
观察环境
请参阅更多信息,了解如何启用和自定义可观察性服务来优化受管集群。
摘要
第 1 章 观察环境简介
启用可观察(observability)服务后,您可以使用 Red Hat Advanced Cluster Management for Kubernetes 深入了解受管集群并进行优化。这些信息可以帮助节约成本并防止不必要的事件发生。
1.1. 观察环境
您可以使用 Red Hat Advanced Cluster Management for Kubernetes 深入了解受管集群并进行优化。启用 observability 服务 operator(multicluster-observability-operator)以监控受管集群的健康状态。在以下部分了解多集群观察服务的架构。
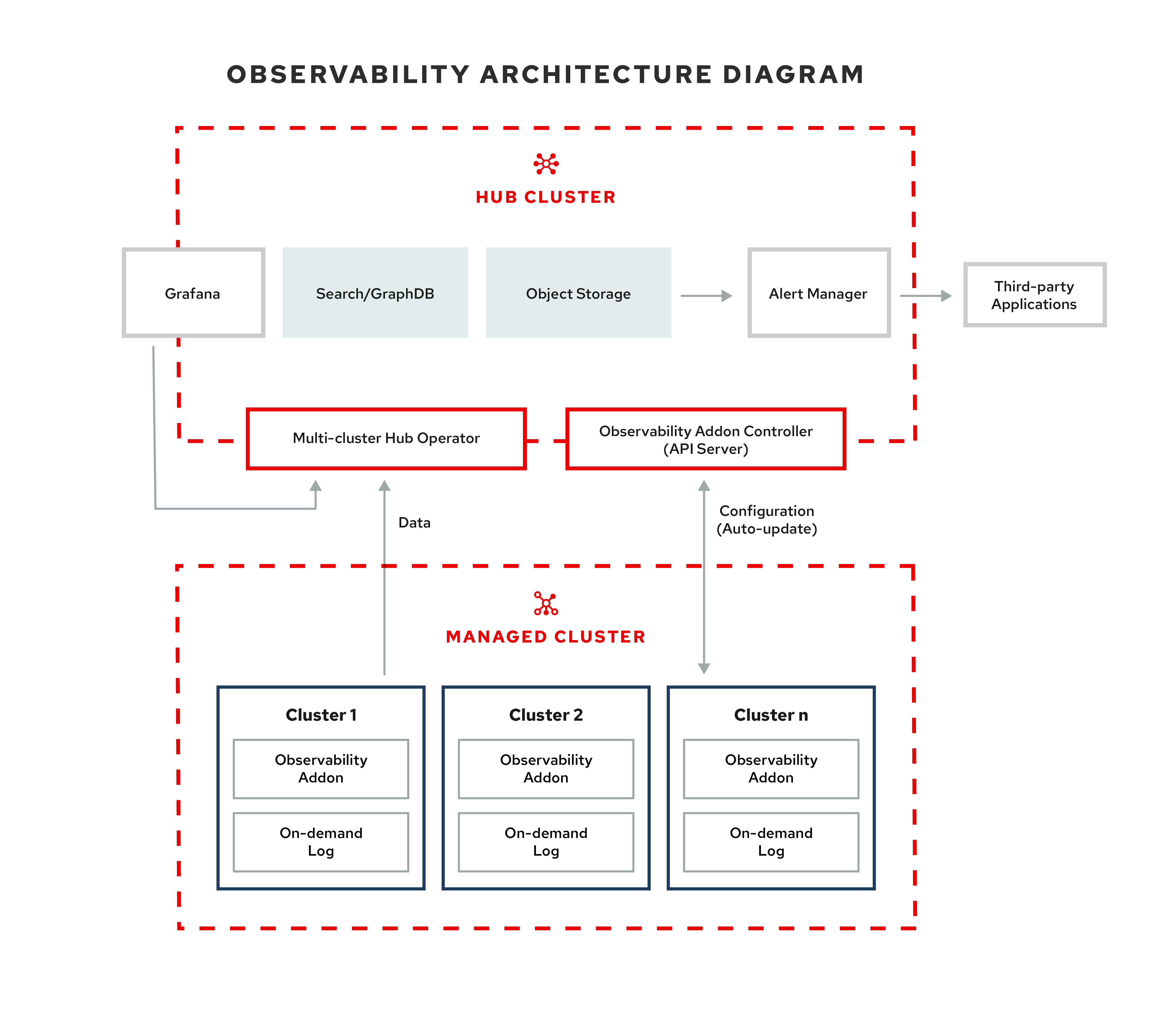
注:按需(on-demand)日志允许工程师实时访问指定 pod 的日志。hub 集群的日志不会被聚合。这些日志可以通过搜索服务以及控制台的其他部分进行访问。
1.1.1. 观察(Observability)服务
默认情况下,产品安装中包含了可观察性(observability)功能,但不启用它。由于对持久性存储的要求,observability 服务默认不会启用。Red Hat Advanced Cluster Management 支持以下 stable 对象存储:
- Amazon S3(或其他 S3 兼容对象存储,如 Ceph)
- Google Cloud Storage
- Azure 存储
- Red Hat OpenShift Container Storage
启用该服务后,observability-endpoint-operator 会自动部署到每个导入或创建的集群中。此控制器从 Red Hat OpenShift Container Platform Prometheus 收集数据,然后将其发送到 Red Hat Advanced Cluster Management hub 集群。
当在 hub 集群中启用可观察性时,通过将 hub 集群作为名为 local-cluster 的受管集群来收集指标。
注:在 Red Hat Advanced Cluster Management 中,只有 Red Hat OpenShift Container Platform 4.x 集群支持 metrics-collector。
observability 服务部署了一个 Prometheus AlertManager 实例,它允许通过第三方应用程序转发警报。它还包括一个 Grafana 实例,通过仪表板(静态)或数据探索启用数据视觉化。Red Hat Advanced Cluster Management 支持 Grafana 的版本 6.4.x。您还可以设计自己的 Grafana 仪表板。如需更多信息,请参阅指定 Grafana 仪表板。
您可以通过创建自定义 记录规则 或 警报规则来自定义可观察性服务。
有关启用可观察性的更多信息,请参阅启用可观察性服务。
1.1.1.1. Observability 证书
Observability 证书会在过期时自动续订。查看以下列表以了解证书自动更新时的影响:
- hub 集群上的组件会自动重启以检索更新的证书。
- Red Hat Advanced Cluster Management 将更新的证书发送到受管集群。
metrics-collector重新启动以挂载更新的证书。注:
metrics-collector可以在证书被删除之前和之后将指标推送到 hub 集群。有关在集群中刷新证书的更多信息,请参阅刷新受管证书。
1.1.1.2. 指标类型
默认情况下,OpenShift Container Platform 使用 Telemetry 服务向红帽发送指标数据。以下附加指标包括在 Red Hat Advanced Cluster Management 中,它们包含在遥测(telemetry)中,但不会显示在 Red Hat Advanced Cluster Management Observe environments overview 仪表板中:
-
visual_web_terminal_sessions_total在 hub 集群上收集。 -
acm_managed_cluster_info在每个受管集群上收集并发送到 hub 集群。
从 OpenShift Container Platform 文档中了解使用遥测来收集并发送哪些指标类型。如需更多信息,请参阅 Telemetry 收集的信息。
1.1.1.3. Observability pod 容量请求
Observability 组件需要 2636mCPU 和 11388Mi 内存来安装可观察性服务。查看以下表了解启用了 observability-addons 的五个受管集群的 pod 容量请求:
表 1.1. Observability pod 容量请求
| Deployment 或 StatefulSet | 容器名称 | CPU(mCPU) | 内存(Mi) | Replicas | Pod 总计 CPU | Pod 内存总量 |
|---|---|---|---|---|---|---|
