeper 节点指定不同的存储类,而不是使用默认存储类。例如,当存储类仅限于不同的可用区或数据中心时,这很有用。您可以使用 overrides 字段来实现这一目的。
在本例中,默认存储类名为 my-storage-class :
使用存储类覆盖的 AMQ Streams 集群示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
labels:
app: my-cluster
name: my-cluster
namespace: myproject
spec:
# ...
kafka:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
zookeeper:
replicas: 3
storage:
deleteClaim: true
size: 100Gi
type: persistent-claim
class: my-storage-class
overrides:
- broker: 0
class: my-storage-class-zone-1a
- broker: 1
class: my-storage-class-zone-1b
- broker: 2
class: my-storage-class-zone-1c
# ...
配置的 overrides 属性后,卷使用以下存储类:
-
ZooKeeper 节点 0 的持久卷将使用
my-storage-class-zone-1a。 -
ZooKeeper 节点 1 的持久卷将使用
my-storage-class-zone-1b。 -
ZooKeeepr 节点 2 的持久卷将使用
my-storage-class-zone-1c。 -
Kafka 代理 0 的持久性卷将使用
my-storage-class-zone-1a。 -
Kafka 代理 1 的持久性卷将使用
my-storage-class-zone-1b。 -
Kafka 代理 2 的持久性卷将使用
my-storage-class-zone-1c。
overrides 属性目前只用于覆盖存储类配置。目前不支持覆盖其他存储配置字段。目前不支持存储配置中的其他字段。
2.1.3.2.2. 持久性卷声明命名
使用持久性存储时,它会使用以下名称创建持久性卷声明:
data-cluster-name-kafka-idx-
用于存储 Kafka 代理 pod
IDx数据的卷的持久性卷声明。 data-cluster-name-zookeeper-idx-
用于为 ZooKeeper 节点 pod
idx存储数据的卷的持久性卷声明。
2.1.3.2.3. 日志目录
Kafka 代理将使用持久性卷作为挂载到以下路径的日志目录:
/var/lib/kafka/data/kafka-log_idx_-
其中
idx是 Kafka 代理 pod 索引。例如/var/lib/kafka/data/kafka-log0。
2.1.3.3. 重新定义持久性卷大小
您可以通过增大现有 AMQ Streams 集群使用的持久性卷的大小来置备存储容量。在使用一个持久性卷或在 JBOD 存储配置中使用多个持久性卷的集群中,支持重新定义持久性卷大小。
您可以增大但不能缩小持久性卷的大小。OpenShift 目前不支持缩小持久卷的大小。
先决条件
- 个 OpenShift 集群,其支持卷大小调整。
- Cluster Operator 正在运行。
- 使用使用支持卷扩展的存储类创建的持久性卷的 Kafka 集群。
步骤
在
Kafka资源中,增大分配给 Kafka 集群和 ZooKeeper 集群的持久性卷的大小。-
要增大分配给 Kafka 集群的卷大小,编辑
spec.kafka.storage属性。 要增大分配给 ZooKeeper 集群的卷大小,请编辑
spec.zookeeper.storage属性。例如,将卷大小从
1000Gi增加到2000Gi:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: persistent-claim size: 2000Gi class: my-storage-class # ... zookeeper: # ...
-
要增大分配给 Kafka 集群的卷大小,编辑
创建或更新资源。
使用
oc apply:oc apply -f your-fileOpenShift 会响应来自 Cluster Operator 的请求,增加了所选持久性卷的容量。完成大小调整后,Cluster Operator 会重启所有使用调整大小持久性卷的 pod。这会自动发生。
其他资源
有关在 OpenShift 中调整持久性卷大小的更多信息,请参阅使用 Kubernetes 重新定义持久性卷 大小。
2.1.3.4. JBOD 存储概述
您可以将 AMQ Streams 配置为使用 JBOD,这是多个磁盘或卷的数据存储配置。JBOD 是为 Kafka 代理提供更多数据存储的一种方法。它还能提高性能。
一个或多个卷描述了 JBOD 配置,每个卷可以 临时 或永久 。JBOD 卷声明的规则和限制与临时和永久存储的规则和限制相同。例如,您无法在置备后更改持久性存储卷的大小。
2.1.3.4.1. JBOD 配置
若要将 JBOD 与 AMQ Streams 搭配使用,存储 类型 必须设置为 jbod。借助 volumes 属性,您可以描述组成 JBOD 存储阵列或配置的磁盘。以下片段显示了 JBOD 配置示例:
# ...
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
- id: 1
type: persistent-claim
size: 100Gi
deleteClaim: false
# ...创建 JBOD 卷后,无法更改 id。
用户可以从 JBOD 配置中添加或删除卷。
2.1.3.4.2. JBOD 和持久性卷声明
当使用持久性存储声明 JBOD 卷时,生成的持久性卷声明的命名方案如下:
data-id-cluster-name-kafka-idx-
其中
id是用于存储 Kafka 代理 podidx数据的卷 ID。
2.1.3.4.3. 日志目录
Kafka 代理将使用 JBOD 卷作为挂载到以下路径的日志目录:
/var/lib/kafka/data-id/kafka-log_idx_-
其中
id是用于存储 Kafka 代理 podidx数据的卷 ID。例如/var/lib/kafka/data-0/kafka-log0。
2.1.3.5. 将卷添加到 JBOD 存储
这个步骤描述了如何在配置为使用 JBOD 存储的 Kafka 集群中添加卷。它不能应用到配置为使用任何其他存储类型的 Kafka 集群。
在已经使用并被删除的 id 下添加新卷时,您必须确保之前使用的 PersistentVolumeClaims 已被删除。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
- 带有 JBOD 存储的 Kafka 集群
步骤
编辑
Kafka资源中的spec.kafka.storage.volumes属性。将新卷添加到 volumes数组。例如,添加 ID 为2的新卷:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false - id: 1 type: persistent-claim size: 100Gi deleteClaim: false - id: 2 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f KAFKA-CONFIG-FILE- 创建新主题或将现有分区重新分配至新磁盘.
其他资源
有关重新分配主题的详情请参考 第 2.1.24.2 节 “分区重新分配”。
2.1.3.6. 从 JBOD 存储中删除卷
这个步骤描述了如何从配置为使用 JBOD 存储的 Kafka 集群中删除卷。它不能应用到配置为使用任何其他存储类型的 Kafka 集群。JBOD 存储始终必须至少包含一个卷。
为避免数据丢失,您必须先移动所有分区,然后再删除卷。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
- 带有两个或多个卷的 JBOD 存储的 Kafka 集群
步骤
- 从要删除的磁盘中重新分配所有分区。分区中仍然分配到将要删除的磁盘中的任何数据都可能会丢失。
编辑
Kafka资源中的spec.kafka.storage.volumes属性。从 volumes 阵列中删除一个或多个卷。例如,删除 ID 为1和2的卷:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... storage: type: jbod volumes: - id: 0 type: persistent-claim size: 100Gi deleteClaim: false # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
其他资源
有关重新分配主题的详情请参考 第 2.1.24.2 节 “分区重新分配”。
2.1.4. Kafka 代理副本
Kafka 集群可以使用多个代理运行。您可以在 Kafka. spec.kafka.replicas 中配置用于 Kafka 集群的代理数量。集群的最佳代理数量需要根据您的具体用例来确定。
2.1.4.1. 配置代理节点的数量
这个步骤描述了如何在新集群中配置 Kafka 代理节点的数量。它只适用于没有分区的新集群。如果您的集群已经定义了主题,请参阅 第 2.1.24 节 “扩展集群”。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
- 尚未定义主题的 Kafka 集群
步骤
编辑
Kafka资源中的replicas属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... replicas: 3 # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
其他资源
如果您的集群已经定义了主题,请参阅 第 2.1.24 节 “扩展集群”。
2.1.5. Kafka 代理配置
AMQ Streams 允许您自定义 Kafka 集群中 Kafka 代理的配置。您可以指定和配置 Apache Kafka 文档 的"Broker Configs"部分中列出的大多数选项。您无法配置与以下区域相关的选项:
- 安全(加密、身份验证和授权)
- 监听程序配置
- 代理 ID 配置
- 日志数据目录的配置
- Broker 间通信
- zookeeper 连接
这些选项由 AMQ Streams 自动配置。
有关代理配置的更多信息,请参阅 KafkaClusterSpec 模式。
监听程序配置
您可以配置监听程序以连接到 Kafka 代理。有关配置监听程序的更多信息,请参阅 Listener 配置
授权对 Kafka 的访问
您可以将 Kafka 集群配置为允许或拒绝用户执行的操作。有关保护对 Kafka 代理的访问的更多信息,请参阅管理对 Kafka 的访问。
2.1.5.1. 配置 Kafka 代理
您可以配置现有的 Kafka 代理,或使用指定配置创建新 Kafka 代理。
先决条件
- OpenShift 集群可用。
- Cluster Operator 正在运行。
步骤
-
打开包含指定集群部署的
Kafka资源的 YAML 配置文件。 在
Kafka资源中的spec.kafka.config属性中,输入一个或多个 Kafka 配置设置。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... config: default.replication.factor: 3 offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 1 # ... zookeeper: # ...应用新配置以创建或更新资源。
使用
oc apply:oc apply -f kafka.yaml其中
kafka.yaml是您要配置的资源的 YAML 配置文件,例如kafka-persistent.yaml。
2.1.6. 监听程序配置
侦听器用于连接到 Kafka 代理。
AMQ Streams 提供了一个 generic GenericKafkaListener 模式,其中包含用于通过 Kafka 资源配置监听器的属性。
The GenericKafkaListener 提供了用于监听器配置的灵活方法。
您可以指定属性来配置 内部 侦听器,以便在 OpenShift 集群内连接,或者指定 外部 侦听器以连接 OpenShift 集群外部。
通用监听程序配置
每个监听程序都 定义为 Kafka 资源中的一个数组。
有关监听器配置的更多信息,请参阅 GenericKafkaListener 模式参考。
通用监听程序配置使用 KafkaListeners 模式参考替换了之前的监听程序配置方法,该参考 已被弃用。但是,您可以使用向后兼容将 旧格式转换为新格式。
KafkaListeners 模式将子属性用于 纯文本、tls 和外部 监听程序,以及每个节点的固定端口。由于架构架构固有的限制,只能配置三个监听器,配置选项仅限于监听器类型。
使用 GenericKafkaListener 模式时,您可以根据需要配置多个监听器,只要它们的名称和端口是唯一的。
您可能希望配置多个外部监听器,例如,以处理来自需要不同身份验证机制的网络的访问。或者,您可能需要将 OpenShift 网络加入外部网络。在这种情况下,您可以配置内部侦听器( 使用ServiceDnsDomain 属性),以便不使用 OpenShift 服务 DNS 域(通常为 .cluster.local)。
配置监听程序来保护对 Kafka 代理的访问
您可以使用身份验证为安全连接配置监听程序。有关保护对 Kafka 代理的访问的更多信息,请参阅管理对 Kafka 的访问。
为 OpenShift 外部的客户端访问配置外部侦听器
您可以使用指定的连接机制(如 loadbalancer),为 OpenShift 环境外的客户端访问配置外部侦听器。有关连接外部客户端的配置选项的更多信息,请参阅配置外部监听程序。
监听程序证书
您可以为启用了 TLS 加密的 TLS 监听程序或者外部监听程序提供自己的服务器证书,称为 Kafka 侦听程序证书。如需更多信息,请参阅 Kafka 侦听程序证书。
2.1.7. zookeeper 副本
zookeeper 集群或ensemble 通常使用奇数的节点(通常为三个、五个或 7 个)运行。
大多数节点必须可用,才能保持有效的仲裁。如果 ZooKeeper 集群丢失其仲裁,它将停止响应客户端,Kafka 代理将停止工作。拥有稳定且高度可用的 ZooKeeper 集群对于 AMQ 流至关重要。
- 三节点集群
- 为了保持仲裁,三节点 ZooKeeper 群集至少需要启动并运行两个节点。它只能容忍一个节点不可用。
- 五节点集群
- 为了保持仲裁,五节点 ZooKeeper 群集至少需要启动并运行三个节点。它可能会容忍两个节点不可用。
- 七节点集群
- 为了保持仲裁,七节点 ZooKeeper 群集至少需要启动并运行四个节点。它可能会容忍三个节点不可用。
出于开发目的,也可以使用单一节点运行 ZooKeeper。
拥有更多节点不一定意味着更好的性能,因为随着集群中节点的数量增加,保持仲裁的成本将会增加。根据可用性要求,您可以决定要使用的节点数量。
2.1.7.1. ZooKeeper 节点数量
可以使用 Kafka.spec.zookeeper 中的 replicas 属性来配置 ZooKeeper 节点的数量。
显示副本配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
replicas: 3
# ...
2.1.7.2. 更改 ZooKeeper 副本数量
先决条件
- OpenShift 集群可用。
- Cluster Operator 正在运行。
步骤
-
打开包含指定集群部署的
Kafka资源的 YAML 配置文件。 在
Kafka资源中的spec.zookeeper.replicas属性中,输入复制的 ZooKeeper 服务器数量。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... replicas: 3 # ...应用新配置以创建或更新资源。
使用
oc apply:oc apply -f kafka.yaml其中
kafka.yaml是您要配置的资源的 YAML 配置文件,例如kafka-persistent.yaml。
2.1.8. zookeeper 配置
AMQ Streams 允许您自定义 Apache ZooKeeper 节点的配置。您可以指定和配置 ZooKeeper 文档 中列出的大多数选项。
无法配置的选项与以下区域相关:
- 安全(加密、身份验证和授权)
- 监听程序配置
- 数据目录的配置
- zookeeper 集群组成
这些选项由 AMQ Streams 自动配置。
2.1.8.1. zookeeper 配置
zookeeper 节点使用 Kafka.spec.zookeeper 中的 config 属性进行配置。此属性包含 ZooKeeper 配置选项作为键。这些值可使用以下 JSON 类型之一描述:
- 字符串
- 数字
- 布尔值
除了那些直接由 AMQ Streams 管理的选项外,用户可以指定和配置 ZooKeeper 文档 中列出的选项。具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
服务器. -
dataDir -
dataLogDir -
clientPort -
authProvider -
quorum.auth -
requireClientAuthScheme
当 config 属性中存在一个禁止选项时,它将被忽略,并会在 Cluster Operator 日志文件中输出警告信息。所有其他选项都传递到 ZooKeeper。
Cluster Operator 不会验证提供的 config 对象中的密钥或值。当提供无效的配置时,ZooKeeper 集群可能不会启动,或者可能会变得不稳定。在这种情况下,Kafka.spec.zookeeper.config 对象中的配置应该被修复,Cluster Operator 会将新配置部署到所有 ZooKeeper 节点。
所选选项有默认值:
-
timeTick,默认值为2000 -
默认值为
5的initLimit -
带有
默认值限制2的同步 -
autopurge.purgeInterval,默认值为1
当 Kafka.spec.zookeeper.config 属性中没有这些选项时,会自动配置这些选项。
使用三个允许的 ssl 配置选项,将特定的 密码套件 用于 TLS 版本。密码套件组合了用于安全连接和数据传输的算法。
ZooKeeper 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
# ...
zookeeper:
# ...
config:
autopurge.snapRetainCount: 3
autopurge.purgeInterval: 1
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 1
ssl.enabled.protocols: "TLSv1.2" 2
ssl.protocol: "TLSv1.2" 3
# ...
2.1.8.2. 配置 ZooKeeper
先决条件
- OpenShift 集群可用。
- Cluster Operator 正在运行。
步骤
-
打开包含指定集群部署的
Kafka资源的 YAML 配置文件。 在
Kafka资源中的spec.zookeeper.config属性中,输入一个或多个 ZooKeeper 配置设置。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... zookeeper: # ... config: autopurge.snapRetainCount: 3 autopurge.purgeInterval: 1 # ...应用新配置以创建或更新资源。
使用
oc apply:oc apply -f kafka.yaml其中
kafka.yaml是您要配置的资源的 YAML 配置文件,例如kafka-persistent.yaml。
2.1.9. zookeeper 连接
zookeeper 服务通过加密和身份验证进行保护,它们不应该由不属于 AMQ Streams 的外部应用程序使用。
但是,如果要使用需要连接到 ZooKeeper 的 Kafka CLI 工具,您可以使用 ZooKeeper 容器中的终端,并连接 localhost:12181 作为 ZooKeeper 地址。
2.1.9.1. 从终端连接到 ZooKeeper
大多数 Kafka CLI 工具可以直接连接到 Kafka。因此,在正常情况下,您应不需要连接到 ZooKeeper。如果需要,您可以按照以下步骤操作。在 ZooKeeper 容器内打开终端,以使用 Kafka CLI 工具需要 ZooKeeper 连接。
先决条件
- OpenShift 集群可用。
- Kafka 集群正在运行。
- Cluster Operator 正在运行。
步骤
使用 OpenShift 控制台打开终端,或者从 CLI 运行
exec命令。例如:
oc exec -it my-cluster-zookeeper-0 -- bin/kafka-topics.sh --list --zookeeper localhost:12181务必使用
localhost:12181。现在,您可以向 ZooKeeper 运行 Kafka 命令。
2.1.10. 实体 Operator
Entity Operator 负责管理正在运行的 Kafka 集群中与 Kafka 相关的实体。
Entity Operator 包括:
- 用于管理 Kafka 主题的主题 Operator
- 管理 Kafka 用户的用户 Operator
通过 Kafka 资源配置,Cluster Operator 可在部署 Kafka 集群时部署 Entity Operator,包括一个或多个操作器。
部署后,实体 Operator 根据部署配置包含操作器。
Operator 会自动配置为管理 Kafka 集群的主题和用户。
2.1.10.1. 实体 Operator 配置属性
使用 Kafka.spec 中的 principal Operator 属性来配置 Entity Operator。
entity Operator 属性支持以下几个子属性:
-
tlsSidecar -
topicOperator -
userOperator -
模板
tlsSidecar 属性包含 TLS sidecar 容器的配置,用于与 ZooKeeper 通信。有关配置 TLS sidecar 的详情请参考 第 2.1.19 节 “TLS sidecar”。
template 属性包含 Entity Operator pod 的配置,如标签、注解、关联性和容限。有关配置模板的详情请参考 第 2.6 节 “自定义 OpenShift 资源”。
topicOperator 属性包含 Topic Operator 的配置。当缺少这个选项时,Entity Operator 会在没有 Topic Operator 的情况下部署。
userOperator 属性包含 User Operator 的配置。当缺少这个选项时,Entity Operator 会在没有 User Operator 的情况下部署。
有关配置 Entity Operator 的属性的更多信息,请参阅 EntityUserOperatorSpec schema 参考。
启用两个运算符的基本配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
如果将空对象({})用于 topicOperator 和 ,则所有属性都使用其默认值。
userOperator
当缺少 topicOperator 和 userOperator 属性时,Entity Operator 不会被部署。
2.1.10.2. 主题 Operator 配置属性
可以使用 topicOperator 对象中的附加选项来配置主题 Operator 部署。支持以下属性:
watchedNamespace-
主题操作器监视
KafkaTopics的 OpenShift 命名空间。默认为部署 Kafka 集群的命名空间。 reconciliationIntervalSeconds-
定期协调之间的间隔(以秒为单位)。
默认90. zookeeperSessionTimeoutSeconds-
ZooKeeper 会话超时,以秒为单位。默认
20。 topicMetadataMaxAttempts-
从 Kafka 获取主题元数据的尝试数量。每次尝试之间的时间都定义为指数回退。考虑在因为分区或副本数量而创建主题需要更多时间时增加这个值。
默认6. 镜像-
image属性可用于配置要使用的容器镜像。有关配置自定义容器镜像的详情,请参考 第 2.1.18 节 “容器镜像”。 资源-
resources属性配置分配给 Topic Operator 的资源数量。有关资源请求和限制配置的详情,请参阅 第 2.1.11 节 “CPU 和内存资源”。 logging-
logging属性配置 Topic Operator 的日志。如需了解更多详细信息,请参阅 第 2.1.10.4 节 “Operator 日志记录器”。
Topic Operator 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
# ...
2.1.10.3. 用户 Operator 配置属性
用户 Operator 部署可以使用 userOperator 对象中的附加选项进行配置。支持以下属性:
watchedNamespace-
用户操作员在其中监视
KafkaUsers的 OpenShift 命名空间。默认为部署 Kafka 集群的命名空间。 reconciliationIntervalSeconds-
定期协调之间的间隔(以秒为单位)。
默认值120. zookeeperSessionTimeoutSeconds-
ZooKeeper 会话超时,以秒为单位。
默认6. 镜像-
image属性可用于配置要使用的容器镜像。有关配置自定义容器镜像的详情,请参考 第 2.1.18 节 “容器镜像”。 资源-
resources属性配置分配给 User Operator 的资源数量。有关资源请求和限制配置的详情,请参阅 第 2.1.11 节 “CPU 和内存资源”。 logging-
logging属性配置 User Operator 的日志记录。如需了解更多详细信息,请参阅 第 2.1.10.4 节 “Operator 日志记录器”。
User Operator 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
userOperator:
watchedNamespace: my-user-namespace
reconciliationIntervalSeconds: 60
# ...
2.1.10.4. Operator 日志记录器
Topic Operator 和 User Operator 具有可配置的日志记录器:
-
rootLogger.level
操作器使用 Apache log4j2 日志记录器实施。
使用 Kafka 资源中的 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j2.properties 进行 描述。
此处我们会看到 内联 和外部 记录示例。
内联日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
logging:
type: inline
loggers:
rootLogger.level: INFO
# ...
userOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
logging:
type: inline
loggers:
rootLogger.level: INFO
# ...
外部日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
# ...
topicOperator:
watchedNamespace: my-topic-namespace
reconciliationIntervalSeconds: 60
logging:
type: external
name: customConfigMap
# ...
其他资源
- 垃圾收集器(GC)日志记录也可以启用(或禁用)。有关 GC 日志的更多信息,请参阅 第 2.1.17.1 节 “JVM 配置”
- 有关日志级别的更多信息,请参阅 Apache 日志记录服务。
2.1.10.5. 配置实体 Operator
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源中的 principalOperator属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... entityOperator: topicOperator: watchedNamespace: my-topic-namespace reconciliationIntervalSeconds: 60 userOperator: watchedNamespace: my-user-namespace reconciliationIntervalSeconds: 60创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.11. CPU 和内存资源
对于每个部署的容器,AMQ Streams 允许您请求特定资源并定义这些资源的最大消耗。
AMQ Streams 支持两种类型的资源:
- CPU
- 内存
AMQ Streams 使用 OpenShift 语法来指定 CPU 和内存资源。
2.1.11.1. 资源限值和请求
资源限值和请求使用以下 资源中的 resources 属性进行配置:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.kafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaBridge.spec
其他资源
- 有关在 OpenShift 中管理计算资源的更多信息,请参阅为容器管理计算资源。
2.1.11.1.1. 资源请求
请求指定要为给定容器保留的资源。保留资源可确保资源始终可用。
如果资源请求针对的是 OpenShift 集群中可用的可用资源,则不会调度该容器集。
资源请求在 requests 属性中指定。AMQ Streams 当前支持的资源请求:
-
cpu -
memory
可以为一个或多个支持的资源配置请求。
使用所有资源的资源请求配置示例
# ...
resources:
requests:
cpu: 12
memory: 64Gi
# ...
2.1.11.1.2. 资源限值
limits 指定给定容器可以消耗的最大资源。限制不是保留的,可能并不总是可用。容器只能在资源可用时才使用资源限制。资源限制应始终大于资源请求。
资源限值在 limits 属性中指定。AMQ Streams 当前支持的资源限制:
-
cpu -
memory
资源可以被配置为一个或多个支持的限制。
资源限制配置示例
# ...
resources:
limits:
cpu: 12
memory: 64Gi
# ...
2.1.11.1.3. 支持的 CPU 格式
支持 CPU 请求和限制,其格式如下:
-
CPU 内核数作为整数(
5个 CPU 内核)或十进制(2.5个 CPU 内核)。 -
数字或 millicpus / millicores(
100m),其中 1000 millicores 相同1 个CPU 内核。
CPU 单元示例
# ...
resources:
requests:
cpu: 500m
limits:
cpu: 2.5
# ...
1 个 CPU 核心的计算能力可能因部署 OpenShift 的平台而异。
其他资源
- 有关 CPU 规格的更多信息,请参阅 CPU 含义。
2.1.11.1.4. 支持的内存格式
内存请求和限值以兆字节、千兆字节、兆字节和千兆字节为单位指定。
-
要指定内存(以 MB 为单位),请使用
M后缀。例如1000M。 -
要指定以 GB 为单位的内存,请使用
G后缀。例如1G: -
要以兆字节为单位指定内存,请使用
Mi后缀。例如1000Mi。 -
要以千兆字节为单位指定内存,请使用
Gi后缀。例如1Gi。
使用不同内存单元的示例
# ...
resources:
requests:
memory: 512Mi
limits:
memory: 2Gi
# ...
其他资源
- 有关内存规格和其他支持单元的详情,请参阅 内存含义。
2.1.11.2. 配置资源请求和限值
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑指定集群部署的资源中的
resources属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... resources: requests: cpu: "8" memory: 64Gi limits: cpu: "12" memory: 128Gi # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
其他资源
- 如需有关该架构的更多信息,请参阅 资源要求 API 参考。
2.1.12. Kafka 日志记录器
Kafka 拥有自己的可配置日志记录器:
-
log4j.logger.org.I0Itec.zkclient.ZkClient -
log4j.logger.org.apache.zookeeper -
log4j.logger.kafka -
log4j.logger.org.apache.kafka -
log4j.logger.kafka.request.logger -
log4j.logger.kafka.network.Processor -
log4j.logger.kafka.server.KafkaApis -
log4j.logger.kafka.network.RequestChannel$ -
log4j.logger.kafka.controller -
log4j.logger.kafka.log.LogCleaner -
log4j.logger.state.change.logger -
log4j.logger.kafka.authorizer.logger
zookeeper 还具有可配置的日志记录器:
-
zookeeper.root.logger
Kafka 和 ZooKeeper 使用 Apache log4j 日志记录器实现。
操作员使用 Apache log4j2 日志记录器实现,因此日志记录配置在 ConfigMap 中使用 log4j2.properties 进行 描述。如需更多信息,请参阅 第 2.1.10.4 节 “Operator 日志记录器”。
使用 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j.properties 进行 描述。
此处我们会看到 内联 和外部 记录示例。
内联日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
# ...
kafka:
# ...
logging:
type: inline
loggers:
kafka.root.logger.level: "INFO"
# ...
zookeeper:
# ...
logging:
type: inline
loggers:
zookeeper.root.logger: "INFO"
# ...
entityOperator:
# ...
topicOperator:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
# ...
userOperator:
# ...
logging:
type: inline
loggers:
rootLogger.level: INFO
# ...
外部日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
# ...
logging:
type: external
name: customConfigMap
# ...
对外部和内联日志记录级别的更改将在不重启的情况下应用到 Kafka 代理。
其他资源
- 垃圾收集器(GC)日志记录也可以启用(或禁用)。有关垃圾回收的更多信息,请参阅 垃圾回收。 第 2.1.17.1 节 “JVM 配置”
- 有关日志级别的更多信息,请参阅 Apache 日志记录服务。
2.1.13. Kafka 机架感知
AMQ Streams 中的机架感知功能有助于在不同机架之间分散 Kafka 代理 Pod 和 Kafka 主题副本。启用机架意识有助于提高 Kafka 代理的可用性以及它们托管的主题。
"rack"可能代表数据中心中的可用性区域、数据中心或实际机架。
2.1.13.1. 在 Kafka 代理中配置机架感知
可以在 Kafka .spec.kafka 的 机架感知。rack 属性中配置 Kafkarack 对象具有一个名为 topologyKey 的必填字段。此键需要与分配给 OpenShift 集群节点的一个标签匹配。OpenShift 在将 Kafka 代理 Pod 调度到节点时使用该标签。如果 OpenShift 集群在云提供商平台上运行,该标签应代表运行该节点的可用性区域。通常,节点使用 topology.kubernetes.io/zone 标签(或旧的 OpenShift 版本上的 failure-domain.beta.kubernetes.io/zone )标记为 topologyKey 值。如需有关 OpenShift 节点标签的更多信息,请参阅 Well-Known Labels、Annotations 和 Taints。这会导致在区间分散代理 pod,并在 Kafka 代理中设置 代理的 broker.rack 配置参数。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
- 请咨询您的 OpenShift 管理员,了解代表节点要部署到的区域 / 机架的节点标签。
将标签用作拓扑键,编辑
Kafka资源中的rack属性。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... rack: topologyKey: topology.kubernetes.io/zone # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
其他资源
- 有关为 Kafka 机架感知配置 init 容器镜像的详情请参考 第 2.1.18 节 “容器镜像”。
2.1.14. healthchecks
健康检查是定期测试,可验证应用的健康状况。当健康检查探测失败时,OpenShift 假定应用不健康,并尝试修复它。
OpenShift 支持两种类型的 Healthcheck 探测:
- 存活度探测
- 就绪度探测
有关探测的详情,请参阅 配置存活度和就绪度探测。这两种探测都用于 AMQ Streams 组件。
用户可以配置所选的存活度和就绪度探测选项。
2.1.14.1. healthcheck 配置
可以使用以下资源中的 livenessProbe 和 属性来配置存活度和就绪度探测:
readinessProbe
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator.tlsSidecar -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.kafkaExporter -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaBridge.spec
Live nessProbe 和 readinessProbe 均支持以下选项:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
有关 livenessProbe 和 readinessProbe 选项的详情请参考 第 B.45 节 “探测 模式参考”。
存活度和就绪度探测配置示例
# ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ...
2.1.14.2. 配置健康检查
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源中的liveness属性。例如:Probe或 readinessProbeapiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.15. Prometheus 指标
AMQ Streams 支持使用 Prometheus JMX 导出器的 Prometheus 指标将 Apache Kafka 和 ZooKeeper 支持的 JMX 指标转换为 Prometheus 指标。启用指标数据后,它们会在端口 9404 上公开。
有关设置和部署 Prometheus 和 Grafana 的更多信息,请参阅 OpenShift 指南中的 Deploying 和 升级 AMQ Streams 中的 介绍 Metrics 到 Kafka。
2.1.15.1. 指标配置
Prometheus 指标通过在以下资源中配置 metrics 属性来启用:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec
当资源中没有定义 metrics 属性时,Prometheus 指标将被禁用。要在不进一步配置的情况下启用 Prometheus 指标导出,您可以将其设置为空对象({})。
在没有任何进一步配置的情况下启用指标的示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics: {}
# ...
zookeeper:
# ...
指标 属性可能包含 Prometheus JMX 导出器的其他配置。
使用其他 Prometheus JMX Exporter 配置启用指标示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
metrics:
lowercaseOutputName: true
rules:
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count"
name: "kafka_server_$1_$2_total"
- pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count"
name: "kafka_server_$1_$2_total"
labels:
topic: "$3"
# ...
zookeeper:
# ...
2.1.15.2. 配置 Prometheus 指标
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源中的metrics属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... metrics: lowercaseOutputName: true # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.16. JMX 选项
AMQ Streams 支持通过在 9999 上打开 JMX 端口从 Kafka 代理获取 JMX 指标。您可以获取有关每个 Kafka 代理的各种指标,例如使用数据,如 BytesPerSecond 值或代理网络的请求率。AMQ Streams 支持打开受密码保护的 JMX 端口或不受保护的 JMX 端口。
2.1.16.1. 配置 JMX 选项
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
您可以使用以下资源中的 jmxOptions 属性配置 JMX 选项:
-
Kafka.spec.kafka
您可以为 Kafka 代理上打开的 JMX 端口配置用户名和密码保护。
保护 JMX 端口
您可以保护 JMX 端口,以防止未经授权的 pod 访问该端口。目前,JMX 端口只能使用用户名和密码进行保护。要启用 JMX 端口的安全性,请将 身份验证 字段中的 type 参数设置为 password :
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
jmxOptions:
authentication:
type: "password"
# ...
zookeeper:
# ...这可让您将 pod 部署到集群中,并使用无头服务来获取 JMX 指标,并指定您要解决的代理。要从 broker 0 获得 JMX 指标,我们解决在无头服务前附加代理 0 的无外设服务:
"<cluster-name>-kafka-0-<cluster-name>-<headless-service-name>"
如果 JMX 端口受到保护,您可以通过在 pod 部署中引用 JMX 机密来获取用户名和密码。
使用打开的 JMX 端口
要禁用 JMX 端口的安全性,请不要填写 身份验证 字段
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
jmxOptions: {}
# ...
zookeeper:
# ...这只会在无头服务上打开 JMX 端口,您可以按照上述方法将 pod 部署到集群中。唯一的区别在于,任何容器集都能够从 JMX 端口读取。
2.1.17. JVM 选项
AMQ 流的以下组件在虚拟机(VM)中运行:
- Apache Kafka
- Apache ZooKeeper
- Apache Kafka Connect
- Apache Kafka MirrorMaker
- AMQ Streams Kafka Bridge
JVM 配置选项针对不同的平台和架构优化性能。AMQ Streams 允许您配置其中一些选项。
2.1.17.1. JVM 配置
使用 jvmOptions 属性,为组件所运行的 JVM 配置支持的选项。
支持的 JVM 选项有助于优化不同平台和架构的性能。
2.1.17.2. 配置 JVM 选项
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑 Kafka、KafkaConnect、
KafkaConnectS2I、KafkaMirrorMaker 或 KafkaBridge资源中的jvmOptions属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... jvmOptions: "-Xmx": "8g" "-Xms": "8g" # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.18. 容器镜像
AMQ Streams 允许您配置将用于其组件的容器镜像。建议仅在特殊情况下覆盖容器镜像,这时您需要使用不同的容器注册表。例如,因为您的网络不允许访问 AMQ Streams 使用的容器存储库。在这种情况下,您应该复制 AMQ Streams 镜像或从源构建它们。如果配置的镜像与 AMQ Streams 镜像不兼容,它可能无法正常工作。
2.1.18.1. 容器镜像配置
使用 image 属性 来指定要使用的容器镜像。
建议仅在特殊情况下覆盖容器镜像。
2.1.18.2. 配置容器镜像
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源中的image属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... image: my-org/my-image:latest # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.19. TLS sidecar
sidecar 是一个在 pod 中运行的容器,但用于支持目的。在 AMQ Streams 中,TLS sidecar 使用 TLS 来加密和解密各种组件和 ZooKeeper 之间的所有通信。
TLS sidecar 用于:
- 实体 Operator
- Sything Control
2.1.19.1. TLS sidecar 配置
可以使用 中的 tlsSidecar 属性配置 TLS sidecar:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator
TLS sidecar 支持以下附加选项:
-
镜像 -
资源 -
logLevel -
readinessProbe -
livenessProbe
resources 属性可用于指定为 TLS sidecar 分配的 内存和 CPU 资源。
image 属性可用于配置要使用的容器镜像。有关配置自定义容器镜像的详情,请参考 第 2.1.18 节 “容器镜像”。
logLevel 属性用于指定日志级别。支持以下日志记录级别:
- emerg
- alert
- crit
- err
- warning
- 备注
- info
- debug
默认值为 notice。
有关为健康检查配置 readinessProbe 和 livenessProbe 属性的更多信息,请参阅 第 2.1.14.1 节 “healthcheck 配置”。
TLS sidecar 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
tlsSidecar:
image: my-org/my-image:latest
resources:
requests:
cpu: 200m
memory: 64Mi
limits:
cpu: 500m
memory: 128Mi
logLevel: debug
readinessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
initialDelaySeconds: 15
timeoutSeconds: 5
# ...
zookeeper:
# ...
2.1.19.2. 配置 TLS sidecar
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源中的tlsSidecar属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... entityOperator: # ... tlsSidecar: resources: requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi # ... cruiseControl: # ... tlsSidecar: resources: requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.20. 配置 pod 调度
当两个应用调度到同一个 OpenShift 节点时,这两个应用可能使用相同的资源,如磁盘 I/O 并影响性能。这可能会导致性能下降。以避免与其他关键工作负载共享节点的方式,仅为 Kafka 使用正确的节点或专用一组节点是如何避免这些问题的最佳方法,调度 Kafka pod 是避免这些问题的最佳方法。
2.1.20.1. 根据其他应用程序调度 pod
2.1.20.1.1. 避免关键应用程序共享节点
Pod 反关联性可用于确保关键应用永远不会调度到同一磁盘上。在运行 Kafka 集群时,建议使用 pod 反关联性来确保 Kafka 代理不与其他工作负载(如数据库)共享节点。
2.1.20.1.2. 关联性
可以使用以下资源中 的关联性属性来配置关联性 :
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
关联性配置可以包含不同类型的关联性:
- pod 关联性和反关联性
- 节点关联性
affinity 属性的格式遵循 OpenShift 规范。如需了解更多详细信息,请参阅 Kubernetes 节点和 pod 关联性文档。
2.1.20.1.3. 在 Kafka 组件中配置 pod 反关联性
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑指定集群部署的资源中的
affinity属性。使用标签指定不应调度到同一节点上的 pod。topologyKey应设置为kubernetes.io/hostname,以指定不应将所选 pod 调度到具有相同主机名的节点。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.20.2. 将 pod 调度到特定的节点
2.1.20.2.1. 节点调度
OpenShift 集群通常包含许多不同类型的工作程序节点。些已针对 CPU 繁重工作负载优化,有些则用于内存,另一些则可能针对存储(快速本地 SSD)或网络进行了优化。使用不同的节点有助于优化成本和性能。要获得最佳性能,务必要允许调度 AMQ Streams 组件以使用正确的节点。
OpenShift 使用节点关联性将工作负载调度到特定的节点上。通过节点关联性,您可以为要在其上调度 pod 的节点创建调度约束。约束指定为标签选择器。您可以使用内置节点标签(如 beta.kubernetes.io/instance-type) 或自定义标签来指定标签,以选择正确的节点。
2.1.20.2.2. 关联性
可以使用以下资源中 的关联性属性来配置关联性 :
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
关联性配置可以包含不同类型的关联性:
- pod 关联性和反关联性
- 节点关联性
affinity 属性的格式遵循 OpenShift 规范。如需了解更多详细信息,请参阅 Kubernetes 节点和 pod 关联性文档。
2.1.20.2.3. 在 Kafka 组件中配置节点关联性
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
标记调度 AMQ Streams 组件的节点。
可以使用
oc label来完成此操作:oc label node your-node node-type=fast-network或者,某些现有标签可以被重复使用。
编辑指定集群部署的资源中的
affinity属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node-type operator: In values: - fast-network # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.20.3. 使用专用节点
2.1.20.3.1. 专用节点
集群管理员可以将选定的 OpenShift 节点标记为污点。具有污点的节点不在常规调度中,一般的 pod 不会调度到它们上运行。只有可以容许节点上设置的污点的服务才可以调度到其中。此类节点上运行的唯一其他服务是系统服务,如日志收集器或软件定义型网络。
污点可用于创建专用节点。在专用节点上运行 Kafka 及其组件可能会有许多优点。同一节点上运行的其他应用程序不会造成干扰或消耗 Kafka 所需的资源。这可提高性能和稳定性。
2.1.20.3.2. 关联性
可以使用以下资源中 的关联性属性来配置关联性 :
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
关联性配置可以包含不同类型的关联性:
- pod 关联性和反关联性
- 节点关联性
affinity 属性的格式遵循 OpenShift 规范。如需了解更多详细信息,请参阅 Kubernetes 节点和 pod 关联性文档。
2.1.20.3.3. 容限(Tolerations)
可以使用以下资源中的 tolerations 属性来配置容限:
-
Kafka.spec.kafka.template.pod -
Kafka.spec.zookeeper.template.pod -
Kafka.spec.entityOperator.template.pod -
KafkaConnect.spec.template.pod -
KafkaConnectS2I.spec.template.pod -
KafkaBridge.spec.template.pod
tolerations 属性的格式遵循 OpenShift 规范。如需了解更多详细信息,请参阅 Kubernetes 污点和容限。
2.1.20.3.4. 设置专用节点并在节点上调度 pod
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
- 选择应当用作专用的节点。
- 确保这些节点上未调度工作负载。
在所选节点上设置污点:
可以使用
oc adm taint来完成此操作:oc adm taint node your-node dedicated=Kafka:NoSchedule另外,也向所选节点添加标签。
可以使用
oc label来完成此操作:oc label node your-node dedicated=Kafka编辑
指定集群部署的资源中的关联性和容限属性。例如:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... template: pod: tolerations: - key: "dedicated" operator: "Equal" value: "Kafka" effect: "NoSchedule" affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: dedicated operator: In values: - Kafka # ... zookeeper: # ...创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
2.1.21. Kafka Exporter
您可以将 Kafka 资源配置为自动在集群中部署 Kafka Exporter。
Kafka Exporter 提取数据作为 Prometheus 指标,主要与偏移、消费者组、消费者滞后和主题相关的数据。
有关设置 Kafka Exporter 以及监控消费滞后性能的原因,请参阅 OpenShift 指南中的部署和升级 AMQ Streams 中的 Kafka Exporter。
2.1.22. 对 Kafka 集群执行滚动更新
此流程描述了如何使用 OpenShift 注解手动触发现有 Kafka 集群的滚动更新。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
查找控制您要手动更新的 Kafka pod 的
StatefulSet的名称。例如,如果您的 Kafka 集群名为 my-cluster,则对应的
StatefulSet名为 my-cluster-kafka。给 OpenShift 中的
StatefulSet资源标注。例如,使用oc annotate:oc annotate statefulset cluster-name-kafka strimzi.io/manual-rolling-update=true-
等待下一次协调发生(默认为每隔两分钟)。只要协调过程检测到注解的
StatefulSet,则会触发注解的滚动更新。当所有 pod 的滚动更新完成后,注解会从StatefulSet中删除。
2.1.23. 执行 ZooKeeper 集群的滚动更新
此流程描述了如何使用 OpenShift 注释手动触发现有 ZooKeeper 集群的滚动更新。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
查找控制您要手动更新的 ZooKeeper pod 的
StatefulSet的名称。例如,如果您的 Kafka 集群名为 my-cluster,则对应的
StatefulSet 被命名为 my-cluster-zookeeper。给 OpenShift 中的
StatefulSet资源标注。例如,使用oc annotate:oc annotate statefulset cluster-name-zookeeper strimzi.io/manual-rolling-update=true-
等待下一次协调发生(默认为每隔两分钟)。只要协调过程检测到注解的
StatefulSet,则会触发注解的滚动更新。当所有 pod 的滚动更新完成后,注解会从StatefulSet中删除。
2.1.24. 扩展集群
2.1.24.1. 扩展 Kafka 集群
2.1.24.1.1. 在集群中添加代理
提高某个主题吞吐量的主要方法是增加该主题的分区数量。这是因为额外的分区允许在集群中的不同代理之间共享该主题的负载。但是,如果每个代理都受到使用更多分区的特定资源(通常是 I/O)限制,则不会增加吞吐量。相反,您需要在集群中添加代理。
当您在集群中添加额外的代理时,Kafka 不会自动为其分配任何分区。您必须决定从现有代理迁移到新代理的分区。
在所有代理之间重新分布分区后,应该减少每个代理的资源利用率。
2.1.24.1.2. 从集群中删除代理
因为 AMQ Streams 使用 StatefulSet 来管理代理 Pod,所以 您无法从集群中删除 任何 pod。您只能从集群中移除一个或多个数字最高的 pod。例如,在一个有 12 个代理的集群中,pod 被命名为 cluster-name-kafka-0 to cluster-name-kafka-11。如果您决定缩减一个代理,则会删除 cluster-name-kafka-11。
在从集群中删除代理前,请确保它没有被分配给任何分区。您还应决定剩余的代理中哪些将负责要停用代理中的每个分区。代理没有分配分区后,您可以安全地缩减集群。
2.1.24.2. 分区重新分配
Topic Operator 目前不支持将副本分配给不同的代理,因此需要直接连接到代理 Pod 以将副本分配到代理。
在代理 pod 中,kafka-reassign-partitions.sh 实用程序允许您将分区重新分配给不同的代理。
它有三种不同的模式:
--generate- 取一组主题和代理,并生成 重新分配 JSON 文件,该文件将导致这些主题的分区分配给这些代理。由于这适用于整个主题,因此当您需要重新分配某些主题的部分分区时,无法使用它。
--execute- 取 重新分配 JSON 文件 并将其应用到集群中的分区和代理。因此获得分区的代理会成为分区领导的追随者。对于给定分区,新代理一旦捕获并加入 ISR(同步副本)后,旧的代理将停止成为追随者,并删除其副本。
--verify-
使用与
--execute步骤相同的 重新分配 JSON 文件,--verify检查文件中的所有分区是否已移到其预期代理中。如果重新分配完成后,--verify 也会移除任何有效的 节流。除非被删除,否则节流将继续影响群集,即使重新分配完成后也是如此。
只能在任何给定时间在集群中运行一个重新分配,且无法取消正在运行的重新分配。如果您需要取消重新分配,请等待它完成,然后执行另一个重新分配以恢复第一次重新分配的影响。kafka-reassign-partitions.sh 将显示此重新版本的重新分配 JSON 作为其输出的一部分。在需要停止进行中的重新分配时,应将非常大的重新分配分成几个较小的重新分配。
2.1.24.2.1. 重新分配 JSON 文件
重新分配 JSON 文件 有一个特定的结构:
{
"version": 1,
"partitions": [
<PartitionObjects>
]
}其中 <PartitionObjects> 是一个用逗号分开的对象列表,例如:
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ]
}
虽然 Kafka 也支持 "log_dirs" 属性,但这不应用于 AMQ Streams。
以下是重新分配 JSON 文件的示例,该文件分配主题 主题a、分区 4 到代理 2、4 和 7,以及 主题 2 的分区 2 分配给 代理 1、5 和 7 :
{
"version": 1,
"partitions": [
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7]
},
{
"topic": "topic-b",
"partition": 2,
"replicas": [1,5,7]
}
]
}JSON 中没有包括的分区不会更改。
2.1.24.2.2. 在 JBOD 卷间重新分配分区
在 Kafka 集群中使用 JBOD 存储时,您可以选择在特定卷及其日志目录之间重新分配分区(每个卷都有一个日志目录)。要将分区重新分配给特定卷,请将 log_dirs 选项添加到重新分配 JSON 文件中的 <PartitionObjects> 中。
{
"topic": <TopicName>,
"partition": <Partition>,
"replicas": [ <AssignedBrokerIds> ],
"log_dirs": [ <AssignedLogDirs> ]
}
log_dirs 对象应包含与 replicas 对象中指定的副本数相同的日志目录 数量。该值应当是日志目录的绝对路径或 any 关键字。
例如:
{
"topic": "topic-a",
"partition": 4,
"replicas": [2,4,7].
"log_dirs": [ "/var/lib/kafka/data-0/kafka-log2", "/var/lib/kafka/data-0/kafka-log4", "/var/lib/kafka/data-0/kafka-log7" ]
}2.1.24.3. 生成重新分配 JSON 文件
此流程描述了如何生成重新分配 JSON 文件,该文件使用 kafka-reassign-partitions.sh 工具为给定主题集重新分配所有分区。
先决条件
- 一个正在运行的 Cluster Operator
-
Kafka资源 - 重新分配分区的一组主题
步骤
准备名为 topic
.json的 JSON 文件,其中列出要移动的主题。它必须具有以下结构:{ "version": 1, "topics": [ <TopicObjects> ] }其中 <TopicObjects> 是一个以逗号分隔的对象列表,例如:
{ "topic": <TopicName> }例如,如果要重新分配
topic-a 和分区,则需要准备类似以下的 topictopic-b 的所有.json文件:{ "version": 1, "topics": [ { "topic": "topic-a"}, { "topic": "topic-b"} ] }将
topic.json文件复制到其中一个代理 pod 中:cat topics.json | oc exec -c kafka <BrokerPod> -i -- \ /bin/bash -c \ 'cat > /tmp/topics.json'
使用
kafka-reassign-partitions.sh命令生成重新分配 JSON。oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list <BrokerList> \ --generate
例如,将
topic-a 和的所有分区移动到 brokertopic-b4和7oc exec <BrokerPod> -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --topics-to-move-json-file /tmp/topics.json \ --broker-list 4,7 \ --generate
2.1.24.4. 手动创建重新分配 JSON 文件
如果要移动特定的分区,可以手动创建重新分配 JSON 文件。
2.1.24.5. 重新分配节流
分区重新分配可能是一个缓慢的过程,因为它涉及到在代理之间传输大量数据。为避免对客户端造成重大影响,您可以限制重新分配过程。这可能会导致重新分配需要更长的时间。
- 如果限流太低,新分配的代理将无法与正在发布的记录保持同步,并且重新分配永远不会完成。
- 如果限流太高,客户端就会受到影响。
例如,对于制作者而言,这可能会比等待确认的正常延迟更高。对于消费者而言,这可能会因为轮询之间延迟较高而导致吞吐量下降。
2.1.24.6. 扩展 Kafka 集群
这个步骤描述了如何在 Kafka 集群中增加代理数量。
先决条件
- 现有的 Kafka 集群。
-
名为 reassignment
.json的重新分配 JSON 文件 描述了如何在放大的集群中将分区重新分配给代理。
步骤
-
通过增加
Kafka.spec.kafka.replicas配置选项,根据需要添加多个新代理。 - 验证新代理 Pod 是否已启动。
将
reassignment.json文件复制到您稍后要执行命令的代理 pod 中:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
例如:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'使用同一代理 pod 的
kafka-reassign-partitions.sh命令行工具执行分区重新分配。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --execute如果您要节流复制,您也可以使用
--throttle选项,每秒使用节流率(以字节为单位)。例如:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --execute
此命令将显示两个重新分配 JSON 对象:第一个记录了正在移动的分区的当前分配。如果稍后需要恢复重新分配,您应该将其保存到本地文件(而不是 pod 中的文件)。第二个 JSON 对象是您在重新分配 JSON 文件中传递的目标重新分配。
如果您需要在重新分配期间更改节流,您可以使用具有不同节流率的同一命令行。例如:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --execute
定期验证是否使用任何代理 Pod 的
kafka-reassign-partitions.sh命令行工具完成重新分配。这与上一步中的命令相同,但使用--verify选项而不是--execute选项。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify例如,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify
-
当
--verify命令报告每个分区成功完成时,重新分配已完成。最后的--verify还会导致移除任何重新分配节流。现在,如果您保存了 JSON,将分配还原到其原始代理中,您可以删除还原文件。
2.1.24.7. 缩减 Kafka 集群
其他资源
这个步骤描述了如何减少 Kafka 集群中的代理数量。
先决条件
- 现有的 Kafka 集群。
-
名为 reassignment
.json的重新分配 JSON 文件 描述在删除了最高编号 Pod 中的代理后,应如何将分区重新分配给集群中的代理。
步骤
将
reassignment.json文件复制到您稍后要执行命令的代理 pod 中:cat reassignment.json | \ oc exec broker-pod -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'
例如:
cat reassignment.json | \ oc exec my-cluster-kafka-0 -c kafka -i -- /bin/bash -c \ 'cat > /tmp/reassignment.json'使用同一代理 pod 的
kafka-reassign-partitions.sh命令行工具执行分区重新分配。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --execute如果您要节流复制,您也可以使用
--throttle选项,每秒使用节流率(以字节为单位)。例如:oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 5000000 \ --execute
此命令将显示两个重新分配 JSON 对象:第一个记录了正在移动的分区的当前分配。如果稍后需要恢复重新分配,您应该将其保存到本地文件(而不是 pod 中的文件)。第二个 JSON 对象是您在重新分配 JSON 文件中传递的目标重新分配。
如果您需要在重新分配期间更改节流,您可以使用具有不同节流率的同一命令行。例如:
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --throttle 10000000 \ --execute
定期验证是否使用任何代理 Pod 的
kafka-reassign-partitions.sh命令行工具完成重新分配。这与上一步中的命令相同,但使用--verify选项而不是--execute选项。oc exec broker-pod -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify例如,
oc exec my-cluster-kafka-0 -c kafka -it -- \ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \ --reassignment-json-file /tmp/reassignment.json \ --verify
-
当
--verify命令报告每个分区成功完成时,重新分配已完成。最后的--verify还会导致移除任何重新分配节流。现在,如果您保存了 JSON,将分配还原到其原始代理中,您可以删除还原文件。 所有分区重新分配完成后,删除的代理不应对集群中的任何分区负责。您可以通过检查代理的数据日志目录是否包含任何实时分区日志来验证这一点。如果代理上的日志目录包含与扩展正则表达式
[a-zA-Z0-9.-]+\ 不匹配的目录。[a-z0-9]+-delete$仍然具有实时分区,不应停止。您可以执行以下命令检查:
oc exec my-cluster-kafka-0 -c kafka -it -- \ /bin/bash -c \ "ls -l /var/lib/kafka/kafka-log_<N>_ | grep -E '^d' | grep -vE '[a-zA-Z0-9.-]+\.[a-z0-9]+-delete$'"
其中 N
是要删除的 Pod数。如果上述命令显示任何输出,则代理仍然有实时分区。在这种情况下,重新分配没有完成,或者重新分配 JSON 文件不正确。
-
确认代理没有实时分区后,您可以编辑
Kafka.spec.kafka.replicas 资源的spec.kafka.replicas,这会缩减Kafka.StatefulSet,从而删除最高数字的代理 Pod。
2.1.25. 手动删除 Kafka 节点
其他资源
此流程描述了如何使用 OpenShift 注解删除现有 Kafka 节点。删除 Kafka 节点包括删除运行 Kafka 代理的 Pod 和相关的 PersistentVolumeClaim (如果集群部署了持久性存储)。删除后,Pod 及其相关的 PersistentVolumeClaim 会被自动重新创建。
删除 PersistentVolumeClaim 可能会导致持久性数据丢失。只有在您遇到存储问题时才应执行以下步骤。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
查找您要删除的
Pod的名称。例如,如果集群命名为 cluster-name,pod 被命名为 cluster-name-kafka-index,其中 索引 以零开始,结尾是副本总数。
给 OpenShift
中的容器集资源标注:使用
oc annotate:oc annotate pod cluster-name-kafka-index strimzi.io/delete-pod-and-pvc=true
- 等待下一次协调,当带有底层持久性卷声明的注解的 pod 被删除后再重新创建。
2.1.26. 手动删除 ZooKeeper 节点
此流程描述了如何使用 OpenShift 注释删除现有的 ZooKeeper 节点。删除 ZooKeeper 节点包括删除运行 ZooKeeper 的 Pod 和相关的 PersistentVolumeClaim (如果集群部署了持久性存储)。删除后,Pod 及其相关的 PersistentVolumeClaim 会被自动重新创建。
删除 PersistentVolumeClaim 可能会导致持久性数据丢失。只有在您遇到存储问题时才应执行以下步骤。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
查找您要删除的
Pod的名称。例如,如果集群名为 cluster-name,pod 被命名为 cluster-name-zookeeper-index,其中 索引 从零开始,结尾是副本总数。
给 OpenShift
中的容器集资源标注:使用
oc annotate:oc annotate pod cluster-name-zookeeper-index strimzi.io/delete-pod-and-pvc=true
- 等待下一次协调,当带有底层持久性卷声明的注解的 pod 被删除后再重新创建。
2.1.27. 用于滚动更新的维护时间窗
通过维护时间窗,您可以计划对 Kafka 和 ZooKeeper 集群进行某些滚动更新,以便在方便的时间启动。
2.1.27.1. 维护时间窗概述
在大多数情况下,Cluster Operator 只更新 Kafka 或 ZooKeeper 集群,以响应对对应 Kafka 资源的更改。这可让您计划何时对 Kafka 资源应用更改,以最大程度降低对 Kafka 客户端应用程序的影响。
但是,在不对 Kafka 资源 进行任何相应的更改的情况下,可能会对 Kafka 和 ZooKeeper 集群进行一些更新。例如,如果 Cluster Operator 管理的 CA(证书授权机构)证书接近到期时间,则 Cluster Operator 将需要执行滚动重启。
虽然 pod 的滚动重启不应影响服务 的可用性 (假设正确的代理和主题配置),这可能会影响 Kafka 客户端应用程序 的性能。通过维护时间窗,您可以调度 Kafka 和 ZooKeeper 集群的自发滚动更新,以便在方便的时间开始。如果没有为群集配置维护时间窗,那么这种自发滚动更新可能会在不方便的时间(如在可预测的高负载期间)发生。
2.1.27.2. 维护时间窗定义
您可以通过在 Kafka.spec.maintenanceTimeWindows 属性中输入字符串数组来配置维护时间窗。每个字符串是一个 cron 表达式,解释为使用 UTC(协调世界时间,其实际用途与 Greenwich Mean Time 相同)。
以下示例配置了一个维护时间窗口,该时间窗口从午夜开始,到 01:59am(UTC)、周日、周一、星期二和周四结束:
# ... maintenanceTimeWindows: - "* * 0-1 ? * SUN,MON,TUE,WED,THU *" # ...
在实践中,维护窗口应当与 Kafka.spec.clusterCa.renewalDays 和 Kafka.spec.clientsCa.renewalDays 属性一同设置,以确保在 配置的维护时间窗口中完成必要的 CA 证书续订。
AMQ Streams 不完全根据给定的窗口调度维护操作。相反,对于每个协调,它会检查维护窗口当前是否"打开"。这意味着,给定时间窗内的维护操作启动可能会被 Cluster Operator 协调间隔延迟。因此维护时间窗必须至少是这个长。
其他资源
- 有关 Cluster Operator 配置的更多信息,请参阅 第 5.1.1 节 “Cluster Operator 配置”。
2.1.27.3. 配置维护时间窗
您可以配置维护时间窗,用于由支持的进程触发的滚动更新。
先决条件
- OpenShift 集群。
- Cluster Operator 正在运行。
步骤
在
Kafka资源中添加或编辑maintenanceTimeWindows属性。例如,允许在 0800 到 1059 之间以及 1400 到 1559 之间的维护,您可以设置maintenanceTimeWindows,如下所示:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka: # ... zookeeper: # ... maintenanceTimeWindows: - "* * 8-10 * * ?" - "* * 14-15 * * ?"创建或更新资源。
这可以使用
oc apply来完成:oc apply -f your-file
其他资源
- 执行 Kafka 集群的滚动更新,请参阅 第 2.1.22 节 “对 Kafka 集群执行滚动更新”
- 执行 ZooKeeper 集群的滚动更新,请参阅 第 2.1.23 节 “执行 ZooKeeper 集群的滚动更新”
2.1.28. 手动续订 CA 证书
在相应证书续订期开始时,集群和客户端 CA 证书会自动续订。如果 Kafka.spec.clusterCa.generateCertificateAuthority 和 Kafka.spec.clientsCa.generateCertificateAuthority 设置为 false,则 CA 证书不会自动续订。
您可以在证书续订期限开始前手动续订其中一个或两个证书。出于安全原因 或更改了证书的续订期或有效期,您可以这样做。
更新的证书使用与旧证书相同的私钥。
先决条件
- Cluster Operator 正在运行。
- 安装 CA 证书和私钥的 Kafka 集群。
步骤
将
strimzi.io/force-renew注解应用到包含您要续订的 CA 证书的Secret。表 2.1. 强制续订证书的 Secret 注解
证书 Secret annotate 命令 集群 CA
kAFKA-CLUSTER-NAME-cluster-ca-cert
oc annotate secret KAFKA-CLUSTER-NAME-cluster-ca-cert strimzi.io/force-renew=true客户端 CA
kAFKA-CLUSTER-NAME-clients-ca-cert
oc annotate secret KAFKA-CLUSTER-NAME-clients-ca-cert strimzi.io/force-renew=true在下一次协调中,Cluster Operator 会为您注解的
Secret生成一个新的 CA 证书。如果配置了维护时间窗,Cluster Operator 将在下一个维护时间窗内第一次协调时生成新的 CA 证书。客户端应用程序必须重新载入由 Cluster Operator 更新的集群和客户端 CA 证书。
检查 CA 证书有效的周期:
例如,使用
openssl命令:oc get secret CA-CERTIFICATE-SECRET -o 'jsonpath={.data.CA-CERTIFICATE}' | base64 -d | openssl x509 -subject -issuer -startdate -enddate -noout
ca-CERTIFICATE-SECRET 是
Secret的名称,这是用于集群 CA证书的 KAFKA-CLUSTER-NAME-cluster-ca-cert和用于客户端 CA 证书的KAFKA-CLUSTER-NAME-clients-ca-cert。ca-CERTIFICATE 是 CA 证书的名称,如
jsonpath={.data.ca\.crt}。该命令会返回
notBefore和notAfter日期,这是 CA 证书的有效周期。例如,对于集群 CA 证书:
subject=O = io.strimzi, CN = cluster-ca v0 issuer=O = io.strimzi, CN = cluster-ca v0 notBefore=Jun 30 09:43:54 2020 GMT notAfter=Jun 30 09:43:54 2021 GMT
从 Secret 删除旧证书。
当组件使用新证书时,旧证书可能仍处于活跃状态。删除旧证书以消除任何潜在的安全风险。
2.1.29. 替换私钥
您可以替换集群 CA 和客户端 CA 证书使用的私钥。替换私钥时,Cluster Operator 会为新私钥生成一个新的 CA 证书。
先决条件
- Cluster Operator 正在运行。
- 安装 CA 证书和私钥的 Kafka 集群。
步骤
将
strimzi.io/force-replace注解应用到包含您要续订的私钥的Secret。表 2.2. 替换私钥的命令
的私钥 Secret annotate 命令 集群 CA
<cluster-name>-cluster-ca
oc annotate secret <cluster-name>-cluster-ca strimzi.io/force-replace=true客户端 CA
<cluster-name>-clients-ca
oc annotate secret <cluster-name>-clients-ca strimzi.io/force-replace=true
在下一次协调中,Cluster Operator 将:
-
为注解的
Secret生成一个新的私钥 - 生成新的 CA 证书
如果配置了维护时间窗,Cluster Operator 将在下一个维护时间窗内第一次协调时生成新的私钥和 CA 证书。
客户端应用程序必须重新载入由 Cluster Operator 更新的集群和客户端 CA 证书。
2.1.30. 作为 Kafka 集群一部分创建的资源列表
以下资源由 OpenShift 集群中的 Cluster Operator 创建:
共享资源
cluster-name-cluster-ca- 使用用于加密集群通信的集群 CA 的机密。
cluster-name-cluster-ca-cert- 使用 Cluster CA 公钥的 secret。这个密钥可以用来验证 Kafka 代理的身份。
cluster-name-clients-ca- 使用用于签署用户证书的 Clients CA 私钥的 secret
cluster-name-clients-ca-cert- 使用 Clients CA 公钥的机密。此密钥可用于验证 Kafka 用户的身份。
cluster-name-cluster-operator-certs- 使用集群操作器密钥与 Kafka 和 ZooKeeper 通信的机密。
zookeeper 节点
cluster-name-zookeeper- StatefulSet,它负责管理 ZooKeeper 节点 pod。
cluster-name-zookeeper-idx- 由 Zookeeper StatefulSet 创建的 Pod。
cluster-name-zookeeper-nodes- 无头服务需要直接解析 ZooKeeper pod IP 地址。
cluster-name-zookeeper-client- Kafka 代理用于连接 ZooKeeper 节点的服务作为客户端。
cluster-name-zookeeper-config- 包含 ZooKeeper 辅助配置的 ConfigMap,由 ZooKeeper 节点 pod 挂载为卷。
cluster-name-zookeeper-nodes- 使用 ZooKeeper 节点密钥的机密。
cluster-name-zookeeper- Zookeeper 节点使用的服务帐户。
cluster-name-zookeeper- 为 ZooKeeper 节点配置的 Pod Disruption Budget。
cluster-name-network-policy-zookeeper- 管理对 ZooKeeper 服务访问的网络策略.
data-cluster-name-zookeeper-idx-
用于为 ZooKeeper 节点 pod
idx存储数据的卷的持久性卷声明。只有在选择了持久存储来调配持久卷以存储数据时,才会创建此资源。
Kafka 代理
cluster-name-kafka- StatefulSet,它负责管理 Kafka 代理 pod。
cluster-name-kafka-idx- 由 Kafka StatefulSet 创建的 Pod。
cluster-name-kafka-brokers- 需要 DNS 直接解析 Kafka 代理 Pod IP 地址的服务。
cluster-name-kafka-bootstrap- 服务可用作 Kafka 客户端的 bootstrap 服务器。
cluster-name-kafka-external-bootstrap- 为从 OpenShift 集群外部连接的客户端引导服务。只有在启用了外部侦听器时才会创建此资源。
cluster-name-kafka-pod-id- 用于将流量从 OpenShift 集群外部路由到单个容器集的服务。只有在启用了外部侦听器时才会创建此资源。
cluster-name-kafka-external-bootstrap-
从 OpenShift 集群外部连接的客户端的引导路由。只有在启用了外部侦听器并设置为 type
route时才会创建此资源。 cluster-name-kafka-pod-id-
从 OpenShift 集群外部的流量路由到单个容器集。只有在启用了外部侦听器并设置为 type
route时才会创建此资源。 cluster-name-kafka-config- 包含 Kafka 辅助配置且由 Kafka 代理 Pod 挂载为卷的 ConfigMap。
cluster-name-kafka-brokers- 使用 Kafka 代理密钥的 secret。
cluster-name-kafka- Kafka 代理使用的服务帐户。
cluster-name-kafka- 为 Kafka 代理配置的 Pod Disruption Budget。
cluster-name-network-policy-kafka- 管理对 Kafka 服务访问的网络策略。
strimzi-namespace-name-cluster-name-kafka-init- Kafka 代理使用的集群角色绑定。
cluster-name-jmx- 用来保护 Kafka 代理端口的 JMX 用户名和密码的 secret。只有在 Kafka 中启用了 JMX 时才会创建此资源。
data-cluster-name-kafka-idx-
用于存储 Kafka 代理 pod
IDx数据的卷的持久性卷声明。只有在选择了持久存储来调配持久卷以存储数据时,才会创建此资源。 data-id-cluster-name-kafka-idx-
用于存储 Kafka 代理 pod
ID的卷 ID 的持久性卷声明。只有在调配持久卷以存储数据时,才会为 JBOD 卷选择持久存储时创建此资源。
实体 Operator
只有在使用 Cluster Operator 部署 Entity Operator 时才会创建这些资源。
cluster-name-entity-operator- 使用主题和用户操作器进行部署.
cluster-name-entity-operator-random-string- 由 Entity Operator 部署创建的 Pod。
cluster-name-entity-topic-operator-config- 带有主题 Operator 辅助配置的 ConfigMap。
cluster-name-entity-user-operator-config- 带有用户 Operator 辅助配置的 ConfigMap.
cluster-name-entity-operator-certs- 使用 Entity Operator 密钥与 Kafka 和 ZooKeeper 通信的 secret。
cluster-name-entity-operator- Entity Operator 使用的服务帐户。
strimzi-cluster-name-topic-operator- Entity Operator 使用的角色绑定。
strimzi-cluster-name-user-operator- Entity Operator 使用的角色绑定。
Kafka Exporter
只有在使用 Cluster Operator 部署 Kafka Exporter 时才会创建这些资源。
cluster-name-kafka-exporter- 使用 Kafka 导出器部署.
cluster-name-kafka-exporter-random-string- 由 Kafka Exporter 部署创建的 Pod。
cluster-name-kafka-exporter- 用于收集消费者滞后指标的服务.
cluster-name-kafka-exporter- Kafka Exporter 使用的服务帐户。
Sything Control
只有在使用 Cluster Operator 部署 Cruise Control 时才会创建这些资源。
cluster-name-cruise-control- 通过 Cruise 控制进行部署.
cluster-name-cruise-control-random-string- 由 Cruise Control 部署创建的 Pod。
cluster-name-cruise-control-config- 包含 Cruise Control 辅助配置的 ConfigMap,并被 Cruise Control pod 作为一个卷挂载。
cluster-name-cruise-control-certs- 使用 Cruise Control 密钥与 Kafka 和 ZooKeeper 通信的机密。
cluster-name-cruise-control- 用于与 Cruise Control 通信的服务.
cluster-name-cruise-control- Cruise Control 使用的服务帐户.
cluster-name-network-policy-cruise-control- 管理对 Cruise 控制服务的访问的网络策略.
JMXTrans
只有在使用 Cluster Operator 部署 JMXTrans 时才会创建这些资源。
cluster-name-jmxtrans- 使用 JMXTrans 部署.
cluster-name-jmxtrans-random-string- 由 JMXTrans 部署创建的 Pod。
cluster-name-jmxtrans-config- 包含 JMXTrans 辅助配置的 ConfigMap,由 JMXTrans pod 挂载为卷。
cluster-name-jmxtrans- JMXTrans 使用的服务帐户.
2.2. Kafka Connect/S2I 集群配置
本节论述了如何在 AMQ Streams 集群中配置 Kafka Connect 或 Kafka Connect with Source-to-Image(S2I)部署。
Kafka Connect 是一个集成工具包,用于使用 Connector 插件在 Kafka 代理和其他系统间流传输数据。Kafka Connect 提供了一个框架,用于将 Kafka 与外部数据源或目标(如数据库)集成,以使用连接器导入或导出数据。连接器是提供所需连接配置的插件。
如果使用 Kafka Connect,您可以配置 KafkaConnect 或 资源。如果您使用 Source-to-Image( KafkaConnect S2IS2I )框架来部署 Kafka Connect,请使用 KafkaConnectS2I 资源。
-
KafkaConnect资源的完整 schema 信息包括在 第 B.79 节 “KafkaConnect模式参考” 中。 -
KafkaConnectS2I资源的完整 schema 包括在 第 B.95 节 “KafkaConnectS2I模式参考” 中。
2.2.1. 配置 Kafka 连接
使用 Kafka Connect 设置到 Kafka 集群的外部数据连接。
使用 KafkaConnect 或 资源的属性来配置 Kafka Connect 部署。此流程中演示的示例适用于 KafkaConnect S2IKafkaConnect 资源,但 KafkaConnectS2I 资源的属性相同。
Kafka 连接器配置
KafkaConnector 资源允许您以 OpenShift 原生方式为 Kafka Connect 创建和管理连接器实例。
在配置中,您可以通过添加 strimzi.io/use-connector-resources 注解来为 Kafka Connect 集群启用 Kafka Connectors。您还可以通过 externalConfiguration 属性为 Kafka Connect 连接器指定外部配置。
使用 Kafka Connect HTTP REST 接口或使用 KafkaConnectors 创建、重新配置和删除连接器。如需有关这些方法的更多信息,请参阅 OpenShift 上部署和升级 AMQ Streams 中的 创建和管理连接器。
连接器配置作为 HTTP 请求的一部分传递给 Kafka Connect,并存储在 Kafka 本身中。ConfigMap 和机密是用于存储配置和机密数据的标准 OpenShift 资源。您可以使用 ConfigMap 和 Secret 配置连接器的某些元素。然后,您可以在 HTTP REST 命令中引用配置值(如果需要,这会使配置保持独立且更安全)。这个方法尤其适用于机密数据,如用户名、密码或证书。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
编辑
KafkaConnect 或资源的KafkaConnectS2Ispec属性。您可以配置的属性显示在此示例配置中:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect 1 metadata: name: my-connect-cluster annotations: strimzi.io/use-connector-resources: "true" 2 spec: replicas: 3 3 authentication: 4 type: tls certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source bootstrapServers: my-cluster-kafka-bootstrap:9092 5 tls: 6 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt config: 7 group.id: my-connect-cluster offset.storage.topic: my-connect-cluster-offsets config.storage.topic: my-connect-cluster-configs status.storage.topic: my-connect-cluster-status key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: true value.converter.schemas.enable: true config.storage.replication.factor: 3 offset.storage.replication.factor: 3 status.storage.replication.factor: 3 externalConfiguration: 8 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey resources: 9 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 10 type: inline loggers: log4j.rootLogger: "INFO" readinessProbe: 11 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metrics: 12 lowercaseOutputName: true lowercaseOutputLabelNames: true rules: - pattern: kafka.connect<type=connect-worker-metrics><>([a-z-]+) name: kafka_connect_worker_$1 help: "Kafka Connect JMX metric worker" type: GAUGE - pattern: kafka.connect<type=connect-worker-rebalance-metrics><>([a-z-]+) name: kafka_connect_worker_rebalance_$1 help: "Kafka Connect JMX metric rebalance information" type: GAUGE jvmOptions: 13 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 14 template: 15 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer: 16 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"
- 1
- 根据需要,使用
KafkaConnect或 KafkaConnectS2I - 2
- 为
Kafka Connect 集群启用 KafkaConnectors。 - 3
- 4
- Kafka Connect 集群的身份验证,使用 TLS 机制 (如下所示)、使用 OAuth bearer 令牌 或基于 SASL 的 SCRAM-SHA-512 或 PLAIN 机制。默认情况下,Kafka Connect 使用纯文本连接连接到 Kafka 代理。
- 5
- 用于连接到 Kafka Connect 集群的 bootstrap 服务器。
- 6
- 使用密钥名称进行 TLS 加密,在其下,TLS 证书以 X.509 格式存储到集群的 X.509 格式。如果证书存储在同一个 secret 中,则可以多次列出证书。
- 7
- Kafka Connect worker ( 而不是连接器)配置。标准 Apache Kafka 配置可能会提供,仅限于不是由 AMQ Streams 直接管理的属性。
- 8
- 使用环境变量(如下所示)或卷 为 Kafka 连接器的外部配置。
- 9
- 10
- 指定 Kafka 连接日志记录器和日志级别 直接(
内联)或通过ConfigMap 间接(外部)添加。自定义 ConfigMap 必须放在log4j.properties 或log4j2.properties键下。对于 Kafka Connectlog4j.rootLogger日志记录器,您可以将日志级别设置为 INFO、ERROR、WARN、TRACE、DEBUG、FATAL 或 OFF。 - 11
- 健康检查以了解 何时重新启动容器(存活度)以及容器何时可以接受流量(就绪度)。
- 12
- Prometheus metrics,本例中通过 Prometheus JMX 导出器配置启用的 Prometheus 指标。您可以使用
metrics: {}来在没有进一步配置的情况下启用指标。 - 13
- 运行 Kafka Connect 的虚拟机(VM)性能优化 JVM 配置选项。
- 14
- 高级选项:容器镜像配置,建议仅在特殊情况下使用。
- 15
- 模板自定义.在这里,pod 被调度为反关联性,因此 pod 不会调度到具有相同主机名的节点。
- 16
- 还 使用 Jaeger 为分布式追踪设置 环境变量。
创建或更新资源:
oc apply -f KAFKA-CONNECT-CONFIG-FILE- 如果为 Kafka Connect 启用了授权,请配置 Kafka Connect 用户以启用对 Kafka Connect consumer 组和主题的访问。
2.2.2. 多个实例的 Kafka Connect 配置
如果您正在运行多个 Kafka Connect 实例,您必须更改以下配置 属性 的默认配置:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: connect-cluster 1
offset.storage.topic: connect-cluster-offsets 2
config.storage.topic: connect-cluster-configs 3
status.storage.topic: connect-cluster-status 4
# ...
# ...
对于具有同一 group.id 的所有 Kafka Connect 实例,三个主题的值必须相同。
除非更改默认设置,否则每个连接到同一 Kafka 集群的 Kafka Connect 实例都使用相同的值部署。实际上,所有实例都合并在一起,在集群中运行并使用相同的主题。
如果多个 Kafka Connect 集群尝试使用相同的主题,Kafka Connect 将无法按预期工作并生成错误。
如果要运行多个 Kafka Connect 实例,请为每个实例更改这些属性的值。
2.2.3. 配置 Kafka Connect 用户授权
这个步骤描述了如何授权用户对 Kafka Connect 的访问。
当 Kafka 中使用任何类型的授权时,Kafka Connect 用户需要对消费者组的读/写访问权限以及 Kafka Connect 的内部主题。
用户组和内部主题的属性由 AMQ Streams 自动配置,或者可以在 KafkaConnect 或 资源的 KafkaConnect S2Ispec 中明确指定。
KafkaConnect 资源中的配置属性示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster 1
offset.storage.topic: my-connect-cluster-offsets 2
config.storage.topic: my-connect-cluster-configs 3
status.storage.topic: my-connect-cluster-status 4
# ...
# ...
此流程演示了在使用 简单 授权时如何提供访问权限。
简单的授权使用由 Kafka AclAuthorizer 插件处理的 ACL 规则来提供正确的访问级别。有关将 KafkaUser 资源配置为使用简单授权的更多信息,请参阅 AclRule schema 引用。
运行多个实例时,使用者组和主题的默认值将有所不同。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
KafkaUser资源中的授权属性,以便为用户提供访问权限。在以下示例中,使用
字面名称值为 Kafka Connect 主题和消费者组配置访问权限:属性 Name offset.storage.topicconnect-cluster-offsetsstatus.storage.topicconnect-cluster-statusconfig.storage.topicconnect-cluster-configsgroupconnect-clusterapiVersion: kafka.strimzi.io/v1beta1 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster spec: # ... authorization: type: simple acls: # access to offset.storage.topic - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-offsets patternType: literal operation: Read host: "*" # access to status.storage.topic - resource: type: topic name: connect-cluster-status patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-status patternType: literal operation: Read host: "*" # access to config.storage.topic - resource: type: topic name: connect-cluster-configs patternType: literal operation: Write host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Create host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Describe host: "*" - resource: type: topic name: connect-cluster-configs patternType: literal operation: Read host: "*" # consumer group - resource: type: group name: connect-cluster patternType: literal operation: Read host: "*"创建或更新资源。
oc apply -f KAFKA-USER-CONFIG-FILE
2.2.4. Kafka Connect 集群资源列表
以下资源由 OpenShift 集群中的 Cluster Operator 创建:
- connect-cluster-name-connect
- 用于创建 Kafka Connect worker 节点 pod 的 Deployment。
- connect-cluster-name-connect-api
- 公开用于管理 Kafka Connect 集群的 REST 接口的服务。
- connect-cluster-name-config
- 包含 Kafka Connect 辅助配置且由 Kafka 代理 Pod 挂载为卷的 ConfigMap。
- connect-cluster-name-connect
- 为 Kafka Connect worker 节点配置的 Pod Disruption Budget。
2.2.5. Kafka Connect(S2I)集群资源列表
以下资源由 OpenShift 集群中的 Cluster Operator 创建:
- connect-cluster-name-connect-source
- 镜像流,用作新构建的 Docker 镜像的基础镜像。
- connect-cluster-name-connect
- BuildConfig,它负责构建新的 Kafka Connect Docker 镜像。
- connect-cluster-name-connect
- 将推送新构建 Docker 镜像的镜像流。
- connect-cluster-name-connect
- DeploymentConfig,它负责创建 Kafka Connect worker 节点 pod。
- connect-cluster-name-connect-api
- 公开用于管理 Kafka Connect 集群的 REST 接口的服务。
- connect-cluster-name-config
- 包含 Kafka Connect 辅助配置且由 Kafka 代理 Pod 挂载为卷的 ConfigMap。
- connect-cluster-name-connect
- 为 Kafka Connect worker 节点配置的 Pod Disruption Budget。
2.2.6. 与 Debezium 集成以捕获更改数据
红帽 Debezium 是一个分布式更改数据捕获平台。它捕获数据库中的行级更改,创建更改事件记录,并将记录流传输到 Kafka 主题。Debezium 基于 Apache Kafka 构建。您可以将 Debezium 与 AMQ Streams 部署和集成。部署 AMQ Streams 后,您可以通过 Kafka Connect 将 Debezium 部署为连接器配置。Debezium 将更改事件记录传递到 OpenShift 上的 AMQ Streams。应用程序可以读取 这些更改事件流,并按发生更改事件的顺序访问更改事件。
Debezium 具有多个用途,包括:
- 数据复制
- 更新缓存和搜索索引
- 简化单体式应用程序
- 数据集成
- 启用流查询
要捕获数据库更改,请使用 Debezium 数据库连接器部署 Kafka Connect。您可以配置 KafkaConnector 资源来定义连接器实例。
有关使用 AMQ Streams 部署 Debezium 的更多信息,请参阅 产品文档。Debezium 文档包括 Debezium 入门 指南,指导您完成设置服务和查看数据库更新事件记录所需的连接器所需的流程。
2.3. Kafka MirrorMaker 集群配置
本章论述了如何在 AMQ Streams 集群中配置 Kafka 镜像Maker 部署以在 Kafka 集群间复制数据。
您可以使用带有 MirrorMaker 或 MirrorMaker 2.0 的 AMQ Streams。MirrorMaker 2.0 是最新版本,为在 Kafka 集群间镜像数据提供了一种更有效的方法。
如果使用 MirrorMaker,您需要配置 KafkaMirrorMaker 资源。
以下流程演示了如何配置资源:
KafkaMirrorMaker 资源的完整 schema 信息包括在 KafkaMirrorMaker schema 引用 中。
2.3.1. 配置 Kafka MirrorMaker
使用 KafkaMirrorMaker 资源的属性来配置 Kafka MirrorMaker 部署。
您可以使用 TLS 或 SASL 身份验证为生产者和使用者配置访问控制。此流程演示了在使用者和制作者侧使用 TLS 加密和身份验证的配置。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
- 源和目标 Kafka 集群必须可用
步骤
编辑
KafkaMirrorMaker资源的spec属性。您可以配置的属性显示在此示例配置中:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: replicas: 3 1 consumer: bootstrapServers: my-source-cluster-kafka-bootstrap:9092 2 groupId: "my-group" 3 numStreams: 2 4 offsetCommitInterval: 120000 5 tls: 6 trustedCertificates: - secretName: my-source-cluster-ca-cert certificate: ca.crt authentication: 7 type: tls certificateAndKey: secretName: my-source-secret certificate: public.crt key: private.key config: 8 max.poll.records: 100 receive.buffer.bytes: 32768 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 9 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS 10 producer: bootstrapServers: my-target-cluster-kafka-bootstrap:9092 abortOnSendFailure: false 11 tls: trustedCertificates: - secretName: my-target-cluster-ca-cert certificate: ca.crt authentication: type: tls certificateAndKey: secretName: my-target-secret certificate: public.crt key: private.key config: compression.type: gzip batch.size: 8192 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 12 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS 13 whitelist: "my-topic|other-topic" 14 resources: 15 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 16 type: inline loggers: mirrormaker.root.logger: "INFO" readinessProbe: 17 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 metrics: 18 lowercaseOutputName: true rules: - pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count" name: "kafka_server_$1_$2_total" - pattern: "kafka.server<type=(.+), name=(.+)PerSec\\w*, topic=(.+)><>Count" name: "kafka_server_$1_$2_total" labels: topic: "$3" jvmOptions: 19 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 20 template: 21 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer: 22 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: 23 type: jaeger
- 1
- 2
- 为 使用者和生产者引导服务器.
- 3
- 4
- 5
- 6
- 使用密钥名称进行 TLS 加密,其中 TLS 证书存储在 X.509 格式供使用者或生产者使用。如果证书存储在同一个 secret 中,则可以多次列出证书。
- 7
- 8
- 9
- 使用特定 密码套件 为 TLS 版本运行外部侦听器的 SSL 属性。
- 10
- 通过将 设置为
HTTPS来 启用主机名验证。空字符串将禁用验证。 - 11
- 如果 abort
OnSendFailure属性 设为true,则 Kafka MirrorMaker 将退出,容器将在发送失败消息后重启。 - 12
- 使用特定 密码套件 为 TLS 版本运行外部侦听器的 SSL 属性。
- 13
- 通过将 设置为
HTTPS来 启用主机名验证。空字符串将禁用验证。 - 14
- 从源镜像到目标 Kafka 集群 的主题白名单 。
- 15
- 16
- 指定日志记录器和日志级别 通过 ConfigMap 直接(
内联)或间接(外部)添加。自定义 ConfigMap 必须放在log4j.properties 或log4j2.properties键下。MirrorMaker 有一个名为mirrormaker.root.logger的日志记录器。您可以将日志级别设置为 INFO、ERROR、WARN、TRACE、DEBUG、FATAL 或 OFF。 - 17
- 健康检查以了解 何时重新启动容器(存活度)以及容器何时可以接受流量(就绪度)。
- 18
- Prometheus metrics,本例中通过 Prometheus JMX 导出器配置启用的 Prometheus 指标。您可以使用
metrics: {}来在没有进一步配置的情况下启用指标。 - 19
- 用于优化运行 Kafka MirrorMaker 的虚拟机(VM)性能的 JVM 配置选项。
- 20
- 高级选项:容器镜像配置,建议仅在特殊情况下使用。
- 21
- 模板自定义.在这里,pod 被调度为反关联性,因此 pod 不会调度到具有相同主机名的节点。
- 22
- 还 使用 Jaeger 为分布式追踪设置 环境变量。
- 23
警告将 abort
OnSendFailure属性设置为false时,制作者会尝试发送主题中的下一个消息。原始消息可能会丢失,因为没有尝试重新发送失败的消息。创建或更新资源:
oc apply -f <your-file>
2.3.2. Kafka MirrorMaker 集群资源列表
以下资源由 OpenShift 集群中的 Cluster Operator 创建:
- <mirror-maker-name>-mirror-maker
- 负责创建 Kafka MirrorMaker pod 的部署。
- <mirror-maker-name>-config
- 包含 Kafka MirrorMaker 的辅助配置的 ConfigMap,并由 Kafka 代理 Pod 挂载为卷。
- <mirror-maker-name>-mirror-maker
- 为 Kafka MirrorMaker worker 节点配置的 Pod Disruption Budget。
2.4. Kafka MirrorMaker 2.0 集群配置
本节论述了如何在 AMQ Streams 集群中配置 Kafka MirrorMaker 2.0 部署。
MirrorMaker 2.0 用于在数据中心内或之间的两个或多个活跃 Kafka 集群之间复制数据。
集群间的数据复制支持以下条件:
- 发生系统故障时恢复数据
- 聚合数据以进行分析
- 对特定集群的数据访问的限制
- 在特定位置置备数据以缩短延迟
如果使用 MirrorMaker 2.0,您需要配置 KafkaMirrorMaker2 资源。
MirrorMaker 2.0 引入了一种全新的在集群间复制数据的方法。
因此,资源配置与以前的 MirrorMaker 版本不同。如果您选择使用 MirrorMaker 2.0,当前没有传统支持,因此任何资源都必须手动转换为新格式。
MirrorMaker 2.0 复制数据的方式如下:
以下流程演示了如何为 MirrorMaker 2.0 配置资源:
KafkaMirrorMaker2 资源的完整 schema 包括在 KafkaMirrorMaker2 架构引用 中。
2.4.1. MirrorMaker 2.0 数据复制
MirrorMaker 2.0 使用源 Kafka 集群的信息,并将其写入目标 Kafka 集群。
MirrorMaker 2.0 使用:
- 源集群配置以使用源集群的数据
- 将数据输出到目标集群的目标集群配置
MirrorMaker 2.0 基于 Kafka Connect 框架,即管理集群间数据传输的 连接器。MirrorMaker 2.0 MirrorSourceConnector 将主题从源集群复制到目标集群。
将数据从一个集群 镜像 到另一个集群的过程是异步的。建议的模式是让信息与源 Kafka 集群一起生成,然后远程使用与目标 Kafka 集群类似的信息。
MirrorMaker 2.0 可以用于多个源集群。
图 2.1. 在两个集群间复制
2.4.2. 集群配置
您可以在 主动/ 被动或主动/主动 集群配置中使用 MirrorMaker 2.0。
- 在 主动/主动 配置中,两个集群都处于活动状态并同时提供相同的数据,如果您想在不同的地理位置在本地提供相同的数据,这很有用。
- 在 主动/被动 配置中,来自主动/被动群集的数据复制到被动群集中,该群集仍处于备用状态,例如,在发生系统故障时进行数据恢复。
预计生产者和消费者只能连接到活跃的集群。
每个目标目的地都需要一个 MirrorMaker 2.0 集群。
2.4.2.1. 双向复制(主动/主动)
MirrorMaker 2.0 架构支持 主动/主动 集群配置中的双向复制。
每个集群使用 源 和远程 主题的概念复制其他集群的数据。由于每个集群中存储了相同的主题,因此 MirrorMaker 2.0 会自动重命名远程主题来代表源集群。原始集群的名称前面是主题名称的前面。
图 2.2. 主题重命名
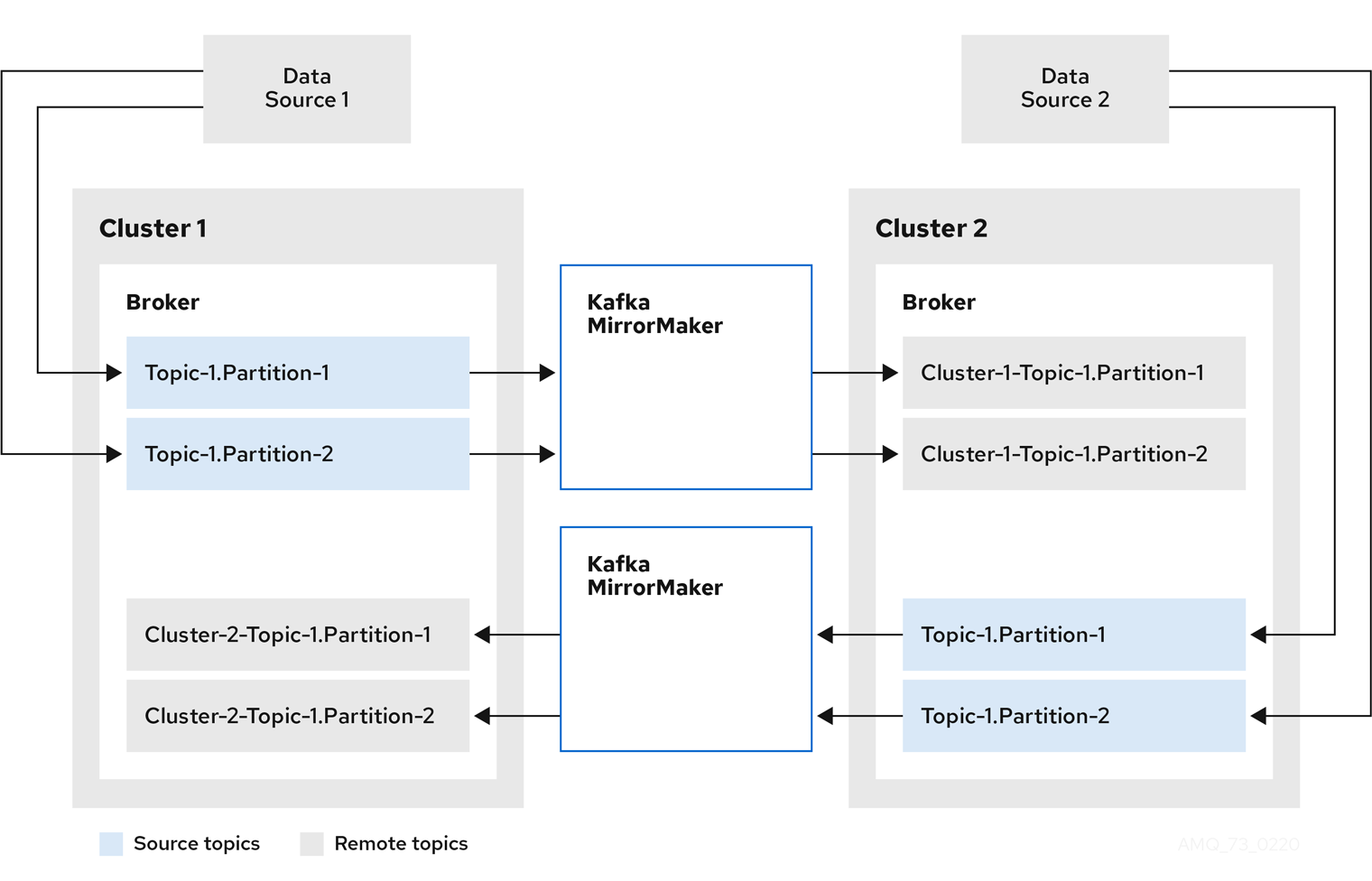
通过标记原始集群,主题不会复制到该集群中。
在配置需要数据聚合的架构时,通过 远程 主题复制的概念非常有用。消费者可以订阅同一群集内的源和远程主题,无需单独的聚合集群。
2.4.2.2. 单向复制(主动/被动)
MirrorMaker 2.0 架构支持 主动/被动 集群配置中的单向复制。
您可以使用 主动/被动 集群配置进行备份,或将数据迁移到另一个集群。在这种情况下,您可能不希望自动重命名远程主题。
您可以通过在 KafkaMirrorMaker2 资源的源连接器配置中添加 IdentityReplicationPolicy 来覆盖自动重命名。应用此配置后,主题会保留其原始名称。
2.4.2.3. 主题配置同步
主题配置会在源集群和目标集群之间自动同步。通过同步配置属性,可以减少重新平衡的需求。
2.4.2.4. 数据完整性
MirrorMaker 2.0 监控源主题,并将配置更改传播到远程主题,检查并创建缺少的分区。只有 MirrorMaker 2.0 可以写入远程主题。
2.4.2.5. 偏移跟踪
MirrorMaker 2.0 使用 内部主题 跟踪消费者组的偏移量。
- 偏移同步 主题映射从记录元数据中复制主题分区的来源和目标偏移
- checkpoint 主题映射源和目标集群中为各个消费者组中复制主题分区的最后提交偏移
检查点 主题的偏移会通过配置预先确定的时间间隔进行跟踪。这两个主题都允许从故障转移上的正确偏移位置完全恢复复制。
MirrorMaker 2.0 使用其 MirrorCheckpointConnector 来发送 检查点 以进行偏移。
2.4.2.6. 连接检查
一个 心跳 的内部主题检查集群之间的连通性。
heartbeat 主题从源集群中复制。
目标集群使用该主题检查:
- 集群之间的连接器正在运行
- 源集群可用
MirrorMaker 2.0 使用其 MirrorHeartbeatConnector 发送执行这些检查 的心跳。
2.4.3. ACL 规则同步
如果没有 使用 User Operator,则可以获得对远程主题的 ACL 访问权限。
如果使用 AclAuthorizer( 没有 User Operator),则管理对代理访问权限的 ACL 规则也适用于远程主题。能够读取源主题的用户可以读取其远程等效内容。
OAuth 2.0 授权不支持以这种方式访问远程主题。
2.4.4. 使用 MirrorMaker 2.0 在 Kafka 集群间同步数据
使用 MirrorMaker 2.0 通过配置同步 Kafka 集群之间的数据。
配置必须指定:
- 每个 Kafka 集群
- 每个集群的连接信息,包括 TLS 身份验证
复制流和方向
- 集群到集群
- 主题
使用 KafkaMirrorMaker2 资源的属性来配置 Kafka MirrorMaker 2.0 部署。
以前版本的 MirrorMaker 继续受到支持。如果要使用为之前版本配置的资源,则必须将其更新为 MirrorMaker 2.0 所支持的格式。
MirrorMaker 2.0 为复制因素等属性提供默认配置值。最小配置(默认值保持不变)会类似如下:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker2
spec:
version: 2.6.0
connectCluster: "my-cluster-target"
clusters:
- alias: "my-cluster-source"
bootstrapServers: my-cluster-source-kafka-bootstrap:9092
- alias: "my-cluster-target"
bootstrapServers: my-cluster-target-kafka-bootstrap:9092
mirrors:
- sourceCluster: "my-cluster-source"
targetCluster: "my-cluster-target"
sourceConnector: {}您可以使用 TLS 或 SASL 身份验证为源和目标集群配置访问控制。此流程显示为源和目标集群使用 TLS 加密和身份验证的配置。
先决条件
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
- 源和目标 Kafka 集群必须可用
步骤
编辑
KafkaMirrorMaker2资源的spec属性。您可以配置的属性显示在此示例配置中:
apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaMirrorMaker2 metadata: name: my-mirror-maker2 spec: version: 2.6.0 1 replicas: 3 2 connectCluster: "my-cluster-target" 3 clusters: 4 - alias: "my-cluster-source" 5 authentication: 6 certificateAndKey: certificate: source.crt key: source.key secretName: my-user-source type: tls bootstrapServers: my-cluster-source-kafka-bootstrap:9092 7 tls: 8 trustedCertificates: - certificate: ca.crt secretName: my-cluster-source-cluster-ca-cert - alias: "my-cluster-target" 9 authentication: 10 certificateAndKey: certificate: target.crt key: target.key secretName: my-user-target type: tls bootstrapServers: my-cluster-target-kafka-bootstrap:9092 11 config: 12 config.storage.replication.factor: 1 offset.storage.replication.factor: 1 status.storage.replication.factor: 1 ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 13 ssl.enabled.protocols: "TLSv1.2" ssl.protocol: "TLSv1.2" ssl.endpoint.identification.algorithm: HTTPS 14 tls: 15 trustedCertificates: - certificate: ca.crt secretName: my-cluster-target-cluster-ca-cert mirrors: 16 - sourceCluster: "my-cluster-source" 17 targetCluster: "my-cluster-target" 18 sourceConnector: 19 config: replication.factor: 1 20 offset-syncs.topic.replication.factor: 1 21 sync.topic.acls.enabled: "false" 22 replication.policy.separator: "" 23 replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy" 24 heartbeatConnector: 25 config: heartbeats.topic.replication.factor: 1 26 checkpointConnector: 27 config: checkpoints.topic.replication.factor: 1 28 topicsPattern: ".*" 29 groupsPattern: "group1|group2|group3" 30 resources: 31 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 32 type: inline loggers: connect.root.logger.level: "INFO" readinessProbe: 33 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 jvmOptions: 34 "-Xmx": "1g" "-Xms": "1g" image: my-org/my-image:latest 35 template: 36 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" connectContainer: 37 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger 38 externalConfiguration: 39 env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: aws-creds key: awsAccessKey - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: name: aws-creds key: awsSecretAccessKey
- 1
- Kafka Connect 版本。
- 2
- 3
- Kafka Connect 的集群 别名.
- 4
- 正在同步 的 Kafka 集群的规格。
- 5
- 源 Kafka 集群的集群 别名。
- 6
- 7
- 8
- 使用源 Kafka 集群的 TLS 证书以 X.509 格式存储的密钥名称进行 TLS 加密。如果证书存储在同一个 secret 中,则可以多次列出证书。
- 9
- 目标 Kafka 集群的集群 别名。
- 10
- 目标 Kafka 集群的身份验证的配置方式与源 Kafka 集群相同。
- 11
- 12
- Kafka Connect 配置.标准 Apache Kafka 配置可能会提供,仅限于不是由 AMQ Streams 直接管理的属性。
- 13
- 使用特定 密码套件 为 TLS 版本运行外部侦听器的 SSL 属性。
- 14
- 通过将 设置为
HTTPS来 启用主机名验证。空字符串将禁用验证。 - 15
- 目标 Kafka 集群的 TLS 加密配置方式与源 Kafka 集群相同。
- 16
- 17
- MirrorMaker 2.0 连接器使用的源集群的集群 别名。
- 18
- MirrorMaker 2.0 连接器使用的目标集群的集群 别名。
- 19
- 创建远程主题的
MirrorSourceConnector配置。配置会覆盖默认配置选项。 - 20
- 在目标集群中创建的已镜像主题的复制因素。
- 21
MirrorSourceConnectoroffset-syncs内部主题的复制因素,用于映射源和目标集群的偏移。- 22
- 启用 ACL 规则同步 时,将应用 ACL 来同步主题。默认值是
true。 - 23
- 定义用于重命名远程主题的分隔符。
- 24
- 添加可覆盖远程主题自动重命名的策略。该主题不会用源集群的名称来附加名称,而是保留其原始名称。此可选设置对主动/被动备份和数据迁移很有用。
- 25
- 执行连接检查
的 MirrorHeartbeatConnector配置。配置会覆盖默认配置选项。 - 26
- 在目标集群中创建的心跳主题的复制因素。
- 27
- 跟踪偏移的
MirrorCheckpointConnector配置。配置会覆盖默认配置选项。 - 28
- 在目标集群中创建的检查点主题的复制因素。
- 29
- 从 定义为正则表达式模式的 源集群进行主题复制。这里我们请求所有主题。
- 30
- 来自 定义为正则表达式模式的 源集群的使用者组复制。在这里,我们按名称请求三个消费者组。您可以使用逗号分隔的列表。
- 31
- 32
- 指定 Kafka 连接日志记录器和日志级别 直接(
内联)或通过ConfigMap 间接(外部)添加。自定义 ConfigMap 必须放在log4j.properties 或log4j2.properties键下。对于 Kafka Connectlog4j.rootLogger日志记录器,您可以将日志级别设置为 INFO、ERROR、WARN、TRACE、DEBUG、FATAL 或 OFF。 - 33
- 健康检查以了解 何时重新启动容器(存活度)以及容器何时可以接受流量(就绪度)。
- 34
- 用于优化运行 Kafka MirrorMaker 的虚拟机(VM)性能的 JVM 配置选项。
- 35
- 高级选项:容器镜像配置,建议仅在特殊情况下使用。
- 36
- 模板自定义.在这里,pod 被调度为反关联性,因此 pod 不会调度到具有相同主机名的节点。
- 37
- 还 使用 Jaeger 为分布式追踪设置 环境变量。
- 38
- 39
- 作为环境变量挂载到 Kafka MirrorMaker 的 OpenShift Secret 的外部配置。
创建或更新资源:
oc apply -f <your-file>
2.5. Kafka Bridge 集群配置
本节论述了如何在 AMQ Streams 集群中配置 Kafka Bridge 部署。
Kafka Bridge 为将基于 HTTP 的客户端与 Kafka 集群集成提供了一个 API。
如果使用 Kafka Bridge,您可以配置 KafkaBridge 资源。
KafkaBridge 资源的完整 schema 信息包括在 第 B.121 节 “KafkaBridge 模式参考” 中。
2.5.1. 配置 Kafka 网桥
使用 Kafka Bridge 向 Kafka 集群发出基于 HTTP 的请求。
使用 KafkaBridge 资源的属性来配置 Kafka Bridge 部署。
为了防止不同 Kafka 网桥实例处理客户端消费者请求时出现问题,必须使用基于地址的路由来确保请求路由到正确的 Kafka Bridge 实例。另外,每个独立的 Kafka Bridge 实例都必须有一个副本。Kafka Bridge 实例具有自己的状态,不与其他实例共享。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
有关运行 以下的说明,请参阅 OpenShift 指南中的部署和升级 AMQ Streams :
步骤
编辑
KafkaBridge资源的spec属性。您可以配置的属性显示在此示例配置中:
apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: my-bridge spec: replicas: 3 1 bootstrapServers: my-cluster-kafka-bootstrap:9092 2 tls: 3 trustedCertificates: - secretName: my-cluster-cluster-cert certificate: ca.crt - secretName: my-cluster-cluster-cert certificate: ca2.crt authentication: 4 type: tls certificateAndKey: secretName: my-secret certificate: public.crt key: private.key http: 5 port: 8080 cors: 6 allowedOrigins: "https://strimzi.io" allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH" consumer: 7 config: auto.offset.reset: earliest producer: 8 config: delivery.timeout.ms: 300000 resources: 9 requests: cpu: "1" memory: 2Gi limits: cpu: "2" memory: 2Gi logging: 10 type: inline loggers: logger.bridge.level: "INFO" # enabling DEBUG just for send operation logger.send.name: "http.openapi.operation.send" logger.send.level: "DEBUG" jvmOptions: 11 "-Xmx": "1g" "-Xms": "1g" readinessProbe: 12 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 image: my-org/my-image:latest 13 template: 14 pod: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: application operator: In values: - postgresql - mongodb topologyKey: "kubernetes.io/hostname" bridgeContainer: 15 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831"
- 1
- 2
- 3
- 使用源 Kafka 集群的 TLS 证书以 X.509 格式存储的密钥名称进行 TLS 加密。如果证书存储在同一个 secret 中,则可以多次列出证书。
- 4
- Kafka Bridge 集群的身份验证,使用 TLS 机制 (此处所示)、使用 OAuth bearer 令牌 或基于 SASL 的 SCRAM-SHA-512 或 PLAIN 机制。默认情况下,Kafka Bridge 在不进行身份验证的情况下连接到 Kafka 代理。
- 5
- 对 Kafka 代理的 HTTP 访问.
- 6
- CORS 访问 指定选定的资源和访问方法.请求中的附加 HTTP 标头描述了允许访问 Kafka 集群的原始数据。
- 7
- 8
- 9
- 10
- 指定 Kafka Bridge 日志记录器和日志级别 直接(
内联)或通过ConfigMap 间接(外部)添加。自定义 ConfigMap 必须放在log4j.properties 或log4j2.properties键下。对于 Kafka Bridge loggers,您可以将日志级别设置为 INFO、ERROR、WARN、TRACE、DEBUG、FATAL 或 OFF。 - 11
- 运行 Kafka 网桥的虚拟机(VM)的 JVM 配置选项 优化性能。
- 12
- 健康检查以了解 何时重新启动容器(存活度)以及容器何时可以接受流量(就绪度)。
- 13
- 高级选项:容器镜像配置,建议仅在特殊情况下使用。
- 14
- 模板自定义.在这里,pod 被调度为反关联性,因此 pod 不会调度到具有相同主机名的节点。
- 15
- 还 使用 Jaeger 为分布式追踪设置 环境变量。
创建或更新资源:
oc apply -f KAFKA-BRIDGE-CONFIG-FILE
2.5.2. Kafka Bridge 集群资源列表
以下资源由 OpenShift 集群中的 Cluster Operator 创建:
- bridge-cluster-name-bridge
- 部署,用于创建 Kafka Bridge worker 节点 pod。
- bridge-cluster-name-bridge-service
- 公开 Kafka Bridge 集群的 REST 接口的服务。
- bridge-cluster-name-bridge-config
- 包含 Kafka Bridge 辅助配置且由 Kafka 代理 Pod 挂载为卷的 ConfigMap。
- bridge-cluster-name-bridge
- 为 Kafka Bridge worker 节点配置的 Pod Disruption Budget。
2.6. 自定义 OpenShift 资源
AMQ Streams 创建几个 OpenShift 资源,如 Deployment、StatefulSet、 Pod 和 Services,它们由 AMQ Streams 操作器管理。只有负责管理特定 OpenShift 资源的操作器才能更改该资源。如果您尝试手动更改由 operator 管理的 OpenShift 资源,Operator 会将您的更改还原。
但是,更改由 Operator 管理的 OpenShift 资源对于执行某些任务很有用,例如:
-
添加控制 Istio 或其他服务如何处理
Pod的自定义标签或注解 -
管理集群如何创建
Loadbalancer-type Services
您可以使用 AMQ Streams 自定义资源中的 template 属性进行此类更改。template 属性在以下资源中受到支持:API 引用提供了有关可自定义字段的更多详情。
Kafka.spec.kafka-
请查看 第 B.53 节 “
KafkaClusterTemplate模式参考” Kafka.spec.zookeeper-
请查看 第 B.63 节 “
ZookeeperClusterTemplate模式参考” Kafka.spec.entityOperator-
请查看 第 B.68 节 “
EntityOperatorTemplate模式参考” Kafka.spec.kafkaExporter-
请查看 第 B.74 节 “
KafkaExporterTemplate模式参考” Kafka.spec.cruiseControl-
请查看 第 B.71 节 “
CruiseControlTemplate模式参考” KafkaConnect.spec-
请查看 第 B.88 节 “
KafkaConnectTemplate模式参考” KafkaConnectS2I.spec-
请查看 第 B.88 节 “
KafkaConnectTemplate模式参考” KafkaMirrorMaker.spec-
请查看 第 B.119 节 “
KafkaMirrorMakerTemplate模式参考” KafkaMirrorMaker2.spec-
请查看 第 B.88 节 “
KafkaConnectTemplate模式参考” KafkaBridge.spec-
请查看 第 B.128 节 “
KafkaBridgeTemplateschema reference” KafkaUser.spec-
请查看 第 B.112 节 “
KafkaUserTemplate模式参考”
在以下示例中,使用 template 属性来修改 Kafka 代理的 StatefulSet 中的标签:
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
labels:
app: my-cluster
spec:
kafka:
# ...
template:
statefulset:
metadata:
labels:
mylabel: myvalue
# ...2.6.1. 自定义镜像拉取策略
AMQ Streams 允许您自定义 Cluster Operator 部署的所有 pod 中容器的镜像拉取策略。镜像拉取策略使用 Cluster Operator 部署中的环境变量 STRIMZI_IMAGE_PULL_POLICY 进行配置。STRIMZI_IMAGE_PULL_POLICY 环境变量可设置为三个不同的值:
Always- 每次 pod 启动或重启时,都会从注册表调取容器镜像。
IfNotPresent- 容器镜像只有在之前没有拉取(pull)时才从注册表中提取。
Never- 容器镜像永远不会从注册表调取。
镜像拉取策略目前只能对所有 Kafka、Kafka Connect 和 Kafka MirrorMaker 集群进行自定义。更改策略会导致所有 Kafka、Kafka Connect 和 Kafka MirrorMaker 集群滚动更新。
其他资源
- 有关 Cluster Operator 配置的更多信息,请参阅 第 5.1 节 “使用 Cluster Operator”。
- 有关镜像拉取策略的更多信息,请参阅 Disruptions。
2.7. 外部日志记录
在为资源设置日志级别时,您可以直接在资源 YAML 的 spec.logging 属性中指定它们:
spec:
# ...
logging:
type: inline
loggers:
kafka.root.logger.level: "INFO"或者您可以指定 外部 日志记录:
spec:
# ...
logging:
type: external
name: customConfigMap
使用外部日志记录时,日志属性在 ConfigMap 中定义。ConfigMap 的名称在 spec.logging.name 属性中引用。
使用 ConfigMap 的优点是日志记录属性在一个位置维护,并可以被多个资源访问。
2.7.1. 为日志记录创建 ConfigMap
要使用 ConfigMap 定义日志属性,您需要创建 ConfigMap,然后在资源 spec 中的日志记录定义中引用它。
ConfigMap 必须包含适当的日志记录配置。
-
Kafka 组件、ZooKeeper 和 Kafka Bridge
的 log4j.properties -
Topic Operator 和 User Operator
的 log4j2.properties
配置必须置于这些属性下。
此处我们演示 ConfigMap 如何定义 Kafka 资源的根日志记录器。
步骤
创建 ConfigMap。
您可以使用位于命令行的
oc以 YAML 文件或属性文件创建 ConfigMap。带有 Kafka 的根日志记录器定义的 ConfigMap 示例:
kind: ConfigMap apiVersion: kafka.strimzi.io/v1beta1 metadata: name: logging-configmap data: log4j.properties: kafka.root.logger.level="INFO"在命令行中使用属性文件:
oc create configmap logging-configmap --from-file=log4j.properties
属性文件定义日志配置:
# Define the logger kafka.root.logger.level="INFO" # ...
在资源的
spec中定义 外部 日志记录,将logging.name设置为 ConfigMap 的名称。spec: # ... logging: type: external name: logging-configmap创建或更新资源。
oc apply -f kafka.yaml
第 3 章 配置外部监听程序
使用外部监听程序向 OpenShift 环境外的客户端公开您的 AMQ Streams Kafka 集群。
在外部监听程序配置中指定要公开 Kafka 的连接 类型。
-
NodePort 使用NodePort服务 -
LoadBalancer 使用Loadbalancer类型服务 -
Ingress使用 KubernetesIngress和 Kubernetes 的 NGINX Ingress Controller -
路由使用 OpenShift路由和 HAProxy 路由器
有关监听器配置的更多信息,请参阅 GenericKafkaListener 模式参考。
路由 只在 OpenShift 中被支持
3.1. 使用节点端口访问 Kafka
此流程描述了如何使用节点端口从外部客户端访问 AMQ Streams Kafka 集群。
要连接到代理,您需要 Kafka bootstrap 地址 的主机名和端口号,以及用于身份验证的证书。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
配置
Kafka资源,并将外部监听程序设置为nodeport类型。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: - name: external port: 9094 type: nodeport tls: true authentication: type: tls # ... # ... zookeeper: # ...创建或更新资源。
oc apply -f KAFKA-CONFIG-FILE为每个 Kafka 代理和外部 bootstrap 服务 创建
NodePort类型服务。bootstrap 服务将外部流量路由到 Kafka 代理。用于连接的节点地址被传播到 Kafka 自定义资源的状态。也使用与
Kafka资源相同的名称来创建用于验证 kafka 代理身份的集群 CA 证书。从 Kafka
资源的状态检索您用来访问 Kafka 集群的 bootstrap 地址。oc get kafka KAFKA-CLUSTER-NAME -o=jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}{"\n"}'如果启用了 TLS 加密,请提取代理认证机构的公共证书。
oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt使用 Kafka 客户端中提取的证书来配置 TLS 连接。如果启用了任何身份验证,您还需要配置 SASL 或 TLS 身份验证。
3.2. 使用 loadbalancers 访问 Kafka
这个步骤描述了如何使用 loadbalancers 从外部客户端访问 AMQ Streams Kafka 集群。
要连接到代理,您需要 bootstrap 负载均衡器的地址, 以及用于 TLS 加密的证书。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
配置
Kafka资源,并将外部监听程序设置为loadbalancer类型。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: - name: external port: 9094 type: loadbalancer tls: true # ... # ... zookeeper: # ...创建或更新资源。
oc apply -f KAFKA-CONFIG-FILELoadBalancer 类型服务和负载均衡器是为每个 Kafka 代理和一个外部 bootstrap 服务 创建的。bootstrap 服务将外部流量路由到所有 Kafka 代理。用于连接的 DNS 名称和 IP 地址会传播到每个服务的状态。也使用与
Kafka资源相同的名称来创建用于验证 kafka 代理身份的集群 CA 证书。从 Kafka
资源的状态检索可用于访问 Kafka 集群的 bootstrap 服务地址。oc get kafka KAFKA-CLUSTER-NAME -o=jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}{"\n"}'如果启用了 TLS 加密,请提取代理认证机构的公共证书。
oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt使用 Kafka 客户端中提取的证书来配置 TLS 连接。如果启用了任何身份验证,您还需要配置 SASL 或 TLS 身份验证。
3.3. 使用 ingress 访问 Kafka
此流程演示了如何使用 Nginx Ingress 从 OpenShift 外部的外部客户端访问 AMQ Streams Kafka 集群。
要连接到代理,需要 Ingress bootstrap 地址的主机名(公告地址 ),以及用于身份验证的证书。
对于使用 Ingress 访问,端口始终为 443。
TLS passthrough
Kafka 通过 TCP 使用二进制协议,但 Kubernetes 的 NGINX Ingress Controller 旨在使用 HTTP 协议。为了能够通过 Ingress 传递 Kafka 连接,AMQ Streams 使用 Kubernetes NGINX Ingress Controller 的 TLS 直通功能。确保在 NGINX Ingress Controller 中为 Kubernetes 部署启用了 TLS passthrough。
由于它使用 TLS passthrough 功能,所以在使用 Ingress 公开 Kafka 时无法禁用 TLS 加密。
有关启用 TLS 直通的更多信息,请参阅 TLS 直通文档。
先决条件
- OpenShift 集群
- 为启用了 TLS passthrough 的 Kubernetes 部署 NGINX Ingress Controller
- 一个正在运行的 Cluster Operator
步骤
配置
Kafka资源,并将外部监听程序设置为ingress类型。指定 bootstrap 服务和 Kafka 代理的 Ingress 主机。
例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: - name: external port: 9094 type: ingress tls: true authentication: type: tls configuration: 1 bootstrap: host: bootstrap.myingress.com brokers: - broker: 0 host: broker-0.myingress.com - broker: 1 host: broker-1.myingress.com - broker: 2 host: broker-2.myingress.com # ... zookeeper: # ...- 1
- bootstrap 服务和 Kafka 代理的 Ingress 主机。
创建或更新资源。
oc apply -f KAFKA-CONFIG-FILE为每个 Kafka 代理创建
ClusterIP类型服务,以及一个额外的 bootstrap 服务。这些服务供 Ingress 控制器用于将流量路由到 Kafka 代理。还会为每个服务创建一个Ingress资源,以使用 Ingress 控制器公开它们。Ingress 主机传播到每个服务的状态。也使用与
Kafka资源相同的名称来创建用于验证 kafka 代理身份的集群 CA 证书。使用 Kafka 客户端中的
配置和端口 443(BOOTSTRAP-HOST:443)中指定的 bootstrap 主机 地址,作为 bootstrap 地址 连接到 Kafka 集群。提取代理认证机构的公共证书。
oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt使用 Kafka 客户端中提取的证书来配置 TLS 连接。如果启用了任何身份验证,您还需要配置 SASL 或 TLS 身份验证。
3.4. 使用 OpenShift 路由访问 Kafka
此流程描述了如何使用路由从 OpenShift 外部的外部客户端访问 AMQ Streams Kafka 集群。
要连接到代理,您需要路由 bootstrap 地址 的主机名以及用于 TLS 加密的证书。
对于使用路由的访问,端口始终为 443。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
配置
Kafka资源,并将外部监听程序设置为路由类型。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: labels: app: my-cluster name: my-cluster namespace: myproject spec: kafka: # ... listeners: - name: listener1 port: 9094 type: route tls: true # ... # ... zookeeper: # ...警告OpenShift Route 地址包含 Kafka 集群的名称、侦听器的名称以及在其中创建的命名空间的名称。例如,my
-cluster-kafka-listener1-bootstrap-myproject(CLUSTER-NAME-kafka-LISTENER-NAME-bootstrap-NAMESPACE)。请注意,地址的长度不超过 63 个字符的最大限制。创建或更新资源。
oc apply -f KAFKA-CONFIG-FILE为每个 Kafka 代理和外部 bootstrap 服务 创建
ClusterIP类型服务。服务将流量从 OpenShift 路由路由到 Kafka 代理。同时也为每个服务创建一个 OpenShiftRoute资源,以利用 HAProxy 负载平衡器公开它们。用于连接的 DNS 地址会传播到每个服务的状态。也使用与
Kafka资源相同的名称来创建用于验证 kafka 代理身份的集群 CA 证书。从 Kafka
资源的状态检索可用于访问 Kafka 集群的 bootstrap 服务地址。oc get kafka KAFKA-CLUSTER-NAME -o=jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}{"\n"}'提取代理认证机构的公共证书。
oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt使用 Kafka 客户端中提取的证书来配置 TLS 连接。如果启用了任何身份验证,您还需要配置 SASL 或 TLS 身份验证。
第 4 章 管理对 Kafka 的安全访问
您可以通过管理每个客户端对 Kafka 代理的访问权限来保护 Kafka 集群。
Kafka 代理和客户端之间的安全连接可以包含:
- 为数据交换加密
- 验证以证明身份
- 允许或拒绝用户执行的操作的授权
本章解释了如何在 Kafka 代理和客户端之间设置安全连接,包含如下所述:
- Kafka 集群和客户端的安全选项
- 如何保护 Kafka 代理
- 如何使用授权服务器进行基于 OAuth 2.0 令牌的身份验证和授权
4.1. Kafka 的安全选项
使用 Kafka 资源配置用于 Kafka 身份验证和授权的机制。
4.1.1. 监听程序验证
对于 OpenShift 集群内的客户端,您可以创建 普通 (无需加密)或 tls 内部 侦听器。
对于 OpenShift 集群外的客户端,您可以创建 外部 侦听器并指定连接机制,可以是 节点端口、负载均衡器、 入口 或 路由 (在 OpenShift 上)。
有关连接外部客户端的配置选项的更多信息,请参阅配置外部监听程序。
支持的验证选项:
- 双向 TLS 身份验证(仅在启用了 TLS 加密的监听器中)
- SCRAM-SHA-512 验证
- 基于 OAuth 2.0 令牌的身份验证
您选择的身份验证选项取决于您要如何验证客户端对 Kafka 代理的访问。
图 4.1. Kafka 侦听程序验证选项
侦听器 身份验证 属性用于指定特定于该侦听器的身份验证机制。
如果没有指定 身份验证 属性,侦听器不会验证通过该侦听器进行连接的客户端。侦听器将接受所有连接,无需身份验证。
在使用 User Operator 管理 KafkaUsers 时,必须配置身份验证。
以下示例显示:
-
为 SCRAM-SHA-512 身份验证配置
的普通监听器 -
具有 mutual TLS 身份验证的 A
tls侦听器 -
具有 mutual TLS 身份验证
的外部监听程序
每个监听程序都使用 Kafka 集群中的唯一名称和端口进行配置。
无法将监听器配置为使用为 Interbroker 通信(9091)和指标(9404)设置的端口。
显示监听器身份验证配置的示例
# ...
listeners:
- name: plain
port: 9092
type: internal
tls: true
authentication:
type: scram-sha-512
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: tls
# ...
4.1.1.1. 双向 TLS 身份验证
双向 TLS 身份验证始终用于 Kafka 代理和 ZooKeeper pod 之间的通信。
AMQ Streams 可以配置 Kafka 以使用 TLS(传输层安全),以提供 Kafka 代理和客户端之间的加密通信,无论是否带有或不使用相互身份验证。为互相或双向身份验证,服务器和客户端都提供证书。当您配置相互身份验证时,代理会验证客户端(客户端身份验证),客户端验证代理(服务器身份验证)。
TLS 身份验证更通常是单向,一个方验证另一方的身份。例如,当 Web 浏览器和 Web 服务器之间使用 HTTPS 时,浏览器会获得 Web 服务器身份验证。
4.1.1.2. SCRAM-SHA-512 验证
SCRAM(销售挑战响应身份验证机制)是一种身份验证协议,可以使用密码建立相互身份验证。AMQ Streams 可以配置 Kafka,以使用 SASL(简单身份验证和安全层) SCRAM-SHA-512 提供未加密和加密客户端连接的身份验证。
当 SCRAM-SHA-512 身份验证与 TLS 客户端连接一起使用时,TLS 协议提供加密,但不用于身份验证。
以下 SCRAM 属性可以安全地在未加密连接中使用 SCRAM-SHA-512:
- 密码不会通过通信通道在明文中发送。相反,客户端和服务器都受到另一用户的挑战,难以提供他们知道验证用户密码的证明。
- 服务器和客户端各自为每个身份验证交换生成新的挑战。这意味着交换具有应对重播攻击的弹性。
当使用 scr am-sha-512 配置 KafkaUser.spec.authentication.type 时,User Operator 将生成由大写和小写 ASCII 字母和数字组成的随机 12 个字符密码。
4.1.1.3. 网络策略
AMQ Streams 自动为每个在 Kafka 代理上启用的监听程序创建一个 NetworkPolicy 资源。默认情况下,NetworkPolicy 会 授予监听器访问所有应用程序和命名空间的权限。
如果要将网络级别的监听器访问限制为仅选择的应用程序或命名空间,请使用 networkPolicyPeers 属性。
使用网络策略作为监听器身份验证配置的一部分。每个监听器都可以具有不同的 networkPolicyPeers 配置。
如需更多信息,请参阅 Listener 网络策略 部分和 NetworkPolicyPeer API 参考。
您的 OpenShift 配置必须支持 Ingress NetworkPolicies,以便在 AMQ Streams 中使用网络策略。
4.1.1.4. 其他监听程序配置选项
您可以使用 GenericKafkaListenerConfiguration 模式 的属性在监听器中添加更多配置。
4.1.2. kafka 授权
您可以使用 Kafka. spec.kafka 资源中的 代理配置授权。如果缺少 authorization 属性为 Kafkaauthorization 属性,则不启用授权,并且客户端没有限制。启用后,授权将应用到所有启用的监听程序。授权方法在 type 字段中定义。
支持的授权选项:
- 简单授权
- OAuth 2.0 授权 (如果您使用基于 OAuth 2.0 令牌的身份验证)
- 打开策略代理(OPA)授权
图 4.2. Kafka 集群授权选项
4.1.2.1. 超级用户
无论访问限制如何,超级用户可以访问 Kafka 集群中的所有资源,并受所有授权机制的支持。
要为 Kafka 集群指定超级用户,请在 superUsers 属性中添加用户主体列表。如果用户使用 TLS 客户端身份验证,则其用户名是其证书主题的通用名称,前缀为 CN=。
带有超级用户的示例配置
authorization:
type: simple
superUsers:
- CN=client_1
- user_2
- CN=client_3
4.2. Kafka 客户端的安全选项
使用 KafkaUser 资源,为 Kafka 客户端配置身份验证机制、授权机制和访问权限。在配置安全性方面,客户端以用户身份表示。
您可以验证并授权用户对 Kafka 代理的访问权限。身份验证允许访问,授权限制了对允许的操作的访问。
您还可以创建对 Kafka 代理具有不受约束访问权限的 超级用户。
身份验证和授权机制必须与 用于访问 Kafka 代理的监听程序规格相符。
4.2.1. 为用户处理识别 Kafka 集群
KafkaUser 资源包含一个标签,用于定义它所属的 Kafka 集群的名称(从 Kafka 资源的名称衍生)。
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
该标签供 User Operator 用于标识 KafkaUser 资源、创建一个新用户,并在后续处理用户时也使用该标签。
如果标签与 Kafka 集群不匹配,User Operator 无法识别 KafkaUser,并且不会创建该用户。
如果 KafkaUser 资源的状态为空,请检查您的标签。
4.2.2. 用户身份验证
使用 KafkaUser.spec 中的 身份验证 属性配置用户身份验证。为用户启用的身份验证机制使用 type 字段指定。
支持的验证机制:
- TLS 客户端身份验证
- SCRAM-SHA-512 验证
如果没有指定身份验证机制,User Operator 不会创建用户或其凭证。
4.2.2.1. TLS 客户端身份验证
要使用 TLS 客户端身份验证,请将 type 字段设置为 tls。
启用了 TLS 客户端身份验证的 KafkaUser 示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
# ...
当 User Operator 创建用户时,它会创建一个名称与 KafkaUser 资源相同的新 Secret。Secret 包含用于 TLS 客户端身份验证的私钥和公钥。公钥包含在用户证书中,由客户端证书颁发机构(CA)签名。
所有键均采用 X.509 格式。
secret 以 PEM 和 PKCS #12 格式提供私钥和证书。
有关保护 Kafka 与 Secret 的通信的更多信息,请参阅 第 11 章 管理 TLS 证书。
带有用户凭证的 Secret 示例
apiVersion: v1
kind: Secret
metadata:
name: my-user
labels:
strimzi.io/kind: KafkaUser
strimzi.io/cluster: my-cluster
type: Opaque
data:
ca.crt: # Public key of the client CA
user.crt: # User certificate that contains the public key of the user
user.key: # Private key of the user
user.p12: # PKCS #12 archive file for storing certificates and keys
user.password: # Password for protecting the PKCS #12 archive file
4.2.2.2. SCRAM-SHA-512 身份验证
要使用 SCRAM-SHA-512 身份验证机制,请将 type 字段设置为 scr am-sha-512。
启用了 SCRAM-SHA-512 身份验证的 KafkaUser 示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: scram-sha-512