| alertmanager | alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-observatorium-thanos-query | thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-observatorium-thanos-query-frontend | thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-observatorium-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-observatorium-thanos-receive-default | thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-observatorium-thanos-rule | thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-observatorium-thanos-store-memcached | memcached | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-observatorium-thanos-store-shard | thanos-store | 100 | 1024 | 3 | 300 | 3072 |
| observatorium-operator | observatorium-operator | 100 | 100 | 1 | 100 | 100 |
| rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
1.1.2. Observability 服务中使用的持久性存储
安装 Red Hat Advanced Cluster Management 时会创建以下持久性卷:
表 1.2. 持久性卷表列表
| 持久性卷名称 | 目的 |
| alertmanager |
Alertmanager 在其存储中保存 |
| thanos-compact | 紧凑器需要本地磁盘空间来存储用于处理的中间数据,以及 bucket 状态缓存。所需空间取决于基础块的大小。紧凑器必须有足够的空间下载所有源块,然后在磁盘上构建紧凑块。磁盘上的数据可以安全地在重新启动之间删除,并且应该是首次尝试使崩溃循环解压器。不过,建议为紧凑器永久磁盘提供压缩器持久磁盘,以便在重启期间高效地使用存储桶状态缓存。 |
| thanos-rule | thanos 标尺通过以固定间隔发出查询来评估 Prometheus 记录和警报规则。规则结果以 Prometheus 2.0 存储格式写回磁盘。 |
| thanos-receive-default | Thanos 接收器接受传入数据(Prometheus 远程写入请求),并将这些数据写入 Prometheus TSDB 的一个本地实例。TSDB 块定期(每 2 小时)上传到对象存储,以进行长期存储和压缩。 |
| thanos-store-shard | 它主要充当一个 API 网关,因此不需要大量的本地磁盘空间。它在启动时加入 Thanos 集群,并公告它可以访问的数据。它在本地磁盘上保留少量的、与所有远程块相关的信息,并与存储桶保持同步。这些数据通常在重启时会被安全地删除,这会增加启动时间。 |
注:时间序列历史数据存储在对象存储中。Thanos 使用对象存储作为指标和与其相关的元数据的主存储。有关对象存储和降级的详情,请参阅启用可观察性服务。
1.2. 启用 observability 服务
监控使用 observability 服务(multicluster-observability-operator)的受管集群的监控状态。
需要的访问权限:集群管理员或 open-cluster-management:cluster-manager-admin 角色。
1.2.1. 先决条件
- 您必须安装 Red Hat Advanced Cluster Management for Kubernetes。如需更多信息,请参阅在线安装。
您必须配置对象存储来创建存储解决方案。Red Hat Advanced Cluster Management 支持带有稳定对象存储的以下云供应商:
- Amazon Web Services S3 (AWS S3)
- Red Hat Ceph (S3 compatible API)
- Google Cloud Storage
- Azure 存储
Red Hat OpenShift Container Storage
重要:当您配置对象存储时,请确保在敏感数据持久化时满足加密要求。有关 Thanos 支持的对象存储的更多信息,请参阅 Thanos 文档。
1.2.2. 启用可观察性
通过创建一个 MultiClusterObservability 自定义资源(CR)实例来启用可观察性服务。在启用可观察性前,请参阅 Observability pod 容量请求 以了解更多信息。完成以下步骤以启用可观察服务:
- 登录到您的 Red Hat Advanced Cluster Management hub 集群。
使用以下命令,为可观察服务创建一个命名空间:
oc create namespace open-cluster-management-observability
生成 pull-secret。如果在
open-cluster-management命名空间中安装了 Red Hat Advanced Cluster Management,请运行以下命令:DOCKER_CONFIG_JSON=`oc extract secret/multiclusterhub-operator-pull-secret -n open-cluster-management --to=-`
如果命名空间中没有定义