# ...
当 User Operator 创建用户时,它会创建一个名称与 KafkaUser 资源相同的新 secret。该机密包含 password 密钥中生成的密码,该密码使用 base64 编码。若要使用该密码,必须对其进行解码。
带有用户凭证的 Secret 示例
apiVersion: v1
kind: Secret
metadata:
name: my-user
labels:
strimzi.io/kind: KafkaUser
strimzi.io/cluster: my-cluster
type: Opaque
data:
password: Z2VuZXJhdGVkcGFzc3dvcmQ= 1
- 1
- 生成的密码 base64 编码。
解码生成的密码:
echo "Z2VuZXJhdGVkcGFzc3dvcmQ=" | base64 --decode
4.2.3. 用户授权
用户授权使用 KafkaUser.spec 中的 授权 属性进行配置。用户启用的授权类型通过 type 字段指定。
要使用简单授权,您可以在 KafkaUser.spec.authorization 中将 type 属性设置为 simple。简单授权使用默认的 Kafka 授权插件 AclAuthorizer。
或者,您可以使用 OPA 授权,或者已使用基于 OAuth 2.0 令牌的身份验证,您也可以使用 OAuth 2.0 授权。
如果没有指定授权,User Operator 不会为用户置备任何访问权限。这种 KafkaUser 是否可以访问资源取决于所使用的授权程序。例如,对于 AclAuthorizer,这由其 allow.everyone.if.no.acl.found 配置决定。
4.2.3.1. ACL 规则
AclAuthorizer 使用 ACL 规则来管理对 Kafka 代理的访问。
ACL 规则为用户授予访问权限,用户在 acls 属性中指定。
有关 AclRule 对象的更多信息,请参阅 AclRule 架构引用。
4.2.3.2. 超级用户访问 Kafka 代理
如果在 Kafka 代理配置中的超级用户列表中添加用户,则允许用户无限访问集群,无论 KafkaUser 中的 ACL 中定义的任何授权限制。
有关配置超级用户访问权限的更多信息,请参阅 Kafka 授权。
4.2.3.3. 用户配额
您可以配置 KafkaUser 资源的 spec 来强制配额,以便用户不会根据字节阈值或 CPU 使用率限制超过对 Kafka 代理的访问。
使用用户配额的 KafkaUser 示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
quotas:
producerByteRate: 1048576 1
consumerByteRate: 2097152 2
requestPercentage: 55 3
有关这些属性的更多信息,请参阅 KafkaUserQuotas 架构引用。
4.3. 保护对 Kafka 代理的访问
要建立对 Kafka 代理的安全访问,您需要配置并应用:
Kafka资源,用于:- 使用指定验证类型创建监听程序
- 为整个 Kafka 集群配置授权
-
通过监听程序安全访问 Kafka 代理的 Kafka
User资源
配置 Kafka 资源以设置:
- 监听程序验证
- 限制对 Kafka 侦听器的访问的网络策略
- kafka 授权
- 超级用户对代理进行无限制访问
身份验证是为每个监听器独立配置的。始终为整个 Kafka 集群配置授权。
Cluster Operator 创建监听程序并设置集群和客户端证书颁发机构(CA)证书,以便在 Kafka 集群中启用身份验证。
您可以通过 安装您自己的证书来替换 Cluster Operator 生成的证书。您还可以将 监听程序配置为使用由外部证书颁发机构管理的 Kafka 侦听器证书。证书以 PKCS #12 格式(.p12)和 PEM(.crt)格式提供。
使用 KafkaUser 启用特定客户端用来访问 Kafka 的身份验证和授权机制。
配置 KafkaUser 资源以设置:
- 与启用的监听器验证匹配的身份验证
- 与启用的 Kafka 授权匹配的授权
- 用于控制客户端资源使用的配额
User Operator 根据所选的身份验证类型,创建代表客户端以及用于客户端身份验证的安全凭证的用户。
其他资源
有关以下模式的更多信息:
-
kafka,请参阅Kafka模式引用。 -
KafkaUser,请参阅KafkaUser架构引用。
4.3.1. 保护 Kafka 代理
此流程演示了在运行 AMQ Streams 时保护 Kafka 代理的步骤。
为 Kafka 代理实施的安全性必须与为需要访问的客户端实施的安全性兼容。
-
Kafka.spec.kafka.listeners[*].authenticationmatchesKafkaUser.spec.authentication -
kafka.spec.kafka.authorization与KafkaUser.spec.authorization匹配
步骤演示了使用 TLS 身份验证的简单授权和监听器的配置。有关监听器配置的更多信息,请参阅 GenericKafkaListener 模式参考。
另外,您可以使用 SCRAM-SHA 或 OAuth 2.0 进行 监听程序身份验证,使用 OAuth 2.0 或 OPA 进行 Kafka 授权。
步骤
配置
Kafka资源。-
配置
授权属性。 配置 listens
属性,以创建具有身份验证的侦听器。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... authorization: 1 type: simple superUsers: 2 - CN=client_1 - user_2 - CN=client_3 listeners: - name: tls port: 9093 type: internal tls: true authentication: type: tls 3 # ... zookeeper: # ...- 1
- 2
- 对 Kafka 拥有无限访问权限的用户主体列表。在使用 TLS 身份验证时,CN 是客户端证书的常用名称。
- 3
- 监听器身份验证机制可以为每个侦听器配置,并 指定为 mutual TLS、SCRAM-SHA-512 或基于令牌的 OAuth 2.0。
如果您要配置外部监听程序,其配置取决于所选的连接机制。
-
配置
创建或更新
Kafka资源。oc apply -f KAFKA-CONFIG-FILE使用 TLS 身份验证配置 Kafka 代理监听程序。
为每个 Kafka 代理 pod 创建一个服务。
创建一个服务作为连接到 Kafka 集群的 bootstrap 地址。
也使用与
Kafka资源相同的名称来创建用于验证 kafka 代理身份的集群 CA 证书。
4.3.2. 保护用户对 Kafka 的访问
使用 KafkaUser 资源的属性来配置 Kafka 用户。
您可以使用 oc apply 创建或修改用户,使用 oc delete 删除现有用户。
例如:
-
oc apply -f USER-CONFIG-FILE -
oc delete KafkaUser USER-NAME
当您配置 KafkaUser 身份验证和授权机制时,请确保它们与等同的 Kafka 配置匹配:
-
KafkaUser.spec.authenticationmatchesKafka.spec.kafka.listeners[*].authentication -
KafkaUser.spec.authorization与Kafka.spec.kafka.authorization匹配
此流程演示了如何使用 TLS 身份验证创建用户。您还可以创建具有 SCRAM-SHA 身份验证的用户。
所需的身份验证取决于为 Kafka 代理监听程序配置的身份验证类型。
Kafka 用户和 Kafka 代理之间的身份验证取决于每个用户的身份验证设置。例如,如果 Kafka 配置中没有启用 TLS 的用户,则无法验证它。
先决条件
- 正在运行的 Kafka 集群使用 Kafka 代理监听程序配置使用 TLS 身份验证和加密。
- 一个正在运行的 User Operator( 通常使用 Entity Operator 部署)。
KafkaUser 中的身份验证类型应与 Kafka 代理中配置的身份验证匹配。
步骤
配置
KafkaUser资源。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster spec: authentication: 1 type: tls authorization: type: simple 2 acls: - resource: type: topic name: my-topic patternType: literal operation: Read - resource: type: topic name: my-topic patternType: literal operation: Describe - resource: type: group name: my-group patternType: literal operation: Read创建或更新
KafkaUser资源。oc apply -f USER-CONFIG-FILE已创建用户,以及名称与
KafkaUser资源相同的 Secret。Secret 包含用于 TLS 客户端身份验证的私钥和公钥。
有关使用安全连接到 Kafka 代理的属性配置 Kafka 客户端的详情,请参考《 部署 AMQ 流指南 》中为 OpenShift 之外的客户端设置访问权限。
4.3.3. 使用网络策略限制对 Kafka 侦听器的访问
您可以使用 networkPolicyPeers 属性将监听器的访问限制为所选应用程序。
先决条件
- 个支持 Ingress NetworkPolicies 的 OpenShift 集群。
- Cluster Operator 正在运行。
步骤
-
打开
Kafka资源。 在
networkPolicyPeers属性中,定义允许访问 Kafka 集群的应用程序 pod 或命名空间。例如,将 a
tls侦听程序配置为只允许来自标签app设置为kafka-client的应用程序 pod 的连接:apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: kafka: # ... listeners: - name: tls port: 9093 type: internal tls: true authentication: type: tls networkPolicyPeers: - podSelector: matchLabels: app: kafka-client # ... zookeeper: # ...创建或更新资源。
使用
oc apply:oc apply -f your-file
其他资源
-
有关该架构的更多信息,请参阅 NetworkPolicyPeer API 参考 和
GenericKafkaListener模式参考。
4.4. 使用基于 OAuth 2.0 令牌的身份验证
AMQ Streams 支持使用 SASL OAUTHBEARER 机制进行 OAuth 2.0 身份验证。
OAuth 2.0 支持应用之间基于令牌的标准化身份验证和授权,使用中央授权服务器发布对资源的有限访问权限的令牌。
您可以配置 OAuth 2.0 身份验证,然后配置 OAuth 2.0 授权。
OAuth 2.0 身份验证也可与 简单 或基于 OPA 的 Kafka 授权 一起使用。
通过使用基于 OAuth 2.0 令牌的身份验证,应用客户端可以访问应用服务器(称为 资源服务器)上的资源,而无需公开帐户凭据。
应用客户端通过访问令牌来进行身份验证,应用服务器也可以使用该令牌来确定要授予的访问权限级别。授权服务器处理关于访问权限的访问和咨询。
在 AMQ Streams 中:
- Kafka 代理充当 OAuth 2.0 资源服务器
- Kafka 客户端充当 OAuth 2.0 应用程序客户端
Kafka 客户端向 Kafka 代理进行身份验证。代理和客户端根据需要与 OAuth 2.0 授权服务器通信,以获取或验证访问令牌。
对于 AMQ Streams 的部署,OAuth 2.0 集成提供:
- 对 Kafka 代理的服务器端 OAuth 2.0 支持
- 客户端 OAuth 2.0 支持 Kafka MirrorMaker、Kafka Connect 和 Kafka Bridge
其他资源
4.4.1. OAuth 2.0 身份验证机制
Kafka SASL OAUTHBEARER 机制用于通过 Kafka 代理建立经过身份验证的会话。
Kafka 客户端使用 SASL OAUTHBEARER 机制与 Kafka 代理启动会话,其中凭证采用访问令牌的形式。
Kafka 代理和客户端需要配置为使用 OAuth 2.0。
4.4.2. OAuth 2.0 Kafka 代理配置
OAuth 2.0 的 Kafka 代理配置涉及:
- 在授权服务器中创建 OAuth 2.0 客户端
- 在 Kafka 自定义资源中配置 OAuth 2.0 身份验证
对于授权服务器,Kafka 代理和 Kafka 客户端都被视为 OAuth 2.0 客户端。
4.4.2.1. 授权服务器上的 OAuth 2.0 客户端配置
要将 Kafka 代理配置为验证在会话启动过程中收到的令牌,推荐的方法是在授权服务器中创建 OAuth 2.0 客户端 定义(配置为 机密 )并启用以下客户端凭证:
-
kafka的客户端 ID(例如) - 客户端 ID 和机密作为身份验证机制
您只需要在使用授权服务器的非公共内省端点时使用客户端 ID 和机密。在使用公共授权服务器端点时,通常不需要凭据,如进行快速本地 JWT 令牌验证一样。
4.4.2.2. Kafka 集群中的 OAuth 2.0 身份验证配置
要在 Kafka 集群中使用 OAuth 2.0 身份验证,例如,您可以使用身份验证方法 oauth 为 Kafka 集群自定义资源指定 TLS 侦听程序配置:
断言 OAuth 2.0 的身份验证方法类型
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
# ...
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: oauth
#...
您可以配置 普通的、tls 和外部 监听程序,但建议您不要使用使用 OAuth 2.0 禁用 TLS 加密 的纯 监听程序 或外部监听程序,因为这会对通过令牌 Sft 进行网络窃取和未经授权的访问造成漏洞。
您可以使用 type: oauth 为安全传输层配置 外部 监听程序,以便与客户端通信。
使用带有外部监听器的 OAuth 2.0
# ...
listeners:
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: oauth
#...
tls 属性默认为 false,因此必须启用。
当您将身份验证类型定义为 OAuth 2.0 后,您可以根据验证类型添加配置,或者作为 快速本地 JWT 验证 或使用内省端点进行令牌验证。
为监听程序配置 OAuth 2.0 的步骤以及描述和示例,请参考 为 Kafka 代理配置 OAuth 2.0 支持。
4.4.2.3. 快速本地 JWT 令牌验证配置
快速本地 JWT 令牌验证在本地检查 JWT 令牌签名。
本地检查可确保令牌:
-
通过包含访问令牌的
Bearer声明值(拼写错误)符合类型 - 有效(未过期)
-
具有与
validIssuerURI匹配的签发者
在配置监听器时,您可以指定一个 validIssuerURI 属性,以便拒绝授权服务器未发布的任何令牌。
在快速本地 JWT 令牌验证期间,不需要联系授权服务器。您可以通过指定 jwksEndpointUri 属性(OAuth 2.0 授权服务器公开的端点)来激活快速本地 JWT 令牌验证。端点包含用于验证签名 JWT 令牌的公钥,这些令牌由 Kafka 客户端作为凭据发送。
与授权服务器的所有通信都应使用 TLS 加密来执行。
您可以在 AMQ Streams 项目命名空间中将证书信任存储配置为 OpenShift Secret,并使用 a tlsTrustedCertificates 属性指向包含信任存储文件的 OpenShift Secret。
您可能希望配置 userNameClaim 以 从 JWT 令牌正确提取用户名。如果要使用 Kafka ACL 授权,则需要在验证过程中根据用户的用户名进行识别。( JWT 令牌中的 子 声明通常是唯一的 ID,而不是用户名。)
用于快速本地 JWT 令牌验证的配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
#...
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: oauth
validIssuerUri: <https://<auth-server-address>/auth/realms/tls>
jwksEndpointUri: <https://<auth-server-address>/auth/realms/tls/protocol/openid-connect/certs>
userNameClaim: preferred_username
maxSecondsWithoutReauthentication: 3600
tlsTrustedCertificates:
- secretName: oauth-server-cert
certificate: ca.crt
#...
4.4.2.4. OAuth 2.0 内省端点配置
使用 OAuth 2.0 内省端点进行令牌验证,将收到的访问令牌视为不透明。Kafka 代理将访问令牌发送到内省端点,该端点使用验证所需的令牌信息进行响应。更重要的是,如果特定访问令牌有效,它将返回最新信息,以及关于令牌何时到期的信息。
要配置基于 OAuth 2.0 内省的验证,您需要指定一个 内省EndpointUri 属性,而不是为快速本地 JWT 令牌验证指定的 jwksEndpointUri 属性。根据授权服务器,您通常必须指定 clientId 和 client Secret,因为内省端点通常受到保护。
内省端点的配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
listeners:
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: oauth
clientId: kafka-broker
clientSecret:
secretName: my-cluster-oauth
key: clientSecret
validIssuerUri: <https://<auth-server-address>/auth/realms/tls>
introspectionEndpointUri: <https://<auth-server-address>/auth/realms/tls/protocol/openid-connect/token/introspect>
userNameClaim: preferred_username
maxSecondsWithoutReauthentication: 3600
tlsTrustedCertificates:
- secretName: oauth-server-cert
certificate: ca.crt
4.4.3. Kafka 代理的会话重新身份验证
Kafka SASL OAUTHBEARER 机制用于 AMQ Streams 中的 OAuth 2.0 身份验证,它支持一个名为 重新身份验证 机制的 Kafka 功能。
当在 oauth 类型监听器的配置中启用重新身份验证机制时,代理通过身份验证的会话会在访问令牌过期时过期。然后,客户端必须通过向代理发送一个新的有效访问令牌来重新验证现有会话,而不丢弃连接。
如果令牌验证成功,则利用现有连接启动新的客户端会话。如果客户端无法重新验证,代理会在进一步尝试发送或接收消息时关闭连接。如果在代理中启用了重新身份验证机制,使用 Kafka 客户端库 2.2 或更高版本的 Java 客户端会自动重新验证。
您可以在 Kafka 资源中启用会话重新身份验证。使用 type: oauth 身份验证为 TLS 侦听器设置 maxSecondsWithoutReauthentication 属性。会话重新身份验证支持两种类型的令牌验证(快速本地 JWT 和内省端点)。有关配置示例,请参阅 第 4.4.6.2 节 “配置 Kafka 代理的 OAuth 2.0 支持”。
有关重新身份验证机制(在 Kafka 版本 2.2 中添加)的更多信息,请参阅 KIP-368。
4.4.4. OAuth 2.0 Kafka 客户端配置
使用以下方法配置了 Kafka 客户端:
- 从授权服务器(客户端 ID 和 Secret)获取有效访问令牌所需的凭证
- 使用授权服务器提供的工具获取有效的长期访问令牌或刷新令牌
发送到 Kafka 代理的唯一信息是访问令牌。用于与授权服务器进行身份验证以获取访问令牌的凭证永远不会发送到代理。
当客户端获取访问令牌时,不需要进一步与授权服务器通信。
最简单的机制是使用客户端 ID 和机密进行身份验证。使用长期访问令牌或长期提供的刷新令牌增加了复杂性,因为对授权服务器工具存在额外的依赖性。
如果您使用长期访问令牌,您可能需要在授权服务器中配置客户端,以增加令牌的最长生命周期。
如果 Kafka 客户端没有直接配置访问令牌,客户端会联系授权服务器在 Kafka 会话启动时交换访问令牌的凭证。Kafka 客户端交换:
- 客户端 ID 和机密
- 客户端 ID、刷新令牌和(可选)Secret
4.4.5. OAuth 2.0 客户端身份验证流
在本节中,我们在 Kafka 会话启动过程中解释和视觉化 Kafka 客户端、Kafka 代理和授权服务器之间的通信流。流程取决于客户端和服务器配置。
当 Kafka 客户端将访问令牌作为凭证发送到 Kafka 代理时,需要验证令牌。
根据所使用的授权服务器以及可用的配置选项,您可能更愿意使用:
- 基于 JWT 签名检查和本地令牌内省的快速本地令牌验证,而不联系授权服务器
- 授权服务器提供的 OAuth 2.0 内省端点
使用快速本地令牌验证需要授权服务器提供 JWKS 端点以及用于验证令牌签名的公共证书。
另一种选择是在授权服务器上使用 OAuth 2.0 内省端点。每次建立新的 Kafka 代理连接时,代理会将从客户端收到的访问令牌传递给授权服务器,并检查响应以确认令牌是否有效。
还可以为以下项配置 Kafka 客户端凭证:
- 使用之前生成的长期访问令牌直接进行本地访问
- 与授权服务器联系以获取要发布的新访问令牌
授权服务器可能只允许使用不透明访问令牌,这意味着无法进行本地令牌验证。
4.4.5.1. 客户端身份验证流示例
您可以在 Kafka 会话验证过程中看到用于不同配置的 Kafka 客户端和代理的通信流。
使用客户端 ID 和 secret 的客户端,代理将验证委派给授权服务器
- Kafka 客户端使用客户端 ID 和机密从授权服务器请求访问令牌,以及可选的刷新令牌。
- 授权服务器生成新的访问令牌。
- Kafka 客户端使用 SASL OAUTHBEARER 机制与 Kafka 代理进行身份验证来传递访问令牌。
- Kafka 代理使用自己的客户端 ID 和 secret,在授权服务器上调用令牌内省端点来验证访问令牌。
- 如果令牌有效,则创建 Kafka 客户端会话。
使用客户端 ID 和 secret 的客户端,代理执行快速本地令牌验证
- Kafka 客户端从令牌端点通过授权服务器进行身份验证,使用客户端 ID 和 secret 以及可选的刷新令牌进行身份验证。
- 授权服务器生成新的访问令牌。
- Kafka 客户端使用 SASL OAUTHBEARER 机制与 Kafka 代理进行身份验证来传递访问令牌。
- Kafka 代理使用 JWT 令牌签名检查和本地令牌内省在本地验证访问令牌。
使用长期访问令牌的客户端,并将代理委派验证到授权服务器
- Kafka 客户端使用 SASL OAUTHBEARER 机制与 Kafka 代理进行身份验证,以传递长期访问令牌。
- Kafka 代理使用自己的客户端 ID 和 secret,在授权服务器上调用令牌内省端点来验证访问令牌。
- 如果令牌有效,则创建 Kafka 客户端会话。
使用长期访问令牌的客户端,代理执行快速本地验证

- Kafka 客户端使用 SASL OAUTHBEARER 机制与 Kafka 代理进行身份验证,以传递长期访问令牌。
- Kafka 代理使用 JWT 令牌签名检查和本地令牌内省在本地验证访问令牌。
快速本地 JWT 令牌签名验证仅适用于短期的令牌,因为如果令牌被撤销,则不会与授权服务器检查。令牌到期将写入令牌中,但取消可以在任何时间发生,因此在不联系授权服务器的情况下无法考虑该令牌。任何发布的令牌都将被视为有效,直到该令牌过期为止。
4.4.6. 配置 OAuth 2.0 身份验证
OAuth 2.0 用于 Kafka 客户端和 AMQ Streams 组件之间的交互。
要将 OAuth 2.0 用于 AMQ Streams,您必须:
4.4.6.1. 将红帽单点登录配置为 OAuth 2.0 授权服务器
这个步骤描述了如何将 Red Hat Single Sign-On 部署为授权服务器,并将其配置为与 AMQ Streams 集成。
授权服务器为身份验证和授权以及用户、客户端和权限的管理提供中央点。红帽单点登录有一个域概念,其中 域 代表一组单独的用户、客户端、权限和其他配置。您可以使用默认的 master 域,或者创建一个新域。每个域公开自己的 OAuth 2.0 端点,这意味着应用客户端和应用服务器都需要使用相同的域。
要将 OAuth 2.0 与 AMQ Streams 搭配使用,您可以使用 Red Hat Single Sign-On 部署来创建和管理身份验证域。
如果您已经部署了红帽单点登录,您可以跳过部署步骤并使用当前的部署。
开始前
您需要熟悉使用红帽单点登录。
有关部署和管理说明,请参阅:
先决条件
- AMQ Streams 和 Kafka 正在运行
对于 Red Hat Single Sign-On 部署:
- 检查 Red Hat Single Sign-On 支持的配置
- 安装需要具有 cluster-admin 角色的用户,如 system:admin
步骤
将红帽单点登录部署到您的 OpenShift 集群。
在 OpenShift Web 控制台中检查部署的进度。
登录红帽单点登录管理控制台,为 AMQ Streams 创建 OAuth 2.0 策略。
部署 Red Hat Single Sign-On 时会提供登录详情。
创建和启用域。
您可以使用现有的 master 域。
- 如果需要,调整域的会话和令牌超时。
-
创建名为
kafka-broker的客户端。 在 选项卡中设置:
-
访问类型 到
机密 -
标准流启用 至
OFF,以禁用此客户端的 Web 登录 -
支持服务于
ON,允许此客户端使用自己的名称进行身份验证
-
访问类型 到
- 单击 Save,然后再继续。
- 在 选项卡中,记下 AMQ Streams Kafka 集群配置中使用的 secret。
为要连接到 Kafka 代理的任何应用程序客户端重复客户端创建步骤。
为每个新客户端创建定义。
在配置中,您将使用名称作为客户端 ID。
接下来要做什么
部署和配置授权服务器后,将 Kafka 代理配置为使用 OAuth 2.0。
4.4.6.2. 配置 Kafka 代理的 OAuth 2.0 支持
这个步骤描述了如何配置 Kafka 代理,以便代理监听程序被启用为使用授权服务器使用 OAuth 2.0 身份验证。
我们建议通过配置 TLS 侦听器在加密接口上使用 OAuth 2.0。不建议纯监听器。
如果授权服务器使用由可信 CA 签名的证书并匹配 OAuth 2.0 服务器主机名,则 TLS 连接可以使用默认设置。否则,您可能需要使用探测器证书或禁用证书主机名验证来配置信任存储。
在配置 Kafka 代理时,在新连接的 Kafka 客户端的 OAuth 2.0 验证过程中,您有两个用于验证访问令牌的机制:
开始前
有关为 Kafka 代理监听程序配置 OAuth 2.0 身份验证的更多信息,请参阅:
先决条件
- AMQ Streams 和 Kafka 正在运行
- 部署了 OAuth 2.0 授权服务器
步骤
在编辑器中更新
Kafka 资源的 Kafka 代理配置()。Kafka.spec.kafkaoc edit kafka my-cluster
配置 Kafka 代理
监听程序配置。每种侦听器的配置不一定是独立的,因为它们是独立的。
此处的示例显示了为外部侦听器配置的配置选项。
示例 1:配置快速本地 JWT 令牌验证
#... - name: external port: 9094 type: loadbalancer tls: true authentication: type: oauth 1 validIssuerUri: <https://<auth-server-address>/auth/realms/external> 2 jwksEndpointUri: <https://<auth-server-address>/auth/realms/external/protocol/openid-connect/certs> 3 userNameClaim: preferred_username 4 maxSecondsWithoutReauthentication: 3600 5 tlsTrustedCertificates: 6 - secretName: oauth-server-cert certificate: ca.crt disableTlsHostnameVerification: true 7 jwksExpirySeconds: 360 8 jwksRefreshSeconds: 300 9 jwksMinRefreshPauseSeconds: 1 10 enableECDSA: "true" 11- 1
- 侦听器类型设置为
oauth。 - 2
- 用于身份验证的令牌签发者的 URI。
- 3
- 用于本地 JWT 验证的 JWKS 证书端点 URI。
- 4
- 在令牌中包含实际用户名的令牌声明(或密钥)。用户名 是用于 标识用户的主体。
userNameClaim值将取决于身份验证流和使用的授权服务器。 - 5
- (可选)激活 Kafka 重新身份验证机制,强制会话过期的时间与访问令牌相同。如果指定的值小于访问令牌过期的时间,客户端必须在实际令牌到期之前重新进行身份验证。默认情况下,会话不会在访问令牌过期时过期,客户端也不会尝试重新身份验证。
- 6
- (可选)用于 TLS 连接到授权服务器的受信任证书。
- 7
- (可选)禁用 TLS 主机名验证。默认为
false。 - 8
- JWKS 证书在过期前被视为有效的时间。默认值为
360秒。如果您指定了更长的时间,请考虑允许访问撤销的证书的风险。 - 9
- JWKS 证书刷新间隔的时间段。间隔必须至少比到期间隔短 60 秒。默认值为
300秒。 - 10
- 连续尝试刷新 JWKS 公钥之间的最小暂停(以秒为单位)。当遇到未知签名密钥时,将在常规定期计划外调度 JWKS 密钥刷新,并且自上次刷新尝试后至少使用指定的暂停。刷新键遵循 exponential backoff 规则,不成功刷新会一直增加暂停,直到它到达
jwksRefreshSeconds。默认值为 1。 - 11
- (可选)如果使用 ECDSA 在授权服务器上签署 JWT 令牌,则需要启用此功能。它使用 BouncyCastle 加密库安装额外的加密供应商。默认为
false。
示例 2:使用内省端点配置令牌验证
- name: external port: 9094 type: loadbalancer tls: true authentication: type: oauth validIssuerUri: <https://<auth-server-address>/auth/realms/external> introspectionEndpointUri: <https://<auth-server-address>/auth/realms/external/protocol/openid-connect/token/introspect> 1 clientId: kafka-broker 2 clientSecret: 3 secretName: my-cluster-oauth key: clientSecret userNameClaim: preferred_username 4 maxSecondsWithoutReauthentication: 3600 5根据您应用 OAuth 2.0 身份验证的方式,以及授权服务器的类型,您可以使用额外的(可选)配置设置:
# ... authentication: type: oauth # ... checkIssuer: false 1 fallbackUserNameClaim: client_id 2 fallbackUserNamePrefix: client-account- 3 validTokenType: bearer 4 userInfoEndpointUri: https://OAUTH-SERVER-ADDRESS/auth/realms/external/protocol/openid-connect/userinfo 5- 1
- 如果您的授权服务器不提供
iss声明,则无法执行签发者检查。在这种情况下,把checkIssuer设置为false,且不指定validIssuerUri。默认值为true。 - 2
- 授权服务器不能提供单个属性来标识常规用户和客户端。当客户端在其自己的名称中进行身份验证时,服务器可能会提供 客户端 ID。当用户使用用户名和密码进行身份验证时,为了获取刷新令牌或访问令牌,服务器可能会提供除客户端 ID 之外 的用户名 属性。使用此回退选项指定用户名声明(attribute),以便在主用户 ID 属性不可用时使用。
- 3
- 在适用
fallbackUserNameClaim的情况下,可能还需要防止用户名声明的值与回退用户名声明的值冲突。请考虑存在名为producer的客户端,但也存在名为producer的常规用户。为了区分这两者,您可以使用此属性向客户端的用户 ID 添加前缀。 - 4
- (仅在使用
内省EndpointUri时)取决于您使用的授权服务器,内省端点可能会也可能不会返回 令牌类型 属性,或者它可能包含不同的值。您可以指定内省端点必须包含的有效令牌类型值。 - 5
- (仅在使用
内省EndpointUri时)可以配置或实施授权服务器,以免在内省端点响应中提供任何可识别的信息。若要获取用户 ID,您可以将userinfo端点的 URI 配置为回退。userNameClaim、fallbackUserNameClaim和fallbackUserNamePrefix设置应用于userinfo端点的响应。
- 保存并退出编辑器,然后等待滚动更新完成。
检查日志中的更新,或者查看 pod 状态转换:
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get po -w滚动更新将代理配置为使用 OAuth 2.0 身份验证。
接下来要做什么
4.4.6.3. 将 Kafka Java 客户端配置为使用 OAuth 2.0
这个步骤描述了如何配置 Kafka 制作者和使用者 API,以使用 OAuth 2.0 与 Kafka 代理交互。
将客户端回调插件添加到 pom.xml 文件,并配置系统属性。
先决条件
- AMQ Streams 和 Kafka 正在运行
- 为对 Kafka 代理的 OAuth 访问部署并配置了 OAuth 授权服务器
- 为 OAuth 2.0 配置 Kafka 代理
步骤
将带有 OAuth 2.0 支持的客户端库添加到 Kafka 客户端的
pom.xml文件中:<dependency> <groupId>io.strimzi</groupId> <artifactId>kafka-oauth-client</artifactId> <version>0.6.1.redhat-00003</version> </dependency>
为回调配置系统属性:
例如:
System.setProperty(ClientConfig.OAUTH_TOKEN_ENDPOINT_URI, “https://<auth-server-address>/auth/realms/master/protocol/openid-connect/token”); 1 System.setProperty(ClientConfig.OAUTH_CLIENT_ID, "<client-name>"); 2 System.setProperty(ClientConfig.OAUTH_CLIENT_SECRET, "<client-secret>"); 3
在 Kafka 客户端配置中的 TLS 加密连接中启用 SASL OAUTHBEARER 机制:
例如:
props.put("sasl.jaas.config", "org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required;"); props.put("security.protocol", "SASL_SSL"); 1 props.put("sasl.mechanism", "OAUTHBEARER"); props.put("sasl.login.callback.handler.class", "io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler");- 1
- 在这里,我们使用
SASL_SSL通过 TLS 连接使用。对未加密的连接使用SASL_PLAINTEXT。
- 验证 Kafka 客户端可以访问 Kafka 代理。
接下来要做什么
4.4.6.4. 为 Kafka 组件配置 OAuth 2.0
这个步骤描述了如何将 Kafka 组件配置为使用授权服务器的 OAuth 2.0 身份验证。
您可以为以下对象配置身份验证:
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
在这种情况下,Kafka 组件和授权服务器会在同一集群中运行。
开始前
有关为 Kafka 组件配置 OAuth 2.0 身份验证的更多信息,请参阅:
先决条件
- AMQ Streams 和 Kafka 正在运行
- 为对 Kafka 代理的 OAuth 访问部署并配置了 OAuth 授权服务器
- 为 OAuth 2.0 配置 Kafka 代理
步骤
创建客户端机密,并将它作为环境变量挂载到组件上。
例如,此处我们为 Kafka Bridge 创建客户端
Secret:apiVersion: kafka.strimzi.io/v1beta1 kind: Secret metadata: name: my-bridge-oauth type: Opaque data: clientSecret: MGQ1OTRmMzYtZTllZS00MDY2LWI5OGEtMTM5MzM2NjdlZjQw 1- 1
clientSecret键必须采用 base64 格式。
为 Kafka 组件创建或编辑资源,以便为身份验证属性配置 OAuth 2.0 身份验证。
对于 OAuth 2.0 身份验证,您可以使用:
- 客户端 ID 和 secret
- 客户端 ID 和刷新令牌
- 访问令牌
- TLS
KafkaClientAuthenticationOAuth 模式参考提供了每个模式的示例。
例如,此处的 OAuth 2.0 使用客户端 ID 和 secret 分配给 Kafka Bridge 客户端,以及 TLS:
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaBridge metadata: name: my-bridge spec: # ... authentication: type: oauth 1 tokenEndpointUri: https://<auth-server-address>/auth/realms/master/protocol/openid-connect/token 2 clientId: kafka-bridge clientSecret: secretName: my-bridge-oauth key: clientSecret tlsTrustedCertificates: 3 - secretName: oauth-server-cert certificate: tls.crt根据您应用 OAuth 2.0 身份验证的方式以及授权服务器的类型,您可以使用额外的配置选项:
# ... spec: # ... authentication: # ... disableTlsHostnameVerification: true 1 checkAccessTokenType: false 2 accessTokenIsJwt: false 3 scope: any 4将更改应用到 Kafka 资源的部署。
oc apply -f your-file
检查日志中的更新,或者查看 pod 状态转换:
oc logs -f ${POD_NAME} -c ${CONTAINER_NAME} oc get pod -w滚动更新配置组件,以使用 OAuth 2.0 身份验证与 Kafka 代理交互。
4.5. 使用基于 OAuth 2.0 令牌的授权
AMQ Streams 支持通过 Red Hat Single Sign-On Authorization Services 使用基于 OAuth 2.0 令牌的授权,它允许您集中管理安全策略和权限。
Red Hat Single Sign-On 中定义的安全策略和权限用于授予对 Kafka 代理上资源的访问权限。用户和客户端与允许对 Kafka 代理执行特定操作的策略进行匹配。
默认情况下,Kafka 允许所有用户对代理进行完全访问,并提供 AclAuthorizer 插件以根据访问控制列表(ACL)配置授权。
zookeeper 存储允许或拒绝基于 用户名 访问资源的 ACL 规则。但是,使用红帽单点登录的 OAuth 2.0 基于令牌的授权为您要对 Kafka 代理实施访问控制提供了极大的灵活性。另外,您可以将 Kafka 代理配置为使用 OAuth 2.0 授权和 ACL。
4.5.1. OAuth 2.0 授权机制
AMQ Streams 中的 OAuth 2.0 授权使用 Red Hat Single Sign-On 服务器授权服务 REST 端点通过对特定用户应用定义的安全策略,并为该用户提供不同资源获得的权限列表,从而通过红帽单点登录来扩展基于令牌的身份验证。策略使用角色和组来匹配用户的权限。OAuth 2.0 授权根据红帽单点登录授权服务中用户收到的授权列表,在本地强制实施权限。
4.5.1.1. Kafka 代理自定义授权器
一个 Red Hat Single Sign-On 授权程序 (KeycloakRBACAuthorizer)由 AMQ Streams 提供。为了能够将 Red Hat Single Sign-On REST 端点用于 Red Hat Single Sign-On 提供的授权服务,您可以在 Kafka 代理上配置自定义授权程序。
授权者根据需要从授权服务器获取授予权限的列表,并在 Kafka Broker 上强制本地实施授权,从而对每个客户端请求做出快速的授权决策。
4.5.2. 配置 OAuth 2.0 授权支持
这个步骤描述了如何使用 Red Hat Single Sign-On Authorization Services 将 Kafka 代理配置为使用 OAuth 2.0 授权服务。
开始前
考虑您需要或希望限制某些用户的访问权限。您可以使用红帽单点登录 组、角色、客户端 和用户 组合在红帽单点登录中配置访问权限。
通常,组用于根据组织部门或地理位置匹配用户。和 角色用于根据用户的功能匹配用户。
通过红帽单点登录,您可以将用户和组存储在 LDAP 中,而客户端和角色则无法以这种方式存储。存储和用户数据访问可能是您选择配置授权策略的一个因素。
无论 Kafka 代理中实施的授权如何,超级用户 始终都对 Kafka 代理具有未经约束的访问权限。
先决条件
步骤
- 访问 Red Hat Single Sign-On Admin 控制台,或使用 Red Hat Single Sign-On Admin CLI 为您在设置 OAuth 2.0 身份验证时创建的 Kafka 代理客户端启用授权服务。
- 使用授权服务为客户端定义资源、授权范围、策略和权限。
- 通过为用户和组分配角色和组,将权限绑定至用户和组。
通过在
编辑器中更新 Kafka 代理配置(Kafka.spec.kafka),将 Kafka代理配置为使用 Red Hat Single Sign-On 授权。oc edit kafka my-cluster
将 Kafka 代理
kafka配置配置为使用keycloak授权,并可以访问授权服务器和授权服务。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: kafka # ... authorization: type: keycloak 1 tokenEndpointUri: <https://<auth-server-address>/auth/realms/external/protocol/openid-connect/token> 2 clientId: kafka 3 delegateToKafkaAcls: false 4 disableTlsHostnameVerification: false 5 superUsers: 6 - CN=fred - sam - CN=edward tlsTrustedCertificates: 7 - secretName: oauth-server-cert certificate: ca.crt grantsRefreshPeriodSeconds: 60 8 grantsRefreshPoolSize: 5 9 #...- 1
- 类型
keycloak启用红帽单点登录授权。 - 2
- 红帽单点登录令牌端点的 URI。对于生产环境,始终使用 HTTPs。
- 3
- 启用了授权服务的 Red Hat Single Sign-On 中的 OAuth 2.0 客户端定义的客户端 ID。通常,
kafka用作 ID。 - 4
- (可选)如果 Red Hat Single Sign-On Authorization Services 策略拒绝访问,则会向 Kafka
AclAuthorizer委派授权。默认为false。 - 5
- (可选)禁用 TLS 主机名验证。默认为
false。 - 6
- (可选)指定的 超级用户.
- 7
- (可选)用于 TLS 连接到授权服务器的受信任证书。
- 8
- (可选)两个连续的时间允许刷新运行。这是活跃会话的最大时间,用于检测 Red Hat Single Sign-On 上用户的任何权限更改。默认值为 60。
- 9
- (可选)用于(并行)活动会话授权的线程数量。默认值为 5。
- 保存并退出编辑器,然后等待滚动更新完成。
检查日志中的更新,或者查看 pod 状态转换:
oc logs -f ${POD_NAME} -c kafka oc get po -w滚动更新将代理配置为使用 OAuth 2.0 授权。
- 以具有特定角色的客户端或用户访问 Kafka 代理,确保他们具有必要的访问权限,或者没有他们应该拥有的访问权限,来验证配置的权限。
第 5 章 使用 AMQ Streams Operator
使用 AMQ Streams 操作器来管理您的 Kafka 集群,以及 Kafka 主题和用户。
5.1. 使用 Cluster Operator
Cluster Operator 用于部署 Kafka 集群和其他 Kafka 组件。
Cluster Operator 使用 YAML 安装文件进行部署。
如需有关部署 Cluster Operator 的信息,请参阅 OpenShift 指南中的 Deploying and upgrade AMQ Streams 中的 部署 Cluster Operator。
有关 Kafka 可用部署选项的详情,请参考 Kafka 集群配置。
在 OpenShift 中,Kafka Connect 部署可以纳入 Source2Image 功能,以提供添加额外连接器的便捷方式。
5.1.1. Cluster Operator 配置
Cluster Operator 可以通过以下支持的环境变量和日志记录配置进行配置。
STRIMZI_NAMESPACEOperator 应操作的命名空间的逗号分隔列表。如果没有设置,设为空字符串,或设置为
*,Cluster Operator 将在所有命名空间中运行。Cluster Operator 部署可能会使用 OpenShift Downward API 自动将其设置为 Cluster Operator 部署到的命名空间。请参见以下示例:env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace-
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS - 可选,默认为 120000 ms。定期协调之间的间隔,以毫秒为单位。
STRIMZI_OPERATION_TIMEOUT_MS- 可选,默认为 300000 ms。内部操作的超时,以毫秒为单位。当在常规 OpenShift 操作需要比平时更长的集群中使用 AMQ Streams 时,这个值应该会增加(例如,因为 Docker 镜像下载速度较慢)。
STRIMZI_KAFKA_IMAGES-
必需。这提供了从 Kafka 版本到相应 Docker 镜像的映射,其中包含该版本的 Kafka 代理。所需语法为空格或用逗号分开的
<version>=<image>对。例如2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.6.7, 2.6.0=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7。这在指定了Kafka.spec.kafka.version属性而不是Kafka.spec.kafka.image时使用,如 第 2.1.18 节 “容器镜像” 所述。 STRIMZI_DEFAULT_KAFKA_INIT_IMAGE-
可选,默认
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7。如果没有将镜像指定为 第 2.1.18 节 “容器镜像” 中的 kafka-init-image,则在代理之前启动的 init 容器的镜像名称(即机架支持)没有指定为kafka-init-image。 STRIMZI_KAFKA_CONNECT_IMAGES-
必需。这提供了从 Kafka 版本到相应 Docker 镜像的映射,其中包含该版本的 Kafka 连接。所需语法为空格或用逗号分开的
<version>=<image>对。例如2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.6.7, 2.6.0=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7。这在指定了KafkaConnect.spec.version属性而不是KafkaConnect.spec.image时使用,如 第 B.1.6 节 “镜像” 所述。 STRIMZI_KAFKA_CONNECT_S2I_IMAGES-
必需。这提供了从 Kafka 版本到相应 Docker 镜像的映射,其中包含该版本的 Kafka 连接。所需语法为空格或用逗号分开的
<version>=<image>对。例如2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.6.7, 2.6.0=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7。这在指定KafkaConnectS2I.spec.version属性而不是KafkaConnectS2I.spec.image时使用,如 第 B.1.6 节 “镜像” 所述。 STRIMZI_KAFKA_MIRROR_MAKER_IMAGES-
必需。这提供了从 Kafka 版本到相应 Docker 镜像的映射,其中包含该版本的 Kafka 镜像制作器。所需语法为空格或用逗号分开的
<version>=<image>对。例如2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.6.7, 2.6.0=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7。这在指定了KafkaMirrorMaker.spec.version属性而不是KafkaMirrorMaker.spec.image时使用,如 第 B.1.6 节 “镜像” 所述。 STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE-
可选,默认
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7。部署主题 Operator 时要使用的镜像名称,如果没有在 Kafka资源第 2.1.18 节 “容器镜像” 中指定为Kafka.spec.entityOperator.topicOperator.image镜像名称。 STRIMZI_DEFAULT_USER_OPERATOR_IMAGE-
可选,默认
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7。部署用户 Operator 时要使用的镜像名称,如果没有在 Kafka资源第 2.1.18 节 “容器镜像” 中指定为Kafka.spec.entityOperator.userOperator.image镜像。 STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE-
Optional, default
registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7.部署 sidecar 容器时要使用的镜像名称,该容器为 Entity Operator 提供 TLS 支持,如果没有将镜像指定为 第 2.1.18 节 “容器镜像” 中的Kafka.spec.entityOperator.tlsSidecar.image。 STRIMZI_IMAGE_PULL_POLICY-
可选。
ImagePullPolicy,它将应用到由 AMQ Streams Cluster Operator 管理的所有 pod 中的容器。有效值有Always、ifNotPresent和Never。如果未指定,则将使用 OpenShift 的默认值。更改策略会导致所有 Kafka、Kafka Connect 和 Kafka MirrorMaker 集群滚动更新。 STRIMZI_IMAGE_PULL_SECRETS-
可选。以逗号分隔的
Secret名称列表。此处引用的 secret 包含从中提取容器镜像的容器注册表的凭据。secret 在imagePullSecrets字段中用于 Cluster Operator 创建的所有Pod。更改此列表会导致所有 Kafka、Kafka Connect 和 Kafka MirrorMaker 集群进行滚动更新。 STRIMZI_KUBERNETES_VERSION可选。覆盖从 API 服务器检测到的 OpenShift 版本信息。请参见以下示例:
env: - name: STRIMZI_KUBERNETES_VERSION value: | major=1 minor=16 gitVersion=v1.16.2 gitCommit=c97fe5036ef3df2967d086711e6c0c405941e14b gitTreeState=clean buildDate=2019-10-15T19:09:08Z goVersion=go1.12.10 compiler=gc platform=linux/amd64KUBERNETES_SERVICE_DNS_DOMAIN可选。覆盖默认的 OpenShift DNS 域名后缀。
默认情况下,OpenShift 集群中分配的服务的 DNS 域名使用默认的后缀
cluster.local。例如,对于代理 kafka-0 :
<cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc.cluster.local
DNS 域名被添加到用于主机名验证的 Kafka 代理证书中。
如果您在集群中使用不同的 DNS 域名后缀,请将
KUBERNETES_SERVICE_DNS_DOMAIN环境变量从默认值改为您用来与 Kafka 代理建立连接的变量。
通过 ConfigMap 配置
Cluster Operator 的日志记录由 strimzi-cluster-operator ConfigMap 配置。
安装 Cluster Operator 时会创建一个包含日志配置的 ConfigMap。此 ConfigMap 在文件 install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml 中描述。您可以通过更改此 ConfigMap 中的 data 字段 log4j2.properties 来配置 Cluster Operator 日志。
要更新日志记录配置,您可以编辑 050-ConfigMap-strimzi-cluster-operator.yaml 文件,然后运行以下命令:
oc apply -f install/cluster-operator/050-ConfigMap-strimzi-cluster-operator.yaml
或者,直接编辑 ConfigMap:
oc edit cm strimzi-cluster-operator
要更改重新加载间隔的频率,请在创建的 ConfigMap 中的 monitorInterval 选项中设置一个时间(以秒为单位)。
如果在部署 Cluster Operator 时缺少 ConfigMap,则会使用默认的日志记录值。
如果在部署 Cluster Operator 后意外删除 ConfigMap,则会使用最新载入的日志配置。创建新 ConfigMap 以 加载新的日志配置。
不要从 ConfigMap 中删除 monitorInterval 选项。
5.1.1.1. 定期协调
虽然 Cluster Operator 会响应从 OpenShift 集群收到所需集群资源的所有通知,但如果操作器没有运行,或者因任何原因未收到通知,则所需的资源将与正在运行的 OpenShift 集群的状态保持同步。
为了正确处理故障切换,由 Cluster Operator 执行定期协调过程,以便它可以将所需资源的状态与当前集群部署进行比较,以便在所有这些部署中保持一致状态。您可以使用 [STRIMZI_FULL_RECONCILIATION_INTERVAL_MS] 变量为定期协调设置时间间隔。
5.1.2. 调配基于角色的访问控制(RBAC)
要使 Cluster Operator 正常工作,需要在 OpenShift 集群中与资源(如 Kafka、Kafka Connect 等)以及受管资源(如 ConfigMap、Pod、 Deployment、 StatefulSet 和 Services )交互。这种权限在 OpenShift 基于角色的访问控制(RBAC)资源中描述:
-
ServiceAccount, -
角色和ClusterRole, -
rolebinding 和ClusterRoleBinding。
除了使用 ClusterRoleBinding 在其自身 ServiceAccount 中运行外,Cluster Operator 还为需要访问 OpenShift 资源的组件管理一些 RBAC 资源。
OpenShift 还包含特权升级保护,可防止在一个 ServiceAccount 下操作的组件授予授予授权 ServiceAccount 没有的其他 特权。因为 Cluster Operator 必须能够创建 ServiceAccount sClusterRoleBindings,以及它管理的资源所需的 RoleBindings,所以 Cluster Operator 还必须具有相同的权限。
5.1.2.1. 委派的权限
当 Cluster Operator 为所需的 Kafka 资源部署资源时,它还会创建 ServiceAccount、 RoleBindings 和 ClusterRoleBindings,如下所示:
Kafka 代理 pod 使用一个名为
cluster-name-kafka的ServiceAccount-
使用机架功能时,
strimzi-cluster-name-kafka-initClusterRoleBinding用来通过ClusterRole(名为strimzi-kafka-broker)对集群中的节点授予这个ServiceAccount访问权限 - 当不使用机架功能时,不会创建绑定
-
使用机架功能时,
-
ZooKeeper pod 使用名为
cluster-name-zookeeper的ServiceAccount Entity Operator pod 使用名为
cluster-name-entity-operator的ServiceAccount-
Topic Operator 生成带有状态信息的 OpenShift 事件,因此
ServiceAccount绑定到名为strimzi-entity-operator的ClusterRole,它通过strimzi-entity-operatorRoleBinding授予此访问权限
-
Topic Operator 生成带有状态信息的 OpenShift 事件,因此
-
KafkaConnect 和资源的 pod 使用名为KafkaConnectS2Icluster-name-cluster-connect的ServiceAccount -
KafkaMirrorMaker的 pod 使用名为cluster-name-mirror-maker的ServiceAccount -
KafkaMirrorMaker2的 pod 使用名为cluster-name-mirrormaker2的ServiceAccount -
KafkaBridge的 pod 使用名为cluster-name-bridge的ServiceAccount
5.1.2.2. ServiceAccount
Cluster Operator 最好使用 ServiceAccount 运行:
Cluster Operator 的 ServiceAccount 示例
apiVersion: v1
kind: ServiceAccount
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
然后,Operator 的 Deployment 需要在其 spec.template.spec.serviceAccountName 中指定 :
Cluster Operator 部署 的部分示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
spec:
replicas: 1
selector:
matchLabels:
name: strimzi-cluster-operator
strimzi.io/kind: cluster-operator
template:
# ...
注意 12 行,其中 strimzi-cluster-operator ServiceAccount 指定为 serviceAccountName。
5.1.2.3. ClusterRoles
Cluster Operator 需要使用 提供所需资源访问的 ClusterRole 运行。根据 OpenShift 集群设置,可能需要集群管理员来创建 ClusterRole。
集群管理员权限只在创建 ClusterRole 时需要。Cluster Operator 不会在集群管理员帐户下运行。
ClusterRole 遵循最小 权限, 仅包含 Cluster Operator 运行 Kafka、Kafka Connect 和 ZooKeeper 集群所需的权限。第一组分配的权限允许 Cluster Operator 管理 OpenShift 资源,如 StatefulSets、Deployment、Pod 和 ConfigMap。
Cluster Operator 使用 ClusterRole 在命名空间范围的资源级别和集群范围的资源级别授予权限:
具有 Cluster Operator 资源命名空间资源的 ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-cluster-operator-namespaced
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
# The cluster operator needs to access and manage service accounts to grant Strimzi components cluster permissions
- serviceaccounts
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
# The cluster operator needs to access and manage rolebindings to grant Strimzi components cluster permissions
- rolebindings
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to access and manage config maps for Strimzi components configuration
- configmaps
# The cluster operator needs to access and manage services to expose Strimzi components to network traffic
- services
# The cluster operator needs to access and manage secrets to handle credentials
- secrets
# The cluster operator needs to access and manage persistent volume claims to bind them to Strimzi components for persistent data
- persistentvolumeclaims
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "kafka.strimzi.io"
resources:
# The cluster operator runs the KafkaAssemblyOperator, which needs to access and manage Kafka resources
- kafkas
- kafkas/status
# The cluster operator runs the KafkaConnectAssemblyOperator, which needs to access and manage KafkaConnect resources
- kafkaconnects
- kafkaconnects/status
# The cluster operator runs the KafkaConnectS2IAssemblyOperator, which needs to access and manage KafkaConnectS2I resources
- kafkaconnects2is
- kafkaconnects2is/status
# The cluster operator runs the KafkaConnectorAssemblyOperator, which needs to access and manage KafkaConnector resources
- kafkaconnectors
- kafkaconnectors/status
# The cluster operator runs the KafkaMirrorMakerAssemblyOperator, which needs to access and manage KafkaMirrorMaker resources
- kafkamirrormakers
- kafkamirrormakers/status
# The cluster operator runs the KafkaBridgeAssemblyOperator, which needs to access and manage BridgeMaker resources
- kafkabridges
- kafkabridges/status
# The cluster operator runs the KafkaMirrorMaker2AssemblyOperator, which needs to access and manage KafkaMirrorMaker2 resources
- kafkamirrormaker2s
- kafkamirrormaker2s/status
# The cluster operator runs the KafkaRebalanceAssemblyOperator, which needs to access and manage KafkaRebalance resources
- kafkarebalances
- kafkarebalances/status
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to access and delete pods, this is to allow it to monitor pod health and coordinate rolling updates
- pods
verbs:
- get
- list
- watch
- delete
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
- list
- watch
- apiGroups:
# The cluster operator needs the extensions api as the operator supports Kubernetes version 1.11+
# apps/v1 was introduced in Kubernetes 1.14
- "extensions"
resources:
# The cluster operator needs to access and manage deployments to run deployment based Strimzi components
- deployments
- deployments/scale
# The cluster operator needs to access replica sets to manage Strimzi components and to determine error states
- replicasets
# The cluster operator needs to access and manage replication controllers to manage replicasets
- replicationcontrollers
# The cluster operator needs to access and manage network policies to lock down communication between Strimzi components
- networkpolicies
# The cluster operator needs to access and manage ingresses which allow external access to the services in a cluster
- ingresses
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "apps"
resources:
# The cluster operator needs to access and manage deployments to run deployment based Strimzi components
- deployments
- deployments/scale
- deployments/status
# The cluster operator needs to access and manage stateful sets to run stateful sets based Strimzi components
- statefulsets
# The cluster operator needs to access replica-sets to manage Strimzi components and to determine error states
- replicasets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to be able to create events and delegate permissions to do so
- events
verbs:
- create
- apiGroups:
# OpenShift S2I requirements
- apps.openshift.io
resources:
- deploymentconfigs
- deploymentconfigs/scale
- deploymentconfigs/status
- deploymentconfigs/finalizers
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
# OpenShift S2I requirements
- build.openshift.io
resources:
- buildconfigs
- builds
verbs:
- create
- delete
- get
- list
- patch
- watch
- update
- apiGroups:
# OpenShift S2I requirements
- image.openshift.io
resources:
- imagestreams
- imagestreams/status
verbs:
- create
- delete
- get
- list
- watch
- patch
- update
- apiGroups:
- networking.k8s.io
resources:
# The cluster operator needs to access and manage network policies to lock down communication between Strimzi components
- networkpolicies
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- route.openshift.io
resources:
# The cluster operator needs to access and manage routes to expose Strimzi components for external access
- routes
- routes/custom-host
verbs:
- get
- list
- create
- delete
- patch
- update
- apiGroups:
- policy
resources:
# The cluster operator needs to access and manage pod disruption budgets this limits the number of concurrent disruptions
# that a Strimzi component experiences, allowing for higher availability
- poddisruptionbudgets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
第二个包括集群范围资源所需的权限。
为 Cluster Operator 带有集群范围资源的 ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-cluster-operator-global
labels:
app: strimzi
rules:
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
# The cluster operator needs to create and manage cluster role bindings in the case of an install where a user
# has specified they want their cluster role bindings generated
- clusterrolebindings
verbs:
- get
- create
- delete
- patch
- update
- watch
- apiGroups:
- storage.k8s.io
resources:
# The cluster operator requires "get" permissions to view storage class details
# This is because only a persistent volume of a supported storage class type can be resized
- storageclasses
verbs:
- get
- apiGroups:
- ""
resources:
# The cluster operator requires "list" permissions to view all nodes in a cluster
# The listing is used to determine the node addresses when NodePort access is configured
# These addresses are then exposed in the custom resource states
- nodes
verbs:
- list
The strimzi-kafka-broker ClusterRole 代表 Kafka pod 中 init 容器所需的访问权限,用于机架功能。如 委派的特权 部分所述,Cluster Operator 还需要此角色才能委派此访问权限。
Cluster Operator 的 ClusterRole,允许它将 OpenShift 节点的访问权限委派给 Kafka 代理 pod
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-kafka-broker
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
# The Kafka Brokers require "get" permissions to view the node they are on
# This information is used to generate a Rack ID that is used for High Availability configurations
- nodes
verbs:
- get
The strimzi-topic-operator ClusterRole 代表 Topic Operator 所需的访问权限。如 委派的特权 部分所述,Cluster Operator 还需要此角色才能委派此访问权限。
Cluster Operator 的 ClusterRole,允许它将对事件的访问委托给主题 Operator
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-entity-operator
labels:
app: strimzi
rules:
- apiGroups:
- "kafka.strimzi.io"
resources:
# The entity operator runs the KafkaTopic assembly operator, which needs to access and manage KafkaTopic resources
- kafkatopics
- kafkatopics/status
# The entity operator runs the KafkaUser assembly operator, which needs to access and manage KafkaUser resources
- kafkausers
- kafkausers/status
verbs:
- get
- list
- watch
- create
- patch
- update
- delete
- apiGroups:
- ""
resources:
- events
verbs:
# The entity operator needs to be able to create events
- create
- apiGroups:
- ""
resources:
# The entity operator user-operator needs to access and manage secrets to store generated credentials
- secrets
verbs:
- get
- list
- create
- patch
- update
- delete
The strimzi-kafka-client ClusterRole 代表组件所需的访问,这些客户端使用客户端机架感知能力。如 委派的特权 部分所述,Cluster Operator 还需要此角色才能委派此访问权限。
Cluster Operator 的 ClusterRole,允许它将对 OpenShift 节点的访问委托给基于 Kafka 客户端的 pod
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-kafka-client
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
# The Kafka clients (Connect, Mirror Maker, etc.) require "get" permissions to view the node they are on
# This information is used to generate a Rack ID (client.rack option) that is used for consuming from the closest
# replicas when enabled
- nodes
verbs:
- get
5.1.2.4. ClusterRoleBindings
Operator 需要 ClusterRoleBindings 和 RoleBindings,它们将其 ClusterRole 与其 ServiceAccount 相关联:包含集群范围资源的 ClusterRole 需要 ClusterRoleBinding。
Cluster Operator 的 ClusterRoleBinding 示例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-cluster-operator-global
apiGroup: rbac.authorization.k8s.io
委派 所需的 ClusterRole 还需要 ClusterRoleBinding :
Kafka 代理 rack-awarness 的 Cluster Operator 的 Cluster RoleBinding 示例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator-kafka-broker-delegation
labels:
app: strimzi
# The Kafka broker cluster role must be bound to the cluster operator service account so that it can delegate the cluster role to the Kafka brokers.
# This must be done to avoid escalating privileges which would be blocked by Kubernetes.
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-kafka-broker
apiGroup: rbac.authorization.k8s.io
和
Kafka 客户端 rack-awarness 的 Cluster Operator 的 Cluster RoleBinding 示例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator-kafka-client-delegation
labels:
app: strimzi
# The Kafka clients cluster role must be bound to the cluster operator service account so that it can delegate the
# cluster role to the Kafka clients using it for consuming from closest replica.
# This must be done to avoid escalating privileges which would be blocked by Kubernetes.
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-kafka-client
apiGroup: rbac.authorization.k8s.io
仅 包含有命名空间资源的 ClusterRole 只会使用 RoleBindings 绑定。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-cluster-operator-namespaced
apiGroup: rbac.authorization.k8s.ioapiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: strimzi-cluster-operator-entity-operator-delegation
labels:
app: strimzi
# The Entity Operator cluster role must be bound to the cluster operator service account so that it can delegate the cluster role to the Entity Operator.
# This must be done to avoid escalating privileges which would be blocked by Kubernetes.
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-entity-operator
apiGroup: rbac.authorization.k8s.io5.2. 使用主题 Operator
当您使用 KafkaTopic 资源创建、修改或删除主题时,Tpic Operator 可确保这些更改反映在 Kafka 集群中。
OpenShift 指南中的部署和升级 AMQ Streams 提供了部署 Topic Operator 的说明:
5.2.1. Kafka 主题资源
KafkaTopic 资源用于配置主题,包括分区和副本的数量。
KafkaTopic 的完整 schema 包括在 KafkaTopic schema 引用 中。
5.2.1.1. 为主题处理识别 Kafka 集群
KafkaTopic 资源包含一个标签,用于定义它所属的 Kafka 集群名称(从 Kafka 资源的名称衍生)。
例如:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: topic-name-1
labels:
strimzi.io/cluster: my-cluster
该标签供主题 Operator 用于标识 KafkaTopic 资源、创建一个新主题,以及后续处理该主题。
如果标签与 Kafka 集群不匹配,主题 Operator 无法识别 KafkaTopic,且不会创建该主题。
5.2.1.2. 处理主题的更改
Topic Operator 必须解决的一个根本问题是没有单一数据源:KafkaTopic 资源和 Kafka 主题都可以独立于 Operator 修改。复杂的情况是,Topic Operator 可能无法实时观察每个末尾的更改(例如,操作器可能会停机)。
为解决这个问题,操作员会保留自己的专用副本,其中包含每个主题的信息。当 Kafka 集群或 OpenShift 中发生更改时,它会同时查看其他系统的状态及其私有副本,以确定需要更改的内容以保持一切同步。每当操作器启动时都会发生同样的事情,并在操作器运行时定期进行。
例如,假设主题 Operator 未在运行,并创建一个 KafkaTopic my-topic。当 Operator 启动时,它将缺少"my-topic"的私有副本,因此可以推断出 KafkaTopic 自上次运行以来已创建。操作器将创建与 my-topic 对应的主题,同时存储 my-topic 的元数据私有副本。
私有副本允许操作员应对在 Kafka 和 OpenShift 中主题配置都已更改的情况,只要这些更改不兼容(例如,更改同一主题配置键,但更改为不同的值)。如果出现不兼容的更改,Kafka 配置胜出,KafkaTopic 将更新来反映这一点。
私有副本保存在 Kafka 本身使用的同一 ZooKeeper 识别中。这缓解了可用性问题,因为如果 ZooKeeper 没有运行,则 Kafka 本身将无法运行,因此即使其无状态也少于 Operator 的可用性。
5.2.1.3. Kafka 主题使用建议
处理主题时,应保持一致。始终在 OpenShift 中直接对 KafkaTopic 资源或主题运行。对于给定主题,避免在这两种方法之间进行定期切换。
使用反映主题性质的主题名称,并记住以后无法更改名称。
如果在 Kafka 中创建主题,请使用有效的 OpenShift 资源名称,否则 Topic Operator 将需要使用符合 OpenShift 规则的名称创建对应的 KafkaTopic。
OpenShift 中的标识符和名称建议在 OpenShift 社区文章中概述了标识符和名称。
5.2.1.4. Kafka 主题命名约定
Kafka 和 OpenShift 分别为 Kafka 和 KafkaTopic.metadata.name 中的主题命名实施自己的验证规则。每个名称都无效。
使用 spec.topicName 属性,可以在 Kafka 中创建有效的主题,其名称对 OpenShift 中的 Kafka 主题无效。
spec.topicName 属性继承 Kafka 命名验证规则:
- 名称不能超过 249 个字符。
-
Kafka 主题的有效字符为 ASCII 字母数字、
.、_和-。 -
该名称不能为. 或
.。但是,可以在名称中使用,如exampleTopic. or.exampleTopic。
不得更改 spec.topicName。
例如:
apiVersion: {KafkaApiVersion}
kind: KafkaTopic
metadata:
name: topic-name-1
spec:
topicName: topicName-1 1
# ...- 1
- 在 OpenShift 中,大写无效。
不能改为:
apiVersion: {KafkaApiVersion}
kind: KafkaTopic
metadata:
name: topic-name-1
spec:
topicName: name-2
# ...一些 Kafka 客户端应用程序(如 Kafka Streams)可以以编程方式在 Kafka 中创建主题。如果这些主题的名称具有无效的 OpenShift 资源名称,Topic Operator 会根据 Kafka 名称为其指定有效的名称。将替换无效字符,并在名称中附加一个哈希值。
5.2.2. 配置 Kafka 主题
使用 KafkaTopic 资源的属性来配置 Kafka 主题。
您可以使用 oc apply 创建或修改主题,使用 oc delete 删除现有主题。
例如:
-
oc apply -f <topic-config-file> -
oc delete KafkaTopic <topic-name>
此流程演示了如何创建带有 10 个分区和 2 个副本的主题。
开始前
在进行更改前请考虑以下几点:
Kafka 不支持 通过
KafkaTopic资源进行以下更改:-
使用
spec.topicName更改主题名称 -
使用
spec.partitions减少分区大小
-
使用
-
您不能使用
spec.replicas来更改最初指定的副本数量。 -
使用键为主题增加
spec.partitions将更改记录的分区方式,这在主题使用 语义分区 时特别有问题。
先决条件
- 正在运行的 Kafka 集群使用 Kafka 代理监听程序配置使用 TLS 身份验证和加密。
- 一个正在运行的主题 Operator( 通常使用 Entity Operator 部署)。
-
要删除主题,请在
Kafka资源的spec.kafka.config 中(default)。delete.topic.enable=true
步骤
准备包含要创建的
KafkaTopic的文件。KafkaTopic 示例apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic metadata: name: orders labels: strimzi.io/cluster: my-cluster spec: partitions: 10 replicas: 2提示在修改主题时,您可以使用
oc get kafkatopic Order -o yaml 获取资源的当前版本。在 OpenShift 中创建
KafkaTopic资源。oc apply -f TOPIC-CONFIG-FILE
5.2.3. 使用资源请求和限值配置主题 Operator
您可以将资源(如 CPU 和内存)分配给 Topic Operator,并为它消耗的资源量设置限制。
先决条件
- Cluster Operator 正在运行。
步骤
根据需要更新编辑器中的 Kafka 集群配置:
oc edit kafka MY-CLUSTER在
Kafka资源中的spec.entityOperator.topicOperator.resources属性中,为 Topic Operator 设置资源请求和限值。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # Kafka and ZooKeeper sections... entityOperator: topicOperator: resources: requests: cpu: "1" memory: 500Mi limits: cpu: "1" memory: 500Mi应用新配置以创建或更新资源。
oc apply -f KAFKA-CONFIG-FILE
5.3. 使用 User Operator
当使用 KafkaUser 资源创建、修改或删除用户时,User Operator 可确保这些更改反映在 Kafka 集群中。
OpenShift 指南中的部署和升级 AMQ Streams 提供了部署 User Operator 的说明:
有关模式的更多信息,请参阅 KafkaUser schema 参考。
验证和授权对 Kafka 的访问
使用 KafkaUser 启用特定客户端用来访问 Kafka 的身份验证和授权机制。
有关使用 KafkUser 管理用户并保护对 Kafka 代理的访问的更多信息,请参阅保护对 Kafka 代理的访问。
5.3.1. 使用资源请求和限值配置 User Operator
您可以将资源(如 CPU 和内存)分配给 User Operator,并为它消耗的资源量设置限制。
先决条件
- Cluster Operator 正在运行。
步骤
根据需要更新编辑器中的 Kafka 集群配置:
oc edit kafka MY-CLUSTER在
Kafka资源中的spec.entityOperator.userOperator.resources属性中,为 User Operator 设置资源请求和限值。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # Kafka and ZooKeeper sections... entityOperator: userOperator: resources: requests: cpu: "1" memory: 500Mi limits: cpu: "1" memory: 500Mi保存文件并退出编辑器。Cluster Operator 会自动应用更改。
5.4. 使用 Prometheus 指标监控 Operator
AMQ Streams 操作器公开 Prometheus 指标数据。指标数据会被自动启用,其中包含以下相关信息:
- 协调数
- Operator 正在处理的自定义资源数量
- 协调的持续时间
- 来自操作器的 JVM 指标
另外,我们提供了一个 Grafana 仪表板示例。
如需有关 Prometheus 的更多信息,请参阅 OpenShift 指南中的 Deploying and upgrade AMQ Streams 中的 引入 Metrics to Kafka。
第 6 章 Kafka Bridge
本章概述了 AMQ Streams Kafka Bridge,并帮助您开始使用 REST API 与 AMQ Streams 交互。
- 要在您的本地环境中尝试 Kafka 网桥,请参阅本章后面的 第 6.2 节 “Kafka Bridge quickstart”。
- 有关配置步骤的详情请参考 第 2.5 节 “Kafka Bridge 集群配置”。
- 要查看 API 文档,请参阅 Kafka Bridge API 参考。
6.1. Kafka 网桥概述
您可以使用 AMQ Streams Kafka Bridge 作为接口,向 Kafka 集群发出特定类型的 HTTP 请求。
6.1.1. Kafka Bridge 接口
Kafka Bridge 提供了一个 RESTful 接口,允许基于 HTTP 的客户端与 Kafka 集群交互。 它提供了与 AMQ Streams 的 Web API 连接的优势,不需要客户端应用程序来解释 Kafka 协议。
API 有两个主要资源( 使用者和 主题 ),它们通过端点公开并可访问,以便与 Kafka 集群中的用户和生产者交互。资源仅与 Kafka 网桥相关,而不是与 Kafka 直接连接的消费者和生产者。
6.1.1.1. HTTP 请求
Kafka Bridge 支持对 Kafka 集群的 HTTP 请求,其方法如下:
- 发送消息到一个主题。
- 从主题检索消息.
- 检索主题的分区列表。
- 创建和删除消费者.
- 订阅消费者了解主题,以便他们开始接收来自这些主题的信息。
- 检索消费者订阅的主题列表。
- 取消订阅消费者的主题.
- 将分区分配给消费者.
- 提交消费者偏移列表。
- 寻找分区,以便使用者开始接受来自第一个或最后一个偏移位置的信息,或者给定的偏移位置。
这些方法提供 JSON 响应和 HTTP 响应代码错误处理。消息可以 JSON 或二进制格式发送。
客户端可以生成和使用消息,而无需使用原生 Kafka 协议。
其他资源
- 要查看 API 文档,包括请求和响应示例,请参阅 Kafka Bridge API 参考。
6.1.2. Kafka Bridge 支持的客户端
您可以使用 Kafka Bridge 将 内部和外部 HTTP 客户端应用程序与 Kafka 集群集成。
- 内部客户端
-
内部客户端是基于容器的 HTTP 客户端,与 Kafka Bridge 本身 在同一个 OpenShift 集群中运行。内部客户端可以访问在 Kafka
Bridge 自定义资源中定义的主机上的 KafkaBridge 和端口。 - 外部客户端
- 外部客户端是在 OpenShift 集群 外部 运行的 HTTP 客户端,其中部署并运行 Kafka Bridge。外部客户端可以通过 OpenShift Route、负载均衡器服务或使用 Ingress 访问 Kafka 网桥。
HTTP 内部和外部客户端集成
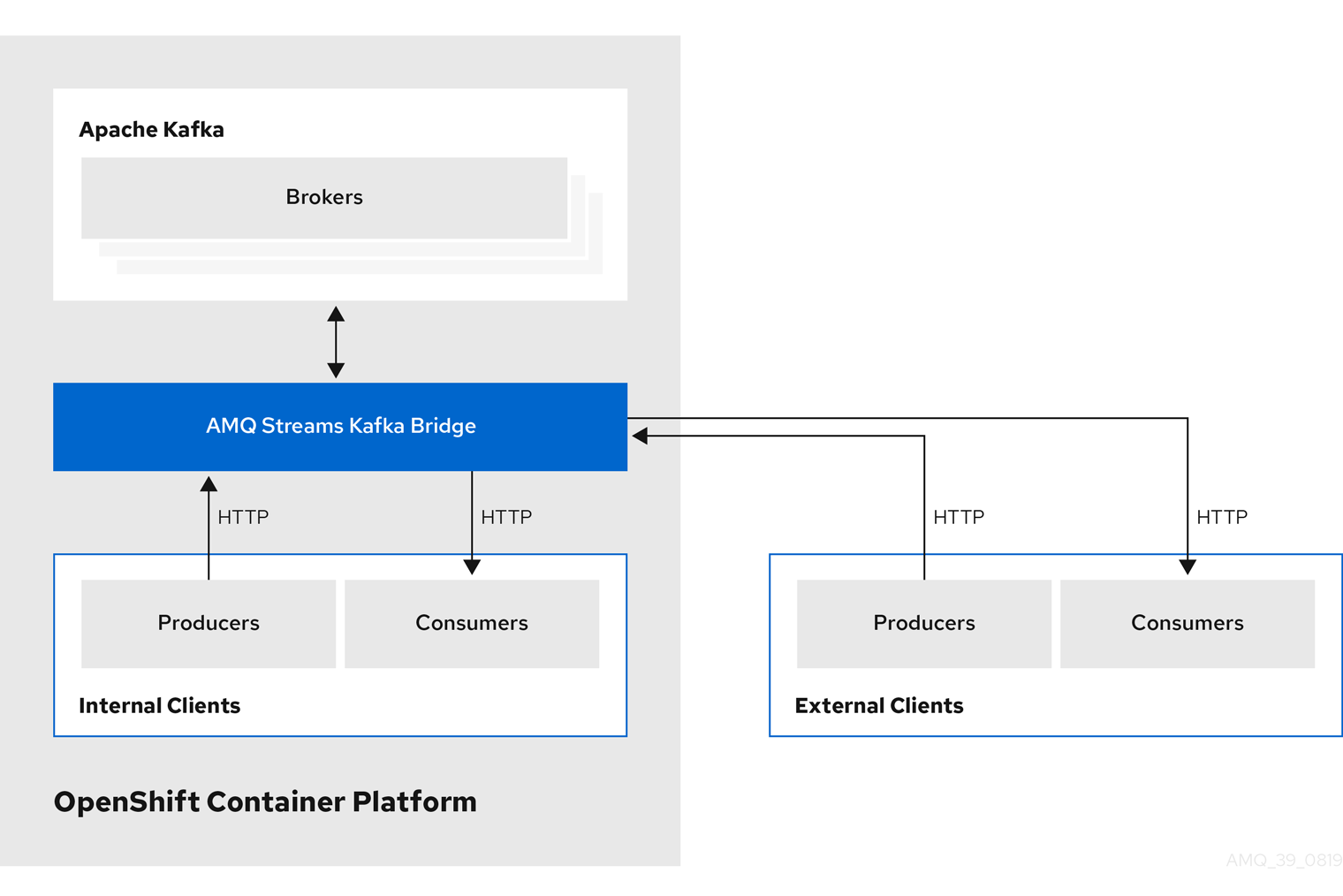
6.1.3. 保护 Kafka 网桥
AMQ Streams 目前不为 Kafka Bridge 提供任何加密、身份验证或授权。这意味着,从外部客户端发送到 Kafka Bridge 的请求是:
- 未加密,且必须使用 HTTP 而不是 HTTPS
- 在没有验证的情况下发送
但是,您可以使用其他方法保护 Kafka 网桥的安全,例如:
- 定义哪些容器集可以访问 Kafka 网桥的 OpenShift Network 策略。
- 带有身份验证或授权的反向代理,如 OAuth2 代理。
- API 网关.
- 具有 TLS 终止的入口或 OpenShift 路由。
当连接到 Kafka Broker 时,Kafka Bridge 支持 TLS 加密以及 TLS 和 SASL 身份验证。在 OpenShift 集群中,您可以配置:
- Kafka Bridge 和 Kafka 集群间的 TLS 或基于 SASL 的身份验证
- Kafka 网桥和 Kafka 集群之间的 TLS 加密连接。
如需更多信息,请参阅 第 2.5.1 节 “配置 Kafka 网桥”。
您可以使用 Kafka 代理中的 ACL 来限制可通过 Kafka Bridge 使用和生成的主题。
6.1.4. 访问 OpenShift 外部的 Kafka 网桥
部署后,AMQ Streams Kafka Bridge 只能由同一 OpenShift 集群中运行的应用程序访问。这些应用程序使用 kafka-bridge-name-bridge-service 服务来访问 API。
如果要使 Kafka Bridge 可供在 OpenShift 集群外运行的应用程序访问,您可以使用以下功能之一手动公开它:
- LoadBalancer 或 NodePort 类型的服务
- Ingress 资源
- OpenShift Routes
如果您决定创建服务,请使用 选择器 中的以下标签来配置服务要将流量路由到的 pod:
# ...
selector:
strimzi.io/cluster: kafka-bridge-name 1
strimzi.io/kind: KafkaBridge
#...- 1
- OpenShift 集群中 Kafka Bridge 自定义资源的名称。
6.1.5. 对 Kafka Bridge 的请求
指定数据格式和 HTTP 标头,以确保向 Kafka Bridge 提交有效的请求。
6.1.5.1. 内容类型标头
API 请求和响应正文始终编码为 JSON。
在执行消费者操作时,如果存在非空正文,
POST请求必须提供以下Content-Type标头:Content-Type: application/vnd.kafka.v2+json
在执行制作者操作时,
POST 请求必须提供Content-Type标头,指定生成的消息的 嵌入式数据格式。这可以是json或二进制。嵌入式数据格式 content-Type 标头 JSON
content-Type: application/vnd.kafka.json.v2+json二进制
content-Type: application/vnd.kafka.binary.v2+json
嵌入式数据格式为每个消费者设置,如下一节所述。
如果 POST 请求 具有空正文,则不能 设置 Content-Type。空正文可用于创建具有默认值的消费者。
6.1.5.2. 嵌入式数据格式
嵌入式数据格式是 Kafka 消息通过 HTTP 从生产者传输到使用 Kafka 网桥的消费者的格式。支持两种嵌入式数据格式:JSON 和二进制.
在使用 /consumers/groupid 端点创建消费者时,POST 请求 正文必须指定嵌入的数据格式(JSON 或二进制)。这在 format 字段中指定,例如:
{
"name": "my-consumer",
"format": "binary", 1
...
}- 1
- 二进制嵌入式数据格式.
创建使用者时指定的嵌入式数据格式必须与它将使用的 Kafka 消息的数据格式匹配。
如果您选择指定二进制嵌入式数据格式,后续制作者请求必须在请求正文中以 Base64 编码的字符串形式提供二进制数据。例如,在使用 /topics/topicname 端点发送信息时,records.value 必须采用 Base64 编码:
{
"records": [
{
"key": "my-key",
"value": "ZWR3YXJkdGhldGhyZWVsZWdnZWRjYXQ="
},
]
}
制作者请求还必须提供与嵌入式数据格式对应的 Content-Type 标头,如 Content-Type: application/vnd.kafka.binary.v2+json。
6.1.5.3. 消息格式
使用 /topics 端点 发送消息时,您将在请求正文中的 record 参数 中输入消息有效负载。
records 参数可以包含任何这些可选字段:
-
消息
标头 -
消息
键 -
消息
值 -
目标
分区
到 /topics 的 POST 请求示例
curl -X POST \
http://localhost:8080/topics/my-topic \
-H 'content-type: application/vnd.kafka.json.v2+json' \
-d '{
"records": [
{
"key": "my-key",
"value": "sales-lead-0001"
"partition": 2
"headers": [
{
"key": "key1",
"value": "QXBhY2hlIEthZmthIGlzIHRoZSBib21iIQ==" 1
}
]
},
]
}'
- 1
- 二进制格式的标头值,编码为 Base64。
6.1.5.4. 接受标头
创建消费者后,所有后续 GET 请求都必须以以下格式提供 Accept 标头:
Accept: application/vnd.kafka.EMBEDDED-DATA-FORMAT.v2+json
EMBEDDED-DATA-FORMAT 是 json 或 二进制。
例如,当使用嵌入的 JSON 数据格式获取订阅的消费者的记录时,包括这个 Accept 标头:
Accept: application/vnd.kafka.json.v2+json
6.1.6. CORS
跨 Origin 资源共享(CORS)允许您指定在 Kafka 网桥 HTTP 配置 中访问 Kafka 集群的允许方法和原始 URL。
Kafka Bridge 的 CORS 配置示例
# ... cors: allowedOrigins: "https://strimzi.io" allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH" # ...
CORS 允许在不同域中的原始源之间 简单 且 预先理解的请求。
简单请求适用于使用 GET、HEAD、POST 方法的标准请求。
预定义的请求会发送 HTTP OPTIONS 请求,作为检查实际请求是否安全发送的初始检查。确认后会发送实际请求。preflight 请求适用于需要更大保护的方法,如 PUT 和 DELETE,以及使用非标准标头。
所有请求都需要其标头中有一个 Origin 值,这是 HTTP 请求的来源。
6.1.6.1. 简单请求
例如:这个简单请求标头将原始文件指定为 https://strimzi.io。
Origin: https://strimzi.io
标头信息添加到请求中。
curl -v -X GET HTTP-ADDRESS/bridge-consumer/records \
-H 'Origin: https://strimzi.io'\
-H 'content-type: application/vnd.kafka.v2+json'
在 Kafka Bridge 的响应中,会返回 Access-Control-Allow-Origin 标头。
HTTP/1.1 200 OK
Access-Control-Allow-Origin: * 1- 1
- 返回星号
(*)表示资源可以被任何域访问。
6.1.6.2. Preflighted 请求
使用 a OPTIONS 方法将初始 preflight 请求发送到 Kafka Bridge。HTTP OPTIONS 请求发送标头信息,以检查 Kafka Bridge 是否允许实际请求。
这里的 preflight 请求检查 POST 请求 是否从 https://strimzi.io 有效。
OPTIONS /my-group/instances/my-user/subscription HTTP/1.1 Origin: https://strimzi.io Access-Control-Request-Method: POST 1 Access-Control-Request-Headers: Content-Type 2
OPTIONS 被添加到 preflight 请求的标题信息中。
curl -v -X OPTIONS -H 'Origin: https://strimzi.io' \ -H 'Access-Control-Request-Method: POST' \ -H 'content-type: application/vnd.kafka.v2+json'
Kafka Bridge 响应初始请求,以确认请求被接受。响应标头返回允许的来源、方法和标头。
HTTP/1.1 200 OK Access-Control-Allow-Origin: https://strimzi.io Access-Control-Allow-Methods: GET,POST,PUT,DELETE,OPTIONS,PATCH Access-Control-Allow-Headers: content-type
如果原始或方法被拒绝,则返回错误消息。
实际请求不需要 Access-Control-Request-Method 标头,因为它已在 preflight 请求中确认,但它确实需要 origin 标头。
curl -v -X POST HTTP-ADDRESS/topics/bridge-topic \
-H 'Origin: https://strimzi.io' \
-H 'content-type: application/vnd.kafka.v2+json'响应中显示允许的来源 URL。
HTTP/1.1 200 OK Access-Control-Allow-Origin: https://strimzi.io
其他资源
获取 CORS 规格
6.1.7. Kafka Bridge API 资源
有关 REST API 端点和描述的完整列表,包括请求和响应示例,请查看 Kafka Bridge API 参考。
6.1.8. Kafka Bridge 部署
您可以使用 Cluster Operator 将 Kafka Bridge 部署到 OpenShift 集群中。
部署 Kafka Bridge 后,Cluster Operator 会在 OpenShift 集群中创建 Kafka Bridge 对象。对象包括 部署、服务和 pod,各自名称都以 Kafka Bridge 自定义资源中指定的名称命名。
其他资源
- 有关部署说明,请参阅 OpenShift 指南中的 Deploying AMQ Streams 中的将 Kafka Bridge 部署到 OpenShift 集群。
- 有关配置 Kafka 网桥的详情,请参考 第 2.5 节 “Kafka Bridge 集群配置”
-
有关为
KafkaBridge资源配置主机和端口的详情请参考 第 2.5.1 节 “配置 Kafka 网桥”。 - 有关集成外部客户端的详情请参考 第 6.1.4 节 “访问 OpenShift 外部的 Kafka 网桥”。
6.2. Kafka Bridge quickstart
使用此快速入门尝试本地开发环境中的 AMQ Streams Kafka Bridge。您将学习如何:
- 将 Kafka Bridge 部署到 OpenShift 集群
- 使用端口转发向本地机器公开 Kafka Bridge 服务
- 生成到 Kafka 集群中主题和分区的信息
- 创建 Kafka 网桥消费者
- 执行基本的消费者操作,如将消费者订阅到主题并检索您生成的信息
在这个快速启动中,HTTP 请求格式化为 curl 命令,您可以将它们复制并粘贴到您的终端。需要访问 OpenShift 集群;若要运行和管理本地 OpenShift 集群,请使用 Minikube、CodeReady Containers 或 MiniShift 等工具。
确保您具有先决条件,然后按照本章中提供的顺序按照任务进行操作。
关于数据格式
在此快速入门中,您将以 JSON 格式(而非二进制)生成和使用消息。有关示例请求中使用的数据格式和 HTTP 标头的更多信息,请参阅 第 6.1.5 节 “对 Kafka Bridge 的请求”。
快速启动的先决条件
- 集群管理员对本地或远程 OpenShift 集群的访问权限。
- 已安装 AMQ Streams。
- 一个正在运行的 Kafka 集群,由 Cluster Operator 在 OpenShift 命名空间中部署。
- Entity Operator 作为 Kafka 集群的一部分被部署并运行。
6.2.1. 将 Kafka Bridge 部署到 OpenShift 集群
AMQ Streams 包含一个 YAML 示例,用于指定 AMQ Streams Kafka Bridge 的配置。对此文件进行一些最小更改,然后将 Kafka Bridge 的实例部署到 OpenShift 集群。
步骤
编辑 example
/bridge/kafka-bridge.yaml文件。apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaBridge metadata: name: quickstart 1 spec: replicas: 1 bootstrapServers: <cluster-name>-kafka-bootstrap:9092 2 http: port: 8080
将 Kafka Bridge 部署到 OpenShift 集群:
oc apply -f examples/bridge/kafka-bridge.yaml
OpenShift 集群中会创建 Quickstart
-bridge部署、服务和其他相关资源。验证 Kafka 网桥是否已成功部署:
oc get deployments
NAME READY UP-TO-DATE AVAILABLE AGE quickstart-bridge 1/1 1 1 34m my-cluster-connect 1/1 1 1 24h my-cluster-entity-operator 1/1 1 1 24h #...
接下来要做什么
将 Kafka Bridge 部署到 OpenShift 集群后,将 Kafka Bridge 服务公开给您的本地机器。
其他资源
- 有关配置 Kafka 网桥的详情请参考 第 2.5 节 “Kafka Bridge 集群配置”。
6.2.2. 将 Kafka Bridge 服务公开到您的本地机器
接下来,使用端口转发将 AMQ Streams Kafka Bridge 服务公开给 http://localhost:8080 上的本地机器。
端口转发仅适用于开发和测试目的。
步骤
列出 OpenShift 集群中 pod 的名称:
oc get pods -o name pod/kafka-consumer # ... pod/quickstart-bridge-589d78784d-9jcnr pod/strimzi-cluster-operator-76bcf9bc76-8dnfm
连接到端口
8080上的quickstart-bridgepod:oc port-forward pod/quickstart-bridge-589d78784d-9jcnr 8080:8080 &
注意如果本地计算机上的端口 8080 已在使用,请使用其它 HTTP 端口,如
8008。
API 请求现在从本地机器的端口 8080 转发到 Kafka Bridge Pod 中的端口 8080。
6.2.3. 生成到主题和分区的消息
接下来,使用主题端点以 JSON 格式生成消息到 主题。您可以在请求正文中为消息指定目的地分区,如下所示。分区 端点 提供了一种备选方法,用于指定所有消息的单一目标分区,作为路径参数。
步骤
在文本编辑器中,为带有三个分区的 Kafka 主题创建 YAML 定义。
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic metadata: name: bridge-quickstart-topic labels: strimzi.io/cluster: <kafka-cluster-name> 1 spec: partitions: 3 2 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824-
将文件保存到 example
/topic目录中,作为bridge-quickstart-topic.yaml。 在 OpenShift 集群中创建主题:
oc apply -f examples/topic/bridge-quickstart-topic.yaml
使用 Kafka Bridge,为您创建的主题生成三个信息:
curl -X POST \ http://localhost:8080/topics/bridge-quickstart-topic \ -H 'content-type: application/vnd.kafka.json.v2+json' \ -d '{ "records": [ { "key": "my-key", "value": "sales-lead-0001" }, { "value": "sales-lead-0002", "partition": 2 }, { "value": "sales-lead-0003" } ] }'-
sales-lead-0001发送至基于密钥哈希的分区。 -
sales-lead-0002直接发送到分区 2。 -
sales-lead-0003通过循环方法发送到bridge-quickstart-topic主题中的分区。
-
如果请求成功,Kafka Bridge 将返回一个
偏移数组,以及200代码和内容类型标头application/vnd.kafka.v2+json。对于每条消息,偏移阵列描述:- 消息发送到的分区
分区的当前消息偏移
响应示例
#... { "offsets":[ { "partition":0, "offset":0 }, { "partition":2, "offset":0 }, { "partition":0, "offset":1 } ] }
接下来要做什么
在向主题和分区生成消息后,创建一个 Kafka 网桥使用者。
其他资源
- API 参考文档中的 POST /topics/{topicname}。
- API 参考文档中的 POST /topics/{topicname}/partitions/{partitionid}。
6.2.4. 创建 Kafka 网桥消费者
在 Kafka 集群中执行任何消费者操作前,您必须首先使用使用者端点创建 消费者。用户称为 Kafka 网桥消费者。
步骤
在名为
bridge-quickstart-consumer-group 的新使用者组中创建一个 Kafka 网桥使用者:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "name": "bridge-quickstart-consumer", "auto.offset.reset": "earliest", "format": "json", "enable.auto.commit": false, "fetch.min.bytes": 512, "consumer.request.timeout.ms": 30000 }'-
用户名为
bridge-quickstart-consumer,嵌入式数据格式则设为json。 - 定义了一些基本的配置设置:
由于
enable.auto.commit设置为false,因此使用者不会自动向日志提交偏移。在此快速入门稍后您将手动提交偏移。如果请求成功,Kafka Bridge 会在响应正文返回使用者 ID(
instance_id)和基本 URL(base_uri),以及200代码。响应示例
#... { "instance_id": "bridge-quickstart-consumer", "base_uri":"http://<bridge-name>-bridge-service:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer" }
-
用户名为
-
复制基本 URL(
base_uri),以便在这个快速启动的其他消费者操作中使用。
接下来要做什么
现在,您已创建了 Kafka 网桥消费者,您可以为 它订阅主题。
其他资源
- API 参考文档中的 POST/consumers/{groupid}。
6.2.5. 将 Kafka 网桥消费者订阅到主题
创建 Kafka 网桥消费者后,使用订阅端点将其 订阅 到一个或多个主题。订阅后,消费者开始收到生成到该主题的所有消息。
步骤
在向主题和分区 生成信息时,将消费者订阅您之前创建的
bridge-quickstart-topic主题:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/subscription \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "topics": [ "bridge-quickstart-topic" ] }'主题数组可以包含一个主题(如下所示)或多个主题。如果要将消费者订阅与正则表达式匹配的多个主题,您可以使用topic_pattern字符串而不是主题数组。如果请求成功,Kafka Bridge 只会返回
204(No Content)代码。
接下来要做什么
在将 Kafka 网桥使用者订阅到主题后,您可以从 消费者检索消息。
其他资源
6.2.6. 从 Kafka Bridge 用户检索最新信息
接下来,通过从 记录 端点请求数据,从 Kafka 网桥使用者检索最新的消息。在生产环境中,HTTP 客户端可以重复调用此端点(在循环中)。
步骤
- 为 Kafka 网桥使用者生成其他信息,如 向主题和分区生成消息 中所述。
将
GET 请求提交到记录端点:curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
创建并订阅 Kafka 网桥消费者后,第一个 GET 请求将返回空响应,因为轮询操作会启动重新平衡过程来分配分区。
重复步骤二,从 Kafka Bridge consumer 检索消息。
Kafka Bridge 返回一个消息的数组来代表响应正文中的主题名称、键、值、分区和偏移全部全部信息
,以及 200 个代码。消息默认从最新的偏移检索。HTTP/1.1 200 OK content-type: application/vnd.kafka.json.v2+json #... [ { "topic":"bridge-quickstart-topic", "key":"my-key", "value":"sales-lead-0001", "partition":0, "offset":0 }, { "topic":"bridge-quickstart-topic", "key":null, "value":"sales-lead-0003", "partition":0, "offset":1 }, #...注意如果返回空的响应,会按照 向主题和分区生成消息 中所述为消费者生成更多记录,然后尝试再次检索消息。
接下来要做什么
从 Kafka 网桥使用者检索消息后,尝试 向日志提交偏移。
其他资源
6.2.7. 将偏移提交到日志
接下来,使用 偏移端点 将偏移手动提交到 Kafka Bridge使用者接收的所有消息的日志中。这是必要的,因为您在创建 Kafka Bridge 用户时,之前创建的 Kafka 网桥消费者 被配置为使用 enable.auto.commit 设置为 false。
步骤
将偏移量提交到
bridge-quickstart-consumer的日志:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/offsets
由于没有提交请求正文,将为消费者收到的所有记录提交偏移。或者,请求正文可以包含一个数组(OffsetCommitSeekList),用于指定您要提交偏移的主题和分区。
如果请求成功,Kafka Bridge 只会返回
204代码。
接下来要做什么
向日志提交偏移后,尝试查找要 偏移的 端点。
其他资源
6.2.8. 寻找分区的偏移
接下来,使用 位置 端点配置 Kafka 网桥使用者,以从特定偏移检索分区的消息,然后从最新的偏移中检索。这在 Apache Kafka 中称为搜索操作。
步骤
为 Quickstart
-bridge-topic主题的分区 0 寻找特定的偏移:curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "offsets": [ { "topic": "bridge-quickstart-topic", "partition": 0, "offset": 2 } ] }'如果请求成功,Kafka Bridge 只会返回
204代码。将
GET 请求提交到记录端点:curl -X GET http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/records \ -H 'accept: application/vnd.kafka.json.v2+json'
Kafka Bridge 从您要查找的偏移返回消息。
通过查找同一分区的最后偏移来恢复默认消息检索行为。这一次使用 position /end 端点。
curl -X POST http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer/positions/end \ -H 'content-type: application/vnd.kafka.v2+json' \ -d '{ "partitions": [ { "topic": "bridge-quickstart-topic", "partition": 0 } ] }'如果请求成功,Kafka Bridge 会返回另一个
204代码。
您还可以使用 位置/探测端点 来查找一个或多个分区的第一个偏移。
接下来要做什么
在这个快速入门中,您已使用 AMQ Streams Kafka Bridge 在 Kafka 集群上执行几个常用操作。现在 ,您可以删除之前创建的 Kafka 网桥消费者。
其他资源
- API 参考文档中的 POST/consumers/{groupid}/instances/{name}/ 位置。
- POST /consumers/{groupid}/instances/{name}/locations/beginning in the API 参考文档中。
- 在 API 参考文档中 POST /consumers/{groupid}/instances/{name}/locations/end。
6.2.9. 删除 Kafka 网桥消费者
最后,删除整个快速入门中使用的 Kafa Bridge 消费者。
步骤
通过向 实例 端点发送
DELETE请求来删除 Kafka 网桥使用者。curl -X DELETE http://localhost:8080/consumers/bridge-quickstart-consumer-group/instances/bridge-quickstart-consumer
如果请求成功,Kafka Bridge 只会返回
204代码。
其他资源
- API 参考文档中的 DELETE /consumers/{groupid}/instances/{name}。
第 7 章 使用带有 3scale 的 Kafka 网桥
您可以将 Red Hat 3scale API 管理与 AMQ Streams Kafka Bridge 部署和集成。
7.1. 使用带有 3scale 的 Kafka 网桥
使用 Kafka 网桥的纯部署,不会置备身份验证或授权,不支持与外部客户端的 TLS 加密连接。
3scale 可以通过 TLS 保护 Kafka 网桥,并提供身份验证和授权。与 3scale 集成还意味着还提供其他功能,如指标、速率限制和计费。
通过 3scale,您可以将不同类型的身份验证用于希望访问 AMQ Streams 的外部客户端的请求。3scale 支持以下类型的身份验证:
- 标准 API 密钥
- 单一随机字符串或哈希充当标识符和机密令牌。
- 应用程序标识符和密钥对
- 不可变标识符和可变 secret key 字符串。
- OpenID Connect
- 用于委派的身份验证的协议.
使用现有的 3scale 部署?
如果您已将 3scale 部署到 OpenShift,并且希望将它与 Kafka 网桥搭配使用,请确保您有正确的设置。
设置在 第 7.2 节 “为 Kafka 网桥部署 3scale” 中描述。
7.1.1. Kafka Bridge 服务发现
3scale 是使用服务发现功能集成的,这需要 3scale 与 AMQ Streams 和 Kafka Bridge 部署到同一个 OpenShift 集群。
您的 AMQ Streams Cluster Operator 部署必须设置以下环境变量:
- STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_LABELS
- STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_ANNOTATIONS
部署 Kafka Bridge 时,公开 Kafka Bridge REST 接口的服务使用注解和标签来发现 3scale。
-
3
scale 使用 discovery.3scale.net=true标签来查找服务。 - 注解提供有关服务的信息。
您可以通过导航到 Kafka Bridge 实例的 Services 来检查 OpenShift 控制台中的配置。您 会看到 Kafka 网桥的 OpenAPI 规格的端点。
7.1.2. 3scale APIcast 网关策略
3scale 与 3scale APIcast 一起使用,后者是部署有 3scale 的 API 网关,为 Kafka 网桥提供单一入口点。
APIcast 策略提供了一种自定义网关运行方式的机制。3scale 为网关配置提供一组标准策略。您还可以创建自己的策略。
如需有关 APIcast 策略的更多信息,请参阅 3scale 文档中的 管理 API 网关。
Kafka Bridge 的 APIcast 策略
policy _config.json 文件提供了 3scale 与 Kafka Bridge 集成的示例策略 配置,该文件定义了:
- 匿名访问
- 标头修改
- 路由
- URL 重写
通过此文件启用或禁用网关策略。
您可以使用此示例作为定义您自己的策略的起点。
- 匿名访问
- 匿名访问策略在没有身份验证的情况下公开服务,在 HTTP 客户端不提供它们时提供默认凭据(用于匿名访问)。策略不是强制的,如果始终需要身份验证,可以禁用或删除。
- 标头修改
标头修改策略允许修改现有的 HTTP 标头,或向通过网关的请求或响应添加新的标头。对于 3scale 集成,策略会为从 HTTP 客户端传递到 Kafka 网桥的每个请求添加标头。
当 Kafka Bridge 收到创建新消费者的请求时,它会返回包含
base_uri字段的 JSON 有效负载,其中包含使用者必须用于所有后续请求的 URI。例如:{ "instance_id": "consumer-1", "base_uri":"http://my-bridge:8080/consumers/my-group/instances/consumer1" }使用 APIcast 时,客户端会将所有后续请求发送到网关,而不是直接发送到 Kafka 网桥。因此 URI 需要网关主机名,而不是网关后面的 Kafka 网桥地址。
使用标头修改策略,标头添加到来自 HTTP 客户端的请求中,以便 Kafka Bridge 使用网关主机名。
例如,通过应用
Forwarded: host=my-gateway:80;proto=http标头,Kafka 网桥向使用者提供以下内容:{ "instance_id": "consumer-1", "base_uri":"http://my-gateway:80/consumers/my-group/instances/consumer1" }X-Forwarded-Path标头承载从客户端到网关的请求中包含的原始路径。此标头与网关支持多个 Kafka Bridge 实例时应用的路由策略严格相关。- 路由
当有多个 Kafka Bridge 实例时,会应用路由策略。请求必须发送到最初创建使用者的同一 Kafka Bridge 实例,因此请求必须指定网关将请求转发到适当的 Kafka Bridge 实例的路由。
每个网桥实例都有一个路由策略名称,路由则使用 名称来执行。部署 Kafka Bridge 时,您可以在
KafkaBridge自定义资源中指定名称。例如,从使用者到以下每个请求(使用
X-Forwarded-Path)http://my-gateway:80/my-bridge-1/consumers/my-group/instances/consumer1转发到:
http://my-bridge-1-bridge-service:8080/consumers/my-group/instances/consumer1URL 重写策略会删除网桥名称,因为它在将请求从网关转发到 Kafka Bridge 时不会用到。
- URL 重写
URL 重新连接策略确保从客户端到特定 Kafka Bridge 实例的请求在将网关的请求转发到 Kafka Bridge 时不包含网桥名称。
网桥名称不用于网桥公开的端点。
7.1.3. TLS 验证
您可以为 TLS 验证设置 APIcast,这需要使用模板自助管理 APIcast 部署。apicast 服务作为路由公开。
您还可以将 TLS 策略应用到 Kafka Bridge API。
如需有关 TLS 配置的更多信息,请参阅 3scale 文档中的 管理 API 网关。
7.1.4. 3scale 文档
部署 3scale 以用于 Kafka Bridge 的步骤假定对 3scale 有一定的了解。
如需更多信息,请参阅 3scale 产品文档:
7.2. 为 Kafka 网桥部署 3scale
要将 3scale 与 Kafka 网桥搭配使用,首先对其进行部署,然后将其配置为发现 Kafka Bridge API。
您还将使用 3scale APIcast 和 3scale toolbox。
- APIcast 由 3scale 提供,作为基于 NGINX 的 API 网关,供 HTTP 客户端连接到 Kafka Bridge API 服务。
- 3scale toolbox 是一个配置工具,用于将 Kafka Bridge 服务的 OpenAPI 规格导入到 3scale。
在这种情况下,您将在同一 OpenShift 集群中运行 AMQ Streams、Kafka、Kafka Bridge 和 3scale/APIcast。
如果您已在与 Kafka 网桥相同的集群中部署了 3scale,您可以跳过部署步骤并使用当前的部署。
对于 3scale 部署:
- 检查 Red Hat 3scale API Management 支持的配置。
-
安装时需要具有
cluster-admin角色的用户,如system:admin。 您需要访问以下 JSON 文件:
-
Kafka Bridge OpenAPI specification (
openapiv2.json) Kafka Bridge 的标头修改和路由
策略(policies_config.json)在 GitHub 上查找 JSON 文件。
-
Kafka Bridge OpenAPI specification (
步骤
将 3scale API 管理部署到 OpenShift 集群。
创建新项目或使用现有的项目。
oc new-project my-project \ --description="description" --display-name="display_name"
部署 3scale.
使用 安装 3scale 指南中提供的信息,通过模板或操作器在 OpenShift 中部署 3scale。
无论您使用哪一种方法,请确保您将 WILDCARD_DOMAIN 参数设置为 OpenShift 集群的域。
记录用于访问 3scale 管理门户的 URLS 和凭据。
为 3scale 授予发现 Kafka Bridge 服务的授权:
oc adm policy add-cluster-role-to-user view system:serviceaccount:my-project:amp通过 OpenShift 控制台或 CLI 验证 3scale 已成功部署到 Openshift 集群。
例如:
oc get deployment 3scale-operator
设置 3scale toolbox。
- 使用 Operating 3scale 指南中提供的信息来安装 3scale toolbox。
设置环境变量以便与 3scale 交互:
export REMOTE_NAME=strimzi-kafka-bridge 1 export SYSTEM_NAME=strimzi_http_bridge_for_apache_kafka 2 export TENANT=strimzi-kafka-bridge-admin 3 export PORTAL_ENDPOINT=$TENANT.3scale.net 4 export TOKEN=3scale access token 5
配置 3scale toolbox 的远程 Web 地址:
3scale remote add $REMOTE_NAME https://$TOKEN@$PORTAL_ENDPOINT/
现在,当您每次运行 toolbox 时,不需要指定 3scale 管理门户的端点地址。
检查您的 Cluster Operator 部署是否有 3scale 发现 Kafka Bridge 服务所需的标签和注解属性。
#... env: - name: STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_LABELS value: | discovery.3scale.net=true - name: STRIMZI_CUSTOM_KAFKA_BRIDGE_SERVICE_ANNOTATIONS value: | discovery.3scale.net/scheme=http discovery.3scale.net/port=8080 discovery.3scale.net/path=/ discovery.3scale.net/description-path=/openapi #...如果没有,请通过 OpenShift 控制台添加属性或尝试重新部署 Cluster Operator 和 Kafka Bridge。
通过 3scale 发现 Kafka Bridge API 服务。
- 使用部署 3scale 时提供的凭据,登录 3scale 管理门户。
- 从 3scale 管理门户,导航到 ,其中您将看到 Kafka Bridge 服务。
点 。
您可能需要刷新页面来查看 Kafka Bridge 服务。
现在,您需要导入该服务的配置。从编辑器执行此操作,但请保持门户打开以检查导入是否成功。
编辑 OpenAPI 规格(JSON 文件)中的 Host 字段,以使用 Kafka Bridge 服务的基本 URL:
例如:
"host": "my-bridge-bridge-service.my-project.svc.cluster.local:8080"
检查
主机URL 中包含正确的内容:- Kafka Bridge 名称(my-bridge)
- 项目名称(my-project)
- Kafka 网桥的端口(8080)
使用 3scale toolbox 导入更新的 OpenAPI 规格:
3scale import openapi -k -d $REMOTE_NAME openapiv2.json -t myproject-my-bridge-bridge-service
导入服务的标头修改和路由策略(JSON 文件)。
查找您在 3scale 中创建的服务 ID。
在这里,我们使用 "jq"实用程序 :
export SERVICE_ID=$(curl -k -s -X GET "https://$PORTAL_ENDPOINT/admin/api/services.json?access_token=$TOKEN" | jq ".services[] | select(.service.system_name | contains(\"$SYSTEM_NAME\")) | .service.id")
导入策略时需要 ID。
导入策略:
curl -k -X PUT "https://$PORTAL_ENDPOINT/admin/api/services/$SERVICE_ID/proxy/policies.json" --data "access_token=$TOKEN" --data-urlencode policies_config@policies_config.json
- 从 3scale Admin Portal,导航到 → ,以检查 Kafka Bridge 服务的端点和策略是否已加载。
- 导航到 → 以创建应用计划。
导航到 → → → 以创建应用。
需要应用才能获取用于身份验证的用户密钥。
(生产环境步骤)要让 API 可供生产网关使用,请提升配置:
3scale proxy-config promote $REMOTE_NAME $SERVICE_ID
使用 API 测试工具,验证您可以通过 APIcast 网关使用调用创建使用者以及为应用程序创建用户密钥来访问 Kafka 网桥。
例如:
https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group?user_key=3dfc188650101010ecd7fdc56098ce95
如果从 Kafka Bridge 返回有效负载,则消费者创建成功。
{ "instance_id": "consumer1", "base uri": "https//my-project-my-bridge-bridge-service-3scale-apicast-staging.example.com:443/consumers/my-group/instances/consumer1" }基础 URI 是客户端要在后续请求中使用的地址。
第 8 章 用于集群重新平衡的精简控制
您可以将 Cruise Control 部署到 AMQ Streams 集群,并使用它来 重新平衡 Kafka 集群。
cruise Control 是一个开源系统,用于自动执行 Kafka 操作,如监控集群工作负载、根据预定义的限制重新平衡集群,以及检测和修复异常情况。它由四个主要组件组成-Load Monitor、Analyzer、Anomaly Detector 和 Executor-以及用于客户端交互的 REST API。AMQ Streams 利用 REST API 支持以下 Cruise Control 功能:
- 从多个 优化 目标生成优化。
- 根据优化建议重新平衡 Kafka 集群。
目前不支持其他 Cruise 控制功能,包括异常检测、通知、写入目标以及更改主题复制因素。
示例 /cruise-control/ 中提供了 Cruise 控制的 YAML 文件示例。
8.1. 为什么使用清理控制?
cruise Control 可减少运行高效、均衡 Kafka 集群所需的时间和工作量。
典型的群集可能会随着时间推移而变得异常加载。处理大量消息流量的分区可能会在可用的代理中不均匀分布。要重新平衡集群,管理员必须监控代理上的负载,并手动将繁忙的分区重新分配给具有备用容量的代理。
整合控制可自动执行集群重新平衡过程。它构造 cluster- 的资源使用率 工作负载模型基于 CPU、磁盘和网络 load-并为更均衡的分区分配生成优化建议(您可以批准或拒绝)。使用一组可配置的优化目标来计算这些假设。
当您批准一个优化建议时,Cruise Control 将其应用到 Kafka 集群。当集群重新平衡操作完成后,代理 Pod 会被更有效地使用,Kafka 集群也会更加均匀地平衡。
其他资源
8.2. 优化目标概述
要重新平衡 Kafka 集群,Cruise Control 使用优化目标来生成 优化方法, 您可以批准或拒绝这些优化。
优化目标是针对 Kafka 集群内工作负载重新分配和资源利用率的限制。AMQ Streams 支持在 Cruise Control 项目中开发的大多数优化目标。支持的目标(按默认降序排列)如下:
- 机架感知
- 副本容量
- capacity :磁盘容量、网络入站容量、网络出站容量、CPU 容量
- 副本发布
- 潜在的网络输出
资源分配 :磁盘利用率分布、网络入站利用率分布、网络出站利用率分布、CPU 利用率分布
注意资源分配目标使用代理 资源的能力限制 来控制。
- 领导字节速率分布
- 主题副本发布
- 领导程序副本发布
- 首选领导选举机制
有关每个优化目标的更多信息,请参阅 Cruise Control Wiki 中的目标。
尚不支持broker 磁盘目标、"写入您自己的"目标和 Kafka 分配程序目标。
AMQ Streams 自定义资源中的目标配置
您可以在 Kafka 和 Kafka Rebalance 自定义资源中配置优化目标。整合控制具有必须要满足 的硬 优化目标配置,以及 主 服务器、默认 和用户提供的 优化目标。资源分布(磁盘、网络入站、网络出站和 CPU)的优化目标受到代理资源 的容量限制。
以下小节更详细地描述了每个目标配置。
硬目标和软目标
硬目标就是在优化调整时 必须满足 的目标。未配置为硬目标的目标称为 软目标。您可以将软目标视为 最佳工作 目标:它们在优化调整 时不 需要满足,而是包含在优化计算中。违反一个或多个软目标但满足所有硬目标的最佳建议是有效的。
粗体控件将计算出符合所有硬目标和尽可能多的软目标(按优先顺序)的优化条件。无法 满足所有硬目标的优化建议被拒绝,不会发送给用户进行审批。
例如,您可能有一个软目标来在集群中平均分发主题的副本(主题副本分发目标)。如果这样做能够实现所有配置的硬目标,挑战控制将忽略此目标。
在 Cruise Control 中,以下 主优化目标是 预先设定为硬目标:
RackAwareGoal; ReplicaCapacityGoal; DiskCapacityGoal; NetworkInboundCapacityGoal; NetworkOutboundCapacityGoal; CpuCapacityGoal
您可以通过编辑 Kafka.spec.cruiseControl.config 中的 hard.goals 属性,在 Cruise Control 部署配置中配置硬目标。
-
要从 Cruise Control 继承预先设置的硬链接,请不要在
Kafka.spec.cruiseControl.config 中指定属性hard.goals -
要改变预先设定的硬目标,请使用其完全限定域名在
hard.goals属性中指定预期的目标。
硬优化目标的 Kafka 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
cruiseControl:
brokerCapacity:
inboundNetwork: 10000KB/s
outboundNetwork: 10000KB/s
config:
hard.goals: >
com.linkedin.kafka.cruisecontrol.analyzer.goals.NetworkInboundCapacityGoal,
com.linkedin.kafka.cruisecontrol.analyzer.goals.NetworkOutboundCapacityGoal
# ...
增加配置的硬目标数量将降低 Cruise 控制产生有效优化判断的可能性。
如果在 KafkaRebalance 自定义资源中指定了 skipHardGoalCheck: true,Cruise Control 不会 检查用户提供的优化目标(在 KafkaRebalance.spec.goals 中)是否包含 所有 配置的硬目标(hard.goals)。因此,如果一些(但不是全部)用户提供的优化目标在 hard.goals 列表中,即使指定了 skipHardGoalCheck: true,Cruise Control 仍会将它们视为硬目标。
主优化目标
主优化目标 适用于所有用户。主优化目标中没有列出的目标不适用于 Cruise 控制操作。
除非更改了 Cruise Control 部署配置,A MQ Streams 将从 Cruise Control 中继承以下 master 优化目标,以降序为优先级:
RackAwareGoal; ReplicaCapacityGoal; DiskCapacityGoal; NetworkInboundCapacityGoal; NetworkOutboundCapacityGoal; CpuCapacityGoal; ReplicaDistributionGoal; PotentialNwOutGoal; DiskUsageDistributionGoal; NetworkInboundUsageDistributionGoal; NetworkOutboundUsageDistributionGoal; CpuUsageDistributionGoal; TopicReplicaDistributionGoal; LeaderReplicaDistributionGoal; LeaderBytesInDistributionGoal; PreferredLeaderElectionGoal
其中六个目标被预先设定为 困难的目标。
为降低复杂性,建议您使用继承的主优化目标,除非您需要 完全排除 在 KafkaRebalance 资源中使用的一个或多个目标。如果需要,可以在配置 默认优化目标时修改主优化目标 的优先级顺序。
您可以在 Cruise Control 部署配置中配置主优化目标:Kafka.spec.cruiseControl.config.goals
-
要接受继承的主优化目标,请不要在
Kafka.spec.cruiseControl.config中指定 target属性。 -
如果您需要修改继承的主优化目标,请在
目标配置选项中以降序排列为目标列表。
如果更改了继承的主优化目标,您必须确保硬目标(如果在 Kafka.spec.cruiseControl.config 中的 属性中配置)是您配置的主优化目标的子集。否则,生成优化时会出现错误。
hard. goals
默认优化目标
精简控制 使用默认优化目标 来生成 缓存优化建议。有关缓存优化建议的详情请参考 第 8.3 节 “优化调整概述”。
您可以通过在 KafkaRebalance 自定义资源中设置 用户提供的优化目标 来覆盖默认优化目标。
除非在 Cruise Control 部署配置 中指定了 default.goals,否则主优化目标将用作默认的优化目标。在这种情况下,缓存的优化建议是使用主优化目标生成的。
-
要将主优化目标用作默认目标,请不要在
Kafka.spec.cruiseControl.config 中指定属性。default.goals -
要修改默认优化目标,请编辑
Kafka.spec.cruiseControl.config 中的属性。您必须使用主优化目标的子集。default.goals
默认优化目标的 Kafka 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
zookeeper:
# ...
entityOperator:
topicOperator: {}
userOperator: {}
cruiseControl:
brokerCapacity:
inboundNetwork: 10000KB/s
outboundNetwork: 10000KB/s
config:
default.goals: >
com.linkedin.kafka.cruisecontrol.analyzer.goals.RackAwareGoal,
com.linkedin.kafka.cruisecontrol.analyzer.goals.ReplicaCapacityGoal,
com.linkedin.kafka.cruisecontrol.analyzer.goals.DiskCapacityGoal
# ...
如果没有指定默认优化目标,则使用主优化目标生成缓存建议。
用户提供的优化目标
用户提供的优化目标 缩小了针对特定优化建议配置的默认目标。您可以根据需要在 KafkaRebalance 自定义资源中的 spec.goals 中设置它们:
KafkaRebalance.spec.goals
用户提供的优化目标可针对不同的情景生成优化。例如,您可能想要在 Kafka 集群间优化领导副本分布,而不考虑磁盘容量或磁盘使用率。因此,您可以创建一个 KafkaRebalance 自定义资源,其中包含领导副本分发的用户提供的目标。
用户提供的优化目标必须:
- 包括所有配置 的硬目标 或发生错误
- 成为主优化目标的子集
要在生成优化建议时忽略配置的硬目标,请将 skipHardGoalCheck: true 属性添加到 KafkaRebalance 自定义资源。请参阅 第 8.7 节 “生成优化分析”。
其他资源
- 第 8.5 节 “精简控制配置”
- Cruise Control Wiki 中的 配置.
8.3. 优化调整概述
优化建议是建议 更改的总结,这些更改将产生更为均衡的 Kafka 集群,在代理间更均匀地分配分区工作负载。每个优化建议都基于用于生成 目标的一组优化目标,受 代理资源配置容量限制的影响。
KafkaRebalance 自定义资源的 Status.Optimization Result 属性中包含了一个优化建议。提供的信息是完整优化建议摘要。使用摘要决定是否:
- 批准优化建议。这指示 Cruise Control 将提议应用到 Kafka 集群并启动集群重新平衡操作。
- 驳回优化建议。您可以更改优化目标,然后产生另一个建议。
所有优化调整都是 空运行 :您无法在不首先生成优化建议的情况下批准集群重新平衡。对可生成的优化说明数量没有限制。
缓存优化建议
整合控制根据配置的默认 优化目标维护缓存优化建议。从工作负载模型生成的缓存优化建议每 15 分钟更新一次,以反映 Kafka 集群的当前状态。如果您使用默认优化目标生成一个优化建议,Cruise Control 将返回最新的缓存建议。
要更改缓存的优化建议刷新间隔,请编辑 Cruise Control 部署配置中的 proposed.expiration.ms 设置。为快速更改集群考虑一个较短的间隔,尽管这会增加 Cruise Control 服务器上的负载。
优化调整的内容
下表描述了优化建议中包含的属性:
表 8.1. 优化建议中包含的属性
| JSON 属性 | 描述 |
|---|---|
|
| 在集群的代理磁盘之间传输的分区副本总数。
重新平衡操作过程中的性能影响 :相对较高,但低于 |
|
| 尚不支持.返回一个空列表。 |
|
| 在独立代理之间移动的分区副本数。 重新平衡操作过程中的性能影响 :相对较高的. |
|
| 对生成优化建议之前和之后的 Kafka 集群的整体 平衡性 进行测量。
分数是通过从 100 减去每个违反软目标的
|
|
|
在同一代理的磁盘之间移动的每个分区副本的大小总和(请参阅
重新平衡操作过程中的性能影响 :变量.数量越大,集群重新平衡所需的时间也越长。在相同代理的磁盘之间移动大量数据比不同代理之间的影响小(请参阅 |
|
| 优化建议所基于的指标窗口数量。 |
|
|
移动到独立代理的每个分区副本的大小总和(请参阅 同时也是 重新平衡操作过程中的性能影响 :变量.数量越大,集群重新平衡所需的时间也越长。 |
|
|
优化建议涵盖 Kafka 集群中分区的百分比。受 |
|
|
如果您在 |
|
| 领导者将切换到不同副本的分区数量。这涉及对 ZooKeeper 配置的更改。 重新平衡操作过程中的性能影响 :相对较低的. |
|
| 尚不支持.返回一个空列表。 |
8.4. 重新平衡性能调优概述
您可以为集群重新平衡调整几个性能调整选项。这些选项控制如何执行重新平衡中的副本和领导移动,以及分配给重新平衡操作的带宽。
分区重新分配命令
优化调整 由单独的分区重新分配命令组成。当您 批准 一个建议时,Cruise Control 服务器将这些命令应用到 Kafka 集群。
分区重新分配命令由以下任一操作类型组成:
分区移动:涉及将分区副本及其数据传输到新位置。分区移动可采用以下两种形式之一:
- Broker 内部移动:分区副本移到不同代理中的日志目录中。
- Broker 内部移动:分区副本会移到同一代理的不同日志目录中。
- 领导运动:这包括切换分区副本的领导机。
批量将控制问题的分区重新分配给 Kafka 集群的命令。集群在重新平衡期间的性能会受到每个批处理中包含的每种移动类型的数量的影响。
副本移动策略
集群重新平衡性能还受到应用于分区重新分配命令 的副本移动策略 的影响。默认情况下,Cruise Control 使用 BaseReplicaMovementStrategy,它只按照生成命令的顺序应用它们。但是,如果在建议早期存在一些非常大的分区重新分配,此策略可能会减慢其他重新分配的应用速度。
海军控件提供了三种备选副本移动策略,可用于优化调整:
-
PrioritizeSmallReplicaMovementStrategy:按最大大小排序重新分配. -
PrioritizeLargeReplicaMovementStrategy:顺序重新分配按大小降序排列. -
PostponeUrpReplicaMovementStrategy:优先分配没有同步副本的分区副本。
这些策略可以配置为序列。第一种策略尝试使用其内部逻辑比较两个分区重新分配。如果重新分配是等效的,那么它会将它们传递给序列中的下一个策略,以确定顺序,以此类推。
重新平衡调优选项
cruise Control 提供多个配置选项来调整上面讨论的重新平衡参数。您可以在 Cruise Control 服务器 或 优化建议 级别设置这些调整选项:
-
Cruise Control 服务器设置可以在 Kafka
.spec.cruiseControl.config 下的 Kafka自定义资源中设置。 -
单独的重新平衡性能配置可以在
KafkaRebalance.spec下设置。
相关配置总结如下:
服务器和 KafkaRebalance 配置 | 描述 | 默认值 |
|---|---|---|
|
| 每个分区重新分配批次中broker 分区移动的最大数量 | 5 |
|
| ||
|
| 每个分区重新分配批次中broker 分区移动的最大数量 | 2 |
|
| ||
|
| 每个分区重新分配批中分区领导更改的最大数量 | 1000 |
|
| ||
|
| 要分配给分区重新分配的带宽(以字节/秒为单位) | 无限制 |
|
| ||
|
| 用于确定执行分区重新分配命令的顺序的策略列表(按优先级顺序排列)。
对于 server 设置,使用逗号分隔的字符串以及策略类的完全限定名称(在每个类名称 |
|
|
|
更改默认设置会影响重新平衡完成所需的时间,以及重新平衡过程中在 Kafka 集群上放置的负载。使用较低值可以减少负载,但会增加所需时间,反之亦然。
8.5. 精简控制配置
Kafka.spec.cruiseControl 中的 config 属性包含作为键的配置选项,其值为以下 JSON 类型之一:
- 字符串
- 数字
- 布尔值
类似于 JSON 或 YAML 的字符串需要用显式引号括起。
除了由 AMQ Streams 直接管理的选项外,您还可以指定并配置 Cruise Control 文档 的"配置"一节中列出的所有选项。特别是,您无法 修改与 此处 提及的其中一个键相等或开头的键的配置选项。
如果指定了 restricted 选项,则忽略它们,并在 Cluster Operator 日志文件中输出警告信息。所有支持的选项都传递给 Cruise Control。
Cruise Control 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
config:
default.goals: >
com.linkedin.kafka.cruisecontrol.analyzer.goals.RackAwareGoal,
com.linkedin.kafka.cruisecontrol.analyzer.goals.ReplicaCapacityGoal
cpu.balance.threshold: 1.1
metadata.max.age.ms: 300000
send.buffer.bytes: 131072
# ...
容量配置
整合控制使用 容量限制 来确定资源分布的优化目标是否受到破坏。这种类型的四个目标:
-
DiskUsageDistributionGoal- 磁盘使用率分布 -
CpuUsageDistributionGoal -CPU 使用率分布 -
NetworkInboundUsageDistributionGoal -网络入站利用率分布 -
NetworkOutboundUsageDistributionGoal -网络出站利用率分布
您可以在 Kafka. spec.cruiseControl 代理资源指定容量限值。它们默认是启用的,您可以更改其默认值。可以使用标准 OpenShift 字节单元(K、M、G 和 T)或其双字节(双倍的幂等)等效项(Ki、Mi、Gi 和 Ti)来为以下代理资源设置容量限制:
中的 brokerCapacity 属性中为 Kafka
-
磁盘- 每个代理的磁盘存储(默认:100000Mi) -
cpuUtilization- CPU 使用率作为百分比(默认:100) -
Inbound
Network- 入站网络吞吐量以每秒字节单位为单位(默认值:10000KiB/s) -
出站网络- 出站网络吞吐量以每秒字节单位为单位(默认值:10000KiB/s)
因为 AMQ Streams Kafka 代理是同构的,所以 Cruise Control 会为其监控的每个代理应用相同的容量限制。
使用 Bbyte 单元的 Cruise Control 代理功能配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
cruiseControl:
# ...
brokerCapacity:
disk: 100Gi
cpuUtilization: 100
inboundNetwork: 10000KiB/s
outboundNetwork: 10000KiB/s
# ...
其他资源
如需更多信息,请参阅 第 B.72 节 “BrokerCapacity schema 参考”。
日志记录配置
精简控制具有自己的可配置日志记录器:
-
cruisecontrol.root.logger
整合控制使用 Apache log4j 日志记录器实施。
使用 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j.properties 进行 描述。
此处我们会看到 内联 和外部 记录示例。
内联日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
# ...
spec:
cruiseControl:
# ...
logging:
type: inline
loggers:
cruisecontrol.root.logger: "INFO"
# ...
外部日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
# ...
spec:
cruiseControl:
# ...
logging:
type: external
name: customConfigMap
# ...
8.6. 部署清理控制
要将 Cruise Control 部署到 AMQ Streams 集群,请使用 Kafka 资源中的 cruise Control 属性定义配置,然后创建或更新资源。
每个 Kafka 集群部署一个 Cruise Control 实例。
先决条件
- OpenShift 集群
- 一个正在运行的 Cluster Operator
步骤
编辑
Kafka资源并添加 cruiseControl属性。您可以配置的属性显示在此示例配置中:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: # ... cruiseControl: brokerCapacity: 1 inboundNetwork: 10000KB/s outboundNetwork: 10000KB/s # ... config: 2 default.goals: > com.linkedin.kafka.cruisecontrol.analyzer.goals.RackAwareGoal, com.linkedin.kafka.cruisecontrol.analyzer.goals.ReplicaCapacityGoal # ... cpu.balance.threshold: 1.1 metadata.max.age.ms: 300000 send.buffer.bytes: 131072 # ... resources: 3 requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi logging: 4 type: inline loggers: cruisecontrol.root.logger: "INFO" template: 5 pod: metadata: labels: label1: value1 securityContext: runAsUser: 1000001 fsGroup: 0 terminationGracePeriodSeconds: 120 readinessProbe: 6 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: 7 initialDelaySeconds: 15 timeoutSeconds: 5 # ...- 1
- 指定代理资源的容量限制。如需更多信息,请参阅 容量配置。
- 2
- 定义 Cruise 控制配置,包括默认优化目标(
默认为默认值),以及对主优化目标(目标)或硬目标(硬目标)的自定义。除了由 AMQ Streams 直接管理的以外,您还可以提供任何 标准 Cruise Control 配置选项。有关配置优化目标的详情请参考 第 8.2 节 “优化目标概述”。 - 3
- 为 Cruise Control 保留的 CPU 和内存资源.如需更多信息,请参阅 第 2.1.11 节 “CPU 和内存资源”。
- 4
- 定义的日志记录器和日志级别通过 ConfigMap 直接(内线)或间接(外部)添加。自定义 ConfigMap 必须放在 log4j.properties 键下。Scope Control 有一个名为 cruise
control.root.logger的日志记录器。您可以将日志级别设置为 INFO、ERROR、WARN、TRACE、DEBUG、FATAL 或 OFF。如需更多信息,请参阅 日志配置。 - 5
- 6
- 7
创建或更新资源:
oc apply -f kafka.yaml验证 Cruise Control 是否已成功部署:
oc get deployments -l app.kubernetes.io/name=strimzi
自动创建的主题
下表显示了部署 Cruise Control 时自动创建的三个主题。这些主题是必需的,清理控制才能正常工作,且不得删除或更改。
表 8.2. 自动创建的主题
| 自动创建的主题 | 创建者 | 功能 |
|---|---|---|
|
| AMQ Streams Metrics Reporter | 将 Metrics Reporter 中的原始指标存储在每个 Kafka 代理中。 |
|
| Sything Control | 存储每个分区派生的指标。它们由 Metric Sample Aggregator 创建。 |
|
| Sything Control | 存储用于创建集群 工作负载模型 的指标示例。 |
为防止删除 Cruise Control 所需的记录,在自动创建的主题中禁用了日志压缩。
接下来要做什么
配置和部署 Cruise Control 后,您可以 生成优化建议。
8.7. 生成优化分析
当您创建或更新 KafkaRebalance 资源时,Cruise Control 会根据配置的 优化目标为 Kafka 集群生成 优化建议。
分析优化建议中的信息,并决定是否批准它。
先决条件
- 您已将 Cruise Control 部署到 AMQ Streams 集群中。
- 您已配置了 优化目标,以及可选 的代理资源容量限制。
步骤
创建
KafkaRebalance资源:要使用
Kafka资源中定义的 默认优化目标,请将spec属性留空:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaRebalance metadata: name: my-rebalance labels: strimzi.io/cluster: my-cluster spec: {}要配置 用户提供的优化目标 而不是使用默认目标,请添加
target属性并输入一个或多个目标。在以下示例中,机架意识和副本容量被配置为用户提供的优化目标:
apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaRebalance metadata: name: my-rebalance labels: strimzi.io/cluster: my-cluster spec: goals: - RackAwareGoal - ReplicaCapacityGoal要忽略配置的硬目标,请添加
skipHardGoalCheck: true属性:apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaRebalance metadata: name: my-rebalance labels: strimzi.io/cluster: my-cluster spec: goals: - RackAwareGoal - ReplicaCapacityGoal skipHardGoalCheck: true
创建或更新资源:
oc apply -f your-fileCluster Operator 从 Cruise Control 请求优化建议。这可能需要一些时间,具体取决于 Kafka 集群的大小。
检查
KafkaRebalance资源的状态:oc describe kafkarebalance rebalance-cr-namecruise Control 返回两个状态之一:
-
PendingProposal:重新平衡操作器正在轮询 Cruise Control API,以检查优化建议是否已就绪。 -
ProposalReady:优化建议可供审核,并在需要时予以批准。优化建议包含在KafkaRebalance资源的Status.Optimization Result属性中。
-
查看优化建议。
oc describe kafkarebalance rebalance-cr-name下面是一个示例:
Status: Conditions: Last Transition Time: 2020-05-19T13:50:12.533Z Status: ProposalReady Type: State Observed Generation: 1 Optimization Result: Data To Move MB: 0 Excluded Brokers For Leadership: Excluded Brokers For Replica Move: Excluded Topics: Intra Broker Data To Move MB: 0 Monitored Partitions Percentage: 100 Num Intra Broker Replica Movements: 0 Num Leader Movements: 0 Num Replica Movements: 26 On Demand Balancedness Score After: 81.8666802863978 On Demand Balancedness Score Before: 78.01176356230222 Recent Windows: 1 Session Id: 05539377-ca7b-45ef-b359-e13564f1458cOptimization Result部分中的属性描述待处理的集群重新平衡操作。有关每个属性的描述,请参阅 优化方法的内容。
接下来要做什么
其他资源
8.8. 批准优化建议
如果 Cruise Control 的状态是 Proposal Ready,则批准由 Cruise Control 生成的 优化建议 。然后,Bootation Control 会将优化建议应用到 Kafka 集群,将分区重新分配给代理并更改分区领导。
这不是空运行。在批准优化建议前,您必须:
- 刷新该提议,以防其过时。
- 仔细检查 提议的内容。
先决条件
- 您已 通过 Cruise 控制生成了一个优化建议。
-
KafkaRebalance自定义资源状态是 ProposalReady。
步骤
执行这些步骤进行您要批准的优化建议:
除非优化建议是新生成的,否则请检查它是否基于当前 Kafka 集群状态的信息。要做到这一点,刷新优化建议以确保它使用最新的集群指标:
使用
刷新给 OpenShift 中的:KafkaRebalance资源标注oc annotate kafkarebalance rebalance-cr-name strimzi.io/rebalance=refresh检查
KafkaRebalance资源的状态:oc describe kafkarebalance rebalance-cr-name-
等待状态更改为 Proposal
Ready。
批准您希望应用 Cruise Control 的优化建议。
给
OpenShift 中的 KafkaRebalance资源标注:oc annotate kafkarebalance rebalance-cr-name strimzi.io/rebalance=approve- Cluster Operator 会检测到注解的资源,并指示 Cruise Control 重新平衡 Kafka 集群。
检查
KafkaRebalance资源的状态:oc describe kafkarebalance rebalance-cr-namecruise Control 返回三个状态之一:
- 重新平衡:集群重新平衡操作正在进行中。
-
Ready:集群重新平衡操作成功完成。
KafkaRebalance自定义资源无法重复使用。 -
NotReady:发生错误-请参阅 第 8.10 节 “修复
KafkaRebalance资源的问题”。
8.9. 停止集群重新平衡
启动后,集群重新平衡操作可能需要一段时间才能完成,并影响 Kafka 集群的整体性能。
如果要停止正在进行中的集群重新平衡操作,请将 stop 注解应用到 KafkaRebalance 自定义资源。这指示 Cruise Control 完成当前的一组分区重新分配,然后停止重新平衡。重新平衡停止后,已完成的分区重新分配已被应用;因此,与在重新平衡操作开始前相比,Kafka 集群的状态会有所不同。如果需要进一步重新平衡,您应该生成一个新的优化建议。
Kafka 集群处于中间(停止)状态的性能可能比初始状态差。
先决条件
-
您已通过注解
KafkaRebalance自定义资源 批准了优化建议。 -
KafkaRebalance自定义资源的状态是重新平衡。
步骤
给
OpenShift 中的 KafkaRebalance资源标注:oc annotate kafkarebalance rebalance-cr-name strimzi.io/rebalance=stop检查
KafkaRebalance资源的状态:oc describe kafkarebalance rebalance-cr-name-
等待状态更改为
Stopped。
其他资源
8.10. 修复 KafkaRebalance 资源的问题
如果在创建 KafkaRebalance 资源或与 Cruise Control 交互时出现问题,则会在资源状态中报告错误,以及如何修复它。资源也进入 NotReady 状态。
要继续进行集群重新平衡操作,您必须修复 KafkaRebalance 资源本身或整个 Cruise Control 部署中的问题。问题可能包括以下几项:
-
KafkaRebalance资源中配置错误的参数。 -
在 Kafka
Rebalance资源中缺少用于指定 Kafka 集群的 Thestrimzi.io/cluster标签。 -
Cruise Control 服务器没有被部署,因为
Kafka资源中缺少 cruiseControl属性。 - 无法访问 Cruise Control 服务器。
修复此问题后,您需要在 KafkaRebalance 资源中添加 刷新 注解。在"刷新"期间,要求来自 Cruise Control 服务器的新优化建议。
先决条件
- 您 已批准了一个优化建议。
-
重新平衡操作的
KafkaRebalance自定义资源的状态是NotReady。
步骤
从
KafkaRebalance状态获取错误信息:oc describe kafkarebalance rebalance-cr-name-
尝试解决
KafkaRebalance 资源中的问题。 给
OpenShift 中的 KafkaRebalance资源标注:oc annotate kafkarebalance rebalance-cr-name strimzi.io/rebalance=refresh检查
KafkaRebalance资源的状态:oc describe kafkarebalance rebalance-cr-name-
等待状态更改为
PendingProposal,或直接变为 ProposalReady。
其他资源
第 9 章 使用 Service Registry 管理模式
本章概述了如何部署 AMQ 流并与红帽服务注册表集成。您可以将服务注册表用作数据流的集中式存储。
Service Registry 支持许多标准工件类型的存储和管理。例如,对于 Kafka,您可以使用基于 AVRO 或 JSON 的 schema 定义。
服务注册表提供 REST API 和 Java REST 客户端,用于通过服务器端端点从客户端应用注册和查询架构。您还可以使用 Service Registry Web 控制台直接浏览和更新模式。您可以将制作者和消费者客户端配置为使用 Service Registry。
还提供了 Maven 插件,以便您可以在构建过程中上传和下载模式。在检查您的架构更新是否与客户端应用兼容时,Maven 插件可用于测试和验证。
其他资源
- Service Registry 文档
- Service Registry 基于 Apicurio Registry 开源社区项目构建,可从 GitHub 获取:apicurio/apicurio-registry
- 另外,GitHub 中也提供了 Service Registry 的演示:Apicurio/apicurio-registry-demo
- Apache Avro
9.1. 为什么使用服务注册表?
使用 Service Registry 将管理模式的过程与客户端应用程序配置分离。您可以通过在客户端代码中指定 URL 来启用应用程序从 registry 中使用 schema。
例如,消息序列化和反序列化的架构可以存储在注册表中,后者随后从使用它们的应用程序引用,以确保它们发送和接收的消息与这些模式兼容。
Kafka 客户端应用程序可以在运行时从 Service Registry 中推送或拉取其模式。
模式可以不断演变,您可以在 Service Registry 中定义规则,例如,确保对 schema 的更改有效且不会破坏应用程序使用以前的版本。服务注册表通过将修改后的架构与以前的架构版本进行比较来检查兼容性。
Service Registry 提供对 Avro 模式的完整架构 registry 支持,供客户端应用程序通过 Service Registry 提供的 Kafka 客户端串行器/deserializer(SerDe)服务使用。
9.2. 制作者模式配置
制作者客户端应用使用序列化程序将其发送到特定代理主题的消息放入正确的数据格式。
要让制作者使用 Service Registry 进行序列化,请执行以下操作:
- 定义模式并将其注册到 Service Registry
- Service Registry 的 URL
- 与消息一起使用的服务 Registry 序列化程序服务
- 在 Service Registry 中查找用于序列化的 schema 的策略
注册模式后,当您启动 Kafka 和 Service Registry 时,您可以访问 schema 来格式化由生产者发送到 Kafka 代理主题的消息。
如果架构已存在,您可以根据服务注册表中定义的兼容性规则,通过 REST API 来创建新版本。版本用于兼容性检查,以作为模式的演进。工件 ID 和 schema 版本代表了一个唯一元,用于标识一个 schema。
9.3. 使用者架构配置
消费者客户端应用程序使用一个反序列工具将所使用的消息从特定的代理主题获取到正确的数据格式。
要让消费者使用 Service Registry 进行反序列化,您需要:
- 定义模式并将其注册到 Service Registry
- Service Registry 的 URL
- 用于消息的 service Registry deserializer 服务
- 输入数据流以进行反序列化
然后,使用写入到被使用的消息中的全局 ID 来检索该架构。因此,收到的消息必须包含全局 ID 以及消息数据。
例如:
# ... [MAGIC_BYTE] [GLOBAL_ID] [MESSAGE DATA]
现在,当您启动 Kafka 和 Service Registry 时,您可以访问 schema,以便格式化从 Kafka 代理主题接收的信息。
9.4. 查找模式的策略
Kafka 客户端 serializer/deserializer 使用 Service Registry 策略 来确定在 Service Registry 中注册消息 schema 的工件 ID 或全局 ID。
对于给定的主题和消息,您可以使用以下 Java 类的实施:
-
ArtifactIdStrategy返回工件 ID -
GlobalIdStrategy返回一个全局 ID
返回的工件 ID 取决于消息中的 键 或 值 是否被序列化。
每个 策略 的类组织在io. apicurio.registry.utils.serde.strategy 软件包中。
默认策略是 TopicIdStrategy,它查找名称与 Kafka 主题接收消息相同的 Service Registry 工件。
例如:
public String artifactId(String topic, boolean isKey, T schema) {
return String.format("%s-%s", topic, isKey ? "key" : "value");
}-
topic参数是接收消息的 Kafka 主题的名称。 -
当消息键被序列化时,
isKey参数为 true,消息值被序列化时为 false。 -
schema参数是消息被序列化/deserialized 的 schema。 -
返回的
artifactID是架构在服务注册表中注册的 ID。
您使用什么查找策略取决于您架构的存储方式和位置。例如,如果您具有具有相同 Avro 消息类型的不同 Kafka 主题,您可以使用使用 记录 ID 的策略。
返回工件 ID 的策略
基于 ArtifactIdStrategy 实施返回工件 ID 的策略。
RecordIdStrategy- 使用架构完整名称的 Avro 特定策略。
TopicRecordIdStrategy- 使用主题名称和架构全名的 Avro 特定策略。
TopicIdStrategy-
(默认)使用主题名称和
键或值后缀的策略。 SimpleTopicIdStrategy- 仅使用该主题名称的简单策略.
返回全局 ID 的策略
基于 GlobalIdStrategy 实施返回全球 ID 的策略。
FindLatestIdStrategy- 根据工件 ID 返回最新 schema 版本的全局 ID 的策略。
FindBySchemaIdStrategy- 匹配架构内容(基于工件 ID)的策略,以返回全局 ID。
GetOrCreateIdStrategy- 尝试根据工件 ID 获取最新架构的策略,如果不存在,则会创建一个新架构。
AutoRegisterIdStrategy- 更新架构的策略,并使用更新的 schema 的全局 ID。
9.5. Service Registry 常量
您可以使用此处概述的常数,将特定的客户端 SerDe 服务和架构查找策略直接配置为客户端。
或者,您也可在属性文件或属性实例中指定常量。
序列化器/序列化器(SerDe)服务的常量
public abstract class AbstractKafkaSerDe<T extends AbstractKafkaSerDe<T>> implements AutoCloseable {
protected final Logger log = LoggerFactory.getLogger(getClass());
public static final String REGISTRY_URL_CONFIG_PARAM = "apicurio.registry.url"; 1
public static final String REGISTRY_CACHED_CONFIG_PARAM = "apicurio.registry.cached"; 2
public static final String REGISTRY_ID_HANDLER_CONFIG_PARAM = "apicurio.registry.id-handler"; 3
public static final String REGISTRY_CONFLUENT_ID_HANDLER_CONFIG_PARAM = "apicurio.registry.as-confluent"; 4查找策略的常量
public abstract class AbstractKafkaStrategyAwareSerDe<T, S extends AbstractKafkaStrategyAwareSerDe<T, S>> extends AbstractKafkaSerDe<S> {
public static final String REGISTRY_ARTIFACT_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.artifact-id"; 1
public static final String REGISTRY_GLOBAL_ID_STRATEGY_CONFIG_PARAM = "apicurio.registry.global-id"; 2转换器的常量
public class SchemalessConverter<T> extends AbstractKafkaSerDe<SchemalessConverter<T>> implements Converter {
public static final String REGISTRY_CONVERTER_SERIALIZER_PARAM = "apicurio.registry.converter.serializer"; 1
public static final String REGISTRY_CONVERTER_DESERIALIZER_PARAM = "apicurio.registry.converter.deserializer"; 2Avro 数据供应商的常量
public interface AvroDatumProvider<T> {
String REGISTRY_AVRO_DATUM_PROVIDER_CONFIG_PARAM = "apicurio.registry.avro-datum-provider"; 1
String REGISTRY_USE_SPECIFIC_AVRO_READER_CONFIG_PARAM = "apicurio.registry.use-specific-avro-reader"; 2DefaultAvroDatumProvider (io.apicurio.registry.utils.serde.avro) 1 ReflectAvroDatumProvider (io.apicurio.registry.utils.serde.avro) 2
9.6. 安装 Service Registry
Service Registry 文档中的使用 AMQ Streams 存储安装 Service Registry 的说明。
您可以根据集群配置安装多个 Service Registry 实例。实例数量取决于您使用的存储类型以及您需要处理的模式数量。
9.7. 将架构注册到服务 registry
以适当格式定义了架构后,如 Apache Avro,您可以将架构添加到服务注册表。
您可以通过以下方法添加 schema:
- Service Registry Web 控制台
- 使用 Service Registry API 的 curl 命令
- Service Registry 提供的 Maven 插件
- 添加到客户端代码中的模式配置
在注册了架构前,客户端应用程序无法使用 Service Registry。
Service Registry Web 控制台
安装 Service Registry 后,您可以从 ui 端点连接到 web 控制台:
+http+://MY-REGISTRY-URL/ui
在控制台中,您可以添加、查看和配置模式。您还可以创建防止将无效内容添加到 registry 的规则。
有关使用 Service Registry Web 控制台的更多信息,请参阅 Service Registry 文档。
curl 示例
curl -X POST -H "Content-type: application/json; artifactType=AVRO" \
-H "X-Registry-ArtifactId: prices-value" \
--data '{ 1
"type":"record",
"name":"price",
"namespace":"com.redhat",
"fields":[{"name":"symbol","type":"string"},
{"name":"price","type":"string"}]
}'
https://my-cluster-service-registry-myproject.example.com/api/artifacts -s 2插件示例
<plugin>
<groupId>io.apicurio</groupId>
<artifactId>apicurio-registry-maven-plugin</artifactId>
<version>${registry.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>register</goal>
</goals>
<configuration>
<registryUrl>https://my-cluster-service-registry-myproject.example.com/api</registryUrl>
<artifactType>AVRO</artifactType>
<artifacts>
<schema1>${project.basedir}/schemas/schema1.avsc</schema1>
</artifacts>
</configuration>
</execution>
</executions>
</plugin>通过(producer)客户端示例进行配置
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", 1 "https://my-cluster-service-registry-myproject.example.com/api"); try (RegistryService service = RegistryClient.create(registryUrl_node1)) { String artifactId = ApplicationImpl.INPUT_TOPIC + "-value"; try { service.getArtifactMetaData(artifactId); 2 } catch (WebApplicationException e) { CompletionStage <ArtifactMetaData> csa = service.createArtifact( ArtifactType.AVRO, artifactId, new ByteArrayInputStream(LogInput.SCHEMA$.toString().getBytes()) ); csa.toCompletableFuture().get(); } }
9.8. 从制作者客户端使用 Service Registry 模式
这个步骤描述了如何将 Java 制作者客户端配置为使用 Service Registry 中的 schema。
步骤
为客户端配置服务注册表的 URL。
例如:
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https://my-cluster-service-registry-myproject.example.com/api"); RegistryService service = RegistryClient.cached(registryUrl);使用序列化程序服务配置客户端,以及在服务注册表中查找架构的策略。
例如:
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https://my-cluster-service-registry-myproject.example.com/api"); clientProperties.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, property(clientProperties, CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, "my-cluster-kafka-bootstrap:9092")); clientProperties.put(AbstractKafkaSerDe.REGISTRY_URL_CONFIG_PARAM, registryUrl_node1); 1 clientProperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); 2 clientProperties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, AvroKafkaSerializer.class.getName()); 3 clientProperties.put(AbstractKafkaSerializer.REGISTRY_GLOBAL_ID_STRATEGY_CONFIG_PARAM, FindLatestIdStrategy.class.getName()); 4
9.9. 在使用者客户端中使用 Service Registry 模式
这个步骤描述了如何将 Java 使用者客户端配置为使用 Service Registry 中的 schema。
步骤
为客户端配置服务注册表的 URL。
例如:
String registryUrl_node1 = PropertiesUtil.property(clientProperties, "registry.url.node1", "https://my-cluster-service-registry-myproject.example.com/api"); RegistryService service = RegistryClient.cached(registryUrl);使用 Service Registry deserializer 服务配置客户端。
例如:
Deserializer<LogInput> deserializer = new AvroKafkaDeserializer <> ( 1 service, new DefaultAvroDatumProvider<LogInput>().setUseSpecificAvroReader(true) ); Serde<LogInput> logSerde = Serdes.serdeFrom( 2 new AvroKafkaSerializer<>(service), deserializer ); KStream<String, LogInput> input = builder.stream( 3 INPUT_TOPIC, Consumed.with(Serdes.String(), logSerde) );
第 10 章 分布式追踪
分布式追踪允许您跟踪分布式系统中应用程序之间的事务处理进度。在微服务架构中,跟踪服务之间的事务处理进度。跟踪数据可用于监控应用性能以及调查目标系统和最终用户应用的问题。
在 AMQ Streams 中,追踪有助于端到端跟踪信息:从源系统到 Kafka,然后从 Kafka 跟踪到目标系统和应用程序。它补充了在 Grafana 仪表板 以及组件日志记录器中查看的指标。
AMQ 流如何支持追踪
对追踪的支持内置在以下组件中:
- Kafka Connect(包括 Kafka Connect with Source2Image 支持)
- MirrorMaker
- MirrorMaker 2.0
- AMQ Streams Kafka Bridge
您可以使用自定义资源中的模板配置属性为这些组件启用和配置追踪。
要在 Kafka 制作者、使用者和 Kafka Streams API 应用程序中启用追踪,您可以使用 OpenTracing Apache Kafka Client Instrumentation 库(包括在 AMQ Streams 中)检测 应用程序 代码。当使用工具时,客户端会生成追踪数据;例如,当生成消息或写入偏移到日志中时。
trace 会根据抽样策略进行抽样,然后在 Jaeger 用户界面中视觉化。
Kafka 代理不支持追踪。
为 AMQ Streams 以外的应用和系统设置追踪不在本章的讨论范围之内。要了解有关此主题的更多信息,请在 OpenTracing 文档中的 搜索"注入和提取"。
流程概述
要设置 AMQ Streams 的追踪,请按照以下步骤操作:
为客户端设置追踪:
使用 tracers 检测客户端:
- 为 MirrorMaker、Kafka Connect 和 Kafka Bridge 设置追踪
先决条件
- Jaeger 后端组件部署到 OpenShift 集群中。有关部署说明,请参阅 Jaeger 部署文档。
10.1. OpenTracing 和 Jaeger 概述
AMQ Streams 使用 OpenTracing 和 Jaeger 项目。
OpenTracing 是一种独立于追踪或监控系统的 API 规范。
- OpenTracing API 用于 检测 应用程序代码
- 工具的应用程序为分布式系统的个别交易生成 追踪
- trace 由定义了特定工作单元的 span 组成
Jaeger 是用于基于微服务的分布式系统的追踪系统。
- Jaeger 实现 OpenTracing API,并为检测提供客户端库
- Jaeger 用户界面允许您查询、过滤和分析 trace 数据

其他资源
10.2. 为 Kafka 客户端设置追踪
初始化 Jaeger tracer,以检测客户端应用程序进行分布式追踪。
10.2.1. 为 Kafka 客户端初始化 Jaeger tracer
使用一组 追踪环境变量 配置并初始化 Jaeger 追踪器。
步骤
在每个客户端应用程序中:
将 Jaeger 的 Maven 依赖项添加到客户端应用程序的
pom.xml文件中:<dependency> <groupId>io.jaegertracing</groupId> <artifactId>jaeger-client</artifactId> <version>1.1.0.redhat-00002</version> </dependency>- 使用 追踪环境变量 定义 Jaeger 追踪器的配置。
从在第 2 步中定义的环境变量创建 Jaeger tracer:
Tracer tracer = Configuration.fromEnv().getTracer();
注意有关初始化 Jaeger tracer 的其他方法,请参阅 Java OpenTracing 库 文档。
将 Jaeger tracer 注册为全局追踪器:
GlobalTracer.register(tracer);
现在,Jaeger tracer 被初始化,供客户端应用程序使用。
10.2.2. 用于追踪的环境变量
在为 Kafka 客户端配置 Jaeger tracer 时,请使用这些环境变量。
追踪环境变量是 Jaeger 项目的一部分,可能会有所变化。如需最新的环境变量,请参阅 Jaeger 文档。
| 属性 | 必需 | 描述 |
|---|---|---|
|
| 是 | Jaeger tracer 服务的名称。 |
|
| 否 |
用于通过用户数据报协议(UDP)与 |
|
| 否 |
用于通过 UDP 与 |
|
| 否 |
|
|
| 否 | 以 bearer 令牌形式发送到端点的身份验证令牌。 |
|
| 否 | 如果使用基本身份验证,则发送到端点的用户名。 |
|
| 否 | 如果使用基本身份验证,则发送到端点的密码。 |
|
| 否 |
用于传播 trace 上下文的格式的逗号分隔列表。默认为标准 Jaeger 格式。有效值为 |
|
| 否 | 指明报告者是否还应记录范围。 |
|
| 否 | 报告器的最大队列大小。 |
|
| 否 | 报告器的清空间隔,以 ms 为单位。定义 Jaeger reporter flushes span 批处理的频率。 |
|
| 否 | 用于客户端 trace 的抽样策略:
要对所有 trace 进行抽样,使用 Constant 抽样策略并将参数设为 1。 如需更多信息,请参阅 Jaeger 文档。 |
|
| 否 | sampler 参数(数字)。 |
|
| 否 | 如果选择了远程抽样策略,要使用的主机名和端口。 |
|
| 否 | 以逗号分隔的 tracer 级别标签列表,这些标签添加到所有报告范围中。
该值也可以引用采用格式 |
10.3. 使用 tracers 强制 Kafka 客户端
检测 Kafka 制作者和消费者客户端,以及 Kafka Streams API 应用程序以实现分布式追踪。
10.3.1. 强制生产者和消费者进行追踪
使用 Decorator 模式或 Interceptors 来检测 Java 制作者和使用者应用代码进行追踪。
步骤
在每个生产者和消费者应用程序的应用程序代码中:
将 OpenTracing 的 Maven 依赖项添加到制作者或消费者的
pom.xml文件中。<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-client</artifactId> <version>0.1.12.redhat-00001</version> </dependency>使用 Decorator 模式或 Interceptors 检测您的客户端应用程序代码。
使用 Decorator 模式:
// Create an instance of the KafkaProducer: KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); // Create an instance of the TracingKafkaProducer: TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer, tracer); // Send: tracingProducer.send(...); // Create an instance of the KafkaConsumer: KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); // Create an instance of the TracingKafkaConsumer: TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer, tracer); // Subscribe: tracingConsumer.subscribe(Collections.singletonList("messages")); // Get messages: ConsumerRecords<Integer, String> records = tracingConsumer.poll(1000); // Retrieve SpanContext from polled record (consumer side): ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);使用 Interceptors:
// Register the tracer with GlobalTracer: GlobalTracer.register(tracer); // Add the TracingProducerInterceptor to the sender properties: senderProps.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingProducerInterceptor.class.getName()); // Create an instance of the KafkaProducer: KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps); // Send: producer.send(...); // Add the TracingConsumerInterceptor to the consumer properties: consumerProps.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, TracingConsumerInterceptor.class.getName()); // Create an instance of the KafkaConsumer: KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps); // Subscribe: consumer.subscribe(Collections.singletonList("messages")); // Get messages: ConsumerRecords<Integer, String> records = consumer.poll(1000); // Retrieve the SpanContext from a polled message (consumer side): ConsumerRecord<Integer, String> record = ... SpanContext spanContext = TracingKafkaUtils.extractSpanContext(record.headers(), tracer);
10.3.1.1. Decorator 模式中的自定义范围名称
span 是 Jaeger 中的逻辑工作单元,具有操作名称、开始时间和持续时间。
要使用 Decorator 模式来检测您的制作者和消费者应用程序,请在创建 TracingKafkaProducer 和 对象时传递 TracingKafka ConsumerBiFunction 对象作为额外参数来定义自定义 span 名称。OpenTracing Apache Kafka Client Instrumentation 库包含多个内置范围名称。
Example:使用自定义范围名称来检测 Decorator 模式中的客户端应用程序代码
// Create a BiFunction for the KafkaProducer that operates on (String operationName, ProducerRecord consumerRecord) and returns a String to be used as the name:
BiFunction<String, ProducerRecord, String> producerSpanNameProvider =
(operationName, producerRecord) -> "CUSTOM_PRODUCER_NAME";
// Create an instance of the KafkaProducer:
KafkaProducer<Integer, String> producer = new KafkaProducer<>(senderProps);
// Create an instance of the TracingKafkaProducer
TracingKafkaProducer<Integer, String> tracingProducer = new TracingKafkaProducer<>(producer,
tracer,
producerSpanNameProvider);
// Spans created by the tracingProducer will now have "CUSTOM_PRODUCER_NAME" as the span name.
// Create a BiFunction for the KafkaConsumer that operates on (String operationName, ConsumerRecord consumerRecord) and returns a String to be used as the name:
BiFunction<String, ConsumerRecord, String> consumerSpanNameProvider =
(operationName, consumerRecord) -> operationName.toUpperCase();
// Create an instance of the KafkaConsumer:
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<>(consumerProps);
// Create an instance of the TracingKafkaConsumer, passing in the consumerSpanNameProvider BiFunction:
TracingKafkaConsumer<Integer, String> tracingConsumer = new TracingKafkaConsumer<>(consumer,
tracer,
consumerSpanNameProvider);
// Spans created by the tracingConsumer will have the operation name as the span name, in upper-case.
// "receive" -> "RECEIVE"
10.3.1.2. 内置范围名称
在定义自定义 span 名称时,您可以在 ClientSpanNameProvider 类中使用以下 BiFunctions。如果没有指定 spanNameProvider,则使用 CONSUMER_OPERATION_NAME 和 PRODUCER_OPERATION_NAME。
| BiFunction | 描述 |
|---|---|
|
|
将 |
|
|
返回 |
|
|
返回消息发送到或检索到的主题的名称,格式为 |
|
|
返回 |
|
|
返回操作名称和主题名称 |
|
|
返回 |
10.3.2. 用于追踪的 Kafka Streams 应用程序
本节论述了如何检测 Kafka Streams API 应用程序进行分布式追踪。
步骤
在每个 Kafka Streams API 应用程序中:
将
opentracing-kafka-streams依赖项添加到 Kafka Streams API 应用程序的 pom.xml 文件中:<dependency> <groupId>io.opentracing.contrib</groupId> <artifactId>opentracing-kafka-streams</artifactId> <version>0.1.12.redhat-00001</version> </dependency>创建
TracingKafkaClientSupplier 供应商界面的实例:KafkaClientSupplier supplier = new TracingKafkaClientSupplier(tracer);
为
KafkaStreams提供供应商接口:KafkaStreams streams = new KafkaStreams(builder.build(), new StreamsConfig(config), supplier); streams.start();
10.4. 为 MirrorMaker、Kafka Connect 和 Kafka Bridge 设置追踪
MirrorMaker、MirrorMaker 2.0、Kafka Connect(包括使用 Source2Image 支持的 Kafka Connect)和 AMQ Streams Kafka Bridge 支持分布式追踪。
MirrorMaker 和 MirrorMaker 2.0 中的追踪
对于 MirrorMaker 和 MirrorMaker 2.0,信息会从源集群追踪到目标集群。追踪数据记录进入和离开 MirrorMaker 或 MirrorMaker 2.0 组件的信息。
Kafka Connect 中的追踪
只有 Kafka Connect 本身生成并使用的消息才会被跟踪。要追踪在 Kafka Connect 和外部系统间发送的信息,您必须在连接器中为这些系统配置追踪。如需更多信息,请参阅 第 2.2.1 节 “配置 Kafka 连接”。
在 Kafka Bridge 中追踪
Kafka Bridge 生成并使用的消息会被跟踪。还会追踪从客户端应用程序发送和接收消息的传入 HTTP 请求。要进行端到端追踪,您必须在 HTTP 客户端中配置追踪。
10.4.1. 在 MirrorMaker、Kafka Connect 和 Kafka Bridge 资源中启用追踪
更新 KafkaMirrorMaker、KafkaMirrorMaker2、KafkaConnect S2IKafkaBridge 自定义资源的配置,以为每个资源指定和配置 Jaeger tracer 服务。更新 OpenShift 集群中启用追踪的资源会触发两个事件:
- 在 MirrorMaker、MirrorMaker 2.0、Kafka Connect 或 AMQ Streams Kafka Bridge 中的集成消费者和生产者中更新拦截器类。
- 对于 MirrorMaker、MirrorMaker 2.0 和 Kafka Connect,追踪代理会根据资源中定义的追踪配置初始化 Jaeger tracer。
- 对于 Kafka Bridge,基于资源中定义的追踪配置的 Jaeger tracer 由 Kafka Bridge 本身初始化。
步骤
为每个 KafkaMirrorMaker、KafkaMirrorMaker2、KafkaConnect、 和 KafkaConnect S2IKafkaBridge 资源执行这些步骤。
在
spec.template属性中配置 Jaeger tracer 服务。例如:Kafka Connect 的 Jaeger tracer 配置
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... template: connectContainer: 1 env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: 2 type: jaeger #...MirrorMaker 的 Jaeger tracer 配置
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaMirrorMaker metadata: name: my-mirror-maker spec: #... template: mirrorMakerContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...MirrorMaker 2.0 的 Jaeger tracer 配置
apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaMirrorMaker2 metadata: name: my-mm2-cluster spec: #... template: connectContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...Kafka Bridge 的 Jaeger tracer 配置
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaBridge metadata: name: my-bridge spec: #... template: bridgeContainer: env: - name: JAEGER_SERVICE_NAME value: my-jaeger-service - name: JAEGER_AGENT_HOST value: jaeger-agent-name - name: JAEGER_AGENT_PORT value: "6831" tracing: type: jaeger #...创建或更新资源:
oc apply -f your-file
第 11 章 管理 TLS 证书
AMQ Streams 支持使用 TLS 协议在 Kafka 和 AMQ Streams 组件之间进行加密通信。Kafka 代理(interbroker 通信)、ZooKeeper 节点之间的通信(交互通信)以及它们和 AMQ Streams 运算符之间的通信始终会被加密。Kafka 客户端和 Kafka 代理之间的通信会根据集群的配置方式加密。对于 Kafka 和 AMQ Streams 组件,也使用 TLS 证书进行身份验证。
Cluster Operator 自动设置并更新 TLS 证书,以在集群中启用加密和身份验证。如果要在 Kafka 代理和客户端间启用加密或 TLS 身份验证,它也会设置其他 TLS 证书。用户提供的证书不会被续订。
您可以为启用了 TLS 加密的 TLS 监听程序或者外部监听程序提供自己的服务器证书,称为 Kafka 侦听程序证书。如需更多信息,请参阅 第 11.8 节 “Kafka 侦听程序证书”。
图 11.1. TLS 安全通信的示例架构
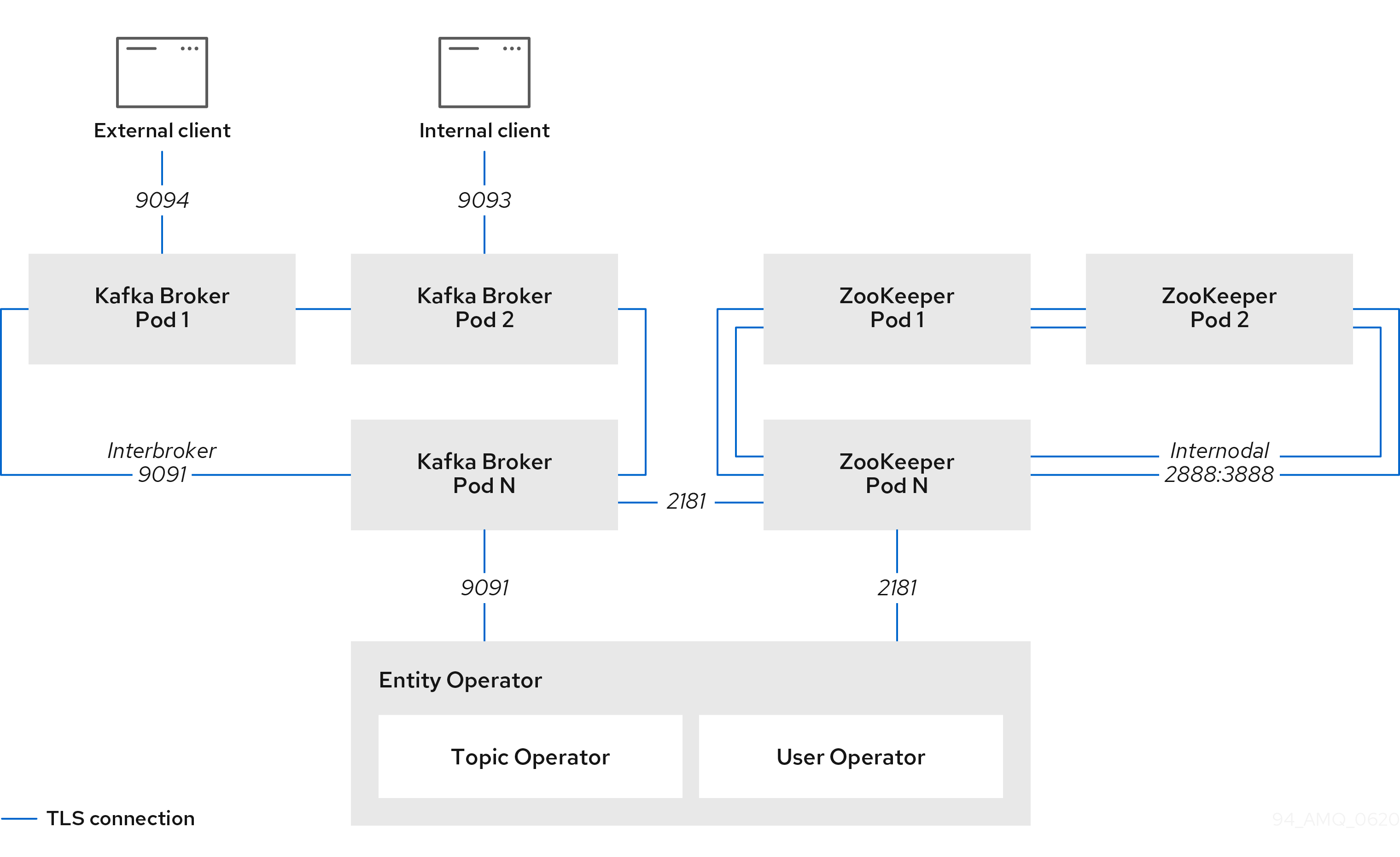
11.1. 证书颁发机构
为了支持加密,每个 AMQ Streams 组件都需要自己的私钥和公钥证书。所有组件证书都由名为 集群 CA 的内部证书颁发机构(CA)签名。
同样,使用 TLS 客户端身份验证连接到 AMQ Streams 的每个 Kafka 客户端应用程序都需要提供私钥和证书。第二个内部 CA(名为 clients CA )用于为 Kafka 客户端签署证书。
11.1.1. CA 证书
集群 CA 和客户端 CA 都具有自签名证书。
Kafka 代理配置为信任由集群 CA 或客户端 CA 签名的证书。客户端不需要连接的组件,如 ZooKeeper,只信任集群 CA 签名的证书。除非禁用外部监听器的 TLS 加密,否则客户端应用必须信任集群 CA 签名的证书。对于执行 mutual TLS 身份验证 的客户端应用,也是如此。
默认情况下,AMQ Streams 会自动生成和更新集群 CA 或客户端 CA 发布的 CA 证书。您可以在 Kafka.spec. clusterCa 和 对象中配置这些 CA 证书的管理。用户提供的证书不会被续订。
Kafka.spec.clientsCa
您可以为集群 CA 或客户端 CA 提供自己的 CA 证书。如需更多信息,请参阅 第 11.1.2 节 “安装您自己的 CA 证书”。如果您提供自己的证书,则必须在需要时手动更新它们。
11.1.2. 安装您自己的 CA 证书
此流程描述了如何安装您自己的 CA 证书和密钥,而不是使用 Cluster Operator 生成的 CA 证书和私钥。
您可以使用此流程安装自己的集群或客户端 CA 证书。
流程描述了 PEM 格式的 CA 证书续订。您还可以使用 PKCS #12 格式的证书。
先决条件
- Cluster Operator 正在运行。
- Kafka 集群尚未部署。
您自己的 X.509 证书和密钥,采用 PEM 格式用于集群 CA 或客户端 CA。
如果要使用不是 Root CA 的集群或客户端 CA,您必须在证书文件中包含整个链。链应该按照以下顺序排列:
- 集群或客户端 CA
- 一个或多个中间 CA
- 根 CA
- 链中的所有 CA 都应配置为 X509v3 基本约束中的 CA。
步骤
将您的 CA 证书放在对应的
Secret 中。删除现有的 secret:
oc delete secret CA-CERTIFICATE-SECRETca-CERTIFICATE-SECRET 是
Secret的名称,它是集群 CA证书的CLUSTER-NAME-cluster-ca-cert,用于客户端 CA 证书的CLUSTER-NAME-clients-ca-cert。忽略任何"Not Exists"错误。
创建并标记新 secret
oc create secret generic CA-CERTIFICATE-SECRET --from-file=ca.crt=CA-CERTIFICATE-FILENAME
将您的 CA 密钥放在对应的
Secret 中。删除现有的 secret:
oc delete secret CA-KEY-SECRETca-KEY-SECRET 是 CA 密钥的名称,这是
用于集群 CA 密钥的用于客户端 CA 密钥。CLUSTER-NAME-cluster-ca,创建新 secret:
oc create secret generic CA-KEY-SECRET --from-file=ca.key=CA-KEY-SECRET-FILENAME
使用 labels
strimzi.io/kind=Kafka和strimzi.io/cluster=CLUSTER-NAME标记 secret:oc label secret CA-CERTIFICATE-SECRET strimzi.io/kind=Kafka strimzi.io/cluster=CLUSTER-NAME oc label secret CA-KEY-SECRET strimzi.io/kind=Kafka strimzi.io/cluster=CLUSTER-NAME
为集群创建
Kafka资源,将Kafka.spec.clusterCa或Kafka.spec.clientsCa对象 配置为不使用 生成的 CA:将集群 CA 配置为使用您自己提供的证书的片段
Kafka资源示例kind: Kafka version: kafka.strimzi.io/v1beta1 spec: # ... clusterCa: generateCertificateAuthority: false
其他资源
- 要续订您之前安装的 CA 证书,请参阅 第 11.3.4 节 “续订您自己的 CA 证书”。
- 第 11.8.1 节 “提供您自己的 Kafka 侦听程序证书”.
11.2. Secrets
AMQ Streams 使用 Secret 来存储 Kafka 集群组件和客户端的私钥和证书。secret 用于在 Kafka 代理之间以及代理与客户端之间建立 TLS 加密连接。它们也用于 mutual TLS 身份验证。
- Cluster Secret 包含用于为 Kafka 代理证书签名的集群 CA 证书,供连接的客户端用于与 Kafka 集群建立 TLS 加密连接以验证代理身份。
- Client Secret 包含用户用来签署自己的客户端证书的客户端 CA 证书,以允许对 Kafka 集群进行相互身份验证。代理通过客户端 CA 证书本身验证客户端身份。
- 用户 Secret 包含私钥和证书,在创建新用户时由客户端 CA 证书生成和签名。密钥和证书用于访问集群时的身份验证和授权。
secret 以 PEM 和 PKCS #12 格式提供私钥和证书。使用 PEM 格式的私钥和证书意味着用户必须从 Secret 中获取,并生成对应的信任存储(或密钥存储),以便在其 Java 应用程序中使用。PKCS #12 存储提供了一个可直接使用的信任存储(或密钥存储)。
所有键的大小都是 2048 位。
11.2.1. PKCS #12 存储
PKCS #12 定义了一个归档文件格式(.p12),用于将加密对象存储在单个文件中并设有密码保护。您可以使用 PKCS #12 在一个位置管理证书和密钥。
每个 Secret 都包含特定于 PKCS #12 的字段。
-
.p12字段包含证书和密钥。 -
.password字段是保护存档的密码。
11.2.2. 集群 CA Secret
下表描述了由 Cluster Operator 在 Kafka 集群中管理的 Cluster Secret。
客户端只需要使用 <cluster> -cluster-ca-cert Secret。所有其他 Secret 仅需要由 AMQ Streams 组件访问。如果需要,您可以使用基于 OpenShift 角色的访问控制来强制实施此操作。
表 11.1. <cluster>-cluster-ca Secret 中的 字段
| 字段 | 描述 |
|---|---|
|
| 集群 CA 的当前私钥。 |
表 11.2. <cluster>-cluster-ca-cert Secret 中的 字段
| 字段 | 描述 |
|---|---|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 |
|
| 集群 CA 的当前证书。 |
<cluster>-cluster-ca-cert 中的 CA 证书必须被 Kafka 客户端应用程序信任,以便在通过 TLS 连接到 Kafka 代理时验证 Kafka 代理证书。
表 11.3. <cluster>-kafka-brokers Secret 中的 字段
| 字段 | 描述 |
|---|---|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 |
|
|
Kafka 代理 pod <num> 的证书。由 |
|
|
Kafka 代理 pod |
表 11.4. <cluster>-zookeeper-nodes Secret 中的 字段
| 字段 | 描述 |
|---|---|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 |
|
|
ZooKeeper 节点 <num> 的证书。由 |
|
|
ZooKeeper pod |
表 11.5. <cluster>-entity-operator-certs Secret 中的 字段
| 字段 | 描述 |
|---|---|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 |
|
|
Entity Operator 和 Kafka 或 ZooKeeper 之间的 TLS 通信证书。由 |
|
| Entity Operator 和 Kafka 或 ZooKeeper 之间的 TLS 通信的私钥。 |
11.2.3. 客户端 CA Secret
表 11.6. 在 <cluster>中由 Cluster Operator 管理的客户端 CA Secret
| Secret 名称 | Secret 中的字段 | 描述 |
|---|---|---|
|
|
| 客户端 CA 的当前私钥。 |
|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 | |
|
| 客户端 CA 的当前证书。 |
<cluster>-clients-ca-cert 中的证书是 Kafka 代理信任的证书。
<cluster>-clients-ca 用于签署客户端应用程序的证书。如果您打算在不使用 User Operator 的情况下发布应用程序证书,则需要对 AMQ Streams 组件和管理员访问权限进行访问。如果需要,您可以使用基于 OpenShift 角色的访问控制来强制实施此操作。
11.2.4. 用户 Secret
表 11.7. 由 User Operator 管理的 secret
| Secret 名称 | Secret 中的字段 | 描述 |
|---|---|---|
|
|
| PKCS #12 存档文件用于存储证书和密钥。 |
|
| 用于保护 PKCS #12 归档文件的密码。 | |
|
| 用户的证书,由客户端 CA 签名 | |
|
| 用户的私钥 |
11.3. 证书续订和有效期周期
集群 CA 和客户端 CA 证书仅在有限时间内有效,称为有效期。这通常定义为生成证书起的天数。
对于自动生成的 CA 证书,您可以配置以下有效周期:
-
Kafka.spec.clusterCa.validityDays中的集群 CA 证书 -
Kafka.spec.clientsCa.validityDays中的客户端 CA 证书
两个证书的默认有效期为 365 天。手动安装的 CA 证书应该定义自己的有效期。
当 CA 证书过期时,仍信任该证书的组件和客户端将不接受来自证书由 CA 私钥签名的对等点的 TLS 连接。组件和客户端需要信任 新的 CA 证书。
为了能在不丢失服务的情况下续订 CA 证书,Cluster Operator 将在旧 CA 证书过期前启动证书续订。
您可以配置续订周期:
-
Kafka.spec.clusterCa.renewalDays中的集群 CA 证书 -
Kafka.spec.clientsCa.renewalDays中的客户端 CA 证书
两个证书的默认续订期限为 30 天。
从当前证书的到期日期起,续订期向后测量。
针对续订期的有效周期
Not Before Not After
| |
|<--------------- validityDays --------------->|
<--- renewalDays --->|
要在创建 Kafka 集群后更改有效期和续订周期,您需要配置并应用 Kafka 自定义资源,并 手动更新 CA 证书。如果您不手动续订证书,在下次自动更新证书时将使用新的句点。
证书的有效性和续订周期的 Kafka 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
# ...
spec:
# ...
clusterCa:
renewalDays: 30
validityDays: 365
generateCertificateAuthority: true
clientsCa:
renewalDays: 30
validityDays: 365
generateCertificateAuthority: true
# ...
在续订期间 Cluster Operator 的行为取决于在 Kafka.spec. clusterCa.generateCertificateAuthority 或 中是否启用了相关设置。
Kafka.spec.clientsCa.generateCertificateAuthority
11.3.1. 使用生成的 CA 的续订过程
Cluster Operator 执行以下流程来更新 CA 证书:
-
生成新的 CA 证书,但保留现有密钥。新证书将旧证书替换为对应
Secret中的名称 ca.crt。 - 生成新的客户端证书(用于 ZooKeeper 节点、Kafka 代理和 Entity Operator)。这并非绝对必要,因为签名密钥尚未更改,但它保持客户端证书的有效性期限与 CA 证书同步。
- 重启 ZooKeeper 节点,以便它们信任新的 CA 证书并使用新的客户端证书。
- 重启 Kafka 代理,以便它们信任新的 CA 证书并使用新的客户端证书。
- 重启主题和用户 Operator,以便它们信任新的 CA 证书并使用新的客户端证书。
11.3.2. 客户端应用程序
Cluster Operator 不知道使用 Kafka 集群的客户端应用程序。
当连接到集群并确保它们正常工作时,客户端应用程序必须:
- 信任 <cluster> -cluster-ca-cert Secret 中发布的集群 CA 证书。
使用其 <user-name> Secret 中发布的凭证来连接到集群。
用户 Secret 以 PEM 和 PKCS #12 格式提供凭证,或者在使用 SCRAM-SHA 身份验证时可以提供密码。User Operator 在创建用户时创建用户凭据。
对于在同一 OpenShift 集群和命名空间中运行的工作负载,可以将机密挂载为卷,以便客户端 Pod 从 Secret 的当前状态构建其密钥存储和信任存储。有关此流程的详情,请参阅配置内部客户端以信任集群 CA。
11.3.2.1. 客户端证书续订
您必须确保在证书续订后客户继续工作。续订过程取决于如何配置客户端。
如果要手动置备客户端证书和密钥,您必须生成新的客户端证书,并确保客户端在续订期内使用这些新证书。如果续订周期结束后未能这样做,则可能导致客户应用程序无法连接到集群。
11.3.3. 手动续订 CA 证书
在相应证书续订期开始时,集群和客户端 CA 证书会自动续订。如果 Kafka.spec.clusterCa.generateCertificateAuthority 和 Kafka.spec.clientsCa.generateCertificateAuthority 设置为 false,则 CA 证书不会自动续订。
您可以在证书续订期限开始前手动续订其中一个或两个证书。出于安全原因 或更改了证书的续订期或有效期,您可以这样做。
更新的证书使用与旧证书相同的私钥。
先决条件
- Cluster Operator 正在运行。
- 安装 CA 证书和私钥的 Kafka 集群。
步骤
将
strimzi.io/force-renew注解应用到包含您要续订的 CA 证书的Secret。表 11.8. 强制续订证书的 Secret 注解
证书 Secret annotate 命令 集群 CA
kAFKA-CLUSTER-NAME-cluster-ca-cert
oc annotate secret KAFKA-CLUSTER-NAME-cluster-ca-cert strimzi.io/force-renew=true客户端 CA
kAFKA-CLUSTER-NAME-clients-ca-cert
oc annotate secret KAFKA-CLUSTER-NAME-clients-ca-cert strimzi.io/force-renew=true在下一次协调中,Cluster Operator 会为您注解的
Secret生成一个新的 CA 证书。如果配置了维护时间窗,Cluster Operator 将在下一个维护时间窗内第一次协调时生成新的 CA 证书。客户端应用程序必须重新载入由 Cluster Operator 更新的集群和客户端 CA 证书。
检查 CA 证书有效的周期:
例如,使用
openssl命令:oc get secret CA-CERTIFICATE-SECRET -o 'jsonpath={.data.CA-CERTIFICATE}' | base64 -d | openssl x509 -subject -issuer -startdate -enddate -noout
ca-CERTIFICATE-SECRET 是
Secret的名称,这是用于集群 CA证书的 KAFKA-CLUSTER-NAME-cluster-ca-cert和用于客户端 CA 证书的KAFKA-CLUSTER-NAME-clients-ca-cert。ca-CERTIFICATE 是 CA 证书的名称,如
jsonpath={.data.ca\.crt}。该命令会返回
notBefore和notAfter日期,这是 CA 证书的有效周期。例如,对于集群 CA 证书:
subject=O = io.strimzi, CN = cluster-ca v0 issuer=O = io.strimzi, CN = cluster-ca v0 notBefore=Jun 30 09:43:54 2020 GMT notAfter=Jun 30 09:43:54 2021 GMT
从 Secret 删除旧证书。
当组件使用新证书时,旧证书可能仍处于活跃状态。删除旧证书以消除任何潜在的安全风险。
11.3.4. 续订您自己的 CA 证书
这个步骤描述了如何续订之前安装的 CA 证书和密钥。您需要在续订期间按照以下步骤替换即将过期的 CA 证书。
您可以使用此流程安装自己的集群或客户端 CA 证书。
流程描述了 PEM 格式的 CA 证书续订。您还可以使用 PKCS #12 格式的证书。
先决条件
- Cluster Operator 正在运行。
- 之前安装自己的 CA 证书和私钥的 Kafka 集群。
- 新群集和客户端 X.509 证书和密钥,格式为 PEM。
它们可使用 openssl 命令生成,例如:
openssl req -x509 -new -days NUMBER-OF-DAYS-VALID --nodes -out ca.crt -keyout ca.key步骤
在
Secret中检查当前 CA 证书的详情:oc describe secret CA-CERTIFICATE-SECRETca-CERTIFICATE-SECRET 是
Secret的名称,这是用于集群 CA证书的 KAFKA-CLUSTER-NAME-cluster-ca-cert和用于客户端 CA 证书的KAFKA-CLUSTER-NAME-clients-ca-cert。创建一个目录,使其包含 secret 中的现有 CA 证书。
mkdir new-ca-cert-secret cd new-ca-cert-secret
获取您要续订的每个 CA 证书的 secret:
oc get secret CA-CERTIFICATE-SECRET -o 'jsonpath={.data.CA-CERTIFICATE}' | base64 -d > CA-CERTIFICATE
将 CA-CERTIFICATE 替换为每个 CA 证书的名称。
将旧的
ca.crt文件重命名为ca-DATE. crt,其中 DATE 是证书到期日期,格式为 YEAR -MONTH-DAYTHOUR-MINUTE-SECONDZ。例如
ca-2018-09-27T17-32-00Z.crt。mv ca.crt ca-$(date -u -d$(openssl x509 -enddate -noout -in ca.crt | sed 's/.*=//') +'%Y-%m-%dT%H-%M-%SZ').crt
将您的新 CA 证书复制到该目录,并将其命名为
ca.crt:cp PATH-TO-NEW-CERTIFICATE ca.crt将您的 CA 证书放在对应的
Secret 中。删除现有的 secret:
oc delete secret CA-CERTIFICATE-SECRETCA-CERTIFICATE-SECRET 是
Secret的名称,在第一步中返回。忽略任何"Not Exists"错误。
重新创建 secret:
oc create secret generic CA-CERTIFICATE-SECRET --from-file=.