multiclusterhub-operator-pull-secret,将openshift-config命名空间中的pull-secret复制到open-cluster-management-observability命名空间中。运行以下命令:DOCKER_CONFIG_JSON=`oc extract secret/pull-secret -n openshift-config --to=-`
然后,在
open-cluster-management-observability命名空间中创建 pull-secret,运行以下命令:oc create secret generic multiclusterhub-operator-pull-secret \ -n open-cluster-management-observability \ --from-literal=.dockerconfigjson="$DOCKER_CONFIG_JSON" \ --type=kubernetes.io/dockerconfigjson为您的云供应商的对象存储创建 secret。您的 secret 必须包含存储解决方案的凭证。例如,运行以下命令:
oc create -f thanos-object-storage.yaml -n open-cluster-management-observability
查看以下受支持对象存储的 secret 示例:
对于 Red Hat Advanced Cluster Management,您的 secret 可能类似以下文件:
apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: s3 config: bucket: YOUR_S3_BUCKET endpoint: YOUR_S3_ENDPOINT insecure: true access_key: YOUR_ACCESS_KEY secret_key: YOUR_SECRET_KEY对于 Amazon S3 或 S3 兼容,您的 secret 可能类似以下文件:
apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: s3 config: bucket: YOUR_S3_BUCKET endpoint: YOUR_S3_ENDPOINT insecure: true access_key: YOUR_ACCESS_KEY secret_key: YOUR_SECRET_KEY对于 Google,您的 secret 可能类似以下文件:
apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: GCS config: bucket: YOUR_GCS_BUCKET service_account: YOUR_SERVICE_ACCOUNT如需了解更多详细信息,请参阅 Google Cloud Storage。
对于 Azure,您的 secret 可能类似以下文件:
apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: AZURE config: storage_account: YOUR_STORAGE_ACCT storage_account_key: YOUR_STORAGE_KEY container: YOUR_CONTAINER endpoint: blob.core.windows.net max_retries: 0如需了解更多详细信息,请参阅 Azure Storage 文档。
对于 OpenShift Container Storage,您的 secret 可能类似以下文件:
apiVersion: v1 kind: Secret metadata: name: thanos-object-storage namespace: open-cluster-management-observability type: Opaque stringData: thanos.yaml: | type: s3 config: bucket: YOUR_OCS_BUCKET endpoint: YOUR_OCS_ENDPOINT insecure: true access_key: YOUR_OCS_ACCESS_KEY secret_key: YOUR_OCS_SECRET_KEY如需了解更多详细信息,请参阅安装 OpenShift Container Storage。
您可以使用以下命令为云供应商检索 S3 access key 和 secret 密钥:
ACCESS_KEY=$(oc -n <your-object-storage> get secret <object-storage-secret> -o yaml | grep AccessKey | awk '{print $2}' | base64 --decode) echo $ACCESS_KEY SECRET_KEY=$(oc -n <your-object-storage> get secret <object-storage-secret> -o yaml | grep SecretKey | awk '{print $2}' | base64 --decode) echo $SECRET_KEY
1.2.2.1. 创建 MultiClusterObservability CR
完成以下步骤以创建 MultiClusterObservability 自定义资源(CR):
通过完成以下步骤,为受管集群创建
MultiClusterObservability自定义资源(mco CR):创建名为