删除您创建的目录:
cd .. rm -r new-ca-cert-secret
将您的 CA 密钥放在对应的
Secret 中。删除现有的 secret:
oc delete secret CA-KEY-SECRETca-KEY-SECRET 是 CA 密钥的名称,这是用于集群 CA 密钥的
KAFKA-CLUSTER-NAME-cluster-ca,用于客户端 CA 密钥的KAFKA-CLUSTER-NAME-clients-ca。使用新 CA 密钥重新创建 secret:
oc create secret generic CA-KEY-SECRET --from-file=ca.key=CA-KEY-SECRET-FILENAME
使用 labels
strimzi.io/kind=Kafka和strimzi.io/cluster=KAFKA-CLUSTER-NAME标记 secret:oc label secret CA-CERTIFICATE-SECRET strimzi.io/kind=Kafka strimzi.io/cluster=KAFKA-CLUSTER-NAME oc label secret CA-KEY-SECRET strimzi.io/kind=Kafka strimzi.io/cluster=KAFKA-CLUSTER-NAME
11.4. 替换私钥
您可以替换集群 CA 和客户端 CA 证书使用的私钥。替换私钥时,Cluster Operator 会为新私钥生成一个新的 CA 证书。
先决条件
- Cluster Operator 正在运行。
- 安装 CA 证书和私钥的 Kafka 集群。
步骤
将
strimzi.io/force-replace注解应用到包含您要续订的私钥的Secret。表 11.9. 替换私钥的命令
的私钥 Secret annotate 命令 集群 CA
<cluster-name>-cluster-ca
oc annotate secret <cluster-name>-cluster-ca strimzi.io/force-replace=true客户端 CA
<cluster-name>-clients-ca
oc annotate secret <cluster-name>-clients-ca strimzi.io/force-replace=true
在下一次协调中,Cluster Operator 将:
-
为注解的
Secret生成一个新的私钥 - 生成新的 CA 证书
如果配置了维护时间窗,Cluster Operator 将在下一个维护时间窗内第一次协调时生成新的私钥和 CA 证书。
客户端应用程序必须重新载入由 Cluster Operator 更新的集群和客户端 CA 证书。
11.5. TLS 连接
11.5.1. zookeeper 通讯
所有端口上的 ZooKeeper 节点以及客户端和 ZooKeeper 之间的通信将被加密。
11.5.2. Kafka Interbroker 通信
Kafka 代理之间的通信通过端口 9091 上的内部监听程序进行,该监听程序默认加密且不能被 Kafka 客户端访问。
Kafka 代理和 ZooKeeper 节点之间的通信也被加密。
11.5.3. 主题和用户 Operator
所有 Operator 使用加密来与 Kafka 和 ZooKeeper 进行通信。在主题和用户 Operator 中,与 ZooKeeper 通信时使用 TLS sidecar。
11.5.4. Sything Control
整合控制使用加密来与 Kafka 和 ZooKeeper 进行通信。与 ZooKeeper 通信时使用 TLS sidecar。
11.5.5. Kafka 客户端连接
Kafka 代理和客户端之间的加密或未加密通信是使用 spec.kafka.listeners 的 tls 属性配置的。
11.6. 配置内部客户端以信任集群 CA
此流程描述了如何配置驻留在 OpenShift 集群中 - 连接到 TLS 侦听器 - 信任集群 CA 证书的 Kafka 客户端。
对于内部客户端而言,最简单的方法是使用卷挂载来访问包含所需证书和密钥的 Secret。
按照步骤配置集群 CA 为基于 Java 的 Kafka Producer、Consumer 和 Streams API 签名的信任证书。
根据集群 CA 的证书格式选择要执行的步骤:PKCS #12(.p12)或 PEM(.crt)。
步骤描述了如何将 Cluster Secret 挂载来验证 Kafka 集群的身份到客户端 pod。
先决条件
- Cluster Operator 必须正在运行。
-
OpenShift 集群中需要有
Kafka资源。 - 您需要在 OpenShift 集群内有一个 Kafka 客户端应用,它将使用 TLS 进行连接,需要信任集群 CA 证书。
-
客户端应用程序必须与
Kafka资源在同一命名空间中运行。
使用 PKCS #12 格式(.p12)
在定义客户端 Pod 时,将集群 Secret 挂载为卷。
例如:
kind: Pod apiVersion: v1 metadata: name: client-pod spec: containers: - name: client-name image: client-name volumeMounts: - name: secret-volume mountPath: /data/p12 env: - name: SECRET_PASSWORD valueFrom: secretKeyRef: name: my-secret key: my-password volumes: - name: secret-volume secret: secretName: my-cluster-cluster-ca-cert在这里,我们要挂载:
- PKCS #12 文件到一个精确的路径,该路径可以被配置
- 密码到环境变量中,可在其中用于 Java 配置
使用以下属性配置 Kafka 客户端:
安全协议选项:
-
security.protocol:使用 TLS 加密(带有或不使用 TLS 身份验证)时,SSL -
security.protocol:在通过 TLS 使用 SCRAM-SHA 身份验证时,SASL_SSL
-
-
导入证书的信任存储位置的 SSL.truststore.location。 -
SSL.truststore.password,密码为用于访问信任存储的密码。 -
SSL.truststore.type=PKCS12标识信任存储类型。
使用 PEM 格式(.crt)
在定义客户端 Pod 时,将集群 Secret 挂载为卷。
例如:
kind: Pod apiVersion: v1 metadata: name: client-pod spec: containers: - name: client-name image: client-name volumeMounts: - name: secret-volume mountPath: /data/crt volumes: - name: secret-volume secret: secretName: my-cluster-cluster-ca-cert- 将证书与使用 X.509 格式的客户端一起使用。
11.7. 配置外部客户端以信任集群 CA
此流程描述了如何配置驻留在 OpenShift 集群外的 Kafka 客户端 - 连接到 外部 监听器 - 以信任集群 CA 证书。设置客户端时,并在续订期间替换旧客户端 CA 证书时,按照以下步骤操作。
按照步骤配置集群 CA 为基于 Java 的 Kafka Producer、Consumer 和 Streams API 签名的信任证书。
根据集群 CA 的证书格式选择要执行的步骤:PKCS #12(.p12)或 PEM(.crt)。
步骤描述了如何从 Cluster Secret 获取验证 Kafka 集群身份的证书。
<cluster-name>-cluster-ca-cert Secret 在 CA 证书续订期间将包含多个 CA 证书。客户端必须将 所有这些 添加到其信任存储中。
先决条件
- Cluster Operator 必须正在运行。
-
OpenShift 集群中需要有
Kafka资源。 - 您需要在 OpenShift 集群外有一个 Kafka 客户端应用,它将使用 TLS 进行连接,需要信任集群 CA 证书。
使用 PKCS #12 格式(.p12)
从生成的
<cluster-name> -cluster-ca-certSecret 中提取集群 CA 证书和密码。oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.p12}' | base64 -d > ca.p12oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.password}' | base64 -d > ca.password使用以下属性配置 Kafka 客户端:
安全协议选项:
-
security.protocol:使用 TLS 加密(带有或不使用 TLS 身份验证)时,SSL -
security.protocol:在通过 TLS 使用 SCRAM-SHA 身份验证时,SASL_SSL
-
-
导入证书的信任存储位置的 SSL.truststore.location。 -
SSL.truststore.password,密码为用于访问信任存储的密码。如果信任存储不需要此属性,则可以省略它。 -
SSL.truststore.type=PKCS12标识信任存储类型。
使用 PEM 格式(.crt)
从生成的
<cluster-name> -cluster-ca-certSecret 中提取集群 CA 证书。oc get secret <cluster-name>-cluster-ca-cert -o jsonpath='{.data.ca\.crt}' | base64 -d > ca.crt- 将证书与使用 X.509 格式的客户端一起使用。
11.8. Kafka 侦听程序证书
您可以为以下类型的监听程序提供自己的服务器证书和私钥:
- 用于 OpenShift 集群内部通信的内部 TLS 侦听器
-
外部监听程序(
路由、负载均衡器、入口和节点端口类型),它们启用了 TLS 加密,用于 Kafka 客户端和 Kafka 代理之间的通信
这些用户提供的证书称为 Kafka 侦听程序证书。
为外部监听程序提供 Kafka 侦听程序证书可让您利用现有安全基础架构,如组织的私有 CA 或公共 CA。Kafka 客户端将使用 Kafka 侦听程序证书而不是由集群 CA 或客户端 CA 签名的证书连接到 Kafka 代理。
在需要时,您必须手动更新 Kafka 侦听程序证书。
11.8.1. 提供您自己的 Kafka 侦听程序证书
此流程演示了如何配置监听程序以使用您自己的私钥和服务器证书,称为 Kafka 侦听程序证书。
您的客户端应用程序应使用 CA 公钥作为可信证书,以验证 Kafka 代理的身份。
先决条件
- OpenShift 集群。
- Cluster Operator 正在运行。
对于每个侦听器,由外部 CA 签名的兼容服务器证书。
- 提供 PEM 格式的 X.509 证书。
- 为每个监听器指定正确的主题备用名称(SAN)。如需更多信息,请参阅 第 11.8.2 节 “Kafka 监听程序服务器证书中的其他主题”。
- 您可以在证书文件中提供包含整个 CA 链的证书。
步骤
创建包含私钥和服务器证书的
Secret:oc create secret generic my-secret --from-file=my-listener-key.key --from-file=my-listener-certificate.crt
编辑集群的
Kafka资源。配置侦听器,以在configuration.brokerCertCertChainAndKey属性中使用您的Secret、证书文件和私钥文件。启用 TLS
加密的负载均衡器外部监听程序配置示例# ... listeners: - name: plain port: 9092 type: internal tls: false - name: external port: 9094 type: loadbalancer tls: true authentication: type: tls configuration: brokerCertChainAndKey: secretName: my-secret certificate: my-listener-certificate.crt key: my-listener-key.key # ...TLS 侦听器的配置示例
# ... listeners: - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true authentication: type: tls configuration: brokerCertChainAndKey: secretName: my-secret certificate: my-listener-certificate.crt key: my-listener-key.key # ...应用新配置以创建或更新资源:
oc apply -f kafka.yamlCluster Operator 会启动 Kafka 集群的滚动更新,该更新会更新监听器的配置。
注意如果您在已由 TLS 或外部监听器使用的
Secret中更新 Kafka 侦听程序证书,还会启动滚动更新。
11.8.2. Kafka 监听程序服务器证书中的其他主题
要将 TLS 主机名验证与您自己的 Kafka 侦听程序证书 一起使用,您必须为每个监听器使用正确的 Subject 备用名称(SAN)。证书 SAN 必须指定主机名:
- 集群中的所有 Kafka 代理
- Kafka 集群 bootstrap 服务
如果您的 CA 支持通配符证书,您可以使用通配符证书。
11.8.2.1. TLS 侦听器 SAN 示例
使用以下示例来帮助您在证书中为 TLS 侦听器指定 SAN 的主机名。
通配符示例
//Kafka brokers *.<cluster-name>-kafka-brokers *.<cluster-name>-kafka-brokers.<namespace>.svc // Bootstrap service <cluster-name>-kafka-bootstrap <cluster-name>-kafka-bootstrap.<namespace>.svc
非通配符示例
// Kafka brokers <cluster-name>-kafka-0.<cluster-name>-kafka-brokers <cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc <cluster-name>-kafka-1.<cluster-name>-kafka-brokers <cluster-name>-kafka-1.<cluster-name>-kafka-brokers.<namespace>.svc # ... // Bootstrap service <cluster-name>-kafka-bootstrap <cluster-name>-kafka-bootstrap.<namespace>.svc
11.8.2.2. 外部监听程序 SAN 示例
对于启用了 TLS 加密的外部监听程序,您需要在证书中指定的主机名取决于外部监听程序 类型。
表 11.10. 每种类型的外部监听器的 sans
| 外部监听程序类型 | 在 SANs 中指定… |
|---|---|
|
|
所有 Kafka 代理 您可以使用匹配的通配符名称。 |
|
|
所有 Kafka 代理 您可以使用匹配的通配符名称。 |
|
| Kafka 代理 Pod 可能调度到的所有 OpenShift 工作程序节点的地址。 您可以使用匹配的通配符名称。 |
第 12 章 管理 AMQ 流
本章论述了维护 AMQ 流部署的任务。
12.1. 使用自定义资源
您可以使用 oc 命令来检索信息,并对 AMQ Streams 自定义资源执行其他操作。
通过将 oc 与自定义资源的 status 子资源一起使用,您可以获取有关资源的信息。
12.1.1. 对自定义资源执行 oc 操作
使用 get、describe、edit 或 delete 等 oc 命令对资源类型执行操作。例如,oc get kafkatopics 检索所有 Kafka 主题的列表,oc get kafkas 检索 所有部署的 Kafka 集群。
引用资源类型时,您可以同时使用单数和复数名称:oc get kafkas 的结果与 oc get kafka 相同。
您还可以使用资源的 短名称。在管理 AMQ Streams 时,学习短名称可节省您时间。Kafka 的短名称为 k,因此您也可以运行 oc get k 以 列出所有 Kafka 集群。
oc get k NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS my-cluster 3 3
表 12.1. 每个 AMQ Streams 资源的长和短名称
| AMQ Streams 资源 | 长名称 | 短名称 |
|---|---|---|
| kafka | kafka | k |
| kafka 主题 | kafkatopic | kt |
| Kafka 用户 | kafkauser | ku |
| Kafka Connect | kafkaconnect | kc |
| Kafka Connect S2I | kafkaconnects2i | kcs2i |
| Kafka Connector | kafkaconnector | kctr |
| Kafka Mirror Maker | kafkamirrormaker | kMM |
| Kafka Mirror Maker 2 | kafkamirrormaker2 | kmm2 |
| Kafka Bridge | kafkabridge | kb |
| kafka 重新平衡 | kafkarebalance | kR |
12.1.1.1. 资源类型
oc 命令还可以使用自定义资源的类别。
所有 AMQ Streams 自定义资源都属于 category strimzi,因此您可以使用 strimzi 来通过一个命令获取所有 AMQ Streams 资源。
例如,运行 oc get strimzi 会列出给定命名空间中的所有 AMQ Streams 自定义资源。
oc get strimzi NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS kafka.kafka.strimzi.io/my-cluster 3 3 NAME PARTITIONS REPLICATION FACTOR kafkatopic.kafka.strimzi.io/kafka-apps 3 3 NAME AUTHENTICATION AUTHORIZATION kafkauser.kafka.strimzi.io/my-user tls simple
oc get strimzi -o name 命令返回所有资源类型和资源名称。o name 选项以 type/name 格式获取输出
oc get strimzi -o name kafka.kafka.strimzi.io/my-cluster kafkatopic.kafka.strimzi.io/kafka-apps kafkauser.kafka.strimzi.io/my-user
您可以将这一 strimzi 命令与其他命令相结合。例如,您可以将其传递到 oc delete 命令以删除单个命令中的所有资源。
oc delete $(oc get strimzi -o name) kafka.kafka.strimzi.io "my-cluster" deleted kafkatopic.kafka.strimzi.io "kafka-apps" deleted kafkauser.kafka.strimzi.io "my-user" deleted
在单个操作中删除所有资源可能很有用,例如测试新 AMQ Streams 功能时。
12.1.1.2. 查询子资源的状态
您也可以传递给 -o 选项的其他值。例如,通过使用 -o yaml,您可以获取 YAML 格式的输出。usng -o json 将以 JSON 形式返回。
您可以查看 oc get --help 中的所有选项。
其中一个最有用的选项是 JSONPath 支持,它允许您传递 JSONPath 表达式来查询 Kubernetes API。JSONPath 表达式可以提取或导航任何资源的特定部分。
例如,您可以使用 JSONPath 表达式 {.status.listeners[?(@.type=="tls")].bootstrapServers} 从 Kafka 自定义资源的状态获取 bootstrap 地址,并在 Kafka 客户端中使用它。
此处,命令找到 tls 侦听器的 bootstrapServers 值。
oc get kafka my-cluster -o=jsonpath='{.status.listeners[?(@.type=="tls")].bootstrapServers}{"\n"}'
my-cluster-kafka-bootstrap.myproject.svc:9093
通过将类型条件更改为 @.type=="external" 或 @.type=="plain",您也可以获取其他 Kafka 侦听器的地址。
oc get kafka my-cluster -o=jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}{"\n"}'
192.168.1.247:9094
您可以使用 jsonpath 从任何自定义资源中提取任何其他属性或属性组。
12.1.2. AMQ Streams 自定义资源状态信息
几个资源具有 status 属性,如下表中所述。
表 12.2. 自定义资源状态属性
| AMQ Streams 资源 | 架构参考 | 在… 上发布状态信息 |
|---|---|---|
|
| Kafka 集群。 | |
|
| Kafka Connect 集群(如果已部署)。 | |
|
| 带有 Source-to-Image 支持的 Kafka Connect 集群(如果已部署)。 | |
|
|
| |
|
| Kafka MirrorMaker 工具(如果已部署)。 | |
|
| Kafka 集群中的主题。 | |
|
| Kafka 集群中的用户。 | |
|
| AMQ Streams Kafka Bridge(如果已部署)。 |
资源的 status 属性提供资源的信息:
-
当前状态,在
status.conditions属性中 -
最后观察到的生成,在
status.observedGeneration属性中
status 属性也提供特定于资源的信息。例如:
-
KafkaConnectStatus为 Kafka Connect 连接器提供 REST API 端点。 -
KafkaUserStatus提供 Kafka 用户的用户名以及存储其凭证的Secret。 -
KafkaBridgeStatus提供 HTTP 地址,外部客户端应用程序可以访问 Bridge 服务。
资源的当前状态可用于跟踪与达到 所需 状态 的资源相关的进度,如 spec 属性所定义。状态条件提供了资源更改的时间和原因,以及防止或延迟 Operator 实现资源所需状态的事件详情。
最后观察到的生成 是 Cluster Operator 最后协调的资源的生成。如果 observedGeneration 的值与 metadata.generation 的值不同,Operator 还没有对资源的最新版本进行处理。如果这些值相同,状态信息反映了对资源的最新更改。
AMQ Streams 创建和维护自定义资源的状态,定期评估自定义资源的当前状态并相应地更新其状态。当使用 oc edit 对自定义资源执行更新时,其状态 不可编辑。此外,更改 状态 不会影响 Kafka 集群的配置。
此处,我们会看到为 Kafka 自定义资源指定的 status 属性。
带有状态的 Kafka 自定义资源
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: spec: # ... status: conditions: 1 - lastTransitionTime: 2019-07-23T23:46:57+0000 status: "True" type: Ready 2 observedGeneration: 4 3 listeners: 4 - addresses: - host: my-cluster-kafka-bootstrap.myproject.svc port: 9092 type: plain - addresses: - host: my-cluster-kafka-bootstrap.myproject.svc port: 9093 certificates: - | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- type: tls - addresses: - host: 172.29.49.180 port: 9094 certificates: - | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- type: external # ...
状态中列出的 Kafka bootstrap 地址不表示这些端点或 Kafka 集群处于 ready 状态。
访问状态信息
您可以从命令行访问资源的状态信息。如需更多信息,请参阅 第 12.1.3 节 “查找自定义资源的状态”。
12.1.3. 查找自定义资源的状态
此流程描述了如何查找自定义资源的状态。
先决条件
- OpenShift 集群。
- Cluster Operator 正在运行。
步骤
指定自定义资源,并使用
-o jsonpath选项应用标准 JSONPath 表达式来选择status属性:oc get kafka <kafka_resource_name> -o jsonpath='{.status}'此表达式返回指定自定义资源的所有状态信息。您可以使用点表示法(如
status.listeners或status.observedGeneration)来微调您希望看到的状态信息。
其他资源
- 第 12.1.2 节 “AMQ Streams 自定义资源状态信息”
- 有关使用 JSONPath 的更多信息,请参阅 JSONPath 支持。
12.2. 使用标签和注解发现服务
服务发现使得在与 AMQ Streams 相同的 OpenShift 集群中运行的客户端应用可以更轻松地与 Kafka 集群交互。
为用于访问 Kafka 集群的服务生成 服务发现 标签和注解:
- 内部 Kafka bootstrap 服务
- HTTP Bridge 服务
该标签有助于使服务可被发现,注释提供了客户端应用程序可用于进行连接的连接详情。
Service 资源的服务发现标签, strimzi.io/discovery 设置为 true。服务发现注释具有相同的密钥,以 JSON 格式提供每个服务的连接详细信息。
内部 Kafka bootstrap 服务示例
apiVersion: v1
kind: Service
metadata:
annotations:
strimzi.io/discovery: |-
[ {
"port" : 9092,
"tls" : false,
"protocol" : "kafka",
"auth" : "scram-sha-512"
}, {
"port" : 9093,
"tls" : true,
"protocol" : "kafka",
"auth" : "tls"
} ]
labels:
strimzi.io/cluster: my-cluster
strimzi.io/discovery: "true"
strimzi.io/kind: Kafka
strimzi.io/name: my-cluster-kafka-bootstrap
name: my-cluster-kafka-bootstrap
spec:
#...HTTP Bridge 服务示例
apiVersion: v1
kind: Service
metadata:
annotations:
strimzi.io/discovery: |-
[ {
"port" : 8080,
"tls" : false,
"auth" : "none",
"protocol" : "http"
} ]
labels:
strimzi.io/cluster: my-bridge
strimzi.io/discovery: "true"
strimzi.io/kind: KafkaBridge
strimzi.io/name: my-bridge-bridge-service12.2.1. 返回服务的连接详情
您可以从命令行或对应的 API 调用时指定发现标签来查找服务。
oc get service -l strimzi.io/discovery=true
在检索服务发现标签时,将返回连接详情。
12.3. 从持久性卷中恢复集群
如果持久性卷(PV)仍然存在,您可以从它们恢复 Kafka 集群。
您可能想要执行此操作,例如:
- 命名空间被意外删除
- 整个 OpenShift 集群会丢失,但 PV 会保留在基础架构中
12.3.1. 从命名空间删除中恢复
由于持久性卷和命名空间之间的关系,可以从删除命名空间中进行恢复。A PersistentVolume (PV)是位于命名空间外的存储资源。PV 使用 PersistentVolumeClaim (PVC)挂载到 Kafka pod 中,该 PVC 驻留在一个命名空间内。
PV 的重新声明(reclaim)策略指定了在删除命名空间时集群如何操作。如果重新声明策略被设置为:
- 删除 (默认)当 PVC 在命名空间中被删除时会删除 PV
- 保留,在删除命名空间时不会删除 PV
为确保意外删除命名空间时,您可以从 PV 中恢复该策略,必须在 PV 规格中使用 persistentVolumeReclaimPolicy 属性重置该 策略 :
apiVersion: v1
kind: PersistentVolume
# ...
spec:
# ...
persistentVolumeReclaimPolicy: Retain另外,PV 可以继承关联的存储类的重新声明策略。存储类用于动态卷分配。
通过为存储类配置 reclaimPolicy 属性,使用存储类的 PV 会使用适当的重新声明策略创建。使用 storageClassName 属性为 PV 配置存储类。
apiVersion: v1 kind: StorageClass metadata: name: gp2-retain parameters: # ... # ... reclaimPolicy: Retain
apiVersion: v1
kind: PersistentVolume
# ...
spec:
# ...
storageClassName: gp2-retain如果您使用 Retain 作为重新声明策略,但要删除整个集群,则需要手动删除 PV。否则它们将不会被删除,并可能导致不必要的资源开支。
12.3.2. 在 OpenShift 集群丢失后进行恢复
当集群丢失时,如果您在基础架构中保留了集群,则可以使用磁盘/卷中的数据来恢复集群。恢复过程与删除命名空间的过程相同,假设 PV 可以恢复并手动创建。
12.3.3. 从持久性卷中恢复已删除的集群
这个步骤描述了如何从持久性卷(PV)中恢复删除的集群。
在这种情况下,Topic Operator 会识别 Kafka 中存在的主题,但 KafkaTopic 资源不存在。
当您进入重新创建集群的步骤时,有两个选项:
当可以恢复所有
KafkaTopic资源时,请使用 Option 1。因此,必须在集群启动前恢复
KafkaTopic资源,以便 Topic Operator 不会删除对应的主题。当无法恢复所有
KafkaTopic资源时,请使用 Option 2。这一次,您在没有 Topic Operator 的情况下部署集群,删除 ZooKeeper 中的 Topic Operator 数据,然后重新部署它,以便 Topic Operator 可以从对应主题重新创建
KafkaTopic资源。
如果没有部署 Topic Operator,您只需要恢复 PersistentVolumeClaim (PVC)资源。
开始前
在这一流程中,必须将 PV 挂载到正确的 PVC 中以避免数据崩溃。为 PVC 指定了一个 volumeName,且必须与 PV 的名称匹配。
如需更多信息,请参阅:
该流程不包括 KafkaUser 资源的恢复,必须手动重新创建。如果需要保留密码和证书,则必须在创建 KafkaUser 资源前重新创建 secret。
步骤
检查集群中的 PV 信息:
oc get pv
为 PV 提供数据信息。
显示对这个流程很重要的列的输出示例:
NAME RECLAIMPOLICY CLAIM pvc-5e9c5c7f-3317-11ea-a650-06e1eadd9a4c ... Retain ... myproject/data-my-cluster-zookeeper-1 pvc-5e9cc72d-3317-11ea-97b0-0aef8816c7ea ... Retain ... myproject/data-my-cluster-zookeeper-0 pvc-5ead43d1-3317-11ea-97b0-0aef8816c7ea ... Retain ... myproject/data-my-cluster-zookeeper-2 pvc-7e1f67f9-3317-11ea-a650-06e1eadd9a4c ... Retain ... myproject/data-0-my-cluster-kafka-0 pvc-7e21042e-3317-11ea-9786-02deaf9aa87e ... Retain ... myproject/data-0-my-cluster-kafka-1 pvc-7e226978-3317-11ea-97b0-0aef8816c7ea ... Retain ... myproject/data-0-my-cluster-kafka-2
- NAME 显示每个 PV 的名称。
- RECLAIM POLICY 显示 PV 会被 保留。
- CLAIM 显示到原始 PVC 的链接。
重新创建原始命名空间:
oc create namespace myproject重新创建原始 PVC 资源规格,将 PVC 链接到适当的 PV:
例如:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: data-0-my-cluster-kafka-0 spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Gi storageClassName: gp2-retain volumeMode: Filesystem volumeName: pvc-7e1f67f9-3317-11ea-a650-06e1eadd9a4c编辑 PV 规格,以删除绑定原始 PVC 的
claimRef属性。例如:
apiVersion: v1 kind: PersistentVolume metadata: annotations: kubernetes.io/createdby: aws-ebs-dynamic-provisioner pv.kubernetes.io/bound-by-controller: "yes" pv.kubernetes.io/provisioned-by: kubernetes.io/aws-ebs creationTimestamp: "<date>" finalizers: - kubernetes.io/pv-protection labels: failure-domain.beta.kubernetes.io/region: eu-west-1 failure-domain.beta.kubernetes.io/zone: eu-west-1c name: pvc-7e226978-3317-11ea-97b0-0aef8816c7ea resourceVersion: "39431" selfLink: /api/v1/persistentvolumes/pvc-7e226978-3317-11ea-97b0-0aef8816c7ea uid: 7efe6b0d-3317-11ea-a650-06e1eadd9a4c spec: accessModes: - ReadWriteOnce awsElasticBlockStore: fsType: xfs volumeID: aws://eu-west-1c/vol-09db3141656d1c258 capacity: storage: 100Gi claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: data-0-my-cluster-kafka-2 namespace: myproject resourceVersion: "39113" uid: 54be1c60-3319-11ea-97b0-0aef8816c7ea nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: failure-domain.beta.kubernetes.io/zone operator: In values: - eu-west-1c - key: failure-domain.beta.kubernetes.io/region operator: In values: - eu-west-1 persistentVolumeReclaimPolicy: Retain storageClassName: gp2-retain volumeMode: Filesystem在这个示例中,删除了以下属性:
claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: data-0-my-cluster-kafka-2 namespace: myproject resourceVersion: "39113" uid: 54be1c60-3319-11ea-97b0-0aef8816c7ea
部署 Cluster Operator。
oc apply -f install/cluster-operator -n my-project重新创建集群。
根据您是否拥有重新创建集群所需的所有
KafkaTopic资源,按照以下步骤执行操作。选项 1 :如果您在丢失集群前存在 所有
KafkaTopic资源,包括__consumer_offset提交偏移等内部主题:重新创建所有
KafkaTopic资源。您必须在部署集群前重新创建资源,否则 Topic Operator 将删除主题。
部署 Kafka 集群。
例如:
oc apply -f kafka.yaml
选项 2 :如果您没有丢失集群前存在的所有
KafkaTopic资源:部署 Kafka 集群,如第一个选项一样,但不通过在部署前从 Kafka 资源中删除
topicOperator属性来不使用 Topic Operator。如果您在部署中包含主题 Operator,主题 Operator 将删除所有主题。
对其中一个 Kafka 代理 Pod 运行
exec命令,以打开 ZooKeeper shell 脚本。例如,其中 my-cluster-kafka-0 是代理 pod 的名称:
oc exec -ti my-cluster-zookeeper-0 -- bin/zookeeper-shell.sh localhost:12181删除整个
/strimzi路径以删除 Topic Operator 存储:deleteall /strimzi
通过使用
topicOperator属性重新部署 Kafka 集群来启用 Topic Operator,以重新创建KafkaTopic资源。例如:
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} 1 #...
- 1
- 在此,我们会显示默认配置,它没有附加属性。您可以使用 第 B.66 节 “
EntityTopicOperatorSpec模式参考” 中描述的属性指定所需的配置。
通过列出
KafkaTopic资源来验证恢复:oc get KafkaTopic
12.4. 调整客户端配置
使用配置属性优化 Kafka 制作者和使用者的性能。
需要最小的配置属性集合,但您可以添加或调整属性以更改生产者和使用者如何与 Kafka 交互。例如,对于制作者,您可以调整消息的延迟和吞吐量,以便客户端能够实时响应数据。或者您可以更改配置以提供更强大的消息持久性保证。
首先,您可以分析客户端指标来测量进行初始配置的位置,然后进行增量更改和进一步比较,直到您拥有所需的配置。
12.4.1. Kafka 生成器配置调整
使用基本制作者配置,以及为特定用例量身定制的可选属性。
调整配置以最大化吞吐量可能会增加延迟,反之亦然。您将需要试验并调优制作者配置,以获得所需的平衡。
12.4.1.1. 基本制作者配置
每个制作者都需要连接和序列化程序属性。通常而言,最好是添加客户端 ID 以进行跟踪,并对制作者使用压缩来减少请求中的批处理大小。
在基本制作者配置中:
- 无法保证分区中消息的顺序。
- 确认到达代理的消息不能保证持久性。
# ... bootstrap.servers=localhost:9092 1 key.serializer=org.apache.kafka.common.serialization.StringSerializer 2 value.serializer=org.apache.kafka.common.serialization.StringSerializer 3 client.id=my-client 4 compression.type=gzip 5 # ...
- 1
- (必需)告诉制作者使用 Kafka 代理的 host:port bootstrap 服务器地址连接到 Kafka 集群。制作者使用该地址来发现和连接集群中的所有代理。在服务器停机时使用逗号分隔列表来指定两个或三个地址,但不需要提供集群中所有代理的列表。
- 2
- (必需)在将每条消息的密钥发送到代理前将其转换为字节。
- 3
- (必需)在将每个消息发送到代理前将每条消息的值转换为字节。
- 4
- (可选)客户端的逻辑名称,用于日志和指标来标识请求的来源。
- 5
- (可选)压缩消息的编码器(发送并可能以压缩格式存储),然后在到达消费者时解压缩。压缩对于提高吞吐量和减少存储负载非常有用,但可能不适用于低延迟应用程序,因为压缩或解压成本可能过高。
12.4.1.2. 数据持久性
您可以使用消息发送确认,应用更大的数据持久性,以最大程度降低消息丢失的可能性。
# ...
acks=all 1
# ...- 1
- 指定
acks=all会强制分区领导将消息复制到一定数量的跟随者,然后确认消息请求已成功收到。由于附加检查,acks=all会增加生产者发送消息和接收确认之间的延迟。
在将确认发送到生产者之前,需要将消息附加至其日志中的代理数量由主题的 min.insync.replicas 配置决定。典型的起点是将主题复制因数为 3,其他代理上有两个内联副本。在这种配置中,如果单个代理不可用,生产者可以继续不受影响。如果第二个代理不可用,生产者将不会收到确认并且无法生成更多消息。
支持 acks=all 的主题配置
# ...
min.insync.replicas=2 1
# ...
- 1
- 使用
2内同步的副本。默认值为1。
如果系统失败,则缓冲区中存在不正确的数据丢失的风险。
12.4.1.3. 订购交付
幂等制作者避免重复,因为消息只发送一次。为消息分配了 ID 和序列号,以确保传送顺序,即使出现故障也是如此。如果您使用 acks=all 来实现数据一致性,则启用幂等性对有序交付有利。
使用幂等方式订购交付
# ... enable.idempotence=true 1 max.in.flight.requests.per.connection=5 2 acks=all 3 retries=2147483647 4 # ...
如果您没有由于性能成本而使用 acks=all 和 幂等性,请将待机(未确认)请求数设置为 1 以保持排序。否则,只有在 Message- B 已写入代理后 Message- A 可能无法成功。
在没有幂等的情况下订购交付
# ... enable.idempotence=false 1 max.in.flight.requests.per.connection=1 2 retries=2147483647 # ...
12.4.1.4. 可靠性保证
仅对写入单个分区一次,Idempotence 非常有用。事务处理与幂等性一起使用时,允许在多个分区间只写入一次。
事务可确保使用相同事务 ID 的消息只生成一次,并且将 所有 消息都成功写入到对应的日志中,或者其中任何消息 都不是.
# ... enable.idempotence=true max.in.flight.requests.per.connection=5 acks=all retries=2147483647 transactional.id=UNIQUE-ID 1 transaction.timeout.ms=900000 2 # ...
transaction .id 的选择对于保持事务保证非常重要。每个事务 id 都应该用于一组唯一的主题分区。例如,这可以通过外部映射主题分区名称到事务 id 来实现,或者通过使用避免冲突的功能计算主题分区名称中的事务 ID。
12.4.1.5. 优化吞吐量和延迟
通常,系统的要求是满足给定延迟内一定比例消息的特定吞吐量目标。例如,以每秒 500,000条消息为目标,95% 的消息会在 2 秒内得到确认。
生产者的消息传递语义(消息排序和持久性)很可能根据您的应用程序的要求进行定义。例如,您可能没有选项在不破坏某些重要属性的情况下使用 acks=0 或 acks=1,或者无法保证应用程序提供。
Broker 重新启动对高百分比统计数据有显著影响。例如,在很长一段时间内,99 百分点延迟由围绕代理重启的行为占据主导地位。在设计基准测试时,或比较基准测试与生产中显示的性能数字时,需要考虑这一点。
根据您的目标,Kafka 提供了多个配置参数和技术来调节吞吐量和延迟的性能。
- 消息批处理(ling
er.ms和batch.size) -
消息批处理会延迟发送消息,希望将发送更多目标为同一代理的消息,允许它们批处理到单个生成请求。批处理是在高吞吐量时返回的更高延迟之间的妥协。基于时间的批处理使用 linger
.ms配置,而基于大小的批处理则使用batch.size配置。 压缩(压缩.type)-
消息压缩增加了制作者延迟(CPU 时间用于压缩消息),但会更小(可能进行磁盘写入),这可以提高吞吐量。压缩是否必要,以及要使用的最佳压缩程度取决于所发送的消息。压缩发生在调用
KafkaProducer.send()的线程上,因此如果此方法的延迟与您需要使用更多线程的应用程序相关。 - pipelining(
max.in.flight.requests.per.connection) - pipelining 意味着在收到对上一个请求的响应前发送更多请求。通常,更多流水线意味着更好的吞吐量,最高是一个阈值,达到其他效果(例如更糟糕的批处理)开始消除对吞吐量的影响。
降低延迟
当您的应用程序调用 KafkaProducer.send() 时,消息为:
- 由任何拦截器处理
- serialized
- 分配给分区
- 已压缩
- 添加到每个分区队列中的批量消息
send() 方法返回的时间点。因此, send() 的时间由以下方法决定:
- 拦截器、序列程序和分区器花费的时间
- 使用的压缩算法
- 等待缓冲区用于压缩所需的时间
批处理将保留在队列中,直到出现以下情况之一:
-
批处理已满(根据
batch.size) -
linger
.ms引入的延迟已过 - 发送方即将向同一代理发送其他分区的消息批处理,也可以添加此批处理
- 生产者被清空或关闭
查看批处理和缓冲的配置,以减轻 send() 阻止对延迟的影响。
# ... linger.ms=100 1 batch.size=16384 2 buffer.memory=33554432 3 # ...
增加吞吐量
通过调整消息传输和完成发送请求前等待的最长时间,提高消息请求的吞吐量。
您还可以通过编写自定义分区程序来替换默认分区,将消息定向到指定分区。
# ... delivery.timeout.ms=120000 1 partitioner.class=my-custom-partitioner 2 # ...
12.4.2. Kafka 使用者配置调整
使用基本使用者配置,以及根据特定用例量身定制的可选属性。
调优您的消费者时,您的主要顾虑是确保它们能高效地应对被窃取的数据量。与制作者调优一样,准备好进行增量更改,直到消费者按预期工作。
12.4.2.1. 基本使用者配置
每个消费者都需要连接和反序列化器属性。通常,最好添加客户端 ID 进行跟踪。
在使用者配置中,无论后续配置如何:
- 消费者从给定的偏移获取并按顺序使用消息,除非偏差被更改为跳过或重新读取消息。
- 代理不知道消费者是否处理了响应,即使对 Kafka 提交偏移也是如此,因为偏移可能会发送到集群中的不同代理。
# ... bootstrap.servers=localhost:9092 1 key.deserializer=org.apache.kafka.common.serialization.StringDeserializer 2 value.deserializer=org.apache.kafka.common.serialization.StringDeserializer 3 client.id=my-client 4 group.id=my-group-id 5 # ...
- 1
- (必需)告诉使用者使用 Kafka 代理的 host:port bootstrap 服务器地址连接到 Kafka 集群。使用者使用该地址来发现并连接到集群中的所有代理。在服务器停机时使用逗号分隔列表来指定两个或三个地址,但不需要提供集群中所有代理的列表。如果您使用负载均衡器服务公开 Kafka 集群,则只需要该服务的地址,因为负载均衡器处理其可用性。
- 2
- (必需)Deserializer 将从 Kafka 代理获取的字节转换为消息密钥。
- 3
- (必需)Deserializer 将从 Kafka 代理获取的字节转换为消息值。
- 4
- (可选)客户端的逻辑名称,用于日志和指标来标识请求的来源。id 也可用于根据处理时间配额对消费者进行限流。
- 5
- (条件) 用户需要 组 ID 才能加入消费者组。
消费者组用于共享通常由多个生产者从给定主题生成的大型数据流。使用 group.id 对消费者进行分组,允许消息分散到不同成员中。
12.4.2.2. 使用消费者组扩展数据消耗
消费者组共享一个由一个或多个生产者从给定主题生成的大型数据流。具有相同 group.id 属性的消费者在同一组中。组中的一个消费者被选为领导,并决定如何将该分区分配给组中的使用者。每个分区只能分配给一个消费者。
如果您还没有足够的消费者作为分区,可以通过添加具有相同 group.id 的更多消费者实例来扩展数据消耗。将更多的消费者添加到组中,超过现有分区,但这意味着如果一个分区停止工作,就表示待机使用者处于待机状态。如果您能够以更少的消费者达到吞吐量目标,就可以节省资源。
同一消费者组中的消费者发送偏移提交和心跳到同一代理。因此组中的消费者数量越多,代理上的请求负载就越大。
# ...
group.id=my-group-id 1
# ...- 1
- 使用组 ID 将使用者添加到消费者组中。
12.4.2.3. 消息排序保证
Kafka 代理从客户接收请求,要求代理从主题、分区和偏移位置列表中发送消息。
用户会按照提交至代理的顺序以单个分区中观察消息,这意味着 Kafka 仅在 单一分区中为消息提供排序保证。相反,如果消费者使用来自多个分区的消息,则使用者观察到的不同分区中消息的顺序不一定反映它们的发送顺序。
如果您需要严格排序一个主题的消息,请为每个使用者使用一个分区。
12.4.2.4. 优化吞吐量和延迟
控制客户端应用调用 KafkaConsumer.poll() 时返回的消息数量。
使用 fetch.max.wait.ms 和 fetch.min.bytes 属性来增加消费者从 Kafka 代理获取的最小数据量。基于时间的批处理使用 fetch.max.wait.ms 配置,而基于大小的批处理则使用 fetch.min.bytes 配置。
如果消费者或代理中的 CPU 使用率较高,则可能是因为消费者的请求太多。您可以调整 fetch.max.wait.ms 和 fetch.min.bytes 属性,以便在较大的批处理中发送请求和消息。通过调整较高的吞吐量,可以降低延迟成本。如果产生的数据量较低,您也可以调整更高的值。
例如,如果您将 fetch.max.wait.ms 设置为 500ms,并且 fetch.min.bytes 设为 16384 字节,则当 Kafka 收到来自消费者的获取请求时,它将在达到任一阈值的第一个阈值时做出响应。
相反,您可以调整 fetch.max.wait.ms 和 fetch.min.bytes 属性来降低端到端延迟。
# ... fetch.max.wait.ms=500 1 fetch.min.bytes=16384 2 # ...
通过增大获取请求大小来降低延迟
使用 fetch.max.bytes 和 max.partition.fetch.bytes 属性来增加消费者从 Kafka 代理获取的最大数据量。
fetch.max.bytes 属性设置一次从代理获取的数据量上限,以字节为单位。
max.partition.fetch.bytes 设置每个分区返回的数据量的最大字节数,必须始终大于 broker 或 max.message.bytes 配置中设置的字节数。
客户端可消耗的最大内存量计算如下:
NUMBER-OF-BROKERS * fetch.max.bytes and NUMBER-OF-PARTITIONS * max.partition.fetch.bytes
如果内存用量可以容纳它,您可以增加这两个属性的值。通过在每个请求中允许更多数据,可以提高延迟,因为获取请求的数量较少。
# ... fetch.max.bytes=52428800 1 max.partition.fetch.bytes=1048576 2 # ...
12.4.2.5. 在提交偏移时避免数据丢失或重复
Kafka 自动提交机制 允许使用者自动提交消息偏移。如果启用,消费者将以 5000ms 间隔提交从轮询代理收到的偏移。
自动提交机制很方便,但会带来数据丢失和复制风险。如果使用者已获取并转换了大量消息,但执行自动提交时,系统会对消费者缓冲区中已处理的消息崩溃,该数据将会丢失。如果系统在处理消息后崩溃,但在执行自动使用前,数据会在重新平衡后在另一个消费者实例上重复。
仅当在下一次轮询到代理或消费者关闭之前处理所有消息时,自动使用才可以避免数据丢失。
为最大程度减少数据丢失或重复的可能性,您可以将 enable.auto.commit 设置为 false,并开发客户端应用程序,使其对提交的偏移拥有更多控制权。或者,您可以使用 auto.commit.interval.ms 减少提交之间的间隔。
# ...
enable.auto.commit=false 1
# ...- 1
- 自动提交设为 false,以提供对提交偏移的更多控制。
通过将 enable.auto.commit 设置为 false,您可以在执行了 所有 处理并且消息已被使用后提交偏移。例如,您可以将应用程序设置为调用 Kafka commitSync 和 commit Async 提交 API。
commitSync API 在从轮询返回的消息批处理中提交偏移。完成批处理中的所有消息后,您将调用 API。如果使用 commitSync API,则应用不会轮询新消息,直到提交批处理中的最后一个偏移。如果这会对吞吐量造成负面影响,您可以降低提交的频率,也可以使用 commitAsync API。commitAsync API 不等待代理响应提交请求,但可能会在重新平衡时造成更多的重复。种常见的做法是将应用中的两个提交 API 与刚才在关闭使用者或重新平衡之前使用的 commitSync API 相结合,以确保最终提交成功。
12.4.2.5.1. 控制事务性消息
考虑在制作者一侧使用事务 id 和启用幂等性(enable.idempotence=true)来保证准确交付。在消费者方面,您可以使用 isolated .level 属性来控制消费者如何读取事务性消息。
isolated .level 属性有两个有效值:
-
read_committed -
read_uncomcommit(默认)
使用 read_comsigned 来确保 只有提交的事务消息会被使用者读取。但是,这会导致端到端延迟增加,因为在代理写入了记录事务结果的事务标记(已承诺 或中止)之前,消费者将无法返回消息 。
# ...
enable.auto.commit=false
isolation.level=read_committed 1
# ...- 1
- 设置为
read_comcommit,以使使用者只读取提交的邮件。
12.4.2.6. 从失败中恢复,以避免数据丢失
使用 session.timeout.ms 和 heartbeat.interval.ms 属性配置时间,以检查并从消费者组中的消费者故障中恢复。
session.timeout.ms 属性指定使用者组中用户的最大时间(毫秒)可以不与代理联系,然后才能被视为不活动,并在组中的活动消费者之间触发 重新平衡。当组重新平衡时,这些分区将重新分配给组的成员。
heartbeat.interval.m s 属性指定 心跳 互相检查之间的间隔,以毫秒为单位表示消费者活跃并连接。heartbeat 间隔必须小于会话超时间隔,通常为第三个。
如果您将 session.timeout.ms 属性设置为 less,则之前检测到失败消费者,并且重新平衡可以更快地进行。但是,请不要设置超时时间,以便代理无法及时收到心跳,并触发不必要的重新平衡。
减少心跳间隔降低了意外重新平衡的可能性,但更频繁的心跳会增加对代理资源的开销。
12.4.2.7. 管理偏移策略
使用 auto.offset.reset 属性控制消费者在未提交偏移时的行为方式,或者不再有效或删除已提交的偏移。
假设您第一次部署使用者应用,并且它从现有主题读取消息。由于这是第一次使用 group.id 时,__consumer_offsets 主题不包含此应用的任何偏移信息。新应用可以从日志开始时开始处理所有现有消息,或者仅处理新消息。默认重置值为 latest,它从分区末尾开始,因此表示丢失了一些消息。为避免数据丢失,但会增加处理量,请将 auto.offset.reset 设置为从分区 开始时开始。
另请考虑使用 early 选项 避免在为代理配置的偏移保留周期(偏移.retention.分钟)终止时丢失信息。如果消费者组或独立消费者不活跃,且在保留周期内未提交偏移,则之前提交的偏移会从 __consumer_offset 中删除。
# ... heartbeat.interval.ms=3000 1 session.timeout.ms=10000 2 auto.offset.reset=earliest 3 # ...
如果单个获取请求中返回的数据量较大,则使用者处理数据之前可能会发生超时。在这种情况下,您可以降低 max.partition.fetch.bytes 或增加 session.timeout.ms。
12.4.2.8. 最小化重新平衡的影响
在组中活跃使用者之间重新平衡分区是以下时间:
- 消费者提交偏移
- 要成立的新消费者组
- 将分区分配给组成员的组领导
- 组中的消费者接收其分配并开始获取
显然,这个过程会增加服务的停机时间,特别是在客户组群集滚动重启期间重复发生时。
在这种情况下,您可以使用 静态成员资格 的概念来减少重新平衡的数量。重新平衡使用者组成员之间均匀分配主题分区。静态成员资格使用持久性,以便在会话超时后在重启期间识别使用者实例。
用户组协调可以使用使用 group. instance.id 属性指定的唯一 id 来识别新的消费者实例。在重启期间,会为消费者分配一个新成员 ID,但作为静态成员,它将继续使用相同的实例 ID,并分配相同的主题分区。
如果使用者应用程序至少没有调用每个 max.poll.interval.ms 毫秒,则消费者将被视为失败,从而导致重新平衡。如果应用无法及时处理轮询返回的所有记录,您可以使用 max.poll.interval.ms 属性来指定来自消费者的新消息轮询间隔(以毫秒为单位)。或者,您可以使用 max.poll.records 属性设置从消费者缓冲区返回的记录数上限,允许您的应用程序处理 max.poll.interval.ms 限制内的记录数量。
# ... group.instance.id=UNIQUE-ID 1 max.poll.interval.ms=300000 2 max.poll.records=500 3 # ...
12.5. 卸载 AMQ 流
此流程描述了如何卸载 AMQ Streams 并删除与部署相关的资源。
先决条件
要执行此步骤,请识别专门为部署创建的资源,并从 AMQ Streams 资源引用。
此类资源包括:
- secret(Custom CA 和证书、Kafka Connect secret 和其他 Kafka secret)
-
日志记录
ConfigMap(类型为外部)
这些是 Kafka、Kafka Connect、、KafkaConnect S2IKafkaMirrorMaker 或 KafkaBridge 配置引用的资源。
步骤
删除 Cluster Operator
Deployment、相关的CustomResourceDefinition 和RBAC资源:oc delete -f install/cluster-operator
警告删除
CustomResourceDefinitions会导致相应自定义资源(Kafka、KafkaConnect、KafkaConnectS2I、KafkaMirrorMaker 或 KafkaBridge)的垃圾回收以及依赖它们的资源(Deployments、StatefulSets 和其他依赖资源)的垃圾回收。- 删除您在先决条件中确定的资源。
附录 A. 常见问题解答
附录 B. 自定义资源 API 参考
B.1. 常见配置属性
常见配置属性应用到多个资源。
B.1.1. replicas
使用 replicas 属性来配置副本。
复制的类型取决于资源。
-
KafkaTopic使用复制因子配置 Kafka 集群中每个分区的副本数。 - Kafka 组件使用副本来配置部署中的 pod 数量,以提供更好的可用性和可扩展性。
在 OpenShift 上运行 Kafka 组件时,可能不需要运行多个副本来获取高可用性。当部署组件的节点崩溃时,OpenShift 将自动将 Kafka 组件容器集重新调度到其他节点。但是,运行带有多个副本的 Kafka 组件可能会提供更快的故障转移时间,因为其他节点将会启动并运行。
B.1.2. bootstrapServers
使用 bootstrapServers 属性来配置 bootstrap 服务器列表。
bootstrap 服务器列表可以引用未在同一 OpenShift 集群中部署的 Kafka 集群。它们还可以引用 AMQ Streams 未部署的 Kafka 集群。
如果在同一 OpenShift 集群中,每个列表必须理想包含名为 CLUSTER-NAME -kafka-bootstrap 和端口号的 Kafka 集群 bootstrap 服务。如果由 AMQ Streams 部署,但在不同的 OpenShift 集群上,列表内容取决于用于公开集群(路由、节点端口或负载均衡器)的方法。
当在由 AMQ Streams 管理的 Kafka 集群中使用 Kafka 时,您可以根据给定集群的配置指定 bootstrap 服务器列表。
B.1.3. ssl
使用三个允许的 ssl 配置选项,将特定的 密码套件 用于 TLS 版本。密码套件组合了用于安全连接和数据传输的算法。
您还可以配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
SSL 配置示例
# ...
spec:
config:
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" 1
ssl.enabled.protocols: "TLSv1.2" 2
ssl.protocol: "TLSv1.2" 3
ssl.endpoint.identification.algorithm: HTTPS 4
# ...
B.1.4. trustedCertificates
通过 set tls 配置 TLS 加密,请使用 trustedCertificates 属性提供带有密钥名称的 secret 列表,并在其中以 X.509 格式存储证书。
您可以使用 Cluster Operator 为 Kafka 集群创建的 secret,或者创建自己的 TLS 证书文件,然后从文件创建 Secret :
oc create secret generic MY-SECRET \ --from-file=MY-TLS-CERTIFICATE-FILE.crt
TLS 加密配置示例
tls:
trustedCertificates:
- secretName: my-cluster-cluster-cert
certificate: ca.crt
- secretName: my-cluster-cluster-cert
certificate: ca2.crt
如果证书存储在同一个 secret 中,则可以多次列出证书。
如果要启用 TLS,但使用 Java 附带的默认公共证书颁发机构集合,您可以将 trustedCertificates 指定为空数组:
使用默认 Java 证书启用 TLS 示例
tls: trustedCertificates: []
有关配置 TLS 客户端身份验证的详情,请参考 KafkaClientAuthenticationTls schema 参考。
B.1.5. 资源
您可以为组件请求 CPU 和内存资源。limits 指定给定容器可以消耗的最大资源。
在 Kafka 资源中设置 Topic Operator 和 User Operator 的资源请求和限值。
使用 reources.requests 和 resources.limits 属性来配置资源请求和限值。
对于每个部署的容器,AMQ Streams 允许您请求特定资源并定义这些资源的最大消耗。
AMQ Streams 支持以下资源类型的请求和限值:
-
cpu -
memory
AMQ Streams 使用 OpenShift 语法来指定这些资源。
有关在 OpenShift 中管理计算资源的更多信息,请参阅为容器管理计算资源。
资源请求
请求指定要为给定容器保留的资源。保留资源可确保资源始终可用。
如果资源请求针对的是 OpenShift 集群中可用的可用资源,则不会调度该容器集。
可以为一个或多个支持的资源配置请求。
资源限值
limits 指定给定容器可以消耗的最大资源。限制不是保留的,可能并不总是可用。容器只能在资源可用时才使用资源限制。资源限制应始终大于资源请求。
资源可以被配置为一个或多个支持的限制。
支持的 CPU 格式
支持 CPU 请求和限制,其格式如下:
-
CPU 内核数作为整数(
5个 CPU 内核)或十进制(2.5个 CPU 内核)。 -
数字或 millicpus / millicores(
100m),其中 1000 millicores 相同1 个CPU 内核。
1 个 CPU 核心的计算能力可能因部署 OpenShift 的平台而异。
有关 CPU 规格的更多信息,请参阅 CPU 含义。
支持的内存格式
内存请求和限值以兆字节、千兆字节、兆字节和千兆字节为单位指定。
-
要指定内存(以 MB 为单位),请使用
M后缀。例如1000M。 -
要指定以 GB 为单位的内存,请使用
G后缀。例如1G: -
要以兆字节为单位指定内存,请使用
Mi后缀。例如1000Mi。 -
要以千兆字节为单位指定内存,请使用
Gi后缀。例如1Gi。
有关内存规格和其他支持单元的详情,请参阅 内存含义。
B.1.6. 镜像
使用 image 属性配置组件使用的容器镜像。
建议仅在需要使用其他容器 registry 或自定义镜像的特殊情况下覆盖容器镜像。
例如,如果您的网络不允许访问 AMQ Streams 使用的容器存储库,您可以复制 AMQ Streams 镜像或从源构建它们。但是,如果配置的镜像与 AMQ Streams 镜像不兼容,它可能无法正常工作。
也可自定义容器镜像的副本,并用于调试。
您可以使用以下资源中的 image 属性来指定用于组件的容器镜像:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
Kafka.spec.entityOperator.topicOperator -
Kafka.spec.entityOperator.userOperator -
Kafka.spec.entityOperator.tlsSidecar -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaMirrorMaker2.spec -
KafkaBridge.spec
为 Kafka、Kafka Connect 和 Kafka MirrorMaker 配置 镜像 属性
Kafka、Kafka Connect(包括使用 S2I 支持的 Kafka Connect)和 Kafka MirrorMaker 支持多个 Kafka 版本。每个组件都需要自己的映像。在以下环境变量中配置了不同 Kafka 版本的默认镜像:
-
STRIMZI_KAFKA_IMAGES -
STRIMZI_KAFKA_CONNECT_IMAGES -
STRIMZI_KAFKA_CONNECT_S2I_IMAGES -
STRIMZI_KAFKA_MIRROR_MAKER_IMAGES
这些环境变量包含 Kafka 版本及其相应镜像之间的映射。映射与 镜像 和 版本 属性一同使用:
-
如果在自定义资源中未
给出镜像或版本,则版本将默认为 Cluster Operator 的默认 Kafka 版本,且镜像将是环境变量中与此版本对应的镜像。 -
如果为
image提供了版本,则使用给定的镜像,且版本假定为 Cluster Operator 的默认 Kafka 版本。 -
如果提供了
version,但镜像没有指定,则使用与环境变量中给定版本对应的镜像。 -
如果同时给定了
版本和映像,则使用给定的镜像。镜像被假定为包含给定版本的 Kafka 镜像。
可以在以下属性中配置不同组件 的镜像 和 版本 :
-
对于
spec.kafka.image和spec.kafka.version中的 Kafka。 -
对于 Kafka Connect、Kafka Connect S2I 和 Kafka MirrorMaker,在
spec.image和spec.version 中。
建议仅提供 版本,不指定 镜像 属性。这降低了配置自定义资源时出错的机会。如果需要更改用于不同 Kafka 版本的镜像,最好配置 Cluster Operator 的环境变量。
在其他资源中配置 image 属性
对于其他自定义资源中的 image 属性,在部署期间将使用给定值。如果缺少 image 属性,将使用 Cluster Operator 配置中指定的 镜像。如果 Cluster Operator 配置中没有定义 镜像名称,则会使用默认值。
对于主题 Operator:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7container image.
-
在 Cluster Operator 配置中的
对于 User Operator:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_USER_OPERATOR_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7container image.
-
在 Cluster Operator 配置中的
对于实体 Operator TLS sidecar:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7container image.
-
在 Cluster Operator 配置中的
对于 Kafka Exporter:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_KAFKA_EXPORTER_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7container image.
-
在 Cluster Operator 配置中的
对于 Kafka 网桥:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_KAFKA_BRIDGE_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-bridge-rhel7:1.6.7container image.
-
在 Cluster Operator 配置中的
对于 Kafka 代理初始化器:
-
在 Cluster Operator 配置中的
STRIMZI_DEFAULT_KAFKA_INIT_IMAGE环境变量中指定的容器镜像。 -
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7container image.
-
在 Cluster Operator 配置中的
对于 Kafka 代理初始化器:
-
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7container image.
-
容器镜像配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
image: my-org/my-image:latest
# ...
zookeeper:
# ...
B.1.7. livenessProbe 和 readinessProbe 健康检查
使用 livenessProbe 和 readinessProbe 属性来配置 AMQ Streams 中支持的健康检查探测。
健康检查是定期测试,可验证应用的健康状况。当健康检查探测失败时,OpenShift 假定应用不健康,并尝试修复它。
有关探测的详情,请参阅 配置存活度和就绪度探测。
Live nessProbe 和 readinessProbe 均支持以下选项:
-
initialDelaySeconds -
timeoutSeconds -
periodSeconds -
successThreshold -
failureThreshold
存活度和就绪度探测配置示例
# ... readinessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: initialDelaySeconds: 15 timeoutSeconds: 5 # ...
有关 livenessProbe 和 选项的更多信息,请参阅 探测模式参考。
readinessProbe
B.1.8. metrics
使用 metrics 属性来启用和配置 Prometheus 指标。
指标 属性也可以包含 Prometheus JMX 导出器的其他配置。AMQ Streams 支持使用 Prometheus JMX 导出器的 Prometheus 指标将 Apache Kafka 和 ZooKeeper 支持的 JMX 指标转换为 Prometheus 指标。
要在不进一步配置的情况下启用 Prometheus 指标导出,您可以将其设置为空对象({})。
启用指标数据后,它们会在端口 9404 上公开。
当资源中没有定义 metrics 属性时,Prometheus 指标会被禁用。
有关设置和部署 Prometheus 和 Grafana 的更多信息,请参阅 OpenShift 指南中的 Deploying 和 升级 AMQ Streams 中的 介绍 Metrics 到 Kafka。
B.1.9. jvmOptions
可以使用以下资源中的 jvmOptions 属性配置 JVM 选项:
-
Kafka.spec.kafka -
Kafka.spec.zookeeper -
KafkaConnect.spec -
KafkaConnectS2I.spec -
KafkaMirrorMaker.spec -
KafkaMirrorMaker2.spec -
KafkaBridge.spec
只支持以下 JVM 选项:
-Xms- 配置 JVM 启动时的最小初始分配堆大小。
-Xmx- 配置最大堆大小。
JVM 设置(如 -Xmx 和 - Xms) 接受的单元是对应镜像中的 JDK java 二进制文件接受的单元。因此,1g 或 1G 表示 1,073,741,824 字节和 Gi 不是有效的单元后缀。这与用于 内存请求和限值 的单位相反,后者遵循 OpenShift 约定,1G 表示 1,000,000,000 字节,1Gi 表示 1,073,741,824 字节
用于 -Xms 和 -Xmx 的默认值取决于是否有为容器配置的 内存请求 限值。
- 如果有内存限制,JVM 的最小和最大内存将设置为与限值对应的值。
-
如果没有内存限制,JVM 的最小内存将设置为
128M。JVM 的最大内存未定义为允许内存根据需要增加,这非常适合测试和开发环境中的单节点环境。
设置 -Xmx 明确需要注意:
-
JVM 的总内存使用量大约为最大堆的 4 ¹,如
-Xmx配置。 -
如果设置
-Xmx时不设置适当的 OpenShift 内存限值,如果 OpenShift 节点遇到内存压力(来自其上运行的其他 Pod),则容器可能会被终止。 -
如果设置
-Xmx时不设置适当的 OpenShift 内存请求,则容器可能会调度到内存不足的节点。在这种情况下,容器不会启动,而是崩溃(如果-Xms 被设置为,或稍后某个时间(如果不是),则容器不会启动。-Xmx
在明确设置 -Xmx 时,建议您这样做:
- 将内存请求和内存限值设置为相同的值
-
使用至少 4.5 的值请求
-Xmx -
考虑将
-Xms设置为与-Xmx相同的值
容器执行很多磁盘 I/O(如 Kafka 代理容器),需要保留一些内存以用作操作系统页面缓存。在这样的容器中,请求的内存应当显著高于 JVM 使用的内存。
配置 -Xmx 和 -Xms 的片段示例
# ... jvmOptions: "-Xmx": "2g" "-Xms": "2g" # ...
在上例中,JVM 会将 2 GiB(=2,147,483,648 字节)用于其堆。其总内存用量大约为 8GiB。
为初始(-Xms)和最大(-Xmx)堆大小设置相同的值可避免 JVM 启动后分配内存,其代价可能是分配超过真正需要的堆数。对于 Kafka 和 ZooKeeper pod,此类分配可能会导致不必要的延迟。对于 Kafka Connect 避免过度分配,可能是最重要的问题,特别是在分布式模式中,过度分配的效果会乘以消费者的数量。
-server
-server 启用服务器 JVM。这个选项可以设为 true 或 false。
配置 -server的片段示例
# ... jvmOptions: "-server": true # ...
当两个选项(-server 和 - XX)都没有指定时,会使用 KAFKA_JVM_PERFORMANCE_OPTS 的默认 Apache Kafka 配置。
-XX
-XX 对象可用于配置 JVM 的高级运行时选项。server 和 -XX 选项用于配置 Apache Kafka 的 KAFKA_JVM_PERFORMANCE_OPTS 选项。
显示 -XX 对象使用的示例
jvmOptions:
"-XX":
"UseG1GC": true
"MaxGCPauseMillis": 20
"InitiatingHeapOccupancyPercent": 35
"ExplicitGCInvokesConcurrent": true
以上示例配置将导致以下 JVM 选项:
-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:-UseParNewGC
当两个选项(-server 和 - XX)都没有指定时,会使用 KAFKA_JVM_PERFORMANCE_OPTS 的默认 Apache Kafka 配置。
B.1.10. 垃圾收集器日志记录
jvmOptions 属性还允许您启用和禁用垃圾收集器(GC)日志记录。默认禁用 GC 日志。要启用它,请按如下方式设置 gcLoggingEnabled 属性:
启用 GC 日志示例
# ... jvmOptions: gcLoggingEnabled: true # ...
B.2. Kafka 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka 和 ZooKeeper 集群和 Topic Operator 的规格。 |
| status | Kafka 和 ZooKeeper 集群和 Topic Operator 的状态。 |
B.3. KafkaSpec 模式参考
用于:kafka
| 属性 | 描述 |
|---|---|
| kafka | Kafka 集群的配置。 |
| zookeeper | ZooKeeper 集群的配置. |
| topicOperator |
属性 |
| entityOperator | 配置实体 Operator. |
| clusterCa | 集群证书颁发机构配置。 |
| clientsCa | 客户端证书颁发机构的配置。 |
| cruiseControl | 清理控制部署的配置.在指定时部署 Cruise Control 实例。 |
| kafkaExporter | 配置 Kafka 导出器.Kafka Exporter 可以提供附加指标,例如主题/分区上消费者组的滞后。 |
| maintenanceTimeWindows | 用于维护任务的时间窗列表(即证书续订)。每次由 cron 表达式定义时窗口. |
| 字符串数组 |
B.4. KafkaClusterSpec 模式参考
用于:KafkaSpec
配置 Kafka 集群。
B.4.1. 监听程序
使用 listens 属性 配置监听程序,以提供对 Kafka 代理的访问。
无需身份验证的普通(未加密)侦听器配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
kafka:
# ...
listeners:
- name: plain
port: 9092
type: internal
tls: false
# ...
zookeeper:
# ...
B.4.2. config
使用 配置 属性将 Kafka 代理配置为带有以下 JSON 类型值之一的密钥:
- 字符串
- 数字
- 布尔值
您可以指定并配置 Apache Kafka 文档中的 "Broker Configs"部分中除由 AMQ Streams 直接管理的选项之外的所有选项。具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
监听程序 -
已公告. -
broker. -
listener. -
host.name -
端口 -
inter.broker.listener.name -
SASL. -
ssl. -
安全性. -
password. -
principal.builder.class -
log.dir -
zookeeper.connect -
zookeeper.set.acl -
authorizer. -
super.user
当 config 属性中存在禁止选项时,会忽略它,并把警告信息输出到 Cluster Operator 日志文件中。所有其他支持的选项都传递给 Kafka。
禁止的选项有例外。对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。您还可以配置 zookeeper.connection.timeout.ms 属性,以设置建立 ZooKeeper 连接的最长时间。
Kafka 代理配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
# ...
config:
num.partitions: 1
num.recovery.threads.per.data.dir: 1
default.replication.factor: 3
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 1
log.retention.hours: 168
log.segment.bytes: 1073741824
log.retention.check.interval.ms: 300000
num.network.threads: 3
num.io.threads: 8
socket.send.buffer.bytes: 102400
socket.receive.buffer.bytes: 102400
socket.request.max.bytes: 104857600
group.initial.rebalance.delay.ms: 0
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
zookeeper.connection.timeout.ms: 6000
# ...
| 属性 | 描述 |
|---|---|
| replicas | 集群中的 pod 数量。 |
| 整数 | |
| 镜像 |
容器集的 docker 镜像。默认值为配置的 |
| 字符串 | |
| storage |
存储配置(磁盘)。无法更新。类型取决于给定对象中 |
| 监听程序 | 配置 Kafka 代理的监听程序。 |
| 授权 |
Kafka 代理的授权配置。类型取决于给定对象中的 |
|
| |
| config | 无法设置带有以下前缀的 Kafka 代理配置属性:监听器、公告的.、代理.、监听器.、host.name、端口、inter.broker.listener.name、sasl.、ssl.、security.、security.builder.class、log.dir、zookeeper.connect、zookeeper.set.acl、 zookeeper.ssl, zookeeper.clientCnxnSocket, authorizer., super.user, cruise.control.metrics.topic, cruise.control.metrics.reporter.bootstrap.servers(以下除外: zookeeper.connection.timeout.ms, ssl.cipher.suites, SSL.protocol, ssl.enabled.protocols,cruise.control.metrics.topic.num.partitions, cruise.control.metrics.topic.replication.factor, cruise.control.metrics.topic.retention.ms,cruise.control.metrics.topic.auto.create.reries, cruise.control.metrics.topic.auto.create.timeout.ms。 |
| map | |
| rack |
配置 |
| brokerRackInitImage |
用于初始化 |
| 字符串 | |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| jvmOptions | 容器集的 JVM 选项. |
| jmxOptions | Kafka 代理的 JMX 选项. |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map | |
| logging |
Kafka 的日志配置。类型取决于给定对象中的 |
| tlsSidecar |
attribute |
| 模板 |
Kafka 集群资源的模板。该模板允许用户指定 |
| version | kafka 代理版本。默认值为 2.6.0。请参阅用户文档以了解升级或降级版本所需的流程。 |
| 字符串 |
B.5. EphemeralStorage 架构参考
用于:JbodStorage, KafkaClusterSpec, ZookeeperClusterSpec
type 属性是一个识别器,它区分了 type EphemeralStorage 的使用。它必须具有 和 PersistentClaimStorage type EphemeralStorage 的值。
| 属性 | 描述 |
|---|---|
| id | 存储标识号.仅对类型为 'jbod" 的存储中定义的存储卷才强制使用。 |
| 整数 | |
| sizeLimit | 当 type=ephemeral 时,定义此 EmptyDir 卷所需的本地存储总量(例如 1Gi)。 |
| 字符串 | |
| type |
必须 |
| 字符串 |
B.6. PersistentClaimStorage 架构参考
用于:JbodStorage, KafkaClusterSpec, ZookeeperClusterSpec
type 属性是一个缺点,它区分 PersistentClaimStorage 和 的使用。它必须具有类型 EphemeralStorage PersistentClaimStorage 的值 persistent-claim。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| Size | 当 type=persistent-claim 时,定义持久性卷声明的大小(如 1Gi)。type=persistent-claim 时是必需的. |
| 字符串 | |
| selector | 指定要使用的特定持久性卷。它包含键:值对,代表用于选择此类卷的标签。 |
| map | |
| deleteClaim | 指定在取消部署集群时是否需要删除持久性卷声明。 |
| 布尔值 | |
| class | 用于动态卷分配的存储类。 |
| 字符串 | |
| id | 存储标识号.仅对类型为 'jbod" 的存储中定义的存储卷才强制使用。 |
| 整数 | |
| overrides |
覆盖单个代理. |
B.7. PersistentClaimStorageOverride 模式参考
| 属性 | 描述 |
|---|---|
| class | 用于这个代理的动态卷分配的存储类。 |
| 字符串 | |
| broker | kafka 代理的 ID(代理标识符)。 |
| 整数 |
B.8. JbodStorage schema reference
type 属性是一个缺点,它区分 JbodStorage 和 的使用。它必须具有类型 EphemeralStorage、PersistentClaimStorage Jbo 。
dStorage 的值 jbo d
| 属性 | 描述 |
|---|---|
| type |
必须为 |
| 字符串 | |
| 卷 | 作为代表 JBOD 磁盘阵列的存储对象的卷列表。 |
B.9. GenericKafkaListener 模式参考
配置监听程序以连接到 OpenShift 内部和外部的 Kafka 代理。
您可以在 Kafka 资源中配置监听程序。
显示监听器配置的 Kafka 资源示例
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
#...
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external1
port: 9094
type: route
tls: true
- name: external2
port: 9095
type: ingress
tls: false
authentication:
type: tls
configuration:
bootstrap:
host: bootstrap.myingress.com
brokers:
- broker: 0
host: broker-0.myingress.com
- broker: 1
host: broker-1.myingress.com
- broker: 2
host: broker-2.myingress.com
#...
B.9.1. 监听程序
您可以使用 Kafka 资源中的 listens 属性配置 Kafka 代理 监听程序。侦听器定义为数组。
监听程序配置示例
listeners:
- name: plain
port: 9092
type: internal
tls: false
Kafka 集群中的名称和端口必须是唯一的。名称最多可包含 25 个字符,包含小写字母和数字。允许的端口号是 9092 及以上,但端口 9404 和 9999 除外,它们已用于 Prometheus 和 JMX。
通过为每个监听器指定唯一的名称和端口,您可以配置多个监听器。
B.9.2. type
该类型设置为 internal,或针对外部监听器,作为 路由、loadbalancer、nodeport 或 ingress。
- internal
您可以使用
tls属性使用或不加密配置内部监听程序。内部监听程序配置示例#... spec: kafka: #... listeners: #... - name: plain port: 9092 type: internal tls: false - name: tls port: 9093 type: internal tls: true authentication: type: tls #...- route
配置外部侦听器以使用 OpenShift
Route和 HAProxy 路由器公开 Kafka。为每个 Kafka 代理 pod 创建一个专用
路由。创建一个额外的Route来充当 Kafka bootstrap 地址。Kafka 客户端可以使用这些路由连接端口 443 上的 Kafka。客户端在端口 443(默认路由器端口)上连接,但流量将路由到您配置的端口,本例中为9094。路由监听程序配置示例#... spec: kafka: #... listeners: #... - name: external1 port: 9094 type: route tls: true #...- ingress
配置一个外部监听程序以使用 Kubernetes
Ingress和 Kubernetes 的 NGINX Ingress Controller 公开 Kafka。为每个 Kafka 代理 Pod 创建一个专用的
Ingress资源。创建一个额外的Ingress资源来充当 Kafka bootstrap 地址。Kafka 客户端可以使用这些Ingress资源连接到端口 443 上的 Kafka。客户端在端口 443(默认控制器端口)上连接,但流量会路由到您配置的端口,以下示例中是9095。您必须使用 GenericKafkaListenerConfigurationBootstrap 和
GenericKafkaListenerConfigurationBroker 属性指定 bootstrap 和每个broker 服务使用的主机名。ingress侦听器配置示例#... spec: kafka: #... listeners: #... - name: external2 port: 9095 type: ingress tls: false authentication: type: tls configuration: bootstrap: host: bootstrap.myingress.com brokers: - broker: 0 host: broker-0.myingress.com - broker: 1 host: broker-1.myingress.com - broker: 2 host: broker-2.myingress.com #...注意使用
Ingress的外部监听程序目前只使用 Kubernetes 的 NGINX Ingress Controller 测试。- LoadBalancer
配置一个外部监听程序来公开 Kafka
Loadbalancer类型服务。为每个 Kafka 代理 pod 创建一个新的负载均衡器服务。创建一个额外的负载均衡器来充当 Kafka bootstrap 地址。Loadbalancers 侦听指定的端口号,以下示例中是端口
9094。您可以使用
loadBalancerSourceRanges属性配置 源范围,以限制对指定 IP 地址的访问。loadbalancer侦听器配置示例#... spec: kafka: #... listeners: - name: external3 port: 9094 type: loadbalancer tls: true configuration: loadBalancerSourceRanges: - 10.0.0.0/8 - 88.208.76.87/32 #...- NodePort
配置外部侦听器以使用
NodePort类型服务公开 Kafka。Kafka 客户端直接连接到 OpenShift 节点。创建额外的
NodePort类型服务作为 Kafka bootstrap 地址。在为 Kafka 代理 Pod 配置公告的地址时,AMQ Streams 使用运行给定 pod 的节点的地址。您可以使用
preferredNodePortAddressType属性配置 第一个地址类型作为节点地址检查。nodeport侦听器配置示例#... spec: kafka: #... listeners: #... - name: external4 port: 9095 type: nodeport tls: false configuration: preferredNodePortAddressType: InternalDNS #...注意在使用节点端口公开 Kafka 集群时,当前不支持 TLS 主机名验证。
B.9.3. 端口
端口号是 Kafka 集群中使用的端口,它可能不是客户端用于访问的端口。
-
LoadBalancer 侦听器使用指定的端口号,如内部监听器一样 -
Ingress和路由监听器使用端口 443 访问 -
NodePort侦听器使用 OpenShift 分配的端口号
对于客户端连接,请使用监听器的 bootstrap 服务的地址和端口。您可以从 Kafka 资源的状态检索它。
检索客户端连接的地址和端口的命令示例
oc get kafka KAFKA-CLUSTER-NAME -o=jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}{"\n"}'
无法将监听器配置为使用为 Interbroker 通信(9091)和指标(9404)设置的端口。
B.9.4. tls
TLS 属性是必需的。
默认情况下不启用 TLS 加密。要启用它,请将 tls 属性设置为 true。
TLS 加密始终与 路由 监听程序一起使用。
B.9.5. 身份验证
监听器的身份验证可指定为:
-
双向 TLS(
tls) -
SCRAM-SHA-512 (
scram-sha-512) -
基于令牌的 OAuth 2.0(
oauth)。
B.9.6. networkPolicyPeers
使用 networkPolicyPeers 配置网络策略,以限制对网络级别的监听器的访问。以下示例显示了用于 普通 和 a tls 侦听器的 networkPolicyPeers 配置。
listeners:
#...
- name: plain
port: 9092
type: internal
tls: true
authentication:
type: scram-sha-512
networkPolicyPeers:
- podSelector:
matchLabels:
app: kafka-sasl-consumer
- podSelector:
matchLabels:
app: kafka-sasl-producer
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
networkPolicyPeers:
- namespaceSelector:
matchLabels:
project: myproject
- namespaceSelector:
matchLabels:
project: myproject2
# ...在这个示例中:
-
只有与标签
app: kafka-sasl-consumer和app: kafka-sasl-producer匹配的应用程序 pod 可以连接到普通的监听程序。应用程序 pod 必须与 Kafka 代理在同一命名空间中运行。 -
只有命名空间中运行的应用容器集与 labels
项目匹配:myproject 和 project:myproject2可以连接到tls侦听器。
networkPolicyPeers 字段的语法与 NetworkPolicy 资源中的 from 字段相同。
与 KafkaListeners 的向后兼容性
GenericKafkaListener 替换 KafkaListeners 模式,它已过时。
要使用 KafkaListeners 模式配置的监听程序转换为 GenericKafkaListener 模式的格式,且向后兼容,请使用以下名称、端口和类型:
listeners:
#...
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: EXTERNAL-LISTENER-TYPE 1
tls: true
# ...- 1
- 选项:
入口、负载均衡器、节点端口、路由
| 属性 | 描述 |
|---|---|
| name | 侦听器的名称。名称将用于识别侦听器和相关 OpenShift 对象。该名称必须在给定的 Kafka 集群内唯一。名称可以包含小写字符和数字,并且最多可包含 11 个字符。 |
| 字符串 | |
| 端口 | Kafka 内侦听器使用的端口号。在给定 Kafka 集群中,端口号必须是唯一的。允许的端口号是 9092 及以上,但端口 9404 和 9999 除外,它们已用于 Prometheus 和 JMX。根据监听程序类型,端口号可能与连接 Kafka 客户端的端口号不同。 |
| 整数 | |
| type |
侦听器的类型。目前支持的类型有
* |
| 字符串([ingress、internal、route、loadbalancer、nodeport] 之一) | |
| tls | 在监听器上启用 TLS 加密。这是必填属性。 |
| 布尔值 | |
| 身份验证 |
此侦听器的身份验证配置.这个类型取决于给定对象中的 |
|
| |
| 配置 | 其他监听器配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
B.10. KafkaListenerAuthenticationTls 模式参考
用于:GenericKafkaListener, KafkaListenerExternalIngress, KafkaListenerExternalLoadBalancer, KafkaListenerExternalNodePort, KafkaListenerExternalRoute, KafkaListenerPlain, KafkaListenerTls
type 属性是一个光盘,它区分使用 KafkaListenerAuthenticationTls 和 KafkaListenerAuthenticationScramSha512, KafkaListenerAuthenticationOAuth。它必须具有类型 KafkaListenerAuthenticationTls 的值 tls。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 |
B.11. KafkaListenerAuthenticationScramSha512 schema reference
用于:GenericKafkaListener, KafkaListenerExternalIngress, KafkaListenerExternalLoadBalancer, KafkaListenerExternalNodePort, KafkaListenerExternalRoute, KafkaListenerPlain, KafkaListenerTls
type 属性是一个光盘,它区分使用 KafkaListenerAuthenticationScramSha512 和 KafkaListenerAuthenticationTls、KafkaListenerAuthenticationOAuth。它必须具有类型 KafkaListenerAuthenticationScramSha512 的值 scr am-sha-512。
| 属性 | 描述 |
|---|---|
| type |
必须是 scr |
| 字符串 |
B.12. KafkaListenerAuthenticationOAuth 模式参考
用于:GenericKafkaListener, KafkaListenerExternalIngress, KafkaListenerExternalLoadBalancer, KafkaListenerExternalNodePort, KafkaListenerExternalRoute, KafkaListenerPlain, KafkaListenerTls
type 属性是一个光盘,它区分使用 KafkaListenerAuthenticationOAuth 类型与 KafkaListenerAuthenticationTls、KafkaListenerAuthenticationScramSha512。它必须具有类型 KafkaListenerAuthenticationOAuth 的值 oauth。
| 属性 | 描述 |
|---|---|
| accessTokenIsJwt |
配置访问令牌是否被视为 JWT。如果授权服务器返回不透明令牌,则必须将此设置为 |
| 布尔值 | |
| checkAccessTokenType |
配置是否执行访问令牌类型检查。如果授权服务器在 JWT 令牌中不包含 'typ' 声明,这应当设为 |
| 布尔值 | |
| checkIssuer |
启用或禁用签发者检查。默认情况下,使用 |
| 布尔值 | |
| clientId | Kafka 代理可用于向授权服务器进行身份验证并使用内省端点 URI 的 OAuth 客户端 ID。 |
| 字符串 | |
| clientSecret | 到包含 OAuth 客户端机密的 OpenShift Secret 的链接,Kafka 代理可使用该 secret 与授权服务器进行身份验证并使用内省端点 URI。 |
| disableTlsHostnameVerification |
启用或禁用 TLS 主机名验证。默认值为 |
| 布尔值 | |
| enableECDSA |
通过安装 BouncyCastle 加密提供程序来启用或禁用 ECDSA 支持。默认值为 |
| 布尔值 | |
| fallbackUserNameClaim |
如果 |
| 字符串 | |
| fallbackUserNamePrefix |
与 |
| 字符串 | |
| introspectionEndpointUri | 令牌内省端点的 URI,可用于验证不透明非 JWT 令牌。 |
| 字符串 | |
| jwksEndpointUri | JWKS 证书端点的 URI,可用于本地 JWT 验证。 |
| 字符串 | |
| jwksExpirySeconds |
配置 JWKS 证书的有效期。到期间隔必须至少为 60 秒,然后 |
| 整数 | |
| jwksMinRefreshPauseSeconds | 连续两次刷新之间的最小暂停。当遇到未知签名密钥时,会立即调度刷新,但会始终等待这一最小暂停。默认值为 1 秒。 |
| 整数 | |
| jwksRefreshSeconds |
配置刷新的 JWKS 证书的频率。刷新间隔必须至少缩短 60 秒,然后 |
| 整数 | |
| maxSecondsWithoutReauthentication | 经过身份验证的会话保持有效的最大秒数,无需重新身份验证。这可启用 Apache Kafka 重新身份验证功能,并使会话在访问令牌过期时过期。如果访问令牌在最长时间前过期,或者达到最大时间,客户端必须重新进行身份验证,否则服务器将丢弃连接。默认情况下不设置 - 经过身份验证的会话不会在访问令牌过期时过期。 |
| 整数 | |
| tlsTrustedCertificates | TLS 连接到 OAuth 服务器的可信证书。 |
| type |
必须是 |
| 字符串 | |
| userInfoEndpointUri | 当内省端点不返回可用于用户 ID 的信息时,用作回退的 User Info Endpoint 的 URI 用于获取用户 ID。 |
| 字符串 | |
| userNameClaim |
来自 JWT 身份验证令牌的声明名称、内省端点响应或用户 Info Endpoint 响应,它们将用于提取用户 ID。默认值为 |
| 字符串 | |
| validIssuerUri | 用于身份验证的令牌签发者的 URI。 |
| 字符串 | |
| validTokenType |
Introspection Endpoint 返回的 |
| 字符串 |
B.13. GenericSecretSource 模式参考
用于:KafkaClientAuthenticationOAuth, KafkaListenerAuthenticationOAuth
| 属性 | 描述 |
|---|---|
| key | 机密值存储在 OpenShift Secret 中的键。 |
| 字符串 | |
| secretName | 包含机密值的 OpenShift Secret 的名称。 |
| 字符串 |
B.14. CertSecretSource 模式参考
用于:KafkaAuthorizationKeycloak, KafkaBridgeTls, KafkaClientAuthenticationOAuth, KafkaConnectTls, KafkaListenerAuthenticationOAuth, KafkaMirrorMaker2Tls, KafkaMirrorMakerTls
| 属性 | 描述 |
|---|---|
| certificate | Secret 中的文件证书的名称。 |
| 字符串 | |
| secretName | 包含证书的 Secret 名称。 |
| 字符串 |
B.15. GenericKafkaListenerConfiguration 模式参考
Kafka 侦听器的配置.
B.15.1. brokerCertChainAndKey
brokerCertChainAndKey 属性仅用于启用了 TLS 加密的监听程序。您可以使用该属性来提供您自己的 Kafka 侦听程序证书。
启用 TLS 加密的负载均衡器 外部监听程序配置示例
listeners:
#...
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: tls
configuration:
brokerCertChainAndKey:
secretName: my-secret
certificate: my-listener-certificate.crt
key: my-listener-key.key
# ...
B.15.2. externalTrafficPolicy
externalTrafficPolicy 属性用于 loadbalancer 和 nodeport 侦听器。在 OpenShift 外部公开 Kafka 时,您可以选择 Local 或 Cluster。local 避免跃点到其他节点并保留客户端 IP,而 群集 则不会。默认值为 Cluster。
B.15.3. loadBalancerSourceRanges
loadBalancerSourceRanges 属性仅用于 负载均衡器侦听器。当在 OpenShift 外部公开 Kafka 时,除了标签和注释外,还会使用源范围来自定义服务的创建方式。
为负载均衡器监听程序配置源范围示例
listeners:
#...
- name: external
port: 9094
type: loadbalancer
tls: false
configuration:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 10.0.0.0/8
- 88.208.76.87/32
# ...
# ...
B.15.4. class
class 属性仅用于 入口 侦听器。
默认情况下,Ingress 类设置为 nginx。您可以使用类属性更改 Ingress 类。
使用 Ingress 类 nginx-internal 类型的 ingress 外部侦听器示例
listeners:
#...
- name: external
port: 9094
type: ingress
tls: false
configuration:
class: nginx-internal
# ...
# ...
B.15.5. preferredNodePortAddressType
preferredNodePortAddressType 属性仅用于 nodeport 监听程序。
使用监听程序配置中的 preferredNodePortAddressType 属性来指定检查为节点地址的第一个地址类型。例如,如果您的部署没有 DNS 支持,或者您只想通过内部 DNS 或 IP 地址公开代理,则此属性很有用。如果找到此类型的地址,则会使用它。如果没有找到首选地址类型,AMQ Streams 会按照标准优先级顺序逐步完成类型:
- ExternalDNS
- ExternalIP
- 主机名
- InternalDNS
- InternalIP
使用首选节点端口地址类型配置的外部监听程序示例
listeners:
#...
- name: external
port: 9094
type: nodeport
tls: false
configuration:
preferredNodePortAddressType: InternalDNS
# ...
# ...
B.15.6. useServiceDnsDomain
useServiceDnsDomain 属性仅用于 内部 监听器。它定义是否使用包含集群服务后缀(通常. cluster.local)的完全限定 DNS 名称。使用ServiceDnsDomain 设置为 false 时,公告的地址在没有服务后缀的情况下生成;例如,my -cluster-kafka-0.my-cluster-kafka-brokers.myproject.svc。使用ServiceDnsDomain 设置为 true 时,公告的地址通过服务后缀生成;例如,my -cluster-kafka-0.my-cluster-kafka-brokers.myproject.svc.cluster.local。默认为 false。
内部监听程序示例配置为使用 Service DNS 域
listeners:
#...
- name: plain
port: 9092
type: internal
tls: false
configuration:
useServiceDnsDomain: true
# ...
# ...
如果您的 OpenShift 集群使用与. cluster.local 不同的服务后缀,您可以在 Cluster Operator 配置中使用 KUBERNETES_SERVICE_DNS_DOMAIN 环境变量来配置后缀。详情请查看 第 5.1.1 节 “Cluster Operator 配置”。
| 属性 | 描述 |
|---|---|
| brokerCertChainAndKey |
引用存放用于此侦听器的证书和私钥的 |
| externalTrafficPolicy |
指定服务将外部流量路由到节点本地或集群范围的端点。 |
| 字符串([本地、集群] 中的一个) | |
| loadBalancerSourceRanges |
CIDR 范围列表(如 |
| 字符串数组 | |
| bootstrap | Bootstrap 配置. |
| 代理 | 按代理配置. |
| class |
配置用于定义将使用哪个 |
| 字符串 | |
| preferredNodePortAddressType |
定义应当将哪种地址类型用作节点地址。可用类型有:
此字段可用于选择将用作首选类型并首先检查的地址类型。如果没有为此地址类型找到地址,则默认顺序中使用其他类型。This 字段只能与 |
| 字符串([外部DNS、ExternalDNS、Hostname、InternalIP、InternalDNS] 之一) | |
| useServiceDnsDomain |
配置 OpenShift 服务 DNS 域是否应该使用。如果设置为 |
| 布尔值 |
B.16. CertAndKeySecretSource 模式参考
用于:GenericKafkaListenerConfiguration、IngressListenerConfiguration、KafkaClientAuthenticationTls、KafkaListenerExternalConfiguration、Node PortListenerConfiguration、TlsListenerConfiguration
| 属性 | 描述 |
|---|---|
| certificate | Secret 中的文件证书的名称。 |
| 字符串 | |
| key | Secret 中的私钥名称。 |
| 字符串 | |
| secretName | 包含证书的 Secret 名称。 |
| 字符串 |
B.17. GenericKafkaListenerConfigurationBootstrap 架构参考
用于:GenericKafkaListenerConfiguration
为外部监听程序配置 bootstrap 服务覆盖。
nodePort、host、loadBalancerIP 和 注解 属性等效的代理服务在 GenericKafkaListenerConfigurationBroker 模式中配置。
B.17.1. alternativeNames
您可以为 bootstrap 服务指定备用名称。名称添加到代理证书中,可用于 TLS 主机名验证。alternativeNames 属性适用于所有类型的外部监听程序。
使用额外 bootstrap 地址配置的外部 路由 监听程序示例
listeners:
#...
- name: external
port: 9094
type: route
tls: true
authentication:
type: tls
configuration:
bootstrap:
alternativeNames:
- example.hostname1
- example.hostname2
# ...
B.17.2. 主机
host 属性与 路由 和 入口 侦听器一起使用,以指定 bootstrap 和每个代理服务使用的主机名。
入口 监听程序配置需要 host 属性值,因为 Ingress 控制器不会自动分配任何主机名。确保主机名解析到 Ingress 端点。AMQ Streams 不会对请求的主机可用并正确路由到 Ingress 端点的任何验证执行任何验证。
入口监听程序的主机配置示例
listeners:
#...
- name: external
port: 9094
type: ingress
tls: true
authentication:
type: tls
configuration:
bootstrap:
host: bootstrap.myingress.com
brokers:
- broker: 0
host: broker-0.myingress.com
- broker: 1
host: broker-1.myingress.com
- broker: 2
host: broker-2.myingress.com
# ...
默认情况下,OpenShift 自动分配路由 侦听器主机。但是,您可以通过指定主机来覆盖分配的路由主机。
AMQ Streams 不执行任何对请求的主机可用的验证。您必须确保它们是免费的,并且可以使用。
路由监听程序的主机配置示例
# ...
listeners:
#...
- name: external
port: 9094
type: route
tls: true
authentication:
type: tls
configuration:
bootstrap:
host: bootstrap.myrouter.com
brokers:
- broker: 0
host: broker-0.myrouter.com
- broker: 1
host: broker-1.myrouter.com
- broker: 2
host: broker-2.myrouter.com
# ...
B.17.3. nodePort
默认情况下,OpenShift 自动分配用于 bootstrap 和代理服务的端口号。您可以通过指定请求的端口号来为 节点端口 监听程序覆盖分配的节点端口。
AMQ Streams 不在请求的端口上执行任何验证。您必须确保它们的免费可用。
使用节点端口覆盖配置的外部监听器示例
# ...
listeners:
#...
- name: external
port: 9094
type: nodeport
tls: true
authentication:
type: tls
configuration:
bootstrap:
nodePort: 32100
brokers:
- broker: 0
nodePort: 32000
- broker: 1
nodePort: 32001
- broker: 2
nodePort: 32002
# ...
B.17.4. loadBalancerIP
在创建负载平衡器时,使用 loadBalancerIP 属性请求特定的 IP 地址。当您需要将负载平衡器与特定 IP 地址搭配使用时,请使用此属性。如果云供应商不支持该功能,则会忽略 loadBalancerIP 字段。
具有特定负载均衡器 IP 地址请求的负载均衡器 类型的外部侦听器示例
# ...
listeners:
#...
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: tls
configuration:
bootstrap:
loadBalancerIP: 172.29.3.10
brokers:
- broker: 0
loadBalancerIP: 172.29.3.1
- broker: 1
loadBalancerIP: 172.29.3.2
- broker: 2
loadBalancerIP: 172.29.3.3
# ...
B.17.5. annotations
使用 annotations 属性向 loadbalancer、nodeport 或 ingress 侦听器添加注解。您可以使用这些注解来检测 DNS 工具,如 外部 DNS,它们会自动为负载均衡器服务分配 DNS 名称。
使用 注解的 loadbalancer 类型的外部侦听器示例
# ...
listeners:
#...
- name: external
port: 9094
type: loadbalancer
tls: true
authentication:
type: tls
configuration:
bootstrap:
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-bootstrap.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
brokers:
- broker: 0
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-0.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 1
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-1.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
- broker: 2
annotations:
external-dns.alpha.kubernetes.io/hostname: kafka-broker-2.mydomain.com.
external-dns.alpha.kubernetes.io/ttl: "60"
# ...
| 属性 | 描述 |
|---|---|
| alternativeNames | bootstrap 服务的其他备用名称。备用名称将添加到 TLS 证书的主题备用名称列表中。 |
| 字符串数组 | |
| 主机 |
bootstrap 主机。此字段将用于 Ingress 资源或 Route 资源,以指定所需的主机名。此字段只能与 |
| 字符串 | |
| nodePort |
bootstrap 服务的节点端口。此字段只能用于 |
| 整数 | |
| loadBalancerIP |
使用此字段中指定的 IP 地址请求 loadbalancer。此功能取决于底层云供应商是否支持在创建负载均衡器时指定 |
| 字符串 | |
| annotations |
添加到 |
| map |
B.18. GenericKafkaListenerConfigurationBroker schema reference
用于:GenericKafkaListenerConfiguration
为外部监听程序配置代理服务覆盖。
您可以在 GenericKafkaListenerConfigurationBootstrap 模式中 看到 nodePort、host、loadBalancerIP 和 annotations 属性的示例配置,它为外部监听器配置 bootstrap 服务覆盖。
代理公告的地址
默认情况下,AMQ Streams 会尝试自动确定 Kafka 集群公告给客户端的主机名和端口。这并不适用于所有情况,因为运行 AMQ Streams 的基础架构可能无法提供可以通过其访问 Kafka 的正确主机名或端口。
您可以指定一个代理 ID,并在外部监听器 的配置 属性中自定义公告的主机名和端口。然后,AMQ Streams 将自动在 Kafka 代理中配置公告的地址,并将其添加到代理证书中,以便用于 TLS 主机名验证。覆盖公告的主机和端口可供所有类型的外部监听器使用。
配置了针对公告地址覆盖的外部 路由 监听程序示例
listeners:
#...
- name: external
port: 9094
type: route
tls: true
authentication:
type: tls
configuration:
brokers:
- broker: 0
advertisedHost: example.hostname.0
advertisedPort: 12340
- broker: 1
advertisedHost: example.hostname.1
advertisedPort: 12341
- broker: 2
advertisedHost: example.hostname.2
advertisedPort: 12342
# ...
| 属性 | 描述 |
|---|---|
| broker | kafka 代理的 ID(代理标识符)。代理 ID 从 0 开始,对应于代理副本数。 |
| 整数 | |
| advertisedHost |
代理的 advertised |
| 字符串 | |
| advertisedPort |
代理的 advertised |
| 整数 | |
| 主机 |
代理主机。此字段将用于 Ingress 资源或 Route 资源,以指定所需的主机名。此字段只能与 |
| 字符串 | |
| nodePort |
每个broker 服务的节点端口。此字段只能用于 |
| 整数 | |
| loadBalancerIP |
使用此字段中指定的 IP 地址请求 loadbalancer。此功能取决于底层云供应商是否支持在创建负载均衡器时指定 |
| 字符串 | |
| annotations |
添加到 |
| map |
B.19. KafkaListeners 模式参考
KafkaListeners 类型已弃用。请改为使用 GenericKafkaListener。
示例配置 请参阅前面的文档。
| 属性 | 描述 |
|---|---|
| plain | 在端口 9092 上配置纯侦听器。 |
| tls | 在端口 9093 上配置 TLS 侦听程序。 |
| external |
在端口 9094 上配置外部侦听器。类型取决于给定对象中的 |
|
|
B.20. KafkaListenerPlain 模式参考
| 属性 | 描述 |
|---|---|
| 身份验证 |
此侦听器的身份验证配置.由于此侦听器不使用 TLS 传输,因此您无法使用 |
|
| |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
B.21. KafkaListenerTls 模式参考
| 属性 | 描述 |
|---|---|
| 身份验证 |
此侦听器的身份验证配置.这个类型取决于给定对象中的 |
|
| |
| 配置 | TLS 侦听器的配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
B.22. TlsListenerConfiguration 模式参考
| 属性 | 描述 |
|---|---|
| brokerCertChainAndKey |
引用存放证书和私钥对的 |
B.23. KafkaListenerExternalRoute schema reference
type 属性是一个 discriminator,它区分使用 KafkaListenerExternalRoute 和 KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort、KafkaListenerExternalIngress。它必须具有类型 KafkaListenerExternalRoute 的值 路由。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| 身份验证 |
Kafka 代理的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| overrides | 覆盖外部 bootstrap 和代理服务以及外部公告的地址。 |
| 配置 | 外部监听器配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
B.24. RouteListenerOverride 模式参考
| 属性 | 描述 |
|---|---|
| bootstrap | 外部引导服务配置. |
| 代理 | 外部代理服务配置. |
B.25. RouteListenerBootstrapOverride 架构参考
| 属性 | 描述 |
|---|---|
| address | bootstrap 服务的额外地址名称。该地址将添加到 TLS 证书的主题备用名称列表中。 |
| 字符串 | |
| 主机 |
bootstrap 路由的主机。此字段将在 OpenShift Route 的 |
| 字符串 |
B.26. RouteListenerBrokerOverride schema reference
| 属性 | 描述 |
|---|---|
| broker | kafka 代理的 ID(代理标识符)。 |
| 整数 | |
| advertisedHost |
代理的 advertised |
| 字符串 | |
| advertisedPort |
代理的 advertised |
| 整数 | |
| 主机 |
代理路由的主机。此字段将在 OpenShift Route 的 |
| 字符串 |
B.27. KafkaListenerExternalConfiguration 模式参考
用于:KafkaListenerExternalLoadBalancer, KafkaListenerExternalRoute
| 属性 | 描述 |
|---|---|
| brokerCertChainAndKey |
引用存放证书和私钥对的 |
B.28. KafkaListenerExternalLoadBalancer schema reference
type 属性是一个 discriminator,它区分使用 KafkaListenerExternalLoadBalancer 和 KafkaListenerExternalRoute、KafkaListenerExternalNodePort、KafkaListenerExternalIngress。它必须具有 类型 KafkaListenerExternalLoadBalancer 的值。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| 身份验证 |
Kafka 代理的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| overrides | 覆盖外部 bootstrap 和代理服务以及外部公告的地址。 |
| 配置 | 外部监听器配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
| tls |
在监听器上启用 TLS 加密。对于启用的 TLS 加密,默认设置为 |
| 布尔值 |
B.29. LoadBalancerListenerOverride 模式参考
用于:KafkaListenerExternalLoadBalancer
| 属性 | 描述 |
|---|---|
| bootstrap | 外部引导服务配置. |
| 代理 | 外部代理服务配置. |
B.30. LoadBalancerListenerBootstrapOverride 模式参考
用于:LoadBalancerListenerOverride
| 属性 | 描述 |
|---|---|
| address | bootstrap 服务的额外地址名称。该地址将添加到 TLS 证书的主题备用名称列表中。 |
| 字符串 | |
| dnsAnnotations |
将添加到 |
| map | |
| loadBalancerIP |
使用此字段中指定的 IP 地址请求 loadbalancer。此功能取决于底层云供应商是否支持在创建负载均衡器时指定 |
| 字符串 |
B.31. LoadBalancerListenerBrokerOverride 模式参考
用于:LoadBalancerListenerOverride
| 属性 | 描述 |
|---|---|
| broker | kafka 代理的 ID(代理标识符)。 |
| 整数 | |
| advertisedHost |
代理的 advertised |
| 字符串 | |
| advertisedPort |
代理的 advertised |
| 整数 | |
| dnsAnnotations |
添加到单个代理的 |
| map | |
| loadBalancerIP |
使用此字段中指定的 IP 地址请求 loadbalancer。此功能取决于底层云供应商是否支持在创建负载均衡器时指定 |
| 字符串 |
B.32. KafkaListenerExternalNodePort schema reference
type 属性是一个 discriminator,它区分使用 KafkaListenerExternalNodePort 类型与 KafkaListenerExternalRoute、KafkaListenerExternalLoadBalancer、KafkaListenerExternalIngress。它必须具有 类型 KafkaListenerExternalNodePort 的值。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| 身份验证 |
Kafka 代理的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| overrides | 覆盖外部 bootstrap 和代理服务以及外部公告的地址。 |
| 配置 | 外部监听器配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
| tls |
在监听器上启用 TLS 加密。对于启用的 TLS 加密,默认设置为 |
| 布尔值 |
B.33. NodePortListenerOverride 模式参考
用于:KafkaListenerExternalNodePort
| 属性 | 描述 |
|---|---|
| bootstrap | 外部引导服务配置. |
| 代理 | 外部代理服务配置. |
B.34. NodePortListenerBootstrapOverride 架构参考
| 属性 | 描述 |
|---|---|
| address | bootstrap 服务的额外地址名称。该地址将添加到 TLS 证书的主题备用名称列表中。 |
| 字符串 | |
| dnsAnnotations |
将添加到 |
| map | |
| nodePort | bootstrap 服务的节点端口。 |
| 整数 |
B.35. NodePortListenerBrokerOverride 架构参考
| 属性 | 描述 |
|---|---|
| broker | kafka 代理的 ID(代理标识符)。 |
| 整数 | |
| advertisedHost |
代理的 advertised |
| 字符串 | |
| advertisedPort |
代理的 advertised |
| 整数 | |
| nodePort | 代理服务的节点端口。 |
| 整数 | |
| dnsAnnotations |
添加到单个代理的 |
| map |
B.36. NodePortListenerConfiguration 模式参考
用于:KafkaListenerExternalNodePort
| 属性 | 描述 |
|---|---|
| brokerCertChainAndKey |
引用存放证书和私钥对的 |
| preferredAddressType |
定义应当将哪种地址类型用作节点地址。可用类型有: 此字段可用于选择将用作首选类型并首先检查的地址类型。如果没有为此地址类型找到地址,则将按默认顺序使用其他类型。 |
| 字符串([外部DNS、ExternalDNS、Hostname、InternalIP、InternalDNS] 之一) |
B.37. KafkaListenerExternalIngress schema reference
type 属性是一个 discriminator,它区分使用 KafkaListenerExternalIngress 的类型与 KafkaListenerExternalRoute、KafkaListenerExternalLoadBalancer、KafkaListenerExternalNodePort。它必须具有类型 KafkaListenerExternalIngress 的 ingress 值。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| 身份验证 |
Kafka 代理的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| class |
配置用于定义将使用哪个 |
| 字符串 | |
| 配置 | 外部监听器配置. |
| networkPolicyPeers | 能够连接到此监听器的同级服务器列表。此列表中的对等点使用逻辑 OR 操作组合。如果此字段为空或缺失,则允许此监听器所有连接。如果此字段存在并且至少包含一项,侦听器仅允许与此列表中至少匹配一项的流量。请参阅 networking.k8s.io/v1 networkpolicypeer 的外部文档。 |
B.38. IngressListenerConfiguration 模式参考
用于:KafkaListenerExternalIngress
| 属性 | 描述 |
|---|---|
| bootstrap | 外部 bootstrap 入口配置。 |
| 代理 | 外部代理入口配置。 |
| brokerCertChainAndKey |
引用存放证书和私钥对的 |
B.39. IngressListenerBootstrapConfiguration 模式参考
用于:IngressListenerConfiguration
| 属性 | 描述 |
|---|---|
| address | bootstrap 服务的额外地址名称。该地址将添加到 TLS 证书的主题备用名称列表中。 |
| 字符串 | |
| dnsAnnotations |
添加到 |
| map | |
| 主机 | bootstrap 路由的主机。此字段将在 Ingress 资源中使用。 |
| 字符串 |
B.40. IngressListenerBrokerConfiguration 模式参考
用于:IngressListenerConfiguration
| 属性 | 描述 |
|---|---|
| broker | kafka 代理的 ID(代理标识符)。 |
| 整数 | |
| advertisedHost |
代理的 advertised |
| 字符串 | |
| advertisedPort |
代理的 advertised |
| 整数 | |
| 主机 | 代理入口的主机。此字段将在 Ingress 资源中使用。 |
| 字符串 | |
| dnsAnnotations |
添加到单个代理的 |
| map |
B.41. KafkaAuthorizationSimple schema 参考
AMQ Streams 中的简单授权使用 AclAuthorizer 插件,即 Apache Kafka 提供的默认访问控制列表(ACL)授权插件。ACL 允许您定义哪些用户有权在细粒度级别上访问哪些资源。
将 Kafka 自定义资源配置为使用简单授权。将 授权 部分中的 type 属性设置为 simple 值,再配置超级用户列表。
为 KafkaUser 配置访问规则,如 ACLRule schema 参考 中所述。
B.41.1. superUsers
用户主体列表被视为超级用户,因此始终允许他们无需查询 ACL 规则。如需更多信息,请参阅 Kafka 授权。
简单授权配置示例
authorization:
type: simple
superUsers:
- CN=client_1
- user_2
- CN=client_3
Kafka 配置选项将被忽略。在 .spec.kafka user中的 config 属性中的 super.授权 属性中指定超级用户。如需更多信息,请参阅 Kafka 代理配置。
type 属性是一个光盘,它区分使用 KafkaAuthorizationSimple 和 KafkaAuthorizationOpa、KafkaAuthorizationKeycloak。它的值 对于 KafkaAuthorizationSimple 类型必须简单。
| 属性 | 描述 |
|---|---|
| type |
必须 |
| 字符串 | |
| superUsers | 超级用户列表。应包含应获得无限访问权限的用户主体列表。 |
| 字符串数组 |
B.42. KafkaAuthorizationOpa 模式参考
要使用 Open Policy Agent 授权,请将 授权 部分中的 type 属性设置为值 opa,并根据需要配置 OPA 属性。
B.42.1. url
用于连接到开放策略代理服务器的 URL。URL 必须包含授权者将查询的策略。必需。
B.42.2. allowOnError
定义授权者无法查询 Open Policy Agent 时应默认允许或拒绝 Kafka 客户端,例如,当它暂时不可用时。默认为 false - 将拒绝所有操作。
B.42.3. initialCacheCapacity
授权者用于避免针对每个请求查询 Open Policy 代理的本地缓存的初始容量。默认值为 5000。
B.42.4. maximumCacheSize
授权者用于避免针对每个请求查询 Open Policy 代理的本地缓存的最大容量。默认值为 50000。
B.42.5. expireAfterMs
本地缓存中保留的记录的过期时间,以避免针对每个请求查询 Open Policy 代理。定义从 Open Policy Agent 服务器重新加载缓存的授权决策的频率。以毫秒为单位.默认为 3600000 毫秒(1 小时)。
B.42.6. superUsers
被视为超级用户的用户主体列表,以便始终允许他们而无需查询 open Policy Agent 策略。如需更多信息,请参阅 Kafka 授权。
Open Policy Agent 授权器配置示例
authorization:
type: opa
url: http://opa:8181/v1/data/kafka/allow
allowOnError: false
initialCacheCapacity: 1000
maximumCacheSize: 10000
expireAfterMs: 60000
superUsers:
- CN=fred
- sam
- CN=edward
type 属性是一个光盘,它区分使用 KafkaAuthorizationOpa 和 KafkaAuthorizationSimple, KafkaAuthorizationKeycloak。它必须具有类型 KafkaAuthorizationOpa 的值 opa。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| url | 用于连接到开放策略代理服务器的 URL。URL 必须包含授权者将查询的策略。这个选项是必需的。 |
| 字符串 | |
| allowOnError |
定义当授权者无法查询 Open Policy Agent 时(例如,当暂时不可用时),是否应允许或拒绝 Kafka 客户端。默认为 |
| 布尔值 | |
| initialCacheCapacity |
授权者用于避免查询开放策略代理的本地缓存的初始容量,每个请求默认值为 |
| 整数 | |
| maximumCacheSize |
授权者用于避免针对每个请求查询 Open Policy 代理的本地缓存的最大容量。默认值为 |
| 整数 | |
| expireAfterMs |
本地缓存中保留的记录的过期时间,以避免针对每个请求查询 Open Policy 代理。定义从 Open Policy Agent 服务器重新加载缓存的授权决策的频率。以毫秒为单位.默认值为 |
| 整数 | |
| superUsers | 超级用户列表,特别是具有无限访问权限的用户主体列表。 |
| 字符串数组 |
B.43. KafkaAuthorizationKeycloak 模式参考
type 属性是一个光盘,它区分使用 KafkaAuthorizationKeycloak 类型与 KafkaAuthorizationSimple, KafkaAuthorizationOpa。它必须具有类型 KafkaAuthorizationKey 。
cloak 的值 key cloak
| 属性 | 描述 |
|---|---|
| type |
必须为 |
| 字符串 | |
| clientId | Kafka 客户端 ID,可用于对 OAuth 服务器进行身份验证并使用令牌端点 URI。 |
| 字符串 | |
| tokenEndpointUri | 授权服务器令牌端点 URI. |
| 字符串 | |
| tlsTrustedCertificates | TLS 连接到 OAuth 服务器的可信证书。 |
| disableTlsHostnameVerification |
启用或禁用 TLS 主机名验证。默认值为 |
| 布尔值 | |
| delegateToKafkaAcls |
如果红帽单点登录授权服务策略 DENIED,则是否应将授权决定委派给"简单"授权者。默认值为 |
| 布尔值 | |
| grantsRefreshPeriodSeconds | 两个连续延长的时间(以秒为单位)运行。默认值为 60。 |
| 整数 | |
| grantsRefreshPoolSize | 用于刷新(active 会话)时授予的线程数。线程越多,并行性越高,作业越快完成。但是,使用更多线程在授权服务器上放置更重的负载。默认值为 5。 |
| 整数 | |
| superUsers | 超级用户列表。应包含应获得无限访问权限的用户主体列表。 |
| 字符串数组 |
B.44. rack 架构参考
用于:KafkaClusterSpec、KafkaConnectS2ISpec、KafkaConnectSpec
| 属性 | 描述 |
|---|---|
| topologyKey |
与分配给 OpenShift 集群节点的标签匹配的键。标签的值用于设置代理的 |
| 字符串 |
B.45. 探测 模式参考
用于:CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaExporterSpec, KafkaMirrorMaker2Spec, KafkaMirrorMakerSpec, TlsSidecar, TopicOperatorSpec, ZookeeperClusterSpec
| 属性 | 描述 |
|---|---|
| failureThreshold | 成功后,将探测视为失败的最少连续失败。默认值为 3。最小值为 1. |
| 整数 | |
| initialDelaySeconds | 首先检查健康检查的第一个前的初始延迟。 |
| 整数 | |
| periodSeconds | 执行探测的频率(以秒为单位)。默认值为 10 秒。最小值为 1. |
| 整数 | |
| successThreshold | 最少连续成功探测才会在失败后认为探测成功。默认为 1。必须为 1 代表存活度.最小值为 1. |
| 整数 | |
| timeoutSeconds | 每次尝试健康检查的超时时间。 |
| 整数 |
B.46. JvmOptions 架构参考
用于:CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec, KafkaMirrorMakerSpec, TopicOperatorSpec, ZookeeperClusterSpec
| 属性 | 描述 |
|---|---|
| -XX | JVM 的 -XX 选项映射。 |
| map | |
| -xms | 到 JVM 的 -Xms 选项. |
| 字符串 | |
| -Xmx | JVM 的 -Xmx 选项. |
| 字符串 | |
| gcLoggingEnabled | 指定是否启用 Garbage Collection 日志记录。默认值为 false。 |
| 布尔值 | |
| javaSystemProperties |
包含其他系统属性的映射,将使用 |
B.47. SystemProperty 架构参考
用于:JvmOptions
| 属性 | 描述 |
|---|---|
| name | 系统属性名称。 |
| 字符串 | |
| 值 | 系统属性值。 |
| 字符串 |
B.48. KafkaJmxOptions 模式参考
| 属性 | 描述 |
|---|---|
| 身份验证 |
用于连接到 Kafka JMX 端口的身份验证配置。类型取决于给定对象中 |
B.49. KafkaJmxAuthenticationPassword 架构参考
type 属性是一个缺点,它区分了使用 KafkaJmxAuthenticationPassword 和将来可能添加的其他子类型。它必须具有类型 KafkaJmxAuthenticationPassword 的值 密码。
| 属性 | 描述 |
|---|---|
| type |
必须为 |
| 字符串 |
B.50. InlineLogging schema 参考
用于:CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec, KafkaMirrorMakerSpec, TopicOperatorSpec, ZookeeperClusterSpec
type 属性是一种分化器,区分类型 InlineLogging 和 的使用。它必须具有类型 ExternalLogging 的值。
Inline Logging
| 属性 | 描述 |
|---|---|
| type |
必须 |
| 字符串 | |
| 日志记录器 | 从日志记录器名称到日志记录器级别的映射. |
| map |
B.51. ExternalLogging 架构参考
用于:CruiseControlSpec, EntityTopicOperatorSpec, EntityUserOperatorSpec, KafkaBridgeSpec, KafkaClusterSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec, KafkaMirrorMakerSpec, TopicOperatorSpec, ZookeeperClusterSpec
type 属性是一种分辨符,它区分类型为 ExternalLogging 的使用。它必须具有类型 和 InlineLogging ExternalLogging 的值 external。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| name |
要从中获取日志记录配置的 |
| 字符串 |
B.52. TlsSidecar 架构参考
用于:CruiseControlSpec, EntityOperatorSpec, KafkaClusterSpec, TopicOperatorSpec, ZookeeperClusterSpec
| 属性 | 描述 |
|---|---|
| 镜像 | 容器的 Docker 镜像。 |
| 字符串 | |
| livenessProbe | Pod 存活度检查. |
| logLevel |
TLS sidecar 的日志级别。默认值为 |
| 字符串([emerg、debug、crit、err、alert、warning、notice、info] 之一) | |
| readinessProbe | Pod 就绪度检查。 |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
B.53. KafkaClusterTemplate 模式参考
| 属性 | 描述 |
|---|---|
| StatefulSet |
Kafka |
| Pod |
Kafka |
| bootstrapService |
Kafka bootstrap |
| brokersService |
Kafka |
| externalBootstrapService |
Kafka 外部 bootstrap |
| perPodService |
用于从 OpenShift 外部访问的 Kafka 每个 pod |
| externalBootstrapRoute |
Kafka 外部 bootstrap |
| perPodRoute |
用于从 OpenShift 外部访问的 Kafka 每个 pod |
| externalBootstrapIngress |
Kafka 外部 bootstrap |
| perPodIngress |
用于从 OpenShift 外部访问每个 |
| persistentVolumeClaim |
所有 Kafka |
| podDisruptionBudget |
Kafka |
| kafkaContainer | Kafka 代理容器模板。 |
| tlsSidecarContainer |
attribute |
| initContainer | Kafka init 容器的模板。 |
B.54. StatefulSetTemplate 模式参考
用于:KafkaClusterTemplate, ZookeeperClusterTemplate
| 属性 | 描述 |
|---|---|
| metadata | 应用到资源的元数据。 |
| podManagementPolicy |
用于这个 StatefulSet 的 PodManagementPolicy。有效值为 |
| 字符串([OrderedReady, Parallel] 中的一个) |
B.55. MetadataTemplate 架构参考
用于:ExternalServiceTemplate, PodDisruptionBudgetTemplate, PodTemplate, ResourceTemplate, StatefulSetTemplate
标签 和 注解 用于标识和组织资源,并在 metadata 属性中进行配置。
例如:
# ...
template:
statefulset:
metadata:
labels:
label1: value1
label2: value2
annotations:
annotation1: value1
annotation2: value2
# ...
标签 和 注解 字段可以包含不包含保留字符串 strimzi.io 的任何标签或注解。包含 strimzi.io 的标签和注解由 AMQ Streams 内部使用,无法配置。
| 属性 | 描述 |
|---|---|
| labels |
添加至资源模板的标签。可用于不同的资源,如 |
| map | |
| annotations |
添加到资源模板的注解。可用于不同的资源,如 |
| map |
B.56. PodTemplate 架构参考
用于:CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaMirrorMakerTemplate, ZookeeperClusterTemplate
PodTemplate 配置示例
# ...
template:
pod:
metadata:
labels:
label1: value1
annotations:
anno1: value1
imagePullSecrets:
- name: my-docker-credentials
securityContext:
runAsUser: 1000001
fsGroup: 0
terminationGracePeriodSeconds: 120
# ...
B.56.1. hostAliases
使用 hostAliases 属性来指定主机和 IP 地址的列表,它们注入到容器集的 /etc/hosts 文件中。
当用户请求集群外的连接时,此配置对于 Kafka Connect 或 MirrorMaker 特别有用。
hostAliases 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
#...
spec:
# ...
template:
pod:
hostAliases:
- ip: "192.168.1.86"
hostnames:
- "my-host-1"
- "my-host-2"
#...
| 属性 | 描述 |
|---|---|
| metadata | 应用到资源的元数据。 |
| imagePullSecrets |
对同一命名空间中的 secret 的引用列表,用于拉取此 Pod 使用的任何镜像。当 Cluster Operator 中的 |
| securityContext | 配置 Pod 级别安全属性和通用容器设置。请参阅 core/v1 podsecuritycontext 的外部文档。 |
| terminationGracePeriodSeconds | 宽限期是向容器集中运行的进程发送终止信号后,以及进程通过 kill 信号强制停止的时间(以秒为单位)。将此值设置为比您的进程预期的清理时间更长。值必须是非负整数。零值表示立即删除。您可能需要为非常大的 Kafka 集群增加宽限期,以便 Kafka 代理有足够的时间在终止前将其工作转移到另一个代理。默认值为 30 秒。 |
| 整数 | |
| 关联性 | pod 的关联性规则。请参阅有关 内核/v1 关联性 的外部文档. |
| 容限(tolerations) | pod 的容限。请参阅 内核/v1 容限 的外部文档。 |
| 容限 数组 | |
| priorityClassName | 用于为 pod 分配优先级的优先级类的名称。如需有关优先级类的更多信息,请参阅 Pod 优先级和抢占。 |
| 字符串 | |
| schedulerName |
用于分配此 |
| 字符串 | |
| hostAliases | 容器集的 HostAliases.HostAliases 是主机和 IP 的可选列表,在指定后将注入到 pod 的主机文件中。请参阅 内核/v1 HostAlias 的外部文档。 |
| HostAlias 数组 |
B.57. resourcetemplate 架构引用
用于:CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaMirrorMakerTemplate, KafkaUserTemplate, ZookeeperClusterTemplate
| 属性 | 描述 |
|---|---|
| metadata | 应用到资源的元数据。 |
B.58. ExternalServiceTemplate 模式引用
当使用 loadbalancers 或节点端口在 OpenShift 外部公开 Kafka 时,除了使用标签和注释外,您还可以使用属性来自定义服务的创建方式。
显示自定义外部服务的示例
# ...
template:
externalBootstrapService:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 10.0.0.0/8
- 88.208.76.87/32
perPodService:
externalTrafficPolicy: Local
loadBalancerSourceRanges:
- 10.0.0.0/8
- 88.208.76.87/32
# ...
| 属性 | 描述 |
|---|---|
| metadata | 应用到资源的元数据。 |
| externalTrafficPolicy |
属性 |
| 字符串([本地、集群] 中的一个) | |
| loadBalancerSourceRanges |
属性 |
| 字符串数组 |
B.59. PodDisruptionBudgetTemplate 模式参考
用于:CruiseControlTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaMirrorMakerTemplate, ZookeeperClusterTemplate
AMQ Streams 为每个新的 StatefulSet 或 Deployment 创建一个 PodDisruptionBudget。默认情况下,pod 中断预算只允许单个 pod 在给定时间不可用。您可以通过更改 PodDisruptionBudget.spec 资源中的 maxUnavailable 属性的默认值来增加允许的不可用 pod 数量。
PodDisruptionBudget 模板示例
# ...
template:
podDisruptionBudget:
metadata:
labels:
key1: label1
key2: label2
annotations:
key1: label1
key2: label2
maxUnavailable: 1
# ...
| 属性 | 描述 |
|---|---|
| metadata |
应用到 |
| maxUnavailable |
不可用 pod 的最大数量,以允许自动 pod 驱除。如果驱除后无法使用 |
| 整数 |
B.60. ContainerTemplate 架构参考
用于:CruiseControlTemplate, EntityOperatorTemplate, KafkaBridgeTemplate, KafkaClusterTemplate, KafkaConnectTemplate, KafkaExporterTemplate, KafkaMirrorMakerTemplate, ZookeeperClusterTemplate
您可以为容器设置自定义安全上下文和环境变量。
环境变量在 env 属性下定义,作为具有 名称和 值 字段的对象列表。以下示例显示了为 Kafka 代理容器设置的两个自定义环境变量和自定义安全上下文:
# ...
template:
kafkaContainer:
env:
- name: EXAMPLE_ENV_1
value: example.env.one
- name: EXAMPLE_ENV_2
value: example.env.two
securityContext:
runAsUser: 2000
# ...
前缀为 KAFKA_ 的环境变量是 AMQ Streams 内部的环境变量,应当避免。如果您设置了 AMQ Streams 已使用的自定义环境变量,则会忽略它,并在日志中记录警告。
| 属性 | 描述 |
|---|---|
| env | 应用于容器的环境变量。 |
| securityContext | 容器的安全上下文.请参阅 内核/v1 安全上下文 的外部文档。 |
B.61. ContainerEnvVar 模式参考
| 属性 | 描述 |
|---|---|
| name | 环境变量键。 |
| 字符串 | |
| 值 | 环境变量值。 |
| 字符串 |
B.62. ZookeeperClusterSpec 模式参考
用于:KafkaSpec
| 属性 | 描述 |
|---|---|
| replicas | 集群中的 pod 数量。 |
| 整数 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| storage |
存储配置(磁盘)。无法更新。类型取决于给定对象中 |
| config | ZooKeeper 代理配置.无法设置具有以下前缀的属性:server.、dataDir、dataLogDir、clientPort、authProvider、quorum.auth、requireClientAuthScheme、snapshot.trust.empty、standaloneEnabled、reconfigEnabled、4lw.commands.whitelist、secureClientPort. SSL., serverCnxnFactory, sslQuorum(除了:ssl.protocol, ssl.quorum.protocol, ssl.enabledProtocols, ssl.quorum.enabledProtocols, ssl.ciphersuites, ssl.ciphersuites, SSL.quorum.ciphersuites、ssl.hostnameVerification、ssl.quorum.hostnameVerification。 |
| map | |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| jvmOptions | 容器集的 JVM 选项. |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map | |
| logging |
ZooKeeper 的日志配置.类型取决于给定对象中的 |
| 模板 |
ZooKeeper 集群资源的模板。该模板允许用户指定 |
| tlsSidecar |
attribute |
B.63. ZookeeperClusterTemplate 模式参考
| 属性 | 描述 |
|---|---|
| StatefulSet |
ZooKeeper |
| Pod |
ZooKeeper |
| clientService |
ZooKeeper 客户端 |
| nodesService |
ZooKeeper 节点 |
| persistentVolumeClaim |
所有 ZooKeeper |
| podDisruptionBudget |
ZooKeeper |
| zookeeperContainer | ZooKeeper 容器的模板。 |
| tlsSidecarContainer |
attribute |
B.64. TopicOperatorSpec 模式参考
TopicOperatorSpec 类型已弃用。请改为使用 EntityTopicOperatorSpec。
用于:KafkaSpec
| 属性 | 描述 |
|---|---|
| watchedNamespace | Topic Operator 应监视的命名空间。 |
| 字符串 | |
| 镜像 | 用于主题 Operator 的镜像。 |
| 字符串 | |
| reconciliationIntervalSeconds | 定期协调之间的间隔。 |
| 整数 | |
| zookeeperSessionTimeoutSeconds | ZooKeeper 会话超时。 |
| 整数 | |
| 关联性 | Pod 关联性规则。请参阅有关 内核/v1 关联性 的外部文档. |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| topicMetadataMaxAttempts | 获取主题元数据的尝试数量。 |
| 整数 | |
| tlsSidecar | TLS sidecar 配置. |
| logging |
日志记录配置.类型取决于给定对象中的 |
| jvmOptions | 容器集的 JVM 选项. |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
B.65. EntityOperatorSpec 模式参考
用于:KafkaSpec
| 属性 | 描述 |
|---|---|
| topicOperator | 配置主题 Operator。 |
| userOperator | User Operator 配置. |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| tlsSidecar | TLS sidecar 配置. |
| 模板 |
Entity Operator 资源模板。该模板允许用户指定如何生成 |
B.66. EntityTopicOperatorSpec 模式参考
| 属性 | 描述 |
|---|---|
| watchedNamespace | Topic Operator 应监视的命名空间。 |
| 字符串 | |
| 镜像 | 用于主题 Operator 的镜像。 |
| 字符串 | |
| reconciliationIntervalSeconds | 定期协调之间的间隔。 |
| 整数 | |
| zookeeperSessionTimeoutSeconds | ZooKeeper 会话超时。 |
| 整数 | |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| topicMetadataMaxAttempts | 获取主题元数据的尝试数量。 |
| 整数 | |
| logging |
日志记录配置.类型取决于给定对象中的 |
| jvmOptions | 容器集的 JVM 选项. |
B.67. EntityUserOperatorSpec 模式参考
| 属性 | 描述 |
|---|---|
| watchedNamespace | User Operator 应监视的命名空间。 |
| 字符串 | |
| 镜像 | 用于 User Operator 的镜像。 |
| 字符串 | |
| reconciliationIntervalSeconds | 定期协调之间的间隔。 |
| 整数 | |
| zookeeperSessionTimeoutSeconds | ZooKeeper 会话超时。 |
| 整数 | |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| logging |
日志记录配置.类型取决于给定对象中的 |
| jvmOptions | 容器集的 JVM 选项. |
B.68. EntityOperatorTemplate 模式参考
| 属性 | 描述 |
|---|---|
| 部署 |
Entity Operator |
| Pod |
Entity Operator |
| tlsSidecarContainer | Entity Operator TLS sidecar 容器的模板。 |
| topicOperatorContainer | Entity Topic Operator 容器的模板。 |
| userOperatorContainer | Entity User Operator 容器的模板。 |
B.69. certificateAuthority schema 参考
用于:KafkaSpec
配置集群中如何使用 TLS 证书。这适用于集群内部通信的证书,也适用于通过 Kafka.spec.kafka.listeners.tls 访问客户端的证书。
| 属性 | 描述 |
|---|---|
| generateCertificateAuthority | 如果为 true,则会自动生成证书颁发机构证书。否则,用户将需要为 Secret 提供 CA 证书。默认值为 true。 |
| 布尔值 | |
| validityDays | 生成的证书的天数应有效。默认值为 365。 |
| 整数 | |
| renewalDays |
证书续订期间的天数。这是证书过期前的天数,可在其中执行续订操作。当 |
| 整数 | |
| certificateExpirationPolicy |
|
| 字符串([replace-key,new-certificate] 之一) |
B.70. CruiseControlSpec 模式参考
用于:KafkaSpec
| 属性 | 描述 |
|---|---|
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| tlsSidecar | TLS sidecar 配置. |
| 资源 | 要保留用于 Cruise 控制容器的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| livenessProbe | 对 Cruise 控制容器的 Pod 存活度检查。 |
| readinessProbe | 对 Cruise 控制容器的 Pod 就绪度检查。 |
| jvmOptions | 清理控制容器的 JVM 选项. |
| logging |
用于清理控制的日志记录配置(log4j1)类型取决于给定对象中的 |
| 模板 |
模板,以指定如何生成 Cruise Control 资源、 |
| brokerCapacity |
Cruise 控制 |
| config | 清理控制配置.有关配置选项的完整列表,请参阅 https://github.com/linkedin/cruise-control/wiki/Configurations。请注意,无法使用以下前缀设置以下属性:bootstrap.servers、client.id、zookeeper.、network.、security.、fail.brokers.zk.path、webserver.http.、webserver.api.urlprefix、webserver.session.path、webserver.accesslog.、2.step. request.reason.required,metric.reporter.sampler.bootstrap.servers, metric.reporter.topic, partition.metric.sample.store.topic, broker.metric.sample.store.topic,capacity.config.file, self.healing., aomaly.detection.ssl. |
| map | |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map |
B.71. CruiseControlTemplate 模式参考
| 属性 | 描述 |
|---|---|
| 部署 |
用于清理控制 |
| Pod |
清理控制 |
| apiService |
Cruise Control API |
| podDisruptionBudget |
Cruise Control |
| cruiseControlContainer | Cruise Control 容器的模板。 |
| tlsSidecarContainer | Cruise Control TLS sidecar 容器的模板。 |
B.72. BrokerCapacity schema 参考
| 属性 | 描述 |
|---|---|
| disk | 磁盘的代理容量(以字节为单位),例如 100Gi。 |
| 字符串 | |
| cpuUtilization | CPU 资源利用率的代理容量以百分比(0 到 100)为单位。 |
| 整数 | |
| inboundNetwork | 入站网络吞吐量的代理容量(以每秒字节为单位),例如 10000KB/s。 |
| 字符串 | |
| outboundNetwork | 代理容量,以每秒字节为单位实现出站网络吞吐量,例如 10000KB/s。 |
| 字符串 |
B.73. KafkaExporterSpec 模式参考
用于:KafkaSpec
| 属性 | 描述 |
|---|---|
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| groupRegex |
用于指定要收集哪些消费者组的正则表达式。默认值为 |
| 字符串 | |
| topicRegex |
用于指定要收集哪些主题的正则表达式。默认值为 |
| 字符串 | |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| logging |
仅记录具有给定严重性或以上的日志消息。有效级别: [ |
| 字符串 | |
| enableSaramaLogging | 启用 Sarama 日志记录,即 Kafka Exporter 使用的 Go 客户端库。 |
| 布尔值 | |
| 模板 | 自定义部署模板和容器集. |
| livenessProbe | Pod 存活度检查。 |
| readinessProbe | Pod 就绪度检查。 |
B.74. KafkaExporterTemplate 模式参考
| 属性 | 描述 |
|---|---|
| 部署 |
Kafka 导出器 |
| Pod |
Kafka 导出器 |
| service |
Kafka Exporter |
| Container | Kafka Exporter 容器的模板。 |
B.75. KafkaStatus 架构参考
用于:kafka
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| 监听程序 | 内部和外部监听器的地址。 |
B.76. 条件 架构参考
用于:KafkaBridgeStatus, KafkaConnectorStatus, KafkaConnectS2IStatus, KafkaConnectStatus, KafkaMirrorMaker2Status, KafkaMirrorMakerStatus, KafkaRebalanceStatus, KafkaStatus, KafkaTopicStatus, KafkaUserStatus
| 属性 | 描述 |
|---|---|
| type | 条件的唯一标识符,用于区分资源中的其他条件。 |
| 字符串 | |
| status | 条件的状态,可以是 True、False 或 Unknown。 |
| 字符串 | |
| lastTransitionTime | 上次类型条件从一个状态变为另一个状态的时间。所需格式为 UTC 时区中的 'yyyy-MM-ddTHH:mm:ssZ'。 |
| 字符串 | |
| reason | 该状况上次转换的原因(CamelCase 中的单个单词)。 |
| 字符串 | |
| message | 指示状况最后一次转换的详细信息的人类可读消息。 |
| 字符串 |
B.77. ListenerStatus 模式参考
用于:KafkaStatus
| 属性 | 描述 |
|---|---|
| type |
侦听器的类型。可以是以下三种类型之一: |
| 字符串 | |
| 地址 | 此侦听器的地址列表。 |
| bootstrapServers |
用于使用此侦听器连接 Kafka 集群的 |
| 字符串 | |
| 证书 |
TLS 证书列表,可用于在连接到给定侦听器时验证服务器的身份。仅为 |
| 字符串数组 |
B.78. ListenerAddress 模式参考
| 属性 | 描述 |
|---|---|
| 主机 | Kafka bootstrap 服务的 DNS 名称或 IP 地址。 |
| 字符串 | |
| 端口 | Kafka bootstrap 服务的端口。 |
| 整数 |
B.79. KafkaConnect 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka Connect 集群的规格。 |
| status | Kafka Connect 集群的状态。 |
B.80. KafkaConnectSpec 模式参考
用于:KafkaConnect
配置 Kafka Connect 集群。
B.80.1. config
使用 config 属性将 Kafka 选项配置为密钥。
标准 Apache Kafka Connect 配置可能会提供,仅限于那些不是由 AMQ Streams 直接管理的属性。
无法配置的选项与以下内容相关:
- Kafka 集群 bootstrap 地址
- 安全(加密、身份验证和授权)
- 侦听器/REST 接口配置
- 插件路径配置
这些值可以是以下 JSON 类型之一:
- 字符串
- 数字
- 布尔值
您可以指定并配置 Apache Kafka 文档 中列出的选项,但那些直接由 AMQ Streams 管理的选项除外。具体来说,键等于或以以下任一字符串开头的配置选项将被禁止:
-
ssl. -
SASL. -
安全性. -
监听程序 -
plugin.path -
REST. -
bootstrap.servers
当 config 属性中存在禁止选项时,会忽略它,并把警告信息输出到 Cluster Operator 日志文件中。所有其他选项将传递给 Kafka Connect。
Cluster Operator 不会验证提供的 config 对象中的密钥或值。当提供无效的配置时,Kafka Connect 集群可能无法启动或变得不稳定。在这种情形中,修复 KafkaConnect.spec.config 或 KafkaConnectS2I.spec.config 对象中的配置,然后 Cluster Operator 可将新配置部署到所有 Kafka Connect 节点。
某些选项有默认值:
-
默认值
connect-cluster的 Group.id -
默认值为
connect-cluster-offsets的offset.storage.topic -
带有默认值
connect-cluster-configs的config.storage.topic -
status.storage.topic,默认值为connect-cluster-status -
key.converter默认值为org.apache.kafka.connect.json.JsonConverter -
value.converter,默认值为org.apache.kafka.connect.json.JsonConverter
如果 KafkaConnect.spec. config 或 属性中不存在这些选项,则会自动配置这些选项。
KafkaConnectS2I.spec.config
禁止的选项有例外。您可以使用三个允许的 ssl 配置选项用于使用 TLS 版本的特定 密码套件 进行客户端连接。密码套件组合了用于安全连接和数据传输的算法。您还可以配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