multiclusterobservability_cr.yaml的MultiClusterObservability自定义资源 YAML 文件。查看以下默认 YAML 文件以查看可观察性:
apiVersion: observability.open-cluster-management.io/v1beta1 kind: MultiClusterObservability metadata: name: observability #Your customized name of MulticlusterObservability CR spec: availabilityConfig: High # Available values are High or Basic enableDownSampling: false # The default value is false. This is not recommended as querying long-time ranges without non-downsampled data is not efficient and useful. imagePullPolicy: Always imagePullSecret: multiclusterhub-operator-pull-secret observabilityAddonSpec: # The ObservabilityAddonSpec defines the global settings for all managed clusters which have observability add-on enabled enableMetrics: true # EnableMetrics indicates the observability addon push metrics to hub server interval: 30 # Interval for the observability addon push metrics to hub server retentionResolution1h: 30d # How long to retain samples of 1 hour in bucket retentionResolution5m: 14d retentionResolutionRaw: 5d storageConfigObject: # Specifies the storage to be used by Observability metricObjectStorage: name: thanos-object-storage key: thanos.yaml statefulSetSize: 10Gi # The amount of storage applied to the Observability StatefulSets, i.e. Amazon S3 store, Rule, compact and receiver. statefulSetStorageClass: gp2您可能想要修改
retentionResolution参数的值。默认情况下禁用了向下采样。如需更多信息,请参阅 Thanos Downsampling 分辨率和保留时间。取决于受管集群的数量,您可能需要更新statefulSetSize。如需更多信息,请参阅 Observability API。要在基础架构机器集上部署,您必须通过更新
MultiClusterObservabilityYAML 中的nodeSelector来为设置设置一个标签。您的 YAML 可能类似以下内容:nodeSelector: node-role.kubernetes.io/infra:如需更多信息,请参阅创建基础架构机器集。
运行以下命令,将可观察 YAML 应用到集群:
oc apply -f multiclusterobservability_cr.yaml
用于 Thanos、Grafana 和 AlertManager 的所有 pod 在
open-cluster-management-observability命名空间中创建。所有连接到 Red Hat Advanced Cluster Management hub 集群的受管集群都会被启用,以将指标数据发送回 Red Hat Advanced Cluster Management Observability 服务。
要验证是否已启用了 observabilty 服务,启动 Grafana 仪表板,查看其中是否包括了相关的数据。完成以下步骤:
- 登录到 Red Hat Advanced Cluster Management 控制台。
- 在导航菜单中选择 Observe environments > Overview。
点击位于控制台标头旁的 Grafana 链接,从您的受管集群中查看指标。
注:如果要排除特定的受管集群收集可观察性数据,请在集群中添加以下集群标签:
observability: disabled。
1.2.3. 禁用可观察性
要禁用可观察性服务,请卸载 observability 资源。请参阅使用命令删除 MultiClusterHub 实例的第 1 步。
要了解更多有关如何定制可观察性的信息,请参阅定制可观察性。
1.3. 定制可观察性
以下部分介绍了对可观察性服务所收集的数据进行自定义、管理和查看的信息。
使用 must-gather 命令收集有关为可观察性资源创建的新信息的日志。如需更多信息,请参阅故障排除文档中的 Must-gather 部分。
1.3.1. 创建自定义规则