Kafka Connect 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
group.id: my-connect-cluster
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
ssl.endpoint.identification.algorithm: HTTPS
# ...
对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。您还可以 配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
B.80.2. logging
Kafka Connect(以及支持 Source2Image 的 Kafka Connect)具有自己的可配置日志记录器:
-
connect.root.logger.level -
log4j.logger.org.reflections
根据运行的 Kafka Connect 插件,还会添加更多日志记录器。
使用 curl 请求获取从任何 Kafka 代理 pod 运行的 Kafka Connect loggers 的完整列表:
curl -s http://<connect-cluster-name>-connect-api:8083/admin/loggers/
Kafka Connect 使用 Apache log4j 日志记录器实施。
使用 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j.properties 进行 描述。有关日志级别的更多信息,请参阅 Apache 日志记录服务。
此处我们会看到 内联 和外部 记录示例。
内联日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
spec:
# ...
logging:
type: inline
loggers:
connect.root.logger.level: "INFO"
# ...
外部日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
spec:
# ...
logging:
type: external
name: customConfigMap
# ...
任何未配置可用的日志记录器将其级别设置为 OFF。
如果使用 Cluster Operator 部署 Kafka Connect,则会动态地更改到 Kafka Connect 日志记录级别。
如果使用外部日志记录,当日志附加程序被更改时会触发滚动更新。
垃圾收集器(GC)
也可以使用 jvmOptions 属性 来启用(或禁用)垃圾收集器日志记录。
| 属性 | 描述 |
|---|---|
| replicas | Kafka Connect 组中的 pod 数量。 |
| 整数 | |
| version | Kafka Connect 版本。默认值为 2.6.0。请参阅用户文档以了解升级或降级版本所需的流程。 |
| 字符串 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| bootstrapServers | 引导服务器以进行连接。这应该以逗号分隔的 <hostname>: ›<port> 对列表指定。 |
| 字符串 | |
| tls | TLS 配置。 |
| 身份验证 |
Kafka Connect 的身份验证配置.这个类型取决于给定对象中的 |
|
| |
| config | Kafka Connect 配置。无法设置带有以下前缀的属性:ssl.、sasl.、security.、listeners、plugin.path、re.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes(除:ssl.endpoint.identification.algorithm 除外) SSL.cipher.suites、ssl.protocol、ssl.enabled.protocols。 |
| map | |
| 资源 | CPU 和内存资源以及请求的初始资源的最大限值。请参阅 内核/v1 资源要求的外部文档。 |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| jvmOptions | 容器集的 JVM 选项. |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| logging |
Kafka Connect 的日志配置.类型取决于给定对象中的 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map | |
| tracing |
Kafka Connect 中的追踪配置。类型取决于给定对象中 |
| 模板 |
Kafka Connect 和 Kafka Connect S2I 资源的模板。该模板允许用户指定如何生成 |
| externalConfiguration | 将数据从 Secret 或 ConfigMap 传递给 Kafka Connect Pod,并使用它们来配置连接器。 |
| clientRackInitImage |
用于初始化 |
| 字符串 | |
| rack | 配置节点标签,该标签将用作 client.rack consumer 配置。 |
B.81. KafkaConnectTls 模式参考
用于:KafkaConnectS2ISpec, KafkaConnectSpec
配置 TLS 可信证书,以连接 Kafka 连接到集群。
B.81.1. trustedCertificates
使用 trustedCertificates 属性提供 secret 列表。
| 属性 | 描述 |
|---|---|
| trustedCertificates | TLS 连接的可信证书。 |
B.82. KafkaClientAuthenticationTls 模式参考
用于:KafkaBridgeSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMakerConsumerSpec, KafkaMirrorMakerProducerSpec
要使用 TLS 客户端身份验证,请将 type 属性设置为 value tls。TLS 客户端身份验证使用 TLS 证书进行身份验证。
B.82.1. certificateAndKey
证书在 certificateAndKey 属性中指定的,始终从 OpenShift 机密加载。在机密中,证书必须以 X509 格式存储在两个不同的密钥下:public 和 private。
您可以使用 User Operator 创建的 secret,或者您可以使用自己的 TLS 证书文件创建用于身份验证的密钥,然后从文件创建 Secret :
oc create secret generic MY-SECRET \ --from-file=MY-PUBLIC-TLS-CERTIFICATE-FILE.crt \ --from-file=MY-PRIVATE.key
TLS 客户端身份验证只能用于 TLS 连接。
TLS 客户端身份验证配置示例
authentication:
type: tls
certificateAndKey:
secretName: my-secret
certificate: my-public-tls-certificate-file.crt
key: private.key
type 属性是一个光盘,它区分使用 KafkaClientAuthenticationTls 和 、KafkaClientAuthenticationScramSha512 KafkaClientAuthenticationPlain、KafkaClientAuthenticationOAuth。它必须具有类型 KafkaClientAuthenticationTls 的值 tls。
| 属性 | 描述 |
|---|---|
| certificateAndKey |
引用存放证书和私钥对的 |
| type |
必须是 |
| 字符串 |
B.83. KafkaClientAuthenticationScramSha512 模式参考
用于:KafkaBridgeSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMakerConsumerSpec, KafkaMirrorMakerProducerSpec
要配置基于 SASL 的 SCRAM-SHA-512 身份验证,请将 type 属性设置为 scr am-sha-512。SCRAM-SHA-512 验证机制需要用户名和密码。
B.83.1. username
指定 username 属性中的用户名。
B.83.2. passwordSecret
在 passwordSecret 属性中,指定一个指向包含密码的 Secret 的链接。
您可以使用 User Operator 创建的 secret。
如果需要,您可以创建一个包含明文密码的文本文件,用于验证:
echo -n PASSWORD > MY-PASSWORD.txt
然后,您可以从文本文件创建 Secret,为密码设置您自己的字段名称(key):
oc create secret generic MY-CONNECT-SECRET-NAME --from-file=MY-PASSWORD-FIELD-NAME=./MY-PASSWORD.txt
Kafka Connect 的 SCRAM-SHA-512 客户端身份验证的 Secret 示例
apiVersion: v1 kind: Secret metadata: name: my-connect-secret-name type: Opaque data: my-connect-password-field: LFTIyFRFlMmU2N2Tm
secretName 属性包含 Secret 的名称,password 属性 包含密码存储在 Secret 中的密钥名称。
不要在 password 属性中指定实际密码。
Kafka Connect 基于 SASL 的 SCRAM-SHA-512 客户端身份验证配置示例
authentication:
type: scram-sha-512
username: my-connect-username
passwordSecret:
secretName: my-connect-secret-name
password: my-connect-password-field
type 属性是一个光盘,它区分使用 KafkaClientAuthenticationScramSha512 和 KafkaClientAuthenticationTls、KafkaClientAuthenticationPlain、KafkaClientAuthenticationOAuth。它必须具有类型 KafkaClientAuthenticationScramSha512 的值 scr am-sha-512。
| 属性 | 描述 |
|---|---|
| passwordSecret |
引用存放密码的 |
| type |
必须是 scr |
| 字符串 | |
| username | 用于身份验证的用户名。 |
| 字符串 |
B.84. PasswordSecretSource 模式参考
用于:KafkaClientAuthenticationPlain, KafkaClientAuthenticationScramSha512
| 属性 | 描述 |
|---|---|
| password | 保存密码的 Secret 中的密钥名称。 |
| 字符串 | |
| secretName | 包含密码的 Secret 名称。 |
| 字符串 |
B.85. KafkaClientAuthenticationPlain 模式参考
用于:KafkaBridgeSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMakerConsumerSpec, KafkaMirrorMakerProducerSpec
要配置基于 SASL 的 PLAIN 身份验证,请将 type 属性设置为 纯文本。SASL PLAIN 身份验证机制需要用户名和密码。
SASL PLAIN 机制将以明文方式在网络上传输用户名和密码。仅当启用了 TLS 加密时,才使用 SASL PLAIN 身份验证。
B.85.1. username
指定 username 属性中的用户名。
B.85.2. passwordSecret
在 passwordSecret 属性中,指定一个指向包含密码的 Secret 的链接。
您可以使用 User Operator 创建的 secret。
如果需要,以明文形式创建一个包含密码的文本文件,以用于验证:
echo -n PASSWORD > MY-PASSWORD.txt
然后,您可以从文本文件创建 Secret,为密码设置您自己的字段名称(key):
oc create secret generic MY-CONNECT-SECRET-NAME --from-file=MY-PASSWORD-FIELD-NAME=./MY-PASSWORD.txt
Kafka Connect PLAIN 客户端身份验证的 Secret 示例
apiVersion: v1 kind: Secret metadata: name: my-connect-secret-name type: Opaque data: my-password-field-name: LFTIyFRFlMmU2N2Tm
secretName 属性包含 Secret 的名称,password 属性 包含密码存储在 机密 中的密钥名称。
不要在 password 属性中指定实际密码。
基于 SASL 的 PLAIN 客户端身份验证配置示例
authentication:
type: plain
username: my-connect-username
passwordSecret:
secretName: my-connect-secret-name
password: my-password-field-name
type 属性是一个光盘,它区分使用 KafkaClientAuthenticationPlain 和 、KafkaClientAuthenticationTls KafkaClientAuthenticationScramSha512、KafkaClientAuthenticationOAuth。它对于类型 KafkaClientAuthenticationPlain 的值必须是 明文 的。
| 属性 | 描述 |
|---|---|
| passwordSecret |
引用存放密码的 |
| type |
必须是 |
| 字符串 | |
| username | 用于身份验证的用户名。 |
| 字符串 |
B.86. KafkaClientAuthenticationOAuth 模式参考
用于:KafkaBridgeSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2ClusterSpec, KafkaMirrorMakerConsumerSpec, KafkaMirrorMakerProducerSpec
要使用 OAuth 客户端身份验证,请将 type 属性设置为 oauth 值。
OAuth 身份验证可使用以下选项之一进行配置:
- 客户端 ID 和 secret
- 客户端 ID 和刷新令牌
- 访问令牌
- TLS
客户端 ID 和 secret
您可以在 tokenEndpointUri 属性中配置授权服务器的地址,以及身份验证中使用的客户端 ID 和客户端机密。OAuth 客户端将连接到 OAuth 服务器,使用客户端 ID 和机密进行身份验证,并获取它将用于与 Kafka 代理进行身份验证的访问令牌。在 clientSecret 属性中,指定一个指向包含客户端 secret 的 Secret 的链接。
使用客户端 ID 和客户端 secret 进行 OAuth 客户端身份验证示例
authentication:
type: oauth
tokenEndpointUri: https://sso.myproject.svc:8443/auth/realms/internal/protocol/openid-connect/token
clientId: my-client-id
clientSecret:
secretName: my-client-oauth-secret
key: client-secret
客户端 ID 和刷新令牌
您可以在 tokenEndpointUri 属性中配置 OAuth 服务器的地址,并与 OAuth 客户端 ID 和刷新令牌一起配置。OAuth 客户端将连接到 OAuth 服务器,使用客户端 ID 进行身份验证并刷新令牌,并获取它将用于与 Kafka 代理进行身份验证的访问令牌。在 refreshToken 属性中,指定包含刷新令牌的 Secret 链接。
+ .使用客户端 ID 和刷新令牌进行 OAuth 客户端身份验证示例
authentication:
type: oauth
tokenEndpointUri: https://sso.myproject.svc:8443/auth/realms/internal/protocol/openid-connect/token
clientId: my-client-id
refreshToken:
secretName: my-refresh-token-secret
key: refresh-token访问令牌
您可以直接配置用于与 Kafka 代理进行身份验证的访问令牌。在本例中,您不用指定 tokenEndpointUri。在 accessToken 属性中,指定包含访问令牌的 Secret 链接。
仅使用访问令牌进行 OAuth 客户端身份验证示例
authentication:
type: oauth
accessToken:
secretName: my-access-token-secret
key: access-token
TLS
使用 HTTPS 协议访问 OAuth 服务器不需要额外的配置,只要其使用的 TLS 证书由可信证书颁发机构签名,并且其主机名列在证书中。
如果您的 OAuth 服务器使用自签名证书,或者由不信任的证书颁发机构签名,您可以在自定义重新创建中配置可信证书列表。The tlsTrustedCertificates 属性包含一个 secret 列表,其密钥名称存储在证书的下面。证书必须以 X509 格式存储。
提供的 TLS 证书示例
authentication:
type: oauth
tokenEndpointUri: https://sso.myproject.svc:8443/auth/realms/internal/protocol/openid-connect/token
clientId: my-client-id
refreshToken:
secretName: my-refresh-token-secret
key: refresh-token
tlsTrustedCertificates:
- secretName: oauth-server-ca
certificate: tls.crt
OAuth 客户端将默认验证 OAuth 服务器的主机名是否与证书主题或其它 DNS 名称匹配。如果不需要,您可以禁用主机名验证。
禁用 TLS 主机名验证示例
authentication:
type: oauth
tokenEndpointUri: https://sso.myproject.svc:8443/auth/realms/internal/protocol/openid-connect/token
clientId: my-client-id
refreshToken:
secretName: my-refresh-token-secret
key: refresh-token
disableTlsHostnameVerification: true
type 属性是一个光盘,它区分使用 KafkaClientAuthenticationOAuth 类型与 KafkaClientAuthenticationTls、KafkaClientAuthenticationScramSha512、KafkaClientAuthenticationPlain。它必须具有类型 KafkaClientAuthenticationOAuth 的值 oauth。
| 属性 | 描述 |
|---|---|
| accessToken | 包含从授权服务器获取的访问令牌的 OpenShift Secret 链接。 |
| accessTokenIsJwt |
配置是否应将访问令牌视为 JWT。如果授权服务器返回不透明令牌,这应当设为 |
| 布尔值 | |
| clientId | Kafka 客户端 ID,可用于对 OAuth 服务器进行身份验证并使用令牌端点 URI。 |
| 字符串 | |
| clientSecret | 含有 OAuth 客户端机密的 OpenShift Secret 链接,Kafka 客户端可以使用该机密对 OAuth 服务器进行身份验证并使用令牌端点 URI。 |
| disableTlsHostnameVerification |
启用或禁用 TLS 主机名验证。默认值为 |
| 布尔值 | |
| maxTokenExpirySeconds | 将访问令牌的寿命限制为指定的秒数。如果授权服务器返回不透明令牌,则应设置此项。 |
| 整数 | |
| refreshToken | 包含刷新令牌的 OpenShift Secret 链接,可用于从授权服务器获取访问令牌。 |
| scope |
针对授权服务器进行身份验证时使用的 OAuth 范围。些授权服务器要求进行此设置。可能的值取决于授权服务器的配置方式。默认情况下,执行令牌端点请求时不指定 |
| 字符串 | |
| tlsTrustedCertificates | TLS 连接到 OAuth 服务器的可信证书。 |
| tokenEndpointUri | 授权服务器令牌端点 URI. |
| 字符串 | |
| type |
必须是 |
| 字符串 |
B.87. Jaegertracing 模式参考
用于:KafkaBridgeSpec, KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec, KafkaMirrorMakerSpec
type 属性是一个分级器,用于区分 JaegerTracing 类型和将来可能添加的其他子类型。它必须具有类型 JaegerTracing 的 jaeger 值。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 |
B.88. KafkaConnectTemplate 模式参考
用于:KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
| 属性 | 描述 |
|---|---|
| 部署 |
Kafka Connect |
| Pod |
Kafka Connect |
| apiService |
Kafka Connect API |
| connectContainer | Kafka Connect 容器的模板。 |
| initContainer | Kafka init 容器的模板。 |
| podDisruptionBudget |
Kafka Connect |
B.89. ExternalConfiguration 架构参考
用于:KafkaConnectS2ISpec, KafkaConnectSpec, KafkaMirrorMaker2Spec
配置外部存储属性,为 Kafka Connect 连接器定义配置选项。
您可以将 ConfigMap 或 Secret 挂载到 Kafka Connect pod 中,作为环境变量或卷。卷和环境变量在 KafkaConnect .spec 和 中的 KafkaConnectS2I.spec externalConfiguration 属性中配置。
应用后,可在开发连接器时使用环境变量和卷。
B.89.1. env
env 属性用于指定一个或多个环境变量。这些变量可以包含 ConfigMap 或 Secret 中的值。
包含环境变量值的 Secret 示例
apiVersion: v1 kind: Secret metadata: name: aws-creds type: Opaque data: awsAccessKey: QUtJQVhYWFhYWFhYWFhYWFg= awsSecretAccessKey: Ylhsd1lYTnpkMjl5WkE=
用户定义的环境变量的名称不能以 KAFKA_ 或 开头。
STRIMZI_
要将值从 Secret 挂载到环境变量,请使用 valueFrom 属性和 secretKeyRef。
设置为 Secret 中值的示例环境变量
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aws-creds
key: awsAccessKey
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aws-creds
key: awsSecretAccessKey
当您的连接器需要与 Amazon AWS 通信时,将 Secret 挂载到环境变量的一个常见用例需要读取 AWS_ACCESS_KEY_ID 和 AWS_SECRET_ACCESS_KEY 环境变量与凭据。
要将 ConfigMap 的值挂载到环境变量,请使用 valueFrom 属性中的 configMapKeyRef,如下例所示。
设置为 ConfigMap 中值的环境变量示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
externalConfiguration:
env:
- name: MY_ENVIRONMENT_VARIABLE
valueFrom:
configMapKeyRef:
name: my-config-map
key: my-key
B.89.2. 卷
您还可以将 ConfigMap 或 Secret 挂载到 Kafka Connect pod 中作为卷。
在以下情况下,使用卷而不是环境变量会很有用:
- 使用 TLS 证书挂载信任存储或密钥存储
- 挂载用来配置 Kafka Connect 连接器的属性文件
具有属性的 Secret 示例
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque stringData: connector.properties: |- 1 dbUsername: my-user 2 dbPassword: my-password
在本例中,名为 mysecret 的 Secret 挂载到名为 connector -config 的卷。在 config 属性中 指定配置提供程序(FileConfigProvider),它将从外部来源加载配置值。Kafka FileConfigProvider 被分配了别名 文件,并将从文件读取和提取要在连接器配置中使用的数据库 用户名和密码 属性值。
外部卷示例设置为来自 Secret 的值
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect
spec:
# ...
config:
config.providers: file 1
config.providers.file.class: org.apache.kafka.common.config.provider.FileConfigProvider 2
#...
externalConfiguration:
volumes:
- name: connector-config 3
secret:
secretName: mysecret 4
卷挂载到 Kafka Connect 容器的 /opt/kafka/external-configuration/<volume-name> 中。例如,名为 connector -config 的卷中的文件将显示在 /opt/kafka/external-configuration/connector-config 目录中。
FileConfigProvider 用于读取连接器配置中挂载的属性文件中的值。
| 属性 | 描述 |
|---|---|
| env | 允许将数据从 Secret 或 ConfigMap 传递给 Kafka Connect Pod 作为环境变量。 |
| 卷 | 允许将数据从 Secret 或 ConfigMap 传递给 Kafka Connect Pod 作为卷。 |
B.90. ExternalConfigurationEnv 模式参考
| 属性 | 描述 |
|---|---|
| name |
传递给 Kafka Connect Pod 的环境变量的名称。环境变量的名称不能以 |
| 字符串 | |
| valueFrom | 传递给 Kafka Connect Pod 的环境变量的值。它可以作为对 Secret 或 ConfigMap 字段的引用来传递。该字段必须指定一个 Secret 或 ConfigMap。 |
B.91. ExternalConfigurationEnvVarSource 模式参考
| 属性 | 描述 |
|---|---|
| configMapKeyRef | 引用 ConfigMap 中的键.请参阅 core/v1 configmapkeyselector 的外部文档。 |
| secretKeyRef | 在机密中引用密钥.请参阅 core/v1 secretkeyselector 的外部文档。 |
B.92. ExternalConfigurationVolumeSource 模式引用
| 属性 | 描述 |
|---|---|
| configMap | 引用 ConfigMap 中的键。只需要指定一个 Secret 或 ConfigMap。请参阅 core/v1 configmapvolumesource 的外部文档。 |
| name | 添加到 Kafka Connect Pod 的卷名称。 |
| 字符串 | |
| Secret | 在机密中引用密钥.只需要指定一个 Secret 或 ConfigMap。请参阅 core/v1 secretvolumesource 的外部文档。 |
B.93. KafkaConnectStatus 模式参考
用于:KafkaConnect
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| url | 用于管理和监控 Kafka Connect 连接器的 REST API 端点 URL。 |
| 字符串 | |
| connectorPlugins | 此 Kafka Connect 部署中可用的连接器插件列表。 |
| labelSelector | 提供此资源的 pod 的标签选择器。 |
| 字符串 | |
| replicas | 用于提供此资源的当前容器集数量。 |
| 整数 |
B.94. ConnectorPlugin 架构参考
用于:KafkaConnectS2IStatus, KafkaConnectStatus, KafkaMirrorMaker2Status
| 属性 | 描述 |
|---|---|
| type |
连接器插件的类型。可用的类型是 |
| 字符串 | |
| version | 连接器插件的版本。 |
| 字符串 | |
| class | 连接器插件的类。 |
| 字符串 |
B.95. KafkaConnectS2I 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka Connect Source-to-Image(S2I)集群的规格。 |
| status | Kafka Connect Source-to-Image(S2I)集群的状态。 |
B.96. KafkaConnectS2ISpec 模式参考
配置支持 Source-to-Image(S2I)支持的 Kafka Connect 集群。
在 OpenShift 上(仅限使用连接器插件)扩展 Kafka Connect 时,您可以使用 OpenShift 构建和 S2I 创建供 Kafka Connect 部署使用的容器镜像。
配置选项使用 Kafka ConnectSpec 模式与 Kafka Connect 配置类似。
| 属性 | 描述 |
|---|---|
| replicas | Kafka Connect 组中的 pod 数量。 |
| 整数 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| buildResources | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| jvmOptions | 容器集的 JVM 选项. |
| 关联性 |
属性 |
| logging |
Kafka Connect 的日志配置.类型取决于给定对象中的 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map | |
| 模板 |
Kafka Connect 和 Kafka Connect S2I 资源的模板。该模板允许用户指定如何生成 |
| 身份验证 |
Kafka Connect 的身份验证配置.这个类型取决于给定对象中的 |
|
| |
| bootstrapServers | 引导服务器以进行连接。这应该以逗号分隔的 <hostname>: ›<port> 对列表指定。 |
| 字符串 | |
| clientRackInitImage |
用于初始化 |
| 字符串 | |
| config | Kafka Connect 配置。无法设置带有以下前缀的属性:ssl.、sasl.、security.、listeners、plugin.path、re.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes(除:ssl.endpoint.identification.algorithm 除外) SSL.cipher.suites、ssl.protocol、ssl.enabled.protocols。 |
| map | |
| externalConfiguration | 将数据从 Secret 或 ConfigMap 传递给 Kafka Connect Pod,并使用它们来配置连接器。 |
| insecureSourceRepository | 当为 true 时,这会使用 'Local' 引用策略和接受不安全源标签的导入策略来配置源存储库。 |
| 布尔值 | |
| rack | 配置节点标签,该标签将用作 client.rack consumer 配置。 |
| 资源 | CPU 和内存资源以及请求的初始资源的最大限值。请参阅 内核/v1 资源要求的外部文档。 |
| tls | TLS 配置。 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| tracing |
Kafka Connect 中的追踪配置。类型取决于给定对象中 |
| version | Kafka Connect 版本。默认值为 2.6.0。请参阅用户文档以了解升级或降级版本所需的流程。 |
| 字符串 |
B.97. KafkaConnectS2IStatus 模式参考
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| url | 用于管理和监控 Kafka Connect 连接器的 REST API 端点 URL。 |
| 字符串 | |
| connectorPlugins | 此 Kafka Connect 部署中可用的连接器插件列表。 |
| buildConfigName | 构建配置的名称。 |
| 字符串 | |
| labelSelector | 提供此资源的 pod 的标签选择器。 |
| 字符串 | |
| replicas | 用于提供此资源的当前容器集数量。 |
| 整数 |
B.98. KafkaTopic 架构参考
| 属性 | 描述 |
|---|---|
| spec | 主题的规范。 |
| status | 主题的状态。 |
B.99. KafkaTopicSpec 模式参考
用于:KafkaTopic
| 属性 | 描述 |
|---|---|
| 分区 | 主题应具有的分区数量。这在主题创建后不能减少。可在主题创建后增加,但务必要了解其结果,特别是对于语义分区的主题。 |
| 整数 | |
| replicas | 主题应具有的副本数。 |
| 整数 | |
| config | 主题配置。 |
| map | |
| topicName | 主题的名称。如果没有,这将默认为主题的 metadata.name。除非主题名称不是有效的 OpenShift 资源名称,否则建议不要设置此项。 |
| 字符串 |
B.100. KafkaTopicStatus 模式参考
用于:KafkaTopic
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 |
B.101. KafkaUser 架构参考
| 属性 | 描述 |
|---|---|
| spec | 用户的规范。 |
| status | Kafka 用户的状态。 |
B.102. KafkaUserSpec 模式参考
用于:kafkaUser
| 属性 | 描述 |
|---|---|
| 身份验证 |
为此 Kafka 用户启用身份验证机制。类型取决于给定对象中的 |
|
| |
| 授权 |
此 Kafka 用户的授权规则。类型取决于给定对象中的 |
| 配额 | 控制客户端使用的代理资源的请求配额。可以强制执行网络带宽和请求速率配额。有关 Kafka 用户配额的 Kafka 文档,请访问 |
| 模板 |
模板,以指定如何生成 |
B.103. KafkaUserTlsClientAuthentication 模式参考
type 属性是一个缺点,它区分了使用 KafkaUserTlsClientAuthentication 和 KafkaUserScramSha512ClientAuthentication 的类型。它必须具有类型 KafkaUserTlsClientAuthentication 的值 tls。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 |
B.104. KafkaUserScramSha512ClientAuthentication 模式参考
type 属性是一个缺点,它从 KafkaUser TlsClientAuthentication 中区分使用类型 。它必须具有类型 KafkaUserScramSha512ClientAuthentication KafkaUserScramSha512ClientAuthentication 的值 scr am-sha-512。
| 属性 | 描述 |
|---|---|
| type |
必须是 scr |
| 字符串 |
B.105. KafkaUserAuthorizationSimple schema 参考
type 属性是一个缺点,它区分了使用 KafkaUserAuthorizationSimple 的类型和将来可能添加的其他子类型。它的值 对于 KafkaUserAuthorizationSimple 类型必须简单。
| 属性 | 描述 |
|---|---|
| type |
必须 |
| 字符串 | |
| ACL | 应应用于此用户的 ACL 规则的列表。 |
|
|
B.106. AclRule 架构参考
用于:KafkaUserAuthorizationSimple
在代理使用 AclAuthorizer 时,为 KafkaUser 配置访问控制规则。
授权的 KafkaUser 配置示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
# ...
authorization:
type: simple
acls:
- resource:
type: topic
name: my-topic
patternType: literal
operation: Read
- resource:
type: topic
name: my-topic
patternType: literal
operation: Describe
- resource:
type: group
name: my-group
patternType: prefix
operation: Read
B.106.1. resource
使用 resource 属性指定规则应用到的资源。
简单授权支持四种资源类型,它们在 type 属性中指定:
-
主题(主题) -
消费者组(
组) -
集群(集群) -
事务 ID(
actionId)
对于主题、组和事务 ID 资源,您可以在 name 属性中指定规则应用到的资源名称。
集群类型资源没有名称。
使用 patternType 属性将名称指定为 字面 或 前缀。
-
字面名称与在
name字段中指定完全相同。 -
前缀名称使用
名称中的值作为前缀,并将规则应用于名称以值开头的所有资源。
B.106.2. type
规则 类型,即允许 或拒绝 (目前不支持)操作。
type 字段是可选的。如果未指定 类型,则 ACL 规则被视为 允许 规则。
B.106.3. 操作
为规则指定允许或拒绝 的操作。
支持以下操作:
- 读
- 写
- 删除
- 更改
- describe
- All
- IdempotentWrite
- ClusterAction
- 创建
- AlterConfigs
- DescribeConfigs
只有某些操作可以与每个资源配合使用。
有关 AclAuthorizer、AclAuthorizer、ACL 和支持的资源与操作组合的详情,请参阅 授权和 ACL。
B.106.4. 主机
使用 host 属性指定允许或拒绝该规则的远程主机。
使用星号(*)来允许或拒绝来自所有主机的操作。host 字段是可选的。如果未指定 主机,则默认使用 * 值。
| 属性 | 描述 |
|---|---|
| 主机 | ACL 规则中描述的操作被允许或拒绝的主机。 |
| 字符串 | |
| 操作 | 允许或拒绝的操作.支持的操作有:read、Write、Create、Delete、Describe、ClusterAction、AlterConfigs、DescribeConfigs、IdempotentWrite 和 All. |
| 字符串([Read, Write, Delete, Alter, Describe, All, IdempotentWrite, ClusterAction, Create, AlterConfigs, DescribeConfigs]) | |
| resource |
指明对其应用给定 ACL 规则的资源。该类型取决于给定对象中的 |
|
| |
| type |
规则的类型。目前唯一支持的类型是 |
| 字符串( [allow, deny] 之一) |
B.107. AclRuleTopicResource 模式参考
用于:AclRule
type 属性是一个 Red Hatcriminator,它区分了 AclRuleTopicResource 和 AclRuleGroupResource、AclRuleClusterResource、AclRuleTransactionalIdResource 的用法。它必须具有类型 AclRuleTopicResource 的值 主题。
| 属性 | 描述 |
|---|---|
| type |
必须成为 |
| 字符串 | |
| name |
给定 ACL 规则所应用的资源名称。可以和 |
| 字符串 | |
| patternType |
描述 resource 字段中所用的模式。支持的类型是 |
| 字符串([前缀、字面] 之一) |
B.108. AclRuleGroupResource 模式参考
用于:AclRule
type 属性是一个 Red Hatcriminator,它区分 AclRuleGroupResource 和 AclRuleTopicResource、AclRuleClusterResource、AclRuleTransactionalIdResource 的用法。它必须具有类型 AclRuleGroupResource 的值 组。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 | |
| name |
给定 ACL 规则所应用的资源名称。可以和 |
| 字符串 | |
| patternType |
描述 resource 字段中所用的模式。支持的类型是 |
| 字符串([前缀、字面] 之一) |
B.109. AclRuleClusterResource 模式参考
用于:AclRule
type 属性是一个 Red Hatcriminator,它区分 AclRuleClusterResource 和 AclRuleTopicResource、AclRuleGroupResource、AclRuleTransactionalIdResource 的用法。它必须具有类型 AclRuleClusterResource 的值 cluster。
| 属性 | 描述 |
|---|---|
| type |
必须是 |
| 字符串 |
B.110. AclRuleTransactionalIdResource 模式参考
用于:AclRule
type 属性是一个离散器,它区分 AclRuleTransactionalIdResource 和 AclRule 、TopicResource、AclRule GroupResource、AclRuleClusterResource AclRuleClusterResource 的用法。它的值必须为 AclRuleTransactionalIdResource 类型。
| 属性 | 描述 |
|---|---|
| type |
必须为 |
| 字符串 | |
| name |
给定 ACL 规则所应用的资源名称。可以和 |
| 字符串 | |
| patternType |
描述 resource 字段中所用的模式。支持的类型是 |
| 字符串([前缀、字面] 之一) |
B.111. KafkaUserQuotas 架构参考
Kafka 允许用户设置 配额 来控制客户端的资源使用。
B.111.1. quotas
配额分为两个类别:
- 网络用量 配额,定义为共享配额的每个客户端组的字节速率阈值
- CPU 使用率 配额,定义为客户端在配额窗口中每个代理的 I/O 线程和网络线程使用的时间百分比
在很多情形中,为 Kafka 客户端使用配额可能会很有用。考虑错误配置的 Kafka 制作者,它以太高的速率发送请求。这种错误配置可能会导致服务拒绝给其他客户端,因此有问题的客户端会被阻止。通过使用网络限制配额,可以防止这种情况严重影响其他客户端。
AMQ Streams 支持用户级配额,但不支持客户端级别的配额。
Kafka 用户配额示例
spec:
quotas:
producerByteRate: 1048576
consumerByteRate: 2097152
requestPercentage: 55
有关 Kafka 用户配额的更多信息,请参阅 Apache Kafka 文档。
| 属性 | 描述 |
|---|---|
| consumerByteRate | 每个客户端组可以在对组中的客户端进行节流前从代理获取的最大字节数的配额。按每个代理定义. |
| 整数 | |
| producerByteRate | 每个客户端组可以发布至代理的最大字节数的配额,然后再对组中的客户端进行节流。按每个代理定义. |
| 整数 | |
| requestPercentage | 每个客户端组的最大 CPU 使用率配额作为网络和 I/O 线程的百分比。 |
| 整数 |
B.112. KafkaUserTemplate 模式参考
为 User Operator 创建的 secret 指定额外的标签和注解。
显示 KafkaUserTemplate的示例
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: my-user
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
template:
secret:
metadata:
labels:
label1: value1
annotations:
anno1: value1
# ...
| 属性 | 描述 |
|---|---|
| Secret |
KafkaUser 资源的模板。该模板允许用户指定如何生成密码或 TLS 证书的 |
B.113. KafkaUserStatus 模式参考
用于:kafkaUser
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| username | 用户名. |
| 字符串 | |
| Secret |
存储凭证的 |
| 字符串 |
B.114. KafkaMirrorMaker 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka MirrorMaker 的规格。 |
| status | Kafka MirrorMaker 的状态。 |
B.115. KafkaMirrorMakerSpec 模式参考
配置 Kafka MirrorMaker。
B.115.1. whitelist
使用 whitelist 属性配置 Kafka MirrorMaker 镜像从源到目标 Kafka 集群的主题列表。
属性允许从最简单的情况下通过单个主题名称到复杂的模式的任何正则表达式。例如,您可以使用 "A|B" 或所有主题(*)来镜像主题 A 和 B。您还可以将用逗号分开的多个正则表达式传递给 Kafka MirrorMaker。
B.115.2. KafkaMirrorMakerConsumerSpec and KafkaMirrorMakerProducerSpec
使用 KafkaMirrorMakerConsumerSpec 和 KafkaMirrorMakerProducerSpec 配置源(消费者)和目标(producer)集群。
Kafka MirrorMaker 总是与两个 Kafka 集群(源和目标)一同工作。要建立连接,源的 bootstrap 服务器和目标 Kafka 集群的 bootstrap 服务器被指定为用逗号分隔的 HOSTNAME:PORT 对列表。每个以逗号分开的列表包含一个或多个 Kafka 代理,或者指向指定为 HOSTNAME:PORT 对的 Kafka 代理 的服务。
B.115.3. logging
Kafka MirrorMaker 拥有自己的可配置日志记录器:
-
mirrormaker.root.logger
MirrorMaker 使用 Apache log4j 日志记录器实现。
使用 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j.properties 进行 描述。有关日志级别的更多信息,请参阅 Apache 日志记录服务。
在这里,我们会看到 内联 和外部 日志记录示例:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaMirrorMaker
spec:
# ...
logging:
type: inline
loggers:
mirrormaker.root.logger: "INFO"
# ...apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaMirrorMaker
spec:
# ...
logging:
type: external
name: customConfigMap
# ...垃圾收集器(GC)
也可以使用 jvmOptions 属性 来启用(或禁用)垃圾收集器日志记录。
| 属性 | 描述 |
|---|---|
| replicas |
|
| 整数 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| whitelist |
镜像中包含的主题列表。此选项允许任何使用 Java 样式的正则表达式的正则表达式。使用白名单 |
| 字符串 | |
| consumer | 源集群配置. |
| producer | 目标集群的配置. |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| jvmOptions | 容器集的 JVM 选项. |
| logging |
MirrorMaker 的日志记录配置.类型取决于给定对象中的 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请参阅 JMX Exporter 文档。 |
| map | |
| tracing |
Kafka MirrorMaker 中的追踪配置。类型取决于给定对象中 |
| 模板 |
模板,以指定如何生成 Kafka MirrorMaker 资源、 |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| version | Kafka MirrorMaker 版本。默认值为 2.6.0。请参阅相关文档,以了解升级或降级版本所需的流程。 |
| 字符串 |
B.116. KafkaMirrorMakerConsumerSpec 模式参考
配置 MirrorMaker 使用者。
B.116.1. numStreams
使用 consumer.numStreams 属性配置使用者的流数。
您可以通过增加消费者线程的数量来提高镜像主题中的吞吐量。消费者线程属于为 Kafka MirrorMaker 指定的使用者组。主题分区在使用者线程之间分配,消费者线程并行使用消息。
B.116.2. offsetCommitInterval
使用 consumer.offsetCommitInterval 属性为使用者配置偏移自动提交间隔。
您可以指定在 Kafka MirrorMaker 消耗源 Kafka 集群的数据后提交偏移的常规时间间隔。时间间隔以毫秒为单位设置,默认值为 84。
B.116.3. config
使用 consumer.config 属性为消费者配置 Kafka 选项。
config 属性包含 Kafka MirrorMaker consumer 配置选项作为键,其值以以下 JSON 类型之一的形式设置:
- 字符串
- 数字
- 布尔值
对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。您还可以 配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
例外
您可以为消费者指定并配置 Apache Kafka 配置文档 中列出的选项。
但是,与以下相关的 AMQ Streams 会自动配置和管理的选项会有例外:
- Kafka 集群 bootstrap 地址
- 安全(加密、身份验证和授权)
- 消费者组标识符
- 拦截器
具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
bootstrap.servers -
group.id -
interceptor.classes -
SSL.(不包括特定例外) -
SASL. -
安全性.
当 config 属性中存在禁止选项时,会忽略它,并把警告信息输出到 Cluster Operator 日志文件中。所有其他选项都传递给 Kafka MirrorMaker。
Cluster Operator 不会验证提供的 config 对象中的密钥或值。当提供无效的配置时,Kafka MirrorMaker 可能无法启动或可能变得不稳定。在这种情况下,Kafka MirrorMaker.spec.consumer.config 对象中的配置应该被修复,Cluster Operator 将推出 Kafka MirrorMaker 的新配置。
B.116.4. groupId
使用 consumer.groupId 属性为使用者配置使用者组标识符。
Kafka MirrorMaker 使用 Kafka 使用者来消耗消息,与任何其他 Kafka 消费者客户端一样。从源 Kafka 集群使用的消息会镜像到目标 Kafka 集群。需要组标识符,因为使用者需要成为分配分区的消费者组的一部分。
| 属性 | 描述 |
|---|---|
| numStreams | 指定要创建的消费者流线程数量。 |
| 整数 | |
| offsetCommitInterval | 以 ms 为单位指定偏移自动提交间隔。默认值为 60000。 |
| 整数 | |
| groupId | 个唯一字符串,用于标识该消费者所属的消费者组。 |
| 字符串 | |
| bootstrapServers | 用于建立与 Kafka 集群的初始连接的 host:port 对列表。 |
| 字符串 | |
| 身份验证 |
用于连接到集群的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| config | MirrorMaker 消费者配置.无法设置带有以下前缀的属性: ssl.、bootstrap.servers、group.id、sasl.、security.、拦截器.classes(ssl.endpoint.identification.algorithm、ssl.cipher.suites、ssl.protocol、ssl.enabled.protocols 除外)。 |
| map | |
| tls | 将 MirrorMaker 连接到集群的 TLS 配置。 |
B.117. KafkaMirrorMakerTls 模式参考
用于:KafkaMirrorMakerConsumerSpec, KafkaMirrorMakerProducerSpec
配置 TLS 可信证书,以将 MirrorMaker 连接到集群。
B.117.1. trustedCertificates
使用 trustedCertificates 属性提供 secret 列表。
| 属性 | 描述 |
|---|---|
| trustedCertificates | TLS 连接的可信证书。 |
B.118. KafkaMirrorMakerProducerSpec schema reference
配置 MirrorMaker 制作者。
B.118.1. abortOnSendFailure
使用 producer.abortOnSendFailure 属性来配置如何处理来自生产者的消息发送失败。
默认情况下,如果在从 Kafka MirrorMaker 发送消息到 Kafka 集群时发生错误:
- Kafka MirrorMaker 容器在 OpenShift 中终止。
- 然后,重新创建容器。
如果 abort OnSendFailure 选项设为 false,则忽略发送错误的消息。
B.118.2. config
使用 producer.config 属性为制作者配置 Kafka 选项。
config 属性包含 Kafka MirrorMaker producer 配置选项作为键,其值在以下 JSON 类型之一中设置:
- 字符串
- 数字
- 布尔值
对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。您还可以 配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
例外
您可以为生产者指定并配置 Apache Kafka 配置文档 中列出的选项。
但是,与以下相关的 AMQ Streams 会自动配置和管理的选项会有例外:
- Kafka 集群 bootstrap 地址
- 安全(加密、身份验证和授权)
- 拦截器
具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
bootstrap.servers -
interceptor.classes -
SSL.(不包括特定例外) -
SASL. -
安全性.
当 config 属性中存在禁止选项时,会忽略它,并把警告信息输出到 Cluster Operator 日志文件中。所有其他选项都传递给 Kafka MirrorMaker。
Cluster Operator 不会验证提供的 config 对象中的密钥或值。当提供无效的配置时,Kafka MirrorMaker 可能无法启动或可能变得不稳定。在这种情况下,Kafka MirrorMaker.spec.producer.config 对象中的配置应该被修复,Cluster Operator 将推出 Kafka MirrorMaker 的新配置。
| 属性 | 描述 |
|---|---|
| bootstrapServers | 用于建立与 Kafka 集群的初始连接的 host:port 对列表。 |
| 字符串 | |
| abortOnSendFailure |
将 MirrorMaker 设置为在失败发送时退出的标记。默认值为 |
| 布尔值 | |
| 身份验证 |
用于连接到集群的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| config | MirrorMaker 制作者配置.无法设置带有以下前缀的属性: ssl.、bootstrap.servers、sasl.、security.、拦截器.classes(ssl.endpoint.identification.algorithm、ssl.cipher.suites、ssl.protocols、ssl.protocols.protocols 除外)。 |
| map | |
| tls | 将 MirrorMaker 连接到集群的 TLS 配置。 |
B.119. KafkaMirrorMakerTemplate 模式参考
| 属性 | 描述 |
|---|---|
| 部署 |
Kafka MirrorMaker |
| Pod |
Kafka MirrorMaker |
| mirrorMakerContainer | Kafka MirrorMaker 容器模板。 |
| podDisruptionBudget |
Kafka MirrorMaker |
B.120. KafkaMirrorMakerStatus 模式参考
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| labelSelector | 提供此资源的 pod 的标签选择器。 |
| 字符串 | |
| replicas | 用于提供此资源的当前容器集数量。 |
| 整数 |
B.121. KafkaBridge 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka 网桥的规格。 |
| status | Kafka 网桥的状态。 |
B.122. KafkaBridgeSpec 模式参考
用于:KafkaBridge
配置 Kafka Bridge 集群。
配置选项与:
- Kafka 集群 bootstrap 地址
- 安全(加密、身份验证和授权)
- 使用者配置
- 制作者配置
- HTTP 配置
B.122.1. logging
Kafka Bridge 有自己的可配置日志记录器:
-
logger.bridge -
logger.<operation-id>
您可以替换 日志记录器中的 为特定操作设置日志级别:
<operation-id> 。<operation-id> logger
-
createConsumer -
deleteConsumer -
订阅 -
取消订阅 -
poll -
assign -
commit -
send -
sendToPartition -
seekToBeginning -
seekToEnd -
寻道 -
healthy -
ready -
openapi
每个操作都按照 OpenAPI 规范定义,并且具有一个对应的 API 端点,该端点用于接收来自 HTTP 客户端的请求。您可以更改每个端点的日志级别,以创建关于传入和传出 HTTP 请求的精细日志信息。
每个日志记录器都必须 配置为 http.openapi.operation.<operation-id>。例如,为 发送 操作日志记录器配置日志级别意味着定义以下内容:
logger.send.name = http.openapi.operation.send logger.send.level = DEBUG
Kafka Bridge 使用 Apache log4j2 日志记录器实施。日志记录器在 log4j2.properties 文件中定义,该文件具有 健康和 就绪 端点的以下默认配置:
logger.healthy.name = http.openapi.operation.healthy logger.healthy.level = WARN logger.ready.name = http.openapi.operation.ready logger.ready.level = WARN
所有其他操作的日志级别默认设置为 INFO。
使用 logging 属性来配置日志记录器和日志记录器级别。
您可以通过直接(内线)指定日志记录器和级别来设置日志级别,或使用自定义(外部)ConfigMap。如果使用 ConfigMap,则将 logging.name 属性设置为包含外部日志配置的 ConfigMap 的名称。在 ConfigMap 中,日志配置使用 log4j.properties 进行 描述。有关日志级别的更多信息,请参阅 Apache 日志记录服务。
此处我们会看到 内联 和外部 记录示例。
内联日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaBridge
spec:
# ...
logging:
type: inline
loggers:
logger.bridge.level: "INFO"
# enabling DEBUG just for send operation
logger.send.name: "http.openapi.operation.send"
logger.send.level: "DEBUG"
# ...
外部日志记录
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaBridge
spec:
# ...
logging:
type: external
name: customConfigMap
# ...
任何未配置可用的日志记录器将其级别设置为 OFF。
如果使用 Cluster Operator 部署 Kafka Bridge,则会动态应用 Kafka Bridge 日志级别。
如果使用外部日志记录,当日志附加程序被更改时会触发滚动更新。
垃圾收集器(GC)
也可以使用 jvmOptions 属性 来启用(或禁用)垃圾收集器日志记录。
| 属性 | 描述 |
|---|---|
| replicas |
|
| 整数 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| bootstrapServers | 用于建立与 Kafka 集群的初始连接的 host:port 对列表。 |
| 字符串 | |
| tls | 将 Kafka Bridge 连接到集群的 TLS 配置。 |
| 身份验证 |
用于连接到集群的身份验证配置。这个类型取决于给定对象中的 |
|
| |
| http | 与 HTTP 相关的配置。 |
| consumer | Kafka 消费者相关配置。 |
| producer | Kafka 制作者相关配置。 |
| 资源 | 要保留的 CPU 和内存资源。请参阅 内核/v1 资源要求的外部文档。 |
| jvmOptions | 目前不支持 pod 的 JVM 选项。 |
| logging |
日志记录 Kafka 网桥配置.类型取决于给定对象中的 |
| enableMetrics | 为 Kafka 网桥启用指标。默认值为 false。 |
| 布尔值 | |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| 模板 |
Kafka Bridge 资源的模板。该模板允许用户指定如何生成 |
| tracing |
在 Kafka 网桥中追踪的配置。类型取决于给定对象中 |
B.123. KafkaBridgeTls 模式参考
| 属性 | 描述 |
|---|---|
| trustedCertificates | TLS 连接的可信证书。 |
B.124. KafkaBridgeHttpConfig schema reference
为 Kafka 网桥配置对 Kafka 集群的 HTTP 访问。
默认 HTTP 配置是 Kafka Bridge 侦听端口 8080。
B.124.1. CORS
除了启用对 Kafka 集群的 HTTP 访问外,HTTP 属性还提供通过跨操作资源共享(CORS)启用和定义 Kafka 网桥访问控制的功能。CORS 是一种 HTTP 机制,它允许浏览器从多个来源访问选定的资源。要配置 CORS,您需要定义允许的资源来源和 HTTP 访问方法列表。对于原始卷,您可以使用 URL 或 Java 正则表达式。
Kafka Bridge HTTP 配置示例
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
http:
port: 8080
cors:
allowedOrigins: "https://strimzi.io"
allowedMethods: "GET,POST,PUT,DELETE,OPTIONS,PATCH"
# ...
| 属性 | 描述 |
|---|---|
| 端口 | 是侦听的服务器的端口。 |
| 整数 | |
| CORS | HTTP 网桥的 CORS 配置. |
B.125. KafkaBridgeHttpCors schema reference
| 属性 | 描述 |
|---|---|
| allowedOrigins | 允许的来源列表。可以使用 Java 正则表达式. |
| 字符串数组 | |
| allowedMethods | 允许的 HTTP 方法列表。 |
| 字符串数组 |
B.126. KafkaBridgeConsumerSpec 模式参考
将 Kafka 网桥的使用者选项配置为密钥。
这些值可以是以下 JSON 类型之一:
- 字符串
- 数字
- 布尔值
您可以为消费者指定并配置 Apache Kafka 配置文档 中列出的选项,但那些直接由 AMQ Streams 管理的选项除外。具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
ssl. -
SASL. -
安全性. -
bootstrap.servers -
group.id
当 config 属性中存在一个禁止选项时,它将被忽略,并会在 Cluster Operator 日志文件中输出警告信息。所有其他选项将传递给 Kafka
Cluster Operator 不验证 config 对象中的键或值。如果提供了无效的配置,Kafka Bridge 集群可能不会启动,或者可能会变得不稳定。修复配置,以便 Cluster Operator 可以将新配置部署到所有 Kafka Bridge 节点。
禁止的选项有例外。对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。
Kafka Bridge consumer 配置示例
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
consumer:
config:
auto.offset.reset: earliest
enable.auto.commit: true
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
ssl.endpoint.identification.algorithm: HTTPS
# ...
| 属性 | 描述 |
|---|---|
| config | Kafka 使用者配置,用于网桥创建的消费者实例。无法设置带有以下前缀的属性: ssl.、bootstrap.servers、group.id、sasl.、security.(ssl.endpoint.identification.algorithm、ssl.cipher.suites、ssl.protocols、ssl.protocols、ssl.enabled.protocols 除外)。 |
| map |
B.127. KafkaBridgeProducerSpec schema reference
将 Kafka 网桥的制作者选项配置为密钥。
这些值可以是以下 JSON 类型之一:
- 字符串
- 数字
- 布尔值
您可以为生产者指定并配置 Apache Kafka 配置文档 中列出的选项,但那些直接由 AMQ Streams 管理的选项除外。具体来说,所有键为等于或以以下任一字符串开头的配置选项将被禁止:
-
ssl. -
SASL. -
安全性. -
bootstrap.servers
当 config 属性中存在一个禁止选项时,它将被忽略,并会在 Cluster Operator 日志文件中输出警告信息。所有其他选项将传递给 Kafka
Cluster Operator 不验证 config 对象中的键或值。如果提供了无效的配置,Kafka Bridge 集群可能不会启动,或者可能会变得不稳定。修复配置,以便 Cluster Operator 可以将新配置部署到所有 Kafka Bridge 节点。
禁止的选项有例外。对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。
Kafka Bridge producer 配置示例
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
producer:
config:
acks: 1
delivery.timeout.ms: 300000
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
ssl.endpoint.identification.algorithm: HTTPS
# ...
| 属性 | 描述 |
|---|---|
| config | Kafka 制作者配置,用于网桥创建的制作者实例。无法设置带有以下前缀的属性:ssl.、bootstrap.servers、sasl. and security. (除 ssl.endpoint.identification.algorithm, ssl.cipher.suites, ssl.protocol, ssl.protocols ssl.enabled.protocols 外)。 |
| map |
B.128. KafkaBridgeTemplate schema reference
| 属性 | 描述 |
|---|---|
| 部署 |
Kafka 网桥 |
| Pod |
Kafka 网桥 |
| apiService |
Kafka Bridge API |
| bridgeContainer | Kafka Bridge 容器的模板。 |
| podDisruptionBudget |
Kafka Bridge |
B.129. KafkaBridgeStatus 模式参考
用于:KafkaBridge
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| url | 外部客户端应用程序可以访问 Kafka 网桥的 URL。 |
| 字符串 | |
| labelSelector | 提供此资源的 pod 的标签选择器。 |
| 字符串 | |
| replicas | 用于提供此资源的当前容器集数量。 |
| 整数 |
B.130. KafkaConnector 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka Connector 的规格。 |
| status | Kafka Connector 的状态。 |
B.131. KafkaConnectorSpec 模式参考
| 属性 | 描述 |
|---|---|
| class | Kafka 连接器的类. |
| 字符串 | |
| tasksMax | Kafka Connector 的任务数量上限。 |
| 整数 | |
| config | Kafka Connector 配置。无法设置以下属性: connector.class、tasks.max。 |
| map | |
| 暂停 | 是否应暂停连接器。默认为false。 |
| 布尔值 |
B.132. KafkaConnectorStatus 模式参考
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| connectorStatus | 连接器状态,如 Kafka Connect REST API 报告。 |
| map | |
| tasksMax | Kafka Connector 的任务数量上限。 |
| 整数 |
B.133. KafkaMirrorMaker2 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka MirrorMaker 2.0 集群的规格。 |
| status | Kafka MirrorMaker 2.0 集群的状态。 |
B.134. KafkaMirrorMaker2Spec 模式参考
| 属性 | 描述 |
|---|---|
| replicas | Kafka Connect 组中的 pod 数量。 |
| 整数 | |
| version | Kafka Connect 版本。默认值为 2.6.0。请参阅用户文档以了解升级或降级版本所需的流程。 |
| 字符串 | |
| 镜像 | 容器集的 docker 镜像。 |
| 字符串 | |
| connectCluster |
用于 Kafka Connect 的集群别名。别名必须与 |
| 字符串 | |
| clusters | 用于镜像的 Kafka 集群。 |
| mirrors | 配置 MirrorMaker 2.0 连接器. |
| 资源 | CPU 和内存资源以及请求的初始资源的最大限值。请参阅 内核/v1 资源要求的外部文档。 |
| livenessProbe | Pod 存活度检查. |
| readinessProbe | Pod 就绪度检查。 |
| jvmOptions | 容器集的 JVM 选项. |
| 关联性 |
属性 |
| 容限(tolerations) |
属性 |
| 容限 数组 | |
| logging |
Kafka Connect 的日志配置.类型取决于给定对象中的 |
| metrics | Prometheus JMX 导出器配置.有关此配置结构的详情,请查看 https://github.com/prometheus/jmx_exporter。 |
| map | |
| tracing |
Kafka Connect 中的追踪配置。类型取决于给定对象中 |
| 模板 |
Kafka Connect 和 Kafka Connect S2I 资源的模板。该模板允许用户指定如何生成 |
| externalConfiguration | 将数据从 Secret 或 ConfigMap 传递给 Kafka Connect Pod,并使用它们来配置连接器。 |
B.135. KafkaMirrorMaker2ClusterSpec 模式参考
配置 Kafka 集群以进行镜像。
B.135.1. config
使用 配置 属性配置 Kafka 选项。
标准 Apache Kafka 配置可能会提供,仅限于不是由 AMQ Streams 直接管理的属性。
对于使用特定 密码套件 作为 TLS 版本进行客户端连接,您可以配置 allowed ssl 属性。您还可以 配置 ssl.endpoint.identification.algorithm 属性来 启用或禁用主机名验证。
| 属性 | 描述 |
|---|---|
| Alias | 用于引用 Kafka 集群的别名。 |
| 字符串 | |
| bootstrapServers |
用于建立与 Kafka 集群连接的以逗号分隔的 |
| 字符串 | |
| config | MirrorMaker 2.0 集群配置。无法设置带有以下前缀的属性:ssl.、sasl.、security.、listeners、plugin.path、re.、bootstrap.servers、consumer.interceptor.classes、producer.interceptor.classes(除:ssl.endpoint.identification.algorithm 除外) SSL.cipher.suites、ssl.protocol、ssl.enabled.protocols。 |
| map | |
| tls | 用于将 MirrorMaker 2.0 连接器连接到集群的 TLS 配置。 |
| 身份验证 |
用于连接到集群的身份验证配置。这个类型取决于给定对象中的 |
|
|
B.136. KafkaMirrorMaker2Tls 模式参考
用于:KafkaMirrorMaker2ClusterSpec
| 属性 | 描述 |
|---|---|
| trustedCertificates | TLS 连接的可信证书。 |
B.137. KafkaMirrorMaker2MirrorSpec 模式参考
| 属性 | 描述 |
|---|---|
| sourceCluster |
Kafka MirrorMaker 2.0 连接器使用的源集群的别名。别名必须与 |
| 字符串 | |
| targetCluster |
Kafka MirrorMaker 2.0 连接器使用的目标集群的别名。别名必须与 |
| 字符串 | |
| sourceConnector | Kafka MirrorMaker 2.0 源连接器的规格。 |
| checkpointConnector | Kafka MirrorMaker 2.0 checkpoint 连接器的规格。 |
| heartbeatConnector | Kafka MirrorMaker 2.0 heartbeat 连接器的规格。 |
| topicsPattern | 与要镜像的主题匹配的正则表达式,如 "topic1|topic2|topic3"。也支持以逗号分隔的列表。 |
| 字符串 | |
| topicsBlacklistPattern | 与要从镜像中排除的主题匹配的正则表达式。也支持以逗号分隔的列表。 |
| 字符串 | |
| groupsPattern | 与要镜像的使用者组匹配的正则表达式。也支持以逗号分隔的列表。 |
| 字符串 | |
| groupsBlacklistPattern | 与使用者组匹配的正则表达式,从镜像中排除。也支持以逗号分隔的列表。 |
| 字符串 |
B.138. KafkaMirrorMaker2ConnectorSpec 模式参考
用于:KafkaMirrorMaker2MirrorSpec
| 属性 | 描述 |
|---|---|
| tasksMax | Kafka Connector 的任务数量上限。 |
| 整数 | |
| config | Kafka Connector 配置。无法设置以下属性: connector.class、tasks.max。 |
| map | |
| 暂停 | 是否应暂停连接器。默认为false。 |
| 布尔值 |
B.139. KafkaMirrorMaker2Status 模式参考
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| url | 用于管理和监控 Kafka Connect 连接器的 REST API 端点 URL。 |
| 字符串 | |
| connectorPlugins | 此 Kafka Connect 部署中可用的连接器插件列表。 |
| connectors | MirrorMaker 2.0 连接器状态列表,如 Kafka Connect REST API 报告。 |
| 映射数组 | |
| labelSelector | 提供此资源的 pod 的标签选择器。 |
| 字符串 | |
| replicas | 用于提供此资源的当前容器集数量。 |
| 整数 |
B.140. KafkaRebalance 模式参考
| 属性 | 描述 |
|---|---|
| spec | Kafka 重新平衡的规格。 |
| status | Kafka 重新平衡的状态。 |
B.141. KafkaRebalanceSpec 模式参考
| 属性 | 描述 |
|---|---|
| 目标 | 通过降低优先级排序的目标列表,用于生成和执行重新平衡提议。支持的目标位于 https://github.com/linkedin/cruise-control#goals。如果提供空的目标列表,则使用 default.goals Cruise Control 配置参数中声明的目标。 |
| 字符串数组 | |
| skipHardGoalCheck | 是否允许在优化后跳过 Kafka CR 中指定的硬目标。当其中一些困难目标妨碍找到平衡解决方案时,这非常有用。默认值为 false。 |
| 布尔值 | |
| excludedTopics | 在优化计算中排除任何匹配主题的正则表达式。此表达式将由 java.util.regex.Pattern 类解析;有关支持的 formar 的更多信息,请查阅该类的文档。 |
| 字符串 | |
| concurrentPartitionMovementsPerBroker | 持续分区副本移动的上限将进入/退出每个代理。默认值为 5。 |
| 整数 | |
| concurrentIntraBrokerPartitionMovements | 每个代理内磁盘之间连续分区副本移动的上限。默认值为 2。 |
| 整数 | |
| concurrentLeaderMovements | 持续分区领导运动的上限。默认值为 1000。 |
| 整数 | |
| replicationThrottle | 上限(以字节/秒为单位)用于移动副本的带宽上。默认情况下没有限制。 |
| 整数 | |
| replicaMovementStrategies | 用于确定生成优化建议中副本移动的执行顺序的策略类名称列表。默认情况下,使用 BaseReplicaMovementStrategy,它将按照生成副本移动的顺序执行副本移动。 |
| 字符串数组 |
B.142. KafkaRebalanceStatus 模式参考
| 属性 | 描述 |
|---|---|
| conditions | 状态条件列表。 |
|
| |
| observedGeneration | 生成 Operator 最后协调的 CRD。 |
| 整数 | |
| sessionId | 与这个 KafkaRebalance 资源相关的 Cruise Control 的会话标识符。Kafka Rebalance operator 使用它来跟踪正在进行的重新平衡操作的状态。 |
| 字符串 | |
| optimizationResult | 描述优化结果的 JSON 对象。 |
| map |
附录 C. 使用您的订阅
AMQ Streams 通过软件订阅提供。要管理您的订阅,请访问红帽客户门户中的帐户。
访问您的帐户
- 转至 access.redhat.com。
- 如果您还没有帐户,请创建一个帐户。
- 登录到您的帐户。
激活订阅
- 转至 access.redhat.com。
- 导航到 My Subscriptions。
- 导航到 激活订阅 并输入您的 16 位激活号。
下载 Zip 和 Tar 文件
要访问 zip 或 tar 文件,请使用客户门户查找要下载的相关文件。如果您使用 RPM 软件包,则不需要这一步。
- 打开浏览器并登录红帽客户门户网站 产品下载页面,网址为 access.redhat.com/downloads。
- 查找 JBOSS INTEGRATION 类别中 的红帽 AMQ Streams 条目。
- 选择所需的 AMQ Streams 产品。此时会打开 Software Downloads 页面。
- 单击组件的 Download 链接。
修订了 2022 年 2 月 13 日 16:51:01 +1000