您可以通过在可观察性资源中添加 Prometheus 记录规则和 警报规则,为可观察性安装创建自定义规则。如需更多信息,请参阅 Prometheus 配置。
- 记录规则可让您根据需要预先计算或计算昂贵的表达式。结果保存为一组新的时间序列。
- 通过警报规则,您可以根据如何将警报发送到外部服务来指定警报条件。
使用 Prometheus 定义自定义规则来创建警报条件,并将通知发送到外部消息服务。注:当您更新自定义规则时,observability-observatorium-thanos-rule pod 会自动重启。
完成以下步骤以创建自定义规则:
- 登录到您的 Red Hat Advanced Cluster Management hub 集群。
在
open-cluster-management-observability命名空间中创建一个名为thanos-ruler-custom-rules的 ConfigMap。键必须被命名为custom_rules.yaml,如下例所示。您可以在配置中创建多个规则:默认情况下,开箱即用的警报规则在
open-cluster-management-observability命名空间中的thanos-ruler-default-rulesConfigMap 中定义。例如,您可以创建一个自定义警报规则,在 CPU 使用量超过了您定义的值时通知您:
data: custom_rules.yaml: | groups: - name: cluster-health rules: - alert: ClusterCPUHealth-jb annotations: summary: Notify when CPU utilization on a cluster is greater than the defined utilization limit description: "The cluster has a high CPU usage: {{ $value }} core for {{ $labels.cluster }} {{ $labels.clusterID }}." expr: | max(cluster:cpu_usage_cores:sum) by (clusterID, cluster, prometheus) > 0 for: 5s labels: cluster: "{{ $labels.cluster }}" prometheus: "{{ $labels.prometheus }}" severity: critical您还可以在
thanos-ruler-custom-rulesConfigMap 中创建自定义记录规则。例如,您可以创建一个记录规则,让您可以获取 pod 的容器内存缓存的总和。您的 YAML 可能类似以下内容:
data: custom_rules.yaml: | groups: - name: container-memory rules: - record: pod:container_memory_cache:sum expr: sum(container_memory_cache{pod!=""}) BY (pod, container)注:如果这是第一个新的自定义规则,它会立即创建。对于 ConfigMap 的更改,您必须使用以下命令重启 observability pod:
kubectl rollout restart statefulset observability-observatorium-thanos-rule -n open-cluster-management-observability。
如果要验证警报规则是否正常工作,请完成以下步骤:
- 访问 Grafana 仪表板,然后选择 Explore 图标。
- 在 Metrics 探索栏中,输入 "ALERTS" 并运行查询。系统中所有处于 pending 或 firing 状态的 ALERTS 都会被显示。
- 如果没有显示警报,查看规则来检查表达式是否正确。
已创建一个自定义规则。
1.3.2. 为 AlertManager 配置规则
集成外部消息工具,如 email、Slack 和 PagerDuty 以接收来自 AlertManager 的通知。您必须覆盖 open-cluster-management-observability 命名空间中的 alertmanager-config secret 来添加集成,并为 AlertManager 配置路由。完成以下步骤以更新自定义接收器规则:
从
alertmanager-configsecret 中提取数据。运行以下命令:oc -n open-cluster-management-observability get secret alertmanager-config --template='{{ index .data "alertmanager.yaml" }}' |base64 -d > alertmanager.yaml运行以下命令,编辑并保存
alertmanager.yaml文件配置:oc -n open-cluster-management-observability create secret generic alertmanager-config --from-file=alertmanager.yaml --dry-run -o=yaml | oc -n open-cluster-management-observability replace secret --filename=-
更新的 secret 可能与以下类似:
global smtp_smarthost: 'localhost:25' smtp_from: 'alertmanager@example.org' smtp_auth_username: 'alertmanager' smtp_auth_password: 'password' templates: - '/etc/alertmanager/template/*.tmpl' route: group_by: ['alertname', 'cluster', 'service'] group_wait: 30s group_interval: 5m repeat_interval: 3h receiver: team-X-mails routes: - match_re: service: ^(foo1|foo2|baz)$ receiver: team-X-mails
您的更改会在修改后立即生效。如需 AlertManager 的示例,请参阅 prometheus/alertmanager。
1.3.3. 添加自定义指标
将指标添加到 metrics_list.yaml 文件中,用来从受管集群中收集数据。
完成以下步骤以添加自定义指标:
- 登录到您的集群。
验证
mco observability已启用。检查status.conditions.message中的以下信息:部署并运行了可观察性组件。运行以下命令:oc get mco observability -o yaml
创建一个包含以下内容的新文件
observability-metrics-custom-allowlist.yaml。将自定义指标名称添加到metrics_list.yaml参数。例如,将node_memory_MemTotal_bytes添加到指标列表中。ConfigMap 的 YAML 可能类似以下内容:kind: ConfigMap apiVersion: v1 metadata: name: observability-metrics-custom-allowlist data: metrics_list.yaml: | names: - node_memory_MemTotal_bytes运行以下命令,在
open-cluster-management-observability命名空间内创建observability-metrics-custom-allowlistConfigMap:oc apply -n open-cluster-management-observability -f observability-metrics-custom-allowlist.yaml
- 通过在 Grafana 仪表板上查看指标,验证您的自定义指标是否从受管集群收集数据。在 hub 集群中,选择 Grafana dashboard 链接。
- 在 Grafana 搜索栏中输入您要查看的指标。
收集自定义指标数据。
1.3.4. 查看和查找数据
通过访问 Grafana 来查看来自受管集群的数据。完成以下步骤,从控制台查看 Grafana 仪表板:
- 登录到您的 Red Hat Advanced Cluster Management hub 集群。
在导航菜单中选择 Observe environments > Overview > Grafana link。
您还可以从 Clusters 页面访问 Grafana 仪表板。在导航菜单中选择 Automate infrastructure > Clusters > Grafana。
- 通过在 Grafana 导航菜单中选择 Explore 图标来访问 Prometheus 指标浏览器。
1.3.5. 禁用可观察性
您可以禁用可观察性,在 Red Hat Advanced Cluster Management hub 集群中停止数据收集。
1.3.5.1. 在所有集群中禁用可观察性
通过删除所有受管集群中的可观察性组件来禁用可观察性。
通过将 enableMetrics 设置为 false 来更新 multicluster-observability-operator 资源。更新的资源可能类似如下:
spec:
availabilityConfig: High # Available values are High or Basic
imagePullPolicy: Always
imagePullSecret: multiclusterhub-operator-pull-secret
observabilityAddonSpec: # The ObservabilityAddonSpec defines the global settings for all managed clusters which have observability add-on enabled
enableMetrics: false #indicates the observability addon push metrics to hub server1.3.5.2. 在单个集群中禁用可观察性
通过完成以下步骤之一禁用特定受管集群上的可观察性:
-
在自定义资源
managedclusters.cluster.open-cluster-management.io中添加observability: disabled标签。 在 Red Hat Advanced Cluster Management 控制台的 Clusters 页面中,完成以下步骤来添加
observability: disabled标签:- 在 Red Hat Advanced Cluster Management 控制台中,选择 Automate infrastructure > Clusters。
- 选择您要禁用发送到可观察性的数据收集的集群名称。
- 选择 Labels。
通过添加以下标签来创建禁用可观察性集合的标签:
observability=disabled
- 选择 Add 添加该标签。
- 选择 Done 以关闭标签列表。
注:当分离带有可观察组件的受管集群时,metric-collector 部署会被删除。
有关使用可观察性服务监控控制台数据的更多信息,请参阅观察环境介绍。
1.4. 设计您的 Grafana 仪表板
您可以通过创建一个 grafana-dev 实例来设计 Grafana 仪表板。
1.4.1. 设置 Grafana 开发人员实例
首先,克隆 stolostron/multicluster-observability-operator/ 存储库,以便您可以运行 tools 文件夹中的脚本。完成以下步骤以设置 Grafana 开发人员实例:
运行
setup-grafana-dev.sh来设置 Grafana 实例。运行脚本时,会创建以下资源:secret/grafana-dev-config、deployment.apps/grafana-dev、service/grafana-dev、ingress.extensions/grafana-dev、persistentvolumeclaim/grafana-dev:./setup-grafana-dev.sh --deploy secret/grafana-dev-config created deployment.apps/grafana-dev created service/grafana-dev created ingress.extensions/grafana-dev created persistentvolumeclaim/grafana-dev created
使用
switch-to-grafana-admin.sh脚本将用户角色切换到 Grafana 管理员。-
选择 Grafana URL
https://$ACM_URL/grafana-dev/并登录。 然后运行以下命令,将切换的用户添加为 Grafana 管理员。例如,使用
kubeadmin登录后,运行以下命令:./switch-to-grafana-admin.sh kube:admin User <kube:admin> switched to be grafana admin
-
选择 Grafana URL
Grafana 开发人员实例已设置。
1.4.2. 设计您的 Grafana 仪表板
设置 Grafana 实例后,您可以设计仪表板。完成以下步骤以刷新 Grafana 控制台并设计您的仪表板:
- 在 Grafana 控制台中,通过在导航面板中选择 Create 图标来创建仪表板。选择 Dashboard,然后单击 Add new panel。
- 在 New Dashboard/Edit Panel 视图中导航到 Query 选项卡。
-
从数据源选择器中选择
Observatorium并输入 PromQL 查询来配置查询。 - 在 Grafana 仪表板标头中点击仪表板标头中的 Save 图标。
- 添加一个描述性名称并点 Save。
1.4.2.1. 使用 ConfigMap 设计 Grafana 仪表板
完成以下步骤,使用 ConfigMap 设计 Grafana 仪表板:
您可以使用
generate-dashboard-configmap-yaml.sh脚本在本地生成仪表板 ConfigMap,并在本地保存 ConfigMap:./generate-dashboard-configmap-yaml.sh "Your Dashboard Name" Save dashboard <your-dashboard-name> to ./your-dashboard-name.yaml
如果您没有运行上述脚本的权限,请完成以下步骤:
- 选择一个仪表板并点 Dashboard settings 图标。
- 在导航框中,点 JSON Model 图标。
-
复制仪表板 JSON 数据,并将其粘贴到
metadata部分。 修改
name并替换$your-dashboard-name。ConfigMap 可能类似以下文件:kind: ConfigMap apiVersion: v1 metadata: name: $your-dashboard-name namespace: open-cluster-management-observability labels: grafana-custom-dashboard: "true" data: $your-dashboard-name.json: | $your_dashboard_json备注:如果您的仪表板不在 General 文件夹中,您可以在此 ConfigMap 的
annotations部分中指定文件夹名称:annotations: observability.open-cluster-management.io/dashboard-folder: Custom
完成 ConfigMap 的更新后,您可以安装它,将仪表板导入到 Grafana 实例。
1.4.3. 卸载 Grafana 开发者实例
卸载实例时,相关资源也会被删除。运行以下命令:
./setup-grafana-dev.sh --clean secret "grafana-dev-config" deleted deployment.apps "grafana-dev" deleted service "grafana-dev" deleted ingress.extensions "grafana-dev" deleted persistentvolumeclaim "grafana-dev" deleted